Kodowanie liczb całkowitych
współczesne procesory mogą wykonywać działania na różnych rodzajach danych, jak liczby, znaki, ciągi zerojedynkowe, ale z punktu widzenia analizy funkcjonowania procesora najważniejsze są liczby całkowite; dokumentacja procesora, a ściślej opisy dostępnych rozkazów są bowiem przedstawione przy założeniu, że działania arytmetyczne będą wykonywane na liczbach całkowitych; odrębne zagadnienie stanowią liczby zmiennoprzecinkowe, które będą omawiane później;
nie oznacza to, że rozkazy nie mogą wykonywać działań na ułamkach czy liczbach mieszanych, ale programista musi przedtem przekształcić algorytm obliczeń w taki sposób, ażeby działania na ułamkach zostały zastąpione przez działania na liczbach całkowitych;
w wielu współczesnych procesorach, w tym w procesorze Pentium, wyróżnia się liczby całkowite bez znaku i liczby całkowite ze znakiem, kodowane zwykle w kodzie U2;
w przypadku liczb bez znaku stosowany jest naturalny kod binarny, a wartość liczby określa formuła
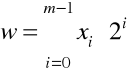
gdzie m oznacza liczbę bitów rejestru lub komórki pamięci;
Przykłady
Liczba dziesiętna |
Reprezentacja binarna jako liczby bez znaku |
|
253 |
8-bit. |
1111 1101 |
|
16-bit. |
0000 0000 1111 1101 |
|
32-bit. |
0000 0000 0000 0000 0000 0000 1111 1101 |
45 708 |
16-bit. |
1011 0010 1000 1100 |
|
32-bit. |
0000 0000 0000 0000 1011 0010 1000 1100 |
2007360447 |
32-bit. |
0111 0111 1010 0101 1110 0011 1011 1111 |
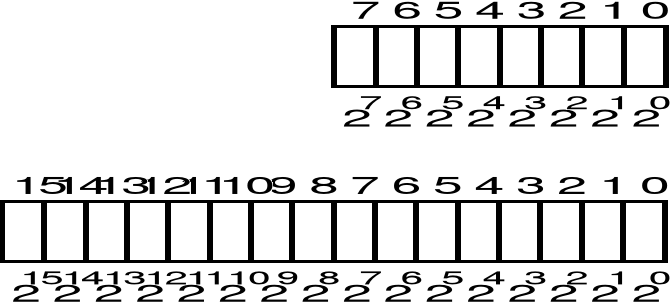
Zakresy liczb:liczby 8-bitowe: <0, 255>liczby 16-bitowe <0, 65535>liczby 32-bitowe <0, 4 294 967 295>
liczby 64-bitowe <0, 18 446 744 073 709 551 615>
(osiemnaście trylionów
czterysta czterdzieści sześć biliardów
siedemset czterdzieści cztery biliony
siedemdziesiąt trzy miliardy
siedemset dziewięć milionów
pięćset pięćdziesiąt jeden tysięcy
sześćset piętnaście)
1 trylion = 1018
w przypadku liczb ze znakiem, kodowanych w systemie U2, wartość liczby określa formuła
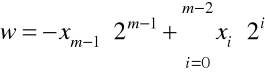
gdzie m oznacza liczbę bitów rejestru lub komórki pamięci.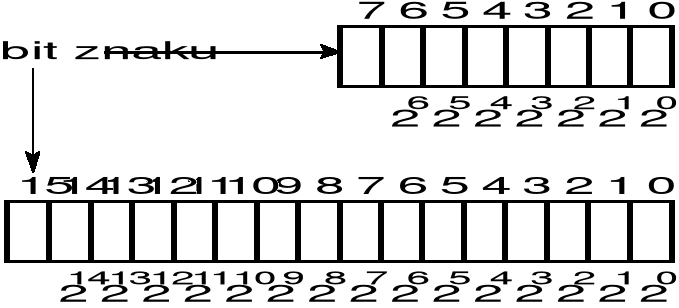
Przykłady
Liczba dziesiętna |
Reprezentacja binarna jako liczby ze znakiem w kodzie U2 |
|
−3 |
8-bit. |
1111 1101 |
|
16-bit. |
1111 1111 1111 1101 |
|
32-bit. |
1111 1111 1111 1111 1111 1111 1111 1101 |
-19828 |
16-bit. |
1011 0010 1000 1100 |
|
32-bit. |
1111 1111 1111 1111 1011 0010 1000 1100 |
2007360447 |
32-bit. |
0111 0111 1010 0101 1110 0011 1011 1111 |
Zakresy liczb w systemie U2:liczby 8-bitowe: <128, +127>liczby 16-bitowe <32768, +32767>liczby 32-bitowe <2 147 483 648, +2 147 483 647>liczby 64-bitowe<9 223 372 036 854 775 808, +9 223 372 036 854 775 807>
Przechowywanie liczb w pamięci komputera
liczby występujące w programach często przekraczają 255 i muszą być zapisywane na dwóch, czterech lub na większej liczbie bajtów;
w produkowanych obecnie procesorach stosuje się dwa podstawowe schematy rozmieszczenia poszczególnych bajtów liczby w pamięci: mniejsze niżej (ang. little endian) i mniejsze wyżej (ang. big endian); sposoby te wyjaśnia poniższy rysunek;
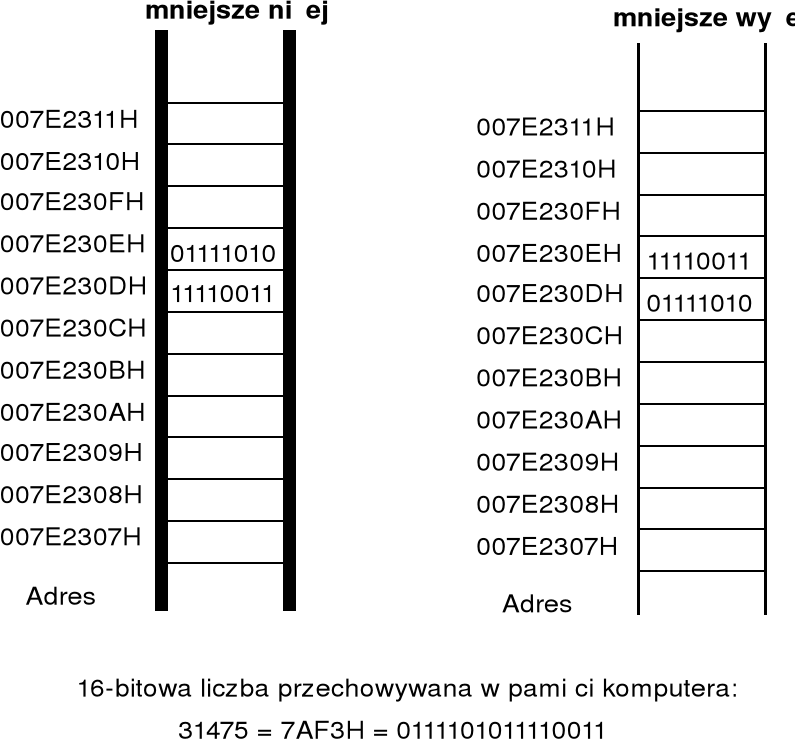
do konwersji liczby zapisanej w formacie mniejsze niżej na format mniejsze wyżej (i odwrotnie) można zastosować instrukcję BSWAP, której argumentem jest rejestr 32-bitowy; sposób działania instrukcji wyjaśnia poniższy rysunek;
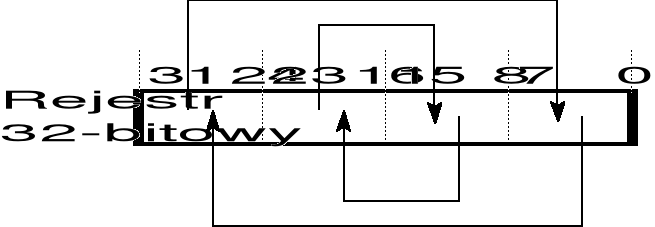
przykładowo, po wykonaniu instrukcji
mov ebx, 12345678H
bswap ebx
rejestr EBX zawierać będzie liczbę 78563412H.
Wprowadzenie do programowania
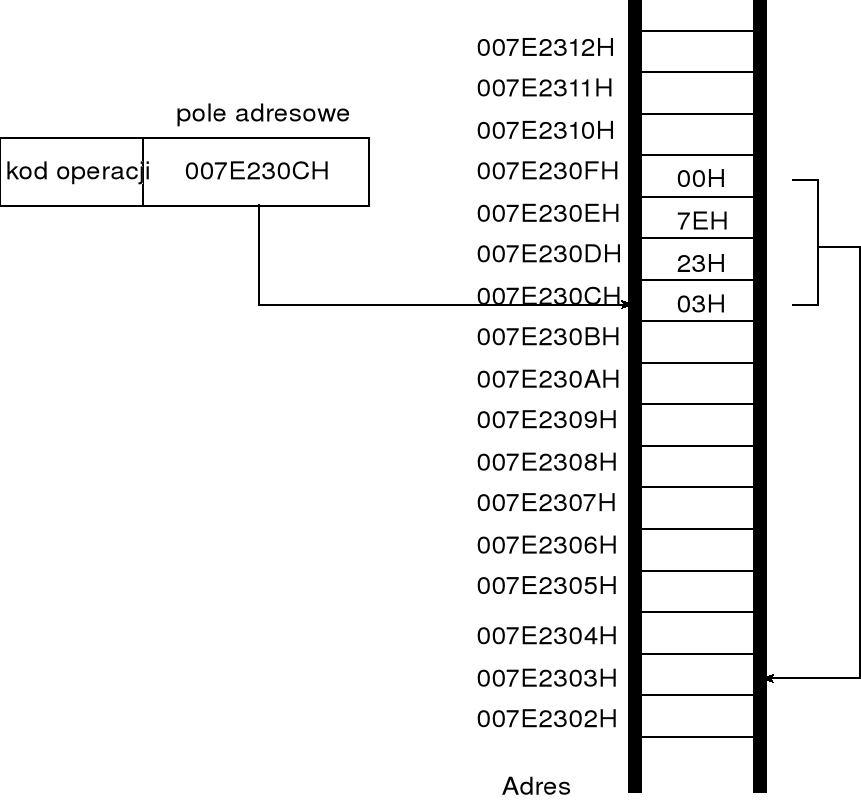
przypuśćmy, że w pamięci głównej (operacyjnej) komputera, począwszy od adresu fizycznego 72308H, znajduje się tablica zawierająca pięć liczb 16-bitowych całkowitych bez znaku; tablica ta stanowi część obszaru danych programu, który zaczyna się od adresu fizycznego 720A0H;
spróbujmy napisać fragment programu, który przeprowadzi sumowanie liczb zawartej w tej tablicy;
dla uproszczenia problemu przyjmiemy, że program wykonywany będzie w trybie 16-bitowym; przyjmiemy również, że w trakcie sumowania wszystkie wyniki pośrednie dadzą się przedstawić w postaci liczby binarnej co najwyżej 16-bitowej — innymi słowy w trakcie sumowania na pewno nie wystąpi przepełnienie (nadmiar);
w procesorach o architekturze segmentowej wszelkie operacje wykonywane na danych znajdujących się w pamięci głównej (operacyjnej) muszą być poprzedzone wpisaniem do rejestru segmentowego adresu wskazującego początek obszaru danych;
w omawianym zadaniu obszar danych programu zaczyna się od adresu fizycznego 720A0H; ponieważ w trakcie wszelkich operacji na danych znajdujących się pamięci operacyjnej (w trybie rzeczywistym) zawartość rejestru segmentowego jest mnożona razy 16, więc do rejestru segmentowego należy wpisać liczbę 720A0H / 16 = 720AH;
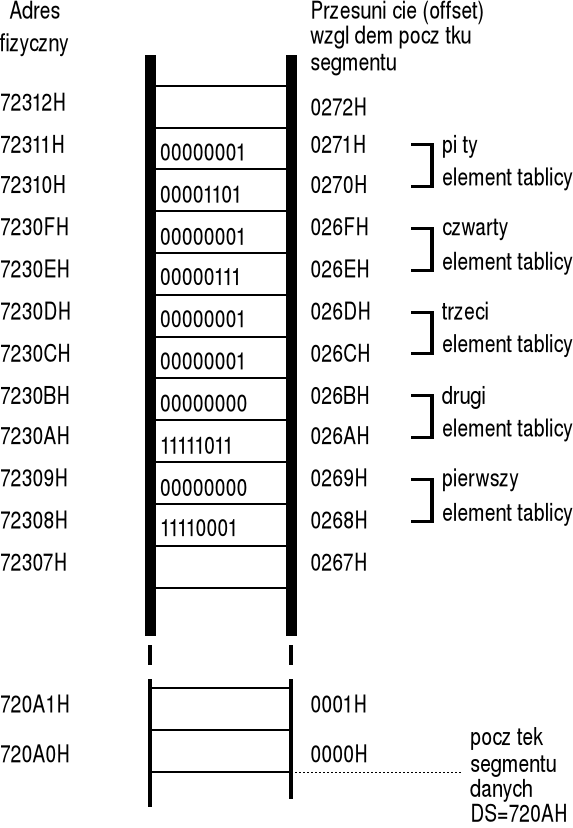
procesor przyjmuje, że obszar danych programu wskazuje rejestr segmentowy DS, do którego powinna zostać wpisana liczba 720AH, co symbolicznie można zapisać w niżej podany sposób:
DS 720AH
lista instrukcji procesora zawiera rozmaite instrukcje przesyłania danych, oznaczone skrótem (mnemonikiem) MOV, wśród których istnieją także instrukcje umożliwiające wpisanie podanej liczby do rejestru;
jednakże zmiany zawartości rejestrów segmentowych następują w programie stosunkowo rzadko, i z tego powodu konstruktorzy procesora ograniczyli zestaw operacji dotyczących rejestrów segmentowych: dostępne rozkazy umożliwiają wpisanie do rejestru segmentowego zawartości innego rejestru ogólnego przeznaczenia lub zawartości lokacji pamięci;
w tej sytuacji wpisanie liczby do rejestru DS wymaga pośrednictwa innego rejestru 16-bitowego, np. BX, co można zapisać symbolicznie
DS BX 720AH
realizacja podanej operacji wymaga więc użycia dwóch instrukcji przesyłania MOV — w zapisie asemblerowym wygląda to tak
mov bx, 720AH
mov ds, bx
łatwo zauważyć, że w zapisie rozkazu (instrukcji) przesyłania pierwszy argument określa cel, czyli "dokąd przesłać", drugi zaś określa źródło, czyli "skąd przesłać" lub "co przesłać":
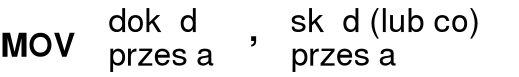
w omawianym tu fragmencie programu mnemonik operacji przesłania zapisywany jest małymi literami (mov), podczas w opisach używa się zwykle wielkich liter (MOV) — obie formy są równoważne;
rozkaz (instrukcja) przesłania MOV jest jednym z najprostszych w grupie rozkazów niesterujących — jego zadaniem jest skopiowanie zawartości podanej komórki pamięci lub rejestru do innego rejestru; w programach napisanych w asemblerze dla procesora Pentium rozkaz przesłania MOV ma dwa argumenty rozdzielone przecinkami;
w wielu rozkazach drugim argumentem może być liczba, która ma zostać przesłana do pierwszego argumentu — tego rodzaju rozkazy określa się jako przesłania z argumentami bezpośrednimi., np.
MOV CX, 7305
przypomnijmy, że rozkazy (instrukcje) niesterujące nie zmieniają naturalnego porządku wykonywania rozkazów, tzn. że po wykonaniu takiego rozkazu procesor rozpoczyna wykonywanie kolejnego rozkazu, przylegającego w pamięci do rozkazu właśnie zakończonego;
rozkazy niesterujące wykonują podstawowe operacje jak przesłania, działania arytmetyczne na liczbach (dodawanie, odejmowanie, mnożenie, dzielenie), operacje logiczne na bitach (suma logiczna, iloczyn logiczny), operacje przesunięcia bitów w lewo i w prawo, i wiele innych;
argumenty rozkazów wykonujących operacje dodawania ADD i odejmowania SUB zapisuje się podobnie jak argumenty rozkazu MOV

podane tu rozkazy dodawania i odejmowania mogą być stosowane zarówno do liczb bez znaku, jak i liczb ze znakiem (formaty liczb omawiane będą w dalszej części wykładu);
podane dwa rozkazy (instrukcje) muszą być oczywiście przekształcone na ciągi zerojedynkowe, zrozumiałe przez procesor
10111011 00001010 01110010 (mov bx, 720AH)
10001110 11011011 (mov ds, bx)
przekształcenie takie wykonywane jest przez asembler — zasady kodowania w asemblerze omawiane będą w dalszej części wykładu;
po załadowaniu rejestru DS położenia poszczególnych elementów tablicy wskazywane będą przez ich odległości od adresu bazowego wskazywanego przez DS — ilustruje to poniższy rysunek
operacje sumowania zapiszemy najpierw w postaci symbolicznej
AX ds:[0268H]
AX AX + ds:[026AH]
AX AX + ds:[026CH]
AX AX + ds:[026EH]
AX AX + ds:[0270H]
równoważny kod asemblerowy ma postać
mov ax, ds:[0268H]
add ax, ds:[026AH]
add ax, ds:[026CH]
add ax, ds:[026EH]
add ax, ds:[0270H]
do sumowania używany jest rozkaz ADD, który przeprowadza sumowanie dwóch wartości wskazanych przez pierwszy i drugi operand, a wynik wpisywany jest do pierwszego operandu; zatem rozkaz
add cel, źródło
wykonuje dodawanie
cel cel + źródło
operandy cel i źródło mogą wskazywać na rejestry lub lokacje pamięci, jednak tylko jeden operand może wskazywać lokację pamięci;
adres lokacji pamięci zapisany w postaci ds:[026EH] wskazuje, że adres fizyczny tej lokacji powinien zostać obliczony na podstawie zawartości rejestru DS, tj. DS 16 + 026EH;
omawiane operacje w postaci zrozumiałej dla procesora wyglądają tak:
10100001 01101000 00000010 (mov ax, ds:[0268H])
00000011 00000110 01101010 00000010 (add ax, ds:[026AH])
00000011 00000110 01101100 00000010 (add ax, ds:[026CH])
00000011 00000110 01101110 00000010 (add ax, ds:[026EH])
00000011 00000110 01110000 00000010 (add ax, ds:[0270H])
Przykład obliczania wyrażenia arytmetycznego
nieco inne zasady dotyczą rozkazów mnożenia i dzielenia; w tej grupie rozkazów położenie mnożnej lub dzielnej jest określone na stałe; podobnie wynik mnożenia lub dzielenia wpisywany jest zawsze do ustalonych rejestrów; zatem w przypadku rozkazu mnożenia MUL wystarczy tylko podać mnożnik, a w przypadku dzielenia DIV tylko dzielnik;

położenie argumentów i wyników rozkazów mnożenia i dzielenia podano w tablicach; rozkazy MUL i DIV stosuje się w operacjach na liczbach bez znaku, a rozkazy IMUL i IDIV w operacjach na liczbach ze znakiem; symbol DX:AX oznacza rejestr 32-bitowy, którego starszą część stanowi rejestr DX, a młodszą część rejestr AX, analogicznie EDX:EAX;
Rozkazy mnożenia MUL i IMUL |
mnożna |
mnożnik |
iloczyn |
mnożenie liczb 8-bitowych |
AL |
podany w polu operandu |
AX |
mnożenie liczb 16-bitowych |
AX |
|
DX:AX |
mnożenie liczb 32-bitowych |
EAX |
|
EDX:EAX |
Rozkazy dzielenia DIV i IDIV |
dzielna |
dzielnik |
iloraz |
reszta |
dzielenie liczby 16-bitowej przez 8-bitową |
AX |
podany w polu operandu |
AL |
AH |
dzielenie liczby 32-bitowej przez 16-bitową |
DX:AX |
|
AX |
DX |
dzielenie liczby 64-bitowej przez 32-bitową |
EDX:EAX |
|
EAX |
EDX |
przykład obliczania wartości wyrażenia arytmetycznego
![]()
założymy, że 16-bitowe zmienne a i b przyjmują wartości całkowite nieujemne i wcześniej zostały wpisane do rejestrów SI i DI;
ADD SI, DI ; dodawanie SI ← SI + DI
ADD SI, 7 ; dodawanie SI ← SI + 7
MOV AX, SI ; przesłanie AX ← SI
SUB DI, 1 ; odejmowanie DI ← DI - 1
MUL SI ; mnożenie DX:AX ← AX ∗ SI
po pomnożeniu 32-bitowy wynik wpisywany jest do rejestrów DX:AX.
Modyfikacje adresowe
podany w poprzedniej części sposób sumowania elementów tablicy jest bardzo niewygodny, zwłaszcza jeśli ilość sumowanych liczb jest duża;
powtarzające się obliczenia wygodnie jest realizować w postaci pętli, ale wymaga to korekcji adresu instrukcji dodawania — w każdym obiegu pętli adres lokacji pamięci wskazujący dodawaną liczbę powinien być zwiększany o 2;
przedstawione problemy rozwiązuje się poprzez stosowanie modyfikacji adresowych — adres lokacji pamięci, na której wykonywane jest działanie określony jest nie tylko poprzez pole adresowe instrukcji, ale zależy również od zawartości jednego lub dwóch wskazanych rejestrów;
w procesorze Pentium dostępne są rozbudowane mechanizmy modyfikacji adresowych:
modyfikatorami mogą być 16-bitowe rejestry ogólnego przeznaczenia: BX, SI, DI, BP, a także ich pary: (BX, SI), (BX, DI), (BP, SI), (BP, DI);
modyfikatorami mogą być dowolne 32-bitowe rejestry ogólnego przeznaczenia: EAX, EBX, ECX, EDX, ESI, EDI, EBP, ESP;
może również wystąpić drugi rejestr modyfikacji spośród ww. wymienionych, z wyłączeniem rejestru ESP;
drugi rejestr modyfikacji może być skojarzony z tzw. współczynnikiem skali, który podawany jest w postaci 1, 2, 4, 8 — podana liczba wskazuje przez ile zostanie pomnożona zawartość drugiego rejestru modyfikacji podczas obliczania adresu;
mechanizmy modyfikacji z użyciem rejestrów 32-bitowych ilustruje poniższy rysunek;
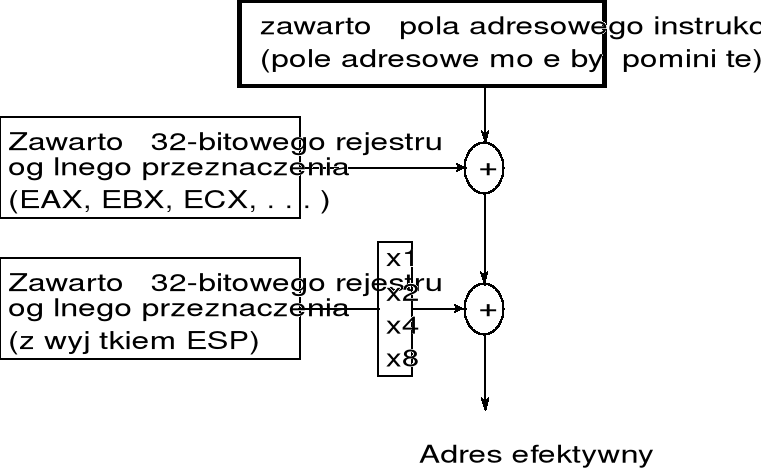
adres efektywny, nazywany również adresem wirtualnym, wskazuje położenie lokacji pamięci względem początku segmentu; na podstawie adresu efektywnego i zawartości rejestru segmentowego procesor oblicza adres fizyczny;
adres efektywny w trybie 32-bitowym obliczany jest modulo 232, tzn. bierze się pod uwagę 32 najmłodsze bity uzyskanej sumy; analogicznie adres efektywny w trybie 16-bitowym obliczany jest modulo 216;
przykładowo, adres efektywny poniższego rozkazu
sub eax, ds:[123H][edx][ecx4]
zostanie jako obliczony jako suma:
liczby 123H,
zawartości rejestru EDX,
zawartości rejestru ECX pomnożonej przez 4;
w literaturze zawartość pierwszego rejestru modyfikacji nazywana jest adresem bazowym, a drugiego adresem indeksowym;
obliczanie adresu efektywnego w trybie 32- i 16-bitowym wg reguły modulo 232 i 216 pozwala uzyskiwać adresy efektywne mniejsze niż zawartość rejestru modyfikacji — odpowiednio duże liczby umieszczone w polu adresowym działają tak liczby ujemne; ilustruje to poniższy przykład (tryb 16-bitowy):
instrukcja mov ....,[bx] + FFFCH
|
|
|
|
. . . |
. . . |
FC |
FF |
rejestr BX |
|
03A9 |
|
adres efektywny powyższej instrukcji MOV wynosi 03A5H i jest mniejszy niż zawartość rejestru BX;
niekiedy pole adresowe instrukcji jest całkowicie pominięte, a wartość adresu określona jest wyłącznie poprzez wskazane rejestry modyfikacji; takie rozwiązanie jest:
niezbędne, jeśli adres lokacji pamięci zostaje obliczony dopiero w trakcie wykonywania programu (nie jest znany ani w trakcie kodowania programu przez programistę ani też podczas translacji) — dotyczy to często kodu generowanego przez kompilatory języków wysokiego poziomu;
szczególnie korzystne w przypadku wielokrotnego odwoływania się do tej samej lokacji pamięci — ponieważ pole adresowe nie występuje, więc instrukcja może być zapisana na mniejszej liczbie bajtów (zwykle 2 bajty);
modyfikacja adresowa z użyciem rejestrów BP lub EBP działa trochę inaczej; rejestry te zostały bowiem zaprojektowane do wspomagania operacji przekazywania parametrów do procedur za pośrednictwem stosu — z tego względu użycie ww. rejestrów jako modyfikatorów powoduje, że procesor będzie używał domyślnego rejestru segmentowego SS a nie DS, co oznacza że operacja zostanie wykonana na danych zawartych w segmencie stosu;
w programach asemblerowych, modyfikację adresową deklaruje się poprzez podanie w polu adresowym rozkazu nazwy rejestru w nawiasie kwadratowym;
na poziomie asemblera podane schematy obliczenia adresu efektywnego z wykorzystaniem modyfikacji adresowych koduje się poprzez podanie nazw rejestrów modyfikacji w nawiasach kwadratowych, np. [bx]; oznacza to, że adres wynikowy (efektywny) rozkazu stanowi sumę liczby umieszczonej w polu adresowym rozkazu i zawartości rejestru modyfikacji adresowej (tu: BX); tego rodzaju operandy instrukcji nazywane są operandami modyfikacji adresowych; przykłady:
mov dh, [ebx]
mov [ecx], esi
mov al, [bx]
sub [bx][di], ax
; zapisy w dwóch poniższych wierszach są równoważne
mov bx, [eax] [edx2]
mov bx, [eax + edx2]
w operandach modyfikacji adresowych mogą także występować nazwy zmiennych i tablic, jak również pewne wartości stałe, np.
mov ax, tablica [ebx+ecx4+14]
posługując się modyfikacją adresową, omawiany wcześniej fragment programu obliczający sumę liczb można zakodować w formie pętli rozkazowej; w kolejnych obiegach pętli adres rozkazu dodawania ADD powinien zwiększać się o 2 — można to łatwo zrealizować poprzez uzależnienie adresu rozkazu od zawartości rejestru modyfikacji adresowej BX;
ponieważ w kolejnych obiegach pętli rejestr BX będzie zawierał liczby 0, 2, 4, ..., więc kolejne adresy efektywne rozkazu ADD, które stanowią sumę pola adresowego (tu: 0268H) i zawartości rejestru BX, będą wynosiły:
0268H, 026AH, 026CH, 026EH, 0270H
tak więc w każdym obiegu pętli do zawartości rejestru AX dodawane będą kolejne elementy tablicy liczb;
mov bx, 720AH
mov ds, bx ; ładowanie rejestru DS
mov cx, 0 ; licznik obiegów pętli
mov ax, 0 ; początkowa wartość sumy
mov bx, 0 ; początkowa zawartość rejestru
; modyfikacji adresowej
ptl_suma:
add ax, ds:[0268H][bx] ; dodanie kolejnego
; elementu tablicy
add bx, 2 ; zwiększenie modyfikatora
loop ptl_suma ; sterowanie pętlą
instrukcja loop stanowi typowy sposób sterowania pętlą: powoduje ona odjęcie 1 od zawartości rejestru CX, i jeśli wynik odejmowania jest różny od zera, to sterowanie przenoszone do instrukcji poprzedzonej podaną etykietą, a przeciwym razie następuje przejście do następnego rozkazu; ponieważ początkowa zawartość rejestru CX wynosiła 5, więc rozkazy wchodzące w skład pętli zostaną powtórzone 5 razy;
rozpatrując rozkaz LOOP jako rozkaz sterujący (skokowy) można powiedzieć, że warunek testowany przez rozkaz jest spełniony, jeśli po odjęciu 1 zawartość rejestru CX jest różna od zera — wówczas następuje skok, który polega na dodaniu do rejestru IP liczby umieszczonej w polu adresu rozkazu LOOP i zwiększeniu IP o 2 (liczba bajtów rozkazu LOOP); jeśli warunek nie jest spełniony, to IP zostaje zwiększony o 2;
modyfikatorami mogą być też rejestry 32-bitowe:
mov bx, 720AH
mov ds, bx
mov cx, 5 ; licznik obiegów pętli
mov ax, 0 ; początkowa wartość sumy
mov ebx, 0268H ; adres początku tablicy
mov edx, 0 ; indeks kolejnego elementu
ptl_suma:
add ax, ds:[ebx+edx2] ; dodanie kolejnego
; elementu tablicy
inc dx
loop ptl_suma ; sterowanie pętlą
Adresowanie pośrednie
omawiane dotychczas rodzaje modyfikacji adresowych polegały na dodawaniu (sumowaniu) zawartości rejestrów modyfikacji z polem adresowym rozkazu; w innych typach procesorów występuje również modyfikacja pośrednia, polegająca na wskazaniu komórki pamięci, w której znajduje potrzebny adres — ilustruje to poniższy rysunek;
w procesorze Pentium adresowanie pośrednie stosowane jest w instrukcjach sterujących (skokowych).
Zasady kodowania w asemblerze
kodowanie programu w asemblerze powinno pozwalać na zapisywanie algorytmów za pomocą pojedynczych instrukcji procesora; także definiowanie danych powinno być realizowane na poziomie pojedynczych bajtów lub słów;
asembler posiada rozmaite środki ułatwiające taki sposób kodowania programu;
najbardziej charakterystycznym elementem asemblera jest możliwość zapisu instrukcji w formie skrótów literowych zwanych mnemonikami;
struktura segmentowa programu w asemblerze stanowi odbicie architektury segmentowej procesorów Pentium;
jeden lub kilka segmentów tworzy moduł, który stanowi jednostkę poddawaną samodzielnej asemblacji;
program składa się z jednego lub kilku modułów; niektóre moduły mogą być kodowane w innych językach programowania.
Formaty wierszy źródłowych
uzup: |
mov |
cx, 78 |
; licznik obiegów |
nazwa wiersza (etykieta) |
akcja, którą należy wykonać |
operandy (określają obiekty, na których zostanie wykonana akcja) |
komentarz |
jeśli w zapisie instrukcji występują dwa operandy, to przyjmuje się, że wynik operacji zostanie wpisany do pierwszego operandu, np.
sub ecx, eax ; obliczenie ECX ECX EAX
var2 |
db |
23 |
; prędkość |
nazwa zmiennej |
dyrektywa |
operand |
komentarz |
num1 |
EQU |
18H |
; wartość max |
nazwa stałej |
dyrektywa |
operand |
komentarz |
Etykiety i zmienne w programie asemblerowym
w pamięci głównej (operacyjnej) przechowywane są instrukcje (rozkazy) i dane programu; instrukcje (rozkazy) programu wykonują działania na danych zawartych w rejestrach i lokacjach pamięci; poszczególne instrukcje i dane zajmują jeden lub więcej bajtów;
w programie asemblerowym niektóre obszary pamięci opatrywane są nazwami:
jeśli nazwa odnosi się do obszaru zawierającego instrukcję (rozkaz) programu, to nazwa taka stanowi etykietę,
jeśli obszar zawiera zmienną (daną), to nazwa obszaru stanowi nazwę zmiennej;
nazwę w sensie asemblera tworzy ciąg liter, cyfr i znaków ? (znak zapytania), @ (symbol at), _ (znak podkreślenia), $ (znak dolara); nazwa nie może zaczynać się od cyfry;
etykietę, wraz ze znakiem : (dwukropka), umieszcza się przed instrukcją, np.
powtorz: mov dl, [ecx]
taka konstrukcja oznacza, że obszar kilku bajtów pamięci, w których przechowywany jest kod podanej instrukcji mov dl, [ecx] ma swoją unikatową nazwę, czyli etykietę; w trakcie asemblacji programu etykiecie przypisywana jest wartość równa odległości pierwszego bajtu obszaru (liczonej w bajtach) od początku segmentu kodu;
zmienne w programie deklaruje się za pomocą dyrektyw:
DB - definiowanie bajtu (8 bitów),
DW - definiowanie słowa (16 bitów),
DD - definiowanie słowa podwójnej długości (32 bity),
DF - definiowanie 6 bajtów (48 bitów);
DQ - definiowanie słowa poczwórnej długości (64 bity),
DT - definiowanie 10 bajtów (80 bitów).
po lewej stronie dyrektywy podaje się nazwę zmiennej, a po prawej wartość początkową; znak zapytania (?) oznacza, że wartość początkowa zmiennej jest nieokreślona; nazwę zmiennej można pominąć; przykłady:
kcal DB 169
linia7a DQ ?
DW 19331
elem_sygn DD 18B706H
alfa dw 4567H, 5678H, 6789H
nazwy zmiennych mogą występować w polu operandu instrukcji — operandy tego rodzaju nazywa się operandami relokowalnymi, ponieważ położenie zmiennych nie jest ustalone podczas kodowania programu, np.:
xor ebx, elem_sygn
add si, alfa [bx]+2
w asemblerze przyjęto, że nazwa zmiennej występująca w polu operandu rozkazu (podobnie jak nazwa rejestru) oznacza, że działanie ma być wykonane na zawartości tej zmiennej;
w trakcie asemblacji nazwie każdej zmiennej przypisywana jest wartość równa odległości (liczonej w bajtach) pierwszego bajtu tej zmiennej od początku segmentu danych; jeszcze raz podkreślamy: omawiana wartość nie jest wartością zmiennej, ale jest przypisywana nazwie zmiennej i określa położenie zmiennej w pamięci;
w polu operandu dyrektywy DB mogą występować także łańcuchy znaków, np.
DB 'Politechnika Gdańska', 0DH, 0AH
jeśli tekst nie mieści się w jednym wierszu (który może zawierać co najwyżej 128 znaków), to można kontynuować w następnym wierszach, za każdym razem poprzedzając go dyrektywą DB;
jeśli podane wartości są liczbami całkowitymi, to asembler tworzy ich reprezentacje binarne przyjmując, że najmniej znaczący bit ma wagę 20 ; liczby dziesiętne poprzedzone znakiem + i liczby bez znaku traktowane są jednakowo: zamiana na kod binarny wykonywana jest przy założeniu, że wszystkie bity w bajcie, w słowie, itd. są bitami znaczącymi (nie występuje bit znaku); dla liczb ujemnych stosuje się kod U2, przy czym przyjmuje się, że bit znaku zajmuje skrajną lewą pozycji bajtu, słowa, itd.; w szczególności oznacza to, że wiersze
DB 128
DB +128
generują takie same kody binarne 10000000;
należy zwracać uwagę na dopuszczalne zakresy zmienności argumentów podanych dyrektyw:
Dyrektywa |
liczby bez znaku |
liczby ze znakiem |
DB |
<0, 255> |
<128, 127> |
DW |
<0, 65535> |
< 32768, 32767> |
DD |
<0, 4294967295> |
<2147483648, 2147483647> |
DF |
<0, 2481> |
<247 , 2471> |
DQ |
<0, 2641> |
<263 , 2631> |
DT |
<0, 2801> |
<279 , 2791> |
w polu operandu omawianych dyrektyw mogą występować zarówno pojedyncze liczby jak i ciągi liczb rozdzielonych przecinkami; jeśli ciąg składa się z jednakowych elementów, to można zastosować operator powtarzania DUP, np. wiersz:
sumy DW 5432H, 5432H, 5432H, 5432H, 5432H
można zapisać w krótszej postaci równoważnej:
sumy DW 5 DUP (5432H)
operator DUP generuje wskazaną ilość elementów podanych w nawiasie — stanowi więc wygodny sposób tworzenia tablic; w nawiasie można także umieścić znak zapytania (?) oznaczający element o nieokreślonej wartości początkowej, co pozwala na tworzenie tablic złożonych z elementów o nieokreślonej wartości początkowej, np.
tabl_wynikow dd 24 dup (?)
za pomocą operatora powtarzania DUP definiuje się zwykle obszar segmentu stosu, np.
stos_pom SEGMENT stack
DW 128 DUP (?)
stos_pom ENDS
powyższy fragment programu opisuje segment stosu zawierający 256 bajtów o nieokreślonej wartości początkowej;
liczby z kropką oddzielającą część ułamkową mogą występować jako operandy dyrektyw DD, DQ, DT - liczby takie są przekształcane na postać zmiennoprzecinkową binarną, i jeśli w programie użyto dyrektywy '.8087', '.287' lub '.387', to format zmiennoprzecinkowy jest zgodny z formatem akceptowanym przez koprocesor arytmetyczny, np.:
c_Eulera DT 0.577215 ; stała Eulera
— — — — — — — — — — — — — — —
fld c_Eulera ; załadowanie stałej Eulera ; na stos koprocesora
Rozmiary operandów
instrukcje procesora Pentium wykonują działania na bajtach (8 bitów), słowach (16-bitów), podwójnych słowach (32-bity), obiektach 48-, 64- i 80-bitowych; jeśli instrukcja wymaga podania dwóch operandów, to prawie zawsze muszą być one jednakowej długości, np.:
sub ecx, edi ; obliczenie ECX ECX EDI
add eax, dx ; błąd !!! — dodawanie zawartości
; rej. 16-bitowego do 32-bitowego
wyjątkowo, jeśli jeden z operandów znajduje się w pamięci, to możliwa jest doraźna zmiana rozmiaru (typu) zmiennej za pomocą operatora PTR, np.
blok_sys dd ? ; zmienna 32-bitowa
— — — — — — — — —
mov cx, word PTR blok_sys
mov dx, word PTR blok_sys+2
w powyższym przykładzie do rejestru CX zostanie wpisana młodsza część 32-bitowej zmiennej blok_sys, a rejestru DX starsza część tej zmiennej; w przypadku pominięcia operatora PTR sygnalizowany byłby błąd asemblacji wynikający z niejednakowej długości obu operandów;
ogólnie: operator PTR używany jest w wyrażeniach adresowych do ścisłego określania atrybutów symbolu występującego w wyrażeniu adresowym; po prawej stronie operatora występuje wyrażenie adresowe, a po lewej atrybut spośród następujących: byte (8 bitów), word (16 bitów), dword (32 bity), fword (48 bitów), qword (64 bity), tword (80 bitów);
operator PTR stosuje się także w przypadkach, gdy wyrażenie adresowe nie pozwala na jednoznaczne przetłumaczenie instrukcji, np. poniższa instrukcja stanowi tzw, odwołanie anonimowe (nie zawiera nazwy zmiennej)
mov [bx], 65
operandy instrukcji nie precyzują czy liczba 65 ma zostać zapisana w pamięci jako liczba 8-bitowa, 16-bitowa czy 32-bitowa — zamiast podanej wyżej instrukcji programista musi wyraźnie określić rozmiar liczby podając jedną z trzech poniższych instrukcji
mov byte PTR [bx], 65
mov word PTR [bx], 65
mov dword PTR [bx], 65
operator PTR stosuje się także przy określaniu adresów instrukcji sterujących (skoków);
reguła dotycząca jednakowej długości operandów nie obowiązuje w odniesieniu do rozkazów MOVSX i MOVZX; rozkazy powodują przepisanie zawartości 8- lub 16-bitowego rejestru (lub zawartości lokacji pamięci) do rejestru 16- lub 32-bitowego; w przypadku rozkazu MOVZX brakujące bity w rejestrze docelowym uzupełniane są zerami, zaś w przypadku MOVSX bity te są wypełniane przez wielokrotnie powielony bit znaku kopiowanego rejestru; przykłady
liczba_proc db 145 ; zmienna 8-bitowa
— — — — — — — — —
movzx edx, liczba_proc
movsx edx, bh
rozkaz MOVSX stosuje się do kopiowania liczb ze znakiem — po zwiększeniu ilości bitów liczby, jej wartość pozostaje niezmieniona.
Operatory OFFSET i SEG w asemblerze
w praktyce programowania posługujemy się zarówno zawartościami pewnych obszarów pamięci, jak też i ich adresami;
bezpośrednie podawanie adresów obszarów pamięci, w których znajdują się instrukcje i dane jest wprawdzie możliwe, ale nie jest zalecane w programowaniu w asemblerze; programy z ustalonymi adresami są mało podatne na zmiany; z tego względu wybór położenia zmiennej lub instrukcji pozostawiamy asemblerowi; ustalanie położenia zmiennych i instrukcji jest możliwe za pomocą operatorów SEG i OFFSET;
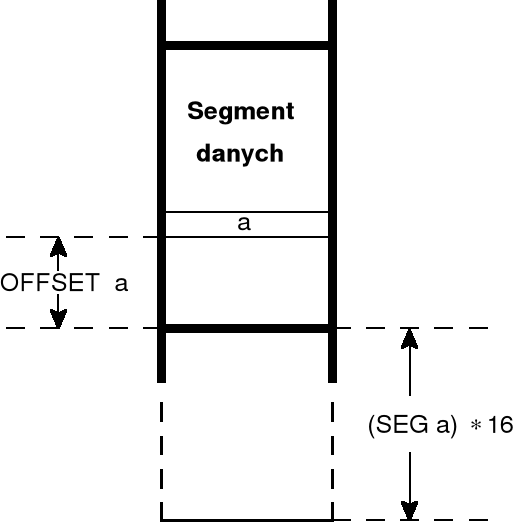
położenie zmiennej lub instrukcji w programie można jednoznacznie określić poprzez podanie adresu fizycznego — dla procesorów Pentium pracujących w trybie rzeczywistym adres fizyczny zawiera 20 bitów;
w praktyce programowania zamiast adresu fizycznego zmiennej lub instrukcji podaje się adres segmentu, w którym ta zmienna (lub instrukcja) została zdefiniowana oraz jej położenie wewnątrz segmentu;
adres segmentu podaje operator SEG w formie liczby 16-bitowej, stanowiącej 16 bardziej znaczących bitów adresu fizycznego segmentu — przyjęto, że brakujące 4 bity z prawej strony zawierają zawsze zera; zatem adres fizyczny segmentu można wyznaczyć przez pomnożenie przez 16 wartości zwracanej przez operator SEG; w praktyce programowania posługujemy się wyłącznie 16-bitowymi adresami segmentów mając na uwadze ww. założenia;
położenie zmiennej (lub instrukcji) wewnątrz segmentu określa się poprzez podanie odległości, liczonej we bajtach, zmiennej od początku segmentu — odległość ta nazywana jest przesunięciem lub offsetem i można ją wyznaczyć za pomocą operatora OFFSET; tak więc dla podanej zmiennej lub etykiety operator OFFSET wyznacza jej położenie, liczone w bajtach, względem początku segmentu, w którym została zdefiniowana (położenie to można odszukać w sprawozdaniu z kompilacji zawartym w pliku .LST);
zastosowanie operatorów SEG i OFFSET wyjaśnia poniższy przykład:
parametry SEGMENT
moc_czynna dw 800
parametry ENDS
— — — — — — — — — — — —
mov ax, SEG parametry
mov ds, ax
mov bx, OFFSET moc_czynna
add word PTR ds:[bx], 75 ; dodanie 75
add ds:moc_czynna, 75 ; dodanie 75
wskutek wykonania dwóch instrukcji oznaczonych zmienna moc_czynna zostanie zwiększona o 75 — taki sam skutek ma wykonanie instrukcji oznaczonej ;
operand zawierający operator OFFSET traktowany jest jako liczba znana już w trakcie kompilacji;
położenie pewnej lokacji pamięci względem początku segmentu można także wyznaczyć za pomocą instrukcji (rozkazu) LEA — podana wyżej sekwencja może być zastąpiona przez sekwencję równoważną:
lea bx, moc_czynna
add word PTR ds:[bx], 75 ; dodanie 75
instrukcja LEA wyznacza adres efektywny rozkazu, czyli położenie lokacji pamięci (względem początku segmentu), na której zostanie wykonana operacja;
instrukcja LEA wyznacza adres efektywny w trakcie wykonywania programu, podczas gdy wartość operatora OFFSET obliczana jest w trakcie translacji programu;
rzeczywiste położenie programu (i wszystkich zawartych w nim segmentów) w pamięci operacyjnej znane będzie dopiero w chwili ładowania tego programu do pamięci, bezpośrednio przed rozpoczęciem jego wykonywania — z tego powodu, w trakcie translacji programu, wartość operatora SEG obliczana jest tak jak gdyby program miał zostać umieszczony w pamięci operacyjnej począwszy od komórki 0; ostateczna korekcja fragmentów programu, w których użyto operatora SEG wykonywana jest przez system operacyjny bezpośrednio przed rozpoczęciem wykonywania programu;
zawartości rejestrów segmentowych CS i SS są zazwyczaj ustawiane przez system operacyjny bezpośrednio przed rozpoczęciem wykonywania programu; rejestry DS, ES, FS i GS, jeśli są używane, to muszą być zainicjalizowane przez program (dyrektywa ASSUME nie ładuje rejestrów segmentowych); typowa sekwencja ładowania rejestru segmentowego wygląda następująco (wpisanie liczby wymaga pośrednictwa innego rejestru roboczego):
mov ax, SEG zm
mov ds,ax
argumentem operatora SEG może być nazwa segmentu, etykiety lub zmiennej;
asembler dopuszcza pominięcie słowa SEG, jeśli argumentem operatora jest nazwa segmentu - wówczas operator SEG występuje w postaci niejawnej; pominięcie operatora SEG zazwyczaj utrudnia analizę programu.
Przedrostek chwilowej zmiany segmentu
w procesorze Pentium (i w poprzednikach) przyjęto, że instrukcje programu umieszczone są w segmencie kodu, którego początek wskazuje rejestr CS (w trybie chronionym segmenty wskazywane za pośrednictwem tablicy deskryptorów), dane umieszczone są w segmencie wskazywanym przez rejestr DS, a stos wskazuje rejestr SS;
powyższe ustalenia mogą być w pewnym zakresie zmienione doraźnie, w odniesieniu do pojedynczej instrukcji, za pomocą dodatkowego bajtu zwanego przedrostkiem chwilowej zmiany segmentu; obowiązują tu następujące reguły:
instrukcje pobierane są zawsze z segmentu kodu wskazywanego przez rejestr CS;
dane przesyłane są z/do segmentu danych wskazywanego przez rejestr DS; poprzedzenie instrukcji przedrostkiem chwilowej zmiany segmentu umożliwia przesyłanie danych z segmentów wskazywanych przez inne rejestry: CS, ES, FS, GS, SS;
operacje stosu (np. PUSH) wykonywane są zawsze w segmencie wskazywanym przez rejestr SS;
jeśli do obliczenia adresu efektywnego instrukcji używany jest rejestr (E)BP, to operacja wykonywana jest na segmencie stosu; wprowadzenie przedrostka chwilowej zmiany umożliwia użycie innego rejestru segmentowego;
Rejestr |
CS |
DS |
ES |
FS |
GS |
SS |
Kod binarny |
00101110 |
00111110 |
00100110 |
01100100 |
01100101 |
00110110 |
Kod szesnastk. |
2EH |
3EH |
26H |
64H |
65H |
36H |
na poziomie asemblera przedrostek chwilowej zmiany segmentu podawany w postaci nazwy rejestru segmentowego wraz z dwukropkiem, np.
sub edx, cs:wynik
dyrektywa asemblera ASSUME jest ściśle związana z przedrostkiem chwilowej zmiany segmentu; dyrektywa ta uwalnia programistę od konieczności wpisywania przedrostka chwilowej zmiany segmentu w zapisie instrukcji odwołujących się do lokacji pamięci; na podstawie informacji podanych w tej dyrektywie asembler automatycznie generuje bajty przedrostków wszędzie tam gdzie jest konieczne;
dyrektywa ASSUME wiąże segmenty programu i rejestry segmentowe, tj. dla każdego segmentu wymienionego na liście tej dyrektywy podaje nazwę rejestru segmentowego (CS, DS, ES, FS, GS, SS), którego zawartość wskazuje początek tego segmentu;
związki opisane za pomocą dyrektywy ASSUME mają charakter obietnicy: dyrektywa ASSUME podaje przewidywane użycie rejestrów segmentowych (sama dyrektywa nie wpływa jednak w żaden sposób na ich zawartość);
wpisanie odpowiednich wartości do rejestrów segmentowych, zgodnie z obietnicą podaną w dyrektywie ASSUME, realizuje się za pomocą konwencjonalnych rozkazów; początkowe zawartości rejestrów CS i SS ustawiane są przez system operacyjny bezpośrednio przed uruchomieniem programu;
dyrektywa ASSUME ma postać
ASSUME CS:<nazwa_seg>, DS:<nazwa_seg>, SS:<nazwa_seg>
ASSUME ES:<nazwa_seg>, FS:<nazwa_seg>, GS:<nazwa_seg>
gdzie <nazwa_seg> oznacza nazwę segmentu (nazwa segmentu musi być zdefiniowana wcześniej za pomocą dyrektywy SEGMENT);
zamiast nazwy segmentu można podać słowo nothing, co oznacza anulowanie związku określonego przez poprzednią dyrektywę ASSUME; przykład:
ASSUME CS:rozkazy, DS:nothing, ES:tablica
ze względu na specyficzny sposób dostępu do danych umieszczonych na stosie, zazwyczaj w dyrektywie ASSUME pomija się segment stosu i rejestr SS;
dyrektywa
ASSUME nothing
anuluje wszystkie dotychczas określone związki;
segment programu może być jednocześnie związany z kilkoma rejestrami segmentowymi;
rejestr segmentowy może być związany z co najwyżej jednym segmentem programu (ten warunek spełniony jest automatycznie, ponieważ każda kolejna dyrektywa ASSUME dotycząca pewnego rejestru segmentowego anuluje związek określony przez poprzednią dyrektywę);
zmiana zawartości rejestru segmentowego musi być poprzedzona odpowiednio zaktualizowaną dyrektywą ASSUME;
niektóre asemblery pozwalają na pominięcie dyrektywy ASSUME przyjmując wówczas ustalenia domyślne; w zasadzie jednak w programie powinna wystąpić dyrektywa ASSUME określająca połączenie przynajmniej dla rejestru CS i segmentu zawierającego rozkazy; połączenia innych segmentów i rejestrów można określić w tej samej dyrektywie albo w innych, umieszczonych w dalszej części programu.
Przykład
wyn_pomiar SEGMENT use16
t_stop db 'Stop'
tabl db 120 dup (?)
wyn_pomiar ENDS
analiza SEGMENT use16
ASSUME CS:analiza, ES:wyn_pomiar
mov ax, SEG wyn_pomiar
mov es,ax
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
mov dh, tabl [bx]
mov dh, es : tabl [bx]
mov dh, wyn_pomiar : tabl [bx]
powyższe trzy instrukcje MOV, mimo różnic w zapisie wyrażenia adresowego, będą przetłumaczone na identyczny kod maszynowy;
kod binarny instrukcji, generowany przez kompilator, zostanie poprzedzony dodatkowym bajtem - przedrostkiem chwilowej zmiany rejestru segmentowego ES;
w przypadku, gdyby podana wyżej dyrektywa ASSUME nie zawierałaby części dotyczącej rejestru ES, to poprawny byłby jedynie drugi rozkaz mov, podczas gdy dwa pozostałe nie zostałyby zaakceptowane przez kompilator — kompilator nie wiedziałby jaki rejestr segmentowy zostanie użyty do przesłania danych z obszaru tabl.
Dyrektywa INCLUDE
niekiedy znaczna cześć programu w asemblerze zawiera fragmenty zaczerpnięte z bibliotek źródłowych, uprzednio starannie przetestowane przez autorów i nie wymagające uwagi programisty; takie fragmenty warto umieścić w odrębnym pliku, który będzie automatycznie odczytywany w trakcie asemblacji, jeśli tylko w programie zostanie umieszczona dyrektywa INCLUDE;
dyrektywa INCLUDE wskazuje plik, którego treść powinna zostać poddana asemblacji, tak jak gdyby była umieszczona w pliku źródłowym;
przykład: dyrektywa
INCLUDE korekcja.inc
powoduje, że asembler przerwie tłumaczenie wierszy źródłowych zawartych w bieżącym pliku, przetłumaczy wszystkie wiersze zawarte w pliku korekcja.inc, po czym powróci do tłumaczenia dalszych wierszy pobieranych z pliku bieżącego;
nazwa pliku może być poprzedzona ścieżką dostępu.
Asemblacja programów
w procesie translacji programu zakodowanego w asemblerze wyróżnia się asemblację, konsolidację (linkowanie) i ładowanie; w językach wysokiego translacja przebiega podobnie, przy czym zamiast asemblacji stosowana jest kompilacja;
w istocie zarówno asemblacja jak i kompilacja mają na celu przekształcenie kodu źródłowego programu na ciąg instrukcji procesora, aczkolwiek uzyskany ciąg (zawarty w pliku z rozszerzeniem .OBJ) wymaga jeszcze dalszych przekształceń, które wykonywane są w trakcie konsolidacji i ładowania;
asemblacja realizowana jest dwuprzebiegowo: w każdym przebiegu czytany jest cały plik źródłowy (ściśle: moduł) od początku do końca;
w pierwszym przebiegu asembler stara się wyznaczyć ilości bajtów zajmowane przez poszczególne instrukcje i dane; jednocześnie asembler rejestruje w słowniku symboli wszystkie pojawiające się definicje symboli (zmiennych i etykiet);
w drugim przebiegu asembler tworzy kompletną wersję przetłumaczonego programu określając adresy wszystkich instrukcji w oparciu o informacje zawarte w słowniku symboli;
w procesie asemblacji programów istotną rolę odgrywa rejestr programowy (tj. definiowany przez asembler), zwany licznikiem lokacji;
licznik lokacji określa lokację w pamięci operacyjnej, do której zostanie przesłany aktualnie tłumaczony rozkaz lub dana; po załadowaniu rozkazu lub danej, licznik lokacji zostaje zwiększony o ilość bajtów zajmowanych przez ten rozkaz lub daną;
w asemblerach dla procesorów Pentium licznik lokacji nie wskazuje adresu fizycznego ładowanej lokacji, lecz jedynie jej położenie względem początku segmentu; w trakcie tłumaczenia pierwszego wiersza segmentu licznik lokacji zawiera 0; w wyrażeniach adresowych licznik lokacji reprezentowany jest przez symbol $;
jeśli asembler napotka wiersz zawierający definicję symbolu, to rejestruje go w słowniku symboli, jednocześnie przypisując temu symbolowi wartość równą aktualnej zawartości licznika lokacji; ponadto zapisywane są także atrybuty symbolu, jak np. far, byte, itp.
Organizacja stosu
w praktyce programowania występują wielokrotnie sytuacje, w których konieczne jest tymczasowe przechowanie zawartości rejestru — zazwyczaj rejestrów ogólnego przeznaczenia jest zbyt mało by przechowywać w nich wszystkie wyniki pośrednie występujące w trakcie obliczeń;
w takich sytuacjach, za pomocą instrukcji MOV, można zapisać zawartości rejestrów we wskazanych lokacjach pamięci operacyjnej; jednak jest zwykle dość niepraktyczne, ponieważ przechowywanie potrzebne jest tylko przez krótki odcinek czasu, natomiast lokacja pamięci musi być rezerwowana na cały czas wykonywania programu;
istnieją jeszcze inne powody, dla których w procesorach wprowadzono mechanizmy organizujące przechowywanie danych w postaci stosu;
stos stanowi pewien obszar pamięci operacyjnej, w którym możliwy jest zapis danych podobny do układania książek na stosie — każdy kolejny zapis "przykrywa" poprzedni;
stos stanowi liniową strukturę danych, dostępną do zapisywania i odczytywania tylko z jednego końca; stos klasyfikowany jest jako struktura danych typu LIFO (ang. Last In, First Out);
ze względu na przechowywanie innych typów danych stos zazwyczaj rośnie w kierunku malejących adresów ("wbrew prawom grawitacji");
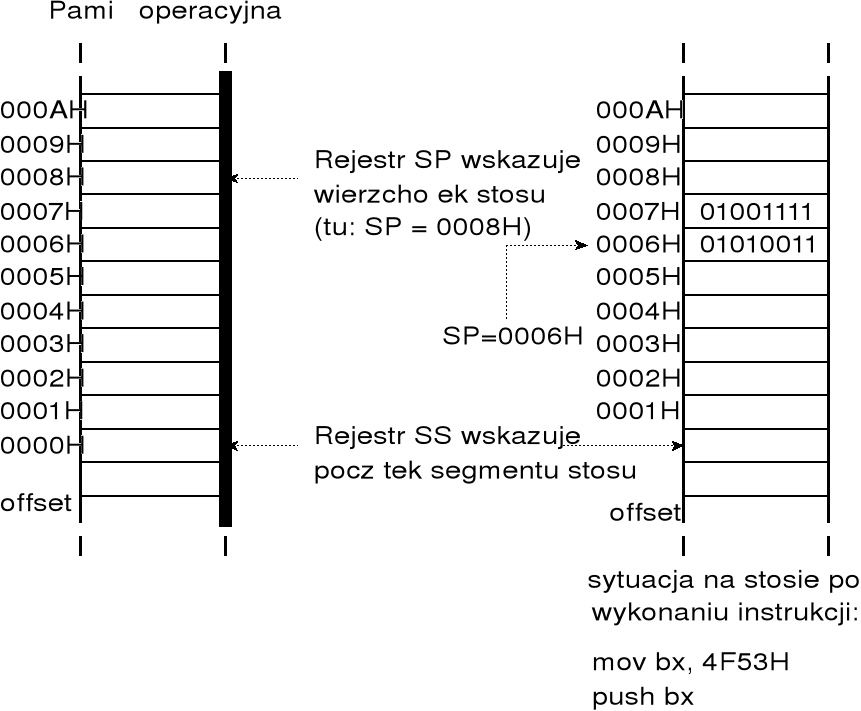
w procesorach Pentium początek obszaru pamięci zajmowanego przez stos wskazuje rejestr segmentowy SS; wskaźnik stosu ESP (lub SP w trybie 16-bitowym) określa położenie wierzchołka stosu, tj. położenie ostatnio zapisanej danej;
zdefiniowano dwie podstawowe operacje stosu:
zapis wykonywany za pomocą instrukcji PUSH, np.
push bx
push edi
odczyt wykonywany za pomocą instrukcji POP, np.
pop edi
pop bx
rejestr ESP (SP) wskazuje wierzchołek stosu, czyli obszar 4- lub 2-bajtowy, w którym przechowywana jest ostatnio zapisana dana; na stosie mogą być zapisywane wyłącznie wartości 16- i 32-bitowe; zatem instrukcja push dh jest błędna!
instrukcja PUSH powoduje zmniejszenie zawartości rejestru ESP o 4 (lub w trybie 16-bitowym SP o 2), a następnie zapisanie wskazanego rejestru do lokacji pamięci wskazanej przez rejestr ESP (SP) licząc od początku segmentu stosu; wartość zapisywana na stosie może znajdować się w rejestrze, a także we wskazanej lokacji pamięci — w tym przypadku instrukcja PUSH wykonuje przesłanie w obrębie pamięci operacyjnej; argumentem instrukcji PUSH może być takze wartość liczbowa;
instrukcja POP powoduje odczytanie zawartości lokacji pamięci wskazanej przez rejestr ESP (SP) licząc od początku segmentu stosu i przesłanie tej zawartości do wskazanego rejestru (lub do lokacji pamieci); nastepnie zawartość rejestru ESP zostaje zwiększona o 4 (lub w trybie 16-bitowym SP o 2);
dodatkową zaletą przechowywania danych na stosie jest krótszy kod instrukcji — zapisanie we wskazanej lokacji pamięci za pomocą instrukcji MOV wymaga podania adresu lokacji pamięci i symbolu (kodu) zapisywanego rejestru; zapisywanie na stosie wymaga podania tylko symbolu zapisywanego rejestru (położenie zapisywanej informacji określa rejestr ESP);
Instrukcje sterujące (skoki) bezwarunkowe
instrukcje sterujące bezwarunkowe zmieniają porządek wykonywania instrukcji, przyjmując że testowany warunek jest zawsze spełniony;
(E)IP (E)IP + <liczba bajtów aktualnie wykonywanej instrukcji>
+ <zawartość pola adresowego instrukcji>
w procesorze Pentium używany jest mnemonik JMP dla różnych typów skoku bezwarunkowego; skoki typu dalekiego (FAR) są obecnie rzadko używane; przykład:
jmp dalej
stosowane są skoki bezpośrednie, jeśli wartość wpisywana (albo dodawana) do rejestru (E)IP podana jest w polu adresowym instrukcji, a także skoki pośrednie, jeśli wartość podana w polu adresowym wskazuje rejestr lub lokację pamięci, w której znajduje się nowa zawartość (E)IP i ewentualnie CS;
przykłady:
jmp bx
jmp dword PTR ds:wybor
Wywołanie i powrót z podprogramu
wywołanie podprogramu realizuje się za pomocą rozszerzonej instrukcji skoku — konieczne jest bowiem zapamiętanie adresu powrotu, zwanego śladem, tj. miejsca, do którego ma powrócić sterowanie po zakończeniu wykonywania podprogramu; w procesorze Pentium adres powrotu zapisuje się na stosie; spotyka się inne typy procesorów, w których ślad zapisywany jest w rejestrach;
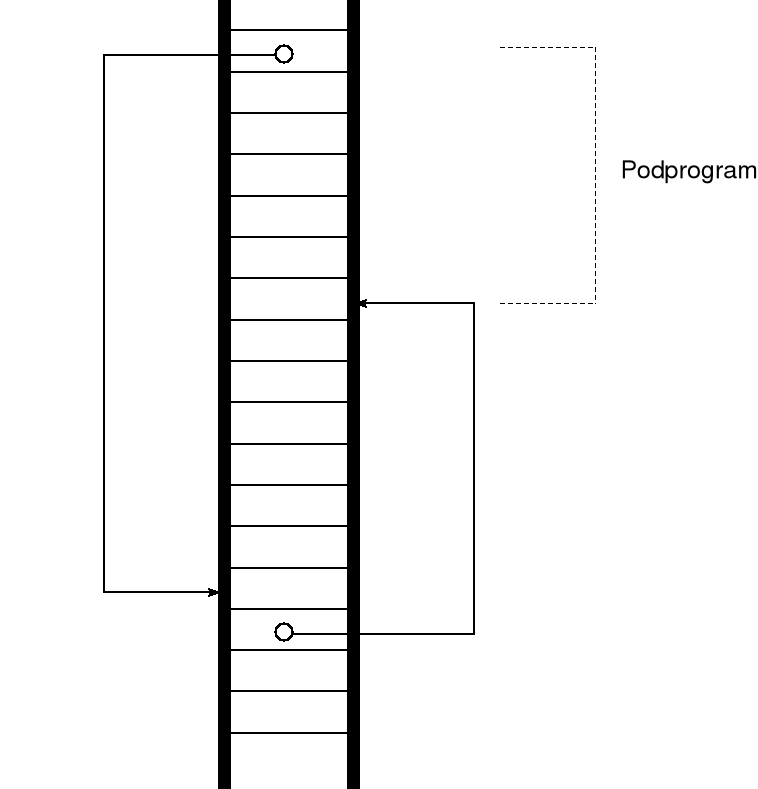
w procesorze Pentium ww. czynności wykonuje instrukcja CALL — występuje ona również w wersji bezpośredniej i pośredniej, a także near i far;
przykładowo, jeśli przyjmiemy, że instrukcja CALL zajmuje trzy bajty począwszy od adresu (offsetu) 5A34H, to kolejna instrukcja po CALL znajduje się w pamięci począwszy od offsetu 5A37H — zatem ostatnia instrukcja podprogramu powinna wpisać do rejestru (E)IP liczbę 5A37H, która powinna znajdować się na wierzchołku stosu; tak więc instrukcja CALL powinna zapisać na stosie liczbę
5A37H = położenie instrukcji CALL + liczba bajtów instrukcji CALL
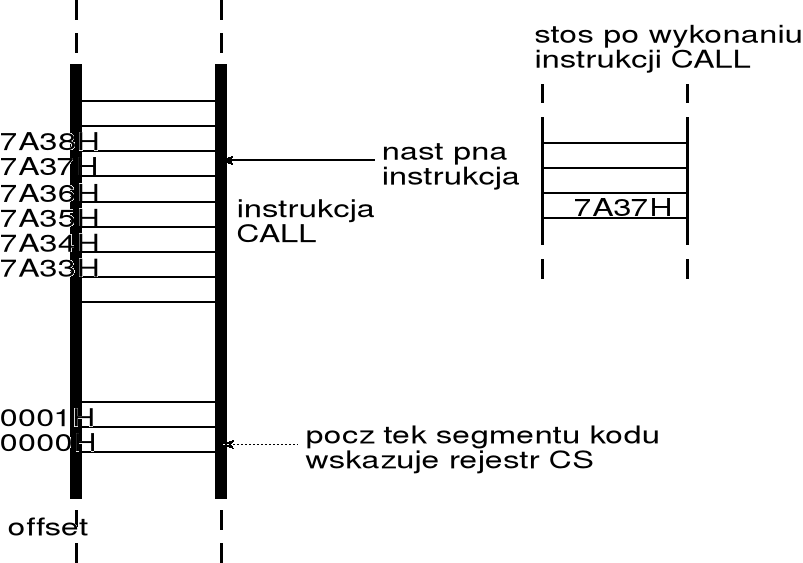
ślad zapisany na stosie wskazuje miejsce w programie, dokąd należy przekazać sterowanie po wykonaniu podprogramu; innymi słowy: w chwili zakończenia wykonywania podprogramu zawartość wierzchołka stosu powinna zostać przepisana do rejestru (E)IP i ewentualnie także do CS — czynności te realizuje instrukcja RET;
w asemblerze podprogram rozpoczyna dyrektywa PROC a kończy dyrektywa ENDP, np.
skasuj PROC
— — — — — —
— — — — — —
skasuj ENDP
instrukcja CALL typu pośredniego używana jest m.in. przez kompilatory jezyka C do implementacji wywoływania funkcji przez wskaźnik, np.
int (wsk) (int p, int q);
if (a < b) wsk = fun1; else wsk = fun2;
c = (wsk) (a, b);
Usługi systemu operacyjnego
w początkowym okresie rozwoju informatyki każdy program był całkowicie samodzielny i w trakcie wykonywania nie korzystał z pomocy innych programów; tego rozdzaju rozwiązania spotyka się współcześnie w mikrokomputerach (mikrokontrolerach) obsługujących nieskomplikowane urządzenia;
zauważono wówczas, że wiele programów ma takie same lub bardzo podobne fragmenty, związane głównie z obsługą urządzeń wejścia/wyjścia (wówczas dalekopisu) — te fragmenty kodu zostały wyodrębnione i została im nadana postać podprogramów; podprogramy te zostały udostępnione innym programom, które mogły je wywoływać w trakcie wykonywania;
w ten sposób zaczęły powstawać systemy operacyjne; później obudowano te podprogramy dodatkowymi modułami, których zadaniem było zarządzanie systemem komputerowym.
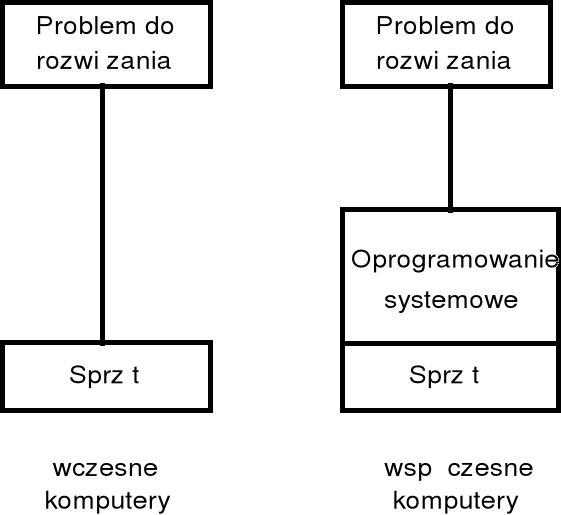
programy wykonywane we współczesnych komputerach ogólnego przeznaczenia zazwyczaj nie mogą bezpośrednio sterować pracą sprzętu, ale jedynie za pośrednictwem usług udostępnianych przez system operacyjny; dokumentacja systemu operacyjnego dostarczana użytkownikom (programistom) zawiera katalog usług, które mogą być wywoływane z poziomu programu;
wywołanie usługi systemu operacyjnego odbywa się zazwyczaj poprzez wywołanie podprogramu systemowego za pomocą rozkazu CALL (lub podobnego); dla każdej usługi systemowej w katalogu podane są szczegółowe informacje o wymaganych parametrach i sposobach przekazywania ich do podprogramów systemowych; w ten zostaje określony pewien interfejs określający sposób porozumiewania się programu z systemem operacyjnym — interfejs ten oznaczany jest skrótem API (ang. application programming interface), co tłumaczy się jako interfejs programowania aplikacji; w aktualnie używanych systemach MS Windows dostępny jest interfejs Win32 API;
usługi systemowe wywoływane są zarówno w programach asemblerowych, jak też w programach tworzonych w językach wysokiego poziomu; w tych ostatnich podaje się nazwę funkcji systemowej, która w trakcie kompilacji zostaje przekształcona na rozkaz CALL z odpowiednimi parametrami;
system Windows wytwarzany jest w kilku wersjach przeznaczonych dla różnych typów procesorów; dlatego też interfejs Win32 API został zdefiniowany na poziomie języka C, co umożliwia przenośność oprogramowania na różne platformy sprzętowe;
zatem wywołanie usługi Win32 API na poziomie kodu asemblerowego wymaga zastosowania dokładnie tego samego standardu, jaki używany jest przez kompilatory języka C — może to być kłopotliwe dla niewprawnych programistów;
oprócz interfejsu Win32 API, system Windows udostępnia także inny interfejs przejęty z używanego dawniej systemu DOS; interfejs określony jest na poziomie asemblera i może być używany jedynie w 16-bitowych programach wykonywanych w trybie V86 (lub w trybie rzeczywistym); usługi tego interfejsu wywołuje się za pomocą rozkazu INT 21H, podając jednocześnie numer usługi w rejestrze AH; dodatkowe parametry umieszcza się w innych rejestrach;
zaletą ww. interfejsu są m.in. proste operacje wprowadzania i wyprowadzania pojedynczych znaków, co koresponduje ze stylem programów pisanych w asemblerze;
ta sama technika wywoływania podprogramów systemowych używana jest także w opisanym niżej systemie BIOS.
System BIOS
sprzęt komputerowy powinien posiadać zdolność wprowadzania i uruchamiania krótkich programów bezpośrednio po włączeniu (lub zresetowaniu) komputera; takie krótkie programy ładujące, zwane bootstrap'ami zawierają kod, który wprowadza do pamięci i uruchamia właściwy system operacyjny; we współczesnych komputerach programy ładujące przechowywane są w pamięci ROM (ang. read-only memory — pamięć tylko do odczytu);
w pamięci ROM obok ww. programów ładujących umieszcza się także programy inicjalizujące, testujące i konfigurujące zainstalowany sprzęt; wstępne testowanie sprzętu przed uruchomieniem systemu operacyjnego zapobiega przed dalszymi powikłaniami, które mogą doprowadzić do uszkodzenia oprogramowania i danych;
w pamięci ROM komputerów osobistych przechowywany jest także pakiet podprogramów wykonujących podstawowe czynności sterowania i obsługi urządzeń (zwykle na poziomie portów);
można więc powiedzieć, że w pamięci ROM znajduje się mini-system operacyjny — w komputerach rodziny IBM PC system ten nosi nazwę BIOS — Basic Input Output System;
m.in. system BIOS zawiera zestaw programów testujących POST (ang. Power On Self Test), uruchamianych po włączeniu komputera;
funkcje usługowe udostępniane przez BIOS dla innych programów tworzą BIOS API (ang. application program interface — interfejs programowania aplikacji); BIOS API oferuje użytkownikowi elementarny zestaw operacji, niezależny od konstrukcji konkretnego komputera (zatem oprogramowanie BIOSu może "wyrównywać" różnice w konstrukcji sprzętu);
aktualnie używane wersje BIOSu posiadają także mechanizmy pozwalające na dynamiczną konfigurację systemu, w zależności od wyposażenia komputera;
system BIOS został tak skonstruowany, że niektóre jego fragmenty mogą być umieszczone są na kartach rozszerzeniowych komputera (np. na karcie sterownika graficznego);
BIOS zapisany jest w pamięci ROM (obecnie zwykle w EEPROM) i zajmuje obszar pamięci począwszy od adresu F000H:0000H; obszar zmiennych systemowych BIOSu umieszczony jest w pamięci RAM począwszy od adresu 0040H : 0000H;
do niedawna zmiana zawartości pamięci ROM wymagała profesjonalnych działań — obecnie stosowane są pamięci EEPROM, które mogą być aktualizowane przez użytkownika komputera;
współczesne systemy operacyjne w komputerach osobistych dość niechętnie korzystają z usług oferowanych przez BIOS API — BIOS pracuje w trybie 16-bitowym i nie jest przystosowany do zaawansowanych metod obsługi (np. wirtualizacji urządzeń); BIOS API był natomiast szeroko wykorzystywany przez system DOS.
Wywoływanie podprogramów systemowych
podprogramy systemowe realizują wiele różnych operacji, w tym podstawowe operacje związane z obsługą urządzeń wejścia/wyjścia w komputerze; w wielu systemach istnieje obowiązkowe pośrednictwo podprogramów systemowych w zakresie obsługi urządzeń;
bezpośrednie wywoływanie podprogramów systemowych wymaga znajomości adresów poszczególnych podprogramów, a te mogą się zmieniać w kolejnych wersjach systemu lub też mogą zależeć od konfiguracji systemu;
istnieją różne techniki wyznaczania adresów; w programach 32-bitowych w systemie Windows wyznaczanie adresów podprogramów w systemowych wykonywane jest bezpośrednio przed rozpoczęciem wykonywania programu; opisana poniżej technika wywoływania jest łatwiejsza do realizacji, ale wykorzystuje wbudowane mechanizmy procesora Pentium (i poprzedników);
w wielu systemach zastosowano wywoływanie podprogramów systemowych w sposób pośredni, za pośrednictwem tablicy adresowej, zawierającej adresy podprogramów systemowych; w takim przypadku programista nie podaje adresu podprogramu, ale indeks w tablicy adresowej;
w kolejnych wersjach systemu adresy zawarte w tablicy ulegają zmianom, ale odwołania do konkretnych podprogramów realizowane są poprzez te same indeksy w tablicy adresowej;
w procesorach Pentium koncepcja ta została zrealizowana za pomocą tablicy adresowej zwanej tablicą wektorów przerwań (w trybie rzeczywistym) lub tablicy deskryptorów przerwań (w trybie chronionym);
struktura tablicy w trybie chronionym jest bardziej złożona; dalsze rozważania dotyczą trybu rzeczywistego, w którym omawiana tablica nosi nazwę tablicy wektorów przerwań;
ze względu na brak mechanizmów ochrony w trybie rzeczywistym tablica wektorów pozwala na wykonywanie interesujących eksperymentów w zakresie sprzętu i oprogramowania; w trybie chronionym podobne eksperymenty są trudne lub niemożliwe do realizacji;
tablica wektorów przerwań zawiera 256 adresów 4-bajtowych i umieszczona jest w pamięci operacyjnej począwszy od adresu fizycznego 0; adresy podprogramów w tej tablicy zapisywane są w układzie segment:offset; pole offset zajmuje dwa bajty o niższych adresach;
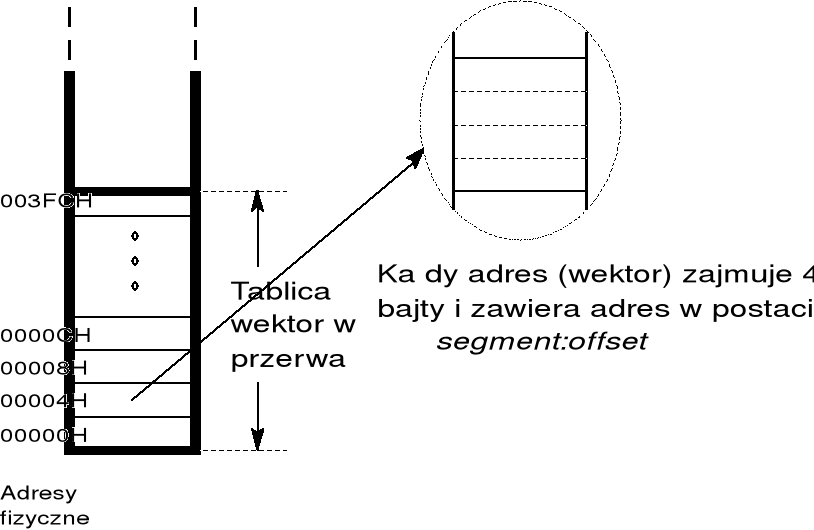
wywoływanie podprogramów za pośrednictwem tablicy wektorów przerwań można by wykonywać za pomocą instrukcji CALL typu pośredniego; jednak dla wygody programowania zdefiniowano instrukcję INT specjalnie dla tego typu wywołań;
w trybie rzeczywistym instrukcja INT może być zastąpiona przez instrukcję CALL typu pośredniego i instrukcję PUSHF; jednak w trybie chronionym podprogramy systemowe muszą być wykonywane na wyższym poziomie uprzywilejowania i instrukcja INT nie może być zastąpiona przez inne instrukcje;
instrukcję INT należy klasyfikować jako instrukcję skoku do podprogramu typu pośredniego, podobną do instrukcji CALL; jednocześnie instrukcja INT wykazuje zewnętrzne podobieństwo do przerwań sprzętowych i tego powodu została nazwana INTerrupt, czyli przerwanie; podobieństwo to może utrudniać zrozumienie istoty mechanizmu przerwań (omawianego w dalszej części wykładu);
instrukcja INT pozostawia ślad na stosie zawierający rejestry (E)IP, CS i rejestr znaczników (E)FLAGS;
ze względu na inną strukturę śladu, zdefiniowano oddzielną instrukcję powrotu z podprogramu IRET — instrukcja ta jest używana w przypadku gdy podprogram został wywołany za pomocą instrukcji INT albo wskutek wystąpienia przerwania sprzętowego lub wyjątku.
Wywoływanie usług (podprogramów) systemowych DOSu i BIOSu
liczba różnych podprogramów systemowych jest zwykle większa od 256, wobec czego zachodzi konieczność tworzenia zestawów podprogramów, nazywanych pakietami; adresu pakietu podany jest w tablicy wektorów przerwań, zaś poszczególne podprogramy identyfikowane są przez ustalone numery; wybór podprogramu następuje poprzez wpisanie odpowiedniego numeru do rejestru, zwykle do AH lub AX;
adres pakietu podprogramów wchodzących w skład systemu DOS/Windows umieszczony jest w wektorze 33 (21H); numer podprogramu podawany jest w rejestrze AH, stąd typowa sekwencja wywołania podprogramu systemowego ma postać, np.
— — — — — —
mov ah, 2
int 21H
znaczna część podprogramów wymaga podania parametrów wejściowych, które najczęściej umieszcza się w ustalonych rejestrach; również wyniki przekazywane są przez rejestry; wykaz wszystkich podprogramów sytemowych wraz z wymaganymi parametrami zawiera dokumentacja systemu operacyjnego; informacje te można znaleźć na znacznej liczbie stron internetowych, a także w wielu książkach — w języku polskim najbardziej obszerny opis zawiera książka Bułhaka i Goczyńskiego, DOS od środka (wraz z suplementem);
funkcje usługowe systemu DOS/Windows, do których parametry przekazywane są przez rejestry robocze, pozostawiają te rejestry niezmienione, chyba że służą one do wyprowadzania wyników;
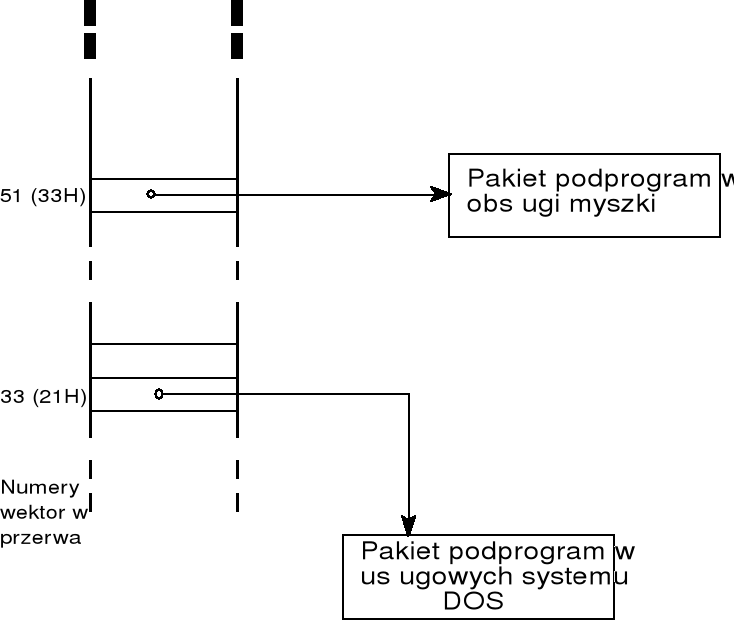
inne wektory przerwań zawierają adresy rozmaitych pakietów podprogramów, m.in. wektor 33H zawiera adres pakietu podprogramów obsługi myszki; kilkanaście wektorów zawiera adresy różnych podprogramów udostępnianych przez system BIOS;
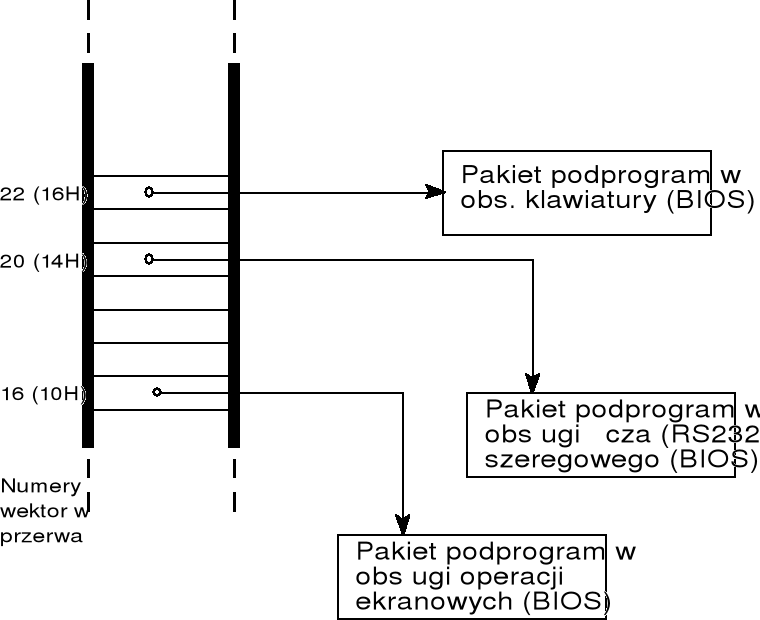
korzystając z usług systemu operacyjnego nie zawsze zdajemy sobie sprawę czy wywołujemy instrukcję procesora czy podprogram systemu operacyjnego; usługi systemu operacyjnego wraz z instrukcjami procesora tworzą pewne środowisko, które częściowo jest realizowane sprzętowo, a częściowo przez usługi systemu operacyjnego — powstaje w ten sposób pewna maszyna wirtualna, w której działa programista.
Przekazywanie parametrów do podprogramów
stosowane są dwa podstawowe sposoby przekazywania parametrów:
przekazywanie przez wartość (ang. call by value) - do podprogramu przekazywana jest bezpośrednio wartość parametru, którym może być liczba, tablica liczb, łańcuch znaków, itp;
przekazywanie przez adres (ang. call by location) - do podprogramu przekazywany jest adres lokacji pamięci, w której znajduje się przekazywana wartość;
przekazywanie adresu zmiennej umożliwia bezpośredni dostęp do niej wewnątrz podprogramu, m.in. pozwala to na wpisanie wyniku uzyskanego w trakcie wykonywania podprogramu bezpośrednio do tej zmiennej; taki sposób pozwala także na dostęp do tablicy bez konieczności przekazywania wartości wszystkich jej elementów;
drogi przekazywania parametrów:
przez rejestry,
przez stos (typowa, powszechnie stosowana metoda),
przez ślad (tj. przez obszary pamięci znajdujące się bezpośrednio za instrukcją CALL lub INT),
przez bufory (tj. przez zarezerwowane obszary pamięci o ustalonych adresach);
przekazywanie parametrów przez rejestry jest charakterystyczne dla funkcji systemowych BIOSu i DOSu.
Technika przekazywania parametrów przez stos
Przykład: podany niżej podprogram oblicza wartość wyrażenia
(długość + 5) szerokość + wysokość
przyjmujemy następujące założenia:
podprorgram obliczający wartość wyrażenia będzie wykonywany w trybie 32-bitowym; w tym trybie cały kod programu umieszczony jest zazwyczaj w tym samym segmencie, co oznacza, że do jego wywoływania powinien zostać użyty rozkaz CALL typu NEAR;
podane parametry, w postaci liczb 32-bitowych bez znaku, wpisywane są na stos przed wywołaniem procedury;
obliczona wartość wyrażenia (zakładamy, że również 32-bitowa) powinna zostać załadowana do rejestru EAX;
obowiązek zdjęcia parametrów ze stosu po wykonaniu obliczeń należy do podprogramu.
jeśli przykładowe wartości parametrów będą wynosiły:
długość = 17
szerokość = 5
wysokość = 7
to wywołanie podprogramu oblicz może mieć postać:
push 17 ; ładowanie parametru 'długość'
push 5 ; ładowanie parametru 'szerokość'
push 7 ; ładowanie parametru 'wysokość'
call oblicz
w wyniku wykonania podanych instrukcji zawartość stosu będzie następująca:
|
|
większe |
|
adresy |
długość |
|
szerokość |
|
wysokość |
mniejsze |
EIP |
adresy |
|
|
|
należy pamiętać, że stos "rośnie" w kierunku malejących adresów — zatem parametr długość znajdować się będzie w lokacji o adresie wyższym niż parametr wysokość.
Odczytywanie parametrów przez instrukcje wewnątrz procedury
odczytywanie parametrów za pomocą instrukcji POP byłoby kłopotliwe: wymagałoby uprzedniego odczytania wartości EIP, a a po wykonaniu obliczeń należało by ponownie załadować tę wartość na stos; odczytane parametry można by umieścić w rejestrach ogólnego przeznaczenia — rejestry te jednak używane są do wykonywania obliczeń i przechowywania wyników pośrednich, wskutek czego nadają się do przechowywania jedynie kilku parametrów;
w celu zorganizowania wygodnego dostępu do parametrów umieszczonych na stosie przyjęto, że obszar zajmowany przez parametry będzie traktowany jako zwykły obszar danych; w istocie stos jest bowiem umieszczony w pamięci RAM i nic nie stoi na przeszkodzie, by w pewnych sytuacjach traktować jego zawartość jako zwykły segment danych;
dostęp do danych zapisanych w segmencie danych wymaga znajomości ich adresów, to samo dotyczy stosu; jednak położenie danych zapisanych na stosie ustalane jest dopiero w trakcie wykonywania programu, i może się zmieniać przy kolejnych wywołaniach podprogramu;
konieczne jest więc opracowanie schematu wyznaczania adresów parametrów umieszczonych na stosie, dostosowanego do aktualnej sytuacji na stosie;
na podanym wcześniej rysunku widać, że parametry podprogramu odległe są o ustaloną liczbę bajtów od wierzchołka stosu (tu: o 4 bajty, na których zapisany jest ślad); ponieważ położenie wierzchołka stosu wskazuje rejestr ESP, więc na podstawie zawartości rejestru ESP można wyznaczyć adresy parametrów;
ponieważ jednak zawartość rejestru ESP może się zmieniać w trakcie wykonywania podprogramu, konieczne jest użycie innego rejestru, którego zawartość, ustalona przez cały czas wykonywania podprogramu, będzie wskazywała obszar parametrów na stosie — rolę tę pełni, specjalnie do tego celu zaprojektowany rejestr EBP;
modyfikacja adresowa wykonywana za pomocą rejestru EBP implikuje użycie rejestru SS jako domyślnego rejestru segmentowego — zatem odczyt pewnej lokacji pamięci, której adres podany jest w rejestrze EBP oznacza w istocie odczyt lokacji pamięci zapisanej na stosie;
jeśli zawartość rejestru EBP jest równa zawartości ESP, to adres określony przez EBP wskazuje wierzchołek stosu, a EBP zwiększony o 4, 8, 12,... wskazuje kolejne, uprzednio zapisane, podwójne słowa na stosie (należy pamiętać, że stos "rośnie" w kierunku malejących adresów, zatem lokacje bardziej odległe od wierzchołka stosu będą miały wyższe adresy).
oblicz PROC
push ebp ; przechowanie EBP na stosie
mov ebp,esp ; po wykonaniu tego rozkazu EBP
; będzie wskazywał wierzchoł. stosu
mov eax, [ebp] + 16 ; ładowanie parametru 'długość'
add eax,5 ; EAX EAX + 5
mul dword PTR [ebp] + 12 ; mnożenie przez 'szerokość'
add eax,[ebp] + 8 ; dodanie parametru 'wysokość'
; wynik obliczeń znajduje się w rejestrze EAX
pop ebp ; odtworzenie EBP
ret 12 ; powrót do programu wywołującego
; i usunięcie parametrów ze stosu
oblicz ENDP
sytuacja na stosie po wykonaniu instrukcji push ebp
|
|
[ebp] + 16 |
długość |
[ebp] + 12 |
szerokość |
[ebp] + 8 |
wysokość |
[ebp] + 4 |
EIP |
[ebp] + 0 |
EBP |
|
|
Uwagi:
użycie operatora PTR w jednoargumentowej instrukcji
mul dword PTR [ebp]+12
jest niezbędne, ponieważ wyrażenie [ebp]+12 wskazuje położenie pewnej lokacji nie precyzując jednak czy chodzi to o bajt czy o słowo;
32-bitowy mnożnik implikuje 64-bitowy wynik mnożenia, umieszczany w rejestrach EDX:EAX; ponieważ przyjęliśmy, że wynik obliczeń będzie liczbą 32-bitową, więc starszą część wyniku mnożenia (w rejestrze EDX) można pominąć.
Prolog i epilog podprogramu
w tak skonstruowanym podprogramie początkowe i końcowe instrukcje mają jednakową postać, niezależnie od czynności wykonywanych przez podprogram — stanowią one prolog i epilog podprogram; zazwyczaj mają one postać:
Prolog Epilog
push ebp mov esp, ebp
mov ebp, esp pop ebp
sub esp, rozmiar ret liczba_bajtów
Instrukcje sub esp, rozmiar i mov esp, ebp potrzebne są tylko wówczas, gdy używane są zmienne dynamiczne (co będzie omówione dalej).
Łączenie języków programowania (programowanie mieszane)
stosowana obecnie technika kompilacji i linkowania pozwala na tworzenie programów kodowanych w kilku językach programowania; najczęściej jednak mamy do czynienia z łączeniem kodu napisanego w języku wysokiego poziomu z kodem w asemblerze;
w praktyce programowania zazwyczaj dostępne są dwie metody dołączania kodu asemblerowego:
1. w formie wstawek asemblerowych umieszczonych bezpośrednio wewnątrz kodu w języku wysokiego poziomu;
2. w formie odrębnych modułów asemblerowych, które są odrębnie kompilowane (asemblowane) i łączone z pozostałym kodem w trakcie linkowania;
poniżej podano przykładowy fragment programu w języku C, w którym występują wstawki asemblerowe
int liczba, wynik;
— — — — — — — — —
liczba = 49 ;
asm {
mov ax, liczba
mov bx, 0
mov dx, 1
}
ptl:
asm {
sub ax, dx
jb zak
inc bx
add dx, 2
jmp ptl
}
zak:
asm mov wynik, bx
wynik += 7;
w instrukcjach asemblerowych można odwoływać się zarówno do zmiennych lokalnych jak i globalnych (zewnętrznych);
stosowanie wstawek asemblerowych nie wymaga oddzielnej kompilacji (asemblacji) — używany jest asembler wbudowany w kompilator języka wysokiego poziomu;
jednak stosowanie wstawek asemblerowych w bardziej skomplikowanych przypadkach nie pozwala na pełne wykorzystanie możliwości właściwych dla kodowania w asemblerze;
stosowanie oddzielnych modułów asemblerowych umożliwia wyraźne wyodrębnienie części asemblerowej, która może być tworzona, np. przez osobę znającą doskonale zagadnienia sprzętowe; metoda ta pozwala na pełne wykorzystanie możliwości kodowania w asemblerze (np. włączenie mechanizmów makroprzetwarzania) i ułatwia diagnostykę programu; w dalszej cześci wykładu zajmować się będziemy wyłącznie tą metodą;
podprogram w asemblerze, przystosowany do wywoływania z poziomu języka wysokiego poziomu, musi być skonstruowany wg tych samych zasad co funkcje (procedury) tego języka; w szczególności należy stosować tę samą technikę przekazywania parametrów jak też odpowiednie nazwy segmentów (i ich atrybuty);
ustalony sposób przekazywania parametrów do/z funkcji (procedury) w danym języku programowania nosi nazwę standardu wywoływania (ang. calling convention); m.in. standard ten określa czy parametry przekazywane są przez rejestry czy przez stos, a jeśli przez stos to w jakiej kolejności są ładowane, czy dopuszcza się zmienną liczbę argumentów, itd.
Typowe standardy wywoływania funkcji
kompilatory języków programowania stosują kilka typowych sposobów przekazywania parametrów do funkcji, znanych jako:
standard Pascal,
standard C
standard StdCall;
czasami stosuje się też standard FastCall, w którym parametry przekazywane są przez rejestry procesora;
główne różnice między standardami dotyczą kolejności ładowania parametrów na stos i obowiązku zdejmowania parametrów, który należy najczęściej do wywołanego podprogramu (funkcji), jedynie w standardzie C zajmuje się tym program wywołujący; w standardzie Pascal parametry wywoływanej funkcji zapisywane są na stos kolejności od lewej do prawej, natomiast w standardzie C i StdCall od prawej do lewej; istnieją też inne różnice, które opisane są dalej;
Standard |
Kolejność ładowania parametrów na stos |
Obowiązek zdjęcia parametrów ze stosu |
Pascal |
od lewej do prawej |
wywołany podprogram |
C |
od prawej do lewej |
program wywołujący |
StdCall |
od prawej do lewej |
wywołany podprogram |
standard wywoływania funkcji i procedur typu Pascal jest szeroko stosowany w różnych systemach programowania (m.in. w systemie Windows); standard StdCall, stanowiący połączenie standardów C i Pascal, stosowany jest w 32-bitowych wersjach Windows do wywoływania funkcji wchodzących w skład interfejsu Win32 API;
warto zwrócić uwagę, że w wielu przypadkach parametry wywołania funkcji mają postać wyrażeń (tak jak w podanym wyżej przykładzie) — w takim przypadku najpierw obliczana jest wartość parametru, która następnie zapisywana jest na stosie;
podane standardy stosowane są w różnych środowiskach programistycznych, m.in. w systemach Borland C/C++ i Microsoft C++ można deklarować funkcje, w których stosowane są ww. standardy;
zasadniczo kompilatory języka C stosują standard C, jednakże umieszczenie w deklaracji funkcji słowa pascal powoduje, że w odniesieniu do tej funkcji stosowana będzie konwencja pascalowa; tak samo w programach kodowanych w Pascalu umieszczenie słowa cdecl w deklaracji powoduje, że do funkcji lub procedury stosowana będzie konwencja języka C; analogicznie słowo register powoduje, że parametry przekazywane będą przez rejestry; szczegółowe zalecenia podane są w dokumentacji kompilatora;
używane są też słowa _stdcall (albo stdcall) i cdecl wprowadzające dla deklarowanych funkcji, odpowiednio, standard StdCall i C;
standard register stanowi najbardziej efektywny sposób przekazywania parametrów, ale jego zastosowanie jego ograniczone ze względu na niewielką liczbę rejestrów procesora (używa się maksymalnie 3 rejestry); w niektórych kompilatorach przyjęto standard register jako domyślny;
typowe asemblery udostępniają dodatkowe dyrektywy (np. ARG) ułatwiające odczytywanie parametrów ze stosu — jednak ze względu na pewne skutki uboczne powinny stosowane ostrożnie.
Uwagi szczegółowe dotyczące sposobu wywoływania funkcji stosowanego przez kompilatory języka C
kompilatory języka C tworzą kod programu przy zastosowaniu techniki przekazywania parametrów "standard C" — parametry przekazywane są przez stos w kolejności odwrotnej, w stosunku do tej, w jakiej zostały podane w kodzie źródłowym;
jeśli używany jest stos 32-bitowy, to parametry krótsze niż 32 bitowe rozszerza się do 32 bitów; analogicznie rozszerza się parametry, gdy używany jest stos 16-bitowy (np. parametry bajtowe ładowane są w postaci słowa 16-bitowego);
po wykonaniu funkcji, obowiązek zdjęcia parametrów ze stosu należy do programu wywołującego;
parametry przekazywane są przez wartość, jedynie tablice przekazywane są przez adres;
wyniki funkcji przekazywane są przez rejestry:
wynik 1-bajtowy przez AL
wynik 2-bajtowy przez AX
wynik 4-bajtowy przez DX:AX (w trybie 16-bitowym) albo przez EAX (w trybie 32-bitowym);
w ten sposób przekazywane są również adresy 16- i 32-bitowe;
jeśli wynikiem funkcji jest liczba zmiennoprzecinkowa typu float lub double, to wynik ten dostępny jest na stosie rejestrów koprocesora (lub programu emulującego koprocesor);
działania wewnątrz funkcji (podprogramu) kodowanej w asemblerze mogą być wykonywane na różnych rejestrach, jednak bezpośrednio przed zakończeniem wykonywania funkcji zawartości niektórych rejestrów muszą być odtworzone wg pierwotnej zawartości; dotyczy to rejestrów ogólnego przeznaczenia: ESI (SI), EDI (DI), EBP (BP), EBX (w trybie 16-bitowym rejestr BX może zostać zmieniony); w przypadku podprogramu wykonywanego w trybie V86 mogą być również zmieniane rejestry segmentowe, ale przed zakończeniem jego wykonywania muszą być odtworzone wartości początkowe;
kompilatory języka C poprzedzają nazwy o zasięgu globalnym znakiem podkreślenia _
Program przykładowy — łączenie programu w języku C z procedurą asemblerową z zastosowaniem konwencji wywoływania funkcji wg standardu C (tryb 32-bitowy).
program wyznacza największy wspólny podzielnik (NWP) dla dwóch liczb naturalnych x i y, stosując poniższy algorytm:
while y <> 0 do
begin
x := x mod y (mod oznacza resztę z dzielenia x/y)
x y (zamiana x, y)
end
moduł w języku C:
#include <stdio.h>
extern int OBL_NWP (unsigned int x, unsigned int y, unsigned int * wyn);
int main (void)
{
unsigned int a, b, w;
int diagn;
printf ("\nProszę podać dwie liczby naturalne: ");
scanf("%u %u", &a, &b);
diagn = OBL_NWP (a, b, &w);
if (!diagn) printf ("\nNWP(%u,%u) = %u\n", a, b, w);
else
{
printf ("\nNiewłaściwe parametry");
return 1;
}
return 0;
}
moduł w asemblerze
.386
public _OBL_NWP
; prototyp funkcji na poziomie języka C
; int OBL_NWP ( unsigned int x,
unsigned int y,
unsigned int * wyn);
zm1 EQU [ebp]-4
_TEXT SEGMENT dword public 'CODE' use32
assume cs:_TEXT
_OBL_NWP PROC near
push ebp
mov ebp,esp
; rezerwacja 4 bajtów na zmienną 'zm1'
sub esp, 4
push ebx
; sprawdzanie czy x > 0 i y > 0
cmp dword PTR [ebp]+8, 0
je blad
cmp dword PTR [ebp]+12, 0
je blad
; petla while
p1: cmp dword PTR [ebp]+12, 0
je zak ;skok, gdy koniec 'while'
mov eax, [ebp]+8
xor edx, edx
div dword PTR [ebp]+12
; iloraz w EAX, reszta w EDX
mov [ebp]+8, edx
; odeslanie reszty do x
; zamiana liczb x, y poprzez zmienna 'zm1'
mov eax, [ebp]+8 ; zm1 <-- x
mov zm1, eax
mov eax, [ebp]+12 ; x <-- y
mov [ebp]+8, eax
mov eax, zm1 ; y <-- zm1
mov [ebp]+12, eax
jmp p1
; odesłanie wyniku obliczenia
; do lokacji wskazanej przez podany adres
zak: mov ebx, [ebp]+16
mov eax, [ebp]+8
mov [ebx], eax
; AX = 0 oznacza poprawne wykonanie funkcji
mov eax, 0
zak1:
pop ebx
mov esp, ebp
pop ebp
ret
blad: mov eax, -1
jmp zak1
_OBL_NWP ENDP
_TEXT ENDS
END
Zmienne statyczne i dynamiczne
w typowym programie w języku wysokiego poziomu (np. w Pascalu) potrzebne są m.in. zmienne, które muszą być dostępne dla różnych procedur i funkcji przez cały czas wykonywania programu - takie zmienne, zwane statycznymi, definiowane są w segmencie danych programu; na poziomie kodu rozkazowego omawiane procedury i funkcje mają postać podprogramów wywoływanych za pomocą instrukcji CALL;
procedury i funkcje, kodowane w językach wysokiego poziomu, wykonują także działania na zmiennych lokalnych, które są potrzebne tylko w trakcie wykonywania procedury czy funkcji (podprogramu); często zmienne takie nie muszą być inicjalizowane;
zmienne lokalne powinny zajmować obszar pamięci przydzielany tylko na czas wykonywania podprogramu — wygodnie jest umieścić ten obszar na stosie — w tym celu wystarczy tylko odpowiednio zmniejszyć wskaźnik stosu ESP, np.:
push ebp ; przechowanie EBP
mov ebp, esp
sub esp, 8 ; rezerwacja 8 bajtów
zmniejszenie rejestru ESP o 8 można interpretować jako zapisanie na stos 8 bajtów o nieokreślonej wartości początkowej — powstaje w ten sposób zarezerwowany obszar 8-bajtowy, w którym będą zapisywane wartości zmiennych lokalnych;
przydzielony obszar pamięci zwalnia się w końcowej części procedury poprzez odpowiednie zwiększenie wskaźnika stosu ESP lub przepisanie ESP EBP;
zmienne lokalne lokowane na stosie nazywane są zmiennymi dynamicznymi; w języku C zmienne takie nazywane są zmiennymi automatycznymi.
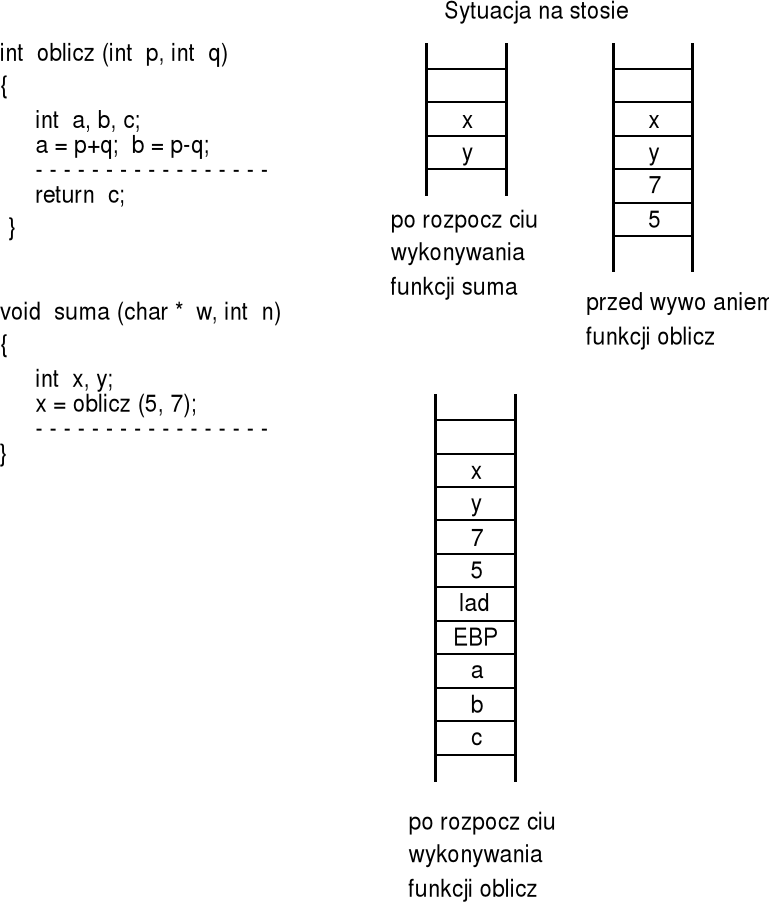
Technika dostępu do zmiennych dynamicznych
sytuacja na stosie po rezerwacji obszaru danych lokalnych
tryb zwyky
|
|
|
|
większe adresy |
parametry przekazywane do procedury
|
|
ślad instrukcji CALL |
|
EBP |
mniejsze adresy |
obszar danych lokalnych |
|
|
|
|
parametry przekazywane do podprogramu, ślad, rejestr EBP oraz obszar danych lokalnych tworzą pewien blok danych, z którego korzysta podprogram; położenie tego bloku na stosie, w zależności od jego zajętości, może się zmieniać przy kolejnych wywołaniach podprogramu; jak pokazano wcześniej adres omawianego bloku wskazuje rejestr ESP, którego zawartość kopiowana jest do rejestru EBP;
zauważmy dalej, że wprowadzenie obszaru danych lokalnych w niczym nie zmieniło sposobu dostępu do parametrów za pomocą rejestru EBP; pojawia się jednak pytanie czy rejestr EBP może wskazywać także zmienne lokalne, których adresy są mniejsze niż zawartość EBP?
adres efektywny, będący sumą zawartości pola adresowego instrukcji i rejestru modyfikacji adresowej, w trybie 32-bitowym obliczany jest modulo 232 — przy takiej regule odpowiednio duże liczby umieszczone w polu adresowym działają tak liczby ujemne (zob. opis modyfikacji adresowych);
zatem ten sam rejestr EBP może służyć zarówno do pobierania parametrów przekazywanych do podprogramu, jak też pobierania i zapisywania zmiennych lokalnych znajdujących się na stosie, np. podane instrukcje wpisują liczby do zmiennych lokalnych na stosie:
; wpisanie liczby 25 do zmiennej 32-bitowej
mov dword PTR [ebp] 4, 25
; wpisanie liczby 31 do zmiennej 64-bitowej
mov dword PTR [ebp] 8, 0
mov dword PTR [ebp] 12, 31
Zastosowanie instrukcji ENTER i LEAVE
lokowanie zmiennych dynamicznych i przekazywanie parametrów za pomocą stosu jest standardową metodą używaną przez kompilatory różnych języków programowania; występujące tu operacje można zakodować w nieco krótszy sposób za pomocą instrukcji ENTER i LEAVE; szczególności ciągi instrukcji podane w obu kolumnach są równoważne:
push ebp
mov ebp, esp enter k, 0
sub esp, k
gdzie k oznacza liczbę bajtów rezerwowanych na stosie jako pamięć dynamiczna procedury; w literaturze działania instrukcji ENTER k, 0 określa się skrótowo jako "tworzenie na stosie obszaru przeznaczonego dla zmiennych lokalnych procedury" (ang. stack frame);
w omawianym przypadku drugi operand instrukcji ENTER ma wartość 0 (tzw. zerowy poziom zagłębienia); instrukcja ENTER z niezerowymi wartościami drugiego parametru jest przeznaczona do wywoływania procedur zagnieżdżonych (np. w Pascalu), i ze względu na niewielkie zastosowanie, i znaczny stopień skomplikowania, nie będzie tu omawiana;
równoważne są także ciągi instrukcji:
mov esp, ebp leave
pop ebp
80
Wyszukiwarka
Podobne podstrony:
Pytania przykl ASK2, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Opracowania
ask4, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Wyklad
ask1, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Wyklad
ask3, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Wyklad
ASK-koło pierwsze pytania z mojej grupy, Edukacja, studia, Semestr IV, Architektura Systemów Kompute
opracowane pytania na ASK@, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Oprac
Projekt 3, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Projekt, Projekt 3
Teoria 2003, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Opracowania pytań
assembler 1, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Projekt, Projekt 1
Pytania przykl ASK1, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Opracowania
TECHNIKA MIKROPROCESOROWA (1), Edukacja, studia, Semestr IV, Technika Mikroprocesorowa
liniowkaWKLEPANE PYTANIA, Edukacja, studia, Semestr IV, Układy Elektroniczne
pytania na smoki, Edukacja, studia, Semestr IV, Technika Mikroprocesorowa
arch02, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Architektura systemów komputerowych
Układy Elektroniczne zagadnienia, Edukacja, studia, Semestr IV, Układy Elektroniczne
arch05, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Architektura systemów komputerowych
arch07, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Architektura systemów komputerowych
Optoelektronika kolo 1, Edukacja, studia, Semestr IV, Optoelektronika, Pytania na koła, zestaw 8
JavaScript- podstawy, Edukacja, studia, Semestr IV, Języki Programowania Wysokiego Poziomu, Java skr
więcej podobnych podstron