
Wydzia l Automatyki, Elektroniki i Informatyki
Instytut Informatyki
Praca dyplomowa
magisterska
Dynamiczny przydzia l pasma u ˙zytkownika
sieci z wykorzystaniem us lugi QoS w systemie
Linux
Spis tre´
sci
4
8
Architektura QoS - Integrated Services . . . . . . . . . . . . .
10
Architektura QoS - Differentiated Services . . . . . . . . . . .
12
Stan aktualny implementacji QoS w systemie Linux
19
Algorytmy kolejkowania pakiet´
ow . . . . . . . . . . . . . . . .
21
Algorytmy kolejkowania FIFO . . . . . . . . . . . . . .
22
Algorytm kolejkowania PRIO (PRIOrities) . . . . . . .
24
Algorytm kolejkowania TBF (Token Bucket Filter) . .
25
Algorytm kolejkowania SFQ (Stochastic Fairness Qu-
eueing) . . . . . . . . . . . . . . . . . . . . . . . . . . .
29
Algorytmy kolejkowania RED (Random Early Detection) 30
Algorytm kolejkowania CBQ (Classful Based Queueing) 33
Algorytm kolejkowania DSMARK (DiffServ Mark)
. .
37
Algorytm kolejkowania CSZ (Clark-Shenker-Zhang) . .
38
ow . . . . . . . . . . . . . . . . . . . . . . . . . .
40
Filtr route . . . . . . . . . . . . . . . . . . . . . . . . .
40
. . . . . . . . . . . . . . . . . . . . . . . . . .
42
1

. . . . . . . . . . . . . . . . . . . .
43
Filtr tcindex . . . . . . . . . . . . . . . . . . . . . . . .
44
Filtr u32 . . . . . . . . . . . . . . . . . . . . . . . . . .
45
ow . . . . . . . .
46
sci rozbudowy implementacji QoS w systemie Linux 49
olny . . . . . . . . . . . . . . . . . . . . . . . .
50
ow kolejkowania . . . . . .
52
Opis implementacji klas ruchu . . . . . . . . . . . . . .
55
. . . . . . . . . .
56
58
n . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
58
et u˙zyty w badaniach . . . . . . . . . . . . . . . . . . . .
59
acego . . . . . . . . . . . . . . . .
60
ow w trybie u˙zytkownika . . . . . . .
61
adra . . . . . . . . . . .
62
azania . . . . . . . . . . . . . . .
63
. . . . . . . . . . . . . . . . . . . .
64
acza . . . . . . . . . . . . . . .
64
ow IP . . . . .
65
82
n . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
82
Badania z wykorzystaniem algorytmu PRIO . . . . . . . . . .
83
Badania wykonane z wykorzystaniem algorytmu TBF . . . . .
99
Badania wykonane z wykorzystaniem algorytmu RED . . . . . 105
109
2


Rozdzia l 1
Cel i zakres pracy
Pr
,
edko´s´
c transferu danych w sieciach komputerowych zale˙zy od aktual-
nego obci
,
a˙zenia sieci (ilo´s´
c przesy lanych przez sie´
c danych). Podej´scie takie
zwi
,
azane jest z histori
,
a powstawania sieci. Pierwsze aplikacje sieciowe oparte
w wi
,
ekszo´sci o przesy l znak´
ow ASCII nie wymaga ly ani du˙zych przepusto-
wo´sci, ani nie stawia ly ogranicze´
n na czas dostarczania pakiet´
ow do punktu
przeznaczenia. Konwergencja sieci komputerowych, telefonicznych oraz tele-
wizyjnych jak
,
a mo˙zemy obserwowa´
c stawia przed projektantami sieci nowe
zadania (przesy l faks´
ow, rozmowy telefoniczne). Aktualnie sieci kompute-
rowe jednak nie zapewniaj
,
a odpowiednich mechanizm´
ow zaimplementowa-
nych w komputerach i urz
,
adzeniach sieciowych steruj
,
acych ruchem pakiet´
ow
w sieciach komputerowych, st
,
ad jako´s´
c obrazu i p lynno´s´
c d´
zwi
,
eku zale˙zy
w znacznym stopniu od nat
,
e˙zenia ruchu w sieciach komputerowych. Jedy-
nym typem sieci, gdzie realnie mechanizmy regulacji ruchu w sieci w za-
le˙zno´sci od potrzeb u˙zytkownika zosta ly zaimplementowane jest sie´
c ATM.
Ze wzgl
,
edu na popularno´s´
c protoko lu IP czyni si
,
e starania stworzenia iden-
tycznych mo˙zliwo´sci w Internecie. Praca ta opisuje wykorzystanie protoko lu
IP w wersji 4 — IPv6, a protok´
o l IP w wersji 6 — IPv6 jest tylko cza-
4

sem wspominany. Je´sli nie podano numeru wersji protoko lu, to omawiany
jest protok´
o l IPv4. Je´sli przyjmiemy, ˙ze klienci p lac
,
a swym operatorom sieci
za dost
,
ep do takich us lug, to dochodzimy do wniosku, ˙ze pewne aplikacje
wymagaj
,
a tego, aby pakiet zosta l dostarczony w pewnym okre´slonym cza-
sie. Rozwi
,
azaniem tego zagadnienia mog loby by´
c zwi
,
ekszenie przepustowo´sci
sieci. Do´swiadczenie pokazuje, ˙ze rozwi
,
azanie tego problemu w taki spos´
ob
jest niemo˙zliwe na d lu˙zsz
,
a met
,
e. Rozwi
,
azaniem mo˙ze by´
c dynamiczny przy-
dzia l pasma u˙zytkownikom.
Niniejsza praca opisuje problem dynamicznego przydzia lu pasma u˙zyt-
kownikowi sieci komputerowej w celu zapewnienia mo˙zliwo´sci korzystania
z us lug sieciowych, przede wszystkim multimedialnych oraz interaktywnych.
Dotycz
,
a one obrazu i d´
zwi
,
eku przesy lanych w sieciach komputerowych.
W tej pracy z powod´
ow przedstawionych powy˙zej opisano problematyk
,
e
tylko dla sieci opartych na protokole IP. Jako dynamiczny przydzia l pasma
przyjmuje si
,
e przydzia l pasma zale˙zny od rodzaju us lugi z jakiej u˙zytkownik
b
,
edzie korzysta l. Nawi
,
azuj
,
ac do analogii z p latnym dost
,
epem, mo˙zemy sobie
wyobrazi´
c, ˙ze klient kt´
ory zap laci l operatorowi sieci za us lug
,
e wy˙zszej jako´sci
powinien mie´
c p lynniejszy dost
,
ep do multimedi´
ow sieciowych
Jako obiekt bada´
n wybrano system operacyjny Linux. S lowo Linux ozna-
cza samo j
,
adro systemu operacyjnego, natomiast system operacyjny dystry-
buowany razem z dodatkowymi programami narz
,
edziowymi i u˙zytkowymi
okre´sla si
,
e jako dystrybucj
,
e Linuksa. Przyk ladowymi dystrybucjami Linuksa
s
,
a Debian i RedHat. System ten znakomicie nadaje si
,
e do wszelkich bada´
n
sieci, poniewa˙z jest on dost
,
epny wraz z pe lnym kodem ´
zr´
od lowym. Liberalna
licencja, na kt´
orej jest wydawany, pozwala opr´
ocz czytania kodu ´
zr´
od lowego
w celu zrozumienia dzia lania systemu operacyjnego r´
ownie˙z swobodn
,
a mody-
fikacj
,
e tego kodu. W systemie Linux dynamiczny przydzia l pasma jest realizo-
5

wany poprzez
”
Gwarancj
,
e jako´
sci us lug”. Cz
,
e´sciej u˙zywa si
,
e r´
ownoznacznego
okre´slenia angielskiego
”
Quality of Service” (QoS ). W dalszej cz
,
e´sci pracy
u˙zywane b
,
edzie bardziej popularne okre´slenie angloj
,
ezyczne (patrz rozdz. 2).
Celem pracy dyplomowej jest analiza zagadnie´
n zwi
,
azanych z QoS
od strony teoretycznej, poznanie jej implementacji w Linuksie oraz zbadanie
czy ruter oparty na komputerze z systemem Linux mo˙ze spe lnia´
c wymagania
stawiane ruterom QoS. Opis implementacji umieszczono w rozdz. 3. Prze-
prowadzenie bada´
n dost
,
epnych mechanizm´
ow pozwoli na ocen
,
e jako´sciow
,
a
implementacji oraz pr´
ob
,
e optymalizacji jej dalszych ulepsze´
n .
W rozdziale drugim przybli˙zona jest og´
olna idea QoS oraz wprowadzone
s
,
a podstawowe poj
,
ecia z ni
,
a zwi
,
azane. W tym celu podzielono QoS na dwa
podej´scia do problemu: IntServ oraz DiffServ. Om´
owiony jest r´
ownie˙z skr´
o-
towo protok´
o l sygnalizacyjny RSVP, a tak˙ze przedstawiony format nag l´
ow-
k´
ow pakiet´
ow IPv4 oraz IPv6. Na koniec przedstawiona jest symbolicznie
droga pakietu w ruterze.
W rozdziale trzecim opisany jest aktualny stan rozwoju implementacji
QoS w Linuksie. W ramach tego opisane s
,
a dost
,
epne filtry (przydzielaj
,
a
przychodz
,
ace pakiety do konkretnych klas ruchu w kt´
orych obowi
,
azuj
,
a usta-
lone algorytmy kolejkowania) oraz algorytmy kolejkowania.
Rozdzia l czwarty opisuje og´
olny schemat implementacji mechanizm´
ow
QoS u˙zywany w Linuksie. Korzystaj
,
ac z tych wytycznych mo˙zna zmodyfi-
kowa´
c dost
,
epne ju˙z algorytmy oraz zaimplementowa´
c kolejne znane z innych
realizacji QoS ni˙z linuksowa, przyk ladowo z ruter´
ow Cisco.
Rozdzia l pi
,
aty przedstawia wykonane badania zachowania si
,
e dost
,
epnych
aktualnie mechanizm´
ow realizacji QoS w Linuksie.
W rozdziale sz´
ostym dokonana jest analiza ilo´sciowa wynik´
ow bada´
n, po
kt´
orej nast
,
epuje analiza ilo´sciowa.
6

W ostatnim rozdziale znajduje si
,
e podsumowanie przeprowadzonych ba-
da´
n. W rozdziale tym wysnuwa si
,
e te˙z wnioski z wynik´
ow ilo´sciowych oraz
jako´sciowych dokonanych pomiar´
ow.
7

Rozdzia l 2
Zasady dzia lania mechanizm´
ow
Quality of Service
Przed laty nikt nie przewidywa l, ˙ze sieci komputerowe b
,
ed
,
a wykorzysty-
wane do transmisji danych multimedialnych (transmisja d´
zwi
,
eku i obrazu)
oraz konwergentnych (wsp´
olne okablowanie dla po l
,
aczenia z Internetem i cen-
tralk
,
a telefoniczn
,
a) dlatego przy tworzeniu sieci Internet jednym z g l´
ownych
za lo˙ze´
n by la prostota rozwi
,
aza´
n. Nie by lo wtedy dost
,
epnych w sieci us lug
interaktywnych (np. WWW ), ani multimedialnych. Nikt r´
ownie˙z nie spo-
dziewa l si
,
e tak gwa ltownego rozwoju Internetu, zar´
owno ilo´sci jego u˙zyt-
kownik´
ow, jak i zapotrzebowania na coraz wi
,
eksze przepustowo´sci. Nale˙zy
r´
ownie˙z pami
,
eta´
c, ˙ze w pocz
,
atkowym okresie sieci komputerowe by ly u˙zy-
wane g l´
ownie w celach naukowych oraz edukacyjnych, a nie rozrywkowych
i handlowych, od u˙zytkownik´
ow ko´
ncowych nie by ly pobierane op laty za do-
st
,
ep do Internetu, wi
,
ec wszyscy mieli dost
,
ep do sieci na tych samych pra-
wach. Dlatego te˙z przyj
,
eto wiele uproszcze´
n konstrukcyjnych. Jednym z nich
jest r´
ownouprawnienie wszystkich transmisji sieciowych. Internet jaki znamy
przekazuje pakiety w my´sl zasady
”
najlepszego wysi lku” [4] (ang. best ef-
8

fort). Oznacza to, ˙ze komputery lub wyspecjalizowane urz
,
adzenia zajmuj
,
ace
si
,
e przekazywaniem pakiet´
ow nazywane ruterami (og´
olnie nazywane w
,
ez lami
sieci), s
,
a zaprojektowane tak, aby jak najszybciej przekazywa´
c dalej otrzy-
mane pakiety. W razie wyst
,
apienia przeci
,
a˙zenia ruchu, pakiety s
,
a przez nie
odrzucane bez faworyzowania jakichkolwiek [28]. Innymi s lowy, przekazuj
,
ac
dalej pakiet w
,
ez ly bior
,
a pod uwag
,
e tylko jego przeznaczenie (
”
gdzie”).
Je´sli chcieliby´smy zwi
,
ekszy´
c elastyczno´s´
c dotychczasowego modelu sieci
i umo˙zliwi´
c faworyzowanie niekt´
orych transmisji, to dochodzimy do wniosku,
ze opr´
ocz przeznaczenia (
”
gdzie”) nale˙zy r´
ownie˙z przesy la´
c pakiety w odpo-
wiednim momencie (
”
kiedy”). Mo˙zna to osi
,
agn
,
a´
c stosuj
,
ac mechanizmy QoS.
Przez QoS rozumie si
,
e sta lo´s´
c w ´sci´sle wyznaczonych granicach nast
,
epu-
j
,
acych parametr´
ow transmisji [4] w sieciach komputerowych:
Przepustowo´
s´
c (ang. throughput) ilo´s´
c danych przesy lanych z jednego
miejsca do drugiego w okre´slonym czasie. Przez ilo´s´
c danych rozumie si
,
e
ilo´s´
c bit´
ow. Ilo´s´
c danych, kt´
ora mo˙ze zosta´
c przes lana danym l
,
aczem,
w praktyce jest ni˙zsza od maksymalnej z powodu op´
o´
znie´
n w transmisji
danych. Jednostk
,
a przepustowo´sci jest bps (bit na sekund
,
e).
Op´
o´
znienie (ang. latency) zw loka w transmisji danych. W ruterze op´
o´
z-
nieniem jest czas up lywaj
,
acy mi
,
edzy przyj´sciem pakietu, a jego prze-
s laniem dalej. Dlatego nazywa si
,
e go r´
ownie˙z czasem propagacji.
Zmienno´
s´
c op´
o´
znienia (ang. jitter) zniekszta lcenie taktowania sygna lu
zachodz
,
ace w trakcie transmisji w sieci, prowadz
,
ace do transmisji pakie-
t´
ow sieciowych w nieregularnych odst
,
epach . W ruterze zmienno´s´
c op´
o´
z-
nienia transmisji pakiet´
ow wychodz
,
acych zachodzi wtedy, gdy sprz
,
e-
towo nie nad
,
a˙za on z obs lug
,
a ruchu sieciowego.
9

Zgodnie z klasyfikacj
,
a IETF (ang. Internet Engineering Task Force) za-
leca si
,
e implementowa´
c QoS na jeden ze sposob´
ow:
1. Integrated Services [14]
2. Differentiated Services [12] [13]
2.1
Architektura QoS - Integrated Services
W architekturze Integrated Services (w skr´
ocie IntServ) zasoby sieci s
,
a
przydzielane dla danej aplikacji na ˙z
,
adanie po uprzedniej rezerwacji. Rezer-
wowa´
c je mo˙zna dla pojedynczego strumienia danych lub agregacji strumieni
danych. W celu rezerwacji stosuje si
,
e algorytm RSVP (ang. ReSerVation
Protocol) [7].
Protok´
o l ten opiera si
,
e na kilku za lo˙zeniach [4]:
• W pe lni obs lugiwane s
,
a transmisje jeden-do-jednego (ang. unicast) oraz
jeden-do-wielu (ang. multicast). W tych drugich ka˙zdemu z odbiorc´
ow
mo˙ze zosta´
c przyznany inny poziom QoS.
• Protok´
o l dzia la jako rozszerzenie protoko lu IP, a nie jako jego substy-
tut. Upraszcza to jego implementacje oraz u latwia wsp´
o lprac
,
e zar´
owno
z IPv4 jak i IPv6. Wymusza to jednak okresowe ponawianie sygnaliza-
cji (ang. soft-state signalling) jako warunek konieczny do utrzymywania
po l
,
aczenia.
• Sesje RSVP s
,
a jednokierunkowe (ang. simplex). Upraszcza to synchro-
nizacj
,
e poprzez wstrzymanie rozpocz
,
ecia transmisji do czasu nadej´scia
potwierdzenia od odbiorcy.
Przed rozpocz
,
eciem w la´sciwej transmisji danych nadawca przesy la wia-
domo´s´
c PATH zawieraj
,
ac
,
a nast
,
epuj
,
ace informacje:
10
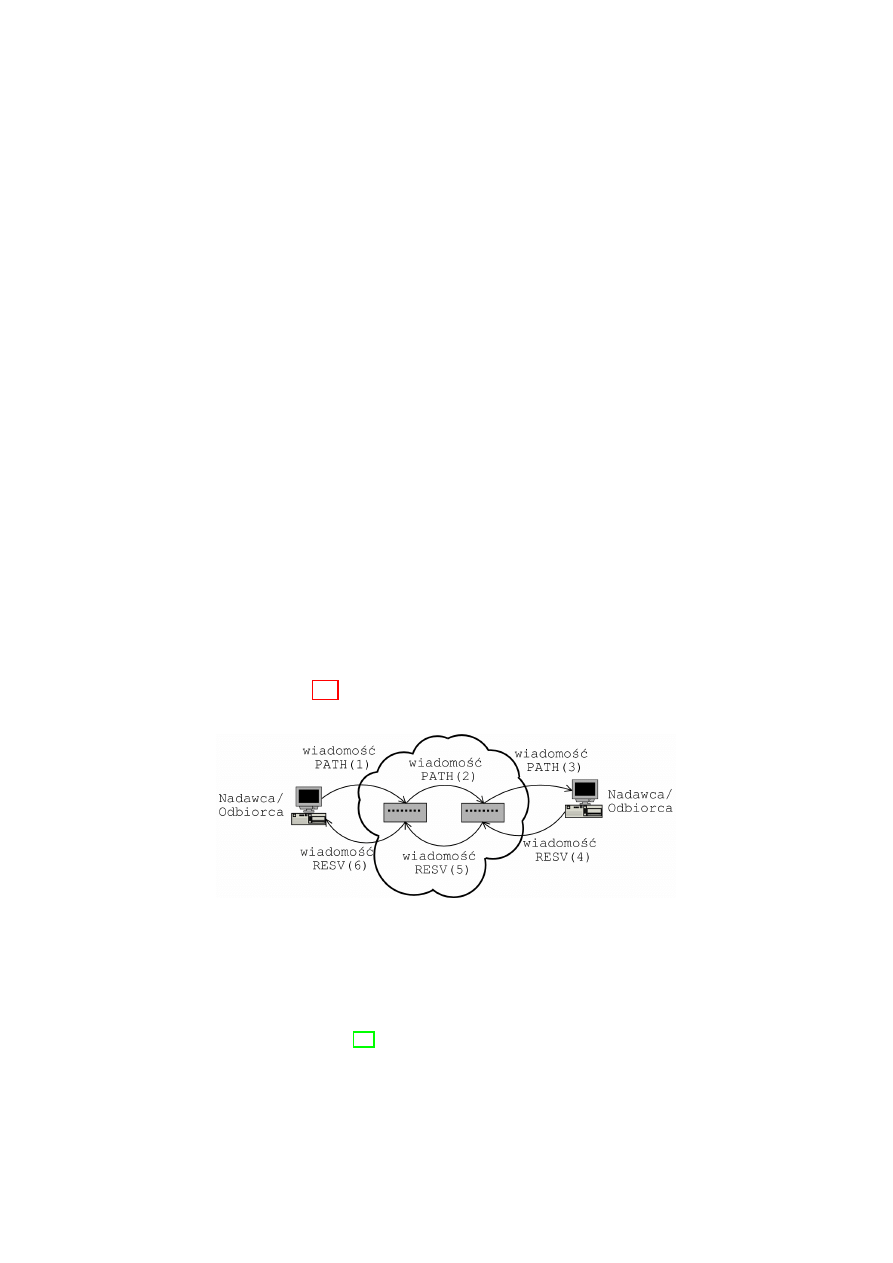
• minimaln
,
a i maksymaln
,
a przepustowo´s´
c ˙z
,
adanego pasma
• minimalne i maksymalne op´
o´
znienie przekazu pakiet´
ow przez sie´
c
• minimaln
,
a i maksymaln
,
a zmienno´s´
c op´
o´
znienia przekazu pakiet´
ow
• typ ˙z
,
adanej us lugi (Guaranteed Service, Controlled Load Service, Best
Effort)
• identyfikacj
,
e pakiet´
ow nale˙z
,
acych do danego strumienia danych (nu-
mery port´
ow, rodzaj protoko lu transportowego itp.)
Ka˙zdy ruter po drodze je´sli mo˙ze dokona´
c ˙z
,
adanej rezerwacji, to prze-
kazuje dalej wiadomo´s´
c PATH, w przeciwnym wypadku wysy la wiadomo´s´
c
odrzucenia zg loszenia do nadawcy. Gdy wiadomo´s´
c PATH dotrze do odbiorcy
informacji, to wysy la on wiadomo´s´
c RESV jako potwierdzenie. Dopiero po
dotarciu tej wiadomo´sci do odbiorcy, zaczyna on transmisj
,
e danych. Rezer-
wacja musi by´
c odnawiana okresowo. Dzia lanie protoko lu sygnalizacyjnego
RSVP obrazuje rys. 2.1.
Rysunek 2.1: Protok´
o l rezerwacji (RSVP)
W tej architekturze dost
,
epne s
,
a trzy typy us lug:
• Guaranteed Service [19] - przeznaczona dla aplikacji wymagaj
,
acych nie-
zawodnej gwarancji parametr´
ow jako´sci przekazu danych zwi
,
azanych
11

z op´
o´
znieniami. Tak rygorystyczne wymagania parametr´
ow transmisji
maj
,
a transmisje obrazu i d´
zwi
,
eku w czasie rzeczywistym.
• Controlled Load Service [20] - przeznaczona dla aplikacji wymagaj
,
acych
bezstratnego przekazu danych i charakteryzuj
,
ac
,
a si
,
e jako´sci
,
a przekazu
lepsz
,
a ni˙z Best Effort. Przyk ladowym zastosowaniem tego typu us lugi
jest obs luga jednokierunkowych transmisji obrazu i d´
zwi
,
eku.
• Best Effort - przeznaczona dla aplikacji nie wymagaj
,
acych parametr´
ow
transmisji w ´sci´sle okre´slonych granicach.
Model ten sprawdza si
,
e jedynie w mniejszych sieciach, gdy˙z w wi
,
ekszych
sieciach pojawiaj
,
a si
,
e problemy ze skalowalno´sci
,
a (zbyt du˙zo komunikat´
ow
sygnalizacyjnych w stosunku do ilo´sci przesy lanych danych). W ostatnich la-
tach opracowywane s
,
a metody zwi
,
ekszania skalowalno´sci protoko lu RSVP
[4]. Pierwsze podej´scie proponuje zwi
,
ekszanie odst
,
ep´
ow wysy lania pakiet´
ow
sygnalizacyjnych w sytuacji, gdy charakterystyki sesji nie zmieniaj
,
a si
,
e. Dru-
gie podej´scie proponuje l
,
aczenie wielu sesji RSVP dzia laj
,
acych w tych sa-
mych sekcjach sieci i posiadaj
,
acych takie same charakterystyki w jedn
,
a sesj
,
e.
2.2
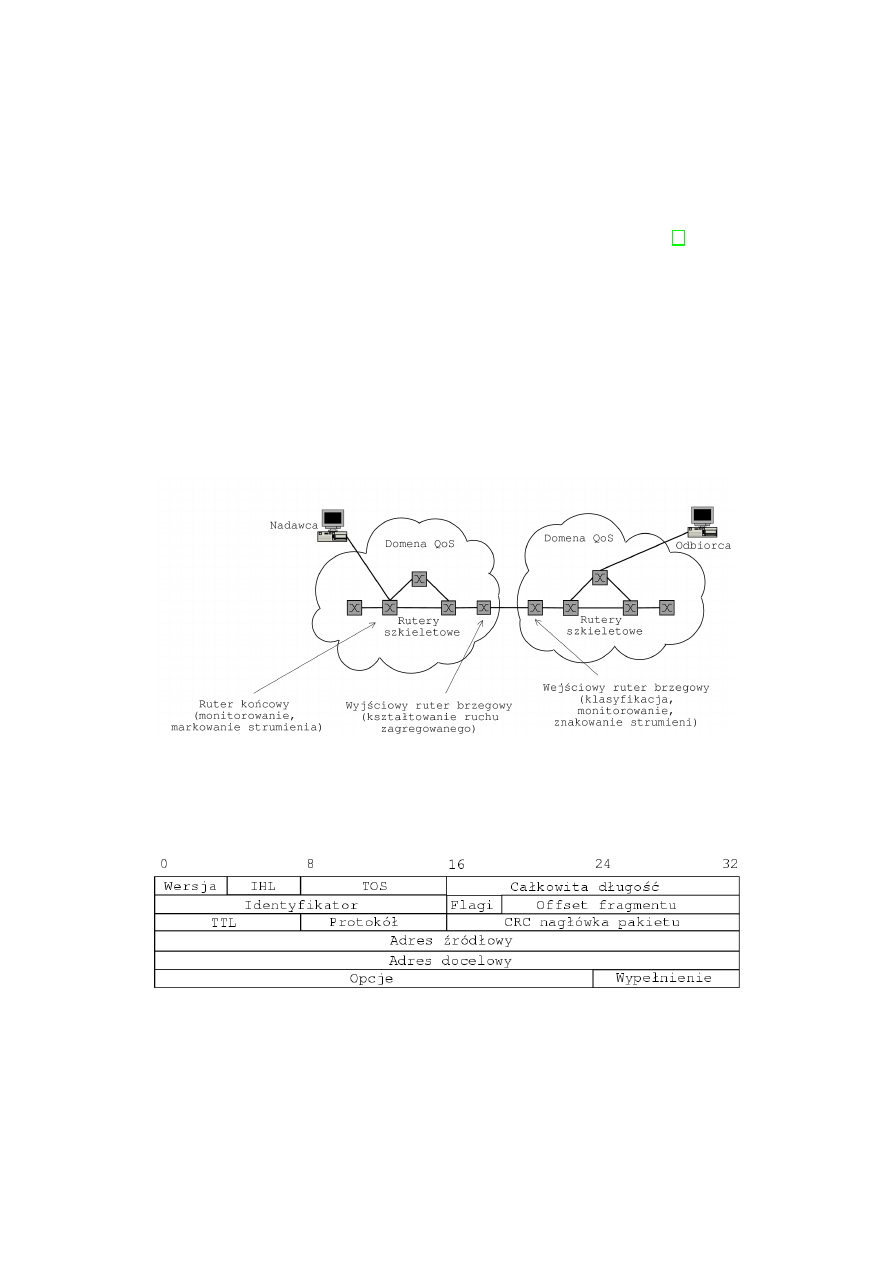
Architektura QoS - Differentiated Services
Architektura Differentiated Services (w skr´
ocie DiffServ lub DS) przedsta-
wiona na rys. 2.2 rozwi
,
azuje problem skalowalno´sci obserwowalny w IntServ.
Wymaga ona definicji klas ruchu na etapie konfiguracji sieci. Pakiety s
,
a przy-
pisywane do poszczeg´
olnych klas przez rutery brzegowe, a znajduj
,
ace si
,
e w
obr
,
ebie domeny QoS rutery rdzeniowe zajmuj
,
a si
,
e wy l
,
acznie przekazywa-
niem pakiet´
ow. Przez domen
,
e QoS (domen
,
e DiffServ) [28] rozumie si
,
e t
,
e
12
cz
,
e´s´
c sieci w ramach kt´
orej zagwarantowana jest ˙z
,
adana jako´s´
c us lug siecio-
wych. Podzia lu pakiet´
ow na klasy ruchu dokonuje si
,
e na podstawie[4]:
• pola Type Of Service (TOS ) w nag l´
owku IPv4,
• pola Traffic Class (TC ) w nag l´
owku IPv6,
• wybranych p´
ol nag l´
owka IP lub nag l´
owka protoko lu warstwy sieciowej
(TCP ).
Rysunek 2.2: Architektura DiffServ
Rysunek 2.3: Nag l´
owek pakietu IPv4
13

Na rys. 2.3 przedstawiony jest nag l´
owek pakietu IPv4. Klasyfikacja pakie-
t´
ow mo˙ze si
,
e odbywa´
c na podstawie zawarto´sci pola TOS (ang. Type of Se-
rvice) o rozmiarze o´smiu bit´
ow. Pierwsze trzy bity okre´slaj
,
a
”
pierwsze´
nstwo”
(ang. precedence) pakietu. Wykorzystywane to jest do ustalania wzgl
,
ednych
priorytet´
ow pakiet´
ow przekazywanych dalej przez rutery. Nast
,
epne cztery
bity maj
,
a znaczenie jak nast
,
epuje [4]:
• 1000 — minimalizacja op´
o´
znienia przesy lania pakietu
• 0100 — maksymalizacja przepustowo´sci
• 0010 — maksymalna pewno´s´c przesy lania pakietu
• 0001 — minimalny koszt przesy lania pakietu
• 0000 — normalne przesy lanie.
Ostatni bit pola TOS jest stale ustawiony na zero.
Mo˙zna tak˙ze przypisywa´
c pakiety do poszczeg´
olnych klas ruchu na pod-
stawie warto´sci innych p´
ol nag l´
owka. Szczeg´
olnie przydatne do tego s
,
a [4]:
• protok´
o l warstwy sieciowej
• adres ´zr´
od lowy
• adres docelowy
Na rys. 2.4 pokazany jest nag l´
owek pakietu IPv6. Pole TOS znane z
poprzedniej wersji protoko lu zosta lo zast
,
apione o´smiobitowym polem
”
klasy
1
Celem jest ograniczenie kosztu przesy lania informacji. Przyk ladow
,
a metod
,
a osi
,
agni
,
e-
cia celu jest przesy lanie pakiet´
ow w chwilach kiedy sie´
c jest najmniej obci
,
a˙zona. Mo˙zna
to osi
,
agn
,
a´
c poprzez zerowanie bitu psh w nag l´
owku pakietu TCP. W ten spos´
ob dystry-
buowane s
,
a listy dyskusyjne oraz
”
poczta hurtowa” (ang. bulk mail) u˙zywana w celach
komercyjnych.
14

Rysunek 2.4: Nag l´
owek pakietu IPv6
ruchu” (ang. traffic class). Na razie wykorzystywane jest sze´s´
c starszych bi-
t´
ow. Bity te nazywane s
,
a DiffServ Code Point (DSCP ) i wykorzystywane s
,
a
w architekturze DiffServ do oznaczania przynale˙zno´sci pakiet´
ow do konkret-
nych klas ruchu. Dwa najm lodsze bity wykorzystywane s
,
a do przenoszenia
informacji ECN (ang. Explicit Congestion Notification). Informacja ta po-
zwala ruterom obs luguj
,
acych ECN elastyczniej decydowa´
c o losie pakiet´
ow
w przypadku, gdy przydzielone danej klasie ruchu pasmo zosta lo przekro-
czone. Ruter w takiej sytuacji mo˙ze przepu´sci´
c pakiet z w l
,
aczonymi bitami
ECN, je´sli ca le pasmo nie zosta lo zaj
,
ete. Daje to mo˙zliwo´s´
c pe lniejszego wy-
korzystania pasma ni˙z w przypadku nie korzystania z bit´
ow ECN.
Klasyfikacji pakiet´
ow mo˙zna dokonywa´
c r´
ownie˙z na podstawie pozosta-
lych p´
ol [4]:
• etykieta strumienia (identyfikacja przynale˙zno´sci pakietu do konkret-
nego strumienia)
• adres ´zr´
od lowy (128-bitowy)
• adres docelowy (128-bitowy)
15
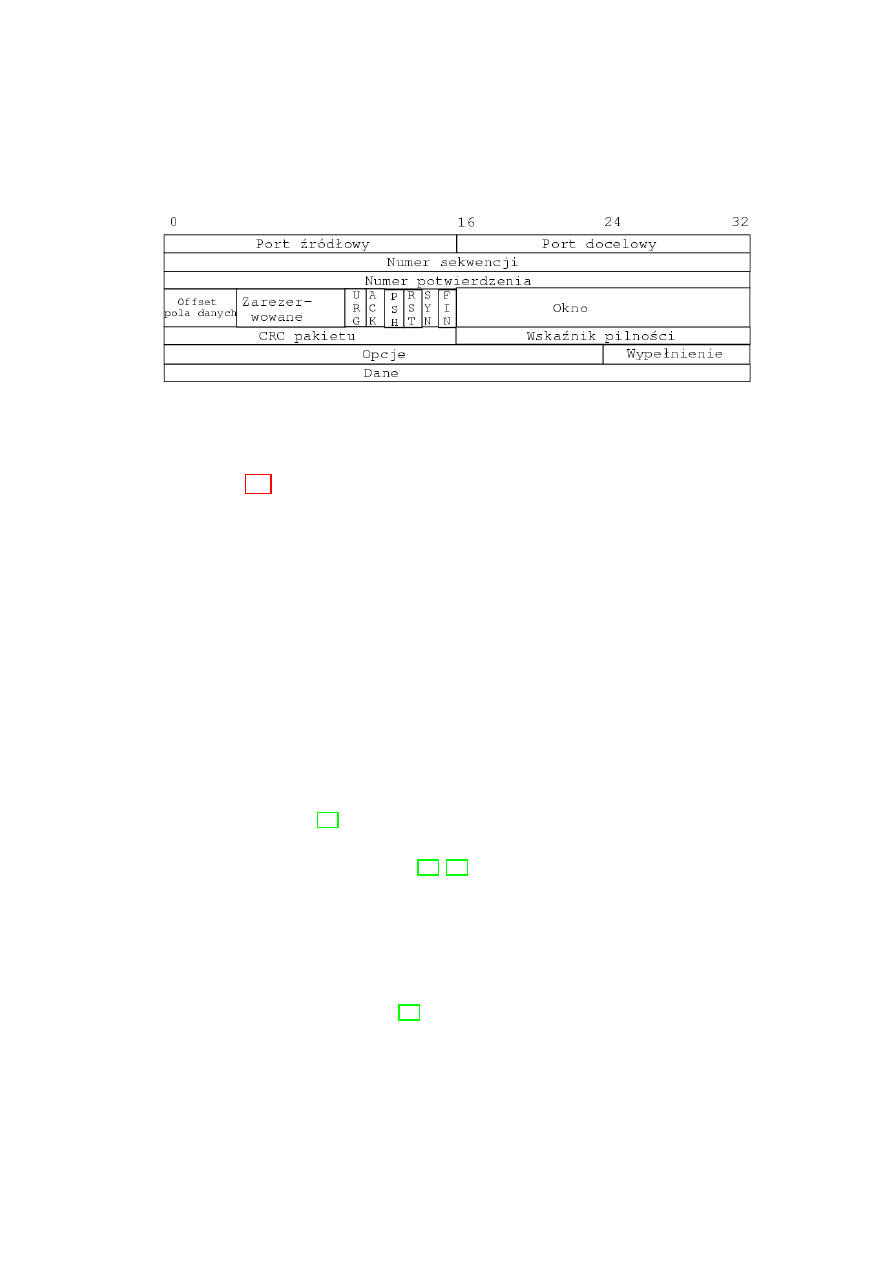
Rysunek 2.5: Nag l´
owek pakietu TCP
Na rys. 2.5 przedstawiony jest nag l´
owek pakietu TCP. Do klasyfikacji
pakiet´
ow wykorzystywane s
,
a tylko dwa pola:
• port ´zr´
od lowy
• port docelowy
Klasy ruchu mo˙zna inaczej przedstawi´
c jako strumienie danych, z kt´
orych
ka˙zdy ma przypisany profil ruchu okre´slaj
,
acy jakie warunki musi spe lni´
c pa-
kiet, aby zosta´
c przypisanym do niego.
Zdefiniowane s
,
a dwa algorytmy przekazywania pakiet´
ow wchodz
,
acych
w sk lad agregacji pakiet´
ow. Og´
olnie okre´slane s
,
a one jako zasady PHB (ang.
Per Hop Behaviour) [15]:
1. Expedited Forwarding (EF) [17, 18] - warto´s´
c pola DSCP (ang. Diffe-
rentiated Services Codepoint) z nag l´
owka IPv6 okre´sla ˙z
,
adan
,
a jako´s´
c
us lugi pod k
,
atem op´
o´
znie´
n przekazywania pakiet´
ow. Je´sli pakiet nie
zawiera si
,
e w profilu ruchu danego strumienia, to zostanie odrzucony.
2. Assured Forwarding (AF) [16] - definiuje si
,
e cztery klasy ruchu i trzy po-
ziomy odrzucania pakiet´
ow w ka˙zdej z nich. Czasem u˙zywa si
,
e poj
,
ecia
16

”
kolorowanie pakiet´
ow”. Pakiet mo˙ze zosta´
c przyj
,
ety do strumienia ru-
chu, odrzucony lub dopuszczony do ruchu
”
warunkowo”, tzn. nast
,
epny
ruter brzegowy mo˙ze go odrzuci´
c je´sli ca la dost
,
epna przepustowo´s´
c sieci
b
,
edzie akurat zaj
,
eta.
Zasady PHB s
,
a zwykle implementowane jako filtry, kolejki i algorytmy ko-
lejkowania.
Obecnie QoS jest realizowany na poziomie warstwy transportowej sieci
(TCP ). Ka˙zdy system jest na tyle wydajny, na ile jest wydajne jego w
,
a-
skie gard lo. W przypadku sieci komputerowych newralgicznymi jej punk-
tami s
,
a rutery, dlatego wi
,
ec g l´
owny ci
,
e˙zar realizacji QoS spoczywa na nich.
W uproszczeniu droga pakietu danych w ruterze wygl
,
ada tak jak na rys. 2.6.
Pakiety s
,
a przyjmowane przez interfejs wej´sciowy, nast
,
epnie podlegaj
,
a
”
de-
multipleksacji”, czyli odrzuceniu nag l´
owk´
ow warstwy fizycznej (np. Ether-
net). Pakiety zaadresowane do rutera s
,
a przesy lane do warstwy sieciowej,
a pozosta le s
,
a
”
przekazywane dalej” (ang. forwading). Nast
,
epnie pakiety prze-
kazywane s
,
a kolejkowane do klas ruchu (ang. traffic class). Ka˙zda z klas ruchu
jest inaczej traktowana i pakiety z niej s
,
a przekazywane do interfejsu wyj-
´sciowego, z kt´
orego z kolei przesy lane s
,
a do nast
,
epnego w
,
ez la sieci.
17
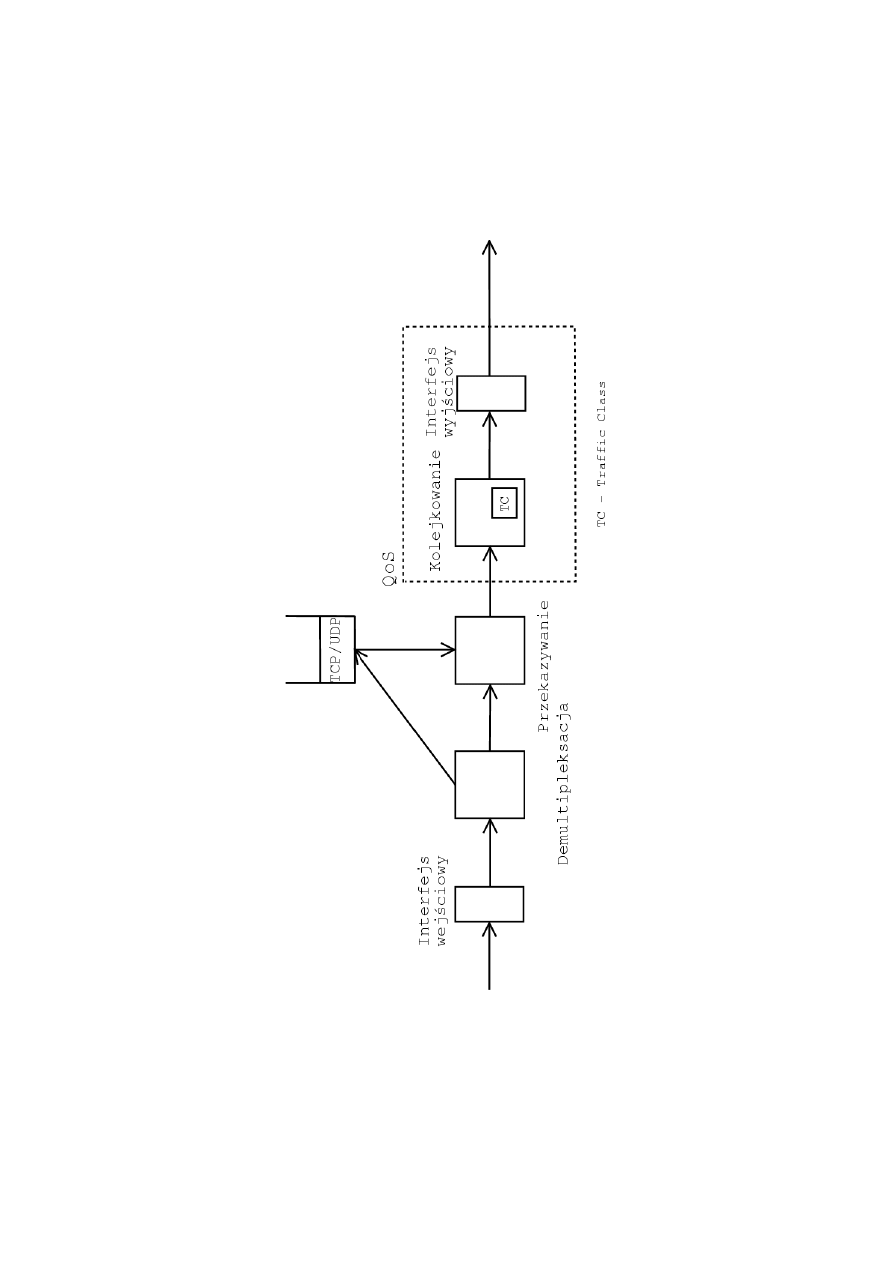
Rysunek 2.6: Droga pakietu w ruterze
18

Rozdzia l 3
Stan aktualny implementacji
QoS w systemie Linux
Opis stanu aktualnego dotyczy najnowszego j
,
adra z ga l
,
ezi stabilnej do-
st
,
epnego w okresie pisania pracy, czyli wersji 2.4.18.
Linux mo˙ze s lu˙zy´
c jako ruter w sieci IntServ, korzystaj
,
ac z demona
RSVPd [8], ale wi
,
ekszy nacisk po lo˙zono w j
,
adrze na umo˙zliwienie realizacji
sieci typu DiffServ. Implementacja linuksowa QoS opiera si
,
e na nast
,
epuj
,
acych
elementach podstawowych, kt´
ore mo˙zna ze sob
,
a l
,
aczy´
c, tworz
,
ac rozbudowan
,
a
hierarchi
,
e klas ruchu. Elementy te rozumie si
,
e w nast
,
epuj
,
acy spos´
ob:
Algorytm kolejkowania (ang. qdisc = queueing discipline)
po´sredniczy w transmisji pakiet´
ow TCP mi
,
edzy j
,
adrem a inter-
fejsem sieciowym. Pakiety wychodz
,
ace s
,
a wstawiane do kolejki przez
ten algorytm, a pakiety wychodz
,
ace s
,
a pobierane z kolejki (a w la´sciwie
klasy) przez j
,
adro i przekazywane sterownikowi karty sieciowej. Algo-
1
W Uniksie
”
demonem” okre´
sla si
,
e program lub jego cz
,
e´
s´
c, kt´
ora nie jest uruchamiana
jawnie, ale oczekuje na wyst
,
apienie pewnego zdarzenia. Przyk ladowym zdarzeniem mo˙ze
by´
c pr´
oba nawi
,
azania przez zdalny proces po l
,
aczenia TCP z konkretnym portem lokalnym.
19

rytmy kolejkowania dziel
,
a si
,
e na zawieraj
,
ace dalsze klasy (np. CBQ )
i bezklasowe (np. TBF ).
Klasa to kolejka w kt´
orej przechowywane s
,
a pakiety kolejkowane przez po-
dany algorytm kolejkowania. Klasa jest identyfikowana na podstawie
32-bitowego identyfikatora klasy (ang. class ID) nadawanego przez ad-
ministratora. Wewn
,
atrz j
,
adra klasa jest identyfikowana z pomoc
,
a we-
wn
,
etrznego identyfikatora klasy (ang. internal class ID) przydzielanego
automatycznie przez j
,
adro przy tworzeniu klasy.
Filtr (ang. classifier) jest przyporz
,
adkowany do konkretnego algorytmu
kolejkowania. Decyduje on w kt´
orej klasie zostanie umieszczony przy-
chodz
,
acy pakiet TCP. Pakiet jest sprawdzany sekwencyjnie przez
wszystkie filtry obs luguj
,
ace dany algorytm kolejkowania a˙z do pierw-
szego dopasowania (analogicznie jak regu ly firewalla). Filtr jest identy-
fikowany wewn
,
atrz j
,
adra z pomoc
,
a wewn
,
etrznego identyfikatora filtra
(ang. internal filter ID) przyznawanego automatycznie przez j
,
adro przy
tworzeniu filtra.
Sterowanie ruchem (ang. traffic control ) polega na wykonywaniu jednej
lub kilku z poni˙zszych operacji:
Kszta ltowanie (ang. shaping) ruchu polega na regulowaniu przepusto-
wo´sci strumienia pakiet´
ow wychodz
,
acych. Poza ograniczaniem dost
,
ep-
nej dla danej klasy przepustowo´sci pozwala r´
ownie˙z na wyg ladzanie
chwilowych przeci
,
a˙ze´
n ruchu. Przyk ladowymi algorytmami kolejkowa-
nia realizuj
,
acymi kszta ltowanie ruchu s
,
a TBF i HTB.
Szeregowanie (ang. scheduling) transmitowanych pakiet´
ow to spos´
ob
na popraw
,
e interaktywno´sci ruchu pochodz
,
acego z wymagaj
,
acych tego
20

klas przy jednoczesnym zagwarantowaniu du˙zej przepustowo´sci klasom
realizuj
,
acym transfery masowe. Przyk ladowe algorytmy kolejkowania
realizuj
,
ace szeregowanie to CBQ, HTB oraz PRIO.
Regulowanie (ang. policing) ruchu [28] polega na monitorowaniu pakie-
t´
ow wchodz
,
acych w celu upewnienia si
,
e, ˙ze nadawca nie lamie zasad
ustalonej wcze´sniej charakterystyki ruchu. R´
ownocze´snie kszta ltowany
jest ruch wchodz
,
acy. Dost
,
epnym algorytmem kolejkowania reguluj
,
acym
ruch jest Ingress.
Odrzucanie (ang. dropping) pakiet´
ow polega na nie obs lugiwaniu pakie-
t´
ow przekraczaj
,
acych ustawione limity przepustowo´sci. Dotyczy ono
zar´
owno ruchu wchodz
,
acego jak i wychodz
,
acego. Przyk ladowym algo-
rytmem tak dzia laj
,
acym jest RED.
3.1
Algorytmy kolejkowania pakiet´
ow
Aktualnie dost
,
epnych standardowo jest sze´s´
c algorytm´
ow kolejkowania.
W razie potrzeby mo˙zna napisa´
c sw´
oj modu l realizuj
,
acy inny algorytm ko-
lejkowania. Nale˙za loby dodatkowo w tym celu zmodyfikowa´
c standardowe
narz
,
edzie s lu˙z
,
ace do konfiguracji klas ruchu tc lub te˙z napisa´
c w lasne.
Wszystkie algorytmy kolejkowania mo˙zna podzieli´
c na:
Algorytmy klasowe (ang. classful) mog
,
a zawiera´
c w sobie kolejne klasy.
Je´sli klasom wewn
,
etrznym zostan
,
a przypisane klasowe algorytmy kolej-
kowania, to r´
ownie˙z one mog
,
a zawiera´
c klasy. Ca lo´s´
c przybiera posta´
c
drzewa klas, a klasy z przypisanymi im algorytmami klasowymi s
,
a w
,
e-
z lami w drzewie. Algorytmami klasowymi s
,
a:
1. PRIO
21
2. CBQ
Algorytmy bezklasowe (ang. classless) nie mog
,
a zawiera´
c w sobie ko-
lejnych klas. Klasy z przypisanymi im algorytmami bezklasowymi s
,
a
li´s´
cmi w drzewie. Algorytmami bezklasowymi s
,
a:
1. PFIFO FAST, PFIFO, BFIFO
2. TBF
3. SFQ
4. CSZ
5. DSMARK
6. RED, GRED
3.1.1
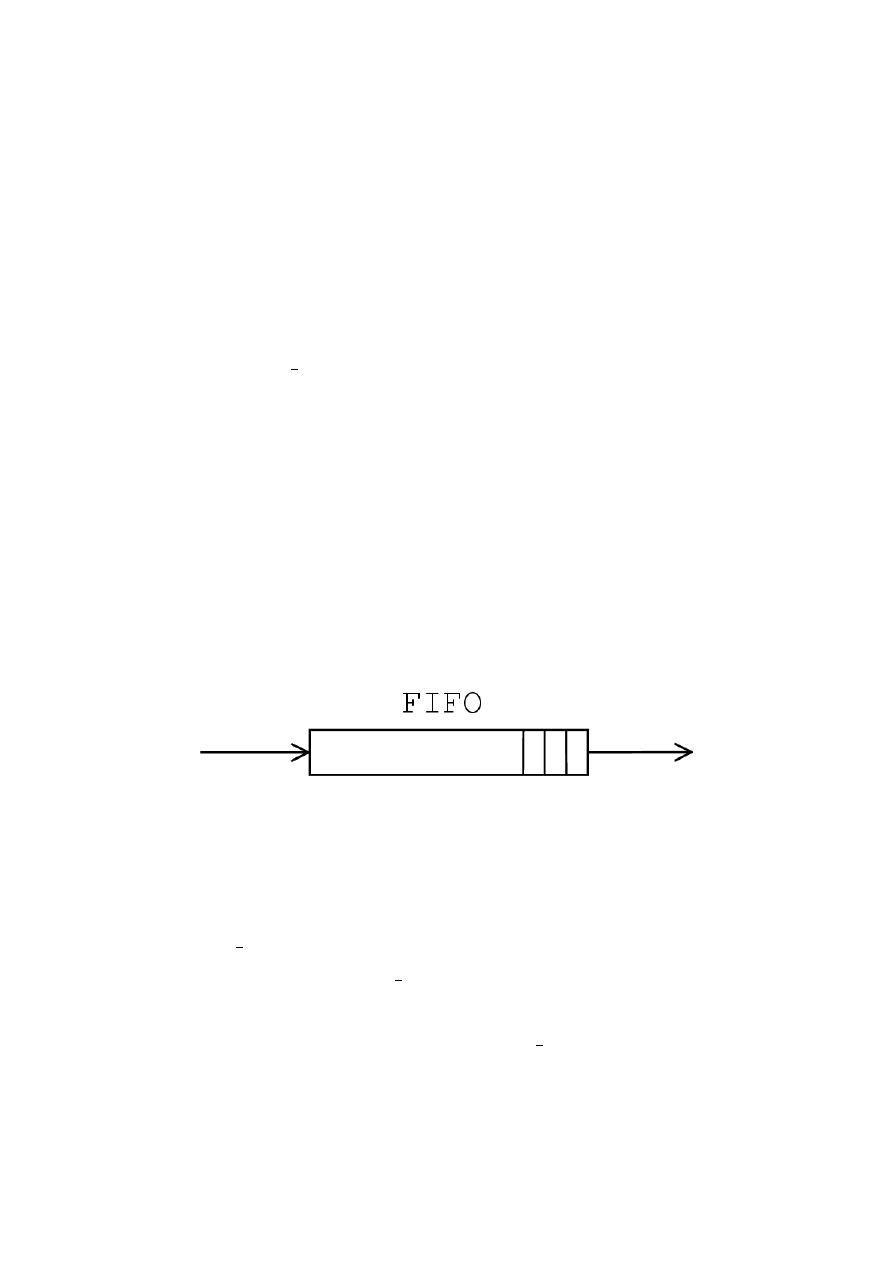
Algorytmy kolejkowania FIFO
Rysunek 3.1: Algorytmy kolejkowania FIFO
Najprostszy z dost
,
epnych algorytm´
ow kolejkowania to rozwini
,
ecie idei
FIFO (First-In First-Out). W j
,
adrze zaimplementowany jest w trzech wer-
sjach: pfifo fast, pfifo oraz bfifo.
Algorytm kolejkowania pfifo fast jest domy´slnym algorytmem kolejkowa-
nia. Oznacza to, ˙ze je´sli nie powi
,
azano nowo stworzonej klasy z ˙zadnym
algorytmem kolejkowania, to zostanie u˙zyty pfifo fast. Wi
,
a˙z
,
e si
,
e to z nie-
dogodno´sci
,
a braku prowadzonych statystyk ruchu pakiet´
ow. W tej odmianie
22

algorytmu FIFO do trzech podkolejek kierowane s
,
a pakiety o r´
o˙znych prio-
rytetach. Mo˙zna sobie wyobrazi´
c ten algorytm kolejkowania jako po l
,
aczenie
trzech klas, z kt´
orych ka˙zda jest obs lugiwana przez algorytm pfifo. Kryte-
rium klasyfikacji pakiet´
ow jest warto´s´
c pola TOS z nag l´
owka pakietu IP.
Pakiety w kolejce o wy˙zszym priorytecie, przyk ladowo nale˙z
,
ace do konwersa-
cji interaktywnej (np. telnet), mog
,
a by´
c kierowane do kolejki o najwy˙zszym
priorytecie. Pakiety wchodz
,
ace w sk lad transmisji masowych np. FTP kie-
rowane s
,
a do kolejki o najni˙zszym priorytecie, a pozosta ly ruch pakiet´
ow
do po´sredniej. Dana kolejka obs lugiwana jest wy l
,
acznie wtedy, gdy nie ma
ju˙z pakiet´
ow w kolejkach o wy˙zszych priorytetach. Je˙zeli nie mo˙zna dopu´sci´
c
nawet do chwilowego
”
zag lodzenia” kolejek o ni˙zszych priorytetach przez ko-
lejki o wy˙zszych priorytetach, to mo˙zna zastosowa´
c zamiast tego algorytmu
kolejkowania algorytm TBF (podsekcja 3.1.3) lub inny kszta ltuj
,
acy ruch pa-
kiet´
ow.
Wersje pfifo oraz bfifo to proste mechanizmy kolejkowania bez dodat-
kowych ulepsze´
n przydatne g l´
ownie w celach statystycznych (domy´slny al-
gorytm kolejkowania pfifo fast nie udost
,
epnia statystyki ruchu pakiet´
ow).
Mo˙zna zastosowa´
c te algorytmy kolejkowania, aby sprawdzi´
c jaki jest gene-
rowanych ruch pakiet´
ow i na podstawie wynik´
ow obserwacji ustali´
c struktur
,
e
klas ruchu odpowiedni
,
a dla danego zastosowania. Algorytmy te przechowy-
wuj
,
a wszystkie pakiety w pojedynczej kolejce FIFO. Rozmiar tej kolejki po-
daje si
,
e w pakietach (dla pfifo) lub w bajtach (dla bfifo). Domy´slny roz-
miar kolejki jest ustawiany przy aktywacji interfejsu sieciowego (np. dla sieci
Ethernet wynosi 100 pakiet´
ow) i mo˙ze by´
c w ka˙zdej chwili odczytany z po-
moc
,
a narz
,
edzia ifconfig. Je´sli kolejka osi
,
agn
,
e la maksymalny dopuszczalny
rozmiar, to nast
,
epne przychodz
,
ace pakiety s
,
a odrzucane.
23

3.1.2
Algorytm kolejkowania PRIO (PRIOrities)
Omawiany algorytm kolejkowania jest uog´
olnion
,
a odmian
,
a algorytmu
pfifo fast. Modyfikacj
,
a w stosunku do wspomnianego algorytmu jest zastoso-
wanie traktowanie podkolejek jako niezale˙znych klas, z kt´
orych ka˙zda mo˙ze
by´
c skojarzona z innym algorytmem kolejkowania. Klasyfikacja pakiet´
ow do
konkretnych podkolejek (ang. bands) mo˙ze odbywa´
c si
,
e na podstawie nast
,
e-
puj
,
acych kryteri´
ow:
• ustawionej opcji gniazdek SO_PRIORITY, kt´
ora pozwala na ustawianie
bit´
ow TOS w nag l´
owkach wszystkich pakiet´
ow IP wysy lanych z danego
gniazdka
• program administruj
,
acy filtrem pakiet´
ow IP iptables potrafi ustawi´
c
bity TOS manipuluj
,
ac bezpo´srednio nag l´
owkami pakiet´
ow IP
• filtr pakiet´
ow, stworzony narz
,
edziem tc, umo˙zliwia bezpo´srednie skie-
rowanie wybranych pakiet´
ow do danej podkolejki
• odwzorowanie priorytet´
ow (ang. priomap = priorities map) pozwala
na kierowanie pakiet´
ow IP na postawie bit´
ow TOS do odpowiedniej
podkolejki
R´
ownie wa˙znym ulepszeniem tego algorytmu w por´
ownaniu do pfifo fast
jest to, ˙ze algorytm jest klasowy. Przek lada si
,
e to na wi
,
eksz
,
a elastyczno´s´
c,
gdy˙z pozwala klasyfikowa´
c pakiety do podkolejek nie tylko na podstawie bi-
t´
ow TOS, ale tak˙ze z pomoc
,
a narz
,
edzia tc. Domy´slnie istniej
,
a trzy podkolejki,
do kt´
orych s
,
a kierowane pakiety z ustawionymi nast
,
epuj
,
aco bitami TOS :
0. minimalne op´
o´
znienie (najwy˙zszy priorytet)
1. maksymalna wiarygodno´s´
c
24
2. minimalny koszt lub maksymalna przepustowo´s´
c (najni˙zszy priorytet)
Je´sli ustawionych jest jednocze´snie kilka warto´sci pola TOS, to pakiet kie-
rowany jest do kolejki o najwy˙zszym mo˙zliwym priorytecie (np. minimalne
op´
o´
znienie w po l
,
aczeniu z maksymaln
,
a przepustowo´sci
,
a kieruje do podko-
lejki 0). Mo˙zna zmieni´
c ilo´s´
c podkolejek, ale wymusza to r´
ownie˙z zmian
,
e
odwzorowania priorytet´
ow.
Analogicznie jak w algorytmie kolejkowania pfifo fast pakiety s
,
a pobie-
rane z podkolejek o ni˙zszych priorytetach dopiero wtedy, gdy nie ma ju˙z
pakiet´
ow w podkolejkach o wy˙zszych priorytetach. Mo˙ze doprowadzi´
c to do
”
zag lodzenia” kolejek o ni˙zszych priorytetach. Najprostszym sposobem unik-
ni
,
ecia takiej sytuacji jest przyporz
,
adkowanie podkolejkom o wy˙zszych prio-
rytetach algorytmu kolejkowania, kt´
ory kszta ltuje ruch (np. TBF ).
3.1.3
Algorytm kolejkowania TBF (Token Bucket Filter)
Rysunek 3.2: Algorytm kolejkowania TBF
25

Opis algorytmu TBF
Algorytm TBF (ang. Token Bucket Filter) przedstawiony na rys. 3.2 na-
le˙zy do klasy algorytm´
ow kszta ltuj
,
acych ruch. Mo˙zna go opisa´
c korzystaj
,
ac
z analogii
”
ciekn
,
acego kube lka” (ang. leaky bucket). Ruch pakiet´
ow regulo-
wany jest z pomoc
,
a
”
˙zeton´
ow” (ang. tokens). Pojedynczy ˙zeton odpowiada
pojedynczemu bajtowi, tak wi
,
ec ilo´s´
c ˙zeton´
ow odpowiada rozmiarowi pakietu
w bajtach z uwzgl
,
ednieniem tego, ˙ze najmniejszy pakiet odpowiada pewnej
ilo´sci ˙zeton´
ow. Mo˙zna tu wyt lumaczy´
c faktem, ˙ze nawet pakiet nie zawiera-
j
,
acy ˙zadnych danych ma pewien rozmiar (np. w sieciach Ethernet minimalny
rozmiar datagramu zawieraj
,
acego pakiet TCP bez danych wynosi 64 bajty).
˙Zetony magazynowane s
,
a w kube lku, z kt´
orego
”
wyciekaj
,
a” razem z wycho-
dz
,
acymi pakietami.
Pocz
,
atkowo kube lek jest w pe lni wype lniony ˙zetonami. ˙Zetony s
,
a genero-
wane ze sta l
,
a cz
,
estotliwo´sci
,
a i s
,
a magazynowane w kube lku, a˙z do jego ca l-
kowitego wype lnienia. Pakiet wychodz
,
acy jest wysy lany do sieci tylko wtedy,
gdy w danej chwili dost
,
epna jest liczba ˙zeton´
ow odpowiadaj
,
aca jego rozmia-
rowi. Je´sli w danej chwili nie jest dost
,
epna wystarczaj
,
aca liczba ˙zeton´
ow, to
pakiety s
,
a wstawiane do kolejki o ograniczonej d lugo´sci. Z chwil
,
a, gdy kolejka
pakiet´
ow si
,
e wype lni, nowe ˙zetony nie s
,
a przyjmowane do kube lka dop´
oki nie
zostanie wys lany do sieci pierwszy pakiet z kolejki. W sytuacji braku dost
,
ep-
nej odpowiedniej ilo´sci ˙zeton´
ow, co uniemo˙zliwia wysy lanie pakiet´
ow, urucha-
miany jest regulator czasowy (ang. watchdog timer), kt´
ory wznowi transmisj
,
e
pakiet´
ow po nadej´sciu wystarczaj
,
acej liczby pakiet´
ow. Magazynowanie pa-
kiet´
ow w kolejce mo˙ze prowadzi´
c do wyst
,
apienia kr´
otkotrwa lych przeci
,
a˙ze´
n
ruchu w sieci. W celu zminimalizowania tych przeci
,
a˙ze´
n korzysta si
,
e z do-
datkowego kube lka o pojemno´sci jednego pakietu (dok ladnie MTU pakietu).
Pakiety nie s
,
a wypuszczane do sieci z maksymaln
,
a pr
,
edko´sci
,
a, ale pakiety s
,
a
26
wypuszczane co kwant czasu j
,
adra (ang. jiffie).
Na platformie sprz
,
etowej PC kwant ten r´
owna si
,
e 10ms. Odwrotno´s´
c
wspomnianego kwantu czasu okre´sla ile kwant´
ow zmie´sci si
,
e w okresie 1s
i oznacza si
,
e jako HZ. Przyjmuj
,
ac wi
,
ec, ˙ze ´sredni rozmiar pakietu wynosi
1000 bajt´
ow, otrzymujemy dok ladne kszta ltowaniu ruch dla przepustowo´sci
nie przekraczaj
,
acych 1
M bit
s
. Mo˙zna kszta ltowa´
c przepustowo´s´
c na wy˙zszym
poziomie, ale wtedy odbywa si
,
e to kosztem dok ladno´sci. Korzystaj
,
ac z ru-
tera programowego opartego o platform
,
e Alpha, mo˙zna osi
,
agn
,
a´
c dok ladne
kszta ltowanie przepustowo´sci do 10
M bit
s
, poniewa˙z kwant czasu j
,
adra na tej
platformie wynosi
1
1024
s.
Algorytm ten umo˙zliwia w prosty spos´
ob przycinanie pasma konkretnego
u˙zytkownika lub grupy u˙zytkownik´
ow (np. pod l
,
aczenie kilku sieci Fast Ether-
net o przepustowo´sci 100
M bit
s
ka˙zda do jednego l
,
acza T1 o przepustowo´sci
1.5
M bit
s
). ozwala on tak˙ze na zapobie˙zenie zag lodzenia klas o ni˙zszych prio-
rytetach przez klasy o wy˙zszych priorytetach generuj
,
ace stale du˙zy ruch.
Wystarczy w takiej sytuacji kszta ltowa´
c ruch wychodz
,
acy z klas o wysokich
priorytetach z pomoc
,
a algorytmu TBF.
Formalny opis algorytmu TBF
Niech R oznacza ˙z
,
adan
,
a przepustowo´s´
c, B g l
,
eboko´s´
c kube lka, a s
i
roz-
miary pakiet´
ow obs lugiwanych w chwilach t
i
. Wtedy ruch pakiet´
ow jest
kszta ltowany zgodnie z oczekiwaniami je˙zeli
∀
i¬k
P
i=k
i=1
s
i
¬ B + R ∗ (t
k
− t
i
)
Niech warto´s´
c pocz
,
atkowa N (t
i
) wyniesie
B
R
a przyrost N (t) w czasie
mo˙zna przedstawi´
c jako
N (t + ∆) = min(
B
R
, N (t) + ∆)
27
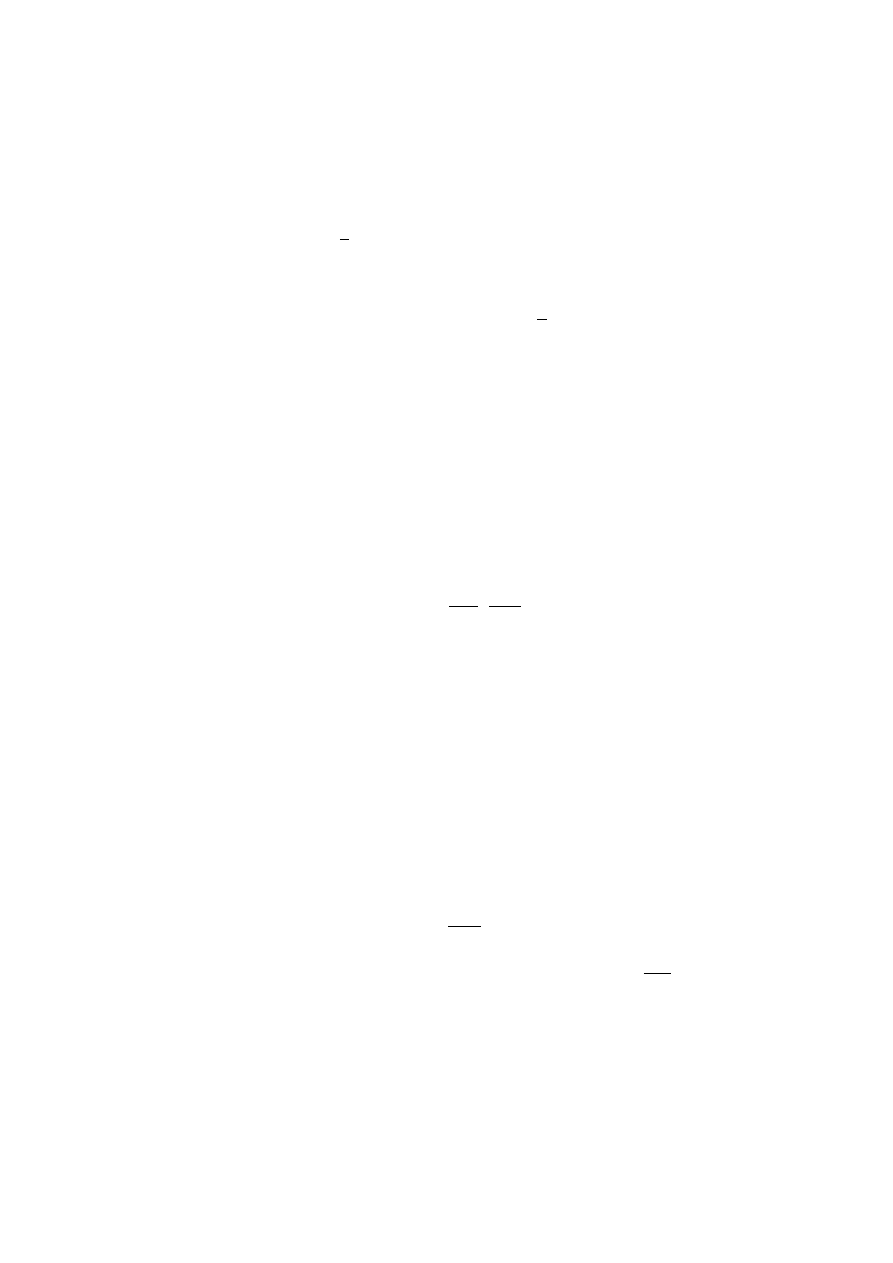
Je˙zeli pierwszy pakiet w kolejce ma d lugo´s´
c S, to mo˙ze by´
c wys lany do sieci
jedynie w chwili t
∗
, gdy
S
R
¬ N (t
∗
. Wtedy warto´s´
c N (t) zmienia si
,
e nast
,
epu-
j
,
aco
N (t
∗
+ 0) = N (t
∗
− 0) −
S
R
Dodatkowy kube lek u˙zywany do kontrolowania szczytowej przepustowo´sci
(ang. peak rate) P powinien mie´
c g l
,
eboko´s´
c M . Mo˙zna zauwa˙zy´
c, ˙ze
P > R
∩
B > M
Dla przypadku, gdy P → ∞ wystarczy u˙zy´
c jeden kube lek zamiast dw´
och.
W trakcie kszta ltowania ruchu op´
o´
znienie transmisji pakiet´
ow (ang. la-
tency) szacowane jest w spos´
ob nast
,
epuj
,
acy
lat = max(
L−B
R
,
L−M
P
)
W sytuacji braku ˙zeton´
ow transmisja jest wstrzymywana i uruchamiany
jest regulator czasowy na okres jednego kwantu czasu (zwykle 10ms). Ozna-
czaj
,
ac cz
,
estotliwo´s´
c odmierzania kwant´
ow czasu przez procesor jako HZ,
a maksymaln
,
a przepustowo´s´
c jako R
max
, mo˙zna napisa´
c
R
max
= B ∗ HZ
a w konsekwencji mo˙zna wyznaczy´
c minimaln
,
a wymagan
,
a g l
,
eboko´s´
c kube lka
dla zapewnienia ˙z
,
adanej przepustowo´sci
B =
R
max
HZ
Przyk ladowo zale˙zno´s´
c ta dla sieci Ethernet o przepustowo´sci 100
M bit
s
nak lada
wym´
og, aby kube lek mia l rozmiar co najmniej 128 kilobajt´
ow.
28
Rysunek 3.3: Algorytm kolejkowania SFQ
3.1.4
Algorytm kolejkowania SFQ (Stochastic Fairness
Queueing)
Ten algorytm kolejkowania jedyne co wykonuje, to szeregowanie pakiet´
ow
wychodz
,
acych. W praktyce polega to na op´
o´
znianiu transmisji wybranych
strumieni pakiet´
ow. Strumie´
n pakiet´
ow przewa˙znie jest to˙zsamy z pojedyn-
cz
,
a transmisj
,
a TCP. Celem nadrz
,
ednym jest zapewnienie
”
sprawiedliwego”
podzia lu dost
,
epnej przepustowo´sci mi
,
edzy wszystkie strumienie w spos´
ob jak
najmniej obci
,
a˙zaj
,
acy procesor.
Do ograniczonej liczby kolejek przydzielane s
,
a pakiety. Realizowane jest to
z pomoc
,
a funkcji haszuj
,
acej, kt´
ora jest regularnie co ustalony wst
,
epnie okres
czasu (przyk ladowo co 10 s) przeliczana w celu zminimalizowania prawdopo-
dobie´
nstwa kolizji. Funkcja haszuj
,
aca [1] wyznacza numer kube lka w kt´
orym
umie´sci´
c pakiet na podstawie nast
,
epuj
,
acych parametr´
ow:
• adres ´zr´
od lowy (w postaci liczby 32-bitowej)
• adres docelowy (w postaci liczby 32-bitowej)
29

• numer protoko lu transportowego
• warto´s´c ca lkowita zmieniaj
,
aca si
,
e co okre´slony odst
,
ep czasu
Pobieranie pakiet´
ow z kube lk´
ow opiera si
,
e na algorytmie cyklicznym
”
round-robin” (rys. 3.3). Mechanizm ten mo˙ze zapewni´
c r´
ownoprawn
,
a ob-
s lug
,
e wielu r´
ownoleg lych konwersacji interaktywnych lub zapobiec zdomino-
waniu l
,
acza przez jedn
,
a konwersacj
,
e generuj
,
ac
,
a du˙zy ruch. Pakiety wysy lane
s
,
a cyklicznie po jednym z ka˙zdego kube lka, dlatego konwersacje sk ladaj
,
ace si
,
e
z wi
,
ekszej ilo´sci mniejszych pakiet´
ow s
,
a wysy lane najszybciej. Efekty pracy
algorytmu s
,
a widoczne jedynie wtedy, gdy ruch wychodz
,
acy zajmuje ca l
,
a
dost
,
epn
,
a dla niego przepustowo´s´
c.
Nale˙zy podkre´sli´
c, ze algorytm ten ma ograniczenia. Do najbardziej wi-
docznych nale˙zy ograniczenie ilo´sci kube lk´
ow (1024) oraz pakiet´
ow w kube lku
(128). Mo˙zna to ograniczenie latwo usun
,
a´
c zmieniaj
,
ac kilka sta lych w kodzie
´
zr´
od lowym j
,
adra [1]. Nast
,
epne ograniczenie wynika z prostoty. Algorytm ten
nie jest na tyle
”
sprawiedliwy” w podziale przepustowo´sci, aby m´
og l zapew-
ni´
c wysok
,
a jako´s´
c us lug w domenie DiffServ. Wynika to z oczekiwa´
n jakie
nak lada si
,
e na wsp´
o lczesne algorytmy
”
sprawiedliwego podzia lu” (np. We-
ighted Fair Queueing - WFQ ), kt´
ore dziel
,
a dynamicznie strumienie pakiet´
ow
do kolejek o zmiennym priorytecie, stosuj
,
ac jako kryterium podzia lu ilo´s´
c
danych przesy lanych danym strumieniem [28]. W ten spos´
ob faworyzowane
s
,
a kr´
otsze transmisje mniejszych ilo´sci danych.
3.1.5
Algorytmy kolejkowania RED (Random Early Detection)
Protok´
o l transportowy TCP posiada mechanizmy wewn
,
etrzne umo˙zli-
wiaj
,
ace regulowanie szybko´sci przyjmowania pakiet´
ow przychodz
,
acych [11].
Odbywa si
,
e to przez odrzucaniu pakiet´
ow, je´sli przychodzi ich za du˙zo i nie
30

mo˙zna nad
,
a˙zy´
c z ich obs lug
,
a. Nadawca powinien wtedy zmniejszy´
c
”
okno
nadawania pakiet´
ow” o po low
,
e, czyli nadawa´
c dwa razy mniej pakiet´
ow jedno-
razowo bez uzyskania potwierdzenia. Mechanizm ten jest prosty i skuteczny,
ale dzia lanie swe zaczyna zbyt p´
o´
zno, gdy ju˙z dosz lo do przeci
,
a˙zenia ruchu
w sieci.
Alternatywnym rozwi
,
azaniem problemu jest u˙zycie algorytm´
ow kolejko-
wania RED (ang. Random Early Detection) lub GRED (ang. Generalised
RED). Algorytmy te nale˙z
,
a do szerszej rodziny algorytm´
ow
”
wczesnego od-
rzucania” (ang. early discard). Pozwalaj
,
a one na kszta ltowanie ruchu wycho-
dz
,
acego poprzez oddzia lywanie na ruch wchodz
,
acy.
Na podstawie podanych ni˙zej parametr´
ow konfiguracyjnych decyduje si
,
e
o losie pakietu:
• min — minimalna d lugo´s´c kolejki przy kt´
orej pakiet mo˙ze zosta´
c zna-
kowany,
• max — d lugo´s´c kolejki dla kt´
orej prawdopodobie´
nstwo znakowania pa-
kietu jest maksymalne,
• avg — ´srednia d lugo´s´c kolejki,
• len — bie˙z
,
aca d lugo´s´
c kolejki,
• W — sta la czasowa filtru (zmniejszaj
,
ac j
,
a dopuszcza si
,
e wyst
,
epowanie
wi
,
ekszych przeci
,
a˙ze´
n w ruchu sieci),
• p — prawdopodobie´
nstwo znakowania pakiet´
ow.
Dalszy los pakietu wygl
,
ada nast
,
epuj
,
aco:
• avg < min : pakiet jest przepuszczany ,
31

• min <= avg < max : pakiet jest znakowany z prawdopodobie´
nstwem
p,
• avg > max : pakiety jest znakowany.
Formalnie zapisuje si
,
e to nast
,
epuj
,
aco:
W = 2
−n
, n ∈ N
maxP = 0.01..0.02
avg = (1 − W ) ∗ avg + w ∗ len
p = maxP ∗
(avg−min)
(max−min)
Znakowanie pakietu (inaczej kolorowanie pakietu) pozwala na
”
warun-
kowe” przes lanie pakietu dalej. Je´sli ruter ma w l
,
aczon
,
a obs lug
,
e ECN
, to
wtedy pakiet jest znakowany i wysy lany dalej, a w przeciwnym razie pakiet
jest od razu odrzucany. Znakowany pakiet b
,
edzie przesy lany dalej dop´
oki
przepustowo´s´
c sieci b
,
edzie wykorzystywana w niewielkim stopniu. Je´sli wy-
korzystanie przepustowo´sci sieci osi
,
agnie wysoki poziom, to pakiet zostanie
odrzucony.
Odmiana GRED (rys. 3.4) r´
o˙zni si
,
e tym, ˙ze tworzy i obs luguje wi
,
ek-
sz
,
a ilo´s´
c kolejek, z kt´
orych ka˙zda charakteryzuje si
,
e innym prawdopodobie´
n-
stwem odrzucenia pakietu. W celu zmniejszenia zapotrzebowania na zasoby
skorzystano z mechanizmu
”
wirtualnych kolejek”, polega to na tym, ˙ze kolejki
s
,
a tworzone w razie potrzeby zgodnie z rozumowaniem, ˙ze kolejka powinna
istnie´
c jedynie wtedy, gdy znajduj
,
a si
,
e w niej pakiety.
Jednym z mo˙zliwych zastosowa´
n tego algorytmu kolejkowania jest realiza-
cja algorytmu przekazywania pakiet´
ow AF (opisany w rozdziale 2). Algorytm
ten zosta l stworzony na potrzeby architektury DiffServ. Wymaga on trzech
r´
o˙znych prawdopodobie´
nstw odrzucania pakiet´
ow.
2
ECN (Explicit Congestion Notification) obja´
snione w rozdziale 2
32
Rysunek 3.4: Algorytm kolejkowania GRED
Obydwa algorytmy pozwalaj
,
a na p lynniejsz
,
a regulacj
,
e generacji pakiet´
ow
przez ´
zr´
od lo ni˙z gdyby odpowiedzialny by l za to jedynie mechanizm TCP.
Wynika to z tego, ˙ze algorytmy RED zaczynaj
,
a odrzuca´
c pakiety wcze´sniej
ni˙z zacznie to czyni´
c protok´
o l TCP. Drug
,
a zalet
,
a stosowania tych algorytm´
ow
na ruterach jest mo˙zliwo´s´
c wykorzystania w wi
,
ekszym stopniu przepustowo-
´sci sieci poprzez dopuszczanie do chwilowych przeci
,
a˙ze´
n. Kolejn
,
a zalet
,
a jest
zwi
,
ekszenie
”
interaktywno´sci” ruchu w sieci poprzez efektywne zmniejszenie
d lugo´sci kolejki.
3.1.6
Algorytm kolejkowania CBQ (Classful Based Queueing)
Algorytm kolejkowania CBQ to jeden z najbardziej elastycznych algoryt-
m´
ow zawartych w linuksowej implementacji QoS. Elastyczno´s´
c wynika bez-
po´srednio z jego klasowo´sci (mo˙zliwo´sci tworzenia klas wewn
,
etrznych) i du˙zej
konfigurowalno´sci. Algorytm ten mo˙ze zar´
owno kszta ltowa´
c ruch wychodz
,
acy
jak i te˙z szeregowa´
c pakiety wychodz
,
ace.
Struktura klas tworzona z wykorzystaniem CBQ ma posta´
c odwr´
oconego
drzewa. Na szczycie znajduje si
,
e klasa g l´
owna (ang. root). Ka˙zda z pozo-
33
Rysunek 3.5: Algorytm kolejkowania CBQ
sta lych klas mo˙ze by´
c w
,
ez lem (ang. node) lub li´sciem (ang. leaf). W
,
ez ly
posiadaj
,
a zar´
owno rodzica jak i potomstwo, a li´scie posiadaj
,
a wy l
,
acznie ro-
dzica. Klasy maj
,
ace wsp´
olnego rodzica okre´slane s
,
a jako rodze´
nstwo (ang.
siblings). Rodze´
nstwo domy´slnie wzajemnie po˙zycza sobie przepustowo´sci,
ale mo˙zna to zachowanie wy l
,
aczy´
c. Przewa˙znie ka˙zda klasa ma jawnie zdefi-
niowany uchwyt (ang. handle), dzi
,
eki kt´
oremu mo˙zna odwo lywa´
c si
,
e bezpo-
´srednio do tej klasy (rodzic i rodze´
nstwo nie potrzebuj
,
a go zna´
c, gdy˙z znaj
,
a
uchwyty generowane automatycznie przez algorytm kolejkowania). Z ka˙zd
,
a
klas
,
a skojarzony jest algorytm kolejkowania, a je´sli nie zosta l ˙zaden jawnie
podany, to u˙zywany jest algorytm pfifo fast. Ka˙zdy w
,
eze l mo˙ze dodatkowo
posiada´
c filtr, kt´
ory przekierowywuje pakiety do odpowiednich klas w´sr´
od
potomstwa.
34

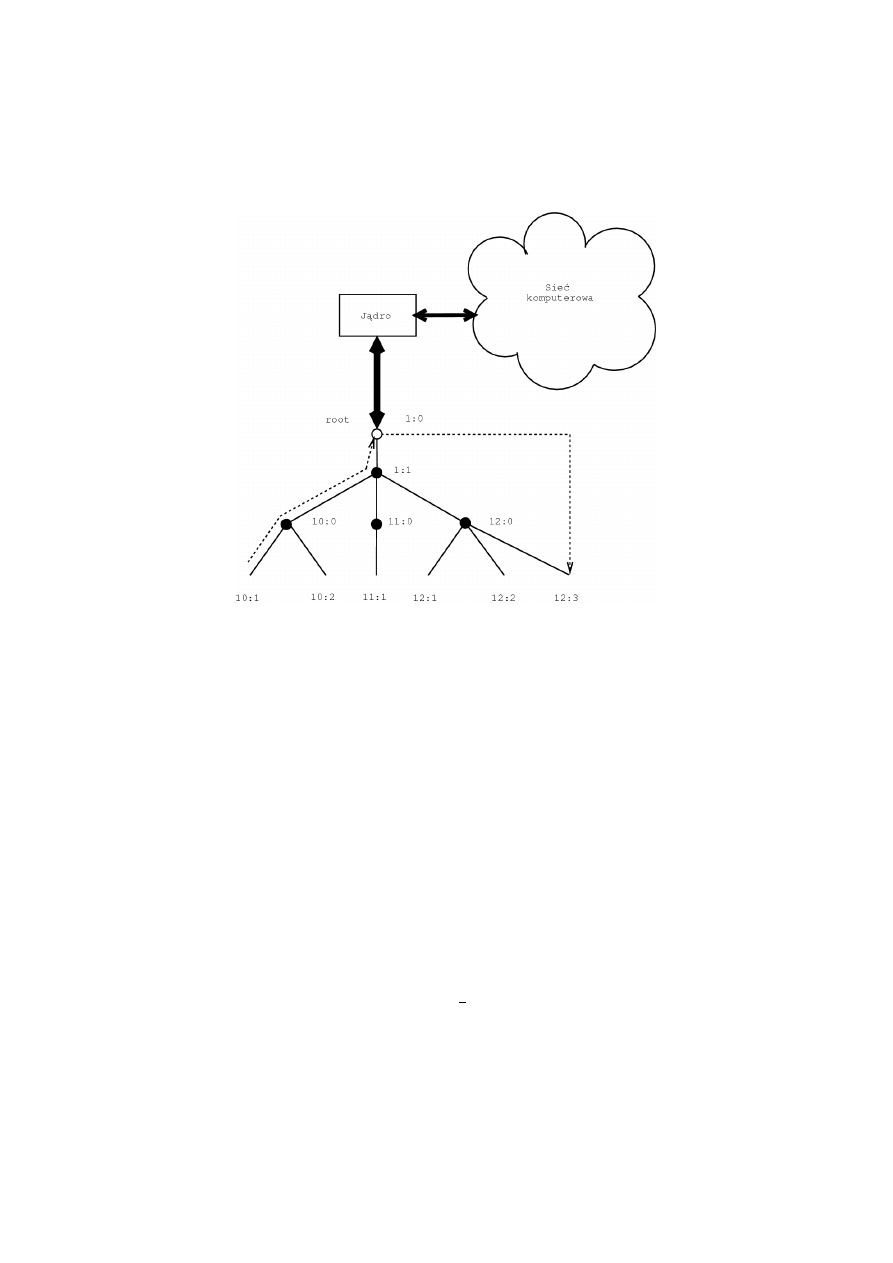
Na rys. 3.5 pokazane s
,
a wzajemne relacje mi
,
edzy klasami (wraz algoryt-
mami kolejkowania i filtrami), Linuksa oraz zewn
,
etrzn
,
a sieci
,
a komputerow
,
a.
Na uwag
,
e zas luguje mechanizm umo˙zliwiaj
,
acy bezpo´srednie przesy lanie pa-
kiet´
ow do odpowiednich klas, podczas gdy pobieranie pakiet´
ow z klas wy-
maga ju˙z po´srednictwa rodzic´
ow.
J
,
adro komunikuje si
,
e wy l
,
acznie z klas
,
a g l´
own
,
a. Pobieranie pakiet´
ow z
klas mo˙ze si
,
e odbywa´
c wy l
,
acznie z po´srednictwem rodzic´
ow, co jest warun-
kiem koniecznym dla dzia lania mechanizmu kszta ltowania ruchu. Pobieranie
pakiet´
ow z klas wykonywane jest wed lug algorytmu WRR (Weighted Round-
Robin). Algorytm WRR jest drobn
,
a modyfikacj
,
a algorytmu
”
round-robin”,
polegaj
,
ac
,
a na przypisaniu r´
o˙znych wag (priorytet´
ow) ka˙zdej klasie. Klasy
o wy˙zszych priorytetach s
,
a sprawdzane w pierwszej kolejno´sci. Wstawianie
pakiet´
ow do klas mo˙ze si
,
e odbywa´
c z pomini
,
eciem ich bezpo´srednich rodzi-
c´
ow. Polega to na przekierowaniu przez jeden z filtr´
ow po drodze pakietu
bezpo´srednio do wybranej klasy. Przekierowywanie pakiet´
ow do wybranych
klas odbywa si
,
e przewa˙znie z pomoc
,
a filtr´
ow. Mo˙zna r´
ownie˙z klasyfikowa´
c
pakiety bezpo´srednio w klasach, nak ladaj
,
ac mask
,
e bit´
ow TOS na pole TOS
z nag l´
owka pakiety IP.
Og´
olny algorytm klasyfikowania (przekierowywania) pakiet´
ow do poszcze-
g´
olnych klas przedstawia si
,
e nast
,
epuj
,
aco [3]:
1. Sprawd´
z filtry przy l
,
aczone do bie˙z
,
acej klasy. Je´sli znajdujesz si
,
e w li-
´sciu, to sko´
ncz, a w przeciwnym wypadku wr´
o´
c do kroku 1.
2. Na l´
o˙z mask
,
e bit´
ow na bity TOS. Je´sli zgadza si
,
e i znajdujesz si
,
e w w
,
e´
zle
to sko´
ncz, a w przeciwnym razie wr´
o´
c do kroku 1.
3. Wstaw pakiet do bie˙z
,
acej klasy.
Poza szeregowaniem pakiet´
ow algorytm CBQ zajmuje si
,
e r´
ownie˙z kszta l-
35

towaniem ruchu wychodz
,
acego. Mechanizm odpowiadaj
,
acy za to polega na
obliczaniu bezczynno´sci i odpowiednim wstrzymywaniu ruchu pakiet´
ow. Ob-
liczenia przeprowadzane s
,
a w oparciu o podany jako jeden z parametr´
ow
algorytmu kolejkowania ´sredni rozmiar pakiet´
ow (zwykle 1000 bajt´
ow). Wy-
znacza si
,
e sta l
,
a EWMA (ang. Exponential Weighted Moving Average), kt´
ora
traktuje nowsze pakiety jako wa˙zniejsze od starszych w stopniu wyk ladni-
czym. Nast
,
epnie od zmierzonego okresu bezczynno´sci l
,
acza sieciowego odej-
mowana jest bezczynno´s´
c obliczona z u˙zyciem EWMA, po czym jest ona
odejmowana od zmierzonej bezczynno´sci, daj
,
ac w wyniku ´sredni
,
a bezczyn-
no´s´
c l
,
acza sieciowego. ´
Srednia bezczynno´s´
c l
,
acza sieciowego mo˙ze przyjmowa´
c
nast
,
epuj
,
ace warto´sci:
• ujemne — l
,
acze jest przeci
,
a˙zone ilo´sci
,
a danych (ang. overlimit)
• zerow
,
a — l
,
acze jest idealnie zr´
ownowa˙zone
• dodatni
,
a — l
,
acze jest niedoci
,
a˙zone ilo´sci
,
a danych (ang. underlimit)
W przypadku przeci
,
a˙zenia l
,
acza transmisja pakiet´
ow b
,
edzie wstrzymy-
wana na taki okres czasu, aby doprowadzi´
c do zr´
ownowa˙zenia l
,
acza. Nie
mo˙zna wykona´
c zr´
ownowa˙zenia obci
,
a˙zenia l
,
acza z dowoln
,
a dok ladno´sci
,
a,
gdy˙z nie jest mo˙zliwe ustalenie czasu oczekiwania na transmisj
,
e z rozdziel-
czo´sci
,
a wi
,
eksz
,
a ni˙z pojedynczy kwant czasu zegara (na platformie PC —
10ms). W przypadku niedoci
,
a˙zenia l
,
acza pakiety b
,
ed
,
a szybciej wysy lane, a˙z
do momentu zr´
ownowa˙zenia obci
,
a˙zenia l
,
acza. W celu zapobie˙zenia mo˙zliwo-
´sci wyst
,
apienia zbyt du˙zych chwilowych przeci
,
a˙ze´
n w ruchu w sieci w trakcie
wyr´
ownywania obci
,
a˙zenia definiowane jest maksymalna bezczynno´s´
c l
,
acza
sieciowego, do kt´
orego jest obcinana w d´
o l dowolnie wysoka wyliczona war-
to´s´
c bezczynno´sci.
36
Przyk ladowym zainteresowaniem CBQ jako algorytmu kolejkowania jest
architektura DiffServ korzystaj
,
aca z us lugi o
”
gwarantowanej jako´sci” (opi-
sana jako Guaranteed Service w rozdz. 2).
3.1.7
Algorytm kolejkowania DSMARK (DiffServ Mark)
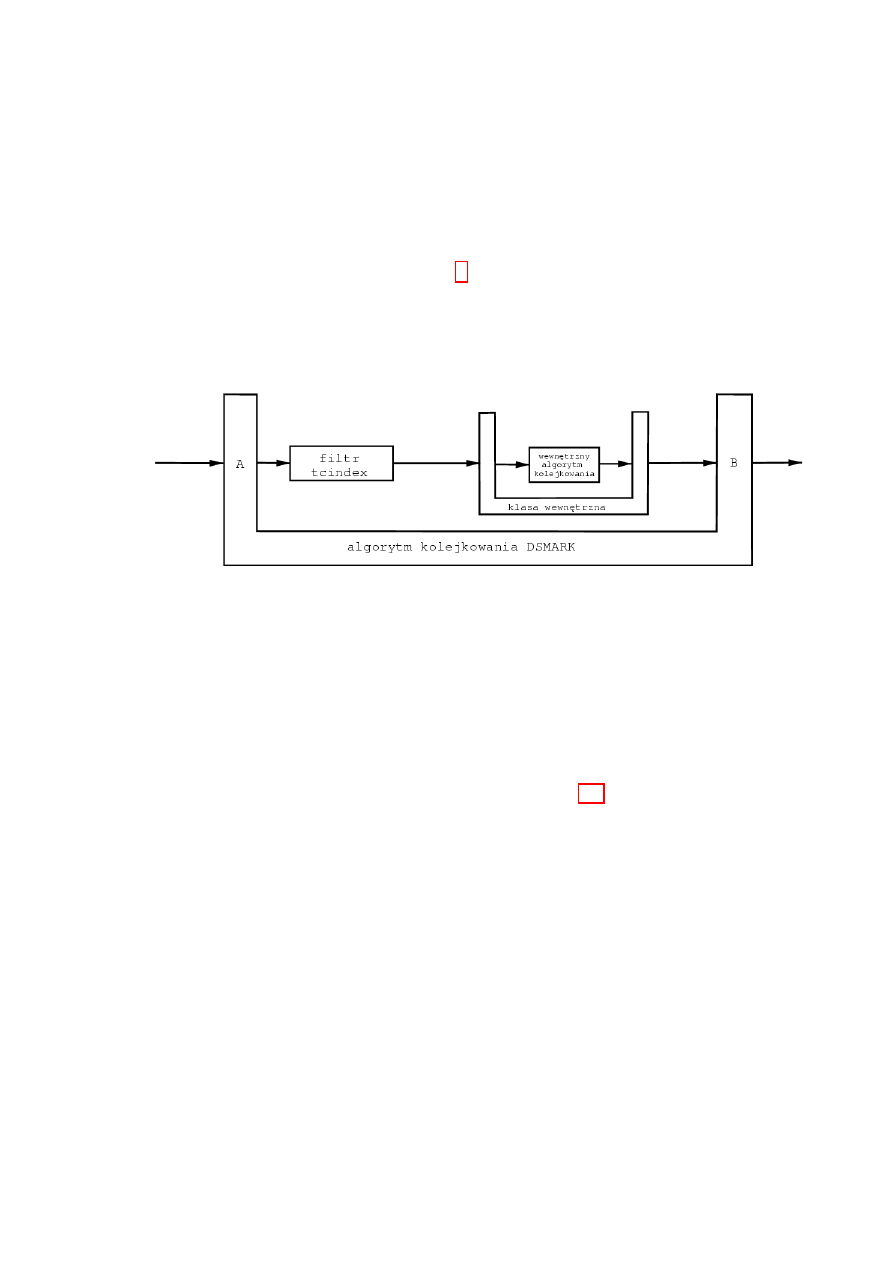
Rysunek 3.6: Algorytm kolejkowania DSMARK
Algorytm kolejkowania DSMARK jest wykorzystywany do realizacji ar-
chitektury DiffServ. Algorytm ten zajmuje si
,
e znakowaniem pakiet´
ow wcho-
dz
,
acych do domeny DS. Znakowanie odbywa si
,
e z po´srednictwem filtra pa-
kiet´
ow tcindex.
Dzia lanie tego algorytmu przedstawione jest na rys. 3.6. Algorytm opisu-
j
,
acy jego dzia lanie przedstawia si
,
e nast
,
epuj
,
aco:
1. punkt A: Je´sli ustawiona jest flaga set_tc_index, to odczytywana jest
warto´s´
c pola DS (TOS ) z nag l´
owka pakietu IP, a nast
,
epnie zapisywana
jest w polu tc_index struktury odzwierciedlaj
,
acej pakiet. W przeciw-
nym przypadku wpisywana jest do tego pola warto´s´
c domy´slna uprzed-
nio zdefiniowana.
2. Filtr tcindex na podstawie pola tc_index przekieruje pakiet do od-
powiedniej klasy
37

3. Pakiet dociera do wewn
,
etrznej klasy, w kt´
orej obowi
,
azuje wewn
,
etrzny
algorytm kolejkowania (np. pfifo).
4. punkt B: Pole tc_index u˙zywane jest jako indeks umo˙zliwiaj
,
acy do-
st
,
ep do tablicy warto´sci (maska, warto´
s´
c). Pierwotna warto´s´
c pola DS
mog la zosta´
c nadpisana przez wewn
,
etrzny algorytm kolejkowania wi
,
ec
odtwarzana jest jego poprzednia warto´s´
c.
3.1.8
Algorytm kolejkowania CSZ (Clark-Shenker-Zhang)
Algorytm ten zosta l opracowany przez trzech autor´
ow, od kt´
orych na-
zwisk wzi
,
a l si
,
e akronim: Clark-Shenker-Zhang [22]. Jest to najbardziej roz-
budowany z dost
,
epnych aktualnie dla Linuksa algorytm´
ow kolejkowania.
Opiera si
,
e on na idei, ˙ze konwersacje z r´
o˙znych klas ruchu s
,
a umiesz-
czane w osobnych kolejkach FIFO+ [22]. Algorytm FIFO+ jest modyfikacj
,
a
algorytmu FIFO , uwzgl
,
edniaj
,
ac
,
a czas przyj´scia pakietu. Przed wys laniem
pakietu do nast
,
epnego rutera obliczany jest i zapisywany w nag l´
owku IP spo-
dziewany czas przyj´scia do niego. Po osi
,
agni
,
eciu tego rutera por´
ownywany
jest on ze spodziewanymi czasami przyj´scia pozosta lych pakiet´
ow z kolejki
i pakiet jest wstawiany do kolejki w odpowiednie miejsce.
Wprowadza si
,
e podzia l konwersacji na:
”
gwarantowanej jako´sci” oraz
”
przewidywanej jako´sci”. Pierwsza grupa to konwersacje aplikacji ˙z
,
adaj
,
a-
cych niezmiennych parametr´
ow transmisji (nie adaptuj
,
acych si
,
e do zmien-
nych parametr´
ow transmisji), a druga to konwersacje aplikacji adaptuj
,
acych
si
,
e do zmiennych parametr´
ow transmisji. Do kolejek o wy˙zszych priorytetach
wstawiane s
,
a pakiety konwersacji o
”
gwarantowanej jako´sci”, a do kolejek
o ni˙zszych priorytetach pakiety konwersacji o
”
przewidywanej jako´sci”. Do
kolejki o najni˙zszym priorytecie, dzia laj
,
acej zgodnie z zasad
,
a
”
najlepszego
38
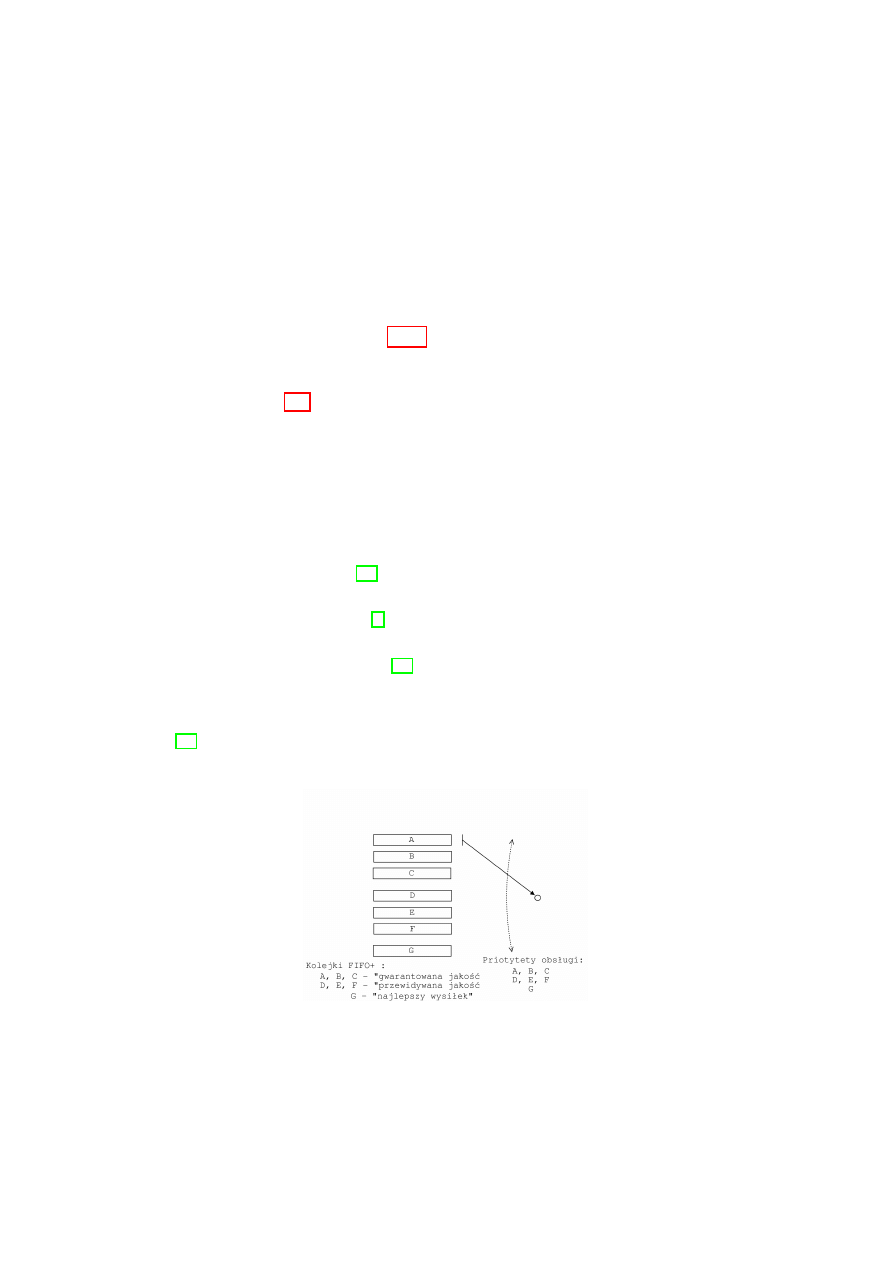
wysi lku”, trafiaj
,
a datagramy, kt´
ore w ten spos´
ob s
,
a przesy lane minimalnym
kosztem. Nale˙zy jeszcze tylko zadba´
c o to, aby kolejki o wy˙zszych priorytetach
nie zag lodzi ly kolejek o ni˙zszych priorytetach. Mo˙zna w tym celu kszta ltowa´
c
ruch wychodz
,
acy z kolejek o najwy˙zszych priorytetach z pomoc
,
a algorytmu
kolejkowania TBF (podsekcja 3.1.3).
Przyk ladowa konfiguracja oparta na algorytmie kolejkowania CSZ poka-
zana jest na rys. 3.7.
Aktualnie implementacja tego algorytmu kolejkowania nie jest w pe lni
funkcjonalna, a w przysz lo´sci algorytm ten b
,
edzie zast
,
apiony zostanie algo-
rytmem klasy HPFQ (ang. Hierarchical Packet Fairness Queueing). Algo-
rytmy takie potrafi
,
a r´
ownolegle obs lugiwa´
c klasy ruchu:
• Guaranteed Service [19]
•
”
najlepszego wysi lku” [4]
• Controlled Load Service [20]
Przyk ladowym algorytmem klasy HPFQ jest algorytm W F
2
Q opisany
w [23].
Rysunek 3.7: Algorytm kolejkowania CSZ
39

3.2
Rodzaje filtr´
ow
Szkielet (ang. framework) konstrukcji filtra pakiet´
ow umo˙zliwia tworzenie
filtr´
ow zawieraj
,
acych elementy wewn
,
etrzne. Elementem takim przyk ladowo
mo˙ze by´
c inny filtr pakiet´
ow. Sk ladowe filtru rozr´
o˙zniane s
,
a z pomoc
,
a uchwy-
t´
ow (ang. handle) 32-bitowych. Uchwyt o numerze 0 odnosi si
,
e do filtru jako
ca lo´sci. Aktualnie ˙zaden ze standardowych filtr´
ow pakiet´
ow dost
,
epnych w j
,
a-
drze nie korzysta z tego mechanizmu zagnie˙zd˙zania filtr´
ow.
Filtry pakiet´
ow dziel
,
a si
,
e na:
• og´
olne (ang. generic) — jeden filtr skojarzony z konkretnym algoryt-
mem kolejkowania klasyfikuje pakiety do wszystkich klas ruchu obs lu-
giwanych przez dany algorytm kolejkowania.
• szczeg´
o lowe (ang. specific) — kilka filtr´
ow skojarzonych z konkretnym
algorytmem kolejkowania klasyfikuje pakiety do klas ruchu obs lugiwa-
nych przez dany algorytm kolejkowania.
3.2.1
Filtr route
Linux obs luguje wiele tablic rutingu (domy´slnie 256). Standardowo przy
wyborze trasy pakiet´
ow sprawdzane s
,
a wpisy w nast
,
epuj
,
acych tablicach
w podanej kolejno´sci:
1. local - znajduj
,
a si
,
e w niej trasy dodawane automatycznie przez j
,
adro
przy podnoszeniu interfejs´
ow oraz trasy broadcastowe;
2. main - znajduj
,
a si
,
e w niej trasy dodawane przez administratora;
3. default - domy´slnie jest pusta.
40

Administrator mo˙ze dodawa´
c trasy do ka˙zdej z wymienionych tablic.
Mo˙ze tak˙ze skasowa´
c wszystkie tablice z wyj
,
atkiem tablicy local. Mo˙zliwe
jest r´
ownie˙z tworzenie nowych tablic rutingu i dodawanie do nich tras.
Dodatkowe mo˙zliwo´sci stwarza u˙zycie
”
rutingu rozszerzonego” (ang. po-
licy routing). Mo˙zliwe jest wtedy podejmowanie decyzji o rutingu na podsta-
wie nast
,
epuj
,
acych parametr´
ow:
• adresu ´zr´
od lowego
• protoko lu sieciowego (np. IP )
• portu protoko lu transportowego (np. port 80 TCP )
• warto´sci pola TOS z nag l´
owka IP
• wej´sciowego interfejsu sieciowego (np. ppp0)
• warto´sci pola ustawianego w pakiecie przez firewall
Ostatnie kryterium rutowania pakiet´
ow pozwala w praktyce na rutowanie
wg zawarto´sci dowolnego pola nag l´
owk´
ow warstwy sieciowej lub transporto-
wej, a nawet zawarto´sci pola danych pakietu. Wykorzystywany do tego jest
mechanizm znakowania pakiet´
ow przez narz
,
edzie iptables
. Znakowanie po-
lega na wpisywaniu dowolnej liczby sta loprzecinkowej 32 bitowej bez znaku
do dodatkowego pola struktury reprezentuj
,
acej ka˙zdy pakiet IP.
Ka˙zda trasa w tablicy rutingu mo˙ze mie´
c przypisan
,
a klas
,
e do kt´
orej trafi
,
a
pakiety kierowane wzd lu˙z tej trasy. Tras
,
e z klas
,
a mo˙zna skojarzy´
c na dwa
sposoby. Mo˙zna to osi
,
agn
,
a´
c przez wpisanie trasy do jednej z tablic rutingu
lub przez zdefiniowanie dziedziny rutuj
,
acej (ang. realm). Nast
,
epnie przy de-
finiowaniu filtra mo˙zna wskaza´
c na wybran
,
a tablic
,
e lub dziedzin
,
e rutuj
,
ac
,
a
jako na ´
zr´
od lo pakiet´
ow do filtrowania.
3
Filtr fw (podsekcja 3.2.2) korzysta jawnie z tego mechanizmu
41

Poni˙zszy przyk lad pokazuje zastosowanie filtra route. Wszystkie pakiety
adresowane do podsieci 192.168.10/24 z po´srednictwem rutera o adresie
192.168.10.1 wychodz
,
ace interfejsem sieciowym eth1 s
,
a kierowane do klasy
o identyfikatorze 1:10. Elementem l
,
acz
,
acym w tym przyk ladzie jest dziedzina
rutuj
,
ac
,
a o identyfikatorze 10.
# ip route add 192.168.10/24 via 192.168.10.1 dev eth1 realm 10
# tc filter add dev eth1 parent 1:0 protocol ip prio 100 \
route to 10 classid 1:10
Najwi
,
eksz
,
a zalet
,
a tego filtra wynikaj
,
ac
,
a z jego prostoty jest du˙za szybko´s´
c
dzia lania
3.2.2
Filtr fw
Kolejny rodzaj filtru korzysta z mo˙zliwo´sci znakowania pakiet´
ow, st
,
ad
pochodzi jego nazwa fw (skr´
ot terminu firewall). Filtr ten potrafi przekiero-
wa´
c pakiety do zdefiniowanych klas na podstawie warto´sci 32 bitowej liczby
sta loprzecinkowej bez znaku wpisanej uprzednio do struktury przedstawia-
j
,
acej pakiet. Do wpisywania wspomnianej liczby s lu˙zy narz
,
edzie konfiguracji
firewalla — iptables.
Jako demonstracj
,
e mo˙zliwo´sci tego elastycznego filtra pokazano ni˙zej za-
bezpieczenie serwera przed atakiem DoS polegaj
,
acym na przesy laniu do niego
du˙zej ilo´sci pakiet´
ow z ustawion
,
a flag
,
a TCP SYN (rozpoczynaj
,
acych po l
,
acze-
nie TCP ) w celu doprowadzenia do przeci
,
a˙zenia serwera, a w konsekwencji
unieruchomienia go.
Pakiet z ustawion
,
a flag
,
a TCP SYN ma wielko´s´
c 40 bajt´
ow (320 bit´
ow), tak
wi
,
ec w przybli˙zeniu trzy takie pakiety maj
,
a l
,
acznie wielko´s´
c 1 kb. Ustawiaj
,
ac
limit przepustowo´sci dla pakiet´
ow z ustawion
,
a flag
,
a TCP SYN na 1 kb, akcep-
tujemy nie wi
,
ecej ni˙z trzy pr´
oby nawi
,
azania po l
,
aczenia w ka˙zdej sekundzie.
42
W tym celu znaczymy ka˙zdym przychodz
,
acy interesuj
,
acym nas interfejsem
sieciowy eth0 pakiet warto´sci
,
a 1. Nast
,
epnie wszystkie uprzednio znaczone
pakiety podlegaj
,
a kszta ltowaniu ruchu i nadmiarowe pakiety s
,
a odrzucane.
# iptables -A PREROUTING -i eth0 -t mangle -p tcp --syn -j MARK \
--set-mark 1
# tc filter add dev eth0 parent ffff: protocol ip prio 50 \
handle 1 fw police rate 1kbit burst 40 mtu 9k drop flowid :1
G l´
own
,
a zalet
,
a tego filtra jest jego elastyczno´s´
c polegaj
,
aca na mo˙zliwo´sci
wykorzystania wszystkiego co oferuje architektura netfilter, z kt´
orej korzysta
narz
,
edzie konfiguracji firewalla iptables. Jednocze´snie mo˙zna uaktywni´
c 256
niezale˙znych filtr´
ow fw.
3.2.3
Filtry rsvp i rsvp6
Filtr rsvp umo˙zliwia klasyfikacj
,
e pakiet´
ow zgodnie z ich przynale˙zno´sci
,
a
do odpowiednich strumieni IntServ. Klasyfikacja jest przeprowadzana na pod-
stawie nast
,
epuj
,
acych parametr´
ow:
• protok´
o l warstwy sieciowej (np. TCP )
• adres docelowy IP
• port docelowy TCP lub GPI
• adres ´zr´
od lowy IP lub maska adres´
ow IP (opcjonalnie)
4
W przypadku korzystania z tunel´
ow IP w celu szyfrowania przesy lania danych zacho-
dzi potrzeba odczytania z nag l´
owka pakietu TCP numer´
ow portu ´
zr´
od lowego i docelowego.
Nag l´
owek TCP zostaje p´
o´
zniej zaszyfrowany, wi
,
ec informacje te zapisuje si
,
e w nag l´
owku
GPI (ang. Generalised Port Identifier) [27], kt´
ory dopisywany jest za nag l´
owkiem IP, a
przed nag l´
owkiem TCP.
43

• port ´zr´
od lowy IP lub etykieta przep lywu (opcjonalnie i dozwolone tylko
je´sli podano adres ´
zr´
od lowy IP lub mask
,
e adres´
ow)
W poni˙zszym przyk ladzie wszystkie pakiety TCP przychodz
,
ace z adresu
192.168.0.10 i adresowane do 192.168.0.1 zostan
,
a przyporz
,
adkowane do
klasy 1:2. Zapewnieniem odpowiedniej jako´sci transmisji zajmie si
,
e algorytm
kolejkowania z klasy 1:2 i nadrz
,
edne.
# tc filter add dev eth0 parent 1:0 protocol ip prio 10 rsvp ipproto tcp \
sender 192.168.0.10 session 192.168.1.1 classid 1:2
Zastosowania filtru rsvp, podobnie jak protoko lu sygnalizacyjnego RSVP,
nie s
,
a ograniczone wy l
,
acznie do architektury IntServ. Protok´
o l sygnaliza-
cyjny RSVP nie jest zale˙zny od konkretnego protoko lu sieciowego, dlatego
te˙z wsp´
o lpracuje zar´
owno z IPv4 jak i IPv6. W przypadku korzystania z pro-
toko lu IPv6 nale˙zy wywo lywa´
c ten filtr, podaj
,
ac nazw
,
e rsvp6. Jednocze´snie
mo˙zna uaktywni´
c 256 niezale˙znych filtr´
ow rsvp.
3.2.4
Filtr tcindex
Nazwa tego filtru, sk ladaj
,
aca si
,
e z dw´
och cz
,
e´sci tc (ang. Traffic Control)
oraz index, nawi
,
azuje do architektury DiffServ. W architekturze DiffServ po-
dzia l pakiet´
ow na klasy ruchu (w tej implementacji to˙zsamych z klasami)
dokonywany jest na podstawie warto´sci pola DS. Pole to to˙zsame jest z po-
lem TOS w nag l´
owku IPv4 oraz polem TC w nag l´
owku IPv6. Warto´s´
c tego
pola przechowywana jest dodatkowo w polu tcindex struktury reprezentu-
j
,
acej ka˙zdy pakiet.
W przypadku u˙zywania algorytmu kolejkowania dsmark warto´s´
c DS mo˙ze
by´
c automatycznie wczytana do zmiennej tcindex. Mo˙zna te˙z wymusi´
c z po-
moc
,
a odpowiedniego parametru wywo lania wpisanie uprzednio zdefiniowanej
44

domy´slnej warto´sci do zmiennej tcindex. Je´sli nie skorzysta si
,
e z ˙zadnej z
wymienionych metod, nale˙zy przypisa´
c warto´s´
c zmiennej tcindex w inny
spos´
ob, aby unikn
,
a´
c niejednoznaczno´sci interpretacji.
W poni˙zszym przyk ladzie opcja set_tc_index u˙zyta w pierwszym po-
leceniu nakazuje algorytmowi kolejkowania dsmark odczyta´
c zawarto´s´
c pola
TOS i wczyta´
c j
,
a do zmiennej tcindex. W drugim poleceniu na warto´s´
c
zmiennej tcindex nak ladana jest maska logiczna 0xfc, a nast
,
epnie wynik
przesuwany jest o dwa bity w prawo. W ten spos´
ob pomija si
,
e bity ECN.
# tc qdisc add dev eth0 handle 1:0 root dsmark indices 64 \
set_tc_index
# tc filter add dev eth0 parent 1:0 protocol ip prio 1 \
tcindex mask 0xfc shift 2
Filtr mo˙ze by´
c wykorzystywany do r´
o˙znych cel´
ow, nie tylko w po l
,
aczeniu
z algorytmem kolejkowania dsmark.
3.2.5
Filtr u32
Nazwa tego najbardziej elastycznego filtra pochodzi od formatu nag l´
ow-
k´
ow protoko l´
ow warstw sieciowej i transportowej, kt´
ore sk ladaj
,
a si
,
e z wie-
lokrotno´sci s lowa 32 bitowego. Filtr ten mo˙ze przyjmowa´
c jako kryterium
klasyfikacji pakiet´
ow do odpowiednich klas dowolne pola z nag l´
owk´
ow war-
stwy sieciowej (IPv4, IPv6 ) lub transportowej (TCP, UDP ). Warto´sci wspo-
mnianych p´
ol mog
,
a by´
c sprawdzane zar´
owno z u˙zyciem nazw symbolicznych
(np. ip dst 192.168.0.1) lub maskowania logicznego jednego, dw´
och lub
czterech kolejnych bit´
ow nag l´
owka (np. match u8 64 0xff at 8).
Pierwszy przyk lad prezentuj
,
acy mo˙zliwo´sci omawianego filtra pokazuje
przekierowanie do klasy 1:0 wszystkich pakiet´
ow posiadaj
,
acych pole TOS z
nag l´
owka IP ustawione na warto´s´
c 0x10 (minimalizacja op´
o´
znienia).
45

# tc filter add dev eth0 parent 1:0 protocol ip prio u32 \
match ip tos 0x10 0xff flowid 1:1
Nast
,
epny przyk lad jest demonstracj
,
a filtrowania pakiet´
ow wzgl
,
edem war-
to´sci pola TTL z nag l´
owka IP. Pakiety, kt´
orych
”
czas ˙zycia” (TTL) wynosi
1, s
,
a kierowane do oddzielnej klasy. W tym celu na dziewi
,
aty bajt nag l´
owka
IP (przesuni
,
ecie o osiem bajt´
ow) nak ladana jest maska 0xff, a wynik po-
r´
ownywany jest z oczekiwana warto´sci
,
a TTL.
# tc filter add dev eth0 parent 1:0 protocol ip prio 10 u32 \
match u8 1 0xff at 8 flowid 1:1
Ostatni przyk lad zastosowania tego filtru sk lada si
,
e z trzech selektor´
ow.
Selektorem nazywa si
,
e pojedynczy warunek. Spe lnienie wszystkich na lo˙zo-
nych warunk´
ow (iloczyn logiczny) jest konieczne, aby filtr przekierowa l pakiet
do odpowiedniej klasy. Pierwszy selektor sprawdza, czy pakiet przyszed l z ad-
resu 192.168.0.2. Nast
,
epny selektor sprawdza, czy pakiet IP zawieraj
,
acy
ten pakiet ma wielko´s´
c dok ladnie 40 bajt´
ow. Ostatni z selektor´
ow sprawdza,
czy w pakiecie jest ustawiona flaga TCP SYN.
# tc filter add dev eth0 parent 1:0 protocol ip prio 10 u32 \
match ip src 192.168.0.2 \
match u8 0x28 0xff at 3 \
match u8 0x10 0xff at nexthdr+13
3.3
Zastosowanie algorytm´
ow kolejkowania i filtr´
ow
W rzeczywistych zastosowaniach u˙zycie pojedynczego algorytmu kolejko-
wania dla jednej klasy, do kt´
orej parametry przydziela jeden filtr jest nie-
wystarczaj
,
ace. Konstruuje si
,
e wtedy hierarchie klas, korzystaj
,
ac z r´
o˙znych
algorytm´
ow kolejkowania i filtr´
ow.
46

Przyk ladowa rozbudowana struktura QoS przedstawiona jest na rys. 3.8.
Na rysunku mo˙zna zobaczy´
c zastosowanie filtr´
ow pakiet´
ow u32 (podsekcja
3.2.5) oraz algorytm´
ow kolejkowania SFQ (podsekcja 3.1.4), PRIO (podsek-
cja 3.1.2), TBF (podsekcja 3.1.3)oraz CBQ (podsekcja 3.1.6).
47
Rysunek 3.8: Przyk ladowa hierarchia klas
48

Rozdzia l 4
Mo ˙zliwo´
sci rozbudowy
implementacji QoS w systemie
Linux
Dzi
,
eki elastycznej i modularnej budowie Linuksa mo˙zna zmieni´
c kod stan-
dardowych algorytm´
ow kolejkowania lub filtr´
ow adaptuj
,
ac je do swych po-
trzeb. Mo˙zna r´
ownie˙z napisa´
c w lasne filtry lub algorytmy kolejkowania, kt´
ore
p´
o´
zniej mo˙zna skompilowa´
c jako modu ly dynamiczne i w razie potrzeby za-
ladowa´
c do j
,
adra systemu Linux.
W rozdziale tym nacisk jest po lo˙zony na budow
,
e wewn
,
etrzn
,
a algorytmu
kolejkowania oraz filtru, co u latwi potencjalnym zainteresowanym napisanie
w lasnego algorytmu kolejkowania lub filtru, b
,
ad´
z te˙z zaimplementowanie pod
system Linux algorytmu kolejkowania lub filtru ju˙z opracowanego teoretycz-
nie.
49

4.0.1
Opis og´
olny
Implementacja sterowania ruchem (ang. traffic control) w ´
zr´
od lach Li-
nuksa rozdzielona jest na kod element´
ow sterowania ruchem (pliki ´
zr´
od lowe
w j
,
ezyku C) oraz na interfejs dost
,
epu do tych element´
ow (pliki nag l´
ow-
kowe w j
,
ezyku C). Jedynym wyj
,
atkiem od tej zasady jest implementacja
filtr´
ow rsvp wraz z rsvp6, kt´
ora umiejscowiona jest w wi
,
ekszo´sci w poje-
dynczym pliku nag l´
owkowym. Wszystkie wymienione ni˙zej nazwy katalog´
ow
i plik´
ow s
,
a podawane wzgl
,
edem g l´
ownego katalogu ze ´
zr´
od lami znajduj
,
acego
si
,
e w /usr/src/linux chyba ˙ze jawnie napisano inaczej.
Komunikacja mi
,
edzy elementami sterowania ruchem dzia laj
,
acymi w try-
bie j
,
adra a programami administracyjnymi dzia laj
,
acymi w trybie u˙zyt-
kownika zapewnia mechanizm rtnetlink
[3]. Mechanizm ten jest od-
mian
,
a og´
olnego mechanizmu netlink wyspecjalizowan
,
a pod k
,
atem ob-
s lugi protoko lu sieciowego IP. Implementacja obydwu wspomnianych me-
chanizm´
ow znajduje si
,
e odpowiednio w podkatalogu net/netlink oraz
pliku net/core/rtnetlink.c, z kolei interfejs jest umieszczony w
na-
st
,
epuj
,
acych plikach nag l´
owkowych: include/linux/netlink.h oraz inc-
lude/linux/rtnetlink.h.
Administrator systemu kontroluje sterowanie ruchem z pomoc
,
a zewn
,
etrz-
nego programu tc. Program ten jest cz
,
e´sci
,
a sk ladow
,
a pakietu iproute, s lu˙z
,
a-
cego m. in. do sterowania rutingiem rozszerzonym. Cz
,
e´s´
c dotycz
,
aca stero-
wania ruchem znajduje si
,
e w podkatalogu iproute2/tc ´
zr´
ode l [2]. Program
ten pozwala na manipulowanie wybranymi elementami sterowania ruchem.
Implementacja obs lugi mechanizm´
ow sterowania ruchem sk lada si
,
e z dw´
och
cz
,
e´sci:
• obs lugi algorytm´
ow kolejkowania i klas ruchu — pliki q_ np. plik
q_tbf.c odpowiada za obs lug
,
e algorytmu kolejkowania TBF (podsek-
50

cja 3.1.3),
• obs lugi filtr´
ow pakiet´
ow — pliki f_ np. plik f_u32.c odpowiada za ob-
s lug
,
e filtru pakiet´
ow u32 (podsekcja 3.2.5).
Jako komunikacj
,
e mi
,
edzy elementami sterowania ruchem a programami
dzia laj
,
acymi w trybie u˙zytkownika traktuje si
,
e komunikacj
,
e mi
,
edzy progra-
mem tc a konkretnymi klasami ruchu, algorytmami kolejkowania oraz filtrami
pakiet´
ow.
Implementacja mechanizm´
ow sterowania ruchem w systemie Linux jest
integraln
,
a cz
,
e´sci obs lugi sieci komputerowych. Sk lada si
,
e ona z nast
,
epuj
,
acych
cz
,
e´sci:
• plik´
ow ´
zr´
od lowych (podkatalog net/sched) nast
,
epuj
,
acych element´
ow
podstawowych:
– algorytm´
ow
kolejkowania
i
klas
—
pliki
sch_
np.
plik
sch_dsmark.c zawiera kod ´
zr´
od lowy implementacji algorytmu ko-
lejkowania DSMARK (podsekcja 3.1.7),
– filtr´
ow pakiet´
ow — pliki cls_ np. plik cls_tcindex zawiera kod
´
zr´
od lowy implementacji filtra tcindex (podsekcja 3.2.4).
• plik´
ow nag l´
owkowych zawieraj
,
acych:
– interfejs po´srednicz
,
acy mi
,
edzy elementami sterowania ruchem
a
programami dzia laj
,
acymi w trybie u˙zytkownika — inc-
lude/net/pkt_sched.h (algorytmy kolejkowania i klasy) oraz in-
clude/net/pkt_cls.h (filtry pakiet´
ow),
– deklaracje u˙zywane tylko wewn
,
atrz j
,
adra i programy dzia laj
,
ace
w trybie j
,
adra — include/linux/pkt_sched.h (algorytmy ko-
51

lejkowania i klasy) oraz include/linux/pkt_cls.h (filtry pakie-
t´
ow).
4.0.2
Opis implementacji algorytm´
ow kolejkowania
Implementacja nowego algorytmu kolejkowania o przyk ladowej nazwie foo
w uproszczeniu sk lada si
,
e z nast
,
epuj
,
acych krok´
ow:
1. Stworzenie pliku foo_sch.c w podkatalogu net/sched/.
2. Zdefiniowanie struktury foo_sched_data przechowywuj
,
acej informacje
pomocnicze dla dzia lania danego algorytmu kolejkowania (np. maksy-
malne d lugo´sci kolejek wewn
,
etrznych).
3. Zdefiniowanie struktury foo_sched przechowuj
,
acej informacje wsp´
o l-
dzielone przez wszystkie r´
ownolegle wykorzystywane instancje danego
algorytmu kolejkowania oraz zawieraj
,
acej w sobie tablic
,
e, kt´
orej ele-
menty maj
,
a posta´
c struktury foo_sched_data.
4. Napisanie kodu nast
,
epuj
,
acych funkcji:
foo_init — inicjalizuje i wst
,
epnie konfiguruje algorytm kolejko-
wania (na podstawie parametr´
ow przekazanych programem tc)
foo_enqueue — wstawia pakiet do kolejki w klasie. Je´
sli wewn
,
atrz
klasy znajduj
,
a si
,
e kolejne klasy, to funkcja ta jest wywo lywana ponow-
nie dla klasy wewn
,
etrznej.
foo_dequeue — zwraca oraz usuwa pakiet z kolejki do wys lania.
Je´sli w kolejce nie ma pakiet´
ow lub nie mo˙zna ich wys la´
c, to zwracany
jest pusty wska´
znik NULL.
foo_requeue — wstawia z powrotem pakiet do kolejki po uprzed-
nim usuni
,
eciu go przez funkcj
,
e foo_dequeue. Pakiet musi by´
c wsta-
52

wiony z powrotem na to samo miejsce w kolejce, z kt´
orego zosta l wcze-
´sniej usuni
,
ety.
foo_drop — usuwa jeden pakiet z ko´
nca kolejki.
foo_change — zmienia konfiguracj
,
e algorytmu kolejkowania (na
podstawie parametr´
ow przekazanych programem tc).
foo_dump — zwraca informacje diagnostyczne przydatne dla ad-
ministratora. Zwyczajowo zwracane s
,
a parametry konfiguracyjne oraz
warto´sci zmiennych stanu (np. foo_sched).
foo_reset — przywraca pocz
,
atkow
,
a konfiguracj
,
e algorytmu ko-
lejkowania. W tym celu wszystkie kolejki s
,
a opr´
o˙zniane, a regulatory
czasowe steruj
,
ace wysy laniem pakiet´
ow s
,
a zatrzymywane.
foo_destroy — usuwa algorytm kolejkowania wraz ze wszystkimi
podrz
,
ednymi klasami ruchu wraz ze skojarzonymi algorytmami kolejko-
wania oraz filtrami, a wszystkie pakiety z tych kolejek s
,
a odrzucane>.
Klasa zawieraj
,
aca ten algorytm kolejkowania pozostaje nienaruszona.
5. Wpisanie nazw wymienionych wy˙zej funkcji do struktury Qdisc_ops.
6. Je´sli nowy algorytm kolejkowania foo ma istnie´
c w postaci dynamicz-
nego modu lu j
,
adra, to nale˙zy wykona´
c co nast
,
epuje:
(a) napisa´
c funkcj
,
e inicjalizuj
,
ac
,
a modu l (wykonywan
,
a po jego za la-
dowaniu przez j
,
adro) i rejestruj
,
ac
,
a go w j
,
adrze — init_module
(b) napisa´
c funkcj
,
e wywo lywan
,
a tu˙z przed wy ladowaniem modu lu
przez j
,
adro i wyrejestrowywuj
,
ac
,
a go z j
,
adra — cleanup_module
(c) zapewni´
c inkrementacj
,
e licznika zabezpieczaj
,
acego przez wy-
ladowaniem
u˙zywanego
modu lu
z
pomoc
,
a
makrodefinicji
53

MOD_INC_USE_COUNT
w
funkcji
foo_init,
czasem
r´
ownie˙z
w foo_change
(d) zapewni´
c dekrementacj
,
e licznika zabezpieczeczaj
,
acego przed
wy ladowaniem u˙zywanego modu lu z pomoc
,
a makrodefinicji
MOD_DEC_USE_COUNT w funkcji foo_destroy
7. Je´sli nowy algorytm kolejkowania foo ma istnie´
c w postaci kodu wkom-
pilowanego statycznie w j
,
adro, to nale˙zy wykona´
c co nast
,
epuje:
(a) umie´sci´
c deklaracje dotycz
,
ace tego algorytmu kolejkowania do-
st
,
epne tylko dla j
,
adra w pliku include/net/pkt_sched.h
(b) umie´sci´
c interfejs po´srednicz
,
acy w komunikacji mi
,
edzy tym algo-
rytmem kolejkowania a programami dzia laj
,
acymi w trybie u˙zyt-
kownika (np. tc) w pliku include/linux/pkt_sched.h
(c) umie´sci´
c
kod
´
zr´
od lowy
algorytmu
kolejkowania
w
pliku
net/sched/sch_foo.c
(d) zainicjowa´
c algorytm kolejkowania w funkcji pktsched_init znaj-
duj
,
acej si
,
e w pliku net/sched/sch_api.c
8. Nale˙zy zmodyfikowa´
c ´
zr´
od la programu tc w spos´
ob nast
,
epuj
,
acy:
(a) stworzy´
c plik q_foo.c
(b) zdefiniowa´
c nast
,
epuj
,
ace funkcje:
• foo_parse_opt — sprawdza poprawno´s´c podanych parame-
tr´
ow wywo lania, a nast
,
epnie przekazuje je algorytmowi kolej-
kowania
• foo_print_opt — wypisuje aktualn
,
a konfiguracj
,
e algorytmu
kolejkowania
54

• foo_print_xstats — wypisuje statystyki algorytmu kolejko-
wania
• explain — wypisuje pomoc odno´snie parametr´
ow przekazy-
wanych algorytmowi kolejkowania
(c) wpisa´
c nazwy powy˙zszych funkcji do struktury qdisc_util
(d) skompilowa´
c poprawion
,
a wersj
,
e programu tc
9. Kompilacji j
,
adra, a nast
,
epnie uruchomienia systemu operacyjnego pod
kontrol
,
a nowego j
,
adra.
10. Je´sli algorytm kolejkowania istnieje w postaci modu lu, to nale˙zy go
za ladowa´
c do j
,
adra z pomoc
,
a programu modprobe.
11. Skonfigurowa´
c sterowanie ruchem z pomoc
,
a programu tc.
4.0.3
Opis implementacji klas ruchu
Opis implementacji nowych klas w programie tc nie r´
o˙zni si
,
e zasadni-
czo od implementacji nowych algorytm´
ow kolejkowania, wi
,
ec w podsekcji tej
om´
owione zostan
,
a jedynie niezb
,
edne zmiany w ´
zr´
od lach j
,
adra.
Implementacja nowej klasy o nazwie foo wygl
,
ada podobnie jak imple-
mentacja nowych algorytm´
ow kolejkowania (podsekcja 4.0.2). Inne s
,
a tylko
funkcje, kt´
ore nale˙zy napisa´
c i umie´sci´
c w pliku foo_sch.c znajduj
,
acym si
,
e
w podkatalogu net/sched. Wymagane s
,
a nast
,
epuj
,
ace funkcje:
• foo_graft — do l
,
acza nowy algorytm kolejkowania do klasy
• foo_get — wyszukuje klas
,
e na podstawie jej identyfikatora i zwraca
jej wewn
,
etrzny identyfikator. Je´sli klasa posiada w lasny licznik odwo la´
n
do niej, to powinien zosta´
c zwi
,
ekszony o jeden.
55

• foo_put — zmniejsza licznik odwo la´
n do tej klasy, je´sli dana klasa go
posiada. Je´sli licznik ten osi
,
agnie zero, to klasa zostanie usuni
,
eta.
• foo_change_class — zmienia konfiguracj
,
e bie˙z
,
acej klasy (na podsta-
wie parametr´
ow przekazanych programem tc).
• foo_delete — usuwa bie˙z
,
ac
,
a klas
,
e. Je´sli klasa posiada w lasny licz-
nik odwo la´
n do niej, to jest on dekrementowany, a klasa jest usuwana
wy l
,
acznie wtedy, gdy osi
,
agnie on zero.
• foo_walk — iteracyjnie wywo luje wszystkie funkcje zwrotne (ang. cal-
lback) skojarzone z klasami wewn
,
etrznymi. Przyk ladowo funkcje takie
mog
,
a zwraca´
c informacje diagnostyczne o klasach.
• foo_leaf — zwraca wska´znik do klasy je´sli jest ona li´sciem drzewa
klas. W przeciwnym przypadku zwracany jest pusty wska´
znik NULL.
• foo_dump — zwraca dane diagnostyczne dotycz
,
ace bie˙z
,
acej klasy.
Cz
,
e´s´
c implementacji dotycz
,
aca zmian w programie tc jest dok ladnie taka
sama jak w przypadku implementacji nowego algorytmu kolejkowania.
4.0.4
Opis implementacji filtr´
ow pakiet´
ow
Proces implementacji nowego filtru o nazwie foo sk lada si
,
e z nast
,
epuj
,
a-
cych krok´
ow:
1. Napisanie poni˙zszych funkcji:
• foo_init — inicjalizuje filtr.
56

• foo_classify — dokonuje klasyfikacji pakietu
• foo_get — szuka filtru o podanym identyfikatorze i zwraca jego
wewn
,
etrzny identyfikator.
• foo_put — sprawdza czy bie˙z
,
acy filtr jest u˙zywany, a je´sli nie
jest, to usuwa go.
• foo_change — zmienia konfiguracj
,
e filtra.
• foo_walk — wywo luje funkcje zwrotne wszystkich element´
ow fil-
tra.
• foo_dump — zwraca informacje diagnostyczne dotycz
,
ace bie˙z
,
acego
filtru.
• foo_delete — usuwa wskazany element sk ladowy filtra.
• foo_destroy — usuwa filtr.
2. Wpisanie nazw tych funkcji do struktury tcf_proto_ops.
3. Nale˙zy zmodyfikowa´
c ´
zr´
od la programu tc w spos´
ob nast
,
epuj
,
acy:
(a) stworzy´
c plik q_foo.c
(b) zdefiniowa´
c nast
,
epuj
,
ace funkcje:
• f_foo_parse_opt — sprawdza poprawno´s´c podanych para-
metr´
ow programu i przekazuje je filtrowi pakiet´
ow.
• f_foo_print_opt — wy´swietla aktualn
,
a konfiguracj
,
e filtra
pakiet´
ow.
(c) skompilowa´
c poprawion
,
a wersj
,
e programu tc.
1
Dozwolonymi wynikami klasyfikacji s
,
a: TC_POLICE_OK (pakiet zostanie przepusz-
czony), TC_POLICE_RECLASSIFY (pakiet b
,
edzie powt´
ornie klasyfikowany, gdy˙z prze-
kroczy l dopuszczalny limit przepustowo´
sci), TC_POLICE_SHOT (pakiet zostanie odrzu-
cony) oraz TC_POLICE_UNSPEC (pakiet zostanie odrzucony lub traktowany jako ruch
niskopriorytetowy)
57

Rozdzia l 5
Badania wykonane bez
w l
,
aczonych mechanizm´
ow QoS
5.1
Cel bada´
n
Badania polega ly na zmierzeniu wp lywu r´
o˙znych czynnik´
ow (po´srednic-
two rutera w transmisji danych, transmisje FTP wykonywane w tle, druga
transmisja interaktywna wykonywana w tle) na zmienno´s´
c op´
o´
znienia w prze-
kazywaniu pakiet´
ow IP (ang. jitter). Sk lada ly si
,
e z dw´
och grup bada´
n. Bada-
nia z pierwszej grupy zosta ly wykonane bez w l
,
aczonych mechanizm´
ow QoS.
W pierwszej grupie znalaz ly si
,
e pomiary op´
o´
znie´
n w transmisjach bezpo´sred-
nich oraz w transmisjach przez nieobci
,
a˙zony ruter. Na drug
,
a grup
,
e z lo˙zy ly
si
,
e pomiary dokonane w sytuacjach, gdy ruter poza interesuj
,
ac
,
a transmisj
,
a
obci
,
a˙zany by l dodatkowymi transmisjami (transmisja interaktywna – echo
oraz transmisje FTP).
58
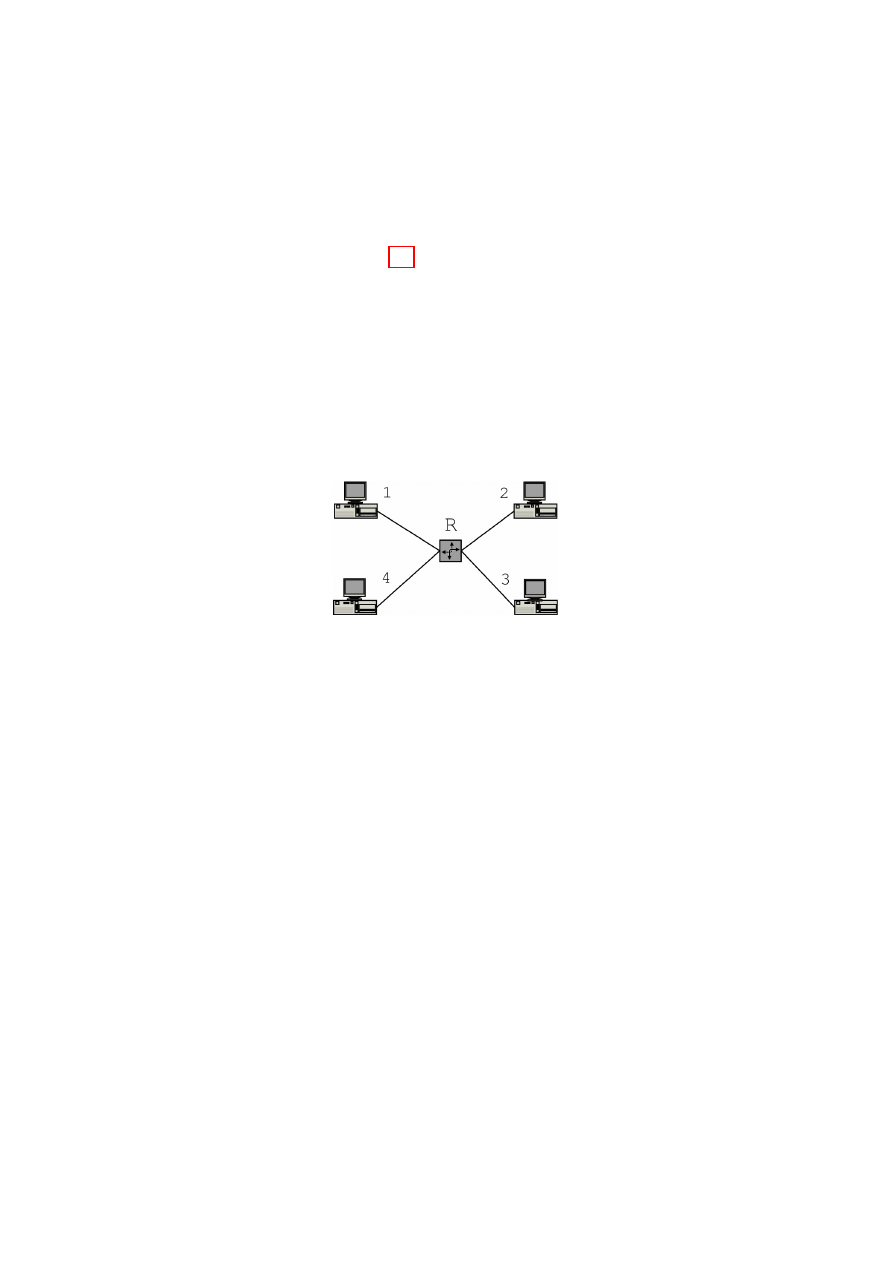
5.2
Sprz
,
et u ˙zyty w badaniach
Stanowisko badawcze (rys. 5.1) sk lada lo si
,
e z nast
,
epuj
,
acych element´
ow:
• ruter programowy (komputer PC oznaczony na rysunkach symbo-
lem R),
• cztery
ko´
nc´
owki
klienckie
(komputery
PC
oznaczone
cyframi
1, 2, 3 i 4).
Rysunek 5.1: Stanowisko badawcze
Jako ruter programowy wykorzystano komputer klasy PC wyposa˙zony
w procesor Intel Pentium 75, pami
,
e´
c operacyjn
,
a wielko´sci 48 MB oraz cztery
karty sieciowe
”
Thick Ethernet” (100 Mbit). Komputer pracowa l pod kon-
trol
,
a systemu GNU/Linux Debian 3.0. Dodatkowo skompilowano specjalnie
pod posiadany sprz
,
et j
,
adro w wersji 2.4.18. Ruter z ko´
nc´
owkami klienckimi
po l
,
aczono okablowaniem sieciowym typu
”
skr
,
etka” kategorii 5.
Jako ko´
nc´
owki klienckie u˙zyto cztery komputery klasy PC. Ka˙zdy z nich
posiada l procesor Intel Pentium III 733, pami
,
e´
c operacyjn
,
a wielko´sci 64 MB
oraz pojedyncz
,
a kart
,
e sieciow
,
a o przepustowo´sci 100 Mbit. Komputery pra-
cowa ly pod kontrol
,
a systemu RedHat Linux w wersji 7.2. R´
ownie˙z dla nich
specjalnie skompilowano j
,
adro w wersji 2.4.18. U˙zycie tego samego j
,
adra
59

na wszystkich komputerach oraz wy l
,
aczenie nieu˙zywanych demon´
ow siecio-
wych (np. serwera poczty) zniwelowa lo wp lyw poszczeg´
olnych dystrybucji
na prowadzone pomiary.
5.3
Opis oprogramowania testuj
,
acego
W celu wykonania oblicze´
n niezb
,
edne jest zmierzenie op´
o´
znienia (czasu)
przekazywania pakiet´
ow IP. Nale˙zy r´
ownie˙z dok ladnie zmierzy´
c chwilowe,
´sredni
,
a i kra´
ncowe warto´sci przepustowo´sci. Mo˙zna to wykona´
c na wiele spo-
sob´
ow. Og´
olnie m´
owi
,
ac, mo˙zna dokona´
c pomiar´
ow w trybie u˙zytkownika
(ang. user mode) lub w trybie j
,
adra (ang. kernel mode).
W uproszczeniu mo˙zna powiedzie´
c, ˙ze tryb j
,
adra to uprzywilejowany tryb
dost
,
epu do procesora. Proces dzia laj
,
acy w tym trybie mo˙ze uczyni´
c wszystko
co umo˙zliwia architektura sprz
,
etowa na kt´
orej jest wykonywany. Proces dzia-
laj
,
acy w tym trybie nie jest ograniczany przez prawa dost
,
epu do plik´
ow oraz
mo˙ze zar´
owno odczytywa´
c jak i zapisywa´
c dane do przestrzeni adresowej in-
nych proces´
ow. Proces taki mo˙ze by´
c uruchomiony jedynie przez administra-
tora danego komputera. W tym trybie dzia laj
,
a
”
w
,
atki j
,
adra” (ang. kernel
threads) oraz dynamiczne modu ly j
,
adra. Jako w
,
atki j
,
adra okre´sla si
,
e frag-
menty j
,
adra pracuj
,
ace niezale˙znie od siebie. Przyk ladowym w
,
atkiem j
,
adra
jest w
,
atek obs lugi przerwa´
n programowych. Natomiast dynamiczne modu ly
j
,
adra to programy niezale˙zne programy, kt´
ore mog
,
a by´
c w l
,
aczane i wy l
,
a-
czane w trakcie pracy systemu operacyjnego. Mog
,
a one r´
ownie˙z przyjmowa´
c
parametry wywo lania. Przyk ladowe zastosowanie dla modu l´
ow to sterowniki
urz
,
adze´
n zewn
,
etrznych np. kart sieciowych w technologii Ethernet.
Z kolei trybem u˙zytkownika okre´sla si
,
e nieuprzywilejowany tryb dost
,
epu
do procesora. Proces dzia laj
,
acy w tym trybie podlega restrykcjom dotycz
,
acy
60

dost
,
epu jedynie do w lasnej przestrzeni adresowej pami
,
eci oraz jedynie do
tych plik´
ow, kt´
orych prawa dost
,
epu na to pozwalaj
,
a. Wszystkie programy
uruchamiane przez zwyk lych u˙zytkownik´
ow oraz cz
,
e´s´
c program´
ow urucha-
miana przez u˙zytkownik´
ow pracuje w tym trybie. Przyk ladowo edytor tekstu,
w kt´
orym napisana zosta la niniejsza praca, pracowa l w trybie u˙zytkownika.
5.3.1
Zasadno´
s´
c pomiar´
ow w trybie u ˙zytkownika
Przyk ladowym rozwi
,
azaniem dzia laj
,
acym w trybie u˙zytkownika jest wy-
korzystanie do pomiaru programu pods luchuj
,
acego ruch w sieci komputero-
wej (ang. sniffer). Nale˙zy uruchomi´
c kilka instancji takiego programu (np.
tcpdump), po jednej na ka˙zdy interesuj
,
acy nas interfejs sieciowy. Pojawia si
,
e
wtedy powa˙zny problem zwi
,
azany z szeregowaniem proces´
ow przez j
,
adro, nie
mo˙zna w latwy spos´
ob zagwarantowa´
c, ˙ze pomiary czasu dokonywane przez
nas luchuj
,
ace programy b
,
ed
,
a bardzo dok ladne. Wynika to z tego, ˙ze j
,
adro
przydziela ka˙zdemu procesowi przez kt´
ory ma dost
,
ep do procesora i po up ly-
wie jego proces zostaje wyw laszczony, nie wiadomo wi
,
ec czy pakietowi A,
kt´
ory pojawi l si
,
e w ruterze przed pakietem B, zostanie przypisany czas nadej-
´scia wcze´sniejszy ni˙z pakietowi B. Problem mo˙zna rozwi
,
aza´
c, uruchamiaj
,
ac
system Linux na maszynie wieloprocesorowej tak, aby ka˙zda instancja pro-
gramu nas luchuj
,
acego pracowa la na oddzielnym procesorze, co w dost
,
epnych
warunkach laboratoryjnych by lo niemo˙zliwe. Dodatkowym minusem podej-
´scia opartego na programach uruchamianych przez u˙zytkownika jest mniejsza
dok ladno´s´
c ni˙z to mo˙zliwe w trybie j
,
adra. Programy takie mog
,
a odczyta´
c czas
systemowy z rozdzielczo´sci
,
a 1µs(10
−6
), czyli znacznie mniej ni˙z cz
,
estotliwo´s´
c
taktowania wsp´
o lczesnych procesor´
ow. Ograniczenie to narzucone jest przez
bibliotek
,
e standardow
,
a j
,
ezyka C i zwi
,
azane jest z postulatem przeno´sno´sci
(na poziomie ´
zr´
od la) oprogramowania napisanego w j
,
ezyku C.
61

5.3.2
Zasadno´
s´
c pomiar´
ow w trybie j
,
adra
Alternatywne podej´scie, czyli dokonanie pomiar´
ow w trybie j
,
adra, mo˙zna
zrealizowa´
c na dwa sposoby. Pierwszym z nich jest zmodyfikowanie ´
zr´
ode l j
,
a-
dra i zapisanie zmian w stosunku do orygina lu w pliku
”
latce” (ang. patch).
Korzystaj
,
ac p´
o´
zniej z tego pliku mo˙zna szybko uzyska´
c zmodyfikowane j
,
adra
z oryginalnego j
,
adra. Drugim sposobem osi
,
agni
,
ecia celu jest napisanie mo-
du lu j
,
adra, kt´
ory mo˙zna za ladowa´
c i wy ladowa´
c dynamicznie w trakcie pracy
systemu Linux. Modu l taki mo˙ze w trakcie ladowania przyjmowa´
c parametry
wywo lania podobnie jak zwyk ly program. Po za ladowaniu modu l traktowany
jest jako integralna cz
,
e´s´
c j
,
adra. Istotne jest r´
ownie˙z to, i˙z raz napisany mo-
du l mo˙zna u˙zywa´
c z p´
o´
zniejszymi wersjami systemu Linux. W przypadku
poprawek bezpo´srednio w j
,
adrze, mo˙zna spodziewa´
c si
,
e konieczno´sci ich mo-
dyfikacji, aby dostosowa´
c zmiany do nowszych wersji j
,
adra.
Mierz
,
ac czasy nadej´scia pakiet´
ow z poziomu j
,
adra mo˙zna uzyska´
c po-
miary z
dok ladno´sci
,
a do pojedynczego cykni
,
ecia zegara procesora. Przy-
k ladowo posiadaj
,
ac ruter z procesorem o cz
,
estotliwo´sci 1GHz, osi
,
agamy
rozdzielczo´s´
c czasu 1ns(10
−9
). Negatywnymi stronami omawianego podej-
´scia s
,
a nieprzeno´sno´s´
c oraz potencjalna niestabilno´s´
c. Nieprzeno´sno´s´
c wi
,
a˙ze
si
,
e z faktem, ˙ze odczyt czasu nast
,
epuje z rejestru TSC, kt´
ory wyst
,
epuje
w procesorach Intela od modelu Pentium. Nie jest to du˙zym problemem,
gdy˙z wszystkie obecnie dost
,
epne na rynku procesory klasy x86 posiadaj
,
a
ten rejestr (zak ladam, ˙ze nie korzysta si
,
e z innych architektur procesor´
ow
np. Alphy). Znacznie powa˙zniejszym problemem jest niestabilno´s´
c, wynika-
j
,
aca z tego, ˙ze proces dzia laj
,
acy w trybie j
,
adra nie jest przez nie kontrolowany
i mo˙ze poprzez zapis lub odczyt spod niew la´sciwego adresu w pami
,
eci spo-
wodowa´
c niestabilno´s´
c ca lego systemu operacyjnego z jego zawieszeniem si
,
e
w l
,
acznie. Utrudnia to testowanie modu lu w trakcie jego tworzenia, ale po
62
jego stworzeniu i przetestowaniu ju˙z nie odgrywa roli.
5.3.3
Opis przyj
,
etego rozwi
,
azania
Badania wchodz
,
ace w sk lad niniejszej pracy zosta ly wykonane w try-
bie j
,
adra. Zdecydowano si
,
e na napisanie modu lu j
,
adra. Rozwi
,
azanie to
jest bardziej elastyczne ni˙z dokonanie zmian bezpo´srednio w j
,
adrze. Mo-
du l po za ladowaniu wypisuje komunikaty, kt´
ore mog
,
a by´
c zapisywane
do pliku (np. /var/log/kernel.log) lub przekazywane kolejki FIFO
(np.
/dev/xconsole), z ktorej mog
,
a by´
c odczytywane przez inny proces
dzia laj
,
acy lokalnie na ruterze lub inny proces zdalny.
Dla ka˙zdego pakietu wchodz
,
acego do rutera lub wychodz
,
acego z niego
ka˙zdy wiersz wygl
,
ada nast
,
epuj
,
aco:
data nazwa rutera kernel: kierunek: czas adres ´
zr´
od lowy > adres docelowy flagi rozmiarB
Znaczenie poszczeg´
olnych kolumn jest nast
,
epuj
,
ace:
• data: czas wpisywany przez j
,
adro (np. Jul 28 15:59:22)
• nazwa rutera: nazwa komputera, kt´
ory jest ruterem (np. o387)
• kierunek: okre´slenie, czy jest to pakiet wchodz
,
acy (coming) czy wycho-
dz
,
acy (leaving)
• czas: dok ladny czas nadej´scia pakietu mierzony w cyklach zegara (np.
18019375715228
• adres ´zr´
od lowy: adres IP nadawcy pakietu wraz z numerem portu (np.
157.158.181.131:35078)
• adres docelowy: adres IP adresata pakietu wraz z numerem portu (np.
157.158.1.3:22)
63

• flagi: ustawione w nag l´
owku TCP flagi (np. PA oznacza psh+ack)
• rozmiar: rozmiar datagramu (np. 40B)
Ca lo´s´
c bada´
n zosta la wykonana z pomoc
,
a standardowego powszechnie
dost
,
epnego oprogramowania:
• tcpdump - program do pods luchiwania ruchu w sieci
• ProFTPD - serwer FTP
• lftp - klient FTP
• inetd - demon sieciowy wywo luj
,
acy inne us lugi i programy (us luga echo
w wersji dla TCP)
Standardowe oprogramowanie nie spe lni lo wszystkich potrzeb, wi
,
ec do-
datkowo napisano program w j
,
ezyku C do wysy lania co okre´slony odst
,
ep
czasu spreparowanych przeze mnie pakiet´
ow TCP. Analiza plik´
ow z logami
wraz z obliczeniami przeprowadzone zosta ly dedykowanymi programami na-
pisanymi w j
,
ezyku Perl.
5.4
Przewodnik po badaniach
5.4.1
Pomiar przepustowo´
sci l
,
acza
Wykonano pomiary szybko´sci transfer´
ow mi
,
edzy komputerami. Pomiary
przeprowadzono zar´
owno w transmisjach z po´srednictwem rutera (rys. 5.2),
jak i w po l
,
aczeniach bezpo´srednich (rys.
5.3), aby oceni´
c wp lyw rutera
na transmisj
,
e.
Wykonano dziesi
,
eciokrotnie pomiary szybko´sci transfer´
ow przy przesy la-
niu pliku o wielko´sci 1MB, 10MB i 100MB z pomoc
,
a protoko lu FTP mi
,
edzy
dwoma komputerami. U´srednione wyniki znajduj
,
a si
,
e w tab. 5.1.
64
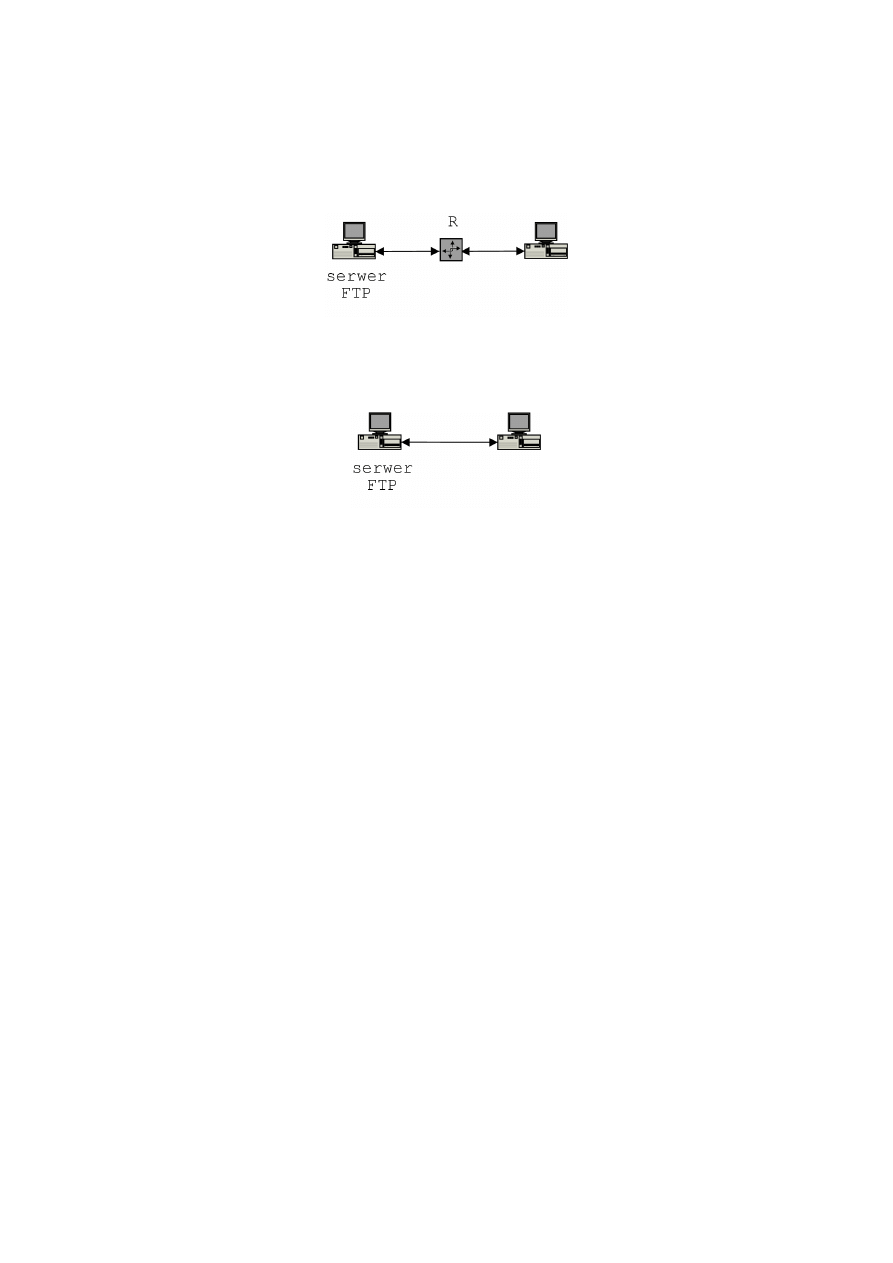
Rysunek 5.2: Transmisja FTP przy po l
,
aczeniu przez ruter
Rysunek 5.3: Transmisja FTP przy po l
,
aczeniu bezpo´srednim
Jedynie przy przesy laniu pliki o wielko´sci 1MB ruter nieznacznie (w gra-
nicach 1%) op´
o´
znia transmisj
,
e. Natomiast ju˙z przy transmisji pliku 10MB
oraz 100MB wp lyw rutera na szybko´s´
c transmisji jest pozytywny. Przyspie-
szenie transmisji po wprowadzeniu rutera wynika st
,
ad, ˙ze ruter zmniejsza
chwilowe przeci
,
a˙zenia transferu poprzez odpowiednie buforowanie przecho-
dz
,
acych przez niego pakiet´
ow sieciowych —
”
wyg ladza” ruch w sieci.
5.4.2
Pomiar op´
o´
znienia przekazywania pakiet´
ow IP
Nast
,
epnie przeprowadzono pomiary op´
o´
znie´
n przekazywania pakiet´
ow IP
oraz ich zmienno´sci (ang. jitter). R´
ownie˙z te badania wykonano dla po l
,
acze´
n
komputer´
ow z po´srednictwem rutera i bez po´srednictwa rutera. Do cel´
ow
testowych wykorzystano us lug
,
e echo w wersji dla TCP udost
,
epnian
,
a przez
serwer sieciowy inetd. Us luga ta polega na odsy laniu z powrotem tego samego
pakietu, kt´
ory nadszed l przed chwil
,
a. Jedynie adresy ´
zr´
od lowy i docelowy
65

Rozmiar pliku [MB]
Po l
,
aczenie bezpo´srednie [Bps]
Po l
,
aczenie przez ruter [Bps]
1
746956
742279
10
655519
754742
100
494265
633246
Tablica 5.1: ´
Srednia przepustowo´s´
c przy przesy laniu plik´
ow FTP
zamieniane s
,
a ze sob
,
a.
Pomiar polega l na mierzeniu odst
,
ep´
ow (interwa l´
ow) czasowych pomi
,
edzy
wysy lanymi pakietami TCP o wielko´sci 1500B. Jako interwa l czasowy rozu-
miany jest odst
,
ep czasu mi
,
edzy wys laniem pakietu przez klienta (nadawca)
a odebraniem go przez serwer (odbiorca). Zosta l on wykonany pi
,
eciusetkrot-
nie dla r´
o˙znych po l
,
acze´
n klienta z serwerem oraz rozmaitych zak l´
oce´
n. Zak l´
o-
ceniami by ly dodatkowe transmisje FTP wielomegabajtowych ilo´sci danych
przechodz
,
acych przez ten sam ruter oraz dodatkowe transmisje echo.
Transmisje bez dodatkowych zak l´
oce´
n
Wykonano pomiary transmisji pakiet´
ow echo bez ˙zadnych zak l´
oce´
n przy
po l
,
aczeniu bezpo´srednim (rys. 5.4) oraz przy po l
,
aczeniu przez ruter (rys. 5.5).
U´srednione wyniki znajduj
,
a si
,
Rysunek 5.4: Transmisja echo przy po l
,
aczeniu bezpo´srednim
66

Rysunek 5.5: Transmisja echo przy po l
,
aczeniu przez ruter
Interwa l czasowy wysy lania
Po l
,
aczenie
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
1
0.001
0.014453
0.035257
0.019911
bezpo´
srednie
10
0.01
0.019675
0.038340
0.020025
100
0.1
0.105180
0.109024
0.108878
1000
1
0.996572
1.001076
1.000007
1
0.001
0.016039
0.019829
0.019761
przez ruter
10
0.01
0.017482
0.033624
0.019926
100
0.1
0.100863
0.108952
0.108834
1000
1
0.991690
1.000076
0.999958
Tablica 5.2: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta
Interwa l czasowy wysy lania
Po l
,
aczenie
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
1
0.001
0.000021
0.122739
0.011300
10
0.01
0.019648
0.038468
0.020027
bezpo´
srednie
100
0.1
0.105168
0.996607
0.117809
1000
1
0.999080
1.001169
1.000125
1
0.001
0.000051
0.019794
0.010154
10
0.01
0.017453
0.142897
0.021235
przez ruter
100
0.1
0.108858
0.991577
0.117936
1000
1
1.000063
1.000191
1.000125
Tablica 5.3: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera
67
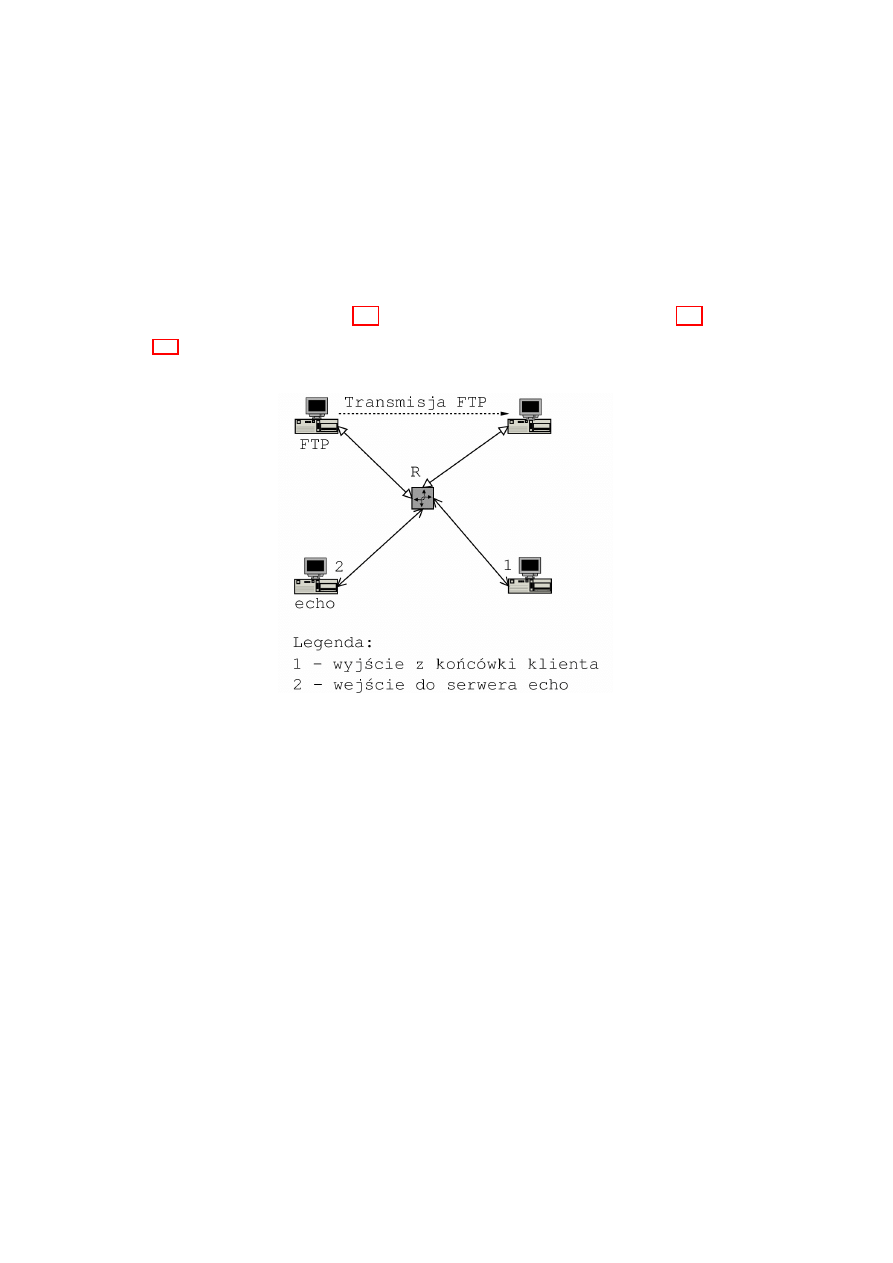
Transmisje z dodatkowymi zak l´
oceniami
Do lo˙zono dodatkowe zak l´
ocenie w postaci pojedynczej transmisji FTP,
po czym wykonano pomiary op´
o´
znie´
n przekazywania pakiet´
ow. Sytuacja ta
przedstawiona jest na rys. 5.6. U´srednione wyniki znajduj
,
a si
,
e w tab. 5.4 oraz
Rysunek 5.6: Transmisja echo przy po l
,
aczeniu przez ruter zak l´
ocana przez
pojedyncz
,
a transmisj
,
e FTP
68
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000024
0.047132
0.019770
20
0.02
0.000023
0.109642
0.029816
30
0.03
0.007641
0.109497
0.040255
40
0.04
0.017919
0.081215
0.049482
50
0.05
0.021742
0.088609
0.059322
60
0.06
0.048739
0.092343
0.069495
70
0.07
0.075660
0.242671
0.080857
80
0.08
0.085501
0.090296
0.089076
90
0.09
0.08715
0.092508
0.089113
100
0.1
0.104528
0.113302
0.108887
1000
1
0.999641
1.000083
1.000038
Tablica 5.4: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy jednej transmisji FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001221
0.060525
0.020193
20
0.02
0.001208
0.092241
0.029742
30
0.03
0.002783
0.098029
0.039981
40
0.04
0.009262
0.087140
0.049608
50
0.05
0.006832
0.090942
0.059125
60
0.06
0.031493
0.093195
0.069320
70
0.07
0.040101
0.243162
0.080680
80
0.08
0.059644
0.130754
0.089336
90
0.09
0.058208
0.118759
0.089049
100
0.1
0.076205
0.146214
0.108689
1000
1
0.966067
1.036311
1.000078
Tablica 5.5: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy jednej transmisji FTP
69
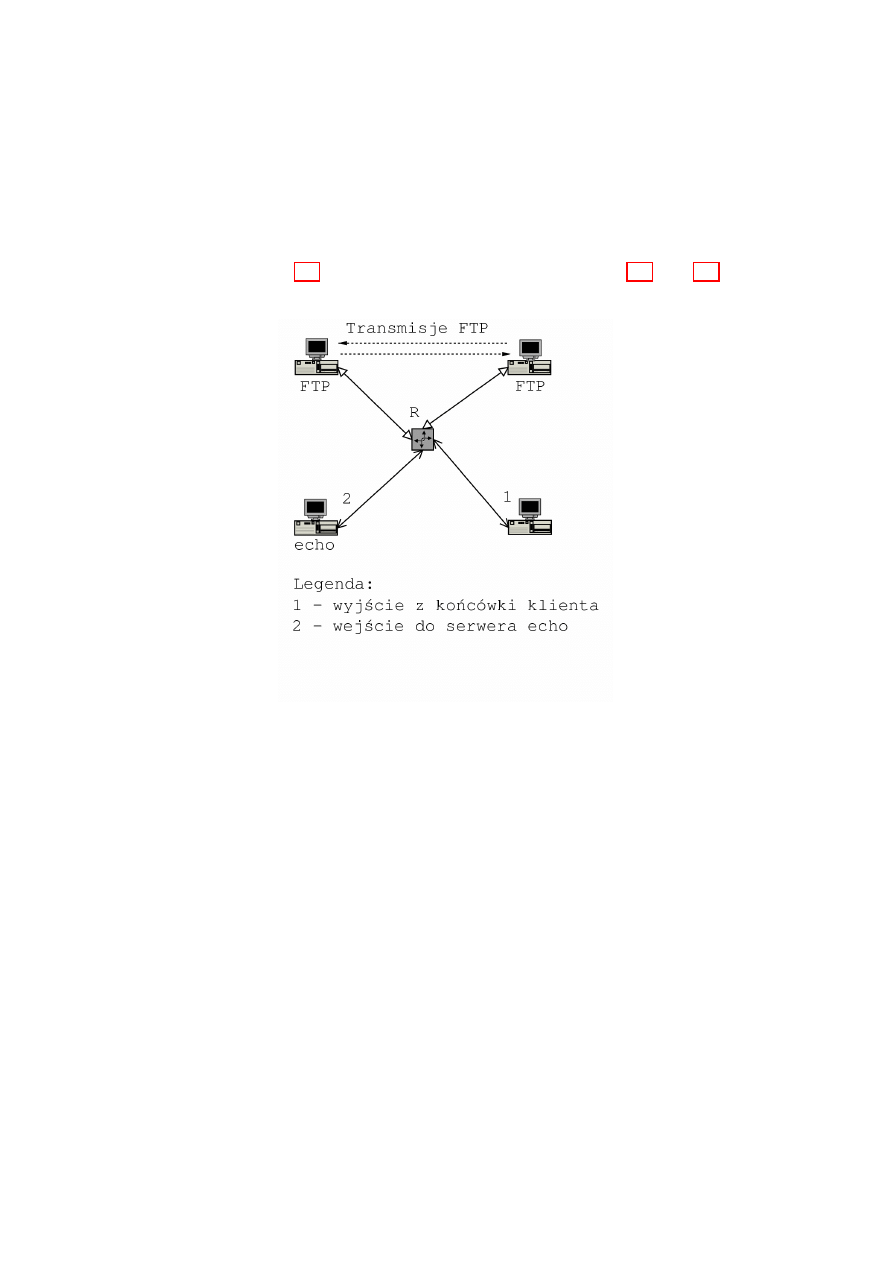
Do lo˙zono kolejne zak l´
ocenie w postaci drugiej transmisji FTP, po czym
wykonano pomiary op´
o´
znie´
n przekazywania pakiet´
ow. Sytuacja ta przedsta-
wiona jest na rys. 5.7. U´srednione wyniki znajduj
,
a si
,
Rysunek 5.7: Transmisja echo przy po l
,
aczeniu przez ruter zak l´
ocana przez
dwie transmisje FTP
70
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000020
0.135074
0.020964
20
0.02
0.000021
0.161962
0.030675
30
0.03
0.000021
0.186652
0.039930
40
0.04
0.000022
0.155015
0.049483
50
0.05
0.000023
0.130363
0.059711
60
0.06
0.000023
0.169308
0.069262
70
0.07
0.000023
0.211906
0.079205
80
0.08
0.072677
0.134711
0.089510
90
0.09
0.041039
0.148767
0.098977
100
0.1
0.048513
0.207868
0.109949
1000
1
0.995435
1.000142
0.999996
Tablica 5.6: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy dw´
och transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001219
0.132987
0.021038
20
0.02
0.001240
0.148864
0.030129
30
0.03
0.001046
0.187965
0.039930
40
0.04
0.001424
0.148929
0.048757
50
0.05
0.001376
0.129185
0.059427
60
0.06
0.001376
0.169068
0.069036
70
0.07
0.001363
0.193549
0.078719
80
0.08
0.043899
0.128606
0.089456
90
0.09
0.016620
0.149602
0.099032
100
0.1
0.012277
0.226049
0.109876
1000
1
0.925434
1.063195
1.000212
Tablica 5.7: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy dw´
och transmisjach FTP
71
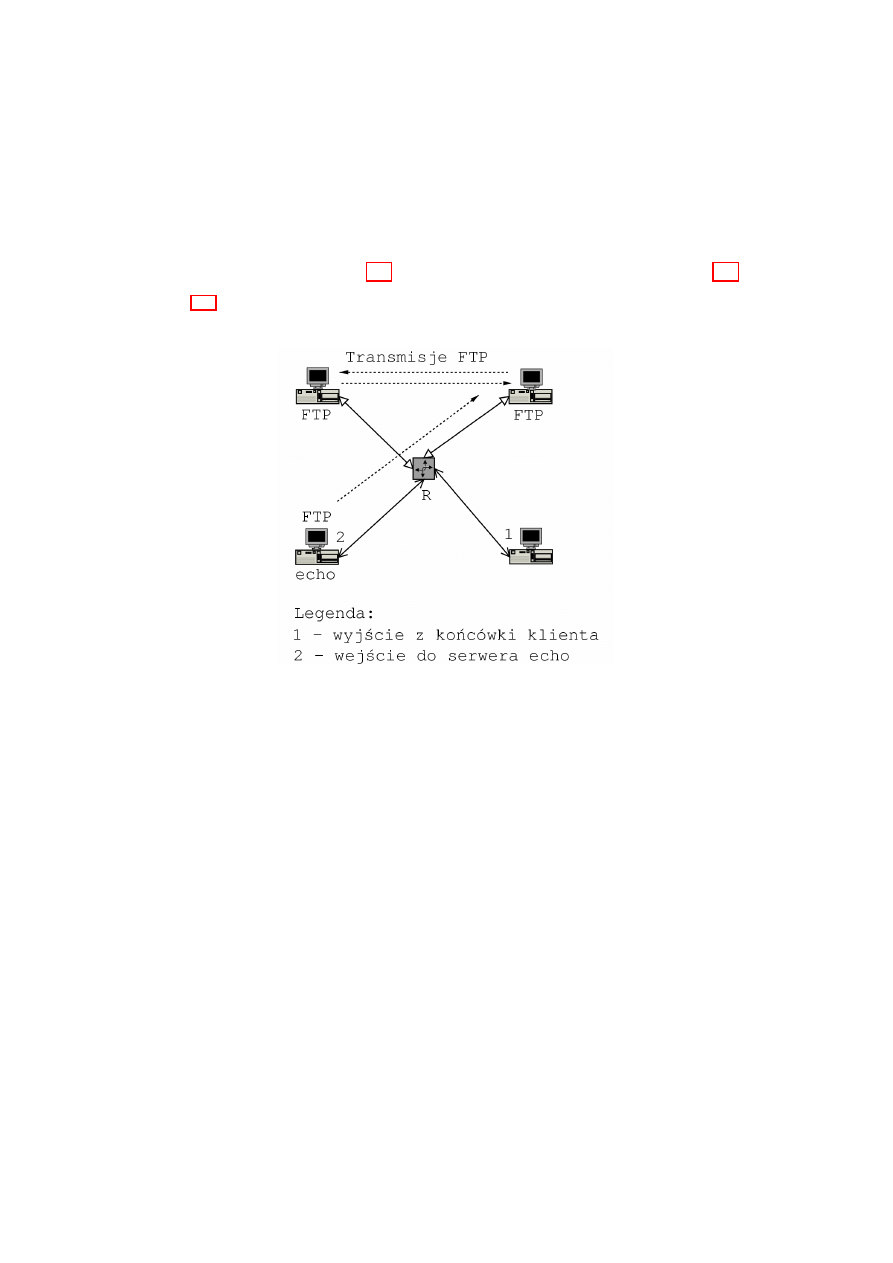
Do lo˙zono dodatkowe zak l´
ocenie w postaci trzeciej transmisji FTP, po
czym wykonano pomiary op´
o´
znie´
n przekazywania pakiet´
ow. Sytuacja ta
przedstawiona jest na rys. 5.8. U´srednione wyniki znajduj
,
a si
,
e w tab. 5.8
oraz 5.9.
Rysunek 5.8: Transmisja echo przy po l
,
aczeniu przez ruter zak l´
ocana przez
trzy transmisje FTP
72
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.232668
0.023340
20
0.02
0.000022
0.256349
0.033539
30
0.03
0.000022
0.199251
0.040567
40
0.04
0.000022
0.235794
0.049922
50
0.05
0.000023
0.119680
0.059364
60
0.06
0.000024
0.182089
0.069230
70
0.07
0.000023
0.255396
0.079957
80
0.08
0.000024
0.182322
0.089056
90
0.09
0.005904
0.191247
0.099005
100
0.1
0.000024
0.240286
0.109862
1000
1
0.991639
1.000129
0.999957
Tablica 5.8: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy trzech transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001053
0.232879
0.023613
20
0.02
0.001208
0.249911
0.033465
30
0.03
0.001028
0.207301
0.040671
40
0.04
0.001044
0.228850
0.049883
50
0.05
0.001406
0.120586
0.059943
60
0.06
0.001206
0.185317
0.069109
70
0.07
0.001220
0.254266
0.079760
80
0.08
0.001220
0.187819
0.089140
90
0.09
0.004323
0.194543
0.099391
100
0.1
0.001392
0.240055
0.109731
1000
1
0.939382
1.053048
0.999843
Tablica 5.9: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy trzech transmisjach FTP
73
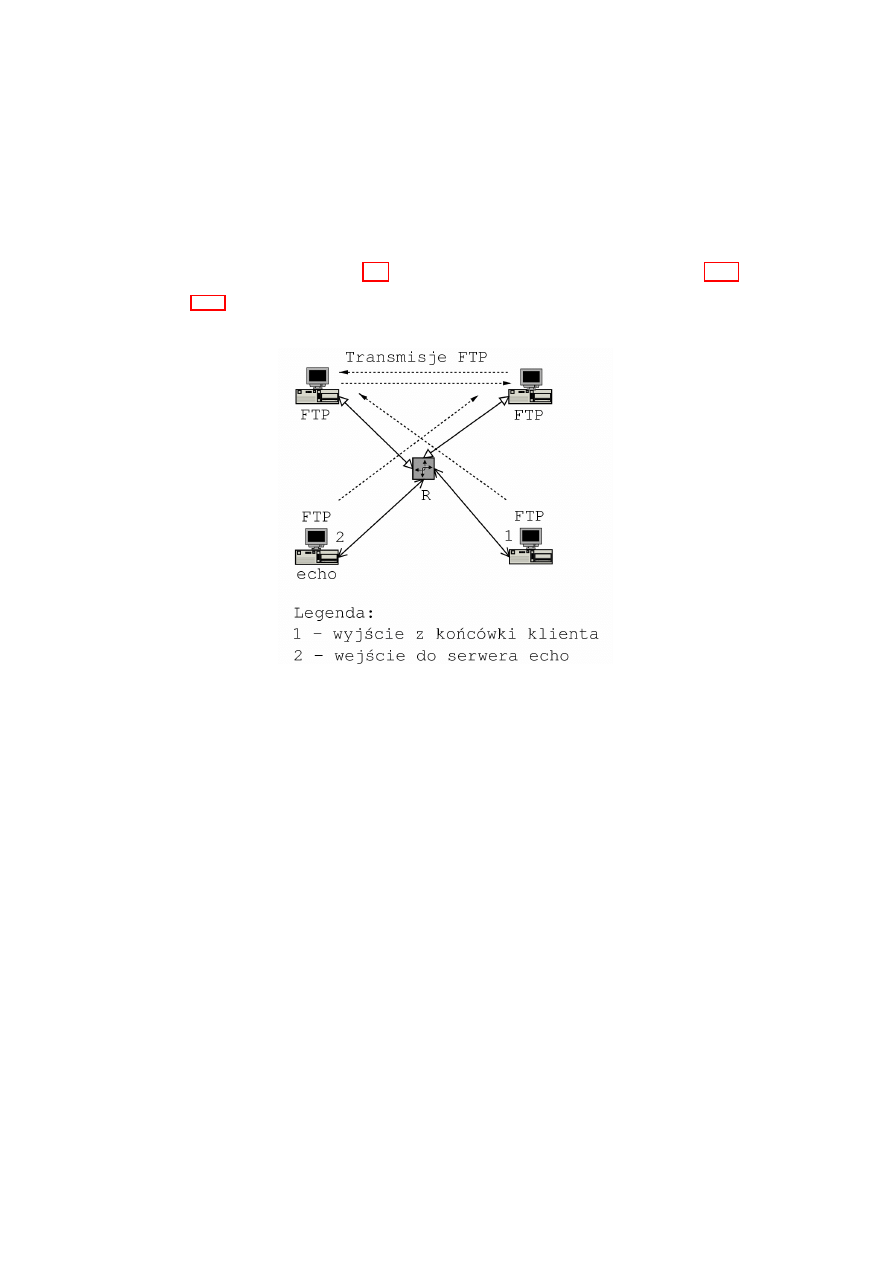
Do lo˙zono dodatkowe zak l´
ocenie w postaci czwartej transmisji FTP, po
czym wykonano pomiary op´
o´
znie´
n przekazywania pakiet´
ow. Sytuacja ta
przedstawiona jest na rys. 5.9. U´srednione wyniki znajduj
,
a si
,
e w tab. 5.10
oraz 5.11.
Rysunek 5.9: Transmisja echo przy po l
,
aczeniu przez ruter zak l´
ocana przez
cztery transmisje FTP
74
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000020
0.114798
0.006528
20
0.02
0.000021
0.114269
0.005555
30
0.03
0.000021
0.082949
0.003302
40
0.04
0.000020
0.082614
0.004843
50
0.05
0.000021
0.073251
0.008533
60
0.06
0.000021
0.072662
0.007106
70
0.07
0.000020
0.109462
0.004978
80
0.08
0.000020
0.143179
0.003893
90
0.09
0.000020
0.080411
0.004719
100
0.1
0.000020
4.911110
0.010326
1000
1
0.000020
0.087505
0.002912
Tablica 5.10: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy czterech transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.178015
0.022632
20
0.02
0.000022
0.219057
0.032522
30
0.03
0.000023
0.206526
0.040703
40
0.04
0.000020
6.495322
0.162033
50
0.05
0.000021
5.386366
0.153751
60
0.06
0.000022
0.225404
0.068525
70
0.07
0.077640
0.238317
0.080825
80
0.08
0.000023
0.244727
0.089026
90
0.09
0.031520
0.164517
0.098994
100
0.1
0.000022
13.355381
0.231340
1000
1
0.997739
1.000608
1.000017
Tablica 5.11: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy czterech transmisjach FTP
75
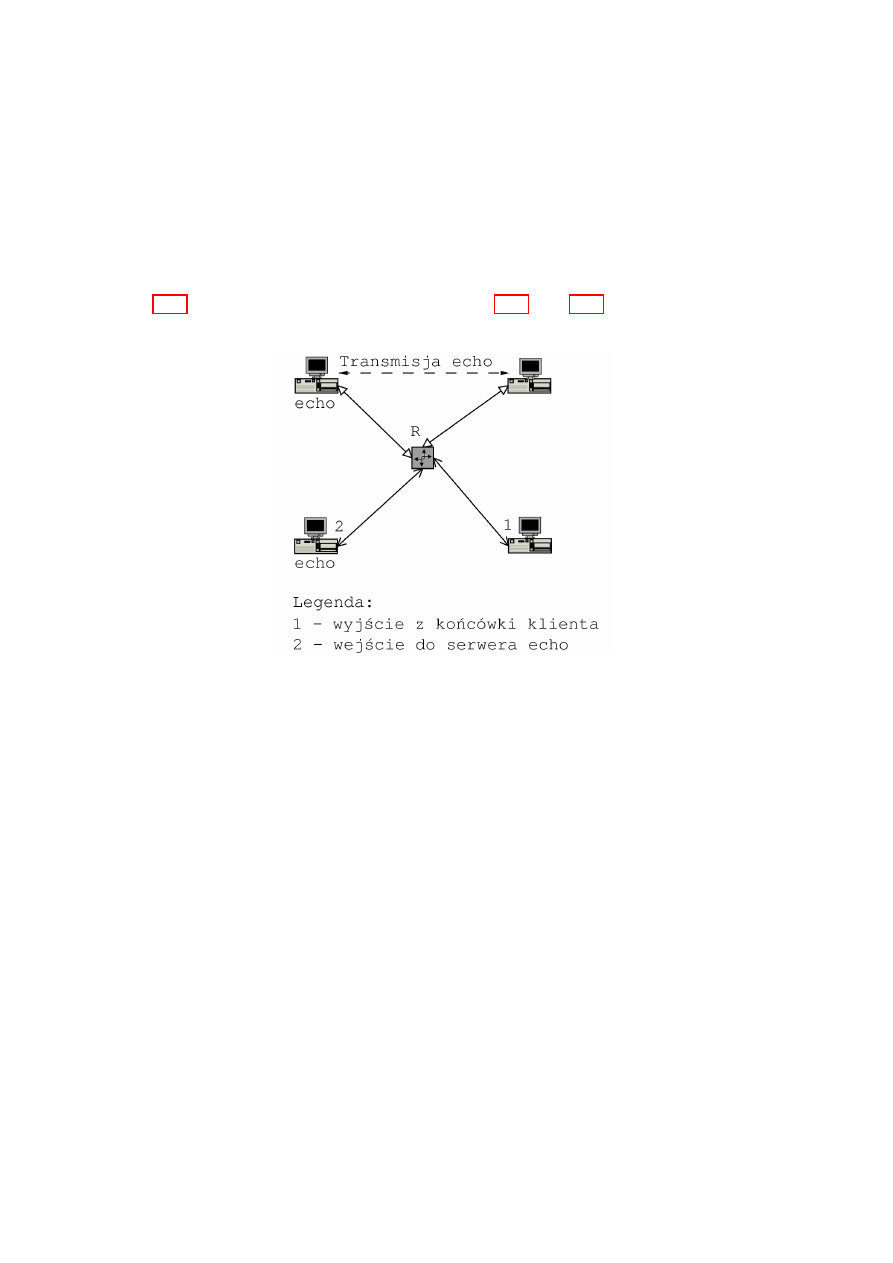
Powr´
ocono do sytuacji bez transmisji FTP, ale do lo˙zono dodatkowe za-
k l´
ocenie w postaci dodatkowej transmisji echo, po czym wykonano pomiary
op´
o´
znie´
n przekazywania pakiet´
ow. Sytuacja ta przedstawiona jest na rys.
5.10. U´srednione wyniki znajduj
,
a si
,
Rysunek 5.10: Transmisja echo przy po l
,
aczeniu przez ruter zak l´
ocana przez
drug
,
a transmisj
,
e echo
76
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.017988
0.019940
0.019784
20
0.02
0.029138
0.029732
0.029698
30
0.03
0.000024
0.290135
0.039589
40
0.04
0.048844
0.049546
0.049500
50
0.05
0.058531
0.059437
0.059400
60
0.06
0.068518
0.069328
0.069302
70
0.07
0.078329
0.079287
0.079202
80
0.08
0.084922
0.093304
0.089106
90
0.09
0.098163
0.099035
0.099005
100
0.1
0.107975
0.115925
0.109006
1000
1
0.999263
1.000068
1.000034
Tablica 5.12: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy r´
ownoleg lej transmisji echo
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.017645
0.020376
0.019781
20
0.02
0.029099
0.029778
0.029700
30
0.03
0.001015
0.290531
0.039591
40
0.04
0.048828
0.049568
0.049504
50
0.05
0.058532
0.059475
0.059404
60
0.06
0.068472
0.069381
0.069307
70
0.07
0.078316
0.079317
0.079208
80
0.08
0.083390
0.094833
0.089111
90
0.09
0.098124
0.099445
0.099013
100
0.1
0.107885
0.115580
0.109014
1000
1
0.999300
1.000188
1.000116
Tablica 5.13: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy r´
ownoleg lej transmisji echo
77
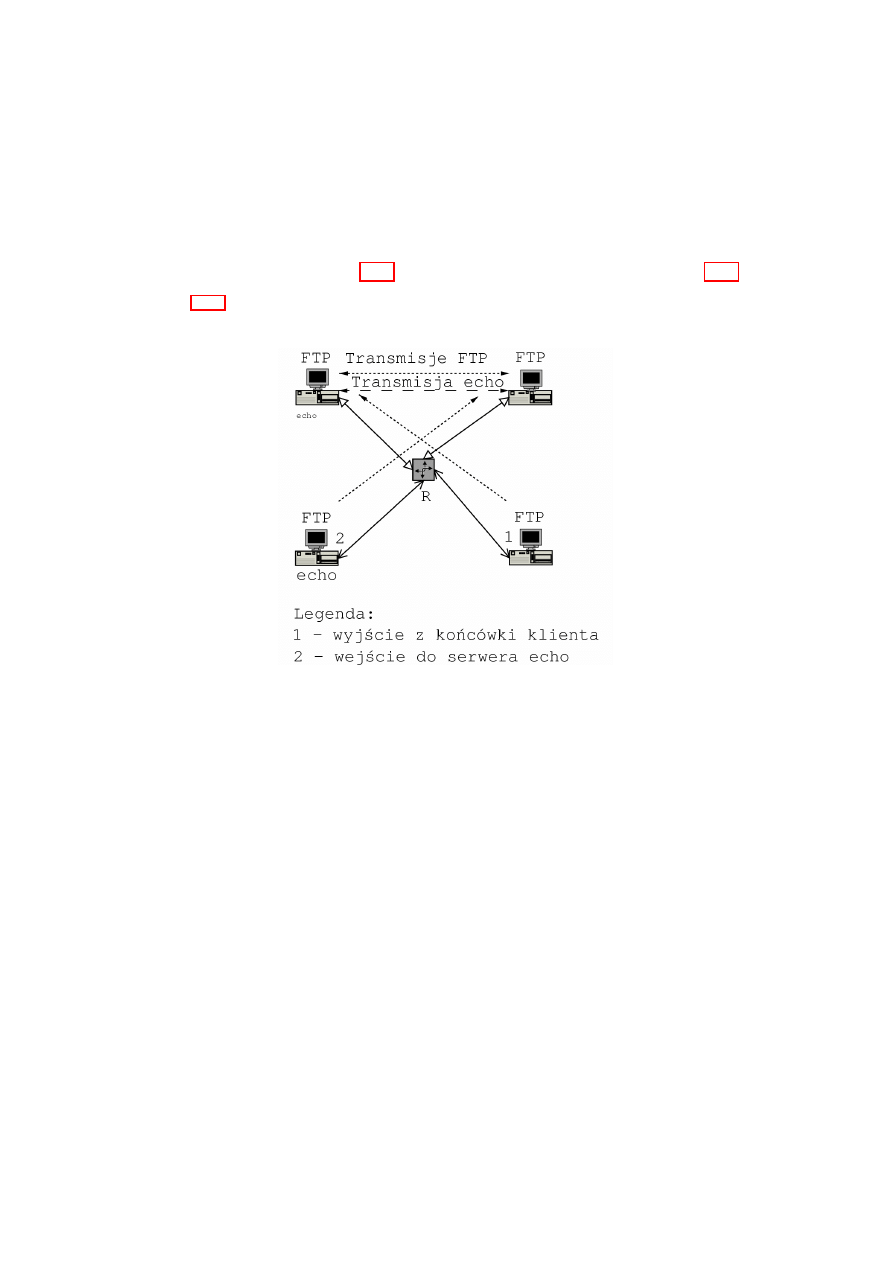
Do lo˙zono dodatkowe zak l´
ocenie w postaci czterech transmisji FTP, po
czym wykonano pomiary op´
o´
znie´
n przekazywania pakiet´
ow. Sytuacja ta
przedstawiona jest na rys. 5.11. U´srednione wyniki znajduj
,
a si
,
e w tab. 5.14
oraz 5.15.
Rysunek 5.11: Transmisja echo przy po l
,
aczeniu przez ruter zak l´
ocana przez
drug
,
a transmisj
,
e echo oraz cztery transmisje FTP
78
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.107957
0.020479
20
0.02
0.000021
0.175317
0.030805
30
0.03
0.000023
0.234044
0.040552
40
0.04
0.000023
0.154487
0.049577
50
0.05
0.000023
0.142766
0.059421
60
0.06
0.000027
0.226315
0.069261
70
0.07
0.000029
0.168799
0.079191
80
0.08
0.000025
0.230867
0.089201
90
0.09
0.025794
0.171598
0.099111
100
0.1
0.083233
0.133768
0.108908
1000
1
0.991799
1.144377
1.001479
Tablica 5.14: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy pi
,
eciu r´
ownoleg lych transmisjach
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000018
0.122161
0.020952
20
0.02
0.000018
0.216222
0.030725
30
0.03
0.001189
0.224939
0.040922
40
0.04
0.001202
0.210858
0.050777
50
0.05
0.001306
0.153896
0.059945
60
0.06
0.001300
0.219455
0.069420
70
0.07
0.001204
0.166524
0.079882
80
0.08
0.001404
0.291819
0.090090
90
0.09
0.035026
0.205485
0.099737
100
0.1
0.038219
0.182717
0.109556
1000
1
0.932953
1.137455
1.001810
Tablica 5.15: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy pi
,
eciu r´
ownoleg lych transmisjach
79
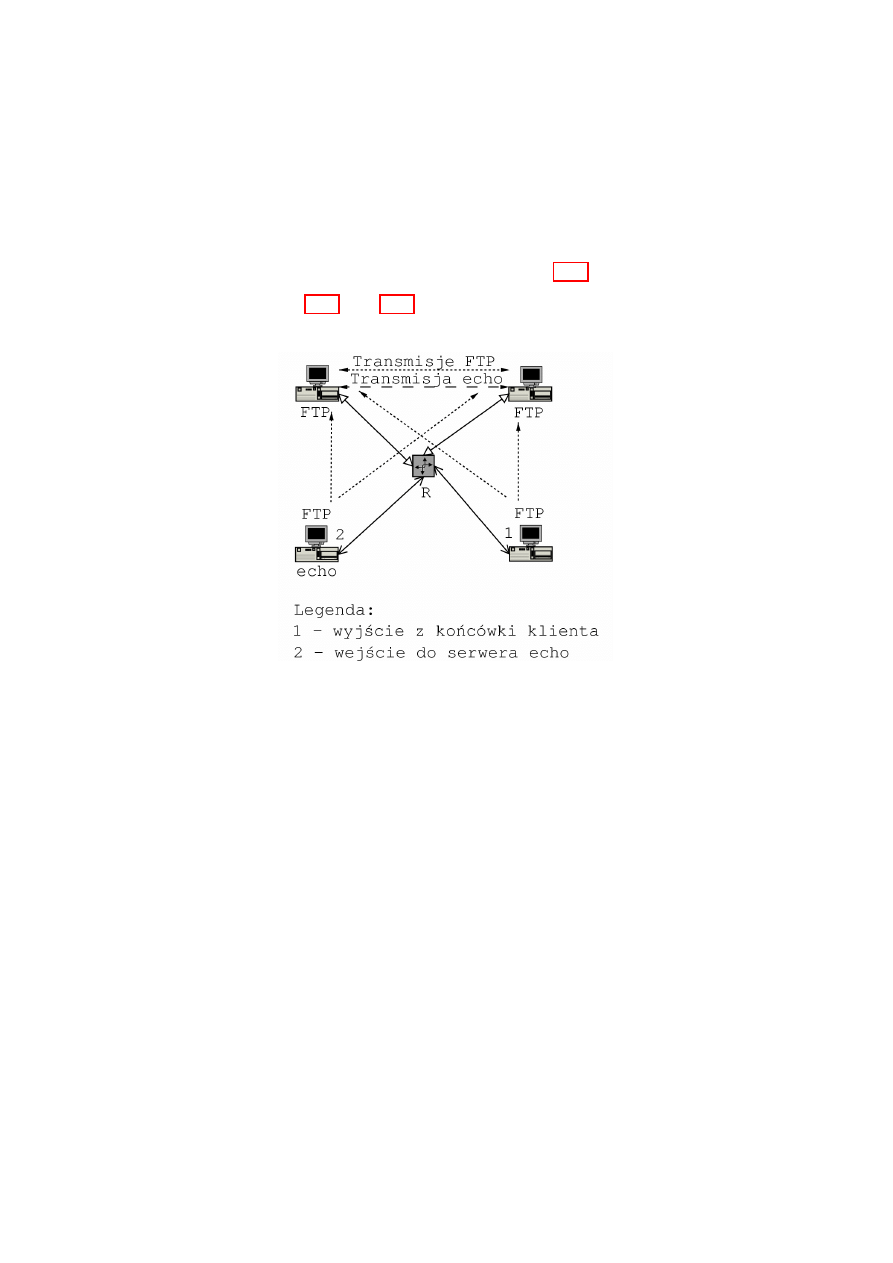
Do lo˙zono dodatkowe zak l´
ocenie w postaci dodatkowej transmisji echo oraz
sze´sciu transmisji FTP, a nast
,
epnie wykonano pomiary op´
o´
znie´
n przekazywa-
nia pakiet´
ow. Sytuacja ta przedstawiona jest na rys. 5.12. U´srednione wyniki
znajduj
,
a si
,
Rysunek 5.12: Transmisja echo przy po l
,
aczeniu przez ruter zak l´
ocana przez
drug
,
a transmisj
,
e echo oraz sze´s´
c transmisji FTP
80
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000023
0.193585
0.022773
20
0.02
0.000022
0.120375
0.021131
30
0.03
0.000023
0.185401
0.030935
40
0.04
0.000024
0.129402
0.039755
50
0.05
0.000026
0.141291
0.049530
60
0.06
0.000025
0.164876
0.059752
70
0.07
0.000025
0.152054
0.069258
80
0.08
0.029578
0.128873
0.079124
90
0.09
0.055432
0.120149
0.089086
100
0.1
0.095892
0.121997
0.108919
1000
1
0.991908
1.139237
1.001561
Tablica 5.16: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy siedmiu r´
ownoleg lych transmisjach
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000855
0.114927
0.021378
20
0.02
0.001040
0.199910
0.031439
30
0.03
0.000968
0.120478
0.040150
40
0.04
0.001206
0.154312
0.050262
50
0.05
0.001218
0.186794
0.061117
60
0.06
0.001221
0.186878
0.070839
70
0.07
0.021498
0.147259
0.080603
80
0.08
0.023551
0.153349
0.090087
90
0.09
0.001419
0.174340
0.099845
100
0.1
0.066775
0.162005
0.110097
1000
1
0.823181
1.133839
1.002453
Tablica 5.17: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy siedmiu r´
ownoleg lych transmisjach
81

Rozdzia l 6
Badania wykonane
z w l
,
aczonymi mechanizmami
QoS
6.1
Cel bada´
n
Badania polega ly na zmierzeniu wp lywu r´
o˙znych czynnik´
ow (po´srednic-
two rutera w transmisji danych, transmisje FTP wykonywane w tle, druga
transmisja interaktywna wykonywana w tle) na op´
o´
znienia w przekazywaniu
pakiet´
ow IP (ang. jitter). Badania zosta ly przeprowadzone z wykorzystaniem
stanowiska opisanego w rozdz. 5. Na badania te sk lada ly si
,
e pomiary transmi-
sji danych przez obci
,
a˙zony ruter dzia laj
,
acy z wykorzystaniem mechanizm´
ow
QoS. Celem tych bada´
n by lo sprawdzenie, czy mechanizmy QoS mog
,
a przy-
bli˙zy´
c op´
o´
znienia przekazywania pakiet´
ow przez obci
,
a˙zony ruter do sytuacji,
gdy ruter nie jest obci
,
a˙zony (badania opisane w rozdz. 5).
82
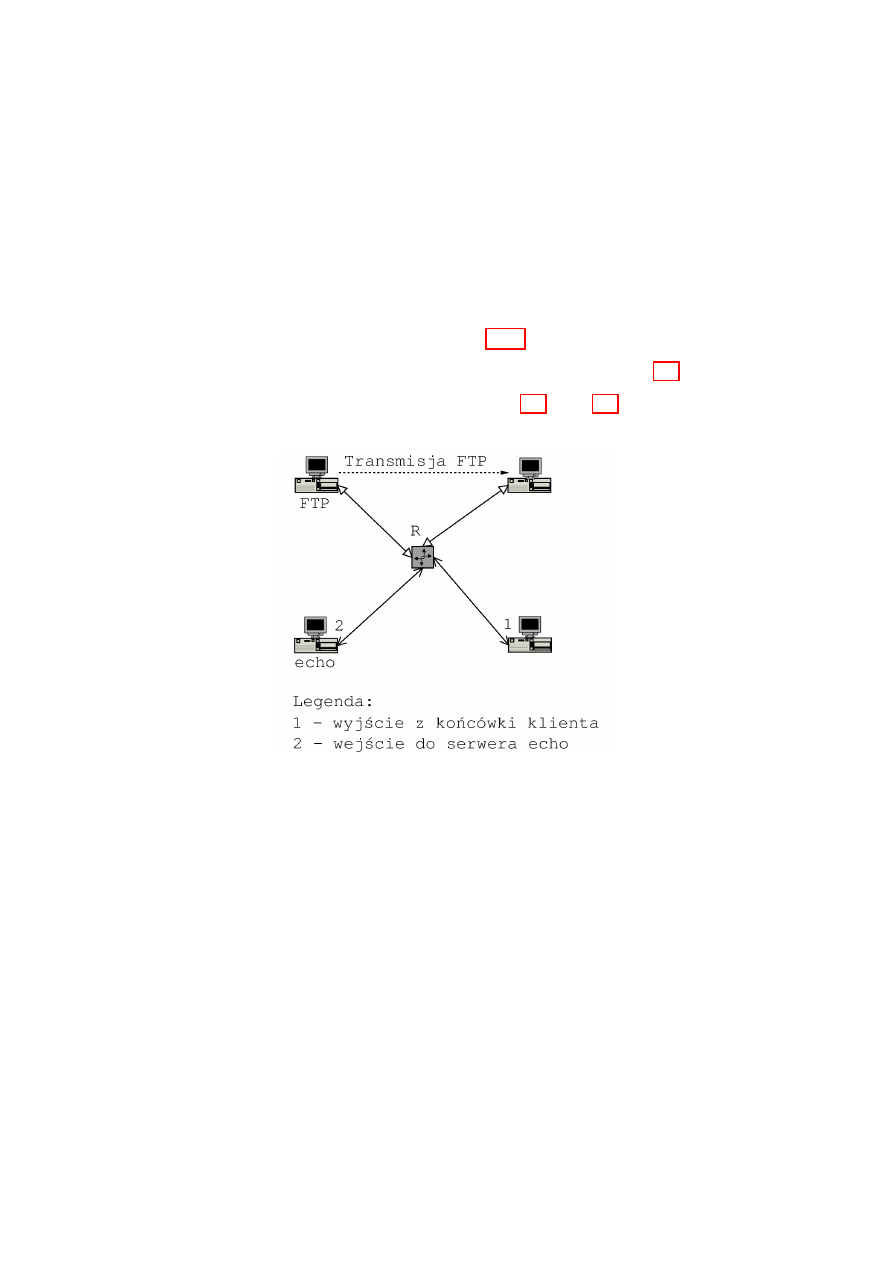
6.2
Badania z wykorzystaniem algorytmu
PRIO
Zmierzono op´
o´
znienia przekazywania pakiet´
ow w trakcie transmisji z wy-
korzystaniem algorytmu PRIO (podsekcja 3.1.2. Dodatkowym obci
,
a˙zeniem
by la jedna transmisja FTP. Sytuacja ta przedstawiona jest na rys. 6.1. U´sred-
nione wyniku tego pomiaru znajduj
,
a si
,
Rysunek 6.1: Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji FTP
83
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.085218
0.019830
100
0.1
0.095642
0.118764
0.108861
1000
1
0.993492
1.000253
0.999976
Tablica 6.1: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy jednej r´
ownoleg lej transmisji FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001048
0.080605
0.019849
100
0.1
0.068598
0.140607
0.108881
1000
1
0.964936
1.023353
0.999971
Tablica 6.2: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy jednej r´
ownoleg lej transmisji FTP
84
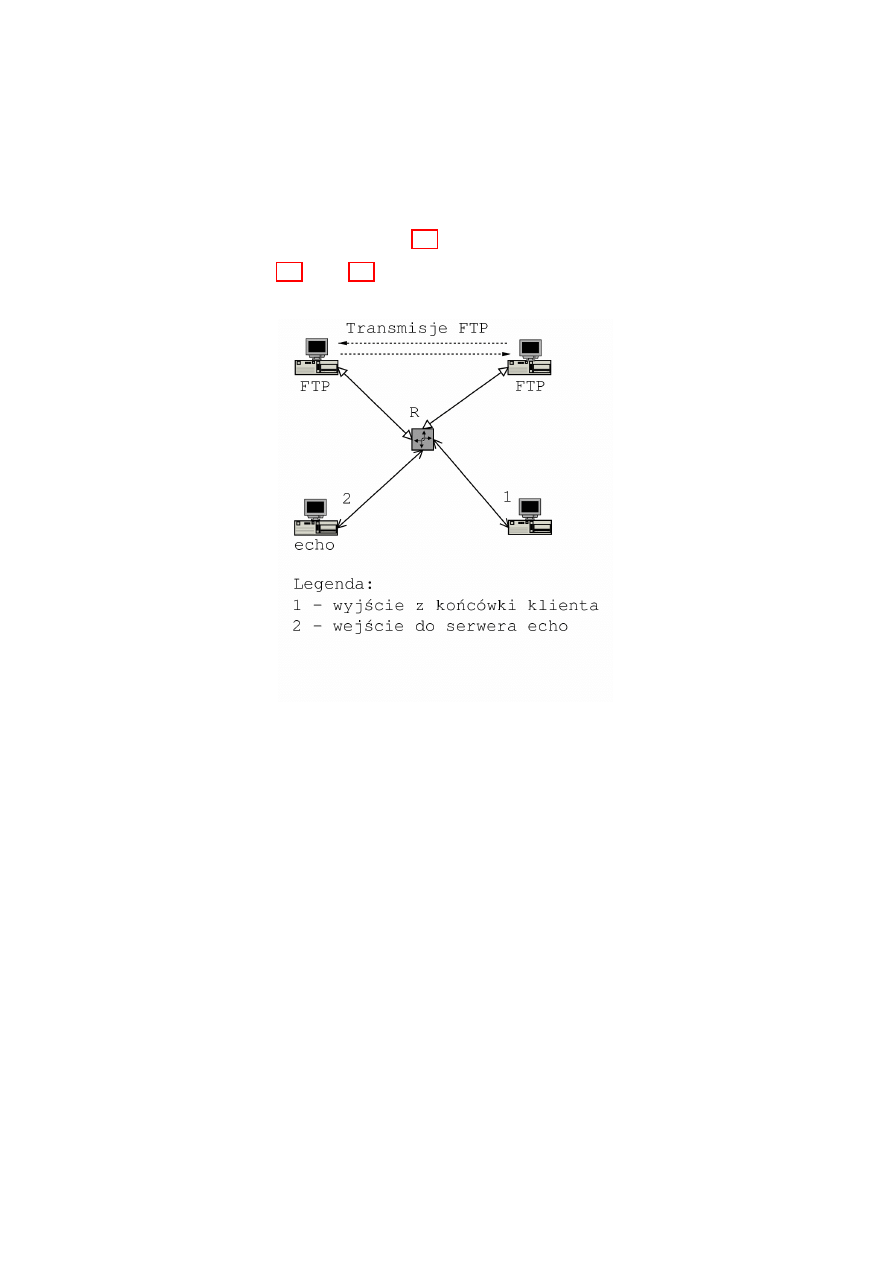
Do lo˙zono dodatkowe zak l´
ocenie w postaci dw´
och transmisji FTP. Sytu-
acja ta przedstawiona jest na rys. 6.2. U´srednione wyniki pomiar´
ow zamiesz-
czone s
,
Rysunek 6.2: Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowych dw´
och transmisjach FTP
85

Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.104263
0.020269
100
0.1
0.098339
0.143924
0.109166
1000
1
0.997552
1.000081
1.000017
Tablica 6.3: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy dw´
och transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001161
0.099931
0.020403
100
0.1
0.059071
0.168140
0.109281
1000
1
0.926992
1.061800
1.000059
Tablica 6.4: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy dw´
och transmisjach FTP
86
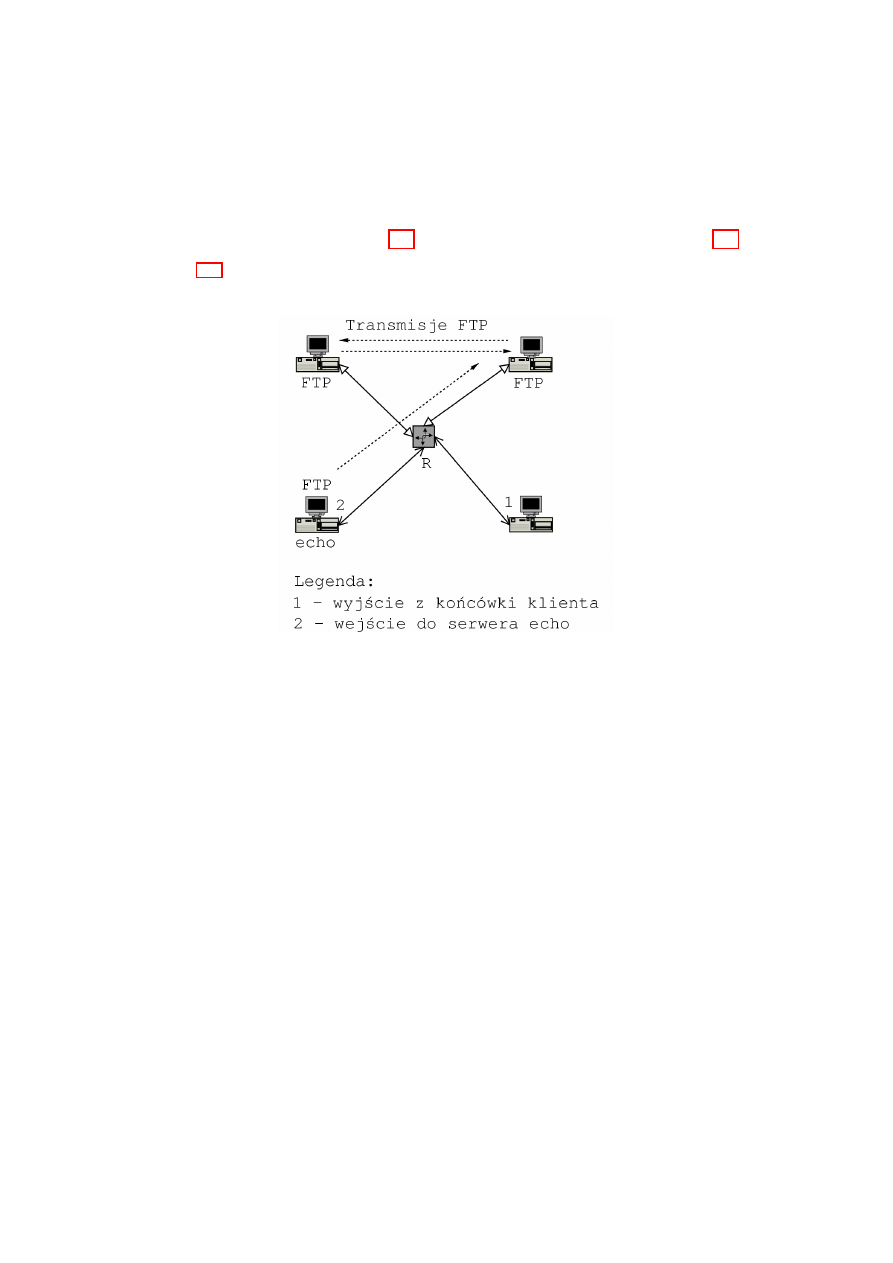
Do lo˙zono dodatkowe zak l´
ocenie w postaci trzeciej transmisji FTP. Sytu-
acja przedstawiona jest na rys. 6.3. U´srednione wyniki znajduj
,
a si
,
e w tab. 6.5
oraz 6.6.
Rysunek 6.3: Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowych trzech transmisjach FTP
87
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.188033
0.022894
100
0.1
0.036477
0.185305
0.108958
1000
1
0.996380
1.000065
1.000005
Tablica 6.5: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy trzech transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001134
0.185643
0.022971
100
0.1
0.028200
0.188852
0.109223
1000
1
0.903677
1.061431
1.000156
Tablica 6.6: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy trzech transmisjach FTP
88
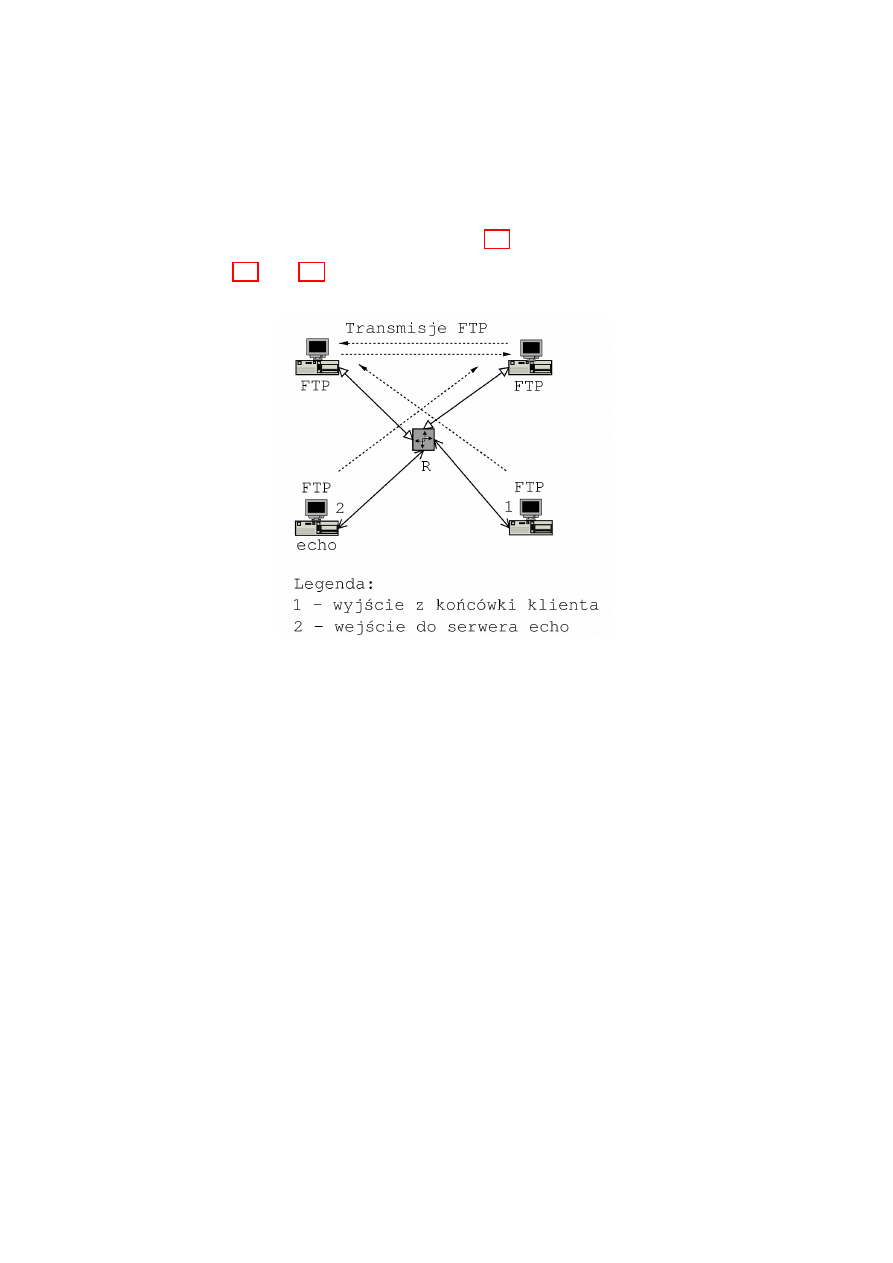
Nast
,
epnie do lo˙zone dodatkowe zak l´
ocenie w postaci czwartej transmisji
FTP. Sytuacja przedstawiona jest na rys. 6.4. U´srednione wyniki znajduj
,
a
si
,
Rysunek 6.4: Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowych czterech transmisjach FTP
89
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000021
0.218573
0.023747
100
0.1
0.013985
0.210690
0.108876
1000
1
0.680404
1.962631
0.997492
Tablica 6.7: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy czterech transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001122
0.215318
0.024141
100
0.1
0.012561
0.208918
0.108853
1000
1
0.658787
2.084703
0.999470
Tablica 6.8: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy czterech transmisjach FTP
90
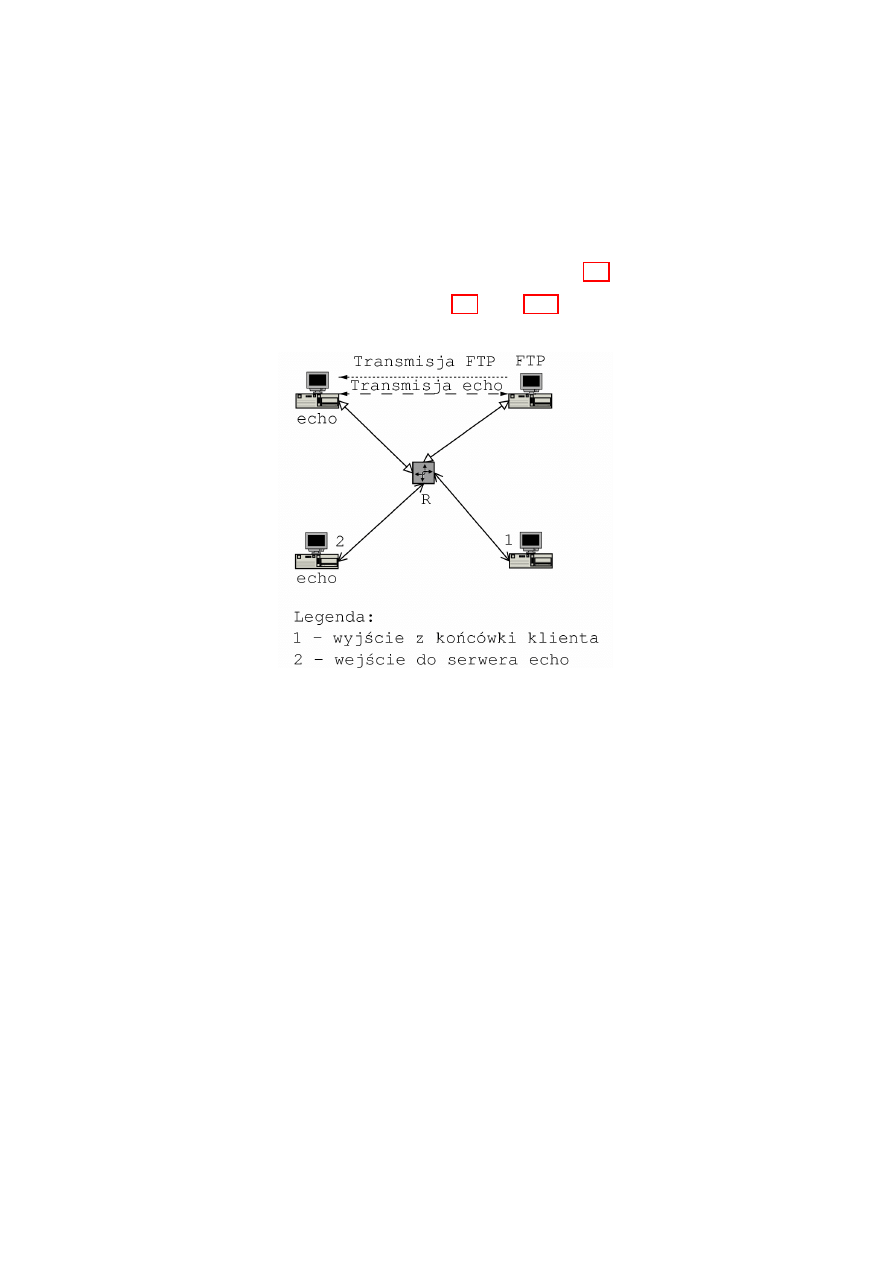
Do lo˙zono drug
,
a transmisj
,
e echo, a ilo´s´
c transmisji FTP zmniejszono do
jednej, po czym zmierzono op´
o´
znienia przekazywania pakiet´
ow w trakcie
transmisji echo. Sytuacja ta przedstawiona jest na rys. 6.5. U´srednione wy-
niku tego pomiaru znajduj
,
a si
,
Rysunek 6.5: Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji echo oraz czterech transmisjach FTP
91
Interwa l czasowy wysy lania
y wysy lania [ms]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.002110
0.079778
0.019891
100
0.101385
0.143802
0.109178
1000
0.993947
1.000080
0.999981
Tablica 6.9: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy r´
ownoleg lej transmisji echo i dodatkowej
transmisji FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001178
0.088238
0.019891
100
0.1
0.082097
0.167983
0.109427
1000
1
0.962866
1.034299
1.000222
Tablica 6.10: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy przy r´
ownoleg lej transmisji echo oraz jednej
transmisji FTP
92
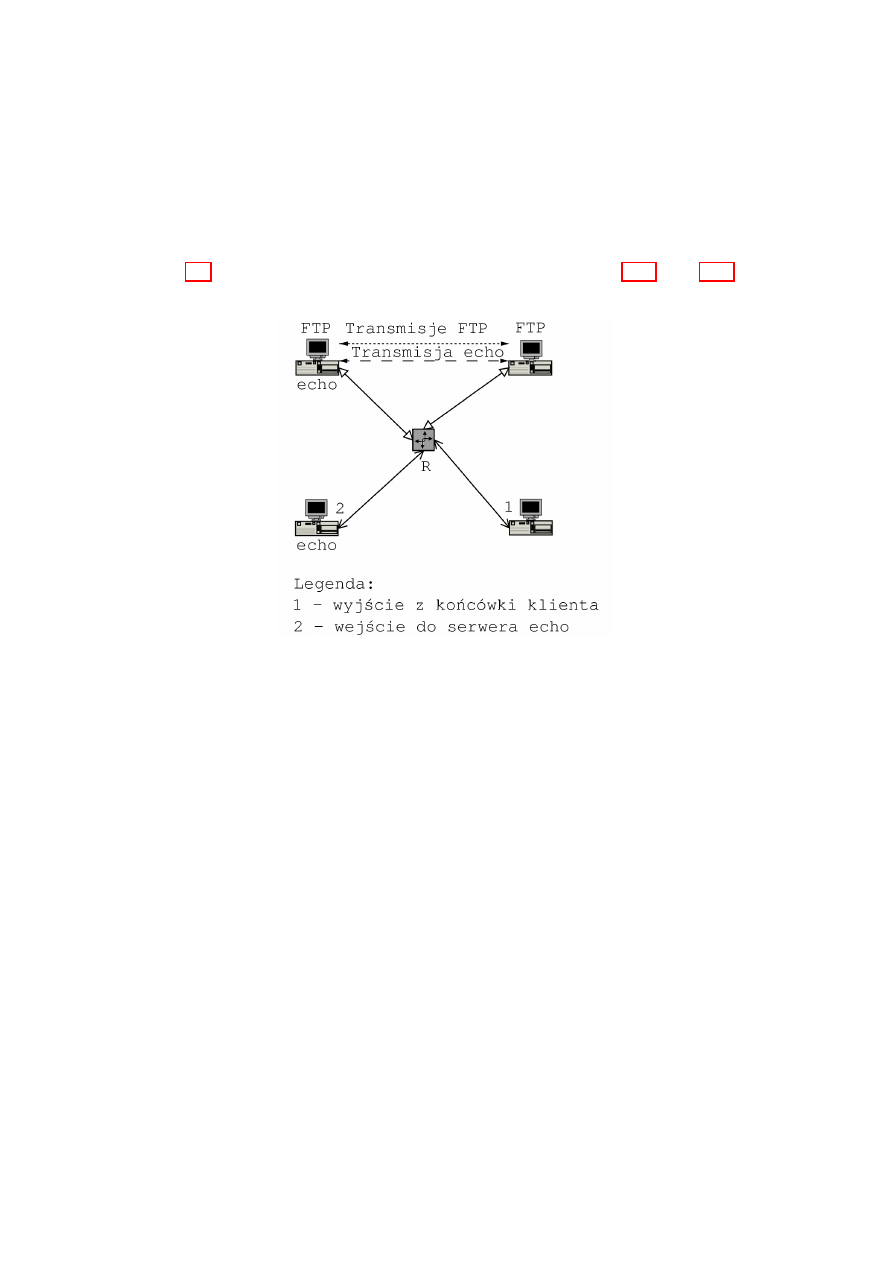
Do lo˙zono drug
,
a transmisj
,
e FTP, po czym zmierzono op´
o´
znienia przekazy-
wania pakiet´
ow w trakcie transmisji echo. Sytuacja ta przedstawiona jest na
rys. 6.6. U´srednione wyniku tego pomiaru znajduj
,
a si
,
Rysunek 6.6: Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji echo oraz dw´
och transmisjach FTP
93
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000021
0.115227
0.020546
100
0.1
0.090363
0.151436
0.109167
1000
1
0.996179
1.000073
1.000003
Tablica 6.11: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy r´
ownoleg lej transmisji echo i dw´
och trans-
misjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001122
0.115419
0.020745
100
0.1
0.065040
0.161493
0.109154
1000
1
0.935454
1.043528
0.999929
Tablica 6.12: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony serwera przy r´
ownoleg lej transmisji echo i dw´
och
transmisjach FTP
94
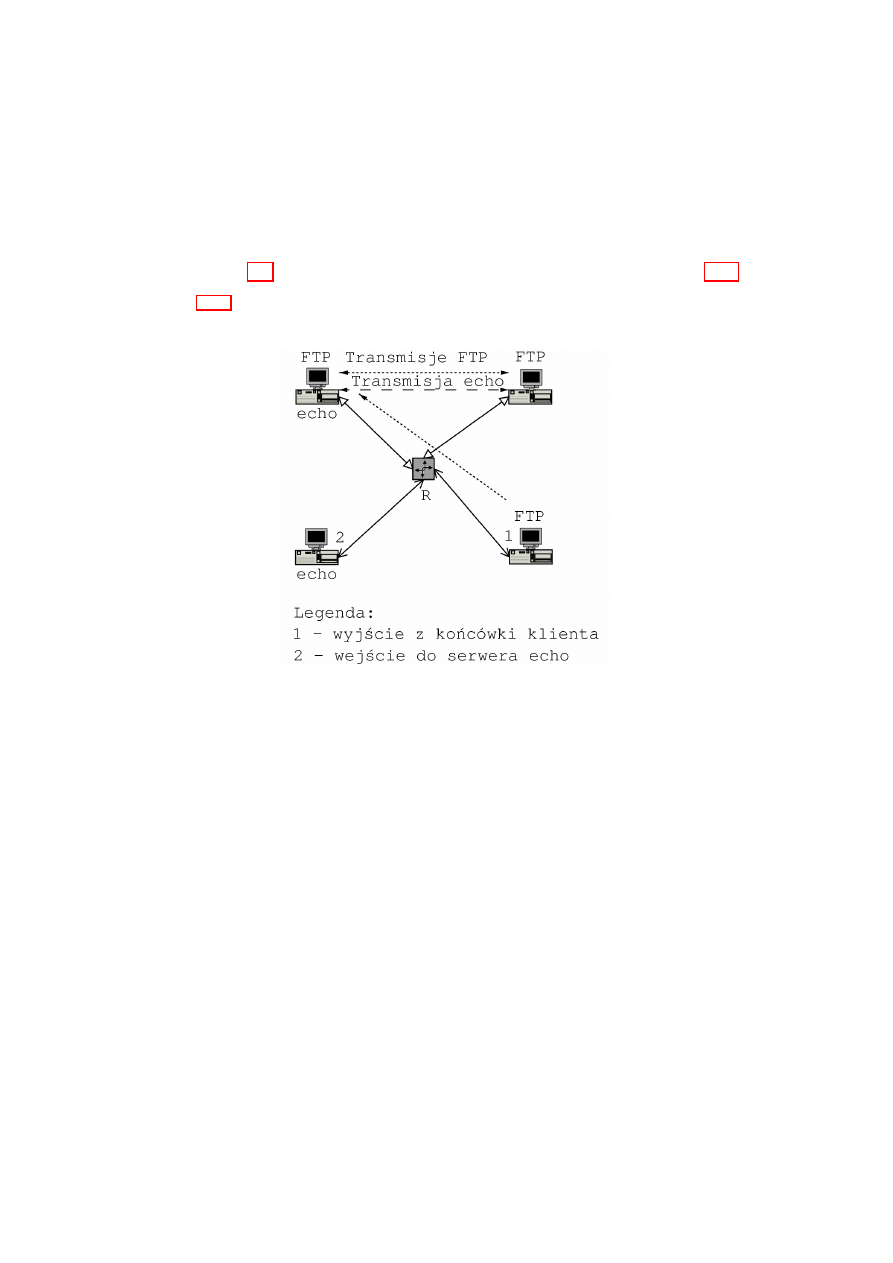
Do lo˙zono trzeci
,
a transmisj
,
e FTP, po czym zmierzono op´
o´
znienia prze-
kazywania pakiet´
ow w trakcie transmisji echo. Sytuacja ta przedstawiona
jest na rys. 6.7. U´srednione wyniku tego pomiaru znajduj
,
a si
,
e w tab. 6.13
oraz 6.14.
Rysunek 6.7: Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji echo oraz trzech transmisjach FTP
95
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.206477
0.023548
100
0.1
0.046517
0.206947
0.109546
1000
1
0.995205
1.000082
0.999993
Tablica 6.13: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy r´
ownoleg lej transmisji echo i trzech transmi-
sjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001143
0.208647
0.023670
100
0.1
0.029283
0.211722
0.109484
1000
1
0.914671
1.058482
1.000026
Tablica 6.14: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony serwera przy r´
ownoleg lej transmisji echo i trzech
transmisjach FTP
96
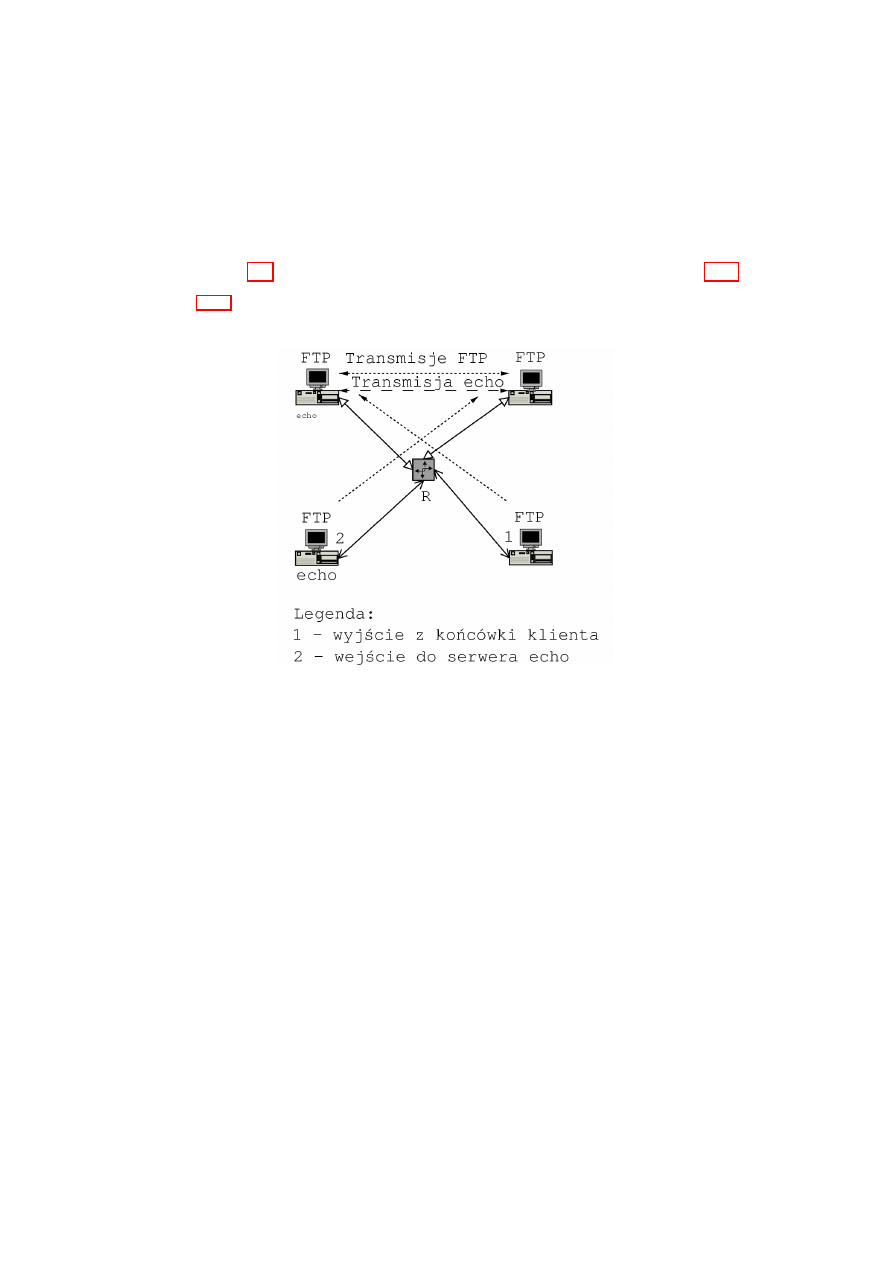
Do lo˙zono czwart
,
a transmisj
,
e echo, po czym zmierzono op´
o´
znienia prze-
kazywania pakiet´
ow w trakcie transmisji echo. Sytuacja ta przedstawiona
jest na rys. 6.8. U´srednione wyniku tego pomiaru znajduj
,
a si
,
e w tab. 6.15
oraz 6.16.
Rysunek 6.8: Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji echo oraz czterech transmisjach FTP
97
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.220649
0.024257
100
0.1
0.046553
0.179133
0.108981
1000
1
0.996028
1.000541
1.000002
Tablica 6.15: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony klienta przy r´
ownoleg lej transmisji echo i czterech
transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001087
0.221625
0.024353
100
0.1
0.019623
0.200774
0.108968
1000
1
0.917508
1.067277
0.999907
Tablica 6.16: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony serwera przy r´
ownoleg lej transmisji echo i czterech
transmisjach FTP
98
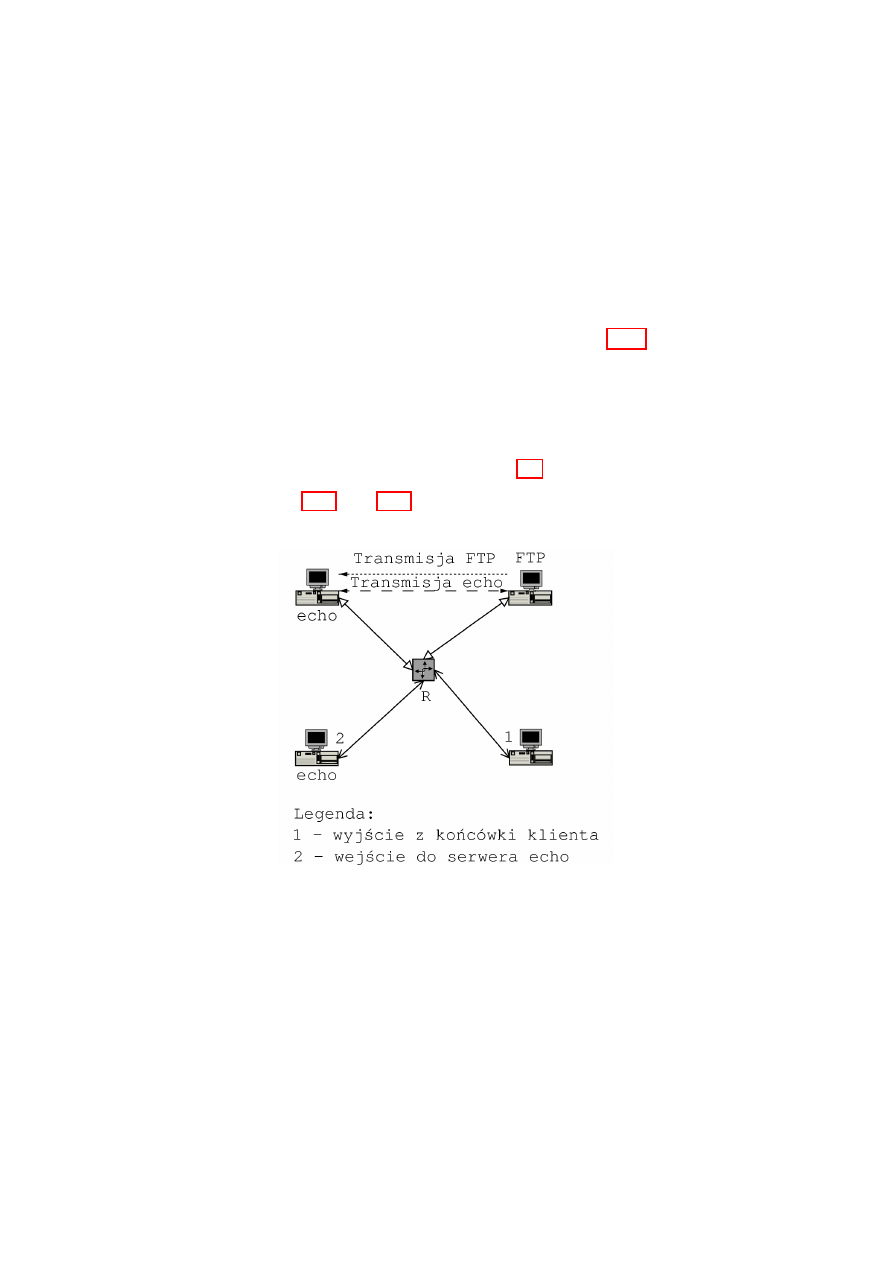
6.3
Badania wykonane z wykorzystaniem al-
gorytmu TBF
Zmierzono op´
o´
znienia przekazywania pakiet´
ow w trakcie transmisji z
wykorzystaniem algorytmu kolejkowania TBF (podsekcja 3.1.3). Algorytm
ten wykorzystany by l do kszta ltowania ruchu pakiet´
ow generowanego przez
transfery FTP.
Zacz
,
eto od zak l´
ocenia w postaci drugiej transmisji echo oraz jednej trans-
misji FTP. Sytuacja przedstawiona jest na rys. 6.9. U´srednione wyniki zgro-
madzone s
,
Rysunek 6.9: Transmisja echo z wykorzystaniem algorytmu TBF przy dodat-
kowej transmisji echo oraz jednej transmisji FTP
99
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000021
0.105156
0.020503
100
0.1
0.098810
0.138890
0.109117
1000
1
0.994620
1.20087
1.002092
Tablica 6.17: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy r´
ownoleg lej transmisji echo i jednej transmisji
FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001227
0.124556
0.024230
100
0.1
0.053717
0.202963
0.128995
1000
1
1.108759
1.475996
1.184452
Tablica 6.18: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony serwera przy r´
ownoleg lej transmisji echo i jednej
transmisji FTP
100
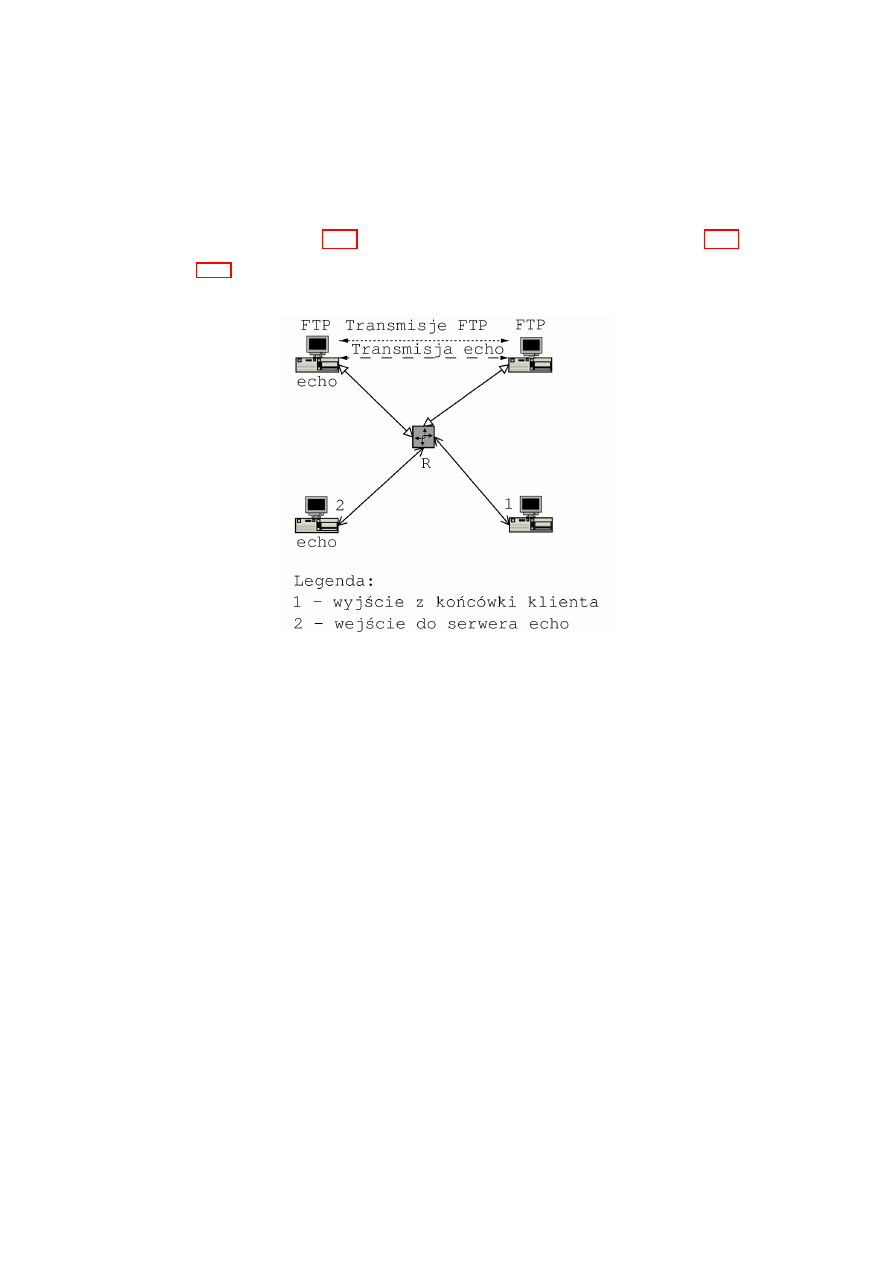
Do lo˙zono zak l´
ocenie w postaci drugiej transmisji FTP. Sytuacja ta przed-
stawiona jest na rys. 6.10. U´srednione wyniki zgromadzone s
,
a w tab. 6.19
oraz 6.20
Rysunek 6.10: Transmisja echo z wykorzystaniem algorytmu TBF przy do-
datkowej transmisji echo oraz dw´
och transmisjach FTP
101
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000022
0.259524
0.025290
100
0.1
0.000023
0.292046
0.108864
1000
1
0.994255
1.000575
0.999985
Tablica 6.19: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony klienta przy r´
ownoleg lej transmisji echo i dw´
och trans-
misjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001025
0.306166
0.029955
100
0.1
0.001168
0.343795
0.128711
1000
1
1.057435
1.291630
1.182050
Tablica 6.20: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony serwera przy r´
ownoleg lej transmisji echo i dw´
och
transmisjach FTP
102
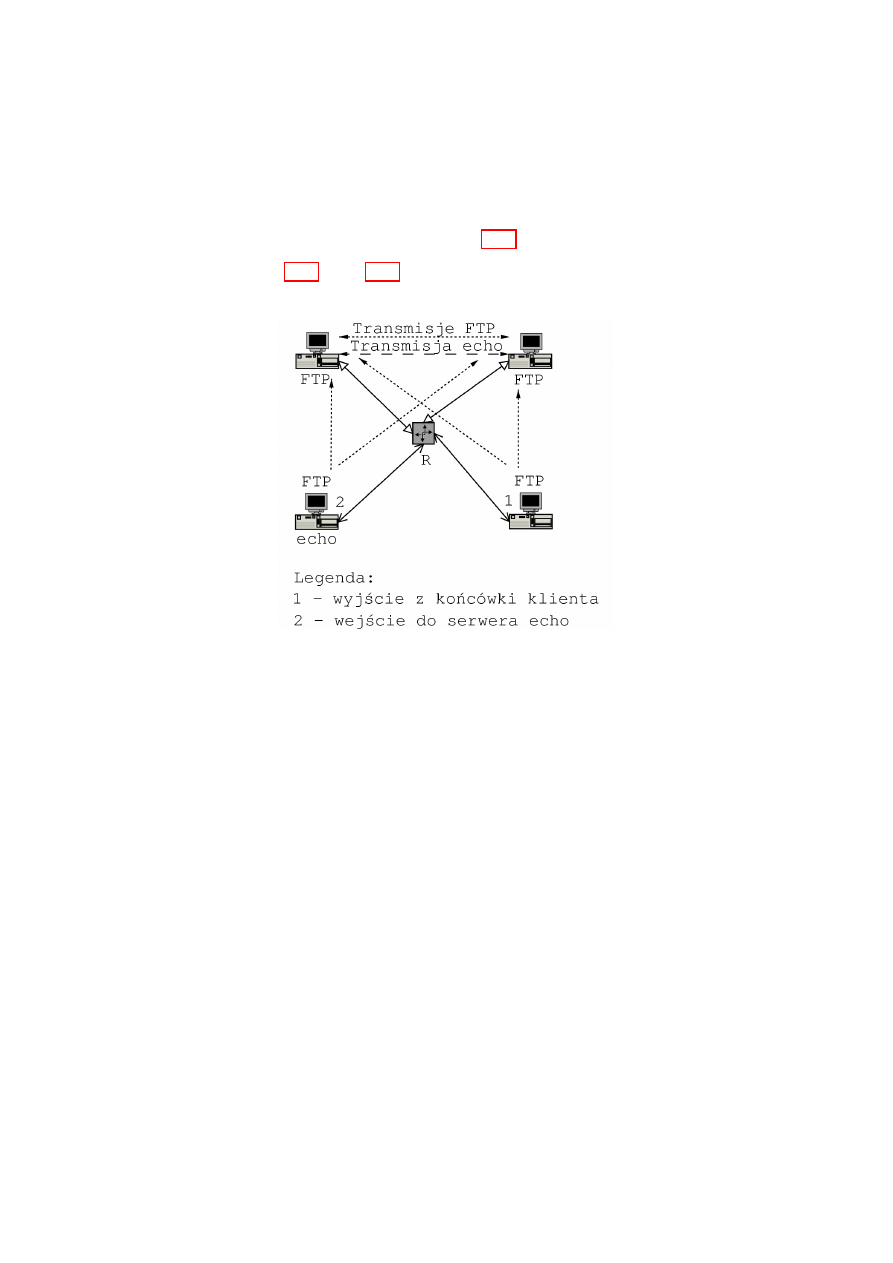
Nast
,
epnie do lo˙zono zak l´
ocenia w postaci dodatkowych czterech transmisji
FTP. Sytuacja przedstawiona jest na rys. 6.11. U´srednione wyniki zgroma-
dzone s
,
Rysunek 6.11: Transmisja echo z wykorzystaniem algorytmu TBF przy do-
datkowej transmisji echo oraz sze´sciu transmisjach FTP
103
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000021
0.494902
0.047233
100
0.1
0.000023
1.177996
0.126182
1000
1
0.307809
1.970862
1.013642
Tablica 6.21: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony klienta przy r´
ownoleg lej transmisji echo i sze´sciu
transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000952
4.737959
0.656889
100
0.1
0.000462
4.982930
0.564265
1000
1
0.000026
4.809246
0.467232
Tablica 6.22: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony serwera przy r´
ownoleg lej transmisji echo i sze´sciu
transmisjach FTP
104
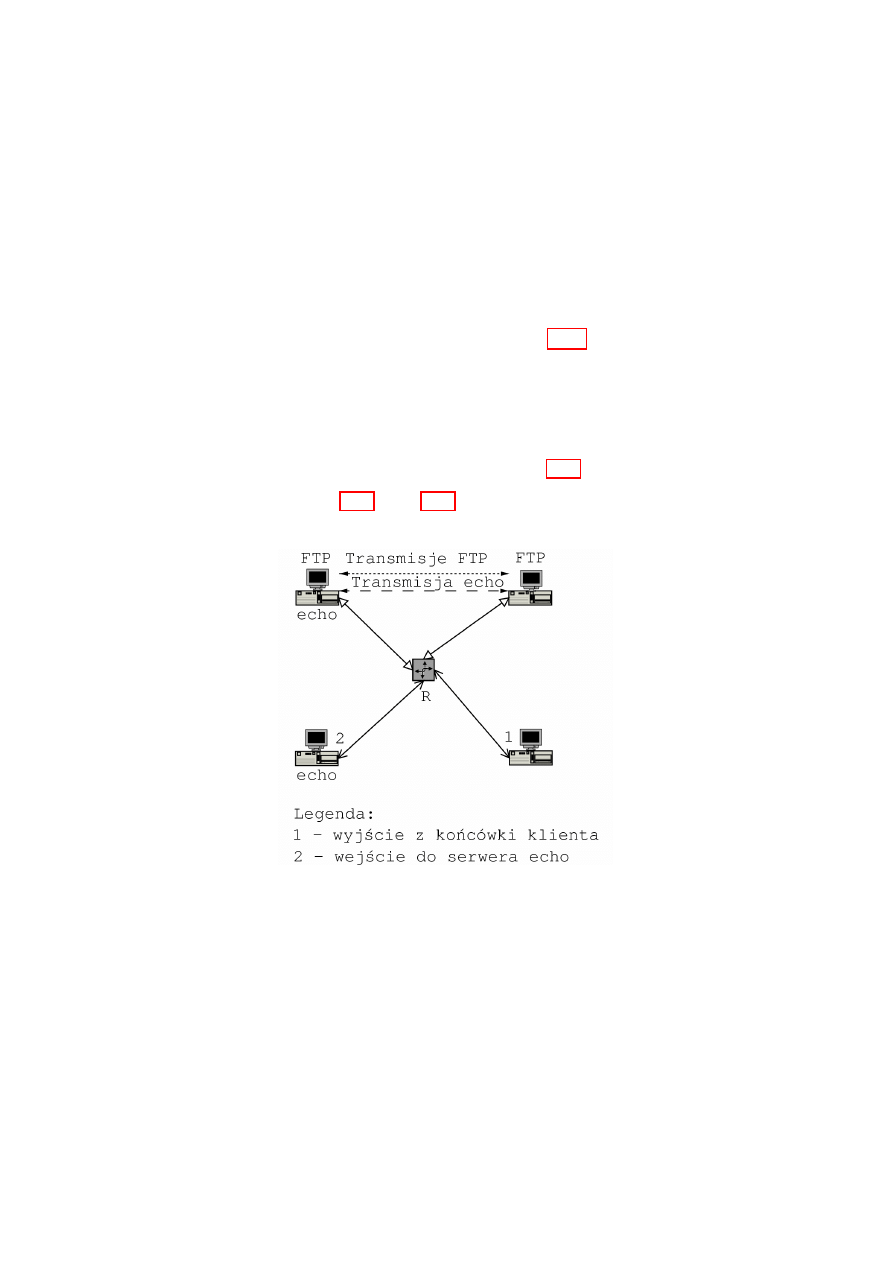
6.4
Badania wykonane z wykorzystaniem al-
gorytmu RED
Zmierzono op´
o´
znienia przekazywania pakiet´
ow w trakcie transmisji z wy-
korzystaniem algorytmu kolejkowania RED (subsec 3.1.5). Algorytm ten wy-
korzystany by l do regulowania ruchu pakiet´
ow generowany w trakcie trans-
misji FTP.
Zacz
,
eto od zak l´
ocenia w postaci drugiej transmisji echo oraz dw´
och trans-
misji FTP. Sytuacja przedstawiona jest na rys.
6.12. U´srednione wyniki
zgromadzone s
,
Rysunek 6.12: Transmisja echo z wykorzystaniem algorytmu RED przy do-
datkowej transmisji echo oraz dw´
och transmisjach FTP
105
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.002406
0.082508
0.020263
100
0.1
0.097322
0.218592
0.110006
1000
1
0.994988
1.000105
0.999991
Tablica 6.23: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony klienta przy r´
ownoleg lej transmisji echo oraz dw´
och
transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001497
0.089278
0.020592
100
0.1
0.044788
0.224570
0.109986
1000
1
0.929579
1.060968
0.999865
Tablica 6.24: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony serwera przy r´
ownoleg lej transmisji echo oraz dw´
och
transmisjach FTP
106
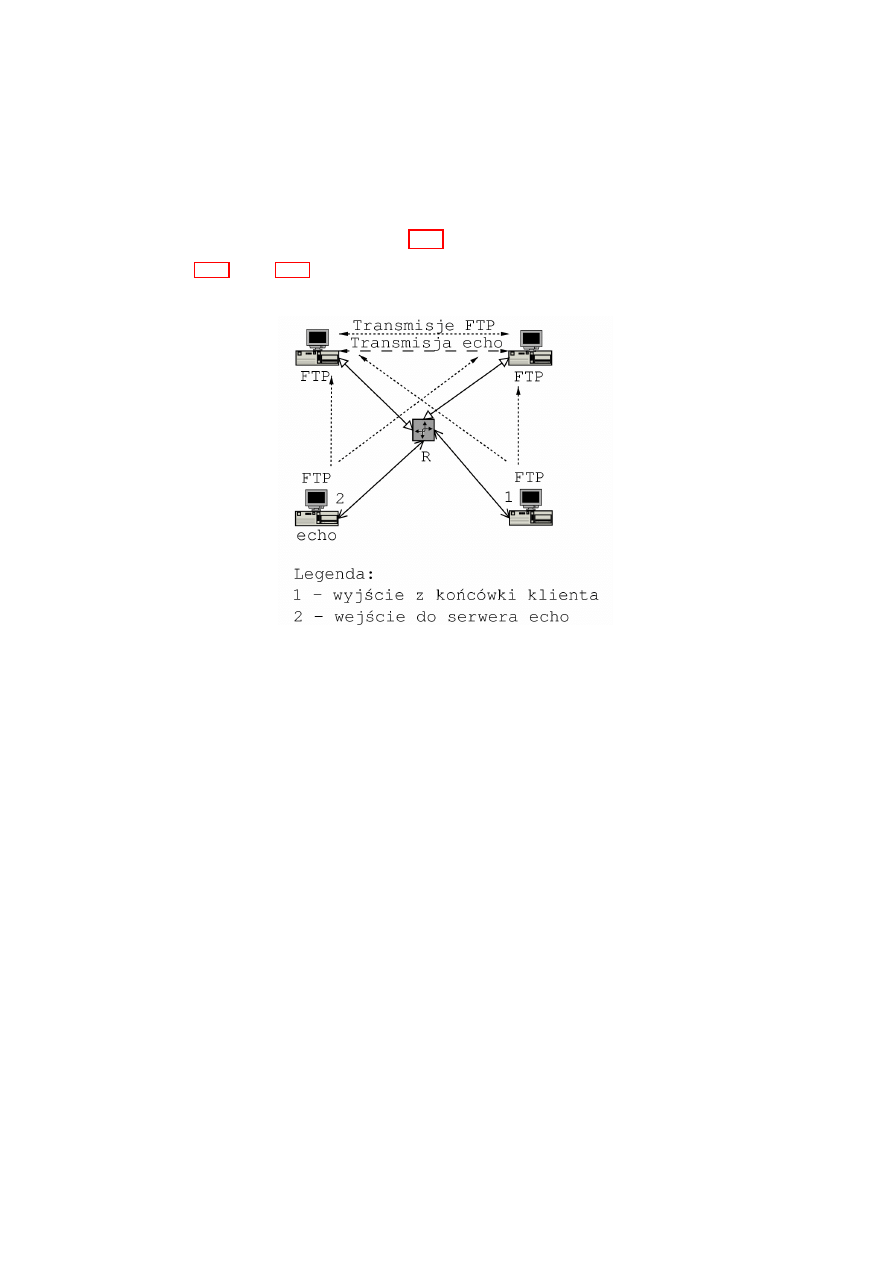
Do lo˙zono zak l´
ocenie w postaci dodatkowych czterech transmisji FTP. Sy-
tuacja przedstawiona jest na rys. 6.13. U´srednione wyniki zgromadzone s
,
a w
Rysunek 6.13: Transmisja echo z wykorzystaniem algorytmu RED przy do-
datkowej transmisji echo oraz sze´sciu transmisjach FTP
107
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.000021
0.272974
0.025631
100
0.1
0.019175
0.239059
0.108855
1000
1
0.997353
1.000765
1.000016
Tablica 6.25: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwe-
rem mierzone od strony klienta przy r´
ownoleg lej transmisji echo oraz sze´sciu
transmisjach FTP
Interwa l czasowy wysy lania
[ms]
[s]
Minimum [s]
Maximum [s]
´
Sredni [s]
10
0.01
0.001176
0.266241
0.025317
100
0.1
0.013522
0.254707
0.109323
1000
1
0.878032
1.104671
1.000324
Tablica 6.26: Pomiary transmisji dla us lugi echo mi
,
edzy klientem i serwerem
mierzone od strony serwera przy r´
ownoleg lej transmisji echo oraz sze´sciu
transmisjach FTP
108

Rozdzia l 7
Podsumowanie oraz wnioski
Analiza wynik´
ow
Na pierwszy rzut oka mo˙zna ju˙z zauwa˙zy´
c, ˙ze wyniki bada´
n op´
o´
znie´
n
przekazywania pakiet´
ow IP przy wysy laniu pakiet´
ow co 1ms (tab. 5.2) s
,
a
bardzo zbli˙zone do wynik´
ow osi
,
agni
,
etych przez wysy lanie pakiet´
ow co 10ms
(tab. 5.2). Wynika to z tego, ˙ze na potrzeby j
,
adra Linuksa czas mierzony
jest w kwantach czasu (ang. jiffies). Na platformie Intela x86 jednostka ta
r´
owna si
,
e 10ms. Wynika z tego, ˙ze pakiety mo˙zna wysy la´
c bez kontroli cza-
sowej (
”
najlepszy wysi lek” [4]) lub w odst
,
epach 10ms, b
,
ad´
z wielokrotno´sciach
10ms. Dlatego te˙z w dalszych pomiarach zaniechano wysy lania pakiet´
ow co
1ms. Dodatkowo mo˙zna zauwa˙zy´
c, ˙ze podobnie jak w przypadku transfer´
ow
wi
,
ekszych ilo´sci danych z pomoc
,
a FTP (tab. 5.1), nawet transmisje nie-
wielkich ilo´sci danych przez ruter s
,
a bardziej p lynne ni˙z te same transmisje
bezpo´srednie (tab. 5.2 oraz 5.3).
Zmierzono op´
o´
znienia zachodz
,
ace w transmisji echo przy r´
ownoczesnym
transferze FTP przechodz
,
acym przez ten sam ruter. Z wynik´
ow tych pomia-
r´
ow mo˙zna wyci
,
agn
,
a´
c nast
,
epuj
,
ace wnioski:
109
• Przy interwa lach czasowych wysy lania pakiet´
ow mniejszych od 100ms
pojawiaj
,
a si
,
e warto´sci mniejsze od zamierzonych. Wynika to ze spo-
sobu w jaki ruter obs luguje pakiety TCP, tzn. je´sli pakiety nie zostaj
,
a
wys lane na czas z powodu przeci
,
a˙zenia, to p´
o´
zniej wysy lane s
,
a szybciej,
aby ´srednie op´
o´
znienie mie´sci lo si
,
e w wymaganych granicach. Takie za-
chowanie rutera mo˙zna zaobserwowa´
c dla interwa l´
ow od 10ms do 60ms
(tab. 5.4).
•
”
Wyg ladzanie ruchu” (u´srednianie op´
o´
znie´
n przekazywania pakiet´
ow)
mo˙zna zaobserwowa´
c g l´
ownie dla interwa l´
ow czasowych 100ms 1s (tab.
6.15. Wynika to z faktu, ˙ze j
,
adro Linuksa na potrzeby w lasne odmierza
czas jako wielokrotno´s´
c jednostki r´
ownej 10ms.
• Prosty algorytm kolejkowania PRIO (opis w podsekcji 3.1.2 a wyniki w
tab. 6.15 i tab. 6.16) dla naszego przypadku okaza l si
,
e por´
ownywalnie
skuteczny jak algorytmy TBF (opis w podsekcji 3.1.3 a wyniki w tab.
6.21 oraz 6.22) oraz RED (opis w podsekcji 3.1.5 a wyniki w tab. 6.25
i tab. 6.26).
Ka˙zdy z u˙zytych algorytm´
ow ma swoje mocne i s labe strony, dlatego te˙z
dla ka˙zdego istniej
,
a zastosowania w kt´
orych mo˙ze sprawowa´
c si
,
e lepiej od
pozosta lych:
• Algorytm kolejkowania PRIO (podsekcja 3.1.2) nadaje si
,
e do prostej
klasyfikacji ruchu na kilka klas ruchu wed lug priorytet´
ow wa˙zno´sci (ruch
o najwy˙zszym priorytecie powinien by´
c obs lugiwany w pierwszej ko-
lejno´sci). Jako kryterium klasyfikacji wystarczy zastosowa´
c bity pola
TOS.
• Algorytm kolejkowania TBF (podsekcja 3.1.3) sprawdza si
,
e w roli czyn-
nika kszta ltuj
,
acego (t lumi
,
acego) ruch. Pozwala on na zapobie˙zenie
”
za-
110

g lodzenia” klas ruchu o ni˙zszym priorytecie przez klasy ruchu o wy˙z-
szym priorytecie.
• Algorytm kolejkowania RED (podsekcja 3.1.5) umo˙zliwia stopniowe re-
gulowanie ruchu wchodz
,
acego. Wykonuje to bardziej elastycznie ni˙z
standardowe mechanizmy protoko lu TCP. Umo˙zliwia r´
ownie˙z bardziej
efektywne wykorzystanie dost
,
epnej przepustowo´sci pasma, warunkowo
przepuszczaj
,
ac cz
,
e´s´
c nadmiarowych pakiet´
ow IP zamiast ich bezwa-
runkowego odrzucania.
Linux stale si
,
e rozwija i w przysz lo´sci do oficjalnej wersji j
,
adra mog
,
a
wej´s´
c dwa opracowane i przetestowane algorytmy, kt´
ore na razie dost
,
epne s
,
a
w postaci laty na j
,
adro.
Pierwszym z nich jest algorytm kolejkowania HTB (ang. Hierarchical To-
ken Bucket). Jest to elastyczny algorytm klasowy o zastosowaniach zbie˙znych
z zastosowaniami algorytmu kolejkowania CBQ (podsekcja 3.1.6). W por´
ow-
naniu z algorytmem CBQ jest bardziej precyzyjny w podziale przepustowo-
´sci na klasy ruchu. Poza tym konfiguracja tego algorytmu jest prostsza, gdy˙z
nie wymaga on ustawiania kilkunastu parametr´
ow konfiguracyjnych tak jak
CBQ, a jedynie kilku.
Drugim algorytmem kolejkowania, kt´
ory w przysz lo´sci czasie mo˙ze sta´
c si
,
e
cz
,
e´sci
,
a oficjalnej ga l
,
ezi j
,
adra, jest WRR (ang. Weighted Round-Robin). Algo-
rytm ten jest uog´
olnion
,
a wersj
,
a klasycznego algorytmu cyklicznego
”
round-
robin”. Modyfikacja w stosunku do pierwowzoru polega na przypisaniu ka˙zdej
z klas ruchu, kt´
or
,
a algorytm ten obs luguje, innej wagi. W zale˙zno´sci od przy-
pisanej klasie wagi, pakietu mog
,
a by´
c cz
,
e´sciej pobierane do wys lania z tej
klasy (wy˙zsza waga klasy) lub rzadziej pobierane do wysy lania (ni˙zsza waga
klasy). Algorytm ten umo˙zliwia w prosty spos´
ob faworyzowanie wybrany
transmisji pakiet´
ow (np. wed lug adres´
ow IP nadawcy i adresata).
111

Niniejsza praca obejmuje swym zakresem tylko cz
,
e´s´
c zagadnienia tytu-
lowego. Bardziej ca lo´sciowe odzwierciedlenie stanu implementacji mechani-
zm´
ow QoS w systemie Linux wymaga loby:
1. poszerzenia zestawu bada´
n
2. powt´
orzenia wszystkich bada´
n na innych platformach sprz
,
etowych
Poszerzenie zestawu bada´
n wymaga loby zdefiniowania dodatkowych
transmisji po l
,
acze´
n, kt´
ore zosta lyby zmierzone. Szczeg´
olnie ciekawe by loby
bardziej rygorystyczne skonfigurowanie mechanizm´
ow
”
kszta ltowania ruchu”
r´
ownolegle ze stworzeniem rozbudowanej hierarchii klas ruchu . Wykorzy-
stane do tego mog
,
a by´
c algorytmy TBF (podsekcja 3.1.3) oraz CBQ (pod-
sekcja 3.1.6). Ciekawe mo˙ze by´
c r´
ownie˙z sprawdzenie skalowalno´sci rozwi
,
a-
za´
n QoS poprzez zwi
,
ekszenie ilo´sci komputer´
ow i po l
,
acze´
n mi
,
edzy nimi, czyli
rozbudow
,
e stanowiska badawczego.
R´
ownie interesuj
,
ace by loby powt´
orzenie wszystkich bada´
n na ca lkowicie
innym stanowisku badawczym. Nale˙za loby w tym celu zmieni´
c komputer pe l-
ni
,
acy rol
,
e rutera programowego na szybszy. Najwi
,
ekszy wp lyw w tym przy-
padku da laby zmiana procesora na szybszy. W ten spos´
ob obs luga wewn
,
etrz-
nych mechanizm´
ow czasowych steruj
,
acych QoS mog laby by´
c szybsza [1]. Dla
uzyskania pe lnego obrazu wydajno´sci implementacji QoS w systemie Linux
dobrze by loby jako ruter programowy u˙zy´
c komputera zbudowanego w opar-
cie o inna platform
,
e sprz
,
etow
,
a ni˙z Intel x86. Mo˙zna w tym celu skorzysta´
c z
platformy Alpha, na kt´
orej kwant czasu j
,
adra wynosi
1
1024
s (dla por´
ownania
na platformie Intel x86 wynosi
1
10
s).
112
Bibliografia
[1] ´
od la Linuksa w wersji 2.4.18, 2002
[2] ´
od la pakietu iproute w wersji z dnia 24.8.2001, 2001
[3] Podr
,
eczniki systemowe dla Linuksa, 2002
[4] G. Armitage:
”
Quality Of Service In IP Networks — Foundations for a
Multi-Service Internet”, Macmillan Technical Publishing USA, 2000
[5] P. Krawczyk:
”
Sterowanie przep lywem danych w Linuxie 2.2”, 2001
[6]
”
Linux Advanced Routing & Traffic Control HOWTO”, 2001
[7] J. Wroclawski
”
The Use of RSVP with IETF Integrated Services”, RFC
2210, wrzesie´
n 1997
[8]
”
RSVP daemon”, sierpie´
n 1998
[9]
”
Internet Protocol Darpa Internet Program Protocol Specification”, STD
5, wrzesie´
n 1981
[10] S. Deering, R. Hinden
”
Internet Protocol, Version 6 (IPv6) Specifica-
tion”, RFC 2460, grudzie´
n 1998
[11]
”
Transmission Control Protocol Darpa Internet Program Protocol Speci-
fication”, STD 7, sierpie´
n 1981
113
[12]
”
Definition of the Differentiated Services Field (DS Field) in the IPv4
and IPv6 Headers”, RFC 2474, grudzie´
n 1998
[13]
”
An Architecture for Differentiated Services”, RFC 2475, grudzie´
n 1998
[14] R. Braden, D. Clark, S. Shenker
”
Integrated Services in the Internet
Architecture: and Overview”, RFC 1633, czerwiec 1994
[15]
”
Per Hop Behavior Identification Codes”, RFC 3140, czerwiec 2001
[16]
”
Assured Forwarding PHB Group”, RFC 2597, czerwiec 1999
[17]
”
An Expedited Forwarding PHB (Per-Hop Behavior”, RFC 3246, marzec
2002
[18]
”
Supplemental Information for the New Definition of the EF PHB
(Expedited Forwarding Per-Hop Behavior”, RFC 3247, marzec 2002
[19] S. Shenker, C. Patridge, R. Guerin
”
Specification of Guaranteed Quality
of Service”, RFC 2212, wrzesie´
n 1997
[20] J. Wroclawski
”
Specification of the Controlled-Load Network Element
Service”, RFC 2211, wrzesie´
n 1997
[21] S. Floyd, V. Jacobson
”
Random Early Detection Gateways for Conge-
stion Avoidance”, sierpie´
n 1993
[22] David D. Clark, Scott Shenker, L. Zhang
”
plications in an Integrated Services Packet Network: Architecture and
Mechanism”, 1992
[23] Jon C.R. Bennett, Hui Zhang
Hierarchical Packet Fair Queueing Algo-
rithms”, pa´
zdziernik 1996
114

[24] S. Floyd, V. Jacobson
”
Link-sharing and Resource Management Models
for Packet Networks”, sierpie´
n 1995
[25] S. Floyd
”
Notes on Class-Based Queuing: Setting Parameters”, luty 1996
[26] S. Floyd
”
Notes on CBQ and Guaranteed Service”, lipiec 1995
[27] L. Berger, T. O’Malley
”
RSVP Extensions for IPSEC Data Flows”, RFC
2207, wrzesie´
n 1997
[28] V. Johnson
”
Technology Backgrounder — Quality of Service — Glossary
of Terms”, 1999
115
Spis rysunk´
ow
o l rezerwacji (RSVP) . . . . . . . . . . . . . . . . . . .
11
Architektura DiffServ . . . . . . . . . . . . . . . . . . . . . . .
13
owek pakietu IPv4 . . . . . . . . . . . . . . . . . . . . . .
13
owek pakietu IPv6 . . . . . . . . . . . . . . . . . . . . . .
15
owek pakietu TCP . . . . . . . . . . . . . . . . . . . . . .
16
Droga pakietu w ruterze . . . . . . . . . . . . . . . . . . . . .
18
Algorytmy kolejkowania FIFO . . . . . . . . . . . . . . . . . .
22
Algorytm kolejkowania TBF . . . . . . . . . . . . . . . . . . .
25
Algorytm kolejkowania SFQ . . . . . . . . . . . . . . . . . . .
29
Algorytm kolejkowania GRED . . . . . . . . . . . . . . . . . .
33
Algorytm kolejkowania CBQ . . . . . . . . . . . . . . . . . . .
34
Algorytm kolejkowania DSMARK . . . . . . . . . . . . . . . .
37
Algorytm kolejkowania CSZ . . . . . . . . . . . . . . . . . . .
39
Przyk ladowa hierarchia klas . . . . . . . . . . . . . . . . . . .
48
Stanowisko badawcze . . . . . . . . . . . . . . . . . . . . . . .
59
aczeniu przez ruter . . . . . . . . . .
65
. . . . . . . .
65
aczeniu bezpo´srednim . . . . . . . . .
66
aczeniu przez ruter . . . . . . . . . .
67
116

e FTP . . . . . . . . . . . . . . . . . . .
68
dwie transmisje FTP . . . . . . . . . . . . . . . . . . . . . . .
70
trzy transmisje FTP . . . . . . . . . . . . . . . . . . . . . . .
72
cztery transmisje FTP . . . . . . . . . . . . . . . . . . . . . .
74
5.10 Transmisja echo przy po l
e echo . . . . . . . . . . . . . . . . . . . . . . .
76
5.11 Transmisja echo przy po l
e echo oraz cztery transmisje FTP . . . . . . .
78
5.12 Transmisja echo przy po l
c transmisji FTP . . . . . . . .
80
Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji FTP . . . . . . . . . . . . . . . . . . . . .
83
Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
. . . . . . . . . . . . . .
85
Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowych trzech transmisjach FTP . . . . . . . . . . . . . . .
87
Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowych czterech transmisjach FTP
. . . . . . . . . . . . .
89
Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji echo oraz czterech transmisjach FTP . . .
91
Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji echo oraz dw´
och transmisjach FTP . . . .
93
117

Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji echo oraz trzech transmisjach FTP . . . .
95
Transmisja echo z wykorzystaniem algorytmu PRIO przy do-
datkowej transmisji echo oraz czterech transmisjach FTP . . .
97
Transmisja echo z wykorzystaniem algorytmu TBF przy do-
datkowej transmisji echo oraz jednej transmisji FTP . . . . . .
99
6.10 Transmisja echo z wykorzystaniem algorytmu TBF przy do-
datkowej transmisji echo oraz dw´
och transmisjach FTP . . . . 101
6.11 Transmisja echo z wykorzystaniem algorytmu TBF przy do-
datkowej transmisji echo oraz sze´sciu transmisjach FTP . . . . 103
6.12 Transmisja echo z wykorzystaniem algorytmu RED przy do-
datkowej transmisji echo oraz dw´
och transmisjach FTP . . . . 105
6.13 Transmisja echo z wykorzystaniem algorytmu RED przy do-
datkowej transmisji echo oraz sze´sciu transmisjach FTP . . . . 107
118

Spis tablic
ow FTP . . . . . .
66
Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta . . . . . . . . . . . . . . . . . . . .
67
Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera . . . . . . . . . . . . . . . . . . . .
67
Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy jednej transmisji FTP
. . . .
69
Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy jednej transmisji FTP . . . .
69
Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy dw´
och transmisjach FTP . . .
71
Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy dw´
71
Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy trzech transmisjach FTP . . .
73
Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy trzech transmisjach FTP
. .
73
5.10 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy czterech transmisjach FTP . .
75
119

5.11 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy czterech transmisjach FTP .
75
5.12 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
ownoleg lej transmisji echo . .
77
5.13 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
77
5.14 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy pi
5.15 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy pi
sjach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
79
5.16 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy siedmiu r´
misjach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
81
5.17 Pomiary transmisji dla us lugi echo mi
rem mierzone od strony serwera przy siedmiu r´
transmisjach . . . . . . . . . . . . . . . . . . . . . . . . . . . .
81
Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy jednej r´
FTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
84
Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy jednej r´
FTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
84
Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy dw´
och transmisjach FTP . . .
86
Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy dw´
86
120

Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy trzech transmisjach FTP . . .
88
Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy trzech transmisjach FTP
. .
88
Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy czterech transmisjach FTP . .
90
Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy czterech transmisjach FTP .
90
Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
. . . . . . . . . . . . . . . . . . .
92
6.10 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy przy r´
echo oraz jednej transmisji FTP . . . . . . . . . . . . . . . . .
92
6.11 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
och transmisjach FTP . . . . . . . . . . . . . . . . . . . . .
94
6.12 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
och transmisjach FTP . . . . . . . . . . . . . . . . . . . . .
94
6.13 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
trzech transmisjach FTP . . . . . . . . . . . . . . . . . . . . .
96
6.14 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
trzech transmisjach FTP . . . . . . . . . . . . . . . . . . . . .
96
121

6.15 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
czterech transmisjach FTP . . . . . . . . . . . . . . . . . . . .
98
6.16 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
czterech transmisjach FTP . . . . . . . . . . . . . . . . . . . .
98
6.17 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
. . . . . . . . . . . . . . . . . . . . . . 100
6.18 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
. . . . . . . . . . . . . . . . . . . . . . 100
6.19 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
och transmisjach FTP . . . . . . . . . . . . . . . . . . . . . 102
6.20 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
och transmisjach FTP . . . . . . . . . . . . . . . . . . . . . 102
6.21 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
. . . . . . . . . . . . . . . . . . . . 104
6.22 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
. . . . . . . . . . . . . . . . . . . . 104
6.23 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
och transmisjach FTP . . . . . . . . . . . . . . . . . . 106
122

6.24 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
och transmisjach FTP . . . . . . . . . . . . . . . . . . 106
6.25 Pomiary transmisji dla us lugi echo mi
mierzone od strony klienta przy r´
oraz sze´sciu transmisjach FTP . . . . . . . . . . . . . . . . . . 108
6.26 Pomiary transmisji dla us lugi echo mi
mierzone od strony serwera przy r´
oraz sze´sciu transmisjach FTP . . . . . . . . . . . . . . . . . . 108
123
Document Outline
- Cel i zakres pracy
- Zasady dzialania mechanizmów Quality of Service
- Stan aktualny implementacji QoS w systemie Linux
- Algorytmy kolejkowania pakietów
- Algorytmy kolejkowania FIFO
- Algorytm kolejkowania PRIO (PRIOrities)
- Algorytm kolejkowania TBF (Token Bucket Filter)
- Algorytm kolejkowania SFQ (Stochastic Fairness Queueing)
- Algorytmy kolejkowania RED (Random Early Detection)
- Algorytm kolejkowania CBQ (Classful Based Queueing)
- Algorytm kolejkowania DSMARK (DiffServ Mark)
- Algorytm kolejkowania CSZ (Clark-Shenker-Zhang)
- Rodzaje filtrów
- Zastosowanie algorytmów kolejkowania i filtrów
- Algorytmy kolejkowania pakietów
- Mozliwosci rozbudowy implementacji QoS w systemie Linux
- Badania wykonane bez wlaczonych mechanizmów QoS
- Badania wykonane z wlaczonymi mechanizmami QoS
- Podsumowanie oraz wnioski
- Bibliografia
- Spis rysunków
- Spis tabel
Wyszukiwarka
Podobne podstrony:
Dynamiczny przydział pasma użytkownika sieci z wykorzystaniem usługi QoS w systemie Linux
Uslugi sieciowe w systemie linux
Laboratorium 11 5 5 Dokumentowanie sieci z wykorzystaniem polece us ugowych
10 Dynamiczne przydzielanie pamieci
Zestawienie wazniejszych cech uzytkowych urzadzen wykorzystywanych do odzysku ciepla, Pomoce naukowe
Jak dostać się do dysku innego komputera w sieci wykorzystując dziury w systemie, edukacja i nauka,
311[15] Z2 06 Użytkowanie sieci i urządzeń elektrycznych w wyrobiskach
Zarządzanie zasobami w sieci z wykorzystaniem wiersza poleceń, Soisk
Sposoby łączenia użytkowników sieci
Adresacja fizyczna i logiczna IP i MAC, !!!Uczelnia, wsti, materialy, I SEM, uzytkowanie sieci
16 Uzytkowanie sieci i urzadzen Nieznany (2)
Model OSI, !!!Uczelnia, wsti, materialy, I SEM, uzytkowanie sieci
Kancelaria zdobyła dane 50 tys użytkowników sieci Orange i domaga się od internautów po 750 zł
%5bebooks pl%5djak+dosta%e6+si%ea+do+dysku+innego+komputera+w+sieci+wykorzystuj%b9c+dziury+w+systemi
3 Wprowadzenie do protokołów routingu dynamicznego, pwr-eit, Lokalne sieci komputerowe- CISCO 2, Cis
Usługi Internetu, Systemy Operacyjne i Sieci Komputerowe
więcej podobnych podstron