
1
Systemy Baz
Systemy Baz
Danych
Danych
(cz. 1.3)
(cz. 1.3)
Prof. dr hab.
Prof. dr hab.
inż
inż
. Sławomir Wiak
. Sławomir Wiak

2
Oracle 8/9
Oracle 8/9

3
System Oracle powstał w wyniku zamówienia
Stanów Zjednoczonych, w firmie Relational
Software Incorporated z Menlo Park w Kalifornii w
roku 1977. Firma postawiła sobie za cel
uruchomienie systemy na dużej gamie platform
komputerowych
Z chwilą osiągnięcia sukcesu firma zmienił nazwę
na Oracle Corporation.
Firma dba o ciągły rozwój systemu, wzbogacając
kolejne wersje o coraz to nowe produkty.
Oracle Corporation jest dziś patentatem na rynku
producentów oprogramowani. Jej dochody sytuuja
ją na trzecim miejscu na świecie, a bezpośrednia
działalność firmy obejmuje ponad 100 krajów.
Sukces polega na tym iż dobrze opracowane bazy
danych w znaczący sposób podnoszą jakość
zarządzania przedsiębiorstwami i instytucjami.

4
Współczesne SZBD składają się z trzech części:
jądra, interfejsu i zestawu narzędzi.
jądra, interfejsu i zestawu narzędzi.
Rysunek ilustruje architekturę systemu ORACLE.
Jądro relacyjnej bazy danych jest wyposażone w
takie funkcje, jak
kontrola współbieżności
,
zarządzanie
transakcjami
,
zarządzanie
słownikiem i zapytaniami.
Dostęp do jądra uzyskuje się za pomocą
odpowiedniej
wersji standardu SQL
. Różne
funkcje SQL są zebrane w narzędzia:

5
SQL*DBA
zawiera
funkcje
potrzebne
administratorowi bazy danych (DBA) do tworzenia,
utrzymywania, uruchamiania, zatrzymywania i
odtwarzania bazy danych.
SQL*Plus
jest interakcyjnym interpreterem SQL
używanym głównie do tworzenia i testowania
instrukcji SQL.
PRO*SQL
dostarcza sposobów integrowania SQL ze
standardowymi językami programowania, takimi jak
C, Fortan, Cobol.
ORACLE Forms
jest narzędziem do tworzenia
aplikacji opartych na formularzach. Używa się go
głównie do tworzenia ekranów do wprowadzania lub
wyszukiwania danych. Z tych ekranów mogą być
bezpośrednio wywoływane obiekty baz danych, np.
programy PL/SQL i wyzwalacze.

6
ORACLE
Graphics
może
być
użyty
do
automatycznego
konstruowania
graficznych
prezentacji
(np.
wykresów
słupkowych,
liniowych i kołowych) dla danych, które są
wynikiem wykonania zapytania na bazie
danych.
ORACLE Reports
jest pakietem do generowania
złożonych raportów
ORACLE TextRetrieval
jest narzędziem, które
dostarcza
sposobów
zarządzania
niestrukturalnymi danymi, np. tekstami i
obrazami
7
SQL*plus
Jądro
Oracle Graphics
Oracle TextRetrieval
SQL*DBA
PL/SQL
Oracle Forms
ORACLE
PRO*SQL

8
Architektura
danych
ORACLE
odwzorowuje
logiczne tabele na fizyczne pliki. Baza danych
ORACLE zawiera przynajmniej 2 pliki dziennika
powtórzeń, przynajmniej 2 pliki kontrolne i
dowolną liczbę plików z danymi.
Plików z danymi używamy
do przechowywania
wszystkich możliwych obiektów baz danych
obsługiwanych przez system ORACLE. Pliki
dziennika powtórzeń rejestrują historię zmian
dokonywanych
na
bazie
danych
przez
transakcje.
Pliki
kontrolne
przechowują
podstawowe
informacje na temat bazy danych ORACLE, na
przykład nazwy wszystkich plików z danymi i
wszystkich plików dziennika powtórzeń.

9
Architekturę oprogramowania ORACLE
możemy
podzielić
na
dwa
podstawowe
składniki:
instancję ORACLE
i
zbiór powiązanych procesów
serwera ORACLE
.
Instancja ORACLE składa się ze zmiennego obszaru
pamięci podręcznej bazy danych, nazywanego
globalnym obszarem systemu, w skrócie
SGA
(System Global Area)
wraz ze zbiorem procesów
drugoplanowych, z których każdy wykonuje
specjalne zadanie w bazie danych.
Procesy serwera ORACLE tworzymy do obsługi
zadań użytkowników lub procesów użytkowników
połączonych z instancją. Zazwyczaj w jednej
chwili kilka z tych procesów jest aktywnych.

10
DBA i programiści aplikacji
mogą
dostrajać działanie ORACLE na wiele
sposobów. Na przykład optymalizacja
zapytania metodą opartą na koszcie jest
wartością domyślną w ORACLE7.
Możemy jednak zmienić to ustawienie na
metodę opartą na heurystyce – zarówno
na początku każdej sesji ORACLE, jak i
do wykonania konkretnego zapytania
SQL.

11
Architektura klient/serwer
Architektura klient/serwer
Przesłanką architektury klient/serwer
jest podział
wykonywania zadań pomiędzy kilka procesorów
znajdujacych się w sieci. Każdy processor jest
dedykowany do określonego zbioru zadań, które
jest w stanie wykonywać najefektywniej, co w
rezultacie
daje
zwiększenie
wydajności
i
skuteczności systemu jako całości.
Rozdzielenie
wykonywania
zadań
pomiędzy
procesory jest dokonywane poprzez
protokół
usług
: jeden procesor, klient, zleca pewną
usługę
drugiemu
procesorowi
zwanym
serwerem, który ma tę usługę zrealizować.
Najbardziej
powszechną
implementacją
architektury klient/serwer
jest odseparowanie
części aplikacji będącej interfejsem użytkownika
od części odpowiedzialnej za dostęp do danych.

12
Oracle Corporation a architektura klient
serwer
W pełni wydajny
relacyjno-
obiektowy
system
zarządzania bazą
danych,
skalowalny
poczynając od
maszyn typu
laptop a kończąc
na maszynach
typu mainframe
Narzędzia
klienckie do
tworzenia
aplikacji dla baz
danych,
wspierających
różnorodne
środowiska GUI (
Oracle Developer
i Oracle
Designer)
Narzędzia sieciowe
umożliwiające
wydajne i
bezpieczne
połączenie się z
bazą wśród wielkiej
gamy protokołów
sieciowych.
(SQL*Net, Oracle
Names,
Multi_Protocol
Interchange, Oracle
Network Manager
13
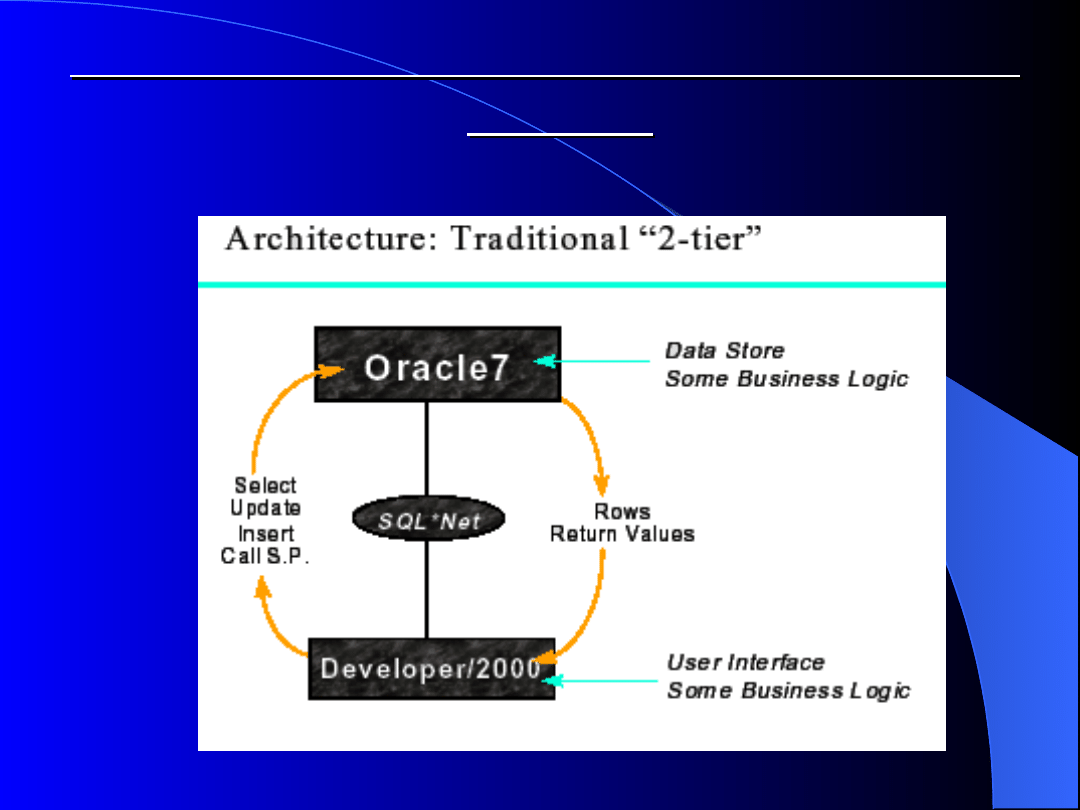
Dwuwarstwowa architektura klient
Dwuwarstwowa architektura klient
serwer
serwer
14
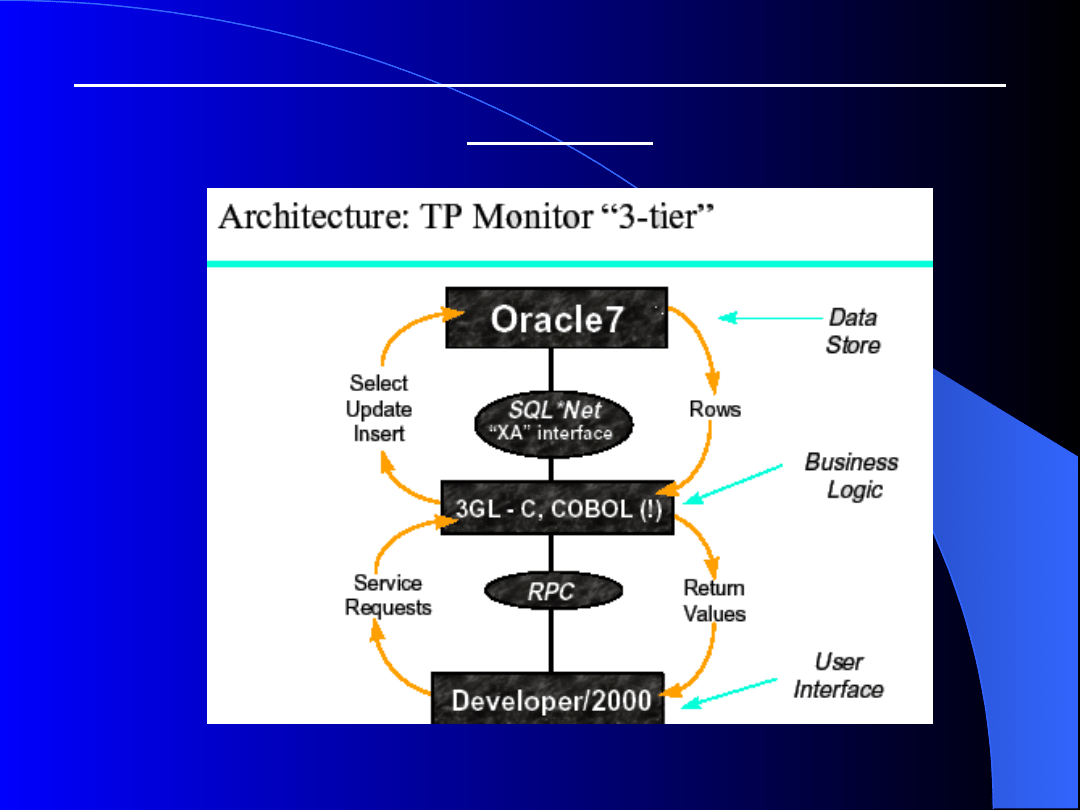
Trójwarstwowa architektura klient
serwer

15
Architektura serwera bazy danych Oracle
Serwer Oracle’a
Serwer Oracle’a to zarówno środowisko, w którym
pracuje baza jak i pliki tworzące bazę danych. Ta
platforma systemowa, jaką jest serwer baz
danych musi odpowiadać coraz większym
wymaganiom użytkowników w stosunku do
programów obsługujących dane składowanie w
systemach
informatycznych.
Obiektowo-
relacyjna baza danych Oracle zapewnia wydajne
i efektywne rozwiązania w zakresie:
realizacji pracy w środowisku klient-serwer
(przetwarzanie rozproszone)

16
Aby w pełni wykorzystywać możliwości komputerów
i sieci komputerowych, Oracle umożliwia podział
funkcjonalny przetwarzania danych na część
kliencką i serwerową. Komputer-serwer, na
którym
uruchomione
jest
oprogramowanie
zarządzające danymi, zapewnia pełną obsługę
składowanych
danych
w
czasie,
gdy
na
komputerze-kliencie uruchomione są aplikacje
interpretujące pozyskane z bazy dane.
składowania i zarządzania dużymi bazami danych
Oracle obsługuje bazy danych osiągające rozmiary
terabajtów.
Aby
zapewnić
zadowalającą
wydajność pracy z tak dużymi zbiorami danych,
oprogramowanie serwera zapewnia możliwość
pełnej kontroli nad procesem ich składowania.

17
obsługi wielu jednoczesnych użytkowników
Serwer Oracle umożliwia jednoczesną pracę wielu
użytkowników bazy, korzystających z różnych
aplikacji operujących na tym samym zbiorze
danych.
możliwości przenoszenia
Oprogramowanie Oracle’a pracuje na wielu typach
komputerów
i
pod
wieloma
systemami
operacyjnymi.
zapewniania dużej dostępności danych
Często zdarza się, że baza danych musi pracować
24 godziny na dobę. Instalacja Oracle’a daje taką
możliwość, nie ma konieczności wprowadzania
przerw w pracy bazy związanych z czynnościami
takimi jak wykonywanie kopii zapasowych czy
usuwanie drobnych uszkodzeń systemu.

18
zapewnienia możliwości kontroli dostępu do
danych
Serwer Oracle’a umożliwia selektywną kontrolę
dostępności danych.
otwarcia na standardy przemysłowe
Oracle stara się dostosować do przemysłowych
standardów
obowiązujących
w
dziedzinie
dostępu do danych, systemów operacyjnych,
interfejsów
użytkownika
oraz
komunikacji
sieciowej.
W
celu
ułatwienia
zarządzania
serwerami
pracującymi
w
heterogenicznym
środowisku, z jednej konsoli administratora
systemu zaimplementowany został protokół
Simple Network Management Protocol (SNMP).
wymuszania spójności danych
Serwer Oracle’a wymusza spójność danych poprzez
zbiór reguł zdefiniowanych w bazie określających
zasady korzystania z danych przez wielu
użytkowników jednocześnie.

19
Rozwiązanie to redukuje koszty utrzymania spójności
danych podczas budowy aplikacji opartych na bazie
Oracle.
możliwości przenoszenia i zgodności oprogramowania
Oprogramowanie
Oracle’a
pracuje
pod
wieloma
systemami
operacyjnymi.
Aplikacje
budowane
narzędziami
Oracle’a
są
zgodne
z
wieloma
przemysłowymi standardami, mogą być przenoszone
pomiędzy systemami operacyjnymi bez konieczności
wprowadzania zasadniczych zamian programowych.
realizacji przetwarzania rozproszonego
W środowisku rozproszonego przetwarzania sieciowego
Oracle umożliwia łączenie danych, składowanych
fizycznie na różnych komputerach, w jedną pod
względem logicznym bazę danych. Taki system
rozproszony, z punktu widzenia użytkownika, niczym
nie różni się od nierozproszonej bazy danych.
Możliwy jest również transparentny dla użytkownika
dostęp do innych niż Oracle źródeł danych.

20
replikacji danych
Oprogramowanie
Oracle’a
umożliwia
wiele
rodzajów replikacji wybranych obiektów lub
zbiorów
danych
do
innych
baz
danych
znajdujących
się
w
obrębie
jednej
sieci
komputerowej.
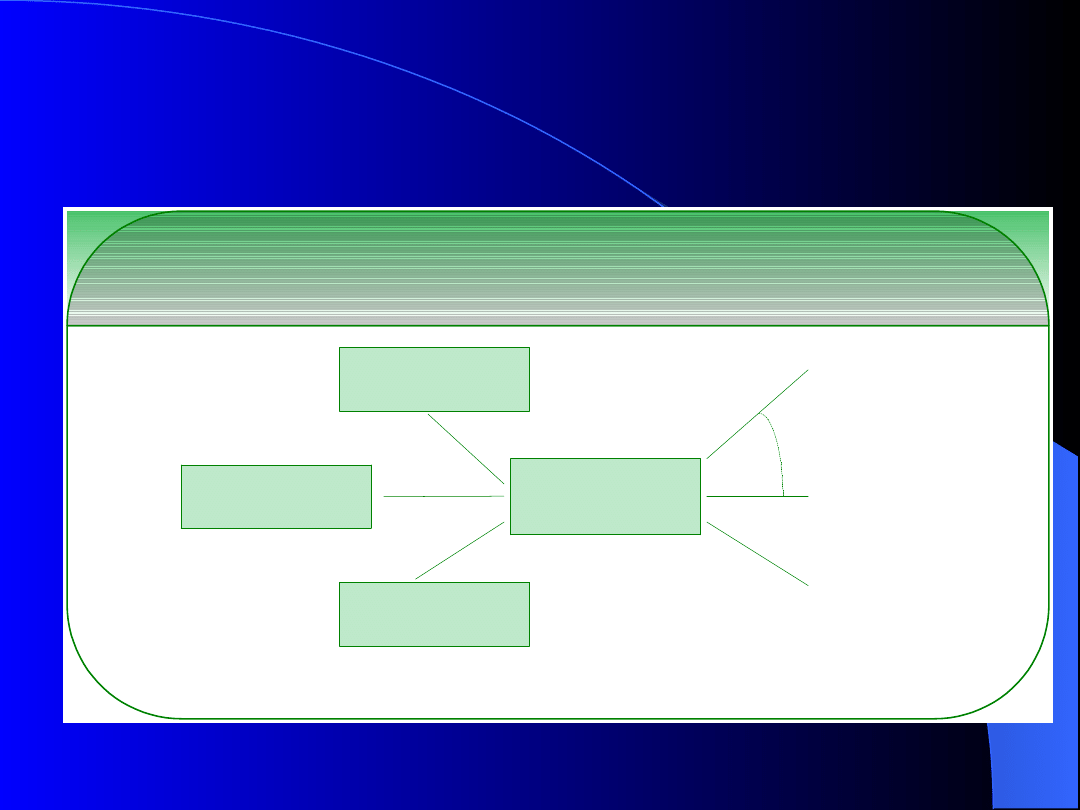
Struktura bazy danych Oracle
Aby system Oracle był użyteczny potrzebna jest
baza danych i instancja. Baza danych to
zorganizowany zbiór danych przechowywany w
plikach danych, instancja to szereg procesów i
obszarów pamięci, które umożliwiają dostęp do
danych. Złożony system zarządzania relacyjną
bazą danych (ang. RDBMS – relational database
managment system) Oracle można podzielić na
trzy prostsze części (patrz rysunek ):
21
procesy pracujące w tle;
obszary pamięci współdzielonej;
przestrzeń składowania danych na dysku.
Obszary
pamięci
Procesy
Pliki danych
Oracle
RDBMS
Narzędzia tworzenia
aplikacji
Aplikacje
Narzędzia realizacji
zapytań
Interfejsy sieciowe
Części składowe RDBMS Oracle

22
Procesy systemu Oracle
Oracle,
podobnie
jak
większość
innych
wieloużytkowych systemów zarządzania bazą
danych,
wykorzystuje
szereg
procesów
pracujących w tle, by umożliwić zapis danych.
Rozdział zadań na wiele procesów pozwala
zmniejszyć złożoność każdego z tych procesów.
Procesy te można przyrównać do szeregu
specjalistów, z których każdy pracuje nad
wybranym zagadnieniem. Głównymi procesami
serwera Oracle są:
Proces DBWR,
Proces LGWR,
Proces PMON,
Proces SMON.
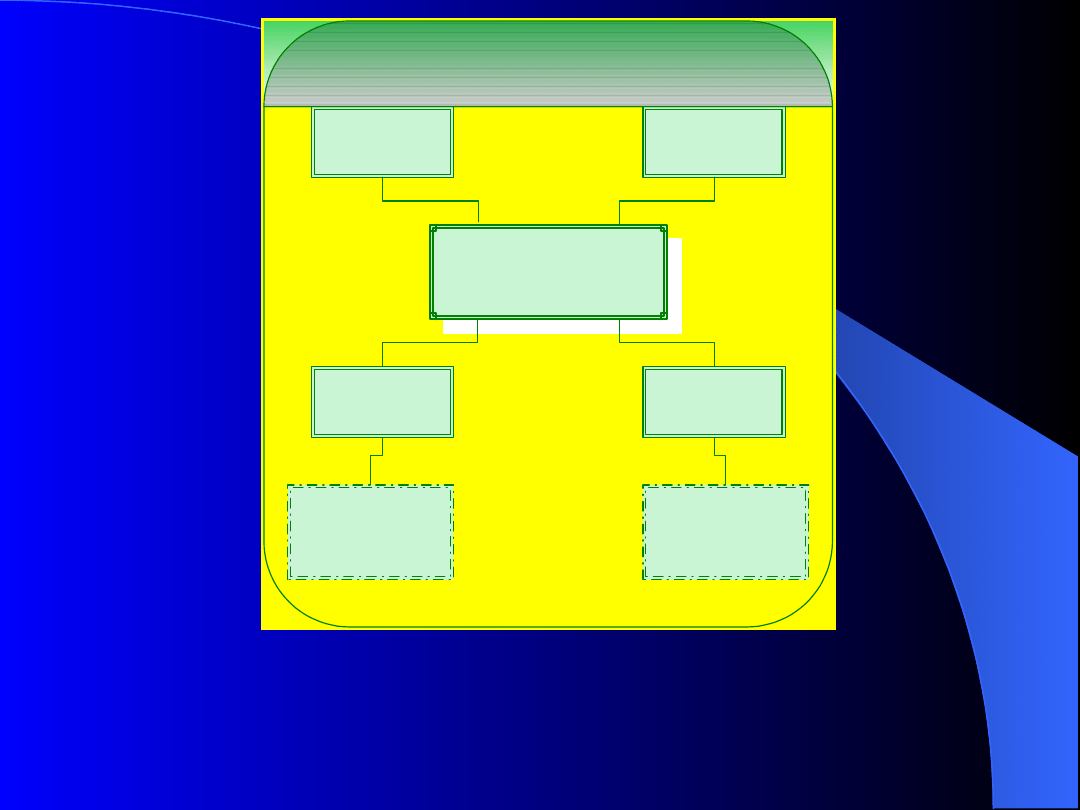
23
Te cztery główne procesy w połączeniu z
odpowiednimi obszarami pamięci tworzą
instancję bazy danych.
Obszary pamięci
DBWR
LGWR
PMON
SMON
Pliki danych
Pliki dziennika
powtórzeń
Główne procesy serwera Oracle

24
Aby zapewnić sobie kontrolę nad poszczególnymi
różnorodnymi
procesami,
Oracle
używa
identyfikatora
systemu
SID
(ang.
System
IDentifier
), który jest najważniejszym parametrem
przy połączeniach z daną instancją bazy danych.
DBWR
-
(ang.
Data Base Writer
) – proces zapisujący
dane wprowadzane przez użytkowników do bazy z
buforów SGA do plików dyskowych; Fizyczny zapis
danych na dysk odbywa się, gdy
Data Base Writer
:
nie znajduje w SGA odpowiedniej liczby wolnych
buforów potrzebnych do bieżącej pracy bazy;
upłynął odpowiednio długi okres bez zapisów (ma
to miejsce przy małej aktywności użytkowników
bazy);
w bazie wykonuje się tzw. CHECKPOINT – czyli
punkt kontrolny – i baza wymusza zapis wszystkich
istotnych informacji z obszaru SGA do plików
dyskowych.

25
Proces ten zmniejsza liczę fizycznych zapisów na dysku,
co przyspiesza pracę bazy i czyni ją bardziej płynną.
Nie trzeba dzięki temu tracić czasu na zapisywanie na
dysku zmian wprowadzonych przez każdego
użytkownika z osobna. Baza wykonuje tę czasochłonną
operację raz na jakiś czas.
LGWR
– (ang.
LoG Writer
) – proces zapisujący pliki
dziennika powtórzeń, czyli historię wszystkich operacji
na bazie. Proces ten uaktywnia się, gdy:
następuje potwierdzenie transakcji przez użytkownika
(COMMIT);
bufory dziennika w SGA są zapełnione w jednej
trzeciej;
DBWR czyści bufory bazy danych;
w bazie wykonywany jest CHECKPOINT;
upłynął odpowiednio długi okres bez zapisów;
baza przygotowuje się do przeprowadzenia transakcji
rozproszonej

26
W instancji Oracle’a może istnieć tylko jeden proces
LGWR.
PMON
– (ang.
Process MONitor
) – monitor procesów
trzymających
pieczę
nad
zasobami
bazy
wykorzystywanymi przez użytkowników bazy. W
praktyce często zdarza się, iż kilku użytkowników bazy
sięga jednocześnie po te same dane. Nie stanowi to
problemu, gdy użytkownicy chcą jedynie oglądać ten
sam fragment bazy. Kłopoty zaczynają się wtedy, gdy
kilku użytkowników jednocześnie chce modyfikować,
na przykład ten sam wiersz. Aby baza zachowała
spójność
istnieje
system
blokad
(LOCK)
zapewniających, że w danej chwili tylko jeden
użytkownik bazy może modyfikować wybrany przez
siebie wiersz. Pozostali użytkownicy muszą czekać na
zakończenie tej operacji.
Process Monitor
zajmuje się
właśnie odzyskiwaniem zasobów bazy zwolnionych
przez użytkowników.

27
Do jego zadań należy:
usuwanie nieprawidłowo zakończonych połączeń;
wycofywanie niezatwierdzonych transakcji;
zwalnianie blokad założonych przez zatwierdzone
procesy;
wykrywanie wewnętrznych zakleszczeń pomiędzy
blokadami zakładanymi na dane bazy i automatyczne
wycofywanie transakcji.
SMON
– (ang.
System MONitor
) – monitor systemu
utrzymujący „porządek” w SGA. Do jego obowiązków
należy:
usuwanie
niepotrzebnych
segmentów
tymczasowych;
wykonywanie automatycznego odtwarzania instancji;
aktualizowanie pliku kontrolnego bazy;
dynamiczne scalanie obszaru pamięci operacyjnej
zajmowanej przez serwer.

28
Zarówno
PMON
, jak i
SMON
działają w bazie
asynchronicznie
i
nie
można
wymusić
ich
aktywności zewnętrznie. Nie można też wpływać na
ich
pracę
przez
zmianę
parametrów
pliku
startowego
bazy.
Ani
użytkownik,
ani
jej
administrator nie wiedzą, kiedy procesy te są
aktywne, a kiedy nie.
W instancji Oracle’a oprócz ww. procesów głównych
mogą także pracować inne procesy pomocnicze.
Zależy to od zadań, jakie baza spełnia, a także od
jej wewnętrznej konfiguracji. Zapewniają one bazie
spójność danych i zwiększają bezpieczeństwo jej
zasobów. Najważniejsze to:
ARCH
– (ang.
ARCHiver process
) – to proces
dokonujący automatycznego archiwizowania plików
dziennika powtórzeń, co umożliwia, na przykład
odtworzenie bazy do stanu przed awarią.

29
RECO – (ang. RECOvery)
– odpowiada za odtwarzanie
rozproszone.
Obsługuje
błędy
transakcji
rozproszonych przez próbę ponownego połączenia.
Proces uaktywniany tylko w przypadku korzystania
z rozproszonych baz danych.
SNPn – (ang. SnaPshot)
– obsługuje automatyczne
odświeżanie replikacji zdalnych tablic (migawek –
ang. snapshot). Proces aktywny tylko w przypadku
korzystania z opcji rozproszonej.
LCKn – (ang. LoCK)
– kontroluje blokady pomiędzy
instancjami serwera równoległego. Używany tylko
w trybie serwera równoległego.
CKPT – (ang. ChecKPoinT process)
– wymusza
uaktualnienie wszystkich fizycznych plików bazy o
informacje znajdujące się aktualnie w buforach
SGA.

30
Snnn
– proces serwera dzielonego (ang.
Shared
serwer
), występujący przy konfiguracji serwera
wielokanałowego, wykonujący polecenia z kolejki
żądań.
Dnnn
– proces rozdzielający (ang.
Dispatcher
),
występujący
przy
konfiguracji
serwera
wielokanałowego, pośredniczący pomiędzy procesami
użytkowników a kolejkami żądań i odpowiedzi.
Obszary pamięci współdzielonej
Pamięć współdzielona jest kluczowym czynnikiem
rzutującym na wydajność systemu RDBMS Oracle.
Przez system Oracle wykorzystywane są obszary
pamięci tj.:
obszar kodu programu;
obszar globalny systemu (SGA);
obszar globalny programu (PGA);
obszary sortowania.
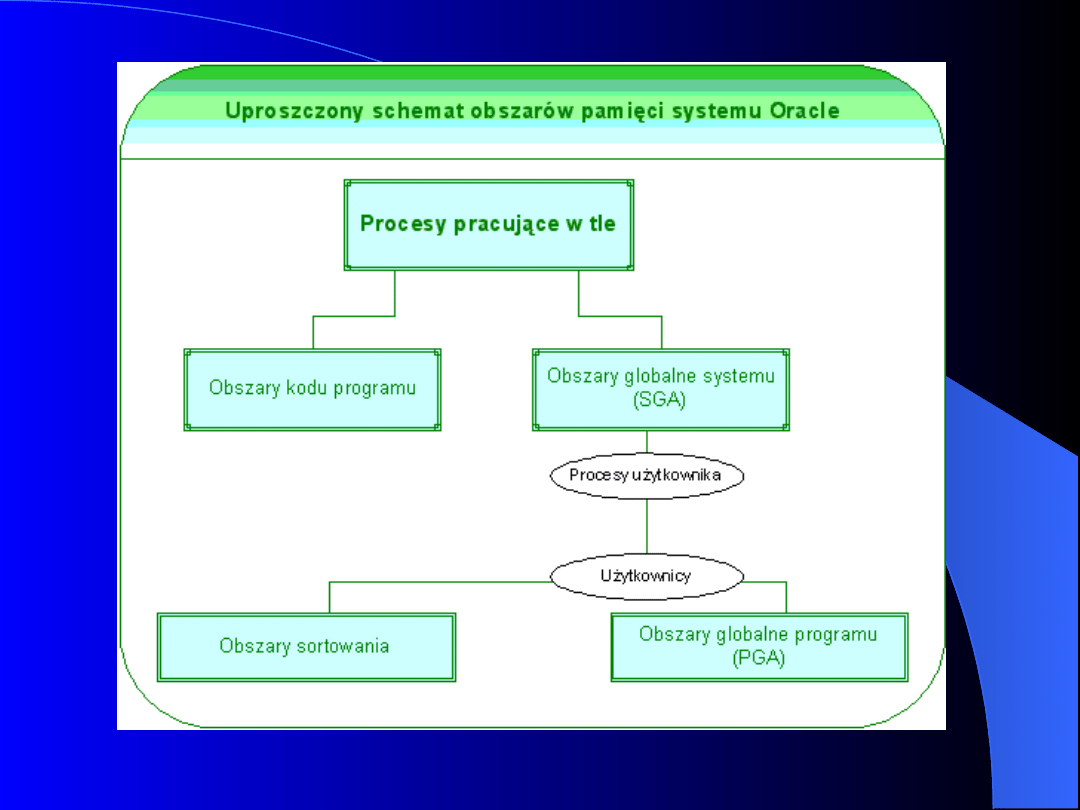
31

32
Obszar kodu programu:
Obszar ten przechowuje
właściwy kod programu dla systemu bazy danych
Oracle. Obszar ten może być współdzielony
pomiędzy instancjami. Jest to program realizujący
działanie bazy, a nie aplikacja stworzona i
uruchomiona przez użytkownika.
SGA:
SGA to serce bazy danych Oracle. Procesy
zapisują transakcje do tego obszaru i pobierają
dane, które są tu umieszczone, by przyśpieszyć
operacje odczytu.
Bez obszaru SGA nie może istnieć żadna baza
Oracle. Składowe obszaru SGA:
o
bufor (blokowy) bazy danych,
o
bufor dziennika powtórzeń,
o
obszar współdzielony,
o
obszar komunikacji międzyprocesowej,
o
zapytania dla wielokanałowego serwera (jeśli jest
używany).

33
Bufor bazy danych
służy do przechowywania
rekordów z różnych tabel bazy danych Oracle
(ponieważ
odczyt
i
zapis
jest
blokowy,
przechowuje całe bloki bazy, które zawierają
dane). Te bloki mogą zawierać zarówno takie,
które zostały odczytane z plików danych jak i te
rekordy, które muszą zostać zapisane do tych
plików.
W efekcie, bufor bazy danych służy jako stacja
pośrednia dla danych, która znajduje się
pomiędzy użytkownikami a plikami danych.
Najłatwiejsza decyzja dotycząca czasu pobytu
bloku w buforze odnosi się do nowych lub
zmodyfikowanych rekordów, które oczekują na
zapis na dysk. Pozostają one w buforze bazy
danych do momentu ich zapisu przez proces
piszący bazy danych.

34
Dla
pozostałych
buforów,
które
przechowują dane pobrane z dysku i nie
są zmienione, system Oracle musi
zdecydować, które należy zatrzymać, a
które
należy
usunąć.
Najbardziej
logiczne wydaje się, aby trzymać w
pamięci te rekordy, które są pobierane
bardzo
często
(np.
standardowe
przeglądanie tabeli) a usunąć te, z
których
nie
korzystamy.
Algorytm
stosujący tę metodę nosi nazwę
LRU
(ang.
least recently used
– najdłużej
niewykorzystywany).

35
Gdy rekord zostaje odczytany z bazy danych przez
zapytanie, blok danych zostaje zachowany w
buforze bazy danych i jest umieszczony na końcu
listy rekordów jako ostatnio użyty. Za każdym
razem, gdy jakiś rekord znajdujący się w buforze
jest wykorzystany zostaje on przeniesiony na
koniec listy najdawniej używanych rekordów.
Gdy wykonane zapytanie potrzebuje miejsca na
dane pobrane z dysku, a wszystkie bloki bufora
są wykorzystane, zostaje nadpisany blok, który
zawiera rekordy na początku listy najdawniej
używanych
rekordów,
o
ile
nie
zostały
zmodyfikowane (ang.
dirty
). Jeśli dane, które
zostały nadpisane, są ponownie potrzebne,
muszą zostać pobrane z dysku. Ten proces
zaoszczędza czas, przechowując dane w pamięci
i ograniczając wolny transfer z dysku.

36
Bufor dziennika powtórzeń
przechowuje kopie
transakcji, które zostały wykonane w bazie i czekają
na zapis do plików powtórzeń. Ten zapis transakcji
pozwala systemowi Oracle na rekonstrukcję danych
w przypadku utraty dysku. Transakcje zapisywane do
dziennika powtórzeń są zachowywane w pamięci, by
zwiększyć wydajność operacji zapisu.
Bufor dziennika powtórzeń został zaprojektowany
wyłącznie do zapisu, do którego wykorzystuje
metodę kolejki
FIFO
(ang.
first-in, first-out
– pierwszy
wchodzi, pierwszy wychodzi) w odniesieniu do
przechowywanych danych.
Wpisy do dziennika są zapisywane w kolejności, w
jakiej się pojawiły, a proces piszący dziennika
przegląda kolejkę i zapisuje jeden lub więcej bloków
do aktywnych plików dziennika. Bufor pliku dziennika
służy jako stacja pośrednia dla wpisów do dziennika,
znajdująca
się
między
procesem
Oracle,
wykonującym określoną aktualizację a plikami
dziennika na dysku.

37
Obszar współdzielony
zawiera trzy sekcje, które
mogą poprawić wydajność systemu:
współdzielone obszary SQL (ang. shared SQL)
przechowuje
przeanalizowane
(ang.
parsed)
zapytanie dla dowolnego użytkownika, by mógł z
niego
korzystać
bez
konieczności
ponownego
dokonywania rozbioru składniowego. Zapytania są
przechowywane w tym obszarze, który jest również
określany jako bufor biblioteki (ang. library cache)
wykorzystujący zmodyfikowany algorytm LRU.
bufory słownika danych (ang. data dictionary cache).
We
wszystkich
zapytaniach
i
transakcjach
wykonywanych w bazie danych system musi wiedzieć,
gdzie się znajdują dane. To obejmuje informacje na
temat: samej bazy danych, jej obiektów (tabel,
widoków,
itd.)
i
użytkowników.
Wszystkie
te
informacje są przechowywane w różnych tabelach
systemowych w bazie danych, dlatego gdy dane
informacje są często wykorzystywane bufor słownika
danych przechowuje je dla zapewnienia systemowi
szybkiego do nich dostępu.

38
kursory (ang. cursors)
przechowują dane
pobrane
z
bazy
danych
dla
dalszego
przetwarzania. System Oracle tworzy swoje
własne wewnętrzne kursory (określane jako
kursory rekursywne, ang. recursive cursors)
przy wykonywaniu poleceń, tj. CREATE TABLE -
takie
polecenia
powodują
wykonanie
uaktualnień w wielu tabelach słownika danych.
Obszar komunikacji międzyprocesowej
jest
wykorzystywany
do
przechowywania
komunikatów przesyłanych między różnymi
procesami związanymi z działaniem bazy danych
Oracle. Wiele cech, tj. na przykład blokada
założona na obiekt przez działający proces jest
przechowywana poprzez ten obszar.

39
Zapytania dla wielokanałowego serwera
pozwalają użytkownikom systemu Oracle na
współdzielenie obszarów pamięci i procesów
wykorzystywanych
do
tworzenia
połączenia
aplikacji użytkownika z bazą danych Oracle.
Jednym ze sposobów monitorowania obszaru SGA
jest wydanie polecenia:
show sga
PGA:
Obszar
globalny
PGA
przechowuje
informacje
dotyczące
pojedynczego
procesu
użytkownika. Każdy użytkownik zajmuje część
obszaru PGA po uzyskaniu połączenia z bazą
Oracle.
Wielkość
zajmowanej
pamięci
jest
uzależniona od systemu operacyjnego i pozostaje
niezmienna tak długo, jak użytkownik jest
podłączony do bazy. Właścicielem obszaru PGA
jest więc proces danego użytkownika i jedynie
użytkownik ma prawo czytać i zapisywać dane do
tego obszaru.

40
Rozmiar obszaru PGA jest uzależniony od wersji
systemu Oracle, który pracuje w różnych systemach
operacyjnych. Trzy parametry mają wpływ na wielkość
PGA dla danej instancji: ilość otwartych połączeń do
bazy, ilość plików danych oraz liczba ról i ilość plików
dziennika.
Obszar sortowania
: Jedną z częściej stosowanych
klauzul w poleceniu wyboru SQL jest klauzula order
by.
Sortowanie
zapytań,
które
nie
zostały
umieszczone w pamięci, może czasami zająć od pięciu
do dziesięciu razy więcej czasu. Dlatego aplikacje
wykonujące operacje sortowania często umieszczane
są właśnie w pamięci fizycznej. Rozmiar obszaru
sortowania zależy głównie od potrzeb aplikacji. Jego
maksymalny rozmiar określa parametr
sort_area_size
w pliku konfiguracyjnym lub brany jest domyślnie do
danego systemu operacyjnego.

41
Po zakończeniu operacji sortowania rozmiar obszaru
jest zmniejszany do wartości określonej przez
parametr
sort_area_retained_size.
Przestrzeń składowania danych na dysku
Przy
instalacji
oprogramowania
Oracle
dla
komputerów PC, kopiowana jest pewna liczba
plików
do
jednego
katalogu
lub
kilku
podkatalogów danego katalogu. Można te pliki
pogrupować na następujące kategorie:
Pliki danych (Database Files):
Pliki danych spełniają
podstawową rolę w systemie Oracle – przechowują
dane w odpowiedniej formie. Nie można ich
odczytywać bezpośrednio, korzystając, np. z
Notepad’a w Microsoft Windows, a zawartość ich
można uzyskać poprzez zapytania SQL. Poprzez
polecenia SQL można określić logiczne struktury:
przestrzenie tabel (ang. tablespace) i tabele.

42
Za fizyczne struktury odpowiada system Oracle.
Administrator bazy DBA łączy te struktury
razem. Każdy plik jest związany z jedną
przestrzenią tabel. Przestrzeń tabel może
składać się z jednego lub więcej plików danych.
DBA określa liczbę plików danych skojarzonych z
daną przestrzenią tabel. Aby uzyskać informacje
na temat położenia plików w systemie należy
użyć polecenia SQL:
SQL> select * from sys.dba_data_files;
Pliki dziennika powtórzeń (Redo Log Files):
Zapisane są w nich dane o bazie służące do
awaryjnego
odtwarzania
danych
bazy.
W
systemie występuje stała, określona liczba
aktywnych
plików
dziennika
powtórzeń,
używanych cyklicznie.

43
Po zakończeniu zapisywania do pierwszego pliku,
transakcje zapisywane są do następnego. Ten
proces postępuje, aż do zapełnienia ostatniego
pliku w sekwencji i następuje rozpoczęcie zapisu
ponownie do pierwszego pliku. Jest to bardzo
istotna sprawa, gdyż system nie będzie mógł
zacząć zapisywać do pierwszego pliku, zanim nie
zostanie
on
całkowicie
skopiowany
do
archiwalnego pliku dziennika. A jeśli system
Oracle nie może przepisać pliku dziennika
powtórzeń do archiwalnego dziennika z powodu,
np. braku miejsca, baza nie może wykonywać
żadnych transakcji. Dlatego bardzo istotne jest
aby sprawdzać, gdzie system zapisuje archiwalne
pliki dziennika, by uniknąć tej sytuacji. Aby
określić jakie pliki dziennika są skojarzone z
instancją należy użyć polecenia:
SQL> select * from v$logfile;

44
Archiwalne pliki dziennika mają zasadniczo dwie
opcje dotyczące miejsca przechowywania.
Pierwszą z nich jest możliwość wykorzystania
miejsca na dysku twardym – drugą, zapis
plików bezpośrednio na taśmę magnetyczną.
Pliki sterujące:
Pliki sterujące są wewnętrzną
częścią systemu Oracle. Nie można ich
edytować, zmieniać rozmiaru czy przenosić w
inne miejsce. Pliki te zawierają nazwę: bazy
danych, plików danych, dzienników powtórzeń
oraz czas, kiedy zostały stworzone. Pliki
sterujące można dodawać, a także je kasować.
Obowiązuje tylko jedna zasada: zawsze musi
być
dostępny
przynajmniej
jeden
plik
sterujący, by móc powtórnie stworzyć inne.

45
Pliki konfiguracyjne:
Pliki konfiguracyjne
umożliwiają „strojenie” bazy. W systemie
wieloużytkowym Oracle wykorzystywane są
dwa podstawowe pliki kontrolne:
init.ora
. Jest to plik główny. Jego właściwa
nazwa pliku zawiera identyfikator instancji
SID, tak więc dla instancji nazwanej gosia plik
kontrolny będzie miał nazwę initgosia.ora;
config.ora
. Zwykle plik
config.ora
zawiera
lokalizację plików kontrolnych, archiwalnych
oraz zrzutów pamięci (ang.
dump files
).
Zawiera również nazwę bazy danych oraz
parametry określające rozmiar bloku bazy
danych (ang.
database block size
).

46
Najczęściej stosowane parametry znajdujące
się w pliku konfiguracyjnym przedstawia
poniższa tabela:
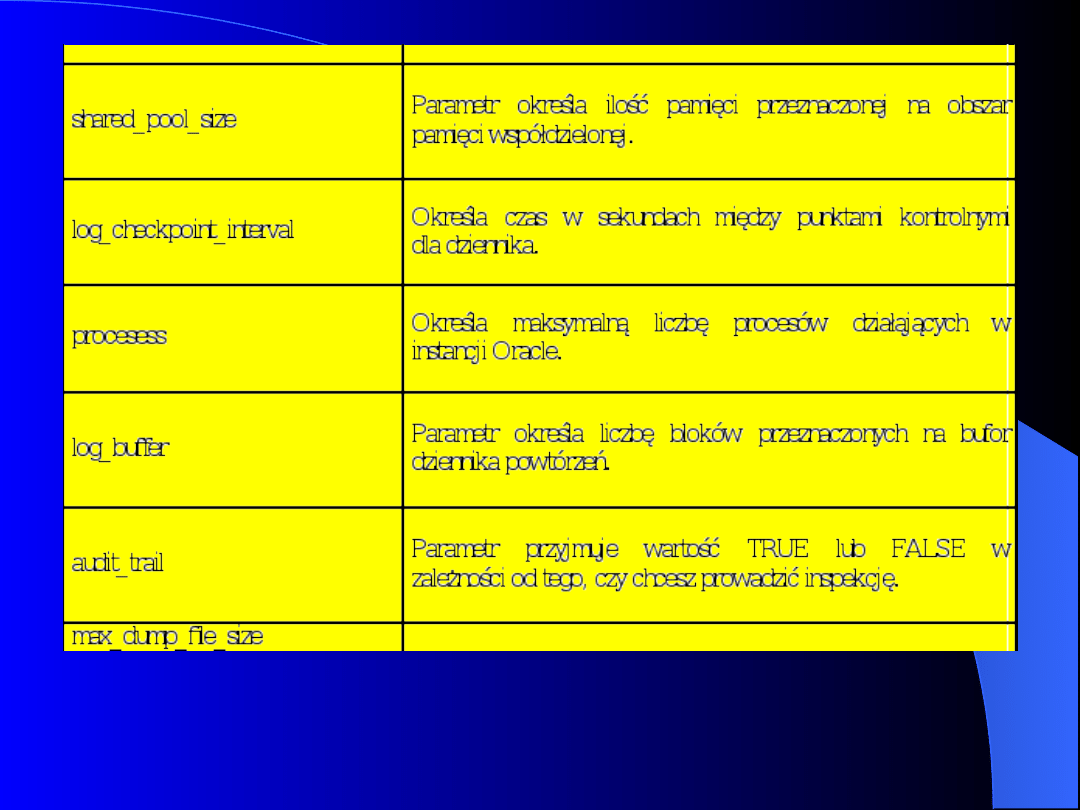
47

48
Pliki rejestrów i śledzenia:
Plikiem
rejestrującym najważniejsze zdarzenia w bazie
jest plik alarmów (ang.
alert log
). Właściwa
nazwa tego pliku zawiera nazwę instancji, z
którą dany plik jest związany, a więc, np.
gosiaALRT.log.
Do pliku tego zapisywane są:
główne operacje wykonywane przez DBA, np.
uruchomienie
lub
zatrzymanie
instancji,
wykonanie poleceń tworzenia, modyfikacji lub
usunięcia bazy danych, jej przestrzeni tabel
lub segmentów wycofań;
wewnętrzne błędy systemu Oracle;
komunikaty o problemach związanych z
serwerem wielokanałowym;
błędy związane z automatycznym
odświeżaniem migawek.

49
Pliki śledzenia są tworzone przez procesy Oracle
pracujące
w
tle
w
przypadku
wykrycia
poważnych problemów lub gdy jeden z
procesów wykryje złe działanie, lub brak innego
procesu pracującego w tle. Treść komunikatu
jest uzależniona od możliwości zidentyfikowania
problemu.
Zwykle
zawiera
datę
i
czas
wystąpienia
problemu,
jaki
proces
go
spowodował, numer komunikatu błędu Oracle
oraz dodatkowe wyjaśnienia.
Zarówno pliki rejestrów jak i śledzenia znajdują
się w miejscu określonym poprzez parametr
BACKGROUND_DUMP_DEST w pliku init.ora,
którego domyślna wartość to
\oracle\admin\nazwa_instancji\bdump.

50
”Wnętrze bazy” Oracle
Baza danych składa się z obiektów. Obiekty to
logiczne
jednostki,
na
których
operują
użytkownicy. Baza danych zawiera:
Tabele
Indeksy
Widoki
Synonimy
Sekwencje
Partycje
Klastry
Procedury i pakiety magazynowe
Typy danych definiowane przez użytkownika
Przestrzenie tabel
Więzy integralności

51
Tabele
Podstawową
jednostką
do
przechowywania
informacji w bazie danych
Oracle są właśnie
tabele
.
Zawierają
one
wiersze
danych
reprezentujące
pojedyncze
encje
(np. PESEL pracowników). Tabele zawierają także
kolumny, które reprezentują atrybuty związane z
wierszami (np. data i miejsce urodzenia dla
danego
pracownika).
W
kolumnach
można
przechowywać także dość złożone typy danych, tj.
obraz wideo, sygnał audio czy rysunki.
Aby utworzyć tabelę korzystamy z pewnych
standardowych poleceń.
Najważniejsze to:
create
table
Urzedy_skarbowe
mówi
systemowi, co należy zrobić (stworzyć tabelę).

52
Każda tabela posiada nazwę, która jest
kombinacją dowolnych dopuszczalnych
znaków i podkreślenia (spacja jest
niedozwolona) o długości do 30 znaków.
Nazwami tabel nie mogą być zastrzeżone
słowa kluczowe, np. order (choć wyraz
order może być częścią dłuższej nazwy).
Po wpisaniu tego polecenia następnie
podajemy nazwy kolumn tabel, a każdej
kolumnie odpowiada typ danych i
rozmiar
.
initrans
oraz
maxtrans
są podobne do
parametrów initial oraz next odnoszących się
do obszarów alokacji, z tą różnicą, że rezerwują
one miejsce w tabeli na zapis transakcji w toku.

53
Miejsce jest rezerwowane w nagłówku tabeli i
składa się z elementów o rozmiarze 23 bajtów. Ta
przestrzeń nie jest odzyskiwana po zakończeniu
transakcji. Maksymalną wartością dla tego
parametru jest 255 choć może być mniejsza w
zależności od systemu operacyjnego. Gdy skończy
się miejsce w tabeli na zapis transakcji, nowe
transakcje muszą czekać, aż zostanie ono
zwolnione po zakończeniu bieżących transakcji.
Jeśli te parametry nie zostaną określone to
zostaną użyte wartości domyślne dla instancji.
tablespace system
określa, gdzie system Oracle
ma utworzyć tabelę – w tym przykładzie jest to
przestrzeń o nazwie, np.
system
. Jeśli przestrzeń
tabeli
nie
zostanie
określona,
zostanie
przydzielona
przestrzeń
domyślna
dla
użytkownika, który tworzy tabelę.

54
storage()
w nawiasie można zawrzeć parametry, które
określają parametry przechowywania dla tej tabeli.
Są to:
initial
lub
next
odpowiadają
rozmiarom
początkowego
i
każdego
następnego
obszaru
alokacji.
pctincrease
jest to wyrażony w procentach
przyrost wielkości każdego następnego obszaru
alokacji, np. gdy wartość początkowa obszaru wynosi
1kB, następnego 2kB,a parametr
pctincrease
ma
wartość 50% to w takim przypadku trzeci obszar
będzie miał rozmiar 3kB (1,5*2kB),a 4,5kB czwarty
(1,5*3kB).
minextents
oraz
maxextens
jest to minimalna i
maksymalna liczba obszarów alokacji, które mogą
istnieć w tabeli.
Jeśli parametry nie zostaną podane powoduje przyjęcie
parametrów domyślnych.

55
Aby stworzyć przykładową tabelę powinniśmy
wydać następujące polecenie:
SQL> create table Urzedy_skarbowe
(nazwa
char(40),
miejscowosc
char(20),
kod_pocztowy
char(6),
ulica
char(20),
numer_domu
number(10))
initrans 1
maxtrans 100
tablespace system
storage (
initial 10k
next 10k
pctincrease 0
minextents 1
maxextents 100);
56
Każda kolumna tabeli posiada nazwę, typ
danych i pewne parametry określające rozmiar
danych. Podstawowe typy danych w systemie
Oracle przedstawia poniższa tabela.
Typ danych
Rodzaj
Stała/zmienna długość
char (rozmiar)
Znakowy
Stała długość (dopełniona spacjami)
varchar2
(rozmiar)
Znakowy
Zmienna długość
(wykorzystywane potrzebne miejsce)
number
(precyzja,skala)
Numeryczny
Zmienna długość
(wykorzystywane potrzebne miejsce)
Liczby mają określoną precyzję i skalę. Precyzja
określa całkowitą liczbę cyfr, z wyłączeniem
wykładnika, jeśli liczba jest wyrażona w notacji
wykładniczej. Skala określa ilość cyfr po przecinku
w zapisie dziesiętnych. Liczba z precyzją 4 i skalą
2 będzie z zakresu –99,99 i +99,99, co zapisuje się
jako number (4,2).
data
Data i czas
Siedem bajtów na kolumnę
(zgodne z rokiem 2000)

57
Indeksy
Aby w szybki sposób przeszukiwać tabele należy
używać indeksów, dzięki którym system Oracle
przegląda niewielki indeks w celu określenia,
jakie wiersze spełniają warunki i następnie
pobiera jedynie te wiersze z tabeli.
long
Znakowy
Zmienna długość
raw (size)
Dowolny
(nieokreślony)
Zmienna długość
long raw
Dowolny
(nieokreślony)
Zmienna długość
rowid
Binarny
Sześć bajtów na wiersz – może być przedstawiona
jako liczba w zapytaniu

58
Indeks jest więc posortowaną listą danych z
jednej lub wielu kolumn tabeli, które są często
wykorzystywane jako kryterium wyboru. Dzięki
temu zamiast przeszukiwać dużą liczb wpisów,
by odnaleźć określoną, np. miejscowość,
wystarczy przejrzeć indeks zawierający nazwę
miejscowości. Gdy system Oracle odnajdzie
nazwę szukanej miejscowości, pobiera blok
danych, który zawiera potrzebne dane.
Ponieważ dane zostały wstępnie posortowane,
system nie musi czytać każdego rekordu w
indeksie. Zamiast tego korzysta z bardziej
wydajnej metody (opartej o zmodyfikowane
drzewo
binarne,
dla
którego
wzór
wyszukiwania przypomina gałęzie drzewa), by
ograniczyć do minimum liczbę rekordów
indeksu, które muszą być zanalizowane.

59
Ponieważ indeksy są listą wartości pobranych z
tabeli, system Oracle musi mieć miejsce na ich
przechowywanie.
Indeksy
mają
podobne
klauzule określające parametry składowania
jak tabel. Aby stworzyć przykładowy indeks
powinniśmy wydać następujące polecenie:
SQL> create index nazwy_urzedow_skarbowych
on Urzedy_skarbowe (nazwa)
tablespace system
storage (
initial 2k
next 2k
pctincrease 0
minextents 1
maxextents 100);

60
Indeks
Tabela
Pobrane
wiersze
Kryterium
Wiersze
spełniające
kryterium
Wyszukiwanie z użyciem indeksu

61
O tym, czy indeks będzie użyty w realizacji
zapytania, decyduje treść zapytania. Oto kilka
przykładów takich uwarunkowań:
1. Indeksy
założone
na
tabeli
nie
są
wykorzystywane, gdy w zapytaniu nie występuje
klauzula
where
, czyli w prostych pytaniach typu:
SQL> select * from Umowy_zlecenia;
2. Indeks będzie wykorzystany, jeżeli kolumna
wymieniona w klauzuli
where
jest kolumną, na
której założony jest indeks:
SQL> select * from Umowy_zlecenia where
nazwy_urzedow_skarbowych=‘Urząd Skarbowy w
Zgierzu’;
jeśli na kolumnie
nazwy_urzedow_skarbowych
został
założony indeks.

62
3. Indeks nie będzie użyty, jeżeli kolumna, na
której założony jest indeks, wymieniona w klauzuli
where jako argument funkcji lub część wyrażenia:
SQL> select * from Umowy_zlecenia where
upper (nazwy_urzedow_skarbowych)=‘Urząd Skarbowy w
Zgierzu’
Indeksy są zarządzane przez system automatycznie,
tzn. gdy jakiś wiersz jest modyfikowany, usuwany
bądź
dodawany,
indeksy
są
automatycznie
aktualizowane zgodnie z dokonanymi zmianami.
Aktualizacja taka zabiera jednak czas systemowi,
dlatego jeśli baza zawiera małe tabele to
przeszukiwanie danych za pomocą indeksów, czy
też bez nich nie ma większego znaczenia, jedynie
dla dużych tabel wykonywanie częstych zapytań
bez indeksów może obciążać system.

63
W zależności od struktury indeksu wyróżnić
możemy indeksy typu:
UNIQUE
– zapewniające występowanie unikatowych
wartości w kolumnie lub kolumnach objętych
indeksem;
NON
UNIQUE
–
zapewniające
najszybszy
z
możliwych dostęp do danych (ten typ indeksu
przyjmowany jest domyślnie);
SINGLE COLUMN
– czyli indeksowanie tylko jednej
kolumny;
CONCATENATED
– indeks obejmujący do 16 kolumn,
zakładany
w
celu
poprawienia
szybkości
przeszukiwania
bazy
lub
zapewnienia
unikatowości wartości w objętych indeksem
kolumnach.

64
Zakładanie na tablicach bazy indeksów w widoczny
sposób przyspiesza pracę bazy tylko wtedy, gdy:
indeksowana tablica
zawiera więcej niż 200
wierszy. Dla tablic mniejszych przyspieszenie
spowodowane wykorzystaniem indeksu nie jest
zauważalne;
indeks zdefiniowany jest na kolumnach
, w których
nie występuje częste powtarzanie się wartości
wpisywanych tam danych, czyli gdy na przykład
mamy tablicę pracowników z kolumną płeć, do
której wpisane są informację o płci to indeksowanie
takiej kolumny nie daje żadnych rezultatów gdyż w
tej kolumnie jest zbyt mała różnorodność danych;
indeks zdefiniowany jest na kolumnach
, często
używanych w klauzulach
where
, lub przy określaniu
warunków łączenia tablic;

65
indeks typu
CONCATENATED
zdefiniowany jest
na kilku kolumnach, często występujących
wspólnie, w klauzulach
where
lub przy
określaniu warunków łączenia tablic.
Aby usunąć indeks z bazy danych należy wydać
polecenie:
SQL> drop index nazwy_urzedow_skarbowych;

66
Widoki
Widok to selekcja z jednej lub więcej tabel. Dane
nie są powielane. Widok jest strukturą, która
obrazuje rzeczywiste dane przechowywane w
tabeli.
Widoki
nie
wymagają
określenia
parametrów przechowywania ani miejsca w
przestrzeni
tabel.
Widoki
oferują
wiele
możliwości:
można stworzyć widok łączący odpowiednie
tabele i pozwolić, aby użytkownicy korzystali z
niego tak, jakby to była zwykła tabela;
można stworzyć widok zawierający te kolumny,
do których użytkownicy powinni mieć dostęp i
nadać im prawa do korzystania jedynie z
widoku, a nie bazowej tabeli;
można użyć widoku, aby nadać kolumnom
pożądane nazwy;

67
w przypadku pracy na tabeli zawierającej
dużą ilość kolumn, można wykorzystać
widoki
do
stworzenia
mniejszych,
łatwiejszych w użyciu struktur.
Dla widoków nie tworzy się indeksów. Widoki
tworzy się za pomocą polecenia
create view
.
Nie można modyfikować widoku – zamiast tego
należy go usunąć i ponownie utworzyć. Można
to zrobić korzystając z pojedynczego polecenia
create or repleace view
zamiast
create view
.
To pozwala na ponownie stworzenie widoku, bez
utraty
związanych
z
nim
przywilejów.
Usuwanie czy tworzenie widoku nie oddziałuje
w żaden sposób na dane w tabeli, z którą dany
widok jest skojarzony.

68
Tablica A
Tablica B
Tworzenie widoków
Kolumna 1
tablicy A
Kolumna 2
tablicy A
Kolumna 1
tablicy B
Kolumna 2
tablicy B
Kolumna 3
tablicy B
Kolumna 2
tablicy A
Kolumna 1
tablicy B
Kolumna 3
tablicy B
Widok A&B

69
Synonimy
Synonim jest to jakby pseudonim nadany tabeli,
który może być używany przy odwołaniach do
tabeli.
Synonim
upraszcza
użytkownikowi
odwoływanie się do tabel, których nie jest
właścicielem.
Gdy użytkownik chce skorzystać z tabeli, której nie
jest
właścicielem,
musi
określić
zarówno
właściciela tabeli, jak i jej nazwę (w formacie
właściciel.nazwa_tabeli
). Jeśli użytkownik odnosi
się do tabel znajdujących się w innej bazie,
format
ten
może
być
jeszcze
bardziej
skomplikowany.
Synonimy upraszczają dostęp do tabeli poprzez
zastąpienie
skomplikowanego
kwalifikatora
nazwą synonimy
.

70
Istnieją dwa rodzaje synonimów – prywatne i
publiczne.
synonimy prywatne – zostały stworzone do
użytku prywatnego użytkownika;
synonimy publiczne – może z nich korzystać
dowolny użytkownik bazy danych.
Uprawnienia
użytkowników
do
tworzenia
synonimów publicznych jak i ich usuwania
powinny być ograniczone. Są trzy podstawowe
przywileje związane z synonimami:
-
CREATE SYNONYM
(pozwala również na usuwanie
prywatnych synonimów),
-
CREATE PUBLIC SYNONYM,
- DROP PUBLIC SYNONYM.

71
Sekwencje
Sekwencje (ang.
sequences
) to narzędzia używane do
generowania
niepowtarzalnych
sekwencji
numerycznych, które można wykorzystywać w
bazie danych. Dzięki tym obiektom bazy danych
można nadać unikatowy numer dla wewnętrznego
klucza
łączącego
dwie
tabele
w
aplikacji.
Największą zaletą sekwencji jest gwarancja, że przy
każdej próbie dostępu do sekwencji otrzymana
wartość będzie niepowtarzalna.
Jeśli użytkownik tworzy tabelę sekwencji i napisze
aplikację,
która
odczyta
następną
dostępną
wartość, zinkrementuje ją, a następnie zaktualizuje
tabelę otrzymaną wartością, to zawsze istnieje
możliwość, że ktoś inny zmieni wartość tego
rekordu nim użytkownik dokończy rozpoczęty
proces aktualizacji. Aby tego uniknąć można
skorzystać z sekwencji.

72
Podkreślenia wymaga fakt, iż nie można cofnąć
wartości sekwencji. Jeśli użytkownik w którymś
momencie zaniecha wstawiania wierszy z
wartością z sekwencji, nie może wtedy już
odzyskać tego numeru sekwencji.
Z sekwencją wiążą się trzy parametry: wartość
początkowa, wartość maksymalna i przyrost
(domyślnie wynosi 1).
Przykład polecenia tworzącego sekwencję:
SQL> create sequence location_id
1.
increment by 1
2.
start with 1
3.
maxvalue 9999999
4.
cycle;
Sequence created.

73
Z sekwencji bardzo łatwo jest korzystać. Przy
tworzeniu sekwencji o nazwie, na przykład
kod_pracownika
, by nadać niepowtarzalny,
wewnętrzny klucz dla każdego pracownika
wprowadzonego do bazy danych pracowników,
można wprowadzić nowy rekord danych i
zagwarantować unikatowość klucza przez
użycie prostego polecenia SQL:
insert into pracownicy
values (kod_pracownika.nextval,
‘Krupiński’,
‘Krzysztof’,
‘123-4567’);

74
Sekwencje nie wymagają szczególnej obsługi, trzeba
jedynie monitorować, czy sekwencja nie osiągnęła
swojej maksymalnej wartości, albo czy podczas
wprowadzania danych nie została pominięta
aktualizacja sekwencji.
Domyślnie są one tworzone w trybie cyklicznym, co
oznacza, że po osiągnięciu maksymalnej wartości
sekwencja rozpocznie się na nowo. To może
powodować problemy, jeśli sekwencja zapisuje
dane dla kolumny z atrybutem niepowtarzalności
lub do indeksu.
Trzeba więc upewnić się, że zarówno sekwencja, jak
i kolumna są wystarczające, by pomieścić dużą
tablicę unikatowych wartości sekwencji. Innym
częstym problemem jest sytuacja, gdy ktoś tworzy
oprogramowanie wykorzystujące własne numery
identyfikacyjne, a nie sekwencje.

75
Gdy użytkownik skorzysta z sekwencji, otrzyma
wartość, która jest już obecna w tabeli. Jeśli
program nie korzysta z sekwencji, należy ją
zaktualizować po zakończeniu działania programu,
aby upewnić się, czy jest spójna.
Partycje
Partycje są wykorzystywane w celu podziału dużych
tabel czy indeksów i rozmieszczenia ich na różnych
dyskach, w oparciu o jeden z atrybutów związany z
taką
tabelą
(np.
z
datą).
Partycje
są
przechowywane w oddzielnych przestrzeniach
tabel. Partycje dają dodatkowe korzyści:
zwiększają
wydajność
przy
operacjach
przeszukiwania poprzez rozłożenie obciążenia
operacji we-wy pomiędzy dyski twarde. Możliwe
jest wykonywanie równoległych operacji na różnych
partycjach,

76
umożliwiają zamianę parametrów przechowywania
dla różnych partycji. Na przykład, dla starych
danych, które pewnie nie będą modyfikowane,
możliwe jest ustawienie minimalnej wartości
parametru
pctfree
i maksymalną
pctused,
jeśli,
któraś
z
przestrzeni
tabel
będzie
niedostępna z powodu uszkodzenia dysku, to
nadal można korzystać z danych w pozostałych
partycjach,
które
nie
znajdowały
się
na
uszkodzonym dysku,
umożliwiają archiwizowanie i odzyskiwanie z kopii
zapasowej pojedynczych partycji. Dzięki temu
można
zaprzestać
archiwizacji
starych,
nie
zmieniających się danych i tworzyć kopię
zapasową jedynie tych danych, które często się
zmieniają.

77
Partycje najlepiej pełnią swoją rolę przy pracy z
dużymi tabelami czy indeksami, a także gdy ze
względu na wydajność należy ograniczyć rozmiar
tabeli, z której system cały czas korzysta.
Natomiast w innych przypadkach stosowane jest
zazwyczaj zwykłe niepartycjonowane tabele.
Klastry
Klaster (ang.
cluster
) to grupa tabel, która
przechowywana jest razem, ponieważ zawierają
pewną liczbę wspólnych kolumn i są często łączone
zapytaniami. Użytkownicy często nie wiedzą, iż
tabele, do których sięgają znajdują się w klastrze.
O
tym
wiedzą
jedynie
programiści
i
administratorzy. Klastry wykorzystywane są często
jeśli występują problemy z wydajnością zapytań,
które zawsze łączą kilka tabel o wspólnych
kolumnach.

78
Procedury i pakiety magazynowane
Procedury magazynowane (ang. stored procedures)
są sposobem na przechowywanie oprogramowania
w bazie danych Oracle. Jeśli więc coś ma być
zapisane jako skrypt PL/SQL (ang.
Procedural
Lanquage/SQL
– jest to proceduralne rozszerzenie
języka SQL umożliwiające wykonywanie rozkazów
warunkowych, pętli itp. w połączeniu z zapytaniami
do bazy) może zostać także zapisane jako
procedura
magazynowana
Oracle.
Kolekcja
procedur może zostać zapisana jako pakiet w bazie
danych. Procedury magazynowane dają wiele
możliwości:
Mechanizmy bezpieczeństwa systemu Oracle
, takie
jak role i nadawane prawa mogą chronić zarówno
dane, jak i oprogramowanie. Zapewnia to również
scentralizowane zarządzanie bezpieczeństwem.

79
Gdy
użytkownik
wykonuje
procedurę
magazynowaną, działa z przywilejami osoby, która
ją stworzyła, a nie z przywilejami, jakie normalnie
użytkownik posiada. To nadaje się doskonale do
pewnych
środowisk,
gdzie
trzeba
stosować
specjalne
mechanizmy
bezpieczeństwa,
pozwalające na śledzenie dokonywanych zmian i
sprawdzanie poprawności danych.
DBA
może
nadać prawo zapisu jedynie użytkownikowi, który
stworzył procedurę magazynową. Użytkownicy,
którzy powinni dokonywać zapisu do bazy nie
posiadają takiego prawa – zamiast tego, mają
prawo do wykonywania procedur (co wymusza
mechanizmy bezpieczeństwa oprogramowania),
które dokonują operacje zapisu. Jeśli próbują
wykonywać polecenia SQL w celu zapisu do danych
tabel, otrzymają komunikat o braku dostępu.

80
Kolejną zaletą procedur magazynowanych jest
to, że Oracle przechowuje zarówno źródło, jak i
wersję przetworzoną przez analizator składni.
To zaoszczędza czas przeznaczony na rozbiór
składniowy poleceń przy każdym wywołaniu.
Procedura magazynowana tworzona jest za
pomocą instrukcji
create procedure
i składa się
z
dwóch części.
Pierwsza z nich to specyfikacja
procedury
–
definiuje
jej
nazwę
oraz
argumenty. Druga to ciało procedury – jest to
blok
PL/SQL
wykonywany
w
momencie
wywołania tejże procedury. Ciało procedury ma
taką samą strukturę jak blok PL/SQL. Zawiera
ono sekcję deklaracyjną, wykonywalną i
obsługi wyjątków, błędów. Pierwsza i trzecia z
tych sekcji są opcjonalne.

81
Poniżej przedstawiona jest składnia do tworzenia
prostej procedury magazynowanej nie pobierającej
żadnych argumentów:
CREATE [OR REPLACE] PROCEDURE
nazwa_procedury IS
[Opcjonalna
sekcja
deklaracyjna,
zawierająca
deklaracje
wszystkich
typów
lokalnych,
zmiennych, stałych, kursorów oraz podprogramów.
Nie występuje tu instrukcja
DECLARE
.]
BEGIN
[Sekcja wykonywalna, uruchamiana w momencie
wywołania procedury]
[
EXCEPTION
opcjonalna sekcja wyjątków]
END;

82
Klauzula
CREATE [OR REPLACE]
instruuje Oracle, by
ten – w przypadku gdy procedura nie istnieje –
utworzył nową, w przeciwnym zaś razie – zmienił
istniejącą.
Procedura
magazynowa
oznaczana
jest
jako
prawidłowa (ang.
valid
) lub nieprawidłowa (ang.
invalid
) w zależności od tego, czy podczas
kompilacji pojawiły się jakieś błędy. Można
wywoływać
tylko
i
wyłącznie
prawidłowe
procedury. Jeśli dowolny z obiektów schematu
(procedura, funkcja, specyfikacja pakietu, tabela,
widok, sekwencja czy synonim), do którego
odwołuje się procedura, ulegnie zmianie, wówczas
znajdzie się ona w stanie nieprawidłowym.
Wszelkie funkcje, procedury i pakiety odwołujące
się do nieprawidłowej procedury są również
oznaczane jako nieprawidłowe.

83
Bez względu na stan wszystkie procedury
magazynowane są umieszczane w bazie danych.
Kiedy aplikacja wywołuje procedurę, Oracle ładuje
ją do obszaru pamięci współdzielonej (SGA), o ile
oczywiście nie znajduje się ona już w tym
obszarze. Procedura prawidłowa wykonywana jest
natychmiastowo,
a
nieprawidłową
Oracle
automatycznie rekompiluje. Jeśli proces ten
zakończy się sukcesem, procedura jest oznaczona
jako prawidłowa i wykonywana, w przeciwnym
razie system zwraca komunikat błędu wykonania.
Pakiet magazynowany (ang.
stored package
) jest to
grupa spokrewnionych procedur i funkcji, które –
dzięki temu, że są przechowywane razem – mogą
współużytkować
zmienne
oraz
lokalne
podprogramy. Pakiet składa się z takich samych
części jak procedura magazynowana oraz funkcja
magazynowana.

84
Przestrzenie tabel
Podstawową jednostką przechowywania bazy danych
jest przestrzeń tabel (ang.
tablespace
). Zawiera
ona obiekty, tj. zestawy tabel, widoki itd., które
przechowują dane. Przestrzeń tabel jest swoistym
łącznikiem z fizycznym nośnikiem informacji.
Przestrzeń tabel składa się z jednego lub więcej
plików danych, a baza danych Oracle może składać
się z jednej lub wielu przestrzeni tabel.
Zwykle jednak przy małych i średnich bazach zaleca
się
stworzenie
choćby
jednej
dodatkowej
przestrzeni dla oddzielenia danych zapisanych
przez użytkowników od danych zawartych w
słowniku bazy.
Nowa baza składa się tylko z przestrzeni tablic
SYSTEM
(tworzonej
automatycznie
w
czasie
zakładania nowej bazy), która zawsze zawiera
tablice tzw. słownika bazy (
Dictionary
), czyli
informacje o wewnętrznej strukturze bazy, jej
użytkownikach i ich przywilejach.

85
Ta przestrzeń systemowa przechowuje również
pisane w
PL/SQL procedury, funkcje, pakiety
.
Duże bazy danych podzielone są zazwyczaj na
wiele przestrzeni. Poniższy rysunek pokazuje
dwie bazy. W skład pierwszej wchodzi tylko
przestrzeń tabel
SYSTEM
, natomiast druga
posiada dodatkowo przestrzeń tabel
DANE
,
przeznaczoną
do
gromadzenia
danych
użytkowników bazy.
Parametry
extents
lub
pct_increase
są
domyślnymi parametrami do przechowywania
(ang.
storage parameters
) dla przestrzeni tabel.
Każdy obiekt zajmujący miejsce w bazie danych
(np. tabela lub indeks) używa predefiniowanych
fragmentów
przestrzeni
określanych
jako
obszary alokacji (ang.
extents
).
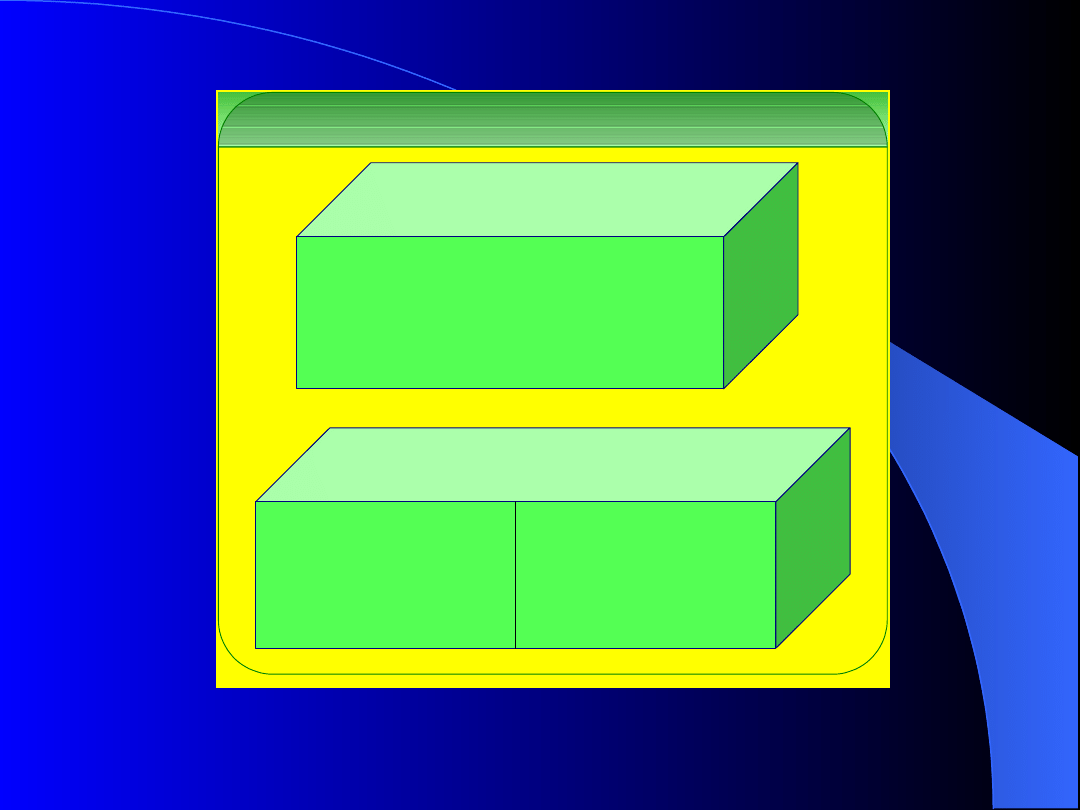
86
BAZA DANYCH
Przestrzeń tabel
SYSTEM
BAZA DANYCH
Przestrzeń tabel
SYSTEM
Przestrzeń tabel
np. DANE
SCHEMAT DWÓCH BAZ DANYCH

87
W sytuacji gdy rekordy są zapisywane do
przestrzeni tabel Oracle grupuje wiersze tabeli w
obszary na dysku określane jako obszary
alokacji. Jest to pomocne, ponieważ system
czyta dodatkowe wiersze do bufora SGA (jest to
dobre rozwiązanie – większość systemów
operacyjnych czyta całe bloki danych z dysku).
Poprzez tworzenie obszarów alokacji będących
wielokrotnością rozmiaru bloku danych systemu
operacyjnego administrator nie musi określać
już na początku projektu wielkości tabeli co
wymusiłoby z kolei konieczność rezerwacji dużej
ilości miejsca przy tworzeniu tabeli, której
rozmiar zwiększałby się powoli.
Maksymalna liczba obszarów alokacji dla danego
obiektu zależy od systemu operacyjnego, ale
zwykle przekracza 100.

88
Przy tworzeniu tabeli, jeśli nie zostaną określone
parametry
przechowywania,
wykorzystane
będą
wartości domyślne dla danej bazy danych. Jeśli nie
zostaną określone domyślne parametry dla bazy
danych, odziedziczone zostaną wartości określone
przez Oracle dla danego systemu operacyjnego.
Podstawowe
parametry
przechowywania
dla
przestrzeni tabel to:
initial_extents
pozwala określić rozmiar pierwszego
obszaru alokacji. Przy tworzeniu obiektu bazy danych
zarezerwowany musi być przynajmniej jeden obszar.
Ważny jest fakt, iż nie można stworzyć obszaru
alokacji większego niż największy ciągły obszar
dostępny do stworzenia pliku danych. Czyli w
przypadku gdy jest dużo dostępnej wolnej przestrzeni,
ale
jest
ona
rozproszona
między
plikami
i
poprzerywana
innymi
obszarami
alokacji,
to
stworzony dla nowego obiektu obszar alokacji w
rzeczywistości będzie niewielki.

89
next_extens
określa rozmiar drugiego obszaru
alokacji. Wszystkie następne obszary będą miały
rozmiar zgodny z tą wielkością powiększony o
współczynnik procentowy.
min_extents
jest to minimalna liczba obszarów.
max_extents
to maksymalna liczba obszarów
alokacji, które mogą być zajmowane przez dany
obiekt. Posiadanie wielu obszarów alokacji może
być przyczyną opóźnienia w otrzymaniu wyników z
powodu czasu jaki jest potrzebny na zlokalizowanie
wszystkich potrzebnych obszarów alokacji.
pct_increase
jest to współczynnik określający
procentowy przyrost wielkości odnoszący się do
każdego
sukcesywnie
zajmowanego
obszaru
alokacji. Jeśli, na przykład mamy tabelę, której
parametr
next_extents
ma wartość 2000 bajtów, a
pct_increase
wynosi 10, to drugi obszar alokacji
będzie miał wielkość 2200 bajtów, trzeci 2420
bajtów itd.

90
Więzy integralności
Więzy
integralności
(ang.
constraints
)
zapewniają poprawność danych wpisywanych
do tabel zarówno przez programistów jak i
przez użytkowników. Więzy integralności,
inaczej ograniczenia, jakie występują w
systemie Oracle przedstawia poniższa tabela:

91
unique
Oznacza, że żadne dwa wiersze nie mogą mieć tej samej
wartości w danej kolumnie (wyjątkiem jest wartość null).
primary key
Jest to klucz główny tabeli. Oznacza, że zostanie
stworzony unikatowy, niepusty (not null) indeks dla danej
kolumny lub kolumn. Każdy wiersz będzie miał różną
wartość, którą można wykorzystać jako wartość
referencyjną.
foregin key
Jest to klucz obcy tabeli. Oznacza, że wartość takiej
kolumny musi być albo pusta, albo odpowiadać wartości
kolumny (kolumn) referencyjnej w tabeli określonej jako
część klucza obcego.
lista wartości
Określa, że kolumna może zawierać wartość z określonej
przy tworzeniu tabeli listy wartości. Jest to stosowane w
przypadkach, gdy kolumna może przyjmować wartość z
ograniczonego zbioru wartości (np. tak/nie, prawda/fałsz).
Używanie listy dopuszczalnych wartości jest szczególnie
przydatne gdy istnieje choćby mała szansa, że lista
dopuszczalnych wartości dla danej kolumny będzie się
zmieniać.

92
Więzy integralności można stosować w pojedynczej
kolumnie, ale także możliwe jest stosowanie
ograniczeń na poziomie tabeli. Pierwsza możliwość
pozwala na zastosowanie więzów dla danej
kolumny, druga natomiast dopuszcza działanie
zarówno na jednej jak i na wielu kolumnach.
Poniższy przykład pokazuje użycie ograniczenia
unique
odnoszącego się do danej kolumny:
SQL> create table Pracownicy
(id_pracownika number(5),
miejsce_zamieszkania
char(20),
kod_pocztowy char(6),
ulica char(20),
numer_domu
number(10),
data_urodzenia date,
constraint C_ID_PRACOWNIKA unique,
umowa
char(20),
status vorchar2(1) check (status in (‘A’, ‘N’)));

93
Kolejny przykład pokazuje użycie ograniczenia
unique
na poziomie tabeli:
SQL> create table Pracownicy2
(id_pracownika
number(5),
miejsce_zamieszkania
char(20),
kod_pocztowy
char(6),
ulica
char(20),
numer_domu
number(10),
data_urodzenia
date,
umowa
char(20),
status
vorchar2(1)
constraint
C_ID_PRACOWNIKA2
unique,
(id_pracownika),
check (status in (‘A’, ‘N’)));

94
Więzy integralności powinny być stosowane wszędzie
tam, gdzie jest to tylko możliwy, ponieważ
zapewniają w prosty sposób integralność danych.
Jednakże podczas wykonywania różnego rodzaju
operacji wsadowych, czy procesów konserwacji
bazy danych, mogą one przeszkadzać, gdyż nie
zezwolą na wprowadzenie do tabeli żadnego
rekordu, który w jakikolwiek sposób naruszyłby
więzy integralności.
Czasami
więc
należy
zastosować
tymczasowe
wyłączenie
ograniczeń
integralnościowych.
Umożliwi to wstawianie do tabeli rekordów
naruszających integralność danych. Rekordy takie
nazywane są wyjątkami od reguł integralności (ang.
constraint exceptions
). Jeśli takie rekordy znajdą
się w tabeli będącej pod wpływem ograniczenia,
muszą zostać skorygowane zanim ograniczenie to
zostanie włączone.
Oracle nie zezwoli
na włączenie
ograniczenia,
jeśli
jakiekolwiek
dane
będą
naruszały definiowaną przezeń regułę.

95
Tak więc rekordy nie poddające się tej zasadzie
muszą
być
przed
włączeniem
ograniczenia
usunięte lub poprawione. Wszystkie rekordy
łamiące więzy integralności mogą być przeglądane
w tabeli wyjątków. Wyłączone ograniczenie może
być wymuszone poprzez instrukcję
alter table
wraz ze słowem kluczowym
enforce.
Tabele, których ograniczenia znajdują się w stanie
wymuszonym, mogą zawierać niepoprawne dane,
jednak nie mogą przyjmować nowych danych
naruszających integralność. Wynika z tego, że
podczas
wymuszania
ograniczenia
nie
jest
wymagane sprawdzanie poprawności wszystkich
danych; dzięki temu operacja wymuszania jest o
wiele szybsza niż operacja włączania. Wymuszone
ograniczenia mogą być włączone w późniejszym
terminie (na przykład w okresie rzadkiego
korzystania z bazy danych), w celu sprawdzenia
integralności danych znajdujących się w tabeli.

96
W celu włączenia, wyłączenia lub wymuszenia
więzów integralności, użytkownik musi być
właścicielem tabeli, lub posiadać uprawnienia
ALTER TABLE
albo
ALTER ANY TABLE.

97

98

99

100

101
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
- Slide 64
- Slide 65
- Slide 66
- Slide 67
- Slide 68
- Slide 69
- Slide 70
- Slide 71
- Slide 72
- Slide 73
- Slide 74
- Slide 75
- Slide 76
- Slide 77
- Slide 78
- Slide 79
- Slide 80
- Slide 81
- Slide 82
- Slide 83
- Slide 84
- Slide 85
- Slide 86
- Slide 87
- Slide 88
- Slide 89
- Slide 90
- Slide 91
- Slide 92
- Slide 93
- Slide 94
- Slide 95
- Slide 96
- Slide 97
- Slide 98
- Slide 99
- Slide 100
- Slide 101
Wyszukiwarka
Podobne podstrony:
Systemy Baz Danych (cz 1 2)
Systemy Baz Danych (cz 1 0)
Systemy Baz Danych (cz 1 2)
SBD wykład 2, student - informatyka, Systemy Baz Danych
SBD wykład 3, student - informatyka, Systemy Baz Danych
SBD wykład 1, student - informatyka, Systemy Baz Danych
SYSTEM B, student - informatyka, Systemy Baz Danych
R. 6-2 Struktura OBD-przyklad 1, Uczelniane, Semestr 2, Zaawansowane Systemy Baz Danych, WYKŁ [OZaik
Systemy baz danych 10
Wprowadzenie do systemow baz danych wprsys
Systemy baz danych Kompletny podrecznik Wydanie II 2
Wprowadzenie do systemow baz danych wprsys
Systemy baz danych w7
perspektywy w systemach baz danych
Systemy baz danych Kompletny podrecznik Wydanie II
Wprowadzenie do systemow baz danych
więcej podobnych podstron