
Ocena wartości dowodu z badania
DNA
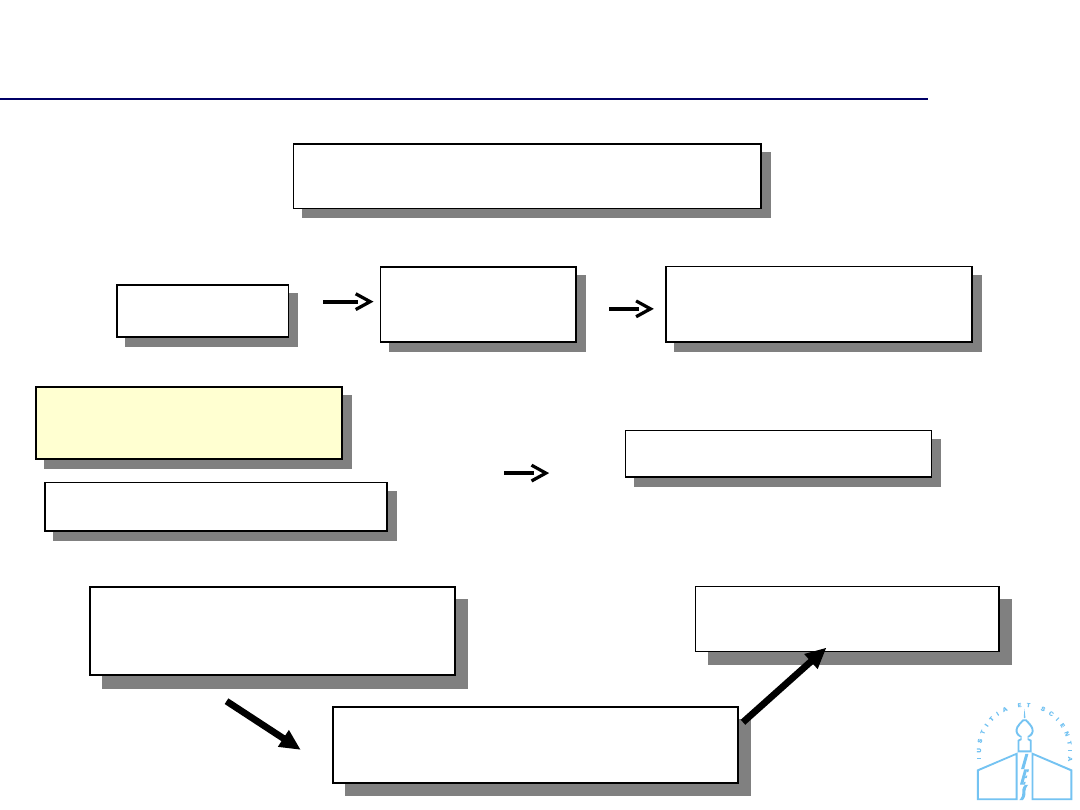
Izolacja
DNA
Izolacja
DNA
Pomiar
stężenia DNA
Pomiar
stężenia DNA
Amplifikacja (PCR) loci
polimorficznych
Amplifikacja (PCR) loci
polimorficznych
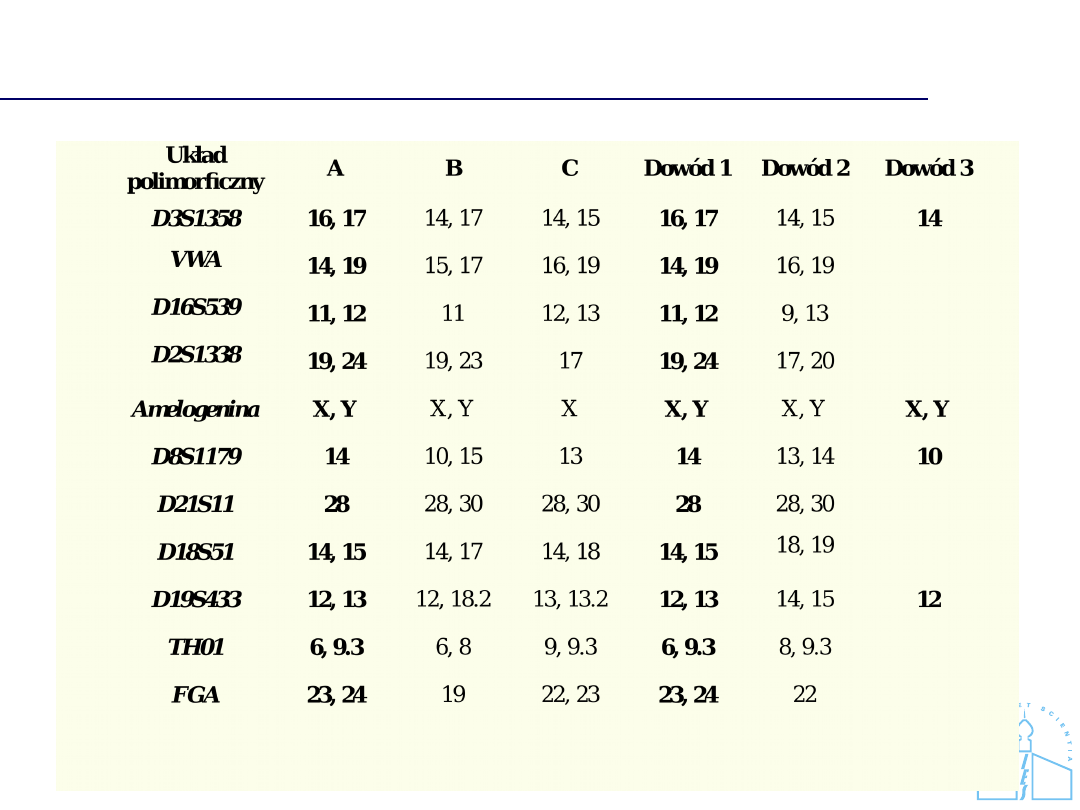
Analiza porównawcza –
próbka dowodowa - próbka
referencyjna
Analiza porównawcza –
próbka dowodowa - próbka
referencyjna
Ocena wartości dowodu z
badania DNA (statystyka)
Ocena wartości dowodu z
badania DNA (statystyka)
Przygotowanie opinii
Przygotowanie opinii
Oględziny dowodów, zabezpieczanie
śladów
Oględziny dowodów, zabezpieczanie
śladów
Elektroforeza fragmentów
DNA
Elektroforeza fragmentów
DNA
Interpretacja wyników
Interpretacja wyników
Ekspertyza genetyczna
Sekwencjonowanie
DNA (mtDNA)
Sekwencjonowanie
DNA (mtDNA)
CSF1P
O
D5S81
8
D21S1
1
TH0
1
TPOX
D13S3
17
D7S82
0
D16S5
39
D18S5
1
D8S11
79
D3S13
58
FG
A
VW
A
AME
L
AME
L
Płeć
Penta
E
Penta
D
D2S133
8
D19S4
33
Wybór markerów genetycznych nie jest
przypadkowy
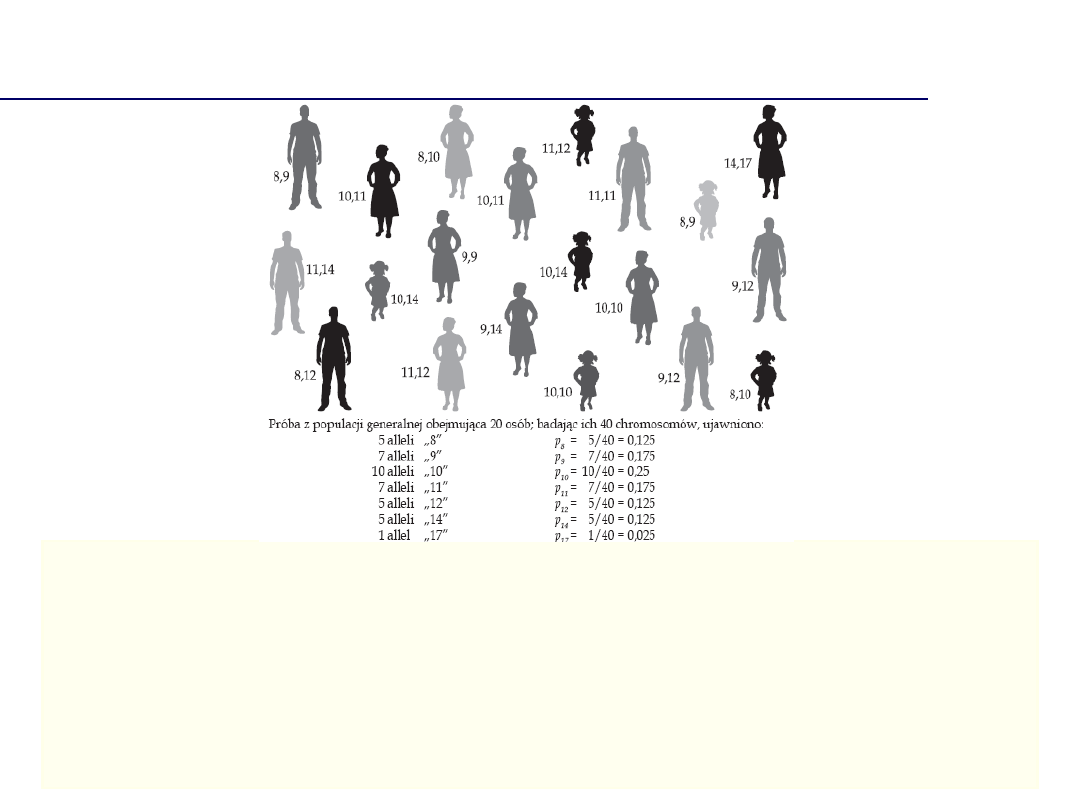
Badania populacyjne
• Ich wyniki stanowią podstawę do wyboru locus jako markera identyfikacyjnego
– Locus powinna charakteryzować wysoka heterozygotyczność
– Zgodność z regułą Hardy’ego-Weinberga (allele niezależne statystycznie w obrębie
locus)
– Brak sprzężenia genetycznego z innymi markerami wykorzystywanymi w procesie
identyfikacji genetycznej (allele niezależne statystycznie dla różnych loci)
• Znajomość częstości alleli niezbędna jest do oceny wartości dowodu z badania DNA

Podstawowa zasada w genetyce populacyjnej, zgodnie z którą
częstości genotypów i alleli w dużych, losowo krzyżujących się
populacjach pozostają niezmienne we wszystkich pokoleniach,
przy założeniu braku mutacji, migracji i doboru naturalnego.
Reguła Hardy’ego – Weinberga

Przykład – reguła Hardy’ego-
Weinberga
• Częstości alleli i genotypów są powiązane za pomocą prostego równania
p
2
+2pq+q
2
= 1
• Częstości genotypów
– AA = 81%
– Aa = 18%
– aa = 1%
• Częstości alleli (populacja 100 osób = 200 alleli)
– A = 162 allele + 18 alleli = 190 alleli = 90% = 0,9 (p)
– a = 2 allele + 18 alleli = 20 alleli = 10% = 0,1 (q)
• p + q = 100% = 1
• Oczekiwana częstość osobników homozygotycznych: AA = 0,9 x 0,9 =
0,81 = p
2
oraz aa = 0,1 x 0,1 = 0,01 = q
2
• Oczekiwana częstość osobników heterozygotycznych: 2 x 0,9 x 0,1 =
0,18 = 2pq
• Reguła HW to przybliżenie stanu rzeczywistego – nie uwzględnia ewolucji
• Zmiany częstości genów w populacjach zachodzą na skutek: 1)mutacji, 2)
działania doboru naturalnego, 3) dryfu genetycznego, 4) migracji

Obliczenia zgodności z regułą Hardy’ego-
Weinberga
• W praktyce porównuje się heterozygotyczność obserwowaną z
heterozygotycznością oczekiwaną (zgodnie z równaniem HW)
• Badania populacyjne pozwalają na określenie
heterozygotyczności obserwowanej (O)
• Za pomocą prostego testu Chi kwadrat możemy ocenić, czy
nasze wyniki są bliskie wartości oczekiwanych (E)
• χ2 = ∑ (O
Aa
– E
Aa
)2/E
Aa
• Test dokładny Fishera można zastosować w tym samym celu
• Oprogramowanie komputerowe umożliwia przeprowadzenie
stosownych obliczeń

Stan równowagi Hardy’ego-Weinberg’a
Marker genetyczny jest w stanie równowagi Hardy’ego-Weinberga, gdy
oczekiwane
częstości genotypów są zgodne z
obserwowanymi
częstościami genotypów.
Stan równowagi HW dowodzi, że marker jest
stabilny genetycznie
nie
obserwujemy działania presji ewolucyjnej lub nieprzypadkowego
kojarzenia.
W praktyce testy mogą wykazać potencjalny nadmiar homozygot, który
często tłumaczony jest poprzez „
wypadanie alleli
”, a więc
niedoskonałość testu powodującą uzyskiwanie fałszywych oznaczeń
jednego allela z dwóch różnych istniejących faktycznie – np. mutacja w
miejscu wiązania startera PCR (allele zerowe).
Stan równowagi Hardy’ego-Weinberga może być zakłócony, gdy:
A. ma miejsce pokrewieństwo wśród rodziców → podwyższona liczba
homozygot.
B. istnieje silna istotna substruktura populacji
C. ma miejsce selekcja – osobnicy o pewnych genotypach przekazują je
wydajniej niż osobnicy o innych genotypach
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
1
2
3
4
5
Allele Number
A
ll
el
e
Fr
eq
u
en
cy
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
1
2
3
4
5
6
7
8
9
Allele Number
A
ll
el
e
F
re
q
u
en
cy
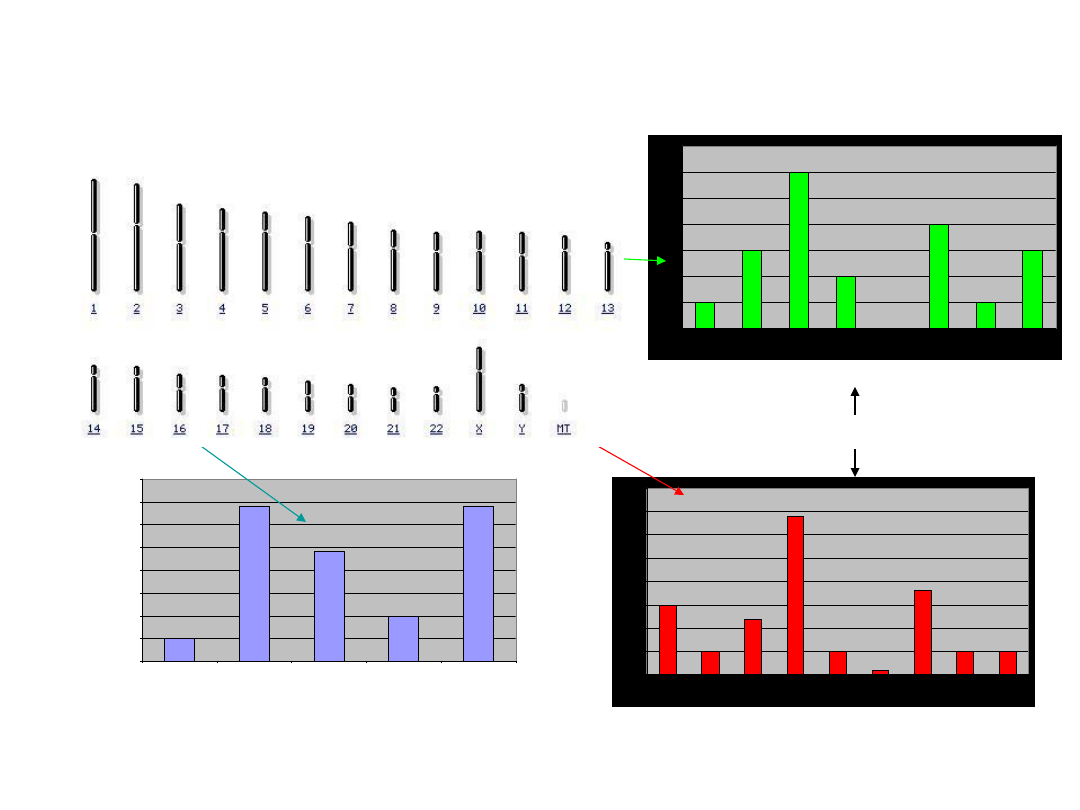
2. Pula alleli jest próbą losową, a każdy allel jest
niezależnym „losem” z jego rozkładu częstości
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1
2
3
4
5
6
7
8
Allele Number
A
ll
el
e
Fr
eq
u
en
cy
Rozkład
skorelowany
1. Zależności pomiędzy allelami w różnych
loci

Trzy prawa prawdopodobieństwa
1. Wartości prawdopodobieństw leżą w zakresie od 0 do 1 (0%-
100%)
2. Zdarzenia mogą się wzajemnie wykluczać. W tym przypadku
prawdopodobieństwa poszczególnych zdarzeń możemy
sumować.
-
Prawdopodobieństwo, że zajdzie jedno z dwóch zdarzeń wzajemnie
wykluczających się jest równe 1 czyli 100 %
- Prawdopodobieństwo zdarzenia H = 1 – prawdopodobieństwo zdarzenia G.
3. Jeśli dwa zdarzenia są niezależne od siebie, to ich
prawdopodobieństwa możemy przemnażać. Wtedy
prawdopodobieństwo, że jednocześnie zajdą niezależne
zdarzenia H i G = iloczynowi prawdopodobieństw dla tych
dwóch zdarzeń

O markerach genetycznych, które są od siebie niezależne (są od siebie
odpowiednio oddalone fizycznie przez co dziedziczą się niezależnie)
mówimy, że są w stanie
równowagi sprzężeń
(linkage equilibrium), są
więc statystycznie niezależne.
Markery zależne są w stanie
nierównowagi sprzężeń
(linkage
disequilibrium) – w tym przypadku nie możemy stosować reguły mnożenia
(zdarzenia nie są niezależne od siebie, a więc trzecie prawo
prawdopodobieństwa nie jest spełnione).
Nierównowaga sprzężeń
(linkage disequilibrium, LD)
Testowanie możemy prowadzić również w oparciu o prosty test Chi
kwadrat

Program Arlequin
Analiza porównawcza ślad - próbka
referencyjna
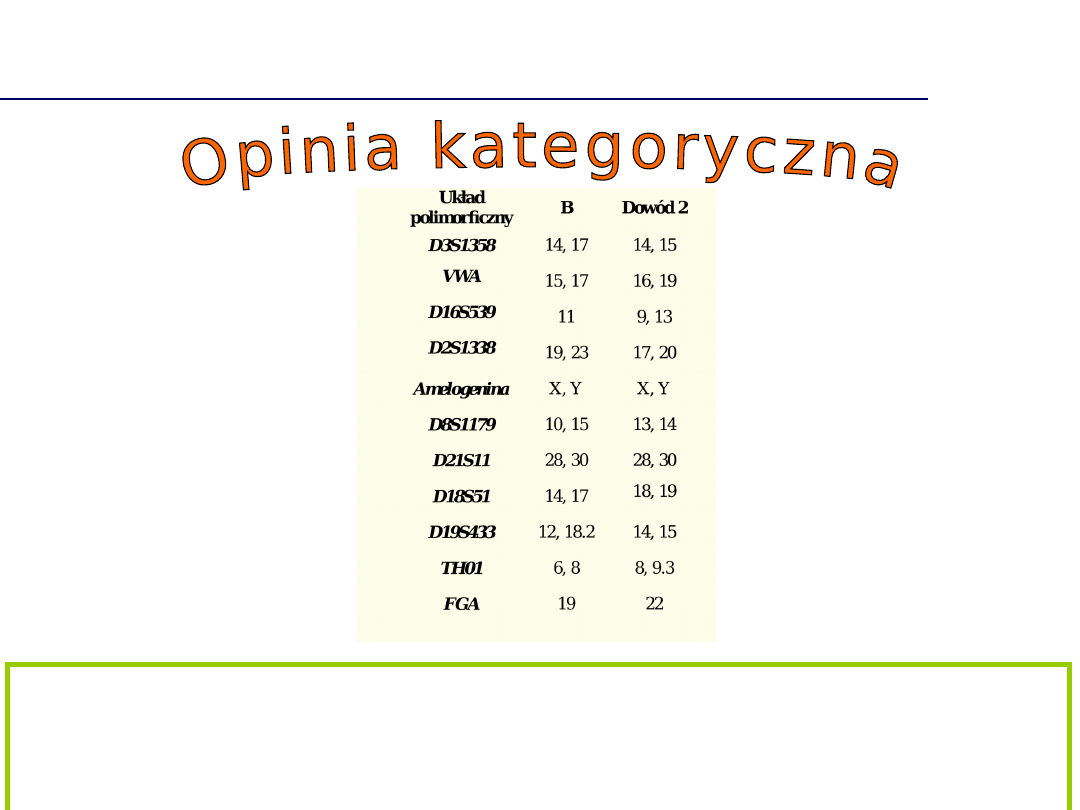
Brak zgodności profili DNA
Porównanie wykazało brak zgodności oznaczonego w próbce
dowodowej profilu DNA z profilem genetycznym oznaczonym w
nadesłanym materiale porównawczym. Należy wykluczyć
możliwość pochodzenia próbki dowodowej od podejrzanego.

Niepełny profil DNA
Częściowy profil genetyczny, który oznaczono w próbce dowodowej
nie pozwala na przeprowadzenie wnioskowania odnośnie zgodności
profili DNA.
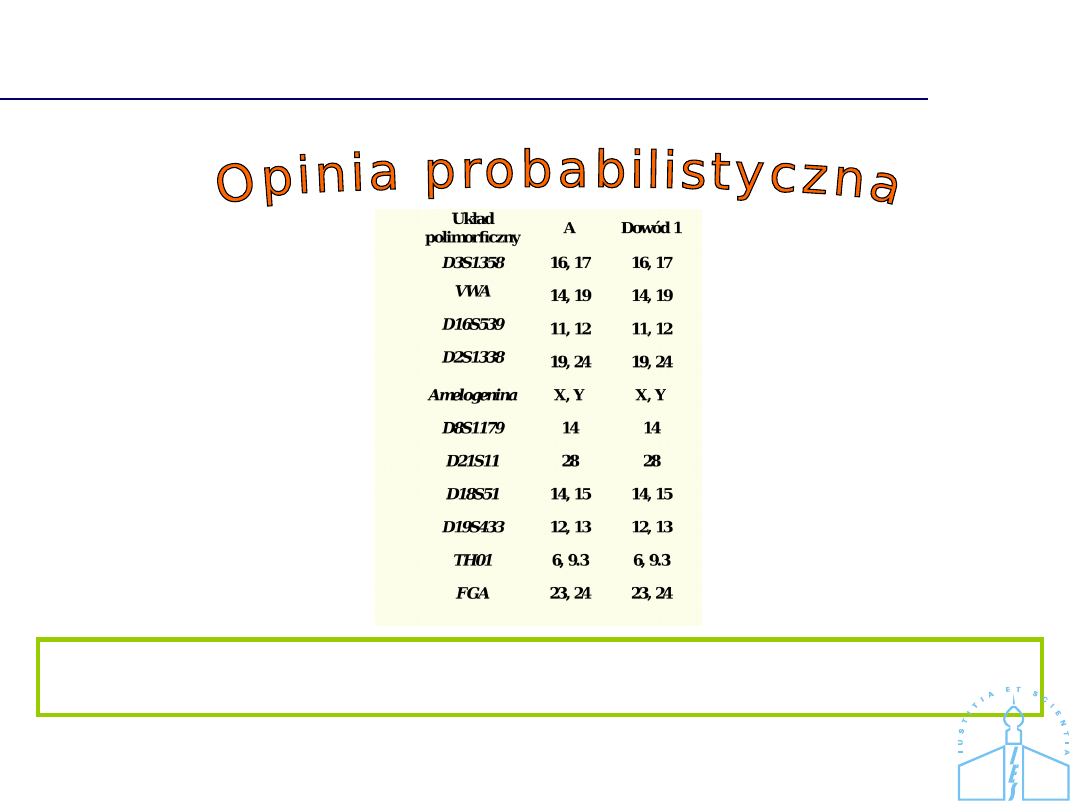
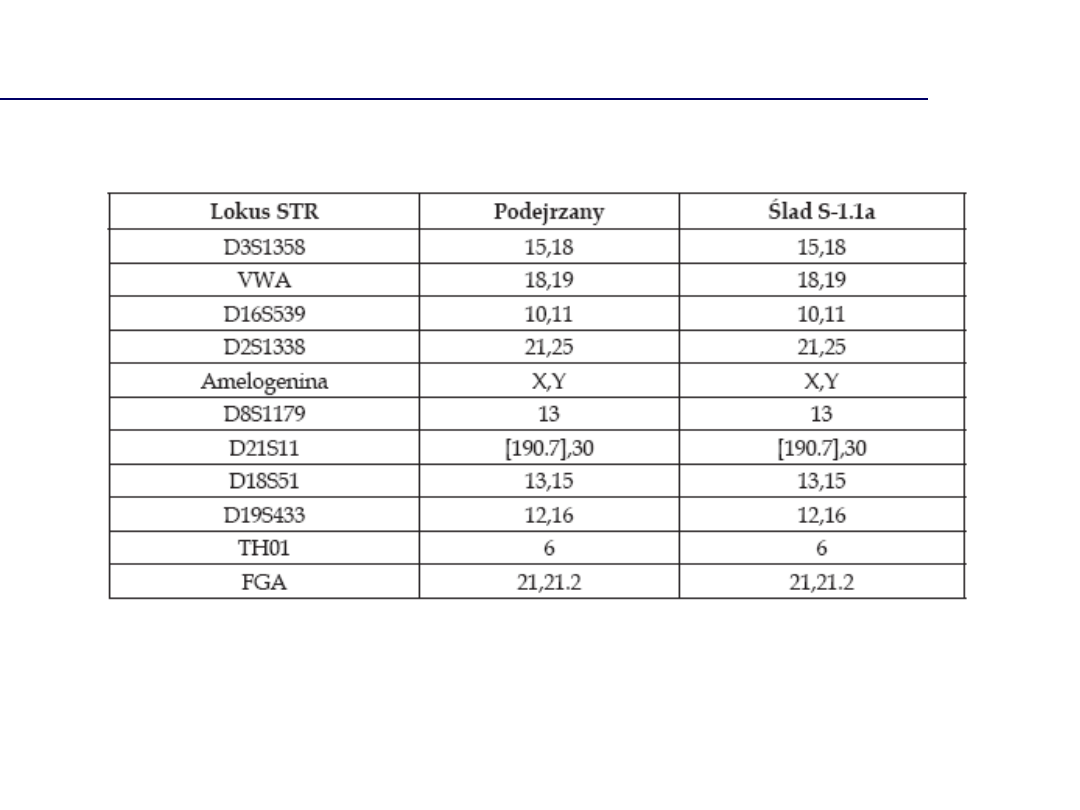
Zgodność profili DNA
Profil DNA oznaczony w próbce dowodowej jest zgodny z profilem DNA
charakterystycznym dla podejrzanego A.
Co dalej ?

1. Sprawca pozostawił swój
materiał biologiczny na miejscu
zdarzenia
2. Podejrzany w wyniku działania
przypadku ma taki sam profil DNA
jak materiał pozostawiony na
miejscu zdarzenia (może też być
blisko spokrewniony ze sprawcą ...)
3. Błąd laboratorium
Powody uzyskania zgodności profili

Oskarżenie:
ślad pochodzi
od
podejrzanego
Obrona: ślad
pochodzi od
nieznanego sprawcy,
podejrzany w wyniku
przypadku ma profil
zgodny z profilem
śladu
Hipoteza oskarżenia i hipoteza obrony

Jak ocenić wartość uzyskanego
dowodu
• Naszym zadaniem jest udzielenie odpowiedzi na pytanie,
czy jest prawdopodobne, że do zgodności profili DNA w
analizowanych próbkach doszło na skutek przypadku ?
• Odpowiedź uzyskamy poprzez obliczenie częstości danego
genotypu (profilu DNA) w populacji.
• Jeśli profil DNA jest częsty (np. ma go 1 na 10 osób)
prawdopodobieństwo przypadkowej zgodności jest wysokie.
• Jeśli jednak okaże się, że profil jest rzadki (np. ma go 1
na 1 miliard osób) prawdopodobieństwo przypadkowej
zgodności jest bardzo niskie.
• Dowód w tym drugim przypadku jest bardzo mocny.

Szansa
a priori
na rzecz winy =
Pr(G)/Pr(nieG)
G
- podejrzany jest winny
nieG
- podejrzany jest niewinny
E
-
dowód z badania DNA

Szansa a priori
na
rzecz winy
podejrzanego -
wynika z wszelkich
informacji
wynikających
z dochodzenia, poza
dowodem
z laboratorium

Szansa a posteriori
na rzecz winy
podejrzanego - ustalona przez sąd -
wynika z wszelkich dopuszczonych
dowodów w sprawie (w tym dow. z
DNA!)
)
(
)
(
)
(
)
(
)
(
)
(
nieG
E
P
G
E
P
nieG
P
G
P
E
nieG
P
E
G
P
Szansa
a
posteriori
Szansa
a priori
Iloraz
wiarygodnoś
ci
Miara wartości dowodu
Prawo Bayesa w postaci szansy
dowód z badania DNA
prawdopodobieństwo
prawdopodobieństwo
winy a priori winy a
posteriori
Dowód z badania DNA modyfikuje
prawdopodobieństwo winy a priori
Prawdopodobieństwo przypadkowej zgodności
(match probability)
Prawdopodobieństwo, że inna
niespokrewniona
osoba wybrana
losowo z populacji ma identyczny profil DNA może być
oszacowane poprzez obliczenie częstości z jaką ten profil DNA
(genotyp) występuje w populacji.
Częstości alleli poznajemy dzięki badaniom
populacyjnym.
Populacyjne bazy danych powinny gromadzić dane
dla osób niespokrewnionych o ustalonym
pochodzeniu etnicznym.
Jaką bazę danych wybrać w celu przeprowadzenia
obliczeń?
-
dla różnych grup etnicznych
- dla jednej grupy etnicznej
- dla regionu np. Małopolski.

P(E|nieG) = prawdopodobieństwo
przypadkowej zgodności dwóch
profili
(match probability, MP)
= prawdopodobieństwo posiadania przez
przypadkową osobę
z populacji profilu DNA zgodnego z
profilem DNA podejrzanego =
częstość
profilu DNA
w populacji
Prawdopodobieństwo przypadkowej zgodności

Kontradyktoryjność procesu
sądowego
Iloraz dwóch prawdopodobieństw
warunkowych:
H
0
– ustalono dowód, bo podejrzany jest winny
H
1
– ustalono dowód, ale doszło do tego przez
przypadek, a podejrzany w rzeczywistości
jest niewinny
LR (likelihood ratio) - iloraz wiarygodności
służy do porównania prawdopodobieństw
dowodu przy założeniu dwóch alternatywnych
twierdzeń (hipoteza zerowa i hipoteza
alternatywna).
zgodność profili DNA
Iloraz wiarygodności LR – stosunek dwóch prawdopodobieństw
tego samego zdarzenia (zgodności profili DNA) przy założeniu
różnych hipotez.
Jak bardzo dowód (ustalona zgodność
profili DNA) zwiększa
prawdopodobieństwo, że to oskarżony
pozostawił dany ślad?”
)
(
)
(
niewinny
jest
podejrzany
DNA
z
dowód
P
winny
jest
podejrzany
DNA
z
dowód
P
LR
Iloraz wiarygodności
)
(
)
(
)
(
)
(
)
(
)
(
nieG
E
P
G
E
P
nieG
P
G
P
E
nieG
P
E
G
P
=

„
uzyskanie zgodności
profilu DNA
podejrzanego
z profilem DNA z miejsca zdarzenia jest
milion
razy bardziej prawdopodobne,
przy założeniu, że jest on sprawcą (źródłem
śladu),
niż
uzyskanie takiej zgodności
,
jeżeli ślad
pozostawiła inna, niespokrewniona
z podejrzanym osoba, a zgodność
podejrzanego jest dziełem przypadku”
Sposób wyrażania wyniku analizy LR

Wartość LR
przekłada się liczbowo na
szansę powtórzenia się danego
zgodnego profilu DNA w populacji
np.
LR = 100 bilionów
szansa powtórzenia się powyższego profilu
DNA w populacji ... wynosi jak
1 na 100
bilionów
niespokrewnionych osób.
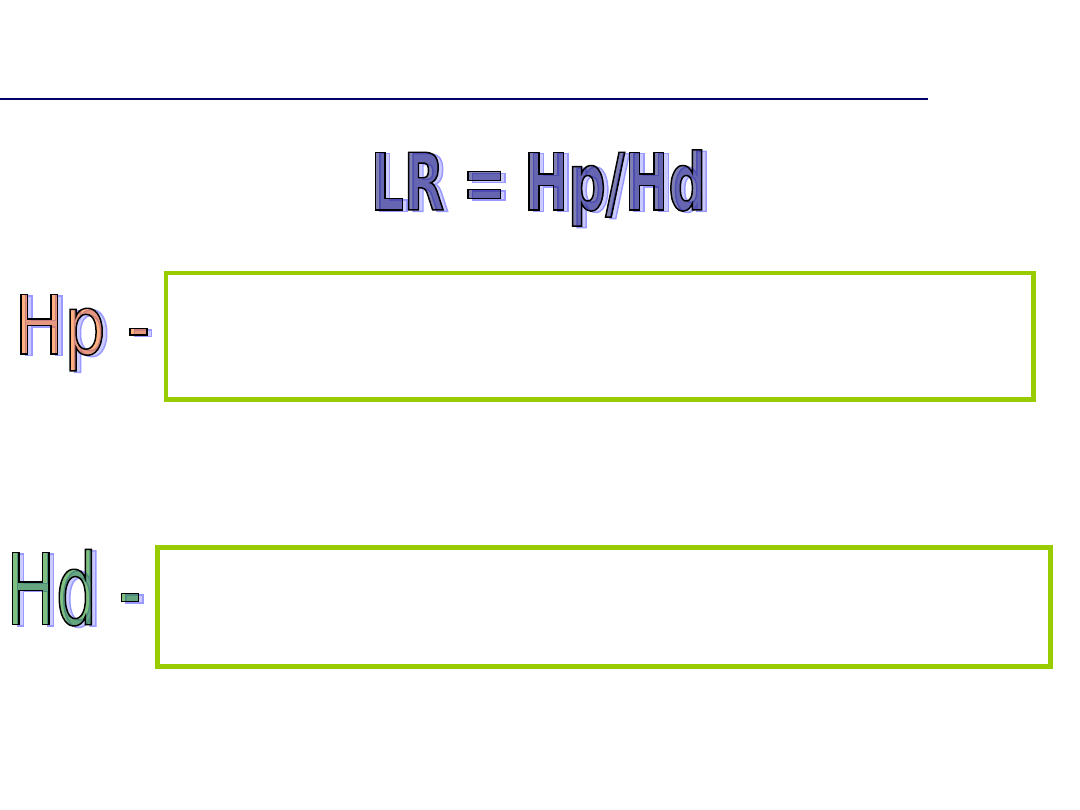
Która hipoteza jest bardziej
prawdopodobna
hipoteza prokuratury – to podejrzany popełnił
przestępstwo. Prawdopodobieństwo zgodności
profili DNA jest wtedy równe 100%; Hp = 1
hipoteza obrony – to inna losowa osoba z populacji
popełniła przestępstwo, a zgodność profili jest
dziełem przypadku
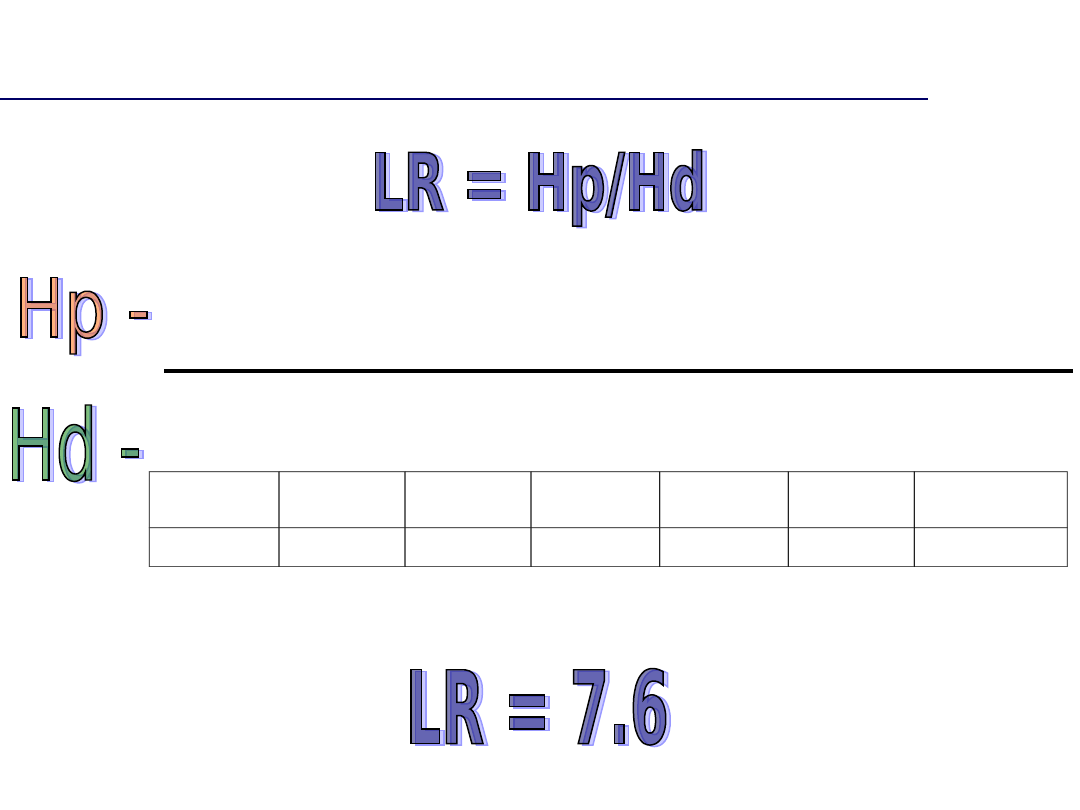
Która hipoteza jest bardziej
prawdopodobna
1
Częstość genotypu w
populacji
Marker
genetyczny
Allel 1
Allel 2
p
q
Wzór
Częstość
genotypu
D3S1358
15
16
0.26159
0.25331
2pq
0.1325
Reguła mnożenia
(product rule)
Częstość profilu DNA obliczana jest poprzez
oszacowanie częstości genotypu dla każdego
locus, a następnie przemnożenie wartości dla
wszystkich loci genetycznych.
Reguła mnożenia może być zastosowana dzięki
niezależności analizowanych markerów
genetycznych.
Która hipoteza jest bardziej
prawdopodobna
1
Częstość genotypu w
populacji
Marker
genetyczny
Allel 1
Allel 2
p
q
Wzór
Częstość
genotypu
D3S1358
15
16
0.26159
0.25331
2pq
0.1325
VWA
17
18
0.28146
0.20033
2pq
0.1128
D16S539
12
11
0.32616
0.32119
2pq
0.2095

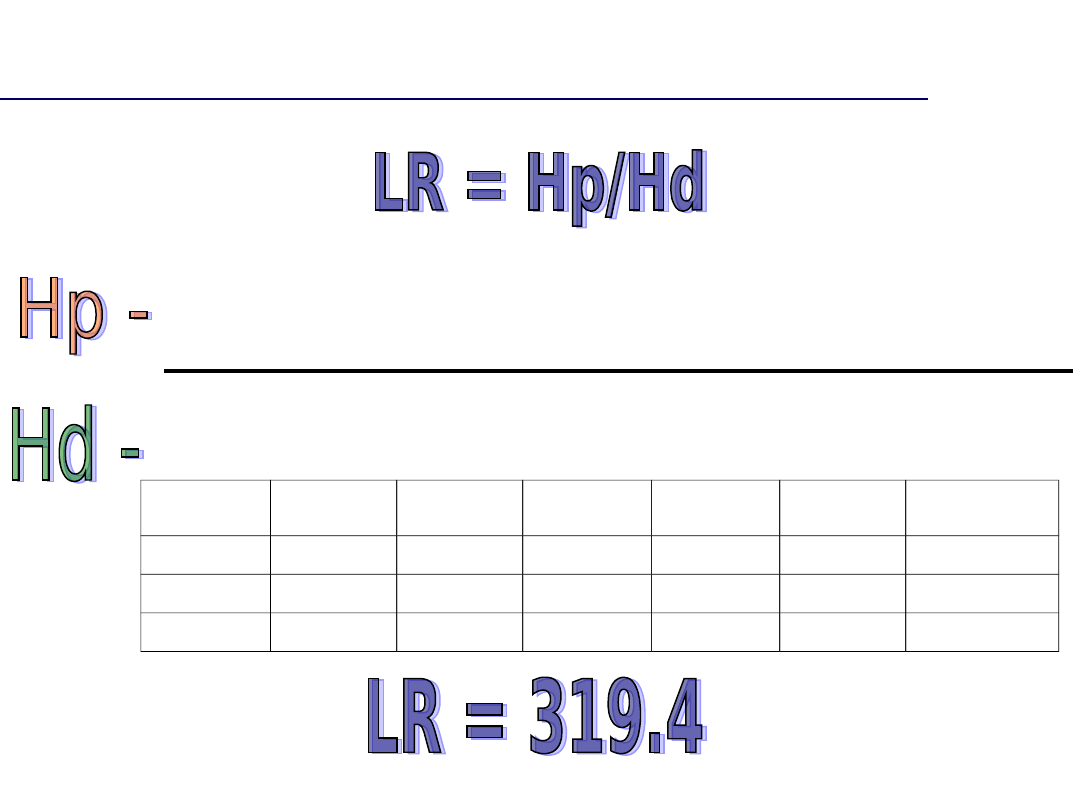
Analiza wielu niezależnych markerów DNA
Marker
genetyczny
Allel 1
Allel 2
p
q
Wzór
Częstość
genotypu
D3S1358
15
16
0.26159
0.25331
2pq
0.1325
VWA
17
18
0.28146
0.20033
2pq
0.1128
D16S539
12
11
0.32616
0.32119
2pq
0.2095
D2S1338
19
24
0.26124
0.22132
2pq
0.1156
D8S1179
13
12
0.30464
0.18543
2pq
0.1130
D21S11
30
29
0.27815
0.19536
2pq
0.1087
D18S51
15
16
0.15894
0.13907
2pq
0.0442
D19S433
12
13
0.16124
0.15426
2pq
0.0497
TH01
9.3
6
0.36755
0.23179
2pq
0.1704
FGA
22
21
0.21854
0.18543
2pq
0.0810
Częstość profilu DNA
1.35 x 10
-10

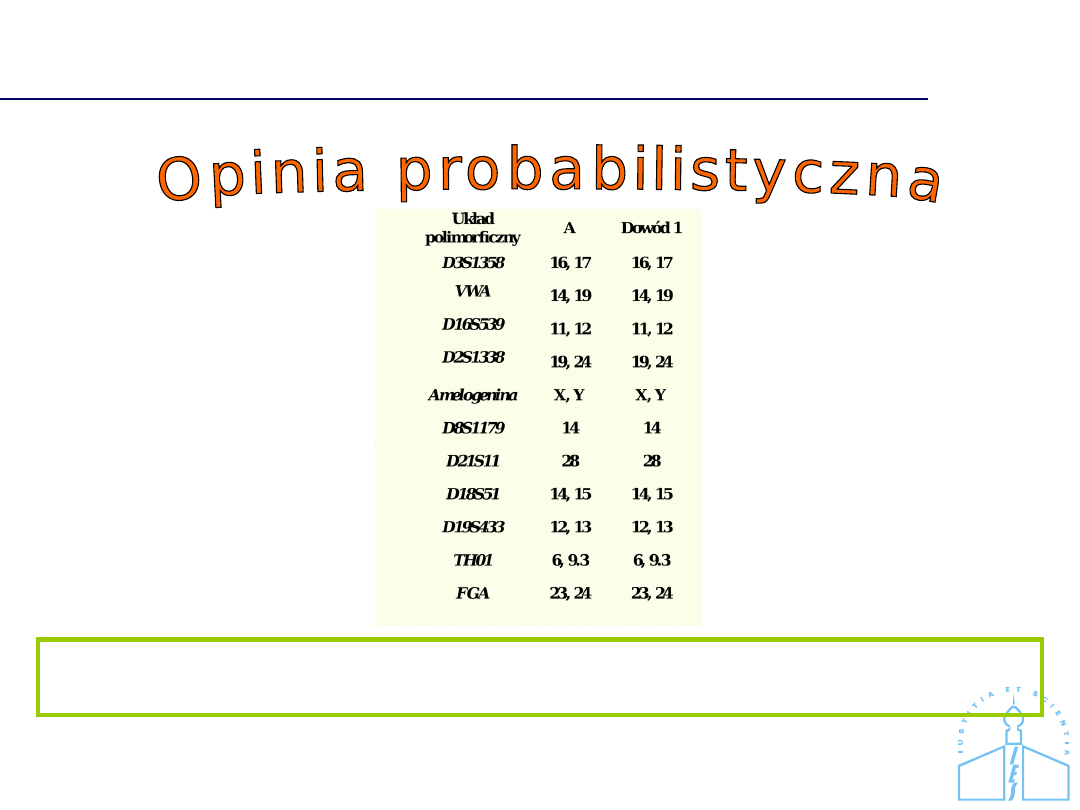
Brak zgodności profili DNA
Profil DNA oznaczony w próbce dowodowej jest zgodny z
profilem DNA charakterystycznym dla podejrzanego A.
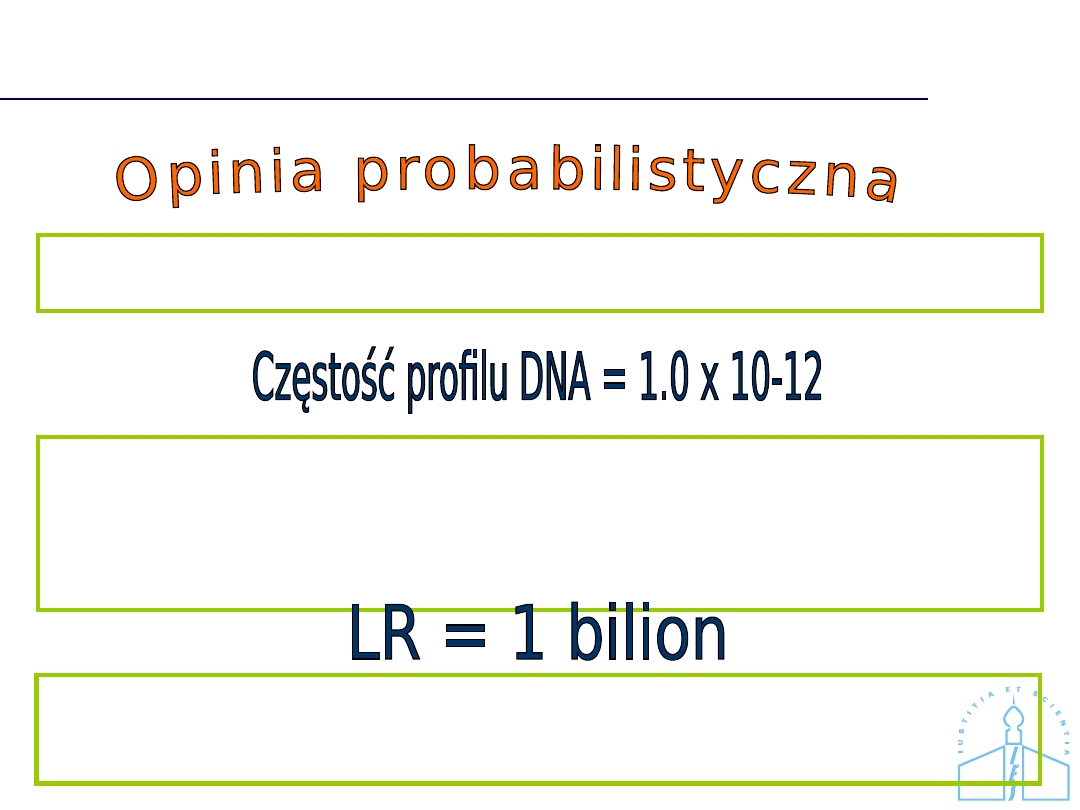
Brak zgodności profili DNA
Prawdopodobieństwo, że ujawniona zgodność jest dziełem przypadku
wynosi
1 x 10-12, innymi słowy teoretyczna szansa powtórzenia się danego
zgodnego profilu DNA w populacji niespokrewnionych mieszkańców
Polski wynosi jak 1: 1 biliona osób.
Profil DNA oznaczony w próbce dowodowej jest zgodny z profilem DNA
charakterystycznym dla podejrzanego A.
Zgodność profili DNA jest 1 bilion razy bardziej prawdopodobna jeśli,
to podejrzany jest źródłem próbki dowodowej, niż jeśli jakaś inna
przypadkowa osoba z populacji stanowi jej źródło.
Wartości ilorazu wiarygodności (LR)
wspomagające hipotezę oskarżenia:
1 - 10 dowód słaby
10 - 100 średni umiarkowany
100 - 1000 umiarkowanie mocny
1000 - 10 000 mocny
10 000 - 100 000 bardzo mocny
wyjątkowo mocny > 1 milion
Skala obrazująca wartość dowodu

N=260 mln mieszkańców USA (System CODIS -
13 loci typu STR) – US FBI październik 1997
Jeżeli z dużą statystyczną precyzją określi się,
że ślad pochodzi od podejrzanego, to znaczy, że
naprawdę od niego pochodzi, a jeżeli inne
dowody przemawiają na korzyść podejrzanego,
należy znaleźć inne wytłumaczenie ustalonej
zgodności:
- naniesienie w innym czasie, niezależnym od
zdarzenia
- ślad mógł być celowo podrzucony
Konserwatywny sposób wypowiadania się co
do źródła pochodzenia śladu przez FBI
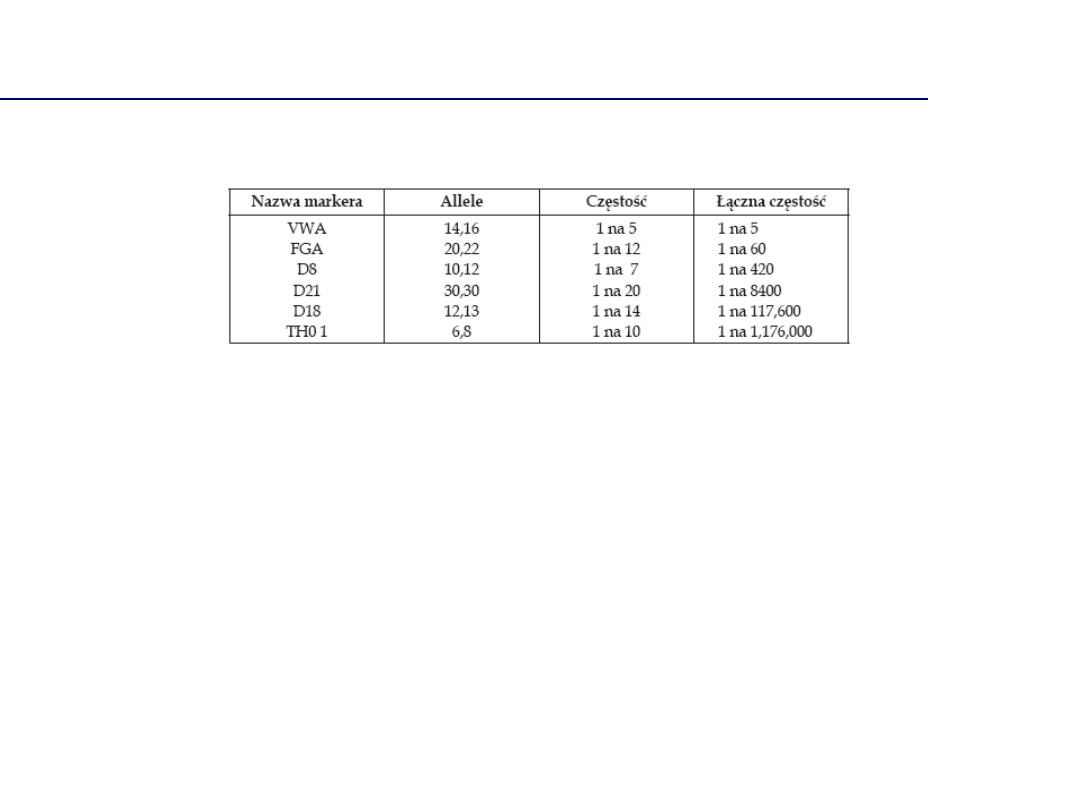
Problem częstości rzadkich alleli
Dla alleli bardzo rzadkich przyjmuje się wartość częstości = 5/2N
(zalecane przez NRC II)
Układ polimorficzny
Siostra NN?
NN
D3S1358
15, 18
15, 18
VWA
17, 18
17, 18
D16S539
12
12
D2S1338
16, 25
16, 25
Amelogenina
X
X, Y
D8S1179
10, 15
10, 15
D21S11
29, 30.2
29, 30.2
D18S51
16, 17
16, 17
D19S433
15, 16
13, 15
TH01
7, 9
7, 9.3
FGA
21, 22
21, 22

• Współczynnik pokrewieństwa F (Theta) – miara poziomu
pokrewieństwa pomiędzy dwiema osobami
• Prawdopodobieństwo, że dana osoba posiada kopię allela
przodka (identical by descent, ibd)
• Dla rodzica i dziecka oraz rodzeństwa F=1/4
• Dla wuja i siostrzenicy F=1/4
• Dla kuzynów pierwszej linii F=1/16
• Przy kojarzeniu w pokrewieństwie oczekiwana częstość
heterozygot jest zredukowana właśnie o współczynnik F
• Przy obliczaniu wartości dowodowej w sprawach dot. spornego
ojcostwa w pokrewieństwie należy zastosować odpowiednią
korektę
Problem pokrewieństwa podejrzanych

Związek z podejrzanym
Prawdopodobieństwo zgodności
Niespokrewniony
1 na miliard
Pierwszy kuzyn
1 na 100 milionów
Pół-rodzeństwo
1 na 10 milionów
Rodzic/dziecko
1 na 1 milion
Rodzeństwo
1 na 10 tysięcy
Problem pokrewieństwa podejrzanych

• Dochodzenie spornego ojcostwa (czy ten mężczyzna
jest biologicznym ojcem dziecka?)
• Dochodzenie spornego pokrewieństwa (czy ten
mężczyzna jest wujkiem dziecka?)
• NN –identyfikacja szczątków ludzkich (czy ten
fragment ludzkiego ciała pochodzi od zaginionego
krewnego?)
Analiza pokrewieństwa (podstawowa)

• Więcej niż jeden analizowany scenariusz
• Masowe groby, katastrofy
• Sprawy imigracyjne
• Jednocześnie można porównywać
pomiędzy sobą tylko dwie alternatywne
hipotezy.
• Zaawansowane programy komputerowe do
rozwiązywania tego rodzaju problemów,
np. DNA_VIEW.
Analiza pokrewieństwa (zaawansowana)
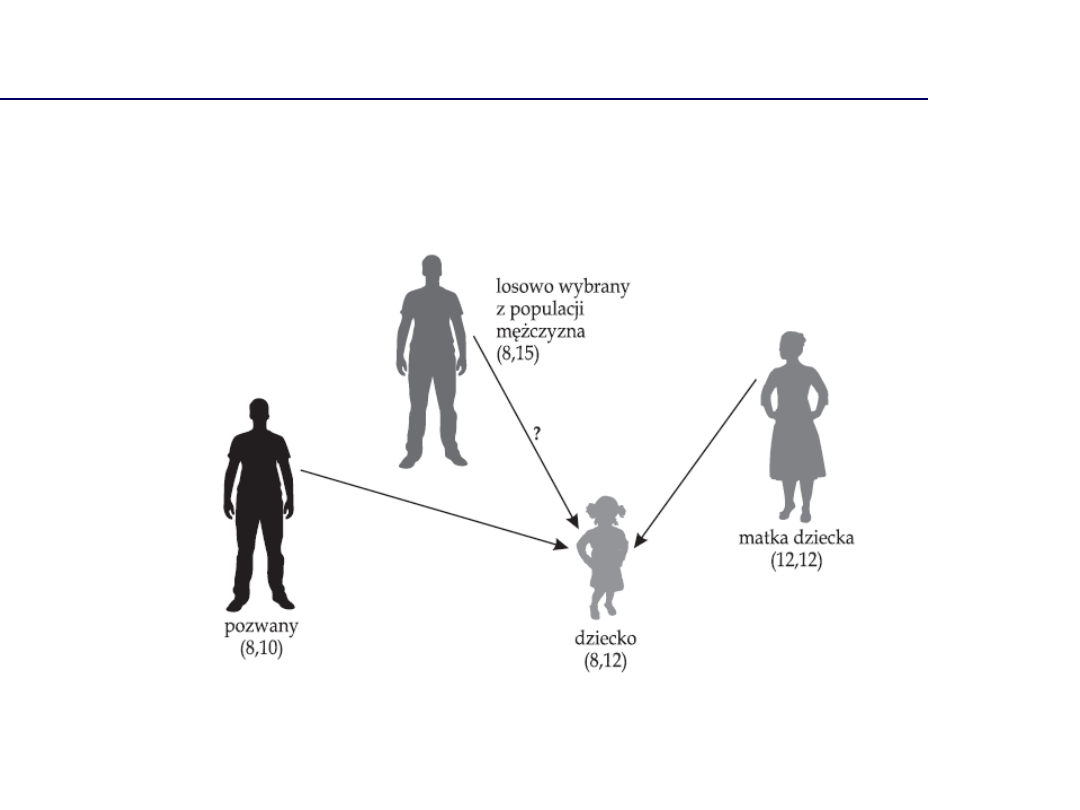
Dochodzenie spornego ojcostwa

Współczynnik ojcostwa
(paternity index, PI
= LR)
Iloraz wiarygodności: H
p
/H
d
H
p
= szansa, że to pozwany przekazał allel
H
d
= szansa, że inny przypadkowy mężczyzna przekazał
allel
H
p
= 1 jeśli ojciec jest homozygotą
H
p
= 0.5 jeśli ojciec jest heterozygotą
D3 :
Matka: 15, 17
Dziecko: 15
Ojciec: 15
15 to allel pochodzący od ojca, częstość = 0.2335
PI = 1/0.2335 = 4.28
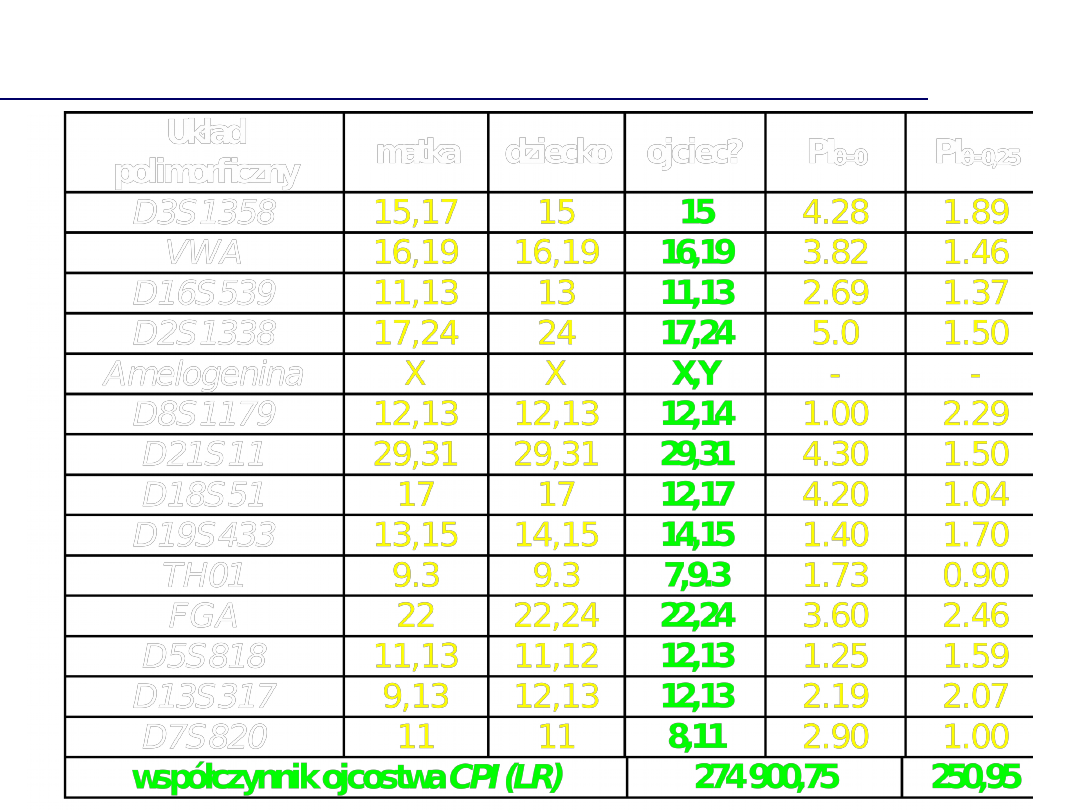
Łączny współczynnik ojcostwa
(combined
paternity index, CPI)

Współczynnik ojcostwa CPI = sumaryczna wartość LR
- Uzyskanie wyników analizy (brak wykluczenia
pozwanego)
jest
100
000
razy
bardziej
prawdopodobne, przy założeniu, że pozwany jest
biologicznym ojcem dziecka ...,
niż uzyskanie powyższych wyników analizy DNA, przy
założeniu, że biologicznym ojcem jest inny
niespokrewniony z nim mężczyzna, a pozwany nie
wyklucza się w wyniku działania przypadku.
Wynik w postaci współczynnika ojcostwa
(LR)

PI = L = 100 000
a priori
p = 0,5 wówczas
[W = L /(L + 1)]
prawdopodobieństwo ojcostwa (a
posteriori) W = 99,999%
Prawdopodobieństwo ojcostwa (W)
•Inny (bardziej przejrzysty dla sądu sposób wyrażenia
prawdopodobieństwa
•Prawdopodobieństwo ojcostwa
W = pL /(pL + 1-p)
• W = Wahrscheinlichkeit (prawdopodobieństwo)
• p = prawdopodobieństwo a priori
• L = PI

PI = L = 100 000
a priori
p = 0.2 wówczas
[W = pL /(pL + 1-p)]
prawdopodobieństwo ojcostwa (a
posteriori) W = 99,996%
Prawdopodobieństwo ojcostwa (W)
• Wiarygodny mężczyzna twierdzi, że oskarżenie kobiety
jest fałszywe
• Statystyka mówi, że np. w podobnych przypadkach tylko 1 raz
na 5 mężczyzna jest winny
• p zamiast 0,5 może zostać ustalone na 1/5 tj. 0.2
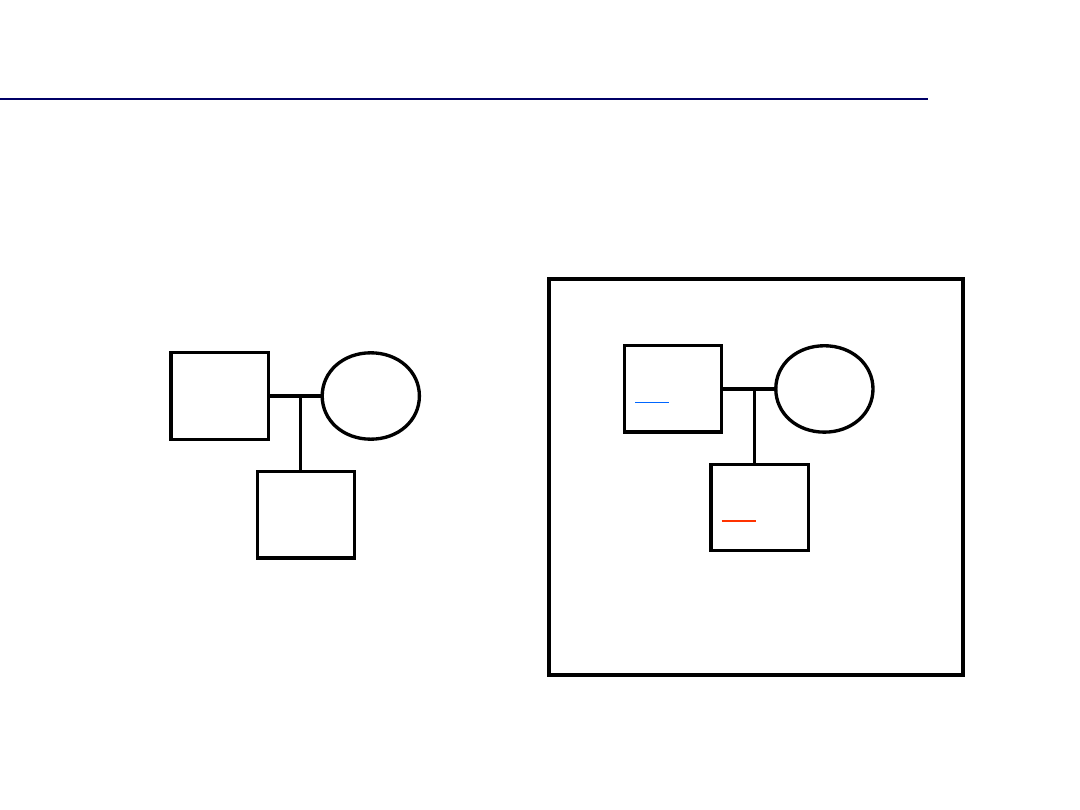
14,18
15,18
15,17
14
,18
13
,17
15,17
Typowa transmisja
alleli (brak mutacji)
Mutacja ojcowska
Problem mutacji w komórkach
płciowych
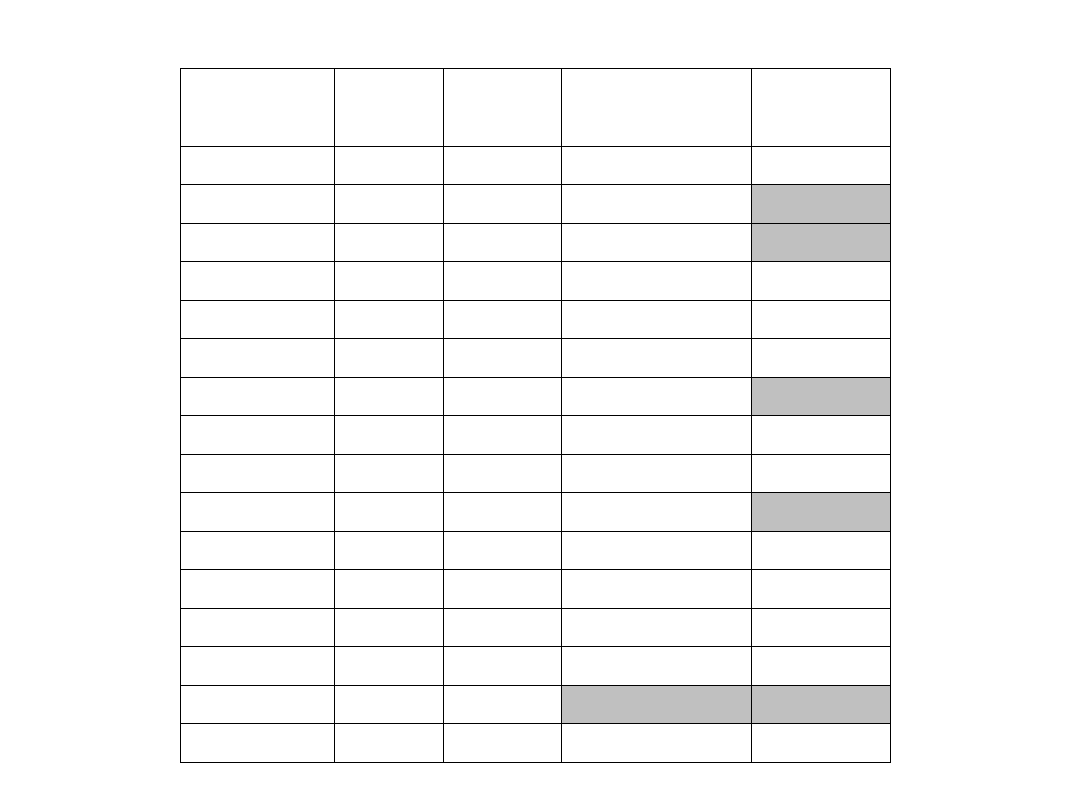
STR
G
M
G
C
G
AF
G
B
D8S1179
12,14
12,14
14,15
14,15
D21S11
29,30.2
30,30.2
29,30
29,30.2
D7S820
9,11
8,11
8,9
9,12
CSF1PO
10
10
10
10
D3S1358
15
15
15
15
TH01
9,9.3
9,9.3
7,9.3
7,9.3
D13S317
8
8,9
8,9
8,13
D16S539
8,12
8,12
8,12
8,12
D2S1338
20,25
17,20
17,20
17,20
D19S433
14,15
13,15
13,14
14,15
vWA
16,17
16,17
17
16,18
TPOX
8
8
8
8
D18S51
13,17
13,17
13,17
13,17
Amelogenin
X
X
X,Y
X,Y
D5S818
11,12
11,13
11,14
11,12
FGA
20
20,23
21,23
21,23
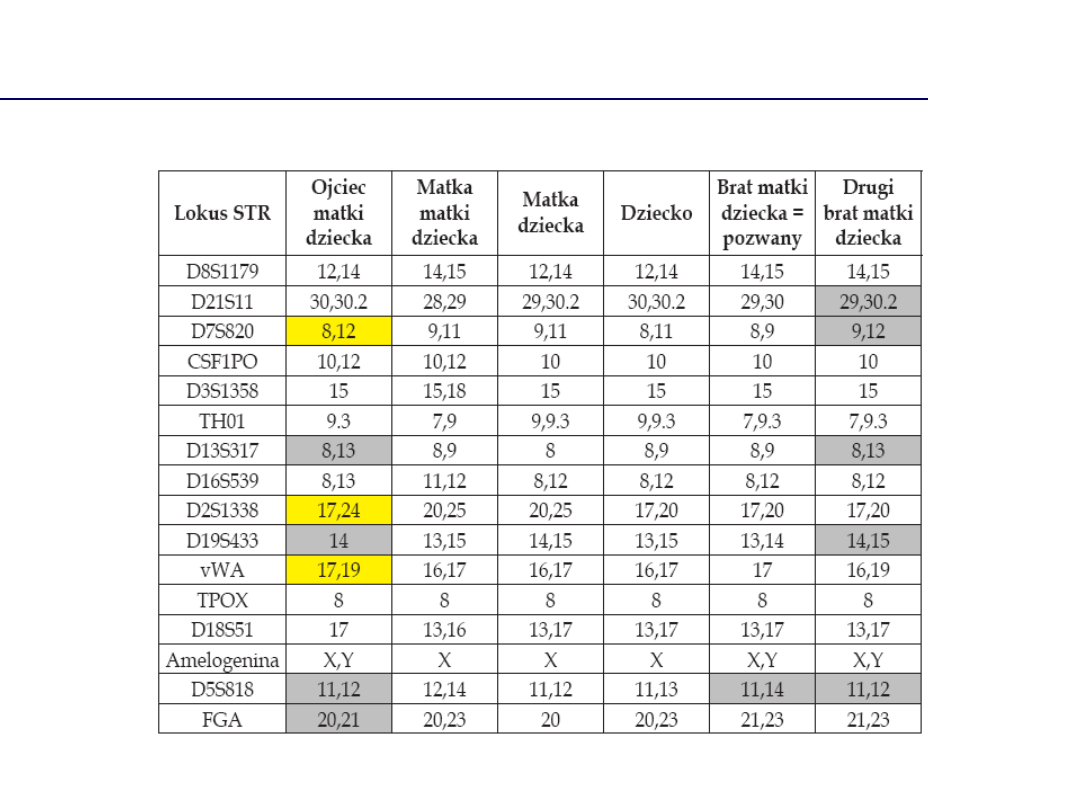
Sprawa dotycząca kazirodztwa
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
Wyszukiwarka
Podobne podstrony:
Zestaw doc opisowych do celów prawnych, Protokol badania KW
Zestaw doc opisowych do celów prawnych Protokol badania KW
Zestaw doc opisowych do celów prawnych, h Protokol badania KW , Wzór protokołu badania KW:
Zestaw doc opisowych do celów prawnych, Protokol badania KW
mapy do celow proj
BN 8931 03 1975 Drogi samochodowe Pobieranie probek gruntu do celów drogowych i lotniskowych
Zestaw doc opisowych do celów prawnych, protokol graniczny2
Zestaw doc opisowych do celów prawnych, protokol graniczny3
Badania lekarskie do pracy
METODY POBIERANIA PRÓBEK DO CELÓW URZĘDOWEJ KONTROLI
Zestaw doc opisowych do celów prawnych, wyrys
Zestaw doc opisowych do celów prawnych wypis
więcej podobnych podstron