SPRAWOZDANIE
HURTOWNIE DANYCH
ZADANIE 6
NARUSZENIA GRANICY PAŃSTWOWEJ
WYKONALI:
KAROLINA DROŻDŻEWSKA
MARCIN DĄBROWSKI
Problem: naruszenie granicy państwowej
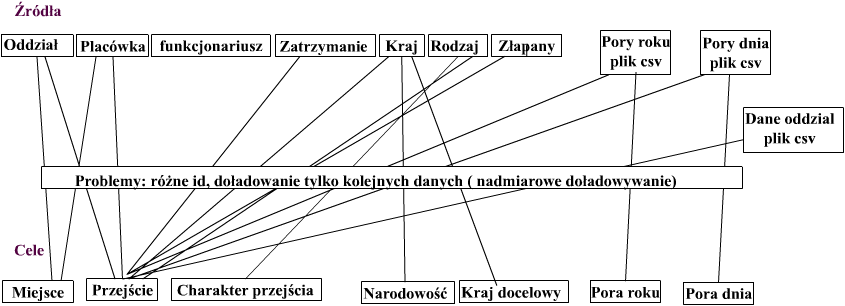
Hurtownia danych, którą stworzyliśmy pozwala na szukanie i analizę trendów w próbach nielegalnego przekroczenia granicy przez obywateli innych państw. Hurtownia ta pozwala ustalić gdzie najczęściej dochodzi do przekroczenia granicy, jaką narodowość mają uchodźcy, jaki jest ich kraj docelowy, czy przekroczenie odbywa się indywidualnie czy grupowo oraz w jakich porach dnia i roku ono następuje. Dzięki hurtowni w prosty i szybki sposób możemy uzyskać interesujące nas zestawienia i na ich podstawie wzmocnić odpowiednie miejsca w określonym czasie.
BAZA DANYCH
MODEL KONCEPTUALNY:
MODEL FIZYCZNY:
MODEL HURTOWNI DANYCH
PROCES ETL
Ładowanie wymiarów
W celu uniknięcia problemu dublowania danych ( inne klucze ), w każdym wymiarze tworzymy klucz surrogate ( czyli klucz tworzony w hurtowni danych ) oraz klucz bussiness, który pobieramy z bazy danych.
Zakładamy również, iż oddział, który nie korzysta z bazy danych, do pliku wpisuje dane słownikowe ( czyli tylko takie dane, które znajdują się w encjach słownikowych, z wyjątkiem danych, które nie są w bazie jako słownikowe )
Charak_map
Tabela RODZAJ w bazie danych jest tabela słownikową. Dane jakie zawiera opisują charakter przejścia granicznego: indywidualny bądź grupowy. Wymiar Charakter przejścia jest zatem ładowany właśnie z tej tabeli. Jedynym problemem jaki nam się pojawia jest fakt, aby dane się nie dublowały po kolejnym doładowaniu wymiaru. W tym celu wykorzystujemy KEY_LOOKUP, który służy do nadmiarowego doładowywania.
KRAJDOC_MAP
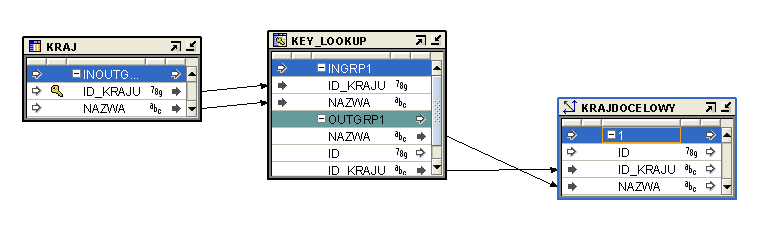
Tabela KRAJ w bazie danych jest tabela słownikową. Znajdują się w niej wymienione kraje. Wymiar KRAJDOCELOWY jest zatem ładowany właśnie z tej tabeli i wskazuje nam kraje, do których obcokrajowcy chcieli nielegalnie przejść. Jedynym problemem jaki nam się pojawia jest fakt, aby dane się nie dublowały po kolejnym doładowaniu wymiaru. W tym celu wykorzystujemy KEY_LOOKUP, który służy do nadmiarowego doładowywania.
NARODOW_MAP
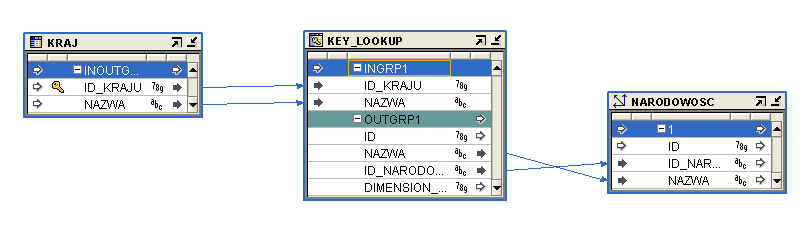
Tabela KRAJ w bazie danych jest tabela słownikową. Znajdują się w niej wymienione kraje. Wymiar NARODOWOŚĆ jest zatem ładowany właśnie z tej tabeli i wskazuje nam kraje, z których pochodzą obcokrajowcy próbujący nielegalnie przejść granice. Jedynym problemem jaki nam się pojawia jest fakt, aby dane się nie dublowały po kolejnym doładowaniu wymiaru. W tym celu wykorzystujemy KEY_LOOKUP, który służy do nadmiarowego doładowywania.
ODDZIAŁ_MAP
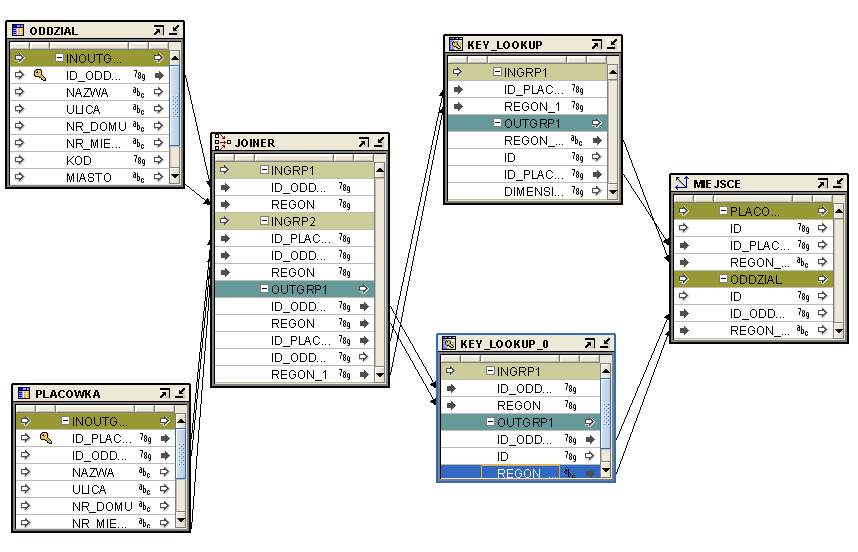
Tabela ODDZIAŁ przechowuje dane o oddziałach, zaś tabela PLACÓWKA dane o placówkach. Każdy oddział może mieć wiele placówek. Do załadowania wymiaru MIEJSCE ( wymiar ma dwa poziomy: ODDZIAL i PLACÓWKA ) potrzebujemy złączyć obie tabele. Efekt taki uzyskamy dzięki JOINER'OWI, który łączy tabele ( tutaj połączenie wygląda tak: ODDZIAŁ.ID_ODDZIAŁU=PLACÓWKA.ID_ODDZIAŁU ). Oczywiście wykorzystujemy również KEY_LOOKUP, aby nie dublować danych
PORADNIA_MAP
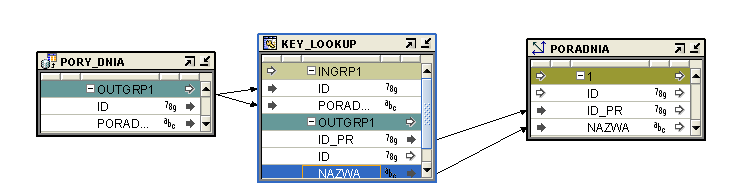
PORY_DNIA to external table - czyli tabela stworzona, aby załadować wymiar z pliku csv. Jest to tabela pomocnicza, która pobiera z pliku PORY_DNIA dane. Plik ten zawiera z góry zdefiniowane pory dnia: przedpołudnie, popołudnie, wieczór oraz noc. Wykorzystujemy KEY_LOOKUP, aby nie dublować danych.
PORAROKU_MAP
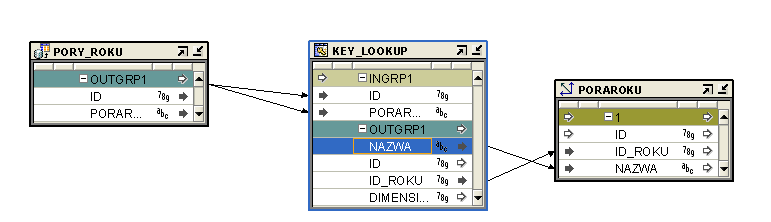
PORY_ROKU to external table - czyli tabela stworzona, aby załadować wymiar z pliku csv. Jest to tabela pomocnicza, która pobiera z pliku PORY_ROKU dane. Plik ten zawiera z góry zdefiniowane pory roku. Wykorzystujemy KEY_LOOKUP, aby nie dublować danych.
ODDZIAŁ_PLIK_MAP
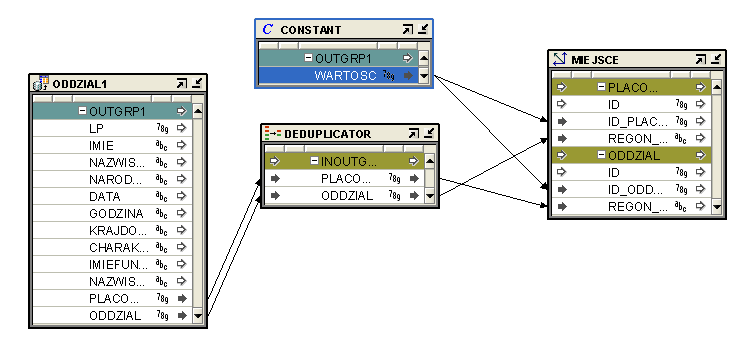
ODDZIAL_1 to external table - czyli tabela stworzona, aby załadować wymiar z pliku csv. Jest to tabela pomocnicza, która pobiera z pliku ODDZIAL dane. Plik ten zawiera dane, które przesyła placówka nie korzystająca z bazy danych. Ładujemy tutaj REGON oddzialu i placówki oraz ich ID. Ponieważ REGON będzie się powtarzał w każdym rekordzie wykorzystujemy de duplikator, aby dodać dany REGON tylko raz. W związku z tym, że w pliku nie dostajemy ID placówki, dodajemy stałą. Z góry wiemy, że jest to 1 oraz 1, gdyż w bazie danych jest to wartość niedostępna ( zarezerwowana właśnie dla tej placówki ).
Ładowanie kostki
Do załadowania kostki potrzebujemy danych z wszystkich tabel. Wszystkie tabele łączymy za pomocą JOINERA łącząc je za pomocą odpowiednich kluczy. W związku z dużą liczbą tabel, które chcemy połączyć warunek JOINERA będzie dosyć rozbudowany:
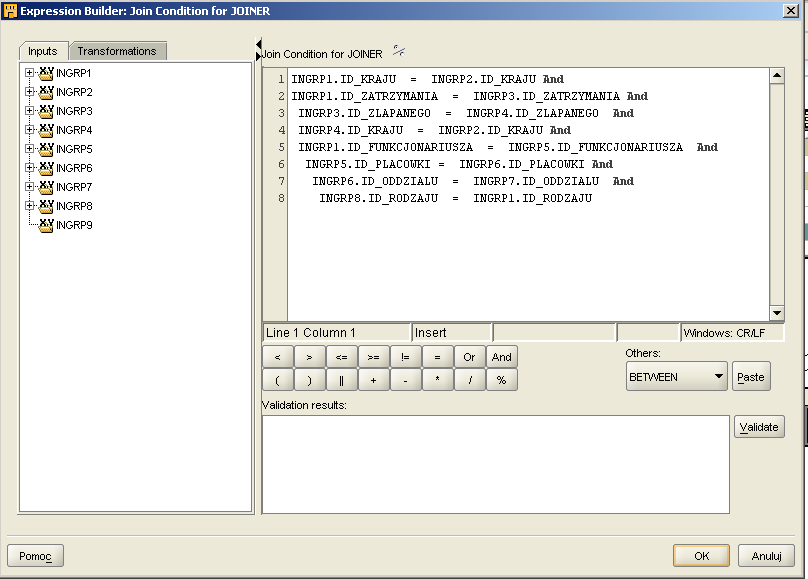
W naszej hurtowni grupowanie odbywa się nie według daty tylko według pory roku i pory dnia. W bazie danych zatrzymanie zapisujemy za pomocą daty i godziny. Aby uzyskać wartości potrzebne do zapisu stworzyliśmy 2 funkcje:
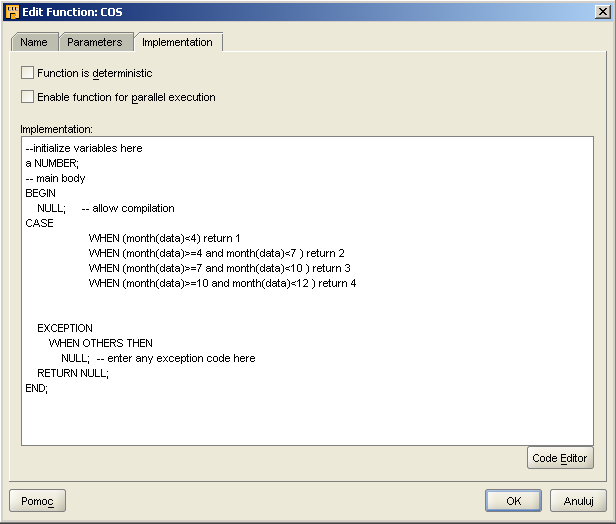
cos
Funkcja ta pobiera pole DATAZ, wybiera z niej miesiąc i w zależności od niego zwraca różne wartości:
Gdy miesiąc ma wartość od 1 do 3 (czyli styczeń, luty, marzec) funkcja zwraca wartość 1
Gdy miesiąc ma wartość od 4 do 6 (czyli kwiecień, maj, czerwiec) funkcja zwraca wartość 2
Gdy miesiąc ma wartość od 7 do 9 (czyli lipiec, sierpień, wrzesień) funkcja zwraca wartość 3
Gdy miesiąc ma wartość od 10 do 12 (czyli październik, listopad, grudzień ) funkcja zwraca wartość 4
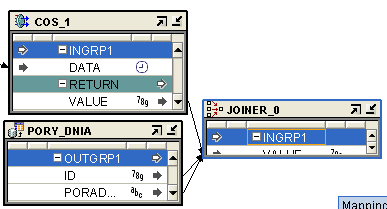
Następnie łączymy wynik funkcji i external table za pomocą JOINERA po odpowiednim ID ( wartośc zwrócona z funkcji = ID danych z pliku ) i otrzymujemy potrzebną nam wartość:
cos2
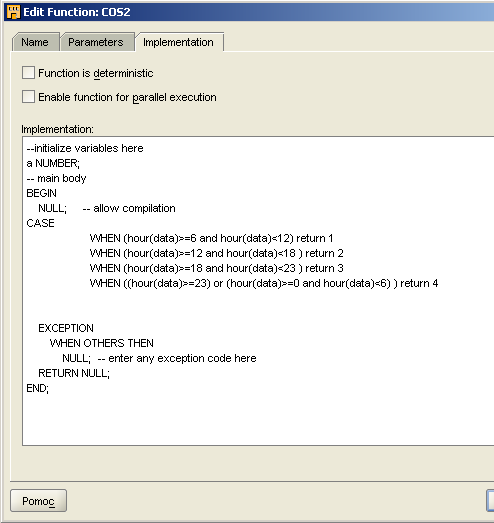
Funkcja ta zwraca w zależności od godziny odpowiedni numerek:
miedzy godziną 6-12 zwraca 1
miedzy godziną 12-18 zwraca 2
miedzy godziną 18-23 zwraca 3
miedzy godziną 23-24 i godzina 0-6 zwraca 4
Następnie łączymy wynik funkcji i external table za pomocą JOINERA po odpowiednim ID ( wartośc zwrócona z funkcji = ID danych z pliku ) i otrzymujemy potrzebną nam wartość:
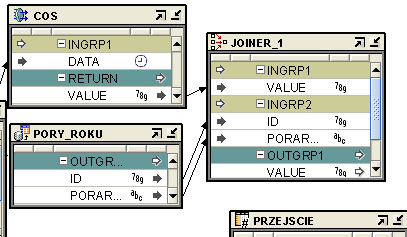
Następnie wszystko grupujemy za pomocą AGGREGATORA i ładujemy.
Ładowanie kostki z pliku
Wyszukiwarka