
Włodzimierz Dąbrowski, Przemysław Kowalczuk,
Konrad Markowski
Bazy danych
ITA-101
Wersja 1
Warszawa, wrzesień 2009

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Strona i-2
2008 Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski.
Autorzy udzielają prawa do bezpłatnego kopiowania i dystrybuowania
wśród pracowników uczelni oraz studentów objętych programem
ITAcademy. Wszelkie informacje dotyczące programu można uzyskać:
pledu@microsoft.com.
Wszystkie inne nazwy firm i producentów wymienione w niniejszym
dokumencie mogą być znakami towarowymi zarejestrowanymi przez ich
właścicieli.
Inne produkty i nazwy firm używane w treści mogą być nazwami
zastrzeżonymi przez ich właścicieli.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Strona i-3
Wprowadzenie
Informacje o kursie
Opis kursu
We współczesnej informatyce coraz większą rolę odgrywa przepływ
informacji. Dane są gromadzone i przekazywane w ilościach dotąd
niespotykanych. Od umiejętnego sterowania przepływem danych zależy los
wielu wielkich firm. Odpowiednia automatyzacja procesu przepływu
informacji daje ogromne wymierne korzyści. Bazy danych i systemy
zarządzania bazami danych służą właśnie temu, by móc przechowywać
nawet ogromne ilości danych bez narażenia na ich utratę oraz by móc
odpowiednio szybko i wygodnie sterować ich przepływem.
Bazy danych wdarły się zarówno do sieci lokalnych w firmach, gdzie
gromadzone są dane na potrzeby pracowników, jak również do Internetu,
gdzie dostęp do nich mają miliardy użytkowników na całym świecie.
Dynamiczny rozwój baz danych implikował powstanie wielu nowych
technologii programowania ukierunkowanych na jeszcze wydajniejsze
wykorzystanie baz danych w aplikacjach.
Z kolei administracja systemami zarządzania bazami danych stała się osobną
gałęzią informatyki, tak jak administracja systemami operacyjnymi
komputerów lub administracja sieciami komputerowymi. Wielu
pracodawców poszukuje wykwalifikowanych specjalistów z zakresu
określonych systemów zarządzania bazami danych (jak Oracle czy MS SQL
Server). Znajomość zarówno teorii baz danych, jak i konkretnego
środowiska pracy z nimi, jest więc okazją podniesienia swoich kwalifikacji.
Wykorzystując możliwości systemu zarządzania bazami danych Microsoft
SQL Server 2008 postaramy się w niniejszym podręczniku zilustrować
podstawowe własności baz danych (w szczególności relacyjnych baz
danych) oraz systemów zarządzania tymi bazami.
Mamy nadzieję, że podręcznik pozwoli Państwu na bliższe zapoznanie się z
tematyką baz danych oraz systemem Microsoft SQL Server 2008. Życzymy
owocnej pracy z naszym podręcznikiem.
Uzyskane kompetencje
Po zrealizowaniu kursu będziesz:
•
Zrozumieć schemat, zaprojektować i zoptymalizować prostą bazę
danych,
•
Administrować serwerem bazodanowym MS SQL Sever 2008 na
poziomie podstawowym,
•
Zaimplementować prostą bazę danych w systemie SZBD opartym o
MS SQL Sever 2008,
•
Tworzyć skrypty w języku T-SQL,
•
Monitorować i dokonywać tuningu baz danych,
•
Dbać o bezpieczeństwo systemów SZBD w podstawowym zakresie,
•
Używać języka XML w procesie komunikacji z SZBD,
•
Tworzyć raporty przy użyciu MS SQL Reporting Services
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Strona i-4
Wymagania wstępne
Aby przystąpić do pracy z podręcznikiem musisz:
•
umieć obsługiwać komputer z zainstalowanym systemem
operacyjnym Microsoft Windows 9X/NT/2000/ME/XP/2003,
•
znać podstawowe zagadnienia dotyczące programowania (m.in.
wiedzieć, co to jest zmienna, procedura, pętla),
•
nie musisz znać teorii baz danych - poznasz ją czytając wykłady
zawarte w niniejszym podręczniku.
Zakres tematyczny kursu
Opis modułów
W Tab. 1 przedstawiony został opis modułów, zawierający podział na
zajęcia. Każde zajęcie jest zaplanowane na 90 minut. Wykładowca może
dostosować harmonogram do swoich potrzeb.
Tab. 1 Zakres tematyczny modułów
Numer moduł
Tytuł
Opis
Moduł 1
Budowa diagramów
ERD
W tym module zajmiemy się pierwszym krokiem, jaki
należy wykonać projektując bazę danych. Będzie nim
identyfikacja encji i narysowanie na diagramie, zwanym
diagramem ERD, zależności między nimi. Prawidłowy i
przejrzysty diagram ERD jest kluczowym czynnikiem
sukcesu dla zaprojektowania, a później eksploatacji bazy
danych.
Moduł 2
Instalacja i
konfiguracja MS SQL
Server 2008
W tym module znajdziesz informację o podstawowych
zadaniach administratora systemu bazodanowego. Do
zadań tych należy instalacja serwera baz danych,
konserwacja oraz aktualizacji serwisów serwera.
Prawidłowe przygotowanie środowiska pracy zapewni
stabilność oraz pozwoli na poznanie systemu
bazodanowego od podstaw.
Moduł 3
Definiowanie i
zarządzanie bazą
danych
Dobry administrator Systemu Zarządzania Bazami Danych
wie wszystko o bazach danych. W dzisiejszych czasach
rola administratora nie ogranicza się do zarządzania
istniejącymi bazami danych, ale również wymaga
umiejętności zakładania, konserwacji oraz aktualizacji baz
danych znajdujących się pod jego opieką. Moduł przybliży
wszystkie te zagadnienia
Moduł 4
Wewnętrzna
struktura bazy
danych
W tym module znajdziesz informacje w jaki sposób w SQL
Server 2008 przechowywane są dane oraz w jaki sposób
przechowywane są podstawowe obiekty w bazie danych.
Moduł 5
Język SQL - DCL, DDL
Język SQL został opracowany w 1987 roku z myślą o
relacyjnych bazach danych. Składa się on z trzech
składowych: języka definiowania danych (DDL), języka
sterowania danymi (DCL) oraz języka operowania na
danych (DML). W module tym zostaną wprowadzone, a
następnie przedstawione na przykładach podstawowe
instrukcje języka definiowania danych – języka SQL DDL
oraz języka sterowania danymi – języka SQL DCL.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Strona i-5
Moduł 6
Język SQL - DML
Język SQL składa się z trzech składowych: języka
definiowania danych (DDL), języka sterowania danymi
(DCL) oraz języka operowania na danych (DML). W
module tym zostaną wprowadzone, a następnie
przedstawione na przykładach podstawowe instrukcje
języka sterowania na danych – języka SQL DML
Moduł 7
Indeksy i transakcje
W module tym znajdziesz informacje na temat dostępu
fizycznego do danych oraz optymalizacji dostępu.
Poznasz indeksy i ich rodzaje a następnie dowiesz się
jakie operacje wykonywane są na indeksach. Dowiesz się,
że jest to parametr niezbędny do zapewnienia
rozsądnych czasów wyszukiwania informacji. W drugiej
części poznasz transakcje, które służą do zapewnienia
spójności bazy danych i mają wpływ na wydajność bazy
danych. Dowiesz się, że obsługa transakcji nie jest rzeczą
łatwą i wymaga rozwiązywania wielu trudnych
problemów.
Moduł 8
Programowanie
zaawansowane
w T-SQL
Programowanie w języku zapytań to ważna umiejętność.
Powinni ją opanować zarówno programiści, jak i
administratorzy. Różne dialekty języka SQL oferują różne
składnie, jednak reguły, jakimi powinien kierować się
tworzący kod, są te same niezależnie od SZBD. Bardzo
często opanowanie w zaawansowanym stopniu składni
jednego języka pozwala w przyszłości na łatwe
opanowanie innego. W module tym znajdziesz
informację na temat zaawansowanego programowania w
T-SQL.
Moduł 9
Procedury
składowane i
wyzwalacze
W module zostanie zaprezentowany sposób działania
oraz podstawy tworzenia procedur składowanych.
Dowiesz na czym polega różnica pomiędzy zwykłym
zapytaniem T-SQL a procedurą składowaną oraz co to jest
kompilacja i rekompilacja procedury. Zostanie
wprowadzony również specjalny rodzaj procedury
składowanej – wyzwalacz.
Moduł 10
Bezpieczeństwo w
bazach danych
W tym module dowiesz się, jak należy rozumieć
bezpieczeństwo baz danych oraz jakie są poziomy
bezpieczeństwa. Ponadto dowiesz się, jakim zagrożeniom
należy przeciwdziałać, a jakich nie da się uniknąć oraz jak
należy planować implementację poszczególnych
poziomów bezpieczeństwa w aplikacji bazodanowej.
Moduł 11
Praca z XML
Wymiana danych z relacyjnymi bazami danych może być
utrudniona ze względu na różnice programowo –
sprzętowe itp. Rozwiązaniem jest język XML, który jest
niezależny od standardów sprzętowych / programowych.
Moduł 12
Praca z Reporting
Services
Aby osiągnąć sukces na dzisiejszym, konkurencyjnym
rynku, przedsiębiorstwa gromadzące duże ilości danych
powinny wprowadzić rozwiązania biznesowe działające w
czasie rzeczywistym zapewniające bezproblemową,
skuteczną wymianę informacji pomiędzy własnymi
oddziałami, swoimi partnerami, a także klientami.
Microsoft SQL Server Reporting Services jest
rozwiązaniem, które pozwala szybko i komfortowo dzielić
i udostępniać dane biznesowe, przy niższych nakładach
rozmaitych zasobów.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Strona i-6
Moduł 13
Budowa interfejsu
W module tym napiszemy aplikację , która będzie
wyciągała informacje z bazy danych Prace Dyplomowe.
Zostanie pokazane jak za pomocą Visual Studio
utworzyć bazę danych, jak połączyć się z bazą danych w
jaki sposób wprowadzać dane. Następnie stworzymy
aplikacje Windows, która będzie korzystała z tych
danych.
Dodatek
Podstawy
W tym module zajmiemy się zebraniem
najważniejszych informacji na temat baz danych
niezbędnych do zrozumienia i pełnego wykorzystania
dalszych modułów. Zebrane, najważniejsze pojęcia nie
zastępują pełnego wykładu na ten temat i nie zwalniają
Cię z przestudiowania wykładu lub podręcznika z
zakresu baz danych. Mają one jedynie na celu zebrać i
utrwalić najważniejsze elementy potrzebne do
wykonywania kolejnych modułów. Zazwyczaj pierwsze
zajęcia laboratorium są zajęciami organizacyjnymi.

ITA-101 Bazy danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 1
Wersja 1.0
Budowa diagramów ERD
Spis treści
Budowa diagramów ERD ...................................................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 7
Porady praktyczne ..................................................................................................................... 12
Uwagi dla studenta .................................................................................................................... 13
Dodatkowe źródła informacji..................................................................................................... 13
Laboratorium podstawowe ................................................................................................................ 14
Problem (czas realizacji 40 min)................................................................................................. 14
Laboratorium rozszerzone ................................................................................................................. 16
Zadanie 1 (czas realizacji 45 min) ............................................................................................... 16
Zadanie 2 (czas realizacji 45 min) ............................................................................................... 16
W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 2/18
Informacje o module
Opis modułu
W tym module zajmiemy się pierwszym krokiem, jaki należy wykonać
projektując bazę danych. Będzie nim identyfikacja encji i narysowanie na
diagramie, zwanym diagramem ERD, zależności między nimi. Prawidłowy
i przejrzysty diagram ERD jest kluczowym czynnikiem sukcesu dla
zaprojektowania, a później eksploatacji bazy danych.
Cel modułu
Celem modułu jest wykształcenie umiejętności budowania poprawnych,
przejrzystych
i dobrze
udokumentowanych
diagramów
ERD
z wykorzystaniem narzędzia MS VISIO.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
rozumiał, czym jest diagram ERD,
•
rozumiał, w jaki sposób buduje się diagramy związków encji na
różnych poziomach abstrakcji,
•
umiał zbudować poprawny diagram ERD,
•
umiał dokonać przekształcenia diagramu ERD tak, aby był on
implementowany w relacyjnej bazie danych.
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
rozumieć, czym jest baza danych i jakie powinna mieć cechy,
•
znać założenia modelu relacyjnego baz danych.
Mapa zależności modułu
Przed przystąpieniem do realizacji tego modułu nie są wymagane inne
moduły.

W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 3/18
Przygotowanie teoretyczne
Przykładowy problem
Wyobraź sobie, że zostałeś poproszony o przygotowanie bazy danych ułatwiającej zarządzanie
przydziałem sal i zajęć na swoim wydziale na uczelni. Pani Jola zajmująca się przydzielaniem sal na
zajęcia chciałaby uzyskać narzędzie do kontroli i monitorowania obciążenia sal przez różne zajęcia
dydaktyczne oraz chciałaby przy tej okazji zminimalizować liczbę popełnianych błędów. Błędy
polegają najczęściej na tym, że w jednej sali umieszczane są w tym samym czasie różne zajęcia lub
na tym, że ta sama grupa studencka ma zajęcia w różnych salach w jednym czasie. Pani Jola
chciałaby też mieć możliwość szybkiego generowania raportów o przydziale sal i zajęć. Dla
uniknięcia nieporozumień przy pracach nad narzędziem wspomagającym pracę pani Joli zostałeś
poproszony o przygotowanie prostego i krótkiego dokumentu przedstawiającego, jakie dane będą
gromadzone w bazie danych i jakie będą między nimi zależności. Dokument ten powinien zostać
zweryfikowany i zaakceptowany przez panią Jolę przed przystąpieniem do dalszych prac.
Podstawy teoretyczne
Przy modelowaniu baz danych możemy posłużyć się notacją graficzną modelowania danych –
diagramem związków encji (ERD, ang. Entity-Relationship Diagram). Jest to model sieciowy
opisujący na wysokim poziomie abstrakcji dane, które są przechowywane w systemie.
Model ERD budowany jest przez analityka. Służy on do zobrazowania w sposób zrozumiały zarówno
dla projektanta, jak i osoby niemającej wykształcenia informatycznego (np. klienta) obiektów
i związków zachodzących w projektowanej dziedzinie problemowej.
Model ERD nie jest związany z konkretną implementacją systemu (np. na serwerze MS SQL czy
Oracle), choć jego odmiany mogą zawierać informacje specyficzne dla danego języka lub
środowiska implementacyjnego. Staje się on wówczas modelem projektowym
Encja
Encja (ang. entity) jest to coś, co istnieje, co odróżnia się od innych, o czym trzeba mieć informacje.
Zbiory encji reprezentują zbiór elementów występujących w rzeczywistym świecie i każdy element
tego zbioru musi posiadać następujące cechy:
•
Każdy element musi być unikalny, jednoznacznie określony, w celu odróżnienia go od
pozostałych.
•
Każdy element musi odgrywać jakąś rolę w projektowanym systemie, nie może zdarzyć się
sytuacji, w której system może działać bez dostępu do danego elementu.
•
Każdy element powinien być opisany przez odpowiednią liczbę atrybutów.
W diagramach ERD encja jest reprezentowana przez prostokąt, a jej nazwa powinna być
rzeczownikiem.
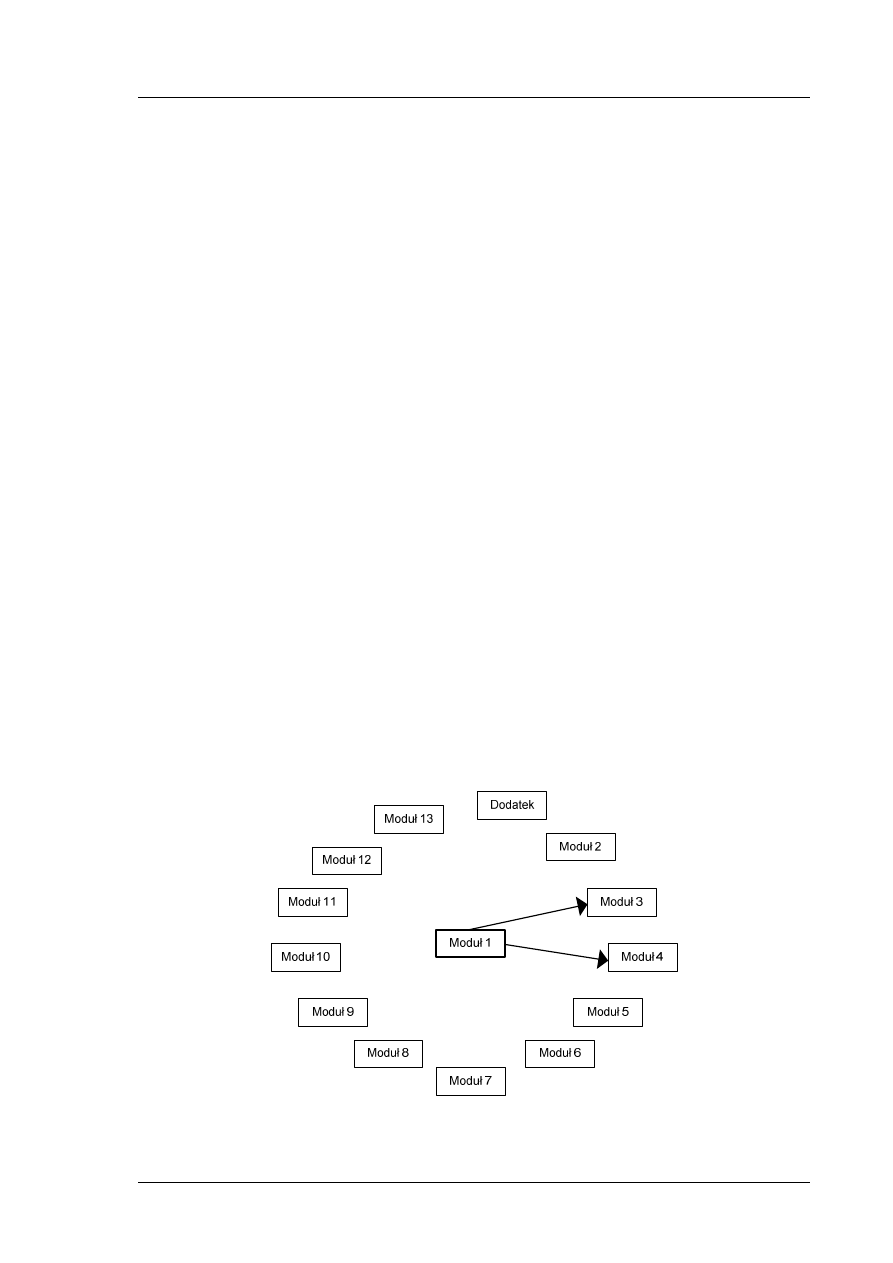
Atrybut
Atrybut (ang. attribute) jest pewną własnością encji, o której chcemy przechowywać informacje.
Atrybut jest reprezentowany przez pewną wartość. Na przykład encja Student może mieć atrybut
Nazwisko reprezentowany przez wartość Kowalski.
Wśród atrybutów encji wyróżniamy jeden atrybut lub zbiór atrybutów, którego wartość w sposób
jednoznaczny identyfikuje instancję (egzemplarz) encji. Taki atrybut lub zbiór atrybutów nazywamy
kluczem głównym encji. Klucz główny oznacza się często na wykresach symbolem PK (ang. Primary
Key) umieszczanym obok nazwy atrybutu.
W.Dąbrowski, P.Kowalczuk, K.Markowski
ITA-101 bazy danych
Drugim rodzajem klucza
nazywamy atrybut encji, który wskazuje na klucz główny innej encji. Klucz obcy oznacza się często
na wykresach symbolem FK (ang.
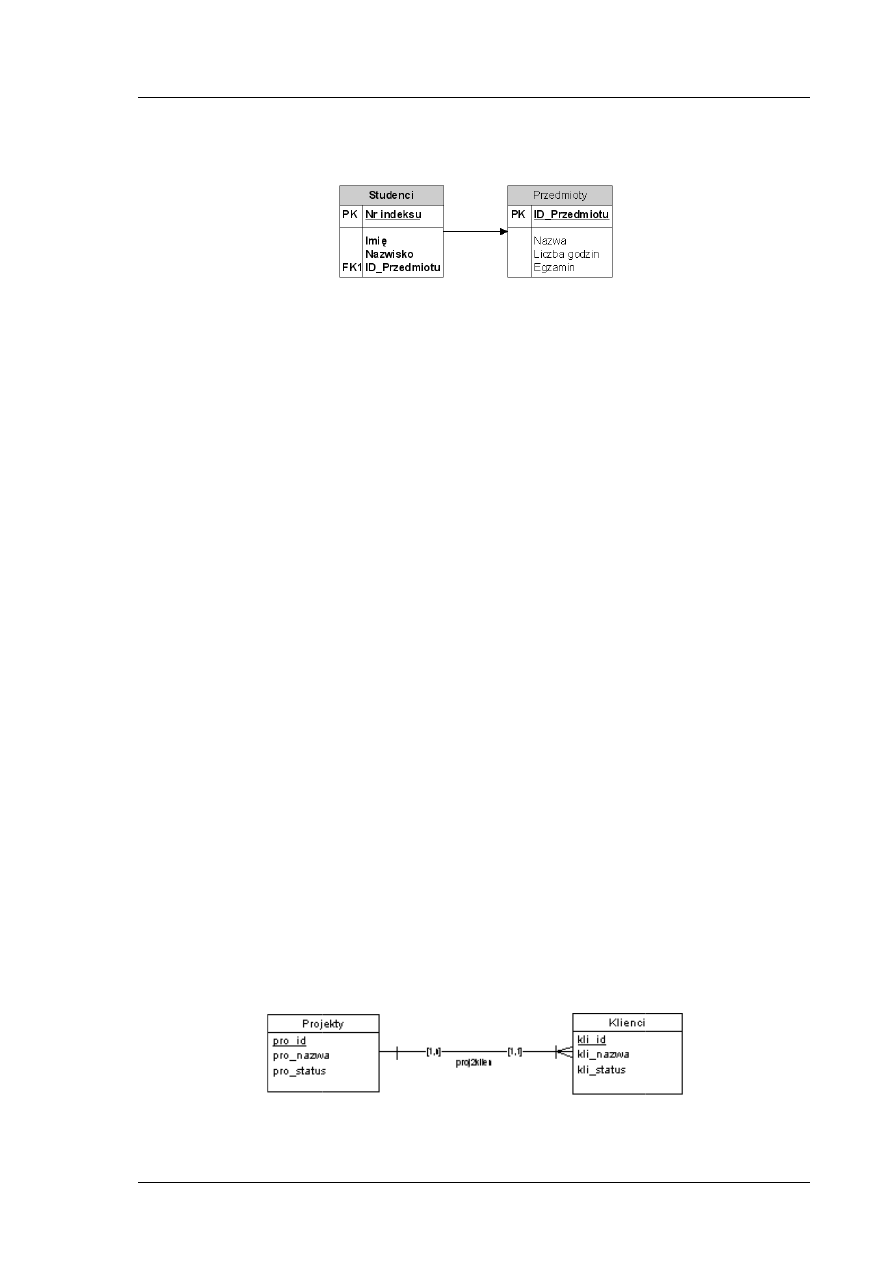
Związek
Bardzo ważnym elementem
i warunki określające te związk
związków to powiązania stopnia drugiego
bierze udział dwóch uczestników (dwie encje). Mogą występować także
powiązana z samą sobą), jak również
W zależności od tego, jakiego typu jest uczestnic
encje na słabe lub regularne.
w powiązaniu, to oznacza, że encja nie może istnieć bez tego powiązania (np. encja
nie może istnieć bez powiązania
w związku jest tylko częściowe, czyli encja może istnieć samodzielnie bez powiązania (np. encja
Klienci może istnieć bez powiązania
Bardzo istotnym czynnikiem określanym przy z
jako maksymalną liczbę instancji jednej encji (wystąpień
z instancją innej encji. Ze względu na wartość mocy możemy wyróżnić trzy typy powiązań:
•
jeden-do-jeden,
•
jeden-do-wiele,
•
wiele-do-wiele.
Związki binarne
Związek jeden-do-jeden (jedno
Jest to najprostszy typ powiązania, występuje wtedy, gdy tylko jedna instancja pierwszej encji jest
powiązana z tylko jedną instancją drugiej encji. Jest to powiązanie
ograniczenia, gdyż warunek jeden do jednego musi być zawsze spełniony. Opcjonalnie przy
powiązaniu jeden może występować również opcja żadne, oznaczana graficznie
Związek jeden-do-wiele (jedno
Najbardziej typowym rodzajem powiązania jest powiązanie jeden
instancja jednej encji może być połączona
na swoją uniwersalność i
Opcjonalnie przy powiązaniu jeden lub wiele może występować również opcja żadne, oznaczana
graficznie w postaci okręgu.
W.Dąbrowski, P.Kowalczuk, K.Markowski
Strona 4/18
stosowanym w bazach relacyjnych jest klucz obcy.
nazywamy atrybut encji, który wskazuje na klucz główny innej encji. Klucz obcy oznacza się często
na wykresach symbolem FK (ang. Foreign Key) umieszczanym obok nazwy atrybutu.
Rys. 1. Przykład klucza obcego (FK1)
Bardzo ważnym elementem w modelu danych są związki (ang. relationship
związki – elementy łączące encje między sobą. Zdecydowana większość
związków to powiązania stopnia drugiego – związki binarne, charakteryzujące się tym, że
bierze udział dwóch uczestników (dwie encje). Mogą występować także
samą sobą), jak również związki ternarne (z trzema uczestnikami).
W zależności od tego, jakiego typu jest uczestnictwo encji w danym związku, możemy podzielić
encje na słabe lub regularne. Encje słabe charakteryzują się całkowitym uczestnictwem
powiązaniu, to oznacza, że encja nie może istnieć bez tego powiązania (np. encja
nie może istnieć bez powiązania z encją Klienci), natomiast uczestnictwo
związku jest tylko częściowe, czyli encja może istnieć samodzielnie bez powiązania (np. encja
może istnieć bez powiązania z encją Zamówienia).
Bardzo istotnym czynnikiem określanym przy związkach jest moc powiązania
jako maksymalną liczbę instancji jednej encji (wystąpień w danej encji), które mogą być powiązane
instancją innej encji. Ze względu na wartość mocy możemy wyróżnić trzy typy powiązań:
jeden (jedno-jednoznaczny)
Jest to najprostszy typ powiązania, występuje wtedy, gdy tylko jedna instancja pierwszej encji jest
tylko jedną instancją drugiej encji. Jest to powiązanie wprowadzające dosyć znaczne
ograniczenia, gdyż warunek jeden do jednego musi być zawsze spełniony. Opcjonalnie przy
powiązaniu jeden może występować również opcja żadne, oznaczana graficznie
wiele (jedno-wieloznaczny)
jbardziej typowym rodzajem powiązania jest powiązanie jeden-do-wiele,
instancja jednej encji może być połączona z jedną lub wieloma instancjami drugiej encji. Ze względu
i małą kłopotliwość, ten typ powiązania jest najczęściej stosowany.
Opcjonalnie przy powiązaniu jeden lub wiele może występować również opcja żadne, oznaczana
postaci okręgu.
Rys. 2. Związek jeden-do-wielu
Moduł 1
Budowa diagramów ERD
bazach relacyjnych jest klucz obcy. Kluczem obcym
nazywamy atrybut encji, który wskazuje na klucz główny innej encji. Klucz obcy oznacza się często
) umieszczanym obok nazwy atrybutu.
relationship) pomiędzy encjami
elementy łączące encje między sobą. Zdecydowana większość
charakteryzujące się tym, że w związku
bierze udział dwóch uczestników (dwie encje). Mogą występować także związki unarne (encja
(z trzema uczestnikami).
danym związku, możemy podzielić
charakteryzują się całkowitym uczestnictwem
powiązaniu, to oznacza, że encja nie może istnieć bez tego powiązania (np. encja Zamówienia
atomiast uczestnictwo encji regularnych
związku jest tylko częściowe, czyli encja może istnieć samodzielnie bez powiązania (np. encja
moc powiązania, która definiuje się
danej encji), które mogą być powiązane
instancją innej encji. Ze względu na wartość mocy możemy wyróżnić trzy typy powiązań:
Jest to najprostszy typ powiązania, występuje wtedy, gdy tylko jedna instancja pierwszej encji jest
wprowadzające dosyć znaczne
ograniczenia, gdyż warunek jeden do jednego musi być zawsze spełniony. Opcjonalnie przy
powiązaniu jeden może występować również opcja żadne, oznaczana graficznie w postaci okręgu.
wiele, w którym pojedyncza
jedną lub wieloma instancjami drugiej encji. Ze względu
jest najczęściej stosowany.
Opcjonalnie przy powiązaniu jeden lub wiele może występować również opcja żadne, oznaczana
W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 5/18
Związek wiele-do-wiele (wielo-wieloznaczny)
Powiązania tego typu występują równie często jak powiązania jeden do wielu, jednak nie dają się
bezpośrednio implementować w relacyjnych bazach danych. Są one realizowane przy pomocy encji
pośrednich (w modelu relacyjnym są to tabele sprzęgające) powiązanych z encjami pierwotnymi
przy pomocy powiązań jeden do wielu.
W powiązaniu wiele-do-wiele encjami głównymi są encje pierwotne, natomiast encją obcą jest
relacja sprzęgająca, która zwiera klucze główne relacji oryginalnej. Dlatego w powiązaniu
jeden-do-wiele pomiędzy relacjami pierwotnymi a relacją obcą, po stronie relacji oryginalnej
znajduje się strona „jeden” powiązania jeden-do-wiele, a po stronie relacji obcej znajduje się strona
„wiele” z tego powiązania. Związki wiele-do-wiele nie są bezpośrednio implementowane
w relacyjnych bazach danych i wymagają dodatkowych przekształceń.
Rys. 3. Związek wiele-do-wielu
Związki unarne
Powiązania tego typu mają tylko jednego uczestnika, czyli relację, która jest powiązana sama ze
sobą. Powiązanie realizowane jest w podobny sposób jak w przypadku powiązań binarnych, ale
odnosi się do jednej encji. Klucz główny tej encji jest dodawany do tej encji.
Rys. 4. Związek unarny
Powiązania unarne tak jak powiązania binarne mogą być różnej mocy. To znaczy mogą występować
powiązania jeden do wielu, które mogą być opcjonalne po stronie „jeden”. Ten typ powiązania jest
stosowany przy odwzorowywaniu struktur hierarchicznych.
Powiązania unarne mogą być również realizowane jako powiązania wiele do wielu. Wtedy,
podobnie jak przy powiązaniach binarnych, muszą być modelowane przy użyciu tabeli sprzęgającej.
Związki ternarne
Są to powiązania, w skład których wchodzą trzy związane ze sobą encje. Powiązania te, podobnie
jak powiązania wiele-do-wiele, nie mogą być realizowane bezpośrednio w relacyjnych bazach
danych.
W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 6/18
Rys. 5. Związek ternarny
Związki ternarne nie są bezpośrednio implementowane w relacyjnych bazach danych i wymagają
dodatkowych przekształceń.
Notacje związków
W praktyce spotkasz się z różnymi sposobami reprezentacji graficznej związków (dla przykładu:
w programach służących m.in. do projektowania diagramów ERD takich jak Visio lub IBM Rational
Rose możliwe jest użycie kilku różnych notacji). Bodaj najpopularniejsza jest notacja czysto
graficzna.
Metody przekształcania związków
Związki binarne wiele-do-wiele oraz związki ternarne nie są implementowane w relacyjnych bazach
danych. Przed zamodelowaniem ich w bazie relacyjnej wymagają one pewnych przekształceń.
Przykłady takich przekształceń zaprezentowane są poniżej
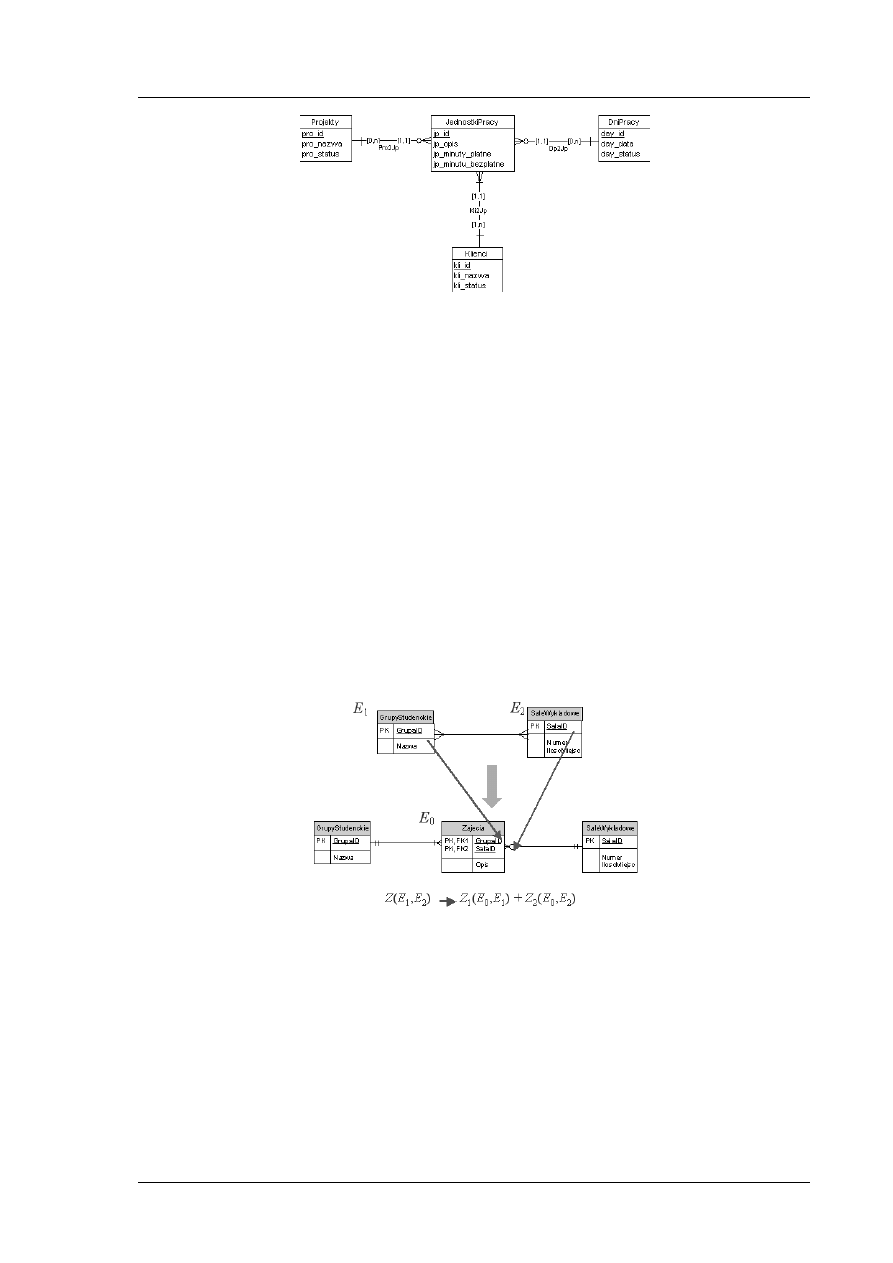
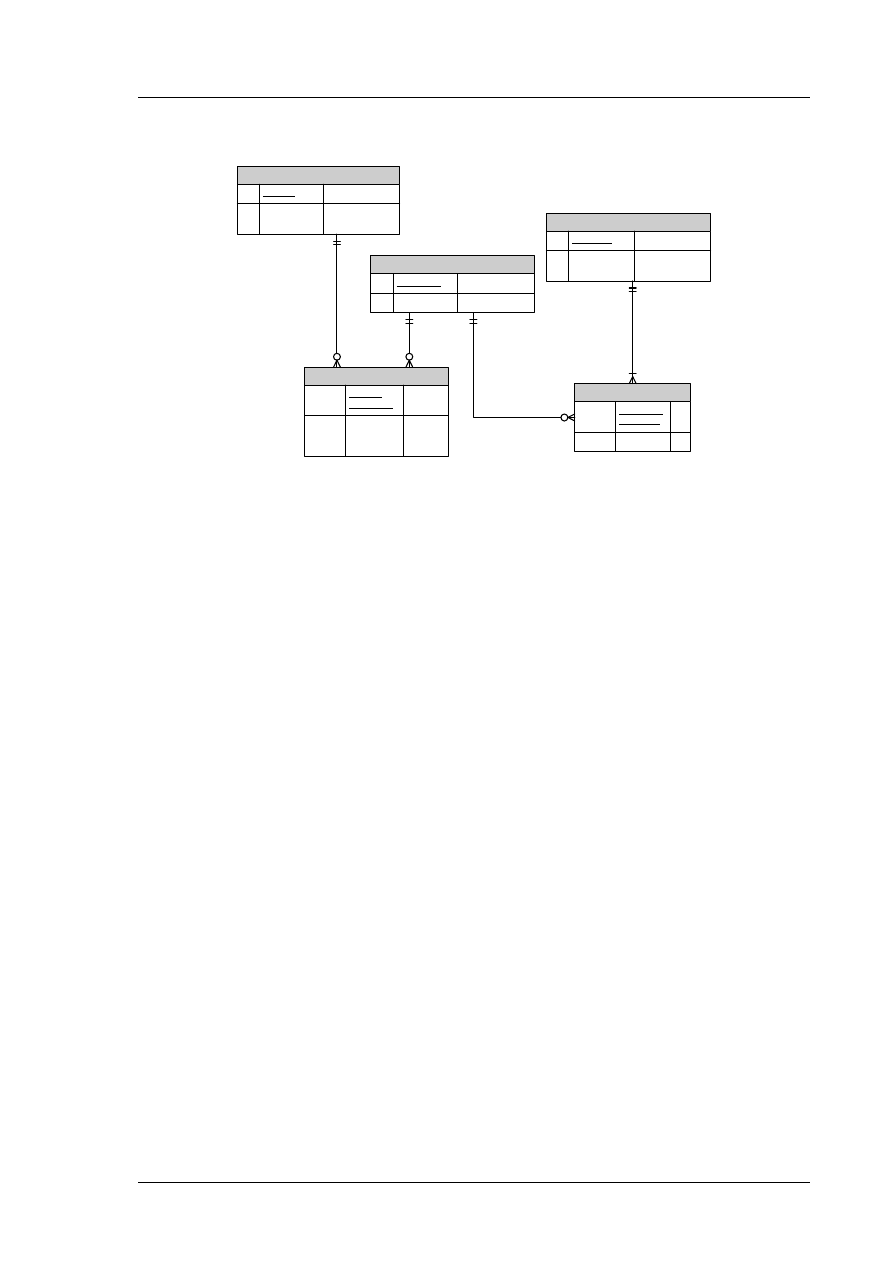
Przekształcanie związków wielo-wieloznacznych
Jeśli mamy związek binarny wielo-wieloznaczny, to należy wprowadzić dodatkową encję oraz dwa
nowe związki jednoznaczne. Nowa encja powinna wśród atrybutów zawierać klucze obce
odnoszące się do kluczy głównych dwóch pozostałych encji.
Rys. 6. Przekształcanie związków binarnych wielo-wieloznacznych
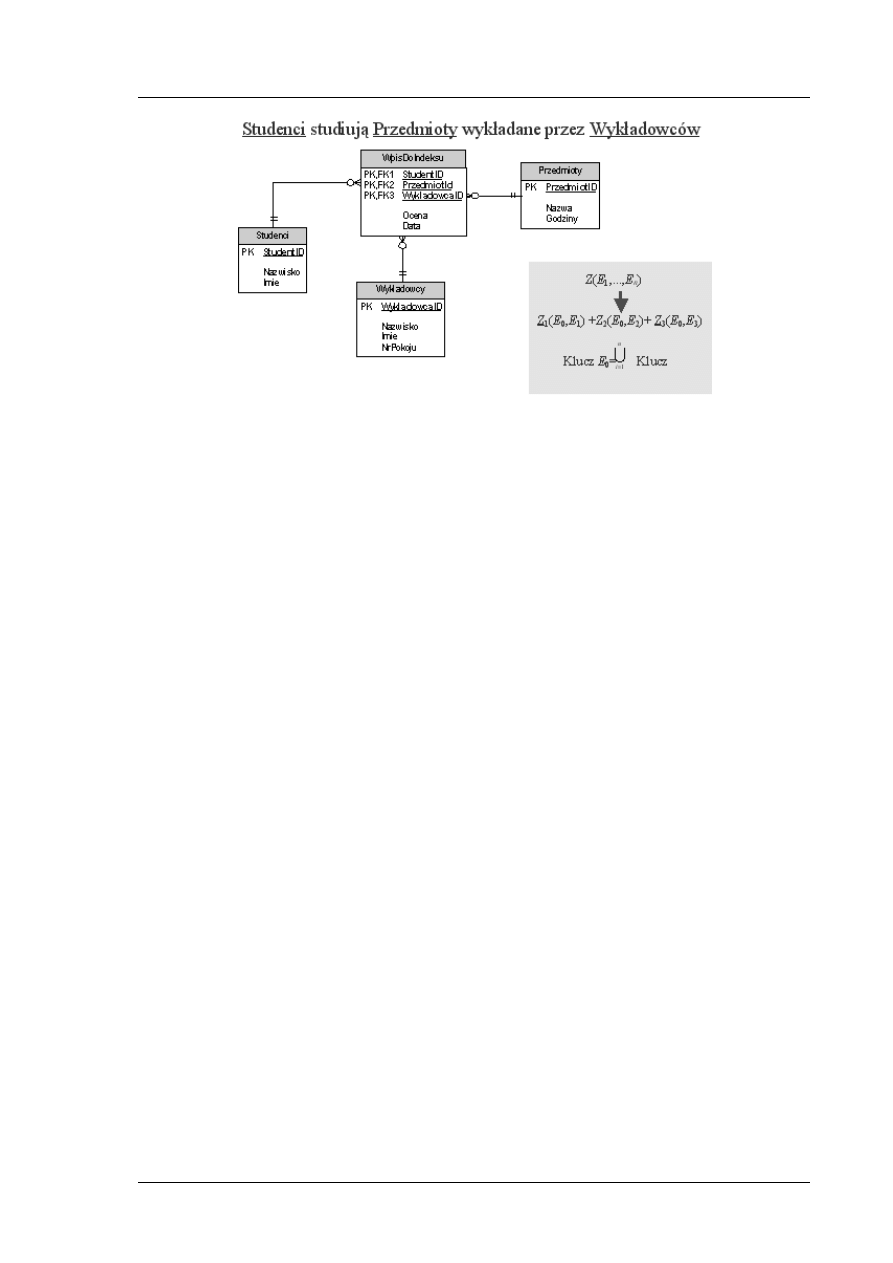
Przekształcanie związków ternarnych
Przy przekształcaniu związków ternarnych postępujemy podobnie jak w wypadku związków wielo-
wieloznacznych binarnych. Wprowadzamy wówczas dodatkową encję oraz 3 nowe związki
jednoznaczne.
W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 7/18
Rys. 7. Przekształcanie związków ternarnych
Podobnie postępujemy, jeśli mamy do czynienia ze związkami o większej liczbie argumentów.
Podsumowanie
W tym rozdziale przedstawione zostało podejście do modelowania konceptualnego bazy danych
z wykorzystaniem techniki zwanej diagramami związków encji.
Dowiedziałeś się, czym jest encja, jakie posiada cechy oraz czym jest związek encji. Pamiętaj, że nie
wszystkie typy związków encji są bezpośrednio implementowane w relacyjnej bazie danych. Związki
typu wiele do wielu oraz związki więcej niż dwu encji wymagają przekształcenia modelu
konceptualnego do postaci dającej się implementować w modelu relacyjnym. Przekształcenie to
polega zazwyczaj na wprowadzeniu dodatkowej encji i dodaniu nowych związków.
Projektując bazę danych warto zawsze rozpocząć modelowanie danych od diagramów ERD.
Diagramy takie powinny przede wszystkim, w pierwszym etapie projektowania, odzwierciedlać
w możliwie przejrzysty sposób dane i zależności występujące w świecie rzeczywistym – na przykład
obiekty biznesowe i zależności między nimi. W pierwszym etapie diagram ERD pokazuje więc często
związki wiele do wielu oraz związki wieloencyjne (rzadziej). Kolejne kroki prowadzą do
przekształcania takiego diagramu aż do postaci modelu zgodnego z modelem relacyjnym.
Przykładowe rozwiązanie
Przypomnijmy problem z początku tego rozdziału dotyczący przygotowania bazy danych
ułatwiającej zarządzanie przydziałem sal i zajęć na wydziale uczelni.
Naszym celem jest przygotowanie modelu danych, który będzie spełniał dwa podstawowe cele:
•
pozwalał zweryfikować wymagania stawiane przez panią Jolę oraz
•
stanowił podstawę do zbudowania relacyjnej bazy danych.
Jak widać musimy posłużyć się językiem wyrazu zrozumiałym zarówno dla osoby niemającej
wykształcenia czy tez doświadczenia informatycznego jak i przydatnym dla informatyka budującego
bazę danych. Jaki środek wyrazu, język wybrać? Dosyć powszechny jest tutaj pogląd, że takim
uniwersalnym środkiem wyrazu spełniającym stawiane przed nami wymagania jest język
obrazkowy – diagramy związków encji.
Sformułujmy więc teraz cel naszych działań w następujący sposób:
Naszym zadaniem jest opracowanie diagramu związków encji, który będzie jednoznacznie
i przejrzyście przedstawiał wymagania pani Joli w zakresie przetwarzanych przez nią danych oraz
umożliwiał zbudowanie na jego podstawie relacyjnej bazy danych.

W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 8/18
Przypominamy, że diagram związków encji powstaje w sposób iteracyjny. Wynikiem naszych prac
powinien być nie jeden diagram, ale zestaw diagramów przedstawiający nasz problem na różnych
poziomach abstrakcji (np. z różną liczbą szczegółów).
Spróbujemy teraz przedstawić w punktach nasze działania. Co więc i w jakiej kolejności powinniśmy
wykonać?
Krok 1
Powinniśmy uważnie wysłuchać, co ma do powiedzenia ekspert dziedzinowy, czyli pani Jola. Na
podstawie zebranych informacji możemy zidentyfikować i wypisać encje występujące w naszym
problemie. Dobrym zwyczajem jest też wypisanie kilku przykładowych instancji encji dla każdej ze
zidentyfikowanych encji.
Krok 2
Powinniśmy zidentyfikować związki występujące między encjami. Dobrze jest nazwać te związki
i określić role, jakie w nich odgrywają poszczególne encje. Koniecznie powinniśmy też
zidentyfikować liczności związków.
Krok 3
Powinniśmy wykonać pierwszy rysunek diagramu związków encji, na którym zamieszczamy:
•
nazwa encji,
•
związki między encjami,
•
liczności związków.
Warto też umieścić na nim nazwy związków i nazwy ról. Często jednak dla zachowania
przejrzystości rysunku rezygnujemy z umieszczania na diagramie ERD tych informacji.
UWAGA: Diagram związków encji będący wynikiem kroku 3 jest często w postaci
nieznormalizowanej i nierealizowalnej w bazie relacyjnej (np. przedstawia związki wiele do wielu).
Na tym etapie najczęściej nie należy dokonywać przekształceń tego diagramu.
Krok 4
Diagram z kroku 3 powinniśmy skonsultować z ekspertem dziedzinowym. Na tym etapie diagram
ERD nie zawiera zbyt wiele szczegółów, jest więc prosty i przejrzysty. Pozwoli nam to na
upewnienie się, że dobrze zrozumieliśmy stawiane przez eksperta wymagania dotyczące
przetwarzanych danych oraz umożliwi dokonanie niezbędnych poprawek i uzupełnień już na tym
wstępnym etapie.
Krok 5
Rozpoczynamy identyfikowanie atrybutów dla każdej z przedstawionych na diagramie encji.
Powinniśmy zidentyfikować wszystkie atrybuty, które są wykorzystywane w procesach
opisywanych przez eksperta dziedzinowego – czyli tak zwane atrybuty biznesowe. Nie wszystkie ze
zidentyfikowanych na tym etapie atrybutów muszą znaleźć swoje odzwierciedlenie w końcowym
projekcie bazy danych.
Na przykład: na pewnym wydziale po drugim roku studiów dokonywany jest przez studenta wybór
specjalizacji dalszych studiów. O klasyfikacji na specjalizację decyduje, w wypadku braku miejsc,
średnia ocen uzyskanych przez studenta z pierwszych czterech semestrów studiów. Dla osoby
opisującej proces klasyfikacji studentów na specjalizację istotnym atrybutem każdego studenta jest
jego średnia z pierwszych czterech semestrów nauki. Powinniśmy dla encji Student
zidentyfikować atrybut biznesowy srednia_z_czterech_semestrow. W trakcie kolejnych
iteracji budowy diagramu ERD możemy zdecydować, że nie będziemy przechowywać w bazie tej
średniej, ale wyliczać ją, gdy będzie potrzebna, na podstawie ocen cząstkowych.

W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 9/18
Krok 6
Diagram z kroku 5 powinniśmy skonsultować z ekspertem dziedzinowym.
Krok 7
Dla każdego atrybutu powinniśmy zidentyfikować i zapisać jego dziedzinę. Pamiętaj, że dziedzina
atrybutu to nie to samo, co jego typ. Dziedzina związana jest z wyższym poziomem abstrakcji
modelu i dotyczy wartości, które może przyjmować atrybut wynikających z modelu biznesowego
procesu. Typ natomiast związany jest z niższym poziomem abstrakcji modelu i dotyczy
reprezentacji danych w silniku bazy danych. Na przykład dziedziną dla atrybutu Ocena może być
zbiór { 2; 3; 3,5; 4; 4,5; 5 }, a typem tego atrybutu Integer.
Krok 8
Diagram lub tabelę z kroku 7 powinniśmy skonsultować z ekspertem dziedzinowym.
Krok 9
Po zaakceptowaniu diagramu związków encji przez eksperta dziedzinowego możemy przystąpić do
normalizacji, określenia kluczy głównych i kluczy obcych, dokonać zmian atrybutów (na przykład
dodać atrybuty sztuczne) oraz przekształcenia związków nierealizowalnych w modelu relacyjnym
(np. zamiana związków wiele do wielu na związki jedne do wielu).
Krok 10
Proponujemy aby w tym kroku określić typy wszystkich atrybutów uwzględniając typy silnika bazy
danych, na której będzie realizowana baza danych, zdefiniować niezdefiniowane jeszcze klucze
główne i klucze obce oraz wskazać pola indeksowane.
Na zakończenie powinniśmy dokonać przeglądu diagramu ERD pod kątem jego spójności
i kompletności. W naszym wypadku zadanie jest dosyć proste, gdyż problem, z którym mamy do
czynienia nie jest skomplikowany. Przystępujemy więc do kolejnych kroków budowy diagramu ERD.
Krok 1
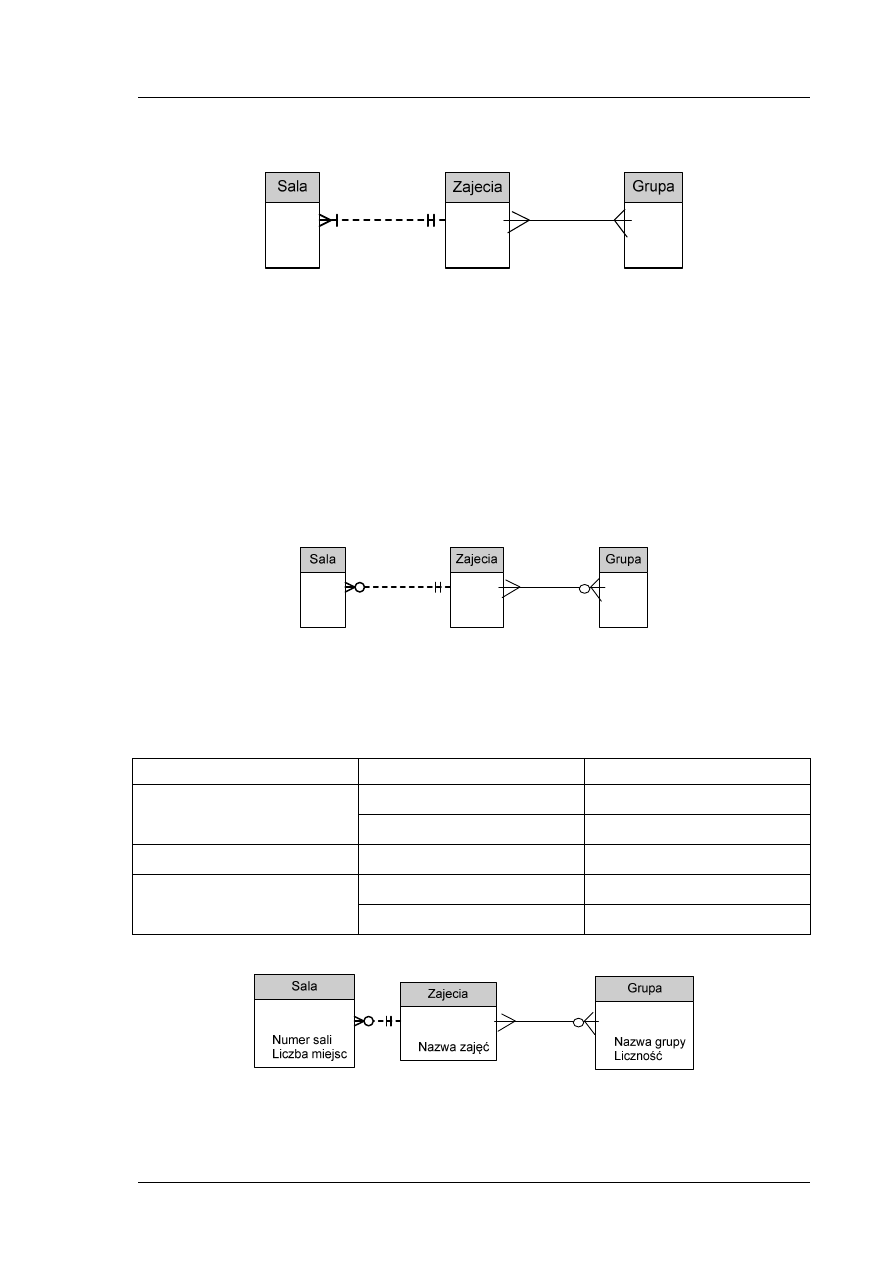
Po spotkaniu z panią Jolą identyfikujemy trzy encje: Sala, Zajecia i Grupa.
Przygotowujemy też zestawienie przykładowych instancji encji.
Tabela 1. Zestawienie instancji encji
Encja
Sala
Zajęcia
Grupa
Przykład
instancji
encji
110
C155
A001
Bazy danych – wykład
Bazy
danych
–
laboratorium
Podstawy informatyki
Programowanie
obiektowe
101
112
203
315c
Krok 2
Identyfikujemy związki:
Tabela 2. Liczności związków
Nazwa związku
Encje
Liczności
Zajecia_w_Sali
Sala, Zajęcia
Wiele do jeden (*..1)
Grupa_na_zajeciach
Grupa, Zajęcia
Wiele do wiele (*..*)
W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 10/18
Krok 3
Przedstawiamy diagram ERD z uwzględnieniem związków i ich liczności.
Rys. 8. Diagram ERD z uwzględnieniem związków i ich liczności
Krok 4
Pani Jola po obejrzeniu naszego diagramu zauważa, że mogą być zajęcia, które w danym semestrze
nie odbywają się, ale znajdują się w katalogu zajęć (np. przedmiot obieralny, który nie został
w danym semestrze wybrany przez wystarczającą liczbę chętnych). Nie są one przypisane do żadnej
sali ani do grupy studentów.
Dostrzegamy też błąd polegający na początkowym przypisaniu do konkretnej sali tylko jednych
zajęć. Oczywiście na taki luksus żaden wydział nie może sobie pozwolić. Zamieniamy liczność
związku Zajęcia_w_Sali na wiele do wielu.
Uwagę tę powinniśmy uwzględnić na naszym diagramie ERD. Wprowadzamy stosowną poprawkę
na diagramie.
Rys. 9. Diagram ERD po uwzględnień poprawy liczności związku
Krok 5
Przystępujemy do identyfikacji atrybutów. Wygodnie jest informacje o atrybutach zebrać w tabeli
podając jednocześnie przykład wartości atrybutu.
Tabela 3. Przykładowe wartości atrybutów
Encja
Atrybut
Przykład
Sala
Numer Sali
C101
Liczba miejsc
120
Zajecia
Nazwa zajęć
Bazy danych – wykład
Grupa
Nazwa grupy
112
Liczność
35
Na diagramie ERD:
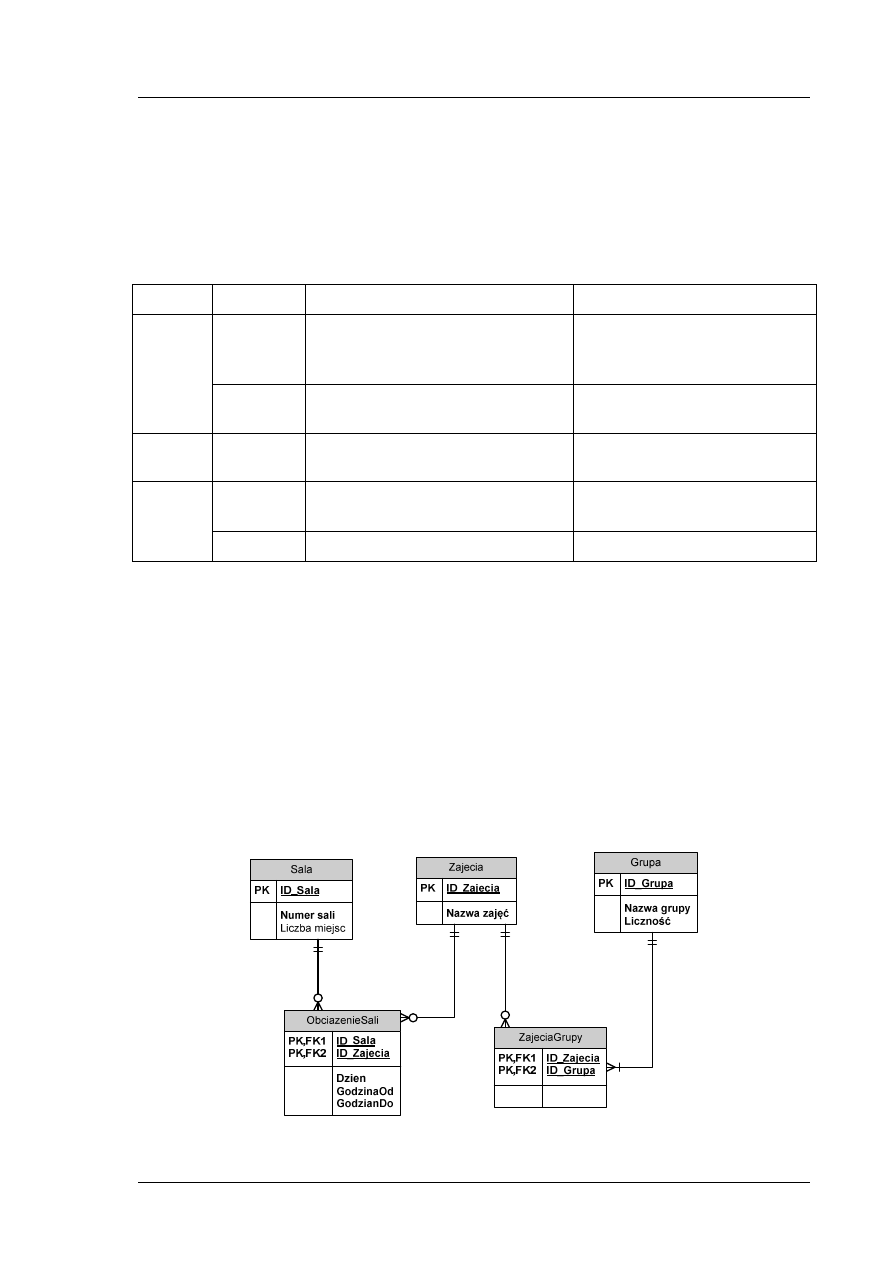
Rys. 10. Diagram ERD z zaznaczonymi atrybutami
W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 11/18
Krok 6
Pokazujemy nasz diagram ERD pani Joli. Jeśli zostanie on zaakceptowany, przechodzimy do kroku
siódmego.
Krok 7
Powinniśmy teraz określić dla każdego atrybutu jego dziedzinę. Najwygodniej będzie nam to
wykonać znowu w postaci tabelki takiej jak tabela xxx uzupełnionej o kolumnę Dziedzina atrybutu.
Tabela 4. Dziedziny atrybutów
Encja
Atrybut
Przykład
Dziedzina atrybutu
Sala
Numer
sali
C101
Ciąg
składający
się
z litery
reprezentującej budynek oraz co
najwyżej czterech cyfr
Liczba
miejsc
120
Przedział od 15 do 250
Zajecia Nazwa
zajęć
Bazy danych – wykład
Lista zajęć
Grupa
Nazwa
grupy
112
Ciąg składający się z 3 lub 4 cyfr
i/lub litery
Liczność 35
Przedział od 12 do 40
Krok 8
Powinniśmy znowu skonsultować wyniki naszej pracy z panią Jolą. Jeśli uzyskamy akceptację,
możemy przejść do kroku dziewiątego. W przeciwnym razie nanosimy poprawki i ponownie
prosimy o akceptację.
Krok 9
Jeśli dobrnęliśmy aż tutaj, to oznacza, że zakończyliśmy konsultację z panią Jolą i możemy
przystąpić do prac zmierzających do nadania naszemu modelowi postaci dającej się
zaimplementować w relacyjnej bazie danych.
W naszym diagramie ERD występują związki wiele do wiele. Są to związki nieimplementowane
bezpośrednio w modelu relacyjnym, dlatego musimy dokonać ich przekształcenia. Wprowadzamy
nowe encje ObciazenieSali i ZajeciaGrupy tak jak na rysunku.
Rys. 11. Diagram ERD
W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 12/18
Informację na diagramie możemy uzupełnić o typy danych, tak jak przedstawiamy to na Rys. 12.
Diagram ERD z typami danych
Sala
PK
ID_Sala
uniqueidentifier
Numer sali
varchar(6)
Liczba miejsc
uniqueidentifier
Zajecia
PK
ID_Zajecia
uniqueidentifier
Nazwa zajęć
varchar(255)
Grupa
PK
ID_Grupa
uniqueidentifier
Nazwa grupy
char(10)
Liczność
smallint
ZajeciaGrupy
PK,FK1
ID_Zajecia
int
PK,FK2
ID_Grupa
int
ObciazenieSali
PK,FK1
ID_Sala
int
PK,FK2
ID_Zajecia
int
Dzien
char(10)
GodzinaOd
char(10)
GodzianDo
char(10)
Rys. 12. Diagram ERD z typami danych
Krok 10
W ostatnim kroku dokonujemy przeglądu naszego modelu ERD. Rzadko kiedy pierwsze podejście
będzie całkowicie wolne od błędów, pomyłek czy niedopatrzeń, dlatego zawsze należy
przeprowadzić weryfikację poprawności diagramu.
Porady praktyczne
•
Pamiętaj, że diagram związków encji ma być zrozumiały nie tylko dla informatyka. Ma on
służyć dialogowi między projektantem a użytkownikiem, który formułuje wymagania dla
przyszłej bazy danych. Modelując dane należy posługiwać się jasnym, prostym i przejrzystym
językiem i formami wyrazu.
•
Budując diagram związków encji nie spiesz się. Nie dokonuj zbyt pochopnie przekształceń
i nie wprowadzaj od razu zbyt wielu szczegółów, nawet jeśli przekształcenia wydają Ci się
oczywiste, a definiowanie typów danych czy określanie kluczy natychmiastowe. Pamiętaj, że
kluczowym elementem budowanych diagramów jest ich czytelność i zrozumiałość dla osoby
definiującej wymagania, czyli tak zwanego eksperta dziedzinowego (w każdym razie
w początkowych etapach tworzenia diagramów ERD).
•
Przy identyfikowaniu encji bardzo zachęcamy do tego, aby zawsze wypisać kilka przykładów
instancji encji. Podejście to pozwala na lepsze zrozumienie świata rzeczywistego i weryfikację
poprawności identyfikacji encji. Nazwa encji często nie oddaje jej istoty i może być różnie
rozumiana przez różne osoby biorące udział w budowaniu modelu danych. Szybko docenisz
tę technikę podczas dialogu z przyszłym użytkownikiem bazy, który z pewnością będzie lepiej
rozumiał prezentowane przez Ciebie modele.
•
Rysowanie diagramów związków encji najlepiej zacząć od rysowania na dużej kartce papieru
lub tablicy. Dopiero pod koniec (krok 9) warto jest przenieść diagramy związków encji do
narzędzia wspomagającego pracę z diagramami ERD. Narzędzi takich jest wiele. My
proponujemy wykorzystać do tego celu program MS Visio – znany i wygodny program do
rysowania wyposażony w specjalny moduł wspomagający projektowanie baz danych.
•
Zwracamy uwagę, że w teorii relacyjnych baz danych pod pojęciem relacji rozumie się
dwuwymiarową tabelę danych. Tabele te odpowiadają na etapie projektowym pojęciu encji,
natomiast powiązania między tabelami (encjami) noszą nazwę związków. W niektórych
aplikacjach i w żargonie informatycznym słowo relacja ma jednak czasem inne znaczenie

W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 13/18
i oznacza powiązanie między tabelami (encjami), czyli związek. Takie nazewnictwo
stosowane jest na przykład w polskich wersjach aplikacji firmy Microsoft.
•
Ostateczny projekt bazy danych zależy w istotnym stopniu od zwyczajów i upodobań
projektanta. Modele ERD bazy danych zbudowane dla tego samego problemu mogą się
różnić. Nie zawsze potrafimy jednoznacznie wskazać, który z modeli jest lepszy. Często są
one po prostu jednakowo dobre.
•
Zwróć uwagę, że notacja proponowana przez nas w tym module nie jest jedyną notacją
stosowaną przy modelowaniu danych. Popularność zyskuje modelowanie baz danych
z wykorzystaniem języka UML. Modelowanie w języku UML bazuje na podejściu obiektowym
do analizy i projektowania systemów. Choć założenia, na których opiera się modelowania
diagramami ERD i językiem UML są inne, to jednak ogólna droga postępowania jest bardzo
podobna. Jeśli znasz język UML i zasady modelowania obiektowego, to do projektowania baz
danych możesz zamiast diagramów ERD wykorzystać diagramy klas języka UML.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium, jeśli:
•
rozumiesz, czym jest encja i związek między encjami,
•
rozumiesz, na czym polega proces dochodzenia do końcowego diagramu związków encji,
•
umiesz dokonać przekształcenia związków nieimplementowanych w relacyjnych bazach
danych do związków binarnych jednoznacznych,
•
potrafisz przedstawić diagram ERD na różnym poziomie abstrakcji,
•
wiesz, jakie jest znaczenie słowa relacja w teorii relacyjnych baz danych i w żargonie
informatycznym.
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Rebeca R. Riordan, Projektowanie relacyjnych baz danych, Microsoft Press, 2000
Książka poświęcona jest praktycznym aspektom projektowania relacyjnych baz
danych w środowisku aplikacji firmy Microsoft. Znajdziesz w niej między innymi
przegląd modeli normalizacyjnych, których nie omawialiśmy w tym module
bezpośrednio. Rebeca Riordan znana jest z łatwego i zrozumiałego języka i łatwości
tłumaczenia zagadnień trudnych. Ten swój talent wykorzystuje również w tej
pozycji. Jeśli nie interesuje Cię zgłębianie teoretycznych podstaw działania baz
danych, a bardziej nastawiony jesteś na praktyczne wykorzystanie wiedzy, to jest to
książka dla Ciebie.
2.
C.J.Date, Wprowadzenie do systemów baz danych, WNT, 2000
Jest to pełny podręcznik do wykładu z baz danych znanego i cenionego na całym
świecie autora. Znajdziesz w nim szersze spojrzenie na problematykę budowy
i modelowania baz danych. Polecamy ją wszystkim, którzy chcieliby poszerzyć
swoje wiadomości z tego zakresu.
3.
System pomocy programu Visio
Jeśli po raz pierwszy spotykasz się z programem Visio, to zajrzyj koniecznie do jego
systemu pomocy. Znajdziesz tam wszystkie niezbędne informacje, aby efektywnie
korzystać z tego oprogramowania.
W.Dąbrowski, P.Kowalczuk, K.Markowski
ITA-101 bazy danych
Laboratorium podstawowe
Problem (czas realizacji
Jesteś projektantem bazy danych.
użytkownikiem bazy) opracowałeś model diagramu związków encji opisany
Przykładowe rozwiązanie. Model
na papierze. Teraz warto jest przenieść tę dokumentację „do
archiwizację modelu, wprowadzanie zmian
Dodatkowo może też skrócić czas projektowania bazy danych dzięki wykorzystaniu narzędzi RAD
(ang. Rapid Application Design
bazy danych wybrana została aplikacji MS Viso 2007. Twoim zadaniem będzie utworzenie przy
pomocy tego programu modelu danych
Zadanie
Tok postępowania
1.
Uruchom
projekt bazy
danych
w programie MS
Visio 2007
•
Uruchom aplikację MS Visio 2007
•
Z panelu
grupę
2.
Wprowadź
tabele
•
W obszarze roboczym wyłącz linie siatki wybierając
Widok
•
Z zasobnika
roboczy (kartka). Na obszarze roboczym zostanie utworzona encja
o
•
Zaznacz encję
element
tekst
•
Powtórz powyższe czynności dla pozostałych encji
W.Dąbrowski, P.Kowalczuk, K.Markowski
Strona 14/18
Laboratorium podstawowe
Problem (czas realizacji 40 min)
Jesteś projektantem bazy danych. W wyniku spotkań z ekspertem dzied
użytkownikiem bazy) opracowałeś model diagramu związków encji opisany
. Model i wszystkie dodatkowe dane (np. tabele) zostały zapisane jedynie
na papierze. Teraz warto jest przenieść tę dokumentację „do komputera”. Umożliwi to łatwiejszą
archiwizację modelu, wprowadzanie zmian i wymianę informacji między członkami zespołu.
Dodatkowo może też skrócić czas projektowania bazy danych dzięki wykorzystaniu narzędzi RAD
Rapid Application Design). Jako aplikację wspomagającą prace na tym etapie budowy modelu
bazy danych wybrana została aplikacji MS Viso 2007. Twoim zadaniem będzie utworzenie przy
pomocy tego programu modelu danych i diagramu ERD zgodne z wymaganiami „papierowymi”.
Tok postępowania
Uruchom aplikację MS Visio 2007.
Z panelu Wprowadzenie do programu Microsoft Office Visio
grupę Diagram modelu bazy danych.
W obszarze roboczym wyłącz linie siatki wybierając
Widok -> Siatka.
Z zasobnika Model encja-relacja przeciągnij element
roboczy (kartka). Na obszarze roboczym zostanie utworzona encja
o nazwie Tabela1.
Zaznacz encję Tabela1. W oknie Właściwości bazy danych
element Definicja, a następnie w polu Nazwa koncepcyjna
tekst Sala.
Nazwa encji na obszarze roboczym powinna zmienić się na
Powtórz powyższe czynności dla pozostałych encji
Rys. 13. Fragment okna programu Visio
Moduł 1
Budowa diagramów ERD
ekspertem dziedzinowym (przyszłym
użytkownikiem bazy) opracowałeś model diagramu związków encji opisany w rozdziale
wszystkie dodatkowe dane (np. tabele) zostały zapisane jedynie
komputera”. Umożliwi to łatwiejszą
wymianę informacji między członkami zespołu.
Dodatkowo może też skrócić czas projektowania bazy danych dzięki wykorzystaniu narzędzi RAD
ikację wspomagającą prace na tym etapie budowy modelu
bazy danych wybrana została aplikacji MS Viso 2007. Twoim zadaniem będzie utworzenie przy
wymaganiami „papierowymi”.
Wprowadzenie do programu Microsoft Office Visio wybierz
W obszarze roboczym wyłącz linie siatki wybierając polecenie
przeciągnij element Encja na obszar
roboczy (kartka). Na obszarze roboczym zostanie utworzona encja
Właściwości bazy danych wskaż
Nazwa koncepcyjna wprowadź
Nazwa encji na obszarze roboczym powinna zmienić się na Sala.
Powtórz powyższe czynności dla pozostałych encji w modelu.
. Fragment okna programu Visio
W.Dąbrowski, P.Kowalczuk, K.Markowski
ITA-101 bazy danych
3.
Wprowadź
atrybuty
•
Zaznacz encję
•
W oknie
•
W kolumnie
•
Na dole okna
wybór
jest inny sterownik wybierz
a w
Microsoft SQL Server
•
jako typ danych
pole jako
symbol budynku
•
Wprowadź pozostałe kolumny tabeli
jest kluczem głównym
Wprowadź atrybuty pozostałych tabel. Pamiętaj
kolumny stanowią kluc
4.
Zmień widok
dokumentu
•
Przejdź do menu
dokumentu bazy danych
modelu ERD.
5.
Dodaj związki
między encjami
•
Z zasobnika
roboczy (kartka). Na obszarze roboczym zostanie utworzona relacja.
Przeciągnij końce relacji odpowiednio na encje
aby uzyskać zakotwiczenie relacji
program wyróżnia encję czerwonym obramowaniem)
•
Wskaż utworzoną relację.
kategorię
fizyczna
•
Przejdź do kate
różnych opcji kardynalności (liczności).
zdaniem kardynalności dla tej relacji.
•
Zdefiniuj pozostałe związki między encjami.
6.
Zmiana notacji
diagramu
•
Wybierz
zmień zaznaczenie opcji
diagramie ERD.
7.
Zapisz model
•
Zapisz model
W.Dąbrowski, P.Kowalczuk, K.Markowski
Strona 15/18
Zaznacz encję Sala.
W oknie Właściwości bazy danych zaznacz element
W kolumnie Nazwa fizyczna wprowadź Numer_Sali
Na dole okna Właściwości bazy danych upewnij się, że zaznaczony jest
wybór Fizyczny typ danych (Microsoft SQL Server)
jest inny sterownik wybierz z menu Baza danych -
a w oknie Sterowniki bazy danych z karty
Microsoft SQL Server.
jako typ danych dla kolumny Numer_Sali wybierz
pole jako wymagane, a w uwagach wpisz: Numer sali; litera oznacza
symbol budynku.
Sprawdź w systemie pomocy co oznacza typ danych
zgadzasz się z takim wyborem typu dla pola Nazwa_Sali
Sprawdź, co stanie się po zmianie wyboru na
danych?
Wprowadź pozostałe kolumny tabeli Sala. Wskaż, że kolumna
jest kluczem głównym w tej tabeli.
Wprowadź atrybuty pozostałych tabel. Pamiętaj
kolumny stanowią klucz główny oraz które wartości są wymagane.
Program MS Visio pozwala na przestawienie modelu ERD
zestawem informacji (np. można ukryć lub pokazać typy danych,
oznaczenia kluczy głównych itd.).
Przejdź do menu Baza danych -> Opcje -> Dokument
dokumentu bazy danych wypróbuj różne ustawienia wyświetlania
modelu ERD.
Jakie opcje należy wybrać, aby na diagramie były widoczne typy
danych zdefiniowane w oknie Właściwości bazy danych
poszczególnych atrybutów?
Z zasobnika Model encja-relacja przeciągnij element
roboczy (kartka). Na obszarze roboczym zostanie utworzona relacja.
Przeciągnij końce relacji odpowiednio na encje Sala
aby uzyskać zakotwiczenie relacji (jeśli następuje zakotwiczeni
program wyróżnia encję czerwonym obramowaniem)
Wskaż utworzoną relację. W oknie Właściwości bazy danych
kategorię Nazwa. W pola Fraza orzeczenia, Fraza odwrotna
fizyczna i Uwagi wpisz odpowiednie Twoim zdaniem wartości.
Przejdź do kategorii Różne. Sprawdź, jaki wpływ na diagram ma wybór
różnych opcji kardynalności (liczności). Ustaw prawidłowe Twoim
zdaniem kardynalności dla tej relacji.
Zdefiniuj pozostałe związki między encjami.
Co należy zrobić, aby w widoku roboczym nie były wyświe
związki?
Wybierz z menu Baza danych -> Opcje -> Dokument
zmień zaznaczenie opcji Kurze łapki. Zaobserwuj zmiany notacji na
diagramie ERD.
Zapisz model w odpowiednim pliku na dysku.
Moduł 1
Budowa diagramów ERD
zaznacz element Kolumny.
Numer_Sali.
upewnij się, że zaznaczony jest
Fizyczny typ danych (Microsoft SQL Server). Jeśli wyświetlany
-> Opcje -> Sterowniki,
karty Sterowniki sterownik
wybierz varchar(6), wskaż to
Numer sali; litera oznacza
systemie pomocy co oznacza typ danych varchar(6). Czy
Nazwa_Sali?
się po zmianie wyboru na Pokaż: Przenośny typ
. Wskaż, że kolumna ID_Sala
Wprowadź atrybuty pozostałych tabel. Pamiętaj o wskazaniu, które
główny oraz które wartości są wymagane.
Program MS Visio pozwala na przestawienie modelu ERD z różnym
zestawem informacji (np. można ukryć lub pokazać typy danych,
Dokument i w karcie Opcje
wypróbuj różne ustawienia wyświetlania
Jakie opcje należy wybrać, aby na diagramie były widoczne typy
Właściwości bazy danych dla
przeciągnij element Relacja na obszar
roboczy (kartka). Na obszarze roboczym zostanie utworzona relacja.
Sala i ObciazenieSali, tak
(jeśli następuje zakotwiczenie, to
program wyróżnia encję czerwonym obramowaniem).
Właściwości bazy danych wskaż
Fraza odwrotna, Nazwa
wpisz odpowiednie Twoim zdaniem wartości.
. Sprawdź, jaki wpływ na diagram ma wybór
Ustaw prawidłowe Twoim
widoku roboczym nie były wyświetlane
Dokument i na karcie Relacja
. Zaobserwuj zmiany notacji na

W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 16/18
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 45 min)
W pewnej uczelni (jeśli nie w każdej) student kończący pewien etap edukacji musi wykonać
i obronić pracę końcową zwaną pracą dyplomową. Praca dyplomowa realizowana jest na koniec
każdego etapu studiów. Tak więc prace dyplomową piszą studenci studiów licencjackich,
inżynierskich i magisterskich. W przyszłości uczelnia planuje poszerzyć swoją ofertę studiów o nowe
rodzaje studiów, które też będą kończyć się pracą dyplomową. Każdy student oprócz imienia
i nazwiska ma przypisany na uczelni jednoznaczny identyfikator w postaci numeru indeksu. Numer
indeksu jest ciągiem złożonym z 10 znaków i w sposób jednoznaczny identyfikuje studenta
studiującego na uczelni.
Student chcąc ukończyć dany rodzaj studiów musi wybrać temat pracy dyplomowej. Z tematem
pracy związany jest oczywiście jej opiekun zwany zazwyczaj promotorem pracy. Zasadą jest, że
jeden temat kierowany jest przez jednego promotora – pracownika uczelni ze stopniem doktora,
doktora habilitowanego lub profesora.
Władze uczelni zachęcają swoich studentów do pisania prac indywidualnych. Ale dopuszczają
również możliwość realizacji prac przez dwóch lub trzech studentów. Więcej osób nie może pisać
jednej pracy dyplomowej.
Po napisaniu praca podlega recenzji. Recenzja wykonywana jest przez jednego lub kilku
pracowników uczelni i oceniana. Każdy recenzent może ocenić pracę w skali od 2 do 5. Praca
oceniana jest również przez promotora.
Do pracy przyporządkowywane są pewne słowa ze z góry zdefiniowanego zbioru. Są to tak zwane
słowa kluczowe, które pozwalają przypisać tematykę pracy do określonego obszaru, a następnie
odnajdywać prace związane z podobną tematyką. Słowami kluczowymi mogą być: informatyka,
systemy operacyjne, konstrukcje żelbetowe itp. Każda praca powinna mieć przypisane co najmniej
jedno słowo kluczowe.
Po napisaniu pracy student przystępuje do obrony pracy. Obrona ta odbywa się w wyznaczonym
dniu i kończy się wystawieniem pracy dyplomowej końcowej, ostatecznej oceny.
Uczelnia chciałaby usprawnić obsługę prac dyplomowych i związanych z tym procesów. Dlatego
planuje opracować system informatyczny wspierający obsługę tych procesów. Pierwszym etapem
prac ma być zbudowanie bazy danych, która będzie spełniać następujące wymagania:
1.
Umożliwi przechowywanie informacji o obronionych pracach dyplomowych wszystkich
studentów uczelni.
2.
Umożliwi szybkie i łatwe wyszukiwanie prac związanych z daną tematyką lub prowadzonych
przez określonego promotora.
3.
Umożliwi raportowanie o pracach dyplomowych:
•
recenzowanych przez pracowników uczelni,
•
obronionych w danym dniu, miesiącu, roku,
•
obronionych na danym rodzaju studiów.
Zaproponuj diagram ERD dla projektowanej bazy danych. Pamiętaj również o udokumentowaniu
przykładowych instancji encji oraz wartości atrybutów, tak jak robiliśmy to w przykładowym
rozwiązaniu w krokach piątym i siódmym. Model zapisz w pliku programu MS Visio.
Zadanie 2 (czas realizacji 45 min)
Wymagania z zadania 1 okazały się niewystarczające. Nasz ekspert dokonał przeglądu wymagań
i dodał uzupełnienia. W poniższym tekście zostały one uwydatnione.

W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 17/18
Zaproponuj diagram ERD dla projektowanej bazy danych po uwzględnieniu rozszerzeń. Pamiętaj
również o udokumentowaniu przykładowych instancji encji oraz wartości atrybutów, tak jak
robiliśmy to w przykładowym rozwiązaniu w krokach piątym i siódmym. Model zapisz w pliku
programu MS Visio.
W pewnej uczelni (jeśli nie w każdej) student kończący pewien etap edukacji musi wykonać
i obronić pracę końcową zwaną pracą dyplomową. Uczelnia składa się kilku wydziałów. Na każdym
wydziale studenci mogą być kształceni na różnych specjalizacjach, a informacja o wydziale
i specjalizacji jest istotna przy wykonywaniu sprawozdań uczelni z obronionych prac dyplomowych.
Praca dyplomowa realizowana jest na koniec każdego etapu studiów. Tak więc prace dyplomową
piszą studenci studiów licencjackich, inżynierskich i magisterskich. W przyszłości uczelnia planuje
poszerzyć swoją ofertę studiów o nowe rodzaje studiów, które też będą kończyć się pracą
dyplomową. Każdy student oprócz imienia i nazwiska ma przypisany na uczelni jednoznaczny
identyfikator w postaci numeru indeksu. Numer indeksu jest ciągiem złożonym z 10 znaków i
w sposób jednoznaczny identyfikuje studenta studiującego na uczelni.
Student chcąc ukończyć dany rodzaj studiów musi wybrać temat pracy dyplomowej. Z tematem
pracy związany jest oczywiście jej opiekun zwany zazwyczaj promotorem pracy. Zasadą jest, że
jeden temat kierowany jest przez jednego promotora – pracownika uczelni ze stopniem doktora,
doktora habilitowanego lub profesora.
Władze uczelni zachęcają swoich studentów do pisania prac indywidualnych. Ale dopuszczają
również możliwość realizacji prac przez dwóch lub trzech studentów. Więcej osób nie może pisać
jednej pracy dyplomowej.
Po napisaniu praca podlega recenzji. Recenzja wykonywana jest przez jednego lub kilku
pracowników uczelni i oceniana. Każdy recenzent może ocenić pracę w skali od 2 do 5. Praca
oceniana jest również przez promotora. Ocena recenzenta i promotora nie może być zbiorczą oceną
pracy, ale musi osobno dotyczyć każdego z autorów pracy.
Do pracy przyporządkowywane są pewne słowa ze z góry zdefiniowanego zbioru. Są to tak zwane
słowa kluczowe, które pozwalają przypisać tematykę pracy do określonego obszaru, a następnie
odnajdywać prace związane z podobną tematyką. Słowami kluczowymi mogą być na przykład:
informatyka, systemy operacyjne, konstrukcje żelbetowe. Każda praca powinna mieć przypisane co
najmniej jedno słowo kluczowe.
Po napisaniu pracy student przystępuje do obrony pracy. Obrona ta odbywa się w wyznaczonym
dniu przed komisją składającą się z 3 członków oraz przewodniczącego i kończy się wystawieniem
ostatecznej oceny każdemu studentowi osobno. W czasie egzaminu każdemu studentowi są
zadawane i protokołowane trzy pytania. Każde z pytań podlega osobnej ocenie.
Uczelnia chciałaby usprawnić obsługę prac dyplomowych i związanych z tym procesów. Dlatego
planuje opracować system informatyczny wspierający obsługę tych procesów. Pierwszym etapem
prac ma być zbudowanie bazy danych, która będzie spełniać następujące wymagania:
1. Umożliwi przechowywanie informacji o obronionych pracach dyplomowych wszystkich
studentów uczelni.
2. Umożliwi szybkie i łatwe wyszukiwanie prac związanych z daną tematyką, wydziałem,
specjalizacją lub prowadzonych przez określonego promotora.
3. Umożliwi raportowanie o pracach dyplomowych:
•
recenzowanych przez pracowników uczelni
•
obronionych w danym dniu, miesiącu, roku
•
obronionych na danym rodzaju studiów

W.Dąbrowski, P.Kowalczuk, K.Markowski
Moduł 1
ITA-101 bazy danych
Budowa diagramów ERD
Strona 18/18
4. Umożliwić szybkie sprawdzenie przebiegu obrony pracy dyplomowej danego studenta, w tym
zadanych pytań i składu komisji.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
Wersja 2.0
Instalacja i konfiguracja Microsoft SQL
Server 2008
Spis treści
Instalacja i konfiguracja MS SQL Server 2008 ...................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 6
Porady praktyczne ..................................................................................................................... 10
Uwagi dla studenta .................................................................................................................... 11
Dodatkowe źródła informacji..................................................................................................... 11
Laboratorium podstawowe ................................................................................................................ 12
Laboratorium rozszerzone ................................................................................................................. 16
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 2/16
Informacje o module
Opis modułu
W tym module znajdziesz informację o podstawowych zadaniach
administratora systemu bazodanowego. Do zadań tych należy instalacja
serwera baz danych, konserwacja oraz aktualizacji serwisów serwera.
Prawidłowe przygotowanie środowiska pracy zapewni stabilność oraz
pozwoli na poznanie systemu bazodanowego od podstaw.
Cel modułu
Celem modułu jest przedstawienie czytelnikowi typowych zagadnień
związanych z instalacją i konfiguracją serwera bazodanowego.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
potrafił zaplanować instalację systemu bazodanowego
•
potrafił przeprowadzić instalację SQL Server 2008 za pomocą
centrum instalacji
•
wstępne opcje dotyczące bezpieczeństwa serwera
•
rozumiał czym są serwisy serwera SQL i jakie mają funkcje
•
wiedział, jak skonfigurować poszczególne serwisy serwera SQL
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
wiedzieć, jak używać oprogramowania Microsoft Virtual PC
•
znać podstawy obsługi systemu Windows 2000 lub nowszego
•
rozumieć, jak przebiega instalacja oprogramowania w systemie
Windows
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, nie istnieje konieczność
wykonania wcześniej żadnego innego modułu.
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 3/16
Przygotowanie teoretyczne
Przykładowy problem
Wdrożenie nowego systemu bazodanowego nie jest procesem trywialnym. W pierwszej kolejności
wykonywana jest analiza potrzeb organizacji w zakresie gromadzenia i przetwarzania informacji.
Następnie można wybrać konkretny system z użytecznymi komponentami. Instalacja systemu, testy
wydajnościowe i integracja z istniejącymi składnikami IT organizacji to niezbędne kroki wdrożenia,
przeważnie oddelegowane do doświadczonego informatyka.
Typowym scenariuszem jest pojawienie się potrzeby przetwarzania coraz większych ilości
informacji w małej firmie, która w związku z dogodnymi warunkami na rynku przeżywa dynamiczny
rozwój. Obsługa rosnącej liczby klientów przysparza coraz więcej kłopotów, głównie działowi analiz.
Na kolejnym zebraniu pada propozycja wdrożenia nowego systemu bazodanowego opartego na
technologii Microsoft SQL Server 2008, który pomoże usprawnić procesy związane z obróbką coraz
większej ilości danych o klientach, co potencjalnie przełoży się na jakość obsługi i przyszłe zyski.
Sygnał i wsparcie finansowe od strony biznesowej jest motorem procesu wdrożenia systemu
bazodanowego przedstawionego w tym module.
Podstawy teoretyczne
Właściwie każde oprogramowanie określane mianem serwera (serwer WWW, serwer baz danych)
działa na podobnej zasadzie – opiera się na uruchomionych w systemie operacyjnym usługach. Od
konfiguracji tych usług zależy, czy i jak będzie funkcjonował serwer.
Instalacja
Aby móc cokolwiek konfigurować, w pierwszej kolejności należy dokonać instalacji tego składnika.
Podstawowym składnikiem, czyli usługą systemu bazodanowego, jest silnik (ang. Database Engine),
odpowiadający za niskopoziomowe przewarzanie danych. Element ten znajdziemy w każdym
systemie bazodanowym, choć różnie może się nazywać. Wszystkie inne elementy bezpośrednio lub
pośrednio korzystają z silnika i w przypadku jego braku lub uszkodzenia po prostu nie działają.
Sam silnik jest jednak bardzo niewygodny w obsłudze z punktu widzenia użytkownika serwera
bazodanowego. W tej sytuacji powstało wiele innych komponentów, które uzupełniają i
usprawniają pracę z takim systemem. Narzędzia graficzne do obsługi i administracji serwera (ang.
Client Tools) są szczególnie pomocne dla administratorów. Serwis analityczny (ang. Analysis
Services) jest nieoceniony przy przetwarzaniu dużej ilości danych. Serwis raportujący (ang.
Reporting Services) usprawnia i uatrakcyjnia prezentację analizowanych danych.
W celu integracji czynności instalacyjnych tych i innych komponentów serwera SQL administrator
do dyspozycji ma narzędzie o nazwie Centrum Instalacji przedstawione na rys. 2.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 4/16
Rys. 2 Nowe Centrum Instalacji
Z tego miejsca można dokonać instalacji nowej instancji serwera SQL (w jednym systemie może być
wiele wystąpień serwera bazodanowego), zmodyfikować komponenty serwera, zainstalować
przykładowe bazy danych lub poczytać dokumentację.
Instalacja nowej instancji serwera SQL wiąże się zawsze z kilkoma etapami:
1.
Określenie komponentów serwera, które będziemy instalować.
2.
Określenie miejsca w systemie operacyjnym, gdzie komponenty będą składowane.
3.
Podanie kont systemowych potrzebnych do uruchomienia poszczególnych usług serwera.
Po zakończeniu procesu instalacji powinniśmy przejrzeć i skonfigurować nowe usługi bazodanowe,
które pojawiły się w naszym systemie operacyjnym.
Usługa serwera
Silnik
Silnik serwera bazodanowego, odpowiedzialny za przechowywanie danych, utrzymywanie
spójności danych i obsługę poleceń języka zapytań najczęściej jest tożsamy z główną usługą
serwera. Aby użytkownicy mogli stale korzystać z tej usługi, powinna być ona uruchomiona
praktycznie zawsze (nie licząc czasu na ewentualne prace administracyjne, wymagające przejścia
serwera w tryb offline).
Dodatkowo, ponieważ niektóre czynności wymagają restartu samej maszyny, usługa ta powinna
być skonfigurowana jako uruchamiana wraz ze startem systemu operacyjnego. Niektóre systemy
operacyjne pozwalają również na określenie zachowań usługi w momencie, gdy zostanie ona
nieoczekiwanie zatrzymana (nie przez użytkownika, a na przykład na skutek awarii).
Dla przykładu, w systemie Microsoft Windows Server można skonfigurować każdą usługę tak, by po
nieoczekiwanym zatrzymaniu była podejmowana próba automatycznego restartu usługi (czyli
ponownego jej uruchomienia).
Usługa automatyzacji zadań
Dobry administrator potrafi wykorzystać zdobycze techniki i zautomatyzować pracę systemu
bazodanowego tak, by mieć przy nim jak najmniej pracy. Do automatyzacji najczęściej służy usługa,
która albo jest oferowana przez system operacyjny, albo jest dostarczana wraz z systemem
bazodanowym. Pozwala ona między innymi na przygotowywanie harmonogramów tworzenia kopii
zapasowych baz danych. Taką usługą w systemie Microsoft SQL Server 2008 jest SQL Server Agent.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 5/16
Należy zadbać o to, by była ona zawsze uruchomiona, a często domyślnie usługi te są wyłączone lub
zatrzymane.
Bezpieczeństwo usług
W trakcie konfiguracji usług należy kierować się pewnymi zasadami, by uniknąć nieprawidłowości w
ustawieniach i w działaniu serwera. Zasady te dotyczą głównie kwestii związanych z
bezpieczeństwem środowiska.
Pierwszą ważną zasadą jest zasada minimalizacji ilości usług. Mówi ona, że należy zawsze
instalować i uruchamiać tylko te usługi, z których w danym momencie korzysta nasz system
bazodanowy. Pozostałe usługi, o ile mogą być zainstalowane (w przyszłości może się okazać, że
jakaś dodatkowa usługa będzie potrzebna), o tyle ich uruchamianie powoduje, że administrator ma
więcej pracy, zaś w systemie znajduje się więcej potencjalnych słabych punktów.
Zasada ta obowiązuje głównie osoby administrujące systemami i sieciami komputerowymi.
Stosowanie się do niej może znacznie zwiększyć bezpieczeństwo systemu.
Druga zasada dotyczy konfiguracji kontekstu usług. Usługi w systemie operacyjnym działają jak
użytkownicy – wykonują operacje i mają określone uprawnienia. W niektórych systemach
(np. Windows) każdej usłudze przyporządkowane jest konto użytkownika. Mówimy, że usługa
pracuje w kontekście użytkownika. Oznacza to, że usługa działa w systemie operacyjnym i w sieci
na takich samych uprawnieniach, jakie zostały określone dla użytkownika.
W związku z tym pojawia się problem wyboru właściwego konta dla usług. Problem ten dotyczy
głównej usługi serwera SQL – silnika oraz usługi odpowiedzialnej za automatyzację zadań w tym
systemie.
Większość systemów operacyjnych oferuje wbudowane konta o kreślonych uprawnieniach.
Niestety, uprawnienia te na ogół są zbyt duże, by konta systemowe można było wykorzystać do
pracy z usługami systemu bazodanowego. Przykładem takiego konta jest konto Local System w
systemach Microsoft Windows.
Konto to działa jako element systemu operacyjnego, co w praktyce oznacza, że ma uprawnienia
nawet większe od tych, jakie posiada administrator systemu. Stąd pierwszy wniosek – na ogół nie
wybieramy wbudowanych kont systemowych dla usług serwera SQL. Powstaje pytanie – jakich w
takim razie kont używać?
Jeśli serwer ma pracować w środowisku rozproszonym, ma mieć możliwość dostępu do innych
serwerów i dodatkowo maszyna znajduje się w domenie, to wybieramy dla usług konto domenowe,
specjalnie utworzone i skonfigurowane. Konto to powinno mieć ustawienia, które pozwolą w
sposób nieprzerwany pracować usłudze.
Zatem – należy ustawić dla tego konta silne hasło, które nie powinno mieć daty wygasania (hasło
nigdy nie wygasa) i nie powinno być zmieniane przez użytkowników (użytkownik nie może zmieniać
hasła, bez opcji użytkownik musi zmienić hasło przy pierwszym logowaniu). Co do uprawnień konta,
należy rozważyć przydzielenie konta do roli lokalnego administratora (dla potrzeb na przykład
automatycznego restartu usługi w przypadku nieoczekiwanego jej zatrzymania).
Czasami taka konfiguracja jest wymagana (na przykład przy instalacji systemu Microsoft SQL Server
w klastrze Microsoft Windows). Dla głównych usług możesz skonfigurować jedno konto (ułatwia to
zdecydowanie administrację kontami). Nazwa konta dla zwiększenia bezpieczeństwa nie powinna
kojarzyć się z systemem bazodanowym.
Narzędzia konfiguracji usług
Większość systemów operacyjnych oferuje narzędzie do zcentralizowanego zarządzania usługami
zainstalowanymi w systemie. Jednak ponieważ ogólna ilość usług w systemach operacyjnych jest
ogromna, a dodatkowo bardzo często usługi systemu bazodanowego wymagają dodatkowych
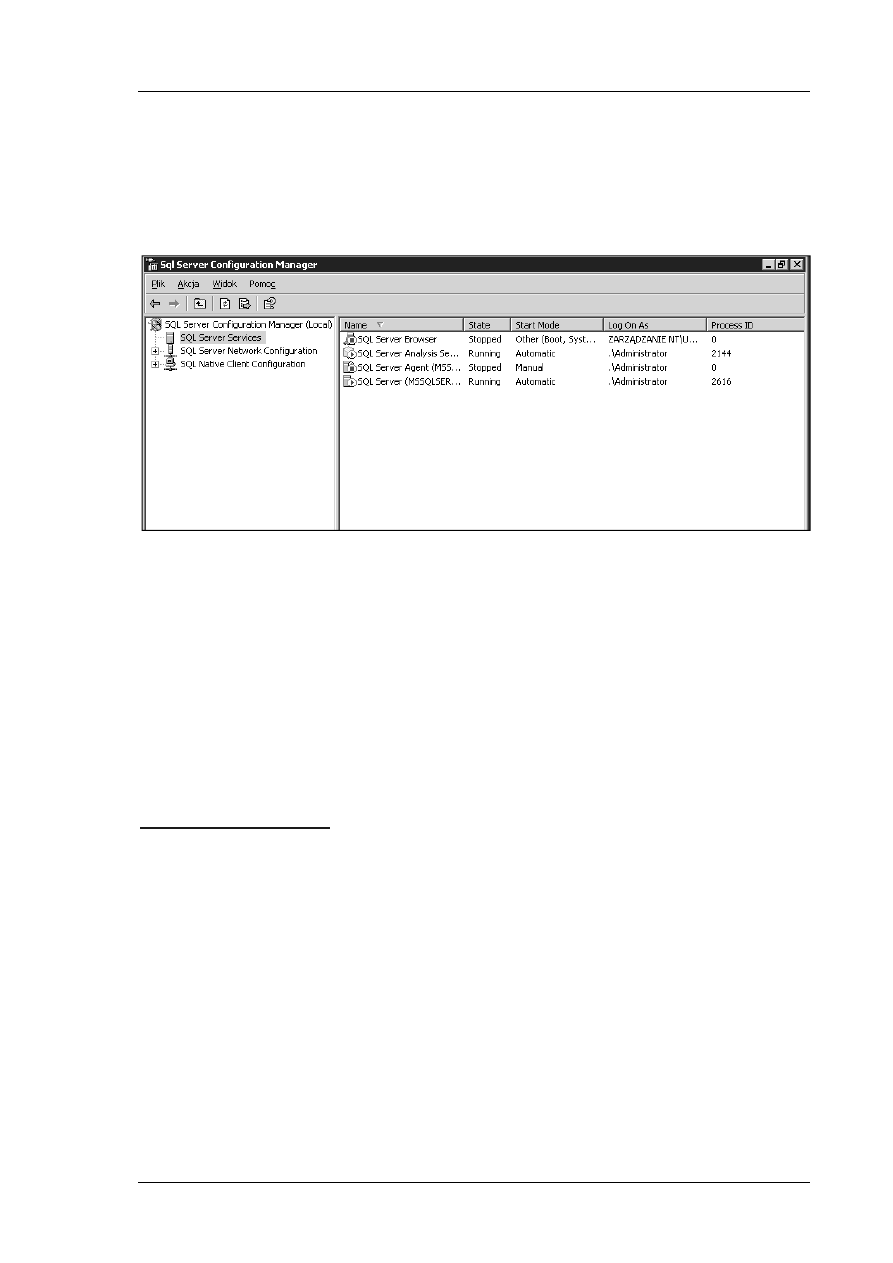
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 6/16
ustawień, producenci zazwyczaj dodają narzędzie (lub zestaw narzędzi) do zarządzania usługami
tylko samego serwera SQL.
Dla przykładu, W systemie Microsoft SQL Server 2008 są dwa narzędzia do zarządzania usługami:
Configuration Manager oraz Reporting Services Configuration. Pierwszy program umożliwia
zarządzanie usługami i protokołami sieciowymi, zaś drugi pozwala dostosować usługę raportowania
serwera SQL. Narzędzie Configuration Manager ilustruje rys. 3.
Rys. 3 Konfiguracja serwisów
Przykładowe rozwiązanie
Wdrożenie systemu bazodanowego opartego na Microsoft SQL Server 2008 przebiega w kilku
etapach.
Pierwszym z nich jest wybór maszyny i systemu operacyjnego, który będzie podstawą dla serwera
SQL. Serwery takie jak serwer baz danych, poczty czy stron internetowych zawsze instalowane są
na gotowym środowisku operacyjnym. My mamy do dyspozycji maszynę z systemem Microsoft
Windows Server 2003, która w pełni odpowiada wymaganiom serwera SQL.
Następnym etapem jest uzupełnienie środowiska o wymagane i opcjonalne komponenty.
Komponenty wymagane, takie jak .NET Framework 2.0 czy MS XML 6, znajduję się na płycie z
plikami instalacyjnymi Microsoft SQL Server 2008. Elementy użyteczne, lecz opcjonalne, takie jak
Microsoft
PowerShell,
można
doinstalować
z
własnego
źródła,
np.
witryny
www.microsoft.com/poland
.
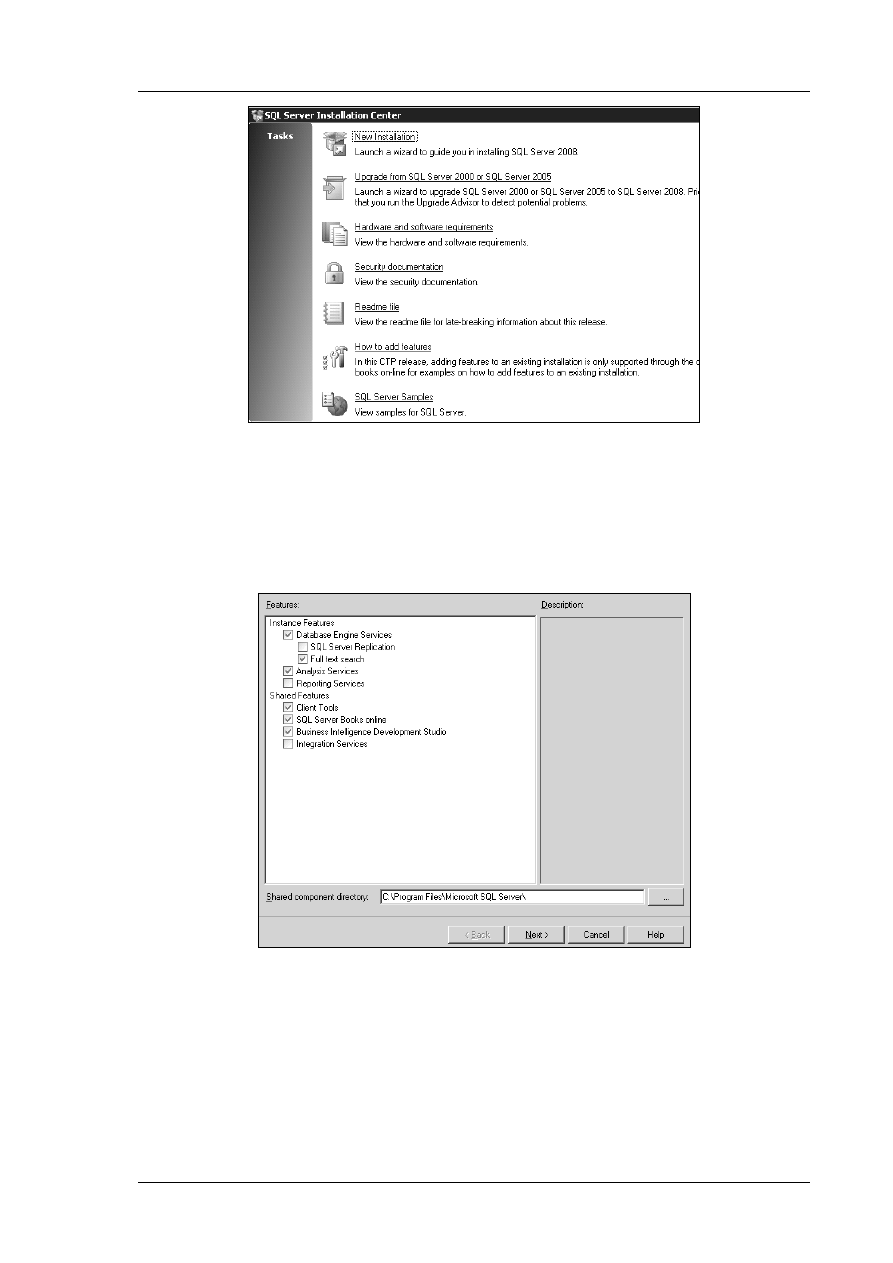
Właściwa instalacja systemu bazodanowego zaczyna się po uruchomieni instalatora Microsoft SQL
Server 2008.
Środkowa grupa opcji (Install) pozwala na uruchomienie właściwego komponentu programu
instalacyjnego (rys. ). W tym kroku instalator jest gotowy do organizacji swojego środowiska w
naszym systemie. Dopiero teraz widać główne okno centrum instalacji środowiska serwera SQL
Server 2008. Można tu dokonać aktualizacji serwera z wersji SQL Server 2000 lub SQL Server 2005,
przeczytać dokumentację, zainstalować komponenty dodatkowe lub przykładowe bazy.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 7/16
Rys. 4 Instalacja nowej instancji serwera SQL
Wybierając instalacje nowej instancji serwera SQL przechodzimy do kroku, w którym należy określić
składniki systemu bazodanowego. Okno komponentów systemu (rys. ) umożliwia wybór instalacji
interesujących nas części środowiska serwera SQL. Z pewnością potrzeby będzie sam silnik bazy
danych (Database Engine Services), jak i graficzny interfejs dla niego (Client Tools). W dalszej
kolejności przydatne okażą się narzędzia analityczne (Analysis Services), narzędzia pomocy (SQL
Server Books online), itp.
Rys. 5 Wybór składników instalacji
W tym kroku mamy możliwość wyboru miejsca składowania plików serwera SQL w systemie. W
profesjonalnych zastosowaniach ze względów wydajnościowych często spotykaną praktyką jest
rozdzielanie plików systemu operacyjnego i serwera bazodanowego pomiędzy różne dyski.
Następnym ważnym krokiem jest nazwanie instancji instalowanego serwera SQL oraz podgląd
instancji już istniejących. Dla mniej doświadczonych użytkowników zaleca się pozostawienie
ustawień standardowych instalatora.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 8/16
Kolejny etap to określenie komponentów serwera oraz sposobów ich uruchamiania. Serwer SQL
składa się z kilku usług, które muszą być uruchamiane za pomocą odpowiedniego konta
użytkownika. Dla naszej maszyny takim kontem jest Administrator. W tym momencie
poszczególne usługi będą uruchamiane z uprawnieniami administratora.
W obecnej wersji serwer SQL oferuje możliwość zapisywania danych w formacie Unicode czyli
międzynarodowym standardzie kodowania znaków. Poprzednie wersje oferowały zapis w
standardach zorientowanych na konkretne języki. Zakładka Collation pozwala na wybór standardu
kodowania danych (np. w celu zachowania kompatybilności ze starszymi bazami) oddzielnie dla
silnika bazy i serwisu analitycznego, co prezentuje rys. .
Rys. 6 Konfiguracja obsługi stron kodowych
Kolejną rzeczą jest ustalenie, jakich użytkowników serwer SQL będzie honorował. Do wyboru są
użytkownicy związani z systemem operacyjnym lub użytkownicy systemowi oraz użytkownicy
wewnętrzni serwera. Na początek wystarczą nam do pracy sami użytkownicy systemowi.
Należy jednak jednoznacznie sprecyzować konto, które będzie miało uprawnienia do
administrowania serwerem SQL. Ilustruje to rys. .

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 9/16
Rys. 7 Konfiguracja typu autoryzacji
W oknie dotyczącym powiadamiania firmy Microsoft o występujących błędach i użyciu zasobów
serwera SQL możemy zgodzić się lub nie na wysyłanie tych informacji. Przed zaznaczeniem
czegokolwiek warto poczytać dokładnie, jakie informacje będą wysyłane.
Pora na podsumowanie opcji instalacji. W oknie Ready to Install możesz przejrzeć wszystkie
zaznaczone uprzednio opcje, jeżeli coś się nie zgadza, zawsze możesz cofnąć się i wprowadzić
zmianę.
Zatwierdzając wybrane opcje rozpoczynamy kopiowanie plików i wykonywanie skryptów
instalacyjnych zgodnie z założeniami ustalonymi przez nas wcześniej. Możemy podejrzeć postęp
instalacji poszczególnych składników serwera SQL.
Po zakończeniu procesu instalacji komponentów serwera SQL możemy przejść do konfiguracji
poszczególnych usług. W tym celu należy posłużyć się programem SQL Server Configuration
Manager dostepnym w grupie aplikacji SQL Server 2008.
W głównym oknie narzędzia konfiguracyjnego widzimy usługi związane z serwerem SQL. Usługa
automatyzacji zadań (SQL Server Agent) jest wyłączona, co nie jest dla nas stanem zadowalającym,
zatem należy ją aktywować.
Aby usługa uruchamiała się wraz ze startem systemu operacyjnego należy zaznaczyć odpowiednią
opcję w zakładce Service, co ilustruje rys. Błąd! Nie można odnaleźć źródła odwołania..

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 10/16
Rys. 8 Konfiguracja serwisów
Serwer SQL przeważnie działa w środowisku sieciowym opartym o protokoły TCP/IP. Ze względów
bezpieczeństwa obsługa tych protokołów domyślnie jest wyłączona. Jeżeli jesteśmy pewni
zabezpieczeń swojej sieci informatycznej, możemy włączyć obsługę TCP/IP dla serwera SQL.
Ostatnim etapem instalacji serwera SQL jest uruchomienie aplikacji zarządzającej SQL Management
Studio i próba połączenia się z istniejącą bazą danych AdventureWorks. Jeżeli to zadanie się
powiedzie, możemy uznać, że posiadamy gotowy do pracy system bazodanowy.
Porady praktyczne
W miarę możliwości dokonuj instalacji serwera SQL na systemie nieobciążonym przez inne serwery.
W praktycznej działalności serwery bazodanowe mocno wykorzystują zasoby sprzętowe takie jak
czas procesora, pamięć operacyjna czy dostęp do dysku twardego. Współdzielenie tych zasobów z
innymi usługami zdecydowanie obniża wydajność obsługi baz danych.
Pamiętaj o możliwości instalacji wielu instancji serwera SQL na jednej maszynie fizycznej.
Umożliwia to logiczne i organizacyjne rozdzielenie poszczególnych grup baz danych a co za tym
idzie lepsza kontrolę nad nimi.
Dodatkowe serwisy możesz doinstalować w miarę potrzeb. Pamiętaj, że każdy z nich to potencjalne
obciążenie dla systemu i luka w zabezpieczeniach. Planując rozszerzanie funkcjonalności serwera
bazodanowego o dodatkowe serwisy warto zastanowić się nad jego rozbudową od strony
sprzętowej.
Już na etapie instalacji serwera bazodanowego warto przemyśleć sprawę bezpieczeństwa
poszczególnych usług. Usługi serwera powinny posiadać dedykowane konta, za pomocą których są
uruchamiane. Wydzielenie kont i przyznanie im wąskiego zakresu praw minimalizuje możliwość
użycia ich przez nieautoryzowane osoby. Więcej o zabezpieczeniach serwera bazodanowego
znajdziesz w module 10.
Dobrą praktyką jest wydzielenie zasobu sieciowego z plikami instalacyjnymi serwera SQL. Pozwoli
to na szybką re-instalację lub dodanie nowych komponentów do systemu. Niezależnie od tego
warto posiadać kopię plików instalacyjnych na nośniku przenośnym (płyta DVD, pendrive, mobilny
dysk twardy itp.), jeżeli zaistniałaby potrzeba instalacji środowiska na maszynie odciętej od sieci
informatycznej. Dotyczy to także systemów towarzyszących serwerowi baz danych takich jak np.:
serwis publikacji stron WWW.
W przypadku stwierdzenia braku dostępu do instancji serwera SQL, w pierwszej kolejności sprawdź,
czy odpowiednie serwisy systemowe są uruchomione. Jeżeli w wyniku jakiegoś konfliktu usługi
serwera SQL zostały wyłączone lub zatrzymane, dokonaj ich ponownej aktywacji. W skrajnym

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 11/16
przypadku należy zrestartować system operacyjny, który może blokować usługi systemu
bazodanowego przez własne usługi zależne.
Nigdy nie zaniedbuj regularnego skanowania systemu operacyjnego, na którym znajduje się system
bazodanowy pod względem obecności wirusów i złośliwego oprogramowania. System bazodanowy
jest centralną składnicą danych organizacji, a ich utrata zawsze jest bardzo kosztowna.
Zawsze sprawdzaj dostępność najnowszych aktualizacji dla systemu bazodanowego, jak i systemu
operacyjnego, na którym serwer SQL jest zainstalowany. Pamiętaj, że nie ma oprogramowania
doskonałego a producenci starają się ulepszać swoje produkty m.in. poprzez udostępnianie
aktualizacji. Widać to wyraźnie w systemach operacyjnych gdzie np.: bez nowych aktualizacji w
ogóle nie można zainstalować niektórych aplikacji.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz, co oznacza serwis systemowy, serwis bazy danych, instalacja serwisu
•
rozumiesz zasadę działania uruchomienia serwisów w kontekście użytkownika
•
umiesz wymienić i opisać podstawowe komponenty systemu bazodanowego
•
umiesz podać przykład zastosowania systemu bazodanowego w praktyce
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Kalen Delaney, Microsoft SQL Server 2005: Rozwiązania praktyczne krok po kroku, Microsoft
Press, 2006
Podręcznika adresowany do projektantów systemów bazodanowych, którzy
opanowali już podstawy idei relacyjnych baz danych. Przedstawia praktyczne
problemy i ich szczegółowe rozwiązania.
2.
Edward Whalen, Microsoft SQL Server 2005 Administrator’s Companion, Microsoft Press, 2006
Jest to przejrzysty przewodnik, zawierający wszystkie informacje potrzebne do
wdrożenia, administrowania i obsługi SQL Server 2005. Znajdziesz w nim wiele
procedur i wskazówek opartych na doświadczeniach profesjonalistów pracujących z
Microsoft SQL Server 2005.
3.
Dusan Petkovic, Microsoft SQL Server 2008: A Beginner's Guide, McGraw-Hill, 2008
Pozycja adresowana do osób zaczynających przygodę z bazami danych. Znajdziemy tu
wprowadzenie do relacyjnych baz danych, sposoby ich projektowania, optymalizacji i w końcu
wdrożenia w najnowszej odsłonie serwera SQL w wersji 2008. Omówienie języka T-SQL w
osobnej, dużej części książki jest kolejną mocną tej pozycji.
4.
http://www.microsoft.com/sql/2008/default.mspx
Tutaj znajdziemy wszystkie podstawowe informacje na temat MS SQL Server 2008 oraz nowości
z nim związane.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
Firma National Insurance w związku z dogodnymi warunkami na rynku
rozwój. Obsługa rosnącej liczby klientów przysparza coraz więcej kłopotów, głównie działowi analiz.
Na ostatnim zebraniu padła propozycja wdrożenia nowego systemu bazodanowego opartego na
technologii Microsoft SQL Server 2008, który pom
większej ilości danych o klientach firmy co potencjalnie przełoży się na jakość obsługi i przyszłe
zyski.
Wdrożenie nowego systemu złożono na barki głównego informatyka firmy, który do tej pory
zajmował się głownie zagadnieniami związanymi z administracją systemami operacyjnymi
i bezpieczeństwem sieci. Jako praktykant dostałeś za zadanie wdrożyć serwera SQL 2008 na
testowej platformie. Twoje doświadczenia z procesu instalacji i konfiguracji serwera będą
wykorzystane przy uruchamianiu systemu roboczego.
Zadanie
Tok postępowania
1.
Uruchom
instalację serwera
SQL Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Klik
•
Na ekranie powinno pokazać się okno instalatora Mi
2008
2.
Dokonaj
konfiguracji
przedinstalacyjnej
•
Z grupy
and Samples
•
Przeczytaj i zaakceptuj postanowienia umowy licencyjnej poprzez
zaznaczenie pola
•
Kliknij przycisk
•
Kliknij przycisk
3.
Dokonaj
•
Kliknij odnośnik
Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 12/16
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
Firma National Insurance w związku z dogodnymi warunkami na rynku
rozwój. Obsługa rosnącej liczby klientów przysparza coraz więcej kłopotów, głównie działowi analiz.
Na ostatnim zebraniu padła propozycja wdrożenia nowego systemu bazodanowego opartego na
technologii Microsoft SQL Server 2008, który pomoże usprawnić procesy związane z obróbką coraz
większej ilości danych o klientach firmy co potencjalnie przełoży się na jakość obsługi i przyszłe
Wdrożenie nowego systemu złożono na barki głównego informatyka firmy, który do tej pory
łownie zagadnieniami związanymi z administracją systemami operacyjnymi
Jako praktykant dostałeś za zadanie wdrożyć serwera SQL 2008 na
testowej platformie. Twoje doświadczenia z procesu instalacji i konfiguracji serwera będą
ystane przy uruchamianiu systemu roboczego.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Maszyna wirtualna używa obrazów ISO płyt CD/DVD na równi z
płytami fizycznymi. Ważne jest, aby w wirtualnym napędzie DVD
umieszczony był obraz płyty o nazwie SQLDEV_ENU.ISO
Kliknij dwukrotnie ikonę Mój komputer, a później
Na ekranie powinno pokazać się okno instalatora Mi
2008, tak jak na rys. :
Rys. 9 Strona główna programu instalacyjnego
Z grupy Install kliknij odnośnik Server components, tools,
and Samples.
Przeczytaj i zaakceptuj postanowienia umowy licencyjnej poprzez
zaznaczenie pola I accept the license terms.
Kliknij przycisk Next.
Kliknij przycisk Install.
Kliknij odnośnik New Installation.
Moduł 2
Instalacja i konfiguracja MS SQL Server 2008
Firma National Insurance w związku z dogodnymi warunkami na rynku przeżywa dynamiczny
rozwój. Obsługa rosnącej liczby klientów przysparza coraz więcej kłopotów, głównie działowi analiz.
Na ostatnim zebraniu padła propozycja wdrożenia nowego systemu bazodanowego opartego na
oże usprawnić procesy związane z obróbką coraz
większej ilości danych o klientach firmy co potencjalnie przełoży się na jakość obsługi i przyszłe
Wdrożenie nowego systemu złożono na barki głównego informatyka firmy, który do tej pory
łownie zagadnieniami związanymi z administracją systemami operacyjnymi
Jako praktykant dostałeś za zadanie wdrożyć serwera SQL 2008 na
testowej platformie. Twoje doświadczenia z procesu instalacji i konfiguracji serwera będą
ISO płyt CD/DVD na równi z
aby w wirtualnym napędzie DVD
SQLDEV_ENU.ISO.
a później CD ROM (D:).
Na ekranie powinno pokazać się okno instalatora Microsoft SQL Server
Strona główna programu instalacyjnego
Server components, tools, Books Online,
Przeczytaj i zaakceptuj postanowienia umowy licencyjnej poprzez
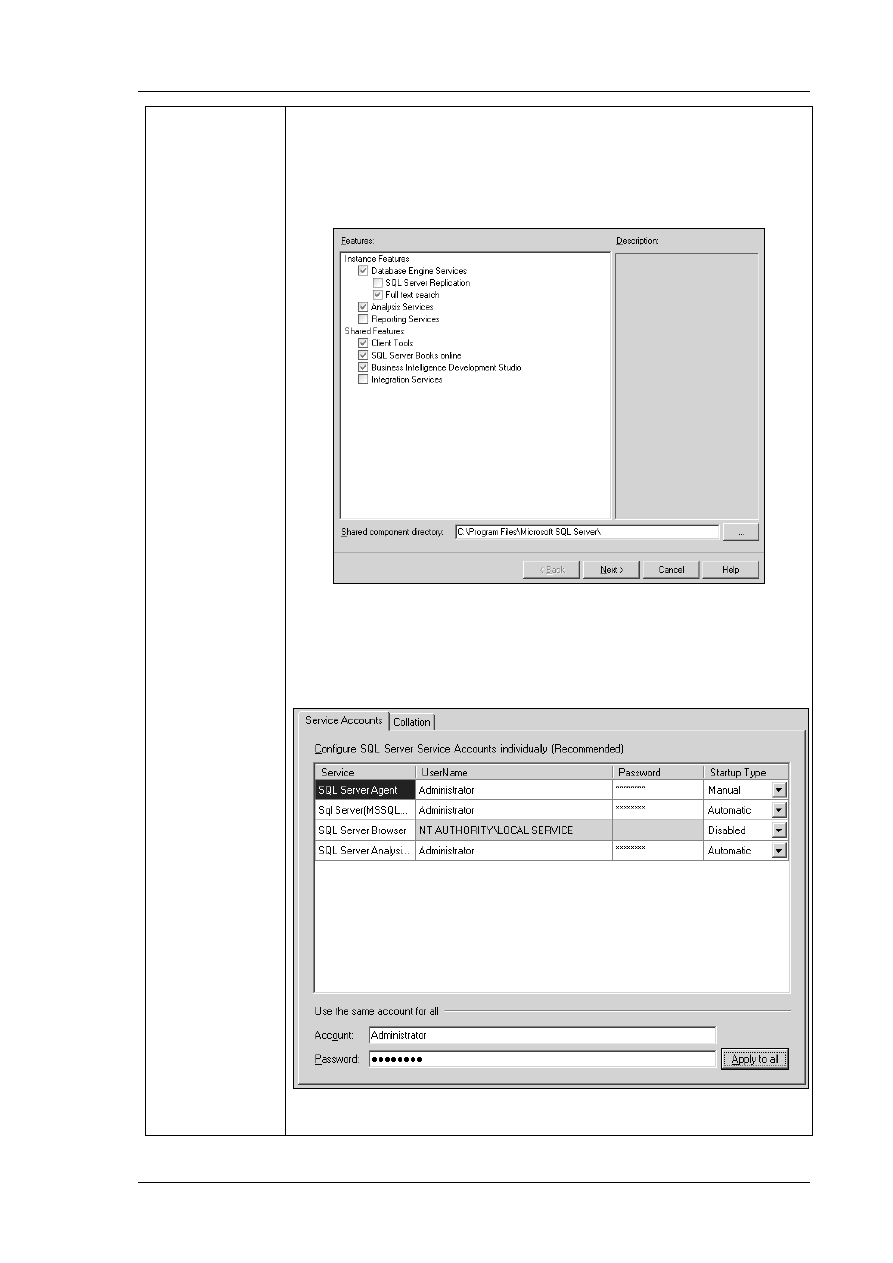
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 13/16
instalacji
właściwej
•
W oknie sprawdzania konfiguracji kliknij przycisk Details, a potem Next.
•
Zgodnie z rys. 1 zaznacz kolejno Database Engine Services, Full text
search, Analysis Services, Client Tools, SQL Server books online,
Business Intelligence Development Studio.
•
Kliknij przycisk Next.
Rys. 10 Wybór składników instalacji
•
Zostaw ustawienia standardowe i kliknij przycisk Next.
•
W polu Account wpisz nazwę Administrator.
•
W polu Password wpisz P@ssw0rd.
•
Kliknij przycisk Apply to All.
Rys. 11 Określenie praw dostępu do składników
•
Kliknij zakładkę Collation.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
•
Dla pola
•
Kliknij pole
•
Z listy
•
Kliknij przycisk
•
Dla pola
•
Z listy
•
Kliknij przycisk
•
Przejdź do następnego okna klikając przycisk
•
Aby dodać konto bieżącego użytkownika (
Add Current User
•
K
•
Aby dodać konto bieżącego użytkownika (
Add Current User
•
K
•
Kliknij
•
Przeczytaj informacje w otwartej stronie WWW
•
Zamknij okno przeglądarki
•
K
•
Kliknij
•
Aby zakończyć ten etap i przejść do podsumowania instalacji
przycisk
•
Wyświetl
dziennik
instalacji
klikając
odnośnik
files
•
Przeczytaj informacje zawarte w dzienniku i zamknij okno notatnika
•
Kliknij przycisk
4.
Konfiguracja
•
Kliknij przycisk
Configuration Tools
Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 14/16
Dla pola Database Engine kliknij przycisk Customize
Kliknij pole Windows collation designator.
Z listy Collation designator wybierz Polish.
Kliknij przycisk OK.
Dla pola Analysis Services kliknij przycisk Customize
Z listy Collation designator wybierz Polish.
Kliknij przycisk OK.
Przejdź do następnego okna klikając przycisk Next
Aby dodać konto bieżącego użytkownika (Administrator
Add Current User.
Kliknij przycisk Next.
Rys. 12 Konfiguracja typu autoryzacji
Dla serwisu analitycznego również należy określić konto z
uprawnieniami administracyjnymi.
Aby dodać konto bieżącego użytkownika (Administrator
Add Current User.
Kliknij przycisk Next.
Kliknij odnośnik View the Microsoft SQL Server.
Przeczytaj informacje w otwartej stronie WWW.
Zamknij okno przeglądarki.
Kliknij przycisk Next.
Kliknij przycisk Install.
Aby zakończyć ten etap i przejść do podsumowania instalacji
przycisk Next.
Wyświetl
dziennik
instalacji
klikając
odnośnik
files\Microsoft SQL Server\100\....
Przeczytaj informacje zawarte w dzienniku i zamknij okno notatnika
Kliknij przycisk Close.
Kliknij przycisk START -> Programy -> Microsoft SQL Server 2008
Configuration Tools -> SQL Server Configuration Manager
Moduł 2
Instalacja i konfiguracja MS SQL Server 2008
Customize.
Customize.
Next.
Administrator), kliknij przycisk
Konfiguracja typu autoryzacji
Dla serwisu analitycznego również należy określić konto z
Administrator), kliknij przycisk
Aby zakończyć ten etap i przejść do podsumowania instalacji, kliknij
Wyświetl
dziennik
instalacji
klikając
odnośnik
C:\Program
Przeczytaj informacje zawarte w dzienniku i zamknij okno notatnika.
Microsoft SQL Server 2008 ->
SQL Server Configuration Manager.
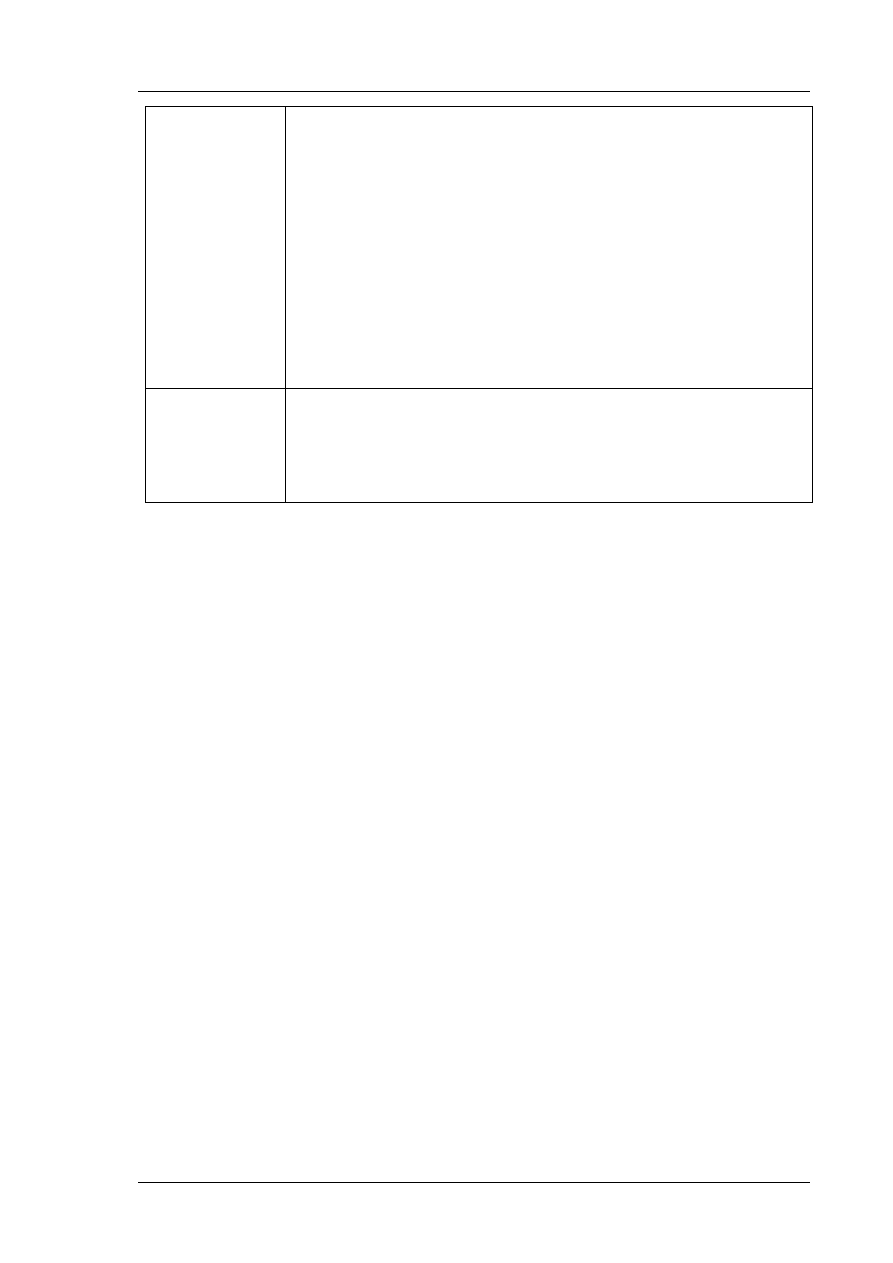
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 15/16
usług serwera
•
W nowym oknie rozwiń drzewo SQL Server Network Configuration
klikając przycisk +.
•
Zaznacz pole SQL Server Services.
•
Kliknij dwukrotnie pole SQL Server Agent.
•
Kliknij przycisk Start.
•
Kliknij na zakładce Service.
•
W polu Start Mode wybierz z listy rozwijanej opcję Automatic.
•
Kliknij przycisk OK.
•
Kliknij pole Protocols for MSSQLSERVER.
•
Kliknij dwukrotnie pole TCP/IP.
•
Dla pola Enabled z listy rozwijanej wybierz Yes.
•
Kliknij przycisk OK.
•
Zamknij okno SQL Server Configuration Manager.
5.
Sprawdzenie
poprawności
instalacji
•
Kliknij przycisk Start -> Programy -> Microsoft SQL Server 2008 ->
Management Studio.
•
W nowym oknie kliknij przycisk Connect.
•
Jeżeli instalacja system jest poprawna, będziesz mógł w polu Object
Explorer rozwinąć drzewo Databases -> AdventureWorks.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 2
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 16/16
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Jesteś głównym informatykiem firmy National Insurance. Niedawne wdrożenie nowego serwera
bazodanowego opartego na Microsoft SQL Server 2008 zakończyło się sukcesem. Firma planuje
rozbudowę infrastruktury informatycznej o farmę serwerów Microsoft SQL Server 2008 i ich
integrację z istniejącymi bazami danych.
W dotychczasowej działalności od strony baz danych wykorzystywane były serwery Microsoft SQL
Server 2000 i Microsoft SQL Server 2005, na których hostowane bazy zawierały dane w języku
polskim i angielskim. Niezbyt dobrze wyglądała sprawa prezentacji danych, każdy z menedżerów
korzystał ze swoich narzędzi, niekompatybilnych ze sobą. Jako dobry administrator poleciłeś
przetestować nowy serwer pod względem kompatybilności z istniejącymi bazami oraz możliwości
nowego serwisu raportującego.
Zadanie polega na instalacji nowej instancji serwera SQL Server 2008 (na nowej, testowej maszynie)
spełniającej kryteria:
•
Pliki bazy danych i pliki systemu operacyjnego są rozdzielone.
•
Zachowana jest kompatybilność wstecz względem używanych wcześniej baz.
•
Instalacja zawiera serwis silnika, serwis analityczny i serwis raportujący.
•
Dostarczone są narzędzia ułatwiające administrację.
•
Dostarczone są przykładowe bazy.
Zespół testowy przygotuje również dokumentację w formie raportu z instalacji.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
Wersja 2.0
Definiowanie i zarządzanie bazą
danych
Spis treści
Definiowanie i zarządzanie bazą danych .............................................................................................. 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ........................................................................................................... 10
Porady praktyczne ..................................................................................................................... 14
Uwagi dla studenta .................................................................................................................... 15
Dodatkowe źródła informacji..................................................................................................... 15
Laboratorium podstawowe ................................................................................................................ 16
Problem 1 (czas realizacji 45 min) .............................................................................................. 16
Laboratorium rozszerzone ................................................................................................................. 26
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 26
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 2/26
Informacje o module
Opis modułu
Dobry administrator systemu zarządzania bazami danych wie wszystko o
bazach danych. W dzisiejszych czasach rola administratora nie ogranicza się
do zarządzania istniejącymi bazami danych, ale również wymaga
umiejętności zakładania, konserwacji oraz aktualizacji baz danych
znajdujących się pod jego opieką. W tym module poznasz sposoby
tworzenia, rozbudowy i zarządzania bazą danych.
Cel modułu
Celem modułu jest przedstawienie czytelnikowi typowych zagadnień
związanych z zakładaniem i konserwacją bazy danych na serwerze Microsoft
SQL Server 2008.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
potrafił zaplanować instalację bazy danych
•
rozumiał czym są pliki bazy, tabele, diagramy, klucze
•
wiedział, jak wykonać kopię bezpieczeństwa bazy oraz jak przywrócić
bazę w razie awarii
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
wiedzieć, jak używać oprogramowania Microsoft Virtual PC
•
znać podstawy obsługi systemu Windows 2000 lub nowszego
•
rozumieć, jakie są elementy diagramu ERD i powiązania między nimi
•
znać podstawy obsługi narzędzia SQL Server Management Studio
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, istnieje konieczność
wykonania wcześniej modułów 1 i 2.
Rys. 1 Mapa zależności modułu
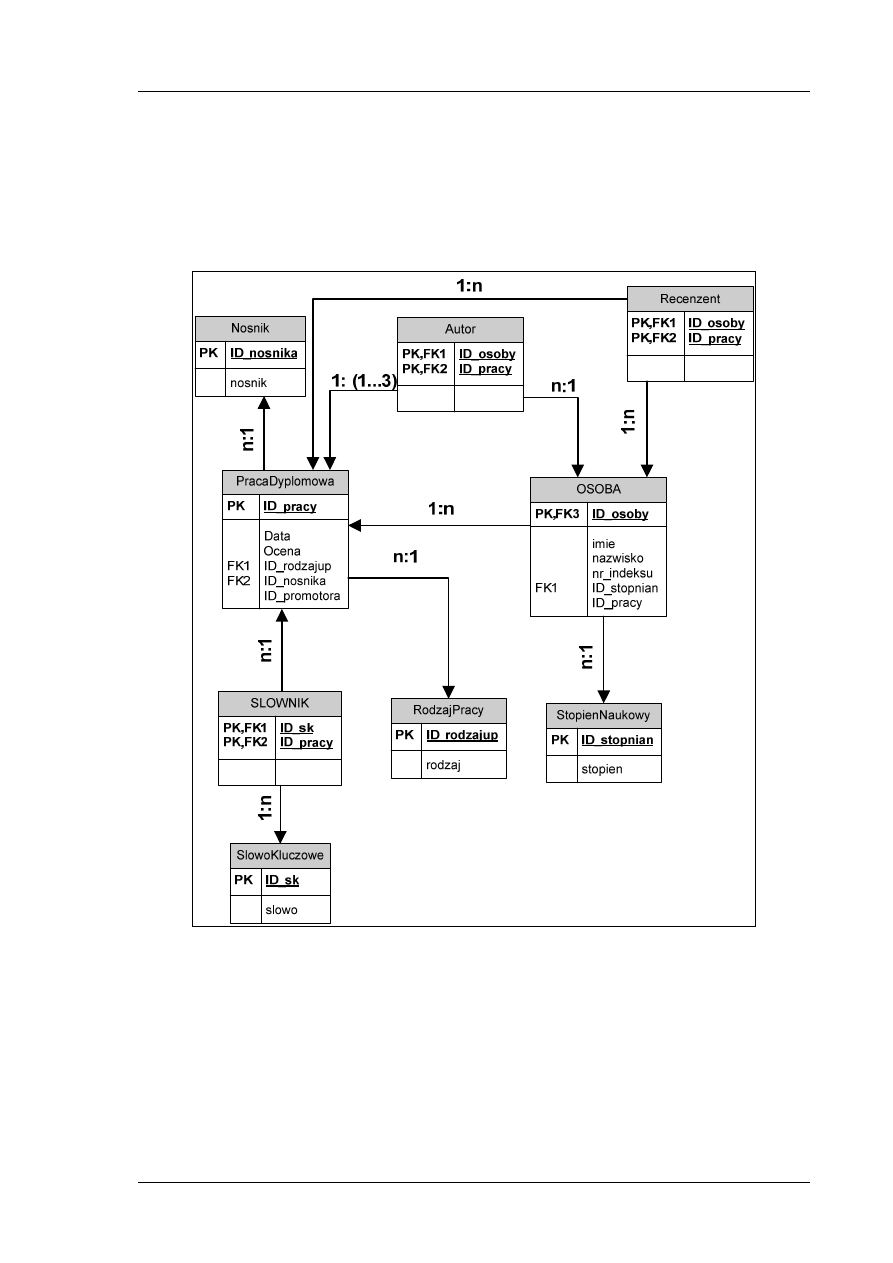
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 3/26
Przygotowanie teoretyczne
Przykładowy problem
Jesteś administratorem systemu bazodanowego w firmie National Insurance. Analitycy w dziale
deweloperskim stworzyli diagram bazy danych dla nowego produktu firmy. Diagram zawiera
informacje o wszystkich tabelach i relacjach bazy. Wskazuje też na możliwe do użycia typy danych.
Diagram bazy danych przedstawiony jest na rys. 2.
Rys. 2 Diagram przykładowej bazy danych
Twoim zadaniem jest założenie bazy danych wraz z odpowiednimi tabelami, ustanowienie kluczy
głównych, powiązań między nimi i określenie dogodnych typów danych. W końcowej fazie
powinieneś wypełnić bazę przykładowymi danymi i zapewnić jej kopię bezpieczeństwa.
Podstawy teoretyczne
Dysponując gotowym projektem relacyjnej bazy danych, jesteś na początku długiej drogi, zanim
baza powstanie na serwerze i rozpocznie swoje życie. Zanim zaimplementujesz bazę danych, musisz
zaplanować wiele ustawień dotyczących różnych aspektów działania bazy.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 4/26
Rozmieszczenie plików bazy danych
Baza danych składa się z plików. Plik bazy można podzielić na pliki danych i pliki dziennika
transakcji. W plikach danych przechowywane są obiekty baz danych, takie jak tabele (wraz z
danymi), indeksy czy procedury składowane. W plikach dziennika transakcji system zapisuje strony
(w przypadku systemów SQL Server strona to blok 8 KB, ale można go zwiększyć) zawierające
modyfikacje danych.
Rozmieszczenie plików odgrywa znaczącą rolę w procesie tworzenia i optymalizacji bazy danych.
Istnieje szereg zasad przydatnych w planowaniu fizycznej implementacji bazy danych. Zasady te to
m.in.:
•
Pliki dziennika transakcji należy umieszczać na innym dysku fizycznym niż pliki danych – w
przypadku awarii jednego z dysków tracimy tylko część bazy.
•
Tabele często występujące razem w złączeniach (ang. joins) należy umieszczać w osobnych
plikach (grupach plików) na osobnych dyskach fizycznych – dzięki temu możliwe jest
równoległe pobieranie danych z tych tabel.
•
Indeksy nieklastrowane należy umieszczać na innych dyskach fizycznych niż ich bazowe
tabele – zyskujesz większą wydajność zapisu danych.
•
Tabele często modyfikowane należy oddzielić fizycznie (umieścić na innym dysku) od tabel
rzadko modyfikowanych – w przypadku większych baz danych upraszcza to proces
wykonywania kopii zapasowych.
•
W przypadku naprawdę dużych instancji bazy stosowane są dedykowane rozwiązania
programowo-sprzętowe typu klastry z wydajnymi macierzami dyskowymi.
Jednoczesne spełnienie wszystkich wymienionych punktów jest raczej niemożliwe, ale w idealnym
przypadku oddzielenie dziennika transakcji od danych i maksymalne rozczłonkowanie danych
pomiędzy tak wiele dysków, jak się da, byłoby rozwiązaniem dającym maksymalne bezpieczeństwo
i wydajność bazy.
Bezpieczeństwo fizyczne danych
Dane, jak i dziennik transakcji można dodatkowo zabezpieczyć przed ewentualnymi awariami
dysków fizycznych. Do tego celu należy użyć macierzy dyskowych z zaimplementowanymi
konfiguracjami RAID (ang. Redundant Array of Independent Disks).
Istnieje wiele konfiguracji RAID, ale do najbardziej znanych i zarazem najczęściej stosowanych
należą: RAID-0, RAID-1, RAID-5 oraz RAID-10. Implementacja RAID może być rozwiązana drogą
sprzętową lub programową w systemie operacyjnym. Rozwiązania różnią się wydajnością i… ceną.
Więcej o systemach RAID i bezpieczeństwie systemów bazodanowych znajdziesz w module 10.
Przy tworzeniu bazy danych administrator musi zdecydować o jej konfiguracji. Konfiguracja ta
dotyczy nie tylko plików bazy danych, ale także pewnych ustawień samej bazy danych. Ustawienia
te decydują o tym, jak będzie się zachowywała baza w trakcie swojego cyklu życia.
Ustawienia dotyczące plików
Po wybraniu odpowiedniej struktury bazy i określeniu jej nazwy przychodzi pora na ustawienie
pewnych właściwości plików bazy danych. Ustawienia te to:
•
ilość i lokalizacja plików
•
wielkość początkowa plików
•
sposób powiększania plików (powinien zostać wybrany automatyczny przyrost rozmiaru)
•
maksymalny rozmiar dla każdego z plików (alternatywnie można maksymalny rozmiar
pozostawić nieokreślony, ale wówczas administrator jest zmuszony do monitorowania
wolnego miejsca na dysku twardym)
•
nazwy logiczne plików

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 5/26
Rys. 3 Właściwości przykładowej bazy danych w SQL Server 2008
W praktyce należy pamiętać o takim ustawieniu rozmiaru początkowego plików, by znalazło się w
nich miejsce na nowe dane. Proces powiększania rozmiaru pliku może niepotrzebnie obciążyć bazę
danych. Co za tym idzie, należy też zadbać o to, by przyrost rozmiaru pliku nie był zbyt mały.
Najlepszym nawykiem jest manualne powiększanie rozmiarów plików poza godzinami, w których
baza jest używana przez największą liczbę użytkowników. Opcja automatycznego powiększania
plików może być ustawiona na wszelki wypadek (gdyby administrator zapomniał o swoich
obowiązkach lub wystąpiła nieoczekiwana sytuacja wymagająca powiększenia pliku). Niemniej
jednak taka automatyzacja jest dyskusyjna ponieważ wpływa na wydajność bazy.
Dziennik transakcji należy ustawić na początek na 20-30% rozmiaru plików danych. W trakcie pracy
bazy danych rozmiar ten można zmienić wedle potrzeb.
Ustawienia dotyczące bazy danych
Równie ważne jak ustawienia plików są ustawienia samej bazy danych. Ustawienia te to na
przykład:
•
ustawienia dotyczące języka, metod sortowania tekstu, znaków dialektycznych
•
ustawienia dotyczące zapisu zmian w dzienniku transakcji (tzw. model przywracania bazy,
ang. recovery model)
•
ustawienia dotyczące statystyk (statystyki to zapis rozkładu danych w kolumnach najczęściej
wykorzystywanych w tabelach, mogą być tworzone i utrzymywane automatycznie)
•
ustawienia dotyczące dostępu do bazy danych (w niektórych sytuacjach niezbędne jest
ograniczenie dostępu do bazy danych dla użytkowników, np. przy przywracaniu bazy danych
z kopii zapasowej)
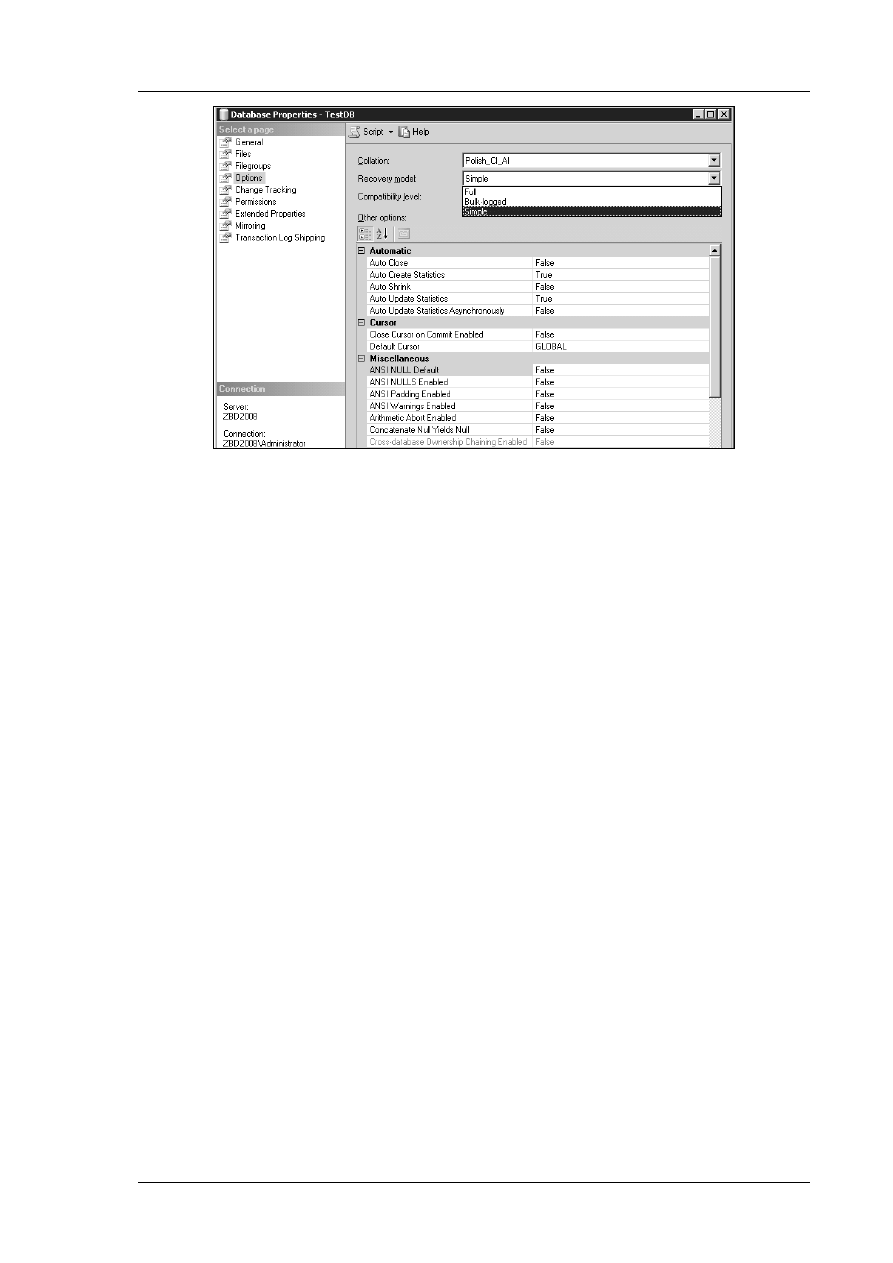
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 6/26
Rys. 4 Opcje przykładowej bazy danych w SQL Server 2008
Ustawienia opcji bazy danych zmieniają się w trakcie działania bazy. Zmiany dokonywane są przy
pomocy narzędzi graficznych (np. SQL Server Management Studio) lub poleceń SQL (np.
ALTER
DATABASE). Do ciekawszych opcji należą polecenia Auto Shrink, która optymalizuje rozmiar
plików (z taką samą wadą jak automatyczne zwiększanie rozmiaru) i
Auto Create Statistics,
która generuje automatycznie statystyki na podstawie dystrybucji wartości w kolumnie danych.
Informacja ta jest używana przez SQL Server Query Optimizer do generowania planu zapytań
bazującego na kosztach używania różnych kolumn.
Tabela bazy danych
Tabela jest dwuwymiarowym zbiorem wzajemnie powiązanych danych dotyczących wspólnego
obszaru lub encji. Składa się ona z kolumn, w których przechowywane są dane, np. w tabeli
Pracownicy przeważnie znajdziemy kolumny takie jak Nazwisko czy PESEL. W relacyjnej bazie
danych relację zachodzą właśnie pomiędzy danymi w poszczególnych kolumnach nazywanych także
atrybutami tabeli.
Pojedynczy rząd obejmujący kolumny reprezentuje instancję danych, czyli rekord (ang. record).
Większość operacji na bazie danych wykonuje się na rekordach lub, częściej, zbiorach rekordów
(ang. recordset).
Do jednoznacznej identyfikacji tabeli służy klucz główny (ang. primary key), który przeważnie jest
dodatkową kolumną z unikatowymi wartościami. Dzięki znajomości tych wartości możemy szybko
wskazać interesujący nas rekord w danej tabeli, a następnie odczytać go lub zmodyfikować.
Tabele możemy utworzyć za pomocą narzędzi graficznych, np. w Management Studio rozwijając w
obszarze Object Explorer odpowiednie menu.
Możemy też posłużyć się odpowiednim poleceniem języka SQL (i tak najczęściej postępuje się w
praktyce):
CREATE TABLE nazwa_tabeli (kolumny_tabeli)
Więcej na ten temat znajdziesz w module 5.
Podczas tworzenia tabeli należy zdefiniować chociaż jedną kolumnę zawierającą dane.
Przechowywane dane mogą być tylko ściśle określonego typu. Typ ten jest wspólny dla całej
kolumny.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 7/26
Typy danych
Typ danych jest pierwszą wielkością jaką definiuje użytkownik dla kolumny tabeli. Typ danych
kolumny kontroluje typ informacji jaka może być przechowywana w kolumnie. Należy zdefiniować
typ danych przez wpisanie za nazwą kolumny słowa kluczowego, może ono wymagać parametrów.
Po zdefiniowaniu typ danych kolumny tabeli jest stałą właściwością i nie powinno być zmieniany.
Można również wykorzystać typy danych do definicji innych struktur przechowujących dane, takich
jak parametry i lokalne zmienne.
Przegląd wybranych typów danych dostępnych na platformie Microsoft SQL Server prezentuje tab.
1
Tab. 1 Podstawowe typy danych dostępne w Microsoft SQL Server
Kategoria
Opis
Typ danych
Szczegóły
Typy binarne Dane zawierają łańcuchy binariów
zapisanych w postaci liczb w
systemie szesnastkowym
(heksadecymalnym).
binary
Dane o stałej przypisanej długości (do 8
KB).
varbinary
Dane o różnej długości aż do
zdefiniowanej maksymalnej (do 8 KB).
image
Dane mogą być różnej długości i
przekroczyć rozmiarem 8 KB.
Typy tekstowe Dane są kombinacją liter, cyfr i
symboli.
char
Dane o stałej przypisanej długości (do 8
KB).
varchar
Dane o różnej długości aż do
zdefiniowanej maksymalnej (do 8 KB).
text
Dane tekstowe o rozmiarze
przekraczającym 8 znaków
Data i czas
Dane są kombinacją dobrze
sformatowanej daty i czasu. Nie
istnieją typy danych opisujące
osobno datę i czas.
datetime
Data z zakresu od 1 stycznia 1753 do 31
grudnia 9999 (jedna wartość zajmuje 8 B).
smalldatetime
Data z zakresu od 1 stycznia 1900 do 6
lipca 2079 (jedna wartość zajmuje 4 B).
datetimeoffset
zapewnia obsługę stref czasowych
datetime2
Wspiera szerszy zakres dat oraz większą
precyzję części ułamkowych sekundy i
także umożliwia określanie precyzji
Typy liczb
dziesiętnych
Dane liczbowe o dokładności do
ostatniej znaczącej cyfry.
decimal
Maksymalnie 38 cyfr, z czego wszystkie
mogą znajdować się po prawej stronie
przecinka. Typ przechowuje dane
dokładne (nie przybliżone).
numeric
W SQL Server jest to odpowiednik typu
decimal.
Typy liczb o
zmiennej
precyzji
Dane są przybliżonymi liczbami
zmiennoprzecinkowymi o
dokładności takiej, jaka może w
danej chwili być obsłużona przez
mechanizmy obliczeniowe.
float
Liczba zmiennoprzecinkowa z zakresu od
-1,79E+308 do 1,79E+308.
real
Liczba zmiennoprzecinkowa z zakresu od–
2.40E + 38 do 2.40E + 38.
Typy liczb
całkowitych
Dane są liczbami całkowitymi.
bigint
Liczba całkowita z zakresu od –2^63
(-9223372036854775808) do 2^63-1
(9223372036854775807). Rozmiar jednej
liczby 8 B.
int
Liczba całkowita z zakresu od
-2 147 483 648 do 2,147,483,647. Rozmiar

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 8/26
Kategoria
Opis
Typ danych
Szczegóły
jednej liczby to 4 B.
smallint
Liczba całkowita z zakresu od -32,768 do
32,767. Rozmiar jednej liczby to 2 B.
tinyint
Liczba całkowita z zakresu od zera do 255.
Rozmiar jednej liczby to 1 B.
Typy
monetarne
Dane reprezentują ujemne lub
dodatnie sumy pieniędzy.
money
Wartość monetarna z zakresu od
-922,337,203,685,477.5808 do
922,337,203,685,477.5807. Rozmiar
jednej wartości to 8 B.
smallmoney
Wartość monetarna z zakresu od
-214,748.3648 do 214,748.3647. Rozmiar
jednej wartości to 4 B.
Typy
specjalne
Dane specjalne to dane, które nie
pasują do innych kategorii.
bit
Dane zawierają wartość 1 albo 0. Używaj
ich, gdy chcesz przedstawić zagadnienia
typu PRAWDA lub FAŁSZ albo TAK lub NIE.
cursor
Typ danych używany przez zmienne lub
parametry wyjściowe procedur
składowanych, które zawierają referencje
do kursora.
timestamp
Typ danych używany do wskazania ciągu
aktywności
uniqueidentifier Dane są 16-bajtowymi szesnastkowymi
liczbami wskazującymi na globalnie
unikalne identyfikatory (GUID). GUID są
użyteczne, gdy wiersz musi być unikalny
pośród wielu wierszy.
SQL_variant
Ten typ danych przechowuje wartości
różnych typów z wyjątkiem typów
text,
ntext, timestamp, image oraz
sql_variant.
table
Typ danych przechowujący zestaw
wyników do dalszego przetwarzania.
Może być używany tylko do definiowania
zmiennych lokalnych lub wartości
zwracanych przez funkcje użytkownika.
Typy Unicode Dane tekstowe zapisane w postaci
Unicode. Zajmują one dwukrotnie
więcej miejsca niż zwykłe dane
tekstowe.
nchar
Dane o stałej przypisanej długości (do
4000 znaków Unicode).
nvarchar
Dane o różnej długości aż do
zdefiniowanej maksymalnej (do 4000).
ntext
Dane mogą długością przekraczać 4000
znaków Unicode.
Przestrzenne
typy danych
Dane przestrzenne to dane, które
identyfikują geograficzne
lokalizacje i kształty, w
szczególności na kuli ziemskiej
Point
Lokalizacja
MultiPoint
Seria punktów
LineString
Seria obejmująca zero lub więcej punktów
połączonych liniami
MultiLineString
Zestaw obiektów LineString
Polygon
Spójny region opisany przez zbiór
zamkniętych obiektów LineString
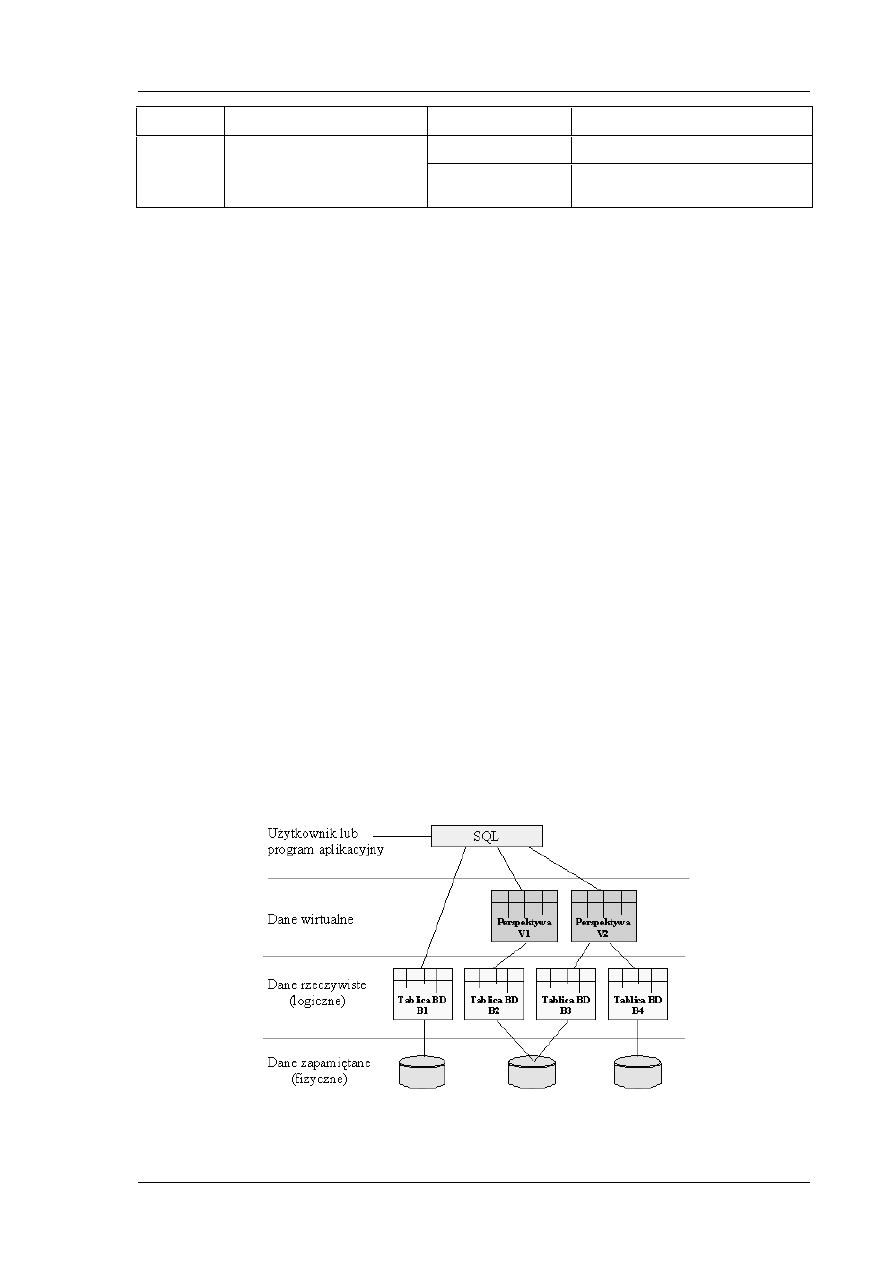
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 9/26
Kategoria
Opis
Typ danych
Szczegóły
MultiPolygon
Zestaw wielokątów
GeometryCollection
Kolekcja typów geometrycznych
Oczywiście nie będziesz używać wszystkich typów danych, ale kilku będziesz używać prawie zawsze
podczas pracy z serwerem Microsoft SQL Server.
Perspektywy
W najprostszym rozumieniu perspektywa (ang. view) jest wirtualną tabelą. W szerokim znaczeniu
perspektywa jest odwzorowaniem globalnego schematu bazy danych na schemat „zewnętrzny”,
przystosowany do potrzeb i przyzwyczajeń konkretnego użytkownika.
Perspektywy stosujemy, aby uprościć (sobie lub użytkownikowi) życie. Powodów stosowania
perspektyw jest wiele:
•
Uproszczenie z punktu widzenia użytkownika modeli pojęciowych – dzięki temu możemy
znacznie uprościć schemat bazy, a tym samym ułatwić użytkownikowi dostęp do danych.
•
Dostosowanie się do punktu widzenia i terminologii dziedziny zastosowań BD – zmiana
schematu wprowadzana przez perspektywę może być wykorzystana na przykład do
dostosowania nazw tabel i kolumn do języka, którym posługuje się użytkownik.
•
Ograniczenie dostępu do obiektów – perspektywy powodują ukrycie przez użytkownikiem
końcowym prawdziwego schematu bazy danych. Może to mieć również pozytywny wpływ na
poprawę bezpieczeństwa danych, gdyż użytkownik nie ma bezpośredniego dostępu do
schematu rzeczywistego.
•
Współdziałanie systemów heterogenicznych (wspólny schemat) – w wypadku systemów
rozproszonych, zbudowanych z różnych systemów baz danych, perspektywa może pomóc w
ukryciu różnic.
•
Przystosowanie starszych systemów do nowszych technologii i wymagań.
Z punktu widzenia użytkownika (i innych procesów) perspektywa powinna być dla niego
przezroczysta, to znaczy, że można na niej wykonywać takie same operacje, jak na „prawdziwych”
tabelach. Warunek przezroczystości perspektyw jest bardzo trudny do spełnienia, gdyż dla
pewnych odwzorowań danych przyjęte środki definicji perspektyw (np. SQL) mogą okazać się
niewystarczające.
Rys. 5 Schemat działania perspektyw

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 10/26
Rodzaje perspektyw
Perspektywy dzielimy na dwie grupy:
•
perspektywy wirtualne
•
perspektywy zmaterializowane
Perspektywy wirtualne
Perspektywa wirtualna istnieje wyłącznie w postaci definicji. Wyliczenie (czyli wyznaczenie zbioru
krotek danej perspektywy, zwane też materializacją perspektywy) następuje w momencie
odwołania się do perspektywy. Wynik ten nie jest później nigdzie przechowywany. Oznacza to, że
każde wywołanie perspektywy wirtualnej powoduje jej ponowne wyliczenie (materializację), co
obciąża zasoby systemu.
Wadą perspektyw wirtualnych jest obciążanie systemu za każdym odwołaniem do procedury
wirtualnej, a tym samym dłuższy czas oczekiwania na materializację perspektywy. Perspektywy
wirtualne mają też szereg zalet.
W sytuacji stosowania perspektyw wirtualnych nie ma dublowania danych oraz problemów z
aktualizacją danych i problemów z przetwarzaniem transakcji.
Perspektywy zmaterializowane
Perspektywa zmaterializowana jest wyliczana (materializowana) w czasie pierwszego użycia.
Następnie wynik tego wyliczenia (dane) są przechowywane, aby móc ich użyć przy ponownym
wywołaniu perspektywy. Dzięki temu kolejne wywołanie perspektywy nie obciąża systemu, a czas
dostępu do danych znacznie się zmniejsza.
Przykładowe rozwiązanie
Posiadając gotowe, przetestowane środowisko bazodanowe przystępujemy do założenia pierwszej
bazy danych. Do zarządzanie bazami danych, w tym ich tworzenia jaki i usuwania służy narzędzie
Management Studio dostępne wraz z podstawową instalacją SQL Server.
Po uruchomieniu narzędzia i połączeniu się z danym serwerem widzimy obszar Object Explorer
wraz z drzewem obiektów Databases. Wybierając opcję tworzenia nowej bazy musimy
sprecyzować jej kilka podstawowych parametrów. Oprócz nazwy dla nowej bazy podajemy lokację i
początkową wielkość pliku dla danych i pliku dla dziennika transakcji. Plików tych może być
sprecyzowanych więcej, jednakże minimum to określenie jednego pliku każdego typu, co pokazuje
rys. 6.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 11/26
Rys. 6 Tworzenie nowej bazy danych
Zaraz po utworzeniu bazy warto przyjrzeć się dostępnym opcjom i od razu dokonać wstępnej
konfiguracji. Przed wypełnieniem bazy danymi należy określić parametry takie jak poziom
kompatybilności bazy z poprzednimi wersjami serwera SQL, dostępność i widoczność przez
poszczególne grupy użytkowników czy zachowanie plików bazy w przypadku zbliżenia się do
poziomu zapełnienia danymi.
Jedną z ważniejszych opcji, która należy zainteresować się od samego początku jest Recovery
model. Opcja ta decyduje o tym, jak dużo informacji o modyfikacjach danych będzie zapisywana do
dziennika transakcji bazy danych.
Listę opcji bazy danych znajdziesz w systemie pomocy Books Online pod hasłem „database options”
(najszybciej znajdziesz ten fragment pomocy używając indeksu dostępnego w Books Online). W tym
kroku dodamy wymagane tabele bazy danych i określimy ich atrybuty.
Po ustaleniu podstawowych parametrów bazy można przejśc do kroku określania jej wyglądu, czyli
tabel i związków pomiędzy nimi. Rozwijając w obszarze Object Explorer drzewo naszej bazy danych
widzimy wszystkie obiekty wchodzące w jej sklad, w tym tabele. Po wybraniu opcji tworzenia nowej
tabeli należy sprecyzować przynajmniej jeden atrybut, czyli kolumnę. Dla danej kolumny
wybieramy nazwę i typ danych, które będzie ona przechowywała. Tutaj należy zdecydować, czy
kolumna ma zawsze zawierać jakieś dane, czy może przechowywać wartości puste (ang. null). Do
kontroli nad warościami pustymi służy pole Allow Nulls, co ilustruje rys. .
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 12/26
Rys. 7 Określanie nazwy i typu danych dla kolumny
Pozostało nam jeszcze ustalić identyfikator naszej tabeli – klucz główny. Kolumna zawierająca
unikalne dane jest dobrym kandydatem dla klucza głównego.
Typowa tabela zawiera wiele kolumn o różnych typach danych oraz klucz główny. Dane
przechowywane w poszczególnych kolumnach są ze sobą skojarzone np. dla tabeli zawierającej
dano o pracy dyplomowej studenta będą tam kolumny reprezentujące temat pracy, datę obrony
czy ocenę z obrony.
Rys. 8 Główna tabela bazy PraceDyplomowe
Najczęstrzym typem związku pomiędzy dwiema tabelami jest wiele-do-wielu. Niestety tego typu
związku nie można w bezpośredni sposób zamodelować w relacyjnej bazie danych. Aby obejść ten
problem, tworzymy niejako sztuczną, pośrednią tablę. Tabela ta posiada tylko dwie kolumny,
wskazujące na łączone tabele.
Ponieważ dla tej tabeli unikalna będzie zarówno jedna jak i druga kolumna, klucz główny możemy
założyć na obydwu jednocześnie. Ilustruje to rys. .
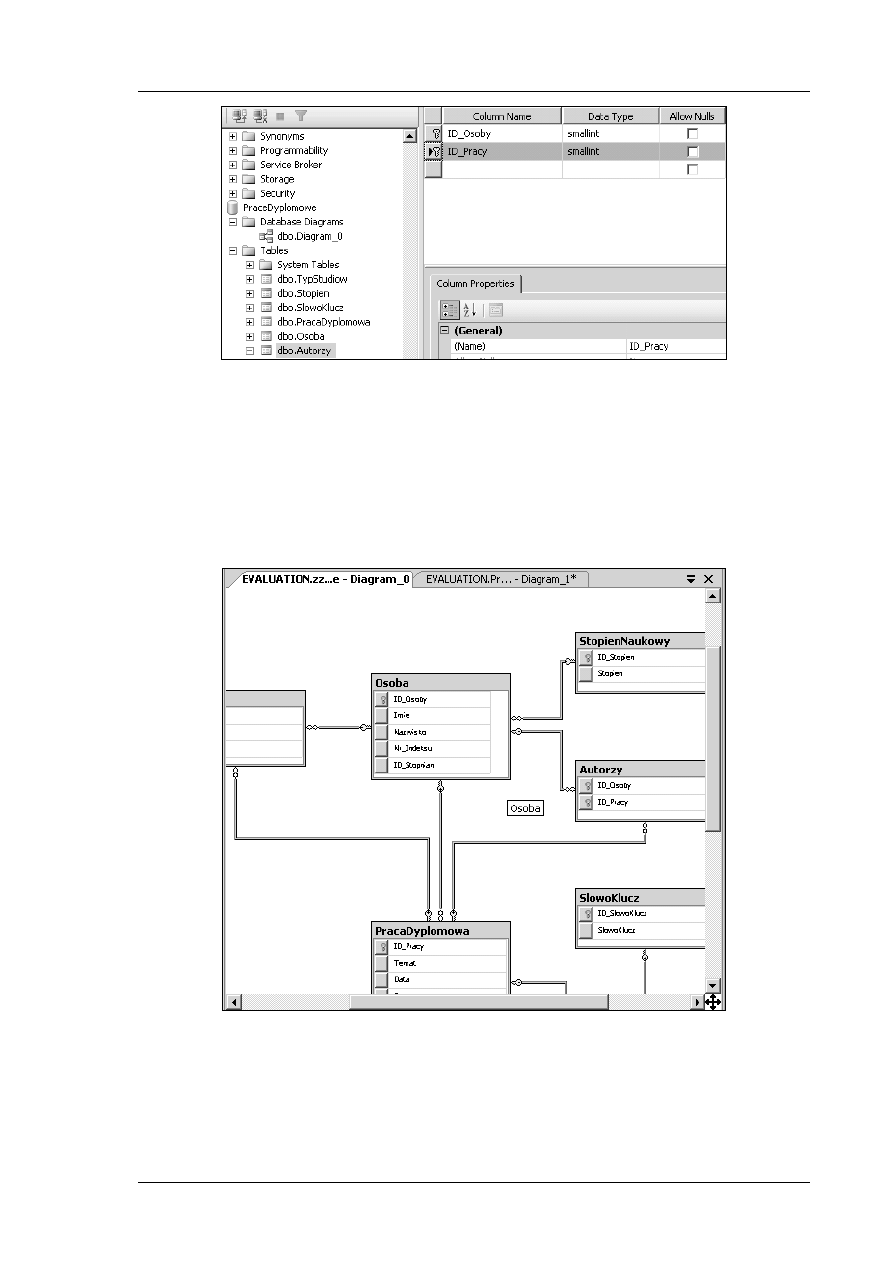
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 13/26
Rys. 9 Tabela Autorzy z kluczem głównym na dwóch kolumnach
Posiadając zdefiniowane wszystkie tabele w bazie danych, następnym krokiem jest utworzenie
związków pomiędzy nimi. Najwygodniej utworzyć je na graficznym diagramie bazodanowym
dostępnym z poziomu Management Studio.
Dla przykładowych tabel po stworzeniu związku zostanie utworzony klucz obcy w tabeli
Autorzy
jako identyfikator powiązanej tabeli
Osoba.
Jako rezultat powinniśmy posiadać diagram tabel i związków pomiędzy nimi bardzo zbliżony do
początkowego diagramu ERD.
Rys. 7 Tworzenie pozostałych kluczy obcych
Posiadając gotową bazę danych warto zrobić jej kopię zapasową przed dalszymi eksperymentami.
Narzędzie Management Studio umożliwia łatwe wykonywanie kopii zapasowej i przywracanie z niej
bazy danych. Rozpoczęcie procedury tworzenia kopii bezpieczeństwa ilustruje rys. 8.
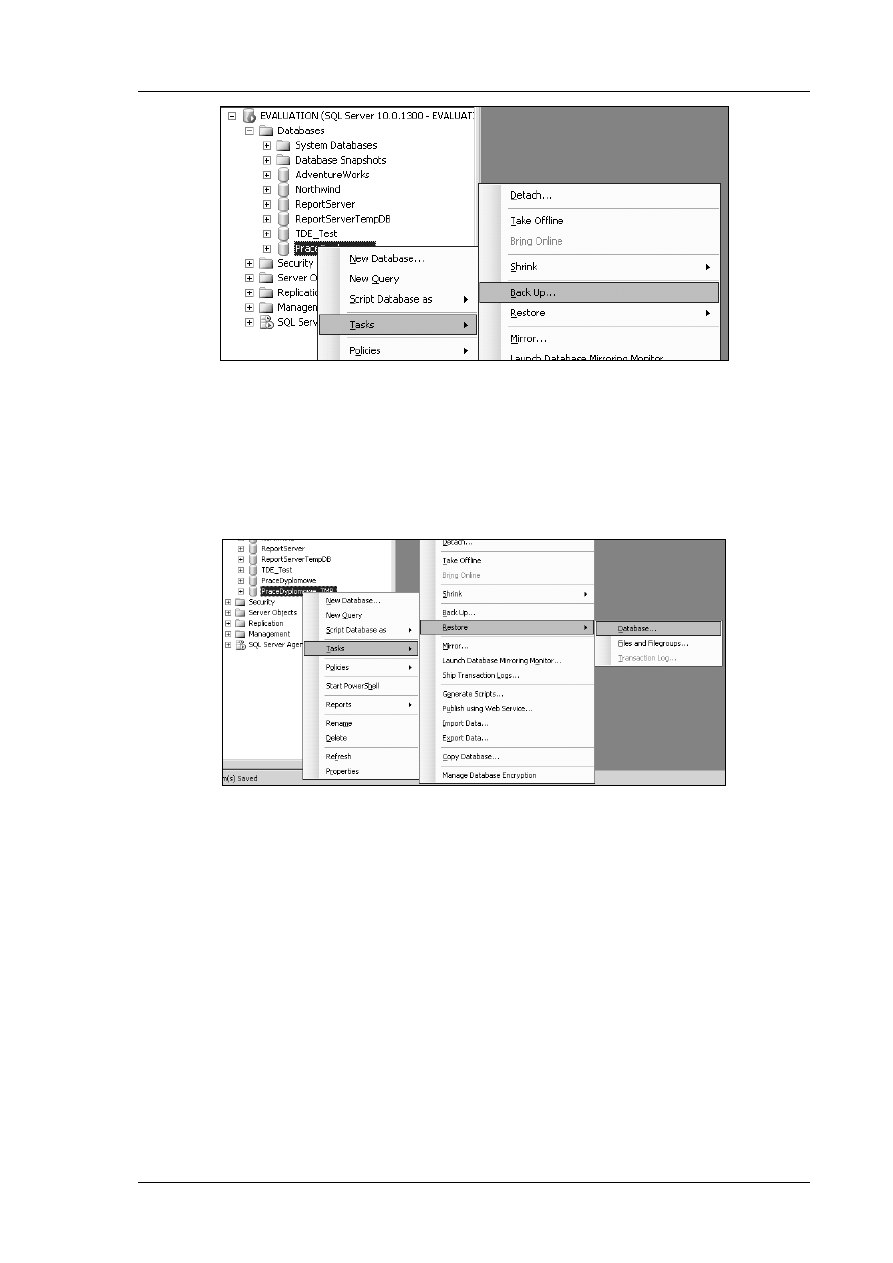
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 14/26
Rys. 8 Uruchamianie procedury kopii bezpieczeństwa
Jeżeli jest to tylko możliwe, należy zmienić nazwę pliku kopii bezpieczeństwa i jego domyślną
lokację. Przeważnie w sieci istnieje dedykowany serwer plików, na którym przechowywane są pliki
kopii bezpieczeństwa.
W celu weryfikacji pliku kopii wygodnie jest odzyskać tak utworzoną bazę do innej, roboczej bazy
danych. Taką roboczą bazę można przeglądać pod względem zgodności i testować nawet na innym
serwerze bazodanowym. Procedurę odzyskiwania dazy z kopii bezpieczeństwa ilustruje rys. 9.
Rys. 9 Odzyskiwanie bazy danych z pliku backup
Porady praktyczne
Zanim przystąpisz do implementacji bazy danych na serwerze, uważnie przyjrzyj się diagramowi
ERD lub diagramowi bazodanowemu. Zrozumienie relacji zawartych na tych diagramach pozwoli
uniknąć błędów w logice bazy. Błędy popełnione na tak wczesnym etapie będą negatywnie
wpływać niemal na każde późniejsze działanie systemu bazodanowego. I z drugiej strony, im więcej
uwagi poświęcimy prawidłowemu projektowi bazy tym bardziej zaprocentuje to w przyszłości.
Upewnij się, że każda tabela ma założony klucz główny, bez niego nie zdziałasz za wiele. Klucz
główny oprócz funkcji identyfikacji danej tabeli pełni również rolę indeksu, który może przyśpieszyć
obsługę danych. Jest on elementem niezbędnym w tabelach systemu bazodanowego niezależnie od
platformy.
Uważnie przemyśl sprawę doboru typów danych. Nie mogą być one za małe dla przechowywanej
wartości, z drugiej strony szastanie zbyt obszernymi typami sumarycznie zmniejsza wydajność bazy.
W szczególności przyjrzyj się nowym możliwościom jakie oferuje w zakresie typów danych MS SQL
2008. Współczesne wymagania co do obsługi danych typu pliki czy hierarchia obiektów znalazły
swoje odzwierciedlenie w nowych serwerach baz danych.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 15/26
Zawsze zapisuj tworzone obiekty typu tabele, diagramy. System nie robi tego automatycznie!
Zapominanie o zapisywaniu swojej pracy może skutkować przykrymi konsekwencji utraty informacji
i co za tym idzie czasu użytkownika serwera baz danych. Wiele operacji w ogóle nie zostanie
wykonana jeżeli np.: zaktualizowana struktura tabeli nie zostanie zapisana do pliku bazy.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz, co oznacza relacja i czym różni się od powiązania w relacyjnych bazach danych
•
rozumiesz zasady przypisywania odpowiednich typów danych do atrybutów tabeli
•
wiesz jak założyć bazę danych i ustalić jej podstawowe parametry
•
umiesz podać przykład diagramu ERD dla typowego zbioru danych
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
William R. Stanek, Vademecum Administratora Microsoft SQL Server 2005, Microsoft Press,
2006
Kompleksowe opracowanie na temat zaplanowania i wdrożenia system bazodanowego
opartego o MS SQL Server 2005 w małym i średnim przedsiębiorstwie. Autorzy postawili na
formułę przedstawiania wielu problemów z praktyki administratora baz danych oraz możliwych
dróg do ich rozwiązania. Książka jest adresowana do praktykujących użytkowników.
2.
Wiesław Dudek, Bazy danych SQL. Teoria i praktyka, Helion, 2006
Książka przedstawia większość zagadnień związanych z przechowywaniem i przetwarzaniem
danych w współczesnych systemach bazodanowych. Znajdują się w niej informacje o relacyjnym
i obiektowym modelu danych oraz najczęściej stosowanych systemach zarządzania bazami
danych.
3.
Strona domowa SQL Server 2008, http://www.microsoft.com/sql/2008/default.mspx
Tutaj znajdziemy wszystkie podstawowe informacje na temat MS SQL Server 2008 oraz nowości
z nim związane.
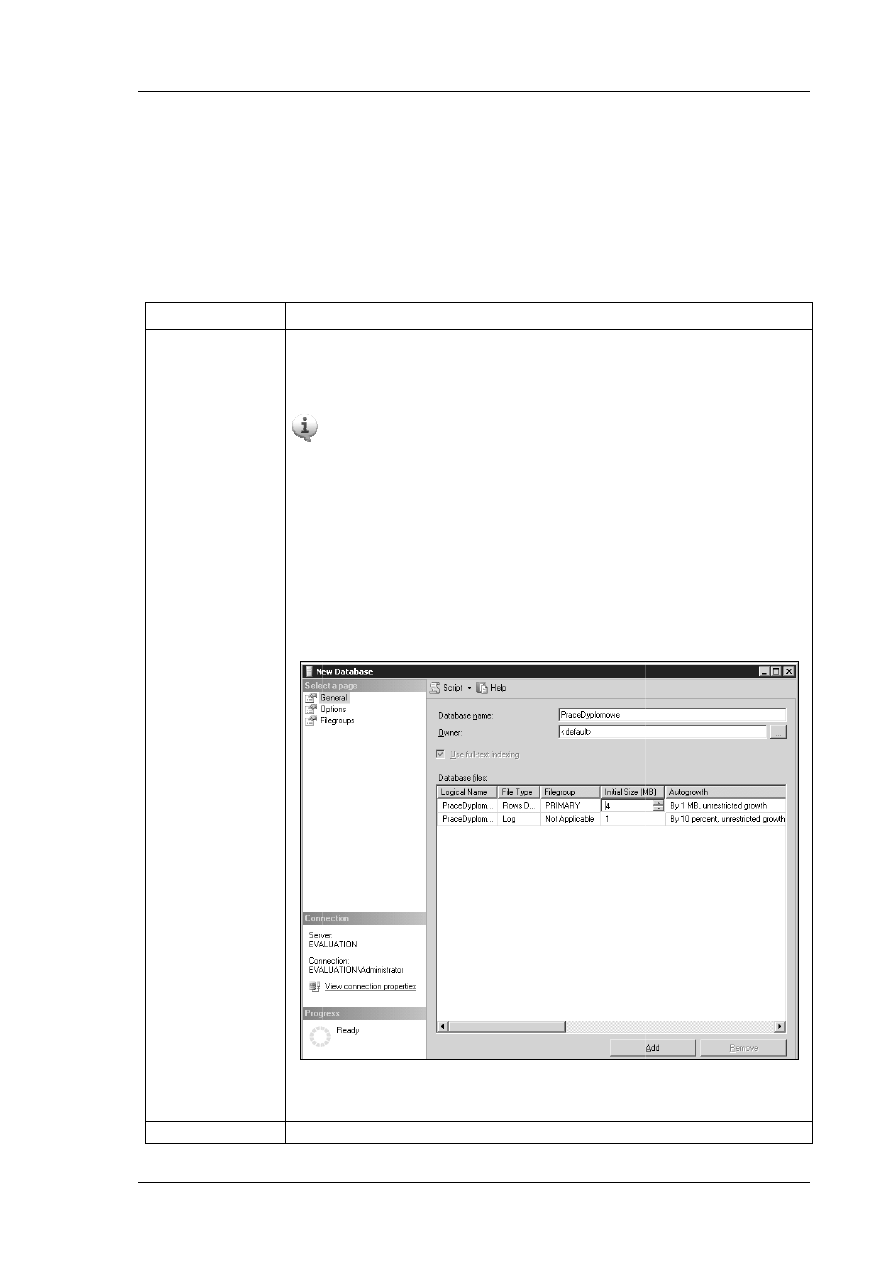
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
W firmie National Insurance trwa właśnie sezon urlopowy. Jako jedyny obecny administrator baz
danych postanowiłeś przetestować implementacje
częścią twojego semestralnego projektu zaliczeniowego. W
zaprojektowany przez kolegę z zespołu
SQL Server 2008 wraz z graficznym interfejsem
zadania.
Zadanie
Tok postępowania
1.
Utwórz bazę
danych
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management
•
W oknie logowania kliknij
•
W oknie
Databases
•
W pole
•
Ustaw początkowe wielkości plików na
pliku dziennika transakcji
•
Kliknij przycisk
2.
Ustaw opcje
•
Kliknij prawym przyciskiem myszy
ski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 16/26
Laboratorium podstawowe
ealizacji 45 min)
W firmie National Insurance trwa właśnie sezon urlopowy. Jako jedyny obecny administrator baz
postanowiłeś przetestować implementacje bazy danych
Prace Dyplomowe
częścią twojego semestralnego projektu zaliczeniowego. Wytyczne do bazy
zaprojektowany przez kolegę z zespołu diagram. Postanowiłeś użyć dostępnego systemu
SQL Server 2008 wraz z graficznym interfejsem SQL Server Management Studio do wykonania tego
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
W oknie Object Explorer kliknij prawym przyciskiem myszy folder
Databases i z menu kontekstowego wybierz New Database
W pole Database name wpisz nazwę bazy danych
Ustaw początkowe wielkości plików na 4 MB dla pliku danych i
pliku dziennika transakcji.
Rys. 10 Tworzenie nowej bazy danych
Kliknij przycisk OK.
Kliknij prawym przyciskiem myszy bazę danych
Moduł 3
Instalacja i konfiguracja MS SQL Server 2008
W firmie National Insurance trwa właśnie sezon urlopowy. Jako jedyny obecny administrator baz
Prace Dyplomowe, która jest
do bazy jasno określa
diagram. Postanowiłeś użyć dostępnego systemu Microsoft
Management Studio do wykonania tego
li nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
kliknij prawym przyciskiem myszy folder
New Database.
wpisz nazwę bazy danych PraceDyplomowe.
dla pliku danych i 1 MB dla
Tworzenie nowej bazy danych
danych PraceDyplomowe i z

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
bazy danych
menu kontekstowego wybierz
•
W oknie
stronie opcj
•
Zmień ustawienie opcji
•
Kliknij przycisk
3.
Dodaj tabele
do bazy danych
•
Kliknij prawym przyciskiem myszy pol
bazy
•
Kliknij opcję
•
Kliknij pol
•
Kliknij pol
•
Odznacz pole
kolumny wartości
ski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 17/26
menu kontekstowego wybierz Properties.
W oknie Database Properties - PraceDyplomowe
stronie opcję Options.
Zmień ustawienie opcji Recovery model na Simple
Rys. 11 Ustawianie właściwości bazy danych
Kliknij przycisk OK.
Listę opcji bazy danych znajdziesz w systemie pomocy
pod hasłem database options (najszybciej znajdziesz ten fragment
pomocy używając indeksu dostępnego w Books Online)
W tym kroku dodamy wymagane tabele bazy danych i określimy ich
atrybuty. Zaczniemy od prostych tabel.
Kliknij prawym przyciskiem myszy pole Tables w rozwiniętym drzewie
bazy PraceDyplomowe.
Kliknij opcję NewTable.
Kliknij pole Column name i wpisz nazwę ID_TypStudiow
Kliknij pole Data Type i z listy rozwijanej wybierz smallint
Odznacz pole Allow null w celu zapobiegania wpisywania do tej
kolumny wartości null.
Moduł 3
Instalacja i konfiguracja MS SQL Server 2008
PraceDyplomowe kliknij po lewej
Simple.
tawianie właściwości bazy danych
systemie pomocy Books Online
pod hasłem database options (najszybciej znajdziesz ten fragment
pomocy używając indeksu dostępnego w Books Online).
W tym kroku dodamy wymagane tabele bazy danych i określimy ich
w rozwiniętym drzewie
ID_TypStudiow.
smallint.
w celu zapobiegania wpisywania do tej
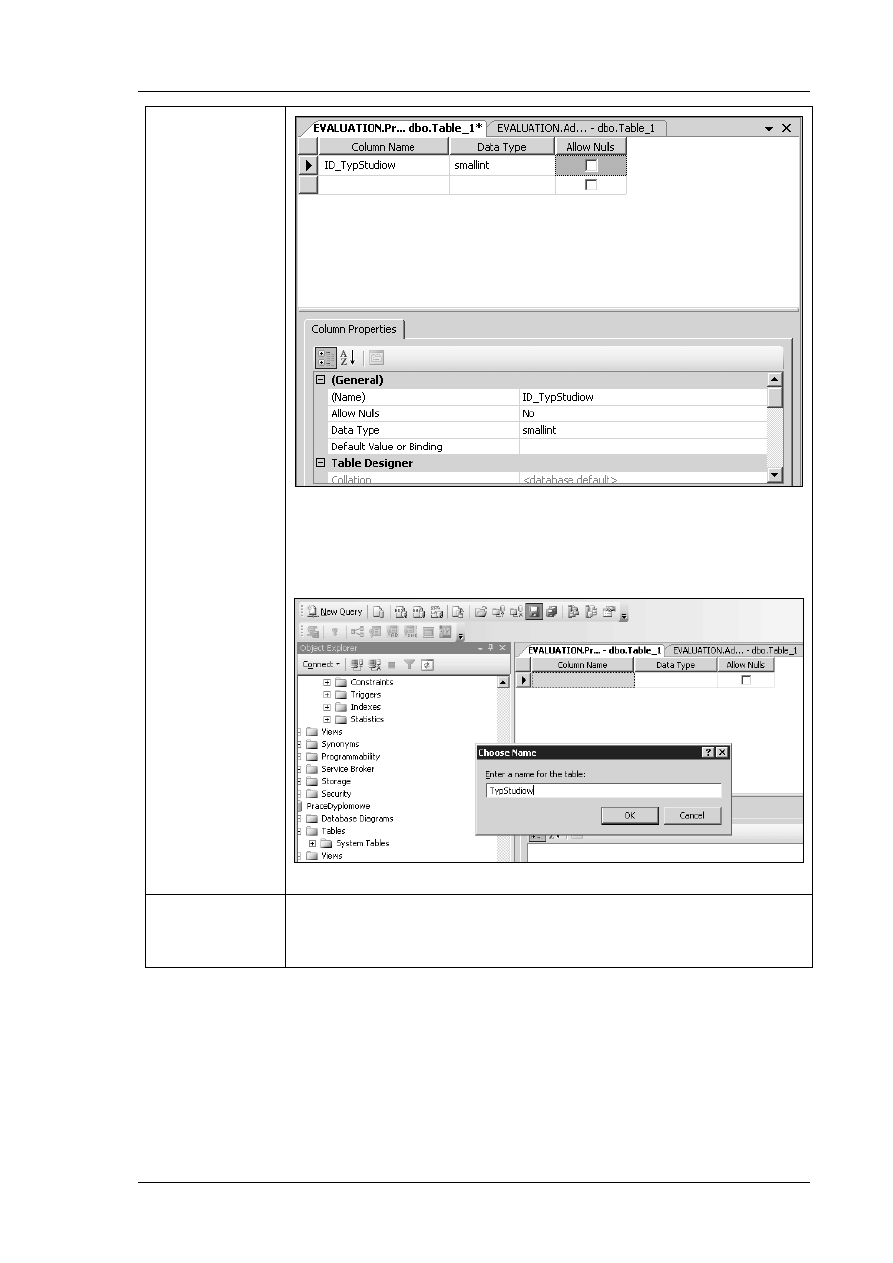
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 18/26
Rys. 12 Określanie nazwy i typu danych dla kolumny
•
Ustal nazwę dla nowej tabeli klikając ikonę dyskietki z górnego paska
zadań.
•
Wprowadź nazwę TypStudiow i kliknij przycisk OK.
Rys. 16 Tworzenie nowej tabeli
4.
Ustal klucz
główny dla tabeli
•
Kliknij prawym klawiszem nazwę kolumny.
•
Kliknij opcję Set Primary Key.
•
Zapisz tabelę klikając ikonę dyskietki.
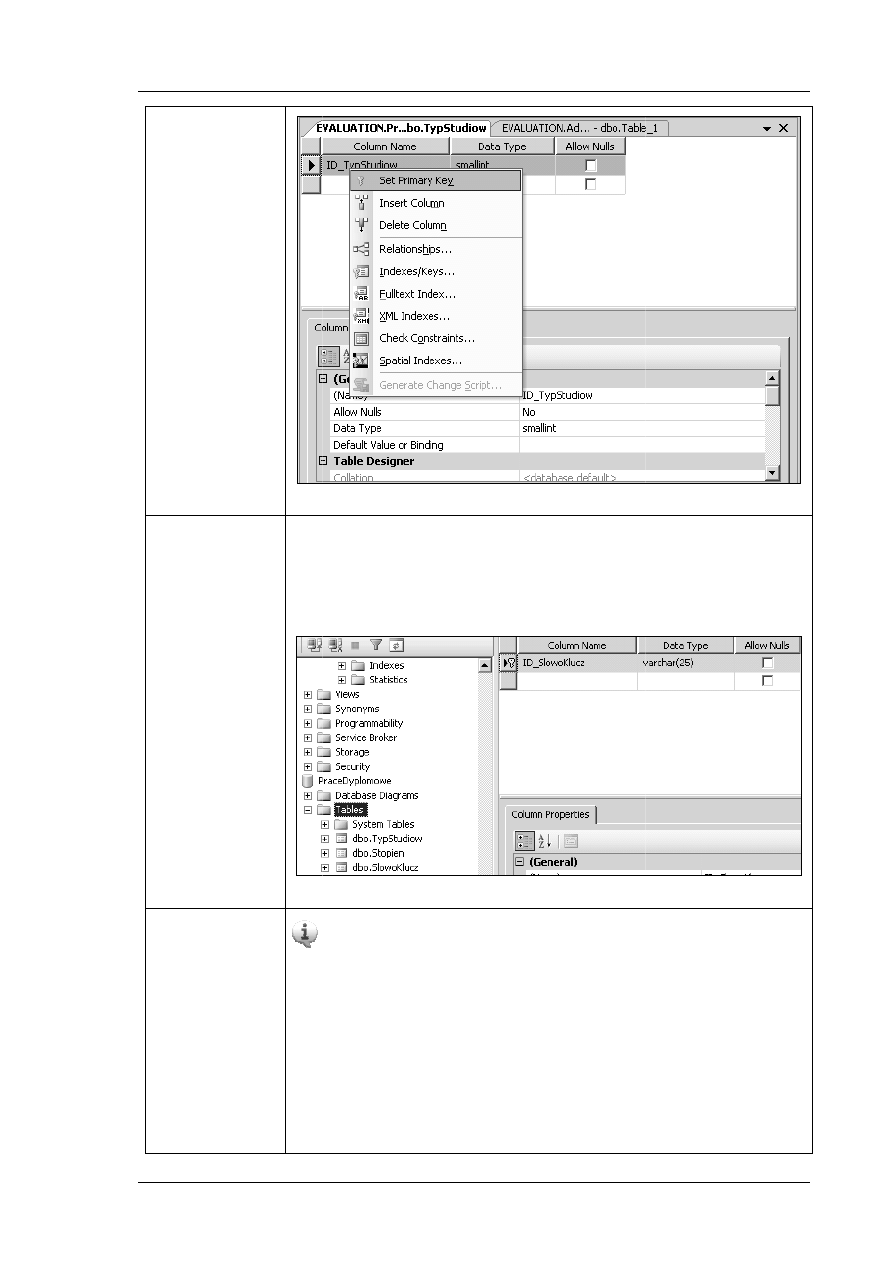
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
5.
Uwórz
pozostałe proste
tabele
•
Bazując na poprzednim schemacie postępowania utwórz tabele
i
ID_SlowoKlucz
•
Jako rezultat powinieneś zobaczyć listę trzech tabel w polu
PraceDyplomowe
6.
Utwórz
główne tabele
bazy
•
Kliknij prawym przyciskiem myszy pol
NewTable
—
—
—
—
—
—
ski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 19/26
Rys. 17 Tworzenie klucza głównego tabeli
Bazując na poprzednim schemacie postępowania utwórz tabele
i SlowoKlucz zawierające odpowiednio kolumny
ID_SlowoKlucz, obydwie z typem danych varchar(25)
Jako rezultat powinieneś zobaczyć listę trzech tabel w polu
PraceDyplomowe.
Rys. 18 Pozostałe proste tabele bazy PraceDyplomowe
Pora na utworzenie głównej tabeli naszej bazy danych. Tabela
PracaDyplomowa jest punktem centralnym bazy i zawiera kolumny
ID_Pracy, Temat, Data, Ocena.
Kliknij prawym przyciskiem myszy pole Tables
NewTable.
—
Wprowadź nazwę dla nowej kolumny ID_Pracy
—
Ustal typ danych dla tej kolumny jako smallint.
—
Wprowadź nazwę dla następnej kolumny jako
—
Ustal typ danych jako varchar(100).
—
Wprowadź nazwę dla trzeciej kolumny jako Data
—
Jako typ danych ustal datetime.
Moduł 3
Instalacja i konfiguracja MS SQL Server 2008
Tworzenie klucza głównego tabeli
Bazując na poprzednim schemacie postępowania utwórz tabele Stopien
zawierające odpowiednio kolumny ID_Stopien i
archar(25).
Jako rezultat powinieneś zobaczyć listę trzech tabel w polu Tables bazy
Pozostałe proste tabele bazy PraceDyplomowe
Pora na utworzenie głównej tabeli naszej bazy danych. Tabela
jest punktem centralnym bazy i zawiera kolumny
Tables i wybierz opcję
ID_Pracy.
.
Wprowadź nazwę dla następnej kolumny jako Temat.
Data.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
—
—
•
Dla każdej kolumny odznacz opcję
•
Ustal klucz główny klikając prawym przyciski
ID_Pracy
•
Zapisz tabelę pod nazwą
•
Kliknij prawym przyciskiem myszy pol
Table
—
—
—
—
—
—
—
—
•
Dla każdej kolumny odznacz opcję
•
Ustal klucz główny klikając prawym przyciskiem myszy na kolumnie
ID_Osoby
•
Zapisz tabelę pod nazwą
ski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 20/26
—
Wprowadź nazwę dla ostatniej kolumny jako Ocena
—
Jako typ danych ustal smallint.
Dla każdej kolumny odznacz opcję Allow null.
Ustal klucz główny klikając prawym przyciski
ID_Pracy i wybierając opcję Set Primary Key.
Zapisz tabelę pod nazwą PracaDyplomowa klikając ikonę dyskietki
Rys. 19 Główna tabela bazy PraceDyplomowe
Następną dużą tabelą jest tabela Osoba przechowująca informacje o
osobach wykonujących prace dyplomowe oraz wykładowcach i
recenzentach
Kliknij prawym przyciskiem myszy pole Tables
Table.
—
Wprowadź nazwę dla nowej kolumny ID_Osoby
—
Ustal typ danych dla tej kolumny jako smallint.
—
Wprowadź nazwę dla następnej kolumny jako
—
Ustal typ danych jako varchar(50).
—
Wprowadź nazwę dla trzeciej kolumny jako Nazwisko
—
Jako typ danych ustal varchar(50).
—
Wprowadź nazwę dla ostatniej kolumny jako Nr_Indeksu
—
Jako typ danych ustal varchar(10).
Dla każdej kolumny odznacz opcję Allow null.
Ustal klucz główny klikając prawym przyciskiem myszy na kolumnie
ID_Osoby i wybierając opcję Set Primary Key.
Zapisz tabelę pod nazwą Osoba klikając ikonę dyskietki
Rys. 13 Tabela Osoba
Moduł 3
Instalacja i konfiguracja MS SQL Server 2008
Ocena.
Ustal klucz główny klikając prawym przyciskiem myszy kolumnę
klikając ikonę dyskietki.
Główna tabela bazy PraceDyplomowe
przechowująca informacje o
osobach wykonujących prace dyplomowe oraz wykładowcach i
i wybierz opcję New
ID_Osoby.
.
Wprowadź nazwę dla następnej kolumny jako Imie.
Nazwisko.
Nr_Indeksu.
Ustal klucz główny klikając prawym przyciskiem myszy na kolumnie
klikając ikonę dyskietki.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
7.
Utwórz tabele
pomocnicze
•
Kliknij prawym przyciskiem myszy pol
Table
—
—
—
—
•
Dla każdej kolumny odznacz opcję
•
Zaznacz z wciśniętym klawiszem
•
Ustal klucz główny klikając prawym przyciskiem myszy na zaznaczeniu i
wybierz opcję
•
Zapisz tabelę pod nazwą
8.
Utwórz
pozostałe tabele
pomocnicze
•
Bazując na poprzednim schemacie postępowania utwórz tabele
i
ID_Pracy
•
Jako rezultat powinieneś zobaczyć listę wszystkich tabel w polu
bazy
9.
Utwórz
związki pomiędzy
•
Kliknij prawym klawiszem myszy pol
PraceDyplomowe
ski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 21/26
Kliknij prawym przyciskiem myszy pole Tables
Table.
—
Wprowadź nazwę dla nowej kolumny ID_Osoby
—
Ustal typ danych dla tej kolumny jako smallint.
—
Wprowadź nazwę dla następnej kolumny jako
—
Ustal typ danych jako smallint.
Dla każdej kolumny odznacz opcję Allow null.
Ponieważ dla tej tabeli unikalna będzie zarówno jedna jak i druga
kolumna, klucz główny możemy założyć na obydwu jednocześnie
Zaznacz z wciśniętym klawiszem Shift obydwie kolumny
Ustal klucz główny klikając prawym przyciskiem myszy na zaznaczeniu i
wybierz opcję Set Primary Key.
Zapisz tabelę pod nazwą Autorzy klikając ikonę dyskietki
Rys. 14 Tabela Autorzy z kluczem głównym na dwóch kolumnach
Bazując na poprzednim schemacie postępowania utwórz tabele
i Recenzent, zawierające odpowiednio kolumny
ID_Pracy oraz ID_Osoby, wszystkie z typem danych
Jako rezultat powinieneś zobaczyć listę wszystkich tabel w polu
bazy PraceDyplomowe.
Rys. 15 Wszystkie tabele bazy PraceDyplomowe
Kliknij prawym klawiszem myszy pole Database Diagrams
PraceDyplomowe.
Moduł 3
Instalacja i konfiguracja MS SQL Server 2008
i wybierz opcję New
ID_Osoby.
.
Wprowadź nazwę dla następnej kolumny jako ID_Pracy.
Ponieważ dla tej tabeli unikalna będzie zarówno jedna jak i druga
klucz główny możemy założyć na obydwu jednocześnie.
obydwie kolumny.
Ustal klucz główny klikając prawym przyciskiem myszy na zaznaczeniu i
klikając ikonę dyskietki.
Tabela Autorzy z kluczem głównym na dwóch kolumnach
Bazując na poprzednim schemacie postępowania utwórz tabele Slownik
zawierające odpowiednio kolumny ID_SlowoKlucz,
, wszystkie z typem danych smallint.
Jako rezultat powinieneś zobaczyć listę wszystkich tabel w polu Tables
Wszystkie tabele bazy PraceDyplomowe
Database Diagrams bazy
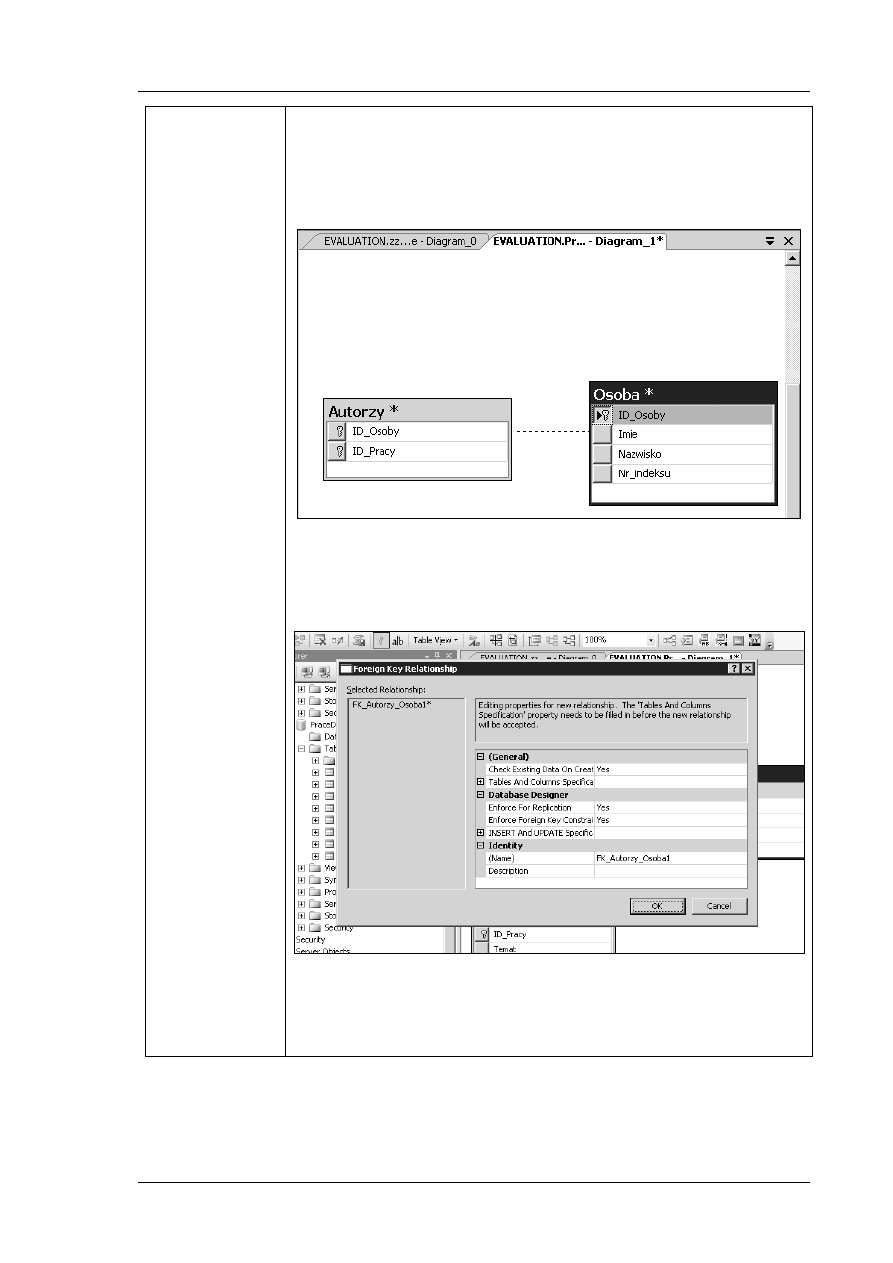
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 22/26
tabelami
•
Wybierz opcję New Database Diagram.
•
W nowym oknie dodaj wszystkie nazwy tabel klikając przycisk Add.
•
Kliknij przycisk Close.
•
Kliknij i przeciągnij kursor myszki pomiędzy pole ID_Osoby tabeli Osoba
a polem ID_Osoby tabeli Autorzy.
Rys. 16 Tworzenie związku pomiędzy tabelami
•
W nowym oknie dotyczącym właściwości związku kliknij przycisk OK.
•
Zostanie utworzony klucz obcy w tabeli Autorzy jako identyfikator
powiązanej tabeli Osoba. Zatwierdź klikając przycisk OK.
Rys. 17 Tworzenie klucza obcego
•
Powtórz tą operację dla każdego związku pomiędzy tabelami zgodnie z
diagramem bazodanowym. Jako rezultat powinieneś otrzymać diagram
jak na rys. 18.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 23/26
Rys. 18 Tworzenie pozostałych kluczy obcych
10.
Wykonaj kopię
zapasową bazy
•
Zamknij wszystkie okna z diagramem i definicjami tabel.
•
Kliknij prawym klawiszem myszy na pole PraceDyplomowe.
•
Z menu wybierz opcję Tasks -> Back Up.
Rys. 26 Uruchamienie procedury kopii bezpieczeństwa
•
W nowym oknie możesz zmienić nazwę pliku kopii bezpieczeństwa i
jego domyślną lokację. Kliknij przycisk OK.
•
Po chwili powinien pojawić się komunikat o prawidłowym zakończeniu
tworzenia kopii bezpieczeństwa.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 24/26
Rys. 27 Tworzenie kopii bezpieczeństwa zakończone sukcesem
•
Kliknij przycisk OK.
11.
Odzyskaj bazę
danych z kopii
bezpieczeństwa
•
Załóż nową bazę danych o nazwie PraceDyplomowe_TMP.
•
Kliknij prawym przyciskiem myszki nazwę nowej bazy danych.
•
Z menu wybierz opcję Tasks -> Restore -> Database.
Rys. 28 Odzyskiwanie bazy danych z kopii bezpieczeństwa
•
W nowym oknie kliknij pole From device.
•
Kliknij ikonę listy wyboru […].
•
Kliknij przycisk Add.
•
Wskaż lokację pliku z kopią zapasową bazy danych.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
•
Kliknij przycisk
•
Kliknij pole
•
Zaznacz pole
•
Kliknij przycisk
ski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 25/26
Rys. 29 Wskazywanie pliku z kopią zapasową
Kliknij przycisk OK.
Kliknij pole Options z listy po lewej stronie.
Zaznacz pole Overwrite an existing database.
Kliknij przycisk OK.
Odzyskanie bazy danych PraceDyplomowe zakończyło się sukcesem.
Możesz sprawdzić, czy nic po drodze nie zginęło
strukturę bazy w obszarze Object Explorer.
Moduł 3
Instalacja i konfiguracja MS SQL Server 2008
Wskazywanie pliku z kopią zapasową
zakończyło się sukcesem.
czy nic po drodze nie zginęło, przeglądając

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 3
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 26/26
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Zachęcony sukcesem w utworzeniu bazy danych
PraceDyplomowe postanowiłeś ją rozbudować.
Przyglądając się uważnie diagramowi dostarczonemu wraz z dokumentacją bazy zauważyłeś, że
przy tworzeniu bazy umknęła Ci tabela reprezentująca nośnik. W bazie nie ma też jak dotąd
żadnych danych. Postanowiłeś podjąć następujące kroki:
•
dodać tabelę z typem nośnika pracy dyplomowej
•
rozbudować bazę o możliwość przechowywania informacji o wydziale i kierunku studenta
•
dodać możliwość zaznaczenia liczby dostarczonych kopii pracy z podziałem na wersję
papierową i elektroniczną
•
dodać możliwość umieszczenia przez recenzenta recenzji pracy i własnej oceny
•
zastanawiasz się też, czy byłaby możliwość automatycznego obliczania średniej z oceny z
recenzji, obrony i promotora pracy
•
zasilić bazę w odpowiednią ilość danych
Tak przygotowaną bazę należy skopiować do bezpiecznej lokacji. Bazując na opcjach dostępnych w
narzędziu Management Studio zastanów się, jak najprościej możesz zarządzać kopiami
bezpieczeństwa.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
Wersja 1.0
Wewnętrzna struktura bazy danych
Spis treści
Wewnętrzna struktura ......................................................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 8
Porady praktyczne ..................................................................................................................... 11
Uwagi dla studenta .................................................................................................................... 12
Dodatkowe źródła informacji..................................................................................................... 12
Laboratorium podstawowe ................................................................................................................ 13
Problem 1 (czas realizacji 25 min) .............................................................................................. 13
Problem 2 (czas realizacji 20 min) .............................................................................................. 17
Laboratorium rozszerzone ................................................................................................................. 19
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 19

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 2/19
Informacje o module
Opis modułu
W tym module znajdziesz informacje, w jaki sposób w SQL Server 2008
przechowywane są dane, jak zbudowana jest strona danych, oraz w jaki
sposób przechowywane są podstawowe obiekty w bazie danych. Dowiesz
się również w jaki sposób należy wyznaczać wielkość pliku danych.
Cel modułu
Celem modułu jest zapoznanie czytelnika z wewnętrzną strukturą
przechowywania danych w SQL Server 2008.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
Wiedział, w jaki sposób zbudowane są strony danych (nagłówek
strony, wiersze danych, tablica przesunięć wierszy)
•
potrafił badać zawartość stron danych używamy instrukcji
DBCC
PAGE, która umożliwia oglądanie nagłówka strony, wierszy danych i
tablicy przesunięć wierszy
•
wiedział jak wygląda struktura wierszy danych
•
potrafił wyświetlić i przeanalizować wiersze danych zapisane w
tabelach
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
potrafić budować diagram ERD (patrz: moduł 1)
•
wiedzieć, w jaki sposób tworzy się nową bazę danych
•
wiedzieć, w jaki sposób tworzy się podstawowe obiekty bazy danych
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznać się z materiałem zawartym
w modułach 1 i 3.
Moduł 4
Dodatek
Moduł 1
Moduł 2
Moduł 3
Moduł 5
Moduł 6
Moduł 7
Moduł 8
Moduł 9
Moduł 10
Moduł 11
Moduł 12
Moduł 13
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Przygotowanie teoretyczne
Przykładowy problem
Jak zapewne wiesz, z SQL Server 2008 można korzystać w bardzo efektywny sposób nie mając
wiedzy na temat sposobu wewnętrznej organizacji danych, jednak w wielu przypadkach dobrze jest
wiedzieć, jak takie przechowywane dane są zorganizowane. Ułatwia to zrozumienie wielu
mechanizmów funkcjonujących w SQL Server 2008
Typowy problem pojawiający
danych, zbudowany diagram ERD, zdefiniowane relacje oraz przypisane atrybutom typy danych.
Nie zawsze jednak etap projektowania jest przeprowadzony we właściwy sposób.
sposób zorganizowane są dane możemy lepiej dobierać typy danych na atrybutach mając
świadomość tego, gdzie fizycznie są one umieszczone. Możemy uniknąć pewnych błędów, na
przykład co do doboru wielkości typu danych. Szczególnie duże znaczenie ma to w przypadku
obiektów typu OLE.
Kolejnym problemem pojawiającym się w tym zagadnieniu jest próba odpowiedzenia sobie na
pytanie, jaka powinna być początkowa wielkość pliku danych i dziennika transakcji w momencie,
kiedy wiemy, ile danych ma zostać wpisanych do naszej bazy. Na podstawie t
kolejności możemy ustawić, o ile pliki danych i dziennika transakcji mają wzrosnąć.
Z punktu widzenia administracji bazą danych są to bardzo ważne problemy, które możemy
rozwiązać dzięki znajomości budowy wewnętrznej struktury w SQL Server
Podstawy teoretyczne
Chociaż z SQL Server można korzystać efektownie bez znajomości wewnętrznej budowy,
zrozumienie szczegółów przechowywania danych pomaga w pisaniu wydajnych aplikacji.
Gdy tworzy się tabelkę, do wielu katalogów systemowych wstawia
niezbędnymi do jej obsługi. Wiersze są dodawane do katalogów systemowych
sysindexes i syscolumns
Dla każdej nowo utworzonej tabeli do widoku
nazwę, identyfikator obiektu
każdej kolumny z nowej tabeli informacje zawierające nazwę kolumny, typ danych i długość. Każda
z kolumn otrzymuje unikatowy identyfikator, który wyznacza kolejność, w jakiej zostały kolumny
zdefiniowane w tabeli.
Na rys. 2 pokazano wiersze, które dodawane są do widoku
tworzenia tabeli
Ksiazka.
Rys.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 3/19
Przygotowanie teoretyczne
Jak zapewne wiesz, z SQL Server 2008 można korzystać w bardzo efektywny sposób nie mając
wiedzy na temat sposobu wewnętrznej organizacji danych, jednak w wielu przypadkach dobrze jest
wiedzieć, jak takie przechowywane dane są zorganizowane. Ułatwia to zrozumienie wielu
mechanizmów funkcjonujących w SQL Server 2008.
Typowy problem pojawiający się w tym zagadnieniu jest następujący. Mamy zaprojektowaną bazę
danych, zbudowany diagram ERD, zdefiniowane relacje oraz przypisane atrybutom typy danych.
Nie zawsze jednak etap projektowania jest przeprowadzony we właściwy sposób.
organizowane są dane możemy lepiej dobierać typy danych na atrybutach mając
świadomość tego, gdzie fizycznie są one umieszczone. Możemy uniknąć pewnych błędów, na
przykład co do doboru wielkości typu danych. Szczególnie duże znaczenie ma to w przypadku
Kolejnym problemem pojawiającym się w tym zagadnieniu jest próba odpowiedzenia sobie na
pytanie, jaka powinna być początkowa wielkość pliku danych i dziennika transakcji w momencie,
kiedy wiemy, ile danych ma zostać wpisanych do naszej bazy. Na podstawie t
kolejności możemy ustawić, o ile pliki danych i dziennika transakcji mają wzrosnąć.
Z punktu widzenia administracji bazą danych są to bardzo ważne problemy, które możemy
rozwiązać dzięki znajomości budowy wewnętrznej struktury w SQL Server 2008.
QL Server można korzystać efektownie bez znajomości wewnętrznej budowy,
zrozumienie szczegółów przechowywania danych pomaga w pisaniu wydajnych aplikacji.
Gdy tworzy się tabelkę, do wielu katalogów systemowych wstawiane są rekordy z informacjami
niezbędnymi do jej obsługi. Wiersze są dodawane do katalogów systemowych
syscolumns.
Dla każdej nowo utworzonej tabeli do widoku
sysobjects dodawany jest wiersz zawierający
nazwę, identyfikator obiektu oraz właściciela nowej tabeli. Widok
syscolumns
każdej kolumny z nowej tabeli informacje zawierające nazwę kolumny, typ danych i długość. Każda
z kolumn otrzymuje unikatowy identyfikator, który wyznacza kolejność, w jakiej zostały kolumny
pokazano wiersze, które dodawane są do widoku
sysobjects
Rys. 2 Informacje katalogowe zapisane po utworzeniu tabeli
Moduł 4
Wewnętrzna struktura
Jak zapewne wiesz, z SQL Server 2008 można korzystać w bardzo efektywny sposób nie mając
wiedzy na temat sposobu wewnętrznej organizacji danych, jednak w wielu przypadkach dobrze jest
wiedzieć, jak takie przechowywane dane są zorganizowane. Ułatwia to zrozumienie wielu
się w tym zagadnieniu jest następujący. Mamy zaprojektowaną bazę
danych, zbudowany diagram ERD, zdefiniowane relacje oraz przypisane atrybutom typy danych.
Nie zawsze jednak etap projektowania jest przeprowadzony we właściwy sposób. Wiedząc w jaki
organizowane są dane możemy lepiej dobierać typy danych na atrybutach mając
świadomość tego, gdzie fizycznie są one umieszczone. Możemy uniknąć pewnych błędów, na
przykład co do doboru wielkości typu danych. Szczególnie duże znaczenie ma to w przypadku
Kolejnym problemem pojawiającym się w tym zagadnieniu jest próba odpowiedzenia sobie na
pytanie, jaka powinna być początkowa wielkość pliku danych i dziennika transakcji w momencie,
kiedy wiemy, ile danych ma zostać wpisanych do naszej bazy. Na podstawie tej informacji w
kolejności możemy ustawić, o ile pliki danych i dziennika transakcji mają wzrosnąć.
Z punktu widzenia administracji bazą danych są to bardzo ważne problemy, które możemy
2008.
QL Server można korzystać efektownie bez znajomości wewnętrznej budowy,
zrozumienie szczegółów przechowywania danych pomaga w pisaniu wydajnych aplikacji.
ne są rekordy z informacjami
niezbędnymi do jej obsługi. Wiersze są dodawane do katalogów systemowych
sysobjects,
dodawany jest wiersz zawierający
syscolumns otrzymuje dla
każdej kolumny z nowej tabeli informacje zawierające nazwę kolumny, typ danych i długość. Każda
z kolumn otrzymuje unikatowy identyfikator, który wyznacza kolejność, w jakiej zostały kolumny
sysobjects i columns podczas

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 4/19
Strony danych
Strony danych są strukturami zawierającymi wszystkie dane (z wyjątkiem
text i image), których
stały rozmiar wynosi 8 KB (8192 bajtów). Składają się one z trzech elementów (rys. 3): nagłówka
strony, wierszy danych i tablicy przesunięć wierszy.
Rys. 3 Struktura strony danych
Nagłówek strony
Nagłówek strony danych zawiera pierwszych 96 bajtów strony danych. Informacje zawarte w
nagłówku pokazano w tab. 1.
Tab. 1 Informacje zawarte w nagłówku strony
Pole
Zawartość
m_poleID
Numer pliku i numer strony bazy danych.
m_nextPage
Numer pliku i nazwa następnej strony. Parametr wyświetlany jeżeli
bieżąca strona należy do łańcucha stron.
m_prev_Page
Numer pliku i nazwa poprzedniej strony. Parametr wyświetlany jeżeli
bieżąca strona należy do łańcucha stron.
m_objID
Identyfikator obiektu, do którego należy bieżąca strona.
m_lsn
Numer LSN używany do modyfikowania tej strony.
m_slotCnt
Łączna liczba wierszy tej strony.
m_level
Poziom strony w indeksie. Dla stron liści wartość zawsze równa 1.
IndexId
Identyfikator indeksu strony. Dla stron danych zawsze wartość równa 1.
m_freeData
Przesunięcie bajtowe pierwszego wolnego obszaru na tej stronie.
pminlen
Liczba bajtów części wiersza zawierającej pola o stałej długości.
m_freeCnt
Liczba niewykorzystanych bajtów na stronie.
m_reservedCnt
Liczba bajtów zarezerwowanych przez wszystkie transakcje.
m_xactReserved
Liczba bajtów zarezerwowanych przez ostatnio uruchomiona transakcje.
m_flagBits
2-bajtowy ciąg bitów zawierający dodatkowe informacje o stronie.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 5/19
Wiersze danych
Za nagłówkiem znajduje się obszar, w którym przechowywane są dane tabeli. Maksymalny rozmiar
pojedynczego wiersza danych wynosi 8060 bajtów. Wiersz danych nie może obejmować kilku stron.
Wyjątek stanowią kolumny, którym przypisano typ
image lub text. Należy zauważyć, iż liczba
wierszy może się różnić w zależności od struktury tabeli oraz przechowywanych danych. Tabele,
które posiadają kolumny o stałej długości będą zawierały na każdej stronie taką samą liczbę wierszy
danych, natomiast tabele zawierające kolumny o różnych długościach będą zawierały na każdej
stronie różną liczbę wierszy danych.
Tablica przesunięć wierszy
Tablica przesunięć wierszy jest blokiem 2-bajtowych wpisów, z których każdy stanowi przesunięcie
na stronie, od którego zaczynają się właściwe dane wiersza. Należy pamiętać o tym, że bajty te nie
są zapisywane w wierszu razem z danymi. Wpływają one jednak na liczbę wierszy mieszczących się
na stronie.
Badanie stron danych
Do badania zawartości stron danych używamy instrukcji
DBCC PAGE, która umożliwia oglądanie
nagłówka strony, wierszy danych i tablicy przesunięć wierszy dla każdej strony bazy danych.
Polecenia tego może używać tylko administrator systemu. Składnię polecenia
DBCC PAGE
pokazano poniżej:
DBCC PAGE ({id_bazy | nazwa_bazy}, numer_pliku, numer_strony[, opcje])
W tab. 2 zostały opisane podstawowe parametry instrukcji
DBCC PAGE
.
Tab. 2 Parametry polecenia DBCC PAGE
Parametr
Opis
id_bazy
Identyfikator bazy danych.
nazwa_bazy
Nazwa bazy danych.
numer_pliku
Numer pliku zawierającego stronę
numer_strony
Numer strony w obrębie pliku.
opcje
Parametr ustawiany opcjonalnie przyjmuje następujące
wartości:
•
0 – domyślnie. Zwraca informacje o nagłówku bufora i
nagłówku strony.
•
1 – zwraca informacje o nagłówku bufora, nagłówku
strony, każdym wierszu (osobno) oraz tablicę przesunięć
wierszy.
•
2 – zwraca informacje o nagłówku bufora, nagłówku
strony, zawartość całej strony oraz tablicę przesunięć
wierszy.
•
3 – zwraca informacje o nagłówku bufora, nagłówku
strony, każdym wierszu (osobno) oraz tablicę przesunięć
wierszy, a po każdym wierszu listę poszczególnych
wartości kolumn.
Przykładowy wynik działania instrukcji
DBCC PAGE
pokazano na rys. 4.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 6/19
Rys. 4 Przykładowy wydruk instrukcji DBCC PAGE
Wydruk instrukcji
DBCC PAGE składa się z czterech sekcji:
1.
BUFFER – przedstawia informacje o buforze danej strony.
2.
PAGE HEADER – pokazuje dane dla pól nagłówka strony.
3.
DATA – zawiera informacje o każdym wierszu tabeli. Dane strony dzielone są na trzy części.
Część pierwsza (lewa kolumna) określa położenie bajtowe w obrębie wiersza, część druga
(środkowe cztery kolumny) zawiera właściwe dane zapisane na stronie, zaś część trzecia
(prawa kolumna) zawiera znakową reprezentacje danych.
4.
OFFSET TABLE – pokazuje zawartość tablicy przesunięć wierszy, która znajduje się na końcu
strony. Pierwszy wiersz fizycznie znajdujący się na stronie jest wierszem numer 6, z
przesunięciem w tablicy przesunięć równym 96.
Struktura wiersza danych
Na rys. 5 pokazano ogólną strukturę wierszy danych. Na pierwszym miejscu znajdują się dane
kolumn o stałej długości. Za nimi znajdują się dane wszystkich kolumn o zmiennej długości.
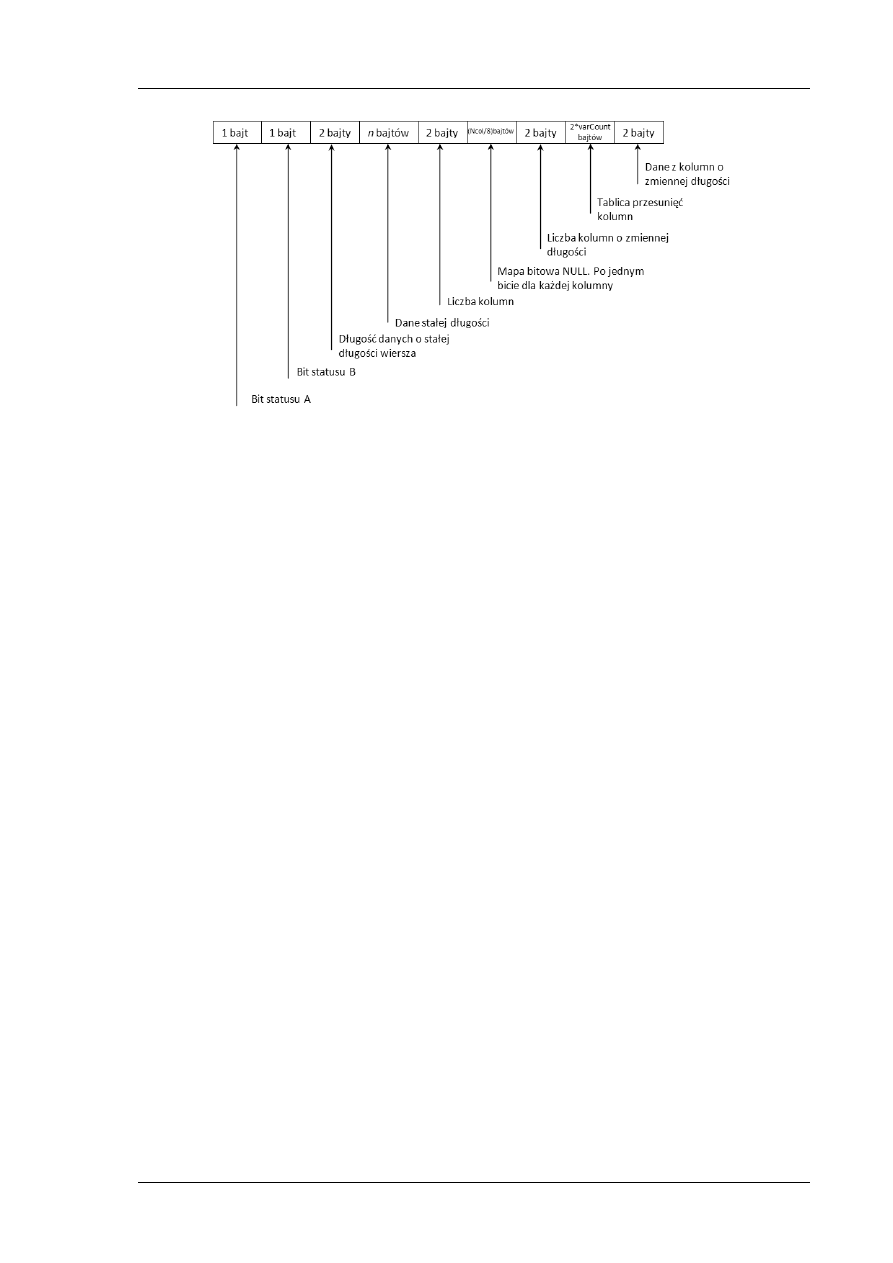
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 7/19
Rys. 5 Struktura wierszy danych
W każdym bloku o stałej długości lub danych o zmiennej długości dane są przechowywane w
kolejności w jakiej kolumny zostały zdefiniowane przy tworzeniu tabeli. Przyjrzyjmy się poniższemu
przykładowi:
CREATE TABLE Proba
{
Kolumna_1 int NOT NULL,
Kolumna_2 char(25) NOT NULL,
Kolumna_3 varchar(60) NULL,
Kolumna_4 int NOT NULL,
Kolumna_5 varchar(20) NOT NULL
}
W powyższym przykładzie w części związanej z danymi o stałej długości wiersze będą zawierały
najpierw dane kolumny
Kolumna_1 następnie Kolumna_2 i wreszcie Kolumna_4. W następnej
kolejności będą występowały dane o zmiennej długości związane odpowiednio z
Kolumną_3 i
Kolumna_5.
Tablice przesunięć kolumn
Wiersz danych, który ma kolumny o stałej długości, nie zawiera licznika zmiennych kolumn ani
tablicy przesunięć kolumn. Wiersz danych, w którym znajdują się kolumny o zmiennej długości,
zawiera tablicę przesunięć kolumn.
Połączenia stron
W SQL Server 2008 strony łączone są ze sobą na każdym poziomie indeksu. Jedynym sposobem, w
jaki SQL Server określa, które strony należą so tabeli, jest zaglądanie do stron IAM tabeli.
Poleceniem
DBCC EXTENTINFO można uzyskać listę wszystkich obszarów należących do obiektu.
W poniższym przykładzie pokazano listę wszystkich obszarów należących do obiektu
Orders w
bazie danych
Northwind.
Osiem pierwszych wierszy wskazuje rozmiar obszaru (
ext_size) równy 1. Wynika to z tego, że
pierwszych osiem stron w tabeli alokowanych jest z obszarów mieszanych. Gdy tabela osiągnie
osiem stron, wówczas SQL Server przydziela jej obszary jednolite po osiem stron każdy.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 8/19
Rys. 6 Wydruk wszystkich obszarów należących do obiektu
Rozmiar danych
Znając strukturę tabel oraz typy danych kolumn w bazie danych, możemy oszacować rozmiar pliku
danych.
Procedura szacowania rozmiaru pliku danych przebiega według następującego schematu:
1.
Na podstawie tabeli określamy rozmiar pojedynczego wiersza. Dla typów danych o stałym
rozmiarze dodajemy liczbę bajtów poszczególnych kolumn, zaś dla typów o zmiennym
rozmiarze przyjmujemy wartość średnią.
2.
Następnie maksymalną liczbę bajtów na pojedynczej stronie danych (8060) dzielimy przez
szacunkową wielkość wiersza. W wyniku otrzymujemy liczbę wierszy mieszczących się na
stronie.
3.
Następnie szacunkową liczbę wierszy dzielimy przez otrzymaną liczbę wierszy na stronie. W
ten sposób otrzymujemy liczbę stron niezbędnych do zapisania danych znajdujących się w
tabeli.
4.
W kolejnym kroku otrzymaną liczbę stron mnożymy przez 8196 B (rozmiar pojedynczej
strony), co daje nam w wyniku wielkość pliku danych.
Przykładowe rozwiązanie
Wyświetlanie wierszy danych
Zanim będziesz mógł wyświetlić wiersze danych w twojej tabeli w bazie danych będziesz musiał
odpowiednio zgromadzić informacje na temat numeru pliku i numeru strony na której interesujące
Cię dane są zawarte. Wyobraźmy sobie, że stworzyliśmy tabelę
Ksiazka o postaci:.
CREATE TABLE [dbo].[Ksiazka]
(
[ID_Ksiazka] [int] IDENTITY(1,1) NOT NULL,
[Tytul] [varchar](50) NULL,
[Autor] [varchar](30) NULL,
[Rok] [char](4) NULL
)
Do nowo powstałej tabeli
Ksiazka wpisujemy trzy dowolne rekordy.
Podczas tworzenia tabeli
Ksiazka do widoku systemowego:
•
sysindexes wstawiany jest nowy wiersz, przechowujący informację o nowym obiekcie
(tabela
Ksiazka), który przed chwilą został stworzony, co możemy zaobserwować na rys. 7.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
•
syscolumns
wstawiane są
atrybutów, z których złożona jest tabela
W celu poprawnego uruchomienia
widoku
sysindexes (0x9D0000000100
na rys. 7). W pierwszym kroku należy zamienić bajty, aby uzyskać ciąg
Pierwsze dwie grupy (
00 01
00 9D) – numer strony. Zatem plik ma numer 1, a strona ma numer 157.
Na rys. 9 pokazano faktyczną zawartość wierszy
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 9/19
Rys. 7 Wstawiony wiersz do tabeli sysindexes
wstawiane są wiersze, przechowujące informację na temat poszczególnych
atrybutów, z których złożona jest tabela
Ksiazka, co możemy zaobserwować
Rys. 8 Wstawione wiersze do tabeli syscolumns
W celu poprawnego uruchomienia polecenia
DBCC PAGE należy pobrać odpowiednią wartość z
0x9D0000000100) i przekształcić ją na adres pliku
). W pierwszym kroku należy zamienić bajty, aby uzyskać ciąg
00 01 00 00 00 9D
00 01) reprezentują 2-bajtowy numer pliku, a ostatn
numer strony. Zatem plik ma numer 1, a strona ma numer 157.
pokazano faktyczną zawartość wierszy tabeli
Ksiazki z bazy danych
Rys. 9 Wiersze danych tabeli Ksiazki
Moduł 4
Wewnętrzna struktura
przechowujące informację na temat poszczególnych
co możemy zaobserwować na rys. 8.
należy pobrać odpowiednią wartość z
strony (kolumna
first
00 01 00 00 00 9D.
bajtowy numer pliku, a ostatnie cztery grupy (
00 00
azy danych
Biblioteka.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 10/19
Polecenie
DBCC PAGE wyświetla wiersze danych w czterech grupach po 4 bajty naraz. W obrębie
każdej z grup bajty wyświetlane są w odwrotnej kolejności.
Szacowanie wielkości pliku danych
W przykładzie tym posłużymy się wcześniej stworzona tabelą
Ksiazki oraz stworzymy nową
tabelę
Czytelnicy oraz tabelę techniczna Ksiazki_Czytelnicy. Dla tej tabeli określimy
wielkość pliku danych.
1.
Określamy rozmiar pojedynczego wiersza w tabeli
Ksiazki, Czytelnicy oraz
Ksiazki_Czytelnicy.
Tabela
Ksiazki
Kolumna
Typ
Rozmiar
ID_Ksiazka
int
4 bajty
Tytul
varchar(200)
200 bajtów
Autor
varchar(50)
50 bajtów
Rok
char(4)
4 bajty
ID_Czytelnik
int
4 bajty
Suma
262 bajtów
Tabela
Czytelnicy
Kolumna
Typ
Rozmiar
ID_Czytelnik
int
4 bajty
Nazwisko
varchar(50)
50 bajtów
Imie
varchar(30)
30 bajtów
Data_urodzenia
smalldatatime
4 bajty
ID_Ksiazka
int
4 bajty
Suma
92 bajtów
Tabela
Ksiazki_Czytelnicy
Kolumna
Typ
Rozmiar
ID_Ksiazka
int
4 bajty
ID_Czytelnik
int
4 bajty
Suma
8 bajtów
2.
Wyznaczamy liczbę wierszy mieszczących się na stronie. W naszym przypadku mamy:
Ksiazki = 8060 / 262 B = 31 wierszy na stronie
Czytelnicy = 8060 / 92 B = 88 wierszy na stronie
Ksiazki_Czytelnicy = 8060 / 8 B = 1008 wierszy na stronie

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 11/19
3.
Przy założeniu, że w tabeli
Ksiazki będzie znajdowało się 5000 rekordów, w tabeli
Czytelnicy 2000 rekordów a w tabeli Ksiazki_Czytelnicy 22000 rekordów,
wyznaczamy liczbę stron niezbędnych do zapisania danych znajdujących się w tabeli.
Ksiazka = 5000 rekordów / 31 wiersze = 162 strony
Czytelnicy = 2000 rekordów / 88 wierszy = 23 strony
Ksiazki_Czytelnicy = 22000 rekordów / 1008 wierszy = 22 strony
4.
Sumujemy liczbę wszystkich stron
162 strony + 23 strony + 22 strony = 207 stron
5.
Obliczamy wielkość pliku danych.
8196 B * 207 stron = 1696572 B= 1,7 MB
Porady praktyczne
•
Widok systemowy
sysindex zawiera dwie ważne kolumny, które reprezentują numery
stron w obrębie bazy danych:
id i first. Kolumna id przechowuje numer identyfikacyjny
bazy danych. Kolumna
first przechowuje wartość, powyżej której znajdują się fizycznie
wpisane rekordy (numer strony danych) oraz numer pliku danych.
•
W sytuacji, kiedy tabela przechowuje dane typu OLE (
text, ntext lub image), rzeczywiste
dane mogą nie być przechowywane na stronach razem z resztą danych wiersza. Wynika to z
faktu, iż dane tego typu zajmują dużo przestrzeni dyskowej a zatem ich fragmenty mogą być
przechowywane w różnych plikach oraz na różnych stronach danych.
•
Z racji tego, iż obiekty typu OLE zajmują dużo przestrzeni dyskowej pamiętaj, że należy
podczas wyboru tego typu danych kilkakrotnie zastanowić się czy jest to niezbędny typ
danych i czy nie można zastąpić go innym lżejszym typem.
•
W celu poprawnego uruchomienia polecenia
DBCC PAGE, należy prawidłowo pobrać
odpowiednia wartość z widoku systemowego
sysindexes i przekształcić ją na adres pliku i
strony.
•
Pamiętaj, że z widoku
sysindexes pobieramy zawartość kolumny first w postaci
heksadecymalnej. W pierwszym kroku należy zawsze zamienić bajty. Uzyskana wartość
składa się z dwóch części: numeru pliku (pierwsze dwie grupy) oraz numeru strony (ostatnie
cztery grupy).
•
Widoki systemowe
sysindexes i syscolumns przechowują wiele różnorodnych informacji
na temat obiektów w ramach bazy danych (data utworzenia, data modyfikacji, itp.)
przydatnych w skutecznych i sprawnych pracach administracyjnych.
•
Pamiętaj, w wielu sytuacjach szacowanie wielkości pliku danych i pliku dziennika transakcji
jest rzeczą bardzo ważną z punktu widzenia administracji serwerem bazodanowym. Ma to
szczególne znaczenie w przypadku przenoszenia bazy danych z innego systemu zarządzania
bazą danych, gdzie znana jest liczba rekordów w poszczególnych obiektach bazy danych.
•
W przypadku, obliczenia wielkości pliku danych wychodzi wartość niecałkowita (patrz
przykładowe obliczenie wielkości pliku danych), np. 5.48MB, wówczas w celu zapewnienia
odpowiedniej przestrzeni na importowane dane należy ustawić wielkość początkową pliku
danych na 6.0MB. Microsoft SQL Server 2008 nie daje możliwości stworzenia bazy danych z
plikiem danych wielkości niecałkowitej.
•
Pamiętaj, w systemowej bazie danych
tempdb dostarczonej z serwerem Microsoft SQL
Server 2008, ustawione są parametry wyjściowe Twojej bazy danych. Jeżeli zmienisz
cokolwiek w tej bazie danych wszystkie bazy tworzone w ramach serwera będą pobierały jej
wartości początkowe.
•
Pamiętaj nigdy nie kasuj baz danych dostarczonych wraz z Microsoft SQL Server 2008.
Operacja ta może doprowadzić do niestabilnej pracy serwera a w niektórych sytuacjach
wręcz do jego poważnego uszkodzenia.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 12/19
•
Pamiętaj w opcji SQL Server 2008 przy tworzeniu bazy danych mamy możliwość ustawienia
wielkości pliku danych oraz wielkości wzrostu pliku danych. Wielkości te są liczbami
całkowitymi z dokładnością do 1 MB. Dobrą praktyką jest ustawienie parametru wzrostu
pliku danych jako 30% wartości pliku danych (jednak nie mniej niż 1MB). Przykładowo dla
pliku danych wielkości 10MB powinniśmy ustawić wielkość wzrostu pliku danych na poziomie
3MB.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz, co oznacza strona danych, nagłówek strony, wiersze danych, tablica przesunięć
wierszy
•
rozumiesz składnię instrukcji
DBCC
•
umiesz przeliczać system heksadecymalny na system dziesiętny
•
znasz podstawowe typy danych w SQL Server 2008
•
umiesz obliczać wielkość pliku danych
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Jeffrey D. Ullman, Jennifer Widom, Podstawowy wykład z systemów baz danych, WNT, 2000
W książce autor w przystępny i zrozumiały sposób przedstawia między innymi jak
zorganizowane jest przechowywanie danych oraz pokazuje, w jaki sposób można
odczytać strony danych.
2.
Christopher J. Date, Wprowadzenie do systemów baz danych, WNT, 2000
W książce tej znajdziemy dużo szczegółowych informacji na temat teorii
przechowywania danych w bazach danych. Znajdzie cie w niej również szczegółową
informację na temat polecenia DBCC, wraz z wieloma wariantami jego użycia w celu
przeglądania danych na bardzo niskim poziomie. Pozycja szczególnie polecana dla
osób pragnących poszerzenie swojej wiedzy z tej tematyki.
3.
Ramez Elmasri, Shamkant B. Navathe, Wprowadzenie do systemów baz danych, Wydawnictwo
Helion, 2005
Podobnie jak w poprzedniej pozycji, w książce tej znajdziemy bardzo szczegółowe
informacje na temat teorii przechowywania danych w bazach danych. Pozycja
szczególnie polecana dla osób pragnących poszerzyć swoją wiedzę z tej tematyki.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Laboratorium podstawowe
Problem 1 (czas realizacji 25 min)
Jesteś administratorem w firmie National
dostępową do twojej bazy danych poprosili Cię jako eksperta o zaprezentowanie sposobu
przechowywania danych w SQL Server 2008. Ma to im pomóc w zrozumienia sposobu
przechowywania danych i ulepszeniu niskopozi
Zadanie
Tok postępowania
1.
Utwórz
testową bazę i
tabelę
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
W oknie logowania kliknij
2.
Utwórz bazę
•
Wykonaj poniższy kod tworzący bazę danych
--
USE master
GO
--
--
IF EXISTS (SELECT *
GO
--
CREATE DATABASE Dyplomowe
ON
( NAME = 'Dyplomowe', FILENAME = N'C:
Server
3072KB , MAXSIZE =
LOG ON
( NAME = 'Dyplomowe_log', FILENAME = N'C:
SQL Server
1536KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
•
Stwórz dwie tabele
--
CREATE TABLE Osoba(
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 13/19
Laboratorium podstawowe
Problem 1 (czas realizacji 25 min)
Jesteś administratorem w firmie National Insurance. Programiści modernizujący aplikacje
dostępową do twojej bazy danych poprosili Cię jako eksperta o zaprezentowanie sposobu
przechowywania danych w SQL Server 2008. Ma to im pomóc w zrozumienia sposobu
przechowywania danych i ulepszeniu niskopoziomowego działania aplikacji.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Wykonaj poniższy kod tworzący bazę danych Dyplomowe
-- (1) Ustawiamy sie na baze danych master
USE master
GO
-- (2) sprawdzmy, czy taka baza juz istnieje;
-- jesli tak, to usuwamy ja
IF EXISTS (SELECT *
FROM master..sysdatabases
WHERE name = 'Dyplomowe')
DROP DATABASE Dyplomowe
GO
-- (3) Tworzymy baze danych Dyplomowe
CREATE DATABASE Dyplomowe
ON
( NAME = 'Dyplomowe', FILENAME = N'C:\Program Files
Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\Dyplomowe.mdf' , SIZE =
3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = 'Dyplomowe_log', FILENAME = N'C:\Program Files
SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\Dyplomowe.ldf' , SIZE =
1536KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
Stwórz dwie tabele: Osoba i Praca. W tym celu wykonaj poniższy kod
-- (3) Tworzenie przykladowych dwoch tabel: Osoba i Praca
CREATE TABLE Osoba(
ID_Osoby smallint
NOT NULL,
Imie varchar(20)
NOT NULL,
Nazwisko varchar(50)
NOT NULL,
Nr_Indeksu
varchar(6)
NOT NULL
Moduł 4
Wewnętrzna struktura
Insurance. Programiści modernizujący aplikacje
dostępową do twojej bazy danych poprosili Cię jako eksperta o zaprezentowanie sposobu
przechowywania danych w SQL Server 2008. Ma to im pomóc w zrozumienia sposobu
omowego działania aplikacji.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
Dyplomowe:
(2) sprawdzmy, czy taka baza juz istnieje;
Program Files\Microsoft SQL
Dyplomowe.mdf' , SIZE =
UNLIMITED, FILEGROWTH = 1024KB )
Program Files\Microsoft
Dyplomowe.ldf' , SIZE =
1536KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
ykonaj poniższy kod:
(3) Tworzenie przykladowych dwoch tabel: Osoba i Praca

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
)
CREATE TABLE Praca(
)
•
Uzupełnij tabele
3.
Sprawdź
zawartość
widoków
systemowych
•
Z menu głównego wybierz
•
Odszukaj plik
•
Na utworzonej bazie danych
--
USE Dyplomowe
GO
--
SELECT name, object_id, type,
GO
•
W wyniku powinieneś otrzymać informację na temat wpisu w widoku
systemowym
•
Wykonaj zapytanie:
--
SELECT object_id, name, column_id,
GO
•
W wyniku
systemowym
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 14/19
CONSTRAINT [PK_Osoba] PRIMARY KEY CLUSTERED
(
[ID_Osoby] ASC
)
CREATE TABLE Praca(
ID_Pracy smallint
NOT NULL,
Temay varchar(200) NOT NULL,
Data smalldatetime NOT NULL,
Ocena smallint
NOT NULL
CONSTRAINT [PK_Praca] PRIMARY KEY CLUSTERED
(
[ID_Pracy] ASC
)
Uzupełnij tabele Osoba i Praca przykładowymi danymi.
Z menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\widoki_systemowe.sql i kliknij Open
Na utworzonej bazie danych Dyplomowe wykonaj poniższe zapytanie
-- (1) Ustaw się n abaze danych Dyplomowe
USE Dyplomowe
GO
-- (2) Informacja o wpisie w widoku sysobjects
ELECT name, object_id, type,
type_desc, create_date, modify_date
FROM [Dyplomowe].[sys].[objects]
WHERE name='Osoba' OR name='Praca'
GO
W wyniku powinieneś otrzymać informację na temat wpisu w widoku
systemowym sysobjects.
Rys. 10 Wpis w widoku systemowym sysobjects
W wyniku wykonania zapytania na tabeli
otrzymasz między innymi informację o numerze identyfikacyjnym
obiektu tabeli object_id. Numer ten będzie Ci pomocny w wyszukaniu
odpowiedniego wpisu w widoku systemowym syscolumns
Wykonaj zapytanie:
-- (3) informacja na temat wpisu w widoku systemowym sy
SELECT object_id, name, column_id,
system_type_id, max_length, collation_name
FROM [Dyplomowe].[sys].[columns]
where object_id='85575343' OR object_id='117575457'
GO
W wyniku powinieneś otrzymać informację na temat wpisu w widoku
systemowym syscolumns.
Moduł 4
Wewnętrzna struktura
CONSTRAINT [PK_Osoba] PRIMARY KEY CLUSTERED
CONSTRAINT [PK_Praca] PRIMARY KEY CLUSTERED
przykładowymi danymi.
Open.
wykonaj poniższe zapytanie:
Informacja o wpisie w widoku sysobjects
W wyniku powinieneś otrzymać informację na temat wpisu w widoku
Wpis w widoku systemowym sysobjects
W wyniku wykonania zapytania na tabeli systemowej sysobject
otrzymasz między innymi informację o numerze identyfikacyjnym
. Numer ten będzie Ci pomocny w wyszukaniu
syscolumns.
(3) informacja na temat wpisu w widoku systemowym syscolumns
system_type_id, max_length, collation_name
where object_id='85575343' OR object_id='117575457'
powinieneś otrzymać informację na temat wpisu w widoku
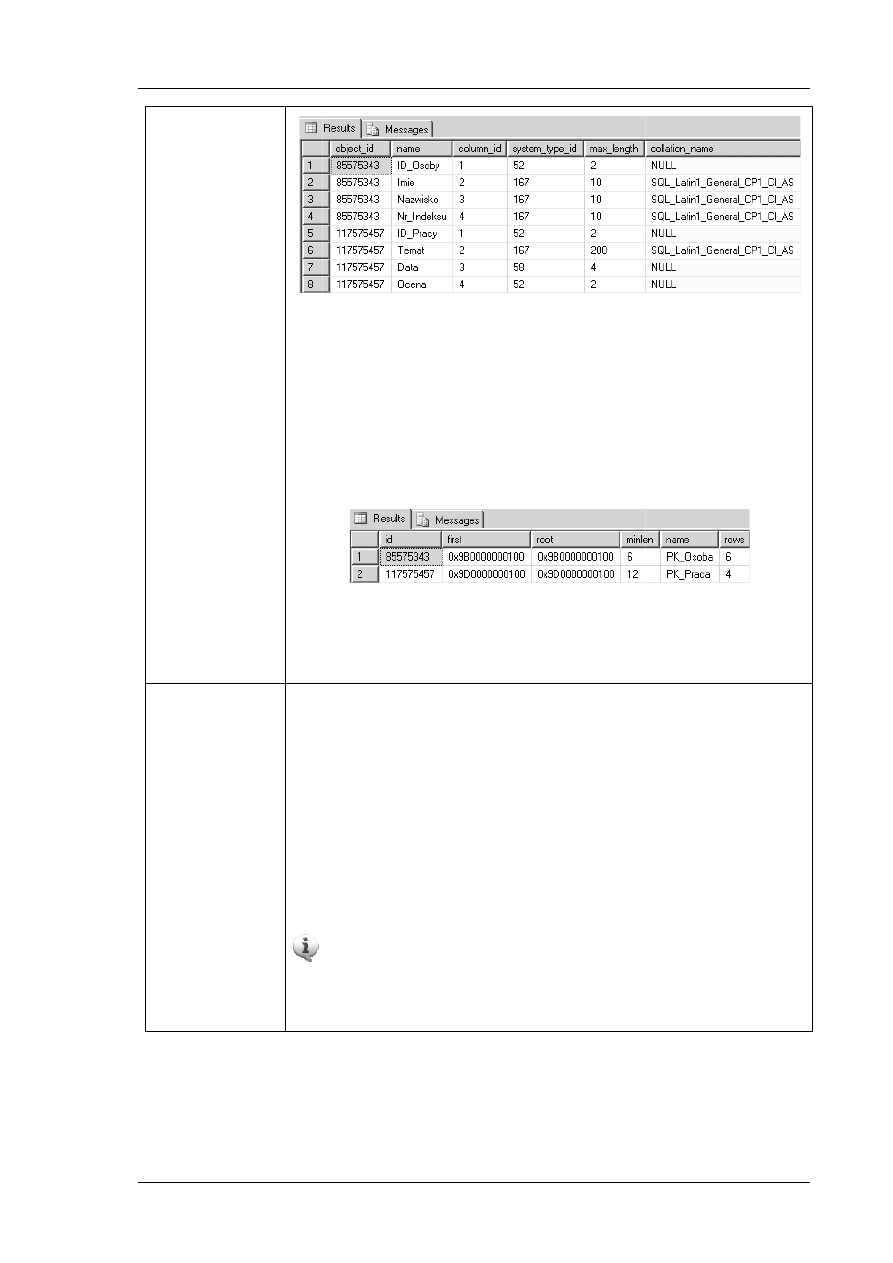
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
•
Wykonaj zapytanie:
--
SELECT id, first, root, minlen, name, rows
FROM [Dyplomowe].[sys].[sysindexes]
WHERE
GO
•
W wyniku powinieneś otrzymać informację na temat wpisu w widoku
systemowym
4.
Zbadaj strony
danych
•
Dla tabeli
(0x9B0000000100
•
Zamień bajty, aby uzyskać ciąg
•
Pierwsze dwie grupy (
ostatnie cztery grupy (
1
•
Z menu głównego wybierz
•
Odszukaj plik
•
Wywołaj instrukcję
DBCC TRACEON(3604)
GO
DBCC PAGE (Dyplomowe,1,155,1)
•
W wyniku powinieneś otrzymać
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 15/19
Rys. 11 Wpis w widoku systemowym syscolumns
Wykonaj zapytanie:
-- (4) Informacja na temat wpisu w widoku systemowym sysindexes
SELECT id, first, root, minlen, name, rows
FROM [Dyplomowe].[sys].[sysindexes]
WHERE name='PK_Osoba' OR name='PK_Praca'
GO
W wyniku powinieneś otrzymać informację na temat wpisu w widoku
systemowym sysindexes.
Rys. 12 Wpis w widoku systemowym sysindexes
Informacja z kolumny first w widoku systemowym
na temat numeru pliku oraz numeru strony, na której przechowywane
są dane z tabeli.
Dla tabeli Osoba odczytaj wartość kolumny first
0x9B0000000100) i przekształć ją na adres pliku strony
Zamień bajty, aby uzyskać ciąg 00 01 00 00 00 9B.
Pierwsze dwie grupy (00 01) reprezentują 2-bajtowy numer pliku, a
ostatnie cztery grupy (00 00 00 9B) numer strony. Zatem plik ma numer
1, a strona ma numer 155.
Z menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\strona_danych.sql i kliknij Open.
Wywołaj instrukcję BDCC PAGE z ustalonymi wcześniej parametrami
DBCC TRACEON(3604)
GO
DBCC PAGE (Dyplomowe,1,155,1)
Instrukcja DBCC TRACEON(3604) nakazuje żeby SQL Server wyświetlił
strony danych na ekranie monitora w sposób przyjazny dla
użytkownika.
W wyniku powinieneś otrzymać informacje jak na
Moduł 4
Wewnętrzna struktura
Wpis w widoku systemowym syscolumns
(4) Informacja na temat wpisu w widoku systemowym sysindexes
W wyniku powinieneś otrzymać informację na temat wpisu w widoku
Wpis w widoku systemowym sysindexes
widoku systemowym zawiera informacje
na temat numeru pliku oraz numeru strony, na której przechowywane
first z widoku sysindexes
ją na adres pliku strony.
.
bajtowy numer pliku, a
) numer strony. Zatem plik ma numer
.
z ustalonymi wcześniej parametrami:
nakazuje żeby SQL Server wyświetlił
danych na ekranie monitora w sposób przyjazny dla
informacje jak na rys. 13.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 16/19
Rys. 13 Wyświetlona strona danych
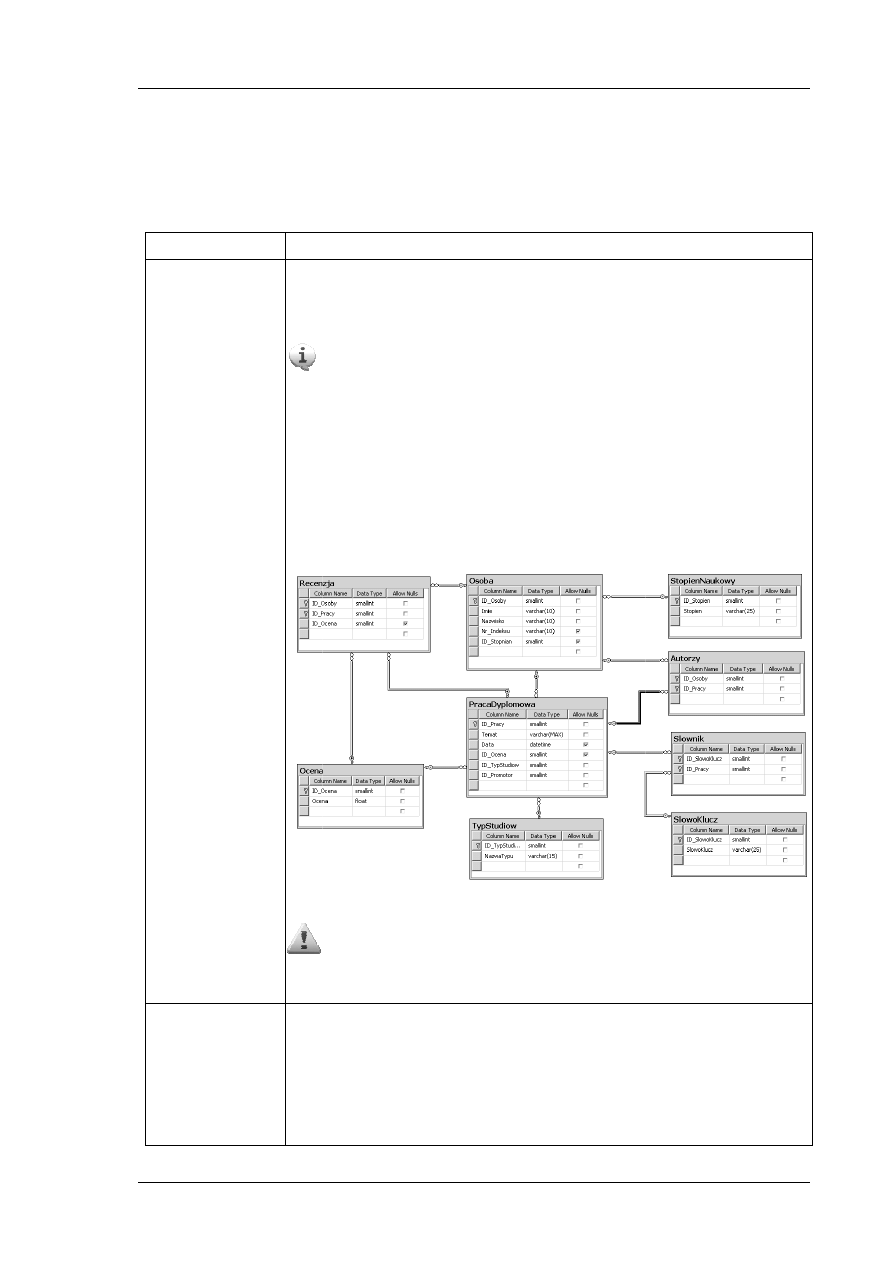
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Problem 2 (czas realizacji 20 min)
Jesteś administratorem w firmie National Insurance.
zaimportowane nowe dane. W tym celu musisz przeprojektować swoja bazę danych i obliczyć
wielkość początkową pliku danych i pliku dziennika transakcji.
Zadanie
Tok postępowania
1.
Utwórz
testową bazę
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Managemen
•
W oknie logowania kliknij
•
Rozwiń węzeł
•
W obrębie bazy danych
Diagram
•
Powinieneś zobaczyć diagram taki jak na Rys. 14.
2.
Oszacuj
wielkość pliku
danych
•
Na
Recenzja = ID_Osoby(2B) + ID_Pracy(2B) + ID_Ocena(2B) = 6B
Osoba = ID_Osoby(2B) + Imie(20B) + Nazwisko(50B) +
Nr_Indeksu(int)(4B) + ID_Stopien(2B) = 78B
StopienNaukowy = ID_Stopien(2B) + Stopien(25B) =
Autorzy = ID_Osoby(2B) + ID_Pracy(2B) = 4B
Slownik = ID_SlowoKlucz(2B) + ID_Pracy(2B) = 4B
SlowoKlucz = ID_SlowoKlucz(2B) + SlowoKlucz(25B) = 27B
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 17/19
Problem 2 (czas realizacji 20 min)
Jesteś administratorem w firmie National Insurance. Wiesz, że do twojej bazy danych maja zostać
zaimportowane nowe dane. W tym celu musisz przeprojektować swoja bazę danych i obliczyć
wielkość początkową pliku danych i pliku dziennika transakcji.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Rozwiń węzeł Database i wybierz PraceDyplomowe
W obrębie bazy danych PraceDyplomowe rozwiń węzeł
Diagram.
Powinieneś zobaczyć diagram taki jak na Rys. 14.
Rys. 14 Diagram bazy danych PraceDyplomowe
W celu wykonania tego zadania należy wykonać moduł
związany z projektowaniem i implementacją bazy danych. Dla
zaprojektowanej bazy danych będziemy szacowali wielkość pliku
danych.
Na podstawie tabeli określ rozmiar pojedynczego wiersza
Recenzja = ID_Osoby(2B) + ID_Pracy(2B) + ID_Ocena(2B) = 6B
Osoba = ID_Osoby(2B) + Imie(20B) + Nazwisko(50B) +
Nr_Indeksu(int)(4B) + ID_Stopien(2B) = 78B
StopienNaukowy = ID_Stopien(2B) + Stopien(25B) =
Autorzy = ID_Osoby(2B) + ID_Pracy(2B) = 4B
Slownik = ID_SlowoKlucz(2B) + ID_Pracy(2B) = 4B
SlowoKlucz = ID_SlowoKlucz(2B) + SlowoKlucz(25B) = 27B
Moduł 4
Wewnętrzna struktura
iesz, że do twojej bazy danych maja zostać
zaimportowane nowe dane. W tym celu musisz przeprojektować swoja bazę danych i obliczyć
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Mirosoft Virtual PC,
dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
PraceDyplomowe
rozwiń węzeł Database
anych PraceDyplomowe
W celu wykonania tego zadania należy wykonać moduł 2 i moduł 3
związany z projektowaniem i implementacją bazy danych. Dla
anych będziemy szacowali wielkość pliku
podstawie tabeli określ rozmiar pojedynczego wiersza:
Recenzja = ID_Osoby(2B) + ID_Pracy(2B) + ID_Ocena(2B) = 6B
Osoba = ID_Osoby(2B) + Imie(20B) + Nazwisko(50B) +
StopienNaukowy = ID_Stopien(2B) + Stopien(25B) = 27B
Slownik = ID_SlowoKlucz(2B) + ID_Pracy(2B) = 4B
SlowoKlucz = ID_SlowoKlucz(2B) + SlowoKlucz(25B) = 27B
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 18/19
TypStudiow = ID_TypStudiow(2B) + NazwaTypu(15B) = 17B
Ocena = ID_Ocena(2B) + Ocena(4B) = 6B
PracaDyplomowa = ID_Pracy(2B) + Temat (char500)(500B) + Data(8B) +
ID_Ocena(2B) + ID_TypStudiow(2B) + ID_Promotor(2B) = 516B
•
Wyznacz liczbę stron niezbędnych do zapisania danych znajdujących się
w tabelach:
Recenzja = 8540 rekordów / 1343 wierszy = 7 stron
Osoba = 5000 rekordów / 103 wierszy = 49 stron
StopienNaukowy = 4 rekordy / 298 wierszy = 1 strona
Autorzy = 4270 rekordów / 2015 wierszy = 3 strony
Slownik = 12810 rekordów / 2015 wierszy = 7 stron
SlowoKlucz = 500 rekordów / 298 wierszy = 2 strony
TypStudiow = 3 rekordy / 474 wierszy = 1 strona
Ocena = 4 rekordy / 1343 wierszy = 1 strona
PracaDyplomowa = 5000 rekordów / 15 wierszy = 334
•
Zsumuj liczbę stron:
Liczba stron = 405 stron
•
Otrzymaną liczbę stron pomnóż przez 8196B (rozmiar pojedynczej
strony), co powinno dać w wyniku wielkość pliku danych:
Wielkość pliku danych = Liczba stron * 8196B = 405 * 8196B =
= 3 319 380 B = 3,32 MB

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 4
ITA-101 Bazy danych
Wewnętrzna struktura
Strona 19/19
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Jesteś głównym administratorem sytemu bazodanowego w firmie BARKA, która zajmuje się
inwestycjami na giełdzie papierów wartościowych. Kierownictwo firmy w wyniku przejęcia
mniejszej firmy TFI START zarządzającej funduszami inwestycyjnymi podjęło decyzje o modernizacji
aplikacji dostępowej do bazy danych oraz rozbudowie istniejącej bazy danych. W związku z tym
pomiędzy Tobą a programistami aplikacji dostępowej powinna istnieć ścisła współpraca. W celu
ulepszeniu niskopoziomowego działania aplikacji poproszono Cię, jako eksperta, o zaprezentowanie
sposobu przechowywania danych w SQL Server 2008. Z drugiej strony wiesz, że po rozbudowie do
twojej bazy danych maja zostać zaimportowane nowe dane za okres ostatnich 5 lat. W tym celu
musisz przeprojektować swoja bazę danych i obliczyć wielkość początkową pliku danych i pliku
dziennika transakcji.
Zadania, jakie przed tobą zostały postawione, są następujące:
1.
Pokaż programistom, w jaki sposób zorganizowane jest przechowywanie danych w
SQL Server 2008.
2.
Przeprojektuj istniejącą bazę danych.
3.
Oblicz, jaka powinna być wielkość pliku danych dla przeprojektowanej bazy danych.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
Wersja 1.0
Język SQL – DCL, DDL
Spis treści
Język SQL – DCL, DDL ............................................................................................................................ 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 7
Porady praktyczne ..................................................................................................................... 11
Uwagi dla studenta .................................................................................................................... 12
Dodatkowe źródła informacji..................................................................................................... 12
Laboratorium podstawowe ................................................................................................................ 14
Problem 1 (czas realizacji 15 min) .............................................................................................. 14
Problem 2 (czas realizacji 30 min) .............................................................................................. 15
Laboratorium rozszerzone ................................................................................................................. 20
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 20
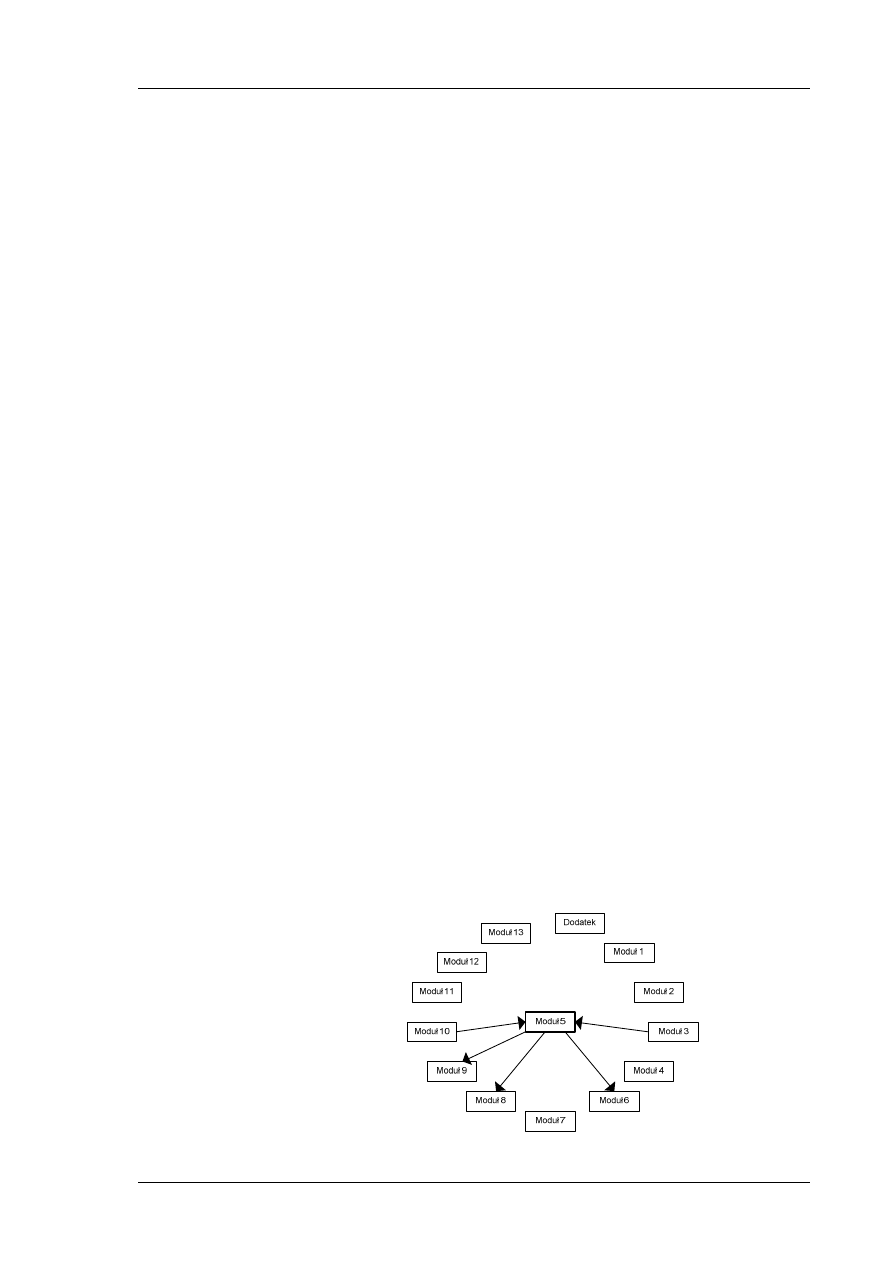
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 2/20
Informacje o module
Opis modułu
Język SQL został opracowany w 1987 roku z myślą o relacyjnych bazach
danych. Składa się on z trzech składowych: języka definiowania danych
(DDL), języka sterowania danymi (DCL) oraz języka operowania na danych
(DML). W module tym znajdziesz podstawowe instrukcje języka
definiowania danych – języka SQL DDL (z ang. Data Definition Language)
oraz języka sterowania danymi – języka SQL DCL (z ang. Data Control
Language).
Cel modułu
Celem modułu jest zaprezentowanie podstaw języka SQL DCL i DDL. W
module tym pokazano składnię częściową instrukcji oraz przykładowe ich
użycie.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
potrafił użyć podstawowych instrukcji języka T-SQL DDC
•
potrafił użyć podstawowych instrukcji języka T-SQL DDL
•
rozumiał mechanizm zarządzania uprawnieniami dostępu do
obiektów bazy danych
•
rozumiał mechanizm manipulowania bazą danych i jej obiektami
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
wiedzieć w jaki sposób stworzyć bazę danych wraz z jej
podstawowymi obiektami
•
wiedzieć, w jaki sposób poruszać się po Microsoft SQL Server
Menagement Studio
•
wiedzieć, w jaki sposób należy zakładać użytkowników i przypisywać
ich do bazy danych
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznać się z materiałem zawartym
w module 3.
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 3/20
Przygotowanie teoretyczne
Przykładowy problem
Jak zapewne wiesz, z bazy danych może korzystać wielu użytkowników, którzy mogą dysponować
różnymi prawami dostępu do różnych obiektów w bazie danych. Najgorszym rozwiązaniem jakie
może istnieć to pełne zaufanie do osób korzystających z bazy i przydzielenie im pełnych praw. Ze
względu na bezpieczeństwo danych zawartych w bazie, warto stosować zasadę ograniczonego
zaufania do użytkownika. Z tego powodu należy zastanowić się, jakie uprawnienia należy przydzielić
poszczególnym użytkownikom lub grupom użytkowników. Dobrze jest wiedzieć, w jaki sposób
można nadawać, odmawiać i cofać prawa dostępu. W kolejnym kroku należy rozważyć, czy
użytkownik powinien mieć dostęp do całego obiektu typu tabela lub widok, czy może wystarczy mu
dostęp do poszczególnych kolumn. Ze względu na bezpieczeństwo, administrator powinien
zastanowić się, czy lepszym rozwiązaniem nie byłoby umożliwienie użytkownikowi lub grupie
użytkowników dostępu do obiektów programowalnych typu procedury składowane, które
wprowadzają kolejny stopień bezpieczeństwa i maskują fizyczną strukturę bazy danych.
Podstawy teoretyczne
W części tej poznasz podstawy języka T-SQL DCL (ang. Data Control Language) i T-SQL DDL (ang.
Data Definition Language). Dowiesz się, w jaki sposób nadawać, odmawiać i usuwać prawa do
wykonywania operacji na poszczególnych obiektach baz danych, takich jak tabele i widoki, oraz w
jaki sposób zarządzać dostępem do programowalnych obiektów. Nauczysz się tworzyć,
modyfikować i usuwać podstawowe obiekty.
Polecenia DCL
Instrukcje języka DCL służą do zarządzania uprawnieniami dostępu do obiektów bazy.
Najważniejszymi poleceniami języka DCL są instrukcje:
•
GRANT – pozwala użytkownikowi lub roli na wykonywanie operacji określonej przez nadane
uprawnienie.
•
DENY – odmawia użytkownikowi lub roli określonego uprawnienia i zapobiega odziedziczeniu
go po innych rolach.
•
REVOKE – usuwa uprzednio nadane lub odmówione uprawnienie.
Modyfikowanie dostępu do tabel
Dostęp do tabeli należy do efektywnych uprawnień, jakimi dysponuje użytkownik. Dostępem tym
można sterować poprzez zarządzanie uprawnieniami na poziomie tabel. Uprawnienia, którymi
można zarządzać, zostały przedstawione w tab. 1.
Tab. 1 Uprawnienia, którymi można zarządzać na poziomie tabel
Usprawnienie
Opis
ALTER
Umożliwia modyfikowanie właściwości tabeli
CONTROL
Zapewnia uprawnienia właściciela
DELETE
Umożliwia usuwanie wierszy tabeli
INSERT
Umożliwia wstawienia wierszy do tabeli
REFERENCES
Umożliwia odwoływanie się do tabel z obcego
klucza
SELECT
Umożliwia wybieranie wierszy tabeli

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 4/20
TAKE OWNERSHIP
Umożliwia przejęcie prawa własności do tabeli
UPDATE
Umożliwia aktualizowanie wierszy tabeli
VIEW DEFINITION
Umożliwia dostęp do meta danych tabeli
Przyznawanie praw dostępu do tabeli
Za pomocą instrukcji
GRANT można przyznawać prawa dostępu dla użytkownika oraz roli bazy
danych. W poniższym przykładzie użytkownik otrzyma uprawnienia
SELECT, INSERT oraz UPDATE
do pewnej tabeli:
GRANT SELECT, INSERT, UPDATE
ON nazwa_tabeli
TO nazwa_uzytkownika
Ograniczanie praw dostępu do tabel
W celu zabronienia użytkownikowi praw dostępu można zetknąć się z dwojaką sytuacją.
1.
Jeśli użytkownik zostały przyznane uprawnienia do tabeli, aby je zdjąć, należy użyć instrukcji
REVOKE:
REVOKE SELECT
ON nazwa_tabeli
TO nazwa_uzytkownika
2.
Może zdarzyć się sytuacja, że mimo zdjęcia uprawnień, użytkownik nadal dysponuje tymi
uprawnieniami, jeżeli należy do roli, której to uprawnienie przyznano. W takim przypadku
należy użyć instrukcji
DENY:
DENY DELETE
ON nazwa_tabeli
TO nazwa_uzytkownika
Zapewnienie dostępu do pojedynczych kolumn
Istnieje również możliwość przyznawania lub odmawiania praw dostępu nie tylko do tabel, ale
również do poszczególnych kolumn. W tab. 2 pokazano uprawnienia dotyczące zarządzaniem
kolumnami tabeli.
Tab. 2 Uprawnienia dotyczące zarządzaniem kolumn tabeli
Uprawnienia
Opis
SELECT
Umożliwia wykonywanie selekcji na kolumnie
UPDATE
Umożliwia aktualizowanie kolumny
REFERENCE
Umożliwia odwoływanie się do kolumny z obcego klucza
Nadawanie praw dostępu do kolumn
Prawa dostępu do pojedynczej kolumny nadajemy poleceniem
GRANT
.
W poniższym przykładzie
użytkownikowi zostanie nadane uprawnienie
SELECT oraz UPDATE dotyczące kolumn kolumna1,
kolumna2 itd. w tabeli:
GRANT SELECT, UPDATE(kolumna1[, kolumna2[,...n]])
ON nazwa_tabeli
TO nazwa_uzytkownika
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 5/20
Odmawianie praw dostępu do kolumn
Podobnie jak w przypadku tabel, tak również w przypadku poszczególnych kolumn przy
odmawianiu praw dostępu użytkownikowi można zetknąć się z dwojaką sytuacją:
1.
Jeśli użytkownik zostały przyznane uprawnienia do poszczególnych kolumn tabeli, aby je
zdjąć, należy użyć instrukcji
REVOKE:
REVOKE UPDATE
ON nazwa_tabeli
TO nazwa_uzytkownika
2.
Może zdarzyć się sytuacja, że mimo zdjęcia uprawnień, użytkownik nadal dysponuje tymi
uprawnieniami, jeżeli należy do roli, której to uprawnienie przyznano. W takim przypadku
należy użyć instrukcji
DENY:
DENY DELETE
ON nazwa_tabeli
TO nazwa_uzytkownika
Zarządzanie dostępem do obiektów programowalnych
Obiekty programowalne, takie jak procedury składowane, mają swój własny kontekst zabezpieczeń.
Zatem po to, żeby użytkownik mógł wykonać procedurę składowaną, potrzebuje odpowiednich
uprawnień. Kiedy aparat bazy danych sprawdzi uprawnienia do wykonywania procedury
składowanej i są one właściwe, wówczas sprawdza, czy użytkownik posiada odpowiednie
uprawnienia do wykonywania operacji wewnątrz obiektów.
Tak jak i inne obiekty, procedury składowane muszą być w odpowiedni sposób zabezpieczone.
Aspekt zabezpieczania procedur składowanych można potraktować dwojako. Z jednej strony
potrzebne są uprawnienia na przykład do tworzenia procedur składowanych, a z drugiej strony
użytkownicy muszą mieć odpowiednie uprawnienia do wywołania tej procedury. Tab. 3
przedstawia uprawnienia dotyczące procedur składowanych.
Tab. 3 Uprawnienia dotyczące procedur składowanych
Uprawnienia
Opis
ALTER
Umożliwia modyfikację właściwości procedury składowanej
CONTROL
Zapewnia uprawnienia właściciela
EXECUTE
Umożliwia wykonywanie procedury składowanej
TAKE OWNERSHIP
Umożliwia przejęcie prawa własności do procedury składowanej
VIEW DEFINITION
Umożliwia przeglądanie meta danych procedury składowanej
W momencie kiedy aplikacja żąda wywołania procedury składowanej, SQL Server musi sprawdzić,
czy użytkownik posiada uprawnienia
EXECUTE dotyczące tej procedury.
GRANT EXECUTE On nazwa_procedury_skladowanej
TO nazwa_uzytkownika
W taki sam sposób możemy odwołać lub odmówić użytkownikowi uprawnienia
EXECUTE.
Polecenia DDL
Instrukcje języka DDL służą do manipulowania bazą danych i jej obiektami. Pozwalają one na:
•
tworzenie nowych obiektów
•
modyfikowanie obiektów już istniejących
•
usuwanie obiektów

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 6/20
Do podstawowych instrukcji języka DDL należą:
•
CREATE – służy do tworzenie nowych obiektów.
•
ALTER – służy do modyfikacji obiektów już istniejących.
•
DROP – służy do usunięcia obiektu już istniejącego.
Tworzenie nowych obiektów
Tworzenie nowych obiektów omówimy w kontekście tabel i widoków. W celu stworzenia nowej
tabeli wywołujemy instrukcję
CREATE TABLE. Składnia częściowa tej instrukcji została
przedstawiona poniżej:
CREATE TABLE nazwa_tabeli (
nazwa_kolumny1 typ_danych [NULL | NOT NULL][,
nazwa_kolumny2 typ_danych [NULL | NOT NULL][,...n]]
)
Przy definiowaniu tabeli należy podać jej nazwę, nazwy jej atrybutów oraz typ danych, które te
atrybuty mogą przyjmować. Dodatkowo określamy, czy dany atrybut może przyjmować wartość
NULL czy nie. Przykład tworzenia tabeli pokazano poniżej:
CREATE TABLE Osoba
(
ID_Osoba int NOT NULL,
Nazwisko char(50) NOT NULL,
Imie char(20) NOT NULL,
Telefon int NULL
)
W podobny sposób tworzymy widoki. W celu stworzenia nowego widoku wywołujemy instrukcję
CREATE VIEW.
Składnia częściowa tej instrukcji została przedstawiona poniżej:
CREATE VIEW nazwa_widoku[(kolumna1, [kolumna2[,...n])]
AS
SELECT wyrazenie_select
Przy definiowaniu widoku należy podać jego nazwę, nazwę kolumn, które będą używane w widoku,
oraz wyrażenie
SELECT, które definiuje widok. Polecenie to może używać nie tylko jedna, ale
również wiele tabel, jak również innych widoków. Przykład tworzenia widoku pokazano poniżej:
CREATE VIEW Praca_dyplomowa(ID_Praca, Nazwisko, Imię, Tytuł)
AS
SELECT ID_Praca, Imię, Nazwisko, Tytuł FROM Praca
Modyfikowanie obiektów
Po stworzeniu obiektu powinniśmy móc go w razie jakiejkolwiek potrzeby zmodyfikować. Do
modyfikacji obiektów (zarówno tabel jak i widoków) służy polecenie
ALTER. W celu modyfikacji
istniejącej tabeli należy zastosować polecenie
ALTER TABLE, którego uproszczona składnię
częściową pokazano poniżej:
ALTER TABLE nazwa_tabeli
{ { ALTER COLUMN nazwa_kolumny | ADD <definicja_kolumny> }
[{ NULL | NOT NULL }] } |
DROP COLUMN nazwa_kolumny }
<definicja_kolumny> ::= nazwa_kolumny typ_danych
Najczęściej polecenie
ALTER TABLE stosuje się do zmiany schematu relacji. Przykład zastosowania
tego polecenia do dodania lub usunięcia kolumny z tabeli pokazano poniżej:
ALTER TABLE nazwa_tabeli ADD nazwa_kolumny typ_danych
ALTER TABLE nazwa_tabeli DROP COLUMN nazwa_kolumny

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 7/20
Podobnie jak tabelę możemy zmodyfikować widok. W celu modyfikacji istniejącego widoku należy
zastosować polecenie
ALTER VIEW, którego uproszczona składnię częściową pokazano poniżej:
ALTER VIEW nazwa_widoku [(kolumna1[, kolumna2[,...n]])]
AS
SELECT wyrazenie_select
Przy modyfikacji widoku należy podać nazwę modyfikowanego widoku, nazwę jednej lub wielu
kolumn, z których składać się ma nowy widok oraz wyrażenie
SELECT, które ma definiować nowy
widok. Przykład zastosowania instrukcji modyfikacji widoku pokazano poniżej:
ALTER VIEW Praca_dyplomowa(Nazwisko, Imię, Tytuł)
AS
SELECT Imię, Nazwisko, Tytuł FROM Praca
Usuwanie obiektów
Po stworzeniu obiektu powinniśmy móc go w razie jakiejkolwiek potrzeby usunąć. Do usuwania
obiektów (zarówno tabel jak i widoków) służy polecenie
DROP. W celu usunięcia istniejącej tabeli,
należy zastosować polecenie
DROP TABLE. Usuwa ono również schemat tabeli. Jego uproszczoną
składnię częściową pokazano poniżej:
DROP TABLE nazwa_tabeli
gdzie w nazwie tabeli podajemy nazwę obiektu, który chcemy usunąć. Przykładowo:
DROP TABLE Osoba
W celu usunięcia istniejącego widoku należy zastosować polecenie DROP VIEW. Jego uproszczoną
składnię częściową pokazano poniżej:
DROP VIEW nazwa_widoku
gdzie w nazwie widoku podajemy nazwę obiektu, który chcemy usunąć. Przykładowo:
DROP VIEW Osoba, PracaDyplomowa
Przykładowe rozwiązanie
Dodawanie użytkowników
Dodawać użytkowników można na dwa sposoby. Pierwszy polega na tworzeniu użytkowników z
poziomu języka T-SQL używając procedur składowanych. Drugi na tworzeniu użytkowników z
poziomu SQL Server Management Studio. Poniżej zaprezentujemy obydwie metody.
Tworzenie użytkowników z poziomu języka T-SQL
Pierwszym krokiem związanym z zarządzaniem użytkownikami jest stworzenie użytkowników
serwera i bazy danych. W tym celu stosujemy systemową procedurę składowaną
sp_addlogin. W
naszym przykładzie stworzymy dwóch użytkowników:
Konsultant1 i Konsultant2.
EXEC sp_addlogin Konsultant1
EXEC sp_addlogin Konsultant2
Następnie powinniśmy zezwolić nowo stworzonym użytkownikom na dostęp do bazy danych. W
tym celu używamy systemowej procedury składowanej
sp_grantdbaccess. W naszym
przykładzie mamy:
EXEC sp_grantdbaccess Konsultant1
EXEC sp_grantdbaccess Konsultant2
Po stworzeniu użytkowników i daniu im możliwości dostępu do bazy danych, w kolejnym kroku
powinniśmy dodać ich do roli. W tym celu używamy systemowej procedury składowanej
sp_addrolemember. W naszym przykładzie mamy:

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 8/20
EXEC sp_addrolemember Obsluga, Konsultant1
EXEC sp_addrolemember Obsluga, Konsultant2
W wyniku stworzyliśmy dwóch użytkowników:
Konsultant1 i Konsultant2, którym nadaliśmy
prawo dostępu do bazy danych, a następnie przydzieliliśmy ich do roli
Obsluga.
Tworzenie użytkowników z poziomu SQL Server Management Studio
W celu stworzenia użytkowników poziomu SQL Server Menagemant Studio, w pierwszym kroku
należy dodać użytkowników do serwera bazodanowego. W tym celu w obrębie Object Explorer
wybieramy katalog Security, a następnie Login. W obrębie zakładki Login wybieramy prawym
przyciskiem myszy New Login, a następnie dodajemy nazwę użytkownika, sposób autoryzacji,
ustawiamy hasło, które użytkownik zmieni przy pierwszym logowaniu, domyślną bazę danych oraz
język domyślny, co pokazano na rys. 2.
Rys. 2 Zakładanie konta na SQL Server 2008 użytkownikowi
W analogiczny sposób tworzymy drugiego użytkownika. W następnym etapie dodajemy obydwu
użytkowników do bazy danych. W tym celu w obrębie Object Explorer wybieramy Datatabase, a
następnie bazę danych, do której chcemy przypisać użytkowników. W naszym przypadku będzie to
baza
Obsluga
. Następnie wybieramy zakładkę Security i Users. W obrębie zakładki
Users
wybieramy prawym przyciskiem myszy New User, a następnie dodajemy użytkownika, który został
wcześniej stworzony na poziomie serwera, co pokazano na rys. 1. W analogiczny sposób
postępujemy z drugim użytkownikiem.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 9/20
Rys. 3 Dodawanie użytkownika do bazy danych
Na końcu należy jeszcze zmienić ustawienia serwera tak, żeby nowi użytkownicy mogli się
zalogować. W tym celu klikamy prawym przyciskiem myszy instancję serwera i wybieramy
Properties, a następnie Security i zaznaczamy opcję SQL Server and Windows Authentication
mode, co pokazano na rys. 4.
Rys. 4 Ustawienie autoryzacji
Zarządzanie uprawnieniami dostępu do tabeli
Podobnie jak w przypadku dodawania użytkowników, tak i teraz podczas nadawania uprawnień
dostępu do tabel możemy uczynić to na dwa sposoby. Pierwszy polega na nadawaniu uprawnień
użytkownikom z poziomu języka T-SQL. Drugi na nadawaniu uprawnień użytkownikom z poziomu
SQL Server Management Studio.
Nadawanie uprawnień z poziomu języka T-SQL
W celu przyznania użytkownikowi prawa dostępu stosujemy instrukcję
GRANT. Przykładowo by
nadać prawo przeglądania i wstawiania danych do tabeli
Klienci stworzonemu wcześniej
użytkownikowi
Konsultant1 możemy zastosować następujące polecenie:
GRANT SELECT, INSERT
ON Klienci
TO Konsultant1
W podobny sposób możemy nadać wspomniane wcześniej uprawnienia roli
Obsluga:
GRANT SELECT, INSERT
ON Klienci
TO Obsluga
Analogicznie odmawiamy (
DENY) lub usuwamy (REVOKE) użytkownikowi lub roli uprawnienia.
W wielu sytuacjach znacznie bezpieczniejszym rozwiązaniem jest przydzielenie użytkownikowi
prawa wykonania procedury składowanej. Załóżmy, że posiadamy procedurę składowaną
proc_klienci, która zwraca w wyniku zbiór wierszy reprezentujących klientów. W naszym
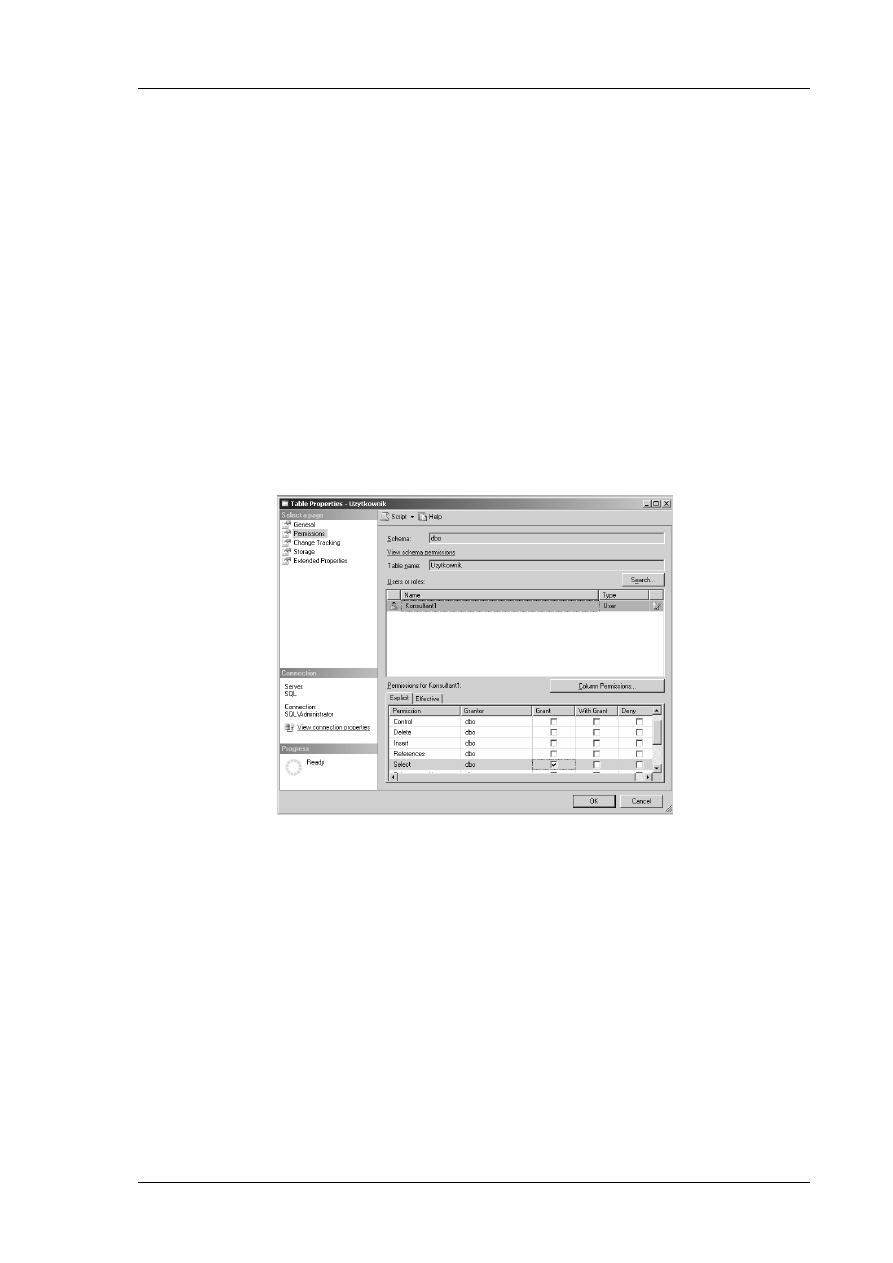
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 10/20
przykładzie przydzielimy prawo wykonania procedury składowanej użytkownikowi
Konsultant2.
Zatem będziemy mieli:
GRANT EXECUTE
ON proc_klienci
TO Konsultant2
W analogiczny sposób możemy przydzielić prawo wykonywania procedury składowanej roli
Obsluga. Zatem będziemy miel:
GRANT EXECUTE
ON proc_klienci
TO Obsluga
Nadawanie uprawnień z poziomu SQL Server Management Studio
W celu nadania użytkownikowi uprawnień dostępu do obiektu typu tabela, należy w obrębie
zakładki Tables wybrać tabelę
Uzytkownik
, a następnie kliknąć prawym przyciskiem myszy i wybrać
Properties. W obrębie okna Table Proberties wybieramy zakładkę Permissions. Mając
zdefiniowanego użytkownika na poziomie bazy danych
Obsluga
, nadajemy mu odpowiednie
uprawnienia. W naszym przypadku dajemy mu możliwość przeglądania tabeli, co pokazano na rys.
5.
Rys. 5 Nadanie uprawnień na tabeli Uzytkownik
Operacje na obiektach
Załóżmy, że chcemy stworzyć nowy obiekt w postaci tabeli, która będzie przechowywała informacje
o klientach. W tym celu stosujemy polecenie
CREATE TABLE, co pokazano poniżej:
CREATE TABLE Klienci
(
ID_Klient int NOT NULL,
Firma char(100) NOT NULL,
Nazwisko char(50) NOT NULL,
Imie char(20) NOT NULL,
Telefon int NULL,
Fax int NULL,
email char(20) NULL
)

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 11/20
Jeżeli użytkownikowi
Konsultant2 chcemy nadać prawo przeglądania danych o klientach,
możemy dla tabeli
Klienci stworzyć widok z udostępnionymi danym, a użytkownikowi dać prawo
dostępu do widoku. Zatem tworzymy widok jak poniżej i nadajemy prawo dostępu do widoku w
analogiczny sposób, jak pokazano wyżej dla obiektu typu tabela.
CREATE VIEW Klienci_Obsluga(Firma, Nazwisko, Imię, Telefon)
AS
SELECT Imię, Nazwisko, Firma, Telefon FROM Klienci
Załóżmy, że chcemy dodać kolumnę przechowująca informacje o stronie internetowej do tabeli
Klienci. Wówczas:
ALTER TABLE Klienci ADD www char(50) NULL
W analogiczny sposób możemy zmodyfikować widok
Klienci_Obsluga tak, żeby użytkownik
Konsultant2 mógł przeglądać adresy stron internetowych klientów. Zatem:
ALTER VIEW Klienci_Obsluga (Firma, Nazwisko, Imię, Telefon, www)
AS
SELECT Imię, Nazwisko, Firma, Telefon, www FROM Klienci
Załóżmy, że chcemy usunąć kolumnę przechowująca informacje o numerze faksu z tabeli
Klienci.
Wówczas:
ALTER TABLE Klienci DROP COLUMN fax
Porady praktyczne
Język T-SQL DCL
•
Przyznawanie lub odmawianie praw dostępu do poszczególnych kolumn zwiększa
elastyczność w zarządzaniu dostępem na przykład do poufnych danych z niektórych kolumn.
•
W zarządzaniu dostępem do obiektów programowalnych występuje zagadnienie łańcucha
praw własności. Łańcuch praw własności jest sekwencją obiektów bazy danych uzyskujących
dostęp do siebie nawzajem. W sytuacji, kiedy w tabeli są wiersze uzyskane z procedury
składowanej, procedura ta jest obiektem wywołującym, a tabela obiektem wywoływanym.
Gdy SQL Server napotka na taki łańcuch, aparat bazy danych sprawdza uprawnienia inaczej
niż w przypadku indywidualnego dostępu do obiektów.
•
Tworzenie użytkowników oraz nadawanie im uprawnień może odbywać się na dwa sposoby.
Pierwszy wymaga znajomości języka T-SQL. Drugi sposób polega na wykorzystaniu
graficznych narzędzi dostępnych w SQL Server Menagement Studio.
•
W przypadku tworzenia użytkowników z poziomu języka T-SQL musimy znać odpowiednie
procedury składowane, których należy w tym celu użyć. W procedurach składowanych
zapisane są ustawienia, które zostaną wprowadzone podczas ich użycia.
•
Możemy nadawać uprawnienia do różnych obiektów w bazie danych. W rozdziale
„Przykładowe rozwiązanie” pokazano w jaki sposób nadawać uprawnienia do obiektu typu
tabela. W analogiczny sposób możemy nadawać uprawnienia do obiekty typu: widok, funkcja
czy procedura składowana.
•
Użytkowników możemy grupować według nadanych im uprawnień. Wówczas możemy
założyć role i pogrupować użytkowników według ról, jakie pełnią w bazie danych. W wyniku
tego możemy przypisać dostęp do obiektów bazy danych nie tylko pojedynczemu
użytkownikowi, ale również grupom użytkowników zapisanych w roli.
Język T-SQL DDL
•
Poleceniem
CREATE możemy utworzyć nie tylko tabelę czy widok, lecz również obiekt
programowalny w postaci procedury składowanej. W tym celu wywołujemy instrukcję
CREATE PROCEDURE. Przykładowa składnia częściowa instrukcji tworzenia procedury bez
parametru została pokazana poniżej:

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 12/20
CREATE PROCEDURE nazwa_procedury
AS
SELECT wyrazenie
•
Polecenie
ALTER, podobnie CREATE, może być stosowane w odniesieniu do obiektu
programowalnego w postaci procedury składowanej. W tym celu wywołujemy instrukcję
ALTER PROCEDURE. Przykładowa składnia częściowa instrukcji modyfikowania procedury
została pokazana poniżej:
ALTER PROCEDURE nazwa_procedury
[WITH { RECOMPILE | ENCRYPTION }]
AS
SELECT wyrazenie
•
W celu usunięcia istniejącej procedury składowanej należy zastosować polecenie
DROP
PROCEDURE. Jego uproszczoną składnię częściową pokazano poniżej:
DROP PROCEDURE nazwa_widoku
•
Tworzenie, modyfikacja i usuwanie może odbywać się na obiektach typu: baza danych,
funkcja, indeks, tabela, procedura składowana, widok, wyzwalacz.
•
Polecenie
CREATE służy do tworzenia wszystkich obiektów baz danych: tabel (CREATE
TABLE), widoków (CREATE VIEW), procedur składowanych (CREATE PROCEDURE),
indeksów (
CREATE INDEX), wyzwalaczy (CREATE TRIGGER). Tylko tymczasowe twory,
takie jak zmienne czy kursory, deklaruje się (nie tworzy) za pomocą polecenia
DECLARE.
•
Do istniejącej tabeli możemy zawsze dodać ograniczenia na istniejąca kolumnę, przykładowo:
ALTER TABLE Osoba_1
ADD CONSTRAINT CK_Nr_Indeksu CHECK (Nr_Indeksu > 10000)
Ograniczenie to wymusza wstawianie w kolumnie
Nr_indeksu liczb całkowitych większych
od 10000.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz zasadę zarządzania uprawnieniami do obiektów bazy danych
•
rozumiesz mechanizm manipulowania bazą danych i jej obiektami
•
umiesz podać przykłady obiektów baz danych, do których można zastosować składnię języka
T-SQL DDL oraz T-SQL DCL
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Kalen Delaney, Microsoft SQL Server 2005: Rozwiązania praktyczne krok po kroku, Microsoft
Press, 2006
W książce autor w przystępny i zrozumiały sposób przedstawia, między innymi, w
jaki sposób nadawać prawa dostępu do bazy danych oraz jak zarządzać rolami.
Następnie pokazuje, jak prosto można nadawać uprawnienia do obiektów bazy
danych typu tabela i widok.
2.
Edward Whalen, Microsoft SQL Server 2005 Administrator’s Companion, Microsoft Press, 2006
W książce autor pokazał, w jaki sposób można zorganizować nadawanie uprawnień
do bazy danych oraz do obiektów bazy danych od strony administracyjnej. Przybliża
również, jak należy planować politykę bezpieczeństwa serwera i bazy danych

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 13/20
poprzez nadawanie odpowiednich uprawnień. Pozycja szczególnie polecana
osobom chcącym poszerzyć wiedzę o tych elementach administracji serwerem.
3.
Deren Bieniek, Randy Dyess, Mike Hotek, Javier Loria, Adam Machanic, Antonio Soto, Adolfo
Wiernik, SQL Server 2005. Implementacja i obsługa, APN Promise, 2006
W książce przedstawiono obie składowe języka T-SQL: DCL i DDL. Pokazano, w jaki
sposób tworzyć użytkowników, nadawać im uprawnienia oraz jak tworzyć,
modyfikować i usuwać podstawowe obiekty bazy danych. Książka szczególnie warta
polecenia ze względu na dużą zawartość ćwiczeń laboratoryjnych.
4.
Dusan Petkovic, Microsoft SQL Server 2008: A Beginner's Guide, McGraw-Hill, 2008
Pozycja napisana w sposób przystępny. Wprowadza w SQL Server 2008 w sposób
szybki i łatwy. Osoba początkująca w SQL Server 2008 znajdzie w niej podstawy z
każdego tematu dotyczącego serwera bazodanowego. W prosty sposób dowiesz
się, jak należy definiować użytkowników i nadawać im uprawnienia oraz jak
tworzyć, modyfikować i usuwać podstawowe obiekty bazy. Pozycja szczególnie
polecana dla osób początkujących.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy Danych
Laboratorium podstawowe
Problem 1 (czas realizacji
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie systemu
skalę uczelniana. Pierwsze z
oraz modyfikacja użytkowników istniejących
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
W oknie logowania kliknij
2.
Utwórz tabelę
•
Z menu głównego wybierz
•
Odszukaj plik
•
Zaznacz i uruchom (
--
USE PraceDyplomowe
GO
--
CREATE TABLE Osoba_1(
)
3.
Zmodyfikuj
tabelę
•
Mając otwarty skrypt
fragment kodu odpowiedzialny za zmianę definicji kolumny
--
ALTER TABLE Osoba_1
GO
•
Dodaj do tabeli
telefonu.
--
ALTER TABLE Osoba_1
GO
•
Dodaj ograniczenia na kolumnę indeks.
(F5
--
ALTER TABLE Osoba_1
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 14/20
Laboratorium podstawowe
Problem 1 (czas realizacji 15 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie systemu prac dyplomowych na Twoim wydziale
Pierwsze zadanie, jakie przed Tobą stoi, to zdefiniowanie nowych użytkowników
oraz modyfikacja użytkowników istniejących.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Z menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Labs\Lab06\ddl.sql.
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (1) Ustawiamy PraceDyplomowe jako baze robocza
USE PraceDyplomowe
GO
-- (2) Tworzymy w bazie danych tabele Osoba_1
CREATE TABLE Osoba_1(
ID_Osoby
smallint
NOT NULL,
Imie
varchar(10)
NOT NULL,
Nazwisko
varchar(10)
NOT NULL,
Nr_Indeksu
varchar(10)
NULL,
ID_Stopnien
smallint
NULL
Mając otwarty skrypt ddl.sql w oknie Query zaznacz i uruchom poniższy
fragment kodu odpowiedzialny za zmianę definicji kolumny
-- (3) zmiana definicji kolumny Nazwisko
ALTER TABLE Osoba_1
ALTER COLUMN Nazwisko varchar(40) NOT NULL
ALTER COLUMN Nr_Indeksu int NULL
GO
Dodaj do tabeli Osoba_1 kolumnę przechowującą informacje o numerze
telefonu. W tym celu zaznacz i uruchom (F5) poniższy fragment ko
-- (4) Dodanie kolumny Telefon
ALTER TABLE Osoba_1
ADD Telefon int
GO
Dodaj ograniczenia na kolumnę indeks. W tym celu z
F5) poniższy fragment kodu.
-- (5) Dodajmy ograniczenie na kolumne Nr_Indeksu
ALTER TABLE Osoba_1
Moduł 5
Język SQL DCL, DDL
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
woim wydziale, którym zarządza, na
to zdefiniowanie nowych użytkowników
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
Ustawiamy PraceDyplomowe jako baze robocza
(2) Tworzymy w bazie danych tabele Osoba_1
zaznacz i uruchom poniższy
fragment kodu odpowiedzialny za zmianę definicji kolumny Nazwisko:
kolumnę przechowującą informacje o numerze
) poniższy fragment kodu:
W tym celu zaznacz i uruchom
(5) Dodajmy ograniczenie na kolumne Nr_Indeksu
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy Danych
GO
•
Usuń ograniczenia nałożone w poprzednim kroku.
uruchom (
--
ALTER TABLE Osoba_1
GO
•
Usuń kolumnę
fragment kodu
--
ALTER TABLE Osoba_1
GO
4.
Usuń tabelę
•
Usu
uruchom (
--
GO
Problem 2 (czas realizacji
W wyniku rozszerzenia systemu zarządzania pracami dyplomowymi na skalę uczelni
zadanie, jakie przed tobą stoi
praw dostępu do obiektów w Twojej bazie danych.
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server
•
W oknie logowania kliknij
2.
Dodaj
użytkowników do
bazy danych
•
Z menu głównego wybierz
•
Odszukaj pliku
•
Zaznacz i uruchom (
6
--
USE PraceDyplomowe
GO
--
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 15/20
ADD CONSTRAINT CK_Nr_Indeksu CHECK (Nr_Indeksu > 10000)
GO
Usuń ograniczenia nałożone w poprzednim kroku.
uruchom (F5) poniższy fragment kodu.
-- (6) Usuwamy ograniczenie na kolumnie Nr_Indeksu
ALTER TABLE Osoba_1
DROP CONSTRAINT CK_Nr_Indeksu
GO
Usuń kolumnę Telefon. W tym celu zaznacz i uruchom (
fragment kodu.
-- (7) Usuwamy kolumne Telefon
ALTER TABLE Osoba_1
DROP COLUMN Telefon
GO
Usuń tabelę Osoba_1. W tym celu mając otwarty skrypt
uruchom (F5) poniższy fragment kodu.
-- (8) Usuwamy tabele Osoba_1
DROP TABLE Osoba_1
GO
Problem 2 (czas realizacji 30 min)
W wyniku rozszerzenia systemu zarządzania pracami dyplomowymi na skalę uczelni
jakie przed tobą stoi, to przydzielenie nowo zdefiniowanym użytkownikom odpowiednich
praw dostępu do obiektów w Twojej bazie danych.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Z menu głównego wybierz File -> Open -> File.
Odszukaj pliku C:\Labs\Lab06\dcl_1.sql.
Zaznacz i uruchom (F5) poniższy fragment kodu. Wynik pokazano na
6.
-- (1) Ustawiamy PraceDyplomowe jako baze robocza
USE PraceDyplomowe
GO
-- (2) Dodajmy dwoch nowych uzytkownikow serwera i bazy danych,
Sekretariat1 i Sekretariat2, umiescmy ich w grupie Dziekanat
EXEC sp_addlogin Sekretariat1
EXEC sp_addlogin Sekretariat2
EXEC sp_grantdbaccess Sekretariat1
EXEC sp_grantdbaccess Sekretariat2
Moduł 5
Język SQL DCL, DDL
T CK_Nr_Indeksu CHECK (Nr_Indeksu > 10000)
Usuń ograniczenia nałożone w poprzednim kroku. W tym celu zaznacz i
(6) Usuwamy ograniczenie na kolumnie Nr_Indeksu
aznacz i uruchom (F5) poniższy
ając otwarty skrypt ddl.sql zaznacz i
W wyniku rozszerzenia systemu zarządzania pracami dyplomowymi na skalę uczelni, kolejne
definiowanym użytkownikom odpowiednich
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
fragment kodu. Wynik pokazano na rys.
(1) Ustawiamy PraceDyplomowe jako baze robocza
(2) Dodajmy dwoch nowych uzytkownikow serwera i bazy danych,
1 i Sekretariat2, umiescmy ich w grupie Dziekanat
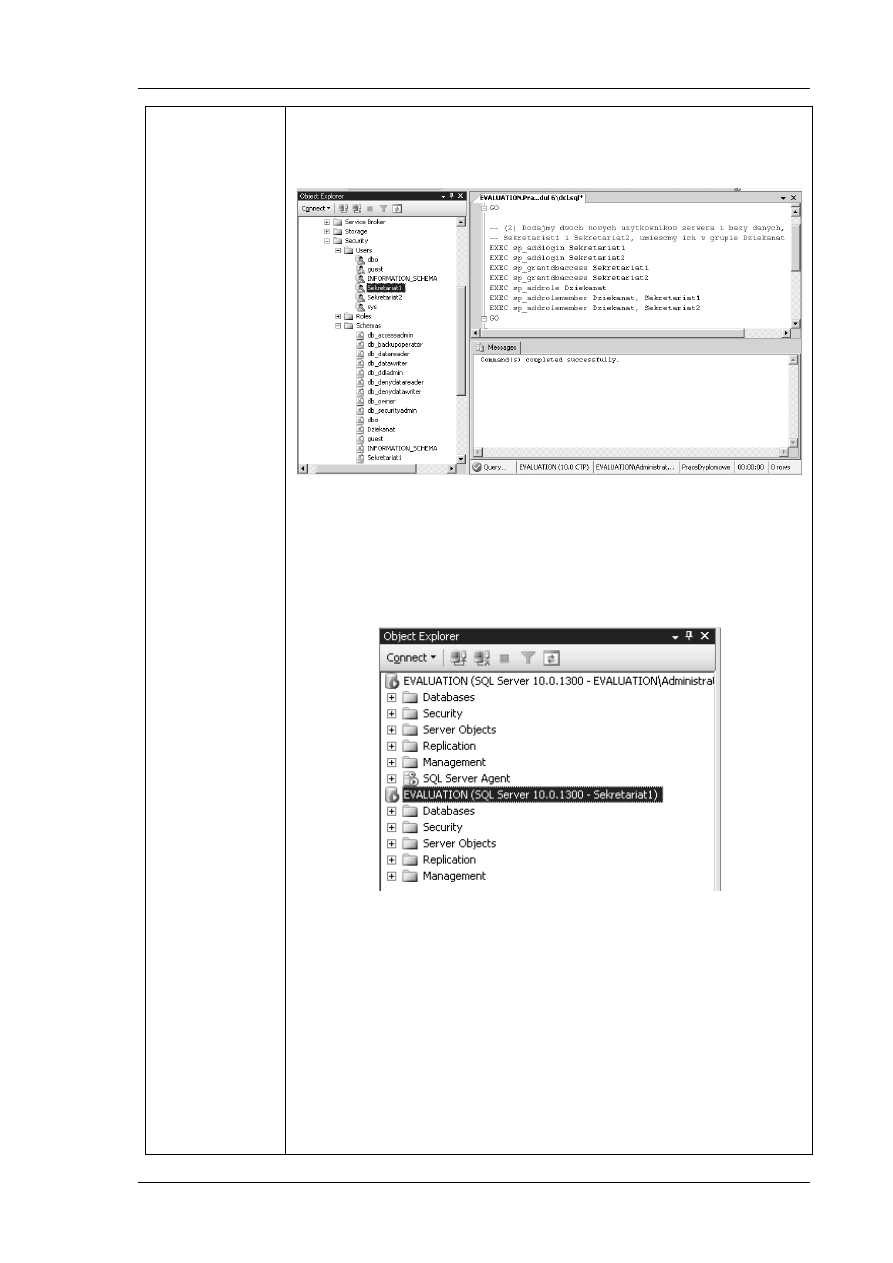
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 16/20
EXEC sp_addrole Dziekanat
EXEC sp_addrolemember Dziekanat, Sekretariat1
EXEC sp_addrolemember Dziekanat, Sekretariat2
GO
Rys. 6 Dodanie użytkowników do bazy danych
•
W oknie Object Explorer kliknij przycisk Connect -> Database Engine.
•
W zakładce Authentication wybierz SQL Server Authentication.
•
W polu Login wpisz użytkownika Sekretariat1. Hasło pozostaw puste.
•
W wyniku powinieneś uzyskać połączenie do drugiej instancji serwera,
co pokazano na rys. 7.
Rys. 7 Podłączenie do drugiej instancji serwera
•
Odszukaj pliku C:\Labs\Lab06\dcl_2.sql.
•
Zaznacz i uruchom (F5) poniższy fragment kodu. Wynik pokazano na rys.
8:
-- (1) Ustawmy PraceDyplomowe jako baze robocza
USE PraceDyplomowe
GO
-- (2) sprawdzamy, czy mamy uprawnienia do wykonania
-- polecenia SELECT na tabeli Osoba
SELECT * FROM Osoba
GO

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy Danych
•
Spróbuj
nadać
uprawnienia
innemu
użytkownikowi
zalogowan
poniższy
--
GRANT SELECT ON Osoba TO S
GO
3.
Nadaj
uprawnienia
•
Przełącz się do okna ze skryptem
•
Zaznacz i uruchom (
--
--
GRANT SELECT ON Osoba TO Sekretariat1
GO
•
Przełącz się do okna ze skryptem
użytkownika
•
Zaznacz i uruchom (
pokazano na
--
USE PraceDyplomowe
GO
--
--
SELECT * FROM Osoba
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 17/20
Pamiętaj, że powyższy fragment kodu zawarty w skrypcie
wykonujemy z zalogowanym użytkownikiem Sekretatiat1
Rys. 8 Sprawdzenie uprawnienia wykonania polecenia SELECY na tabeli Osoba
Wykonanie poprzedniego polecenia nie powiodło
domyślne uprawnienia nowego użytkownika nie pozwalają na
wykonanie żadnego polecenia w bazie danych. Skoro nie mamy
uprawnień do wykonywania poleceń, tym bardziej nie możemy ich
nadawać.
Spróbuj
nadać
uprawnienia
innemu
użytkownikowi
zalogowanym jako Sekretariat1. W tym celu zaznacz i uruchom (
poniższy fragment kodu:
-- (3) Spróbujmy nadać uprawnienia innemu użytkown
GRANT SELECT ON Osoba TO Sekretariat2
GO
Podjąłeś
nieudaną
próbę
nadania
innemu
użytkownikowi
(Sekretariat2) uprawnień do wykonywania polecenia
Osoba.
Przełącz się do okna ze skryptem dcl_1.sql.
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (3) Nadaj uprawnienia do wykonywania polecenia SELECT
-- w tabeli Osoba użytkownikowi Sekretariat1
GRANT SELECT ON Osoba TO Sekretariat1
GO
Przełącz się do okna ze skryptem dcl_2.sql uruchomionego w kontekście
użytkownika Sekretariat1.
Zaznacz i uruchom (F5) poniższy fragment kodu. Wynik uruchomienia
pokazano na rys. 9:
-- (1) Ustawmy PraceDyplomowe jako baze robocza
USE PraceDyplomowe
GO
-- (2) sprawdzamy, czy mamy uprawnienia do wykonania
-- polecenia SELECT na tabeli Osoba
SELECT * FROM Osoba
GO
Moduł 5
Język SQL DCL, DDL
taj, że powyższy fragment kodu zawarty w skrypcie dcl_2.sql
Sekretatiat1
Sprawdzenie uprawnienia wykonania polecenia SELECY na tabeli Osoba
Wykonanie poprzedniego polecenia nie powiodło się, ponieważ
omyślne uprawnienia nowego użytkownika nie pozwalają na
wykonanie żadnego polecenia w bazie danych. Skoro nie mamy
uprawnień do wykonywania poleceń, tym bardziej nie możemy ich
Spróbuj
nadać
uprawnienia
innemu
użytkownikowi,
będąc
aznacz i uruchom (F5)
uprawnienia innemu użytkownikowi
nadania
innemu
użytkownikowi
) uprawnień do wykonywania polecenia SELECT w tabeli
(3) Nadaj uprawnienia do wykonywania polecenia SELECT
uruchomionego w kontekście
fragment kodu. Wynik uruchomienia
(1) Ustawmy PraceDyplomowe jako baze robocza
(2) sprawdzamy, czy mamy uprawnienia do wykonania

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy Danych
•
Zaznacz i uruchom (
--
--
GRANT SELECT ON Osoba TO Sekretariat
GO
4.
Cofnij
uprawnienia
•
Przełącz się do okna, w którym masz uruchomiony skrypt
•
Zaznacz i uruchom (
--
--
REVOKE SELECT ON Osob
GO
•
Przełącz się do okna, w którym masz uruchomiony skrypt
•
Zaznacz i uruchom (
--
--
SELECT * FROM Osoba
GO
5.
Odbierz
uprawnienia
•
Przełącz się do okna, w którym masz uruchomiony skrypt
•
Zaznacz i uruchom (
--
--
GRANT SELECT ON Osoba TO Sekretariat1
GO
•
Przełącz się do okna, w którym masz uruchomiony skrypt
•
Zaznacz i uruchom (
--
--
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 18/20
Rys. 9 Sprawdzenie uprawnien do wykonania polecenia SELECT
Zaznacz i uruchom (F5) ponownie poniższy fragment kodu
-- (3) Nadaj uprawnienia do wykonywania polecenia SELECT
-- w tabeli Osoba użytkownikowi Sekretariat2
GRANT SELECT ON Osoba TO Sekretariat2
GO
I tym razem nie udaje się nadać praw innemu użytkownikowi
nadanie uprawnień do wykonywania polecenia nie jest równoznaczne
z umożliwieniem nadawania uprawnień innym użytkownikom.
Przełącz się do okna, w którym masz uruchomiony skrypt
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (4) Cofnij uprawnienia do wykonywania polecenia SELECT
-- w tabeli Osoba użytkownikowi Sekretariat1
REVOKE SELECT ON Osoba FROM Sekretariat1
GO
Przełącz się do okna, w którym masz uruchomiony skrypt
Zaznacz i uruchom (F5) ponownie poniższy fragment kodu
-- (2) sprawdźmy, czy mamy uprawnienia do wykonania
-- polecenia SELECT na tabeli Osoba
SELECT * FROM Osoba
GO
Po cofnięciu uprawnień do wykonania polecenia
tego fragmentu skryptu powinno zwrócić informację o błędzie.
Przełącz się do okna, w którym masz uruchomiony skrypt
Zaznacz i uruchom (F5) ponownie poniższy fragment kodu
-- (3) Nadaj uprawnienia do wykonywania polecenia SELECT
-- w tabeli Osoba użytkownikowi Sekretariat1
GRANT SELECT ON Osoba TO Sekretariat1
GO
Przełącz się do okna, w którym masz uruchomiony skrypt
Zaznacz i uruchom (F5) ponownie poniższy fragment kodu
-- (2) sprawdzmy, czy mamy uprawnienia do wykonania
-- polecenia SELECT na tabeli Osoba
Moduł 5
Język SQL DCL, DDL
Sprawdzenie uprawnien do wykonania polecenia SELECT
fragment kodu:
(3) Nadaj uprawnienia do wykonywania polecenia SELECT
I tym razem nie udaje się nadać praw innemu użytkownikowi, czyli
nadanie uprawnień do wykonywania polecenia nie jest równoznaczne
z umożliwieniem nadawania uprawnień innym użytkownikom.
Przełącz się do okna, w którym masz uruchomiony skrypt dcl_1.sql.
(4) Cofnij uprawnienia do wykonywania polecenia SELECT
Przełącz się do okna, w którym masz uruchomiony skrypt dcl_2.sql.
fragment kodu:
, czy mamy uprawnienia do wykonania
Po cofnięciu uprawnień do wykonania polecenia SELECT uruchomienie
informację o błędzie.
Przełącz się do okna, w którym masz uruchomiony skrypt dcl_1.sql.
fragment kodu:
(3) Nadaj uprawnienia do wykonywania polecenia SELECT
Przełącz się do okna, w którym masz uruchomiony skrypt dcl_2.sql.
fragment kodu:
(2) sprawdzmy, czy mamy uprawnienia do wykonania
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy Danych
SELECT * FROM Osoba
GO
•
Przełącz się do okna, w którym masz uruchomiony skrypt
•
Zaznacz i uruchom (
--
--
DENY SELECT ON Osoba TO Dziekanat
GO
•
Przełącz się do okna, w którym masz uruchomiony skrypt
•
Zaznacz i uruchom (
--
--
SELECT * FROM Osoba
GO
6.
Przekaż
uprawnienia
•
Przełącz się do okna w którym masz uruchomiony skrypt
•
Zaznacz i uruchom (
--
--
--
--
GRANT SELECT ON Osoba TO Sekretariat1 WITH GRANT OPTION
GO
•
Przełącz się do okna, w którym masz uruchomiony skrypt
•
Zaznacz i uruchom (
--
GRANT SELECT ON Osoba TO Sekretariat2
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 19/20
SELECT * FROM Osoba
GO
Przełącz się do okna, w którym masz uruchomiony skrypt
Zaznacz i uruchom (F5) ponownie poniższy fragment kodu
-- (5) Zabroń wykonywania polecenia SELECT
-- w tabeli Osoba grupie Dziekanat
DENY SELECT ON Osoba TO Dziekanat
GO
Powyższy kod spowoduje zabronienie wszystkim użytkownikom w
grupie Dziekanat (czyli u nas konkretnie użytkownikom
Sekretariat2) wykonywania polecenia SELECT w tabeli
Przełącz się do okna, w którym masz uruchomiony skrypt
Zaznacz i uruchom (F5) ponownie poniższy fragment kodu
-- (2) sprawdzmy, czy mamy uprawnienia do wykonania
-- polecenia SELECT na tabeli Osoba
SELECT * FROM Osoba
GO
Tym razem okaże się, że nie możemy wykonać polecenia
Dzieje się tak dlatego, że przed momentem zabroniliśmy grupie
Dziekanat, do której należy użytkownik, w którego kontekście
pracujemy, wykonywania polecenia SELECT.
Przełącz się do okna w którym masz uruchomiony skrypt
Zaznacz i uruchom (F5) ponownie poniższy fragment kodu
-- (6) nadaj uprawnienia do wykonywania polecenia SELECT
-- w tabeli Osoba uzytkownikowi Sekretariat1
-- z opcja nadawania przez uzytkownika uprawnien
-- do wykonywania polecenia SELECT w tej tabeli
GRANT SELECT ON Osoba TO Sekretariat1 WITH GRANT OPTION
GO
Przełącz się do okna, w którym masz uruchomiony skrypt
Zaznacz i uruchom (F5) ponownie poniższy fragment kodu
-- (3) sprobujmy nadac uprawnienia innemu uzytkownikowi
GRANT SELECT ON Osoba TO Sekretariat2
GO
Moduł 5
Język SQL DCL, DDL
Przełącz się do okna, w którym masz uruchomiony skrypt dcl_1.sql.
ent kodu:
Powyższy kod spowoduje zabronienie wszystkim użytkownikom w
(czyli u nas konkretnie użytkownikom Sekretariat1 i
w tabeli Osoba.
Przełącz się do okna, w którym masz uruchomiony skrypt dcl_2.sql.
fragment kodu:
(2) sprawdzmy, czy mamy uprawnienia do wykonania
Tym razem okaże się, że nie możemy wykonać polecenia SELECT.
Dzieje się tak dlatego, że przed momentem zabroniliśmy grupie
, do której należy użytkownik, w którego kontekście
Przełącz się do okna w którym masz uruchomiony skrypt dcl_1.sql.
) ponownie poniższy fragment kodu:
(6) nadaj uprawnienia do wykonywania polecenia SELECT
z opcja nadawania przez uzytkownika uprawnien
do wykonywania polecenia SELECT w tej tabeli
GRANT SELECT ON Osoba TO Sekretariat1 WITH GRANT OPTION
Przełącz się do okna, w którym masz uruchomiony skrypt dcl_2.sql.
niższy fragment kodu:
(3) sprobujmy nadac uprawnienia innemu uzytkownikowi

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 5
ITA-101 Bazy Danych
Język SQL DCL, DDL
Strona 20/20
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma zarządzająca bazą
AdventureWorks planuje rozszerzenie i modernizację systemu w celu
spełnienia pewnych standardów. W związku z modernizacją systemu bazodanowego,
najprawdopodobniej ulegną zmianie pewne obiekty w bazie danych (część najprawdopodobniej
zostanie zmodyfikowanych, część stworzonych, a część usuniętych) oraz uprawnienia
poszczególnych użytkowników oraz grup użytkowników do poszczególnych obiektów w bazie
danych (tabel, widoków, procedur składowanych, funkcji itp.).
Zadania, jakie przed Tobą stoją, to:
1.
Podjęcie decyzji, które obiekty w bazie danych pozostaną bez zmian, a które zostaną
zmodyfikowane lub usunięte.
2.
Zdefiniowanie nowych użytkowników oraz zmodyfikowanie użytkowników istniejących w
celu przydzielenia im praw do obiektów w zmodernizowanej bazie danych.
3.
Przeorganizowanie grupy użytkowników i nadanie im uprawnień do obiektów bazy danych.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
Wersja 1.0
Język SQL – DML
Spis treści
Język SQL – DML ................................................................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 7
Porady praktyczne ....................................................................................................................... 9
Uwagi dla studenta .................................................................................................................... 10
Dodatkowe źródła informacji..................................................................................................... 10
Laboratorium podstawowe ................................................................................................................ 12
Problem 1 (czas realizacji 45 min) .............................................................................................. 12
Laboratorium rozszerzone ................................................................................................................. 19
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 19
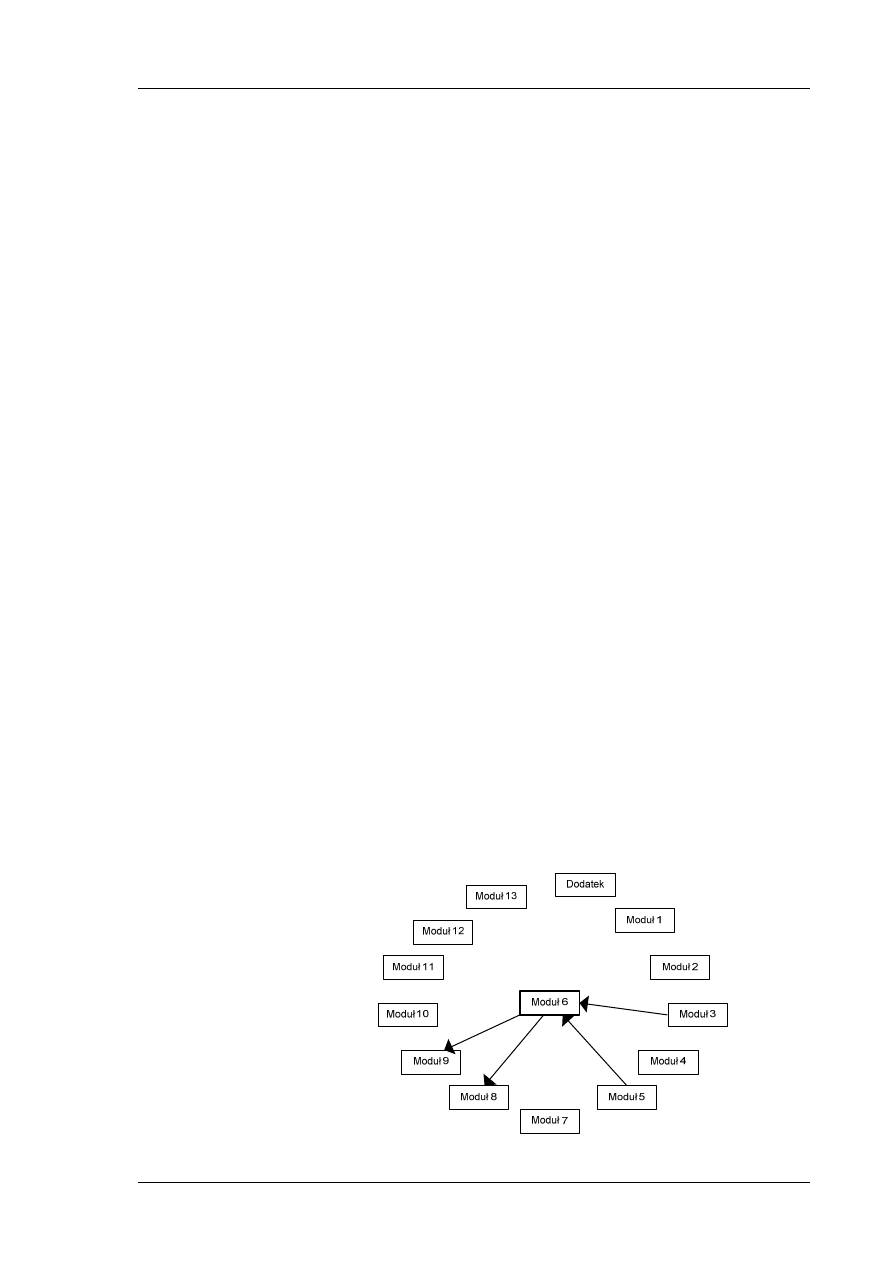
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 2/19
Informacje o module
Opis modułu
Język SQL składa się z trzech składowych: języka definiowania danych (DDL),
języka sterowania danymi (DCL) oraz języka operowania na danych (DML).
W module tym dowiesz się w jaki sposób można pobierać i przeglądać dane,
formatować zestawy wyników oraz konstruować proste zapytania używając
jeżyka T-SQL DML.
Cel modułu
Celem modułu jest zapoznanie słuchacza z podstawowymi instrukcjami
języka T-SQL DML, służącego do manipulowania danymi, oraz pokazanie
sposobu używania zaprezentowanych instrukcji.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
potrafił używać podstawowych instrukcji języka SQL DML
•
potrafił pobierać i modyfikować dane w zawarte w bazie
•
potrafił formatować zestaw wyników i przedstawiać je w przejrzystej
formie
•
potrafił konstruować proste zapytania do bazy danych Microsoft SQL
Server 2008
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
wiedzieć, w jaki sposób stworzyć bazę danych wraz z jej
podstawowymi obiektami (patrz: moduł 3)
•
wiedzieć, w jaki sposób poruszać się po Microsoft SQL Server
Management Studio
•
potrafić definiować użytkowników i przydzielać im uprawnienia
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznać się z materiałem zawartym
w modułach 3 i 5.
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 3/19
Przygotowanie teoretyczne
Przykładowy problem
Z bazy danych może korzystać wielu użytkowników, dysponujących różnorakimi uprawnieniami i
mających dostęp do różnych obiektów w bazie danych. Głównym ich zadaniem jest przeszukiwanie
danych w niej zawartych według pewnych reguł, które wcześniej zostały zdefiniowane przez
administratora, projektanta i programistę bazy danych. W związku z tym podstawowym zadaniem,
jakie stoi przed osobami odpowiedzialnymi za prawidłowe funkcjonowanie bazy danych, jest
określenie, jakie polecenia będą używane do pobierania z niej danych
Kolejnym problemem, z jakim często możemy się spotkać, jest wprowadzanie, modyfikacja oraz
import i eksport danych pomiędzy różnymi bazami. Eksport nie powinien sprawiać większych
kłopotów, natomiast problem może stanowić import danych z innych systemów zarządzania
bazami danych. Może on wynikać z odmiennej wewnętrznej struktury przechowywania danych w
różnych systemach, jak również z niespójności typów danych w nich zawartych. Dobrze jest
wiedzieć, w jaki sposób można poradzić sobie z potencjalnymi problemami przy importowaniu
danych.
Podstawy teoretyczne
W części tej pokazany zostanie sposób budowy poleceń odczytujących dane zawarte w bazie.
Rozpoczniemy od prezentacji prostych poleceń
SELECT. Następnie prześledzimy informacje na
temat złączeń używanych do pobierania danych z wielu tabel. Na końcu prześledzimy, w jaki sposób
można łatwo wprowadzać, modyfikować i kasować dane zawarte w bazie.
Wybieranie potrzebnych danych
Najprostszym sposobem pozyskiwania danych z pojedynczej tabeli jest wykonanie instrukcji
SELECT. Instrukcja ta służy do odczytywania danych przechowywanych w bazie danych. Sposób
wywołania instrukcji znajduje się poniżej:
SELECT [{ ALL | DISTINCT }] lista_wyboru
FROM nazwa_tabeli[,…n]
WHERE warunek_wyszukiwania
Jeżeli chcemy pobrać wszystkie kolumny z tabeli, możemy w liście wyboru podać gwiazdkę,
przykładowo:
SELECT * FROM nazwa_tabeli
Powyższe polecenie zwraca wszystkie dane zawarte w wybranej tabeli. Zazwyczaj odczytywanie
wszystkich kolumn z tabeli nie jest konieczne, a wykonywanie takiego zapytania może spowodować
wiele problemów.
Załóżmy, że potrzebne są nam dane tylko z niektórych kolumn z danej tabeli. Wówczas po słowie
SELECT należy wymienić nazwy tych kolumn w takiej kolejności, w jakiej chcemy, aby zostały
wyświetlone. Przykładowo:
SELECT employeeid, lastname, firstname, title
FROM employees
Gdy tabela zawiera małą liczbę wierszy, czas potrzebny na ich zwrócenie jest akceptowalny. W
sytuacji, gdy tabela składa się z milionów wierszy, zwracanie ich wszystkich nie jest dobrym
rozwiązaniem, dlatego powinno się wydobywać tylko potrzebne wiersze. Należy w związku z tym
odpowiedzieć sobie na pytania: które kolumny są potrzebne? Które wiersze są potrzebne?
Udzielenie odpowiedzi na te pytania powinno pomóc przy tworzeniu przyjaznych dla serwera
zapytań.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 4/19
W celu ograniczenia liczby wierszy dokonujemy filtrowania rekordów. Służy do tego klauzula
WHERE, którą możemy zawrzeć w instrukcji SELECT. Przykładowo:
SELECT SELECT employeeid, lastname, firstname, title
FROM employees
WHERE employeeid = 5
Należy pamiętać, iż warunki wyszukiwania, które możemy stosować po słowie
WHERE, są
różnorodne i dają dużą swobodę filtrowania rekordów. Warunki te mogą:
•
korzystać z operatorów porównania
•
korzystać z porównywania ciągów
•
korzystać z operatorów logicznych
•
pobierać zakresu wartości
•
korzystać z listy wartości jako kryterium wyszukiwania
•
pobrać wartości nieznane
Operator porównania
Operator porównania (=) użyty w klauzulu
WHERE powoduje, że zwracane są tylko te rekordy,
których wartość w zadanej kolumnie jest równa podanej. Przykładowo:
SELECT lastname, city
FROM employees
WHERE country = 'USA'
Operator LIKE
Operator
LIKE służy do porównywania ciągów znaków, które powinny być do siebie podobne.
Wraz z operatorem
LIKE można stosować znaki maskujące „%”, reprezentujące dowolny ciąg
znaków. Przykładowo:
SELECT companyname
FROM customers
WHERE companyname LIKE '%Restaurant%'
W wyniku otrzymamy nazwy firm zawierające w sobie słowo „Restaurant”.
Operatorem o odwrotnym działaniu jest operator
NOT LIKE. Jego zastosowanie powoduje
zwrócenie rekordów, które nie spełniają podanego warunku podobieństwa. Przykładowo:
SELECT companyname
FROM customers
WHERE companyname NOT LIKE 'D%'
W wyniku otrzymamy nazwy firm które nie rozpoczynają się na literę „D”.
Operatory logiczne AND i OR
Czasem zachodzi potrzeba połączenia kilku warunków w celu wyodrębnienia potrzebnych danych.
Do łączenia warunków można użyć operatorów logicznych
AND i OR.
Operator
AND zapewnia prawdziwość wielu warunków. Przykładowo:
SELECT company, Date
FROM customers
WHERE (company LIKE '%Restaurant%') AND (Date='2001-07-08')
W wyniku otrzymamy zestaw danych składający się z nazw firm zawierających w sobie słowo
„Restaurant”, które to firmy zostały założone dnia 8 lipca 2001 roku.
Operator
OR używany jest wówczas, gdy przynajmniej jeden z warunków musi być spełniony.
Przykładowo:

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 5/19
SELECT company, Date
FROM customers
WHERE (company LIKE '%Restaurant%') OR (Date='2001-07-08')
W wyniku otrzymamy zestaw danych składający się z nazw firm zawierających w sobie słowo
„Restaurant” lub firmy, które to firmy zostały założone dnia 8 lipca 2001 roku.
Często zachodzi potrzeba połączenia operatorów
AND i OR w celu otrzymania wymaganych danych.
Przykładowo:
SELECT company, productid, Date
FROM customers
WHERE (company LIKE '%Restaurant%' OR productid=20) AND (Date='2001-07-08')
W wyniku otrzymamy zestaw danych składających się z nazw firm zawierających w sobie słowo
„Restaurant” lub numer identyfikacyjny o wartości 20, które to firmy zostały założone dnia 8 lipiec
2001 roku.
Wyszukiwanie z listy wartości
Do wyszukiwania wartości z podanej listy służy słowo
IN. Przykładowo:
SELECT companyname, country
FROM suppliers
WHERE country IN ('Japan', 'Italy')
W wyniku zapytania otrzymamy wszystkie nazwy firm, które mieszczą się w Japonii lub we
Włoszech.
Wyszukiwanie wartości nieznanych
Bazy danych pozwalają na przechowywanie wartości
NULL w niektórych polach. Wyszukiwanie
rekordów o nieokreślonych lub pustych wartościach ma wiele praktycznych zastosowań.
Przykładowo:
SELECT companyname, fax
FROM suppliers
WHERE fax IS NULL
W wyniku wykonania zapytania otrzymamy wszystkie nazwy firm, dla których wartość pola
fax jest
pusta.
Wprowadzanie danych
Podstawą dodawania informacji jest instrukcja
INSERT. Korzysta ona z następującej składni:
INSERT INTO [nazwa_serwera.][nazwa_bazy_danych.]
[nazwa_schematu.]nazwa_tabeli
(nazwa_pola1[,nazwa_pola2[,…n]])
VALUES
(wartosc1[,wartosc2[,…n]])
Przykładowo:
INSERT INTO customers
(customersid, companyname, address, city, phone, fax)
VALUES (‘PECOF’, ‘Pecos Coffee Company’, ‘1900 Street’, ‘London’,
‘(604)555-3392’, ‘(604)555-3393’)
Czasami zachodzi potrzeba wstawienia pustego wiersza do tabeli. Wstawianie takie dokonuje się w
następujący sposób:
INSERT INTO [nazwa_serwera.][nazwa_bazy_danych.]
[nazwa_schematu.]nazwa_tabeli DEFAULT VALUES

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 6/19
Zdarza się, że występuje potrzeba przeniesienia informacji z jednego systemu bazodanowego do
drugiego bez utraty danych. Zadanie to można zrealizować przy pomocy wielu metod. Omówimy
tutaj dwa sposoby przenoszenia danych: z wykorzystaniem narzędzia
BCP
oraz instrukcji
BULK
INSERT
.
Narzędzie
BCP
uruchamiane jest z wiersza poleceń. Pozwala ono na import i eksport danych
wielkich rozmiarów.
BCP
wymaga podania nazwy bazy danych źródła, nazwy tabeli lub widoku,
identyfikatora działania (
in lub out) oraz nazwy zewnętrznego pliku danych. Podstawowa składnia
jest następująca:
BCP baza_danych.schemat.{ nazwa_tabeli | nazwa_widoku }
{ in | out }
nazwa_pliku_zewnętrznego
modyfikator_zabezpieczeń
modyfikator_formatu
Poniższy przykład eksportuje rekordy z tabeli
Product do pliku CSV:
bcp AdventureWorks.Production.Product out "Products.txt" –T -c
Następnie można zaimportować dane za pomocą składni:
bcp AdventureWorks.Production.Product2 in "Products.txt" –T -c
Może zdarzyć się sytuacja, że zajdzie potrzeba zaimportowania informacji do bazy danych, ale ze
względów bezpieczeństwa nie będzie można użyć narzędzia
BCP. Istnieje polecenie T-SQL, które
pozwala na rozwiązanie tego problemu. Do wstawiania danych do bazy z poziomu języka T-SQL
służy instrukcja
BULK INSERT, której przykładowe wywołanie ma postać:
BULK INSERT
[AdventureWorks].[Production].[Product2]
FROM 'C:\Product.txt'
WITH
(
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
CODEPAGE = 'ACP'
)
Usuwanie danych
Istnieją sytuacje, kiedy musimy usunąć część lub wszystkie informacje z bazy danych. Przykładem
może być skasowanie błędnie wprowadzonych rekordów lub gdy chcemy pozbyć się starych
informacji z tabel historycznych. We wszystkich tych sytuacjach korzysta się z polecenia
DELETE.
Poniżej przedstawiono podstawową składnię polecenia
DELETE.
DELETE FROM [nazwa_serwera.][nazwa_bazy_danych.]
[nazwa_schematu.]nazwa_tabeli
WHERE warunki
Wiersze można usunąć korzystając z dowolnych kolumn tabeli w klauzuli
WHERE
.
Przykładowo:
DELETE FROM AdventureWorks.Person.Address
WHERE AddressID = 1
Warunek w klauzuli
WHERE może zostać użyty z dowolnymi argumentami do usuwania informacji,
także tymi, które określają zakresy danych i korzystają z logicznych kombinacji
AND, OR i NOT.
Przykładowo:
DELETE FROM Production.Product
WHERE (MakeFlag = 1)
AND
(ReorderPoint BETWEEN 200 AND 600)

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 7/19
AND
(SellStarDate<CONVERT(DATETIME, '2000-01-01 00:00:00', 102))
Czasami istnieje potrzeba usunięcia wierszy z tabeli na postawie warunków dotyczących innej tabeli
lub tabel. Najlepszym sposobem jest wówczas użycie operatora
IN. Przykładowo:
DELETE FROM [AdventureWorks].[Production].[ProductInventory]
WHERE ProductID In
(
SELECT ProductID
FROM Production.Product
WHERE (MakeFlag = 1)
AND
(ReorderPoint BETWEEN 200 AND 600)
AND
(SellStarDate<CONVERT(DATATIME,'2000-01-01 00:00:00', 102))
Najlepszą kontrolę nad operacjami w bazie danych zapewniają procedury składowane. W takiej
sytuacji implementacja procedury składowanej jest podobna do implementacji innych działań
definiowanych wewnątrz procedury składowanej. Przykładowo:
CREATE PROCEDURE [Sales].[CurrencyRate_Delete] @id int
AS
DELETE FROM [AdventureWorks].[Sales].[CurrencyRate]
WHERE CurrencyRateID = @id
GO
Uaktualnianie danych
Do modyfikacji danych w tabelach używa się polecenia
UPDATE. Jego podstawowa składnia jest
następująca:
UPDATE [nazwa_serwera.][nazwa_bazy_danych.]
[nazwa_schematu.]nazwa_tabeli
SET nazwa_kolumny = nowa_wartosc
[WHERE warunek]
Polecenie
UPDATE oczywiście można stosować bez warunku WHERE.
Przykładowe rozwiązanie
Wprowadzanie danych
Żebyśmy mogli wybierać jakiekolwiek dane, w pierwszym kroku powinniśmy zasilić naszą bazę
danych przykładowymi wartościami. Załóżmy, że mamy tabelę
Ksiazki w bazie danych
Biblioteka. Strukturę tabeli Ksiazki
pokazano na rys. 2.
Rys. 2 Tabela Ksiazki w bazie danych Biblioteka
Pokażemy dwa sposoby wstawiania przykładowych danych do tabeli
Ksiazki. Sposób pierwszy
polega na wstawieniu pojedynczego wiersza za pomocą instrukcji
INSERT. Przykładowo:
INSERT INTO Ksiazki
(ID_Ksiazka, Nazwisko, Imie, Tytul, Wydawnictwo, Rok_wydania, CD)
VALUES ('1', 'Kowalski', 'Jan', 'Programowanie baz danych',
'Microsoft Press', '2006', '1')
W wyniku wykonania powyższej instrukcji tabela
Ksiazki będzie zawierała jeden rekord, co
pokazano na rys. 3.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 8/19
Rys. 3 Tabela Ksiazki po wstawieniu rekordu
Ja widać sposób ten nie jest zbyt efektywny przy wstawianiu większej liczby danych. W sytuacji
kiedy mamy do zaimportowania tysiące rekordów, lepszym rozwiązaniem jest użycie na przykład
instrukcji
BULK INSERT. Załóżmy że dane, które chcemy zaimportować, znajdują się w pliku
ksiazki.txt, w postaci jak pokazano na rys. 4.
Rys. 4 Dane zawarte w pliku książki.txt
Wówczas wywołanie instrukcji importu będzie wyglądało w następujący sposób:
BULK INSERT Ksiazki
FROM 'C:\ksiazki.txt'
WITH
(
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
CODEPAGE = 'ACP'
)
Poważny problem pojawiłby się w sytuacji, kiedy w kolumnie
CD przechowywalibyśmy wartości
typu logicznego. Wówczas przy eksporcie danych do pliku wartość logiczna
TRUE lub FALSE
zostałaby zamieniona na wartość tekstową 0 lub 1. Jeżeli w kolejnym kroku chcielibyśmy
zaimportować te same dane do bazy, wówczas pojawiłby się błąd związany z niezgodnością typów
danych (kolumna ma typ logiczny, a z pliku importujemy dane tekstowe).
Wybieranie danych
Jeżeli nasza baza danych jest już uzupełniona danymi, to w kolejnym kroku możemy zastanowić się,
jakie dane mogą być najczęściej wybierane przez użytkowników. Przykładowo dla tabeli
Ksiazki
użytkownik najczęściej może wyszukiwać książki po:
•
imionach autorów
•
wydawnictwie
•
roku wydania
•
informacji o płycie CD
•
kombinacji: autor, wydawnictwo, rok wydania i informacje o płycie CD
Przykładowo jeżeli chcielibyśmy znaleźć autora o nazwisku Kowalski, wówczas instrukcja
SELECT
mogłaby mieć następującą postać:
SELECT Nazwisko, Imie, Tytul FROM Ksiazki
WHERE Nazwisko='Kowalski'
Natomiast jeżeli chcielibyśmy znaleźć autorów o nazwisku Kowalski lub Andziński, wówczas
instrukcja
SELECT mogłaby wyglądać w ten sposób:
SELECT Nazwisko, Imie, Tytul FROM Ksiazki
WHERE (Nazwisko='Kowalski') OR (Nazwisko='Andziński')

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 9/19
W sytuacji kiedy chcielibyśmy znaleźć autorów, których nazwisko kończy się na -ski, wówczas
moglibyśmy sformułować instrukcję SELECT następująco:
SELECT Nazwisko, Imie, Tytul FROM Ksiazki
WHERE Nazwisko LIKE '%ski'
Oczywiście moglibyśmy do tego dołączyć jeszcze wyszukiwanie po dacie, wówczas otrzymalibyśmy:
SELECT Nazwisko, Imie, Tytul, Rok FROM Ksiazki
WHERE (Nazwisko LIKE '%ski') AND (Rok='2003')
W sytuacji kiedy chcemy znaleźć autora o nazwisku zakończonym na -ski, który wydał w 2003 roku
książkę z dołączoną płytą CD, możemy użyć następującego zapytania:
SELECT Nazwisko, Imie, Tytul, Rok, CD FROM Ksiazki
WHERE (Nazwisko LIKE '%ski' OR Rok='2003') AND (CD='1')
Najbardziej skomplikowanego zapytania potrzebujemy wówczas, gdy chcemy znaleźć autora o
nazwisku zakończonym na -ski, którego książka wraz z dołączoną płytą CD została wydana w 2003
roku nakładem wydawnictwa Selion. Wówczas zapytanie może przyjąć postać:
SELECT Nazwisko, Imie, Tytul, Rok, Wydawnictwo, CD FROM Ksiazki
WHERE (Nazwisko LIKE='%ski' OR Rok='2003') AND
(Wydawnictwo='Selion') AND (CD='1')
Porady praktyczne
Uwagi ogólne
•
Najlepszą kontrolę nad operacjami wykonywanymi na bazie danych zapewniają procedury
składowane. Dzięki nim możesz zapewnić jednolity model dostępu do bazy z poziomu
aplikacji, a także poprawić bezpieczeństwo i wydajność. Z tych powodów powinieneś
rozważyć użycie procedur składowanych we własnych aplikacjach.
•
Tworzenie dynamicznych poleceń wstawiania danych może zagrażać bezpieczeństwu bazy,
dlatego wielce prawdopodobnie jest, że administrator będzie preferował zabezpieczenia
tabel przez odmowę uprawnień zapisu do tabeli. Z tego powodu dobrym rozwiązaniem jest
zarządzanie operacjami wstawiania danych za pomocą procedur składowanych.
Wybieranie danych
•
Użycie polecenia
SELECT * FROM Department odczytuje wszystkie kolumny z tabeli.
Zazwyczaj nie potrzebujemy informacji o wszystkich kolumnach, natomiast wykonanie
takiego zapytania bez potrzeby może spowodować sporo problemów. Przykładowo:
a)
Aplikacje mogą działać nieprawidłowo po dodaniu nowych kolumn do tabeli. Jeśli ich
twórcy nie przewidzieli takiego możliwości, nieoczekiwane kolumny zostaną
niepoprawnie obsłużone.
b)
Jeśli zostaną wybrane wszystkie kolumny, optymalizator zapytań nie będzie używał
niektórych indeksów.
•
Jeśli zajdzie potrzeba wykorzystania w klauzuli
WHERE operatorów logicznych AND i OR, warto
rozważyć stosowanie nawiasów. Pozwalają one precyzyjnie określić kolejność wykonywania
operacji logicznych.
•
W wielu przypadkach możemy na wiele sposobów otrzymać tan sam efekt wywołania
zapytania. Przykładowo następujące dwa zapytania zwracają te same rekordy:
SELECT company, Date
FROM customers
WHERE year(ShipDate)=2001 and month(ShipDate)=7
SELECT company, Date

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 10/19
FROM customers
WHERE ShipDate between '2001-07-01' and '2001-07-31'
Pierwsze z zapytań odczytuje datę i miesiąc. Po odczytaniu wszystkich wierszy wykonuje
obliczenia i je porównuje. Drugie zapytanie wykonuje tylko porównanie, bez obliczeń,
ponadto jeżeli na kolumnie
ShipDate znajduje się indeks, to zostanie on użyty – a zatem
zapytanie drugie jest szybsze.
•
Można używać jednej, kilku lub wszystkich kolumn do utworzenia warunku w klauzuli
WHERE.
Jego wydajność można poprawić poprzez:
a)
zastosowanie klucza głównego w warunku
b)
użycie kolumn, które są indeksowane
Wprowadzanie, usuwanie i uaktualnianie danych
•
Aby skasować wszystkie wiersze z tabeli, zamiast instrukcji
DELETE można użyć instrukcji
TRUNCATE TABLE. Różnica w stosunku do instrukcji DELETE polega na tym, iż zadanie
kasowania odbywa się szybciej. Używając
TRUNCATE TABLE trzeba mieć pewność, że tabela
nie ma żadnych związków z innymi tabelami.
•
Możne usuwać wiersze z tabeli za pośrednictwem widoków, jednak występują tutaj pewne
ograniczenia:
a)
Można usunąć wiersze tylko z jednej tabeli.
b)
Użytkownik musi posiadać uprawnienia do usuwania dla widoku.
•
Można wykonywać zadania uaktualniające korzystając z widoków. W takiej sytuacji istnieją
pewne ograniczenia:
a)
Uaktualnienia są dozwolone tylko dla kolumn z pojedynczej tabeli.
b)
Użytkownik musi mieć uprawnienia do zapisu dla widoku.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz składnię języka T-SQL DML
•
umiesz skonstruować podstawowe zapytania do bazy danych
•
umiesz zaimportować dane do swojej bazy danych
•
umiesz modyfikować dane w swojej bazie danych
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Kalen Delaney, Microsoft SQL Server 2005: Rozwiązania praktyczne krok po kroku, Microsoft
Press, 2006
W książce autor przedstawia między innymi w jaki sposób pobierać dane z instancji
SQL Server za pomocą języka T-SQL. Pozycja polecana dla osób, które chciałyby
dowiedzieć się nieco więcej na temat praktycznych metod pobierania danych.
2.
Kalen Delaney, Podstawy baz danych krok po kroku, APN Promise, 2006
Bardzo dobra książka dla osób początkujących. W łatwy i przejrzysty sposób
pokazano, jak należy odczytywać dane z SQL Server, jak je wybierać, modyfikować,
usuwać i uaktualniać. Książka oprócz teorii zawiera dużo przykładów.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 11/19
3.
Deren Bieniek, Randy Dyess, Mike Hotek, Javier Loria, Adam Machanic, Antonio Soto, Adolfo
Wiernik, SQL Server 2005. Implementacja i obsługa, APN Promise, Warszawa 2006
W książce przedstawiono pracę z językiem T-SQL DML. Pokazano, w jaki sposób
tworzyć zapytania, formatować wynikowy zbiór wierszy oraz modyfikować dane.
Książka szczególnie polecana ze względu na dużą zawartość ćwiczeń
laboratoryjnych.
4.
Dusan Petkovic, Microsoft SQL Server 2008: A Beginner's Guide, McGraw-Hill, 2008
Pozycja napisana w sposób przystępny. Wprowadza w SQL Server 2008 w sposób
szybki i łatwy. Osoba początkująca w SQL Server 2008 znajdzie w niej podstawy z
każdego tematu dotyczącego serwera bazodanowego. W prosty sposób dowiesz się
jak należy tworzyć zapytania, formatować wyniki zapytań oraz modyfikować dane.
Pozycja szczególnie polecana dla osób początkujących.
Włodzimierz Dąbrowski, Przemysław
ITA-101 Bazy danych
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie
dotąd na Twoim wydziale. Zadanie
najczęściej będą wykonywali użytkownicy na
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
W oknie logowania kliknij
2.
Utwórz tabelę
testową
•
Z menu głównego wybierz
•
Odszukaj plik
•
Zaznacz i uruchom (
--
USE PraceDyplomowe
GO
SELECT ID_Osoby, Imie, Nazwisko, Nr_Indeksu, ID_Stopnian
INTO Osoba_kopia
FROM Osoba
GO
INSERT INTO Os
ID_Stopnian)
VALUES ('6','Pawel','Zaremba','65432','3')
GO
3.
Zapoznaj się z
poleceniem
SELECT
•
Zaznacz i uruchom (
wyświetlenie zawartości całej tabeli
na
--
SELECT *
FROM Osoba_kopi
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 12/19
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie na skalę uczelnianą systemu prac dyplomowych
. Zadanie, jakie przed Tobą stoi, to zdefiniowanie nowych zapytań, które
najczęściej będą wykonywali użytkownicy na Twojej bazie danych.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pl
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Z menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Labs\Lab06\dml_1.sql.
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (1) Przygotuj tabele do testowania polecen jezyka DML
USE PraceDyplomowe
GO
SELECT ID_Osoby, Imie, Nazwisko, Nr_Indeksu, ID_Stopnian
INTO Osoba_kopia
FROM Osoba
GO
INSERT INTO Osoba_kopia(ID_Osoby, Imie, Nazwisko, Nr_Indeksu,
ID_Stopnian)
VALUES ('6','Pawel','Zaremba','65432','3')
GO
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
wyświetlenie zawartości całej tabeli Osoba. Wynik działania pokazano
na rys. 5:
-- (2) Wyswietl cala zawartosc tabeli Osoba_k
SELECT *
FROM Osoba_kopia
GO
Moduł 6
Język SQL DML
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
prac dyplomowych, którym zarządzała
to zdefiniowanie nowych zapytań, które
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
(1) Przygotuj tabele do testowania polecen jezyka DML
SELECT ID_Osoby, Imie, Nazwisko, Nr_Indeksu, ID_Stopnian
oba_kopia(ID_Osoby, Imie, Nazwisko, Nr_Indeksu,
) poniższy fragment kodu odpowiedzialny za
. Wynik działania pokazano
(2) Wyswietl cala zawartosc tabeli Osoba_kopia
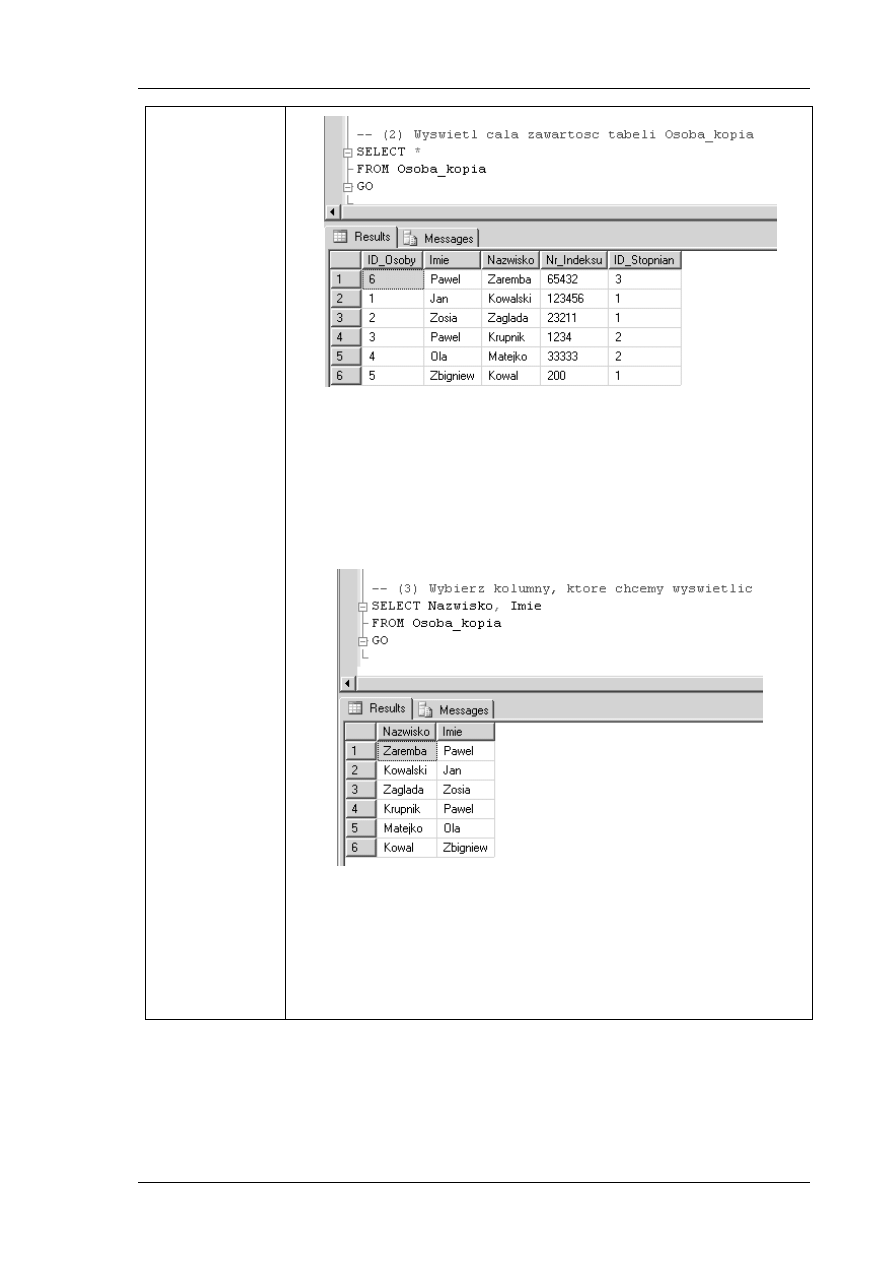
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 13/19
Rys. 5 Wynik wyświetlenia całej zawartości tabeli Osoba_kopia
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
wyświetlenie dwóch kolumn: Nazwisko i Imie. Wynik działania
pokazano na rys. 6:
-- (3) Wybierz kolumny, ktore chcemy wyswietlic
SELECT Nazwisko, Imie
FROM Osoba_kopia
GO
Rys. 6 Wynik wyświetlenia dwóch kolumn Nazwisko i Imię
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
dodanie literału i aliasu. Wynik działania pokazano na rys. 7:
-- (4) Dodajemy literal i alias
SELECT 'Imie i nazwisko: ' + Nazwisko + ' ' + Imie AS Osoba
FROM Osoba_kopia
GO
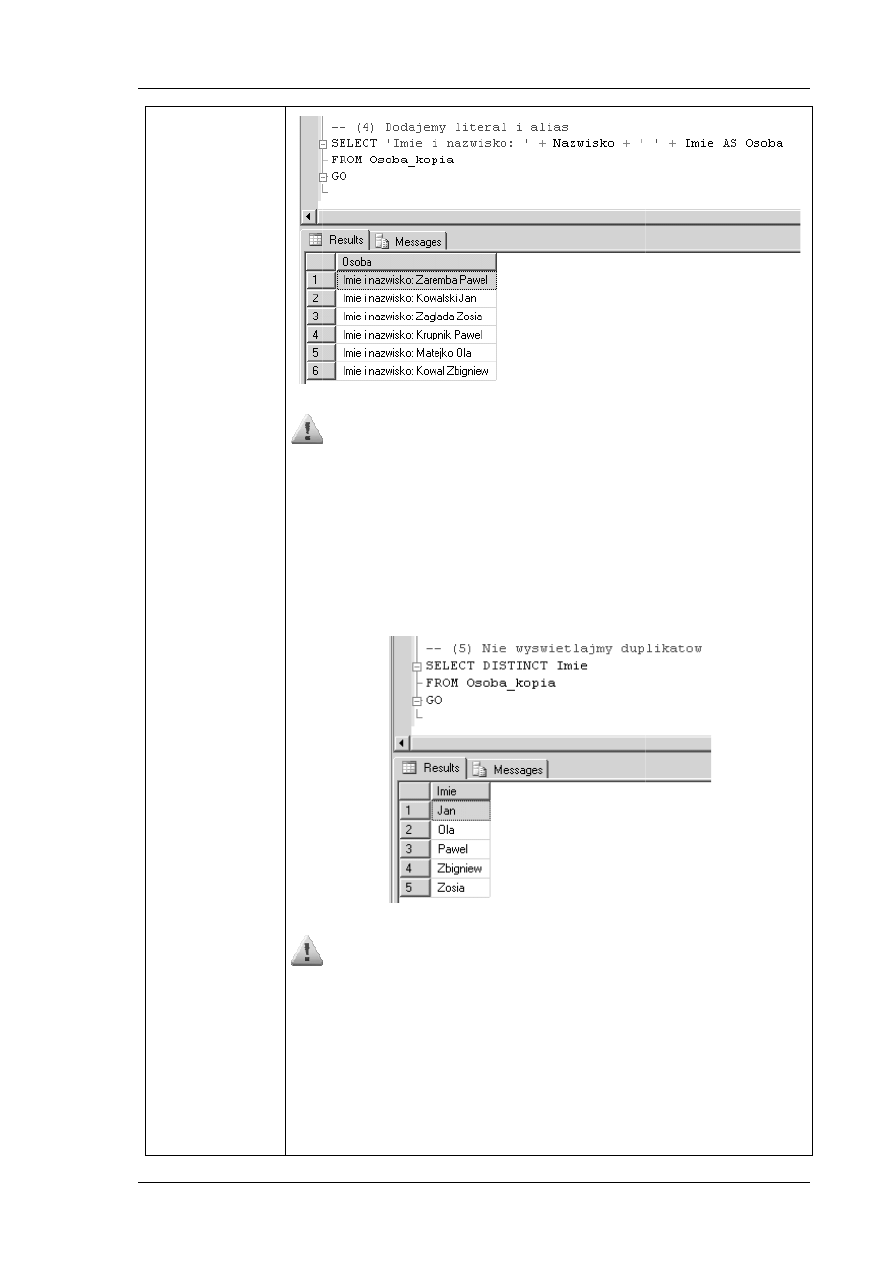
Włodzimierz Dąbrowski, Przemysław
ITA-101 Bazy danych
•
Zaznacz i uruchom (
wyświetlanie duplikatu. Wynik działania pokazano na
--
SELECT DISTINCT Imie
FROM Osoba_kopia
GO
•
Zaznacz i uruchom (
sortowanie rosnące i malejące. Wynik działania pokazano na
--
SELECT Imie, nazwisko
FROM Osoba_kopia ORDER BY Nr_Indeksu
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 14/19
Rys. 7 Wynik dodania literału i aliasu
Alias nie jest nazwą własną. Jest to tylko tymczasowy (istniejący tylko
dla zapytania, w którym został zdefiniowany,
na stałe) nagłówek kolumny. Może zawierać napis będący nazwą innej
kolumny lub obiektu bazy danych.
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za nie
wyświetlanie duplikatu. Wynik działania pokazano na
-- (5) Nie wyswietlajmy duplikatow
SELECT DISTINCT Imie
FROM Osoba_kopia
GO
Rys. 8 Wynik zapytania bez wyświetlania duplikatów
Słowo DISTINCT, oprócz usunięcia duplikatów z wyników, ignoruje
także wartości puste w zbiorze rekordów (tzn. gdy w wybranym
zestawie zdarzy się wiersz, w którym wszystki
zostanie on wyświetlony).
Zaznacz i uruchom (F5) poniższy fragment kodu odpowied
sortowanie rosnące i malejące. Wynik działania pokazano na
-- (6) sortujmy rekordy rosnaco (ASC) i malejaco (DESC)
SELECT Imie, nazwisko Nr_Indeksu
FROM Osoba_kopia ORDER BY Nr_Indeksu – DESC
GO
Moduł 6
Język SQL DML
Wynik dodania literału i aliasu
nie jest nazwą własną. Jest to tylko tymczasowy (istniejący tylko
nie zapisywany nigdzie
na stałe) nagłówek kolumny. Może zawierać napis będący nazwą innej
) poniższy fragment kodu odpowiedzialny za nie
wyświetlanie duplikatu. Wynik działania pokazano na rys. 8:
Wynik zapytania bez wyświetlania duplikatów
oprócz usunięcia duplikatów z wyników, ignoruje
także wartości puste w zbiorze rekordów (tzn. gdy w wybranym
wszystkie pola są puste, nie
) poniższy fragment kodu odpowiedzialny za
sortowanie rosnące i malejące. Wynik działania pokazano na rys. 9:
(6) sortujmy rekordy rosnaco (ASC) i malejaco (DESC)

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 15/19
Rys. 9 Wynik sortowania
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
ogranicenie liczby rekordów. Wynik działania pokazano na rys. 10.
-- (7) ograniczmy liczbe rekordow
SELECT Imie, Nazwisko
FROM Osoba_kopia
WHERE Nazwisko = 'Rawa'
GO
Rys. 10 Wynik ograniczenia liczby rekordów
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
ogranicenie liczby rekordów z użyciem operatora wiekszości. Wynik
działania pokazano na rys. 11:
-- (8) wyprobujmy operator wiekszosci
SELECT Imie, Nazwisko, Nr_Indeksu
FROM Osoba_kopia
WHERE Nr_Indeksu >= 110
GO
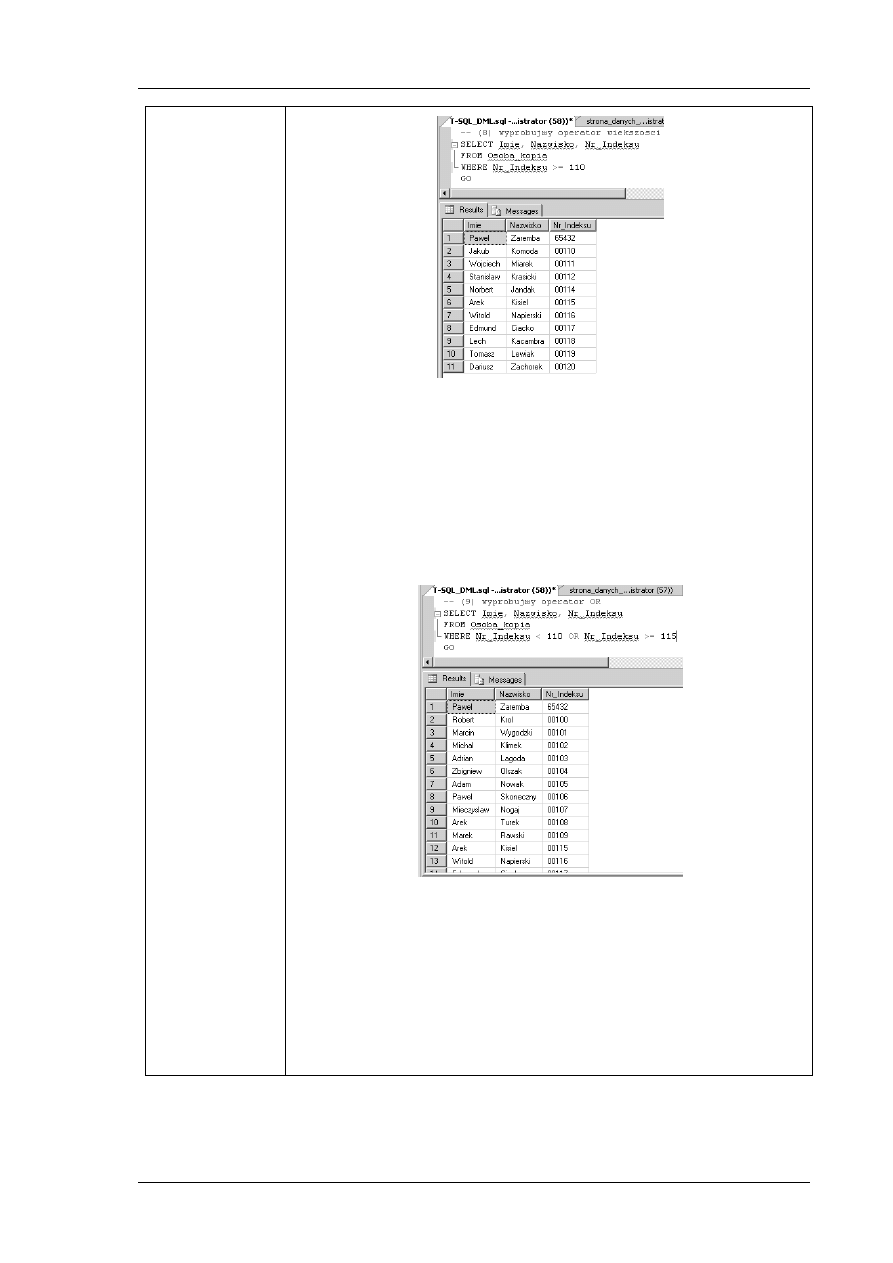
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 16/19
Rys. 11 Wynik ograniczenia liczby rekordów z uzyciem operatora większości
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
ogranicenie liczby rekordów z użyciem operatora OR. Wynik działania
pokazano na rys. 12:
-- (9) wyprobujmy operator OR
SELECT Imie, Nazwisko, Nr_Indeksu
FROM Osoba_kopia
WHERE Nr_Indeksu < 110 OR Nr_Indeksu >= 115
GO
Rys. 12 Wynik ograniczenia liczby rekordów z uzyciem operatora OR
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
ogranicenie liczny rekordów z wyszukiwaniem w zbiorze wartości.
Wynik działania pokazano na rys. 13.
-- (10) wyszukajmy w zbiorze wartosci
SELECT Imie, Nazwisko
FROM Osoba_kopia
WHERE Nazwisko IN ('Rawa','Nowak')
GO

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 17/19
Rys. 13 Wynik ograniczenia liczby rekordów z wyszukiwaniem w zbiorze wartości
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
ogranicenie liczny rekordów z wyszukiwaniem w przedziale wartości.
Wynik działania pokazano na rys. 14.
-- (11) wyszukajmy w przedziale wartosci
SELECT Imie, Nazwisko, Nr_Indeksu
FROM Osoba_kopia
WHERE Nr_Indeksu BETWEEN 110 AND 115
GO
Rys. 14 Wynik ograniczenia liczby rekordów z wyszukiwaniem w przedziale wartości
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
ogranicenie liczny rekordów z użyciem operatora LIKE. Wynik działania
pokazano na rys. 15.
-- (12) uzyjmy operatora LIKE
SELECT Imie, Nazwisko, Nr_Indeksu
FROM Osoba_kopia
WHERE Nazwisko LIKE '[A-F]%'
GO
Rys. 15 Wynik ograniczenia liczby rekordów z użyciem operatora LIKE
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
zliczanie liczny rekordów. Wynik działania pokazano na rys. 16.
-- (13) zliczmy rekordy w tabeli
SELECT Count(*) AS [Liczba osob]
FROM Osoba_kopia
GO

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 18/19
Rys. 16 Zliczanie liczby rekordów
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
dodanie nowego rekordu:
-- (14) dodajmy nowy rekord
INSERT INTO Osoba_kopia(ID_Osoby, Imie, Nazwisko, Nr_Indeksu,
ID_Stopnian)
VALUES ('7','Marek','Kogut','35472','2')
GO
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
zmianę istniejącego rekordu:
-- (15) zmienmy istniejacy rekord
UPDATE Osoba_kopia
SET Nazwisko = 'Kogucinski'
WHERE LastName = 'Kogut'
GO
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
zmianę istniejącego rekordu:
-- (16) usunmy rekord
DELETE FROM Osoba_kopia
WHERE Nazwisko = 'Kogucinski'
GO
•
Zaznacz i uruchom (F5) poniższy fragment kodu odpowiedzialny za
usunięcie tabeli:
-- (17) usunmy zawartosc tabeli
TRUNCATE TABLE Osoba_kopia
GO

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 6
ITA-101 Bazy danych
Język SQL DML
Strona 19/19
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma zarządzająca bazą
AdventureWorks planuje rozszerzenie i modernizacje systemu w celu
spełnienia pewnych standardów. Rozszerzenie to wiąże się z modyfikacją struktury bazy danych
oraz importem do bazy danych wielu milionów rekordów. W konsekwencji w związku z
modernizacją systemu bazodanowego oraz spełnienia standardów muszą zostać przebudowane
zapytania wysyłane do obiektów bazy danych. W związku z tym część zapytań powinna zostać
usunięta, część zmodyfikowana, a część od nowa utworzona.
Zadania jakie przed Tobą stoją to:
1.
Podjęcie decyzji, w jaki sposób usprawnić proces importu wielu milionów danych do systemu
bazodanowego.
2.
Podjęcie decyzji, które zapytania w bazie danych pozostaną bez zmian, a które zostaną
zmodyfikowane lub usunięte.
3.
Podjęcie decyzji, jakie nowe zapytania powinny zostać utworzone.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
Wersja 1.0
Indeksy i transakcje
Spis treści
Indeksy i transakcje .............................................................................................................................. 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 9
Porady praktyczne ..................................................................................................................... 12
Uwagi dla studenta .................................................................................................................... 13
Dodatkowe źródła informacji..................................................................................................... 14
Laboratorium podstawowe ................................................................................................................ 15
Problem 1 (czas realizacji 30 min) .............................................................................................. 15
Problem 2 (czas realizacji 15 min) .............................................................................................. 18
Laboratorium rozszerzone ................................................................................................................. 20
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 20
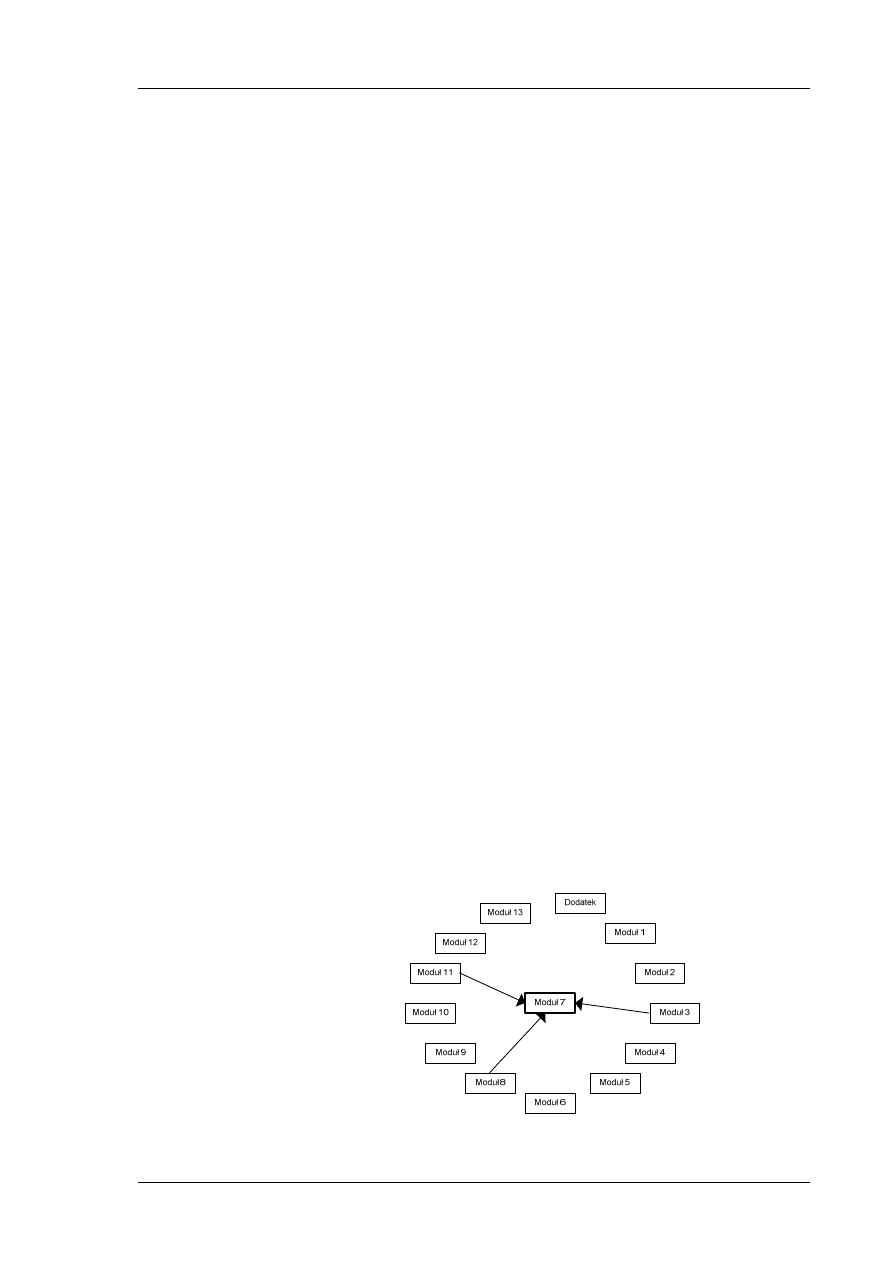
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 2/20
Informacje o module
Opis modułu
W module tym znajdziesz informacje na temat dostępu fizycznego do
danych oraz optymalizacji dostępu. Poznasz indeksy i ich rodzaje, a
następnie dowiesz się, jakie operacje wykonywane są na indeksach. W
drugiej części poznasz transakcje, które służą do zapewnienia spójności bazy
danych i mają wpływ na wydajność bazy danych. Dowiesz się, że obsługa
transakcji nie jest rzeczą łatwą i wymaga rozwiązywania wielu trudnych
problemów.
Cel modułu
Celem modułu jest zapoznanie czytelnika z podstawowymi mechanizmami
indeksowania oraz struktury pisania transakcji. Zostaną przedstawione
proste przykłady, które mają pokazać mechanizmy obowiązujące w
metodach indeksowania oraz w transakcjach.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
wiedział, na czym polega zasada działania indeksów
•
potrafił we właściwy sposób dobierać politykę indeksowania
•
znał zasadę funkcjonowania transakcji
•
potrafił we właściwy sposób pisać proste transakcje
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
umieć stworzyć bazę danych wraz z jej podstawowymi obiektami
(patrz: moduł 3)
•
znać zaawansowane mechanizmy programowania w języku T-SQL
(patrz: moduł 9)
•
znać podstawowe mechanizmy bezpieczeństwa (patrz: moduł 11)
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznać się z materiałem zawartym
w modułach 3, 8 i 11.
Rys. 1 Mapa zależności modułu
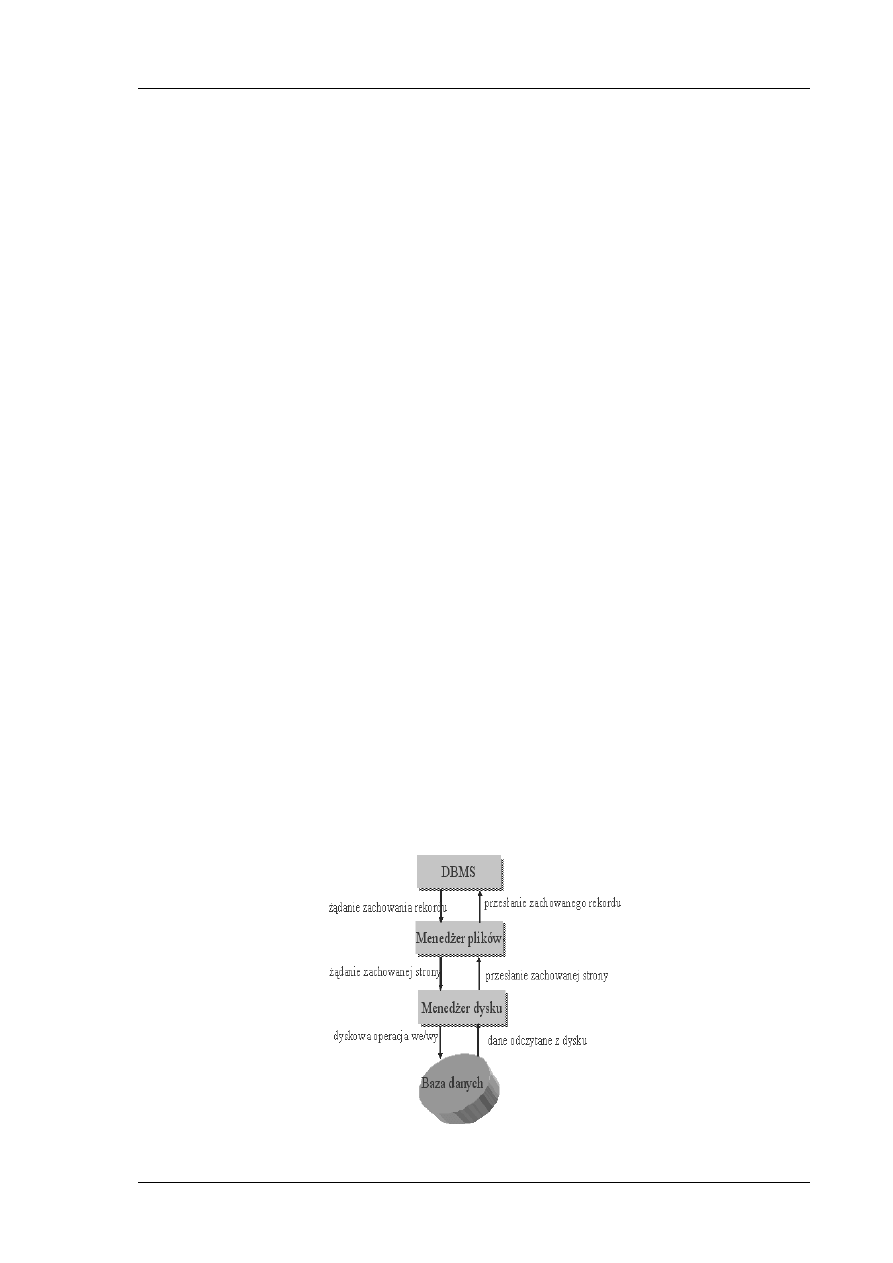
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 3/20
Przygotowanie teoretyczne
Przykładowy problem
Tak jak już Wiesz z bazy danych może korzystać wielu użytkowników, dysponujących różnorakimi
uprawnieniami i mających dostęp do różnych obiektów w bazie danych. W związku z tym jednym z
podstawowych zadań, jakie stoi przed osobami odpowiedzialnymi za prawidłowe funkcjonowanie
bazy danych, jest dobór odpowiedniej polityki indeksowania, która pozwoli na szybsze
przeszukiwanie bazy danych. Bezpośrednio z polityką indeksowania bazy danych związana jest
optymalizacja i strojenie bazy danych, między innymi poprzez przebudowę indeksów.
Kolejnym mechanizmem, z jakim bardzo często możemy się spotkać, są transakcje. Według definicji
są to operacje, które są niepodzielne i muszą być wykonane w całości. Innym ważnym zadaniem
transakcji jest zapewnienie spójności bazy danych oraz umożliwienie równoległych operacji na niej.
W celu dobrego pisania transakcji potrzebna jest znajomość zaawansowanego programowania w
języku T-SQL. Transakcje stanowią bardzo ważny element programowania baz danych i powinny
być pisane profesjonalnie. Przykładem transakcji może być wypłata pieniędzy z bankomatu,
płatność kartą debetową itp.
Podstawy teoretyczne
Dostęp fizyczny do danych
Zrozumienie mechanizmu dostępu do danych zapisanych w bazie danych jest bardzo istotne dla
zrozumienia zasad działania indeksów.
Jak wiadomo, dane w bazach danych w sposób trwały są zapisywane na dyskach optycznych,
magnetycznych lub rodzinach nośników o dostępie bezpośrednim, takich jak macierze RAID (ang.
Redundant Array of Independent Disks). Zasady działania tego typu nośników oraz pojęcia głowicy,
cylindrów, strony danych itp. powinny być Ci znane z przedmiotu „Podstawy Informatyki” lub
podobnego.
System zarządzania bazami danych najczęściej nie zajmuje się fizyczną obsługą dysków. W procesie
dostępu do danych biorą udział:
•
Menedżer plików – posiada wiedzę o strukturze systemu plików i jest odpowiedzialny za
odszukanie odpowiedniego pliku.
•
Menedżer dysku – posiada wiedzę na temat fizycznej organizacji dysku i jest odpowiedzialny
za odnalezienie odpowiedniej strony danych.
Schemat łańcucha dostępu do danych pokazany jest na rys. 2.
Rys. 2 Schemat dostępu do danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 4/20
Optymalizacja dostępu
Zasadniczy czas dostępu do danych bazy to czas odczytu danych z dysków. W celu optymalizacji
tego dostępu stosuje się metodę zwaną klastrowaniem.
Klastrowanie polega na dążeniu do utrzymania logicznie powiązanych rekordów blisko siebie na
dysku. Taka organizacja danych znacznie przyspiesza dostęp do nich. Aby odczytać dane powiązane,
głowica nie musi wykonywać dużych ruchów, a tym samym maleją czasy wyszukiwania.
Rozróżniamy dwa rodzaje klastrowania:
•
Klastrowanie wewnątrzplikowe – polega na grupowaniu rekordów obok siebie wewnątrz
jednego pliku.
•
Klastrowanie międzyplikowe – polega na umieszczaniu na stronie obok siebie rekordów
pochodzących z więcej niż jednego pliku (tabeli).
Optymalizacja dostępu do danych sprowadza się w zasadzie do odpowiedniego zarządzania
stronami i decydowania, w jaki sposób dane mają być klastrowane.
Więcej na temat fizycznej struktury danych możesz znaleźć w module 4
Indeksy i ich zastosowanie
Zastanowimy się teraz nad problemem wyszukiwania danych w tabeli. Na przykład załóżmy, że w
tabeli
Studenci chcemy znaleźć studenta o nazwisku Nowak.
Tab. 1 Przykładowa tabela bazy studentów
ID
Nazwisko
Imie
Wydzial
1
Olacki
Jan
Elektryczny
2
Babicki
Adam
Mechaniczny
3
Nowak
Jerzy
Elektryczny
1
Adamski
Adam
Elektronika
Wiersze zapisane są w bazie w kolejności ich wpisywania i nie są w szczególny sposób sortowane.
Co robi wobec tego system, kiedy wydajemy polecenie odnalezienia rekordu zawierającego
informacje o Nowaku, np.:
SELECT imie, nazwisko FROM Studenci WHERE Nazwisko = 'Nowak'
System musi przeszukać całą tabelę (skanowanie wszystkich stron danych zawierających dane z
tabeli) i przejrzeć wszystkie rekordy tej tabeli, aby mieć pewność, że odnalazł rekordy zawierające
nazwisko Nowak. Operacja taka jest oczywiście czasochłonna.
Podobnie jest, gdy w książce poszukujemy jakiegoś hasła (na przykład w podręczniku do baz danych
szukamy informacji o indeksach). Aby znaleźć szukaną informację, powinniśmy przeczytać całą
książkę. Na szczęście niektóre książki są wyposażone na końcu w specjalne zestawienie haseł – czyli
w indeks.
Nasze postępowanie przebiega wówczas następująco:
1.
Odszukujemy poszukiwane hasło w indeksie, który jest uporządkowany alfabetycznie (co
znacznie ułatwia nam odnalezienie hasła).
2.
Odczytujemy w indeksie numer strony, na której hasło to występuje w książce.
3.
Otwieramy książkę na odpowiedniej stronie.
4.
Przeglądamy stronę w poszukiwaniu naszego hasła.
5.
Odczytujemy informacje związane z szukanym hasłem.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 5/20
Idea działania indeksów w bazie danych jest dokładnie taka sama.
Indeks określony na atrybucie A relacji jest mechanizmem, który pozwala na efektywne
wyszukiwanie krotek o ustalonej wartości składowej atrybutu A. Jak więc wyglądałby indeks dla
tabeli
Studenci?
Indeks określany jest dla konkretnego pola. Mówimy wówczas, że pole to jest polem
indeksowanym. W wypadku tabeli
Studenci możemy jako pole indeksowane wybrać pole
Nazwisko, wówczas założenie indeksu na tym polu będzie oznaczało założenie przez system
dodatkowej tabeli, w której umieszczone zostaną nazwiska studentów z tabeli
Studenci oraz
przesłanki, gdzie należy szukać (na której stronie danych) pełnej informacji o wybranych
studentach. Dodatkowo rekordy w tabeli indeksu zostaną posortowane w kolejności alfabetycznej
nazwisk. Poszukiwanie naszego studenta Nowaka będzie teraz przebiegać znacznie szybciej.
Działanie i rola indeksów polega głównie na przyspieszeniu wyszukiwania rekordów w bazie
danych. Niestety obciążają one dodatkowo system w czasie aktualizacji lub wstawiania danych,
bowiem oprócz umieszczenia rekordu w bazie musi on również dokonać wpisu w tabeli indeksu
oraz ponownie posortować trzymane w niej rekordy.
Zalety i wady stosowania indeksów zebrano w tab. 2.
Tab. 2 Zalety i wady stosowania indeksów
Zalety
Wady
Przyspieszają dostęp do danych
Zajmują miejsce na dysku
Wymuszają unikatowość wierszy
Zwiększają obciążenie systemu
Niektóre z pól warto indeksować, inne natomiast nie powinny być nigdy indeksowane. Do pierwszej
grupy można zaliczyć:
•
klucze podstawowe i obce (często są indeksowane automatycznie)
•
pola, po których często następuje wyszukiwanie
•
pola, do których dostęp następuje w ustalonej, uporządkowanej kolejności
Nie należy indeksować:
•
pól, do których rzadko odwołują się zapytania
•
pól, które zawierają tylko kilka wartości unikatowych
•
pól zawierających dane typu image, bit czy obiekt OLE
Indeksy mogą być zakładane na jednym polu lub na kilku jednocześnie.
Rodzaje indeksów
Indeksy można klasyfikować w różny sposób. My podzielimy indeksy na dwie grupy:
•
indeksy grupowane (klastrowe)
•
indeksy niegrupowane (nieklastrowe)
Indeksy grupowane
Indeks grupowany działa na podobnej zasadzie, co książka telefoniczna. Zawiera strony szybkiego
dostępu do danych (w książce telefonicznej na początku znajduje się alfabetyczny spis mówiący o
tym, na której stronie szukać nazwisk, firm czy instytucji zaczynających się na daną literę alfabetu).
Strony te są ułożone w odwrócone drzewo i przechowują tylko ułożone alfabetycznie wartości
indeksowanego pola oraz wskaźniki do stron znajdujących się w niższej warstwie drzewa.
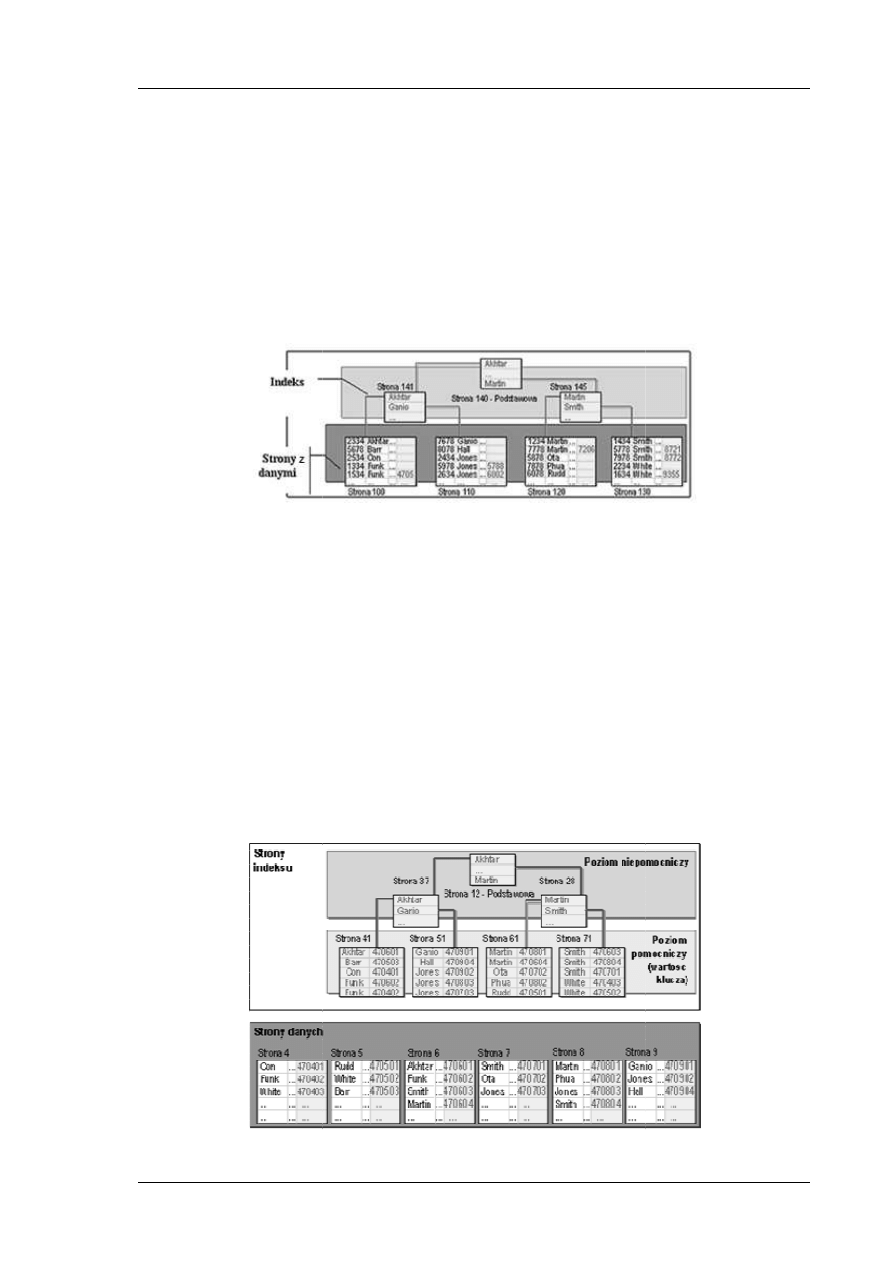
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Na samym dole drzewa znajdują się strony zawierające posortowane wg indek
(w książce telefonicznej zawartość też jest posortowana
Przeszukiwanie indeksu odbywa się z góry na dół na następującej zasadzie: porównywana jest
szukana wartość pola indeksowanego z wartościa
indeksu – jeśli znajdzie się wartość „większa” od wartości szukanej, wtedy następuje skok jeden
poziom niżej do strony wskazywanej przez ostatnią pozycję (na ostatnio sprawdzanej stronie), która
nie była „większa” od szukanej wartości.
Każda pozycja na stronach zawiera wskaźnik do strony danych jeden poziom niżej w hierarchii
indeksu. Dzięki takiej strukturze przeszukiwane są tylko wybrane strony z danymi, nie zaś wszystkie
strony zawierające dane z wybranej tabel
Indeksy niegrupowane
Indeks niegrupowany działa na podobnej zasadzie,
telefonicznej). Indeks niegrupowany budowany jest na stronach danych, które nie są sortowane.
Składa się z co najmniej dwó
Na stronach poziomu niepomocniczego, podobnie jak w przypadku indeksu grupowanego,
przechowywane są wartości indeksowanego pola ze wskaźnikami do poziomu niżej w drze
indeksu.
Strony poziomu pomocniczego zwane też liśćmi i zawierają wskaźniki do konkretnych stron danych
(które nie są posortowane). Wskaźnik taki zawiera następujące dane: ID pliku, numer strony,
numer wiersza na stronie.
Przeszukiwanie indeksu niegrup
grupowanym. Po dojściu do poziomu pomocniczego następują skoki do stron danych (do
konkretnych wierszy).
emysław Kowalczuk, Konrad Markowski
Strona 6/20
Na samym dole drzewa znajdują się strony zawierające posortowane wg indek
(w książce telefonicznej zawartość też jest posortowana – wg nazwisk lub nazw firm czy instytucji).
Przeszukiwanie indeksu odbywa się z góry na dół na następującej zasadzie: porównywana jest
szukana wartość pola indeksowanego z wartościami zapisanymi (i posortowanymi) na stronach
jeśli znajdzie się wartość „większa” od wartości szukanej, wtedy następuje skok jeden
poziom niżej do strony wskazywanej przez ostatnią pozycję (na ostatnio sprawdzanej stronie), która
” od szukanej wartości.
Każda pozycja na stronach zawiera wskaźnik do strony danych jeden poziom niżej w hierarchii
indeksu. Dzięki takiej strukturze przeszukiwane są tylko wybrane strony z danymi, nie zaś wszystkie
strony zawierające dane z wybranej tabeli.
Rys. 3 Indeks grupowany
Indeks niegrupowany działa na podobnej zasadzie, co indeks w typowej książce (ale nie w
telefonicznej). Indeks niegrupowany budowany jest na stronach danych, które nie są sortowane.
óch poziomów: poziomu niepomocniczego i poziomów pomocniczych
Na stronach poziomu niepomocniczego, podobnie jak w przypadku indeksu grupowanego,
przechowywane są wartości indeksowanego pola ze wskaźnikami do poziomu niżej w drze
Strony poziomu pomocniczego zwane też liśćmi i zawierają wskaźniki do konkretnych stron danych
(które nie są posortowane). Wskaźnik taki zawiera następujące dane: ID pliku, numer strony,
Przeszukiwanie indeksu niegrupowanego odbywa się na podobnej zasadzie, jak w indeksie
grupowanym. Po dojściu do poziomu pomocniczego następują skoki do stron danych (do
Rys. 4 Indeks niegrupowany
Moduł 7
Indeksy i transakcje
Na samym dole drzewa znajdują się strony zawierające posortowane wg indeksowanego pola dane
wg nazwisk lub nazw firm czy instytucji).
Przeszukiwanie indeksu odbywa się z góry na dół na następującej zasadzie: porównywana jest
mi zapisanymi (i posortowanymi) na stronach
jeśli znajdzie się wartość „większa” od wartości szukanej, wtedy następuje skok jeden
poziom niżej do strony wskazywanej przez ostatnią pozycję (na ostatnio sprawdzanej stronie), która
Każda pozycja na stronach zawiera wskaźnik do strony danych jeden poziom niżej w hierarchii
indeksu. Dzięki takiej strukturze przeszukiwane są tylko wybrane strony z danymi, nie zaś wszystkie
indeks w typowej książce (ale nie w
telefonicznej). Indeks niegrupowany budowany jest na stronach danych, które nie są sortowane.
poziomów pomocniczych.
Na stronach poziomu niepomocniczego, podobnie jak w przypadku indeksu grupowanego,
przechowywane są wartości indeksowanego pola ze wskaźnikami do poziomu niżej w drzewie
Strony poziomu pomocniczego zwane też liśćmi i zawierają wskaźniki do konkretnych stron danych
(które nie są posortowane). Wskaźnik taki zawiera następujące dane: ID pliku, numer strony,
owanego odbywa się na podobnej zasadzie, jak w indeksie
grupowanym. Po dojściu do poziomu pomocniczego następują skoki do stron danych (do

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 7/20
Operacje na indeksach
Indeksy są najczęściej tworzone automatycznie dla kluczy głównych oraz pól, dla których ma być
wymuszona unikatowość. Można też tworzyć je dla innych pól, korzystając z polecenia języka
SQL
CREATE INDEX.
Poniżej podano przykład utworzenia indeksu grupowanego dla dla pola
Nazwisko w tabeli
Recenzent:
USE PraceDyplomowe
CREATE CLUSTERED INDEX cl_nazwisko
ON Recenzent (Nazwisko)
Indeks może też być zakładany na kilku polach jednocześnie. Poniższy przykład pokazuje sposób
definiowania unikalnego indeksu na polach
Nazwisko i Imie tabeli Osoba:
CREATE UNIQUE INDEX Indeks_Osoba
ON Osoba (Nazwisko, Imie)
Założenie takiego indeksu spowoduje, że będzie możliwe wprowadzanie jedynie unikatowych par
imię-nazwisko.
Transakcje
Transakcja jest ciągiem operacji wykonywanych na bazie danych, które są niepodzielne i muszą być
wykonane w całości. Jest więc jednostką logiczną operowania na bazie. Podlega ona kontroli i
sterowaniu.
Każda transakcja może składać się z następujących operacji:
•
czytanie danej x przez transakcję T
•
zapisanie danej x przez transakcję T
•
wycofanie transakcji T
•
zatwierdzenie transakcji T
Transakcje służą do zapewnienia spójności bazy danych oraz umożliwiają równoległe wykonywanie
operacji na niej. Jeśli wiele procesów działa jednocześnie na bazie danych, to może łatwo dojść do
utraty spójności danych, a co za tym idzie do błędów i otrzymywania niewłaściwych rezultatów
operacji.
Transakcja zabezpiecza również przed częściowym wykonaniem zbioru operacji, które mogą być
przerwane, na przykład w wyniku awarii. Klasycznym przykładem jest operacja polegająca na
wypłacaniu pieniędzy z bankomatu. W uproszczeniu operacje realizowane w czasie wypłaty
pieniędzy z bankomatu są następujące:
1.
Klient wczytuje kartę magnetyczną i jest rozpoznawany.
2.
Klient określa sumę wypłaty.
3.
Konto klienta jest sprawdzane.
4.
Konto jest zmniejszane o sumę wypłaty.
5.
Wysyłane jest zlecenie do kasy.
6.
Bankomat odlicza sumę i koryguje stan gotówki w bankomacie.
7.
Bankomat wypłaca klientowi pieniądze.
Zaistnienie awarii w kroku 5 lub 6 może prowadzić do niezbyt przyjemnej sytuacji dla posiadacza
konta. Transakcje pozwalają na uniknięcie tego typu niespodzianek.
Postulaty AICD
Każda transakcja powinna spełniać cztery postulaty. Są to tak zwane postulaty AICD.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
1.
Atomowość (ang. atomicity
operacje, albo żadna.
2.
Spójność (ang. consistency
zakończeniu stan jest również spójny (w międzyczasie stan może być chwilowo niespójny).
3.
Izolacja (ang. isolation
ich działania. Czynności wykonane przez daną t
aż do jej zakończenia.
4.
Trwałość (ang. durability
dysku) i nie mogą być odwrócone przez zdarzenia losowe (np. wyłączenie prądu).
Transakcje w SQL
W języku SQL każda transakcja rozpoczyna się słowem
COMMIT oznaczającą pomyślne zakończenie transakcji lub operacją
wycofanie transakcji.
Dowolne polecenie
SELECT
Transakcja trwa aż do wydania komendy
cofającej). Transakcja może objąć dowolną liczbę
CREATE i innych.
Stosowanie zamków oraz problem
Zarządzanie transakcjami wymaga zastosowania specjalnego modułu (zwanego
oraz protokołu zarządzania transakcjami. W celu uniknięcia problemów ze współbieżnym dostępem
stosuje się mechanizmy blokady dostępu do danych
Wyróżniamy dwa typy zamków:
•
Zamek typu X – założenie zamka tego typu całkowicie blokuje dostęp do obiektu dla innych
transakcji.
•
Zamek typu S – założenie zamka tego typu powoduje, że inne transakcje mogą czytać dane,
ale nie mogą ich modyfikować.
Najczęściej stosowanym w bazach relacyjnych protokołem zarządzania transakcjami jest protokół
blokowania dwufazowego 2PL (ang.
następujące:
1.
Jeśli dana operacja pi(x) może być wykonana, to planista zakłada bl
transakcji Ti i operację przekazuje do wykonania. Jeśli natomiast operacja ta nie może być
wykonana, to umieszcza ją w kolejce.
2.
Zdjęcie założonej blokady może nastąpić dopiero wtedy, gdy operacja zostanie wykonana.
3.
Jeśli nastąpiło zdjęcie jakiejkolwiek blokady założonej dla transakcji T, to dla tej transakcji nie
można założyć żadnej innej blokady.
Postępując zgodnie z tymi zasadami przebieg wykonania transakcji wymusza dwie fazy obsługi
transakcji. W pierwszej fazie są zakładane blokady
druga jest znacznie szybsza od pierwszej.
emysław Kowalczuk, Konrad Markowski
Strona 8/20
atomicity) – w ramach jednej transakcji wykonują się albo wszystkie
operacje, albo żadna.
consistency) – o ile transakcja zastała bazę danych w spójnym stanie, po jej
zakończeniu stan jest również spójny (w międzyczasie stan może być chwilowo niespójny).
isolation) – transakcja nie wie nic o innych transakcjach i nie musi uwzględniać
ich działania. Czynności wykonane przez daną transakcję są niewidoczne dla innych transakcji
aż do jej zakończenia.
durability) – po zakończeniu transakcji jej skutki są na trwale zapamiętane (na
dysku) i nie mogą być odwrócone przez zdarzenia losowe (np. wyłączenie prądu).
W języku SQL każda transakcja rozpoczyna się słowem
BEGIN TRANSACTION
oznaczającą pomyślne zakończenie transakcji lub operacją
ROLLBACK
SELECT, INSERT, UPDATE, DELETE czy CREATE rozpoczyna transakcję.
Transakcja trwa aż do wydania komendy
COMMIT (potwierdzającej) lub
cofającej). Transakcja może objąć dowolną liczbę poleceń
SELECT, INSERT
Stosowanie zamków oraz problem z zakleszczaniem
Zarządzanie transakcjami wymaga zastosowania specjalnego modułu (zwanego
oraz protokołu zarządzania transakcjami. W celu uniknięcia problemów ze współbieżnym dostępem
stosuje się mechanizmy blokady dostępu do danych, tzw. zamki.
Wyróżniamy dwa typy zamków:
założenie zamka tego typu całkowicie blokuje dostęp do obiektu dla innych
założenie zamka tego typu powoduje, że inne transakcje mogą czytać dane,
ale nie mogą ich modyfikować.
ajczęściej stosowanym w bazach relacyjnych protokołem zarządzania transakcjami jest protokół
blokowania dwufazowego 2PL (ang. two-phase locking). Reguły pracy protokołu 2PL są
Jeśli dana operacja pi(x) może być wykonana, to planista zakłada bl
transakcji Ti i operację przekazuje do wykonania. Jeśli natomiast operacja ta nie może być
wykonana, to umieszcza ją w kolejce.
Zdjęcie założonej blokady może nastąpić dopiero wtedy, gdy operacja zostanie wykonana.
ie jakiejkolwiek blokady założonej dla transakcji T, to dla tej transakcji nie
można założyć żadnej innej blokady.
Postępując zgodnie z tymi zasadami przebieg wykonania transakcji wymusza dwie fazy obsługi
transakcji. W pierwszej fazie są zakładane blokady, a w drugiej następuje ich zdejmowanie. Faza
druga jest znacznie szybsza od pierwszej.
Rys. 5 Protokół blokowania dwufazowego 2PL
Moduł 7
Indeksy i transakcje
w ramach jednej transakcji wykonują się albo wszystkie
w spójnym stanie, po jej
zakończeniu stan jest również spójny (w międzyczasie stan może być chwilowo niespójny).
transakcja nie wie nic o innych transakcjach i nie musi uwzględniać
ransakcję są niewidoczne dla innych transakcji
po zakończeniu transakcji jej skutki są na trwale zapamiętane (na
dysku) i nie mogą być odwrócone przez zdarzenia losowe (np. wyłączenie prądu).
BEGIN TRANSACTION, a kończy operacją
ROLLBACK, oznaczającą
rozpoczyna transakcję.
(potwierdzającej) lub
ROLLBACK (zrywającej,
INSERT, UPDATE, DELETE,
Zarządzanie transakcjami wymaga zastosowania specjalnego modułu (zwanego modułem planisty)
oraz protokołu zarządzania transakcjami. W celu uniknięcia problemów ze współbieżnym dostępem
założenie zamka tego typu całkowicie blokuje dostęp do obiektu dla innych
założenie zamka tego typu powoduje, że inne transakcje mogą czytać dane,
ajczęściej stosowanym w bazach relacyjnych protokołem zarządzania transakcjami jest protokół
). Reguły pracy protokołu 2PL są
Jeśli dana operacja pi(x) może być wykonana, to planista zakłada blokadę na daną x dla
transakcji Ti i operację przekazuje do wykonania. Jeśli natomiast operacja ta nie może być
Zdjęcie założonej blokady może nastąpić dopiero wtedy, gdy operacja zostanie wykonana.
ie jakiejkolwiek blokady założonej dla transakcji T, to dla tej transakcji nie
Postępując zgodnie z tymi zasadami przebieg wykonania transakcji wymusza dwie fazy obsługi
, a w drugiej następuje ich zdejmowanie. Faza
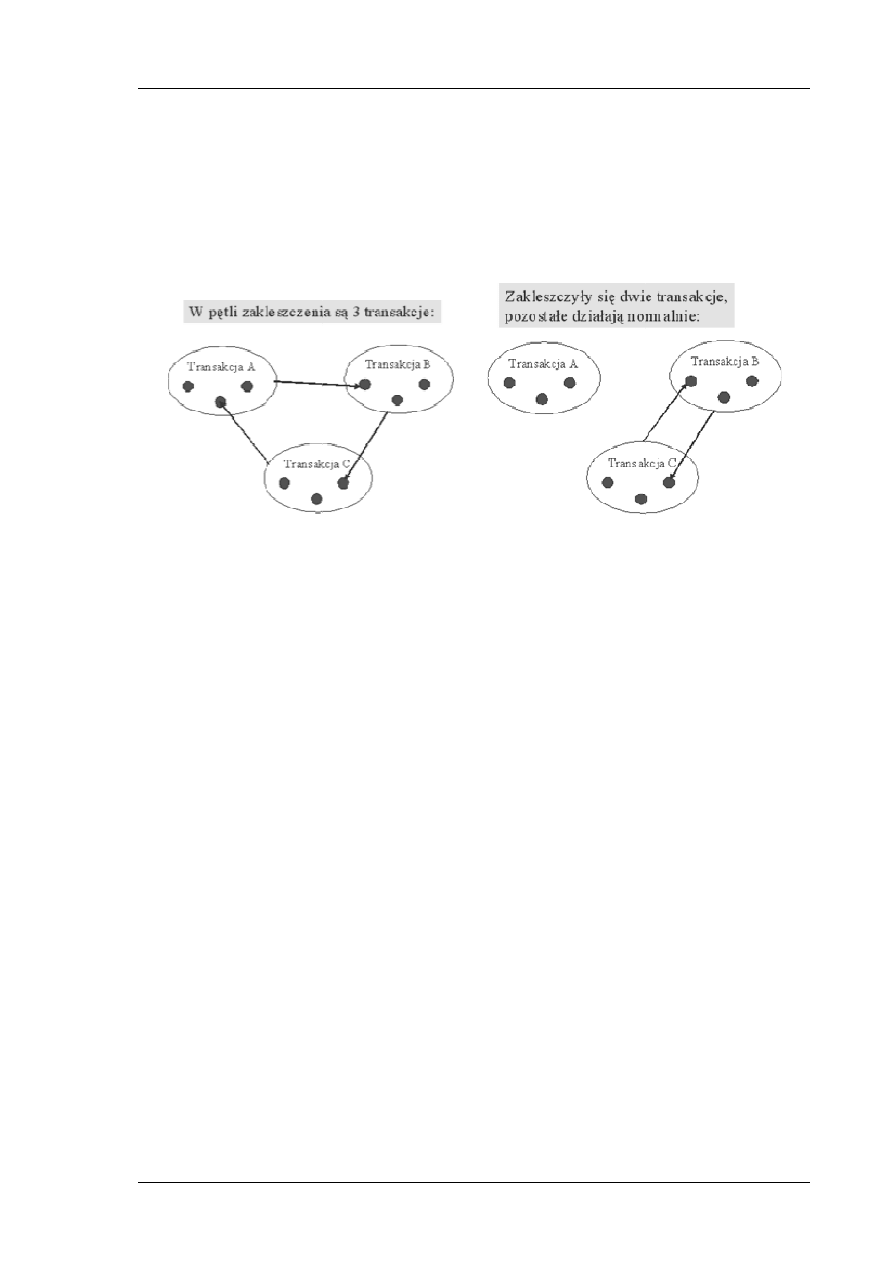
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Stosowanie zamków może prowadzić do zjawiska zwanego
tym, że transakcje blokują się, oczekując siebie nawzajem. Powodem powstania zakleszczeń jest
konieczność oczekiwania na
Weźmy pod uwagę dwie transakcje A i B. Transakcja A blokuje zasób X i żąda dostępu do zasobu
Transakcja B blokuje zasób Y i żąda dostępu do zasobu X. W wyniku tego dochodzi do zakleszczenia
i żadna z transakcji nie może wykonywać swojej akcji.
Inne przykłady zakleszczeń są pokazane na
Stemple czasowe oraz ziarnistość transakcji
Każda transakcja w momencie startu do
precyzyjny, aby móc po nim
danych, transakcja działa na swoich własnych kopiach aż do potwierdzenia.
Każdy obiekt bazy danych przechowuje dwa stemple czasowe: transakcji, która ostatnio brała
obiekt do czytania i transakcji, która ostatnio brała obiekt do modyfikacji. W momencie
potwierdzenia sprawdza się stemple transakcji oraz wszystkich pobranych przez nią obiektów.
Można dość łatwo wyprowadzić reguły zgodności, np. jeżeli obiekt był aktualizowany i st
obiekcie do aktualizacji jest taki sam, jak stempel transakcji, to
w przeciwnym razie należy
na obiekcie do aktualizacji jest starszy niż ste
w przeciwnym razie należy ją
Z problemem zakładania zamków wiąże się również problem ziarnistości. Ziarnistość oznacza
decyzję, co będzie niepodzielną jednostką, na którą zak
dotyczyć: bazy danych, relacji, rekordu, elementu rekordu, pojedynczego atrybutu, fizycznej strony
pamięci.
Grube ziarna mogą zapewnić znaczny poziom bezpieczeństwa, jednak dają niewielki stopień
współbieżności procesów. Z kolei małe ziarna wiążą się z dużymi nakładami na zakładanie zamków
oraz ich obsługę.
Przykładowe rozwiązanie
Optymalizacja bazy danych
Bardzo często działająca od jakiegoś czasu baza danych, na której wykonuje się bardzo dużo
operacji, zaczyna działać woniej niż podczas pierwszego uruchomienia. Wówczas do głównego
zadania administratora bazy danych należy zoptymalizowanie
tego celu może posłużyć nam narzędzie SQL Server Profiler.
emysław Kowalczuk, Konrad Markowski
Strona 9/20
Stosowanie zamków może prowadzić do zjawiska zwanego zakleszczaniem.
transakcje blokują się, oczekując siebie nawzajem. Powodem powstania zakleszczeń jest
konieczność oczekiwania na zwolnienie zasobu, do którego dostęp potrzebują.
Weźmy pod uwagę dwie transakcje A i B. Transakcja A blokuje zasób X i żąda dostępu do zasobu
Transakcja B blokuje zasób Y i żąda dostępu do zasobu X. W wyniku tego dochodzi do zakleszczenia
i żadna z transakcji nie może wykonywać swojej akcji.
Inne przykłady zakleszczeń są pokazane na rys. 6.
Rys. 6 Zakleszczenie transakcji
Stemple czasowe oraz ziarnistość transakcji
Każda transakcja w momencie startu dostaje unikalny stempel czasowy. Stempel ten jest
nim rozróżniać transakcje. Żadna zmiana nie jest nanoszona do bazy
danych, transakcja działa na swoich własnych kopiach aż do potwierdzenia.
Każdy obiekt bazy danych przechowuje dwa stemple czasowe: transakcji, która ostatnio brała
zytania i transakcji, która ostatnio brała obiekt do modyfikacji. W momencie
potwierdzenia sprawdza się stemple transakcji oraz wszystkich pobranych przez nią obiektów.
Można dość łatwo wyprowadzić reguły zgodności, np. jeżeli obiekt był aktualizowany i st
obiekcie do aktualizacji jest taki sam, jak stempel transakcji, to transakcja
w przeciwnym razie należy ją zerwać i uruchomić od nowa. Jeżeli obiekt był tylko czytany i stempel
na obiekcie do aktualizacji jest starszy niż stempel transakcji, to transakcja może zostać wykonana
w przeciwnym razie należy ją zerwać i uruchomić od nowa.
Z problemem zakładania zamków wiąże się również problem ziarnistości. Ziarnistość oznacza
decyzję, co będzie niepodzielną jednostką, na którą zakłada się blokady. Poziomy ziarnistości mogą
dotyczyć: bazy danych, relacji, rekordu, elementu rekordu, pojedynczego atrybutu, fizycznej strony
Grube ziarna mogą zapewnić znaczny poziom bezpieczeństwa, jednak dają niewielki stopień
rocesów. Z kolei małe ziarna wiążą się z dużymi nakładami na zakładanie zamków
Przykładowe rozwiązanie
Optymalizacja bazy danych
Bardzo często działająca od jakiegoś czasu baza danych, na której wykonuje się bardzo dużo
zaczyna działać woniej niż podczas pierwszego uruchomienia. Wówczas do głównego
zadania administratora bazy danych należy zoptymalizowanie jej oraz przebudowa indeksów. Do
tego celu może posłużyć nam narzędzie SQL Server Profiler.
Moduł 7
Indeksy i transakcje
. Zakleszczanie polega na
transakcje blokują się, oczekując siebie nawzajem. Powodem powstania zakleszczeń jest
zasobu, do którego dostęp potrzebują.
Weźmy pod uwagę dwie transakcje A i B. Transakcja A blokuje zasób X i żąda dostępu do zasobu Y.
Transakcja B blokuje zasób Y i żąda dostępu do zasobu X. W wyniku tego dochodzi do zakleszczenia
staje unikalny stempel czasowy. Stempel ten jest na tyle
rozróżniać transakcje. Żadna zmiana nie jest nanoszona do bazy
Każdy obiekt bazy danych przechowuje dwa stemple czasowe: transakcji, która ostatnio brała
zytania i transakcji, która ostatnio brała obiekt do modyfikacji. W momencie
potwierdzenia sprawdza się stemple transakcji oraz wszystkich pobranych przez nią obiektów.
Można dość łatwo wyprowadzić reguły zgodności, np. jeżeli obiekt był aktualizowany i stempel na
transakcja może zostać wykonana,
od nowa. Jeżeli obiekt był tylko czytany i stempel
transakcja może zostać wykonana,
Z problemem zakładania zamków wiąże się również problem ziarnistości. Ziarnistość oznacza
łada się blokady. Poziomy ziarnistości mogą
dotyczyć: bazy danych, relacji, rekordu, elementu rekordu, pojedynczego atrybutu, fizycznej strony
Grube ziarna mogą zapewnić znaczny poziom bezpieczeństwa, jednak dają niewielki stopień
rocesów. Z kolei małe ziarna wiążą się z dużymi nakładami na zakładanie zamków
Bardzo często działająca od jakiegoś czasu baza danych, na której wykonuje się bardzo dużo
zaczyna działać woniej niż podczas pierwszego uruchomienia. Wówczas do głównego
oraz przebudowa indeksów. Do
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 10/20
SQL Server Profiler to potężne choć rzadko wykorzystywane narzędzie do analizy problemów z
wydajnością bazy danych. Wykorzystując profiler do przechwytywania śladów (ang. traces)
aktywności bazy danych można analizować wzorce zapytań, aby wykryć problemy z wydajnością
nawet przed ich uwidocznieniem w aplikacjach.
W pierwszym kroku należy zdefiniować ślad. Wewnątrz silnika bazy danych SQL Server udostępnia
podsystem zdarzeń nazwany SQL Trace, który opiera się na zewnętrznych interfejsie. Interfejs ten
pozwala na wywoływanie SQL Trace z wykorzystaniem różnorodnych parametrów.
SQL Server Profiler uruchamia się z menu SQL Server 2008 Performance Tools. Po jego otworzeniu
należy wybrać
File, a następnie New Trace, co pokazano na rys. 7.
Rys. 7 Definicja śladu
Każdy definiowany ślad musi zostać nazwany (w naszym przykładzie użyliśmy nazwy
Test).
Następnie następuje wybór wzorca. Istnieje kilka wzorców, które najczęściej są monitorowane.
Oczywiście możemy ustawić pusty wzorzec i sami zdefiniować opcje. Na rys. 7 użyliśmy
predefiniowanego wzorca Tuning. Następnie ustawiamy sposób zapisu. Mamy możliwość zapisu do
pliku lub do tabeli. Zapis do tabeli nie jest polecany, gdyż SQL Trace może generować setki tysięcy
wierszy danych śladu na minutę na obciążonym serwerze.
Gdy ślad jest w pełni zdefiniowany, należy go tylko uruchomić i zbierać dane. W tym celu należy
kliknąć Run. Wynik działania śladu pokazano na rys. 8.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 11/20
Rys. 8 Uruchomienie śladu
Po zakończeniu zbierania śladu kolejnym etapem jest użycie narzędzia Database Engine Tuning
Advisor (DTA). Odgrywa ono ważną rolę w rozwiązywaniu problemów związanych z wydajnością,
pozwalając wpływać na optymizator zapytań w celu otrzymania zaleceń dla indeksów,
indeksowanych widoków lub partycji, które mogą zwiększyć wydajność.
W celu uruchomienia DTA należy z zakładki Tools wybrać Database Engine Tuning Advisor.
Następnie należy połączyć się z serwerem, wybrać plik obciążający do analizy – ten, do którego
zapisaliśmy zbierany ślad (rys. 9) – oraz określić opcje strojenia (rys. 10).
Rys. 9 Definiowanie ogólnych opcji strojenia bazy danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 12/20
Rys. 10 Definiowanie strojenia bazy danych
Po skonfigurowaniu opcji strojenia DTA można zacząć analizę klikając Start Analysis, co pokazano
na rys. 11.
Rys. 11 Strojenie bazy danych
Po wykonaniu analizy otrzymujemy zalecenia na przykład dotyczące przebudowy indeksów, które
możemy zastosować względem naszej bazy danych.
Porady praktyczne
Indeksowanie kolumn
•
Indeksy powinny być planowane z myślą o najczęściej wykonywanych w Twojej bazie danych
zapytaniach
SELECT z klauzulą WHERE. Pierwszym krokiem powinno być zatem wypisanie
najczęściej wykonywanych zapytań (koniecznie z klauzulą
WHERE)
•
Microsoft SQL Server umożliwia utworzenie w tabeli jednego indeksu grupowanego oraz 249
indeksów niegrupowanych. Pojedynczy indeks można założyć na maksymalnie 16 polach. To

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 13/20
jednak tylko maksymalne możliwości serwera. W praktyce w bazach danych OLTP (ang.
online transaction processing) nie tworzy się więcej niż 8 do 10 indeksów związanych z
pojedynczą tabelą.
•
Należy pamiętać, iż nie wszystkie zapytania wykorzystują indeksy. Np. w Microsoft SQL
Server zapytanie:
SELECT imie, nazwisko FROM osoby WHERE nazwisko LIKE '%mar%'
nie wykorzysta indeksu grupowanego na polu
nazwisko, ponieważ niemożliwe będzie
porównanie wartości wzorca z wartościami na stronach indeksu.
•
Indeksy mają kluczowe znaczenie dla optymalizacji wydajności baz danych. Dobrze
zaprojektowane indeksy mogą znacząco poprawić szybkość operacji przeszukiwania bazy
danych (najczęściej wykonywana operacja i dotyczy największych ilości danych), ale źle
zaplanowane mogą spowodować efekt odwrotny do pożądanego. Z tego powodu należy
starannie zaplanować ich strukturę.
•
Database Engine Tuning Advisor (DTA) to znacznie udoskonalony następca narzędzia Index
Tuning Wizard dostarczanego wraz z SQL Server 2000.
•
Żeby Database Engine Tuning Advisor (DTA) mógł przeprowadzić optymalizację bazy danych
w oparciu o plik zawierający ślad, musi on mieć co najmniej 2 MB zebranych danych.
Transakcje
•
Zakleszczenia są poważnym problemem i mają istotny wpływ na wydajność systemu. Walka z
zakleszczeniami może przebiegać według dwu metod:
a)
Wykrywanie zakleszczeń i rozrywanie pętli zakleszczenia – detekcja zakleszczenia
wymaga skonstruowania grafu czekania (ang. wait-for graph) i tranzytywnego domknięcia
tego grafu (złożoność gorsza niż n * n). Rozrywanie pętli zakleszczenia polega na wybraniu
transakcji „ofiary” uczestniczącej w zakleszczeniu, a następnie jej zerwaniu i
uruchomieniu od nowa. Wybór „ofiary” podlega różnym kryteriom – może nią być
transakcja najmłodsza, najmniej pracochłonna, o niskim priorytecie itp.
b)
Niedopuszczanie do zakleszczeń – istnieje wiele tego rodzaju metod, np.:
•
Wstępne żądanie zasobów – przed uruchomieniem każda transakcja określa potrzebne
jej zasoby. Nie może później nic więcej żądać. Wada: zgrubne oszacowanie żądanych
zasobów prowadzi do zmniejszenia stopnia współbieżności.
•
Czekasz-umieraj (ang. wait-die) – jeżeli transakcja próbuje dostać się do zasobu, który jest
zablokowany, to natychmiast jest zrywana i powtarzana od nowa. Metoda może być
nieskuteczna dla systemów interakcyjnych (użytkownik może się denerwować
koniecznością dwukrotnego wprowadzania tych samych danych) oraz prowadzi do spadku
efektywności (sporo pracy idzie na marne).
•
Postulat możliwości odtworzenia stanu systemu sprzed wywołani transakcji w wypadku jej
awarii (wycofania) możliwy jest dzięki m.in. zastosowaniu osobnego dziennika transakcji.
Mogą być w nim zapisywane wszystkie dane, na których pracuje transakcja lub też tylko dane
różnicowe. Należy jednak pamiętać, że obsługa transakcji wiąże się z dodatkowymi
nakładami i obciążeniem dla systemu.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz mechanizm działania i polityki indeksowania
•
rozumiesz zasadę działania transakcji
•
znasz składnię nakładania indeksów na poszczególne pola
•
rozumiesz sposób działania transakcji

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 14/20
•
rozumiesz mechanizm zakleszczania transakcji
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Kalen Delaney, Microsoft SQL Server 2005: Rozwiązania praktyczne krok po kroku, Microsoft
Press, 2006
W książce autor przedstawia między innymi w jaki sposób należy stosować
transakcje w celu zapewnienia bezpiecznej współbieżności bazy danych. Pokazuje
jak należy definiować transakcje w SQL Server oraz jak zarządzać odseparowanymi
transakcjami. W pozycji tej znajdziesz dużo rozwiązań praktycznych.
2.
Deren Bieniek, Randy Dyess, Mike Hotek, Javier Loria, Adam Machanic, Antonio Soto, Adolfo
Wiernik, SQL Server 2005. Implementacja i obsługa, APN Promise, 2006
W książce obszernie przedstawiono zagadnienia związane z tworzeniem indeksów
oraz transakcjami. Znajdziesz tu potrzebne informacje na temat struktury indeksu,
tworzenia indeksów klastrowych i nieklastrowych oraz na temat tworzenia
transakcji. Znajdziesz tutaj również szczegółowe informacje na temat optymalizacji
bazy danych oraz przebudowy indeksów. Książka szczególnie polecana ze względu
na dużą zawartość ćwiczeń laboratoryjnych.
3.
Ramez Elmasri, Shamkant B. Navathe, Wprowadzenie do systemów baz danych, Helion, 2005
W książce tej znajdziemy dużo szczegółowych informacji na temat indeksowania
oraz zagadnień związanych z przetwarzaniem transakcji. Pozycja szczególnie
polecana dla osób pragnących poszerzyć swoją wiedzę z tej tematyki.
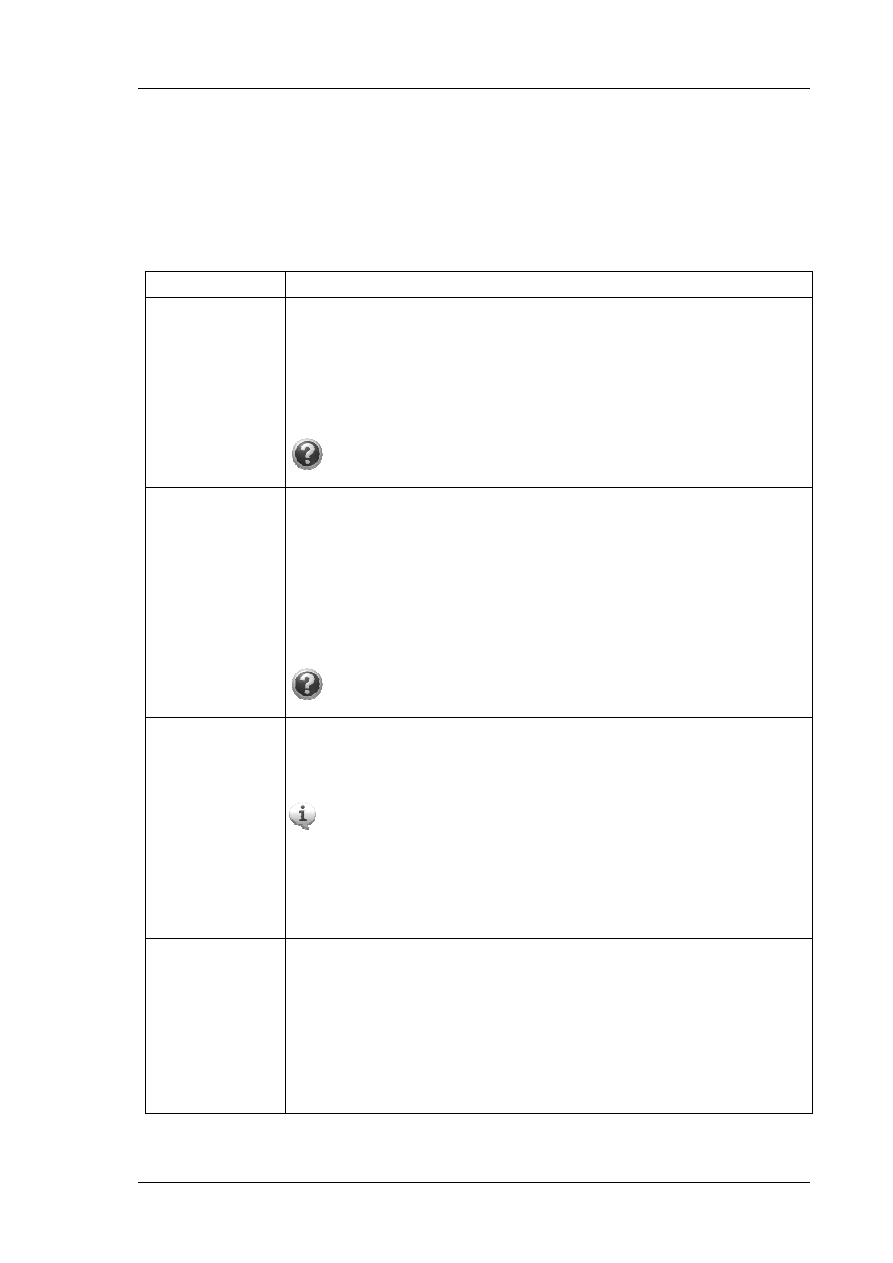
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Laboratorium podstawowe
Problem 1 (czas realizacji 30
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie
dotąd na Twoim wydziale. Zadanie
Zadanie
Tok postępowania
1.
Stwórz listę
najczęściej
wykonywanych
zapytań
•
Wypisz
najczęściej
wykonywane
zapytania
na
bazie
danych
PraceDyplomowe
—
—
—
—
2.
Wybierz pola
do indeksowania
•
Mając przed sobą listę najczęściej wykonywanych zapytań oraz
strukturę tabel
indeksowania są kolumny lub kombinacje kolumn, które:
—
—
—
—
3.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
W oknie logowania kliknij
4.
Przygotuj
tabelę
•
Z menu głównego wybierz
•
Odszukaj plik
•
Kliknij w menu głównym programu SQL Server M
Tools
•
W oknie
•
W pozycji odpowiadającej kombinacji klawiszy
sp_helpindex
12
emysław Kowalczuk, Konrad Markowski
Strona 15/20
Laboratorium podstawowe
(czas realizacji 30 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie na skalę uczelnianą systemu prac dyplomowych
. Zadanie, jakie przed Tobą stoi, to zaplanowanie struktury indeksów.
Tok postępowania
Wypisz
najczęściej
wykonywane
zapytania
na
bazie
danych
PraceDyplomowe, służące do wyszukiwania prac:
—
według tytułów
—
według autorów
—
według promotorów
—
według recenzentów
Zastanów się, jakie inne zapytania z klauzulą
WHERE
dla bazy danych PraceDyplomowe.
Mając przed sobą listę najczęściej wykonywanych zapytań oraz
strukturę tabel zaplanuj strukturę indeksów
indeksowania są kolumny lub kombinacje kolumn, które:
—
narzucają porządek sortowania (indeks grupowy)
—
przechowują wartości częściej odczytywane niż modyfikowane
—
są wykorzystywane do łączenia (JOIN) lub wyszukiwania (
danych
—
przechowują różnorodne wartości
Zastanów się, jakie inne kolumny są dobrymi kandydatami na to
założyć na nie indeks.
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Z menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Lab08\Indeksy.sql i kliknij Open.
Kliknij w menu głównym programu SQL Server M
Tools -> Customize.
W oknie Customize kliknij przycisk Keybord.
W pozycji odpowiadającej kombinacji klawiszy
sp_helpindex i wciśnij OK. Wynik powyższych operacji pokazano na
12.
Moduł 7
Indeksy i transakcje
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
prac dyplomowych, którym zarządzała
zaplanowanie struktury indeksów.
Wypisz
najczęściej
wykonywane
zapytania
na
bazie
danych
służące do wyszukiwania prac:
WHERE można utworzyć
Mając przed sobą listę najczęściej wykonywanych zapytań oraz
strukturę indeksów. Kandydatami do
indeksowania są kolumny lub kombinacje kolumn, które:
narzucają porządek sortowania (indeks grupowy)
ytywane niż modyfikowane
) lub wyszukiwania (WHERE)
Zastanów się, jakie inne kolumny są dobrymi kandydatami na to, żeby
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
.
Kliknij w menu głównym programu SQL Server Management Studio na
W pozycji odpowiadającej kombinacji klawiszy Ctrl+F1 wpisz
. Wynik powyższych operacji pokazano na rys.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
•
Stwórz kopie tabeli
--
IF EXISTS (
DROP TABLE Osoba_kopia
GO
SELECT Imie, Nazwisko, Nr_Indeksu
INTO Osoba_kopia
FROM Osoba
GO
•
Uruchom zapytanie do tabeli
--
SELECT * FROM Osoba
GO
•
Podkreśl w edytorze słowo
CTRL+F1
informację pokazaną na
--
EXEC sp_helpindex Osoba_kopia
GO
emysław Kowalczuk, Konrad Markowski
Strona 16/20
Rys. 12 Definicja klawiszy skrótu
Dzięki zdefiniowaniu klawiszy skrótu w prosty sp
wywoływać z klawiatury procedurę składowaną
wyświetla informacje o indeksach w wybranej tabeli.
Stwórz kopie tabeli Osoba:
-- (2) Tworzymy kopie tabeli Osoba
IF EXISTS (
SELECT name
FROM sysobjects
WHERE name='Osoba_kopia')
DROP TABLE Osoba_kopia
GO
SELECT Imie, Nazwisko, Nr_Indeksu
INTO Osoba_kopia
FROM Osoba
GO
Uruchom zapytanie do tabeli Osoba_kopia:
-- (3) Wyswietl zawartość tabeli Osoba_kopia
SELECT * FROM Osoba_kopia
GO
Podkreśl w edytorze słowo Osoba (nazwa twojej tabeli) i wciśnij
CTRL+F1 lub wykonaj poniższy fragment skryptu.
informację pokazaną na rys. 13.
-- (4) zobaczmy indeksy w tabeli
EXEC sp_helpindex Osoba_kopia
GO
Moduł 7
Indeksy i transakcje
Dzięki zdefiniowaniu klawiszy skrótu w prosty sposób będziesz mógł
wywoływać z klawiatury procedurę składowaną sp_helpindex, która
wyświetla informacje o indeksach w wybranej tabeli.
(nazwa twojej tabeli) i wciśnij
lub wykonaj poniższy fragment skryptu. Powinieneś zobaczyć
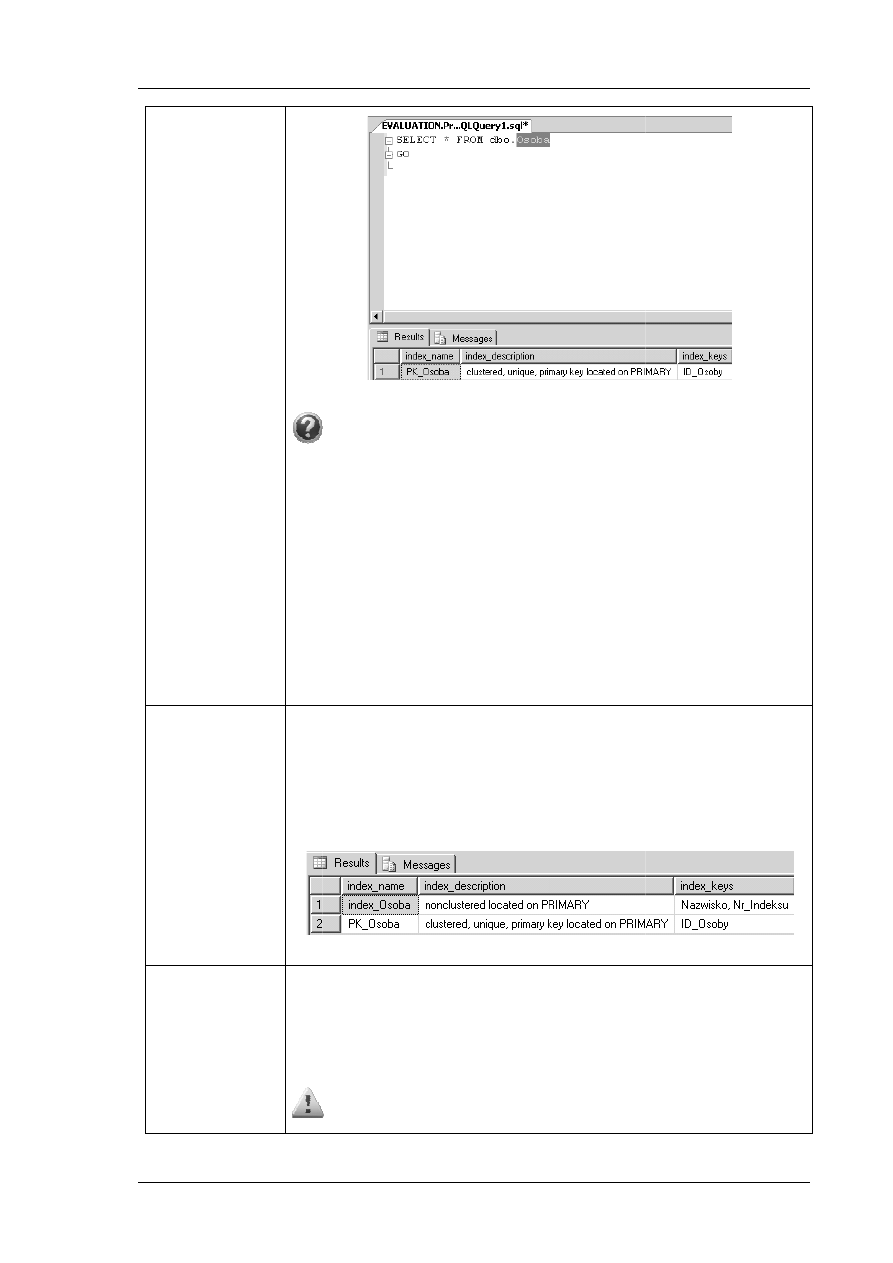
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
•
Włącz pomiar statystyk wejścia/wyjścia ilości skanowanych stron
wykonując poniższe polecenie:
--
SET statistic io on
GO
•
Zaznacz i uruchom (
--
--
SELECT * FROM Osoba
WHERE Nr_Indeksu > 1000 AND Nazwisko = 'K%'
GO
5.
Utwórz indeks
•
Zaznacz i uruchom (
--
CREATE INDEX index_Osoba ON Osoba(Nazwisko, Nr_Indeksu)
GO
•
Ponownie podkreśl w edytorze słowo
wciśnij
6.
Przetestuj
indeks
•
Zaznacz i uruchom (
--
--
SELECT * FROM Osoba
WHERE Nr_Indeksu > 1000 AND Nazwisko =
GO
emysław Kowalczuk, Konrad Markowski
Strona 17/20
Rys. 13 Informacja o indeksach w tabeli Osoba
Zastanów się, dlaczego w wyniku wywołania procedury składowanej
odpowiedzialnej za wyświetlanie informacji o indeksach pojawia się
wpis z indeksem PK_Osoba, skoro żaden indeks nie został założony?
Włącz pomiar statystyk wejścia/wyjścia ilości skanowanych stron
wykonując poniższe polecenie:
-- (5) Wlacz statystyki wejscia/wyjscia ilosci skanowanych stron
SET statistic io on
GO
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (6) wykonajmy proste wyszukiwanie po Nr_Indeksu
-- oraz po nazwisku
SELECT * FROM Osoba
WHERE Nr_Indeksu > 1000 AND Nazwisko = 'K%'
GO
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (7) utworzmy indeks niegrupowany
CREATE INDEX index_Osoba ON Osoba(Nazwisko, Nr_Indeksu)
GO
Ponownie podkreśl w edytorze słowo Osoba (nazwa twojej tabeli) i
wciśnij CTRL+F1. Powinieneś zobaczyć informację pokazaną na
Rys. 14 Informacja o indeksach w tabeli Osoba
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (6) wykonajmy proste wyszukiwanie po Nr_Indeksu
-- oraz po nazwisku
SELECT * FROM Osoba
WHERE Nr_Indeksu > 1000 AND Nazwisko = 'K%'
GO
Zauważ, iż wynik będzie oczywiście taki sam, ale pojawi się różnica w
statystykach.
Moduł 7
Indeksy i transakcje
macja o indeksach w tabeli Osoba
Zastanów się, dlaczego w wyniku wywołania procedury składowanej
informacji o indeksach pojawia się
, skoro żaden indeks nie został założony?
Włącz pomiar statystyk wejścia/wyjścia ilości skanowanych stron
(5) Wlacz statystyki wejscia/wyjscia ilosci skanowanych stron
(6) wykonajmy proste wyszukiwanie po Nr_Indeksu
CREATE INDEX index_Osoba ON Osoba(Nazwisko, Nr_Indeksu)
(nazwa twojej tabeli) i
. Powinieneś zobaczyć informację pokazaną na rys. 14.
Informacja o indeksach w tabeli Osoba
(6) wykonajmy proste wyszukiwanie po Nr_Indeksu
Zauważ, iż wynik będzie oczywiście taki sam, ale pojawi się różnica w
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Problem 2 (czas realizacji 15 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie
dotąd na Twoim wydziale. Zadanie jakie przed Tob
bazy danych.
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Manageme
•
W oknie logowania kliknij
2.
Przygotuj
tabelę
•
Z menu głównego wybierz
•
Odszukaj plik
•
Zaznacz kod, który wyświetla fragment tabeli, oznaczony w komentarzu
(1)
--
USE PraceDyplomowe
GO
--
SELECT *
FROM Osoba
WHERE ID_Osoby IN (1,2)
•
Zaznacz kod, który próbuje wykonać transakcje
--
BEGIN
BEGIN TRY
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
END CATCH
IF @@TRANCOUNT > 0
GO
emysław Kowalczuk, Konrad Markowski
Strona 18/20
Problem 2 (czas realizacji 15 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie na skalę uczelnianą systemu prac dyplomowych
. Zadanie jakie przed Tobą stoi to stworzenie transakcji dla rozwijanej
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Z menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Lab08\Transakcje.sql i kliknij Open
Zaznacz kod, który wyświetla fragment tabeli, oznaczony w komentarzu
(1) i (2).
-- (1) Ustaw sie na bazie danych PraceDyplomowe
USE PraceDyplomowe
GO
-- (2) Wyswietlamy dwa pierwsze rekordy z tabeli Osoba
SELECT *
FROM Osoba
WHERE ID_Osoby IN (1,2)
Zaznacz kod, który próbuje wykonać transakcje:
-- (3) Przykladowa transakcja
BEGIN TRANSACTION
BEGIN TRY
UPDATE Osoba
SET Nazwisko = 'Kochan'
WHERE ID_Osoby = 2
UPDATE Osoba
SET Nazwisko = 'Kowalski'
WHERE ID_Osoby = 6
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() as ErrorState,
ERROR_PROCEDURE() as ErrorProcedure,
ERROR_LINE() as ErrorLine,
ERROR_MESSAGE() as ErrorMessage
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION
END CATCH
IF @@TRANCOUNT > 0
COMMIT TRANSACTION
GO
Moduł 7
Indeksy i transakcje
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
prac dyplomowych, którym zarządzała
e transakcji dla rozwijanej
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
Open.
Zaznacz kod, który wyświetla fragment tabeli, oznaczony w komentarzu
(1) Ustaw sie na bazie danych PraceDyplomowe
(2) Wyswietlamy dwa pierwsze rekordy z tabeli Osoba

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
emysław Kowalczuk, Konrad Markowski
Strona 19/20
Powyższy kod podejmuje próbę wykonania transakcji złożonej z
dwóch operacji UPDATE. Próba wykonania pierwszej z nich spowoduje
błąd, ponieważ wartości w kolumnie ID_Osoby
być unikalne, a polecenie próbuje wstawić duplikat wartości 2, która
już istnieje w rekordzie drugim tabeli. Przechwytywanie błędów
odbywa się przy użyciu bloków TRY...CATCH, które poznałeś w module
9.
Zastanów się, jak powinieneś zmodyfikować
żeby zakończyła się powodzeniem?
Moduł 7
Indeksy i transakcje
konania transakcji złożonej z
. Próba wykonania pierwszej z nich spowoduje
ID_Osoby w tabeli Osoby muszą
unikalne, a polecenie próbuje wstawić duplikat wartości 2, która
rugim tabeli. Przechwytywanie błędów
, które poznałeś w module
zmodyfikować powyższą transakcję,

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 7
ITA-101 Bazy danych
Indeksy i transakcje
Strona 20/20
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma zarządzająca bazą
AdventureWorks planuje rozszerzenie i modernizację systemu w celu
spełnienia pewnych standardów. W związku z modernizacją systemu bazodanowego, a zatem
zmianą struktury fizycznej bazy danych, najprawdopodobniej będzie musiała nastąpić przebudowa
struktury indeksów. Poza przebudową indeksów będzie musiała zapewne nastąpić modernizacja
istniejących transakcji tak, żeby odpowiadały one nowej strukturze fizycznej przebudowanej bazy
danych.
Zadania jakie przed Tobą stoją to:
1.
Podjęcie decyzji, które obiekty w bazie danych pozostaną bez zmian, a które zostaną
zmodyfikowane lub usunięte.
2.
Podjęcie decyzji, na które pola opłaca się nałożyć indeks i jakiego typu te indeksy powinny
być.
3.
Podjęcie decyzji, które transakcje należy zmodernizować i czy nie trzeba będzie dodać
nowych transakcji.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
Wersja 1.0
Programowanie zaawansowane
w T-SQL
Spis treści
Programowanie zaawansowane w T-SQL ........................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 6
Porady praktyczne ....................................................................................................................... 6
Uwagi dla studenta ...................................................................................................................... 7
Dodatkowe źródła informacji....................................................................................................... 7
Laboratorium podstawowe .................................................................................................................. 8
Problem 1 (czas realizacji 30 minut) ............................................................................................ 8
Problem 2 (czas realizacji 15 minut) .......................................................................................... 10
Laboratorium rozszerzone ................................................................................................................. 12
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 12
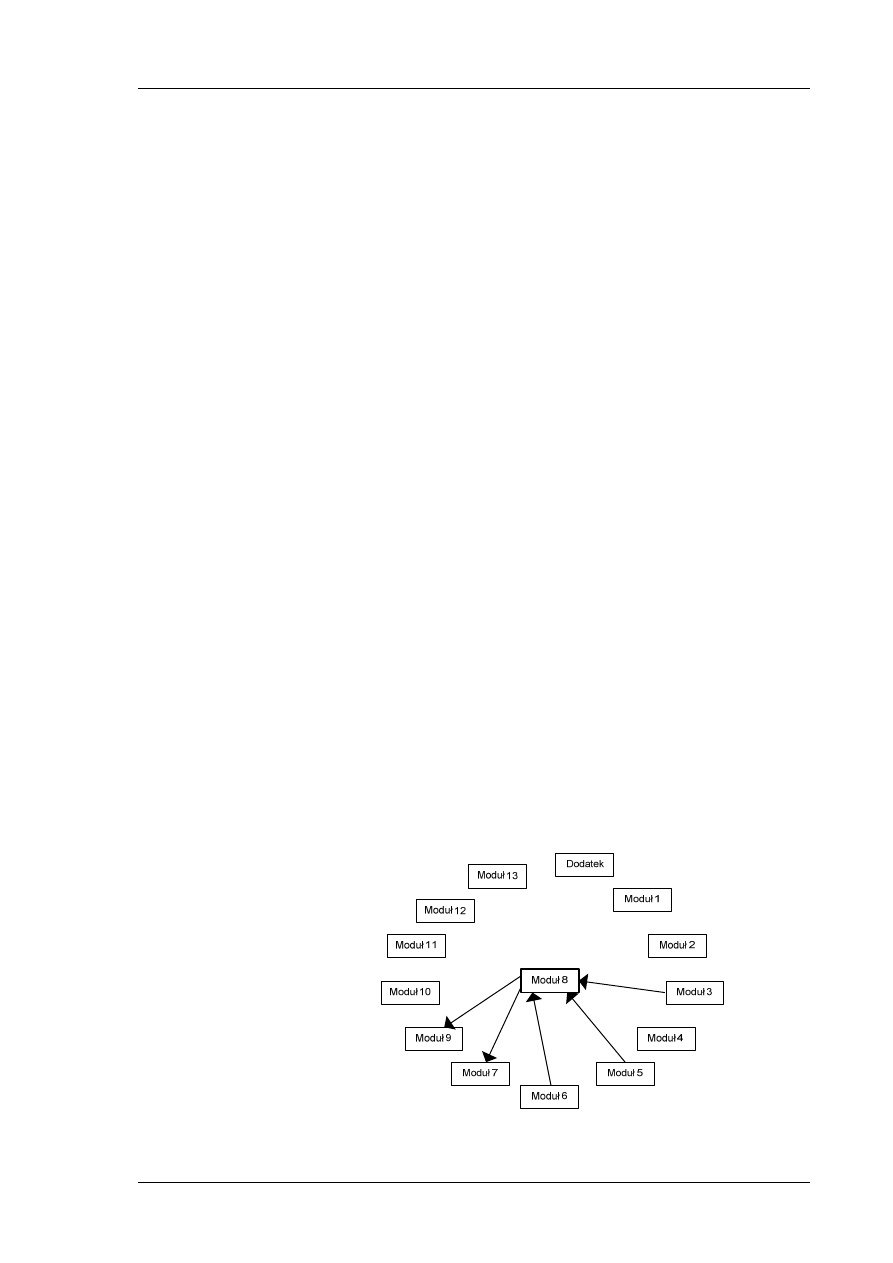
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
ITA-101 Bazy danych
Programowanie zaawansowane w T-SQL
Strona 2/12
Informacje o module
Opis modułu
Programowanie w języku zapytań to ważna umiejętność. Powinni ją
opanować zarówno programiści, jak i administratorzy. Różne dialekty języka
SQL oferują różne składnie, jednak reguły, jakimi powinien kierować się
tworzący kod, są te same niezależnie od systemu zarządzania bazami
danych. W module tym znajdziesz informację na temat zaawansowanego
programowania w T-SQL. Dowiesz się w jaki sposób korzystać z instrukcji
sterujących, kursorów oraz jak funkcjonuje obsługa błędów.
Cel modułu
Celem modułu jest zapoznanie czytelnika z zaawansowanymi elementami
języka T-SQL, takimi jak instrukcje sterujące, kursory, obsługa błędów itp.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
potrafił użyć instrukcji sterujących w języku T-SQL
•
rozumiał sposób działania i funkcjonowania kursorów
•
wiedział, w jaki sposób działa obsługa błędów
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
potrafić stworzyć bazę danych wraz z jej podstawowymi obiektami
(patrz: moduł 3)
•
potrafić napisać podstawowe instrukcje w języku T-SQL DCL i T-SQL
DDL (patrz: moduł 5)
•
potrafić pisać zapytania w języku T-SQL DML (patrz: moduł 6)
•
rozumieć podstawową składnię języka T-SQL
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznać się z materiałem zawartym
w modułach 3, 5 i 6.
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
ITA-101 Bazy danych
Programowanie zaawansowane w T-SQL
Strona 3/12
Przygotowanie teoretyczne
Przykładowy problem
Podczas wytwarzania bazy danych wiąże ze sobą grupę osób, do której należą projektant bazy
danych, administrator systemu zarządzania bazą danych, administrator bazy danych oraz
programista bazy danych. Bardzo ważne jest, żeby wszyscy biorący udział w wytwarzaniu systemu
bazodanowego współdziałali ze sobą na różnych etapach. Najwięcej wspólnego z programowaniem
w T-SQL ma programista bazy danych. Od niego w dużej mierze zależy, czy wytworzone funkcje,
procedury składowane, wyzwalacze i inne elementy będą działały we właściwy sposób. To on jest
odpowiedzialny za przygotowanie odpowiednich elementów programowych, które następnie
będzie wykorzystywał projektant aplikacji i programista aplikacji dostępowej. Również od niego w
pewnym stopniu zależy bezpieczeństwo danych gromadzonych w bazie. W związku z tym powinien
on dysponować odpowiednią wiedzą i posiadać pewne umiejętności z zakresu zaawansowanego
programowania w języku T-SQL. Znajomość tego języka oraz dobre nawyki wynikające z praktyki
programowania są bardzo ważne. Podstawowymi składowymi języka T-SQL są instrukcje sterujące,
kursory i obsługa błędów.
Podstawy teoretyczne
Język T-SQL stale ewoluuje. Z języka zapytań stał się właściwie językiem programowania baz
danych. Programiści tworzący oprogramowanie mogą łatwo nauczyć się T-SQL dzięki istniejącym
analogiom do tradycyjnych języków programowania proceduralnego. Jednymi z częściej używanych
konstrukcji są instrukcje sterujące.
Instrukcje sterujące
Instrukcja sterująca
IF…ELSE daje możliwość warunkowego wykonywania bloków kodu. W
implementacji T-SQL wygląda ona jak poniżej:
IF warunek_logiczny
{ wyrazenie_sql | wyrazenie_blokowe }
ELSE
{ wyrazenie_sql | wyrazenie_blokowe }
Należy zwrócić uwagę, że jeśli blok po słowie
IF lub ELSE składa się z wielu linii kodu, musisz użyć
składni
BEGIN…END. Wówczas:
IF warunek_logiczny
BEGIN
{ wyrazenie_sql | wyrazenie_blokowe }
END
ELSE
BEGIN
{ wyrazenie_sql | wyrazenie_blokowe }
END
Poniższy kod przedstawia przykładowe użycie instrukcji sterującej
IF…ELSE:
IF @zmienna > 100
PRINT 'Zmienna jest większa niż 100'
ELSE
BEGIN
PRINT 'Zmienna jest mniejsza niż 100'
SET @zmienna = 0 -- zerowanie zmiennej
END
Kolejna instrukcja sterująca to pętla
WHILE. W T-SQL wygląda ona następująco:
WHILE wyrazenie_logiczne
{ wyrazenie_sql | wyrazenie_blokowe }

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
ITA-101 Bazy danych
Programowanie zaawansowane w T-SQL
Strona 4/12
[ BREAK ]
{ wyrazenie_sql | wyrazenie_blokowe }
[ CONTINUE ]
{ wyrazenie_sql | wyrazenie_blokowe }
Wyrażenie logiczne powinno zwracać wartość
TRUE lub FALSE. Podobnie jak w przypadku
instrukcji sterującej
IF…ELSE, jeśli wyrażenie SQL składa się z wielu linii kodu, musisz użyć właśnie
składni
BEGIN…END. W instrukcji WHILE występują dwie istotne instrukcje:
•
BREAK – powoduje wyjście z pętli WHILE
•
CONTINUE – powoduje rozpoczęcie kolejnej interacji pętli WHILE
Poniższy kod przedstawia przykładowe użycie instrukcji sterującej
WHILE:
DECLARE @zmienna int
SET @zmienna = 0
WHILE @zmienna < 10
BEGIN
PRINT 'Iteracja nr ' + CAST(@zmienna AS varchar(2))
SET @zmienna = @zmienna + 1
END
Należy pamiętać, że pętla
WHILE może być wykonywana w nieskończoność, jeśli programista nie
zapewni wyjścia z pętli.
Kursory
Kursor to obiekt, który umożliwia poruszanie się po wynikach zapytania rekord po rekordzie.
Umożliwia on przetwarzanie rekordów jeden po drugim, co daje możliwość zaawansowanego
formatowania wyników wyszukiwania danych (ale w ściśle określonej kolejności, determinowanej
przez wynik zapytania użytego w definicji kursora).
Deklaracja kursora w języku T-SQL wygląda następująco:
DECLARE nazwa_kursora CURSOR [ { LOCAL | GLOBAL } ]
[ { FORWARD_ONLY | SCROLL } ]
[ { STATIC | KEYSET | DYNAMIC | FAST_FORWARD } ]
[ { READ_ONLY | SCROLL_LOCKS | OPTIMISTIC } ]
[ TYPE_WARNING ]
FOR wyrazenie_select
[ FOR UPDATE [ OF nazwa_kolumny [,…n] ] ]
[;]
Poniższy kod przedstawia przykładowe użycie kursora
:
DECLARE Employee_Cursor CURSOR FOR
SELECT LastName, FirstName
FROM Northwind.dbo.Employees
WHERE LastName like 'B%'
OPEN Employee_Cursor
FETCH NEXT FROM Employee_Cursor
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM Employee_Cursor
END
CLOSE Employee_Cursor
DEALLOCATE Employee_Cursor

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
ITA-101 Bazy danych
Programowanie zaawansowane w T-SQL
Strona 5/12
Składnia specjalna
Nowoczesne dialekty języka SQL obfitują w specjalne elementy składniowe, które znacznie
rozszerzają jego funkcjonalność. Przykładem takiej składni może być
PIVOT. Składnia ta umożliwia
stworzenie tabeli wynikowej z zapytania
SELECT, w której w nagłówkach wierszy i kolumn znajdują
się wartości z tabel źródłowych.
USE AdventureWorks
GO
SELECT VendorID, [164] AS Emp1, [198] AS Emp2, [223] AS Emp3, [231] AS
Emp4, [233] AS Emp5
FROM
(SELECT PurchaseOrderID, EmployeeID, VendorID
FROM Purchasing.PurchaseOrderHeader) p
PIVOT
(
COUNT (PurchaseOrderID)
FOR EmployeeID IN
( [164], [198], [223], [231], [233] )
) AS pvt
ORDER BY VendorID;
Zapytanie zamieszczony powyżej może przykładowo wygenerować następujący wynik:
VendorID Emp1 Emp2 Emp3 Emp4 Emp5
1 4 3 5 4 4
2 4 1 5 5 5
3 4 3 5 4 4
4 4 2 5 5 4
5 5 1 5 5 5
Powyższy wynik obrazuje możliwości tej składni, umożliwiając zbudowanie tabeli wyświetlającej
ilość zamówień u wybranych producentów, dokonanych przez pięciu pracowników (każdy
pracownik o określonym
EmployeeID).
Obsługa błędów
W trakcie wykonywania kodu SQL mogą wystąpić nieprzewidziane błędy, wynikające z różnych
przyczyn. Mogą to być błędy powstałe wskutek narzuconych w bazie danych ograniczeń lub na
przykład błędy spowodowane próbami wykonania niedozwolonych operacji. Wykrycie tych błędów
i odpowiednia reakcja na nie to zadanie dla programisty baz danych.
Błędy wykrywamy najczęściej w:
•
transakcjach – po wykryciu błędu wycofujemy transakcję
•
procedurach składowanych – wykrywamy błędy powstałe głównie w wyniku niepoprawnych
wartości parametrów podanych przez użytkownika
•
wyzwalaczach – podobnie jak w transakcjach, po napotkaniu błędu wycofywana jest
transakcja wywołująca wyzwalacz
•
blokach kodu SQL – wszelkie rozbudowane bloki kodu wymagają wykrywania błędów
Metod pozwalających na wykrycie błędów jest wiele. Można zastosować instrukcje sterujące, np.
IF…ELSE, do sprawdzania wartości zmiennych, by w ten sposób zapobiegać wystąpieniu błędów.
Drugą metodą jest wykorzystanie istniejących w systemie zarządzania bazami danych funkcji
pozwających wykrywać błędy. W systemie Microsoft SQL Server taką funkcją jest
@@ERROR, która
zwraca numer ostatnio napotkanego błędu w bieżącej sesji.
Aktualnie istnieją także inne, przez wielu uznawane za lepsze metody wykrywania i obsługi błędów.
Chodzi o strukturalną obsługę wyjątków. Przez wyjątek rozumiemy błąd, który wymaga obsługi.
Poniżej pokazano składnię
TRY…CATCH
(ang. try – próbuj, catch – przechwyć):

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
ITA-101 Bazy danych
Programowanie zaawansowane w T-SQL
Strona 6/12
BEGIN TRY
{ wyrazenie_sql | wyrazenie_blokowe }
END TRY
BEGIN CATCH
{ wyrazenie_sql | wyrazenie_blokowe }
END CATCH
Jeśli wyrażenie SQL składa się z wielu linii kodu, podobnie jak w przypadku instrukcji sterujących
IF…ELSE i WHILE musisz użyć składni BEGIN…END.
Przykładowe rozwiązanie
Przykładowe użycie instrukcji sterującej
Rozważmy przykład, w którym średnia cena produktu jest mniejsza od 100 zł. Jeżeli maksymalna
cena jest większa od 300 zł, wówczas w pętli
WHILE
podwajamy ją. Pętla ta wykonuje się do
momentu, gdy maksymalna cena jest większa od 300 zł. Po spełnieniu warunku wychodzimy z pętli
i wyświetlamy komunikat dla użytkownika.
USE AdventureWorks;
GO
WHILE (SELECT AVG(ListPrice) FROM Production.Product) < 100
BEGIN
UPDATE Production.Product
SET ListPrice = ListPrice * 2
SELECT MAX(ListPrice) FROM Production.Product
IF (SELECT MAX(ListPrice) FROM Production.Product) > 300
BREAK
END
PRINT 'Wyświetlony komunikat po wyjściu z pętli';
Przykładowe użycie TRY…CATCH
Poniższy fragment kodu obrazuje przykładową obsługę wyjątków przy pomocy składni
TRY…CATCH.
W celu zilustrowania obsługi błędów, wewnątrz bloku
TRY dokonujemy dzielenia przez zero, które
jest niewykonalne. Wówczas wywoływany jest wyjątek, który jest przechwytywany w bloku
CATCH.
Po przechwyceniu wyjątku wyświetlany jest odpowiedni komunikat zdefiniowany przez
programistę.
BEGIN TRY
-- generujemy błąd
SELECT 1/0;
END TRY
BEGIN CATCH
-- obsługujemy błąd
RAISERROR('Nie dzielimy przez zero',16,1)
END CATCH
Porady praktyczne
•
Funkcja wykrywania błędów
@@ERROR zwraca numer ostatniego błędu lub 0, jeśli wykonanie
polecenia T-SQL zakończyło się powodzeniem. Na poniższym przykładzie pokazano użycie
funkcji
@@ERROR do sprawdzenia naruszenia ograniczenia, do którego może dojść w sytuacji
modyfikacji danych:
UPDATE EmployeePayHistory
SET PayFrequency = 4
WHERE EmployeeID = 1
IF @@ERROR = 547

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
ITA-101 Bazy danych
Programowanie zaawansowane w T-SQL
Strona 7/12
PRINT 'naruszone ograniczenie.'
GO
•
Informacje na temat błędu mogą być uzyskiwane przy użyciu funkcji
ERROR_NUMBER (numer
błędu) i
ERROR_MESSAGE (komunikat błędu).
•
SQL Server udostępnia trzy rodzaje programowalnych obiektów: funkcje, procedury
składowane i wyzwalacze. W celu poprawnego pisania elementów programowalnych należy
znać zaawansowane elementy języka T-SQL. Zamiast wykonywania pojedynczego polecenia
lub komendy, obiekty te umożliwiają tworzenie bogatej logiki programistycznej, która
zawiera pętle, kontrolę przepływu, podejmowanie decyzji i rozwidlenia.
•
Zdolność do uruchamiania transakcji i przeznaczenie ich do pozostawienia lub wycofania nie
wystarczy do efektywnego radzenia sobie z problemem. W tym przypadku niezbędnym
składnikiem jest zdolność do programowanego wykrywania i obsłużenia błędów.
•
Wewnątrz bloku
CATCH możemy ustalić co spowodowało błąd i przekazać informacje na jego
temat używając systemu obsługi błędów języka T-SQL. Najczęściej używanymi funkcjami tego
rodzaju są
ERROR_NUMBER i ERROR_MESSAGE. Zwracają one numer i opis błędu.
•
Używając funkcji
ERROR_NUMBER i ERROR_MESSAGE w bloku instrukcji CATCH możemy
zdecydować, czy potrzeba użyć
ROLLBACK do cofnięcia transakcji.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz, co oznacza instrukcja sterująca
•
rozumiesz zasadę działania kursorów
•
umiesz zdefiniować prostą pętlę
•
umiesz podać przykład obsługi błędów
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Kalen Delaney, Microsoft SQL Server 2005: Rozwiązania praktyczne krok po kroku, Microsoft
Press, 2006
W książce autor w przystępny i zrozumiały sposób przedstawia podstawowe
mechanizmy zaawansowanego programowania w języku T-SQL. Książka polecana
szczególnie dla osób początkujących.
2.
Edward Whalen, Microsoft SQL Server 2005 Administrator’s Companion, Microsoft Press, 2006
W książce autor pokazał zaawansowane mechanizmy programowania w języku
T-SQL, które mogą zostać wykorzystane do programowania w bazach danych takich
obiektów jak funkcje, procedury składowane, wyzwalacze i transakcje. Pozycja
szczególnie polecana dla osób chcących poszerzyć swoją wiedzę na temat
programowania baz danych.
3.
Deren Bieniek, Randy Dyess, Mike Hotek, Javier Loria, Adam Machanic, Antonio Soto, Adolfo
Wiernik, SQL Server 2005. Implementacja i obsługa, APN Promise, 2006
W książce tej, podobnie jak w powyższej pozycji, przedstawiono elementy
zaawansowanego programowania w języku T-SQL. Pokazano praktyczne
zastosowanie zaawansowanych mechanizmów T-SQL. Książka polecana dla osób
początkujących, jak również chcących poszerzyć swoją wiedzę.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Laboratorium podstawowe
Problem 1 (czas realizacji
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od
firma planuje rozszerzenie na skalę uczelnian
dotąd na Twoim wydziale. Zadanie jakie przed Tob
mechanizmu wybierania danych z
odpowiedniej formie.
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
W oknie logowania kliknij
2.
Przetestuj
instrukcję
sterującą CASE
•
Z menu głównego wybierz
•
Odszukaj plik
•
Zaznacz i uruchom kod ze skryptu
na
USE PraceDyplomowe
GO
SELECT
FROM Ocena E
INNER JOIN Osoba C
ON E.ID_Ocena = C.ID_Osoby
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Programowanie zaawansowane w T
Strona 8/12
Laboratorium podstawowe
Problem 1 (czas realizacji 30 minut)
firmie National Insurance. Właśnie dowiedziałeś się od
planuje rozszerzenie na skalę uczelnianą systemu prac dyplomowych
woim wydziale. Zadanie jakie przed Tobą stoi to stworzenie
mechanizmu wybierania danych z twojej bazy danych oraz przedstawienie tych danych w
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Z menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Labs\Lab06\Case.sql.
Zaznacz i uruchom kod ze skryptu Case.sql. Wynik działania pokazano
na rys. 2.
USE PraceDyplomowe
GO
SELECT
C.Nazwisko, C.Imie,
CASE
WHEN E.ID_Ocena = '2' THEN 'trzy'
ELSE 'inna'
END AS Gender
FROM Ocena E
INNER JOIN Osoba C
ON E.ID_Ocena = C.ID_Osoby
GO
Moduł 8
Programowanie zaawansowane w T-SQL
firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
prac dyplomowych, którym zarządzała
stworzenie zaawansowanego
oraz przedstawienie tych danych w
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
. Wynik działania pokazano
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
ITA-101 Bazy danych
Programowanie zaawansowane w T-SQL
Strona 9/12
Rys. 2 Wynik działania skryptu z użyciem instrukcji CASE
3.
Zastosuj
stronicowanie
danych
•
Z menu głównego wybierz File -> Open -> File.
•
Odszukaj pliku C:\Labs\Lab06\Stronicowanie.sql
•
Zaznacz i uruchom kod ze skryptu Stronicowanie.sql. Wynik działania
pokazano na rys. 3.
USE PraceDyplomowe
GO
SELECT T.Nazwisko
FROM (
SELECT
Nazwisko,
ROW_NUMBER() OVER(ORDER BY ID_Stopnian) AS Pozytywna
FROM Osoba
) AS T
WHERE T.Pozytywna BETWEEN 2 AND 6
GO

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Problem 2 (czas realizacji
Kolejne zadanie związane z rozbudową systemu prac dyplomowych jakie przed Tobą stoi to
oprogramowanie obsługi błędów (przechwytywanie i obsługa) z użyc
mechanizmów, jakimi dysponuje SQL Server.
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Manageme
•
W oknie logowania kliknij
2.
Utwórz tabelę
archiwizacji
błędów
•
Z menu głównego wybierz
•
Odszukaj pliku
•
Zaznacz i uruchom kod ze skryptu
której będą
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Programowanie zaawansowane w T
Strona 10/12
Rys. 3 Wynik stronicowania danych
Powyższe zapytanie stanowi rozwiązanie problemu stronicowania
danych. W tym wypadku wynikiem jest lista osób z tabeli
czym wyświetlone zostają nazwiska osób, które z pracy otrzymały
ocenę pomiędzy 3 a 5, biorąc pod uwagę sortowanie według kolum
ID_Stopnian. Zapytanie zadziała tak samo, nawet gdy numeracja w tej
kolumnie nie będzie ciągła. Wykorzystuje ono podzapytanie, w którym
dla każdego wiersza generowana jest liczba porządkowa za pomocą
funkcji ROW_NUMBER (funkcja ta musi przed generowanie
określić kryterium sortowania, stąd klauzula ORDER BY
Problem 2 (czas realizacji 15 minut)
Kolejne zadanie związane z rozbudową systemu prac dyplomowych jakie przed Tobą stoi to
oprogramowanie obsługi błędów (przechwytywanie i obsługa) z użyc
jakimi dysponuje SQL Server.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Z menu głównego wybierz File -> Open -> File.
Odszukaj pliku C:\Labs\Lab09\Errors.sql
Zaznacz i uruchom kod ze skryptu Errors.sql, który tworzy tabele, w
której będą zapisywane informacje o błędach
Moduł 8
Programowanie zaawansowane w T-SQL
Powyższe zapytanie stanowi rozwiązanie problemu stronicowania
danych. W tym wypadku wynikiem jest lista osób z tabeli Osoby, przy
czym wyświetlone zostają nazwiska osób, które z pracy otrzymały
ocenę pomiędzy 3 a 5, biorąc pod uwagę sortowanie według kolumny
Zapytanie zadziała tak samo, nawet gdy numeracja w tej
kolumnie nie będzie ciągła. Wykorzystuje ono podzapytanie, w którym
dla każdego wiersza generowana jest liczba porządkowa za pomocą
(funkcja ta musi przed generowaniem wartości
ORDER BY).
Kolejne zadanie związane z rozbudową systemu prac dyplomowych jakie przed Tobą stoi to
oprogramowanie obsługi błędów (przechwytywanie i obsługa) z użyciem zaawansowanych
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
, który tworzy tabele, w

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
--
USE PraceDyplomowe
GO
--
--
CREATE TABLE TabelaBledow
(
)
GO
3.
Przechwytywa
nie błędów
•
Zaznacz i uruchom (
--
BEGIN TRY
END TRY
BEGIN CATCH
END CATCH
GO
4.
Przeglądanie
informacji o
wystąpieniu błędu
•
Zaznacz i uruchom (
--
SELECT * FROM TabelaBledow
GO
Wynik działania pokazano na
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Programowanie zaawansowane w T
Strona 11/12
-- (1) Ustawiamy się na baze danych PraceDyplomowe
USE PraceDyplomowe
GO
-- (2) Tworzymy tabele w ktorej bedzie przechowywana informacja o
-- bledach
CREATE TABLE TabelaBledow
ErrorID int IDENTITY(1,1) PRIMARY KEY,
ErrorNumber int NOT NULL,
ErrorMessage nvarchar(200) NOT NULL,
ErrorDate datetime DEFAULT GETDATE()
GO
Powyższy kod tworzy tabelę TabelaBledow, która będzie zawierała
informacje o występujących błędach. W kolumnie
zapisany zostanie numer błędu, w kolumnie
komunikat błędu, zaś w kolumnie ErrorDate
wystąpienia błędu (wartość domyślna – bieżąca data i czas
generowana przy pomocy funkcji systemowej GETDATE
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (3) Implementacja obslugi przechwytywania bledow
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT TabelaBledow(ErrorNumber, ErrorMessage)
SELECT ERROR_NUMBER(), ERROR_MESSAGE()
END CATCH
GO
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (4) Wyswietlenie zawartosci tabeli bledow
SELECT * FROM TabelaBledow
GO
Wynik działania pokazano na rys. 4.
Rys. 4 Informacja o błędzie
Moduł 8
Programowanie zaawansowane w T-SQL
(1) Ustawiamy się na baze danych PraceDyplomowe
) Tworzymy tabele w ktorej bedzie przechowywana informacja o
, która będzie zawierała
informacje o występujących błędach. W kolumnie ErrorNumber
w kolumnie ErrorMessage –
ErrorDate – data i godzina
bieżąca data i czas – jest
GETDATE).
obslugi przechwytywania bledow
INSERT TabelaBledow(ErrorNumber, ErrorMessage)
(4) Wyswietlenie zawartosci tabeli bledow

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 8
ITA-101 Bazy danych
Programowanie zaawansowane w T-SQL
Strona 12/12
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma zarządzająca bazą
AdventureWorks planuje rozszerzenie i modernizacje systemu w celu
spełnienia pewnych standardów. W związku z modernizacją systemu bazodanowego
najprawdopodobniej ulegną zmianie pewne metody wybierania danych. Wydaje się zasadne
stworzenie bardziej wyrafinowanych metod wybierania danych w oparciu o zaawansowane
konstrukcje języka T-SQL. Prawdopodobnie również w związku z wejściem na wyższy poziom
programowania w T-SQL będziesz musiał wprowadzić strukturalną obsługę błędów.
Zadanie jakie przed Toba stoi to:
1.
Podjęcie decyzji, które zapytania w bazie danych pozostaną bez zmian, które zostaną
zmodyfikowane i zastąpione czymś bardziej złożonym wykorzystując zaawansowane
możliwości języka T-SQL, a które będą musiały zostać całkowicie usunięte.
2.
Zaplanowanie struktury obsługi błędów dla zapytań istniejących w systemie bazodanowym.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
Wersja 1.0
Procedury składowane i wyzwalacze
Spis treści
Procedury składowane i wyzwalacze ................................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 8
Porady praktyczne ..................................................................................................................... 13
Uwagi dla studenta .................................................................................................................... 14
Dodatkowe źródła informacji..................................................................................................... 14
Laboratorium podstawowe ................................................................................................................ 16
Problem 1 (czas realizacji 10 min) .............................................................................................. 16
Problem 2 (czas realizacji 10 min) .............................................................................................. 17
Problem 3 (czas realizacji 15 min) .............................................................................................. 18
Problem 4 (czas realizacji 10 min) .............................................................................................. 19
Laboratorium rozszerzone ................................................................................................................. 21
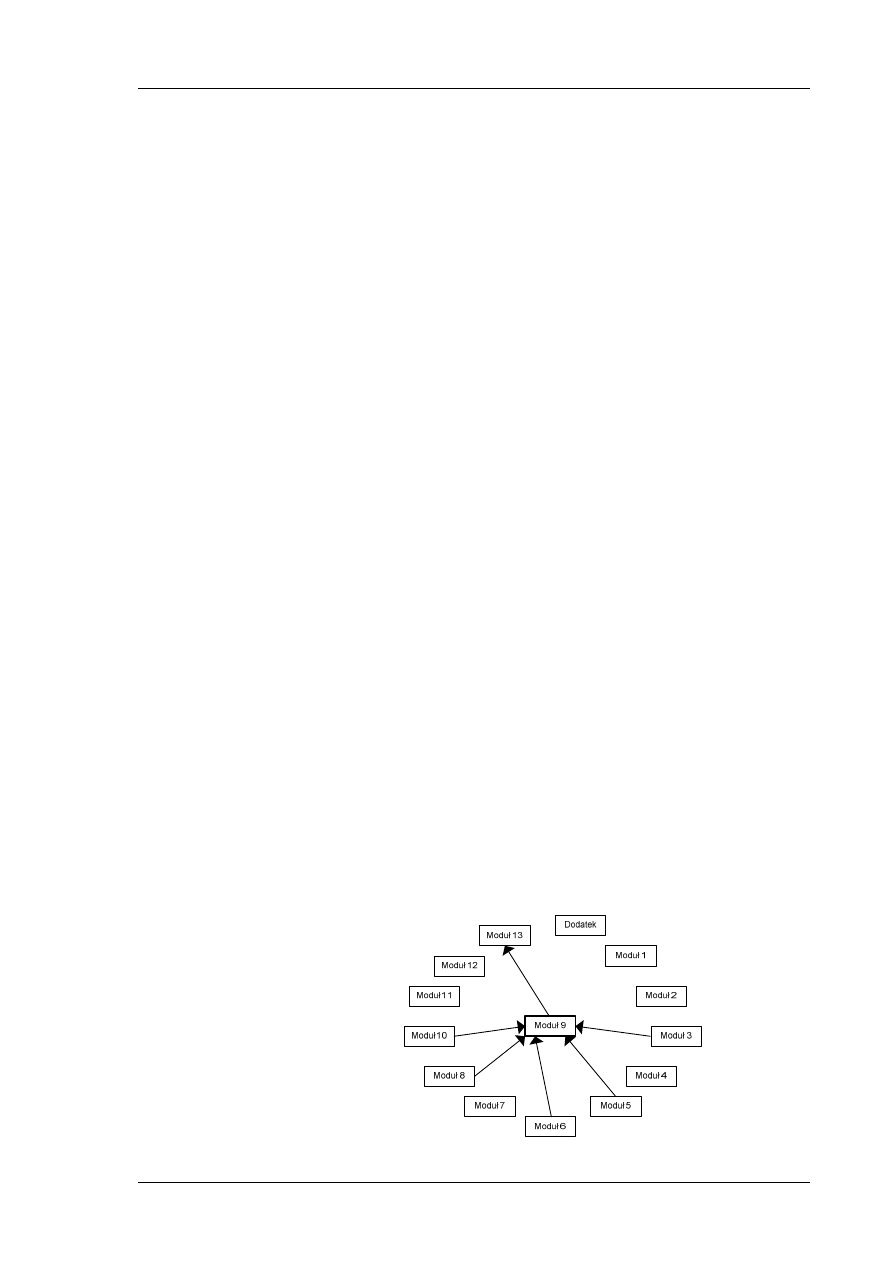
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 2/21
Informacje o module
Opis modułu
W tym module znajdziesz informacje na temat sposobu działania oraz
podstaw tworzenia procedur składowanych. Dowiesz się, na czym polega
różnica pomiędzy zwykłym zapytaniem T-SQL a procedurą składowaną oraz
co to jest kompilacja i rekompilacja procedury. Poznasz również specjalny
rodzaj procedury składowanej – wyzwalacz.
Cel modułu
Celem modułu jest zapoznanie czytelnika z procedurami składowanymi oraz
wyzwalaczami w środowisku bazodanowym Microsoft SQL Server 2008 oraz
zaprezentowanie, jak wykorzystać je w przykładowym projekcie.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
wiedział, jak napisać własną procedurę składowaną
•
umiał rozbudowywać gotowe procedury składowane
•
umiał tworzyć proste wyzwalacze
•
umiał zarządzać wyzwalaczami
•
umiał wykorzystywać wyzwalacze do optymalizacji i automatyzacji
działania SQL Server 2008
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
potrafić samodzielnie stworzyć bazę danych wraz z jej obiektami
(patrz: moduł 4)
•
znać podstawową składnię języka T-SQL
•
umieć napisać własne zapytania w języku T-SQL (patrz: moduły 5 i 6)
•
znać zaawansowane mechanizmy języka T-SQL (patrz: moduł 8)
•
wiedzieć, na czym polega bezpieczeństwo w bazach danych (patrz:
moduł 10)
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznać się z materiałem zawartym
w modułach 3, 5, 6, 8 i 10.
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 3/21
Przygotowanie teoretyczne
Przykładowy problem
Podczas wytwarzania bazy danych wiąże ze sobą grupę osób, do której należą projektant bazy
danych, administrator systemu zarządzania bazą danych, administrator bazy danych oraz
programista bazy danych. Bardzo ważne jest, żeby wszyscy biorący udział w wytwarzaniu systemu
bazodanowego współdziałali ze sobą na różnych etapach. Najwięcej wspólnego z programowaniem
w T-SQL ma programista bazy danych. Od niego w dużej mierze zależy, czy wytworzone funkcje,
procedury składowane, wyzwalacze i inne element będą działały we właściwy sposób. To on jest
odpowiedzialny za przygotowanie odpowiednich elementów programowych, które następnie
będzie wykorzystywał projektant aplikacji i programista aplikacji dostępowej.
Kolejnym zadaniem jakie stoi przed programistą i administratorem bazy danych jest stworzenie
odpowiedniej liczby wyzwalaczy, które są pewnym rodzajem procedur składowanych, z tymże
wywoływanych niejawnie. Należy pamiętać, iż użycie procedur składowanych prowadzi do
powstania kolejnej warstwy separującej użytkownika końcowego od fizycznych danych, tym samym
powodując maskowanie fizycznej struktury bazy. Z tego powodu bardzo ważne jest przemyślane i
odpowiednie przygotowanie zbioru procedur składowanych.
Podstawy teoretyczne
Procedury składowane
Procedura składowana (ang. stored procedure) jest nazwanym zbiorem poleceń w języku SQL, który
jest przechowywany na serwerze baz danych i jest kompilowany przy pierwszym wykonaniu.
Procedury wnoszą do środowiska bazodanowego przetwarzanie warunkowe i możliwości
programistyczne.
W systemie zarządzania bazami danych wykonanie dowolnego fragmentu kodu języka SQL wiąże
się z pewnym ciągiem czynności – począwszy od sprawdzenia składni, aż po kompilację i
wykonanie.
Proces wykonywania zapytania przez SQL Server
Proces wykonania pojedynczego zapytania w języku T-SQL w Microsoft SQL Server 2008 dzieli się
na następujące etapy:
1.
Sprawdzenie i rozdzielenie kodu na fragmenty - dokonywany jest podział kodu na fragmenty
nazywane symbolami. Proces ten nazywamy często nazywany jest analizą leksykalną.
2.
Sprawdzenie kodu pod względem poprawności semantycznej i syntaktycznej –
dokonywana jest kontrola poprawności semantycznej, czyli sprawdzenie, czy kod nie
odwołuje się do nieistniejących obiektów lub nie używa nieistniejących poleceń oraz kontrola
poprawności syntaktycznej, podczas której sprawdzana jest poprawność użytej składni.
3.
Standaryzacja wyodrębnionej części kodu – silnik wykonywania zapytań zapisuje kod w
jednoznacznej postaci (np. usuwa niepotrzebne symbole).
4.
Optymalizacja – Microsoft SQL Server posiada wewnętrzny proces zwany Optymalizatorem
Zapytań, który wybiera optymalny sposób dostępu do danych, tzn. taki plan wykonania
zapytania (ang. execution plan), w którym serwer będzie skanował (przeszukiwał)
najmniejszą ilość stron danych (o fizycznej strukturze danych w Microsoft SQL Server możesz
przeczytać w module 6). Na optymalizację szczególny wpływ ma struktura indeksów oraz
sposób łączenia tabel.
5.
Kompilacja i wykonanie – zapytanie jest kompilowane według optymalnego planu
wykonania i w takiej postaci wykonywane.
6.
Zwrócenie wyników – wyniki zapytania zwracane są do klienta.
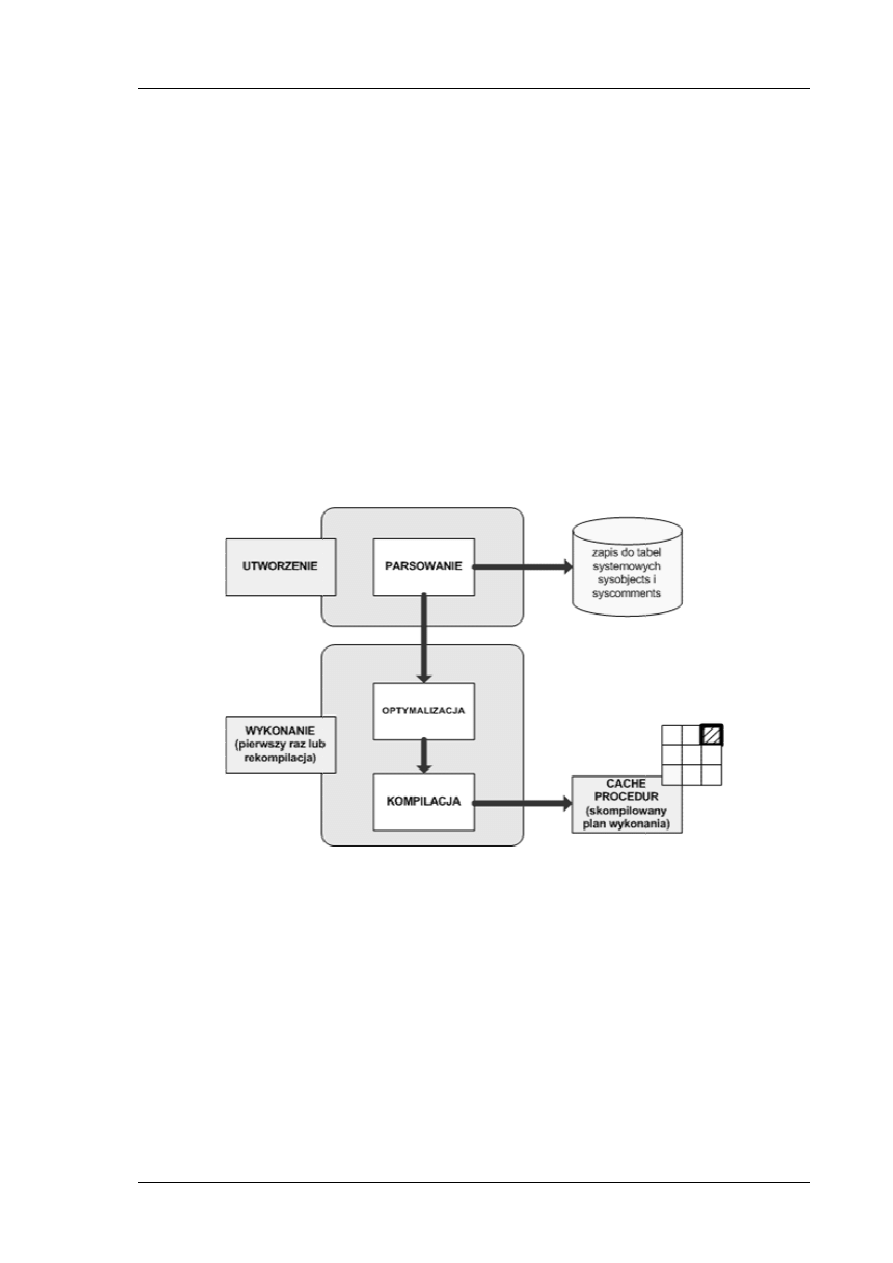
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Proces wykonywania procedury składowanej
Wykonywanie procedur składowanych odbywa się inaczej niż wykonywanie pojedyncz
zapytania SQL. Utworzenie
podzielić na następujące krok
1.
Utworzenie definicji procedury składowanej
PROCEDURE.
2.
Sprawdzanie kodu procedury pod względem poprawności
poprawności syntaktycznej kodu procedury
3.
Zapamiętanie procedury w bazie danych
są zapisywane do odpowiednich
syscomments).
4.
Wywołanie procedury
parametrami poleceniem
5.
Właściwe wykonanie procedury
6.
Buforowanie planu wykonania
w tzw. buforze procedur
Na rys. 2 pokazano schemat tworzenia i wykonania procedury składowanej w
Server 2008.
Rys. 2 Tworzenie i wykonanie procedury składowanej w SQL Server 2008
Rekompilacja procedur składowanych
Czasami zachodzi potrzeba ponownej kompilacji procedury składowanej. Dzieje się tak, gdy
wydajność skompilowanej procedury gwałtownie spada (może tak być z wielu powodów, np.
zmiany struktury indeksów lub zapisania dużej ilości rekordów), gdy istnieje potr
procedury przy każdym jej wykonaniu (powody mogą być te same, co w pierwszej sytuacji) lub gdy
zmianie ulega kod samej procedury (gdy użyjemy polecenia
Rekompilacji, czyli ponownej kompilacji procedury, można dokonać na dw
•
dodając w definicji procedury klauzulę
•
używając specjalnej systemowej procedury rekompilującej (w
procedura
sp_recompile
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Procedury składowane i wyzwalacze
Strona 4/21
Proces wykonywania procedury składowanej
Wykonywanie procedur składowanych odbywa się inaczej niż wykonywanie pojedyncz
e i pierwsze wykonanie procedury w Microsoft
podzielić na następujące kroki:
Utworzenie definicji procedury składowanej – wykonywane jest
Sprawdzanie kodu procedury pod względem poprawności – dokonywana jest kontrola
poprawności syntaktycznej kodu procedury.
Zapamiętanie procedury w bazie danych – nazwa procedury i jej kod
do odpowiednich widoków systemowych bazy danych (
łanie procedury – procedura składowana jest wywoływana
parametrami poleceniem
EXEC.
Właściwe wykonanie procedury – optymalizacja planu wykonania i kompilacja.
Buforowanie planu wykonania – skompilowany optymalny plan wykonania jest zapisywan
buforze procedur, skąd jest wczytywany przy następnym wywołaniu procedury.
pokazano schemat tworzenia i wykonania procedury składowanej w
Tworzenie i wykonanie procedury składowanej w SQL Server 2008
Rekompilacja procedur składowanych
Czasami zachodzi potrzeba ponownej kompilacji procedury składowanej. Dzieje się tak, gdy
wydajność skompilowanej procedury gwałtownie spada (może tak być z wielu powodów, np.
zmiany struktury indeksów lub zapisania dużej ilości rekordów), gdy istnieje potr
procedury przy każdym jej wykonaniu (powody mogą być te same, co w pierwszej sytuacji) lub gdy
zmianie ulega kod samej procedury (gdy użyjemy polecenia
ALTER PROCEDURE
Rekompilacji, czyli ponownej kompilacji procedury, można dokonać na dwa sposoby:
definicji procedury klauzulę
WITH RECOMPILE.
żywając specjalnej systemowej procedury rekompilującej (w Microsoft
sp_recompile).
Moduł 9
Procedury składowane i wyzwalacze
Wykonywanie procedur składowanych odbywa się inaczej niż wykonywanie pojedynczego
icrosoft SQL Server można
ywane jest polecenie
CREATE
dokonywana jest kontrola
procedury i jej kod (tzw. ciało procedury)
systemowych bazy danych (
sysobjects oraz
a jest wywoływana z odpowiednimi
optymalizacja planu wykonania i kompilacja.
kompilowany optymalny plan wykonania jest zapisywany
przy następnym wywołaniu procedury.
pokazano schemat tworzenia i wykonania procedury składowanej w środowisku SQL
Tworzenie i wykonanie procedury składowanej w SQL Server 2008
Czasami zachodzi potrzeba ponownej kompilacji procedury składowanej. Dzieje się tak, gdy
wydajność skompilowanej procedury gwałtownie spada (może tak być z wielu powodów, np.
zmiany struktury indeksów lub zapisania dużej ilości rekordów), gdy istnieje potrzeba kompilacji
procedury przy każdym jej wykonaniu (powody mogą być te same, co w pierwszej sytuacji) lub gdy
ALTER PROCEDURE).
a sposoby:
Microsoft SQL Server jest to

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 5/21
Tworzenie procedur składowanych
Do tworzenia procedur składowanych używamy polecenia języka SQL
CREATE PROCEDURE (lub w
skrócie
CREATE PROC):
CREATE { PROC | PROCEDURE } [nazwa_schematu.]nazwa_procedury
[ @parametr typ_danych[,…n] ]
[ WITH <opcje_procedury> [,…n] ]
[ FOR REPLICATION ]
AS
cialo_procedury
<opcja_procedury> ::=
[ ENCRYPTION ]
[ RECOMPILE ]
[ EXECUTE_AS_Clause ]
W definicji procedury składowanej określamy:
•
nazwę procedury
•
nazwy
•
typy danych
•
kierunek działania parametrów procedury
•
ciało procedury (kod wykonywany przez procedurę)
Opcjonalnie możemy również zadeklarować, czy procedura ma być przy każdym wykonaniu
rekompilowana.
Poniżej podano przykład utworzenia prostej procedury składowanej nie zawierającej żadnych
parametrów:
CREATE PROCEDURE p_pracownicy
AS
SELECT imie, nazwisko
FROM Osoby
Wywołanie procedury składowanej
Do wywołania procedury składowanej służy polecenie
EXECUTE (lub w skrócie EXEC):
[ { EXEC | EXECUTE } ]
[ @return_status = ]
{ module_name [ ;numer ] | @module_name_var }
[ [ @parametr = ] { wartość
| @zmienna [ OUTPUT ]
| [ DEFAULT ]
}
]
[,…n]
[ WITH RECOMPILE ]
Przykładowo dla utworzonej wcześniej procedury składowanej
p_pracownicy wywołanie będzie
wyglądało w następujący sposób:
EXEC p_pracownicy
GO
Parametry procedur składowanych
Procedury składowane mogą przyjmować parametry wywołania. Ilość i typ danych, które należy
podać przy wywołaniu procedury składowanej, określamy w trakcie tworzenia procedury (używając
polecenia
CREATE PROCEDURE). W zależności od tego, czy parametry będą potrzebne do

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 6/21
wykonania procedury, czy też mają być one przez procedurę zwrócone, wyróżniamy dwa rodzaje
parametrów: wejściowe (
INPUT) oraz wyjściowe (OUTPUT).
Możliwe jest też zdefiniowanie w procedurze parametru przejściowego (będącego jednocześnie
wejściowym i wyjściowym), czyli parametru, którego wartość podajemy przy wywołaniu, a która
może zostać zmieniona podczas działania procedury.
CREATE PROCEDURE p_pracownicy
@nazwisko varchar(40)='Smith'
AS
SELECT imie, nazwisko
FROM Osoby
WHERE nazwisko=@nazwisko
GO
Zalety i wady procedur składowanych
Procedury składowane dzięki temu, że są zapisane na serwerze oraz dzięki skompilowanemu
planowi wykonania przechowywanemu w buforze procedur posiadają dwie zasadnicze zalety:
•
zwiększają wydajność bazy danych
•
ograniczają ruch w sieci (przesyłane są tylko nazwy procedur i wartości parametrów)
Ponadto procedury składowane mają kilka zalet z punktu widzenia programistów aplikacji
bazodanowych:
•
Zapewniają jedną logikę biznesową dla wszystkich aplikacji klienckich.
•
Przesłaniają szczegóły tabel w bazie danych (przezroczystość struktury dla zwykłego
użytkownika aplikacji).
•
Umożliwiają modyfikację danych bez bezpośredniego dostępu do tabel bazy danych.
•
Dostarczają mechanizmów bezpieczeństwa (można nadawać uprawnienia do wykonywania
procedur poszczególnym użytkownikom bazy danych).
•
Umożliwiają programowania modularne (procedura zostaje zapisana w bazie danych, skąd
można ją wielokrotnie wywoływać; procedurę może pisać osoba wyspecjalizowana w bazach
danych – programista aplikacji jedynie ją wywoła).
•
Zapewniają szybsze wykonanie (jeśli wymagane jest wykonanie dużej liczby zapytań,
procedury składowane są szybsze, ponieważ wykonują się na serwerze, są optymalizowane i
umieszczane w pamięci przy pierwszym wykonaniu).
•
Zmniejszają ruch sieciowy (jeśli zachodzi potrzeba wykonania wielu zapytań w T-SQL na raz,
można je zastąpić wywołaniem jednej procedury składowanej).
Jeśli w ogóle można mówić o wadach procedur składowanych, to w zasadzie można wspomnieć o
kilku aspektach:
•
Następstwem rekompilacji czasem jest zmniejszenie wydajności procedury (czyli
administrator baz danych musi wiedzieć, kiedy przeprowadzić rekompilację).
•
W przypadku zagnieżdżania procedur składowanych należy pamiętać o tym, że zmienia się
kontekst wykonania (procedura zagnieżdżana wykonuje się z uprawnieniami innej
procedury).
•
Wreszcie, aby tworzyć dobre (tzn. poprawnie działające) procedury składowane niezbędne
jest poznanie zaawansowanych mechanizmów języka programowania baz danych (np. T-
SQL), takich jak zmienne, funkcje i procedury systemowe czy obsługa błędów.
Wyzwalacze
Wyzwalacz (ang. trigger) jest specjalnym rodzajem procedury składowanej. W przeciwieństwie do
zwykłej procedury składowanej wyzwalacz nie może zostać jawnie wywołany.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 7/21
Wyzwalacz jest wywoływany w reakcji na określone akcje. Akcje te to wykonanie przez użytkownika
określonego polecenia SQL (
INSERT, UPDATE, DELETE) na danej tabeli, dla której został określony
wyzwalacz.
Tworzenie wyzwalaczy
Wyzwalacze tworzymy używając polecenia
CREATE TRIGGER. W definicji wyzwalacza określamy:
•
nazwę wyzwalacza
•
dla jakiej tabeli tworzymy wyzwalacz
•
na jakie akcje wyzwalacz będzie reagował
•
jakiego typu wyzwalacz tworzymy
•
ciało wyzwalacza (odpowiednik ciała procedury składowanej) – czyli kod wykonywany przez
wyzwalacz
W SQL Server 2008 istnieją trzy rodzaje wyzwalaczy:
1.
Wyzwalacze obsługujące operacje DML (ang. Data Manipulation Language), czyli
INSERT
,
UPDATE
oraz
DELETE
wykonywane na tabeli lub widoku.
CREATE TRIGGER [nazwa_schematu.]nazwa_wyzwalacza
ON { table | view }
[ WITH <dml_opcje_wyzwalacza> [,…n] ]
{ FOR | AFTER | INSTEAD OF }
[ INSERT ] [ , ] [ UPDATE ] [ , ] [ DELETE ]
[ WITH APPEND ]
[ NOT FOR REPLICATION ]
AS wyrazenie_sql [ ; ] [,…n]
<dml_opcje_wyzwalacza> ::=
[ ENCRYPTION ]
[ EXECUTE AS Clause ]
2.
Wyzwalacze obsługujące operacje DDL (ang. Data Definition Language), czyli
CREATE,
ALTER, DROP oraz pewne procedury składowane, które wykonują operacje DDL.
CREATE TRIGGER nazwa_wyzwalacza
ON { ALL SERVER | DATABASE }
[ WITH <ddl_opcje_wyzwalacza> [,…n] ]
{ FOR | AFTER } { rodzaj_zdarzenia | event_group } [,…n]
AS wyrazenie_sql [ ; ] [,…n]
<ddl_opcje_wyzwalacza> ::=
[ ENCRYPTION ]
[ EXECUTE AS Clause ]
3.
Wyzwalacze obsługujące zdarzenie logowania (
LOGON), które jest wywoływane, kiedy
ustalana jest sesja logującego się użytkownika.
CREATE TRIGGER nazwa_wyzwalacza
ON ALL SERVER
[ WITH <opcje_wyzwalacza_logon> [,…n] ]
{ FOR | AFTER } LOGON
AS wyrazenie_sql [ ; ] [,…n]
<opcje_wyzwalacza_logon> ::=
[ ENCRYPTION ]
[ EXECUTE AS Clause ]

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 8/21
Zastosowanie wyzwalaczy
Wyzwalacze znajdują wiele zastosowań w bazach danych. Przede wszystkim stosujemy wyzwalacze
wszędzie tam, gdzie w inny sposób nie da się weryfikować integralności danych, a zwłaszcza ich
zgodności z regułami logiki biznesowej. Na przykład chcemy, by w pewnej kolumnie tabeli
wstawiane były tylko wartości unikalne, ale jednocześnie zezwalamy na wstawienie wartości
NULL.
Jedynym rozwiązaniem jest użycie wyzwalacza, który sprawdzi, czy wstawiana właśnie wartość już
w danym polu wystąpiła, a jeżeli użytkownik wstawia wartość
NULL, to wyzwalacz mu na to
pozwoli (tego efektu nie można osiągnąć innymi metodami, np. używając indeksów, ustawiając
właściwość unikalności kolumny lub używając kryteriów sprawdzających dane wstawiane w
kolumnę).
Drugie zastosowanie to wszelkiego typu automatyzacja zadań administracyjnych w bazie danych
(wszelkiego rodzaju „przypominacze”, obsługa nietypowych działań czy chociażby wysyłanie
wiadomości przez email lub pager).
Wreszcie z uwagi na pewne cechy wyzwalacze pozwalają na określony typ przetwarzania
transakcyjnego.
Przykładowe rozwiązanie
Tworzenie i uruchomienie procedury składowanej
W cel utworzenia nowej procedury składowanej należy z paska narzędziowego wybrać New Query i
wpisać kod procedury. Przykładowo:
CREATE PROCEDURE dbo.getAllCustomers
AS
BEGIN
SELECT [CustomerID], [CompanyName]
FROM [Northwind].[dbo].[Customers]
END
Następnie należy wykonać skrypt wciskając F5 lub wybierając z paska narzędziowego Execute. Jeśli
procedura składowana została utworzona poprawnie, powinieneś otrzymać komunikat
„Command(s) completed successfully” oraz zauważyć, że została dodana nowa procedura
składowana w obszarze Object Explorer, w gałęzi Databases -> Northwind -> Programmability ->
StoredProcedures, co pokazano na rys. 3.
Jeśli procedury nie widać w wyżej wymienionej gałęzi, należy ją odświeżyć. Jeśli procedura jest już
utworzona, a mimo to zażądano kolejnego jej utworzenia, to otrzymamy następujący komunikat:
„There is already an object named ‘getAllCustomers’ in the databases”.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 9/21
Rys. 3 Tworzenie nowej procedury
Aby uruchomić procedurę składowaną, wystarczy użyć polecenia
EXECUTE (lub krócej EXEC).
Można także kliknąć prawym klawiszem myszki procedurę i wybrać Execute Stored Procedure, co
wywoła okienko, w którym można przekazać do procedury jakieś parametry. Na rys. 4 widać, że
rozwijane menu udostępnia także inne opcje, takie jak modyfikacja lub usunięcie.
Rys. 4 Wywołanie procedury
Inne metody tworzenia procedur składowanych
Inną metoda tworzenia procedury składowanej jest skorzystanie z gotowego schematu procedury.
W tym celu kliknij prawym przyciskiem myszy na gałęzi Stored Procedures i wybierz New
StoredProcedure – uzyskasz w ten sposób gotowy schemat procedury składowanej, co pokazano
na rys. 5.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 10/21
Rys. 5 Tworzenie nowej procedury według wzorca
Procedury składowane a polisy
W SQL Server 2008 wprowadzono politykę opartą o Management Framework dla silnika SQL, dzięki
której zarządzanie serwerem będzie bardziej zautomatyzowane w oparciu o pewne reguły, a nie
skrypty.
Zadaniem DMF (z ang. Declarative Management Framework) jest umożliwienie administratorowi
zarządzania serwerami za pomocą definiowanych przez administratora reguł. W SQL Server 2008
mamy gotowe szablony reguł oparte o najlepsze praktyki zaimplementowane w narzędziu Best
Practices Analyzer, używanym przez administratorów z poprzednimi wersjami systemu SQL Server.
Korzystając z mechanizmu polis możemy stworzyć restrykcje dla procedur składowanych o postaci:
brak możliwości definiowania przez programistę bazy danych procedur składowanych z prefiksem
„sp_”. Restrykcję tę wprowadzimy na bazie danych
Biblioteka.
W ramach Object Explorer rozwijamy zakładkę Management a następnie Policy Menagement. W
pierwszym kroku należy dodać warunki, jakie będą dołączone do polisy.
Jako pierwszy stwórzmy warunek, który będzie pilnował, żeby nazwa procedury składowanej nie
posiadała prefiksu „sp_”. Konfigurację tego warunku pokazano na rys. 6.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 11/21
Rys. 6 Stworzenie warunku na procedurę składowaną
Następnie należy stworzyć warunek dotyczący bazy danych, na której polisa, którą za chwilę
założymy, będzie działała. Zostało to zilustrowane na rys. 7.
Rys. 7 Stworzenie warunku na bazę danych
W kolejnym kroku należy wystawić polisę i dodać do niej wcześniej stworzone warunki.
Konfiguracje wystawiania polisy pokazano na rys. 8.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 12/21
Rys. 8 Założenie polisy
Kiedy mamy już wystawiona polisę i chcemy ją przetestować, powinniśmy kliknąć prawym
przyciskiem myszy bazę danych
Biblioteka i wybrać New Query. Następnie w edytorze możemy
wpisać następujący kod, służący do utworzenia pustej procedury składowanej:
CREATE PROCEDURE sp_testowa
AS
GO
Zauważmy, ze wystąpił błąd. Procedura nie została utworzona, gdyż zadziałała restrykcja DMF, co
pokazano na rys. 9.
Rys. 9 Błąd procedury i zadziałanie polisy
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 13/21
Tworzenie wyzwalacza
Stwórzmy wyzwalacz, którego zadaniem będzie nie dopuścić do zalogowania wskazanego przez nas
użytkownika. W tym celu na początku dodajemy użytkownika
zbd_user i kojarzymy go z bazą
danych
AdventureWorks. Następnie tworzymy odpowiedni wyzwalacz, który nie pozwoli
użytkownikowi zalogować się do Microsoft SQL Server Management Studio. W tym celu klikamy
prawym przyciskiem myszy bazę
AdventureWorks i z menu kontekstowego wybieramy New
Query. W oknie edycji zapytania wpisujemy następujący kod:
USE AdventureWorks
GO
CREATE TRIGGER trgRestrictUser
ON ALL SERVER WITH EXECUTE AS 'sa'
FOR LOGON
AS
BEGIN
IF (ORIGINAL_LOGIN() = 'zbd_user' AND APP_NAME() = 'Microsoft SQL
Server Management Studio')
ROLLBACK;
END
Aby przetestować działanie utworzonego wyzwalacza, uruchamiamy drugą instancję SQL Server
Management Studio. W oknie Connect to Server Authentication wybieramy SQL Server
Authentication, w polu Login wpisujemy zbd_user, a w polu Password – user. Następnie klikamy
Connect. W efekcie powinien pokazać się błąd logowania jak na rys. 10.
Rys. 10 Bład logowania
Porady praktyczne
Procedury składowane
•
W Microsoft SQL Server przy kontroli poprawności kodu procedury w trakcie jej tworzenia
serwer nie sprawdza, czy istnieją obiekty (tabele, widoki), do których procedura się
odwołuje. Sprawdzenie to następuje dopiero przy wykonaniu procedury (w przypadku
odwołania do nieistniejącego obiektu procedura zgłosi błąd).
•
Rekompilacja procedury składowanej nie oznacza utworzenia procedury na nowo. Oznacza
utworzenie nowego planu wykonania i zapisanie go do bufora procedury na miejsce
poprzednio skompilowanego planu tej samej procedury.
•
Systemowe procedury składowane w systemie Microsoft SQL Server 2008 są
przechowywane w bazie
master, zaś w ich nazwach pojawia się prefiks „sp_”.
•
Zgodnie z dobra praktyka programowania baz danych, procedury składowane użytkownika w
SQL Server 2008 nie powinny zaczynać się od prefiksu „sp_”. Prefiksem tym obarczone są
systemowe procedury składowane. W sytuacji kiedy kompilator zobaczy procedurę
składowaną o takiej nazwie, będzie jej szukał w procedurach systemowych jako tych, które
już są skompilowane, a ich plan wykonania jest zapamiętany w buforze procedur. Dopiero
kiedy jej tam nie znajdzie zacznie ją kompilować według poznanego schematu. Spowoduje to
wydłużenie czasu wykonania procedury składowanej.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 14/21
•
Stworzenie polisy, która nie pozwoli programiście utworzyć procedury składowanej
zaczynającej się od prefiksu „sp_” spowoduje, że pierwsza próba stworzenia procedury o
takiej nazwie pociągnie za sobą konieczność uruchomienia sprawdzenia polisy, a zatem czas
wykonania polecenia nieznacznie się wydłuży. Kolejna próba stworzenia procedury
niezgodnej z polisą spowoduje natychmiastowe wyświetlenie komunikatu o naruszeniu
restrykcji.
•
Z punktu widzenia bezpieczeństwa fizycznej struktury bazy danych procedury składowane
stanowią dodatkowy poziom izolacji pomiędzy warstwą aplikacji dostępowej do bazy danych
a warstwą fizyczna bazy danych.
•
Poprzez
zastosowanie
procedur
składowanych
możemy
uniknąć
jednego
z
najpopularniejszych ataków na bazę danych, tzw. Wstrzykiwania kodu SQL z racji tego iż w
sieci pomiędzy bazą danych a aplikacją dostępową nie jest przesyłany kod SQL tylko nazwa
procedury składowanej wraz z jej parametrami.
Wyzwalacze
•
Wyzwalacze mogą być tworzone bezpośrednio w Microsoft SQL Server 2008 Database
Engine za pomocą zwykłych zapytań napisanych w języku T-SQL lub poprzez specjalne
metody w Microsoft .NET Framework Common Language Runtime (CLR), które po
utworzeniu importowane są do instancji serwera bazodanowego.
•
Microsoft SQL Server 2008 pozwala na tworzenie wielu wyzwalaczy dla specyficznego
zdarzenia.
•
Do tworzenia wyzwalaczy potrzebne są specjalne uprawnienia w bazie danych.
•
Następujące instrukcje języka T-SQL nie są dozwolone w wyzwalaczach DML:
ALTER
DATABASE, LOAD DATABASE, RESTORE DATABASE, CREATE DATABASE, LOAD LOG,
RESTORE LOG, DROP DATABASE i RECONFGURE. Dodatkowo powyższe instrukcje nie mogą
być użyte wewnątrz ciała wyzwalacza DML.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz, co to jest procedura składowana oraz wyzwalacz
•
rozumiesz zasadę działania procedur składowanych i wyzwalaczy
•
znasz składnię zaawansowanego języka Transact-SQL
•
umiesz dodawać użytkowników do SQL Server
•
rozumiesz różnicę pomiędzy różnymi rodzajami wyzwalaczy
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Deren Bieniek, Randy Dyess, Mike Hotek, Javier Loria, Adam Machanic, Antonio Soto, Adolfo
Wiernik, SQL Server 2005 Implementacja i obsługa, APN Promise, 2006
W książce obszernie przedstawiono zagadnienia związane z programowaniem baz
danych. Szczegółowo omówiono zagadnienia dotyczące procedur składowanych i
wyzwalaczy. Omówiono w niej implementacje procedur składowanych oraz w jaki
sposób przyznawać do nich uprawnienia. Pokazano implementacje wyzwalaczy
(DML i DDL). Książka szczególnie polecana ze względu na dużą zawartość ćwiczeń
laboratoryjnych.
2.
Kalen Delaney, Podstawy baz danych krok po kroku, APN Promise, 2006

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 15/21
Bardzo dobra książka dla osób początkujących. Pokazano w niej praktyczne
zastosowanie wyzwalaczy i procedur składowanych. Książka oprócz teorii zawiera
wiele przykładów.
3.
Dusan Petkovic, Microsoft SQL Server 2008: A Beginner's Guide, McGraw-Hill, 2008
Pozycja napisana w sposób prosty. Wprowadza w SQL Server 2008 w sposób szybki
i łatwy. Osoba początkująca w SQL Server 2008 znajdzie w niej podstawy z każdego
tematu dotyczącego serwera bazodanowego. W prosty sposób dowiesz się, jak
tworzyć proste procedury składowane bez parametrów i z parametrami oraz jak
posługiwać się wyzwalaczami. Pozycja polecana zarówno dla osób początkujących,
jak i zaawansowanych.
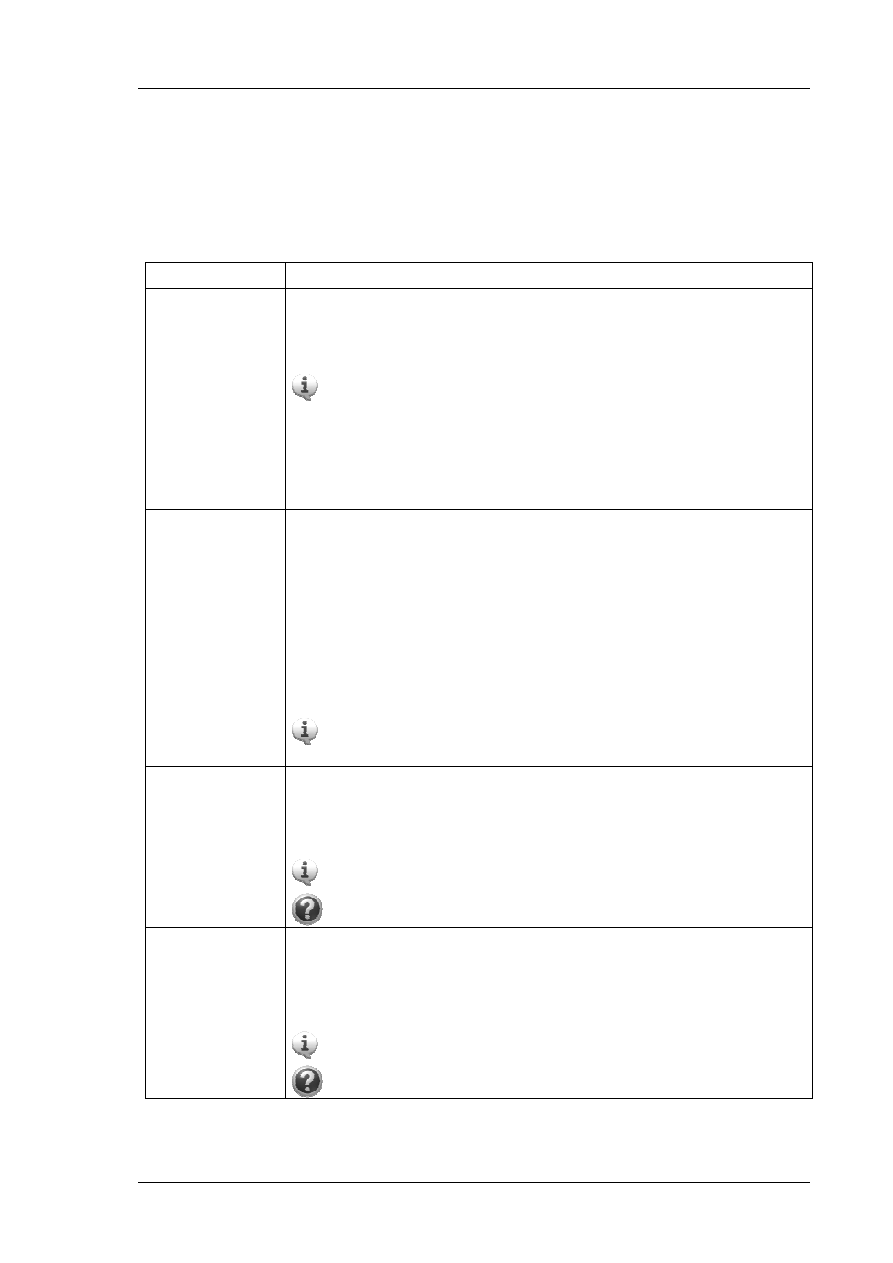
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Laboratorium podstawowe
Problem 1 (czas realizacji 10
Jesteś programistą bazodanowym w
swojego szefa, że firma planuje rozszerz
którym zarządzała jak dotąd na Twoim wydziale
już istniejących procedur składowanych.
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
W oknie logowania kliknij
2.
Uzyskaj
informacje o bazie
danych
•
Z menu głównego wybierz
•
Odszukaj plik
•
Zaznacz i uruchom
procedurę systemową
--
USE PraceDyplomowe
GO
--
EXEC sp_helpdb
3.
Uzyskaj
informacje o
obiektach bazy
danych
•
Zaznacz i uruchom
procedurę systemową
--
EXEC sp_help dbo.Prace
4.
Uzyskaj
informacje o
indeksach tabeli
•
Zaznacz kod, który wywołuje procedurę systemową
--
EXEC sp_helpindex dbo.Prace
•
Wciśnij
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Procedury składowane i wyzwalacze
Strona 16/21
Laboratorium podstawowe
Problem 1 (czas realizacji 10 min)
programistą bazodanowym w firmie National Insurance. Właśnie dowiedziałeś się od
że firma planuje rozszerzenie na skalę uczelnianą systemu
zarządzała jak dotąd na Twoim wydziale. Pierwsze zadanie, jakie przed Tob
procedur składowanych.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
Z menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Labs\Lab09\ProcedurySystemowe
Zaznacz i uruchom (F5) poniższy fragment kodu, który wywołuje
procedurę systemową sp_helpdb:
-- (1) Ustawiamy sie na baze danych PraceDyplomowe
USE PraceDyplomowe
GO
-- (2) Wywolanie procedury systemowej sp_helpdb
EXEC sp_helpdb PraceDyplomowe
Procedura sp_helpdb zwraca informacje o wybranej bazie danych
(rozmiar, listę plików i informacje o nich).
Zaznacz i uruchom (F5) poniższy fragment kodu, który wywołuje
procedurę systemową sp_help:
-- (3) Wywolanie procedury systemowej sp_help
EXEC sp_help dbo.Prace
Procedura sp_help zwraca informacje o wybranym obiekcie bazy
danych.
Czy w tabeli dbo.Prace jest jakakolwiek kolumna typu
Zaznacz kod, który wywołuje procedurę systemową
-- (4) Wywolanie procedury systemowej sp_helpindex
EXEC sp_helpindex dbo.Prace
Wciśnij F5, aby uruchomić zaznaczony fragment kodu.
Procedura sp_helpindex zwraca listę i opis indeksów założonych na
kolumnach w wybranej tabeli.
Czy w tabeli dbo.Prace jest nałożony jakiś indeks?
Moduł 9
Procedury składowane i wyzwalacze
firmie National Insurance. Właśnie dowiedziałeś się od
systemu prac dyplomowych,
jakie przed Tobą stoi to analiza
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Mirosoft Virtual PC,
dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
ProcedurySystemowe.sql i kliknij Open.
poniższy fragment kodu, który wywołuje
(1) Ustawiamy sie na baze danych PraceDyplomowe
(2) Wywolanie procedury systemowej sp_helpdb
zwraca informacje o wybranej bazie danych
poniższy fragment kodu, który wywołuje
(3) Wywolanie procedury systemowej sp_help
zwraca informacje o wybranym obiekcie bazy
jest jakakolwiek kolumna typu bit?
Zaznacz kod, który wywołuje procedurę systemową sp_helpindex.
(4) Wywolanie procedury systemowej sp_helpindex
, aby uruchomić zaznaczony fragment kodu.
zwraca listę i opis indeksów założonych na
jest nałożony jakiś indeks?
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Problem 2 (czas realizacji
Po dokonaniu analizy procedur już istniejących
postawione, to zdefiniowanie
już istniejących procedur składowanych.
składowanymi bez parametrów.
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
W oknie logowania kliknij
2.
Utwórz
procedurę
składowaną
•
Z
•
Odszukaj plik
Open
•
Zaznacz kod, który wywołuje procedurę składowaną
--
USE PraceDyplomowe
GO
--
CREATE PROCEDURE Promotorzy
AS
BEGIN
SELECT [Nazwisko], [Imie]
FROM Promotor
END
•
Wciśnij
3.
Uruchom
procedurę
składowaną
•
Zaznacz kod, który wywołuje procedurę
--
EXEC Promotorzy
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Procedury składowane i wyzwalacze
Strona 17/21
Problem 2 (czas realizacji 10 min)
Po dokonaniu analizy procedur już istniejących, kolejne zadanie, jakie
to zdefiniowanie procedur składowanych dla nowych użytkowników oraz modyfikacja
już istniejących procedur składowanych. W pierwszej kolejności powinieneś zająć się procedurami
składowanymi bez parametrów.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Labs\Lab10\Procedura_bez_parametrow.sql
Open.
Zaznacz kod, który wywołuje procedurę składowaną
-- (1) Ustawiamy sie na baze danych PraceDyplomowe
USE PraceDyplomowe
GO
-- (2) Tworzymy procedure skladowana uzytkownika
CREATE PROCEDURE Promotorzy
AS
BEGIN
SELECT [Nazwisko], [Imie]
FROM Promotor
END
Innym sposobem stworzenia procedury składowanej jest kliknięcie
prawym przyciskiem myszy gałęzi Stored Procedures
StoredProcedure – uzyskasz w ten sposób gotowy schemat procedury
składowanej.
Wciśnij F5, aby uruchomić zaznaczony fragment kodu.
Jeśli procedura składowana została utworzona poprawnie, powinieneś
otrzymać komunikat „Command(s) completed successfully
zauważyć, że została dodana nowa procedura składowana w
Explorer, w gałęzi Databases -> PraceDyplomowe
-> StoredProcedures. Jeśli procedury nie widać w w/w gałęzi, odśwież
ją. Jeśli procedura jest już utworzona, a mimo to zażądano kolejnego
jej utworzenia, to powinieneś otrzymać komunikat „There is already
object name ‘Promotorzy’ in the database”.
Zaznacz kod, który wywołuje procedurę Promotorzy
-- (3) Wywolujemy procedure skladowana Promotorzy
EXEC Promotorzy
GO
Innym sposobem na wywołanie procedury składowanej jest kliknięcie
Moduł 9
Procedury składowane i wyzwalacze
jakie zostało przed Tobą
nowych użytkowników oraz modyfikacja
W pierwszej kolejności powinieneś zająć się procedurami
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
_bez_parametrow.sql i kliknij
Zaznacz kod, który wywołuje procedurę składowaną Promotorzy:
raceDyplomowe
(2) Tworzymy procedure skladowana uzytkownika
Innym sposobem stworzenia procedury składowanej jest kliknięcie
ed Procedures i wybranie New
uzyskasz w ten sposób gotowy schemat procedury
, aby uruchomić zaznaczony fragment kodu.
Jeśli procedura składowana została utworzona poprawnie, powinieneś
completed successfully” oraz
zauważyć, że została dodana nowa procedura składowana w Object
PraceDyplomowe -> Programmability
Jeśli procedury nie widać w w/w gałęzi, odśwież
utworzona, a mimo to zażądano kolejnego
komunikat „There is already
Promotorzy:
procedure skladowana Promotorzy
Innym sposobem na wywołanie procedury składowanej jest kliknięcie
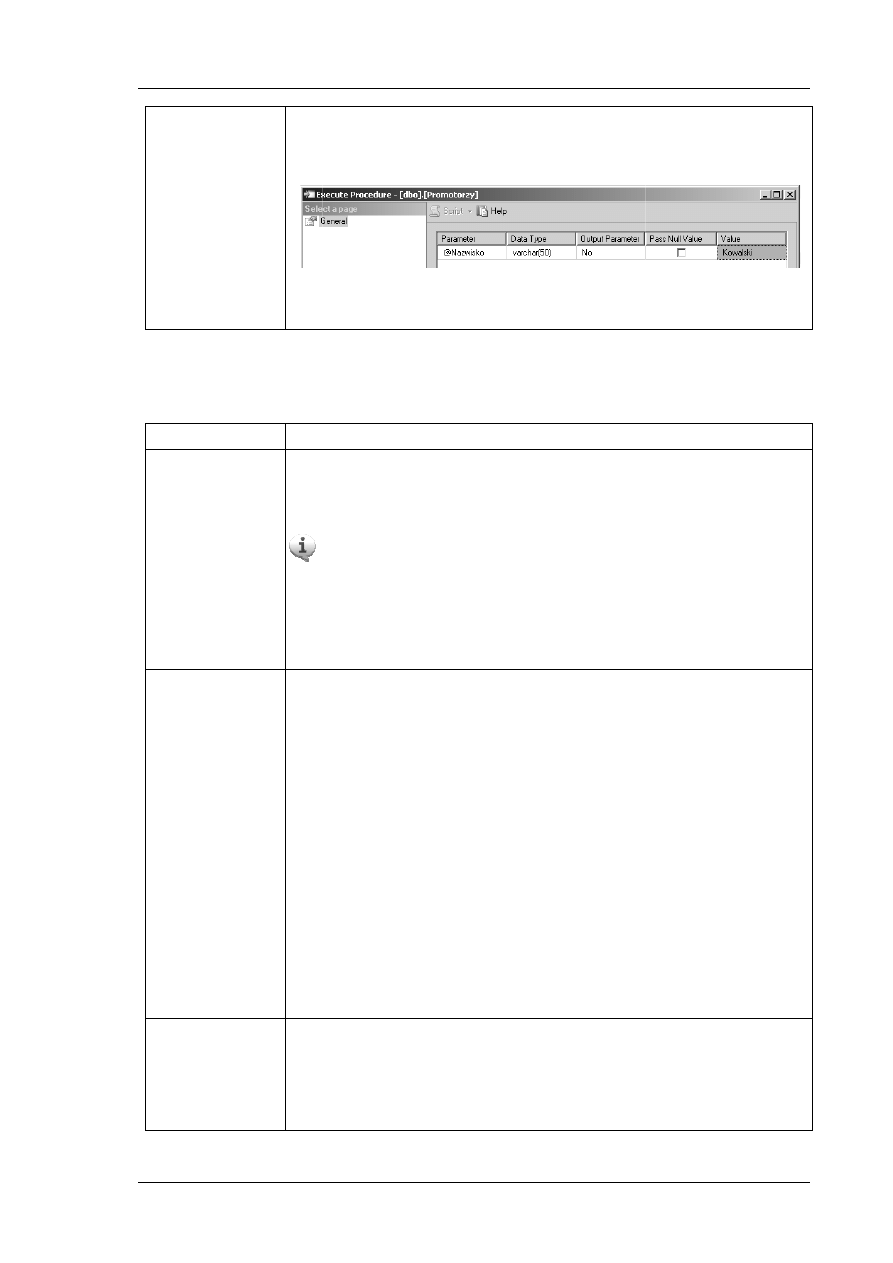
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
•
Wciśnij
Problem 3 (czas realizacji
Kolejne zadanie, jakie powinieneś wykonać
użytkowników oraz modyfikacja
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
W oknie logowania kliknij
2.
Utwórz
procedurę
składowaną
•
Z
•
Odszukaj plik C
Open
•
Zaznacz kod, który wywołuje procedurę składowaną
--
USE
GO
--
CREATE PROCEDURE dbo.
@Nazwisko
AS
BEGIN
SELECT *
FROM [
WHERE [
END
•
Wciś
3.
Uruchom
procedurę
składowaną
•
Zaznacz kod, który wywołuje procedurę
uruchomić zaznaczony fragment kodu
--
EXEC Promotorzy
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Procedury składowane i wyzwalacze
Strona 18/21
prawym przyciskiem myszy na procedurze Promotorzy
Execute Stored Procedure, co wywoła okienko, w którym można
przekazać do procedury jakieś parametry, jak na
Rys. 11 Wywołanie procedury składowanej z parametrem
Wciśnij F5, aby uruchomić zaznaczony fragment kodu.
Problem 3 (czas realizacji 15 min)
jakie powinieneś wykonać, to zdefiniowanie procedur składowanych dla
użytkowników oraz modyfikacja już istniejących procedur składowanych z parametrami
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Labs\Lab10\Procedura_z_parametr
Open.
Zaznacz kod, który wywołuje procedurę składowaną
-- (1) Ustawiamy sie na baze danych PraceDyplomowe
USE PraceDyplomowe
GO
-- (2) Tworzymy procedure skladowana użytkownika z parametrem
REATE PROCEDURE dbo.Promotorzy
Nazwisko VARCHAR(30)
AS
BEGIN
SELECT *
FROM [PraceDyplomowe].[dbo].[Osoba]
WHERE [PraceDyplomowe].[dbo].[Osoba].[nazwisko
END
Wciśnij F5, aby uruchomić zaznaczony fragment kodu.
Zaznacz kod, który wywołuje procedurę Promotorzy
uruchomić zaznaczony fragment kodu:
-- (3) Wywolujemy procedure skladowana z parametrem
EXEC Promotorzy @Nazwisko='Kowalski'
GO
Moduł 9
Procedury składowane i wyzwalacze
Promotorzy i wybranie
co wywoła okienko, w którym można
, jak na rys. 11.
Wywołanie procedury składowanej z parametrem
fragment kodu.
procedur składowanych dla nowych
już istniejących procedur składowanych z parametrami.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
z_parametrami.sql i kliknij
Zaznacz kod, który wywołuje procedurę składowaną Promotorzy:
(1) Ustawiamy sie na baze danych PraceDyplomowe
(2) Tworzymy procedure skladowana użytkownika z parametrem
nazwisko] = @Nazwisko
, aby uruchomić zaznaczony fragment kodu.
Promotorzy. Wciśnij F5, aby
(3) Wywolujemy procedure skladowana z parametrem
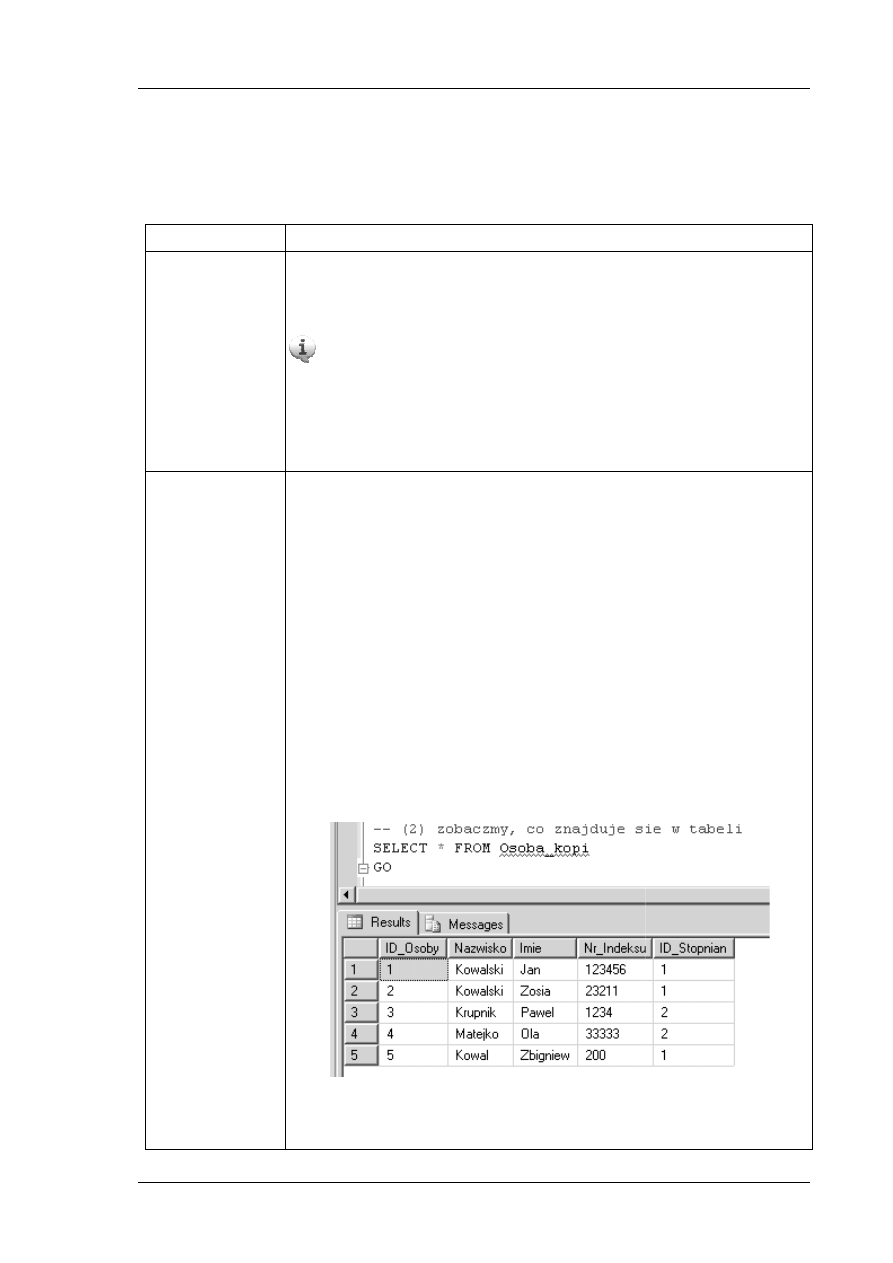
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
Problem 4 (czas realizacji
Po zdefiniowaniu procedur składowanych wynikających z
pracujesz, kolejnym etapem jest stworzenie odpowiedniej liczby wyzwalaczy.
powinien obsługiwać następujący warunek:
dyplomantów.
Zadanie
Tok postępowania
1.
Nawiąż
połączenie z SQL
Server 2008
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Manageme
•
W oknie logowania kliknij
2.
Utwórz
wyzwalacz
•
Z
•
Odszukaj plik
•
Zaznacz i uruchom (
--
USE PraceDyplomowe
GO
--
SELECT ID_Osoby, Nazwisko, Imie, Nr_Indeksu, ID_Stopnian
INTO Osoba_kopi
FROM Osoba
GO
•
Zaznacz i uruchom (
Wynik pokazano na
--
SELECT * FROM Osoba_kopi
GO
•
W obrębie okna
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Procedury składowane i wyzwalacze
Strona 19/21
Problem 4 (czas realizacji 10 min)
Po zdefiniowaniu procedur składowanych wynikających ze zmian, jakie zachodzą w firmie
kolejnym etapem jest stworzenie odpowiedniej liczby wyzwalaczy.
en obsługiwać następujący warunek: każdy opiekun może mieć maksymalnie 10
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
W oknie logowania kliknij Connect.
menu głównego wybierz File -> Open -> File.
Odszukaj plik C:\Labs\Lab10\Wyzwalacz_1.sql i kliknij
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (1) Ustawiamy się na baze danych PraceDyplomowe
USE PraceDyplomowe
GO
-- (2) przygotujmy tabele do testowania wyzwalaczy
SELECT ID_Osoby, Nazwisko, Imie, Nr_Indeksu, ID_Stopnian
INTO Osoba_kopi
FROM Osoba
GO
Zaznacz i uruchom (F5) fragment kodu oznaczonego w komentarzu (
Wynik pokazano na rys. 12:
-- (3) zobaczmy, co znajduje sie w tabeli
SELECT * FROM Osoba_kopi
GO
Rys. 12 Sprawdzenie zawartości tabe
W obrębie okna Object Explorer wybierz Osoba ->
Moduł 9
Procedury składowane i wyzwalacze
jakie zachodzą w firmie, w której
kolejnym etapem jest stworzenie odpowiedniej liczby wyzwalaczy. Jeden z wyzwalaczy
każdy opiekun może mieć maksymalnie 10
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
i kliknij Open.
PraceDyplomowe
(2) przygotujmy tabele do testowania wyzwalaczy
SELECT ID_Osoby, Nazwisko, Imie, Nr_Indeksu, ID_Stopnian
) fragment kodu oznaczonego w komentarzu (3).
Sprawdzenie zawartości tabeli
> Triggers.
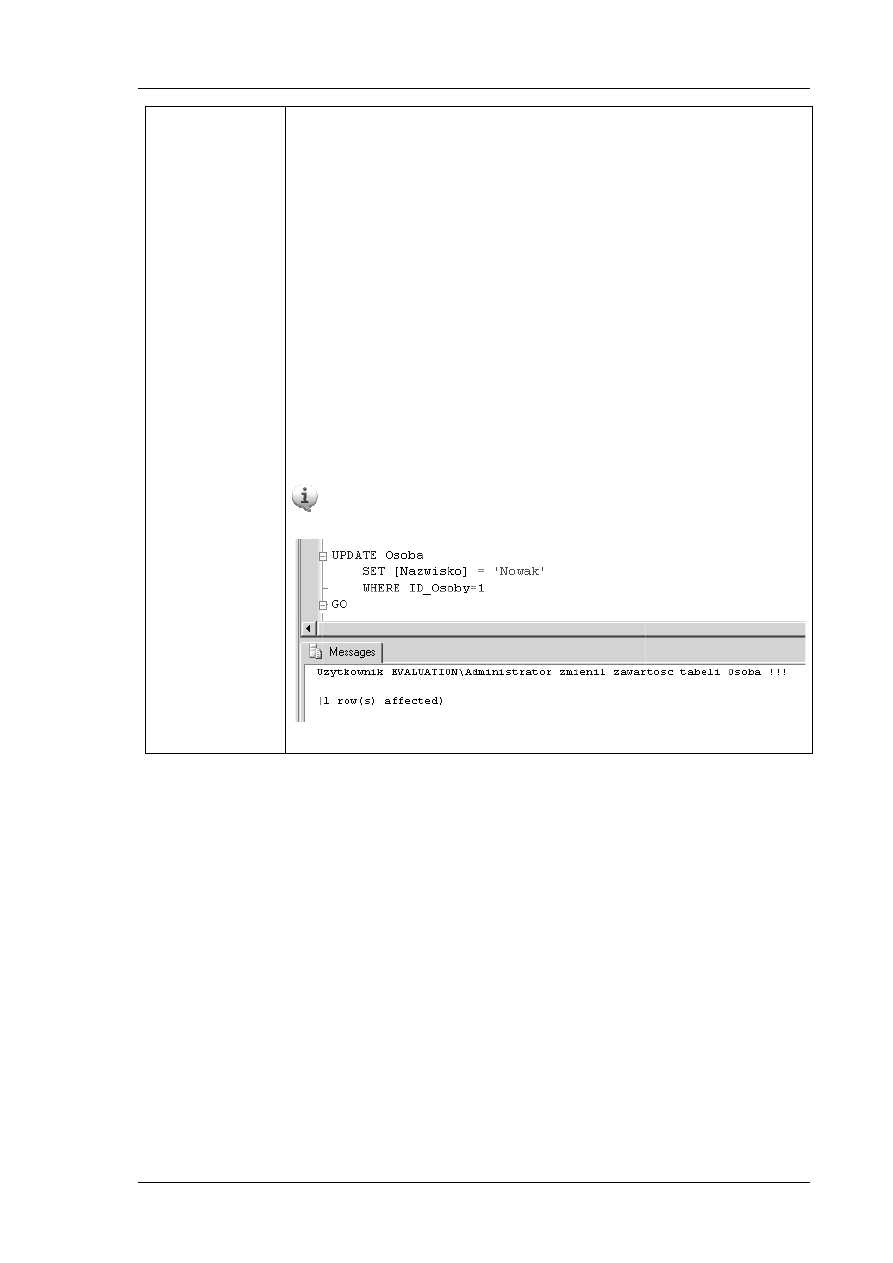
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy danych
•
Wci
•
Zaznacz i uruchom (
--
CREATE TRIGGER Ocenay
ON Osoba
AFTER INSERT, UPDATE
AS
DECLARE @username as varchar(30)
SELECT @username = SYSTEM_USER
PRINT 'Uzytkownik '+ @username + ' zmienil zawartosc tabeli
Osoba!!!'
GO
•
W celu zobaczenia działania
zapytanie:
--
UPDATE O
GO
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Procedury składowane i wyzwalacze
Strona 20/21
Wciśnij prawy przycisk myszy i wybierz New Trigger
Zaznacz i uruchom (F5) poniższy fragment kodu:
-- (4) Tworzymy nowy wyzwalacz
CREATE TRIGGER Ocenay
ON Osoba
AFTER INSERT, UPDATE
AS
DECLARE @username as varchar(30)
SELECT @username = SYSTEM_USER
PRINT 'Uzytkownik '+ @username + ' zmienil zawartosc tabeli
Osoba!!!'
GO
W celu zobaczenia działania wyzwalacza
zapytanie:
-- (5) Sprawdzamy dzialanie wyzwalacza
UPDATE Osoba
SET [Nazwisko] = 'Nowak'
WHERE ID_Osoby=1
GO
Jeśli wyzwalacz zadziałał poprawnie, w oknie
pojawić się komunikat o treści przedstawionej na
Rys. 13 Sprawdzanie efektu działania wyzwalacza
Moduł 9
Procedury składowane i wyzwalacze
New Trigger.
PRINT 'Uzytkownik '+ @username + ' zmienil zawartosc tabeli
wywołaj następujące
zadziałał poprawnie, w oknie Messages powinien
ci przedstawionej na rys. 13.
Sprawdzanie efektu działania wyzwalacza

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 9
ITA-101 Bazy danych
Procedury składowane i wyzwalacze
Strona 21/21
Laboratorium rozszerzone
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma zarządzająca bazą
AdventureWorks planuje rozszerzenie i modernizacje systemu. W
związku z modernizacją systemu bazodanowego oraz w celu spełnienia standardów
bezpieczeństwa, dostęp do obiektów bazy danych powinien odbywać się poprzez procedury
składowane. W wyniku tego część procedur składowanych powinna zostać zmodyfikowana i
przekompilowana, część powinna zostać napisana od początku, a część powinna zostać usunięta.
Kolejnym pojawiającym się problemem jest kwestia spójności zmodyfikowanej bazy danych. W tym
celu powinny zostać zmodyfikowane, utworzone lub usunięte wyzwalacze służące do
zaimplementowania pewnych warunków.
Zadanie, jakie przed Tobą stoi, to:
1.
Podjęcie decyzji, jakie nowe procedury składowane i wyzwalacze powinny zostać utworzone
w celu poprawienia bezpieczeństwa bazy danych.
2.
Podjęcie decyzji, które procedury składowane w bazie danych pozostaną bez zmian, a które
zostaną zmodyfikowane lub usunięte.
3.
Podjęcie decyzji, które wyzwalacze w bazie danych pozostaną bez zmian, a które zostaną
zmodyfikowane lub usunięte.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
Wersja 2.0
Bezpieczeństwo w bazach danych
Spis treści
Bezpieczeństwo w bazach danych ....................................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 6
Porady praktyczne ..................................................................................................................... 10
Uwagi dla studenta .................................................................................................................... 10
Dodatkowe źródła informacji..................................................................................................... 10
Laboratorium podstawowe ................................................................................................................ 12
Problem 1 (czas realizacji 45 min) .............................................................................................. 12
Laboratorium rozszerzone ................................................................................................................. 17
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 17
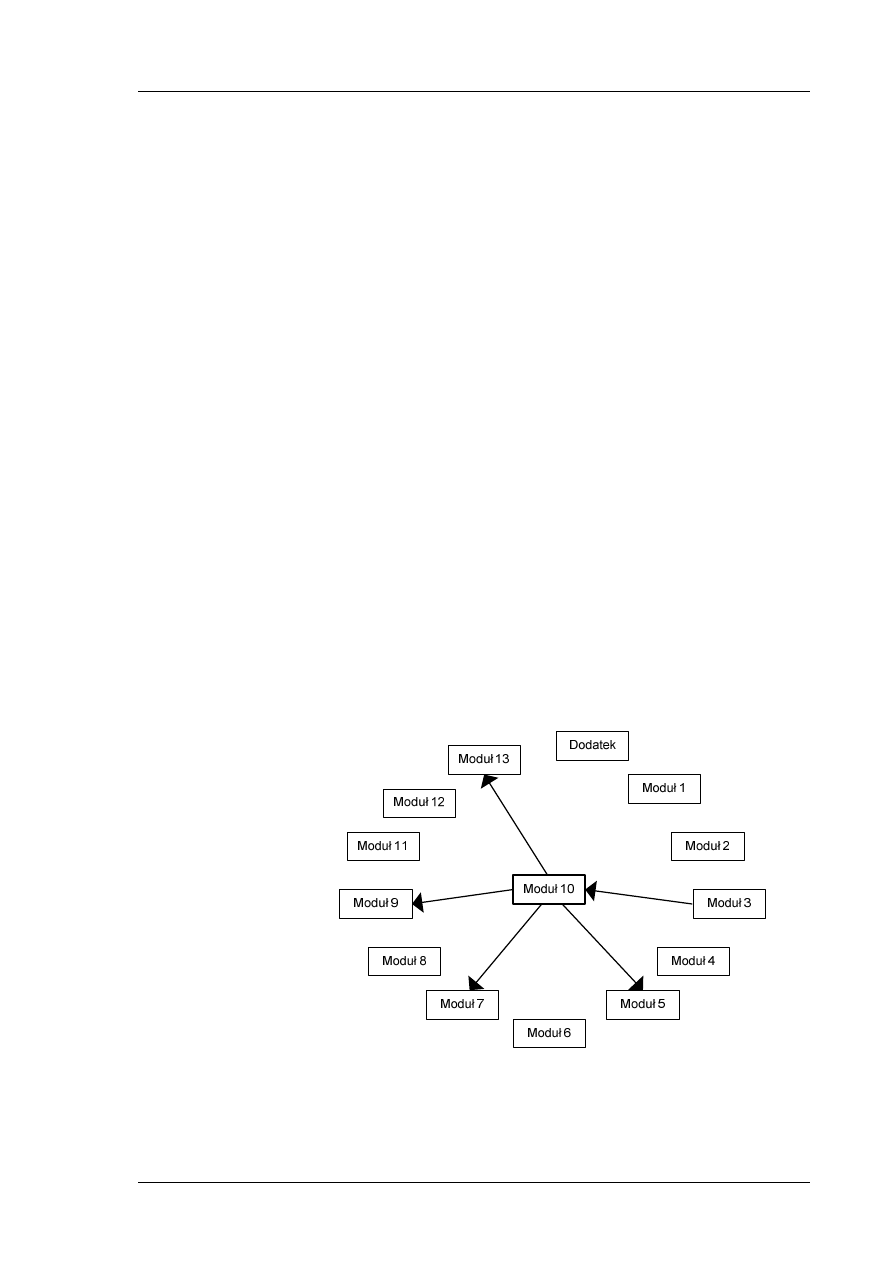
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 2/17
Informacje o module
Opis modułu
W tym module dowiesz się, jak należy rozumieć bezpieczeństwo baz danych
oraz jakie są poziomy bezpieczeństwa. Ponadto dowiesz się, jakim
zagrożeniom należy przeciwdziałać, a jakich nie da się uniknąć oraz jak
należy planować implementację poszczególnych poziomów bezpieczeństwa
w aplikacji bazodanowej.
Cel modułu
Celem modułu jest przedstawienie czytelnikowi typowych zagadnień
związanych z zabezpieczeniami dostępu do danych w SQL Server 2008.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
wiedział jakie mechanizmy uwierzytelniania wspiera SQL Server 2008
•
potrafił dodać użytkownika i nadać mu odpowiednie prawa
•
rozumiał czym są schematy zabezpieczeń
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
wiedzieć, jak używać oprogramowania Microsoft Virtual PC
•
znać podstawy obsługi systemu Windows 2000 lub nowszego
•
znać podstawy obsługi SQL Server Management Studio
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, istnieje konieczność
wykonania wcześniej modułu 3.
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 3/17
Przygotowanie teoretyczne
Przykładowy problem
Firma National Insurance wdrożyła Microsoft SQL Server 2008. Założono na nim kilka baz i hurtowni
danych. Ze względu na pilne potrzeby firmy szybko też zasilono bazy z dostępnych źródeł danych.
Dostęp do poszczególnych baz danych zrealizowany jest poprzez dedykowane aplikacje łączące się
z serwerem Microsoft SQL Server 2008 na prawach administratora. W pierwszych tygodniach po
wdrożeniu system dział sprawnie lecz później pojawiły się problemy z wydajnością i dostępem do
danych. Niektórzy menadżerowie zauważyli szereg niezgodności, informacje jakie wprowadzali nie
zgadzały się z danymi w raportach uzyskanych z systemu. Po krótkim czasie okazało się, że osoby
nieuprawnione mają dostęp do poufnych danych, nie ma także żadnej polityki bezpieczeństwa dla
serwerów bazodanowych.
Rozwiązanie tego problemu złożono na barki głównego informatyka, jako osoby kompetentnej i
odpowiedzialnej za rozwój systemu bazodanowego firmy. W pierwszymi krokami jakie podjął on po
otrzymaniu zadania był dokładny przegląd stanu obecnego systemu i porównanie go z wytycznymi i
najlepszymi praktykami z zakresu bezpieczeństwa bazodanowego.
Podstawy teoretyczne
Pojęcie bezpieczeństwa baz danych wiąże się nieodłącznie z bezpieczeństwem serwera baz danych.
W hierarchii bezpieczeństwo takiego serwera stoi wyżej niż bezpieczeństwo pojedynczej bazy,
ponieważ brak zabezpieczeń na tym poziomie pociąga za sobą brak zaufania do pojedynczych baz
danych znajdujących się na serwerze.
Bezpieczeństwo serwera baz danych to:
•
zapewnienie stabilnego i w miarę możliwości bezawaryjnego działania serwera baz danych
•
zapewnienie uprawnionym użytkownikom dostępu do odpowiednich baz danych
•
ograniczenie dostępu do danych dla użytkowników nieuprawnionych
•
zapewnienie jak najmniejszej ingerencji serwera baz danych w działanie systemu
operacyjnego komputera
Bezpieczeństwo baz danych natomiast dotyczy następujących aspektów:
•
umożliwienie tylko autoryzowanym użytkownikom wykonywania odpowiednich operacji na
bazie danych
•
zapewnienie bezpieczeństwa fizycznego bazy danych (odpowiednia strategia kopii
zapasowych)
Mówiąc o bezpieczeństwie należy rozróżniać dwa pojęcia: uwierzytelnienie oraz autoryzacja.
Pierwsze pojęcie oznacza identyfikację użytkownika na podstawie jego nazwy i hasła. Z kolei
autoryzacja jest fazą następującą po poprawnym uwierzytelnieniu i polega na określeniu
uprawnień przypadających uwierzytelnionemu użytkownikowi.
Poziomy bezpieczeństwa
W najogólniejszym ujęciu można wyodrębnić następujące poziomy bezpieczeństwa:
•
bezpieczeństwo fizyczne danych
•
bezpieczeństwo sieci
•
bezpieczeństwo domeny
•
bezpieczeństwo maszyny lokalnej
•
bezpieczeństwo serwera baz danych
•
bezpieczeństwo bazy danych
•
bezpieczeństwo aplikacji bazodanowej

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 4/17
Bezpieczeństwa doskonałego nie można w praktyce nigdy zapewnić, ale można podjąć kroki, by
zapobiegać skutkom wszelkich awarii, katastrof lub niepożądanych ingerencji czynnika ludzkiego.
Aby zadbać o globalne bezpieczeństwo, należy zaplanować strategię na każdym z wymienionych
poziomów.
Bezpieczeństwo fizyczne danych
Poziom bezpieczeństwa fizycznego danych określa, czy w przypadku awarii sprzętu, katastrofy (jako
katastrofę rozumiemy nie tylko czynniki naturalne, jak np. powodzie, lecz także kradzieże i inne
wpływy czynnika ludzkiego) lub fizycznego uszkodzenia plików danych jesteśmy w stanie odtworzyć
dane i jak długo baza danych (lub serwer baz danych) będzie niedostępny dla użytkowników. Na
tym poziomie należy też odpowiedzieć na pytanie, czy kopie danych są bezpieczne (m.in. czy
niepowołane osoby nie mają do nich dostępu).
Bezpieczeństwo sieci
Poziom bezpieczeństwa sieci określa, czy dane są bezpiecznie przesyłane w sieci. Szczególnie
dotyczy to ściśle poufnych danych, tj. numerów kart kredytowych czy danych personalnych
klientów firmy.
Bezpieczeństwo domeny
Poziom bezpieczeństwa domeny określa, czy komputery w domenie (w szczególności kontrolery
domeny) są odpowiednio zabezpieczone. W dobie integracji serwerów baz danych (np. Microsoft
SQL Server) z systemami operacyjnymi, w przypadku braku zabezpieczeń w systemie operacyjnym
bezpieczeństwo serwera baz danych spada do minimum.
Bezpieczeństwo serwera baz danych
Poziom bezpieczeństwa serwera baz danych określa, czy serwer baz danych jest odpowiednio
zabezpieczony przed nieuprawnionymi użytkownikami (fizycznie – maszyna – oraz wirtualnie –
odpowiednie mechanizmy uwierzytelniające).
Bezpieczeństwo bazy danych
Poziom bezpieczeństwa bazy danych określa, czy dostęp do bazy danych i ról w bazie danych jest
odpowiednio skonfigurowany (na ogół jest to sprawa konfiguracji w systemie bazodanowym).
Bezpieczeństwo aplikacji bazodanowej
Poziom bezpieczeństwa aplikacji bazodanowej określa, czy kod aplikacji klienckiej współpracującej z
bazą danych jest napisany w sposób bezpieczny (czy aplikacja nie umożliwia zmniejszenia
bezpieczeństwa na którymkolwiek z pozostałych poziomów). Szczególnie należy tu zwrócić uwagę
na dane wprowadzane przez użytkowników.
Implementacja różnych poziomów bezpieczeństwa
Każdy z poziomów bezpieczeństwa wymaga podjęcia określonych kroków przez administratorów
systemów i baz danych.
Implementacja bezpieczeństwa fizycznego
Zadaniem administratora baz danych jest zapewnienie tolerancji błędów dysków fizycznych dla
systemu i dla danych oraz zaplanowanie strategii sporządzania i przechowywania kopii zapasowych.
Tolerancję błędów dysków fizycznych można osiągnąć używając woluminów RAID (ang. Redundant
Array of Independent Disks) typu RAID-1 lub RAID-5.
Implementacja RAID-1 polega na jednoczesnym przechowywaniu danych na dwóch fizycznych
dyskach stanowiący jeden dysk logiczny (dwie kopie danych – w przypadku awarii jednego dysku,
drugi nadal umożliwia dostęp do danych). Oznacza to, że 50% pojemności woluminu typu RAID-1

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 5/17
jest przeznaczone na przechowywanie danych, a druga połowa służy do przechowywania kopii
danych.
RAID-5 to dysk logiczny składający się z co najmniej trzech dysków fizycznych (z każdego dysku
wolumin zabiera tyle samo przestrzeni dyskowej). W woluminach typu RAID-5 część przestrzeni
dyskowej jest poświęcana na zapis tzw. danych parzystości (niezbędnych do odzyskania danych w
przypadku awarii jednego z dysków wchodzących w skład woluminu). Im więcej dysków wchodzi w
skład woluminu, tym mniej przestrzeni dyskowej zajmują dane parzystości (mniejsza nadmiarowość
danych).
Najlepszym rozwiązaniem w kwestii zapewnienia tolerancji błędów dysków fizycznych są sprzętowe
woluminy RAID pracujące z kontrolerami SCSI, z uwagi na szybszą pracę niż RAID programowy.
Niestety jest to jednocześnie najdroższe rozwiązanie.
Kopie bezpieczeństwa, zwane też kopiami zapasowymi (ang. backup), powinny być przechowywane
bądź na zewnętrznym nośniku (taśmy, płyty CD lub inne nośniki) lub na innym komputerze niż ten,
z którego kopiujemy dane. Ponadto nośniki z kopiami zapasowymi powinny być przechowywane w
innym miejscu niż maszyna, z której pochodzą dane (zmniejszamy ryzyko utraty danych w
przypadku pożarów czy powodzi).
Strategia kopii zapasowych powinna być zaplanowana przez administratora baz danych i
administratora systemu operacyjnego. Należy zaplanować strategię, która odpowiada potrzebom
firmy, tzn. należy odpowiedzieć na pytanie, czy ważniejsze jest szybkie sporządzanie kopii
zapasowych, czy też istotniejsze jest jak najszybsze przywracanie danych po awarii. Na ogół
strategia musi uwzględnić obie kwestie. Stąd najczęściej powtarzanym schematem sporządzania
kopii zapasowych jest wykonywanie co tydzień kopii wszystkich danych oraz codzienne
wykonywanie kopii przyrostowych (tylko dane zmodyfikowane danego dnia).
W budowaniu strategii kopii zapasowych należy też uwzględnić „godziny szczytu” pracy serwera
(proces wykonywania kopii zapasowych pociąga za sobą dodatkowe obciążenie serwera). Dlatego
na ogół operacje te są wykonywane w godzinach nocnych i są planowane w ten sposób, by nie
kolidowały z czasem, gdy użytkowanie serwera przez klientów jest najintensywniejsze.
Implementacja bezpieczeństwa sieci
Przy planowaniu bezpieczeństwa sieci należy zadać sobie pytanie, czy dane przesyłane z naszego
serwera baz danych są poufne. Jeśli tak, to możemy zastosować dostępne protokoły szyfrujące,
takie jak SSH czy IPSec. Oprócz implementacji sieciowych protokołów szyfrujących do transmisji
danych, należy ograniczyć ilość danych wysyłanych w świat do niezbędnego minimum (najlepiej nie
„przedstawiać się” zbytnio w sieci – ujawnienie oprogramowania serwera baz danych to pierwszy
krok do zachwiania bezpieczeństwa naszego serwera).
Implementacja bezpieczeństwa komputerów i domen
Aby zapewnić komputerom i domenom niezbędny poziom bezpieczeństwa, należy trzymać się kilku
zasad.
Nie należy instalować serwerów baz danych na serwerach kluczowych dla domeny (kontrolery
domeny). Najlepsza struktura domeny to taka, w której każdy serwer pełni pojedynczą funkcję (np.
serwer aplikacji, serwer plików, serwer baz danych itd.).
Niezbędna jest odpowiednia polityka administratorów systemu (lub domeny), czyli:
•
utrzymywanie aktualnego poziomu zabezpieczeń systemu operacyjnego oraz serwera baz
danych
•
odpowiednia polityka bezpiecznych haseł użytkowników
•
zmiana nazw kont administratorskich
•
monitorowanie logowania do systemu (domeny)

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 6/17
•
ograniczanie dostępu do plików i folderów
•
nadawanie minimalnych wymaganych uprawnień dla użytkowników i grup
•
jak najmniejsze wykorzystywanie kont administratorskich
•
implementacja „zapór ogniowych” (ang. firewall)
•
ograniczenie fizycznego dostępu do serwerów i kontrolerów domeny
•
uruchamianie usług serwera baz danych przy użyciu konta użytkownika specjalnie
stworzonego w tym celu (nie administratora) i zapewnienie stabilności tego konta (np. nigdy
nie wygasające hasło)
Implementacja bezpieczeństwa serwera baz danych i samych baz
Pod hasłem bezpieczeństwa serwera baz danych rozumiemy umożliwienie korzystania z serwera
tylko osobom do tego uprawnionym. Większość systemów zarządzania bazami danych oferuje
uwierzytelnianie użytkowników na dwóch poziomach: na poziomie serwera (użytkownik może
dostać się do serwera) oraz na poziomie bazy danych (użytkownik serwera ma dostęp do
konkretnej bazy danych).
Mechanizmy uwierzytelniania i autoryzacji są różne i zależą od konkretnego środowiska
bazodanowego. Zazwyczaj użytkownicy dzieleni są na role (grupy), natomiast rolom nadawane są
określone uprawnienia. Ponadto niezbędnym nawykiem administratora baz danych powinno być
rejestrowanie i monitorowanie zdarzeń na serwerze w poszukiwaniu nietypowych zdarzeń.
Implementacja bezpieczeństwa aplikacji bazodanowej
Piętą achillesową systemu informatycznego współpracującego z bazą danych często jest interfejs
użytkownika (od strony programistycznej i implementacji logiki biznesowej). Szczególnie chodzi tu o
umożliwienie użytkownikom oddziaływania na serwer baz danych lub nawet na system operacyjny
serwera z poziomu aplikacji klienckiej.
Należy ze szczególną uwagą projektować aplikacje bazodanowe. Oto kilka zasad, którymi należy się
kierować przy tworzeniu interfejsów dla tych aplikacji:
•
zachowaj przezroczystość aplikacji i bazy danych (nie pokazuj informacji o źródle aplikacji i o
strukturze bazy danych), szczególnie uważaj na komunikaty domyślne aplikacji (lepiej ustawić
swoje, które powiedzą tylko, że wystąpił błąd)
•
nigdy nie ufaj użytkownikowi aplikacji i wpisywanym przez niego wartościom
•
sprawdzaj, czy wejście jest tym, czego oczekujesz i odrzucaj wszystko inne wartości
•
walidację wejścia przeprowadzaj na wielu poziomach
•
używaj wyrażeń regularnych
•
staraj się nie używać konkatenacji do tworzenia zapytań SQL (zamiast tego użyj procedur z
parametrami)
•
łącz się z bazą danych używając w miarę najmniej uprzywilejowanego konta użytkownika
Przykładowe rozwiązanie
Zapewnienie bezpieczeństwa serwerowi bazodanowemu jest sprawą złożoną i rozciągniętą na kilka
poziomów. Z punktu widzenia administratora systemu podstawowym poziomem jest kwestia
autoryzacji użytkowników, którzy mają dostęp do serwera SQL. Narzędzie SQL Server Management
Studio umożliwia kontrolę nad wieloma parametrami nie tylko bazy danych, ale też samego
serwera. Jedną z grup interesujących nas parametrów jest sposób uwierzytelniania użytkowników,
co ilustruje rys. 2. Serwer SQL może wykorzystywać do uwierzytelniania własne konta
użytkowników lub dodatkowo honorować konta systemu operacyjnego.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 7/17
Rys. 2 Opcje bezpieczeństwa serwera
Mieszany tryb uwierzytelniania, który jest zaznaczony na rys. 2, pozwala na łączenie się z serwerem
także użytkownikom, którzy nie mają kont w systemie Windows w sieci, w której pracuje serwer.
Dobrą praktyką jest monitorowanie nieudanych prób logowania do systemu, co zapewnia opcja
Login auditing.
Inną interesującą grupą są obiekty związane wewnętrznymi kontami użytkowników serwera SQL
dostępne w polu Logins. Procedura tworzenia nowego użytkownika jest podobna do analogicznej
procedury w systemie operacyjnym co ilustruje rys. 3.
Rys. 3 Tworzenie nowego loginu
Jeśli Microsoft SQL Server 2008 zainstalowany jest na komputerze pracującym pod kontrolą
systemu Microsoft Windows Server 2003, można wymusić odpowiednią politykę bezpieczeństwa
haseł serwera baz danych dzięki polisom systemu operacyjnego.
Po założeniu odpowiednich kont możemy sprawdzić, czy logowanie do serwera przebiegało
pomyślnie czy też były z tym jakieś problemy. Do monitorowania aktywności serwera służy
dziennik. Przykładową zawartość dziennika serwera SQL pokazuje rys. 4.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 8/17
Rys. 4 Dziennik systemowy SQL Server 2008
Dobry administrator śledzi przynajmniej nieudane próby logowania do systemu. Dziennik pokazany
na rys. 4 to dziennik to po prostu zdarzeń systemu Windows. Przeglądarka dziennika systemu SQL
Server umożliwia jednoczesne przeglądanie wszystkich zapisywanych w tym systemie informacji.
Utworzenie konta dla danego użytkownika nie oznacza jeszcze przyznanie mu jakichkolwiek praw
poza możliwością połączenia z serwerem. Aby dany użytkownik mógł skorzystać z baz danych
należy w kontekście danej bazy przyznać mu prawo do połączenia się z nią. Po rozwinięciu drzewa
bazy w obszarze Object Explorer widzimy pole Security, gdzie możemy ustalać, który użytkownik
posiada dostęp i na jakich zasadach, co ilustruje rys. 5.
Rys. 5 Dodawanie użytkownika do bazy danych
Podobny efekt możemy uzyskać uruchamiając odpowiednią sekwencję kodu języka SQL. Do
nadawania i odbierania uprawnień użytkownikom służą polecenia
GRAND i REVOKE, tak jak to
pokazuje rys. 6. Należy jednak zauważyć, że do uruchomienia danego kodu SQL musimy posiadać
konto, które:
•
ma dostęp do danej bazy
•
posiada odpowiednie uprawnienia np. administracyjne w kontekście tej bazy
W innym wypadku kontrolowanie uprawnień z poziomu języka SQL nie powiedzie się.
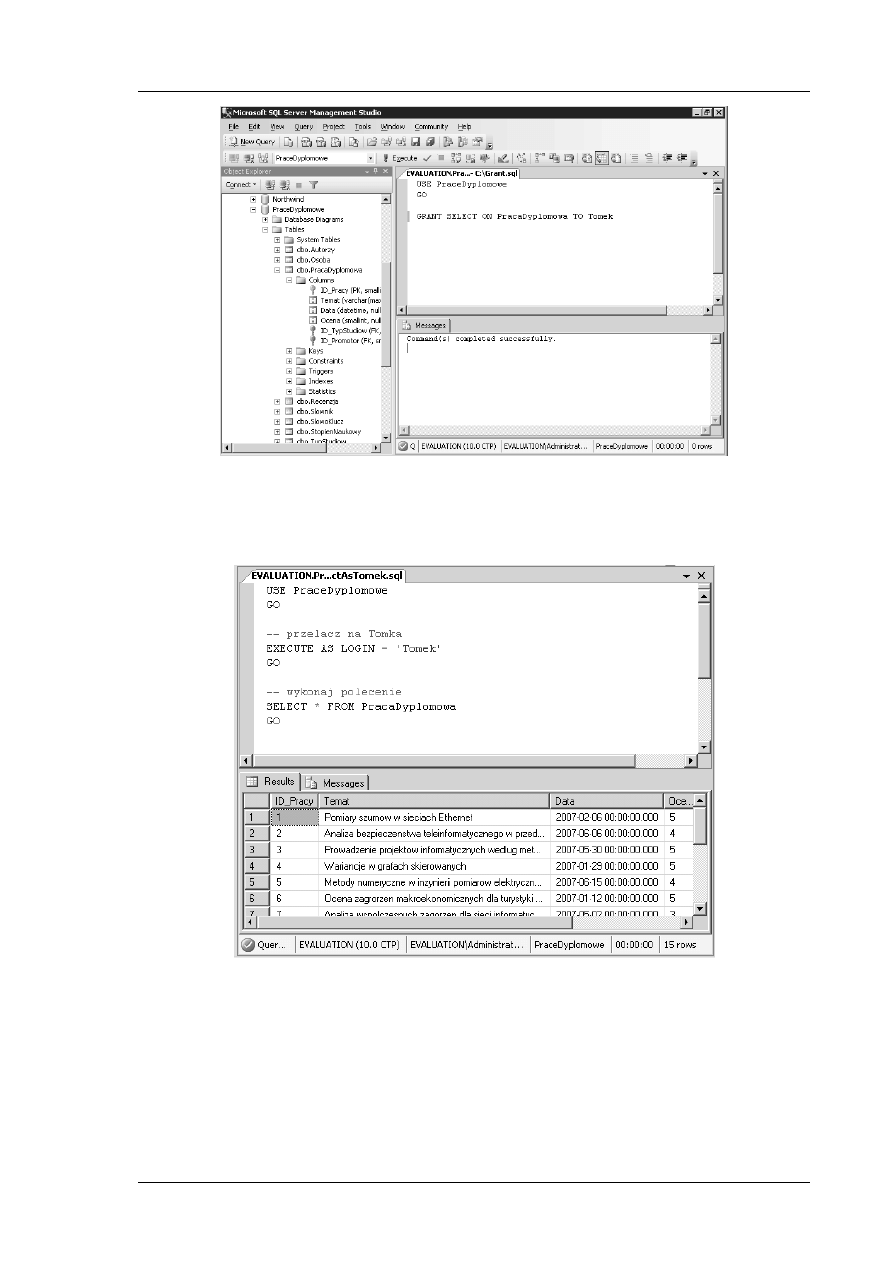
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 9/17
Rys. 6 Nadanie uprawnień użytkownikowi Tomek
Jeżeli posiadamy w systemie kilka kont użytkowników, które są odpowiednio skonfigurowane i
posiadają uprawnienia dostępu do bazy, możemy przełączać pomiędzy nimi kontekst
wykonywanych poleceń SQL. Służy do tego polecenie
EXECUTE AS, jak pokazano na rys. 7.
Rys. 7 Wykonanie kodu SQL w kontekście użytkownika Tomek
Komenda
EXECUTE AS pozwala zmienić kontekst wykonywania poleceń na wybranego
użytkownika. Powrót do pierwotnego kontekstu zapewnia polecenie
REVERT.
W rzeczywistych systemach pojawia się wiele kont i grup użytkowników. Pomoc w zapanowaniu
nad mnogością kont zapewniają schematy. Schematy to przestrzenie nazw lub pojemniki na obiekty
w bazie danych. Upraszczają one zarządzanie uprawnieniami w bazie danych oraz stanowią
element niezbędny do poprawnego rozwiązywania nazw w systemie Microsoft SQL Server 2008.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 10/17
Schematy umożliwiają nadawanie uprawnień na wiele obiektów jednocześnie. Wystarczy umieścić
je w jednym schemacie. Ponadto schematy pozwalają uniknąć sytuacji, w których usunięcie
użytkownika z bazy jest niemożliwe, gdy jest on właścicielem obiektów w bazie danych (wcześniej
trzeba zmienić właścicieli wszystkich obiektów, których właścicielem jest wspomniany użytkownik).
Do tworzenia schematów służy polecenie
CREATE SCHEMA. Więcej informacji na temat tworzenia i
zarządzania schematami znajduje się w laboratorium podstawowym i Books Online na stronie firmy
Microsoft.
Porady praktyczne
Nigdy nie myśl, że system i serwer baz danych są bezpieczne. Jest to jedna z podstawowych zasad
przy projektowaniu lub inspekcji mechanizmów zabezpieczających systemy, nie tylko
informatyczne. Takie podejście znacznie zwiększa szanse na znalezienie luki lub potencjalnego
problemu.
Nigdy nie ufaj temu, co użytkownik podaje na wejściu do systemu. Jeżeli przewidujesz możliwość
wprowadzania danych przez użytkownika zawsze staraj się prawidłowo i uważnie obsługiwać
pojawiające się informacje automatycznie odrzucając wartości, których się w danej sytuacji nie
spodziewasz.
Zachowuj zasadę minimalnych uprawnień w stosunku do użytkownika. Prawidłowe podejście z
punktu widzenia bezpieczeństwa to w pierwszym kroku zabranie użytkownikowi wszystkich
uprawnień w systemie a dopiero później ostrożne przydzielenie mu takich jakie wydają się być
niezbędne. Wprowadza to oczywiście wydłużenie czasu dostosowania systemu do pracy w pełnym
wymiarze oraz swoiste niezadowolenie użytkowników ale jest niezbędne. Zasada ta jest szczególnie
ważna dla użytkowników typu serwis systemowy i implikuję kolejną o nazwie „domyślnie
zamknięte”. Obszary działania systemu takie jak porty dostępu, protokoły komunikacyjne czy same
bazy danych jeżeli nie są w danej chwili używane powinny mieć status zamkniętych dla
użytkownika. Dopiero formalna potrzeba użycia danej części systemu może ją aktywować.
Eliminuje to znakomitą część prób włamań na nieużywane, „uśpione” ale ciągle aktywne zasoby.
Regularnie szukaj nieprawidłowości w systemie. Systemy informatyczne to najczęściej twory o
silnej dynamice podlegające ciągłym zmianom. Zmiany te mogą tworzyć nowe, potencjalne „furtki”
dla włamywaczy. Inną sprawą jest niedoskonałość samego oprogramowania. Co prawda dla
rozwijanych systemów co jakiś czas wydawane są aktualizacje jednakże praktyka wskazuje, że łatki
takie potrafią naprawiać jedną część a jednocześnie stwarzać luki gdzie indziej.
Bądź na bieżąco z technologiami i technikami programistycznymi aby wiedzieć jak reagować na
potencjalne zagrożenia. Wiedza ta w przypadku systemów bazodanowych jest szczególnie cenna
gdyż cześć funkcjonalności administrator może sam bezpośrednio oprogramować a co za tym idzie
posiadać nad nią całkowita kontrolę.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz, co oznacza serwis systemowy, serwis bazy danych, instalacja serwisu
•
rozumiesz zasadę działania uruchomienia serwisów w kontekście użytkownika
•
umiesz wymienić i opisać podstawowe komponenty systemu bazodanowego
•
umiesz podać przykład zastosowania systemu bazodanowego w praktyce
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Kalen Delaney, Microsoft SQL Server 2005: Rozwiązania praktyczne krok po kroku, Microsoft
Press, 2006

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 11/17
Podręcznik ten jest idealną pomocą dla użytkowników, który postawili już pierwsze kroki w
systemach bazodanowych. Dużo ćwiczeń i kodów źródłowych odnoszących się do sytuacji
spotykanych w praktyce jest doskonałą bazą do rozwiązywani problemów pojawiających się w
rzeczywistości.
2.
Edward Whalen, Microsoft SQL Server 2005 Administrator’s Companion, Microsoft Press, 2006
Kompleksowe opracowanie na temat zaplanowania I wdrożenia system bazodanowego
opartego o MS SQL Server 2005 w małym i średnim przedsiębiorstwie. Autorzy postawili na
formułę przedstawiania wielu problemów z praktyki administratora baz danych oraz możliwych
dróg do ich rozwiązania. Książka jest adresowana do praktykujących użytkowników.
3.
Dusan Petkovic, Microsoft SQL Server 2008: A Beginner's Guide, McGraw-Hill, 2008
Pozycja adresowana do osób zaczynających przygodę z bazami danych. Znajdziemy tu
wprowadzenie do relacyjnych baz danych, sposoby ich projektowania, optymalizacji i w końcu
wdrożenia w najnowszej odsłonie serwera SQL w wersji 2008. Omówienie języka T-SQL w
osobnej, dużej części książki jest kolejną mocną tej pozycji.
4.
Strona domowa SQL Server 2008, http://www.microsoft.com/sql/2008/default.mspx
Tutaj znajdziemy wszystkie podstawowe informacje na temat MS SQL Server 2008 oraz nowości
z nim związane.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
Pierwszym zadaniem, jakie sobie postawiłeś
Server 2008 pod względem tworzenia użytkowników, nadawania im uprawnień i kontroli nad tymi
uprawnieniami. W celach testowych
założoną na serwerze
Evaluation
Zadanie
Tok postępowania
1.
Zmień tryb
uwierzytelniania
•
Uruchom maszynę wirtualną
—
—
•
Kliknij
SQL Server Management Studio
•
Po lewej stronie ekranu w oknie
przyciskiem myszy nazw
kontekstowego wybierz opcję
•
W lewej części okna
•
Zaznacz opcję
•
Kliknij
•
Kliknij
restartu usługi serwera.
•
Dokonaj
2.
Utwórz loginy
•
W oknie
•
Prawym przyciskiem myszy kliknij
wybierz
•
W polu
•
Zaznacz opcję
•
W pola
•
Odznacz o
•
Kliknij
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 12/17
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
jakie sobie postawiłeś, jest zbadanie możliwości serwera
2008 pod względem tworzenia użytkowników, nadawania im uprawnień i kontroli nad tymi
uprawnieniami. W celach testowych postanowiłeś wykorzystać roboczą bazę
Evaluation.
Tok postępowania
Uruchom maszynę wirtualną BD2008.
—
Jako nazwę użytkownika podaj Administrator.
—
Jako hasło podaj P@ssw0rd.
Jeśli nie masz zdefiniowanej maszyny wirtualnej w
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
D:\VirtualPC\Dydaktyka\BD2008.vhd.
Kliknij Start. Z grupy programów Microsoft SQL Server 2008
SQL Server Management Studio.
Po lewej stronie ekranu w oknie Object Explorer
przyciskiem myszy nazwę serwera (EVALUATION
kontekstowego wybierz opcję Properties.
W lewej części okna z listy Select a page wybierz Security
Zaznacz opcję SQL Server and Windows Authentication Mode
Kliknij OK.
Kliknij OK w oknie informującym o tym, że nowe ustawienia wymagają
restartu usługi serwera.
Dokonaj restartu maszyny i połącz się ponownie z serwerem SQL
W oknie Object Explorer rozwiń zawartość folderu
Prawym przyciskiem myszy kliknij Logins i z menu kontekstowego
wybierz New Login.
W polu Login name wpisz Tomek.
Zaznacz opcję SQL Server authentication.
W polach Password i Confirm password wpisz P@ssw0rd
Odznacz opcję User must change password at next login
Kliknij OK.
Moduł 10
Instalacja i konfiguracja MS SQL Server 2008
zbadanie możliwości serwera Microsoft SQL
2008 pod względem tworzenia użytkowników, nadawania im uprawnień i kontroli nad tymi
roboczą bazę
PraceDyplomowe,
Jeśli nie masz zdefiniowanej maszyny wirtualnej w Microsoft Virtual
PC, dodaj nową maszynę używając wirtualnego dysku twardego z pliku
Microsoft SQL Server 2008 uruchom
Explorer kliknij prawym
EVALUATION) i z menu
Security.
Windows Authentication Mode.
w oknie informującym o tym, że nowe ustawienia wymagają
połącz się ponownie z serwerem SQL.
rozwiń zawartość folderu Security.
i z menu kontekstowego
P@ssw0rd.
User must change password at next login.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 13/17
Rys. 8 Tworzenie nowego loginu
3.
Przeprowadź
audyt prób
logowania
•
Z menu głównego wybierz File -> New -> Database Engine Query.
•
W oknie Connect to Database Engine z listy Authentication wybierz SQL
Server Authentication.
•
W polu Login wpisz Tomek, zaś pole Password pozostaw puste.
•
Kliknij OK.
•
W oknie komunikatu o nieudanej próbie logowania kliknij OK.
•
Zamknij okno logowania klikając Cancel.
•
W oknie Object Explorer rozwiń zawartość folderu Management.
•
Prawym przyciskiem myszy kliknij SQL Server Logs i wybierz View -> SQL
Server and Windows Log.
•
Przeczytaj informację o nieudanej próbie logowania użytkownika
Tomek.
•
Zamknij okno dziennika systemowego.
Rys. 9 Dziennik systemowy SQL Server 2008
•
Utwórz jeszcze jeden login w systemie. Po skonfigurowaniu wszystkich
opcji loginu (nazwa, hasło, itd.) w górnej części okna wybierz Script.
Przyjrzyj się składni polecenia, które pojawi się w oknie edytora.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 14/17
4.
Dodaj
użytkownika do
bazy danych
•
W oknie Object Explorer rozwiń zawartość folderu Databases.
•
Rozwiń zawartość bazy danych PraceDyplomowe.
•
W bazie PraceDyplomowe rozwiń zawartość folderu Security.
•
Prawym przyciskiem myszy kliknij folder Users i wybierz New User.
•
W oknie Database User - New w pola User name i Login name wpisz
Tomek (klikając na przycisku z trzema kropkami masz możliwość wyboru
istniejącego loginu z listy), a w polu Default schema wpisz Sales.
•
W górnej części okna kliknij Script.
•
Kliknij OK i obejrzyj skrypt, który został wygenerowany.
Rys. 10 Dodawanie użytkownika do bazy danych
5.
Nadaj
uprawnienia
użytkownikowi
•
Z menu głównego wybierz File -> Open -> File.
•
Odszukaj plik Grant.sql i kliknij Open.
•
Wciśnij F5, aby uruchomić kod. Kod ten nadaje uprawnienia do
wykonywania
polecenia
SELECT
na
tabeli
PracaDyplomowa
użytkownikowi Tomek.
6.
Wykorzystaj
stworzonego
użytkownika
•
Z menu głównego wybierz File -> Open -> File.
•
Odszukaj plik SelectAsTomek.sql i kliknij Open.
•
Wciśnij F5, aby uruchomić kod. Wykona on polecenie SELECT jako
użytkownik Tomek, któremu odpowiednie uprawnienia nadałeś w kroku
5.
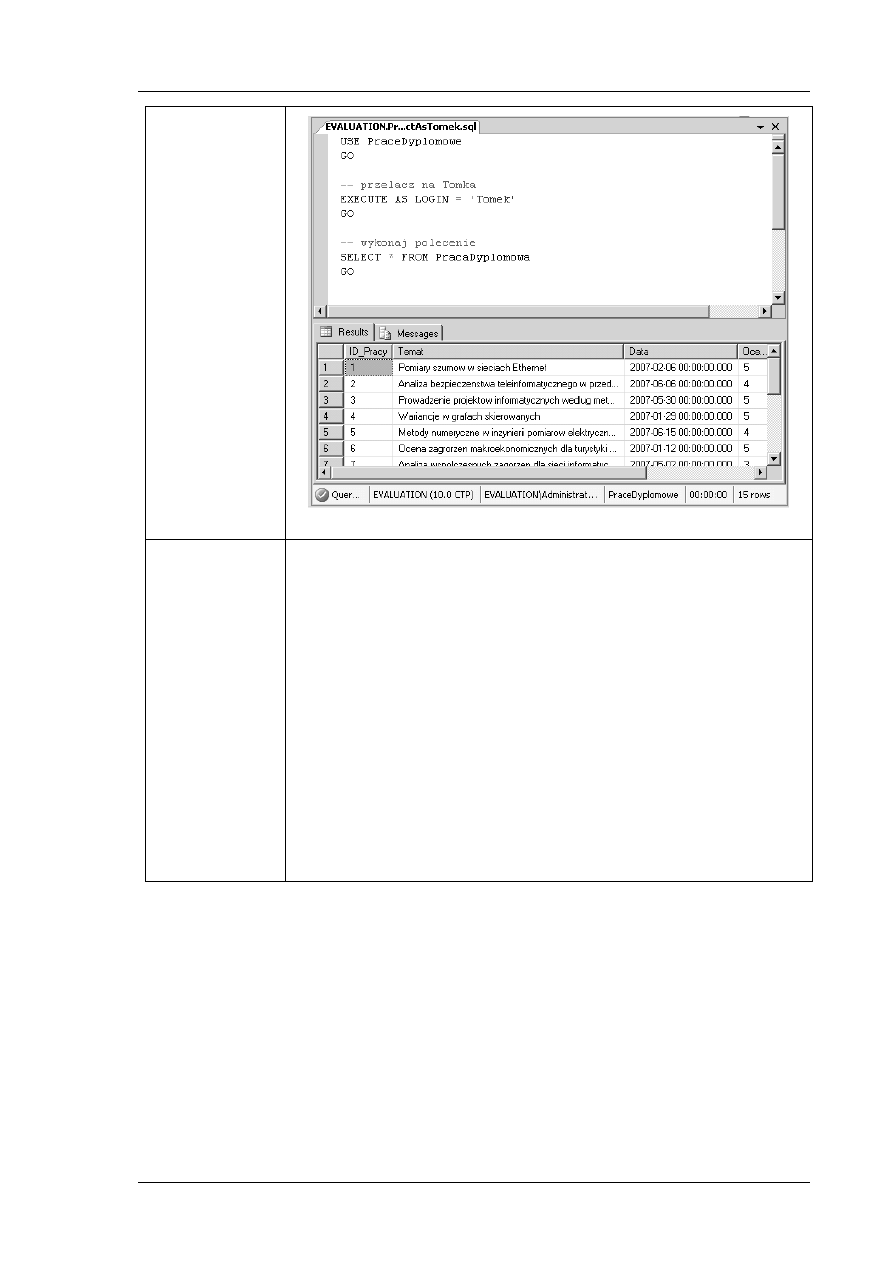
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 15/17
Rys. 11 Wykonanie kodu SQL w kontekście użytkownika Tomek
7.
Utwórz
właściciela
schematu
•
Z menu głównego wybierz File -> Open -> File.
•
Odszukaj plik Schema.sql i kliknij Open.
•
Zaznacz kod, który tworzy użytkownika Janek, będącego właścicielem
nowego schematu:
USE PraceDyplomowe
GO
CREATE LOGIN Janek
WITH
PASSWORD = 'P@ssw0rd' MUST_CHANGE
, CHECK_EXPIRATION = ON
, CHECK_POLICY = ON
GO
CREATE USER Janek
FOR LOGIN Janek
WITH DEFAULT_SCHEMA = dbo
GO
•
Wciśnij F5, by uruchomić zaznaczony kod.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
8.
Utwórz
schemat
•
Zaznacz
NewSchema
oraz nadaje uprawnienia do wykonywania polecenia
użytkownikowi
--
CREATE SCHEMA NewSchema AUTHORIZATION Janek
CREATE TABLE NewTable(col1 int, col2 int)
GRANT SELECT ON NewTable TO Tomek
GO
9.
Uzyskaj
dostęp do danych
•
Zaznacz kod, który przełączy kontekst użytkownika na login
--
EXECUTE AS LOGIN = 'John';
•
Wciśnij
•
Zaznacz kod, który wykona próbę dostępu do danych
--
SELECT * FROM NewTable
•
Wciśnij
•
Zaznacz kod, który wykona ponownie próbę dostępu do danych
--
SELECT * FROM NewSchema.NewTable
•
Wciśnij
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 16/17
Rys. 12 Tworzenie nowego użytkownika SQL Server
Zaznacz i uruchom (F5) poniższy fragment kod, który tworzy schemat
NewSchema dla użytkownika Janek, tabelę NewTable
oraz nadaje uprawnienia do wykonywania polecenia
użytkownikowi Tomek:
--Tworzymy schemat
CREATE SCHEMA NewSchema AUTHORIZATION Janek
CREATE TABLE NewTable(col1 int, col2 int)
GRANT SELECT ON NewTable TO Tomek
GO
Zaznacz kod, który przełączy kontekst użytkownika na login
-- Zmieniamy kontekst (w SQL 2000 - setuser 'John')
EXECUTE AS LOGIN = 'John';
Wciśnij F5, by uruchomić zaznaczony kod.
Zaznacz kod, który wykona próbę dostępu do danych
-- Error!!! Nie ma Sales.NewTable ani dbo.NewTable
SELECT * FROM NewTable
Wciśnij F5, by uruchomić zaznaczony kod.
Próba wykonania powyższego kodu spowoduje wyświetlenie
komunikatu o błędzie, ponieważ nie istnieje obiekt o nazwie
Sales.NewTable (Sales to domyślny schemat dl
ani obiekt o nazwie dbo.NewTable.
Zaznacz kod, który wykona ponownie próbę dostępu do danych
-- Ok.
SELECT * FROM NewSchema.NewTable
Wciśnij F5, by uruchomić zaznaczony kod.
Powyższy kod zostanie poprawnie wykonany, ponieważ
uprawnienia do wykonywania operacji na schemacie
będąc jego właścicielem.
Moduł 10
Instalacja i konfiguracja MS SQL Server 2008
Tworzenie nowego użytkownika SQL Server
kod, który tworzy schemat
NewTable w tym schemacie
oraz nadaje uprawnienia do wykonywania polecenia SELECT na tabeli
Zaznacz kod, który przełączy kontekst użytkownika na login John:
setuser 'John')
Zaznacz kod, który wykona próbę dostępu do danych:
ales.NewTable ani dbo.NewTable
spowoduje wyświetlenie
komunikatu o błędzie, ponieważ nie istnieje obiekt o nazwie
to domyślny schemat dla użytkownika John)
Zaznacz kod, który wykona ponownie próbę dostępu do danych:
Powyższy kod zostanie poprawnie wykonany, ponieważ Janek ma
uprawnienia do wykonywania operacji na schemacie NewSchema,

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 10
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 17/17
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Stworzenie użytkowników i powiązanie ich z odpowiednimi prawami do danych w bazach firmy
National Insurance znacznie zwiększyło poziom bezpieczeństwa systemu bazodanowego.
Monitoring dzienników systemowych pokazał, które aplikacje klienckie i którzy użytkownicy
sprawiali problemy. Widać było także wyraźne rezultaty zabezpieczeń w postaci odrzuconych
nieuprawnionych prób dostępu do danych. Wyniki tych działań zachęciły zarząd firmy do wsparcia
dalszych prac nad bezpieczeństwem systemu bazodanowego. Jako główny administrator masz za
zadanie zapoznać się z możliwościami szyfrowania danych zawartymi w Microsoft SQL Server 2008
oraz wdrożyć je w firmie.
•
Zapoznaj się z możliwościami wykorzystania elementów kryptografii w SQL Server 2008 (plik
cryptography.sql).
•
Spróbuj wykorzystać szyfrowanie i certyfikaty cyfrowe do zabezpieczenia poszczególnych
tabel bazy danych.
Wszystkie eksperymenty mają być dokonywane na bazie
PraceDyplomowe. Jako rezultat masz
napisać raport zawierający przykłady zastosowania możliwości szyfrowania danych i autoryzacji
dostępu do nich.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
Wersja 1.0
Praca z XML
Spis treści
Praca z XML .......................................................................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 4
Porady praktyczne ....................................................................................................................... 8
Uwagi dla studenta ...................................................................................................................... 8
Dodatkowe źródła informacji....................................................................................................... 8
Laboratorium podstawowe .................................................................................................................. 9
Problem 1 (czas realizacji 45 min) ................................................................................................ 9
Laboratorium rozszerzone ................................................................................................................. 15
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 15
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 2/15
Informacje o module
Opis modułu
Wymiana danych z relacyjnymi bazami danych może być utrudniona ze
względu na różnice programowo – sprzętowe itp. Rozwiązaniem jest język
XML, który jest niezależny od standardów sprzętowych / programowych.
Cel modułu
Celem modułu jest zapoznanie się z możliwościami zastosowania języka
XML w MS SQL 2008.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
wiedzieć, jak uzyskać dokument XML ze zwykłego wyniku zapytania
•
nauczysz się sterować zapisem danych do dokumentu XML
•
będziesz umiał zapisać informacje z dokumentu XML do bazy danych
•
nauczysz się przeprowadzać walidację danych XML według zadanych
schematów
•
poznasz język XQuery, który umożliwia wykonywanie operacji na
danych XML
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
wiedzieć, jak używać oprogramowania Microsoft Virtual PC
•
znać podstawy obsługi systemu Windows 2000 lub nowszego
•
znać podstawy obsługi SQL Server Management Studio
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na Rys. 1, istnieje konieczność
wykonania wcześniej modułu 3.
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 3/15
Przygotowanie teoretyczne
Przykładowy problem
Firma National Insurance wykupiła niedawno udziały w mniejszej, prężnie działającej firmie
informatycznej Miracle. Ponieważ dział IT w Miracle używał innej architektury bazodanowej,
nastąpił problem z wymianą danych pomiędzy centralą a nowym oddziałem. Informatycy obydwu
oddziałów wpadli na pomysł użycia uniwersalnego języka XML do wymiany danych pomiędzy
platformami. Przed podjęciem stosownych działań dyrektor działu IT postanowił sprawdzić, co
oferuje system MS SQL Server 2008 w tym zakresie.
Podstawy teoretyczne
XML (ang. eXtensible Markup Language) jest językiem znaczników (jak HTML), w którym to
programista decyduje o tym, jaka będzie struktura znaczników. W ostatnich latach XML zyskał
ogromną popularność jako format idealny do wymiany danych między aplikacjami, nośnik
konfiguracji aplikacji, format zapisu danych. Znajomość możliwości XML i standardów skojarzonych
jest dziś właściwie niezbędna nie tylko w pracy z bazami danych, ale również z technologiami
programistycznymi.
W dzisiejszym świecie informacja jest przechowywana w różnych formatach. Jednym z dość często
spotykanych formatów jest XML. Oznacza to, że system bazodanowy powinny oferować możliwość
zapisu w swoich strukturach (w swoich bazach danych) danych przemieszanych ze znacznikami
XML.
Format danych
Każdy system bazodanowy oferuje bogaty zestaw typów danych. Wśród tych typów można znaleźć
sporo typów przechowujących tekst. Ponieważ XML jest formatem tekstowym, może być
przechowywany jako tekst, ale typ danych, który w bazach danych ma służyć do przechowywania
danych XML, powinien charakteryzować się czymś więcej niż tylko możliwością zapisu znaczników i
zaszytych w nich informacji.
Jedną z podstawowych właściwości dokumentu XML jest wymóg, który mówi, że dokument XML
musi posiadać odpowiednią formę. Oznacza to, że:
•
dokument ma jeden element główny (ang. root), w którym zawarte są pozostałe elementy
•
pojedynczy znacznik nie zawiera dwóch atrybutów o takiej samej nazwie
•
wartości atrybutów powinny znaleźć się w ogranicznikach (cudzysłowy lub apostrofy)
•
znaczniki nie powinny się „zazębiać”.
Poniższy listing ilustruje przykładowy fragment poprawnego dokument XML:
<panstwa>
<panstwo nazwa="Polska">
<stolica>Warszawa</stolica>
<obszar>312680</obszar>
<ludnosc>38456785</ludnosc>
<glowne_miasta>Wrocław</glowne_miasta>
<glowne_miasta>Gdańsk</glowne_miasta>
<glowne_miasta>Kraków</glowne_miasta>
<glowne_miasta>Poznań</glowne_miasta>
</panstwo>
<panstwo nazwa="Niemcy">
<stolica>Berlin</stolica>
<obszar>356910</obszar>
<ludnosc>81700000</ludnosc>
<glowne_miasta>Monachium</glowne_miasta>
</panstwo>

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 4/15
<panstwo nazwa="Czechy">
<stolica>Praga</stolica>
<obszar>78703</obszar>
<ludnosc>10300000</ludnosc>
</panstwo>
</panstwa>
Idealny format do przechowywania danych XML powinien zapewniać automatyczną kontrolę
poprawności zapisu danych.
Walidacja
Bardzo często struktura dokumentów XML jest w jednoznaczny sposób określona przy pomocy
innych standardów, takich jak XML Schema czy DTD (ang. Document Type Definition). Szczególnie
XML Schema jest doskonałym formatem opisującym struktury XML. Idealnie zatem byłoby, gdyby
system bazodanowy umożliwiał wykorzystanie standardów walidujących XML do kontroli struktury
danych zapisywanych w bazach danych.
MS SQL Server 2000 wprowadził możliwość konwersji danych pobieranych z bazy do dokumentu
XML oraz danych z tych plików na wiersze bazy danych. Umożliwiają to słowa kluczowe języka
Transact-SQL:
•
FOR XML
•
OPENXML
MS SQL Server 2005 rozszerza możliwości w/w słów kluczowych, dzięki czemu można sterować
sposobem tworzenia dokumentu XML (dokładne informacje w dokumentacji do tych poleceń).
Dodatkowo umożliwiono tworzenie natywnych typów danych XML pozwalających na tworzenie
własnych zmiennych oraz dodawanie kolumn do danych XML. Odpowiedzialne za to jest polecenie
CREATE
XML
SCHEMA
COLLECTION
(dokumentacja:
http://msdn2.microsoft.com/en-
us/library/ms176009.aspx), a w połączeniu z XQuery (język pozwalający na pisanie zapytań
przeszukujących
dokumenty
XML,
dokumentacja:
http://msdn2.microsoft.com/en-
us/library/ms189075(SQL.100).aspx) pozwala na pisanie zapytań do treści XML, których wynik
także jest przedstawiony w dokumencie XML. Innym udoskonaleniem jest możliwość nadania
indeksów kolumnom typu XML. Pozwala to na zwiększenie ogólnej wydajności.
MS SQL 2008 wprowadził dalsze udoskonalenia w zakresie walidacji danych. Dodano możliwość
stworzenia schematu który może być dopasowany do dowolnych danych. Dodano słowo kluczowe
let
do
XQuery
(podstawy
można
opanować
na
bazując
na
tutorialach:
http://www.w3schools.com/xquery/default.asp) dzięki, któremu można przypisywać wartości do
zmiennych. Ponadto za pomocą XQuery można wykonywać operacje na danych XML za pomocą
insert, replace value of, delete, modify, a MS SQL Server 2008 pozwala na użycie danych
XML jako argumentu dla polecenia
insert.
Przykładowe rozwiązanie
Rozpoczynając pracę z plikami XML należy zastanowić się jakie dane będziemy w nich
przechowywać. Dane z bazy wybieramy np.: poleceniem SELECT. Aby trafiły one do pliku XML na
końcu skryptu SQL należy dopisać sekwencję FOR XML z odpowiednimi parametrami. Przykładowo,
wybierając dane z tabeli Customers utworzenie pliku XML zapewni nam sekwencja
FOR XML RAW('Customer'), ELEMENTS, ROOT
Po uruchomieniu takiego kodu w Management Studio jako rezultat pojawi nam się odnośnik do
pliku XML tak jak pokazano na Rys. 2:
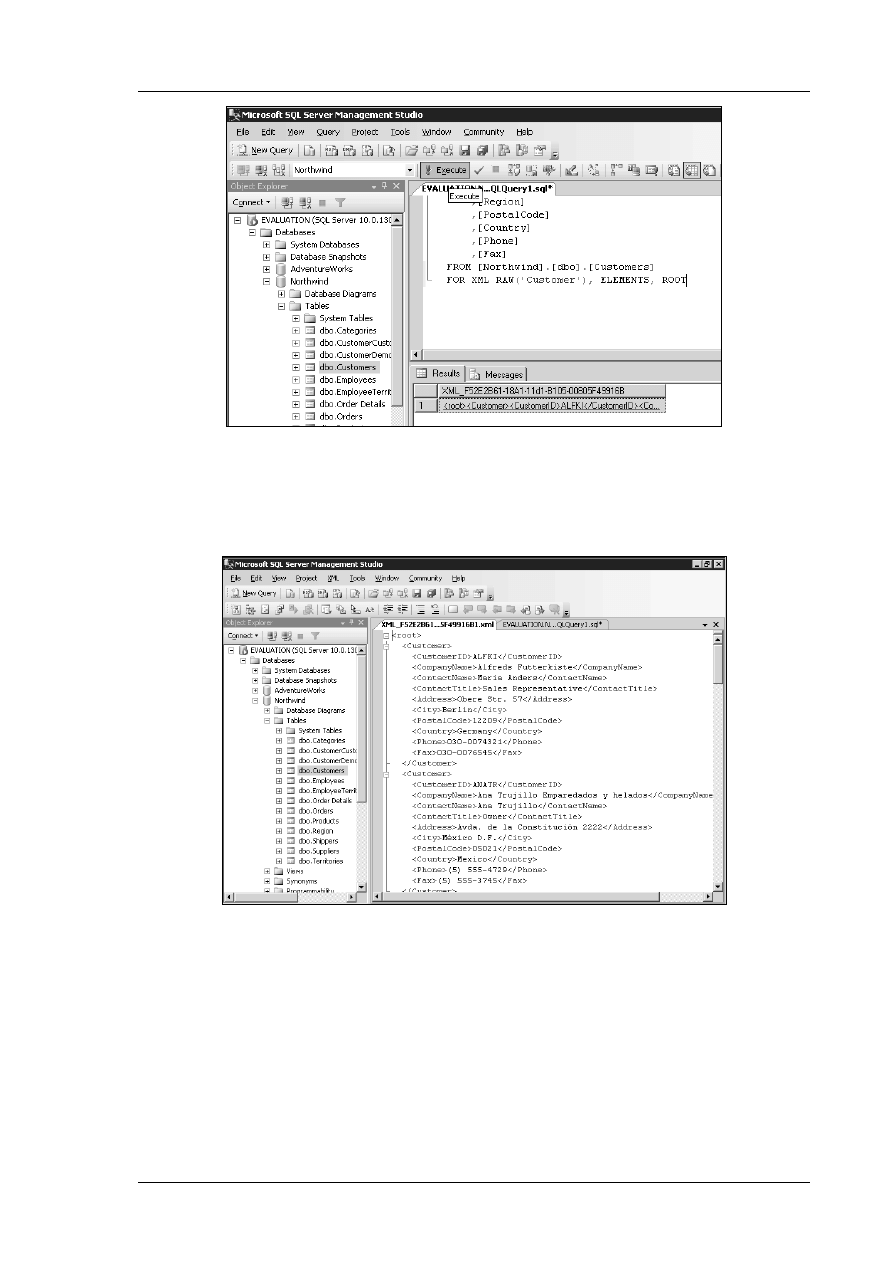
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 5/15
Rys. 2 Generowanie kodu XML
W tym momencie uzyskaliśmy wynik zapytania w postaci dokumentu XML. Klikając na odnośnik
możemy obejrzeć strukturę pliku a następnie zapisać go jako zwykły plik systemowy. Znając
podstawy języka XML łatwo wprowadzać modyfikacje i rozbudowywać tego typu pliki nawet poza
środowiskiem bazodanowym. Wystarczy dysponować dowolnym edytorem testu.
Rys. 3 Wyświetlenie kodu XML
Pracując z plikami XML zawsze należy zwracać uwagę na sposób kodowania znaków. Warto
wymusić odpowiednie kodowanie umieszczając na początku pliku następującą sekwencję
<?xml version="1.0" encoding="utf-16"?>
Co prawda same polecenia XML nie zawierają w swojej strukturze znaków narodowych ale dane
pojawiające się w plikach przeważnie takie posiadają. Aby uniknąć przekłamań rozsądnie
rozpocząć plik XML tak jak pokazano na rys 4.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
W tym momencie posiadamy pełnowartościowy plik XML zawierający dane z naszej bazy.
uzyskane dane można z łatwością przenieść do innej bazy danych np. MySql, ponieważ zostały
zapisane w uniwersalnym formacie (należy jedynie pamiętać
Isnieje możliwość wyeksportowania do pliku XML bardziej złożonych danych. Poniższy kod SQL
wybierze wszystkie zamówienia, których
declare @CustomerID nchar(5)
select @CustomerID = 'ALFKI'
SELECT 1
NULL as Parent,
CustomerID as [Customer!1!customerid],
ContactName as [Customer!1],
NULL as [Order!2!orderid],
NULL as [Order!2]
FROM Customers
where Customers.CustomerID = @CustomerID
UNION
SELECT
2 as tag,
1 as parent,
Customers.CustomerID,
Customers.ContactName,
Orders.OrderID,
Orders.ShipAddress
FROM Customers, Orders
WHERE (Customers.CustomerID = @CustomerID)
AND (Customers.CustomerID = Orders.CustomerID)
FOR XML EXPLICIT
Możemy więc jasno i precyzyjnie określi interesujący nas zakres danych, który będzie
wyeksportowany z systemu bazodanowego.
Porównaj działanie polecenia
ELEMENTS, ROOT
http://msdn2.microsoft.com/en
Posiadając gotowy plik XML zawierający dane wyeksportowane z systemu bazodanowego może
w prosty sposób wczytać te dane do swojej bazy. W ty
typu XML i wczytać do tak zadeklarowanej zmiennej dane ze wskazanego pliku. Taką operację
wykonuje przykładowy kod SQL:
DECLARE @xmlDoc XML
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK 'C:
SINGLE_NCLOB ) AS xmlData)
SELECT @xmlDoc
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 6/15
Rys. 4 Dodanie tagu kodowania
W tym momencie posiadamy pełnowartościowy plik XML zawierający dane z naszej bazy.
uzyskane dane można z łatwością przenieść do innej bazy danych np. MySql, ponieważ zostały
zapisane w uniwersalnym formacie (należy jedynie pamiętać o odpowiednim kodowa
Isnieje możliwość wyeksportowania do pliku XML bardziej złożonych danych. Poniższy kod SQL
wybierze wszystkie zamówienia, których ID_Klienta jest równe "ALFKI".
declare @CustomerID nchar(5)
select @CustomerID = 'ALFKI'
as Tag,
NULL as Parent,
CustomerID as [Customer!1!customerid],
ContactName as [Customer!1],
NULL as [Order!2!orderid],
NULL as [Order!2]
where Customers.CustomerID = @CustomerID
Customers.ContactName,
FROM Customers, Orders
WHERE (Customers.CustomerID = @CustomerID)
AND (Customers.CustomerID = Orders.CustomerID)
y więc jasno i precyzyjnie określi interesujący nas zakres danych, który będzie
wyeksportowany z systemu bazodanowego.
Porównaj działanie polecenia FOR XML z atrybutami RAW, AUTO oraz
(oraz bez tych opcji) i innymi zgodnie z dokumentacją na:
http://msdn2.microsoft.com/en-us/library/ms173812.aspx
Posiadając gotowy plik XML zawierający dane wyeksportowane z systemu bazodanowego może
w prosty sposób wczytać te dane do swojej bazy. W tym celu należy posłużyć się zmiennymi T
typu XML i wczytać do tak zadeklarowanej zmiennej dane ze wskazanego pliku. Taką operację
wykonuje przykładowy kod SQL:
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK 'C:\pliczek.xml', CODEPA
SINGLE_NCLOB ) AS xmlData)
Moduł 11
Instalacja i konfiguracja MS SQL Server 2008
W tym momencie posiadamy pełnowartościowy plik XML zawierający dane z naszej bazy. Tak
uzyskane dane można z łatwością przenieść do innej bazy danych np. MySql, ponieważ zostały
o odpowiednim kodowaniu znaków).
Isnieje możliwość wyeksportowania do pliku XML bardziej złożonych danych. Poniższy kod SQL
y więc jasno i precyzyjnie określi interesujący nas zakres danych, który będzie
oraz PATH oraz atrybutami
(oraz bez tych opcji) i innymi zgodnie z dokumentacją na:
Posiadając gotowy plik XML zawierający dane wyeksportowane z systemu bazodanowego możemy
m celu należy posłużyć się zmiennymi T-SQL
typu XML i wczytać do tak zadeklarowanej zmiennej dane ze wskazanego pliku. Taką operację
.xml', CODEPAGE='utf-16',
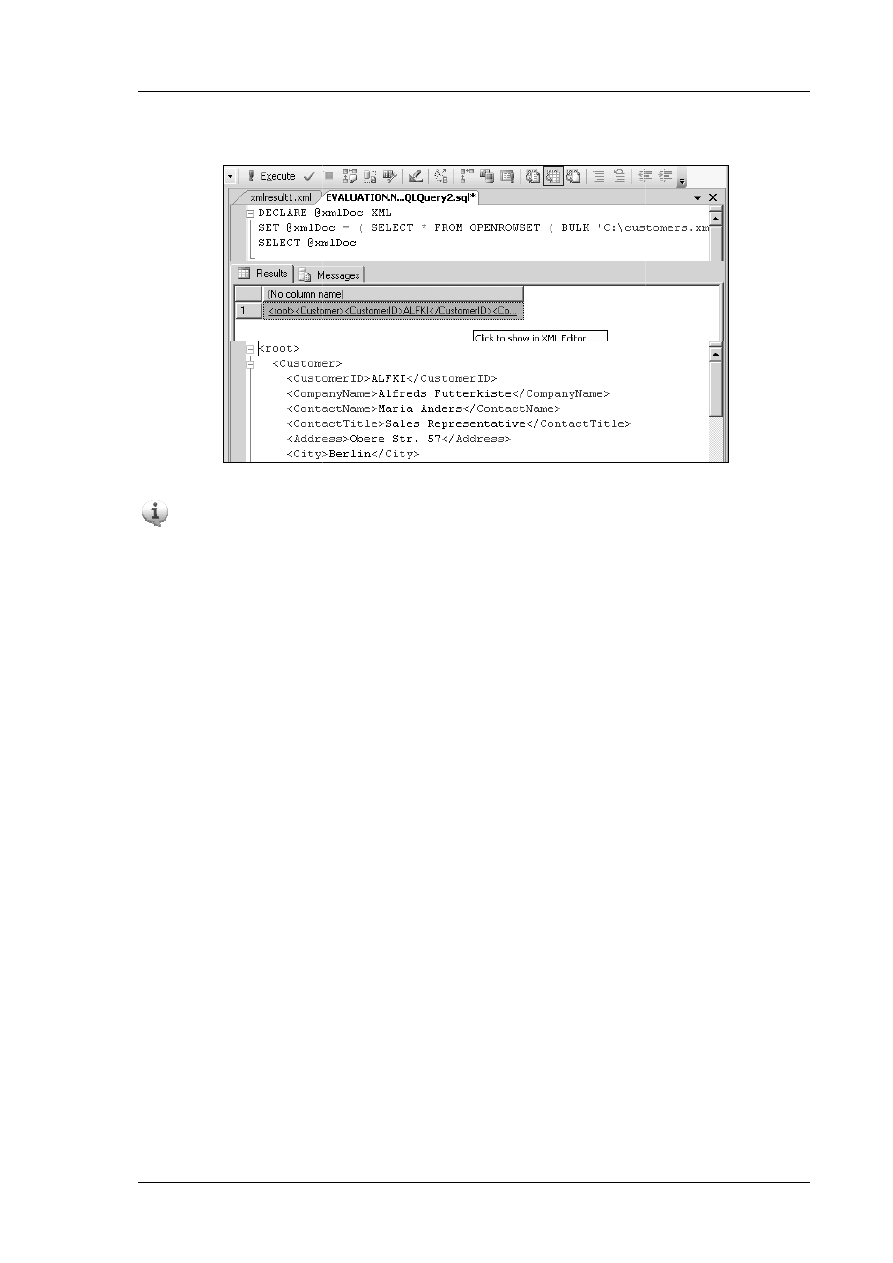
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
Wynikiem jest wczytana treść wcześniej utworzonego pliku, znajdująca się w jednej kolumnie typu
XML co ilustruje rysunek 5.
W operowaniu na danych XML pomocny jest
typu dokumentów.
Do tej pory jedynie wyświetlaliśmy
aby za pomocą pliku mapującego dokonać
mapujący odzwierciedla dane z pliku XML na tabele w
<?xml version="1.0" ?>
<Schema xmlns="urn:schemas
xmlns:dt="urn:schemas
xmlns:sql="urn:schemas
<ElementType name="CustomerID" dt:type="string" />
<ElementType name="CompanyName" dt:type="string" />
<ElementType name="City" dt:type="string" />
<ElementType name="ROOT" sql:is
<element type="Customer" />
</ElementType>
<ElementType name="Customer" sql:relation="Customers">
<element type="CustomerID" sql:field="CustomerId" />
<element type="CompanyName" sql:field="CompanyName" />
<element type="City" sql:field="City" />
</ElementType>
</Schema>
Pozostaje nam tylko stworzyć odpowiedni skrypt
do bazy według zadanego wcześniej schematu:
Set objBL = CreateObject("SQLXMLBulkLoad.SQLXMLBulkLoad")
objBL.ConnectionString = "Prov
Catalog=Northwind;Integrated Security=SSPI;"
objBL.ErrorLogFile = "c:
objBL.Execute "c:\customersmapping.xml", "c:
Set objBL = Nothing
Skrypt połączy się z naszym serwerem bazodanowym a
plikami XML co ilustruje rysunek
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 7/15
Wynikiem jest wczytana treść wcześniej utworzonego pliku, znajdująca się w jednej kolumnie typu
Rys. 5 Wczytanie pliku XML
W operowaniu na danych XML pomocny jest XQuery, czyli język zapytań właśnie dla tego
Do tej pory jedynie wyświetlaliśmy zawartość wczytanego pliku XML. Nic nie stoi na przeszkodzie
pomocą pliku mapującego dokonać jego zapisu w odpowiedniej tabeli
odzwierciedla dane z pliku XML na tabele w przykładowej bazie Northwind:
<?xml version="1.0" ?>
<Schema xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:xml:datatypes"
xmlns:sql="urn:schemas-microsoft-com:xml-sql" >
<ElementType name="CustomerID" dt:type="string" />
<ElementType name="CompanyName" dt:type="string" />
<ElementType name="City" dt:type="string" />
<ElementType name="ROOT" sql:is-constant="1">
type="Customer" />
<ElementType name="Customer" sql:relation="Customers">
<element type="CustomerID" sql:field="CustomerId" />
<element type="CompanyName" sql:field="CompanyName" />
<element type="City" sql:field="City" />
Pozostaje nam tylko stworzyć odpowiedni skrypt Visual Basic, który zrealizuje wstawianie danych
do bazy według zadanego wcześniej schematu:
Set objBL = CreateObject("SQLXMLBulkLoad.SQLXMLBulkLoad")
objBL.ConnectionString = "Provider=SQLOLEDB;Data Source=EVALUATION;Initial
Catalog=Northwind;Integrated Security=SSPI;"
objBL.ErrorLogFile = "c:\error.log"
customersmapping.xml", "c:\customers.xml"
Skrypt połączy się z naszym serwerem bazodanowym a następnie wykona zapy
plikami XML co ilustruje rysunek 6.
Moduł 11
Instalacja i konfiguracja MS SQL Server 2008
Wynikiem jest wczytana treść wcześniej utworzonego pliku, znajdująca się w jednej kolumnie typu
, czyli język zapytań właśnie dla tego
zawartość wczytanego pliku XML. Nic nie stoi na przeszkodzie
wiedniej tabeli bazy danych. Plik
bazie Northwind:
ry zrealizuje wstawianie danych
ider=SQLOLEDB;Data Source=EVALUATION;Initial
następnie wykona zapytania SQL zgodnie z

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 8/15
Rys. 6 Wynik zapytania do bazy po aktualizacji danych
Porady praktyczne
Praca z plikami XML może być wydajna i przyjemna. Warto jednak zaznaczyć, że szczególnie
początkujący użytkownicy mogą popełniać drobne, ale męczące błędy związane głównie z
nieścisłościami w nazewnictwie:
•
Zawsze sprawdzaj poprawność nazw wszelkich plików i ich ścieżek dostępu. Często
niemożność zlokalizowania pliku skutkuje komunikatami o innych błędach.
•
Poprawne określenie kodowania zapobiega przekłamaniom w obróbce danych. Czasami złe
kodowanie w ogóle wyklucza wykonanie danej operacji.
•
Dowiedź się nieco więcej o podstawach programowania w VBscript. Jest to bardzo prosty,
obiektowy język programowania, wykorzystywany w budowie skryptów.
•
Czytaj uważnie dziennik błędów. W większości przypadków dziennik wskazuje na poprawne
rozwiązanie problemu.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz, czym różni się język XML od HTML
•
rozumiesz zasadę działania struktury XML Schema
•
umiesz zdefiniować przykładową strukturę pliku XML
•
umiesz podać przykład zastosowania narzędzia XQuery.
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
William R. Stanek, Microsoft XML – Vademecum, Microsoft Press, 2002
2.
Elizabeth Castro, Po prostu XML, Helion, 2001
3.
Priscilla Walmsley, Wszystko o XML Schema, WNT, 2007
4.
Przemysław Kozienko, Krzysztof Gwiazda, XML na poważnie, Helion, 2002
5.
Scott Short , Zastosowanie XML do tworzenia usług internetowych na platformie Microsoft .NET,
Microsoft Press 2003

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 9/15
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
Jesteś administratorem systemu bazodanowego w firmie National Insurance. Twój szef zlecił Ci
rozpoznanie możliwości płynących z użycia języka XML w systemie MS SQL Server 2008. W
pierwszej kolejności postanowiłeś użyć narzędzi dostępnych w systemie na roboczym serwerze
Evaluation i sprawdzonej bazie danych Northwind.
Zadanie
Tok postępowania
1.
Nawiązywanie
połączenia z SQL
Server 2008
•
Zaloguj się do maszyny wirtualnej BD jako użytkownik Administrator z
hasłem P@ssw0rd.
•
Kliknij Start. Z grupy programów Microsoft SQL Server 2008 uruchom
SQL Server Management Studio.
•
W oknie logowania kliknij Connect.
2.
Wygenerowan
ie pliku XML na
podstawie danych
z bazy
•
W oknie Object Explorer rozwiń listę tabel bazy danych
Northwind -> Databases -> Tables.
•
Kliknij prawym klawiszem myszki tabelę Customers i wybierz opcję
Select Top 1000 Rows.
Rys. 7 Wybieranie danych z bazy Northwind
•
W okienku, które się pokaże, zamień wartość 1000 na 10 (nie potrzeba
tyle danych do testów), a na samym końcu skryptu dopisz:
FOR XML RAW('Customer'), ELEMENTS, ROOT
•
wykonaj zapytanie klikając przycisk Execute.
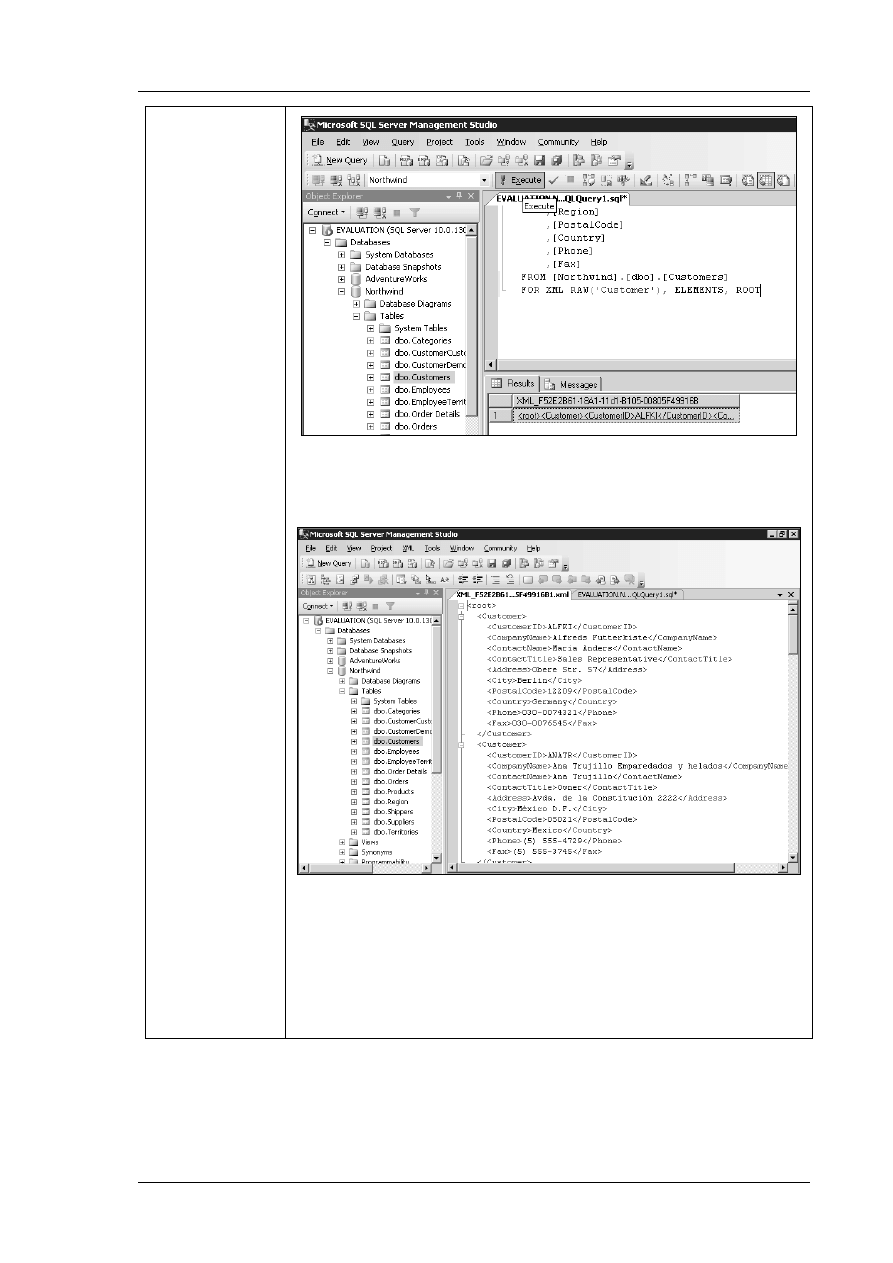
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 10/15
Rys. 8 Generowanie kodu XML
•
Kliknij na odnośnik <Root><Customer>… w celu otwarcia okna z kodem
XML.
Rys. 9 Wyświetlenie kodu XML
•
zapisz ten wynik do pliku: c:\customers.xml klikając na menu File->Save
As.
•
Możesz otworzyć plik w przeglądarce, aby zobaczyć jego strukturę,
jednak zanim to zrobisz, dopisz na samym początku, najlepiej w
edytorze w MS SQL, następującą linię:
<?xml version="1.0" encoding="utf-16"?>

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
•
zamkni
3.
Wczytanie
danych XML do
MS SQL
•
Kliknij przycisk
•
Wpisz następujący kod SQL do nowego okna zapytania:
DECLARE @xmlDoc XML
SET @xmlDoc
'C:
SELECT @xmlDoc
•
Kliknij przycisk
4.
Odczyt danych
XML - poruszanie
się po drzewie
danych
•
Zmień zapytanie SQL z poprzedniego zadania na następujące:
DECLARE @xmlDoc XML
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK
'C:
SELECT @xmlDoc.query(
'<Customers>
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 11/15
Rys. 10 Dodanie tagu kodowania
zamknij utworzone zapytania w głównym oknie Management Studio
Kliknij przycisk NewQuery.
Wpisz następujący kod SQL do nowego okna zapytania:
DECLARE @xmlDoc XML
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK
'C:\customers.xml', CODEPAGE='utf-16', SINGLE_NCLOB ) AS xmlData)
SELECT @xmlDoc
Kliknij przycisk Execute.
Rys. 11 Wczytanie pliku XML
Jeśli nie można wczytać pliku albo na początku treści pojawiają
tzw. „krzaczki”, to proszę się cofnąć do momentu zapisu i zamiast
przez edytor z MSSQL, proszę zapisać metodą kopiowania i wklejania
treści dokumentu XML do notatnika
W operowaniu na danych XML pomocny jest
zapytań właśnie dla tego typu dokumentów.
Zmień zapytanie SQL z poprzedniego zadania na następujące:
DECLARE @xmlDoc XML
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK
'C:\customers.xml', CODEPAGE='utf-16', SINGLE_NCLOB ) AS xmlData)
SELECT @xmlDoc.query(
'<Customers>
Moduł 11
Instalacja i konfiguracja MS SQL Server 2008
Management Studio
Wpisz następujący kod SQL do nowego okna zapytania:
= ( SELECT * FROM OPENROWSET ( BULK
16', SINGLE_NCLOB ) AS xmlData)
Jeśli nie można wczytać pliku albo na początku treści pojawiają się
to proszę się cofnąć do momentu zapisu i zamiast
przez edytor z MSSQL, proszę zapisać metodą kopiowania i wklejania
W operowaniu na danych XML pomocny jest XQuery, czyli język
Zmień zapytanie SQL z poprzedniego zadania na następujące:
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK
16', SINGLE_NCLOB ) AS xmlData)

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 12/15
{
for $i in /root/Customer
where $i/Country="Mexico"
return
<Order>
{$i/CompanyName}
</Order>
}
</Customers>'
)
•
Uruchom zapytanie klikając przycisk Execute.
•
Kliknij na odnośnik do kodu XML.
Rys. 12 Generowanie kodu XML
5.
Eksport
wybranych
danych do pliku
XML
•
Kliknij przycisk NewQuery.
•
W nowym oknie wpisz następujący kod SQL:
use Northwind
declare @CustomerID nchar(5)
select @CustomerID = 'ALFKI'
SELECT 1 as Tag,
NULL as Parent,
CustomerID as [Customer!1!customerid],
ContactName as [Customer!1],
NULL as [Order!2!orderid],
NULL as [Order!2]
FROM Customers
where Customers.CustomerID = @CustomerID
UNION
SELECT
2 as tag,
1 as parent,
Customers.CustomerID,
Customers.ContactName,
Orders.OrderID,
Orders.ShipAddress
FROM Customers, Orders
WHERE (Customers.CustomerID = @CustomerID)
AND (Customers.CustomerID = Orders.CustomerID)
FOR XML EXPLICIT
•
Kliknij na nowy odnośnik do kodu XML.
•
Dodaj w pierwszej linijce pliku określenie kodowania znaków:
<?xml version="1.0" encoding="unicode"?>

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
•
Kliknij na menu
•
Zapisz kod XML do pliku
•
Kliknij przycisk
•
W nowym oknie wpisz następują
DECLARE @xmlDoc XML
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK 'C:
Settings
SINGLE_NCLOB ) AS xmlData)
SELECT @xmlDoc
SELECT @xmlDoc.query(
'<Orders>
{
for $i in /Custo
let $count :=count($i/Order)
return
<OrdersNumber>
{$i/Customer}
<ItemCount>{$count}</ItemCount>
</OrdersNumber>
}
</Orders>')
•
Kliknij na nowy odnośnik do kodu XML
6.
Zapisanie
wczytanych
danych XML do
tabeli za pomocą
pliku mapującego
•
Kliknij menu
•
Wpisz w oknie notatnika następujący kod XML, w którym znajdować się
będą informacje, które chcemy zapisać w bazie:
<?xml version="1.0" encoding="unicode"?>
<root>
</root>
•
Zapisz plik pod nazwą
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 13/15
Rys. 13 Dodanie tagu kodowania znaków
Kliknij na menu File->Save As.
Zapisz kod XML do pliku C:\explicit.xml.
W następnym kroku wczytasz wcześniej zapisany plik explicit.xml i
uruchomisz zapytanie SQL zliczające ilość wystąpień tagu Order,
każdego elementu Customer:
Kliknij przycisk NewQuery.
W nowym oknie wpisz następujący kod SQL:
DECLARE @xmlDoc XML
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK 'C:
Settings\Administrator\Desktop\explicit.xml', CODEPAGE='unicode',
SINGLE_NCLOB ) AS xmlData)
SELECT @xmlDoc
SELECT @xmlDoc.query(
'<Orders>
for $i in /Customer
let $count :=count($i/Order)
return
<OrdersNumber>
{$i/Customer}
<ItemCount>{$count}</ItemCount>
</OrdersNumber>
</Orders>')
Kliknij na nowy odnośnik do kodu XML.
Rys. 14 Wyświetlenie wyników z kodu XML
Kliknij menu START->Programs->Accessories->Notepad
Wpisz w oknie notatnika następujący kod XML, w którym znajdować się
będą informacje, które chcemy zapisać w bazie:
<?xml version="1.0" encoding="unicode"?>
<root>
<Customer>
<CustomerID>Test</CustomerID>
<CompanyName>Teeest</CompanyName>
<City>Warsaw</City>
</Customer>
</root>
Zapisz plik pod nazwą c:\customers.xml.
Moduł 11
Instalacja i konfiguracja MS SQL Server 2008
Dodanie tagu kodowania znaków
W następnym kroku wczytasz wcześniej zapisany plik explicit.xml i
uruchomisz zapytanie SQL zliczające ilość wystąpień tagu Order,
SET @xmlDoc = ( SELECT * FROM OPENROWSET ( BULK 'C:\Documents and
explicit.xml', CODEPAGE='unicode',
Wyświetlenie wyników z kodu XML
>Notepad.
Wpisz w oknie notatnika następujący kod XML, w którym znajdować się

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 14/15
•
W oknie notatnika kliknij menu File->New.
•
Wpisz następujący kod XML, który odzwierciedla dane z pliku XML na
tabele w bazie Northwind:
<?xml version="1.0" ?>
<Schema xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:xml:datatypes"
xmlns:sql="urn:schemas-microsoft-com:xml-sql" >
<ElementType name="CustomerID" dt:type="string" />
<ElementType name="CompanyName" dt:type="string" />
<ElementType name="City" dt:type="string" />
<ElementType name="ROOT" sql:is-constant="1">
<element type="Customer" />
</ElementType>
<ElementType name="Customer" sql:relation="Customers">
<element type="CustomerID" sql:field="CustomerId" />
<element type="CompanyName" sql:field="CompanyName" />
<element type="City" sql:field="City" />
</ElementType>
</Schema>
•
Zapisz plik pod nazwą c:\customersmapping.xml.
•
W oknie notatnika kliknij menu File->New.
•
Wpisz następujący skrypt Visual Basic, który zrealizuje wstawianie
danych do bazy według zadanego wcześniej schematu:
Set objBL = CreateObject("SQLXMLBulkLoad.SQLXMLBulkLoad")
objBL.ConnectionString = "Provider=SQLOLEDB;Data
Source=EVALUATION;Initial Catalog=Northwind;Integrated
Security=SSPI;"
objBL.ErrorLogFile = "c:\error.log"
objBL.Execute "c:\customersmapping.xml", "c:\customers.xml"
Set objBL = Nothing
•
Zapisz plik pod nazwą c:\ Insertcustomers.vbs.
•
Przejdź na dysk lokalny C: i uruchom plik Insertcustomers.vbs.
Rys. 15 Wynik zapytania do bazy po aktualizacji danych
Możesz sprawdzić za pomocą SQL Management Studio->Object Explorer,
czy rzeczywiście zaszły zmiany w tabeli Customers bazy Northwind.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 11
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 15/15
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Zapoznałeś się z podstawami obsługi języka XML w firmowym systemie bazodanowym.
Postanowiłeś wykorzystać zdobytą wiedzę do przeniesienia danych z bazy
PraceDyplomowe
znajdującej się w centrali do bazy w nowym oddziale firmy. Zanim jednak dane trafią do oddziału,
będziesz chciał zweryfikować poprawność zapisu w plikach XML:
•
Utwórz skrypty SQL zapisujące do plików XML jak najwięcej informacji z bazy danych
PraceDyplomowe
•
Utwór nową, roboczą bazę
PraceDyplomowe_TEMP
•
Odzyskaj zapisane dane do bazy
PraceDyplomowe_TEMP za pomocą odpowiedniego
skryptu Visual Basic.
Zapisz swoje uwagi w pliku raportu i przedyskutuj z innymi zespołami.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
Wersja 1.0
Praca z Reporting Services
Spis treści
Praca z Reporting Services ................................................................................................................... 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 6
Porady praktyczne ..................................................................................................................... 12
Uwagi dla studenta .................................................................................................................... 12
Dodatkowe źródła informacji..................................................................................................... 13
Laboratorium podstawowe ................................................................................................................ 14
Problem 1 (czas realizacji 45 min) .............................................................................................. 14
Laboratorium rozszerzone ................................................................................................................. 24
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 24
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 2/24
Informacje o module
Opis modułu
Aby
osiągnąć
sukces
na
dzisiejszym,
konkurencyjnym
rynku,
przedsiębiorstwa gromadzące duże ilości danych powinny wprowadzić
rozwiązania biznesowe działające w czasie rzeczywistym zapewniające
bezproblemową, skuteczną wymianę informacji pomiędzy własnymi
oddziałami, swoimi partnerami, a także klientami. Microsoft SQL Server
Reporting Services jest rozwiązaniem, które pozwala szybko i komfortowo
dzielić i udostępniać dane biznesowe, przy niższych nakładach rozmaitych
zasobów.
Cel modułu
Celem modułu jest zapoznanie się z podstawową funkcjonalnością systemu
raportowania w MS SQL Server 2008.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
poznasz podstawy MS SQL Server Reporting Services
•
dowiesz się, jak zainstalować narzędzie MS SQL Server Reporting
Services
•
nauczysz się, jak wykorzystywać MS SQL Server Reporting Services do
tworzenia raportów
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
wiedzieć jak używać oprogramowania Microsoft Virtual PC
•
znać podstawy obsługi systemu Windows 2000 lub nowszego
•
znać podstawy obsługi SQL Management Studio
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na Rys. 1, istnieje konieczność
wykonania wcześniej modułu 3.
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 3/24
Przygotowanie teoretyczne
Przykładowy problem
W firmie National Insurance dyrektor działu marketingu został poproszony o przygotowanie akcji
marketingowej skierowanej do klientów firmy. Liczba klientów w bazie danych wynosi około
miliona osób, a koszt dotarcia do każdego klienta – 10 PLN. Akcja dotyczy luksusowego produktu,
którym zainteresowani mogą być wybrani klienci. Jesteś specjalistą analitykiem w dziale IT i masz
dostęp do bazy danych firmy. Administrator nowego serwera MS SQL Server wskazał na
interesującą usługę o nazwie Reporting Services, pozwalającą w ciekawy i wygodny sposób
przedstawiać dane pobierane z bazy. Postanowiłeś zapoznać się z nową usługą.
Podstawy teoretyczne
MS SQL Server Reporting Services jest platformą raportującą, która używana jest do zarządzania
tabelarycznymi, macierzowymi lub innymi raportami zawierającymi dane z wielowymiarowych
źródeł. Raporty tworzone za pomocą MS SQL Server Reporting Services mogą być udostępniane i
zarządzane przez sieć WWW. Podstawowe komponenty MS SQL Server Reporting Services to:
•
pełny zestaw narzędzi do tworzenia, zarządzania i udostępniania raportów
•
serwer raportujący (ang. Report Server) udostępniający i przetwarzający raporty w wielu
formatach danych (np. HTML, PDF, TIFF, Excel, CSV, etc.)
•
API, za pomocą, którego programiści i deweloperzy mogą rozszerzyć, zintegrować (dane i
przetwarzanie raportów) oraz utworzyć aplikacje do zarządzania raportami.
Dane źródłowe dla raportów tworzonych za pomocą MS SQL Server Reporting Services mogą
pochodzić z relacyjnych lub wielowymiarowych zbiorów danych. Ich dostawcą może być SQL
Server, Analysis Services, Oracle lub inny dostawca danych, taki jak ODBC lub OLE DB. Raporty
mogą mieć postać tabelaryczną, macierzową lub dowolną inną, można też tworzyć raporty ad-hoc
(przy wykorzystaniu predefiniowanych modeli).
Swoją funkcjonalnością i metodami wizualizacji MS SQL Server Reporting Services przewyższa
dotychczasowe rozwiązania raportowe, między innymi dzięki opartej na sieci WWW wizualizacji.
W dalszej części przyjrzymy się podstawowym cechom MS SQL Server Reporting Services.
Raporty
•
Dane źródłowe w postaci relacyjnej, wielowymiarowej, a także XML – dane do raportów
mogą być dostarczone przez MS SQL Server, Analysis Services, Oracle (poprzez .NET
Framework), ODBC, OLE DB, a także ze zbiorów zapisanych w formacie XML.
•
Raporty mogą być prezentowane za pomocą rozmaitych rozkładów, takich jak tabele (np. dla
danych kolumnowych), macierze (np. dla danych streszczonych), wszelakie wykresy (dane
prezentowane graficznie), a także rozkład dowolny, oparty na dowolnie ustawianych
kontrolkach i polach wewnątrz kontenera. W razie potrzeby możliwe jest połączenie różnych
rozkładów w jednym raporcie.
•
Raporty typu ad-hoc – istnieje możliwość tworzenia i zapisywania raportów bezpośrednio na
serwerze raportującym za pomocą aplikacji ClickOnce (Report Builder). Raporty ad-hoc
wykonywane są poprzez klienta ściąganego z serwer raportującego.
•
Udoskonalone przeglądanie raportów – istnieje możliwość dodania interaktywnych
elementów (np. linki), zapewniających dostęp do spokrewnionych raportów, a także do
raportów bardziej szczegółowych. Do raportów można także dodać skrypty napisane w
języku Visual Basic.
•
Parametryzacja raportów – istnieje możliwość dodawania parametrów do raportów, żeby
uszczegółowić zapytanie lub przefiltrować zbiór danych. Parametry dynamiczne pobierają
wartości w czasie wykonywania na podstawie wyboru użytkownika.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 4/24
•
Możliwość prezentacji danych w wielu formatach – format prezentacji może być zmieniany
w trakcie oglądania raportu. Dostępne formaty: HTML, MHTML, PDF, XML, CSV, TIFF oraz
Excel.
•
Dodatkowe kontrolki – funkcjonalność Reporting Services można rozszerzać za pomocą
dodatkowych kontrolek dostarczanych przez formy trzecie Dodatkowe kontrolki wymagają
specjalnego rozszerzenia przetwarzającego dane.
•
Nawigacja – istnieje możliwość dodawania zakładek oraz map do większych raportów, by
ułatwić poruszanie się po nich.
•
Agregacja danych – dane mogę być łączone i streszczane za pomocą kontrolek i wyrażeń.
Dostępne operacje to m.in. suma, średnia, min, max i wiele innych.
•
Elementy graficzne – do raportów można dodawać rozmaite elementy graficzne.
Projektowanie raportów i modeli
•
Projektowanie raportów – tworzenie raportów za pomocą rozbudowanej aplikacji
dostarczanej wraz z Business Intelligence Development Studio. Aplikacja ta niesamowicie
ułatwia proces tworzenia raportów poprzez m.in. definiowanie rozkładu, publikowanie
raportu, generator zapytań oraz wiele innych, a wszystko to może być wykonywane krok po
kroku.
•
Projektowanie modeli – narzędzie to umożliwia definiowanie wzorców/modeli do
automatycznego generowania raportów w trybie ad-hoc.
•
Generator raportów – generator raportów umożliwia tworzenie raportów w trybie ad-hoc
opartych na wcześniej zdefiniowanych modelach.
Udostępnianie i administracja
•
Konfiguracja Raporting Services – udostępnianie i utrzymywanie serwera raportującego za
pomocą graficznego interfejsu użytkownika, używanego między innymi do konfiguracji kont,
wirtualnych, folderów, kluczy szyfrowania.
•
Zarządca raportów – za pomocą zarządcy raportów można nadzorować m.in. tworzenie
raportów, historie raportów oraz ustalać limity na najróżniejsze parametry, takie jak np. czas
przetwarzania.
•
Integracja Raporting Services z SQL Server Management Studio, SQL Server Configuration
Manager oraz narzędziami Surface Area Configuration.
•
Możliwość zarządzania serwerem z poziomu linii komend.
•
Użytkownicy serwera przypisani są do ról z których każda ma wyznaczone uprawnienia i
prawa dostępu. Poziom bezpieczeństwa serwera wzrasta.
Dostęp do raportów i ich dostarczanie:
•
Możliwość dostępu poprzez sieć WWW za pomocą zwykłej przeglądarki internetowej.
•
Możliwość integracji Reporting Services z Microsoft SharePoint Portal.
•
Możliwość przechowywania raportów i zarządzania nimi we własnej przestrzeni pracy.
•
Reporting Services umożliwia ustawienie subskrypcji, za pomocą której raport będzie trafiał
na adres e-mail jako załącznik lub link do strony. Format raportu może być dowolnie
definiowany.
Programowanie i rozszerzalność:
•
Report Definition Language (RDL) – RDL opisuje wszystkie możliwe elementy raportu za
pomocą języka XML. Zachowanie każdego raportu w czasie wykonywania jest zdefiniowane
w specjalnym pliku XML. RDL jest językiem rozszerzalnym, można do niego dodawać własne
definicje.
•
SOAP API – możliwość dostępu do Reporting Services z poziomu napisanej przez siebie
aplikacji.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 5/24
•
Dostęp URL – każdy element raportu może mieć własny adres URL i być osiągalny
bezpośrednio z sieci.
•
WMI – Reporting Services zawiera własnego dostawcę WMI, za pomocą którego można
zarządzać serwisem Report Server Windows.
Przypadki użycia Reporting Services
•
Raporty biznesowe – wiele przedsiębiorstw używa oprogramowania raportującego
dystrybuując informację do użytkowników, którzy zajmują się podejmowaniem decyzji (np.
wynajdywanie nowych możliwości czy analiza zagrożeń). Reporting Services zawiera całe
spektrum gotowych do użycia narzędzi, za pomocą których można utworzyć, udostępnić, a
także zarządzać raportami w danej organizacji. Narzędzie administracyjne i autoryzacyjne
zawierają: Report Designer, SQL Server Management Studio, Report Manager oraz Reporting
Services Configuration. Użytkownicy biznesowi mogą używać Report Manager, SharePoint, a
także zwykłej przeglądarki internetowej, żeby oglądać raporty na żądanie lub dokonać
subskrypcji raportów tak, aby były dostarczane wprost do skrzynki poczty elekronicznej.
•
Raporty ad-hoc – użytkownicy, którzy pracują z danymi biznesowymi często potrzebują
możliwości utworzenia lub zmiany raportu „na szybko”. Reporting Services ma wbudowany
generator raportów, specjalne narzędzie za pomocą którego można wybrać wzorzec i model
raportu, przeciągnąć pola danych i elementy graficzne na projekt raportu, utworzyć
podstawowy raport i całość zapisać na serwerze. Raporty typu ad-hoc wymagają specjalnych
predefiniowanych modeli, utworzonych w generatorze modeli, a następnie zapisanych na
serwerze do dalszego wykorzystania.
•
Wbudowane raporty – istnieje możliwość wykorzystania Reporting Services, aby w napisanej
przez siebie aplikacji zapewnić mechanizmy raportowania. Aby było to możliwe, należy użyć
generatora raportów do stworzenia raportu dla danych dostępnych publicznie lub z aplikacji,
a następnie za pomocą API zdefiniować dostępność i zachowanie wszystkich elementów
raportu, który ma być załączony do tworzonej aplikacji. Jako fragment aplikacji należy
umieścić bazę danych, na której zbudowany został raport, oraz inne konieczne metadane. W
czasie wykonywania aplikacji jej kod wywołuje Report Server Web Service, poprzez który
otrzymuje się dane dotyczące raportu. Jeśli tworzona aplikacja nie wymaga pełnej
funkcjonalności, do przeglądania raportu można wykorzystać zwykła kontrolkę RaportViewer
dostępną w Visual Studio 2005.
•
Integrowanie raportów – ponieważ raporty często prezentują dane z wielu źródeł, bardzo
użyteczne jest integrowanie wielu źródeł danych na jednym raporcie. Dlatego zamiast
wykonywać nowy raport dla każdego źródła danych często dużo bardziej użyteczne jest
dodawanie danych do jednego raportu i wyświetlanie ich za pomocą zestawu kontrolek i
elementów graficznych.
•
Raportowanie przez WWW – dla pracowników, którzy nie pracują w centrali, ale np. w
biurach regionalnych, można udostępniać raporty poprzez sieć WWW, ale należy wtedy
zwrócić szczególną uwagę na bezpieczeństwo.
•
Dostosowywanie środowiska Reporting Services do własnych wymagań – narzędzie i
aplikacje domyślnie dostarczane z Reporting Services są oparte na interfejsie
programistycznym i dostępne dla wszystkich użytkowników. Oznacza to, że domyślnie
dostarczone narzędzie można zastąpić dowolnymi innymi, dostępnymi lub napisanymi przez
samego siebie. Do tego właśnie celu służy WMI Reporting Services.
•
Rozszerzanie dostępnej funkcjonalności – Reporting Services zostało zaprojektowane tak, by
można było je dowolnie rozszerzać. Istnieje możliwość tworzenia własnych rozszerzeń dla
wsparcia dodatkowych typów źródeł danych, dostarczanie raportów, a także ich
bezpieczeństwa. Złożoność procesu tworzenia dodatkowych rozszerzeń zależy głównie od
stopnia skomplikowania danego rozszerzenia, a także jego funkcjonalności. Więcej na ten
temat można dowiedzieć się sięgając do dokumentacji RDL.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 6/24
Przykładowe rozwiązanie
W pierwszej kolejności należy stworzyć nowy raport odpowiedniego typu. Najwygodniej posłużyć
się nowym narzędziem serwera 2008 o nazwie Business Intelligence Development Studio.
Wybieramy projekt o typie Report Server zgodnie z rysunkiem 2.
Rys. 2 Tworzenie nowego projektu raportu
Kolejnym krokiem jest określenie źródła danych dla naszego raportu. Możemy skorzystać z
dowolnych źródeł dostępnych w naszym systemie bazodanowym. W typowej sytuacji źródłem
będzie baza danych umieszczona na firmowym serwerze SQL. Tutaj także doprecyzowujemy zakres
danych poprzez podanie odpowiedniego zapytania SQL typu SELECT.
Rys. 3 Wskazanie serwera SQL jako źródła danych
Po utworzeniu połączenia z bazą danych możemy przystąpić do modelowania wizualnego wyglądu
raportu. Jak pokazano na rysunku 4 metodą ‘przeciągnij i upuść’ przesuwamy interesujące nas pola
do głównego okna programu.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 7/24
Rys. 4 Modelowanie raportu
Oczywiście najważniejsze są pola reprezentujące poszczególne kolumny danych z bazy. Stanowią
one trzon raportu, ich wybór musi być przemyślany.
Rys. 5 Ustalanie nazw i zawartości kolumn raportu
W każdej chwili możemy podejżeć jak w danym momecie będzie wyglądał nasz raport od strony
odbiorcy. Jest to przydatne szczególnie wówczaj, gdy testujemy różne pomysły na prezentację
strony graficznej raportu. Rysunek 6 ilustruje podgląd prostego raportu we wczesnej fazie
konstrukcji.
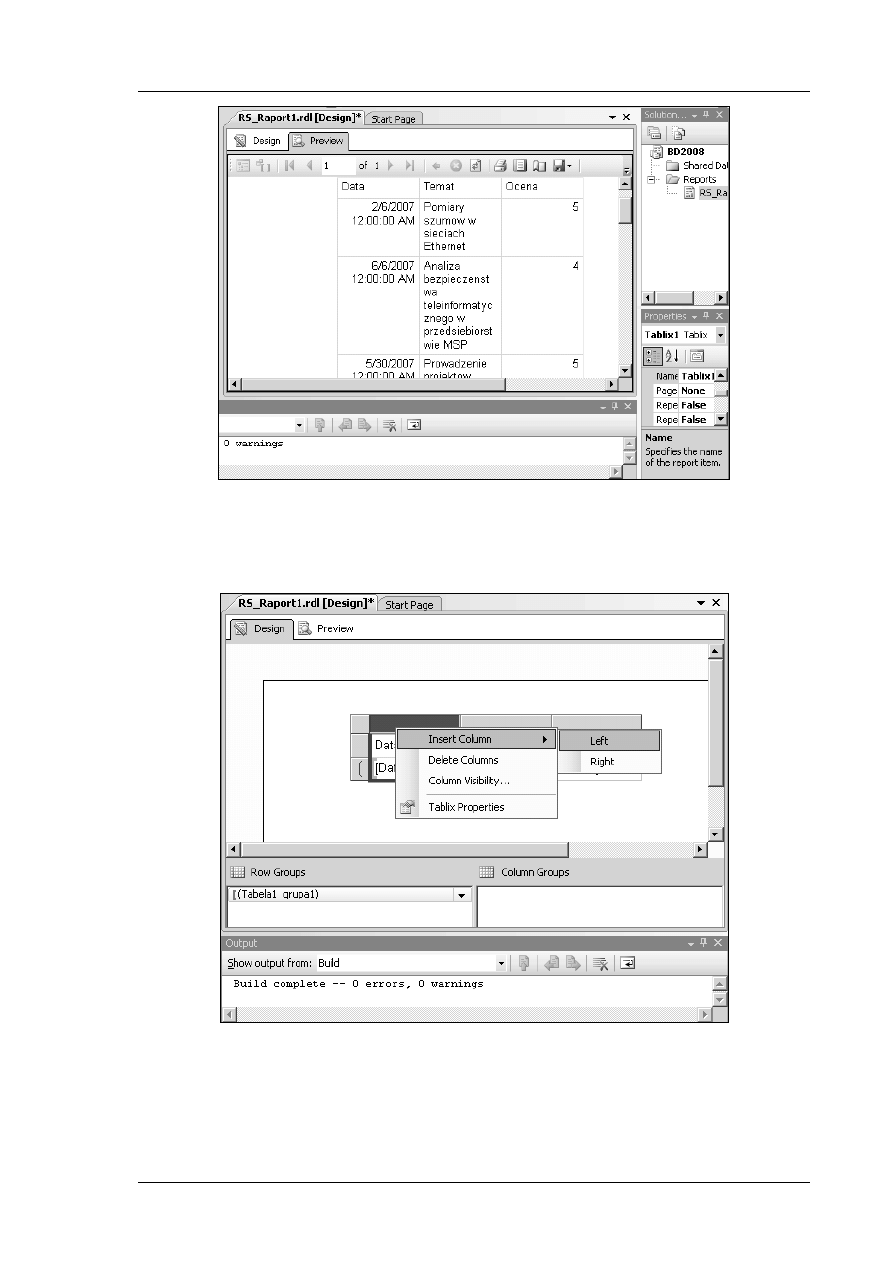
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 8/24
Rys. 6 Podgląd gotowego raportu
Podczas projektowania raportu dodajemy i modyfikujemy kolumny i wiersze z danymi. Rozbudowa
raportu w Business Intelligence Studio jest bardzo intuicyjna i szybka. Na tym etapie projektowanie
można porównać do konstrukcji arkusza danych w arkuszu kalkulacyjnym.
Rys. 7 Dodawanie kolumn do raportu
Każde z dodanych pól reprezentuje grupę danych z bazy. Grupę tą można dowolnie zmieniać
poddawać przekształceniom zaglądając do właściwości danego pola. Rysunek 8 ilustruje
właściwości pola Nazwisko, które odwołuje się do odpowiedniego atrybutu wskazanej tabeli w
bazie danych PraceDyplomowe.
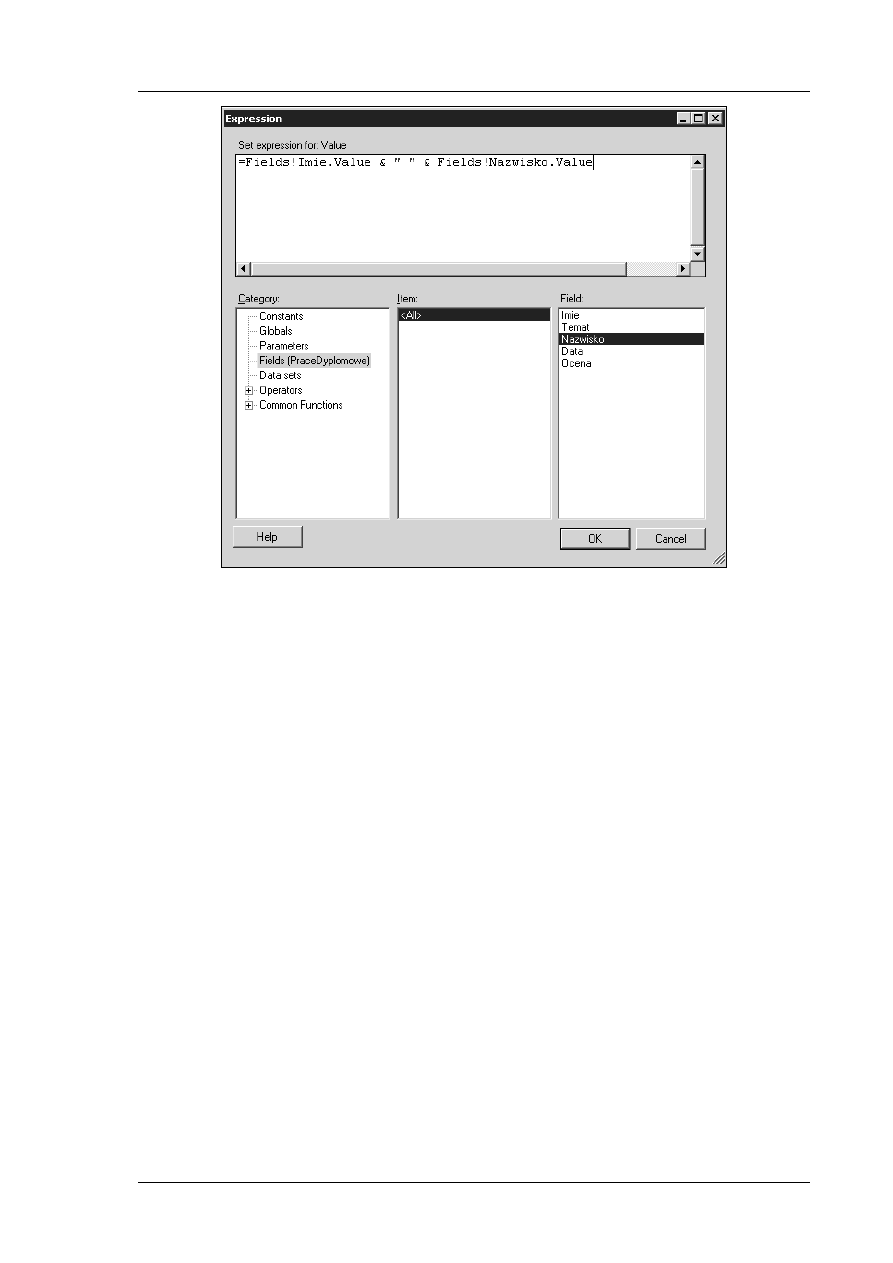
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 9/24
Rys. 8 Ustalanie zawartości nowych kolumn
Właściwości danego pola nie tylko wskazują skojarzone źródło danych ale także pozwalają na
rozbudowaną manipulację tymi danymi. Konwersja, wyliczanie, zmiana wyglądu czy formatu
wyświetlania danych dokonywana jest poprzez wpisanie (lub wybranie z menu kontekstowego)
odpowiedniego wyrażenia w polu Expression. Przykładowo zastosowanie agregacji uśredniającej
dane z powiązanej bazy ilustruje rysunek 9.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 10/24
Rys. 9 Dodanie funkcji agregującej do nowego pola raportu
Zmiana formatu wyświetlania daty także nie jest sprawą skomplikowaną. Odpowiednie wyrażenie
można zbudować poprzez kilka kliknięć myszką.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
Rys.
Po ustaleniu wszystkich pól i ich właściwości nadeszla pora do publik
odbiorców. Publikacja przebiega w dwóch etapach: generowanie finalnej wersji raportu oraz
przesłanie go na wskazany serwer WWW. Serwer stron WWW musi być wcześniej przygotowany (a
z pewnością musimy posiadać na nim odpowiednie u
Adres URL serwera należy podać w
Wygodniej i zapobiegliwej jest jednak
raportującego używając Reporting S
Jak pokazano na rysunku 1
WWW.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 11/24
Rys. 10 Ustalanie formatu wyświetlania daty w polu raportu
Po ustaleniu wszystkich pól i ich właściwości nadeszla pora do publikacji raportu dla właściwych
odbiorców. Publikacja przebiega w dwóch etapach: generowanie finalnej wersji raportu oraz
przesłanie go na wskazany serwer WWW. Serwer stron WWW musi być wcześniej przygotowany (a
z pewnością musimy posiadać na nim odpowiednie uprawnienia do zamieszczania kodu HTML).
Adres URL serwera należy podać w polu TargetServerURL w narzędziu Business Intelligence Studio.
Wygodniej i zapobiegliwej jest jednak dokonać tego wraz z konfiguracją całego serwera
Reporting Services Configuration Manager z grupy SQL Server 2008.
Jak pokazano na rysunku 11 Gotowy raport możemy obejżeć w dowolnej przeglądarce stron
Moduł 12
Instalacja i konfiguracja MS SQL Server 2008
acji raportu dla właściwych
odbiorców. Publikacja przebiega w dwóch etapach: generowanie finalnej wersji raportu oraz
przesłanie go na wskazany serwer WWW. Serwer stron WWW musi być wcześniej przygotowany (a
prawnienia do zamieszczania kodu HTML).
Business Intelligence Studio.
dokonać tego wraz z konfiguracją całego serwera
z grupy SQL Server 2008.
Gotowy raport możemy obejżeć w dowolnej przeglądarce stron

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 12/24
Rys. 11 Podgląd strony WWW z raportem
Porady praktyczne
•
W niektórych systemach usługa raportowania nie jest standardowo zainstalowana z MS SQL
Server. Dodaj tę usługę osobno lub poproś administratora systemu o doinstalowanie.
•
Przed przystąpieniem do pracy z serwerem raportującym upewnij się, że usługa Reporting
Services jest włączona w systemie. Unikniesz dzięki temu długiego szukania przyczyn
odmowy generowania raportu.
•
Dla często generowanych typów raportów stwórz swoją bazę szablonów raportów.
Znajdować się w niej będą raporty obejmujące swoim zakresem najczęstsze zapytania do
bazy. Zawsze będą pod ręką, a ich modyfikacja jest bardzo łatwa.
•
Jeżeli nie potrafisz szybko stworzyć zapytania SQL, posłuż się graficznym narzędziem do
konstrukcji zapytań. Aby go użyć, jako połączenie z serwerem SQL wybierz ODBC.
•
Upewnij się, że posiadasz dostęp do konta uprawnionego do publikacji raportów na serwerze
WWW. Bez tych praw będziesz mógł tylko podejrzeć raporty w narzędziu Bussines
Intelligence Development Studio.
•
Zadbaj o dostępność odpowiednio przygotowanego serwera WWW. Serwer taki powinien
być dostępny z punktu widzenia narzędzia raportującego oraz widoczny dla Twoich
odbiorców raportów.
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz, co oznacza budowa raportu typu ad-hoc
•
rozumiesz zasadę działania generowania raportu na serwerze WWW
•
umiesz zdefiniować rolę języka RDL
•
umiesz podać przykład serwisów, z którymi Reporting Server dobrze się integruje.
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 13/24
Dodatkowe źródła informacji
1.
Stacia Misner, Hitachi Consulting, Microsoft SQL Server 2005 Reporting Services krok po kroku,
Microsoft Press, 2006
2.
William R. Stanek, Vademecum Administratora Microsoft SQL Server 2005, Microsoft Press,
2006
3.
Sikha Saha Bagui, Richard Walsh Earp, Business SQL dla SQL Server 2005. Wprowadzenie,
O’Reilly, 2007
4.
http://www.wss.pl
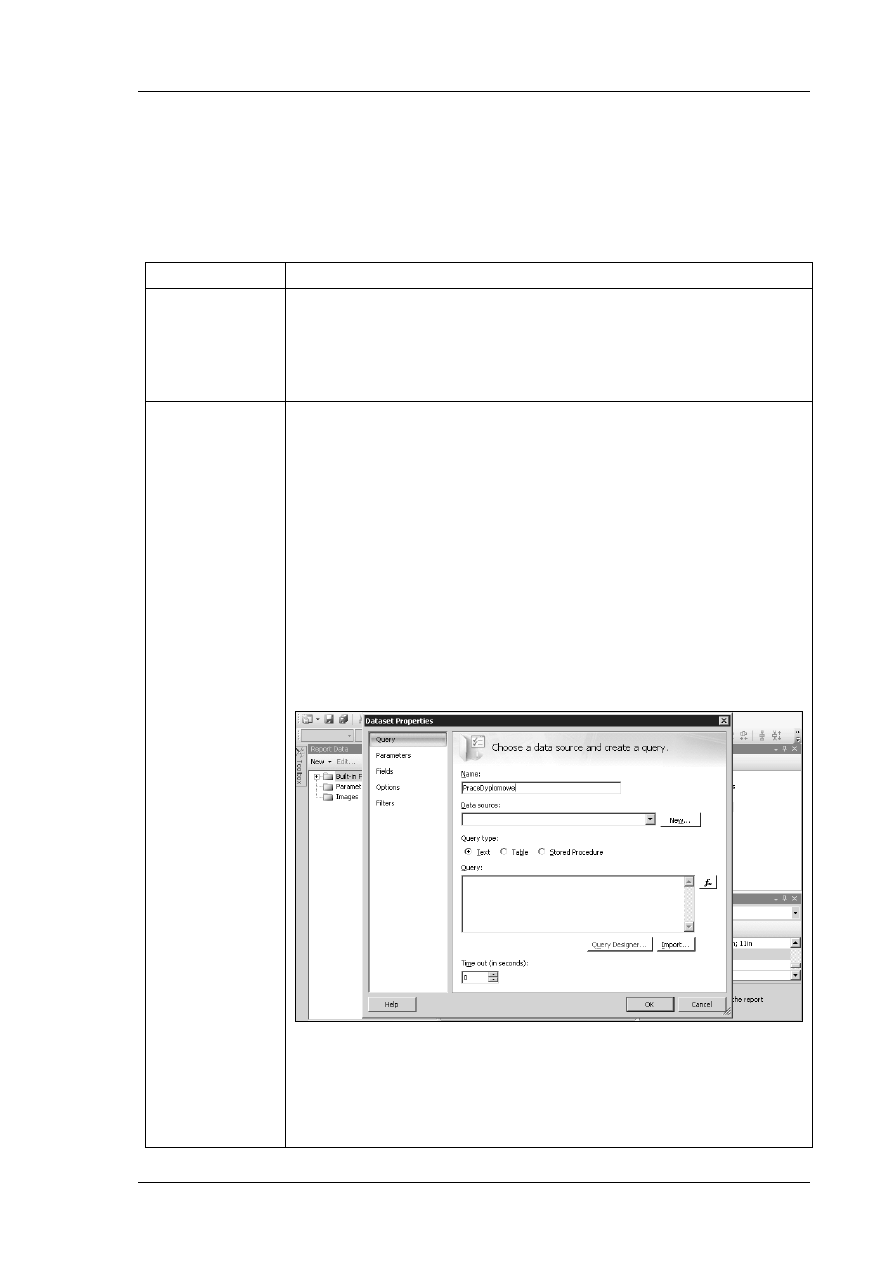
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 14/24
Laboratorium podstawowe
Problem 1 (czas realizacji 45 min)
Administrator systemu bazodanowego nadał ci odpowiednie prawa do testowego serwera
bazodanowego o nazwie Evaluation. Wskazał też bazę danych PraceDyplomowe jako źródło
danych, które zazwyczaj wykorzystuje do eksperymentów. Postanowiłeś użyć Reporting Services do
wydobycia i prezentacji danych z bazy PraceDyplomowe.
Zadanie
Tok postępowania
1.
Nawiązywanie
połączenia z SQL
Server 2008
•
Zaloguj się do maszyny wirtualnej BD jako użytkownik Administrator z
hasłem P@ssw0rd.
•
Kliknij Start. Z grupy programów Microsoft SQL Server 2008 uruchom
SQL Server Management Studio.
•
W oknie logowania kliknij Connect.
2.
Tworzenie
nowego raportu
•
Kliknij Start. Z grupy programów Microsoft SQL Server 2008 uruchom
SQL Server Business Intelligence Development Studio.
•
Z menu wybierz File -> New -> Project.
•
W oknie New Project wybierz Report Server Project.
•
Wprowadź w polu Name nazwę projektu BD2008.
•
Kliknij przycisk OK.
•
W oknie Solution Explorer kliknij prawym klawiszem myszy na Reports -
> Add -> New item.
•
W oknie Add new item wybierz Report, a następnie wprowadź nazwę
raportu: RS_Raport1.rdl.
•
kliknij Add.
•
Następnie należy utworzyć połączenie z bazą. W oknie Report Data
wybierz z menu New -> Dataset.
•
W oknie Dataset Properties w polu Name wpisz PraceDyplomowe,
Rys. 12 Tworzenie nowego zbioru danych dla raportu
•
kliknij przycisk New.
•
W oknie Data Source Properties w polu Name wpisz PraceDyplomowe.
•
wybierz Type -> Microsoft SQL Server.
•
kliknij przycisk Edit.
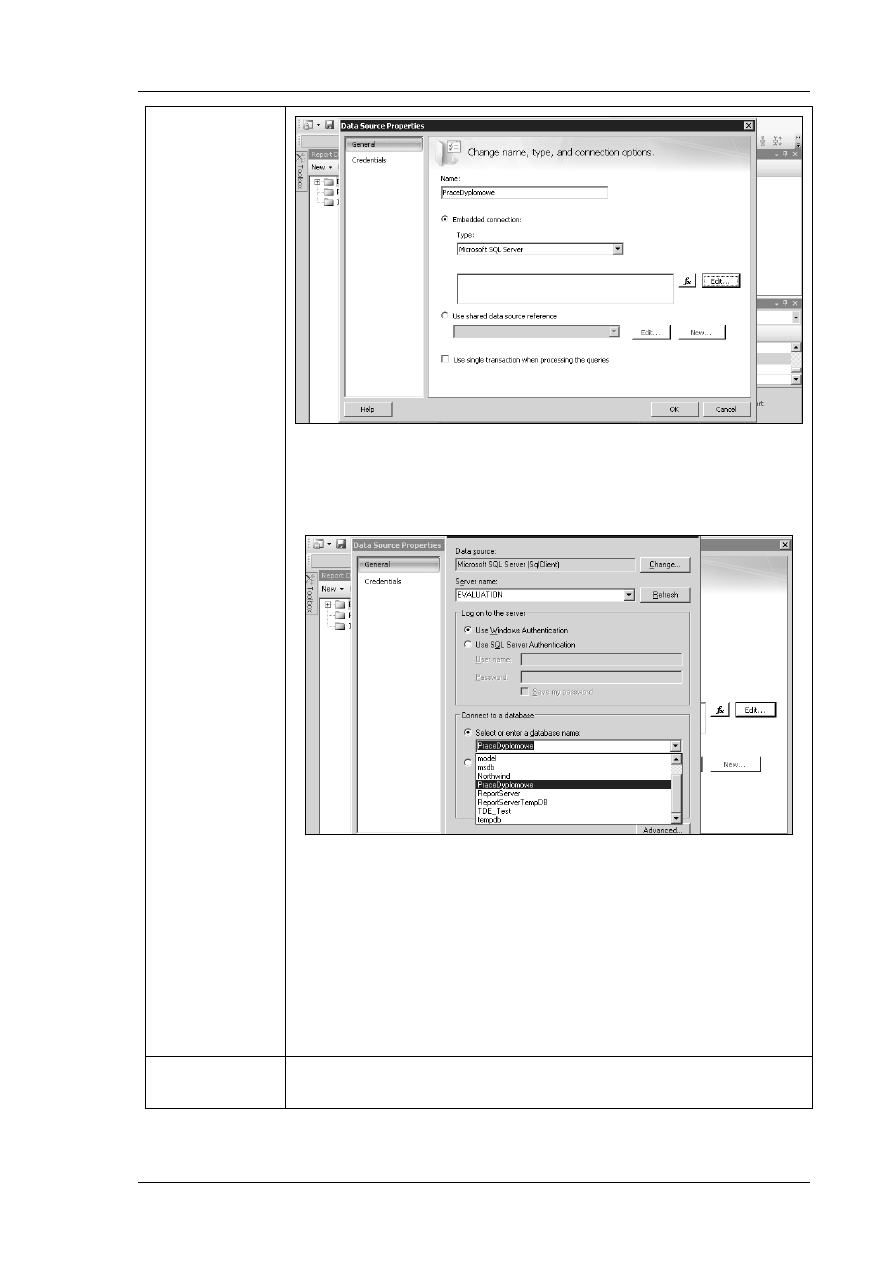
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 15/24
Rys. 13 Wskaznie serwera SQL jako źródła danych
•
W oknie Connection Properties/Server Name wybierz nazwę serwera,
na którym zainstalowana jest baza danych (EVALUATION).
•
W polu Select or enter database name wybierz bazę PraceDyplomowe.
Rys. 14 Wskazanie bazy danych jako źródła danych
•
Zatwierdź klikając przycisk OK, a następnie raz jeszcze OK.
•
W oknie Dataset Properties w polu Query wprowadź zapytanie SQL do
bazy danych:
SELECT Osoba.Imie, PracaDyplomowa.Temat, Osoba.Nazwisko,
PracaDyplomowa.Data, PracaDyplomowa.Ocena
FROM Osoba
INNER JOIN PracaDyplomowa ON Osoba.ID_Osoby =
PracaDyplomowa.ID_Promotor
•
Kliknij przycisk OK.
3.
Projektowanie
raportu
•
Kliknij pole Toolbox.
•
Za pomocą kursora przeciągnij obiekt Table na środek ekranu.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 16/24
Rys. 15 Modelowanie raportu
•
Kliknij zakładkę Report Data.
•
Z okna Report Data przeciągnij pole Data do pierwszej kolumny
stworzonej tabeli.
•
Przeciągnij pole Temat do środkowej kolumny.
•
Przeciągnij pole Ocena do trzeciej kolumny.
Rys. 16 Ustalanie nazw i zawartości kolumn raportu
•
Aby zobaczyć wygenerowany raport, wybierz zakładkę Preview.
4.
Grupowanie
danych
•
Aby dodać grupę do raportu w tabeli, kliknij prawym klawiszem myszy
na szarą obwódkę tabelki na wysokości drugiego wiersza.
•
Z menu wybierz DetailsGroup Group -> Properties.
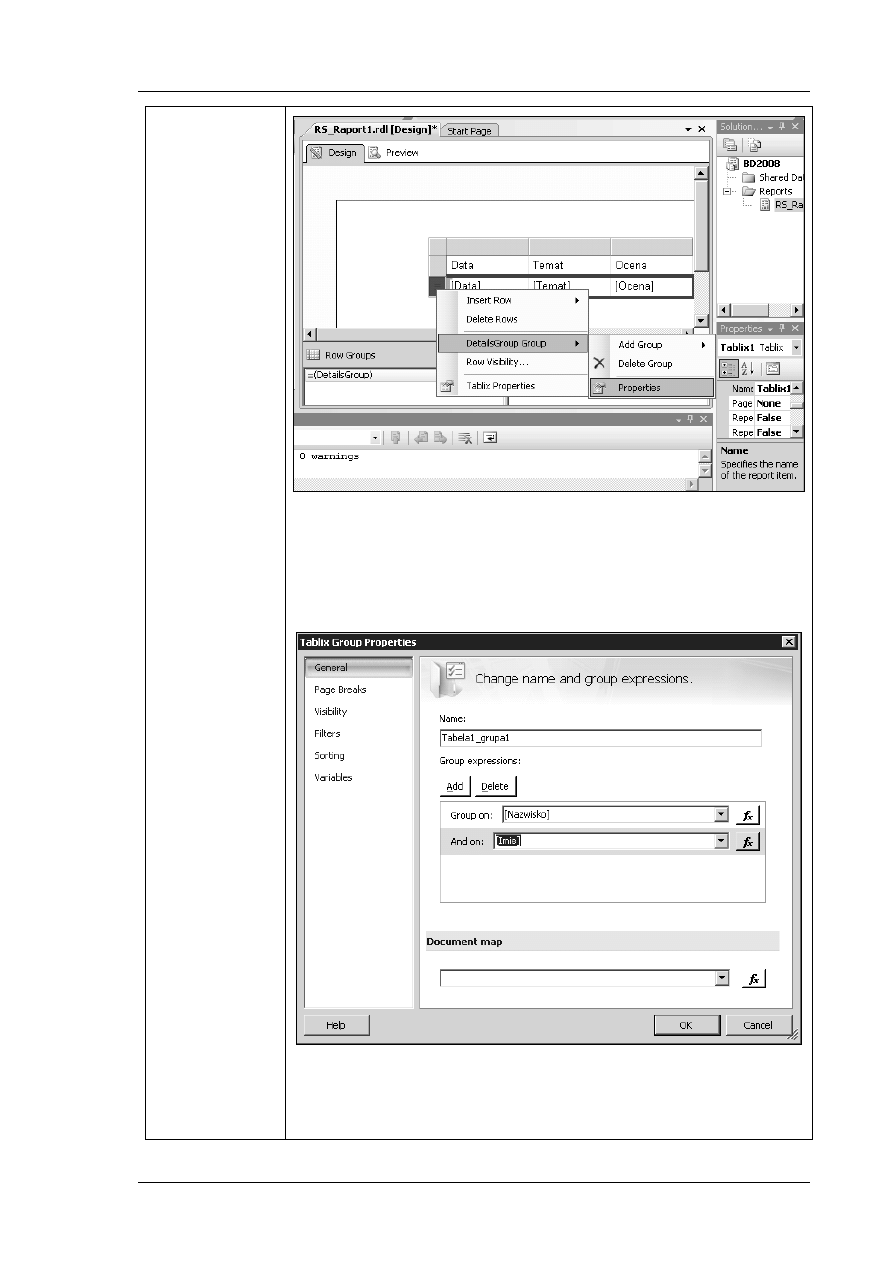
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 17/24
Rys. 17 Tworzenie grup danych
•
W oknie Tablix Group Properties w polu Name wpisz Tabela1_grupa1.
•
następnie kliknij przycisk Add.
•
w polu Group On wybierz opcję [Nazwisko].
•
następnie kliknij przycisk Add.
•
w polu And On wybierz opcję [Imie].
Rys. 18 Wybór danych w obrębie grupy
•
W zakładce Sorting kliknij przycisk Add.
•
następnie w polu Sort By wybierz opcję [LastName], Order A to Z.
•
Kliknij przycisk Add i w polu Then By wybierz opcję [FirstName], Order
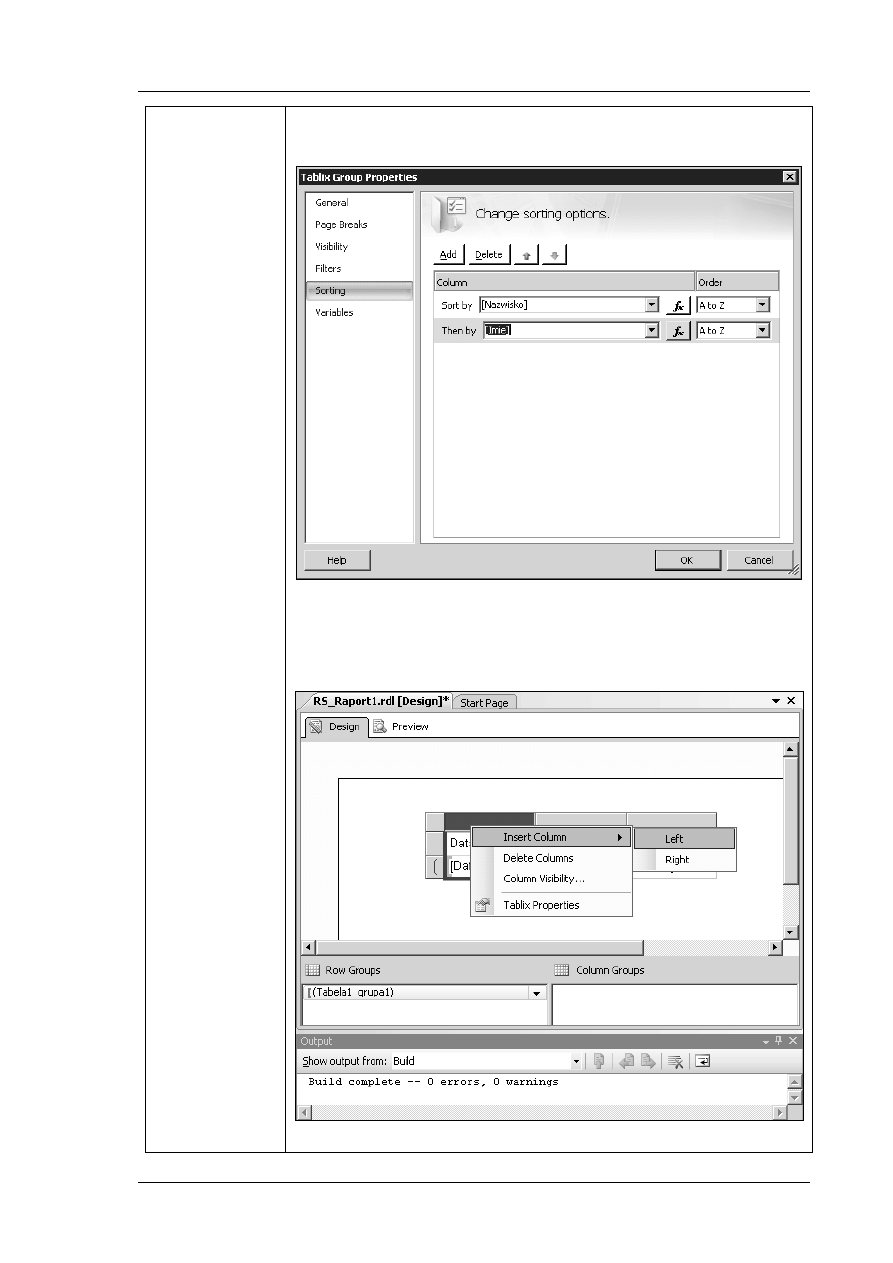
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 18/24
A to Z.
•
Zatwierdzić kliknięciem przycisku OK.
Rys. 19 Wybór danych w obrębie grupy
•
W tym celu należy kliknij prawym przyciskiem myszy na szarą ramkę nad
kolumną OrderDate.
•
z menu wybierz Insert Column -> Left.
Rys. 20 Dodawanie kolumn do raportu
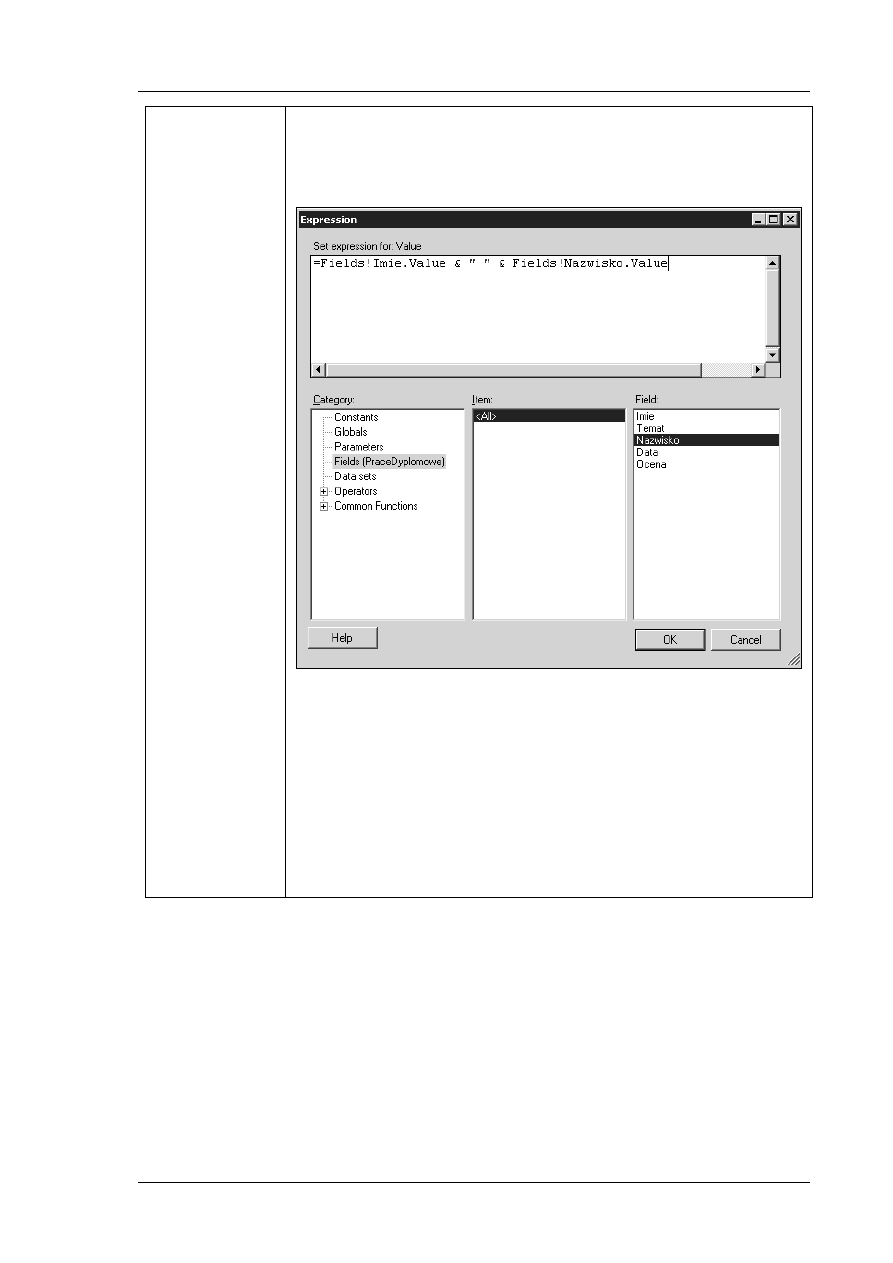
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 19/24
•
W pierwszym wierszu nowej kolumny wpisz nazwę kolumny –
Dyplomant.
•
W drugim wierszu nowej kolumny kliknij prawym przyciskiem myszy i z
menu wybierz Expression.
Rys. 21 Ustalanie zawartości nowych kolumn
•
Zatwierdź kliknięciem przycisku OK.
•
Kliknij przycisk Preview.
•
Kolejnym krokiem będzie pogrupowanie wyników wg nazwiska, a
następnie daty obrony.
•
Kliknij prawym przyciskiem myszy na szarą ramkę wokół tabelki na
wysokości drugiego wiersza.
•
Z menu wybierz Tabla1_groupa1 Group -> Properties.
•
Następnie kliknij w oknie Tablix Group Properties przycisk Add
•
w nowym polu Add On wybierz wartość Order Date.
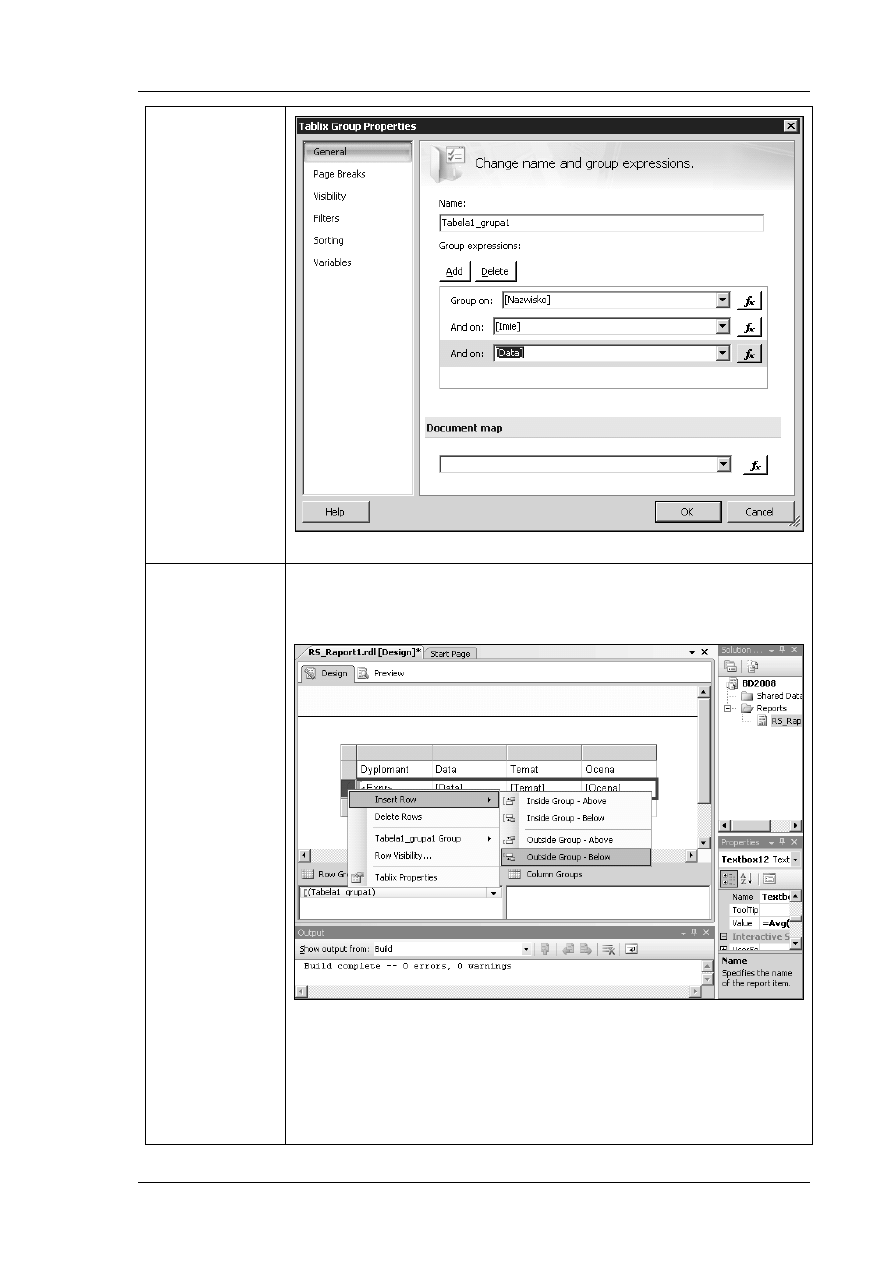
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 20/24
Rys. 22 Pogrupowanie danych w nowej kolumnie
5.
Dodanie
funkcji
agregujących
•
Kliknij prawym klawiszem myszy na szarą obwódkę tabeli na wysokości
drugiego wiersza.
•
Z menu wybierz Insert Row -> Outside Group – Below.
Rys. 23 Dodanie nowego wiersza
•
W ostatniej kolumnie w ostatnim wierszu kliknij prawym klawiszem
myszy i wybierz Expressions.
•
W oknie Expression w kolumnie Category wybierz zakładkę Common
Functions -> Aggregate
•
następnie w polu Item wybierz Avg.
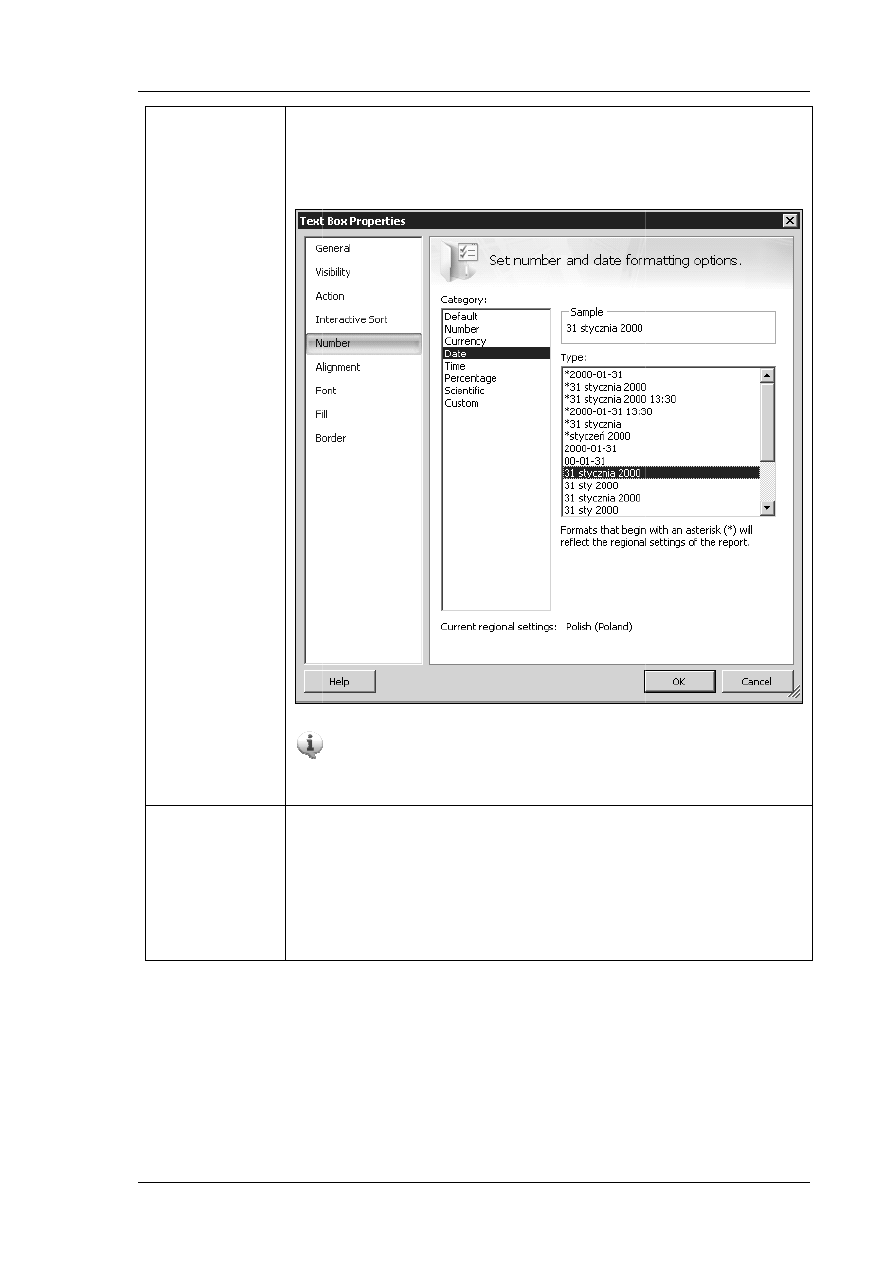
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
6.
Formatowanie
wyświetlanych
danych
•
kliknij prawym klawiszem myszy na komórkę zawierającą formułę daty
•
z menu wybierz
•
W oknie
•
w polu
7.
Publikowanie
gotowego raportu
•
W oknie Solution Explorer kliknij prawym klawiszem myszy na
BD2008
•
W oknie
jest wybrana opcja
•
wybierz przycisk
•
w polu
•
zamknij okno klikając przycisk
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 21/24
kliknij prawym klawiszem myszy na komórkę zawierającą formułę daty
z menu wybierz Textbox Properties.
W oknie Text Box Properties kliknij Number -> Date
w polu Type wybierz dowolny format.
Rys. 24 Ustalanie formatu wyświetlania daty w polu raportu
Analogicznie można przeprowadzić formatowanie pola, na którym
wyświetlana jest ilość pieniędzy (Number -> Currency
pól.
W oknie Solution Explorer kliknij prawym klawiszem myszy na
BD2008 -> Properties.
W oknie BD2008 Property Pages upewnij się, czy w polu
jest wybrana opcja Active Release.
wybierz przycisk Configuration Manager.
w polu Active Solution Configuration wybierz Release
zamknij okno klikając przycisk Close.
Moduł 12
Instalacja i konfiguracja MS SQL Server 2008
kliknij prawym klawiszem myszy na komórkę zawierającą formułę daty
> Date.
Ustalanie formatu wyświetlania daty w polu raportu
Analogicznie można przeprowadzić formatowanie pola, na którym
> Currency), a także innych
W oknie Solution Explorer kliknij prawym klawiszem myszy na
czy w polu Configuration
Release.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA
-
101 Bazy Danych
•
W polu
•
Zatwierdź klikając przycisk
•
Kliknij
•
Jeśli to konieczne
umieszczania raportów na serwerze
•
Jeśli wszystkie czynności zostały wykonane poprawnie
zostanie wyświetlona strona zawierająca raport.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Instalacja i konfiguracja MS SQL Server 2008
Strona 22/24
Rys. 25 Generowanie raportu
W polu TargetServerURL podaj adres URL serwera raportującego
adres URL serwera można znaleźć otwierając Reporting Services
Configuration Manager w zakładce Web Service URL
Zatwierdź klikając przycisk OK.
Kliknij Menu -> Debug -> Start without debugging
Jeśli to konieczne, podaj hasło i login osoby upoważnionej do
umieszczania raportów na serwerze.
Rys. 26 Generowanie raportu
Jeśli wszystkie czynności zostały wykonane poprawnie
zostanie wyświetlona strona zawierająca raport.
Moduł 12
Instalacja i konfiguracja MS SQL Server 2008
serwera raportującego.
adres URL serwera można znaleźć otwierając Reporting Services
Configuration Manager w zakładce Web Service URL.
without debugging
podaj hasło i login osoby upoważnionej do
Jeśli wszystkie czynności zostały wykonane poprawnie, automatycznie

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 23/24
Rys. 27 Podgląd strony serwera WWW z raportami
•
Kliknij na odnośnik do raportu. Raport będzie wygenerowany i
wyświetlony w oknie przeglądarki.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 12
ITA
-
101 Bazy Danych
Instalacja i konfiguracja MS SQL Server 2008
Strona 24/24
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Pierwsze testy nowego narzędzia raportującego wypadły pomyślnie. Dyrektor Działu Marketingu
firmy National Insurance polecił przygotować kilka raportów o stanie sprzedaży kluczowych
produktów. Uzyskałeś dostęp do bazy AdventureWorks, w której przechowywane są informacje
m.in. na temat pracowników, sprzedaży, produktów i kluczowych transakcji. Twoim zadaniem jest
przygotowanie zwięzłych i efektownych raportów zawierających dane z ostatniego miesiąca (lub
kwartału) o:
•
Sprzedanych produktach
•
Sprzedawcach
•
Zawartych transakcjach
•
Wielkości sprzedaży
•
Miejscach największej sprzedaży
•
Producentach najpopularniejszych produktów
Raporty należy opublikować w firmowej sieci intranet na wskazanym (domyślnym) serwerze
WWW. Do utworzenia i publikacji raportu należy użyć narzędzia Reporting Services.

ITA-101 Bazy Danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
Wersja 1.0
Budowa interfejsu
Spis treści
Budowa interfejsu ................................................................................................................................ 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Przykładowe rozwiązanie ............................................................................................................. 5
Porady praktyczne ....................................................................................................................... 8
Uwagi dla studenta ...................................................................................................................... 9
Dodatkowe źródła informacji....................................................................................................... 9
Laboratorium podstawowe ................................................................................................................ 11
Problem 1 (czas realizacji 45 minut) .......................................................................................... 11
Laboratorium rozszerzone ................................................................................................................. 16
Zadanie 1 (czas realizacji 90 min) ............................................................................................... 16
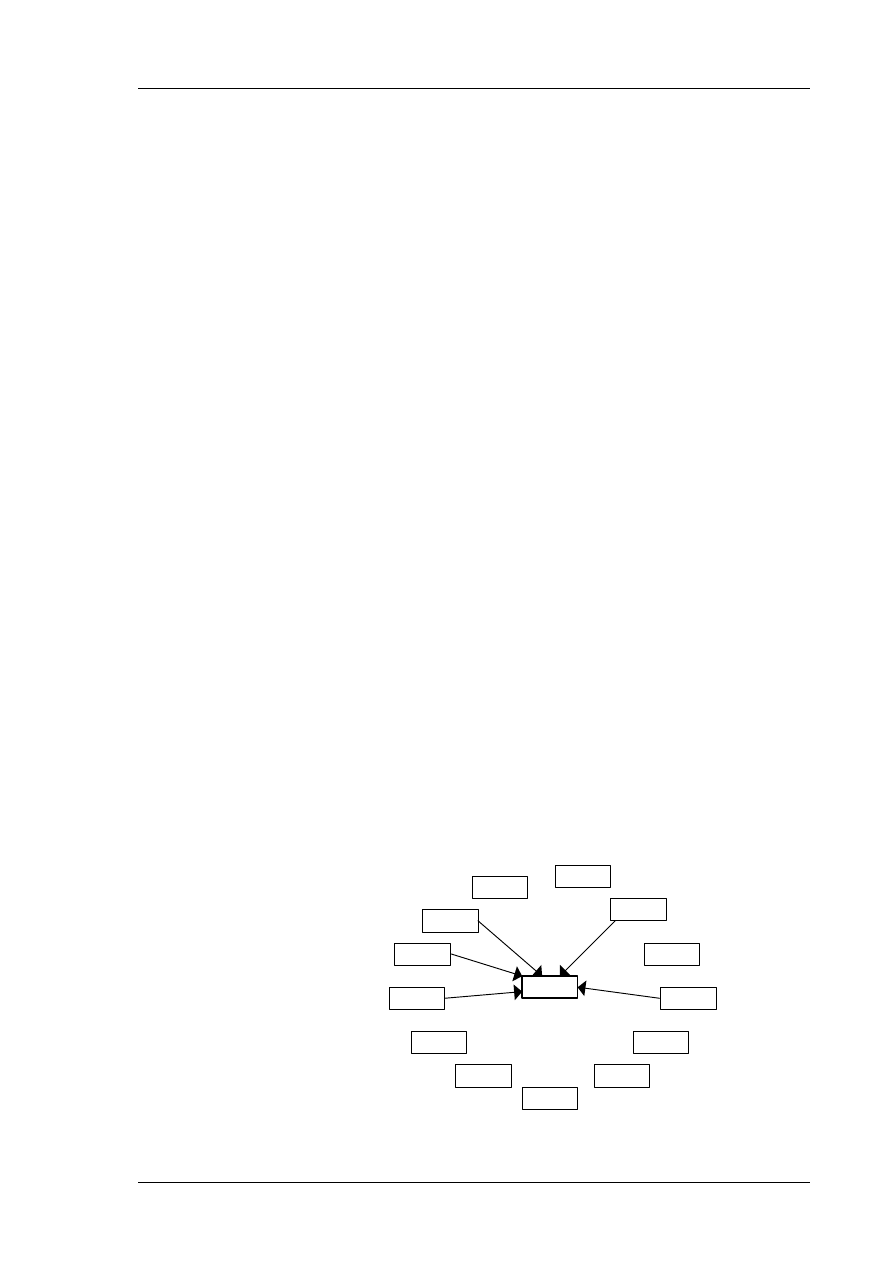
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 2/16
Informacje o module
Opis modułu
W module tym zobaczysz, jak napisać aplikację, która będzie wyciągała
informacje z bazy danych prac dyplomowych. Dowiesz się, jak za pomocą
Visual Studio utworzyć bazę danych, połączyć się z nią i wprowadzić do niej
dane. Następnie zobaczysz, jak stworzyć aplikację Windows, która będzie
korzystała z tych danych.
Cel modułu
Celem modułu jest zapoznanie czytelnika z podstawami programowania w
Visual Studio 2008 w takim stopniu, żeby potrafił samodzielnie stworzyć
aplikację dostępową do danych zgromadzonych w bazie danych.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
potrafił samodzielnie stworzyć prostą aplikację dostępu do danych
•
potrafił stworzyć bazę danych za pomocą Microsoft Visual Studio
2008
•
potrafił nawiązać połączenie z bazą danych Microsoft SQL Server
2008
•
umiał poruszać się po Microsoft Visual Studio 2008
•
wiedział co to jest ADO.NET
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
•
potrafić zaprojektować bazę danych
•
potrafić zaimplementować bazę danych wraz z jej obiektami
•
potrafić tworzyć proste procedury składowane i wyzwalacze
•
potrafić definiować użytkowników i nadawać im uprawnienia
Mapa zależności modułu
Zgodnie z mapą zależności przedstawioną na rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznać się z materiałem zawartym
w modułach 1, 3, 9, 10 i 11.
Moduł 13
Dodatek
Moduł 1
Moduł 2
Moduł 3
Moduł 4
Moduł 5
Moduł 6
Moduł 7
Moduł 8
Moduł 9
Moduł 10
Moduł 11
Moduł 12
Rys. 1 Mapa zależności modułu

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 3/16
Przygotowanie teoretyczne
Przykładowy problem
Ostatnim etapem wytwarzania bazy danych wraz z dostępem do niej z poziomu aplikacji jest
konstrukcja interfejsu użytkownika. Istnieje wiele metod i narzędzi do tworzenia graficznego
interfejsu użytkownika. Począwszy od rozwiązań prostszych, a co za tym idzie przeważnie nie
wykorzystujących dobrodziejstw, jakie daje nam baza danych postawiona na SQL Server 2008, do
rozwiązań profesjonalnych, wykorzystujących możliwości serwera bazodanowego.
Jeżeli baza danych została profesjonalnie zaprojektowana, zaimplementowana i oprogramowana,
to wykorzystując na przykład Microsoft Visual Studio 2008 jesteśmy w stanie w łatwy sposób
stworzyć aplikację dostępową o wysokim poziomie bezpieczeństwa wykorzystując wszystkie
zaawansowane mechanizmy zabezpieczeń dostępne w SQL Server 2008. Aplikacja taka będzie
odporna na typowe zagrożenia typu SQL Injection, gdyż zapytania zostaną ukryte w procedurach
składowanych, a zatem haker będzie widział jedynie, że po sieci przesyłane są pewne funkcje wraz z
parametrami. Należy podkreślić fakt, iż w celu stworzenia bezpiecznej bazy danych i aplikacji
dostępowej wymagana jest ciągła współpraca różnych członków zespołu projektowego, począwszy
od projektanta, administratora i programisty bazy danych, poprzez projektanta interfejsu
użytkownika, a skończywszy na projektancie i programiście aplikacji dostępowej.
Podstawy teoretyczne
Rzadko wprowadza się dane do bazy za pomocą SQL Server 2008 za pomocą SQL Server
Management Studio. Zwykle daje się możliwość wprowadzania danych użytkownikom za pomocą
aplikacji dostępowej do bazy danych. Dane można również importować z różnych źródeł
zewnętrznych lub tworzyć je za pomocą skryptów SQL, co zostało przedstawione we wcześniejszych
modułach.
W dalszej części skoncentrujmy się na tworzeniu aplikacji Windows, która komunikuje się z SQL
Server 2008 korzystając z ADO.NET.
Co to jest ADO.NET
ADO.NET zapewnia jednolity dostęp zarówno do źródeł danych, takich jak na przykład SQL Server
2008, jak również źródeł danych publikowanych za pomocą OLE DB lub XML. Należy zauważyć, iż
aplikacje, które współdzielą dostęp do danych, mogą korzystać właśnie z ADO.NET w celu łączenia
się ze źródłami, pobierania danych oraz manipulowania nimi.
Siłą ADO.NET jest wyraźne rozdzielenie dostępu do danych od manipulowania danymi na
niezależnie odseparowane składniki. Składniki te mogą być wykorzystywane razem lub osobno.
ADO.NET wykorzystuje tzw. dostawców danych, za pomocą których można tworzyć połączenia z
bazami danych, wykonywać polecenia i odbierać wyniki. Wyniki te mogą po pierwsze być
przetwarzane bezpośrednio, a po drugie mogą trafiać do zbioru danych, tzw. obiektów DataSet.
W takiej sytuacji dane są udostępniane użytkownikom w dowolny sposób. Warto wspomnieć, że
obiekty DataSet można wykorzystywać niezależnie od dostawców ADO.NET do lokalnego
zarządzania danymi oraz w aplikacjach wczytujących dane w formacie XML.
Klasa ADO.NET znajduje się w podzespole System.Data.dll i jest zintegrowana z klasami XML
znajdującymi się w podzespole System.Xml.dll. W momencie kompilacji kodu odwołującego się do
przestrzeni nazw
System.Data
należy wskazać zarówno System.Data.dll, jak również
System.Xml.dll.
ADO.NET zapewnia programistom tworzącym aplikacje w środowisku .NET Framework sposób
dostępu do danych oraz coś bardzo ważnego – możliwość programowego manipulowania nimi.
Manipulacja oczywiście może odbywać się również na innych źródłach danych, na przykład na
źródle XML.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 4/16
Dostęp do danych z użyciem ADO.NET
Tworząc aplikacje korzystające z ADO.NET można spotkać się z różnymi wymaganiami dotyczącymi
pracy z danymi. W pewnych sytuacjach wystarczy wyświetlenie danych w formularzu, innych razem
trzeba opracować na przykład sposób wymiany informacji z inną firmą.
Niezależnie od tego, co zamierzamy robić z danymi, warto poznać kilka podstawowych zasad
dotyczących obsługi danych w ADO.NET. Być może nigdy nie będziemy musieli znać szczegółów
obsługi danych, natomiast kluczową sprawą jest zrozumienie architektury danych w ADO.NET,
poznanie podstawowych komponentów oraz sposobu ich współpracy.
ADO.NET a uwierzytelnianie otwartego połączenia z bazą danych
W tradycyjnych aplikacjach typu klient/serwer komponenty ustanawiały połączenie z bazą danych i
utrzymywały to połączenie przez cały czas działania aplikacji. Z kilku względów metoda ta nie jest
zbyt praktyczna:
•
Otwarte połączenie z bazą danych zajmuje wiele zasobów systemowych, które mogłyby
zostać wykorzystane do innych celów. W wyniku utrzymywania stałego połączenia z bazą
danych zmniejsza się liczba równocześnie utrzymywanych połączeń. Obciążenie
spowodowane utrzymywaniem otwartych połączeń zmniejsza ogólną wydajność aplikacji.
•
Bardzo trudne jest skalowanie aplikacji, która wymaga otwartego połączenia z bazą danych.
Należy pamiętać o tym, że aplikacja, która nie jest w pełni skalowalna, może na przykład
dobrze działać z czterema użytkownikami, ale w żaden sposób nie poradzi sobie z setką
równoczesnych użytkowników. Wymóg łatwej skalowalności dotyczy szczególnie aplikacji
internetowych, gdyż obciążenie witryny internetowej może w bardzo niewielkim czasie
zwiększyć się nawet o kilka rzędów wielkości.
•
W aplikacjach internetowych komponenty nie są ze sobą połączone. W momencie kiedy
serwer zakończy przetwarzanie i transmisję dokumentu w odpowiedzi na żądanie
przeglądarki, pomiędzy serwerem a przeglądarką nie jest utrzymywane żadne połączenie.
Połączenie jest wznawiane w chwili kolejnego żądania, a zatem utrzymywanie otwartego
połączenia z bazą w żaden sposób się nie opłaca, ponieważ nie jesteśmy w stanie
przewidzieć, czy klient będzie jeszcze potrzebował dostępu do danych.
•
Model, którego działanie oparte jest na utrzymywaniu otwartych połączeń ze źródłami
danych może przyczynić się do tego, że wymiana danych będzie skomplikowana i
niepraktyczna. Jeśli dwa komponenty muszą mieć dostęp do tych samych danych, obydwa
muszą utrzymywać połączenie ze źródłem danych lub musi być dostępny jakiś inny sposób
przekazywania danych.
Między innymi z wyżej wymienionych powodów dostęp do danych w ADO.NET został
zaprojektowany w taki sposób, aby przede wszystkim oszczędnie korzystać z połączeń. A zatem
aplikacje utrzymują połączenie z bazą danych tylko na czas odczytywania lub zapisywania danych.
Ponieważ bazy danych nie muszą utrzymywać nieaktywnych połączeń, mogą obsłużyć znacznie
więcej użytkowników.
Współpraca z bazami danych za pomocą obiektów Command
Jednym z najpowszechniejszych zadań dostępu do danych jest odczytanie danych z bazy, a
następnie wykonanie na nich jakichś operacji. W czasach wielkiej liczby informacji bardzo często
dochodzi do sytuacji, że aplikacja musi przetworzyć nie jeden rekord, lecz ich cały zbiór. W wielu
przypadkach przetwarzane dane pochodzą nie z jednej, lecz z wielu tabel.
Rekordy, które czytane są przez aplikację, traktowane są jako grupa. Na przykład aplikacja może
zezwolić użytkownikowi na przejrzenie listy wszystkich autorów o nazwisku Kowalski, a następnie
sprawdzić wszystkie książki napisane przez jednego Kowalskiego, potem przez kolejnego
Kowalskiego i tak dalej.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 5/16
Takie każdorazowe odwoływanie się do bazy danych, gdy aplikacja potrzebuje kolejnego rekordu
do przetworzania jest niepraktyczne. W myśl tego, co zostało powiedziane wcześniej, takie
podejście może zniwelować zalety płynące z utrzymywania małej liczby jednocześnie otwartych
połączeń. Pewnym rozwiązaniem jest tymczasowe przechowywanie odczytanych z bazy rekordów i
praca na takim tymczasowym zbiorze.
Na tym właśnie polega idea obiektu DataSet. DataSet jest swego rodzaju buforem, w którym
znajdują się przechowywane rekordy pobrane z bazy danych. Obiekt ten działa podobnie do
wirtualnej składnicy danych, a zatem zawiera jedną lub więcej tabel. Tabele te są fragmentami
tabel rzeczywistej bazy danych. Ponadto obiekt DataSet posiada informacje o relacjach pomiędzy
tymi tabelami oraz o ograniczeniach wartości danych, jakie mogą się znaleźć w tych tabelach.
Należy pamiętać, że dane przechowywane w DataSet nie są pełnym odzwierciedleniem fizycznej
tabeli. Są one niewielkim podzbiorem danych przechowywanych w bazie. Zaletą jednak jest to, że
można z nimi pracować w sposób podobny do pracy z danymi z rzeczywistej bazy danych.
Czasem zdarza się że aplikacja musi zapisać dane do bazy. Dane te można przetwarzać wewnątrz
obiektu DataSet, a następnie przesłać je do podstawowej bazy danych.
Dane przechowywane w formacie XML
Wszystkie dane są przesyłane ze składnicy danych do DataSet, a następnie z DataSet do innych
komponentów. ADO.NET do przesyłania danych wykorzystuje format XML. Pliki XML mogą być
używane jak każde inne źródło danych. Ich zawartość można łatwo wczytać do obiektu DataSet.
XML jest podstawowym formatem danych w ADO.NET. API w ADO.NET automatycznie tworzą pliki
lub strumienie XML (na podstawie DataSet) i wysyłają je do innego komponentu. Następnie
komponent taki może wywołać inne API, by ponownie wczytać XML do obiektu DataSet.
Oparcie protokołów wymiany danych na XML przynosi wiele korzyści:
•
XML jest standardem przemysłowym, a zatem komponenty obsługi danych w jednej aplikacji
mogą wymieniać dane z komponentami w innej aplikacji. Warunkiem jest obsługa przez
aplikację formatu XML.
•
XML jest formatem tekstowym. Danych w postaci XML nie zawiera informacji binarnych, a
zatem można je przesyłać za pomocą dowolnego protokołu – na przykład HTTP.
Przykładowe rozwiązanie
Tworzenie bazy danych z poziomu Microsoft Visual Studio 2008
Bazę danych, do której będziemy tworzyli aplikacje dostępową, można stworzyć na dwa sposoby.
Sposób pierwszy polega na definiowaniu bazy danych wraz z jej obiektami z poziomu SQL Server
2008. Sposób ten poznałeś w poprzednich modułach. Sposób drugi polega na stworzeniu bazy
danych z poziomu Microsoft Visual Studio 2008.
Definicja bazy danych Dziekanat
Aby stworzyć bazę danych w Visual Studio 2008, w pierwszym kroku uruchamiamy środowisko.
Następnie w oknie Database Explorer klikamy prawym przyciskiem myszy Data Connections i
wybieramy Add Connection, co pokazano na rys. 2.
W obrębie okna definicji połączenia z bazą danych możemy ustawić źródło danych oraz wskazać
istniejący lub stworzyć nowy plik bazy danych. W kolejnym etapie określamy sposób autoryzacji.
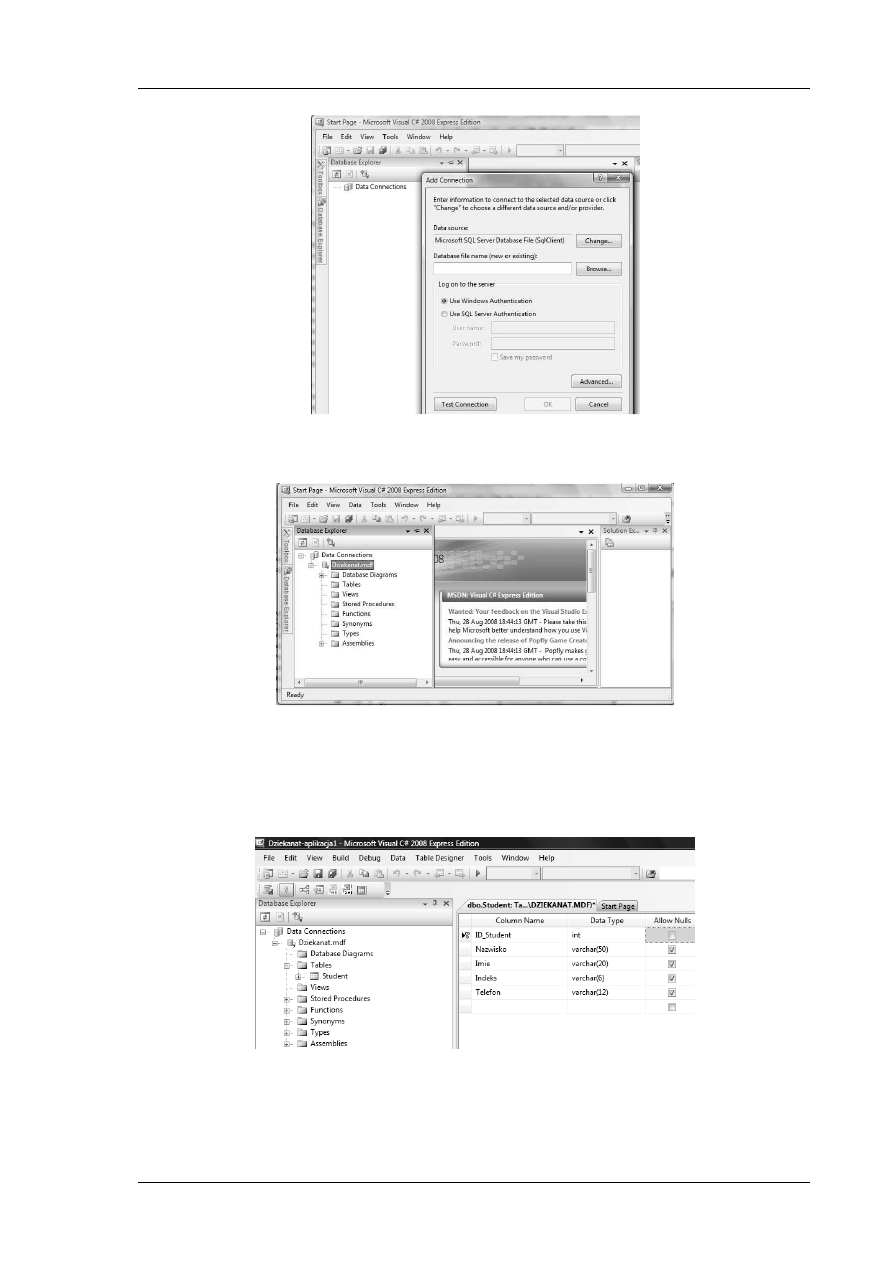
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 6/16
Rys. 2 Okno definicji połączenia z bazą danych
Stwórzmy testową bazę danych Dziekanat. Wynik pokazano na rys. 3.
Rys. 3 Testowa baza danych dziekanat
Definicja tabeli, diagramu, widoku
W kolejnym kroku należy zdefiniować podstawowe obiekty bazy danych – tabele i widoki. W tym
celu klikamy prawym przyciskiem myszy katalog Tables i wybieramy Add New Table. Tworzenie
przykładowej tabeli Student pokazano na rys. 4.
Rys. 4 Przykładowa tabela Student
W analogiczny sposób definiujemy pozostałe tabele w bazie danych. Następnie wypełniamy ją
przykładowymi danymi. Ostatnim krokiem jest stworzenie przykładowego widoku. W tym celu
klikamy prawym przyciskiem myszy zakładkę Views i wybieramy Add New View. Następnie w oknie
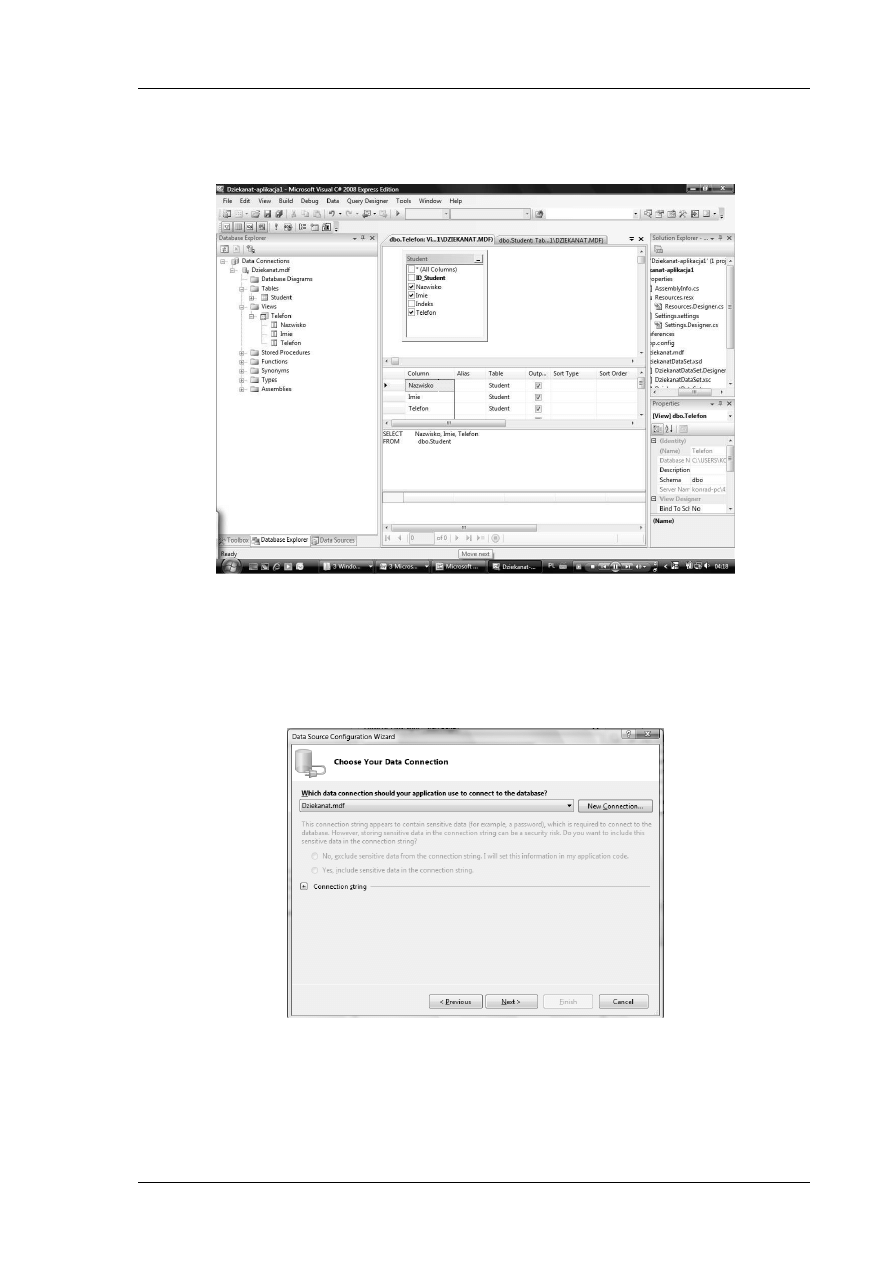
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 7/16
Add Table wybieramy tabele, których będziemy używali w definiowanym widoku. Kolejny krok to
wybór kolumn, które mają zostać użyte w definicji widoku. Na rys. 5 pokazano przykładowy widok
na przedmioty, na które zapisani są studenci.
Rys. 5 Definicja widoku na przedmioty, na które zapisani są studenci
Tworzenie zestawu danych w Microsoft Visual Studio 2008
Stwórzmy aplikację dostępową do zarządzania bazą danych przygotowaną w poprzednich krokach.
Aby utworzyć obiekt DataSet, w pasku Data Sources klikamy odsyłacz Add New Data Sources.
Pierwszy ekran konfiguracji źródła danych umożliwia wybór typu źródła danych, które chcemy
połączyć. Wybieramy Dziekanat.mdf, co pokazano na rys. 6.
Rys. 6 Wybór źródła danych
Następnie wybieramy wszystkie obiekty z bazy danych, które mają zostać uwzględnione w obiekcie
DataSet – zatem wybieramy wszystkie tabele i widok. W wyniku powyższych operacji projekt
powinien wyglądać mniej więcej tak, jak na rys. 7.
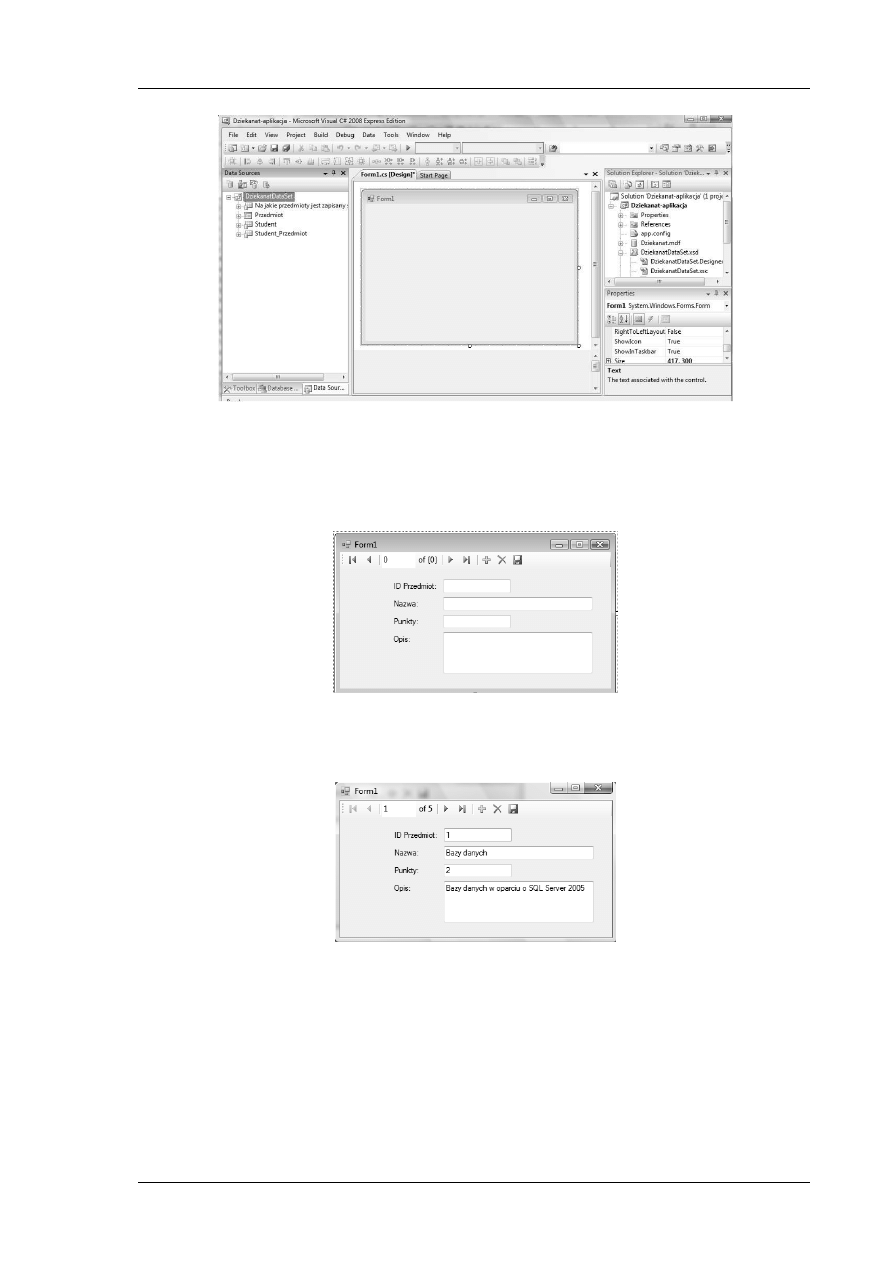
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 8/16
Rys. 7 Projekt aplikacji Dziekanat
Następnie w panelu Data Sources wybieramy węzeł Przedmiot i klikamy wskazującą w dół strzałkę,
rozwijając listę. Wybieramy prezentację danych jako widok siatki danych. Spowoduje to pobranie
do formularza wszystkich pól z obiektu DataSet w wielu wierszach w postaci siatki komórek, co
pokazano na rys. 8.
Rys. 8 Stworzony formularz
W celu uruchomienia aplikacji należy wybrać przycisk F5. Wynik skompilowanej aplikacji
przedstawia rys. 9.
Rys. 9 Wynik działania aplikacji
Porady praktyczne
•
Jeśli korzystamy z obiektów SqlCommand z właściwością CommandType ustawioną na Text i
przy ich pomocy przekazujemy do bazy danych informacje otrzymane od klienta, informacje
te należy zawsze poddać procesowi walidacji. Niektórzy użytkownicy mogą próbować wysłać
zmodyfikowane lub dodatkowe polecenia SQL w celu zdobycia dostępu do danych lub
uszkodzenia bazy danych. Z tego względu bardzo ważne jest, żeby zawsze przed
przekazaniem do bazy wprowadzonych przez użytkownika danych przeprowadzić proces

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 9/16
walidacji, czy dane te są poprawne. Najlepszą praktyką jest stosowanie procedur
składowanych.
•
Należy pamiętać, że DataSet jest tylko kontenerem przechowującym dane. Aby odczytać i
zapisać dane z bazy należy użyć obiektu DataAdapter. DataAdapter zawiera jeden lub
więcej obiektów SqlCommand używanych do wypełnienia pojedynczej tabeli obiektu
DataSet. Obiekt ten zawiera cztery obiekty SqlCommand (do pobierania, dopisywania,
uaktualniania i usuwania rekordów).
•
Konfiguracja aplikacji jest przechowywana w pliku XML o takiej samej nazwie jak plik
wykonywalny .exe.
•
W wyniku skonfigurowania obiektu DataSet został utworzony plik .xsd, czyli dokument
schematu XML definiujący wewnętrzna strukturę zestawu danych. Pamiętaj, że zestaw
danych jest przechowywany w pamięci reprezentującej jedną lub wiele tabel z bazy danych.
ADO.NET będzie korzystał z pliku schematu przy współpracy z aplikacją.
•
Przeważnie w projektach mamy jedna bazę danych, ale nie jest niczym niezwykłym potrzeba
komunikowania się z dwiema lub więcej bazami danych. Z tego powodu połączenia z bazami
danych ułożone są w drzewiastej strukturze, w której każda baza danych jest
reprezentowana przez osobny węzeł.
•
Dopóki nie zapiszemy projektu, znajduje się on w tymczasowym folderze. Po zapisaniu
wszystkich plików projektu baza danych zostanie zapisana razem z innymi plikami projektu.
•
Nie wszystkie kontrolki Windows można podłączyć do źródeł danych. Te, które można,
posiadają właściwości DataBindings.
•
Po przeciągnięciu zestawu danych ponad obszar projektowania, do znajdującego się niżej
szarego panelu są dodawane nowe pozycje. Dolna część obszaru projektowania nazywamy
panelem komponentów. Visual Studio umieszcza w nim kontrolki, które nie posiadają
graficznej reprezentacji.
•
W Visual Studio istnieje możliwość zastosowania metody „Smart Defaults”. Polega ona na
sprawdzeniu, czy tabela z zestawu danych oprócz ID lub klucza głównego zawiera jakąś
kolumnę typu tekstowego. Jeżeli tak, to kolumna ta jest podłączana do kontrolki.
•
Gdy zajrzysz do panelu Properties obiektu tabeli, zobaczysz że w Visual Studio automatycznie
są generowane cztery typy instrukcji: SELECT, INSERT, DELETE oraz UPDATE. Są to
instrukcje, które umożliwiają przygotowanie w pełni działającej aplikacji bez pisania kodu
źródłowego
Uwagi dla studenta
Jesteś przygotowany do realizacji laboratorium jeśli:
•
rozumiesz co to jest ADO.NET
•
rozumiesz na czym polega dostęp do danych poprzez ADO.NET
•
potrafisz stworzyć prosta bazę danych korzystając z Visual Studio 2008
•
potrafisz stworzyć prosty formularz obiektu typu tabela
Pamiętaj o zapoznaniu się z uwagami i poradami zawartymi w tym module. Upewnij się, że
rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze zrozumieniem tematu zawartego
w uwagach, przeczytaj ponownie informacje z tego rozdziału i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Patrice Pelland, Projektuj sam. Microsoft Visual C# 2008, APN Promise,
W książce autor w prosty i przejrzysty sposób prezentuje, jak należy poruszać się po
Microsoft Visual Studio 2008, jak tworzyć proste projekty. Pozycja szczególnie
polecana dla osób początkujących.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 10/16
2.
Kalen Delaney, Microsoft SQL Server 2005: Rozwiązania praktyczne krok po kroku, Microsoft
Press, 2006
W książce autor w przystępny i zrozumiały sposób przedstawia podstawowe
mechanizmy związane z bezpieczeństwem bazy danych przy założeniu dostępu do
niej poprzez aplikację kliencką pisaną w Microsoft Visual Studio. Pozycja polecana
zarówno dla osób początkujących, jak i pragnących poszerzyć swoją wiedzę z tej
tematyki.
3.
Nick Randolph, David Gardner, Professional Visual Studio 2008, Wrox, 2008
W książce autor w prosty i przejrzysty sposób omawia zaawansowane mechanizmy
dostępne w Microsoft Visual Studio 2008. Prezentuje, jak należy poruszać się w tym
środowisku oraz jak tworzyć proste i zaawansowane projekty. W książce znajdziesz
rozszerzony
opis
ADO.NET.
Pozycja
szczególnie
polecana
dla
osób
zaawansowanych, chcących poszerzyć swoją wiedzę z zakresu programowania
aplikacji klienckich.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 11/16
Laboratorium podstawowe
Problem 1 (czas realizacji 45 minut)
Jesteś administratorem w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma planuje rozszerzenie systemu prac dyplomowych, którym zarządza na Twoim wydziale,
dodając nową funkcjonalność związaną z wyszukiwaniem informacji o tym, na jakie przedmioty
chodzili studenci podczas pięciu lat studiów. Zadanie, jakie przed Tobą stoi, to zmodyfikowanie
struktury fizycznej bazy danych oraz stworzenie modułu aplikacyjnego.
Zadanie
Tok postępowania
1.
Utwórz
projekt
•
Uruchom Microsoft Visual Studio 2008, wybierając Start -> Programy ->
Microsoft Visual C# 2008.
•
Z menu głównego wybierz File -> New Project -> Windows Form
Application.
•
Nadaj nazwę dla projektu Dziekanat-aplikacja.
2.
Utwórz bazę
danych
•
W obrębie okna Database Explorer wybieramy Data Connections.
•
Kliknij prawym przyciskiem myszy Data Connections i wybierz Add
Connection.
•
W polu Data Sources ustaw Microsoft SQL Server database File
(SqlClient).
•
W polu Database file name (new or existing) wpisz nazwę bazy danych
Dziekanat.
Rys. 10 Definicja połączenia do bazy danych
3.
Zdefiniuj
tabele
•
W panelu Database Explorer prawym przyciskiem myszy kliknij ikonę
folderu Tables i wybierz Add New Table.
•
Zdefiniuj kolumny nowej tabeli jak na rys. 11 i zapisz ją pod nazwą
Student.
Rys. 11 Definicja tabeli Student
•
Dodaj kolejną tabelę, zdefiniuj jej kolumny jak na rys. 12 i zapisz ją pod

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 12/16
nazwą Przedmiot.
Rys. 12 Definicja tabeli Przedmiot
•
Dodaj kolejną tabelę, zdefiniuj jej kolumny jak na rys. 13 i zapisz ją pod
nazwą Student_Przedmiot.
Rys. 13 Definicja tabeli Student_Przedmiot
4.
Zdefiniuj
Diagram
•
Przejdź do panelu Database Explorer, prawym przyciskiem myszy kliknij
węzeł Database Diagram i wybierz Add New Diagram.
•
Wybierz wszystkie tabele i kliknij Add.
•
Kliknij przycisk Close, aby poinformować Visual Studio, że już masz
wszystkie potrzebne tabele.
•
Połącz tabele związkami jak na rys. 14.
Rys. 14 Diagram bazy danych Dziekanat
5.
Zdefiniuj
widok
•
Przejdź do panelu Database Explorer, prawym przyciskiem myszy kliknij
węzeł Views i wybierz Add New View.
•
Wybierz tabele Student, Przedmiot i Student_Przedmiot, które
potrzebne są do utworzenia widoku i kliknij Add.
•
Kliknij przycisk Close, aby poinformować Visual Studio, że już masz
wszystkie potrzebne tabele.
•
Zaznacz kolumny, które chcesz żeby weszły do definiowanego widoku.
Wynik pokazano na rys. 15.
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
ITA-101 Bazy Danych
6.
Uwórz obiekt
DataSet
•
Przejdź do panelu
Sources
•
Wybierz
•
Wybier
•
Zaznacz opcję
•
W
Finish
7.
Utwórz
interfejs
użytkownika
•
Przejdź do panelu
Label
•
W oknie właściwości w polu
dziekanatu
•
Przejdź
TabCotrol
•
W oknie właściwości w polu
Studenci
17
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Strona 13/16
Rys. 15 Definicja widoku
Przejdź do panelu Data Sources i kliknij odsyłacz
Sources.
Wybierz Database, a następnie kliknij przycisk Next
Wybierz bazę danych Dziekanat.mdf i kliknij przycisk
Zaznacz opcję Yes, save the connection as.
Wybierz wszystkie tabele i widoki z bazy danych
Finish.
W Data Sources powinno pojawić się nowo
danych, co pokazano na rys. 16.
Rys. 16 Zdefiniowane połączenie z bazą danych Dziekanat
Przejdź do panelu Toolbox, a następnie przeciągnij na
Label.
W oknie właściwości w polu Text wpisz Mini aplikacja obsługi
dziekanatu.
Przejdź do panelu Toolbox, a następnie przeciągnij na
TabCotrol.
W oknie właściwości w polu Text dla kolejnych
Studenci, Przedmioty i Na jakie przedmioty uczęszczają studenci
17).
Moduł 13
Budowa interfejsu
i kliknij odsyłacz Add New Data
Next.
przycisk Next.
z bazy danych, a następnie kliknij
nowo zdefiniowane źródło
Zdefiniowane połączenie z bazą danych Dziekanat
przeciągnij na formularz obiekt
Mini aplikacja obsługi
a następnie przeciągnij na formularz obiekt
kolejnych zakładek wpisz:
Na jakie przedmioty uczęszczają studenci (rys.

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 14/16
Rys. 17 Dodane obiekty Label i TabControl
•
Przejdź do panelu Data Sources i rozwiń zakładkę Student.
•
Kliknij wskazującą w dół strzałkę, rozwijając listę.
•
Wybierz Details jako prezentację danych i przeciągnij na formularz na
zakładkę Studenci (rys. 18).
Rys. 18 Zakładka „Studenci”
•
Przejdź do panelu Data Sources i rozwiń zakładkę Przedmiot.
•
Kliknij wskazującą w dół strzałkę, rozwijając listę.
•
Wybierz Details jako prezentację danych i przeciągnij na formularz na
zakładkę Przedmiot (rys. 19).
Rys. 19 Zakładka „Przedmioty”
•
Przejdź do panelu Data Sources i rozwiń zakładkę Na jakie przedmioty
jest zapisany student.
•
Kliknij wskazującą w dół strzałkę, rozwijając listę.
•
Wybierz DataGridView jako prezentację danych i przeciągnij na
formularz na zakładkę Na jakie przedmioty uczęszczają studenci (rys.
20).

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 15/16
Rys. 20 Zakładka „Na jakie przedmioty uczęszczają studenci”
•
Uruchom aplikację wybierając przycisk F5. Wynik skompilowanej
aplikacji przedstawia rys. 21.
Rys. 21 Wynik działania aplikacji

Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
Moduł 13
ITA-101 Bazy Danych
Budowa interfejsu
Strona 16/16
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 90 min)
Jesteś programistą w firmie National Insurance. Właśnie dowiedziałeś się od swojego szefa, że
firma zarządzająca bazą AdventureWorks planuje rozszerzenie i modernizacje systemu w celu
spełnienia pewnych standardów. W związku z modernizacją systemu bazodanowego
najprawdopodobniej ulegną zmianie pewne metody wybierania danych w celu zapewnienia
wyższego poziomu bezpieczeństwa. Dostaniesz dodatkowe procedury składowane i funkcje, które
będziesz musiał wykorzystać w nowym module aplikacji klienckiej.
Zadanie, jakie przed Tobą stoi, to:
1.
Podjęcie decyzji, jakie procedury składowane powinny zostać napisane dla nowego modułu
bazy danych oraz jak ich użyć w aplikacji klienckiej.
2.
Podjęcie decyzji, jak ma wyglądać interfejs użytkownika.

ITA-101 Bazy danych
Włodzimierz Dąbrowski, Przemysław Kowalczuk, Konrad Markowski
DODATEK A
Wersja 1.0
Podstawy
Spis treści
Podstawy .............................................................................................................................................. 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Przykładowy problem .............................................................. Błąd! Nie zdefiniowano zakładki.
Podstawy teoretyczne.................................................................................................................. 3
Uwagi dla studenta .................................................................................................................... 11
Dodatkowe źródła informacji..................................................................................................... 11

W.Dąbrowski, P.Kowalczuk, K.Markowski
Dodatek A
ITA-101 bazy danych
Podstawowe pojęcia
Strona 2/11
Informacje o module
Opis modułu
W tym module zajmiemy się zebraniem najważniejszych informacji na
temat baz danych niezbędnych do zrozumienia i pełnego wykorzystania
dalszych modułów. Zebrane, najważniejsze pojęcia nie zastępują pełnego
wykładu na ten temat i nie zwalniają Cię z przestudiowania wykładu lub
podręcznika z zakresu baz danych. Mają one jedynie na celu zebrać
i utrwalić najważniejsze elementy potrzebne do wykonywania kolejnych
modułów. Zazwyczaj pierwsze zajęcia laboratorium są zajęciami
organizacyjnymi.
Cel modułu
Celem modułu jest utrwalenie i sprawdzenie rozumienia podstawowych
pojęć z baz danych oraz przygotowanie do pracy z kolejnymi modułami
kursu.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
•
rozumiał czym jest baza danych,
•
rozumiał na czym polega model relacyjnej bazy danych,
•
umiał swobodnie poruszać się wśród podstawowych pojęć baz
danych.
Wymagania wstępne
Ten moduł nie ma wymagań wstępnych. Możesz od razu rozpocząć pracę
z tym modułem.
Mapa zależności modułu
Przed przystąpieniem do realizacji tego modułu nie jest wymagane
zapoznanie się z materiałem zawartym w innych modułach.

W.Dąbrowski, P.Kowalczuk, K.Markowski
Dodatek A
ITA-101 bazy danych
Podstawowe pojęcia
Strona 3/11
Przygotowanie teoretyczne
Podstawy teoretyczne
Na pewno pojęcie bazy danych nie jest dla Ciebie nowe. Pewnie każdy korzystał też z jakiejś bazy
danych. Czy jednak zastanawiałeś się, co to jest baza danych? Od kiedy ludzie posługują się bazami
danych? Właśnie na te i inne podstawowe pytania dotyczące pojęcia baz danych spróbujemy
odpowiedzieć w tym module.
Zastanów się, co rozumiesz pod pojęciem bazy danych, co to takiego? Zapisz swoje określenie,
a następnie porównaj z naszym.
Bazą danych (ang. database) będziemy nazywać trwały, zamknięty i dobrze zorganizowany
magazyn danych. Baza danych charakteryzuje się trzema ważnymi cechami: trwałością,
ograniczonością (zamkniętością) i dobrą organizacją (co dla kogo jest dobre jest rzeczą dyskusyjną
– postaramy się jednak sprecyzować, co dla nas będzie oznaczać dobra organizacja magazynu).
Trwałość bazy danych
Trwałość oznacza, że dane zapisane w bazie danych są w niej zapisane w sposób nieulotny. Nie
można zbudować bazy danych w pamięci operacyjnej komputera, gdyż po dołączeniu zasilania
dane w niej zapisane są tracone. Na trwały magazyn danych dobrze natomiast nadaje się kamień
(zapisy dokonane w kamieniu przetrwały tysiące lat), papier (ten nie jest już tak trwały) czy dyski
magnetyczne lub inne nośniki magnetooptyczne. Trwałość danych zapisanych w bazie danych jest
bardzo ważnym postulatem. Wszystkie współczesne systemy baz danych muszą go spełniać.
Ograniczoność bazy danych
Ograniczoność oznacza, że w bazie danych nie można zapisać zupełnie dowolnych danych. Baza
oparta jest na pewnym modelu rzeczywistości (modelu danych). Modele te mogą być bardzo różne
i niektóre z nich pokrótce omówimy w dalszej części. Model danych definiowany jest przez
projektanta bazy danych. Określa on, w jaki sposób dane występujące w rzeczywistości (np. dane
adresowe studentów) będą reprezentowane w bazie. Przyjęty model ogranicza więc (determinuje)
dane, które możemy trwale przechowywać w bazie.
Dobra organizacja bazy danych
Aby zbiór danych można było uważać za bazę danych, musi on być odpowiednio zorganizowany.
Organizacja ta musi zapewniać możliwość nie tylko sprawnego umieszczania danych w bazie, ale
również możliwość odszukiwania i odczytywania danych już w niej zapisanych. Jeśli więc znalezienie
danych zapisanych w magazynie wymaga od nas miesiąca przeglądania zapisanych danych, to taki
magazyn nie może być uznany za bazę danych.
Baza danych to oczywiście każdy magazyn danych spełniający powyższe warunki. Ludzkość
dostrzegła potrzebę tworzenia baz danych już bardzo dawno. J. Diamond w swojej książce Guns,
Germs and Steel: The Fastest of Human Societies twierdzi, że bazy danych istniały od czasów, kiedy
cywilizacja umeryjska i egipska zaczęły korzystać z pisma klinowego i hieroglifów do zapisu
informacji w formie trwałej i możliwej do odczytania na każde żądanie. Stosowane w tamtych
czasach nośniki danych były mało wygodne. Nasza cywilizacja przez całe wieki budowała swoje bazy
danych wykorzystując jako trwały nośnik danych papier. Bazy „papierowe” mają jednak bardzo
wiele wad, takich jak duże rozmiary magazynu, trudności w wyszukiwaniu danych, brak
wielodostępu itd. Do budowy i obsługi baz danych nadają się natomiast znakomicie maszyny
cyfrowe. Dzisiaj mówiąc „baza danych” mamy w zasadzie na myśli komputerowe bazy danych.
W dalszej części naszych wykładów pod pojęciem bazy danych będziemy więc rozumieli bazę
zorganizowaną i zarządzaną z wykorzystaniem komputera.

W.Dąbrowski, P.Kowalczuk, K.Markowski
Dodatek A
ITA-101 bazy danych
Podstawowe pojęcia
Strona 4/11
Gdzie i w jakim celu stosuje się bazy danych
Bazy danych spotykamy właściwie na każdym kroku. Każdy na pewno korzystał z bazy papierowej
takiej jak encyklopedia, książka telefoniczna czy kartoteka w bibliotece. Bazy danych są też
powszechne w świecie informatyki. Większość systemów informatycznych współpracuje z bazami
danych, gdyż muszą one przechowywać dane. Są aplikacje, których głównym zadaniem jest
przechowywanie, zarządzanie i udostępnianie danych. Potocznie są one nazywane bazami danych
lub, dla podkreślenia faktu istnienia odpowiednich dodatków ułatwiających pracę, aplikacjami
bazodanowymi. Należy jednak mieć świadomość, że znakomita większość aplikacji to aplikacje,
które współpracują z bazami danych mniej lub bardziej skomplikowanymi.
Zastanowimy się teraz nad najważniejszymi cechami bazy danych, które powinna ona spełniać, aby
mogła sprostać stawianym przed nią dzisiaj wymaganiom.
Proponujemy, abyś przyjrzał się dowolnej bazie danych, z którą się spotkałeś, przeanalizował jej
cechy (te, które ma i które Twoim zdaniem powinna mieć) i wypisał je. Następnie sprawdź, ile
z wypisanych przez Ciebie cech pokrywa się uznanymi przez nas za najważniejsze.
Zgodność z rzeczywistością
Postulat zgodności danych zapisanych w bazie z rzeczywistością jest jednym z ważniejszych
postulatów stawianych bazom danych. Na przykład, jeśli baza opisuje dane osobowe pracowników,
takie jak ich imię, nazwisko, telefon, adres zamieszkania, stanowisko itd., to postulat zgodności
z rzeczywistością oznacza, że w chwili, gdy pracownik zmienia stanowisko pracy (a tym samym
również telefon), to również w bazie danych dokonywane są odpowiednie zmiany danych.
Postulat zgodności z rzeczywistością oznacza, że dane zgromadzone w bazie są danymi
prawdziwymi, odpowiadającymi faktycznemu stanowi świata, którego dotyczą. Na pewno każdy
z nas spotkał się z bazą, która nie spełniała tego postulatu i przechowywała dane dawne już
nieaktualne.
Z takimi bazami często spotykam się dzisiaj zaglądając do oferty sklepów i firm internetowych.
Niezwykle rzadko zdarza się, aby dane podawane w bazach udostępnianych przez te podmioty były
prawdziwe. Najczęściej nie zgadzają się ani ceny towarów, ani ich dostępność w magazynie.
Powoduje to nie tylko stratę naszego czasu (bo i tak trzeba zadzwonić do „żywego człowieka”), ale
również utratę zaufania do firmy, która udostępnia bazę z danymi niezgodnymi z rzeczywistością.
Spełnienie postulatu zgodności z rzeczywistością nie jest łatwe. Trudności nie leżą w zasadzie po
stronie technicznej, ale po stronie ludzkiej. Nie można (jak na razie) całkowicie zautomatyzować
procesów biznesowych i w każdym z nich niezbędnym ogniwem jest człowiek. Aby zapewnić
zgodność danych przechowywanych w bazie z danymi rzeczywistymi, trzeba opracować i stosować
w firmie odpowiednie procedury.
Na przykład w wypadku zmiany stanowiska przez pracownika, dział kadr mógłby (obowiązkowo)
przesyłać odpowiednie zgłoszenie do operatora bazy (albo wprowadzać samodzielnie) z informacją
o zaistniałych zmianach. Sposób przesyłania takiego zgłoszenia, jego zawartość, określenie
odpowiedzialności itd. powinien być właśnie określony w takiej procedurze.
Problem aktualności danych w bazie jest jednym z trudniejszych problemów do rozwiązania,
szczególnie kiedy w przedsiębiorstwie działa wiele różnych systemów i baz danych. Dlatego też
obserwuje się dzisiaj silną tendencję do integracji różnych systemów w jeden spójny system, który
potrafiłby automatycznie wymieniać dane między swymi modułami (częściami). Rozwiązania tego
typu noszą nazwę rozwiązań EAI (ang. Enterprise Architecture Integration) i są oferowane
i rozwijane przez wiodących dostawców systemów bazodanowych.

W.Dąbrowski, P.Kowalczuk, K.Markowski
Dodatek A
ITA-101 bazy danych
Podstawowe pojęcia
Strona 5/11
Ilustracja fragmentu rzeczywistości
Projektując bazę danych należy pamiętać, że stanowi ona pewien model otaczającego nas świata.
Aby baza spełniała swoje zadania, musi być ilustracją kompletnego i dobrze zdefiniowanego
fragmentu rzeczywistości. Można oczywiście zbudować działającą bazę danych, która będzie
pozwalała na poprawne wprowadzanie, usuwanie i modyfikację danych, ale która nie będzie
związana ze światem rzeczywistym. Przydatność takiej bazy stoi oczywiście pod znakiem zapytania.
Aby spełnić ten postulat, należy prawidłowo zdefiniować dziedzinę problemową, która będzie
modelowana za pomocą bazy oraz wykonać odpowiadający tej rzeczywistość model logiczny bazy.
Określaniem wymagań i budową modelu logicznego bazy danych będziemy się zajmować
w module 2.
Kontrola replikacji danych
Replikacja danych oznacza reprezentowanie w bazie tego samego faktu w wielu jej miejscach lub
w różnych formach. Na przykład baza danych zawierająca informacje o dostawach towarów może
przechowywać nazwę i adres dostawcy w specjalnej liście dostawców współpracujących z naszą
firmą oraz te same dane w wykazie zamówień. Taka sytuacja jest zazwyczaj niepożądana. Może ona
prowadzić do:
•
niepotrzebnego zwiększenia miejsca zajmowanego przez bazę,
•
niepotrzebnego angażowania mocy obliczeniowych w przeprowadzanie operacji w wielu
miejscach (np. zmiana adresu dostawcy będzie musiała być wykonana i na liście dostawcy
i przy każdym zamówieniu),
•
powstania błędów i niezgodności danych gromadzonych w bazie z danymi rzeczywistymi (np.
zapomnimy o zmianie adresu dostawcy przy zamówieniach z lipca).
Czasem jednak zachodzi potrzeba replikacji danych. Może ona wynikać ze względów
wydajnościowych lub ze względów bezpieczeństwa. Trzeba jednak zawsze pamiętać, że jeśli
decydujemy się na zastosowanie (dopuszczenie) replikacji, to zawsze należy poświęcić jej
szczególną uwagę, aby pozostawała pod kontrolą.
Spójny model danych
Baza danych powinna być zbudowana na podstawie spójnego modelu. Spójny model danych
oznacza, że fragment rzeczywistości, którego dotyczy baza został zamodelowany w jednym
z możliwych modeli oraz że dane i pojęcia (np. pojęcie faktury) reprezentowane w bazie będą ze
sobą połączone tworząc jedną spójną logicznie całość.
Spójny model należy zapewnić na etapie projektowania logicznego bazy, a jego wyegzekwowanie
w czasie eksploatacji bazy jest możliwe dzięki narzuceniu na bazę odpowiednich warunków
i więzów (np. związków, o których więcej w module 2).
Współbieżny dostęp do danych
Można sobie oczywiście wyobrazić bazę (a nawet znaleźć takie działające bazy), która będzie
umożliwiać dostęp w danej chwili tylko jednemu użytkownikowi. Taka cecha nie powinna nikogo
z nas dziwić, gdyż wiele baz papierowych, z których korzystamy działa w ten właśnie sposób. Nie
jest to jednak wygodne, w szczególności jeśli baza ma służyć wielu użytkownikom. Problem ten
zauważono już dawno i radzono sobie z nim powielając zbiory danych. Na przykład książka
telefoniczna jest drukowana w wielu tysiącach egzemplarzy, dzięki czemu z danych w niej
zawartych może jednocześnie korzystać wielu użytkowników. Nikogo jednak nie trzeba
przekonywać, jak wiele wad ma to rozwiązanie.
Systemy komputerowe pozwalają na dostęp do danych wielu użytkownikom jednocześnie.
Oczywiście udostępnienie danych wielu osobom na raz stwarza dodatkowe problemy związane
z zarządzaniem dostępem do tych danych i wymaga odpowiedniego zaprojektowania i organizacji
bazy danych.
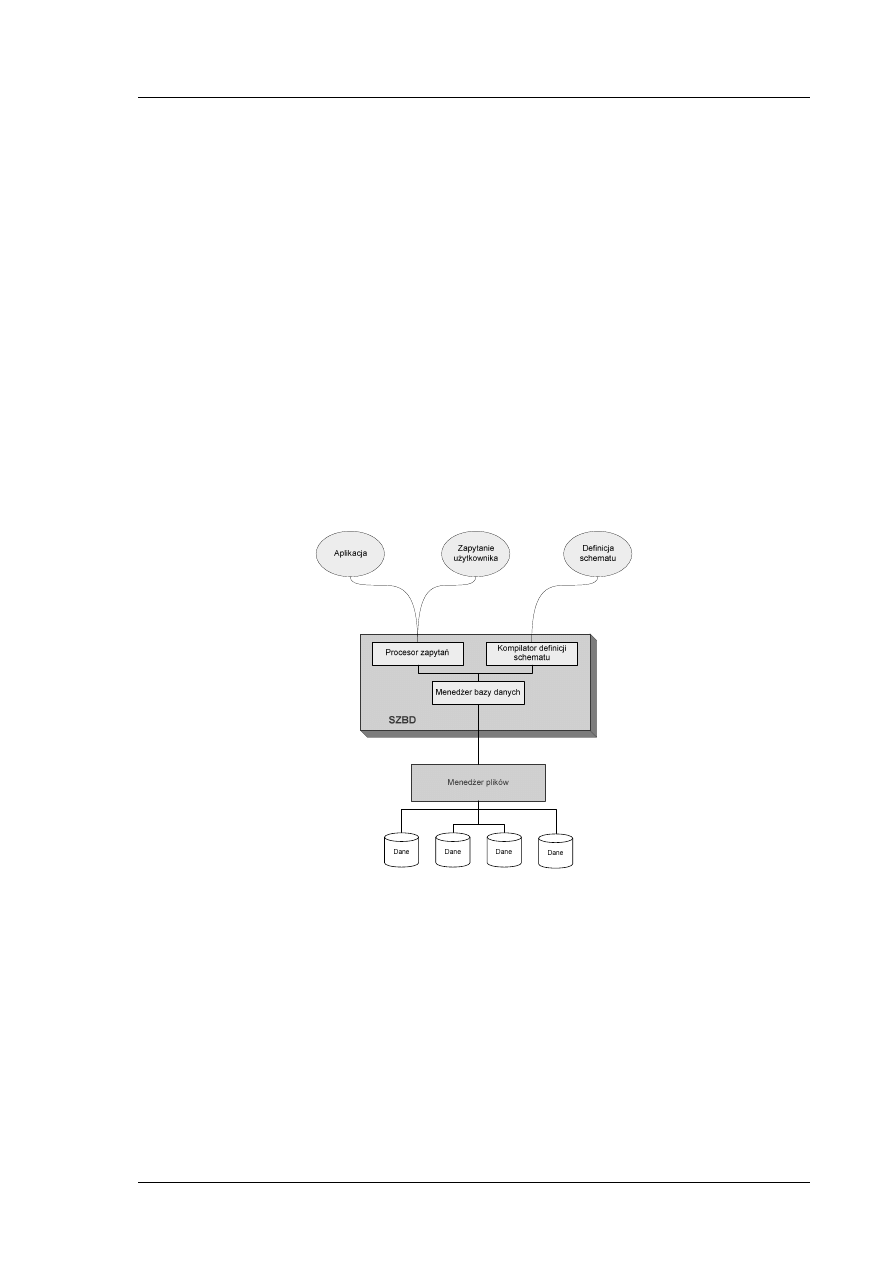
W.Dąbrowski, P.Kowalczuk, K.Markowski
Dodatek A
ITA-101 bazy danych
Podstawowe pojęcia
Strona 6/11
Bezpieczeństwo danych
Bazy danych są dzisiaj obecne w bardzo wielu miejscach i instytucjach, wspomagają nasze życie
codzienne i biorą udział w licznych procesach biznesowych. Są w nich gromadzone informacje
finansowe, księgowe, dane osobowe, transakcje bankowe itp. Z oczywistych powodów wymagają
one ochrony. Dobra baza danych musi zapewniać odpowiednie mechanizmy identyfikacji,
uwierzytelnienia, autoryzacji, poufności, integralności i dostępności.
Rodzaje, klasyfikacja i przykłady SZBD
Sprostanie wymaganiom stawianym dzisiaj bazom danych nie jest łatwe, dlatego budowane są
złożone systemy zawierające zbiór gotowych narzędzi zapewniających odpowiedni dostęp,
manipulację i aktualizację do danych gromadzonych w systemach komputerowych. Narzędzia te to
Systemy Zarządzania Bazą Danych – w skrócie SZBD (ang. Database Management Systems –
DBMS).
Do najważniejszych cech charakteryzujących SZBD możemy zaliczyć:
•
operowanie na dużych i bardzo dużych zbiorach danych,
•
zarządzanie złożonymi strukturami,
•
działanie w długim cyklu życia.
Schemat SZBD wraz z otaczającym go środowiskiem pokazuje poniższy Rys. 1 System Zarządzania
Bazami Danych.
Rys. 1 System Zarządzania Bazami Danych
SZBD składa się z:
•
menedżera bazy danych (ang. DB manager) – jego rola polega na zarządzaniu obiektami
bazy danych
•
procesora zapytań (ang. query procesor) – jego rola polega na przetwarzaniu zapytań
(poleceń) kierowanych do bazy danych,
•
kompilatora definicji schematu (ang. pattern compiler) – jego rola polega na przetwarzaniu
definicji obiektów znajdujących się w bazie na postać zrozumiałą dla menedżera bazy.
Jak widać na rys. 1.1, SZBD komunikuje się jednej strony z menedżerem plików (ang. file manager),
a z drugiej z warstwą wyższego poziomu. Menedżer plików jest odpowiedzialny za obsługę
fizycznych nośników danych – zna i rozumie sposób organizacji tych nośników (systemu plików).

W.Dąbrowski, P.Kowalczuk, K.Markowski
Dodatek A
ITA-101 bazy danych
Podstawowe pojęcia
Strona 7/11
W warstwie wyższego poziomu mogą natomiast znajdować się aplikacje użytkownika (ang.
application), zapytania formułowane przez użytkownika (ang. user query), narzędzia do
definiowania schematu bazy danych (ang. pattern description) itp.
Na rynku dostępnych jest wiele Systemów Zarządzania Bazami Danych dostarczanych przez różnych
producentów. Do najważniejszych należą:
•
Oracle
•
MS SQL Server
•
DB2
•
Sybase
•
Informix
•
Adabase
•
ObjectStore
•
MS Access
oraz wiele innych.
Kryteria doboru SZBD
Wybór odpowiedniego systemu SZBD nie jest łatwy. Przed podjęciem decyzji warto jest rozważyć
wiele aspektów związanych zarówno z tym co baza danych ma robić, jak i innymi uwarunkowaniami
po stronie dostawcy systemu i jego użytkownika.
Do najważniejszych kryteriów doboru SZBD należą:
•
Wydajność (ang. performance) – określa, jak szybko system będzie reagował na wydawane
mu polecenia, ile jednocześnie będzie potrafił obsłużyć zleceń czy użytkowników.
•
Skalowalność (ang. scalability) – określa, jak zmieni się działanie systemu (jego wydajność),
jeśli wzrośnie liczba użytkowników lub danych. Cecha ta określa również możliwość adaptacji
systemu do nowych warunków obciążenia i możliwość jego rozbudowy w celu sprostania
nowym, większym obciążeniom.
•
Funkcjonalność (ang. functionality) – określa, jakie funkcje są dostępne w systemie. Warto
zwrócić uwagę zarówno na funkcje wykorzystywane przez użytkownika, jak i administratora
czy projektanta takiego systemu. Najczęściej brak odpowiednich funkcji – szczególnie
potrzebnych projektantom i administratorom pociąga za sobą konieczność dokupienia
dodatkowych narzędzi i zwiększa koszty systemu.
•
Zgodność ze standardami – oznacza spełnienie przez system pewnych zasad i reguł uznanych
za powszechne, czyli standardów (np. standard języka, standard protokołu, itp.). Spełnienie
powszechnie stosowanych standardów uniezależnia nas od dostawcy systemu i pozwala na
dokładanie do niego innych elementów proponowanych przez różnych dostawców
(oczywiście jeśli są godne ze standardem).
•
Łatwość użycia (ang. usability) – jest ważną cechą systemu. Zdarzają się systemy o bardzo
dobrych parametrach wydajnościowych lub dużej niezawodności, które jednak są tak trudne
w obsłudze, że użytkownicy z nich rezygnują. Ocena tej cechy zależy od użytkownika
systemu, jego przygotowania i doświadczenia. Jest więc cechą subiektywną i ten sam system
przez różnych użytkowników może być zakwalifikowany jako łatwy lub trudny w użyciu.
•
Niezawodność (ang. reliability) – oznacza, jak często system przestaje działać. Oczywiście, im
większa niezawodność systemu, tym większe są jego koszty wytworzenia. Trzeba więc
wyważyć
odpowiednią
proporcję
między
niezawodnością
systemu
a potrzebami
użytkownika. Choć każdy chciałby, aby jego system działał bezbłędnie (był niezawodny) w jak
największym stopniu, to jednak często jesteśmy gotowi zaakceptować przestój systemu
trwający godzinę w zamian za przystępną cenę.
•
Wspomaganie (ang. support) – oznacza zapewnienie odpowiedniej pomocy przez dostawcę
systemu. Z całą pewnością jest to bardzo ważna cecha systemu. Z pewnością warto zapłacić
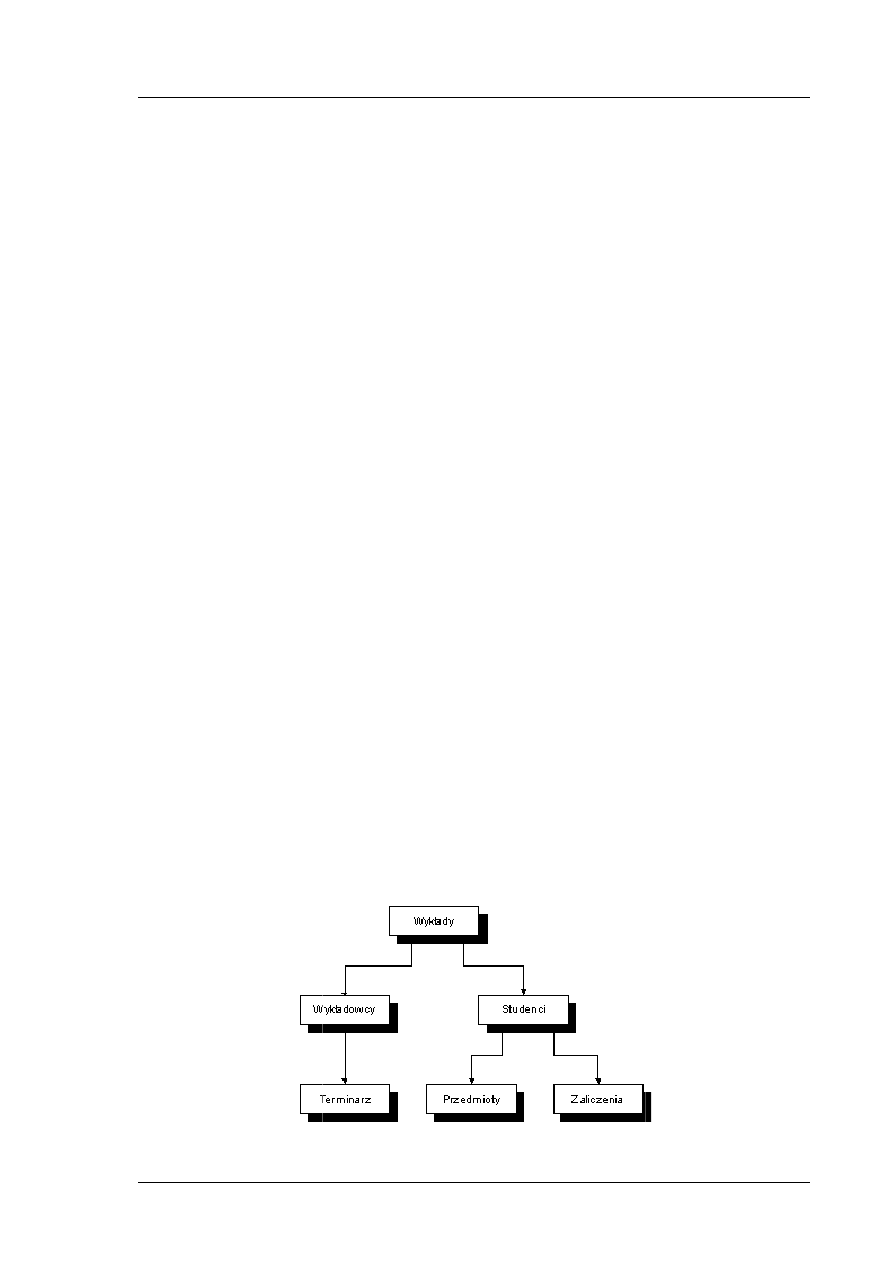
W.Dąbrowski, P.Kowalczuk, K.Markowski
ITA-101 bazy danych
wyższą cenę za produkt, którego producent zapewnia dobry
przecież systemów niezawodnych
o sposobie ich użytkowania.
•
Środowisko (ang. environment
działać nasz system.
•
Cena (ang. price) – oznacza nie tylko koszt zakupu systemu, ale również wszystkie pozostałe
koszty związane z
eksploatacji. Koszt zakupu jest cz
Użytkownicy baz danych i
Wśród najważniejszych grup użytkowników systemów SZBD możemy wyróżnić następujące grupy:
•
Administrator systemu
systemem. To on definiuje bazy danych
globalnym itp.
•
Administrator bazy danych
ma pod swoją opieką. Ma on uprawnienia do zakładania
ale tylko w obrębie danej bazy danych.
•
Programista aplikacji
będzie wspomagał użytkowanie bazy (np. procedur składowanych).
•
Operator – czuwa nad codzienną eksploatacją bazy. Czuwa nad wykonaniem kopii
bezpieczeństwa i wykonuje inne proste, codzienne czynności admnistracyjne.
•
Użytkownik (ang. user
pozostałych grup.
Modele struktury logiczne
Modele struktury logiczn
odzwierciedlić rzeczywistość, której baza dotyczy oraz mają zasadniczy
i działanie bazy. Dzisiaj najpopularniejszym modelem stosowanym
Obok niego funkcjonują też inne modele
popularność model obiektowy.
Model hierarchiczny
Model hierarchiczny przypomina odwrócone drzewo. Jeden
a pozostałe tworzą gałęzie
związkami ojciec-syn.
Związki takie charakteryzują się tym, że
z wieloma innymi obiektami podrzędnymi (synowie), natomiast tylko
nadrzędnym w stosunku do niego (jego ojcem).
W.Dąbrowski, P.Kowalczuk, K.Markowski
Strona 8/11
ższą cenę za produkt, którego producent zapewnia dobry i stabilny serwis. Nie ma
przecież systemów niezawodnych w stu procentach ani systemów, które nie kryją tajemnic
sposobie ich użytkowania.
environment) – określa, na jakim sprzęcie czy systemie operacyjnym będzie
oznacza nie tylko koszt zakupu systemu, ale również wszystkie pozostałe
wdrożeniem tego systemu oraz przewidywanymi kosztami jego
eksploatacji. Koszt zakupu jest często tylko elementem składowym ogólnej ceny systemu.
i ich rola w systemie
Wśród najważniejszych grup użytkowników systemów SZBD możemy wyróżnić następujące grupy:
Administrator systemu (ang. system administrator) – jego zadaniem jes
systemem. To on definiuje bazy danych w systemie, zakłada użytkowników
Administrator bazy danych (ang. database administrator) – administruje jedynie bazą, którą
ma pod swoją opieką. Ma on uprawnienia do zakładania i administrowania obiektami bazy
obrębie danej bazy danych.
Programista aplikacji (ang. application programmer) – jego rolą jest pisanie kodu, który
e wspomagał użytkowanie bazy (np. procedur składowanych).
czuwa nad codzienną eksploatacją bazy. Czuwa nad wykonaniem kopii
wykonuje inne proste, codzienne czynności admnistracyjne.
user) – to ktoś wykonujący czynności nie wchodzące
Modele struktury logicznej bazy danych
ej bazy danych mogą być bardzo różne. Modele te starają się
ść, której baza dotyczy oraz mają zasadniczy wpływ na implementacje
działanie bazy. Dzisiaj najpopularniejszym modelem stosowanym w SZBD jest
Obok niego funkcjonują też inne modele – starszy model hierarchiczny i
model obiektowy.
przypomina odwrócone drzewo. Jeden z elementów pełni role korzenia,
pozostałe tworzą gałęzie i liście. W modelu tym występują związki między obiektam
Związki takie charakteryzują się tym, że obiekt nadrzędny (ojciec) może pozostawać
wieloma innymi obiektami podrzędnymi (synowie), natomiast tylko
stosunku do niego (jego ojcem).
Rys. 2. Model hierarchiczny
Dodatek A
Podstawowe pojęcia
stabilny serwis. Nie ma
stu procentach ani systemów, które nie kryją tajemnic
czy systemie operacyjnym będzie
oznacza nie tylko koszt zakupu systemu, ale również wszystkie pozostałe
wdrożeniem tego systemu oraz przewidywanymi kosztami jego
ęsto tylko elementem składowym ogólnej ceny systemu.
Wśród najważniejszych grup użytkowników systemów SZBD możemy wyróżnić następujące grupy:
jego zadaniem jest nadzór nad całym
systemie, zakłada użytkowników o charakterze
administruje jedynie bazą, którą
administrowania obiektami bazy
jego rolą jest pisanie kodu, który
czuwa nad codzienną eksploatacją bazy. Czuwa nad wykonaniem kopii
wykonuje inne proste, codzienne czynności admnistracyjne.
czynności nie wchodzące w zakres obowiązków
j bazy danych mogą być bardzo różne. Modele te starają się
wpływ na implementacje
SZBD jest model relacyjny.
i zyskujący sobie powoli
elementów pełni role korzenia,
modelu tym występują związki między obiektami zwane
obiekt nadrzędny (ojciec) może pozostawać w związku
wieloma innymi obiektami podrzędnymi (synowie), natomiast tylko z jednym obiektem
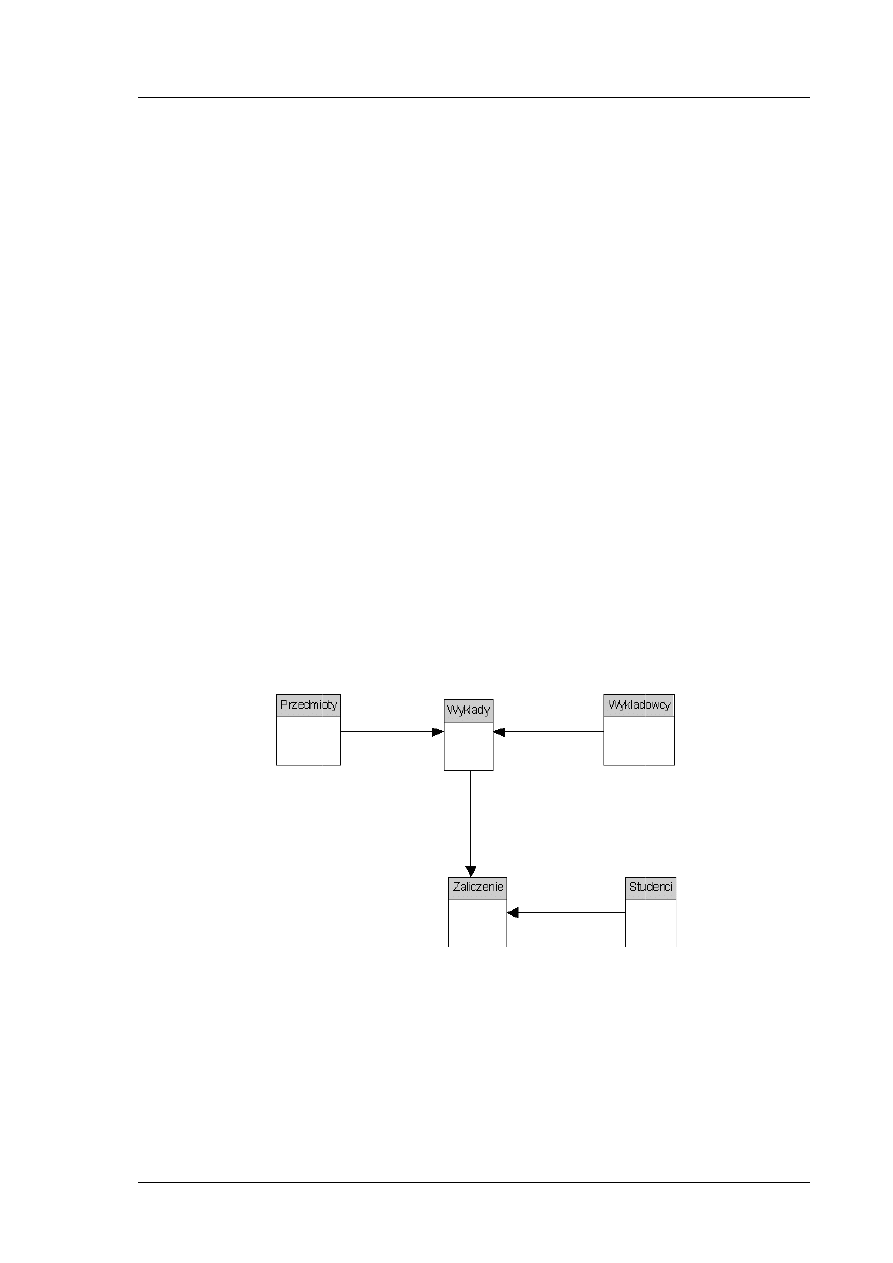
W.Dąbrowski, P.Kowalczuk, K.Markowski
ITA-101 bazy danych
Na Rys. 2 przedstawiono przykład modelu hierarchicznego dla bazy przechowującej informacje
o wykładach, wykładowcach oraz studentach uczęszczających na te wykłady.
Model hierarchiczny ma jednak wiele w
•
niemożność zapisania
roku nie prowadzi wykładów)
•
nadmiarowość danych (np. dane
i przedmiotach),
•
brak możliwości obsługi bardziej złożonych związków między obiektami (np. związków
do wiele”).
Zaletą tego modelu jest łatwość (a co za tym idzie szybkość) dojścia do szukanych danych (idziemy
od korzenia wzdłuż gałęzi aż do celu), ale pod warunkiem
Model hierarchiczny stosowany jest dziś
drzewiastą) oraz w wielu popularnych aplikacjach (np. MS Outlook, Lotus Notes).
Model relacyjny
W celu wyeliminowania wad modelu
siedemdziesiątych nowy model zwany
relacyjnego opracował dr E. Codd pracując
tytułem Relacyjny model logiczny dla dużych banków danych
podstawach matematycznych
Idea modelu relacyjnego bazuje na pojęciu
przechowywane w tabelach (relacjach). T
związkami. Rysunek rys. 1.
relacyjnych jest ich znaczna rozbieżność
modelować. Pozwalają za to n
(powtarzalność) i pozwalają na łatwe wyszukiwanie danych.
Bazy danych oparte na modelu relacyjnym są obecnie najbardziej rozpowszechnionym rodza
baz danych.
Model obiektowy
Obecnie technologią, która pozwala najlepiej odwzorowywać świat rzeczywisty
oprogramowania, jest technologia obiektowa.
programowania jak C++ czy Java.
przy tworzeniu dużych i złożonych projektów.
W.Dąbrowski, P.Kowalczuk, K.Markowski
Strona 9/11
przedstawiono przykład modelu hierarchicznego dla bazy przechowującej informacje
wykładach, wykładowcach oraz studentach uczęszczających na te wykłady.
Model hierarchiczny ma jednak wiele wad. Do najważniejszych należą:
niemożność zapisania w bazie danych, które nie mają ojca (np. wykładowcy, który
roku nie prowadzi wykładów),
nadmiarowość danych (np. dane o przedmiocie są wpisane w bazie dwa razy
brak możliwości obsługi bardziej złożonych związków między obiektami (np. związków
Zaletą tego modelu jest łatwość (a co za tym idzie szybkość) dojścia do szukanych danych (idziemy
od korzenia wzdłuż gałęzi aż do celu), ale pod warunkiem, że znamy strukturę tego modelu.
Model hierarchiczny stosowany jest dziś w systemach plików (struktura katalogów ma strukturę
wielu popularnych aplikacjach (np. MS Outlook, Lotus Notes).
W celu wyeliminowania wad modelu hierarchicznego opracowano na początku lat
siedemdziesiątych nowy model zwany modelem relacyjnym. Podstawy teoretyczne dla modelu
relacyjnego opracował dr E. Codd pracując w firmie IBM i opublikował w roku 1970
logiczny dla dużych banków danych. Model ten oparty jest na silnych
podstawach matematycznych, głównie teorii mnogości.
Idea modelu relacyjnego bazuje na pojęciu relacji – czyli tabeli. Wszystkie dane
tabelach (relacjach). Tabele te mogą być ze sobą powiązane tak zwanymi
. Rysunek rys. 1.3 przedstawia przykład modelu relacyjnego. Zasadniczą wadą modeli
relacyjnych jest ich znaczna rozbieżność w stosunku do świata rzeczywistego, który mają
modelować. Pozwalają za to na efektywne przechowywanie danych, obniżają redundancję danych
pozwalają na łatwe wyszukiwanie danych.
Rys. 3. Model relacyjny
Bazy danych oparte na modelu relacyjnym są obecnie najbardziej rozpowszechnionym rodza
Obecnie technologią, która pozwala najlepiej odwzorowywać świat rzeczywisty
oprogramowania, jest technologia obiektowa. O jej sukcesie świadczy popularność takich języków
programowania jak C++ czy Java. Technologia obiektowa jest obecnie dominującym narzędziem
złożonych projektów.
Dodatek A
Podstawowe pojęcia
przedstawiono przykład modelu hierarchicznego dla bazy przechowującej informacje
wykładach, wykładowcach oraz studentach uczęszczających na te wykłady.
bazie danych, które nie mają ojca (np. wykładowcy, który w danym
bazie dwa razy – w wykładach
brak możliwości obsługi bardziej złożonych związków między obiektami (np. związków „wiele
Zaletą tego modelu jest łatwość (a co za tym idzie szybkość) dojścia do szukanych danych (idziemy
namy strukturę tego modelu.
systemach plików (struktura katalogów ma strukturę
wielu popularnych aplikacjach (np. MS Outlook, Lotus Notes).
hierarchicznego opracowano na początku lat
. Podstawy teoretyczne dla modelu
roku 1970 w książce pod
. Model ten oparty jest na silnych
. Wszystkie dane w tym modelu są
abele te mogą być ze sobą powiązane tak zwanymi
przedstawia przykład modelu relacyjnego. Zasadniczą wadą modeli
stosunku do świata rzeczywistego, który mają
a efektywne przechowywanie danych, obniżają redundancję danych
Bazy danych oparte na modelu relacyjnym są obecnie najbardziej rozpowszechnionym rodzajem
Obecnie technologią, która pozwala najlepiej odwzorowywać świat rzeczywisty w projektowaniu
jej sukcesie świadczy popularność takich języków
Technologia obiektowa jest obecnie dominującym narzędziem

W.Dąbrowski, P.Kowalczuk, K.Markowski
Dodatek A
ITA-101 bazy danych
Podstawowe pojęcia
Strona 10/11
Obiektowość nie ogranicza się jedynie do nowego sposobu organizacji kodu w językach
programowania. Jest ona pewną ideologią w informatyce, której cechą jest chęć dopasowania
modeli pojęciowych stosowanych w informatyce do modelu świata postrzeganego przez człowieka.
Jest to kolejny krok w ewolucji kontaktów człowiek-maszyna (a ściślej programista-komputer).
Śledząc, nawet pobieżnie, rozwój języków programowania widzimy, że ewolucja ta przebiega ciągle
w stronę ułatwiania życia człowiekowi. Wynika to z rozwoju technologii i związanego z tym
zwiększania złożoności modelowanych procesów. Bez wprowadzania nowych metod, wyższych
poziomów abstrakcji w projektowaniu i programowaniu , człowiek szybko staje się najsłabszym
ogniwem w procesie tworzenia oprogramowania.
Większość producentów systemów relacyjnych baz danych wyposaża obecnie swoje produkty
w rozszerzenia obiektowe. Są one implementowane w różnym stopniu i zakresie. Obejmują takie
funkcje jak obsługa abstrakcyjnych typów danych, klas, przechowywanie obiektów, wyzwalacze,
procedury składowane. Podstawą takiego systemu jest najczęściej ten sam „silniczek”, jaki był
stosowany w wersji relacyjnej – dobry i sprawdzony, ale pisany z myślą o modelu relacyjnym, a nie
obiektowym. Systemy tego typu nie spełniają w pełni paradygmatu obiektowości, mogą być
traktowane raczej jako rozszerzenie systemów relacyjnych o pewne atrakcyjne cechy umożliwiające
efektywne tworzenie aplikacji, a nie jako pełnowartościowe systemy obiektowe.
Systemy w pełni obiektowe zrywają natomiast z założeniami modelu relacyjnego i opierają się
w całości na technologii obiektowej. Zapewniają tradycyjną funkcjonalność bazy danych (trwałość,
integralność danych, obsługę wielodostępu, odtwarzanie danych) przy zastosowaniu obiektowego
modelu danych. Wiele tego typu systemów obsługuje również bardziej zaawansowane funkcje jak
np. obsługa rozproszonych baz danych.
Systemy obiektowych baz danych są najlepiej dopasowane do potrzeb zorientowanych obiektowo
aplikacji przetwarzających duże ilości danych oraz obsługujących wielu użytkowników. Istniejące
rozwiązania obejmują różne zakresy funkcjonalności – od prostych systemów przeznaczonych do
obsługi małej liczby użytkowników, dostosowanych do jednego języka programowania, aż do
bardzo zaawansowanych rozwiązań, w których wydajny serwer obiektowej bazy danych jest
sercem całego systemu serwera aplikacji.
Należy jednak zwrócić uwagę, że systemy obiektowe ciągle stanowią przedmiot badań i nie
osiągnęły jeszcze pełnej dojrzałości.
Podsumowanie
Współczesne systemy informatyczne wykorzystują bazy danych, od małych baz budowanych
specjalnie na ich potrzeby, aż po duże i bardzo duże uniwersalne bazy i systemy baz danych.
W zasadzie trudno byłoby znaleźć program komputerowy, który nie korzystałby z baz danych.
Nie każdą strukturę przechowującą dane możemy jednak uznać za bazę danych. Baza danych musi
charakteryzować się odpowiednimi cechami. Ponieważ dzisiaj przed bazami danych stawia się coraz
większe wymagania związane z wydajnością, bezpieczeństwem itd. Wymaganiom tym mogą
sprostać dopiero Systemy Zarządzania Bazami Danych, które są wyposażone w odpowiednie
mechanizmy zapewniające bezpieczeństwo, spójność, wydajność i łatwość obsługi.
Modele baz danych są różne. Do najpopularniejszych należą model hierarchiczny, relacyjny
i obiektowy. Każdy z nich nadaje się do innych celów, a najbardziej rozpowszechnionym modelem
w bazach spotykanych w rozwiązaniach przemysłowych jest model relacyjnym. Nasze zajęcia
poświęcone są właśnie temu modelowi.

W.Dąbrowski, P.Kowalczuk, K.Markowski
Dodatek A
ITA-101 bazy danych
Podstawowe pojęcia
Strona 11/11
Uwagi dla studenta
W tym module nie jest przewidziane laboratorium. Jeśli chcesz się przekonać, czy jesteś gotowy do
wykonywania laboratoriów w kolejnych modułach, zastanów się i odpowiedz na następujące
pytania:
•
czy rozumiesz, czym jest baza danych,
•
czy potrafisz uzasadnić stosowanie baz danych do przechowywania danych zamiast
innych struktur,
•
czy umiesz wymienić podstawowe cechy baz danych,
•
czy rozumiesz założenia modelu relacyjnego?
Jeśli potrafisz na te pytania odpowiedzieć twierdząco, to jesteś przygotowany do dalszej drogi przez
świat baz danych. Jeśli nie, to zapoznaj się ponownie z uwagami i poradami zawartymi w tym
module. Upewnij się, że rozumiesz omawiane w nich zagadnienia. Jeśli masz trudności ze
zrozumieniem tematu zawartego w uwagach, przeczytaj ponownie informacje z tego rozdziału
i zajrzyj do notatek z wykładów.
Dodatkowe źródła informacji
1.
Jeffrey D. Ullman, Jennifer Widom, Podstawowy wykład z systemów baz danych, WNT, 2000
Książka zawiera pełny akademicki wykład z baz danych. Znajdziesz w niej szerokie
omówienie wszystkich przedstawianych w tym module pojęć wraz z licznymi
przykładami. Jeśli jesteś zainteresowany odrobiną teorii i chciałbyś dogłębnie
zrozumieć jak działają bazy danych to jest to książka dla Ciebie.
2.
Rebeca R. Riordan, Projektowanie relacyjnych baz danych, Microsoft Press, 2000
Książka poświęcona jest praktycznym aspektom projektowania relacyjnych baz
danych w środowisku aplikacji firmy Microsoft. Rebeca Riordan znana jest
z łatwego i zrozumiałego języka i łatwości tłumaczenia zagadnień trudnych. Ten
swój talent wykorzystuje również w tej pozycji. Jeśli nie interesuje Cię zgłębianie
teoretycznych podstaw działania baz danych, a bardziej nastawiony jesteś na
praktyczne wykorzystanie wiedzy, to jest to książka dla Ciebie.
3.
C.J.Date, Wprowadzenie do systemów baz danych, WNT, 2000
Jest to pełny podręcznik do wykładu z baz danych znanego i cenionego na całym
świecie autora. Znajdziesz w nim szersze spojrzenie na problematykę budowy
i modelowania baz danych. Polecamy ją wszystkim, którzy chcieliby poszerzyć
swoje wiadomości z tego zakresu.
Wyszukiwarka
Podobne podstrony:
ITA 101 BazyDanych podręcznik kursuMSSQL
ITA 101 Modul 03
ITA 101 Modul 02
ITA 101 Modul 06
ITA 101 Modul 13
ITA 101 Modul 11
ITA 101 Modul 04
ITA 101 Modul 09
ITA 101 Modul Dodatek A
ITA 101 Modul 08
ITA 101 Modul 07
ITA 101 Modul 10
ITA 101 Modul 12
ITA 101 Modul 01
ITA 101 Modul 05
ITA 101 Modul 02 v2
więcej podobnych podstron