
1. Architektury aplikacji sieciowych:
- Sieci klient serwer (dwuwarstwowe)- wersja oprogramowania klienckiego i serwerowego wykonują zadania na podstawie innego kodu lub
mają wspólny kod, ale realizujący odmienne funckje. W większości przypadków aplikacje klienckie i serwerowe działają w różnych
systemach. Wzajemne rozmieszczanie jednostek klienckich i serwerów nie jest w żaden sposób ograniczane, jeśli tylko będą się one mogły
komunikować. Protokoły realizacji usługi: http, SNMP, RMI, .NET, TCP, UDP, COBRA itp.
- sieci wielowarstwowe – Odmiana architektury klient-serwer, w której w transakcji między klientem a serwerem uczestniczą usługi
pośrednie. Jednostka kliencka wymienia dane z serwerem pośredniczącym, a serwer pośredniczący komunikuje się z serwerem
zasadniczym. Serwer końcowy przekazuje informacje do klienta również z wykorzystaniem serwera pośredniczącego.
- Architektura trójwarstwowa – jest powszechnie stosowaną implementacją architektury n-warstwowej. Podstawowe funkcje sieciowe w
aplikacji trójwarstwowej są rozdzielone zgodnie z założeniami:
- warstwa kliencka (warstwa prezentacji) zapewnia użytkownikowi możliwość operowania aplikacją i zarządzania systemem.
- warstwa pośrednicząca (warstwa logiki) obsługuje interakcje użytkownika w formie niezależnych transakcji.
- warstwa serwerowa (warstwa danych) składa się z serwerów aplikacji oraz usług, które zapewniają dostęp do zgromadzonych informacji.
- sieci P2P (peer-to-peer) – Aplikacje w tym modelu wykorzystują bezpośrednie połączenia między parami tymczasowo połączonych hostów
nazywanych węzłami. Każdy komuter (peer) może być zarówno serwerem jak i klientem dla innych węzłów. Węzły sieci P2P mogą być
heterogeniczne.
Zastosowanie:
• sieci dystrybucji plików (Bit Torrent)
• wymiany plików (eMule)
• telefoni internetowej (Skype)
• telewizji internetowej (PPLive)
- sieci kratowe lub rozproszone - metoda trasowania danych, która daje możliwość ustanawiania stałych połączeń w sieci zbudowanej z
wielu połączonych między sobą węzłów. Jeśli nie wszystkie węzły mogą wymieniać się bezpośrednio danymi między sobą, są przesyłane
przez sąsiadów, czyli podobnie jak w sieciach P2P. Sieci tego typu potrafią również dokonać automatycznej zmiany konfiguracji oraz
naprawy w przypadku awarii niektórych węzłów lub zmiany ich położenia.
- hybrydowe połączenia wymienionych rozwiązań
2. Protokoły warstwy aplikacji
http - protokół przesyłania dokumentów hipertekstowych. To protokół sieci WWW. Za pomocą protokołu HTTP przesyła się żądania
udostępnienia dokumentów WWW i informacje o kliknięciu odnośnika oraz informacje z formularzy. Zadaniem stron WWW jest
publikowanie informacji – natomiast protokół HTTP właśnie to umożliwia. Protokół HTTP jest użyteczny, ponieważ udostępnia
znormalizowany sposób komunikowania się komputerów ze sobą. Określa on formę żądań klienta (tj. np. przeglądarki www) dotyczących
danych oraz formę odpowiedzi serwera na te żądania. Jest zaliczany do protokołów bezstanowych (ang. stateless) z racji tego, że nie
zachowuje żadnych informacji o poprzednich transakcjach z klientem.
FTP- protokół transferu plików – protokół komunikacyjny typu klient-serwer wykorzystujący protokół TCP według modelu TCP/IP (krótko:
połączenie TCP), umożliwiający dwukierunkowy transfer plików w układzie serwer FTP – klient FTP. Do komunikacji wykorzystywane są dwa
połączenia TCP. Jedno z nich jest połączeniem kontrolnym za pomocą którego przesyłane są polecenia, a drugie służy do transmisji danych.
Połączenie za pomocą protokołu FTP (krótko: połączenie FTP) może działać w dwóch trybach: aktywnym i pasywnym.
SMTP – protokół komunikacyjny opisujący sposób przekazywania poczty elektronicznej w Internecie. To względnie prosty, tekstowy
protokół, w którym określa się co najmniej jednego odbiorcę wiadomości a następnie przekazuje treść wiadomości. Demon SMTP działa
najczęściej na porcie 25.
DNS – system serwerów, protokół komunikacyjny oraz usługa zapewniająca zamianę adresów znanych użytkownikom Internetu na adresy
zrozumiałe dla urządzeń tworzących sieć komputerową. Adresy DNS składają się z domen internetowych rozdzielonych kropkami. DNS to
złożony system komputerowy oraz prawny. Zapewnia z jednej strony rejestrację nazw domen internetowych i ich powiązanie z numerami
IP. Z drugiej strony realizuje bieżącą obsługę komputerów odnajdujących adresy IP odpowiadające poszczególnym nazwom.

POP3 – to protokół internetowy z warstwy aplikacji pozwalający na odbiór poczty elektronicznej ze zdalnego serwera do lokalnego
komputera poprzez połączenie TCP/IP. Ogromna większość współczesnych internautów korzysta z POP3 do odbioru poczty. Kiedy
użytkownik połączy się z siecią, to korzystając z POP3 może pobrać czekające na niego listy do lokalnego komputera. Jednak protokół ten
ma wiele ograniczeń:
- połączenie trwa tylko, jeżeli użytkownik pobiera pocztę i nie może pozostać uśpione,
- każdy list musi być pobierany razem z załącznikami i żadnej jego części nie można w łatwy sposób pominąć - istnieje co prawda komenda
top, ale pozwala ona jedynie określić przesyłaną liczbę linii od początku wiadomości,
- wszystkie odbierane listy trafiają do jednej skrzynki, nie da się utworzyć ich kilku,
- serwer POP3 nie potrafi sam przeszukiwać czekających w kolejce listów.
SSL – jest to protokół, mający za zadanie zapewnić bezpieczeństwo przesyłanych danych, a w szczególności: poufność przesyłanych danych,
ich integralność (czyli pewność, że nie zostały w żaden sposób zmienione oraz dotarły w całości). Protokół ten ponadto służy do
uwierzytelniania - daje gwarancję, że komputer przesyłający dane jest na prawdę tym, za który się podaje.
UDP - Jest to protokół bezpołączeniowy, więc nie ma narzutu na nawiązywanie połączenia i śledzenie sesji (w przeciwieństwie do TCP). Nie
ma też mechanizmów kontroli przepływu i retransmisji. Korzyścią płynącą z takiego uproszczenia budowy jest większa szybkość transmisji
danych i brak dodatkowych zadań, którymi musi zajmować się host posługujący się tym protokołem. Z tych względów UDP jest często
używany w takich zastosowaniach jak wideokonferencje, strumienie dźwięku w Internecie i gry sieciowe, gdzie dane muszą być przesyłane
możliwie szybko, a poprawianiem błędów zajmują się inne warstwy modelu OSI. Przykładem może być VoIP lub protokół DNS.
3. Technologie dynamicznych stron WWW.
Serwer - PHP (Personal Home Page),ASP (Active Server Pages),JSP (Java Serwer Pages),SSI (Server Side Include),CGI (Common Gateway
Interface),Servlety,Serwery aplikacji
Klient - (X)HTML (Extensible HyperText Markup Language),XML (Extensible Markup Language),CSS (Cascading Style Sheets),JavaScript,
VBScript (Visual Basic Scripting Edition),AJAX (Asynchronous JavaScript and XML),Flash,Aplety Javy
4. Podstawy języków znaczników: HTML, XHTML.
<HTML></HTML> - Znaczniki dokumentu. Między nimi umieszczana jest cała treść dokumentu.
<HEAD></HEAD> - zawiera podstawowe informacje o dokumencie.
<BODY></BODY> - zawiera konkretną treść dokumentu: znaczniki i tekst strony WWW
<TITLE></TITLE> - Tekst zawarty między znacznikami jest tytułem strony widocznym w belce tytułowej przeglądarki. Znacznik używany jest
w sekcji HEAD.
<META></META> - Szczegółowo opisuje zawartość dokumentu.
<!-- --> - Komentarz niewidoczny w oknie przeglądarki, tylko w kodzie HTML.
<P></P> - Oznacza blok nowego akapitu.
<BR> - Złamanie wiersza bez nowego akapitu.
<B></B> - Czcionka pogrubiona.
<I></I> - Czcionka pochylona.
<BLINK></BLINK> - Czcionka migająca.
<U></U> - Czcionka podkreślona.
<STRIKE></STRIKE> - Czcionka przekreślona.
<SUP></SUP> - Indeks górny
<SUB></SUB> - Indeks dolny
<FONT></FONT> - Ustala czcionkę
<Hn></Hn> - Nagłówek powoduje utworzenie nowego akapitu i wpisany tekst przyjmuje wartość n – od 1 do 7. H1 to największy nagłówek,
a H7 – najmniejszy
<HR> - Linia pozioma.
<CENTER></CENTER> - Wyśrodkowanie.
<RIGHT></RIGHT> - Wyrównanie do prawej strony.
<LEFT></LEFT> - Wyrównanie do lewej strony.
<JUSTIFY></JUSTIFY> - Wyjustowanie.
<UL> <LI> </LI> </UL> - Lista nieuporządkowana wyświetla wykaz nienumerowany.
<OL> <LI> </LI> </OL> - Lista uporządkowana sporządza wykaz numerowany.
<A href=”nazwa”>tekst świadczący o istnieniu odsyłacza</A> - Tworzy połączenie do pliku – po podaniu nazwy pliku lub do strony WWW
po podaniu jej adresu.
<A href=mailto:e-mail>tekst świadczący o istnieniu odsyłacza</A> - Odsyłacz umożliwiający internaucie wysłanie poczty e-mail ze strony.
<A href=”#nazwa”>tekst świadczący o istnieniu odsyłacza</A> - Odsyłacz umożliwiający internaucie przejście do określonego wcześniej
miejsca na stronie WWW „nazwa”.
<IMG SRC=”nazwa pliku”> - Umożliwia umieszczenie grafiki na stronie.
<TABLE></TABLE> - W ramach znaczników TABLE umieszcza się definicje rzędów, komórek, tytuł tabeli, nagłówki wierszy i kolumn oraz
dane mające znajdować się w tabeli.

<TH></TH> - Znacznik nagłówka używany w ramach znaczników TABLE.
<TR></TR> - Znacznik wiersza używany w ramach znaczników TABLE.
<TD></TD> - Znacznik kolumny używany w ramach znaczników TABLE.
<CAPTION></CAPTION> - Znacznik opisu tabeli używany w ramach znaczników TABLE.
5. Technologia XML. Elementy dokumentu XML.
XML (Extensible Markup Language) - wywodzi się od języka SGML i jest językiem znaczników służącym do opisu danych. Dane
przechowywane są w postaci tekstowej w dokumencie ściśle określonej strukturze. XML możemy uznać za:
- technologie opisu i przechowywania danych,
- rodzinę technologii do prezentacji i przetwarzania danych
- podstawowy składnik nowoczesnych technologii rozproszonych.
- XML jest stosowany również do opisu swoich własnych rozszerzeń.
Podstawowymi składnikami dokumentu XML są:
- elementy,
- atrybuty, które są umieszczane w elementach, jako dodatkowe informacje.
Elementy mogą być przy tym:
- nie puste — posiadające treść,
- puste — bez treści.
Oprócz tego w dokumencie XML można umieszczać:
- deklaracje,
- instrukcje przetwarzania,
- jednostki.
6. Opis struktury dokumentu DTD.
<!DOCTYPE …> - określa typ dokumentu, zawiera lub wskazuje definicję typu
dokumentu DTD (Definition Type Document).
<!ENTITY …> - definiuje jednostki (fragment tekstu dokumentu), do których
wielokrotnie można się odwoływać.
<!NOTATION …> - definiuje notacje, poprzez które można określać typy
danych zewnętrznych.
<!ELEMENT …> - deklaruje element (opisuje zawartość elementu).
<!ATTLIST …> - deklaruje listę atrybutów elementu.
<![IGNORE[ …]> - umożliwia wyłączanie z przetwarzania pewnych
fragmentów dokumentu.
<![INCLUDE[ …]> - umożliwia włączanie do przetwarzania pewnych
fragmentów dokumentu.<!ATTLIST : : : >
definicja encji <!ENTITY : : : >
7. Deklaracja XML. Przestrzenie nazw.
<?xml version="1.0" standalone="yes"?>
<przykład>
<typ>niezwykle oryginalny</typ>
Witaj świecie!
</przykład>
<![CDATA[Tekst]]> - umozliwia wstawienie tekstu który nie będzie sparsowany
Przestrzen nazw:
[1]
NSAttName
::=
[2]
PrefixedAttName ::= 'xmlns:'
[ NSC:
Leading "XML"
]
[3]
DefaultAttName ::= 'xmlns'
[4]
NCName ::= (
Letter
| '_') (
/* An XML
Name
, minus the ":"
*/
[5]
NCNameChar ::=
Letter
|
Digit
| '.' | '-' | '_' |
CombiningChar
|
Extender
8. Scheamt xml-schema
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="note">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="to" type="xsd:string"/>
<xsd:element name="from" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
Każdy element w schemacie ma prefiks xsd:, który jest powiązany z przestrzenią nazw XML Schema poprzez
deklarację postaci xmlns:xsd=
http://www.w3.org/2001/XMLSchema

9. Łączenie schematu z dokumentem.
<?xml version=”1.0”?>
<!-- Dokument XML, korzystający ze schematu: -->
<!-- Schemat znajduje się w pliku, w tym samym miejscu co dokument XML -->
<elementKorzen
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xsi:noNameSpaceschemaLocation=”xsdFile.xsd”>
. . . . . . . . . . . . . . .
<!-- zasadnicza treść dokumentu XML zgodnego ze schematem -->
</elementKorzen>
10. Przetwarzanie dokumentów XML
a) API oparte o drzewa (DOM) - Mapowanie dokumentu XML na drzewo elementów przechowywane w całości w pamięci.
b) API oparte o zdarzenia (SAX) - Parsowanie dokumentów XML generując zdarzenia po napotkaniu elementów dokumentu. Aplikacja musi
dostarczyć funkcje obsługi zdarzeń podobnie jak aplikacja GUI dostarcza funkcje obsługi zdarzeń elementów graficznego
interfejsu użytkownika.
<?xml version=‘‘1.0’’?>
<dvd>
<tytul>Rambo I</tytul>
<aktor>Sylvester Stallone</aktor>
</dvd>
Zdarzenie numer: 1
Nazwa zdarzenia:
Początek dokumentu
<?xml version=”1.0”?>
<dvd>
<tytul>Rambo I</tytul>
<aktor>Sylvester Stallone</aktor>
</dvd>
Zdarzenie numer: 2
Nazwa zdarzenia:
Początek elementu: “dvd”
ITD...
11. Przestrzenie nazw. Lokalizowanie schematu.
<?xml version=”1.0”?>
<elementKorzen
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xsi:noNameSpaceschemaLocation=”www.przyklad.pl/xsdFile.xsd”>
. . . . . . . . . . . . . . .
<!-- zasadnicza treść dokumentu XML zgodnego ze schematem -->
</elementKorzen>
12. Poprawność strukturalna dokumentu XML.
Poprawność dokumentu XML dzielimy na składniową i strukturalną, przy czym warunkiem koniecznym poprawności strukturalnej jest
poprawność składniowa. Poprawność składniowa wymaga spełnienia wzmiankowanych wcześniej warunków, pozwalających
oprogramowaniu przetwarzającemu zidentyfikować znaczniki i odtworzyć na ich podstawie hierarchię elementów dokumentu.
Z kolei poprawność strukturalna wymaga określenia schematu dokumentu, z którym zawartość dokumentu jest zgodna. Budowa takiego
dokumentu obejmuje: prolog, który przy stosowaniu DTD zawiera deklarację albo odwołanie do zewnętrznej definicji typu dokumentu -
DTD (Document Type Definition). Warunkiem poprawności strukturalnej jest wówczas zgodność treści dokumentu (nazwy i struktura
elementów) z podaną specyfikacją DTD.
Dokument XML, jako dokument poprawny strukturalnie powinien być wyposażony w formalny opis jego części składowych (nie jest to
konieczne ale zalecane). Taki opis w dużej mierze pozwala na uzyskanie pełnej kontroli nad powstającymi w oparciu o niego, wypełnionymi
treścią egzemplarzami dokumentu. Klasyfikacja dokumentów pod względem typów, ułatwia też ich przetwarzanie.

13. Technologie warstwy prezentacji dokumentów: CSS.
Arkusz stylów CSS to lista dyrektyw (tzw. reguł) ustalających w jaki sposób ma zostać wyświetlana przez
zawartość wybranego elementu (lub elementów) (
. Można w ten sposób opisać wszystkie pojęcia
odpowiedzialne za prezentację elementów dokumentów internetowych, takie jak rodzina czcionek, kolor tekstu,
, odstęp
międzywierszowy lub nawet pozycja danego elementu względem innych elementów bądź okna przeglądarki. Wykorzystanie arkuszy stylów
daje znacznie większe możliwości
elementów na stronie, niż oferuje sam (X)HTML.
Przykład:
html, body {
background-color: #fff;
color: #000;
margin: 0;
padding: 0;
}
#top {
width: 780px;
}
14. Technologie transformacji: XSLT, XSL FO.
XSLT - oparty na
. Pozwala na przetłumaczenie dokumentów z jednego formatu
dowolny inny format zgodny ze składnią
),
jak również na zwykły
i czysty tekst
nagłowek
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
XSL FO - oparty na
język znaczników, stosowany do formatowania dokumentów. Według starego podziału XSL-FO jest częścią
zbioru opracowanych przez
technik do transformacji i formatowania danych XML. Inne części XSL to
. W nowym podziale
nie ma takiego rozróżnienia, XSL-FO jest nazywany po prostu XSL.
W przeciwieństwie do
, dokumenty XML nie zawierają wbudowanego układu wizualnego. XSL-FO jest językiem, który może
być użyty do nadania dokumentowi XML układu na stronie, kolorów, czcionek itd. z przeznaczeniem wyniku dla ekranu komputerowego,
drukarki czy innych mediów. W tym sensie pełni on podobną funkcję jak style
, ale jest potężniejszy i bardziej elastyczny, zwłaszcza jeśli
chodzi np. o stronicowanie i przewijanie.
15. Obiektowy model dokumentu XML. Struktura drzewa dokumentu DOM.
DOM - sposób reprezentacji złożonych dokumentów
. Model ten jest niezależny od platformy
Standard
, pozwalających na dostęp do struktury dokumentów oraz jej modyfikację poprzez
tworzenie, usuwanie i modyfikację tzw. węzłów (
nodes).
Dla większości języków programowania istnieją biblioteki obsługujące DOM dla plików
. Najbardziej zaawansowane z nich to
i MS XML. Standard W3C definiuje interfejsy DOM tylko dla języków

16. Przetwarzanie strukturalne w DOM
Document Object Model, w skrócie DOM jest to obiektowa reprezentacja dokumentu XML, również zdefiniowana przez World Wide Web
Consortium ([dom98]). Jest to jedno z najczęściej stosowanych rozwiązań, pomimo tego, że to właśnie w tym modelu wręcz niemożliwe jest
zwolnienie pamięci zajmowanej przez dokument do czasu zakończenia jego przetwarzania. Konieczne jest też przechowywanie w pamięci
całego dokumentu wyjściowego (nie można zwolnić tej pamięci usuwając fragmenty już gotowe). Technika ta jest szczególnie popularna w
językach obiektowych (Java, C++), ponieważ strukturę dokumentu XML można w naturalny sposób przedstawić w postaci drzewa obiektów
odpowiadających węzłom.
17. Nawigacja i wyszukiwanie XPath.
XPath - ścieżkowy język zapytań dla dokumentów XML. Język do nawigacji po dokumentach XML.
OPERATORY NAWIGACJI:
Operatory nawigacji (osie (axes)):
Self - bieżący węzeł (zwany kontekstem: context node ),
Parent - rodzic aktualnego węzła (pusty dla węzła korzenia),
Child - bezpośrednie podelementy
Descendant - całe drzewo podelementów poniżej aktualnego,
Descendant-or-self – potomkowie oraz aktualny węzeł,
Ancestor - przodkowie aktualnego węzła
Ancestor-or-self - przodkowie oraz aktualny węzeł
Following-sibling - kolejne węzły na tym samym poziomie hierarchii.
Preceding-sibling - wcześniejsze węzły na tym samym poziomie
Following - wszystkie kolejne węzły (bez potomków),
Preceding - wszystkie poprzednie węzły (bez przodków).
Drzewo węzłów:
XPath rozróżnia siedem typów węzłów:
Element.
Tekst.
Przestrzeń nazw.
Instrukcję przetwarzania.
Komentarz.
Węzeł dokumentu.
Predykaty wyszukiwania
Operatory porównania:
=, !=, >, >=, <, <=
Operatory logiczne:
and or not
Operatory arytmetyczne:
+, -, *, div, mod
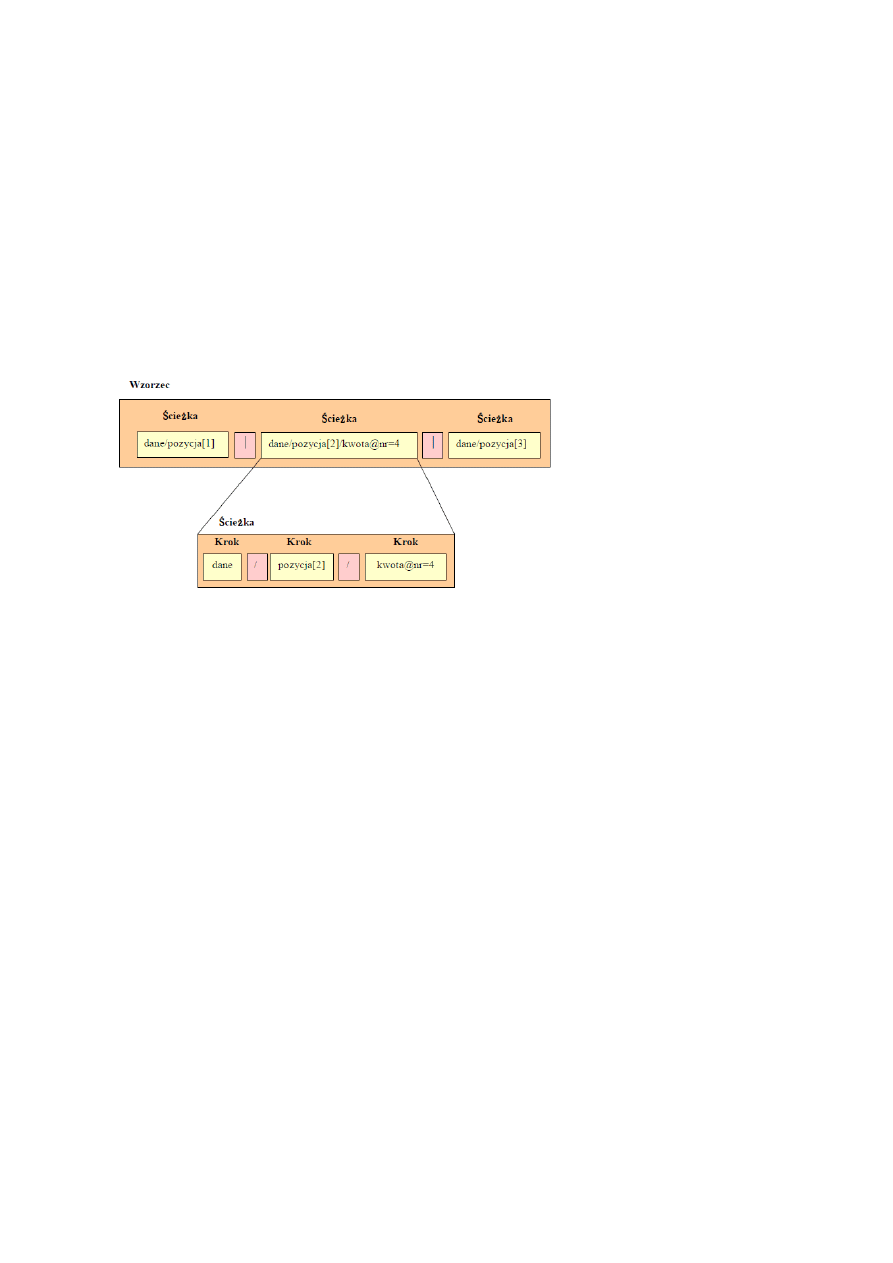
- //dane/pozycja[okres = ”Styczeń”] - oznacza wybranie elementów pozycja, dla których podelement okres ma wartość ”Styczeń”;
- //pozycja[wartosc*1.22 >1000] - oznacza wybranie elementów pozycja, dla których iloczyn lementu wartość oraz liczby 1,22 jest większy
od 1000;
XPath wykorzystywany w standardach:
- W transformacjach XSLT do określania, które fragmenty dokumentu XML mają podlegać danej transformacji.
- W odsyłaczach XLink - do wskazywania (adresowania) części dokumentu XML w odesłaniach hipertekstowych.
- W wyrażeniach XPointer (rozszerzenie XPath).
- W schematach XML-Schema do zapewnienia unikatowości w elementach i atrybutach niepowtarzalnych.
- W pytaniach XQuery - do tworzenia zapytań.
Technologia XPath:
- XPath - specyfikacja języka służącego do adresowania, odczytywania i przeszukiwania drzew DOM dokumentów XML.
- XPath używa opisu “ścieżek” do nawigowania po dokumencie XML (XPath stosuje notację przypominającą ścieżki dostępu w systemach
plików).
- Wynikiem ewaluacji wyrażenia XPath jest zbiór węzłów spełniających warunki selekcji.
- XPath zawiera wbudowaną bibliotekę standardowych funkcji.
- XPath jest głównym elementem XSLT.
- XPath jest standardem W3C.
18. Budowa wyrażeń Xpath. Funkcje.
XPath (wersja 1.0) wyróżnia następujące typy zwracanych wartości:
Boolean - wartość logiczna.
number - liczba
string - łańcuch tekstu.
node-set - zbiór węzłów (zbiór uporządkowany, podtrzymuje oryginalną kolejność pobranych elementów).
Budowa wyrażeń XPath
Ścieżka (location path) (ciąg określający przetwarzanie) jest zbudowana z kroków oddzielonych symbolem „/”. Krok może reprezentować:
- Element.
- Atrybut.
- Wywołanie funkcji.
Ścieżki we wzorcu (pattern), poprzedzielane są symbolem „|”.
Budowa kroku w wyrażeniu XPath
Składnia pojedynczego kroku ma następującą strukturę:
1. Kierunek (axis)
2. Podwójny dwukropek "::"
3. Symbol "*" (selekcjonuje dowolny element)
4. Nazwa elementu, albo wywołanie funkcji:
- node() - dowolny węzeł widoczny z bieżącego kontekstu,
- text() - zawartość tekstowa bieżącego węzła-kontekstu
- comment() - komentarze w bieżącym kontekście
- processing-instruction() - instrukcje przetwarzania w bieżącym kontekście.
Składnia pojedynczego kroku ma następującą strukturę:
1. self::* - dostęp do aktualnego węzła.
2. preceding::pozycja - dostęp do poprzedzających aktualny węzeł elementów o nazwie pozycja.
3. preceding::text() - dostęp do poprzedzających aktualny węzeł zawartości tekstowych.
4. following-sibling::node() - dostęp do elementów występujących na tym samym poziomie, co aktualny węzeł i będących jego
następnikami.
5. following-sibling::comment() - dostęp do komentarzy występujących na tym samym poziomie, co aktualny węzeł i będących jego
następnikami.
6. ancestor: :procesing-instruction() - dostęp do instrukcji przetwarzania występujących w węzłach-przodkach.
Funkcje wbudowane:
Tekstowe:
concat(łańcuch1, łańcuch2, ...) - konkatenacja.
contains(łańcuch, wzorzec) - sprawdzenie, czy zawiera podłańcuch równy wzorcowi.
normalize-space(łańcuch) - normalizacja (usunięcie spacji nadmiarowych).
starts-with(łańcuch, wzorzec) - sprawdzenie, czy łańcuch zaczyna się od podanego wzorca.
string-length(łańcuch) - bada długość wzorca.

Liczbowe:
ceiling(liczba), floor(liczba), round(liczba) – zaokrąglenia,
sum(wyrażenie_zwracające_zbior_węzłow) - sumowanie wartości z węzłów zwracanych przez wyrażenie.
number(...) - konwersja warto.ci innego typu na numer
Logiczne:
false(),true(),not() - wartości prawda, fałsz oraz funkcja zanegowania.
boolean() - konwersja wartości innego typu na boolean.
Funkcje dotyczące węzłów
Liczbowe:
ceiling(liczba), floor(liczba), round(liczba) - zaokr.glenia.
sum(wyra.enie_zwracaj.ce_zbior_w.z.ow) - sumowanie warto.ci z
w.z.ow zwracanych przez wyra.enie.
number(...) - konwersja warto.ci innego typu na number
Logiczne:
false(),true(),not() - warto.ci prawda, fa.sz oraz funkcja zanegowania.
boolean() - konwersja warto.ci innego typu na boolean.
19. Dynamiczne witryny www z wykorzystaniem technologii AJAX.
AJAX (ang. Asynchronous JavaScript and XML, asynchroniczny JavaScript i XML) – technologia tworzenia aplikacji internetowych, w której
interakcja użytkownika z serwerem odbywa się bez przeładowywania całego dokumentu, w sposób asynchroniczny. Ma to umożliwiać
bardziej dynamiczną interakcję z użytkownikiem niż w tradycyjnym modelu, w którym każde żądanie nowych danych wiąże się z
przesłaniem całej strony HTML.
Na technologię tę składa się parę elementów:
XMLHttpRequest - klasa umożliwiająca asynchroniczne przesyłanie danych; dzięki asynchroniczności w trakcie pobierania danych
użytkownik może wykonywać inne czynności, można także pobierać dane jednocześnie z wielu miejsc.
JavaScript - mimo użycia w nazwie, może to być de facto dowolny język skryptowy funkcjonujący po stronie użytkownika (np. JScript czy
VBScript).
XML - język znaczników, poprzez który miałyby być opisane odbierane informacje. W praktyce jednak dane często przekazywane są w
innym formacie, przy czym odbierane są wtedy jako tekst. Mogą to być zarówno gotowe fragmenty HTML, jak i fragmenty kodu JavaScript
(zob. JSON), może to być też format specyficzny dla danego zastosowania.
Teoretycznie są to wszystkie wymagane elementy, jednak w praktyce używane są jeszcze odpowiednie skrypty funkcjonujące po stronie
serwera i współpracujące z bazą danych. Można sobie jednak bez nich poradzić, jeśli wszystkie potrzebne dane zostały już wcześniej
wygenerowane (np. zawartość poszczególnych stron prostego serwisu).
Wady i zalety AJAX:
Udostępnianie treści strony poprzez język skryptowy ogranicza dostęp do niej dla części użytkowników. Dotyczy to zarówno osób celowo
blokujących sobie skrypty (np. ze względu na wysokie obciążenie komputera), jak i używających czytników ekranowych (w których obsługa
skryptów może być mocno ograniczona). Problem ten można obejść udostępniając alternatywne, bardziej tradycyjne rozwiązania
przynajmniej dla podstawowych funkcji serwisu internetowego. To jednak znacząco zwiększa koszty wprowadzania nowych rozwiązań i np.
portale posiadające obsługę kont pocztowych udostępniają czasem starsze wersje interfejsu.
Utrudnione jest automatyczne pobieranie stron, gdyż programy takie nie interpretują zwykle języków skryptowych. Możliwość dowolnego
pobierania zawartości serwisu nie musi być jednak korzystna z punktu widzenia właścicieli serwisu.
Bezpośrednie indeksowanie przez serwisy wyszukujące może być utrudnione, jednak wystarczy zadbać o dostarczanie linków
wyświetlających całą treść strony lub stworzyć mapę witryny.
Część starych skryptów do analizy ruchu na stronie oparta jest o klasyczny model udostępniania całych stron (konieczność odświeżenia
całości). Nowsze skrypty potrafią jednak uwzględnić właściwy pomiar oglądalności stron. Można również bez przeszkód analizować logi
żądań wysyłanych do serwera WWW.
Wadą rozwiązań w znaczącym stopniu opartych na AJAX jest fakt, że przestaje funkcjonować tradycyjny schemat przeglądania stron
umożliwiający swobodne poruszanie się w przód i w tył. Na przykład jeśli kliknięcie w link powoduje wywołanie skryptu zmieniającego
wnętrze strony (menu pozostaje bez zmian), to użytkownik nie będzie mógł się cofnąć korzystając z przycisku "Wstecz" przeglądarki.

Twórcy serwisu WWW mogą jednak zbudować analogiczny mechanizm rozwijając go nawet do wycofywania zmian w konkretnym
fragmencie strony.
20. Komponenty witryny: skrypty JS, JSP, mechanizm SSI.
SSI (ang. Server Side Includes) to prosty mechanizm skryptowy służący do dynamicznego generowania stron WWW na serwerze WWW.
Używany przede wszystkim do włączania zdefiniowanych plików do dokumentu wynikowego (include). Pozwala na zagnieżdżanie w kodzie
dokumentu wartości zmiennych serwera i wyników działania programów uruchomionych po stronie serwera. Domyślnie pliki generowane
(filtrowane) przez SSI mają rozszerzenie .shtml.
Przykłady dyrektyw
zwrócenie nazwy wykonywanego pliku
<!--#echo var="DOCUMENT_NAME" -->
adres IP klienta
<!--#echo var="REMOTE_ADDR" -->
data i godzina na serwerze
<!--#echo var="DATE_LOCAL" -->
JSP (ang. JavaServer Pages) to technologia umożliwiająca tworzenie dynamicznych dokumentów WWW w formatach HTML, XHTML,
DHTML oraz XML z wykorzystaniem języka Java, wplecionego w kod HTML danej strony. W tym aspekcie, jest to rozwiązanie podobne do
PHP.
Strona JSP w procesie translacji jest zamieniana na serwlet (z reguły mała aplikacja napisana w Javie uruchamiana po stronie serwera w
kontenerze serwletów). Każde wywołanie strony JSP z poziomu klienta (przeglądarki) wykonywane jest przez skompilowany serwlet. Jeśli
użyta zostanie prekompilacja (kompilacja wstępna) to już podczas uruchamiania aplikacji wszystkie strony JSP zostaną przetłumaczone na
serwlety.
Strony JSP składają się z następujących elementów:
- treść statyczna - przepisywana bez modyfikacji do generowanego dokumentu
- dyrektywy JSP - informacje kontrolujące proces generowania dokumentu
- elementy skryptowe - skryplety (kod w języku Java kontrolujący proces generowania dokumentu) oraz elementy składniowe tzw.
Expression Language
- akcje JSP - tagi XML wywołujące określone metody serwerowe
Skrypty JS JavaScript (JS) – skryptowy język programowania, stworzony przez firmę Netscape, najczęściej stosowany na stronach
internetowych. Pod koniec lat 90. XX wieku organizacja ECMA wydała na podstawie JavaScriptu standard języka skryptowego o nazwie
ECMAScript. Głównym autorem JavaScriptu jest Brendan Eich.
Zastosowanie:
Najczęściej spotykanym zastosowaniem języka JavaScript są strony WWW. Skrypty służą najczęściej do zapewnienia interaktywności
poprzez reagowanie na zdarzenia, sprawdzania poprawności formularzy lub budowania elementów nawigacyjnych. Podczas wzbogacania
funkcjonalności strony internetowej istotne jest, aby żaden element serwisu nie stał się niedostępny po wyłączeniu obsługi JavaScriptu w
przeglądarce. Skrypt JavaScriptu ma znacznie ograniczony dostęp do komputera użytkownika (o ile nie zostanie podpisany cyfrowo).
Niektóre strony WWW zbudowane są z wykorzystaniem JavaScriptu po stronie serwera, jednakże znacznie częściej korzysta się w tym
przypadku z innych języków.
W języku JavaScript można także pisać pełnoprawne aplikacje. Fundacja Mozilla udostępnia środowisko złożone z technologii takich jak
XUL, XBL, XPCOM oraz JSLib. Umożliwiają one tworzenie korzystających z zasobów systemowych aplikacji o graficznym interfejsie
użytkownika dopasowującym się do danej platformy. Przykładem aplikacji napisanych z użyciem JS i XUL może być klient IRC o nazwie
ChatZilla, domyślnie dołączony do pakietu Mozilla. Microsoft udostępnia biblioteki umożliwiające tworzenie aplikacji JScript jako część
środowiska Windows Scripting Host. Ponadto JScript.NET jest jednym z podstawowych języków środowiska .NET. Istnieje także stworzone
przez IBM środowisko SashXB dla systemu Linux, które umożliwia tworzenie w języku JavaScript aplikacji korzystających z GTK+, GNOME i
OpenLDAP.
Implementacja

W języku HTML za umieszczanie skryptów JS odpowiedzialny jest
element <script> z argumentem type o wartościtext/javascript oraz
argumentem language o wartości javascript. Atrybut language jest
jednak przestarzały i zaleca się go pomijać.
<
script type
=
"text/javascript"
language
=
"JavaScript 1.5"
>
alert
(
12
>
6
)
;
</
script
>
Jeżeli kod znajduje się w dokumencie XHTML, w celu uniknięcia
zinterpretowania niektórych operatorów jako elementów składni
języka należy otoczyć skrypt sekcją CDATA lub zapisać je w postaci
encji
[7]
. W XHTML nie można używać argumentu language w
znaczeniu określenia wersji języka JS (atrybut, jeżeli jest użyty,
powinien przyjąć dwuznakowe wartości opisane standardem ISO 639,
np. EN, DE, PL).
<
script type
=
"text/javascript"
>
/* <![CDATA[ */
alert
(
12
>
6
)
;
/*]]> */
</
script
>
Zewnętrzne skrypty dodajemy także przy użyciu powyższego
znacznika, uwzględniając jedynie parametr src z nazwą pliku
zawierającego kod skryptu.
dla samodzielnych plików
JavaScript to application/javascript lub przestarzały text/javascript
[8]
.
<
script type
=
"text/javascript"
src
=
"code.js"
></
script
>
21. Bazowy stos technologii SOAP.
SOAP (Simple Object Access Protocol) to prosty protokół komunikacyjny oparty najęzyku XML, umożliwiający przekazywanie wywołań
zdalnych komponentów Web Services. SOAP może współdziałać z dowolnym niskopoziomowym sieciowym mechanizmem transportowym,
np. HTTP, HTTPS, SMTP, JMS, RMI. Podstawowymi znacznikami wykorzystywanymi do budowy komunikatów SOAP są:
<Envelope> – otacza cały komunikat,
<Header> – zawiera informacje nagłówkowe,
<Body> – zawiera informacje o żądaniu i odpowiedzi,
<Fault> – opisuje błędy, jakie wystąpiły podczas przetwarzania wywołania.
Protokół SOAP umożliwia wywoływanie komponentów Web Service w dwóch trybach:
(1) Remote Procedure Call (RPC) i (2) dokumentowym (documentoriented).
Tryby te różnią się formą przekazywania parametrów. W trybie RPC wywołanie ma charakter tradycyjny – komponentowi przekazywana
jest lista parametrów formalnych wraz z ich bieżącymi wartościami. W trybie dokumentowym usługa otrzymuje tylko jeden parametr
wywołania, którym jest dokument XML. Wywołania komponentów usługowych Web Services mogą mieć charakter synchroniczny lub
asynchroniczny. W trybie wywołania synchronicznego aplikacja klienta wysyła żądanie uruchomienia zdalnej funkcji biznesowej i
wstrzymuje pracę aż do chwili otrzymania wyników jej realizacji. Tryb ten może opierać się na komunikacji HTTP, HTTPS, RMI/IIOP, SMTP,
itp. W trybie wywołania asynchronicznego aplikacja klienta wysyła żądanie uruchomienia zdalnej funkcji biznesowej lecz nie oczekuje na jej
wynik, kontynuując działanie. Tryb ten może opierać się na komunikacji HTTPR, JMS, IBM MQSeries Messaging, MS Messaging, itp. Zwykle
tryb synchroniczny jest wykorzystywany przez komponenty RPC, natomiast tryb asynchroniczny – przez komponenty dokumentowe.
22. Budowa i przetwarzanie komunikatu SOAP.
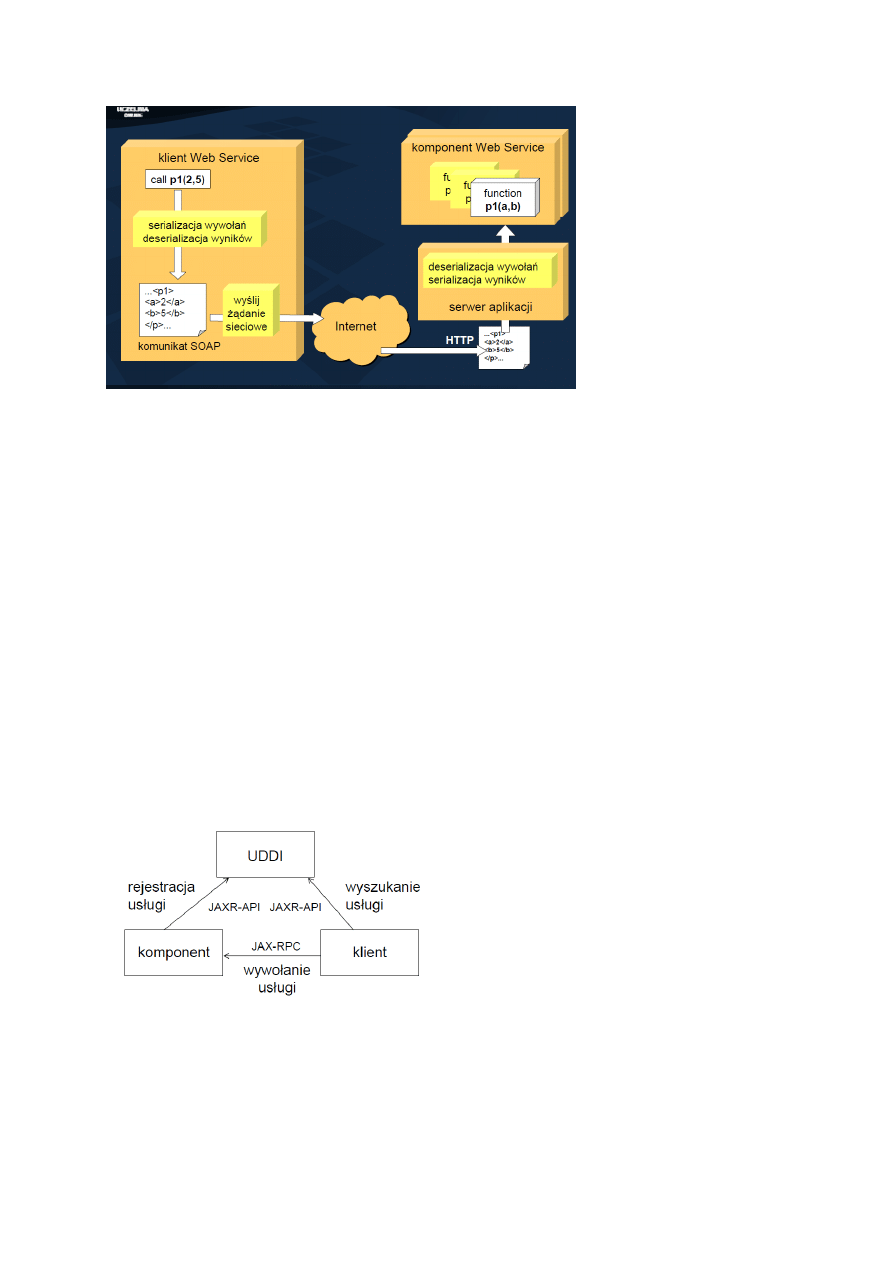
Klient Web Service zapisuje treść wywołania komponentu w postaci komunikatu SOAP, stanowiącego rodzaj serializacji wywołania w
formacie XML. Komunikat SOAP jest przekazywany za pośrednictwem wybranego protokołu sieciowego (najczęściej HTTP) do zdalnego
serwera aplikacji. Serwer aplikacji dokonuje deserializacji komunikatu SOAP w celu ekstrakcji pierwotnego zapisu wywołania komponentu
Web Service, a następnie lokalnie przekazuje sterowanie do właściwej jednostki programowej komponentu.
Ewentualne wyniki pracy komponentu mogą być w analogiczny sposób przekazane zwrotnie do klienta – następuje wówczas serializacja
wyników do komunikatu SOAP, przesłanie sieciowe, a w ostatnim kroku deserializacja wyników po stronie klienta. Komponenty usługowe
Web Service mogą pracować w trybie bezstanowym (ulotne wartości zmiennych pomiędzy wywołaniami) lub stanowym (nieulotne
wartości zmiennych pomiędzy wywołaniami). Mogą również korzystać z dostępnych mechanizmów sesji, np. HTTPSession, oraz
uwierzytelniania, np. HTTP Basic Authentication.
23, 24. Specyfikacja UDDI publikowania, rejestrowania i wyszukiwania usług webowych. Elementy architektury UDDI.
UDDI - Rozproszony katalog (rejestr biznesowy) – umożliwiający firmom i aplikacjom w szybki i łatwy sposób znajdować i używać usług Web
Services. Zawiera informacje dotyczące zarówno samych firm, jak i zarejestrowanych przez nie usług. Pełni role swoistej „książki
adresowej”, w której skład wchodzą:
- „białe strony” (ang. white pages) - informacje dotyczące dostawcy usługi (adres, dane kontaktowe)
- „żółte strony” (ang. yellow pages) - wykaz dostawców usług ułożony według klasyfikacji przemysłowej
- „zielone strony” (ang. green pages) - opisy usług wraz z odnośnikami do nich
Rejestr UDDI
- Specjalizowana baza danych
- Trzy poziomy opisu komponentów
UDDI Business Registry (UBR) – publiczny rejestr, który logicznie jest scentralizowany, natomiast fizycznie rozproszony i replikowany.
25. Język opisu usług webowych WSDL.
Język WSDL
• Opis interfejsu komponentu Web Service
• Automatyczne generowanie kodu źródłowego klienta Web Service
• Język znaczników XML

WSDL to język znaczników XML służący do opisu technicznych parametrów
połączenia sieciowego aplikacji-klienta z komponentem Web Service. Strukturę
znaczników dokumentu WSDL przedstawiono na slajdzie. Role wymienionych
znaczników są następujące. Znacznik <definitions> otacza całą zawartość
dokumentu. Znaczniki <service> wraz ze znacznikami <port> definiują adresy
punktów dostępowych dla usługi. Znaczniki <portType> służą do deklaracji funkcji
biznesowych oferowanych przez usługę. Znaczniki <binding> określają metody
kodowania parametrów wywołania i parametrów zwrotnych usługi.
Przykład:
Jest to dokument opisujący usługę o nazwie „demo” zawierającą jedną metodę
„multiply(int val1, int val2)”.
<definitions name="demo" ...>
<message name="multiply0Request">
<part name="val1" type="xsd:int"/>
<part name="val2" type="xsd:int"/>
</message>
<message name="multiply0Response">
<part name="return" type="xsd:int"/>
</message>
<portType name="DemoPortType">
<operation name="multiply">
<input name="multiply0Request" message="tns:multiply0Request"/>
<output name="multiply0Response" message="tns:multiply0Response"/>
</operation>
</portType>...
Wyszukiwarka
Podobne podstrony:
odpowiedzi pdf id 332621 Nieznany
Odpowiedzi z robotyki id 33268 Nieznany
ODPOWIEDZI FIZYKA id 332483 Nieznany
biologia odpowiedzi zp id 88136 Nieznany
odpowiedzi biologia id 85891 Nieznany
angielski odpowiedzi zp id 2213 Nieznany (2)
odpowiedzi 11 id 332300 Nieznany
odpowiedzi edytow id 332475 Nieznany
angielski odpowiedzi zr id 2213 Nieznany (2)
odpowiedzi pdf id 332621 Nieznany
odpowiedzi do testu id 332437 Nieznany
Klucz odpowiedzi id 236518 Nieznany
odpowiedzibezpieczenstwo id 332 Nieznany
Odpowiedzi testu BHP id 332669 Nieznany
odpowiedzi na pytania 2 id 3325 Nieznany
konspekt odpowiedzialnosc id 24 Nieznany
OPRACOWANE ODPOWIEDZI id 337615 Nieznany
Odpowiedzi na otwarte id 332578 Nieznany
Odpowiedzi do MCS i Wytrz id 33 Nieznany
więcej podobnych podstron