ROLA I ISTOTA STATYSTYKI
Termin statystyka pochodzi od łacińskiego słowa “status” co oznacza państwo.
Obecnie terminu tego używamy w sensie zestawień liczbowych, czy też w sensie zbierania i porządkowania pewnych danych (materiał statystyczny).
Nie wystarcza już samo zbieranie i porządkowanie danych nasuwa się konieczność wyrażania właściwości całego materiału liczbowego za pomocą jednej lub kilku specjalnych liczb, które by materiał statystyczny najlepiej charakteryzowały. Liczby te nazywamy statystykami.
Stąd definicja statystyki jako nauki traktującej o metodach ilościowych badania (charakteryzowania) prawidłowości zjawisk masowych.
Zjawisko masowe to takie zjawisko, które badane w dużej masie zdarzeń wykazuje pewną prawidłowość, jakiej nie można zaobserwować w pojedynczym przypadku.
Każde zjawisko kształtuje się pod wpływem dwojakiego rodzaju przyczyn:
głównych - podstawowych (typowych);
ubocznych - przypadkowych (nietypowych).
Przyczyny główne działają na każde zjawisko w sposób jednakowy. Ich istota wypływa z charakteru zjawiska - działają w ściśle określonym kierunku.
Przyczyny uboczne, zwane również przyczynami nietypowymi działają na każde zjawisko w sposób odmienny. Źródłem tych przyczyn są czynniki zewnętrzne.
Przyczyny główne wywołują prawidłowość w procesach (zjawiskach) masowych, uboczne zaś powodują odchylenia od tej prawidłowości.
Głównym celem statystyki jest nie tylko poznanie występujących prawidłowości, lecz także ich wyrażenie ilościowe.
Większość informacji statystycznych uzyskujemy drogą badań częściowych. Oznacza to, że z tzw. zbiorowości generalnej, obejmującej wszystkie badane jednostki, dokonujemy w sposób losowy wyboru pewnej jej części, zwanej zbiorowością próbną, co ilustruje poniższy rys. Charakterystyki uzyskane na podstawie zbiorowości próbnej są zazwyczaj traktowane jako podstawa do uogólnień, mają zatem charakteryzować zbiorowość generalną.
Parametry zbiorowości próbnej (analiza statystyczna)
Podstawowe pojęcia statystyczne
Zbiorowością statystyczną nazywamy zbiór dowolnych elementów podobnych pod względem określonych cech (lecz nie identycznych), poddanych badaniom statystycznym.
Badana zbiorowość statystyczna musi być jednoznacznie określona i wyodrębniona. Czynimy to zazwyczaj ustalając cel badania, gdy precyzujemy, kogo lub co mamy zaliczać do badanej zbiorowości.
Badana zbiorowość musi być jednorodna, tj. składać się z jednostek, które nie różnią się od siebie z punktu widzenia celu badania.
Poszczególne jednostki (elementy), które wchodzą w skład badanej zbiorowości statystycznej, mają wspólną cechę (właściwość), a równocześnie różnią się między sobą innymi cechami.
Liczba elementów zbiorowości generalnej może być skończona, wówczas jej liczebność (liczbę elementów tej zbiorowości) oznaczamy przez N lub nieograniczona.
Jeżeli elementy zbiorowości generalnej poddajemy badaniom ze względu na jedną cechę, to mamy do czynienia ze zbiorowością jednowymiarową (jednocechową). W przypadku rozpatrywania wielu cech mówimy o zbiorowości wielowymiarowej (wielocechowej).
Zbiorowość próbna (próbka) jest to podzbiór zbiorowości generalnej, obejmujący część jej elementów - wybranych w określony sposób, które podlegają badaniu, a wyniki uzyskane na tej drodze uogólniamy na zbiorowość generalną.
Liczbę elementów próby, zwaną liczebnością próby, oznaczamy przez n, przy czym n<N.
Mówimy, że próba jest duża gdy n>30, a mała gdy n ≤ 30.
Od próby wymagamy, by była reprezentatywna, tzn. by z przyjętą dokładnością opisywała strukturę zbiorowości generalnej.
Reprezentatywność próby zależy od dwóch czynników:
sposobu doboru próby,
wielkości (liczebności) próby.
Wyróżnić można dwie procedury pobierania próby:
wybór losowy,
wybór celowy.
Wybór elementu ze zbiorowości jest losowy, gdy każdy element tej zbiorowości ma jednakową szansę znalezienia się w próbie.
O próbie, która spełnia postulat losowego wyboru, mówimy, że jest nieobciążona, tzn. że struktura jej jest podobna do struktury zbiorowości generalnej.
Jeśli próba jest nieobciążona i odpowiednio duża (liczna), to jest reprezentatywna. Jeśli próba jest losowa, to wraz ze wzrostem jej liczebności wzrasta stopień reprezentatywności. W tym przypadku działa prawo wielkich liczb.
Celowy wybór polega na tym, że o tym czy dany element znajdzie się w próbie decyduje badacz. Stopień jej reprezentatywności zależy wyłącznie od jakości przeprowadzonej selekcji. Próba ta nie podlega prawu wielkich liczb.
Nie zawsze istnieje możliwość zapewnienia pełnych warunków losowości w czasie pobierania próby, dlatego też korzystamy z różnych technik (schematów) jej losowania.
Losowanie niezależne (zwrotne) polega na tym, że po każdym ciągnieniu jednostki wraca ona do zbiorowości generalnej. Jest to próba z powtórzeniami.
Losowanie zależne (bezzwrotne) ma miejsce wówczas, gdy raz wylosowany element nie bierze udziału w dalszym losowaniu. Jest to próba bez powtórzeń.
Jeśli zbiorowość generalna jest liczna, to jest rzeczą obojętną, który ze schematów zastosujemy. Jeżeli zbiorowość generalna jest niewielka, to należy stosować schemat losowania zależnego, ponieważ zwiększa się efektywność estymatorów (parametrów zbiorowości generalnej).
Jednostką statystyczną (badaną jednostką) nazywamy poszczególny element wchodzący w skład badanej zbiorowości statystycznej. Przy ustalaniu celu badania, określając zbiorowość statystyczną, musimy również ściśle ustalić, co jest w danym przypadku jednostką badaną.
Na ogół nie badamy zbiorowości statystycznej pod względem wszystkich cech występujących u wszystkich jednostek należących do tej zbiorowości, lecz wyróżniamy je pod względem pewnych, z góry ustalonych cech.
Przedmiotem badania mogą być różne cechy badanej zbiorowości, mogą to być więc cechy zarówno ilościowe (mierzalne), jak i jakościowe (niemierzalne).
Cecha ilościowa (mierzalna) daje się wyrazić bezpośrednio za pomocą jednostek miary. Cecha jakościowa (niemierzalna) nie daje się wyrazić bezpośrednio za pomocą jednostek miary.
Miary położenia
Miary położenia, zwane ogólnie przeciętnymi, charakteryzują zbiorowość statystyczną niezależnie od różnic występujących pod względem przyjętej cechy między jej pomiarami u poszczególnych jednostek statystycznych.
Miary położenia informują o przeciętnym poziomie wartości rozważanej cechy w badanej zbiorowości statystycznej - co oznacza, że dają syntezę tej cechy. Ponieważ celem przeciętnych jest scharakteryzowanie zbiorowości statystycznej jako całości ( a nie poszczególnych jej jednostek), możemy je nazwać również cechami zbiorczymi.
Istnieje kilka rodzajów przeciętnych. Przeciętne podzielimy na dwie grupy:
średnie,
przeciętne pozycyjne.
Wśród średnich wyróżniamy:
arytmetyczną,
geometryczną,
harmoniczną,
kwadratową.
Wśród przeciętnych pozycyjnych wyróżniamy:
wartość modalną,
wartość przeciętną
kwartyle.
Stosowana symbolika. Zmienne (cechy mierzalne) oznaczamy końcowymi literami alfabetu łacińskiego, przy czym dużymi literami - zmienne zbiorowości generalnej (zmienne losowe), literami małymi (z indeksami u dołu z prawej strony) - konkretne wartości zmiennych (badanej cechy) każdej jednostki badanej próby.
Średnia arytmetyczna
I. Średnia arytmetyczna prosta.
Zakładamy, że dokonujemy pomiaru ustalonej cechy u każdej jednostki wchodzącej w skład próby, której liczebność jest ustalona (określona) i wynosi n.
Zakładamy, że jednostki próby zostały ponumerowane indeksem i przy czym z faktu ustalonej liczebności próby wynika, że indeks i zmienia się od 1, 2, ...., n.
Wyniki pomiarów ustalonej cechy u jednostek próby są następujące:
x1, x2, ..., xn
Widzimy więc, że wartość tej samej cechy mierzona u poszczególnych jednostek, jest różna (wśród liczb x1, x2, ..., xn nie ma liczb jednakowych).
Charakterystyką zbiorczą tej próby, a zatem i całej zbiorowości generalnej jest średnia arytmetyczna.
Średnią arytmetyczną oznaczać będziemy literą M i określamy następująco:
M = ![]()
(1)
a więc jest to suma wartości cechy wszystkich jednostek próby, podzielona przez liczebność (n) tej próby.
Średnią arytmetyczną M możemy wyrazić także w postaci wzoru:
M = ![]()
(1.a)
II. Średnia arytmetyczna ważona.
Zakładamy, że dokonujemy pomiaru ustalonej cechy u każdej jednostki wchodzącej w skład próby, której liczebność jest ustalona (określona) i wynosi n.
Zakładamy, że pomiar wyróżnionej cechy u jednostek wchodzących w skład próby jest taki, że wiele jednostek próby ma tę samą liczbową wartość wyróżnionej cechy.
Oznacza to, że różnych liczbowo wartości mierzonej cechy jest w tym przypadku mniej niż wynosi liczebność próby.
Założymy, że tych wartości cechy dla danej próby jest k sztuk.
Przyjmujemy w takim przypadku, że gdy:
liczbowa wartość cechy jest równa x1, to tę wartość cechy zanotowano u f1 jednostek należących do próby;
liczbowa wartość cechy jest równa x2, to tę wartość cechy zanotowano u f2 jednostek należących do próby;
liczbowa wartość cechy jest równa x3, to tę wartość cechy zanotowano u f3 jednostek należących do próby;
itd.
oraz
liczbowa wartość cechy jest równa xk, to tę wartość cechy zanotowano u fk jednostek należących do próby;
Ogółem
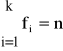
co oznacza, że u każdej jednostki dokonano pomiaru cechy oraz wynik pomiaru zaklasyfikowano do jednej z wyżej wymienionych klas.
Dla takiego przypadku średnia arytmetyczna liczona jest wg następującego wzoru:
![]()
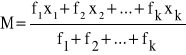
(2)
lub według wzoru równoważnego:
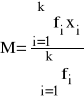
(2.a)
III. Średnia arytmetyczna dla przedziału klasowego.
Zakładamy, że dokonujemy pomiaru ustalonej cechy u każdej jednostki wchodzącej w skład próby, której liczebność jest ustalona (określona) i jest równa n.
Zakładamy ponadto, że są ustalone przedziały liczbowe w sensie liczby tych przedziałów oraz ich rozpiętości (długości), oznaczone przez (
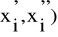
, przy czym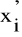
jest dolną granicą przedziału, natomiast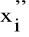
- górną.
Indeksem i zanumerowaliśmy przedziały oraz przyjmujemy, że indeks i przebiega następujący zbiór numerów i=1, 2, ..., k, co oznacza, że danych jest k przedziałów, które noszą nazwę przedziałów klasowych.
Pomiar badanej cechy u każdej jednostki zbiorowości statystycznej powoduje zaklasyfikowanie wyniku pomiaru tej cechy (a zatem i samej jednostki statystycznej) do jednego z wyżej omówionych przedziałów klasowych. Przyjmujemy, że liczba jednostek statystycznych zaklasyfikowanych na podstawie wyniku pomiaru do i-tego przedziału klasowego jest równa fi .
Wprowadzimy pojęcie środka i-tego przedziału klasowego, który oznaczymy przez
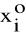
. Wartość liczbową środka przedziału klasowego wyznaczamy w sposób następujący:
![]()
= 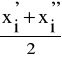
Z uwzględnieniem powyższych założeń, średnia arytmetyczna dla takiego przypadku wyraża się wzorem:
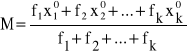
(3)
lub wzorem równoważnym:
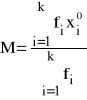
(3.a)
Średnia arytmetyczna daje prawdziwą charakterystykę zbiorowości statystycznej, jeśli badana cecha jednostek zbiorowości statystycznej nie bardzo różni się od siebie lub jeśli nie ma wyraźnej tendencji skupiania się wartości tej cechy w wyodrębnione grupy, a więc jeśli badana zbiorowość jest jednorodna. Jedyną poważną jej wadą jest to, że duży wpływ na nią wywierają najmniejsza i największa wartość badanej cechy zbiorowości.
Jeśli zbiorowość statystyczna jest jednorodna wówczas średnia arytmetyczna wyraża ogólną prawidłowość tej zbiorowości.
ŚREDNIA GEOMETRYCZNA
Średnia geometryczną stosujemy przede wszystkim wtedy, gdy mamy do czynienia z taką badaną cechą jednostek zbiorowości statystycznej, dla której występują znaczne różnice między wynikami pomiarów tej cechy u różnych jednostek zbiorowości. Średnia geometryczna jest mniej wrażliwa na wartości ekstremalne (krańcowe), niż średnia arytmetyczna.
Średnia geometryczna prosta.
Zakładamy, że badana cecha prowadzona będzie na próbce składającej się z n jednostek. Zakładamy, że jednostki statystyczne w próbie zostały ponumerowane zmienną i, przy czym zmienna i przebiega zbiór i=1,2, .., n.
Zakładamy, że pomiar cechy u różnych jednostek zbiorowości próbnej dał następujące wyniki:
wartość badanej cechy u pierwszej jednostki statystycznej w próbie jest równa x1;
wartość badanej cechy u drugiej jednostki statystycznej w próbie jest równa x2;
wartość badanej cechy u trzeciej jednostki statystycznej w próbie jest równa x3;
itd., oraz
wartość badanej cechy u n-tej (ostatniej wg numeracji) jednostki statystycznej w próbie jest równa xn;
Jak z powyższego wynika na skutek pomiaru cechy u każdej jednostki statystycznej otrzymaliśmy dla każdej jednostki inną wartość liczbową.
W tym przypadku średnią geometryczną, oznaczoną symbolem G, obliczamy na podstawie wzoru:
G = ![]()
(4)
Ponieważ wyciąganie pierwiastka wysokiego stopnia jest pracochłonne, a liczebność próby może być duża, korzystamy z postaci logarytmicznej tego wzoru, tj.:
log G = ![]()
co czytamy: logarytm średniej geometrycznej jest średnią arytmetyczną logarytmów poszczególnych wartości jednostek zbiorowości próbnej (próby).
Średnia geometryczna ważona.
Zakładamy, że badana cecha prowadzona będzie na próbce składającej się z n jednostek. Zakładamy, że jednostki statystyczne w próbie zostały ponumerowane zmienną i, przy czym zmienna i przebiega od i=1,2, .., n.
Zakładamy, że pomiar wyróżnionej cechy u jednostek wchodzących w skład próby jest taki, że wiele jednostek próby ma tę samą liczbową wartość wyróżnionej cechy. Oznacza to, że różnych liczbowo wartości mierzonej cechy jest w tym przypadku mniej niż wynosi liczebność próby.
Założymy, że tych wartości cechy dla danej próby jest k sztuk, (k<n).
Przyjmujemy w tym przypadku że, gdy:
liczbowa wartość cechy jest równa x1, to tę wartość cechy zanotowano u f1 jednostek należących do próby (f1 liczebność 1-szej klasy);
liczbowa wartość cechy jest równa x2, to tę wartość cechy zanotowano u f2 jednostek należących do próby(f2 liczebność 2-tej klasy);
liczbowa wartość cechy jest równa x3, to tę wartość cechy zanotowano u f3 jednostek należących do próby (f3 liczebność 3-tej klasy);
itd.;
oraz
liczbowa wartość cechy jest równa xk, to tę wartość cechy zanotowano u fk jednostek należących do próby (fk liczebność k-tej klasy);
Ogółem
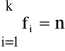
co oznacza, że u każdej jednostki dokonano pomiaru cechy oraz wynik pomiaru zaklasyfikowano do jednej z wyżej wymienionych klas.
Dla takiego przypadku średnia geometryczna liczona jest wg następującego wzoru:
G = 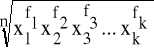
(5)
lub wg wzoru zapisanego w postaci logarytmicznej:
log G 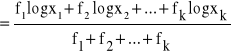
Średnia geometryczna różni się od innych charakterystyk liczbowych tym, że obliczana dla danych wśród których choć jedna wartość równa się zeru jest równa zero. Średnia geometryczna nadaje się do charakteryzowania cech, które przyjmują wartości dodatnie. Jest ona mniej wrażliwa na wartości skrajne niż średnia arytmetyczna. Jej zaletą jest to, że zmniejsza wpływ różnic, które często są przypadkowe i nie mają większego znaczenia dla badanej cechy.
ŚREDNIA HARMONICZNA
Stosowana jest wtedy, gdy wartości cechy jednostek statystycznych podane są w formie odwrotności, tj. gdy wartości jednej zmiennej podane są w przeliczeniu na stałą jednostkę innej zmiennej (np. 80km/godz.) lub wyrażone są w innej złożonej postaci.
Średnia harmoniczna prosta.
Zakładamy, że badana cecha prowadzona będzie na próbce składającej się z n jednostek. Zakładamy, że jednostki statystyczne w próbie zostały ponumerowane zmienną i, przy czym zmienna i przebiega zbiór i=1,2, .., n.
Zakładamy, że pomiar cechy u różnych jednostek zbiorowości próbnej dał następujące wyniki:
wartość badanej cechy u pierwszej jednostki statystycznej w próbie jest równa x1;
wartość badanej cechy u drugiej jednostki statystycznej w próbie jest równa x2;
wartość badanej cechy u trzeciej jednostki statystycznej w próbie jest równa x3;
itd., oraz
wartość badanej cechy u n-tej (ostatniej wg numeracji) jednostki statystycznej w próbie jest równa xn;
Jak z powyższego wynika rezultat pomiaru cechy u każdej jednostki statystycznej jest różny.
W tym przypadku średnią harmoniczną, oznaczoną symbolem H, obliczamy na podstawie wzoru:
H = 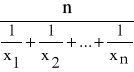
(6)
Średnia harmoniczna jest odwrotnością średniej arytmetycznej odwrotności poszczególnych wartości cechy jednostek zbiorowości statystycznej.
Średnia harmoniczna ważona.
Zakładamy, że badana cecha prowadzona będzie na próbce składającej się z n jednostek. Zakładamy, że jednostki statystyczne w próbie zostały ponumerowane zmienną i, przy czym zmienna i przebiega od i=1,2, .., n.
Zakładamy, że pomiar wyróżnionej cechy u jednostek wchodzących w skład próby jest taki, że wiele jednostek próby ma tę samą liczbową wartość wyróżnionej cechy. Oznacza to, że różnych liczbowo wartości mierzonej cechy jest w tym przypadku mniej niż wynosi liczebność próby.
Założymy, że tych wartości cechy dla danej próby jest k sztuk, (k<n).
Przyjmujemy w tym przypadku że, gdy:
liczbowa wartość cechy jest równa x1, to tę wartość cechy zanotowano u f1 jednostek należących do próby (f1 liczebność 1-szej klasy);
liczbowa wartość cechy jest równa x2, to tę wartość cechy zanotowano u f2 jednostek należących do próby(f2 liczebność 2-tej klasy);
liczbowa wartość cechy jest równa x3, to tę wartość cechy zanotowano u f3 jednostek należących do próby (f3 liczebność 3-tej klasy);
itd.;
oraz
liczbowa wartość cechy jest równa xk, to tę wartość cechy zanotowano u fk jednostek należących do próby (fk liczebność k-tej klasy);
Ogółem
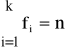
co oznacza, że u każdej jednostki dokonano pomiaru cechy oraz wynik pomiaru zaklasyfikowano do jednej z wyżej wymienionych klas.
Dla takiego przypadku średnia harmoniczna ważona H, liczona jest wg następującego wzoru:
H = 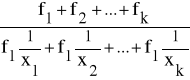
(7)
lub wg wzoru postaci:
H = 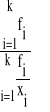
(7.a)
ŚREDNIA KWADRATOWA
Średniej kwadratowej używamy bardzo rzadko. Można obliczać tę średnią w przypadkach, gdy pomiar cechy badanych jednostek zbiorowości statystycznej daje wyniki zarówno dodatnie jak i ujemne.
Średnia kwadratowa prosta.
Zakładamy, że badana cecha prowadzona będzie na próbce składającej się z n jednostek. Zakładamy, że jednostki statystyczne w próbie zostały ponumerowane zmienną i, przy czym zmienna i przebiega zbiór i=1,2, .., n.
Zakładamy, że pomiar cechy u różnych jednostek zbiorowości próbnej dał następujące wyniki:
wartość badanej cechy u pierwszej jednostki statystycznej w próbie jest równa x1;
wartość badanej cechy u drugiej jednostki statystycznej w próbie jest równa x2;
wartość badanej cechy u trzeciej jednostki statystycznej w próbie jest równa x3;
itd., oraz
wartość badanej cechy u n-tej (ostatniej wg numeracji) jednostki statystycznej w próbie jest równa xn;
Jak z powyższego wynika rezultat pomiaru cechy u każdej jednostki statystycznej jest różny.
W tym przypadku średnią kwadratową, oznaczoną symbolem K, obliczamy na podstawie wzoru:
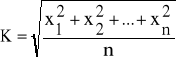
(8)
lub przy użyciu wzoru równoważnego, postaci:
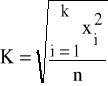
(8.a)
Średnia kwadratowa ważona.
Zakładamy, że badana cecha prowadzona będzie na próbce składającej się z n jednostek. Zakładamy, że jednostki statystyczne w próbie zostały ponumerowane zmienną i, przy czym zmienna i przebiega zbiór i=1,2, .., n.
Zakładamy, że pomiar wyróżnionej cechy u jednostek wchodzących w skład próby jest taki, że wiele jednostek próby ma tę samą liczbową wartość wyróżnionej cechy. Oznacza to, że różnych liczbowo wartości mierzonej cechy jest w tym przypadku mniej niż wynosi liczebność próby.
Założymy, że tych wartości cechy dla danej próby jest k sztuk, (k<n).
Przyjmujemy w tym przypadku że, gdy:
liczbowa wartość cechy jest równa x1, to tę wartość cechy zanotowano u f1 jednostek należących do próby (f1 liczebność 1-szej klasy);
liczbowa wartość cechy jest równa x2, to tę wartość cechy zanotowano u f2 jednostek należących do próby(f2 liczebność 2-tej klasy);
liczbowa wartość cechy jest równa x3, to tę wartość cechy zanotowano u f3 jednostek należących do próby (f3 liczebność 3-tej klasy);
itd.;
oraz
liczbowa wartość cechy jest równa xk, to tę wartość cechy zanotowano u fk jednostek należących do próby (fk liczebność k-tej klasy);
Ogółem
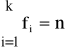
co oznacza, że u każdej jednostki dokonano pomiaru cechy oraz wynik pomiaru zaklasyfikowano do jednej z wyżej wymienionych klas.
Dla takiego przypadku średnia kwadratowa ważona K, wyznaczana będzie na podstawie wzoru:
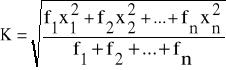
(9)
lub przy użyciu wzoru równoważnego, postaci:
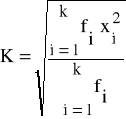
(9.a)
OGÓLNE UWAGI O ŚREDNICH
Średnia arytmetyczna, geometryczna, harmoniczna i kwadratowa należą do tzw. średnich klasycznych. Służą one do globalnej charakterystyki wartości badanej cechy jednostek zbiorowości statystycznej. Rolę swoją wypełniają wtedy, gdy badana zbiorowość statystyczna jest jednorodna.
Wspólną cechą poznanych średnich jest to, że ich wielkość zależy od wartości wszystkich jednostek badanej zbiorowości.
Średnie należy traktować jako narzędzie analizy, zwłaszcza przy porównaniu dwu lub kilku zbiorowości. Sens statystyki polega przede wszystkim na możności czynienia porównań. Obliczanie i porównywanie różnych średnich ma charakter formalny bez wnikania w istotę zbiorowości oraz bez wnikania w istotę cechy badanej.
Wszystkie średnie sprowadzają się do średniej arytmetycznej za pomocą pewnych przekształceń. Każda z nich jednak ma swoisty logiczny sens i musi być logicznie interpretowana.
Wiadomo, że średnie spełniają warunek
H < G < M < K
oraz wiadomo, że wybór średniej zależy przede wszystkim od charakteru zjawiska, które chcemy poznać.
PRZECIĘTNE POZYCYJNE
W odróżnieniu od średnich, przeciętne pozycyjne wyznaczamy na podstawie danych otrzymanych z pomiarów wartości wyróżnionej cechy, które zostały uporządkowane rosnąco lub malejąco.
Mediana (wartość środkowa)
Mediana jest to wartość cechy jednostki statystycznej położonej w badanej zbiorowości statystycznej w ten sposób, że liczba jednostek mających wartość nie mniejszą jest równa liczbie jednostek mających wartość nie większą niż mediana.
W przypadku, gdy liczba jednostek w zbiorowości jest nieparzysta medianą jest wartość jednostki środkowej niezależnie od tego czy wartości uporządkowane są rosnąco, czy malejąco.
Oznaczymy przez x1 najmniejszą wartość cechy w badanej zbiorowości. Przez x2 oznaczymy kolejną najmniejszą wartość cechy w zbiorowości przy założeniu, że poprzednią najmniejszą wartość ze zbiorowości wyłączyliśmy. Powtarzając wielokrotnie powyższą procedurę wykluczania ze zbiorowości najmniejszej wartości oraz poszukiwania wśród pozostałych wartości najmniejszej wartości badanej zbiorowości zostaną uporządkowane rosnąco w poniżej przedstawiony sposób:
x1, x2, x3, ..., xn
I. Przyjmujemy, że liczba wszystkich jednostek w zbiorowości jest równa n i przyjmujemy, że n jest to liczba nieparzysta. W takim przypadku mediana, którą oznaczymy przez Me, daje się wyrazić w postaci następującego wzoru:
Me = 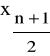
(11)
II. W przypadku, gdy liczba jednostek w zbiorowości jest parzysta, tzn. w przypadku, gdy n jest liczbą parzystą, mediana wyraża się wzorem:
Me = 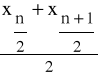
(12)
III. Dla przypadku, gdy dane statystyczne uporządkowane są w szereg klasowy rozdzielczy, tzn. dla przypadku, gdy dane statystyczne rozlokowane są w klasach szeregu rozdzielczego co powoduje, że liczebności fs każdej klasy szeregu rozdzielczego jest znana oraz znana jest liczba klas szeregu klasowego rozdzielczego a także szerokość klasy
- mediana, wyraża się wzorem:
Me = l0 + 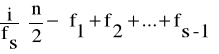
(13)
gdzie:
l0 - dolna granica przedziału, w którym znajduje się mediana,
i - wielkość przedziału klasowego,
fS - liczebność tego przedziału, w którym znajduje się mediana,
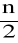
- połowa ogólnej liczebności danych,f1 + f2 +...+fs-1 - suma liczebności klas poprzedzających przedział, w którym znajduje się mediana (liczebność kumulacyjna).
Wartości ćwiartkowe (kwartyle)
Wartości ćwiartkowe są również przeciętnymi pozycyjnymi.
Wartość ćwiartkowa pierwsza (dolna), oznaczona symbolem Q1 jest to wartość jednostki, która dzieli zbiorowość statystyczną w ten sposób, że Ľ jednostek ma od niej wartości nie większe, a ľ nie mniejsze.
Wartość ćwiartkową pierwszą wyznaczamy według wzoru:
Q1= l0 + 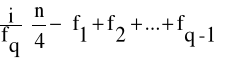
(14)
l0 - dolna granica przedziału, w którym znajduje się wartość ćwiartkowa pierwsza,
i - wielkość przedziału klasowego,
fq - liczebność tego przedziału, w którym znajduje się wartość ćwiartkowa pierwsza,
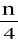
- czwarta część ogólnej liczebności danych,f1 + f2 +...+fq-1 - suma liczebności klas poprzedzających przedział, w którym znajduje się wartość ćwiartkowa pierwsza (liczebność kumulacyjna).
Wartość ćwiartkowa trzecia (górna), oznaczona symbolem Q3 jest to wartość jednostki, która dzieli zbiorowość statystyczną w ten sposób, że ľ jednostek ma od niej wartości nie większe, a Ľ nie mniejsze.
Wartość ćwiartkową trzecią wyznaczamy według wzoru:
Q3= l0 + 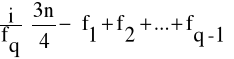
(15)
l0 - dolna granica przedziału, w którym znajduje się wartość ćwiartkowa trzecia,
i - wielkość przedziału klasowego,
fq - liczebność tego przedziału, w którym znajduje się wartość ćwiartkowa trzecia,
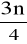
-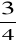
ogólnej część liczebności danych,f1 + f2 +...+fq-1 - suma liczebności klas poprzedzających przedział, w którym znajduje się wartość ćwiartkowa trzecia (liczebność kumulacyjna).
WARIANCJA (ŚREDNIOKWADRATOWE ODCHYLENIE)
I. Zakładamy, że dokonujemy pomiaru ustalonej cechy u każdej jednostki wchodzącej w skład próby, której liczebność jest ustalona (określona) i wynosi n. Zakładamy, że jednostki próby zostały ponumerowane indeksem i przy czym z faktu ustalonej liczebności próby wynika, że indeks i zmienia się od 1, 2, ...., n.
Wyniki pomiarów ustalonej cechy u jednostek próby są następujące:
x1, x2, ..., xn
Widzimy więc, że wartość tej samej cechy mierzona u poszczególnych jednostek, jest różna (wśród liczb x1, x2, ..., xn nie ma liczb jednakowych).
Wariancją wartości pomiarów ustalonej cechy jednostek zbiorowości statystycznej nazywamy średnią arytmetyczną kwadratów odchyleń poszczególnych jednostek zbiorowości statystycznej od ich średniej arytmetycznej.
Wariancja wyraża się wzorem:
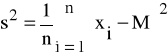
(16)
dla przypadku, gdy liczebność zbiorowości spełnia warunek n>30, tj. zbiorowość statystyczna jest duża.
Dla przypadku, gdy liczebność zbiorowości spełnia warunek n<30, tj. zbiorowość statystyczna jest mała, wariancja wyraża się wzorem:
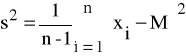
(17)
W obu przypadkach wielkość M jest średnią arytmetyczną obliczoną dla danej zbiorowości statystycznej i dla obu wyżej przedstawionych przypadków wyraża się wzorem:
M = ![]()
II. Zakładamy, że dokonujemy pomiaru ustalonej cechy u każdej jednostki wchodzącej w skład próby, której liczebność jest ustalona (określona) i wynosi n. Zakładamy, że pomiar wyróżnionej cechy u jednostek wchodzących w skład próby jest taki, że wiele jednostek próby ma tę samą liczbową wartość wyróżnionej cechy. Oznacza to, że różnych liczbowo wartości mierzonej cechy jest w tym przypadku mniej niż wynosi liczebność próby.
Założymy, że tych wartości cechy dla danej próby jest k sztuk.
Przyjmujemy w takim przypadku, że gdy:
liczbowa wartość cechy jest równa x1, to tę wartość cechy zanotowano u f1 jednostek należących do próby;
liczbowa wartość cechy jest równa x2, to tę wartość cechy zanotowano u f2 jednostek należących do próby;
liczbowa wartość cechy jest równa x3, to tę wartość cechy zanotowano u f3 jednostek należących do próby;
itd.;
oraz
liczbowa wartość cechy jest równa xk, to tę wartość cechy zanotowano u fk jednostek należących do próby;
Ogółem
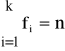
co oznacza, że u każdej jednostki dokonano pomiaru cechy oraz wynik pomiaru zaklasyfikowano do jednej z wyżej wymienionych klas.
Dla powyższego przypadku wariancję wyznaczamy na podstawie poniższego wzoru:
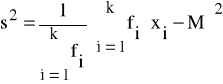
(18)
gdzie wszystkie wielkości występujące we wzorze zostały wcześniej zdefiniowane.
ODCHYLENIE STANDARDOWE
Odchylenie standardowe jest pierwiastkiem kwadratowym z wariancji. Odchylenie standardowe wyznaczane jest na podstawie poniższych wzorów:
s = 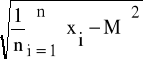
(19)
dla przypadku, gdy liczebność próby jest większa od 30 elementów, oraz wzorem
s = 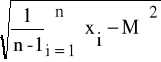
(20)
gdy liczebność próby jest mniejsza niż 30 elementów.
Natomiast, dla przypadku gdy próba przedstawiona jest w postaci szeregu klasowego rozdzielczego, odchylenie standardowe wyznaczane jest na podstawie wzoru:
s =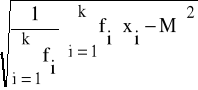
(21)
Odchylenie standardowe ma sens statystyczny wtedy, gdy znamy wartość średniej arytmetycznej, od której było liczone.
Odchylenie standardowe stanowi podstawowe pojęcie w teorii hipotez statystycznych, przy wyznaczaniu współczynnika korelacji.
KORELACJA DWÓCH ZMIENNYCH
Przedmiotem poprzednich rozważań było badanie struktury takiej zbiorowości statystycznej, każda jednostka której posiadała jedną wyróżnioną cechę. Zbiorowość taką charakteryzowaliśmy za pomocą pewnych stałych wielkości, parametrów.
W wielu jednak przypadkach dla poznania całokształtu zagadnienia potrzebna jest analiza zbiorowości z punktu widzenia kilku cech, które pozostają ze sobą w pewnym związku - wzajemnie się warunkują.
Zakładamy więc, że badamy zbiorowość statystyczną, w której każda jednostka posiada dwie wyróżnione cechy, które będą przedmiotem badania.
Podstawowym problemem statystyki w przypadku badania dwóch cech (dwóch zmiennych) jest stwierdzenie, czy między nimi zachodzi jakiś związek, jakaś zależność i czy ten związek jest bardziej czy mniej ścisły.
Pojęcia zależności, jak i pojęcia ścisłości, na pozór jasne intuicyjnie, sprawiają niemało trudności pod względem logicznym.
Badaniem zależności między zmiennymi zajmuje się dział statystyki zwany teorią korelacji i regresji.
Zależność korelacyjna występuje wówczas, gdy określonym wartościom jednej zmiennej przyporządkowane są pewne średnie z kilku wartości drugiej zmiennej. Oznacza to, że w tym przypadku możemy jedynie ustalić, jak zmieni się - średnio biorąc wartość jednej cechy w zależności od zmian wartości drugiej cechy.
Funkcja regresji
Zakładamy, że dokonaliśmy pomiaru wartości wyróżnionych cech X oraz Y u każdej jednostki zbiorowości statystycznej.
Niech zbiorowość statystyczna liczy n jednostek.
Zgodnie z poprzednimi oznaczeniami, niech
x1, x2, x3, ..., xn
są wartościami cechy X, natomiast
y1, y2, y3, ..., yn
są wartościami cechy Y u badanych jednostek zbiorowości statystycznej.
Przyjmujemy, że na osiach układu współrzędnych (x,y) punkty te będą naniesione, patrz rysunek poniżej:
y
x1 x2 x3 xn x
Chodzi więc o dopasowanie linii prostej do „smugi” punktów tak, aby suma kwadratów odległości zadanych yi dla i=1, 2, ..., n od yi wyznaczonych przez prostą y= a + bx, dla zadanych xi, była minimalna. Fakt ten matematycznie wyrażamy w postaci następującego zapisu:
F = 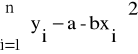
A więc należy tak dobrać współczynniki a oraz b prostej y=a+ bx, aby powyższe wyrażenie osiągało wartość minimalną.
Współczynniki a oraz b wyznaczamy z poniższego układu równań:
n∗a + b ![]()
= ![]()
(22)
a ![]()
+b ![]()
= 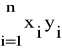
(23)
Otrzymaliśmy układ dwóch równań z dwoma niewiadomymi, dla rozwiązania którego zastosujemy metodę wyznaczników.
Oznaczymy przez W wyznacznik główny postaci:
W =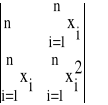
(24)
Natomiast wyznacznik dla wyznaczenia niewiadomej a, oznaczymy przez Wa, i ma on postać:
Wa =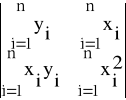
(25)
W takim razie niewiadoma a, wyznaczona może być z równości:
a = ![]()
(26)
przy czym zamiast licznika oraz mianownika wstawia się wartości wyznaczników Wa oraz W.
W analogiczny sposób wyznaczymy niewiadomą b. W tym celu określimy wyznacznik Wb w sposób następujący:
Wb = 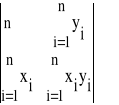
(27)
W takim razie niewiadoma b, wyznaczona może być z równości:
b = ![]()
(28)
Oczywiście wartość wyznacznika W jest równa
W = 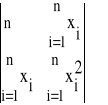
= n ![]()
- ![]()
![]()
(29)
Natomiast wyznacznika Wa jest równa
Wa =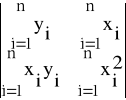
= ![]()
![]()
- ![]()
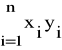
(30)
Oraz wartość wyznacznika Wb jest równa
Wb = 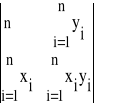
= n 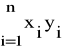
- ![]()
![]()
(31)
co kończy procedurę wyznaczania wartości liczbowych współczynników, niewiadomych a oraz b umożliwiając tym samym zapis prostej y = a +bx spełniającej nałożone na nią wymagania.
Wartość współczynnika b=byx, wziętego z powyższego równania, ma następującą interpretację, a mianowicie wyraża, o ile przeciętnie (średnio) zmieni się (wzrośnie lub zmniejszy się) wartość y (zmienna zależna) jeśli x (zmienna niezależna) wzrośnie o jednostkę. Fakt ten może mieć interesujące zastosowania.
Można także badać zależność wartości cechy X od wartości cechy Y. Przeprowadzając analogiczne rozważania, otrzymujemy, że dla rozpatrywanego przypadku zmienna x staje się zmienną zależną natomiast zmienna y będzie zmienną niezależną.
Poszukujemy w tym przypadku równania regresji postaci:
x = a' + b'y (32)
dla którego niewiadomymi są współczynniki a' oraz b'.
Analogiczny dla rozpatrywanej sytuacji układ równań przybiera postać:
n.a' + b' ![]()
= ![]()
(33)
a'![]()
+ b' ![]()
= 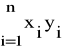
(34)
Dla wyznaczenia niewiadomych a' oraz b' stosujemy powyżej przedstawione podejście.
Oznaczymy przez W wyznacznik główny postaci:
W =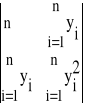
(35)
Natomiast wyznacznik dla wyznaczenia niewiadomej a', oznaczymy przez Wa', i ma on postać:
Wa' =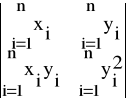
(36)
W takim razie niewiadoma a', wyznaczona może być z równości:
a' = ![]()
(37)
przy czym zamiast licznika oraz mianownika wstawia się wartości wyznaczników Wa' oraz W.
W analogiczny sposób wyznaczymy niewiadomą b'. W tym celu określimy wyznacznik Wb' w sposób następujący:
Wb' = 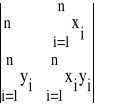
(38)
W takim razie niewiadoma b', wyznaczona może być z równości:
b' = ![]()
(39)
Oczywiście wartość wyznacznika W jest równa
W =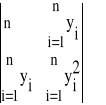
=n ![]()
- ![]()
![]()
(40)
Natomiast wyznacznika Wa' jest równa
Wa' =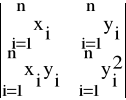
=![]()
![]()
- ![]()
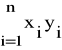
(41)
Oraz wartość wyznacznika Wb' jest równa
Wb' = 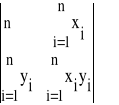
= n 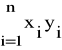
- ![]()
![]()
(42)
co kończy procedurę wyznaczania wartości liczbowych współczynników, niewiadomych a' oraz b' umożliwiając tym samym zapis prostej x = a' +b'y spełniającej nałożone na nią wymagania.
Wartość współczynnika b'=b'xy, wziętego z powyższego równania, ma następującą interpretację, a mianowicie wyraża, o ile przeciętnie (średnio) zmieni się (wzrośnie lub zmniejszy się) wartość x (zmienna zależna) jeśli y (zmienna niezależna) wzrośnie o jednostkę. Fakt ten może mieć także interesujące zastosowania.
Współczynnik korelacji liniowej
Współczynnik korelacji liniowej służy do mierzenia stopnia ścisłości związku korelacyjnego między cechą X oraz cechą Y.
Niech zbiorowość statystyczna liczy n jednostek. Zgodnie z poprzednimi oznaczeniami, niech
x1, x2, x3, ..., xn
są wartościami cechy X, natomiast
y1, y2, y3, ..., yn
są wartościami cechy Y u badanych jednostek zbiorowości statystycznej.
Oznaczymy przez r współczynnik korelacji liniowej i wyznaczać będziemy z poniżej przedstawionej zależności:
r = 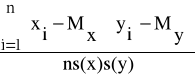
(43)
gdzie:
Mx - wartość średnia cechy X;
My - wartość średnia cechy Y;
n - liczebność badanej zbiorowości;
s(x) - standardowe odchylenie cechy X;
s(y) - standardowe odchylenie cechy Y;
Współczynnik korelacji liniowej jest to stosunek sumy iloczynów odchyleń poszczególnych wartości zmiennej X oraz Y od ich średnich arytmetycznych do iloczynu odchyleń standardowych obydwu zmiennych i ogólnej liczebności zbiorowości statystycznej.
Współczynnik korelacji przyjmuje wartości z przedziału <-1,1>. Orientacyjnie przyjęto, że korelacja między dwiema cechami jest wyraźna, jeśli współczynnik korelacji r≥0,5; średnia - jeśli 0,3<r<0,5 oraz niewyraźna, jeśli r≤0.3.
WYZNACZANIE NIEZBĘDNEJ LICZEBNOŚCI PRÓBY
Zadaniem jest oszacowanie wartości średniej populacji.
Zakładamy, że populacja, dla której mamy oszacować wartość średnią ma rozkład normalny.
Przyjmujemy, że wariancja s2 populacji jest nieznana natomiast znana jest wartość wariancji s^2 obliczona dla małej próby wstępnej o liczebności elementów równej n0.
Wartość średnią populacji chcemy oszacować w taki sposób, że przyjmujemy wielkość współczynnika ufności 1-α (który może mieć interpretację liczby pomyłek w oszacowaniach np. na sto dokonanych oszacowań wartości średniej populacji) oraz przyjmujemy błąd szacunku który nie powinien przekroczyć z góry zadanej wartości. Maksymalny błąd szacunku jest równy połowie długości przedziału ufności wyznaczonego dla zadanej, wstępnej liczebności próby.
Dokonując szacunku wartości średniej populacji możemy szacunek ten otrzymać z błędem mniejszym niż maksymalny.
Niezbędną do tego celu liczebność próbki spełniającej nałożone na nią wymagania ustala się na podstawie wzoru:
n = 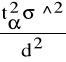
gdzie:
σ^2 - wariancja wyznaczona dla małej, wstępnej próby o liczebności n0;
tα - wartość odczytana z tablic rozkładu t-Studenta dla przyjętego współczynnika ufności 1-α oraz dla tzw. n0-1 stopni swobody w taki sposób , że P(-tα < t < tα) = 1-α.
Wariancję σ^2 dla małej, wstępnej liczebności próby obliczamy wg wzoru
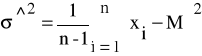
gdy liczebność próbki wstępnej nie przekracza 30 elementów, natomiast wg wzoru
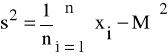
gdy liczebność próbki przekracza liczbę 30 elementów.
Dla obliczenia wartości średniej potrzebna jest znajomość wartości średniej, którą wyznaczamy wg wzoru
M = ![]()
Wartość wielkości tα wyznaczamy z tablic rozkładu t-Studenta. Aby tę wielkość odczytać z tablic należy ustalić w jakim wierszu oraz w jakiej kolumnie wielkość nas interesująca się znajduje.
Numer wiersza ustala się w wyniku odjęcia jedynki od liczebności próbki wejściowej, tzn. gdy liczebność próbki początkowej była równa n0=5 elementów, to interesująca nas wielkość tα będzie znajdować się w czwartym wierszu tablicy rozkładu t-Studenta.
Numer kolumny ustala się na podstawie wartości współczynnika ufności 1-α. Jeśli wartość współczynnika ufności 1-α jest równa 0,9 to przyjmujemy, że 1-α = 0,9 a stąd α=0,1 tzn. interesujący nas współczynnik tα znajdował się będzie w kolumnie, w której α=0,1.
Obliczenie wielkości d poprzedzone będzie wyznaczeniem przedziału ufności. Lewy koniec przedziału ufności A, obliczamy wg wzoru
A = M - tα ![]()
Natomiast prawy koniec B, obliczamy wg wzoru
B = M + tα ![]()
Wielkość d wyznaczamy wg wzoru
d = ![]()
Podstawiając do wzoru na liczebność optymalnej próbki „ułamek” wielkości d wyznaczamy liczebność próbki spełniającą założone wymagania.
1
34
Zbiorowość próbna
Zbiorowość generalna
Linia regresji
y = a + bx
yn
y2
y1
Wyszukiwarka