
Contents

Podzapytanie wierszowe
zwraca co najwyżej jeden rekord, zawierający jedną lub wiele wartości.
Dopuszcza stosowanie operatorów logicznych.
Podzapytanie tablicowe
zwraca zbiór rekordów zawierających jedną lub wiele wartości. Dopuszcza
się stosowanie operatorów IN, ANY, ALL.
Podzapytania skorelowane
:
podzapytanie wykonywane wielokrotnie - raz dla każdego rekordu przeglądanego przez
zapytanie zewnętrzne,
w podzapytaniu odwołanie do wyrażenia z zapytania zewnętrznego.
Klauzula HAVING
- określa, które zgrupowane rekordy są wyświetlane w instrukcji SELECT
zawierającej klauzulę GROUP BY. Gdy klauzula GROUP BY połączy rekordy, klauzula HAVING
wyświetla wszystkie zgrupowane rekordy, które spełniają warunki określone w klauzuli HAVING.
Operator EXISTS
- przyjmuje wartość prawdy gdy podzapytanie zwróci przynajmniej jeden rekord.
Mądra literatura: Stosowany do podzapytań skorelowanych. Pozwala ustalić, czy pożądane przez nas
dane znajdują się w wyniku podzapytania skorelowanego.
sprawdza czy kolejne elementy z jednego zbioru znajdują swój odpowiednik w drugim zbiorze.
Przywileje - przydatne pojęcia
:
przywilej - prawo wykonywania przez użytkownika określonej akcji w bazie danych lub
dostępu do określonego obiektu,

użytkownik - osoba lub aplikacja, która jest uprawniona do dostępu do danych zgromadzonych
w bazie danych,
schemat - zbiór logicznych struktur danych, przypisany jest do każdego użytkownika, należy
rozumieć go jako konto użytkownika.
Rodzaje przywilejów
:
systemowe - prawa wykonania określonej akcji lub operacji na wskazanym typie obiektu
w schemacie bazy danych np.:
create session,
create table,
create any table,
select any table - pozyskiwanie danych z dowolnej tabeli,
insert any table - dopisywanie danych,
drop any view,
obiektowe - prawa wykonania określonej operacji na wskazanym obiekcie w określonym
schemacie bazy danych np.:
select on wypożyczenia
alter on klienci
execute on wyszukaj_samochod,
references on klienci.
Autoryzacja
:
proces weryfikacji uprawnień użytkownika do wykonywania określonych operacji na bazie
danych,
ograniczenia mogą dotyczyć operacji, obiektów i wykorzystania zasobów systemowych bazy
danych.
Uwierzytelnianie
:
weryfikacja tożsamości użytkownika bazy danych,
metody realizacji uwierzytelnień: przez SZBD, przez system operacyjny, przez usługę sieciową,
wielowarstwowe.
Przywileje systemowe - polecenia
:
nadawanie przywilejów:
GRANT <przywileje>
TO <użytkownicy> | PUBLIC

[WITH ADMIN OPTION];
PUBLIC służy do nadania przywilejów wszystkim użytkownikom,
WITH ADMIN OPTION umożliwia przekazanie przywileju innym użytkownikom.
odbieranie przywilejów:
REVOKE <przywileje>
FROM <użytkownicy> | PUBLIC;
przykład:
GRANT CREATE SESSION, SELECT ANY TABLE TO B;
GRANT CREATE TABLE TO A;
REVOKE SELECT ANY TABLE FROM B.
Przywileje obiektowe - polecenia
:
nadawanie przywilejów:
GRANT <przywileje> | ALL ON <obiekt>
TO <użytkownicy> | PUBLIC
[WITH GRANT OPTION];
odbieranie przywilejów:
REVOKE <przywileje> | ALL ON <obiekt>
FROM <użytkownicy> | PUBLIC;
[CASCADE CONSTRAINTS];
przykład:
GRANT SELECT ON klienci TO B;
GRANT UPDATE(marka, model) ON samochody TO A;
REVOKE DELETE ON klienci FROM B.
Sekwencje
:
automatyczny licznik generujący nową wartość liczbową przy każdym jej wywołaniu,
obiekty upraszczające proces tworzenia jednoznacznych identyfikatorów rekordów w bazie,
stosowanie sekwencji pozwala na generowanie niepowtarzalnych numerów, co upraszcza
tworzenie kluczy głównych o wartościach unikatowych.
Sekwencje - polecenia
:
tworzenie sekwencji:
CREATE SEQUENCE nazwa sekwencji

[START WITH liczba całkowita] – deklaruje wartość liczbową od której ma
zaczynać sie numeracja
[INCREMENT BY liczba całkowita] – o ile zwiększona będzie wartość
sekwencji przy każdym kolejnym jej wywołaniu
[MINVALUE liczba całkowita]
[MAXVALUE liczba całkowita]
sprawdzanie aktualnej wartości sekwencji:
SELECT nazwa_sekwencji.CURRVAL
FROM DUAL
generacja i zwrot kolejnej wartości sekwencji:
SELECT nazwa_sekwencji.NEXTVAL
FROM DUAL.
Tabela DUAL
:
jest tworzona automatycznie przez bazę danych w ramach słownika danych,
znajduje sie ona w schemacie użytkownika SYS, ale jest dostępna pod nazwą DUAL dla
wszystkich pozostałych użytkowników,
składa sie z jednej kolumny DUMMY – wykorzystywana jest w instrukcjach SELECT.
Pierwsza postać normalna
:
tabela jest w pierwszej postaci normalnej, wtedy i tylko wtedy, gdy każdy atrybut niekluczowy
jest funkcjonalnie zależny od klucza głównego,
zabrania definiowania złożonych atrybutów, które są wielowartościowe,
tabele, które dopuszczają definiowanie złożonych atrybutów to tabele zagnieżdżone (koncepcja
ta nie mieści się w ramach klasycznego relacyjnego modelu).
Definicja zależności funkcyjnej
:
Atrybut B tabeli R jest funkcyjnie zależny od atrybutu A tej tabeli, jeżeli zawsze każdej wartości
a trybutu A odpowiada nie więcej niż jedna wartość b atrybutu B.
Definicja pełnej zależności funkcyjnej
:
Atrybut A jest w pełni zależny funkcjonalnie od zbioru atrybutów B, gdy jest zależny funkcjonalnie od
całego zbioru, a nie od podzbioru atrybutów z B.
Druga postać normalna:
tabela R jest w drugiej postaci normalnej, jeśli jest w pierwszej postaci normalnej i każdy atrybut
niekluczowy jest w pełni funkcyjnie zależny od klucza głównego.
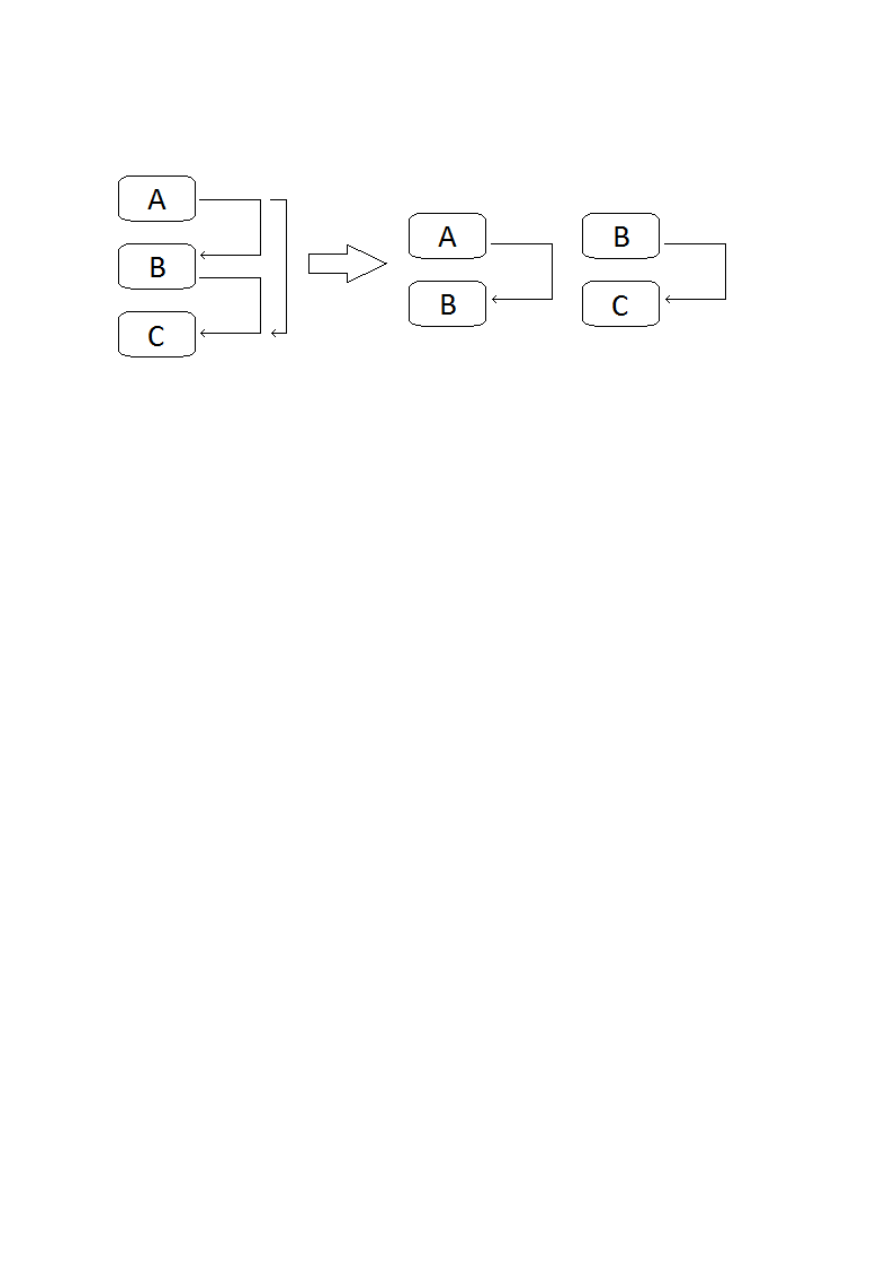
Usuwanie zależności funkcyjnych (przechodnich):
Trzecia postać normalna
:
tabela jest w trzeciej postaci normalnej, jeżeli jest w drugiej postaci normalnej i każdy atrybut
niekluczowy jest w zależny bezpośrednio od klucza głównego.
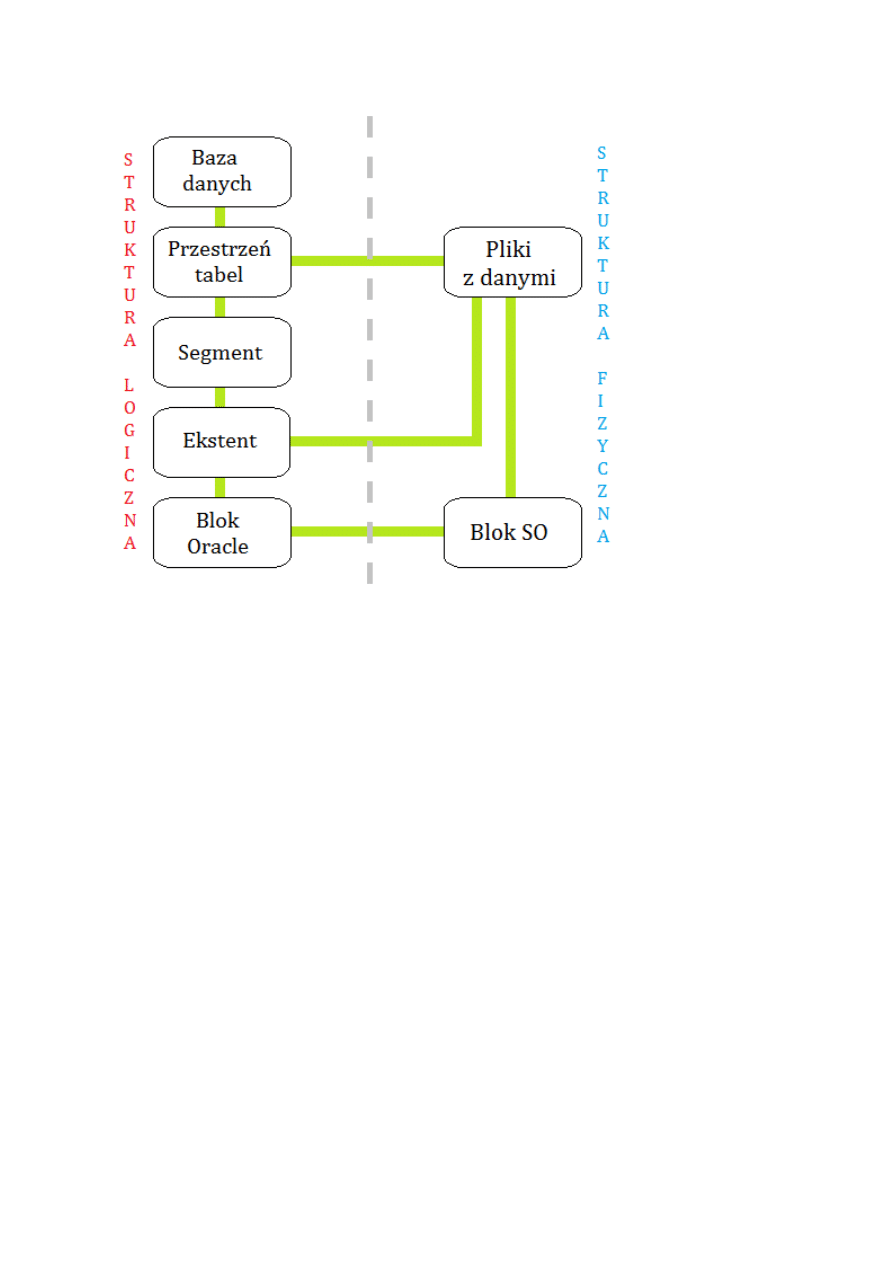
Struktura systemu Oracle
:
procesy drugoplanowe,
obszar globalny systemu (SGA),
pliki bazy danych,
pliki dziennika powtórzeń,
pliki kontrolne,
pliki startowe.
Baza danych
odnosi się do fizycznego składowania informacji, jest bytem fizycznym – składa się
z plików zapisanych na dyskach.
Instancja
odnosi się do oprogramowania działającego na serwerze, zapewniającego dostęp do
informacji w bazie danych, jest bytem logicznym – składa się ze struktur w pamięci i procesów na
serwerze.
W
pliku kontrolnym
zawarte są informacje dotyczące położenia innych plików fizycznych
tworzących bazę danych – plików danych i plików dziennika powtórzeń oraz kluczowe
informacje dotyczące treści i statusu bazy danych:
nazwa bazy danych i czas jej utworzenia,
nazwy i położenie plików danych i plików dziennika powtórzeń,
informacje o przestrzeniach tabel,
historia dziennika, archiwalne informacje dziennika,
informacje o zestawie kopii zapasowych,

informacje o kopiach plików danych,
informacje o punktach kontrolnych.
Pliki danych
:
każdy plik składa się z bloków bazy danych Oracle, złożonych z bloków SO na dysku,
rozmiar bloku Oracle waha się od 2KB do 32KB (parametr DB_BLOK_SIZE),
rozmiar bloku to najmniejsza ilość danych, którą można zapisać lub odczytać,
pierwszy blok każdego pliku danych to nagłówek pliku danych – zawiera on najważniejsze
informacje, konieczne do utrzymania spójności baz danych,
Najważniejszy element nagłówka to struktura punktu kontrolnego – logiczny znacznik czasu,
wskazujący moment zapisania ostatniej zmiany w pliku danych,
Ma on kluczowe znaczenie w procesie odtwarzania bazy danych, ponieważ określa, z których
dzienników powtórzeń należy skorzystać przy doprowadzaniu pliku danych do stanu sprzed
awarii,
z punktu widzenia warstwy fizycznej, plik danych jest składowany jako zbiór bloków systemu
operacyjnego.
Pliki danych posiadają trzy poziomy organizacji
:
bloki danych,
ekstenty,
segmenty,
każda przestrzeń tabel składa się z jednego lub więcej segmentów,
każdy segment składa się z jednego lub wielu ekstentów,
każdy ekstent składa się ze spójnego ciągu bloków alokowanych jako całość.
Pliki dziennika powtórzeń
:
zawierają nagranie zmian dokonywanych w bazie, będących efektem transakcji i
wewnętrznych operacji Oracle,
zapisanie zmian w dzienniku transakcji pozwala odtworzyć zmiany utracone na skutek awarii,
zabezpieczając dzięki temu spójność transakcji,
każda z instancji Oracle używa wątku powtórzeń w celu zapisania zmian dokonywanych
w bazie,
Oracle utrzymuje wiele kopi dziennika powtórzeń, dokonuje zapisu do wszystkich elementów
dziennika powtórzeń synchronicznie,
po zapełnieniu jednego pliku dziennika powtórzeń, automatycznie rozpoczyna korzystanie
z następnego.
Instancja bazy danych
– zbiór procesów oraz obszar pamięci współdzielonej zwanej Globalnym
Obszarem Systemowym (SGA) obsługujący jedną bazę danych.
Rodzaje organizacji instancji
:
single-process,
multiple-process.

Globalna przestrzeń systemowa
:
instancja jest metodą wykorzystywaną do dostępu do danych, składającą się z procesów
i pamięci współdzielonej,
instancja (suma buforów pod wspólną nazwą Globalna przestrzeń systemowa SGA) – obszar
pamięci współużytkowanej wykorzystywany przez Oracle’a do przechowywania informacji
kontrolnych instancji Oracle’a,
SGA jest przydzielana podczas uruchamiania instancji i zwalniana podczas jej zatrzymywania,
bufory pamięci podręcznej bazy danych – przechowują ostatnio używane bloki danych; gdy
użytkownik chce uzyskać dostęp do bloku danych, który nie znajduje się w pamięci podręcznej,
blok ten musi zostać wczytany z dysku i w niej zapisany,
bufory dziennika powtórzeń – czyli zmian wprowadzonych do bazy – wykorzystywane do
odtwarzania po awarii systemu,
pula współużytkowania – buforowane są różnego rodzaju obiekty, którymi mogą się dzielić
użytkownicy np. zapytania i fragmenty zapytań SQL oraz ich wyniki, informacje ze słownika
danych,
Oracle automatycznie zarządza pamięcią alokowaną w globalnym obszarze programu (Program
Global Area) instancji.
Proces punktu kontrolnego
(CKPT) może przejąć zadanie realizacji punktu kontrolnego normalnie
wykonywanego przez LGWR.
Monitor systemu (SMON)
– odpowiedzialny jest za porządki, do jego obowiązków należy:
odtwarzanie systemu po awarii w czasie uruchamiania instancji,
usuwanie niepotrzebnych segmentów tymczasowych,
aktualizowanie pliku kontrolnego bazy,
scalanie wolnych rozszerzeń w ramach segmentu.
Monitor procesów (PMON)
– zajmuje się odtwarzaniem procesów usługowych, które uległy awarii,
odpowiedzialny jest za:
usuwanie nienormalnie zakończonych połączeń,
wycofywanie niezatwierdzonych transakcji,
czyszczenie buforów,
zwalnianie zajętych zasobów,
wykrywanie wewnętrznych zakleszczeń pomiędzy blokadami zakładanymi na dane bazy
i automatyczne wycofywanie transakcji.
Archiwizator (ARCH)
dokonuje archiwizacji online plików dziennika powtórzeń.

Przestrzeń tabel może zawierać:
segment danych,
segment indeksu,
segment przywracania,
segment tymczasowy.
Odpowiednik ERD w UML – gdzieś z internetów
Diagram związków encji ERD (ang. Entity Relationship Diagram) wywodzi się z podejścia
strukturalnego, diagram klas (ang. class diagram) jest diagramem języka UML (ang. Unified Modeling
Language), który wspiera podejście obiektowe.
Diagram związków encji jest statyczną, konceptualną reprezentacją modelu danych systemu. ERD
przedstawia encje oraz związki między nimi. Encja jest jednoznacznie identyfikowalnym składnikiem
analizowanej dziedziny przedmiotu, o której informacja jest lub może być zbierana i przechowywana.
Diagram związków encji stanowi podstawę dla utworzenia schematu bazy danych. Diagram klas jest
statyczną reprezentacją systemu. Diagram przedstawia klasy systemu, ich zawartość oraz związki
między klasami. Klasa jest uogólnieniem zbiorów obiektów, które mają takie same właściwości,
tj. atrybuty, operacje, związki i znaczenie.
Odpowiednikiem ERD w języku UML jest stereotypowany diagram klas – stereotyp klasy <<table>>,
który zawiera wyłącznie klasy analityczne (takie, których obiekty będą lub mogą być utrwalane
i przechowywane w bazie danych systemu).
Relacyjny model danych:
relacyjny model danych został opracowany przez E. F. Codda w latach 70-80,
od połowy lat 80 stał się podstawą architektury większości popularnych SZBD.
Definicja danych:
model relacyjny oparty jest na tylko jednej podstawowej strukturze danych – relacji,
pojęcie relacji można uważać za pewną abstrakcję intuicyjnego pojęcia tabeli,
relacyjna baza danych zawiera kolekcję tablic (relacji).
Podstawowe teorie dla relacyjnych baz danych:
algebra relacyjna,
rachunek relacyjny,
teoria normalizacji.
Klucze główne i obce:
jeden lub wiele atrybutów K, które spełniają unikalność (nie istnieją dwie krotki, które posiadają
tą samą wartość dla K),
klucz główny – jeden z kluczy kandydatów,

klucz obcy – jeden z atrybutów, który wskazuje klucz główny innej lub tej samej relacji,
integralność referencyjna – wartości kluczy obcych, muszą być określone na podstawie zbioru
korespondujących kluczy.
Reguły Codda:
reguła informacyjna,
reguła gwarantowanego dostępu,
uporządkowana obsługa wartości NULL,
aktywny katalog dostępny na bieżąco, oparty na modelu relacyjnym,
reguła dotycząca podjęzyka obsługi danych o pełnych możliwościach,
reguła aktualizacji perspektyw,
polecenia wstawiania, aktualizacji oraz usuwania w języku wysokiego poziomu,
fizyczna niezależność danych,
logiczna niezależność danych,
niezależność integralnościowa,
niezależność dystrybucyjna,
reguła nieprowadzenia "działalności wywrotowej".
Relacyjny model danych:
atrybut musi mieć unikalną nazwę,
atrybut krotki nie może być wielowartościowy,
wartość atrybutu nie może być złożona,
wartością atrybutu nie może być wskaźnik,
wartości kolumn są tego samego typu,
nie mogą istnieć dwie identyczne krotki.
Algebra relacyjna:
zwyczajne działania algebry zbiorów: suma, przecięcie i różnica zastosowane do tabeli,
operacje zawężania tabeli:
selekcja,
projekcja,
operacje tworzenia wierszy z innych wierszy pochodzących z różnych tabel:
iloczyn kartezjański,
operacje złączenia,
operacje przemianowania.
Algebra relacyjna
- tabele R i S, do których można zastosować operacje teoriomnogościowe, muszą
spełniać następujące warunki:
schematy tabel R i S muszą mieć identyczne zbiory atrybutów,

należy uporządkować atrybuty tabeli R i S w ten sposób, aby w obu tabelach kolejność
atrybutów była taka sama.
Złączenia zewnętrzne
:
złączenie lewostronne,
złączenie prawostronne,
złączenie obustronne,
półzłączenia.
TRANSFORMACJA MODELU LOGICZNEGO DO FIZYCZNEGO
Obiekty modelu logicznego
Obiekty modelu fizycznego
encja
tabela
atrybut encji
kolumna tabeli
identyfikator encji
klucz główny tabeli
związek
klucz obcy i reguły integralności
Wyszukiwarka
Podobne podstrony:
avr spis tresci
c Spis treści
167 170 spis tresci
kd spis tresci
MS 2011 1 spis tresci
02 SPIS TREŚCI
Projekt 2 - Spis treści, Inżynieria Środowiska, Oczyszczanie Gazów
spis-tresci-pr.-spadkowe, Prawo
spis tresci pppipu, studia, rok II, PPPiPU, od Ani
SPIS TREŚCI
Spis treści
3 spis tresci
spis tresci
Spis treści
spis tresci do prawoznawstwo
Spis treści pająk
2 spis tresci
1[2] Ziemie polskie w Q Spis treści
więcej podobnych podstron