
Wyszukiwanie i indeksowanie
wideo
Rafał Poniatowski 164761
Wrocław, 14 marca 2011r.

Plan prezentacji
1. Podstawowe pojęcia
2. COBRA - indeksowanie meczy tenisowych
3. System indeksujący mecz baseballowy
4. Prosty system indeksacji dla bibliotek
cyfrowych
5. Indeksowanie
6. Bibliografia
1/42

„Indexowanie wideo jest kluczem do
przyszłości internetu.”
- Mark Randall, szef strategiczny firmy Adobe
2/42

Indeksowanie danych
• Indeksowanie – pojęcie ściśle związane z
bazami danych. Polega na tworzeniu
struktury danych w bazie danych, której
celem będzie poprawa szybkości operacji
pobierania danych.
• Bezpośrednio
wynika
z
tego
fakt
wydłużenia czasu zapisu tych danych do
bazy
oraz
zwiększenie
ilości
zajmowanego na dysku miejsca.
3/42

Wideo
• Poprzez
„wideo”
rozumiemy
dane
audiowizualne, kolokwialne określane po prostu
jako „filmy”, czy „filmiki”. Jak każdy wie jest
to ważna część współczesnego internetu.
• Trzecia
najczęściej
odwiedzana
witryna
internetowa na świecie, YouTube, zajmuje się
niemal
wyłącznie
hostingiem
oraz
indeksowaniem wideo.
4/42

Indeksowanie wideo
• Znaczenie
indeksowania
w
obrębie
danych
audiowizualnych jest szersze i nieco inne niż w
odniesieniu do innych przypadków.
• Indeksowanie
wideo
ma
umożliwić
nie
tylko
przyspieszenie wyszukiwania żądanych zasobów, ale
przede
wszystkim
pozwolić
użytkownikom
na
odnalezienie skomplikowanych treści.
• Definicja indeksowania wideo [C. Snoek, M. Worring,
Multimodal Video Indexing, 2005] mówi, że „jest to
proces
automatycznego
przypisywania
etykiet
odnoszących się do treści”.
5/42

Popularne sposoby indeksowania
• Większość spotykanych filmów video indeksowana
jest jedynie po tagach nadawanych przez autora
filmu lub przez innych użytkowników.
• Sprowadza się to w dużej mierze do wyszukiwania
danych tekstowych, podczas gdy możliwości związane
z danymi wideo są znacząco większe.
• Istnieje
szereg podejść do problemu. Jest to
dziedzina stale rozwijająca się, a poszczególne
rozwiązania różnią się zazwyczaj nie tylko pod
względem złożoności, ale i podejścia do problemu.
6/42

Możliwości indeksowania wideo
• Zapytania typu: „Pokaż mi filmy z
leworęcznymi zawodniczkami tenisowymi, które
w przeszłości wygrały Australian Open, w
których podbiegają pod siatkę”.
7/42

COBRA
Constraint-Based Awareness Management Framework
• Framework stworzony na Uniwersytecie
Twente w Niderlandach.
• Opracowany z myślą o indeksowaniu meczów
tenisowych.
• Zgodny ze standardem MPEG-7.
• Zastosowano
kilka
modeli
i
technik
rozpoznawania
zawartości
obrazu.
Zwiększyło to możliwości obsługi zdarzeń
różnego rodzaju.
8/42

Budowa modelu COBRA
• W
celu
zautomatyzowania
wydobywania
konceptów (obiektów i zdarzeń) do COBRA’y
dodane zostały moduły rozszerzające, które
przechowują konkretną wiedzę.
• Istnieje np.: rozszerzenie dodające obsługę
gramatyk, w Cobrze pomagającej opisywać
wysokopoziomowe
koncepty
poprzez
formalizację sposobu ich zapisu.
9/42

Zasada działania modelu COBRA
• Na samej górze znajduje się detektor obiektów
(Feature Detector Engine - FDE). Zarządza on procesem
rozpoznawania obrazu i jest odpowiedzialny
za
uruchamianie innych modułów.
• FDE znajduje obiekt (nasze wideo) dla którego
uruchamia moduł segmentatora.
• Jego zadaniem jest podział video na pojedyncze ujęcia.
Granice ujęć rozpoznawane są na podstawie różnic w
histogramach kolorów sąsiednich klatek.
• Tym samym sposobem odbywa się klasyfikowanie ujęć
do czterech kategorii: gra (zwykłe ujęcie od góry),
zbliżenie (na zawodnika), widownia, inne.
10/42
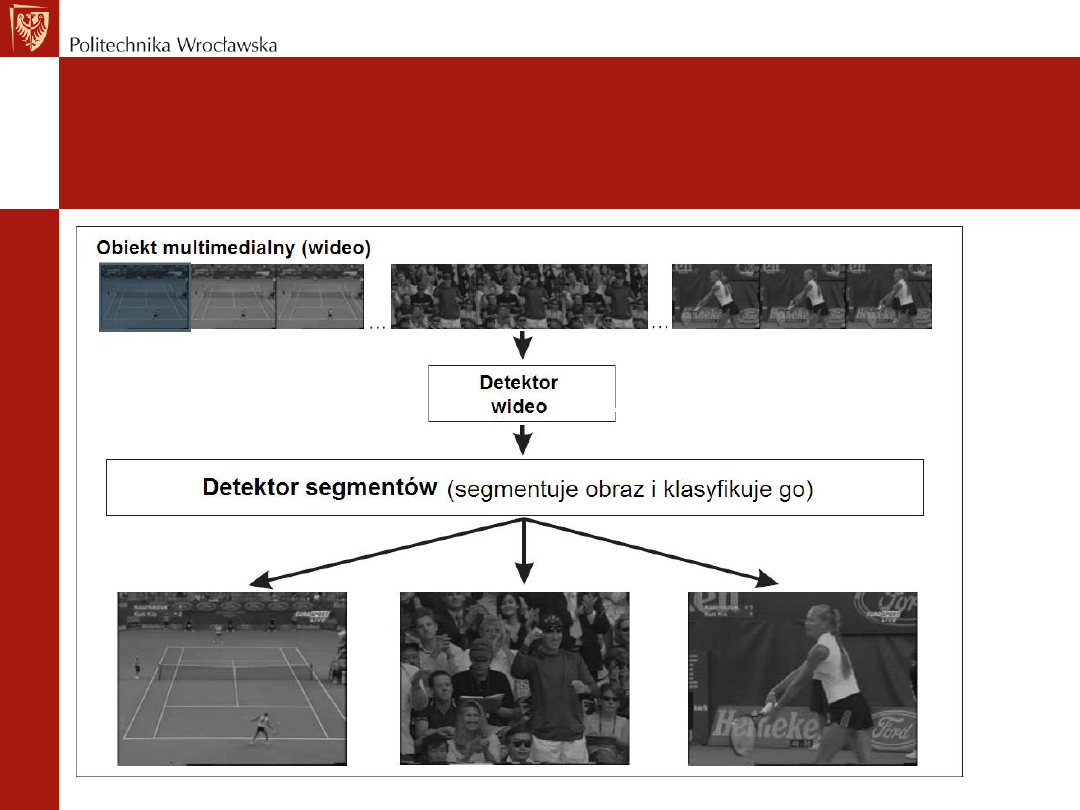
Schemat wstępnego działania Cobry
11/42

Sposób klasyfikacji ujęć
• Ujęcia „gra” rozpoznawane są na podstawie
dominacji jednego koloru (problemem są różne
kolory nawierzchni).
• Ujęcia
„zbliżenia”
rozpoznawane
są
gdy
wykryjemy nagromadzenie koloru bliskiego
pigmentowi skóry (znowuż- różne rasy ludzkie).
• Dodatkowo do klasyfikacji wykorzystywane są
takie
cechy
obrazu
jak
charakterystyka
entropii, średni kolor i średnie odchylenie.
12/42

Rozpoznano ujęcie „gry”
• Detektor obiektów uruchamia detektor tenisowy.
Zadaniem tego drugiego jest podział obrazu na
kort oraz na zawodników.
• By to zrobić wykorzystuje przybliżone statystyki
koloru kortu i wstępnie dzieli klatkę na
podprostokąty.
• W
następnych
klatkach
algorytm
próbuje
przewidzieć pozycję zawodnika i szuka go w
wyliczonym miejscu.
• Tym samym algorytmem rozpoznajemy detale
dotyczące zawodnika.
13/42

Rozpoznawanie detali zawodnika
• Zawodnik
jest
wyrażony
binarnie
(monochromatycznie).
• Znając kształt sylwetki zawodnika podczas gry
staramy się zmaksymalizować liczbę wydobytych
informacji poprzez gruntowną analizę uzyskanego
obrazu zawodnika.
• Chcielibyśmy znać nie tylko jego obecną pozycję na
obrazku (x;y), ale także położenie na korcie (np.:
prawe
pole
serwisowe),
jego
środek
masy,
kierunek, mimośród.
14/42

Rozpoznawanie rodzajów zagrań
• Położenie zawodnika i jego ruch w czasie definiują konkretne
zdarzenia np.: granie przy siatce, gra z daleka (baseline).
• Takie zdarzenie jest relacją czasoprzestrzenną, ponieważ
zarówno czas jak i miejsce w którym znajduje się zawodnik
definiują typ zdarzenia.
• Analiza ruchów zawodnika pozwala na określenie typu
zdarzenia (np.: zawodnik biegnie do siatki – gra przy siatce),
które to określane jest poprzez pewne reguły i warunki.
• Za sprawdzanie faktu spełnienia warunków, bądź nie,
odpowiadają detektory zdarzeń.
• Zostały one zaimplementowane wg. koncepcji białych i
czarnych skrzynek (znów- dla większej skuteczności,
odporności na zróżnicowane dane wejściowe).
15/42
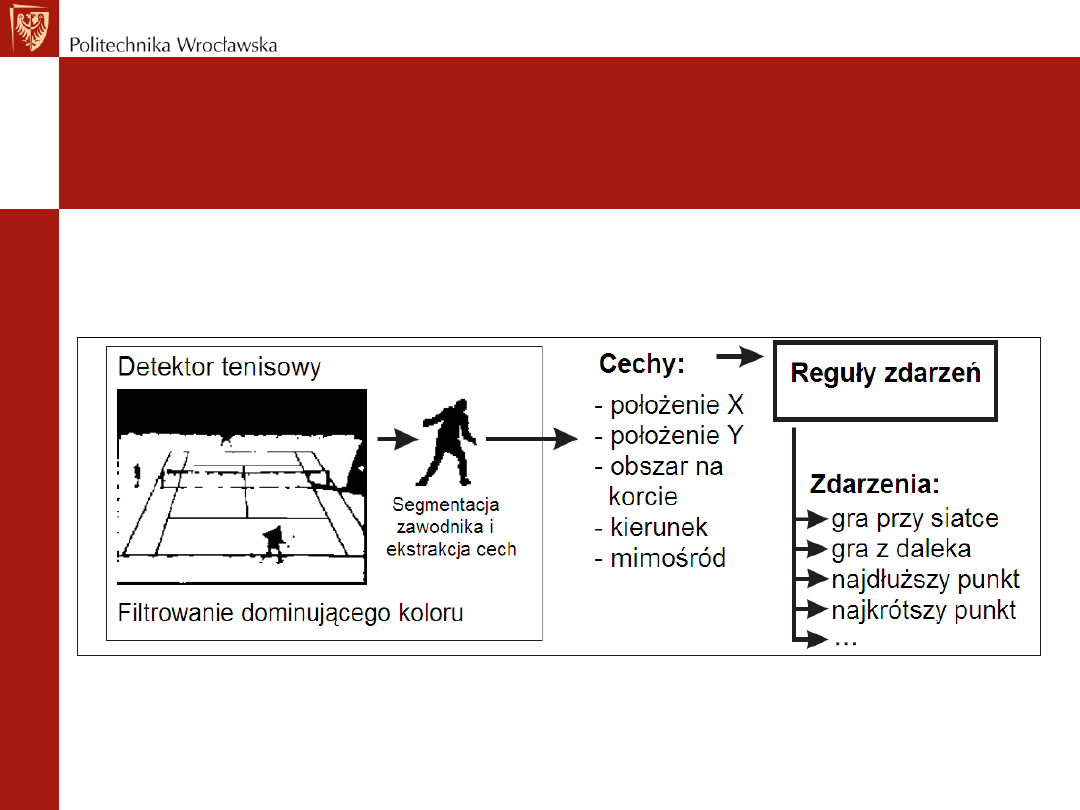
Schemat rozpoznawania zdarzeń
16/42

Podsumowanie systemu COBRA
• Po
przetworzeniu
meczu
tenisowego
dysponujemy dogłębną wiedzą na temat jego
szczegółów.
• Mamy na przykład możliwość obejrzenia samych
zagrań przy siatce.
• W przypadku zastosowania systemu na stronie
internetowej
użytkownicy
mogą
zgłaszać
szczegółowe
zapytania,
które
zostaną
błyskawicznie obsłużone (takie jak to o
leworęczne zawodniczki).
17/42

Prosty system wspomagający VIVO
• VIVO (A Video Indexing and Visualization
Organizer) – proste narzędzie dedykowane dla
małych
bibliotek
cyfrowych.
Służy
do
wprowadzania danych video, ich edycji i
zarządzania meta-danymi.
• Może zarządzać zarówno danymi video, jak i
danymi tekstowymi.
18/42
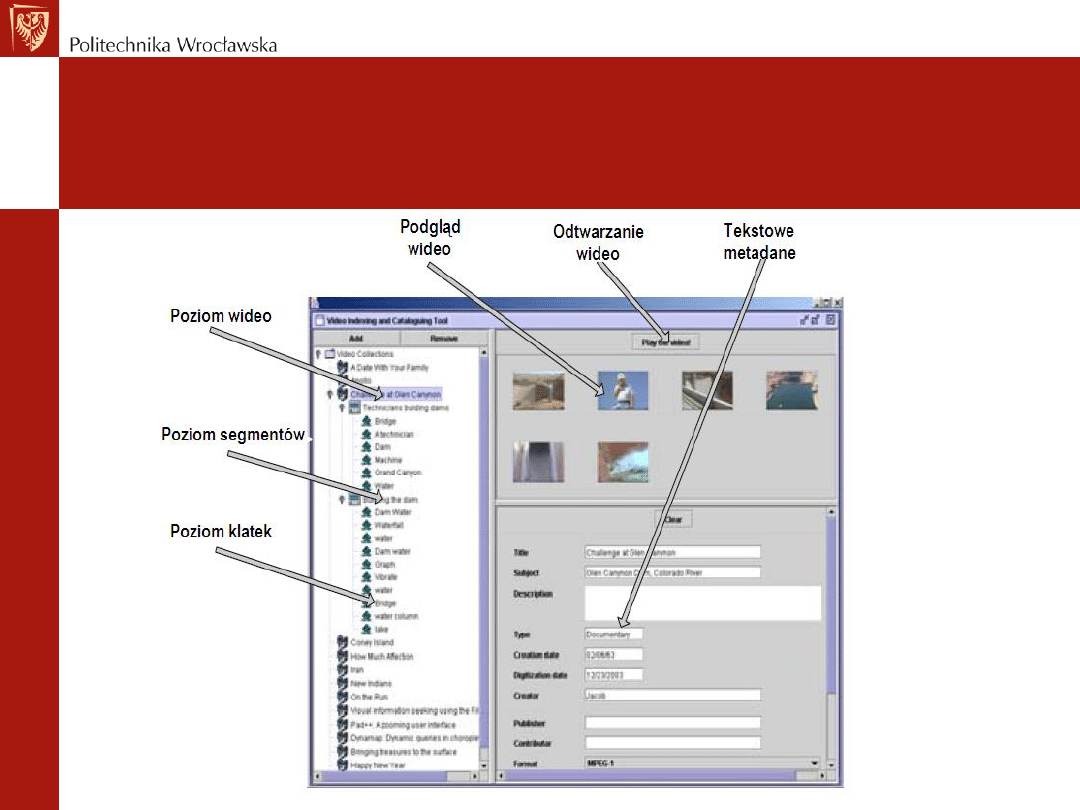
Okno aplikacji VIVO
19/42

Struktura danych w VIVO
• Do
reprezentacji
danych
wykorzystuje
się
wielopoziomową strukturę (np.: video segment
klatka),
dzięki
czemu
każdemu
z
obiektów
przekazywane mogą być przypisane do wyższych warstw
meta-dane (np.: autor, data dodania).
• Dla każdego video wykorzystywane są tzw. storyboardy,
które jak udowodniły badania przeprowadzone na
Uniwersytecie Północnej Karoliny w 2002, zwiększają
efektywność szukania zasobów wideo.
20/42
Przykład storyboardu
21/42

Możliwości zastosowania VIVO
• Pomijając aspekt wydajności (niepewna dla
bardzo dużych środowisk) jest to dobre, a
przede wszystkim darmowe, rozwiązanie dla
małych stron zajmujących się indeksowaniem
danych wideo.
• Funkcjonalność
jest
porównywalna
z
przeciętnym serwisem tego typu.
• Jest to rozwiązanie przestarzałe, proste i nie
kontynuowane. VIVO jest rodzajem prototypu i
miało na celu wskazać drogę rozwoju.
22/42

System indeksowania meczy
baseballowych
• Opracowany przez NHK (Japan Broadcasting
Corporation)
• Celem
było
zautomatyzowanie
procesu
przypisywania indeksów do poszczególnych ujęć
z meczy baseballowych.
• Do rozwiązania problemu użyto wzorcowania
(patternization) scen oraz Ukrytych Modeli
Markowa (HMM - Hidden Markov Models),
których
działanie
opiera
się
na
sieci
bayesowskiej.
23/42

Trzy problemy indeksowania
• CO
indeksować? Np.: cały dokument,
pojedynczą ramkę?
• JAK
indeksować?
Wybór
sposobu
przypisywania wydobytych informacji.
• JAKIE
informacje
zawrzeć?
Np.:
nazwiska piłkarzy, co w obecnej chwili
robią, oba na raz.
24/42

Indeksowanie baseballu - idea
• Ideą rozwiązania problemu jest podział ujęć meczu na
prostokąty, które zawierają pewien obraz oraz na
przypisane do nich wektorów ruchu.
• Ujęcia wyrażone są jako ciągi symboli powiązane z
kadrami
i
odpowiednio
zaklasyfikowane
do
poszczególnych wydarzeń meczowych. Są to zagrania
baseballowe np.: home-run, single-hit, walk.
• Chcemy przypisać odpowiednie meta-indeksy do
poszczególnych scen. Pomogają w tym Ukryte Modele
Markowa, które zostały do tego celu odpowiednio
zaprojektowane, tak by system potrafił rozróżniać
zdarzenia.
25/42

Indeksowanie baseballu - zdarzenia
• Przykładowe ujęcia zostały wycięte z wielu meczów baseballu.
Utworzono w taki sposób zbiory uczące oraz testowe. Łącznie
zgromadzono ponad 480 ujęć.
• Każde z ujęć zostało manualnie przypisane do jednej z siedmiu
kategorii „indeksów-zdarzeń”:
1. home-run
2. double
3. single-hit,
4. walk
5. fly-out
6. infield-grounder
7. strike-out
• Taki zestaw indeksów zdarzeń uzasadniony jest względną łatwością ich
rozróżnienia i ostatecznie poprawnego zaklasyfikowania ujęć.
26/42

Przykładowe ujęcie meczowe
Kadry przedstawiają zdarzenie- zagranie „double”
27/42
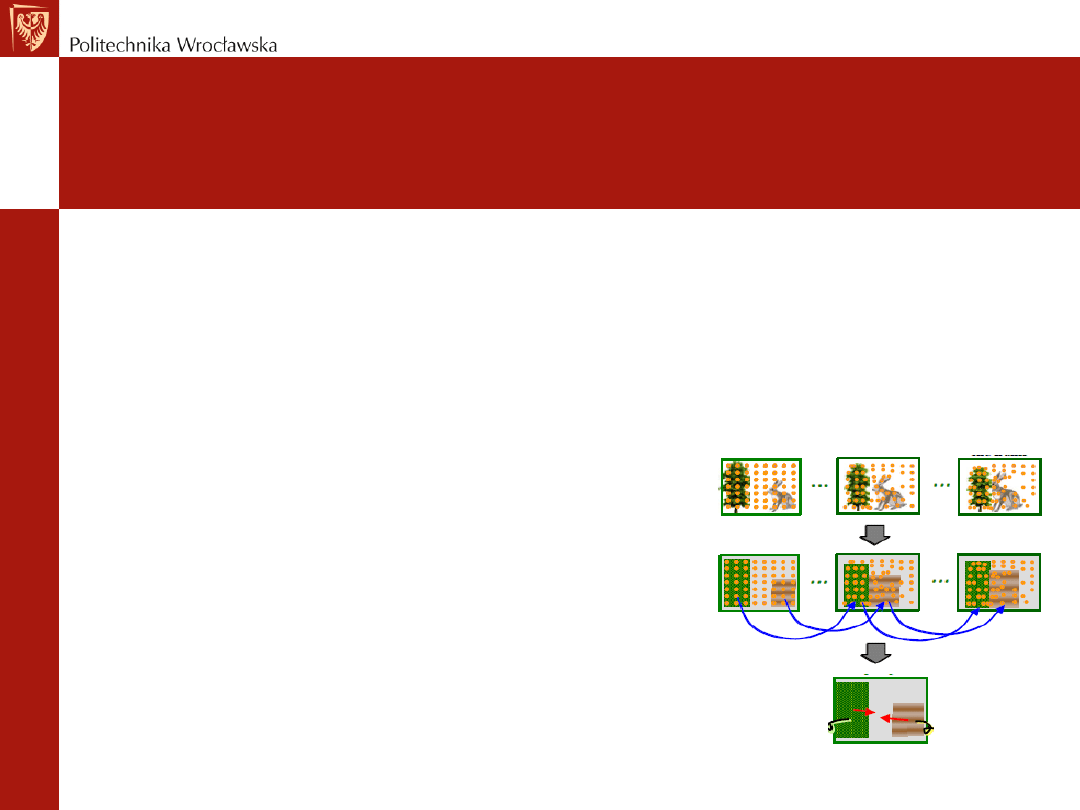
Uczenie Ukrytych Modeli Markowa
• Schemat uczenia i kroki trenowania:
- wykryj zmiany kadrów w ujęciach i przypisz indeks wydarzenia
do każdego z nich
- opisz każde z ujęć ciągiem symboli
-
ustaw
parametry
HMM
używając
sekwencji
symboli
odpowiedniej dla każdego zdarzenia
•
Po tym etapie następuje proces analizy
kadrów poprzez nałożenie na obraz
punktów śledzących obiekty
(tracking points), co ma na celu
przypisanie obiektu do jednego z
istniejących wzorców.
28/42
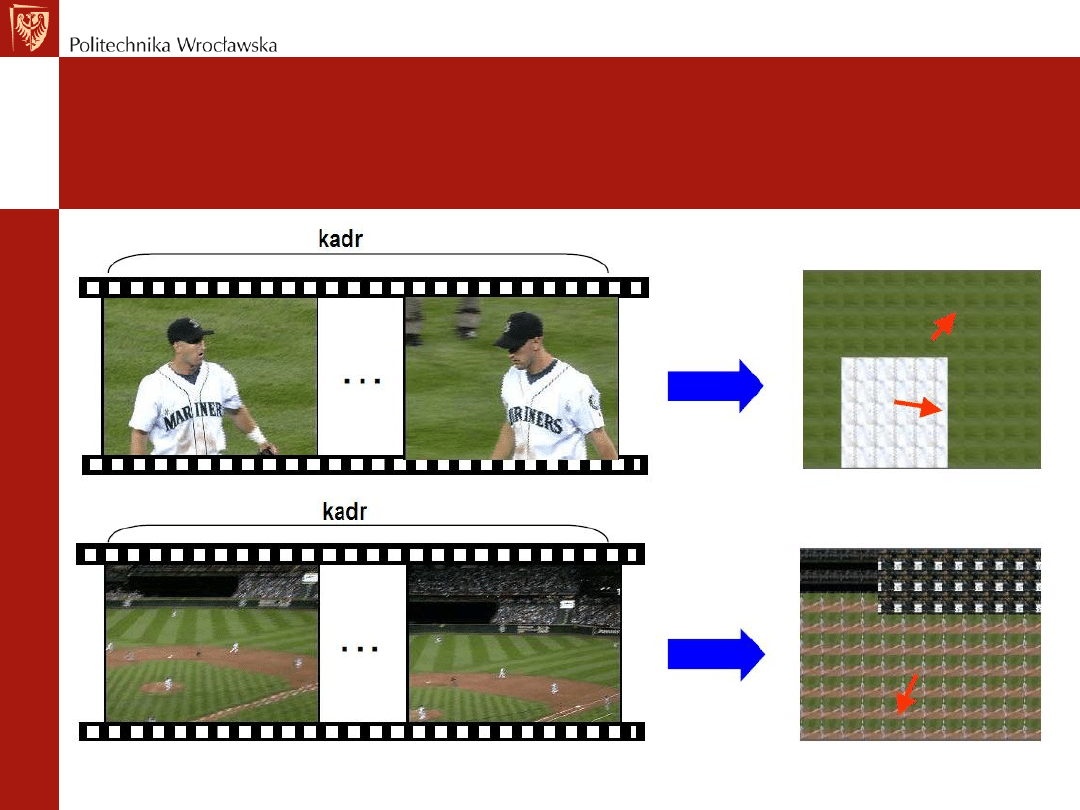
Przykładowe wzorcowanie kadru
29/42
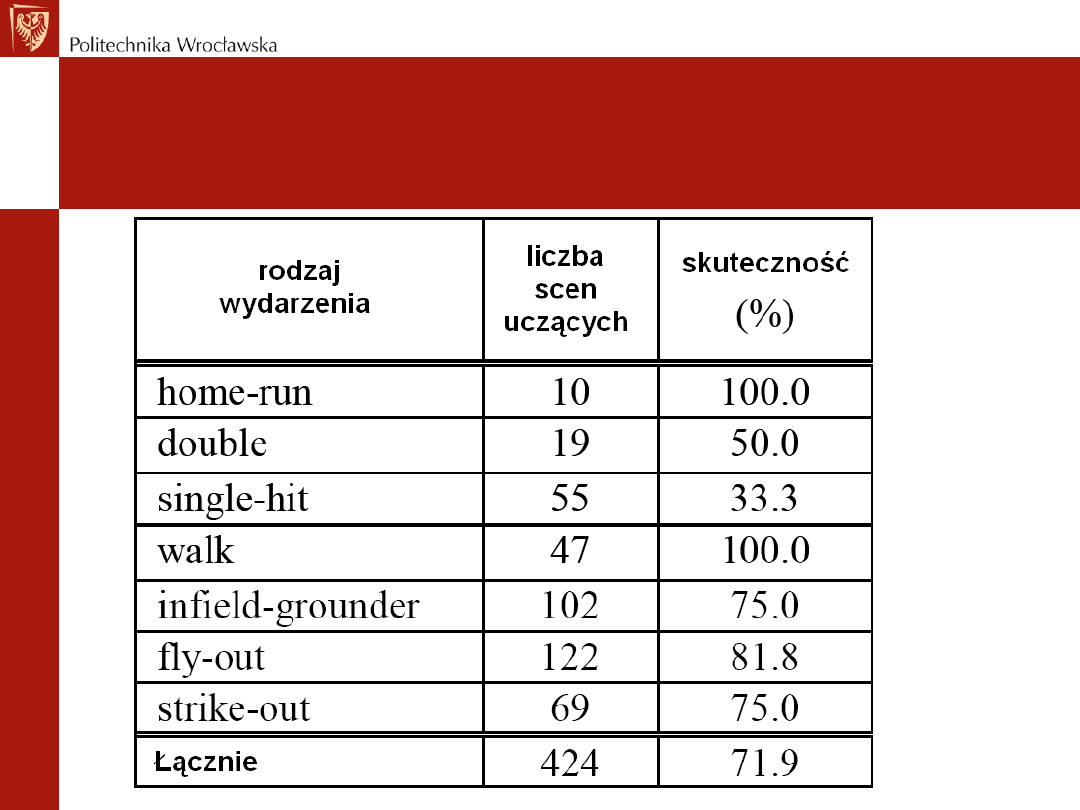
Podsumowanie skuteczności
rozponawania zagrań baseballowych
30/42

Semantyczne indeksowanie wideo
1/2
• Obecnie
popularnym
kierunkiem
rozwoju
indeksowania wideo jest tzw. semantyczne
indeksowania wideo (semantic video indexing).
• By pokazać czym ono jest zastanówmy się
chwilę nad p
ytaniem: co widzimy n
a poniższym
obrazku?
31/42

Semantyczne indeksowanie wideo
2/2
• Z pewnością większość ludzi
stwierdzi, że są tu pokazane
palmy, plaża i zachód słońca.
• Jednak dla przeciętnej
wyszukiwarki obrazów czy wideo
będzie to tym z czym zostało to
zdjęcie skojarzone np.: prognozą
pogody na stronie BBC, ponieważ
taki meta-znacznik przypisany został do tego obrazu.
• Popatrzmy na 3 możliwości opisania tego obrazu pod względem
jego zawartości, rożniące się stopniem złożoności:
- zachód słońca (trywialny przypadek- nawet średni kolor o tym mówi)
- palmy (trudny przypadek)
- Hawaje (niemożliwe do zgadnięcia)
32/42

Idea semantycznego indeksowania
wideo
• Czym jest zatem semantyczne indeksowanie wideo? Po
poprzednich slajdach i analizie obrazu łatwiej jest
zrozumieć istotę zagadnienia.
• Podczas gdy przy zwykłym indeksowaniu skupiamy się na
słowach kluczowych, przy indeksowaniu content-based
skupiamy
się
na
zawartości
wideo,
którego
się
spodziewamy w indeksowaniu semantycznym operujemy
na konceptach- obiektach których rodzaju nie znamy.
Operujemy na wyższym poziomie abstrakcji, próbujemy
zidentyfikować te koncepty.
• Potrafiąc wyszczególnić z klatki obrazu poszczególne
obiekty chcemy być w stanie określić ich typ (są
drzewami, palmami, plażą, prognozą pogody?).
33/42

Definicja semantycznego
indeksowania wideo
„Jest to proces automatycznego
rozpoznawania obecności
semantycznego konceptu w strumieniu
wideo”
• Rozumiane jako dogłębna analiza zawartości
strumienia wideo.
34/42

Problemy związane z zagadnieniem
• Małe podobieństwo tych samych obiektów oglądanych
z różnej perspektywy.
»
Ten sam obiekt
• Duże podobieństwo różnych obiektów oglądanych z
podobnej perspektywy.
»
»
Różne obiekty
35/42

Generyczne indeksowanie semantyczne
• Rozwinięciem semantycznego indeksowania jest zagadnienie
generycznego indeksowania semantycznego (general semantic
video indexing).
• Jest jednym ze szczytowych osiągnięć technik wyszukiwania
informacji, ale wciąż jest jeszcze intensywnie rozwijane i nie
występuje poza fazą beta.
• Polega
na
zwracaniu
filmów
video
(jedynie
samych
interesujących nas ujęć) dla niemal każdego zapytania np.:
„pokaż mi filmy na których widać idącego George W. Busha”.
• Wyszukiwanie semantyczne jest problemem wymagającym
zastosowania
komponentów
najwyższej
jakości
(moduły
rozpoznawania obrazu) oraz potężnych zasobów finansowych.
• Końcowy efekt z pewnością zwróci się bardzo szybko ze względu
na nieosiągalną wcześniej jakość wyników zapytań.
36/42

Dlaczego jest to takie trudne?
Ponieważ jest tak wiele obiektów, które należy rozróżniać
37/42

Algorytm znajdowania ścieżek
• Przebiegiem procesu steruje
algorytm znajdowania
ścieżek (ang. semantic pathfinder algorithm).
• W generycznym indeksowaniu semantycznym system
składa się z wielu niezależnych algorytmów detekcji
obiektów (np.: drzew, samochodów, twarzy). Wymaga
to możliwie najwyższej jakości każdego z komponentów.
• Obraz obok przedstawia przykładową
strukturę hierarchii detektorów.
• Wierzchołki to obiekty, a linie to
relacje między nimi np.: detektor
chmur jest specjalizacją obiektu
niebo itd.
38/42

Algorytm znajdowania ścieżek
• Odpowiedni algorytm pozwala na:
- przyspieszenie pracy (nie bierzemy
pod uwagę
wszystkich możliwości, lecz działamy „logicznie” –
jeśli obiekt nie jest zielony to staramy się nie
sprawdzać czy jest to trawa)
- unikanie błędów związanych z niepoprawnym
przypisaniem
indeksu
(decyzje
podejmujemy
stopniowo np.: czy obiekt jest bardziej niebiem, czy
bardziej ziemią, potem przechodzimy dalej)
- ułatwienie procesu wizualizacji dochodzenia do
rozwiązania i zwrócenia podobnych wyników
39/42

Przykładowy interfejs
40/42

Podsumowanie indeksowania semantycznego
• Generyczne indeksowanie semantyczne otwiera nową
drogę
w
dziedzinie
wyszukiwania
informacji
audiowizualnych.
• Zasada jego działania zaczyna przypominać pracę
ludzkiego mózgu, przez co podnosi istotnie trafność
zwracanych wyników.
• Aby opracować najlepszy system uczeni z różnych
dziedzin muszą dać z siebie wszystko co najlepsze i
działać
we
wspólnym
celu.
Potrzeba
świetnie
działających detektorów obiektów, dobrego algorytmu
znajdowania ścieżek, koordynacji oraz motywacji i
chęci działania.
41/42

Bibiografia
• M. Petkovic, R. van Zwol, H.E. Blok, Content-based Video Indexing for the
Support of Digital Library Search, 2002
•
Meng Yang, Xiangming Mu & Gary Marchionini, VIVO -A Video Indexing and
Visualization Organizer
• Takahiro Mochizuki, Makoto Tadenuma, Nobuyuki Yagi, BASEBALL VIDEO
INDEXING USING PATTERNIZATION OF SCENES AND HIDDEN MARKOV
MODEL, 2005
• Dr Marcel Worring, University of Amsterdam, Semantic Video Search Indexing
and Concept Detection, 2008
• Cees Cees G.M. G.M. Snoek Snoek & Arnold W.M. & Arnold W.M. Smeulder,
Video Search Engines, 2010
• Mark Randall, Beep.TV, www.beet.tv/2008/04/ndexing-is-key.html
• http://www.reelseo.com/semantic-video-indexing/

Koniec
Dziękuję za uwagę i zachęcam do zadawania pytań
XX/YY
Wyszukiwarka
Podobne podstrony:
Czy wyszukiwarka Google indeksuje dokumenty PDF
Czy wyszukiwarka Google indeksuje dokumenty PDF
000 Alfabetyczny indeks zawodów do KZiS (Dz U 28 08 14,poz 1145)st 22 12 2014
3 Narzędzia wyszukiwawcze i źródła informacji ppt
Pierwsze miejsce w wyszukiwarkach
BIK karwowski islamskie indeksy gieldowe
12 indeksyid 13457
Jak stworzyć prostą wyszukiwarkę dla własnych stron WWW, PHP Skrypty
Geo Wideo, religioznawstwo, fainomenon
Darmowa wyszukiwarka - styl TWILIGHT
Wyszukiwanie drzewo
Indeks glikemiczny
więcej podobnych podstron