
Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
3
OBLICZENIA RÓWNOLEGŁE
Temat 6:
Narzędzia i środowiska
programowania równoległego
Prowadzący:
dr inż. Zbigniew TARAPATA
pok.225, tel.: 83-73-38
e-mail:
Zbigniew.Tarapata@wat.edu.pl
http://
tarapata.
tarapata.
strefa
strefa
.pl
.pl
/
/
p_obliczenia_rownolegle
p_obliczenia_rownolegle
/
/

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
4
Realizacja modelu równoległości danych – High Performance Fortran.
High Performance Fortran jest rozszerzeniem Fortranu 95 –
popularnego języka programowania naukowo-inżynierskiego.
Realizuje on model programowania z równoległością danych, głównie
dla operacji wektorowych i macierzowych. Zawiera rozszerzenia w
postaci dyrektyw kompilatora uzupełniających standardowe instrukcje
Fortranu. Język ten z założenia ma udostępniać model programowania
praktycznie realizowalny, prostszy niż inne i równie efektywny.
W celu zrównoleglenia działania poprzez przypisanie danych
poszczególnym procesom High Performance Fortran udostępnia
dyrektywy określające ułożenie procesorów:
!HPF$ PROCESSORS, DIMENSION(3,4):: P1
!HPF$ PROCESSORS, DIMENSION(2,6):: P2
!HPF$ PROCESSORS, DIMENSION(12):: P3
!HPF$ PROCESSORS, DIMENSION(2,2,3):: P4
W jednym programie może istnieć wiele zdefiniowanych układów
procesorów, wykorzystywanych w różnych miejscach do realizacji
różnych operacji.
Przypisanie (dystrybucja) danych odbywa się za pomocą
dyrektywy DISTRIBUTE, np.:
!HPF$ PROCESSORS, DIMENSION(4):: P
REAL, DIMENSION(10):: T1, T2

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
5
!HPF$ DISTRIBUTE T1(BLOCK) ONTO P
!HPF$ DISTRIBUTE T1(CYCLIC) ONTO P
Określenie BLOCK oznacza podział tablicy na bloki przypisywane
kolejnym procesorom, określenie CYCLIC oznacza przypisywanie
kolejnych wyrazów tablicy kolejnym procesorom z okresowym
zawijaniem.
Wykonanie równoległe odbywa się poprzez:
•
realizację standardowych operacji wektorowych Fortranu
95
A+B, A*B, A(B*C) – operacje dozwolone dla macierzy
zgodnych, tj. mających ten sam kształt,
•
pętli operujących na wszystkich elementach macierzy:
FORALL ( i=1..n, j=1..m, A[i,j].NE.0 ) A(i,j) = 1/A(i,j)
Równoległość jest uzyskiwana niejawnie – programista nie określa,
które operacje są wykonywane na konkretnym procesorze.
Unified Parallel C.
Unified Parallel C (UPC) to bardzo wygodne w użyciu rozszerzenie
języka C służące do programowania równoległego. Oparte jest ono na
modelu programowania równoległego o pamięci fizycznie
rozproszonej, logicznie współdzielonej. UPC to niewielkie i bardzo
wygodne w użyciu narzędzie pozwalające tworzyć wydajne programy.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
6
Najprostszy program wypisujący komunikaty Hello World z
każdego procesora (wraz z numerami procesów oraz liczbą tych
procesów) wygląda następująco:
#include <upc_relaxed.h>
#include <stdio.h>
void main(){
printf("Hello World from THREAD %d (of %d
THREADS)\n",MYTHREAD,THREADS);
}
Każdy procesor (tutaj nazywany wątkiem - THREAD) uruchamia
równolegle własną kopię powyższego programu. Pierwsza linia kodu,
poprzez dołączenie pliku nagłówkowego upc_relaxed.h,
specyfikuje sposób korzystania z pamięci. W UPC sposoby obsługi
pamięci są dwa:
•
upc_relaxed.h - procesy mogą odczytywać zmienne
współdzielone dowolnie w każdej chwili. Korzystanie z tego
sposobu jest preferowane, gdyż umożliwia kompilatorom lepszą
optymalizację.
•
upc_strict.h - współdzielone zmienne i dane
synchronizowane są za każdym razem przed dostępem do nich.
Oznacza to, że jeśli współdzielona zmienna jest aktualnie
modyfikowana przez jeden proces, pozostałe procesy będą
czekać aż do synchronizacji przed odczytaniem jej wartości.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
7
Dalsza część powyższego programu jest zwykłym kodem języka C.
Do wypisania komunikatu używamy funkcji printf. Korzystamy
jednak z dwóch zmiennych dostępnych dzięki załączeniu pliku
nagłówkowego UPC:
•
THREADS - oznacza liczbę procesów, które uczestniczą w
aktualnym uruchomieniu programu,
•
MYTHREAD - oznacza numer procesu aktualnie uruchomionego.
Dla lepszego wyjaśnienia znaczenia zmiennych THREADS i
MYTHREAD prześledźmy następujący przykład:
#include <upc_relaxed.h>
#include <stdio.h>
void main(){
if(MYTHREAD==0){
printf("Starting execution at THREAD %d\n",MYTHREAD);
}
printf("Hello World from THREAD %d (of %d
THREADS)\n",MYTHREAD,THREADS);
}
Program ten jest bardzo podobny do wcześniejszego, z tą różnicą,
że warunek zawarty w instrukcji if specyfikuje, iż proces o numerze
0 dodatkowo wywoła funkcję printf wypisując na standardowe
wyjście komunikat "Starting execution at THREAD 0".

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
8
Równoległe pętle for - upc_forall.
W UPC mamy możliwość implementacji pętli, których kolejne
iteracje uruchamiane będą przez różne procesy. Struktura wywołania
takiej pętli jest następująca:
upc_forall( wyrażenie; wyrażenie; wyrażenie; wskazanie)
Czwarty parametr pętli upc_forall może być albo liczbą
naturalną tłumaczoną na (liczba % THREADS); lub adresem
który wskazuje na konkretny proces do którego adres ten jest
przypisany. Oto dwa krótkie przykłady użycia upc_forall:
upc_forall(i=0;i<N;i++;i) {
printf("THREAD %d (of %d THREADS) performing iteration
%d\n",MYTHREAD,THREADS,i);
}
Powyższa pętla wypisze numery procesów wraz z liczbą
reprezentującą numer iteracji przez te procesy wykonywanej. Iteracja
o numerze i będzie wykonywana przez proces o numerze i %
THREADS.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
9
W drugim przykładzie widzimy, iż proces który ma wykonywać
daną iterację może zostać również wskazany przez adres pamięci do
niego przydzielony:
1: #include <upc_relaxed.h>
2: #include <stdio.h>
3: #define N 10
4: shared [2] int arr[10];
5:
6: int main() {
7: int i=0;
8: upc_forall(i=0;i<N;i++;&arr[i]) {
9: printf("THREAD %d (of %d THREADS) performing
iteration %d\n",MYTHREAD,THREADS,i);
10: }
11: return 0;
12: }
Linijka:
4: shared [2] int arr[10];
definiuje tablicę liczb typu integer o wymiarze 10. Pamięć ta
rozdzielona jest pomiędzy procesy, po 2 elementy tablicy dla każdego
procesu cyklicznie. W deklaracji tej tablicy kluczowe jest użycie
słówka shared (opisanego poniżej). Czwarty parametr
pętli upc_forall to adres kolejnych elementów tablicy arr. Adres
ten tłumaczony jest na identyfikator procesu któremu dany adres jest
przypisany. Wybrany proces realizuje następnie kod przypisany dla
danej iteracji. Oznacza to, że iteracja i wykonywana jest przez proces
do którego przypisany jest adres &arr[i].

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
10
Zmienne współdzielone - wyrażenie shared.
Aby zrozumieć wszystkie oznaczenia związane z wyrażeniem
shared należy skomentować krótko pomysł, który kryje się za
modelem pamięci fizycznie rozproszonej, logicznie współdzielonej.
Otóż przestrzeń pamięciowa w UPC dzieli się na prywatną i
współdzieloną. Każdy proces ma swoją własną przestrzeń prywatną
oraz porcję przestrzeni współdzielonej. Prywatna pamięć obsługiwana
jest tak jak w zwykłym języku C. Cała przestrzeń współdzielona
podzielona jest na części, z których każda przypisana jest logicznie do
przestrzeni pamięciowej jednego z procesów. Widać to na poniższym
rysunku:
Rysunek A.1. Pamięć współdzielona i prywatna.
Tablice współdzielone logicznie rozdystrybuowane w blokach po
procesorach to tablice widziane przez wszystkie procesy, natomiast
fizycznie przechowywane w pamięci przypisanej do jednego z
procesów. Aby zdefiniować współdzieloną pamięć musimy użyć
słówka kluczowego shared. Mamy do dyspozycji następujące
kombinacje:

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
11
1: int local_counter; //prywatna zmienna
2: shared int global_counter; //współdzielona zmienna
3: shared int array1[N]; //współdzielona tablica
4: shared [N/THREADS] int array2[N]; //współdzielona tablica
5: shared [] int array3[N]; //współdzielona tablica
6: shared int *ptr_a; //prywatny wskaźnik do współdzialonej
pamięci
7: shared int *shared ptr_c; //współdzielony wskaźnik do
współdzielonej pamięci
Komentarza wymaga różnica pomiędzy trzema zdefiniowanymi
tablicami array1, array2, array3. Zwykle polecenie
shared ma następującą formę:
shared [rozmiar_bloku] typ nazwa_zmiennej
Powyższy zapis należy czytać w następujący sposób: zmienna o
nazwie nazwa_zmiennej o typie typ jest współdzielona
pomiędzy wszystkimi procesami i zostaje rozdystrybuowana
cyklicznie pomiędzy wszystkimi procesami w blokach wielkości
rozmiar_bloku. Jeśli wielkość bloku nie jest podana wówczas
przyjmowana jest wielkość 1. Nieskończoną wielkość bloku
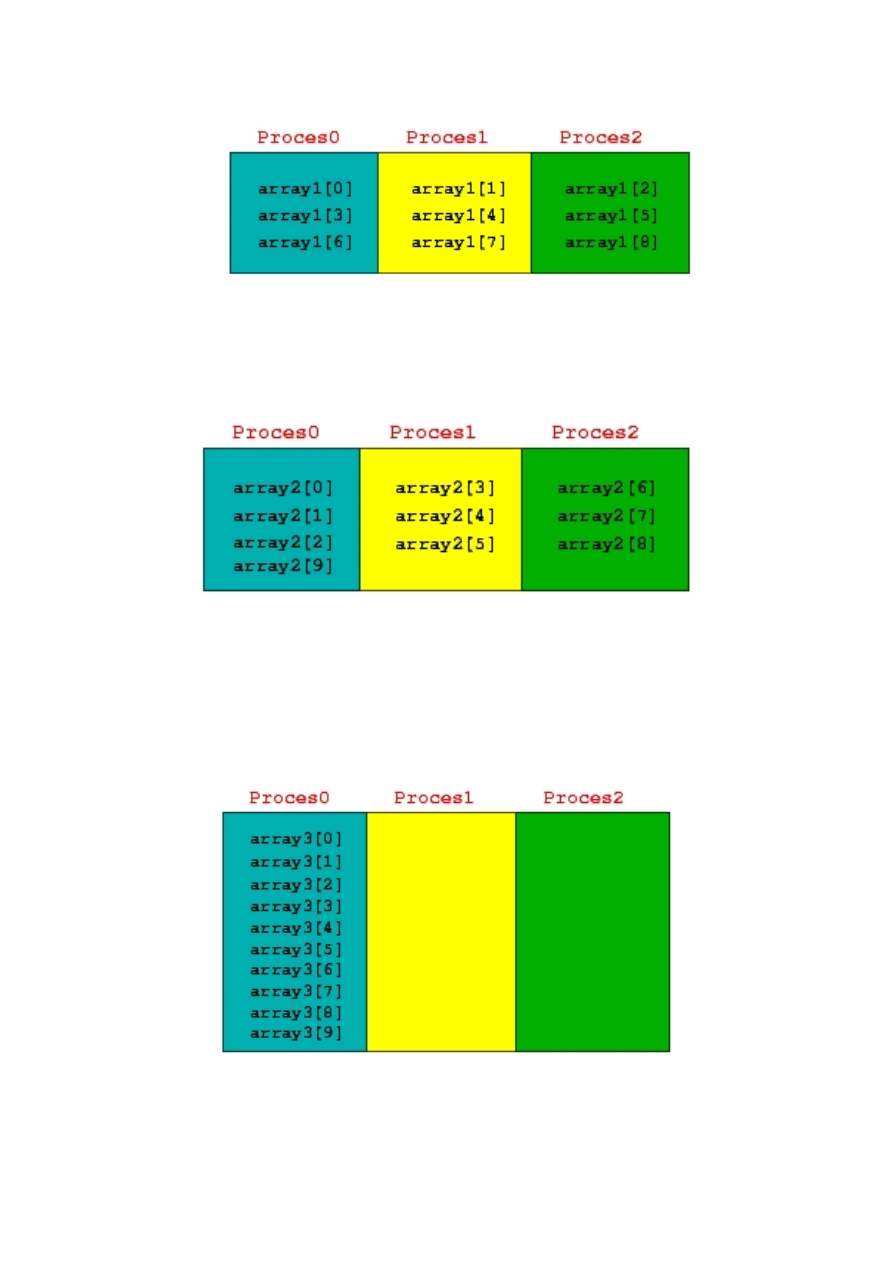
oznaczamy []. Na kolejnych trzech rysunkach pokazany jest sposób
rozdystrybuowania pamięci pomiędzy procesami dla tablic array1,
array2, array3.
Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
12
Rysunek A.2. Rozłożenie elementów tablicy array1 po procesach z
rozmiarem bloku równym 1 dla N=9 oraz THREADS=3.
Rysunek A.3. Rozłożenie elementów tablicy array2 po procesach z
rozmiarem bloku równym N/THREADS dla N=10 oraz
THREADS=3.
Rysunek A.4. Rozłożenie elementów tablicy array3 po procesach z
nieskończonym rozmiarem bloku [] dla N=10 oraz THREADS=3.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
13
Synchronizacja procesów i dostępu do pamięci w UPC.
Bariery upc_barrier.
Polecenie upc_barrier służy do synchronizacji procesów.
Umieszczenie go w kodzie oznacza tak naprawdę postawienie bariery
w kodzie, tzn. żaden proces nie ma prawa przekroczyć bariery (linii w
kodzie) dopóki wszystkie procesy do niej nie dotrą. Bariery
wykorzystywane są najczęściej gdy występuje zależność danych
pomiędzy procesami. Oto prosty przykład:
1: #include <upc_relaxed.h>
2: #include <stdio.h>
3:
4: shared int a=0;
5: int b;
6:
7: int computation(int temp) {
8: return temp+5;
9: }
10:
11: int main(){
12: int result=0, i=0;
13: do {
14: if(MYTHREAD==0) {
15: result=computation(a);
16: a=result*THREADS;
17: }
18: upc_barrier;
19: b=a;
20: printf("THREAD %d: b=%d\n",MYTHREAD,b);
21: i++;
22: } while(i<4);
23: return 0;
24: }

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
14
W linii 16 powyższego kodu procesor o numerze 0 uaktualnia
wartość zmiennej a, współdzielonej przez wszystkie procesy. W linii
19 wszystkie procesy dokonują uaktualnienia swojej prywatnej
zmiennej b przypisując im aktualną wartość zmiennej a. Zauważmy,
że gdybyśmy nie umieścili bariery w linii 18 wówczas nie mielibyśmy
gwarancji, że wszystkie prywatne zmienne b zostały uaktualnione
najnowszą wartością zmiennej a.
Blokowanie dostępu do zmiennej - upc_lock/upc_unlock.
Dzięki użyciu blokad upc_lock/upc_unlock możemy
uzyskać gwarancję, że pewna zmienna nie będzie czytana przez
proces jeśli jest w danej chwili uaktualniana przez inny proces.
Przykład:
Zapoznamy się teraz z implementacją algorytmu obliczającego
liczbę Pi ze wzoru:
∫
+
=
Π
1
0
2
1
1
4
x
i całkowania numerycznego metodą
prostokątów.
Wersja szeregowa takiego programu wygląda następująco:

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
15
//Przyklad szeregowy - calkowanie numeryczne
//Obliczanie liczby Pi
#include<math.h>
#define N 1000000
#define f(x) (1.0/(1.0+x*x))
float pi=0.0;
void main(void)
{
int i;
for(i=0;i<N;i++)
pi+=(float) f( (0.5+i)/(N) );
pi*=(float)(4.0/N);
printf("PI=%f\n",pi);
}

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
16
Wersja równoległa zaimplementowana przy pomocy UPC wygląda
tak:
//Przyklad UPC - calkowanie numeryczne
//Obliczanie liczby Pi
#include<upc_relaxed.h>
#include<math.h>
#define N 1000000
#define f(x) (1.0/(1.0+x*x))
upc_lock_t *l;
shared float pi=0.0;
void main(void)
{
float local_pi=0.0;
int i;
l=upc_all_lock_alloc();
upc_forall(i=0;i<N;i++;i)
local_pi+=(float) f( (0.5+i)/(N) );
local_pi*=(float)(4.0/N);
upc_lock(l);
pi+=local_pi;
upc_unlock(l);
upc_barrier;
if(MYTHREAD==0) printf("PI=%f\n",pi);
if(MYTHREAD==0) upc_lock_free(l);
}
Przykład ten jest bardzo fajny, gdyż widać tutaj zarówno użycie
bariery upc_barrier jak i zabezpieczenia upc_lock . Przed
równoczesnym dostępem z więcej niż jednego procesora
zabezpieczona jest współdzielona zmienna pi.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
17
Dostępność UPC, wspierane platformy.
UPC jest wspierane przez kompilatory na niektórych komputerach
firmy Cray ale również HP, SGI czy Sun. Dostępne są również pewne
darmowe implementacje, dokumentacje i przykłady:
•
Michigan Technological University (http://www.upc.mtu.edu/)
•
George Washington University (http://www.gwu.edu/~upc/)
•
Berkeley Unified Parallel C (UPC) Project (http://upc.lbl.gov/).
OpenMP.
OpenMP jest to API pozwalające tworzyć kod wykonywany
równolegle w maszynach z pamięcią współdzieloną. Jest to zbiór
rozszerzeń do języków C, C++ i FORTRAN. Składa się ono z trzech
elementów:
•
Dyrektyw preprocesora
•
Funkcji bibliotecznych
•
Zmiennych środowiskowych
Dzięki temu API programiści są w stanie tworzyć aplikacje,
których kod może być wykonywany przez wiele wątków równolegle.
Jak zobaczymy dalej, nie jest konieczna bezpośrednia obsługa wątków
a OpenMP jest niezależne od systemu, na którym kompilujemy kod.
OpenMP jest powszechnie przyjętym standardem i wynikiem wielu
lat badań nad tworzeniem programów wykonywanych równolegle.
Wersja standardu 1.0 ukazała się dla języka FORTRAN w 1997 roku,
a już w 1998 dostępna była dla C/C++. W Visual C++ 2005 do
czynienia mamy z wersją OpenMP 2.0, która ukazała się w 2002 roku.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
18
OpenMP działa na maszynach z pamięcią współdzieloną. Oznacza
to, że wszystkie procesory mają dostęp przynajmniej do fragmentów
pamięci wpólnej. Dodatkowo system działa na jednej kopii systemu
operacyjnego a komunikacja procesorów polega na zapisie i odczycie
ze wspomnianej wcześniej wspólnej pamięci. Warunki te spełnia
idealnie większość dostępnych obecnie komputerów w tym również
dobrze nam znane komputery klasy PC.
Gdzie zatem warto użyć OpenMP? Zdecydowanie przeznaczone
ono jest do systemów, które potrafią wykonywać kod w wielu
wątkach równolegle oraz wymagają sporej mocy obliczniowej. Mogą
być to aplikacje począwszy od gier, poprzez obróbkę dźwięku i
obrazu a skończywszy na obliczeniach naukowych. Mówi się, że
znajduje ono zastosowanie w małych i średnich aplikacjach
wykonujących intensywne obliczenia a najlepiej jeżeli obliczenia te
wykonywane są w pętlach. Dyrektywy OpenMP bazują na dyrektywie
preprocesora #pragma w C/C++:
#pragma omp dyrektywa [wyrażenie [wyrażenie]…]
Najbardziej podstawowe pragmy omp to parallel, for, sections i
section, np.:
#pragma omp parallel
#pragma omp for
#pragma omp sections
#pragma omp section

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
19
We wstępie przyjrzyjmy się następującej pętli for:
void main()
{
double Table[1000];
for(int i=0;i<1000;i++)
DoSomething(Table[i]);
}
może zostać zrównoleglona w następujący sposób:
void main()
{
double Table[1000];
#pragma omp parallel for
for(int i=0;i<1000;i++)
DoSomething(Table[i]);
}
Zaledwie jedna linia kodu, a dysponując odpowiednim
kompilatorem i opowiednim sprzętem możemy powyższą pętlę
wykonywać równolegle przez wiele wątków.
Wątki a OpenMP
Równoległość wykonywania kodu z wykorzystaniem opisywanego
standardu polega na wykorzystaniu wątków. OpenMP to standard,
który ma być niezależny od platformy, został on zatem
zaprojektowany tak, iż programista nie ma bezpośrednio do czynienia
z tworzeniem, synchronizacją i niszczeniem wątków
charakterystycznych dla danej platformy. Za pomocą pragm OpenMP
Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
20
steruje się ilością tworzonych wątków, synchronizacją oraz dostępem
do danych. Działanie programu stworzonego za pomocą tego
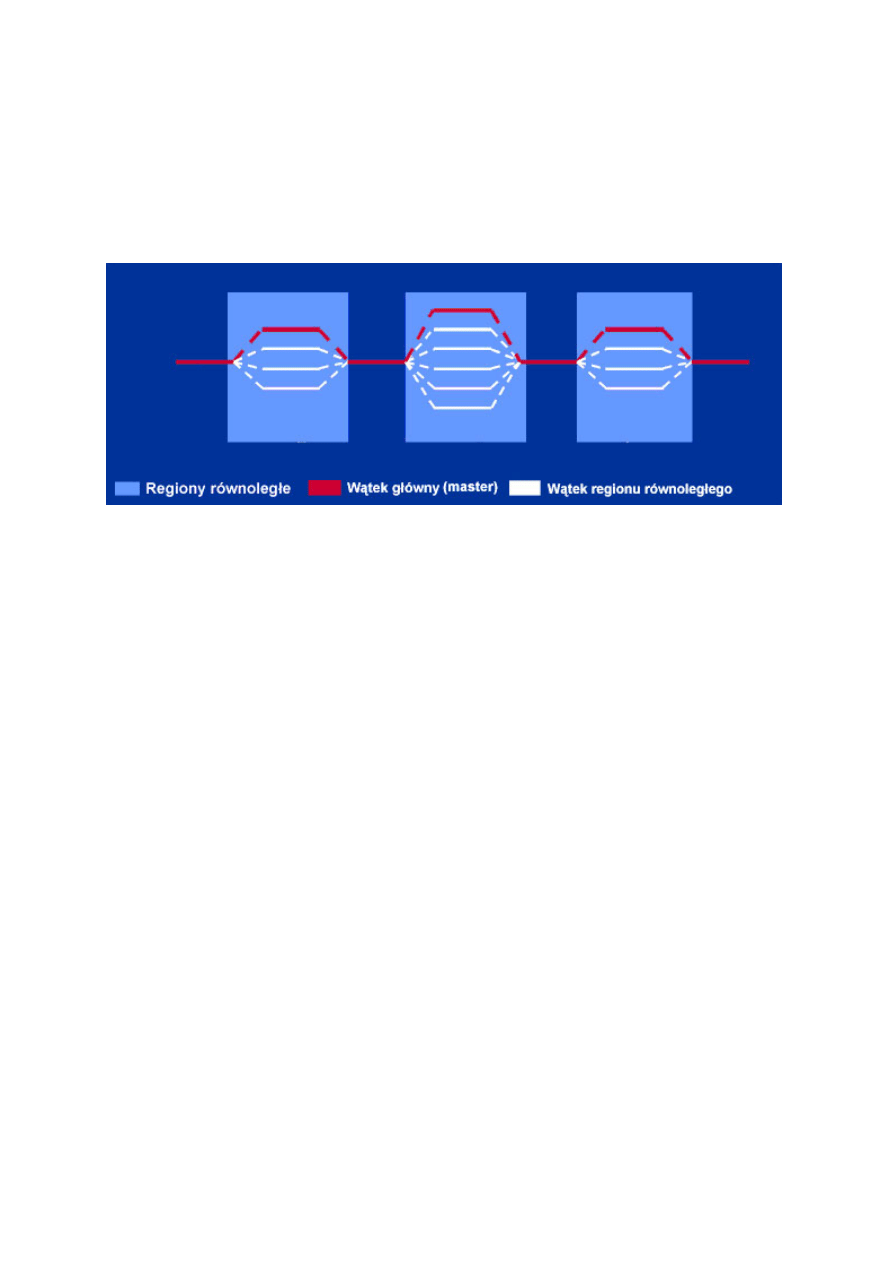
standardu dobrze zilustrować może następujący rysunek.
Rysunek A.5. Wątki w OpenMP.
OpenMP działa na zasadzie fork-join. Na samym początku program
startuje z jednym wątkiem, zwanym wątkiem głównym (ang. master
thread). Tuż po starcie znajdujemy się w sekwencyjnym regionie
kodu. W momencie, gdy wejdziemy w region równoległy, zostaje
stworzona odpowiednia pula wątków, do każdego wątku przypisana
zostają odpowiednie dane odpowiednio zainicjalizowane. Każdy
wątek ma określony kod do wykonania. Następuje współbieżne
wykonanie kodu poszczególnych wątków (czyli następuje
rozwidlenie, z ang. fork). Gdy wątek kończy swoją pracę może lub nie
wymagać synchronizacji z pozostałymi wątkami. Po zakończniu pracy
wszystkich wątków dane zostają zsynchronizowane do wątku
głównego i następuje wykonanie kolejnego regionu sekwencyjnego
(następuje „połączenie” wątków, z ang. join).

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
21
Wszystkie elementy a mianowicie ilość wątków, kod, zmienne
przypisane do wątków, sposoby synchronizacji określa programista za
pomocą dyrektyw, modyfikatorów dyrektyw i funkcji czasu
wykonania.
PVM (Parallel Virtual Machine)
W skład oprogramowania wchodzi kilka programów i biblioteka
podprogramów pozwalająca na tworzenie aplikacji działających
równolegle na kilku komputerach (nawet o różnych architekturach).
Programista dostaje do ręki narzędzia pozwalające na pisanie
aplikacji, które dzielą problem obliczeniowy na kilka (najczęściej
identycznych, ale mniejszych) zadań, przekazywanie im danych i
synchronizacje ich wykonania.
Wykorzystanie możliwości systemu wymaga (najczęściej) takiego
zaprojektowania algorytmu zadania, aby łatwo dzieliło się na
fragmenty możliwe do równoległego wykonania. Nie mogą to być
zadania zbyt małe, a wymagające przekazywania znacznych ilości
danych gdyż wówczas synchronizacja zadań zużywa znaczną część
przepustowości sieci.
Zaletą systemu jest to, że dostępny jest na wszystkich praktycznie
platformach sprzętowych dostępnych na uczelni (SUN, SGI, IBM,
HP, komputery PC pracujące pod Linuxem).

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
22
PVM tworzony był na University of Tennessee, The Oak Ridge
National Laboratory i Emory University. Jego pierwsza wersja została
napisana w ORNL w 1989 roku. Następnie przepisano ją zupełnie w
University of Tennessee i udostępniono jako wersję drugą w marcu
1991. Wersja trzecia ukazała się w 1993 roku.
Dzisiaj PVM nie jest już aktywnym projektem, ale nadal stosuje się
go w programowaniu równoległym.
Opis działania PVM
PVM jest narzędziem służącym głównie do pośrednictwa w
wymianie informacji pomiędzy procesami uruchomionymi na
oddzielnych maszynach, oraz do zarządzania nimi za pośrednictwem
konsoli pvm. Z punktu widzenia obecnej definicji maszyny wirtualnej,
pvm w sumie nie zasługuje na swoją nazwę, powinien się bardziej
nazywać "zarządca procesów zrównoleglonych", jednakże historia
pvm sięga dawnych czasów, kiedy to nazewnictwo było trochę inaczej
rozumiane.
W dużym uproszczeniu PVM pozwala na "połączenie" większej
ilości komputerów w jeden. Odbywa się to na zasadzie dołączania
kolejnych hostów (komputerów), na których został zainstalowany i
skonfigurowany pvm. Podłączanie hosta jest w uproszczeniu
procedurą połączenia przez rsh, uruchomieniu demona pvm, i
dostarczenia mu informacji o tym kto jest jego "rodzicem" oraz o
parametrach istniejącej sieci.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
23
W momencie kiedy cała "maszyna wirtualna" już jest
skonfigurowana, rola pvm sprowadza się do stanowienia pomostu
wymiany informacji pomiędzy procesami, które się w pvm
„zarejestrują” oraz umożliwienia administrowana stanem
zarejestrowanych w pvm procesów. Z takiego punktu widzenia pvm
można nazwać raczej „demonem komunikacji międzyprocesowej” i
można to podeprzeć najprostszym argumentem, mianowicie pvm nie
stanowi interfejsu do systemu operacyjnego lub maszyny na której
działa dany proces.
PVM pozwala zautomatyzować proces uruchamiania aplikacji na
innych komputerach. Jeżeli uruchomimy z poziomu normalnej konsoli
program, który następnie zarejestruje się w pvm i użyje funkcji
pvm_spawn(), aby uruchomić dolną ilość procesów, to już rolą PVM
będzie zatroszczenie się, gdzie zostaną one uruchomione, oraz samo
ich uruchomienie (możliwe jest podanie parametru uściślającego
lokalizacje docelową uruchomienia). W przypadkach obliczeń, gdzie
procesy-„dzieci”, rodzą się i umierają w bliżej nieokreślonych
interwałach i te zjawiska się przeplatają, zautomatyzowanie
dostarczane przez PVM okazuje się bardzo pomocne, ponieważ
"odciąża" programistę z potrzeby troski o prawidłowe rozłożenie
obliczeń na hosty.
Identyfikacja w pvm odbywa się przez oddzielne numery
identyfikacyjne przydzielane procesom w momencie rejestrowania się
w pvm. Numery te stanowią zupełną abstrakcję od systemu

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
24
operacyjnego i sprzętu, na którym uruchomiony jest dany proces.
Numer identyfikacyjny jest bardzo istotnym elementem pvm,
ponieważ stanowi on niejako adres danego procesu i jest on
niepowtarzalny w zakresie pojedynczej maszyny pvm. Adres jest
wykorzystywany przy wszystkich procedurach dotyczących innych
procesów, można przesłać informacje pod dany adres, można „zabić”
zdany adres i wiele innych.
Pojęcia „przyłączenie się do pvm” czy też „zarejestrowanie się w
pvm” znaczą dokładnie to samo i oznaczają wywołanie po raz
pierwszy jakiejkolwiek procedury pvm, przez co demon pvm
przydziela danemu procesowi numer identyfikacyjny i zapisuje
informacje o nim w swojej bazie procesów.
Podstawowe cechy środowiska PVM
- zarządzanie zasobami,
- możliwość dodania/usunięcia węzła z komputera wirtualnego,
- zarządzanie procesami,
- dynamiczne uruchamianie/usuwanie procesów,
- komunikacja między procesami na zasadzie wymiany komunikatów
(ang. message passing),
- niezawieszające wysłanie informacji, zawieszające i niezawieszające
odebranie informacji, grupowe operacje komunikacyjne,
- możliwość dynamicznego tworzenia grup procesów (zadań) -
dowolne zadanie może przyłączyć się do grupy lub porzucić ją w

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
25
dowolnym momencie czasu,
- tolerowanie defektów - komputer wirtualny automatycznie wykrywa
defekty, co daje możliwość dostosowania jego funkcjonowania do
aktualnej konfiguracji.
Przykłady dziedzin, w których wykorzystywany jest PVM
- prognoza pogody i modelowanie klimatu,
- biologia molekularna,
- modelowanie procesów spalania,
- rzeczywistość wirtualna,
- chemia kwantowa,
- rozpoznawanie obrazów,
- dynamika płynów,
- algebra liniowa,
- metoda Monte Carlo,
- metoda elementów skończonych,
- optymalizacja kombinatoryczna,
- modelowanie struktury białka,
- modelowanie sekwencji DNA.
Przesyłanie informacji pomiędzy programami.
W pvm wyróżniamy dwa rodzaje wysyłania informacji: blokujące i
nieblokujące. Przesyłanie blokujące to takie, które blokuje program
wysyłający na procedurze wysłania do momentu aż program
odbierający wywoła procedurę otrzymywania informacji i na odwrót,

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
26
blokuje program odbierający na procedurze odbierania do momentu,
aż zostaną mu wysłane jakieś informacje przez program nadający.
Przesyłanie nieblokujące - jak wynika z nazwy - jest pozbawione tych
negatywnych czynników, jednakże wymaga ono nieraz wsparcia przez
„procesy zewnętrzne (proces pvmmsg)”, oraz niejednokrotnie
wymaga synchronizacji procesów w celu ich skomunikowania.
Dlatego dla prostych programów przeważnie wykorzystuje się
przesyłanie blokujące.
Do przesyłania informacji w pvm stosuje się "bufory". Każdy
proces który zarejestruje się w pvm wywołując dowolną jego
procedurę (najczęściej stosuje się wywołanie pvm_mytid()), zostaje
wyposażony w jeden bufor nadawczy i jeden bufor odbiorczy.
Możliwe jest użycie buforów innych niż domyślne, jednakże wymaga
to ich utworzenia.
Procedura przesyłania dzieli się na:
1. Wysłanie informacji przez program „nadający”
1. inicjację bufora wysyłania
2. spakowanie danych do bufora
3. wysłanie wiadomości
2. Odebranie informacji przez programy „odbierające”
1. odebranie wiadomości
2. rozpakowanie informacji z bufora

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
27
Do bufora można spakować więcej niż jedną informację w celu
wysłania ich większej ilości na raz, jednakże należy pamiętać o ich
rozpakowaniu z bufora odbiorczego w odpowiedniej kolejności.
Przykładowe procedury przesyłania informacji.
Komunikacja punkt-punkt.
pvm_send
int retval = pvm_send(int tid ,int msgtag);
Parametry
•
tid - identyfikator procesu ,do którego ma zostać wysłany
komunikat.
•
msgtag - liczba całkowita, definiowana przez użytkownika jako
etykieta komunikatu (powinna być >=0).
•
retval - kod statusu zwracany przez funkcję (retval < 0 oznacza
błąd podczas wykonania operacji).
pvm_recv
int retval = pvm_recv(int tid ,int msgtag);
Parametry
•
tid - identyfikator procesu ,od którego ma zostać odebrany
komunikat.
•
msgtag - liczba całkowita, definiowana przez użytkownika jako
etykieta komunikatu (powinna być >=0).

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
28
•
retval - kod statusu zwracany przez funkcję (retval < 0 oznacza
błąd podczas wykonania operacji).
Komunikacja grupowa
pvm_mcast
int retval = pvm_mcast( int *tids, int ntask, int msgtag );
Parametry
•
tids - tablica liczb całkowitych o ntask elementach
zawierających identyfikatory zadań procesów, do których ma
zostać wysłany komunikat.
•
ntask - ilość procesów, do których będzie wysłany komunikat.
•
msgtag - liczba całkowita, definiowana przez użytkownika jako
etykieta komunikatu (powinna być >=0).
•
retval - kod statusu zwracany przez funkcję (retval < 0 oznacza
błąd podczas wykonania operacji).
Funkcja wysyła komunikat asynchronicznie do wszystkich
procesów, których identyfikatory zadań są zapamiętane w tablicy tids
z wyjątkiem procesu wysyłającego. Etykieta msgtag jest
wprowadzona dla rozróżniania przesyłanych komunikatów.
Proces odbierający komunikat może zrobić to albo funkcją
pvm_recv(), albo pvm_nrecv().

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
29
MPI (Message Passing Interface)
MPI (ang. Message Passing Interface, Interfejs Transmisji
Wiadomości) - standard przesyłania komunikatów pomiędzy
procesami programów równoległych działających na jednym lub
więcej komputerach. Pierwsza wersja standardu ukazała się w maju
1994 r. Standard MPI implementowany jest najczęściej w postaci
bibliotek, z których można korzystać w programach tworzonych w
różnych językach programowania, np. Fortran, C, C++, Ada.
Opis
MPI jest specyfikacją biblioteki funkcji opartych na modelu
wymiany komunikatów dla potrzeb programowania równoległego.
Transfer danych pomiędzy poszczególnymi procesami programu
wykonywanymi na procesorach maszyn będących węzłami klastra
odbywa się za pośrednictwem sieci.
Program w MPI składa się z niezależnych procesów operujących na
różnych danych (MIMD). Każdy proces wykonuje się we własnej
przestrzeni adresowej, aczkolwiek wykorzystanie pamięci
współdzielonej też jest możliwe.
Główną zaletą standardu jest przenośność. Udostępnia on zbiór
precyzyjnie zdefiniowanych metod, które mogą być efektywnie
zaimplementowane. Stał się on punktem wyjściowym do stworzenia
praktycznego, przenośnego, elastycznego i efektywnego narzędzia do
przesyłania komunikatów (ang. message passing). Standard MPI

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
30
pozwala na jego zastosowanie zarówno w komputerach równoległych,
jak i heterogenicznych sieciach stacji roboczych.
Standard nie zabrania, aby poszczególne procesy były
wielowątkowe. Nie są też udostępnione mechanizmy związane z
rozłożeniem obciążenia pomiędzy poszczególne procesy, z
architekturą rozkładu procesorów, z dynamicznym tworzeniem i
usuwaniem procesów. Procesy są identyfikowane poprzez ich numer
w grupie w zakresie 0 .. groupsize-1.
Główne własności MPI
•
umożliwia efektywną komunikację bez obciążania procesora
operacjami kopiowania pamięci,
•
udostępnia funkcje dla języków C/C++, Fortan oara Ada,
•
specyfikacja udostępnia hermetyczny interfejs programistyczny,
co pozwala na skupienie się na samej komunikacji, bez wnikania
w szczegóły implementacji biblioteki i obsługi błędów,
•
definiowany interfejs zbliżony do standardów takich jak: PVM,
NX czy Express,
•
udostępnia mechanizmy komunikacji punkt - punkt oraz
grupowej,
•
może być używany na wielu platformach, tak równoległych jak i
skalarnych, bez większych zmian w sposobie działania.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
31
Zalety MPI
•
dobra efektywność w systemach wieloprocesorowych,
•
dobra dokumentacja,
•
bogata biblioteka funkcji,
•
jest to program public-domain,
•
przyjął się jako standard.
Wady MPI
•
statyczna konfiguracja jednostek przetwarzających,
•
statyczna struktura procesów w trakcie realizacji programu,
•
brak wielowątkowości.
Porównanie PVM i MPI.
PVM - standard de facto środowiska do przetwarzania
równoległego i rozproszonego w heterogenicznych sieciach maszyn
sekwencyjnych, równoległych i wektorowych.
MPI - standard biblioteki funkcji opartej na modelu obliczeń
równoległych z wymianą komunikatów.
Osiągnięcie maksymalnej wydajności to główny priorytet
przestrzegany przy opracowaniu standardu MPI i jego
implementacjach dla systemów masywnie równoległych - MPP;

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
32
dlatego dość powszechnie oczekuje się, że MPI będzie w stanie
zapewnić większą wydajność niż PVM dla architektur MPP.
Przenośność a interoperacyjność.
- oba środowiska zapewniają przenośność czyli możliwość realizacji
na różnych platformach,
- tylko PVM zapewnia interoperacyjność czyli możliwość
komunikowania się i współpracy różnych platform,
- zapewnienie interoperacyjności odbija się na wydajności,
- interoperacyjność PVM dotyczy również języków programowania -
bezproblemowe komunikowanie się programów napisanych w
językach C (C++) i Fortran.
PVM opiera się na koncepcji maszyny wirtualnej, która może być
traktowana jako rozproszony system operacyjny, umożliwiający
integrację różnych stacji roboczych, komputerów osobistych i MPP w
jedną całość:
- pozwala to realizować funkcje dynamicznego zarządzania
procesami,
- dopiero standard MPI-2 przewiduje taką możliwość,

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
33
- PVM dostarcza bogate możliwości w zakresie dynamicznego
zarządzania zasobami (dołączanie / odłączanie węzłów), podczas gdy
MPI został zaprojektowany z myślą o środowisku statycznym.
Nie przewidując tworzenia maszyny wirtualnej, standard MPI
realizuje koncepcję topologii wirtualnych, pozwalających
użytkownikowi - programiście w łatwy sposób opisywać strukturę
komunikowania się procesów aplikacji.
W odróżnieniu od MPI, środowisko PVM zapewnia bazowe
mechanizmy tolerowania defektów.
TotalView - debugger do programów równoległych.
Uruchomianie programów - znajdywanie i usuwanie błędów - jest
pracochłonne oraz wymagające dużej ilości czasu. Dobre narzędzia
programistyczne pozwalają uprościć i skrócić ten proces. Dlatego
obecnie stosowane środowiska do tworzenia aplikacji sekwencyjnych,
jak np. MS Visual Studio, czy Borland JBuilder posiadają
zintegrowany debugger.
Programy równoległe cechuje większa złożoność i podatność na
błędy. Niestety, brak jest tu wciąż standardowych pakietów
oferujących zintegrowane środowisko podobne do wyżej
wymienionych. Dlatego stworzono osobny i niezależny debugger,
pozwalający sprawnie uruchamiać programy równoległe. Totalview

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
34
jest najpopularniejszym i jednym z najlepszych programów tego typu.
Jest dostępny na wiele platform systemowych. Można go używać do
uruchamiania programów stworzonych przy pomocy różnych technik
programowania równoległego.
Aplikacja TotalView jest interakcyjnym i symbolicznym
debuggerem. Pozwala na śledzenie wykonywania programu na
poziomie kodu źródłowego, zatrzymywanie testowanego programu
(poprzez określenie punktów kontrolnych) oraz sprawdzanie wartości
zdefiniowanych zmiennych. W każdej chwili użytkownik może
obserwować interesujące go zmienne, moduły i etykiety. Aplikacja
TotalView używana jest w programie wykonywalnym,
skompilowanym za pomocą kompilatorów CAL (Cray Assembly
Language), C++, C, Fortran 77, Fortran 90 lub Pascal.
Uruchomienie.
Użytkownik musi zalogować się na SR2201. Istnieje kilka metod
wystartowania debuggera
• totalview program - działa jak w przypadku klasycznego
debuggera. Uruchamia program (jeden proces) i przejmuje
nad nim kontrolę.
• totalview - uruchamia sam debugger. Korzystając z listy
działających procesów można przejąć kontrolę nad dowolnym
z nich. Możliwość ta jest zresztą zawsze dostępna.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
35
• totalview core program - do analizy core file
• mpirun <parametry dla MPI> -tv program - inicjalizuje
środowisko MPI, uruchamia równoległe aplikacje i
przekazuje je pod kontrolę Totalview, pozwala zatrzymać
procesy przy MPI_Init()
• totalview -pvm - opcja pozwalająca na współpracę z PVM
Obsługa.
Totalview to program z graficznym interfejsem użytkownika. Jego
obsługa sprowadza się do przełączania pomiędzy oknami,
wskazywania myszą na miejsca w kodzie programu, wyboru opcji z
menu i obsługi okien dialogowych. Zaawansowani użytkownicy mogą
oczywiście używać skrótów klawiszowych.
Totalview może naraz kontrolować wiele programów, każdy
program może składać się z wielu procesów, każdy proces może mieć
wiele wątków. Osobne okno pokazuje listę procesów, nad którymi
Totalview przejął kontrolę. Użytkownik może otworzyć osobne okno
do śledzenia każdego procesu, może też użyć jednego okna i
przełączać się pomiędzy procesami poprzez kliknięcie na odpowiedni
przycisk.

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
36
Rysunek A.6. Wygląd TotalView

Obliczenia równoległe
dr inż. Zbigniew Tarapata
Temat nr 6: Narzędzia i środowiska programowania równoległego
37
Możliwości.
Debugger wyświetla tekst programu (C, C++, Fortran). Klikając na
wybrane miejsca w programie można ustawić pułapki, wyświetlić
zawartość zmiennej itp. Można przełączyć się na poziom asemblera.
Debugger rozpoznaje typ zmiennych i pokazuje ich wartość w
odpowiedni sposób. Dla zmiennych złożonych (rekordy, tablice)
można żądać wyświetlenia wartości składowych przez kliknięcie na
nie. Wartości wybranych zmiennych można monitorować w sposób
ciągły. Stos procesu (zagnieżdżone wywołania funkcji) jest
uwidoczniony.
Wstawione w kod pułapki mogą dotyczyć pojedynczego procesu,
lub wszystkich procesów wchodzących w skład aplikacji (istotne dla
programów SPMD). Ta druga opcja bardzo ułatwia uruchamianie
programów MPI.
Wbudowany interpreter C, C++, Fortanu pozwala na dołączanie
dodatkowego kodu i jego modyfikacje w trakcie działania programu.
W połączeniu ze specjalnymi instrukcjami w Totalview uzyskujemy
możliwość tworzenia pułapek warunkowych.
Wyszukiwarka
Podobne podstrony:
or wyklad 1 id 339025 Nieznany
or wyklad 4 id 339027 Nieznany
or wyklad 3 id 339026 Nieznany
or wyklad 1 id 339025 Nieznany
or wyklad 4b id 339029 Nieznany
or wyklad 4a id 339028 Nieznany
or wyklad 4b id 339029 Nieznany
LOGIKA wyklad 5 id 272234 Nieznany
ciagi liczbowe, wyklad id 11661 Nieznany
Dzialanie czynnikow srodowiskow Nieznany
0 konspekt wykladu PETid 1826 Nieznany
AF wyklad1 id 52504 Nieznany (2)
Neurologia wyklady id 317505 Nieznany
Wykład 5 TOKSYKOLOGIA ŚRODOWISKA
Domek drewniany narzedziowy 333 Nieznany (3)
MATERIALY DO WYKLADU CZ VIII i Nieznany
08 Programowanie w srodowisku j Nieznany (2)
więcej podobnych podstron