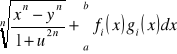
25. Dokumentacja
Dokumentacja jest jednym z najbardziej pożądanych, ale też najczęściej pomijanych aspektów programowania. Wymagania dotyczące dokumentacji są różne w różnych firmach. W niektórych tworzenie dokumentacji jest traktowane jako niezbędna część całego procesu produkcji oprogramowania. Zdarza się często, że niektóre firmy tworzą dokumentację już po ukończeniu programu (szczególnie gdy zamówienie ma nieprzekraczalny termin wykonania lub pod naciskiem otoczenia). W praktyce obserwuje się tendencję, że planowany jest tylko czas na wykonanie zadania, a prawie nigdy nie przewiduje się czasu na właściwy opis tego, co zostało zrobione w programie, ani tego, co miał na myśli programista piszący kod. Wszyscy programiści, którzy musieli przeglądać kod napisany przez innych, doceniają prawdopodobnie wagę tego zagadnienia.
Jeżeli nie jest to wymagane przez przepisy lub kontrakt, to dokumentacja powstaje rzadko kiedy. Często komentarze w kodzie nie odpowiadają zawartości, ponieważ kod bywa poprawiany, a komentarze nie.
Jeśli spojrzymy na to jako użytkownik, a nie programista, to także dostrzeżemy podobne zjawiska. Brak zmian w dokumentacji przy zmianach w programie prowadzi często do irytacji a nawet do poważniejszych szkód.
Na to wszystko nie ma prostej recepty. Tworzenie dokumentacji jest jak tworzenie kodu — ono także wymaga dyscypliny, aby wynik można było uznać za prawidłowy. Nauczenie się poprawnego dokumentowania programów wymaga praktyki i umiejętności krytycznej oceny swojej pracy. Z drugiej strony, dokumentacja jest jedną z najbardziej widocznych cech projektu i jeśli jest wykonana dobrze, to może przynieść dodatkowe zamówienia lub umocnić dobrą opinię o programiście.
W tym rozdziale pokażemy gdzie należy szukać użytecznych informacji o programach oraz omówimy kilka narzędzi wspomagających tworzenie własnych programów. Narzędzia te dostarczają także informacji niezbędnych do powstania dokumentacji tworzonego programu. Głównym tematem będzie tworzenie dokumentacji zewnętrznej, czyli stron podręcznika systemowego i innych dokumentów, które można wydrukować, natomiast mniejszy nacisk położymy na komentarze umieszczane w kodzie programu.
Określenie odbiorców pracy
Pierwszym krokiem przy tworzeniu dokumentacji powinno być poprawne określenie jej odbiorców. Osoby użytkujące program rzadko kiedy będą zainteresowane tymi samymi zagadnieniami, co osoby odpowiedzialne za utrzymywania programu w ruchu. Można zgrubnie podzielić użytkowników dokumentacji na cztery kategorie, jednak założenia ściśle spełnione przez role użytkowników programu mogą z czasem się zmienić jeśli rozpatrujemy użytkowników dokumentacji.
Użytkownicy: korzystają z dokumentacji głównie do celów edukacyjnych. Zadają oni pytania: Do czego służy ten przycisk? W jaki sposób dokonujemy rezerwacji? Można więc zakładać, że nigdy nie będą musieli korzystać z wiersza poleceń naszego programu.
Zaawansowani użytkownicy i administratorzy systemu: tę kategorię odbiorców tworzą osoby zainteresowane utrzymaniem działającego programu i jego konserwacją. Z natury ich zainteresowań wynika, że chcąc wiedzieć więcej będą myśleć o błędach w działaniu programu lub o jego dostrajaniu.
Integratorzy: do tej kategorii należą osoby biorące udział w większych projektach, w których jako elementy całości wykorzystywane są całe pakiety lub pojedyncze programy.
Programiści: użytkownicy należący do tej kategorii będą się interesować polepszeniem funkcjonalności programu poprzez dodawanie nowych właściwości.
Dokumentacja użytkownika: interfejs graficzny
Użytkownicy w większości korzystają z interfejsu graficznego lub jakiejś jego namiastki. W naszej książce wiodącym tematem była do tej pory aplikacja do obsługi wypożyczalni płyt DVD, a więc tutaj również posłuży nam jako przykład. Bardzo prosto możemy wyróżnić dwa rodzaje użytkowników: personel wypożyczalni i użytkownicy łączący się ze stroną WWW wypożyczalni. Rozpoczniemy od użytkowników lokalnych.
Dokumentacja dla lokalnych GUI
Interfejsy graficzne najlepiej można udokumentować wyposażając aplikację w system pomocy, zawierający dużo ilustracji. Pomoc kontekstowa (czyli informacje pomocnicze zależne od tego, jaka czynność jest w danym momencie wykonywana) jest także godna uwagi. Pomoc kontekstowa może mieć różną postać, począwszy od wyświetlenia wskazówki czy wyskakującego okna z objaśnieniami, aż do specjalnego okna pomocniczego pokazującego się po naciśnięciu jakieś kombinacji klawiszy (np. CTRL-F1). Należy pamiętać, aby wszystkie elementy interfejsu graficznego i ich współdziałanie zostały udokumentowane.
Niestety, trudno jest uzyskać zwarty system pomocy. W większości pakietów pomocniczych nie ma do tego odpowiednich narzędzi i wielu programistów tworzy własne rozwiązania. W dalszej części tego rozdziału będziemy więc szukać niezbędnego minimum, które musi spełniać system pomocy w interfejsie graficznym.
Pomoc kontekstowa
Najlepszą metodą zapewnienia pomocy jest jej udostępnienie jak najbliżej tych miejsc, których ona ma dotyczyć. W Microsoft Windows oznacza to np. wskazanie jakiegoś elementu kursorem i naciśnięcie klawiszy CTRL-F1. W tym momencie pojawia się informacja pomocnicza lub w przypadku aplikacji Office — tzw. Asystent Pomocy podający „użyteczne” informacje.
Kliknięcie prawym klawiszem myszy może powodować wyświetlenie menu kontekstowego, pokazującego działania dozwolone dla wskazanego obiektu i w tym menu może się znaleźć opcja pomocy. Oczywistą zaletą kontekstowego systemu pomocy jest to, że działa on w sposób natychmiastowy. Niestety, bardzo trudno taki system wprowadzić jeżeli w pakiecie do tworzenia interfejsu graficznego nie ma narzędzia przeznaczonego do tego celu. Jeżeli programista zdecyduje się zrobić to sam, to nie ma łatwego zadania, ponieważ musi przechwytywać naciśnięcia klawiszy i ruchy myszą.
Innym rozwiązaniem jest globalna funkcja pomocy, która z oczywistych względów nie działa w sposób kontekstowy. Zazwyczaj taka pomoc w programie jest przedstawiana jako lista uporządkowanych hierarchicznie zagadnień, opisujących w mniejszym lub większym stopniu działanie programu (przeważnie jednak w mniejszym). Eleganckim kompromisem jest utworzenie takiej funkcji, w której można przejść do specyficznego zagadnienia kierując się niewielką dozą intuicji.
Pomoc kontekstowa „dla ubogich”
Całkiem zgrabną sztuczką stosowaną przy tworzeniu strukturalnego systemu pomocy jest skorzystanie z usług oferowanych przez przeglądarkę i zastosowanie formatu HTML. Przy pewnej znajomości HTML można uzyskać wynik spełniający podstawowe potrzeby, do którego można dodawać obsługę zdarzeń za pomocą języka JavaScript, zestawy ramek, arkusze stylów i inne elementy. Omawiając to rozwiązanie ograniczymy się tylko do zagadnień podstawowych, aby nie utracić ogólności rozważań.
Po naciśnięciu przycisku Help w oknie interfejsu graficznego naszej przykładowej aplikacji utworzonej w rozdziale 9. mamy tylko możliwość przeczytania dodatkowej informacji o autorach programu. Mamy zamiar dołączyć do tego nasz system pomocy. Jest to trochę bardziej skomplikowane niż dodawanie nowego przycisku (opisane także w tamtym rozdziale), ponieważ polega na dodaniu uchwytu obsługującego kod wzywający przeglądarkę HTML z adresem strony zawierającej treść pomocy.
„Zrzuty” ekranowe: Należy utworzyć kopie obrazów każdego menu, okien dialogowych i okna głównego występujących w interfejsie graficznym. Najprostszym programem do tworzenia takich obrazków jest xwd, ale istnieją też bardziej specjalistyczne narzędzia w pakiecie ImageMagick lub autonomiczny programy xgrabsc. Aby zebrane elementy graficzne można było wykorzystać, należy zmienić ich format z xwd na format obrazu interpretowany przez przeglądarkę (może to być np. PNG). Do tego celu można użyć programów xwdtopnm i pnmtopng z zestawu narzędziowego PBMPLUS lub pakietu ImageMagick. Program GIMP także umożliwia przechwytywanie zawartości ekranu i zapis obrazu w formacie PNG lub innych.
Strony HTML: Należy utworzyć pustą stronę HTML dla każdego wykonanego obrazu ekranowego.
Dodanie obrazka do strony HTML: Następnie należy dodać obraz do strony HTML. Jeżeli nie jest używany edytor typu WYSIWYG, to można to uczynić używając atrybutów ISMAP i USEMAP, tak jak w poniższym przykładzie:
<IMG SRC="dvdstore.png"
ALT="Ten obrazek pokazuje wygląd okna DVDStore"
ISMAP="ismap"
USEMAP="#dvdstore-map">
rysunek ze strony 892 |
Dołączenie mapy do obrazka na stronie HTML: Teraz należy utworzyć mapę do obrazu i dodać ją do strony HTML. Mapa to po prostu lista obszarów odpowiadających elementom interfejsu na obrazku. W naszym przykładzie wygląda to następująco:
<MAP NAME="dvdstore-map">
<AREA SHAPE="rect"
COORDS="102,39,186,83"
ALT="Disconnect Button"
HREF="#ExplanationOfDisconnectButton">
<AREA SHAPE="rect"
COORDS="200,39,299,83"
ALT="Rent Button"
HREF="#ExplanationOfRentButton">
<!-- ETC. -->
</MAP>
Opisywane obszary są zaznaczone na rysunku powyżej prostokątnymi obrysami. Cały proces może być bardzo pracochłonny, a więc nie należy się wzbraniać przed zastosowaniem takich narzędzi jak Netscape Composer.
Dołączenie objaśnień do strony HTML: Pozostały do wykonania jeszcze tylko opisy działania każdego z przycisków. Można to zrobić tak jak w przykładowym kodzie poniżej. Dzięki temu użytkownik klikając na różne elementy obrazka na ekranie tak jakby były one przyciskami powoduje wyświetlenie odpowiedniego opisu w przeglądarce HTML. Trzeba pamiętać o użyciu zakotwiczeń w kodzie HTML odwołujących się do podanych wyżej odnośników:
<CENTER>
<A NAME="ExplanationOfDisconnectButton">
<H1>The Disconnect Button</H1>
</A>
</CENTER>
Tutaj opis przycisku Disconnect.
<P>
<CENTER>
<A NAME="ExplanationOfRentButton">
<H1>The Rent Button</H1>
</A>
</CENTER>
Tutaj opis przycisku Rent.
<P>
Można także dodać jakąś animację do strony HTML. Można nawet użyć zestawu ramek, umieszczając obrazek w górnej ramce, a opisy w ramkach wywoływanych kliknięciem na odpowiedni element mapy. Innymi słowy, można tutaj wykazać się pomysłowością.
Zaletą takiego sposobu dokumentowania jest to, że drukowana wersja dokumentacji elektronicznej może posłużyć jako podręcznik użytkownika. Dodatkowo, jeśli programista zdecyduje się na modyfikację interfejsu graficznego lub zastosowanie innego zestawu narzędzi albo innego środowiska programowania, to oprócz wymiany obrazków niewiele trzeba będzie zmieniać w samej dokumentacji.
Dokumentacja dla interfejsów WWW
Projektując interfejs WWW dla systemu korzystamy z wielu jego zalet. Po pierwsze, dołączamy do niego ograniczony zestaw funkcji, tak aby użytkownik mógł eksperymentować bez obawy o uszkodzenie danych. Mamy także dość miejsca na rozbudowane instrukcje, które w przypadku lokalnego interfejsu graficznego mogłyby przeszkadzać użytkownikowi intensywnie korzystającemu z aplikacji.
Ważne jest, aby czytelnie oznaczyć zadania spełniane przez poszczególne pola interfejsu, np. słowo „Tytuł” jest używane do oznaczenia tytułu grzecznościowego w adresach („Pan”, „Pani”) oraz tytułu zawodowego.
Dobrym zwyczajem jest dołączanie atrybutu ALT do każdego znacznika, który na to pozwala. Wówczas użytkownik przesuwając kursor nad polem edycyjnym lub przyciskiem widzi wskazówkę wyświetlaną przez przeglądarkę. Etykiety pól edycyjnych można przekształcić w odnośniki do miejsc, w których dostępne są szersze objaśnienia, tak jak w poniższym fragmencie kodu. Z prostej definicji pola do wprowadzania danych:
<TABLE>
<TR>
<TD>Your name:
<TD><INPUT TYPE="text" NAME="name" LENGTH=250>
</TABLE>
po przekształceniu uzyskujemy:
<TABLE>
<TR>
<TD><A> HREF="ExplanationOfNameField">Your name:</A>
<TD><INPUT TYPE="text" NAME="name" ALT="Tutaj krótki opis nazwy pola"
LENGTH=250>
</TABLE>
Przy jakichś specyficznych operacjach ważny jest opis poszczególnych etapów działań. W naszym przykładzie procedura rezerwacji płyty DVD może zawierać dodawanie pozycji do koszyka zakupów, a następnie wysyłkę zamówienia. Te etapy powinny być wyraźnie oznakowane.
Trzeba pamiętać, że nie wszystkie przeglądarki działają jednakowo. Niektóre osoby mogą także oglądać naszą stronę WWW na komputerze podręcznym, inne w telefonie komórkowym WAP albo na podobnych urządzeniach z ograniczonymi możliwościami wyświetlacza. To wszystko trzeba przewidywać tworząc dokumentację elektroniczną do programu.
Dokumentacja dla zaawansowanego użytkownika lub administratora systemu
Zaawansowany użytkownik lub administrator systemu będzie w większości przypadków wiedział o wiele więcej o działaniu systemu niż inni. W swojej pracy przeważnie będzie on korzystał z dodatkowych programów, które nie zawsze są wyposażone w interfejs graficzny. Zasady tworzenia dokumentacji programów z interfejsem graficznym podane w poprzednim podrozdziale dotyczą także tej kategorii użytkowników. Zmienia się jedynie zakres omawianych zagadnień, a więc teraz zajmiemy się innym rodzajem dokumentacji, przeznaczonej dla zaawansowanych.
Opcje wiersza poleceń: możliwość użycia --help
Podczas posługiwania się narzędziami korzystającymi z wiersza poleceń zdarza się dosyć często, że potrzebna jest jakaś rzadko używana opcja lub wyświetlenie listy wszystkich dostępnych opcji programu. W grupie programów narzędziowych GNU wszystko jest ułatwione, ponieważ każdy program ma opcję --help, po użyciu której nastąpi wyświetlenie listy opcji (w mniej lub bardziej skrótowej formie). Przykładowo użyjemy w taki sposób polecenia cat:
$ cat --help
Usage: cat [OPTION] [FILE]...
Concatenate FILE(s), or standard input, to standard output.
-A, --show-all equivalent to -vET
-b, --number-nonblank number nonblank output lines
-e equivalent to -vE
-E, --show-ends display $ at end of each line
-n, --number number all output lines
-s, --squeeze-blank never more than one single blank line
-t equivalent to -vT
-T, --show-tabs display TAB characters as ^I
-u (ignored)
-v, --show-nonprinting use ^ and M- notation, except for LFD and TAB
--help display this help and exit
--version output version information and exit
With no FILE, or when FILE is -, read standard input.
Report bugs to <bugtextutils@gnu.org>.
Na podstawie tego przykładu możemy stwierdzić, że pomoc dostępna z wiersza poleceń powinna zawierać co najmniej następujące pozycje:
Nazwa: oznacza nazwę programu. Tę informację często kieruje się do pliku, a więc użycie nazwy programu może posłużyć w tym pliku jako punkt odniesienia.
Sposób użycia: informacja powinna podawać wykaz używanych opcji i argumentów programu. Należy czytelnie oznaczyć, które argumenty są obowiązkowe, które są opcjonalne oraz podać ich kolejność, jeśli jest to istotne.
Szczegółowe informacje o sposobie korzystania: Przy niewielkiej liczbie argumentów obsługiwanych przez program można tu podać w kolejnych wiersza opisy wszystkich opcji i argumentów. Trzeba przy tym zwrócić uwagę na to, aby nie cytować całego podręcznika systemowego. Jedna lub dwie strony informacji na ekranie powinny stanowić maksimum, które może być efektywnie wykorzystane do szybkiego zapoznania się z tematem. Więcej niż jedna strona tekstu wymaga zastosowania dodatkowych narzędzi przy przeglądaniu, np. more, less lub most, co może być męczące.
Strony podręcznika systemowego
Użytkownicy chcący skorzystać z programu mają możliwość szybkiego uzyskania skróconych informacji za pomocą opcji --help. Jeżeli potrzebne są informacje bardziej szczegółowe, to zazwyczaj są one podawane w postaci tzw. stron podręcznika systemowego (manpage).
Strony te są jedną z najstarszych postaci dokumentacji elektronicznej i można je znaleźć już w najwcześniejszych wersjach systemu UNIX.
Strona podręcznika systemowego może być wyświetlona za pomocą polecenia man. Aby dowiedzieć się, jak to działa, należy użyć polecenia man man. Wkrótce przedstawimy sposób tworzenia własnych stron podręcznika systemowego, ale najpierw podamy podstawowe informacje.
Polecenie man ma swojego krewniaka w postaci polecenia apropos, które pomaga w lokalizacji informacji na podstawie słów kluczowych, a nie nazwy programu. Zazwyczaj apropos jest aliasem dla polecenia man -k. Można tu podawać dowolne słowa kluczowej jako argumenty, a w wyniku zostanie wyświetlona lista odpowiednich programów lub stron podręcznika systemowego. Oto przykład:
$ apropos noweb
nodefs (1) - find definitions in noweb file
noindex (1) - build external index for noweb document
noroots (1) - print roots of noweb file
notangle (1) - noweb, a literate-programming tool
nountangle (1) - noweb, a literate-programming tool
noweave (1) - noweb, a literate-programming tool
noweb (1) - a simple literate-programming tool
nowefilters (7) - filters and parsers for use with noweb
nowestyle (7) - LaTeX package for noweb
nuweb2noweb (1) - convert nuweb files to noweb form
Sekcje podręcznika systemowego
Strony podręcznika systemowego utworzono dla zróżnicowanych programów, począwszy od prostych narzędzi wywoływanych w wierszu poleceń do procedur używanych w standardowej bibliotece języka C i formatów plików używanych przez różne programy. Jeśli jednak te strony zbierzemy w całość, to dosyć szybko korzystanie z nich stanie się niewygodne. Takie strony podręcznika systemowego zawierałyby dość dużo materiału, a użytkownicy nie mogliby się w nich doszukać początku opisu danego zagadnienia. Dlatego właśnie wprowadzono sekcje podręcznika systemowego. Każda sekcja zawiera specyficzny rodzaj informacji.
Wyróżnia się tu 9 podstawowych kategorii:
Programy lub polecenia dostępne dla wszystkich użytkowników.
Wywołania systemowe (funkcje obsługiwane przez jądro).
Wywołania funkcji bibliotecznych (zawartych w bibliotekach systemowych).
Pliki specjalne (zwykle umieszczane w katalogu /dev).
Formaty plików i konwencje nazewnicze, np. /etc/passwd.
Gry.
Makropolecenia i zasady ich stosowania.
Polecenia do zarządzania systemem (zwykle zarezerwowane dla użytkownika root).
Funkcje jądra (niestandardowe).
Odwołania do specyficznych sekcji podręcznika systemowego są zazwyczaj oznaczane przez podanie numeru sekcji w nawiasach. Pisząc więc o poleceniu man można użyć zapisu man(1), ponieważ mamy na myśli program (lub polecenie wydawane z wiersza poleceń).
Zdarza się, że program i funkcja biblioteczna mają te same nazwy, jak np. printf. Aby więc wyświetlić stronę podręcznika systemowego z opisem programu printf, należy użyć polecenia:
$ man printf
Można także użyć innej wersji tego polecenia:
$ man 1 printf
żądając jawnie wyświetlenia opisu programu, czyli sekcji 1. Jeżeli potrzebna jest informacja na temat funkcji bibliotecznej printf, to należy użyć innego polecenia:
$ man 3 printf.
W niektórych systemach w podręczniku systemowym mogą występować dodatkowe kategorie, np. jedną z częściej spotykanych jest kategoria local.
Utrzymywanie porządku
Od narodzin systemu UNIX powstało bardzo wiele bibliotek. Niektóre z nich mają olbrzymie rozmiary. W systemie autora tego rozdziału dokumentacja biblioteki X składa się 935 stron podręcznika systemowego opisujących struktury i funkcje stosowane podczas tworzenia programów dla środowiska X11 Window System. Do oznaczania stron w podsekcjach stosowane są tam odnośniki składające się z numeru głównej sekcji i oznaczenia literowego. Przykładowo: wspomniane 935 stron można znaleźć w podsekcji 3x, zaś funkcje biblioteki Tk są opisane w sekcji 3tk.
Najczęściej spotykane elementy strony podręcznika systemowego
Strona podręcznika systemowego (manpage) ma zdefiniowaną strukturę, składającą się z elementów obowiązkowych i opcjonalnych umieszczonych w określonym porządku. Najczęściej występują następujące części:
NAME: Część NAME jest jedynym obowiązkowym składnikiem strony. Zawiera ona nazwę opisywanego programu i jego jednowierszowy krótki opis.
SYNOPSIS: Ta część zawiera skrótowy opis interfejsu programu lub funkcji. Jest ona przeznaczona dla osób, które chcą sobie szybko przypomnieć sposób użycia programu.
DESCRIPTION: Element ten zawiera opis rzeczywistych operacji wykonywanych przez polecenie lub funkcję. Opisuje się tu sposób użycia argumentów w poleceniu oraz to, co ono pobiera i co wytwarza. Zwróćmy uwagę na to, że w tej części nie podaje się szczegółowych informacji na temat wewnętrznych operacji ani opcji — taki zakres informacji nadaje się bardziej do umieszczenia w części USAGE lub OPTIONS.
RETURN VALUES: Tutaj opisywane są możliwe wartości, zwracane przez funkcję do wywołującego ją programu oraz towarzyszące temu okoliczności.
EXIT STATUS: Program może także zwracać jakąś wartość, nazywaną zazwyczaj statusem wyjściowym. Jest on opisywany właśnie w tej części, a nie w części RETURN VALUES.
OPTIONS: W tej części zawarte są opisy opcji przyjmowanych przez program lub argumentów przyjmowanych przez wywołanie funkcji, a także sposób ich działania na zachowanie programu lub funkcji.
USAGE: Jest to część przeznaczona na przykłady zastosowania programu lub funkcji.
FILES: W tej części opisane są pliki używane przez program lub funkcję. Dotyczy to plików konfiguracyjnych, skryptów rozruchowych oraz plików wykorzystywanych bezpośrednio w działaniu programu. Zwyczajowo podaje się tutaj pełne ścieżki do opisywanych plików.
ENVIRONMENT: W tym miejscu opisywane są wszystkie zmienne środowiskowe wpływające na działanie programu lub funkcji, a także ich specyficzne działanie.
DIAGNOSTICS: Większość programów posługuje się komunikatami o błędach lub ostrzeżeniami. W tej części umieszcza się listę najczęściej spotykanych ostrzeżeń lub komunikatów o błędach, łącznie z opisem okoliczności, w których mogą się one pojawić.
SECURITY: Ta część zawiera listę możliwych zagrożeń, wnoszonych przez program do systemu. Takimi zagrożeniami mogą być np. ustawienie bitu setuid lub podatność na wymuszane pierwszeństwo w dostępie do katalogu /tmp.
CONFORMING TO: Tutaj umieszcza się listę rzeczywistych i umownych standardów, z którymi jest zgodny opisywany program lub funkcja (np. POSIX.1 lub ANSI).
NOTES: Jest to miejsce na zamieszczenie uwag nie pasujących do innych części.
BUGS: Programiści tworzący kod nie są doskonali. Wynik ich pracy działa zazwyczaj bardzo dobrze, ale w pewnych okolicznościach nie można tak twierdzić. Takie okoliczności i sposoby ich unikania (jeśli to jest możliwe) oraz wskazówki do poprawy sytuacji (jeżeli to jest możliwe) podaje się właśnie w tej części.
AUTHOR: W tej części wymienione są osoby, które uczestniczyły w tworzeniu programu. Zwyczajowo podaje się tu także sposób kontaktowania się z autorami.
SEE ALSO: Jest to część poświęcona zarówno na listę stron podręcznika systemowego powiązanych z omawianym zagadnieniem, jak i odnośniki do innych powiązanych dokumentów. Zwyczajowo ta część jest umieszczana na samym końcu.
Czasami potrzebny jest tylko krótki opis tego, co robi dane polecenie, a nie jego pełne objaśnienie. Zamiast man można wówczas użyć pokrewnego polecenia whatis. Polecenie to (najczęściej jest to alias dla man -l) wyszukuje w podręczniku systemowym podany argument i zwraca jego krótki opis podawany w części NAME.
Podręcznik systemowy za zasłoną: troff
Program man nie może sam wykonywać swojej magicznej pracy. Pod maską ma on ukryty wydajny silnik, który dokonuje wymaganego formatowania tekstu. Sam man, zgodnie z zasadą utrzymywania prostoty i modularności obowiązującą w systemie UNIX, tylko zarządza stronami podręcznika systemowego. Do wyświetlania tych stron man wykorzystuje rodzinę programów roff(1) (skrót od run off). Są wśród nich troff(1) (czyli program do składu) oraz nroff(1) (jego ulepszona wersja). Rozpowszechniany bezpłatnie groff(1) (od słów GNU roff) realizuje funkcje obydwu poprzedników i dodatkowo ma jeszcze więcej możliwości.
Program troff był pierwotnie opracowany jako program do składu dla specyficznej drukarki, jaką była naświetlarka firmy Graphic Systems. Naświetlarka obsługiwała cztery kroje pisma w różnych odmianach (prosty, kursywa i pogrubiony), alfabet grecki i trochę znaków specjalnych oraz symboli matematycznych. Znaki mogły być umieszczane w dowolnym miejscu strony. Z powodu tego ścisłego powiązania ze specyficzną naświetlarką polecenia programu troff przypominają kod maszynowy.
Na szczęście napisano kilka interfejsów do tego programu (w postaci makropoleceń), które nieco ułatwiły tworzenie obsługiwanych przez niego dokumentów. W systemie Linux są one instalowane jako emulator programu troff, który umożliwia odczyt stron podręcznika systemowego. Program groff jest o wiele bardziej funkcjonalny niż jego poprzednik powstały w 1974 r. i umożliwia wytwarzanie plików w formacie PostScript i innych. Dzięki temu strony podręcznika systemowego można oglądać nie tylko na ekranie, ale drukować je na drukarkach obsługujących PostScript.
Tworzenie własnej strony podręcznika systemowego
Najprostszą metodą na rozpoczęcie pracy nad nową stroną będzie skopiowanie już istniejącej i następnie jej modyfikacja. Należy zapoznać się także ze składnią poleceń używanych w makroinstrukcji MAN programu troff. Przykład pokażemy w dalszej części, a na początku przedstawimy nieco teorii. Chcąc zapoznać się z tymi zagadnieniami bezpośrednio na komputerze należy użyć polecenia:
$ man 7 man
Obwiązuje tu kilka prostych reguł:
Polecenia (lub makropolecenia) programu troff składają się z kropki i następujących za nią dwóch liter. Wielkość liter ma znaczenie, a więc .pp oznacza coś innego niż .PP.
Polecenia występują zazwyczaj w oddzielnych wierszach, w których podawane są także argumenty tych poleceń (jeśli są wymagane).
Istnieje kilka poleceń używanych wewnątrz wierszy (rozpoczynają się one od znaku „\”, za którym następuje litera) — omówimy je w dalszej części rozdziału.
Znaki specjalne i wstępnie zdefiniowane napisy są poprzedzane oznaczeniem „\*”, za którym następuje litera lub oznaczeniem „\*(”, za którym następują dwie litery.
Na stronie podręcznika można stosować komentarze, poprzedzając je tylnym ukośnikiem i pojedynczym cudzysłowem (\") — wszystkie znaki występujące w danym wierszu za takim oznaczeniem będą ignorowane.
Jeżeli strona podręcznika ma korzystać z jakiegoś preprocesora występującego w programie troff (np. tbl do interpretacji tabel lub eqn do wyświetlania wyrażeń matematycznych), to na początku pliku powinien znaleźć się następujący komentarz:
\" t
Taki wpis oznacza, że strona powinna być najpierw przetworzona za pomocą preprocesora tbl. Należy jednak postępować z tym ostrożnie. W niektórych systemach strony podręcznika systemowego nie są przetwarzane za pomocą ulepszonej odmiany programu troff, ale za pomocą jakichś jego wersji zawierających ograniczony zestaw poleceń. Trzeba więc unikać korzystania ze wszelkich sztuczek dostępnych w „pełnokrwistym” programie. Strona powinna rozpoczynać się od polecenia .TH, które oznacza „nagłówek tabeli”. Polecenie to ma następującą składnię:
.TH title section date source manual
Poszczególne pola mają tu następujące znaczenie:
title: Tu wpisywany jest tytuł strony podręcznika systemowego.
section: Tu wpisywany jest numer sekcji podręcznika systemowego, do której należy dana strona (numery zawierają się w przedziale od 1 do 9, jak opisano wcześniej).
date: Data ostatniej modyfikacji strony. Należy pamiętać o zmianie tego wpisu po każdej modyfikacji.
source: Tutaj podaje się miejsce, skąd pochodzi program opisywany na stronie. W świecie dystrybucji Linuksa może to być nazwa dystrybucji, nazwa fragmentu dystrybucji lub nazwa pakietu zawierającego program.
manual: Nazwa podręcznika systemowego, w skład którego wchodzi dana strona.
Pola date, source i manual są opcjonalne. Jeżeli jakiś argument zawiera spacje, to należy go ująć w cudzysłów.
Jak już wspomniano wcześniej, strony podręcznika systemowego mogą zawierać wiele części i sekcji, ale tylko jeden element musi być obowiązkowo podany: sekcja NAME. Każda sekcja jest formatowana za pomocą makropolecenia .SH, za którym następuje nazwa sekcji. Sekcja NAME jest traktowana w specjalny sposób, ponieważ jej zawartość jest (lub może być) używana przez inne programy. Dlatego właśnie stosuje się w niej specjalne formatowanie:
.SH NAME
hello \- THE greeting printing program.
Zwróćmy uwagę na użycie tylnego ukośnika przed znakiem „-”.
Przez lata wprowadzono wiele konwencji ustalających zasady pisania podręcznika systemowego. W świecie Linuksa takimi podstawowymi zasadami są:
Argumenty funkcji zawsze oznacza się kursywą, nawet w części SYNOPSIS, a w reszcie nazwy funkcji jest stosowana czcionka pogrubiona, jak w poniższym przykładzie:
int myfunction(int argc, char **argv);
Nazwy plików należy zawsze pisać kursywą (/usr/include/stdio.h), z wyjątkiem nazw używanych w części SYNOPSIS, gdzie pliki dołączane oznacza się czcionką pogrubioną:
#include <stdio.h>
Makrodefinicje specjalne, pisane zwykle wielkimi literami, wyróżnia się pogrubieniem:
MAXINT
W wyliczeniach kodów błędów stosuje się pogrubienie (z tej listy zazwyczaj korzysta makropolecenie .TP).
Każdy odnośnik do innej strony podręcznika (lub do innego zagadnienia na tej samej stronie) jest wyróżniany pogrubioną czcionką. Oznaczenia sekcji podręcznika zapisuje się krojem prostym tuż za odnośnikiem, czyli:
man(7)
Kroje pisma
Do oznaczania krojów pisma używane są następujące polecenia:
.R tekst
Powoduje pojawienie się tekstu wyświetlonego krojem prostym (zwykłym). Jeżeli w danym wierszu nie występuje żaden tekst, to makropolecenie dotyczy następnego wiersza. Krój prosty jest krojem domyślnym, do którego następuje powrót po wykonaniu dowolnego makropolecenia.
.B tekst
Powoduje pojawienie się tekstu wyświetlonego krojem pogrubionym. Jeżeli w danym wierszu nie występuje żaden tekst, to pogrubienie dotyczy następnego wiersza.
.I tekst
Powoduje pojawienie się tekstu wyświetlonego kursywą. Jeżeli w danym wierszu nie występuje żaden tekst, to kursywa pojawi się w następnym wierszu.
.SB tekst
Powoduje pojawienie się tekstu wyświetlonego w tym samym lub następnym wierszu krojem pogrubionym o zmniejszonym rozmiarze znaków.
.BI tekst
Powoduje pojawienie się tekstu , w którym wyrazy są wyświetlane naprzemiennie najpierw z pogrubieniem, a potem kursywą. Dany tekst musi występować w tym samym wierszu, co makropolecenie. Zapis „.BI to słowo oraz inne” oznacza więc, że na ekranie pojawi się tekst „to słowo oraz inne”.
.IB tekst
Działa odwrotnie niż poprzednie makropolecenie, tzn. najpierw występują wyrazy wyświetlane kursywą a potem z pogrubieniem. Dany tekst musi występować w tym samym wierszu, co makropolecenie.
.BR tekst
Alternatywne wyświetlanie słów tekstu z pogrubieniem i krojem prostym (najpierw występują wyrazy pogrubione a potem wyświetlane krojem prostym). Dany tekst musi występować w tym samym wierszu, co makropolecenie.
.RN tekst
Alternatywne wyświetlanie słów tekstu krojem prostym i z pogrubieniem (najpierw występują wyrazy wyświetlane krojem prostym a potem pogrubione). Dany tekst musi występować w tym samym wierszu, co makropolecenie.
Akapity
Nowy akapit rozpoczyna się od polecenia .PP.
Tabele
Makropolecenia programu tbl mogą być używane do tworzenia tabel, ale zazwyczaj lepiej (i łatwiej) użyć do tego celu makropolecenia .TP. Makropolecenie to tworzy wcięty akapit z etykietą, dając namiastkę tabeli. Aby więc wstawić tabelę, należy najpierw umieścić wiersz zawierający makropolecenie .TP, za którym podaje się wcięcie. Tabelę kończy się wierszem zawierającym samo makropolecenie .TP.
Instalacja strony podręcznika systemowego
Zazwyczaj strony podręcznika systemowego są przechowywane w katalogu o nazwie man, zawierającym kilka podkatalogów o nazwach man1, man2 itd. Jeden podkatalog przeznaczony jest dla jednej sekcji podręcznika. Powszechnie umieszcza się te katalogi w hierarchii /usr/man lub /usr/local/man, zależnie od specyficznych ustawień i odmiany systemu operacyjnego.
Program man szuka katalogów najwyższego poziomu sprawdzając zmienną środowiskową MANPATH. Zmienna ta, podobnie jak zmienna PATH, zawiera listę katalogów man najwyższego poziomu pooddzielanych dwukropkami.
Przykładowa strona podręcznika systemowego
Oto obiecany przykład strony podręcznika, opisującej opcje wiersza poleceń interfejsu graficznego aplikacji do obsługi wypożyczalni DVD.
.TH DVDSTORE 1
.\" Note that the name should be in CAPS, followed by the section.
.SH NAME
dvdstore \- The GUI fronted to the DVD-store database management program.
.SH SYNOPSIS
.B dvdstore
.I [\-u USER] [\-p PASSWORD] [\-\-help] [ GNOME options ]
.SH DESCRIPTION
This manual page documents briefly the
.BR dvdstore
GUI program.
This manual page was written for Professional Linux Programming.
.PP
The
.B dvdstore
program is the graphical fronted for the DVD-store program. It allows one
to manage the DVD-store's inventory as well as general maintenance of
everything that goes on in the store.
.SH OPTIONS
.TP
.B \-?, \-\-help
Show summary of options.
.TP
.B \-u, \-username
Connect as the specified user.
.TP
.B \-p, \-password
Use the specified password for the user.
.TP
.I GNOME options
The standard GNOME options apply to this program. For full details, read
the chapter on GNOME in the Professional Linux Programming Book.
.SH AUTHOR
This manual page was written by Ronald van Loon.
Podane niżej dwa „zrzuty ekranowe” pokazują wygląd strony przykładowej podręcznika na terminalu i po przekształceniu na kod HTML. Aby wyświetlić stronę na terminalu, należy ją zachować w pliku o nazwie dvdstore.1 w katalogu man1 (w niektórych dystrybucjach stosuje się kompresję stron podręcznika, a więc być może trzeba będzie tak postąpić). Następnie wydajemy polecenie:
$ man dvdstore
rysunek ze strony 902 |
Możemy przekształcić plik dvdstore.1 na kod HTML i wyświetlić go w przeglądarce. Trzeba przy tym pamiętać, aby użyć nowszej wersji programu groff, która obsługuje HTML (informacja o tym jest podana na stronie podręcznika systemowego do tego programu). Jeżeli mamy odpowiednią wersję programu groff, to stosowne polecenia dokonujące konwersji i wyświetlające wynik w przeglądarce są następujące:
$ groff -T html -man dvdstore.1 >dvdstore.html
$ netscape dvdstore.html
rysunek ze strony 903 |
Tworzenie stron podręcznika dla API
Można utworzyć aplikację składającą się z interfejsu wykorzystywanego przez użytkownika i biblioteki funkcji, które mogą być używane przez inne programy. Przykładem takiego podejścia jest nasz interfejs programowy do bazy danych. Użytkownicy chcący skorzystać z tego API mogą nie pamiętać specyficznych wywołań funkcji i będą chcieli to sobie przypominać raczej podczas pracy na komputerze, a nie przeglądając książkę. Świadczy to o potrzebie napisania podręcznika systemowego. Większość funkcji systemowych ma odpowiadające sobie strony podręcznika. Jako przykład zamieszczamy niżej taką stronę dla polecenia memcpy (informacje o prawach autorskich pominięto ze względu na brak miejsca):
.\" References consulted:
.\" Linux libc source code
.\" Lewine's _POSIX Programmer's Guide_ (O'Reilly & Associates, 1991)
.\" 386BSD man pages
.\" Modified Sun Jul 25 10:41:09 1993 by Rik Faith (faith@cs.unc.edu)
.TH MEMCPY 3 "April 10, 1993" "GNU" "Linux programmer's Manual"
.SH NAME
memcpy \- copy memory area
.SH SYNOPSIS
.nf
.B #include <string.h>
.sp
.BI "void *memcpy(void *" dest ", const void *" src ", size_t " n );
.fi
.SH DESCRIPTION
The \fBmemcpy()\fP function copies \fIn\fP bytes from memory area
\fIsrc\fP to memory area \fIdest\fP. The memory areas may not
overlap. Use \fBmemmove\fP(3) if the memory areas do overlap.
.SH "RETURN VALUE"
The \fBmemcpy()\fP function returns a pointer to \fIdest\fP.
.SH "CONFORMING TO"
SVID 3, BSD 4.3, ISO 9899
.SH "SEE ALSO"
.BR bcopy "(3), " memccpy "(3), " memmove "(3), " strcpy "(3), " strncpy(3)
Po utworzeniu biblioteki funkcji wskazane jest napisanie stron podręcznika systemowego oddzielnie dla każdej z funkcji. W dalszej części tego rozdziału spróbujemy pokazać, jak powinna być zorganizowana praca: pisanie kodu i dokumentacji powinno odbywać się równocześnie i obydwie czynności powinny być ze sobą zgodne.
Nowsza generacja stron podręcznika — pliki info
W ramach projektu GNU opracowano kilka narzędzi dla systemu UNIX przypominających narzędzia spotykane w dystrybucjach Linuksa. Programy te mają zazwyczaj swoje strony podręcznika systemowego, ale większość informacji na ich temat można znaleźć na stronach zwanych info.
Strony info są generowane na podstawie specjalnego pliku, czyli tzw. texinfo. Zawiera on strukturalny format, na podstawie którego można tworzyć inne formaty. Taka koncepcja jest także stosowana w wielu programach wykorzystywanych do tworzenia dokumentacji, opisanych w następnych podrozdziałach.
Format przeznaczony do wyświetlania na ekranie jest zwany plikiem info. Plik ten ma strukturę węzłową, dzięki czemu można się przemieszczać do odpowiednich stron info korzystając z hiperłączy.
Przeglądanie informacji na temat specyficznego polecenia GNU można rozpocząć za pomocą polecenia info. Po wywołaniu tego polecenia bez argumentów zostanie wyświetlona lista opcji do wyboru. Jeżeli użyjemy argumentu jak niżej:
$ info progname
to powinniśmy otrzymać informacje na temat specyficznego programu o nazwie progname.
Aby stało się możliwe uzyskiwanie informacji w taki sposób, należy w systemie zainstalować program info. Użytkownicy pakietu Emacs mają także dodatkową możliwość przeglądania tych informacji korzystając ze specjalnego trybu pracy.
Do przeglądania stron info w trybie graficznym można się posłużyć programem xinfo, ale jest on już dość przestarzały i dlatego nie występuje we wszystkich dystrybucjach Linuksa. W razie potrzeby można go pobrać z serwera ftp.x.org. W środowisku GNOME można skorzystać z przeglądarki plików pomocniczych. Polecenie:
$ info command
wywoła stronę podręcznika systemowego powiązaną z poleceniem command lub plikiem o podanej nazwie. Oto przykłady takiego wyświetlenia informacji o programie ls w terminalu i za pomocą przeglądarki plików pomocniczych GNOME, które uzyskuje się za pomocą polecenia:
$ info ls
rysunki ze strony 905 |
Wszystko o strukturze: od pojedynczego programu do systemów rozproszonych
W poprzednim podrozdziale opisaliśmy kilka metod stosowanych w tworzeniu dokumentacji pojedynczych modułów, takich jak autonomicznie działający program, funkcja lub plik. Zwykle uważa się, że program stanowi mniejszą cząstkę większej całości. Nasza przykładowa aplikacja do obsługi wypożyczalni płyt DVD jest tego dobrym przykładem. Nie jest to jedna aplikacja, ale kilka — niektóre z nich są używane jako interfejs, zaś inne stanowią zaplecze. Każda z tych części realizuje specyficzne zadania i ich współdziałanie wymaga specjalnej uwagi. Wszystkie składniki zostały opisane w osobnych rozdziałach.
Opis budowy stron podręcznika systemowego zawierał pewne wskazówki na temat struktury wewnętrznej. W następnych podrozdziałach chcemy pokazać sposób wykorzystania innych narzędzi, służących do opisu większych aplikacji.
Tworzenie zwięzłej, czytelnej i przede wszystkim użytecznej dokumentacji jest rzemiosłem prawie że artystycznym. Obowiązuje tu kilka zasad ogólnych:
Trzeba spojrzeć na opisywane programy z oddalenia, uświadamiając sobie zależności danego programu od danych wyjściowych z innych programów.
Należy zrobić listę wszystkich aplikacji, od których zależy opisywana aplikacja i wskazać ich przetestowane wersje. Na tej liście znajdą się tak oczywiste programy jak powłoka, awk lub perl.
Oszacować minimalny rozmiar obszaru na dysku i wydajność procesora niezbędne do instalacji i uruchomienia programu.
Utworzyć szczegółową listę znanych i przewidywanych problemów związanych z bezpieczeństwem (włączając nawet te, które mają małe prawdopodobieństwo wystąpienia) — chodzi tu między innymi o ściganie się w dostępie do zasobów, czy korzystanie z katalogu /tmp.
Opisać krok po kroku sposób kompilacji programów (w przypadku aplikacji rozpowszechnianych w postaci źródłowej) i instalacji (dla dystrybucji binarnych lub po kompilacji).
Na zakończenie należy pamiętać o podaniu sposobu kontaktowania się z autorami, aby użytkownicy mogli nadsyłać informacje o dostrzeżonych błędach lub propozycje zmian w kodzie.
Narzędzia dokumentacyjne
W tym miejscu należałoby podać jakieś przykłady, ale nie ma jednej dobrej recepty na wszystko. Omówimy więc kolejno same narzędzia używane do tworzenia dokumentacji.
Opisywane tu programy mają kilka elementów wspólnych:
Korzystają z języka znaczników, dzięki czemu łatwiej jest skoncentrować się na strukturze materiału pomocniczego i przeskakiwać z polecenia do polecenia bez większego kłopotu.
Posługują się czystym tekstem, a więc informację można modyfikować za pomocą prawie każdego edytora w dowolnym systemie operacyjnym.
Podstawowym formatem tekstu jest w nich zazwyczaj kod US-ASCII (siedmiobitowy) i do definiowania „obcych” znaków trzeba używać specjalnych trybów pracy.
Jako zasadę ogólną przyjęto w tych narzędziach, że użytkownik nie powinien się zbyt mocno skupiać nad składem tekstu. Inaczej mówiąc: na pewno nie są to narzędzia posługujące się zasadą „to co widzisz, jest bliskie temu, co chciałbyś otrzymać”.
Jest to wielka zaleta w porównaniu do takich programów jak Microsoft Word, w których może się zdarzyć, że po spędzeniu kilku godzin nad edycją tabeli wstawionej na początku dokumentu i usunięciu jakiegoś akapitu ze środka okazuje się, że cały dokument jest napisany w języku norweskim (zgodnie z informacją podawaną przez program do kontroli pisowni).
Stare, ale jare: TeX i LaTeX
Pierwszym programem (a w zasadzie należałoby mówić o pierwszym systemie składu tekstu), który należy wskazać, jest TeX utworzony przez Donalda E. Knutha. Jego pierwotna wersja powstała w roku 1978, a poważniejsze przeobrażenie przeszedł w roku 1984. TeX nie jest rozwijany bardzo aktywnie, ponieważ po prostu nie musi. Najnowsza wersja ma numer 3.14159 i przyjęto zasadę, że każda następna nie wnosząca wiele modyfikacji będzie mieć numer powiększony o kolejną cyfrę dziesiętną liczby „pi”. Istnieje też powiązany z nim program o nazwie METAFONT, który służy do definiowania znaków. LaTeX i TeX są zazwyczaj dołączane do dystrybucji Linuksa. Omówimy je tutaj łącznie.
TeX można traktować prawie jak język programowania. Faktycznie, posługując się nim utworzono nawet łamigłówkę „Wieże Hanoi”! TeX umożliwia bardzo dokładną kontrolę wszystkiego, co ma być umieszczone na stronie, jeśli tylko użytkownik zgłębi jego tajniki. Nie musimy jednak wchodzić aż tak głęboko.
Pisanie surowego dokumentu dla programu TeX rzadko kiedy jest przyjemne — tutaj, podobnie jak w programie troff, łatwiej będzie posługiwać się makropoleceniami. Jednym z takich pakietów makropoleceń, które zyskały popularność, jest LaTeX opracowany przez Lesliego Lamporta w roku 1985. W tabeli zamieszczonej na końcu tego rozdziału podano więc listę większości poleceń pakietu LaTeX, a nie ich odpowiedniki w programie TeX. Program TeX jest bardzo przydatny w sytuacjach, gdy dokument jest nafaszerowany takimi wzorami jak w poniższym przykładzie:
Taki wzór można bardzo łatwo zapisać posługując się czystym tekstem. W rzeczywistości ten rozdział był napisany za pomocą pakietu LaTeX, a następnie został przekształcony na format Microsoft Word za pomocą narzędzi, które omówimy już niedługo.
Sposób działania programów TeX i LaTeX
Podobnie jak w każdym dobrym języku programowania, w pakiecie LaTeX są także wykorzystywane symbole rzadko używane w współczesnych tekstach spotykanych w codziennej praktyce. Na przykład znak „\” służy do wprowadzenia polecenia (z argumentami lub bez) albo znaku specjalnego. Znak procentu „%” symbolizuje komentarz. Znaki akcentowane (np. áèïôñ) uzyskuje się dodając odpowiednie prefiksy przed odpowiadającym im znakiem ASCII:
\'a\'e\"\i\^o\~n
Taki zapis powoduje wstawienie znaków akcentowanych.
W pakiecie LaTeX stosuje się nawiasy sześcienne do grupowania elementów i do wprowadzania argumentów makropoleceń wewnętrznych. Polecenie działa od nawiasu otwierającego do nawiasu zamykającego.
Liczba nawiasów grupujących jest zminimalizowana dzięki temu, że poszczególne sekcje dokumentu zarządzane są za pomocą tzw. środowiska. Rozpoczynają się one od polecenia \begin{nazwa_sekcji}, a kończą na \end{nazwa_sekcji} — tekst między tymi dyrektywami jest przetwarzany. Jeśli więc chcemy wstawić listę numerowaną, to rozpoczynamy ją używając środowiska enumerate, zaś lista nienumerowana rozpoczyna się od itemize.
Dokument programu LaTeX rozpoczyna się od preambuły, w której określa się m.in. tytuł i autora oraz wprowadza środowisko dokumentu. Wcześniej należy jednak przekazać do programu informację o tym, w jakim środowisku dany dokument ma być przetwarzany.
Jako przykład możemy rozważyć niniejszy akapit. Stanowi on fragment książki, a więc w programie LaTeX do określenia klasy dokumentu (documentclass) musimy użyć makropolecenia \documentclass{book}. Makropolecenia mogą mieć także argumenty opcjonalne, które podaje się w nawiasach kwadratowych przed argumentami obowiązkowymi. Makropolecenie \documentclass ma np. opcjonalny argument określający format arkusza papieru a4paper.
Zazwyczaj nie ma potrzeby podawania formatu arkusza, ponieważ „rodzimy” format jest ustawiany w docelowym systemie automatycznie — i to ten system troszczy się o odpowiednie ustawienie elementów formatujących wiążących się z rozmiarami arkusza. Format arkusza można ustawiać wówczas, gdy dokument ma być przekształcony do postaci PDF (tym jednak zajmiemy się w dalszej części rozdziału)
Posłużmy się więc przykładem:
% To jest wiersz komentarza, który nie pojawi się w tekście wyjściowym
% Teraz kilka informacji dla strony tytułowej książki
\title{Professional Linux Programming}
\author{Neil \and Rick \and Ronald \and Others}
\date{\today}
% Ten dokument jest przeznaczony dla środowiska book
\documentstyle[a4paper]{book} % Styl LaTeX 2e
% \documentstyle[a4]{book} % Styl LaTeX 2.09 - obecnie nieużywany
% Rzeczywisty dokument rozpoczyna się tutaj:
\begin{document}
\maketitle % wykonanie strony tytułowej
\tableofcontents % generacja spisu treści wstawianego tuż po stronie
% tytułowej
\chapter*{Introduction} % Pierwszy rozdział.
Tutaj prezentacja...
Teraz lista numerowana:
Prezentacja rozpoczyna się od:
\begin{enumerate}
\item Pozdrowień
\item Wymiany nazwisk
\item Wymiany wizytówek
\end{enumerate}
\chapter{Requirements} % Inny rozdział
\section{Important Requirements} % Podrozdział
\section{Etc.} % Inny podrozdział
\chapter{Final words}
\end{document}
W powyższym przykładzie mamy kilka nieznanych jeszcze elementów, takich jak rozdziały i podrozdziały. Są one formatowane zgodnie z wewnętrznymi zasadami programu LaTeX. Wspaniałą rzeczą jest to, że nie trzeba się koncentrować na wyglądzie rozdziału, ponieważ tym zajmuje się wydawca dołączając do dokumentu odpowiednie style. Dzięki temu jego skład będzie zgodny z wymaganiami drukarni. Dokument pozostaje niezmiennie ten sam, co oznacza możliwość skoncentrowania się na treści a nie na takich elementach jak wprowadzanie kursywy lub podkreśleń. Porównajmy to z programem troff, w którym wszystko trzeba wykonywać samemu!
Produkt końcowy
Przetwarzanie pliku w programie LaTeX jest bardzo proste:
$ latex nazwa_pliku
Tradycyjnie nazwom plików nadaje się końcówkę .tex, ale nie jest to obowiązkowe.
LaTeX przetwarza plik wiersz po wierszu i wypisuje przetworzony tekst w ramkach o orientacji poziomej (hbox) lub pionowej (vbox), układając je sekwencyjnie na stronie. Projektanci GNOME zapożyczyli ten pomysł do swojego programu zarządzającego układem elementów. LaTeX numeruje automatycznie rozdziały oraz podrozdziały, chyba że specjalnie zostanie to zakazane (trzeba wówczas użyć symbolu „*” w rozdziale wprowadzającym).
W procesie przetwarzania powstają cztery pliki, których nazwy składają się z nazwy obrabianego dokumentu i dodanej odpowiedniej końcówki:
.dvi — ten plik zawiera faktyczny wynik przetwarzania dokumentu.
.log — plik zawierający opis czynności wykonanych przez LaTeX.
.aux — plik zawierający polecenia, które mogą zostać użyte podczas następnych przetwarzań.
.toc — plik zawierający aktualne informacje odnoszące się do spisu treści przetworzonego dokumentu.
Niestety, to jeszcze nie koniec. Zapoznamy się teraz z wynikami naszej pracy.
Oglądanie wyniku przetwarzania
Plik .dvi wytworzony przez LaTeX nie zależy od rodzaju urządzenia wyjściowego. Zawiera on informacje o sposobie wizualizacji dokumentu. Występuje tu podobieństwo do działania wirtualnej maszyny Java, tylko zamiast niej mamy wirtualną maszynę TeX. Istnieje wiele rozwiązań umożliwiających wizualizację pliku .dvi. Jednym z najczęściej stosowanych jest program o nazwie dvips, który na podstawie pliku .dvi tworzy plik w formacie PostScript. Program xdvi służy do wyświetlania pliku .dvi na ekranie terminala graficznego. Użytkownicy nie dysponujący środowiskiem X mogą skorzystać z programu dvisvga wyświetlającego wynik na monitorze pracującym w trybie SVGA.
Jeżeli w systemie nie był jeszcze wyświetlany żaden plik .dvi, to po uruchomieniu jednego ze wspomnianych wyżej programów zostaną utworzone odpowiednie zestawy czcionek. Jest to normalne działanie programu TeX — ponieważ nie jest on uzależniony od rozdzielczości urządzenia wyjściowego, to użyte w dokumencie czcionki także nie powinny od tego zależeć. Trudno byłoby przetrzymywać wszystkie zestawy czcionek dla każdej drukarki i każdego wyświetlacza, które można sobie wyobrazić, a więc są one generowane zgodnie z wymaganiami konkretnego urządzenia przez program Metafont. Po generacji czcionek są one zazwyczaj przetrzymywane w buforze, a więc następne wywołanie przeglądarki plików DVI odbywa się znacznie szybciej. Początkowo może się to wydawać nieco dziwaczne, ale dzięki takiemu podejściu dokument wyjściowy będzie wyglądał tym lepiej, im dla lepszej drukarki zostanie wygenerowany, a to gwarantuje najlepszą z możliwych rozdzielczość druku.
Tworzenie lepiej wyglądających dokumentów
Jeżeli teraz obejrzymy swój dokument, to okaże się, że brakuje mu kilku elementów. Dokument rozpoczyna się od strony tytułowej, ale spis treści jest pusty (na stronie widnieje tylko napis „Contents”). Jest to normalne zjawisko, ponieważ LaTeX nie jest programem jasnowidzącym i nie wie, gdzie kończy się dokument. Spis treści zazwyczaj zawiera także numery stron, a te będą przecież znane dopiero wtedy, gdy LaTeX zakończy przetwarzanie dokumentu! Aby uzupełnienie spisu treści było możliwe, LaTeX zapisuje do pliku z rozszerzeniem nazwy .toc wszystkie informacje, które powinny się znaleźć w spisie treści. Makropolecenie \tableofcontents wyszukuje taki plik i wstawia go do dokumentu (jeśli można będzie taki plik znaleźć). Następnie LaTeX kontynuuje przetwarzanie reszty dokumentu.
W wyniku takiego sposobu działania programu należy uruchomić LaTeX trzykrotnie. Podczas pierwszego przebiegu zostanie utworzony plik z początkowym spisem treści, podczas drugiego ten plik zostanie dołączony do dokumentu, a przy trzecim przebiegu nastąpi korekta o dodatkowe strony powstałe po dodaniu spisu treści.
To samo dotyczy odnośników do różnych części dokumentu. Ich zawartość także nie jest znana dopóty, dopóki LaTeX nie przetworzy dokumentu przynajmniej raz.
Można znaleźć wiele wskazówek i sztuczek pomagających uruchamiać LaTeX szybciej i w sposób bardziej efektywny, a ich najlepszym źródłem jest książka „A Guide to LaTeX”, której autorami są Helmut Kopka i Patrick W. Daly (wyd. Addison-Wesley, ISBN 0-201398-25-7).
Ponowne spojrzenie na pliki info
Pamiętamy wzmiankę o plikach info z poprzednich podrozdziałów. Plik info jest faktycznie wytwarzany z czegoś, co nazywa się plikiem TeXinfo. Jest to plik o specyficznym formacie, który zyskał popularność po utworzeniu kilku narzędzi GNU przez Richarda Stallmana znanego z pakietu Emacs i FSF. Plik TeXinfo zawiera kombinację poleceń do składu tekstu dla drukowania (z programu TeX) oraz hiperłączy i odnośników z podręcznika systemowego (części info). W zależności od użytego programu na podstawie tego pliku można utworzyć plik .dvi nadający się do druku lub plik .info do przeglądania za pomocą polecenia info.
Nowy gatunek: HTML, XML i DocBook
LaTeX i TeX nie są jedynymi programami, które ułatwiają tworzenie strukturalnych dokumentów bez poświęcania zbytniej uwagi zagadnieniom składu. SGML (korzystający z metaznaczników) został utworzony specjalnie do tego celu. Nie definiuje on samodzielnie języka znaczników, ale umożliwia opisanie elementów dokumentu za pomocą tzw. definicji typu dokumentu (DTD). Pojawił się też następny konkurent, który może być użyty do tworzenia struktury dokumentu, czyli XML. Język XML to nic innego, jak nowa definicja typu dokumentu dla SGML, nieco silniej związania z wymaganiami, które muszą spełniać poszczególne znaczniki. W XML każdy znacznik musi mieć swój początek i koniec, nie ma też znaczników opcjonalnych.
Zarówno SGML, jak i XML są przede wszystkim metajęzykami — w tym sensie, że nie można w nich wykonać niczego bez uprzedniego szczegółowego opisu używanych znaczników i ich atrybutów.
Główną ideą wiążącą SGML i XML jest zajmowanie się strukturą dokumentu, a nie jego wyglądem. Interpretacja znaczników jest zostawiona programom zewnętrznym, pomimo tego, że formaty dokumentów SGML i XML mogą być definiowane i sprawdzane pod względem poprawności składniowej przez takie programy jak sgmls, jeżeli tylko jest dostępna specyfikacja DTD.
HTML
Konkretnym przykładem specyfikacji DTD w języku SGML jest bez wątpienia powszechnie używany HTML. Sądząc po różnorodności kolorowych i błyskających stron WWW, nikt prawdopodobnie nie pamięta, że HTML pierwotnie był stosowany do nadawania struktury dokumentom i wstawiania do nich hiperłączy. Tej pierwotnej specyfikacji HTML raczej nikt nie będzie używał w biurze prasowym. Zamiast tego wyświetlanie i formatowanie dokumentu (czyli nagłówki i kroje pisma) odbywa się w przeglądarkach.
Po wielu latach od ogłoszenia pierwszej specyfikacji HTML zaczęto wracać do pierwotnej koncepcji strukturalnych dokumentów i oddzielać prezentację od faktycznej treści za pomocą arkuszy kaskadowych stylów (CSS) i ich odpowiedników w XML.
Napisano już dosłownie setki książek na temat HTML, zapominając o innych ważnych technologiach tworzenia dokumentów, jak np. DocBook.
Rzut oka na DocBook
Celem specyfikacji DocBook jest udostępnienie struktury dokumentu bez narzucania reguł formatowania. Jest ona przeznaczona dla tych użytkowników, którzy muszą napisać tekst o określonej strukturze bez zgłębiania się w szczegółowe zagadnienia techniczne.
Specyfikacja DocBook, podobnie jak HTML, wywodzi się z SGML, ale źródła ich pochodzenia są odmienne. DocBook wprowadzono w roku 1991. w ramach wspólnego projektu HaL Computer Systems i wydawnictwa O'Reilly. Obecnie standard ten jest zarządzany przez Organization for the Advancement of Structured Information Standards (OASIS). Jego najnowsze wydanie oznaczone numerem 3.1 było opublikowane w lutym 1999 r. właśnie przez OASIS. Wyczerpujący opis i odwołania literaturowe dotyczące tego standardu można znaleźć w książce wydawnictwa O'Reilly pt. DocBook: The Definitive Guide (ISBN: 1-565925-80-7). Z tych ponad 600 stron wybraliśmy tutaj tylko samą istotę specyfikacji DocBook, a więc nie należy tego traktować jako pełny materiał odniesienia. Dokumentacja w postaci elektronicznej jest dostępna w Internecie pod adresem http://docbook.org. W dystrybucji Linuksa o nazwie Debian jest rozprowadzany pakiet Docbook, który zawiera pliki wymagane do pracy w standardzie DocBook.
DocBook zawiera omówienie wszystkiego, co jest potrzebne w strukturalnym dokumencie. W wielu zagadnieniach pokrywa się to z podejściem do struktury dokumentu stosowanym w programie LaTeX. Za zawartość dokumentu odpowiada autor, a wydawca zajmuje się wszystkimi zagadnieniami związanymi z formatowaniem i składem. Niektórzy autorzy nie chcą się pozbawiać kontroli nad formatowaniem i można to zaakceptować tylko wtedy, gdy wydawca nie musi przekazywać czytelnikowi jednolicie sformatowanej książki (stanowiącej np. fragment serii wydawniczej).
Zaletą stosowania specyfikacji DocBook jest to, że istnieją liczne narzędzia umożliwiające przekształcanie dokumentu DocBook i arkusza stylu na inne formaty, łącznie z HTML, TexInfo i stronami podręcznika systemowego. Dzięki temu oszczędzamy sobie kłopotów związanych z potrzebą uczenia się zasad odmiennego formatowania i składu, a także możemy udostępniać swoje dokumenty w wielu dobrze znanych formatach.
Poniższa tabela zawiera listę niektórych elementów struktury dokumentu spotykanych w różnych omawianych tu narzędziach. Wychodzimy z założenia, że użytkownik będzie tworzył dokumentację zawierającą rozdziały, podobnie jak w książce. W przypadku artykułów elementy także będą podobne. Lista nie wyczerpuje wszystkich możliwości, ale na jej podstawie można ocenić, które narzędzie nadaje się najlepiej do rozwiązania problemu.
Tabela powinna pokazać pewne specyficzne cechy opisywanych narzędzi. Można z niej wywnioskować, że LaTeX ma odchylenia matematyczne, HTML służy do wszystkiego ale niezbyt się przyda osobie tworzącej dokumentację, która musi dysponować wszystkimi możliwościami (odnośniki, tabele, spis treści). DocBook mogłaby wybrać osoba początkująca, ponieważ jest to specyfikacja korzystająca z SGML/XML, można się jej szybko nauczyć i istnieje kilka narzędzi ułatwiających posługiwanie się tym standardem.
Opis |
HTML |
DocBook |
LaTeX |
Oznaczenie komentarza |
<-- wszystko w znaczniku -- będzie ignorowane> |
<-- wszystko w znaczniku -- będzie ignorowane> |
% wszystko za znakiem % jest ignorowane |
Preambuła dokumentu |
<HTML><HEAD> |
<DOCTYPE book PUBLIC"-//OASIS//DTD DocBook V3.1//EN> <book> |
\documentclass[a4paper]{book} |
Początek informacji o dokumencie |
|
<bookinfo> |
|
Informacja o autorach |
<AUTHOR> Nazwisko pierwszego autora, Nazwisko drugiego autora </AUTHOR> |
<authorgroup><-- dla wielu autorów> <author> <firstname>Imię pierwszego autora</firstname> <surname>Nazwisko pierwszego autora </surname> </author> <author> <firstname>Imię drugiego autora</firstname> <surname>Nazwisko drugiego autora </surname> </author> </authorgroup> |
\author{Nazwisko pierwszego autora \and Nazwisko drugiego autora} |
Koniec informacji o dokumencie |
|
</bookinfo> |
|
Tytuł |
<TITLE>W tym miejscu tytuł</TITLE> |
<title>W tym miejscu tytuł</title> |
\title{W tym miejscu tytuł} |
Początek dokumentu |
</HEAD> |
|
\begin{document} |
Strona tytułowa |
<BODY> |
Informacja wygenerowana z podanego wyżej elementu bookinfo |
\maketitle |
Spis treści |
Niedostępny, trzeba zrobić samemu |
<toc><-- zwykle generowany automatycznie> <tocpart> <tocchap> <tocentry pagenum="1">Rozdział pierwszy<\tocentry> <toclevel1> <tocentry pagenum="1">Podrozdział pierwszy</tocentry> </toclevel1> </tocchap> </tocpart> </toc> |
\tableofcontents |
Początek rozdziału |
Niedostępny, trzeba zrobić samemu (lub mieć wygenerowany przez innych) <H1>Tytuł rozdziału</H1> |
<chapter> <title>Tytuł rozdziału</title> |
\chapter{Tytuł rozdziału} |
Początek podrozdziału |
<H2>Tytuł podrozdziału</H2> |
<sect1><title>Tytuł podrozdziału</title> |
\section{Tytuł podrozdziału} |
Początek podrozdziału niższego rzędu |
<H3>Tytuł podrozdziału niższego rzędu</H3> |
<sect2><title>Tytuł podrozdziału niższego rzędu </title> |
\subsection{Tytuł podrozdziału niższego rzędu} |
Początek podrozdziału jeszcze niższego rzędu |
<H4>Tytuł podrozdziału jeszcze niższego rzędu</H4> |
<sect3><title>Tytuł podrozdziału jeszcze niższego rzędu</title> |
\subsubsection{Tytuł podrozdziału jeszcze niższego rzędu} |
Początek listy numerowanej |
<OL> |
<orderlist> |
\begin{enumerate} |
Pozycja numerowana |
<LI>W tym miejscu pozycja |
<listitem>W tym miejscu pozycja</listitem> |
\item W tym miejscu pozycja |
Koniec listy numerowanej |
</OL> |
</orderlist> |
\end{enumerate} |
Początek listy nienumerowanej |
<UL> |
<itemizedlist> |
\begin{itemize} |
Pozycja |
<LI>W tym miejscu pozycja |
<listitem>W tym miejscu pozycja</listitem> |
\item W tym miejscu pozycja |
Koniec listy nienumerowanej |
</UL> |
</itemizedlist> |
\end{itemize} |
Koniec dokumentu |
</BODY></HTML> |
</book> |
\end{document} |
Ostatnie pociągnięcia pędzlem: pliki HOWTO i FAQ
Poprzednie podrozdziały były poświęcone narzędziom do tworzenia dokumentacji wykonywanej przed wydaniem aplikacji. Moment ten nie oznacza jeszcze końca cyklu tworzenia dokumentacji.
Z upływem czasu autorzy otrzymują coraz to nowe pytania. Dotyczą one zazwyczaj mniej ważnych zagadnień, które nie zostały jasno opisane w dokumentacji, albo sposobów zastosowania aplikacji w większym projekcie, którym nie poświęcono zbyt wiele uwagi.
Pierwszym odruchem autora jest natychmiastowa osobista odpowiedź na wszystkie pytania, ale po pięciu odpowiedziach na to samo pytanie cierpliwość szybko znika. W tym momencie dobrym pomysłem może być połączenie odpowiedzi na najczęściej zadawane pytania i zapis ich do pliku nazywanego „Frequently Asked Questions” (w skrócie FAQ).
Całkiem dobrym rozwiązaniem jest też utworzenie tzw. pliku HOWTO (czyli „jak to zrobić?”), w którym zawarte będą odpowiedzi na szczegółowe pytania dotyczące konfiguracji i przystosowania aplikacji do pracy w specyficznych warunkach. Umieszcza się tutaj krótkie wskazówki na temat sposobu uruchamiania i utrzymywania aplikacji, których prześledzenie zajmie o wiele mniej czasu niż przeczytanie całej dokumentacji.
Warto także wspomnieć o dobrym zwyczaju umieszczania pliku README, w którym podaje się najważniejsze informacje do zapamiętania, informacje kontaktowe i sztuczki instalacyjne. Ważne są także pliki TODO z opisem rzeczy pozostałych do wykonania, Changelog ze szczegółowym zapisem zmian wprowadzanych w aplikacji (nawet najdrobniejszych!) oraz pliki NEWS z informacjami o poważniejszych modyfikacjach i dodanych właściwościach.
Dokumentacja dla programisty
Dotarliśmy do momentu, gdy została napisana dokumentacja dostępna podczas pracy programu (pliki pomocnicze) przeznaczona dla użytkowników oraz podręcznik zawierający pełniejszy opis zagadnień, a być może także pliki FAQ i HOWTO. Skrzynki pocztowe twórcy zaczynają się zapełniać podziękowaniami i kopiami metryk urodzenia pierworodnych dzieci, którym nadano jego imię w podzięce za stworzenie dzieła.
Niestety, do skrzynki trafią nie tylko same podziękowania. Znajdą się tu także raporty o błędach, żądania nowych właściwości, żądania dodatkowych wyjaśnień na temat kodu — to wszystko wystąpi z bardzo dużym prawdopodobieństwem.
Prawdopodobnie twórca nie będzie miał czasu na obsługę tych wszystkich żądań. Na szczęście nie musi tego robić (i to jest jedna z zalet otwartego oprogramowania)! Zależnie od wartości użytkowej i popularności aplikacji, zgłoszą się chętni do poprawiania błędów, ulepszania aplikacji i zmian kodu. Aplikacja przestanie być owocem wysiłków jednej lub kilku osób, stając się polem działań na szeroką skalę. Związane z tym zagrożenia są opisane w książce Erica Raymonda pt. The Cathedral and the Bazaar. Jej elektroniczna wersja znajduje się pod adresem podanym w rozdziale 1.
Przy przejściu do grupy projektów otwartych bardzo pomocne będzie dobre udokumentowanie kodu. Dokumentacja użytkowa opisana w poprzednich podrozdziałach umożliwi niektórym osobom zapoznanie się z funkcjonalnym obliczem programu. Programiści wymagają jednak czegoś więcej na poziomie technicznym i wdrożeniowym. To oni właśnie potrzebują dobrze udokumentowanego kodu.
Niektórzy twierdzą, że dobrze udokumentowany kod to mit, ponieważ w praktyce materiał źródłowy zawiera bardzo mało komentarzy. W wielu wypadkach komentarze te są niepoprawne, ponieważ pierwotny kod został zastąpiony nowszą wersją, różniącą się logicznie od oryginału. Komentarze ze starego kodu są zazwyczaj pozostawiane, ale niczego już nie wyjaśniają. Odstępstwa ot tych obserwacji można spotkać w obszarach, w których obowiązkowo musi być używany poprawny kod, np. w zastosowaniach wojskowych, albo w systemach o krytycznym znaczeniu, jak np. w lotnictwie.
Jedną z głównych przyczyn zjawiska, że dokumentowanie programów i algorytmów jest o wiele rzadziej spotykane niż dokumentowanie działania aplikacji, są trudności występujące przy określaniu ich poprawności lub sprawdzaniu. Inną przyczyną bywa także to, że dokumentacja i kod są często oddzielane od siebie, szczególnie wtedy, gdy objętość dokumentacji przekracza kilka wierszy tekstu.
Jeżeli tworzy się kod zgodny z jakimś standardem, to odnośniki do poszczególnych fragmentów normy mogą bardzo się przydać, np. standardami są także dokumenty RFC i RFP. Jeżeli nie istnieje dokument podstawowy (np. RFC) wykorzystywany w projekcie, to można go utworzyć samemu posługując się wcześniej opisanymi metodami.
Rozpocznijmy jednak od przykładu.
Zastosowanie metody „POD” w języku Perl
Jeżeli czytelnik jest zaznajomiony z językiem Perl, to zna także zapewne oznaczanie komentarzy za pomocą znaku „#”. Nie wszyscy jednak wiedzą o tym, że Perl pozwala na wplatanie fragmentów „prozy” bez konieczności stosowania całych bloków wierszy rozpoczynających się od tego znaku. Co więcej, z tych fragmentów można utworzyć strony podręcznika systemowego, pod warunkiem przestrzegania kilku reguł. Mechanizm ten nazywany jest skrótowo POD od słów Plain Old Documentation.
Pełny opis POD jest dostępny jako strona podręcznika systemowego perlpod(1). Oto jego główne właściwości:
Sekcję POD można rozpocząć w dowolnym miejscu kodu języka Perl tam gdzie wstawia się nową instrukcję.
Program do wycinania i przekształcania sekcji POD szuka pierwszego pustego wiersza poprzedzającego tę sekcję. Wiersz ten powinien być rzeczywiście pusty, a nie na taki wyglądać (należy więc zawracać uwagę na pozostawiane spacje).
Sekcja POD rozpoczyna się od znaku równości, za którym następuje polecenie POD.
Sekcja POD kończy się wierszem, w którym na początku umieszczony jest tekst =cut. Pozostała część tego wiersza jest ignorowana.
W sekcji POD występują trzy rodzaje akapitów:
Akapit dosłowny: Jest to wcięty blok tekstu (rozpoczynający się od spacji lub znaku tabulacji), który będzie kopiowany bez zmian przez procesor POD.
Akapit poleceń: Jest to akapit rozpoczynający się od znaku równości, za którym następuje polecenie wraz z argumentami.
Tekst traktowany literalnie: Jest to po prostu blok tekstu o dowolnej treści. Wewnątrz tego tekstu mogą być użyte pewne wbudowane sekwencje poleceń (patrz niżej).
POD dysponuje następującymi poleceniami:
pod — rozpoczyna zwykłą sekcję POD.
cut — kończy sekcję POD.
head1, head2, Level 1 oraz Level 2 — oznaczają nagłówki odpowiednich poziomów.
Do tworzenia list służą polecenia over n, item tekst i back. Argument n za poleceniem over oznacza wielkość wcięcia, zaś tekst oznacza rodzaj listy (numbers dla listy numerowanej, * dla listy ze znacznikami, dowolny tekst dla nagłówka). Faktyczna treść pozycji listy powinna być zapisana w następnym wierszu.
for format text — oznacza, że jeśli stosowany jest format format, to text zostanie umieszczony w strumieniu wyjściowym.
begin format, end format — działa tak samo jak for, lecz dla większych bloków tekstu.
Na zakończenie pokażemy, jak dodać kilka znaczników smarkup do tekstu, korzystając z konstrukcji X<tekst>, w której X oznacza jedną z następujących pozycji:
I |
tekst pisany kursywą, używany do wyróżniania lub zmiennych |
B |
tekst pogrubiony, używany dla nazw opcji i programów |
S |
tekst zawierający spacje niedzielące |
C |
Kod traktowany literalnie |
L |
Dowiązanie (odnośnik) do tekst |
F |
tekst jest nazwą pliku |
X |
tekst jest wartością w indeksie |
Z |
Znak o szerokości zerowej (tekst powinien być pusty) |
E |
tekst jest znakiem escape |
Przykłady zastosowania POD można znaleźć w każdej dystrybucji pakietu Perl.
Istnieje kilka programów przekształcających POD (ze skryptu języka Perl) na inne formaty:
pod2html: Zamienia część POD skryptu języka Perl na format HTML.
pod2man: Zamienia część POD skryptu języka Perl na format troff (czyli man).
pod2latex: Zamienia część POD skryptu języka Perl na format LaTeX.
pod2text: Zamienia część POD skryptu języka Perl na czysty tekst.
Programowanie literackie
W poprzednim podrozdziale pokazaliśmy przykładową konstrukcję dokumentacji wynikającą po prostu z danego języka. Niestety, w językach nie dysponujących takimi możliwościami, takie podejście do tworzenia dokumentacji nie jest możliwe.
Na szczęście istnieje rozwiązanie ogólne, które można zastosować w prawie każdym używanym współcześnie języku programowania, ale wymaga ono zmiany punktu widzenia na samą istotę programowania.
Najbardziej należy zmienić sposób traktowania dokumentacji, która ma się stać ważnym elementem pracy, a nie samo tworzenie kodu. Inaczej mówiąc, liczy się idea, a nie jej wdrożenie. Jeżeli ktoś zajmował się zagadnieniami inżynierii oprogramowania albo projektował systemy lub aplikacje niekoniecznie sam zajmując się pisaniem całego kodu, to takie podejście jest dla niego zupełnie naturalne.
Tylko nadludzie mogliby wyprodukować w pierwszym podejściu doskonały kod, natomiast w rzeczywistości odbywa się to tak, że najpierw programista zastanawia się sam lub z kolegami nad najlepszym sposobem rozwiązania problemu. Po uzyskaniu jakiejś ogólnej idei rozpoczyna się pisanie kodu. Niestety, ten moment zetknięcia się ze specyficznym wdrożeniem pomysłu i sam pierwotny pomysł może stać się niedostępny dla innych jeżeli najpierw sama idea nie zostanie opisana. W praktyce bywa tak, że rozważane są także alternatywne rozwiązania, które są następnie odrzucane z różnych powodów bez śladu jakiejkolwiek dokumentacji. Jest to jedna z większych niedogodności dla innych, którzy później mają rozwijać pierwotny projekt.
Takiej sytuacji można jednak zapobiec stosując np. technikę zwaną „programowaniem literackim”. Została ona pokazana (a może nawet wynaleziona) przez Donalda Knutha. Do programu TeX, pierwotnie napisanego w języku Pascal, wyprodukował on dwa programy narzędziowe. Do wycinania kodu z dokumentu służył program o nazwie tangle, zaś program weave był przeznaczony do wycinania dokumentacji.
Jak to działa?
W tym podrozdziale pokażemy zastosowanie jednego z narzędzi programowania literackiego o nazwie noweb. Jest ono dostępne dla systemu Linux, przynajmniej w dystrybucji Debian. W innych dystrybucjach prawdopodobnie można je także znaleźć. Początkowe litery „no” w nazwie „noweb” są wzięte od dwóch początkowych liter imienia autora, czyli Normana Ramsey'a. Istnieje wprawdzie wiele innych narzędzia pozwalających dokładniej kontrolować skład i formatowanie, ale noweb jest jednym z naszych faworytów ze względu na łatwość obsługi i duże możliwości, wykraczające poza podstawowe zasady programowania literackiego. Bardziej wydajnymi programami tego typu są fweb, funnelweb i szeroko doceniany cweb.
Program noweb rozróżnia w dokumencie dwa rodzaje sekcji, zwanych klockami (chunks). Są klocki dokumentacyjne zawierające opisy i klocki kodowe, zawierające kod.
Klocek dokumentacyjny rozpoczyna się od znaku @, za którym następuje znak nowego wiersza lub spacja. Klocek kodowy rozpoczyna się od dwóch trójkątnych nawiasów otwierających << umieszczonych na początku wiersza, za którymi następuje nazwa klocka (mogąca zawierać spacje), dwa trójkątne nawiasy zamykające >> i znak równości =.
W klocku dokumentacyjnym można stosować dowolne polecenia składu tekstu, np. używane przez LaTeX lub język HTML. Jeżeli wymagane jest podanie fragmentu kodu w klocku dokumentacyjnym, to należy go otoczyć podwójnymi nawiasami kwadratowymi: [[kod]].
Klocki kodowe mogą zawierać zarówno dowolne elementy kodu zapisane w jakimś języku programowania, jak i odwołania do innych klocków zapisane w postaci: <<tu nazwa>>. Nie narzuca się żadnych ograniczeń na język programowania, a w jednym dokumencie można także używać różnych języków.
Jako przykład niech posłuży niewielki program napisany w języku C, który oblicza rekurencyjne wartość silni. Oto nasz plik przeznaczony dla pakietu noweb:
@ Ten plik pokazuje zastosowanie narzędzi noweb. Pokażemy tu przykład funkcji obliczające w sposób rekurencyjny wartośc silni. Na początku podajemy opis ogólny programu. Nasz plik z programem nazywa się [[factorial.c]] i zawiera prostą funkcję [[main()]] wywołującą naszą funkcję do obliczania silni, wpisującą wynik do [[stdout]] i kończącą działanie.
<<factorial.c>>=
<<Dołączenie wymaganych plików nagłówkowych>>
<<Kod funkcji do obliczania silni>>
int main(void)
{
int result = <<Wywołanie funkcji silni z argumentem równym 5>> ;
printf ("Funkcja obliczająca silnię zwróciła %d jako wynik.\n",result);
return 0;
}
Mamy tu przykład programowania literackiego metodą „z góry na dół”. Najpierw występuje objaśnienie tego, co pojawi się w dalszych częściach, a następnie z klocków, które nie zostały jeszcze zdefiniowane, jest tworzony plik z kodem źródłowym factorial.c. W kilku wierszach prostego kodu można więc wyjaśnić swoje zamiary i przedstawić podstawowy zarys pracy, zaś koncentracja uwagi na pojedynczych zagadnieniach ułatwia zrozumienie programu okazjonalnym czytelnikom.
Oto pozostała część pliku:
@ Aby ta funkcja [[main]] działała poprawnie, musimy dołączyć plik nagłówkowy [[stdio.h]] dla definicji [[printf()]].
<<Dołączenie wymaganych plików nagłówkowych>>=
#include <stdio.h>
@ Jaka jest definicja silni? Po prostu użyjemy [[n! = n * (n-1)!]]. To sugeruje, że nasza funkcja do obliczania silni będzie miała jeden argument oraz że trzeba użyć rekurencji. Nazwijmy naszą funkcję [[factorial()]] i załóżmy, że typ [[int]] będzie wystarczający zarówno dla argumentu, jak i dla wyniku.
<<Kod funkcji do obliczania silni>>=
int factorial(int n)
{
<<Sprawdźmy, czy n mieści się w dozwolonym przedziale>>
return <<wynik wywołania [[n * factorial(n-1)]]>>;
}
@ Kiedy nasz parametr [[n]] nie mieści się w dozwolonym przedziale? Poprawna odpowiedź brzmi: kiedy jest mniejszy lub równy zero. W takim wypadku silnia nie jest określona. Wydaje się, że nie warto zatrzymywać programu kiedy to się stanie, a więc zwracamy po prostu 1 jako odpowiedź jeśli argument wykroczył poza zakres:
<<Sprawdźmy, czy n mieści się w dozwolonym przedziale>>=
if (n <+ 0)
return 1;
@ Dodatkową zaletą takiego podejścia jest to, że mamy teraz punkt wyjścia z naszej funkcji, który jest wymagany w metodach rekurencyjnych (w przeciwnym wypadku działają one bez końca).
Napisanie reszty kodu naszej funkcji jest już proste: po prostu wywołujemy ją ponownie, lecz z pomniejszonym argumentem:
<<wynik wywołania [[n * factorial(n-1)]]>>=
n * factorial(n-1)
@ Teraz nasza funkcja jest już w pełni zdefiniowana. Możemy wywołać ją z naszego programu głównego i otrzymamy:
<<Wywołanie funkcji silni z argumentem równym 5>>=
factorial(5)
I to już wszystko! Aby utworzyć teraz plik factorial.c wystarczy wywołać program notangle:
$ notangle -Rfactorial.c factorial.nw >factorial.c
W wyniku działania tego programu na plik wejściowy factorial.nw otrzymamy następujący plik factorial.c:
#include <stdio.h>
int factorial(int n)
{
if (n <= 0)
return 1;
return n * factorial(n-1) ;
}
int main(void)
{
int result = factorial(5) ;
printf ("Funkcja obliczająca silnię zwróciła %d jako wynik.\n",result);
return
}
Kod ten można skompilować i sprawdzić, czy wynik jego działania będzie poprawny (czyli 120). Jeżeli do kodu trzeba dołączyć komentarze lub dokumentację, to należy użyć programu nountangle. W praktyce nie jest to wymagane, jeżeli zmiany są wprowadzane w pliku początkowym, a nie w wygenerowanym kodzie źródłowym, chociaż obecność komentarzy w tym kodzie może się czasami przydać.
Na tym jednak jeszcze nie kończymy, ponieważ nie uzyskaliśmy dotychczas dokumentacji! Produkujemy ją za pomocą polecenia noweave, które automatycznie tworzy indeksy do wszystkich zastosowanych funkcji:
$ noweave -autodefs c -index factorial.nw >factorial.tex
W wyniku otrzymujemy plik dla programu LaTeX. Po trzykrotnym uruchomieniu tego programu (jak opisano wcześniej) możemy wyświetlić dokumentację np. za pomocą polecenia xdvi:
rysunek ze strony 920 |
I to już naprawdę wszystko! Czyż nie należy tego traktować jako łatwej i wydajnej metody tworzenia dobrze udokumentowanego kodu (lub dobrze zakodowanej dokumentacji)?
Programowanie literackie wagi lekkiej
Czytelnik jest zapewne oszołomiony pomysłem pisania książek na temat swoich programów lub nie potrafi pisać wyjaśnień tak dobrze, jak kod. W większości wypadków lżejsze podejście do tego zagadnienia może być do przyjęcia.
To, co jest opisane niżej, działa tylko dla programów pisanych w języku C. Mamy tu na myśli narzędzie zwane c2man, w którym przyjęto proste założenie: komentarze powinny być umieszczane w kodzie programu po każdym elemencie typu wyliczeniowego, każdym elemencie struktury i każdym argumencie funkcji, tak jak w poniższym przykładzie wziętym ze strony podręcznika systemowego programu c2man:
enum Place
{
HOME, /* Home, Sweet Home */
WORK, /* where I spend lots of time */
MOVIES, /* Saturday nights mainly */
CITY, /* New York, New York */
COUNTRY /* Bob's Country Bunker */
}
;
/*
* do some useful work for a change.
* This function will actually get some productive
* work done, if you are really lucky.
* returns the number of milliseconds in a second.
*/
int dowork(int count, /* how much wwork to do */
enum Place where, /* where to do the work */
long fiveclock /* when to knock off */
Po wywołaniu programu c2man z pliku nagłówkowego zostanie utworzona strona podręcznika systemowego zawierająca sekcje NAME, SYNOPSIS, PARMETERS, DESCRIPTION i RETURNS wypełnione treścią komentarzy wstawionych do kodu źródłowego, z zachowaniem odpowiedniej wielkości liter. Przy elementach typu wyliczeniowego podane będą także ich poprawne wartości.
Jak już wspomnieliśmy, takie podejście może wystarczyć dla dokumentowania funkcji bibliotecznych, ale nie pozwala na skorzystanie ze wszystkich dobrodziejstw programowania literackiego omówionych w poprzednim podrozdziale.
Wymiana dokumentów
Jeżeli dokumentacja została napisana, ale nikt z jej odbiorców nie może jej odczytać, to wysiłek twórcy pójdzie całkowicie na marne. Zdarza się wówczas, gdy np. użytkownik Microsoft Windows przekazuje użytkownikowi systemu Linux plik utworzony za pomocą programu Microsoft Word. Jeżeli odbiorca nie dysponuje jakimś oprogramowaniem umożliwiającym odczyt takich dokumentów (np. czymś z serii Linux Office lub programem mswordview dokonującym przekształcenia na HTML), to niewiele może zrobić. Nawet jeżeli uda się skorzystać z któregoś ze wspomnianych programów, to przekształcenie nigdy nie będzie wystarczająco dokładne.
Oczywiście, to samo odnosi się do sytuacji odwrotnej jeżeli np. nasz program został udokumentowany za pomocą pakietu troff i wynik jest przekazywany użytkownikowi Microsoft Windows. Pomimo tego, że troff jest prawdopodobnie dostępny na tej platformie, to nie jest on idealnym formatem nadającym się do wymiany dokumentacji.
Potrzebny jest więc wspólny mianownik. Mamy tu kilka możliwości:
Czysty tekst: To działa zawsze, przynajmniej w kręgu języka angielskiego i dokumentów stosujących inne standardy kodowania z serii ISO-8859. Chińczycy, Japończycy i Rosjanie nie mają takiego szczęścia. Oczywiście, w takiej dokumentacji traci się formatowanie i elementy graficzne. Może to stanowić zaletę, ale często nią nie jest.
HTML: Ten format ma znaczną przewagę nad czystym tekstem i pozwala na wprowadzenie pewnej struktury dokumentu, która może być odczytana przez różne systemy.
PDF: Format PDF (Portable Document Format) został opracowany przez firmę Adobe. Wykorzystano w nim PostScript, ale z pewnymi ograniczeniami, ułatwiającymi przetwarzanie dokumentu. Program Acrobat Reader jest dostępny dla wielu systemów, łącznie z Linuksem. Można także użyć pakietu ghostscript, który także obsługuje format PDF. Program ten potrafi także odfiltrować tekst z pliku PDF. Alternatywną przeglądarką plików PDF w systemie Linux jest xpdf.
Pliki PDF
Ręczne tworzenie plików PDF lepiej pozostawić ekspertom, którzy poruszają się na co dzień w kręgu języka PostScript. Dla większości śmiertelników nie jest to zadanie, które można łatwo wykonać.
Podczas pisania tego rozdziału firma Adobe nie dysponowała wersją programu Acrobat dla systemu Linux. Na szczęście istnieje alternatywne rozwiązanie, z którego mogą skorzystać użytkownicy tworzący dokumentację w programu LaTeX. Narzędzie o nazwie pdflatex umożliwia nie tylko tworzenie plików dvi, ale także plików PDF, które można odczytywać na każdej platformie. Sposób użycia tego programu jest banalny: po prostu w wierszach poleceń należy zastąpić wywołania latex wywołaniami pdflatex.
Podsumowanie
W tym rozdziale omówiliśmy bardzo wiele różnych postaci dokumentacji. Pokazano także różne kategorie odbiorców tej dokumentacji (zwykli użytkownicy, zaawansowani użytkownicy i administratorzy, programiści). Przedyskutowano różne formy dokumentacji elektronicznej, takie jak np. pomoc kontekstowa w interfejsie graficznym, strony podręcznika systemowego i pliki info.
Jeżeli tworzona dokumentacja nie jest prosta, lecz składa się z pewnej liczby modułów, to warto skorzystać ze specyficznego systemu dokumentowania, jeśli myśli się o rozwoju programu. Jako możliwe rozwiązania przedstawiono tu LaTeX i DocBook.
Próbując pokazać pewne możliwości przekształcenia pisania programu w postaci pracy literackiej upiekliśmy dwie pieczenie na jednym ogniu, ponieważ omówiliśmy wstępnie koncepcję programowania literackiego.
22 Część I ♦ Podstawy obsługi systemu WhizBang (Nagłówek strony)
22 F:\helion\korekta\R-25-t.doc