

http://www.ddj.com
#369 FEBRUARY 2005
PROGRAMMER
SOFTWARE
TOOLS FOR THE
PROFESSIONAL
Dr Dobbs
,
.
Dr.Dobbs
,
O U R N A L
J
SOFTWARE
TOOLS FOR THE
PROFESSIONAL
PROGRAMMER
WEB SERVICES
WEB SERVICES
The Java Web Services
Developer Pack
Amazon.com
Web Services
&
Ruby
GIS Web Services
&
MS Word
SOAs
&
ESBs
Building the
DDJ
Eclipse Web Search Plug-In
The Java Web Services
Developer Pack
Amazon.com
Web Services
&
Ruby
GIS Web Services
&
MS Word
SOAs
&
ESBs
Building the
DDJ
Eclipse Web Search Plug-In
Automating
Localization
Java
Cryptography
&
X.509
Authentication
Algorithms
For
Dynamic
Shadows
Extending
UML
Inside the
uIP Stack
Automating
Localization
Java
Cryptography
&
X.509
Authentication
Algorithms
For
Dynamic
Shadows
Extending
UML
Inside the
uIP Stack
Enhancing .NET Web Services
Report Services
&
ASP.NET
Whidbey C++ Syntax
Enhancing .NET Web Services
Report Services
&
ASP.NET
Whidbey C++ Syntax
DR. DOBB’S JOURNAL (ISSN 1044-789X) is published monthly by CMP Media LLC., 600 Harrison Street, San Francisco, CA 94017; 415-947-6000. Periodicals Postage Paid at San Francisco and at
additional mailing offices. SUBSCRIPTION: $34.95 for 1 year; $69.90 for 2 years. International orders must be prepaid. Payment may be made via Mastercard, Visa, or American Express; or via U.S.
funds drawn on a U.S. bank. Canada and Mexico: $45.00 per year. All other foreign: $70.00 per year. U.K. subscribers contact Jill Sutcliffe at Parkway Gordon 01-49-1875-386. POSTMASTER: Send
address changes to Dr. Dobb’s Journal, P.O. Box 56188, Boulder, CO 80328-6188. Registered for GST as CMP Media LLC, GST #13288078, Customer #2116057, Agreement #40011901. INTERNATIONAL
NEWSSTAND DISTRIBUTOR: Worldwide Media Service Inc., 30 Montgomery St., Jersey City, NJ 07302; 212-332-7100. Entire contents © 2005 CMP Media LLC.
Dr. Dobb’s Journal
is a registered trademark of CMP Media LLC. All rights reserved.
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
5
C O N T E N T S
FEBRUARY 2005 VOLUME 30, ISSUE 2
NEXT MONTH:
The future is
here, as we March into the
world of 64-bit computing.
F E A T U R E S
Java Web Services & Application Architectures
16
by Eric J. Bruno
Eric use the Java Web Service Developer Pack to build a financial portal.
SOAs & ESBs
24
by James Pasley
James examines Service-Oriented Architectures and the role of the Enterprise Service Bus when deploying SOAs.
Ruby/Amazon & Amazon Web Services
30
by Ian MacDonald
The Ruby/Amazon toolkit is a high-level abstraction of Amazon Web Services for the Ruby programming language.
GIS Web Services and Microsoft Word
36
by Keith Bugg
Here’s a Geographical Information Systems application that lets you embed a map into a Microsoft Word document.
Java Cryptography & X.509 Authentication
40
by Snezana Sucurovic and Zoran Jovanovic
Our authors use the Java Crypto API to implement X.509 authentication in a distributed system.
Building an Eclipse Web-Search Plug-In
43
by Michael Pilone
This Eclipse plug-in lets you search DDJ’s online archives.
Automating Localization
47
by Hew Wolff
Converting existing systems to local languages can be a laborious process — making it ideal for automation.
Algorithms for Dynamic Shadows
50
by Sergei Savchenko
Geometrically correct dynamic graphic shadows can add realism to your graphical applications.
Extending UML
56
by Timothy E. Meehan and Norman Carr
Extended Activity Semantics (XAS) notation lets you model user interactions by extending UML.
Integrating Reporting Services into ASP.NET
S1
by David Lloyd
David designs and deploys a report using Reporting Services, a free add-on to SQL Server 2000.
New Syntax C++ in .NET Version 2
S6
by Richard Grimes
Richard examines how generics are declared in Whidbey C++ and how they relate to C++ templates.
Enhancing .NET Web Services
S12
by Eric Bergman-Terrell
SoapEx demonstrates how you can modify SOAP requests/responses and debug web-service calls with a network
packet analyzer.
E M B E D D E D S Y S T E M S
Inside the uIP Stack
61
by Drew Barnett and Anthony J. Massa
uIP lets you to add network support to small form factor, DSP-based embedded systems.
C O L U M N S
Programming Paradigms
66
by Michael Swaine
Embedded Space
69
by Ed Nisley
Chaos Manor
72
by Jerry Pournelle
Programmer’s Bookshelf
77
by Martin Heller
F O R U M
EDITORIAL
8
by Jonathan Erickson
LETTERS
10
by you
Dr. Ecco's
Omniheurist Corner
12
by Dennis E. Shasha
NEWS & VIEWS
14
by Shannon Cochran
OF INTEREST
78
by Shannon Cochran
SWAINE’S FLAMES
80
by Michael Swaine
R E S O U R C E
C E N T E R
As a service to our readers, source
code, related files, and author
guidelines are available at http://
www.ddj.com/. Letters to the
editor, article proposals and
submissions, and inquiries can
be sent to editors@ddj.com, faxed
to 650-513-4618, or mailed to Dr.
Dobb’s Journal, 2800 Campus
Drive, San Mateo CA 94403.
For subscription questions, call
800-456-1215 (U.S. or Canada). For
all other countries, call 902-563-4753
or fax 902-563-4807. E-mail sub-
scription questions to ddj@neodata
.com or write to Dr. Dobb’s Journal,
P.O. Box 56188, Boulder, CO 80322-
6188. If you want to change the
information you receive from CMP
and others about products and
services, go to http://www.cmp
.com/feedback/permission.html or
contact Customer Service at the
address/number noted on this page.
Back issues may be purchased
for $9.00 per copy (which in-
cludes shipping and handling).
For issue availability, send e-mail
to orders@cmp.com, fax to 785-
838-7566, or call 800-444-4881
(U.S. and Canada) or 785-838-
7500 (all other countries). Back
issue orders must be prepaid.
Please send payment to Dr.
Dobb’s Journal, 4601 West 6th
Street, Suite B, Lawrence, KS
66049-4189. Individual back articles
may be purchased electronically at
http://www.ddj.com/.

P U B L I S H E R
E D I T O R - I N - C H I E F
Michael Goodman
Jonathan Erickson
E D I T O R I A L
MANAGING EDITOR
Deirdre Blake
MANAGING EDITOR, DIGITAL MEDIA
Kevin Carlson
SENIOR PRODUCTION EDITOR
Monica E. Berg
NEWS EDITOR
Shannon Cochran
ASSOCIATE EDITOR
Della Wyser
ART DIRECTOR
Margaret A. Anderson
SENIOR CONTRIBUTING EDITOR
Al Stevens
CONTRIBUTING EDITORS
Bruce Schneier, Ray Duncan, Jack Woehr, Jon Bentley,
Tim Kientzle, Gregory V. Wilson, Mark Nelson, Ed Nisley,
Jerry Pournelle, Dennis E. Shasha
EDITOR-AT-LARGE
Michael Swaine
PRODUCTION MANAGER
Douglas Ausejo
I N T E R N E T O P E R A T I O N S
DIRECTOR
Michael Calderon
SENIOR WEB DEVELOPER
Steve Goyette
WEBMASTERS
Sean Coady, Joe Lucca
A U D I E N C E D E V E L O P M E N T
AUDIENCE DEVELOPMENT DIRECTOR
Kevin Regan
AUDIENCE DEVELOPMENT MANAGER
Karina Medina
AUDIENCE DEVELOPMENT ASSISTANT MANAGER
Shomari Hines
AUDIENCE DEVELOPMENT ASSISTANT
Melani Benedetto-Valente
M A R K E T I N G / A D V E R T I S I N G
MARKETING DIRECTOR
Jessica Hamilton
ACCOUNT MANAGERS see page 79
Michael Beasley, Cassandra Clark, Ron Cordek,
Mike Kelleher, Andrew Mintz, Erin Rhea,
SENIOR ART DIRECTOR OF MARKETING
Carey Perez
DR. DOBB’S JOURNAL
2800 Campus Drive, San Mateo, CA 94403
650-513-4300. http://www.ddj.com/
CMP MEDIA LLC
Gary Marshall President and CEO
John Day Executive Vice President and CFO
Steve Weitzner Executive Vice President and COO
Jeff Patterson Executive Vice President, Corporate Sales &
Marketing
Mike Mikos Chief Information Officer
William Amstutz Senior Vice President, Operations
Leah Landro Senior Vice President, Human Resources
Mike Azzara Vice President/Group Director Internet Business
Sandra Grayson Vice President & General Counsel
Alexandra Raine Vice President Communications
Robert Faletra President, Channel Group
Vicki Masseria President CMP Healthcare Media
Philip Chapnick Vice President, Group Publisher Applied
Technologies
Michael Friedenberg Vice President, Group Publisher
InformationWeek Media Network
Paul Miller Vice President, Group Publisher Electronics
Fritz Nelson Vice President, Group Publisher Network
Computing Enterprise Architecture Group
Peter Westerman Vice President, Group Publisher Software
Development Media
Joeseph Braue Vice President, Director of Custom Integrated
Media Solutions
Shannon Aronson Corporate Director, Audience Development
Michael Zane Corporate Director, Audience Development
Marie Myers Corporate Director, Publishing Services
PROGRAMMER
SOFTWARE
TOOLS FOR THE
PROFESSIONAL
Dr.Dobbs
,
O U R N A L
J
American Buisness Press
Printed in the
USA
6
Dr. Dobb’s Journal, February 2005
http://www.ddj.com

I
n the spirit of “if it was important enough to mention once, it’s worth mentioning twice,” it’s time
to look back and catch up on some of the items I’ve previously wasted this space on.
In the November 2004 issue, for instance, I talked about how Teresis (a Los Angeles-based
provider of digital workflow solutions for television) and Rapidtext (a national transcription services
company) teamed up to bring jobs to Marshall, Missouri. As it turns out, the Marshall Plan isn’t the
only kid on the back forty, at least in terms of outsourcing jobs to rural America. Rural Sourcing Inc.
(http://www.ruralsource.com/) is a Jonesboro, Arkansas, startup founded in 2003 with the goal of
supporting economic expansion by creating high-technology employment opportunities in rural
America. Rural Sourcing, founded by Kathy White (former CIO of Cardinal Health, one of
Information Week’s top 10 CIOs in 1997, and former associate professor of information technology at
the University of North Carolina, Greensboro), has set up two facilities in Arkansas, one in New
Mexico, and a soon-to-be-opened operation in North Carolina.
In March 2002, I looked at the prospects of wind-generated electricity. At the time, wind turbines in
the U.S. were generating about 4500 megawatts of electricity. The good news is that, by the end of
2003, U.S. capacity reached 6374 megawatts, and utility wind-power projects underway will create
another 3000 megawatts of wind capacity in the U.S. over the next five years. According to some
estimates, producing more than 1 million megawatt-hours of electricity by the 170 wind turbines at
three-year-old Gray County Wind Farm in Montezuma, Kansas, alone would have required 606,000 tons
of coal, or more than 12 billion cubic feet of natural gas. Moreover, fossil-fuel plants generating the
same amount of electricity would have released into the air 1 million tons of carbon dioxide, 2650 tons
of sulfur dioxide, 2170 tons of nitrogen oxides, and 52 pounds of mercury.
In October 2004, I pointed out that iTunes downloads were pushing iPod sales, while iPods sales
were driving Macintosh sales. More interestingly, iPods seemed to be propelling the migration of
Windows users to Macs. According to a survey by financial firm Piper Jaffray, this trend is continuing,
with 6 percent of iPod users switched from Windows-based PCs to Macs, and another 7 percent
saying they are planning to. Factors influencing the decision to switch include ease of use, the
entertainment value, and the perception of better security.
Last month, I prattled on about how new programming languages seemed to pop up all the time.
While Caml, Delphi, and Python aren’t new, there is news about them. For starters, Borland has
recently released Delphi 2005 (http://www.borland.com/delphi/), which lets you target both Win32
and .NET. Second, Python 2.4 (http://www.python.org/2.4/) has finally been released with a boatload
of new features, ranging from decimal data types to multiline imports. Third, it’s okay to admit that
you don’t know much about Caml, a functional language developed in 1984 by INRIA (a French
computer science research institute). However, you can learn more about it in Developing
Applications with Objective Caml,
a book by Emmanuel Chailloux, Pascal Manoury, and Bruno
Pagano that was recently translated into English from French and made freely available in PDF or
HTML format (http://caml.inria.fr/oreilly-book/).
Also in the January 2005 issue, I made reference to a recent DDJ survey. In truth, we routinely
participate in a number of studies. The NOP/CMP Professional Developer Panel, for instance, surveys
several hundred software engineers, many of whom are DDJ readers. To me, one of the more
interesting factoids that turned up was that 84 percent of the respondents agreed with the statement
that “open-source tools are an important addition to my toolkit,” and 95 percent concurred that “open
source is here to stay.” What was reassuring, however, was that this exuberance for open source was
tempered by realism, in that only 40 percent agreed that “in an ideal world, all software would be
open source,” while 98 percent “prefer using both open source and proprietary software.”
As for programming languages, C/C++ was the language used professionally by 61 percent of
those surveyed, SQL by 55 percent, Java by 44 percent, Perl by 28 percent, and C# by 23 percent.
This study was generally in sync with the TIOBE Programming Community Index
(http://www.tiobe.com/tiobe_index/tekst.htm), which attempts to gauge language popularity via
Google and Yahoo! searches. According to a recent TPC Index, C held the top spot for languages
with a 17.9 percent rating, followed by Java with 14.8 percent, C++ with 13.8 percent, Perl with 9.7
percent, SQL with 3.0 percent, and C# with 1.5 percent. (Note that I’ve abbreviated the TPC list for
purposes of comparison.)
Finally, in July 2004, I mentioned that “SOCOM II: U.S. Navy SEALs” was my current favorite online
PlayStation2 game. Still is. Okay, I’ve tried “Red Dead Revolver,” “Star Wars: Battlefront,” and “MVP
Baseball 2004” (and I still can’t hit a curve ball, let alone throw one). That said, “Tom Clancy’s Ghost
Recon 2,” with its over-the-shoulder camera view and great graphics, looks promising. I’ll let you
know the next time I catch up and look back.
Looking Back,
Catching Up
Jonathan Erickson
editor-in-chief
jerickson@ddj.com
E D I T O R I A L
8
Dr. Dobb’s Journal, February 2005
http://www.ddj.com

Ed’s Shibboleth
Dear DDJ,
I’d like to offer a different perspective on
Ed Nisley’s “Shibboleth” column in the
April 2004 issue. I’ve been working in the
tech industry, first as a UNIX (mostly
SunOS/Solaris) system administrator and
later as a web application programmer,
for 11 years, in the Silicon Valley.
It seems to me that there are some shib-
boleths that distinguish between east coast
and west coast techies, because my ex-
perience differs somewhat from Ed’s in a
few respects:
• I’ve never heard anyone say “bine” for
/bin, and “libe” for /lib is very rare in
my experience. It’s always “bin” and al-
most always “lib.”
• I don’t see any distinction in the way
“G” is pronounced in “GNU” versus
“GNOME” versus “GNUPLOT.”
• SQL is nearly always “see’ kwel” out
here. I work at Oracle, but MS Sequel
Server and My Sequel are pronounced
that way, too. (Side note: San Carlos Air-
port, a general aviation airport just one
freeway exit south of Oracle’s HQ cam-
pus, has the airport code SQL. But it
had that code (due to the city name)
before Oracle existed, and Larry uses
San Jose anyway…).
• The GIF debate was settled by Com-
puServe years ago, “jiff.” But the hard
“g” still lingers on in some circles.
• Would anyone actually pronounce
“coax” as “cokes”? (shudder) Yes, that
is a true shibboleth.
• 68030 is simple: “six’-tee-ate-oh-three-
oh.” But I see Ed’s point.
And a few things Ed’s column made me
think of:
• Another shibboleth: / is often pro-
nounced “back’-slash” erroneously by
nontechies. It drives me nuts because
that’s what \ is called. I’m surprised he
didn’t mention that one.
• I’d love to see an article about the his-
tory of the names for some of the fun-
ny punctuation symbols on our key-
boards. Octothorpe is my favorite too,
by the way.
• Out west, “geek” is a badge of honor
and “nerd” is an insult. I hear that it’s
the opposite on the east coast, at least
the MIT area.
• Regarding last names, I believe Teddy
was “roo’-zee-velt” while FDR was
“row’-zee-velt.”
• My wife went to Lehigh too (class of
’78). Back then the team was the “En-
gineers.” We went back a few years ago
and found they had changed it to
“Mountain Hawks.” I guess that means
her BSEE degree is now an “Electrical
Mountain Hawking” degree?
William R. Ward
bill@wards.net
Database Systems
Dear DDJ,
The “Database Systems” article by Shasha
and Bonnet (DDJ, December 2004) was
an excellent description of some of the
pitfalls of databases and their use. Al-
though it has probably already been
pointed out, Listing One, as is, would
mean that Bob and Alice are surely head-
ed to divorce court. However, if we
change the second executeUpdate state-
ment to read nbrows = stmt.executeUp-
date(tosavings)
, we may well save their
marriage.
George B. Durham
gdurha1@erols.com
Dough, Ray, Me
Dear DDJ,
In a letter to the editor December 2004,
Remi Ricard complains that si rather than
ti is the seventh solfege note of the scale.
Here is an excellent page on the subject —
http://www.brainyencyclopedia.com/
encyclopedia/s/so/solfege.html. I think ti
has precedence and comes from the orig-
inal Italian.
Galt Barber
fasola@cruzio.com
Do Re Mi II
Dear DDJ,
Who cares what the French say (Do Re Mi
was invented by an Italian, to start with),
when the correct American way of saying
is: fa-so-la-ti-do. And Rodgers and Ham-
merstein are not to blame for this: That hon-
or goes to one John Curwen of Heck-
mondwike, West Yorkshire (1816 –1880),
who modified the solfege so that every note
would start with a different letter. The les-
son to be learned from this: Why listen to
your teacher, when you can look it up in
the Wikipedia (http://en.wikipedia.org/wiki/
Solfege/).
Jost Riedel
riedel@reservoir2.de
The Numbers Game
Dear DDJ,
Jonathan Erickson’s characterization of the
Bureau of Labor Statistics employees who
produce employment statistics as
“crooked” is outrageous and totally un-
founded (“Editorial,” DDJ, November
2004). I work as a consultant with em-
ployees of federal statistical agencies in-
cluding the BLS. I know of no instance of
fabrication or illegality in creation of em-
ployment statistics that would support his
slur. Integrity requires you either sub-
stantiate your allegation or retract it and
apologize in print.
Seth Grimes
grimes@altaplana.com
Jonathan responds: Thanks for your note
Seth, and I appreciate your taking the
time to write. It sounds like that you’re
clearly more an expert in statistical ana-
lysis than I, but I’ll do the best I can here.
In particular, I’d point to two recent re-
ports out of the BLS: In the July
“birth/death” adjustment, the BLS added
182,000 jobs to avoid reporting a net job
loss of more than 100,000 for June. More-
over, in its “payroll” surveys, the BLS ex-
cludes proprietors, self-employed, farm
workers, and domestic workers. Con-
sidering the ever increasing number of
freelancers and consultants due to full-
time employment loss, this seems disin-
genuous and designed to spread erro-
neous information. And as I mentioned
in my editorial, the difference between
either 23,200 or 51,800 lost jobs in Mis-
souri is significant, particularly since the
“adjustment” was made so quickly. It is
interesting how the changes are always
down in numbers when it comes to re-
porting job losses in an election year.
They’re never adjusted upwards. I’m sure
there are similar scenarios. So yes, the
pattern does suggest that something is
going on — that the numbers are being
tweaked for whatever reasons. In no way
did I imply — nor do I believe — that all
of the hard-working employees of the
BLS are crooked. I respect their work
and the effort they put forward. That
said, someone, somewhere, somehow
does seem to be adjusting the numbers
for whatever purposes. Thanks again and
I hope I have addressed some of your
concerns.
DDJ
L E T T E R S
,
D
C E
N T
S
2
2
2
2
OB
B S
PO
S
T
10
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
D R . E C C O ’ S O M N I H E U R I S T C O R N E R
S
aturday afternoon in Ecco’s Mac-
Dougal Street apartment: Tyler and
Liane were comparing strategies for
the Voronoi game. Ecco and I dis-
cussed connections between monster
groups and string theory.
“The math is pretty,” Ecco said after a
while. “My current avocation is to work out
an experimental design to see whether a
rapidly pulsed energy source could give
evidence of those high-dimensional vibra-
tional strings…” We all have our hobbies.
The buzzer rang. Ecco looked out from
his second-floor window. “Some official
visitors,” he said not altogether approv-
ingly. He collected his papers and put them
into a large envelope — his filing system.
“Children,” he said to Liane and Tyler,
“our spook friends are back.” Liane found
a pad. She gave a sheet to Tyler. He start-
ed to doodle.
Our four visitors all wore suits. Three
took out a kind of wand and scanned the
room. The other one, evidently in au-
thority, sat and watched. The three nod-
ded and stood behind the seated figure.
“My code name is Purple,” the seated
man said. “I will tell you only the details
you have to know. We need to resolve
this problem in the next 20 minutes if pos-
sible.
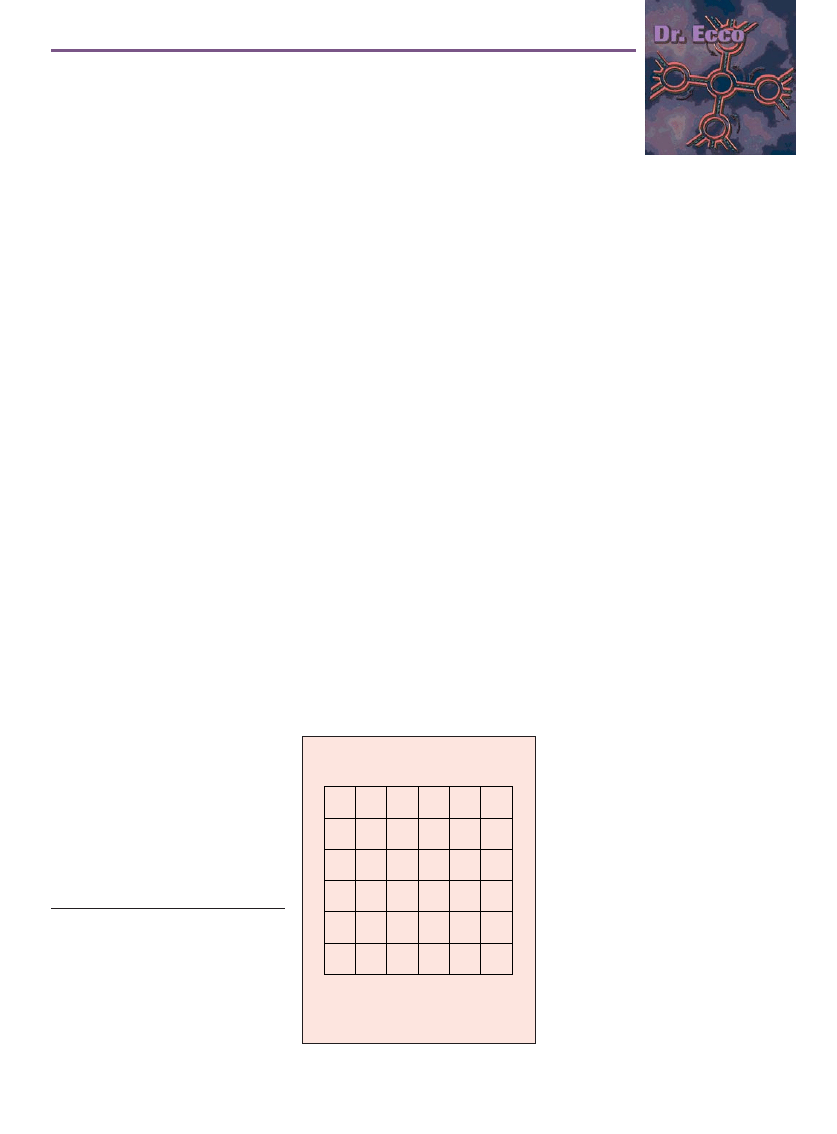
“Imagine a road grid with seven rows
as in Figure 1. Some bad guys have placed
a tunnel from the bottom, beginning at
the road marked Start, to the top at End.
The tunnel follows the roads somehow
but may wind around. It is also a simple
path (no dead ends and no loops along
the way). You want to probe a minimum
number of times and yet be able to find
the exact route of the tunnel.
“A probe device takes an hour to set
up. If you set up a probe on a street, you
can tell whether it follows the street. If
you set it up on an intersection, you can
tell whether the tunnel passes through the
intersection, and if so, which adjacent
streets it goes to.
“If the tunnel is at most eight blocks
long and starts at Start and ends at End,
then what is the minimum number of
probe devices you would need to guar-
antee determining the precise route of the
tunnel in one hour?
“Also, if you had only one probe, what
is the minimum time it would take to guar-
antee determining the outcome?”
Ecco, Liane, and Tyler conferred for a
while. Finally, they sketched an answer.
Mr. Purple studied it.
“I can’t thank you enough,” he said. “I
think this is exactly what I need, though
I’m not completely sure. The tunnel might
be 10 or even 12 blocks long. We don’t
think so, but we can’t rule it out.
“Can you answer the above two ques-
tions if the tunnel could be 10 blocks or
12 blocks long?”
I left before Ecco and his talented fam-
ily could find an answer.
For the solution to last month’s
puzzle, see page 68.
DDJ
Dig That!
Dennis E. Shasha
Dennis is a professor of computer science
at the Courant Institute, New York Uni-
versity. His latest books include
Dr. Ecco’s
Cyberpuzzles: 36 Puzzles for Hackers
and Other Mathematical Detectives
(W.W. Norton, 2002) and Database Tun-
ing: Principles, Experiments, and Trou-
bleshooting Techniques (Morgan Kauf-
man, 2002). He can be contacted at
DrEcco@ddj.com.
12
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 1.
End
Start
1
2
3
4
5
6
7

14
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
OASIS Ratifies UBL
After six years of development, the OASIS
standards group has ratified the Universal
Business Language (UBL) 1.0 specification
(http://docs.oasis-open.org/ubl/cd-UBL-1.0/).
UBL “is designed to provide a universally
understood and recognized commercial
syntax for legally binding business docu-
ments and to operate within a standard
business framework such as ISO 15000
(ebXML).” It provides a library of XML
schemas for common, reusable data com-
ponents (“Address,” “Item,” and “Payment,”
for example); a set of XML schemas for
business documents (“Order,” “Dispatch
Advice,” “Invoice,” and the like); and sup-
port for customization.
Google Scholar Launched
Google has launched the Google Scholar
service, a new search facility that index-
es academic research, including technical
reports, preprints, abstracts, and peer-
reviewed papers (http://scholar.google
.com/). Participating groups include the
ACM, IEEE, and the Online Computer Li-
brary Center. Google Scholar orders search
results by relevance to your query. This
ranking takes into account the full text of
each article, along with the author, pub-
lication, and how often it has been cited
in scholarly literature. The search also an-
alyzes and extracts citations and presents
them as separate results.
Remembering
Kenneth Iverson
APL inventor Kenneth E. Iverson died in
Toronto, Ontario at the age of 84. Among
his distinctions were the U.S. National Medal
of Technology and the Turing Award; he
was also an IBM Fellow. It was as an as-
sistant professor at Harvard in the 1950s
that Iverson first began working on APL.
The Iverson Notation, as it was originally
known, was designed to express mathe-
matical algorithms clearly and concisely.
At IBM in the 1960s, he and Adin D.
Falkoff developed APL, short for “a pro-
gramming language.” In the early 1990s,
Iverson and Roger Hui created the J lan-
guage, which is based on APL as well as
the FP and FL functional programming lan-
guages. Unlike APL, J requires no special
character set; it uses ASCII characters for all
primitives. Iverson worked with Jsoftware
Inc. to document and promote this language.
Along with the National Medal of Tech-
nology and the Turing Award, Iverson was
granted the Harry M. Goode Memorial
Award, and was named a Computer Pio-
neer Charter Recipient by IEEE CS.
IBM Sweeps
Supercomputer Rankings
NEC’s Earth Simulator, which topped the
biannual Top500 rankings (http://www
.top500.org/) of the world’s most power-
ful supercomputers for two-and-a-half
years, has finally lost its crown. The latest
edition of the Top500 list puts IBM’s Blue
Gene/L in first place. Blue Gene/L — now
located in Rochester, New York but des-
tined for the Lawrence Livermore Nation-
al Laboratory in California — clocked at
70.72 teraflops on the Linpack benchmark.
IBM says it hopes to deliver a theoretical
maximum of 360 teraflops next May, when
the system is complete. It will comprise
64 racks carrying 65,000 dual-processor
chips, but will consume only a fraction of
the power that Earth Simulator requires.
The second-place supercomputer is also
new: SGI’s Columbia system at the NASA
Ames Research Center in Mountain View,
California, which performed at 51.87 ter-
aflops. Columbia consists of 20 machines
connected by InfiniBand. Each one has
512 processors and runs its own instance
of Linux, although SGI is working to con-
nect the machines into groups of four
sharing an operating system.
Earth Simulator, a mammoth 32,500-
square-foot system located in Yokohama,
Japan, now holds third place on the
Top500 list. That spot was formerly occu-
pied by Virginia Tech’s Mac-based System
X, last year’s surprise entry into the list.
System X has since been upgraded to Ap-
ple Computer’s Xserve G5 server, which
improved its benchmark score by 19 per-
cent; however, even its new 12.25 teraflop
performance isn’t enough to compete
against the mightiest of the new super-
computers. System X has slipped to sev-
enth place in the rankings. It’s likely, how-
ever, that System X remains the winning
system when performance is considered
against price. It costs $5.2 million to de-
ploy and $600,000 to upgrade to the Xserve
G5— as compared to nearly $100 million
for Blue Gene/L.
“Trusted Mobile Platform”
Specification Drafted
IBM, Intel, and NTT DoCoMo are pro-
moting their “Trusted Mobile Platform,”
defining security-oriented hardware, soft-
ware, and protocol requirements for mo-
bile devices (http://www.trusted-mobile
.org/). According to the companies, “The
specification will help make advanced mo-
bile devices/applications more secure and
help protect against viruses and other
threats…In addition, it defines a set of pro-
tocols that allow the security state of a de-
vice to be shared with other devices in the
network, enabling device-level trust to be
extended into the larger network.”
NASA Gives
Researchers Millions
NASA has awarded a $58 million grant to
three professors at the University of South-
ern California’s Information Sciences In-
stitute for the development and analysis of
systems that are construction based, com-
puter based, and logistical, respectively.
Senior research scientist Wei Min Shen re-
ceived $28 million for his “Modular, Multi-
functional Reconfigurable Superbot” study,
to build and analyze shape-shifting robot
modules that are self reconfiguring and
capable of autonomous connection to
each other. John Damoulakis received
$18.1 million for his “Fault-Aware, Modu-
lar, Reconfigurable Space Processor” pro-
ject, to produce reliable space-computing
systems capable of fault comprehension
and self repair. Robert Neches received
$15 million for “Coordinated Multisource
Maintenance-on-Demand,” which will ex-
amine ways to help the space agency use
improved cost-benefit analysis as it re-
lates to the expected requirements for
equipment against the probability of mal-
function.
AI Isn’t a Crime
The Classification System for Serial Crim-
inal Patterns (CSSCP), a neural network-
based system developed by computer
scientists Tom Muscarello and Kamal
Dahbur at DePaul University, examines
crime case records, assigns numerical val-
ues to aspects of each crime (type of of-
fense, perpetrator’s gender, age, height,
and type of weapon), then builds a de-
scriptive profile of the crime. Unlike neu-
ral networks that require training, the
CSSCP is based on Kohonen networks,
which do not require training or human
intervention. When CSSCP detects simi-
larities between crimes, it compares the
time and place to see if it is possible for
the criminal to have committed both
crimes.
News & Views
Dr. Dobb’s
News & Views
SECTION
A
MAIN NEWS
DR. DOBB’S
JOURNAL
February 1, 2005

A
web site can see, potentially, millions of Internet users in
a day. This makes performance and scalability a big issue
in web-site development. Web-site performance is mea-
sured in response time, or how long it takes for a user’s
browser to receive HTML after a request. Scalability is the ca-
pacity to maintain good performance even when large numbers
of users simultaneously — and continuously — make requests.
To achieve scalability, the hardware and software that make up
a web site are typically segmented into tiers like those in Fig-
ure 1.
The web tier is where user requests are first handled and
queued. The application tier is where the business logic — and
code — behind the web site resides. The data tier, sometimes
called the “enterprise information system” (EIS) tier, contains
databases or legacy systems as data sources. Depending on the
web site, some tiers can be combined or segmented even more.
Sun, for instance, defines further subtiers with its model-view-
controller architecture (MVC).
The Service Tier
Web services are often used to expose application functionali-
ty to paying customers, or to integrate legacy systems with new-
er applications. However, web services can become part of an
application’s design to help achieve component isolation, gain
greater scalability, and ease development. In this article, I pro-
pose adding a new tier to the traditional multitiered architec-
ture — the service tier.
An architecture without a service tier has a huge flaw— the
lack of data hiding or abstraction. Without a service tier, appli-
cation code must have intimate knowledge of the data sources
and associated details, such as database schemas or low-level
software APIs. Adding a service tier to your architecture — one
that contains web services that abstract the data sources from
the core business logic code — solves this problem.
A service tier should be designed to achieve the following
goals:
• Abstraction. Hide the details of the data sources (schemas,
APIs, and so on).
• Simplicity. Generally simplify the process of accessing data.
The purpose of adding a tier is to add simplicity to the de-
sign of the software as a whole. Introducing complexity here
defeats the purpose of abstraction.
• Loose coupling. As with all software layers, the service tier
and the other tiers should be loosely coupled, with an inter-
face that truly hides all implementation details.
• Performance. Although nothing is free, the addition of the ser-
vice tier should not introduce a significant amount of perfor-
mance overhead.
16
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Java Web Services &
Application
Architectures
Eric is a consultant in New York, and has worked extensively in
Java and C++ developing real-time trading and financial ap-
plications. He can be contacted at eric@ericbruno.com.
ERIC J. BRUNO
Building better architectures with web services
“An architecture without a service
tier has a huge flaw”
In general, a service tier that achieves these goals can pro-
vide other benefits to application developers. First, there is greater
potential for software reuse as the service tier is accessed through
a generic interface. Second, a more efficient development pro-
cess is achieved as the application tier and the service tier can
be developed independently. For example, developers strong in
JSP or ASP can concentrate on building applications, while
database developers (or developers familiar with an external
API) can build portions of the service tier. This helps to avoid
maintenance problems that come from mixing database queries
in application-tier code. Third, system interdependencies (and
associated complexity) are greatly reduced. A well-designed ser-
vice tier lets backend data systems change and evolve inde-
pendently and transparently from the software components that
use them. Finally, true implementation independence is achieved,
as the service tier components can be written in a language or
environment different than that of the application.
The Simple Object Access Protocol (SOAP) is perhaps the best
choice when implementing components of a service tier. SOAP
not only achieves the architectural goals and benefits, but yields
other practical benefits as well. For example, a SOAP web ser-
vice can be deployed across multiple servers, and load balanced
using existing HTTP load-balancing technology. The SOAP pro-
tocol itself defines a strict contract for communication between
layers. In addition, SOAP— being based on XML — provides the
right level of abstraction, allowing for implementation indepen-
dence.
In Figure 2, a web application architecture enhanced with a
service tier, the web tier and application tier have been combined
for simplicity. The elegance of the design comes from the degree
of separation and abstraction achieved across the tiers. The ap-
plication code becomes simpler as it no longer deals with the de-
tails of individual data sources. SOAP adds consistency to the way
data is requested from and returned to the application code.
The Java Web Service Developer Pack
Java has long been the leading choice for web application de-
velopment. Sun positioned Java as a powerful platform with which
to build web services when it introduced the Java Web Service
Developer Pack (WSDP) about two years ago. Now at Version
1.4, the Java WSDP provides all of the APIs, tools, and infras-
tructure you need to build web services that support the im-
portant standards such as:
• SOAP with attachments.
• Web Services Description Language (WSDL).
(continued from page 16)
18
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 2:
Web architecture with a service tier.
Client Browser
or Application
HTTP
HTML
Java
(Servlet,
JSP, EJB)
.NET
W
eb/Application Tier
Ser
vice Tier
Data Tier
Database
HTTP
Java
(WSDP)
.NET
PHP
API, JDBC, ODBC, ADO…
XML
Raw
Data
Legacy System
Other
<SOAP-ENV:Envelope xmlns:SOAP
ENV=”http://schemas.xmlsoap.org/soap/envelope/”>
<SOAP-ENV:Header />
<SOAP-ENV:Body>
<
<G
Ge
et
tD
Da
at
ta
a>
>
<
<s
sy
ym
mb
bo
ol
l>
>M
MS
SF
FT
T<
</
/s
sy
ym
mb
bo
ol
l>
>
<
<n
na
am
me
e>
>M
Mi
ic
cr
ro
os
so
of
ft
t
C
Co
or
rp
p<
</
/n
na
am
me
e>
>
<
<C
CI
IK
K>
>0
00
00
00
07
78
89
90
01
19
9<
</
/C
CI
IK
K>
>
<
</
/G
Ge
et
tD
Da
at
ta
a>
>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
Example 1:
Financial portal SOAP request message.
Figure 1:
Typical web application architecture.
Client
Browser
Web Tier
DMZ
Web
Server
Web
Server
Application
Tier
App
Server
App
Server
Data or Enterprise
Information
System Tier
External
Services
Legacy System
Database
Figure 3:
Sample financial portal architecture.
HTML
Financial Portal
(Java Servlet on
Tomcat 5.0)
Quotes
Web Service
(JWSDP/SAAJ)
yahoo.com
SEC.gov
Fundamentals
Web Service
(JWSDP/SAAJ)
W
eb/Application Tier
Ser
vice Tier
Data Tier
SOAP/HTTP
HTTP
XML
Raw
Data

• Universal Description, Discovery, and Integration registry
(UDDI).
• Web Services Interoperability (WS-I).
• Web Services Security (WSS and XWS-Security).
• Security Assertion Markup Language (SAML).
For more information on the Java WSDP (along with software
downloads), see http://java.sun.com/webservices/index.jsp. There
are download bundles available for Sun’s J2EE 1.4-compatible
application server, Sun’s Java web server, and Apache’s Tomcat
web server/Servlet container. I suggest starting with the Tomcat
container, which is an open-source project from Apache-Jakarta
(http://jakarta.apache.org/tomcat/). It’s free, works well, and is
available on many platforms.
The Java WSDP integrates XML parsing using JAXP; WSDL
and low-level SOAP messaging using JAX-RPC; XML to Java bind-
ing using JAXB; UDDI using JAXR; and high-level SOAP mes-
saging with attachments using SAAJ. For a detailed overview,
see the Java Web Service’s Tutorial (http://java.sun.com/web-
services/docs/1.4/tutorial/doc/index.html).
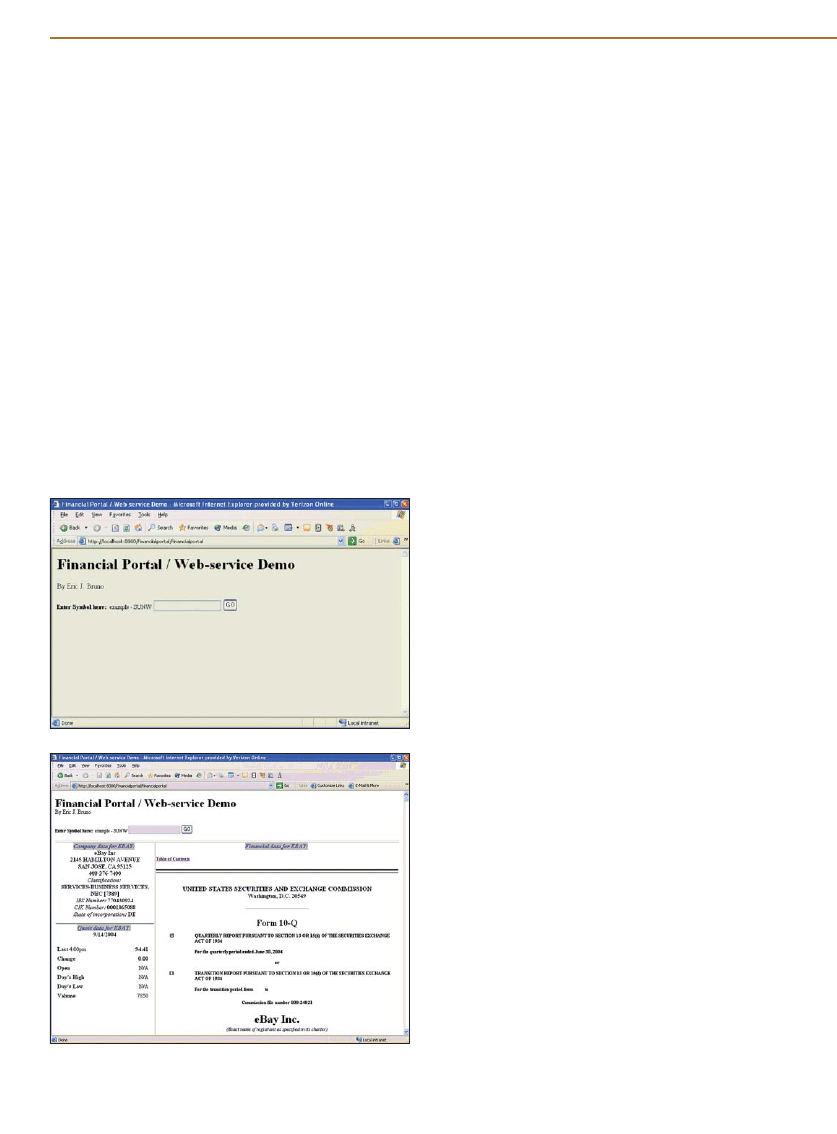
A Sample Application:
The Financial Portal
The sample web application (available electronically; see “Re-
source Center,” page 5) I present here is a basic financial por-
tal. The portal displays stock quotes, company fundamental data,
and company financial data (balance sheet, income statement,
and cash flow statement) when a company’s ticker symbol is en-
tered. I’ve chosen to use the Java WSDP bundle that comes with
the Tomcat 5.0 web container. The code uses the SOAP with
Attachments API for Java (SAAJ) to build two SOAP servers and
one client, as well as JAXP for parsing the XML payloads of the
SOAP messages. Figure 3 illustrates the basic architecture for the
application.
The application contains two SOAP web services — a Quotes
Service and a Fundamentals Service — which are written using
SAAJ. To use SAAJ, your Java code must extend the class,
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
19
Example 2:
Sample application directory structure.
com.sun.xml.messaging.soap.server.SAAJServlet, contained with-
in the file saaj-coms.jar. Doing this, your class basically becomes
a Java Servlet capable of receiving SOAP requests by overrid-
ing the method, onMessage. This method provides the SOAP re-
quest as a parameter, and lets you return a SOAP response.
The Quotes and Fundamentals services both wait for a SOAP
request that looks like the XML in Example 1. The contents of
the SOAP body are in bold, and contain the company’s stock
symbol, name, and the central index key (CIK) as assigned by
the Securities Exchange Commission (SEC).
When the Quotes Service receives a SOAP request, it is parsed
and checked to ensure it contains all of the data needed. Listing
One shows the code that receives and parses a simple SOAP re-
quest message. After the request is parsed, the Quotes Service
makes an HTTP request to Yahoo using the company’s stock tick-
er. The result from Yahoo is comma-delimited quote data, which
is parsed and formatted into an XML SOAP body to be sent
back to the SOAP client. The code for generating the SOAP re-
sponse is shown in Listing Two. It is important to note that us-
ing Yahoo for quote data is for illustrative purposes only, and
should not be distributed in any way.
The Fundamentals Service works in a similar fashion. SOAP
requests are received and parsed to gather the needed data,
which includes the company’s ticker symbol and CIK. Next, the
service makes an FTP request to the SEC’s FTP servers to ob-
tain the latest financial filings for the given company. The FTP
response contains basic company information — such as address
and business classification — as well as the financial filings in
HTML form. Next, the service creates a SOAP response that con-
tains the company’s fundamental data in the SOAP body, with
the HTML filings added as a SOAP attachment. The code for this
can be seen in Listing Three.
SOAP requests are made to both web services (Listing Four)
from a Java Servlet that contains the application code called
the “Financial Servlet.” This Servlet generates an HTML form
for users to enter company ticker symbols, as in Figure 4.
When a symbol is submitted, a SOAP request is made to the
Quotes service as well as the Fundamentals service. The SOAP
responses are received and parsed, and an HTML web page
(Figure 5) is generated containing all of the quote, funda-
mental, and financial data from the SOAP messages and the
attachment.
This application illustrates how segmenting retrieval into a ser-
vice tier can be a major design improvement. For example, the
web services in this application can be distributed across mul-
tiple servers, where the work of gathering quote and funda-
mental data can occur in parallel instead of serially. Future mod-
ifications, such as a change in the source for quote data, can be
made without changing any deployed applications. Only the
Quotes service would need to change. The SOAP interface com-
pletely hides the implementation details.
Building and
Deploying Web Services
The sample financial portal application assumes that the appli-
cation will be deployed and run within the Tomcat 5.0 web con-
tainer, although it should run within any J2EE web container
without major changes.
The Java WSDP comes with the Apache Ant build tool
(http://ant.apache.org/). To use Ant, you must write XML scripts
that build and deploy your Java software. An Ant script for the
financial portal application is included with the sample code.
The script contains paths to the JAR files needed during com-
pilation, such as those for SAAJ, JAXP, and J2EE. You may need
to modify these paths for your system. It is assumed that the ap-
plication code exists in the path c:\dev\FinancialWebApp\Fi-
nancialPortal, with the directory structure in Example 2, which
is a standard J2EE WAR structure.
The source code files exist within the directory, WEB-INF/src,
where the complete path matches each component’s package
name. The same subdirectory structure is used for the compiled
class files within WEB-INF/classes. The Ant script contains the
target, “compile,” which looks for the source files in the prop-
er source paths, and places the compiled class files in the prop-
er output paths.
The WEB-INF directory contains the deployment descriptor,
web.xml, for the entire web application, containing the Quotes
web service, the Fundamental web service, and the financial
portal Servlet (Listing Five). The Ant script contains the target,
“war,” which uses the JAR utility to package up the entire di-
rectory structure into a file named “FinancialPortal.war.” This
archive contains the class files, the application deployment de-
scriptor, and other miscellaneous files that make up the finan-
cial portal application.
The next step is to inform Tomcat of the existence of the sam-
ple web application. First, locate the path, tomcat- jwsdp-
1.4/conf/Catalina/localhost, in the directory where you installed
the Java WSDP/Tomcat bundle. In this location, add an appli-
cation context file named “financialportal.xml,” which tells Tom-
cat where to find the application’s WAR file. The contents of this
file are simple and can be seen in Listing Six.
Once these steps are complete, the web application is ready
to run. When Tomcat is started, it will automatically read the
file, financialportal.xml, and attempt to deploy the web appli-
cation (the financial portal) referenced within. When loaded, the
application reads an index file that tells it where to locate the
20
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 4:
Company ticker request HTML form.
Figure 5:
Financial portal company data screen.
financial filings for all U.S. public companies. This step requires
around 30 seconds, after which the application will be ready for
requests.
The index file that the application uses is located on the SEC’s
FTP servers at ftp://ftp.sec.gov/edgar/full-index/master.idx/.
Companies file with the SEC periodically, so you will need to
download this file occasionally to keep up to date. The Funda-
mentals Service can be enhanced to download this file auto-
matically based on a schedule.
Finally, open a browser and type http://localhost:8080/
financialportal to display the company ticker request page. If you
chose a port other than 8080 when you installed Tomcat, you
must modify this URL accordingly. Enter a valid U.S. company
ticker, such as EBAY, and around one minute later, you will see
that company’s quote data, fundamentals, and financial filings.
Conclusion
Building a SOAP web service is ideal when you need to expose
data and/or functionality to customers. Even if customers are
never directly exposed to it, building a service tier (an entire
layer of web services within your application) adds value to an
application’s architecture by limiting the coupling between com-
ponents and by creating the potential for future reuse.
Conceivably, the service tier can be extended beyond the
boundaries of one application. The service tier can become a
company-wide deployment of web services available to all ap-
plications in your organization. Thus, the need for a metadata
service — a service that describes all available web services —
may arise.
The Java Web Service Developer Pack contains all of the tools
and support necessary to build web services in Java. Combined
with the open-source web container, Tomcat, you can build web
services to be deployed on a Windows or UNIX system with lit-
tle or no modification. If you choose to deploy to Tomcat on
Linux, for example, your web service infrastructure costs will
be nothing more than the hardware to run on — with no OS or
application server licenses to purchase. That makes Java a pow-
erful choice when building web services.
DDJ
Listing One
public SOAPMessage onMessage(SOAPMessage message)
{
try {
// The envelope contains the message header, body, and attachments
SOAPEnvelope env = message.getSOAPPart().getEnvelope();
SOAPBody bdy = env.getBody();
// Get the ticker symbol
Iterator iter = bdy.getChildElements();
SOAPElement node = getNode("GetData", iter);
if ( node != null )
{
iter = node.getChildElements();
symbol = getNodeValue("symbol", iter);
}
// Get the quote data from Yahoo
String data = getQuoteData( symbol );
// ...
}
catch(Exception e) {
return null;
}
}
Listing Two
// Create the SOAP reply message
SOAPMessage replyMsg = msgFactory.createMessage(); // part of SAAJ
SOAPEnvelope env = replyMsg.getSOAPPart().getEnvelope();
SOAPBody bdy = env.getBody();
// Add the quote data to the message
bdy.addChildElement(env.createName("symbol")).addTextNode( symbol );
bdy.addChildElement(env.createName("last")).addTextNode( last );
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
21
(continued on page 22)

bdy.addChildElement(env.createName("date")).addTextNode( date );
bdy.addChildElement(env.createName("time")).addTextNode( time );
bdy.addChildElement(env.createName("change")).addTextNode( change );
bdy.addChildElement(env.createName("open")).addTextNode( open );
bdy.addChildElement(env.createName("low")).addTextNode( low );
bdy.addChildElement(env.createName("high")).addTextNode( high );
bdy.addChildElement(env.createName("volume")).addTextNode( volume );
return replyMsg;
Listing Three
// Create the SOAP reply message
SOAPMessage replyMsg = msgFactory.createMessage();
SOAPEnvelope env = replyMsg.getSOAPPart().getEnvelope();
SOAPBody bdy = env.getBody();
// Add the fundamental data to the SOAP body
...
// Add the financial HTML as a SOAP Attachment
AttachmentPart ap = replyMsg.createAttachmentPart(financialHTML,"text/html");
replyMsg.addAttachmentPart(ap);
return replyMsg;
Listing Four
// Create a SOAP request message
MessageFactory msgFactory = MessageFactory.newInstance();
SOAPMessage soapMsg = msgFactory.createMessage();
SOAPEnvelope envelope = soapMsg.getSOAPPart().getEnvelope();
SOAPBody bdy = env.getBody();
// Add the request data to the SOAP body
SOAPBodyElement bdyElem = bdy.addBodyElement(
envelope.createName("GetData"));
bdyElem.addChildElement(envelope.createName("symbol")).addTextNode( symbol );
bdyElem.addChildElement(envelope.createName("name")).addTextNode(companyName);
bdyElem.addChildElement(envelope.createName("CIK")).addTextNode( companyCIK );
SOAPConnectionFactory scf = SOAPConnectionFactory.newInstance();
con = scf.createConnection();
// Send the request to the Quote Service
URL urlEndpoint = new URL( "http://localhost:8080/quotes" );
SOAPMessage quoteReply = con.call( soapMsg, urlEndpoint );
// Send the request to the Fundamentals Service
urlEndpoint = new URL( "http://localhost:8080/fundamentals" );
SOAPMessage fundReply = con.call( soapMsg, urlEndpoint );
Listing Five
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN"
"http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
<web-app>
<display-name>Financial Portal</display-name>
<description>
Displays company quote and financial data
</description>
<servlet>
<servlet-name>
fundservlet
</servlet-name>
<servlet-class>
com.fundamentals.FundServlet
</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet>
<servlet-name>
quoteservlet
</servlet-name>
<servlet-class>
com.quotes.QuoteServlet
</servlet-class>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet>
<servlet-name>
FinancialServlet
</servlet-name>
<servlet-class>
com.financialportal.FinancialServlet
</servlet-class>
<load-on-startup>3</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>
fundservlet
</servlet-name>
<url-pattern>
/fundamentals
</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>
quoteservlet
</servlet-name>
<url-pattern>
/quotes
</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>
FinancialServlet
</servlet-name>
<url-pattern>
/financialportal
</url-pattern>
</servlet-mapping>
</web-app>
Listing Six
<Context
path="/financialportal"
docBase="c:/dev/FinancialWebApp/FinancialPortal/FinancialPortal.war"
debug="1">
<Logger className="org.apache.catalina.logger.FileLogger"
prefix="finance_log."
suffix=".txt"
timestamp="true"/>
</Context>
DDJ
22
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
(continued from page 21)

T
he design principals of Service-
Oriented Architectures (SOAs) are
widely considered to be best practice
when solving integration problems or
as part of business process modeling. An
Enterprise Service Bus (ESB) gives you the
tools and infrastructure necessary to build
an SOA. But with all the components and
tools provided, you can lose sight of the
SOA while working on the ESB. Conse-
quently, care must be taken to ensure that
the end result is a new architecture, and
not just a better way to perform point-to-
point integration. In this article, I present
an overview of SOA, describe the ESB’s
role, and present tasks you can expect to
tackle when deploying an SOA.
Service-Oriented Architecture
An SOA is a way of approaching the task
of creating software. You can think of it
as either a collection of architectural con-
cepts or a programming model. These con-
cepts should be understood and followed
carefully to make effective use of an ESB.
Within an SOA, all functionality is provid-
ed by services. This provides a level of
flexibility in deploying and reusing services
not previously attained — services that:
• Are remotely accessible over asyn-
chronous or synchronous transports.
• Have a well-defined interface described
in an implementation- independent
manner.
• Are self contained, and can be used in-
dependently of any other services.
• Perform a specific task.
• Are loosely coupled. In other words,
loosely coupled APIs should be:
coarse-grained, representing an over-
all business function or service; based
on the exchange of documents rather
than the datatypes used in RPC-style
APIs (this typically means that opera-
tions will have a single input or out-
put parameter that is defined using
XML Schema); accept a range of dif-
ferent documents that contain the req-
uisite information; not include explic-
it or implicit state assumptions (that is,
be connectionless); and are dynami-
cally discoverable at runtime rather
than statically bound.
However, an SOA is more than just a
collection of services — it adds a number
of principals, of which interoperability is
the most important and the core to the
idea of SOA. Interoperability is achieved
through the use of Standards. The web-
services Standards stand out above all oth-
ers in satisfying this requirement.
Another core feature of an SOA is the
reuse of existing assets. Deployment of an
SOA within an organization is an exercise
in creating services from the existing IT
systems and infrastructure.
Once an SOA is in place, the existing
IT systems within an organization can be
viewed as services that provide business
functions. These are easily integrated be-
cause they provide well-defined interfaces
and can be accessed using standard pro-
tocols and transports. This provides the ba-
sis on which to orchestrate services into
new services that reflect business pro-
cesses.
The Role of the ESB
The deployment of an SOA requires the
conversion of existing systems into ser-
vices. The tasks involved in achieving this
may be repeated for each system and a
common set of components may be need-
ed to provide additional functionality. An
ESB is a collection of servers and com-
ponents that provide these functions and
a set of tools to assist in the conversion
of existing systems to services. The ESB:
• Solves integration problems at the trans-
port layer by supporting Standards-
based transports such as HTTP. It also
supports a variety of commonly used
transports such as MQSeries, or even
shared folders for batch-processing ap-
plications, so that existing systems can
be exposed as services supporting new
transports.
• Provides for the routing of messages
across various transports.
• Provides tools to help expose the ex-
isting systems as web services; for ex-
ample, a wizard to convert CORBA IDL
SOAs & ESBs
Ensuring that your
ESB delivers an SOA
JAMES PASLEY
James is chief architect at Cape Clear Soft-
ware. He can be contacted at james
.pasley@capeclear.com.
24
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
“Care must be taken
to ensure that the
end result is a new
architecture, and not
just a better way
to perform
point-to-point
integration”
to WSDL. In addition, it provides the
runtime piece to convert SOAP requests
to the web service into IIOP requests
to the CORBA Object. You can expect
to find such tools for multiple classes of
systems such as Java, J2EE, databases,
and mainframes.
• Provides adapters to a variety of pack-
aged applications such as SAP or Peo-
pleSoft. However, with the proliferation
of web- services Standards, many of
these applications are providing web-
service interfaces directly. Therefore, the
need for the ESB to provide such
adapters reduces over time.
• May also host services. While the em-
phasis remains on the reuse of existing
systems, an ESB can be used as a pow-
erful application-development environ-
ment. Features such as database inte-
gration and adapters to applications
(SAP, for example) ensure rapid appli-
cation development.
• Addresses quality-of-service issues such
as security and data validation, which
arise as a result of exposing services to
a variety of clients.
• Provides for the transformation of both
XML and other document formats.
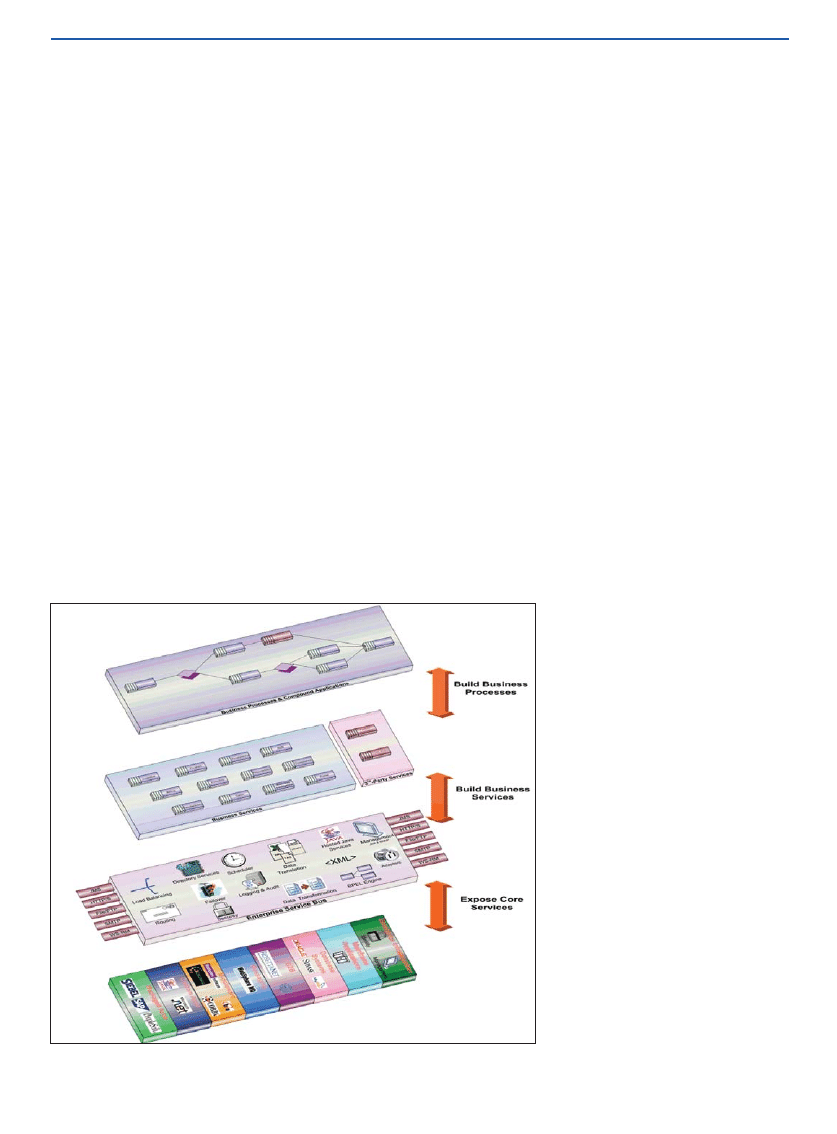
The Lifecycle of an Integration Project
The lifecycle of a software project that
uses an ESB can be thought of as con-
structing an SOA in layers, starting at the
existing infrastructure. As such, there is a
natural progression to the development of
services within an SOA; see Figure 1.
The steps involved can be grouped to-
gether into three categories:
• Exposing the existing systems as core
services.
• Building business services from these
core services.
• Using the business services to achieve
business process modeling.
An SOA emphasizes the reuse of exist-
ing assets, so exposing the existing sys-
tems is a natural starting point. This must
be balanced with the emphasis on creat-
ing services that reflect business needs
and not technology. This means that the
top-down approach should also be con-
sidered. That said, in this article, I follow
a bottom-up approach because it facili-
tates a better explanation of the tasks in-
volved.
Exposing Core Services
Exposing existing IT systems as services
is typically the first task you perform when
using an ESB. ESBs provide a number of
tools to help with this. For programming
APIs (such as Java, EJB, or CORBA), wiz-
ards automatically generate WSDL from
the APIs. For messaging systems, trans-
ports are provided to expose particular
queues as web services.
For batch-processing systems, the doc-
uments processed are often text-based and
typically consist of fixed-width fields. The
payload of the exposed web service
should be XML to achieve maximum in-
teroperability. This requires transforma-
tion of the payload document. ESBs can
provide tools (such as Cape Clear’s Data
Interchange) to facilitate the creation of
transforms between varieties of document
formats. Because no formal description of
the data formats may exist, this task can-
not reach the same level of automation as
is achieved for programming APIs. De-
pending on the nature of the existing sys-
tems, the creation of these transforms can
be a significant part of the development
effort. As a result, the tools to support this
should be reviewed carefully when se-
lecting an ESB, to ensure that this task
does not become a programming one.
With the tools provided by the ESB, you
have solved a number of integration issues
and have added web-service front-ends to
your existing systems. The web services
have the following features that, depend-
ing on the nature of the existing systems,
may not have been present before:
• Can be invoked remotely, over a standard
transport by a variety of web-service
clients.
• Has an XML-based payload format.
• Uses a standardized protocol envelope
(SOAP Envelope).
• Has a formal description of the inter-
face (WSDL and XML Schema).
• The payloads in messages are validated
against the WSDL/XML Schema to en-
sure that invalid data is not passed on
to the application.
Building Business Services
The first stage in the lifecycle of a project
solves many integration issues by creating
web services from the existing systems.
This fulfills a number of the characteristics
of a service as defined by the SOA. The
web services can be invoked remotely,
have well- defined interfaces, and (de-
pending on the systems they were creat-
ed from) are self contained. However, oth-
er aspects may not be there. Web services
that conform to the SOA definition can be
thought of as “business services,” based
on the requirement that they perform a
specific task or business function.
This is the point at which you need to
take a step back and consider what you’ve
done. To turn these web services into ser-
vices as defined by SOA, you may have
to reconsider the API to each service and
evaluate whether they can be described
as loosely coupled.
The web services created from main-
frame or batch-processing systems most
likely already meet these remaining re-
quirements because they process docu-
ments in an asynchronous manner. The
(continued from page 24)
26
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 1:
Phases of an ESB project.

web services created from the other sys-
tems are more likely to be fine-grained,
RPC-based, synchronous systems. If the
web services automatically generated from
the existing systems cannot be described
as loosely coupled, then new descriptions
(WSDL) should be created.
To illustrate loosely coupled services,
consider how a customer might purchase
car insurance. In the first scenario, the cus-
tomer could use the telephone to carry
out the transaction. This approach is syn-
chronous — it requires an operator to be
available to handle the customer’s request.
The telephone conversation forms a con-
nection in the context of which the inter-
actions take place. The exchanges are fine-
grained — the operator asks a series of
individual questions to obtain the neces-
sary information.
Now consider a second scenario, in
which the customer fills out a form and
mails it to the insurance company. This
approach is course grained and handles
documents. It is asynchronous — it does
not require an operator to be present at
the exact time the customer fills out the
form. This second scenario is consistent
with the principals of an SOA, while the
first one is not.
Look at this example again, but this
time in code. Consider the Java API in
Listing One that is to be exposed as a
web service. It has a method to initiate
the interaction — one that provides some
additional data. Another method is used
to return the quoted price, and finally, one
that processes the application and bills the
customer.
Running a JAX-RPC-compliant, WSDL-
generation tool over this kind of a Java
interface results in the WSDL in Listing
Two. This solves a number of integration
issues; for example, a .NET client that in-
vokes on this web service can now be
written. However, to create a loosely cou-
pled service from this, a new WSDL in-
terface must be designed. For this, you
need a WSDL editor.
The granularity of the API should be in-
creased to provide fewer operations, but
ones that accept documents as parame-
ters. At the same time, the API should be
made connectionless by eliminating the
use of the reference parameter. This leaves
you with two operations —calculateQuote
and processApplication. Both of these op-
erations accept the application document
as a parameter. This may seem inefficient,
but it is done to ensure that the API is
connectionless. Applying these principles
to the WSDL results in Listing Three. In
this new WSDL:
• The data types from the original WSDL
have been combined under a single el-
ement (InsuranceApplication) to form
a document.
• There are just two operations: calcu-
lateQuote and processApplication.
• Both of the operations take the entire
InsuranceApplication as input.
• The responses are returned to the caller
asynchronously, via a callback API (In-
suranceServiceCallBack).
In light of the aforementioned example,
the following guidelines should be applied
to WSDL files as part of evaluating
whether they can be described as loose-
ly coupled. New WSDL files should be
created where necessary.
• portTypes should have a small number of
operations that reflect the business tasks.
• Each operation should have a single pa-
rameter defined as a document.
• The API should not include the concept
of a session, or operations that depend
on data passed to previous operations.
• The API should support asynchronous
interactions. A separate interface (port-
Type) should be provided for respons-
es that the server needs to send back to
the client.
Implementing the New Service
An ESB provides tools to generate Java
skeleton implementations for web services.
This new WSDL can be used to generate
such a Java skeleton, providing the basis
for the implementation of the new service.
This service can act as a client of the auto-
generated service.
Of course, the equivalent changes could
be made to the original Java API. How-
ever, there are benefits to working at the
XML level. An important part of an SOA
is the definition of data types within the
XML Schema that can be reused across
different services. The use of common
data types defined using XML Schema
should be considered as early as possible
when working with an SOA. This greatly
reduces the amount of data transforma-
tion that must be performed later when
reusing these services.
Implementing Service Policies
By now, you have created business ser-
vices that can be easily integrated and
reused. However, exposure to business
partners or deployment within an enter-
prise requires additional functionality. This
is functionality that can be provided by
the ESB itself and is typically common to
all services.
These features can also be described
by the WSDL or by policy statements in-
cluded within the WSDL; see Figure 2.
This step in the project lifecycle can be
considered the point at which the WSDL
changes from being a description of the
API to becoming a contract between the
service and its clients. The additional fea-
tures provided by the ESB, such as secu-
rity, management capabilities, auditing,
logging, or even custom features can be
added. These can be added across the dif-
ferent services implemented using an in-
terceptor or message-handler framework.
This is an area where you can expect an
ESB to provide components that can be
easily combined with the services you
have built.
Building Business Processes
With services that reflect business func-
tions in place on the ESB, new services
that model complete business process-
es can be created. Business Process Ex-
ecution Language (BPEL) is a language
(continued from page 26)
28
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 2:
Implementing the service policy.

Listing One
public class CustomerDetails {
public String name;
public String street;
public String city;
public String state;
}
public class CarDetails {
public String make;
public String model;
}
public class BillingInfo {
public String creditCardNumber;
public String exprityDate;
}
public interface InsurancePortType {
public String createApplication( CustomerDetails customer );
public void setCarDetails( String reference, CarDetails details );
public Decimal calculateQuote( String reference );
public void processApplication( String reference, BillingInfo info );
}
Listing Two
<?xml version="1.0" encoding="UTF-8"?>
<definitions name="Insurance"
targetNamespace="http://capeclear.com/CarInsurance.wsdl"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns="http://capeclear.com/CarInsurance.wsdl"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:xsd1="http://capeclear.com/CarInsurance.xsd">
<types>
<xsd:schema targetNamespace="http://capeclear.com/CarInsurance.xsd">
<xsd:complexType name="BillingInformation">
<xsd:sequence>
<xsd:element name="creditCardNumber" type="xsd:string"/>
<xsd:element name="expiryDetails" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="CustomerDetails">
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="street" type="xsd:string"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string"/>
<xsd:element name="age" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="CarDetails">
<xsd:sequence>
<xsd:element name="make" type="xsd:string"/>
<xsd:element name="model" type="xsd:string"/>
<xsd:element name="serialnumber" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>
</types>
<message name="setCarDetailsResponse" />
<message name="createApplicationResponse">
<part name="return" type="xsd:string"/>
</message>
<message name="setCarDetails">
<part name="reference" type="xsd:string"/>
<part name="carDetails" type="xsd1:CarDetails"/>
</message>
<message name="calculateQuoteResponse">
<part name="return" type="xsd:decimal"/>
</message>
<message name="processApplicationResponse" />
<message name="processApplication">
<part name="reference" type="xsd:string"/>
<part name="billingInfo" type="xsd1:BillingInformation"/>
</message>
<message name="createApplication">
<part name="customer" type="xsd1:CustomerDetails"/>
</message>
<message name="calculateQuote">
<part name="reference" type="xsd:string"/>
</message>
<portType name="InsurancePortTypeServer">
<operation name="calculateQuote">
<input message="tns:calculateQuote"/>
<output message="tns:calculateQuoteResponse"/>
</operation>
<operation name="createApplication">
<input message="tns:createApplication"/>
<output message="tns:createApplicationResponse"/>
</operation>
<operation name="processApplication">
<input message="tns:processApplication"/>
<output message="tns:processApplicationResponse"/>
</operation>
<operation name="setCarDetails">
<input message="tns:setCarDetails"/>
<output message="tns:setCarDetailsResponse"/>
</operation>
</portType>
</definitions>
Listing Three
<?xml version="1.0" encoding="UTF-8"?>
<wsdl:definitions name="InsuranceService"
targetNamespace="http://capeclear.com/CarInsurance.wsdl"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns="http://capeclear.com/CarInsurance.wsdl"
xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsd1="http://capeclear.com/CarInsurance.xsd">
<wsdl:types>
<xsd:schema targetNamespace="http://capeclear.com/CarInsurance.xsd">
<xsd:element name="InsuranceApplication">
<xsd:complexType>
<xsd:sequence>
<xsd:element name=
"CustomerDetails" type="xsd1:CustomerDetails"/>
<xsd:element name=
"CarDetails" type="xsd1:CarDetails"/>
<xsd:element name=
"BillingInformation" type="xsd1:BillingInformation"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:complexType name="BillingInformation">
<xsd:sequence>
<xsd:element name="creditCardNumber" type="xsd:string"/>
<xsd:element name="expiryDetails" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="CustomerDetails">
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="street" type="xsd:string"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string"/>
<xsd:element name="age" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="CarDetails">
<xsd:sequence>
<xsd:element name="make" type="xsd:string"/>
<xsd:element name="model" type="xsd:string"/>
<xsd:element name="serialnumber" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema> </wsdl:types>
<wsdl:message name="calculateQuote">
<wsdl:part element="xsd1:InsuranceApplication" name="reference"/>
</wsdl:message>
<wsdl:message name="calculateQuoteResponse">
<wsdl:part name="return" type="xsd:decimal"/>
</wsdl:message>
<wsdl:message name="processApplication">
<wsdl:part element="xsd1:InsuranceApplication" name="application"/>
</wsdl:message>
<wsdl:message name="processApplicationResponse">
<wsdl:part name="policyNumber" type="xsd:string"/>
</wsdl:message>
<wsdl:portType name="InsuranceServiceCallBack">
<wsdl:operation name="QuoteDetails">
<wsdl:input message="tns:calculateQuoteResponse"/>
</wsdl:operation>
<wsdl:operation name="ApplicationDetails">
<wsdl:input message="tns:processApplicationResponse"/>
</wsdl:operation>
</wsdl:portType>
<wsdl:portType name="InsuranceService">
<wsdl:operation name="calculateQuote">
<wsdl:input message="tns:calculateQuote"/>
</wsdl:operation>
<wsdl:operation name="processApplication">
<wsdl:input message="tns:processApplication"/>
</wsdl:operation>
</wsdl:portType>
</wsdl:definitions>
DDJ
designed for just this purpose. A BPEL
editor should be provided to enable the
existing services to be combined into
processes. The ease with which new
business processes can be developed de-
pends in part on how successful the de-
sign of the business services has been.
BPEL is a language designed to model
business processes — it is not a place to
solve integration issues. These should be
solved in the lower layers.
Conclusion
An ESB provides effective tools and ser-
vices that can be used to construct an
SOA. However, careful thought and plan-
ning is required in order to ensure that
the resulting system is truly an SOA. This
requires a good understanding of the prin-
cipals of SOA to evaluate the output of
the tools provided by the ESB. The effort
put into the design of individual services
exposed on the ESB results in benefits
when the task of business-process mod-
eling is performed.
DDJ
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
29

I
t used to be that if you wanted to ac-
cess the vast wealth of data on the Web,
you fired up a web browser and
hopped from page to page, selectively
reading as you went. That was fine for
quickly looking something up or whiling
away the time, but the Web has become
an increasingly valuable research and busi-
ness tool. Research is often defined in
practical terms as the need to process and
categorize large quantities of data, while
business transactions are usually more ef-
ficiently handled by computers than hu-
mans, so the desire to automate these pro-
cesses is natural and inevitable. That’s
where a browser ceases to be the right
tool for the job.
Various technologies enable program-
matic access to the Web without the need
for tedious and error-prone screen scrap-
ing — REST, XML-RPC, and SOAP are the
best known amongst these. These tech-
nologies have encouraged information
providers to make their data available not
just in old-fashioned HTML for interactive
consumption, but also as structured data
that can be programmatically queried,
parsed, and manipulated.
The net result is that large web sites —
especially those that conduct commerce on
the Web — have developed APIs through
which their users and affiliates can search
for information and conduct business. eBay,
Google, salesforce.com, and Amazon, for
example, all offer web APIs via which users
may mine databases and transact business.
These are usually, but not always, free to
use, as they encourage the development of
third-party products, and in turn, lead to
the growth of a wider community around
the company’s business.
In this article, I examine Amazon Web
Services (AWS), one of the more com-
prehensive APIs offered by web commerce
companies. There are a number of dif-
ferent ways of using AWS. For example,
Amazon offers both a REST- and a SOAP-
based API. The choice of which to use is
up to developers and is largely a question
of taste, which is why Amazon chose to
offer both.
At this point, there’s nothing to stop you
from reading the API documentation and
immediately starting to code an applica-
tion in your favorite programming lan-
guage, but you’ll soon find yourself spend-
ing time on the mechanics of the API,
rather than just dealing with the data you
want to extract.
Happily, a number of people have writ-
ten wrapper libraries around AWS, re-
moving the need for you to parse XML,
deal with common error conditions, and
program around limitations in the under-
lying API. Here, I look at the Ruby/Ama-
zon toolkit, which is a high-level abstrac-
tion of AWS I wrote for the Ruby
programming language (http://www.caliban
.org/ruby/ruby-amazon.shtml).
Ruby has been rapidly gaining ground
as a highly viable alternative to Perl,
Python, and Java for general scripting, sys-
tem administration, and applications pro-
gramming (http://ruby-lang.org/). Com-
ing equipped with strong XML, HTTP(S),
XML-RPC, and SOAP libraries, it fortunately
also lends itself very well to web-services
programming.
Ruby/Amazon has some convenient,
time-saving features, such as the ability to
cache search results for later recall and
the option to find all results for a given
search, rather than obtain just the single
page of 10 results that the underlying API
returns. Without a higher level wrapper
library acting as an intermediary, achiev-
ing the same result would entail retriev-
ing each consecutive page yourself, until
no more results were returned.
AWS has undergone a number of revi-
sions since its inception in 2002 and is
currently at Version 3.1. At the time of writ-
ing, AWS 4.0 is in beta testing and is a
complete rewrite of the API. I focus here
on 3.1, as that is the version in the most
widespread use.
Before starting, you should get a de-
veloper token by registering at http://
www.amazon.com/gp/aws/registration/
registration-form.html/. While there, it is
a good idea to apply for an Associates ac-
count (https://associates.amazon.com/
exec/panama/associates/apply/). This lets
you earn referral fees for any customers
you bring to Amazon via applications you
create that take advantage of AWS.
You’re ready to roll. If you need to use
an HTTP proxy, define it now in the UNIX
environment variable $http_proxy; see List-
ing One. As you can see, I am choosing to
display information about a product’s name,
author, price, and availability. Each prop-
erty of the product is available as an in-
stance variable of the corresponding object.
In Listing One, the object is passed into the
Ruby/Amazon &
Amazon Web Services
Automating
e-commerce with a
convenient interface to
Amazon’s AWS API
IAN MACDONALD
Ian is a a senior system administrator
for Google. He can be contacted at ian@
caliban.org.
30
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
“One of the more
advanced features
offered by
Ruby/Amazon is the
option of customer
geolocation”

search block as an iterator. To display a list
of available properties for any given prod-
uct, you can call the properties method of
the corresponding product object.
Not every product has every type of
property. For example, a book will have
authors, but no directors, while a DVD is
the opposite. Even within a single prod-
uct category, some products will have
properties that others are missing. Some
properties, however, such as the price, are
logically common to all products; every-
thing has a price at Amazon. At this writ-
ing, Listing One yields the results in Fig-
ure 1. Rather than use the iterator block
form of the search, this would also have
worked as well:
response = r.keyword_search
('ruby programming', 'books')
Using this approach, response now con-
tains the literal REST response returned
by AWS; you can print or puts it and see.
This is sometimes useful for the purpose
of debugging. You can still iterate over
the products by calling each iterator on
the products array:
response.products.each do |p|
# Process product data
end
Amazon Standard Item Numbers (ASINs,
see Figure 1) are at the heart of the Ama-
zon product catalog, as they provide ev-
ery product in the catalog with a unique
identifier. For a book, the ASIN is the same
as the ISBN number, but for other items,
it’s an arbitrary alphanumeric string con-
cocted by Amazon. Many of the AWS API
calls deal directly with ASINs to unique-
ly identify the product in question, so
you’ll likely find yourself passing them
around a lot.
If you didn’t elect to use caching at the
time of request object instantiation, you
can elect to do so now by establishing a
cache object for future searches. The cache
directory given is created, if it does not
already exist.
r.cache = Cache.new( '/tmp/amazon' )
From this point forward, new searches
are not repeated if they were already con-
ducted less than 24 hours ago. Amazon
allows the caching and reuse of most data
for 24 hours, although this changes from
time to time, so check the latest terms and
conditions (available in the API ZIP file).
Using the cache facility can vastly improve
the performance of your application, so
it is used by default if you do not speci-
fy a preference.
You can make life easier for yourself by
specifying your usual requirements for
new Request objects in a configuration
file, to be found at either /etc/amazonrc
or ~/.amazonrc. For example:
dev_token = 'D23XFCO2UKJY82'
associate = 'calibanorg-20'
cache_dir = '/tmp/amazon/cache'
locale = 'de'
Now, any Request objects you create in-
herit these characteristics. They can still be
manually overridden as required, however.
The underlying concept of Listing One
can be inverted to produce a program that
notifies you whenever a new album by
your favorite artist appears in the Amazon
catalogue for preorder. This works by
looking for products whose availability
contains the string “not yet released.” In
Listing Two, the “favourites” array con-
tains tuples of product names and catalog
sections. The program then searches the
relevant parts of the UK catalogue for
matching products that have not yet been
released. It may be useful to mail the out-
put of this program to yourself on a week-
ly basis. When run, the output looks like
Figure 2.
As a final demonstration of the useful-
ness of this kind of monitoring, I present
a program that is designed to be run au-
tomatically on a daily basis. It tracks the
price of an item in the “electronics” sec-
tion of the catalog and produces output
whenever the price changes.
Items in Amazon’s catalog can under-
go quite a lot of price fluctuation within
a relatively short period of time. Some-
times, the price of an expensive item drops
$50.00 or more, only to rise again mere
hours later. I don’t know why this hap-
pens, but knowing that it does and hav-
ing AWS at your disposal lets you take ad-
vantage of these fluctuations to buy at a
favorable moment.
Have a look at Listing Three. Replace
the ASIN with that of a product in which
you’re interested and run the program
once an hour or so, perhaps from cron.
There are many kinds of searches that
can be performed via AWS. You’ve already
seen #keyword_search and #asin_search
in the example programs, but there are
other common search types, such as #ac-
tor_search, #artist_search, #author_search,
(continued from page 30)
32
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 1:
Output from Listing One.
Programming Ruby: The Pragmatic Programmers' Guide by Dave Thomas, Chad
Fowler, Andy Hunt (ASIN 0974514055) for $44.95
Not yet released.
Ruby Developer's Guide by Michael Neumann, Lyle Johnson, Robert Feldt,
Lyle Johnson, Jonothon Ortiz (ASIN 1928994644) for $32.97
Usually ships in 11 to 12 days
Sams Teach Yourself Ruby in 21 Days by Mark Slagell (ASIN 0672322528)
for $28.39
Usually ships in 1 to 3 weeks
Ruby In A Nutshell by Yukihiro Matsumoto (ASIN 0596002149) for $16.47
Usually ships in 24 hours
The Ruby Way by Hal Fulton (ASIN 0672320835) for $27.19
Usually ships in 24 hours
Making Use of Ruby by Suresh Mahadevan, Suresh Mahadevan, Rashi Gupta,
Shweta Bhasin, Madhushree Ganguly, Ashok Appu (ASIN 047121972X) for $23.80
Usually ships in 24 hours
Game Programming with Python, Lua, and Ruby by Tom Gutschmidt (ASIN
1592000770) for $26.39
Usually ships in 24 hours
Figure 2:
Output from Listing Two.
Bullet CD by Trafik
(ASIN B0002NRMMY)
Only Fools And Horses - Sleepless In Peckham DVD
(ASIN B0002PC39Y)
Only Fools And Horses - The Complete Series 1 To 7 DVD
(ASIN B0002XOZSS)
Only Fools And Horses - Christmas Specials DVD
(ASIN B0002XOZV0)
The Office: Christmas Specials [2003] DVD
(ASIN B0001WHUFK)
The Office: Complete Box Set (Series 1 - 2 plus Christmas Specials) [2001] DVD
(ASIN B0002IAQFY)
and #director_search, as well as a slew of
other, more esoteric searches.
For example, if you have an Amazon wish-
list, you can look it up with a line like this:
r.wishlist_search( '18Y9QEW3A4SRY' )
The parameter to the method call is the
alphanumeric wishlist ID.
Or, if you want to get more specific and
you’re looking for a book, the power
search may be what you need. The fol-
lowing would find all books published by
O’Reilly & Associates in the Amazon cat-
alog and sort them by publishing date:
r.power_search("publisher:o’reilly", 'books',
HEAVY, ALL_PAGES, '+daterank')
This can take quite some time to return,
as it will have to look up in excess of 1000
products.
I won’t go into any of the other eso-
teric searches here. Read the AWS and
Ruby/Amazon documentation, experi-
menting as you go, to get a feel for what
is possible.
One thing worth noting is that the AWS
search methods can take many more pa-
rameters than illustrated by the programs
I present here. For example, I’ve been per-
forming “heavy” searches by default, which
return all the information available for a
given product. You can also specify a “lite”
search, which returns fewer properties and
is, therefore, theoretically faster to execute.
Use the Amazon::Search::HEAVY and
Amazon::Search::LITE constants to speci-
fy the weight of the search. The weight is
either the second or the third argument to
the method, depending on the particular
method call.
Another parameter of interest is the
page parameter. This specifies which page
of up to 10 responses to return for the giv-
en search. If you play around with the
various search methods without supply-
ing a page number, you’ll quickly notice
that you are never returned more than 10
products for a given search. This is be-
cause you’re only looking at the first page
of results, since the default page to re-
trieve is the first.
Instead of using the default of 1 (or any
other integer), try passing the constant
Amazon::Search::ALL_PAGES for a search
that you suspect would yield a high num-
ber of hits, such as the power search. This
constant signals to Ruby/Amazon that it
should carry out as many background
AWS operations as required to return all
hits for a given search query. If you chose
a generic search, it could be quite some
time before you get back your results.
I now leave searches to concentrate on
a different area of AWS where Ruby/Ama-
zon can be of assistance.
If you want to build your own online
store, but don’t wish to invest in any stock,
you can use the gigantic Amazon catalog
as your inventory, have Amazon take care
of the postage, packing, invoicing, and dis-
patch, and simply sit back and earn refer-
ral fees on any items sold via your site.
One way to achieve this is the so-called
“remote shopping cart” feature of AWS. This
is one of the areas where Ruby/Amazon
can take a lot of the work out of your
hands, as the required tracking of shopping
cart IDs and security tokens is handled in-
ternally by the objects you create. You won’t
even know these elements exist, much less
need to deal with them manually.
Listing Four takes a list of ASINs from
the command line, and adds each of the
corresponding products to a new remote
shopping cart. Finally, it spits out the pur-
chase URL of the new cart; see Figure 3.
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
33
http://www.amazon.com/exec/obidos/shopping-basket?cart-id=002-1095509-6210461%26associate-id
=calibanorg-20%26hmac=%2BWlRcRNiMD6KJ9UuUeNPMvqnVDY=
Figure 3:
Output from Listing Four.

Listing One
#!/usr/bin/ruby -w
# Use the Ruby/Amazon library
require 'amazon/search'
# Include the constants, classes and methods from the Amazon::Search module
include Amazon::Search
# Create a new request object, passing in my AWS developer's token, my
# Associates ID, the locale in which I wish to work (the US or amazon.com in
# this case) and the fact that I do not wish to use a results cache.
#
# Only the first parameter is required. The locale defaults to US and a cache
# is used unless specified otherwise. Even the need for the first parameter
# can be avoided by entering it in ~/.amazonrc.
#
r = Request.new( 'D23XFCO2UKJY82', 'calibanorg-20', 'us', false )
# Search for for items related to Ruby programming in the books section of the
# Amazon catalogue. Pass each product found into a block, calling the product
# object p on each iteration.
#
r.keyword_search( 'ruby programming', 'books' ) do |p|
authors = p.authors.join( ', ' )
# Information for books that are currently in print or soon to be available.
unless p.availability =~ /not available/
printf( "%s by %s (ASIN %s) for %s\n%s\n\n", p.product_name, authors,
p.asin, p.our_price, p.availability )
end
end
Listing Two
#!/usr/bin/ruby -w
require 'amazon/search'
# Construct an array of search strings and product catalog in which to search.
favourites = [
[ 'global underground', 'music' ],
[ 'the divine comedy', 'music' ],
[ 'only fools horses', 'dvd' ],
[ 'the office', 'dvd' ],
[ 'minder', 'dvd' ]
]
q = Amazon::Search::Request.new( 'D23XFCO2UKJY82' )
# I wish to search the British (amazon.co.uk) catalogue.
q.locale = 'uk'
favourites.each do |search_string, category|
r = q.keyword_search( search_string, category )
r.products.each do |p|
if p.availability =~ /not yet released/i
case p.catalogue
when 'Music'
printf( "%s CD by %s\n(ASIN %s)\n\n", p.product_name, p.artists, p.asin )
when 'DVD'
printf( "%s DVD\n(ASIN %s)\n\n", p.product_name, p.asin )
end
end
end
end
Listing Three
#!/usr/bin/ruby -w
require 'amazon/search'
include Amazon::Search
# The iRiver iHP140 jukebox
asin = 'B0001G6UAW'
# Look it up
r = Request.new( 'D23XFCO2UKJY82' )
resp = r.asin_search( asin )
# Quit if we didn't get a response
exit unless resp
new_price = resp.products[0].our_price
begin
# Read the price from the last check
cur_price = File::readlines( '/tmp/price' ).to_s.chomp
rescue Errno::ENOENT # File won't exist the first time we are run
cur_price = '0'
end
# Quit if there's no price change
exit if new_price == cur_price
# Write new price out to file and stdout
File.open( '/tmp/price', 'w') { |file| file.puts new_price }
printf( "Price of %s has changed from %s to %s\n",
resp.products[0].product_name, cur_price, new_price )
Listing Four
#!/usr/bin/ruby -w
require 'amazon/shoppingcart'
include Amazon
DEV_TOKEN = 'D23XFCO2UKJY82'
sc = ShoppingCart.new( DEV_TOKEN )
ARGV.each { |asin| sc.add_items( asin, 1 ) }
puts sc.purchase_url
DDJ
If that URL were subsequently entered into
a browser, the contents of the remote cart
would be uploaded to the local shopping
cart of the browser’s user.
This feature lets you tie your users
more closely to your online store by
seamlessly integrating shopping-cart fa-
cilities in your own site. This alleviates
the need to link away to Amazon for the
actual purchase, which would carry with
it the risk of the customer continuing his
browsing from there, rather than return-
ing to your site to potentially earn you
more referral fees.
One of the more advanced features
offered by Ruby/Amazon is the option
of customer geolocation. This is inter-
nally orchestrated via MaxMind’s GeoIP
library (http://www.maxmind.com/). For
this feature to work, you need to have
GeoIP installed, along with the associ-
ated Ruby bindings (http://www.rubynet
.org/modules/net/geoip/).
The idea here is that you capture the
host name or IP address of the customer
connecting to your web site and then use
that information to determine the Ama-
zon site at which the customer is most
likely to want to shop.
For example, a CGI (or mod_ruby,
http://modruby.net/en/) script might con-
tain something like this:
require 'amazon/locale'
require 'amazon/search'
include Amazon::Search
locale =
Amazon::Locale::get_locale_by_addr
( ENV['REMOTE_ADDR']
)
r = Request.new( 'D23XFCO2UKJY82',
'calibanorg-20', locale )
If, for example, the customer were com-
ing from 217.110.207.55, the locale of the
Request object would now be set to de,
which corresponds with amazon.de. All
future searches would now take place
within the German catalogue. You can use
this to try to intelligently and transparent-
ly connect the customer with the product
catalogue in which he or she is most like-
ly to be interested.
Your customers don’t have to be phys-
ically located in one of the actual coun-
tries that Amazon serves via AWS for geo-
location of the locale to succeed. For
example, Irish customers would be local-
ized to the UK site, Swiss customers to the
German site, and Canadians would find
themselves localized to the U.S. ama-
zon.com site.
What else could you do with Ruby/
Amazon? Perhaps you maintain a database
of your book collection, just to keep track
of everything. Wouldn’t it be nice if you
could associate each book in your col-
lection with a picture of its cover? Well,
one of the properties you can retrieve for
books in Amazon’s vast catalog is im-
age_url_large, which is a URL to a large
image of the book’s cover (there are also
small and medium variants). Alexandria
(http://alexandria.rubyforge.org/) is a
GNOME application written with this ex-
act purpose in mind. It lets you enter and
manage your book collection and calls
upon Ruby/Amazon to fetch images of
the items in it.
Ruby/Amazon is a convenient, time-
saving interface to Amazon’s AWS API.
By extension, it demonstrates that Ruby
is a serious contender for general web-
service programming.
DDJ
34
Dr. Dobb’s Journal, February 2005
http://www.ddj.com

G
eographical Information Systems
(GIS) are making inroads into ap-
plications ranging from utilities and
facility management, to city plan-
ning and security, among others. In this
article, I present a GIS application that
lets you embed a map into a Microsoft
Word document simply by highlighting
an address in the text. As such, this arti-
cle is a convergence of several distinct
technologies: GIS, Visual Basic for Appli-
cations (VBA), web services, and word
processing.
To build the sample program (actual-
ly, a Word macro), you need to have in-
stalled on your PC Microsoft Word 2002
(or higher), Internet Explorer 5.x (or high-
er), and the Microsoft SOAP Toolkit 3.0.
However, to use the code I present here,
you need to set up a web service on a
protected intranet. You can easily replace
my web service with your own or use a
third-party subscription web service such
as Microsoft’s MapPoint (http://www
.mappoint.com/).
Listing One is the code for the Word
macro. The Word document that accom-
panies this article is available electroni-
cally; see “Resource Center,” page 5. To
view and open the Word document, press
ALT+F11. The execution of the sample
program is a two-part operation:
1. Highlight a street address for Knoxville,
Tennessee.
2. Right click your mouse and choose “Val-
idate address…” from the context menu.
If an invalid address is highlighted, a
message box appears informing you that
the address is invalid; otherwise, you are
presented with a dialog box that lets you
select various map “themes” (an aerial
photo, zoning restrictions, and so on) as
well as specifying a map size and scale.
Nearly all the heavy lifting in this pro-
gram is performed by a web service that
lives on the Internet (or an intranet) and
performs discrete operations; in this ex-
ample, the web service first validates an
address, then returns a map at the request
of users. The beauty of web services is
that you don’t have to know anything
about their inner workings — you simply
use them. Web services expose their meth-
ods, which makes it easy to know what
data you have to pass in (in this example,
an address as a string), and what you get
back (again, a string representing the URL
of a map). The other nice thing about web
services is that they can be written in one
language, but called from any other. My
web service is written in Visual Basic; how-
ever, you could call it from a C# or C++
application. In short, web services go a
long way toward delivering on the promise
of seamless, heterogeneous, distributed
computing.
The KGIS Address Web Service
The web service used by my Word macro
is a product of Knoxville Geographic In-
formation Systems (KGIS) of Knoxville,
Tennessee. KGIS is responsible for main-
taining all the geographical data for Knox
County, and is a consortium of the city
of Knoxville, Knox County, and the
Knoxville Utilities Board (KUB). KGIS is
thus responsible for supporting a wide
user base with diverse data needs. The
primary GIS tool is ArcIMS from ESRI
(http://www.esri.com/). ArcIMS generates
the map that gets inserted into a Word
document when an address is validated.
The web service I use in this article does
not actually return a map image, but
rather, the URL of the map image. The
main point here is that a web service ex-
ists that validates an address (for Knox
County, Tennessee) and returns you a ref-
erence to a map of that address.
The web service itself is integrated in a
Microsoft Word document as a macro. This
entire problem of inserting a map into
Word can be broken down into three
steps:
1. Create the macro that calls the web
service.
2. Provide a way for the user to call the
web service.
3. Do something with the result.
GIS Web Services and
Microsoft Word
VBA and macros
carry the load
KEITH BUGG
Keith is a software developer for Staff IT
in Oak Ridge, TN. He can be contacted at
kebugg@comcast.net.
36
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
“Nearly all the
heavy lifting in this
program is
performed by a web
service”
To create a Word macro, select Tools->
Macro->Macros… from the toolbar. This
launches a dialog that lists all current
macros, plus, displays a Create button. En-
ter the name of your macro and click this
button. This launches the VBA editor,
which defaults to editing a subroutine with
the same name as your macro from the
previous screen. The code for my macro
(available electronically; see Validate_Ad-
dress( )) is responsible for reading the ad-
dress that users select (highlight), and con-
figuring the structures needed by the web
service. This is done by using the Selec-
tion object; see Example 1.
Saving the selected string is necessary
for two reasons. First, you need to read
the string containing the address. Second,
if the address turns out to be valid and
users want to see a map, I insert a blank
line immediately below the highlighted ad-
dress for inserting the map. I then re-
highlight the address. Saving the start-
ing/ending locations of the address string
lets me do this. It also gives users visual
feedback as to which address they se-
lected.
One final caveat regarding macros —
you may need to adjust your security set-
tings in Word before this macro executes.
Select Tools->Macros->Security… on the
toolbar and enable macros.
Calling a Web Service
The next step is to provide a way for users
to call the web service from inside Word.
For my sample program, I modified the
context menu that appears when you
right-click in Word; see Figure 1. Begin
by clicking Customize under Tools on the
main menubar of Word. Select the Tool-
bars tab and check the box next to Short-
cut Menus. That opens the shortcut menu
bar editor; see Figure 2.
Next, select Text from the Shortcut
Menus toolbar, and add the text for the
context menu (Validate Address…). Then,
on the Customize dialog, select Commands
and then Macros. Add the name of the
macro here; see Figure 3.
The Code
The code exists in a macro called Test( ).
In the sample Word document (available
electronically), you can access the code
by pressing ALT+F11 to open the macro
editor. The code declares many different
variables; some of these are related to call-
ing my map service. The generic variables
are concerned with getting the text that
users have highlighted, namely, sSelection.
The contents of this variable must be
checked for nonvisible ASCII characters.
The only thing you want to pass to the
web service is a valid street address. Ex-
ample 2 does just that.
Once you have the address, you have
to validate it against the KGIS database
(again, your project would use your
database). If valid, the dialog box in Fig-
ure 4 appears, letting users select the prop-
erties of the map for the given address.
This dialog is called UserForm1 in the
project. The Theme combobox is popu-
lated with the values Topographic, Aeri-
al Photo, Case Parcel Map, and Zoning.
The web service uses this information to
return the type of map. Scale and Size are
self explanatory. The Owner Data com-
bobox is an additional criterion peculiar
to the KGIS web service. Its values are
Map ONLY, Owner Info., and Owner Info./
Parcel ID. Normally just a map would be
returned, but the other options allow in-
formation about the owner of the address
and the parcel to be returned as well.
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
37
Figure 1:
Modifying the context menu.
Figure 2:
The shortcut menu editor.
Example 1:
Using the Selection object.
sSelection = Selection
iStart = Selection.Range.Start ' save the highlighted address
iEnd = Selection.Range.End
Example 2:
Pass a valid street address to the web service.
sSelection = Selection
iStart = Selection.Range.Start
iEnd = Selection.Range.End
iLastChar = Asc(Mid(sSelection, (iEnd - iStart), 1))
If iLastChar = 32 Or iLastChar = 116 Then
iEnd = iEnd - 1
sSelection = Left(sSelection, (iEnd - iStart) + 1)
End If
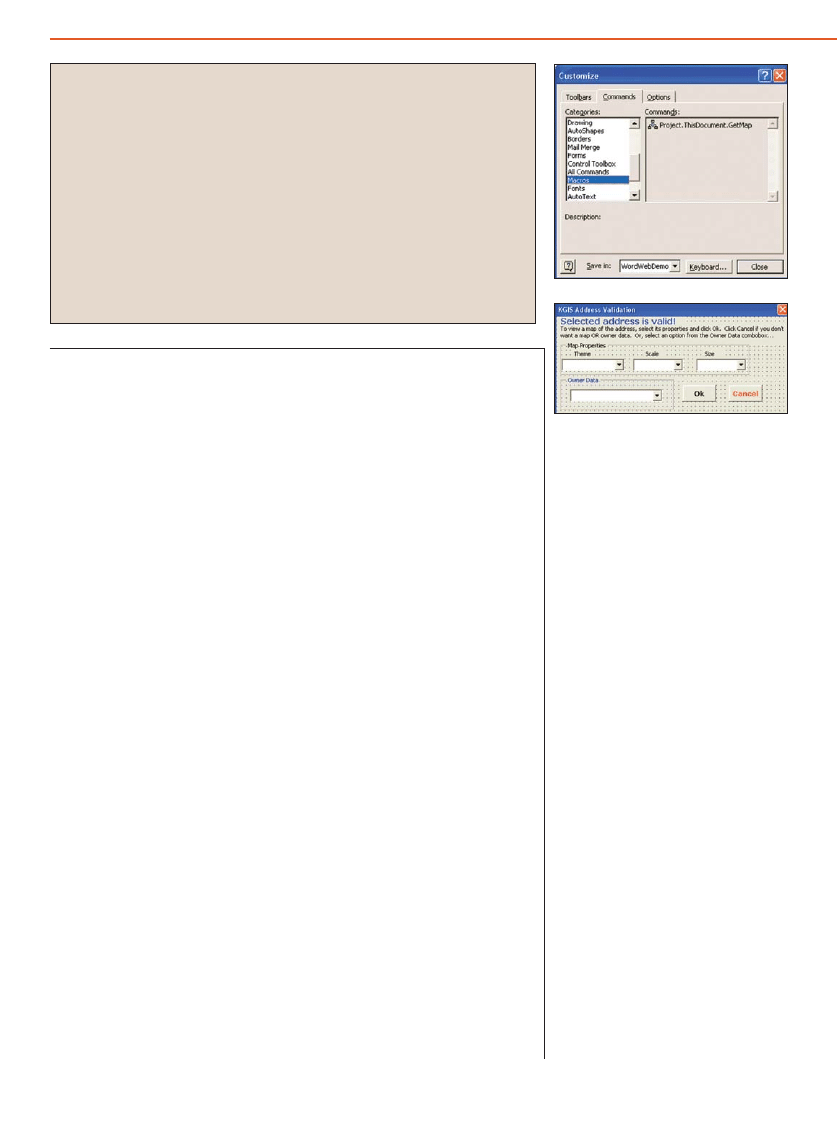
After users have made their selections
on this dialog and clicked the OK but-
ton, the real fun starts. The structures
used by the web service are complet-
ed and the web service is called using
this line:
sMapURL =
myMap.wsm_GetMapByAddressMSLink
(CLng(Val (myAddrInfo.AddrMSLINK)),
myMapProps)
The web service returns the URL of a
map that lives on the server. The next
programming chore is to get this image
into the Word document. This is done by
first creating a temporary file in the user’s
TEMP directory, then copying the JPEG
map image to this file. Once on the local
machine, it’s a snap to insert it into Word;
see Example 3. The line in bold is a little-
known API call that does all the work.
According to the documentation, its func-
tion is to “Download bits from the Inter-
net and save them to a file”— exactly
what you want. Finally, a Selection object
is created for an InLineShape, and the
map/JPEG is assigned to the AddPicture
method. You now have a map in your
Word document.
Conclusion
There are a number of Internet sites that
provides maps identifying stores, points
of interests, and the like. With the merg-
ing of GIS with the Office tools, you can
greatly extend and enhance the utility of
your GIS-related applications.
DDJ
38
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 4:
Selecting the map properties.
Dim sMapParams() As String
sMapParams = Split(sMapURL, "|")
Dim obj As InlineShape
Dim sNewImage As String
'
szTempDir = Environ("TEMP") ' get temp. folder
szTempFileName = fso.GetTempName() ' get a temp. filename
'
' remove the .tmp extension and change to .jpg
'
szTempFileName = Left(szTempFileName, 9)
szTempFileName = szTempDir & "\" & szTempFileName & "jpg"
sNewImage = sMapParams(0) '
e
er
rr
r
=
=
U
UR
RL
LD
Do
ow
wn
nl
lo
oa
ad
dT
To
oF
Fi
il
le
e(
(0
0,
,
s
sN
Ne
ew
wI
Im
ma
ag
ge
e,
,
s
sz
zT
Te
em
mp
pF
Fi
il
le
eN
Na
am
me
e,
,
0
0,
,
0
0)
)
Selection.InlineShapes.AddPicture FileName:=szTempFileName,
SaveWithDocument:=True
Example 3:
Inserting a map into a Word document.
Figure 3:
Adding the macro.

Listing One
Private Declare Function URLDownloadToFile Lib "urlmon" Alias _
"URLDownloadToFileA" (ByVal pCaller As Long, ByVal szURL As String, _
ByVal szFileName As String, ByVal dwReserved As Long, _
ByVal lpfnCB As Long) As Long
' This is the prototype for calling a Web service from inside a Word doc
Sub Test()
Dim sSelection As String
Dim sValidAddr, sTheme, sScale, sSize As String
Dim iStart, iEnd, iResult, iLastChar, k As Integer
Dim selOrig As Selection
Dim sMapURL As String
Dim bLoop As Boolean
Dim myMap As clsws_GetMap
Dim myMapProps As struct_MapSettings
Dim localFileName, szTempDir, szTempFileName As String
Dim fso As New FileSystemObject
Dim err As Long
'
Set selOrig = Selection
sSelection = Selection
iStart = Selection.Range.Start
iEnd = Selection.Range.End
iLastChar = Asc(Mid(sSelection, (iEnd - iStart), 1))
' Code to strip off a trailing <cr>, comma, space, or period
bLoop = True
k = 0
Do While bLoop '
iLastChar = Asc(Mid(sSelection, ((iEnd - k) - iStart), 1))
If ((iLastChar >= 65 And iLastChar <= 90) Or
(iLastChar >= 97 And iLastChar <= 122)) Then
bLoop = False
Else
k = k + 1
End If
Loop
sSelection = Left(sSelection, ((iEnd - k) - iStart))
Dim myGetAddress As clsws_GetAddress
Dim myAddrInfo As struct_AddressInfo
Dim mySearchInfo As struct_SearchProperties
Set mySearchInfo = New struct_SearchProperties
Set myGetAddress = New clsws_GetAddress
mySearchInfo.AddressStyle = "FullAddress"
mySearchInfo.SearchMethod = "Exact"
mySearchInfo.SpatialSearch = "None"
mySearchInfo.FullAddress = sSelection
Set myAddrInfo = myGetAddress.wsm_GetAddressInfo(mySearchInfo)
sValidAddr = myAddrInfo.MatchStatus
If sValidAddr = "Exact" Then
'
UserForm1.Show (vbModal) 'show UserForm1
iResult = UserForm1.sResult
sTheme = UserForm1.sTheme
sScale = UserForm1.sScale
sSize = UserForm1.sSize
Unload UserForm1 ' transfered values, so safe to unload the Form
' does user want a map or an owner card?
Select Case iResult
Case 1
' *************************
' * User wants a map *
' *************************
Selection.Paragraphs(1).Range.InsertParagraphAfter
Selection.MoveDown ' this is required!
'now get the map
Set myMap = New clsws_GetMap
Set myMapProps = New struct_MapSettings
myMapProps.MapScale = sScale ' set scale user picked
myMapProps.MapType = sTheme ' set theme user picked
Select Case sSize
Case "Small"
myMapProps.MapHeight = 300
myMapProps.MapWidth = 400
'
Case "Medium"
myMapProps.MapHeight = 400
myMapProps.MapWidth = 500
'
Case "Large"
myMapProps.MapHeight = 500
myMapProps.MapWidth = 600
End Select
'myMapProps.UseExtents = False
myMapProps.UseScale = True
sMapURL = myMap.wsm_GetMapByAddressMSLink(CLng(Val
(myAddrInfo.AddrMSLINK)), myMapProps)
Dim sMapParams() As String
sMapParams = Split(sMapURL, "|")
Dim obj As InlineShape
Dim sNewImage As String
'
szTempDir = Environ("TEMP") ' get temp. folder
szTempFileName = fso.GetTempName() ' get temp file name
' remove the .tmp extension and change to .jpg
szTempFileName = Left(szTempFileName, 9)
szTempFileName = szTempDir & "\" & szTempFileName & "jpg"
sNewImage = sMapParams(0) '
err = URLDownloadToFile(0,sNewImage,szTempFileName,0,0)
Selection.InlineShapes.AddPicture
FileName:=szTempFileName, SaveWithDocument:=True
Selection.MoveLeft Unit:=wdCharacter, Count:=1,
Extend:=wdExtend
With Selection.InlineShapes(1)
With .Borders(wdBorderLeft)
.LineStyle = wdLineStyleSingle
.LineWidth = wdLineWidth050pt
.Color = wdColorAutomatic
End With
With .Borders(wdBorderRight)
.LineStyle = wdLineStyleSingle
.LineWidth = wdLineWidth050pt
.Color = wdColorAutomatic
End With
With .Borders(wdBorderTop)
.LineStyle = wdLineStyleSingle
.LineWidth = wdLineWidth050pt
.Color = wdColorAutomatic
End With
With .Borders(wdBorderBottom)
.LineStyle = wdLineStyleSingle
.LineWidth = wdLineWidth050pt
.Color = wdColorAutomatic
End With
.Borders.Shadow = False
End With
With Options
.DefaultBorderLineStyle = wdLineStyleSingle
.DefaultBorderLineWidth = wdLineWidth050pt
.DefaultBorderColor = wdColorAutomatic
End With
' restore the highlight to orig. addr string
ActiveDocument.Range(iStart, iEnd).Select
' now delete the file in the TEMP directory
fso.DeleteFile szTempFileName, False
Case 2 ' user wants OWNER CARD info, no Parcel ID
Selection.Paragraphs(1).Range.InsertParagraphAfter
Selection.MoveDown ' this is required!
Set myMap = New clsws_GetMap
Set myMapProps = New struct_MapSettings
myMapProps.MapScale = sScale ' set scale user picked
myMapProps.MapType = sTheme ' set theme user picked
myMapProps.MapHeight = 500
myMapProps.MapWidth = 600
myMapProps.UseScale = True
sMapURL = myMap.wsm_GetMapByAddressMSLink(CLng(
Val(myAddrInfo.AddrMSLINK)), myMapProps)
Selection.InsertAfter Text:=vbCrLf
Selection.InsertAfter Text:=CStr(myAddrInfo.Owner) & vbCrLf
Selection.InsertAfter Text:=
CStr(myAddrInfo.OwnerMailingAddr_1) & vbCrLf
Selection.InsertAfter Text:=
CStr(myAddrInfo.OwnerMailingAddr_2) & vbCrLf
'
ActiveDocument.Range(iStart, iEnd).Select ' restore original
selection
Case 3 ' user wants OWNER CARD info, and Parcel ID
Selection.Paragraphs(1).Range.InsertParagraphAfter
Selection.MoveDown ' this is required!
Set myMap = New clsws_GetMap
Set myMapProps = New struct_MapSettings
myMapProps.MapScale = sScale ' set scale user picked
myMapProps.MapType = sTheme ' set theme user picked
myMapProps.MapHeight = 500
myMapProps.MapWidth = 600
'myMapProps.UseExtents = False
myMapProps.UseScale = True
sMapURL = myMap.wsm_GetMapByAddressMSLink(CLng(
Val(myAddrInfo.AddrMSLINK)), myMapProps)
Selection.InsertAfter Text:=vbCrLf
Selection.InsertAfter Text:=CStr(myAddrInfo.Owner) & vbCrLf
Selection.InsertAfter Text:=
CStr(myAddrInfo.OwnerMailingAddr_1) & vbCrLf
Selection.InsertAfter Text:=
CStr(myAddrInfo.OwnerMailingAddr_2) & vbCrLf
Selection.InsertAfter Text:=CStr(myAddrInfo.ParcelID)
Selection.InsertAfter Text:=vbCrLf
'
ActiveDocument.Range(iStart, iEnd).Select
' restore original selection
End Select
Else
MsgBox "That address is NOT VALID!", vbCritical Or vbOKOnly
End If
End Sub
DDJ
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
39

M
ost systems use passwords as a ver-
ification of claimed identity. How-
ever, conventional passwords have
disadvantages. For one thing, they
can easily be shared among users or be-
come easy targets for eavesdropping. An-
other way for proving identity is by the use
of digital certificates, also known as “digi-
tal IDs.” The most widely accepted format
for digital certificates is defined by the ITU-
T X.509 International Standard, enabling
certificates to be read or written by any ap-
plication complying with X.509. In short,
X.509 is a Standard that makes it possible
to identify someone on the Internet.
Authentication methods specified on
X.509 are based upon public-key crypto-
systems. For users to trust the authentica-
tion procedure, the procedure needs to get
the other user’s public key from a source
that it trusts. The source, called a “certifi-
cation authority” (CA), uses the public-key
algorithm to certify the public key, pro-
ducing a certificate. Because certificates are
unforgeable, they can be published by be-
ing placed in the Directory, without the
need for the latter to make special efforts
to protect them.
As shown in Listing One(a), in addi-
tion to the public key of the certificate
owner, digital certificates contain the fol-
lowing:
• Serial number of the certificate.
• Digital signature of the issuer.
• Owner’s name.
• Expiration date of the public key.
• Name of the issuer (the CA that issued
the Digital ID).
• Extensions that provide some addition-
al information.
Digital certificates are signed with the
CA’s private key. The protocol used by
applications to obtain the certificate from
the Directory is the Directory Access Pro-
tocol (DAP), specified in ITU-T Recom-
mendation X.519.
Standards-compliant applications that
use the authentication framework need to
specify the protocol exchanges that must
be performed to achieve authentication
based upon the authentication informa-
tion obtained from the Directory. In this
article, we present an application based
on the authentication protocol given in
the Comité Européen de Normalisation
(CEN) Standard for medical information
systems — CEN ENV 13729 “Health Infor-
matics — Secure User Identification: Strong
Authentication Using Microprocessor
Cards” (see Figure 1). In this protocol, a
reply attack (sending of old messages) is
prevented by the entity that requires au-
thentication through sending a generated
random number on which the entity that
proves identity creates a digital signature.
X.509 supports one-way authentication,
where only one party proves identity, and
two-way authentication, which is mutual
identification. The Standard also describes
three-way authentication, which involves
one additional data transfer. In our appli-
cation, one-way authentication is applied
(two-way could be applied analogously).
We use Java Crypto API for the realiza-
tion of authentication in a distributed sys-
tem, where clients access servers in the
system via a central server. All certificates
are generated centrally on demand and
imported in a central repository— the key-
store. Certificates are signed with the “CA”
key; that is, a private key that belongs to
a central server. Certificates and private
key files are sent to clients before au-
thentication begins. Clients import certifi-
cates and private keys into a local key-
store using the AppletImportCertificates
applet (available electronically; see “Re-
source Center,” page 5). This application
has been tested using Tomcat 4.1 and
Netscape 6 with a Java 1.3.0_1 plugin. Be-
fore running the application, a read/write
permissions must be added to the java.pol-
icy file on directory javaPlugIn_home/java/
lib/security.
The application comprises several ap-
plets and one servlet:
• AppletGenerateCAKeys, which generates
a private key for creating a digital sig-
nature on all certificates in the system.
• AppletGenerateCertificates, which gen-
erates a certificate for a user whose
name is in X500 format and places it in
Java Cryptography &
X.509 Authentication
Putting the Java
cryptography
architecture to work
SNEZANA SUCUROVIC
AND ZORAN JOVANOVIC
Snezana is a researcher at Belgrade’s In-
stitute Mihailo Pupin and can be con-
tacted at snezana@impcs.com. Zoran is
director of the Belgrade University Com-
puting Center.
40
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
“The Java Crypto
Architecture is a
provider-based
framework that is
independent of
algorithms”
a keystore with a given alias and pass-
word. It also generates the files “cert-
File” + X500Name and “privKey” + X500
Name, which are sent to a client offline
(Figure 2).
• AppletImportCertificate, which creates
the .keystore file on the client side and
imports the obtained certificate and pri-
vate key (Figure 3).
• AppletLogin, which sends an access re-
quest and generates a digital signature on
RND using a local keystore (Figure 4).
• LoginServlet, which sends RND and ver-
ifies the signature using the keystore.
In our application, access control is
achieved using certificate extensions that
contain a ROLE belonging to a certificate
owner. Each extension is identified by an
Object Identifier, which, according to ASN.1,
is a string of integer values assigned by the
Registration Authority; see Listing One(b).
Java Cryptography Architecture
The first version of Java Crypto Architec-
ture (JCA), contained in JDK1.1, included
an API for a digital signature and message
digest. Version 1.2 was the first to include
an infrastructure supporting X.509 v3 cer-
tificates.
JCA is a provider-based framework that
provides a particular functionality (Mes-
sage Digest, Digital Signing) and is inde-
pendent of algorithms, and there exist
providers that implement algorithms.
The infrastructure supporting X.509 cer-
tificates involves these services:
• Key management (introduced in JDK1.1).
• Generation and verification of digital sig-
nature (introduced in JDK1.1).
• Keystore management (introduced in
JDK1.2).
Keys in JCA can have a “transparent” or
an “opaque” representation. The opaque
representation has three characteristics: an
algorithm, coded form, and format. The
most important attribute of the opaque
representation is its coded form that per-
mits, when necessary, the keys to be used
out of JVM; for example, when the keys
are sent to some other party. Contrary to
this, the most important characteristic of
the transparent representation is the pos-
sibility of access to single parts of a key.
In our application, we have used the
opaque representation of keys only.
The algorithm in the opaque represen-
tation of a key denotes an algorithm (such
as DSA and RSA) in which a given key is
used together with the hash function al-
gorithm (for example, MD5withRSA or
SHA1withRSA).
A format is the format in which keys
are coded (X.509 for a public key and
PKCS#8 for a private key, for example).
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
41
Figure 1:
Authentication protocol
according to X.509 and CEN ENV
13729.
Figure 3:
AppletImportCertificate.
Local
System
Remote
System
Request Access
Send RND
Send Signed RND
Verify
Signature
Sign RND with Private
Key of Local System
Send ACK
Figure 2:
AppletGenerateCertificates.
Figure 4:
AppletLogin.

Listing One
(a)
Certificate ::= SIGNED {SEQUENCE{
version [0] Version DEFAULT v1,
serialNumber CertificateSerialNumber,
signature AlgorithmIdentifier,
issuer Name,
validity Validity,
subject name,
subjectPublicKeyInfo SubjectPublicKeyInfo,
issuerUniqueIdentifier [1] IMPLICIT UniqueIdentifier OPTIONAL,
subjectUniqueIdentifier [2] IMPLICIT UniqueIdentifier OPTIONAL,
extensions [3] Extensions OPTIONAL }}
Validity ::= SEQUENCE {
notBefore Time,
notAfter Time
}
(b)
Extensions ::= SEQUENCE SIZE (1..MAX) OF Extension
Extension ::= SEQUENCE {
extnId OBJECT IDENTIFIER,
critical BOOLEAN DEFAULT FALSE,
extnValue OCTET STRING
-- DER coded value
}
Listing Two
SubjectPublicKeyInfo ::= SEQUENCE {
Algorithm AlgorithmIdentifier,
SubjectPublicKey BIT STRING
}
AlgorithmIdentifier : := SEQUENCE {
Algorithm OBJECT IDENTIFIER,
Parameters ANY DEFINED BY algorithm OPTIONAL
}
Listing Three
PrivateKeyInfo ::= SEQUENCE {
Version Version,
PrivateKeyAlgorithm PrivateAlgorithmIdentifier,
PrivateKey PrivateKey,
Attributes [0] IMPLICIT Attributes OPTIONAL
}
Version ::= INTEGER
PrivateKeyAlgorithm ::= AlgorithmIdentifier
PrivateKey ::= OCTET STRING
Attributes ::= SET OF Attribute
Listing Four
X509CertInfo certinfo = new X509CertInfo();
CertificateVersion cv = new CertificateVersion(CertificateVersion.V3);
... etc
certinfo.set(certinfo.VERSION,cv);
... etc
X509CertImpl cert = new X509CertImpl(certinfo);
Listing Five
(a)
Magic number (big-endian integer),
Version of this file format (big-endian integer),
Count (big-endian integer),
followed by "count" instances of either:
{
tag=1 (big-endian integer),
alias (UTF string)
timestamp
encrypted private-key info according to PKCS #8
(integer length followed by encoding)
cert chain (integer count, then certs; for each cert,
integer length followed by encoding)
}
(b)
{
tag=2 (big-endian integer)
alias (UTF string)
timestamp
cert (integer length followed by encoding)
}
ended by a keyed SHA1 hash (bytes only) of
{ password + whitener + preceding body }
DDJ
The name of ASN.1 data type for a pub-
lic key is SubjectPublicKeyInfo, and this
data type is defined in the X.509 Standard.
The SubjectPublicKeyInfo is defined in the
X.509 Standard in ASN.1 terms, as in List-
ing Two.
Similar to this, the ASN.1 data type that
represents private keys is named “Pri-
vateKeyInfo” and defined in the PKCS#8
Standard. PKCS#8 denotes a Standard
whose full name is “Private Key Informa-
tion Syntax Standard” (see http://www
.rsa.com/). In Listing Three, Attribute is a
data type consisting of an attribute type
(given as an OBJECT IDENTIFIER) and
one or more values. Certificates are gen-
erated by creating first the class X509Cert-
Info and then all the attributes of a cer-
tificate; see Listing Four. After that, a CA
private key is used to create a digital sig-
nature on a certificate.
The keystore database can be used to
manage the repository of keys and cer-
tificates. Several different actual imple-
mentations may exist, each of them be-
ing characterized by a particular type. At
present, there also exists keytool, a key-
store management tool that is started from
the command line. There is also a built-
in default implementation provided by
Sun. According to this implementation, a
keystore is a file of JKS format. In Sun’s
implementation, passwords are used to
protect each private key as well as the
entire keystore.
Keystore type determines the format of
information contained in the keystore as
well as the algorithms used for protecting
private keys and the keystore itself. Dif-
ferent keystore implementations are not
compatible. “JKS,” a default keystore type
(implemented by Sun), is specified in the
line keystore.type=jks, from the file java_
home/jre/lib/java.security. If some other
keystore implementation is used, the type
of that implementation (“pkcs12,” for in-
stance) should be entered into this file.
A KeyStore class represents a collection
of keys and certificates. There are two
types of entry:
• Key Entry contains sensitive informa-
tion. Keys are stored in a protected for-
mat to prevent unauthorized access.
Typically, a key stored in this entry is a
private key or a private key with a chain
of certificates corresponding to a pub-
lic key. Private keys and the string of
certificates associated to them are used
for the authentication of the entity to
which the keystore also belongs.
• Trusted Certificate Entry contains the
certificate of a public key that belongs
to some other entity. It is referred to as
a trusted certificate because the keystore
owner trusts that the public key in the
certificate really belongs to the identity
presenting itself as the certificate own-
er. This type of entry performs the au-
thentication of other parties.
Each entry in the keystore is identified
by an “alias” string. In case of a private
key and an associated chain of certificates,
the alias distinguishes between the dif-
ferent methods an identity can use for au-
thentication purposes. For example, an
entity may authenticate itself using vari-
ous CA. Listings Five(a) and Five(b) illus-
trate the JKS data format
Conclusion
The Java Cryptography Architecture 1.2
and later support X.509 certificates. A DSA
algorithm with 1024-bit key length is im-
plemented in a default provider. Moreover,
Java supports keystore, an in-memory col-
lection of keys and certificates (http://
java.sun.com/j2se/1.4.2/docs/api/java/
security/KeyStore.html). In this article,
we’ve implemented X.509 authentication
according to the CEN ENV 13729 Standard.
Although authentication protocols appear
simple, the choice of a protocol is impor-
tant, because protocol steps may interfere
with some auxiliary relations satisfied by
symmetric or asymmetric cryptosystems.
DDJ
42
Dr. Dobb’s Journal, February 2005
http://www.ddj.com

T
ext-editor development and command-
line compiling have gone the way of
the Dodo bird, as today’s developers
demand more sophisticated tools that
provide functionality ranging from exten-
sibility and seamless integration of com-
ponents, to increased productivity and
ease of use. This new generation tool,
dubbed an “integrated development envi-
ronment” (IDE), packages all of these fea-
tures and more into a single application.
In particular, the Eclipse IDE has come to
the forefront of IDE technology. Eclipse
(http://www.eclipse.org/) provides a sta-
ble, highly extensible, and robust plug-in
architecture on which an IDE for Java is
constructed.
The Eclipse IDE is really a combination
of the Eclipse Platform and a number of
well-crafted plug-ins. This plug-in archi-
tecture lets you add new functionality
rapidly as new plug-ins are developed, as
well as customization by individual users.
In this article, I present an Eclipse plug-
in that supports a simple online reference
search of the Dr. Dobbs Journal (DDJ )
web site. The complete source code and
related files are available electronically;
see “Resource Center,” page 5. [Editor’s
Note: This plug-in assumes that you have
a Premium Subscription to http://www
.ddj.com/.]
Exploring the PDE
The Plug- in Development Environment
(PDE), included with Eclipse 3.0, provides
a number of views and editors that make
it straightforward to build Eclipse plug-
ins. In fact, the PDE is implemented as a
collection of plug-ins itself that let you
create all the required plug-in components
without having to know a great deal about
the underlying details. The PDE assists in:
• Editing the plug-in manifest.
• Specifying the required runtime envi-
ronment.
• Defining extension points.
• Testing and debugging.
• Deploying the final plug-in.
Because developing a plug-in without
the PDE can be complex and time con-
suming, I use the PDE to create the exam-
ple reference search plug-in in this article.
Generating a Template
After installing Eclipse, the first step in de-
veloping a plug-in is to generate a tem-
plate plug-in project to use as a starting
point. The PDE makes this process sim-
ple with its integrated wizards and edi-
tors. Select File|New|Project in the main
menu to display the New Project wizard.
The first page of the wizard asks you to
select the type of project. Select Plug-in
Development|Plug-in Project as the pro-
ject type and click Next to display the New
Plug- in Project wizard. Enter a project
name of “DDJSearch” into the first field,
leave the defaults for the rest of the fields,
and then click Next. The next page is the
Plug-in Content page (Figure 1), which
lets you define many of the important at-
tributes about your plug-in, such as:
• Plug-in ID, a unique identifier for your
plug-in. By convention, this is the base
package of your plug-in.
• Plug- in Version, the initial version of
your plug-in.
• Plug-in Name, the name of your plug-
in as it appears in the software config-
uration list.
Building an Eclipse
Web-Search Plug-In
A plug-in to search
DDJ archives
MICHAEL PILONE
Michael is a software engineer and re-
searcher for the Department of Defense at
the Naval Research Laboratory in Wash-
ington, D.C. He also founded and oper-
ates as CTO of Zizworks Inc. (http://www
.zizworks.com/), a web-application and
custom- software development company.
“Unfortunately,
there is no standard
dialog for
performing a web
search”
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
43
• Plug- in Provider, the provider of the
plug-in. By convention, this is the au-
thor’s name or web site.
• Runtime Library, the library that the
plug-in is packaged into for deployment.
By convention, this is the name of the
plug-in in lowercase.
• Plug-in Class Name, the main class name
for your plug-in that is instantiated by
Eclipse at startup.
Edit the values in this page to match
Figure 1 and click Next to display the Tem-
plate page. On this page, you can choose
a template plug-in to use as your base.
Select the check box to use a template
and then select the Hello, World template.
This basic template creates an action set
extension, which provides a single menu
and toolbar item. Click Finish to close the
wizard and generate the new project.
Once the project is generated, you are
presented with the plug-in Overview Ed-
itor (Figure 2). The form-based editor
serves as the heart of the PDE for editing,
testing, and deploying your plug-in. This
editor gives an overview of the plug-in
metadata as well as links to common ac-
tions to perform on the plug-in. Under
the Testing heading in the lower right,
click Launch a Runtime Workbench to
launch a new Eclipse workbench with
your Hello, World plug-in installed. Once
the new workbench appears, click the
Sample Menu|Sample Action menu item
added by your plug-in. Congratulations,
with a few clicks of a wizard, you just cre-
ated an Eclipse plug-in that adds an ac-
tion and displays a dialog box! Of course,
there is no need to stop here; a plug-in
can and should be much more useful.
(Don’t forget to close the testing work-
bench!)
Customizing the Plug-In
The menu item added by the sample plug-
in needs to have a useful name if users are
going to find it, so the first thing you want
to do is change the name of the menu and
action the plug-in creates. The menu and
action name information is defined as an
extension to the Eclipse User Interface (UI)
plug-in extension point org.eclipse.ui.ac-
tionSet. Select the Extensions tab at the
bottom of the editor to view the exten-
sions currently in use (Figure 3). It is im-
portant to understand that the extension
mechanism is used by Eclipse to provide
a shared location in the tool, allowing plug-
ins to add functionality and be discovered.
Hooking into the Eclipse Platform is done
by adding extensions to extension points
that are defined by other plug-ins. The ex-
tension point mechanism is powerful in
that it lets you extend the application in-
definitely by installing new plug-ins. Defin-
ing a new extension point is beyond the
scope of this article; however, your plug-
in makes use of the existing extension
point, org.eclipse.ui.actionSet.
You can see that a menu named “Sam-
ple Menu” is added to the extension point
with a single action named “Sample Ac-
tion.” Select the Sample Menu (menu) item
in the tree and change the label on the
right to read “DDJ Search.” This changes
the text that will appear in the main menu
bar of the application. The action, Sample
Action (action), has many more properties
than the menu, but the process is similar.
Change the label field to read “Perform
Search.” You can leave the other fields with
default values for now; however, before
deployment, you may want to change
some of these properties. Using the ex-
tensions editor, you can also add new ac-
tions or entirely new extensions by using
the Add button. To see the changes ap-
plied, save the new values (Ctrl-S), flip
back to the Overview tab, and launch a
runtime workbench just like before.
In the extension editor, the properties
of the action just defined declare the name
of the actual Standard Widget Toolkit
(SWT) action class that is notified when
the action is invoked in the class field.
The Hello, World template you started with
defines this action to be an instance of the
org.mpilone.ddj.actions.SampleAction
class. For this example, to add the brows-
er functionality desired, you can just edit
the SampleAction class; however, in the
future, it may make more sense to create
a new class and change the value of the
property. Open the class by double click-
ing on it in the left Package Explorer tree.
This reveals the Java editor. At this point,
the changes to be made are SWT specif-
ic and not directly related to the Eclipse
plug-in framework.
When the action is activated by users,
Eclipse triggers the public void run(IAction
action) method, so this is where you start
to insert your code. In this method, you
add code to display a dialog containing the
SWT browser widget, which loads a URL
from the Internet using HTTP transport.
The browser widget, org.eclipse.swt.brows-
er.Browser, is a complex widget with a sim-
ple API that uses the native system HTML
engine to render web sites. The widget re-
spects the user’s configuration, cookies,
and cache on Windows and Linux using
Internet Explorer and Mozilla, respective-
ly. Replace the code in the method to cre-
ate and display the new search dialog with
the following:
public void run(IAction action) {
SearchDialog dialog =
new SearchDialog(window.getShell( ));
dialog.open( );
}
Unfortunately, there is no standard di-
alog for performing a web search, so the
SearchDialog class is a custom class that
you need to create.
To create the SearchDialog class, right
click on the org.mpilone.ddj package in the
Package Explorer and select New|Class.
In the New Class dialog, set the name of
the class to “SearchDialog” and the parent
class to org.eclipse.swt.widgets.Dialog (Fig-
ure 4). Once the SearchDialog class is cre-
ated, enter Listing One to define the brows-
er component. Most of this code is the SWT
component creation and layout. However,
the line:
44
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 1:
The New Plug-in Project
dialog with the customized values.
Figure 2:
The PDE plug-in overview
editor with the values generated from
the template.
Figure 3:
The PDE plug-in extensions
editor displaying the template’s Sample
Menu item.
browser.setUrl("http://www.ddj.com").
is important because it informs the brows-
er to load the given URL and render the
HTML page. This command handles all of
the network communication, rendering
details, and HTTP transport. At this point,
the SearchDialog class is defined, letting
the SampleAction compile, and complet-
ing the basic search functionality re-
quested. To see the changes in action,
save the new values (Ctrl-S), flip back to
the Overview tab, and launch a runtime
workbench. Remember that, because the
browser widget is using the native HTML
engine, the users’s cookies and configu-
ration should be available, letting them
log into the destination site and use the
premier features without extra code re-
quired by you.
Finishing Touches
The final features to add to the plug-in
are some simple usability items. Once
users start searching with the reference
search plug-in, they may want basic web-
navigation support such as back and for-
ward buttons. Adding the buttons is triv-
ial and requires only a few extra lines of
SWT code. The buttons can be created
and added to a toolbar on the dialog as
shown here:
ToolBar navBar
= new ToolBar(shell, SWT.NONE);
navBar.setLayoutData(new GridData
(GridData.FILL_HORIZONTAL |
GridData.HORIZONTAL_ALIGN_END));
final ToolItem back =
new ToolItem(navBar, SWT.PUSH);
back.setText("Back");
back.setEnabled(false);
The first two lines create a toolbar
where the rest of the buttons are attached.
The last three lines create the button, set
the text, and set it to be disabled. The
same three lines would be repeated for
any other buttons desired, such as for-
ward and close buttons.
The next bit of code ties the button’s
click to a listener that performs an action
on the browser:
back.addListener(SWT.Selection,
new Listener( ) {
public void handleEvent(Event event) {
browser.back();
}});
With the listener added, when the
Back button is clicked, the browser is
told to go back to the previous page.
Notice that the browser maintains the
history so you do not have to. Again, the
code would be repeated for the Forward
button.
Lastly, the button state must be updat-
ed as the browser moves from URL to
URL. To do this, simply add a location lis-
tener to the browser and update the but-
tons in the call back:
browser.addLocationListener
(new LocationListener( ) {
public void changed(LocationEvent event)
{
Browser browser =
(Browser)event.widget;
back.setEnabled
(browser.isBackEnabled( ));
forward.setEnabled
(browser.isForwardEnabled( ));
}
public void changing
(LocationEvent event) {
}});
The buttons now reflect the state of the
history in the browser by asking the
browser if it is possible to go forward or
backward. Again, you do not have to han-
dle the details of tracking the user’s surf-
ing. The final dialog source code with the
aforementioned modifications can be seen
in Listing Two. Launch the runtime work-
bench and activate the search action in
the menu to display the reference search
dialog with the new navigation button
(Figure 6). Perform some searches, log in,
or just browse the site and watch how the
navigation buttons stay in perfect sync
with your actions.
Packaging and Deploying
Packaging and deploying is the process
of bundling up all of the required files
that define your new plug- in. Once the
plug-in is packaged, it can easily be dis-
tributed and installed on other Eclipse
IDEs. The PDE plug- in editor provides
a Build tab that allows you to customize
the final packaged build for both a bi-
nary release (executable files only) and
a source release (all java and build
files). For most plug- ins you can use
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
45
Figure 5:
The Export Plug-in dialog
configured to export the plug-in as a
single ZIP archive.
Figure 6:
The final reference search dialog displaying the DDJ search page with
a user logged in.
Figure 4:
The New Java Class dialog
with the values to create the
SearchDialog class.

Listing One
package org.mpilone.ddj;
import org.eclipse.swt.SWT;
import org.eclipse.swt.browser.*;
import org.eclipse.swt.layout.GridData;
import org.eclipse.swt.layout.GridLayout;
import org.eclipse.swt.widgets.*;
/** A basic dialog with a large HTML search
* area with some simple navigation. */
public class SearchDialog extends Dialog {
/** Constructs the dialog as a child of the given parent shell.
* @param parent the parent of this dialog */
public SearchDialog(Shell parent) {
super(parent);
setText("DDJ Reference Search");
}
/** Opens the dialog and displays it on the screen. The dialog will
* be modal and remain open until closed by the user. */
public void open() {
// Create the shell with a dialog trim and title text.
Shell parent = getParent();
final Shell shell = new Shell(parent, SWT.RESIZE |
SWT.DIALOG_TRIM | SWT.APPLICATION_MODAL);
shell.setText(getText());
// Set the basic layout
GridLayout layout = new GridLayout();
layout.numColumns = 1;
shell.setLayout(layout);
// Create the browser and setup the layout information to
// allow it to fill all available space in the dialog.
final Browser browser = new Browser(shell, 0);
GridData gridData = new GridData(700, 500);
gridData.grabExcessHorizontalSpace = true;
gridData.grabExcessVerticalSpace = true;
gridData.horizontalAlignment = GridData.FILL;
gridData.verticalAlignment = GridData.FILL;
browser.setLayoutData(gridData);
// Tell the browser to load the URL desired. It may
// make more sense for this to be a property in a production release.
browser.setUrl("http://www.ddj.com");
// Pack the shell to resize everything.
shell.pack();
shell.open();
Display display = parent.getDisplay();
// Display the shell and process events
// as long as the user hasn't closed the dialog.
while (!shell.isDisposed()) {
if (!display.readAndDispatch()) display.sleep();
}
}
}
Listing Two
public void open() {
// Create the shell with a dialog trim and title text.
Shell parent = getParent();
final Shell shell = new Shell(parent, SWT.RESIZE |
SWT.DIALOG_TRIM | SWT.APPLICATION_MODAL);
shell.setText(getText());
// Set the basic layout
GridLayout layout = new GridLayout();
layout.numColumns = 1;
shell.setLayout(layout);
// Create the tool bar with the basic buttons: back, forward,
// close. The back and forward buttons default to close since
// they will be updated as the browser loads pages.
ToolBar navBar = new ToolBar(shell, SWT.NONE);
navBar.setLayoutData(new GridData(GridData.FILL_HORIZONTAL
| GridData.HORIZONTAL_ALIGN_END));
final ToolItem back = new ToolItem(navBar, SWT.PUSH);
back.setText("Back");
back.setEnabled(false);
final ToolItem forward = new ToolItem(navBar, SWT.PUSH);
forward.setText("Forward");
forward.setEnabled(false);
final ToolItem close = new ToolItem(navBar, SWT.PUSH);
close.setText("Close");
// Create the browser and setup the layout information to
// allow it to fill all available space in the dialog.
final Browser browser = new Browser(shell, 0);
GridData gridData = new GridData(700, 500);
gridData.grabExcessHorizontalSpace = true;
gridData.grabExcessVerticalSpace = true;
gridData.horizontalAlignment = GridData.FILL;
gridData.verticalAlignment = GridData.FILL;
browser.setLayoutData(gridData);
// Tell the browser to load the URL desired. It may
// make more sense for this to be a property in a production release.
browser.setUrl("http://www.ddj.com");
// Add listeners to respond to the button clicks.
back.addListener(SWT.Selection, new Listener() {
public void handleEvent(Event event) {
browser.back();
}
});
forward.addListener(SWT.Selection, new Listener() {
public void handleEvent(Event event) {
browser.forward();
}
});
close.addListener(SWT.Selection, new Listener() {
public void handleEvent(Event event) {
shell.close();
}
});
// Add a listener to update the state of the buttons
// based on the state of the browser while the user is surfing.
browser.addLocationListener(new LocationListener() {
public void changed(LocationEvent event) {
Browser browser = (Browser)event.widget;
back.setEnabled(browser.isBackEnabled());
forward.setEnabled(browser.isForwardEnabled());
}
public void changing(LocationEvent event) {
}
});
// Pack the shell to resize everything.
shell.pack();
shell.open();
Display display = parent.getDisplay();
// Display the shell and process events
// as long as the user hasn't closed the dialog.
while (!shell.isDisposed()) {
if (!display.readAndDispatch()) display.sleep();
}
}
DDJ
the default values. In the lower right
corner of the Overview tab, there are
two steps listed under the Deploying
heading: editing the build configuration
(which I just talked about), and ex-
porting the plug- in for deployment.
Since you are going to use the default
build configuration, skip step one and
click the Export Wizard option in step
two to display the wizard.
The export wizard is a single page di-
alog (Figure 5) that lets you specify some
last minute packaging options, such as:
• Selecting the plug-ins to package.
• Specifying the exported file type.
• Selecting the exported file location.
• Creating an ANT target for future de-
ployment.
For simple distribution, it is best to cre-
ate a single ZIP output file without the
source, since you just want to let other
users use the plug-in but not develop it.
Select a logical destination for the output
file and name it “ddjsearch.zip” and click
the Finish button. The ZIP file is generat-
ed and it contains everything required
for users to extract and install the plug-
in. You can open the plug-in in a ZIP-
compatible application (Window’s Ex-
plorer) and browse the file hierarchy,
which contains the root plug-ins directo-
ry, a directory for your plug-in, and all
the metadata and class files. To install the
plug-in into another Eclipse IDE, extract
the ZIP archive into the root Eclipse in-
stall directory. Great job, you can now
place your ZIP file on your web site and
tell all your friends to try your new refer-
ence search plug-in!
DDJ
46
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
“The ZIP file
contains everything
required for users to
extract and install
the plug-in”

W
eb interfaces for configuration and
management have been showing
up in all kinds of networked de-
vices — cable modems, routers,
and printers — as an efficient way to pro-
vide a GUI to any client with a browser.
You can think of the embedded web in-
terface as a specialized, small-footprint web
application. We’ve been building these in-
terfaces for years. In one recent short and
simple project, we translated our embed-
ded web interface into Japanese.
The funny thing is, we basically did this
same project a year ago. All this work is
part of the web interface for our client’s
family of home-networking devices, which
we’ve been developing since early 2002.
The last part of this work was a major
rewrite: We added a flexible XML inter-
face between the user interface and the
device’s back end, and we threw in the
localization feature, too. But the project
had been dormant for months, and the
client still had not built our latest code
into any actual products.
Then (as in the end of the movie Spinal
Tap), the project was suddenly revived by
interest from Japan, where the client want-
ed to sell an older model of the same de-
vice. But the older model was running the
preXML web interface code, which had no
localization built in. If we returned to this
obsolete codebase, how long would it take
us to add localization? We had an excellent
estimate based on our previous experience,
but could we cut it down this time?
I didn’t think we could, because the lo-
calization process is pretty straightforward.
By “localization,” I mean the same thing
as “globalization” (oddly) or “internation-
alization.” You go through the files look-
ing for English text strings, and pull them
into a big “language table,” assigning each
one a unique key. The web server loads
this language table into its memory, and
whenever it needs to display a text string,
it looks up the key in this table. Translate
your language table into a new language,
and you’ve translated the whole web in-
terface. Okay, you also have images that
display text, so you need to prepare and
serve a new set of images for each lan-
guage, but the language table is the main
thing. For the previous localization effort,
our hapless web designer had to go
through a hundred HTML files and pick
out all the text strings. Tedious, certainly,
but not complicated.
Fortunately, my boss had an idea: Could
we automate some of this process? Sure-
ly we could tell a program how to pick
out a text string from a bunch of HTML
code, such as:
<title>My Favorite Device</title>
The more I thought about this, the more
I liked it. We’d be done sooner, and no
one would have to read through all that
HTML, so I could stick to writing nice
code and our web designer could stick to
designing beautiful images. As someone
said, “I’d rather write code to write code
than write code.”
There were still definite risks, of course.
On the positive side, we were familiar
with the codebase. On the negative side,
the automated localizer had to cope with
a fairly complex codebase: HTML, lots of
client-side JavaScript, and some server-
side JavaScript code as well, not to men-
tion some text strings that were still em-
bedded in the C code of the web server.
And Japanese might be hard to work with:
I worried about finding the right charac-
ter encoding, what the right browser plat-
form would be, and whether I could even
test the code on my system. The client
provided someone to do the translation,
but he was in Japan and we hadn’t
worked with him before.
We estimated four programmer-weeks
for the localization itself (two weeks less
than our previous experience) and another
couple of weeks for other tasks such as
preparing the Japanese images.
Localization
The localization would be mainly text pro-
cessing, so I needed some kind of script-
ing language with good support for reg-
ular expressions (REs). Python or Perl
would be an obvious choice, but I was
more familiar with Java, so I started with
that. I used the Apache Regexp package
and tried a simple test. It was an AI prob-
lem, like spam filtering: A person can eas-
ily recognize text strings just by looking
at the HTML code, and I wanted a pro-
gram to approximate that intuitive filter-
ing process. For example, here’s one that
picks out plain text between HTML tags,
such as “My Favorite Device” in the afore-
mentioned HTML code:
[^%]>\s
∗
([A-Z][A-Za-z0-9 .,:/\(\)\-'\"&;!]+)\s
∗
<[^%]
REs form their own language, one that
is very useful but hard to read and docu-
ment. Here’s how this RE works. At the
beginning, it says there must be the end
Automating
Localization
Regular expressions
make a tough job easier
HEW WOLFF
Hew is a senior engineer for Art & Log-
ic. He can be contacted at hewwolff@
sonic.net.
“Programs are much
better at repetitive
checking than you
are, so use them”
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
47

of an HTML tag and that server-side code
ending with “%>” doesn’t count. Then
there may be some whitespace, followed
by our text (enclosed in parentheses so
that we can pull it out and do something
with it), and finally more possible white-
space and the beginning of another HTML
tag. The text itself must begin with a cap-
ital letter and may contain letters, num-
bers, and reasonable punctuation.
The first regular expressions that I tried
did well. Encouraged by these early re-
sults, I started adding more REs to cover
more cases. The HTML, server- side
JavaScript, client-side JavaScript, and C
code all contained different kinds of text
strings. So, for example, I wrote an RE to
grab all the client-side JavaScript for fur-
ther processing by other REs. The local-
izer was taking shape.
The localizer filter made two kinds of
mistakes: It might grab some code as a
text string (a false positive), or it might ig-
nore a text string as code (a false nega-
tive). False positives are easier to clean up
than false negatives: You’re removing a
key from the language table, rather than
inventing a new key and inserting it into
the language table in the right place. False
positives are also easier to find. To test
the filter by hand, I tweaked the localiz-
er to replace each text string with a
“marked” version in brackets, such as “{{My
Favorite Device}}.” Then I ran the web in-
terface and looked carefully at the text
strings. A false negative showed up as an
unmarked text string. But a false positive
usually showed up dramatically; for ex-
ample, as a blank page when the Java-
Script code choked on a marked string.
So in my testing, I was more lenient about
false positives, and I wound up with about
50 false positives and only two false neg-
atives. The false negatives began with
“11b” and “11g” (as in the 802.11 wireless
standards), which look more like code
than text. Converter.java, the localizer code,
is available electronically (see “Resource
Center,” page 5).
Testing
Very soon I realized that this project was
ideal for test- driven development (also
known as “test-first development”). In this
approach, you maintain a test suite to-
gether with the application. To add some
functionality, you add a test, check that
the test fails with the current code, and —
only then — add some code to make the
test pass. Although I’ve often included au-
tomated testing in my work informally,
this was my first serious attempt to fol-
low this approach, which is one of the
core practices of Extreme Programming.
I was inspired by Roger Lipscombe’s Ro-
man numeral example (see http://www
.differentpla.net/node/view/58), in which
some beautiful code grows organically be-
fore your eyes. The schedule on this pro-
ject was somewhat relaxed, which allowed
me to experiment a bit. (Or maybe it was
the success of the experiments that kept
the schedule relaxed; it’s hard to tell.)
Here the test suite was a small set of
web source files, together with localized
versions that I prepared by hand. I peri-
odically ran the localizer in a special mode,
which processed the test files and com-
pared the current output with the correct
output. Whenever this comparison choked,
I fixed the problem, rewriting the test or
the code depending on which looked
right. The test suite became a distilled ver-
sion of the web codebase, containing all
the interesting cases.
The localizer turned out to be a strange
application. First of all, it didn’t have to
be perfect. If it could make the right de-
cision 99 percent of the time, I could clean
up the other cases by hand in a day or
so. I figured there would be a cleanup
stage. For example, I was assuming that
brand names such as “AppleTalk” should
not be translated, but the client might lat-
er decide that they should be. On the oth-
er hand, although perfection was not a
goal, performance was important. The lo-
calizer was designed to run just once for
real. Although I ran it many times to test
it during development, once the official
localization was done and I started edit-
ing the web files by hand, running the lo-
calizer again would wipe out that work.
To justify writing it, it had to perform well
on its single run. In fact, that’s how I de-
cided when the localizer was done: when
refining it further would take longer than
the cleanup.
But performance in terms of running
time was not very important in this ap-
plication. It ran the test suite in about eight
seconds and chewed through the whole
2-MB codebase in about 15 seconds,
which was a bit slow, but acceptable.
Sometimes I combed through the lo-
calized output looking for bugs to add to
the test suite. Sometimes a small change
to an RE would trigger an unexpected
problem, and I would thrash around
changing REs until they worked again.
Sometimes my code started to look ugly
and I stopped to refactor it, relying on the
test suite and the compiler to tell me if I’d
broken anything.
Sometimes I cheated on the test-driven
process. I would find myself writing the
code before the test, especially if both
were trivial. Or I would fix a localizer bug
by rewriting the web code to avoid some
exceptional case. It might seem easier just
to leave those exceptions to the cleanup,
but doing even a small amount of local-
ization by hand is tedious. Also, when I
was writing the simple testing framework,
I didn’t bother adding a test for the frame-
work itself. Actually, the step in the pro-
cess where you break the old test, al-
though it may seem pointless, provides a
good check on the integrity of the test
suite and framework. It guarantees that
the test can catch bugs and hasn’t been
accidentally disabled.
But in the end, I was confident that the
localizer was reliable — and written in nice
clean code, too. It should be easy to reuse
large parts of the localizer code. I doubt
this will happen, though, because I imag-
ine the requirements will be too different
next time. We’ll probably just throw away
the test suite along with the code. This is
a shame because a test suite really shines
in maintenance. But the general approach,
as documented in the code and here, is
still useful.
The localization ended up taking about
three programmer-weeks. This was well
within our budget, but still seemed slow
to me, although it was fun. I had hoped
that test-driven development would mag-
ically turn me into a fast developer, which
did not happen. But it fit well with an evo-
lutionary style of development, in which
you stay close to running code all the time
and add features gradually. I find this phi-
losophy comfortable, and it’s perfect for
a small project such as this one.
Translation
The translation got off to a shaky start. I
had only a narrow channel to communi-
cate with the Japanese translator because
of the time difference: I could post a mes-
sage for him and get a terse response the
next day. At first he was unclear about his
part in the project, but I explained the
project’s background in detail, and that
seemed to help.
I handed over the language table, which
had about 1500 entries, and the transla-
tion came back surprisingly soon. How-
ever, it had the wrong number of lines.
Although I could only read the keys, it
seemed clear that some lines had been
duplicated, merged, and generally man-
gled. This was not too surprising for such
a long file. I wrote a little script to com-
pare the keys in the English and Japanese
versions, and that made it easy to fix the
problems.
What I was slow to realize was that I
could keep this script around as part of
the build process. It caught more mis-
takes as I continued to tweak the lan-
guage tables. I was still absorbing a key
idea of test- driven development: Auto-
mate anything you can. Programs are
much better at repetitive checking than
you are, so use them.
The obvious character encoding to try
was UTF-8, the 8-bit Unicode Transfor-
mation Format created by Rob Pike and
48
Dr. Dobb’s Journal, February 2005
http://www.ddj.com

Ken Thompson (http://www.ietf.org/rfc/
rfc3629.txt/). Among other things, it’s de-
signed to work well with C code, and it’s
well supported by web browsers. In short,
it worked beautifully. The Japanese strings
passed successfully through the web serv-
er C code and the client-side JavaScript,
and — at least on my machine — were cor-
rectly displayed by the browser using the
character set already installed in Windows.
I was not able to type Japanese text into
the input controls, but I copied and past-
ed some from my browser, and that
seemed to work fine, too.
At one point, I noticed some suspicious
characters in the Japanese text in the
browser — something like “?A?” Looking at
the language table in a hex editor and us-
ing Markus Kuhn’s reference (http://www
.cl.cam.ac.uk/~mgk25/unicode.html), there
did seem to be some bad UTF-8 charac-
ters. I found out that I had corrupted the
language file text strings somehow while
editing. (What do you expect when dif-
ferent people are using Word and Emacs
to edit the same large file?) Because the
keys were not affected, the checking script
I had written did not catch the problem.
I decided to integrate some UTF-8 ver-
ification into the language build. First, I
looked around for existing Java support
but was disappointed. Java supports UTF-
8, but apparently does not support de-
bugging UTF-8 text. For example, if b is
a byte array, you can convert it into a
string using either
new String(b, "UTF-8");
or
(new DataInputStream
(new ByteArrayInputStream(b))).readUTF();
But neither of these techniques identi-
fy the location of a bad character, and in
any case, Java has its own, slightly in-
compatible version of UTF-8. So I wrote
my own UTF-8 verifier, taking this as an
opportunity to try out the popular JUnit
testing framework (http://www.junit.org/).
JUnit was lightweight — I hate a giant
download — and easy to incorporate. My
favorite feature was the assert methods
built into the TestCase class, which were
handy for expressing what’s supposed to
be true. Also, it was reassuring to see the
brief report of tests passed and time
elapsed. JUnit has a bunch of features that
only kick in for larger projects, such as a
nice way to group test cases into suites,
but already I could see the appeal. (Check
Utf8.java; the UTF-8 checker is available
electronically.)
Again, I found that the test-driven ap-
proach produced satisfying, clean code —
slowly. The basic algorithm came out in
three short methods. I spent much more
time on the test code, putting in thor-
ough coverage of the various kinds of
characters.
Conclusion
Next time, I might try different tools be-
cause mine had some problems. For ex-
ample, for efficiency I had to use little
scripts to build and run the code, which
might have been easier with an interac-
tive scripting language like Python. A for-
mal build tool such as Ant might also have
helped. Sun’s free Java SDK is nice, but
at one point the Java Virtual Machine be-
gan crashing with weird exceptions, which
I fixed by upgrading. The Java code
wound up at around 600 lines, which
seems long, and as I mentioned, it was
kind of slow. The Apache Regexp docu-
mentation was sketchy (what’s the prece-
dence of the various operators?). But over-
all, I was happy with my choices. I would
try something new mostly for my own ed-
ucation.
I would definitely try the test-driven ap-
proach again. I won’t use it all the time
(for example, I’m still frustrated by the dif-
ficulties of writing automated tests for GUI
applications), but I’ll use it whenever I
can. And I’ll recommend UTF-8 to all my
friends.
Finally, when you’re facing weeks of
tedious coding, consider automating it
somehow. Programming should be inter-
esting; if it’s repetitive, something’s wrong.
A quick experiment could save you a lot
of time.
DDJ
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
49

S
hadows are among the most notice-
able visual cues and are important for
human perception. Consequently, ac-
curate rendering of shadows is para-
mount for realistic computer-generated
images. In this article, I examine five al-
gorithms that generate dynamic shadows
in 3D graphics applications. I’ve imple-
mented these algorithms in the Small Dy-
namic Shadows Library (available elec-
tronically; see Resource Center, page 5),
a freely available OpenGL-based library.
Finding regions of space shadowed
from a given light source implies solving
the visibility problem for that light source.
In other words, if a viewing camera is to
replace the light source, all points in space
visible for that camera should be illumi-
nated, whereas all points hidden from this
imaginary camera are shadowed. In gen-
eral, generating shadows for moving or
animating objects is more difficult than
producing static shadows. A common, al-
beit simplistic, approach is to draw a dark
spot underneath moving objects. Even
when approximate or geometrically in-
correct, this is visually better than not hav-
ing any shadows at all. The dark spot de-
picting the shadow can have soft edges,
further improving its appearance. Many
popular video games (from “Return to the
Castle of Wolfenshtein” to “Grand Theft
Auto 3”) rely on this technique. One ap-
proach used to improve the appearance
of this spot shadow is to elongate it into
the direction opposite to the predominant
light source. Another approach is to draw
multiple intersecting dark spots. This
works well in many instances, especially
low-light intensity environments.
Although faking dynamic dark spot
shadows is still in use, it is hardly enough
to draw a compelling picture of the vir-
tual world. Luckily, with the improvements
in computer performance, it is now pos-
sible to consider more advanced ap-
proaches producing geometrically correct
dynamic shadows.
Planar Shadows
One popular solution for a constrained
situation where dynamic shadows are al-
ways cast onto a plane is to find a pro-
jection matrix that squishes the object to
that plane and draws the entire model the
second time with the found transform and
an ambient dark, near black color (see Fig-
ure 1). Although constrained, such a sit-
uation often occurs in sport games that
represent playing fields and players cast-
ing shadows.
It is not too difficult to find the required
transformation matrix. If a normal to a
plane where the projection is sought is n
and some point on that plane is P, then
the plane equation could be represented
as n(X – P)= 0, where X is any point on
that plane. Given a light source L and an
arbitrary point on the model M (Figure 2),
Example 1(a) holds because the distance
from the light source to the projection
point X – L relates to the distance from the
light source to point M in the same way
the distance from the light source to the
plane relates to the distance from the light
source to the point M projected onto the
direction of the normal n(L – M) (Figure
2). Thus, the projection point relates to
the point on the model as in Example
1(b), or in vector notation, represented as
in Example 1(c). Thus, this transforma-
tion, with some simple arithmetic, can be
described as a 4
×
4 matrix transforming
any point on the model M into a point on
the plane X; see Example 1(d).
However, there are several potential
complications with this algorithm, starting
with the possibility of Z fighting. After all,
the shadow model is drawn on top of the
previously drawn plane. Thus, Z values
of the two will be near equal, resulting in
some pixels from the shadow appearing
intermittent with the pixels from the plane.
A common solution is to push the pro-
jection plane slightly above the shadow-
receiving plane.
A second problem exists due to the ma-
trix, which you have derived; it projects
onto an infinite plane, where what you
usually want is more limited (a table top
rather than an infinite ground plane, for
example). Stenciling techniques can help.
When the surface receiving the shadow
is drawn, you also simultaneously draw
into the stencil buffer, whereas when the
shadow model is drawn, the stencil test
is performed to check if the current pix-
el also belongs to the previously drawn
limited surface. In many situations, a des-
tination alpha test can be used as a sub-
stitute for a stenciling test.
Finally, to improve performance, you
could use separate shadowing and draw-
ing models. Because shadows (as impor-
tant as they are) are not what catch the eye
Algorithms for
Dynamic Shadows
Creating geometrically
correct dynamic
graphic images
SERGEI SAVCHENKO
Sergei is the author of 3D Graphics Pro-
gramming: Games and Beyond and can
be contacted at sergei_savchenko@
hotmail.com.
50
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
“To improve
performance, you
could use separate
shadowing and
drawing models”
first, shadow models could be consider-
ably simpler and use a smaller number of
triangles than the rendering models.
Projective Textures
The main drawback of the planar shad-
ows is, of course, the severe limitation that
is placed onto shadow receivers. Quite of-
ten, it is necessary to cast shadows onto
objects of an arbitrary shape. Texture map-
ping and procedural generation of texture
coordinates can help. In most graphics
pipelines, it is possible to specify a texture-
coordinate generation matrix that is ap-
plied to spatial coordinates. The result of
this multiplication is used as texture co-
ordinates. Thus, you can produce a shad-
ow by first computing a black-on-white
image of the shadow caster (see Figure 3)
as seen from the position of the light
source, further using it as a texture for
shadow receivers whose texture coordi-
nates are generated procedurally based
on the view transformation as observed
from the light-source position.
The first step of the algorithm is to draw
the black-on-white image of the shadow
from the position of the light source. As-
sume that the light source is positioned at
point L, and some point on the model M
is projected into the texel T (see Figure
4). The first step of the transformation is
the rotation of the object-space point into
the light-space coordinate system. The lat-
ter is chosen so that its k axis (Figure 4)
points along the direction from the cen-
ter of the shadow caster to the position
of the light source. Directions of the oth-
er two axes are not particularly relevant
(since the orientation of the image in the
plane is not that relevant), so you can ar-
bitrarily choose the i axis to be perpen-
dicular to the Y axis of the object space.
The last axis j is mutually perpendicular
to the first two.
Thus, the axes of the light- source
coordinate system can be computed as in
Example 2(a). Knowing the axes, the ro-
tation part of the transformation from the
object space into the light-source space
can be represented by Example 2(b). To
project the point, however, you also need
to translate the result of the application of
Example 2(b) along the view direction by
the distance from the light source to the
shadow caster. Furthermore, you apply
the perspective transform that determines
how big the object is in the image, and
finally you potentially need a view-port
transform (not represented in the formu-
la) to position the shadow caster’s pro-
jection in the middle of the image; see Ex-
ample 2(c).
The perspective transform lets you adapt
the size of the projected shadow caster to
occupy the entire texture. This transform
thus depends on the size of the texture
buffer and the bounding radius of the
shadow caster.
For the second step of the algorithm,
you use a rendered image of the shad-
ow caster as a texture map on shadow-
receiving objects. The same transform as
that used in the projection is also used for
procedural texture-coordinate generation.
Thus, a vertex on the shadow receiver ob-
tains a proper texture coordinate corre-
sponding to the view from the light
source. However, you may have to alter
the view-port transform since the range
of texture coordinates may be limited and
different from the view-port transform
used in the projection. As Figure 5 illus-
trates, this algorithm lets you cast shad-
ows on objects of an arbitrary shape.
There are several drawbacks to this al-
gorithm. First, a shadow is obtained on
both front- (light-source facing) and back-
facing sides of the shadow receiver. It is
because there are points on both sides of
a closed object that map to the same shad-
ow map texel according to the transform
that we have found. You can deal with this
problem by choosing very low-ambient il-
lumination so that the back-facing poly-
gons are very dark.
It is also somewhat difficult to take care
of the concave shadow receivers with this
method, particularly when the shadow
caster happens to be placed in one of the
cavities of the receiver. Suppose a single
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
51
Example 1:
Planar shadows.
(X—L) n(L—P)
X=L +
x
y
z
nPL
x
—(n
x
M
x
+n
y
M
y
+n
z
M
z
)L
x
+(nL—nP)M
x
nL—n
x
M
x
—n
y
M
y
—n
z
M
z
)
nPL
y
—(n
x
M
x
+n
y
M
y
+n
z
M
z
)L
y
+(nL—nP)M
y
nL—n
x
M
x
—n
y
M
y
—n
z
M
z
)
nL—nP—n
x
L
x
—n
x
L
y
—n
x
L
z
—n
x
nL—nP—n
y
L
y
—n
y
L
z
—n
y
L
x
—n
z
L
x
nPL
x
M
x
M
y
M
z
1
nPL
y
nPL
z
nL
—n
z
L
y
—n
y
nL—nP—n
z
L
z
—n
z
nPL
z
—(n
x
M
x
+n
y
M
y
+n
z
M
z
)L
z
+(nL—nP)M
z
nL—n
x
M
x
—n
y
M
y
—n
z
M
z
)
=
(M—L)=
=
nL—nP
(nL—nM)L+(nL—nP)M—(nL—nP)L
nPL—nML+(nL—nP)M
nL—nM
nL—nM
nL—nM
=
(M—L) n(L—M)
(a)
(b)
(c)
(d)
x
y
z
1
=
Figure 1:
Planar shadows.
Figure 2:
Projection onto a plane.
L
M
X
P
n
Figure 3
: Shadow texture.

model is representing a tunnel through
which a shadow caster is moving — the
shadow may potentially be mapped onto
both the floor and ceiling of this tunnel.
Because both the floor and ceiling are
modeled by the same object (and thus,
use the same texture-coordinate genera-
tion matrix), it is impossible to suppress
the drawing of an extra shadow. Conse-
quently, it may be necessary to subdivide
the scene further and use more complex
line- of-sight calculations to determine
which objects are casting shadows onto
which other objects.
Generally, extra calculations of which
objects cast shadows onto which objects
complicate practical implementations of
this algorithm considerably. The algorithm
is also sensitive to the resolution of the
texture where the shadow image is ren-
dered. If it is too small, the shadow is
blocky. If that is not enough, with this al-
gorithm, it is hard to model multiple ob-
jects casting shadows onto the same re-
ceiver. However, there is an elegant
solution that falls somewhat in between
this algorithm and that of shadow Z
buffer.
Despite these drawbacks, this is one of
the more popular algorithms. A large num-
ber of excellent games (from “SSX” to
“MGS2”) use variations of this approach.
Shadow Volumes
Besides the drawbacks of projective tex-
tures just described, there are effects that
are simply impossible to do with their help
alone; for instance, self shadowing is quite
problematic. The shadow volumes algo-
rithm overcomes this difficulty.
A shadow volume is an extrusion of
the silhouette of a shadow caster that
delimits all points in space shadowed by
this caster. You can build the volume by
finding the silhouette edges of a model
and extruding them away from the light
source. The shadow volumes algorithm
draws shadows as a postprocessing step.
It works by first drawing the scene with-
out any shadows and then drawing (in
a particular way) the shadow volumes
into a separate image while using the Z
buffer of the original image. It, thus, be-
comes possible to find all pixels that
should have been shadowed and then
we can adjust the image of the scene by
blending with, or stenciling against, the
found shadow mask.
The key idea of the algorithm is to first
borrow the Z buffer from the drawn im-
age of the scene. When shadow volumes
(which are assumed to be closed polyhe-
drons) are drawn, their pixels are drawn
an odd number of times for the shadowed
regions and an even number of times for
the illuminated regions (Figure 6). Indeed,
because object B is shadowed, only the
front side of the shadow volume is drawn
(the backside is prevented from drawing
by the Z test, since you have borrowed the
Z buffer from the original scene where ob-
ject B was drawn). This is not the case with
object A and the other shadow volume.
This observation lets you formulate the
following algorithm: First you draw the
scene as is, without any shadow volumes.
Following that, you continue using the Z
buffer from the first image, but switch off
Z buffer updates. If you have a stencil
buffer permitting positive and negative val-
ues, you draw the front faces of the shad-
ow volumes with value 1 into the stencil
buffer (initialized with all zeroes) and draw
the back faces with the value of –1. Con-
sequently, you obtain a stencil where illu-
minated pixels are marked with a 0 and
shadowed pixels with a positive integer.
You can now apply the stencil to the orig-
inal image so that only illuminated pixels
remain in it. A variation of this approach
is possible if the graphics pipeline supports
flexible accumulation of colors. In such a
case, you can create a binary image where
shadowed pixels are black, and blend such
an image over the original scene image.
Note that you need to paint front- and
back-facing sides of the shadow volumes
in different colors to account for a situa-
tion where two shadow volumes intersect.
The difficulty of this algorithm is, of
course, in the necessity to build the shad-
ow volumes. Even with static light, you
may have to recalculate the shadow vol-
umes for dynamic objects whose sil-
houette from the position of a light
52
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 5:
Shadow texture projected
onto a sphere and a plane.
Figure 4:
Projective texture.
L
i
j
k
M
y
z
x
T
Example 2:
Projective textures.
0
0
0
L—M
i
x
j
x
k
x
0
i
y
j
y
k
y
0
i
z
j
z
k
z
0 1
0
0
1
0
0
1
0
0
1
0
0
1
f
0
0
0
0
L—M
k=
k
×
i
k
×
i
j=
(0 1 0)
×
j
(0 1 0)
×
j
i=
(a)
(b)
(c)
T
x
T
y
T
z
1
=
M
x
M
y
M
z
1
0
0
1
0
0
1
0
0 0
1
0
0
—d
0
0
0
k
x
j
x
i
x
0
k
y
j
y
i
y
0 0
k
z
j
z
i
z
0
0
0
1

source may change every frame. To build
a shadow volume, you have to extrude
the silhouette edges in the direction away
from the light source (Figure 7). An edge
in the model is a silhouette edge if one
of the triangles joined at that edge faces
towards the light source, whereas the
other triangle faces away. This fact can
be easily tested by computing the dot
product of the triangle’s normal and the
direction of view for this triangle. Thus,
by traversing all edges and computing
two dot products per edge, we find all
silhouette edges. To do that efficiently,
you can precompute edge-based repre-
sentation of the model where two trian-
gles are given for every edge.
In real life, many models have some ar-
tifacts that complicate the process just de-
scribed. Some edges may hang so that they
have only a single triangle. Other edges
may be joins of more than two triangles.
The most reasonable solution is to edit mod-
els designated for use with this algorithm
in such a way that they are closed polyhe-
drons and don’t contain the situations just
described. At the very least, you can use
special, refined shadow models for gener-
ation of the shadow volumes, whereas less
strict drawing models can be used for ren-
dering. Such strategies are more reasonable
in practice than trying to complicate a sil-
houette-detection algorithm by searching
closed loops of edges and so forth.
The length of the volume is also diffi-
cult to compute. If the length is too long,
much of the fill rate of the graphics ac-
celerator is wasted. You may also get into
a situation when a shadow volume is pro-
jected onto a thin wall and you observe
a shadow on an opposite side of that wall
just because the volumes are too long. If
the length is short (and the volumes are
open), this can produce nasty artifacts. In-
deed, it is common not to close the vol-
umes from above (the model itself fills
that gap) nor from the bottom that likely
intersects with shadow receivers of the
world. There are instances, however, when
closing the volumes is still necessary. If
the camera moves inside a shadow vol-
ume, the clipping plane opens the volume
and interferes with the algorithm, and you
can’t determine shadowed pixels correct-
ly because the algorithm is based on the
assumption that the volumes are closed
(thus, every illuminated pixel is drawn at
least twice — once from the front-facing
surface of the volume and once from the
back-facing surface).
One solution is to introduce an extra
shadow-drawing pass (at least for the vol-
umes that are likely to be clipped by the
front plane). In this pass, you disable the
Z test and reverse the integers used to
paint front and back faces. The effect of
this operation is that you compute the
caps on the shadow volumes and can pro-
ceed with the actual drawing of the vol-
umes without worrying about a situation
where the camera may be inside.
Shadow Maps
Shadow volumes have several significant
shortcomings — one is the necessity to
construct volumes for dynamic objects on-
the-fly every frame. There is an old alter-
native algorithm that requires neither
building triangles dynamically nor severe
limitations on an object’s shape — the
shadow maps algorithm.
In its classical form, the shadow maps
algorithm requires some special hardware
support. Nonetheless, there are variations
of it (or approximations) that can be done
in software only.
The classical shadow-maps algorithm
requires access to the Z buffer. It first com-
putes the image of the scene from the po-
sition of the light source. The Z buffer of
this image is saved as a texture and
mapped onto the scene to be viewed by
the camera. This could be done in a man-
ner described for projective textures. Of
course, Z values stored in the texture cor-
respond to points visible from the light
source. If for any point, you can compute
the distance to the light source directly
and compare it with the texel value that
is mapped onto this point, you can de-
termine if the point is illuminated by the
light source. If the distances are the same,
it is illuminated; if the distances are dif-
ferent (notably, the distance computed
directly is larger than that stored in the
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
53
Figure 6:
Crossing shadow volumes.
L
A
B
V
Figure 7:
Wire frames of constructed shadow volumes and the resulting image.
Figure 8:
Shadowed and illuminated points.
L
A
C
B
V

corresponding texel), it implies that some-
thing else was closer to the light source
and the given point is shadowed. In Fig-
ure 8, point B is shadowed because its
distance to the light source is larger than
the distance that was recorded in the tex-
ture (notably, the distance to point C).
This is not the case for point A, which is
illuminated.
One step of this algorithm (notably,
computing the distance to the light source
from some point when viewing the scene
by the camera) normally requires some
hardware assistance, or at least flexibility
in the graphics pipeline. However, it is still
possible to approximate this algorithm by
using only commonly available operations.
Illumination calculations for attenuated-
point light sources allow coloring objects
based on the distance to the light sources.
Blending several images together permits
you to mark the pixels that should have
been shadowed.
Consider this algorithm: You first draw
the image of the scene from the position
of the light source. You only use ambient
white light for this light source that is lin-
early attenuated with distance. Normally,
three attenuation coefficients are present
in most renderers and the intensity of the
attenuated light is computed as in Exam-
ple 3. For this algorithm, you only need a
linear attenuation coefficient set to a value
dependent on how large the scene is —
that is, dependent on where this light
should stop producing any contribution.
Thus, with such illumination set up, pixels
that are closer will appear brighter, where-
as pixels that are further away from the
light source will be dimmer (see Figure 9).
As the next step of the algorithm, you
compute two images from the position of
the camera. In one image, you project
onto all objects the texture computed dur-
ing the previous step using projection from
the light source. It is done with the help
of the mechanism described for projective
textures. For the second image, compute
the scene with the same attenuated light
source as was used on the first step. Fig-
ure 10 demonstrates the two images,
which contain the approximations to dis-
tances to the light source. The color of the
point closest to the light source also col-
ors all pixels further along the way in the
left image. In the right image, every pix-
el is colored depending on its own dis-
tance only. By subtracting from the value
of every pixel in the left image the value
of the corresponding pixel in the right im-
age, you can mark shadowed pixels. If
the result of subtraction is positive, the
pixel is shadowed; if it is zero, it must
have been illuminated (see Figure 11).
By scaling the values of the shadow
mask up and clamping from above, you
can obtain a binary shadow mask where
all shadowed pixels are white and illumi-
nated pixels are black. Note also that neg-
ative values indicate regions that were not
mapped with the computed texture in the
left image of Figure 10. These points could
be considered as illuminated.
As the last step, you draw the scene
with normal illumination and subtract from
this image the shadow mask. That is, from
every pixel of the image, you will subtract
from its value the value of the corre-
sponding pixel of the shadow mask. The
right image in Figure 11 illustrates the re-
sult. Note that in the case of OpenGL, the
subtraction of images can be done with
the help of the accumulation buffer.
A significant drawback to this algorithm
is due to potential artifacts that may ap-
pear on open models illuminated from the
inside. A pixel illuminated from the back
face of a polygon is not distinguished from
the pixel illuminated from the front. Thus,
if a light shines into an opening on an ob-
ject, you may observe a light spot on the
side of the object opposite to the open-
ing. The algorithm is not sensitive to these
situations. Better modeling of objects en-
sures that there is no one polygon. Thick
surfaces will help avoid these problems.
The most significant drawback, how-
ever, is the necessity to do multiple ren-
dering passes per every light source pro-
ducing shadows. On the positive side, the
algorithm is very general and inherently
produces self shadowing without placing
significant limits on the shape of the mod-
els in the scene. Finally, there is no need
to construct geometry on the fly— an ex-
pensive process.
Priority Maps
The main difference between shadow
maps and priority maps is that shadow
maps compute approximations of dis-
tances per pixel, while priority maps do
54
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 11:
Shadow mask and resulting image.
Example 3:
Shadow maps.
I(d)=I
light
C
const
+C
linear
d+C
quadratic
d
2
1
Figure 9:
Shadow map texture.
Figure 10:
Obtaining shadow mask.

it on a per-object basis. By sorting all ob-
jects based on their distance to the light
source, you can assign ambient color to
every object so that the closest is the
brightest, and the farthest is the dimmest.
The following steps are similar to the
shadow maps algorithm. The texture map
is drawn from the position of the light
source using assigned ambient colors. Fur-
thermore, the camera image is drawn
twice — once using a previously comput-
ed texture map projected onto all objects,
and the second time using the object’s as-
signed colors. The two images are sub-
tracted to obtain the binary shadow map
that is then subtracted from the actual im-
age drawn using proper illumination of
the scene.
As the resulting image illustrates (see
Figure 12), the ability to produce self
shadows has been lost. Indeed, the en-
tire object is drawn with the same color,
and thus, only the shadows produced by
other objects can be computed. The use
of sorting in this algorithm also assumes
that the objects are not particularly elon-
gated and placed in complex configura-
tions. Otherwise, sorting may not be able
to place all objects into an unambiguous
order.
The greatest advantage of this algorithm
is the simplicity with which it handles mul-
tiple shadow casters on multiple shadow
receivers, something quite complicated in
the case of projected textures alone.
Conclusion
All of the algorithms I’ve described have
strengths and weaknesses. Planar shad-
ows limit the shape of shadow receivers
to planes only. Projective textures have
difficulties with multiple casters on the
same receiver and erroneously produced
shadows. Shadow volumes require gen-
erating additional geometry and need mul-
tiple drawing passes. Shadow maps need
too many passes and tend to produce ar-
tifacts as do priority maps.
On the other hand, planar shadows are
trivial to implement, as are projective tex-
tures. Shadow volumes permit self shad-
owing and easily allow for multiple cast-
ers on the same receivers. Shadow maps
don’t require building any data structures
dynamically and place only moderate lim-
itations on the models. Priority maps in-
herit many good features of projective tex-
tures and shadow maps.
DDJ
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
55
Figure 12:
Priority map texture and the resulting image.

Extending UML
P R O G R A M M E R ’ S T O O L C H E S T
W
e develop complex scientific ap-
plications and integration between
different instrument, inventory,
and financial systems. To get a
better handle on scope and requirements,
we began using UML. However, the more
we used Activity Diagrams to model the
end-user tasks and user interaction at the
screen, the more we recognized a gap in
UML — there is no way to actually mod-
el user interaction that illustrates the steps
and required actions users perform to
complete their tasks.
Upon examination, we identified a pat-
tern of what users needed to do on
screen — enter this, read that, select next,
and submit all. We then saw a direct cor-
relation between user function and the
type of GUI elements we were using to
perform that function. Consequently, we
devised what we call “Extended Activity
Semantics” (XAS) to model the business
tasks and required user interactions to
complete those tasks. From this mapping,
we can automatically generate GUI ele-
ments and simultaneously develop more
accurate requirements.
In this article, we present XAS notation
and show how you can use it to design
user activity. We then describe how the
notation can be directly mapped to GUI
components to simultaneously construct
user interfaces. By applying a simple
heuristic between the notation and UI
components, we generate a construct for
the forward and reverse engineering of
user interfaces and activity diagrams. To
illustrate how XAS notation can be used,
we present Guibot, a CASE tool we de-
veloped.
Background
UML provides a good foundation for for-
ward and reverse engineering of class di-
agrams, and there are numerous tools that
produce lots of software based on UML
class diagrams. However, for user activity
and accompanying user interfaces, class
diagrams leave a flat, incomplete view of
the user activity. Sequence diagrams and
collaboration diagrams produce a dynamic
view coupling user activity to the GUI
functions and middleware, but they don’t
translate well to end users during eluci-
dation of use cases and functional re-
quirements.
In short, GUI designers find UML cum-
bersome and complain that it produces
unnecessary work rather than eliminating
it. Compounding this problem are the user
stories that analysts typically produce as
verbose written narratives. Furthermore,
user storyboards implemented through
written narratives leave too much inter-
pretation and inference by code develop-
ers because a narrative offers no inherent
mechanism for verifying its own com-
pleteness. This deficiency is underscored
by industry practices, which are still
plagued by problems of bridging the com-
munication gap between those who con-
sume software and the technologists who
create it.
Often, prototype user interfaces are
used to elicit end-user requirements, but
they suffer from only providing a static
view of user activity (a “snapshot” view),
and fail to express a dynamic model of
the end-user’s workflow. By modeling the
task-based steps necessary for the end
user to achieve the goal/purpose of a use
case, UML activity diagrams overcome
many of these problems. They succeed in
illustrating the scenarios of the tasks per-
formed by end users to achieve their goals,
yet to stakeholders unfamiliar with activ-
ity diagrams, they are insufficient to pro-
vide a clear picture of the software sys-
tem “to be.”
From our experience of elaborating soft-
ware requirements for complex systems,
domain experts and stakeholders are hun-
gry for such visualization early in the spec-
ification of a new software project. Using
existing tools, we have found that the best
Automatic production
of user interfaces
TIMOTHY E. MEEHAN
AND NORMAN CARR
Tim is a principal software engineer
and Norman a web- site designer for
Nuvotec and coinventors of Extended
Activity Semantics. They can be con-
tacted at tim.meehan@guibot.com and
norman.carr@guibot.com, respectively.
56
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
“GUI designers
find UML
cumbersome”

way to provide such vision to stakehold-
ers is via an approach employing both
static UI prototypes and activity diagrams
to complement one another. This method
yields greater end-user involvement in the
design and specification of user activity,
provides better user satisfaction, and re-
sults in a more accurate and detailed def-
inition of end-user requirements early in
the project lifecycle.
Subsequently, through such a process
of drafting user prototypes in parallel with
activity diagrams, we have determined that
user interaction at the interface could be
directly represented by a notational sup-
plement to activity diagrams, which in turn
can be mapped back to GUI components,
which we employ in our Guibot tools.
UI Behavior
Users perform defined sets of irreducible
actions with respect to user interfaces —
input, review, select, and command. We
represent these actions as inputters, out-
putters, selectors, and action invokers.
User actions such as drag-and-drop are
composite actions of these irreducible ac-
tions, where drag-and- drop would be
select-and-input. In addition, there is a
multiplicity — formatting of the informa-
tion in to and out of the system and con-
ditions surrounding the information.
The Multiplicity denotes whether the
action is required or optional, or whether
it requires multiple actions, such as one
or many selections to be made. Format-
ting describes the presentation of the in-
formation, such as the format of a date
input or output. The Conditions for an ac-
tion define what is allowed or needed,
such as a “date entry must be earlier than
today,” or a “password must be longer
than some number of characters.”
In the use of activity diagrams, prose
in the business language of the end user
is generally written to describe these ac-
tions and constraints. Although the UML
specification does state that pseudocode
and programming language code can be
used in developing activity diagrams, in
the context of eliciting requirements from
end users, we have found their own busi-
ness language is the most effective. As
an extension to activity diagrams, we
added the following XAS notation to
translate such “business actions” into user
interactions:
• Inputter: >>, where the user provides
information to the system.
• Outputter: <<, where the system pro-
vides information to users.
• Selector:
∇
or V, where users select from
a predetermined choice of output.
• Action Invoker: !, where users signal the
system to provide an action or contin-
uance.
• Multiplicity: m..n defines the multiplic-
ity of each user interaction.
• Label : DataType, which specifies the
plain-language label of the data and the
data type, or the command for the ac-
tion invoker.
• Mask/Filter: |, where the data format is
represented.
• Condition: [ ], where any conditions ap-
plied to the interaction are specified.
The complete grammar for inputters,
outputters, and selectors, therefore, is re-
spectively expressed as:
>>,<<, V m..n label :
datatype | mask [conditions]
while for action invokers it is:
! command [conditions]
Applying XAS
Figure 1, a typical activity diagram pre-
sented in the UML 1.5 specification, illus-
trates customer ordering services from the
sales department and a stockroom filling
the order. While this example is a satisfac-
tory description of the general workflow,
these action states require more detail to
describe the process for both end users
and software developers when it comes to
human/computer interface issues.
By adding XAS to each action state that
requires user interaction in Figure 1, we
can detail the interactions required and
any requirements surrounding these user
interactions that are necessary to complete
the task. Figure 2(a) is a more detailed ac-
tivity diagram employing XAS and more
comprehensively describing user activity.
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
57
In Figure 2(a), the customer selects 1
to n services, then to pay for those ser-
vices, the system outputs the order
amount, formatted as $*.##, although the
grammar for the format can be of the an-
alyst’s choosing. Here we specify any dol-
lar amount with the condition that the or-
der amount must equal the sum of the
amounts of each individual service. When
the order is collected, the order is received
by the customer, expressed with the con-
dition that the collection date is less than
or equal to the delivery due date.
In Figure 2(b), the sales department se-
lects the order, reviews the payment sub-
mitted, and processes the payment. When
the order is filled by the stockroom, the
sales department delivers the order to the
customer with the specified condition that
the delivery date is less than or equal to
the delivery due date.
In Figure 2(c), the stockroom selects an
order with the condition it has not been
filled, and then processes the order in or-
der to fill it.
Mapping XAS to the GUI
To automatically generate GUI proto-
types, we have developed a mapping be-
tween the activity diagram elements and
the notation elements of Extended Activity
(continued from page 57)
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
59
Figure 1:
Typical activity diagram from UML 1.5 specification.
Figure 2(a):
Addition of XAS to the
action states in Figure 1 for the
customer swimlane.
Figure 2(b):
Addition of XAS to the
action states in Figure 1 for the sales
swimlane.
Semantics; see Table 1. Swimlanes repre-
sent the view for the actor and are repre-
sented by a GUI form. The action state
groups the user interaction and is repre-
sented by GUI groupboxes or panels. In-
putters typically are text boxes, text areas,
and grids. Outputters typically are labels,
grids, image boxes, and read-only text ar-
eas. Single selectors typically are com-
boboxes, single selection list boxes, radio
buttons, or treeviews. Multiselectors are
typically multiselection list boxes, grids,
checkboxes, and list views. Action in-
vokers are typically command buttons, hy-
perlinks, menu items, and image buttons.
Guibot, for example, directly maps the
activity diagram elements and the XAS to
GUI components. Figure 2 automatically
produces the GUI prototypes for the cus-
tomer, sales, and stockroom swimlanes
in Figures 3(a), 3(b), and 3(c). The re-
sulting prototype allows immediate un-
derstanding between users and analysts,
and defines the expectations for the
coder.
If you add an input box to the Pay pan-
el in the Customer user interface in Fig-
ure 3(a) for security code (csc) entry for
credit cards, the action state is updated
with the new inputter information via the
mapping between notational elements and
the GUI components; see Figure 4.
Conclusion
The XAS extensions let us maximize the
benefits that activity diagrams offer. Rapid
prototyping gathers faster buy-in from the
customer and faster elaboration of their
business needs. Less ambiguous software
requirements are generated earlier, obvi-
ating the need for onerous or extended
iterations. The extended activity diagrams
are implementation agnostic, allowing
technologists to determine the best im-
plementation path. For small projects or
short discussions, we even whiteboard the
notation to expedite communication.
DDJ
60
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 4:
Reverse engineering of GUI component to XAS notation for an
action state.
Figure 3(b):
The GUI prototype
produced by the XAS notation in the
sales swimlane in Figure 2(b).
Figure 3(c):
The GUI prototype
produced by the XAS notation in the
stockroom swimlane in Figure 2(c).
Activity Diagram Element/Notation
GUI Component
Swimlane
Form
Action State
Groupbox, Panel
Inputters >>
Input box, text area, grid
Outputters <<
Label, grid, image box, text content.
Selectors 0..1 (single selection)
Combobox, list box, radio button, tree view
Selectors 0..n (multiple selection)
List box, grid, checkbox, list view
! command
Command button, hyperlink, menu, image button
Table 1:
XAS to GUI component mapping.
Figure 3(a):
The GUI prototype
produced by the XAS notation in the
customer swimlane in Figure 2(a).
Figure 2(c):
Addition of XAS to the
action state in Figure 1 for the
stockroom swimlane.
http://www.ddj.com
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
S1
Integrating Reporting
Services into ASP.NET
A
s anyone who has developed a
business-oriented ASP.NET solution
knows, the need for snazzy-looking
reports is both a recurring theme
and (more often than not) a pain in the
neck. Ignorant of layout requests, end
users have a magical way of trying your
data- sculpting abilities to the max. In
the past, you would have had to pur-
chase a reporting application that inte-
grated (with varying degrees of success)
with Visual Studio, and hope that the
vendor’s integration was worth the price
of admission. Luckily, Microsoft heard
our collective moans and responded
with a free add- on to SQL Server that
lets you develop reports similar to Mi-
crosoft Access and Crystal Reports for
.NET. In this article, I examine the pro-
cess of designing and deploying a re-
port using SQL Server Reporting Services
and show how to stream the report as
a PDF document from a web service in
ASP.NET applications.
Reporting Services is a free/evaluation
add-on to SQL Server 2000 (http://www
.microsoft.com/sql/reporting/) that does
an excellent job of addressing most ma-
jor concerns in terms of creating and de-
livering reports. Out of the box, Report-
ing Services offers features such as
conditional formatting and suppression
based on grouping “level” of the data, piv-
ot table-like functionality, and the ability
to export documents to e-mail, XML, and
PDF. Reporting Services also lets you call
your own .NET assemblies to retrieve data
and perform other customizations.
XML Architecture
Microsoft implements Reporting Services
through a series of .NET web services and
a form of XML called the “Report Defini-
tion Language” (RDL). All report defini-
tions and metadata are defined in an RDL
document. When a report instance needs
to be created (ad hoc or for a given sched-
ule), the Reporting Services Server retrieves
the RDL document, interprets the design
elements, retrieves the data, and then ren-
ders the report in the requested format.
Figure 1 illustrates this architecture. Though
Reporting Services makes extensive use of
XML, designing reports is straightforward
and can be done without ever seeing the
underlying RDL. How is this possible? It is
possible because Reporting Services’ in-
herent XML/.NET web-services architec-
ture is particularly well-suited for integra-
tion into existing ASP.NET applications.
Since the RDL is interpreted at runtime, re-
ports do not have to be compiled either
as part of your ASP.NET application or as
a separate assembly. Modifying the layout
or the data in a report becomes as simple
as publishing a new version of the RDL
document to the Reporting Services serv-
er. This feature alone would have saved
me countless hours over the years trying
to troubleshoot deployment-related issues,
especially considering about one out of
every three deployments seemed to be
only for report-related issues.
Setting up Reporting Services
Although Reporting Services is designed
for various multiserver configurations, the
example I present here uses the same ma-
chine for the ASP.NET, Report Services,
and database server. At a bare minimum,
your computer needs:
• Windows 2003 Server or Windows XP
Professional with SP1 (or later).
• SQL Server 2000 with SP3a (or later).
• Microsoft Visual Studio .NET 2003.
• Internet Explorer 6.0.
When you go through the default in-
stallation of Reporting Services, it creates
the necessary databases in SQL Server and
a web-based Report Server administration
tool called “Report Manager.” It then in-
stalls the project template type for Report-
ing Services reports in Visual Studio .NET
2003. My examples use the Northwind
database that comes with the default in-
stallation of SQL Server 2000 (the complete
source code for this example is available
electronically; see “Resource Center,” page
5). If you do not have (or have modified)
the Northwind database, you can install or
reinstall it as described in an MSDN article:
http://msdn.microsoft.com/library/
default.asp?url=/library/en- us/tsqlref/
ts_north_2ch1.asp.
Start by launching Visual Studio .NET
2003, creating a new blank solution, and
adding a new project. Notice that in the
New Project dialog box, you have a new
Project Types folder called “Business In-
telligence Projects,” as in Figure 2. The
first project type is the Report Project Wiz-
ard that steps you through the process of
creating a simple report. I use the stored
procedure Employee Sales By Country in
Using web services to
generating reports
DAVID LLOYD
David is a consultant at Softagon Corp.
He can be reached at dlloyd@softagon.com.
W I N D O W S / . N E T D E V E L O P E R
“Records from your
database are bound
to Reporting
Services reports
through Datasets”
the Northwind database for the example
report. Select the Report Project project
type to create a blank project.
Getting the Data Together
You will have two folders in the project —
Shared Data Sources and Reports. Shared
Data Sources are similar to ODBC files in
that they let you select the OLE DB
provider for the connection, specify the
server and database, and the login au-
thentication mechanism. Using Shared Data
Sources, you can manage how reports con-
nect to data sources independently of each
report’s design. Reports can also use more
than one Shared Data Source, which is
useful for cross-server reports and reports
with subreports. For this example, I am
only using the Northwind database on my
local machine. To add a Shared Data
Source, right- click on the Shared Data
Sources folder and select Add New Data
Source. In the Data Link Properties dialog
box that appears, select your local machine
for the server name and the Northwind
database for the database on that server.
Click OK to continue. Figure 3 shows the
connection properties I used to configure
the connection to that database.
On the Reports folder in your Report
project, right-click and select Add New
Item and select Report. Call the report
SalesByYear. You are then presented with
a design screen with three panels: Data,
Layout, and Preview. The first task is to
configure the report to use the Employee
Sales By Country stored procedure.
Records from your database are bound
to Reporting Services reports through
Datasets. Datasets are results of a query
or stored procedure against a Shared Data
Source or a report-specific data source.
Just as you can use more than one Shared
Data Source in a report, you can use more
than one Dataset. One important thing to
note: Dataset objects (lowercase “s”) are
not the same as ADO.NET DataSet objects
(uppercase “S”). ADO.NET DataSet objects
cannot be used as a Dataset object,
although I hope that Microsoft adds this
feature in the future.
To set up the Dataset for this example,
select <New Dataset…> in the drop-down
box on the Data tab of the report. You
get a dialog box like that in Figure 4. For
this example, you want to name your
Dataset SalesByYearResults, select the
Northwind database, select Command
Type StoredProcedure, and type Employ-
ee Sales By Country for the query string.
Once you have entered this information,
click on the Parameters tab.
Since this Dataset utilizes a stored pro-
cedure, you have to supply two parame-
ters — @Beginning _Date and @Ending _
Date. Just to set up the Dataset, type in
the two parameters, set their values to
=null, and click OK. When you close this
dialog box and return the Data tab, no-
tice that nothing really happened, which
is not surprising considering that no dates
were selected. To make this report use-
ful, you need to add Report Parameters
that can be fed to this Dataset.
To add Report Parameters, click the Re-
ports item on the Standard Menu Bar and
select Report Parameters. Click Add on
the dialogue box that opens. Here, type
Beginning _Date for the Name and the
Prompt, select DateTime for the Data
Type, and click OK. Repeat this process
to add an Ending _Date parameter. Al-
though this example uses Report Param-
eters with client-supplied values, you can
create Report Parameters who derive their
value from another query (implemented
as another Dataset). This is a useful fea-
ture if your reports involve more than data
source or reports that require a combina-
tion of stored procedures and custom SQL.
Once you have added both Report Pa-
rameters, edit the SalesByYearResults
Dataset by clicking on the ellipses next to
the Dataset name on the Data tab. Click
on the Parameters tab. If you select the
drop-down boxes for the parameter val-
ues, you notice the new report parame-
ters. Select the appropriate Report Param-
eter for each and click OK. Now when you
return to the Data tab of your report de-
signer and hit the exclamation point (the
Run query command), you are prompted
for the Beginning and Ending dates. I used
“05/19/1996” and “05/20/1998” for testing,
but you can pick whatever date ranges
you wish. If all is well, you see the results
of the query on this tab.
A Simple Report
Design to Get You Started
Once you have the data issues sorted out,
you can start designing the report. Re-
porting Services has much to offer when
it comes to customizing and formatting re-
ports. Because this article focuses on in-
tegrating Reporting Services into existing
ASP.NET applications (and not about how
to create exceptionally mind- blowing
reports), I will keep the example simple.
(For information about creating those
mind-blowing reports, refer to the sam-
ples provided with Reporting Services, as-
suming you chose to install them.)
Designing elements of the report is as
easy as dragging elements from the Re-
port Items tool bar and editing their prop-
erties. Almost all properties of the ele-
ments you can add to a report can be
assigned through an expression. When
S2
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
http://www.ddj.com
Figure 1:
Reporting Services architecture.
Report
Services Server
ASP.NET App
Browser
Reporting
Services DB
(SQL Server)
OLEDB
Data Source
Report
Configuration and
Scheduling
Report Data
Reporting Service Web-Service Class
Figure 2:
Business Intelligence projects type.
Figure 3:
Connection properties.
you click <Expression…> in the drop-
down list for various properties (Visibili-
ty, Value, BackgroundColor, and so on),
you get a dialog box that lets you use a
combination of Report Parameters, Dataset
Fields, and report-specific information
(like report execution time) to determine
the value of a property. You can even use
the IIF (“if and only if”) operator for con-
ditional assignment and aggregation func-
tions such as SUM and COUNT.
To begin making the report, select the
Layout tab of the report. On the Standard
menu bar, click the Reports item and se-
lect Page Header. A Page Header section
becomes visible on the report designer.
Drag a TextBox item to the Page Head-
er Section. Click on the TextBox and type
in Employee Sales By Year. Now click on
the Preview tab of the report. Fill in the
two text boxes for beginning and ending
date and click View Report; the report
compiles and is previewed. You’ll find
yourself going to the Preview tab often,
as you check to make sure the custom
expression properly format elements with-
in the report.
To add something interesting to the re-
port, drag a Table item from the Report
Items Toolbox on to the Body of your re-
port. Tables such as ASP.NET DataGrid
objects are a tabular way to represent data
bound to a set of records. The first thing
you want to do is to bind the Table to
your Dataset. This can be done by right-
clicking the properties and assigning the
Dataset in the General tab in Figure 5. Al-
though it is not necessary, this step en-
ables Intellisense-like functionality for fields
used in expressions.
In the Table Header section of the Table,
type Shipping Date at the top of one col-
umn and Sales Amount at the top of an-
other one. In the Detail section of the
Table, right-click on the cell under Ship-
ping Date. Click the drop-down box for
the Value property and select Fields!Ship-
pingDate.Value. Repeat these steps for the
cell under the Sale Amount column, se-
lecting Fields!SalesAmount.Value. In the end,
the Design Tab should look like Figure 6.
Deploying the Report
Now that you have a functional, albeit bor-
ing, report, it is time to deploy it to your
Report Server. Going to the Reporting Ser-
vices project properties, you see a dialog
box like Figure 7. Enter “http://localhost/
ReportServer” into the TargetServerURL
field. You can also optionally set the Tar-
getFolder field if you want your code de-
ployed to a particular folder. Click OK to
close this dialog box. Now when you se-
lect Deploy Solution from the Build Menu,
it copies the Shared Data Source file and
your report to your Report Server.
To view the report on the Report Serv-
er, open the Report Manager web site on
your local machine by going to http://
localhost/Reports/Pages/Folder.aspx. Here
you can navigate to your report and it pro-
vides you with an interface similar to the
Preview tab of your report in Visual Stu-
dios 2003.
Calling the Report
Through a Web Service
Listings One and Two present code for a
report launcher page I used in a name-
space called “NorthwindBI.” Create a new
ASP.NET project called “NorthwindBI” and
include the code.
To call the Report Server web service,
you must first add a new Web Reference
to your project. In your NorthwindBI
ASP.NET project, right-click on references
and select Add Web Reference… In the URL
field, type http://localhost/ReportServer/
ReportService.asmx as in Figure 8. You
may leave the Web Reference Name field
localhost or give it another name. If you
give the Web Reference a different name,
make sure you update your Page direc-
tives accordingly.
As you can see, the render method of
the ReportingService object rs takes nu-
merous arguments. The ones you should
be most concerned with are the Param-
eterValue array, the format string, and the
Report Path. (For information on the oth-
er parameters that get passed to and get
returned from the render method, see
http://msdn.microsoft.com/library/
default.asp?url=/library/en-us/RSPROG/
htm/rsp_ref_soapapi_service_lz_6x0z.asp.)
When running the ASP.NET application,
it takes the date variables from your page
and passes it to the render method. In this
example, I set the format for report to be
in PDF. You can select any of the stan-
dard export types Reporting Services sup-
ports; however, PDF is a good choice in
an ASP.NET environment as it is support-
ed by many browsers and operating sys-
tems. There is also less variation on how
the report is displayed among these plat-
forms.
When you receive the byte array back
from the render method, the only task
left is to stream that to the requesting
client. The code in the method Stream-
ToPDF (Listing Two) adds the proper
header code to the Response object for
the binary stream. Notice that the <form>
tag in Listing One has the properties: enc-
Type="multipart/form-data "target="_blank".
This ensures that the page properly han-
dles the returning stream and opens the
PDF document in a new window. You
may also want to check that the MIME
type application/pdf is properly config-
ured in IIS.
Conclusion
Given its XML roots and .NET infras-
tructure, there are all kinds of ways that
Reporting Services can be extended. But
for now, if you have an ASP.NET appli-
cation that uses SQL Server and don’t
particularly feel like going through the
cost and frustration of using a third-par-
ty reporting tool outside of Visual Stu-
dio, choosing Reporting Services is a no-
brainer.
DDJ
S4
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
http://www.ddj.com
Figure 5:
Assigning the Dataset.
Figure 6:
Design Tab.
Figure 7:
Deploying the report.
Figure 8:
Calling the report through a
web service.
Figure 4:
Setting up a Dataset.
(continued from page S2)

Listing One
<%@ Page language="c#" Codebehind="ReportLauncher.aspx.cs"
AutoEventWireup="false" Inherits="NorthwindBI.ReportLauncher" %>
<HTML>
<HEAD>
<title>Report Launcher Web Form</title>
<meta content="Microsoft Visual Studio .NET 7.1" name="GENERATOR">
<meta content="C#" name="CODE_LANGUAGE">
<meta content="JavaScript" name="vs_defaultClientScript">
<meta content="http://schemas.microsoft.com/intellisense/ie5"
name="vs_targetSchema">
</HEAD>
<body>
<form id="ReportForm" method="post" runat="server"
encType="multipart/form-data" target="_blank">
<table>
<tr>
<td><b>Report Launcher Web Form</b></td>
</tr>
<tr>
<td><asp:label id="lblMessage"
Runat="server"></asp:label></td>
</tr>
<tr>
<td> </td>
</tr>
<tr>
<td>
<table>
<tr>
<td colSpan="2">Please enter information
for the Report</td>
</tr>
<tr>
<td colSpan="2"> </td>
</tr>
<tr>
<td>Beginning Date:
</td>
<td><asp:textbox id="txtBeginningDate"
Runat="server"></asp:textbox>
<asp:requiredfieldvalidator
id="rfvBeginningDate"
Runat="server"
ErrorMessage="Beginning
Date is required."
ControlToValidate=
"txtBeginningDate">
</asp:requiredfieldvalidator>
<asp:comparevalidator id=
"cvBeginningDate" Runat="server"
ErrorMessage="Beginnging Date
must be a Date."
Type="Date" Operator="DataTypeCheck"
ControlToValidate="txtBeginningDate">
</asp:comparevalidator></td>
</tr>
<tr>
<td>End Date:
</td>
<td><asp:textbox id="txtEndDate"
Runat="server"></asp:textbox>
<asp:requiredfieldvalidator id="rfvEndDate"
Runat="server" ErrorMessage="End Date
is required." ControlToValidate=
"txtEndDate">
</asp:requiredfieldvalidator>
<asp:comparevalidator id="cvEndDate"
Runat="server" ErrorMessage=
"End Date must be a Date."Type="Date"
Operator="DataTypeCheck"
ControlToValidate="txtEndDate">
</asp:comparevalidator></td>
</tr>
<tr>
<td colSpan="2"> </td>
</tr>
<tr>
<td align="right" colSpan="2"><asp:button
id="btnSubmit" Runat="server"
Text="Run Report"></asp:button></td>
</tr>
</table>
</td>
</tr>
</table>
</form>
</body>
</HTML>
Listing Two
using System;
using System.Collections;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Web;
using System.Web.SessionState;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.HtmlControls;
using System.IO;
using NorthwindBI.localhost; // To reference the Web Service, it
// will be <project name>.<web reference name>
namespace NorthwindBI
{
/// <summary>
/// Summary description for ReportLauncher.
/// </summary>
public class ReportLauncher : System.Web.UI.Page
{
protected System.Web.UI.WebControls.TextBox txtBeginningDate;
protected System.Web.UI.WebControls.Button btnSubmit;
protected System.Web.UI.WebControls.RequiredFieldValidator
rfvBeginningDate;
protected System.Web.UI.WebControls.CompareValidator cvBeginningDate;
protected System.Web.UI.WebControls.RequiredFieldValidator rfvEndDate;
protected System.Web.UI.WebControls.CompareValidator cvEndDate;
protected System.Web.UI.WebControls.Label lblMessage;
protected System.Web.UI.WebControls.TextBox txtEndDate;
private void Page_Load(object sender, System.EventArgs e)
{
}
#region Web Form Designer generated code
override protected void OnInit(EventArgs e)
{
// CODEGEN: This call is required by the ASP.NET Web Form Designer.
InitializeComponent();
base.OnInit(e);
}
/// <summary>
/// Required method for Designer support - do not modify
/// the contents of this method with the code editor.
/// </summary>
private void InitializeComponent()
{
this.btnSubmit.Click +=
new System.EventHandler(this.btnSubmit_Click);
this.Load += new System.EventHandler(this.Page_Load);
}
#endregion
private void btnSubmit_Click(object sender, System.EventArgs e)
{
// Initialize Web Service
ReportingService rs = new ReportingService();
rs.Credentials = System.Net.CredentialCache.DefaultCredentials;
//Setup Parameters for Report
ParameterValue[] parms = new ParameterValue[2];
parms[0]= new ParameterValue();
parms[0].Name = "Beginning_Date";
parms[0].Value = txtBeginningDate.Text;
parms[1]= new ParameterValue();
parms[1].Name = "Ending_Date";
parms[1].Value = txtEndDate.Text;
//Setup Arguements for the render method
byte[] results = null; // Results always returns as a byte array
string reportPath = "/NorthwindBusinessIntelligence/SalesByYear";
//Do not include root path (i.e "http://...")
string format = "PDF";
//other formats include "IMAGE", "HTML5", et. al
string historyID = null;
string devInfo = @"<DeviceInfo><Toolbar>False</Toolbar>
</DeviceInfo>"; //Turns off menu bar for the page
DataSourceCredentials[] credentials = null;
string showHideToggle = null;
string encoding;
string mimeType;
Warning[] warnings = null;
ParameterValue[] reportHistoryParameters = null;
string[] streamIDs = null;
try
{
// Call the Reporting Service "render" method to get byte[]
results = rs.Render(reportPath, format, historyID, devInfo,
parms, credentials, showHideToggle, out encoding,
out mimeType, out reportHistoryParameters, out warnings,
out streamIDs);
StreamToPDF(results);
}
catch (Exception ex)
{
this.lblMessage.Text = ex.Message;
}
}
private void StreamToPDF(byte[] report)
{
// Buffer this pages output until the PDF is complete.
Response.Buffer = true;
// Tell the browser this is a PDF document so it
// will use an appropriate viewer.
Response.ContentType = "application/pdf";
// Added appropriate headers
Response.AddHeader("Content-Disposition","inline;
filename=Report.pdf");
Response.AddHeader("Content-Length", report.Length.ToString());
// Write the PDF stream out
Response.BinaryWrite(report);
// Send all buffered content to the client
Response.Flush();
}
}
}
DDJ
http://www.ddj.com
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
S5
S6
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
http://www.ddj.com
New Syntax C++ in
.NET Version 2
I
n this final installment of my miniseries
about the new version of C++ in Whid-
bey, I examine some of the new lan-
guage features. First, I look at how
generics are declared in C++ and how they
relate to C++ templates. I then describe
the new syntax to declare managed ar-
rays, and finally look at some of the new
operators used for casts, pointers, and ac-
cessing type objects.
Generics
Perhaps the biggest change in the run-
time for Whidbey is the support for
generics. Managed C++ is both a con-
sumer and provider of generics. In addi-
tion, the new version of Managed C++
can also use C++ templates. Since gener-
ics are a .NET concept, Managed C++ can
use generic classes and methods written
in other languages. Indeed, the Frame-
work library contains several generic
classes; in particular, generic collection
classes in the System.Collections.Gener-
ic namespace. The syntax for using gener-
ics is similar to templates. Listing One is
a class that is based on a generic pa-
rameter of type T using the modifier
generic<class T >. A class can be based
on more than one generic parameter. If this
is the case, then you provide a comma-
separated list of these parameters in the
generic<> modifier.
Once you have declared the generic pa-
rameters, you are free to use them in the
class. In Listing One, the constructor takes
a parameter of this type, and uses this to
initialize the field t. The generic type is used
without the handle syntax (^), both in the
declaration of the parameter and when you
use the generic type parameter in your
code. In Listing One, three instances of this
generic type are created — one provides
int as the generic parameter, another pro-
vides String^, and the third ArrayList^. The
code in the Test class is used to provide
the implementations for these three con-
structed types, but the Test<> class is used
directly for the two constructed types that
take reference parameters. A new type is
created for the constructed type that takes
the value type. In spite of these details, the
Test<> class still provides the functionality
for all of the constructed types, whether
the generic parameter is a value type or
reference type. Since the generic class does
not know what type will be used at run-
time, you should use reference syntax when
using fields or method parameters of the
generic type. If the generic type argument
is a value type, then the object created from
that type argument will still be a value type,
and the object will not be boxed, even
though the instance is accessed through
pointer syntax.
The compiler has no knowledge of the
possible members that the object will have.
Consequently, you can only access the
Object members. You might be tempted
to cast the object to another type; how-
ever, dynamic_cast<> won’t work because
objects of the generic parameter type are
not declared with handle syntax and the
type used in dynamic_cast<> must have
handle syntax. Using any other type of
cast is unsatisfactory because no runtime
check is performed. Consequently, an in-
valid cast could occur producing an in-
valid handle. The solution is to get the
compiler to do some more work, and this
happens with constraints.
When you declare a generic type, you
can also declare constraints on what the
type parameter can be. For example, if
your generic class should be based on a
disposable type, you can make this a con-
straint; see Listing Two. In this code, the
constraint T : IDisposable is applied, which
means that the type that can be used for
the generic type parameter must imple-
ment IDisposable. If the type does not im-
plement this interface, then the compiler
issues an error. If the type does obey the
constraint, then the code within the gener-
ic type can use the type as if it is the type
in the constraint. So, in Listing Two, I do
not have to cast the t field to IDisposable
because the constraint is satisfied: The
code can call the IDisposable methods di-
rectly. Constraints can have a list of one
or more interfaces, and you can have a
constraint that the type argument has a
specific class as a base class. If you pro-
vide a base class constraint, it should be
an additional constraint to the interface
constraints.
Managed C++ also supports generic
methods. All the concepts I have described
for classes are applicable to methods. So
you can declare a generic method with
the generic keyword and a list of the type
parameters; the method can then use the
type for its parameters. A generic method
can also have constraints; the code in the
method can assume that the type satisfies
the constraints, so you do not need to cast
to the type parameter constraint. Listing
Three is an example of this. The class
From generics to
templates—and
back again
RICHARD GRIMES
Richard is the author of Programming
with Managed Extensions for Microsoft
Visual C++ .NET 2003 (Microsoft Press,
2003). He can be contacted at richard@
richardgrimes.com.
W I N D O W S / . N E T D E V E L O P E R
“Generics are not as
flexible as C++
templates ”

Printer has a method called PrintDoc
that must take a type that derives from
IPrintable.
Again, there is a difference between con-
structed generic types with value types as
the type parameter and those with refer-
ence types as the type parameter. If the
generic is given a value type, the runtime
creates a specialized type at runtime for
each value type used for the generic type
parameter. This is similar in some ways to
templates, except that the type is created
at runtime, not compile time. The reason
why multiple types are created is because
instances of value types can be of differ-
ent sizes, so if a constructed type has a
field that is a value type, the runtime must
be able to allocate enough memory for the
field. If you pass a reference type as the
generic type parameter, then regardless of
the actual type, the runtime always creates
an instance of a generic type. For exam-
ple, in Listing One, the Test<String^> and
Test<ArrayList^> instances will both be
created from the Test<T> class. The rea-
son is that all reference types are accessed
through reference handles, which always
have the same size, so no changes need
to be made to Test<T>.
Generics and Templates
So where do templates fit into this? Well,
Managed C++ supported templates from
the first version, but only on native types.
These native types would be compiled to
IL because the compiler would essential-
ly expand the template and generate a val-
ue type for the instantiated type. In Whid-
bey, you can apply a C++ template to a
managed class with the same meaning as
templates in native code — the compiler
generates an instantiated type at compile
time from the type parameters that you
provide.
This is the major difference between
generics and templates: Generics are con-
structed at runtime from the generic type
and the type arguments, whereas tem-
plates are instantiated at compile time to
generate a new type. Further, a generic
type can exist in a different assembly to
the constructed type, whereas a managed
template class cannot be exported from
an assembly; therefore, the managed tem-
plate class must be in the same assembly
as the managed instantiated type.
Generics are not as flexible as C++
templates and do not support special-
ization or partial specialization (that is,
a specialization for a specific type or a
subset of types). Generics do not allow
the type parameter to be used as the
base class to the generic and you can-
not provide default parameters to the
generic type. Further, type parameters of
generics can be constructed generic
types, but not generic types. Templates
applied to a managed class can do all of
these things.
Arrays
The way that arrays are declared has
changed in Whidbey. In earlier versions
of Managed C++, you used a syntax sim-
ilar to native C++ to declare and allocate
an array. In Whidbey, this syntax is only
used for native arrays of native types; man-
aged arrays are of the type array<>. For
example, the old syntax to allocate an ar-
ray looks like this:
String _ _ gc
*
a[ ] = new String _ _ gc
*
[4];
The new syntax uses array<> in the
stdcli::language namespace:
array<String^>^ a = gcnew array<String^>(4);
Using array<> makes the code more
readable, especially when you consider
how arrays are returned from functions.
Listing Four shows the old syntax and new
syntax for returning an array from a
method. While syntactically correct, the
old style appears confusing, and if the
method has a long parameter list, it is easy
to misread the method header and expect
it to return a string rather than an array of
strings. The new syntax is clearer and eas-
ier to read.
The syntax for declaring multidimen-
sional arrays is straightforward — there is
a version of array<> that takes the array
type and the number of dimensions as pa-
rameters:
// Two dimensional 10 x 10 array
array<String^, 2>^ a2 = gcnew array<String^,
2>(10, 10);
Before leaving arrays, it is worth point-
ing out that the language now supports
functions with a variable number of pa-
rameters, similar to how C# allowed this
to happen with the params keyword.
Declaring the method is straightforward:
The last parameter of the method should
be an array parameter and marked with
the [ParamArray] attribute. The method
gets access to the method parameters
through this array. The real difference
comes in using the method. In previous
versions of Managed C++, you would have
to create the array in the calling code to
pass to the method. In the new version
of the language, the compiler generates
the array for you. Listing Five illustrates
this. As you can see, the average method
is called with a list of integers, and the
compiler generates the array<int> to be
passed to the method.
Casts
Since the first version, Managed C++ has
supported the C++ cast operators dynam-
ic_cast<>, static_cast<>, const_cast<>, and
reinterpret_cast<>. dynamic_cast<> per-
forms a runtime type check, and if the type
cannot be cast to the requested type, the
return will be a null value (in Whidbey,
this is nullptr); this is usually used when
you are not sure about the type being cast.
Therefore, any code that has a dynam-
ic_cast<> is accompanied with a check for
a null value. static_cast<> converts with-
out a type check and is usually used when
you know that the type cast will succeed.
Managed types used as parameters or vari-
ables can be marked with const, which will
add a Microsoft.VisualC.IsConstModifier
modifier to the parameter or variable. This
modifier makes sense only to C++, but it
is nevertheless useful in your code be-
cause it gets the compiler to perform
checks on how parameters are used. The
const_cast<> operator has the same func-
tion as it does in native C++: It is used to
remove the constness of a variable. Fi-
nally, reinterpret_cast<> has the same
meaning as it does in native C++: It is
used to cast between two unrelated types.
In general, you will not use reinter-
pret_cast<> with managed types because
.NET has strong typing.
Earlier versions of Managed C++ pro-
vided the cast operator _ _try_cast<>. This
was intended to be used only in debug
builds in the places where you would
expect to use static_cast<>. This cast op-
erator would throw an exception if the
cast failed, letting your testing determine
that the static_cast<> was inappropriate
so you could make adjustments to your
code. In release builds, you would re-
place calls to _ _try_cast<> with calls to
static_cast<>.
The _ _try_cast<> operator is no longer
available, replaced with the safe_cast<>
operator. However, this new operator has
an important difference. The operator is
guaranteed to generate verifiable IL, and
this is important because static_cast<> will
not produce verifiable IL. If you want to
create safe code (/clr:safe), you should
use the safe_cast<> operator. Unlike stat-
ic_cast<>, this operator also performs a
runtime check on a type and throws an
InvalidCastException if the types are un-
related.
Another use of safe_cast<> is to ex-
plicitly box value types. The new version
of C++ implicitly boxes value types if you
use a value type when an object is re-
quired, but the safe_cast<> operator can
be used to explicitly perform the cast:
int i = 42;
int^ p = safe_cast<int^>(i);
Unboxing is always explicit and again,
safe_cast<> is the operator to use. So fol-
lowing on the previous example:
int j = safe_cast<int>(p);
(continued from page S6)
S8
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
http://www.ddj.com

Interior Pointers
C++ is a flexible and powerful language
and one way this power expresses itself
is through interior pointers. As the name
suggests, interior pointers give you access
to memory within objects. An interior
pointer is a pointer to memory within the
managed heap and lets you manipulate
this memory directly. Interior pointers are
clearly dangerous, so any code that uses
interior pointers is not verifiable.
To declare an interior pointer, you use
the interior_ ptr<> operator and to initial-
ize it, you use the & operator on a field
member of an object. One use of interior
pointers is to gain access to the memory
allocated for an array. Once you have an
interior pointer, you can perform pointer
arithmetic on it like a native pointer and
dereference the pointer to access the data
that it points to. In effect, this breaks the
encapsulation of managed objects. Listing
Six illustrates a straightforward use for an
interior pointer. The code creates an ar-
ray of 10 integers, then obtains an interi-
or pointer to the first item in the array. In
the for loop, the pointer is dereferenced
to get access to the memory within the ar-
ray, and this is initialized with the index
variable in the loop. With each iteration,
the pointer is incremented so that it points
to the next item in the array.
Another example of interior pointers in-
volves managed strings. The vcclr.h header
file contains a function called PtrTo-
StringChars that is used to get access to the
array of Char in the managed string. This
function returns an interior_ptr<const Char>.
The reason that the type is const is because
strings are immutable; therefore, you should
not change the string. Further, the charac-
ter array in a string is fixed in size and so
you must keep within these bounds to pre-
vent your code from corrupting the string.
However, with this knowledge in mind and
with judicial use of const_cast<>, Listing
Seven shows how to change a character in
a string using an interior pointer.
As an example of the danger of interi-
or pointers, take a look at Listing Eight.
Here, I define a reference type that has
two 64-bit integers and a string as fields.
The KillMe method obtains an interior
pointer on the x field and uses this to
change the fields in the object by assign-
ment through the dereferenced interior
pointer. The interior pointer is then in-
cremented to give access to the y mem-
ber, which changes and is then incre-
mented again so that it points to the s
member. However, since the type of the
interior pointer is _ _int64, it means that
the pointer will attempt to write a 64-bit
integer over the handle of the string mem-
ber (and since the handle will be 32 bits
on a 32-bit system, presumably this ac-
tion will overwrite some other value on
the managed heap). The consequence of
this last action will be to corrupt the man-
aged heap, so that when the string mem-
ber is accessed in the Dump method, an
exception is thrown. This exception can-
not be caught, the managed heap is cor-
rupted, and so the process is forcibly shut
down. Be wary of interior pointers!
Pinning Pointers
You should not write code like Listing Sev-
en. Managed strings are immutable; hence,
you should not change a string like this.
The real reason for PtrToStringChars is to
give access to the Unicode array in the
string so that you can pass it to unman-
aged functions as a const wchar_t
* point-
er. However, there is a problem with pass-
ing an interior pointer to native code.
During the time that the native code is ex-
ecuting, the garbage collection (GC) could
perform a collection and compact the man-
aged heap. If this occurs, the string object
could be moved and so the interior point-
er becomes invalid. This is not a problem
if the interior pointer is used in managed
code because the GC tracks the use of in-
terior pointers and changes the pointer val-
ue accordingly. However, the GC cannot
track the use of interior pointers passed to
native code. To get around this issue, the
pointer should be pinned. When you pin
an interior pointer, the runtime will pin the
entire object; pinning tells the GC that the
object should not be moved in memory.
To perform pinning, you create a pinning
pointer with pin_ ptr<>. For example:
http://www.ddj.com
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
S9
T
he May Community edition of Vi-
sual Studio .NET 2005 is available
free to MSDN subscribers and to
nonsubscribers for a small fee from
http://lab.msdn.microsoft.com/vs2005/
get/default.aspx.
In addition, the full C++ compiler is
available through the “express” version
of Visual C++; this version does not in-
clude the unmanaged MFC or ATL li-
braries. See http://lab.msdn.microsoft
.com/express/visualc/default.aspx.
This site requires that you have a .NET
passport and that you provide registra-
tion information. After registration, you
are sent a confirmation e-mail with a
link to the download site.
— R.G.
Where to Get Whidbey C++

pin_ptr<wchar_t> pinchars =
PtrToStringChars(s);
_putws(pinchars);
Here, pin_ ptr<> pins the string, and
the interior pointer to this pinned ob-
ject is passed to the CRT function
_ putws, which prints out the value of
the string. The object is pinned for the
lifetime of the pinning pointer. In IL,
variables are declared at method scope,
so the pinning pointer will be valid for
the entire lifetime of the method. How-
ever, you can get around this problem
by assigning the pinning pointer to
nullptr after you have finished using it,
which indicates that the pinning point-
er is no longer being used, so the ob-
ject can be moved by the GC.
Type Objects
Each type has a static object called the
“type” object, which is obtained by calling
the Object::GetType method on an object.
If you don’t have an object, then you have
to use some other mechanism to get a type
object. In earlier versions of Managed C++,
this was achieved with the _ _typeof oper-
ator. In Whidbey, this operator has been
renamed typeid<>, the type is passed as
the parameter to the operator, which then
returns the type object. Incidentally, gener-
ic types also have type objects, as do con-
structed types. For example this code:
Console::WriteLine
(typeid< Dictionary<int,int> >);
prints this at the command line:
System.Collections.Generic.Dictionary`2
[System.Int32,System.Int32]
In other words, the Dictionary type has
two type parameters (indicated by `2),
and the constructed type has provided
Int32 for both of these parameters. In the
current beta, it is not possible to get the
type object for a generic type: You must
provide type parameters.
DDJ
S10
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
http://www.ddj.com
Listing One
generic <class T>
ref class Test
{
T t;
public:
Test(T a)
{
t = a;
}
String^ ToString() override
{
return String::Format("value is {0}", t->ToString());
}
};
void main()
{
Test<int>^ t1 = gcnew Test<int>(10);
Console::WriteLine(t1);
Test<String^>^ t2 = gcnew Test<String^>("hello");
Console::WriteLine(t2);
Test<ArrayList^>^ t3 = gcnew Test<ArrayList^>(gcnew ArrayList);
Console::WriteLine(t3);
}
Listing Two
generic<class T> where T : IDisposable
ref class DisposableType
{
T t;
public:
DisposableType(T param) {t=param;}
void Close()
{
t->Dispose();
}
};

Listing Three
interface class IPrintable
{
void Print();
};
ref class Printer
{
public:
generic<class T> where T : IPrintable
void PrintDoc(T doc)
{
doc->Print();
}
};
Listing Four
// Old Syntax
String* Create(int i) __gc[]
{
return new String __gc*[i];
}
// New Syntax
array<String^>^ create(int i)
{
return gcnew array<String^>(i);
}
Listing Five
using namespace System;
using namespace stdcli::language;
double average([ParamArray] array<int>^ arr)
{
double av = 0.0;
for (int j = 0 ; j < arr->Length ; j++)
av += arr[j];
return av / arr->Length;
}
void main()
{
Console::WriteLine("average is {0}", average(9, 3, 4, 2));
}
Listing Six
const int SIZE = 10;
array<int>^ a = gcnew array<int>(SIZE);
interior_ptr<int> p = &a[0];
for (int i = 0; i < SIZE; ++I, ++p)
*p = i;
Listing Seven
String^ s = "hello";
interior_ptr<const Char> ptr = PtrToStringChars(s);
interior_ptr<Char> p = const_cast< interior_ptr<Char> >(ptr);
Console::WriteLine(s); // prints hello
*p = 'H';
Console::WriteLine(s); // prints Hello
Listing Eight
// Illustrating the danger in interior_ptr<>
using namespace System;
using namespace stdcli::language;
ref class Bad
{
__int64 x;
__int64 y;
String^ s;
public:
Bad()
{
x = 1LL; y = 2LL; s = "test";
}
void KillMe()
{
Dump();
interior_ptr<__int64> p = &x;
*p = 3LL; // Change x
Dump();
p++;
*p = 4LL; // Change y
Dump();
p++;
*p = 5LL; // Change s
// Dump will kill the process when it tries to access s
Dump();
}
void Dump()
{
Console::WriteLine("{0} {1} {2}", x, y, s);
}
};
void main()
{
Bad^ bad = gcnew Bad;
bad->KillMe();
}
DDJ
http://www.ddj.com
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
S11

S12
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
http://www.ddj.com
Enhancing .NET
Web Services
C
alling a web service from a .NET ap-
plication couldn’t be easier. Just select
the Project/Add Web Reference menu
item. Add a URL to the WSDL file that
describes the web service. Press Add Ref-
erence and a proxy class is automatically
created. This proxy class includes methods
corresponding to each of the web service’s
methods. Calling any of these proxy class
methods generates a SOAP (XML) request,
sends it to the server, retrieves the SOAP
response, and converts it into a response
object. But what if you want to request
compressed responses, or access or even
change the requests and responses? In this
article, I show how to ask for compressed
responses, capture and optionally modify
SOAP requests/responses, and debug web-
service calls with a network packet ana-
lyzer program. I’ve included SoapEx, a sam-
ple application (available electronically; see
“Resource Center,” page 5) that demon-
strates these techniques. SoapEx (see Fig-
ure 1) is a .NET Windows Forms program
written in C#. It requires the .NET 1.1
framework and Windows 2000/XP or lat-
er. Build it in Visual Studio .NET 2003 by
opening SoapEx\SoapEx.sln. You can also
install the app by running setup.exe in the
setup folder.
When you run SoapEx, it calls the
Google web service. Check the Compress
Response checkbox to request a com-
pressed response. Check the Modify Soap
Request and Response checkbox to
change the SOAP requests and respons-
es. You’ll need a license key to use the
Google web service. Press the Get License
Key button to get one, or go to http://
www.google.com/apis/. In either case, it
will take only a minute or two to apply
for a license key and receive it via e-mail.
Press Call Web Service to send the web-
service request and retrieve the response.
The SOAP request/responses are displayed
in the Results text box. Pressing the IP Ad-
dresses button displays the IP address of
your machine and the server hosting the
web service. These IP addresses are use-
ful for troubleshooting web-service calls
with Packetyzer.
Many web services can return results in
compressed format to conserve bandwidth.
Given the verbosity of XML, compression
can drastically reduce bandwidth con-
sumption. Unfortunately, .NET web-service
proxies do not ask for compressed results
by default. But it’s easy to correct this sit-
uation. The first step is to create a new
class derived from the web-service proxy
class. (For example, SoapEx has the Com-
pressedGoogleSearch class, which is derived
from the GoogleSearchService proxy class.)
Then override the derived class’s GetWeb-
Request method to specify an HTTP head-
er Accept-Encoding value of gzip, deflate
(Listing One). The Accept-Encoding head-
er specifies the compression formats that
the client can cope with. The SoapEx ap-
plication can decompress both gzipped and
deflated responses. The second step is to
override your derived class’s GetWebRe-
sponse method to return a Compressed-
WebResponse object. The CompressedWeb-
Response object will be able to decompress
web-service responses.
When the server returns the results,
they are in gzip format, deflated format,
or uncompressed. Bear in mind that the
Accept-Encoding header is only a sug-
gestion, not a demand. The Compressed-
WebResponse.GetResponseStream method
decompresses the response Stream if it
is actually compressed (Listing Two). Get-
ResponseStream determines the response
format by inspecting webResponse.Con-
tentEncoding (see the code inside the try
block). If the response is compressed, the
correct inputStream is selected: GZipIn-
putStream for gzip, InflaterInputStream
for deflate. A BinaryReader object is cre-
ated to read bytes from the inputStream.
As the inputSource is read, the uncom-
pressed data is written to the result Stream
using a BinaryWriter. If the response was
not compressed, the result Stream is set
to the original, uncompressed Stream. In
Extending and
debugging web services
ERIC BERGMAN-TERRELL
Eric has developed everything from data
reduction software for particle bombard-
ment experiments to software for travel
agencies. He can be contacted at ericterrell@
comcast.net.
W I N D O W S / . N E T D E V E L O P E R
“Many web services
can return results in
compressed format
to conserve
bandwidth”
any case, the result Stream is returned at
the end of GetResponseStream.
The CompressedWebResponse class uses
the #ziplib library (available at http://www
.icsharpcode.net/OpenSource/SharpZipLib/)
to decompress responses. .NET 2.0 will
include built-in libraries for gzip compres-
sion and decompression.
Strictly speaking, you can enable com-
pressed responses without deriving a class
from the proxy class. You could override
GetWebRequest and GetWebResponse in the
original proxy class. But changes to the
proxy class will be undone if you ever need
to regenerate the proxy in the future. Com-
pressing responses on the server and de-
compressing them on the client consumes
additional CPU cycles on both server and
client, but the savings in bandwidth is like-
ly to justify the processing cost. At least at
the moment, the Google web service does
not return compressed responses, perhaps
because the responses tend to be small.
SoapEx requests compressed responses,
and is ready to decompress them if they
are returned in the future.
SoapExtensions
A SoapExtension enables your program
to wiretap web-service calls and even
change the SOAP requests and respons-
es. SoapExtensions are not tied to a par-
ticular web service. If your application
calls multiple web services, they will all
be manipulated by a SoapExtension.
.NET’s SoapExtension mechanism lets cus-
tom code be called at various stages of
the web-service call process. If you de-
rive a class from SoapExtension, your
class’s ProcessMessage method (Listing
Three) will be called at the stages of the
web-service call process listed in Table 1.
If you intend to capture and/or change
SOAP requests and responses, override
the ChainStream method in Listing Three.
The argument to ChainStream is a Stream
containing the current SOAP request or
response. In your overridden Chain-
Stream, save the Stream argument and
create, save, and return another Stream
argument. For example, the sample ap-
plication saves the argument as oldStream,
and creates and returns a new Stream
named “newStream.”
After .NET has created a SOAP request
by serializing the request proxy object,
you can capture the SOAP request, and
even modify it. Just take the original re-
quest, which is stored in newStream,
change the XML, and store it in oldStream
(see ProcessRequest in Listing Four). When
the client receives a SOAP response, the
XML can be captured and changed before
it’s deserialized into a response proxy ob-
ject. To modify a response, take the orig-
inal response stored in oldStream, change
the XML, and store it in newStream (see
ProcessResponse).
You can see SoapEx capture and dis-
play SOAP requests and responses by
pressing the Call Web Service button and
looking in the Results text box. To see
SoapEx modify requests and responses,
check the Modify Soap Request and Re-
sponse checkbox, and press the Call Web
Service button. Then look at the Results
text box. The request and response will
be modified by “pretty-printing” them with
indentation. I confess: SoapEx’s modifi-
cations to SOAP requests/responses are
somewhat contrived. But if you have con-
trol over both the client and server, you
can use SoapExtensions to modify requests
and responses to implement proprietary
compression, encryption, and so on.
Configuring SoapExtensions
A SoapExtension can be wired into an
application using a configuration file. For
Windows Forms applications, put the
configuration settings in a file with the
same name as the executable, with an
extra .config on the end. For example,
the SoapEx’s configuration file is named
SoapEx.exe.config (Listing Five). For
ASP.NET applications, store the same
configuration information in a Web.con-
fig file.
The <add> element is where the
SoapExtension is specified. The type at-
tribute specifies the full name of the
SoapEx class in namespace.class format,
followed by the name of the assembly con-
taining the SoapExtension. If there are
multiple SoapExtensions, the priority at-
tribute determines the order in which they
are applied. SoapExtensions with higher
priorities are applied before ones with
lower priorities. Priority 0 is the highest,
1 is the next highest, and so on. SoapEx-
tensions with a group attribute of 0 have
the highest relative priority.
Debugging Web Services
Sometimes, the Visual Studio debugger is
not sufficient to debug web services. It’s
often important to see the exact bytes go-
ing over the wire during a web-service
call. For example, when a web-service re-
sponse isn’t well- formed XML, the re-
sponse proxy object will be null, and
you’ll want to inspect the actual response
that the server returned. In these sorts of
situations, I recommend Network Chem-
istry’s Packetyzer program (Figure 2), avail-
able at http://www.networkchemistry
.com/products/packetyzer/. When you
(continued from page S12)
S14
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
http://www.ddj.com
Figure 1:
SoapEx sample app.
Figure 2:
Packetyzer.
Stage
Description
BeforeSerialize
SOAP request has not yet been created from the request
proxy object.
AfterSerialize
SOAP request has been created but has not yet been sent
to the server.
BeforeDeserialize
SOAP response has been received, but has not yet been
converted to a response proxy object.
AfterDeserialize
Data has been converted to a response proxy object.
Table 1:
Stages of web-service calls.
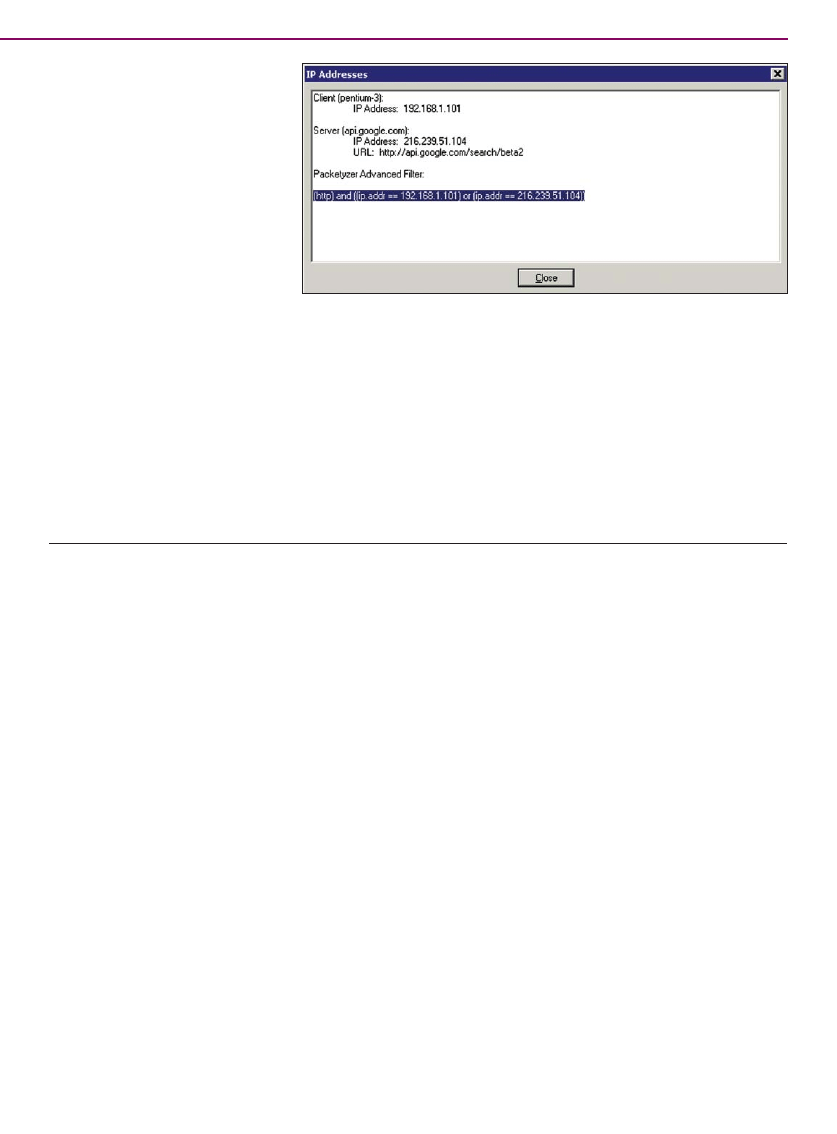
launch Packetyzer 3.0.1, the Capture Op-
tions dialog lets you “Capture packets in
promiscuous mode,” which I don’t
recommend. If your machine has a
promiscuous network card, Packetyzer
can display traffic from your machine and
other machines on the network. Unless
you need to monitor other machines’ traf-
fic, promiscuous mode just slows down
the debugging process.
Launch Packetyzer and then launch
SoapEx. Click on the IP Addresses but-
ton, which will launch a dialog box (Fig-
ure 3). Select the line below the “Pack-
etyzer Advanced Filter” and press Ctrl+C
to copy it into the clipboard. Then go to
Packetyzer and click the Display Filter
drop- down combobox. Press Ctrl-V to
paste the filter and press Apply to apply
it. This filter specifies that Packetyzer will
display HTTP network traffic between
your machine and the web server that im-
plements the web service. I recommend
taking the time to learn Packetyzer’s fil-
tering mechanism — filters can make
Packetyzer much more convenient and
efficient.
Select Session/Start Capture in Pack-
etyzer’s main menu. Then press SoapEx’s
Call Web Service button. Give Packetyzer
a few seconds to capture the traffic. Se-
lect Session/Stop capture. Then click on
the rows in the list control in the top, right
corner of the screen (Figure 2). As you
click on the rows, you’ll see the entire
conversation that SoapEx had with the
web server. To see the entire conversa-
tion in one stream, right-click any row in
the list control and select Follow TCP Flow.
Then select the Decode tab and you’ll see
the web-service request and response in
a convenient textual format.
Conclusion
The next time you use Visual Studio’s Add
Web Reference feature, consider creating
derived proxy classes to specify com-
pressed responses. The bandwidth that
you save may pay for the modest effort
of creating a derived class that requests
compressed responses. And consider us-
ing a SoapExtension to capture your ap-
plication’s SOAP requests and responses
for debugging purposes. Finally, down-
load Packetyzer and install it. You’ll want
to have it handy the next time you need
to do any serious web-service debugging.
DDJ
(Listings begin on page S16.)
http://www.ddj.com
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
S15
Figure 3:
IP addresses dialog.

Listing One
protected override WebRequest GetWebRequest(Uri uri)
// Update the request's HTTP headers to specify that
// we can accept compressed (gzipped, deflated) responses
{
WebRequest request = base.GetWebRequest(uri);
// If user checked the Compressed Response checkbox
if (compressResponse)
{
request.Headers.Add("Accept-Encoding", "gzip, deflate");
}
return request;
}
protected override WebResponse GetWebResponse(WebRequest request)
// If we've requested compressed responses, return a WebResponse
// derivative that's capable of uncompressing it.
{
WebResponse result;
// If user checked the Compressed Response checkbox
if (compressResponse)
{
result = new CompressedWebResponse((HttpWebRequest) request);
}
else // no compression requested, return stock WebResponse object
{
result = base.GetWebResponse(request);
}
// Keep track of content length to measure bandwidth savings.
responseContentLength = result.ContentLength;
return result;
}
Listing Two
public override Stream GetResponseStream()
// Decompress the web service response and return it in a stream.
{
Stream result = null;
// Clean up previously-used BinaryReader and BinaryWriter.
if (reader != null)
{
reader.Close();
reader = null;
}
if (writer != null)
{
writer.Close();
writer = null;
}
try
{
// Get response.
HttpWebResponse webResponse = (HttpWebResponse) request.GetResponse();
Stream inputStream = null;
bool decompress = true;
// Get an input stream based on the type of compression, if any.
if (webResponse.ContentEncoding == "gzip")
{
inputStream = new
GZipInputStream(webResponse.GetResponseStream());
}
else if (webResponse.ContentEncoding == "deflate")
{
inputStream = new
InflaterInputStream(webResponse.GetResponseStream());
}
else
{
// Response wasn't compressed, return the original, uncompressed stream.
result = webResponse.GetResponseStream();
decompress = false;
}
// If response was actually compressed, decompress it.
if (decompress)
{
// Decompress the input stream.
reader = new BinaryReader(inputStream);
result = new MemoryStream();
writer = new BinaryWriter(result);
int bytesRead;
byte[] buffer = new byte[1024];
do
{
// Read from compressed buffer and store the decompressed
// bytes in the buffer.
bytesRead = reader.Read(buffer, 0, buffer.Length);
// Write decompressed buffer to the result stream.
writer.Write(buffer, 0, bytesRead);
} while (bytesRead > 0);
writer.Flush();
result.Position = 0;
}
}
catch (Exception ex)
{
MessageBox.Show(ex.Message, "Exception",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
}
// Returned decompressed response.
return result;
}
Listing Three
public override void ProcessMessage(SoapMessage message)
// Hook into the web service process at various stages.
{
switch (message.Stage)
{
case SoapMessageStage.BeforeSerialize:
break;
case SoapMessageStage.AfterSerialize:
// Capture and optionally modify SOAP request.
ProcessRequest(message);
break;
case SoapMessageStage.BeforeDeserialize:
// Capture and optionally modify SOAP response.
ProcessResponse(message);
break;
case SoapMessageStage.AfterDeserialize:
break;
default:
throw new Exception("invalid stage");
}
}
public override Stream ChainStream(Stream stream)
// Save the stream representing the SOAP request or response
{
oldStream = stream;
newStream = new MemoryStream();
return newStream;
}
Listing Four
private void ProcessRequest(SoapMessage message)
// Capture and optionally modify the SOAP request.
{
newStream.Position = 0;
using (MemoryStream memoryStream = new MemoryStream())
{
CopyStream(newStream, memoryStream);
// Capture original SOAP request.
OriginalSoapRequest = GetStreamText(memoryStream);
// If user has checked the Modify SOAP Request and Response checkbox...
if (modify)
{
// "Pretty-print" SOAP request XML with indentation.
ModifiedSoapRequest = ModifySOAP(memoryStream, oldStream);
}
else
{
CopyStream(memoryStream, oldStream);
}
}
}
private void ProcessResponse(SoapMessage message)
// Capture and optionally modify the SOAP response.
{
using (MemoryStream memoryStream = new MemoryStream())
{
CopyStream(oldStream, memoryStream);
OriginalSoapResponse = GetStreamText(memoryStream);
// If user has checked the Modify SOAP Request and Response checkbox
if (modify)
{
ModifiedSoapResponse = ModifySOAP(memoryStream, newStream);
}
else
{
CopyStream(memoryStream, newStream);
}
}
newStream.Position = 0;
}
Listing Five
<configuration>
<system.web>
<webServices>
<soapExtensionTypes>
<add type="SoapExDLL.SoapTraceModify, SoapExDll"
priority="1"
group="0" />
</soapExtensionTypes>
</webServices>
</system.web>
</configuration>
DDJ
S16
Dr. Dobb’s Journal Windows/.NET Supplement, February 2005
http://www.ddj.com
More .NET on DDJ.com
ASP.NET2theMax: Skin Your Pages
ASP.NET’s themes let you alter the appearance of all controls in an app.
Themes, or “skins,” can be applied at various levels—to an individual page,
to all pages within a site, to an entire web server.
Windows Security: Scripting Patch Deployment with WUA API
Perform patch updates from the command line using VBScript and the
Windows Update Agent API—no Internet Explorer required.
Available online at http://www.ddj.com/topics/dotnet/
O
n one hand, adding networking
support to embedded devices can
be a daunting task, primarily be-
cause network stacks are so re-
source intensive. On the other hand, go-
ing to the trouble of adding networking
support makes standardized access to de-
vices possible because these protocols are
portable across many platforms. TCP/IP,
for instance, makes it possible for a wire-
less sensor node to communicate using
the native protocol of most networking
infrastructures, where each node in the
sensor network can be accessed by a
desktop PC, Tablet PC, PDA, or even cell-
phones.
Networking support also improves the
basic feature set each node is capable of
supporting. For example, if an alarm con-
dition occurs in the network, the device
with the fault can generate e-mail and
send it off to instantly notify the network
operator about the problem. Another ben-
efit is that web-based management can be
easily incorporated into all devices with
network support. Technicians can then
connect directly to a sensor node for con-
figuration and monitoring using a stan-
dard PDA equipped with a standard web
browser. In effect, the sensor node’s web
server and HTML pages are the new user
interface for the device.
There are a number of available net-
work stacks that target deeply embedded
systems where processor cycles and mem-
ory are limited. In this article, we take an
in-depth look at one of these — the uIP
network stack— and then port it to a DSP-
based wireless sensor board.
Figure 1, for instance, is a sensor net-
work made up of nodes that incorporate
a network stack and a web server to en-
able web-based management. Individual
network nodes can then be controlled and
monitored through HTML pages sent by
the nodes’ web server, as in Figure 2. The
File Transfer Protocol (FTP) can be used
in a networked sensor node to update ex-
isting software for feature upgrades or bug
fixes. Dynamic sensor node configuration
information can also be sent to a particu-
lar sensor node.
Networking & Wireless Sensor Nodes
One of the keys in deciding which stack
best fits your device is determining the re-
source requirements for the software. The
amount of data each node in your system
needs to transmit and receive during com-
munication sequences should also dictate
which solution is right for your design.
For example, if your sensor node wakes
up every hour to transmit a few bytes of
data, a compact network stack imple-
mentation is ideal. On the other hand, sys-
tems that are constantly transmitting large
packets of data might need a stack im-
plementation that offers better packet
buffer management.
It is important when evaluating and se-
lecting a lightweight network stack im-
plementation that it allows communica-
tion with standard, full-scale TCP/IP de-
vices. An implementation that is special-
ized for a particular device and network
might cause problems by limiting the abil-
ity to extend the nodes’ network capabil-
ities in other generic networks. It is al-
ways possible to implement your own
network stack, and this might be neces-
sary depending on your particular device’s
needs. However, with the assortment of
solutions available in the open-source
community, leveraging existing technolo-
gy lets you quickly move development
ahead.
The following software network stacks
are open-source solutions for smaller sen-
sor nodes that must take into account re-
source usage. This list is not comprehen-
sive, but rather a starting point for further
investigation:
• lwIP (http://www.sics.se/~adam/lwip/).
The “lightweight IP” stack is a simpli-
fied but full-scale TCP/IP implementa-
tion. lwIP is designed to be run in a
multithreaded system with applications
executing in concurrent threads; how-
ever, it can also be implemented on a
system with no real-time operating sys-
tem (RTOS). The protocols include In-
ternet Control Message Protocol (ICMP),
Inside the uIP Stack
“The uIP stack was
designed
specifically for
resource-constrained
embedded devices”
Adding network
support to a
DSP-based
embedded system
DREW BARNETT
AND ANTHONY J. MASSA
Drew is a wireless-communications/DSP
systems engineer and president of Elin-
trix (http://www.elintrix.com/) where he
is currently engaged in the development
of networked radio and sensor products.
He can be contacted at dbarnett@elintrix
.com. Anthony is cofounder and chief en-
gineer of software development at Elintrix
and author of
Embedded Software De-
velopment with eCos. He can be contact-
ed at amassa@elintrix.com.
E M B E D D E D S Y S T E M S
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
61
Dynamic Host Configuration Protocol
(DHCP), Address Resolution Protocol
(ARP), and User Datagram Protocol
(UDP). It provides support for multiple
local network interfaces and is flexible
enough to let it be easily used on a wide
variety of devices and scaled to fit dif-
ferent resource requirements.
• OpenTCP (http://www.opentcp.org/).
Tailored to 8- and 16- bit microcon-
trollers, OpenTCP incorporates the ICMP,
DHCP, BOOTP (Bootstrap Protocol),
ARP, and UDP protocols. There are also
several applications included with
OpenTCP, such as a Trivial File Trans-
fer Protocol (TFTP) server, a Post Office
Protocol Version 3 (POP3) client to re-
trieve e-mail, Simple Mail Transfer Pro-
tocol (SMTP) support to send e-mail,
and a Hypertext Transfer Protocol
(HTTP) server for web-based access.
• TinyTCP (http://www.unusualresearch
.com/tinytcp/tinytcp.htm). TinyTCP is de-
signed to be modular and only include
the software required by the system. For
example, different protocols can be com-
piled in/out based on configuration. It
provides a BSD-compatible socket li-
brary and includes the ARP, ICMP, UDP,
DHCP, BOOTP, and Internet Group
Management Protocol (IGMP) protocols.
• uC/IP (http://ucip.sourceforge.net/). Pro-
nounced “mew-kip,” uC/IP is designed
for microcontrollers and based on BSD.
Intended to be used with the uC/OS
RTOS. Protocol support includes ICMP
and Point-to-Point Protocol (PPP).
• uIP (http://www.sics.se/~adam/uip/).
The “micro IP” stack is designed to in-
corporate only the absolute minimal set
of components necessary for a full
TCP/IP stack. There is support for only
a single network interface. Application
examples included with uIP are SMTP
for sending e-mail, telnet server/client,
an HTTP server and web client, and Do-
main Name System (DNS) resolution.
In addition, some RTOSs include or have
network stacks ported to them. One such
example is eCos (http://ecos.sourceware
.org/), an open-source RTOS that includes
both the OpenBSD and FreeBSD network
stacks as well as application layer support
with an embedded web server (for more
information, see Embedded Software De-
velopment with eCos, by Anthony Massa,
Prentice Hall PTR, 2003).
If a network stack is included or already
exists in your device, several embedded
web servers are available to incorporate
web-based control. One such open-source
solution is the GoAhead WebServer (http://
www.goahead.com/; see “Integrating the
GoAhead WebServer & eCos,” by Antho-
ny Massa, DDJ, November 2002).
There are also resources that detail a
ground-up approach to developing a small
TCP/IP stack intended for embedded sys-
tems (TCP/IP Lean: Web Servers for Em-
bedded Systems, by Jeremy Bentham, CMP
Books, 2002).
The uIP Network Stack
The uIP (pronounced “micro IP”) stack
was designed specifically for resource-
constrained embedded devices (http://
www.sics.se/~adam/uip/). Nevertheless,
it is a full TCP/IP stack implementation,
and its size and resource requirements
make it ideal for applications such as wire-
less sensor nodes. Any processor that con-
tains a reasonable amount of internal
memory can support the entire network
stack on board, eliminating the added ex-
pense of external RAM; see Figure 3.
uIP utilizes a single global buffer, which
has a configurable size based on the max-
imum packet length supported, for in-
coming and outgoing packets. Because of
this, the application must process the in-
coming packet before the next packet ar-
rives, or the application can copy the data
into its own buffer for processing later. In-
coming data is not stored into the pack-
et buffer until after the application has
processed the previous data.
The standard socket interface is the BSD
socket API. This interface relies on an un-
derlying multitasking operating system to
function properly. Due to this requirement
and needed overhead, uIP does not sup-
port the socket interface. Instead uIP uses
events. Therefore, data arriving on a con-
nection (or an incoming connection re-
quest) causes an event to be sent to the
application for processing.
To avoid buffering outgoing data be-
fore it has been acknowledged, uIP re-
quires the application to assist in packet
retransmissions. When the uIP stack de-
termines that a retransmission must occur,
an event is sent to the application. The
application reproduces the data previously
sent. Sending data the first time and dur-
ing a retransmission is the same from the
application’s perspective; therefore, the
same code can be used. The complexity
for determining when the retransmission
must take place is contained in the uIP
stack itself, eliminating this from the ap-
plication.
To examine the resource requirements
for the uIP stack implementation, the At-
mel AVR processor architecture and the
GNU compiler Version 3.3 were used to
perform measurements. Table 1 gives re-
source usage for a uIP configuration with
one listening TCP port, 10 TCP connection
slots, 10 ARP table entries, a packet buffer
of 400 bytes, and the simple HTTP server.
uIP includes a Perl script for convert-
ing web pages into static memory arrays
so they can be incorporated in the com-
piled code. This eliminates the need for
any type of filesystem when using the web
server.
The total RAM usage is dependent on
various configurable components within
uIP. These components are easily set up
in the uIP options include file. Things you
can configure include the number of TCP
connections supported to save RAM and
the amount of memory allocated for the re-
ceive/transmit buffer, especially if packet
sizes are typically smaller on the network.
62
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 1:
The wireless sensor network
map gives an overview of the individual
nodes that make up the entire sensor
network.
Figure 2:
Clicking on each network-
enabled node lets users examine and
control the parameters associated with
an individual sensor node.
Module
Code Size
RAM Usage
ARP
1324
118
IP/ICMP/TCP
3304
360
HTTP Server
994
110
Checksum Functions
636
0
Packet Buffer
0
400
TOTAL
6258
988
Table 1:
uIP memory usage, in bytes, for a typical system.
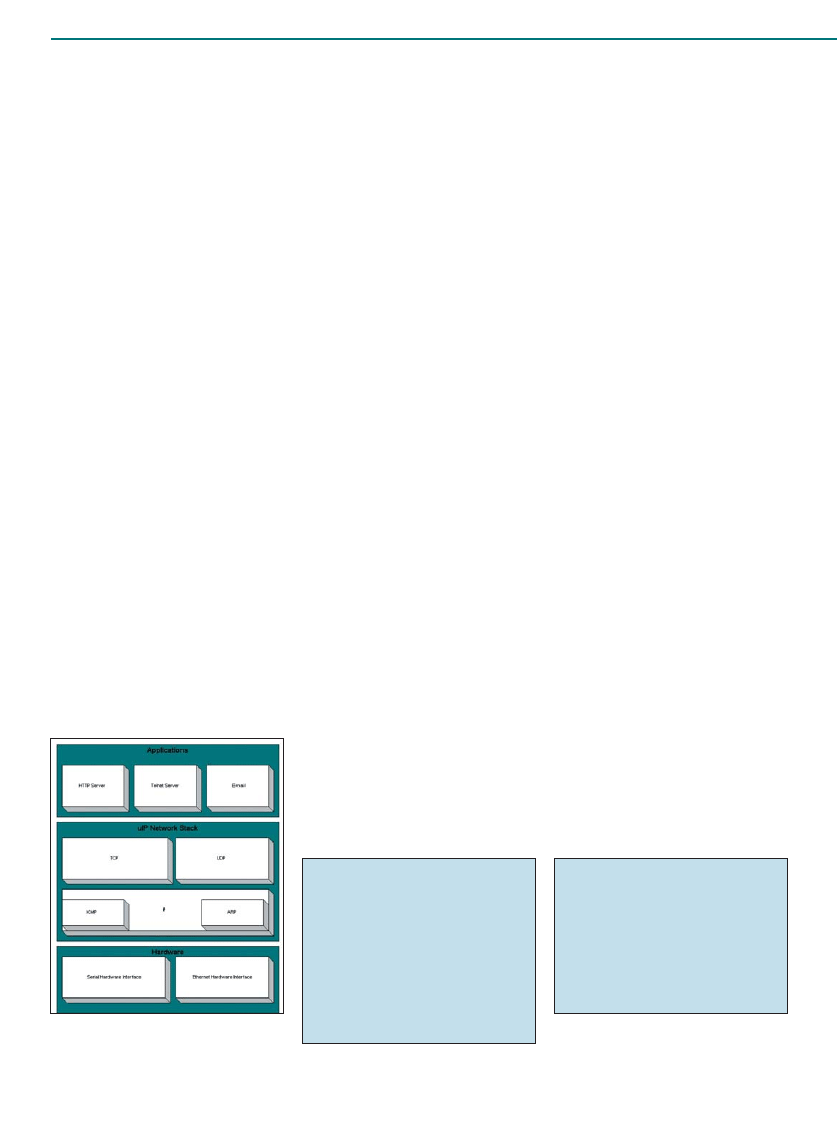
Certain code modules can be eliminat-
ed altogether if you’re using a serial net-
work interface. Serial protocols are avail-
able, such as the Serial Line Interface
Protocol (SLIP) or the more robust PPP
protocol. Opting for a serial interface in-
stead of Ethernet allows ARP support code
and the ARP table to be removed. Not us-
ing UDP can also reduce the code size.
These options are easily removed, via
macros, in the uIP stack.
The flow of incoming packets can be
throttled by adjusting the maximum seg-
ment size of incoming data allowed by the
sensor node. Other system optimizations
that are ideal for wireless sensor networks
are available, but require more in-depth
configuration. Areas for further investiga-
tion include TCP/IP header compression
techniques to reduce overhead of the var-
ious protocol headers. This is best for sen-
sor systems comprised of nodes that typ-
ically transmit smaller data packets.
For TCP, packet retransmission schemes
are available that move the resending of
lost packets closer to the destination of
the data rather than relying on the source
point. This can also reduce the length that
an acknowledgement needs to travel
through the system.
Porting the uIP Stack to the
TMS320C5509 DSP
To further examine the uIP stack, we
built a prototype wireless radio sensor
board that was based on the TMS-
320C5509 digital-signal processor from
Texas Instruments. For most ports of the
uIP stack, the TCP/IP code doesn’t need
to be modified. However, unique features
of the TMS320C5509 DSP made it neces-
sary for us to change uIP core files. Fig-
ure 4 illustrates the uIP directory struc-
ture. A new architecture-specific directory,
with files copied from the UNIX directo-
ry, can be created for the new port.
The radio sensor board does not have
a typical Ethernet port used with network
stacks; this is an add-on module that is
currently not present on the main board.
This system uses a software-based serial
port for network connectivity. Some host
configuration is necessary in order to set
up the host PC to communicate using SLIP
over the serial port.
The uIP stack includes an example SLIP
driver, which we modified to accommo-
date the radio sensor board hardware. The
original SLIP driver polls the serial port
for incoming data and stores each char-
acter, applying the SLIP data translation
changes where necessary, as it arrives.
The sensor board code uses an interrupt
for serial port, allowing the ISR to store
the incoming data. When a complete net-
work packet is received, a flag is set to
start the processing of the data.
One of the major differences between
the C5509 and most processors is the treat-
ment of the char type. On the C5509, a
char is 16 bits rather than 8 bits, as found
on typical processors. This adds some
challenges to porting the uIP code that is
designed to accommodate an 8-bit char
type. In the C5509 world, a char, short,
and int are all at 16 bits and data space
memory is addressed 16 bits at a time.
As data comes in to the serial driver, it
is stored into a buffer. The data in the
buffer in a typical system (with an 8-bit
char type) would look similar to Figure
5(a), while Figure 5(b) shows the buffer
in the C5509 system. When a structure is
overlaid on this data buffer for parsing,
the members of the structure do not con-
tain the correct data values. Because of
this difference, the main structure for the
TCP/IP header, uip_tcpip_hdr (located in
the uip.h file), must be modified. Fur-
thermore, the code that uses this structure
must also be modified.
Listing One(a) is the original uip_
tcpip_hdr header structure. Structure
members that are of type u8_t do not
need to be modified, because the only
difference on the C5509 platform is that
these types will occupy 16 bits of memo-
ry each instead of the typical 8 bits. How-
ever, the u16_t type members do need to
be changed. Listing One(b) is the modi-
fied structure to accommodate the C5509-
based prototype board.
Next, these structure changes are in-
corporated into the uIP networking code.
An example of code using the new struc-
ture is in uip.c, where the TCP source and
destination port numbers are swapped to
format the header of an outgoing packet.
Listing Two(a) is the original code, and
Listing Two(b) the modified code. Other
variables that pose the same issue between
the C5509 platform and a standard pro-
cessor are also modified in a similar way.
In this example, BUF is a uip_tcpip_hdr
pointer type and points to the start of the
incoming network packet. Because we
changed the original srcport from a 16-bit
unsigned short into an array of two 16-bit
unsigned short elements, we need to store
the srcport array elements properly. This
example also shows the destport code
modification.
These modifications are done through-
out the uIP source code. Another file that
needs attention is uip_arch.c, which is lo-
cated in the architecture-specific directo-
ry. This file contains the TCP and IP check-
sum routines.
After porting the uIP networking code
to the C5509, the main processing loop is
(continued from page 62)
64
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Figure 3:
uIP network stack block
diagram showing supported protocols
and included applications.
Figure 4:
uIP directory structure.
uip-0.9 - main directory for uIP stack version 0.9
apps - application modules
httpd - web server module
fs - web server file system files
resolv - DNS resolution module
smtp - SMTP e-mail module
telnet - Telnet client module
telnetd - Telnet server module
webclient - HTTP client module
doc - uIP documentation
uip - main uIP stack source files
unix - architecture specific files
(a)
Address Data
0x0000 45 00 00 30 7D 64 40 00
0x0008 80 06 d3 fc c0 a8 14 0a
(b)
0x0000 0045 0000 0000 0030 007D 0064 0040 0000
0x0008 0080 0006 00d3 00fc 00c0 00a8 0014 000a
Figure 5:
(a) Data buffer in 8-bit char
system; (b) data buffer in 16-bit char
C5509 system.
“One of the major
differences between
the C5509 and most
processors is the
treatment of the
char type”

Listing One
(a)
typedef struct {
/* IP header. */
u8_t vhl,
tos,
len[2],
ipid[2],
ipoffset[2],
ttl,
proto;
u16_t ipchksum;
u16_t srcipaddr[2],
destipaddr[2];
/* TCP header. */
u16_t srcport,
destport;
u8_t seqno[4],
ackno[4],
tcpoffset,
flags,
wnd[2];
u16_t tcpchksum;
u8_t urgp[2];
u8_t optdata[4];
} uip_tcpip_hdr;
(b)
typedef struct {
/* IP header. */
u8_t vhl,
tos,
len[2],
ipid[2],
ipoffset[2],
ttl,
proto;
u16_t ipchksum[2];
u16_t srcipaddr[4],
destipaddr[4];
/* TCP header. */
u16_t srcport[2],
destport[2];
u8_t seqno[4],
ackno[4],
tcpoffset,
flags,
wnd[2];
u16_t tcpchksum[2];
u8_t urgp[2];
u8_t optdata[4];
} uip_tcpip_hdr;
Listing Two
(a)
/* Swap port numbers. */
tmp16 = BUF->srcport;
BUF->srcport = BUF->destport;
BUF->destport = tmp16;
(b)
/* Swap port numbers. */
tmp16 = ((BUF->srcport[1] << 8) | BUF->srcport[0]);
BUF->srcport[0] = BUF->destport[0];
BUF->srcport[1] = BUF->destport[1];
BUF->destport[0] = (tmp16 & 0x00FF);
BUF->destport[1] = ((tmp16 >> 8) & 0x00FF);
Listing Three
// Initialize and start the uIP timer to fire every 1 ms.
timer_init();
// Initialize the serial port for use with the uIP stack.
serial_init();
// uIP networking stack related initialization.
slipdev_init();
uip_init();
httpd_init();
// Main processing loop.
while (1)
{
// If we get a length greater than zero, we know a packet is ready for
// processing. Otherwise, we call the periodic function once per second.
uip_len = slipdev_poll();
if (uip_len == 0)
{
// Call the periodic function once per second and loop through all
// connections.
if (ulTimer0Count >= 1000)
{
ulTimer0Count = 0;
for (uiConn = 0; uiConn < UIP_CONNS; uiConn++)
{
uip_periodic( uiConn );
// If the periodic function resulted in data that needs to
// to be sent out, length is set to a value greater than zero.
if (uip_len > 0)
slipdev_send();
}
}
}
else
{
// Process the incoming data.
uip_input();
// If the input function resulted in data that needs to
// to be sent out, the length is set to a value greater than zero.
if (uip_len > 0)
slipdev_send();
}
} // End of main loop.
DDJ
implemented. Listing Three shows a slight-
ly modified version of the processing loop
included in the uIP source code.
The initialization is performed for all of
the necessary drivers and uIP modules in-
cluding the serial port (serial_init), timer
(timer_init), and SLIP drivers (slipdev_init),
as well as the uIP stack (uip_init), and the
HTTP web server (httpd_init).
The slipdev_ poll function checks to see
if the serial driver has received a packet.
If a packet has arrived, the uip_len is set
to the packet length. The data is then pro-
cessed by calling uip_input, which is a
macro that calls the main uIP processing
routine uip_ process for handling the re-
ceived packet.
If a data packet has not been received,
a timer count is checked to see if it is
time to call the periodic function (aptly
named uip_ periodic). The timer counter,
ulTimer0Count, is incremented every mil-
lisecond in the timer interrupt service rou-
tine. The periodic routine also calls the
main processing routine, uip_ process, to
maintain any open connections in the
system.
There are a few things to keep in mind
during the porting process:
• If a timer is not available, a variable can
be used to count when a second has
occurred and, therefore, when to call
the periodic function. However, the code
will have to be calibrated based on pro-
cessor clock, and any modifications to
the code affect this timing.
• It might be helpful to enable debugging
in the uIP stack to get output from the
code. Setting the macro UIP_LOGGING
to 1 in the file uipopt.h located in the
architecture-specific directory can do this.
• Also included with the web-server code
is a Perl script that generates C code
from HTML files. This can be found un-
der the httpd\fs directory.
• Various uIP stack parameters, such as
the number of simultaneous network
connections and packet buffer size, can
be customized in the file uipopt.h.
Conclusion
Embedding a networking stack is no
longer an arduous task that requires an
enormous amount of resources. As we’ve
shown, there are a number of solutions
that use the TCP/IP protocol suite for com-
munication. Tailoring one of the network
stack solutions to the specific characteris-
tics of the sensor node device ensures the
system will operate at its most optimum
level and utilize system resources best. We
would like to thank Adam Dunkels, de-
veloper of the uIP stack, for his support
during the porting process.
DDJ
“Embedding a
networking stack is
no longer an
arduous task”
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
65

P
erhaps the title this month should be
“Programmer Paradigms.” Several
things I’ve read recently have got me
thinking about different kinds of pro-
grammers: the lone coder versus the con-
nector, the troubleshooter versus the ar-
chitect, the guerrilla versus the soldier.
Few of us, perhaps, would fit unambigu-
ously into one category or another, but
we can probably all see what label fits us
best. The challenging question, though,
is: How well does the kind of program-
mer you are fit into the time and situation
in which you currently find yourself? And
if the fit is not ideal, can you change your-
self? Can you change your environment?
(I’m just asking; I don’t have the answers.)
The Lone Coder
A Slashdotter asked a disturbing question
last November. “Is the lone coder dead?”
CyNRG asked. “The little guy. The one-
person software company. Can it still ex-
ist today?” CyNRG’s corn wasn’t economics
or code complexity or even Microsoft’s
dominance of the software market, but
software patents. Will the need to ensure
that no idea in your code is covered by
some obscene obvious-tweak patent soon
mean that the Lone Coder can no longer
afford to sell software? “The amount of
money required to perform the due dili-
gence research seems like it would be
greater than the amount of money need-
ed to develop the software, or even the
total revenues that the software could ever
generate,” CyNRG moaned. “Please some-
one tell me I’m wrong!” CyNRG can’t have
been satisfied with the discussion that this
plea generated on Slashdot. Mostly it was
variations on bogus news reports and au-
topsies of the Lone Coder’s death (death
by overdose of Jolt, and so on); arguments
that he didn’t die, he just moved overseas;
and rejection of the whole Lone Coder
theory in favor of a Second Coder on the
Grassy Knoll. To a comedian, everything
looks like a straight line. I still think that
the fate of the Lone Coder is an interest-
ing question, but if you want to send me
your thoughts on it, I just wanted you to
know that I’ve read all the obvious jokes.
We all are Lone Coders, though, when it
comes to programming for that very spe-
cial client — ourselves. And we all keep
looking for better tools for our homemade-
software toolkits.
Mathematica
I really want Mathematica to be a tool in
my toolkit. Whenever a new version
comes out, I hack away for a weekend
trying to get a handle on it, but the learn-
ing curve rises ahead of me and I only ad-
vance a small step, while I’ve fallen back
one and a half since my last effort. The
learning curve has so far kept me from
exploiting the serious power that’s in this
product.
The new string-handling capabilities in
the latest release could change that. Wol-
fram Research suggests using the new fea-
tures for web site manipulations, data min-
ing, or DNA processing. While I’m not
heavily into DNA processing, manipulat-
ing text is something I do a lot of —
whether for something as mundane as pre-
processing text for web publishing or as
frivolous as trying to write a program to
generate crossword puzzles for my own
amusement. Mathematica’s analytical pow-
er combined with the new string-handling
capabilities immediately suggested some
uses. Such as, “how many unique words
are there in a sample of my DDJ columns?”
“What are the most common words?”
“How about a bar graph showing the fre-
quencies of words in my columns?” This
time I found myself getting farther up that
curve.
Mathematica supports different pro-
gramming paradigms and modes of op-
erating, but it is above all designed to
make it easy to play around with variables
and calculations in an interactive way. You
work in a workbook, which remembers
values of previous calculations so that you
can build up very elaborate but flexible
what-if structures.
I wrote the following code to read all
my 2004 “Programming Paradigms”
columns and combine their texts into one
long string. Nothing startling, but note the
specification of multiple files with Grep-
like notation in the second line. This
makes myColumns be a list with entries
like “PP0401.txt,” “PP0402 revised.rtf,” and
so on:
SetDirectory["../Documents/Paradigms/"]
myColumns = FileNames["PP04
*
"]
For[rawText = "";
i = 1,
i 2 Length[myColumns],
i++,
rawText = StringJoin[rawText,
Import[myColumns[[i]], "Text"]]]
The 32K-word string rawtext needed
some massaging before I could do statis-
tics on it. I appreciated the interactive na-
ture of Mathematica when it came to iden-
tifying the punctuation and other
characters that I needed to strip out to
have just words left. It took several pass-
es with different word lists to come up
with a list of 25 characters to ignore.
Loners and
Guerrillas
Michael Swaine
P R O G R A M M I N G P A R A D I G M S
Michael is editor-at-large for DDJ. He can
be contacted at mike@swaine.com.
66
Dr. Dobb’s Journal, February 2005
http://www.ddj.com

Mathematica is big on treating actions
as data; the first line below (which I’ve
abbreviated) defines a list of replacement
operations (replace “.” by “ ”), which is
then used by the built- in function
StringReplace. Other built-in functions turn
letters to lowercase and return a list of the
individual words. (Lists in Mathematica
are denoted by braces: {}.)
ignoreChars = {"." -> " ", "?" -> " "...}
wordList = StringSplit[ToLowerCase
[StringReplace[rawText, ignoreChars]]]
Mathematica’s programming paradigm
of choice is functional programming, and
like that classic functional language Lisp,
Mathematica loves lists. And because Math-
ematica was created to do symbolic math,
it knows about operations like Union,
which treats lists as sets. When applied to
a single list of words, Union eliminates all
duplicate words.
uniqueWords = Union[wordList]
Now I had my vocabulary list for my
2004 columns and could start doing statis-
tics on it.
Length[uniqueWords]
That one-liner told me that I used 4766
unique words in the 12 columns of 2004.
Most of the other statistical manipulations
that I’d like to do, like computing the most
common words or looking at word se-
quences, are also one-liners. But graph-
ing the results wasn’t much more difficult,
after I loaded the Graphics module.
For[favoriteWords = {};
i = 1,
i 2 Length[uniqueWords],
i++,
AppendTo[favoriteWords, Length
[Cases[wordList, uniqueWords[[i]]]]]
]
<< Graphics'Graphics'
BarChart[favoriteWords, BarOrientation ->
Horizontal, BarLabels -> uniqueWords]
A glance at that graph shouted “Too
Much Information,” so I went back a step
and trimmed down the favoriteWords list
to just the most common ones, testing dif-
ferent parameters to get a readable graph.
And so on. Before the weekend was over,
I had built a statistical “Programming
Paradigms” column generator. I was re-
lieved to see that my Mathematica skills
aren’t good enough that I can replace my-
self as a columnist.
There’s nothing here that couldn’t be
done in any other language, and in some
languages it could doubtless be done just
as succinctly. But Mathematica is power-
fully interactive and operates at a symbolic
level that can be exploited to do surpris-
ing things. And its own vocabulary is very
deep: If the quick-and-dirty code I wrote
proved inefficient, I could have spent a
little more time plumbing the language’s
depths for other ways to do the calcula-
tions. That wasn’t necessary in this case,
because Mathematica is well tuned under
the hood. Operations that look wildly in-
efficient generally run faster than you’d
guess. On my 1.8-GHz iMac G5, these
wasteful string manipulations ran too fast
to bother optimizing.
And I didn’t even exploit all the new
string manipulation features.
EPL
This one won’t go in my own toolkit, but
it might find a place in yours.
Spheres, a spin-off from Caltech, has
come out with a new programming lan-
guage that is event based. That doesn’t
sound too revolutionary, but the kinds of
events they have in mind are financial
transactions and attempts to break into a
computer system. A programming lan-
guage designed from the ground up to
deal with such events is certainly worth a
look. An early version, called EPL (Event
Programming Language) Server, is avail-
able and can be used royalty free.
EPL Server isn’t intended to replace oth-
er programming languages, but to inter-
face with them and to simplify a small set
of tasks. The model is designed to:
• Monitor information across multiple ap-
plications.
• Filter irrelevant data.
• Detect actionable changes in patterns
and trends.
• Notify applications when events occur.
What’s new about EPL is not the tech-
nology, which is familiar. Other compa-
nies and industry groups are working on
standards and technologies for business
event processing. As reported on Cnet’s
Builder.com.com, KnowNow has devel-
oped similar software to send data to
many destinations based on an event. Ef-
forts are afoot to create an industry-wide
language for automating business pro-
cesses, called Business Process Execution
Language (BPEL), for which languages or
rule engines to handle events will pre-
sumably be required. The fact that we will
probably soon have billions of RFID tags
broadcasting their meagre bits of infor-
mation everywhere we go suggests that
we need a model of programming that
deals opportunistically with the events that
impinge on it. And so on. EPL Server is
an interesting tool that may become an
important tool for swimming in that sea
of digital events.
But what I find interesting about EPL
Server, in the context of programmer
paradigms, is the philosophical model. The
EPL programmer is less an architect, more
a troubleshooter. The language encour-
ages a worldview that accepts that things
happen on their own schedule and need
to be dealt with. It is a philosophy of deal-
ing with what is thrown at you rather than
trying to engineer top-down control. EPL
Server is certainly not a Lone Coder’s pro-
gramming language. But there is an aspect
of it that at least feels incompatible with
the top-down control philosophy.
Them
Here is a different psychological profile
of a programmer: One who possesses so-
cial skills, enjoys working in groups, and
is a born networker. Such a programmer
would hardly mourn the death of the Lone
Coder. This is the kind of programmer that
I like to call “Them.”
Occasionally, I have to pretend — to my-
self, especially — to be one of Them. I
found a book that helps. Fearless Change,
by design pattern experts Mary Lynn
Manns and Linda Rising (Addison-Wesley
2005; ISBN 0201741571), is not a book that
loners would naturally gravitate toward.
The authors unabashedly admit to being
connectors, and the whole thrust of their
book (and of the patterns they present) is
connecting. It’s all about design patterns
for effecting change in groups.
To a comedian, everything looks like a
straight line, and if all you have is a ham-
mer, every problem looks like a nail. So
naturally, these born networkers argue for
solving the problem of introducing change
into groups by their preferred method of
working to recruit others to your cause,
rather than by the time-honored technique
of core- dumping every detail of your
brainstorm onto everyone within three feet
of you and stomping out of the room in
a huff when the clueless losers don’t im-
mediately get it.
To each his or her own? Yes, but some-
times their own works better than our
own; and those least like us have the most
to teach us, if we are open to learning
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
67
“Spheres has come
out with a new
programming
language that is
event based”
from them. As a natural loner, I find that
this book speaks only to that underde-
veloped social lobe of my brain, but the
question is: How well does it do that? Pret-
ty well, I think, on balance, but for those
of us whose need is great, there is a de-
sign pattern to help. The authors refer-
ence it on page 253:
Teach yourself to play a role so that ob-
servers believe you are extroverted, bold,
and outgoing. Teach yourself to recognize
the situations in which this role is appro-
priate and to gather your resources and
play the role. http://csis.pace.edu/~bergin/
patterns/introvertExtrovert.html.
It’s just one of the places in the book
where a subversive, Machiavellian tone
comes through. I like that.
Book-Reading Patterns
I don’t know why no one has yet come
up with a set of design patterns for read-
ing books. It’s such a common activity,
and so often poorly done. Think how
much time you would have saved by now
if you’d had a few good book-reading
patterns like the following:
• Ignore Pages Numbered in Roman Nu-
merals. That’s a good pattern to follow
with this book. If you already know what
design patterns are, skip the Preface. Un-
less you’re in it, skip the Acknowledg-
ments. And especially skip the Fore-
word: It’s all buzzphrases in bad
grammar. There; I’ve saved you xxii
pages of reading.
• The Typical Nonfiction Book Would
Make a Good Article. In reading the pat-
terns that make up half of this book,
just read the boldface sections. That may
be all you need, but if you need more,
read just the italicized sections. If you
need still more, go ahead and read the
full text and don’t be embarrassed: The
design pattern Just Enough may be one
that you still haven’t wrapped your mind
around.
• Dead Trees, Dead Information. In the
age of the Internet, any information you
glean from a book is at least a year out
of date. This does not necessarily make
it useless, but it does constrain the kinds
of information that it makes sense to try
to get from this dead tree medium.
Design patterns are a good example of
the kind of information that books actu-
ally do convey well. Design patterns ben-
efit from having some whiskers. It takes
time to know that a candidate really mer-
its being elected to patternhood.
Information in books is also informa-
tion that you may have come across be-
fore. But familiarity does not necessarily
make information worthless. As the au-
thors point out, if we never needed to be
reminded of things we have already
learned, we would never make the same
mistake twice. Familiar information, pre-
sented in a systematic way, can be very
useful if that system works for you.
Is that the case with this book? You’ll
have to decide. The book consists of a
collection of patterns, each described in
about three pages, plus 12 chapters dis-
cussing a philosophy of organizational
change and describing how to use the pat-
terns, plus four case studies, including
Sun’s experience in using patterns in in-
troducing J2EE applications. Here are some
of the themes that the authors emphasize
in the chapters:
• Three elements must be considered in
effecting change in an organization:
the change agent, the culture, and the
people.
• A pattern is a way of capturing expertise.
• Initiating change, maintaining it, over-
coming resistance, and converting the
masses are all about politics.
And here are some of the patterns:
• Ask for Help. (This is a tough one for
some of us.)
• Do Food. (Making food available at a
meeting changes the nature of the event.)
• External Validation. (I advised you to skip
the Foreword, but I wouldn’t advise an
author not to include a Foreword.)
• Just Enough. (See above.)
• Just Say Thanks. (See below.)
Guerrilla Action
In my humble opinion, the great insight of
the early 21st Century will be that individ-
uals are more powerful than institutions;
that a dedicated indigenous guerrilla move-
ment can always wear down an invading
army; that you can’t defeat terrorism with
bombs; that ad hoc, self-organizing task
groups work and management-composed
committees don’t.
The authors of this book, unlike this
columnist, avoid such political pro-
nouncements, but they clearly understand
the power of guerrilla movements. Their
book shows little respect for the structures
of power, except as obstacles to get
around or weaknesses to exploit. As I said,
Machiavellian.
“How do I sell my executive team on
doing this stuff?” they ask, and, quoting
consultant Jim Highsmith, they answer,
“Don’t. Just do it. They don’t know what
you’re doing anyway.” That’s also a recipe
for resisting change: The authors describe
the powerful passive resistance that Car-
ly Fiorina met when she tried to impose
top-down changes at HP.
The book freely acknowledges that
people are not rational, that we use facts
to justify emotionally-arrived-at decisions.
It then presents techniques for getting
things done anyway, despite this funda-
mental irrationality, by the use of proven
patterns.
Whether the things you get done are
rational or not is another question.
Okay, that’s it for this month. Thanks
for reading.
DDJ
68
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Solution to “The Luck of the 4,”
DDJ, January 2005.
Here are Tyler’s expressions for 11– 40.
Twenty of these numbers required only
three 4s. I’ll report your solutions to
the open problems in a future column.
11 = 44/4
12 = 4
*
sqrt(4/.4R)
13 = (4/.4R)+ 4
14 = 4/.4+ 4
15 = (4/(0.4
*
sqrt(.4R)))=4/(0.4
*
(2/3))=(3/2)
*
10
16 = 4
*
4
17 = 4
*
4+ 4/4
18 = 4
*
4+sqrt(4)
19 = 4!– sqrt(4)/0.4
20 = 4
*
4+ 4
21 = 4!– sqrt(4/.4R)
22 = 4!– sqrt(4)
23 = 4!– 4/4
24 = 4!
25 = 4!+ 4/4
26 = 4!+sqrt(4)
27 = 4!+sqrt(4/.4R)
28 = 4!+ 4
29 = 4!+sqrt(4)/0.4
30 = 4!+ 4+sqrt(4)
31 = 4+ 4!+sqrt(4/.4R)
32 = 4!+ 4+ 4
33 = 4!+ 4/.4R
34 = 4!+ 4/.4
35 = 4!+sqrt(4)+ 4/.4R
36 = 4!+sqrt(4)+ 4/.4
37 = 4!+ 4+ 4/.4R
38 = 4!+ 4+ 4/.4
39 = 44 – sqrt(4)/0.4
40 = 4
*
(4/.4)
Dr. Ecco Solution
“Individuals are
more powerful than
institutions”

T
he National Cyber Security Alliance
recently released the results of a study
showing how difficult it is to achieve
even minimal security on consumer
PCs. The disparity between users’ expec-
tations and reality should be particularly
scary for folks working on embedded con-
sumer products.
As of last October, about 3/4 of the sur-
veyed users felt reasonably safe from the
usual assortment of online threats, despite
the fact that 2/3 have outdated antivirus
software and 2/3 (presumably a different
subset) lack firewall protection. Essential-
ly none have any protection against ad-
ware or spyware, and in fact, 9/10 haven’t
a clue what that means.
The result is predictable: 2/3 have ex-
perienced at least one virus infection, 1/5
have a current infection, and 4/5 have ad-
ware or spyware infestations. The NCSA
actually measured those numbers by send-
ing technicians to examine the PCs. The
study did not report on worms or back-
door programs, perhaps lumping those
with viruses.
Many of the talks at last year’s Embed-
ded Systems Conference dealt with secu-
rity techniques and practices, but the
ground truth indicates the battle has little
to do with technology. Let’s compare ex-
pectations and requirements with the ac-
tual results.
Boot, But Verify
Transactions, pretty much by definition,
have at least two sides. In the PC realm,
we’ve been mostly concerned with verify-
ing that the server on the far end is what
it claims to be, taking for granted that the
PC end is honest. That level of trust is cer-
tainly unjustified now, and for distributed
embedded systems, it verges on wishful
thinking.
Several ESC talks described the re-
quirements for a Trusted Computing Plat-
form, one that is known to contain only
valid hardware and software. During the
power-on sequence, the hardware must
verify that it has a correct, trusted config-
uration, using only known-good software
that is either internal to the CPU or pro-
tected by a cryptographic hash stored in-
side the CPU.
The verification extends well beyond
the familiar BIOS sanity checks that most
people disable to reduce boot time. The
CPU must ensure that no potentially ma-
licious devices are present, perhaps by
preventing further execution if the system
contains hardware that’s not on a list of
preapproved devices.
After the hardware checks itself, it must
verify that the main system software is cor-
rect. Because that code is generally too
large for on-chip storage, the hardware
uses more crypto hashes. The entire soft-
ware image or just key components can
be hashed, with the obvious space-versus-
time tradeoffs.
Once you have a system running trust-
ed software atop trusted hardware, you
can be reasonably sure that the entire con-
figuration will behave consistently, if not
necessarily correctly. From that point on-
ward, however, it must ensure that only
trusted hardware is connected and only
trusted software is loaded and executed,
because a single exposure can lead to a
successful exploit.
Based on a quick thumb check of the
Trusted Computing Group’s numerous pa-
pers and documents, I’d say the TCG’s ini-
tial focus is on large organizations, both
governmental and industrial, which can and
must maintain tight control over their IT fa-
cilities. The cost of virus and worm
episodes has become so great that any al-
ternative seems preferable to the status quo.
Unfortunately, high security presents a
considerable challenge for IT departments
that normally deal with commodity hard-
ware. It’s feasible, if not easy, to keep
thousands of systems running with fungi-
ble components. It’s essentially impossi-
ble to maintain thousands of unique con-
figurations with mutually incompatible
components.
The Trusted Platform Module (TPM)
specs describe methods to implement
nearly any security model you’d like, but
getting it right requires considerable up-
front planning and rigorous follow through.
That level of attention to detail may be
feasible for large institutions, but the rest
of us simply can’t cope.
The NCSA numbers reveal how difficult
the challenge will be. Only 6 percent of
users thought their PCs had a virus at the
moment, 44 percent claimed to have clean
PCs, and half simply didn’t know. The
NCSA technicians actually found 25 per-
cent of dial-up and 15 percent of broad-
band PCs had at least one virus. The av-
erage infection rate was 2.4 viruses per
machine and the maximum was 213 (yes,
on a single PC!).
Enforcing a security model on unwill-
ing participants is a recipe for disaster.
Trouble in Paradise
Let’s assume that all hardware must have
a known provenance before it can be used
by a trusted system. This may be feasible
for embedded systems with tight access
controls, but is probably impossible in the
general case.
Suppose, for example, that the system
uses a generic PC-style keyboard with a
PS/2 interface. Each keyboard could in-
clude a unique identification number that
would be accepted only by a specific CPU.
Alternatively, all approved keyboards
could include a common identifier ac-
ceptable to any system. The ID must be
wrapped in crypto to prevent spoofing or
unauthorized duplication.
But that’s not enough. To maintain se-
curity, your keyboards must be tamper ev-
ident, if not tamper proof, to prevent the
introduction of unauthorized hardware.
Consider what would happen if someone
Security Measures
Ed Nisley
E M B E D D E D S P A C E
Ed’s an EE, PE, and author in Pough-
keepsie, NY. Contact him at ed.nisley@ieee
.org with “
Dr Dobbs” in the subject to
avoid spam filters.
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
69

added a hardware recorder either inside
the keyboard case or between the key-
board and the system: They would cap-
ture all manual data going into the system.
There is simply no electrical way to de-
tect a hardware keystroke recorder be-
tween the keyboard and the PC, which
means once it’s inserted, it won’t be found
unless someone specifically looks for it.
Commercial recorders monitor the data
stream on the PS/2 wires for the keystroke
sequence that activates them, but that’s
entirely optional. Any decent hardware
engineer could cook up a recorder that
sniffs data from the wires, depends on ex-
ternal hardware for a data dump, and fits
neatly on your thumbnail.
Here’s an example of how much dam-
age a simple logger can cause: In 2001
and 2002, Juju Jiang installed a software
keystroke logger on PCs in various Kinko’s
copy centers, then retrieved the logs using
the PC in his apartment. Several Kinko’s
customers had accessed their home PCs
using a commercial remote-access pro-
gram and Jiang’s logger snagged their user
IDs and passwords. He later used that in-
formation to access their PCs, open new
accounts using their personal informa-
tion, and transfer money from their ex-
isting accounts.
Jiang was only caught because one of
the victims noticed his PC creating an ac-
count on its own, acting “as if by remote
control” (which was, in fact, the case).
There was enough evidence to trace the
intrusion to Jiang, indict, prosecute, and
convict him.
The same reasoning applies to any pe-
ripheral: If it’s not mechanically secured
and physically suborned, you must as-
sume its data stream can be monitored,
either instantly or stored for later recov-
ery. Keyboards are the obvious weak spot,
but USB, serial, and parallel ports provide
nice access points. While a hardware ex-
ploit requires two intrusions, one to plant
the device and a second to recover it, the
actual data collection doesn’t depend on
easily discovered software hacks.
The specs for a Trusted Platform Mod-
ule require tamper-resistant or tamper-
evident packaging, but do not define the
physical security requirements of the en-
tire system. For widely distributed systems,
whether PCs or embedded devices, it’s
safe to assume they have no physical se-
curity at all and that the hardware can be
compromised at will. That makes internal
security measures moot, as they can be
bypassed with enough time and patience.
The Jiang case and the NCSA study both
show that most people simply don’t no-
tice unexpected behavior, never mind sur-
reptitious information leakage. Only half
of the users said that their machines had
adware or spyware programs, while NCSA
technicians found 9/10 of dial-up and 3/4
of broadband PCs were infected. The av-
erage infected machine had 93 “ad-
ware/spyware components,” whatever
those are, and the worst-hit machine had
1059 (!) components.
Although the price of freedom may be
eternal vigilance, it’s obvious that we can-
not depend on ordinary folks for sufficient
attention to the details of secure computing.
Business Opportunities
My friend Aitch recently described an
embedded-system business opportunity
based on the convergence of two trends.
While it’s not exactly legal, there’s excel-
lent upside potential. Send me a suitcase
of small bills if it works for you.
It seems there’s a growing underground
of automotive hotrodders who trick out
their cars with all manner of performance-
enhancing gadgets — turbochargers, su-
perchargers, water injectors, you name it.
They also modify the engine control com-
puter firmware to further improve per-
formance. As you might expect, these
modified engines tend to poot out some-
what more unwanted emissions than their
factory-stock brethren.
Many states or urban areas now include
pollution measurements as part of their
annual automobile inspections. Those
measurements require complex dynamo-
meters, expensive buildings, and trained
technicians, but, now that all vehicles have
on-board engine controllers, why not just
take advantage of the information avail-
able through the standard OBD (On-Board
70
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
WIBUbDDJalt.indd 1
10/7/04 5:31:58 PM

Diagnostic) connectors in every car? If the
engine controller reports no faults or un-
usual situations, the car passes the in-
spection and taxpayers save the cost of
all that infrastructure. What’s not to like?
Here’s the deal. Stick a cleverly coded
microcontroller on the back of an OBD
connector and sell it to the hotrodders,
who tuck the official OBD connector up
inside the dashboard, put the gimmicked
OBD connector in its place, and drive off
to their car inspection. The microcontroller
responds to the inspection station’s in-
quiries with “Nothing to see here. Move
along, move along.”
Aitch suggests that $100 retail would
move OBD spoofers off the loading dock
at warp speed.
Many ESC speakers observed that se-
curity must be included in the overall sys-
tem design and that it cannot be grafted
on after the first exploit goes public. The
OBD system started as a simple diagnos-
tic tap but is becoming part of a legislat-
ed system with legal force behind it. If
you think Windows has security flaws,
think about that situation for a moment.
Pop quiz: Estimate the number of test
instruments that must be replaced in or-
der to accommodate trusted engine com-
puters and inspection stations. Extra cred-
it: Estimate a lower bound for the half-life
of the existing engine population.
Back at home, it’s widely agreed that
Microsoft sells XBox gaming consoles at
a loss to gain market share. Because MS
also derives royalties from each unit of
game software to offset the hardware
loss, the XBox includes rather stringent
controls on just what software it will ac-
cept, to the extent that it spits out un-
approved CDs or DVDs. Consider it as
a first approximation to a trusted com-
puting platform.
Days after the XBox first appeared on
the market, Bunnie Huang figured out
how to bypass the boot-code protection
hardware. His methodology, presented at
the 2002 Cryptographic Hardware and Em-
bedded Systems conference, should be re-
quired reading for anybody trying to dis-
tribute trusted hardware in a consumer
device. Summary: It won’t work.
During the ensuing arms race, some-
one discovered a security hole in the “save
game” feature of several XBox programs:
You could save a game to a memory card,
replace the file with something completely
different, and reload it. The contents of
the saved file, perhaps a Linux boot im-
age, then runs without catching the at-
tention of any of the security gadgetry. Of
course, that hole isn’t present in current
XBoxes.
Isn’t it interesting that Microsoft patches
economic leaks immediately, while leaving
some security holes to languish for years?
Hash Happens
Most security measures depend on cryp-
tographic hashes to ensure the integrity
of large messages (or files or documents
or whatever). A good hash algorithm has
two key attributes: The probability that
two messages will produce the same hash
value (“collide”) is low and the difficulty
of finding such a colliding message is high.
Although their achievement didn’t
achieve mainstream headline status, a team
of researchers recently published an al-
gorithm that, given a message and its cor-
responding MD5 hash, produces a mod-
ified message with the same hash value.
The fact that two messages can have the
same MD5 hash value is not surprising.
The trouble arises from being able to cre-
ate a message with the same hash as the
first. Moore’s Law tells us that once some-
thing can be done, it will be done much
faster in only a few years.
While this is not yet a catastrophic prob-
lem, it does show how you can get ev-
erything right and still have a security fail-
ure. If you’ve ever used an MD5 hash to
verify a downloaded file, there’s now the
possibility (admittedly, a small one) that
the file you get may not be the file you
expect, even though the hash is bit-for-
bit correct.
The Trusted Computing Group chose
SHA1 as the TPM hashing algorithm long
before news of the MD5 compromise ap-
peared. There are speculations about
cracking SHA1, but, for the present, it
seems secure.
Pop quiz: Assume you had sold a few
hundred thousand gizmos that validate
new firmware downloads using MD5
hashes and signatures. How would you
convert the units to use SHA1, given that
attackers can spoof your files? Essay: De-
scribe how you’ll get your users to care.
Reentry Checklist
Two things are quite clear: Consumers can’t
be trusted with security decisions and hard-
ware cannot be secured from customers.
The former implies that any security mea-
sures must not require user intervention;
the latter implies that you cannot depend
on trusted hardware in the field.
Therefore, your overall system must be
resilient enough to survive the failure of
any defense and any unit. The XBox ex-
ploit shows how even a fairly complex se-
curity system can be penetrated with sur-
prising ease. If all the units are identical,
then one exploit is all it takes. Scary
thought, eh?
The NCSA study is at http://www
.staysafeonline.info/news/safety_study_v04
.pdf with the summarizing press release
at http://www.staysafeonline.info/news/
NCSA-AOLIn-HomeStudyRelease.pdf.
The Trusted Computing Group is at
https://www.trustedcomputinggroup.org/
home. The architecture document at
https://www.trustedcomputinggroup.org/
downloads/TCG_1_0_Architecture_Overview
.pdf mentions that keyboards and mice
must include validation credentials.
Details on a typical keystroke logger
are at http://www.4hiddenspycameras
.com/memkeystrok.html. The documents
for the Juju Jiang case are at http://www
.cybercrime.gov/jiangIndict.htm and http://
www.cybercrime.gov/jiangPlea.htm. It
seems Kinko’s now restores the drive im-
ages each week, which is a step in the
right direction.
A quick overview of OBD-III can be
found at http://lobby.la.psu.edu/_107th/
093_OBD_Service_Info/Organizational_
Statements/SEMA/SEMA_OBD_frequent_
questions.htm. The usual searches will
produce hotrodding information.
Andrew “Bunnie” Huang performed the
initial Xbox hacks and reported his find-
ings at http://www.xenatera.com/bunnie/
proj/anatak/xboxmod.html. Pay particu-
lar attention to the trusted-computing part
of his presentation at http://ece.gmu.edu/
crypto/ches02/talks_files/Huang.pdf.
Microsoft countered the saved-game bug
in short order with an automatic update,
as reported at http://www.theinquirer
.net/?article=11548.
More on MD5 and SHA1 hashing is at
http://www.secure-hash-algorithm-md5-
sha-1.co.uk/. The original paper describing
the MD5 break is at http://eprint.iacr.org/
2004/199.pdf.
“Trust, but verify” was President Rea-
gan’s take on nuclear disarmament. If you
don’t recognize “Nothing to see here,” get
a Star Wars DVD set and discover how
much movie special effects have improved
in recent years. “And Now for Something
Completely Different” was a 1971 Monty
Python video compilation.
DDJ
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
71
“Enforcing a
security model on
unwilling
participants is a
recipe for disaster”
T
he first time I ever heard of Google
was when Darnell Gadberry came
over in some excitement to alert me
to a new search engine. He called it
“google” but, having read Mathematics
and the Imagination, by Edward Kasner
et al., I thought he said “googol,” which
is the number 10
10^10
. It took me some
time to get my head straight.
Since that time, Google has created a
number of revolutions. As a company, it
has gone public in a way that enriched
early stock buyers rather than investment
bankers, while its search engines have
changed scholarship the world over. The
Internet always did contain a great deal
of information and had the potential to let
you do a lot of research without having
to go down to libraries, but without
Google, it was so hard to find anything
that many of us went to the library any-
way. Now I rarely visit one of those sep-
ulchers of knowledge.
There’s money in a good search en-
gine, and Google has found a way to ex-
tract some profits from it, which may or
may not get it into Microsoft’s sights. But
Google has a huge head start. For one
thing, Google already has the infra-
structure: A server farm reportedly of
more than 100,000 Intel boxes running
Linux. And it is adding boxes so fast that
if one dies, it’s just abandoned in place,
with no attempt to fix or even remove
it. If Microsoft is serious about getting
into the search game, it needs compa-
rable facilities.
Google has another advantage. With
most companies, Microsoft can lose often
but only has to win once before the bat-
tle is over and The Borg absorbs its ene-
my. Google, however, is now big enough
to lose a couple of battles and still be
around.
That is, if they lose at all. Microsoft was
betting heavily on the Windows File Sys-
tem in Longhorn to help with its search
problems — the desktop Search engine is
notoriously slow and clunky — but now
WFS is apparently not to be in the first re-
lease of Longhorn.
Microsoft doesn’t get into fights it can’t
win, and Google has considerable advan-
tages in the search engine wars. A pitched
battle between these giants would harm
both, probably to the advantage of Apple.
After all, almost a year ago, Steve Jobs
showed live a demo of something as good
as Windows File System, and that may be
shipping in a couple of months. My guess
is that the war won’t happen, and Google
president Eric Schmidt’s flat statement that
Google isn’t building a browser (http://
www.marketingvox.com/archives/2004/
10/25/google_ceo_no_browser_effort/) was
a public signal to that effect.
Some Lessons in Troubleshooting
Chaos Manor is now pretty thoroughly
converted to gigabit Ethernet switches.
The general product line we have used is
D-Link. As I have noted before, D-Link
equipment Just Works, and the documen-
tation is sufficient and in good English —
not that gigabit Ethernet switches need
documentation.
You may recall from last month that I
first went to gigabit when Fry’s had a
blowout sale on AirLink gigabit switches,
and I bought several of them. In particu-
lar, I bought a 5-port 1000-base-T switch,
which went up at “Ethernet Central.”
Alas, although the AirLink 5-port was
plugged into a powerstrip that suppos-
edly has surge protection, it wasn’t con-
nected to a UPS. This turned out to be a
Big Mistake, for several reasons. First, of
course, if there’s a power failure while
you are using your Ethernet connection,
either for connection to the Internet or for
file transfers, you won’t be able to finish
those jobs and shut down gracefully. Sec-
ondly, a UPS — at least, the Falcon on-
line UPS systems I use — offers far more
surge protection than any powerstrip.
About a week after I installed the Air-
Link 5-port gigabit switch, it rained in Los
Angeles. Rain here is usually either noth-
ing or a big deal — and this time it was a
big deal, with storms and lightning and
thunder. It got bad enough that Roberta
shut everything down in her office, but I
was working on something and couldn’t
be bothered. Sure enough, a few minutes
later we had a short power failure. My
computers kept working due to the Fal-
con UPS systems, but of course I lost In-
ternet communications. I began shutting
systems down. There are enough of them
that this took some time, and before I was
done, the power came back on.
I went back to work, but found I still
didn’t have communications. My first move
was to go reset the cable modem by pow-
ering it off, then back on. That’s on a UPS,
so it stayed on until I reset it. When it
came back up, all the lights came on —
steady green for power, rapidly blinking
cable connection light quickly going to
steady green to indicate lockon, and green
for the “PC” Ethernet connection light. The
data light blinked a couple of times indi-
cating traffic. All was well.
Only it wasn’t. When I got back to my
desk, I didn’t have any Internet connec-
tions with my main communications sys-
tem. Time to do some troubleshooting.
The first thing was to look at the sys-
tem’s Ethernet port. Green light on, yel-
low light blinking, just what I expect. Trace
the Ethernet cable to the AirLink Gigabit
switch, note what port I’m connected to,
and look at the lights for that port. All the
port lights for the switch are blinking fu-
riously; once again, just what I’d expect.
Next, go to the cable room and see if
everything there is connected. All seems
well. The problem isn’t the cable modem,
and it’s not out there in the Internet. All
that is working, so the difficulty is between
my computer and the cable modem.
Hmm. Pournelle’s Law says that 90 per-
cent of the time, it’s a cable or cable con-
nector. Could rats have gnawed the cable?
They certainly could have. The last time
we had any work done here, the con-
struction people didn’t seal the access
ways to the area under the house. Rats
got in, and gnawed through the signal ca-
ble for my air conditioner. Another got a
telephone line, and yet another managed
to get into the washing machine motor,
bringing both himself and the clothes
washer motor to a spectacularly messy
end, as a very surprised Maytag man found
when called in. We have sealed the ac-
cess ports — some of them were very ob-
scure, and we only found one when Sable,
our dog, trapped a rat in the barbeque
pit, and when the rat was released it made
a bee line for a part of the foundation we
The Google Revolution
Jerry Pournelle
C H A O S M A N O R
Jerry is a science-fiction writer and senior
contributing editor to
BYTE.com. You can
contact him at jerryp@jerrypournelle.com.
72
Dr. Dobb’s Journal, February 2005
http://www.ddj.com

hadn’t looked at. But now, all the ways
under the house are sealed off and we’ve
been trapping rats ever since. I think we
have them all. Sable hasn’t been excited
about anything skittering around the house
for a couple of weeks.
And even if it was a rat, there was hard-
ly time to gnaw through an Ethernet ca-
ble in the 10 minutes or so the power was
off. This had to be a different problem.
Failure without Grace
The next step was to do some serious trou-
bleshooting work isolating the problem.
Back to Anastasia, the main communica-
tions system. Could she ping anything?
Yes. No. Yes. Hmm. That’s decidedly
odd. Mostly I can’t get DNS resolution for
anything, but if I type in an actual nu-
merical URL, I can get maybe one ping
out of 10 returned. Do ipconfig /all and
look at the result. Seems normal, but I
can’t ping Imperator (the Active Directo-
ry Server) by name or by URL address
number. On a whim, I did ipconfig /re-
lease, then ipconfig /renew. That had a re-
sult. Now I wasn’t connected to anything.
I couldn’t get an address from Imperator.
No DHCP service.
Another machine in here had the same
problem. In fact, all the machines con-
nected to the AirLink 5-port gigabit Eth-
ernet switch had the same problem. No,
or very intermittent, communications, even
though the lights on the AirLink blinked
furiously. I got out a different 5- port
switch, connected it, and everything
worked fine. The problem had been the
AirLink all along, and I would have spot-
ted it instantly if the darned thing had just
failed.
Instead, it failed in the worst possible
way, with all its lights blinking as if it were
still working, when in fact, it was as dead
as a doornail.
D-Link Gigabit
The next day, I found myself down at the
Shrine Auditorium for the Microsoft Dig-
ital Entertainment Anywhere show, where
D-Link had an exhibition on the show
floor. It didn’t take long to negotiate one
of their Wireless Media Players and to tell
them my tale of woe about the AirLink
switch. D-Link’s Brad Morse asked why I
hadn’t used D-Link, and I had to explain
that our request had probably been lost,
and I don’t like to look like I am grubbing
for equipment.
A couple of days later, I got the D-Link
24-Port gigabit switch as well as several
5-Port switches. I replaced the dead Air-
Link 5-port (actually replaced the older
10/100 switch that temporarily took its
place) with one of the D-Link 5-ports, and
put the 24-port system in the cable room
where it replaced three different switch-
es — two of them older 10/100, and a 5-
port gigabit switch. Then I went around
replacing all the AirLink switches with D-
Link. I can’t blame the AirLink for suc-
cumbing to a power spike, but I fault it
most grievously for failing so ungraceful-
ly. When things die, they ought to look
dead, not cheerfully continue to blink
lights as if nothing were wrong.
The bottom line here is that all the D-
Link gigabit equipment worked as I ex-
pected it to work, and whenever I plug
in a machine capable of gigabit commu-
nications, it just works. Gigabit file trans-
fers are some three- to five-times faster
than doing the same thing at 100 megabits.
I can’t call it any closer than that: That is,
I have transferred the same file between
the same two machines, the only differ-
ence being the Ethernet switch (D-Link
gigabit versus a Netgear 100). And while
the transfer times at 100 megabits are con-
sistent, at 1000 megabits they vary in no
discernible pattern, with 3
×
being about
the slowest and 5
×
about the fastest. I had
the same results with the AirLink switch
when it was working, so it’s not a D-Link
problem, and is probably caused by over-
loading Windows.
I’m about to add a couple of Linux box-
es capable of gigabit speeds, and I’ll do
the same test with those. More when I
know more.
D-Link gigabit switches Just Work, and
the time saved is significant.
Building Your Ethernet
Alex notes that when he is called in to
troubleshoot a small business network, a
good part of the time the trouble is a failed
hub. Murphy’s Law dictates that the hub
is behind someone’s desk, covered with
dust, and its location isn’t recorded on any
document. Moreover, it cascades to an-
other hub, rather than to a switch, and it’s
not at all obvious whether it needs to be
connected as an uplink or downlink (on
hubs that makes a difference; modern
switches may not make a distinction).
There are rules about how many stages
of cascade you can have for hubs. It’s
called the “5-4-3 rule,” and it mandates
that between any two nodes on the net-
work, there can only be a maximum of
five segments, connected through four re-
peaters or concentrators, and only three
of the five segments may contain user con-
nections.
There are reasons for this. The Ether-
net protocol requires that a signal sent out
over the LAN reach every part of the net-
work within a specified length of time.
The 5-4-3 rule ensures this, and thinking
about it can make your head explode.
If you are planning a network there’s
an easier way: Get a D-Link 24-port gi-
gabit switch, put that in a central place,
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
73

and when you wire your establishment,
have enough cables pulled so that you
have an outlet everywhere you might want
a computer. This will likely turn out to be
more lines than computers, and so what?
It may even turn out to be more than 24
lines, and again, so what? Just connect up
the ones you’ll use, and if you move a
computer, you just plug it into a new Eth-
ernet outlet.
Of course, most of us don’t have that
luxury, and when I designed this part of
Chaos Manor I wired it for ARCnet, and
when we later abandoned the ARCNet ca-
bles in place and pulled Ethernet wires, I
didn’t plan enough outlets, so I need to
cascade switches in several places. I’m
giving you advice I haven’t followed, but
then at Chaos Manor, we do a lot of silly
things so you don’t have to.
Upgrading to Gigabit
Now that I have replaced all the switches
with D-Link gigabit (24-port at the central
location, 5-port out on the periphery), I
could, in theory, put gigabit Ethernet
boards in the machines that don’t have it
on the motherboard. I am not going to do
that, and I don’t advise you to do it. In the
first place, if you put a gigabit board into
a PCI slot, the PCI bus itself slows things
to below a gigabit. The best I have ever
been able to do in upgrading from 100
megabit by adding a gigabit board is to
about double the throughput. Now that
isn’t anything to sneeze at, but it’s not the
Earth, either. Note that gigabit-to-gigabit
throughputs tend to be three- to five-times
faster than 100 megabit (the best I ever got
was about 6
×
, and that was only once).
Note also that motherboards with a
faster slot bus like PCI-Express will very
likely have gigabit Ethernet on board. It
seems reasonable, then, to just let nature
take its course. Replace the switches, and
as you upgrade your systems, you’ll au-
tomatically upgrade to gigabit Ethernet. It
may be worth putting a gigabit card in a
server, since that’s used a lot and doubling
its throughput is probably worth the ef-
fort, but don’t be surprised if there’s no
effect whatsoever. The best way to speed
up server operations is to replace the
motherboard with one that has gigabit Eth-
ernet on a bus designed to handle it.
Winding Down
The game of the month is Rome: Total War.
It takes an hour to install, what with all the
options, and the online updating, and the
rest of it. I have some complaints, but I sure
like it. Fair warning: It eats time. I wouldn’t
bother with the Prima Game Guide book,
which gives no more information than the
excellent manual that comes with the game.
If you want some strategy guidance, Google
“smackus maximus.”
I have two books of the month, both on
the same theme. First. Cowboy Capitalism:
European Myths, American Reality, by Olaf
Gersemann (Cato Institute, 2004). The pub-
lisher is Cato Institute, which should be
warning enough of the viewpoint, but the
arguments are sound and there is a lot of
data, unlike the usual tome on economic
policy. The second book is Bill Blunden’s
Offshoring It: The Good, The Bad, and The
Ugly (Apress, 2004), which once again is
long on data, and intelligently discusses an
important subject.
The Computer Book of the Month is
Getting Permission: How to License & Clear
Copyrighted Materials Online and Off, by
Richard Stim (Nolo Press, 2000). This is
comprehensive and useful for anyone
compiling materials for publication. The
other computer book of the month is Mac
OS X Power Hound, Panther Edition, by
Rob Griffiths (O’Reilly & Associates, 2004).
It’s a compilation of tricks and procedures
for Mac users, and I suspect it will be as
useful to experienced Mac users as it has
been to me. There’s just a lot of good stuff
in there.
DDJ
74
Dr. Dobb’s Journal, February 2005
http://www.ddj.com

P R O G R A M M E R ’ S B O O K S H E L F
T
ransmitting wisdom and experience
can be difficult in any sphere of ac-
tivity. Probably the closest that soft-
ware architects have come to a reli-
able way of transmitting their wisdom and
experience is by abstracting patterns from
their applications.
Patterns are a form of “chunking,”
which provides both a higher level way
of thinking about a subject, and a com-
mon vocabulary. If I recognize the open-
ing moves in a chess game as the Queen’s
Gambit, I know the choices before me
and their most likely consequences. If I
tell another chess player I played Queen’s
Gambit Declined, my meaning is clear
without having to detail the moves made.
Similarly, if I recognize that I have an ap-
plication that needs to load and display
what could turn out to be a very large
database, I know I can avoid bringing the
entire database into memory with a Lazy
Load pattern, and I can mention the pat-
tern to another software developer with-
out having to draw diagrams to explain
what I mean.
Patterns don’t generally represent new
inventions: What they reflect are old in-
ventions that could be used for other
things. Wheels, threads, and gears are all
common patterns for mechanical engi-
neers. Patterns are for things that are done
over and over, so that you don’t have to
reinvent them each time you need them,
even if the application varies each time.
There have been a number of books
on software patterns over the last 9 or 10
years. Probably the best known is the sem-
inal Design Patterns by Gamma, Helm,
Johnson, and Vlissides (Addison-Wesley,
1995), also known as the “Gang of Four”
or “GoF.” The Gang of Four patterns are
fairly low level but universal: creational
patterns, such as Factory Method and Sin-
gleton; structural patterns, such as Com-
posite and Proxy; and behavioral patterns,
such as Iterator and State. Since the pub-
lication of Design Patterns, higher level
and more applied patterns, such as the
aforementioned Lazy Load, have become
fodder for books.
Martin Fowler is well known as an
OOD/OOP guru (or “object bigot,” as he
calls himself), and is the author of Analysis
Patterns, UML Distilled, Planning Extreme
Programming, and Refactoring. In his fifth
book, Patterns of Enterprise Application Ar-
chitecture, Fowler discusses 40 design pat-
terns that are appropriate for enterprise ap-
plications. As Fowler explains in the preface:
Enterprise applications are about the dis-
play, manipulation, and storage of large
amounts of often complex data and the sup-
port or automation of business processes
with that data. Examples include reserva-
tion systems, financial systems, supply chain
systems, and many others that run modern
business. Enterprise applications have their
own particular challenges and solutions,
and they are different from embedded sys-
tems, control systems, telecoms, or desk-
top productivity software.
The book has two major sections: the
narratives and the patterns. Fowler expects
you to read through all the narratives and
then use the patterns for reference as the
need arises.
The narratives introduce some common
problems encountered in enterprise ap-
plications and discuss their solutions at a
high level, so that you can get a feel for
which patterns solve what problems, and
for how the patterns interrelate. The chap-
ters in Part 2 are detailed references to the
patterns themselves, covering how they
work, when to use them, and sample ap-
plications and implementations. The sam-
ple code is written in Java or C#, and il-
lustrated with UML diagrams. The front
inside cover of the book lists the patterns
alphabetically; the back inside cover is a
“cheat sheet” for finding the correct pat-
tern to solve a problem.
Patterns of Enterprise Application Ar-
chitecture covers domain logic patterns,
like Domain Model and Table Module; data
source architectural patterns, like Table
Data Gateway and Data Mapper; object-
relational behavioral patterns, such as Unit
of Work and Lazy Load; object-relational
structural patterns, such as Foreign Key
Mapping and Concrete Table Inheritance;
object-relational metadata mapping pat-
terns, such as Query Object and Reposi-
tory; web presentation patterns, such as
Model View Controller and Front Con-
troller; distribution patterns; offline con-
currency patterns; session state patterns;
and base patterns, such as Gateway, Lay-
er Supertype, and Registry. The book does
not cover asynchronous messaging, rich-
client interfaces, validation, error handling,
security, or refactoring.
Although he wrote the bulk of the ex-
position and sample code himself, Fowler
had five contributors: David Rice,
Matthew Foemmel, Edward Hieatt, Robert
Mee, and Randy Stafford. Rice assisted
with the excellent chapter on concur-
rency, and provided several patterns;
Foemmel assisted with several examples
and patterns; Hieatt and Mee provided
the Repository pattern; Stafford provid-
ed the Service Layer pattern.
Overall, Patterns of Enterprise Applica-
tion Architecture is an excellent treatment
of its subject matter. If you are an archi-
tect or developer working on Enterprise
or Enterprise-style applications — that is,
applications that work with large amounts
of data — you’ll find the time spent learn-
ing these patterns more than worthwhile,
whether they are new to you or familiar.
DDJ
Enterprise Patterns
Martin Heller
Martin is a web and Windows program-
ming consultant and Senior Contributing
Editor at
BYTE.com. He can be contact-
ed at http://www.mheller.com/.
http://www.ddj.com
Dr. Dobb’s Journal, February 2005
77
Patterns of
Enterprise
Application
Architecture
Martin Fowler
Addison-Wesley, 2003
533 pp., $49.99
ISBN 0321127420

Macrovision has updated its installation
software to InstallShield 10.5. New fea-
tures include a network repository to share
common elements, Assemblies that reuse
components across different products, and
the ability to edit any XML file. The new
Trialware feature lets you easily build eval-
uation versions of software. InstallShield
10.5 also supports the latest version of Mi-
crosoft Software Installer, MSI 3.0.
Macrovision Corp.
2830 De La Cruz Boulevard
Santa Clara, CA 95050
408-743-8600
http://www.macrovision.com/
Absoft has announced Cluster Builder’s
Kit 2.0 to replace its Beowulf Tool Kit 1.0.
Absoft is also selling and supporting a new
High Performance Computing Software
Developers’ Kit for IBM Linux on POW-
ER clusters and servers, and is preparing
to release its IBM XL Fortran Advanced
Edition compiler Version 8.1 for Mac OS
bundled with Visual Numerics’ IMSL For-
tran Numerical Library 5.0.
Absoft Corp.
2781 Bond Street
Rochester Hills, MI 48309
248-853-0050
http://www.absoft.com/
Elegance Technologies has developed C-
Sharpener for VB, an add-in to Microsoft
Visual Studio that automatically converts
Visual Basic .NET code to C#. C-Sharpen-
er for VB is integrated with Visual Studio
.NET, and can be launched from within
Visual Studio; a wizard guides you through
the translation process. Symbol table tech-
nology is used to perform the conversion.
C-Sharpener for VB does a syntactic and
semantic analysis, including a full symbol
tree with referenced assemblies.
Elegance Technologies
1721 Green Valley Road
Havertown, PA 19083
484-431-1775
http://www.elegancetech.com/
Tech-X Corporation is offering OptSolve++
Version 2.1, a library providing imple-
mentations of algorithms for solving and
optimization of nonlinear multidimensional
user-defined merit functions. Nonlinear
optimization algorithms include Powell,
Conjugate Gradient, Nonlinear Simplex,
and Levenberg-Marquardt. OptSolve++ li-
braries are available for Windows, Linux,
or Mac OS X, and OptSolve++ Pro pro-
vides library and cross-platform source
code for Linux, Mac OS X, and Windows.
Tech-X Corp.
5621 Arapahoe Avenue, Suite A
Boulder, CO 80303
303-448-0727
http://www.txcorp.com/
Zope X3 is the next major Zope release
and has been written from scratch based
on the latest software-design patterns and
the experiences of Zope 2. The “X” in the
name stands for “experimental” because
this release does not try to provide any
backward compatibility to Zope 2. Zope
is an open-source web-application server
primarily written in Python. It features a
transactional object database that can store
content, custom data, dynamic HTML tem-
plates, scripts, a search engine, relational
database (RDBMS) connections, and code.
Zope Corp.
Lafayette Technology Center
513 Prince Edward Street
Fredericksburg, VA 22401
540-361-1700
http://zope.org/
Klocwork has updated its static analysis
tools, which extend support for Java across
the entire family to include application se-
curity testing. inForce for Java, inSight for
Java, and inSpect for Java let you under-
stand and analyze large Java architectures
with very complex relationships along mul-
tiple dimensions. The new versions include
system-level analysis and defect detection
and prevention capabilities you as a plug-
in for Eclipse, a plug-in for the Rational
Application Developer for WebSphere, or
as a standalone capability.
Klocwork
35 Corporate Drive, 4th Floor
Burlington, MA 01803
866-556-2967
http://www.klocwork.com/
Windward Studios has made available
Windward Reports 3.0, its Microsoft Word-
based report-layout process. With 3.0,
Windward Reports is now available for
use in .NET programs. A new AutoTag
add-in for Microsoft Word simplifies data
layout and data-source mapping, and re-
duces the size of tags on the template
page. Users can also write JavaBeans that
perform final processing on the output of
a tag; map to SQL, XML or custom data
sources; and call Windward Reports di-
rectly from Java.
Windward Studios Inc.
PMB 115, 637 B South Broadway
Boulder, CO 80305
303-499-2544
http://www.windwardreports.com/
GridinSoft Notepad 2.7 is designed to keep
the simplicity Notepad offers while adding
code-editing features you need, such as cus-
tomizable syntax highlighting, a spell check-
er that works for 10 different languages si-
multaneously, console command support,
a hex editor, a math expression evaluator,
support for the LaTeX format, bookmarks,
drag-and-drop support, and 10 other op-
tions lacking in the original Notepad.
GridinSoft
Proletarskaya 54/56
39617 Kremenchuk Ukraine
http://www.gridinsoft.com/
Afalina has released Version 2.1 of Add-in
Express .NET, a .NET component library
for developing MS Office COM add-ins,
SmartTags, and Excel RTD Servers. Add-in
Express .NET installs technology-specific
wizards that generate projects in Visual Ba-
sic, C#, Visual C++, J#, and Delphi.
Afalina Co. Ltd.
149 Barykina Street
Gomel, BY Belarus
+375-232-473-466
http://www.add-in-express.com/
AppForge Crossfire 5.5 provides applica-
tion development for Palm OS, Symbian,
and Pocket PC mobile devices using the
Microsoft Visual C# development environ-
ment. Other features include built-in sup-
port for radio frequency identification
(RFID), support for Microsoft Windows
Mobile-Based Smartphone, Motorola A1000
devices and support for Pocket PC 2003
second edition extended features.
AppForge Inc.
3348 Peachtree Road NE
Tower Place 200, Suite 625
Atlanta, GA 30326
678-686-9000
http://www.appforge.com/
DDJ
O F I N T E R E S T
78
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Dr. Dobb’s Software Tools Newsletter
What’s the fastest way of keeping up with new
developer products and version updates? Dr.
Dobb’s Software Tools e-mail newsletter, delivered
once a month to your mailbox. This unique
newsletter keeps you up-to-date on the latest in
SDKs, libraries, components, compilers, and the
like. To sign up now for this free service, go to
http://www.ddj.com/maillists/.

F
rom the weekly AwareSoft SoftWare Small Successes Pattern and Buzzword Brown Bag:
Barney: Well, you’ll all be happy to hear that I’ve been doing Corridor Politics with our Corporate Angel, as
well as a bit of Whispering in the General’s Ear and Bridge Building, and yesterday, I got a Royal Audience
to Test the Waters.
Chas: That’s great, Barney, because we need to Plant the Seeds, and the best way to do that is to Stay
in Touch and Involve Everyone.
Annie: Not to mention getting a Guru on Our Side.
Barney: We need to do all of that if we’re going to get Corporate Buy-In and build an Early Majority.
But in today’s Brown Bag, I think it’s Time for Reflection. Would anyone care to Shine the Spotlight on
our Strategic Vision?
Chas: I’ll give it a shot, Barney. Basically, it’s that all Stakeholder Communities within our Corporate
Culture should embrace a Fear Less pattern regarding Digital Rights Management of our Intellectual
Property.
Annie: Which means that we should Just Do It and Open-Source our Core Capabilities.
Chas: It all comes down to Total Cost of Ownership up and down the Value Chain, doesn’t it, Barney?
Barney: You’ve got my Buy-In on that, Chas, but what do the rest of you Early Adopters think?
Rollie: I mean, like, for our Software Ecosystem, isn’t Digital Rights Management basically an instance
of You Aren’t Gonna Need It?
Chas: Actually, it’s YouAren’tGonnaNeedIt. Extreme Programming concepts are pronounced as one word
with InterCaps. Patterns are pronounced as separate words, capitalized.
Fred: If this is a Brown Bag, shouldn’t we adopt the Do Food pattern?
Barney: So in the spirit of Sustained Momentum and proceeding Step by Step, could someone articu-
late the proposed Business Model?
Chas: I believe the model is Give Away the Software and Charge for Support, Barney.
Barney: I’m going to invoke the Just Say Thanks pattern, Chas, because that’s exactly right.
Fred: If we can afford to Give Away the Software, why can’t we Do Food?
Barney: But as we all know, every Business Model serves the Core Values articulated in a Mission State-
ment. Anybody want to PowerPoint our proposed Mission Statement?
Chas: It’s Zero-Prerequisites Software for Clueless Losers, Barney.
Annie: Uh, actually, I think that was a joke. Didn’t we change it to Extremism in Ease of Use is No Vice?
Rollie: Uh-uh. That one failed to get External Validation. Red-State political references are okay, but
Barry Goldwater is by current standards Too Liberal. The official proposed Mission Statement is Empow-
ering Users through Transparent Functionality.
Barney: Right, Rollie. So I think we have Group Consensus. And if it’s The Right Time, we ought to be
able to get Buy-In from all the Stakeholders in the Corporate Family.
Fred: Well, you’re not getting my Buy-In unless I get something to eat.
Barney: So in summary: Give Away the Software and Charge for Support, Zero-Prerequisites Software,
Extreme Ease of Use, Transparent Functionality.
Chas: That’s it, Barney. Is it time for Next Steps now?
Cyn: If I can just inject a contrarian note, I do see one problem with all this.
Barney: Well, that’s why you’re our Champion Skeptic, Cyn. By adopting the Personal Touch and engag-
ing in Bridge Building, we can encompass a whole Greek Chorus of Devil’s Advocates. Because if we’re
not open to challenging input, we miss out on the Holistic Diversity that comes from Q
Cyn: Here’s what concerns me, Barn. If the business model is Give Away the Software and Charge for
Support, then our viability as a company rests entirely on designing the software so that it needs a whole
lot of of support. And it’s not really clear to me how you reconcile that with those very nice-sounding
Core Values.
Barney: Um, yes, well…Is there a pattern that applies to Cyn’s input, Rollie?
Rollie: Yeah. Too Much Information.
Disclaimer: To the best of my knowledge or five minutes of Googling, whichever comes first,
there is no company named AwareSoft SoftWare, although there is at least one programmer using
the name awaresoft in various forum postings. My use of the term is satirical in intent and maybe
in effect and has no connection with any actual person or entity. In fact, neither does anything in
this column.
S W A I N E ’ S F L A M E S
The Capital Gang
Michael Swaine
editor-at-large
mike@swaine.com
80
Dr. Dobb’s Journal, February 2005
http://www.ddj.com
Document Outline
- EEn
- Cover
- TOC
- Editorial - Looking Back, Catching Up
- Letters
- Dr. Ecco's Omniheurist Corner - Dig That!
- Dr. Dobb's News & Views
- Java Web Services & Application Architectures
- SOAs & ESBs
- Ruby/Amazon & Amazon Web Services
- GIS Web Services and Microsoft Word
- Java Cryptography & X.509 Authentication
- Building an Eclipse Web-Search Plug-In
- Automating Localization
- Algorithms for Dynamic Shadows
- Programmer's Toolchest - Extending UML
- Windows/.NET Developer - Integrating Reporting Services into ASP.NET
- Windows/.NET Developer - New Syntax C++ in .NET Version 2
- Windows/.NET Developer - Enhancing .NET Web Services
- Embedded Systems - Inside the uIP Stack
- Programming Paradigms - Loners and Guerrillas
- Embedded Space - Security Measures
- Chaos Manor - The Google Revolution
- Programmer's Bookshelf - Enterpise Patterns
- Of Interest
- Swaine's Flames - The Capital Gang
Wyszukiwarka
Podobne podstrony:
aai volume 11 issue 1 article 583
aai volume 19 issue 2 article 1 Nieznany (2)
orl volume 11 issue 3 article 1055
aai volume 14 issue 3 article 846
orl volume 11 issue 2 article 1044
John Milbank The Return of Mediation, or The Ambivalence of Alain Badiou Angelaki, Volume 12, Issu
orl volume 13 issue 3 article 1207
aai volume 18 issue 4 article 1136
orl volume 11 issue 4 article 1076
orl volume 10 issue 2 article 971
Textual Practice Volume 26 issue 3 2012 [doi 10 1080 0950236x 2012 684936] Tew, Philip Acts of reco
orl volume 12 issue 4 article 1157
30 31 407 pol ed02 2005
kpk, ART 577 KPK, I KZP 30/04 - z dnia 20 stycznia 2005 r
30 31 407 pol ed02 2005
Journal of Chinese Cinemas Volume 2 Issue 1
więcej podobnych podstron