
ul. Warszawska 24, 31-155 Kraków, tel/fax (+48 12) 628 20 41, e-mail:
sekretariat@iigw.pl
, internet: www.iigw.pl
INSTYTUT INŻYNIERII I GOSPODARKI WODNEJ
POLITECHNIKA KRAKOWSKA im. TADEUSZA KOŚCIUSZKI
Piotr Nowak
OCENA WYDAJNOŚCI
HYDROMETEOROLOGICZNYCH BAZ DANYCH
W MYSQL 5.0
praca magisterska
studia dzienne
kierunek studiów:
informatyka
specjalność:
informatyka stosowana w inżynierii środowiska
promotor:
dr inż. Robert Szczepanek
nr pracy:
2069
data złożenia: ................................
K
R A K Ó W
2 0 0 7

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
2
Spis Treści:
SPIS TREŚCI: ................................................................................................................................. 2
1.
WSTĘP...................................................................................................................................... 4
1.1.
C
EL PRACY
.......................................................................................................................... 4
1.2.
O
PIS PROBLEMU
.................................................................................................................. 4
1.3.
Z
AWARTOŚĆ PRACY
............................................................................................................ 4
1.4.
K
RYTERIA OCENY
................................................................................................................ 6
1.4.1.
Wydajność zapisu ..................................................................................................... 6
1.4.2.
Wydajność wyszukiwania ....................................................................................... 6
1.4.3.
Objętość....................................................................................................................... 7
1.5.
T
EORETYCZNE PODSTAWY SYSTEMÓW BAZODANOWYCH
.................................................... 8
1.5.1.
Język SQL.................................................................................................................... 8
1.5.2.
Relacyjny model danych......................................................................................... 9
1.5.3.
Formalny zapis operacji na modelu relacyjnym .............................................. 9
1.5.4.
Normalizacja baz danych...................................................................................... 13
1.5.5.
Pojęcie postaci normalnej .................................................................................... 14
1.5.6.
Hurtownie danych................................................................................................... 17
1.5.7.
Systemy MySQL/PostgresSQL............................................................................. 19
1.6.
W
YMAGANIA SPRZĘTOWE
................................................................................................. 21
1.6.1.
Propozycja konfiguracji obsługującej projektowany system...................... 21
2.
WYMAGANIA FUNKCJONALNE.................................................................................... 23
2.1.
Z
AŁOŻENIA PROJEKTOWANEGO SYSTEMU
......................................................................... 23
2.1.1.
Rodzaj informacji zasilających system ............................................................. 23
2.1.2.
Format gromadzonych danych ........................................................................... 24
2.1.3.
Przewidywana ilość danych zasilająca system............................................... 25
2.1.4.
Możliwe sposoby dostępu do danych ................................................................ 27
2.2.
F
UNKCJE PODSTAWOWE
.................................................................................................... 29
2.2.1.
Gromadzenie danych z systemu czujników .................................................... 29
2.2.2.
Archiwizacja danych w dłuższym horyzoncie czasowym............................. 29
2.2.3.
Umożliwienie klientom dostępu do danych ..................................................... 30
2.3.
P
ROPOZYCJE ROZSZERZEŃ FUNKCJONALNOŚCI
................................................................ 31
2.3.1.
Zapis danych, a detekcja błędów....................................................................... 31
2.3.2.
Wykorzystanie logiki rozmytej w detekcji błędów ........................................ 32
2.3.3.
Określanie właścicieli przechowywanych pomiarów ..................................... 34
2.3.4.
Obsługa różnych poziomów użytkowników ..................................................... 34
2.3.5.
Automatyczne powiadomienia ............................................................................ 35
2.3.6.
Synchronizacja z bazami „zaprzyjaźnionymi” ................................................ 36
2.3.7.
Obsługa płatnego dostępu do danych............................................................... 37
2.3.8.
System monitorowania danych w czasie rzeczywistym .............................. 37
2.4.
PROPOZYCJE
ZWIĘKSZENIA
WYDAJNOŚCI ......................................................... 39
2.4.1.
Mechanizm cacheingu............................................................................................ 39
2.4.2.
Rozwiązanie softwarowe – AdoDB ..................................................................... 41
2.4.3.
Wydzielenie wyspecjalizowanych serwerów ................................................... 42
2.4.4.
System rozproszony............................................................................................... 43
3.
PROJEKTOWANE PROPOZYCJE ROZWIĄZAŃ ...................................................... 44
3.1.
D
ANE ZAPISANE W JEDNEJ TABELI
.................................................................................... 44
3.2.
K
AŻDY POMIAR W OSOBNYM REKORDZIE
......................................................................... 46
3.3.
T
RZECIA POSTAĆ NORMALNA
............................................................................................ 47
4.
SCENARIUSZE DOSTĘPU DO DANYCH .................................................................... 49

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
3
4.1.
N
AJCZĘŚCIEJ WYKORZYSTYWANE KWERENDY
................................................................... 49
4.2.
O
PIS SPOSOBU PROWADZENIA POMIARÓW CZASU WYKONANIA
...................................... 50
4.2.1.
Środowisko testowe ............................................................................................... 51
4.2.2.
Sposób prowadzenia pomiarów.......................................................................... 51
4.3.
P
ORÓWNANIE WYDAJNOŚCI SCHEMATÓW W OBSŁUDZE ZAPYTAŃ
.................................... 53
4.3.1.
Wpływ zastosowania indeksów na czas obsługi zapytań............................ 53
4.4.
K
RYTERIA OCENY PROPONOWANYCH ROZWIĄZAŃ
............................................................ 54
4.4.1.
Objętość..................................................................................................................... 55
4.4.2.
Wydajność zapisu ................................................................................................... 55
4.4.3.
Wydajność odczytu................................................................................................. 55
5.
ZESTAWIENIE UZYSKANYCH WYNIKÓW .............................................................. 56
5.1.
Z
ESTAWIENIE WYDAJNOŚCI ROZWIĄZAŃ
......................................................................... 56
5.1.1.
Objętość..................................................................................................................... 56
5.1.2.
Wydajność zapisu ................................................................................................... 60
5.1.3.
Wydajność odczytu................................................................................................. 64
5.2.
W
YBÓR ODPOWIEDNIEGO ROZWIĄZANIA
......................................................................... 74
6.
ANALIZA WYNIKÓW........................................................................................................ 83
6.1.
Z
ALETY WYBRANEGO ROZWIĄZANIA
................................................................................. 85
6.2.
W
ADY WYBRANEGO ROZWIĄZANIA
................................................................................... 86
7.
WNIOSKI .............................................................................................................................. 87
8.
SPISY...................................................................................................................................... 89
8.1.
S
PIS
I
LUSTRACJI
............................................................................................................... 89
8.2.
S
PIS TABEL
....................................................................................................................... 90
8.3.
L
ITERATURA
...................................................................................................................... 91
8.4.
L
INKI
................................................................................................................................. 91
9.
ABSTRAKT ............................................................................................................................ 92

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
4
1. WSTĘP
1.1. Cel pracy
Przedmiotem rozważań tej pracy jest badanie wydajności
różnych schematów bazy danych hydrometeorologicznych. Baza ta,
ma w założeniu odpowiadać za gromadzenie i przetwarzanie danych,
z terenu jednego powiatu. Badanie zostanie przeprowadzone
w środowisku MySQL 5.0 i obejmie trzy propozycje schematów
bazodanowych.
Wyniki
przeprowadzonych
testów
pozwolą
udokumentować proces „odnajdywania” najlepszego rozwiązania.
1.2. Opis problemu
Problemem, który w założeniu, ta praca ma rozwiązać, jest
wydajne
gromadzenie
i
udostępnianie
klientom,
danych
hydrometeorologicznych. Taka definicja problemu pozwala zauważyć
dwa pod problemy. Pierwszy z nich, to wydajne gromadzenie danych.
Można to rozumieć jako problem zagwarantowania wydajnego zapisu
do bazy danych. Drugi, wydajne udostępnianie, to problem
wydajności odczytu informacji zgromadzonych w systemie.
1.3. Zawartość pracy
Zgodnie z praktyką tworzenia rozwiązań informatycznych,
projektowanie systemu zostało podzielone na szereg etapów.
Pierwszym z nich jest zgromadzenie informacji na temat rodzaju
i ilości danych, które system będzie magazynował. Następnym
krokiem jest określenie funkcjonalności jaką system powinien
udostępniać. Na tym etapie należy określić jakie zestawy danych
powinny być łatwo dostępne, dane z jakiego okresu czasu powinny
być udostępniane w czasie rzeczywistym.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
5
Oraz czy istnieje konieczność implementacji różnych poziomów
dostępu do informacji zgromadzonej w projektowanym systemie. Po
ustaleniu na jakiej ilości, jakich danych system będzie pracował, oraz
jakie możliwości przetwarzania danych powinien oferować, opisany
zostanie proces tworzenia rozwiązań kandydujących. Rozwiązaniem
kandydującym jest każdy schemat bazodanowy, którego wydajność
nie została jeszcze sprawdzona i skonfrontowana z innymi
propozycjami. W założeniu, każde z tych rozwiązań spełnia
postawione warunki użyteczności, a zatem każde z nich mogłoby
zostać użyte podczas wdrażania opisywanego systemu. Należy jednak
porównać
rozwiązania
kandydujące
poprzez
szereg
testów
stworzonych na podstawie analizy wymogów funkcjonalnych. Testy te
mają na celu sprawdzenie, czy dane rozwiązanie spełnia wymogi
wydajności zapisu, odczytu i objętości.
Zestawienie wyników testów przeprowadzanych w izolowanym
środowisku bazodanowym pozwoli zilustrować, które z rozwiązań
najlepiej funkcjonuje w zadanych warunkach. Efektem powziętych
wysiłków
będzie
opis
zachowania
proponowanych
rozwiązań
w poszczególnym teście. Dzięki temu możliwe będzie podjęcie
racjonalnej decyzji, które z rozwiązań jest najlepsze dla zadanych
warunków działania projektowanego systemu na zadanym terenie,
z uwzględnieniem specyficznych wymagań mogących wystąpić.
Dodatkowo, można przeprowadzić analizę możliwości rozwoju
danych rozwiązań kandydujących w celu zwiększenia funkcjonalności
lub ułatwienia obsługi. Na tym etapie należy zadać pytanie czy, a jeśli
tak, to jakie dodatkowe usługi system powinien posiadać. Czy istnieje
potrzeba implementacji rozwiązań typu database cache (AdoDB) lub
Global Proxy (Akamai) lub też rozproszenia systemu, aby zbieranie
danych odbywało się lokalnie, a archiwizacja na głównym serwerze.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
6
1.4. Kryteria oceny
Przystępując do projektowania, należy określić kryteria oceny
jakości systemu. W badaniu jakości rozwiązań rozpatrywane będą
trzy kryteria:
Wydajność zapisu
Wydajność odczytu
Objętość
1.4.1. Wydajność zapisu
W
systemie
bazodanowym
można
wyszczególnić
dwa
podstawowe rodzaje operacji. Są to operacje zapisu i odczytu danych.
Z punku widzenia użytkowników, wydajność tych operacji decyduje
o jakości systemu. Ze względu na zakładaną początkową liczbę stacji
pomiarowych tj. około 50, częstotliwość dokonywania pomiarów
tj. około 1 serii na 10 minut, oraz zakładanego rozwoju sieci
pomiarowej w przyszłości - wydajność zapisu danych jest
podstawowym kryterium branym pod uwagę podczas projektowania
systemu agregującego dane z wielu źródeł. Dodatkowo, na wydajność
zapisu mają duży wpływ czynniki zewnętrzne, nie związane
z zastosowanym schematem bazy danych. Zaliczają się do nich
parametry łącza jakie obsługuje serwer bazodanowy, ilość pamięci
przydzielonej procesowi serwera, dopuszczalna ilość konkurujących
połączeń przychodzących, rodzaj urządzeń fizycznie magazynujących
dane – dysków twardych, oraz sposób ich podłączenia. Z punktu
widzenia oprogramowania bazodanowego, zapis nowych danych jest
jedną z najszybszych operacji. Twórcy oprogramowania włożyli sporo
wysiłku aby ten proces maksymalnie zoptymalizować.
1.4.2. Wydajność wyszukiwania
Jako, że głównym zastosowaniem baz danych jest ułatwianie
dostępu do wyspecyfikowanego wycinka większego zbioru informacji,

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
7
projektując taki system nie można pominąć kwestii wygody
użytkownika podczas dostępu do poszukiwanych danych. Podczas
rozpatrywania zagadnień wydajności dostępu do danych, czynniki
zewnętrzne także nie pozostają bez znaczenia, jednakże ich
znaczenie nieco się zmienia, np. szybkość łącza internetowego
obsługującego serwer ma mniejsze znaczenie ze względu na fakt, iż
rzadko przychodzą żądania ilości danych objętościowo dorównujących
tym, jakie musza być zapisywane. Nie można jednak pominąć
ograniczeń fizycznych, wynikających ze specyfikacji użytego sprzętu
komputerowego. Można ograniczyć ich wpływ stosując rozwiązania
zwiększające wydajność odczytu i zapisu, takie jak szybkie dyski
SCSI, macierze dyskowe RAID oparte o dyski (S)ATA, lub także
o dyski SCSI.
1.4.3. Objętość
Wraz z upływem czasu i przyrostem przechowywanych
informacji, pojawi się także problem składowania takich ilości danych.
Dla przykładu, w sytuacji gdy w systemie działa 500 stacji
pomiarowych, z których każda gromadzi 20 pomiarów co 10 minut,
objętość surowych danych będzie przyrastała o 0.25MB co każdą
godzinę, jeśli zapisu dokonujemy używając liczb całkowitych. Jeśli
użyjemy typu zmiennoprzecinkowego Double będzie to 0.5MB na
godzinę. Baza zasilana taką ilością danych po 10 latach osiągnie
ogólny rozmiar 20.5GB przy liczbach całkowitych i 41GB przy liczbach
zmiennoprzecinkowych. Można więc zauważyć, że sama zmiana typu
przechowywanych danych pozwala zaoszczędzić połowę miejsca.
Niestety przetwarzanie takich danych przechowywanych w liczbach
całkowitych wiązałoby się z wykorzystaniem większej mocy
obliczeniowej do ich późniejszego przetwarzania. Dodatkowo, to
proste wyliczenie nie uwzględnia faktu powiększania się ilość stacji
monitorujących w czasie.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
8
1.5. Teoretyczne podstawy systemów bazodanowych
1.5.1. Język SQL
SQL stał się najpopularniejszym relacyjnym językiem zapytań
bazodanowych. Nazwa jest skrótem od Structured Query Language
(Strukturalny Język Zapytań). W 1974 r. Donald Chamberlin i inni
zdefiniowali SEQUEL (Structured English Query Language). Po raz
pierwszy został wprowadzony w prototypie IBM zwanym SEQUEL-XRM
w 1974-75 r. W latach 1976-77 powstała poprawiona wersja SEQUEL
nazwana SEQUEL/2 , a nazwę tą następnie zmieniono na SQL.
Nowy prototyp System R, wprowadzony przez IBM w 1977r.
obejmował większą część SEQUEL/2 (teraz SQL) jak i wprowadzał
wiele zmian do SQL. Sukces i akceptacja pierwszych użytkowników
spowodował,
że
IBM
rozpoczęła
wprowadzanie
pierwszych
komercyjnych produktów opartych na technologii Systemu R,
zawierających SQL. [Wikipedia, 2007-08-29]
Przez następne lata IBM i inni producenci stworzyli produkty
korzystające z technologii SQL, takie jak:
SQL/DS (IBM)
DB2 (IBM)
ORACLE (Oracle Corp.)
DG/SQL (Data General Corp.)
SYBASE (Sybase Inc.)
Obecnie SQL jest standardem oficjalnym. W 1982 r. Komitet
Baz Danych X3H2 Amerykańskiego Instytutu Standardów ANSI
(American National Standards Institute) przedstawił propozycję
standardu języka relacyjnego, który zawierał dialekt IBM i został
przyjęty w 1986 r. Rok później standard ten został również
zaakceptowany przez Międzynarodową Organizację Standaryzacji ISO
(International Organization for Standardization). Oryginalna wersja
standardu jest nieformalnie nazywana SQL/86. W 1989 r. standard

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
9
został rozszerzony i ponownie było to rozszerzenie nieformalnie,
a nowy standard nazwano SQL/89.
Komitety ISO i ANSI przez wiele lat pracowały nad
zdefiniowaniem bardziej rozbudowanej wersji standardu nazwanej
SQL2 lub SQL/92. Ta wersja w 1992 r. została przyjęta jako:
"International Standard ISO/IEC 9075:1992, Database Language
SQL". Szczegółowy opis SQL/92 podano w Date and Darwen, 1997.
1.5.2. Relacyjny model danych
Jak wspomniano wcześniej, SQL jest językiem relacyjnym.
Oznacza to, że jest oparty na relacyjnym modelu danych,
opublikowanym po raz pierwszy przez E.F.Codd'a w 1970 roku. Baza
danych oparta na modelu relacyjnym, jest bazą postrzeganą przez
użytkowników jako zbiór tabel. Tabela składa się z wierszy i kolumn,
gdzie każdy wiersz reprezentuje rekord, a każda kolumna atrybuty
rekordów zawartych w tabeli. Definiując tabelę, możemy określać
atrybuty rekordów oraz jakiego rodzaju dane będą reprezentować
dany atrybut. [David M. Kroenke, 1997]
1.5.3. Formalny zapis operacji na modelu relacyjnym
Model relacyjny może być zapisany w postaci podzbioru
iloczynu kartezjańskiego z listy dziedzin. Od tej teoretycznej relacji
bierze się nazwa tego modelu. W rzeczywistości dziedzina, inaczej
domena, jest po prostu zbiorem wartości. Na przykład, dziedziną jest
zbiór liczb całkowitych lub zbiór łańcuchów znakowych o długości 20
znaków, czy też zbiór liczb rzeczywistych.
Iloczyn kartezjański dziedzin:
D1, D2, ... Dk
zapisany jako:
D1 × D2 × ... × Dk
jest zbiorem wszystkich krotek
v1, v2, ... vk, takich jak v1 D1, v2 D2, ... vk Dk.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
10
Na przykład, gdy mamy k=2, D1={0,1} oraz D2={a,b,c} wtedy
D1 × D2 jest {(0,a),(0,b),(0,c),(1,a),(1,b),(1,c)}.
Relacją jest dowolny podzbiór iloczynu kartezjańskiego jednej lub
wielu dziedzin [Ramez Elmasri, Shamkant B. Navathe, 2005]:
R D1 × D2 × ... × Dk.
Na przykład {(0,a),(0,b),(1,a)} jest relacją; tzn. zbiorem
D1 × D2 wspomnianych wyżej.
Elementy relacji są nazywane krotkami. Każda relacja jakiegoś
iloczynu kartezjańskiego
D1 × D2 × ... × Dk
jest zbiorem krotek.
Każda relacja jest odzwierciedlana tabelą i może być
przeglądana w taki sam sposób jak tabela. Nazwy kolumn nazywane
atrybutami odgrywają główną rolę w definicji schematu relacji.
Schematem relacji R jest dowolny zbiór atrybutów A1, A2, ...
Ak. Dla każdego atrybutu Ai, 1 <= i <= k, jest dziedzina Di, skąd
brane są wartości atrybutów. Często schemat relacji zapisuje się
w ten sposób:
R(A1, A2, ... Ak).
Aby możliwe było wykonywanie operacji na modelu danych SQL
należy użyć jednego z dwóch rodzajów zapisu wyrażeń relacyjnych.
Są to algebra relacyjna oraz rachunek relacji. Te dwa języki
formalne
dodają
do
modelu
zbiór
operacji
umożliwiających
manipulowanie danymi przechowywanymi w bazie danych.
Algebra relacyjna stanowi podstawowy zbiór operacji dla
modelu relacyjnego. Operacje należące do tego zbioru umożliwiają

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
11
użytkownikowi wykonywanie podstawowych zapytań wyszukiwania,
a ich wynikiem jest zawsze nowa relacja tworzona z użyciem jednej
lub więcej relacji istniejących wcześniej. Oznacza to, że wynikiem
wykonania jednej operacji algebry relacyjnej jest relacja, mogąca być
użytą w wykonaniu innej / kolejnej operacji tej algebry. Sekwencja
takich operacji tworzy wyrażenie algebry relacyjnej, którego
wynikiem także jest relacja (np. wynik zapytania do bazy danych lub
żądania przeszukiwania).
Algebra relacyjna jest jednym z najważniejszych elementów
modelu relacyjnego ponieważ:
stanowi formalna podstawę dla operacji tego modelu.
Jest wykorzystywana podczas implementowania i optymalizowania
zapytań RDBMS
Niektóre z elementów tej algebry zostały włączone do języka
zapytań SQL
Operacje składające się na algebrę relacyjną można podzielić na
2
grupy.
Jedna
grupa
obejmuje
operacje
na
zbiorach
z matematycznej teorii zbiorów – w formalnym modelu relacyjnym
każda relacja jest zbiorem krotek. Operacje tej grupy to:
suma
część wspólna
różnica
iloczyn kartezjański
Druga grupa to zbiór operacji opracowanych specjalnie na
potrzeby relacyjnego modelu danych. Grupę tą można podzielić na
dwie podgrupy. Pierwsza to, operacje unarne, czyli operujące na
pojedynczych relacjach. Druga to, operacje binarne, czyli operujące
na dwóch tablicach.
Do grupy operacji unarnych zaliczamy:
selekcja – (SELECT) jest niezbędna do wyznaczenia takiego
podzbioru krotek z relacji, który spełni warunek selekcji. Operację

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
12
taką można traktować jak pewnego rodzaju filtr, który przepuszcza
jedynie krotki spełniające zdefiniowany warunek. Warunek selekcji
może być prosty – definiować wymóg tylko dla jednego parametru
krotki lub złożony – będący koniunkcją lub alternatywą warunków
prostych.
projekcja – w przeciwieństwie to operacji selekcji, projekcja
wybiera pewne kolumny z tabeli. Umożliwia ona rzutowanie
istniejącej relacji do formy, którą tworzą jedynie kolumny będące
przedmiotem zainteresowania w danej chwili.
Do grupy operacji binarnych zaliczamy:
złączania – (JOIN) operacja ta jest wykorzystywana do łączenia
występujących w dwóch różnych relacjach, połączonych ze sobą
krotek w pojedyncze krotki. Ta operacja jest bardzo ważna dla
relacyjnych baz danych, które zawierają więcej niż jedną relację.
Daje ona możliwość przetwarzania istniejących związków pomiędzy
relacjami.
dzielenia – przykładem tego specjalnego rodzaju operacji, może
być realizacja zapytania: „znajdź wszystkie stacje prowadzące
pomiary takich samych parametrów jak stacja ‘Żywiec 1’”.
Operacja dzielenia definiuje realizację takiego zapytania jako
następującą procedurę.
o
Odnalezienie listy pomiarów przeprowadzanych przez
stację „Żywiec 1” i umieszczenie jej w pośredniej relacji
POMIARY_ZYWIEC1.
o
Stworzenie relacji POMIAR_STACJA zawierającej krotki
w postaci
o
<id_pomiaru, id_stacji>
o
Dopiero dla tych dwóch relacji pośrednich stosujemy
właściwą operację dzielenia, która w wyniku zwróci
relację złożoną z oczekiwanych krotek.
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
13
Rachunek relacji stanowi element systemu, zapewniający
deklaratywną notację definiowania relacyjnych zapytań na bardziej
abstrakcyjnym poziomie. Wyrażenie rachunku relacji tworzy nową
relację, której zawartość określają wartości zmiennych opisujące
zakresy krotek relacji przechowywanych w bazie danych. Wyrażenie
rachunku relacji nie określa kolejności wykonywania operacji,
a jedynie informacje jakie powinny się znaleźć w wygenerowanym
wyniku.
1.5.4. Normalizacja baz danych
Normalizacja to technika modelowania danych, której celem
jest zapewnienie organizacji elementów danych taki sposób, aby były
one przechowywane tylko w jednym miejscu [Allen S, 2006]. Zawiera
w sobie tworzenie tabel i wyznaczanie relacji pomiędzy tymi tabelami.
Normalizując bazę danych należy dążyć do wyeliminowania zjawisk:
Nadmiarowości
Niespójnych zależności
Nadmiarowość występuje gdy w obrębie tabeli lub bazy,
wielokrotnie
powtarza
się
ta
sama
informacja.
Przykładem
nadmiarowości może być tabela, gdzie każdy pomiar oznaczony jest
nazwą stacji z jakiej został pobrany.
Tabela 1. Przykładowa tabela z nadmiarowością danych
Stacja
Polozenie
czas_pomiaru
temp2m
temp0m
Żywiec1
5311’45’’N 1311’45’’E
2007-04-22 12:00:11
11C
12C
Żywiec2
5511’45’’N 2111’45’’E
2007-04-22 12:00:14
16C
17C
Żywiec1
5311’45’’N 1311’45’’E
2007-04-22 12:00:21
11C
12C
Żywiec1
5311’45’’N 1311’45’’E
2007-04-22 12:00:31
12C
14C
W powyższym przykładzie widać, że informacja w 2 pierwszych
kolumnach powtarza się. Oznacza to, że wraz ze zwiększaniem się
ilości zapisanych pomiarów, objętość bazy danych będzie wzrastać
niewspółmiernie do ilości pomiarów.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
14
W przypadku systemów przechowujących tak duże ilości
informacji, jak w przypadku projektowanego systemu dla pomiarów
hydrometeorologicznych,
strata
związana
z
niepotrzebnie
przechowywanymi danymi byłaby ogromna. Dodatkowym problemem
byłaby modyfikacja zawartych danych. Jeśli w tabeli z pomiarami
przechowywano by także numer telefonu do operatora stacji, a po
pewnym czasie numer ten uległby zmianie – należałoby zmienić
wszystkie rekordy dotyczące pomiarów dokonanych dla tej stacji.
Operacja taka byłaby bardzo kosztowna z punktu widzenia
zapotrzebowania
na
zasoby
i
mogłaby
zakłócić
poprawne
funkcjonowanie systemu.
Niespójne zależności. O ile poszukiwanie danych o numerze
telefonu do stacji Żywiec1 w tabeli Stacje, jest bardzo intuicyjne, to
szukanie numeru telefonu do osoby odpowiedzialnej za tę stację nie
jest poprawną drogą do rozwiązania problemu. Numer telefonu
takiego pracownika jest przypisany do osoby pracującej na danej
placówce – więc taka informacja powinna być przeniesiona do tabeli
Pracownicy. Niespójna zależność może oznaczać niemożliwość
dotarcia do takiej informacji. Może to być spowodowane błędnym
zaplanowaniem relacji w strukturze bazy danych.
1.5.5. Pojęcie postaci normalnej
Istnieje kilka postaci normalizacji baz danych. Każda z nich
nazywana jest „Postacią normalną”. Jeśli w danej strukturze
bazodanowej spełniona jest pierwsza z nich, uważa się, że baza
danych „jest w pierwszej postaci normalnej”. Jeśli spełnione są trzy
pierwsze zasady, rozważana struktura „jest w trzeciej postaci
normalnej”. Możliwe są wyższe poziomy normalizacji, uważa się
jednak, że trzecia postać normalna jest najwyższym poziomem
wymaganym w większości przypadków. [Kent, W., 1983]

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
15
Podobnie jak z wieloma teoretycznymi specyfikacjami, świat
rzeczywisty nie zawsze pozwala w pełni dopasować projektowane
rozwiązanie do postaci normalnych. Ogólnie, normalizacja wymaga
dodatkowych tabel, a niektórzy klienci, zamawiający rozwiązanie,
uważają taki fakt za zbędną komplikację. Jednak, jeśli podejmuje się
decyzję o odejściu od którejś z trzech pierwszych zasad normalizacji,
należy upewnić się, że projektowany system nie sprawi problemów
z nadmiarowością lub niespójnymi zależnościami. Pierwsza postać
normalna wymaga:
wyeliminowania powtarzających się grup w tabelach
utworzenia oddzielnej tabeli dla każdego zestawu danych
pokrewnych
określenia klucza podstawowego (Primary Key – (PK)) dla każdego
zestawu danych pokrewnych [Kent, W., 1983]
Nie należy używać pól w jednej tabeli do przechowywania
podobnych informacji. Przykładem może być zapis stacji z której
pochodzi pomiar.
Tabela 2. Przykład tabeli przechowującej Stacje pomiarowe
id_stacji (PK)
nazwa
Polozenie
1
Żywiec1
5311’45’’N 1311’45’’E
2
Żywiec2
5511’45’’N 2111’45’’E
Tabela 3. Przykład tabeli przechowującej Pomiary przed normalizacją
Id_pomiaru
stacja1
stacja2
czas_pomiaru
temp2m
temp0m
1
1
2007-04-22 12:00:11
11C
12C
2
2
2007-04-22 12:00:14
16C
17C
3
1
2007-04-22 12:00:21
11C
12C
4
1
2007-04-22 12:00:31
12C
14C
Niestety, rozwiązanie takie jest bardzo nieelastyczne. Jeśli do
naszego systemu dodamy jeszcze jedną stację - cała nasza struktura
będzie wymagała przebudowy. Operacja taka jest możliwa, ale
wymaga zastosowania dodatkowego oprogramowania i może się
okazać niebezpieczna dla informacji przechowywanych w już
istniejących polach.
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
16
Druga postać normalna wymaga:
utworzenia oddzielnych tabel dla zestawów wartości odnoszących
się do wielu rekordów
ustalenia powiązania tabel za pomocą klucza obcego [Kent, W., 1983]
Zobrazowaniem tej sytuacji może być utworzenie tabeli Stacje
i w tabeli Pomiary przechowywać, zamiast pól z przykładu (stacja,
położenie) jedynie pole id_stacji (klucz obcy – Foreign Key (FK)),
a informacje związane ze stacją zapisywać w tabeli Stacje.
Tabela 4. Przykład tabeli przechowującej Stacje pomiarowe
id_stacji (PK)
nazwa
polozenie
1
Żywiec1
5311’45’’N 1311’45’’E
2
Żywiec2
5511’45’’N 2111’45’’E
Tabela 5. Przykład tabeli przechowującej Pomiary po sprowadzeniu do drugiej postaci
normalnej
id_pomiaru (PK)
id_stacji (FK)
czas_pomiaru
temp2m
temp0m
1
1
2007-04-22 12:00:11
11C
12C
2
2
2007-04-22 12:00:14
16C
17C
3
1
2007-04-22 12:00:21
11C
12C
4
1
2007-04-22 12:00:31
12C
14C
Rekordy nie powinny zależeć od niczego poza kluczem
podstawowym (względnie kluczem kompozytowym jeśli jest to
konieczne).
Trzecia postać normalna wymaga:
wyeliminowania pól, które nie zależą od klucza [Kent, W., 1983]
Wartości w rekordzie, które nie są częścią klucza, nie należą do
tabeli. Ogólnie, jeśli jakaś grupa pól odnosi się do więcej niż jednego
rekordu tabeli, należy rozważyć umieszczenie tych pól w osobnej
tabeli. W praktyce może być rozsądniej zastosować trzecią postać
normalną tylko do danych często się zmieniających. Jeśli istnieją pola
zależne, przy takiej konstrukcji bazy danych, należy zaplanować
aplikacje tak, aby wymagać od użytkownika weryfikacji wartości
w tych polach.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
17
1.5.6. Hurtownie danych
Hurtownia danych jest dużym systemem, który organizuje dane
tak, aby można było dotrzeć do większości informacji w nim
przechowywanych. Innymi słowy „… to coś więcej niż dane, to cały
proces służący przekazaniu danych ze źródła do tabeli, a następnie
dostarczeniu danych z tabeli do analityków [Anahory, S., & Murray, D.,
1997]”. Hurtownie danych mogą być i są używane w praktycznie
wszystkich aspektach biznesowych, rządowych czy edukacyjnych.
Wiele firm posiada ogromne ilości danych, które składowane są
w sposób uniemożliwiający swobodne korzystanie z nich. Hurtownie
danych organizują i udostępniają te dane analitykom, tak aby mogli
oni podejmować lepsze decyzje. Systemy takie mogą zbierać różne
dane z wielu źródeł i wyznaczać powiązania pozwalające wszystkim
typom informacji współgrać ze sobą. Ten typ rozwiązania posiada
zalety niedostępne w innych systemach bazodanowych. Inne typy
rozwiązań koncentrują swoją uwagę na składowaniu danych najlepiej
odpowiadających aplikacji jaką mają obsługiwać, a hurtownie danych
posuwają się o krok dalej, koncentrując się na danych samych
w sobie. Inną zaletą takich rozwiązań jest integracja danych, stabilne,
poprawne wartości i zapis nowych informacji w czasie rzeczywistym.
Systemy hurtowni danych umożliwiają wywoływanie kwerend dla
całościowych i posortowanych zestawów danych. Posiadanie jednego
pełnego źródła informacji dla użytkowników, daje pewność, że
wysłana kwerenda zwróci wynik tak bliski kompletnemu, jak to tylko
możliwe. [William H. Inmon, Richard D. Hackathorn, 1994]
Pojęcie hurtowni danych zawiera w sobie oprogramowanie,
sprzęt i siłę ludzką potrzebne do utrzymania takiego systemu.
Z pośród mnogości terminów związanych z teorią hurtowni danych
najważniejsze to:

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
18
Load Manager(s)
Load Interface – opcjonalny komponent ułatwiający korzystanie
z Load managera.
Query Manager(s) -
User Interface – Interfejs użytkownika
Data Storage Area – Skład danych
Określenie Load Manager opisuje aplikację lub zespół aplikacji
obsługujących interakcję pomiędzy użytkownikiem i Składem danych.
Te swoiste bufory maskują składowanie danych w hurtowni. Procesy
te odpowiadają za pobranie danych oraz za znalezienie optymalnego
miejsca do przechowywania indeksów tych informacji do użytku dla
przyszłych wyszukiwań.
Interfejs użytkownika to kluczowy komponent systemu
hurtowni danych, którego implementacja jest krytyczna dla sukcesu
takiego systemu. Ten interfejs musi czynić system intuicyjnym tak,
aby użytkownicy byli w stanie się go nauczyć i przy jego pomocy
podejmować decyzje.
Query Manager odpowiada za wysyłanie zapytań do Składu
danych mających zaspokoić żądania z interfejsu użytkownika.
Interakcja pomiędzy tymi podsystemami stanowi serce całego
systemu.
Szacuje się, że statystycznie tylko co druga próba wdrożenia
systemu hurtowni danych kończy się sukcesem. Takie statystyki
w połączeniu z kosztem wdrożenia profesjonalnej hurtowni na
poziomie 1 mln USD stanowią, że ryzyko niepowodzenia jest spore.
Z punktu widzenia opisywanego systemu bazodanowego,
podejście jakie prezentuje teoria hurtowni danych nie wydaje się
najlepszym rozwiązaniem. Przede wszystkim, projektowany system
ma stanowić ułatwienie pracy i dostępu do informacji w małych
jednostkach terenowych takich jak powiaty lub gminy, a w takiej skali
system nie będzie gromadził aż takiej ilości różnych informacji, aby
uzasadnione było użycie rozwiązań dla dużych firm i korporacji.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
19
1.5.7. Systemy MySQL/PostgresSQL
MySQL i PostgreSQL to dwa najbardziej rozpowszechnione
systemy bazodanowe spośród rozwiązań na licencji Open-Source na
rynku. Pierwsza zasadnicza różnica pomiędzy tymi systemami to
sposób w jaki powstają. Pierwszy jest produktem szwedzkiej firmy
MySQL AB, natomiast drugi jest tworzony przez społeczność open-
source. Skandynawski produkt znajduje zastosowanie przy małych
instalacjach i średnich, które w prosty, a szybki sposób mają
obsługiwać
bazę
danych,
podczas
gdy
PostgreSQL,
często
porównywany do rozwiązań Oracle znakomicie sprawdza się przy
większych projektach. PostgreSQL to osadzane języki proceduralne,
wykonywane przez bazę danych, wśród których znajdują się: Perl,
Pyton, Tcl i inne. System umożliwia ponadto tworzenie funkcji
w języku C, kompilowanych dalej do dynamicznych bibliotek.
Zarówno MySQL jak i PostgreSQL to także API do wielu języków
C/C++, Pyton, Perl oraz Java poprzez JDBC i ogólne podłączanie
poprzez sterownik ODBC. Oba systemy udostępniają dużą liczbę
typów: liczby, ciągi znakowe, obiekty binarne (ang. Binary Large
Objects, BLOB), data i czas, typy wyliczeniowe, zestawy. Co warto
zaznaczyć, w systemach bazodanowych dana kolumna może zostać
dostosowana do pewnej wielkości danych, które zamierzamy w niej
przechowywać,
tym
samym
uzyskujemy
większą
wydajność
i mniejsze zużycie pamięci (również dyskowej). Przykładem może być
zastosowanie typu TINYINT zamiast INT. Oprócz tego istnieje
możliwość definiowania niektórych typów danych jako narodowych
(różne standardy kodowania na poziomie krotek).
Nowa, piąta wersja MySQL bardzo zbliża się pod względem
funkcjonalnym do rozwiązania PostgreSQLa. Obsługuje niedostępne
w poprzednich wersjach procedury składowane (ang. stored
procedures), kursory (ang. cursors), wyzwalacze (ang. triggers) oraz
perspektywy.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
20
PostgreSQL posiada mechanizm wyzwalaczy, które mogą być
przyłączane do tabel lub widoków. Wyzwalacze mogą być definiowane
w
PL/pgSQL,
PL/Perl,
PL/Python
lub
PL/Tcl.
W
bazie
zaimplementowano obsługę wielu typów indeksów takich jak
B-drzewo, Hash, R-drzewo i GiST. Indeksy posiadają szereg nowych
możliwości, m.in. mogą powstawać jako wynik funkcji, a nie
pochodzić od wartości kolumny, mogą reprezentować część tabeli,
poprzez dodanie klauzuli WHERE podczas wykonywania zapytania
CREATE INDEX. PostgreSQL ma zaimplementowany mechanizm MVCC
(ang. Multiversion Concurrency Control) do zarządzania transakcjami.
Mechanizm ten umożliwia udostępnienie tej samej krotki więcej niż
jednej transakcji. Równocześnie może istnieć przynajmniej kilka
wersji tej samej krotki, które nie są widoczne dla innych
użytkowników do zakończenia danych transakcji. Dzięki temu baza
danych wydajnie zachowuje zasadę ACID. ACID to skrót od
angielskich słów: Atomicity - atomowość, Consistency - spójność,
Isolation - izolacja, Durability - trwałość. [Wikipedia, 2007-09-10]
Określają one warunki jakie powinny spełniać transakcje w bazach
danych.
atomowość transakcji oznacza, iż każda transakcja albo wykona
się w całości, albo zostanie anulowana.
spójność transakcji oznacza, że po wykonaniu transakcji, system
będzie spójny, czyli nie zostaną naruszone żadne zasady
integralności.
izolacja transakcji oznacza, iż jeżeli dwie transakcje wykonują się
współbieżnie, to zazwyczaj (zależnie od poziomu izolacji) nie widzą
zmian przez siebie wprowadzanych.
trwałość danych oznacza, że system potrafi uruchomić się
i udostępnić spójne i nienaruszone dane zapisane w ramach
zatwierdzonych transakcji, na przykład po nagłej awarii zasilania.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
21
Pomimo tylu dostępnych rozwiązań PostgreSQL jest systemem
w pełni zgodnym ze standardem SQL i na każdym etapie rozwoju ta
zgodność była nadrzędnym celem twórców, co przez dłuższy czas
było problematyczne dla MySQL.
1.6. Wymagania sprzętowe
Projektując system informatyczny, należy uwzględniać także
jego część sprzętową. Wynika to z faktu, że nawet najlepiej
zaprojektowana aplikacja nie będzie pracować poprawnie na źle
dobranym sprzęcie. Dodatkowo, dokonując wyboru należy brać pod
uwagę
niezawodność,
serwis
i
wsparcie
techniczne
dla
poszczególnych elementów systemu.
1.6.1. Propozycja konfiguracji obsługującej projektowany
system
Podstawową decyzją jaką należy podjąć przy planowaniu
budowy zestawu sprzętowego do obsługi systemu bazodanowego jest
określenie, czy komputer przeznaczony do obsługi systemu
bazodanowego będzie dedykowany, czy współdzielony z innymi
usługami takimi jak na przykład serwer HTTP (HyperText Transport
Protocol). Biorąc pod uwagę ilość informacji, jakie system będzie
przetwarzał, należy skłaniać się ku rozwiązaniu z dedykowaną
maszyną serwera baz danych. W początkowym okresie działania
systemu
wystarczy
pojedyncza
maszyna
obsługująca
zapis,
wyszukiwania oraz archiwizację starszych pomiarów.
Kwestią kluczową będzie prędkość odczytu i zapisu danych na
dyskach. Najwydajniejszym rozwiązaniem byłaby macierz dyskowa
zbudowana z szybkich dysków SCSI. Rozwiązania takie stosuje się
w systemach mocno obciążonych dostępem do danych. Alternatywą
mogą być dyski konwencjonalne spięte w macierz RAID0.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
22
Rozwiązanie takie sprawdziło się w przypadku „farm serwerów”
firmy Google, której większość powierzchni dyskowej, przekraczającej
(według szacunków po opublikowaniu w lutym 2007r. raportu
dotyczącego awaryjności dysków) 20 PB (petabajtów), składa się
z „tańszych” dysków. W późniejszym okresie agregacji danych należy
rozważać przeniesienie tabel z danymi archiwalnymi na inny serwer,
najlepiej na fizycznie inną maszynę. Jeśli założymy, że nie jest
priorytetem szybki dostęp do danych archiwalnych, serwer
obsługujący te dane, nie będzie musiał spełniać tak wysokich
wymagań jak podstawowa maszyna.
Problemem, którego nie można zbagatelizować, jest kwestia
pamięci dostępnej dla serwera bazodanowego. Jeśli baza danych ma
działać sprawnie, jak najwięcej operacji powinno być wykonywane
bezpośrednio w pamięci, która ma znacznie większą prędkość
zapisu/odczytu danych niż najszybsze nawet dyski.
Do rozważenia pozostaje kwestia mocy obliczeniowej. Jest to
problem trudny do rozwiązania szacując ilość informacji. Producenci
sprzętu serwerowego nie chcą udostępniać danych dotyczących
realnego sprawowania się sprzętu przy np. obsłudze dużych baz
danych.
Wydaje
się
jednak
racjonalne
twierdzenie,
że
dwuprocesorowy komputer oparty o technologie Intel Core 2 Duo,
Intel Xeon, AMD Operon będzie odpowiednim rozwiązaniem.
W kwestii systemu operacyjnego rozważać można wybór
pomiędzy
produktem
Microsoft
–
Windows
2003
Server,
a OpenSurce’owym Linuxem lub jego komercyjną dystrybucją
serwerową. Otwarty system wydaje się lepszym wyborem ze względu
na
mniejszą
ilość
problemów
ze
współpracą
z
innym
oprogramowaniem. Polityka giganta z Redmond wymusza niejako
wykorzystanie technologii i rozwiązań pochodzących od tego samego
producenta, co może znacząco utrudnić późniejsze modyfikacje,
rozbudowy i/lub integracje z innymi systemami.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
23
2. WYMAGANIA FUNKCJONALNE
2.1. Założenia projektowanego systemu
Na początku każdego procesu projektowego należy zaznajomić
się z typami danych, ich formatem, ilością, wymaganą tolerancją
błędów, sposobem gromadzenia, a przede wszystkim ze sposobem,
w jaki zgromadzone dane mają być potem udostępniane klientom.
Określenie tych założeń na samym początku procesu projektowego,
pozwala
w
pewnym
stopniu,
przewidywać
problemy,
jakie
rozpatrywane rozwiązanie może nieść za sobą w poszczególnych
dziedzinach.
Wiedza
na
temat
danych
przechowywanych
w projektowanym systemie jest także ważna ze względu na
określenie spodziewanej poprawności danych. Dla przykładu można
podać przypadek pomiaru temperatury. Jeśli z założeń wiadomo, że
mierzona wartość określa temperaturę powietrza na wysokości
2 metrów, to przewidywany zakres temperatur, jakie można uznać za
poprawne w naszym klimacie to ok. -40C - 50C. Wartości nie
mieszczące się w tym zakresie można uznać za mało prawdopodobne
lub błędne. Natomiast wiedząc, że mierzona wartość oznacza
temperaturę oleju w silniku, zakres poprawnych wartości będzie
diametralnie różny od przedstawionego powyżej.
2.1.1. Rodzaj informacji zasilających system
W przypadku systemu gromadzenia danych z pomiarów
hydrometeorologicznych, rejestrowanych w systemie ciągłym przy
wykorzystaniu mierników cyfrowych do bazy danych trafiają dane
opisujące wartości parametrów środowiska. Są to wartości obrazujące
takie wielkości jak:

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
24
Temperatura na poziomie gruntu
Temperatura na wysokości 2m
Wilgotność powietrza
Opad
Opad wykroplenia
Suma Opadów
Ciśnienie atmosferyczne
Prędkość wiatru
Kierunek wiatru
Promieniowanie słoneczne
Strumień ciepła gruntowego
Wszystkie te wielkości mają charakter numeryczny i najlepiej
obrazowane są za pomocą zmiennoprzecinkowych typów danych.
Dodatkowo, przy każdym pomiarze konieczne jest zapisanie
informacji lokalizujących te dane na osi czasu i przypisującej je do
stacji, która te pomiary przeprowadziła. Wartości te to:
Identyfikator pomiaru – unikatowa wielkość określająca kolejny
numer pomiaru zapisanego w bazie – liczba całkowita.
Identyfikator stacji – pole identyfikujące stacje z której dany
zestaw pomiarów pochodzi – liczba całkowita.
Czas dokonania pomiaru
Czas zapisania pomiaru w systemie
2.1.2. Format gromadzonych danych
Dane
pomiarowe
reprezentują
wielkości
parametrów
środowiska. A więc konieczna jest możliwość zapisu wartości
z dokładnością do kilku miejsc po przecinku. Istnieje kilka możliwości
realizacji systemu bazodanowego dla dużej ilości danych.
Podstawowym sposobem jest gromadzenie danych w formacie
zmiennoprzecinkowym. Format ten jest najprostszą reprezentacją
rzeczywistych wartości parametrów środowiska.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
25
Zaletą takiego rozwiązania jest brak konieczności przetwarzania
danych, w celu „odzyskania” rzeczywistych wartości, przed
udostępnieniem ich klientowi. Za wadę można uznać znaczne (około
dwukrotne) zwiększenie objętości bazy przy przechowywaniu wartości
zmiennoprzecinkowych w stosunku do bazy trzymającej dane jako
liczby całkowite.
Drugą możliwością jest zapis informacji w formacie liczb
całkowitych.
Rozwiązanie
takie
wymaga
dodatkowego
przechowywania
informacji
o
sposobie
odzyskania
wartości
oryginalnej. Informacją taką jest mnożnik, czyli liczba przez jaką
wartość zapisaną należy podzielić aby otrzymać rzeczywistą wartość
parametru. Zaletą takiego rozwiązania jest oszczędność na objętości
bazy danych, niestety niesie ono ze sobą konieczność dodatkowego
przetwarzania wydobytych z bazy danych lub przekazania klientowi
informacji, jak takie dane przetworzyć.
Trzecim
rozwiązaniem,
przeznaczonym
głównie
do
archiwizowania danych pochodzących ze starszych pomiarów, jest
zapis wartości jako tekst o określonej długości, z określonym
sposobem wydzielania danych. Rozwiązanie takie sprawdza się przy
zapisie danych, do których nie ma wymogu natychmiastowego
dostępu. Znacząco zwiększa ono czas dostępu do informacji, ale
pozwala utrzymać prostą strukturę bazy danych archiwalnych.
2.1.3. Przewidywana ilość danych zasilająca system
Przewiduje się, że na standardowym obsługiwanym przez
system obszarze będzie funkcjonowało od 5 do 50 stacji
pomiarowych, rejestrujących maksymalnie 20 różnych parametrów
środowiska każda. Tabela 6. obrazuje ile wartości pomiarów będzie
trzeba przechować w bazie po upływie zadanego czasu.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
26
5
10
50
100
200
500
1
30
365
1825
3650
0
1 000 000 000
2 000 000 000
3 000 000 000
4 000 000 000
5 000 000 000
6 000 000 000
il
o
ś
ć
p
o
m
ia
ró
w
liczba stacji
c
z
a
s
p
o
m
ia
ró
w
[
d
n
i]
Rys. 1 Przyrost liczby gromadzonych pomiarów w czasie dla założonej liczby stacji.
Tabela 6. Liczba pomiarów w zależności od ilości stacji i czasu działania systemu
Czas gromadzenia pomiarów
Liczba
stacji
10
minut
1
godzina
1 dzień
1 miesiąc
1 rok
5 lat
10 lat
1
20
120
2 880
86 400
1 036 800
5 184 000
10 368 000
2
40
240
5 760
172 800
2 073 600
10 368 000
20 736 000
5
100
600
14 400
432 000
5 184 000
25 920 000
51 840 000
10
200
1 200
28 800
864 000
10 368 000
51 840 000
103 680 000
50
1 000
6 000
144 000
4 320 000
51 840 000
259 200 000
518 400 000
100
2 000
12 000
288 000
8 640 000
103 680 000
518 400 000 1 036 800 000
200
4 000
24 000
576 000 17 280 000
207 360 000 1 036 800 000 2 073 600 000
500
10 000
60 000
1 440 000 43 200 000
518 400 000 2 592 000 000 5 184 000 000
Tabela 7. Pokazuje jaka może być różnica pomiędzy objętością
bazy przy zapisie danych za pomocą pól typu zmienno przecinkowych
a liczb całkowitych. W przypadku projektowanego systemu użyty
zostanie typ zmienno przecinkowy. Wybór ten zagwarantuje, że czasy
uzyskiwane
z
uruchamiania
kwerend
testowych
nie
będą
zniekształcone konwersją z liczb całkowitych na zmiennoprzecinkowe.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
27
Tabela 7. Objętość pomiarów w zależności od typu danych i okresu działania systemu.
Czas gromadzenia pomiarów
Typ
zapisu
10
minut
[MB]
1
godzina
[MB]
1 dzień
[MB]
1 miesiąc
[MB]
1 rok
[MB]
5 lat
[MB]
10 lat
[MB]
Double
0,08000
0,48000 11,52000 345,60000 4 147,20000 20 736,00000 41 472,00000
Integer
0,04000
0,24000
5,76000 172,80000 2 073,60000 10 368,00000 20 736,00000
2.1.4. Możliwe sposoby dostępu do danych
Projektowany system zakłada możliwość szybkiego dostępu do
najnowszych danych. Długość czasu, z jakiego dane powinny być
dostępne na bieżąco, należy ustalić indywidualnie dla każdej
implementacji systemu.
Podział na informację bieżącą i archiwalną określa pośrednio
sposób dostępu do informacji. Dzięki rozdzieleniu danych nowych od
starszych zyskujemy na szybkości przeszukiwania tych pierwszych.
Archiwizacja niesie za sobą jednak spadek dostępności danych
archiwalnych. Czas oczekiwania na starsze dane może być dłuższy ze
względu na konieczność odzyskania informacji z archiwum, jak i na
fakt, że żądania danych bieżących powinny mieć pierwszeństwo.
Możliwe są 3 sposoby skorzystania z danych zgromadzonych
w systemie:
Bezpośredni dostęp do bazy danych – ze względu na kwestie
bezpieczeństwa, trudności merytorycznych związanych z obsługą
Systemu Zarządzania Relacyjną Bazą Danych (RDBMS), problemami
z wygodnym eksportowaniem danych, sposób ten nie powinien być
rozważany
w
kontekście
innym
niż
wykonanie
czynności
administracyjno konserwacyjnych.
Interfejs
WWW
poprzez
stronę
internetową
–
Bardzo
rozpowszechniony i wygodny sposób na realizację zadań z zakresu
udostępniania danych klientom. Jego podstawową zaletą jest brak
konieczności instalacji dodatkowego oprogramowania na komputerze
klienta / użytkownika.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
28
Dodatkowym atutem jest fakt, że dobrze zaprojektowany
interfejs może dawać ogromne możliwości w zakresie formatowania
prezentowanych danych, ograniczania dostępu do wybranych części
informacji,
kontroli
tożsamości
osób
próbujących
skorzystać
z zasobów systemu, a także monitorowania czynności wykonywanych
przez osoby korzystające z systemu. Sporą zaletą jest także swoboda
modyfikacji i usprawnień. Aby dodać nową funkcjonalność wystarczy
zmodyfikować kod na serwerze WWW i wszyscy klienci natychmiast
mają dostęp do nowych możliwości. Wadą takiego rozwiązania jest
niewątpliwie większe zapotrzebowanie na zasoby sprzętowe serwera.
Wynika to z faktu, że aby dostarczyć klientowi możliwość korzystania
z systemu bazodanowego za pośrednictwem interfejsu WWW,
konieczne jest uruchomienie dodatkowej usługi, obsługującej
generowanie stron z danymi poszukiwanymi przez klientów. Jeśli
rozważamy przypadek, gdzie z systemu ma korzystać bardzo
ograniczona liczba klientów, zagadnienie to nie stanowi problemu,
gdyż usługę taką może z powodzeniem udostępniać ten sam serwer,
który obsługuje samą bazę. Gdy jednak w planach pojawi się większa
ilość osób korzystających z systemu, może się okazać konieczne
zastosowanie komputerów dedykowanych usługom WWW.
Aplikacja systemowa – rozwiązanie eliminujące problem
dodatkowych zasobów potrzebnych na udostępnianie użytkownikom
interfejsu dostępowego. Aplikację taką klient instaluje na swoim
komputerze i za jej pomocą korzysta z zasobów systemu
bazodanowego.
Dzięki
takiemu
rozwiązaniu
można
uniknąć
problemów z zabezpieczeniami serwerów WWW, które są często
podstawowym punktem ataków ze strony osób starających się
uzyskać nieautoryzowany dostęp do informacji chronionej. Kolejnym
plusem na rzecz takiego rozwiązania jest korzyść wynikająca
z
przeprowadzania
obliczeń
(jeśli
takie
są
konieczne
aby
zaprezentować klientowi poszukiwaną przez niego informacje)
bezpośrednio na komputerze klienta.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
29
Pozwala to znacząco odciążyć serwery zajmujące się obsługą
systemu. Wadą takiego rozwiązania jest niewątpliwie problem
z wprowadzaniem nowych wersji oprogramowania. Operacja taka
wymaga zainstalowania poprawki lub całego programu na każdym
z komputerów klienckich. Sytuacja taka, gdy klient musi co pewien
czas instalować nowe oprogramowanie, może być odbierana przez
klientów jako niepotrzebna strata czasu.
2.2. Funkcje podstawowe
2.2.1. Gromadzenie danych z systemu czujników
Podstawową funkcją projektowanego systemu jest gromadzenie
danych spływających z czujników. Ze względu na przewidywaną
częstotliwość
z
jaką
poszczególne
czujniki
będą
wysyłały
zgromadzone informacje, ta część funkcjonalności stanowi kluczowy
punkt systemu. W systemach bazodanowych zapis informacji jest
jedną
z
najszybszych
operacji.
Szczególnie,
jeśli
zapis
przeprowadzany jest bezpośrednio do jednej tabeli. Należy jednak
pamiętać, że projektowany system powinien umożliwiać w łatwy
sposób implementacje rozwiązań walidujących zapisywane dane.
2.2.2. Archiwizacja danych w dłuższym horyzoncie czasowym
W systemach gromadzących duże ilości danych, z czasem
pojawia się problem zarządzania posiadanymi danymi. Na przykład
operacje wyszukiwania stają się znacznie wolniejsze przy bardzo
dużych tabelach. W związku z takim niepożądanym efektem, należy
zaplanować, w jaki sposób magazynować dane pochodzące z bardziej
odległej przeszłości. Przeniesienie starszych danych do innej tabeli,
nazywanej „tabela archiwalną” pozwoli odciążyć tabelę do której
odbywa się zapis. Rozwiązanie takie pociąga za sobą szereg
konsekwencji.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
30
Między innymi, jest to możliwość dłuższego oczekiwania na
niektóre zestawy danych, poszukiwane przez użytkowników, co
wynika bezpośrednio z konieczności przeglądania dodatkowej tabeli
(archiwalnej), w której może zostać użyty inny format zapisu danych.
Pozytywnym efektem będzie sprawniejsze obsługiwanie kwerend
poszukujących danych najnowszych – wprost z tabeli gromadzącej
pomiary z czujników.
2.2.3. Umożliwienie klientom dostępu do danych
Do
tej
pory
opisano
jedynie
część
funkcjonalności
odpowiedzialną za gromadzenie i zapis danych. Jednak samo
gromadzenie danych nie jest celowe, jeśli nie ma możliwości
sprawnego wykorzystania zapisanej informacji. W związku z tym
faktem, projektowany system musi umożliwiać klientom łatwy dostęp
do poszukiwanej informacji. Ze względu na dużą różnorodność
gromadzonych danych (temperatura, opad i wiele innych) istnieje
ogromna ilość przypadków w jakich może istnieć zapotrzebowanie na
dostęp to informacji. System powinien wychodzić naprzeciw
oczekiwaniom i umożliwiać dostęp do każdego poszukiwanego
podzbioru informacji. Ponieważ rodzaj przechowywanych danych,
pomimo
ich
różnorodności,
jest
stały
–
parametry
hydrometeorologiczne
–
można
wyznaczyć
listę
najczęściej
poszukiwanych zestawów danych. Zestawy takie nazywane dalej
„scenariuszami testowymi” reprezentują najczęściej wykonywane
kwerendy lub zestawy kwerend. Zakres scenariuszy standardowych
na potrzeby tej pracy zostanie ustalony odgórnie i przetestowany
indywidualnie na każdej propozycji schematu bazodanowego.
Podejście takie pozwoli porównać poszczególne propozycje pod kątem
wydajności obsługi scenariuszy standardowych.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
31
2.3. Propozycje rozszerzeń funkcjonalności
2.3.1. Zapis danych, a detekcja błędów
Dane
zasilające
system
mogą
ulegać
zniekształceniom
powodowanym błędami przesyłu lub błędami pomiaru (uszkodzenie
czujnika, złe wyskalowanie). Należy rozważyć możliwości takiego
zaprojektowania systemu, aby automatycznie zminimalizować wpływ
danych błędnych na całość posiadanej informacji. Jeżeli możliwe jest
wychwycenie części błędnych danych jeszcze przed zapisem
i oznaczenie ich odpowiednio to wynik zapytania, jaki trafi do klienta
w odpowiedzi, będzie bardziej wiarygodny i nie będzie wymagał
dodatkowych zabiegów sprawdzających poprawność danych.
Najprostszym sposobem detekcji błędów jest określenie
„z góry” ograniczeń wprowadzanych wartości. Ustawione wartości
dolnego i górnego ograniczenia pozwalają zaimplementować system
stosunkowo prostych reguł, na podstawie których pomiar może zostać
oznaczony jako błędny. Oznaczenie takie pozwoli pominąć go podczas
wyszukiwania danych dla klientów.
Do określenia stopnia poprawności danych można użyć prostych
reguł jak:
weryfikacja czasu pomiaru i czasu odebrania zestawu danych
weryfikacja poprawności napływających danych.
Obie te reguły składają się na prosty mechanizm weryfikacji
napływających informacji. Ma on na celu zapewnić, że dane
przechowywane w systemie są, z dużym prawdopodobieństwem,
poprawne.
Pierwsza z nich sprawdza czy czas dokonania pomiaru nie jest
późniejszy lub równy czasowi odebrania zestawu przez system
bazodanowy.
Jeśli
tak
jest
można
stwierdzić,
że
dane
najprawdopodobniej zostały źle zakodowane do wysłania lub
niepoprawnie rozkodowane po odebraniu.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
32
Jeśli zostanie wykryta taka sytuacja, można odrzucić cały
zestaw danych lub sprawdzać pojedyncze wartości czy odpowiadają
ogólnemu trendowi dla poszczególnych grup danych.
Zagadnienie detekcji błędów może zostać umieszczone poza
samą bazą danych, w oprogramowaniu obsługującym system
bazodanowy. W przypadku tego opracowania takie założenie pozwoli
uniknąć dodatkowego narzutu czasu, spowodowanego sprawdzaniem
poprawności zapisywanych danych.
2.3.2. Wykorzystanie logiki rozmytej w detekcji błędów
Napływające dane można weryfikować za pomocą narzędzi
takich jak teoria zbiorów rozmytych. Ta, sformułowana w 1995 roku
teoria, zmienia tradycyjne podejście do teorii zbiorów, w którym to,
czy dany element należy do zbioru określają dwa stany – należy i nie
należy. W teorii zbiorów rozmytych określa się nie tylko to, czy
element należy do zbioru, ale także w jakim stopniu. Odbywa się to
za pomocą przypisania elementowi liczby z zakresu [0,1], gdzie
0 oznacza, że element nie należy do zbioru, a 1, że jest w 100%
częścią zbioru. Zbiorem rozmytym nazywa się taki zbiór, którego
wszystkie elementy mają przypisaną wartość przynależności. Wartość
ta w teorii nazywa się „funkcją przynależności”. Z punktu widzenia
weryfikacji danych, najciekawsze w teorii zbiorów rozmytych jest
podejście lingwistyczne. Zmiennej lingwistycznej, w przeciwieństwie
do tradycyjnej zmiennej, przyporządkowuje się nie liczby a wartości
lingwistyczne, takie jak dobry, zielony. Te zaś reprezentują
odpowiednie zbiory rozmyte. Koncepcja zmiennych lingwistycznych
jest zaczerpnięta ze sposobu, w jaki mózg człowieka radzi sobie
z cechami, które mają wartość ciągłą. Posługując się zmiennymi
lingwistycznymi, przyjmującymi jedną z 9 wartości, człowiek jest
w stanie prowadzić samochód a nawet samolot [Czasopismo „Professional
Programming Software for SAP DB” - artykuł “Zbiory rozmyte”, grudzień 2004].

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
33
Konstruowanie zmiennych lingwistycznych, które będą łatwe do
interpretowania, nie jest jednak sprawą prostą i wymaga spełnienia
poniższych wymogów:
Rozróżnialność – każda wartość lingwistyczna powinna mieć
znaczenie semantyczne, a jej zbiór rozmyty musi się dać łatwo
rozróżnić od innych zbiorów rozmytych,
Odpowiednia liczba elementów – liczebność przestrzeni
lingwistycznej zmiennej powinna być zgodna z liczbą etykiet
tworzonych przez człowieka do opisu zmiennej (około 5-7),
Kompleksowe pokrycie – zmienna lingwistyczna powinna
zapewniać pokrycie całej przestrzeni rozważań,
Normalizacja zbiorów – każdy zbiór rozmyty powiązany
z wartością lingwistyczną powinien być zbiorem normalnym, tzn.
musi istnieć, co najmniej jeden element o wartości funkcji
przynależności równej 1.
Korzystając z powyższej wiedzy można wyznaczyć zmienną
lingwistyczną
określającą
prawdopodobieństwo
poprawności
testowanego pomiaru. W przypadku oznaczania zbioru danych można
posłużyć się etykietami: nieprawdopodobna, mało prawdopodobna,
prawdopodobna, bardzo prawdopodobna, pewna. Takie rozbicie
pozwala prowadzić bardzo zróżnicowane analizy posiadanych danych.
Można wyobrazić sobie sytuację, gdy wyszukuje się dane do analizy
opadów lub zmian temperatury na zadanym terenie. Przy takich
badaniach klient będzie zainteresowany tylko danymi o wysokim
prawdopodobieństwie
poprawności.
Z
drugiej
strony,
można
wyszukiwać stacje, których czujniki wymagają przeglądu lub kalibracji
– wystarczy wyszukać stacje z największą ilością pomiarów
oznaczonych jako nieprawdopodobne i lub mało prawdopodobne.
Dodatkowym atutem takiego rozwiązania jest łatwość podejmowania
decyzji co do kwestii, czy dana informacja kwalifikuje się do
archiwizacji. Nie wydaje się rozsądne archiwizowanie danych
wątpliwej jakości.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
34
Implementacja takiego rozwiązania nie nastręcza większych
problemów, poza podjęciem decyzji, czy logika ma zostać
zaimplementowana w bazie, czy zaszyta w aplikacji obsługującej
system bazodanowy. Ze względu na możliwość tworzenia procedur
w nowych wersjach systemów zarządzania bazami danych , wydaje
się rozsądne zapisanie logiki w bazie danych. Jedna z możliwości
implementacji
to
utworzenie
tabeli
z
zapisem
przedziałów
określających zakresy prawdopodobnych wyników pomiaru. Można
zastosować jednakową funkcję przynależności dla wszystkich
pomiarów, lub wprowadzić możliwość przyporządkowania różnych
funkcji dla różnych typów pomiarów.
2.3.3. Określanie właścicieli przechowywanych pomiarów
W systemach gromadzących duże ilości danych, potencjalnie
z różnych źródeł, pojawia się problem określania, kto jest
właścicielem danych. Jeśli rozważamy sytuację, w której dane mogą
być zapisywane z wielu źródeł, może zdarzyć się tak, że poszczególne
stacje czujnikowe mają różnych właścicieli, a w związku z tym, dane
także są objęte różnymi prawami własności. W takiej sytuacji należy
znaleźć rozwiązanie pozwalające w prosty sposób rozróżniać do kogo
należą dane. Najprostsza implementacja to przypisanie właścicieli do
poszczególnych stacji i określanie praw do danych po numerze stacji
z której konkretne informacje pochodzą.
2.3.4. Obsługa różnych poziomów użytkowników
Z aplikacji bazodanowych korzysta z reguły całe grono
użytkowników. Najczęściej są oni podzieleni na grupy ze względu na
pełnione funkcje w systemie. Grupami, jakie można wyszczególnić
w praktycznie każdym systemie, są administratorzy i użytkownicy.
Grupy te różnią się poziomem uprawnień i zakresem obowiązków.
Administratorzy odpowiadają za utrzymanie serwisu w stanie
umożliwiającym klientom bezproblemową pracę.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
35
Najczęściej administratorzy posiadają uprawnienia zwykłych
użytkowników, wzbogacone o dodatkowe możliwości. Przydzielony
wachlarz
uprawnień
umożliwia
administratorom
pomoc
użytkownikom,
wprowadzanie
poprawek
do
oprogramowania
aplikacji, dbanie o bezproblemowy dostęp do aplikacji. Użytkowników
nie interesują zagadnienia utrzymania aplikacji w ruchu – dla nich
jest ona narzędziem pracy, źródłem niezbędnych informacji. Grupa
użytkowników może dzielić się dodatkowo na podgrupy z dodatkowo
wyspecjalizowanymi
uprawnieniami.
Projektowane
rozszerzenie
funkcjonalności systemu powinno spełniać wymogi bezpiecznego
rozdzielenia funkcji korzystających z niego grup użytkowników oraz
umożliwiać jak najprostszą i przeźroczystą pracę administratorów.
Przez termin przeźroczysta praca, należy rozumieć możliwość
wykonywania zadań konserwacyjnych w sposób niezauważalny dla
użytkowników lub przynajmniej nie uniemożliwiający lub utrudniający
im pracy.
2.3.5. Automatyczne powiadomienia
W
dużych
systemach,
przechowujących
ogromne
ilości
informacji, użytkownicy często mają problem z wychwyceniem
nowych danych z interesującego ich zakresu. Dotyczy to zwłaszcza
sytuacji, gdy użytkownik zainteresowany jest wychwyceniem zmiany
w cyklicznie zapisywanych danych. Przykładem może być sytuacja
monitorowania poziomu wód w rzekach na zadanym obszarze. Osoba,
zajmująca
się
takim
zagadnieniem,
będzie
zainteresowana
wychwyceniem nagłego podniesienia się poziomu wody. W celu
rozwiązania takiego problemu można zaimplementować system
indywidualnego i konfigurowalnego monitoringu napływających
danych. Po wykryciu, że dane układają się we wzorzec zdefiniowany
w filtrze użytkownika, system może wysyłać powiadomienia
dostępnymi kanałami. W powszechnym zastosowaniu do takich celów
używane są takie kanały komunikacyjne jak:

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
36
sieci komórkowe – wiadomości SMS
komunikatory internetowe – Gadu Gadu, Jabber, AIM, ICQ itp.
Najłatwiejszy do zaimplementowania jest system powiadomień
wysyłanych na email użytkownika. Ma on niestety podstawową wadę
– powiadomienie zostanie odebrane, gdy użytkownik sprawdzi swoją
skrzynkę pocztową lub jeśli ma włączony program monitorujący
pocztę. Więcej pracy jest z komunikatorami internetowymi, które
jednak dają większe szanse dotarcia do użytkownika – komunikatory
internetowe z reguły są włączane wraz z komputerem i oczekują na
nadejście wiadomości. Systemem wymagającym najwięcej pracy jest
obsługa wysyłania wiadomości SMS bezpośrednio na telefon
użytkownika. Rozwiązanie to, pozwala dotrzeć do użytkownika nawet
jeśli ma on wyłączony komputer lub aktualnie nie znajduje się w jego
bezpośrednim otoczeniu.
2.3.6. Synchronizacja z bazami „zaprzyjaźnionymi”
Zagadnienie to umożliwia łatwą wymianę danych pomiędzy
systemami przechowującymi podobne dane, ale z innych źródeł.
Można wyszczególnić dwie podstawowe metody realizacji takiego
rozwiązania. Pierwsza, gdzie dane pomiędzy systemami są okresowo
synchronizowane i druga, w której nie przesyła się całości danych
pomiędzy bazami, a jedynie, na żądanie klienta, jedna baza odpytuje
drugą o dane jakich może jej brakować. Pierwsze z rozwiązań daje
dodatkowy plus w postaci tworzenia dodatkowej kopii danych
w drugim systemie, niestety sporym minusem jest ogromna ilość
danych przesyłana pomiędzy tymi systemami. Drugi system nie
generuje takiego ruchu na łączach, ale może powodować opóźnienia
w pozyskiwaniu danych podczas wyszukiwania dla klienta.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
37
2.3.7. Obsługa płatnego dostępu do danych
Dodatkową funkcjonalnością, o jaką można wzbogacić system,
jest odsprzedaż danych osobom i organizacjom trzecim. Projektując
takie
rozwiązanie
należy
najpierw
zaimplementować
system
użytkowników, ze względu na konieczność określenia praw własności
dla
konkretnych
danych.
Po
określeniu
grupy
właścicieli
i zgromadzeniu danych tych osób / instytucji potrzebnych do
zrealizowania transakcji należy zaplanować jak ma wyglądać system
sprzedaży, w których jego miejscach można wprowadzić promocje,
rabaty i jak będą przechowywane dane. Dodatkowo można skorzystać
z usług takich pośredników jak np. PayPal.
2.3.8. System monitorowania danych w czasie rzeczywistym
Jako
ostatni
przykład
możliwości
rozbudowy
systemu
bazodanowego przedstawiony zostanie projekt monitoringu danych,
w czasie rzeczywistym, już na wejściu do systemu. Takie podejście
daje użytkownikom możliwości śledzenia zmian danych natychmiast
po ich odnotowaniu w systemie. Dodatkową zaletą jest fakt, że taki
system nie powodowałby dodatkowego obciążenia bazy danych
kwerendami wyciągającymi dane. W założeniu wyświetlane byłyby
dane tuż przed zapisem i odświeżane natychmiast w momencie
odnotowania nowej wartości danego parametru. Systemy takie
działają z powodzeniem w innych branżach, między innymi
w bankowości, gdzie wykorzystuje się takie rozwiązania do
monitorowania rynków finansowych. Ich podstawowym zadaniem jest
dostarczenie użytkownikowi informacji o zmianach cen i wartości
aktywów.
Najnowsze
implementacje
umożliwiają
także
poszczególnym
użytkownikom
zdefiniowanie
jakie
informacje
i w jakiej formie mają być im prezentowane. W przypadku danych
hydrometeorologicznych, analogiczna funkcjonalność mogłaby zostać
zaimplementowana do monitorowania czynników środowiskowych.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
38
Użytkownicy mieliby do dyspozycji cały wachlarz funkcji
udostępnianych przez takie systemy. Między innymi mogłoby to być:
przeglądanie
danych
spływających
do
systemu
w
czasie
rzeczywistym
wyświetlanie historii poszczególnych parametrów
możliwość dokładnego określenia pochodzenia danych
oglądanie zmian w postaci wykresów
indywidualne konfiguracje prezentacji danych
Rozwiązanie
takie
może
bazować
na
architekturze
klient-serwer, czyli asymetrycznej architekturze oprogramowania,
umożliwiającej
rozdzielenie
pewnych
funkcjonalności,
w
celu
zwiększenia elastyczności i ułatwienia wprowadzania zmian w każdej
z części systemu. Polega to na ustaleniu, że serwer zapewnia usługi
dla klientów, którzy mogą komunikować się z serwerem wysyłając
żądanie (request). Podstawowe i najczęściej używane serwery to:
serwer pocztowy, serwer WWW, serwer plików, serwer aplikacji.
Z usług jednego serwera może zazwyczaj korzystać wielu klientów.
W takim przypadku, serwer byłby odpowiedzialny za przechwytywanie
informacji na drodze do systemu bazodanowego, przeprowadzenie
wstępnej walidacji i rozesłanie w zestandaryzowanym formacie, na
przykład XML, do klientów. Ten typ rozwiązania sprawdzi się
doskonale, jeśli zakładamy, że serwer proponowanego rozwiązania
zostanie umieszczony na tej samej maszynie co oprogramowanie
zapisujące dane do systemu bazodanowego. Jeśli z jakiegoś powodu
nie jest to możliwe, można taki system rozszerzyć o dodatkowy
poziom aplikacji tzw. „Backend Server”. Jego zadaniem jest
przechwytywanie danych napływających do systemu, podobnie jak
w przypadku serwera aplikacji, ale w tym przypadku nie wysyła on
danych do klientów, tylko za pomocą przyjętego protokołu rozsyła je
po sieci tak, aby mogły one być odebrane przez faktyczny serwer
aplikacji.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
39
Protokołem używanym w takim przypadku może stać się na
przykład Tibco Rendezvous
1
. Dane po takiej początkowej obróbce,
i przesłaniu do aplikacji klienckich zasilają odpowiednie części
interfejsu użytkownika. Projektując taki interfejs należy zwrócić
uwagę na wybór sposobu implementacji. Jeśli jako podstawową
platformę wybrana zostanie opcja np. biblioteki MFC (Microsoft
Foundation Class), czyli opcja dostarczania osobnego pakietu
klienckiego napisanego pod wybrany system operacyjny, należy
rozważyć jakie systemy operacyjne będą musiały być obsługiwane.
Jeśli podjęta zostanie decyzja o implementacji w środowisku
webowym, za pomocą technologii takich jak Java Enterprise Edition,
Spring MVC i JavaScript, trzeba brać pod uwagę konieczność
zwrócenia większej uwagi na kwestie optymalizacji działania aplikacji.
Wynika to z faktu, że interfejsy webowe napisane w JavaScript bazują
w dużej mierze na możliwościach przeglądarek, w jakich zostają
uruchamiane. Te z kolei, nie charakteryzują się wysoką wydajnością
obsługi skomplikowanych skryptów JavaScript. Nie jest to także
bezpośrednio uzależnione od klasy użytego procesora – np. Internet
Explorer 6 nadal wykorzystuje tylko jeden rdzeń niezależnie od
zastosowanego procesora.
2.4. PROPOZYCJE ZWIĘKSZENIA WYDAJNOŚCI
2.4.1. Mechanizm cacheingu
Cache (pamięć podręczna nazywana także buforem) to
mechanizm, w którym ostatnio pobierane dane dostępne ze źródła
o długim czasie dostępu (tzw. wysokiej latencji) i niższej
przepustowości
są
przechowywane
w
pamięci
o
lepszych
parametrach. Cache jest elementem właściwie wszystkich systemów.
1
Więcej informacji na stronie producenta:
http://www.tibco.com/software/messaging/rendezvous/default.jsp

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
40
Przykładem może być współczesny procesor, który ma 2 albo
3 poziomy pamięci cache oddzielającej go od pamięci RAM. Innym
przykładem jest dostęp do dysku, który jest buforowany w pamięci
RAM.
Przykładem
najbliższym
użytkownikom
współczesnych
komputerów
jest
cache
buforujący
strony
WWW
otwierane
w przeglądarce. Strony internetowe mogą być buforowane zarówno
przez samą przeglądarkę, jak i na zupełnie niezależnych serwerach
nazywanych serwerami Proxy. Na bardzo podobnej zasadzie działa
wewnętrzny cache bazy danych, który gromadzi wyniki ostatnio
wykonanych zapytań w osobnej tabeli. Systemy te są tak wydajne
dzięki lokalności odwołań - jeśli nastąpiło odwołanie do pewnych
danych, jest duża szansa, że w najbliższej przyszłości będą one
potrzebne
ponownie.
Niektóre
systemy
buforujące
próbują
przewidywać, które dane będą potrzebne i pobierają je wyprzedzając
żądania.
Mechanizm buforowania może być realizowany na różne
sposoby. Praktycznie w każdym przypadku istnieje możliwość wyboru
pośród kilku sposobów wdrożenia takiego rozwiązania. W przypadku
systemów opartych o technologie bazodanowe, w większości
przypadków wewnętrzny cache bazy danych pozostaje włączony
w znaczącym stopniu ograniczając czas potrzebny na dwukrotne
wyszukanie tego samego zestawu danych.
W
projektowanym
systemie
przewiduje
się
możliwość
późniejszego wzbogacenia jego funkcjonalności o rozwiązania
buforujące, umieszczone poza bazą danych. Czyli wprowadzenie
kolejnego poziomu tego rozwiązania. Projekt przewiduje dwie
możliwości wdrożenia rozwiązań buforujących. Mogą one zostać
wprowadzone niezależnie, gdy zostanie wybrane tylko jedno z nich,
a mogą także występować jednocześnie.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
41
2.4.2. Rozwiązanie softwarowe – AdoDB
AdoDb, czyli Active Data Objects Data Base, to zestaw bibliotek
i klas, które standaryzują funkcje obsługi baz danych języka PHP.
Jego podstawowym założeniem jest ukrycie różnic pomiędzy różnymi
systemami bazodanowymi i udostępnienie prostych i jednolitych
funkcji wykonywania zapytań bazodanowych. Dodatkowym atutem
jest fakt, że zmiana systemu RDBMS obsługującego system
wykorzystujący ADOdb, będzie wymagała minimalnych zmian
w kodzie źródłowym. Inne unikatowe funkcje ADOdb to:
Łatwy do zrozumienia dla programistów Windows.
Udostępnia kod do obsługi zapisu nowych i aktualizacji rekordów,
który może być w łatwy sposób zaadoptowany do współpracy
z innym systemem bazodanowym.
Wbudowano w niego system „metatypów”, co umożliwia
przezroczyste konwertowanie takich typów jak CHAR, TEXT,
STRING do ekwiwalentów na różnych systemach RDBMS.
Jest
łatwy
do
przeniesienia
pomiędzy
systemami,
dzięki
wyodrębnieniu funkcji obsługi bazy danych. Wystarczy zmienić
wartość zmiennej konfigurującej.
Zastosowanie ADOdb do dodatkowego buforowania zwracanych
wyników z bazy danych ma zastosowanie, gdy system jest obciążony
interakcja z wieloma użytkownikami, którzy mają zbliżone potrzeby
w kwestii poszukiwanych informacji. Jest to rozwiązanie działające
poza samym systemem bazodanowym co uniezależnia go np. od
skonfigurowanego na danym serwerze limitu pamięci przeznaczonego
na cache kwerend. W tym przypadku, buforowanie określa się
długością trwania, standardowo 60 minut, a nie jak w np. w MySQL
objętością tabeli buforującej.
Niewątpliwą zaletą tego rozwiązania jest jego cena. Ponieważ
ADOdb rozpowszechniane jest na licencji BSD, więc może być
wykorzystywane nieodpłatnie także w projektach komercyjnych.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
42
Wadą jest konieczność specyficznej implementacji kodu
systemu obsługującego bazę danych. Zaimplementowanie tego
rozwiązania do istniejącego systemu, szczególnie napisanego
proceduralnie, może się okazać bardzo kosztowne.
2.4.3. Wydzielenie wyspecjalizowanych serwerów
Rozwiązanie to polega na rozdzieleniu systemu na kilka
serwerów i określeniu konkretnych zadań dla każdego z nich.
Konkretnych implementacji takiego systemu rozproszonego może być
wiele i byłoby bardzo trudne określenie, który z nich byłby najlepszy.
Należałoby przeprowadzić serie testów na wybranych konfiguracjach
i wyznaczyć maksimum wydajności przy minimalnych kosztach.
Najprostszą konfiguracją byłby system złożony z dwóch
maszyn. Jedna odpowiedzialna tylko za gromadzenie danych, a druga
obsługująca interfejs użytkownika i korzystająca z odrębnej bazy
danych. Baza ta, byłaby okresowo synchronizowana z bazą maszyny
gromadzącej nowe dane. Założenie do implementacji takiego
rozwiązania mówi, że niewielka zwłoka w aktualizacji danych
dostępnych dla klientów nie powoduje problemów w ich pracy.
Ponieważ projektowany system może być wykorzystywany do
określania aktualnej sytuacji powodziowej na zadanym terenie musi
istnieć sposób na pozyskiwanie danych w czasie rzeczywistym.
Problem ten można rozwiązać implementując różne poziomy
użytkowników,
gdzie
ci
odpowiedzialni
za
prognozowanie
ewentualnych niebezpieczeństw mają dane pobierane bezpośrednio
z serwera gromadzącego dane. Innego rozwiązania wymaga
przypadek, gdy zakładamy, że wszyscy pracownicy klienta mają mieć
dostęp do najnowszych danych, a jedynie, dane serwowane za
pośrednictwem strony internetowej dla osób z zewnątrz, są
opóźnione. Przypadek ten można zaimplementować obciążając Server
gromadzący dane obsługą interfejsu dla pracowników, a druga
maszyna może służyć za serwer obsługujący ruch z Internetu.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
43
2.4.4. System rozproszony
Rozwiązanie
to
zakłada
rozbudowę
systemu.
Chodzi
o przypadek, gdy sieć czujników rozrasta się poza jeden powiat lub
liczba stacji pomiarowych wzrasta powyżej założonego maksimum
i ruch w sieci zaczyna być niemożliwy do obsłużenia przez pojedynczą
bazę danych. W takiej sytuacji należy rozważyć możliwość
rozproszenia systemu gromadzenia danych na więcej niż jedną
maszynę. Planując taka operację należy zastanowić się, jak ważna
będzie możliwość dostępu do całości danych na bieżąco. Zakłada się,
że nie będzie to bardzo częsty przypadek i można zaakceptować nieco
wydłużony czas poszukiwania informacji z wielu serwerów. Jeśli
podjęta zostanie decyzja o wprowadzeniu w życie takiego
scenariusza,
należy
odpowiednio
przygotować
infrastrukturę
serwerową. Należy wytyczyć, gdzie umieszczony zostanie główny
serwer bazodanowy, a gdzie pozostawione będą serwery buforujące
bieżące dane. Proponowane rozwiązanie powinno zakładać okresową
synchronizację baz buforujących z bazą główną. Ma to na celu
umożliwienie
łatwego
wyszukiwania
po
całości
informacji.
Synchronizacja taka powinna odbywać się raz na dobę. Najlepiej
w
godzinach
minimalnego
obciążenia
systemu
ze
strony
użytkowników. W efekcie powstania takiego systemu otrzymamy kilka
możliwości pracy z danymi. Jeśli użytkownik z góry określi, na danych
z jakiego obszaru będzie pracował, można automatycznie przełączyć
go na bazę obsługującą dany region.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
44
3. PROJEKTOWANE PROPOZYCJE ROZWIĄZAŃ
3.1. Dane zapisane w jednej tabeli
Najprostsza propozycja rozwiązania kandydującego, mająca
spełniać większość wymogów stawianych przed projektowanym
systemem. Została ona utworzona przy założeniu, że wszystkie dane,
które gromadzone są w systemie, stanowią integralną całość. Wynika
to z faktu, że dla klientów np. dane opadu lub temperatury nie mają
wartości jeśli nie są odniesione do konkretnej lokalizacji. Schemat
określany dalej numerem I jest w istocie pojedynczą tabelą,
gromadzącą wszystkie dane dotyczące pomiaru. Są to takie
informacje jak:
Nazwa stacji na której dokonano pomiaru
Lokalizacja stacji pomiarowej
Czas dokonania pomiaru
Wartości mierzonych parametrów
Czas zapisu pomiaru w systemie
Rys 2. Schemat I – Wszystkie gromadzone dane zapisywane są w jednej tabeli.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
45
Niestety ogromną wadą tego typu rozwiązań są problemy
z wprowadzaniem jakichkolwiek korekt do danych opisujących
pomiar. Problem taki można łatwo zilustrować na przykładzie sytuacji
gdzie zakładamy, że po roku gromadzenia pomiarów okaże się, że
zachodzi
konieczność
zmiany
formatu
numeru
stacji
(pole
stationNumber),
z
liczbowego
na
kombinację
znaków
alfanumerycznych. W takim przypadku należałoby zmodyfikować
wszystkie dotychczas zapisane rekordy z pomiarami, zapisując nową
wartość numeru stacji. Po roku gromadzenia pomiarów z 500 stacji
byłoby to około 500 (stacji) *365 (dni) * 24 (godziny) * 6 (pomiarów
na godzinę) = 26,28 mln rekordów. Operacja taka zajęła by ogromną
ilość czasu i w znaczącym stopniu ograniczyła możliwości systemu
w zakresie obsługi bieżących usług dla klientów. Za inny przykład
sytuacji, w której ten schemat nie będzie optymalny można uznać
problem
archiwizacji
starszych
informacji.
W
związku
z nadmiarowością takiej struktury danych, również archiwum
cechowałoby
się
niepotrzebnym
narzutem
powielających
się
informacji. Ten problem jednak jest łatwiejszy do zneutralizowania –
wystarczy przechowywać dane archiwalne w nieco zmienionej
strukturze. Np. w drugiej postaci normalnej. Do zalet stosowania
struktury z jedną tabelą należą bez wątpienia:
łatwość tworzenia zapytań
prostota ustalania indeksów
Prostota zapytań obsługujących taka strukturę danych polega
na braku konieczności łączenia wyników pobieranych z wielu tabel lub
przeszukiwania innych tabel pod kątem określenia warunków do
odnalezienia poszukiwanego zakresu informacji. Natomiast tworzenie
indeksów jest o tyle ułatwione, że nie ma możliwości powstania
skomplikowanych związków pomiędzy różnymi tabelami.
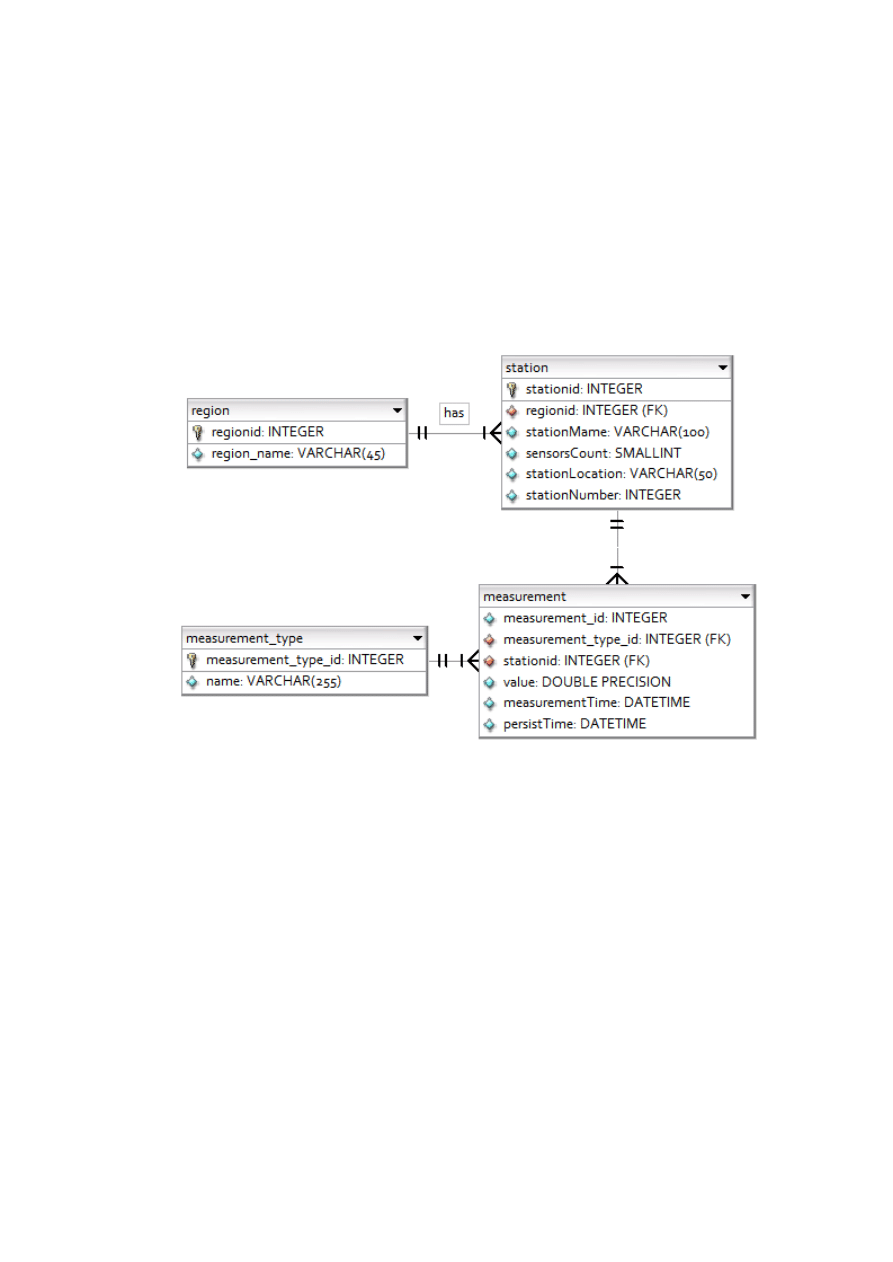
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
46
3.2. Każdy pomiar w osobnym rekordzie
Ta propozycja schematu bazodanowego stanowi przykład
rozbicia modelu danych na obiekty atomowe. W terminologii
bazodanowej obiekt atomowy, to taki którego nie sposób podzielić.
Postępując zgodnie z tą zasadą poszczególne rekordy tabeli
measurement przechowują pojedyncze wartości, których typ
określony jest w tabeli measurement_type.
Rys 3. Schemat II – Poszczególne wartości pomiarów przechowywane jako osobne rekordy.
Dzięki temu istnieje możliwość zidentyfikowania poszczególnych
pomiarów po określonym w nich typie. Tabela measurement zostaje
zredukowana do podstawowych pól, czyli:
measurement_id – unikalny identyfikator pomiaru
station_id – klucz obcy relacji z tabelą station
measurement_type_id
–
klucz
obcy
relacji
z
tabelą
measurement_type
measurementTime – czas dokonania pomiaru
persistTime – czas zapisu pomiaru w systemie
value – wartość parametru.
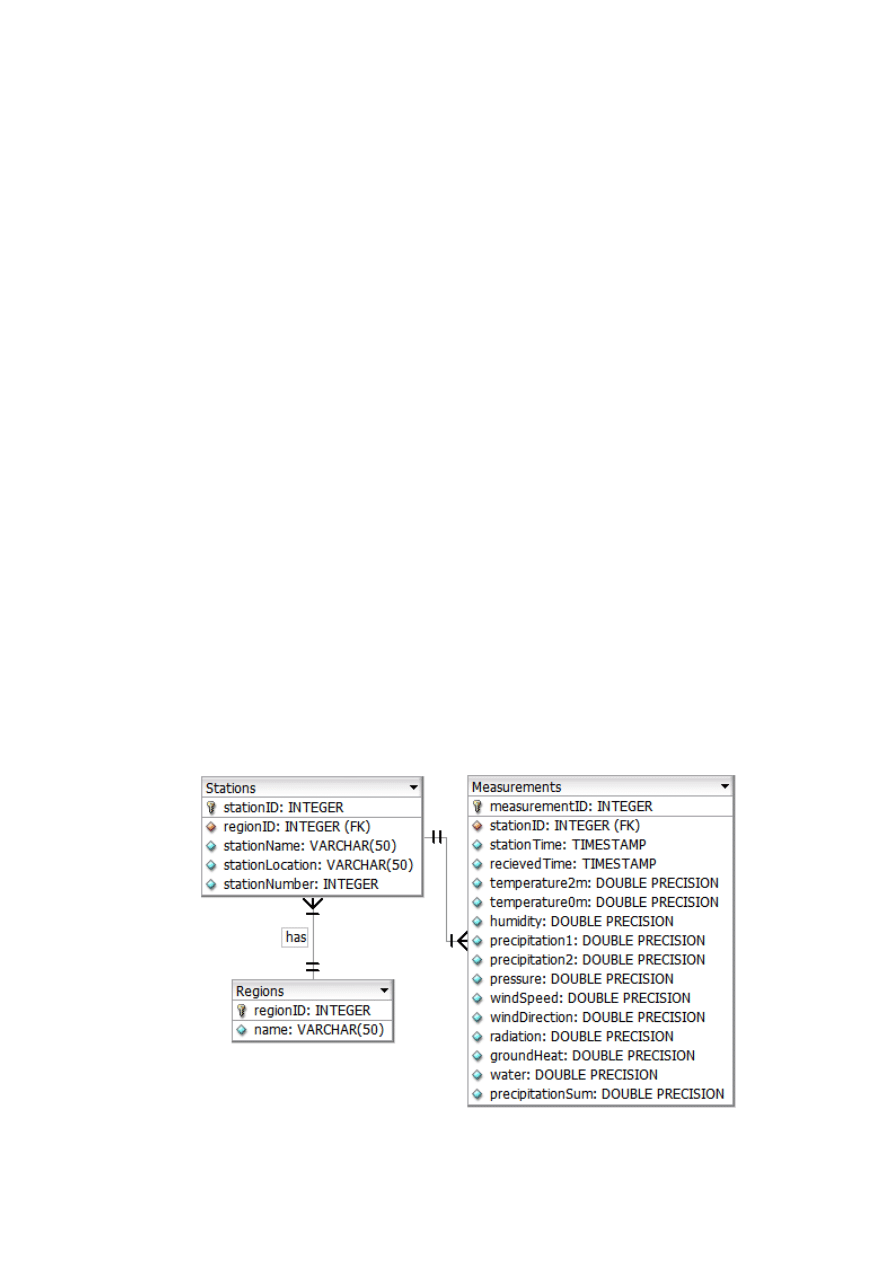
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
47
Podejście takie zmienia nieco definicję terminu pomiar.
W poprzednich przypadkach za pomiar (Measurement) uznawany był
kompletny
zestaw
parametrów
mierzonych
na
danej
stacji
pomiarowej. Tymczasem, w tym przypadku za pomiar uznaje się
pojedynczą wartość parametru. Zapis taki w znaczącym stopniu
upraszcza operacje wyszukiwania danych jednego typu. Wiąże się
jednak
ze
znacznym
zwiększeniem
objętości
bazy
danych.
Dodatkowym
minusem
jest
w
tym
przypadku
trudniejsze
wyszukiwanie zestawu różnych parametrów dla zadanego regionu lub
stacji.
3.3. Trzecia postać normalna
W tym rozwiązaniu z tabeli Measurements opisanej w rozdziale
3.1 wydzielono dane dotyczące lokalizacji z której dany zestaw
parametrów został pobrany. Efektem jest zestaw trzech tabel:
region
station
measurements
Tabele te odpowiadają fizycznym modelom istniejącym
w rzeczywistej sieci pomiarowej.
Rys 4. Schemat III – Tabele odzwierciedlające fizyczne modele danych.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
48
Dzięki temu rozdzielone zostają wartości pomiarów, od danych
określających ich lokalizację. Dodatkową zaletą takiego rozwiązania
jest łatwość edycji informacji dotyczących stacji lub regionów. Takie
podejście do problemu pozwala na swobodniejsze planowanie
sposobu w jaki gromadzone dane powinny być następnie
archiwizowane. Nie występuje także zjawisko nadmiarowości
w postaci ciągłego przepisywania danych lokalizacyjnych.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
49
4. SCENARIUSZE DOSTĘPU DO DANYCH
4.1. Najczęściej wykorzystywane kwerendy
W
każdym
systemie,
pośród
całej
projektowanej
funkcjonalności można wyznaczyć taką, która będzie wykorzystywana
najczęściej. W przypadku systemu gromadzącego dane z pomiarów
parametrów
hydrometeorologicznych,
operacją
najczęściej
wykorzystywaną
będzie
udostępnianie
zgromadzonych
danych
użytkownikom. Dane, przed wysłaniem do klienta muszą zostać
najpierw odnalezione w systemie. W systemach bazodanowych
operację taką przeprowadza się na podstawie kryteriów wyszukiwania
podanych przez użytkownika. Kryteria te określają dziedzinę
informacji, jaka danego klienta interesuje, a także dokładny
przedział, jaki należy klientowi zwrócić. Kryteria te mogą być
wprowadzane za pośrednictwem interfejsu użytkownika na stronie
WWW lub bezpośrednio w systemie bazodanowym za pośrednictwem
udostępnianej przez dany serwer konsoli. Określenie czynności oraz
kryteriów
jej
przeprowadzenia
pozwala
zbudować
kwerendę
(zapytanie) do bazy danych. Czynnością w tym kontekście może być
np. operacja selekcji, a kryteriami, określenie zakresu z jakiego
selekcja ma zwrócić dane klientowi.
Podstawową funkcją systemu jest gromadzenie danych, wobec
czego operacje zapisu danych do bazy traktowane są priorytetowo.
Przewiduje się test aplikacji pod kątem zapisu pełnego pakietu
danych, czyli symulacje zapisu danych ze stacji posiadającej komplet
czujników.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
50
Bardziej skomplikowana jest sytuacja z pobieraniem danych
z systemu. Wynika to z faktu, że użytkownicy będą bardziej
zainteresowani
wartościami
jednego
parametru
na
zadanym
obszarze, niż kompletu danych z danej stacji. Dlatego też, badaniu
podlegać będzie średni czas dostępu do wybranego podzbioru,
składającego się z jednego do trzech parametrów ze stacji na
zadanym obszarze. Stosując takie podejście, można pokusić się
o określenie sytuacji, w jakiej szybki dostęp do danych będzie
najbardziej potrzebny. Za taką sytuację można uznać zagrożenie
powodziowe, występujące na pewnym obszarze. W takim przypadku
najważniejszymi parametrami są: poziom wody (water) i wysokość
opadu (precipitation). Wydajność systemu zostanie przetestowana za
pomocą scenariuszy testowych. Scenariusze testowe zostały tak
dobrane, aby jak najlepiej odzwierciedlały zapytania, zlecane
systemowi
przez
użytkowników.
Do
przeprowadzenia
testów
przygotowano poniższy zestaw scenariuszy:
Wyszukanie sum godzinowych opadów dla danej stacji.
Wyszukanie wartości przekraczających ustalone wartości graniczne.
Wybranie ekstremalnych wartości parametru z pominięciem
wykraczających poza zakres.
Podstawowe statystyki, takie jak średnie wartości parametrów.
Pozyskiwanie sumy opadów na zadanym terenie (objętym zadaną
liczbą stacji pomiarowych) dla ostatnich 3 godzin.
4.2. Opis sposobu prowadzenia pomiarów czasu wykonania
Procedura testowa została zaplanowana tak, aby poszczególne
fazy testów nie wpływały na siebie oraz aby zapewnić maksymalną
możliwą powtarzalność otrzymywanych wyników. Środowisko testowe
zbudowane zostało w oparciu o powszechnie dostępne komponenty,
które jednak działają z powodzeniem w dużych instalacjach
serwerowych.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
51
4.2.1. Środowisko testowe
W celu uzyskania wiarygodnych wyników wszystkie testy
przeprowadzone zostały na tym samym serwerze. Maszyna ta na czas
testów stanowiła izolowane środowisko bazodanowe i nie obsługiwała
żadnych innych zadań.
Tabela 8. Specyfikacja serwera testowego
Komponent
Typ
Wersja / Wielkość
System bazodanowy
MySQL
5.0.38
Język skryptowy
PHP
5.2.1
Procesor
Athlon64
3200+ (2000Mhz)
Pamięć RAM
DDR 3200
1GB
System operacyjny
Ubuntu Linux
7.04 (Feisty Fawn) kernel 2.16.20
Dysk twardy
Western Digital
SATA WD800JD-22LS 80GB
4.2.2. Sposób prowadzenia pomiarów
Do realizacji scenariuszy testowych wykorzystane zostały
skrypty napisane w języku PHP5. W środowisku testowym utworzone
zostały dwa rodzaje skryptów. Pierwszy z nich służy do uruchomienia
testów wydajności zapisu do bazy danych, drugi uruchamia
scenariusze testujące wyszukiwanie danych. Aby możliwe było
analizowanie rzeczywistych czasów wykonania kwerend, został
wyłączony wewnętrzny cache systemu MySQL.
Pierwszy skrypt ma za zadanie sprawdzenie wydajności zapisu
do bazy danych i porównanie czasów wykonania określonej ilości
zapisów do tabeli bez indeksów oraz z indeksami. Istotę jego
działania obrazuje pseudokod:

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
52
Iteracja po zmiennej indeksów: z indeksami, bez indeksów {
Iteracja po ilości stacji w systemie: 5, 25, 50 {
Iteracja po długości okresu: 1 miesiąc, 1 rok, 5 lat {
Jeżeli z indeksami: utwórz indeksy
Rozpocznij pomiar czasu
Zapisz kolejno n pomiarów; n : ilość pomiarów
Zakończ pomiar czasu
Wypisz czas zużyty na zapis do bazy
Wypisz objętość bazy po zapisie
Jeżeli z indeksami: usuń indeksy
}
}
}
Zadaniem drugiego skryptu jest przeprowadzenie testów
wydajności wyszukiwania danych. Jest podobnie skonstruowany do
skryptu testującego zapis:
Iteracja po ilości stacji w systemie: 5, 25, 50 {
Iteracja po długości okresu: 1 miesiąc, 1 rok, 5 lat {
Zapisz kolejno n pomiarów; n : ilość pomiarów
Iteracja po scenariuszu testowym: 1, 2, 3, 4, 5 {
Rozpocznij pomiar czasu
Uruchom scenariusz testowy X
Zakończ pomiar czasu
Wypisz czas potrzebny na wykonanie scenariusza
Utwórz indeksy
Rozpocznij pomiar czasu
Uruchom scenariusz testowy X
Zakończ pomiar czasu
Wypisz czas potrzebny na wykonanie scenariusza
Usuń indeksy
}
}
}
Oba skrypty w trakcie prowadzenia testów wypisują aktualne
wyniki, które z kolei są zapisywane w pliku tekstowym. Następnie
dane przenoszone są do arkusza programu Excel w celu dalszego
przetwarzania.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
53
4.3. Porównanie wydajności schematów w obsłudze
zapytań
Głównym celem tego opracowania jest odpowiedź na pytanie,
które z przedstawionych wcześniej rozwiązań spełni pokładane w nim
oczekiwania co do optymalnej wydajności i użyteczności podczas
pozyskiwania danych zgromadzonych w systemie. Przedstawiony
wcześniej
schemat
przeprowadzenia
pomiarów
ma
zapewnić
jednakowe warunki dla testów każdej z propozycji. Wyniki
przeprowadzonych testów zostaną następnie zestawione w postaci
tabel i wykresów co pozwoli w wygodny sposób prześledzić, które
rozwiązanie najlepiej spełnia wymogi stawiane przed projektem.
4.3.1. Wpływ zastosowania indeksów na czas obsługi zapytań.
Indeksy to struktura, która przyspiesza wyszukiwanie danych
w Bazie. Indeksy przypominają zakładki z literami alfabetu
w katalogach. Jeżeli szukamy czegoś na literę „D” nie szukamy juz
gdzie indziej tylko za zakładka z literą „D”. Oczywiście zbyt wiele
kolumn oznaczonych jako indeksy nie spowoduje przyspieszenia,
a wręcz przeciwnie, spowolnią proces. Indeksy przyspieszają
przeszukiwanie danych (SELECT), ale spowalniają modyfikacje
(INSERT, UPDATE i DELETE). Spowolnienie tych ostatnich wynika
wprost z konieczności zapisu nie tylko danych w tabeli, ale także
aktualizacji indeksu dla tych informacji. To z kolei, wymaga
przesortowania już posiadanych danych tak, aby nowe informacji
znalazły się w odpowiednich miejscach.
Na
indeksy
najlepiej
nadają
się
kolumny
zawierające
niepowtarzalne dane, czyli wszelkiego typu identyfikatory. Do
utworzenia indeksu najlepiej nadaje się pole unikalne, czyli
w przypadku tabeli z pomiarami measurement_id. W tym przypadku,
indeks tworzony jest automatycznie, ponieważ pole jest w tej tabeli
kluczem głównym.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
54
Jako indeksy można też użyć kolumn, które będą często
wykorzystywane do filtrowania danych, czyli pola występujące
w warunku WHERE. W przypadku tabeli z pomiarami, powinno to być
pole station_id lub w przypadku schematu I stationName.
Indeksy mogą być tworzone dla jednego lub wielu pól. Możemy
utworzyć indeks dla pól temperature0m i temeperature2m jeżeli
będziemy często przeszukiwać bazę według takiego kryterium. Można
także utworzyć więcej niż jeden indeks dla tabeli. Dokładnie, MySQL
umożliwia utworzenie 64 indeksów dla jednej tabeli typu MyISAM,
ale należy unikać tworzenia zbyt wielu indeksów.
Korzystając z przedstawionej powyżej teorii można określić, że
indeksy mogą mieć decydujący wpływ na wydajność prezentowanych
propozycji. Dzięki ich zastosowaniu, zmienia się zależność czasu
wykonania kwerendy od ilości danych w bazie.
4.4. Kryteria oceny proponowanych rozwiązań
Przystępując do testów rozwiązań kandydujących, należy
wyszczególnić
jakie
ich
cechy
mają
największe
znaczenie.
W przypadku systemu bazodanowego należy brać pod uwagę takie
zagadnienia jak:
Objętość
Wydajność zapisu
Wydajność odczytu
Należy pamiętać o głównym przeznaczeniu systemu. Jeśli
system ma być nastawiony na jak największą wydajność zapisu lub/i
odczytu rozsądnie będzie uznać, że objętość bazy danych nie stanowi
wielkiego problemu. Jeśli natomiast wiadome jest, że nie ma potrzeby
gwarantować klientom szybkiego dostępu do danych, można wybrać
rozwiązanie najlepsze pod kątem objętości.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
55
4.4.1. Objętość
Jest to jeden z najważniejszych parametrów jeśli rozważa się
problem baz danych mających przechowywać ogromne ilości danych.
Od niego zależy wybór ilości miejsca dostępnego na serwerze. Na
objętość bazy danych wpływają takie czynniki jak:
Długość okresu gromadzenia danych
Zastosowany schemat bazy danych
Sposób implementacji indeksów
Typ danych przechowywanych w tabelach
4.4.2. Wydajność zapisu
Parametr pomijany bardzo często w opisach schematów baz
danych. Jednym z powodów takiego podejścia jest fakt, że operacja
zapisu do bazy jest jedną z najszybszych. W tym miejscu należy
zaznaczyć, że tak się dzieje tylko jeśli nie zachodzą dodatkowe
czynniki. Takim czynnikiem wpływającym na szybkość zapisu mogą
być na przykład nienajlepiej dobrane indeksy dla tabeli, na przykład
za duża ich liczba.
4.4.3. Wydajność odczytu
Zdecydowanie jeden z najważniejszych parametrów systemu
bazodanowego. W przeważającej większości systemów to właśnie na
odczyt danych kładzie się największy nacisk. Sytuacja ta wynika
z faktu, że informacja jest na tyle użyteczna, na ile łatwo do niej
dotrzeć. Istnieją wprawdzie systemy bazodanowe zajmujące się
głównie magazynowaniem informacji, ale jest to znikomy procent
implementacji.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
56
5. ZESTAWIENIE UZYSKANYCH WYNIKÓW
5.1. Zestawienie wydajności rozwiązań
Testom wydajności poddane zostały rozwiązania:
Wszystkie dane zgromadzone w jednej tabeli – dalej oznaczane „I”
Każdy pomiar w osobnym rekordzie – oznaczane dalej jako „II”
Trzecia postać normalna – rozwiązanie oznaczane nr „III”
Każdemu z rozwiązań kandydujących przypisany został numer.
Ma to na celu ułatwić identyfikację poszczególnych schematów
w dalszej części dokumentu. Opisując cechy omawianych rozwiązań
będą one określane jako Schemat X, gdzie X oznacza rozwiązanie
kandydujące o numerze I, II lub III.
5.1.1. Objętość
Sprawdzenie objętości bazy danych po zapisaniu pewnej ilości
pomiarów, polega na odczytaniu rozmiaru plików przechowujących,
odpowiadającą testowanemu schematowi, bazę danych.
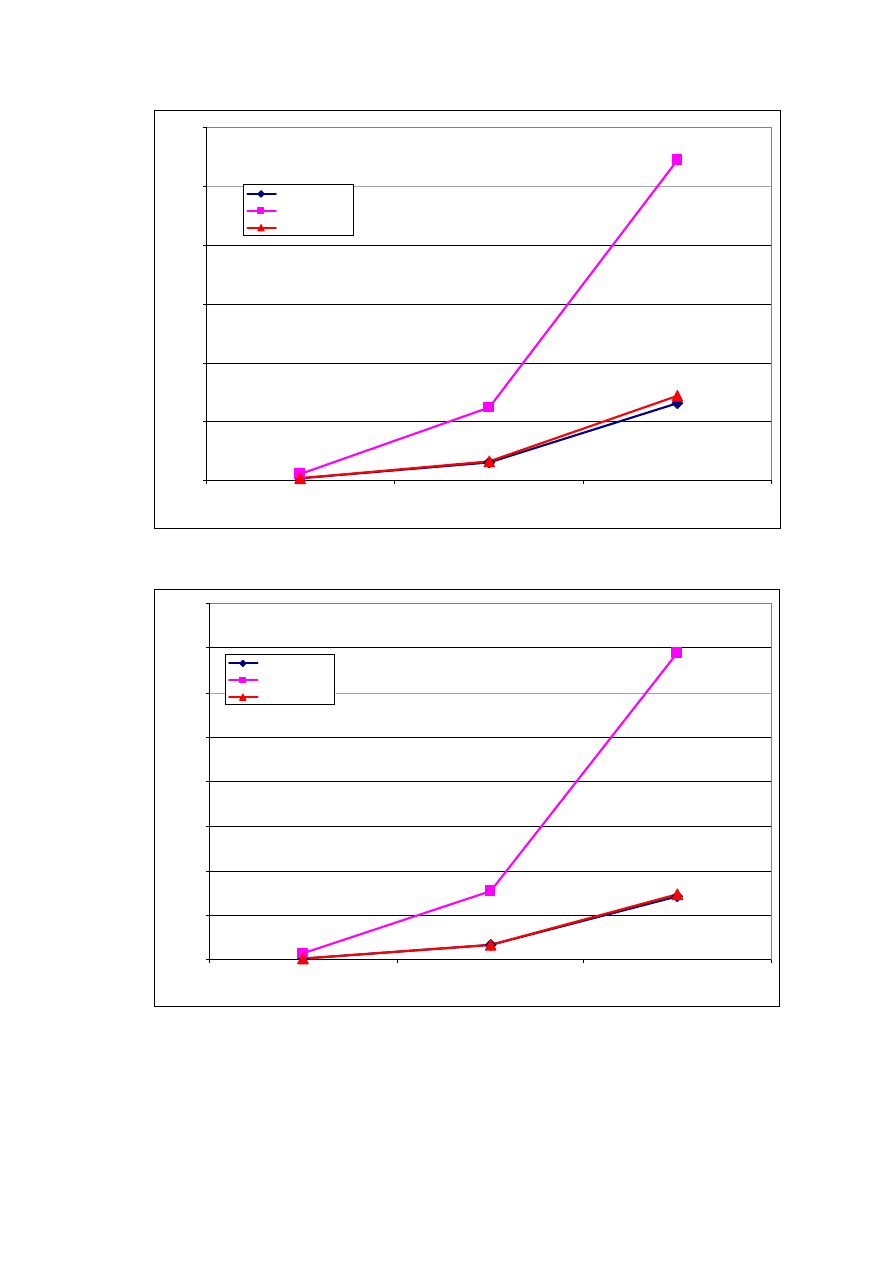
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
57
0
100
200
300
400
500
600
1
12
60
miesiące
o
b
ję
to
ś
ć
[
M
B
]
III schemat
II Schemat
I Schemat
Rys. 5. Zależność objętości plików bazy danych od czasu gromadzenia pomiarów dla systemu
5 stacji i tabeli przechowującej pomiary bez indeksów.
0
100
200
300
400
500
600
700
800
1
12
60
miesiące
o
b
ję
to
ś
ć
[
M
B
]
III schemat
II Schemat
I Schemat
Rys. 6. Zależność objętości plików bazy danych od czasu gromadzenia pomiarów dla systemu
5 stacji i tabeli przechowującej pomiary z indeksami.
Na rysunkach 6 i 7 można zauważyć, że pod względem
objętości, rozwiązanie II znacząco odstaje od dwóch pozostałych. Ma
to miejsce nawet w najprostszym przypadku gdy dane gromadzone
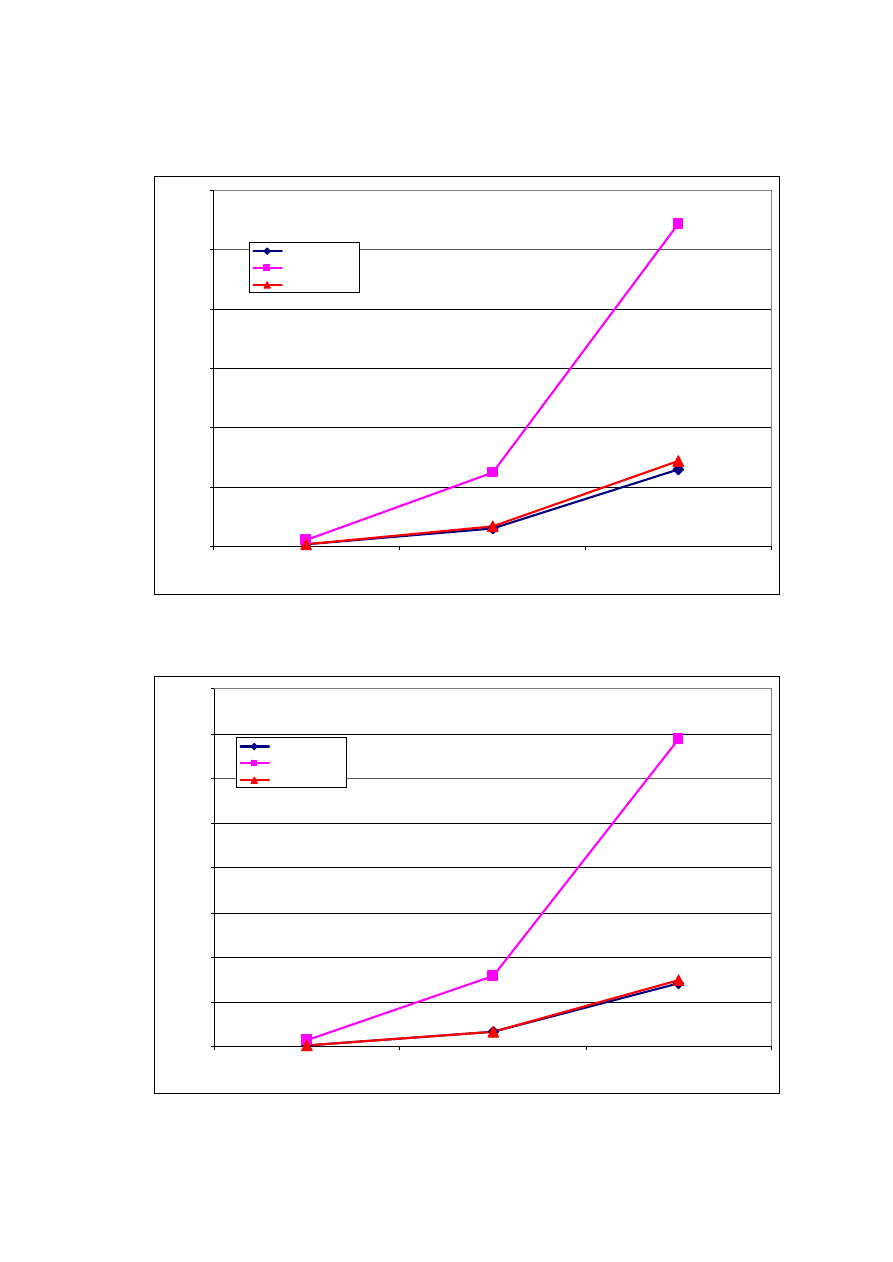
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
58
są z 5 stacji pomiarowych. Stosunek ten pozostaje niezmienny
niezależnie od ilości stacji z jakich gromadzone są pomiary:
0
1000
2000
3000
4000
5000
6000
1
12
60
miesiące
o
b
ję
to
ś
ć
[
M
B
]
III schemat
II Schemat
I Schemat
Rys. 7. Zależność objętości plików bazy danych od czasu gromadzenia pomiarów dla systemu
50 stacji i tabeli przechowującej pomiary bez indeksów.
0
1000
2000
3000
4000
5000
6000
7000
8000
1
12
60
miesiące
o
b
ję
to
ś
ć
[
M
B
]
III schemat
II Schemat
I Schemat
Rys. 8. Zależność objętości plików bazy danych od czasu gromadzenia pomiarów dla systemu
50 stacji i tabeli przechowującej pomiary z indeksami.
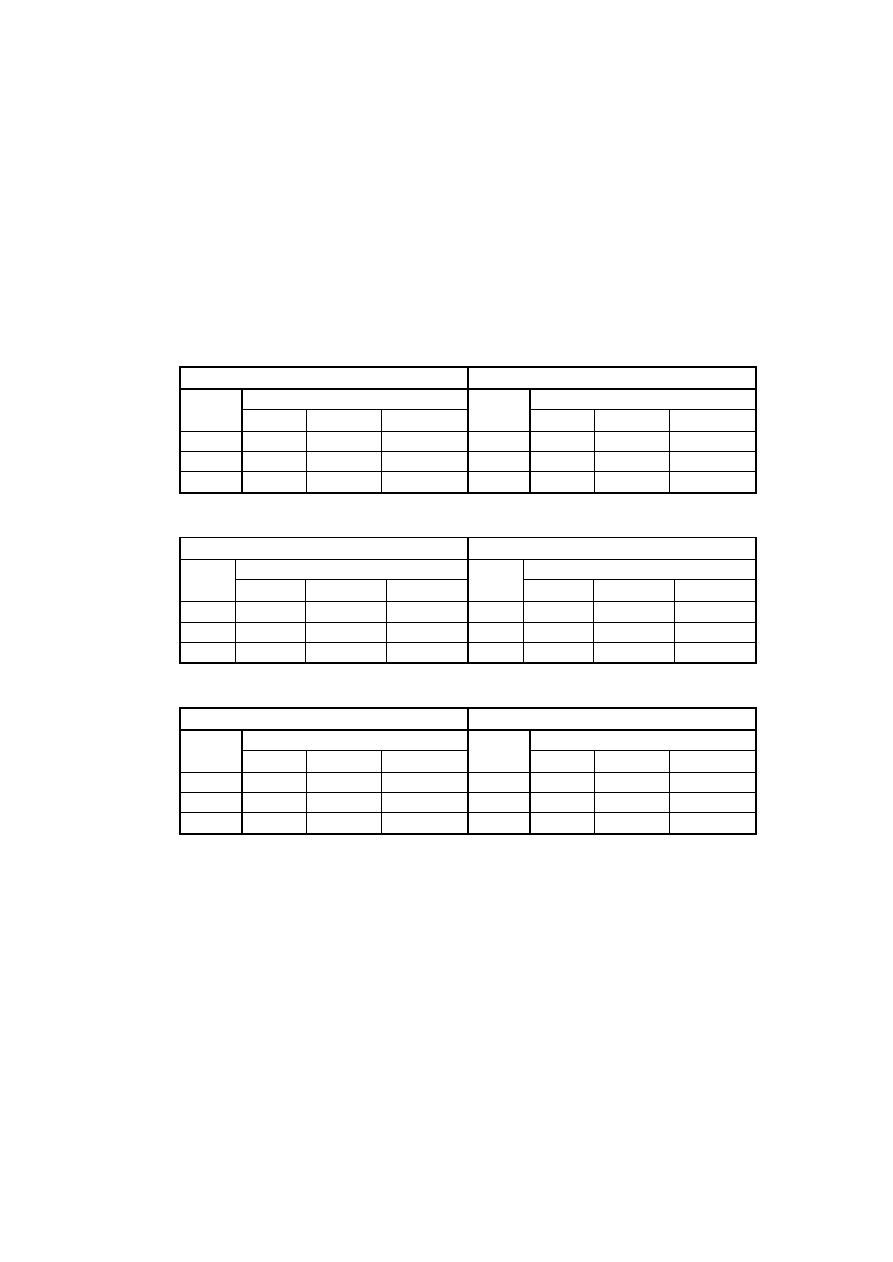
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
59
Taka sytuacja jest pewnego rodzaju zwiastunem tego jaka
będzie charakterystyka systemu opartego na rozwiązaniu II. Wynika
to z faktu, że w operacjach bazodanowych objętość bazy jest
czynnikiem wpływającym na czas wykonania zapytań, którego nie
można pominąć w rozważaniach.
Komplet wyników pomiarów przyrostu objętości bazy w czasie:
Tabela 9. Objętość bazy danych [MB] dla schematu I
bez stosowania indeksów
z zastosowanymi indeksami
Miesiące
Miesiące
liczba
stacji
1
12
60
liczba
stacji
1
12
60
5
3
32
143
5
3
34
148
25
14
164
717
25
15
170
740
50
29
328
1434
50
30
340
1482
Tabela 10. Objętość bazy danych [MB] dla schematu II
bez stosowania indeksów
z zastosowanymi indeksami
Miesiące
Miesiące
liczba
stacji
1
12
60
liczba
stacji
1
12
60
5
11
124
543
5
14
154
688
25
56
623
2718
25
70
787
3417
50
113
1246
5436
50
140
1579
6861
Tabela 11. Objętość bazy danych [MB] dla schematu III
bez stosowania indeksów
z zastosowanymi indeksami
Miesiące
Miesiące
liczba
stacji
1
12
60
liczba
stacji
1
12
60
5
2
29
130
5
3
32
141
25
13
149
650
25
14
161
704
50
27
298
1301
50
29
323
1408
Przedstawione powyżej, w tabelach 9, 10, 11, wyniki pokazują,
że objętość danych zapisanych w schemacie II znacznie przewyższa
objętość danych zapisanych w schematach I i III. Można zauważyć,
że objętość danych zapisanych we wszystkich rozwiązaniach
przyrasta proporcjonalnie do ilości stacji i czasu. Schemat II
charakteryzuję się tak gwałtownym przyrostem objętości plików bazy
danych, ponieważ wymaga zapisania 11 rekordów, gdy schematy
I i III zgromadza tylko 1 rekord.
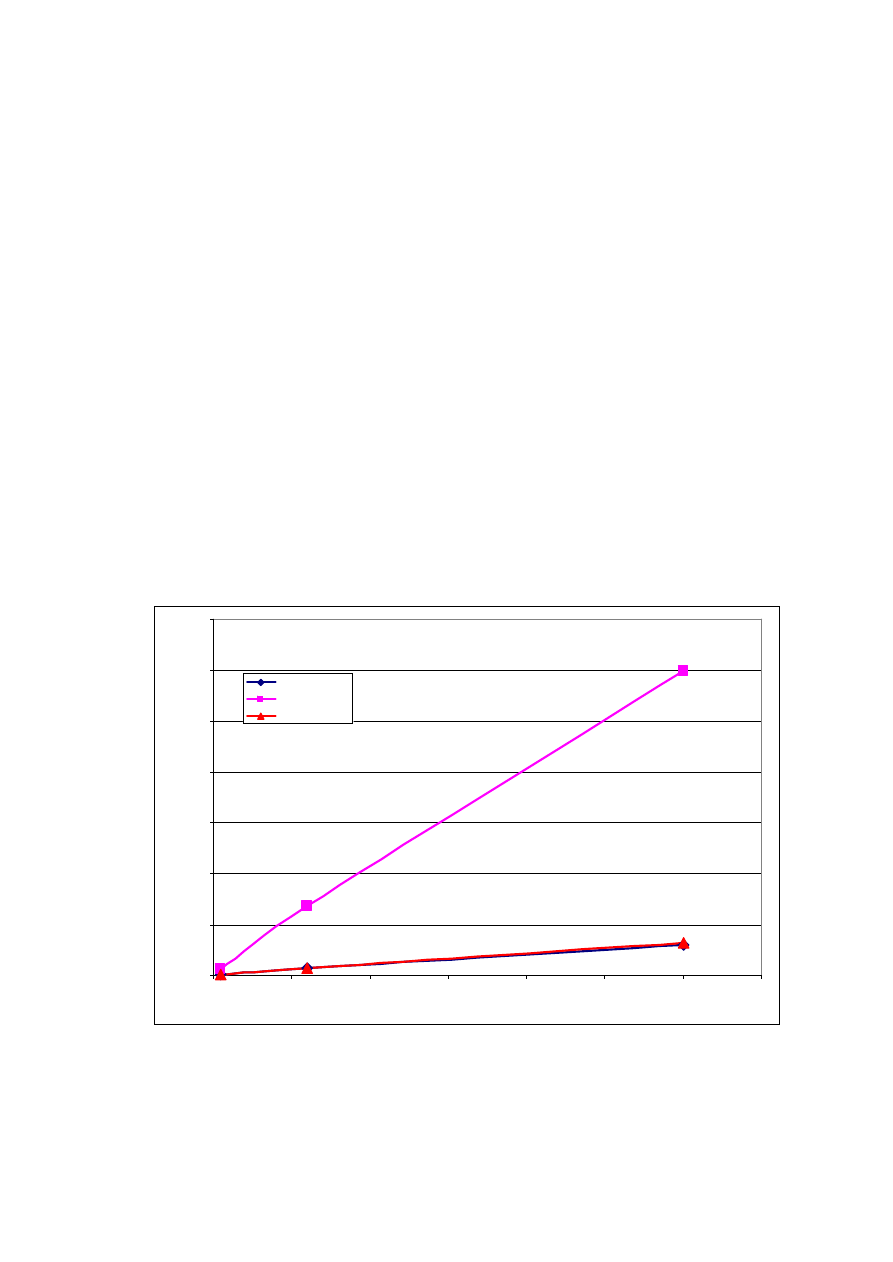
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
60
Można także zaobserwować, że objętość plików bazy danych nie
jest w bezpośredniej korelacji z ilością rekordów w bazie. Można to
zauważyć ponieważ ilość rekordów zapisanych w schemacie II jest,
co zostało powiedziane już wcześniej, 11 razy większa niż
w schematach I i III, a rozmiar plików bazy danych zwiększył się
tylko około czterokrotnie.
5.1.2. Wydajność zapisu
W tym rozdziale przeprowadzona zostanie analiza wydajności
rozwiązań pod kątem zapisu danych. Aby wyniki były możliwe do
wizualizacji, pomiary przeprowadzone zostały na zróżnicowanej ilości
danych. W tym celu do bazy zostaną zapisane dane z 1 miesiąca,
1 roku i 5 lat. Czasy, potrzebne do zapisu wszystkich zestawów dla
poszczególnych schematów, pozwolą zaobserwować jaka różnica
dzieli poszczególne schematy.
0
200
400
600
800
1000
1200
1400
0
10
20
30
40
50
60
70
miesiące
c
z
a
s
[
s
]
III schemat
II Schemat
I Schemat
Rys 9. Zależność czasu zapisu danych od długości okresu gromadzenia pomiarów dla
systemu 5 stacji i tabeli przechowującej pomiary bez indeksów
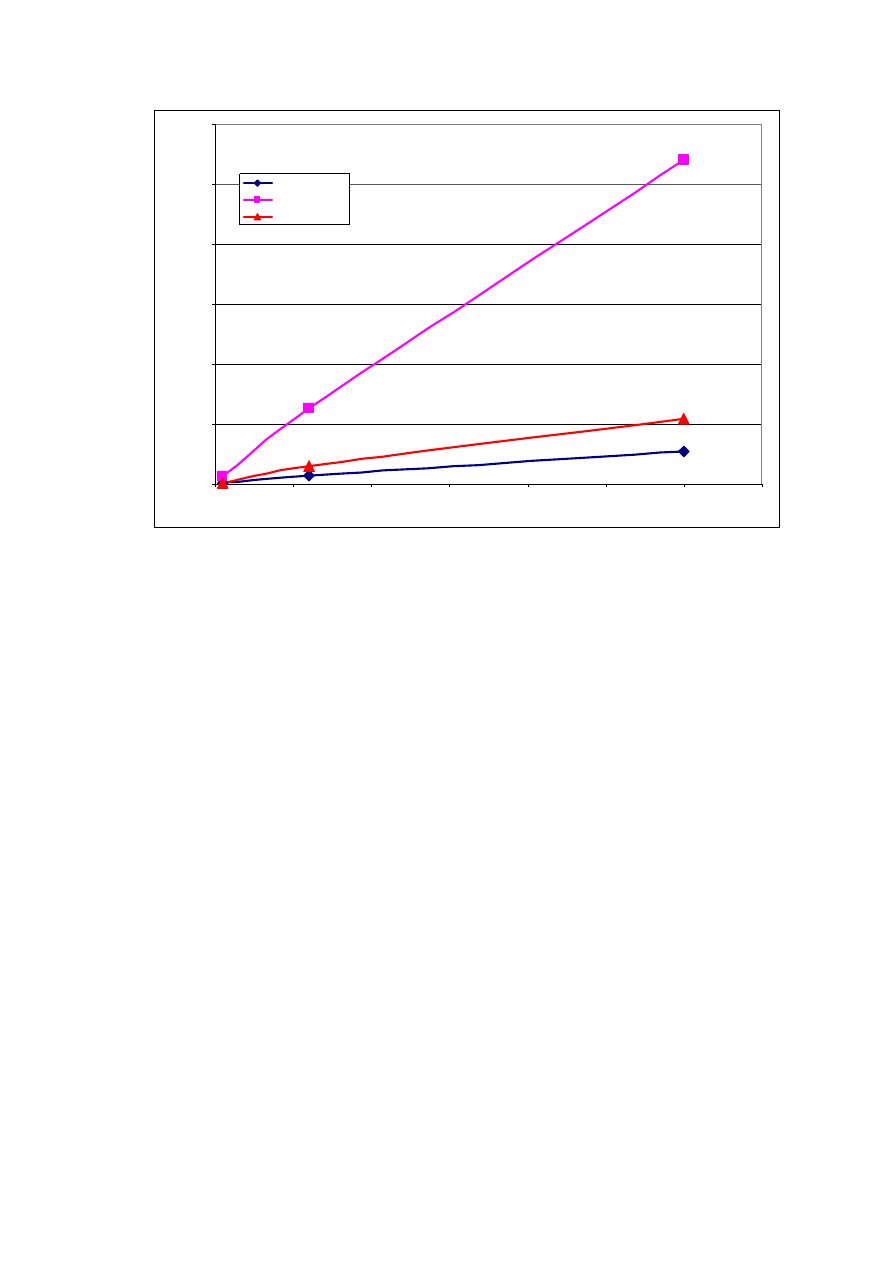
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
61
0
200
400
600
800
1000
1200
0
10
20
30
40
50
60
70
miesiące
c
z
a
s
[
s
]
III schemat
II Schemat
I Schemat
Rys. 10. Zależność czasu zapisu danych od długości okresu gromadzenia pomiarów dla
systemu 5 stacji i tabeli przechowującej pomiary z indeksami
Obserwując na rysunkach 9 i 10 zachowanie schematów dla
najprostszego systemu obsługującego jedynie 5 stacji pomiarowych,
nie sposób nie zauważyć wpływu znacznie szybciej przyrastającej
objętości plików bazy danych schematu II na czas zapisu nowych
rekordów. Znacznie większa ilość rekordów w tym schemacie sprawia,
że czas zapisu nowych przyrasta praktycznie liniowo.
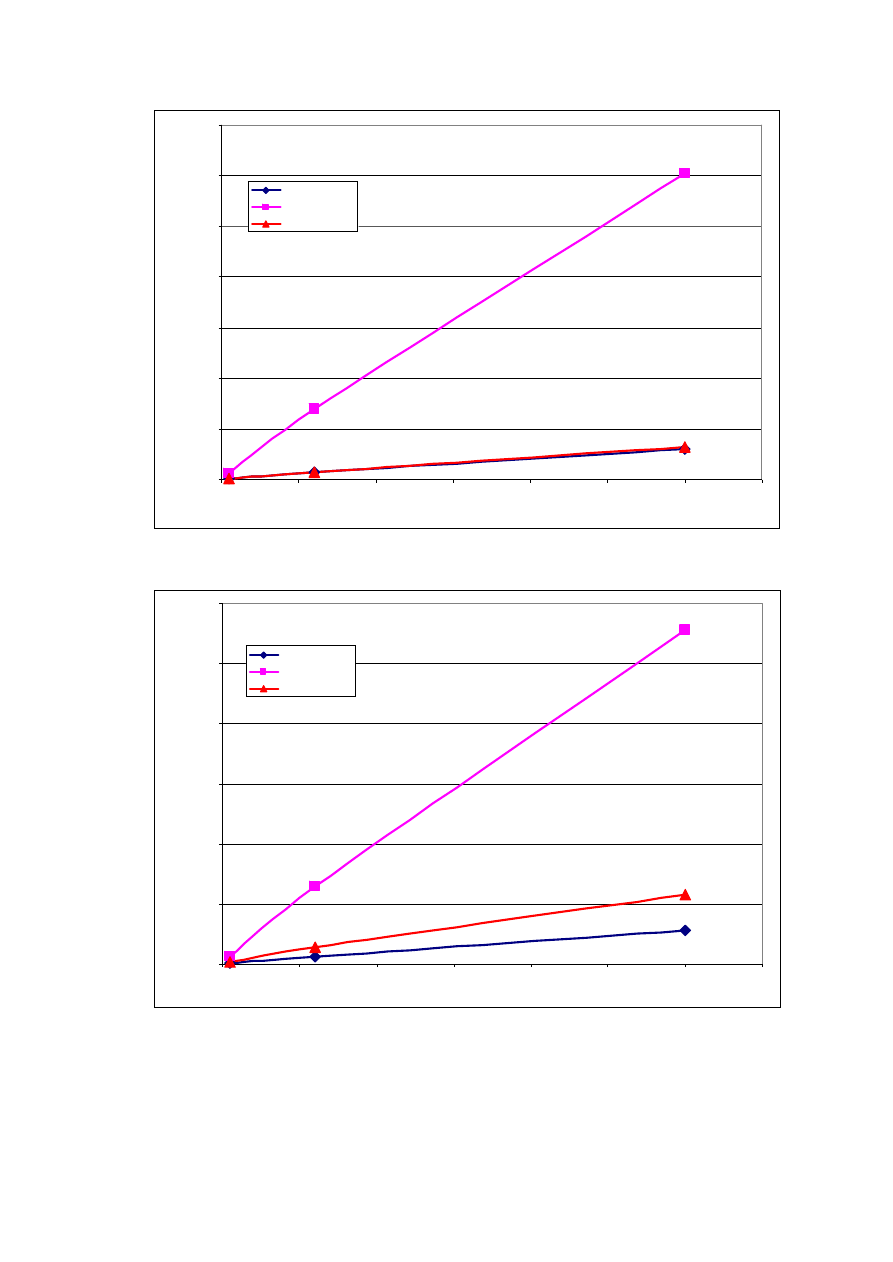
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
62
0
2000
4000
6000
8000
10000
12000
14000
0
10
20
30
40
50
60
70
miesiące
c
z
a
s
[
s
]
III schemat
II Schemat
I Schemat
Rys. 11. Zależność czasu zapisu danych od długości okresu gromadzenia pomiarów dla
systemu 50 stacji i tabeli przechowującej pomiary bez indeksów.
0
2000
4000
6000
8000
10000
12000
0
10
20
30
40
50
60
70
miesiące
c
z
a
s
[
s
]
III schemat
II Schemat
I Schemat
Rys. 12. Zależność czasu zapisu danych od długości okresu gromadzenia pomiarów dla
systemu 50 stacji i tabeli przechowującej pomiary z indeksami.
Analiza wyników pomiarów czasu potrzebnego na zapisanie
porcji danych z zadanego okresu, ujawniła, że w tym przypadku także
schemat II znacząco odstaje od konkurentów.
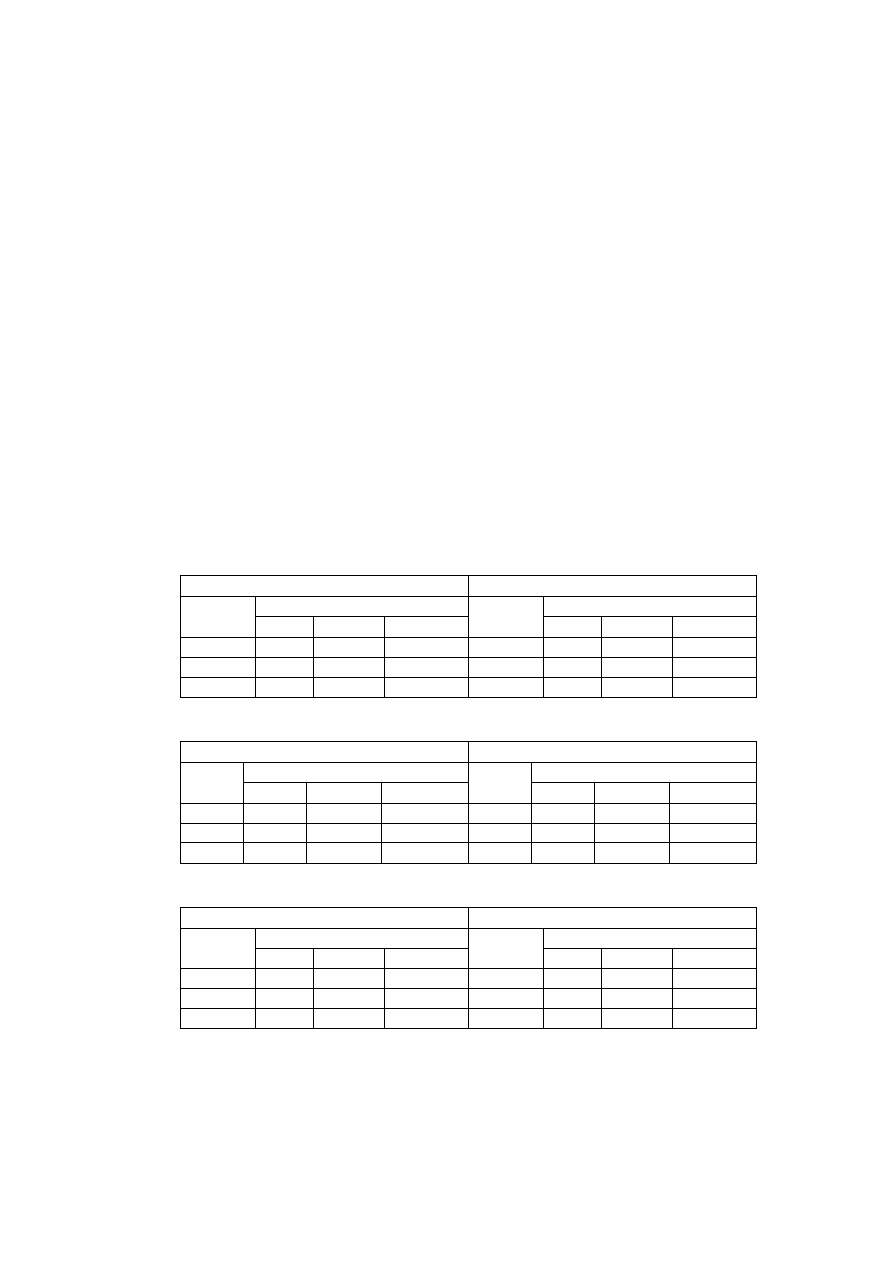
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
63
Fakt ten wynika bezpośrednio z punktu poprzedniego, czyli
znacznie większej objętości bazy II. W przypadku testów wydajności
zapisu pojawiła się także pewna rozbieżność pomiędzy schematem I
a II. Można zaobserwować, że zastosowanie indeksów znacząco
(dwukrotnie) wydłuża czas potrzebny do zapisania tej samej ilości
danych w schemacie I.
Analizując zachowanie się poszczególnych schematów w tym
teście, można zauważyć różnicę we wpływie jaki na czas zapisu ma
stosowanie indeksów. W przypadku Schematu I, czas zapisu uległ
wydłużeniu o około 50%. Dla Schematu II i III odnotowano
skrócenie się czasu zapisu o odpowiednio 8% i 7%.
Zestawienie kompletnych wyników pomiarów czasu zapisu
danych, z różnych okresów i dla różnej liczby stacji pomiarowych.
Tabela 12. Czas zapisu danych [s] dla schematu I
bez stosowania indeksów
z zastosowanymi indeksami
Miesiące
Miesiące
liczba
stacji
1
12
60
liczba
stacji
1
12
60
5
3
29
127
5
5
61
218
25
13
147
641
25
27
292
1115
50
27
296
1306
50
57
546
2317
Tabela 13. Czas zapisu danych [s] dla schematu II
bez stosowania indeksów
z zastosowanymi indeksami
Miesiące
Miesiące
liczba
stacji
1
12
60
liczba
stacji
1
12
60
5
25
274
1198
5
23
253
1080
25
126
1387
6030
25
116
1278
5528
50
252
2772
12109
50
232
2598
11135
Tabela 14. Czas zapisu danych [s] dla schematu III
bez stosowania indeksów
z zastosowanymi indeksami
Miesiące
Miesiące
liczba
stacji
1
12
60
liczba
stacji
1
12
60
5
3
27
118
5
3
29
108
25
12
136
596
25
11
127
550
50
25
274
1195
50
23
258
1109
Przedstawione powyżej wyniki potwierdzają wniosek z testów
przyrostu objętości. Rozmiar bazy danych decyduje o wydłużeniu
czasu zapisu nowych rekordów.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
64
Natomiast można zauważyć bardziej bezpośredni związek
pomiędzy liczbą rekordów w bazie i czasem zapisu nowych danych,
niż pomiędzy ilością rekordów, a objętością plików na dysku.
W przypadku czasu zapisu do bazy opartej o schemat II, jest on 9x
dłuższy niż dla schematu I bez stosowani indeksów i 4x dłuższy niż
ten sam schemat ale z zastosowaniem indeksów. Przeprowadzając
analogiczne porównanie ze schematem III można zauważyć ze czas
zapisu do schematu II jest około 10x dłuższy w obu przypadkach
indeksowania.
5.1.3. Wydajność odczytu
Do określenia wydajności odczytu danych z poszczególnych
rozwiązań,
posłużą
kwerendy
odpowiadające
testom
zaproponowanym w rozdziale 4.1. Kwerendom testowym zostały
przypisane numery dla poprawy czytelności wykresów:
K1: Znalezienie sum godzinowych opadów dla zadanej stacji.
K2: Wyszukanie wartości przekraczających ustalone wartości
graniczne.
K3: Wybranie ekstremalnych wartości parametru z pominięciem
wykraczających poza zakres.
K4: Podstawowe statystyki, takie jak średnie wartości parametrów.
K5: Pozyskiwanie sumy opadów na zadanym terenie (objętym
zadaną liczba stacji pomiarowych) dla ostatnich 3 godzin.
Każda z kwerend została uruchomiona dla danego schematu
z indeksem i bez indeksu. Do testów indeks został utworzony na polu
station_id w tabeli measurements. Ponieważ w Schemacie I nie ma
takiego pola, indeksowanie oraz wyszukiwanie odbywa się po
stationName.
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
65
0
10
20
30
40
50
60
70
80
1
12
60
1
12
60
1
12
60
I
II
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 4
Kwerenda 5
Rys. 13. Zestawienie czasu wyszukiwania dla systemu 5 stacji i tabeli przechowującej
pomiary bez indeksów.
0
1
2
3
4
5
6
7
8
9
10
1
12
60
1
12
60
1
12
60
I
II
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 4
Kwerenda 5
Rys. 14. Zestawienie czasu wyszukiwania dla systemu 5 stacji i tabeli przechowującej
pomiary z indeksami
Na rysunkach 13 i 14, ponownie można zaobserwować bardzo
negatywny wpływ objętości bazy danych schematu II na czasy
wykonania zapytań testowych.
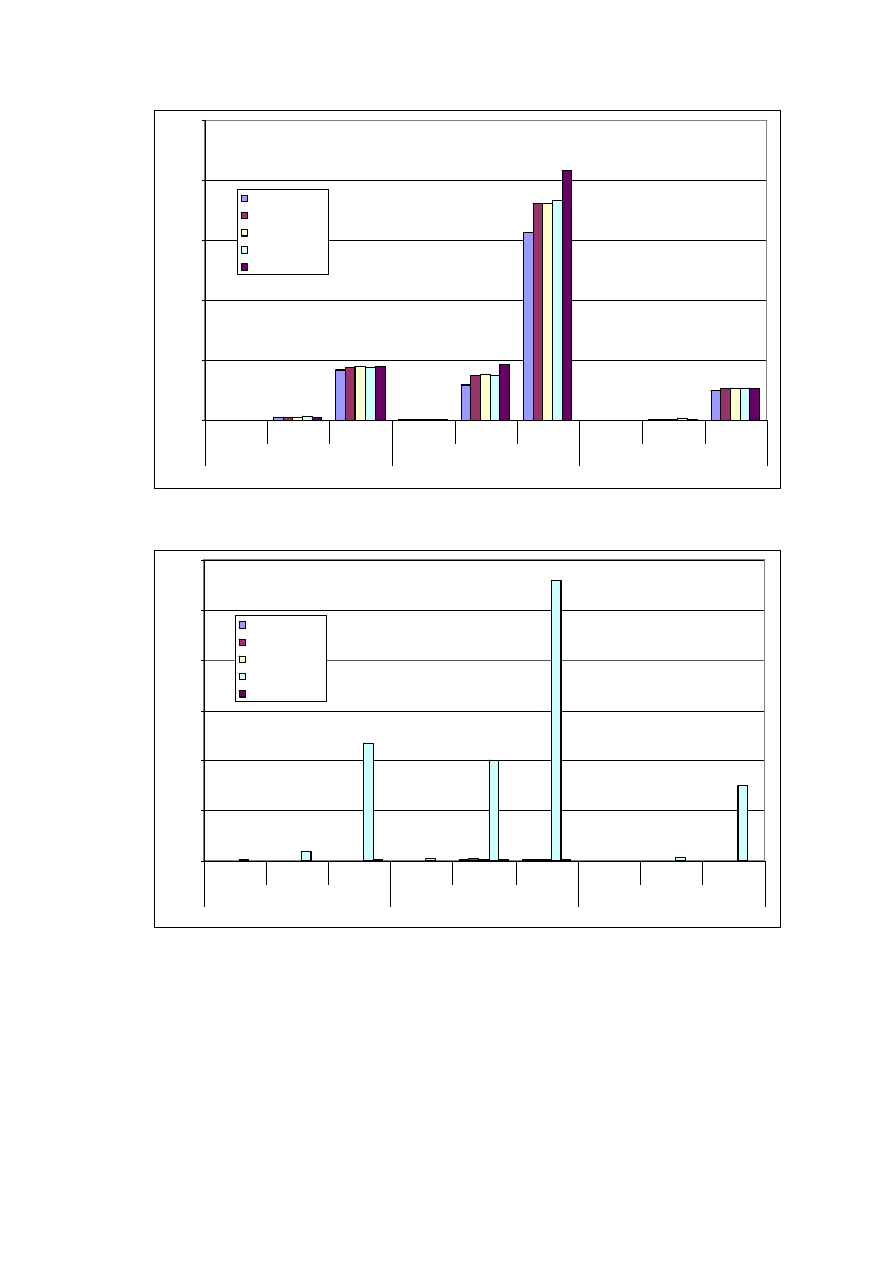
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
66
0
50
100
150
200
250
1
12
60
1
12
60
1
12
60
I
II
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 4
Kwerenda 5
Rys. 15. Zestawienie czasu wyszukiwania dla systemu 50 stacji i tabeli przechowującej
pomiary bez indeksów
0
20
40
60
80
100
120
1
12
60
1
12
60
1
12
60
I
II
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 4
Kwerenda 5
Rys. 16. Zestawienie czasu wyszukiwania dla systemu 50 stacji i tabeli przechowującej
pomiary z indeksami
Powyższe zestawienie wyników pomiarów dla wszystkich trzech
schematów ujawnia, że schemat II nie dorównuje pozostałym także
pod względem szybkości wyszukiwania danych. W dodatku różnice są
tak duże, że utrudniają analizę wyników lepszych rozwiązań.
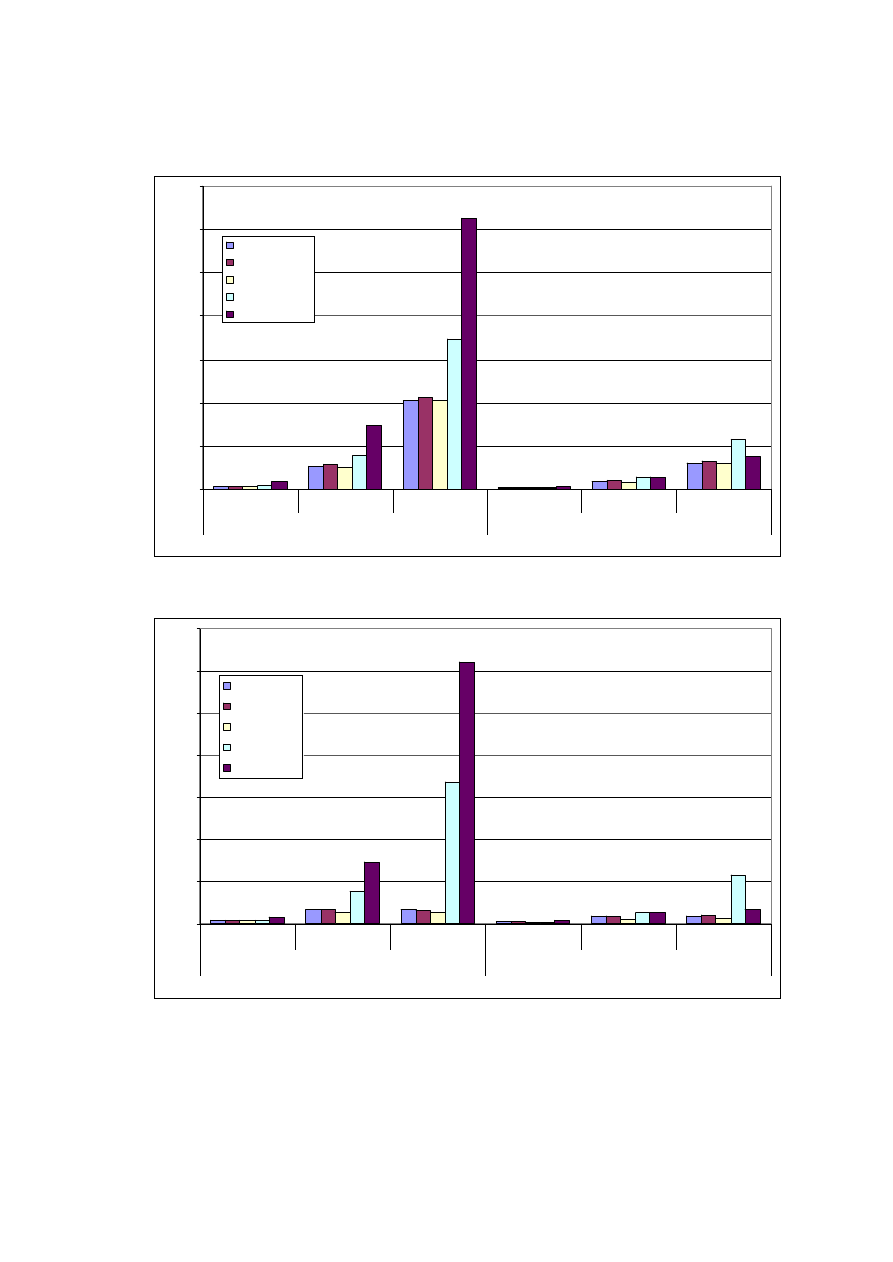
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
67
Dlatego poniżej przedstawione zostanie zestawienie wyników z
wykluczeniem rozwiązania II.
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
1
12
60
1
12
60
I
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 4
Kwerenda 5
Rys. 17. Zestawienie czasu wykonania kwerend testowych dla systemu 5 stacji i tabeli
przechowującej pomiary bez indeksów, z pominięciem schematu II
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
1
12
60
1
12
60
I
III
schem at / ilość m iesięcy
c
z
a
s
[
s
]
Kw erenda 1
Kw erenda 2
Kw erenda 3
Kw erenda 4
Kw erenda 5
Rys. 18. Zestawienie czasu wykonania kwerend testowych dla systemu 5 stacji i tabeli
przechowującej pomiary z indeksami, z pominięciem schematu II
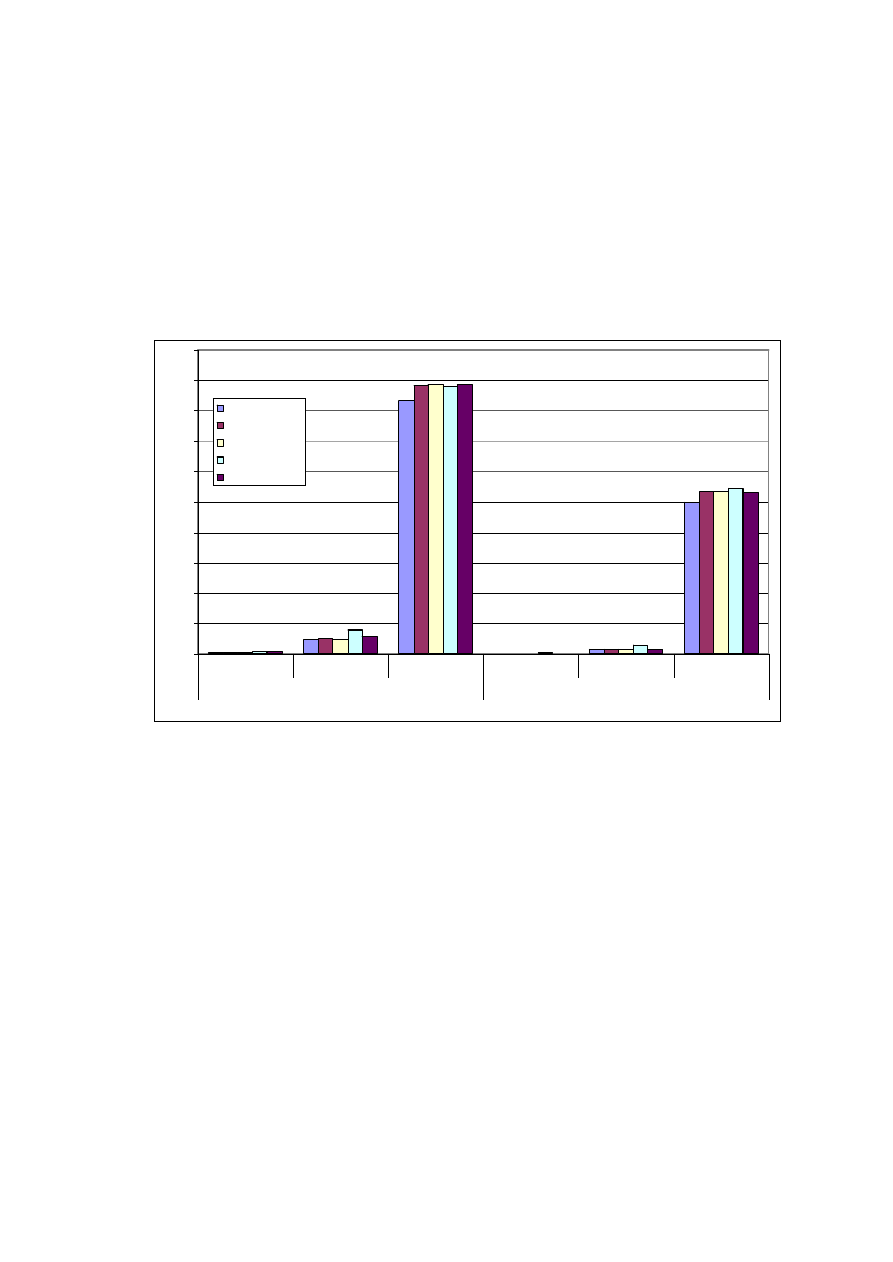
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
68
Przyglądając się wynikom testu tego najprostszego przypadku
odczytu danych i pamiętając o wynikach testów objętości i zapisu,
można zauważyć ogólne trendy zachowania się opisywanych
schematów. Widać wyraźnie, że dla okresu 1 miesiąca czasy
schematów I i III nie odbiegają od siebie znacząco. Jednak im więcej
danych zgromadzone jest w systemie tym bardziej uwidaczniają się
różnice pomiędzy tymi schematami.
0
5
10
15
20
25
30
35
40
45
50
1
12
60
1
12
60
I
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 4
Kwerenda 5
Rys. 19. Zestawienie czasu wykonania kwerend testowych dla systemu 50 stacji i tabeli
przechowującej pomiary bez indeksów, z pominięciem schematu II
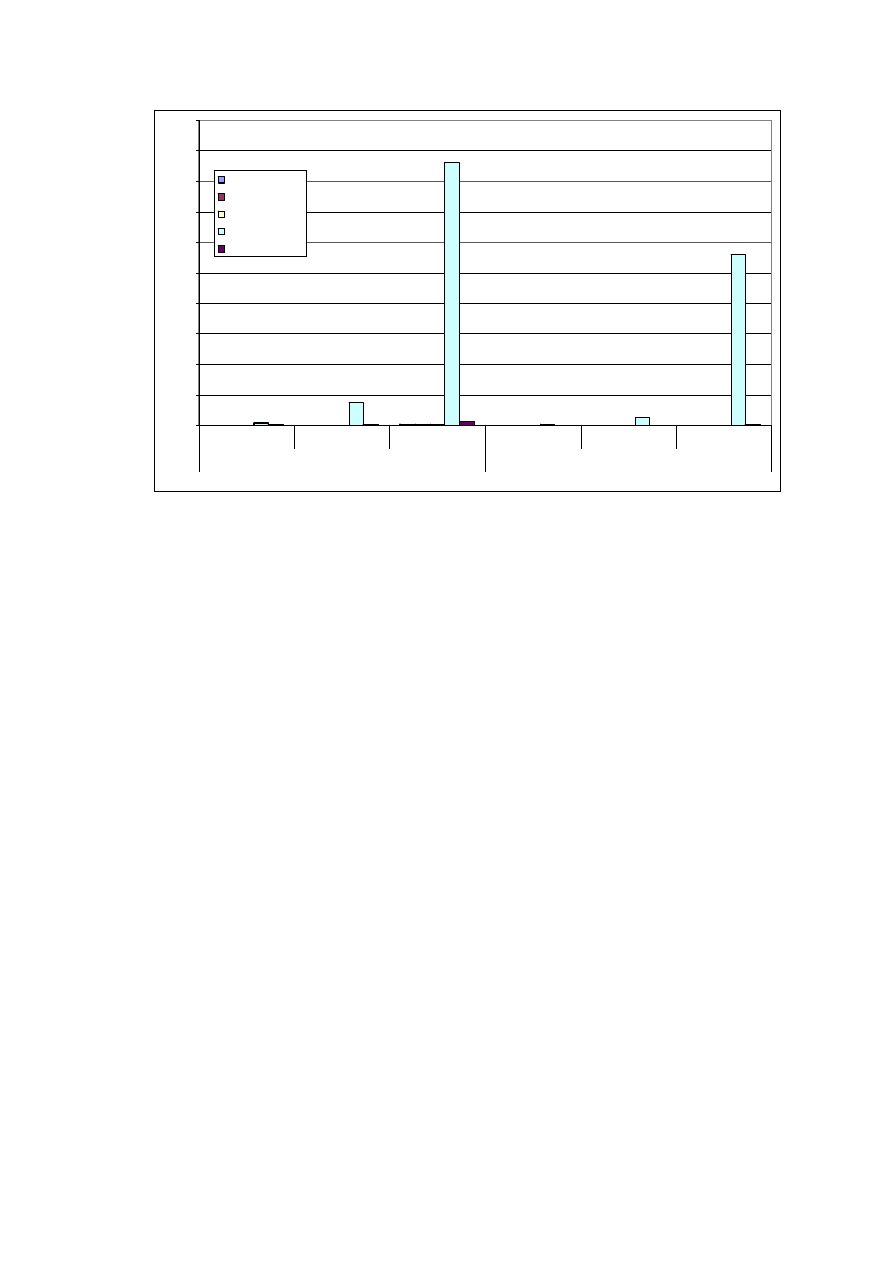
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
69
0
5
10
15
20
25
30
35
40
45
50
1
12
60
1
12
60
I
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 4
Kwerenda 5
Rys. 20. Zestawienie czasu wykonania kwerend testowych dla systemu 50 stacji i tabeli
przechowującej pomiary z indeksami, z pominięciem schematu II
Po pominięciu schematu II można zaobserwować różnice
pomiędzy schematami I a III. Dodatkowo wykresy na rysunkach 19
i 21, pokazują że kwerendy korzystające z większości rekordów, jak
to ma miejsce przy kwerendzie 4, nie korzystają z indeksów. Przez to
na powyższych wykresach (Rysunki 18 do 21) nadal trudno jest
zaobserwować różnice dzielące schemat I i III. Dlatego też poniżej
zamieszczone zostanie kolejne zestawienie. Nie będzie ono
uwzględniało Kwerendy 4, co pozwoli zaobserwować zachowanie
systemu przy najczęściej używanych kwerendach.
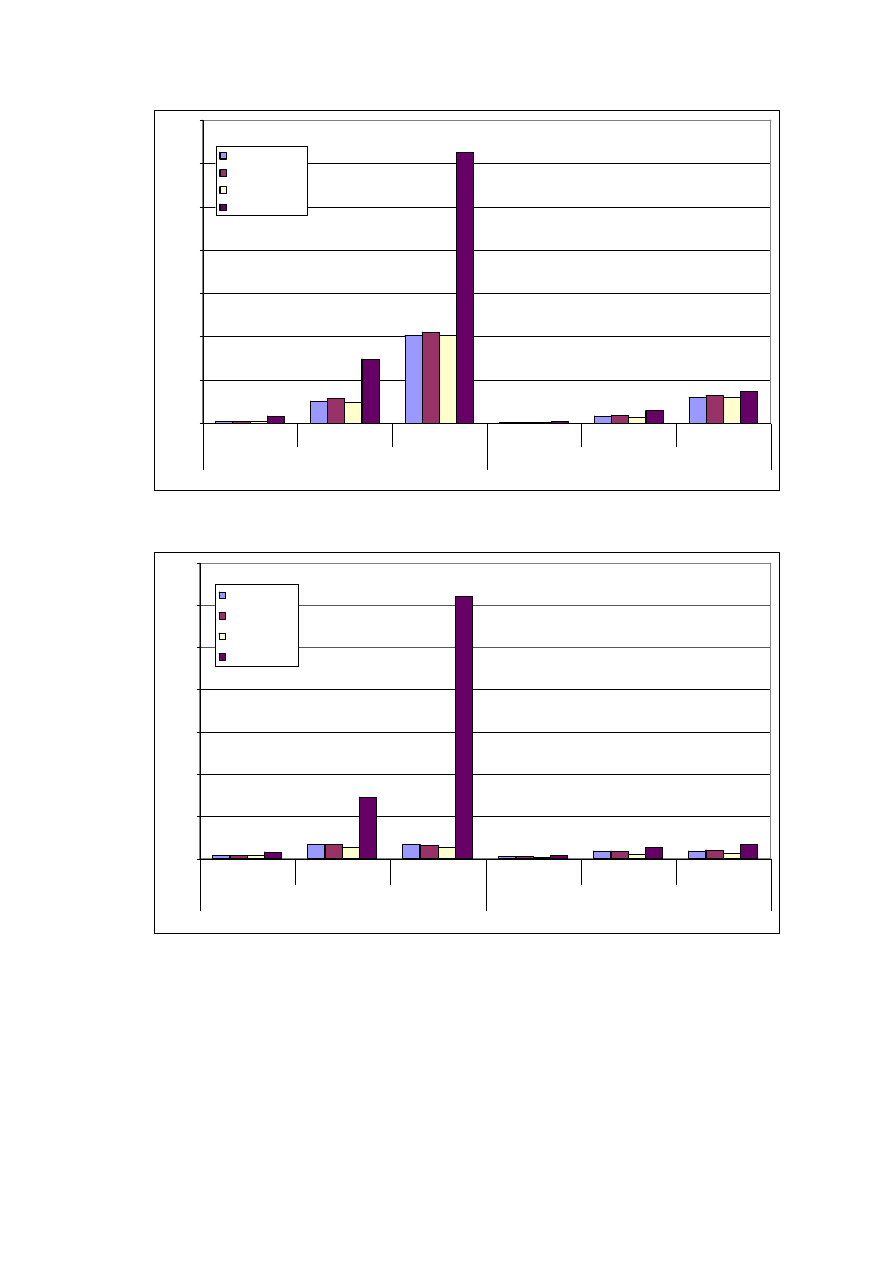
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
70
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
1
12
60
1
12
60
I
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 5
Rys. 21. Zestawienie czasu wykonania kwerend testowych dla systemu 5 stacji i tabeli
przechowującej pomiary bez indeksów, z pominięciem schematu II i Kwerendy 4
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
1
12
60
1
12
60
I
III
schem at / ilość miesięcy
c
z
a
s
[
s
]
Kw erenda 1
Kw erenda 2
Kw erenda 3
Kw erenda 5
Rys. 22. Zestawienie czasu wykonania kwerend testowych dla systemu 5 stacji i tabeli
przechowującej pomiary z indeksami, z pominięciem schematu II i Kwerendy 4
Rysunki 21. i 22 pokazują, że przy stosunkowo małym systemie
obsługującym 5 stacji schemat I nie sprawdza się przy obsłudze
Kwerendy 5.
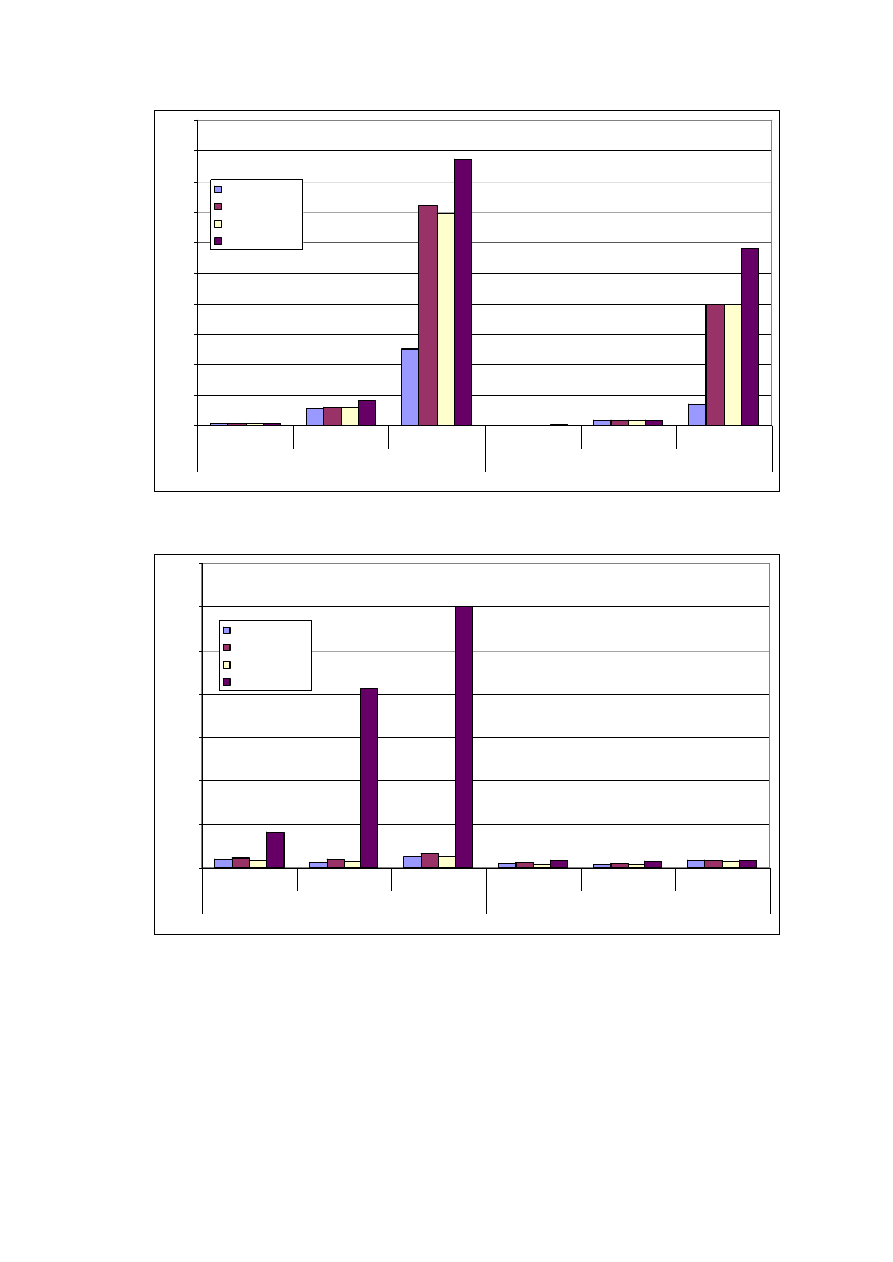
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
71
0
2
4
6
8
10
12
14
16
18
20
1
12
60
1
12
60
I
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 5
Rys. 23. Zestawienie czasu wykonania kwerend testowych dla systemu 25 stacji i tabeli
przechowującej pomiary bez indeksów, z pominięciem schematu II i Kwerendy 4
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1
12
60
1
12
60
I
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 5
Rys. 24. Zestawienie czasu wykonania kwerend testowych dla systemu 25 stacji i tabeli
przechowującej pomiary z indeksami, z pominięciem schematu II i Kwerendy 4
Wykresy na rysunkach 23 i 24 pokazują, że dla systemu 25
stacji pomiarowych schemat I prezentuje słabszą wydajność
podstawowych kwerend (K1, K2, K3) w stosunku do Schematu III.
Kwerenda 5 okazuje się swoistą piętą Achillesową schematu I.
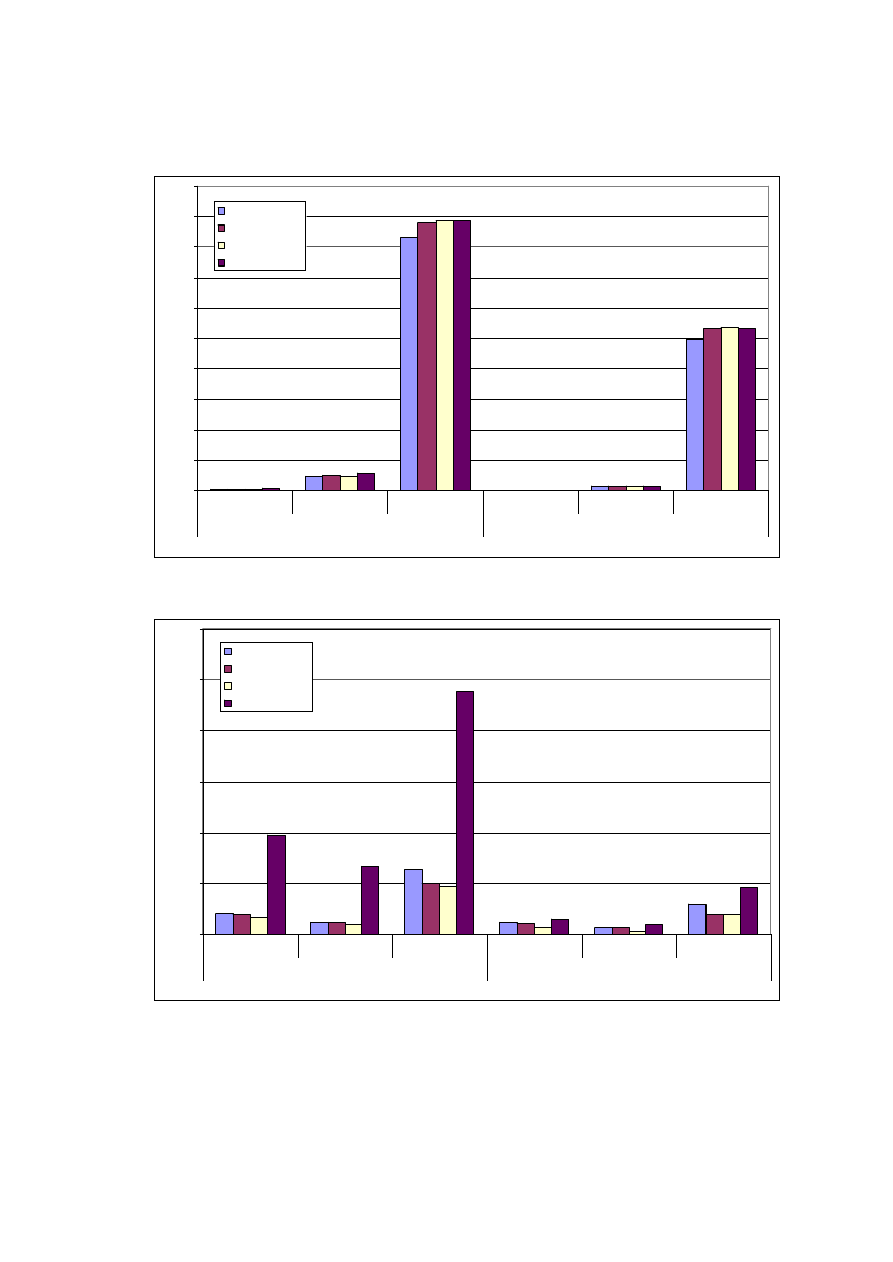
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
72
W tym przypadku czas wykonania tego zapytania jest o rząd
wielkości dłuższy niż z zastosowaniem schematu III.
0
5
10
15
20
25
30
35
40
45
50
1
12
60
1
12
60
I
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 5
Rys. 25. Zestawienie czasu wykonania kwerend testowych dla systemu 50 stacji i tabeli
przechowującej pomiary bez indeksów, z pominięciem schematu II i Kwerendy 4
0.0
0.1
0.2
0.3
0.4
0.5
0.6
1
12
60
1
12
60
I
III
schemat / ilość miesięcy
c
z
a
s
[
s
]
Kwerenda 1
Kwerenda 2
Kwerenda 3
Kwerenda 5
Rys. 26. Zestawienie czasu wykonania kwerend testowych dla systemu 50 stacji i tabeli
przechowującej pomiary z indeksami, z pominięciem schematu II i Kwerendy 4
Wykresy na rysunkach 25 i 26 dokumentują wyniki testów
przeprowadzone dla symulacji systemu obsługującego dużą sieć 50
stacji pomiarowych.
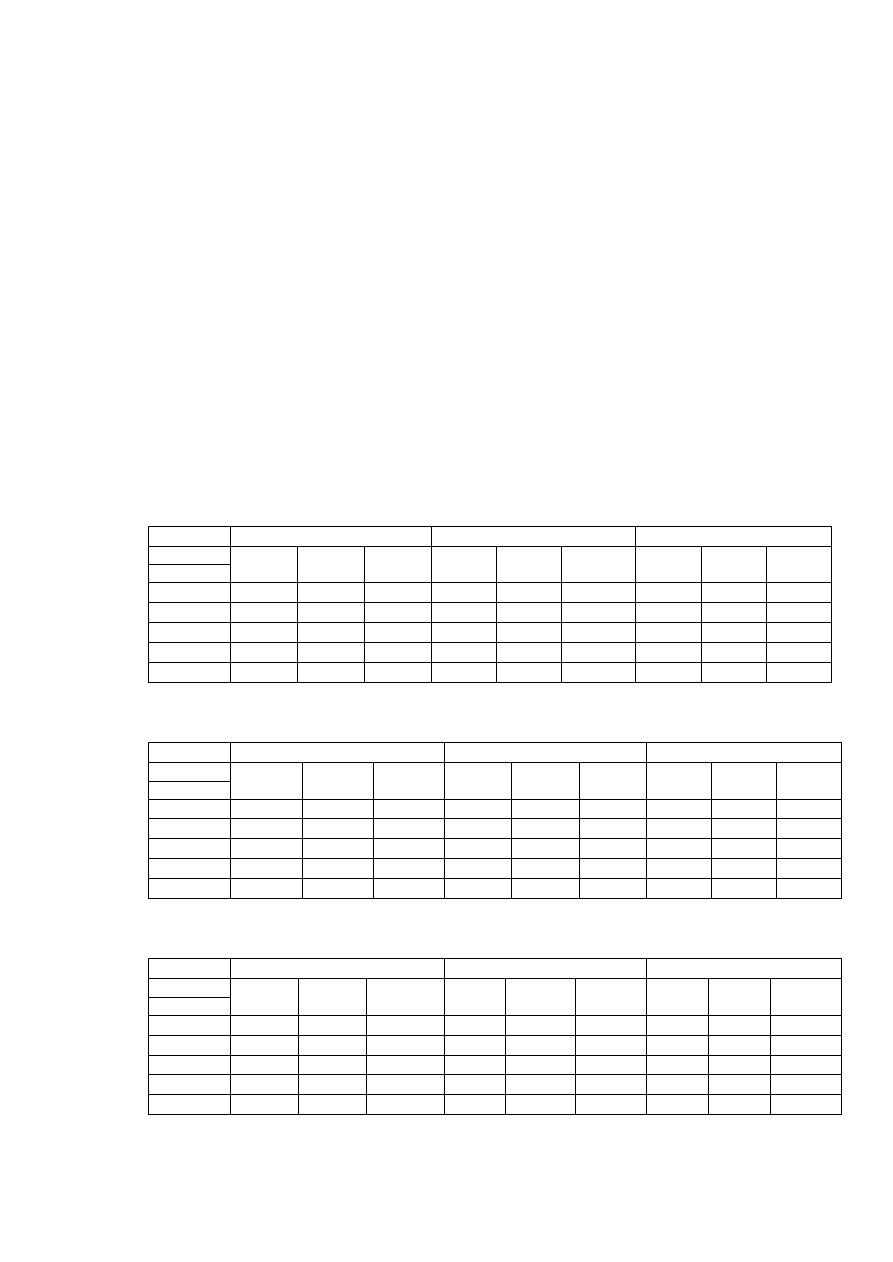
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
73
Przy tak dużej ilości danych testowych uwidocznione zostają
nawet niewielkie różnice w wydajności rozwiązań. Wyraźnie można
zaobserwować różnicę pomiędzy testowanymi schematami. Widać
także, że stosowanie indeksów powoduje opóźnienia w działaniach
systemu przy niewielkiej ilości danych w nim zgromadzonych.
Objawia się to dłuższymi czasami wykonania kwerend dla danych z
jednego miesiąca, niż z jednego roku. Dla systemu obsługującego 50
stacji czas wykonania kwerendy 5 uległ skróceniu, w stosunku do
systemu z 25 stacjami. Sytuacja ta ma związek z zastosowanym
indeksem. Dopiero przy takiej ilości stacji zastosowanie indeksu
pozwoliło skrócić czas wykonania kwerendy.
Tabela 15. Zestawienie czasów wyszukiwania [s] dla poszczególnych schematów przy
systemie 5 stacji i tabeli przechowującej wyniki bez indeksów
Schemat
I
II
III
Miesiące
Kwerenda
1
12
60
1
12
60
1
12
60
1
0.02509
0.25730
1.01723 0.07902 0.77846
69.03832
0.01019 0.08928 0.29976
2
0.02723
0.28662
1.05334 0.06566 0.70720
34.24004
0.01078 0.09834 0.32297
3
0.02206
0.24366
1.02190 0.06163 0.71036
31.39790
0.00689 0.07204 0.29682
4
0.03333
0.39087
1.73664 0.08056 0.92845
33.18582
0.01234 0.13320 0.57296
5
0.08705
0.74057
3.12429 0.07454 0.78181
38.51185
0.01878 0.14323 0.37102
Tabela 16. Zestawienie czasów wyszukiwania [s] dla poszczególnych Schematów przy
systemie 5 stacji i tabeli przechowującej wyniki z indeksami
Schemat
I
II
III
Miesiące
Kwerenda
1
12
60
1
12
60
1
12
60
1
0.03942
0.16662
0.17034
0.08903
0.82104
3.39466 0.02194 0.08867 0.08816
2
0.03704
0.16374
0.15652
0.08197
1.22617
3.86107 0.01963 0.09111 0.10272
3
0.03255
0.13113
0.13388
0.07962
1.25648
2.47958 0.01345 0.04985 0.06724
4
0.03304
0.38703
1.68221
0.08026
0.98775
8.85851 0.01400 0.13175 0.57055
5
0.09080
1.36430
2.48125
0.09080
1.36430
2.48125 0.03273 0.13191 0.16067
Tabela 17. Zestawienie czasów wyszukiwania [s] dla poszczególnych Schematów przy
systemie 25 stacji i tabeli przechowującej wyniki bez indeksów
Schemat
I
II
III
Miesiące
Kwerenda
1
12
60
1
12
60
1
12
60
1
0.10704
1.14416
4.99105 0.33057
3.91572 75.51242 0.03362 0.31914
1.41100
2
0.11749
1.20488
14.42514 0.35870 12.05723 78.96825 0.03473 0.34499
7.91140
3
0.11298
1.18516
13.95440 0.32489 11.47294 80.28558 0.03165 0.33988
7.90125
4
0.16611
1.92720
15.42025 0.44885 12.14457 82.12093 0.06165 0.71430
9.07666
5
0.16746
1.63968
17.42070 0.35777 11.00756 88.80611 0.04463 0.34622 11.56543
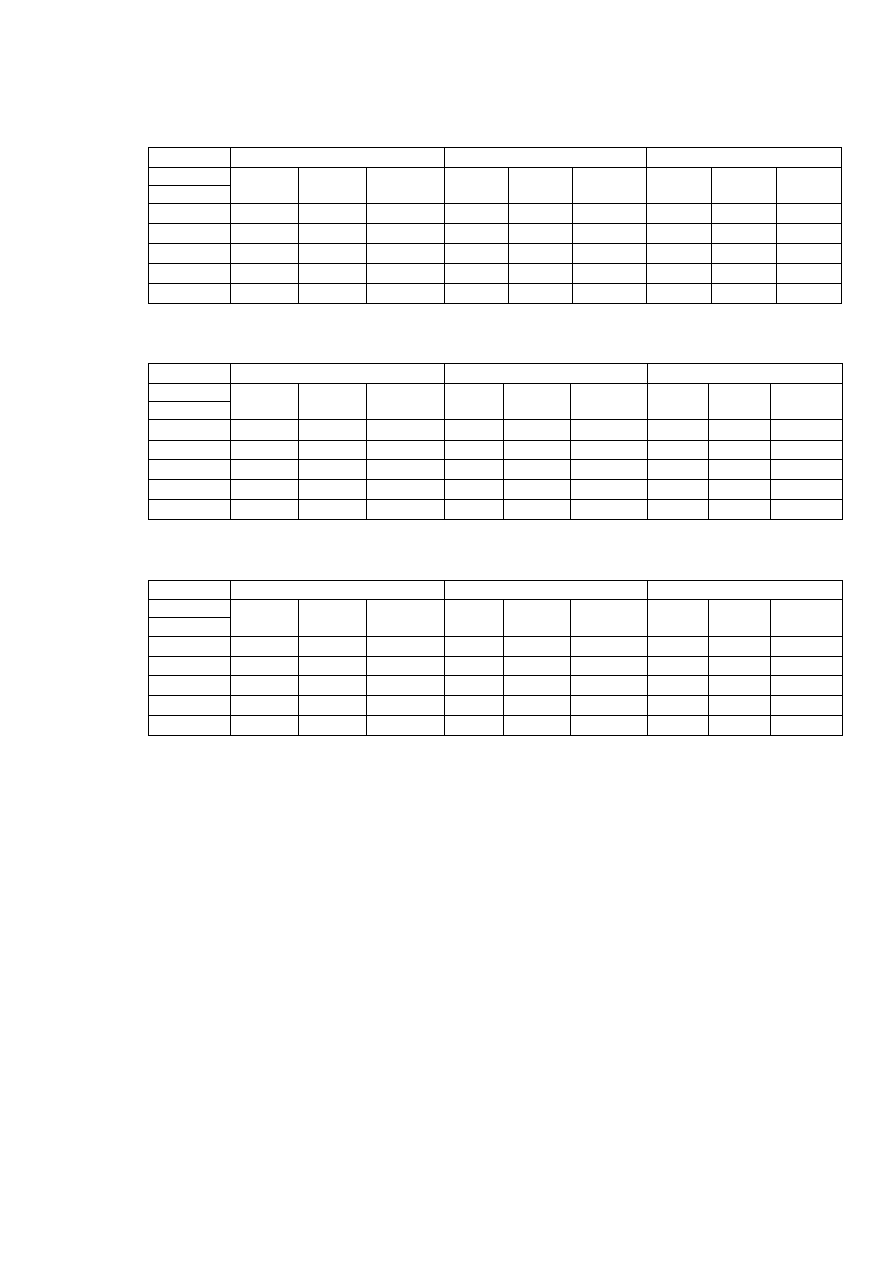
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
74
Tabela 18. Zestawienie czasów wyszukiwania [s] dla poszczególnych Schematów przy
systemie 25 stacji i tabeli przechowującej wyniki z indeksami
Schemat
I
II
III
Miesiące
Kwerenda
1
12
60
1
12
60
1
12
60
1
0.03986
0.02489
0.04942 0.19575 0.46015
0.48185 0.02181 0.01310 0.03280
2
0.04389
0.03860
0.06240 0.18301 0.44813
0.28443 0.02251 0.02057 0.03470
3
0.03247
0.03144
0.04967 0.18330 0.45611
0.33035 0.01438 0.01472 0.02993
4
0.16435
1.88793
11.54036 0.41873 7.60002
57.32280 0.06735 0.65740 6.33396
5
0.16243
0.82197
1.19924 0.19810 0.44386
0.30144 0.03246 0.03058 0.03656
Tabela 19. Zestawienie czasów wyszukiwania [s] dla poszczególnych Schematów przy
systemie 50 stacji i tabeli przechowującej wyniki bez indeksów
Schemat
I
II
III
Miesiące
Kwerenda
1
12
60
1
12
60
1
12
60
1
0.21277
2.27752
41.56857 0.66677 29.82824 156.50204 0.05990 0.63151 24.85482
2
0.22331
2.42672
44.05970 0.65949 37.57112 180.43608 0.06773 0.67513 26.60841
3
0.22012
2.36727
44.32734 0.64884 38.34521 180.41408 0.06983 0.68310 26.72964
4
0.33350
3.86821
43.97431 0.84774 37.81477 183.10341 0.13273 1.34382 27.20114
5
0.29018
2.76135
44.34751 0.71056 46.35121 208.03617 0.07306 0.69253 26.53468
Tabela 20. Zestawienie czasów wyszukiwania [s] dla poszczególnych Schematów przy
systemie 50 stacji i tabeli przechowującej wyniki z indeksami
Schemat
I
II
III
Miesiące
Kwerenda
1
12
60
1
12
60
1
12
60
1
0.03964
0.02354
0.12616 0.09836
0.44620
0.47202 0.02307 0.01306
0.05943
2
0.03810
0.02306
0.09866 0.08513
0.68822
0.48302 0.02035 0.01168
0.03848
3
0.03363
0.01859
0.09242 0.17633
0.44979
0.46696 0.01376 0.00724
0.03838
4
0.33116
3.79494
47.14505 0.91800 40.21995 111.88453 0.12459 1.31142 29.99671
5
0.19598
0.13253
0.47658 0.10007
0.50166
0.48054 0.03031 0.01942
0.09095
5.2. Wybór odpowiedniego rozwiązania.
Kierując się wynikami zestawionymi w rozdziale 6.2, można
z całą pewnością uznać schemat II za rozwiązanie nie nadające się
do zaimplementowania. Pozostaje wyeliminować jedno z dwóch
pozostałych rozwiązań aby uzyskać odpowiedź na pytanie, który
z przedstawionych schematów jest najlepsza propozycją. W tym celu
otrzymane wyniki zostaną ponownie zestawione i przeanalizowane.
Jednak należy pamiętać, że już w poprzednim zestawieniu wyniki
wskazywały, że schemat III sprawdza się lepiej niż schemat I.
Poniżej ogólne zestawienie czasów wykonania kwerend dla obu
schematów.
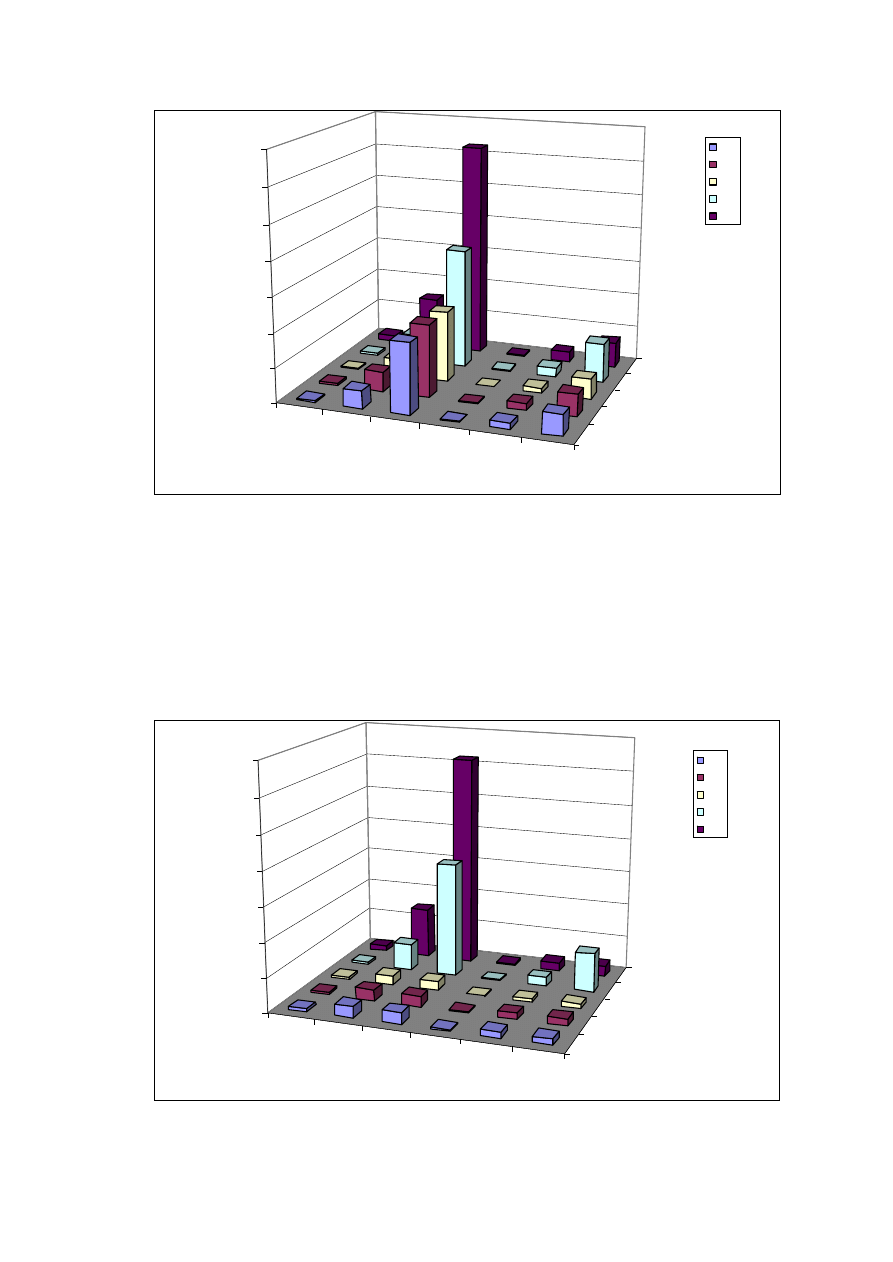
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
75
1
I
12
I
60
I
1
III
12
III
60
III
K1
K2
K3
K4
K5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
c
z
a
s
[
s
]
schemat / miesiące
k
w
e
re
n
d
a
K1
K2
K3
K4
K5
Rys. 27. Zobrazowanie różnic w czasach wykonania kwerend dla systemu 5 stacji i tabeli
przechowującej wyniki bez indeksów, z pominięciem schematu II
Już w najprostszym przypadku, gdy system zbiera dane tylko
z 5 stacji pomiarowych, można zaobserwować różnicę pomiędzy
czasami wykonania kwerend dla schematu I i III. W przypadku bazy
danych bez zastosowanych indeksów możemy mówić o trzykrotnie
krótszym czasie dla schematu III.
1
I
12
I
60
I
1
III
12
III
60
III
K1
K2
K3
K4
K5
0
1
1
2
2
3
3
4
c
z
a
s
[
s
]
schemat / miesiące
k
w
e
r
e
n
d
a
K1
K2
K3
K4
K5
Rys. 28. Zobrazowanie różnic w czasach wykonania kwerend dla systemu 5 stacji i tabeli
przechowującej wyniki z indeksami, z pominięciem schematu II
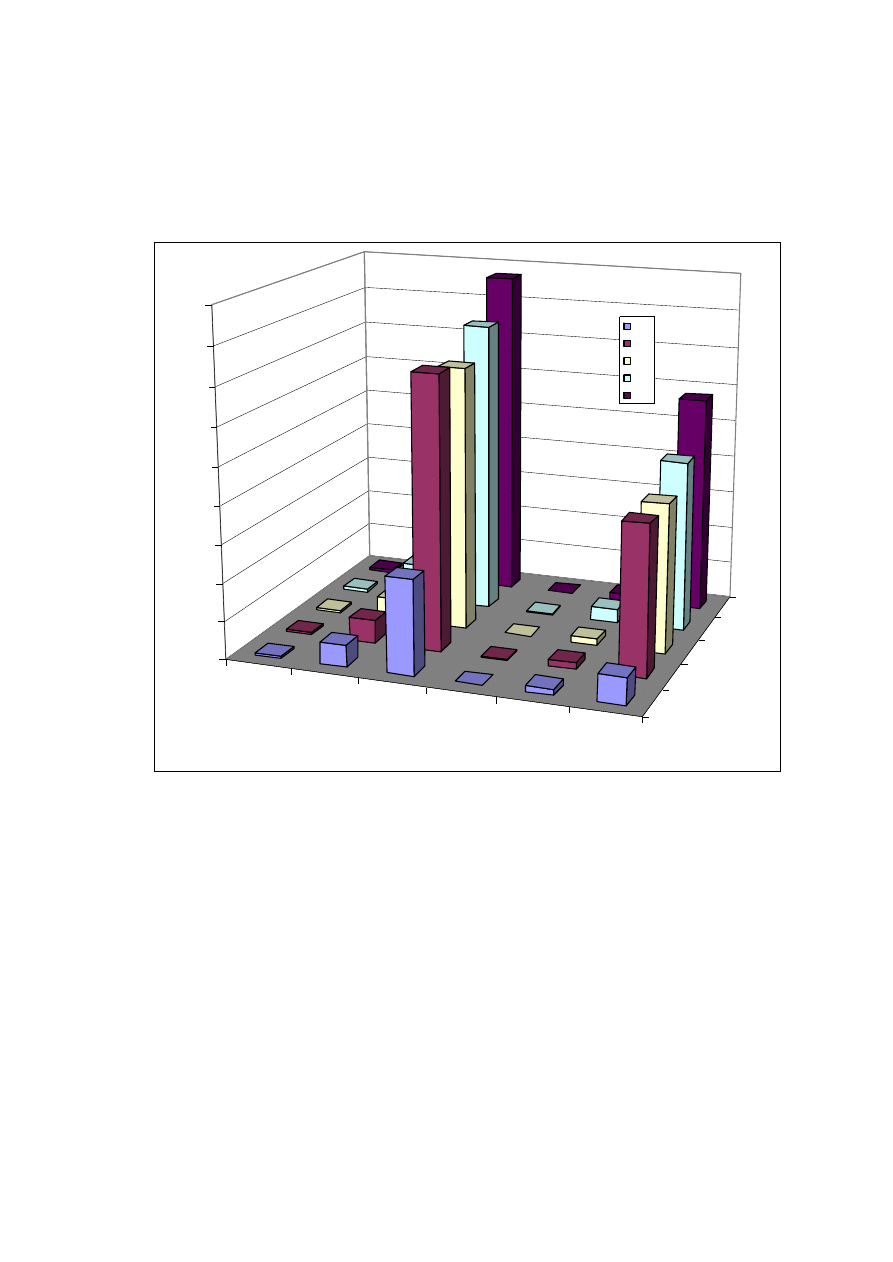
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
76
Rysunek 28 pokazuje, że po zastosowaniu indeksów, nadal
czasy pomierzone dla schematu III są krótsze, ale różnica zmniejsza
się do dwóch razy.
1
I
12
I
60
I
1
III
12
III
60
III
K1
K2
K3
K4
K5
0
2
4
6
8
10
12
14
16
18
c
z
a
s
[
s
]
schemat / miesiące
k
w
e
re
n
d
a
K1
K2
K3
K4
K5
Rys. 29. Zobrazowanie różnic w czasach wykonania kwerend dla systemu 25 stacji i tabeli
przechowującej wyniki bez indeksów, z pominięciem schematu II
Powyżej, na rysunkach 28 i 29, zestawiono wyniki pomiarów dla
systemu gromadzącego dane z 25 stacji pomiarowych. Przedstawione
dane pokazują, że dla okresu pomiarowego 12 miesięcy, kwerendy
zwrócą wynik trzy do czterech razy szybciej jeśli użyty zostanie
schemat III. Natomiast po okresie pięciolecia dla większości
kwerend, różnica ta zmniejsza się do niecałych dwóch razy.
Obserwując otrzymane wyniki, można uznać, że bez zastosowania
indeksów, nie powinno się przechowywać danych z okresu dłuższego
niż 1 rok.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
77
1
I
12
I
60
I
1
III
12
III
60
III
K1
K2
K3
K4
K5
0
2
4
6
8
10
12
c
z
a
s
[
s
]
schemat / miesiące
k
w
e
re
n
d
a
K1
K2
K3
K4
K5
Rys. 30. Zobrazowanie różnic w czasach wykonania kwerend dla systemu 25 stacji i tabeli
przechowującej wyniki z indeksami, z pominięciem schematu II
Sytuacje poprawia zastosowanie indeksów. Jak widać na
powyższym zestawieniu, dla kwerend 1,2 i 3, systemy zachowują się
prawie identycznie (różnice rzędu 0.2, 0.01 sekundy). Kwerenda 4 ze
względu na zastosowane grupowanie i testowanie niemal wszystkich
rekordów, nie podlega takiemu przyspieszeniu w obu przypadkach, co
można było zaobserwować także w poprzednich zestawieniach.
Rozbieżność widać natomiast przy kwerendzie 5. Schemat III
znacznie lepiej obsługuje taki typ zapytania.
Ponieważ na rysunku 30 czas wykonania Kwerendy 4 jest
znacząco dłuższy niż innych kwerend, zaciera on różnice pomiędzy
kwerendami
potrzebującymi
mniej
czasu.
Dlatego
poniżej
zamieszczony zostaje wykres z pominięciem Kwerendy 4.
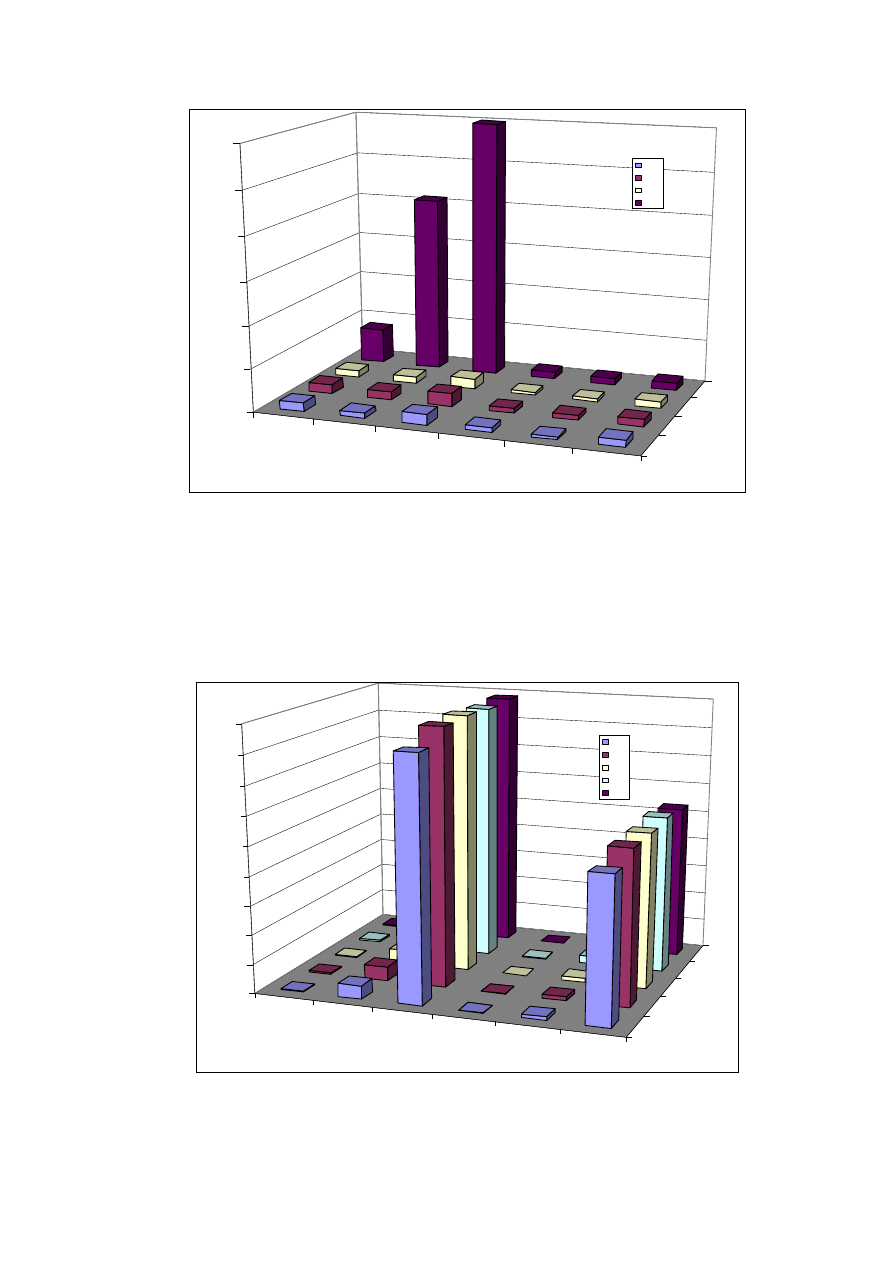
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
78
1
I
12
I
60
I
1
III
12
III
60
III
K1
K2
K3
K5
0.0
0.2
0.4
0.6
0.8
1.0
1.2
c
z
a
s
[
s
]
schema t / mie siące
k
w
e
re
n
d
a
K1
K2
K3
K5
Rys. 31. Zobrazowanie różnic w czasach wykonania kwerend dla systemu 25 stacji i tabeli
przechowującej wyniki z indeksami, z pominięciem schematu II i Kwerendy 4
Na rysunku 31 wyraźnie widać różnice w czasach wykonania
poszczególnych
kwerend.
Z
otrzymanych
wyników
można
wnioskować, że kwerendy wykonywane na schemacie III potrzebują
przynajmniej dwukrotnie mniej czasu na wykonanie.
1
I
12
I
60
I
1
III
12
III
60
III
K1
K2
K3
K4
K5
0
5
10
15
20
25
30
35
40
45
c
z
a
s
[
s
]
schemat / miesiące
k
w
e
re
n
d
a
K1
K2
K3
K4
K5
Rys. 32. Zobrazowanie różnic w czasach wykonania kwerend dla systemu 50 stacji i tabeli
przechowującej wyniki bez indeksów, z pominięciem schematu II
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
79
Najbardziej złożony przypadek systemu obsługującego dane
z 50 stacji pomiarowych, pokazuje dobitnie, że przechowywanie
w tabeli bez indeksów tak dużej ilości danych nie spełni żadnych
oczekiwań. Dodatkowo można zauważyć, że różnica w czasach
pomiędzy 12 miesiącami a 60, rośnie wykładniczo.
1
I
12
I
60
I
1
III
12
III
60
III
K1
K2
K3
K4
K5
0
5
10
15
20
25
30
35
40
45
c
z
a
s
[
s
]
schemat / miesiące
k
w
e
re
n
d
a
K1
K2
K3
K4
K5
Rys. 33. Zobrazowanie różnic w czasach wykonania kwerend dla systemu 50 stacji i tabeli
przechowującej wyniki z indeksami, z pominięciem schematu II
Po zastosowaniu indeksów nawet na tak dużej tabeli czasy
wykonania kwerend spadają do wartości znacznie poniżej 1 sekundy
(około 0.03 sekundy). Niezmienna pozostaje kwestia kwerendy 4.
Czas jej wykonania jest tak długi, że zaciera różnice pomiędzy
pozostałymi zapytaniami. Dlatego poniżej załączony zostaje wykres
oparty na tym z rysunku 33, ale z pominięciem kwerendy 4.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
80
1
I
12
I
60
I
1
III
12
III
60
III
K1
K2
K3
K5
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
0.50
c
z
a
s
[
s
]
schemat / miesiące
k
w
e
re
n
d
a
K1
K2
K3
K5
Rys. 34. Zobrazowanie różnic w czasach wykonania kwerend dla systemu 50 stacji i tabeli
przechowującej wyniki z indeksami, z pominięciem schematu II i Kwerendy 4
Wykres na rysunku 34. pokazuje wyraźnie różnice dzielące
schemat I i III. Czasy wykonania kwerend dla schematu III są
znacznie krótsze niż w przypadku schematu I. Dla wszystkich
kwerend, do których wykonania wykorzystywane są indeksy, widać że
dla małej ilości danych (z jednego miesiąca) czas wykonania
kwerendy wydłuża się, w stosunku do okresu 1 roku. Ten negatywny
wpływ indeksów na wydajność wyszukiwania został zobrazowany na
rysunku 35. Efekt ten spowodowany jest koniecznością wykonania
dodatkowych operacji związanych z obsługą indeksów, poza sama
kwerendą. Ten dodatkowy czas nie jest zauważalny w przypadku
dużych ilości danych, ale uwidacznia się przy małych tabelach. [Gavin
Powell, 2005-12]
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
81
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
1
12
60
miesiące
c
z
a
s
[
s
]
Schemat III
Schemat I
Rys. 35. Wpływ indeksów na czas wykonania Kwerendy 1.
Poniżej na rysunkach 36 i 37 przedstawione zostało
bezpośrednie porównanie schematów I i III uzależnione od liczby
stacji pomiarowych obsługiwanych przez system.
0
5
10
15
20
25
30
35
40
45
50
5
25
50
liczba stacji
c
z
a
s
[
s
]
Schemat I
Schemat III
Rys. 36. Czas wykonania Kwerendy 2 odniesiony do ilości stacji pomiarowych, tabela
przechowująca pomiary bez indeksów, pomiary gromadzone przez 5 lat.
Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
82
Rysunek 36. to wykres porównujący czasy wykonania Kwerendy
2 w zależności od ilości stacji pomiarowych obsługiwanych przez
system. To porównanie zostało przeprowadzone na bazie danych bez
zastosowania indeksów, widać że czas wykonania kwerendy wydłuża
się szybciej jeśli zastosowano Schemat I.
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.18
5
25
50
liczba stacji
c
z
a
s
[
s
]
Schemat I
Schemat III
Rys. 37. Czas wykonania Kwerendy 2 odniesiony do ilości stacji pomiarowych, tabela
przechowująca pomiary z indeksami, pomiary gromadzone przez 5 lat.
Powyżej, na rysunku 37. przedstawiono porównanie czasu
wykonania Kwerendy 2 w zależności od ilości stacji pomiarowych
w systemie. W tym przypadku zostały utworzone indeksy na tabeli
measurements dla pola station_id lub stationName (dla schematu I).
Na tym porównaniu można zaobserwować, że czas wykonania
kwerendy dla schematu I cały czas przewyższa czas schematu III,
i zmienia się gwałtowniej przy zwiększeniu liczby stacji.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
83
6. ANALIZA WYNIKÓW
Analizując uzyskane wyniki i zestawiając je z założeniami
przedstawionymi wcześniej dla projektowanego systemu, można
uznać, że schemat III najlepiej sprawdzi się w projektowanym
systemie. Dodatkowo, aby zapewnić poprawne działanie systemu
także w długim horyzoncie czasowym, należy rozważyć rozbudowę
schematu III o mechanizm archiwizacji starszych pomiarów.
Podejście takie zagwarantuje, że w tabeli measurements liczba
rekordów nie będzie rosła w nieskończoność. Można to osiągnąć za
pomocą dodatkowych skryptów, sprawdzających czy w tabeli tej nie
znajdują się rekordy starsze niż pewien założony okres. Odpowiednie
ustalenie długości okresu, po którym dane mają zostać przeniesione
do
archiwum,
pozwoli
zachować
czas
wykonania
kwerend
statystycznych, czyli sprawdzających wszystkie lub większość
rekordów, na zadowalającym poziomie.
Przeprowadzone testy pokazały, że najprostsza struktura bazy
danych, jaką jest pojedyncza tabela (schemat I), byłaby wielokrotnie
wydajniejsza niż teoretycznie lepiej zaprojektowana struktura
rozdzielająca poszczególne pomiary na pojedyncze rekordy (schemat
II). Zaistniała różnica wynika z trzech podstawowych czynników:
Objętości plików bazy danych – odczyt z dysków twardych jest
bardzo powolny, więc skanowanie ogromnych (ok. 6GB po 5 latach
i 50 stacjach w systemie) plików jest uciążliwe.
Ilości rekordów w tabeli z pomiarami – jeśli założymy, że z każdej
stacji pomiarowej zapisywane jest 11 parametrów, to wprost
można określić ze w przypadku schematu II w bazie znajdzie się
11 razy więcej rekordów z pomiarami. Dodatkowym utrudnieniem
w tym przypadku jest fakt, że w tabeli measurements nie ma
bezpośrednio
zapisanej
informacji
o
typie
pomiaru
przechowywanego w danym rekordzie. Powoduje to, że przy

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
84
wyszukiwaniu
zadanego
typu
parametru
konieczne
jest
dokonywanie porównania czy typ pomiaru z danego rekordu jest
tym, jaki interesuje klienta zlecającego wyszukiwanie.
Projektowany system obsługuje klientów, których zapytania mają
charakter przekrojowy, a więc wymagają przeglądania sporej części
zgromadzonych rekordów. W takim przypadku zagadnienie
fizycznej objętości bazy, jak i ilości rekordów przestają być tylko
problemem zapewnienia miejsca na dysku twardym.
Opierając się na otrzymanych wynikach i decydując się na
schemat III lub jego wersję rozwiniętą o system archiwizacji
starszych danych należy pamiętać o zaletach i wadach przyjętego
rozwiązania. Takie podejście pozwoli w przyszłości skutecznie
zaplanować prace nad implementacją i wdrożeniem systemu, a także
zapewni wygodę pracy nad jego późniejszym utrzymaniem.
Dodatkowym atutem jest znacznie mniejsza podatność schematu III
na rozpiętość obsługiwanego systemu pomiarowego. Uzyskiwane
wyniki zmieniają się znacznie mniej gwałtownie w stosunku do ilości
stacji lub okresu gromadzenia pomiarów, niż w przypadku schematu
I.
Wyniki testów uwidoczniły, że w wyniku zastosowaniu
indeksów, schemat III notuje dłuższe czasy wykonania kwerend dla
małej ilości danych. Sytuacja taka ma miejsce na przykład
w porównaniu czasów zapytań testowych dla okresu 1 miesiąca
i 1 roku. Opóźnienie to nie stanowi jednak problemu ze względu na
bardzo krótki czas wykonania kwerendy dla tak małej liczby rekordów
w tabeli. O ile opóźnienie nie stanowi problemu w sensie wydajności
systemu, może stanowić podpowiedź co do optymalnej ilości danych
w tabeli z pomiarami.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
85
Analizując wyniki testów można określić, że system najlepiej
będzie działał, jeżeli w tabeli z pomiarami przechowywane będą
pomiary z około 1 roku. Można to osiągnąć tworząc dodatkową tabelę
z pomiarami starszymi niż sprzed roku. Starsze pomiary można
archiwizować okresowo, na przykład raz na miesiąc.
6.1. Zalety wybranego rozwiązania
Schemat III okazał się najlepszym wyborem w kontekście
projektowanego systemu dzięki połączeniu ze sobą takich cech jak:
Umiarkowany rozmiar bazy danych
Zminimalizowana ilość rekordów przechowujących dane pomiarowe
Brak konieczności sprawdzania typu pomiaru przy wyszukiwaniu
zadanego parametru
Prostota zapisu danych – nie ma potrzeby rozbijania każdego
zestawu danych przesłanego ze stacji pomiarowej, na kilka
kwerend zapisujących.
Pod względem wydajności schemat III na tle rozwiązań I i II
prezentuje się bardzo dobrze. Nie wymaga przeprowadzania
dodatkowych operacji podczas zapisu danych lub odczytu z bazy.
Jego struktura sprzyja także sprawnej obsłudze zapytań, jakie będą
najbardziej interesowały klientów. Klienci korzystający z bazy danych
pomiarów parametrów środowiska, potrzebują danych odniesionych
do konkretnej lokalizacji. Schemat III umożliwia wygodne utworzenie
indeksów dla pól używanych w określaniu lokalizacji, na której dane
zostały pobrane. To duża zaleta, ponieważ przy tak dużej ilości
danych, poprawnie utworzone indeksy pozwalają znacząco skrócić
czas wykonania zapytań, a co za tym idzie - znacząco poprawić
interakcje użytkownika z systemem.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
86
6.2. Wady wybranego rozwiązania
Decydując się na wybór pewnego rozwiązania trzeba być
świadomym wad, jakie wybrany schemat posiada. W przypadku
schematu III największą wadą będzie stosunkowo mała skalowalność
systemu. Jeśli bowiem zajdzie konieczność obsługi więcej niż jednego
regionu ilość danych w tabeli measurements będzie przyrastała
proporcjonalnie szybciej. Taka sytuacja niesie za sobą, jak wykazano
w testach, zwiększenie objętości bazy i co za tym idzie, wydłużenie
czasu wykonania kwerend. Należy także pamiętać, że schemat III
jest podatny na spowolnienie zapisu przez stosowanie indeksów.
Poza kwestią wydajności stosując schemat III ograniczamy
elastyczność systemu w kwestii udostępniania danych innym
podmiotom. Samo udostępnienie jest oczywiście możliwe, ale
kontrola dostępu, może okazać się trudna. Jako przykład może
posłużyć sytuacja, gdy klient płaci za dostęp do wybranego
parametru, na przykład temperatury. Jeśli zajdzie taka sytuacja,
schemat bazodanowy nie wspiera kontroli dostępu do konkretnych
danych. Nie ma możliwości identyfikowania konkretnych parametrów
bezpośrednio w bazie danych. W takim przypadku można
implementować kontrolę dostępu w warstwie aplikacji obsługującej
system, ale rozwiązanie nie będzie tak elastyczne jak identyfikowanie
praw użytkownika wprost na zasobach bazy danych.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
87
7. WNIOSKI
Celem pracy była ocena wydajności hydrometeorologicznych
baz danych, stworzonych w środowisku MySQL 5.0. Wynik
przeprowadzonej
oceny
ma
posłużyć
rozwiązaniu
problemu
wydajnego
gromadzenia
i
udostępniania
danych
hydrometeorologicznych. W ocenie jakości rozwiązań rozpatrywano
trzy kryteria: wydajność zapisu, wydajność odczytu oraz objętość
bazy danych.
Cel został osiągnięty, wyniki przeprowadzonych testów
pozwoliły określić charakterystyki poszczególnych rozwiązań.
Schemat I, to rozwiązanie przewidujące przechowywanie
wszystkich danych w pojedynczej tabeli. Pomimo, że spełniał
wymagania funkcjonalne, prezentował gorszą wydajność niż schemat
III – wydzielający dane lokalizacyjne do osobnych tabel. Jego piętą
Achillesową okazała się kwerenda wyszukująca sumy opadów dla
wybranej stacji, z ostatnich 3 godzin.
Schemat II, który zakładał rozdzielenie poszczególnych
pomiarów na pojedyncze rekordy, okazał się całkowicie nietrafioną
koncepcją. Zapis każdego zestawu danych, otrzymanego ze stacji,
wymagał utworzenia 11 rekordów, zamiast 1 w pozostałych
rozwiązaniach. Takie podejście zaowocowało dziesięciokrotnym
zwiększeniem objętości bazy danych oraz znacznym wydłużeniem
czasu wykonania zapytań.
Schemat III, okazał się najlepszą propozycją. Spełnia on
stawiane wymagania funkcjonalne, a także prezentuje dobry
stosunek wydajności do objętości. We wszystkich testach okazał się
wydajniejszy od schematu I.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
88
Wyniki testów pokazały też, długi czas wykonania kwerendy
wyszukującej sumy opadów dla poszczególnych stacji. Czas ten, nie
powinien mieć negatywnego wpływu na codzienna pracę systemu.
Wynika to z faktu, że jako zapytanie statystyczne, kwerenda ta jest
stosunkowo rzadko wykorzystywana.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
89
8. Spisy
8.1. Spis Ilustracji
R
YS
.
1
P
RZYROST LICZBY GROMADZONYCH POMIARÓW W CZASIE DLA ZAŁOŻONEJ LICZBY STACJI
. 26
R
YS
2.
S
CHEMAT
I
–
W
SZYSTKIE GROMADZONE DANE ZAPISYWANE SĄ W JEDNEJ TABELI
. ............ 44
R
YS
3.
S
CHEMAT
II
–
P
OSZCZEGÓLNE WARTOŚCI POMIARÓW PRZECHOWYWANE JAKO OSOBNE
REKORDY
.................................................................................................................................... 46
R
YS
4.
S
CHEMAT
III
–
T
ABELE ODZWIERCIEDLAJĄCE FIZYCZNE MODELE DANYCH
. ......................... 47
R
YS
.
5.
Z
ALEŻNOŚĆ OBJĘTOŚCI PLIKÓW BAZY DANYCH OD CZASU GROMADZENIA POMIARÓW DLA
SYSTEMU
5
STACJI I TABELI PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
................................ 57
R
YS
.
6.
Z
ALEŻNOŚĆ OBJĘTOŚCI PLIKÓW BAZY DANYCH OD CZASU GROMADZENIA POMIARÓW DLA
SYSTEMU
5
STACJI I TABELI PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
. .................................. 57
R
YS
.
7.
Z
ALEŻNOŚĆ OBJĘTOŚCI PLIKÓW BAZY DANYCH OD CZASU GROMADZENIA POMIARÓW DLA
SYSTEMU
50
STACJI I TABELI PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
. ............................ 58
R
YS
.
8.
Z
ALEŻNOŚĆ OBJĘTOŚCI PLIKÓW BAZY DANYCH OD CZASU GROMADZENIA POMIARÓW DLA
SYSTEMU
50
STACJI I TABELI PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
................................. 58
R
YS
9.
Z
ALEŻNOŚĆ CZASU ZAPISU DANYCH OD DŁUGOŚCI OKRESU GROMADZENIA POMIARÓW DLA
SYSTEMU
5
STACJI I TABELI PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
................................ 60
R
YS
.
10.
Z
ALEŻNOŚĆ CZASU ZAPISU DANYCH OD DŁUGOŚCI OKRESU GROMADZENIA POMIARÓW
DLA SYSTEMU
5
STACJI I TABELI PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
............................ 61
R
YS
.
11.
Z
ALEŻNOŚĆ CZASU ZAPISU DANYCH OD DŁUGOŚCI OKRESU GROMADZENIA POMIARÓW
DLA SYSTEMU
50
STACJI I TABELI PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
. ..................... 62
R
YS
.
12.
Z
ALEŻNOŚĆ CZASU ZAPISU DANYCH OD DŁUGOŚCI OKRESU GROMADZENIA POMIARÓW
DLA SYSTEMU
50
STACJI I TABELI PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
.......................... 62
R
YS
.
13.
Z
ESTAWIENIE CZASU WYSZUKIWANIA DLA SYSTEMU
5
STACJI I TABELI PRZECHOWUJĄCEJ
POMIARY BEZ INDEKSÓW
........................................................................................................... 65
R
YS
.
14.
Z
ESTAWIENIE CZASU WYSZUKIWANIA DLA SYSTEMU
5
STACJI I TABELI PRZECHOWUJĄCEJ
POMIARY Z INDEKSAMI
............................................................................................................... 65
R
YS
.
15.
Z
ESTAWIENIE CZASU WYSZUKIWANIA DLA SYSTEMU
50
STACJI I TABELI
PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
............................................................................. 66
R
YS
.
16.
Z
ESTAWIENIE CZASU WYSZUKIWANIA DLA SYSTEMU
50
STACJI I TABELI
PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
................................................................................. 66
R
YS
.
17.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
5
STACJI I TABELI
PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
,
Z POMINIĘCIEM SCHEMATU
II ............................ 67
R
YS
.
18.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
5
STACJI I TABELI
PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II................................ 67
R
YS
.
19.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
50
STACJI I
TABELI PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
,
Z POMINIĘCIEM SCHEMATU
II ................ 68
R
YS
.
20.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
50
STACJI I
TABELI PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II.................... 69
R
YS
.
21.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
5
STACJI I TABELI
PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
,
Z POMINIĘCIEM SCHEMATU
II
I
K
WERENDY
4 ... 70
R
YS
.
22.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
5
STACJI I TABELI
PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II
I
K
WERENDY
4....... 70
R
YS
.
23.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
25
STACJI I
TABELI PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
,
Z POMINIĘCIEM SCHEMATU
II
I
K
WERENDY
4 ............................................................................................................................. 71
R
YS
.
24.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
25
STACJI I
TABELI PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II
I
K
WERENDY
4 ................................................................................................................................................ 71

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
90
R
YS
.
25.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
50
STACJI I
TABELI PRZECHOWUJĄCEJ POMIARY BEZ INDEKSÓW
,
Z POMINIĘCIEM SCHEMATU
II
I
K
WERENDY
4 ............................................................................................................................. 72
R
YS
.
26.
Z
ESTAWIENIE CZASU WYKONANIA KWEREND TESTOWYCH DLA SYSTEMU
50
STACJI I
TABELI PRZECHOWUJĄCEJ POMIARY Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II
I
K
WERENDY
4 ................................................................................................................................................ 72
R
YS
.
27.
Z
OBRAZOWANIE RÓŻNIC W CZASACH WYKONANIA KWEREND DLA SYSTEMU
5
STACJI I
TABELI PRZECHOWUJĄCEJ WYNIKI BEZ INDEKSÓW
,
Z POMINIĘCIEM SCHEMATU
II .................. 75
R
YS
.
28.
Z
OBRAZOWANIE RÓŻNIC W CZASACH WYKONANIA KWEREND DLA SYSTEMU
5
STACJI I
TABELI PRZECHOWUJĄCEJ WYNIKI Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II...................... 75
R
YS
.
29.
Z
OBRAZOWANIE RÓŻNIC W CZASACH WYKONANIA KWEREND DLA SYSTEMU
25
STACJI I
TABELI PRZECHOWUJĄCEJ WYNIKI BEZ INDEKSÓW
,
Z POMINIĘCIEM SCHEMATU
II .................. 76
R
YS
.
30.
Z
OBRAZOWANIE RÓŻNIC W CZASACH WYKONANIA KWEREND DLA SYSTEMU
25
STACJI I
TABELI PRZECHOWUJĄCEJ WYNIKI Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II...................... 77
R
YS
.
31.
Z
OBRAZOWANIE RÓŻNIC W CZASACH WYKONANIA KWEREND DLA SYSTEMU
25
STACJI I
TABELI PRZECHOWUJĄCEJ WYNIKI Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II
I
K
WERENDY
4
................................................................................................................................................... 78
R
YS
.
32.
Z
OBRAZOWANIE RÓŻNIC W CZASACH WYKONANIA KWEREND DLA SYSTEMU
50
STACJI I
TABELI PRZECHOWUJĄCEJ WYNIKI BEZ INDEKSÓW
,
Z POMINIĘCIEM SCHEMATU
II .................. 78
R
YS
.
33.
Z
OBRAZOWANIE RÓŻNIC W CZASACH WYKONANIA KWEREND DLA SYSTEMU
50
STACJI I
TABELI PRZECHOWUJĄCEJ WYNIKI Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II...................... 79
R
YS
.
34.
Z
OBRAZOWANIE RÓŻNIC W CZASACH WYKONANIA KWEREND DLA SYSTEMU
50
STACJI I
TABELI PRZECHOWUJĄCEJ WYNIKI Z INDEKSAMI
,
Z POMINIĘCIEM SCHEMATU
II
I
K
WERENDY
4
................................................................................................................................................... 80
R
YS
.
35.
W
PŁYW INDEKSÓW NA CZAS WYKONANIA
K
WERENDY
1. .................................................. 81
R
YS
.
36.
C
ZAS WYKONANIA
K
WERENDY
2
ODNIESIONY DO ILOŚCI STACJI POMIAROWYCH
,
TABELA
PRZECHOWUJĄCA POMIARY BEZ INDEKSÓW
,
POMIARY GROMADZONE PRZEZ
5
LAT
. ................ 81
R
YS
.
37.
C
ZAS WYKONANIA
K
WERENDY
2
ODNIESIONY DO ILOŚCI STACJI POMIAROWYCH
,
TABELA
PRZECHOWUJĄCA POMIARY Z INDEKSAMI
,
POMIARY GROMADZONE PRZEZ
5
LAT
. ................... 82
8.2. Spis tabel
T
ABELA
1.
P
RZYKŁADOWA TABELA Z NADMIAROWOŚCIĄ DANYCH
..................................................... 13
T
ABELA
2.
P
RZYKŁAD TABELI PRZECHOWUJĄCEJ
S
TACJE POMIAROWE
.............................................. 15
T
ABELA
3.
P
RZYKŁAD TABELI PRZECHOWUJĄCEJ
P
OMIARY PRZED NORMALIZACJĄ
........................... 15
T
ABELA
4.
P
RZYKŁAD TABELI PRZECHOWUJĄCEJ
S
TACJE POMIAROWE
.............................................. 16
T
ABELA
5.
P
RZYKŁAD TABELI PRZECHOWUJĄCEJ
P
OMIARY PO SPROWADZENIU DO DRUGIEJ POSTACI
NORMALNEJ
................................................................................................................................ 16
T
ABELA
6.
L
ICZBA POMIARÓW W ZALEŻNOŚCI OD ILOŚCI STACJI I CZASU DZIAŁANIA SYSTEMU
..... 26
T
ABELA
7.
O
BJĘTOŚĆ POMIARÓW W ZALEŻNOŚCI OD TYPU DANYCH I OKRESU DZIAŁANIA SYSTEMU
.
................................................................................................................................................... 27
T
ABELA
8.
S
PECYFIKACJA SERWERA TESTOWEGO
.............................................................................. 51
T
ABELA
9.
O
BJĘTOŚĆ BAZY DANYCH
[MB]
DLA SCHEMATU
I............................................................ 59
T
ABELA
10.
O
BJĘTOŚĆ BAZY DANYCH
[MB]
DLA SCHEMATU
II....................................................... 59
T
ABELA
11.
O
BJĘTOŚĆ BAZY DANYCH
[MB]
DLA SCHEMATU
III ...................................................... 59
T
ABELA
12.
C
ZAS ZAPISU DANYCH
[
S
]
DLA SCHEMATU
I ................................................................. 63
T
ABELA
13.
C
ZAS ZAPISU DANYCH
[
S
]
DLA SCHEMATU
II................................................................ 63
T
ABELA
14.
C
ZAS ZAPISU DANYCH
[
S
]
DLA SCHEMATU
III .............................................................. 63
T
ABELA
15.
Z
ESTAWIENIE CZASÓW WYSZUKIWANIA
[
S
]
DLA POSZCZEGÓLNYCH SCHEMATÓW PRZY
SYSTEMIE
5
STACJI I TABELI PRZECHOWUJĄCEJ WYNIKI BEZ INDEKSÓW
................................. 73
T
ABELA
16.
Z
ESTAWIENIE CZASÓW WYSZUKIWANIA
[
S
]
DLA POSZCZEGÓLNYCH
S
CHEMATÓW PRZY
SYSTEMIE
5
STACJI I TABELI PRZECHOWUJĄCEJ WYNIKI Z INDEKSAMI
..................................... 73
T
ABELA
17.
Z
ESTAWIENIE CZASÓW WYSZUKIWANIA
[
S
]
DLA POSZCZEGÓLNYCH
S
CHEMATÓW PRZY
SYSTEMIE
25
STACJI I TABELI PRZECHOWUJĄCEJ WYNIKI BEZ INDEKSÓW
............................... 73

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
91
T
ABELA
18.
Z
ESTAWIENIE CZASÓW WYSZUKIWANIA
[
S
]
DLA POSZCZEGÓLNYCH
S
CHEMATÓW PRZY
SYSTEMIE
25
STACJI I TABELI PRZECHOWUJĄCEJ WYNIKI Z INDEKSAMI
................................. 74
T
ABELA
19.
Z
ESTAWIENIE CZASÓW WYSZUKIWANIA
[
S
]
DLA POSZCZEGÓLNYCH
S
CHEMATÓW PRZY
SYSTEMIE
50
STACJI I TABELI PRZECHOWUJĄCEJ WYNIKI BEZ INDEKSÓW
............................... 74
T
ABELA
20.
Z
ESTAWIENIE CZASÓW WYSZUKIWANIA
[
S
]
DLA POSZCZEGÓLNYCH
S
CHEMATÓW PRZY
SYSTEMIE
50
STACJI I TABELI PRZECHOWUJĄCEJ WYNIKI Z INDEKSAMI
................................... 74
8.3. Literatura
[1.] Allen S., 2006, “Modelowanie danych”, Apress, w Polsce: Helion.
[2.] Anahory, S., & Murray, D., 1997, “Data Warehousing in the Real World”,
Harlow
[3.] Czasopismo „Professional Programming Software for SAP DB” - artykuł
“Zbiory rozmyte”, grudzień 2004
[4.] Codd, E. F., 1970, "A relational model of data for large shared data
banks", Communications of the ACM
[5.] Date, C. J., Darwen, H., 2000, “Foundation for Future Database Systems:
The Third Manifesto”, 2nd edition, Addison-Wesley Professional.
[6.] Date, C.J., 2003, “An Introduction to Database Systems”, Eighth Edition,
Addison Wesley.
[7.] David M. Kroenke, 1997, “Database Processing: Fundamentals, Design,
and Implementation”, Prentice-Hall, Inc.
[8.] Elmasri R., Navathe B. S., 2005, “Wprowadzenie do systemów baz
danych”, Addison-Wesley, w Polsce: Helion
[9.] Inmon H. William, Hackathorn D. Richard, 1994, “Using the Data
Warehouse”, John Wiley & Son's
[10.] Kent, W., 1983, “A Simple Guide to Five Normal Forms in Relational
Database Theory”, Communications of the ACM, vol. 26
[11.] Lightstone S., Teorey T., Nadeau T., 2005, “Database Modeling & Design:
Logical Design, 4th edition”, Morgan Kaufmann Press
[12.] Lightstone S., Teorey T., Nadeau T., 2007, “Physical Database Design: the
database professional's guide to exploiting indexes, views, storage, and
more”, Morgan Kaufmann Press
[13.] Powell G., 2005, “Beginning Database Design”, Wrox Publishing
[14.] Pyle, Dorian, 2003, “Business Modeling and Data Mining”, Morgan
Kaufmann
[15.] Schneider D. Robert, 2005, „MySQL Database Design and Tuning”, MySQL
Press
8.4. Linki
[L1]
http://www.edm2.com/0612/msql7.html
- Wprowadzenie do Relacyjnych baz
danych.
[L2]
http://en.wikipedia.org/wiki/Relational_database
- Relacyjne bazy danych
[L3]
http://en.wikipedia.org/wiki/Database
- Historia baz danych
[L4]
http://en.wikipedia.org/wiki/Database_management_system
- Systemy
zarządzania bazami danych
[L5]
http://en.wikipedia.org/wiki/Relational_model
- Relecyjny model danych
[L6]
http://www.databasejournal.com/sqletc/article.php/1469521
- Relacyjne bazy
danych – wprowadzenie.

Piotr Nowak „Ocena wydajności hydrometeorologicznych baz danych w MySQL 5.0.”
92
9. ABSTRAKT
Na
przestrzeni
ostatnich
lat,
dokonała
się
rewolucja
w technologiach pomiarowych. Tradycyjne mierniki analogowe są
wypierane przez nowocześniejsze urządzenia cyfrowe. Szybki rozwój
technologii cyfrowych spowodował lawinowy przyrost ilości danych
gromadzonych przez różne systemy pomiarowe. Szczególnym
przypadkiem takiego systemu, jest system monitoringu środowiska.
Ta
praca
jest
opisem
badania
wydajności
baz
danych
hydrometeorologicznych, stworzonych w środowisku MySQL 5.0.
W dokumencie zawarte są podstawy teoretyczne systemów
bazodanowych. Określono także kryteria według jakich można
dokonać oceny jakości schematu bazy danych. Sformułowano
wymagania
funkcjonalne
jakie
musi
spełniać
baza
danych
hydrometeorologicznych. Wyjaśnione zostały takie pojęcia jak:
relacyjny model danych oraz normalizacja baz danych. Na podstawie
przedstawionej
teorii,
zostały
zaproponowane
trzy
schematy
bazodanowe oraz zestaw testów wydajności. Przeprowadzone testy
pozwoliły wytypować najlepsze z zaproponowanych rozwiązań.
Analiza wyników uwidoczniła zagadnienia, na jakie należy zwrócić
szczególną uwagę projektując bazę danych.
Aktualna sytuacja w branży IT pokazuje, że projektując system
informatyczny, nie można pominąć kwestii zastosowania technologii
bazodanowej. Twierdzenie to tyczy się zarówno dużych systemów
komercyjnych, jak i mniejszych, akademickich lub biurowych.
Wyszukiwarka
Podobne podstrony:
Systemy Baz Danych (cz 1 2)
bd cz 2 jezyki zapytan do baz danych
Modele Baz Danych 2
cwiczonko drugie z baz danych na stopieniek
Access 2002 Projektowanie baz danych Ksiega eksperta ac22ke
Opis baz danych zgodny z TERYT
Oracle8i Podrecznik administratora baz danych or8pab
Bazy danych i mysql od podstaw Nieznany (3)
Instrukcja korzystania z eduk baz danych iScala Enterprise WSB Wrocław
problematyka masoowego dostepu do baz danych mity i fakty mqsixoztwl26gv7afh6a6hsnoalkzz6a5q7na7a M
Projektowanie baz danych
WYKLAD I - wprowadzenie modele baz danych, Uczelnia, sem V, bazy danych, wyklad Rudnik
Projektowanie baz danych Wykłady Sem 5, pbd 2006.01.07 wykład03, Podstawy projektowania
Oracle9i Podrecznik administratora baz danych or9pab
Materia dodatkowy nt Baz Danych encr
KOMENDY BAZ DANYCH, edu, bazy
access zaawansowane projektowanie baz danych, SPIS TREŚCI
Bazy danych - podstawowe kroki w projektowaniu cz 2 - wyklady, Zajęcia z Baz Danych - MS Access, cz
więcej podobnych podstron