7652915402
4. OCR
Rozpoznawanie tekstu stanowi niełatwe zadanie dla automatycznego systemu komputerowego. Danymi źródłowymi dla algorytmów rozpoznawczych mogą być tutaj zeskanowane teksty pisane, zapisane w formacie obrazu cyfrowego. Działanie algorytmu rozpoznającego tekst jest w uproszczeniu następujące:
1. Określenie kierunku, w którym biegnie tekst (w zależności od języka)
2. Podzielenie obrazu na obszary w których znajduje się tekst
3. Podzielenie uzyskanych obszarów na wiersze
4. Podzielenie wierszy na znaki
W powyższym etapie przydatne zdają się mechanizmy opisane w rozdziale 3. Kiedy już każdy znak zostanie wyodrębniony jako unikalny obszar następuje 2 etap - rozpoznawanie. Obszar znaku zostaje podzielony na cztery ćwiartki, a każda poddawana jest porównaniu z bazą wzorców. Jeżeli przynajmniej 3 ćwiartki zostaną sklasyfikowane jednakowo, znak zostaje uznany za zidentyfikowany. Gdy w ten sposób wydzielone zostanie całe słowo, następuje próba jego klasyfikacji za pomocą wewnętrznego słownika.
Opisany przed chwilą 2 etap, dotyczący rozpoznawania poszczególnych znaków, zahacza o tematykę rozpoznawania obrazów. Jest to odrębny od analizy dział, zajmujący się rozpoznawaniem konkretnych obiektów. Istnieje wiele metod rozpoznawania, jednakże dla OCR można podać jako przykład metodę wzorców.
4.1. Metoda Wzorców
W intuicyjnej definicji metoda wzorców polega na porównywaniu zbioru danych wejściowych ze zbiorem wzorcowym. Oczywistym jest fakt, że nie należy przyjmować ustalania zgodności tylko pod warunkiem 100% identyczności danych wejściowych oraz wyjściowych. Należy przyjąć pewien próg akceptowalnego poziomu zgodności, dla którego przyjmujemy identyczność obiektów.
Z definicji:
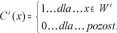
Wzór 1
C - odwzorowanie 9 Copyright © blackMasoon 2009
Wyszukiwarka
Podobne podstrony:
Nr 3 p-laktoglobulina - potencjalny nośnik witaminy D 537 wymaganiom stanowi niełatwe wyzwanie dla
Temat 7. DZIAŁALNOŚĆ WSPOMAGAJĄCA ZADANIA BADAWCZE zadanie 1. Rozwój i utrzymanie systemu komputerow
Temat 6. ZADANIA WSPOMAGAJĄCE DZIAŁALNOŚĆ BADAWCZĄ zadanie 1. Rozwój i utrzymanie systemu komputerow
Zadanie 32. a. Jaką minimalną liczbę stanów musi mieć deterministyczny automat skończony rozpoznając
ZADANIE PROJEKTOWE NR 4Modelowanie i projektowanie układu sterowania dla wybranego systemu automatyz
Grupa B: Zadanie: ułożenie klasowego tekstu życzeń urodzinowo-odrodzeniowych dla Polski - Jubilatki;
DSC01461 Zadanie 37 <tcre z zaburzeń rytmu serca stanowi bezpośreone zagrożenie dla życia paqenta
Zadanie 1Zadanie 1 Rachunek predykatów I rzędu stanowi podstawę teoretyczną dla a)
Wyposażenie stanowiska pracy: - treść zadania dla pary uczniów. -
więcej podobnych podstron