
WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
1
PODSTAWY
PROGRAMOWANIA
kurs I - część 1
PROWADZĄCY: dr inż. Marcin Głowacki
E-Mail:
Marcin.Glowacki@pwr.wroc.pl
Pok.907 C-5
Wrocław 2012

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
2
LITERATURA PODSTAWOWA:
[1] Grębosz J., Symfonia C++, Standard, Editions 2000,
Kraków, 2005, 2008, 2010
[2] Stroustrup B., Język C++, WNT, Warszawa 2004
[3] Eckel B., Thinking in C++, Helion, Gliwice 2002
[4] Wróblewski P., Algorytmy, struktury danych i techniki
programowania. Helion, 2009
LITERATURA UZUPEŁNIAJĄCA:
[1] Kernighan R., Ritchie C., Język C, PWN, Warszawa
[2] Segewick C., Algorytmy w C++. W.N.-T., Warszawa,
1999
[3] Lippman S. B., Lajoie J., Podstawy języka C++, WNT,
Warszawa 2003
Neapolitan R., Naimipour K., Podstawy algorytmów z
przykładami w C++. Wyd. Helion, 2004
ZALICZENIE
- test końcowy z wykładu
Ocena końcowa = 1/3*ćwiczeń + 1/3*laboratorium + 1/3*wykład

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
3
1.
PRZEGLĄD PARADYGMATÓW PROGRAMOWANIA:
Paradygmat programowania jest to wzorzec programowania przedkładany w danym okresie
rozwoju informatyki ponad inne lub szczególnie ceniony w pewnych okolicznościach lub
zastosowaniach - zbiór mechanizmów jakich programista używa pisząc program.
Przykłady paradygmatów:
-
programowanie imperatywne - (Assembler, Basic, Fortran, Pascal, C) to prosty sposób
programowania, w którym program postrzegany jest jako szereg instrukcji dla komputera.
Związany jest ściśle z budową sprzętu komputerowego o architekturze von Neumanna, w
którym wykonywane są poszczególne instrukcje w kodzie maszynowym zmieniające
globalny stan maszyny
o
sekwencja poleceń zmieniających krok po kroku stan maszyny, czyli zawartość
pamięci oraz rejestrów i znaczników procesora
o
przykładowo, instrukcje podstawienia działają na danych pobranych z pamięci i
umieszczają wynik w pamięci – tzw. zmienne symbolizują komórki pamięci
-
programowanie proceduralne - procedury i powroty (return), GOSUB (BASIC), CALL
FAR i CALL NEAR(ASSEMBLER), polega na dzieleniu kodu na procedury, czyli
fragmenty wykonujące ściśle określone operacje. Procedury nie powinny korzystać ze
zmiennych globalnych (w miarę możliwości), lecz pobierać i przekazywać wszystkie dane
(czy też wskaźniki do nich) jako parametry wywołania.
o
program był traktowany jako seria procedur, działających na danych
o
procedura (funkcja) jest zestawem specyficznych, wykonywanych jedna po drugiej
instrukcji.
-
programowanie strukturalne - (PASCAL) hierarchiczne dzielenie kodu na bloki, z
jednym punktem wejścia i jednym lub wieloma punktami wyjścia. Chodzi o nieużywanie
lub ograniczenie instrukcji skoku (goto). Dobrymi strukturami są, np. instrukcja
warunkowe (if, if...else), pętle (while, repeat), wyboru (case, ale nie switch z C itp.).
Strukturalność zakłócają instrukcje typu: break, continue, switch (w C itp.),
o
idea główna to „dziel i rządź.”
-
każde zadanie jest rozbijane na zestaw mniejszych
zadań składowych
-
programowanie obiektowe – (C#) zbiór porozumiewających się ze sobą obiektów,
zawierających w sobie dane i metody przetwarzania tych danych, czyli wykonywania
pewnych operacji na tych danych, programowanie obiektowe wzbogacone o dziedziczenie i
polimorfizm – kod programu sam się orientuje z jakim typem obiektu ma do czynienia i
dobiera właściwą funkcję realizującą domyślną akcję (podobnie jak
przeładowanie/przeciążenie funkcji i operatorów, które same rozpoznają z jakimi
argumentami mają do czynienia)
o
pojawia się pojęcie klasy i obiektów tej klasy
o
obiekty zawierają dane w postaci zmiennych i metody operujące na tych danych
o
łatwa rozbudowa i korzystanie z elementów wcześniej zdefiniowanych
o
związanie funkcji ze strukturą przetwarzanych danych
o
abstrakcja, dziedziczenie i hermetyzacja danych
o
polimorfizm = „wiele form” – jedna nazwa może przybierać wiele form, forma
aktualna jest związana z daną klasą obiektu
o
tęzyki imperatywno-obiektowe to: C++, Perl, PHP, Java, Python

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
4
-
programowanie zdarzeniowe - program jest cały czas bombardowany zdarzeniami
(ang.events), na które musi odpowiedzieć, i że przepływ sterowania w programie jest
całkowicie niemożliwy do przewidzenia z góry. Programowanie zdarzeniowe jest
dominującym typem programowania GUI.
o
zdarzenia to naciśnięcia myszy, klawiszy, żądania odświeżenia przez system
okienkowy, różne zdarzenia sieciowe itd.
o
mocno powiązane ze środowiskami wieloprocesowymi i z graficznymi
ś
rodowiskami systemów operacyjnych oraz z programowaniem obiektowym.
KLASYCZNE PROJEKTOWANIE PROGRAMU:
-
Rozpoznanie i analiza problemu
-
-
Projektowanie programu
o
Identyfikacja zachowań systemu: kto/co -> akcja -> kogo/czego -> rezultat (gracz-
>rzuca ->kostką -> liczba pomiędzy 1 i 6)
Identyfikacja struktur danych
Wskazanie bloków funkcjonalnych – algorytm (minimum blokowy)
o
Usystematyzowanie i uszczegółowienie
Tworzenie nowych typów i struktur danych (jeśli są potrzebne)
Ustalenie hierarchii zmiennych i ich zasięgu
Określenie wzajemnych zależności – która funkcje wydają rozkazy, a która
spełniają polecenia, które funkcje wymieniają się usługami – GRAF
WSPÓŁPRACY
Podsystemy – znajdowanie grup obiektów, które realizują odrębne
funkcjonalnie zadania, np. obsługa menu
o
Składanie modelu – określanie stanów, sekwencji działań oraz cykli życiowych dla
danych oraz funkcji
-
Implementacja
-
Testowanie
-
Uruchomienie i poprawki
ANALIZA PROBLEMU
•
Od szczegółu do ogółu (wstępujące)
niepodzielne części łączy się w większe fragmenty
•
Od ogółu do szczegółu (zstępujące)
bloki funkcjonalne uściśla się do operacji elementarnych
•
W praktyce TECHNIKI MIESZANE
•
Struktura danych
WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
5
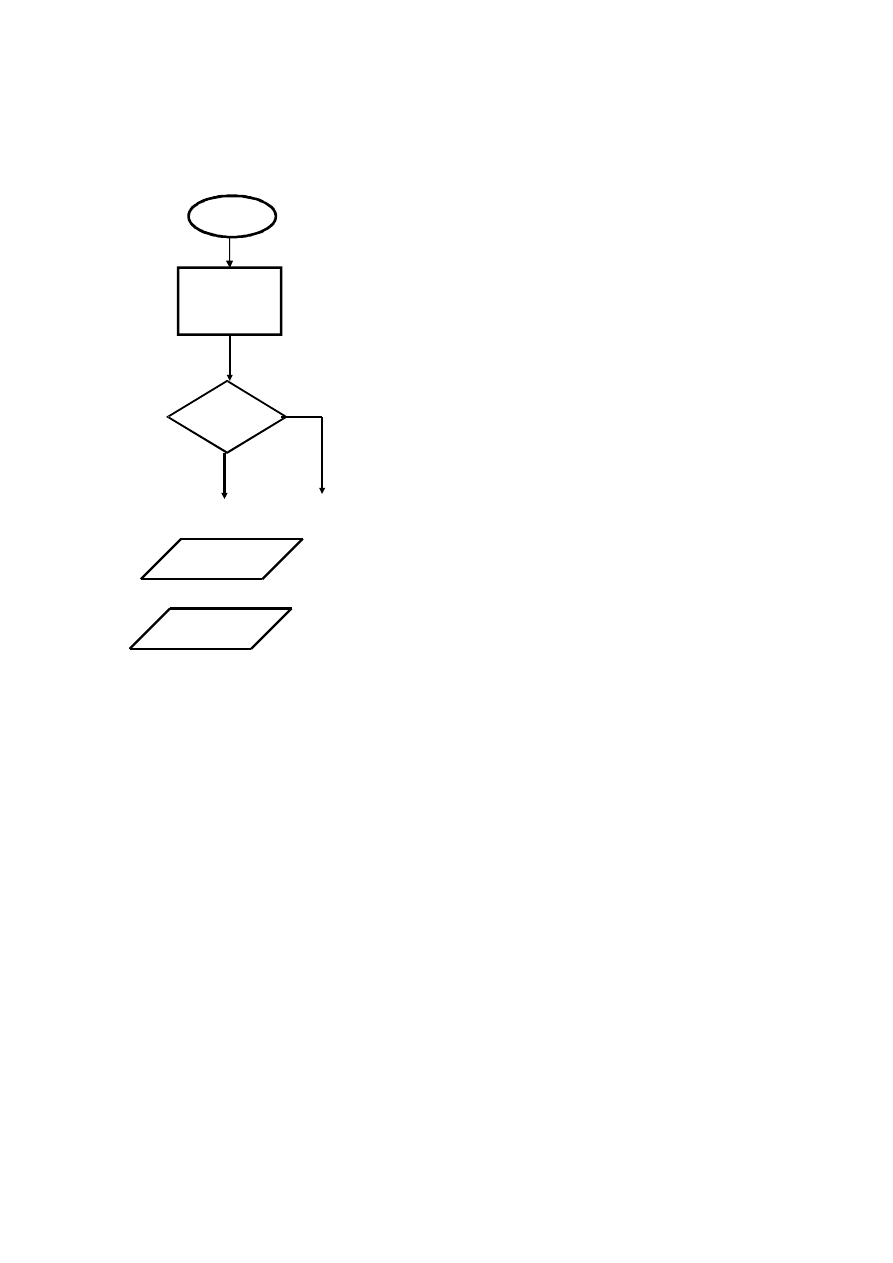
ALGORYTM - SCHEMAT BLOKOWY
•
START, STOP
•
OPERACJA WYKONAWCZA
•
OPERACJA WARUNKOWA
•
OPERACJA WEJŚCIA/ WYJŚCIA
START
i=0
j=j+1
if
i<3
TAK
NIE
wyświetl
i
podaj k
WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
6
IMPLEMENTACJA
Język programowania i narzędzia programistyczne
-
stopień złożoności języka
-
poziom abstrakcji realizowanych funkcji
-
projekty z kodem z różnych języków
Podział na odrębne moduły tworzone w zespole programistów
Właściwe zarządzanie projektem
Język C <-> Assembler
Poziomy maszynowe
L4 – C++
int A, B, C;
//fragment danych
…
A
=
B
+
C;
//fragment programu
L3 – Asembler (Intel x86)
L1 – kod maszynowy (Intel x86)
(.data)
SEGMENT danych
cc dw (?) ;
(offset cc = 0103h)
bb dw (?) ;
(offset bb = 0105h)
aa dw (?) ;
(offset aa = 0107h)
(.code)
SEGMENT programu
...
(*) mov ax, cc
1010 0001 (A1h)
0000 0011 0000 0001 (0103h)
(*+3) add ax, bb
0000 0011 0000 0110 (0306h)
0000 0101 0000 0001 (0105h)
(*+7) mov aa, ax
1010 0011 (A3h)
0000 0111 0000 0001 (0107h)
#include <stdio.h>
int main() {
printf("Hello world");
}
_TEXT segment byte public 'CODE’
; void main()
_main proc near
; {
; printf("Hello world");
push offset DGROUP:s@
call
near ptr _printf
pop
cx
; }
ret
_main endp
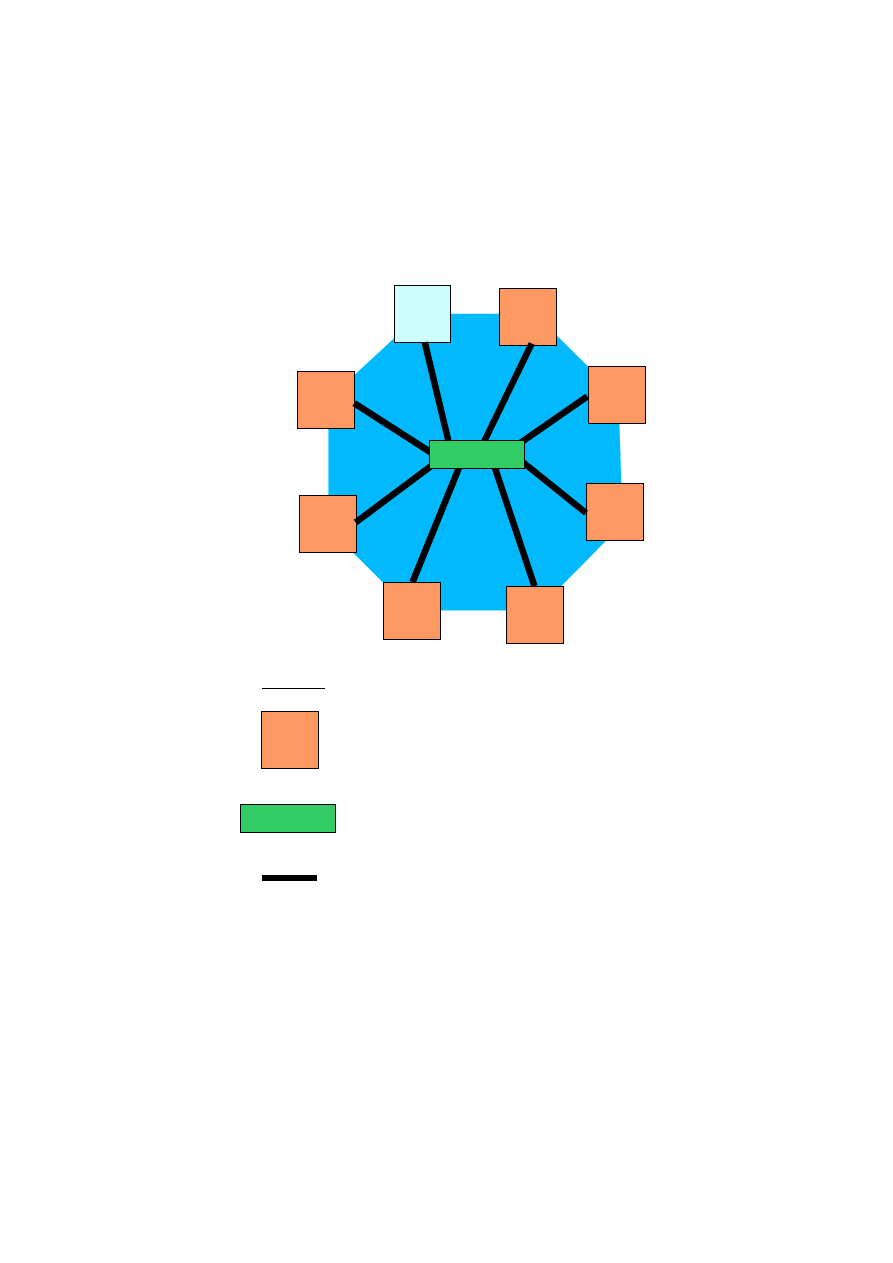
WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
7
MODEL PRZETWARZANIA
– wpływ na sposób zakodowania programu
-
z podziałem czasu (przełączanie zadań)
-
czasu rzeczywistego
-
równoległe (wiele procesorów)
-
rozproszone (w sieci komputerowej, klastrze)
KOMP
KOMP
KOMP
KOMP
KOMP
KOMP
KOMP
KOMP
Zarządzający
klastrem
Bardzo szybkie łącze np., Gigabit Ethernet
KOMP
Komputer wchodzący w skład klastra
Legenda
SWITCH
SWITCH
Przełącznik sieciowy np., Gigabit Ethernet
WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
8
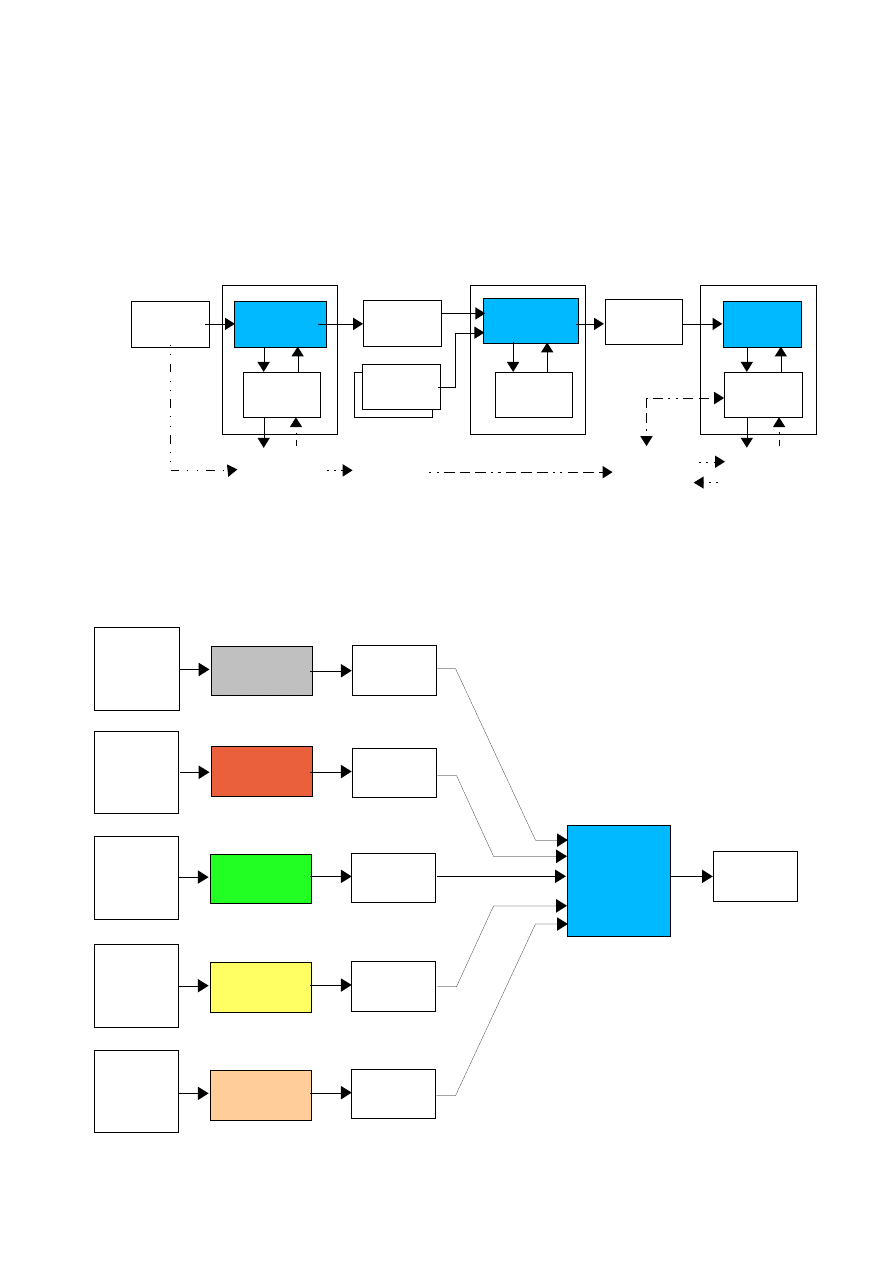
KOMPILACJA i KONSOLIDACJA
Pseudo-kompilatory generują tzw. bajtkod – kod pośredni, który na etapie wykonywania jest
przekształcany w kod maszynowy – mikrokod wykonywany wewnątrz procesora. Mikrokod jest
różny dla różnych typów procesora.
Program
ź
ródłowy
Kompilator
Program
wynikowy
Konsolidator
Program
wykonalny
Program
ładujący
Procesor
Procesor
Procesor
Procesor
Inne
moduły
Tekst programu
(.cpp)
Moduły - objects
(.o lub .obj)
Plik
wykonywalny
Pseudo-
kompilator
Kod
pośredni
Interpreter
Kod
maszynowy
Inne moduły z kodem pośrednim:
mogą pochodzić z innych kompilatorów dowolnych innych języków programowania:
-
Pascal, Asembler, Fortran, Cobol, Modula 2 itd.
Program
ź
ródłowy
C
Program
ź
ródłowy
Pascal
Program
ź
ródłowy
Asembler
Program
ź
ródłowy
Fortran
Kompilator
C
Program
wynikowy
Kompilator
Pascal
Program
wynikowy
Kompilator
C++
Program
wynikowy
Kompilator
Asembler
Program
wynikowy
Kompilator
Fortran
Program
wynikowy
Konsolidator
Program
wykonalny
Program
ź
ródłowy
C++

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
9
PREPROCESOR KOMPILATORA
•
Przed uruchomieniem kompilatora
•
Dyrektywy rozpoczynające się od: # (hash, krzyżyk)
#include <nazwa>
//dla domyślnej lokalizacji plików nagłówkowych
lub
#include ”nazwa”
//dla plików nagłówkowych z bieżącej kartoteki
•
Definicja symbolu lub stałej:
#define NMAX 100
#define cośtam
•
Dyrektywa warunkowa:
Przykład:
#ifndef p_sumaP
//jeśli wcześniej nie było zdefiniowane p_sumaP
#define p_sumaH
/*to trzeba zdefiniować p_sumaH i dołączyć
odpowiedni plik nagłówkowy */
#include ”p_suma.h”
//Umieszczenie treści pliku p_suma.h w tym miejscu
#endif
Inny przykład:
#define unix
//informacja na początku, że kompilacja w systemie Unix
.....
#ifdef unix
#include ”unix.h”
//dołącz jakiś własny plik nagłówkowy unix.h
#endif
#ifndef unix
//dla innego systemu niż unix
#include system.h
//dołącz jakiś własny plik nagłówkowy system.h
#endif
PROGRAM WYKONALNY
•
Kompilacja programu źródłowego
•
Binarny moduł wynikowy typu „obiekt”
•
Łączenie modułów - Link
•
Program uruchamialny: .com, .exe
•
Uruchamianie krokowe - Debug
URUCHOMIENIE i PRZETESTOWANIE
Faza wdrożenia i obserwacja zachowania programu w warunkach rzeczywistej eksploatacji
Odnajdowanie przyczyn błędnego działania programu (ang. TROUBLESHOOTING)
•
Błędy kompilacji (składniowe)
•
Błędy logiczne
•
Błędy funkcjonalne
•
Pomyłki fazy projektowania
Obsługa „potencjalnych” błędów użytkownika
•
Zmiany i rozszerzenia

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
10
ZALECENIA OGÓLNE:
1. Funkcje:
–
≥
10 linijek programu,
–
wielokrotne powtórzenia.
–
wcięcia w tekście programu
–
spójny system nazw, np. zgodne z systemem węgierskim
2. Wyczerpujące komentarze w programach:
–
komentarz do końca linii: //
for (i=1;i<5;i++) {
//pętelka służąca do pokazu zaleceń ogólnych dla studentów
if (iLiczba == 7)
. . .
}
–
blok komentarza: /* blok */
for (i=1;i<5;i++) {
/*inna pętelka z wykluczoną instrukcją, która nie jest już potrzebna, ale
może się przydać później w fazie uruchomienia. Po zakończeniu fazy uruchomienia takie
zbędne instrukcje i bloki komentarzy można usunąć np., żeby nie dawać sobie powodu do
wstydu i wyśmiewania przez następne pokolenia
if (iLiczba == 7) */
iLiczba--;
. . .
}
ZŁOTA ZASADA
(nieznanego autora - przekazywana z pokolenia na pokolenie)
Cyt. rady starszego kolegi:
Program działa tak jak go napisałeś,
a nie tak jak Ci się wydawało, że go napisałeś.

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
11
2.
REPREZENTACJA DANYCH
Dane przechowywane i przetwarzane w komputerach są postaci cyfrowej, zatem w postaci liczb o
pierwotnej postaci liczb binarnych – zapisanych w
systemie dwójkowym
.
Dane, które zapisane są w pamięci komputera to tzw.
zmienne
, ze względu na fakt, że ich wartości
mogą być modyfikowane w trakcie działania programu. Każda zmienna jest określonego typu i
posiada unikalną nazwę lub wskazanie w postaci adresu czyli miejsca w pamięci operacyjnej.
Wyróżniono trzy typy zmiennych, w zależności od zasięgu dostępności danych w różnych
miejscach programu:
Globalne
– deklarowane na początku programu, przed funkcją główną: main() ) dostępne w
każdym miejscu programu. Rezydują w pamięci przez cały czas funkcjonowania programu w
miejscu na stałe zarezerwowanym.
Lokalne
– dostępne w bloku, w którym zostały zadeklarowane i używane tylko w jego obszarze,
np. w funkcji głównej lub innych zdefiniowanych funkcjach. Przeznaczone są do lokalnego
przetwarzania i dlatego mają charakter tymczasowy – znikają po zakończeniu funkcji lub nie są
dostępne po opuszczeniu funkcji, np. w celu realizacji innej funkcji, a po powrocie są nadal
dostępne. Każde jednak nowe wywołanie funkcji tworzy na nowo zestaw zadeklarowanych
zmiennych z ich wartościami początkowymi. Tworzone są w pamięci podręcznej programu, w
przestrzeni, która może być wielokrotnie użyta do deklarowania różnych zmiennych lokalnych.
Statyczne
– podobnie jak zmienne lokalne dostępne są w bloku, w którym zostały zadeklarowane, z
tą jednak różnicą, że zachowują swoją wartość podczas ponownego wywołania funkcji. Musza
posiadać stałą rezerwację w pamięci, podobnie jak zmienne globalne.
Widoczność zmiennych, zmienne statyczne oraz zjawisko przesłaniania zostanie omówione w
dalszej części kursu.
DEKLARACJE ZMIENNYCH
Deklaracja zmiennej polega na wskazaniu typu zmiennej i nazwy. Nie można zakładać, że zmienne
posiadają istotną wartość początkową, która może być przypadkowa. Nie można zakładać, że
będzie to zero dla zmiennych przechowujących liczby. Możliwe jest zadeklarowanie zmiennych z
wartościami początkowymi:
Typ nazwa_zmiennej = wartość_początkowa;
int a,b,c;
float d,e,f;
double g,h;
Inicjalizacja wartości początkowych:
int a=0,b=1,c=5;
float d=0.1,e=0.5,f=7;
double g=0,h=0;

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
12
W języku C definicje zmiennych mają ustalone miejsce, zwykle na początku programu lub funkcji.
W języku C++ dopuszczono większą swobodę co do miejsca umieszczenia deklaracji zmiennych –
zwykle mogą się pojawiać w dowolnym miejscu programu, np. przed ich pierwszym użyciem lub
nawet w trakcie ich użycia:
for (int i=0;i<100;i++){
...
}
int a= (int b=5) + (int c=7);
//to tylko przykład - proszę nie stosować takich praktyk.
Poprawiła się wygoda użycia zmiennych, ale jednocześnie pojawić się bałagan. Należy stosować
przede wszystkim rozsądek i utrzymywać w równowadze rozproszenie deklaracji zmiennych oraz
porządek i czytelność programu.
STRUKTURA PROGRAMU
W przypadku rozbudowanych programów może być bardzo zróżnicowana. Dla prostych
przypadków można przyjąć ogólną strukturę składającą się z dyrektyw dołączenia plików
nagłówkowych
#include
, następnie zmiennych globalnych
Przykładowa postać ogólna struktury programu:
#include <iostream>
//pliki nagłówkowe
int konto, licznik;
//zmienne
globalne
int
XYZ
(int dana1, int dana2){
int wynik, suma, m,n;
//zmienne
lokalne
w funkcji XYZ
….
return suma;
//powrót z funkcji
}
int
main()
{
int a=0, b, c;
//zmienne
lokalne
w funkcji głównej
...
XYZ(b,10);
//wywołanie funkcji XYZ
for (
int i=0
; i<10; i++){
...
}
return 0;
//powrót z kodem – 0 jeśli poprawne zakończenie
}

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
13
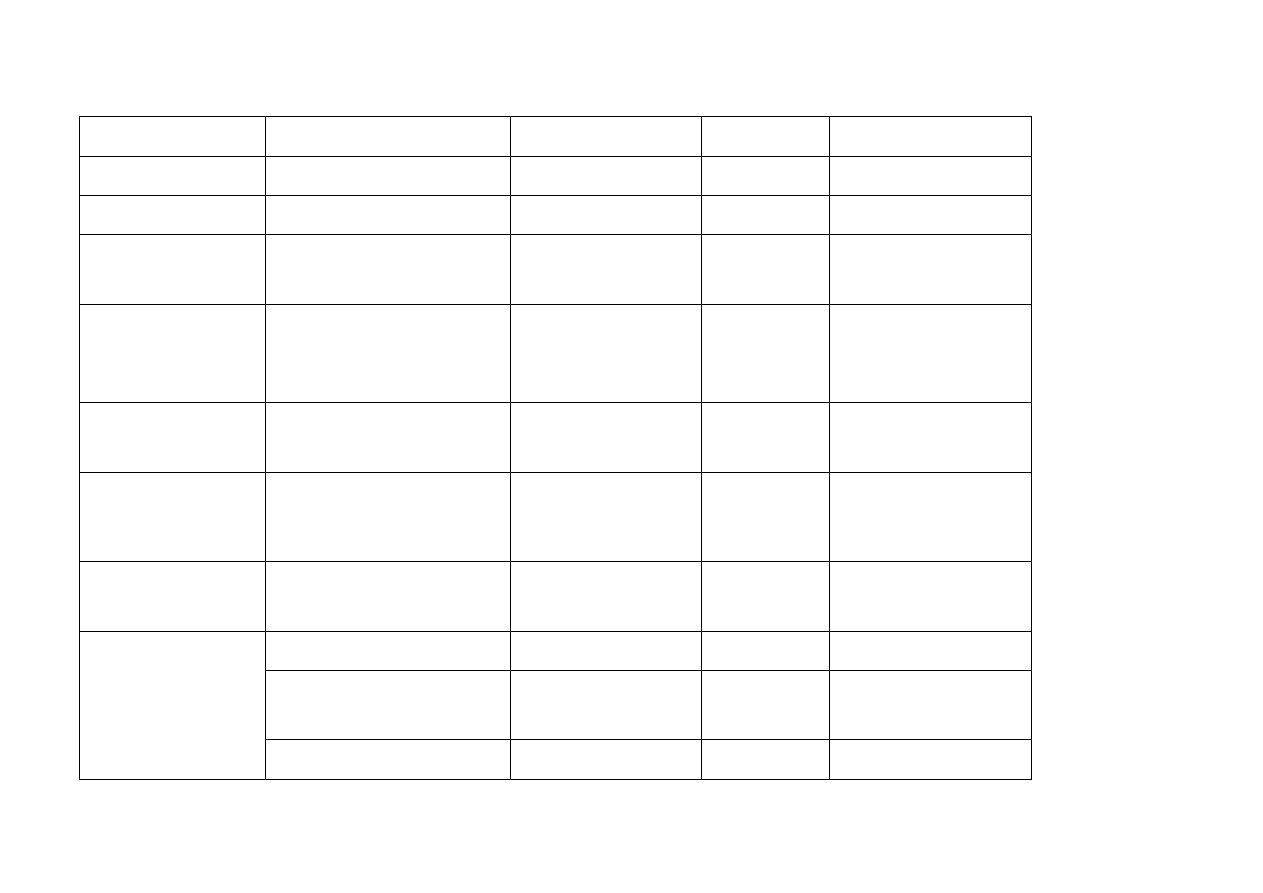
TYPY DANYCH – WBUDOWANE
Zarówno w języku C, jak i w języku C++ wyróżniamy pięć podstawowych typów danych:
int
— typ całkowity. Używany jest do zapamiętywania i zapisywania liczb całkowitych.
float
— typ zmiennopozycyjny (zmiennoprzecinkowy).
double
— typ zmiennoprzecinkowy podwójnej długości. Zmienne typu
float
oraz
double
umożliwiają zapamiętywanie i zapisywanie liczb posiadających część całkowitą i
ułamkową. Część ułamkową oddzielamy kropką.
char
— typ znakowy stosowany do zapamiętywania i zapisywania znaków ASCII oraz
krótkich liczb reprezentowanych na 8 bitach. Na niektórych architekturach zajmuje może zajmować
więcej niż jeden bajt.
void
— typ pusty. Za jego pomocą można deklarować funkcje nie zwracające żadnych wartości
oraz funkcje, które nie pobierają argumentów. Dodatkowo możliwe jest tworzenie
ogólnych wskaźników.
Rozmiar typu <=> zakres liczb
jest uzależniony od architektury procesora (zwykle 16 lub 32 bity) oraz kompilatora. W
nowoczesnych, 32-bitowych procesorach rodziny Pentium z najnowszymi kompilatorami,
liczby
całkowite
mają
cztery bajty
.
Znak
jest zawsze pojedynczą literą, cyfrą lub symbolem i zajmuje pojedynczy bajt pamięci.
WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
14
TYPY ZMIENNYCH
Nazwa
Przykład deklaracji
Zakres
Bajtów
Zastosowanie
Litera,
char cZnak;
- 128 ... 127
1
Teksty
Litera bez znaku
unsigned char ucMala;
0 ... 255
1
Male liczby
Mała liczba całkowita
short int siLiczba;
short siLiczba;
0 ... 255
0 ... 65535
1
2
Małe liczby całkowite
Liczba całkowita
int liczba
-32768 ... 32767
–2 147 483 648 do 2 147
483 647
2
4
Liczby całkowite
Liczba naturalna
unsigned int i,j,k;
unsigned
0 ... 65535
0 ... 4 294 967 295
2
4
Liczba naturalna
Duża liczba całkowita
long int lDuza_liczba;
long lDuza_liczba;
–2 147 483 648 do 2 147
483 647
-2^31 ... 2^31-1
4
8
Duże liczby całkowite
B. duże liczby naturalne unsigned long int ulBduza;
unsigned long ulBduza;
0 ... 2^64-1
0 ... 2^128-1
8
16
Bardzo duże liczby
naturalne
Zmiennoprzecinkowa
float fLiczba;
±(1,2e-38 ... 3,4e38)
4
Z przecinkiem
double float dfUlamek;
double dfUlamek;
±(2,2e-308 ... 1,79e308)
8
long double ldXduza
-3,3e-4932 ... 1,1e4932
16

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
15
REPREZENTACJA LICZB STAŁOPOZYCYJNYCH
Bit znaku dodawany jest na początku liczby blokując jeden bit, pozostała część liczby zapisana jest w naturalnym kodzie binarnym (NKB) lub w
kombinacjach z modułem lub operacją negowania liczby.
NKB to zapis liczby w
naturalnym kodzie binarnym
sumy kolejnych potęg liczby 2.
ZM to zapis
znak-moduł
(ang. sign-magnitude) utworzono przez dodanie jednego bitu do modułu (wartości bezwzględnej liczby zakodowanej w
NKB). Występuje podwójna reprezentacja zera.
U1 – kod uzupełnień do 1 (ang. 1s complement) Najbardziej znaczący bit jest bitem znaku (0-liczba dodatnia, 1-liczba ujemna). Jeśli liczba jest
dodatnia to wartość liczby zakodowana jest w NKB, a jeśli liczba posiada znak ujemny to negacja pozostałej części liczby stanowi jej wartość poniżej
zera. Występuje podwójna reprezentacja zera.
U2 – kod uzupełnień do 2 (ang. 2s complement) Najbardziej znaczący bit jest bitem znaku (0-liczba dodatnia, 1-liczba ujemna). Jeśli liczba jest
dodatnia to wartość liczby zakodowana jest w NKB, a jeśli liczba posiada znak ujemny to negacja pozostałej części liczby, po dodaniu 1 stanowi jej
wartość poniżej zera. Występuje pojedyncza reprezentacja zera.
BIAS – kod polaryzowany używany do zapisu cechy liczb zmiennopozycyjnych. Najbardziej znaczący bit jest bitem znaku (1-liczba dodatnia, 0-liczba
ujemna). Dalej podobnie jak w U2. Jeśli liczba jest dodatnia to wartość liczby zakodowana jest w NKB, a jeśli liczba posiada znak ujemny to negacja
pozostałej części liczby, po dodaniu 1 stanowi jej wartość poniżej zera. Występuje pojedyncza reprezentacja zera.
BCD – kod binarny liczb dziesiętnych reprezentowanych w postaci tetrad (czwórek bitów) reprezentujących kolejne cyfry dziesiętne. Każda tetrada
koduje cyfrę w NKB. Pierwszy bit jest bitem znaku (0-liczba dodatnia, 1-liczba ujemna)
Liczba
ZM
U1
U2
BIAS
BCD
-128
10000000
00000000
-127
11111111
10000000
10000001
00000001
1000100100111
-126
11111110
10000001
10000010
00000010
1000100100110
...
...
...
...
...
...
-1
10000001
11111110
11111111
01111111
1000000000001
0
10000000
11111111
00000000
10000000
1000000000000
0
00000000
00000000
00000000
10000000
0000000000000
1
00000001
00000001
00000001
10000001
0000000000001
2
00000010
00000010
00000010
10000010
0000000000010
3
00000011
00000011
00000011
10000011
0000000000011
4
00000100
00000100
00000100
10000100
0000000000100
...
...
...
...
...
...
126
01111110
01111110
01111110
11111110
0000100100110
127
01111111
01111111
01111111
11111111
0000100100111
WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
16
REPREZENTACJA LICZB ZMIENNOPOZYCYJNYCH
Binarny zapis liczb składa się z trzech części kodowanych o osobnych polach:
-
jednobitowe pole
znaku
(ang. sign)
-
n – bitowe pole części ułamkowej zwane
mantysą S
(ang significant part)
-
m – bitowe pole części wykładniczej zwane
cechą E
(ang. exponent part)
Liczba A = +/- S * B
+/- E
gdzie B jest podstawą wykładnika i zwykle przyjmuje się 2, 10, 16
Część ułamkowa mantysa S jest zawsze z przedziału: [0.5, 1) lub inaczej 0.5 <= S < 1
A w postaci binarnej:
0.1
00...0 <= S =<
0.1
11 ....1 co oznacza 0*2
0
+ 1*2
-1
+ 0* .... =0.5
Można zauważyć, że dwie pierwsze pozycje binarne dla całego przedziału są
takie same
zatem:
0.1
a
-2
a
-3
… a
-(n+1)
co oznacza: 1*2
-1
+ a
-2
* 2
-2
+ a
-3
* 2
-3
+ ... + a
-(n+1)
* 2
-(n+1)
Przykładowe długości cechy i mantysy [bity]
Komputer
Słowo
Znak
Mantysa
Cecha
VAX11
32
1
23
8
Intel
80
1
64
15
Standard
IEEE754
64
32
1
1
48
23
15
8
Standard IEEE 754 dla mantysy 23 bitowej i cechy 8 bitowej umożliwia zapis liczb
od 0.5*2
-128
do (1-2
-24
) 2
+127
-(1-2
-24
) 2
+127
- 0.5*2
-128
+0.5*2
-128
+(1-2
-24
) 2
+127
0
Przykład przeliczenia danej dziesiętnej na binarną postać zmiennoprzecinkową:
Liczbę: 0,625625 * 10
3
można przedstawić jako 625,625
Osobno traktując część całkowitą 625 można ją zapisać binarnie jako
10 0111 0001
Część ułamkowa: 0,625 jest sumą 0,5 i 0,125 czyli 1*2
-1
+ 0* 2
-2
+ 1*2
–3
zatem 0.
101
W rezultacie otrzymujemy liczbę
10 0111 0001
.
101
Ponieważ część całkowita mieści się na 10 bitach normalizujemy liczbę przesuwając przecinek o
10 pozycji w lewo – robiąc z niej ułamek z częścią wykładnika o wartości 10:
0.1001110001
101
* 2
10
ale odrzucamy również przy zapisie mantysy dwa pierwsze bity:
0.1
001110001101
Bit znaku
Mantysa
Cecha
0 (dodatnia)
0011 1000 1101
0000 0000 000
1
0001010
znak cechy (zapis polaryzowany BIAS)
Trudność może sprawić przekształcenie części ułamkowej do mantysy. Często trzeba
normalizować liczbę dziesiętną do odpowiedniego zakresu aby część ułamkowa mieściła się w
zakresie od 0,5 do 1.

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
17
Przykład. Sprawdzanie rozmiarów typów zmiennych istniejących w twoim
komputerze
#include <iostream>
int main(){
using std::cout;
cout << "Rozmiar zmiennej typu int to:\t\t"<< sizeof(int) << " bajty.\n";
cout << "Rozmiar zmiennej typu short int to:\t"<< sizeof(short) << " bajty.\n";
cout << "Rozmiar zmiennej typu long int to:\t"<< sizeof(long) << " bajty.\n";
cout << "Rozmiar zmiennej typu char to:\t\t"<< sizeof(char) << " bajty.\n";
cout << "Rozmiar zmiennej typu float to:\t\t"<< sizeof(float) << " bajty.\n";
cout << "Rozmiar zmiennej typu double to:\t"<< sizeof(double) << " bajty.\n";
cout << "Rozmiar zmiennej typu bool to:\t"<< sizeof(bool) << " bajty.\n";
return 0;
}
UWAGA: W twoim komputerze rozmiary zmiennych mogą być inne.
Efekt:
Rozmiar zmiennej typu
int
to: 4 bajty.
Rozmiar zmiennej typu
short int
to: 2 bajty.
Rozmiar zmiennej typu
long int
to: 4 bajty.
Rozmiar zmiennej typu
char
to: 1 bajty.
Rozmiar zmiennej typu
float
to: 4 bajty.
Rozmiar zmiennej typu
double
to: 8 bajty.
Rozmiar zmiennej typu
bool
to: 1 bajty.

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
18
DEFINICJA TYPÓW przez typedef
Dla przykładu ciągłe wpisywanie
unsigned short int
może być żmudne, a co gorsza, może
spowodować wystąpienie błędu.
C++ umożliwia użycie słowa kluczowego
typedef
(od
type definition
, definicja typu), dzięki
któremu możesz stworzyć skróconą formę takiego zapisu.
Dzięki skróconemu zapisowi tworzony jest
synonim
, lecz
nie jest to nowy typ
.
Przy zapisywaniu synonimu typu używa się słowa kluczowego
typedef
, po którym wpisuje się
istniejący typ, zaś po nim nową nazwę typu.
Na przykład:
typedef unsigned short int USHORT;
tworzy nową nazwę typu,
USHORT
, której można użyć wszędzie tam, gdzie mógłbyś użyć
zapisu
unsigned short int
.
Przykład użycia
typedef
// *****************
// Demonstruje użycie słowa kluczowego typedef
#include <iostream>
typedef unsigned short int USHORT; //definiowane poprzez: typedef
int main() {
using std::cout;using std::endl;
USHORT Width = 5;
USHORT Length;
Length = 10;
USHORT Area = Width * Length;
// UWAGA: * (gwiazdka) oznacza mnożenie.
cout << "Szerokosc:" << Width << "\n";
cout << "Dlugosc: " << Length << endl;
cout << "Obszar: " << Area <<endl;
return 0;
}
Analiza
W linii 4. definiowany jest synonim
USHORT
dla typu
unsigned short int
.
Efekt:
Szerokosc:5
Dlugosc: 10
Obszar: 50

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
19
STAŁE
Do przechowywania danych służą także stałe - wartość stałej nie ulega zmianie. Podczas
tworzenia stałej trzeba ją zainicjalizować, później nie można już przypisywać jej innej wartości.
C++ posiada dwa rodzaje stałych:
literały
i
stałe symboliczne
.
LITERAŁY
Literał jest wartością wpisywaną bezpośrednio w danym miejscu programu. Na przykład:
int mojWiek =
19
;
mojWiek
jest zmienną typu
int
i może być przypisywana dowolna wartość z zakresu
int
w
dowolnym momencie działania programu w miejscu dostępu do zmiennej;
19
jest literałem. Programista umawia się sam ze sobą, że nie będzie zmieniał wartości literału w
trakcie działania programu. WARTOŚĆ TA MOŻE ALE NIE POWINNA BYĆ ZMIENIANA.
STAŁE SYMBOLICZNE
Stała symboliczna jest reprezentowana poprzez swoją nazwę - po zainicjalizowaniu stałej, nie
można później zmieniać jej wartości.
•
Definicja klasyczna z użyciem dyrektywy preprocesora
#define
przez proste podstawienie
tekstu:
#define STUDENCI 89
gdzie stała
STUDENCI
nie ma określonego typu (
int
,
char
, itd.). Za każdym razem, gdy
preprocesor natrafia na słowo
STUDENCI
, zastępuje je napisem
89
.
•
Definicja stałych za pomocą
const
, gdzie stała posiada swój typ
const unsigned short int STUDENCI = 89;
Stała ma typ, którym jest
unsigned short int
.
Zalety
const
:
-
kod programu jest łatwiejszy w konserwacji i jest bardziej odporny na błędy,
-
kompilator może wymusić użycie jej zgodnie z tym typem.
UWAGA Stałe nie mogą być zmieniane podczas działania programu. Jeśli chcesz na
przykład
zmienić wartość stałej
STUDENCI
, musisz zmodyfikować kod źródłowy, po czym
skompilować program ponownie.
Możliwy jest zapis liczb w formie wykładniczej:8e2 (8*10
2
), 10.4e8 (10.4*10
8
), 5.2e-3 (5.2*10
-3
)
STAŁE WYLICZENIOWE
Stałe wyliczeniowe umożliwiają tworzenie nowych typów, a następnie definiowanie ich
wartości, które ograniczają się do wartości określonych w definicji typu.
Na przykład, możesz zadeklarować typ
COLOR
(kolor) jako wyliczenie, dla którego możesz
zdefiniować pięć wartości:
RED
,
BLUE
,
GREEN
,
WHITE
oraz
BLACK
.
Składnię definicji wyliczenia stanowią słowo kluczowe
enum
, nazwa typu, otwierający nawias
klamrowy, lista wartości oddzielonych przecinkami, zamykający nawias klamrowy oraz średnik.

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
20
Przykład:
enum
COLOR
{
RED, BLUE, GREEN, WHITE, BLACK
};
W efekcie nowe wyliczenie otrzymuje nazwę
COLOR
, tj. tworzony jest nowy typ.
-
RED
(czerwony) jest stałą symboliczną o wartości
0
,
-
BLUE
(niebieski) jest stałą symboliczną o wartości
1
,
-
GREEN
(zielony) jest stałą symboliczną o wartości
2
, itd.
Każda wyliczana stała posiada wartość całkowitą. Jeśli tego nie określisz, zakłada się że pierwsza
stała ma wartość
0
, następna
1
, itd. Każda ze stałych może zostać zainicjalizowana dowolną
wartością. Stałe, które nie zostaną zainicjalizowane, będą miały wartości naliczane począwszy od
wartości od jeden większej od wartości stałych zainicjalizowanych. Zatem, jeśli napiszesz:
enum
COLOR
{ RED=100, BLUE,
GREEN=500
, WHITE, BLACK=700 };
To:
-
RED
będzie mieć wartość
100
,
-
BLUE
będzie mieć wartość
101
,
-
GREEN
wartość
500
,
-
WHITE
(biały) wartość
501
,
-
BLACK
(czarny) wartość
700
.
Możesz definiować zmienne typu
COLOR
, ale mogą one przyjmować tylko którąś z wyliczonych
wartości (w tym przypadku
RED
,
BLUE
,
GREEN
,
WHITE
lub
BLACK
, albo
100
,
101
,
500
,
501
lub
700
). Zmiennej typu
COLOR
możesz przypisać dowolną wartość koloru.
W rzeczywistości możesz przypisać jej dowolną wartość całkowitą, nawet jeśli nie odpowiada
ona dozwolonemu kolorowi - dobry kompilator powinien w takim przypadku wypisać
ostrzeżenie. Należy zdawać sobie sprawę, że stałe wyliczeniowe to w rzeczywistości zmienne
typu
unsigned int
oraz że te stałe odpowiadają zmiennym całkowitym. Możliwość nazywania
wartości okazuje się bardzo pomocna, na przykład podczas pracy z kolorami, dniami tygodnia
czy podobnymi zestawami.
Przykład stałych wyliczeniowych
#include <iostream>
int main() {
enum Days { Sunday, Monday, Tuesday,
Wednesday, Thursday, Friday, Saturday };
Days today;
today = Monday;
//przypisanie
if (today == 0 || today == Saturday)
//sprawdzanie warunku
std::cout << "\nUwielbiam weekendy!\n";
else
std::cout << "\nWracaj do pracy.\n";
return 0;
}
Efekt:
Wracaj do pracy.
WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
21
Analiza
W linii 3. definiowana jest stała wyliczeniowa
Days
(dni), posiadająca siedem, odpowiadających
dniom tygodnia, wartości. Każda z tych wartości jest wartością całkowitą, numerowaną od
0
w
górę (tak więc
Monday
— poniedziałek — ma wartość
1
)1.
Tworzymy też zmienną typu
Days
— tj. zmienną, która będzie przyjmować wartość z listy
wyliczonych stałych. W linii 7. przypisujemy jej wartość wyliczeniową
Monday
, którą następnie
sprawdzamy w linii 9.
Program podobny do poprzedniego, ale wykorzystujący stałe całkowite
#include <iostream>
int main() {
const int Sunday = 0;
const int Monday = 1;
const int Tuesday = 2;
const int Wednesday = 3;
const int Thursday = 4;
const int Friday = 5;
const int Saturday = 6;
int today;
today = Monday;
if (today == Sunday || today == Saturday)
std::cout << "\nUwielbiam weekendy!\n";
else
std::cout << "\nWracaj do pracy.\n";
return 0;
}
Analiza
ISTOTNY FAKT: Amerykanie liczą dni tygodnia zaczynając od niedzieli.
Wynik działania tego programu jest identyczny z wynikiem programu z listingu 3.7. W tym
programie każda ze stałych (
Sunday
,
Monday
, itd.) została zdefiniowana jawnie i nie istnieje typ
wyliczeniowy
Days
. Stałe wyliczeniowe mają tę zaletę, że się same dokumentują —
przeznaczenie typu wyliczeniowego
Days
jest oczywiste.
Efekt:
Wracaj do pracy.

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
22
PRZESTRZEŃ NAZW
Istnieje zdefiniowana (wbudowana) przestrzeń nazw std (od standard).
W języku C++ używamy nazw dla standardowych plików nagłówkowych bez .h na końcu – jest
ich około 50. Własne lub inne niestandardowe pliki nagłówkowe nadal zwykle nazywane są z
rozszerzeniem .h.
#include <iostream>
a nie tak jak poprzednio
#include <iostream.h>
(ang. obsolete)
Użycie zmiennych i funkcji wymaga wskazania do jakiej przestrzeni nazw należą.
Można to zrobić na trzy sposoby:
1.
definicja globalna przestrzeni nazw
przed main deklarujemy:
using namespace std;
int main() {
…..
cout<<”Coś tam”;
}
2.
definicja lokalna użycia przestrzeni nazw
w main oraz w innych funkcjach – wewnątrz klamry
int main () {
using std::cout;
….
cout<<”Coś tam”;
….
}
3.
bezpośrednie wskazanie przestrzeni nazw, do której należy dana funkcja przy każdym
wywołaniu funkcji
int main () {
…
std::cout<<”Coś tam”;
…
}

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
23
ZNAKI
Zmienne znakowe (typu
char
) zwykle mają rozmiar jednego bajtu, co wystarczy do przechowania
jednej z 256 wartości. Typ
char
może być interpretowany jako mała liczba (od
0 do 255) lub jako element zestawu kodów ASCII. Skrót ASCII pochodzi od słów American
Standard Code for Information Interchange. Zestaw znaków ASCII oraz jego odpowiednik ISO
(International Standards Organization) służą do kodowania wszystkich liter (alfabetu
łacińskiego), cyfr oraz znaków przestankowych.
UWAGA Komputery nie mają pojęcia o literach, znakach przestankowych i zdaniach.
Rozpoznają tylko liczby. Zauważają tylko odpowiedni poziom napięcia na określonym złączu
przewodów. Jeśli występuje napięcie, jest ono symbolicznie oznaczane jako jedynka, zaś gdy
nie występuje, jest oznaczane jako zero. Poprzez grupowanie zer i jedynek, komputer jest w
stanie generować wzory, które mogą być interpretowane jako liczby, które z kolei można
przypisywać literom i znakom przestankowym.
W kodzie ASCII mała litera „a” ma przypisaną wartość 97. Wszystkie duże i małe litery,
wszystkie cyfry oraz wszystkie znaki przestankowe mają przypisane wartości pomiędzy 0 a 127.
Dodatkowe 128 znaków i symboli jest zarezerwowanych dla „wykorzystania” przez producenta
komputera, choć standard kodowania stosowany przez firmę IBM stał się niejako
„obowiązkowy”.
UWAGA ASCII wymawia się jako „eski.”
ZNAKI i LICZBY
Gdy w zmiennej typu
char
umieszczasz znak, na przykład „a”, w rzeczywistości jest on liczbą
pochodzącą z zakresu od 0 do 255. Kompilator wie jednak, w jaki sposób odwzorować znaki
(umieszczone wewnątrz apostrofów) na jedną z wartości kodu ASCII.
Przykład wypisywania znaków na podstawie ich kodów
#include <iostream>
int main(){
for (int i = 32; i<128; i++)
std::cout << (char) i;
return 0;
}
Ten prosty program wypisuje znaki o wartościach od 32 do 127.
Efekt:
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEF
GHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijkl
mnopqrstuvwxyz{|}~_

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
24
ZNAKI SPECJALNE
Kompilator C++ rozpoznaje pewne specjalne znaki formatujące.
Znak
Oznacza
\a
Alarm (dzwonek)
\b
Backspace (znak wstecz)
\f
Form feed (koniec strony)
\n
New line (nowa linia)
\r
Carriage return (powrót „karetki”; powrót na
początek linii)
\t
Tab (tabulator)
\v
Vertical tab (tabulator pionowy)
\'
Single quote (apostrof)
\"
Double quote (cudzysłów)
\?
Question mark (znak zapytania)
\\
Backslash (lewy ukośnik)
\0oo
Zapis ósemkowy
\xhhh
Zapis szesnastkowy
Przed użyciem znaków specjalnych jako zwykłych znaków tj, \ ‘ ” 0 ? powinien pojawić się \
zdejmujący znaczenie specjalne, np. ” \” ”, ‘\’ ’, ‘\0’ (znak Zero – Null)

WYKŁADY cz.1 v.5 (2012) Podstawy programowania 1
(dr.inż Marcin Głowacki)
25
KONWERSJE / RZUTOWANIE TYPÓW
Jeśli podczas przetwarzania danych w operacji pojawiają się zmienne typów niespodziewanych
lub niezgodnych z definicją może następować jawna lub niejawna konwersja typów zmiennych.
Konwersje niejawne występują w wyniku próby automatycznego dopasowania przez kompilator
typów zmiennych dla wykonania zadanej operacji, np.:
int m,n;
n=10;
m=n+1.2345;
W ostatnim wierszu dokonana została automatyczna konwersja zmiennej n na double, a następnie
po wykonaniu dodania konwersja sumy do typu int zanim nastąpiło przypisanie do m.
W wyniku operacji m będzie równe 11 (nastąpi odcięcie części ułamkowej, a nie zaokrąglenie).
Konwersja jawna jest wywoływana świadomie przez programistę.
Formy zapisu jawnej konwersji:
dany_typ wynik, wyrażenie_1;
inny_typ wyrażenie_2;
-
forma funkcji
wynik = wyrażenie_1 + dany_typ(wyrażenie_2);
-
forma rzutowania
wynik = wyrażenie_1 + (dany_typ)wyrażenie_2;
Przykład:
int m,n;
n=10;
m=n+int(1.2345);
Unika zbędnych konwersji niejawnych (n nie będzie konwertowane na double i double na int).
Rezultat obliczeń będzie taki sam jak w poprzednim przykładzie.
Przykład:
#include <iostream>
int main() {
using std::cout; using std::endl;
int wynik_i,m,n,a;
float wynik_f,b;
m=4;n=10; a=10;b=4;
wynik_i=n+int(1.2345);
cout << "wynik_i: " << wynik_i <<endl;
wynik_f=n+1.2345;
cout << "wynik_f: " << wynik_f <<endl;
wynik_i=n/m;
cout << "wynik_i: " << wynik_i <<endl;
wynik_f=a/b;
cout << "wynik_f: " << wynik_f <<endl;
return 0;
}
Efekt:
Sam się przekonaj !
Wyszukiwarka
Podobne podstrony:
Informa cz2 v5 id 213359 Nieznany
Informa cz3 v5 id 213360 Nieznany
Informacje dla inwestora id 213 Nieznany
Informa cz4 v6 id 213362 Nieznany
Informa wyklad petle id 716506 Nieznany
inform r1 rozw id 288565 Nieznany
Informa cz2 v3 id 213358 Nieznany
Informacja pod ochrona id 21351 Nieznany
informatyka model PP id 214055 Nieznany
informatyka pp arkusz1 id 21382 Nieznany
Informa cz4 v9 id 213363 Nieznany
Informa cz4 v3 id 213361 Nieznany
Informacje dla inwestora id 213 Nieznany
Informa cz4 v6 id 213362 Nieznany
INFORM EXCEL2007 2 id 716490 Nieznany
cw4 telex cz1 id 123468 Nieznany
więcej podobnych podstron