
5.04.21
Artur&Artur
1
Hazardy sterowania
Typowe problemy
Sprzętowe i programowe
metody
ich rozwiązywania

5.04.21
Artur&Artur
2
Wprowadzenie
• Hazardy sterowania mogą
powodować opóźnienia w potoku,
znacznie przekraczające opóźnienia,
spowodowane hazardami danych.
• Zrozumienie tych zagadnień jest
kluczowe przy projektowaniu
możliwie najszybciej wykonujących
się programów.

5.04.21
Artur&Artur
3
Skok
Rozkaz skoku może:
• zmienić zawartość licznika rozkazów PC o
4 (skok nieefektywny)
• Zmienić zawartość licznika rozkazów PC o
wartość, wynikającą z zawartości
ALUOutput (skok efektywny)
Rozkazy skoku mogą być bezwarunkowe i
warunkowe
5.04.21
Artur&Artur
4
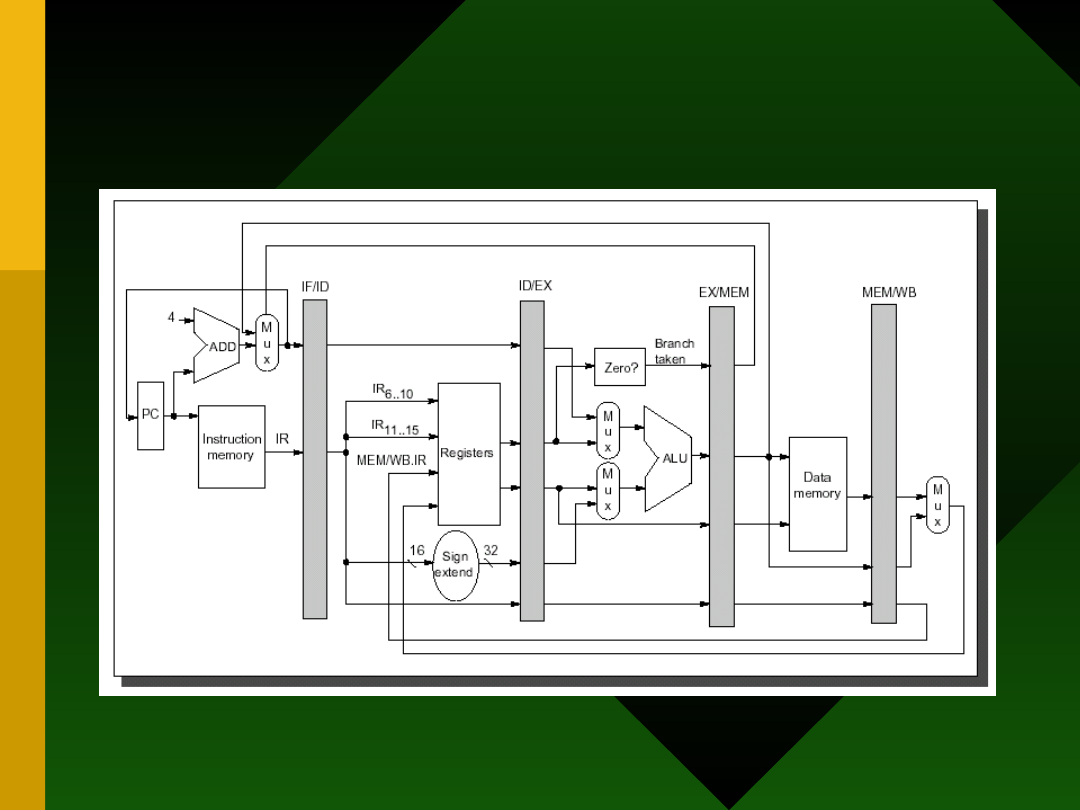
Datapath procesora DLX

5.04.21
Artur&Artur
5
Realizacja skoku

5.04.21
Artur&Artur
6
Realizacja skoku w potoku
DLX: metoda najprostsza

5.04.21
Artur&Artur
7
Realizacja skoku w potoku
DLX: metoda najprostsza
• Najprościej: po zdekodowaniu
rozkazu skoku można zablokować
potok aż do obliczenia w fazie MEM
nowej zawartości PC i warunku cond
• Następnie należy powtórzyć IF dla
nowego rozkazu
• Efekt: 3 cykle opóźnienia

5.04.21
Artur&Artur
8
Sposoby redukcji
opóźnienia skoku (ang.
branch penalty)
• Wcześniej w potoku dowiedzieć się,
czy skok jest efektywny (ang.
taken), czy nieefektywny (ang. not
taken)
• Wcześniej w potoku obliczyć adres
efektywny skoku (ang. address of
the branch target)

5.04.21
Artur&Artur
9
Modyfikacje potoku
• W procesorze DLX skoki warunkowe
BEQZ i BNEZ można testować na
koniec fazy ID
• Również pod koniec tej fazy należy
wobec tego obliczyć oba adresy
skoku: zarówno efektywnego, jak i
nieefektywnego (dodatkowa ALU)
5.04.21
Artur&Artur
10
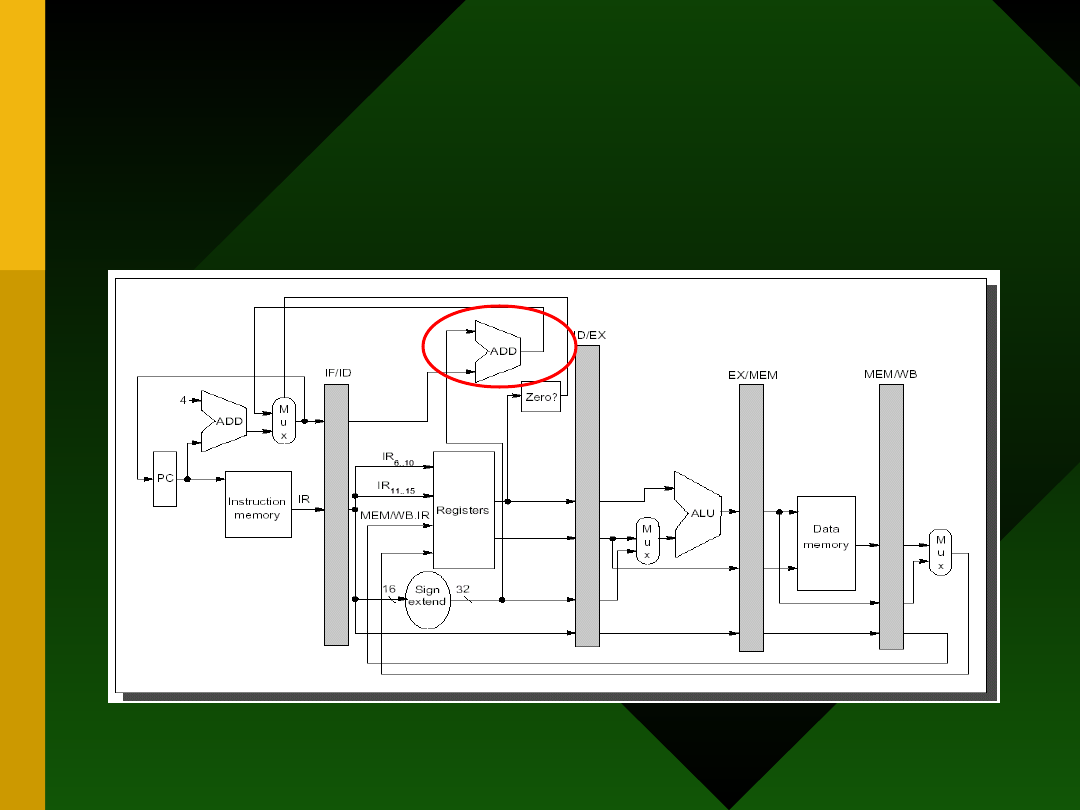
Zmodyfikowana struktura
potoku DLX

5.04.21
Artur&Artur
11
Nowy opis działania potoku

5.04.21
Artur&Artur
12
Ogólna reguła dla branch
penalty
• Im głębszy potok, tym większe
opóźnienia, związane z realizacją
rozkazów skoku!
• Jest to związane z koniecznością
opróżnienia potoku z instrukcji,
następujących w kodzie programu po
instrukcji skoku, i pobrania nowych.

5.04.21
Artur&Artur
13
Występowanie skoków w
programach
• Skoki bezwarunkowe (jump, call, ret)
• Skoki warunkowe – w przód, w tył
• Ponieważ skoki warunkowe w tył są
używane do realizacji pętli, będą
częściej efektywne (rzędu 80%), niż
skoki w przód (rzędu 60%)

5.04.21
Artur&Artur
14
Schematy zachowania
potoku przy skokach
1. Zatrzymać potok (ang. freeze):
łatwa do realizacji, ale
wprowadzająca stały koszt realizacji
skoku – nie można redukować go
mimo poznania statystycznego
opisu zachowania programu

5.04.21
Artur&Artur
15
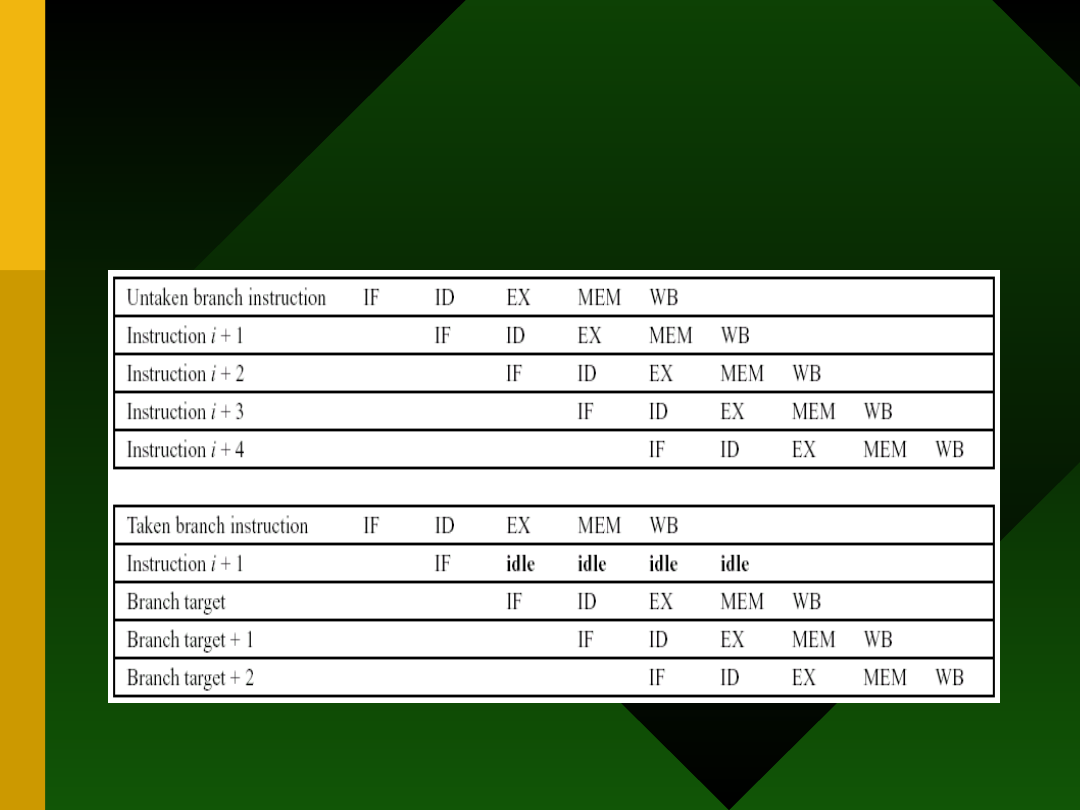
Schematy zachowania
potoku przy skokach
2. Predict-not-taken: założenie, że
wszystkie skoki są nieefektywne i
kontynuowanie obliczeń dla
następnych instrukcji w sekwencji.
Konieczność „cofania się w czasie”
jeśli skok jest efektywny –
stosowany w DLX
5.04.21
Artur&Artur
16
Schematy zachowania
potoku przy skokach

5.04.21
Artur&Artur
17
Schematy zachowania
potoku przy skokach
3. Predict-taken: założenie, że
wszystkie skoki są efektywne, i
natychmiast po obliczeniu adresu
efektywnego, pobieranie następnych
instrukcji spod nowego adresu –
opłacalny w bardziej skomplikowanych
maszynach, gdzie adres jest znany
wcześniej, niż warunki, wpływające na
efektywność skoku.

5.04.21
Artur&Artur
18
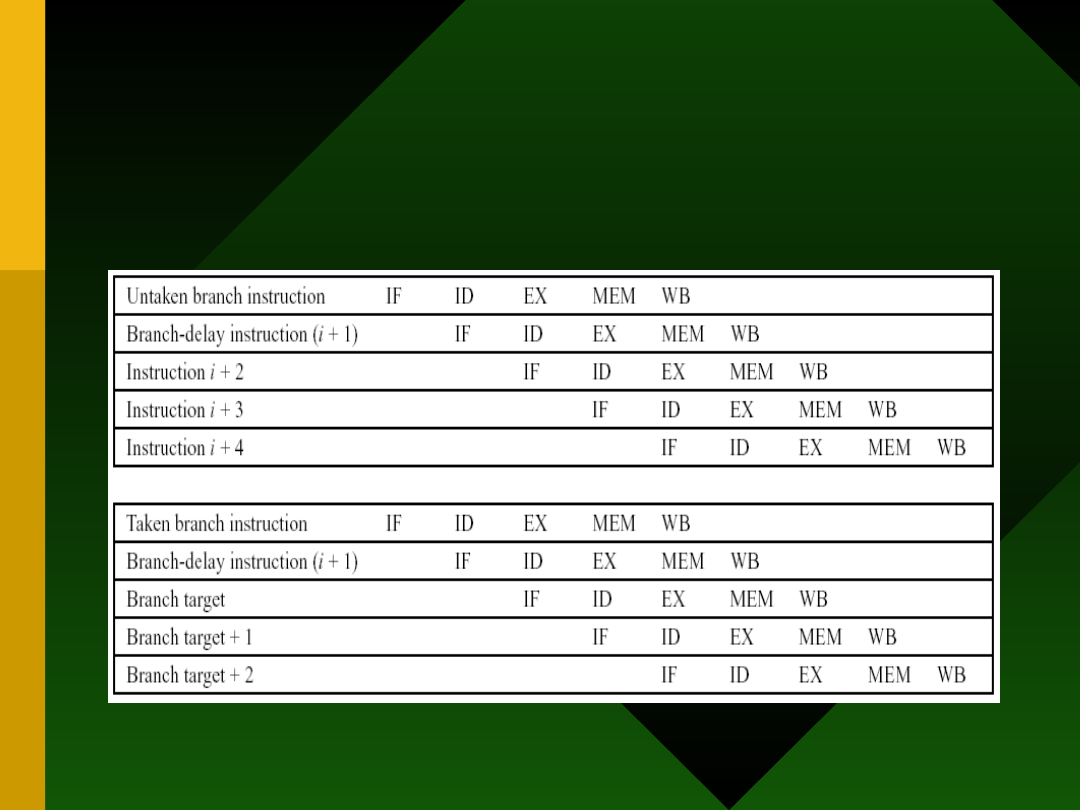
Schematy zachowania
potoku przy skokach
4. Skok opóźniony (ang. delayed
brach): zastosowanie brach-delay
slot, czyli „miejsca” na instrukcję
bądź instrukcje, które są
wykonywane niezależnie od tego,
czy skok jest efektywny, czy nie!
5.04.21
Artur&Artur
19
Delayed Branch

5.04.21
Artur&Artur
20
Gdyby DLX stosował ten
schemat realizacji skoków
• Jeśli wprowadzilibyśmy miejsce na jedną
instrukcję, wykonywaną niezależnie od tego,
czy skok jest efektywny, czy nie, a
instrukcją, następującą w slocie po instrukcji
skoku była kolejna instrukcja skoku, to co?
• Aby uniknąć tego kłopotu, zakłada się, że w
slocie nie wolno umieszczać instrukcji skoku.

5.04.21
Artur&Artur
21
Trzy sposoby
wykorzystania skoku
opóźnionego

5.04.21
Artur&Artur
22
Trzy sposoby
wykorzystania skoku
opóźnionego
• Sposób a) jest wykorzystywany
najchętniej i polega na wypełnieniu
slotu niezależną instrukcją sprzed
instrukcji skoku

5.04.21
Artur&Artur
23
Trzy sposoby
wykorzystania skoku
opóźnionego

5.04.21
Artur&Artur
24
Trzy sposoby
wykorzystania skoku
opóźnionego
• Sposób b) jest wykorzystywany, gdy a)
jest niemożliwy(R1, jako rejestr
warunku skoku, jest jednocześnie
rejestrem przeznaczenia dla instrukcji
ADD. Polega na wypełnieniu slotu
instrukcją, skopiowana z celu skoku.
Korzystny dla pętli, gdzie
prawdopodobieństwo efektywności
skoku jest wysokie.

5.04.21
Artur&Artur
25
Trzy sposoby
wykorzystania skoku
opóźnionego

5.04.21
Artur&Artur
26
Trzy sposoby
wykorzystania skoku
opóźnionego
• Sposób c) jest wykorzystywany, gdy
a) i b) są niemożliwe. Polega na
wypełnieniu slotu instrukcją,
przesuniętą z sekwencji po skoku
nieefektywnym. Korzystny dla
sytuacji, gdy prawdopodobieństwo
efektywności skoku jest niskie.

5.04.21
Artur&Artur
27
Trzy sposoby
wykorzystania skoku
opóźnionego

5.04.21
Artur&Artur
28
Trzy sposoby
wykorzystania skoku
opóźnionego
• Każdy z tych przypadków musi być
odpowiednio obsłużony przez
kompilator optymalizujący! Jeśli
niemożliwe jest wprowadzenie do
slotu instrukcji użytecznej,
kompilator powinien wpisać tam
NOP.
5.04.21
Artur&Artur
29
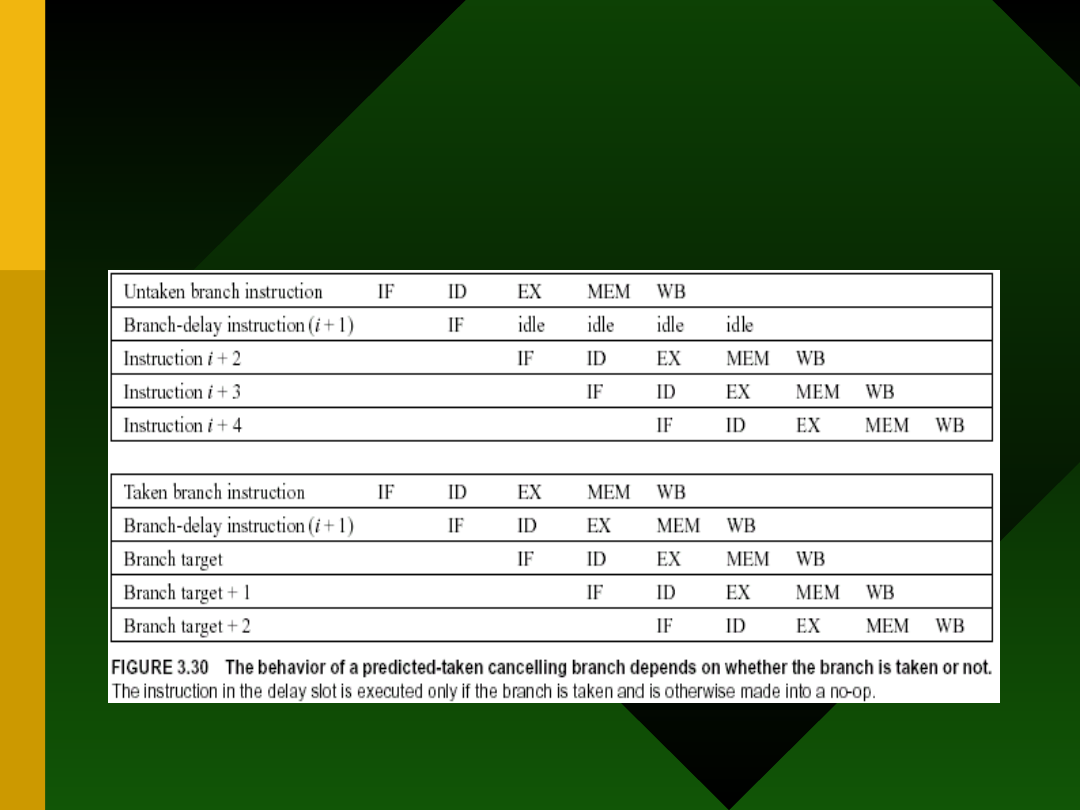
Skok opóźniony -
cancelling

5.04.21
Artur&Artur
30
Techniki zwiększania
Instruction-Level
Parallelism
• Rozwijanie pętli (ang. loop unrolling) CH
• Harmonogramowanie (ang. scheduling) RAW
• Stosowanie tablicy wyników (ang. score
boarding) RAW
• Zmiana nazw rejestrów (ang. register
renaming) WAR i WAW
• Dynamiczne przewidywanie skoków (ang.
dynamic branch prediction) CH

5.04.21
Artur&Artur
31
Przykład kodu źródłowego

5.04.21
Artur&Artur
32
Komentarz do przykładu
Założenia:
• R1: zawiera początkowo adres
elementu tablicy o najwyższym adresie
• F2: zawiera wartość skalara s
• Dla prostoty obliczeń zakładamy też, że
element x[1] jest w PAO pod adresem 8

5.04.21
Artur&Artur
33
Prosty kod asemblerowy
dla DLX
5.04.21
Artur&Artur
34
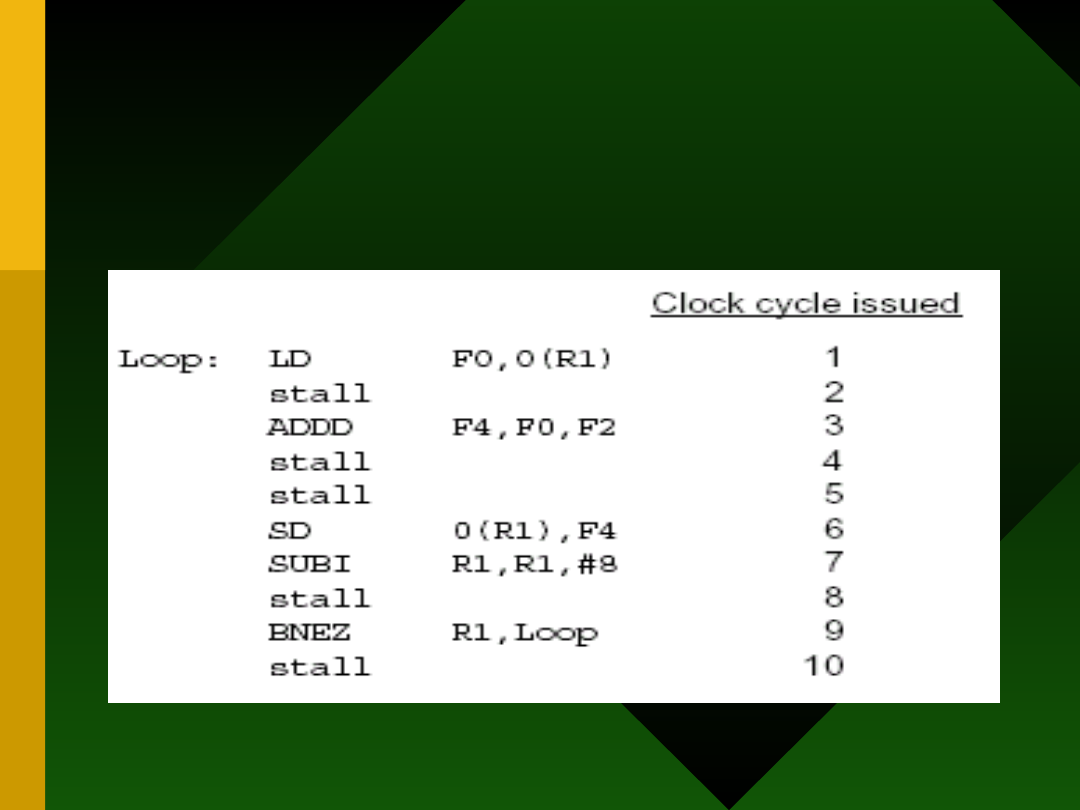
Wykonanie

5.04.21
Artur&Artur
35
Po schedulingu

5.04.21
Artur&Artur
36
Ulepszenie: z 10 na 6 cykli
• Ale tylko 3 cykle przetwarzają
element tablicy, a 3 pozostałe służą
do zarządzania pętlą!
• Rozwińmy więc pętlę!

5.04.21
Artur&Artur
37
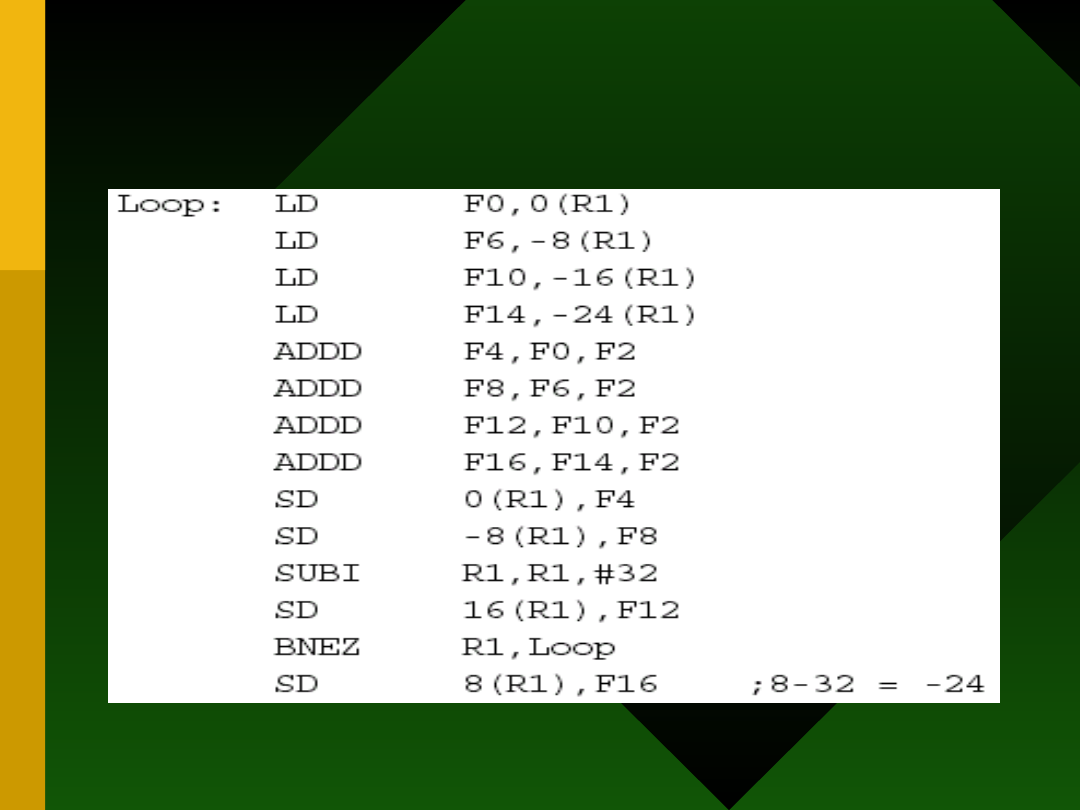
Po rozwinięciu

5.04.21
Artur&Artur
38
Zysk?
• Ta pętla wykona się w ciągu 28 cykli:
każdy LD powoduje 1 stall, każdy
ADDD to 2 stalle, SUBI to 1 stall, skok
też 1, plus 14 cykli na użyteczne
instrukcje. To daje 7 cykli na każdy
element tablicy: gorzej niż
poprzednio (tam było 6 cykli), ale to
jeszcze nie koniec.
5.04.21
Artur&Artur
39
Scheduling w rozwiniętej
pętli

5.04.21
Artur&Artur
40
Zysk?
• Czas wykonania takiej pętli zmalał do
14 cykli, czyli średnio 3,5 cyklu na
jeden element tablicy!
• Koszt administracji pętlą zmalał do 0,5
cyklu na element!
• Zmiana z 10 do 3,5 cyklu na element!

5.04.21
Artur&Artur
41
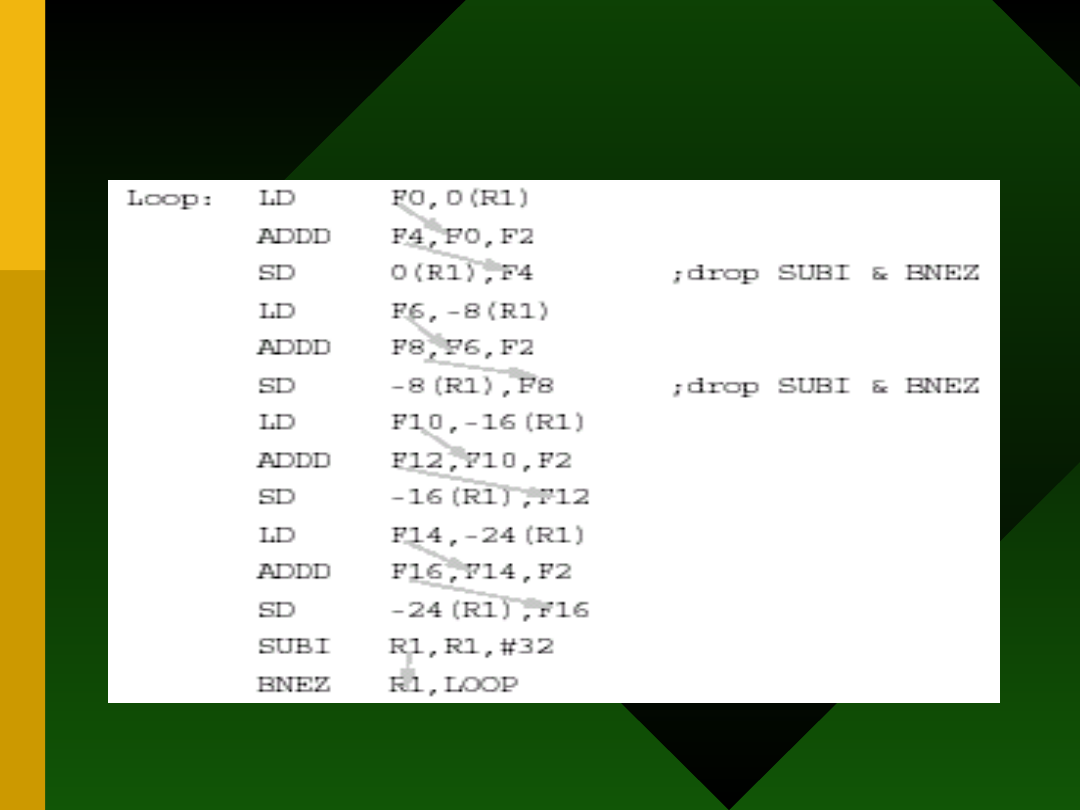
Zmniejszenie zależności danych

5.04.21
Artur&Artur
42
Data (sz) &name (cz) dependences
5.04.21
Artur&Artur
43
Register renaming

5.04.21
Artur&Artur
44
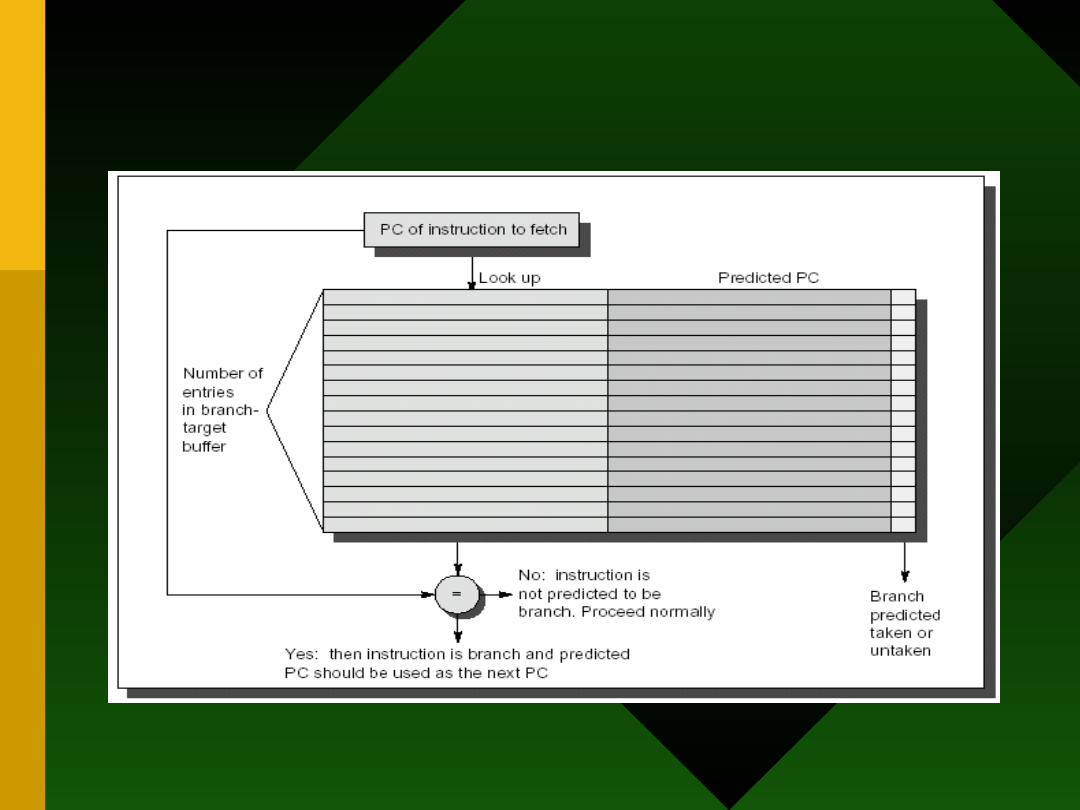
Dynamiczne
przewidywanie skoków
• Branch-prediction buffer
• Branch-history table
• Branch-target buffers
5.04.21
Artur&Artur
45
BTB

5.04.21
Artur&Artur
46
Zakończenie
• Hazardy sterowania mogą
powodować opóźnienia w potoku,
znacznie przekraczające opóźnienia,
spowodowane hazardami danych
• Zrozumienie tych zagadnień jest
kluczowe przy projektowaniu
możliwie najszybciej wykonujących
się programów.

5.04.21
Artur&Artur
47
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
Wyszukiwarka
Podobne podstrony:
Hazardy sterowania
Hazardy sterowania
Hazardy sterowania
Układy Napędowe oraz algorytmy sterowania w bioprotezach
PODSTAWY STEROWANIA SILNIKIEM INDUKCYJNYM
Sterowce
WYKŁAD 02 SterowCyfrowe
wykład 4 Sterowanie zapasami
Sterowniki PLC
Wykład VII hazard, realizacja na NAND i NOR
12 Podstawy automatyki Układy sterowania logicznego
Instrukcja do zad proj 13 Uklad sterowania schodow ruchom
41 Sterowanie
J Kossecki, Cele i metody badania przeszłości w różnych systemach sterowania społecznego
Automatyka i sterowanie, Pomiary w energetyce
więcej podobnych podstron