
Laboratorium Baz Danych
PostgreSQL
(Procedury składowane, triggery, reguły)
Autor:
dr inż. Aleksandra Werner
dr inż. Małgorzata Bach

1.
Wprowadzenie
Historia rozwoju PostgreSQL sięga 1973 roku, kiedy to dr Michael Stonebraker wraz z Eugene
Wong rozpoczęli na Uniwersytecie Kalifornijskim w Berkeley badania nad relacyjnymi systemami baz
danych. Efektem tych badań był system zarządzania relacyjną bazą danych Ingres. Próba rozszerzenia
modelu relacyjnego o elementy ułatwiające modelowanie z natury coraz bardziej skomplikowanej
rzeczywistości oraz nowych dziedzin zastosowań (np. w systemach wspomagania projektowania czy
systemach wspomagania podejmowania decyzji) zaowocowała powstaniem systemu post-relacyjnego
Postgres (post-ingres). W mia
rę rozwoju i zwiększania funkcjonalności, baza danych otrzymała nazwy
Postgres95 i ostatecznie PostgreSQL, aby z jednej strony upamiętnić pierwowzór a z drugiej zaznaczyć
zgodność ze standardem SQL.
Systemy PostgreSQL oferuje kilka dodatkowych konstrukcji
, poszerzających w znaczący sposób
jego siłę wyrazu w stosunku do tradycyjnie rozumianego modelu relacyjnego. Są to: abstrakcyjne typy
atrybutów i złożone struktury danych, zagnieżdżone relacje, atrybuty proceduralne (wirtualne), dziedziczenie
(ang. inheritance), zapytania historyczne. W
niniejszym opracowaniu zostaną omówione niektóre z tych
dodatkowych elementów.
2.
Typy danych
Konwencjonalne relacyjne bazy danych oferowały bardzo ubogi zestaw typów danych, często
zredukowany do liczb, łańcuchów znaków i dat. Jest to wystarczające w przypadku tworzenia prostych
aplikacji ewidencyjnych, natomiast zdecydowanie niewystarczające w przypadku nowoczesnych dziedzin
zastosowań baz danych.
PostgreSQL prócz standardowych typów, charakterystycznych dla większości serwerów SQL, dysponuje
typami bardziej złożonymi (np. współrzędne geograficzne, opisy figur geometrycznych) wraz ze stosownymi
operatorami (np. warunek odległości pomiędzy punktami geograficznymi, warunek przecięcia się figur itd.).
Istnieje również możliwość rozszerzenia zestawu predefiniowanych typów danych o nowe tzw. abstrakcyjne
typy danych (ang. abstract data types
– ADT).
Tradycyjne relacje posiadają płaską, jednowymiarową strukturę (pierwsza postać normalna
wymaga, aby atrybuty były atomowe). Utrudnia to modelowanie złożonych encji. W post-relacyjnych bazach
danych istnieje możliwość definiowania atrybutów złożonych, które rekurencyjnie mogą składać się ze
zbioru innych atrybutów prostych (atomowych) i złożonych.
Przykłady zastosowania typów strukturalnych
Tablice
Za
łóżmy, że chcemy zapamiętać informacje o kwartalnych premiach pracowników pewnego
przedsiębiorstwa.
W tradycyjnym systemie relacyjnym musielibyśmy stworzyć tablicę o następującym schemacie:
Premie (nazwisko, numer_kwartału, premia_kwartalna)
gdzie: atrybut
nazwisko
jest typu znakowego (np. varchar),
atrybut
numer_kwartału
jest typu całkowitego (np. int4),
atrybut
premia_kwartalna
jest typu zmiennoprzecinkowego (np. float).
W języku SQL realizujemy to poleceniem:
CREATE TABLE Premie (Nazwisko varchar, Numer_kwartału int4, Premia_kwartalna float)
Możliwość wykorzystania w systemie PostgreSQL tablic jedno lub wielowymiarowych o stałym lub
zmiennym rozmiarze pozwala na zapamiętanie informacji o premiach (
premia_kwartalna)
jako tablicę
czteroelementową, której wskaźnikiem będzie numer kwartału:
CREATE TABLE Premie1 (Nazwisko varchar, Premia_kwartalna integer[])
W pierwszym ujęciu każdemu pracownikowi odpowiadają cztery rekordy, w których zapamiętana jest
premia, jaką otrzymał w poszczególnych kwartałach (tabela 1).
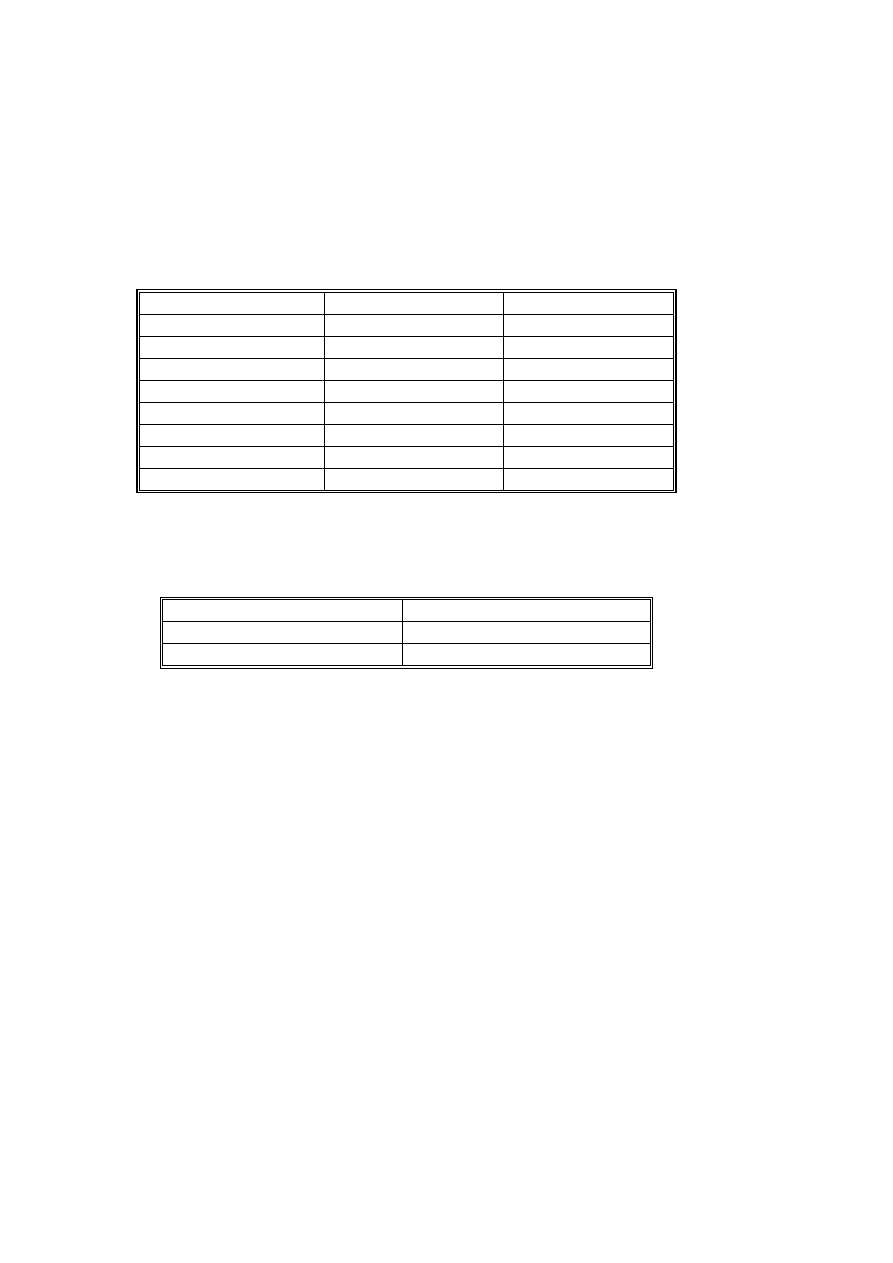
Tabela 1
Przykładowa zawartość relacji Premie dla dwóch pracowników
Nazwisko
Numer_kwartału
Premia_kwartalna
Nowak
1
200
Nowak
2
400
Nowak
3
300
Nowak
4
600
Pawelski
1
300
Pawelski
2
400
Pawelski
3
300
Pawelski
4
800
Wykorzystując możliwości systemu PostgreSQL, można te same dane przedstawić również tak:
Tabela 2
Przykładowa zawartość relacji Premie1 dla dwóch pracowników
Nazwisko
Premia_kwartalna
Nowak
{200,400,300,600}
Pawelski
{300,400,300,800}
W przedstawionej powyżej relacji
Premie1
do zapamiętania tej samej informacji wystarczają dwa
rekordy, a więc wielkość pliku, w którym zapisywane są dane, jest znacznie mniejsza.
Aby określić wielkości premii, jaką otrzyma pracownik
Pawelski
w trzecim kwartale w pierwszym przypadku
należy zadać pytanie:
SELECT Premia_kwartalna FROM Premie
WHERE nazwisko=’Pawelski’ AND Numer_kwartału=3
w drugim:
SELECT Premie1.Premia_kwartalna[3] FROM Premie1 WHERE nazwisko=’ Pawelski’
Domyślnie PostgreSQL stosuje dla tablic numerację od jedynki (tzn. pierwszym elementem jest array[1] a
ostatnim array[n]). Istnieje możliwość „wyciągnięcia” fragmentu tablicy poprzez podanie górnej i dolnej
granicy danego wymiaru (np. zapis
Premia_kwartalna[1..3]
odnosi się do pierwszych trzech kwartałów).
PostgreSQL pozwala również na definiowanie własnych (niestandardowych) typów danych. Służy do tego
instrukcja CREATE TYPE. Przykładowo poleceniem:
CREATE TYPE Punkt AS (x real, y real);
tworzymy typ, który może zostać wykorzystany dla zapamiętania współrzędnych punktu.
W PostgreSQL od wersji 8.3 istnieje możliwość tworzenia tablic typów złożonych. Mechanizm
zagnieżdżonych relacji jest szczególnym przypadkiem złożonych struktur danych. Wartością atrybutu może
być relacja, która z użytkowego punktu widzenia jest traktowana podobnie jak relacja zewnętrzna. W
szczególności zatem, relacja zagnieżdżona może zawierać atrybuty, których wartościami są kolejne relacje.

Prostym przykładem wykorzystania relacji zagnieżdżonych może być encja Pracownik_z_dzieckiem,
modelowana jako krotka o atrybutach prostych, takich jak imię, nazwisko, PESEL, oraz atrybutu Dzieci
będącego zagnieżdżoną relacją o krotności odpowiadającej liczbie dzieci określonego pracownika.
CREATE TABLE dzieciaki (imie varchar(15), data_ur timestamp);
CREATE TABLE pracownik_z_dzieckiem
(imie varchar(15), nazwisko varchar(15), PESEL varchar(11), dzieci dzieciaki[]);
Dziedziczenie
W systemie PostgreSQL istnieje możliwość definiowania relacji na bazie innych, wcześniej
utworzonych relac
ji przez wskazanie rozszerzeń i/lub różnic. Jest to mechanizm podobny do mechanizmu
dziedziczenia obiektowych baz danych.
Utwórzmy tabelę Pracownik:
CREATE TABLE Pracownik (imie varchar(15), nazwisko varchar(15), PESEL varchar(11), data_ur
timestamp)
oraz tabelę
Pracownik_Na_Zlecenie
:
CREATE TABLE Pracownik_Na_Zlecenie (nr_zlecenia varchar(16))
INHERITS (Pracownik);
wprowadźmy przykładową wartość do tabeli
Pracownik_Na_Zlecenie
:
INSERT INTO Pracownik_Na_Zlecenie (nr_zlecenia, imie, nazwisko, PESEL, dat_ur) VALUES(‘abc-
25/9’, 'Tomasz', 'Wicek', '44444444444', '2-12-1978');
Każde wystąpienie encji Pracownik_Na_Zlecenie dziedziczy (ang. inherits) wszystkie atrybuty (tj. imię,
nazwisko, PESEL oraz datę urodzenia) z encji nadrzędnej (inaczej klasy - rodzica) Pracownik.
Pracownik_na_zlecenie posiada dodatkowo atrybut nr_zlecenia.
Po wykonaniu polecenia:
SELECT * FROM Pracownik;
Otrzymamy informacje o wszystkich pracownikach, zarówno tych pracujących na zlecenie jak i tych
pracujących na etacie. Aby wyświetlić informacje tylko o pracownikach posiadających umowę o pracę
(pracujących na etacie) należy wykonać polecenie:
SELECT * FROM ONLY Pracownik;
W PostgreSQL możliwe jest wielo-dziedziczenie (o wielo-dziedziczeniu mówimy w sytuacji, gdy
obiekt danej klasy można zaliczyć do dwóch lub więcej klas bardziej ogólnych). Przykładowo
Pracujący_student może dziedziczyć zarówno z relacji Pracownik jak i Student:
CREATE TABLE Pracujacy_Student () INHERITS (Pracownik, Student);.
3.
Funkcje składowane, reguły i triggery
Jes
zcze kilkanaście lat temu, większość systemów baz danych było systemami pasywnymi, czyli
takimi, w których wszystkie operacje manipulowania danymi były związane tylko i wyłącznie z realizacją
żądań użytkowników. Obecnie większość systemów „żyje” również wtedy, gdy nie są do nich jawnie
kierowane żadne transakcje (żądania użytkowników). Oznacza to, że w bazach tych istnieje możliwość
zmian stanu ich krotek (obiektów) również na skutek zajścia określonego zdarzenia. Systemy aktywnych
baz danych są wyposażone w mechanizmy (odpowiedni język) definiowania i przetwarzania reguł
aktywnych (ang. Event-Condition-Action (ECA)).

Funkcje składowane
Czasami wygodniej jest dokonywać pewnych operacji na bazie poprzez wywołanie funkcji
(procedury), a nie listę kolejnych zapytań SQL.
W systemie PostgreSQL składnia polecenia tworzącego lub modyfikującego funkcję jest (w pewnym
uproszczeniu) następująca:
CREATE [OR REPLACE] FUNCTION nazwa ([typ argumentu [,...]])
RETURNS typ_wyniku
AS
$$
/* to jest delimiter początkowy – może być dowolnym znakiem lub ciągiem znaków*/
/* tu mogą się pojawić deklaracje poprzedzone słowem DECLARE */
ciało funkcji
$$
/*
to jest delimiter końcowy */
LANGUAGE
nazwa_języka
„Ciało funkcji” może być zdefiniowane (napisane) w języku deklaratywnym SQL, lub jednym z kilku
dostępnych w PostgreSQL języków proceduralnych: PL/pgSQL, PL/TCL, PL/Perl, PL/Python.
W ramach ćwiczeń laboratoryjnych będzie używany język SQL i PL/pgSQL
Załóżmy, że w naszej bazie zdefiniowana została tablica Wypłaty, w której przechowywane są informacje
o
zarobkach poszczególnych pracowników (atrybut stawka). Zdefiniujemy funkcję jedno-argumentową
premia, której zadaniem będzie obliczenie premii wynoszącej 25% stawki danego pracownika.
CREATE FUNCTION Premia(real) RETURNS double precision AS
$$
SELECT 0.25 * $1;
/* $1 odnosi się do parametru, którego wartość /
należy podać przy wywołaniu funkcji */
$$
LANGUAGE 'sql'
W celu wywo
łania funkcji używamy polecenia SELECT
SELECT Premia(Wyplaty.stawka) AS zaskorniak FROM Wyplaty
Przedstawiona poniżej funkcja Pracownik_dobrze_opłacany, jako wynik dostarcza informacje
o
wszystkich pracownikach, dla których spełniony jest warunek: placa > $1.
CREATE FUNCTION Pracownik_dobrze_opłacany (int4) RETURNS setof Wyplaty
AS
$$
SELECT * FROM Wyplaty WHERE stawka > $1
$$
LANGUAGE ‘sql’
W powyższym przykładzie typ wyniku został określony jako setof Wyplaty, co oznacza, że jako wynik
wykonania funk
cji otrzymamy zbór rekordów tablicy Wypłaty spełniających warunki określone w definicji
funkcji (po słowie where). Przykładowo, po wykonaniu polecenia:
SELECT * FROM Pracownik_dobrze_opłacany(1500);
otrzymamy informacje o osobach, których płaca przekracza 1500 zł.
Usunięcie funkcji odbywa się przy pomocy instrukcji:
DROP FUNCTION
nazwa_funkcji ([typ_arg {,typ_arg}]);

Triggery
Triggery (wyzwalacze) są to zapisane w bazie danych procedury, które są wykonywane
("wyzwalane" - ang. fire
) w sposób niejawny np. przez następujące polecenia DML: INSERT, UPDATE,
DELETE.
Triggery i funkcje składowane (przedstawione w poprzednim punkcie) różnią się sposobem wywołania. –
Funkcje są jawnie wykonywane przez użytkownika, aplikację albo trigger, a triggery (jeden lub więcej) są
niejawnie wywoływane w momencie, kiedy wystąpi określone zdarzenie (nie ma znaczenia, jaki użytkownik
jest podłączony do bazy, ani która aplikacja jest używana).
Definiowanie procedur wyzwalanych jest następująca:
CREATE TRIGGER nazwa
BEFORE | AFTER
/*czy trigger ma być wykonany przed czy po zdarzeniu*/
INSERT | UPDATE | DELETE
/*których zdarzeń trigger dotyczy, można łączyć kilka spjnikiem OR)*/
ON tabela
FOR EACH ROW | STATEMENT
/*czy trigger ma być wywołany raz na rekord, czy raz na instrukcję*/
EXECUTE PROCEDURE nazwa_funkcji (parametry);
/*co ma być wywołane jako obsługa triggera;
nazwa funkcji
odnosi się do wcześniej zdefiniowanej funkcji
zwracającej wartość typu trigger
*/
Wyzwalacz związany jest zawsze z procedurą, która określa jego działanie. Wewnątrz niej dostępne są
specjalne zmienne, z których najważniejsze to:
OLD
– reprezentująca stan wiersza tabeli przed modyfikacją;
NEW
– reprezentująca stan wiersza tabeli po modyfikacji.
Stwórzmy tablicę Punkty
CREATE TABLE Punkty(x integer, y integer);
Następnie zdefiniujmy funkcje, której zadaniem będzie sprawdzenie czy nowe wartości przypisywane
atrybutom x i y (w skutek wykonania operacji INSERT lub UPDATE) są mniejsze lub równe 10, jeśli tak, to
stare wartości zostaną zmienione na nowe, w przeciwnym przypadku pozostawiane są stare wartości.
Ponieważ przy wykonywaniu operacji INSERT nie jest dostępna stara wartość, dlatego zażądamy, aby
w
przypadku próby dopisania nowych wartości, które nie spełniają wspomnianego wyżej kryterium, funkcja
zwracała wartość pustą (NULL).
CREATE OR REPLACE FUNCTION Sprawdz() RETURNS trigger AS
$$
BEGIN
IF (NEW.x <=10 or NEW.y <=10) THEN
RETURN NEW;
ELSE
RETURN OLD;
END IF;
RETURN NULL;
END;
$$
LANGUAGE PLPGSQL;
Teraz stworzymy trigger
CREATE TRIGGER Test BEFORE INSERT OR UPDATE ON Punkty
FOR EACH ROW EXECUTE PROCEDURE Sprawdz();

Po stworzeniu takiego triggera polecenie INSERT spowoduje dodanie nowych wartości x i y tylko wtedy,
gdy będą one nie większe niż 10. Polecenie UPDATE spowoduje zmianę zapisanych wcześniej w tablicy
wartości tylko wtedy, gdy nowe proponowane wartości będą spełniały warunek zdefiniowany w funkcji
Sprawdz (x<=10 i y<=10)
Trigger usuwa się poleceniem:
DROP TRIGGER nazwa ON tabela;
Reguły
PostgreSQL oferuje jeszcze jeden t
yp elementów aktywnych – reguły. Reguły są szybsze niż
wyzwalacze, ale posiadają mniejsze możliwości. Pozwalają na zdefiniowanie instrukcji SQL, które powinny
być automatycznie dołączone do podawanych przez użytkownika poleceń lub wykonane zamiast nich.
In
strukcja definiowania reguł jest następująca:
CREATE RULE
nazwareguły AS ON zdarzenie TO obiekt [WHERE warunek]
DO [ALSO|INSTEAD] [akcja | (akcje) | NOTHING];
Zdarzenie wraz z warunkiem określają, kiedy reguła powinna być zastosowana. Zdarzenie wiąże się
z
wykonaniem jednego z poleceń: SELECT, INSERT, UPDATE, DELETE, natomiast warunek może być
dowolnym wyrażeniem logicznym zapisanym w języku SQL. Akcja może być określona pojedynczą
instrukcją SQL, bądź ich ciągiem ujętym w nawiasy okrągłe. Słowo kluczowe INSTEAD można opuścić, lecz
wtedy reguła nie będzie wykonywana zamiast wskazanej operacji.
Za pomocą reguł można na przykład tworzyć modyfikowalne widoki, które normalnie nie są obsługiwane
przez PostgreSQL.
Poniżej przedstawiono przykładowy ciąg poleceń SQL, które obrazują zagadnienie modyfikowalnych
widoków:
CREATE TABLE osoby (imie varchar(15), nazwisko varchar(15), data_ur timestamp, adres varchar(25);
CREATE VIEW prac_view AS
SELECT imie, nazwisko FROM osoby WHERE data_ur< '01-01-1979';
CREATE RULE r1 AS ON INSERT TO prac_view
DO INSTEAD INSERT INTO osoby VALUES (NEW.imie, NEW.nazwisko);
Literatura:
1)
A. Werner, M. Bach: „Rozszerzenia modelu relacyjnego w eksperymentalnym systemie Postgres95”,
Zeszyty Naukowe Politechniki Śląskiej, 1997.
2) A. Werner,
Instrukcja laboratoryjna: „Tworzenie Triggerów (Implementacja w DBMS Oracle)”.
3) http://wazniak.mimuw.edu.pl/index.php?title=Zaawansowane_systemy_baz_danych
4) www.postgresql.org/
Wyszukiwarka
Podobne podstrony:
Postgres PostGIS
Postgrad Med J 2001 Woolfson 68 74
PostgreSQL 7
PHP PostgreSQL
PostgreSQL, SQL, SQL, PSQL-wyklady borzyszkowski, PSQL-wyklady borzyszkowski, Ftp, Sql
konserwacja-bazy-postgresql
PostgreSQL Leksykon kieszonkowy psqllk
Postgres lab23
konserwacja bazy postgresql
Odzyskiwanie bazy danych PostgreSQL
BEZPIECZEŃSTWO DOSTĘPU DO DANYCH MS SQL SERVER POSTGRESQL, 9 semestr, SQL, RÓŻNE
Professional Linux Programming, R-04-t, PLP - Rozdział 4: Interfejsy PostgreSQL
Postgres lab2
Postgres PostGIS
Rozdzial 3 PostgreSQL
PostgreSQL 7 2 cwiczenia praktyczne cwpsql
więcej podobnych podstron