
Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
1
Wykład 5
Fizyczne projektowanie bazy danych
(Paul Beynon-Davies, Systemy baz danych )
Zawartość wykładu:
1) Logiczne projektowanie bazy danych
2) Fizyczne projektowanie bazy danych
3) Zdefiniowanie wydajności
4) Przykład projektowania wydajnej relacyjnej bazy danych

Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
2
1. Logiczne projektowanie bazy danych - niezależnie od implementacji
•
Konstruowanie modelu reguł działalności stosowanych w pewnej organizacji w
postaci relacji czyli tabel
2. Fizyczne projektowanie bazy danych - zależnie od implementacji
•
Analiza wyników logicznego projektu
•
Uwzględnienie wymagań wydajnościowych
•
Uwzględnienie wymagań pamięciowych
•
Implementacja przy użyciu mechanizmów wybranego Systemu Zarządzania Bazą
Danych
Produkty wejściowe projektowania fizycznego
1. Model logiczny typu relacyjnego (diagramy związków encji, tabele jako
odwzorowanie diagramu związków encji)
2. Przybliżone oszacowanie liczby wierszy w tabelach – analiza ilości
3. Szacunkowa analiza sposobów użycia tabel za pomocą rodzaju i częstości
występowania operacji, które będą prawdopodobnie oddziaływać na tabele w
naszej bazie danych – analiza użycia
4. Lista więzów integralności – analiza więzów integralności
5. Lista najczęściej wykonywanych raportów
Produkty wyjściowe projektowania fizycznego
1. Struktury plików zadeklarowane w wybranym języku definiowania danych
(Data Definition Language - DDL)
2. Indeksy na strukturach plików
3. Klastry plików
4. Zbiór powiązań wewnętrznych wyrażony w DDL i dodatkowych więzów
integralności wyrażony w wybranym języku integralności danych (Data
Integrity Language - DIL)
5.
Zbiór zapytań zoptymalizowany do działania w konkretnej bazie danych
(zapytanie zoptymalizowane – taka forma zapytania, która podaje odpowiedź w
możliwie najkrótszym czasie). Wybór zapytania do optymalizacji jest
dokonywany na podstawie analizy użycia, ilości i integralności.
Przyjmuje się dalej, że zapytanie to zarówno czytanie jak zmiana stanu bazy
danych (wstawianie, usuwanie i modyfikacja)

Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
3
3. Zdefiniowanie wydajności
Wydajność jest wyrażana za pomocą:
−
czasów reakcji systemu (czas oczekiwania na wykonanie zapytania oraz czas
wykonania zapytania)
−
przepustowości (średnia liczba zapytań obsłużonych przez system w określonym
czasie) itp
Wydajność zależy od:
−
złożoności obliczeniowej zapytania
−
liczby zapytań oczekujących na wykonanie
−
algorytmów szeregowania zapytań
−
parametrów czasowych sprzętu
−
zapotrzebowania na zasoby (pamięć operacyjną, dyski)
Aby zdefiniować wydajność systemu, trzeba zdefiniować misję aplikacji:
•
analiza ilości – maksymalna i średnia liczba krotek, zmienność liczby krotek
•
analiza użycia- priorytetowa lista najważniejszych zapytań, bo najczęściej
wykonywanych – należy określić oczekiwaną minimalną częstotliwość tych
zapytań
•
analiza integralności – sposób obsługi więzów integralności
Decyzje dotyczące dostrajania bazy danych pod względem wydajności
1. podziały pionowy i poziomy tabel
2. tworzenie mechanizmów dostępu związanych z przechowywaniem
3. dodawanie indeksów
4. denormalizacja
5. więzy integralności
6. wykorzystanie SZBD

Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
4
Ad. 1) Podział tabel powinien prowadzić do zmniejszenia czasu wykonania
najczęściej wykonywanych zapytań (przykład 1)
Ad. 2)
sekwencyjność (małe tabele, średnie i duże tabele, gdy należy udostępnić ponad
20% wierszy, dla dowolnych tabel w przypadku zapytań o niskim priorytecie)-
pętle zewnętrzne zapytań powinny być krótsze o zagnieżdżonych
haszowanie (jako główna ścieżka dostępu do pliku, zbudowana na kluczach
głównych)
klastry (umieszczanie w jednym klastrze dane używane w operacji złączeń)
Ad. 3)
Kompromis między czasem wykonywania zapytań oraz czasem modyfikowania,
wstawiania i usuwania danych
indeksy na kluczach głównych (obowiązkowe)
indeksy na kluczach obcych
indeksy wtórne
Ad. 4)
Stosowanie denormalizacji jest stosowane, gdy inne metody zawiodą
Np. Wprowadzenie tablicy łączącej tablicę tytul i tablice ksiazka
Ksiazka_i_tytul (Id_ksiazka_tytul, tytul, autor, ISBN, cena, numer)
Ad. 5) Implementowanie więzów integralności:
•
a) wewnętrznie: określa się więzy integralność encji (ze względu na klucz
główny), więzy integralność referencyjnej (klucze obce w zasadzie nie
powinny być równe null), więzy integralności dziedziny (np. wartości
typ_tytulu muszą pochodzić z dziedziny {Techniczna, Beletrystyczna}
•
proceduralnie: np. procedury wyzwalane
•
nieproceduralnie: zastosowanie centralnych słowników danych, co umożliwia
utrzymywanie więzów integralności niezależnie od programów użytkowych
Ad. 6)
Wybór Systemu Zarządzania Bazą Danych może mieć różny wpływ na wydajność
bazy danych
−
typ optymalizacji
−
praca wielowątkowa
−
zapytania interpretowane podczas wykonywania zapytania są wolniejsze- jednak
poprawia się ich wydajność, gdy baza jest zmienna lub dostęp do danych ma
charakter losowy
−
zapytania skompilowane są szybsze od interpretowanych
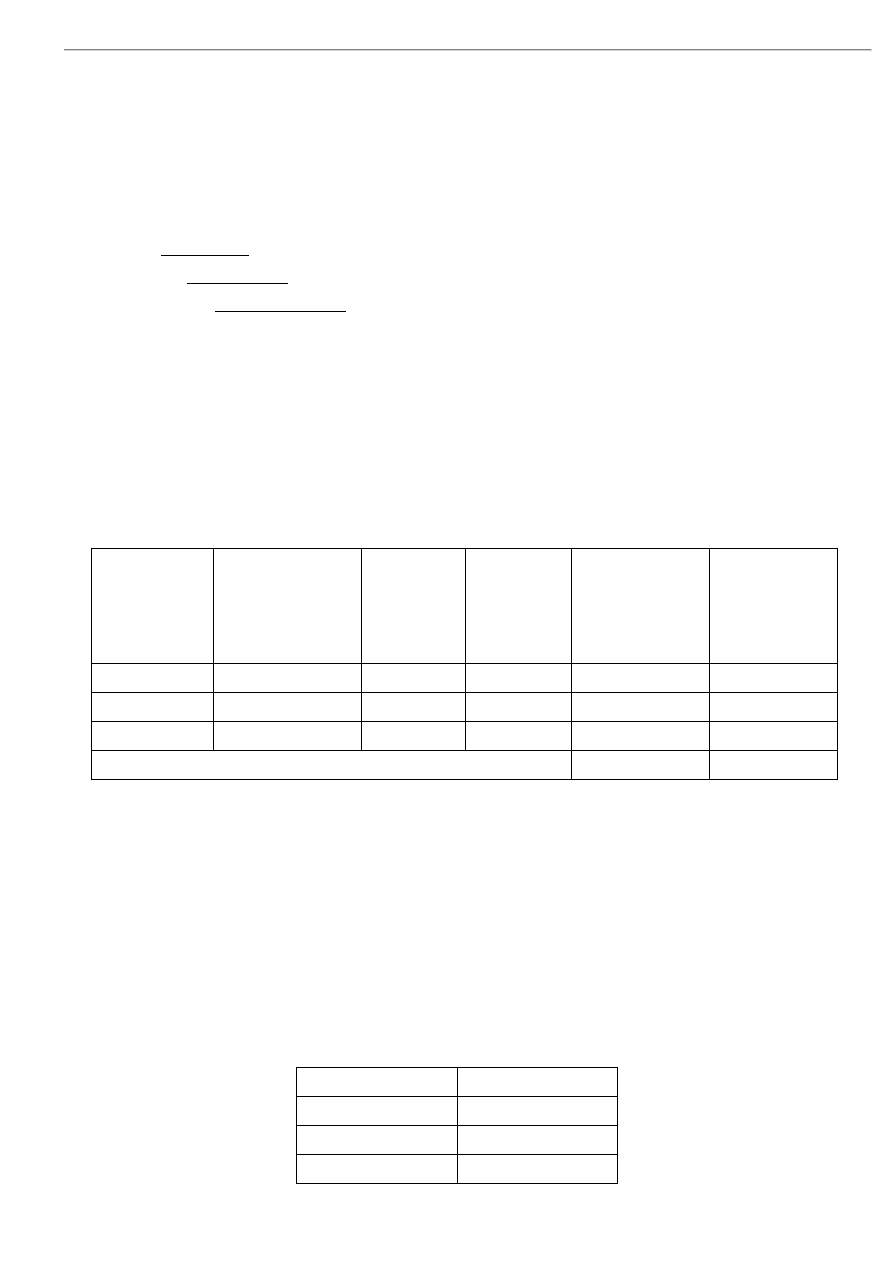
Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
5
4. Przykład projektowania wydajnej relacyjnej bazy danych
4.1. Produkty wejściowe
4.1.1. Model relacyjny (pominięto etap analizy czyli tworzenia diagramu związków
encji i odwzorowania w tabele)
Baza Katalog książek składa się z następujących tabel:
Tytul (Id_tytulu, tytul, autor, ISBN, typ_ksiazki)
Ksiazka (Id_ksiazki, numer_ksiazki, Id_tytulu_)
Rezerwacje(Id_rezerwacji, data, Id_tytulu_)
Uwaga: atrybut typ_ksiazki umożliwia klasyfikację książek na książki techniczne i
beletrystyczne
4.1.2. Analiza ilości
•
Oszacowanie maksymalnej liczby krotek (danych) czyli maksymalnego rozmiaru
tabeli pozwala oszacować rozmiar pamięci dyskowej
•
Oszacowanie średniej liczby krotek (średniego rozmiaru tabeli), które mogą być
zapisane w bazie danych, daje możliwość oceny modelu dostępu do danych
Tabela Maksymalna
liczba wierszy
a
Średnia
liczba
wierszy
b
Rozmiar
kolumn
(krotki)
c
Maksymalny
rozmiar
tabeli
a*c
Średni
rozmiar
tabeli
b*c
Tytul
5 000
3 000
49
245 000
147 000
Ksiazka
100 000
30 000
9
900 000
270 000
Rezerwacje 100 000
50 000
8
800 000
400 000
Suma
1 945 000
817 000
4.1.3. Analiza użycia
•
Identyfikacja podstawowych zapytań, wymaganych w bazie danych jako ciągi
operacji: wstawiania, modyfikowania, wyszukiwania i usuwania,
•
Zmienność pliku w ciągu roku
−
w tym samym czasie usuwa się 50 i dodaje 50 tytułów, czyli 50/5000=1%
−
w tym samym czasie usuwa się 1000 i dodaje się 1000 książek, czyli
1000/100000=1%
−
w tym samym czasie usuwa się 10000 rezerwacji i zakłada nowych 10000
rezerwacji, czyli 10000/10000=100%.
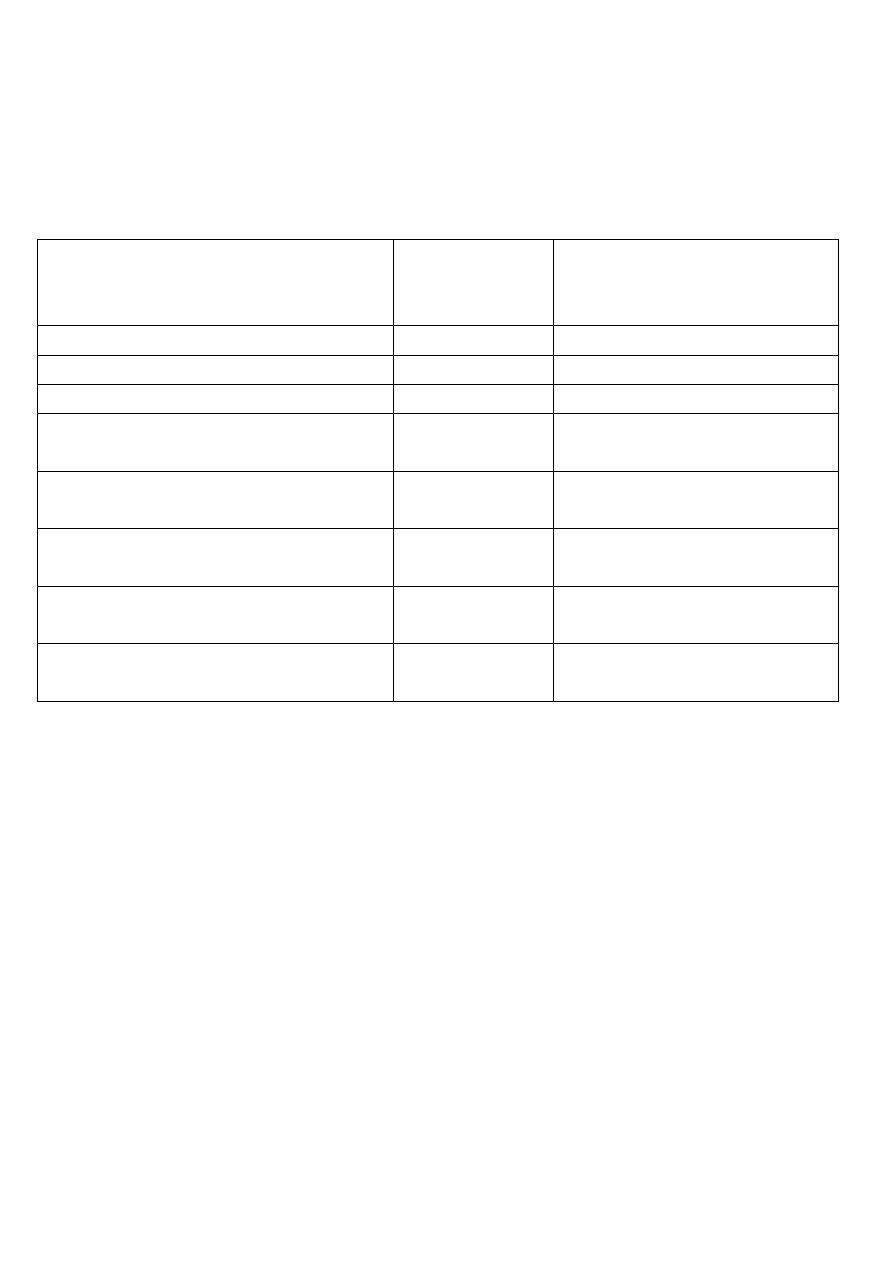
Tabela Zmienność
Tytul Mała
Ksiazka Mała
Rezerwacja duża
Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
6
•
Analiza wymagań dotyczących dostępu
Rozmiar i zmienność pliku mają wpływ na dostęp do bazy danych:
Im większy plik, tym większa konieczność zastosowania specjalnych struktur
dostępu do baz danych
Im bardziej zmienny plik, tym bardziej konieczne są jak najmniej czasochłonne
struktury dostępu do baz danych
Zapytanie Częstotliwość
wykonywania
Konieczność
zapewnienia najkrótszego
czasu wykonania zapytania
Podaj tytuły książek
Raz na rok
-
Podaj autorów książek
Raz na rok
-
Podaj tytuły książek technicznych Raz na miesiąc -
Podaj numery książek
technicznych
Raz dziennie
-
Podaj tytuły beletrystyczne
Wiele razy
dziennie
+ (przykład)
Podaj zarezerwowane tytuły
beletrystyczne
Wiele razy
dziennie
+ (przykład)
Rezerwacje tytułów technicznych
lub beletrystycznych
Wiele razy
dziennie
+
Podaj książki beletrystyczne
Wiele razy
dziennie
+ (przykład)
4.1.4. Analiza integralności
Trzy typy więzów integralności wewnętrznej:
•
klucza głównego (np. Id_ksiazki w tabeli Ksiazka nie może być równy null)
•
klucza obcego (np. Id_tytulu_ w tabeli Ksiazka nie może być równy null)
•
dziedziny wartości np. atrybut typ_tytulu {Techniczna, Beletrystyczna} może
przybierać tylko dwie wartości: Techniczna lub Beletrystyczna
Typy więzów integralności dodatkowej:
•
więzy przejścia np. jeśli żadna książka o danym tytule nie była wypożyczona
przez rok, należy te książki wraz tytułem usunąć z bazy danych
•
więzy statyczne: liczba rezerwacji danego tytułu nie może przekroczyć podwójnej
liczby książek o tym tytule
Obsługa więzów integralności jest czasochłonna.

Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
7
4.2. Produkty wyjściowe – zoptymalizowane zapytania (p.1-3, str. 3)
Zastosowania różnych metod dostępu do danych poprawiające wydajności bazy
danych – (1) podział tabel, (2) sekwencyjność w dostępie do baz danych, klastry,
(3) użycie indeksów.
4.2.1. Pytanie
zawierające selekcję na tabeli Tytul – często zadawane pytanie o
tytuły beletrystyczne
Tytul
(Id_tytulu, tytul, autor, ISBN, typ_ksiazki)
a) liczba krotek w tabeli Tytul jest równa n,
b) 0.9 n to krotki zawierające wartość atrybutu typ_tytulu=’Techniczna’
c) 0.1 n to krotki zawierające wartość atrybutu typ_tytulu=’Beletrystyczna’
d) na stronie pliku przechowuje się t krotek, stąd mamy n/t. Zakłada się
najgorszy wariant, w którym każda krotka jest na innej stronie, czyli t=1
Pytanie
Select * From Tytul
Where typ_tytulu=’Techniczna’
Czasochłonność w technice sekwencyjnej
Do i:= 1 to n
if Tytul[i].typ_ksiazki=’Beletrystyczna’
Dodaj krotkę Tytul[i] do wynikowej tabeli
T1’=t1’+t2’
t1’= n - czasochłonność czytania krotek z tabeli Tytul
t2’=0.1n - czasochłonność zapisu krotek z tabeli Tytul o
typ_Tytulu=’Beletrystyczna’
T1’=1.1n
Czasochłonność po dodaniu indeksu na atrybucie typ_tytulu w tabeli Tytul
Do i:= 1 to 0.1n
//następuje bezpośrednie odwołanie poprzez indeks ‘Beletrystyczna’ do
0.1n
krotek w tabeli Tytul
if Tytul[i].typ_ksiazki=’Beletrystyczna’
Dodaj krotkę Tytul[i] do wynikowej tabeli
T1’’=t1’’+t2’’
t1’’= 0.1n - czasochłonność czytania krotek z tabeli Tytul
t3’’= 0.1n - czasochłonność zapisu krotek z tabeli Tytul jako wyniku selekcji
T1’’=0.1n+0.1=0.2n
T1’’=0.2n

Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
8
Czasochłonność po podziale tabeli Tytul – poziomy (podział na tytuly
techniczne i beletrystyczne) i pionowy (odrzucenie atrybutu typ_tytulu)
Tytul_Techniczny(Id_tytulu, tytul, autor, ISBN)
Tytul_Beletrystyczny(Id_tytulu, tytul, autor, ISBN)
Do i:= 1 to 0.1n
// if Tytul[i].typ_ksiazki=’Beletrystyczna’
nie jest wykonywane, gdyż następuje
// bezpośrednie odwołanie do
0.1n
krotek w tabeli
Tytul_Beletrystyczny
dedykowanej
// typ_tytulu=’Beletrystyczna’
Dodaj krotkę Tytul_Beletrystyczny[i] do wynikowej tabeli
T1’’’=t1’’’+t2’’’
t1’’’= 0.1n - czasochłonność czytania krotek z tabeli Tytul_Beletrystyczny
t3’’’= 0.1n - czasochłonność zapisu krotek z tabeli Tytul_Beletrystyczny
T1’’=0.1n+0.1n=0.1n
T1’’=0.2n
T1’’=T1’’
Różnica między rozwiązaniami:
delta T = T1’-T1’’=0.9n
Wniosek: podział tabeli Tytul oraz założenie indeksu dają identyczną czasochłonność
wykonania zapisu w przypadku, gdy zostanie pominięta obsługa indeksu.
W przeciwnym wypadku rozwiązanie z podziałem tabeli Tytul jest najlepsze.
4.2.2. Pytania zawierające złączenia dwóch tabel – często zadawane pytanie o
zarezerwowane tytuly beletrystyczne
Tytul (Id_tytulu, tytul, autor, ISBN, typ_tytulu)
Rezerwacje(Id_rezerwacji, data, _Id_tytulu)
Np. Pytanie:
Select * From Tytul, Rezerwacje
Where typ_ksiazka=’Beletrystyczna’
And Id_tytulu=_Id_tytulu;
e) liczba krotek w tabeli Tytul jest równa n, gdzie 0.1 n to krotki zawierające
wartość atrybutu typ_tytulu=’Beletrystyczna’
f) w
tabeli
Rezerwacje znajduje się r krotek oraz r>n
g) w tabeli Rezerwacje znajduje się p krotek jako zarezerwowanych książek
beletrystycznych oraz p
≈
0.1r
h) na
stronie pliku przechowuje się t krotek, stąd mamy r/t oraz n/t. Zakłada się
najgorszy wariant, w którym każda krotka jest na innej stronie, czyli t=1

Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
9
Czasochłonność w technice sekwencyjnej
Do i:= 1 to n
if Tytul[i].typ_tytulu=’Beletrystyczna’
//prawda dla 0.1n krotek
Do k:=1 to p1
//liczba krotek zarezerwowanych dla danego tytułu beletrystycznego
if Tytul[i].Id_tytulu = Rezerwacje[k]._Id_tytulu
//następuje bezpośredni odczyt
//w tabeli
Rezerwacje
dzięki indeksowi na kluczu obcym _
Id_tytulu
Dodaj krotkę Tytul[i]*Rezerwacje[k] do wynikowej tabeli
T1’=t1’+t2’+t3’
t1’= n - czasochłonność czytania krotek z tabeli Tytul
t2’= 0.1np - czasochłonność czytania krotek z tabeli Rezerwacje i testowań
warunków (drugi argument to testowanie zaindeksowanych kluczy
obcych dla (w sumie) p krotek z tabeli Rezerwacje)
t3’= p - czasochłonność zapisu złączonych krotek z tabel Rezerwacje i Tytul
T1’ = n +0.1np+p
Uwaga: Jeśli r <n, czyli gdy liczba wszystkich rezerwacji jest mniejsza niż liczba
tytułów
Do k:= 1 to r
//istnieje tylko jeden tytul posiadający klucz główny równy kluczowi obcemu w tabeli Rezerwacje
//
Tytul[i].Id_tytulu = Rezerwacje[k]._Id_tytulu
Do i:=X[k] to X[k] //X[k] - indeks Id_tytulu
if Tytul[i].typ_tytulu=’Beletrystyczna’
Dodaj krotkę Tytul[i]*Rezerwacje[k] do wynikowej tabeli
T1’=t1’+t2’+t3’
t1’=r - czasochłonność czytania krotek z tabeli Rezerwacje
t2’=r*1 - czasochłonność czytania indeksowanych krotek (klucz główny) z tablicy
Tytul czyli Tytul[i].Id_tytulu = Rezerwacje[k]._Id_tytulu
t3’=p - czasochłonność zapisu złączonych krotek z tabel Rezerwacje i Tytul
T1’=2r+p
Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
10
Czasochłonność po dodaniu indeksu na atrybucie typ_tytulu w tabeli Tytul
Do i:= 1 to 0.1n
//
następuje bezpośrednie odwołanie poprzez indeks ‘Beletrystyczna’ do
0.1n
krotek w tabeli
Tytul
if Tytul[i].typ_ksiazki=’Beletrystyczna’ –
Do k|:= 1 to p1
//liczba krotek odpowiadająca danemu tytułowi typu ’Beletrystyczna’
//
następuje bezpośredni odczyt w tabeli
Rezerwacje
dzięki indeksowi na kluczu obcym _
Id_tytulu
if Rezerwacje[k]._Id_tytulu=Tytul[i].Id_tytulu –
Dodaj krotkę Rezerwacje[k] * Tytul[i] do wynikowej tabeli
T1’’=t1’’+t2’’+t3’’
t1’’= 0.1n - czasochłonność czytania krotek z tabeli Tytul
t2’’=0.1n*p - czasochłonność czytania krotek z tabeli Rezerwacje i testowań
warunków (drugi argument to testowanie zaindeksowanych kluczy
głównych dla (w sumie) p krotek z tabeli Rezerwacje)
t3’’= p - czasochłonność zapisu złączonych krotek z tabel Rezerwacje i Tytul
T1’’=0.1n+0.1np+p
Czasochłonność w technice sekwencyjnej po podziale tabeli Tytul – poziomy
(podział na tytuly techniczne i beletrystyczne) i pionowy (odrzucenie atrybutu
typ_tytulu)
Tytul_Techniczny(Id_tytulu, tytul, autor, ISBN)
Tytul_Beletrystyczny(Id_tytulu, tytul, autor, ISBN)
Rezerwacje(Id_rezerwacji, numer, _Id_tytulu)
Do i:= 1 to 0.1n
//mamy 0.1n krotek w tabeli Tytul_Beletrystyczny
//instrukcja nie wykona się, gdyż następuje bezpośrednie odwołanie do
0.1n
krotek w tabeli
//
Tytul_Beletrystyczny
dedykowanej typ_tytulu=’Beletrystyczna’
//if Tytul[i].typ_ksiazki=’Beletrystyczna’
-
Do k|:= 1 to p1
//liczba krotek odpowiadająca danemu tytułowi typu ’Beletrystyczna’
// następuje bezpośredni odczyt w tabeli
Rezerwacje
dzięki indeksowi na kluczu obcym _
Id_tytulu
if Rezerwacje[k]._Id_tytulu_=Tytul_Beletrystyczny[i].Id_tytulu
Dodaj krotkę Rezerwacje[k] * Tytul_Beletrystyczny[i] do wynikowej tabeli
T1’’’=t1’’’+t2’’’+t3’’’
t1’’’= 0.1n - czasochłonność czytania krotek z tabeli Tytul_Beletrystyczny
t2’’’= 0.1np - czasochłonność czytania krotek z tabeli Rezerwacje i testowań
warunków (drugi argument to testowanie zaindeksowanych kluczy
głównych dla p (w sumie) krotek z tabeli Rezerwacje)
t3’’’= p - czasochłonność zapisu złączonych krotek z tabel Rezerwacje i
Tytul_Beletrystyczny
T1’’’=0.1n+0.1np+p

Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
11
T1’’= T2’’’
Różnica między rozwiązaniami:
delta T = T1’-T1’’=0.9n
Wniosek: Rozwiązanie z dodatkowym indeksem na atrybucie typ_tytulu i podziałem
tabeli Tytul ma tę samą czasochłonność, jeśli pominie się czasochłonność obsługi
indeksu. W przeciwnym wypadku czasochłonność obsługi indeksu powoduje, że
podział tabel Tytul jest najlepszy. Najgorszy przypadek to odczyt sekwencyjny bez
indeksu i podziału tabel.
4.2.3. Pytania zawierające złączenia dwóch tabel – często zadawane pytanie o
ksiązki beletrystyczne
Tytul (Id_tytulu, tytul, autor, ISBN, typ_tytulu)
Ksiazka (Id_ksiazki, numer, Id_tytulu_)
Np. Pytanie:
Select * From Tytul, Ksiazka
Where typ_ksiazka=’Beletrystyczna’
And Id_tytulu=Id_tytulu_;
i) liczba krotek w tabeli Ksiazka jest równa m
j) liczba krotek w tabeli Ksiazka odpowiadająca tytułom o wartości atrybutu
typ_tytulu równym „Beletrystyczna’ jest równa q
k) na stronie pliku przechowuje się t krotek, stąd mamy m/t. Zakłada się najgorszy
wariant, w którym każda krotka jest na innej stronie, czyli t=1
Czasochłonność w technice sekwencyjnej
Do i:= 1 to n
if Tytul[i].typ_ksiazki=’Beletrystyczna’
//prawda dla 0.1n krotek
Do j:=1 to q1
//liczba krotek zarezerwowanych dla danego tytułu beletrystycznego
if Tytul[i].Id_tytulu = Ksiazka[j].Id_tytulu_
//następuje bezpośredni odczyt
//w tabeli
Ksiazka
dzięki indeksowi na kluczu obcym
Id_tytulu_
Dodaj krotkę Ksiazka[j] * Tytul[i] do wynikowej tabeli
T1’=t1’+t2’+t3’
t1’= n - czasochłonność czytania krotek z tabeli Tytul
t2’=0.1nq - czasochłonność czytania krotek z tabeli Ksiazka i testowań warunków
(drugi argument to testowanie zaindeksowanych kluczy obcych dla
(w sumie) q krotek z tabeli Ksiazka)
t3’= q - czasochłonność zapisu złączonych krotek z tabel Ksiazka i Tytul
T1’=n+0.1nq+q
Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
12
Czasochłonność po dodaniu indeksu na atrybucie typ_tytulu w tabeli Tytul
Do i:= 1 to 0.1n
//
następuje bezpośrednie odwołanie poprzez indeks ‘Beletrystyczna’ do 0.1n krotek w tabeli
Tytul
if Tytul[i].typ_ksiazki=’Beletrystyczna’ –
Do j|:= 1 to q1
//liczba krotek odpowiadająca danemu tytułowi typu ’Beletrystyczna’
//
następuje bezpośredni odczyt w tabeli
Ksiazka
dzięki indeksowi na kluczu obcym
Id_tytulu_
if Ksiazka[j].Id_tytulu_=Tytul[i].Id_tytulu –
Dodaj krotkę Ksiazka[j] * Tytul[i] do wynikowej tabeli
T1’’=t1’’+t2’’+t3’’
t1’’= 0.1n - czasochłonność czytania krotek z tabeli Tytul
t2’’= 0.1n*q - czasochłonność czytania krotek z tabeli Ksiazka i testowań warunków
(drugi argument to testowanie zaindeksowanych kluczy głównych dla
(w sumie) q krotek z tabeli Ksiazka)
t3’’= q - czasochłonność zapisu złączonych krotek z tabel Ksiazka i Tytul
T1’’=0.1n+0.1nq+q
Czasochłonność w technice sekwencyjnej po podziale tabeli Tytul - poziomy
(podział na tytuly techniczne i beletrystyczne) i pionowy (odrzucenie atrybutu
typ_tytulu)
Tytul_Techniczny(Id_tytulu, tytul, autor, ISBN)
Tytul_Beletrystyczny(Id_tytulu, tytul, autor, ISBN)
Ksiazka(Id_ksiazki, numer, Id_tytulu_)
Do i:= 1 to 0.1n
//mamy 0.1n krotek w tabeli Tytul_Beletrystyczny
//nie jest wykonywane, gdyż następuje bezpośrednie odwołanie do 0.1n krotek w tabeli
//
Tytul_Beletrystyczny
dedykowanej typ_tytulu=’Beletrystyczna’
//if Tytul[i].typ_ksiazki= ’Beletrystyczna’
Do j|:= 1 to q1
//liczba krotek odpowiadająca danemu tytułowi typu ’Beletrystyczna’
//następuje bezpośredni odczyt w tabeli
Ksiazka
dzięki indeksowi na kluczu obcym
Id_tytulu_
if Ksiazka[j].Id_tytulu_=Tytul_Beletrystyczny[i].Id_tytulu
Dodaj krotkę Ksiazka[j] * Tytul_Beletrystyczny[i] do wynikowej tabeli
T1’’’=t1’’’+t2’’’+t3’’’
t1’’’= 0.1n - czasochłonność czytania krotek z tabeli Tytul_Beletrystyczny
t2’’’= 0.1n*q - czasochłonność czytania krotek z tabeli Ksiazka i testowań
warunków (drugi argument to testowanie zaindeksowanych kluczy
głównych dla q (w sumie) krotek z tabeli Ksiazka)
t3’’’= q - czasochłonność zapisu złączonych krotek z tabel Ksiazka i
Tytul_Beletrystyczny
T1’’’=0.1n+0.1n*q+q

Zofia Kruczkiewicz, I-6, p325 C3
Internetowe bazy danych, Wykład 5
13
T1’’= T2’’’
Różnica między rozwiązaniami:
delta T = T1’-T1’’=0.9n
Wniosek:
Rozwiązanie z dodatkowym indeksem na atrybucie typ_tytulu i podziałem
tabeli Tytul ma tę samą czasochłonność, jeśli pominie się czasochłonność obsługi
indeksu. W przeciwnym wypadku czasochłonność obsługi indeksu powoduje, że
podział tabeli Tytul jest najlepszy. Najgorszy przypadek to odczyt sekwencyjny bez
indeksu i podziału tabeli.
Wyszukiwarka
Podobne podstrony:
Projekt Bazy Danych
Projekt bazy danych dla Przycho Nieznany
Wzor projektu bazy danych (3), INIB rok II, PIOSI janiak
etapy projektowania bazy danych, Pomoce naukowe, studia, informatyka
Access2 Projektowanie bazy danych, Ogrodnictwo 2011, INFORMATYKA, Informatyka, MS Access
projekt bazy danych, PWR, Zarządzanie, SEMESTR VI, Przedsięw. inf. w zarządzaniu
Wzor projektu bazy danych, INIB rok II, PIOSI janiak
projekt bazy danych (4 str), Ekonomia, ekonomia
projekt bazy danych (4 str), Ekonomia
WYKŁAD V - projektowanie bazy danych, Uczelnia, sem V, bazy danych, wyklad Rudnik
Projekt bazy danych(1)
Projekt Bazy Danych
Projekt bazy danych dla Przycho Nieznany
Wzor projektu bazy danych (3), INIB rok II, PIOSI janiak
mazur & mazur, bazy danych P, Projekt bazy danych krajowej agencji pracy tymczasowej
2 Bazy danych projektowanie wykład
więcej podobnych podstron