70040 lastscan13 (9)
efektywność =
Sterowanie {pamięć mikrokodu) zawiera układ szeregowania operacji i pamięć ROM mikrokodów. Układ steruje potokami stałoprzecinkowymi, zmiennoprzecinkowym, obsługą wyjątków, pułapek i przerwań. Podwojona stałoprzecinkowa jednostka arytmetyczno-logiczna ALU pracuje jednak z pojedynczym plikiem rejestrowym
Układ stronicowania jest załączany ustawieniem bitu PO w rejestrze CRO i zawiera osobne bufory dla każdej pamięci podręcznej. Każdy bufor antycypacji translacji umożliwia jednoczesną obsługę dwóch adresów liniowych czyli jednoczesną translację adresu strony dla obu potoków Układ umożliwia obsługę stron o rozmiarze 4kB (12 bitowy adres na stronie, dwupoziomowa translacja adresu strony) łub 4MB (22 bitowy adres na stronie, 10 bitowy adres strony, translacja adresu jednopoziomowa)..
Jednostka zmiennoprzecinkowa ma 3 osobne bloki dodawania, mnożenia i dzielenia, co pozwała przyspieszyć wykonanie złożonych instrukcji zmiennoprzecinkowych.
Potokowe wykonanie instrukcji
Elementami struktury funkcjonalnej procesora Pentium wpływającymi na szybkość przetwarzania sa
• dedykowana pamięć podręczna kodu
• blok antycypacji pobierania kodu
• układ prognozy skoku
• podwojona potokowa jednostka stałoprzecinkowa
• połolowa jednostka zmiennoprzecinkowa
Linia kodu pobrana z pamięci podręcznej kodu łub w przypadku chybienia z pamięci zewnętrznej (podręcznej lub głównej) jest przepisywana do aktywnej kolejki rozkazów. Pobranie jednej linii z pamięci podręcznej (32 bajty) następuje każdorazowo, gdy w Ki for ze jest dość wolnego miejsca. 64-bajiowa pojemność każdego bufora zapewnia wyeliminowanie zwłoki w pobieraniu kodów kolejnych instrukcji.
Dwie kolejne instrukcje z początku bufora FIFO (kolejki) są przesyłane jednocześnie do układów wstępnego dekodowania Dl obu potoków i w razie stwierdzenia możliwości jednoczesnego wykonania są kierowane współbieżnie do obu potoków. Instrukcje wykonywane współbieżnie są synchronizowane. Wstrzymanie któregokolwiek z potoków powoduje jednoczesne wstrzymanie drugiego potoku. Jeśli instrukcje muszą być wykonane sekwencyjnie, wówczas usuwana jest instrukcja z jwtoku V i kierowana ponownie do potoku U wraz z kolejną instrukcja kierowaną do potoku V.
Jeżeli którakolwiek z jednocześnie dekodowanych instrukcji jest instrukcją rozgałęzienia naslępuje uaktywnienie układu prognozy rozgałęzienia (branch prediction) Jeśli rozgałęzienie jest przewidywane, to bufor kolejki jest przełączany i kolejne instrukcje, począwszy od adresu docelowego rozgałęzienia są kierowane do innej kolejki
Jeśli prognoza była trafna, lo kolejne instrukcje są pobierane do bloków wstępnego dekodowania z aktywnej kolejki. Jeśli jednak prognoza była błędna, co zostaje stwierdzone dopiero w fazie wykonania rozkazu, wówczas i kolejne instrukcje, począwszy od adresu docelowego rozgałęzienia są kierowane do innej kolejki
Jeśli prognoza była trafna, lo kolejne instrukcje są pobierane do bloków wstępnego dekodowania z aktywnej kolejki. Jeśli jednak prognoza była błędna, co zostaje stwierdzone dopiero w fazie wykonania rozkazu, wówczas i kolejne instrukcje, począwszy od adresu docelowego rozgałęzienia są kierowane do innej kolejki.
Jeśli prognoza była trafna, lo kolejne instrukcje są pobierane do bloków wstępnego dekodowania z aktywnej kolejki. Jeśli jednak prognoza była błędna, co zostaje stwierdzone dopiero w fazie wykonania rozkazu, wówczas i kolejne instrukcje, począwszy od adresu docelowego rozgałęzienia są kierowane do innej kolejki.
Jeśli prognoza była trafna, to kolejne instrukcje są pobierane do bloków wstępnego dekodowania z aktywnej kolejki Jeśli jednak prognoza była błędna, co zostaje stwierdzone dopiero w fazie wykonania rozkazu, wówczas musi nastąpić ponowne przełączenie kolejek, opróżnienie kolejki błędnie wypełnionej oraz kolejnych rozkazów z drugiej kolejki (zostały one umieszczone lam przed przełączeniem). W takim wypadku potok U (V) musi być wstrzymany na 3 (4) takty (instrukcje w fazach Dl, D2 oraz EX powinny być unieważnione) Podobna sytuacja występuje przy nieprawidłowej prognozie braku skoku. Powstaje wtedy dodatkowa zwłoka na wypełnienie aktywnej kolejki nowymi instrukcjami Po wykonaniu rozkazu rozgałęzienia, niezależnie od trafności prognozy, w układzie prognozy następuje uaktualnienie historii skoków
Prognoza skoku jest dokonywana na podstawie zawartości bufora adresów docelowy ch rozgałęzień BTB {branek target buffer) Bufor len jest czlerodrożną pamięcią monitorującą (Inok-aside) o 256 wejściach Każde wejście zawiera:
• bit ważności wejścia
• dwa bity historii rozgałęzienia
• adres źródłowy rozkazu rozgałęzienia
Szansa rozgałęzienia jest kodowana na parze bitów, której przypisywane są odpowiednio poziomy:
• bardzo prawdopodobny (strongfy taken. ST)
• prawdopodobny {weakly taken, WT)
• małoprawdopodobny {weakly not taken,WNT)
• nieprawdopodobny {strongly not taken, SNT)
Rozgałęzienie jest prognozowane przy wyższych poziomach szansy wykonania (prawdopodobny lub bardzo prawdopodobny). Wykonanie skoku powoduje podwyższenie, nic wykonanie obniżenie poziomu szansy jego wystąpienia (jeśli jest to możliwe). Gdy adres jest wpisany BTB, pierwszą prognozą jest „nieprawdopodobny” (SNT). nawei w przypadku skoku bezwarunkowego. Po pierwszym wykonaniu rozgałęzienia adres rozkazu rozgałęzienia jest wpisywany do bufora a bity historii ustawiane jako „bardzo prawdopodobny” (ST) Trafna pierwsza prognoza nie wystąpienia rozgałęzienia nie powoduje wpisu do bufora
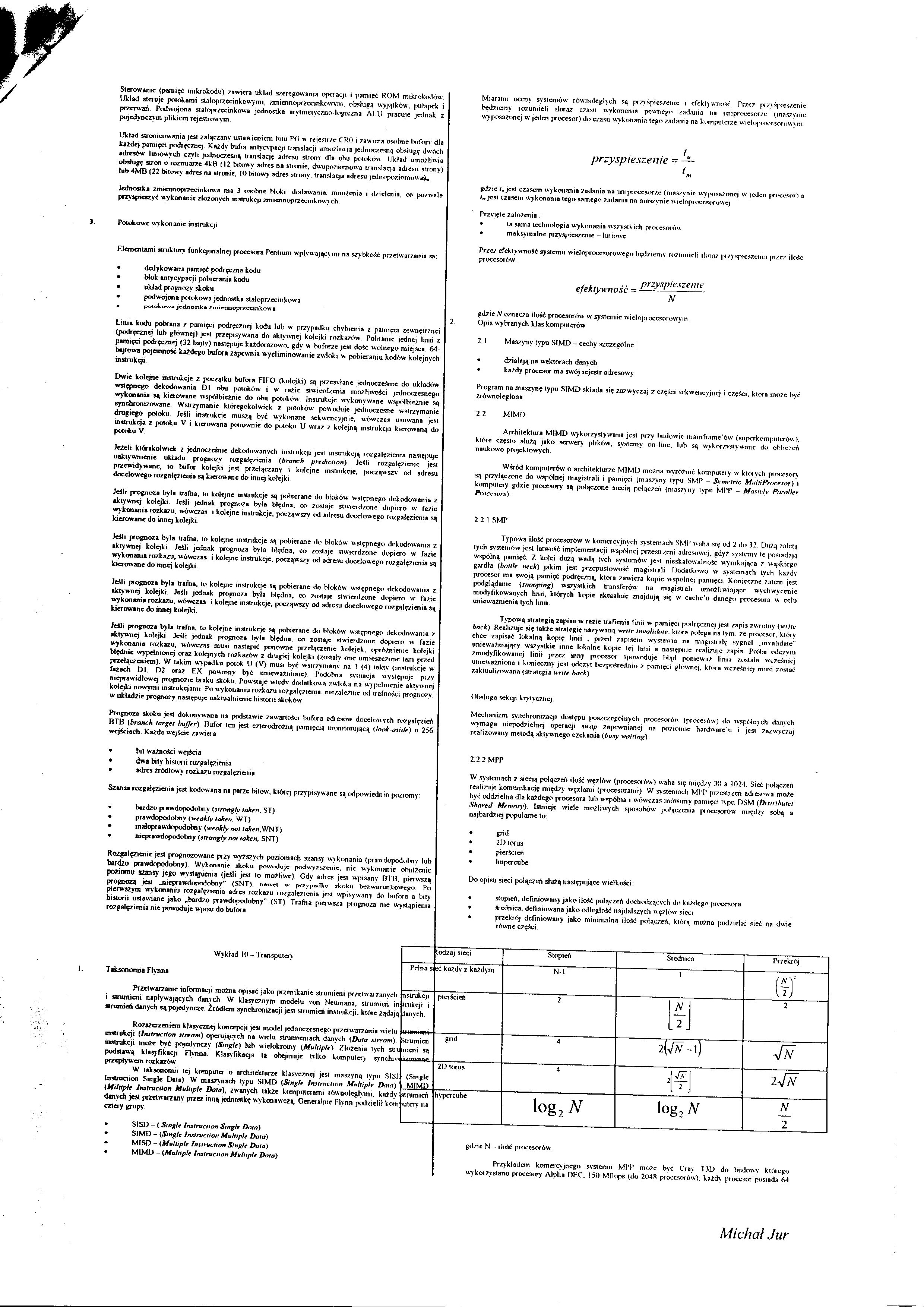
Miarami oceny systemów równoległych są przyśpieszenie i efektywność Przez przyśpieszenie będziemy rozumieli iloraz czasu wykonania pewnego zadania na un i procesorze (maszynie wyposażonej w jeden procesor) do czasu wykonania tego zadania na komputerze wieloprocesorowym.
r
przyspieszenie - —
t
gdzie K jest czasem wykonania zadania na uniproccsor/.e (maszynie wyposażonej w jeden procesor} a lm jest czasem wykonania tego samego 2ndania nn maszynie wieloprocesorowej
Przyjęte założenia:
• la sama technologia wykonania wszystkich procesorów
• maksymalne przyspieszenie - liniowe
Przez efektywność systemu wieloprocesorowego będziemy rozumieli iloraz przyspieszenia przez ilość procesorów.
przyspieszenie
N
gdzie jV oznacza ilość procesorów w systemie wieloprocesorowym Opis wybranych klas komputerów
2.1 Maszyny typu SIMD - cechy szcz.ególne.
• działają na wektorach danych
• każdy procesor ma swój rejestr adresowy
Program na maszynę typu SIMD składa się zazwyczaj z części sekwencyjnej i części, która może być zrównoleglona.
2.2 M1MD
Architektura M1MD wykorzystywana jest przy budowie mainfratneów (superkomputerów), które często służą jako serwery plików, systemy on-linc, lub są wykorzystywane do obliczeń naukowo-projektowych.
Wśród komputerów o architekturze M1MD można wyróżnić komputery w których procesory są przyłączone do wspólnej magistrali i pamięci (maszyny typu SMP - Symetrie MuhiProcesor) i komputery gdzie procesory są połączone siecią połączeń (maszyny typu MIT - Masiv!y Paraller Pmceson).
2.2 t SMP
Typowa ilość procesorów w komercyjnych systemach SMP waha się od 2 do 32 Dużą zaletą łych systemów jest łatwość implementacji wspólnej przestrzeni adresowej, gdyż systemy te posiadają wspólną pamięć. Z kolei dużą wadą tych systemów jest nieskalowalność wynikająca z wąsktego gardła (bottle neck) jakim jest przepustowość magistrali rXxlalkowo w systemach tych każdy procesor ma swoją pamięć podręczną która zawiera kopie wspólnej pamięci Konieczne zatem jest podglądanie (snooping) wszystkich transferów na magistrali umożliwiające wychwycenie modyfikowanych linii, których kopie aktualnie znajdują się w cache’u danego procesora w celu unieważnienia tych linii.
Typową strategią zapisu w razie trafienia linii w pamięci podręcznej jest zapis zwrotny (wriie back) Realizuje się także strategię nazywaną write Inualielote, która polega na tym, że procesor, który chce zapisać lokalną kopię linii , przed zapisem wystawia na magistialę sygnał „imalidate" unieważniający wszystkie inne lokalne kopie tej linii a następnie realizuje zapis Próba odczytu zmodyfikowanej linii przez inny procesor spowoduje błąd ponieważ linia została wcześniej unieważniona i konieczny jest odczyt bezpośrednio z pamięci głównej, która wcześniej musi zostać zaktualizowana (strategia write hack).
Obsługa sekcji krytycznej.
Mechanizm synchronizacji dostępu poszczególnych procesorów (procesów) do wspólnych danych wymaga niepodzielnej operacji swap zapewnianej na poziomie hardware'u i jest zazwyczaj realizowany metodą aktywnego czekania (busy waiting).
2.2.2 MPP
W systemach z siecią połączeń ilość węzłów (procesorów) waha się między 30 a 1024. Sieć połączeń realizuje komunikację między węzłami (procesorami). W systemach MPP przestrzeń adresowa może być oddzielna dla każdego procesora lub wspólna i wówczas mówimy pamięci typu DSM (Distrihutet Shared Memory). Istnieje wiele możliwych sposobów połączenia procesorów między sobą a najbardziej popularne to:
• gnd
• 2D torus
• pierścień
• hupereube
Do opisu sieci połączeń służą następujące wielkości:
• stopień, definiowany jako ilość połączeń dochodzących do każdego procesora
• średnica, definiowana jako odległość najdalszych węzłów sieci
• przekrój definiowany jako minimalna ilość połączeń, którą można podżielić sieć na dwie równe części.
|
Wykład 10- Transputery Taksonomia Flynna Przetwarzanie informacji można opisać jako przenikanie strumieni przetwarzanych i strumieni napływających danych W klasycznym modełu von Neumana, strumień in strumień danych są pojedyncze. Źródłem synchronizacji jest strumień instrukcji, które żądają |
łodzaj sieci |
Stopień |
Średnica |
Przekrój | |||
|
Pełna |
.*ć każdy z każdym |
N-l |
1 |
(tI | |||
|
nslrukcji trakcji i danych. |
pierścień |
2 |
N .2. |
2 | |||
|
instrukcji (Insiruction stream) operujących na widu strumieniach danych (Data snram) instrukcji może być pojedynczy (Single) łub wielokrotny (Multiple). Złożenia tych sm podstawą klasyfikacji Flvnna. Klasyfikacja ta obejmuje tylko komputery svnchro przepływem rozkazów W taksonomii tej komputer o architekturze klasycznej jest maszyną typu SISI Insiruction Single Data) W maszynach typu SIMD (Single Insiruction Multiple Data) (Miltiple Insiruction Multiple Data), zwanych także komputerami równoległymi, każdy danych jest przetw arzany przez inną jednostkę wykonawczą. Generalnie Flynn podzielił kom cztery grupy: |
Strumień nieni są |
grid |
4 |
2(Vy-i) |
Jn | ||
|
(Single MIMD |
2D toras |
4 |
JŁ 2 |
2J~N | |||
|
strumień )utery na |
hypereube |
log2 N |
log2 N |
N 2 | |||
SłSD - ( Single Insiruction Single Dala) SIMD - {Single Insiruction Multiple Dota) MISD - (Multiple Insiruction Single Data) MIMD - (Multiple Insiruction Multiple Dota)
gdzie N - ilość procesorów.
Przykładem komercyjnego systemu MPP może być Cray T3D do budowy którego wykorzystano procesory Alpha DEC, 150 Mflops (do 2048 procesorów), każdy procesor posiada 64
MichaI Jur
Wyszukiwarka
Podobne podstrony:
Image600 r W skład mikrokomputera wchodzi: — układ sterowania mikroprogramem (MCU)
Jak dz5 Pamięć programu Układ sterowania Pamięćdanych Uldadarytmetyczno- logiczny UkładWe/wy
Slajd8 Układ wykonawczy zawiera: i* V 1. Układ sterowania z reje
Struktura sprzętowa komputerowego systemu sterowania Pamięci zewnętrzne Proces sterowany Kanał
Slajd31 Efekty biosymulacyjne ❖ Poprawa mikrokrążenia krwi ❖
img394 f. prawidłowe odpowiedzi B i D27. Mikrokosmki: a. zawiera
Politechnika Poznańska Studium podyplomowe Instytut Sterowania Inżynieria Mikrokomputerowa i
Politechnika Poznańska Studium podyplomowe Instytut Sterowania Inżynieria Mikrokomputerowa i
Politechnika Poznańska Studium podyplomowe Instytut Sterowania Inżynieria Mikrokomputerowa i
Politechnika Poznańska Studium podyplomowe Instytut Sterowania Inżynieria Mikrokomputerowa i
IMGD71 (2) sterownik (regulator) element wykonawczy układ pomiarowy
PRZEK1. Jest on sterowany przez mikrokomputer w głowicy. Na styki ruchome tego przekaźnika wchodzi s
więcej podobnych podstron