
Mariusz Chmielewski - ISI WAT
1
por. mgr inż. Mariusz Chmielewski
Instytut Systemów Informatycznych
Wydział Cybernetyki
Wojskowa Akademia Techniczna
Techniki Internetowe

Mariusz Chmielewski - ISI WAT
2
Plan wykładu
Plan wykładu
• Internet - organizacja sieci Internet
• Podstawowe protokoły sieci Internet
• Protokół HTTP
– Anatomia protokołu
– Przykładowa sesja
– Zasady wykorzystania
• Języki i technologie obecne w sieci Internet
– Prezentacja - HTML, CSS, JavaScript, Flash
– Logika – PHP, VBS, ASP, JSP, ActionScript
• Usługa WWW
• Podstawy HTML

Mariusz Chmielewski - ISI WAT
3
Organizacja sieci Internet
Organizacja sieci Internet
• Internet stał się przełomem technologicznym i
społecznym ostatniego ćwierćwiecza.
• Technologie opracowane dla potrzeb Internetu
rozprzestrzeniły się na inne rozwiązania m.in.
systemy klient-serwer, systemy rozproszone
• Według definicji sformułowanej w dokumencie
RFC 1463 (specyfikacji, standardu) system
nazywany Internetem złożony jest z
następujących elementów:
– połączone sieci oparte o protokoły TCP/IP;
– społeczność, która używa i rozwija tą sieć;
– zbiór zasobów znajdujących się w tej sieci.

Mariusz Chmielewski - ISI WAT
4
Organizacja sieci Internet
Organizacja sieci Internet
• Trójelementowa definicja wprowadza dobre
rozróżnienie pomiędzy technicznymi aspektem
Internetu,
– połączone sieci oparte o protokoły TCP/IP (aspekt
technologiczny);
– społeczność, która używa i rozwija tą sieć (aspekt
społeczny);
– zbiór zasobów znajdujących się w tej sieci (aspekt
informacyjny).
• Użytkowanie Internetu jest to nic innego jak
działanie członków społeczności przy pomocy
sieci, mające na celu odnalezienie i wykorzystanie
znajdujących się w niej zasobów informacyjnych.

Mariusz Chmielewski - ISI WAT
5
Organizacja sieci Internet
Organizacja sieci Internet
• Wraz z ewolucją Internetu, standardów opisu
zasobów, organizacji sieci:
– zwiększa się liczba zasobów informacyjnych,
– pojawiają się nowe ich kategorie zasobów,
– problemem staje się znalezienie trafnych
dostępnych informacji na dany temat.
• Rolę przewodnika pełnią w nim katalogi
zasobów internetowych i usługi wyszukiwarki.
• Rozwój informatyki oraz technologii związanej
z siecią Internet spowodował wiele
negatywnych skutków dotyczących
przeszukiwania ogromnych zasobów
informacyjnych.

Mariusz Chmielewski - ISI WAT
6
Problemy Internetu – Semantyczny Web
Problemy Internetu – Semantyczny Web
• Jednym z wielu problemów jest poprawna
klasyfikacja przeglądanych stron oraz interpretacja
meta danych zawartych w nagłówkach HTML, które
przez wielu twórców stron są nadużywane by
zwiększyć popularność strony.
• Wyszukiwarki internetowe korzystają z coraz
bardziej wyszukanych algorytmów przeszukiwania
pełnokontekstowego oraz oceny witryn
internetowych.
• Nowa technologia – semantyczny opis danych
– Wykorzystuje sie standardy opisu danych semantycznych
RDF, OWL, DAML służące jako nowe narzędzie
pozwalające na integrację wielu źródeł danych oraz
automatyzację procesu przeszukiwania sieci i
samoorganizacji sieci Internet.

Mariusz Chmielewski - ISI WAT
7
Budowa sieci Internet
Budowa sieci Internet
• Technologia sieci Internet powstała w
bezpośredniej styczności z rozwojem
sieci telekomunikacyjnych.
• Z punktu widzenia złożoności, sieci
komputerowe można podzielić na
grupy:
– LAN (Local Area Network)
– CAN (Campus Area Network)
– MAN (Metropolitan Area Network)
– WAN (Wide Area Network )
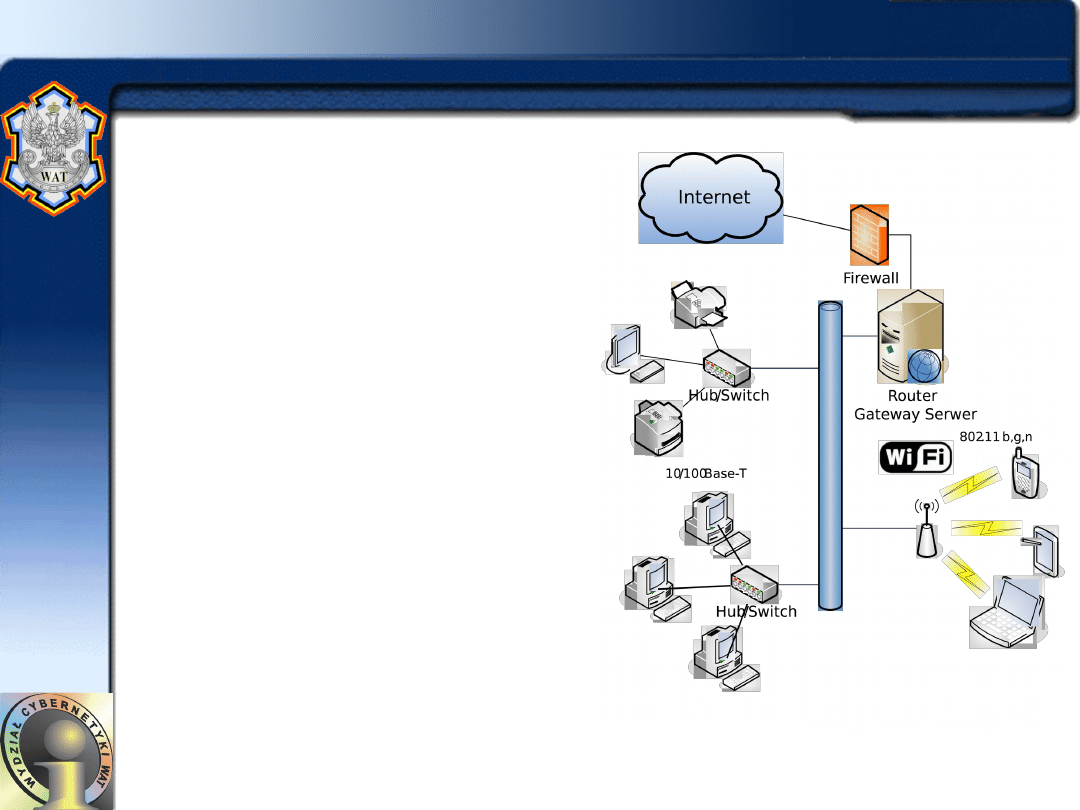
Mariusz Chmielewski - ISI WAT
8
Local Area Network
Local Area Network
• LAN (Local Area Network) -
najpowszechniej spotykany
rodzaj sieci, który składa się z
kilkudziesięciu do kilkuset
komputerów połączonych w
miarę możliwości jednolitym
nośnikiem.
– Sieci te zainstalowane są na
niewielkim obszarze (np. w
jednym budynku, w firmach).
– Sieci te składają się z kilku do
kilkudziesięciu komputerów
spiętych ze sobą w konfigurację
magistralową, opartą na kanale
przewodowym w postaci np.
kabla koncentrycznego, lub w
gwiazdę (jest to gwiazda
logiczna, jednakże fizycznie
widziana jest jako szyna-
magistrala).

Mariusz Chmielewski - ISI WAT
9
Metropolitan Area Network
Metropolitan Area Network
• MAN - Metropolitan Area Network - sieć WAN
obejmująca niewielki obszar geograficzny:
– sieci tego rodzaju budowane są w dużych
miastach; charakteryzują się wysoką
przepustowością i są używane przede wszystkim
przez urządzenia badawcze i w zastosowaniach
komercyjnych o nasilonym przepływie danych
VoIP, telekonferencje, systemy CMS.
– Zasadniczo sieci takie obejmują jedno miasto lub
region.
– Dodatkowo ze względu na specyfikę tematyczną
wydziela się sieci uczelniane (CAN - Campus Area
Network) dedykowane społecznościom
akademickim.
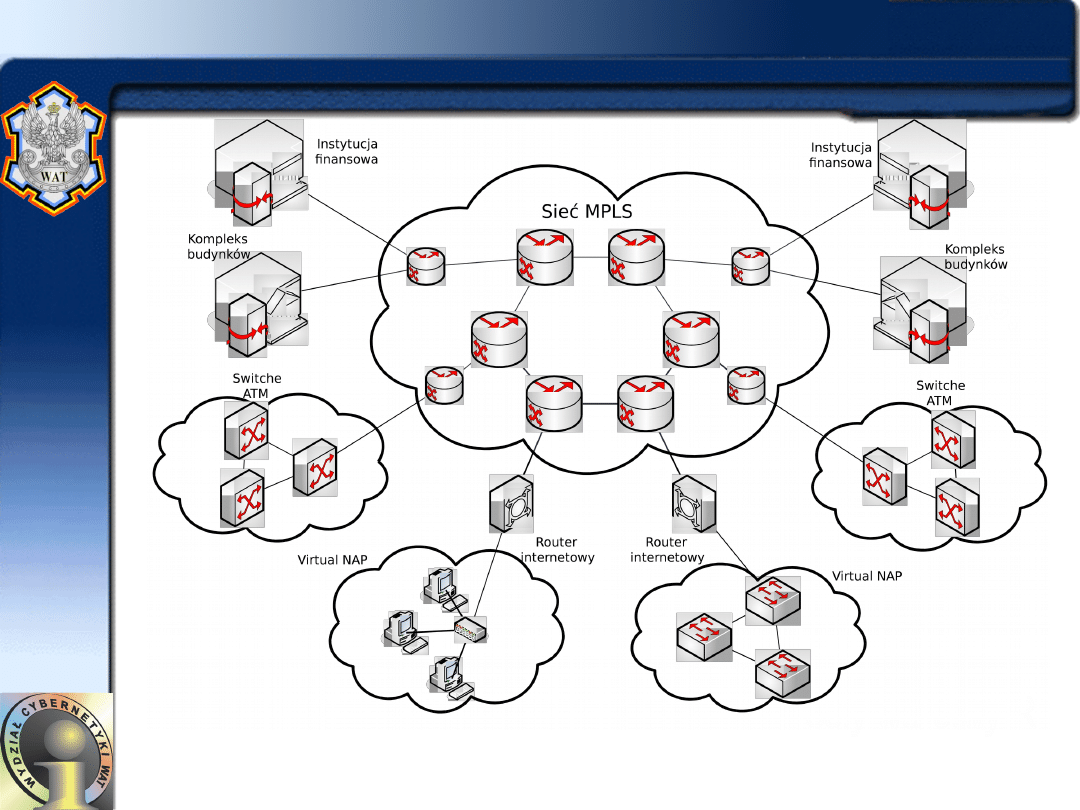
Mariusz Chmielewski - ISI WAT
10
Metropolitan Area Network
Metropolitan Area Network

Mariusz Chmielewski - ISI WAT
11
Wide Area Network
Wide Area Network
• WAN - Wide Area Network - większość sieci
rozległych to kombinacje sieci lokalnych i
dodatkowych połączeń między nimi.
– przykład: tego typu sieci mogą być sieci ISDN (Integrated Services
Digital Network) będące sieciami cyfrowymi z integracją usług.
– ISDN wykorzystuje łącza telefoniczne, istniejące okablowanie
sieciowe.
• WAN to sieć rozległa:
–
bazująca na połączeniach telefonicznych,
–
złożona z komputerów znajdujących się w dużych
odległościach od siebie,
–
łącząca ze sobą użytkowników na terenie całego kraju;
–
wymagane jest zaangażowanie publicznej sieci
telekomunikacyjnej;
–
sieć rozległa łączy sieci lokalne LAN i miejskie MAN.

Mariusz Chmielewski - ISI WAT
12
Wide Area Network
Wide Area Network
• Do realizacji połączeń dla sieci WAN zastosuje się
routery, których zadaniem jest realizowanie pomostu
pomiędzy oddalonymi sieciami oraz realizowanie
dostępu do Internetu.
• Bezpieczeństwo routera od strony sieci komputerowej
jest nadzorowane przez procedurę autoryzacyjną
kontrolującą logowanie użytkowników do urządzenia.
• WAN wykorzystuje łącza: kablowe, światłowodowe,
mikrofalowe oraz satelitarne.
– Nie można także zapomnieć o sieci NASK (Naukowa i
Akademicka Sieć Komputerowa) i najbardziej chyba znanej
sieci WAN, którą jest Internet.
– Sieci rozległe są aktualnie tworzone i bardzo szybko rozwijają
się. Na świecie powstaje wiele sieci rozległych, zarządzanych
i wykorzystywanych przez wielkie korporacje przemysłowe,
banki, uczelnie.
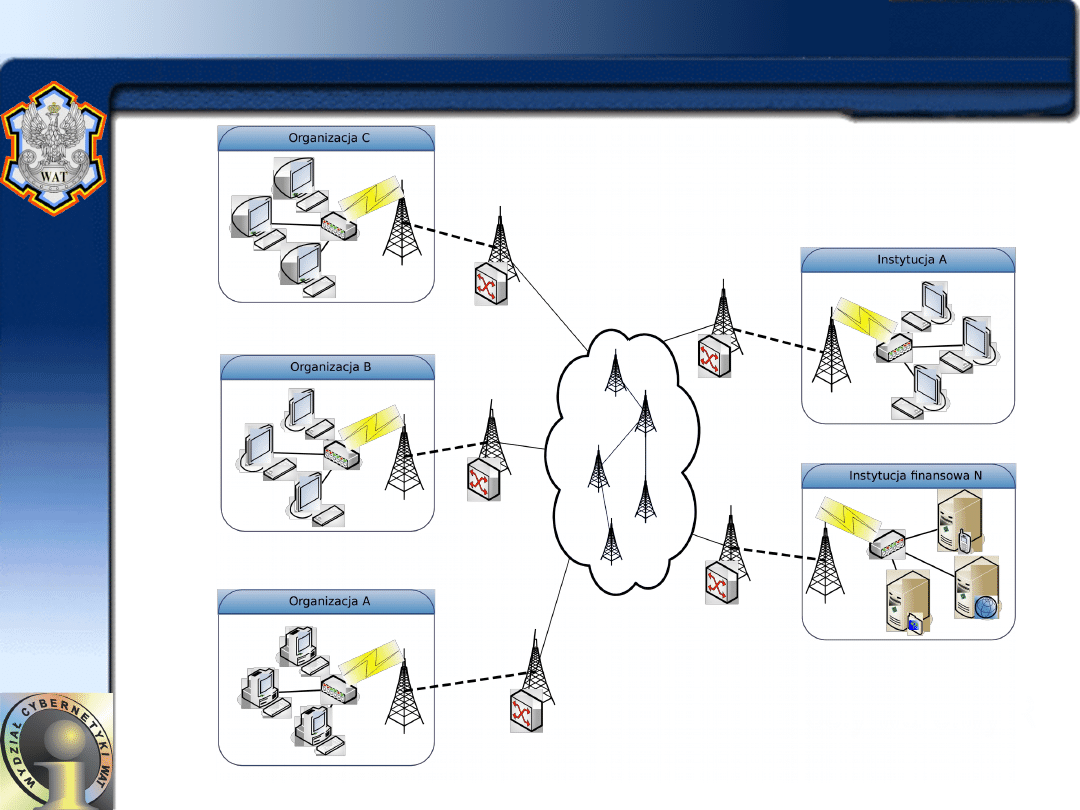
Mariusz Chmielewski - ISI WAT
13
Wide Area Network
Wide Area Network

Mariusz Chmielewski - ISI WAT
14
Protokoły internetowe
Protokoły internetowe
• Protokoły internetowe to podzbiór
protokołów komunikacyjnych, mający
zastosowanie w środowisku sieci Internet.
• Protokoły internetowe to zbiór ścisłych
reguł i kroków postępowania, które są
automatycznie wykonywane przez
urządzenia w celu nawiązania łączności i
wymiany danych.
• Do najpopularniejszych należą
protokołów obecnych w sieci Internet
należą:

Mariusz Chmielewski - ISI WAT
15
TCP/IP (ang.
TCP/IP (ang.
Transmission Control Protocol /
Transmission Control Protocol /
Internet Protocol)
Internet Protocol)
•
Pakiet najbardziej rozpowszechnionych protokołów
komunikacyjnych współczesnych sieci komputerowych.
– jest standardem komunikacji otwartej - otwartość oznacza tu
możliwości komunikacji między dowolnymi typami urządzeń, bez
względu na ich fizyczną różnorodność.
– zwany jest także stosem protokołów ze względu na strukturę
warstwową, w której ramka protokołu wyższej warstwy jest
zawarta jako dane w protokole warstwy niższej.
•
Termin bezpołączeniowy oznacza, że sesja nie jest
ustanawiana przed rozpoczęciem wymiany danych.
•
Termin zawodny oznacza, że dostarczenie pakietu nie jest
gwarantowane. Protokół IP zawsze próbuje dostarczyć
pakiet. Pakiet IP może zostać zagubiony, dostarczony nie
w kolejności, zdublowany lub opóźniony. Protokół IP nie
naprawia takich błędów.
• Rozpoznawanie dostarczonych i odzyskiwanie utraconych pakietów
wykonywane jest przez protokoły warstwy wyższej, np. protokół TCP.
• IPv4 Opracowany pod koniec lat 70-tych na zlecenie Departamentu
Obrony USA, miał za zadanie połączyć różne rodzaje wojskowych
sieci WAN w jedną zunifikowaną sieć ARPANet.

Mariusz Chmielewski - ISI WAT
16
IP
IP
v4 - IPv6
v4 - IPv6
• Rosnący w siłę elektroniczny biznes domaga się z kolei poprawy
bezpieczeństwa danych przesyłanych siecią.
• Aby nadążyć za stałą ekspansją Internetu, musiała nastąpić
nowelizacja ujawniające się obecnie w protokole IPv4 słabości a także
uzyskać pewien "zapas" na przyszłość.
• Do najważniejszych zmian IPv6 należą:
– Dłuższe adresy. Dotychczasowe adresy 32-bitowe zastąpione zostały 128-
bitowymi.
– Adres IPv6 składa się z ośmiu 16-bitowych części oddzielonych nie
pojedynczymi kropkami, ale dwukropkami. Przykładowy adres przybierze
więc formę: 1AA4:2C39:EFF4:877D: 12345:4G3E:5HBB:C47D.
– Większa elastyczność i nowe struktury adresowe. Trzy formaty adresów:
mające już swoje odpowiedniki w IPv4
– Unicast, multicast, anycast - (Wprowadzony w protokole IPv6 nowy tryb
adresowania pakietów. Anycast przewiduje możliwość transmisji danych
do najbliższych (bliżej nieokreślonych) hostów-bram spośród wielu
dostępnych z danej lokalizacji, z zamiarem powierzenia jednemu z nich
zadania dalszego przekierowania pakietu ).
– Uproszczony i bardziej elastyczny format nagłówków pakietów.
– Zwiększenie bezpieczeństwa pakietów. Wprowadzono elementy
zapobiegania najczęściej spotykanym atakom oraz wbudowane opcje
szyfrowania i identyfikacji hostów (za pomocą towarzyszącego protokołu
IPsec). Tym samym zapewnione zostało bezpieczeństwo na całej długości
połączenia.

Mariusz Chmielewski - ISI WAT
17
UDP – (ang. User Datagram Protocol )
UDP – (ang. User Datagram Protocol )
• jest standardem TCP/IP zdefiniowanym w specyfikacji RFC
768
• jest używany wymiennie zamiast TCP do szybkiego,
uproszczonego, mniej niezawodnego przesyłania danych
między hostami,
• jest usługą wymiany datagramów bez ustanowionego
połączenia, która nie zapewnia dostarczenia i sprawdzania
sekwencji datagramów,
• host źródłowy wymagający niezawodnych połączeń
powinien korzystać z protokołu TCP lub programu, który
posiada wbudowane własne usługi sprawdzania sekwencji i
potwierdzania,
• port UDP funkcjonuje jako pojedyncza kolejka komunikatów,
która służy do odbierania wszystkich datagramów przez
program określony za pomocą numeru portu protokołu,
• oznacza to, że programy UDP mogą jednocześnie odbierać
kilka komunikatów. Strona serwera każdego programu
wykorzystującego port UDP oczekuje na komunikaty
przychodzące do znanego numeru portu.

Mariusz Chmielewski - ISI WAT
18
HTTP (ang. Hypertext Transfer Protocol)
HTTP (ang. Hypertext Transfer Protocol)
•
To protokół sieci WWW (ang. World Wide Web),
•
obecną definicję HTTP stanowi RFC 2616.
•
za pomocą protokołu HTTP przesyła się żądania
udostępnienia dokumentów WWW i informacje o
kliknięciu odnośnika oraz informacje z formularzy.
•
zadaniem stron WWW jest publikowanie dowolnej
ustandaryzowanej informacji,
•
HTTP udostępnia znormalizowany sposób
komunikowania się komputerów ze sobą, określa on
formę żądań klienta dotyczących danych oraz formę
odpowiedzi serwera na te żądania.
•
jest zaliczany do protokołów bezstanowych (ang.
stateless) z racji tego, że nie zachowuje żadnych
informacji o poprzednich transakcjach z klientem
(po zakończeniu transakcji wszystko "przepada").

Mariusz Chmielewski - ISI WAT
19
HTTP (ang. Hypertext Transfer Protocol)
HTTP (ang. Hypertext Transfer Protocol)
•
taka budowa pozwala to znacznie zmniejszyć
obciążenie serwera, jednak jest kłopotliwe w
sytuacji, gdy np. trzeba zapamiętać konkretny
stan dla użytkownika, który wcześniej łączył się
już z serwerem.
•
najczęstszym rozwiązaniem tego problemu jest
wprowadzenie mechanizmu cookies.
•
inne podejścia to m.in. sesje po stronie serwera,
ukryte parametry (gdy aktualna strona zawiera
formularz) oraz parametry umieszczone w URL-
u (jak np. /index.php?userid=3).
•
HTTP standardowo korzysta z portu nr 80 (TCP).

Mariusz Chmielewski - ISI WAT
20
HTTPS (ang. HyperText Transfer Protocol Secure)
HTTPS (ang. HyperText Transfer Protocol Secure)
•
to szyfrowana wersja protokołu HTTP
•
zamiast używać w komunikacji klient-serwer
niezaszyfrowanego tekstu, szyfruje go za
pomocą technologii SSL.
•
zapobiega to przechwytywaniu i zmienianiu
przesyłanych danych
•
HTTPS działa domyślnie na porcie nr 443 w
protokole TCP
•
protokół HTTP jest warstwę wyżej (korzystającą
z warstwy SSL), najpierw następuje więc
wymiana kluczy SSL, a dopiero później żądanie
HTTP.
•
powoduje to, że jeden adres IP może serwować
tylko jedną domenę lub też tylko subdomeny
danej domeny (zależnie od certyfikatu).

Mariusz Chmielewski - ISI WAT
21
FTP (ang. File Transfer Protocol)
FTP (ang. File Transfer Protocol)
• protokół typu klient-serwer, który umożliwia przesyłanie plików z i na
serwer poprzez sieć TCP/IP,
• protokół ten jest zdefiniowany przez IETF w RFC 959, jest protokołem
8-bitowym, dlatego nie wymaga specjalnego kodowania danych na
postać 7-bitową, tak jak ma to miejsce w przypadku poczty
elektronicznej (standardy MIME, base64, quoted-printable,
uuencode).
• do komunikacji wykorzystywane są dwa połączenia TCP, jedno z nich
jest połączeniem kontrolnym za pomocą którego przesyłane są np.
polecenia do serwera, drugie natomiast służy do transmisji danych
m.in. plików.
• FTP działa w dwóch trybach: aktywnym i pasywnym, w zależności od
tego, w jakim jest trybie, używa innych portów do komunikacji.
– jeżeli FTP pracuje w trybie aktywnym, korzysta z portów: 21 dla poleceń
(połączenie to jest zestawiane przez klienta) oraz 20 do przesyłu danych.
Połączenie nawiązywane jest wówczas przez serwer;
– jeżeli FTP pracuje w trybie pasywnym wykorzystuje port 21 do poleceń i
port o numerze > 1024 do transmisji danych, gdzie obydwa połączenia
zestawiane są przez klienta.
W sieciach ukrytych za firewallem komunikacja z aktywnymi serwerami FTP jest
możliwa, tylko pod warunkiem, jeżeli odpowiednie porty na firewallu
(routerze) są zwolnione.

Mariusz Chmielewski - ISI WAT
22
SMTP (ang. Simple Mail Transfer Protocol)
SMTP (ang. Simple Mail Transfer Protocol)
• protokół komunikacyjny opisujący sposób przekazywania poczty
elektronicznej w Internecie,
• względnie prosty, tekstowy protokół, w którym określa się co najmniej
jednego odbiorcę wiadomości (w większości przypadków weryfikowane
jest jego istnienie), a następnie przekazuje treść wiadomości,
• demon SMTP działa najczęściej na porcie 25,
• protokół ten nie radził sobie dobrze z plikami binarnymi, ponieważ
stworzony był w oparciu o czysty tekst ASCII. W celu kodowania plików
binarnych do przesyłu przez SMTP stworzono standardy takie jak MIME.
W dzisiejszych czasach większość serwerów SMTP obsługuje
rozszerzenie 8BITMIME pozwalające przesyłać pliki binarne równie łatwo
jak tekst,
• SMTP nie pozwala na pobieranie wiadomości ze zdalnego serwera. Do
tego celu służą protokoły POP3 lub IMAP,
• Jednym z ograniczeń pierwotnego SMTP jest brak mechanizmu
weryfikacji nadawcy, co ułatwia rozpowszechnianie niepożądanych
treści poprzez pocztę elektroniczną (wirusy, spam),
Żeby temu zaradzić stworzono rozszerzenie SMTP-AUTH, które jednak jest tylko
częściowym rozwiązaniem problemu - ogranicza wykorzystanie serwera
wymagającego autoryzacji do zwielokrotniania poczty. Nadal nie istnieje metoda,
dzięki której odbiorca autoryzowałby nadawcę – nadawca może "udawać" serwer
i wysłać dowolny komunikat do dowolnego odbiorcy.

Mariusz Chmielewski - ISI WAT
23
POP3 (ang. Post Office Protocol version 3)
POP3 (ang. Post Office Protocol version 3)
• to protokół internetowy z warstwy aplikacji pozwalający na
odbiór poczty elektronicznej ze zdalnego serwera do lokalnego
komputera poprzez połączenie TCP/IP.
• ogromna większość klientów korzysta z POP3 do odbioru
poczty,
• w przypadku krótkotrwałego połączenia z siecią, poczta nie
jest w stanie poprawnie dotrzeć protokołem SMTP. W takiej
sytuacji w sieci istnieje specjalny serwer, który przez SMTP
odbiera przychodzącą pocztę i ustawia ją w kolejce. Kiedy
użytkownik połączy się z siecią, to korzystając z POP3 może
pobrać czekające na niego listy do lokalnego komputera,
• komunikacja POP3 może zostać zaszyfrowana z
wykorzystaniem protokołu SSL. Jest to o tyle istotne, że w
POP3 hasło przesyłane jest otwartym tekstem, o ile nie
korzysta się z opcjonalnej komendy protokołu POP3, APOP.
• protokół POP3, podobnie, jak inne protokoły internetowe (np.
SMTP, HTTP) jest protokołem tekstowym, czyli w odróżnieniu
od protokołu binarnego, czytelnym dla człowieka.
• komunikacja między klientem pocztowym, a serwerem
odbywa się za pomocą czteroliterowych poleceń

Mariusz Chmielewski - ISI WAT
24
POP3 (ang. Post Office Protocol version 3)
POP3 (ang. Post Office Protocol version 3)
• Jednak protokół ten ma wiele ograniczeń:
– połączenie trwa tylko, jeżeli użytkownik pobiera
pocztę i nie może pozostać uśpione,
– do jednej skrzynki może podłączyć się tylko
jeden klient równocześnie,
– każdy list musi być pobierany razem z
załącznikami i żadnej jego części nie można w
łatwy sposób pominąć - istnieje co prawda
komenda top, ale pozwala ona jedynie określić
przesyłaną liczbę linii od początku wiadomości,
– wszystkie odbierane listy trafiają do jednej
skrzynki, nie da się utworzyć ich kilku,
– serwer POP3 nie potrafi sam przeszukiwać
czekających w kolejce listów.

Mariusz Chmielewski - ISI WAT
25
IMAP (ang. Internet Message Access Protocol)
IMAP (ang. Internet Message Access Protocol)
• to internetowy protokół pocztowy
zaprojektowany jako następca POP3,
• w przeciwieństwie do POP3, który umożliwia
jedynie pobieranie i kasowanie poczty, IMAP
pozwala na zarządzanie wieloma folderami
pocztowymi oraz pobieranie i operowanie na
listach znajdujących się na zdalnym
serwerze,
• IMAP pozwala na ściągnięcie nagłówków
wiadomości i wybranie, które z wiadomości
chcemy ściągnąć na komputer lokalny,
• pozwala na wykonywanie wielu operacji,
zarządzanie folderami i wiadomościami.

Mariusz Chmielewski - ISI WAT
26
XMPP (ang. Extensible Messaging and Presence
XMPP (ang. Extensible Messaging and Presence
Protocol)
Protocol)
• protokół bazujący na języku XML
umożliwiający przesyłanie w czasie
rzeczywistym wiadomości oraz statusu,
• XMPP to próba ustalenia standardu w oparciu
o istniejące rozwiązania Jabbera,
• Protokół ma zastosowanie nie tylko w
komunikatorach, ale również w innych
systemach błyskawicznej wymiany informacji,
• IETF opublikowało RFC dotyczące XMPP w
statusie Proposed Standard,
• protokół ma zastosowanie nie tylko w
komunikatorach, ale również w innych
systemach błyskawicznej wymiany informacji,

Mariusz Chmielewski - ISI WAT
27
IRC (ang. Internet Relay Chat)
IRC (ang. Internet Relay Chat)
• to jedna ze starszych usług sieciowych umożliwiająca
rozmowę na tematycznych lub towarzyskich kanałach
komunikacyjnych, jak również prywatną z inną podłączoną
aktualnie osobą,
• usługa ta funkcjonuje w architekturze klient-serwer, tj.
fizycznie składa się z grupy połączonych ze sobą na stałe
serwerów oraz programów-klientów,
• programy klienckie uruchamiane są przez końcowych
użytkowników lokalnie – na ich własnych komputerach, lub
zdalnie, za pośrednictwem usługi SSH lub telnet,
• rozmowy w sieci IRC odbywają się na tzw. kanałach,
• na ekranie użytkownika przewijają się od dołu do góry
ekranu komunikaty wysyłane przez osoby piszące na
danym kanale. Komunikaty te pojawiają się zaraz po ich
wysłaniu, a ich kolejność jest identyczna z kolejnością
napływania do serwera,
• uczestnicy nie używają zwykle w IRC swoich prawdziwych
imion i nazwisk, lecz posługują się krótkimi pseudonimami,

Mariusz Chmielewski - ISI WAT
28
Anatomia połączenia HTTP
Anatomia połączenia HTTP
• HTTP zaliczany do protokołów bezstanowych (ang. stateless) z racji
tego, że nie zachowuje żadnych informacji o poprzednich transakcjach
z klientem (po zakończeniu transakcji wszystko "przepada")
• Metody HTTP:
– GET - pobranie zasobu wskazanego przez URI, może mieć postać
warunkową jeśli w nagłówku występują pola warunkowe takie jak "If-
Modified-Since"
– HEAD - pobiera informacje o zasobie, stosowane do sprawdzania
dostępności zasobu
– PUT - przyjęcie danych w postaci pliku przesyłanych od klienta do serwera
– POST - przyjęcie danych przesyłanych od klienta do serwera (np.
wysyłanie zawartości formularzy)
– DELETE - żądanie usunięcia zasobu, włączone dla uprawnionych
użytkowników
– OPTIONS - informacje o opcjach i wymaganiach istniejących w kanale
komunikacyjnym
– TRACE - diagnostyka, analiza kanału komunikacyjnego
– CONNECT - żądanie przeznaczone dla serwerów proxy pełniących funkcje
tunelowania

Mariusz Chmielewski - ISI WAT
29
Anatomia połączenia HTTP - Typowe zapytanie
Anatomia połączenia HTTP - Typowe zapytanie
HTTP
HTTP
1.
GET / HTTP/1.1
2.
Host: host.com
3.
User-Agent: Mozilla/5.0 (X11; U; Linux i686; pl; rv:1.8.1.7) Gecko/20070914
Firefox/2.0.0.7
4.
Accept:
text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=
0.8
5.
Accept-Language: pl,en-us;q=0.7,en;q=0.3
6.
Accept-Charset: ISO-8859-2,utf-8;q=0.7,*;q=0.7
7.
Keep-Alive: 300
8.
Connection: keep-alive
9.
CRLF
1.
(prośba o zwrócenie dokumentu o URI / zgodnie z protokołem HTTP 1.1)
2.
(wymagany w HTTP 1.1 nagłówek Host służący do rozpoznania hosta, jeśli
serwer na jednym IP obsługuje kilka VirtualHostów)
3.
(nazwa aplikacji klienckiej)
4.
(akceptowane (bądź nieakceptowane dla q=0) przez klienta typy plików)
5.
(preferowany język strony - nagłówek przydatny przy Language negotiation)
6.
(preferowane kodowanie znaków, patrz strona kodowa)
7.
(czas, jaki klient chce zarezerwować do następnego zapytania w przypadku
połączenia Keep-Alive)
8.
(chęć nawiązania połączenia stałego Keep-Alive z serwerem HTTP/1.0)
9.
znak powrotu karetki i nowej linii

Mariusz Chmielewski - ISI WAT
30
Anatomia połączenia HTTP - Typowe zapytanie
Anatomia połączenia HTTP - Typowe zapytanie
HTTP
HTTP
1. HTTP/1.1 200 OK
2. Date: Sun, 11 Jul 2004 12:04:30 GMT
3. Server: Apache/2.0.50 (Unix) DAV/2
4. Set-Cookie: PSID=d6dd02e9957fb162d2385ca6f2829a73; path=/
5. Expires: Thu, 19 Nov 1981 08:52:00 GMT
6. Cache-Control: no-store, no-cache, must-revalidate
7. Pragma: no-cache
8. Keep-Alive: timeout=15, max=100
9. Connection: Keep-Alive
10. Transfer-Encoding: chunked
11. Content-Type: text/html; charset=iso-8859-2
12. CRLF
13. zawartość dokumentu
1. (kod odpowiedzi HTTP, w tym wypadku zakceptowanie i zwrócenie zawartości)
2. (czas serwera)
3. (opis aplikacji serwera)
4. (nakazanie klientowi zapisania Cookie)
5. (czas wygaśnięcia zawartości zwróconego dokumentu. Data w przeszłości zabrania
umieszczenie dokumentu w cache. Jest to stara metoda zastąpiona przez Cache-Control)
6. (no-store zabrania przechowywania dokumentu na dysku, nawet gdy nie jest to cache. must-
revalidate nakazuje bezwzględnie stosować się do wytycznych i sprawdzić swieżość
dokumentu za każdym razem)
7. (informacje dotyczące Cache'owania zawartości. Stara, niestandardowa metoda.)
8. (ustawienia wariantu Keep-Alive )
9. (akceptacja połączenia Keep-Alive dla klientów HTTP/1.0)
10. (typ kodowania zawartości stosowanej przez serwer)
11. (typ MIME i strona kodowa zwróconego dokumetu)
12. znak powrotu karetki i nowej linii

Mariusz Chmielewski - ISI WAT
31
Anatomia połączenia HTTP – kody informacyjne
Anatomia połączenia HTTP – kody informacyjne
kod
opis słowny
znaczenie/zwrócony zasób
100
Continue
Kontynuuj - prośba o dalsze
wysyłanie zapytania
101
Switching Protocols
Zmiana protokołu
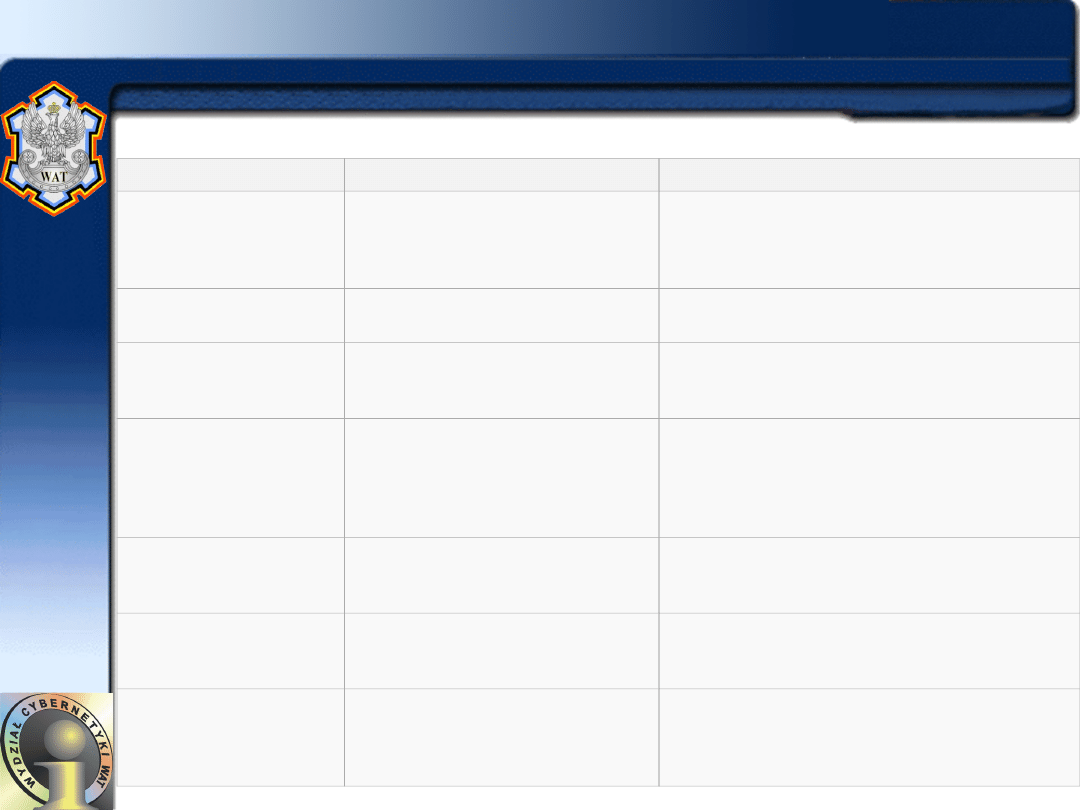
Mariusz Chmielewski - ISI WAT
32
Anatomia połączenia HTTP – Kody powodzenia
Anatomia połączenia HTTP – Kody powodzenia
kod
opis słowny
znaczenie/zwrócony zasób
200
OK
Zawartość żądanego dokumentu
(najczęściej zwracany nagłówek
odpowiedzi w komunikacji
)
201
Created
Utworzono - wysłany dokument został
zapisany na serwerze
202
Accepted
Przyjęto - zapytanie zostało przyjęte do
obsłużenia, lecz jego zrealizowanie jeszcze
się nie skończyło
203
Non-Authoritative Information
Informacja nieautorytatywna - zwrócona
informacja nie odpowiada dokładnie
odpowiedzi pierwotnego serwera, lecz
została utworzona z lokalnych bądź
zewnętrznych kopii
204
No content
Brak zawartości - serwer zrealizował
zapytanie klienta i nie potrzebuje zwracać
żadnej treści
205
Reset Content
Przywróć zawartość - serwer zrealizował
zapytanie i klient powinien przywrócić
pierwotny wygląd dokumentu
206
Partial Content
Część zawartości - serwer zrealizował tylko
część zapytania typu GET, odpowiedź musi
zawierać nagłówek
Range
informujący o
zakresie bajtowym zwróconego elementu
Mariusz Chmielewski - ISI WAT
33
Anatomia połączenia HTTP – Kody
Anatomia połączenia HTTP – Kody
przekierowania
przekierowania
kod
opis słowny
znaczenie/zwrócony zasób
300
Multiple Choices
Wiele możliwości - istnieje więcej niż jeden sposób
obsłużenia danego zapytania, serwer może podać adres
zasobu, który pozwala na wybór jednoznacznego
zapytania spośród możliwych
301
Moved Permanently
Trwale przeniesiony - żądany zasób zmienił swój
w przyszłości zasób powinien być szukany pod
wskazanym nowym adresem
302
Found
Znaleziono - żądany zasób jest chwilowo dostępny pod
innym adresem a przyszłe odwołania do zasobu
powinny być kierowane pod adres pierwotny
303
See Other
Zobacz inne - odpowiedź na żądanie znajduje się pod
innym URI i tam klient powinien się skierować. To jest
właściwy sposób przekierowywania w odpowiedzi na
żądanie metodą POST.
304
Not Modified
Nie zmieniono - zawartość zasobu nie podległa zmianie
według warunku przekazanego przez klienta (np. data
ostatniej wersji zasobu pobranej przez klienta -
przeglądarki)
305
Use Proxy
Użyj serwera proxy - do żądanego zasobu trzeba
odwołać się przez serwer
Location
odpowiedzi
306
Kod nieużywany, aczkolwiek zastrzeżony dla starszych
wersji protokołu
307
Temporary Redirect
Tymczasowe przekierowanie - żądany zasób znajduje
się chwilowo pod innym adresem URI, odpowiedź
powinna zawierać zmieniony adres zasobu, na który
klient zobowiązany jest się przenieść

Mariusz Chmielewski - ISI WAT
34
Anatomia połączenia HTTP – Kody błędu aplikacji
Anatomia połączenia HTTP – Kody błędu aplikacji
klienta
klienta
kod
opis słowny
znaczenie/zwrócony zasób
400
Bad Request
Nieprawidłowe zapytanie - żądanie nie może być
obsłużone przez serwer z powodu błędnej składni
zapytania
401
Unauthorized
Nieautoryzowany dostęp - żądanie zasobu, który wymaga
uwierzytelnienia
402
Payment Required
Wymagana opłata - odpowiedź zarezerwowana na
przyszłość
403
Forbidden
Zabroniony - serwer zrozumiał zapytanie lecz
konfiguracja bezpieczeństwa zabrania mu zwrócić
żądany zasób
404
Not Found
Nie znaleziono - serwer nie odnalazł zasobu według
podanego URI ani niczego co by wskazywało na istnienie
takiego zasobu w przeszłości
405
Method Not Allowed
Niedozwolona metoda - metoda zawarta w żądaniu nie
jest dozwolona dla wskazanego zasobu, odpowiedź
zawiera też listę dozwolonych metod
406
Not Acceptable
Niedozwolone - zażądany zasób nie jest w stanie zwrócić
odpowiedzi mogącej być obsłużonej przez klienta według
informacji podanych w zapytaniu
407
Proxy Authentication
Required
Wymagane uwierzytelnienie do serwera proxy -
analogicznie do kodu 401, dotyczy dostępu do serwera
proxy
408
Request Timeout
Koniec czasu oczekiwania na żądanie - klient nie przesłał
zapytania do serwera w określonym czasie

Mariusz Chmielewski - ISI WAT
35
Anatomia połączenia HTTP – Kody błędu aplikacji
Anatomia połączenia HTTP – Kody błędu aplikacji
klienta
klienta
kod
opis słowny
znaczenie/zwrócony zasób
409
Conflict
Konflikt - żądanie nie może być zrealizowane, ponieważ
występuje konflikt z obecnym statusem zasobu, ten kod
odpowiedzi jest zwracany tylko w przypadku
podejrzewania przez serwer, że klient może nie znaleźć
przyczyny błędu i przesłać prawidłowego zapytania
410
Gone
Zniknął (usunięto) - zażądany zasób nie jest dłużej
dostępny i nie znany jest jego ewentualny nowy adres
URI; klient powinien już więcej nie odwoływać się do
tego zasobu
411
Length required
Wymagana długość - serwer odmawia zrealizowania
zapytania ze względu na brak nagłówka
Content-Length
w
zapytaniu; klient może powtórzyć zapytanie dodając doń
poprawny nagłówek długości
412
Precondition Failed
Warunek wstępny nie może być spełniony - serwer nie
może spełnić przynajmniej jednego z warunków
zawartych w zapytaniu
413
Request Entity Too Large
Encja zapytania zbyt długa - całkowita długość zapytania
jest zbyt długa dla serwera
414
Request-URI Too Long
Adres URI zapytania zbyt długi - długość zażądanego
URI jest większa niż maksymalna oczekiwana przez
serwer
415
Unsupported Media Type
Nieznany sposób żądania - serwer odmawia przyjęcia
zapytania, ponieważ jego składnia jest niezrozumiała dla
serwera
416
Requested Range Not
Satisfiable
Zakres bajtowy podany w zapytaniu nie do obsłużenia -
klient podał w zapytaniu zakres, który nie może być
zastosowany do wskazanego zasobu
417
Expectation Failed
Oczekiwana wartość nie do zwrócenia - oczekiwanie
podane w nagłówku
Expect
żądania nie może być
spełnione przez serwer lub - jeśli zapytanie realizuje
serwer proxy - serwer ma dowód, że oczekiwanie nie
będzie spełnione przez następny w łańcuchu serwer
realizujący zapytanie

Mariusz Chmielewski - ISI WAT
36
Anatomia połączenia HTTP – Kody błędu
Anatomia połączenia HTTP – Kody błędu
wewnętrznego
wewnętrznego
kod
opis słowny
znaczenie/zwrócony zasób
500
Internal Server Error
Wewnętrzny błąd serwera - serwer napotkał
niespodziewane trudności, które uniemożliwiły
zrealizowanie żądania
501
Not Implemented
Nie zaimplementowano - serwer nie dysponuje
funkcjonalnością wymaganą w zapytaniu; ten kod jest
zwracany gdy serwer otrzymał nieznany typ zapytania
502
Bad Gateway
Błąd bramy - serwer - spełniający rolę bramy lub
proxy - otrzymał niepoprawną odpowiedź od serwera
nadrzędnego i nie jest w stanie zrealizować żądania
klienta
503
Service Unavailable
Usługa niedostępna - serwer nie jest w stanie w danej
chwili zrealizować zapytania klienta ze względu na
przeciążenie
504
Gateway Timeout
Przekroczony czas bramy - serwer - spełniający rolę
bramy lub proxy - nie otrzymał w ustalonym czasie
odpowiedzi od wskazanego serwera HTTP, FTP, LDAP
itp. lub serwer DNS jest potrzebny do obsłużenia
zapytania
505
HTTP Version Not
Supported
Wersja HTTP nie obsługiwana - serwer nie obsługuje
bądź odmawia obsługi wskazanej przez klienta wersji
HTTP

Mariusz Chmielewski - ISI WAT
37
Architektury klient-serwer
Architektury klient-serwer
• W
tym
podejściu
system
jest
postrzegany
jako
zbiór
usług
oferowanych klientom, którzy z nich
korzystają.
W
takich
systemach
odmiennie traktuje się serwery i klientów
– W takiej architekturze program użytkowy jest
modelowany jako zbiór usług oferowanych przez
serwery i zbiór klientów, którzy z tych usług
korzystają.
– Klienci muszą znać dostępne serwery, ale zwykle
nie muszą wiedzieć o istnieniu innych klientów.
– Klienci i serwery są oddzielnymi procesami.
– Procesy i procesory systemu nie muszą być
wzajemnie jednoznacznie przyporządkowane.
Mariusz Chmielewski - ISI WAT
38
Architektury klient-serwer
Architektury klient-serwer
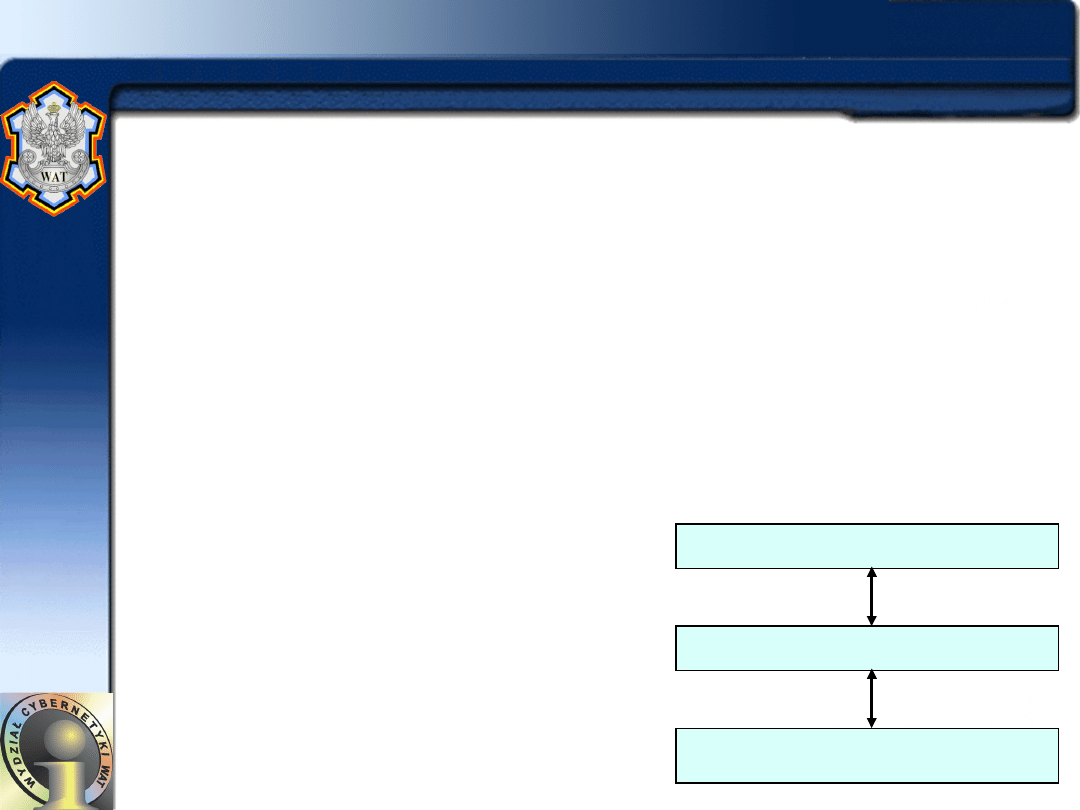
• Projektowanie systemu klient-serwer za
pomocą architektury warstwowej:
–
Warstwa
prezentacji
dotyczy
przedstawiania
informacji użytkownikowi i całego kontaktu z
użytkownikiem.
–
W warstwie przetwarzania implementuje się logikę
programu użytkowego.
–
Warstwa zarządzania danymi jest odpowiedzialna za
wszystkie operacje na bazie danych
Warstwa przetwarzania
Warstwa zarządzania danymi
Warstwa prezentacji

Mariusz Chmielewski - ISI WAT
39
Architektury klient-serwer
Architektury klient-serwer
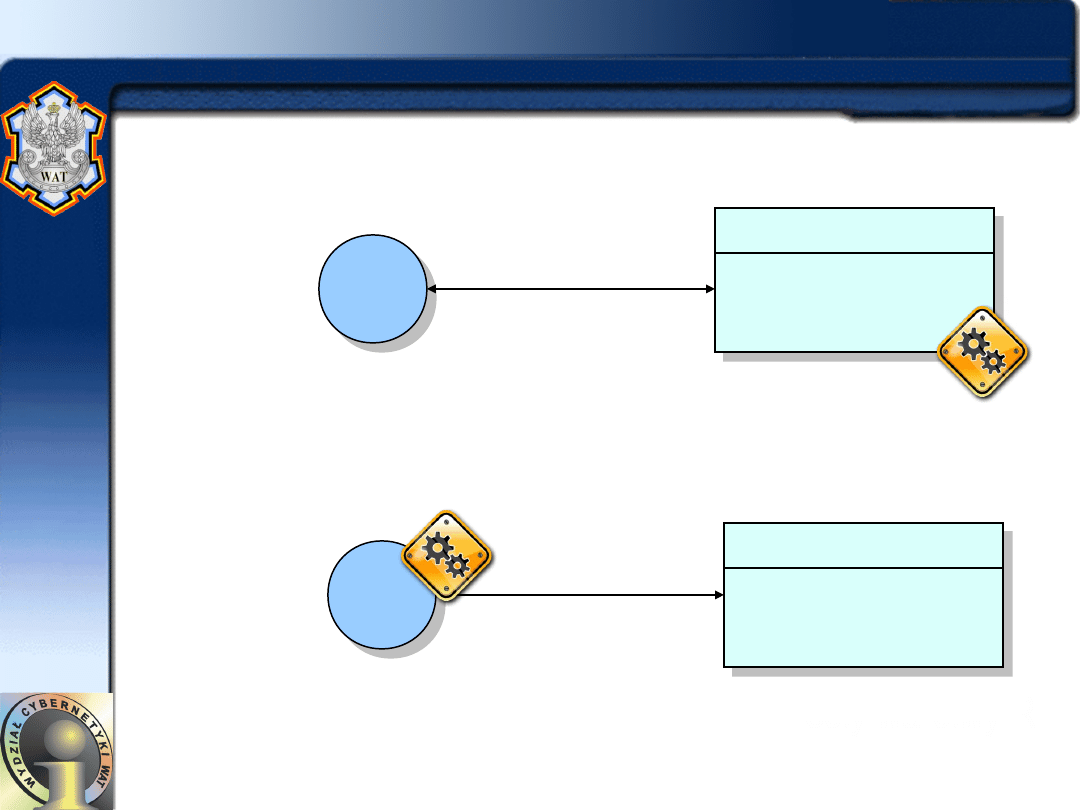
• Model klienta cienkiego
– W tym modelu całość przetwarzania i zarządzania
danymi ma miejsce na serwerze. Jedynym zadaniem
klienta
jest
uruchomienie
oprogramowania
prezentacyjnego. Cechą szczególną cienkiego klienta
jest
niezależność
od
obsługiwanej
aplikacji
serwerowej (jej zmiana nie pociąga za sobą
konieczności wymiany oprogramowania klienta).
Dodatkowym atutem jest niewielkie zapotrzebowanie
na moc przetwarzania.
• Model klienta grubego
– W tym modelu serwer odpowiada jedynie za
zarządzanie danymi. Oprogramowanie u klienta
implementuje logikę programu użytkowego i kontakt
z serwerem. Oprogramowanie użytkowe wykonywane
są bezpośrednio i autonomicznie na stacji, dokonując
przetwarzania danych oraz wymiany danych z
użytkownikiem i innymi komputerami w sieci.
Mariusz Chmielewski - ISI WAT
40
Architektury klient-serwer
Architektury klient-serwer
Klient
Klient
Klient
Klient
Prezentacja
Prezentacja
Przetwarzanie
Model
cienkiego
klienta
Model
klienta
grubego
Serwer
Zarządzanie
danymi
Przetwarzanie
Serwer
Zarządzanie
danymi

Mariusz Chmielewski - ISI WAT
41
Model cienkiego klienta
Model cienkiego klienta
• Architektura dwuwarstwowa z cienkim klientem
jest najprostszym rozwiązaniem, które można
wykorzystać w scentralizowanych systemach
odziedziczonych
ewoluujących
w
kierunku
architektur klient-serwer.
– Interfejs użytkowy działa jako serwer i obsługuje
przetwarzanie użytkowe oraz zarządzanie danymi.
– Model klienta cienkiego może być również
zaimplementowany tam, gdzie klienci są raczej
prostymi
urządzeniami
sieciowymi,
a
nie
komputerami osobistymi albo stacjami roboczymi.
– Na takim urządzeniu sieciowym działa przeglądarka Sieci
oraz interfejs użytkownika realizowany przez ten system.
– Najważniejsza wadą modelu klienta cienkiego jest
duże obciążenie przetwarzaniem zarówno sieci, jak
i serwera.

Mariusz Chmielewski - ISI WAT
42
Model klienta cienkiego
Model klienta cienkiego
• Zalety
– centralne zarządzanie oprogramowaniem
– niewielkie wymagania dla urządzeń klienckich
– brak konieczności modyfikacji (rozbudowy)
urządzeń klienckich mimo wzrostu wymagań
funkcjonalnych aplikacji
• Wady
– ograniczona funkcjonalność, limitowana
stosowanym protokołem
– opóźniona interakcja z użytkownikiem związana z
opóźnieniami sieci
– duże obciążenia komunikacyjne, możliwe zwyżki
kosztów komunikacji

Mariusz Chmielewski - ISI WAT
43
Model grubego klienta
Model grubego klienta
• Wykorzystuje się dostępną moc obliczeniową klienta
przekazując mu zarówno przetwarzanie związane z
logiką programu użytkowego, jak i prezentację.
– Serwer pełni rolę serwera transakcji, który zarządza
transakcjami w bazie danych.
– Znanym przykładem architektury tego typu są systemy
bankomatów. Bankomat jest tam klientem, a serwerem jest
komputer główny obsługujący bazę danych kont klientów.
– Wszelkiego rodzaju gry sieciowe World of Warcraft,
CounterStrike itp. Są również oparte na idei grubego klienta
ze względu na konieczność wykorzystania skomplikowanych
modeli oraz algorytmów 3D
– W modelu klienta grubego przetwarzanie jest
bardziej efektywne niż w wypadku modelu klienta
cienkiego, zarządzanie systemem jest natomiast
trudniejsze w tym pierwszym modelu.

Mariusz Chmielewski - ISI WAT
44
Architektura wielowarstwowa
Architektura wielowarstwowa
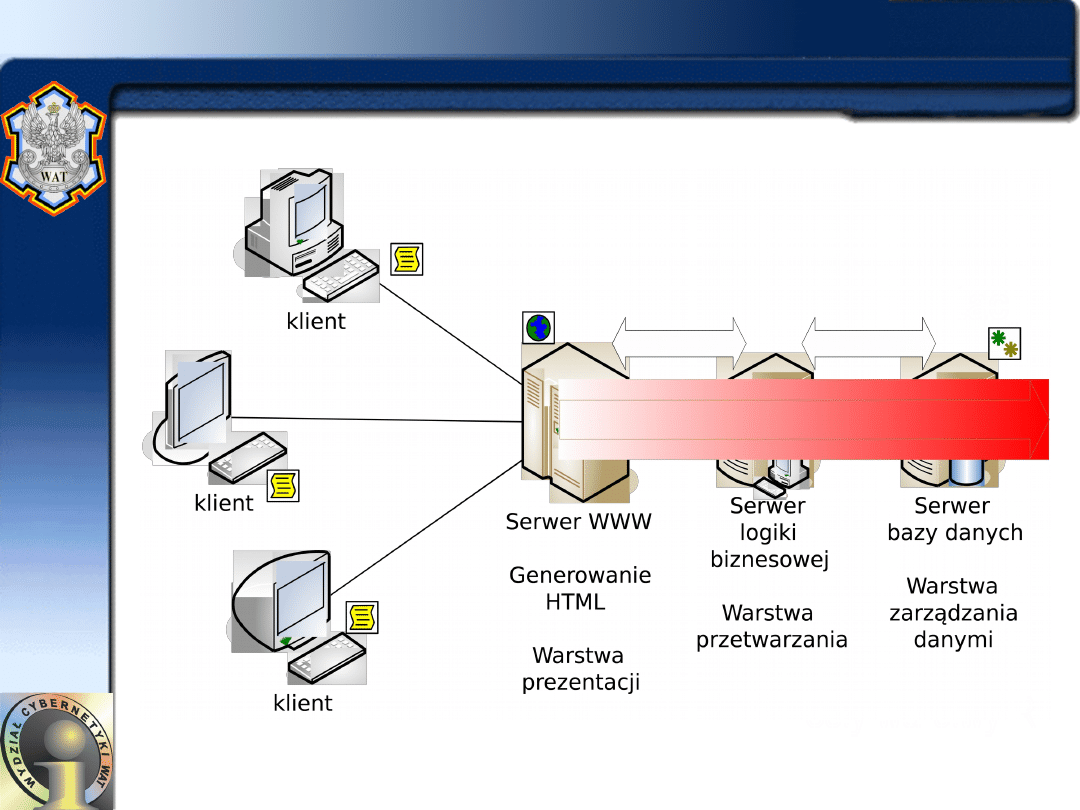
• W tej architekturze prezentacja, przetwarzanie
użytkowe i zarządzanie danymi są logicznie
oddzielonymi procesami.
–
W przypadku architektury wielowarstwowej nie jest
konieczne fizyczne wyodrębnianie oddzielnych maszyn
obsługujących logiczne warstwy aplikacji.
–
Pojedynczy komputer serwera może obsługiwać
zarówno przetwarzanie użytkowe, jak i zarządzanie
danymi programu użytkowego jako dwa oddzielne
logicznie serwery.
• Elastyczność takiej budowy zapewnia również
możliwość
budowy
farmy
serwerów
obsługujących load-balancing w ramach jednej
logicznej warstwy.
Mariusz Chmielewski - ISI WAT
45
Architektura wielowarstwowa
Architektura wielowarstwowa

Mariusz Chmielewski - ISI WAT
46
Zastosowania różnych architektur
Zastosowania różnych architektur
Architektura
Zastosowania
Architektura
Systemy odziedziczone, w których oddzielenie
przetwarzania użytkowego od zarządzania
dwuwarstwowa
danymi jest niepraktyczne
klient-serwer
Programy użytkowe wykonujące dużo obliczeń, ale w małym
stopniu (albo wcale)
z klientami cienkimi
zarządzające danymi, np. kompilatory
Programy użytkowe dużo korzystające z danych (przeglądanie i
zapytywanie), ale
wykonujące mało (albo wcale) obliczeń użytkowych
Architektura
Programy użytkowe, w których obliczenia są wykonywane u
klienta przez COTS (kompo-
dwuwarstwowa
nenty z półki), np. Microsoft Exel
klient-serwer
Programy użytkowe wymagające złożonego obliczeniowo
przetwarzania danych,
z klientami grubymi
np. przedstawiania graficznego danych
Programy użytkowe ze względnie stabilną funkcjonalnością oferowaną
użytkownikowi,
stosowane w środowisku ze starannie ustalonym zarządzaniem
systemem
Architektura
Ogromne programy użytkowe z setkami lub tysiącami
użytkowników
trójwarstwowa
Programu użytkowe, w których zarówno dane, jak i
programy są płynne
lub wielowarstwowa Programy użytkowe, w których integruje się dane z wielu źródeł
klient-serwer

Mariusz Chmielewski - ISI WAT
47
Języki programowania
Języki programowania
• Języki kompilowane:
Przetwarzanie wykonywane przez kompilator dzielone na
kilka faz:
• Analiza leksykalna – tokenisation - wybranie sekwencji znaków
i wytworzenie z niej sekwencji żetonów odpowiadających
elementom języka -liczby, słowa kluczowe, identyfikatory, itd..
• Analiza składniowa – parsing – wybranie sekwencji tokenów i
budowanie z nich drzewa przetwarzania odpowiadającego
strukturze gramatycznej programu (drzewa rozbioru)
• Optymalizacja drzewa – wykonywana opcjonalnie
• Generowanie kodu maszynowego – wybranie drzewa
przetwarzania
i
wyprodukowanie
kodu
maszynowego
odpowiadającego instrukcjom (w grę wchodzą również kod
asembassembly language, or some intermediate code, or …)
• Optymalizacja kodu – wykonywana opcjonalnie
• Linkowanie, ładowanie, uruchamianie – dołączenie bibliotek
składowych, realokacja w pamięci

Mariusz Chmielewski - ISI WAT
48
Języki programowania
Języki programowania
• Języki interpretowalne:
Przetwarzanie wykonywane przez
interpreter dzielone na kilka faz, w
przeciwieństwie do kompilacji nie
wymaga generowania kodu
maszynowego. Zakłada się jednak
konieczność przed wykonaniem takiego
programu wykonanie:
– Analizy leksykalnej
– Analizy składniowej
– Emulacji oraz symulacji

Mariusz Chmielewski - ISI WAT
49
Działanie interpretera
Działanie interpretera
• Interpreter w przeciwieństwie do kompilatora,
tłumaczy kod do wykonywalnego kodu
maszynowego lub kodu pośredniego, który jest
następnie zapisywany do pliku w celu
późniejszego wykonania.
• Wykonanie programu za pomocą interpretera jest
wolniejsze, a do tego zajmuje więcej zasobów
systemowych niż wykonanie kodu skompilowanego,
lecz może zająć relatywnie mniej czasu niż kompilacja
i uruchomienie.
• Jest to zwłaszcza ważne przy tworzeniu i testowaniu
kodu kiedy cykl edycja-interpretacja-debugowanie
może często być znacznie krótszy niż cykl edycja-
kompilacja-uruchomienie-debugowanie.
• Interpretacja kodu jest wolniejsza niż
uruchamianie skompilowanego kodu ponieważ
interpreter musi analizować każde wyrażenie i
następnie wykonać akcję, a kod skompilowany
jedynie wykonuje akcję.

Mariusz Chmielewski - ISI WAT
50
Działanie interpretera
Działanie interpretera
• W implementacjach będących w pełni interpreterami
wykonanie wielokrotne tego samego fragmentu kodu
wymaga wielokrotnej interpretacji tekstu.
• Ta analiza nazywana jest "kosztem interpretacji".
Dostęp do zmiennych jest także wolniejszy w
interpreterze ze względu na odwzorowanie
identyfikatorów na miejsca pamięci musi zostać
dokonane podczas uruchomienia lub pracy a nie
podczas kompilacji.
• Języki interpretowalne:
– Bash
– Maxima
– Perl
– PHP
– Python
– Ruby
– Java?
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
Wyszukiwarka
Podobne podstrony:
Techniki internetowe W1 Internet
Techniki internetowe kontakt, zaliczenie
Techniki internetowe W3 XML
TECH INT lab8 2014, Studia - Politechnika Opolska, Semestr 6, Techniki Internetowe
TECH INT lab12 2014, Studia - Politechnika Opolska, Semestr 6, Techniki Internetowe
TECH INT lab6 2014, Studia - Politechnika Opolska, Semestr 6, Techniki Internetowe
TECH INT lab7 2014, Studia - Politechnika Opolska, Semestr 6, Techniki Internetowe
TECH INT lab9 2014, Studia - Politechnika Opolska, Semestr 6, Techniki Internetowe
praca dyplomowa wytyczne 2011 03 02, Studia - Politechnika Opolska, Semestr 6, Techniki Internetowe
Z Wykład 16.03.2008, Zajęcia, II semestr 2008, Techniki Internetowe
IT Techniki Internetu
Praca Dyplomowa technikum internet, Informatyka
Techniki internetowe W2 HTML
interna W1
Techniki internetowe kontakt, zaliczenie
Technika Frame Relay jako metoda połączenia przedsiębiorstw do sieci WAN i do internetu, PREZENTACJA
Internetowe BD notatki w1
Zaawansowane techniki projektowania serwisów Internetowych, 2431, Prace, Informatyka
więcej podobnych podstron