
Wykłady ze Statystyki matematycznej
Dr Adam Kucharski
Spis treści
2
3
Funkcje opisujące zmienną losową . . . . . . . . . . . . . . . . . . . . . . . . . . .
3
Charakterystyki liczbowe rozkładu . . . . . . . . . . . . . . . . . . . . . . . . . .
4
5
Rozkład dwupunktowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5
Rozkład dwumianowy (Bernoulliego) . . . . . . . . . . . . . . . . . . . . . . . . .
5
Rozkład Poissona . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5
6
Rozkład normalny (Gaussa) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6
Rozkład chi-kwadrat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6
Rozkład t-Studenta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7
7
Przedział ufności dla wartości oczekiwanej . . . . . . . . . . . . . . . . . . . . . .
7
Przedział ufności dla wskaźnika struktury . . . . . . . . . . . . . . . . . . . . . .
8
Testowanie hipotez statystycznych
9
Weryfikacja hipotez o wartości przeciętnej . . . . . . . . . . . . . . . . . . . . . .
10
Weryfikacja hipotezy o poziomie wskaźnika struktury . . . . . . . . . . . . . . . .
10
Weryfikacja hipotez o równości dwóch wartości oczekiwanych . . . . . . . . . . .
11
Weryfikacja hipotez o równości dwóch wskaźników struktury . . . . . . . . . . . .
11
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
12
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
12
a . . . . . . . . . . . . . . . . . . . . . . . . . . .
12
Współczynnik zbieżności T-Czuprowa . . . . . . . . . . . . . . . . . . . .
12
Współczynnik V-Cramera . . . . . . . . . . . . . . . . . . . . . . . . . . .
13

Wykłady ze Statystyki matematycznej
2
1
Badanie statystyczne
Badania statystyczne, jakim poddawane są zbiorowości można podzielić na dwie kategorie:
• całkowite (pełne);
• częściowe.
Z tym pierwszym mamy do czynienia, kiedy bezpośredniej obserwacji podlegają wszystkie
elementy zbiorowości generalnej. Choć jest to lepsza z metod, to napotykamy na problemy
związane zazwyczaj z bardzo dużą jednostek tworzących daną zbiorowość. Rosną bowiem koszty
badania, czas i wysiłek potrzebne na jego przeprowadzenie.
Dlatego znacznie częściej spotyka się badanie częściowe, z którego wnioski przenosi się na po-
pulację generalną. Wybór elementów podlegających obserwacji może zostać dokonany w sposób
świadomy bądź losowy. W tym drugim wypadku będziemy mówili o tzw. próbie reprezen-
tatywnej, a zastosowaną metodę nazwiemy metodą reprezentacyjną. Otrzymane wyniki
stanowią podstawę wnioskowania statystycznego, które łączy w sobie elementy rachunku praw-
dopodobieństwa i statystyki matematycznej. Tak więc na podstawie części elementów wyciągamy
wnioski odnośnie całej populacji generalnej.
Dobór elementów do próby może odbywać się na zasadzie losowania:
• niezależnego (ze zwrotem wylosowanego elementu do zbiorowości);
• zależnego (wylosowany element już nie wraca do zbiorowości).
W drugim z przypadków, wynik każdego następnego losowania zależy od wyników poprzednich.
Lepszym rozwiązaniem jest więc wariant pierwszy, ale należy zauważyć, że przy bardzo licznej
zbiorowości zależność między wynikami losowania zależnego będzie niewielka.
Inny podział schematów losowania to:
• losowanie nieograniczone – losujemy elementy bezpośrednio z całej próby;
• warstwowe – zbiorowość najpierw zostaje podzielona na jednorodne podzbiory (warstwy),
a losowań dokonuje się oddzielnie z każdej warstwy.
Wyróżniamy także losowanie:
• indywidualne – losujemy oddzielnie poszczególne elementy np. pojedyncze osoby;
• zespołowe – losowaniu podlegają naturalne zespoły elementów np. osoby w danym prze-
dziale wiekowym.
Niezależnie od schematu losowania, przeprowadzając badanie statystyczne częściowe należy
liczyć się z możliwością popełnienia błędu podczas uogólniania wyników na całą próbę. Wystę-
pujące błędy podzielimy na dwie grupy:
• losowe – maleją ze wzrostem liczby wybieranych elementów;
• systematyczne – nie maleją ze wzrostem liczby wybieranych elementów.

Wykłady ze Statystyki matematycznej
3
2
Zmienna losowa
Pojęcie zmiennej losowej jest kluczowym pojęciem dla wnioskowania statystycznego. Można ją
traktować jako odpowiednik cechy mierzalnej ze statystyki.
Zmienną losową rzeczywistą (jednowymiarową) określoną na przestrzeni zdarzeń ele-
mentarnych Ω nazywamy funkcję X, która zdarzeniom elementarnym przyporządkowuje liczby
rzeczywiste (X : Ω → R) i spełnia warunek: dla dowolnej liczby rzeczywistej t zbiór zdarzeń ele-
mentarnych, dla których wartości zmiennej losowej są mniejsze niż t jest zdarzeniem losowym.
Zmienne losowe dzieli się na dwie ważne klasy:
1. zmienne skokowe (dyskretne), które przyjmują skończony lub przeliczalny zbiór wartości;
2. zmienne ciągłe, które przyjmują dowolne wartości z określonego przedziału.
2.1
Funkcje opisujące zmienną losową
Jedną z podstawowych charakterystyk zmiennej losowej jest dystrybuanta – funkcja, która jest
równa prawdopodobieństwu tego, że zmienna losowa przyjmie wartość mniejszą niż pewna liczba
x. Ogólnie zapiszemy:
F (x) = P (X < x)
(1)
Własności dystrybuanty:
• 0 6 F (x) 6 1
• jest funkcją niemalejącą;
• jest funkcją przynajmniej lewostronnie ciągłą;
•
lim
x→−∞
F (x) = 0
• lim
x→∞
F (x) = 1
Zazwyczaj jednak korzysta się z definicji dystrybuanty empirycznej. Jest to możliwe, ponieważ
dystrybuanta dla konkretnego punktu nie istnieje.
F (x) = P (X 6 x)
(2)
Oprócz dystrybuanty do opisu zmiennych losowych wykorzystuje się również inne funkcje.
Dla zmiennych skokowych będzie to rozkład prawdopodobieństwa:
P (X = x
i
) = p
i
(3)
Jest to zbiór takich par (x
i
, p
i
), dla których x
i
są to wartości przyjmowane przez zmienną X z
prawdopodobieństwami p
i
. Dystrybuanta zmiennej skokowej:
F (x) =
X
x
i
<x
p
i
(4)
W przypadku zmiennej losowej ciągłej, odpowiednikiem rozkładu prawdopodobieństwa jest
funkcja gęstości. Musi ona spełniać następujące warunki:
1. f (x)
> 0
2.
∞
R
−∞
f (x)dx = 1
Dystrybuantę zmiennej losowej ciągłej opisuje wzór:
F (x) =
x
Z
−∞
f (x)dx
(5)

Wykłady ze Statystyki matematycznej
4
2.2
Charakterystyki liczbowe rozkładu
Oprócz dystrybuanty, do opisu zmiennej losowej służą pewne wartości liczbowe zwane parame-
trami rozkładu. Spośród nich najważniejsze to: wartość oczekiwana i wariancja. Pierwsza z
nich informuje o przeciętnym poziomie zmiennej losowej, wokół którego skupiają się jej wartości.
Wariancja mierzy rozrzut wartości zmiennej losowej wokół wartości oczekiwanej.
Wartość oczekiwaną zmiennej losowej skokowej obliczamy:
E(X) = m =
n
X
i=1
x
i
p
i
(6)
Wartość oczekiwaną zmiennej ciągłej obliczamy:
E(X) = m =
∞
Z
−∞
xf (x)dx
(7)
Własności wartości oczekiwanej:
1. E(c)=c, gdzie c – pewna stała;
2. E(cX)=cE(X);
3. E(X ± Y ) = E(X) ± E(Y );
4. a
6 b ⇒ a 6 E(X) 6 b;
5. X
6 Y ⇒ E(X) 6 E(Y ).
Wariancję zmiennej losowej skokowej obliczamy:
V (X) = D
2
(X) =
n
X
i=1
(x
i
− E(X))
2
p
i
=
n
X
i=1
x
2
i
p
i
− (E(X))
2
(8)
Wariancję zmiennej losowej ciągłej obliczamy:
V (X) = D
2
=
∞
Z
−∞
(x − E(X))
2
f (x)dx =
∞
Z
−∞
x
2
f (x)dx − (E(X))
2
(9)
Własności wariancji:
1. D
2
(c) = 0;
2. D
2
(c + X) = D
2
(X);
3. D
2
(cX) = c
2
D
2
(X);
4. D
2
(X ± Y ) = D
2
(X) + D
2
(Y ).
Zazwyczaj, zamiast wariancji podaje się wartość odchylenia standardowego, które jest pierwiast-
kiem kwadratowym z wariancji.

Wykłady ze Statystyki matematycznej
5
3
Wybrane rozkłady skokowe
3.1
Rozkład dwupunktowy
Zmienna losowa X ma rozkład dwupunktowy jeżeli przyjmuje tylko dwie wartości x
1
i x
2
a jej
funkcja prawdopodobieństwa określona jest następująco:
P (X = x
1
)
=
p
(10)
P (X = x
2
)
=
q
Przy czym p+q=1.
Szczególnym przypadkiem jest rozkład zero-jedynkowy, dla którego rozkład prawdopodo-
bieństwa wygląda następująco:
P (X = 1)
=
p
(11)
P (X = 0)
=
q
Rozkład ten znajduje zastosowanie szczególnie wtedy kiedy mamy do czynienia z cechą
niemierzalną dwudzielną jak np. przy grupowaniu osób według płci. Jego dystrybuanta określona
jest następująco:
F (x) =
0
dla
x 6 0
q
dla
0 < x 6 1
1
dla
x > 1
(12)
Wartość oczekiwana i wariancja są równe odpowiednio: E(X)=p i V(X)=pq
3.2
Rozkład dwumianowy (Bernoulliego)
Zmienna losowa X ma rozkład dwumianowy jeżeli jej funkcję rozkładu opisuje wzór:
P (X = k) =
n
k
p
k
q
n−k
(13)
Gdzie: p+q=1 oraz k = 0, 1, 2, ..., n.
Wartość oczekiwana i wariancja są równe odpowiednio: E(X)=np i V(X)=npq
Rozkład ten opisuje tzw. eksperyment Bernoulliego, który polega na tym, że przeprowadzamy
n (n
> 2) niezależnych doświadczeń. Ich wynikiem może tylko jeden z dwóch stanów: sukces
albo porażka. Prawdopodobieństwo sukcesu oznaczamy p zaś porażki q.
3.3
Rozkład Poissona
Zmienna losowa X ma rozkład Poissona jeżeli przyjmuje wartości k = 0, 1, 2, ... z prawdopodo-
bieństwami opisanymi wzorem:
P (X = k) =
m
k
k!
e
−m
(14)
Gdzie m jest stałą dodatnią.
Rozkład ten przydaje się kiedy liczba doświadczeń w eksperymencie Bernoulliego jest duża
zaś prawdopodobieństwo sukcesu niewielkie. Przyjmuje się, że kiedy spełniono warunki:
1. prawdopodobieństwo sukcesu jest mniejsze od 0,2;
2. liczba doświadczeń wynosi 20 lub więcej;

Wykłady ze Statystyki matematycznej
6
wtedy rozkład dwumianowy można przybliżyć rozkładem Poissona, zgodnie ze wzorem:
P (X = k) =
np
k
k!
e
−np
(15)
Jeżeli wykorzystujemy przybliżenie według powyższego wzoru, wówczas nie musimy znać n i p.
Wystarczy znać iloczyn np będący wartością oczekiwaną zmiennej losowej X.
4
Wybrane rozkłady ciągłe
4.1
Rozkład normalny (Gaussa)
Zmienna losowa X ma rozkład normalny z wartością oczekiwaną m i odchyleniem standardowym
σ (co zapisujemy X − N (m, σ)) jeżeli jej funkcja gęstości dana jest wzorem:
f (x) =
1
σ
√
2π
e
−
(x − m)
2
2σ
2
(16)
Kształt krzywej opisanej przez podaną wyżej funkcję gęstości zależy od dwóch parametrów:
m i σ. Ogólnie funkcja gęstości rozkładu normalnego ma następujące własności:
1. Jest symetryczna względem prostej x = m;
2. W punkcie x = m osiąga wartość maksymalną;
3. Prawdopodobieństwo tego, że zmienna X przyjmie wartości z przedziału
< m − 3σ, m + 3σ > jest w przybliżeniu równe 1.
Dla zmiennej X o dowolnym rozkładzie normalnym można przeprowadzić przekształcenie zwane
standaryzacją:
Z =
X − m
σ
(17)
Zmienna losowa Z ma wówczas rozkład normalny z wartością oczekiwaną zero i odchyleniem
standardowym równym jeden (Z − N (0, 1)). Rozkład taki nazywamy normalnym standaryzowa-
nym. Jego dystrybuanta jest stablicowana dla wartości dodatnich. W innych przypadkach należy
dokonać przekształceń opartych o własności rozkładu.
4.2
Rozkład chi-kwadrat
Zmienna losowa ma rozkład chi-kwadrat (χ
2
) z k stopniami swobody jeżeli można ją przedstawić:
X
2
1
+ X
2
2
+ . . . + X
2
k
(18)
Gdzie X
1
, X
2
, . . . , X
k
są niezależnymi zmiennymi losowymi o rozkładzie normalnym standary-
zowanym. Wartość oczekiwana i wariancja są równe odpowiednio: E(χ
2
) = k i V (χ
2
) = 2k.
Zmienna o rozkładzie χ
2
przyjmuje wartości dodatnie, a kształt krzywej opisującej jej funkcję
gęstości zależy od liczby stopni swobody.
Rozkład został stablicowany. Dla ustalonych wartości liczby stopni swobody k oraz prawdo-
podobieństwa α odczytuje się wartość:
P (χ
2
k
> χ
2
α
) = α
(19)
Dla k > 30 rozkład ten jest zbieżny do rozkładu normalnego o parametrach: N (
√
2k − 1, 1).

Wykłady ze Statystyki matematycznej
7
4.3
Rozkład t-Studenta
Zmienna losowa ma rozkład t-Studenta o k stopniach swobody jeżeli da się ją przedstawić:
T =
Z
χ
2
k
√
k
(20)
Gdzie Z − N (0, 1) oraz χ
2
k
to niezależne zmienne losowe.
Jest to rozkład symetryczny o wartości oczekiwanej równej E(T
k
) = 0, wariancji równej
V (T
k
) = k/(k − 2) i kształcie zbliżonym do rozkładu normalnego. W tablicach znajdują się
wartości dla ustalonej liczby stopni swobody k oraz prawdopodobieństwa α spełniające warunek:
P (|T
k
| > t
α
) = α
(21)
Jeżeli liczba stopni swobody jest większa niż 30, korzysta się z tablic rozkładu N (0, 1).
5
Estymacja przedziałowa
Estymacją nazwiemy szacowanie wartości parametrów lub postaci rozkładu teoretycznego ce-
chy w populacji generalnej na podstawie rozkładu empirycznego uzyskanego dla próby. Kiedy
poszukujemy parametru np. wartości oczekiwanej wówczas mówimy o estymacji parametrycz-
nej. Jeżeli zaś zajmujemy się postacią funkcyjną rozkładu czy też dystrybuanty, wtedy mamy
do czynienia z estymacją nieparametryczną.
Dla podstawowych parametrów rozkładu zmiennej losowej przyjmujemy następujące esty-
matory:
• dla wartości oczekiwanej – średnią arytmetyczną z próby;
• dla wariancji – wariancję z próby.
Rozróżniamy dwa rodzaje estymacji:
1. punktową, w której poszukujemy liczbowej oceny parametru;
2. przedziałową, w której otrzymujemy pewien przedział zawierający nieznaną wartość para-
metru z zadanym z góry prawdopodobieństwem.
Przedziałem ufności nazywamy taki przedział, który z zadanym z góry prawdopodobień-
stwem (1 − α) zwanym poziomem ufności zawiera nieznaną wartość szacowanego parametru.
Poziom ufności jest zazwyczaj bliski 1 np. 0,9. Różnicę między dolną a górną granicą wzmian-
kowanego przedziału nazywamy długością przedziału ufności. Jej połowa stanowi tzw. maksy-
malny błąd szacunku.
Ze wzrostem liczebności próby (przy ustalonym poziomie ufności) rośnie dokładność oszaco-
wania. Z kolei przy stałej liczebności próby, ze wzrostem poziomu ufności dokładność ta spada.
5.1
Przedział ufności dla wartości oczekiwanej
Przedział ufności dla wartości oczekiwanej m wyznacza się w oparciu o średnią arytmetyczną z
próby. Jeżeli cecha X w populacji generalnej ma rozkład N (m, σ) to średnia arytmetyczna ¯
X
ma rozkład N (m,
σ
√
n
). Wynika stąd, że statystyka U =
¯
X − m
σ
√
n ma rozkład N (0, 1).
Jeżeli cecha ma w populacji generalnej rozkład normalny o znanym odchyleniu standardowym
σ, wówczas liczbowy przedział ufności dla wartości oczekiwanej m ma postać:
P (¯
x − u
α
σ
√
n
< m < ¯
x + u
α
σ
√
n
) = 1 − α
(22)
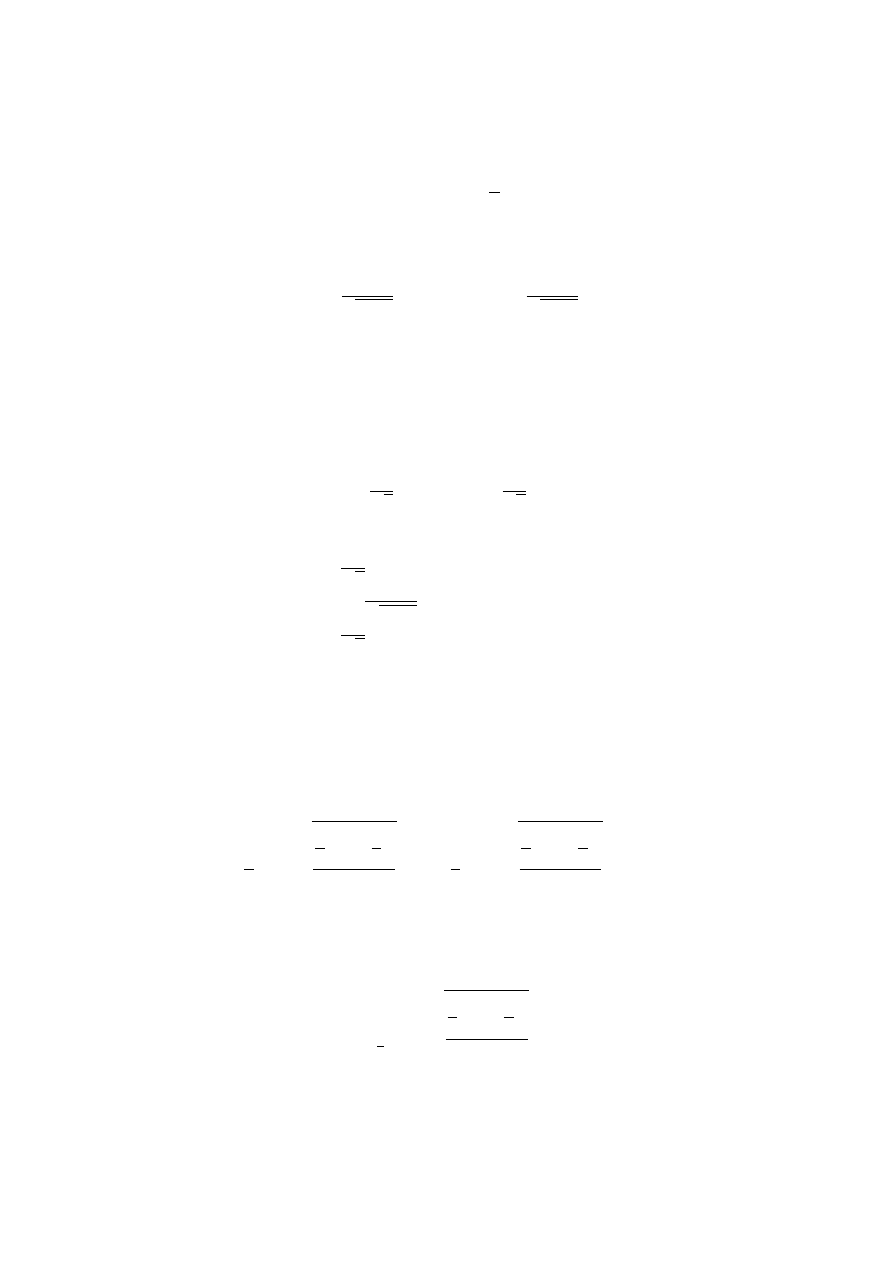
Wykłady ze Statystyki matematycznej
8
gdzie: ¯
x oznacza średnią arytmetyczną z próby.
W tablicach rozkładu normalnego odczytujemy taką wartość u
α
tak, aby zachodziło:
Φ(u
α
) = 1 −
α
2
(23)
Jeżeli cecha ma w populacji generalnej rozkład normalny o nieznanym odchyleniu standardo-
wym σ i próba jest mała (n
6 30), wówczas liczbowy przedział ufności dla wartości oczekiwanej
m ma postać:
P (¯
x − t
α,n−1
s
√
n − 1
< m < ¯
x + t
α,n−1
s
√
n − 1
) = 1 − α
(24)
gdzie s oznacza odchylenie standardowe z próby.
Wartość t
α,n−1
odczytujemy z tablic rozkładu t-Studenta w taki sposób, że:
P (|T
n−1
| > t
α,n−1
) = α
(25)
Jeżeli cecha ma w populacji generalnej rozkład normalny o nieznanym odchyleniu standardo-
wym σ i próba jest duża (n > 30), wówczas liczbowy przedział ufności dla wartości oczekiwanej
m ma postać:
P (¯
x − u
α
s
√
n
< m < ¯
x + u
α
s
√
n
) = 1 − α
(26)
Maksymalny błąd szacunku wynosi odpowiednio:
d
¯
x
=
u
α
σ
√
n
,
gdy znamy σ;
t
α,n−1
s
√
n − 1
,
gdy nie znamy σ i n
6 30;
u
α
s
√
n
,
gdy nie znamy σ i n
> 30.
(27)
Na podstawie powyższych wzorów można wyznaczyć taką liczebność próby, aby uzyskać
oszacowanie zgodne z zadanym z góry błędem szacunku.
5.2
Przedział ufności dla wskaźnika struktury
Przedział ufności dla wskaźnika struktury p wyznacza się tylko na podstawie dużych (n
> 100)
prób. Liczbowy przedział ufności, dla zadanego z góry poziomu ufności 1 − α ma postać:
P
k
n
− u
α
v
u
u
u
t
k
n
1 −
k
n
n
< p <
k
n
+ u
α
v
u
u
u
t
k
n
1 −
k
n
n
= 1 − α
(28)
gdzie: k oznacza liczbę elementów posiadających wyróżniony wariant cechy.
Maksymalny błąd szacunku wynosi:
d
k
n
= u
α
v
u
u
u
t
k
n
1 −
k
n
n
(29)

Wykłady ze Statystyki matematycznej
9
6
Testowanie hipotez statystycznych
Hipotezą statystyczną nazywamy osąd spełniający dwa warunki:
1. dotyczy rozkładu lub jego parametrów w zbiorowości generalnej;
2. jego słuszność da się sprawdzić na podstawie wyników z badania reprezentacyjnego.
Rodzaje hipotez statystycznych:
1. parametryczne – dotyczą parametrów rozkładu np. wartości oczekiwanej;
2. nieparametryczne – dotyczą charakteru rozkładu.
Metodę weryfikacji hipotez statystycznych nazywamy testem statystycznym. Jest to me-
toda postępowania, określająca sposób sprawdzania słuszności hipotezy i warunki w jakich po-
dejmujemy decyzję o uznaniu bądź nie hipotezy za poprawną. Weryfikacji dokonuje się jednak w
oparciu o losową próbę, co oznacza możliwość popełnienia błędu. Rozróżniamy dwa ich rodzaje:
Błąd pierwszego rodzaju: Na podstawie wyników z próby podejmujemy decyzję o odrzuce-
niu weryfikowanej hipotezy, którą w rzeczywistości należy uznać za słuszną. Prawdopodo-
bieństwo popełnienia tego błędu oznaczymy α
Błąd drugiego rodzaju: Na podstawie wyników z próby podejmujemy decyzję o uznaniu
weryfikowanej hipotezy za słuszną, podczas gdy w rzeczywistości jest ona nieprawdziwa.
Prawdopodobieństwo popełnienia tego błędu oznaczamy β.
Wartości prawdopodobieństw α i β są ze sobą związane: im wyższe jest α tym niższe β i
odwrotnie. Z kolei test statystyczny powinien zostać tak skonstruowany, aby zapewnić jak naj-
mniejsze prawdopodobieństwo podjęcia niewłaściwej decyzji. Kompromisem w tej sytuacji są
tzw. testy istotności. Zapewniają one możliwie małe prawdopodobieństwo popełnienia błę-
du drugiego rodzaju przy przyjętym z góry, akceptowalnym poziomie prawdopodobieństwa α
zwanym tu poziomem istotności. Ustalany jest on zwykle na niskim np. 0,05 poziomie.
Testy istotności określają kiedy odrzucić weryfikowaną hipotezę, jeśli wyniki z próby wskazują
na jej fałszywość. Nie dają jednak tak zdecydowanego rozstrzygnięcia jeżeli próba losowa nie
pozwala wskazać, że hipoteza jest fałszywa. Możemy jedynie stwierdzić, że nie potrafimy dowieść
jej niesłuszności.
Etapy weryfikacji testu statystycznego:
1. Definiujemy hipotezę zerową (H
0
), która podlegać będzie weryfikacji.
2. Definiujemy hipotezę alternatywną (H
1
), która może przyjmować wszystkie rozwiąza-
nia poza tymi zawartymi w H
0
.
3. Dokonujemy wyboru sprawdzianu hipotezy czyli zmiennej losowej o znanym rozkładzie.
4. Ustalamy obszar krytyczny. Powierzchnię tworzącą rozkład wspomniany w poprzednim
etapie dzielimy na dwa obszary: obszar odrzucenia H
0
, którego powierzchnia wynosi α
i zawiera wartości decydujące o odrzuceniu H
0
oraz obszar przyjęcia H
0
o powierzchni
równej 1 − α. Wyróżniamy następujące obszary odrzucenia:
(a) prawostronny gdy wartość parametru dla H
1
jest większa od tej dla H
0
;
(b) lewostronny gdy wartość parametru dla H
1
jest mniejsza od tej dla H
0
;
(c) obustronny gdy wartość parametru dla H
1
jest różna od tej dla H
0
;
5. Obliczamy wartość sprawdzianu hipotezy dla próby i porównujemy z obszarem odrzuce-
nia. Jeżeli wynik z próby znalazł się w tym obszarze, wtedy za słuszną uznajemy H
1
. W
przeciwnym wypadku stwierdzamy jedynie brak podstaw do odrzucenia H
0
.
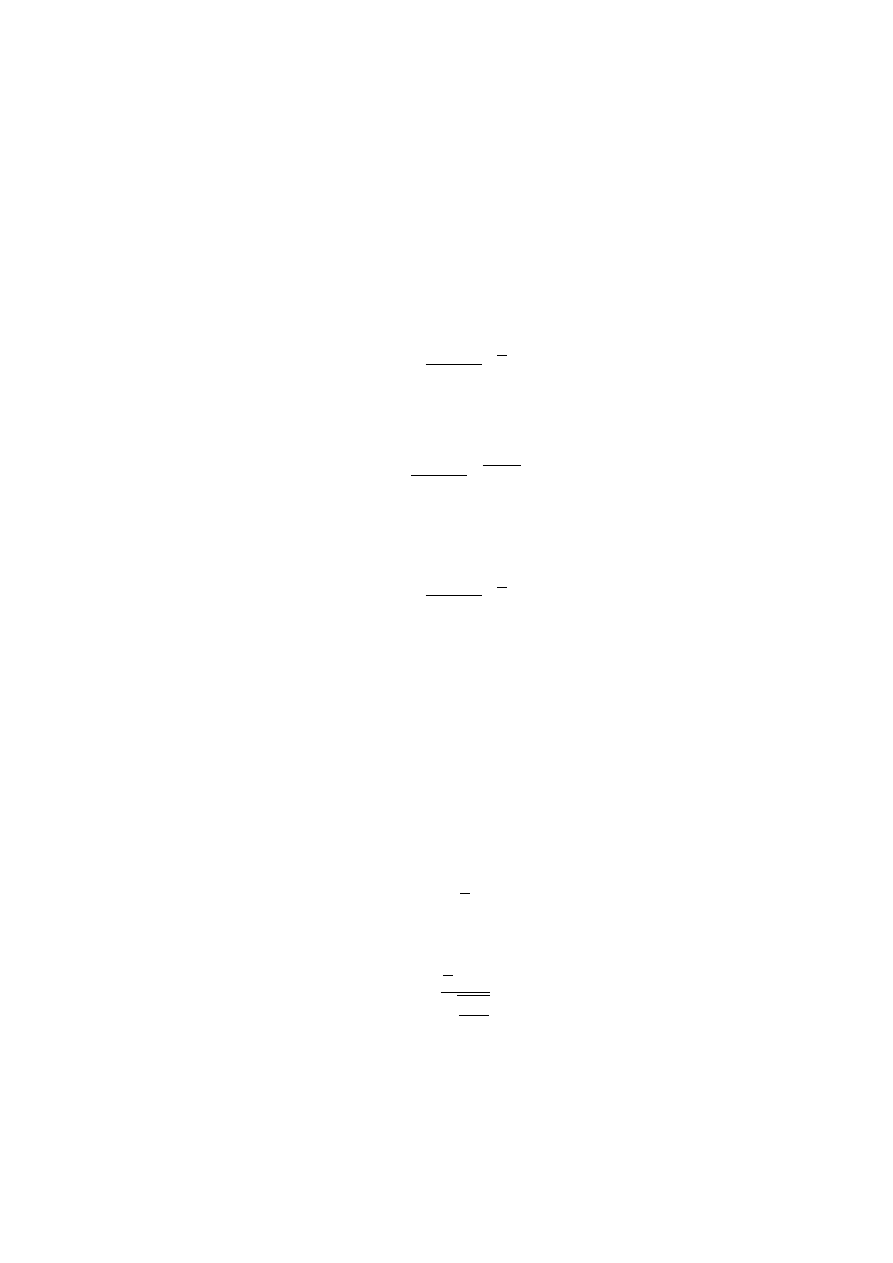
Wykłady ze Statystyki matematycznej
10
6.1
Weryfikacja hipotez o wartości przeciętnej
Na początek formułujemy hipotezę zerową, która podlegać ma weryfikacji:
H
0
: m = m
0
Definicja hipotezy alternatywnej H
1
zależy od celu badania.
Podobnie jak to miało miejsce w przypadku konstrukcji przedziałów ufności dla wartości
oczekiwanej m, rodzaj statystyki testu zależy od naszej wiedzy na temat rozkładu zmiennej
w zbiorowości generalnej, o którym zakładamy, że jest to rozkład normalny. Jeżeli znamy jego
odchylenie standardowe σ wówczas weryfikacji dokonujemy w oparciu o wzór:
U =
¯
X − m
0
σ
√
n
(30)
Statystyka ta ma rozkład normalny: N(0, 1).
Jeżeli nie znamy wartości σ a próba jest mała (n
6 30) wówczas korzystamy z następującej
statystyki testu:
T =
¯
X − m
0
s
√
n − 1
(31)
Gdzie s jest odchyleniem standardowym z próby. Ta z kolei statystyka ma rozkład t-Studenta o
n-1 stopniach swobody.
W przypadku dysponowania dużą próbą sięgamy po wzór:
U =
¯
X − m
0
s
√
n
(32)
Powyższa statystyka ma rozkład N(0, 1).
Kształt i rozmiary obszaru odrzucenia zależą od wartości poziomu istotności α, wybranej
statystyki oraz rodzaju hipotezy alternatywnej.
6.2
Weryfikacja hipotezy o poziomie wskaźnika struktury
Weryfikacji hipotez dla wskaźnika struktury p dokonujemy tylko wtedy, gdy dysponujemy od-
powiednio dużą (n
> 100) próbą. W takiej sytuacji konstruujemy hipotezę zerową postaci:
H
0
: p = p
0
Jako sprawdzianu weryfikującego postawioną hipotezę używamy wskaźnika struktury dla
próby:
w =
k
n
(33)
gdzie: k oznacza liczbę jednostek posiadających wyróżniony wariant cechy
Statystyka testu ma postać:
U =
k
n
− p
0
r p
0
q
0
n
(34)
gdzie: q
0
= 1 − p
0
Statystyka ta ma rozkład N(0, 1). Obszar odrzucenia konstruuje się podobnie jak w przy-
padku weryfikacji hipotezy o wartości oczekiwanej dla tego samego rozkładu.
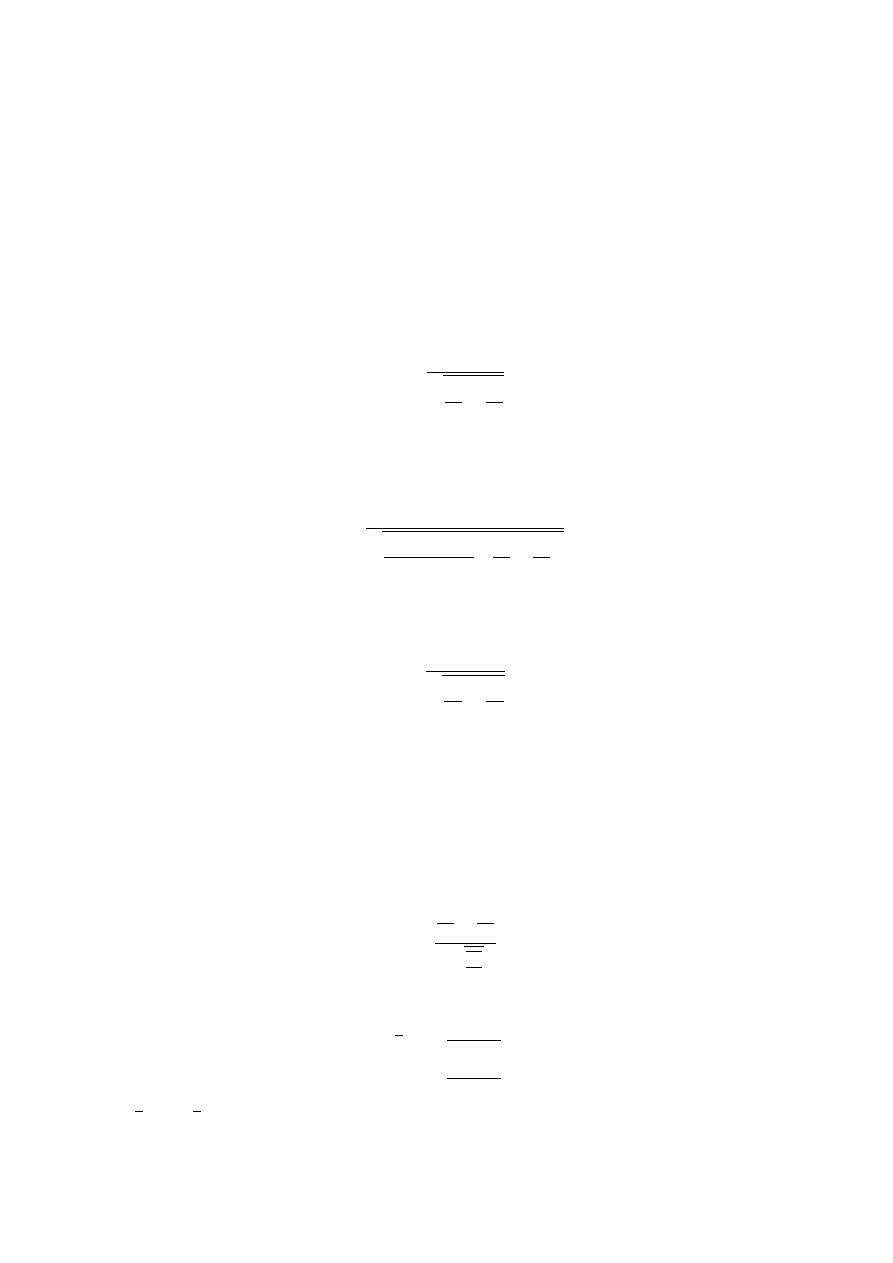
Wykłady ze Statystyki matematycznej
11
6.3
Weryfikacja hipotez o równości dwóch wartości oczekiwanych
Niekiedy dysponujemy dwiema zbiorowościami generalnymi lub dwoma podzbiorami dla tej
samej zbiorowości. Należy wówczas sprawdzić czy różnica między wartościami oczekiwanymi
wyznaczonymi dla tychże grup wynika z faktu, że mamy do czynienia z badaniem częściowym
czy też jest ona statystycznie istotna a same zbiorowości różnią się z punktu widzenia tego
parametru. Formułowana hipoteza zerowa wygląda następująco:
H
0
: m
1
= m
2
Zakładamy, że w obu zbiorowościach zmienna losowa ma rozkład normalny. Jeżeli znamy
odchylenia standardowe (σ
1
i σ
2
) tych rozkładów wtedy sięgamy po statystykę:
U =
¯
X
1
− ¯
X
2
s
σ
2
1
n
1
+
σ
2
2
n
2
(35)
Powyższa statystyka ma rozkład N(0, 1).
W przypadku kiedy nie znamy odchyleń standardowych σ
1
i σ
2
zaś n
1
6 30 oraz n
2
6 30
wtedy weryfikacji hipotezy dokonujemy w oparciu o wzór:
T =
¯
X
1
− ¯
X
2
s
n
1
S
2
1
+ n
2
S
2
2
n
1
+ n
2
− 2
1
n
1
+
1
n
2
(36)
Statystyka ta ma rozkład t-Studenta o n
1
+ n
2
− 2 stopniach swobody.
Z kolei gdy dysponujemy dużymi (n
1
> 30 i n
2
> 30) próbami korzystamy ze statystyki o
rozkładzie N(0, 1) postaci:
U =
¯
X
1
− ¯
X
2
s
S
2
1
n
1
+
S
2
2
n
2
(37)
6.4
Weryfikacja hipotez o równości dwóch wskaźników struktury
Tego typu weryfikacji dokonujemy, kiedy chcemy sprawdzić czy udział jednostek o wyróżnio-
nym wariancie cechy jest w obu zbiorowościach taki sam. Definicja hipotezy zerowej wygląda
następująco:
H
0
: p
1
= p
2
Liczebności prób muszą być odpowiednio duże: n
1
> 100 oraz n
2
> 100. Do weryfikacji
używamy statystyki:
U =
k
1
n
1
−
k
2
n
2
r pq
n
(38)
gdzie:
p
=
k
1
+ k
2
n
1
+ n
2
(39)
n
=
n
1
n
2
n
1
+ n
2
(40)
zaś q = 1 − p.
Powyższy sprawdzian ma rozkład normalny standaryzowany.
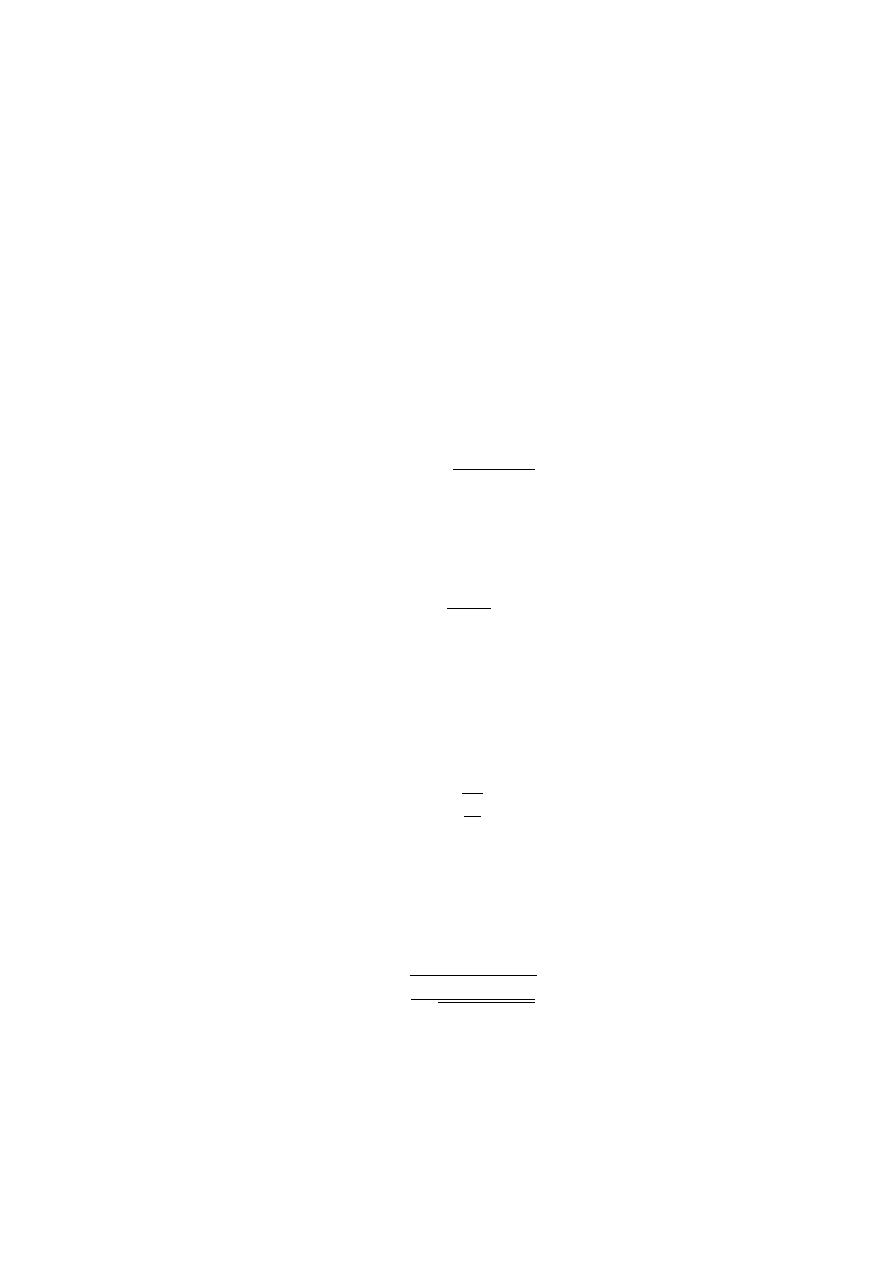
Wykłady ze Statystyki matematycznej
12
6.5
Test niezależności χ
2
Kiedy badamy zbiorowość ze względu na dwie cechy często chcemy wiedzieć czy występuje
między nimi zależność. Jednym z możliwych sposobów jest sięgnięcie po test niezależności χ
2
zaliczany do grupy testów nieparametrycznych. Można go używać do badania występowania
zależności w następujących przypadkach:
• obie cechy są mierzalne;
• obie cechy są niemierzalne;
• jedna z cech jest mierzalna zaś druga niemierzalna.
Dane do tego testu zazwyczaj grupuje się w postaci tablicy korelacyjnej (dwudzielnej), co
oznacza konieczność dysponowania sporym zbiorem obserwacji.
Konstruuje się hipotezę zerową postaci: „cechy X i Y są niezależne” wobec hipotezy alter-
natywnej: „cechy X i Y nie są niezależne”. Sprawdzianem testu jest statystyka:
χ
2
=
s
X
i=1
r
X
j=1
(n
ij
− ˆ
n
ij
)
2
ˆ
n
ij
(41)
Statystyka ta ma rozkład χ
2
o k = (r − 1)(s − 1) stopniach swobody. W teście występuje
wyłącznie prawostronny obszar odrzucenia.
Wartości liczebności teoretycznych ˆ
n
ij
oblicza się na podstawie rozkładów brzegowych tablicy
korelacyjnej:
ˆ
n
ij
=
n
i•
n
•j
n
(42)
6.6
Miary zależności oparte na χ
2
Poniżej opisane miary mogą służyć do opisu siły zależności między cechami, zwłaszcza jakościo-
wymi.
6.6.1
Współczynnik ϕ − Y ule
0
a
Opisuje go wzór:
ϕ =
r
χ
2
n
(43)
Jeżeli:
r =2, s – dowolne, wtedy 0
6 ϕ 6 1,
r > 2, s – dowolne, wtedy ϕ może być większe od 1.
6.6.2
Współczynnik zbieżności T-Czuprowa
Opisuje go wzór:
T =
s
χ
2
n
p(r − 1)(s − 1)
(44)
Jeżeli:
r = s, wtedy 0 6 T 6 1,
r 6= s, wtedy T może być znacznie mniejsze od 1.

Wykłady ze Statystyki matematycznej
13
6.6.3
Współczynnik V-Cramera
Opisuje go wzór:
V =
s
χ
2
n min(r − 1, s − 1)
(45)
Współczynnik ten przyjmuje wartości: 0
6 V 6 1 przy czym jeżeli:
r = s, wtedy V = T ,
r 6= s, wtedy V > T .
Interpretacja wszystkich współczynników jest podobna: wartość bliska zero oznacza brak
zależności między cechami, im bliższa jedności tym owa zależność jest silniejsza.
Document Outline
- Badanie statystyczne
- Zmienna losowa
- Wybrane rozkªady skokowe
- Wybrane rozkªady ci¡gªe
- Estymacja przedziaªowa
- Testowanie hipotez statystycznych
Wyszukiwarka
Podobne podstrony:
Boratyńska A Wykłady ze statystyki matematycznej
Wymagania odnośnie projektu na zaliczenie wykładu ze Statystyki matematycznej
opracowanie pytań na wykład ze statystyki, STUDIA, SEMESTR IV, Statystyka matematyczna i planowanie
Wyniki sprawdzianu ze statystyki matematycznej i teorii estymacji z dn 23.01.13
WYKŁADY- DEFINICJE, Konspekt wykładów ze statystyki
Wyniki kolokwium ze statystyki matematycznej i teorii estymacji z dn 31.01.13
Zadania na zaliczenie wykładu ze statystyki
PROGRAM WYKŁADÓW ZE STATYSTYKI, statystyka
x2, wykłady i notatki, statystyka matematyczna
Rozklad statystyk z proby, wykłady i notatki, statystyka matematyczna
Wyniki sprawdzianu ze statystyki matematycznej i teorii estymacji z dn 31.01.13
Wyniki kolokwium ze statystyki matematycznej i teorii estymacji z dn 07.02.13
Wykłady ze statystyki opisowej dla psychologów
zagadnienia na egzamin ze statystyki matematycznej zima 2014, Statystyka matematyczna
248649, wykłady i notatki, statystyka matematyczna
Wykłady Trzpiot, statystyka matematyczna(1)
zadania ze statystyki matemat
więcej podobnych podstron