Proces pozyskiwania danych jest nazywany badaniem statycznym.
Pojęcie statystyki matematycznej.
Populacja generalna
Badanie statyczne dotyczy zawsze pewnej zbiorowości, której elementami są obiekty materialne lub zjawiska. W statystyce matematycznej badana zbiorowość statyczna nazywa się populacją generalną lub zbiorowością generalną.
Populacja generalna skończona - jeżeli zbiór jej elementów jest skończony.
Populacja generalna nieskończona - dotyczy zazwyczaj zjawiska, a nie obiektu materialnego.
Cecha statyczna
Elementy populacji generalnej mogą mieć różne właściwości (i najczęściej nie mają), które podlegają obserwacji. Te właściwości nazywa się cechami statycznymi lub krótko cechami.
Te właściwości, które mają charakter ilościowy nazywa się cechami mierzalnymi (wzrost, waga). Właściwości jakościowe (np. płeć, kolor włosów) nazywa się cechami niemierzalnymi. Przeważająca część statystyki matematycznej dotyczy analizy mierzalnej.
Rozkład cechy.
Jeżeli elementy populacji różnią się między sobą wartościami analizowanej cechy, to mówi się o rozkładzie cechy w populacji.
Próba
Podzbiór elementów populacji generalnej podlegającej badania nazywa się próbą
Wnioskowanie statyczne.
Podstawowym zagadnieniem pojawiającym się w badaniach częściowych jest możliwość uogólnienia uzyskanych na podstawie próby wyników, na całą populację oraz oszacowanie popełnionych przy tym błędów. Takie działania nazywa się wnioskowaniem statystycznym.
Wyróżnia się dwa podstawowe typy problemów:
- estymacja (szacowanie) nieznanych wartości parametrów rozkładu cechy.
- sprawdzanie (weryfikacja) hipotez dotyczących wartości parametrów rozkładu lub postaci samego rozkładu.
Cechy skokowe i ciągłe
Cechy statyczne (mierzalne), które przyjmują wartości całkowite nazywa się cechami skokowymi lub dyskretnymi.
Cechy przyjmujące wartości rzeczywiste nazywa się cechami ciągłymi.
EMPIRYCZNY ROZKŁAD CECHY.
Empiryczny rozkład cechy stanowi podstawę dla wszystkich analiz badanej cechy.
Jeżeli próba dotycząca jednej cechy mierzalnej nie jest zbyt liczna, tzn. dotyczy Ł 30 jednostek, to wstępne jej opracowanie polega na uszeregowaniu w porządku rosnącym danych liczb. Otrzymany w ten sposób ciąg liczb nazywa się szeregiem pozycyjnym.
Jeżeli liczebność próby jest duża (>30) to pierwszym etapem jej opracowania jest dokonanie grupowania czyli klasyfikacji. Grupowanie polega na podziale próby na podzbiory zwane grupami lub klasami, a wartością reprezentującą poszczególne klasy są ich środki. Przedziały klasowe oraz ich liczebność, czyli liczby jednostek prób należących do jednej klasy tworzą razem tzw. szereg rozdzielny.
Zmienna Losowa
Określenie intuicyjno-poglądowe:
Wielkość, która w wyniku doświadczenia przyjmuje określoną wartość znaną po zrealizowaniu doświadczenia.
Definicja:
Zmienna losowa jest to taka zmienna, która w wyniku doświadczenia przybiera jedną: tylko jedną wartość ze zbioru tych wartości, jakie ta zmienna może przyjąć.
Z wartościami zmiennej losowej związane są określone prawdopodobieństwa, tak więc zmienna losowa przybiera różne wartości z różnym prawdopodobieństwem.
P(X=xi)=pi
Prawdopodobieństwo pi można traktować jako funkcję wartości przyjmowanych przez zmienną losową. Oznacza się ją następująco:
pi=f(xi)
Funkcja ta charakteryzuje się tym, że suma prawdopodobieństw jest równa jedności:
![]()
Rodzaje zmiennych losowych:
- zmienne losowe skokowe (dyskretne)
- zmienne losowe ciągłe
Określenie:
Zmiennymi losowymi skokowymi nazywamy takie zmienne losowe, które mają skończony lub przeliczalny zbiór wartości.
Przykłady zmiennych losowych dyskretnych:
- liczba urodzeń w Polsce
- ocena uzyskiwana na egzaminie z wybranych przedmiotów
Określenie:
Zmiennymi losowymi ciągłymi nazywamy takie zmienne losowe, które mogą przybierać dowolne wartości liczbowe z pewnego przedziału liczbowego.
Przykłady zmiennych losowych ciągłych:
- wzrost, waga, wiek człowieka
- wytrzymałość belki na zginanie
Rozkład zmiennej losowej.
Niech X jest zmienną losową dyskretną, która może przyjmować wartości x1, x2, ... odpowiednio z prawdopodobieństwem p1, p., ... Każdej realizacji zmiennej X przyporządkowanie jest więc pewne prawdopodobieństwo. Te prawdopodobieństwo można traktować jako funkcję określoną na zbiorze wartości, jakie może przyjmować X.
Określenie:
Rozkładem skokowej zmiennej losowej X nazywa się prawdopodobieństwo tego, że zmienna X przybiera wart. xi (i- 1,2,...)
P(X=xi)=pi
przy czym
![]()
Dystrybuanta zmiennej losowej (Skumulowane Prawd.)
Dystrybuanta zmiennej losowej X nazywamy funkcją oznaczoną przez F(x) określoną
F(x)=P(X<x)
Określa ona prawdopodobieństwo tego, że zmienna losowa X przyjmuje jakąkolwiek wartość mniejszą od z góry przyjętej danej wartości x. Dystrybuanta może być określona w przedziale obustronnie ograniczonym lub jednostronnie, dwustronnie nieograniczonym. Dystrybuanta F(x) określona w przedziale <a,b> posiada następujące wartości:
- jest funkcją malejącą
- jest funkcją co najmniej lewostronnie ciągłą
- F(a)=0, F(b)=1
Znając dystrybuantę F(x), można obliczyć prawdopodobieństwo tego, że zmienna losowa przyjmuje jakąś wartość leżącą pomiędzy wartościami: x1 i x2
P(x1≤X<x2)=F(x2)-F(x1)
Dystrybuantę można także stosować dla znalezienia prawdopodobieństwa takiego zdarzenia, że badana zmienna losowa X przyjmuje wartość większą równą x. Ponieważ badane zdarzenie jest przeciwne zdarzeniu z prawd. F(x), to
P(X≥x)=1-F(x)
Zmienna losowa ciągła
Zakładając, że wartości x przyjmowane przez zmienną losową X, zmieniają się w sposób ciągły w przedziale <a,b>, otrzymujemy granicę:
![]()
którą nazywamy funkcją gęstości prawd. zmiennej losowej ciągłej.
ROZKŁADY TEORETYCZNE ZMIENNEJ LOSOWEJ DYSKRETNEJ.
Rozkład jednopunktowy
Zmienna losowa X ma rozkład jednopunktowy czyli rozkład Diraca, gdy istnieje ............
Rozkład dwupunktowy
P(x=a)=p
P(x=b)=1=p=q 0<p<1
Funkcje rozkładu prawd.
Rozkład równomierny
Zmienna losowa ma rozkład równomierny, gdy dla ciągu punktów x1<x2< ... <xq prawd.
P(X=xk)=1/q , k=1,2,...,q
Funkcja rozkładu prawd.
1/q dla X=x1,x2, ..., xq
0 dla X≠x1,x2, ..., xq
Rozkład dwumianowy - Bermoulli'ego
Zmienna losowa ma rozkład dwumianowy, gdy funkcja rozkładu prawd. ma postać:
P(x)=(nx) ⋅ px ⋅ (1-p)n-x x=0,1,...,n
n - liczba naturalna
p - liczba rzeczywista, p∈(0,1)
Wartość oczekiwana (średnia)
E(x)=n ⋅ p
Wariancja:
D2(x) = n ⋅ p ⋅ (1-p)
Rozkład Poissona
Jeżeli zmienne losowe x1, x2, ... ,xn mają rozkład dwumianowy o parametrach n i p=![]()
(2=const, 2>0) to ciąg funkcji prawdopodobieństwa
Pn(x) = (nx) ⋅ px ⋅ (1-p)n-x ,x=0, 1, ..., n
dąży dla każdego x=0, 1, ... do funkcji
P(x)=![]()
Rozkłady zmiennych losowych ciągłych
Rozkład jednostajny (prostokątny, równomierny).
Zmienna losowa ma rozkład jednostajny (na przedziale (a,b)), jeżeli jej gęstość prawd. jest określona wzorem
0 dla x<a i x>b (a<b)
f(x) = ![]()
dla a<x<b
Dystrybuanta - otrzymujemy ją jako całkę z funkcji gęstości prawdopodobieństwa
0 dla x≤a
F(x) = ![]()
dla a≤x<b
Rozkład normalny (Gaussa)
Uznawany za najważniejszy rozkład w teorii prawdopodobieństwa. Znaczenie rozkładu normalnego wynika z następujących faktów:
- Rozkład normalny jest modelem dla losowych błędów pomiarów. Jeżeli błąd pomiaru nieznanej
wielkości jest sumą wielu małych losowych błędów, zarówno dodatnich jak i ujemnych, to suma
ma rozkład z mniejszą lub większą dokładnością, zawsze bliski rozkładu normalnego.
- Wiele zjawisk fizycznych choć nie podlega rozkładowi norm. Może być opisywanych za pomocą
tego rozkładu po odpowiedniej transformacji. Na przykład czas zdatności niektórych maszyn jest
zmienną losową o dodatnim współczynniku asymetrii. Gdy jednak będziemy bardziej rozpatrywać
log takiej zmiennej to okaże się, że ma ona rozkład normalny
- Rozkład norm. Stanowi dobre przybliżenie dla innych rozkładów, np. rozkładu dwumianowego.
Gęstość prawd. zmiennej losowej o rozkładzie norm.
F(x) = 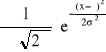
σ>0
Oznaczenia:
N(μ,σ)
μ - wartość średnia oczekiwana
σ - odchylenie standardowe
Reguła trzech σ
Jeżeli X jest zmienną losową ciągłą o rozkładzie N(μ,σ) to zachodzi:
P(μ-3σ≤x≤(μ+3σ)=0,9973
tzn. Takie jest prawdopodobieństwo, że zmienna losowa przyjmie takie wartości, które różnią się od wartości oczekiwanej μ nie więcej niż o +/- 3 odchylenia standardowego σ.
Rozkład wykładniczy
Zmienna losowa X ma wykładniczy rozkład prawd., jeśli jej gęstość prawd. wyraża się wzorem:
0 dla x≤0
f(x) =
![]()
dla x>0, λ>0
Parametr λ jest związany z wartością oczekiwaną i wariancją następującymi zależnościami:
E(x) =
D2(x) =
Dystrybuanta
0 dla x≤0
F(x) =
1 - exp(-λx) dla x>0
Rozkład Γ (gamma)
Funkcją gamma (całka Eulera drugiego rodzaju):
Γ(x) = 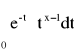
0<x<∞
Rozkład dsi - kwadrat χ2
Rozkładem χ2 o n stopniach swobody nazywamy rozkład zmiennej losowej, która jest sumą n niezależnych zmiennych losowych o standardowym rozkładzie normalnym N(0,1):
Xn = przy czym Xk ma rozkład N(0,1)
Gęstość prawd. zmiennej losowej o rozkładzie χ2:
0 dla x≤0
fn(y) = 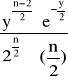
dla x>0
n - liczba stopni swobody
Rozkład t - Studenta
Jeżeli zmienna losowa Y ma rozkład normalny N(0,1), zaś zmienna losowa S jest od Y niezależna i S2 ma rozkład χ2 o n stopniach swobody, to zmienna losowa t:
t = ![]()
ma gęstość prawdopodobieństwa
f(t) = 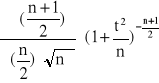
-∞<t<∞
Zmienna t ma rozkład t - Studenta o n stopniach swobody
Rozkład F - Snedecora
Iloraz dwóch niezależnych zmiennych losowych ![]()
i ![]()
, takich, że Y ma rozkład χ2 o n stopniach swobody, a X ten sam rozkład o m Stopniach swobody.
F =
ma rozkład nazywany rozkładem F - Snedecora
Funkcja gęstości prawd. zmiennej losowej o rozkładzie F - Snedecora o (n,m) stopniach swobody.
0 dla x≤0
F(x) =
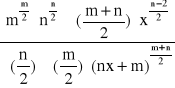
dla x>0
ESTYMACJA PRZEDZIAŁOWE PARAMETRÓW
Metoda estymacji przedziałowej to dokonanie szacunku param. w postaci takiego przedziału (zwanego przedziałem ufności), który z dużym prawd. obejmuje prawdziwą wartość parametru.
Przedział ufności dla średniej
Model I
Badana cecha w populacji generalnej ma rozkład normalny N(μ,σ). Wartość średniej μ jest nieznana, odchylenia standardowe σ w populacji jest znane. Z populacji tej pobrane próbę o liczebności n elementów, wylosowanych niezależnie. Podziałem ufności dla średniej μ populacji otrzymuje się ze wzoru.
P{- ![]()
gdzie:
1-α - jest prawd. przyjętym z góry i nazywanym współczynnikiem ufności (w zast. praktycznych: 1-α≥0,9).
uα - jest wartością zmiennej losowej U o rozkładzie normalnym
- średnia arytmetyczna z próby obliczenia wg zależności:
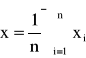
i na lewo od -uα
Wartość uα dla każdego współczynnika ufności 1-α wyznacza się z rozkładu normalnego standaryzowanego N(0,1) w taki sposób by spełniona była relacja:
P{-uα<u<uα} = 1-α
uα jest taką wartością zmiennej losowej o rozkładzie normalnym standaryzowanym, że pole powierzchni pod krzywą gęstości w przedziale (-uα,uα) wynosi 1-α, a pod krzywą gęstości na prawo od uα wynosi po α/2.
Model II
Badana cecha w populacji generalnej ma rozkład normalny N(μ,α). Nieznana jest zarówno wartość średnia μ, jak i odchylenie standardowe σ w populacji.
Z populacji tej wylosowano niezależnie małą próbę o liczebności n(n<30) elementów. Przedział ufności dla średniej μ populacji otrzymuje się wówczas ze wzoru:
P{-tα![]()
<μ<+tα![]()
}=1-α
gdzie:
s=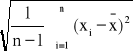
jest odchyleniem standardowym z próby.
Wartość tα oznacza wartość zmiennej t Studenta, odczytaną z tablicy tego rozkładu dla n-1 stopni swobody w taki sposób, by dla danego z góry prawdopodobieństwa 1-α spełniona byla relacja:
P{-tα<t<tα} = 1-α
Zasada wyznaczania wartości tα jest podobna jak w modelu I.
Model III
Badana cecha w populacji generalnej ma rozkład normalny N(μ,α) bądź dowolny inny rozkład o średniej μ i skończonej wartości σ2 (nieznanej). Z populacji tej pobrano do próby n niezależnych obserwacji, przy czym liczebność próby jest duża (co najmniej kilkadziesiąt). Wtedy przedział ufności dla średniej μ populacji wyznacza się ze wzoru jak w modelu I, z tą tylko różnicą, że zamiast σ we wzorze tym używamy wartości odchylenia standardowego s z próby.
Przedział ufności dla wariancji
W zależności od tego, czy próba jest mała, czy duża, przedział ufności dla wariancji buduje się odpowiednio w oparciu o rozkład χ2 (dzi - kwadrat) bądź o rozkład normalny.
Model I
Badana cecha w populacji generalnej ma rozkład normalny N(μ,σ) o niezależnych parametrach μ i σ. Z populacji tej wylosowano niezależnie do próby n elementów (n jest małe tj. N<30). Z próby obliczono wariancję s2. Wówczas przedział ufności dla wariancji σ2 populacji generalnej określony jest wzorem:
P{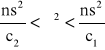
} = 1-α
gdzie:
s2=![]()
s2 jest wariancją z próby, a współczynniki c1 i c2 są wartościami zmiennej χ2 wyznaczonymi z tablicy rozkładu χ2 dla n-1 stopni swobody oraz współczynnika ufności 1-α w taki sposób, by spełnione były relacje:
P(χ2<c1) = 1/2 α
P(χ2≥c2)= 1/2 α
Ponieważ powszechnie używane tablice rozkładu χ2 posiadają prawdopodobieństwo P(χ2≥χ2α), zatem dla określonego współczynnika ufności 1-α wartość c1 znajdujemy z tablic rozkładu χ2 dla prawdopodobieństwa 1-α/2, natomiast wartość c2 dla prawdopodobieństwa α/2.
Model II
Badana cecha w populacji generalnej ma rozkład normalny N(μ,σ) lub zbliżony do normalnego o nieznanych parametrach μ i σ. Z populacji tej wylosowano niezależnie dużą liczbę n elementów (n co najmniej kilkadziesiąt). Z próby tej obliczono odchylenie standardowe s = . Wtedy przybliżony przedział ufności dla odchylenia standardowego σ populacji generalnej jest określony wzorem:
P{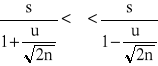
} = 1-α
gdzie:
uα jest wartością zmiennej normalnej standaryzowanej U, wyznaczoną w taki sposób dla ustalonego 1-α z tablicy rozkładu N(0,1), by spełniona była relacja:
P{-uα<U<uα)=1-α
2
Wyszukiwarka
Podobne podstrony:
SMiPE - Kolokwium wykład ściąga 1, STUDIA, SEMESTR IV, Statystyka matematyczna i planowanie eksperym
Statystyka matematyczna - ściąga 02, STUDIA, SEMESTR IV, Statystyka matematyczna i planowanie eksper
SMiPE - Kolokwium wykład ściąga 2, STUDIA, SEMESTR IV, Statystyka matematyczna i planowanie eksperym
Statystyka3, STUDIA, SEMESTR IV, Statystyka matematyczna i planowanie eksperymentu, SMiPE
4 Rozklad normalny, STUDIA, SEMESTR IV, Statystyka matematyczna i planowanie eksperymentu, SMiPE
opracowanie pytań na wykład ze statystyki, STUDIA, SEMESTR IV, Statystyka matematyczna i planowanie
01 instrukcja mini, Studia, ZiIP, SEMESTR IV, Statystyka matematyczna i planowanie eksperymentu
STATYSTYKA MATEMATYCZNA-sciaga, Automatyka i Robotyka, Semestr IV, Statystyka Matematyczna
Statystyka2, POLITECHNIKA ŚLĄSKA Wydział Mechaniczny-Technologiczny - MiBM POLSL, Semestr 4, StudiaI
Statystyka5, POLITECHNIKA ŚLĄSKA Wydział Mechaniczny-Technologiczny - MiBM POLSL, Semestr 4, StudiaI
statystyka1, POLITECHNIKA ŚLĄSKA Wydział Mechaniczny-Technologiczny - MiBM POLSL, Semestr 4, StudiaI
Zarzadzanie i systemy jakosci - sciaga I, STUDIA, SEMESTR IV, Podstawy zarządzania, pz, Zarzadzanie,
ściąga fizjo, WNOŻCiK (moje studia), Semestr IV, Fizjologia człowieka
Statystyka2, ۞ Płyta Studenta Politechniki Śląskiej, Semestr 4, Smipe - Statystyka matematyczna i pl
0 MathCAD, ۞ Płyta Studenta Politechniki Śląskiej, Semestr 4, Smipe - Statystyka matematyczna i plan
MK warstwowe.odpowiedzi, STUDIA, SEMESTR IV, Materiały kompozytowe
BETON SCIAGA, budownictwo studia, semestr II, Materiały budowlane
więcej podobnych podstron