Autor: Katarzyna Ragin-Skorecka
1 z 40
PROJEKTOWANIE SYSTEMÓW INFORMATYCZNYCH
Kierunek Zarządzanie i Marketing
Materiały www.me.put.poznan.pl
Prowadzący mgr inż. Katarzyna Ragin-Skorecka, mgr inż. Adam Radecki
1. CYKL ŻYCIA OPROGRAMOWANIA
Produkcja i eksploatacja oprogramowania jest procesem, który powinien być realizowany
w systematyczny sposób. Istnieje szereg modeli cyklu życia oprogramowania. Wprowadzają
one pewne fazy życia programu, określają czynności wykonywane w poszczególnych fazach
oraz ustalają kolejność ich realizacji. Modele cyklu życia oprogramowania pozwalają
uporządkować przebieg prac, ułatwiają planowanie zadań oraz monitorowanie przebiegu ich
realizacji.
Można wyróżnić kilka modeli cyklu życia oprogramowania. Każdy z nich ma zalety i wady.
Klasycznym modelem jest kaskadowy model cyklu życia oprogramowania. Na
rys.
1.1
przedstawiono rozbudowaną wersję tego modelu.
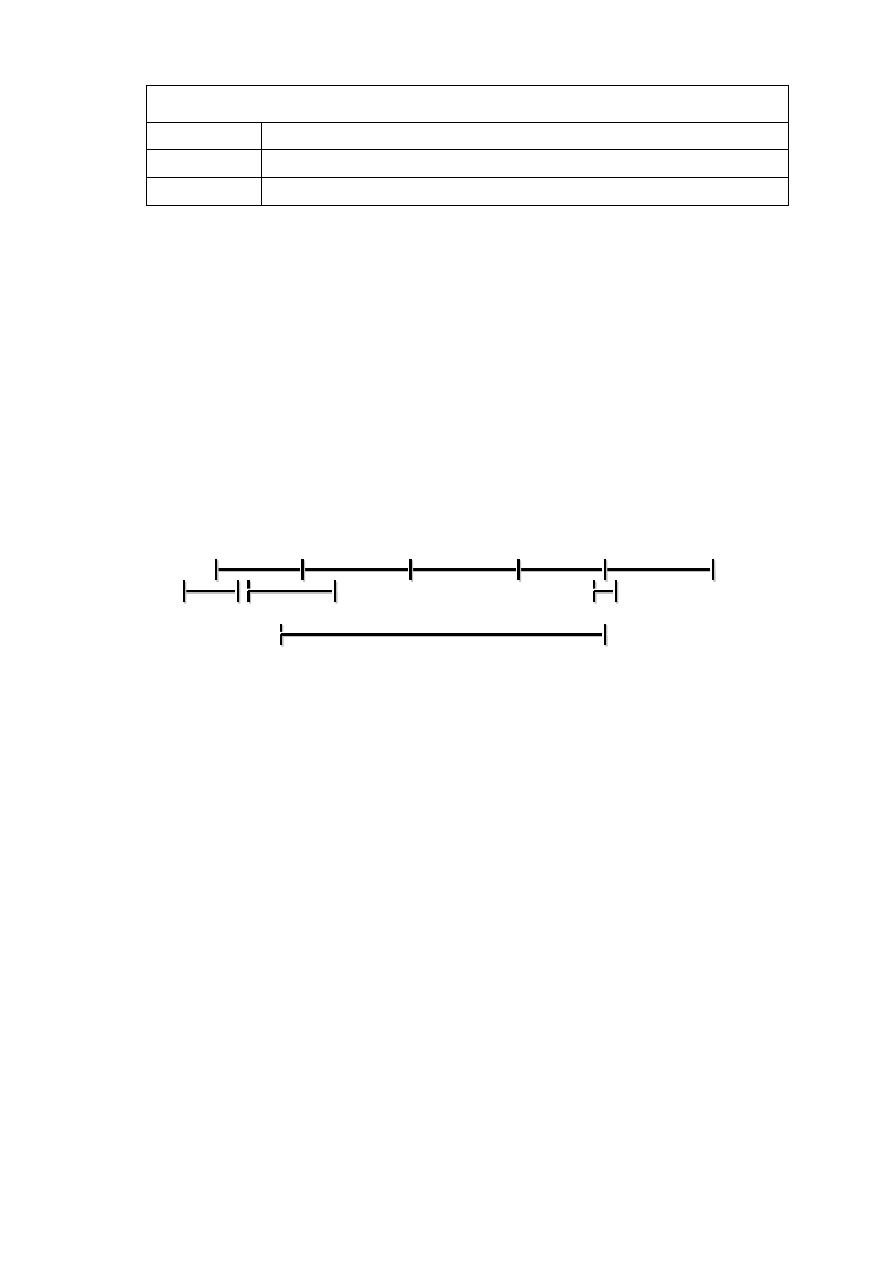
Rys. 1.1. Rozszerzony model kaskadowy
W powyższym modelu wyróżniono następujące fazy podstawowe: określanie wymagań,
projektowanie, implementacja, testowanie, konserwacja, oraz fazy rozszerzające model:
strategiczna, analizy, dokumentacji, instalacji. Dodatkowe etapy częściowo nakładają się
na
podstawowe. Model ten powstał jako analogia w
stosunku do
sposobu prowadzenia
przedsięwzięć w innych dziedzinach inżynierii. W
poszczególnych fazach cyklu życia
oprogramowania są realizowane następujące zadania:
• faza strategiczna – wykonywana przed formalnym podjęciem decyzji o realizacji
przedsięwzięcia, podjęcie strategicznych decyzji dotyczących dalszych etapów prac, ogólne
określenie wymagań,
• faza określania wymagań – określenie celów oraz szczegółowych wymagań wobec
tworzonego systemu,
• faza analizy – budowa logicznego modelu systemu; należy uwzględnić 5 kategorii: interakcje
systemu ze światem zewnętrznym, struktura systemu, przepływ danych, abstrakcyjne
struktury danych, dynamika zachowań systemu,
• faza projektowania – stworzenie szczegółowego projektu systemu spełniającego ustalone
wcześniej wymagania; na podstawie modelu logicznego projektuje się fizyczną strukturę
Określanie
wymagań
Projektowanie
Implementacja
Testowanie
Konserwacja
Faza
strategiczna
Analiza
Dokumentacja
Instalacja

Autor: Katarzyna Ragin-Skorecka
2 z 40
systemu, na którą składa się: software (modele algorytmów, procedury wywołania),
hardware oraz projekt alokacji software w hardware,
• faza implementacji – polega ona na zakodowaniu algorytmów w konkretnym języku
programowania przy uwzględnieniu fizycznej struktury oraz wykonanie testów
poszczególnych modułów,
• faza testowania – integracja poszczególnych modułów połączona z testowaniem
podsystemów oraz całego oprogramowania,
• faza instalacji – przekazanie systemu użytkownikowi,
• faza dokumentacji – wytwarzanie dokumentacji dla użytkownika, przebiega równolegle
z produkcją oprogramowania,
• faza konserwacji – wykorzystanie oprogramowania przez użytkowników, producent
konserwuje oprogramowanie (usuwanie błędów, zmiana i rozszerzanie funkcji systemów).
Zalety modelu kaskadowego wiążą się przede wszystkim z łatwością zarządzania
przedsięwzięciem. Model ten ułatwia planowanie, harmonogramowanie oraz monitorowanie
produkcji oprogramowania. Wadą jest: narzucenie twórcom oprogramowania ścisłej kolejności
wykonywanych prac, wysoki koszt błędów popełnionych we wczesnych fazach, długa przerwa
w kontaktach z klientem.
Wymienione wady modelu kaskadowego stały się przyczyną powstania szeregu innych modeli
cyklu życia oprogramowania. Należą do nich:
• realizacja kierowania dokumentami,
• prototypowanie,
• programowanie odkrywcze,
• realizacja przyrostowa,
• model spiralny,
• formalne transformacje.
W większości tych modeli główne fazy są analogiczne do modelu kaskadowego. Nie powstał
model idealny, w każdym z nich są jakieś wady. Modele różnią się przydatnością w poszczególnych
sytuacjach. Poza tym w jednym przedsięwzięciu można je łączyć ze sobą w zależności od potrzeb.
Wybór odpowiedniego sposobu prowadzenia przedsięwzięcia jest jedną z najważniejszych decyzji
przy tworzeniu oprogramowania.
Projekt systemu informatycznego powstaje w fazie analizy. Celem fazy określania wymagań jest
odpowiedź na pytanie „co i przy jakich ograniczeniach system ma robić”. Wynikiem jest zbiór
wymagań, czyli zewnętrzny opis systemu. W fazie projektowania pytamy „jak system ma zostać
zaimplementowany”. Wynikiem jest projekt oprogramowania, czyli opis sposobu implementacji.
Faza analizy ma udzielić odpowiedzi na pytanie „jak system ma działać”. Wynikiem jest logiczny
model systemu, opisujący sposób realizacji przez system postawionych wymagań, lecz abstrahujący
od szczegółów implementacyjnych. Ta faza jest nazywana również fazą modelowania.
Logiczny model pozwala lepiej zrozumieć postawiony problem i dokładniej określić wymagania
systemu. Model staje się podstawą projektu. Tworzony system będzie stanowił fragment większej
Autor: Katarzyna Ragin-Skorecka
3 z 40
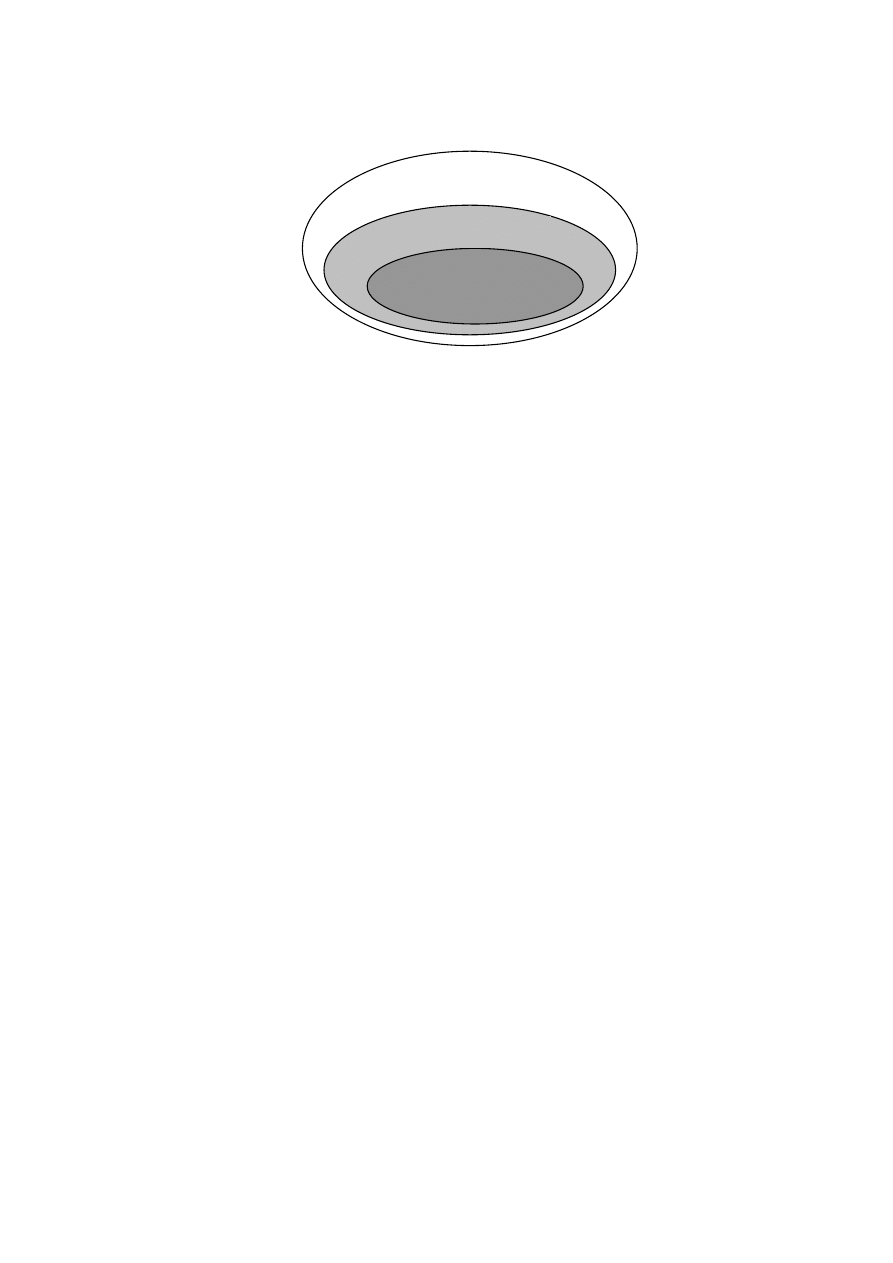
całości, zwanej dziedziną problemu. Fragment dziedziny problemu, który powinien zostać objęty
przez tworzony system zwany jest zakresem odpowiedzialności systemu (rys. 1.2).
Rys. 1.2. Dziedzina problemu, model i zakres odpowiedzialności systemu
Tworzony w fazie analizy model z reguły wykracza poza zakres odpowiedzialności systemu.
Wynika to z następujących przyczyn:
• ujęcie w modelu pewnych fragmentów dziedziny problemu nie będących częścią systemu
czyni model bardziej zrozumiałym,
• na etapie modelowania może nie być jasne, które elementy modelu będą realizowane
przez stworzone oprogramowanie, a jakie w sposób sprzętowy lub ręczny,
• w pewnych przypadkach może być zrozumiałe, że dostępne środki nie pozwolą na realizację
całości systemu, celem analizy może być np. wykrycie tych fragmentów dziedziny problemu,
których wspomaganie za pomocą oprogramowania będzie szczególnie przydatne.
2. METODY PROJEKTOWANIA SYSTEMÓW INFORMATYCZNYCH
Istnieją dwie główne grupy metod analizy. Tradycyjne nazywane są metodami strukturalnymi.
Metody obiektowe pojawiły się później i cały czas są rozwijane. Ich podstawą jest wyróżnianie
w systemie składowych łączących w sobie możliwość przechowywania danych oraz wykonywania
pewnych operacji.
Projektowanie strukturalne charakteryzuje się zasadą poziomu abstrakcji. Oznacza to, że system
traktowany jest jako hierarchiczna struktura, składająca się z poziomu zerowego. Następnie
w sposób rekurencyjny uszczegóławia się poziom n, poprzez zbudowanie dla każdego poziomu n
podstruktury n+1.
Analiza strukturalna rozpoczyna się od budowy dwóch różnych modeli systemu: modelu danych
będącego opisem pasywnej części systemu oraz modelu funkcji opisującego część aktywną
systemu. Następnie te dwa modele są integrowane. Wynikiem tej integracji jest model przepływów
danych. W metodzie Yourdona tworzy się model środowiska, behawioralny oraz funkcjonalny.
Ostatni z wymienionych jest najważniejszy, ponieważ definiuje rodzaj i sposób wykonywania
założonych procesów. Model środowiska określa granicę między systemem a środowiskiem jego
działania oraz interfejsy między systemem a jego otoczeniem (np. przepisy gospodarcze, warunki
organizacyjne, inne systemy informatyczne). Model behawioralny wskazuje jak system powinien
się zachowywać, aby oddziaływać na otoczenie zgodnie z oczekiwaniami użytkownika.
Zakres
odpowiedzialności
systemu
Model
Dziedzina problemu
Autor: Katarzyna Ragin-Skorecka
4 z 40
Analiza obiektowa opiera się na tworzeniu obiektów. Obiekt to twór posiadający tożsamość
(nazwa), stan (atrybuty, właściwości) i zachowanie (operacje). Obiekty są grupowane w klasy
złożone z obiektów o podobnych stanach i zachowaniu.
Obiektowość dotyczy również aspektów obiektów. Należą do nich: abstrakcja, dziedziczenie,
polimorfizm, hermetyzacja (kapsułkowanie), wysyłanie, powiązania i
agregacja. Abstrakcja
oznacza odfiltrowanie cech i operacji nieistotnych. Dziedziczenie polega na przejmowaniu
wszystkich atrybutów i operacji z klasy, w której znajduje się rozważany obiekt i z klas będących
nadklasami w stosunku do danej klasy. Polimorfizm oznacza, że ta sama nazwa operacji może
w różnych klasach oznaczać różne działania. Hermetyzacja (kapsułkowanie) polega na ukryciu
działania obiektu, tzn. obiekty ukrywają wewnętrzną część swych operacji przed światem
zewnętrznym i przed innymi obiektami. Pozwala to uniknąć niebezpieczeństwa złych działań,
a w przypadku zmiany źle funkcjonującego obiektu, likwiduje potrzebę zmiany w pozostałych
obiektach. Porozumiewanie się między obiektami następuje poprzez wysyłanie komunikatów,
inicjujących daną operację. Obiekty pozostają ze sobą w różnych związkach. Dla każdego
powiązania można ustalić liczebność (ile obiektów z jednej klasy jest powiązanych z iloma
obiektami drugiej klasy). Agregacja jest typem powiązania. Składa się ze zbioru obiektów będących
komponentami. Specjalnym rodzajem jest agregacja całkowita, w której obiekt będący
komponentem może istnieć jedynie jako składowa część całości.
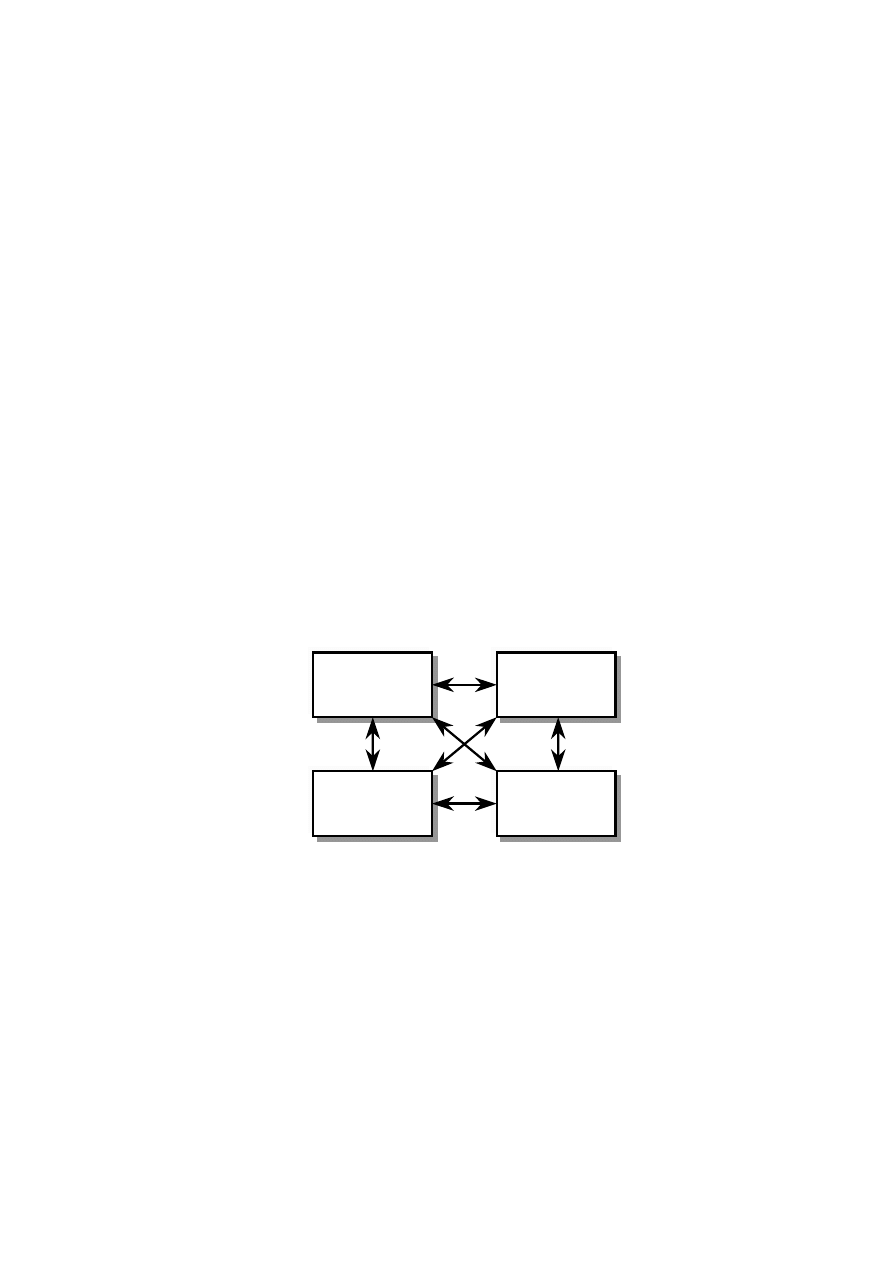
W procesie budowy modelu obiektowego można wyróżnić cztery główne zadania (rys. 2.1).
Trzy służą budowie statycznego modelu klas. Celem ostatniego jest zamodelowanie sposobu w jaki
obiekty współpracują ze sobą wykonują funkcje systemu.
Rys. 2.1. Proces budowy modelu obiektowego
Budowa modelu obiektowego nie ma charakteru liniowego, a poszczególne zadania
wykonywane są iteracyjnie. Kolejność tworzenia poszczególnych diagramów zależy od projektanta.
Diagram to schemat przedstawiający zbiór bytów. Jest on najczęściej grafem, w którym
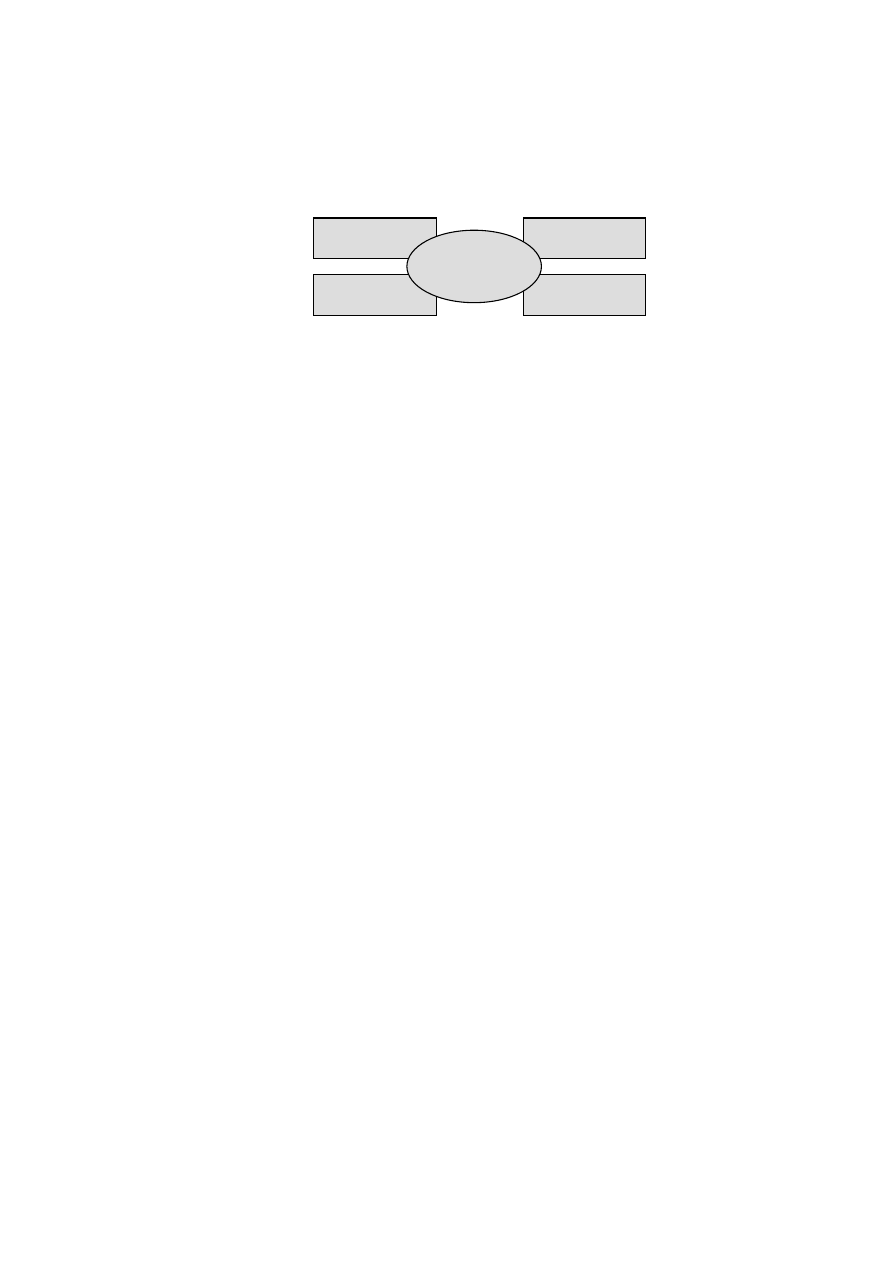
wierzchołkami są elementy, a krawędziami związki. Podczas modelowania struktury rozpatruje się
pięć perspektyw architektury systemu (rys. 2.2).
W perspektywie przypadków użycia rozpatruje się zachowanie systemu widziane
przez użytkowników, analityków i osób wykonujących testy. Perspektywa projektowa kładzie
nacisk na słownictwo danego zadania i na sposób jego realizacji. Pomaga ona w zapisywaniu
wymagań funkcjonalnych. W perspektywie procesowej zwraca się uwagę na wątki i procesy, które
kształtują mechanizmy współbieżności i synchronizacji w systemie. Dotyczy ona przede wszystkim
efektywności, skalowalności i przepustowości systemu. Perspektywa implementacyjna odpowiada
Identyfikacja
klas i obiektów
Identyfikacja
związków
klas i obiektów
Identyfikacja
metod
i komunikatów
Identyfikacja
i definiowanie
pól
Autor: Katarzyna Ragin-Skorecka
5 z 40
za zarządzanie konfiguracją poszczególnych wersji systemu, złożonych z niezależnych
komponentów i plików. W perspektywie wdrożeniowej kładzie się nacisk na sprzęt, na którym
system zostanie uruchomiony.
Rys. 2.2. Perspektywy modelowania architektury systemu
System informatyczny to kombinacja oprogramowania i sprzętu zapewniająca rozwiązanie
problemu biznesowego. System dla klienta tworzą analitycy – odpowiedzialni za dokumentację
oraz programiści – zajmujący się napisaniem programu i jego wdrożeniem. Podstawowym
problemem podczas tworzenia oprogramowania jest właściwe zrozumienie wizji klienta
i przełożenie jej na język zrozumiały przez programistów.
3. WYBRANE METODY PROJEKTOWANIA STRUKTURALNEGO
Najbardziej rozpowszechnioną metodyką analizy strukturalnej jest metodyka opracowana
przez E. Yourdona. Metodyki strukturalne używają trzech rodzajów modeli do opisu systemu:
• model danych – opisujący obiekty w systemie i relacje pomiędzy nimi,
• model dynamiki – opisujący oddziaływania pomiędzy obiektami,
• model funkcjonalny – opisujący transformacje danych w systemie.
Model danych opisuje statyczną strukturę systemu, grupując dane w kolekcje zwane obiektami.
Odpowiednikiem graficznym tego modelu jest diagram ERD (Entinity Relationship Diagram
– diagram obiekt-relacja-atrybut).
Model dynamiki opisuje te aspekty systemu, które zmieniają się w czasie. Model ten używany
jest do specyfikacji aspektów kontrolnych (sterowania) w systemie. Graficznym odpowiednikiem
dla tego modelu jest diagram stanów (State Transition Diagram).
Model funkcjonalny opisuje transformacje wartości danych wewnątrz systemu. Odpowiednikiem
graficznym dla tego modelu jest diagram przepływu danych (DFD – Data Flow Diagram).
3.1. DIAGRAM PRZEPŁYWU DANYCH (DFD)
Model funkcjonalny specyfikuje rezultaty obliczeń bez odniesienia, kiedy i jak zostały one
wykonane. Jest on głównym modelem dla programów nieinteraktywnych, których głównym
zadaniem jest obliczanie wartości funkcji.
Diagram Przepływu Danych (Data Flow Diagram – DFD) służy do przedstawienia
funkcjonalnego modelu projektowanego systemu. Jest on grafem, którego węzły są procesami,
a łuki przepływami danych. Przedstawia on procesy, które transformują dane, przepływy danych,
Opracowanie
układu systemu
Rozmieszczenie
Dostarczenie
Instalacja
Scalanie systemu
Zarządzanie
konfiguracją
Perspektywa
procesowa
Perspektywa
wdrożeniowa
Perspektywa
implementacyjna
Perspektywa
projektowa
Perspektywa
przypadków
użycia
Słownictwo
Funkcjonalność
Zachowanie
Efektywność
Skalowalność
Przepustowość

Autor: Katarzyna Ragin-Skorecka
6 z 40
które przenoszą dane, terminatory oznaczające obiekty zewnętrzne (poza systemem) będące
źródłem danych wchodzących do systemu lub miejscem, gdzie wpływają dane wychodzące
z systemu oraz składy danych, gdzie dane są przechowywane pasywnie. Istotą diagramu jest
pokazanie rodzajów i kierunków przepływających danych.
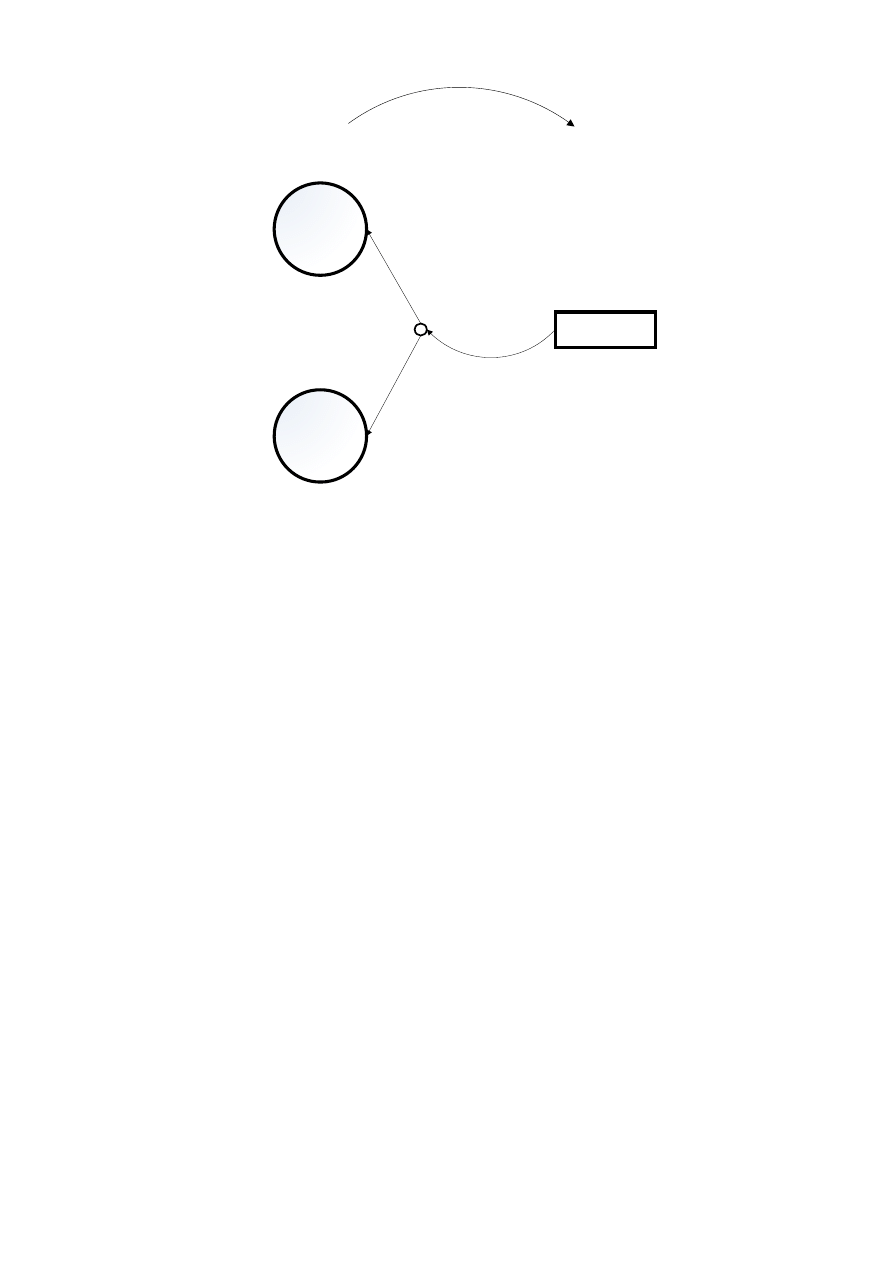
3.1.1. PROCES
Głównym elementem na DFD jest proces. Synonimem tej nazwy jest funkcja lub transformacja.
Proces pokazuje tę część systemu, która transformuje wejścia na wyjścia. Graficznie proces jest
reprezentowany przez okrąg (rys. 3.1). Nazwa procesu jest pojedynczym słowem, frazą lub prostym
zdaniem. Właściwą nazwą procesu w języku polskim powinna być fraza czasownikowa lub zdanie
zawierające taką frazę.
Rys. 3.1. Symbol procesu na diagramie przepływu danych
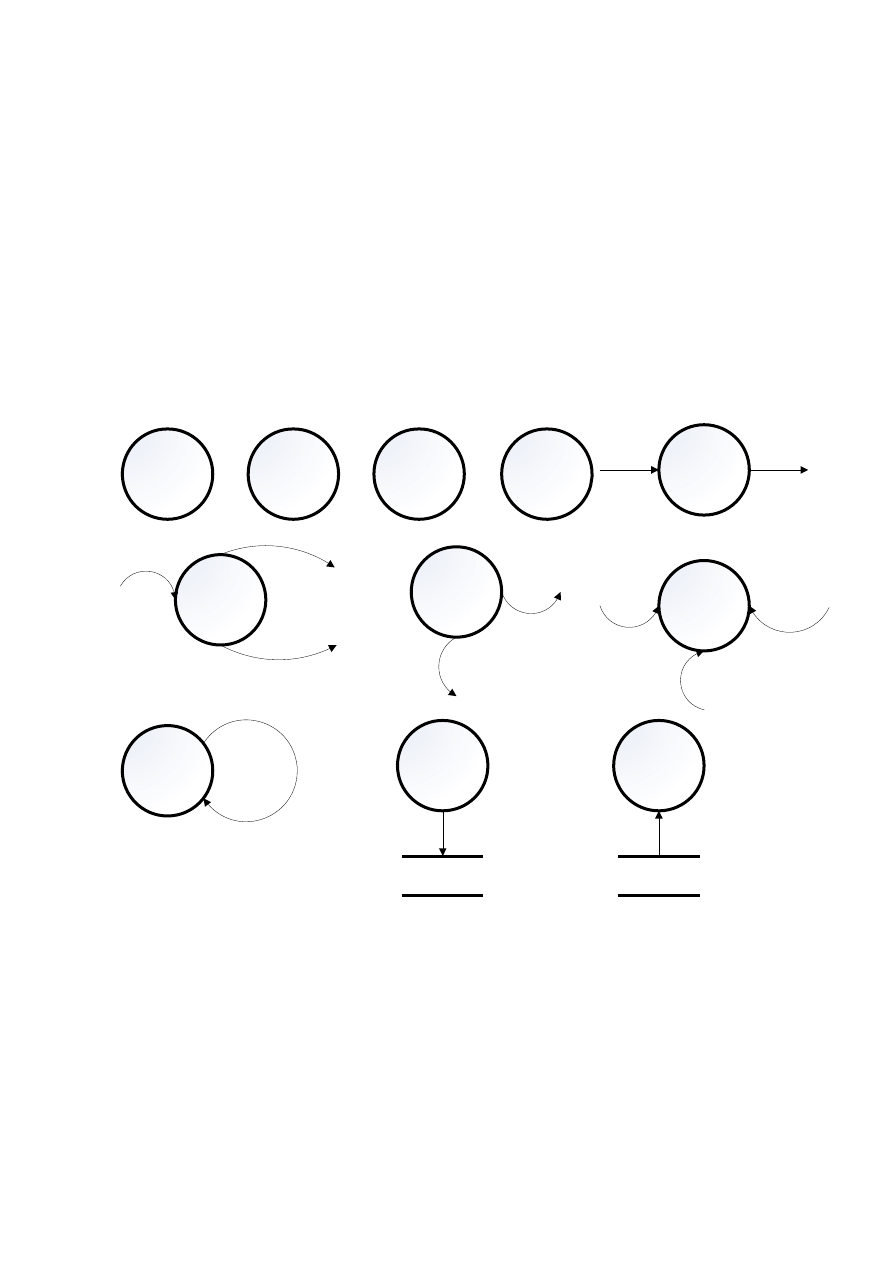
3.1.2. SKŁAD DANYCH
Skład danych (zbiór danych wewnętrznych) jest używany do modelowania kolekcji danych.
Notacją dla niego są dwie równoległe linie z jego nazwą w środku (rys. 3.2). Zwykle nazwa składu
danych jest liczbą mnogą nazwy pakietów, które wchodzą raz wychodzą ze składu danych.
Ten obiekt wprowadza się wtedy, gdy te same dane są wykorzystywane przez co najmniej dwa
różne procesy w rożnym czasie. Ten typ składu danych jest niezależny od technologii, jaka będzie
użyta w zaimplementowanym systemie.
Rys. 3.2. Symbol składu danych na diagramie przepływu danych
Zawartość składu danych nie zmienia się, jeśli pakiet informacji pobrano za pośrednictwem
przepływu. W przypadku przepływów do składu danych zmienia się jego zawartość.
3.1.3. PRZEPŁYW DANYCH
Przepływ jest używany do opisania ruchu porcji danych lub pakietów informacyjnych z jednej
części systemu do innej. Przepływy reprezentują dane w ruchu. Graficzną reprezentacją przepływu
danych jest strzałka wchodząca lub wychodząca z procesu (rys. 3.3). Dla większości systemów
przepływy danych reprezentują dane takie jak bajty, znaki, komunikaty, liczny
zmiennoprzecinkowe. Przepływy mogą się rozgałęziać lub zbiegać. Przypadek rozgałęziających się
przepływów danych (rys. 3.4) oznacza, że duplikaty porcji danych przesyłane są w różne miejsca
systemów albo, że złożony pakiet danych jest podzielony na kilka mniejszych, które są przesyłane
w rożne miejsca systemu.
1
Obliczanie
podatku
dochodowego
Zamówienia
Autor: Katarzyna Ragin-Skorecka
7 z 40
Rys. 3.3. Symbol przepływu danych na diagramie przepływu danych
Rys. 3.4. Przypadek rozgałęziającego się przepływu danych PLAN SPRZEDAŻY
(pozostałe przepływ danych nie zostały pokazane)
Przepływ wychodzący ze składu danych jest normalnie interpretowany jako czytanie lub dostęp
do informacji w zbiorze danych. W szczególności oznacza to, że:
• wyszukano i pobrano pojedynczy pakiet ze składu danych (np. rekord),
• wyszukano i pobrano więcej niż jeden pakiet ze składu danych,
• wyszukano i pobrano porcję jednego pakietu (np. pola rekordu),
• wyszukano i pobrano porcje więcej niż jednego pakietu /(np. niektóre pola wielu rekordów).
Jeżeli przepływ nie ma etykiety, oznacza to, że pełen pakiet informacji jest wyszukiwany
i pobrany (np. wszystkie rekordy). Jeżeli etykieta na przepływie jest taka sama jak na składzie
danych, ale w liczbie pojedynczej, to pobrano jedno wystąpienie pakietu. Jeżeli etykieta
na przepływie jest taka sama jak na składzie danych (liczba mnoga), to pobrano wielokrotne
wystąpienie pakietu ze składu. Jeżeli nazwa przepływu jest inna niż nazwa składu danych,
to pobrano jeden lub więcej komponentów jednego lub więcej wystąpień pakietu.
Przepływ do składu danych jest często interpretowany jako zapis, modyfikacja lub usunięcie.
W szczególności może oznaczać jedną z możliwości:
• jeden lub więcej pakietów dołożono do składu danych (funkcja append),
• jeden lub więcej pakietów usunięto ze składu danych,
• jeden lub więcej pakietów zmodyfikowano.
3.1.4. TERMINATOR (OBIEKT ZEWNĘTRZNY)
Terminator pokazuje obiekty zewnętrzne, z którymi komunikuje się system. Mogą nimi być:
osoba lub grupa osób, grupa komórek organizacyjnych wewnątrz organizacji, zewnętrzna
organizacja, inny system, użytkownik – wszystkie poza kontrolą projektowanego systemu.
Terminator jest reprezentowany graficznie przez prostokąt (rys. 3.5).
Zapytanie klienta
2.3
Kalkulacja
kosztów
zmiennych
2.4
Analiza progu
rentowności
Plan sprzedaży
Plan sprzedaży
Plan sprzedaży
Dział Marketingu

Autor: Katarzyna Ragin-Skorecka
8 z 40
Rys. 3.5. Symbol terminatora na diagramie przepływu danych
Terminatory znajdują się poza systemem, który jest modelowany, zawartość terminatora jest
poza dziedziną projektowania. Przepływy łączące terminatory do różnych procesów (lub składów
danych) reprezentują interfejsy pomiędzy systemem a światem zewnętrznym. Nie można pokazać
żadnej relacji, która istnieje pomiędzy terminatorami na DFD. Jeżeli istnieją jakieś relacje
pomiędzy terminatorami istotne dla projektowanego systemu, terminatory te stają się częścią
systemu i powinny być projektowane jako procesy.
3.1.5. PROJEKTOWANIE DFD
Przed rozpoczęciem tworzenia DFD należy określić, jakie funkcje ma realizować system,
w jakich procesach, przez jakie terminatory i z jakich składów danych powinno się korzystać.
Projektowanie zaczyna się od stworzenia diagramu kontekstu, który w kolejnych krokach
uszczegóławia się. Dzielenie funkcjonalności procesu ogólnego kończy się, gdy na diagramie
potomnym znajduje się jeden terminator.
Diagram kontekstu reprezentuje cały system jako pojedynczy proces oraz zewnętrzne
terminatory powiązane z nim przepływami. Diagram ten zawiera następujące ważne charakterystyki
systemu:
• osoby, organizacje albo systemy, z którymi komunikuje się system są terminatorami,
• określa te dane, które system otrzymuje z zewnętrznego świata i które muszą być
przetwarzane,
• określa dane wytwarzane przez system i przesyłane do zewnętrznego świata,
• określa składy danych, które rozdzielają system i terminatory.
Następnie diagram kontekstu rozbija się na serię kilku poziomów, wprowadzających więcej
szczegółów niż poziom wyżej. Przy rozwijaniu procesów na podpoziomy należy przestrzegać
następujących reguł:
• każdy poziom powinien zawierać nie więcej niż połowę ogólnej liczby procesów i składów
danych w systemie,
• prosty system powinien mieć nie więcej niż 2-3 poziomy, średni – 3-5 poziomów,
duży do 8 poziomów,
• nie wszystkie procesy (części systemu) muszą być rozwijane do tej samej liczby poziomów
(nie wszystkie mają równy stopień złożoności),
• składy danych na różnych poziomach powinny być pokazywane w następujący sposób:
o
pokaż skład na najwyższym poziomie, kiedy po raz pierwszy jest on użyty jako
interfejs pomiędzy dwoma procesami,
o
pokaż go następnie w każdym diagramie niższego rzędu, który dalej opisuje
lub rozwija te procesy,
• przepływy wchodzące i wychodzące z procesu na jednym poziomie muszą odpowiadać
przepływom wchodzącym i wychodzącym z całego diagramu na następnym, niższym
poziomie, który jest rozwinięciem tego procesu (bilansowanie względem DFD).
Kontrahent
Autor: Katarzyna Ragin-Skorecka
9 z 40
Jako nazwy dla procesów, terminatorów, składów danych, przepływów należy wybierać frazy
mające samodzielne znaczenie (proces powinien oznaczać nazwę wykonywanej funkcji). W nazwie
nie powinno być elementów wskazujących, jak dany proces jest realizowany.
Należy numerować procesy. Ich kolejność nie ma nic wspólnego z kolejnością ich wykonywania
przez system. Są natomiast podstawą do hierarchicznego numerowania schematów w przypadku
diagramów wielopoziomowych. Proces ogólny otrzymuje numer pojedynczy (np. 1, 2). Procesy
szczegółowe są numerowane zgodnie z zasadą: drugi poziom uszczegółowienia
NrProcesu.NrPodprocesuPoziomu1 (np. 1.1, 2.1, 2.2, 2.3, 2.4), trzeci poziom
NrProcesu.NrPodprocesuPoziomu1.NrPodprocesuPoziomu2 (np. 1.1.1, 1.1.2, 2.1.1), itd.
Należy wystrzegać się bardzo złożonych DFD, zawierających zbyt dużo procesów, składów
danych, terminatorów. Złożoność redukuje się poprzez rozbijanie go na wiele poziomów. Przyjmuje
się zasadę, że DFD nie powinien zawierać więcej niż 7-10 procesów. Wyjątkiem jest diagram
kontekstu.
Rys. 3.6. Typowe błędy popełniane przy projektowaniu diagramu przepływu danych
a) nie nazwany proces, b) umieszczenie warunku zamiast nazwy procesu, c), d) zła nazwa procesu, e) nie nazwany
proces i przepływy, f) nieprawidłowe rozdzielenie przepływów, g) brak wejść do procesu, h) brak wyjść z procesu,
i) przepływ z procesu do tego samego procesu, j) brak wejść do procesu i wyjścia z składu danych, k) brak wyjść
z procesu i wejścia do składu danych
Diagram przepływu danych powinien być logicznie spójny i spójny ze wszystkimi DFD
powiązanymi z nim. Typowe błędy popełniane przy projektowaniu DFD są pokazane na rys. 3.6.
Wynikają one z następujących zasad:
• należy unikać procesów, które mają tylko wejścia, natomiast nie posiadają żadnych wyjść,
• należy unikać procesów, które mają tylko wyjścia, natomiast nie posiadają żadnych wejść,
2
Jabłka
a)
1
IF X>3 GO
TO wynik
b)
c)
d)
3
Rekord klienta
e)
f)
7.3
Obliczenie AAA
XXX
AAA
AAA
g)
5
Naliczenie
odsetek
A
H
RR
h)
6
Naliczenie
odsetek
H
H
AA
j)
2.2
Obliczenie CC
2.2
Obliczenie CC
AAAAAA
AAAAAA
k)
PP
PP
i)
2.3
Kalkulacja
kosztów
zmiennych
CCC
Autor: Katarzyna Ragin-Skorecka
10 z 40
• należy unikać nie etykietowanych (nie nazwanych) przepływów i procesów,
• należy unikać składów danych takich, do których się tylko zapisuje, albo takich, z których
się tylko czyta; typowy skład danych powinien mieć wejścia i wyjścia.
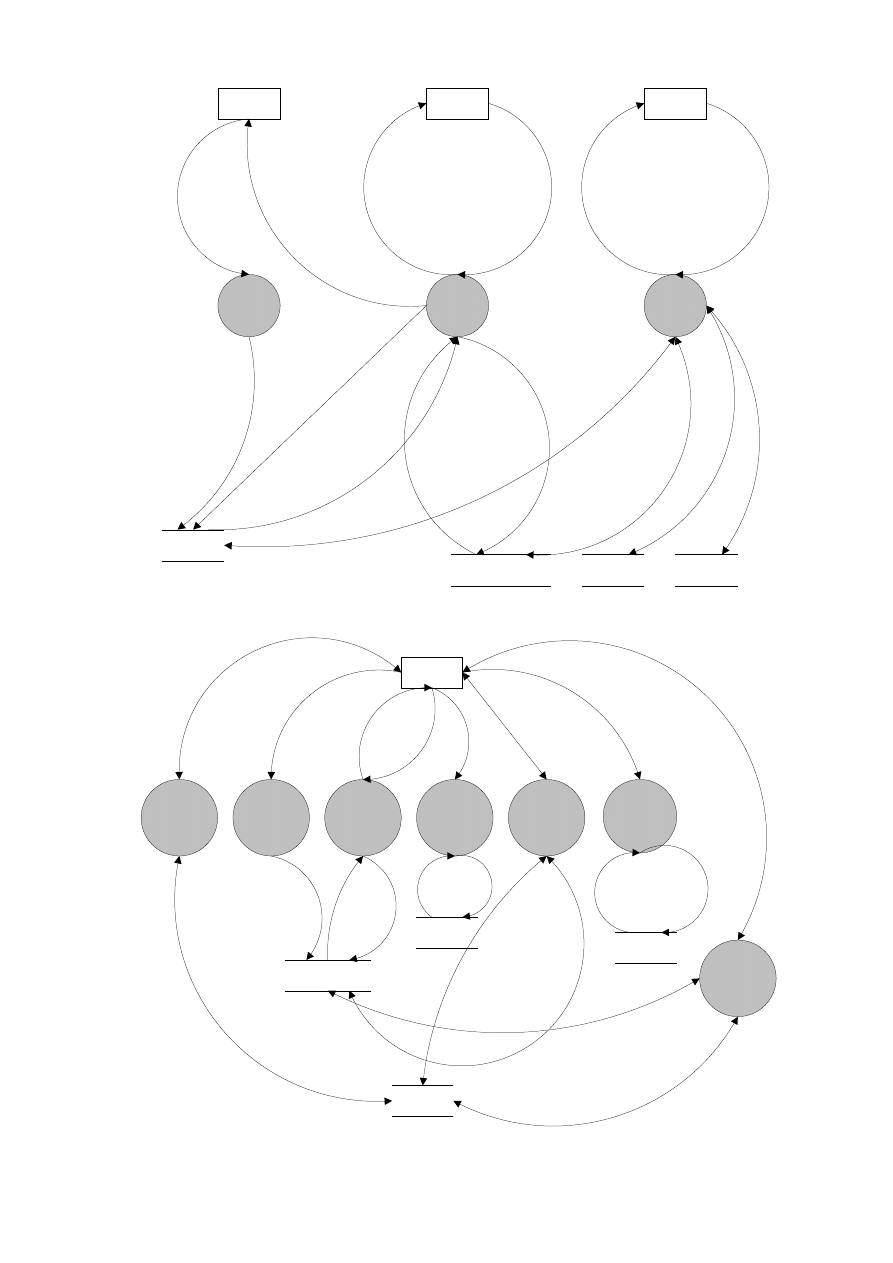
Rys. 3.7. Diagram kontekstu dla systemu rekrutacji na studia
Zawiadomienie o egzaminie
Zawiadomienie o decyzji
Rekrutacja
na studia
1
Kandydat
Dane
kandydatów
Sale
egzaminacyjne
Wzory
zawiadomień
Komisja
rekrutacyjna
Administrator
Wyniki postępowania
kwalifikacyjnego
Podanie
Dane kandydata
Raporty
Dane kandydata
Wyniki egzaminów
Kryteria przyjęcia
Zapytania SQL
Przydzielenie sal
Operacje na danych
Raporty
Operacje na danych
Limity przyjęć
Pojemność i dostępność sal
Wzory zawiadomień
Zapytania SQL
Wczytane podania
Dane kandydatów
Operacje na bazie danych
kandydatów
Dane do zapytań SQL
Operacje na bazie
danych zawiadomień
Operacje na bazie
danych wyników
Operacje na bazie
danych sal
Autor: Katarzyna Ragin-Skorecka
11 z 40
Rys. 3.8. Diagram pierwszego poziomu dla systemu rekrutacji na studia
Rys. 3.9. Wybrany diagram drugiego poziomu dla systemu rekrutacji na studia
Kryterium
Lista
Id osoby
Id osoby
Komisja
Rekrutacyjna
Weryfikacja
danych kandydata
1.2.1
Dodanie wyników
egzaminów
1.2.2
Podjęcie decyzji o
przyjęciu
kandydata
1.2.3
Przydzielenie sal
na egzamin
1.2.4
Definiowanie
zapytań
1.2.5
Drukowanie
zawiadomień
1.2.6
Wygenerowanie
standardowych list
kandydatów
1.2.7
Dane
kandydatów
Wyniki postępowania
rekrutacyjnego
Sale
egzaminacyjne
Wzory
zawiadomień
Końcowa ilość punktów
Ocena z egzaminu
Decyzja
Id osoby
Przedmiot
Zapytania SQL
Zestawienia
Rodzaj zawiadomienia
Dane kandydata
Rezerwacja
Data
Godzina
Przedmiot
Lokalizacja
Pojemność
Id osoby
Rodzaj
Korespondencja
seryjna
Id osoby
Ocena
Decyzja
Id osoby
Punkty
Zapytanie SQL
Zestawienia
Zapytanie SQL
zestawienia
Zapytanie SQL
Zestawienia
Zapytanie SQL
Zestawienia
Operacje na bazie danych
Operacje na bazie danych
Operacje
kandydata
1.1
Operacje
komisji
rekrutacyjnej
1.2
Operacje
administratora
1.3
Kandydat
Komisja
rekrutacyjna
Administrator
Dane
kandydatów
Sale
egzaminacyjne
Wzory
zawiadomień
Wyniki postępowania
rekrutacyjnego
Dane osobowe
Dane o ukończonej szkole
Dane o przedmiocie na
egzamin
Dane o wybranym kierunku
studiów
Sprawdzone dane kandydata
Wyniki postępowania
kwalifikacyjnego
Decyzja o przyjęciu
kandydata
Przydzielenie sal na egzamin
Zapytania SQL
Operacje na bazie danych
Zapytania SQL
Limit przyjęć
Wczytanie podań
Dane kandydata
Raporty
Dane kandydata
Dane o salach
Dane o zawiadomieniach
Raporty
Zawiadomienie o egzaminie
Zawiadomienie o decyzji
Dane osobowe
Dane o szkole
Dane o ocenach na
świadectwie
Przedmioty na egzamin
Kierunek studiów
Operacje na bazie danych
Dane o kandydatach
Raporty
Dane ze świadectwa
Id Osoby
Wybrany przedmiot
Ocena z egzaminu
Operacje na bazie danych
Operacje na bazie danych
Decyzja

Autor: Katarzyna Ragin-Skorecka
12 z 40
Diagram przepływu danych nie odpowiada na szereg pytań proceduralnych, takich jak: kiedy
dane wchodzą do procesu, czy przepływ danych jest wynikiem zapytania systemu, czy istnieje
współzależność pomiędzy przepływem wchodzącym a wychodzącym. Na te pytania powinny
odpowiedzieć inne diagramy, opisujące pozostałe aspekty systemu.
3.2. SPECYFIKACJA PROCESU
Specyfikacja procesu odnosi się do każdego najniższego (nierozkładalnego) procesu
na Diagramie Przepływu Danych. Jest to język opisu procesów występujących w projektowanym
lub modernizowanym systemie informatycznym.
Do specyfikacji procesów używane są konstrukcje tzw. „structured english”. Poniżej podano
listę kilkunastu czasowników zorientowanych na akcje, używanych jako słowa kluczowe
w konstrukcjach językowych specyfikujących proces:
• GET (ACCEPT, READ)
• PUT (DISPLAY, WRITE)
• FIND (SEARCH, LOCATE)
• ADD
• SUBTRACT
• MULTIPLY
• DIVIDE
• COMPUTE
• DELETE
• FIND
• VALIDATE
• MOVE
• REPLACE
• SET
• SORT.
W specyfikacji procesu używa się konstrukcji językowych podobnych do konstrukcji w językach
programowania. Można je wielokrotnie zagnieżdżać. Są to następujące instrukcje sterujące:
• IF warunek(1) THEN
zdanie(1)
ELSE
zdanie(2)
ENDIF
• DO CASE
CASE zmienna=wartosc(1)
zdanie(1)
CASE zmienna=wartosc(2)
zdanie(2)
...
CASE zmienna=wartosc(n)
zdanie(n)
Autor: Katarzyna Ragin-Skorecka
13 z 40
OTHERWISE
zdanie(n+1)
ENDCASE
• DO WHILE warunek(1)
zdanie(1)
ENDDO
• FOR zmienna(1)=wartosc(1) TO wartosc(2) STEP wartosc(3)
zdanie(1)
NEXT zmienna(1)
Proces: 1.2.3.1
Nazwa: Wyliczenie liczby punktów za świadectwo
Dane wejściowe: wczytane wybrane oceny ze świadectwa
Dane wyjściowe: ranking kandydatów ze względu na liczbę punktów ze świadectwa
OPEN baza danych z podaniami kandydatów
FOR i=1 TO Ilość Kandydatów STEP 1
FIND Kandydat o numerze i
N1=(O1+ O2+ O3+ O4+ O5+ O6+ O7)/7
N2=O8
N3=O9
N4=O10
N5=O11
IF (N1, N2, N3, N4, N5) < >0 THEN
NK=(N1+ N2+ N3+ N4+ N5)*100
Zapisz wynik
ELSE
Komunikat o błędzie
END IF
NEXT i
PRINT ranking ocen za świadectwo
CLOSE baza danych z podaniami kandydatów
Rys. 3.10. Przykład specyfikacji procesu
Wykorzystując tę metodę opisu systemu informatycznego należy dla każdego procesu podać:
indeks procesu (z diagramu DFD) i jego nazwę, dane wejściowe oraz dane wyjściowe. Następnie
przebieg procesu należy opisać słownie, wykorzystując elementy języków programowania. Opis ten
powinien łatwo dawać się przekształcić w algorytm (w postaci schematu blokowego).

Autor: Katarzyna Ragin-Skorecka
14 z 40
3.3. DIAGRAM OBIEKT-RELACJA-ATRYBUT (ERD)
Diagram obiekt-relacja-atrybut, zwany diagramem ERD (Entinity Relationship Diagram), jest
używany do modelowania danych, które są zwykle składowane w składach danych na diagramie
DFD. Diagram ERD jest konceptualną reprezentacją otaczającego świata, składającego się
z obiektów i relacji pomiędzy nimi. ERD definiuje informacje, którymi system zarządza, które
wytwarza, usuwa, a także relacjami, które utrzymywane są przez bazę danych. Diagram ten jest
grafem, którego węzły reprezentowane są przez obiekty (będące abstraktami świata rzeczywistego),
natomiast łuki odzwierciedlają relacje pomiędzy obiektami.
W diagramie ERD porcje informacji są zwykle grupowane w obiekty (entinity). Dla każdego
obiektu można podać listę jego atrybutów. Każdy obiekt jest zwykle powiązany relacjami z innymi
obiektami w systemie. Relacja między dwoma obiektami jest reprezentowana przez linię
i powiązanie. Powiązanie zawiera informację o stopniu relacji (cardinality), tzn. 1:1, 1:m, m:n.
Istnieje kilka najbardziej rozpowszechnionych notacji graficznych diagramów ERD, Notacje te
są w zasadzie równoważne i różnią się jedynie wyglądem symboli graficznych, dlatego do opisu
wybrano najbardziej rozpowszechnioną notację Martina.
3.3.1. TYPY OBIEKTÓW
Typ obiektu jest reprezentowany przez kolekcję (zbiór) obiektów (rzeczy) realnego świata.
W tym zbiorze każde wystąpienie ma następującą charakterystykę:
• każde wystąpienie musi być zdefiniowane naukowo,
• każde z nich pełni niezbędną rolę w budowanym systemie (system nie może działać
bez dostępu do wystąpień obiektu),
• każde wystąpienie może być opisane przez co najmniej jeden atrybut, z których każdy
ma swoją dziedzinę,
• te same atrybuty opisują każde wystąpienie tego samego typu obiektu.
Rys. 3.11. Typy obiektów na diagramie ERD według notacji Martina
Wystąpienie obiektu oznacza szczególny egzemplarz obiektu (np. Jan Kowalski jest
wystąpieniem obiektu OSOBA). Dziedzina jest listą dopuszczalnych wartości atrybutu lub grupy
atrybutów (np. cena, budżet mogą mieć dziedzinę „złoty”). Unikalny identyfikator to dowolna
kombinacja atrybutów lub relacji niezbędnych i wystarczających do wyizolowania pojedynczego
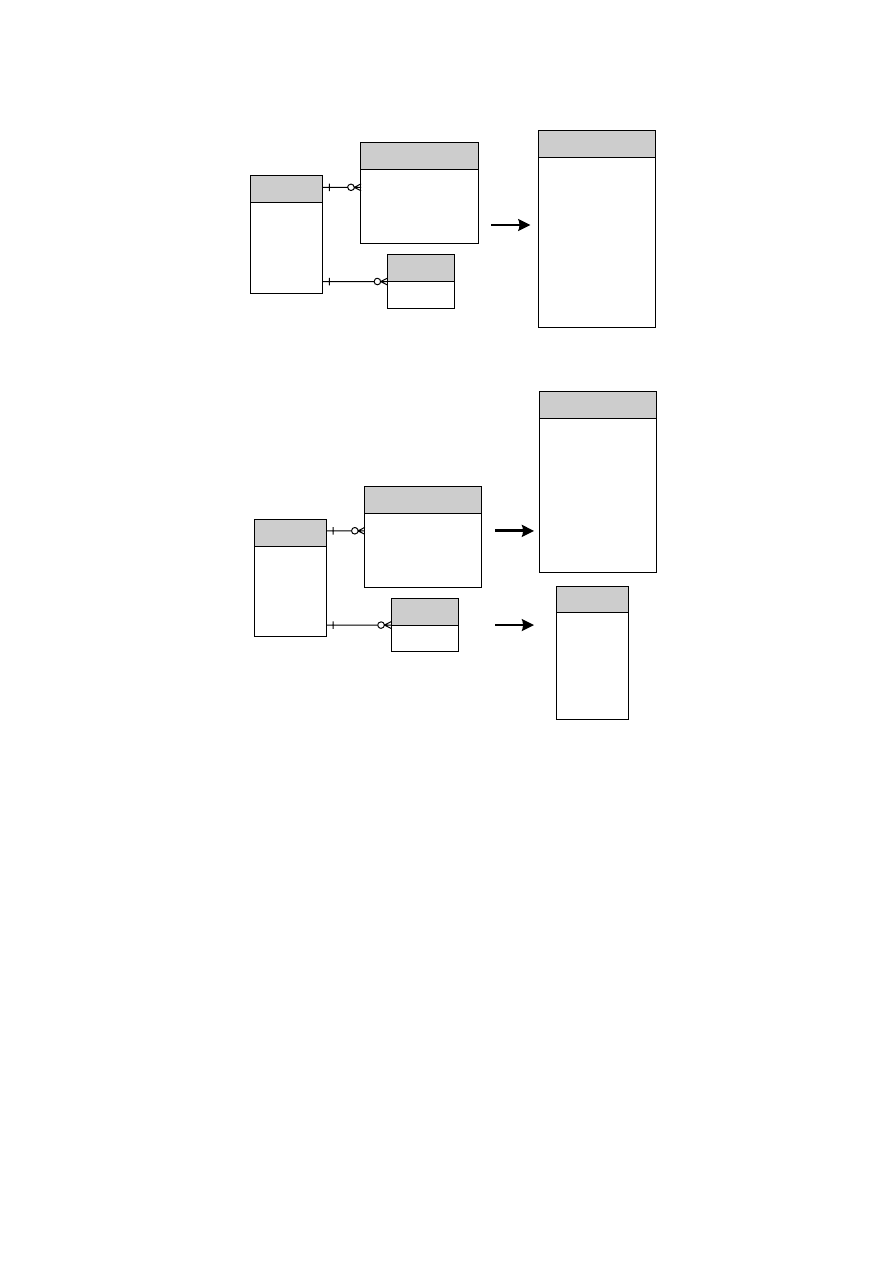
wystąpienia obiektu. Na diagramie ERD wyróżnia się trzy typy obiektów (rys. 3.11):
• obiekt – jest reprezentowany przez prostokąt i ma nazwę , która jest rzeczownikiem
w liczbie pojedynczej. Oznacza dowolny znaczący element, o którym informacja powinna
być znana lub utrzymywana. Obiektami mogą być fizycznie istniejące pojęcia (np. pojazd,
budynek) lub pojęcia abstrakcyjne (np. centrum kosztów, jednostka organizacyjna).
• słaby obiekt – jest reprezentowany przez prostokąt narysowany podwójną linią. Jest
obiektem, który może istnieć tylko wtedy, gdy jest podwiązany do innych obiektów. Słabe
obiekty mogą zależeć tylko od jednego wystąpienia obiektu i dlatego mogą być powiązane
relacją 1:1 lub 1:m w stosunku do tego obiektu. Słabymi obiektami są również obiekty,
Obiekt
Obiekt asocjacyjny
Obiekt słaby
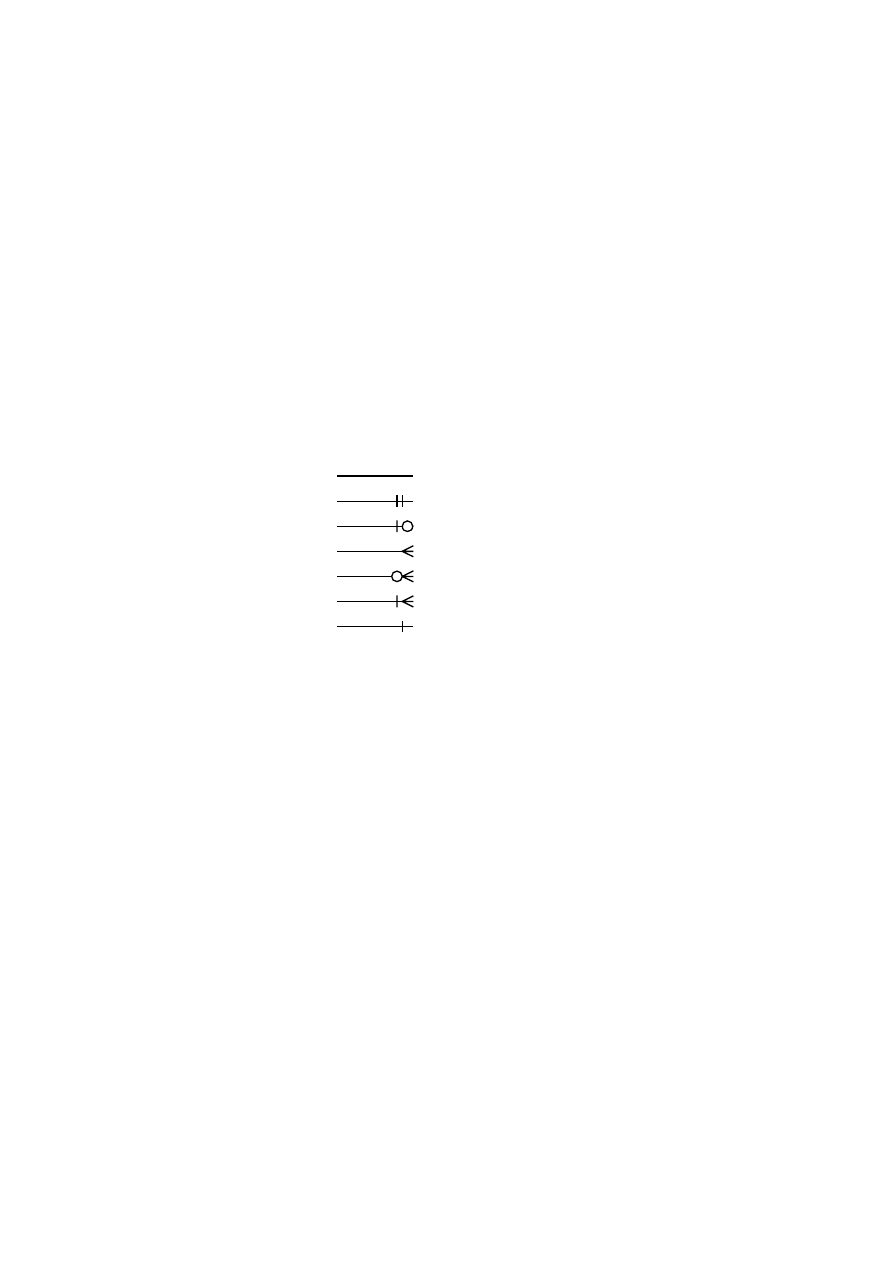
Autor: Katarzyna Ragin-Skorecka
15 z 40
które nie mają własnych atrybutów kluczowych i dlatego są zależne od innych obiektów.
Taki słaby typ obiektu ma częściowy klucz, który jest zdefiniowany jako minimalny zbiór
atrybutów, identyfikujący unikalnie ten obiekt do tego samego wystąpienia obiektu
właściciela.
• asocjacyjny obiekt – reprezentuje przypadek, gdy dwa obiekty są związane relacją,
natomiast trzeci obiekt (asocjacyjny obiekt) przechowuje informacje o relacji pomiędzy
nimi. Obiekty asocjacyjne są często używane do projekcji relacji n:m łączącej dwa obiekty
na dwie relacje 1:m i 1:n.
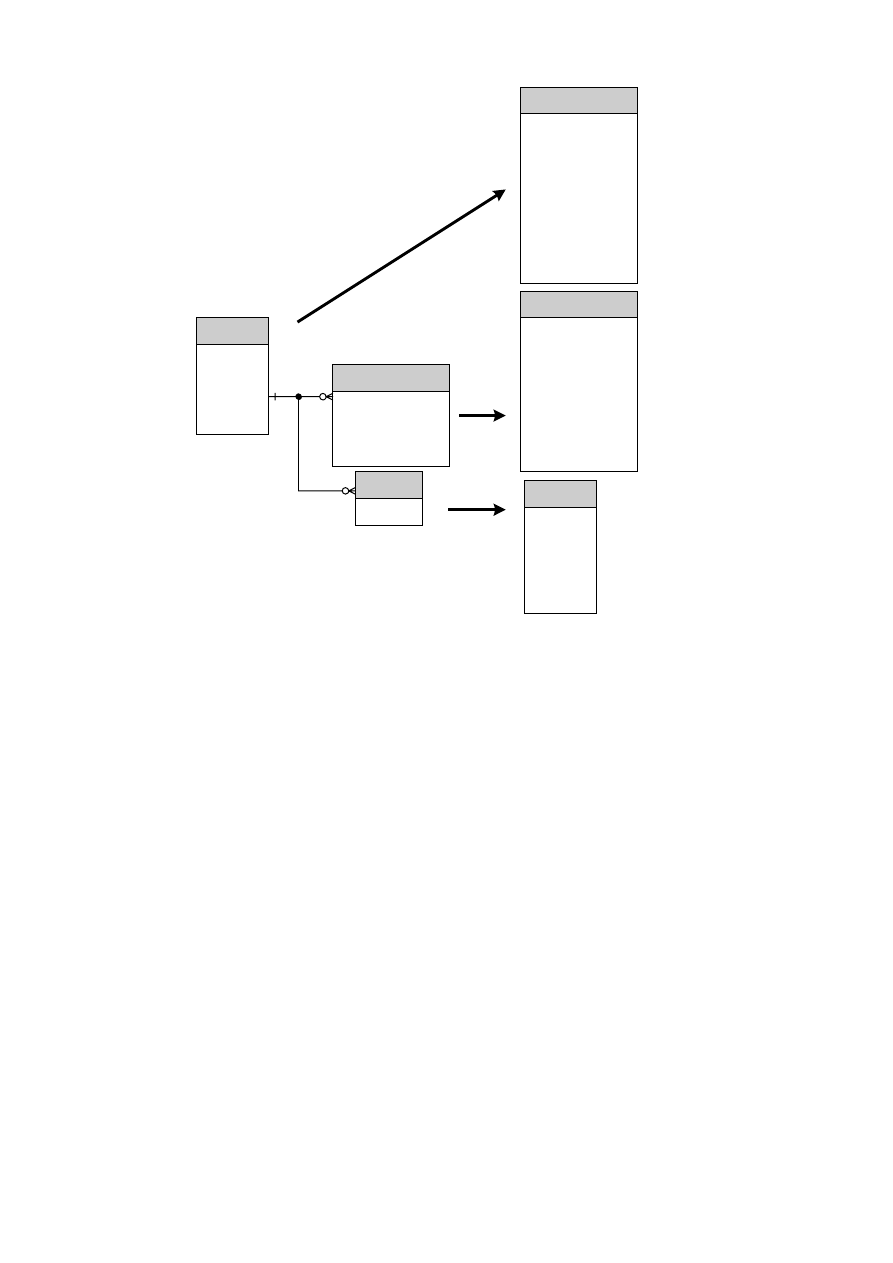
3.3.2. RELACJE
Relacja to nazwane powiązanie pomiędzy dwoma obiektami. Relacja wymaga pojedynczego
lub wielokrotnego wystąpienia obiektów biorących udział w relacji. Nazwa relacji wraz z nazwami
połączonych z nią obiektów stanowi zdanie o określonym znaczeniu, np.: FORMA-PRAWNA
dla PRZEDSIĘBIORSTWO (OBIEKT1 nazwa relacji OBIEKT2). Nazwy relacji powinny być tak
zbudowane, aby można było utworzyć semantykę przedmiotowej relacji.
Rys. 3.12. Symbole wzajemnego wykluczania, relacji, wskaźnika supertypu-subtypu według notacji Martina
Na rys. 3.12 pokazano możliwe zakończenia relacji. Znajdują się tam również wskaźniki
supertypu-subtypu. Supertyp jest to typ obiektu, który zawiera jedną lub więcej subkategorii,
podwiązanych za pomocą relacji. Subtypy danego obiektu muszą się wzajemnie wykluczać.
3.3.3. PROJEKTOWANIE DIAGRAMU ERD
Konceptualny model danych, którego odzwierciedleniem są diagramy ERD, przekształcany jest
w jeden z modeli baz danych: relacyjny, sieciowy, hierarchiczny. Nazywa się to projektowaniem
logicznym danych. Poniżej przedstawiono model relacyjny:
• ustalenie kluczy głównych i obcych,
• normalizacja danych,
• modelowanie tablic.
Dwa pierwsze etapy zostały omówione na wcześniejszych zajęciach z informatyki
(projektowanie baz danych). Omówienia wymaga etap trzeci.
Brak liczebności
1:1
0:1
M:N
0:M
1:M
Subtype
Autor: Katarzyna Ragin-Skorecka
16 z 40
Rys. 3.13. Mapowanie struktur supertyp-subtyp na pojedynczą tablicę
Rys. 3.14. Mapowanie struktur supertyp-subtyp na oddzielne tablice
Osoba
Nazwisko
Tytuł
Płeć
Adres
DataUr
Pracownik
IdPracownika
DataZatrudnienia
Stanowisko
Wynagrodzenie
Klient
IdKlienta
LUDZIE
NrOsoby
Typ
Nazwisko
Tytuł
Płeć
Adres
DataUr
Wynagrodzenie
Stanowisko
DataZatrudnienia
Osoba
Nazwisko
Tytuł
Płeć
Adres
DataUr
Pracownik
IdPracownika
DataZatrudnienia
Stanowisko
Wynagrodzenie
Klient
IdKlienta
PRACOWNICY
IdPracownika
Nazwisko
Tytuł
Płeć
Adres
DataUr
DataZatrudnienia
Stanowisko
Wynagrodzenie
KLIENCI
IdKlienta
Nazwisko
Tytuł
Płeć
Adres
DataUr
Autor: Katarzyna Ragin-Skorecka
17 z 40
Rys. 3.15. Mapowanie relacji wzajemnego wykluczania się dla subtypów
Stworzenie końcowego diagramu ERD wymaga określenia kluczy głównych i dokonania
normalizacji danych. Następne kroki są następujące:
• mapowanie prostych obiektów (pozbawionych subtypów) – obiekt staje się tablicą, jej
nazwa to nazwa obiektu w liczbie mnogiej; każdy atrybut staje się kolumną, unikalny
identyfikator obiektu staje się kluczem głównym,
• mapowanie relacji – relacje są implementowane przez mapowanie ich na klucze obce,
• mapowanie struktur supertyp-subtyp (rys. 3.13, 3.14, 3.15) – projektowanie oddzielnej,
oddzielnych tablic, lub interpretacja subtypów poprzez relację wzajemnego wykluczania się,
4. WYBRANE JĘZYKI PROJEKTOWANIA OBIEKTOWEGO – UML
UML (Unified Modelling Language – zunifikowany język modelowania) został wymyślony
przez G. Boocha, J. Rambaugha i I. Jacobsona w połowie lat 90. Powstał on z potrzeby stworzenia
notacji, którą analitycy, twórcy oprogramowania i klienci zaakceptowaliby jako standardową. Język
ten miał umożliwić stworzenie planu systemu informatycznego zrozumiałego przez każdą ze stron
projektu. Dodatkowo narzucił potrzebę częstych i szczegółowych konsultacji podczas
identyfikowania problemu biznesowego.
UML jest językiem projektowania wysokiego poziomu służącym do wizualnego modelowania
systemów informatycznych. Pozwala on na tworzenie planów systemów informatycznych w sposób
LUDZIE
NrOsoby
Typ
Nazwisko
Tytuł
Płeć
Adres
DataUr
Wynagrodzenie
Stanowisko
DataZatrudnienia
Osoba
Nazwisko
Tytuł
Płeć
Adres
DataUr
Pracownik
IdPracownika
DataZatrudnienia
Stanowisko
Wynagrodzenie
Klient
IdKlienta
PRACOWNICY
IdPracownika
Nazwisko
Tytuł
Płeć
Adres
DataUr
DataZatrudnienia
Stanowisko
Wynagrodzenie
KLIENCI
IdKlienta
Nazwisko
Tytuł
Płeć
Adres
DataUr

Autor: Katarzyna Ragin-Skorecka
18 z 40
zrozumiały i przejrzysty. Zastosowanie standardowych technik opisu wymagań i ograniczeń
projektu ułatwia efektywną wymianę informacji i zdecydowanie poprawia zdefiniowanie wymagań
klienta.
UML zawiera elementy graficzne grupowane w postaci diagramów oraz zasady łączenia tych
elementów. Celem diagramów jest pokazanie wielu perspektyw systemu. W ten sposób tworzymy
model, który opisuje co system ma robić (ale nie określa jak system ma być zaimplementowany).
4.1. DIAGRAM KLAS
Klasy to słownik i terminologia określonego zakresu wiedzy. Klasa to kategoria lub grupa
rzeczy, które mają podobne atrybuty i wspólne zachowania.
W UML-u ikona klasy to prostokąt (rys. 4.1). Jest on podzielony na trzy pola. W części
najwyższej jest umieszczona nazwa klasy, w środkowej jej atrybuty, w najniższej działania
(czynności). Diagram klas składa się z pewnej liczby takich ikon połączonych liniami
wskazującymi zależności między klasami.
+przyjmijNaStudia()
+zdajEgzamin()
+zaliczSesję ()
+chodźNaZajęcia()
-numerAlbumu : Integer
-imię : String
-nazwsko : String
-adres : String
-kod : String
-miasto : String
-wku : Boolean
Student
Rys. 4.1. Ikona klasy
Zgodnie z konwencją nazwą klasy jest słowo pisane z wielkiej litery. Jeżeli nazwa klasy składa
się z kilku wyrazów, każde słowo pisane jest z dużej litery i bez odstępu, np: TerminZaliczenia.
Klasy, które nie posiadają żadnych obiektów nazywamy klasami abstrakcyjnymi. Ich nazwy
piszemy kursywą (np. Klasa).
Jeżeli chcemy ująć nazwę klasy i jej należność do konkretnego pakietu, to w prostokącie
umieszczamy nazwę pakietu, a nazwę klasy po podwójnym dwukropku z prawej strony (rys. 4.2).
Tak zapisana nazwa klasy, to nazwa ścieżkowa.
Maszyny Tokarskie::TKD20
Rys. 4.2. Klasa i jej nazwa ścieżkowa
Atrybut jest właściwością klasy. Opisuje zakres wartości, które można przypisywać
do poszczególnych obiektów klasy. Zgodnie z konwencją jednowyrazowy atrybut pisany jest
z małej litery. Jeżeli nazwa składa się z większej liczby wyrazów, są one łączone i wszystkie poza
pierwszym rozpoczynają się z wielkiej litery. W ikonie klasy można podać specyfikację typu
wartości atrybutu (patrz rys. 4.1), np. string (napis), real (liczba zmiennoprzecinkowa), integer
(liczba całkowita), boolean (wartość logiczna), itd.
Operacja to działanie (czynność), które może wykonać klasa lub które na danej klasie może
wykonać osoba albo inna klasa. Nazwa operacji jest pisana z małej litery. Jeżeli składa się
z większej liczby wyrazów, to słowa należy połączyć i napisać z wielkiej litery oprócz wyrazu
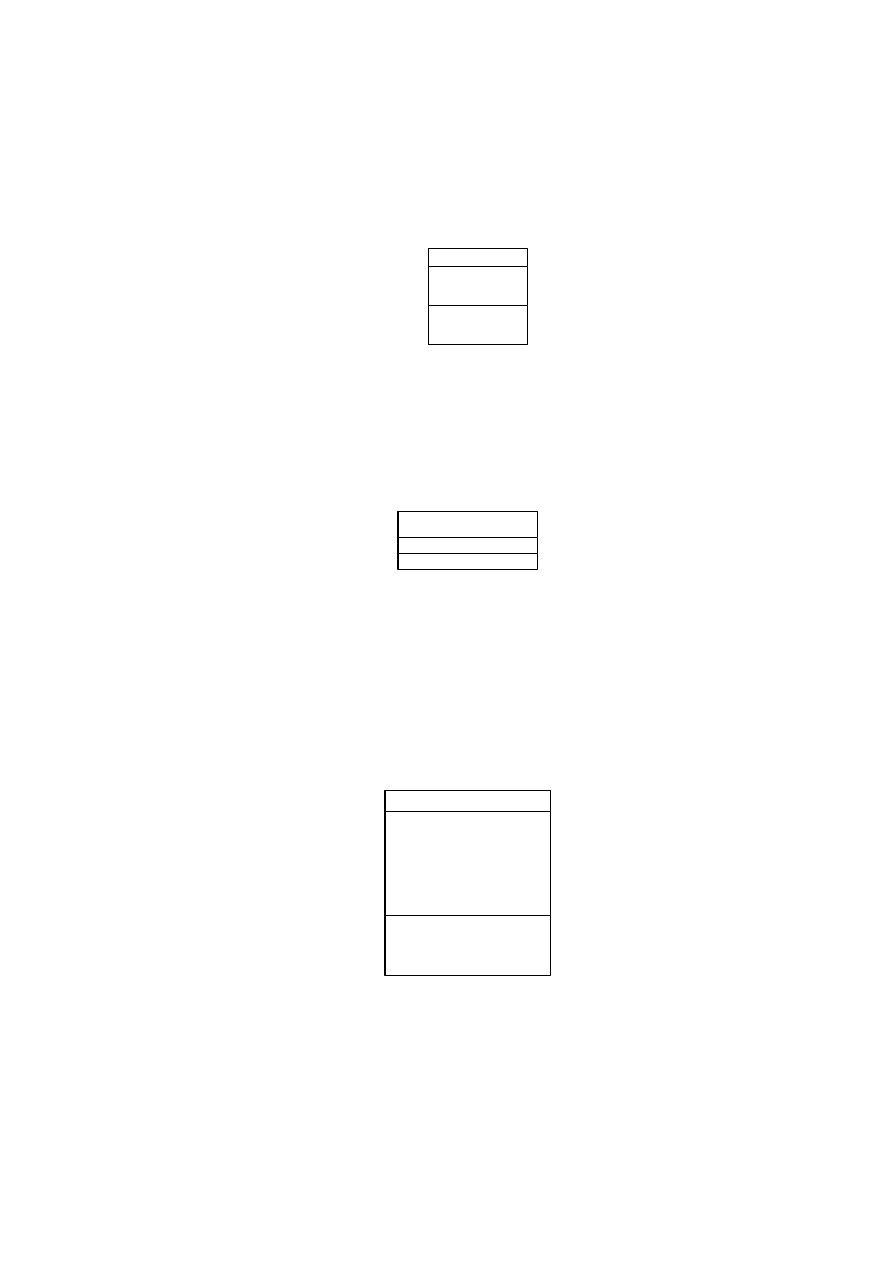
Autor: Katarzyna Ragin-Skorecka
19 z 40
pierwszego. Do operacji można dołączyć dodatkowe informacje. W nawiasie należy umieścić
parametr, będący podstawą działania operacji oraz jego typ.
W praktyce mamy do czynienia z większą liczba klas. W tym przypadku
nie ma uzasadnienia pokazywanie wszystkich atrybutów każdej klasy, gdyż może doprowadzić to
do nieczytelności diagramu. Wystarczy przedstawić część atrybutów i operacji lub te elementy
w ogóle pominąć (rys. 4.3).
+przygotuj()
+sprawdź()
+...()
-przedmiot
-egzaminator
-...
Egzamin
Rys. 4.3. Ikona klasy bez wymienienia wszystkich atrybutów i operacji
W przypadku, gdy lista atrybutów jest długa można wykorzystać stereotypy. Stereotypy
pozwalają na tworzenie elementów specyficznych dla problemu, pozwalają przekształcać istniejące
elementy w inne. Są one przedstawiane w postaci nazwy ujętej w podwójne nawiasy kątowe
(rys. 4.4).
«type»
UrządzenieElektryczne
Rys. 4.4. Przykład zastosowania stereotypu
Ikona klasy pozwala na podanie jeszcze jednego typu informacji. W obszarze pod listą operacji
można wymienić zobowiązania klasy. Zobowiązanie to opis tego, co klasa ma robić (czyli zadań
do realizacji których mają służyć atrybuty i operacje).
Dodatkowo można umieszczać ograniczenia. Jest to tekst zapisany w nawiasach klamrowych.
Ograniczenie określa jedna lub więcej zasad obowiązujących dana klasę (rys. 4.5). Do klas można
dołączać dodatkowe informacje. Są to notatki. Dotyczą one atrybutów i operacji.
+przyjmijNaStudia()
+zdajEgzamin()
+zaliczSesję ()
+chodźNaZajęcia()
-numerAlbumu : Integer
-imię : String
-nazwsko : String
-adres : String
-kod : String
-miasto : String
-wku : Boolean
Student
Rys. 4.5. Przykład ograniczenia
Podczas rozmów z klientem lub ekspertem z danej dziedziny poznajemy rzeczowniki, które
mogą stać się klasami lub atrybutami i czasowniki, które mogą zostać operacjami. Tworząc projekt
systemu informatycznego należy wykorzystywać informacje zebrane u nabywcy.
{numerAlbumu = 5 cyfr}
Autor: Katarzyna Ragin-Skorecka
20 z 40
4.2. DIAGRAM OBIEKTÓW
Obiekt to egzemplarz należący do klasy. Jest to konkretny element klasy, posiadający konkretne
atrybuty i operacje.
numerAlbumu = 65632
imię = Anna
nazwsko = Nowak
adres = Kocia 2
kod = 60-620
miasto = Poznań
wku = nie dotyczy
Osoba1 : Student
Rys. 4.6. Ikona obiektu
UML-owa reprezentacja obiektu to prostokątna ikona z podkreśloną nazwą (rys. 4.6). Nazwa
egzemplarza podana jest przed dwukropkiem, a nazwa klasy – po dwukropku.
4.3. ZWIĄZKI KLAS
Zdefiniowanie klas, które wystąpią w tworzonym oprogramowaniu jest pierwszym krokiem
tworzenia modelu systemu. Oddzielnie istniejące klasy należy ze sobą powiązać, stworzyć relacje.
Istnieją następujące związki między klasami: powiązania, liczebność, powiązania kwalifikowane,
powiązania zwrotne, dziedziczenie i uogólnienie, zależność, agregacje, agregacje całkowite,
interfejsy i realizacje.
4.3.1. POWIĄZANIA
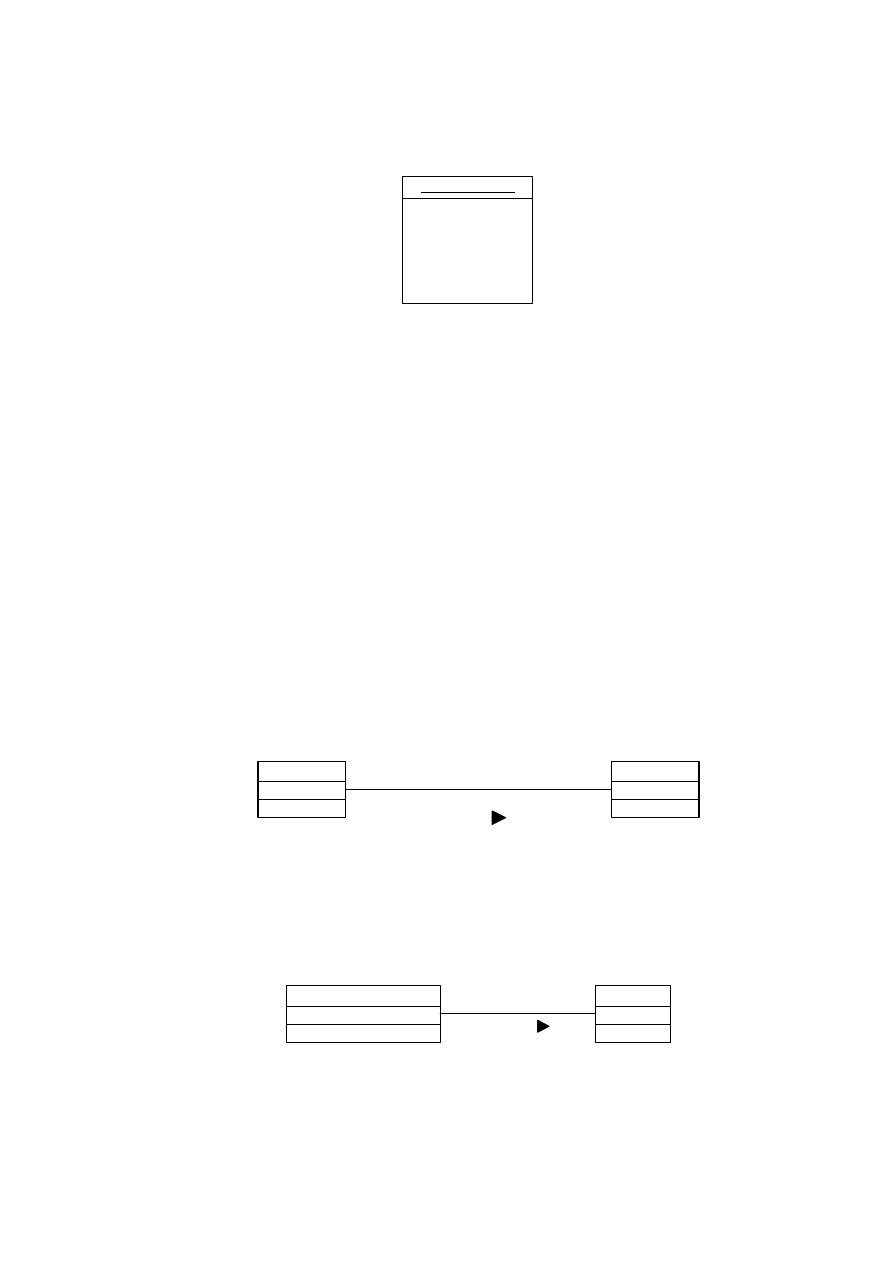
Powiązanie występuje wtedy, gdy między klasami istnieje związek znaczeniowy. Przedstawiamy
je jako linię łączącą dwie klasy z nazwą związku wypisaną nad linią. Należy też pokazywać zwrot
związku przy wykorzystaniu wypełnionego trójkąta skierowanego we właściwą stroną (rys. 4.7).
Obok klas można umieścić opisy związane z rolą spełniana w tym związku.
Zawodnik
Drużyna
Pracownik
Pracodawca
Gra w
Rys. 4.7. Przykład powiązania między klasami
Czasami powiązanie pomiędzy dwiema klasami musi spełniać pewne wymagania. Określamy
je przez opisanie w pobliżu linii powiązania. Na rysunku 4.8 przedstawiono dwie klasy
ObsługaTelefonicznaBanku oraz Klient i powiązanie pomiędzy nimi ograniczone kolejnością
połączenia {ordered}
ObsługaTelefonicznaBanku
Klient
Obsługuje
{ordered }
Rys. 4.8. Powiązanie z nałożonym ograniczeniem
Innym typem ograniczenia jest związek {or} zapisany na linii przerywanej, łączącej linie dwóch
powiązań. Jest to powiązanie określające wybór jednej z dwóch możliwości (rys. 4.9).
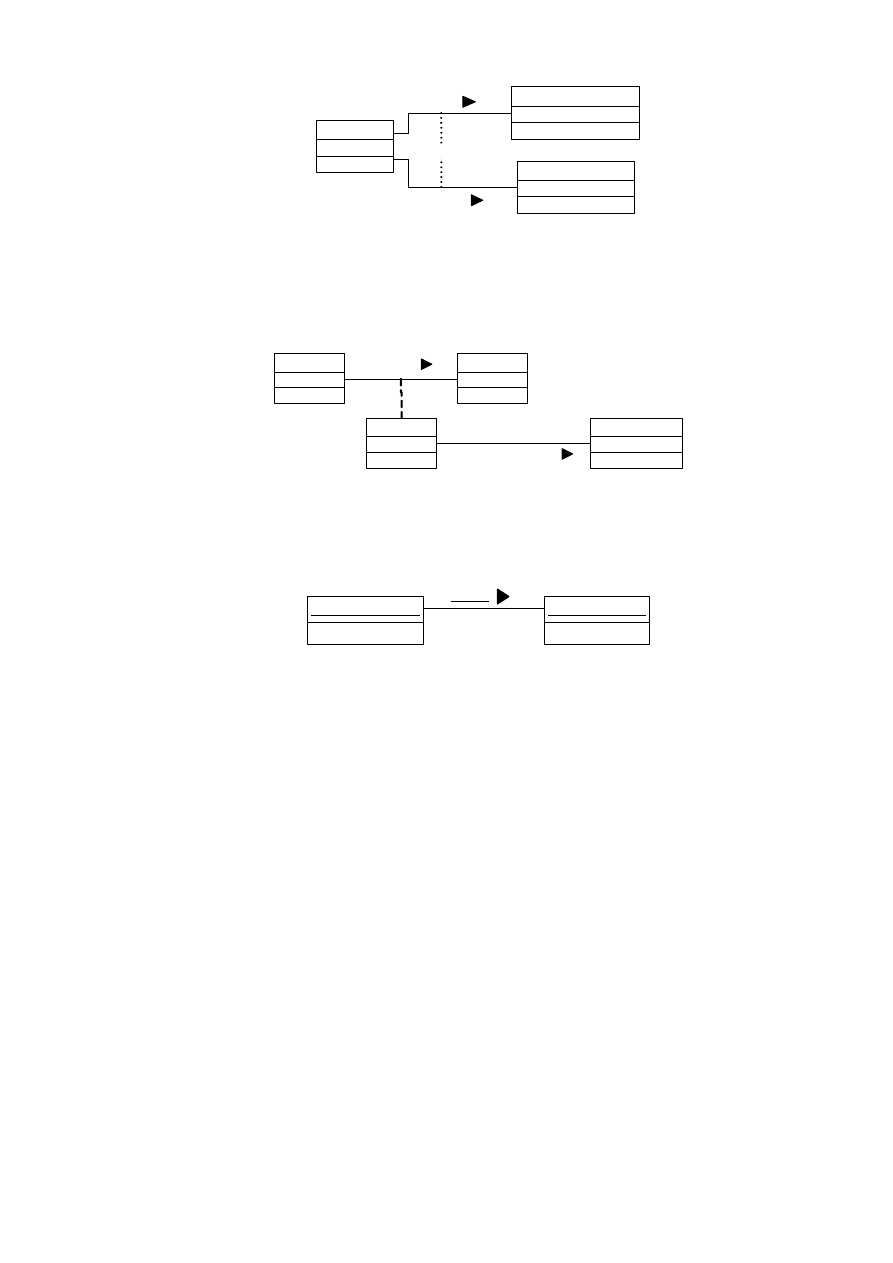
Autor: Katarzyna Ragin-Skorecka
21 z 40
Student
KierunekEkonomiczny
KierunekTechniczny
Wybiera
Wybiera
{OR}
Rys. 4.9. Związek {or} między dwoma powiązaniami
Powiązanie może mieć atrybuty i operacje, tak samo jak klasa. W tym przypadku mamy
do czynienia z klasą powiązania. Oznaczamy ją jako prostokątną ikonę, połączoną linią przerywaną
z linią powiązania (rys. 4.10).
Zawodnik
Drużyna
Gra w
Kontrakt
GłównyMenadżer
Negocjowany przez
Rys. 4.10. Przykład klasy powiązania
Klasa powiązania może być powiązana z innymi klasami. Jest to przedstawione na rysunku
powyżej.
jan nowak : Zawodnik
poznania : Drużyna
Gra w
Rys. 4.11. Przykład wiązania
W przypadku powiązania dwóch obiektów, mówimy o wiązaniu. Przedstawiamy je w postaci
linii łączącej dwa obiekty, a nazwę wiązania podkreślamy (rys. 4.11).
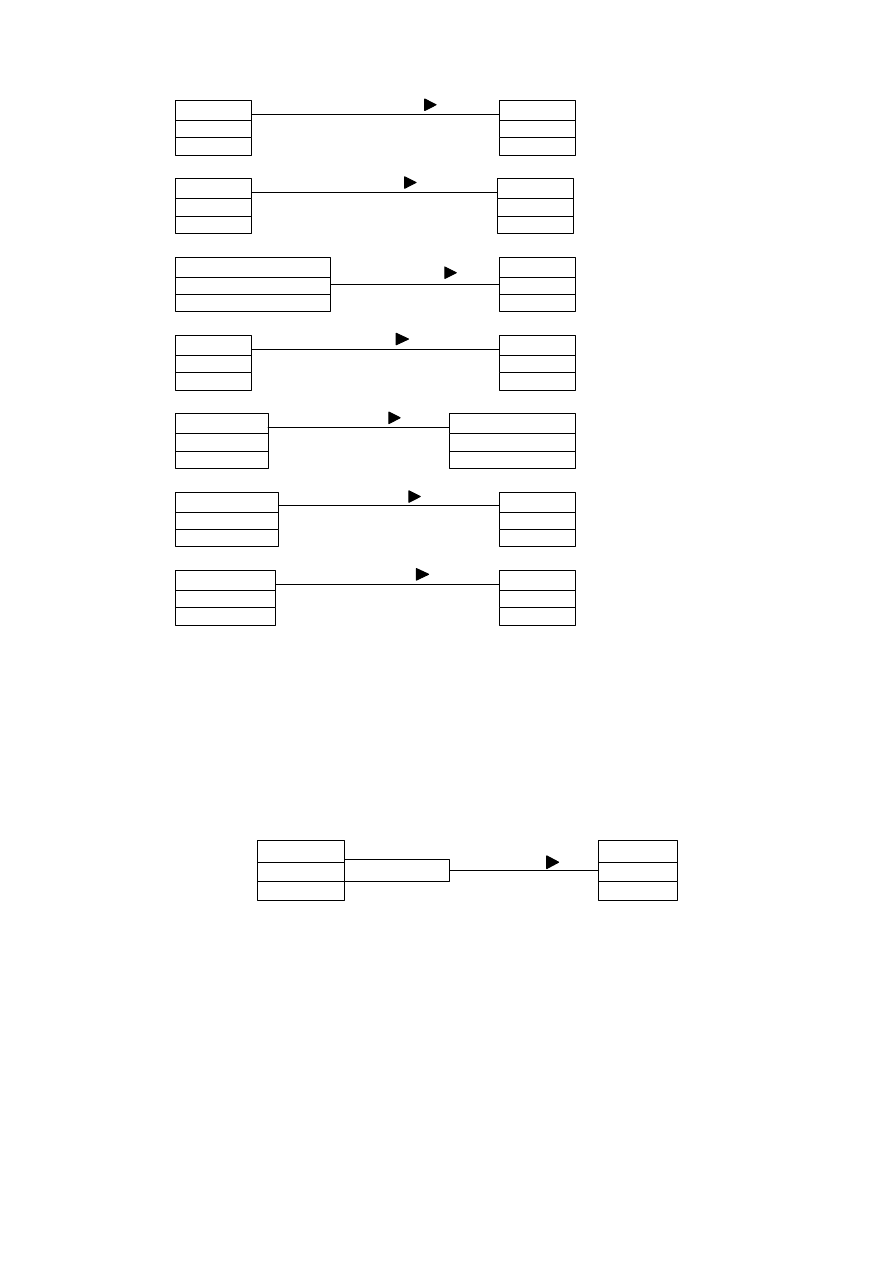
4.3.2. LICZEBNOŚĆ
Liczebność określa ilość obiektów jednej klasy powiązanych z określoną ilością drugiej klasy.
Na rysunku 4.12 są pokazane przykłady oznaczania liczebności w konkretnych powiązaniach.
Autor: Katarzyna Ragin-Skorecka
22 z 40
Mąż
Żona
1
1
Jest ożeniony z
Jeden-do-jednego
Nauczyciel
Uczeń
1
*
Naucza
Jeden-do-wielu
ObsługaTelefonicznaBanku
Klient
1
1...*
Obsługuje
Jeden-do-jednego
lub więcej
Dom
Komin
StudentDzienny
GodzinaObowiązkowa
RowerTrzykołowy
Koło
PojamnikNaJajka
Jajko
Jeden-do-zera
lub jednego
Jeden-do-
od 12 do 18
Jeden-do-trzech
Jeden-do-6 lub 10
1
0,1
1
12...18
1
3
1
6,10
Ma
Zalicza
Ma
Zawiera
Rys. 4.12. Przykłady liczebności
4.3.3. POWIĄZANIA KWALIFIKOWANE
W przypadku powiązania o liczebności jeden-do-wielu należy uwzględnić problem
wyszukiwania. Gdy obiekt z jednej klasy ma wybrać obiekt z drugiej klasy, przy czym ma być
spełniony szczególny warunek, jest on zazwyczaj określany przez specjalny atrybut powiązania.
Tym atrybutem jest zwykle jakiś identyfikator (np. numer zamówienia).
Recepcjonista
Rezerwacja
1
*
Numer rezerwacji
Znajduje
Rys. 4.13. Kwalifikator powiązania
W UML-u informacja identyfikująca nazywana jest kwalifikatorem. Jej symbolem jest niewielki
prostokąt umieszczony na linii powiązania od strony klasy dokonującej wyszukiwania (rys. 4.13).
Stosowanie kwalifikatora redukuje liczebność powiązania jeden-do-wielu do liczebności
jeden-do-jednego.
4.3.4. POWIĄZANIA ZWROTNE
Mogą zachodzić przypadki powiązania klasy samej ze sobą wtedy, gdy obiekty klasy mogą
pełnić różne role. Nazywamy to powiązaniem zwrotnym. Przedstawiamy to na diagramie kreśląc
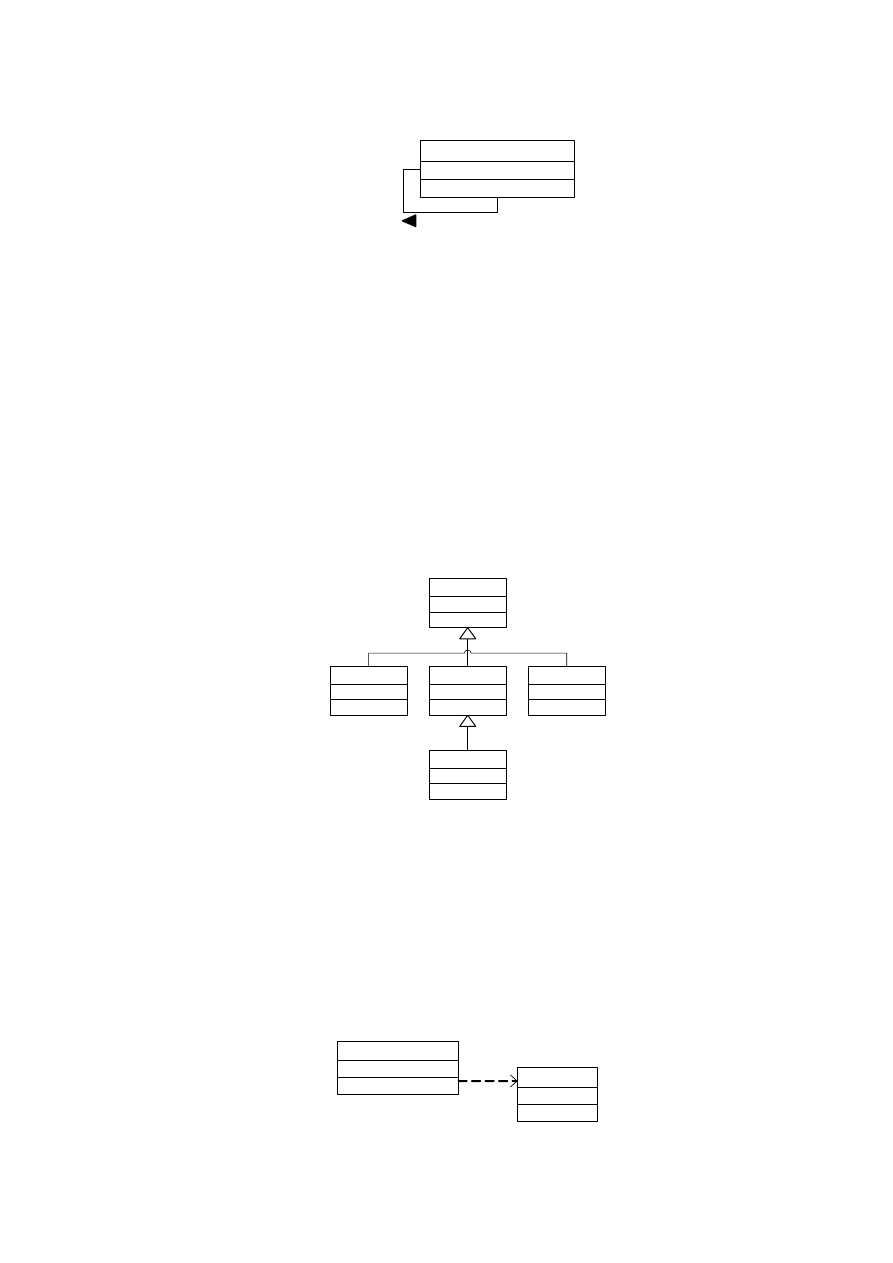
Autor: Katarzyna Ragin-Skorecka
23 z 40
linię powiązania od prostokątnej ikony klasy z powrotem do tej ikony. Na tej linii powiązania
zaznaczamy rolę obiektów i nazwę powiązania, jego zwrot i liczebność.
UżytkownikSamochodu
1
0..4
kierowca
pasażer
wiezie
Rys. 4.14. Przykład powiązania zwrotnego
Na rysunku 4.14 przedstawiono przykład powiązania zwrotnego. UżytkownikSamochodu może
być pasażerem lub kierowcą. Użytkownik pełniący rolę kierowcy wiezie zero lub więcej pasażerów.
4.3.5. DZIEDZICZENIE I UOGÓLNIENIE
Dziedziczenie (uogólnienie) polega na dziedziczeniu atrybutów klasy nadrzędnej (nadklasa,
przodek) przez klasę podrzędną (podklasa, potomek). Nadklasa jest klasą ogólniejszą od podklasy.
Ogólnie mówiąc potomek może być podstawiony za przodka. Oznacza to, że potomek może
wystąpić wszędzie tam, gdzie występuje przodek. Stwierdzenie odwrotne nie jest prawdziwe.
Hierarchia dziedziczenia może dotyczyć większej ilości poziomów. Podklasa jednej klasy może
być nadklasą innej klasy. Na linii łączącej podklasę z nadklasą umieszczamy niewypełniony trójkąt
wskazujący nadklasę (rys. 4.15). Ten rodzaj połączenia oznacza zwrot „jest rodzajem”.
Zwierzę
Płaz
Ssak
Gad
Koń
Rys.4.15. Hierarchia dziedziczenia w królestwie zwierząt
Klasa może nie mieć nadklasy (przodka) i wówczas nazywamy ja klasą-korzeniem. Klasa, która
nie ma podklasy (potomka), to klasa-liść. Jeżeli klasa ma dokładnie jednego przodka, to mówimy
o dziedziczeniu pojedynczym, a jeżeli przodków jest więcej – o multidziedziczeniu.
4.3.6. ZALEŻNOŚCI
Zależność występuje wtedy, gdy jedna klasa używa innej klasy. Najczęściej zaznaczamy to,
stosując nazwę jednej klasy w sygnaturze drugiej.
+wyświetlFormularz()
System
Formularz
Rys. 4.16. Przykład zależności
Autor: Katarzyna Ragin-Skorecka
24 z 40
Na diagramie zależność jest przedstawiana jako linia przerywana łącząca dwie zależne klasy.
Grot strzałki wskazuje na klasę, od której druga klasa zależy (rys. 4.16).
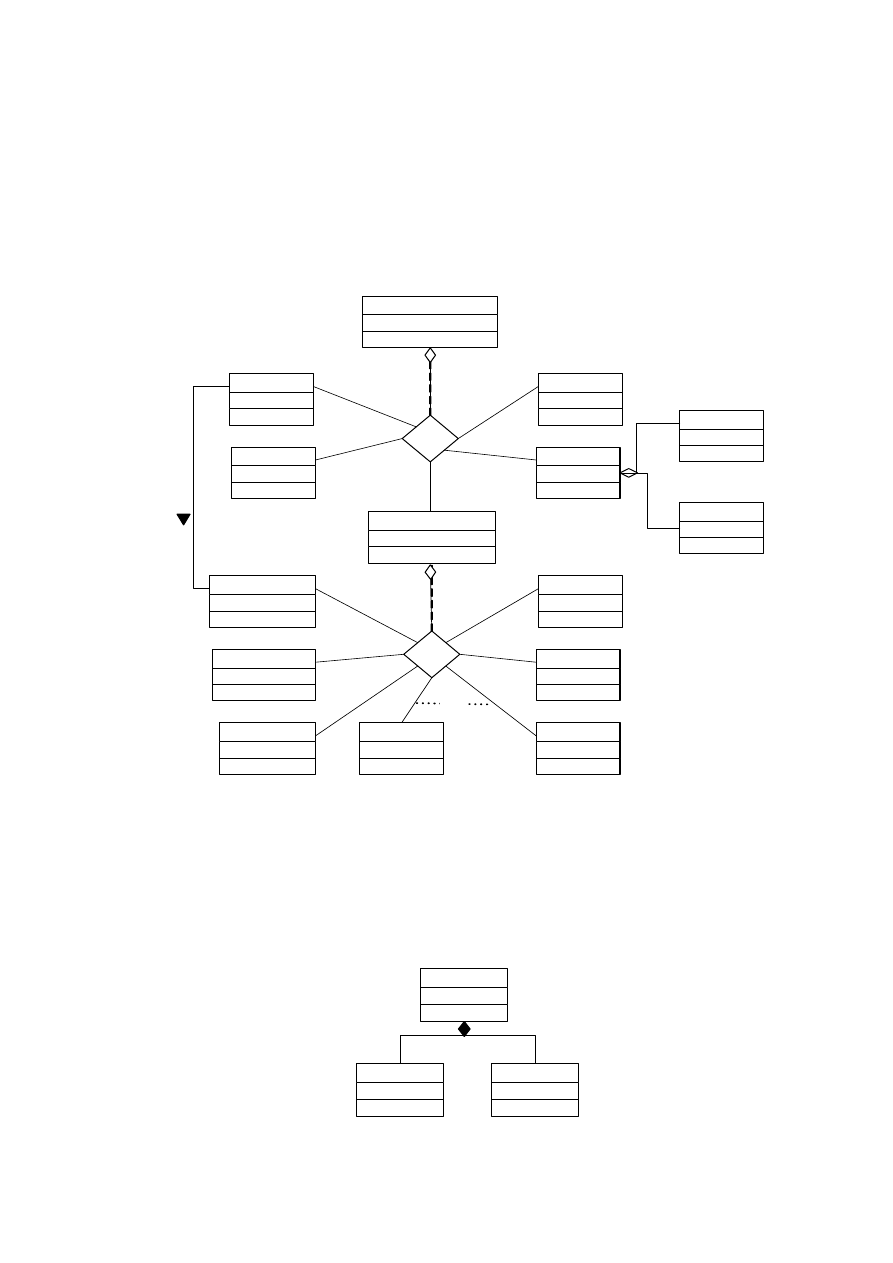
4.3.7. AGREGACJE
Związek między klasą i jej komponentami nazywamy agregacją lub związkiem całość-część.
Agregację przedstawiamy jako hierarchię z klasą całkowitą na górze i komponentami poniżej.
Oznaczamy ją od strony całości znakiem rombu umieszczonym na linii powiązania całości
z komponentami. Na rysunku 4.17 przedstawiono system komputerowy w postaci agregacji.
1
1
1
1
1..*
1
SystemKomputerowy
Głośnik
Klawiatura
Monitor
Mysz
Przycisk
KulkaMyszy
1
1
1
1..
*
1
1
1
1..*
JednostkaCentralna
1
1..*
1
1
StacjaDyskietek
DyskTwardy
Ram
NapędCD
NapędDVD
KartaGraficzna
KartaDżwiękowa
{OR}
1
1..*
Jes
t p
ołą
cz
o
ny
z
Rys. 4.17. Przykład agregacji z ograniczeniem
Między komponentami agregacji może wystąpić związek {or}. Umieszczamy to ograniczenie
na linii przerywanej zawartej między dwoma liniami powiązań całość-część (patrz rys. 4.17).
Agregacja całkowita (inaczej kompozyt) to szczególnie silny typ agregacji, w której każdy
komponent może należeć tylko do jednej całości. Agregację całkowitą oznaczamy tak samo
jak agregację zwykła, tylko romb jest wypełniony (rys. 4.18).
Stół
Blat
Noga
1
1
1
1..*
Rys. 4.18. Agregacja całkowita
Autor: Katarzyna Ragin-Skorecka
25 z 40
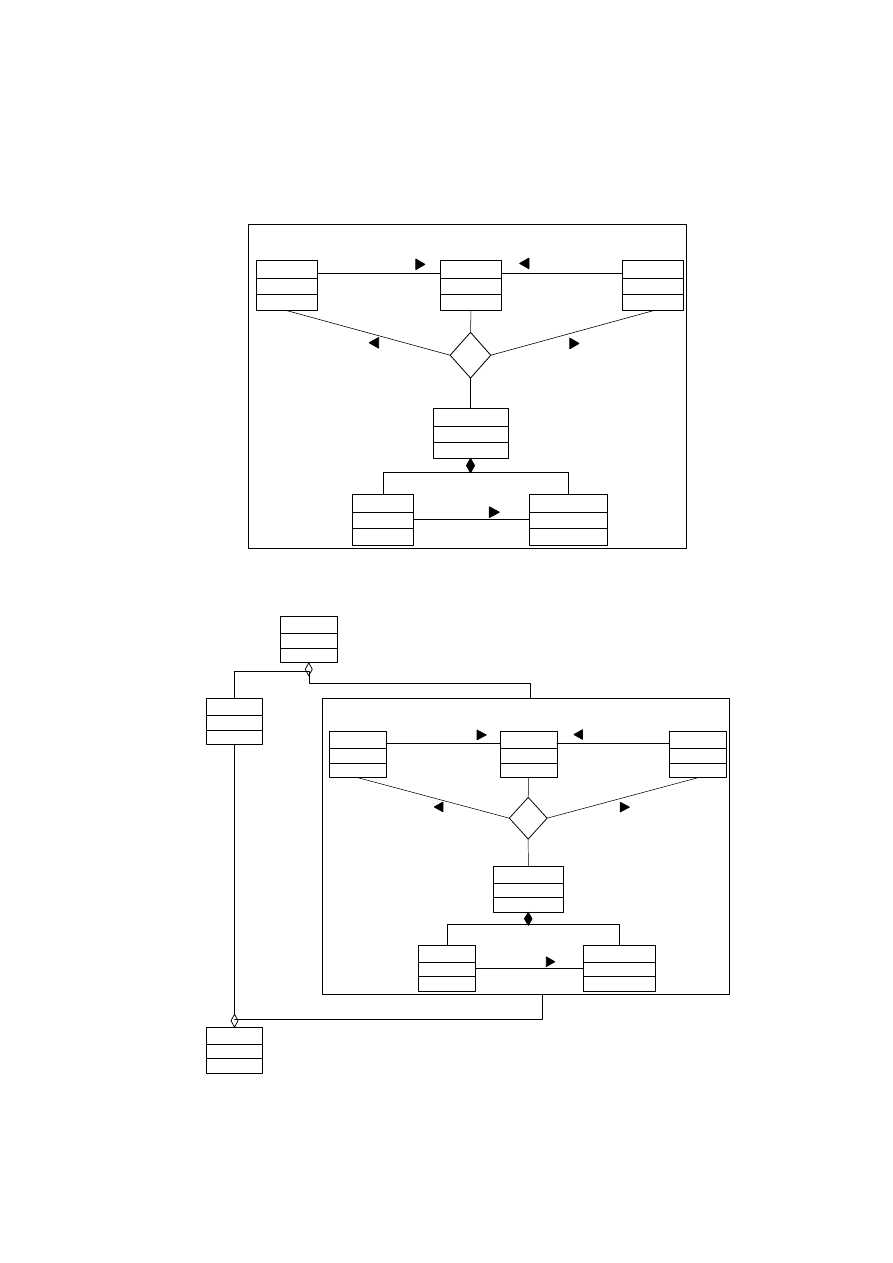
4.3.8. OTOCZENIA
Podczas modelowania systemu wyłaniają się zestawy klas, takie jak agregacje i agregacje
całkowite. Te zestawy należy wyróżnić spośród innych elementów diagramu. Służą do tego
otoczenia (diagramy otoczenia). Taki diagram jest szczegółową mapą większego fragmentu.
Otoczenie oraz diagram otoczenia są przedstawione na rysunkach poniżej (rys. 4.19 i 4.20).
Rękaw
Korpus
Kołnierzyk
SytemGuzikowy
Guzik
DzurkaOdGuzika
1
1
1
1
Włożony w
1
1
1
1
*
1
*
1
1
1
Jest przyszyty do
Jest przyszyty do
Jest przyszyty do
Jest przyszyty do
Koszula
Rys. 4.19. Otoczenie agregacji całkowitej
Szafa
Spodnie
Garderoba
Rękaw
Korpus
Kołnierzyk
SytemGuzikowy
Guzik
DzurkaOdGuzika
1
1
1
1
Włożony w
1
1
1
1
*
1
*
1
1
1
Jest przyszyty do
Jest przyszyty do
Jest przyszyty do
Jest przyszyty do
Koszula
1
*
1
*
1
1
1
1
Rys. 4.20. Diagram otoczenia systemowego
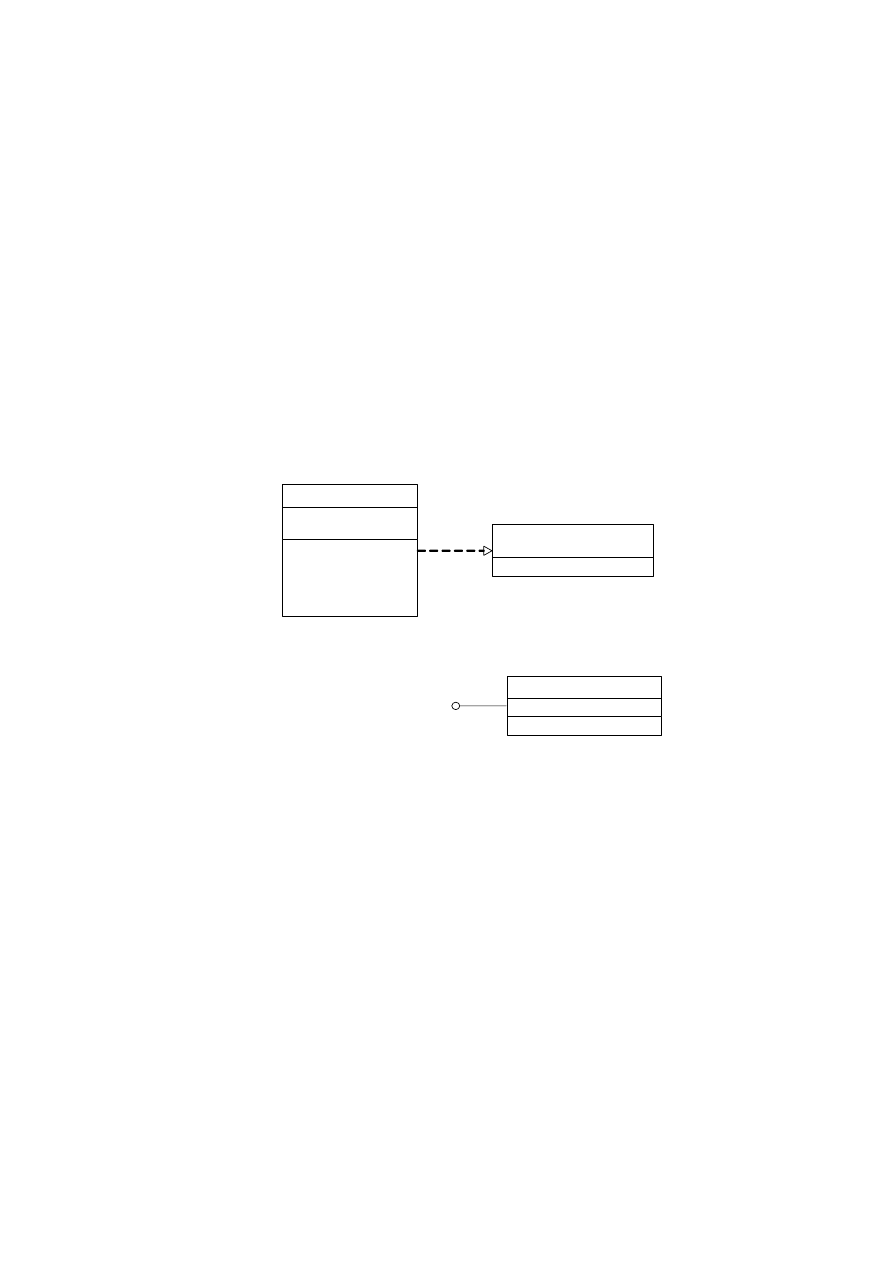
Autor: Katarzyna Ragin-Skorecka
26 z 40
Każda klasę przedstawioną na rysunku 4.20 można przedstawić w jej otoczeniu. Następnie
można je umieścić na diagramie otoczenia.
4.3.9. INTERFEJSY I REALIZACJE
Po stworzeniu pewnej liczby klas, można zauważyć, że część z nich zawiera te same operacje
z tymi samymi sygnaturami, chociaż nie mają wspólnej nadklasy. W tym przypadku można
dla jednej klasy napisać programy realizujące jej operacje i potem używać ich w innych klasach.
Drugą możliwością jest stworzenie zestawu operacji dla klas jednego systemu, by potem używać
je w innym systemie. W obu rozwiązaniach dochodzimy do powtarzalnego zestawu operacji, który
w UML-u nazywa się interfejsem. Interfejs jest zestawem operacji, które określają pewien aspekt
zachowania klasy i związany z tym zbiór operacji, które klasa udostępnia innym klasom.
Interfejs jest przedstawiany za pomocą prostokątnej ikony. Ponieważ jest to zestaw operacji,
dlatego nie ma atrybutów. Nazwa jest pisana z dużej litery i poprzedzona napisem <<Interface>>
(rys. 4.21). Związek między klasą i interfejsem nazywany jest realizacją. Przedstawiamy ją
w postaci przerywanej linii z niewypełnionym trójkątnym grotem na końcu.
+naciśnijKlawisz ()
«interface»
KlawiaturaMaszynyDoPisania
+Ctrl()
+Alt()
+PgUp()
+PgDown()
+...()
-nazwaFirmowa
-liczbaKlawiszy
KlawiaturaKomputerowa
Rys. 4.21. Ikona interfejsu i jej powiązanie z klasą
KlawiaturaMaszynyDoPisania
KlawiaturaKomputerowa
Rys. 4.22. Uproszczony sposób przedstawienia interfejsu i realizacji
Interfejs może być też oznaczony przez kółko połączone z klasą za pomocą linii ciągłej
(rys. 4.22). Jest to uproszczony sposób przedstawienia klasy realizującej interfejs.
4.3.10. WIDOCZNOŚĆ
Widoczność stosujemy do atrybutów i operacji. Oznacza ona zakres, w jakim inne klasy mogą
korzystać z atrybutów i operacji danej klasy (lub z operacji i jej interfejsów). Istnieją trzy poziomy
widoczności:
• public (publiczny) – oznacza rozciągnięcie prawa korzystania na inne klasy,
• protected (chroniony) – ograniczenie prawa korzystania do klas dziedziczących z danej
klasy,
• private (prywatny) – jedynie klasa oryginalna może używać atrybutów i operacji.
Autor: Katarzyna Ragin-Skorecka
27 z 40
+zmieńGłośność()
+zmieńKanał()
-wyświetlObrazNaEkranie()
+...()
+nazwaFirmowa
+nazwaModelu
+...
Telewizor
+przyspiesz()
+hamuj()
#ustawLicznikKilometrów()
+...()
+producent
+nazwaModelu
-...
Samochód
Rys. 4.23. Przykład widoczności atrybutów i operacji
Poziomy widoczności oznaczamy specjalnymi znakami umieszczanymi przed nazwami operacji
i atrybutów. Są one następujące: poziom public „+”, poziom protected „#”, poziom private „–”.
Przykład pokazano na rysunku 4.23.
4.3.11. ZASIĘG
Zasięg jest związany z atrybutami, operacjami i ich związkiem z systemem. Mamy dwa rodzaje
zasięgu: instance (egzemplarzowy) i classiefier (klasyfikatorowy). W zasięgu egzemplarzowym
każdy element klasy przechowuje własne wartości atrybutu lub operacji. W
zasięgu
klasyfikatorowym istnieje tylko jedna wartość atrybutu lub operacji wspólna dla wszystkich
egzemplarzy klasy. Obiekty spoza tej grupy nie mają dostępu do wartości o
zasięgu
klasyfikatorowym. Nazwa atrybutu lub operacji o zasięgu klasyfikatorowym jest podkreślana.
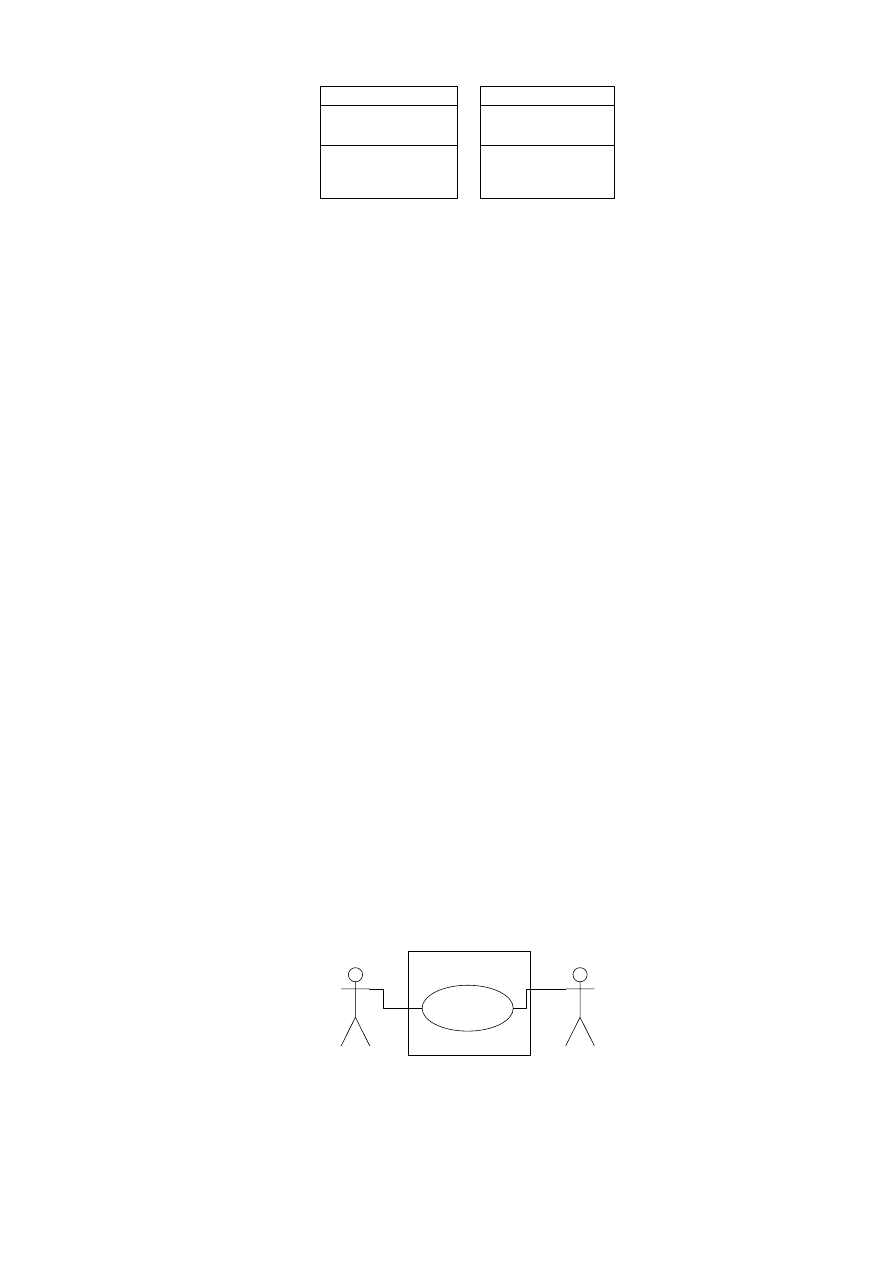
4.4. DIAGRAM PRZYPADKÓW UŻYCIA
Głównym elementem analizy projektowanego systemu jest określenie przypadków użycia.
Przypadek użycia to zbiór scenariuszy opisujących używanie systemu. Każdy scenariusz to ciąg
zdarzeń. Każdy ciąg jest inicjowany przez aktora – osobę, inny system, urządzenie, upływ czasu.
Wszystkie przypadki użycia mogą być stosowane wielokrotnie. Jeden sposób (zawieranie)
pozwala na wmontowanie ciągu kroków jednego przypadku użycia w ciąg kroków innego
przypadki. Drugi sposób (rozszerzanie) polega na tworzeniu nowego przypadku przez dodawanie
kroków do już istniejącego przypadku.
Aktor inicjuje przypadek użycia i aktor (ten sam lub inny) otrzymuję jakąś wartość przez ten
przypadek utworzoną. Przedstawiamy to w następujący sposób: aktor inicjujący jest umieszczony
na lewo od przypadku użycia, a aktor czerpiący korzyść na prawo. Nazwę przypadku użycia
umieszcza się w elipsie lub pod nią. Ciągła linia powiązania łączy aktora z przypadkiem użycia
i reprezentuje komunikację między nimi. Przypadki użycia umieszcza się w prostokącie z nazwą
systemu, aktorzy są poza nim.
Top Package::Aktor1
Top Package::Aktor2
Przypadek użycia
System
*
*
*
*
Rys. 4.24. Model przypadków użycia
Aktorzy, przypadki użycia i linie łączące tworzą razem model przypadków użycia.
Jest on pokazany na rysunku 4.24.
Autor: Katarzyna Ragin-Skorecka
28 z 40
Diagramy przypadków użycia są zwykle częścią dokumentacji projektu przeznaczonej
dla klientów i programistów. Każdy diagram znajduje się na oddzielnej stronie. Oddzielną stronę
tworzy się także dla scenariusza każdego przypadku użycia. Znajdują się tam następujące elementy:
• aktor, który inicjuje przypadek użycia,
• warunki wstępne przypadku użycia,
• kroki scenariusza,
• warunki końcowe scenariusza,
• aktor, który czerpie korzyść z przypadku użycia.
Innym sposobem pokazania kroków scenariusza jest diagram czynności. Jest to graficzne
przedstawienie kolejnych etapów konkretnego przypadku użycia. Jest to sposób, który zapewnia
czytelność i przejrzystość w przedstawianiu informacji.
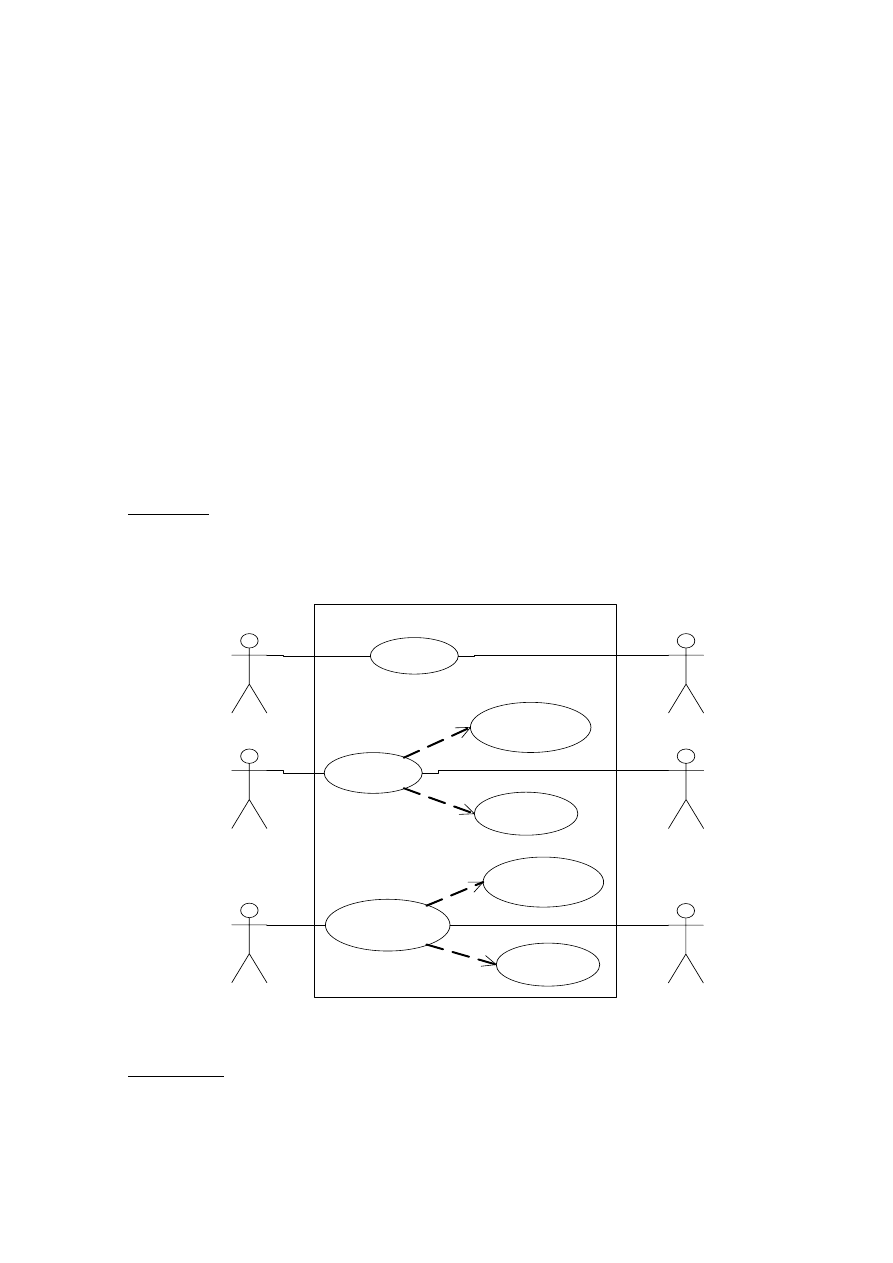
4.5. ZWIĄZKI MIĘDZY PRZYPADKAMI UŻYCIA
Między przypadkami użycia zachodzą związki. Należą do nich: zawieranie, rozszerzanie,
uogólnienie, grupowanie.
Zawieranie pozwala na wielokrotne użycie ciągu kroków z jednego przypadku użycia wewnątrz
innego. Ten związek oznaczamy linią przerywana zakończoną grotem strzały na niezależny
przypadek użycia (ten od którego zależy inny przypadek). Nad linią związku umieszczamy
stereotyp <<include>> (rys. 4.25).
Top Package::Kupujący
Top Package::Dostawca
Top Package::Inkasent
Top Package::Kupujący
Top Package::Dostawca
Top Package::Inkasent
Automat do napojów
Kup napój
*
*
Dostarcz towar
Zainkasuj pieniądze
* *
*
*
*
*
*
*
Udostępnij wnętrze
Udostępnij wnętrze
Zlikwiduj dostęp
Zlikwiduj dostęp
*
*
<<include >>
<<include>>
<<include >>
<<include>>
Rys. 4.25. Model przypadków użycia z zawieraniem
Rozszerzanie polega na tworzeniu nowych przypadków użycia przez dodawanie kroków
do przypadków już istniejących. Może mieć ono miejsce jedynie w wybranych punktach ciągu
kroków przypadku podstawowego. Punkty te nazywamy miejscami rozszerzenia. Rozszerzenie
przedstawiamy za pomocą oznaczenia zależności (linii przerywanej z grotem strzały) z ujętą
Autor: Katarzyna Ragin-Skorecka
29 z 40
w nawiasy francuskie nazwą stereotypu <<extend>>. Punkt rozszerzenia wpisuje się w wewnątrz
elipsy przypadku użycia pod jego nazwą (rys. 4.26).
Dostarcz towar
______________
napełnij pojemniki
Udostępnij wnętrze
Zlikwiduj dostęp
<<include >>
<<include >>
Dostarcz towar wg wyników sprzedaży
<<extend >>
Rys. 4.26. Diagram przypadków użycia z rozszerzeniem
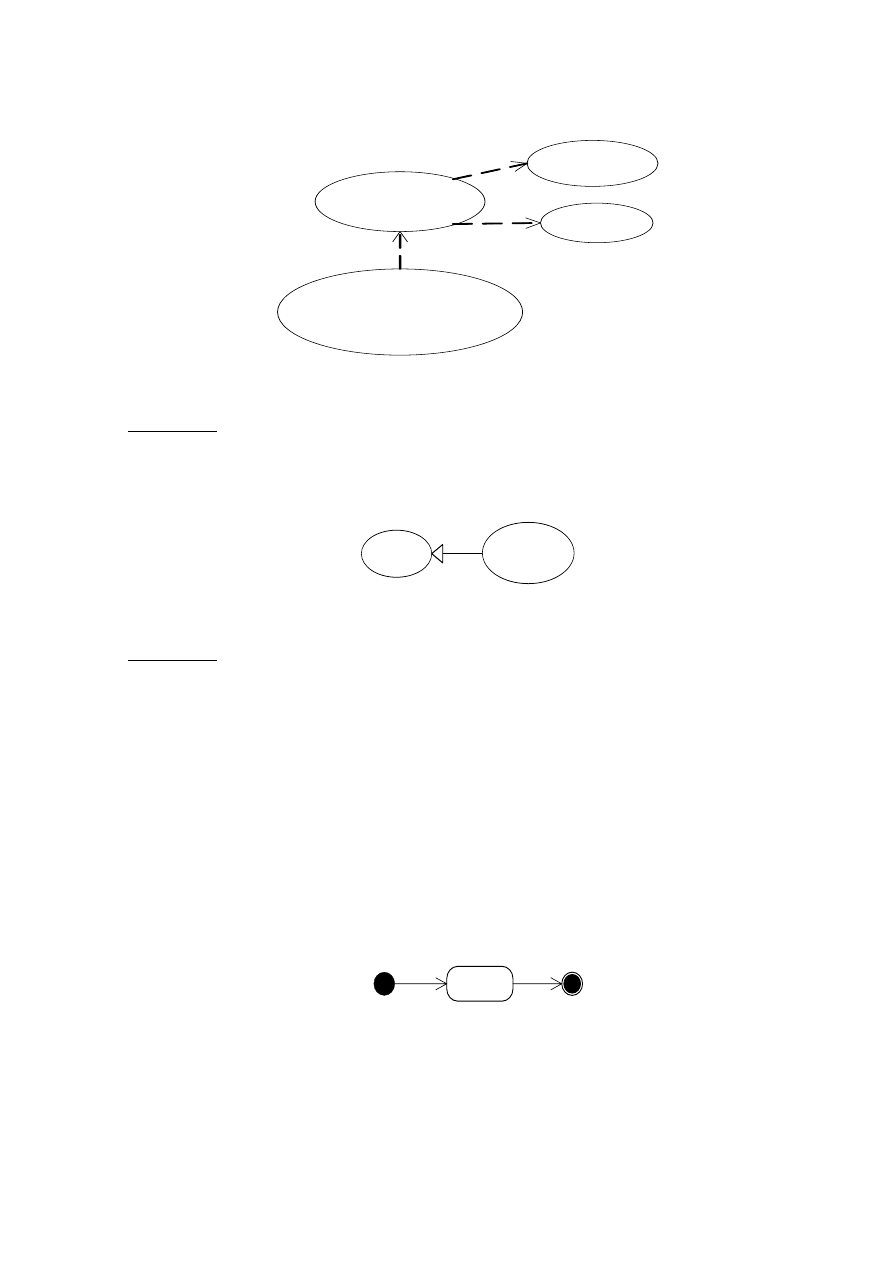
Uogólnienie oznacza, że jeden przypadek użycia dziedziczy z innego przypadku użycia.
Potomek może dziedziczyć zachowania i wartości po przodku. Przedstawiamy je za pomocą linii
ciągłej z niewypełnionym grotem wskazującym przodka (rys. 4.27). Związek uogólnienia może
dotyczyć również aktorów.
Kup napój
Kup kubek napoju
Rys. 4.27. Dziedziczenie zachowania między przypadkami użycia
Grupowanie jest sposobem tworzenia zestawów przypadków klas. Najprostszym sposobem
porządkowania jest grupowanie związanych przypadków użycia w pakiety. Zgrupowane przypadki
są pokazywane wewnątrz ikony.
4.6. DIAGRAM STANÓW
Diagram stanów prezentuje stany obiektu i przejścia między nimi od rozpoczynającego ciąg
stanu początkowego po ostatni w kolejności stan końcowy. Diagram stanów pokazuje stany
pojedynczego obiektu.
Nazwę stanu piszemy z wielkiej litery i jeżeli jest to możliwe podajemy w formie rzeczowników
odczasownikowych (np. Czytanie, Faksowanie, ale Bezczynny). Symbolami diagramu stanów jest
prostokąt z zaokrąglonymi rogami (stan), linia ciągła z grotem strzały (przejście), okrąg wypełniony
(stan początkowy) oraz „bycze oko” (stan końcowy) (rys. 4.28).
Stan
Rys. 4.28. Symbole diagramu stanów
Ikonę stanu można podzielić na trzy obszary. W górnym polu znajduje się nazwa stanu,
w środkowym – zmienne, w najniższym – czynności. Zmienne stanu to np. liczniki i zegary.
Czynności to zdarzenia i akcje. Najczęściej używa się: entry (wejdź – określa, co dzieje się
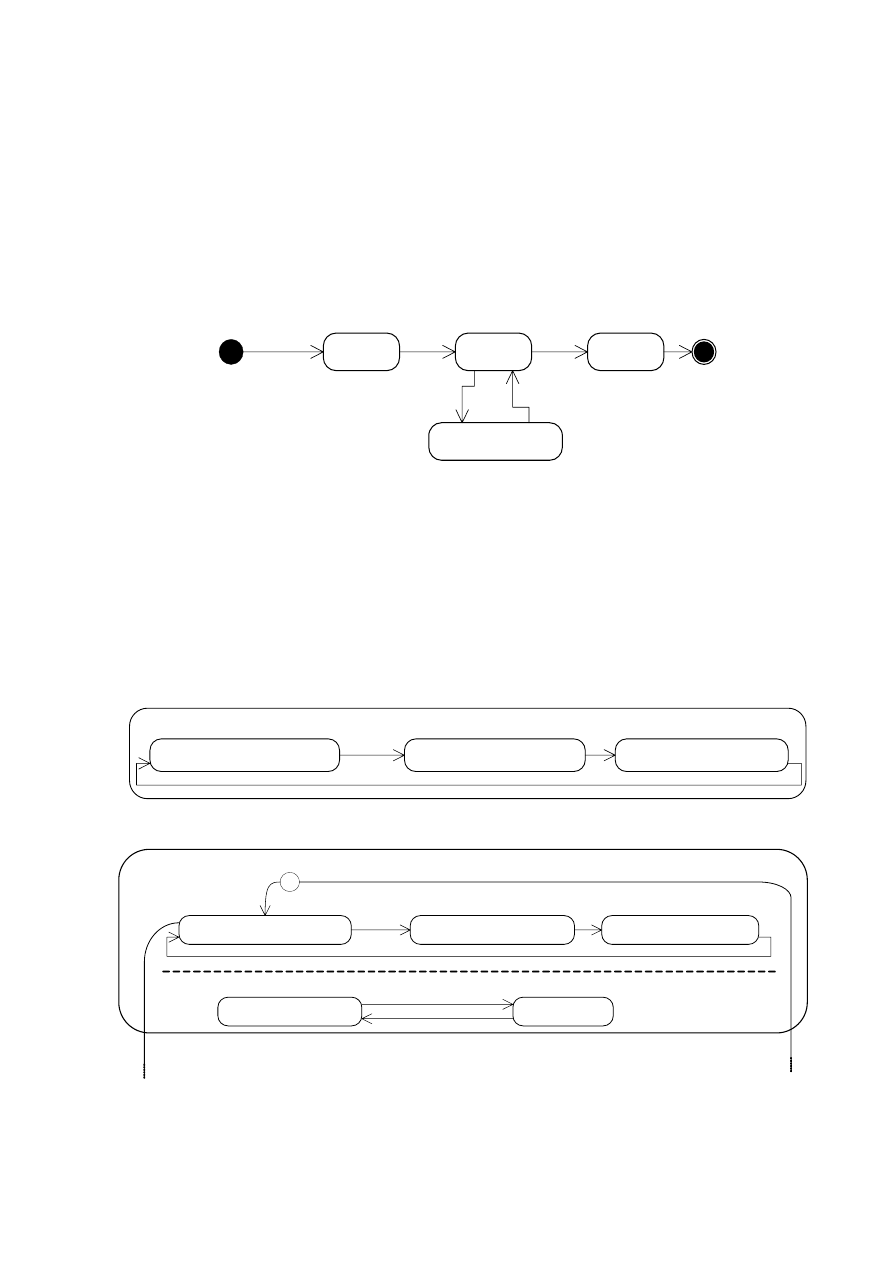
Autor: Katarzyna Ragin-Skorecka
30 z 40
przy wejściu do stanu), exit (wyjdź – określa, co dzieje się przy wyjściu ze stanu), do (wykonaj
– określa, co się dzieje, gdy system pozostaje w danym stanie).
Dodatkowe informacje mogą być umieszczane obok linii przejść. Można wskazać zdarzenie,
które jest przyczyną przejścia (zdarzenie uruchamiające) oraz obliczenie (akcję), które zostaje
wykonane i powoduje przejście z jednego stanu w drugi.
Zdarzenia i akcje zapisujemy w najniższej części ikony stanu. Ukośnikiem oddzielamy zdarzenie
uruchamiające od akcji. Może zajść sytuacja, że zdarzenie powodujące przejście nie jest skojarzone
z żadną akcją lub zachodzi w wyniku ukończenia wszystkich akcji. Mówi się wtedy o przejściu
bez zdarzenia uruchamiającego (rys. 4.29).
Włączanie
Działanie
Wyłączanie
Oszczędzanie Monitora
Włącz PC
Wyłącz
[czasMinął]
Uderzenie klawisz lub
poruszenie myszą
Rys. 4.29. Diagram stanów GUI
Na diagramach stanów umieszcza się również warunki dozoru. Jeżeli warunek zostanie
spełniony, to następuje przejście z jednego stanu do drugiego. Warunek dozoru jest warunkiem
logicznym.
Podczas trwania w jednym stanie mogą następować zmiany w ramach tego stanu,
bez wychodzenia z niego. Mamy do czynienia z podstanami. Wyróżniamy dwa rodzaje podstanów:
sekwencyjne i współbieżne. Podstany sekwencyjne występują w określonej kolejności (rys. 4.30).
W podstanach współbieżnych dwa ciągi zdarzeń występują jednocześnie (rys. 4.31).
Oczekiwanie Na Działanie Użytkownika
Rejestrowanie Działania Użytkownika
Wizualizacja Działania Użytkownika
Działanie
Działanie
Użytkownika
Rys. 4.30. Sekwencyjne podstany stanu Działanie GUI
Oczekiwanie Na Działanie Użytkownika
Rejestrowanie Działania Użytkownika
Wizualizacja Działania Użytkownika
Działanie
Działanie
Użytkownika
Śledzenie Zegara Systemowego
Uaktualnienie Obrazu
[minąłWyznaczonyCzas ]
H*
[czasMinął ]
Uderzenie klawisz lub
poruszenie myszą
Rys. 4.31. Podstany współbieżne i sekwencyjne stanu Działanie GUI oraz głęboki stan wznowienia
W UML-u istnieje oznaczenie wskazujące, że stan złożony pamięta swoje aktywne podstany,
gdy obiekt przechodzi do innego stanu. Tym symbolem jest litera H (history) zamknięta
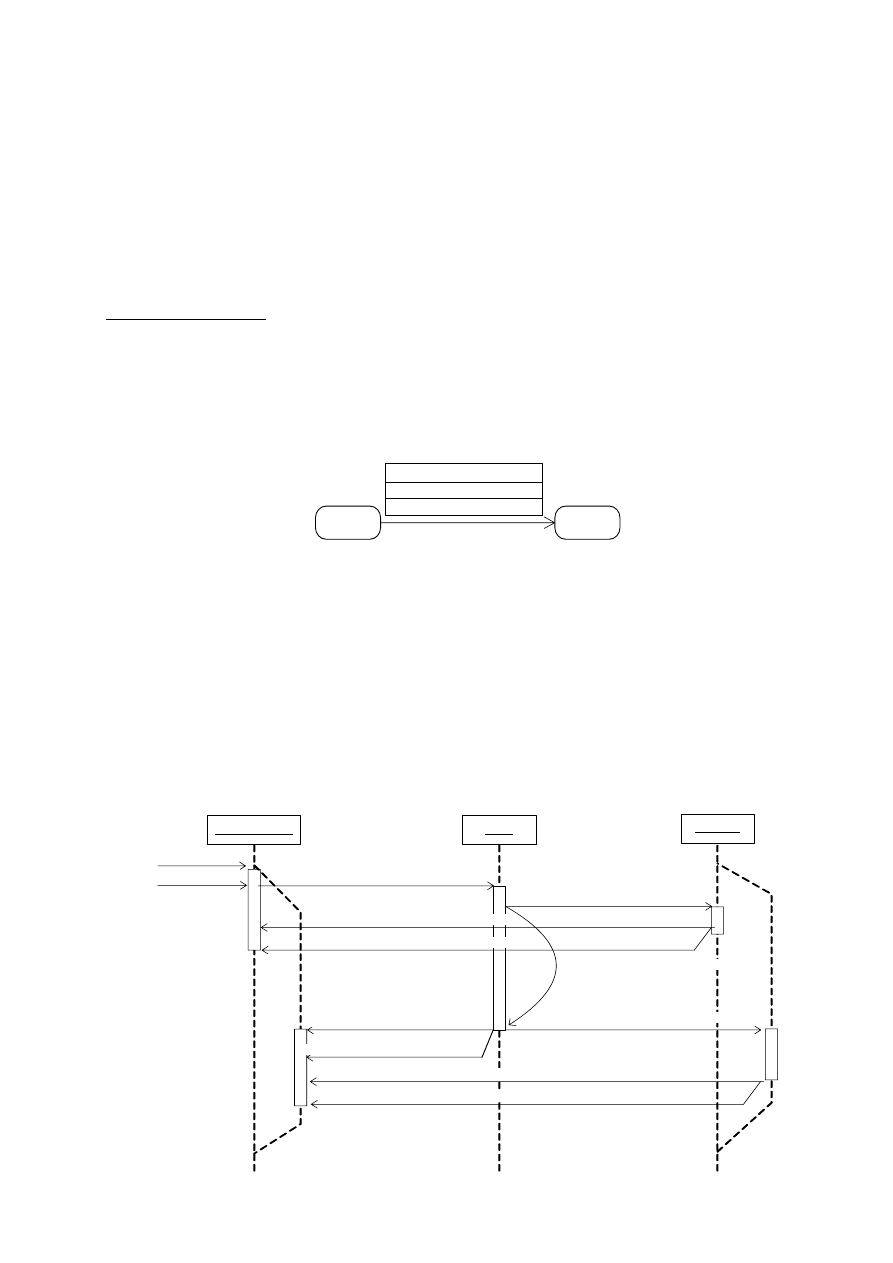
Autor: Katarzyna Ragin-Skorecka
31 z 40
w niewielkim kółku i połączona linia ciągłą z zapamiętywanym podstanem wskazanym przez grot
strzałki (rys. 4.31). Taki stan nazywa się stanem wznowienia. Możemy mieć do czynienia ze stanem
głębokiego wznowienia (zapamiętywanie wszystkich podstanów) oraz ze stanem płytkiego
wznowienia (zapamiętywanie podstanów najwyższego poziomu zagnieżdżenia). Stan głębokiego
wznowienia oznaczamy literą H*.
Stan wznowienia, stan początkowy i stan końcowy nazywane są pseudostanami. Nie mają one
zmiennych stanu oraz czynności.
Komunikaty i sygnały
Obiekty kontaktują się ze sobą przez wysyłanie komunikatów. Komunikat uruchamiający
dla obiektu otrzymującego jest sygnałem. Wysłanie sygnału jest równoważne ze stworzeniem klasy
sygnału i przesłanie jej do obiektu otrzymującego. Sygnał ma właściwości reprezentowane
przez atrybuty. Dla sygnałów można stworzyć diagram klas ukazujący hierarchię dziedziczenia
sygnałów.
<<Signal>> polecenieWyłączenia
Działanie
Wyłączanie
Rys. 4.32. Przykład ikony klasy <<>Signal>>
W UML-u stosuje się rozszerzenie diagramu klas dla oznaczenia sygnału. W każdej ikonie klasy
reprezentującej sygnał umieszcza się oznaczenie <<Signal>> (rys. 4.32).
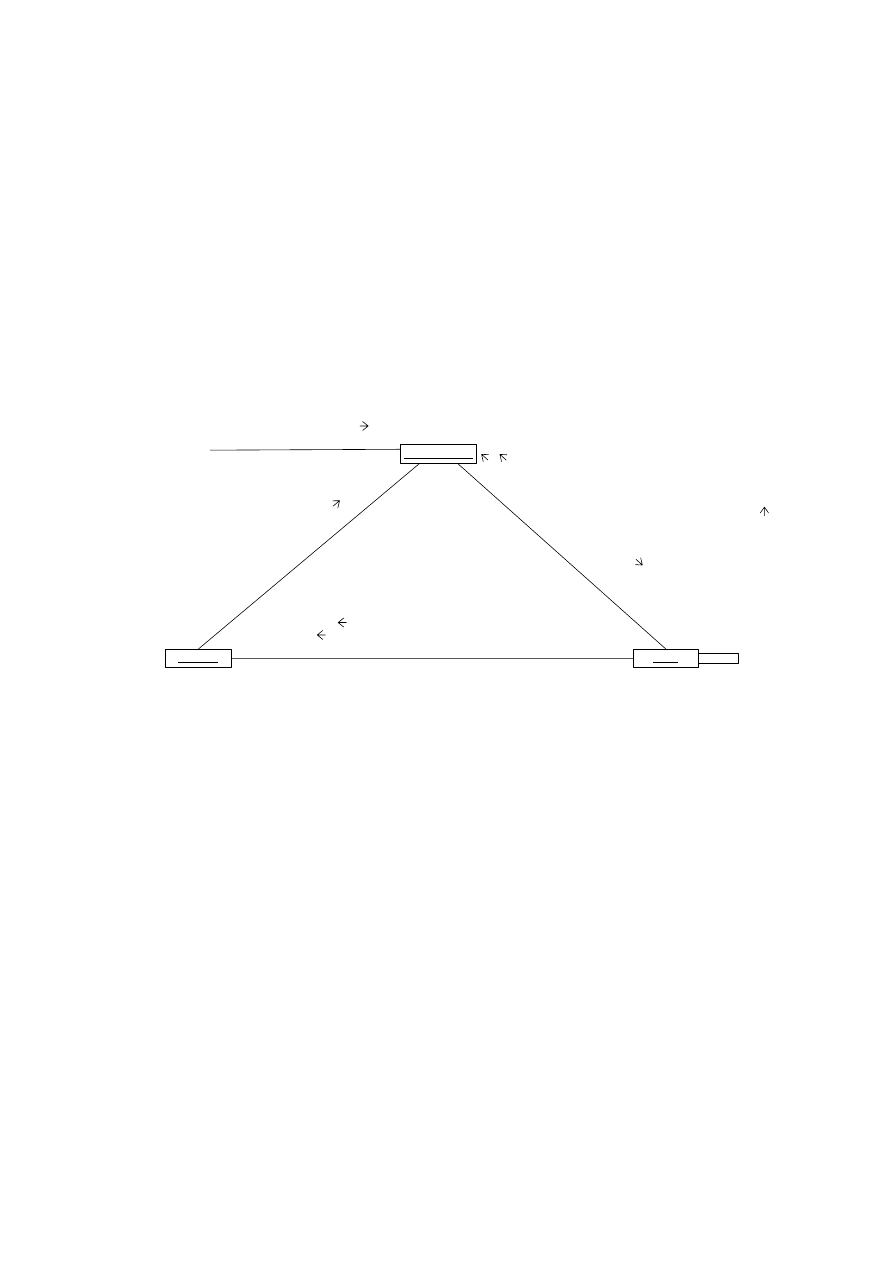
4.7. DIAGRAM PRZEBIEGU
Diagram przebiegu pokazuje jak w zależności od czasu przebiega komunikowanie się danego
obiektu z innym. Diagram ten składa się z obiektów przedstawionych w postaci standardowych
prostokątnych ikon (z podkreślonymi nazwami), komunikatów (pokazanych jako linie ciągłe
z grotami strzałek) i czasu (pokazanego jako przesunięcie wzdłuż pionowej osi) (rys. 4.33).
:PrzódAutomatu
:Kasa
:Podajnik
wrzuć(Wpłata)
wybierz(Wybór)
wyślij (Wypłata, Wybór)
[Wpłata = Cena] sprawdź(Wybór)
[Wybór w Zapasie] dostarcz(Wybór)
[Wyboru brak w Zapasie] wyświetl(Komunikat)
[Wpłata > Cena] sprawdźCzyJestReszta
[Reszta w Rezerwie] sprawdź(Wybór)
[Reszta w Rezerwie] wypłać(Resztę)
[Wybór w Zapasie] dostarcz(Wybór)
[Wyboru brak w Zapasie] wyświetl(Komunikat)
[Reszty brak w Rezerwie] zwróć(Wpłata)

Autor: Katarzyna Ragin-Skorecka
32 z 40
Rys. 4.33. Ogólny diagram przebiegu dla automatu sprzedającego napoje
Obiekty są umieszczane na diagramie od góry z lewej strony. Układa się je w taki sposób,
aby zapewnić czytelność diagramu. Od każdego obiektu w dół biegnie przerywana linia, nazywana
linią życia obiektu. Wąski prostokąt umieszczony wzdłuż niej to aktywacja. Przedstawia
on wykonywanie operacji przez obiekt. Długość prostokąta aktywacji określa czas jej trwania.
Komunikat przesyłany między obiektami biegnie od linii życia obiektu wysyłającego do linii
życia obiektu docelowego. Obiekt może też wysyłać komunikat sam do siebie. Mamy trzy rodzaje
komunikatów:
• prosty – jest przekazywaniem sterowania od obiektu do obiektu,
• synchroniczny – po wysłaniu komunikatu obiekt oczekuje na odpowiedź i dopiero po jej
otrzymaniu przechodzi do dalszych działań,
• asynchroniczny – po wysłaniu komunikatu obiekt kontynuuje własne działanie,
bez oczekiwania na odpowiedź.
Na diagramie przebiegu komunikaty przedstawiamy za pomocą linii zakończonych strzałkami.
Dla każdego rodzaju komunikatu jest inny grot (rys. 4.34).
Komunikat Prosty
Komunikat synchroniczny
Komunikat asynchroniczny
Rys. 4.34. Symbole komunikatów na diagramie przebiegu
Czas na diagramie przebiegu przedstawiany jest jako przesunięcie względem osi pionowej.
Odliczanie zaczyna się od góry diagramu, a upływowi czasu odpowiada przesunięcie w dół.
Diagram przebiegu jest dwuwymiarowy. Obiekty są przedstawiane od lewej do prawej.
Przesunięcie wzdłuż osi pionowej z góry na dół odpowiada upływowi czasu. Między liniami życia
umieszczane są komunikaty (patrz rys. 4.33). Na diagramie przebiegu można pokazać stany
obiektu. Umieszczamy je wtedy zamiast prostokąta aktywacji.
Ze względu na ilość przedstawionych na diagramie scenariuszy możemy wyróżnić
egzemplarzowy i ogólny diagram przebiegu. Na diagramie egzemplarzowym jest przedstawiony
jeden scenariusz przebiegu. Na diagramie ogólnym przedstawione są wszystkie scenariusze
(patrz rys. 4.33).
Podczas przebiegu może powstać nowy obiekt. Przedstawiamy go tak jak pozostałe obiekty,
ale umieszczamy go na wysokości odpowiadającej czasowi jego powstania. Komunikat, który
tworzy obiekt to Create() [Utwórz()].
Diagramy często zawierają rozgałęzienia (if) i pętle (while). Warunki rozgałęzienia zapisujemy
w nawiasach prostokątnych. Warunek pętli jest zapisywany w nawiasie prostokątnym
poprzedzonym gwiazdką (*).
Autor: Katarzyna Ragin-Skorecka
33 z 40
4.8. DIAGRAM KOOPERACJI
Diagram kooperacji jest semantycznie równoważny diagramowi przebiegu. Oba typy diagramów
można przekształcać zamiennie w siebie. Diagram przebiegu pokazuje uporządkowanie w czasie,
diagram kooperacji – w przestrzeni.
Diagram kooperacji jest rozszerzeniem diagramu obiektów. Pokazuje powiązania między
obiektami i komunikaty przesyłane między nimi.
Komunikaty są prezentowane przez strzałki umieszczane wzdłuż linii powiązań istniejących
między obiektami. Strzałka jest zawsze zwrócona w stronę obiektu przyjmującego komunikat
pokazywany na etykiecie umieszczonej obok. Komunikaty zazwyczaj nakazują wykonanie pewnej
operacji. Na początku komunikatu umieszcza się numer określający kolejność komunikatu
na diagramie. Po dwukropku wpisuje się komunikat. Na końcu w nawiasie umieszcza się parametry
operacji (jeżeli istnieją) (rys. 4.35).
:PrzódAutomatu
:Podajnik
:Kasa
wrzuć(Wpłata, Wybór)
1: w
yślij(
W
pła
ta, W
ybó
r)
[Re
szta
jes
t w
rez
erw
ie] 3
.2: z
wró
ć(R
esz
ta)
[Re
szty
bra
kw
rez
erw
ie]3
.3:z
wr(R
esz
ta,K
om
unik
at)
4:
do
sta
rcz
(W
yb
ór)
[Wpłata=Cena] 2.1: dostarcz(Wybór)
[Reszta jest w Rezerwie] 3.1: dostarcz(Wybór)
[W
pł
at
a>
C
en
a]
2
.2
: sp
ra
w
dzC
zy
Je
st
R
es
zt
a(
W
pł
at
a,
C
ena
)
Rys. 4.35. Diagram kooperacji dla automatu sprzedającego napoje
Na diagramie kooperacji niektóre komunikaty zależą od spełnionego warunku. Dotyczą one tego
samego komunikatu, a mogą być przekazywane w różny sposób. Po numerze komunikatu stawiamy
kropkę i kolejne numery wariantu wiadomości (rys. 4.35). Taki zabieg nazywa się zagnieżdżeniem.
Na diagramie kooperacji można umieszczać warunki rozgałęzienia i pętli. Treść warunku
umieszcza się w nawiasie prostokątnym (rys. 4.35). Warunek while jest poprzedzony gwiazdką.
Na diagramie kooperacji można umieścić zmiany stanu obiektu. Stan wpisujemy wewnątrz
prostokąta obiektu. Na diagramie umieszcza się prostokąt ukazujący obiekt w zmienionym stanie.
Oba prostokąty łączy się przerywaną linią opisaną stereotypem <<become>> (stań się) (rys. 4.36).
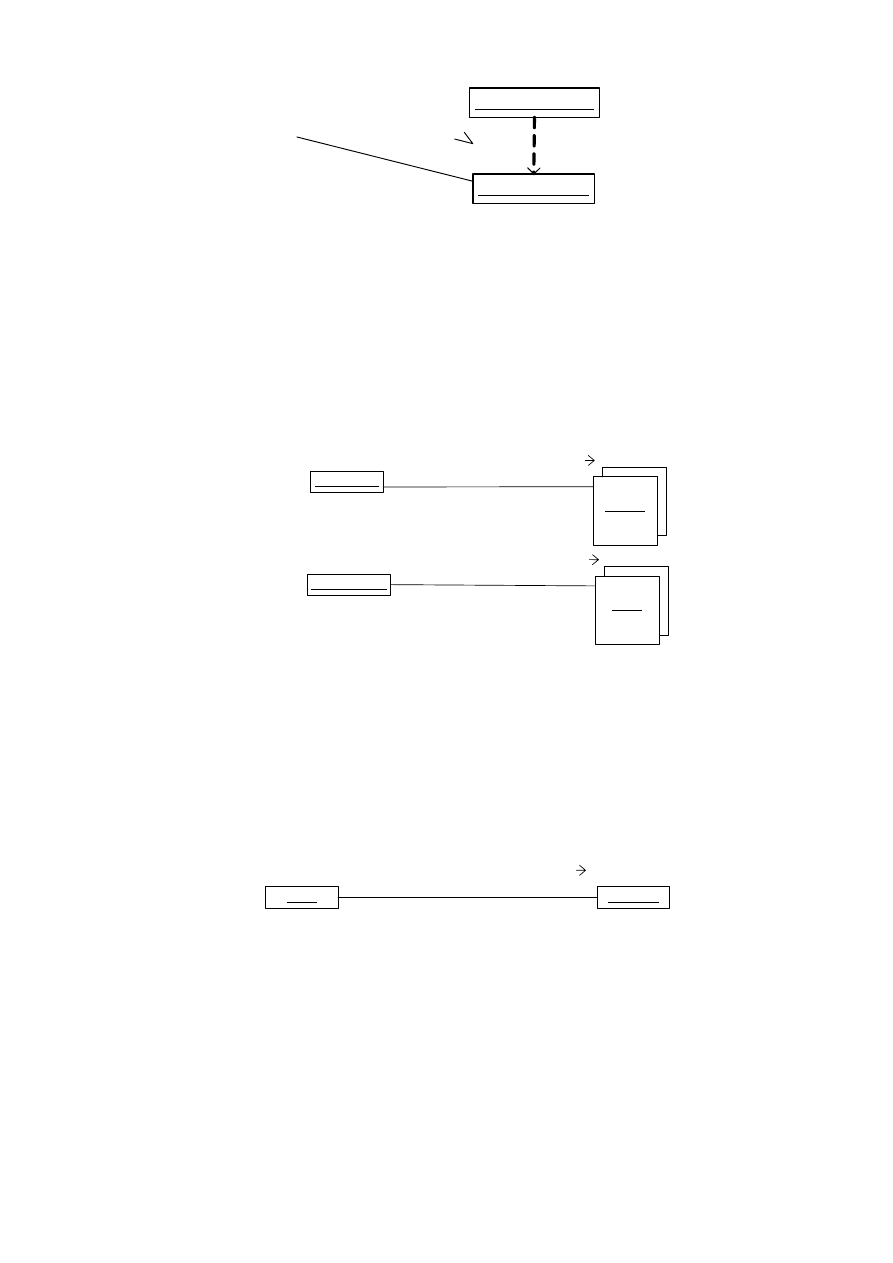
Autor: Katarzyna Ragin-Skorecka
34 z 40
:GUI[Włączanie]
:GUI[Działanie]
<<become>>
naciśnijK
lawisz
Rys. 4.36. Zmiany stanu na diagramie kooperacji
Tworzenie nowego obiektu jest umieszczane na diagramie w postaci ikony nowego obiektu.
Na linii komunikatu umieszcza się stereotyp <<create>>.
Zdarza się, że jeden obiekt wysyła jeden komunikat do wielu obiektów. Na diagramie obiekty
wielokrotne zaznacza się przez ciąg nachodzących na siebie prostokątów. Aby zaznaczyć,
że komunikat jest przesyłany do wszystkich obiektów, umieszcza się warunek w nawiasie
prostokątnym poprzedzonym gwiazdką. W przypadku, gdy jest ważna kolejność wysyłania
komunikatu, w nawiasie umieszcza się warunek określający porządek (rys. 4.37).
:Student
:Wykładowca
*[wszyscy] 1:polećWykonać(zadanie)
a)
b)
:Klient
:UrzędnikBanku
[miejsce w kolejce = 1...n] 1: obsłuz()
Rys. 4.37. Przesyłanie komunikatu do obiektów wielokrotnych
a) dowolna kolejność wysyłania komunikatu, b) określona kolejność wysyłania komunikatu
Wysyłany komunikat może być żądaniem wykonania operacji i zwrócenia wyniku. W UML-u
taki warunek przedstawia się za pomocą specjalnej składni. Nazwę wartości, która ma być
zwrócona, piszemy po lewej stronie, potem wstawiamy symbol „:=”. Za nim wpisujemy operację,
która ma być wykonana z podanymi w nawiasie wielkościami, służącymi jako argumenty wyliczeń
(rys. 4.38). Prawą stronę wyrażenia nazywamy sygnaturą komunikatu.
:Klient
:Kalkulator
1: cenaBrutto:=wylicz(cenaNetto, podatek)
Rys. 4.38. Diagram kooperacji pokazujący składnię zwracania wyniku
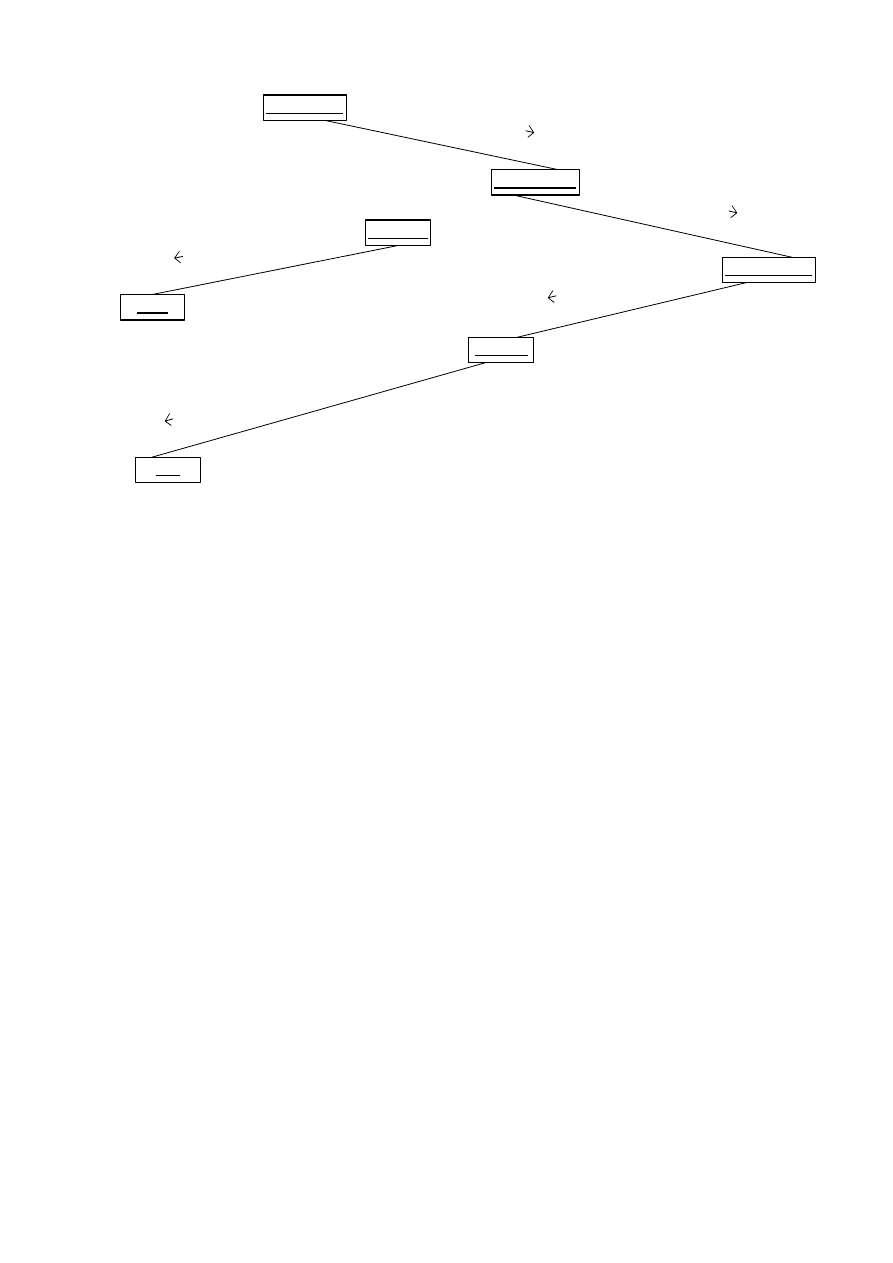
W niektórych iteracjach wybrany obiekt steruje przepływem komunikatów. Obiekt aktywny
może wysyłać komunikaty do obiektów pasywnych i wchodzić w interakcje z innymi obiektami
aktywnymi. Taki obiekt przedstawiamy w prostokącie o pogrubionych krawędziach.
Autor: Katarzyna Ragin-Skorecka
35 z 40
PrezesMarketingu
DyrektorSprzedaży
KierownikSprzedaży
Sprzedawca
Klient
SpecjalistaPR
Gazeta
1: przeprowadź(ka
mpania, produkt)
2: przydziel(kamp
ania, produkt)
3: sprzed
aj(kampa
nia, prod
ukt)
*[wybra
ni klienc
i] 4: zap
roponujT
elefonic
znie(kam
pania, p
rodukt)
2,3 / dajOg
łoszenie(ka
mpania, p
rodukt)
Rys. 4.39. Synchronizacja komunikatów na diagramie kooperacji
Można spotkać się z taką sytuacją, że obiekt wysyła komunikat tylko wtedy, gdy wcześniej
zostało wysłanych kilka innych. Oznacza to, że obiekt musi zsynchronizować swój komunikat ze
zbiorem innych komunikatów. Taki komunikat ma następującą składnię: lista numerów
komunikatów, które muszą być wcześniej zakończone, znak ukośnika „/”, komunikat (rys. 4.39).
4.9. DIAGRAM CZYNNOŚCI
Diagram czynności jest podobny do schematu blokowego. Pokazuje kroki, punkty
podejmowania decyzji i rozgałęzienia. Jest on rozszerzeniem diagramu stanu, ale nacisk położony
jest na czynności.
Na diagramie czynność reprezentowana jest przez zaokrąglony prostokąt. Po zakończeniu
procesów składających się na daną czynność następuje automatyczne przejście do następnej
czynności – przedstawiane przez strzałkę z odpowiednim zwrotem. Punkt startowy jest
reprezentowany przez czarne wypełnione kółko, stan końcowy – w postaci byczego oka. Przykład
diagramu jest pokazany na rysunku 4.40.
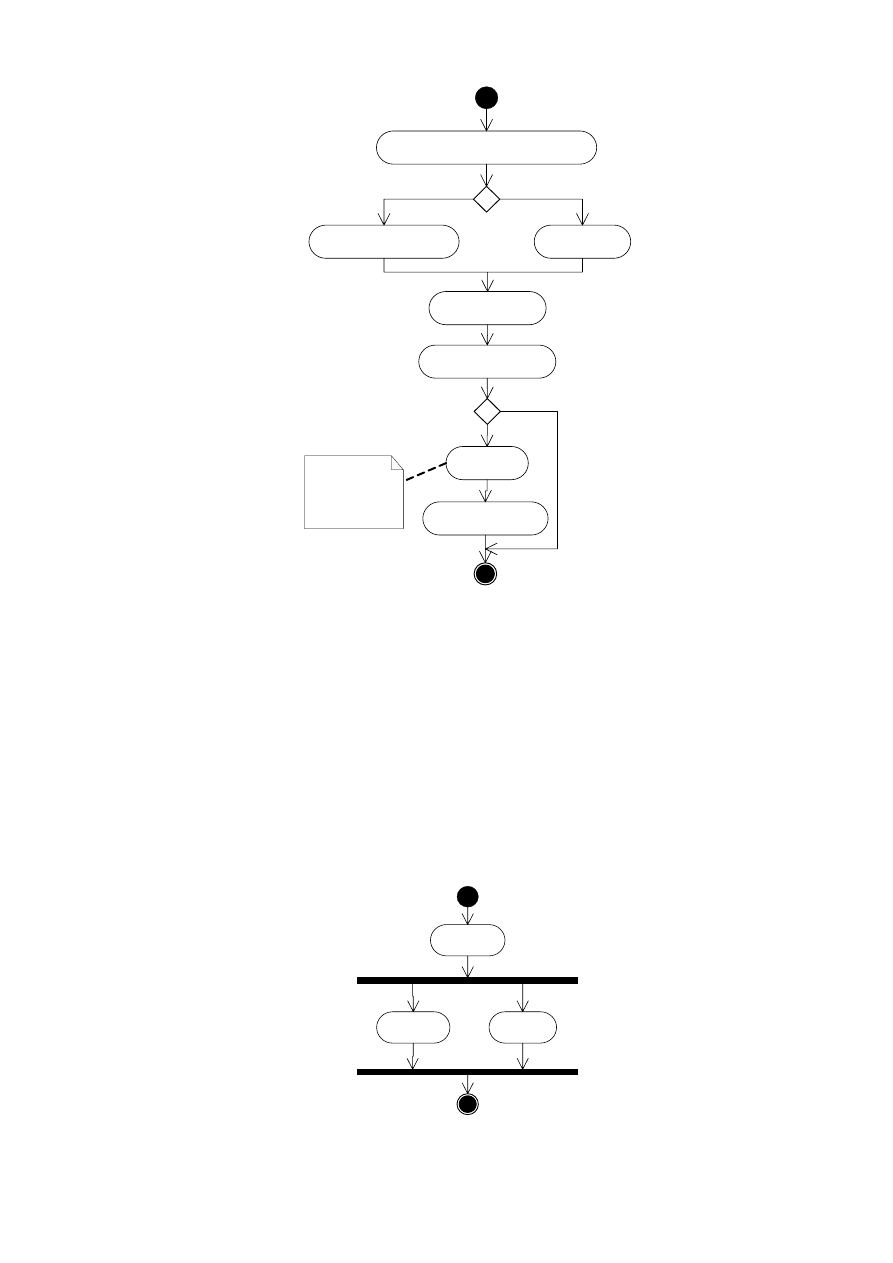
Autor: Katarzyna Ragin-Skorecka
36 z 40
Zadzwoń do klienta i umów go na spotkanie
Przygotuj salę konferencyjną
Przygotuj laptopa
Spotkaj się z klientem
Wyślij list podsumowujący
Utwórz projekt
Wyślij projekt do klienta
[spotkanie w firmie]
[spotkanie poza firmą]
[ustalenie problemu]
[bez ustalenia problemu]
Zobacz
diagram
czynności
dla tworzenia
dokumentu
Rys. 4.40. Diagram czynności dla procesu biznesowego spotkania z klientem
Ciąg czynności zazwyczaj zawiera sytuacje wymuszające podjęcie decyzji. Warunek stawiany
w sytuacji decyzyjnej wymusza wybór jednej z kilku wykluczających się możliwości. Punkt,
w którym podejmowane są decyzje, nazywa się rozgałęzieniem. Przedstawia się go w postaci
rombu, z którego wychodzą dwie lub więcej ścieżek postępowania. Warunki dozoru umieszczane są
w nawiasach prostokątnych (rys. 4.40).
Podczas modelowania czynności możliwe są sytuacje występowania dwóch lub więcej
czynności równocześnie. Przepływ sterowania będzie następował współbieżnie. To rozwidlenie jest
pokazane na diagramie w postaci grubej, prostopadłej do przejścia linii i równoległych ścieżek
wychodzących z niej. Podobnie wygląda scalenie tych ścieżek (rys. 4.41).
Skończ pracę
Weź prysznic
Odpręż się
Rys. 4.41. Ścieżki współbieżne na diagramie czynności
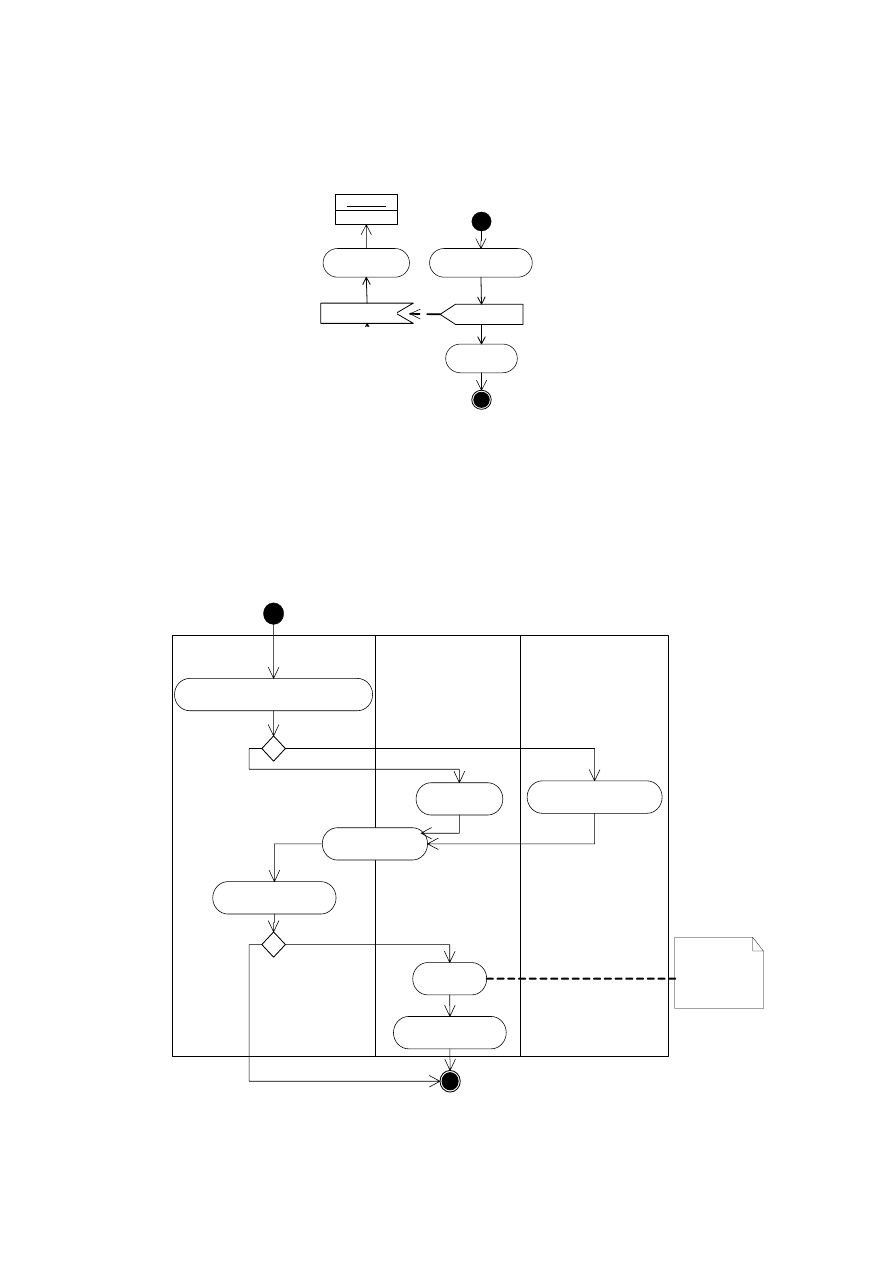
Autor: Katarzyna Ragin-Skorecka
37 z 40
W ciągu czynności może zdarzyć się wysłanie sygnału. Przyjęcie sygnału powoduje wykonanie
czynności. Symbolem wysłania sygnału jest pięciokąt wypukły, a symbolem jego otrzymania
– pięciokąt wklęsły (rys. 4.42). W języku UML-u oba pięciokąty symbolizują odpowiednio
zdarzenie wyjściowe i zdarzenie wejściowe.
Telewizor
Pokaż nowy kanał
Naciśnij numer kanału
Stan czujności
<no receive action>
<no send action>
zmień(kanał)
zmień(kanał)
zdalnie.naciśnijPrzycisk (kanał)
Rys. 4.42. Wysyłanie i otrzymywanie sygnału na diagramie czynności
Na diagramach czynności można pokazać, kto jest odpowiedzialny za wykonanie każdej
czynności wchodzącej w skład procesu (podział obowiązków). Służą temu równoległe segmenty
nazywane torami. Każdy tor jest przypisany do konkretnego aktora odpowiedzialnego
za wykonanie danej czynności (rys. 4.43). Nazwa aktora jest umieszczona na górze toru. Przejścia
mogą przecinać granice torów.
Agent sprzedaży
Konsultatnt
Służby techniczne
Zadzwoń do klienta i umów go na spotkanie
Przygotuj salę konferencyjną
Przygotuj laptopa
Spotkaj się z klientem
Wyślij list podsumowujący
Utwórz projekt
Wyślij projekt do klienta
[spotkanie w firmie]
[spotkanie poza firmą]
[ustalenie problemu]
[bez ustalenia problemu]
Zobacz
diagram
czynności
dla tworzenia
dokumentu
Rys. 4.43. Torowa wersja diagramu czynności dla procesu biznesowego spotkania z klientem (por. rys. 4.40)
Autor: Katarzyna Ragin-Skorecka
38 z 40
Zastosowanie kilku rodzajów diagramów na jednym powoduje powstanie diagramu
hybrydowego. Przykładem jest umieszczenie symboli sygnałów na diagramie czynności
lub diagramu czynności w ikonie obiektu.
4.10. DIAGRAM KOMPONENTÓW
Komponenty są elementami oprogramowania – fizycznymi, wymiennymi częściami systemu.
Komponentem może być np. tabela, baza danych, plik wykonywalny, biblioteka dołączana
dynamicznie, dokument, itd. Modele komponentów tworzy się, aby:
• klienci mogli zobaczyć pełną strukturę systemu,
• twórcy oprogramowania znali strukturę, do której muszą dążyć,
• twórcy dokumentacji i plików pomocy rozumieli, o czym piszą,
• możliwe było wielokrotne stosowanie komponentów.
Operacje komponentu są dostępne jedynie przez interfejs. Relację między komponentem
i interfejsem nazywamy realizacją. Komponent może udostępniać interfejs innym komponentom,
dzięki czemu mogą one korzystać z jego operacji. Jedne komponenty mogą korzystać z usług
innych. Interfejs komponentu dostarczający usługi nazywamy interfejsem eksportowanym,
a interfejs korzystający z usług – interfejsem importowanym.
Interfejsy mają duże znaczenie dla zastępstwa i wielokrotnego używania komponentów. Jeden
komponent może być zastąpiony przez drugi, jeżeli nowy pasuje do tego samego interfejsu
co poprzedni. Komponent z jednego systemu może zostać użyty w innym systemie, jeżeli system
ten będzie mógł za pomocą jego interfejsu uzyskać dostęp do jego operacji.
Podczas projektowania systemów mamy do czynienia z trzema rodzajami komponentów.
Komponenty wdrożenia są podstawą systemu wykonywalnego (np. biblioteki dołączane
dynamicznie DLL, pliki wykonywalne, kontrolki ActiveX). Komponenty procesu wytwórczego
są podstawą do generowania komponentów wdrożenia (np. pliki z danymi, pliki kodów
źródłowych). Komponenty wykonania są tworzone jako rezultat działania systemu.
Diagram komponentów zawiera komponenty, interfejsy i związki. Mogą na nim pojawić się
również inne elementy. Symbol komponentu to prostokąt z „bolcami”. Wewnątrz jest wpisana
nazwa. Można również umieścić nazwę pakietu i klasy, których implementacją jest dany
komponent (patrz rys. 4.44).
AWTEventMulticaster
AWTEventMulticaster
ItemListener
+itemStateChanged()
<<Interfejs>> ItemListener
Rys. 4.44. Ikona komponentu i powiązanie z interfejsem
Interfejs przedstawia się w formie prostokąta zawierającego informacje i
połączonego
z komponentem przerywaną linią z pustym trójkątnym grotem oznaczającym realizację
lub w formie okręgu połączonego z komponentem linią ciągłą (rys. 48). Można również
przedstawić związek między komponentem i interfejsem importowanym. Zależność tą przedstawia
się przy pomocy linii przerywanej zakończonej otwartym grotem strzałki.
Autor: Katarzyna Ragin-Skorecka
39 z 40
4.11. DIAGRAM WDROŻENIA
Diagram wdrożenia pokazuje fizyczną architekturę systemu komputerowego. Głównym
elementem sprzętowym jest węzeł – zastępuje każdy rodzaj zasobów komputerowych. Istnieją
dwa typu węzłów. Pierwszy z nich to procesor (ang. processor). Jest to węzeł, który może wykonać
kod komponentu. Drugi typ węzła to urządzenie (ang. device). Jest to pewnego rodzaju interfejs
dla świata zewnętrznego (np. drukarka, monitor).
W UML-u ikoną reprezentującą węzeł jest sześcian. Umieszczamy w nim nazwę węzła
i za pomocą stereotypu określamy rodzaj zasobów, który reprezentuje (rys. 4.45). Nazwa węzła jest
tekstem. Jeżeli węzeł jest częścią pakietu, to jego nazwę można przedstawić w postaci nazwy
ścieżkowej. Sześcian węzła można podzielić na sekcje i dodać informacje np. o komponentach
wdrożonych w tym węźle.
<<Processor>>
Dostawca Usług
Internetowych
<<Device>>
Monitor
<<Device>>
Modem
<<Device>>
Drukarka
<<Processor>> PC
Windows XP
Ms Office XP
Internet Explorer
Połączenie komutowane
Internet
Rys. 4.45. Diagram wdrożenia domowego systemu komputerowego
Na diagramie można również pokazać połączenia między dwoma lub więcej węzłami.
Informacje o połączeniu pokazuje się w formie stereotypu. Na diagramie mogą również znaleźć się
innego rodzaju zależności, np. agregacje.
4.12. INNE ELEMENTY
4.12.1. PAKIETY
Grupowanie w pakiecie pozwala na łączenie elementów diagramu w grupę. W ten sposób
organizuje się najczęściej klasy lub komponenty.
Maszyny Tokarskie
Rys. 4.46. Ikona pakietu
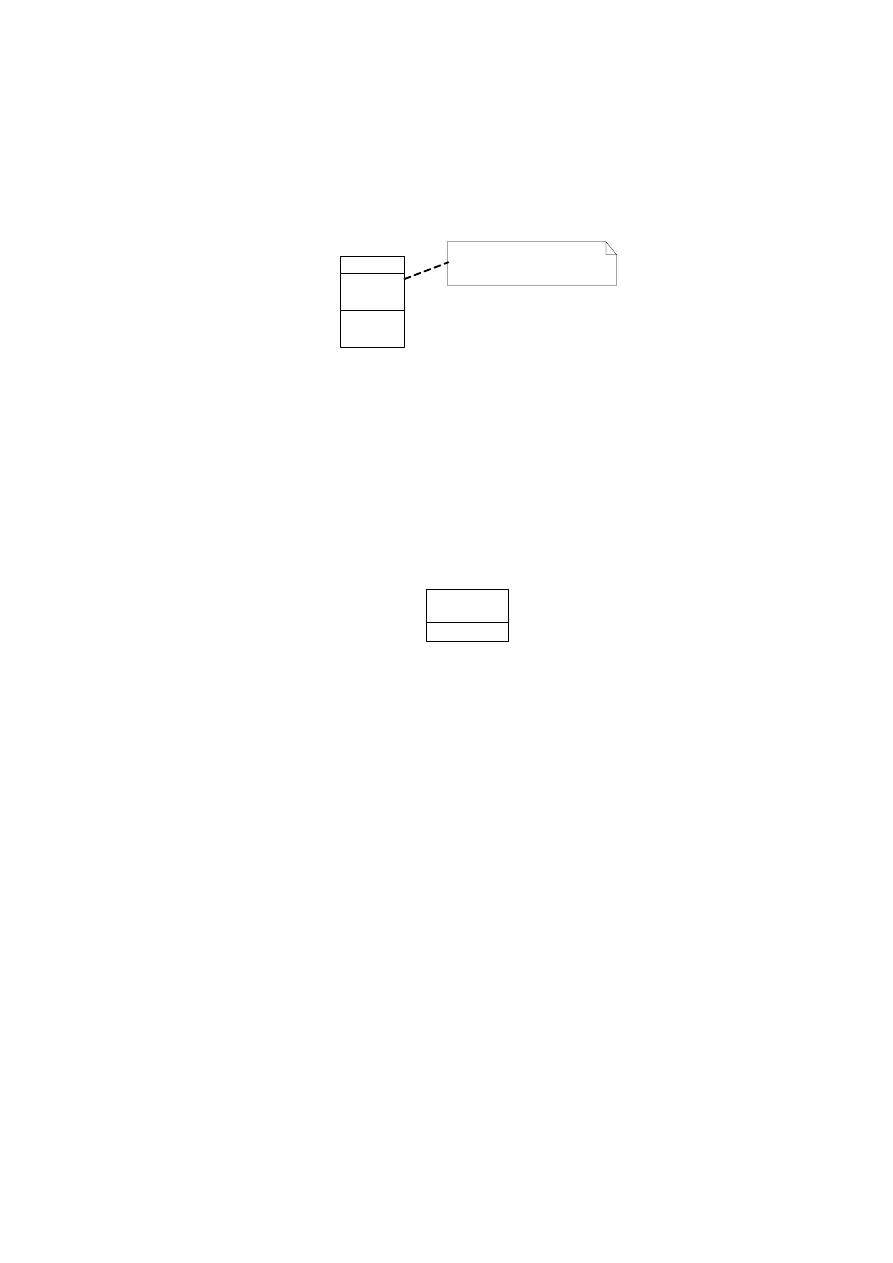
Autor: Katarzyna Ragin-Skorecka
40 z 40
Ikona pakietu to rysunek teczki z zakładką (rys. 4.46). Nazwa pakietu jest pisana z wielkiej
litery, słowa są rozdzielone.
4.12.2. NOTATKI
Notatki zawierają dodatkowe informacje, które można umieścić na diagramach. Notatkę
reprezentuje ikona w postaci prostokąta z zagiętym rogiem (rys. 4.47).
+przygotuj()
+sprawdź()
+...()
-przedmiot
-egzaminator
-...
Egzamin
Sprawdzić prowadzących zajęcia
Rys. 4.47. Ikona notatki i połączenie jej z wybranym elementem
Wewnątrz prostokąta wpisujemy tekst objaśniający lub wstawiamy znak graficzny. Notatkę
dodajemy do diagramu, łącząc ją przerywaną linią z elementem, do którego się odnosi.
4.12.3. STEREOTYP
Stereotypy pozwalają na tworzenie elementów specyficznych dla problemu, pozwalają
przekształcać istniejące elementy w inne. Są one przedstawiane w postaci nazwy ujętej w podwójne
nawiasy kątowe (rys. 4.48).
«interface»
Klasa1
Rys. 4.48. Stereotyp pozwala na tworzenie nowych elementów na podstawie istniejących
Dobrym przykładem jest interfejs. Obejmuje on tylko operacje bez atrybutów. Jest to zestaw
operacji, które mają być wielokrotnie wykonywane w modelu.
LITERATURA
1. Booch G., Rumbaugh J., Jacobson I., WNT, Warszawa, 2001, 2002,
2. Pilone Dan, UML – leksykon kieszonkowy, Helion, Gliwice, 2003,
3. Roszkowski J., Analiza i projektowanie strukturalne, Helion, Gliwice, 2004,
4. Schmuller Joseph, UML dla każdego, Helion, Gliwice, 2003,
Wyszukiwarka
Podobne podstrony:
getattach,mid,20450,mpid,8,uid,d8638cf2a8171765,min,0,nd,1
getAttachment
eko, getAttachment, Testy Ekologia
getAttachment
getAttachment3
getAttachment 2
getAttachment8
getattach,mid,20450,mpid,7,uid,d8638cf2a8171765,min,0,nd,1
getAttachment(3)
getAttachment4
getAttachment3
getAttachment2
getAttachment6
getattach,mid,1501,mpid,3,uid,65f3bb31d13129b6,min,0,nd,1
getattach,mid,266,mpid,3,nd,1,,uid,def2f25897d9a3ac
więcej podobnych podstron