SPIS TREŚĆI
1 SPIS TREŚĆI
Spis rysunków
Rysunek 1. Format komórki ATM
Spis tabel
Tabela 1. Klasy usług
Cel pracy
Celem mojej pracy dyplomowej była optymalizacja algorytmów warstwy sterowania przeciążeniem w sieci szerokopasmowej ATM. W pracy przedstawiłem problem przeciążenie w sieciach ATM, opisałem i dokonałem porównania najbardziej znanych algorytmów kontroli przeciążenia.
Niestety, dostępny pakiet symulacyjny COMNET III w wersji podstawowej nie umożliwia implementacji poszczególnych niestandardowych algorytmów kontroli przeciążenia, które są jeszcze w fazach testów i standaryzacji. Symulacje tych algorytmów można przeprowadzić w pakiecie OPNET firmy MIL3 lub w pakiecie COMNET III w wersji rozszerzonej o kompilator SIM???, pozwalającym na implementację niestandardowych rozwiązań. Ze względu na niedostępność wymienionych pakietów w pracy wykorzystałem symulacje przeprowadzone przez organizacje zajmujące się rozwojem i standaryzacją technologii ATM i symulacje przeprowadzone na uczelniach w Stanach Zjednoczonych i Niemczech.
Wstęp
Współcześnie tworzone sieci ATM osiągają bardzo duże rozmiary zarówno ze względu na rozpiętość geograficzną, jak i też liczbę podłączonych do niej urządzeń końcowych. ATM staje się obecnie najbardziej rozpowszechnianą technologią szkieletową dla złożonych sieci korporacyjnych, miejskich i regionalnych, zaczyna także powoli wkraczać do sieci lokalnych.
Sieci w standardzie ATM powinny zapewnić użytkownikom wydajność, efektywność i zagwarantować wynegocjonowane parametry jakościowe przez cały czas połączenia.
Technologia ATM, aby sprostać stawianym jej wymaganiom, potrzebuje odpowiednich algorytmów sterowania ruchem i kontroli przeciążeniem.
Kontrola przeciążenia jest odpowiedzialna za efektywną, wydajną i bezbłędną transmisję danych. Kontrola ta jest jednym z najbardziej istotnych zagadnień we wszystkich szybkich sieciach komputerowych.
Przyczynami powstawania przeciążenia są: fluktuacja strumieni pakietów, niezgodność przepustowości łącz, „wybuchowość” ruchu w sieci a także awarie wewnątrz sieci. Przykładowo transmisja skompresowanego obrazu video może być przyczyną fluktuacji strumieni pakietów. Niezgodność przepustowości łącz spowodowana jest m.in. koniecznością współpracy bardzo szybkich nowoczesnych łącz wraz ze starych wolnymi łączami, które nie znikną z chwilą wprowadzenia szybkich łączy i będą jeszcze długo używane. Rozpiętość przepustowości łącz ciągle się zwiększa. Dzisiaj istnieją sieci o łączach od prędkości 9,6 kbps do 1Gbps, jutro będziemy mieli sieci składające się z łączy od prędkości 9,6 kbps do kilku Gbps. Wzrastająca niejednorodność potęguje problem przeciążenia.
Aby zapewnić efektywność sieci i zapobiec stratom danych na skutek w/w przyczyn, potrzebujemy efektywnych metod badających stan sieci i podejmujących odpowiednie reakcje w celu uniknięcia przeciążenia. Algorytmy sterowania przeciążeniem, którymi się zająłem w niniejszej pracy, są takimi metodami.
W pracy krótko opisałem technologie ATM: architekturę protokołu, format komórki ATM i rodzaje połączeń. Następnie przedstawiłem problem przeciążenia, przyczyny powstawania i próby jego rozwiązania. W dalszej części pracy sklasyfikowałem i powiązałem poszczególne metody kontroli przeciążenia z rodzajami ruchu w sieci ATM. W rozdziale 11 opisałem zasadę działania najbardziej znanych algorytmów kontroli przeciążenia. W następnych rozdziałach bazując na dostępnych symulacjach dokonałem porównania, analizy algorytmów kontroli przeciążenia.
Podstawowe informacje o sieci ATM
[ 5,8]
Technologia ATM (Asynchronous Transfer Mode) powstała w wyniku kompromisu między dwoma już funkcjonującymi technikami cyfrowej transmisji szerokopasmowej: STM (Synchronous Transfer Mode) i PTM (Packet Transfer Mode), łącząc zalety istniejących technologii przy jednoczesnej eliminacji większości wad tych systemów. Technika STM jest stosowana w sieciach ISDN, PTM zaś w lokalnych sieciach komputerowych. Wywodząca się z telekomunikacji technologia ATM jest coraz częściej postrzegana jako technika łącząca standard przekazów telekomunikacyjnych sieci SDH (Synchronous Digital Hierarchy) na poziomie warstwy fizycznej z różnymi sieciami komputerowymi.
Informacja w standardzie ATM jest przesyłana w postaci krótkich komórek o stałej długości (48 bajtów informacji + 5 bajtów nagłówka). Nagłówek jest niezbędny w celu zrealizowania przezroczystego transportu informacji użytkownika przez sieć ATM bez zakłóceń, straty czy też nadmiernego opóźnienia.
Standard ATM jest techniką telekomunikacyjną typu połączeniowego, co oznacza, że faza przesyłania informacji właściwej jest poprzedzona fazą zestawiania połączenia. W tej fazie wstępnej następuje negocjowanie kontraktu pomiędzy „klientem” sieci a „administracją” sieci. Na podstawie parametrów deklarowanych przez użytkownika (typ usługi, przewidywana przepływność), sieć decyduje, czy można zagwarantować odpowiedni poziom jakości obsługi dla nowopojawiającego się zgłoszenia i dla wszystkich innych aktualnie realizowanych. Zadeklarowane w fazie wstępnej parametry zgłoszenia mogą podlegać renegocjacji. Transmisja w sieci ATM odbywa się poprzez zestawienie łącza logicznego (kanał wirtualny, ścieżki wirtualne).
Topologie i interfejsy sieci ATM
[5,8]
Sieci oparte o technologie ATM są konfigurowane jako gwiazda lub hierarchiczna gwiazda (w przypadku połączeń miedzy przełącznikami) z przełącznikiem ATM w centrum. Wyróżnia się dwa typy interfejsów:
UNI (User Network Interface), który łączy sprzęt użytkownika (Customer Premises Equipment) z siecią ATM, czyli odpowiada za styk użytkownik-sieć publiczna. Interfejs UNI powinien zapewnić użytkownikowi podłączenie do publicznej sieci urzadzenia typu: terminal, urządzenie sieci LAN/MAN, przełącznik.
NNI (Network Node Interface), styk sieciowy umieszczony pomiędzy węzłami ATM. Interfejs łączący tylko porty przełączników ATM - tzn. za ich pośrednictwem łączone są sieci i podsieci ATM. (styk sieć publiczna-sieć publiczna).
Komórka ATM
[5,8]
Sieć ATM do przesyłania danych wykorzystuje pakiety o jednakowej długości 53 bajtów (48 bajtów informacji i 5 bajtów nagłówku). Stała długość pakiety upraszcza sterowanie ruchem i zarządzanie zasobami sieci. W dalszej części pracy przedstawię budowę komórki ATM i rodzaje występujących komórek.
Format komórki ATM
GFC (Generic Flow Control) - cztery bity kontroli przepływu stosowane w przypadku interfejsu UNI kiedy z jednego interfejs korzysta kilka przyłączonych stacji. W przypadku nie wykorzystywania funkcji kontroli przepływu pole to zawiera same zera. Pole GFC może być wykorzystane przez użytkownika w celu wydzielenia w ramach jego prywatnej sieci wielu klas usług z realizacją różnych wartości QOS.
VPI/VCI (Virtual Path Identifier / Virtual Channel Identifier) - bity identyfikacji wirtualnej ścieżki (VPI) i kanału (VCI) tworzące tzw. routing field - pole decydujące o routingu-transmisji komórki w sieci, miedzy węzłami ATM. Jak wcześniej pokazałem., sieć ATM jest protokółem wymagającym fazy nawiązania połączenia dla ustanowienia wirtualnego połączenia na fizycznych łączach ( uaktualnienia tablic w punktach komutacyjnych). VPI/VCI służą do identyfikacji danej komórki z konkretnym połączeniem i są wykorzystywane do multipleksowania, demultipleksowania i komutacji komórek w węzłach sieci ATM, przyporządkowuje się je danemu połączeniu na czas transmisji i obowiązują na odcinku miedzy węzłami sieci. Ze względu na małe rozmiary komórek stosowanie pełnych adresów byłoby bardzo nieekonomiczne, dlatego stosuje się właśnie takie etykiety unikalne tylko w obrębie interfejsu. Ogólnie rzecz biorąc w węzłach sieci odbywa się wymiana wartości VPI/VCI na inne - ważne na odcinku do następnego węzła. Używając takiego mechanizmu warstwa ATM może asynchronicznie przeplatać w jednym fizycznym medium komórki z wielu połączeń.
PT (Payload Type) - 3-bitowe pole służące do identyfikacji typu informacji jaka niesie komórka. Pozwala ono na odróżnienie danych użytkownika od informacji kontrolnych - związanych z serwisem i zarządzaniem zasobami sieci.
CLP (Cell Loss Priority) - bit określający porządek, w jakim sieć będzie odrzucała komórki w przypadku jej zatłoczenia - kiedy istnieje niebezpieczeństwo przepełnienia bufora w węźle. Komórki z ustawionym bitem CLP (CLP=1) w pierwszej kolejności zostaną odrzucone, dając możliwość obsłużenia komórek o wyższym priorytecie (w sytuacji awaryjnej).
HEC (Header Error Control) - pole kontrolne informacji przenoszonej przez nagłówek. Pojedyncze błędy mogą być korygowane a większa liczba błędów tylko wykrywana.
Pole informacyjne -pole przeznaczone na dane użytkownika.
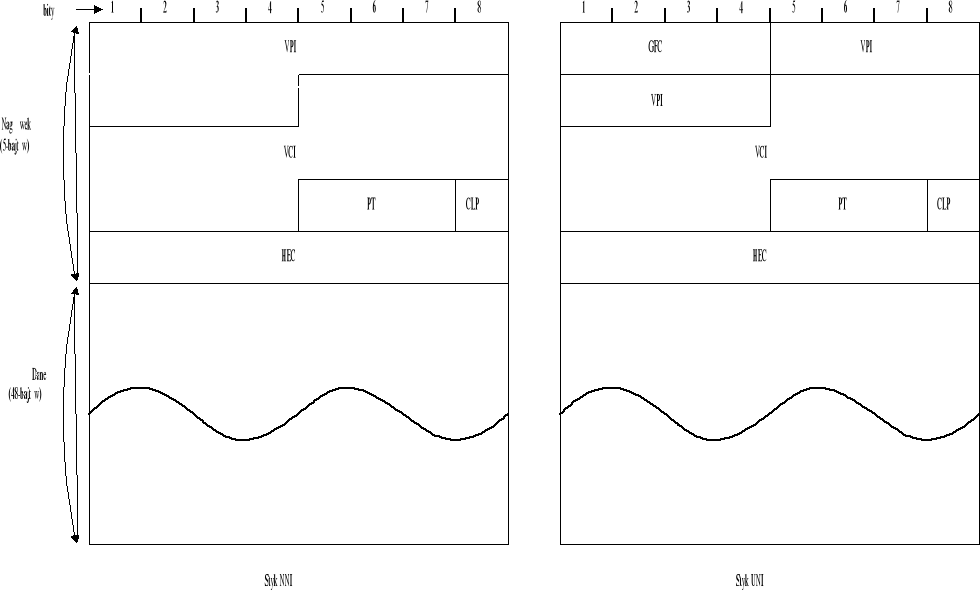
Rysunek 1. Format komórki ATM
Typy komórek
Standard ATM wyróżnia kilka typów komórek, mogących pojawić się w sieci:
komórki „puste” (idle cells), komórki nie przenoszące żadnej informacji a jedynie mają za cel dostosowanie szybkości przepływu pomiędzy warstwą ATM a warstwą fizyczną. Komórki te są generowane i usuwane przez warstwę fizyczną;
komórki „poprawne” (valid cells) -przesyłane w warstwie fizycznej, które mają prawidłowy nagłówek lub których nagłówek został zmodyfikowany przez proces weryfikacji;
komórki „niepoprawne” (invalid cells), których nagłówek zawiera błędy nie usunięte przez proces weryfikacji, komórki tego typu są usuwane przez warstwę fizyczną;
komórki „przydzielone” (assigned cells), występujące w warstwie ATM i dostarczające usługi dla aplikacji;
komórki nieprzydzielone (unassigned cells), czyli wszystkie komórki warstwy ATM, które nie są „przydzielone”
Architektura protokołu ATM
[5,8,15]
Dla pełnego omówienia standardu ATM niezbędne jest umieszczenie go w uniwersalnej strukturze OSI (Open System Interconnection).
Rysunek 2. Warstwy ATM
Chociaż standard ATM definiuje trzy warstwy, nie jest słuszne przypuszczenie, że odpowiadają one trzem dolnym warstwom modelu odniesienia ISO OSI. Właściwsze jest traktowanie warstwy fizycznej ATM oraz warstwy ATM jako odpowiednika warstwy fizycznej w modelu OSI, natomiast warstwy adaptacji (ang. AAL) jako odpowiednika warstwy łącza danych wg OSI. Wskazuje na to porównanie usług podstawowych realizowanych przez odpowiednie warstwy. Łącze wirtualne oferowane przez warstwę ATM odpowiada warstwie fizycznej. Udostępnia ono usługę transmisji bajtów informacji w konfiguracji punkt-punkt lub punkt-wielopunkt z określoną prędkością. Jeśli chodzi o warstwę AAL, to oferuje ona usługi dotyczące dostępu do łącza, przydzielania pasma, nie zapewnia natomiast procedur typowych dla warstwy sieciowej, związanych z routingiem czy adresacją końcówek sieci. Według ITU-T te dodatkowe funkcje powinny rezydować w warstwie powyżej AAL.
Warstwa fizyczna
Zasadniczą funkcją warstwy fizycznej jest poprawna transmisja komórek w medium fizycznym pomiędzy różnymi elementami sieci ATM. Warstwa ta dzieli się na dwie podwarstwy:
podwarstwę medium fizycznego (Physical Medium Sublayer), której zadaniem jest transmisja bitów i fizyczny dostęp do medium. Podstawowe operacje związane są taktowaniem bitów, kodowaniem i konwersją do postaci sygnałów optycznych lub elektrycznych w zależności od stosowanego medium.
podwarstwę zbieżności transmisji (Physical Transmission Convergence Sublayer), której rolą ogólnie jest zamiana ciągu komórek na ciąg bitów i vice versa. W warstwie tej możemy wyróżnić następujące funkcje:
Cell Rate Decoupling -wstawianie (oraz usuwanie po drugiej stronie łącza) pustych komórek. Ponieważ strumień danych niekoniecznie wypełnia całą przepływność łącza, niezbędne jest dodawanie pustych komórek tak, aby zapewnić ciągłość ich strumienia i zgodność z przepływnością bitów w medium;
HEC Generation (Verification) -obliczanie i sprawdzanie nadmiaru kodowego dla każdej komórki i umieszczanie go w polu HEC nagłówka;
Cell Delineation -wydzielanie komórki z ramki, polegające na wskazaniu początku i końca poprawnego pakietu;
Transmission Frame Generation (Recorvery) And Adaptation. -umieszczanie (wydzielanie) komórki z ramki transmisyjnej. Sieć ATM może korzystać z sieci transmisyjnej , o strukturze ramkowanej i wówczas trzeba dostosować strumień pakietów do ramki, np. do ramki SDH lub G.703.
Warstwa ATM
Warstwa ATM jest zespołem funkcji niezależnych od medium transmisyjnego, dostarczających możliwości przezroczystego transferu informacji użytkownika. Warstwa definiuje budowę komórki ATM i związane z tym sposoby jej transportu przez sieć, zarządzania ruchem, ustalania jakości połączeń. Podstawowymi funkcjami warstwy ATM są:
tworzenie i rozpakowywanie nagłówka
multipleksacja i demultipleksacja komórek
realizacja doboru trasy dla komórek
realizacja translacji VCI lub/i VPI
realizacja procedur sterowania przepływem
Warstwa adaptacji ATM
Aby sieć ATM przenosiła szeroka gamę usług o różnych charakterystykach ruchu oraz różnych wymaganiach systemowych, uzależnieniach czasowych itp., niezbędna jest adaptacja różnych klas aplikacji do jednolitej warstwy ATM. Funkcje te wypełnia Warstwa Adaptacji ATM (AAL - ATM Adaptation Layer).
Zdefiniowano cztery protokoły warstwy adaptacji ATM:
AAL1 - wspomaga usługi połączeniowe. wymagające stałej prędkości transmisji (ang. CBR -Constant Bit Rate), charakteryzujące się uzależnieniem czasowym pomiędzy nadawcą a odbiorcą (taktowanie i opóźnienie). Realizuje następujące funkcje:
Segmentacja i desegmentacja jednostek informacyjnych,
Zmniejszanie wpływu zmiennego opóźnienia komórek,
Reakcja na stratę komórek lub zmianę ich kolejności,
Odtwarzanie w odbiorniku częstotliwości zegara nadajnika,
Monitorowanie i obsługa błędów pola kontrolnego AAL.
AAL2 -wspomaga usługi połączeniowe, wymagające zmiennej (przydzielanej dynamicznie) prędkości transmisji (ang. VBR - Variable Bit Rate). Realizuje następujące funkcje:
Segmentacja i desegmentacja jednostek informacyjnych,
Korekcja błędów dla usług audio i video,
Synchronizacja terminali poprzez przesyłanie znaczników czasu,
Obsługa zagubionych i niesekwencyjnych komórek.
AAL3/4 - wspomaga usługi o zmiennym zapotrzebowaniu na przepustowość, zarówno połączeniowe, jak tez bezpołączeniowe (klasy usług "C" i "D"). Początkowo istniały dwa oddzielne protokoły AAL3 oraz AAL4 odpowiednio dla usług połączeniowych i bezpołączeniowych. Spełnia następujące funkcje, które są aktywne w zależności od trybu pracy:
Segmentacja i desegmentacja jednostek informacyjnych,
Reakcja na błędy,
Wskazywanie typu informacji,
Określanie maksymalnej wielkości buforów po stronie odbiorczej potrzebnych do skompletowania przesyłanej wiadomości.
AAL5 - wspomaga usługi połączeniowe o zmiennym zapotrzebowaniu na przepustowość. W stosunku do AAL3/4 jest on wersją znacznie odchudzoną m.in. poprzez uproszczenie korekcji błędów. Dzięki temu większe pole w komórce ATM przeznaczone jest na informacje użytkownika (warstwy wyższej). Upraszcza się także obróbka komórki oraz implementacja protokołu. Zakwalifikowano go jako wspomagającego klasę usług "C", chociaż istnieją projekty wykorzystania go do transportu usług bezpołączeniowych (projekt ATM Forum - "LAN-emulation" oraz specyfikacja IETF dotycząca transportu protokołu IP przez sieć ATM).
Kanał wirtualny
[5,8]
Komórki należące do jednego połączenia tworzą kanał wirtualny (Virtual Channel). Kanał wirtualny realizuje jednokierunkową transmisję danych w sieci ATM. Wiele kanałów wirtualnych może jednocześnie korzystać z tych samych łączy fizycznych, kanały te są rozróżniane na podstawie VCI i VPI zawartych w nagłówku komórki ATM.
Ponieważ komórki ATM mogą być wysyłane z dowolną (ustaloną na etapie zestawienia połączenia) szybkością transmisji i innymi ustalonymi parametrami, kanał wirtualny musi cechować się dowolnie dużym pasmem przepustowym. Jest to jedna z cech sieci ATM, umożliwiająca na realizację idei sieci szerokopasmowej, umożliwiającej zestawienie połączenia dla każdej aplikacji w elastyczny sposób.
W sieci ATM jest realizowane połączenie typu kanał wirtualny (VCC -Virtual Channel Connection), które oznacza zestawienie pewnej liczby łączy typu kanał wirtualny w celu utworzenia trasy pomiędzy punktami dostępu do sieci ATM dla przezroczystej transmisji danych. Połączenie VCC jest połączeniem jednokierunkowym. W celu zestawienia połączenia dwukierunkowego konieczne jest zestawienia pary połączeń typu VCC, po jednym w każdym kierunku. Połączenia VCC mogą mieć także strukturę wielopunktową, wykorzystywaną na przykład w przypadku usług konferencyjnych. Zgodnie z rekomendacjami ITU-T możliwe jest utworzenie kanału wirtualnego na jeden z wymienionych sposobów:
bez wykorzystania procedur sygnalizacyjnych, na podstawie subskrypcji usługi;
wykorzystując procedury metasygnalizacji -w taki sposób są tworzone specjalne kanały sygnalizacyjne;
wykorzystując specjalne kanały sygnalizacyjne (signaling VCC) -w taki sposób są tworzone „klasyczne” kanały wirtualne w chwili nadejścia nowego zgłoszenia;
wykorzystując procedury sygnalizacyjne typu użytkownik-użytkownik, np. tworzenie odrębnego kanału sygnalizacyjnego na bazie już istniejącego połączenia typu ścieżki wirtualnej.
Ścieżka wirtualna
[5,8]
Pewna grupa kanałów wirtualnych tworzy ścieżkę wirtualną, która ma przypisane pasmo wirtualne, możliwe do rezerwacji i egzekwowania.
Koncepcja ścieżki wirtualnej i kanałów polega na przeprowadzaniu połączeń w sieci tą samą trasą, razem zgrupowanych i mogących być częściowo obsługiwanych wspólnie. Przykładowo, zmiana przebiegu trasy ścieżki wirtualnej na wskutek uszkodzenia, powoduje automatyczną zmianę przebiegu wszystkich związanych z nią kanałów wirtualnych. Komórki ATM należące do danej ścieżki wirtualnej identyfikowane są na podstawie pole VPI (Virtual Path Identfier) znajdującego się w nagłówku danej komórki. Głównymi zaletami wprowadzenia koncepcji ścieżki wirtualnej są:
zlikwidowanie konieczności translacji nagłówka w przypadku połączeń typu ścieżka wirtualna pomiędzy węzłami sieci, uproszczony dobór trasy;
zwiększone możliwości kontroli i sterowania w sieci;
zwiększona elastyczność sieci ATM;
Multipleksacja
[5]
Multipleksacja jest operacją łączenia wielu strumieni danych w jednym elemencie komutacyjnym lub transmisyjnym. W sieciach ATM stosuje się technikę multipleksacji etykietowanej LM (Label Multiplex) interpretującej na bieżąco zawartość odpowiednich pół identyfikatorów VPI i VCI w komórkach nadchodzących asynchronicznie z wielu źródeł. W przypadku spiętrzeń (burstiness) strumieni cyfrowych ponad deklarowaną średnią przepływność sieć (przełącznik ATM) jest przygotowana na chwilowy wzrost aktywności przez poszerzenie istniejącego pasma.
Klasy usług w sieci ATM
[5, 6, 7, 8, 14]
Architektura sieci ATM pozwala na jednoczesną transmisję ruchu składającego się z głosu, video i danych. W celu zapewnienia określonej jakości obsługi ruchu w sieci, zdefiniowano pięć klas usług biorąc pod uwagę następujące parametry:
uzależnienie czasowe między nadawcą a odbiorcą (wymagane lub nie)
szybkość transmisji (stała lub zmienna)
tryb transmisji (połączeniowy lub bezpołączeniowy)
Klasy określają charakterystykę ruchu, wymaganą jakość obsługi i definiują także takie funkcje jak routing, kontrolę zgłoszenia, alokację zasobów i kontrolę ruchu. Nie przewidziano wszystkich kombinacji powyższych parametrów, lecz wyróżniono jedynie cztery podstawowe klasy usług. Zestawiono oraz scharakteryzowano je krótko w tabeli.
|
Klasa A |
Klasa B |
Klasa C |
Klasa D |
Relacje czasowe dla transmisji danych |
wymagane
|
nie wymagana |
||
Przepływność bitowa |
stała |
zmienna |
||
Tryb połączenia |
połączeniowy |
bezpołączeniowy |
||
Zastosowanie |
Emulacja obwodów synchronicznych |
Transmisja głosu i obrazu (po kompresji) |
Przesyłanie danych z/do sieci Frame-Realay |
Przesyłanie danych z/do sieci LAN |
Rodzaj połączenia w sieci ATM |
CBR |
rt-VBR |
nrt-VBR |
ABR |
Tabela 1. Klasy usług
Klasy A, B, C oraz D oznaczane są niekiedy odpowiednio jako klasy 1, 2, 3 oraz 4. W literaturze spotyka się również pojęcie tzw. Klasy 0. Terminem tym określa się rodzaj obwodów w sieciach ATM, dla których nie zdefiniowane są usługi QOS, czyli nie zapewnia się dla nich kontroli przepływu komórek.
Klasa A
W obrębie tej klasy zdefiniowano połączenie typu CBR (Constant Bit Rate), dla którego należy zagwarantować stałe pasmo przepustowe dla całego czasu trwania połączenia, niezależnie od faktycznego jego wykorzystania. Połączenie typu CBR charakteryzują parametry:
PCR (Peak Cell Ratio) -określa gwarantowane stałe pasmo przepustowe podczas transmisji komórek w danym połączeniu;
CDV (Cell Delay Variation) -określa zmienność (dopuszczalny zakres zmian) opóźnienia podczas transmisji poszczególnych komórek w danym połączeniu;
Max CTD (Maximum Cell Transfer Delay) -określa maksymalne opóźnienie podczas transmisji poszczególnych komórek w danym połączeniu;
CLR (Cell Loss Ratio) -współczynnik określający bieżący stosunek liczby komórek straconych do łącznej liczby komórek przetransmitowanych w danym połączeniu.
W praktyce należy dążyć do tego, aby parametry CDV i CLR były bliskie zeru. W przypadku, gdy w danym momencie strumień danych w połączeniu typu CBR przekroczy dopuszczalną prędkość PCR, komórki zostaną odrzucone przez węzeł, w którym zjawisko to zostało wykryte. Połączenia tego typu stosuje się do emulacji obwodów synchronicznych (np. łączenie central telefonicznych), przesyłania głosu, video (np. video konferencje).
Klasa B i C
Początkowo dla obu tych klas zdefiniowano jeden typ połączeń -VBR (Variable Bit Rate), dla którego należy zagwarantować stałe pasmo przepustowe z możliwością jego chwilowego zwiększenia. Dalsze standaryzacja tych klas doprowadziła do wyróżnienia dwóch podklasy: rt-VBR (real time VBR) oraz nrt-VBR (non-real time VBR). Dla połączeń typy nrt-VBR definiuje się parametry:
PCR (Peak Cell Ratio) -określa maksymalne pasmo przepustowe podczas transmisji komórek w danym połączeniu;
SCR (Sustained Cell Ratio) -określa gwarantowane stałe pasmo przepustowe w danym połączeniu;
mean CTD (Mean Cell Transfer Delay) -określa średnie opóźnienie podczas transmisji poszczególnych komórek w danym połączeniu;
CLR (Cell Loss Ratio) -współczynnik określający bieżący stosunek liczby komórek straconych do łącznej liczby komórek przetransmitowanych w danym połączeniu.
MBS (Maximum Burst Size) -określa maksymalny czas, w którym strumień komórek może przekroczyć parametr SCR, nie przekraczając jednak PCR
W praktyce należy dążyć do tego, aby parametr CLR był bliski zeru. W przypadku, gdy w danym momencie strumień danych w połączeniu typu VBR przekroczy dopuszczalną prędkość PCR, komórki zostaną odrzucone przez węzeł, w którym zjawisko to zostało wykryte. Natomiast w przypadku przekroczenia tylko parametru SCR, przepływ komórek nie będzie blokowany przez czas określony parametrem MBS. Węzeł sieci może zablokować transmisję komórek, jeżeli zostaną jednocześnie przekroczone parametry PCR i MBS.
Połączenie typu rt-VBR musi dodatkowo zapewnić izochroniczność transmisji, zdefiniowano więc dodatkowo dwa parametry: CVD i Max CTD (znaczenie tych parametrów jak w połączeni CBR). Dla połączenie rt-VBR nie określa się parametru Mean CTD.
Połączenia typu nrt-VBR stosuje się przeważnie do przesyłania danych pomiędzy sieciami Frame-Relay lub X.25 w obrębi sieci ATM. Natomiast przykładem usługi rt-VBR jest transmisja skompresowanego obrazu video.
Klasa D
W obrębie której zdefiniowano połączenie typu ABR (Avaiable Variable Bit Rate), dla którego należy zapewnić możliwie jak największe pasmo przepustowe, ale przy założeniu, że nie nastąpi odrzucenie komórek wskutek przeciążenia tych połączeń. Realizacja połączeń typu ABR w sieci ATM możliwa jest tylko wtedy, gdy w węzłach sieci istnieją odpowiednie mechanizmy kontroli przeciążenia. Mechanizmy te zostaną omówione w dalszej części pracy. Dla połączeń typu ABR, ATM Forum zdefiniowało dwa podstawowe parametry:
PCR (Peak Cell Ratio) -określa maksymalne pasmo przepustowe podczas transmisji komórek w danym połączeniu;
MCR (Minimum Cell Rate) -określa minimalne pasmo przepustowe podczas transmisji komórek w danym połączeniu;
Klasa 0
W klasie tej zdefiniowano połączenie typu UBR (Unspecified Bit Rate) nie gwarantujące żadnych parametrów jakościowych. Usługa ta wykorzystuje pozostałe pasmo transmisji w sieci ATM i w sytuacji natłoku komórki należące do tego rodzaju połączenia są odrzucane w pierwszej kolejność. Kontrolą przepływu, niezawodnością transmisji zajmują się wyższe warstwy transmisji takie jak. TCP. Połączenia typu UBR stosuje się przeważnie do przesyłania danych takich jak: poczta, transfer plików.
Problem przeciążenia
[2, 3, 4, 10, 12, 15]
Termin „przeciążenie” odnosi się do sytuacji, kiedy sumaryczne zapotrzebowanie na zasoby sieciowe przekracza aktualne możliwości sieci. Występowanie przeciążenia w sieciach z przełączaniem pakietów, jest rezultatem stosowania multipleksacji statystycznej, której celem jest maksymalizować wykorzystanie zasobów sieciowych. Przeciążenie może być także spowodowane awarią wewnątrz sieci, ale ponieważ przypadek ten występuje bardzo rzadko, został on pominięty w niniejszej pracy.
Jako przykład przyczyny występowania przeciążenia przeanalizuję pracę przełącznika ATM o N portach wejściowych (oczywiście mamy równocześnie N portów wyjściowych), do których wpływa N strumieni komórek. Jeżeli założymy, że pojemność buforów wyjściowych wynosi M to możemy stwierdzić, że w danej chwili do portu wyjściowego (określonego na podstawie pola VPI/VCI i informacji zawartej w tablicy połączeń) może być skierowanych nie więcej niż M komórek. W przypadku kiedy więcej niż M komórek jest skierowanych do danego portu wyjściowego, to część z nich musi pozostać w buforach wejściowych do czasu uzyskania dostępu do danego wyjścia przełącznika. Ponieważ bufory wejściowe i wyjściowe mają ograniczoną pojemność, to łatwo zauważyć, że nadchodzące do przełącznika komórki, które zastają pełny bufor wejściowy są tracone.
Kontrola przeciążenia w sieci jest przedmiotem wielu publikacji, albowiem obecnie stosowane w sieciach pakietowych mechanizmy są nieefektywne dla zastosowań w ATM
Istnieje kilka błędnych przekonań, mówiących że problem przeciążenia może być rozwiązany automatycznie poprzez rozwój nowej technologii i jej zastosowanie np. wymianę urządzeń sieciowych na bardziej wydajne.
Przedstawię dwa takie poglądy:
Przeciążenia spowodowane jest zbyt małą pojemnością buforów. Problem ten zostanie rozwiązany, kiedy pamięci staną się na tyle tanie, aby można było stosować bufory o bardzo dużych pojemnościach.
Niestety większa pojemność buforów nie rozwiążę problemu przeciążenia. Sieci skonstruowane z przełączników o nieskończonej pojemności buforów są podatne tak samo na przeciążenia jak sieci z przełącznikami o małych buforach. Dla tych ostatnich zbyt duży ruch spowoduje przepełnienie buforów i stratę komórek (Rysunek 3 a). W sieci z przełącznikami o nieskończonej pojemności buforów (Rysunek 3 b) kolejka i opóźnienie może się stać na tyle długie, że za nim komórki wyjdą z bufora, większość z nich jest już „time-out” i są jeszcze raz retransmitowane przez wyższe warstwy sieci, co powoduje jeszcze większe przeciążenie.
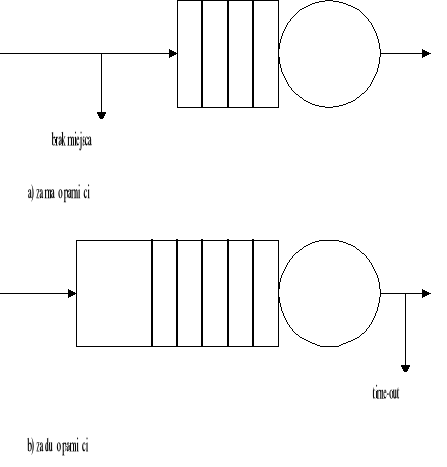
Rysunek 3.Wielkość bufora a problem przeciążenia
Przeciążenie spowodowane jest wolnymi łączami. Problem zostanie rozwiązany, kiedy szybkie łącza staną się ogólnie dostępne.
Stwierdzenie to nie zawsze jest prawdziwe, czasami zwiększanie przepustowości łącza może zwiększyć problem przeciążenia. Nowe szybkie łącza muszą współpracować ze starszymi i wolniejszymi łączami. Następujący eksperyment pokazuje, że wdrażanie szybkich łącz, bez odpowiedniej kontroli przeciążenia może obniżyć wydajność całej sieci.[2]. Rysunek 4 pokazuje cztery węzły połączone ze sobą szeregowo trzema łączami o przepustowości 19.2 kbit na sekundę. Czas transferu zwykłego pliku wynosił pięć minut. Zamianie łącza pomiędzy dwoma pierwszymi węzłami na łącze o przepustowości 1Mbit/s spowodowała zwiększenie czasu transmisji plik do siedmiu godzin. Z szybszym łączem dane przychodziły do pierwszego routera z większą prędkością niż przepustowość wyjścia, prowadziło to do powstawania długich kolejek, przepełnienia bufora i stratę komórek, powodując konieczność retransmisji, co zwiększało czas transmisji.
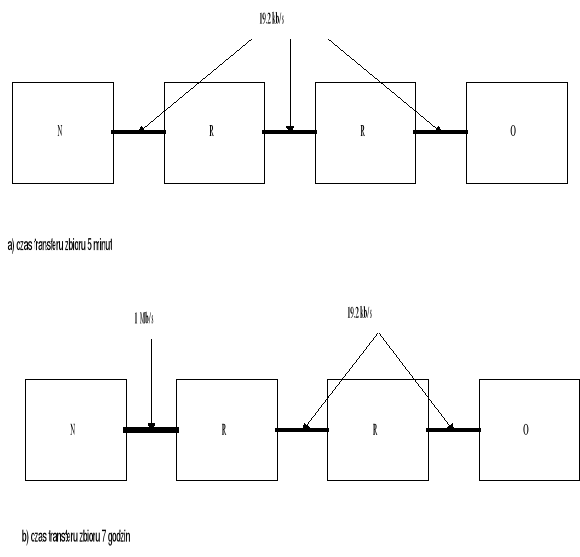
Rysunek 4 Wymiana części łączy a problem przeciążenia
Wymiana wszystkich łączy na szybsze także nie rozwiąże problemu przeciążenia. Przedstawiona przykładowa konfiguracja na Rysunek 5 pokazuje ten problem. Jeżeli węzły A i B zaczną nadawać do węzła C w tym samym czasie spowoduje to powstanie przeciążenia.
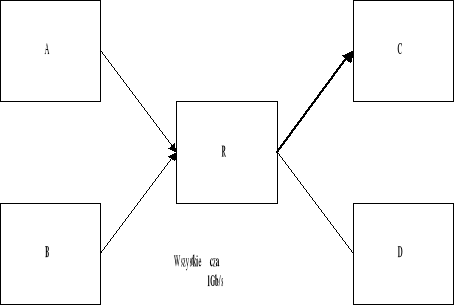
Rysunek 5. Wymiana wszystkich łączy a problem przeciążenia
Przeciążenie jest problemem dynamicznym, żadne statyczne rozwiązanie nie będzie wystarczające do jego rozwiązania. Strata pakietów na skutek małej pojemności bufora, jest symptomem, nie przyczyną przeciążenia. Wzrastająca ilość szybkich sieci prowadzi do coraz większego zróżnicowania współistniejących sieci, powodując, że problem kontroli przeciążenia staje się coraz ważniejszym problemem. Odpowiednia metody zarządzania zasobami sieci ATM i kontrola przeciążenia ruchu w sieci zwiększy jej efektywność i wydajność.
Na zakończenie tego punktu omówię niektóre funkcje i procedury przedstawione przez ATM Forum, które powinny znaleźć zastosowanie w zarządzaniu zasobami sieci ATM.
sterowanie przyjęciem zgłoszenia (Connection Admission Control) -Kiedy nowe zgłoszenie przybywa do węzła sieci ATM, użytkownik deklaruje zbiór parametrów ruchowych i wymagany poziom jakości obsługi (QOS). Wykorzystując te informacje oraz znając stan sieci, blok realizujący funkcję CAC decyduje o zaakceptowaniu lub odrzuceniu nowo przybywającego zgłoszenia.
kontrola parametrów użytkownika (Usage Parameter Control), zapewnia wymuszenie zgodności parametrów zgłoszenia zadeklarowanych na etapie akceptacji z tymi, które występują w trakcie transmisji.
sterowanie priorytetem (Priority Control) Końcowy węzeł sieci ATM może generować komórki o różnym priorytecie używając bitu CLP. Urządzenia sieci mogą selektywnie odrzucać komórki o niższym priorytecie, jeżeli np. w ten sposób zapobiegają przeciążeniu.
Traffic Shaping -kształtowanie charakterystyki przepływu informacji na podstawie danych uzyskanych z sieci lub wyżej wymienionych funkcji.
Problem przeciążenia może być częściowo rozwiązany poprzez zastosowanie wyżej wymienionych funkcji. Jednak w większości przypadkach występowania przeciążenia w sieciach ATM należy zastosować wspólnie wyżej wymienione funkcje i algorytmy kontroli przeciążenia.
Obecnie ATM Forum jest w trakcie standaryzacji algorytmów. Algorytmy, które zostały przedstawione w ATM Forum i uzyskały największe zainteresowanie zostaną omówione w dalszej części pracy.
Wymagania stawiane kontroli przeciążenia
[1, 2]
Celem zastosowania algorytmów kontroli przeciążenia i sterowania ruchem jest zapewnienie utrzymania wynegocjowanych parametrów QOS dla wszystkich rodzajów połączeń w sieci ATM i efektywne wykorzystanie zasobów sieciowych. Algorytmom kontroli przeciążenia stawia się szereg wymagań, którymi powinny się charakteryzować. Głównymi wymaganiami są:
Skalowalność
Algorytm nie może być ograniczony przepustowością łączy, odległością, ilością przełączników lub ilością wirtualnych kanałów. Ten sam algorytm powinien być stosowany zarówno w lokalnych sieciach komputerowych (LAN) jak i w rozległych sieciach (WAN)[1].
Optymalność(sprawiedliwość)
W dzielonym środowisku przepustowość jednego źródła zależy od żądań innych źródeł. Algorytm powinien „sprawiedliwie” rozdzielić dostępne pasmo pomiędzy aktywne kanały wirtualne. Żadne z realizowanych równorzędnych połączeń nie może być faworyzowane.
Odporność
Algorytm powinien być „nieczuły” na niewielkie odchylenia parametrów. Na przykład niezgodność jednego z parametrów lub strata ramki kontrolnej nie powinna zmieniać gwałtownie stanu sieci. Algorytm powinien także izolować użytkowników i chronić ich zasoby.
Implementowalność
Algorytm nie powinien być zbyt skomplikowany, czasochłonny. Algorytm nie może dyktować szczegółowo architektury przełącznika
Klasyfikacja metod kontroli przeciążenia
[4, 10]
Algorytmy przeciążenia mogą być klasyfikowane w zależności od czasu, kiedy działają w sytuacji przeciążenia. Wychodzenia z przeciążenia jest mechanizmem, który próbuje zmienić już przeciążony zasób do stanu nie przeciążonego tak szybko jak jest to tylko możliwe. Zapobieganie przeciążeniu jest metodą dla której wystąpienie przeciążenia jest niemożliwe. Jednak metoda ta powoduje nieefektywne wykorzystanie dostępnego pasma przepustowego w sieci. Unikanie przeciążenia jest metodą, która stara się stale utrzymywać zasoby sieci w stanie nie przeciążonym, ale jednocześnie zapewniając efektywność wykorzystania jej zasobów. Użytkownicy sieci wymagają od sieci efektywności, wydajności, dlatego też większość proponowanych metod kontroli przeciążenia należy do metod unikających przeciążenia. Jednak, szybkie zmiany pomiędzy stanami sieci (przeciążona -nie przeciążona) są nieuniknione, dlatego też, metody wychodzenia z przeciążenia są więc zwykle integralną częścią metod kontroli przeciążenia. Jedną z metod wychodzenia z przeciążenia jest metoda odrzucania całych pakietów (packet discard).
Mechanizmy kontroli przepływu danych, które dostosowują prędkość transmisji zapobiegając występowaniu zatłoczenia w sieciach ATM mogą być ogólnie klasyfikowane jako: open-loop i close-loop. Kontrola typu open-loop jest stosowana dla połączeń, których charakterystykę ruchu można precyzyjnie określić a wymagania jakościowe znane są z góry. Połączenie w kontroli typu open-loop specyfikuje swoje wymagania co do zasobów sieci, które, jeśli są dostępne, następnie są rezerwowane na czas trwania połączenia.
Kontrola typu close-loop jest odpowiednia dla sieci dla których zasoby nie mogą zostać zarezerwowane lub kiedy ruch w sieci nie może być sprecyzowany. W kontroli tej dostępne zasoby sieci muszą być „sprawiedliwie” i efektywnie dzielone między wieloma użytkownikami. W kontroli tej źródło stale próbkuje stan sieci i dostosowuje swoją prędkość transmisji w zależności od otrzymanego sprzężenia zwrotnego. Ważną cechą kontroli typu close-loop jest to, że wydajność, efektywność tej metody zależy od opóźnienia sprzężenia zwrotnego. Różnica czasu pomiędzy zmianą prędkości transmisji źródła a czasem kiedy źródło zobaczy efekt tej zmiany nazwana jest round-trip-time. Reakcja systemów opartych na metodach ze sprzężeniem zwrotnym ograniczona jest opóźnieniem sprzężenia zwrotnego i może tylko kontrolować przeciążenia, które trwają dużej niż round-trip-time w danej sieci.
Metody kontroli przeciążenia można jeszcze klasyfikować ze względu na typ kontroli jaki wprowadzają: credit-based lub rate-based. W przypadku wykorzystania kontroli typu rate-based, komórki sterujące zawierają informacje o bieżącym dostępnym paśmie przepustowym dla danego typu połączenia. Jeśli którykolwiek z przełączników ATM, biorący udział w realizacji danego połączenia, wykryje fakt przeciążenia tego połączenia (tzn. nastąpi odrzucenie przynajmniej jednej komórki ATM zawierającej dane użytkownika), to zawartość komórki sterującej zostanie zmieniona tak, aby zmniejszyć prędkość transmisji źródła i nie dopuścić do dalszego gubienia komórek danych. Metoda rate-based pozwala więc na bardzo efektywne wykorzystanie dostępnego pasma.
Odmiennie natomiast działa metoda typu credit-based. Komórki sterujące przenoszą informacje nie o dostępnym paśmie przepustowym, lecz o stopniu zapełnienia buforów odbiorczych przełączników oraz urządzeń brzegowych realizujących dane połączenia. Komórki te noszą nazwę kredytów. Urządzenie odbierające strumień komórek ATM na bieżąco informuje urządzenie nadawcze, które ten strumień transmituje, o stanie swojego wewnętrznego bufora wejściowego. Jeśli bufor ten zostanie wyczerpany, to urządzenie nadawcze nie otrzyma „kredytów” i w ten sposób nie będzie mogło dalej wysyłać danych.
Do efektywnego działania, obydwie metod potrzebują znać stan sieci. Typ sprzężenia jaki jest używany do badania stanu sieci jest następnym kryterium klasyfikacji metod kontroli przeciążenia. Z jawnym sprzężeniem zwrotnym (explicit feedback) elementy sieci wysyłają komunikaty wskazujące ich stan (zajętość buforów, wolne pasmo itp.) do punktów kontrolnych. Jeżeli metody kontroli przeciążenia poznają stan sieci poprzez pomiary transmisji (np. porównanie zmierzonej przepustowości i przepustowości oczekiwanej) lub poznają stan sieci przez zdarzenia takie jak time-out, informacje zawarte w potwierdzeniach, to sprzężenie zwrotne jest „ukryte” (implicit feedback). Kontrola z jawnym sprzężeniem zwrotnym pozwala na bardziej precyzyjne dostosowywanie parametrów transmisji, w odróżnieniu od kontroli z „ukrytym” sprzężeniem zwrotnym, która jest bardziej skomplikowana i czasochłonna.
Kiedy kontrola przeciążenia ma miejsce tylko w końcach systemu, jest nazwana end-to-end control. W kontroli tej pośrednie elementy sieci generują i wysyłają potrzebne informacje kontrolne do końca systemu. W metodach link-by-link, pośrednie elementy sieci wymieniają pomiędzy sobą informacje i dopasowują swoją prędkość w zależności od otrzymanej informacji (sprzężenia zwrotnego) od sąsiada. Na przykład jeżeli w przełączniku odbierającym transmisje bufor zbliża się do przepełnienia, przełącznik może wysłać do przełącznika wysyłającego żądanie zmniejszenie prędkości transmisji zapobiegając tym samym przepełnieniu bufora. W metodzie end-to-end tylko końcówki systemu mogą regulować charakterystykę ruchu.
Kontrola przeciążenia a typy połączeń ATM
[10, 3, 4, 7, 9]
Standard ATM zdefiniował pięć typów połączeń CBR, rt-VBR, nrt-VBR, ABR i UBR. Szczegółowo typy połączeń zostały omówione na początku pracy. Przedstawię teraz metody stosowane w zarządzaniu ruchem i kontrolą przeciążeniem dla poszczególnych typów połączeń.
Ważnym kryterium wyboru metody kontroli przeciążenia jest charakterystyka połączenia (ruchu) w sieci. Ogólnie rodzaje połączeń w sieci ATM możemy podzielić na dwie grupy: gwarantowane i best-effort, czyli połączenia, które starają się wykorzystać maksymalnie pozostałe pasmo po połączeniach gwarantowanych. Do gwarantowanych połączeń zaliczamy: połączenie typu CBR i rt-VBR. Dla połączeń tych musimy m.in. określić gwarantowane pasmo przepustowe jak i też maksymalne możliwe opróżnienie. Dodatkowo dla połączenia VBR określamy maksymalny czas, przez który połączenie może transmitować dane z większą prędkością. Wymagania te są znane z góry i połączenia te nie mogą być przyjęte do realizacji, jeżeli sieć nie może zapewnić ich realizacji. Kontrola przeciążenia dla tych połączeń w sieci ATM jest realizowana wspólnie poprzez sterowanie przyjęciem zgłoszenia (CAC -Call Admission Control) i rezerwacją pasma przepustowego na cały czas transmisji.
Do połączeń typu best-effort możemy zaliczyć połączenie typu ABR i UBR.
Połączenie UBR nie gwarantuje żadnych parametrów jakościowych. Przesyłanie danych odbywa się z jak największą możliwą prędkością, ale bez kontroli ich przepływu (co prowadzi zwykle do częstych odrzuceń całych serii komórek ATM dla tego połączenia). Kontrolą przepływu, przeciążenia dla tego typu połączenia zajmują się warstwy wyższe np. TCP.
Połączenie ABR, definiuje połączenie niewrażliwe na zmienne opóźnienie, dla którego należy zapewnić możliwie jak największe pasmo przepustowe, ale przy minimalizacji ilości odrzuconych komórek. Połączenia tego typu mogą spowodować zatłoczenie, kiedy zsumowane żądania pasma przepustowego przekroczą dopuszczalny dostępny zakres pasma. Połączenia typu ABR potrzebują mechanizmów zarządzania przeciążeniem, które byłyby wstanie sprawiedliwie rozdzielić pasmo pomiędzy użytkowników zapewniając jednocześnie maksymalne wykorzystanie tego pasma jak i zminimalizować ilość straconych komórek.
W sytuacji zatłoczenia, połączenia typu UBR są odrzucane od razu, połączenia CBR i VBR mają zagwarantowane pasmo i nie mogą być zmieniane i odrzucane. Parametry połączenia typu ABR mogą być właściwie dowolnie zmieniane (oprócz minimalnej i maksymalnej prędkości), dlatego też połączenia tego typu są najbardziej narażone na wystąpienie przeciążenia.
Obecnie mechanizmy kontroli przeciążenia dla ruchu ABR są jednym z największych problemów dla organizacji ATM Forum. Żadne z zaproponowanych metod nie doczekały się jeszcze standardu. ATM Forum jedynie zdefiniował format komórki zarządzającej i mechanizmy dla urządzenia nadawczego i odbiorczego, pozostawiając producentom urządzeń sieciowy „wolną rękę” przy wyborze algorytmów kontroli przeciążenia dla przełączników.
Zalecenia ATM Forum, format komórki zarządzającej jak i przykładowe mechanizmy kontroli przeciążenia zostaną w następnym rozdziale.
Algorytmy zarządzania przeciążeniem
Parametry ruchu ABR
W połączeniu typu ABR do kontroli ruchu i przeciążenia używane są następujące parametry:
PCR (Peak Cell Ratio) -określa maksymalne pasmo przepustowe podczas transmisji komórek w danym połączeniu;
MCR (Minimum Cell Rate) -określa minimalne pasmo przepustowe podczas transmisji komórek w danym połączeniu;
ICR (Initial Cell Rate) -określa początkową prędkość transmisji, którą źródło ustawia po połączeniu lub określonym czasie bez aktywności;
RIF (Rate Increase Factor) lub AIR(Additive Increase Rate) -współczynnik określający maksymalną wielkość jednorazowego zwiększenia pasma przepustowego podczas transmisji komórek;
Nrm -określa liczbę komórek danych, które źródło może wysłać pomiędzy transmisją komórki zarządzającej RM (Resource Management Cell);
Mrm -kontroluje przydział pasma pomiędzy komórkami RM a komórkami z danymi;
RDF (Rate Decrease Factor) - współczynnik zmniejszenia pasma przepustowego podczas transmisji komórek w sytuacji przeciążenia;
ACR (Allowed Cell Rate) -określa pasmo przepustowe powyżej którego źródło nie może nadawać;
CRM (Xrm) -określa maksymalną ilość komórek RM, które mogą być wysłane bez otrzymania komórki potwierdzającej RM.
ADTF (ACR Decrase Time Factor) -określa czas od nadanie ostatniej komórki RM po którym nadawca musi zredukować prędkość do ICR;
Trm -określa czas pomiędzy kolejnymi wysyłanymi komórkami RM
RTT (Round Trip Time) -czas propagacji komórki od źródła do odbiorcy i z powrotem.
CDF (Cutoff Decrease Factor) XDF (Xrm Decrease Factor) -współczynniki redukcji dozwolonego pasma przepustowego ACR, używany z CRM
Format komórki zarządzającej
[4, 7]
Komórka zarządzająca RM (Resource Management Cell) używana jest w ruchu ABR i przenosi informacje sterujące zwierające m.in. aktualną prędkość transmisji, informacje o przeciążeniu. Komórka ta jest generowana przez urządzenie nadające dane (źródło danych) do urządzenia odbiorczego (odbiorcy), urządzenie odbiorcze pod odebraniu komórki RM powinno odesłać ją do nadawcy. W zależności od algorytmu kontroli przeciążenia i ruchu komórka ta może być także zmieniana lub wygenerowana przez urządzenie pośrednie: przełącznik.
Tabela 2 przedstawia dokładną strukturę komórki RM. Opis poszczególny pól komórki RM:
Header -Pięć pierwszych bajtów jest standardowym nagłówkiem komórki ATM z ustawionym dla VPC: PTI=110 i VCI=6 oraz dla VCC: PTI=110
ID -Protocol ID Identyfikator protokółu. Dla usługi typu ABR wartość jest równa zawsze 1.
DIR-Direction. Kierunek komórki RM w odniesieniu do transmitowanych danych. Żródło ustawia DIR=0 a powracająca komórka RM ma ustawione DIR=1. Wartość ta może być tylko zmieniona przez element sieci, który zmienia kierunek komórki RM.
BN -Backwards Explicit Congestion Notification - BECN. Źródło ustawia wartość BN=0. Sieć lub przeznaczenie może wygenerować BECN ustawiająć BN=1, wskazując, że komórka RM nie jest wygenerowana przez źródło.
CI -Congestion Indication Wartość CI=1 wskazuje na wystąpienie przeciążenia, wartość CI=0 w każdym innym przypadku. Element sieciowy (np. przełącznik) może wysłać komórkę RM do źródło ruchu z ustawionym CI=1, oznaczającą wystąpienie przeciążenia, spowoduje to zmniejszenie wartości ACR przez źródło ruchu.
NI -No Increase NI=1 powiadamia źródło ruchu, aby nie zwiększało wartość ACR. Parametr ten używany jest zwykle, kiedy przełącznik jest bliski wystąpienia przeciążenia.
RA -Request/ Acknowledge Parametr nie jest używany w ruchu typu ABR.
ER -Explicit Cell Rate Wartość używana, do ustawienia parametru ACR źródła ruchu.
CCR -Current Cell Rate Parametr ten ustawiany jest przez źródło w chwili generowania komórki RM i wynosi aktualną wartość ACR.
MCR-Minimum Cell Rate
QL-Queue Length Parametr nie jest używany w ruchu typu ABR.
SN-Sequence Number Parametr nie jest używany w ruchu typu ABR.
CRC-10-CRC-10 Parametr CRC jest standardową sumą kontrolną generowaną dla wszystkich komórek ATM.
Pole |
Bajt |
Bit |
Opis |
Wartość początkowa generowana przez: |
|
|
|
|
|
źródło |
przełącznik lub odbiorcę |
Header |
1-5 |
W1 |
ATM Header |
RM-VPC: VCI=6 i PTI=110 RM-VCC: PTI=110 |
|
ID |
6 |
W |
Protocol Identifier |
1 |
|
DIR |
7 |
8 |
Direction |
0 |
1 |
BN |
7 |
7 |
BECN Cell |
0 |
1 |
CI |
7 |
6 |
Congestion Indication |
0 |
Albo CI=1 albo NI=1 |
NI |
7 |
5 |
No Increase |
0 lub 1 |
|
RA |
7 |
4 |
Request/ Acknowledge |
0 |
|
Reserved |
7 |
3-1 |
Reserved |
0 |
|
ER |
8-9 |
W |
Explicit Cell Rate |
Wartość nie większa niż parametr PCR |
Dowolna wartość |
CCR |
10-11 |
W |
Current Cell Rate |
Parametr ACR |
0 |
MCR |
12-13 |
W |
Minimum Cell Rate |
Parametr MCR |
0 |
QL |
14-17 |
W |
Queue Length |
0 lub ustawione zgodnie z I.371 |
|
SN |
18-21 |
W |
Sequence Number |
0 lub ustawione zgodnie z I.371 |
|
Reserved |
22-51 |
W |
Reserved |
6A (hex) dla każdego bajta |
|
Reserved |
52 |
8-3 |
Reserved |
0 |
|
CRC-10 |
52 |
2-1 |
CRC-10 |
Suma kontrolna obliczona zgodnie z rekomendacją I.610 |
|
|
53 |
W |
|
|
|
W1 - wszystkie bity wykorzystane
Tabela 2 Format komórki zarządzającej RM
Zasady kontroli przepływu dla ruchu ABR
[4, 7]
ATM Forum zdefiniował ogólne zasady dla ruchu typu ABR.
Komórki sterujące RM dla ruchu ABR powinny być generowane z CLP=0, jednak w niektórych sytuacjach, przedstawionych poniżej, urządzenie może wygenerować komórki RM z CLP=1. Wszystkie inne komórki wysyłane są z CLP=0. Komórki z CLP=0 nazywane są in-rate RM-cell, a z CLP=1 out-of-rate RM-cell.
Jednym z zastosowań komórek RM typu out-of-rate jest udostępnienie możliwości zwiększenia prędkości dla połączenia z ACR=0. Źródło może użyć komórek out-of-rate, aby próbkować stan sieci i ewentualnie zwiększyć prędkość.
Zasady dla urządzenia nadawczego (źródła):
Wartość ACR nie powinna nigdy przekroczyć PCR, ani też nie powinna być mniejsza niż MCR. Źródło nie może generować komórek in-rate przekraczając aktualną prędkość ACR. Źródło może zawsze wysyłać komórki in-rate z prędkością równą lub mniejszą niż ACR.
Przed wysłaniem pierwszych komórek, po zestawieniu połączenia, źródło musi ustawić parametr ACR=ICR. Pierwszą wygenerowaną komórką musi być komórka sterująca RM typu forward
Po wysłaniu pierwszej komórki (in-rate forward RM), kolejne komórki powinny być wysyłane w następującej kolejności:
Następną komórką in-rate będzie forward RM, gdy:
przynajmniej Mrm komórek in-rate zastało wysłanych i upłynął czas Trm
lub
Nrm-1 komórek in-rate zostało wysłanych.Następną komórką in-rate będzie backward RM, jeżeli warunek 3.A nie został spełniony, komórka backward RM czeka na wysłanie, jak również:
nie została wysłana komórka backward RM od czasu wysłania ostatniej komórki forward RM.
lub
nie ma żadnych komórek z danymi do wysłaniaNastępną komórką in-rate będzie komórka z danymi, jeżeli oba warunki 3.A i 3.B nie są spełnione, a dane czekają na wysłanie.
Komórki spełniające założenia 1, 2, 3 powinny mieć ustawiony bit CLP=0
Przed wysłaniem komórki forward in-rate RM, jeżeli ACR>ICR i czas, który upłynął od wysłania ostatniej komórki forward in-rate RM jest większy niż ADTF, ACR powinna być zmniejszona do ICR.
Przed wysłaniem komórki forward in-rate RM i po zastosowaniu pkt. 5, jeżeli przynajmniej CRM komórek forward in-rate RM zostało wysłanych od momentu otrzymania komórki backward in-rate RM z ustawionym bitem BN=0, wartość ACR powinna być zredukowana przynajmniej do ACR*CDF, chyba że wartość ta byłaby mniejsza od MCR, wówczas ACR=MCR.
Po zastosowaniu zasady 5 i 6, wartość ACR powinna być umieszczona w polu CCR wychodzącej komórki forward RM. Następne komórki in-rate powinny być wysyłane z nową ustaloną prędkością.
Kiedy źródło otrzyma komórkę backward RM z ustawionym parametrem CI=1, to wartość ACR powinna być zredukowana przynajmniej do ACR*RDF, chyba że wartość ta byłaby mniejsza od MCR, wówczas ACR=MCR. Jeżeli backward RM ma ustawione CI=0 i NI=0, to ACR może być zwiększone o wartość nie większą niż RIF*PCR, ale ACR nie może przekroczyć PCR. Jeżeli źródło otrzyma backward RM z NI=1 nie powinno zwiększać wartości ACR.
Po otrzymaniu backward RM i obliczeniu wartości ACR wg pkt. 8, źródło ustawia wartość ACR jako minimum z wartości ER i wartości ACR wg pkt. 8, ale nie mniejszą niż MCR.
Źródło powinno ustawiać wszystkie wartości komórki RM zgodnie z Tabela 2.
Komórki forward Rm mogą być wysłane jako out-of-rate. (tzn. z inną prędkością niż ACR, CLP=1) z prędkością nie większą niż TCR.
Źródło musi wyzerować EFCI dla wszystkich transmitowanych komórek.
Zasady dla urządzenia odbiorczego:
Po otrzymaniu komórki, wartość EFCI powinna być zapamiętana.
Odbiorca powinien zwrócić otrzymaną komórkę forward RM zmieniając: bit DIR z forward na backward, BN=0 a pola CCR, MCR, ER, CI i NI powinny być niezmienione z wyjątkiem:
Jeżeli zachowana wartość EFCI jest ustawiona to CI=1, a wartość EFCI powinna być wyzerowana.
Urządzenie odbiorcze, będące w stanie „wewnętrznego” przeciążenia, może zredukować wartość ER do prędkości jaką może obsłużyć lub/i ustawić CI=1 i NI=1. Odbiorca powinien również wyzerować QL i SN, zachowując wartości tych pól lub ustawić je zgodnie z I.371.
Jeżeli odbiorca otrzyma kolejną ramkę forward RM, a inna „odwrócona” komórka RM czeka na transmisje to:
Zawartość starej komórki może być nadpisana przez nową komórkę
Stara komórka może być wysłana jako out-of-rate lub usunięta.
Nowa komórka musi zostać wysłana.
Niezależnie od wybranego wariantu w pkt. 3, zawartość starszej komórki nie może być wysłana po wysłaniu nowszej komórki.
Urządzenie odbiorcze może wygenerować komórkę backward RM nie mając odebranej komórki forward RM. Prędkość takiej komórki powinna być ograniczona do 10komórek na sekundę, na połączenie. Odbiorca generując tą komórkę ustawia również CI=1 lub NI=1, BN=1 i kierunek na backward. Pozostałe wartości komórki RM powinny być ustawione zgodnie z Tabela 2.
Jeżeli odebrana komórka forward RM ma CLP=1, to wygenerowana na jej podstawie komórka backward może być wysłana jako in-rate lub out-of-rate.
„odwrócenie” odnosi się do procesu wygenerowania komórki backward RM jak odpowiedzi na otrzymaną komórkę forward RM
Przykładowe algorytmy
Algorytm credit-based
[1, 4, 6]
Algorytm kontroli przeciążenia (kontroli przepływu) typu credit-based opiera się na przekazywaniu „kredytów” od odbiorcy do nadawcy. Przykładem takiego algorytmu może być algorytm: „Flow Controlled Virtual Circuit (FCVC).
Każde łącze składa się z dwóch węzłów: nadawcy i odbiorcy, którymi może być przełącznik lub końcowe urządzenie sieci. Każdy węzeł obsługuje oddzielną kolejkę (bufor) dla każdego kanału wirtualnego. Odbiorca monitoruje długość kolejki dla każdego kanału wirtualnego i określa liczbę komórek (kredyt), które mogą być transmitowane przez dany kanał. Nadawca może wysłać tylko tyle komórek na ile pozwala mu przydzielony kredyt. Jeżeli jest aktywny tylko jeden kanał wirtualny na łączu, kredyt musi być na tyle duży, aby całe pasmo przepustowe łącza było wykorzystane przez cały czas, tj.
Kredyt≥Przepustowość łącza (w komórkach) X czas roundtrip
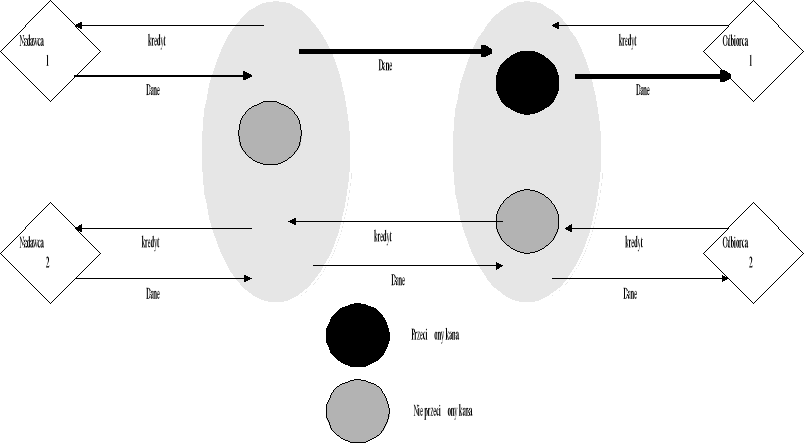
Rysunek 6 Zasada działania algorytmu typu credit-based.
Omówiona zasada działania była pierwszą wersją algorytmu FCVC, posiadającą jeszcze kilka poważnych wad. Jedną z najpoważniejszych wad było, że, jeżeli kredyt nie dotarł z powodu nieprzewidzianych sytuacji, odbiorca o tym nie wiedział i nie wysyłał nowych kredytów, nadawca nie mógł wysyłać komórek z braku kredytów. Problem ten został rozwiązany poprzez wprowadzenie synchronizacji kredytów między nadawcą a odbiorcą. Zasada działania algorytmu synchronizacji jest następująca: dla każdego kanału wirtualnego nadawca liczy ilość komórek wysłanych a odbiorca ilość komórek odebranych, wartości te są co pewien czas wymieniane pomiędzy nadawcą a odbiorcą. Różnica między ilością komórek wysłanych przez nadawcę a ilością komórek odebranych przez odbiorcę stanowi ilość komórek „zagubionych”. Odbiorca przydziela więc dodatkowe (utracone) kredyty nadawcy.
FECN i BECN
[1, 3, 4]
Algorytm sterowania przeciążenia typu FECN (Forward explicit congestion notification) jest przykładem algorytmu używającego jako sprzężenia zwrotnego, bitu EFCI (explicit forward congestion indication) w nagłówku komórki ATM.
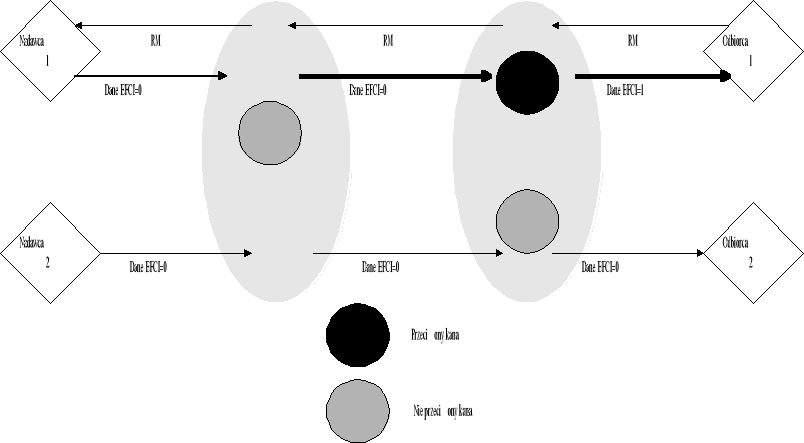
Rysunek 7. Zasada działania algorytmu FECN
W metodzie tej przełącznik monitoruje długość kolejki w buforze. Jeżeli długość kolejki przekroczy ustalony próg (oznaczający możliwość wystąpienia przeciążenia) przełącznik ustawia bit EFCI dla danych komórek. Urządzenie końcowe, które otrzymało komórki z zaznaczonym bitem EFCI, generuje ramkę kontrolną, informującą o wystąpieniu przeciążenia i wysyła ją do nadawcy. Nadawca używa informacji zawartej w ramce kontrolnej do zmniejszenia lub zwiększenia prędkości transmisji.
Rysunek 7 pokazuje zasadę działania algorytmu FECN. Przełącznik 2 wykrywa przeciążenie (kolejka w buforze przekroczyła dany próg) i ustawia bit EFCI dla wszystkich komórek należących do pierwszego kanału wirtualnego. Odbiorca po dostaniu komórek z bitem EFCI generuje i wysyła komórkę sterującą (RM) informującą nadawcę o fakcie wystąpienia przeciążenia. Nadawca, jeżeli otrzyma komórkę RM, zmniejszy prędkość transmisji danych.
Podobnym algorytmem sterowania przeciążeniem, jest algorytm zwany backward explicit congestion notification -BECN. Algorytm różni się tylko tym, że komórka sterująca RM jest generowana przez urządzenie, które wykryło przeciążenie (przełącznik) a nie tylko przez urządzenie odbiorcze. Oczywistą zaletą metody BECN nad FECN jest szybsza reakcja na wystąpienie przeciążenia. Następną zaletą jest niezależność od systemu końcowego (w algorytmie FECN odbiorca generuje RM), ponieważ urządzenia sieciowe same generują komórki sterujące. Jednak metoda BECN wymaga od bardziej rozbudowanych przełączników, potrafiących nie tylko generować komórki sterujące ale także filtrować informacje o przeciążeniu. Proces filtrowania informacji o przeciążenia jest niezbędny, aby móc zapobiec nadmiernej liczbie generowanych komórek sterujących.
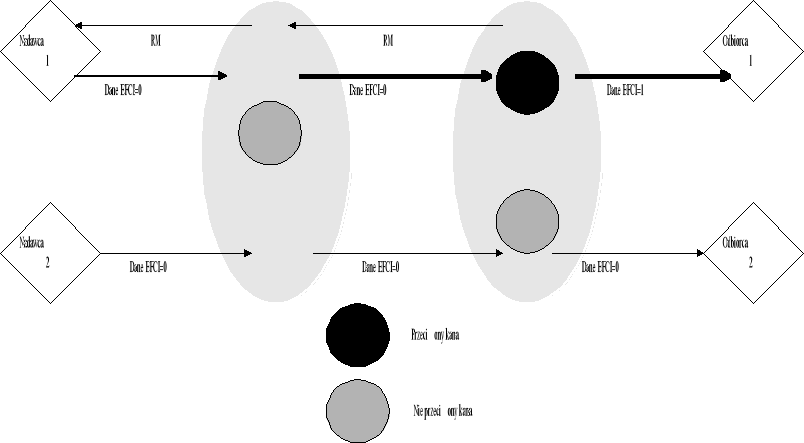
Rysunek 8. Zasada działania algorytmu BECN
W obydwóch algorytmach FECN i BECN, przełącznik wykrywa przeciążenie, kiedy długość kolejki przekroczy dany próg. Nadawca, jeżeli odebrał komórkę sterującą zmniejsza prędkość transmisji danych. Prędkość ta może być automatycznie zwiększona przez źródło, jeżeli nadawca nie otrzymał komórki sterującej przez z góry określony czas, do prędkości ustalonej podczas ustanawiania połączenia (PCR). Największą wadą obydwu metod jest brak odporność na niektóre sytuacje, np. jeżeli podczas przeciążenia komórka sterująca nie będzie mogła dotrzeć do nadawcy, to nadawca nie wiedząc o wystąpieniu zwiększy swoją prędkość transmisji, co spowoduje jeszcze większe przeciążenie.
Proportional Rate Control Algorithm (PRCA)
[1, 3, 4]
W opisanych powyżej algorytmach FECN i BECN, bazujących na ujemnym sprzężeniu zwrotnym (tzn. źródło zmniejszało swoją prędkość po dostaniu komórki sterującej), występował problem zwiększania się przeciążenia na skutek utraty komórek sterujących. W celu usunięcia tej wady zaproponowano algorytm PRCA, bazujący na dodatnim sprzężeniu zwrotnym. W algorytmie tym, źródło zwiększa prędkość transmisji danych tylko wtedy gdy dostanie komórkę sterującą, jeżeli źródło nie dostanie komórki sterującej to samo zmniejsza prędkość. Zmiana prędkości transmisji jest proporcjonalna do aktualnej prędkości danego źródła.
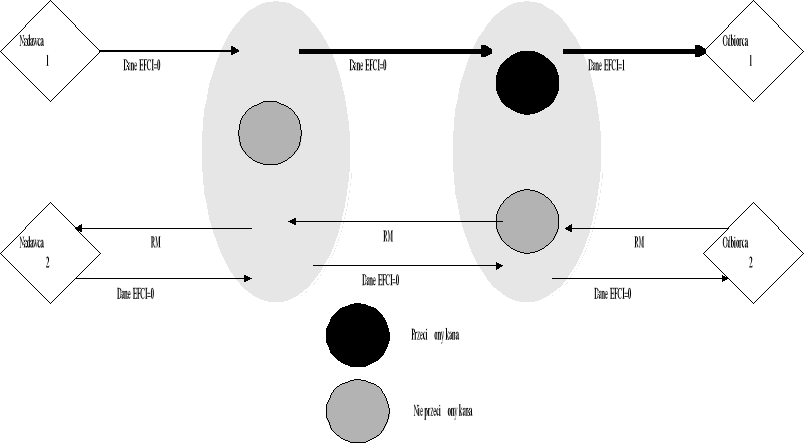
Rysune-k 9 Zasada działania algorytmu PRCA
Zasada działania algorytmu jest następująca: Źródło (nadawca) wysyła wszystkie komórki danych z ustawionym bitem EFCI z wyjątkiem pierwszej i N-tej komórki. Parametr N jest ustalany w początkowej fazie łączenia i wielkość jego wpływa na czas reakcji na przeciążenie. Jeżeli odbiorca odbierze komórkę danych z wyzerowanym bitem EFCI i nie samo przeciążone, to generuje i wysyła komórkę sterującą RM. Źródło zwiększa prędkość transmisji, jeżeli tylko otrzyma komórkę RM od odbiorcy. Przełącznik, który wykryje przeciążenie może ustawić bit EFCI lub usunąć komórkę sterującą RM, wysłaną przez odbiorcę. Źródło zaczyna zmniejszać prędkość transmisji od momentu nie dostania komórki RM, aż do chwili gdy sieć przestanie być przeciążona i źródło dostanie komórkę RM.
Algorytm PRCA rozwiązuje problem występujący w algorytmach BECN i FECN, ale zauważono inny problem, tzn. niesprawiedliwy przedział pasma. Jeżeli, mamy sieć zbudowaną z kilku przełączników i poziom przeciążenia jest taki sam na wszystkich przełącznikach, to kanał wirtualny przechodzący przez większą ilość przełączników ma większe prawdopodobieństwo dostania komórki z ustawionym bitem EFCI (wskazującym na przeciążenie) niż kanał wirtualny przechodzący przez mniejszą ilość przełączników. Jeżeli p jest prawdopodobieństwem ustawienie bitu EFCI przy przejściu przez jeden przełącznik(hop), to prawdopodobieństwo ustawienia EFCI dla kanału wirtualnego VC składającego się z n przełączników wynosi 1-(1-p)n lub np. Tak więc „dłuższy” kanał wirtualny ma mniejszą szansę na zwiększenie prędkości transmisji i częściej musi zmniejszać prędkość niż „krótszy” kanał wirtualny. Problem ten nazwano „beat-down problem” . Rysunek 10 przedstawia konfigurację sieci składającą się z 4 przełączników i 4 kanałów wirtualnych. Przeprowadzone symulacje[3] (Rysunek 11) wykazały, że prędkość transmisji dla kanału 4, zastała zredukowana do zbyt małej wielkości w porównaniu do innych kanałów. Wystąpił więc niesprawiedliwy przedział dostępnego pasma.
Rysunek 10 Konfiguracja testowa dla metody PRCA
Rysunek 11 Symulacja metody PRCA
Enhanced PRCA (EPRCA)
[1, 3, 4, 11]
Omówiony wcześniej algorytm PRCA okazał się zbyt wolny. Sprzężenie zwrotne używane w algorytmie PRCA mówiło tylko o braku wystąpienia przeciążenia i pozwalało na zwiększenie prędkości przez źródło. Ustalanie optymalnej prędkości związane było z koniecznością wysłania kilku komórek zarządzających. Algorytm EPRCA powstał przez połączeni algorytm PRCA i algorytmu typu explicit-rate,(tzn. algorytmu używającego sprzężenia zwrotnego przenoszącego więcej informacji. np. aktualna prędkość, prędkość optymalna). Zasada działania algorytmu jest następująca:
Źródło wysyła wszystkie komórki z danymi, z ustawionym bitem EFCI=0. Komórka zarządzająca RM jest wysyłana co n komórek danych. Komórka RM zawiera aktualną prędkość CCR(current cell rate)), prędkość docelową ER(explicit rate) i bit informujący o przeciążeniu CI (congestion indication). Źródło ustawia wartość ER na swoją maksymalną dozwoloną prędkość PCR(peak cell rate) i ustawia bit CI=0.
Przełącznik oblicza współczynnik fairshare, czyli optymalne pasmo przepustowe dla danego połączenia i jeżeli potrzeba to redukuje wartość ER w powracającej komórce RM do wartości fairshare. Używając ważonej średniej potęgowej obliczamy dozwoloną średnią przepływność bitową MACR (mean allowed cell rate), współczynniki fairshare przyjmuje część wartości obliczonej średniej.
MACR = (1 - α) MACR - αCCR
Fairshare = SW_DPF x MACR
gdzie, α jest współczynnikiem (rzędem) średniej potęgowej, SW_DPF jest mnożnikiem (zwanym współczynnikiem switch down pressure) bliskim, ale poniżej jedności. Sugerowane wartości dla α to 1/16 a dla SW_DPF to 7/8.
Źródło zmniejsza aktualną prędkość nadawania ACR po każdej nadanej komórce:
ACR = ACR x RDF
gdzie, RDF jest współczynnikiem redukcji.
Jeżeli źródło odbierze powrotną komórkę zarządzającą RM (nie mającą ustawionego bitu CI) zwiększa prędkość nadawania:
jeżeli CI = 0 to ACR = min(ACR + AIR, ER, PCR)
gdzie, AIR jest współczynnikiem zwiększenia.
Odbiorca monitoruje także bit EFCI w komórkach danych i jeżeli ostatnio odebrana komórka miała ustawiony ten bit, odbiorca ustawia bit CI w generowanej komórce zarządzającej RM.
Przełącznik oprócz ustawienia prędkości ER może także, jeżeli długość jego kolejki przekroczy ustalony próg ustawić bit CI w powracającej komórce RM.
Target Utilization Band (TUB) Congestion Avoidance Scheme
[1, 4]
TUB jest algorytmem należących do grupy algorytmów zapobiegających stanom przeciążenia. Przedstawiony algorytm utrzymuje stale zajętości pasma na poziomie 85%-90%, nie pozwalając na zbyt dużą transmisję, która spowodowałaby przeciążenie łącza. Zasada działania jest następująca:
Dla każdego przełącznika, definiujemy prędkość wyjściową niewiele poniżej przepustowości łącza wyjściowego ok. 85%-90%. Prędkość wejściowa jest mierzona w określonych, krótkich odcinkach czasu. Liczymy współczynnik wykorzystania pasma (load factor) z.
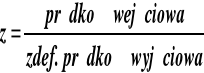
Algorytm rozróżnia dwie sytuacje:
Jeżeli obliczony współczynnik z jest daleki od 1 (tzn. prędkość wyjściowa jest mniejsza lub większa o 10% od zadeklarowanej prędkości wyjściowej), znaczy to, że przełącznik jest albo silnie przeciążony albo jego wykorzystanie jest niewielkie. Wszystkie kanały wirtualne przechodzące przez dany przełącznik są wówczas zmuszone do zmiany swojej prędkości, dzieląc prędkość przez współczynnik z.
![]()
Jeżeli parametr z jest bliski 1, pomiędzy 1-delta i 1+delta dla małej delty, przełącznik generuje różne sprzężenie zwrotne dla każdego kanału wirtualnego, przeładowanego lub nie wykorzystanego.
![]()
Źródła, które transmitują dane z większą prędkością niż obliczony współczynnik fairshare muszą zmniejszyć swoją prędkość dzieląc ją przez z/(1-delta). Źródła, które transmitują dane ze zbyt małą prędkością, zwiększają ją dzieląc ją przez z/(1+delta).
Explicit Rate Indication for Congestion Aviodance (ERICA)
[1, 3, 4]
Algorytm ERICA stara się maksymalnie wykorzystać dostępne pasmo łącza, zachowując jednocześnie sprawiedliwy przedział pasma. Algorytm pozwala źródłom, transmitującym z prędkością równą lub większą z obliczonym współczynnikiem fairshare, na zwiększenie prędkości transmisji w kanale wirtualnym, jeżeli dany kanał wymaga większej przepustowości a łącze nie jest w pełni wykorzystane.
Dla algorytmu tego, definiujemy prędkość wyjściową większą niż dla poprzednio omówionego algorytm, 90-95% przepustowości łącza. Przełącznik oblicza współczynnik fairshare:
![]()
Prędkość, którą dodatkowa źródło może użyć:
![]()
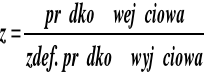
Przełącznik ustawia prędkość źródła na prędkość największą (Fairshare lub Vcshare)
Informacje wykorzystywane przy obliczeniach w algorytmie, dostarczane są komórkami RM z urządzenia nadawczego i odbiorczego.
Zaletą tego algorytmu jest prostota i łatwość przeprowadzanych obliczeń.
Congestion Avoidance Using Proportional Control (CAPC)
[1, 3, 4, 11]
Algorytm został zaproponowany przez Andy Barnhart'a z Hughes Systems. W algorytmie, podobnie jak w ERICA, przełącznik stara się utrzymać współczynnik wykorzystania pasma z blisko jedności. Przełącznik mierzy prędkość wejściową danych, oblicza z i na podstawie tych danych aktualizuje fairshare-maksymalną prędkością z jaką może pracować dany kanał wirtualny.
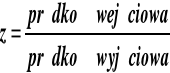
Algorytm rozróżnia dwie sytuacje:
Jeżeli stopień wykorzystania pasma jest mniejszy od zakładanego: z<1, współczynnik fairshare jest zwiększany:
Faishare=Faishare*Min(ERU, 1+(1-z)*Rup),
gdzie Rup jest parametrem pomiędzy (0.0.25 a 0.1), ERU określa maksymalne jednorazowe zwiększenie pasma i standardowo wynosi 1,5.
Jeżeli stopień wykorzystania pasma jest większy od zakładanego: z>1, współczynnik fairshare jest zmniejszany:
Faishare=Faishare*Max(ERF, 1-(1-z)*Rdn),
gdzie Rdn jest parametrem pomiędzy (0.2 a 0.8), ERF określa minimalne jednorazowe zmniejszenie pasma i standardowo wynosi 1,5.
Źródło nie może nigdy transmitować z większą prędkością niż obliczony współczynnik fairshare.
Dodatkowo, oprócz obliczanego współczynnika z, algorytm pozwala na ustawienia progu kolejki w przełączniku. Jeżeli długość kolejki przekroczy ustalony próg, przełącznik ustawia bit wystąpienia przeciążenia CI (Congestion Indication) we wszystkich komórkach zarządzających RM. Zapobiega to przed zwiększaniem prędkości transmisji przez urządzenia nadawcze i pozwala na zmniejszenie długości kolejek w buforze.
Algorytm MIT
[1, 3, 4, 11]
Po raz pierwszy algorytm MIT został zaproponowany przez Anna Charny z Massachusetts Institute of Technology (MIT).
Algorytm ten do obliczenia współczynnika fairshare używa procedury iteracyjnej. Najpierw, współczynnik fairshare obliczany jest poprzez podzielenie dostępnego pasma przepustowego przez ilość aktywnych kanałów wirtualnych. Wszystkie kanały, które transmitują dane z prędkością poniżej obliczonego współczynnika fairshare, są zwane „underloading VC”. Jeżeli liczba kanałów „underloading VC” zwiększa się z iteracją, współczynnik fairshare jest obliczany według wzoru:
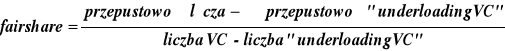
Procedura ta powtarzana jest dopóki nie osiągnie się stanu stabilnego, gdzie liczba "underloading VC” i współczynnik fairshare nie będzie się zmieniał. Anna Charny pokazała w swojej pracy, że zwykle dwie iteracje wystarczą do osiągnięcia zadawalającego rezultatu. Jednak mogą wystąpić sytuacje, dla których obliczenie współczynnika fairshare składać się będzie z n operacji, gdzie n jest liczbą kanałów wirtualnych. Dla przełączników ATM, które obsługują tysiące kanałów wirtualnych, liczba obliczeń koniecznych do wykonania stanie się bardzo duża i nie może być wykonana na dostępnym dzisiaj sprzęcie.
Wybór metody kontroli przeciążenia
[1, 2, 3, 4, 7, 10, 11, 12]
Wybór metod kontroli przeciążenia jest obecnie największym problem organizacji ATM Forum, zajmującej się standaryzacją ATM. Istnieje kilka sprzecznych podejść do kontroli przeciążenia w sieci ATM, które prowadzą do powstawania różnych metod kontroli przeciążenia. Niektóre podejścia po długich rozważaniach zostały zatwierdzone, inne są ciągle dyskutowane i otwarte na nowe rozwiązania. Przedstawię teraz kilka różnych proponowanych podejść do metod kontroli przeciążenia.
algorytm typu credit-based czy typu rate-based?
W idealnych warunkach algorytm typu credit-based gwarantuje zerową stratę komórek na wskutek przeciążenia, podczas którego długość kolejki nie może wzrosnąć powyżej danych kredytów. Metoda typu rate-based nie może zagwarantować straty komórek. Podczas przeciążenia, istnieje możliwość zbyt gwałtownego wzrostu kolejki w buforze i jego przepełnienie, powodując utratę komórek. Algorytm credit-based pozwala także na bardzo szybkie osiągnięcie maksymalnego wykorzystanie pasma przez kanały wirtualne, w odróżnieniu od algorytmów typu rate-based, które potrzebują kilku lub kilkunastu komórek zarządzających do pełnego wykorzystania pasma. Jednak algorytm credit-based wymaga osobnej kolejki (bufora) w przełączniku dla każdego wirtualnego kanału (dotyczy to również nieaktywnych VC), co czyni ten algorytm bardzo skomplikowanym w realizacji.
ATM Forum po długich debatach zaakceptował algorytmy typu rate-based, a odrzucił tymczasowo credit-based. Głównym powodem odrzucenia algorytmu credit-based była konieczność implementacji osobnej kolejki, która okazała się na razie zbyt skomplikowana i droga.
Open-loop czy close-loop
W metodzie typu close-loop nadawca dostosowuje swoją prędkość na podstawie informacji z otrzymanego sprzężenia zwrotnego. Metoda typu open-loop nie potrzebują sprzężenia zwrotnego między nadawcą a odbiorcą, przykładem takiej metody jest rezerwacja.
Metoda typu close-loop jest za wolna w obecnych szybkich sieciach o dużym zasięgu, czas jaki upłynie zanim źródło odbierze sprzężenie zwrotne jest zbyt długi i tysiące komórek może zostać straconych. Z drugiej strony, jeżeli już wystąpi przeciążenie i trwa ono długo, to rozładowanie przeciążenia może nastąpić tylko poprzez wysłanie żądania zmniejszenia prędkości do nadawcy.
Połączenie ABR zostało zaprojektowany w celu maksymalnego wykorzystania pozostałego pasma i źródło nadające w tym połączeniu musi znać stan sieci.
typ sprzężenia zwrotnego
Obecnie stosowane są dwa typy sprzężenia zwrotnego binarny i typu explicit. Binarne sprzężenia zwrotne pozwala nam tylko na poinformowaniu o występowaniu przeciążenia. Używając sprzężenia typu explicit możemy przenieś nim więcej informacji o stanie sieci, które pozwolą na szybszą reakcję na pojawiające i znikające sytuacje przeciążenia.
W większości nowych metod stosowane jest sprzężenia typu explicit, niektóre metody stosują równocześnie dwa typy sprzężenia.
ATM Forum sprecyzował format komórki zarządzającej (sprzężenia zwrotnego) dla ruchu ABR.
wykrywanie przeciążenia: wielkość kolejki czy przyrost kolejki
Wykrywanie przeciążenia w buforach może odbywać się na dwa sposoby:
ustalenie progu w buforze, którego przekroczenie oznacza stan przeciążenia
mierzenie prędkości zapełniania bufora
Ustalenie progu w buforze jest najprostszym sposobem wykrywania przeciążenia, jednak metoda ta nie odzwierciedla faktycznego stanu sieci. Np. kolejka z 1000 komórek nie jest bardziej „przeciążona” niż kolejka z 10 komórkami, jeżeli dane z pierwszej kolejki wychodzą szybciej niż przychodzą, a w drugim przypadku odwrotnie. Mierzenie prędkości zapełniania bufora pozwala nam ocenić aktualny stan sieci oraz przewidzieć późniejsze zmiany.
Porównanie metod kontroli przeciążenia
[1, 3, 10]
W rozdziale tym porównam trzy algorytmy kontroli przeciążenia. W celu porównania algorytmów skorzystam z symulacji przeprowadzonych przez niezależne organizacje. Symulacje zostały przeprowadzone za pomocą własnych pakietów symulacyjnych. Chcąc powtórzyć podobne symulacje lub chcąc rozszerzyć zakres symulacji należałoby albo napisać do tego celu program albo zakupić odpowiedni pakiet symulacyjny. Jednym z takich komercyjnych programów umożliwiających przeprowadzenie symulacji metod kontroli przeciążenia jest pakiet OPNET firmy MIL3. Inne znane dostępne pakiet nie pozwalają na zbyt dużą ingerencję w mechanizmy kontroli przeciążenia.
Do symulacji trzech algorytmów zostanie użyta konfiguracja sieci składająca się z pięciu przełączników i z siedmiu par: nadawca-odbiorca. Odległość pomiędzy dwoma sąsiednimi przełącznikami wynosi 1000km a między przełącznikiem a węzłem sieci 100m. Wszystkie łącza mają przepustowość równą 45Mb/s.
Uwzględniając odległość połączenia w symulacji możemy wyróżnić trzy rodzaj połączeń:
Długodystansowe: połączenie od nadawcy 0 przechodzi przez cztery przełączniki. Połączenie to oznaczymy jaki VC0.
Średniodystansowe: połączenia od nadawcy 1 i 4 składają się z dwóch przełączników. Połączenia oznaczamy odpowiedni VC1 i VC4.
Krótkodystansowe: połączenia od nadawcy 2, 3, 5 i 6 przechodzą tylko przez jeden przełącznik. Połączenia oznaczamy odpowiedni VC2, VC3, VC5 i VC6.
Konfigurację testową przedstawia Rysunek 12.
Symulacja dotyczyć się będzie jednego z ważniejszych aspektów działania algorytmu, tzn. „sprawiedliwego” rozdziału dostępnego pasma pomiędzy poszczególne kanały wirtualne. Używając metody sugerowanej przez ATM Forum możemy obliczyć optymalne teoretyczne pasmo dla każdego połączenia (współczynnik fairshare). Obliczenia te zostały przedstawione w Tabela 3
VC0 |
VC1 |
VC2 |
VC3 |
VC4 |
VC5 |
VC6 |
3.75 |
3.75 |
7.5 |
3.75 |
3.75 |
7.5 |
11.25 |
Tabela 3 Oczekiwane pasma przepustowe dla każdego połączenia w Mb/s
Symulacje zostały przeprowadzone dla dwóch parametrów ICR (initial cell rate), czyli początkowej prędkości nadawania, równych PCR i PCR/20.
Rysunek 12. Testowa konfiguracja sieci
Algorytm CAPC
Dla wszystkich urządzeń nadawczych startujących z parametrem ICR=PCR/20 osiągnięto prawie idealne wyniki. Wszystkie kanały wirtualne mające podobną drogę połączenia otrzymały prawie takie samo pasmo przepustowe. Dostępne pasmo zostało sprawiedliwie rozdzielone, jedynie można zauważyć krótkotrwały okres nieustalony.
Jednak dla parametru startowego ICR=PCR, zauważono błąd w algorytmie. Podczas długiego przeciążenia spowodowanego ustawieniem parametrów początkowych, przełączniki kilkukrotnie redukowały pasmo przepustowe dla poszczególnych kanałów, współczynnik fairshare osiągnął w końcu wartość 0. Wartość współczynnika fairshare pozostała równe 0 nawet kiedy wszystkie kanały przestały nadawać. Wyniki testów przedstawione zostały w tabeli Tabela 4 i na rysunku 13.
Rysunek 13. Średnia przepustowość uzyskana dla algorytmu CAPC
VC0 |
VC1 |
VC2 |
VC3 |
VC4 |
VC5 |
VC6 |
3.5 |
3.6 |
7.2 |
3.6 |
3.6 |
7.2 |
10.8 |
Tabela 4 Osiągnięte pasmo przepustowe dla połączeń w algorytmu CAPC
Algorytm ERPCA
Algorytm ERPCA do obliczenia optymalnego pasma przepustowego dla każdego połączenia używa informacji zawartych w odbieranych komórkach RM. Algorytm ten jest najprostszym z symulowanych algorytmów. Symulacja wykazała, że w porównaniu do algorytmu CAPC, osiągającego stabilny i ustalony stan w krótkim odcinku czasy, osiągnięta przepustowość dla danego połączenia jest niestabilna i silnie oscyluje wokół optymalnej przepustowości. Zmieniając współczynniki algorytmu można uzyskać różną charakterystykę przepustowości. Dla większego parametru α możemy osiągnąć szybką reakcję na stan sieci, ale kosztem większej oscylacji przepustowości. Dla małego parametru α możemy osiągnąć stabilizację przepustowości, ale kosztem dłuższego stanu nieustalonego. Wyniki osiągnięte w symulacji przedstawia Tabela 5 i Rysunek 15.
VC0 |
VC1 |
VC2 |
VC3 |
VC4 |
VC5 |
VC6 |
3.3 |
3.7 |
7 |
3.7 |
4 |
7.6 |
11.6 |
Tabela 5 Osiągnięte pasma przepustowe dla połączeń w algorytmie ERPCA
Rysunek 14. Średnia przepustowość uzyskana dla algorytmu EPRCA
Algorytm MIT
Algorytm MIT jest najbardziej skomplikowanym algorytmem, wymagającym wielu obliczeń. Obliczenia te jednak nie są skomplikowane i nie wprowadzają zbyt dużego obciążenia obliczeniowego.
Rezultatem wprowadzenia większej ilości obliczeń jest osiągnięta stabilność, bardzo dobre wykorzystanie całego dostępnego pasma i „sprawiedliwe” jego rozdzielenie pomiędzy wszystkie kanały wirtualne.
Wyniki osiągnięte w symulacji przedstawia Tabela 1 i Rysunek 15.
VC0 |
VC1 |
VC2 |
VC3 |
VC4 |
VC5 |
VC6 |
3.4 |
3.6 |
7.3 |
3.9 |
3.7 |
7.5 |
11.2 |
Tabela 6 Osiągnięte pasma przepustowe dla połączeń w algorytmie MIT
Rysunek 15. Średnia przepustowość uzyskana dla algorytmu MIT
Podsumowanie
Algorytmy kontroli przeciążenia powinny się cechować: skalowalnością, optymalnością, odpornością i implementowalnością. Z opisów algorytmów i analizy symulacji wynika, że żaden z przedstawionych algorytmów nie spełnia w pełni wszystkich cech. Żaden algorytm ze względu na brak niektórych standardów nie może być implementowany jednocześnie w sieciach lokalnych i rozległych. W bardzo szybkich nowopowstających sieciach rozległych ATM algorytmy typu rate-based są zbyt wolne i nie nadążają czasami za gwałtownymi zmianami stanów sieci. Algorytmy typu credit-based pozbawione tej wady, ze względu na konieczność implementacji osobnych kolejek dla każdego kanału wirtualnego w przełącznikach są obecnie zbyt skomplikowane technologicznie aby mogły być wdrożone. ATM Forum wstrzymała z tego powodu pracę nad algorytmami credit-based i zajęła się udoskonalaniem algorytmów typu rate-based.
Algorytmy bazujące na bitowym sprzężeniu zwrotnym okazały się zbyt wolne, a brak informacji w sprzężeniu zwrotnym na temat stanu sieci (dostępne pasmo, prędkość transmisji) nie umożliwia efektywnej kontroli ruchem. Algorytmy te także w niektórych specyficznych konfiguracja nie sprawiedliwie rozdzielały dostępne pasmo, faworyzując niektórych użytkowników. Najlepszymi do tej pory okazały się algorytmy: CAPC, ERPCA i MIT. Jednak algorytmy te nie są także idealnymi metodami kontroli przeciążenia. Wszystkie trzy algorytmy sprawiedliwie rozdzielają dostępne pasmo. Algorytm CAPC nie rodził sobie z długotrwałym, początkowym przeciążeniem, powodując zatrzymanie transmisji. Algorytm ERPCA, jeden z najprostszych algorytmów, cechował się dość dużymi oscylacjami przydzielanego pasma i nie osiągał stabilizacji takiej jak pozostałe algorytmy. Najlepszym algorytmem okazał się algorytm MIT, który „najsprawiedliwiej” rozdzielił pasmo przepustowe, osiągną szybko stabilizację prędkości ruchu dla poszczególnych użytkowników. Algorytm ten wymaga prostych obliczeń dla każdego kanału wirtualnego, co w przypadku konfiguracji testowej składającej się z 7 kanałów wirtualnych nie stanowiło problem. Jednak w rzeczywistych warunkach przełącznik obsługuje jednocześnie tysiące kanałów wirtualnych, ilość nieskomplikowanych obliczeń i czas w jakim mają być wykonane wówczas rośnie na tyle, że przekraczają one obecnie moc dostępnych procesorów mogących być zastosowanych w przełącznikach.
Jak widać nie istnieje jeszcze „idealny” algorytm kontroli przeciążeniem. Prace nad niektórymi słabszymi algorytmami zostały wstrzymane, najlepsze algorytmy są w ciągłej fazie udoskonaleń i testów.
Organizacje standaryzacyjne muszą wybrać jeden najlepszy algorytm albo też zdecydować się na kilka algorytmów i starać się zapewnić kompatybilność pomiędzy poszczególnymi algorytmami. Jest to trudny wybór, którego organizacjom do tej pory nie udało się dokonać. Problem przeciążenia jeszcze długo będzie tematem otwartym, czekającym na nowe, lepsze rozwiązania.
Niniejsza praca stanowi próbę przedstawienia problemu przeciążenia i analizy dostępnych metod jego rozwiązania. Posiadając odpowiedni pakiet symulacyjny można kontynuować rozpoczętą pracę nad problemem przeciążenia, np. wybierając jeden z algorytmów, spróbować optymalizować jego parametry a nawet starać się modyfikować algorytm, likwidując jego wady. Badania takie dałyby ogromną wiedzę nie tylko na temat problemu przeciążenia, ale także na temat całej technologii ATM.
Bibliografia
Raj Jain, „Congestion Control And Traffic Management In ATM Netowrks: Recent Advances and A Survey”
Raj Jain, “Congestion Control in Computer Networks: Issue and Trends”
Kai-Yeung Siu, Hong-Yi Tzeng: “Intelligent Congestion Control for ABR Service in ATM Networks”
Fang Lu, “ATM Congestion Control”
Krzysztof Wajda, „Sieci szerokopasmowe”
NETFORUM 5/97, Mariusz Przygodzki: Usługi multimedialne w sieciach ATM
ATM Forum Technical Committee: Traffic Management Specification Version 4.0
NETWORLD Wydanie Specjalne: Vademecum Teleinformatyka cz.2
ATM Forum, „ATM User-Network Interface Specification Version 3.1”
Lampros Kalampoukas, „Congestion Management in High Speed Networks”
Dorgham Sisalem, Henning Schulzrine, „Switch Mechanisms for the ABR Service: A comparison Study”
Raj Jain, „Myths About Congestion Management in High-Speed Networks”
NETWORLD, „Szybkie sieci teleinformatyczne”
NETWORLD Wydanie Specjalne, „Mała encyklopedia teleinformatyki”
T. D. Banys, M. Bednarski, „ATM”
Raj Jain, Shiv Kalyanaraman and Ram Viswanathan: The OSU Scheme for Congestion Avoidance in ATM Networks Using Explicit Rate Indication
United States Patent (Number 5633859): Method and Apparatus for congestion management in computer networks using explicit rate indication
Raj Jain, Shiv Kalyanaraman, Rohit Goyal,Sonia Fahmy, Fang Lu:ERICA+: Extensions to the ERICA Switch Algorithm
Shivkumar Kalyanaraman, Raj Jain, Sonia Fahmy, Rohit Goyal, and Bobby Vandalore, "The ERICA Switch Algorithm for ABR Traffic Management in ATM Networks,"
Anna Charny, David D. Clark, Raj Jain, "Congestion Control with Explicit Rate Indication,"
"The OSU Scheme for Congestion Avoidance using Explicit Rate Indication," ATM Forum/94-0883, September 1994.
Raj Jain, Shiv Kalyanaraman and Ram Viswanathan, " Simulation Results: The EPRCA+ Scheme"
Raj Jain, Shiv Kalyanaraman, Ram Viswanathan, and Rohit Goyal, ATM Forum/95-0178R1, A Sample Switch Algorithm, February 1995,
5
Wyszukiwarka
Podobne podstrony:
PROTOKOŁY WARSTWY SIECIOWEJ, informatyka, sieci komputerowe
Silnik skokowy sterowany komputerem
mowa do sterowania komputerem osobistym
Algorytm Procesu Uruchomena Komputera, Systemy operacyjne
Algorytm Procesu Uruchomienia Komputera w DOS, Informatyka, DOS
Zdalne sterowanie komputerem bez użycia Internetu
Oprogramowanie do sterowania komputerem poprzez Sieć
( =Twoje KABELKI opisy kabli gniazd i połączeń = Zdalne sterowanie komputera PC za pomoca dowolnego
OKLADKA Roznorodne algorytmy obliczen i ich komputerowe realizacje indd Roznorodne algorytmy i ich
2003 02 Zasilacz sterowany komputerowo
22 Gecow, Algorytmy ewolucyjne i genetyczne, ewolucja sieci zlozonych i modele regulacji genowej a m
3 Warstwa dostepu do sieci Ethernet
Radiowe sterowanie wylacznikami w sieci elektroenergetycznej
Algorytm optymalny i algorytm RPT
dr inż Jarosław Michalski, Sterowniki programowalne i sieci przemysłowe, Komunikacja szeregowa ET200
2.3.1 Używanie warstw do analizy problemów związanych z przepływem informacji, 2.3 Modele działania
więcej podobnych podstron