Temat 5:
AUTOMATYCZNE ROZPOZNAWANIE MOWY
Burzliwy rozwój telefonii w latach czterdziestych po raz pierwszy w pełni uświadomił potrzebę automatycznego rozpoznawania mowy: urządzenie automatycznego rozpoznawania wymawianych cyfr numeru abonenta mogłoby zastąpić operatora zestawiającego połączenia w centrali telefonicznej. Jednakże próby zbudowania takiego urządzenia, które radziłoby sobie ze zmiennością sygnału mowy, były nieudane. Znaleziono wówczas rozwiązanie alternatywne w postaci, znanej do dzisiaj w niewiele zmienionej postaci, automatycznej łącznicy telefonicznej.
Później, w latach pięćdziesiątych, rozwój komputerów był kolejnym impulsem dla prób zastosowania mowy, jako najbardziej naturalnego sposobu, w komunikacji między człowiekiem i maszyną.
Najogólniej wyróżnia się trzy metody automatycznego rozpoznawania mowy:
akustyczno - fonetyczna,
rozpoznawania wzorców,
sztucznej inteligencji.
Metody akustyczno-fonetyczne
Metody akustyczno-fonetyczne (acoustic-phonetic approach) automatycznego rozpoznawania mowy bazują na założeniu, że:
istnieje skończona liczba dźwięków (symboli dźwiękowych) języka mówionego,
dźwięki są w pełni rozróżnialne poprzez zbiór charakterystyk akustycznych pozyskiwanych z sygnału rozpoznawanej mowy.
Każdy dźwięk jest generowany przy określonej konfiguracji traktu głosowego. Liczba możliwych konfiguracji traktu głosowego jest nieograniczona, lecz ze względu na możliwości percepcji sygnału mowy przez człowieka, liczba rozpoznawanych dźwięków mowy w każdym znanym języku jest skończona.
Rozróżnialność dźwięków jest trudnym do spełnienia wymaganiem, ponieważ sygnał mowy charakteryzuje się dużą zmiennością związaną z mówcą, wpływem kanału transmisji oraz kontekstem (sąsiedztwem innych dźwięków).
Sygnał mowy jest sekwencją jednostek akustycznych, które są realizacją fizyczną indeksowanych unikalną nazwą jednostek fonetycznych.
W rozpoznawaniu akustyczno - fonetycznym najczęściej stosuje się najmniejszą jednostkę mowy - fonem, traktowany jako zespół cech dystynktywnych (jego realizacją fizyczną jest głoska, czyli dźwięk). Stosowana też bywa sylaba, w której zasadniczą rolę odgrywa samogłoska.
Rozpoznawanie mowy metodami akustyczno-fonetycznymi polega na sekwencyjnym dekodowaniu segmentów sygnału mowy na podstawie charakterystyk akustycznych tego sygnału i znanych związków między tymi charakterystykami i jednostkami fonetycznymi.
W rozpoznawaniu akustyczno-fonetycznym charakterystyki akustyczne sygnału mowy najczęściej mają związek ze sposobem wytwarzania mowy przez człowieka, w szczególności z modelem typu źródło - filtr.
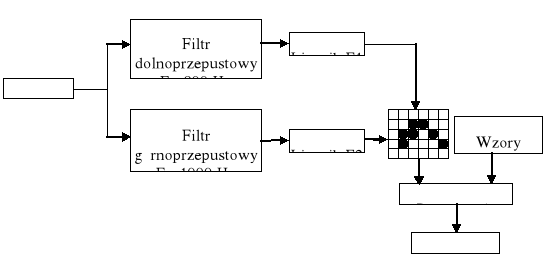
Podstawową strukturę systemów rozpoznawania mowy metodami akustyczno-fonetycznymi zilustrowano na rys. 1.
Rys. 1
Analiza sygnału: najczęściej stosowana jest analiza widmowa wykorzystująca jedną z trzech technik: bank filtrów, liniowe kodowanie predykcyjne (LPC) lub dyskretne przekształcenie Fouriera (FFT).
Wykrycie cech akustycznych umożliwia rozpoznanie jednostek fonetycznych.
Cechy akustyczne związane są z:
pobudzeniem:
częstotliwość tonu podstawowego,
energia sygnału,
obecność w pobudzeniu sygnału okresowego i/lub przypadkowego, oznaczająca dźwięczność lub bezdźwięczność fonemów;
traktem głosowym:
częstotliwości formantowe, zwykle pierwsze trzy, będące maksimami lokalnymi częstotliwościowej charakterystyki amplitudowej traktu głosowego,
obecność w transmitancji traktu głosowego zer charakterystycznych dla dźwięków nosowych, czyli nosowość fonemu,
stosunek energii składowych wysoko- i nisko-częstotliwościowych.
Cechy akustyczne wyznaczane są przez równoległy układ detektorów, a ich liczba powinna zapewnić jednoznaczne rozróżnienie wszystkich fonemów (stąd cechy te nazywa się wyróżniającymi lub dystynktywnymi).
Najważniejszy i najtrudniejszy jest etap segmentacji i indeksacji (klasyfikacji):
najpierw wyszukiwane są dyskretne w czasie fragmenty (segmenty) sygnału mowy, w których ich cechy akustyczne są stałe lub zmieniają się niewiele;
następnie przypisuje się tym segmentom zgodnie z wyznaczonymi cechami akustycznymi jeden lub więcej indeksów (symboli fonetycznych). Wykorzystuje się tutaj eksperymentalnie wyznaczone wzory odniesienia (reference pattern) dla wszystkich rozpoznawanych jednostek fonetycznych. Wzory odniesienia najczęściej mają postać wiedzy o występowaniu lub braku jakichś cech albo wartości progowych lub wzajemnych zależności (proporcji) zmierzonych wcześniej cech akustycznych.
Aby prawidłowo rozpoznać mowę niezbędny jest jeszcze jeden krok zwany sterowaniem rozpoznawaniem, w którym do wyznaczenia końcowego wyniku wykorzystuje się wiedzę o ograniczeniach realizowanego zadania rozpoznawania mowy (słowa muszą pochodzić ze słownika właściwego dla zadania, ciągi słów spełniać reguły syntaktyki i semantyki właściwe dla gramatyki języka).
Próbę indeksowania segmentów sklasyfikowanych jako samogłoski ilustruje rys. 2. Do rozróżnienia samogłosek wykorzystano trzy parametry: częstotliwość pierwszego formantu F1, częstotliwość drugiego formantu F2 oraz długość (czas trwania) segmentu D. Jak widać nie wystarczają one do jednoznacznego rozróżnienia samogłosek `a' oraz `o', a także `i' oraz `y'.
Rys. 2
W rozpoznawaniu akustyczno - fonetycznym w sposób naturalny znalazły zastosowanie metody klasyfikowania fonemów za pomocą drzewa binarnego - teoria cech wyróżniających (distinctive feature).
Zasada rozpoznawania: podział dychotomiczny zbioru fonemów
Każdy z fonemów jest reprezentowany przez co najwyżej 12 cech akustycznych o wartościach binarnych (np. dźwięczność, wybuchowość, szumowość, nosowość, ciągłość itd.).
Ten binarny podział jest powtarzany aż do momentu, kiedy podzbiór będzie jednoelementowy, czyli rozpoznawany pojedynczy fonem zostanie jednoznacznie zakwalifikowany.
Zasada podziału fonemów (dla języka angielskiego) przedstawia rys. 3.
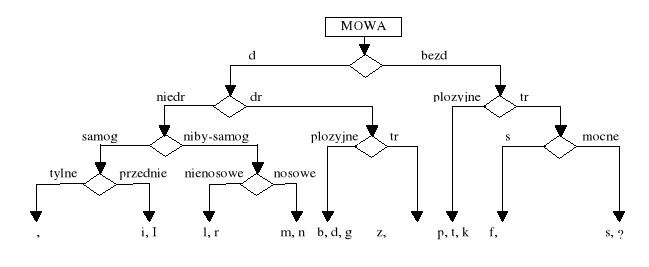
Rys. 3
Jakość indeksacji mierzona jest wskaźnikiem dopasowania, który może mieć sens prawdopodobieństwa. Zwykle indeksacja jest niejednoznaczna, gdyż jednemu segmentowi przypisywany jest więcej niż jeden symbol fonetyczny. Wówczas wynikiem tego etapu rozpoznawania jest nie pojedyncza sekwencja, lecz sieć symboli fonetycznych z przypisanymi wartościami wskaźników dopasowania.
Przykładowy wynik etapu klasyfikacji w procesie automatycznego rozpoznawania liczb dwucyfrowych przedstawiony został na rys. 4 (zastosowano symbole transkrypcji fonetycznej). Jest to sekwencja czasowa zbiorów rozpoznanych z różną jakością fonemów - miarą jakości może być prawdopodobieństwo).
Rys. 4
Jednym z możliwych rozwiązań w analizowanym przykładzie jest słowo ŚEDEMNAŚĆE (czyli siedemnaście w transkrypcji gramatycznej). Innym możliwym rozwiązaniem jest słowo JEDENAŚĆE (jedenaście). Oznacza to, że wynik rozpoznania mowy w przykładzie jest niejednoznaczny, chociaż pierwszy z nich jest bardziej prawdopodobny (lepiej dopasowany do sygnału wejściowego).
Metody akustyczno-fonetyczne automatycznego rozpoznawania mowy są interesującą ideą, ponieważ umożliwiają rozpoznawanie sygnału mowy w czasie rzeczywistym, bez konieczności wcześniejszego tworzenia modeli rozpoznawanych jednostek fonetycznych. Jednak mimo ponad 40 lat ich rozwijania, są trudne do praktycznej realizacji i wymagają jeszcze rozległych badań oraz głębszego zrozumienia problemów.
Problem segmentacji początkowo omijano zakładając, że rozpoznawane są słowa izolowane (proces został nazwany dopasowywaniem słów).
Jedną z pierwszych prób zbudowania urządzenia rozpoznającego wykorzystującego wzory akustyczne podjęto w 1952 r. w Bell Laboratories: urządzenie rozpoznające cyfry wypowiadane w sposób izolowany przez określonego mówcę (rys. 5). Podstawą rozpoznawania był utworzony (w procesie uczenia) dla każdej cyfry wzorzec odniesienia, będący trajektorią formantów pierwszego F1 (z zakresu częstotliwości 200-800 Hz) i drugiego F2 (z zakresu częstotliwości 500-2500 Hz), zapisaną w tablicy o wymiarach 6x5. Częstotliwości formantów F1 i F2 były aproksymowane na podstawie zliczanej liczby przejść przez zero sygnału mowy. Dodatkowo wyznaczany był czas przebywania trajektorii w każdym elemencie tablicy.
Rys. 5.
Metoda rozpoznawania wzorów
W metodzie rozpoznawania wzorów (pattern-recognition approach) do rozpoznawania mowy wykorzystuje się wzory (próbki), będące najczęściej sekwencją obserwacji pozyskiwanych z segmentów wydzielanych z sygnału mowy za pomocą okna o stałej długości.
W przeciwieństwie do metod akustyczno - fonetycznych nie wyznacza się charakterystyk akustycznych związanych ze sposobem wytwarzania sygnału mowy, jak również nie wydziela się z sygnału mowy segmentów odpowiadających jednostkom fonetycznym.
Strukturę systemów rozpoznawania mowy metodą rozpoznawania wzorów zilustrowano na rys. 6.
Charakterystyczne dla systemów rozpoznawania mowy metodą rozpoznawania wzorów są dwa tryby pracy: „tryb uczenia” (treningowy), w którym z wypowiedzi uczących pozyskuje się zbiór wzorów odniesienia i „tryb rozpoznawania”, w którym pozyskiwany z rozpoznawanej wypowiedzi wzór testowy jest porównywany z każdym wzorem odniesienia.
Liczność zbioru wzorów odniesienia w każdym miejscu wypowiadanego zdania może być zmniejszana np. drogą wykorzystywania reguł prostej gramatyki o skończonej liczbie stanów do rozpoznawania kolejnych jednostek fonetycznych.
Identyfikacja wzoru odniesienia najlepiej dopasowanego do wzoru testowego stanowi wynik rozpoznawania.
Rys. 6.
Wynikiem rozpoznawania mowy, zwykle niejednoznacznym, w pierwszym jego etapie jest sekwencja symboli fonetycznych, a w drugim, wyraz czy fraza. Zastosowanie różnych reguł (ograniczeń) gramatyki pozwala na zmniejszenie niepewności rozpoznawania również w procesie budowania rozpoznanej sekwencji symboli fonetycznych, wyrazu czy frazy.
Metoda rozpoznawania wzorów jest chętnie stosowana z powodu jej prostoty, odporności na zakłócenia ze strony środowiska oraz niezależności na zmiany słownictwa, zbioru charakterystyk, algorytmów porównywania i reguł decyzyjnych. Liczne jej aplikacje pokazały wysoką skuteczność w realizacji zadania automatycznego rozpoznawania mowy.
Kluczem do sukcesu w tej metodzie rozpoznawania jest proces porównywania wzorów testowych i odniesienia.
Dość wcześnie zaczęto stosować technikę zwaną liniową normalizacją czasową, która pozwoliła przezwyciężyć trudności związane ze zmiennością czasu trwania wymawianych słów. Długości wzorów były normalizowane do standardowego czasu trwania drogą wydłużania (skracania) przez zastosowanie wyznaczonego rozszerzenia (kompresji) skali czasu równomiernie dla całej próbki. Porównanie otrzymanych w ten sposób wzorów o stałej długości polega na obliczeniu odległości euklidesowej między tymi wzorami.
Stopniowo uświadomiono sobie, że proste dopasowanie próbek akustycznych (acoustic patterns) jest niewystarczające. Próbki akustyczne wymawianych słów cechowały się dużym zróżnicowaniem (i to zarówno dla próbek pochodzących od różnych mówców, jak i od tego samego mówcy).
Jednym z pierwszych urządzeń pracującym poprawnie z wieloma mówcami był system rozpoznawania samogłosek zbudowany w MIT Lincoln Laboratories (1959).
Zastosowano częstotliwość tonu podstawowego (pitch frequency) wyznaczaną dla każdego z mówców do normalizacji częstotliwości formantów, otrzymywanych za pomocą 35-kanałowego banku filtrów, zarówno uśrednionych wzorców odniesienia jak i rozpoznawanych fonemów.
Normalizację czasu trwania próbek zastosowano w urządzeniu zbudowanym przez Denesa i Mathews (1960): wzorce odniesienia były tworzone (jako wartość średnia 17-kanałowego analizatora widma) z wielu wypowiedzi każdego słowa, proces rozpoznawania zaczynał się od normalizacji czasu trwania próbek sygnału rozpoznawanego.
Powstawały również realizacje sprzętowe:
- w Radio Research Lab w Tokio (1961): urządzenie rozpoznawania samogłosek (analizator widma wykorzystujący bank filtrów, którego wyjścia podane na układ logiczny, podejmujący decyzję o rozpoznanej samogłosce;
- w NEC Laboratories (1963): stanowiły one początek wielce skutecznego programu badawczego w zakresie rozpoznawania mowy w NEC;
W tym samym czasie podjęto próby rozpoznawania nie tylko samogłosek i cyfr.
Wymagało to segmentowania sygnału mowy na jednostki fonetyczne, takie jak fonemy. Jest to trudny do wykonania proces, ponieważ zwykle dźwięki mowy łączą się płynnie z sąsiednimi i trudno wyznaczyć ich granice.
W latach 60-tych zainicjowano trzy kluczowe projekty badawcze, które miały ogromny wpływ na badania i rozwój rozpoznawania mowy w następnych latach:
w RCA Laboratories (1964): rozwiązał problem nierównomierności skali czasu w sygnale mowy poprzez wykorzystanie zbioru prostych metod normalizacji czasowej, bazujących na możliwości dokładnego wykrycia początku i końca sygnału mowy;
W tym samym czasie w ZSRR Vinczuk (1968) zaproponował zastosowanie metod programowania dynamicznego do czasowego dopasowania pary wypowiedzi słownych; na Zachodzie wyniki ujrzały światło dzienne dopiero w latach 80-tych;
Kolejnym osiągnięciem lat 60-tych były pionierskie badania Reddy'ego (1966) w rozpoznawaniu mowy ciągłej wykorzystującego dynamiczne śledzenie fonemów. Badania te zapoczątkowały długi i udany program badań rozpoznawania mowy na Carnegie Mellon University, który do dzisiaj pozostaje światowym liderem w systemach rozpoznawania mowy ciągłej.
Próbowano również zastosować do rozpoznawania wzorców mowy sztuczne neurony i elementy z progiem adaptacyjnym - Talbert (1963) i Nelson (1967).
Zastosowanie wiedzy lingwistycznej (linguistic approach): pierwsze próby ignorowały wiedzę lingwistyczną, wyjątkiem był system zbudowany przez Fry i Denes (1958) z University College w Anglii; ich system rozpoznawał cztery samogłoski i dziewięć spółgłosek; wykorzystywał oprócz analizatora widma i urządzenia dopasowania wzorców także zgromadzone dane statystyczne o częstości występowania sekwencji fonemów języka angielskiego; zastosowanie tej najprostszej wiedzy o składni języka zwiększyło prawie dwukrotnie poziom rozpoznawania słów zawierających co najmniej dwa fonemy.
W latach 70-tych badania osiągnęły wiele znaczących wyników. Przede wszystkim rozpoznawanie wypowiedzi izolowanych lub dyskretnych stało się wykonalne i użyteczne.
Przyczynili się do tego:
- Veliczko i Zagorujko z Rosji, którzy zastosowali idee rozpoznawania wzorców do rozpoznawania mowy,
- Sakoe i Chiba z Japonii, którzy pokazali jak można skutecznie zastosować metody programowania dynamicznego;
- oraz Itakura z USA, którego badania pokazały jak idee liniowego kodowania predykcyjnego (LPC), wcześniej zastosowanego do oszczędnego kodowania mowy, mogą być rozszerzone w systemach rozpoznawania mowy poprzez zastosowanie odpowiednich miar odległości, bazujących na parametrach widmowych LPC.
Również w latach 70-tych rozpoczęła swoją długoletnią działalność na polu rozpoznawania mowy z obszernego słownika grupa badaczy w IBM.
W końcu w AT&T Bell Labs rozpoczęto serię eksperymentów, których celem było zbudowanie systemu rozpoznawania mowy naprawdę niezależnego od mówcy. Aby to osiągnąć zastosowano złożone algorytmy grupowania do określenia liczby różnych wzorców wymaganych do reprezentowania wszystkich odmian różnych słów dla obszernej populacji użytkowników. Badania były prowadzone przez ponad dziesięć lat i w rezultacie techniki tworzenia wzorców niezależnych od mówcy są obecnie dobrze rozpoznane i szeroko stosowane.
W latach 80-tych badania skupiły się głównie na problematyce rozpoznawania słów połączonych.
Celem tych badań było stworzenie odpornego systemu zdolnego do rozpoznawania płynnie wymawianych łańcuchów słów (np. cyfr), bazującego na dopasowaniu połączonych wzorców pojedynczych słów. Sformułowano i zastosowano wiele rozmaitych algorytmów rozpoznawania słów połączonych.
Badania dotyczące mowy w latach 80-tych charakteryzowały się przejściem od technologii wykorzystujących szablony do metod modelowania statystycznego, w szczególności do modeli ukrytych Markowa.
Na początku metodologia HMM opanowana w kilku laboratoriach (IBM, Institute for Defense Analyses, Dragon Systems); od połowy lat 80-tych, po publikacjach o metodach i teorii HMM, jest wykorzystywana w praktycznie wszystkich laboratoriach na świecie.
W końcu lat 80-tych powróciła do łask idea zastosowania sztucznych sieci neuronowych do rozpoznawania mowy, pojawiło się kilka nowych systemów.
W latach 80-tych DARPA (Defense Advanced Research Project Agency) finansowała prace nad systemem rozpoznawania mowy ciągłej dla 1000-wyrazowego słownika w zadaniu zarządzania bazą danych. Program DARPA jest kontynuowany dla zadania rozpoznawania mowy naturalnej w serwisie informacji o lotach. Inny, coraz powszechniejszy kierunek prac to rozpoznawanie mowy w sieciach telefonicznych w celu automatyzacji i doskonalenia usług operatorskich.
Metody sztucznej inteligencji
sztuczna inteligencja, system ekspertowy
(artificial intelligence, expert system)
Wiedza była pozyskiwana z różnych źródeł. Sygnał zawiera wiedzę:
akustyczną, dotyczącą sygnału fizycznego,
fonetyczną, dotyczącą dźwięków języka,
leksykalną, dotyczącą słów języka,
syntaktyczną, dotyczącą gramatyki,
semantyczną, dotyczącą znaczenia,
pragmatyczną, dotyczącą dziedziny zadań i aplikacji.
Na początku lat 70-tych uważano, że zastosowanie takiej wiedzy pomoże rozwiązać problem rozpoznawania zdań i dłuższych fragmentów mowy. W USA główny wysiłek, wspierany przez ARPA, skierowano na pokonanie problemów rozpoznawania mowy ciągłej. Wszystkie urządzenia rozpoznające mowę oczywiście wykorzystywały wiedzę akustyczną, lecz w tym czasie przestała być ona najważniejsza.
Niemal obowiązkowe stało się wykorzystywanie wiedzy o słowniku - należy znać strukturę każdego słowa w słowniku, wyrażoną jako sekwencja fonemów. Do systemu opracowanego przez Greena i Ainswortha (1972) włączono liczący 1000 słów Basic English Dictionary. Ta wiedza, wraz ze wskaźnikami prawdopodobnych błędów w rozpoznawaniu fonemów, była wykorzystana do dekodowania sekwencji słów z sekwencji fonemów, zawierających błędy wtrącania, opuszczania i zamiany.
Wymowa słów i fonemów zmienia się zależnie od ich sąsiedztwa. Zasady fonetyczne, które opisują te zmiany, mogą być wykorzystywane do ulepszenia urządzeń rozpoznających mowę (Oshika, 1974). Również charakterystyki prozodyczne, pozyskiwane z obserwacji zmian częstotliwości podstawowej, a także energia oraz parametry dźwięczności sygnału mowy mogą być wykorzystane w systemach rozpoznawania mowy (Lea, 1973).
Z kolei wiedzę syntaktyczną wykorzystał w urządzeniu rozpoznawania mowy Tappert (1974). Procesor akustyczny tworzył zakłóconą transkrypcję fonetyczną, z której formowana była struktura (w postaci drzewa), reprezentująca możliwe dopasowania sekwencji słów do tej transkrypcji. Do wyboru najbardziej prawdopodobnej ścieżki w tym drzewie zastosowano ograniczenia syntaktyczne. Dla słownika 250 słów i gramatyki o skończonej liczbie stanów, uzyskano prawidłowe rozpoznanie zdań w 54 % przypadków, podczas gdy rozpoznanie słów było na poziomie 91 % (eksperyment przeprowadzono dla pojedynczego, wcześniej przeszkolonego mówcy).
Wiedzę semantyczną zastosował Woods (1975) w systemie rozumienia mowy SPEECHLIS. Była to sieć reprezentująca skojarzenia między słowami i pojęciami, np. rozpoznanie słowa „chemical” powodowało, że procesor semantyczny mógł sugerować poszukiwanie słów „analysis” i „element” w rozpoznawanym sygnale mowy.
Wiedzę pragmatyczną włączył Reddy (1973) do systemu o nazwie HEARSAY. W aplikacji tego systemu w programie gry w szachy stan szachownicy był wykorzystywany do określenia prawdopodobnych ruchów. Ta wiedza pozwalała na dedukcję zbioru prawdopodobnych wypowiedzi.
Większość systemów opracowanych w tym czasie stosowało oddzielne moduły dla każdego źródła wiedzy lingwistycznej. Problemem było połączenie tych różnych źródeł wiedzy. Rozpatrywano różne struktury łączące te moduły. Największym sukcesem była integracja różnych źródeł wiedzy w sieć - taki sposób zastosowano w systemach Dragon (Baker, 1975) i HARPY (Lowerre, 1976).
Podczas gdy głównym kierunkiem badań w tym okresie było wykorzystanie wiedzy lingwistycznej, ważne wydarzenia miały miejsce w innych dziedzinach. Urządzenie niezależnego od mówcy rozpoznawania cyfr (Sambur i Rabiner, 1975) automatycznie normalizowało parametry akustyczne. W teście, w którym wzięło udział 25 mężczyzn i 30 kobiet uzyskano poziom błędów 2,7 % dla dobrych warunków akustycznych i 5,6 % w zakłóconej sali komputerowej.
Najistotniejsze było to, że urządzenie rozpoznawania mowy znane pod nazwą Threshold Technology VIP-100 (Ackroyd, 1974) osiągnęło poziom, umożliwiający mu wejście na rynek. Dedykowany dla indywidualnego użytkownika system miał słownik składający się z 32 słów lub fraz i osiągnął poziom rozpoznawania 100 % dla fonetycznie różnorodnych słów.
Podczas ostatnich dwóch dekad zainteresowanie automatycznym rozpoznawaniem mowy wzrosło ogromnie - dotyczy to zarówno badań w laboratoriach jak i aplikacji dostępnych na rynku. U podstaw tych prac nie leży żadne szczególne podejście teoretyczne, ale zastosowano wiele bardziej zaawansowanych matematycznie algorytmów.
Główny postęp w rozpoznawaniu słów izolowanych osiągnięto po zastosowaniu algorytmów programowania dynamicznego. Umożliwiło to wprowadzenie nieliniowego w czasie dopasowanie sygnału do próbek odniesienia. Algorytm programowania dynamicznego zastosowali Veliczko i Zalgorujko (1970) w systemie rozpoznawania 200 słów rosyjskich z 5 % błędem. Również Sakoe i Chiba (1978) optymalizowali algorytmy programowania dynamicznego, osiągając 0,2 % poziom błędu dla japońskich cyfr. Później Sakoe (1979) rozpatrywał dwupoziomowy algorytm programowania dynamicznego jako sposób na rozpoznawanie sekwencji połączonych cyfr (dokładność rozpoznawania: 99,6 % w systemie NEC DP200). Bardziej efektywny algorytm został opracowany przez Bridle'a i Browna (1979) dla systemu LOGOS.
Wiele algorytmów bazowało na modelach stochastycznych, dających zachęcające wyniki (Jelinek, 1976). System bazujący na modelach HMM został opracowany przez Levinsona (1983) - proces uczenia wykorzystywał 1000 cyfr wypowiedzianych przez 50 kobiet i 50 mężczyzn, poziom poprawnego rozpoznawania osiągnął 96 %. Także rynkowe systemy Verbex 1800 i Dragon System bazowały na HMM.
Klatt (1977) zbudował system bazujący na jednostkach fonetycznych, w którym wszystkie możliwe wypowiedzi są reprezentowane jako ścieżka przez sieć. De Mori i Laface (1980) zastosowali algorytmy zbiorów rozmytych do etykietowania fonetycznego mowy ciągłej. Dla języka francuskiego Mercier (1980) opracował system rozumienia mowy KEAL, a dla języka niemieckiego Niemann (1982) system rozpoznawania mowy ciągłej.
W Polsce: publikowane prace nad automatycznym rozpoznawaniem mowy pojawiły się w połowie lat 60-tych.
Prace były powadzone najpierw w oddziałach warszawskim i poznańskim Instytutu Podstawowych Problemów Techniki PAN, a później w AGH, Politechnice Wrocławskiej i Politechnice Poznańskiej. Dotyczyły teorii automatycznego rozpoznawania mowy, rozpoznawania fonemów, słów z ograniczonego słownika.
Nazwiska:
R. Gubrynowicz W. Jassem, J. Kacprowski J. Motylewski R. Tadeusiewicz Cz. Basztura J Jurkiewicz, E. Tyburycy S. Grocholewski
A obecnie?
Program DARPA: systemy rozpoznawania mowy ciągłej i spontanicznej, z obszernego słownika, z wysoką niezawodnością (ATIS, transkrypcja audycji z wiadomościami, SWITCHBOARD); integracja systemów transkrypcji z wydzielaniem i wyszukiwaniem informacji; maszynowe wykrywanie, ekstrakcja, streszczanie i tłumaczenie ważnych informacji dźwiękowych, ich transkrypcja gramatyczna.
Rozpoznawanie odporne mowy (niezgodność między warunkami uczenia i testowania: zakłócenia tła, mikrofony, różne głosy, kanały transmisji)
Rozpoznawanie mowy spontanicznej - 5-letni program w Japonii
Multimodalne rozpoznawanie mowy - łączenie informacji dźwiękowej i wizualnej
Systemy dialogowe (miary pewności rozpoznawania mowy)
7
Wyszukiwarka
Podobne podstrony:
Techniki analizy sygnału mowy, Wisniewski.Andrzej, Analiza.Obrazow.I.Sygnalow, Materialy
T1 Rys Wytwarzanie, Wisniewski.Andrzej, Analiza.Obrazow.I.Sygnalow, Materialy
Przegląd stanu technologii języka naturalnego, Wisniewski.Andrzej, Analiza.Obrazow.I.Sygnalow, Mater
Pomaranska Bielecka M Wisniewski M 2010 Analiza przepisow prawa definiujacych
RYS AUTOMATYKA
Grochola Katarzyna, Wiśniewski Andrzej Gry i zabawy małżeńskie i pozamałżeńskie
C3 4 Analiza widmowa sygnalow czasowych
Japońskie techniki inwestycyjne, Analiza techniczna i fundamentalna, Analiza techniczna i fundamenta
UzupeLnienie do szybkich metod mikrobiologicznej analizy żywności, Studia - materiały, semestr 4, Mi
Analiza i przetwarzanie sygnałów1
Analiza ekonomiczna Wyk, materiały ekonomia UWM, Analiza Ekonomiczna
Analiza ekonomiczna bezwskaznikow, materiały ekonomia UWM, Analiza Ekonomiczna
Szybka analiza amfetaminy w ludzkim materiale biologicznym z wykorzystaniem metody mikroekstrakcj
Sprawozdanie SKM Analiza komunikatów sygnalizacyjnych na styku S w sieciach ISDN
Cw 2 analiza czasowa sygnalow wibroakustycznych
pps 1 analiza zdeterminowanych sygnałów analogowych
analizator widma sygnału
4 aws, aws p, Analiza widmowa sygnałów
Proces analizy rentowności przedsiębiorstwa, materiały liceum i studia, WSZiB Kraków, Analiza finans
więcej podobnych podstron