Ekonometria to:
to nauka o mierzeniu zjawisk ekonomicznych (dosłownie)
nauka o mierzeniu związków występujących między procesami ekonomicznymi a innymi zjawiskami np. społecznymi, przyrodniczymi, technicznymi, demograficznymi itp.(dokładnie)
określenie wszelkich zastosowań metod statystycznych i matematycznych do rozwiązywania zagadnień ekonomicznych (szeroko)
(wg O. Lange) - nauka zajmująca się ustalaniem za pomocą metod statystycznych konkretnych, ilościowych prawidłowości zachodzących w życiu gospodarczym (klasycznie)
Ekonometria menedżerska
Ekonomia menedżerska - formułuje podstawy decyzji podejmowanych w przedsiębiorstwie.
Ekonometria menedżerska - nauka o mierzeniu związków występujących między zjawiskami ekonomicznymi a innymi zjawiskami w procesie podejmowania decyzji w przedsiębiorstwie.
Rozszerzenie definicji O. Langego - Ekonomia menedżerska - nauka zajmująca się ustalaniem za pomocą metod statystycznych i matematycznych, konkretnych ilościowych prawidłowości zachodzących w życiu gospodarczym, w celu określenia warunków i czynników wyznaczających optymalne decyzje.
Model ekonometryczny
(wg Z. Czerwińskiego) - może być rozumiany ogólnie, intuicyjnie jako obraz, odbicie, odwzorowanie określonego obiektu w określonym języku.
Model ekonometryczny - również będzie układem równań odwzorowującym wyróżnione zależności między zjawiskami ekonomiczno - społecznymi.
Część związków można mierzyć a niektóre nie.
Związki mierzalne nazywane są korelacyjnymi.
Y = f (x1, x2 ......xkς)
y - zjawisko badane
x1,x2-zjawiska, czynniki
ς- składnik losowy (psi,) - jest to łączny efekt oddziaływania na zmienną y, oddziałuje na te i inne czynniki, które nie zostały uwzględnione bezpośrednio w zbiorze x.
Jest to zmienna losowa o określonym rozkładzie.
E(ς) = 0; D2(ς) = δ2 = const. (δ2 - wariancja)
Wg S. Bartosiewicza- model ekonometryczny to ustalona stochastyczna zależność wyróżnionego lub wyróżnionych zjawisk ekonomicznych od zjawisk czynników. Formułuje układ funkcji (lub funkcja) na ogół wielu zmiennych aproksymujących z pewną dokładnością opisywany fragment rzeczywistości ekonomicznej.
Składniki modelu:
Zmienne,
Parametry,
Składnik losowy.
Zmienne w modelu dzielimy na:
Endogeniczne - objaśniane przez poszczególne równania modelu {y};
Objaśniające
egzogeniczne - objaśnia kształtowanie się zmiennych endogenicznych, same przez model objaśniane nie są {xi}. Wśród nich może być zmienna czasowa „t”.
zmienne opóźnione lub z wyprzedzeniem czasowym np.(xit-1, xit-2, .......xit-s, yt-1).
Parametry związane są z konkretną postacią analityczną modelu
Model liniowy
yt=α1x1t + α2x2t +...............+ α0ςt
αi = ( i=1,2.... k) - parametry strukturalne, od nich zależy wartość funkcji opisującej kształtowanie się zmiennej endogenicznej.
ai - oszacowanie parametrów αi (zmienna losowa).
Parametry struktury stochastycznej modelu - to parametry rozkładu składnika losowego ςt np. E(ςt), D2(ςt), ρ(ςt, ςt-s) - (współczynnik korelacji modelu)
Klasyfikacja modeli ekonometrycznych.
Wg modelów poznawczych.
Przyczynowo - skutkowe (przyczynowo - opisowe).
Zmienna endogeniczna x jest obiektywną przyczyną kształtowania się zmiennej y. Model taki ma największe walory poznawcze.
Symptomatyczne -wyglądają jak te wyżej. Zmienne x są zmiennymi silnie skorelowanymi ze zmienną endogeniczną. Przykładem może być zależność między dochodem narodowym a liczbą ludności w wieku produkcyjnym.
Tendencji rozwojowych - modele, w których mamy jedną zmienną (zmienna czasowa t) i ten model opisuje mechanizm rozwoju zjawisk w czasie. Budowane są głównie w celach produktywnych budowy prognoz).
Autoregresyjne - zmienna y jest opisywana przez funkcje samych siebie z okresów poprzednich za jego pomocą można przedstawiać inwestycje.
Modele od 1 do 4 zakładają, że struktura ekonomiczna, którą opisują jest stała.
Adaptacyjne - budowane są w ten sposób, że w miarę powstawania nowych informacji ten model budowany jest na nowo.
Modele są wykorzystywane w celach poznawczych do prognoz i podejmowania decyzji.
Etapy budowania modelu
Sprecyzowanie przedmiotu badania - wybór zjawiska badanego.
Specyfika równań modelu
Zmienne (analiza merytoryczna)
Postać analityczna (analiza merytoryczna i formalna).
3. Zbieranie danych statystycznych.
Analiza własności wybranych zmiennych (analiza formalna) m.in.
Zmienność wartości;
Symetria rozkładu;
Stopień skorelowania z innymi zmiennymi.
Estymacja parametrów strukturalnych modelu;
Weryfikacja modelu, ocena dokładności opisu badanego zjawiska.
Wykorzystanie modelu np. do wnioskowania w przyszłość lub symulacji zachowania badanego zjawiska w określonych warunkach.
Metoda nośników informacji (Z. Helwiga).
y - zmienna objaśniana
xj - potencjalna zmienna objaśniająca j = 1,2 .... k
Dana jest macierz obserwacji na wszystkich zmiennych , n - liczba obserwacji
Na podstawie tych obserwacji obliczamy elementy wektora Ro , który zawiera współczynnik korelacji pomiędzy zmienną y a poszczególnymi zmiennymi.
R0 = ![]()
= [rj] j=1,2,,,,,k
rj - współczynnik korelacji liniowej zmiennych y, xj
R - macierz zawierająca współczynnik korelacji pomiędzy parametrami x i potencjalną zmienną objaśniającą j.
R = 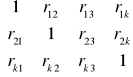
= j =1,2, ,k; i = 1,2,, k = [rij]
rij= współczynnik korelacji liniowej zmiennych xi yj
Liczba kombinacji zmiennych objaśniających
L=2k-1
np. k =3 → L= 23-1 = 7
Kombinacje:
1) x1 2) x2 3) x3
4) x1; x2 5) x1; x3 6) x2; x3
7) x1; x2; x3
xj - nośnik informacji
j-ta - kandydatka na zmienną objaśniającą.
Pojemność indywidualna j-tego nośnika informacji w l-tej kombinacji
hlj=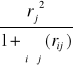
hlj = 1, 2, ..... k
l = 1, 2, ... (2k - 1)
hlj Є [0,1]
Interesuje nas czy jest to korelacja dodatnia czy ujemna
Najlepszy będzie ten zbiór, który będzie miał największą sumę pojemności indywidualnych.
Pojemność integralna kombinacji nośników
Hi=![]()
Hi Є [0,1]
kl - liczba zmiennych wchodzących w skład badanej informacji.
Kombinacja optymalna
Hl = max Hl
Wykład 28.04.2001r.
Przykład
Biuro podróży działające w pewnym mieście przeprowadziło badania współzależności pomiędzy rocznymi wydatkami na turystykę zagraniczną Yt (w 100 zł na osobę) a przeciętnym dochodem x1t (w 100 zł na osobę w rodzinie), liczbą dzieci w rodzinie x2t i przecietną ceną wycieczki x3t w 100 zł . Na podstawie wyników badania ankietowego obliczono następujące współczynniki korelacji pomiędzy wyróżnionymi zmiennymi:
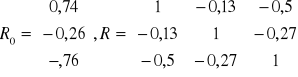
Stosując metodę Hellwiga wybrać optymalną kombinację zmiennych objaśnianych kształtowanie się wydatków na podróże zagraniczne.
K=3
Badane podzbiory zmiennych:
1. {X1t}
2. {X2t}
3. {X3t}
4. {X1t, X2t}
5. {X1t; X3t}
6. {X2t; X3t}
7. {X1t; X2t; X3t}
L=2k-1=8-1=7
Pojemność indywidualna nośnika informacji j w l-tej kombinacji:
Hlj=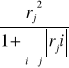
pojemność indywidualna
L = 1,2,.........7, i,j = 1,2,3
Pojemność integralna = suma pojemności indywidualnych
Hl= ![]()
Kombinacja optymalna
Hopt= max1H1
Obliczenia
h11 = r12= (0,74)2 = 0,5476
h22=r22 = (-0,26)2=0,0676
h33=r32=(-0,76)2=0,5776
h41=
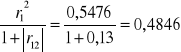
h42=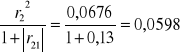
5. h51=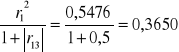
h53= 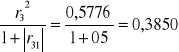
6. h62=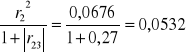
h63=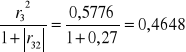
7. h71=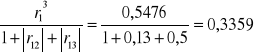
h72=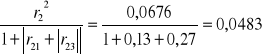
h73=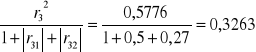
H1=0,5476
H2=0,0676
H3=0,5776
H4=h41+h42=0,4846+0,0598=0,5444
H5=h51+h53=03650+0,3850=0,75
H6=h62+h63=0,0532+0,4548=0,508
H7=h71+h72+h73=0,3359+0,0483+0,3263=0,7105
Hopt=H5
Xopt={X1t, X3t}
Model
Yt=α1x1t+α2x3t+α0+ςt
Lub
Yt=α1x1t+β2x3t+γ+ςt
Dalszy etap budowy modelu:
Funkcja potęgowa wykorzystywana jest przy modelowaniu produkcji, popytu, podaży.
Yt=α0+x1α +α2α+ ..........
Mogą być inne postacie analityczne niż liniowe
Etap estymacji parametru modelu
Estymacja - przypisywanie nieokreślonym dotąd parametrom konkretnych wartości liczbowych. Wykorzystuje się w tym celu informacje o realizacjach zmiennych yt i xt
Metoda najmniejszych kwadratów MNK
MNK polega na znajdowaniu takich wartości ocen parametrów strukturalnych modelu, by suma kwadratów odchyleń zaobserwowanych (empirycznych) wartości i zmiennej y, od jej wartości teoretycznych wyznaczonych przez model była najmniejsza w przypadku jednej zmiennej objaśniającej.
MNK polega na znajdowaniu takiej prostej , która jest najlepiej dopasowana, do wszystkich punktów empirycznych, czyli minimalizowana jest sumą kwadratów reszt (ut).
Reszta modelu ut = yt - yt* = yt - a1x1 - a0
yt* - wartość teoretyczna, wartość wyliczona z modelu.
Oznaczenia
Model
yt = ![]()
Model oszacowany
yt=![]()
Reszta modelu
ut = yt - yt* = yt - ![]()
= yt - α1x1t - αx2t - α3x3t - ............- u0
Zapis macierzowy
Model y = xα+ς xkt=1
Model oszacowany y = xa + u
Wektor reszt u = y - xa
Y(nx1) x(nx1) α(nx1) a(nx1) ς(nx1) u(nx1)
α - wektor prawdziwych parametrów modelu.
Warunek MNK
Q=![]()
Czyli
Q= ut u = (y - xa)t- (y - xa) = min
Q= yty-2ytxa + atxtxa = min
![]()
warunek konieczny - minimum
![]()
stąd
xty = xtxa xtx - dodatnie określany
a = (xtx)-1xty
warunek dostateczny minimum
![]()
x)
w punkcie a=(xtx) funkcja a ma ekstremum minimum
Klasyczne założenia MNK
Zmienne objaśniające x są nielosowe i niewspółliniowe k<n;
Istnieje n populacji składników losowych, o nadziejach matematycznych E(ςt)=0 i stałych wariancjach o skończonych wartościach δ2 =D2(ςt) = const, t= 1, 2, 3, ...... n
Realizacje zmiennych tworzą proces czysto losowy tzn., że następuje po sobie realizacja składnika losowego , są nieskorelowane, czyli ρ(ςt; ςts)= 0 dla t ≠ s
składniki losowe są nieskorelowane ze zmiennymi objaśniajacymi.
Jeżeli ww. założenia są spełnione to estymator ma dobre własności tzn.
jest nieobciążony;
zgodny;
najbardziej efektywny;
Nieobciążoność estymatora polega na tym, że średnia wartość jest równa prawdziwemu parametrowi
Nieobciążoność - „a”
E(a) = α
Estymator zgodny to taki, w którym przy n rosnacym prawdopodobieństwo popełnienia błędu szacunku maleje
Najbardziej efektywny to estymator obarczony jest najmniejszym błędem
Ocena rzędu dokładności otrzymanych ocen parametrów.
Błędy średnie szacunku
1. Błąd szacunku i-tego parametru
ai-αi
2. Macierz wariancji i kowariancji estymatorów
D2(a) = δ2(xTx)-1
D(a) =![]()
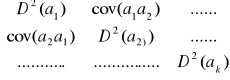
3. Wariancja estymatora i-tego parametru
D2(ai)=δ2-eij
jest miarą dokładności oszacowań
eij - i-ty element diagonalny macierzy (xTx)-1
Błąd średni szacunku i-tego parametru
D(ai) = ![]()
Dla dowolnego parametru
αi ≈ ai ± D(ai)
Nieobciążoną oceną wariancji składnika losowego jest wariancja resztowa
S2=![]()
nt = yt - yt*
* - wariancja kosztowa
S2=![]()
S - odchylenie resztowe, odchylenie standardowe reszt.
S=![]()
Nieobciążona ocena wariancji estymatora parametru αi
d2(ai) = S2Cii
Średni błąd estymatora i-tego parametru
d(ai) = S ![]()
Dla dowolnego parametru αi mamy
αi ≈ ai ± d(ai)
Model oszacowany
Yt=a1x1t + a2x21+..............................+akxkt+ut
Miary zgodności modelu z danymi empirycznymi
odchylenie standardowe reszt - s
s = 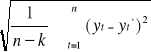
![]()
s - informuje o ile średnio rzecz biorąc zaobserwowana wartości zmiennej endogenicznej
odchylają się od wartości wyznaczonych na podstawie oszacowanego modelu
współczynnik zmienności przypadkowej - w
![]()
w -informuje jaki procent wartości zmiennej objaśnionej modelu, stanowi odchylenie
resztowe
![]()
Dla modelu liniowego oszacowanego, MNK mamy:
współczynnik zbieżności
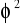
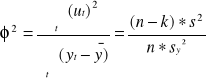
![]()
- wskazuje jaka część całkowitej zmienności zmiennej endogenicznej stanowi
zmienność niewyjaśniona przez model, zmienność przypadkowa
współczynnik determinacji R2
R2=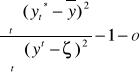
R2 ![]()
(0,1) wskazuje jaką część całkowitej zmienności zmiennej y, stanowi zmienność wyjaśniona przez model, zdeterminowana przez zmienne objaśniające.
Skorygowany współczynnik determinacji
![]()
Eliminacje wpływu ilości zmiennych objaśniających na wartość współczynnika determinacji.
Wykład 29.04.2001r.
Przykład
W 10 kolejnych okresach stwierdzono następujące przeciętne wielkości zatrudnienia X1 (w tys. osób), produkcji wyrobu X2 (w tys. sztuk) oraz całkowitych kosztów produkcji Y (mln. zł.)
t |
Yt |
X1t |
X2t |
X1t2 |
X1t*x2t |
X1t*yt |
X1t*yt |
X2t*yt |
Yt2 |
1 |
350 |
0,7 |
10 |
0,49 |
100 |
7 |
245 |
3500 |
122500 |
2 |
352 |
0,8 |
11 |
0,64 |
121 |
8,8 |
281,6 |
3872 |
123904 |
3 |
357 |
0,9 |
11 |
0,81 |
121 |
9,9 |
321,3 |
3927 |
127449 |
4 |
350 |
0,9 |
10 |
0,81 |
100 |
9 |
315 |
3500 |
122500 |
5 |
364 |
0,9 |
13 |
0,81 |
169 |
11,7 |
327,6 |
4732 |
122496 |
6 |
365 |
1,1 |
12 |
1,21 |
144 |
13,2 |
401,5 |
4380 |
133225 |
7 |
364 |
1,1 |
12 |
1,21 |
144 |
13,2 |
400,4 |
4368 |
132496 |
8 |
371 |
1,2 |
14 |
1,44 |
196 |
16,8 |
445,2 |
5194 |
137641 |
9 |
376 |
1,2 |
14 |
1,44 |
196 |
16,8 |
451,2 |
5264 |
141376 |
10 |
371 |
1,2 |
13 |
1,44 |
169 |
15,6 |
445,2 |
4823 |
137641 |
Σ |
3620 |
10 |
120 |
10,3 |
1460 |
122 |
3634 |
43560 |
1301228 |
Σx1 Σx21
Model
![]()
![]()
gdzie X(10x3) ; Y(10x1) n = 10
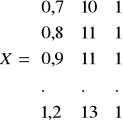
; 
; ![]()
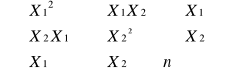
![]()
Wyznacznik macierzy

wg La'Plasa
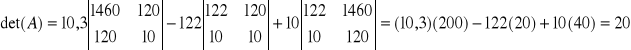
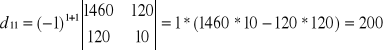
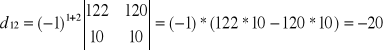
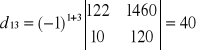
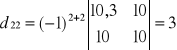
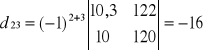
![]()
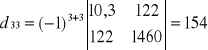
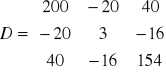
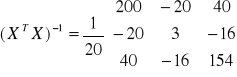
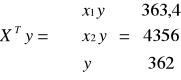
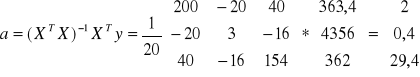
Model oszacowany
![]()
Jeżeli zatrudnienie wzrośnie o 1000 osób to przeciętne koszty całkowite wzrosną o 2 *10 mln zł.,x2 nie ulegnie zmianie
Jeśli wielkość produkcji wzrośnie o 1000 szt. , spowoduje to wzrost kosztów o(0,4*10 mln) 4 mln zł. przy założeniu , że zatrudnienie nie ulegnie zmianie
Sprawdzamy czy model jest dostatecznie dokładny. Przeprowadzamy etap weryfikacji modelu. Od wariancji resztowej odejmujemy miernik określający dokładność danych
![]()
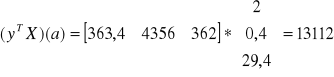
![]()
![]()
Błąd średni szacunku
![]()
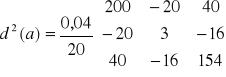
![]()
d(a1)= 0,632
![]()
d(a2)= 0,077
![]()
d(a3)= 0,555
![]()
(0,632) (0,077) (0,555)
Gdybyśmy wielokrotnie liczyli ten parametr to średni błąd wyniósł by ± 0,632
W jakim stopniu model został dopasowany do danych empirycznych:
![]()
- przeciętna wielkość
wartości liczone z modeli różniły by się przeciętnie o ± 0,2 mln zł
Współczynnik zmienności przypadkowej
![]()
Współczynnik zbieżności
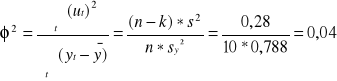
![]()
zmienność przypadkowa nie wyjaśniona przez model stanowi 4% zmienności Y
lub
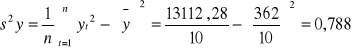
Współczynnik determinacji
![]()
= 96% - model opisuje koszty całkowite w 96 %
![]()
- wskazuje jaką część całkowitej zmienności zmiennej yt stanowi zmienność wyjaśniona przez model, zdeterminowana przez zmienne wyjaśniające (jaka część y została zdeterminowana przez model).
Testowanie hipotez statystycznych
Hipoteza statystyczna - dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcjonalnej lub wartości parametrów)Prawdziwość tego przypuszczenia jest oceniana na podstawie wyników z próby losowej.
Test statystyczny - reguła postępowania, która każdej możliwej próbie przyporządkowuje decyzje przyjęcia lub odrzucenia hipotezy. Jest to reguła rozstrzygająca jakie wyniki z próby pozwolą uznać sprawdzoną hipotezę za słuszną , a jakie za fałszywą.
Zasady budowy testu
Formułowanie hipotezy podlegającej weryfikacji H0 oraz hipotezy alternatywnej H1, będącej zaprzeczeniem hipotezy sprawdzanej , którą przyjmujemy za prawdziwą kiedy odrzucamy H0.
Określenie obszaru przestrzeni próby, takiego, że jeśli wynik z próby znajduje się w tym obszarze , to sprawdzona hipotezę zerową odrzucamy, a jeśli nie to hipotezę przyjmujemy. Obszar ten nazywa się obszarem odrzucenia hipotezy lub kryterium testu.
Definiowanie i obliczanie wartości statystycznych z próby nazywamy sprawdzeniem hipotezy. Wartość ta jest podstawą decyzji o przyjęciu lub odrzuceniu hipotezy.
Ustalenie poziomu istotności α, czyli prawdopodobieństwa popełnienia błędu polegającego na odrzuceniu hipotezy prawdziwej.
Test „F”
H0 : α1 = α2 = ............. αk = 0 (z wyjątkiem wyrazu wolnego)
H1 : przyjmujemy jeden z parametrów αi ≠ 0
Jeżeli Y ma rozkład normalny to sprawdzian hipotezy jest dany wzorem:
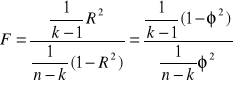
F - ma rozkład Fischera-Snadecora o k-1 i n-k stopniach swobody
Jeżeli dla założonego α
F > Fα to H0 odrzucamy
Badanie istotności parametrów strukturalnych
H0 : αi = 0 hipoteza sprawdzana
H1 : αi ≠ 0 hipoteza alternatywna
Sprawdzianem hipotezy jest zmienna t
![]()
- sprawdzian hipotezy
![]()
ti - ma rozkład Studenta o (n-k) stopniach swobody
tα - wartość zmiennej t dla poziomu istotności α i n-k stopni swobody
Gdy ![]()
![]()
to H0 odrzucamy
Gdy ![]()
to nie ma podstaw do odrzucenia
Estymacja przedziałowa
Estymacja przedziałowa - szacowanie nieznanych wartości parametrów poprzez podanie przedziałów liczbowych, w których zakłada się, że będą zawierać prawdziwe wartości poszukiwanych parametrów z ustalonym z góry prawdopodobieństwem
γ = 1- α
gdzie: γ - to współczynnik ufności
Przedział ufności dla parametru αi
P{ai - tαd(ai) < αi < ai + tαd(ai)}= γ
tα - wartość krytyczna dla zmiennej losowej w rozkładzie t - Studenta dla n - k stopni swobody przy ustalonym poziomie ufności α
Test F
Ho : α1 = α2 = α3 = 0
H1 : przyjmujemy jeden z parametrów αi ≠ 0
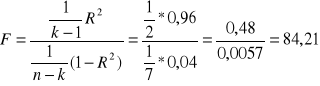
![]()
- poziom istotności
![]()
![]()
odrzucamy
Badamy poszczególne parametry za pomocą t-Studenta
Istotność parametrów strukturalnych modelu
Ho : α1 = 0
H1 : α1 ≠ 0
![]()
dla ![]()
i przy ![]()
; ![]()
![]()
H0 odrzucamy na korzyść H1 3,1646 > 2,365
Ho : α2 = 0
H1 : α2 ≠ 0
![]()
![]()
H0 odrzucamy na korzyść H1
Ho : α3 = 0
H1 : α3 ≠ 0
![]()
![]()
H0 odrzucamy na korzyść H1
Wszystkie parametry są statystycznie istotne.
Właściwości rozkładu reszt modelu
Reszty w dobrym modelu powinny :
być losowe
mieć symetryczny rozkład
nie powinny być między sobą skorelowane (żądamy by nie występowała autokorelacja reszt)
wariancje składowych losowych i reszt powinny być stałe (jednorodne) - stabilność wariancji
normalność
Gdy powyższe warunki są spełnione mówimy, że estymator ma dobre własności.
Do badanie losowości wykorzystuje się test serii.
Test serii
H0 : reszty modelu są losowe
H1 : reszty modelu nie są losowe
Oznaczenia:
A gdy nt > 0
B gdy nt < 0 gdy nt = 0 pomijamy
C - empiryczna liczba serii
n1- liczba reszt dodatnich
nα- liczba reszt ujemnych
Dla poziomu istotności ![]()
i ![]()
odczytujemy z tablic odpowiednio C1 i C2
Jeżeli C1 < C < C2 to H0 nie ma podstaw do odrzucenia
Jeżeli C![]()
C1 lub C ![]()
C2 to H0 odrzucamy
Wykład 13.05.2001r.
Symetria reszt
H0 - reszty są symetryczne
H0 : 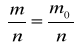
![]()
H0 : ![]()
m - liczba reszt dodatnich
H1 : ![]()
n - liczba obserwacji
gdy n ![]()
30 to „t” ma rozkład studenta o n-1 stopniach swobody
n > 30 rozkład normalny
![]()
- H0 nie odrzucamy
![]()
- H0 odrzucamy
Brak autokorelacji
Autokorelacja składników losowych modelu.
Jedno z klasycznych założeń MNK dotyczyło kowariancji składników losowych odległych od siebie o s- jednostek czasu
![]()
Jeżeli założenie to nie jest spełnione tzn, gdy zachodzi nierówność
![]()
to składniki losowe są skorelowane , występuje autokorelacja składników losowych odległych od siebie o s- jednostek czasu (jeżeli s=1 zachodzi autokorelacja rzędu pierwszego).
Jeśli jest to zależność liniowa to mamy następujący model
![]()
gdzie: p - współczynnik autokorelacji rzędu pierwszego spełniający nierówność
-1 ![]()
![]()
Przyczyny autokorelacji:
Błędy w budowie modelu ekonometrycznego
pominięcie istotnych zmiennych objaśniających
niewłaściwa postać analityczna modelu
wprowadzenie zmiennych o niewłaściwych opóźnieniach
Okres przyjęty za jednostkę jest krótszy od czasów działania czynników przypadkowych tzw. autokorelacja czysta
Test DURBINA WATSONA
H0 : p1 = 0 (p - ro)
H1 : p1 > 0
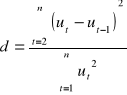
![]()
,
jeżeli: r1 = 0 to d = 2
r1= 1 to d = 0
r1 = -1 to d = 4
Dla ustalonego n, k-1, α i n>15 z tablic odczytujemy d1 i du (interesuje nas liczba zmiennych a nie liczba parametrów).
Gdy:
d > du - H0 przyjmujemy
d < d1 - H0 odrzucamy
d2
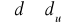
test nie daje odpowiedzir1< 0 , obliczamy d* = 4 - d
Gdy H0 jest prawdziwa to E(d) = 2
Jeżeli d![]()
to prawdopodobnie p1![]()
(czyli autokorelacja nie istnieje)
Test jednorodności wariancji GOLDFELDA QUANDTA
Czynności:
podział próby na dwie równe części
opuszczamy około 4 do 8 środkowych elementów
szacujemy parametry modeli
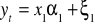
i
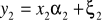
w obu próbachobliczamy wariancje resztowe dla obu modeli, czyli
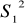
i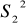
Test:
H0 : ![]()
H1 : ![]()
Jeżeli H0 jest prawdziwa to:
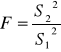
ma rozkład Fischera Snedecora o m1 = (n2 - k) i m2 = (n1 - k) stopniach swobody.
Jeżeli przy poziomie istotności ![]()
F > Fα
to hipotezę o jednorodności wariancji należy odrzucić.
Test moralności rozkładu składnika losowego JARQUE BERA
H0 : składnik losowy ma rozkład normalny
H1 : składnik losowy modelu nie ma rozkładu normalnego
Statystyka testu
![]()
gdzie:
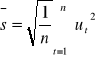
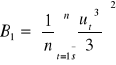
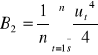
Dowodzi się, że statystyczna JB ma rozkład χ2 (chi) z dwoma stopniami swobody.
Dla α = 0,05 wartość krytyczna testu wynosi 5,991, czyli gdy JB > 5,991to H0 o normalnym rozkładzie należy odrzucić
Test serii (ciąg dalszy przykładu ze str. 12)
t |
yt |
y*t |
ut |
X1t2 |
1 |
35,0 |
34,8 |
0,2 |
A (1) |
2 |
35,2 |
35,4 |
-0,2 |
B (2) |
3 |
35,7 |
35,6 |
0,1 |
A (3) |
4 |
35,0 |
35,2 |
-0,2 |
B (4) |
5 |
36,4 |
36,4 |
0 |
|
|
36,5 |
36,4 |
0,1 |
A (5) |
|
36,4 |
36,4 |
0 |
|
8 |
37,1 |
37,4 |
-0,3 |
B (6) |
9 |
37,6 |
37,4 |
0,2 |
A (7) |
10 |
37,1 |
37 |
0,1 |
A (7) |
Σ |
362 |
362 |
0,0 |
|
H0 : reszty są losowe
H1 : reszty nie są losowe
Empiryczna ilość serii - C = 7
n1 = 5 reszty dodatnie
n2 = 3 reszty ujemne n1 - n2 = 5 - 3 = 2
dla α = 0,5 Cα = 2 taka, że P{C< Cα}=α
C > Cα nie ma podstaw do odrzucenia H0
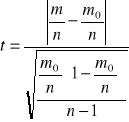
Test serii
H0 :![]()
H1 : ![]()
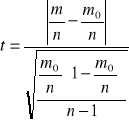
m- reszty dodatnie = 5 , n - ogólna liczba reszt = 8
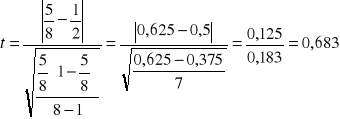
α = 0,05 ; n - 1 = 7 ; tα = 2,365
![]()
< tα - nie ma podstaw do odrzucenia H0
Analiza reszt - test Durbina Watsona
t |
yt |
y*t |
ut |
ut-1 |
ut - ut-2 |
(ut - ut-2)2 |
ut2 |
|
35,0 |
34,8 |
0,2 |
- |
- |
- |
0,04 |
|
35,2 |
35,4 |
-0,2 |
0,2 |
-0,4 |
0,16 |
0,04 |
3 |
35,7 |
35,6 |
0,1 |
-0,2 |
0,3 |
0,09 |
0,01 |
4 |
35,0 |
35,2 |
-0,2 |
0,1 |
-0,3 |
0,09 |
0,04 |
5 |
36,4 |
36,4 |
0 |
-0,2 |
0,2 |
0,04 |
0 |
6 |
36,5 |
36,4 |
0,1 |
0 |
0,1 |
0,01 |
0,01 |
7 |
36,4 |
36,4 |
0 |
0,1 |
-0,1 |
0,01 |
0 |
8 |
37,1 |
37,4 |
-0,3 |
0 |
-0,3 |
0,09 |
0,09 |
9 |
37,6 |
37,4 |
0,2 |
-0,3 |
0,5 |
0,25 |
0,04 |
10 |
37,1 |
37 |
0,1 |
0,2 |
-0,1 |
0,01 |
0,01 |
|
362 |
362 |
0,0 |
|
|
0,75 |
0,28 |
H0 : p1 = 0 reszty przepisujemy z poprzedniej kolumny (odległe od siebie o 1)
H1 : p1 > 0
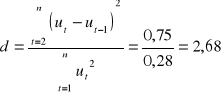
d* = 4 - d = 4 - 2,68 = 1,32
dla n =10 , k -1 = 2, α= 0,05 dl = 0,697 , du = 1,641 0,697 < d* < 1641
Test nie daje jednoznacznej odpowiedzi.
Własności składników losowych
Sferyczność składników losowych
Jeżeli klasyczne założenia MNK w stosunku do składników losowych są spełnione, czyli gdy:
nie występuje autokorelacja,
wariancje są stałe, jednorodne,
to macierz wariancji i kowariancji składowych losowych dana jest wzorem:
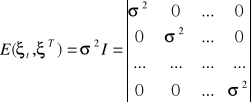
wtedy składniki losowe są sferyczne
Niesferyczność składników losowych
Pierwsza forma niesferyczności to autokorelacja.
Druga forma niesferyczności to niejednorodność wariancji.
W warunkach niesferyczności nie można stosować MNK ponieważ estymatory obciążone są dużymi błędami.
Metoda Cochrane'a Orcutt'a
Transformacja zmiennych.
yt* = yt -ρyt-1
(ρ z próby w przykładzie = - 0,48)
xit* = xit - ρxit-1 i = 1, 2, ..... k
gdy xut = 1 to xut* = 1 - ρ (w praktyce ρ = r)
Powrót do modelu pierwotnego
ai* = ai
a0* = a0(1 - r )
![]()
gdy ![]()
, stosujemy metodę różniczki zupełnej
![]()
- wzór na wyraz wolny
Analiza szeregów czasowych - budowa modeli tendencji rozwojowych
Modele tendencji rozwojowych budowane są na podstawie szeregów czasowych.
Szereg czasowy to zbiór uporządkowanych w czasie realizacji zmiennych.
Części składowe szeregów czasowych Yt:
składowa systematyczna f(t) - to efekt oddziaływania na zmienną stałego zestawu czynników zwanych przyczynami głównymi
składowa przypadkowa ξt - to składnik losowy, wahania przypadkowe
Yt ={ f(t) ; ξt }
Formy składowej systematycznej:
trend - tendencja rozwojowa, długookresowa skłonność do jednokierunkowych zmian (wzrost lub spadek)wartości zmiennej prognozowanej , opisowej
przeciętny stały poziom zjawiska dodanego - występuje wtedy gdy w szeregu czasowym nie występuje tendencja rozwojowa.
Wahania regularne - wahania wokół trendu lub stałego przeciętnego poziomu zmiennej powtarzające się w tych samych okresach ze stałym bądź zmiennym nasileniem, są wśród nich:
wahania cykliczne - długookresowe rytmiczne wahania wartości Yt wokół trendu lub stałego przeciętnego poziomu, powtarzające się w okresach dłuższych niż rok, związane z cyklami koniunkturalnymi gospodarki.
wahania sezonowe - wahania wartości Yt wokół trendu lub stałego przeciętnego poziomu powtarzające się w obrębie roku , wynikające z np. występowania pór roku, zwyczajów ludności itp.
wahania krótkookresowe - powtarzające się w okresach krótszych niż rok, np. w kwartałach, miesiącach, tygodniach, dniach ....
Modele trendu
Model addytywny - zaobserwowane wartości zmiennej Yt są sumą wszystkich bądź tylko niektórych składowych szeregu czasowego
Y
t
Model multiplikatywny - zaobserwowane wartości zmiennej Yt są iloczynem wszystkich bądź tylko niektórych składowych szeregu czasowego
Metoda analityczna - polega na tym, że w oparciu o wstępny wykres ustalamy konkretną postać analityczną trendu i na podstawie danych statystycznych szacujemy postać tej funkcji.
Typowe postacie funkcji trendu:Metoda mechaniczna - oblicza się średnie ruchome. Wygładzanie szeregu czasowego polega na przyporządkowaniu kolejnym realizacjom szeregu empirycznego wartości średnich obliczonych sekwencyjnie na podstawie np. k<n obserwacji. Obliczona średnia przypada na środkowy okres biorący udział w liczeniu.
Wyodrębnienie tendencji rozwojowej, wygładzenie szeregu
metoda analityczna
metoda mechaniczna
Eliminacja tendencji rozwojowej (wyrzucamy t z szeregu)
Z tego co zostało wyrzucamy efekty przypadkowe (eliminacja wahań periodycznych)
Surowe wskaźniki periodyczne , jest ich tyle ile jest faz cyklów wahań.Korygowanie wskaźników surowych, obliczanie wskaźników czystych
s*j w modelu multiplikatywnym - informuje o ile procent poziom zjawiska w danej i-tej fazie wahań jest niższy lub wyższy od poziomu jaki osiągnęłoby zjawisko gdyby jego rozwój następował zgodnie z tendencją rozwojową
s*j w modelu addytywnym - informuje o ile jednostek poziom zjawiska w danej i-tej fazie wahań jest niższy lub wyższy od poziomu jaki osiągnęłoby zjawisko gdyby jego rozwój następował zgodnie z tendencją rozwojową
Znany jest model ekonometryczny wyjaśniający kształtowanie się zmiennej dla , której należy zbudować prognozę.
Struktura opisywanych przez model zjawisk jest stabilna w czasie tzn., że model jest aktualny również w okresie prognozowanym „T”.
Rozkład składnika losowego nie ulega zmianom w czasie.
Znane są dla okresu prognozowanego „T” wartości zmiennych objaśniających występujących w modelu będącym podstawą predykcji.
Dopuszczalna jest ekstrapolacja modelu poza zaobserwowany w próbie obszar zmienności zmiennych objaśniających.
mierzy rząd dokładności predykcji przy założeniu, że przyjęte przy obliczaniu prognozy wartości zmiennych objaśniających faktycznie się realizują
zależy od wielkości próby
jest nie mniejsza od wariancji składnika losowego
Y = T + W + P
Y
Y =T * W * P
Każdą analizę szeregu czasowego należy rozpocząć od wykonania wykresu na podstawie którego ustalamy czy trend można przedstawić za pomocą funkcji zmiennej czasowej t.
Metody używane do wyznaczenia funkcji trendu.
![]()
- funkcja liniowa
![]()
- funkcja logarytmiczna
![]()
![]()
- funkcja wykładnicza
![]()
![]()
- funkcja hiperboliczna
![]()
- funkcja potęgowa
![]()
- trend logistyczny
Załóżmy, że dane są wartości zmiennej y1, y2, y3, .... yn i niech k=3, wtedy średnie ruchome obliczane są następująco:
![]()
![]()
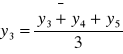
k = 3
yt |
y*t |
y2 y3 y4 .. .. yn |
- y1 y2 y3 .. .. - |
Jeżeli k jest liczbą parzystą np. równą 4, wtedy średnie ruchome obliczane są w drodze tzw. centrowania , czyli
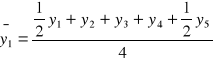
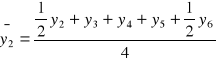
itd.
Liczba elementów na podstawie których oblicza się kolejne średnie czyli k najczęściej równa jest ilości okresów w całym cyklu wahań.
k=4
|
y*t |
y2 y3 y4 yn-1 yn |
- - y1 y2 - - |
Wyznaczanie wahań periodycznych (regularnych wahań)
Gdy chcemy zbadać jakość zjawiska wykorzystujemy zmienne 0, 1 (zerojedynkowe)
Vi - i = 1, 2, ....... m - liczba faz w cyklu wahań
|
1 dla i-tej fazy wahań 0 dla pozostałych m-1 faz wahań |
Załóżmy, że m = 4 (kwartały)
|
V1 |
V2 |
V3 |
V4 |
I II III IV |
1 0 0 0 |
0 1 0 0 |
0 0 1 0 |
0 0 0 1 |
I II III IV |
1 0 0 0 |
0 1 0 0 |
0 0 1 0 |
0 0 0 1 |
Model Klein'a pozwala opisać cały model
![]()
każda zmienna ma swój parametr (wyraz wolny - jedynki)
f(t) - funkcja trendu
![]()
- stałe parametry i = 1, 2, ...... m
Vit - zmienne zerojedynkowe
Ponieważ:
![]()
suma parametrów = 0, to możemy pominąć jeden parametr a brakujący szacujemy ze wzoru
![]()
(nie szacujemy ostatniego parametru)
Wtedy model jest następujący:
![]()
czyli
![]()
Metoda wskaźnikowa wyznaczania efektów periodycznych
Parametry mierzy się w jaki sposób odchyla się realizowana zmienna Y od poziomu wyznaczonego przez trend w wyniku obserwacji i-tej fazy wahań.
Metoda wskaźnikowa wyznaczania efektów periodycznych przeprowadzana jest w 4 etapach.
obliczamy wartość teoretyczną y*ti
model addytywny model multiplikatywny
![]()
![]()
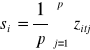
gdzie:
si - wskaźnik surowy dla okresu i
j - 1, 2, ... p , kolejny numer cyklu w badanym szeregu
p - liczba jednoimiennych faz w szeregu (grupy faz)
Jeśli ![]()
w modelu addytywnym lub ![]()
w modelu multiplikatywnym, to obliczamy średnią wartość wskaźników i korygujemy nią wskaźniki surowe.
![]()
![]()
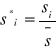
model addytywny model multiplikatywny
Interpretacja wskaźników :
Przykład z materiałów „ sprzedaż konserw warzywnych w poszczególnych kwartałach”
Prognozowanie zmiennej endogenicznej w przyszłości
Predykcja ekonometryczna - ogół zasad i metod prognozowania w przyszłości na podstawie odpowiedniego modelu ekonometrycznego. Celem tego procesu jest prognoza.
Prognoza ekonometryczna yTp - wynik procesu predykcji przy przyjętych z góry założeniach.
![]()
i = 1, 2, ...... k
ai - oszacowanie i-tego parametru strukturalnego modelu
xit - wartość i-tej zmiennej objaśniającej modelu w okresie prognozowym T
Podstawowe założenia predykcji ekonometrycznej prognozowania w przyszłości
Zasada predykcji nieobciążonej
![]()
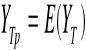
Zasada predykcji wg największego prawdopodobieństwa
![]()
Mierzenie dokładności prognoz
Mierniki EX ANTE - charakterystyki lub prawdopodobieństwa, które są obliczane na podstawie znajomości rozkładu zmiennej prognozowanej błędów predykcji. Miary te informują już w momencie budowania prognozy, jaki będzie rząd dokładności przewidywania.
Mierniki EX POST - charakterystyki rozkładu błędów predykcji lub częstości względne realizacji trafnych prognoz zaobserwowane w wyniku porównywania prognoz z odpowiadającymi im realizacjami zmiennej prognozowanej.
Realizacja błędów prognoz.
UT = yT - yTp
yT - realizacja zmiennej yT w czasie T
yTp - prognoza dla okresu T
Wariancja predykcji
Podstawowy miernik ex ante w warunkach predykcji nieobciążonej i powtarzalnej, opartej na modelu liniowym oszacowanym MNK
![]()
gdzie:
![]()
- transponowany wektor założonych dla okresu prognozowanego T wartości zmiennych
objaśniających
![]()
- macierz wariancji i kowariancji estymatorów
![]()
- wariancja resztowa
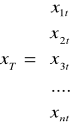
- wektor kolumnowy
V2 - wariancja
Wariancja predykcji :
Średni błąd predykcji
![]()
Błąd średni predykcji informuje o ile średnio rzecz biorąc w długim ciągu predykcji rzeczywiste realizacje yT będą się odchylać (in plus i in minus) od wartości obliczonej prognozy.
Średni względny błąd predykcji
![]()
Wyraża stosunek średniego błędu predykcji do jej wartości.
Okres empirycznej weryfikacji prognoz Iep - to m elementarny odcinek czasowy w przeszłości z którego pochodzą dane dotyczące prognoz i realizacji zmiennej wykorzystywane do obliczania wartości mierników ex post.
Miary ex post
Średni błąd prognozy
![]()
m - długość okresu empirycznej weryfikacji prognoz, liczba okresów prognozowanych
yT - realizacja zmiennej yT w okresie T
yTp - prognoza dla okresu T
Empiryczna wariancja predykcji
![]()
![]()
- MSE
sp - średni empiryczny błąd prognozy = RMSE
![]()
Średni absolutny błąd prognozy
![]()
![]()
Przykład:
Dany jest model:
Yt = 19,338 X1t + 724,331 X2t - 26996,73 + ut
Gdzie:
Yt - samochody osobowe zarejestrowane tys. szt. (stan w dniu 31 XII)
X1t - drogi publiczne o twardej nawierzchni w tys. km. (stan w dniu 31 XII)
X2t - liczba ludności w kraju w mln. Osób (stan w dniu 31 XII)
T = 1976, 1977, ...., 1990.
Prognoza na rok 1991, przy założeniu, że X1T = 225,7 tys. km , X2T = 38,3 mln. osób
YtP = 19,338* 225,7 + 724,331* 38,3 -26996,73 = 5109,734 tys. szt.
Prognoza na rok 1992, przy założeniu, że X1T = 229,1 tys. km , X2T = 38,4 mln. osób
YtP = 19,338* 229,1 + 724,331* 38,4 -26996,73 = 5247,916 tys. szt.
Wariancja predykcji, średni względny błąd predykcji (na rok 1991)
Wiemy ponadto, że:
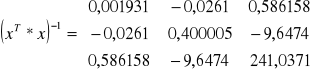
, s2 = 27340,97
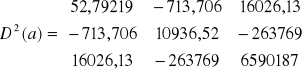
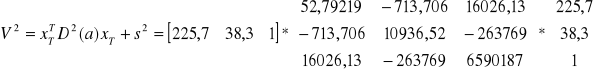
+
+ 27340,97 = 39934,32
![]()
![]()
Ekonometria menedżerska
24
Tutaj musi być najmniej (minimalnie)
Składnik losowy
reszta
Wartość teoretyczna
![]()
![]()
![]()
![]()
Całkowita
zmienność yt
Zmienność objaśniona zmiennej yt
Zmienność resztowa ut
błąd
Moduł- wartość bezwzględna
y*t =2xn + 0,4x2t + 29,4
y*1 =2* 0,7 + 0,4*10 +29,4 = 34,8
y*2 = 2*0,8 + 0,4*11 + 29,4 = 35,4
ut = yt - y*t
u1 = 35 -34,8 = 0,2
u2 = 35,2 -35,4 = -0,2
( empiryczna ilość serii)
A - reszty dodatnie
B - reszty ujemne
Reszty zerowe pomijamy
trend
Odchylenia od trendu o stałej amplitudzie
0
t
trend
Amplitudy wahań wokół trendu są coraz większe lub mniejsze
Szereg teoretycznych wartości jest o 4 elementy krótszy
|
V1-V3 V*1t |
V2-V3 V*2t |
I II III |
1 0 -1 |
0 1 -1 |
I II III |
1 0 -1 |
0 1 -1 |
Wyszukiwarka