Co to jest baza danych?
Baza danych jest zbiorem logicznie uporządkowanych danych oraz ich opisów. Stałym elementem baz danych jest katalog systemu w którym znajdują się opisy struktur danych. W poprawnie zaprojektowanym systemie baz danych możliwe jest modyfikowanie struktury danych bez naruszenia zawartości danych.
Omów poznane metody wprowadzania danych do baz.
1. skanowanie - proces konwersji danych do formatu stosowanego w tworzonej bazie danych [np. z nośnika papierowego do postaci elektronicznej].
Należy wyróżnić 2 przypadki:
seryjne skanowanie dokumentów o zunifikowanej strukturze [np. dane z biletów lotniczych]
skanowanie dokumentów o niejednorodnym formacie.
2. wprowadzanie danych do formularzy
3. konwersie danych elektronicznych
4. dane generowane przez aplikacje
Omów pułapki: luka, wachlarz.
pułapka typu wachlarz - sytuacja, w której model odzwierciedla związek pomiędzy pewnymi typami encji, ale droga pomiędzy niektórymi elementami obu typów encji jest nieokreślona.
pułapka typu luka - sytuacja, w której brakuje powiązań pomiędzy niektórymi elementami obu typów encji.
Co to są postacie normalne relacji?
Postać relacji w bazie danych, w której nie występuje redundancja. Doprowadzeniu relacji do takiej postaci służy normalizacja bazy danych.
Omów zasady poprawnego organizowania obiegu informacji.
Omów tok postępowania przy wprowadzaniu danych z dokumentów skanowanych.
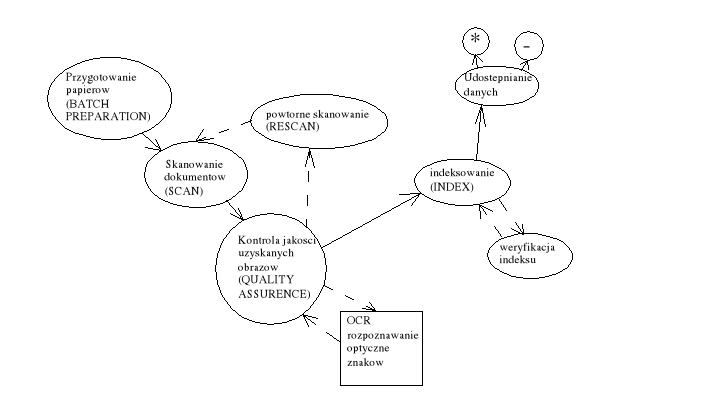
proces OCR jest zawsze obciążony błędem w związku z tym trzeba się liczyć, z błędnie odczytanymi znakami ok. 3% OCR korzystają ze słowników dla podniesienia poprawności odczytu.
indeksowanie jest procesem opatrzenia dokumentu lub dodania do jego zawartości unikalnego znaku, jest to klucz do relacji zawierających dane dokumenty
* - mapy bitowe np. TIFF
- - SQL indices - przez udostępnianie klucza do dokumentu
przygotowanie
przygotowanie dokumentu - określanie typu dokumentów oraz pola indeksowania
przygotowanie dokumentów - przygotowanie fizyczne
określanie stref które będą poddawane analizie OCR
skanowanie
wczytywanie danych
powtórne skanowanie
analiza zawartości odczytanych danych
przetwarzanie obrazów - image processing
korekta kątowego usytuowania skanowanego obrazu
rozpoznawanie kodów paskowych - kody paskowe są standardowym sposobem oznaczania typów dokumentów przewidzianych do masowego (seryjnego) skanowania. Rozpoznanie kodu paskowego decyduje o sposobie przetwarzania skanowanego dokumentu. [ Dokumenty mogą składać się z wielu obrazów skanowanych. Analiza zawartości dokumentu może więc wymagać połączenia wielu obrazów składowych w dokument wynikowy. Przykładem może być skanowanie dokumentów wielostronicowych ]
rozpoznawanie znaków OCR - odczyt zawartości dokumentu.
Omów poznane typy zależności funkcjonalnych.
Porównaj systemy baz danych z dedykowanymi systemami gromadzenia danych.
Struktura systemu zarządzania bazą danych.
procesor zapytań
program zarządzający bazą danych
program zarządzający plikami
program procesor języka DML
kompilator języka DDL
program zarządzający katalogiem systemu
system kontroli dostępu
procesor zapytań
system kontroli poprawności poleceń
optymalizator zapytań
program zarządzający transakcjami
system do harmonogramowania zadań
system usprawniający odtwarzanie systemu z przed awarii
Pojęcia: relacja, encja, atrybut, krotka, tabela, wiersz, kolumna, rekord, pole.
Logiczny i fizyczny model bazy danych.
Omów rodzaje użytkowników baz danych.
Związki encji.
Redundancja danych.
Omów wady i zalety systemów baz danych.
Eliminacja redundancji danych (nadmiarowości)
Spójność danych
Możliwość uzyskania większej ilości informacji z tych samych danych
Możliwość współdzielenia danych
Ulepszona kontrola integralności danych
Wyższa wydajność programistów
Złożoność
Rozmiar
Dodatkowe koszty sprzętu
Koszt konwersji danych
Wydajność
Omów na przykładach pojęcie atrybutu i jego dziedziny.
Pojecie klucza - definicje i przykłady.
Co to jest proces normalizacji?
Procesy logiczne.
Omów postacie normalne.
Postaci nieznormalizowane.
Omów składnię SQL.
SQL DML - język manipulowania danymi
SQL DDL - język operacji na strukturach
SQL DCL - język kontroli nad danymi
Pojęcia: denormalizacja relacji, dekompozycja, modele danych.
kryterium |
Dedykowana struktura plików |
Baza danych |
dostęp do danych |
izolowany |
współdzielony |
redundancja |
występuje |
jest eliminowana |
struktura danych |
zdefiniowana w aplikacji |
niezależna od aplikacji, możliwość jej zmiany bez naruszenia danych |
zbiór zapytań |
zamknięty i zdefiniowany dla danej aplikacji |
zewnętrzny, ogólny zbiór (język) zapytań |
przechowywanie danych |
w strukturach aplikacji |
niezależnie od aplikacji |
złożoność sytemu |
niska |
duża |
powiązania miedzy danymi |
brak |
występują |
inne cechy |
+ możliwość optymalizacji szybkości działania i objętości + możliwość budowy systemów działających w czasie rzeczywistym
|
+ spójność danych |
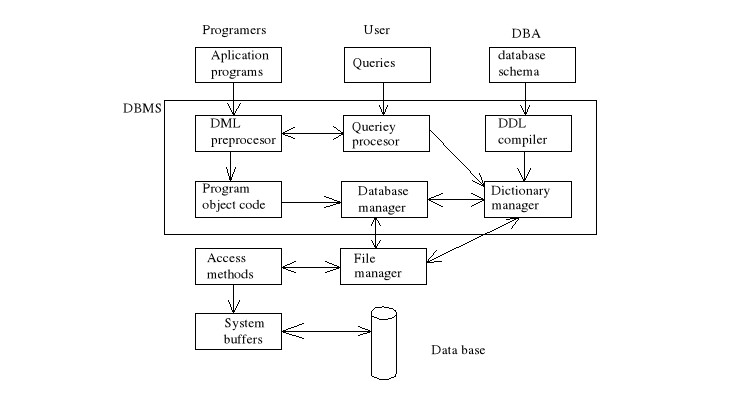
Podstawowe elementy systemu zarządzania bazą danych:
Elementy programu zarządzającego bazą danych:
relacja - zbiór krotek, który może być reprezentowany w postaci tabeli.
encja - obiekt - to obiekt dający się zidentyfikować na podstawie swoich atrybutów. [np. studenci, pracownicy].
atrybut - kolumna(element tabeli) - cechy encji które dają się wyrażać przez przydanie im pewnych wartości [np. imię, nazwisko].
krotka - rekord - wiersz(element tabeli) - to ciąg (skończony), którego kolejnymi elementami są dane o określonych typach [np. 345, „Jan”, „Kowalski”, 19790702].
tabela - jest wydzielonym logicznie zbiorem danych, zorganizowanych w formie tabeli. Pojedyncza tabela jest reprezentacją encji, relacji między encjami, lub stanowi zawartość całej bazy danych.
pole - wartość atrybutu, którego dziedzina jest zbiór dopuszczalnych wartości.
Model logiczny określa sposób rozmieszczenia danych, charakter powiązań między nimi, ogólnie sposób zachowywania sie systemu.
Model fizyczny to propozycja konkretnej realizacji (implementacji) modelu logicznego.
administrator bazy danych - projektuje strukturę baz danych, przydziela uprawnienia użytkownikom, określa perspektywy użytkownika, tworzy kopie bezpieczeństwa danych, w niektórych systemach wyróżnia się administratora danych oraz administratora bazy danych.
programiści aplikacji - użytkownicy budujący procedury (w języku DML) pozwalające na pozyskiwanie informacji z danych.
użytkownicy naiwni - wszyscy użytkownicy którzy dostęp do danych i informacji uzyskują za pośrednictwem mechanizmu perspektyw.
W modelach logicznych wyróżnia się encje mocne i słabe. Istnienie encji mocnej nie zależy od występowania elementów innych typów encji (encje słabe - odwrotnie).
Związek określa fakt istnienia pewnego rodzaju połączenia pomiędzy elementami różnych typów encji. Związek określany jest przez jego stopień. Stopniem związku nazywamy powiązania różnych typów encji, których elementy można w danym związku jednocześnie wystąpić.
Rodzaje związków: jeden-do-jednego, jeden-do-wielu, wiele-do-wielu.
W powiązaniach pomiędzy encjami mogą występować powiązania rekursyjne których powinno sie unikać.
Redundancja jest to występowanie wielu zapisów tych samych danych. Kontrola redundancji zaczyna się już na etapie projektowania baz danych. W przypadku relacyjnych baz danych proces który zapewnia uporządkowanie danych w poszczególnych zbiorach zwany jest normalizacją.
anomalie modyfikacji - podczas modyfikacji wartość nie zostanie poprawiona we wszystkich krotkach .
anomalie usunięć - usunięcie wartości atrybutu może spowodować utratę części danych (całej krotki).
Zalety:
Wady:
Atrybut jest cechą encji. [np. encja pudełko zawiera atrybuty: rodzaj, szerokość, długość, wysokość].
Dziedzina atrybutu to zbiór wartości jakie może przyjąć atrybut [np. wartości atrybutu wysokość musza być większe od zera].
Klucz główny - oznacza wybrany zestaw atrybutów jednoznacznie identyfikujący każda krotkę tej relacji.
Klucz kandydujący - oznacza wybrany zestaw atrybutów jednoznacznie identyfikujący każda krotkę tej relacji, ale niebędący kluczem głównym (spośród kluczy kandydujących wybiera się klucz główny).
Klucz obcy - oznacza wybrany zestaw atrybutów niebędący kluczem głównym tej tabeli, ale ich wartości są wartościami klucza głównego innej tabeli.
klucze mogą być jednoelementowe [np. id] lub wieloelementowe [np. nazwisko, imie, data_urodzenia]
Proces przekształcania reprezentacji bazy danych (nazywany również rozkładem odwracalnym), polegający na odnajdywaniu logicznych związków między elementami danych. W każdym etapie normalizacja bazy strukturę danych dzieli się na coraz więcej tabel z zachowaniem podstawowych związków między elementami danych.
Pierwsza postać normalna (1NF) - wartości atrybutów relacji R są elementarne tzn. są to pojedyncze wartości określonego typu, a nie zbiory wartości. [np. Płeć: męska / Imię: Robert, Adam => Płeć: męska / Imię: Robert || Płeć: męska / Imię: Adam]
Druga postać normalna (2NF) - atrybuty nie wchodzące w skład klucza są zależne od całego klucza (nie tylko od jego części). [np. tabela: id_produktu, wymiar, producent => tabela1: id_produktu, wymiar / tabela2: id_producenta, nazwa]
Trzecia postać normalna (3NF) - każdy atrybut wtórny relacji R jest tylko bezpośrednio zależny od klucza głównego. [np. tabela: id_produktu, id_producenta, adres, cena => tabela1: id_produktu, id_producenta, cena / tabela2: id_producenta, nazwa, adres]
Czwarta i piąta postać normalna są w zasadzie używane wyłącznie przy okazji rozważań teoretycznych.
Postaci nieznormalizowane to takie, które zawierają grupy powtórzeniowe (występuje redundancja).
SQL:
Przykładowe polecenia:
SELECT - pobranie z bazy danych,
INSERT - umieszczenie danych w bazie,
UPDATE - zmiana danych,
DELETE - usunięcie danych z bazy.
Przykładowe polecenia:
CREATE - utworzenie struktury (bazy, tabeli, indeksu, itp.),
DROP - całkowite usunięcie struktury,
ALTER - zmiana struktury (dodanie kolumny do tabeli, zmiana typu danych w kolumnie tabeli).
GRANT - przydzielanie uprawnień użytkownikom,
REVOKE - zabieranie uprawnień użytkownikom.
Denormalizacja - wprowadzenie kontrolowanej nadmiarowości do bazy danych w celu przyspieszenia wykonywania na niej operacji.
Dekompozycja relacji - podział atrybutów relacji R miedzy dwa schematy nowych relacji.
Modele baz danych: relacyjny, obiektowy, obiektowo-relacyjny, semistrukturalny (XML), hierarchiczny, sieciowy
Wyszukiwarka
Podobne podstrony:
1 Tworzenie bazy danychid 10005 ppt
bazy danych II
Bazy danych
Podstawy Informatyki Wykład XIX Bazy danych
Bazy Danych1
eksploracja lab03, Lista sprawozdaniowych bazy danych
bazy danych druga id 81754 Nieznany (2)
bazy danych odpowiedzi
Bazy danych
notatek pl g owacki,bazy danych Nieznany
BAZY DANYCH SQL (2)
Bazy danych kolo 2 1 id 81756 Nieznany
Projekt Bazy Danych
Microsoft PowerPoint 02 srodowisko bazy danych, modele
in2 modelowanie bazy danych
kolokwium sklepy1, WAT, SEMESTR V, PWD, Bazy danych od maslaka
Długi wstęp, NAUKA, WIEDZA, Bazy danych
więcej podobnych podstron