ullman223 (2)

4 52 7. SYSTEMOWE ASPEKTY Jt-ZYKA SQ1.
Nazwa serwera zależy od konkretnej instalacji. Można ją zastąpić słowem DEFAULT i wówczas instrukcja spowoduje dołączenie komputera klienta do tego serwera, który jest specyfikowany jako domniemany.
Nazwa połączenia może być istotna. Możemy się bowiem chcieć do niej odwoływać, jako że SQL2 umożliwia jednoczesne otwarcie kilku połączeń, ale tylko jedno jest aktywne w danej chwili. Aby przełączać się pomiędzy połączeniami stosujemy instrukcję set ccnneCTION, np. przełączenie się do połączenia connl może być spowodowane w następujący sposób:
SET CONNECTION connl;
Połączenie aktywne uprzednio przechodzi w stan uśpieniu aż do chwili ponownego uaktywnienia na skutek innego polecenia SET CONNECTION, w którym jest jawnie podana jego nazwa.
7 nazwy połączenia korzysta się również przy jego usuwaniu. Na przykład połączenie connl można unieważnić, korzystając z następującej instrukcji:
DISĆONNECT connl;
Wykonanie tej instrukcji powoduje zakończenie połączenia connl, w tym przypadku nie jest ono w stanie uśpienia i nie można go już uaktywnić.
Jeśli jednak mamy pewność, że nie zajdzie potrzeba odwołania się do połączenia, to nie trzeba go nazywać i można AS i nazwę pominąć w instrukcji CONNECT. Można także wcale nie korzystać z instrukcji CONNECT TO. Jeśli wydamy jakiekolwiek polecenie SQL, to system połączy stację klienta ze standardowym serwerem SQL.
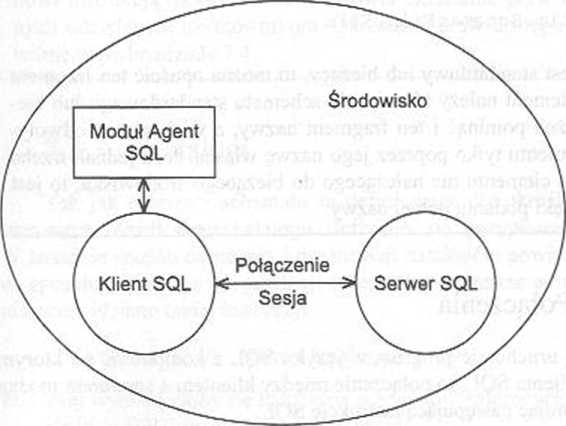
RYSUNEK 7.13 Współdziałanie klienta i serwera
7.3.6. Sesje
Działania w języ ku SQL, które są przetwarzane w trakcie połączenia, tworzą sesję. Istnienie sesji jest nieodłączne od połączenia, które ją rozpoczęło. Na przykład, jeśli połączenie przechodzi w stan uśpienia, to sesja także jest w uśpieniu i reaktywacja połączenia przez instrukcje set CONNECTION uaktywnia także uśpioną sesję. Na rysunku 7.13 zostały przedstawione połączenie i sesja jako dwa elementy łącza między klientem a serwerem.
W każdej sesji istnieje katalog bieżący i schemat bieżący w ramach tego katalogu. Można je określić, wykonując instrukcje SET SCHEMA lub SET CATALOG, które omówiliśmy w p. 7.3.2 i 7.3.3. W każdej sesji istnieje także autoryzowany w niej użytkownik, co zostanie opisane w podrozdziale 7.4.
7.3.7. Moduły
Moduł oznacza program użytkowy zapisany w języku SQL2. W standardzie SQL2 zostały' wyróżnione trzy rodzaje modułów i każda implementacja powinna umożliwiać korzystanie co najmniej z jednego z nich.
1. Generyczny interfejs SQL. Użytkownik może wprowadzać instrukcje SQL bezpośrednio z terminala i są one natychmiast uruchamiane na serwerze. W tym trybie każda pojedyncza instrukcja stanowi moduł. Taki właśnie tryb przetwarzania braliśmy pod uwagę w przedstawianych przykładach, ale w praktyce korzysta się z niego raczej rzadko.
2. SQL osadzony. Ten styl programowania został omówiony w podrozdziale 7.1; tam instrukcje SQL były zapisywane wewnątrz programów utworzonych w języku podstawowym i te wstawki SQL poprzedza się instrukcją EXEC SQL. Zakłada się, że instrukcje SQL są zastępowane przez preprocesor wywołaniami funkcji bibliotecznych i w stosownej chwili są one wykonywane przez system SQL w trakcie przemarzania programu podstawowego.
3. Prawdziwe moduły. Najczęściej w języku SQL stosuje się moduły, które stanowią zbior\r funkcji lub procedur, część z nich jest zapisana w języku podstawowym, część w SQL. Komunikują się one ze sobą za pośrednictwem parametrów- lub zmiennych dzielonych.
Wykonanie modułu nazywa się agentem SOL. Na rysunku 7.13 przedstawiono moduł i agenta jako jeden element, uruchamiający klienta SQL po to, by utworzyć połączenie. Należ}’ pamiętać jednak o tym, że różnica między modułem a agentem jest analogiczna do różnicy między programem a procesem, pierwszy z nich jest kodem, a drugi wykonaniem tego kodu.
Wyszukiwarka
Podobne podstrony:
43271 ullman221 (2) 7. SYSTEMOWE ASPEKTY Jl-ZYKA SQL RYSUNHK 7.11 Organizacja elementów bazy danych
17514 ullman224 (2) 454 7 SYSTEMOWE ASPEKTY JĘZYKA SQI.7.4. Bezpieczeństwo i autoryzacja użytkownika
42485 ullman206 (2) 41$ 7. SYSTEMOWE ASPEKTY JĘZYKA SQI.7.1.2. Interfejs między językiem SQL i
47839 ullman216 (2) 438 7. SYSTEMOWE ASPEKTY JĘZYKA SQI. do. Wartości atrybutów określają więc numer
18974 ullman230 (2) 400 7. SYSTEMOWE ASPEKTY JĘZYKA SQL d) Usuwanie z przykładu 5.
więcej podobnych podstron