
Architektury komputerów i procesorów
Paweł Dudzik, Adrian Guzik
AGH Kraków
Kraków, 6 lipca 2011
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
1 / 48

Plan wykładu
1
Maszyna Turinga - koncept maszyny komputerowej
2
Pojęcie architektury komputera
3
Architektury komputera
4
Klastry i obliczenia równoległe
5
Architektury procesorów
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
2 / 48

Plan wykładu
1
Maszyna Turinga - koncept maszyny komputerowej
2
Pojęcie architektury komputera
3
Architektury komputera
4
Klastry i obliczenia równoległe
5
Architektury procesorów
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
2 / 48

1.1. Maszyna Turinga - co to takiego ?
Pod koniec lat trzydziestych ubiegłego wieku Alan Turing nie posiadał do
swojej dyspozycji komputerów, ponieważ w owym czasie ich jeszcze nie
było (w powszechnym użyciu). Dlatego na potrzeby swoich badań nad
problemami obliczalności opracował model maszyny, który można
zrealizować nawet na kartce papieru.
Maszyna Turinga
zbudowana jest z trzech głównych elementów:
nieskończonej taśmy zawierającej komórki z przetwarzanymi
symbolami,
ruchomej głowicy zapisująco-odczytującej,
układu sterowania głowicą.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
3 / 48

1.2. Nieskończona taśma
Nieskończona taśma jest odpowiednikiem współczesnej pamięci
komputera. Taśma dzieli się na komórki, w których umieszczone zostały
symbole, czyli po prostu znaki przetwarzane przez maszynę Turinga.
Symbole te stanowią odpowiednik danych wejściowych. Maszyna Turinga
odczytuje te dane z kolejnych komórek i przetwarza na inne symbole, czyli
dane wyjściowe. Wyniki obliczeń również są zapisywane w komórkach
taśmy. Można definiować różne symbole dla maszyny Turinga. Najczęściej
rozważa się jedynie symbole 0, 1 oraz tzw. znak pusty - czyli zawartość
komórki, która nie zawiera żadnej danej do przetworzenia.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
4 / 48

1.3. Ruchoma głowica zapisująco-odczytująca
Aby przetwarzać dane, maszyna Turinga musi je odczytywać i zapisywać
na taśmę. Do tego celu przeznaczona jest właśnie głowica
zapisująco-odczytująca, która odpowiada funkcjonalnie urządzeniom
wejścia/wyjścia współczesnych komputerów lub układom odczytu i zapisu
pamięci. Głowica zawsze znajduje się nad jedną z komórek taśmy. Może
ona odczytywać zawartość tej komórki oraz zapisywać do niej inny symbol
- na tej zasadzie odbywa się przetwarzanie danych - z jednych symboli
otrzymujemy inne. Oprócz odczytywania i zapisywania symboli w
komórkach głowica wykonuje ruchy w prawo i w lewo do sąsiednich
komórek na taśmie. W ten sposób może się ona przemieścić do dowolnie
wybranej komórki taśmy.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
5 / 48

1.4. Układ sterowania głowicą
Przetwarzaniem informacji zarządza układ sterowania głowicą. Jego
współczesnym odpowiednikiem jest procesor komputera. Układ ten
odczytuje za pomocą głowicy symbole z komórek taśmy oraz przesyła do
głowicy symbole do zapisu w komórkach. Dodatkowo nakazuje on głowicy
przemieścić się do sąsiedniej komórki w lewo lub w prawo.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
6 / 48

1.5. Przykład działania maszyny Turinga (1/4)
W celu zobrazowania konstrukcji tabeli stanów przeanalizujmy maszynę
Turinga, która dla alfabetu wejściowego E = {a, b} podwaja symbole w
słowie (ab otrzymujemy aabb, aba otrzymujemy aabbaa).
E = {a, b} - alfabet
T = {O, a, b} - O to znak pusty.
Słowo na taśmie zapisane jest jako ciąg symboli postaci na przykład:
O O O a b O O O .
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
7 / 48
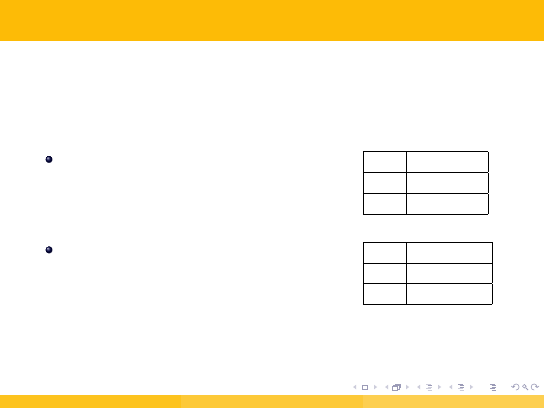
1.5. Przykład działania maszyny Turinga (2/4)
Na początku w kolumnie wypisujemy wszystkie symbole i stan początkowy
q0 :
Jeżeli będąc w stanie q0 odczytanym
symbolem będzie O to pozostajemy
nadal w tym stanie i wykonujemy ruch
o jedno pole w prawo.
MT
q0
O
q0 / a, P
a
-
jeżeli będąc w stanie q0 odczytanym
symbolem będzie ”a” to wpisujemy w
jego miejsce O i przechodzimy w prawo
do stanu q1
MT
q0
O
q0 / a, P
a
q1 / O, P
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
8 / 48

1.5. Przykład działania maszyny Turinga (3/4)
Będąc w stanie q1 musimy iść tak długo w prawo aż pominiemy wszystkie
symbole łącznie z pierwszym symbolem O . Wtedy w miejsce drugiego O
(może się ono znajdować po kilku symbolach z alfabetu wejściowego)
wpisujemy ”a” i przechodzimy do stanu q3. Jedynym słusznym symbolem
napotkanym w tym stanie jest O , w miejsce którego wpisujemy drugie ”a”
i przechodzimy do stanu q4 (stan powrotu). Jeżeli będąc w tym stanie
przejdziemy nad wszystkimi symbolami i napotkamy symbol O, to
sprawdzamy, czy są jeszcze jakieś symbole wejściowe na taśmie. Jeżeli tak
to zaczynamy algorytm od początku, w przeciwnym razie przechodzimy do
stanu końcowego q13. Analogicznie wygląda sytuacja dla ”b”.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
9 / 48

1.5. Przykład działania maszyny Turinga (4/4)
Ostateczny wygląd tabeli stanów:
gdzie SK to stan końcowy.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
10 / 48

Plan wykładu
1
Maszyna Turinga - koncept maszyny komputerowej
2
Pojęcie architektury komputera
3
Architektury komputera
4
Klastry i obliczenia równoległe
5
Architektury procesorów
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
11 / 48
2.1. Architektura komputera - co to takiego ?
Architektura komputera
jest to sposób organizacji elementów tworzących komputer.
Pod tym pojęciem rozumie się organizację połączeń elementów
komputera - pamięci, procesora i urządzeń wejścia-wyjścia.
Innym, stosowanym potocznie, znaczeniem terminu architektura
komputera jest typ procesora wraz z zestawem jego instrukcji.
Właściwszym określeniem w tym przypadku jest model programowy
procesora (ang. ISA - Instruction Set Architecture).
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
12 / 48

2.2. Klasyfikacja architektur
Architektury komputerowe można zaklasyfikować do trzech grup:
ze względu na sposób organizacji pamięci i wykonywania programu:
Architektura von Neumanna,
Architektura harvardzka,
Architektura mieszana,
ze względu na rodzaj połączeń procesor-pamięć i sposób ich
wykorzystania (taksonomia Flynna):
SISD (Single Instruction Single Data) – skalarne
SIMD (Single Instruction Multiple Data) – wektorowe (macierzowe)
MISD (Multiple Instruction Single Data) – strumieniowe
MIMD (Multiple Instruction Multiple Data) – równoległe
ze względu na sposób podziału pracy i dostęp procesora do pamięci.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
13 / 48

Plan wykładu
1
Maszyna Turinga - koncept maszyny komputerowej
2
Pojęcie architektury komputera
3
Architektury komputera
4
Klastry i obliczenia równoległe
5
Architektury procesorów
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
14 / 48
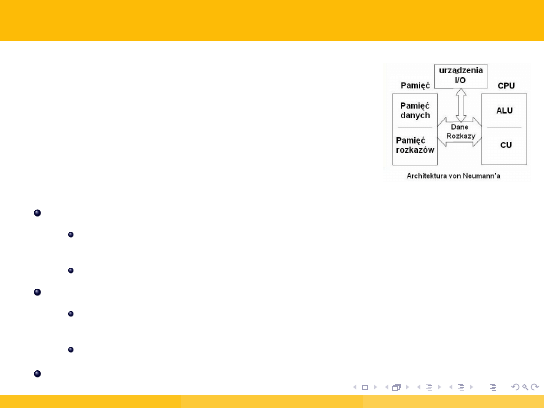
3.1 Architektura von Neumanna (1/2)
Pierwszy rodzaj architektury komputera,
opracowanej przez Johna von Neumanna, Johna W.
Mauchly’ego oraz Johna Presper Eckerta w 1945
roku.
Polega na ścisłym podziale komputera na trzy podstawowe części:
procesor
(CPU — Central Processing Unit)
z wydzieloną częścią sterującą oraz częścią arytmetyczno-logiczną
(ALU),
instrukcje są wykonywane sekwencyjnie,
pamięć komputera
(RAM — Random Access Memory)
zawierająca dane i sam program (instrukcje), które są przechowywane
w postaci liczb — nierozróżnialne,
jednorodna, liniowa (sekwencyjnie adresowana),
urządzenia wejścia/wyjścia
(I/O — Input/Output)
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
15 / 48

3.1 Architektura von Neumanna (2/2)
System komputerowy zbudowany w oparciu o architekturę von
Neumanna powinien:
mieć skończoną i funkcjonalnie pełną listę rozkazów,
mieć możliwość wprowadzenia programu do systemu komputerowego
poprzez urządzenia zewnętrzne i jego przechowywanie w pamięci w
sposób identyczny jak danych,
dane i instrukcje w takim systemie powinny być jednakowo dostępne
dla procesora,
Podane warunki pozwalają przełączać system komputerowy z
wykonania jednego zadania na inne bez fizycznej ingerencji w
strukturę systemu, a tym samym gwarantują jego uniwersalność.
Bez analizy programu trudno jest określić czy dany obszar pamięci
zawiera dane czy instrukcje. Wykonywany program może się sam
modyfikować traktując obszar instrukcji jako dane, a po przetworzeniu
tych instrukcji — danych — zacząć je wykonywać.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
16 / 48

3.2 Architektura harvardzka
W odróżnieniu od architektury von Neumanna,
pamięć danych programu jest oddzielona od pamięci
rozkazów.
Prostsza budowa przekłada się na większą szybkość działania, dlatego
ten typ architektury jest często wykorzystywany w procesorach
sygnałowych oraz przy dostępie procesora do pamięci cache.
Separacja pamięci danych od pamięci rozkazów sprawia, że
architektura harwardzka jest obecnie powszechnie stosowana w
mikrokomputerach jednoukładowych, w których dane programu są
najczęściej zapisane w nieulotnej pamięci ROM, natomiast dla danych
tymczasowych wykorzystana jest pamięć RAM (wewnętrzna lub
zewnętrzna).
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
17 / 48
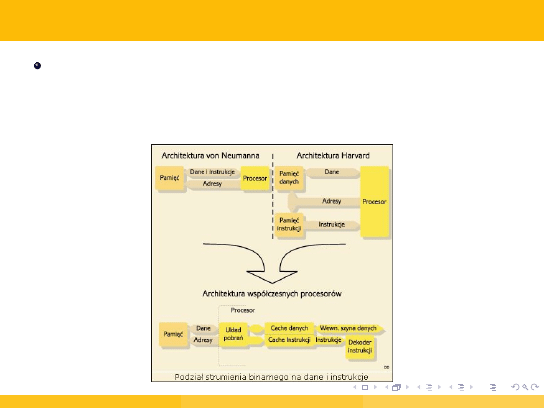
3.3 Architektura mieszana (Harvard-Princeton)
Hierarchia pamięci w architekturze Harvard-Princeton charakteryzuje
się częściowym rozdzieleniem hierarchii pamięci. Co najmniej jeden
poziom pamięci jest oddzielny dla hierarchii pamięci instrukcji i
danych.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
18 / 48

3.4. Rozszerzona taksonomia Flynna (1/5)
1968 - Michael Flynn, zakłada, że komputer przetwarza strumienie
danych na podstawie strumieni instrukcji.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
19 / 48

3.4. Rozszerzona taksonomia Flynna (2/5)
AUT
- Urządzenia bez strumieni danych nie są komputerami —
komputer musi (zgodnie z def.) przetwarzać dane.
NISD
- No Instruction Stream - Single Data Stream.
NIMD
- No Instruction Stream - Multiple Data Stream
Same dane mogą nieść informacje o tym, jak je przetwarzać - komputery
sterowne przepływem danych.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
20 / 48

3.4. Rozszerzona taksonomia Flynna (3/5)
SISD
najbardziej rozpowszechniony typ architektury,
przykład: procesor von Neumanna,
SIMD
jedna instrukcja powoduje wykonanie tej samej
operacji na wielu kompletach danych -
równoległość na poziomie danych,
przykład: procesor wektorowy lub macierzowy,
dodatkowe listy rozkazów: MMX, SSE, SSE2,
SSE3, 3DNow!, AltiVec.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
21 / 48
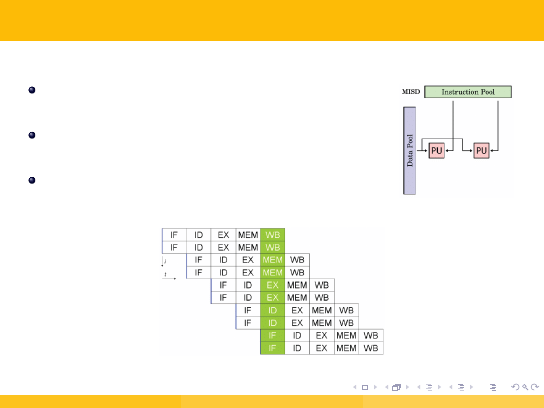
3.4. Rozszerzona taksonomia Flynna (4/5)
MISD
ta klasa jest problematyczna — trudno wskazać
wzorcowego reprezentanta tego typu,
maszyny potokowe - równoległość na poziomie
instrukcji,
przykład: procesory superskalarne, GPU,
redundant parallelism.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
22 / 48
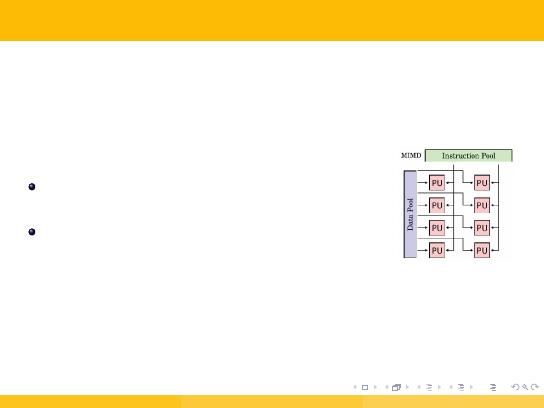
3.4. Rozszerzona taksonomia Flynna (5/5)
MIMD
procesory mogą funkcjonować asynchronicznie
na oddzielnych strumieniach danych,
klasa bardzo szeroka - dalsze podziały,
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
23 / 48

3.5. Rozszerzenie klasy MIMD (Johnson, 1988)
Kryteria podziału:
Struktura pamięci:
Sposób komunikacji:
GM = global memory
SV = shared variable
DM = distributed memory
MP = message passing
A zatem wyróżniamy następujące podklasy MIMD:
GMSV,
GMMP,
DMSV,
DMMP,
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
24 / 48

3.6. Podział ze względu na sposób podziału pracy i
dostępu procesora do pamięci
SMP (Symmetric Multiprocessing),
ASMP (Asymmetric Multiprocessing),
NUMA (Non-Uniform Memory Access),
ccNUMA (cache coherent Non-Uniform Memory Access),
AMP (Asynchronous Multiprocessing),
MPP (Massively Parallel Processors).
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
25 / 48

3.7. Architektura współczesnego komputera (1/2)
Współczesna architektura
oparta jest na idei von Neumana, podstawowy zestaw zbudowany jest z
jednostki centralnej(CPU), pamięci, urządzeń IO (wejścia/wyjścia),
pamięci masowej, klawiatury i monitora.
We współczesnych komputerach na płycie głównej znajdują się wszystkie
podstawowe elementy:
procesor
złącza pamięci
złącza kart rozszerzeń
złącza dysków
złącza urządzeń peryferyjnych
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
26 / 48
3.7. Architektura współczesnego komputera (2/2)
Chipset
ważny komponent płyty głównej, zestaw dwóch wyspecjalizowanych
układów zwanych mostkami - południowym i północnym.
Mostek:
południowy (southbridge) - zawiera układy odpowiedzialne za
współpracę z urządzeniami wejścia/wyjścia, w tym np. steroniwki
magistral PCI, złączy LPT i USB,
północny (northbridge) - zawiera szybkie interfejsy do procesora,
pamięci operacyjnej, magistral AGP lub PCI Express oraz mostka
południowego.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
27 / 48

3.8. CPU - procesor, mikroprocesor (1/2)
W prawie każdej jednostce CPU możemy wyróżnić następujące bloki
ALU - jednostka arytmetyczno-logiczna, wykonuje ona operacje
logiczne na dostarczonych jej danych,
CU – układ sterowania (Control Unit), zwany też dekoderem
rozkazów, odpowiedzialny jest on za dekodowanie dostarczonych
instrukcji i odpowiednie sterowanie pozostałymi jego blokami,
Rejestry – umieszczone wewnątrz mikroprocesora komórki pamięci o
niewielkich rozmiarach, służące do przechowywania tymczasowych
wyników obliczeń.
CPU komunikuje się z otoczeniem za pomocą szyny danych i szyny
adresowej.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
28 / 48

3.8. CPU - procesor, mikroprocesor (2/2)
Obecnie używane są układy mikroprocesorowe:
Firmy Intel - procesory dwurdzeniowe (Core 2 Duo),
czterodzeniowe(Core 2 Quad) - technologia 65 nm,
Firmy AMD - układy dwu,trzy i czterordzeniowe Phenom II -
technologia 45 nm,
najnowsze układy obu firm - Core i7, Bloomfield, Nehalem -
technologia 45 nm, 256 KB L2 cache, 8 MB L3 cache, 780 milionów
tranzystorów,
obecnie jest gotowa technologia 32 nm do produkcji nowych układów.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
29 / 48

3.9. System-on-Chip - SoC (1/2)
SoC
mianem tym określa się układ scalony zawierający kompletny system
elektroniczny, w tym układy cyfrowe, analogowe (także radiowe) oraz
cyfrowo-analogowe. Poszczególne moduły tego systemu, ze względu na ich
złożoność, pochodzą zwykle od różnych dostawców. Przykładowo
jednostka centralna pochodzi od jednego dostawcy, a porty komunikacji
szeregowej od innego. Typowym obszarem zastosowań SoC są systemy
wbudowane, a najbardziej rozpowszechnionym przedstawicielem tego
rozwiązania są systemy oparte na procesorze ARM.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
30 / 48

3.9. System-on-Chip - SoC (2/2)
Typowy układ typu SoC składa się z elementów takich jak:
pojedynczy mikroprocesor, mikrokontroler lub rdzeń DSP,
bloki pamięci złożone z modułów RAM, ROM, EEPROM lub FLASH,
układy czasowo-licznikowe,
kontrolery transmisji szeregowej lub równoległej (np. UART, SPI,
USB, Ethernet),
przetworniki analogowo-cyfrowe lub cyfrowo-analogowe,
obwody zarządzania zasilaniem
Niektóre układy SoC mogą zawierać kilka jednostek obliczeniowych. Są
one określane mianem MPSoC (ang. Multiprocessor System-on-Chip).
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
31 / 48
3.10. GPU
GPU (ang. Graphics Processing Unit)
koprocesor graficzny - jest główną jednostką obliczeniową znajdującą się w
kartach graficznych. Jako pierwsza tego terminu użyła firma NVIDIA,
wprowadzając na rynek karty graficzne GeForce 256. To przełomowe
wydarzenie dla akceleracji grafiki w systemach domowych miało miejsce 31
sierpnia 1999 roku, wcześniej systemy takie były dostarczane wyłącznie
jako specjalizowane systemy profesjonalne. Głównym zadaniem GPU było
wykonywanie obliczeń potrzebnych do uzyskania akcelerowanej grafiki 3D,
co spowodowało częściowe odciążenie procesora CPU z konieczności
wykonywania tego zadania. W tej sytuacji mógł on zająć się innymi
obliczeniami, co skutkowało zwiększeniem wydajności komputera podczas
renderowania grafiki. Nowoczesne procesory graficzne wyposażone są w
szereg instrukcji, których nie posiada procesor komputera.
Potentami na rynku kart graficznych są - NVIDIA, AMD, Intel
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
32 / 48

3.11. Rodzaje GPU
procesory zintegrowane - rozwiązaniem stosowanym przez wielu
producentów płyt głównych jest instalacja procesora graficznego
zintegrowanego z chipsetem na mostku północnym. Jest to przede
wszystkim tańsze rozwiązanie, gdyż wdrażane jest w trakcie produkcji
samych płyt głównych i nie pochłania dodatkowych zasobów, ale
zainstalowane w ten sposób układy graficzne charakteryzują się o
wiele mniejszą wydajnością.
procesory do dedykowanych kart graficznych - najbardziej
zaawansowane układy znajdujących się na osobnym podzespole,
montowane za pomocą slotów jak PCI Express x16 lub AGP
charakteryzujących się wysoką przepływnością danych. Procesory
projektowane są do współpracy z pamięcią RAM znajdującą się na
kartach graficznych (obecnie jest to wersja GDDR5). Dzięki
technologiom CrossFire i SLI nowoczesne płyty główne zapewniają
współpracę wielu procesorów graficznych równocześnie na jednej
platformie, zwiększając tym samym wydajność całego systemu.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
33 / 48

3.12. APU
APU - Accelerated Processing Unit
zintegrowany układ scalony łączący w jednym układzie krzemowym CPU i
GPU. Układ przekładające większość obliczeń na bardziej wydajne
procesory graficzne, w celu zwiększenia wydajności komputera. Obecnie na
rynku są układy AMD Fusion. NVIDIA pracuję nad układami NVIDIA
Denver.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
34 / 48

Plan wykładu
1
Maszyna Turinga - koncept maszyny komputerowej
2
Pojęcie architektury komputera
3
Architektury komputera
4
Klastry i obliczenia równoległe
5
Architektury procesorów
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
35 / 48

4.1. Klastry komputerowe - definicja
Klaster komputerowy
grupa połączonych jednostek komputerowych, które współpracują ze sobą
w celu udostępnienia zintegrowanego środowiska pracy. Komputery
wchodzące w skład klastra (będące członkami klastra) nazywamy węzłami
(ang. node). Jedną z najbardziej popularnych implementacji klastrów
obliczeniowych jest klaster typu Beowulf gdzie rolę węzłów pełnią wydajne
komputery klasy PC. Obecnie najszybszy klaster komputerowy w Polsce to
superkomputer Zeus znajdujący się w zasobach obliczeniowych
Akademickiego Centrum Komputerowego Cyfronet AGH.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
36 / 48

4.2. Typy klastrów
W istniejących rozwiązaniach klastrowych można wyodrębnić trzy
podstawowe klasy wynikające z celów budowy takich rozwiązań:
klastry wydajnościowe - pracujące jako zespół komputerów, z
których każdy wykonuje własne zadania obliczeniowe.
klastry niezawodnościowe - pracujące jako zespół komputerów
dublujących nawzajem swoje funkcje (łączenie równoległe). W razie
awarii jednego z węzłów, następuje automatyczne przejęcie jego
funkcji przez inne węzły.
klastry równoważenia obciążenia - pracujące jako zespół
komputerów, z których każdy wykonuje własne zadanie z puli zadań
skierowanych do całego klastra. W takiej sytuacji pojedynczy
komputer może wykonywać niezależne zadanie lub współpracować z
kilkoma innymi węzłami klastra wykonując podzadanie większego
zadania obliczeniowego.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
37 / 48

4.3. Obliczenia równoległe - definicja
Obliczenia równoległe
forma wykonywania obliczeń, w której wiele instrukcji jest wykonywanych
jednocześnie. Taka forma przetwarzania danych jest wykorzystywana
głównie przy wykorzystaniu superkomputerów (np. klastrów). Ze względu
na skalę można wyróżnić obliczenia równoległe na poziomie:
bitów,
instrukcji,
danych,
zadań,
którym sprzęt wspomaga operacje.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
38 / 48

4.4. Metody sprzętowe wspomagania obliczeń
równoległych (1/2)
procesory wielordzeniowe - procesor z kilkoma jednostkami
wykonawczymi, mogą wykonywać jednocześnie instrukcje pochodzące
z różnych ciągów instrukcji,
symetryczne systemy wieloprocesorowe - system komputerowy z
wieloma identycznymi procesorami, które operują na wspólnej pamięci
za pośrednictwem magistrali
przetwarzanie rozproszone - jest systemem komputerowym o
rozproszonej pamięci, w którym elementy przetwarzające połączone są
przez sieć komputerową. Komputery rozproszone są wysoce
skalowalne
przetwarzanie klastrowe - wiele komputerów, traktowane jako całość -
jeden superkomputer,
komputery masowo równoległe - jeden komputer zarządzający wieloma
procesorami,
Obliczenia w gridach - sieć rozproszona, komunikacja za pomocą
Internetu
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
39 / 48

4.4. Metody sprzętowe wspomagania obliczeń
równoległych (2/2)
specjalistyczne urządzenia do przetwarzania równoległego:
rekonfigurowalne systemy obliczeniowe - składa się z procesora
ogólnego przeznaczenia oraz programowalnych układów logicznych
FPGA,
GPGPU (ang. General-Purpose Computing on Graphics Processing
Units) - wykonywanie obliczeń ogólnego przeznaczenia za pomocą
procesora karty graficznej,
specjalizowane układy scalone - układy projektowane do realizacji ściśle
określonego zadania, większa wydajność w porównaniu z komputerem
ogólnego przeznaczenia,
procesory wektorowe - jest procesorem lub systemem komputerowym,
który wykonuje te same instrukcje na dużych zbiorach danych.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
40 / 48

Plan wykładu
1
Maszyna Turinga - koncept maszyny komputerowej
2
Pojęcie architektury komputera
3
Architektury komputera
4
Klastry i obliczenia równoległe
5
Architektury procesorów
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
41 / 48

5.1. Architektura CISC
CISC
(Complex Instruction Set Computers):
duża liczba rozkazów (instrukcji),
mała optymalizacja — niektóre rozkazy potrzebują dużej liczby cykli
procesora do wykonania: każda instrukcja może wykonać kilka
operacji niskiego poziomu,
występowanie złożonych, specjalistycznych rozkazów,
duża liczba trybów adresowania,
do pamięci może się odwoływać bezpośrednio duża liczba rozkazów,
mniejsza od RISC-ów częstotliwość taktowania procesora,
powolne działanie dekodera rozkazów,
np. x86, AMD, M68000.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
42 / 48

5.2. Architektura RISC (1/2)
RISC
(Reduced Instruction Set Computers):
zredukowana liczba uproszczonych rozkazów do niezbędnego
minimum — ich liczba wynosi kilkadziesiąt - upraszcza to znacznie
dekodowanie rozkazów,
redukcja trybów adresowania, dzięki czemu kody rozkazów są
prostsze, bardziej zunifikowane, co dodatkowo upraszcza wspomniany
wcześniej dekoder rozkazów; ponadto wprowadzono tryb adresowania,
który ogranicza ilość przesłań,
ograniczenie komunikacji pomiędzy pamięcią, a procesorem (do
przesyłania danych pomiędzy pamięcią, a rejestrami służą dedykowane
instrukcje) — pozostałe instrukcje mogą operować wyłącznie na
rejestrach,
zwiększenie liczby rejestrów,
do pamięci może się odwoływać bezpośrednio duża liczba rozkazów,
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
43 / 48

5.2. Architektura RISC (2/2)
dzięki przetwarzaniu potokowemu wszystkie rozkazy wykonują się w
jednym cyklu maszynowym, co pozwala na znaczne uproszczenie
bloku wykonawczego, a zastosowanie superskalarności także na
umożliwienie równoległego wykonywania rozkazów.
np. DEC Alpha, ARC, ARM, AVR, MIPS, PA-RISC, PowerPC,
UltraSPARC.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
44 / 48

5.3. Architektura VLIW (1/2)
VLIW
(Very Long Instruction Word):
architektura ta charakteryzuje się maksymalnie daleko idącym
uproszczeniem jednostek sterujących (CU) w samym mikroprocesorze,
wykorzystanie techniki wcześniejszego wykonania instrukcji
(Out-of-Order Execution), ale cała złożoność przepływu sterowania w
mikroprocesorze, czyli wykonywania rozkazów, przerzucono na
kompilator,
rezygnacja z całej logiki sterowania wymusiła dostarczenie do
procesora wystarczającej liczby danych sterujących: z tego powodu
pojedyncze rozkazy posiadają w sobie już zdekodowane (lub wstepnie
zdekodowane) sygnały sterujące, dane oraz, co najważniejsze,
”instrukcje” dedykowane dla konkretnych jednostek wykonawczych
mikroprocesora; tak stworzona pojedyncza instrukcja procesora VLIW
ma wielkość rzędu setek bitów – 256 lub więcej.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
45 / 48

5.3. Architektura VLIW (2/2)
obecnie procesory VLIW są oparte na architekturze RISC, zazwyczaj z
kilkoma jednostkami obliczeniowymi,
np. NXP TriMedia, Intel Itanium IA-64, SHARC DSP, Texas
Instruments C6000 DSP.
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
46 / 48

Bibliografia (1/2)
Strona 1 Liceum Ogólnokształcącego, Lębork, Dostępna w Internecie:
http://www.lo1.lebork.pl/doc/budowa_komputera_v1.pdf
Strona Studia Informatyczne Beta, Dostępny w Internecie:
http://wazniak.mimuw.edu.pl/index.php?title=
Architektura_Komputer%C3%B3w/Wyk%C5%82ad_1:_Teoria
http://wazniak.mimuw.edu.pl/index.php?title=
Architektura_Komputer%C3%B3w/Wyk%C5%82ad_5:_Model_
programowy_procesora_w_podej%C5%9Bciu_CISC_i_RISC
Strona eioba.pl, Maszyna Turinga, Dostępna w Internecie:
http://www.eioba.pl/a/1hd/maszyna-turinga
Strona Uniwerystetu Śląskiego, Maszyna Turinga, Dostępna w
Internecie:
http://prac.us.edu.pl/~boryczka/WDI/Turing/turing.htm
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
47 / 48

Bibliografia (2/2)
Encyklopedia Wikipedia, Dostępna w Internecie:
http://pl.wikipedia.org/wiki/Architektura_komputera
http://pl.wikipedia.org/wiki/Architektura_harwardzka
http://pl.wikipedia.org/wiki/CISC
http://pl.wikipedia.org/wiki/RISC
http://pl.wikipedia.org/wiki/VLIW
http://en.wikipedia.org/wiki/Flynn%27s_taxonomy
http://ortografia4.appspot.com/wiki/Taksonomia_Flynna
http://pl.wikipedia.org/wiki/System-on-a-chip
http://pl.wikipedia.org/wiki/Procesor_karty_graficznej
http:
//en.wikipedia.org/wiki/Accelerated_processing_unit
http:
//pl.wikipedia.org/wiki/Obliczenia_r%C3%B3wnoleg%C5%82e
Paweł Dudzik, Adrian Guzik (AGH Kraków)
Architektury komputerów i procesorów
Kraków, 6 lipca 2011
48 / 48
Document Outline
- Plan wykładu
- Maszyna Turinga
- Pojecie - architektura komputera
- Architektury komputera
- Klastry
- Architektury procesorów
- Bibliografia
Wyszukiwarka
Podobne podstrony:
ARCHITEKTURA KOMPUTEROW1A
Architektura Komputera, Informatyka, Płyta Główna
Architektury Komputerów zagadnienia
Architektura komputerów I 16 12 2008
gulczas 2001 opracowanie, Politechnika Wrocławska - Materiały, architektura komputerow 2, egzamin, o
Architektura komputerów I 09 12 2008
Architektura komputerów i systemy operacyjne
Architektura Komputerów wiedza ogólna
ak projekt, Studia, PWR, 4 semestr, Architektura komputerów 2, projekt
Tematy cwiczen, Architektóra komputerów
ako pytania zadania cz2 2010, Studia - informatyka, materialy, Architektura komputerów
Architektura komputerów I 25 11 2008
Architektura Komputerow lista 3
AK test, stud, IV semestr, Architektura Komputerow
Podstawy architektury komputera, Szkoła, Systemy Operacyjnie i sieci komputerowe, utk, semestr II
więcej podobnych podstron