
Komputerowe Systemy
Sterowania Produkcją
Aspekt akwizycji danych (Data
Acquisition)
i eksploatacji danych (Data Mining) dla
potrzeb analiz w branży motoryzacyjnej
TEMAT
:
Wykonawcy:
Adrian Nowicki
Dawid Hoppe
Klaudia Wasiela
Magdalena Jurgielewicz
Remigiusz Kujawiński

Agenda
1. Akwizycja danych
2. Data Mining
3. Data Mining w Produkcji
4. Analiza danych w produkcji
5. Eksploracyjna analiza danych

Agenda
1. Akwizycja danych
2. Data Mining
3. Data Mining w Produkcji
4. Analiza danych w produkcji
5. Eksploracyjna analiza danych
Aspekty akwizycji danych
Pochodzenie
systemów
pomiarowych
Gromadzenie
przez wielu
użytkowników
Stabilność
procedur
pomiarowych
oraz
przetwarzania
danych
Rejestrowanie
niejednorodnyc
h danych
Artykuł: Akwizycja i wstępne opracowanie danych niejednorodnych na potrzeby systemów data mining na przykładzie przemysłu odlewniczego, dr inż. R.
Sika, prof. dr hab. inż. Z.Ignaszak

Odlewnia jako złożony system
produkcyjny
Jakość
wyrobu
końcowego
Jakość
wyrobu
końcowego
• Dostęp do
procesu
• Znajomość
jego
konsekwencji
• Zakres analiz
i prognoz
• Wybrany przez
odlewnię
system
sterowania
jakością
• Dostęp do
procesu
• Znajomość
jego
konsekwencji
• Zakres analiz
i prognoz
• Wybrany przez
odlewnię
system
sterowania
jakością
Artykuł: Akwizycja i wstępne opracowanie danych niejednorodnych na potrzeby systemów data mining na przykładzie przemysłu odlewniczego, dr inż. R.
Sika, prof. dr hab. inż. Z.Ignaszak
Automatyczne
Kokila
Zmiana
temperatury
kokili
Rejestracja
przez sensor
wybranej
wartości
Przetworzenie
danych na
sygnał
elektryczny
Transmisja do
rejestratora
Źródło: Opracowanie własne
Obszary gromadzenia danych -
przykłady
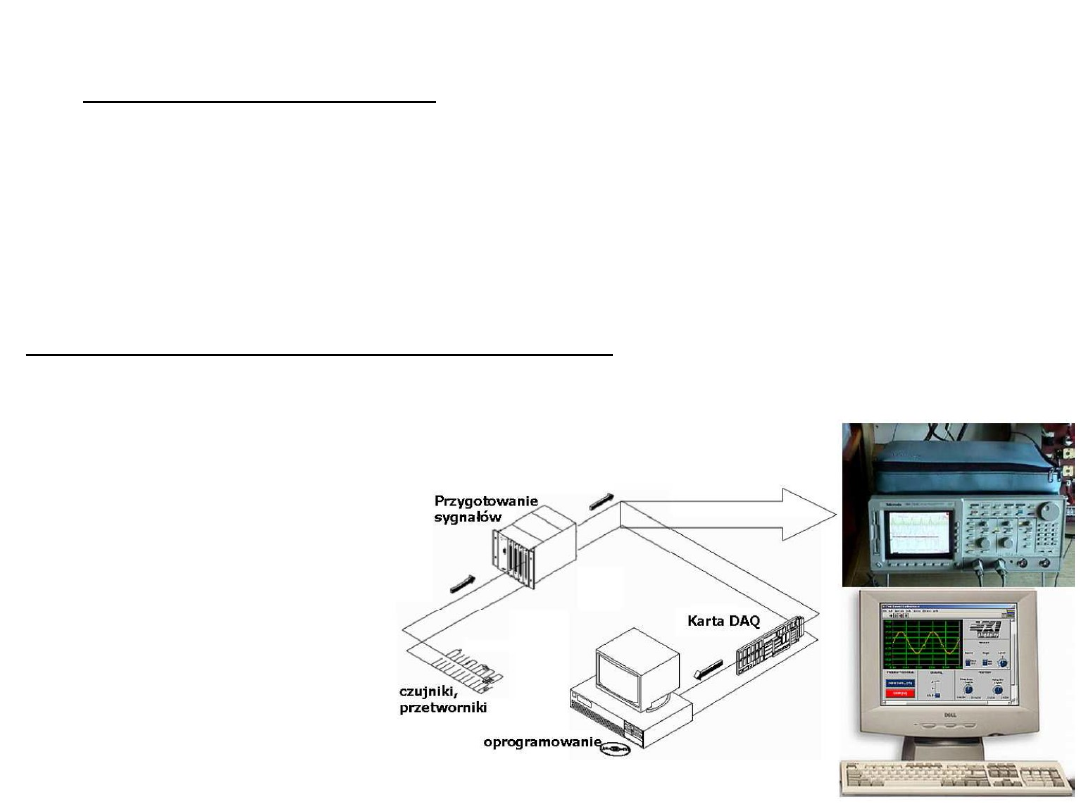
Akwizycja danych
Najbardziej uniwersalnym rozwiązaniem do akwizycji danych jest
komputer wyposażony w karty DAQ (DAQ – ang. Data Acquisition),
inaczej zwanymi kartami pomiarowymi lub zaawansowanymi
przetwornikami analogowo-cyfrowymi.
Typowe parametry opisujące karty DAQ to:
liczba wejść/wyjść analogowych,
maksymalna częstotliwość próbkowania/generowania,
zakres pomiarowy
rozdzielczość
Źródło: http://www.cim.pw.edu.pl/zoios_oceny/sensoryka/cw1-akwizycja.pdf

Źródło: http://www.cim.pw.edu.pl/zoios_oceny/sensoryka/cw1-akwizycja.pdf
Akwizycja danych (AD)
to proces polegający na
zbieraniu danych opisujących
świat rzeczywisty, a następnie
na przekształceniu tych
danych w postać numeryczną
możliwą do obróbki przez
komputer.
Systemy akwizycji danych
(DAQ – Data Acquisition
Systems) przekształcają
sygnały analogowe do postaci
cyfrowej, jako zbiór wartości
numerycznych.
Działanie systemów AD opiera się
na dwóch podstawowych
procesach:
dyskretyzacja sygnałów w
czasie (próbkowanie)
dyskretyzacja wartości
sygnałów (kwantowanie).
Akwizycja danych w zadaniach procesu
produkcyjnego
Symulacja
• Pre-processing
• Zmiany w odlewie w fazie
projektowania
Kontrola
• Kontrola procesów i sterowanie
• Zakłócenia w czasie
rzeczywistym
Identyfika
cja
• Nieprawidłowości w procesie
• Potencjalne zakłócenia
Artykuł: Akwizycja i wstępne opracowanie danych niejednorodnych na potrzeby systemów data mining na przykładzie przemysłu odlewniczego, dr inż. R.
Sika, prof. dr hab. inż. Z.Ignaszak

Agenda
1. Akwizycja danych
2. Data Mining
3. Data Mining w Produkcji
4. Analiza danych w produkcji
5. Eksploracyjna analiza danych
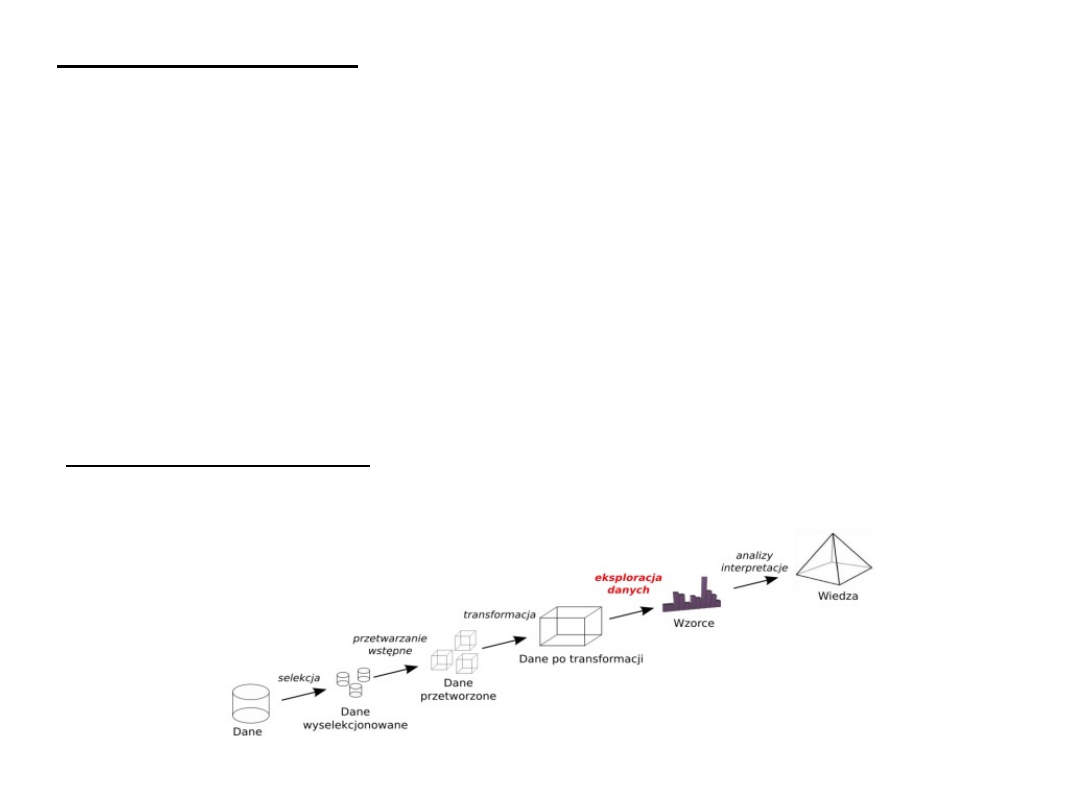
Pojęcie eksploracji danych jest potocznie rozumiana jako
odkrywanie wiedzy w bazach danych. Integruje ono kilka dziedzin
takich jak:
Statystyka,
Systemy baz danych,
Sztuczna inteligencja,
Maszynowe uczenie się,
Optymalizacja.
Cel eksploracji danych: wykorzystanie właściwego algorytmu dla
znajdowania zależności
i schematów w przygotowanym zbiorze danych, a następnie ich
reprezentacja w postaci formalnej, zrozumiałej dla użytkownika.
http://www.obserwatoriumit.pl/site/assets/files/1059/eksploracja_danych.pdf
Data Mining
Fazy odkrywania wiedzy

Popularne w tej dziedzinie eksploracji danych określenie "garbage
in, garbage out" oznacza że model zbudowany w oparciu o słabej
jakości dane będzie również mało efektywny.
Odkrywane w procesie eksploracji danych wzorce przedstawiane są
w postaci:
wizualizacji na wykresach,
metod statystycznych,
sieci neuronowych,
drzew decyzyjnych,
metod uczenia maszynowego,
logiki rozmytej,
zbiorów przybliżonych.
Data Mining
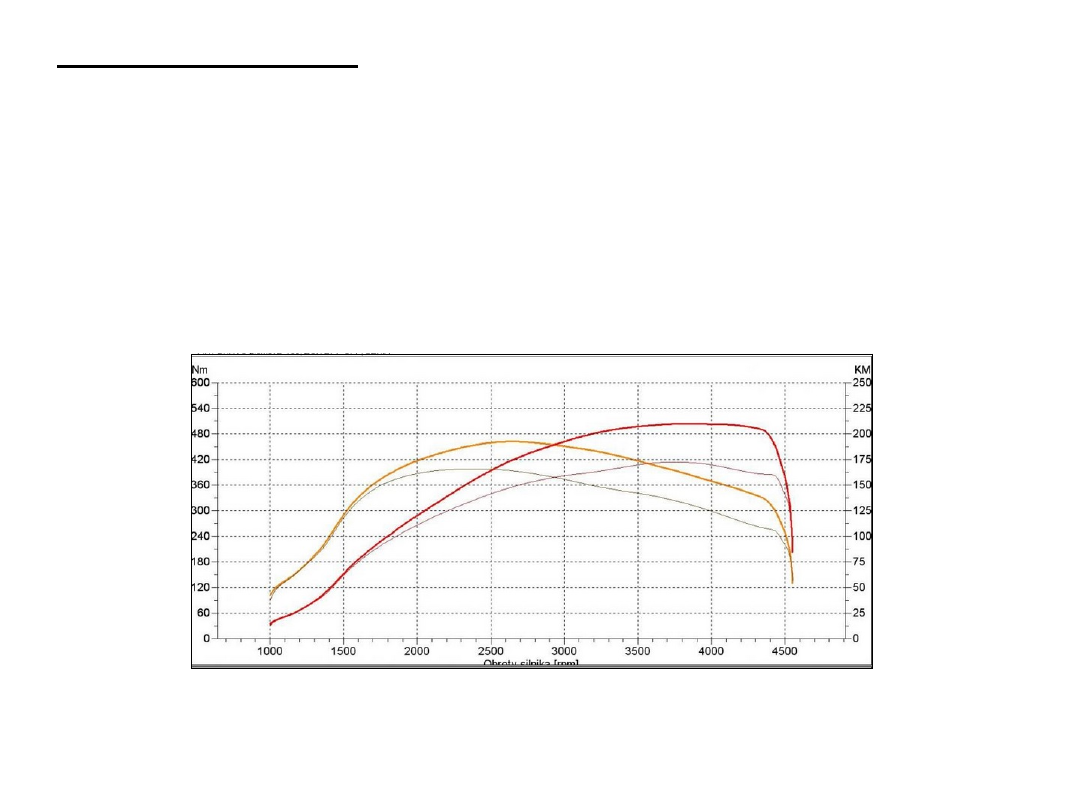
wizualizacje na wykresach - dzięki wizualizacji możemy łączyć
wielkie zbiory danych i pokazać wszystkie dane jednocześnie.
Wizualizacje ułatwiają dostrzeżenie pewnych własności, których przy zwykłej
analizie człowiek nie jest w stanie dostrzec.
Dzięki wizualizacji danych zdecydowanie łatwiej podjąć trafną decyzję.
http://www.forum.alfaholicy.org/tuning_mechaniczny/25421-wykresy_z_hamownii_naszych_alf-
12.html
Data Mining
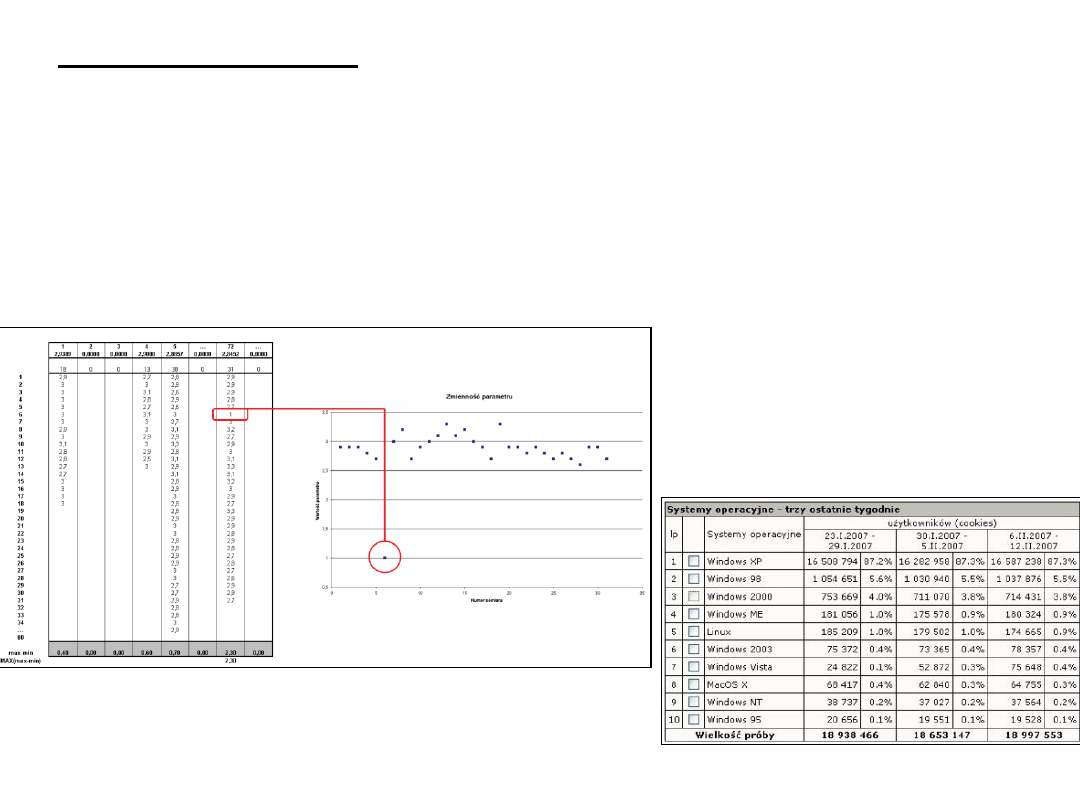
metody statystyczne – są podstawą do eksploracji danych
(występują metody opisowe oraz metody graficzne).
Oparte są na silnych podstawach teoretycznych i mocnych założeniach co do
danych.
Metody statystyczne są ukierunkowane na testowanie hipotez oraz szacowanie
nieznanych wartości parametrów.
Źródło: 1. Artykuł: Akwizycja i wstępne opracowanie danych niejednorodnych na potrzeby systemów data mining na przykładzie przemysłu odlewniczego,
dr inż. R. Sika, prof. dr hab. inż. Z.Ignaszak 2. www.ranking.pl
Data Mining
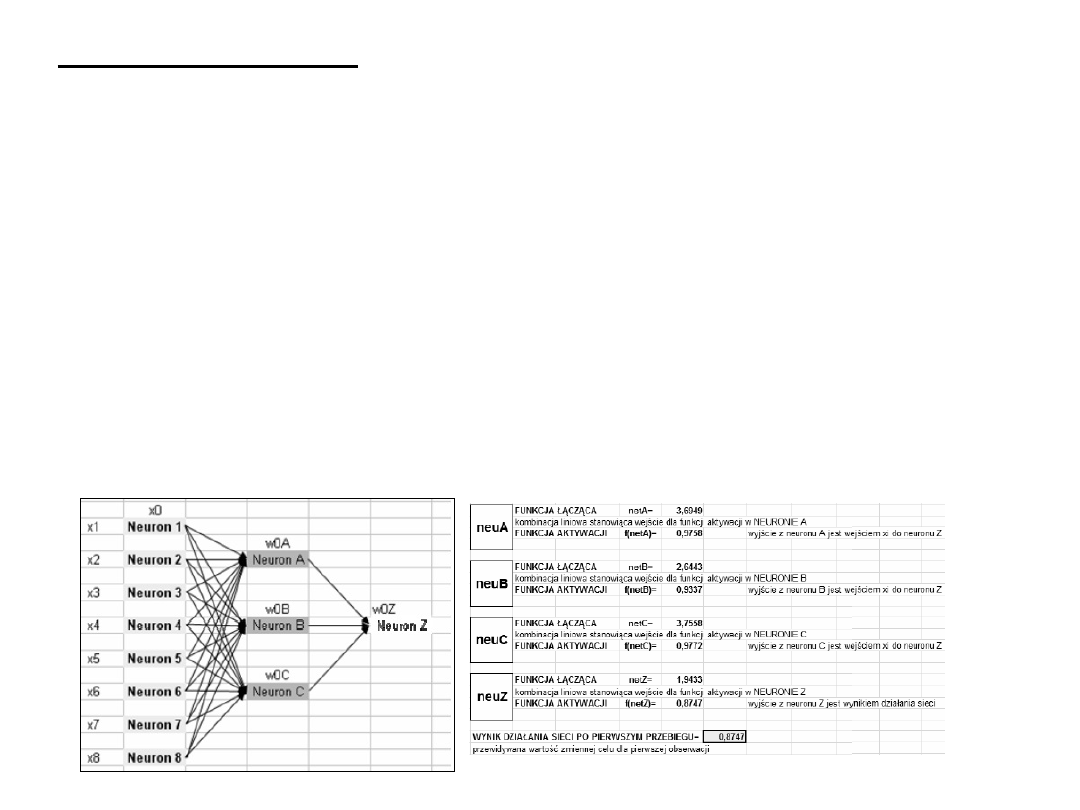
sieci neuronowe – należą do kategorii układów uczących się. Powszechnie
stosowane instrumenty statystyczne i narzędzia do przetwarzania sygnałów.
Stanowią techniki analityczne tworzone na wzór procesu uczenia w systemie
poznawczym
i
funkcji
neurologicznych
mózgu
i zdolne do przewidywania nowych obserwacji (określonych zmiennych) na
podstawie innych obserwacji (dokonanych na tych samych lub innych
zmiennych) po przeprowadzeniu procesu tzw. uczenia w oparciu o istniejące
dane.
Zastosowanie:
sterowanie procesami (np. monitorowanie urządzeń produkcyjnych
i regulowanie na bieżąco parametrów procesu),
sterowanie pracą silnika (określanie zużycia paliwa na podstawie
wskazań czujników oraz przeprowadzanie regulacji - jest to forma
sterowania procesem),
Data Mining
Artykuł: Data acquisition in modeling using neural networks and decision trees, dr inż. R. Sika, prof. dr hab. inż. Z.Ignaszak
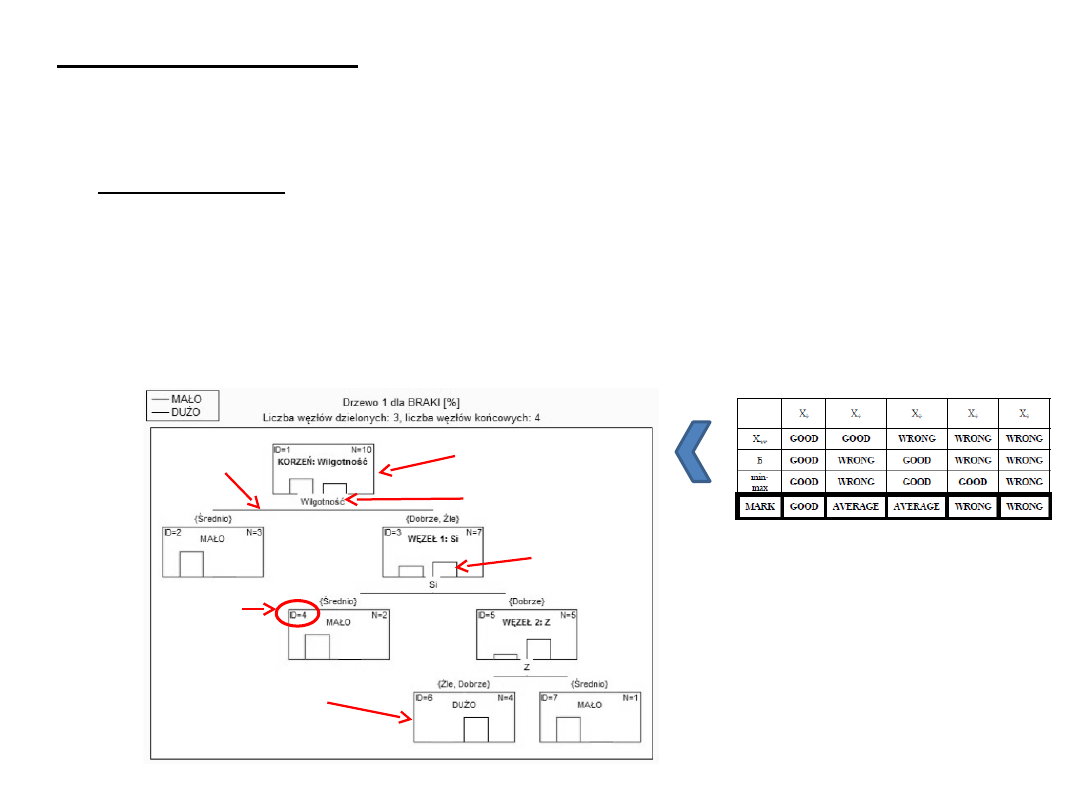
Data Mining
Drzewa decyzyjne - graficzny sposób wspierania procesu decyzyjnego.
Zastosowanie: wszędzie tam gdzie mamy problemy decyzyjne z wieloma
rozgałęziającymi się wariantami oraz kiedy podejmujemy decyzję
w warunkach ryzyka.
Drzewo decyzyjne reprezentuje pewien proces podziału zbioru obiektów
na jednorodne klasy. Punktem wyjścia jest zbiór zawierający wszystkie
analizowane obiekty; w trakcie analizy jest dzielony na określoną liczbę
podzbiorów. W kolejnych krokach każdy z podzbiorów podlega dalszemu
podziałowi. Na końcu analizy każdy obiekt stanowi oddzielną klasę.
Drzewa decyzyjne charakteryzują się strukturą hierarchiczną.
Artykuł: Data acquisition in modeling using neural networks and decision trees, dr inż. R. Sika, prof. dr hab. inż. Z.Ignaszak
Węzeł
decyzyjny/dzielony
Kryterium
podziału
Węzeł końcowy
Histogram
przypadków
Nr węzła
Nowy
węzeł
Algorytm CART (ang.
Classification And Regression
Tree)

metody uczenia maszynowego (ang. Machine Learning) –
jedna z najważniejszych poddziedzin sztucznej inteligencji.
Następuje użycie danych tworząc model pozwalający na przewidywanie
zachowania dla przyszłych danych, czasami wyrażając swoją wiedzę w
symbolicznej postaci.
Następuje analiza procesów uczenia się oraz tworzenie systemów, które
doskonalą swoje działanie na podstawie doświadczeń z przeszłości. Adaptacja do
rzeczywistego i zmiennego środowiska → np. robotów.
Często dane są w postaci przykładów.
Czasami jest jedyną drogą budowy modeli, jeśli wiedza nie
jest znana lub nie można jej pozyskać.
Przykłady:
Sterowanie pojazdem (ALVINN)
Automatyzacja systemów produkcji i wydobycia
(przemysł, górnictwo)
Źródło: http://www.tuexperto.com/wp-
content/uploads/2009/10/toyota_phexpo05_band_500x3521.jpg
Data Mining
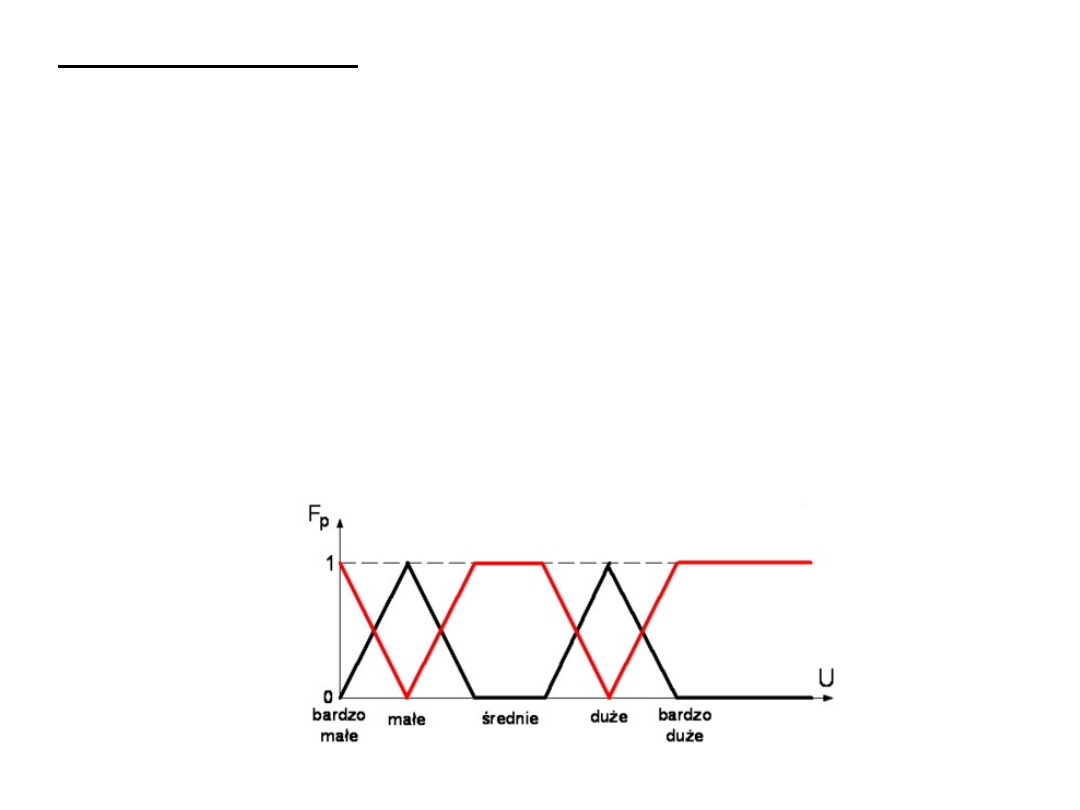
logika rozmyta (ang. Fuzzy logic) – służy do obrazowania
informacji nieprecyzyjnych, nieokreślonych bądź niekonkretnych.
Znajduje zastosowanie wszędzie tam, gdzie nie posiadamy
wystarczającej wiedzy o modelu matematycznym rządzącym
danym zjawiskiem oraz tam gdzie odtworzenie tego modelu staje
się nieopłacalne lub nawet niemożliwe.
zastosowanie: w elektronicznych systemach sterowania
pojazdami,
maszynami
i automatami.
w logice rozmytej występują stany 0 (fałsz), stan 1 (prawda) oraz
szereg wartości pomiędzy tymi stanami. Dzięki temu możliwe jest
opisywanie takich cech obiektów jak: bardzo, trochę, średnio,
mało, nie za wiele.
http://wazniak.mimuw.edu.pl/index.php?title=Grafika:UETP_M8_Slajd33.png
Data Mining
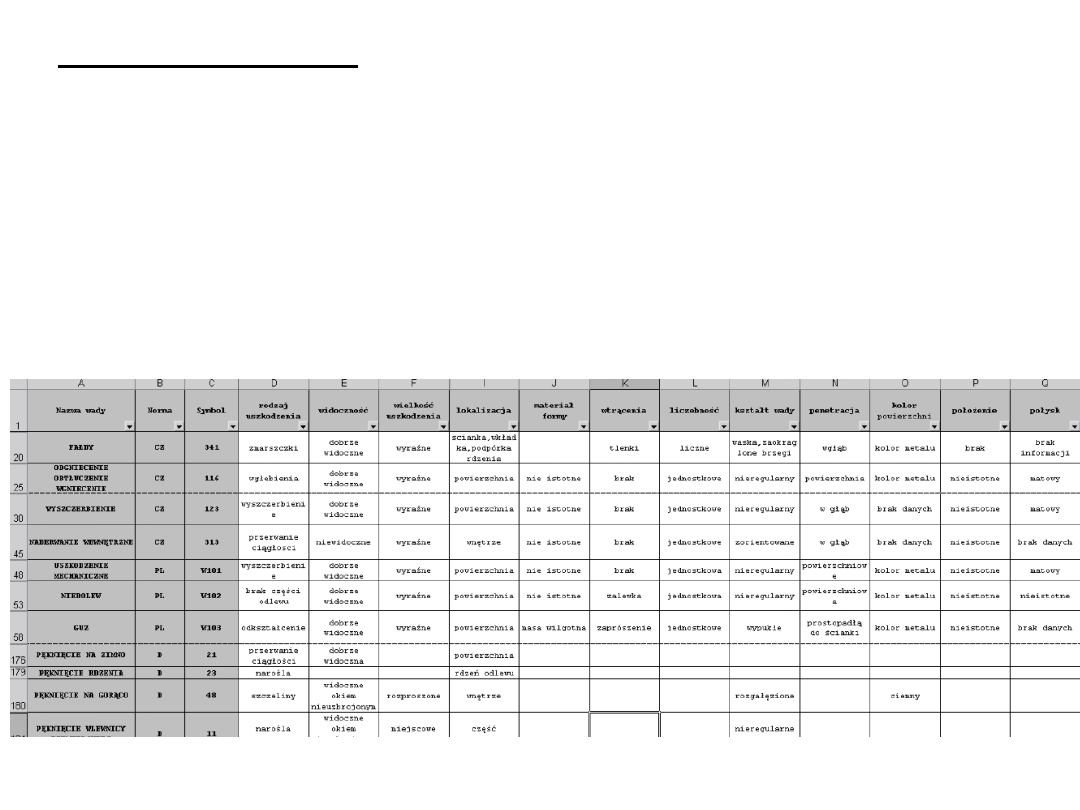
zbiory przybliżone (ang. rough set) – są matematyczną
metodą zajmującą się modelowaniem niepewności.
Definiowane są za pomocą dolnego i górnego przybliżenia
zbioru. Wynikiem analizy danych za pomocą teorii zbiorów
przybliżonych jest zbiór reguł decyzyjnych, które stanowią zwartą
reprezentację wiedzy łatwą do interpretacji.
Przykład zastosowania zbiorów przybliżonych dla diagnostyki wad
odlewów w systemie RoughCast
Źródło: http://winntbg.bg.agh.edu.pl/rozprawy2/10290/full10290.pdf
Data Mining
Fragm. tabeli decyzyjnej dla
staliwa
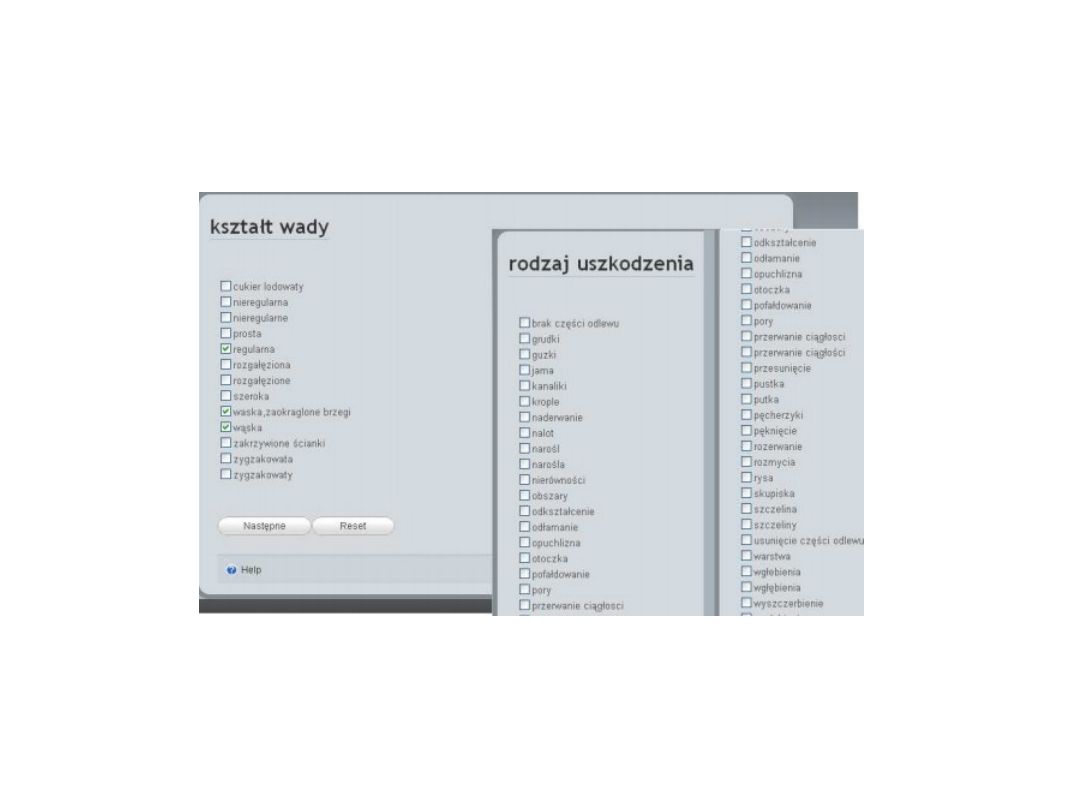
Zbiory przybliżone
Dialog z użytkownikiem rozpoczyna się od formularza zawierającego
poszczególne dopuszczalne wartości dla pierwszego atrybutu
warunkowego z tabeli decyzyjnej.
Użytkownik zatwierdza wybrane atrybuty, dzięki czemu system ma
możliwość obliczenia górnego i dolnego przybliżenia dla
utworzonego w ten sposób zapytania.
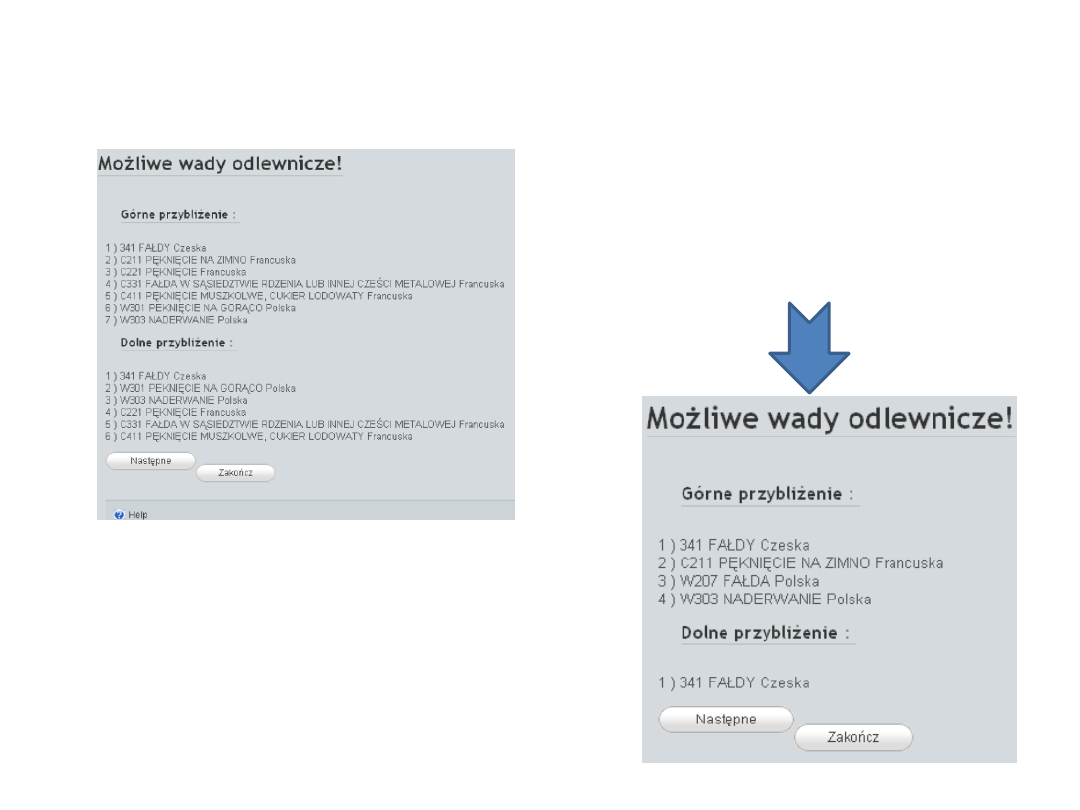
Zbiory przybliżone
Obliczone przybliżenia górne i dolne w pojedynczym kroku wnioskowania
są prezentowane użytkownikowi.
Taki dialog prowadzony jest do momentu
wyczerpania
pytań
(atrybutów
warunkowych), lub do chwili w której
użytkownik zakończy dialog, gdyż wynik
przybliżeń jest już satysfakcjonujący.
Wynik końcowy
zawierający poszukiwaną
wadę

Agenda
1. Akwizycja danych
2. Data Mining
3. Data Mining w Produkcji
4. Analiza danych w produkcji
5. Eksploracyjna analiza danych
Data mining w Produkcji
ZADANIE: odkrywanie regularności i związków występujących w
danych,
które początkowo są nie znane.
CEL: Uzyskanie wyników użytecznych dla właściciela danych.
Data mining jest to proces:
selekcji
eksploracji
modelowania dużych ilości danych
Źródło: Z.Ignaszak, R.Sika; Akwizycja I wstępne opracowanie danych niejednorodnych na potrzeby na
przykładzie przemysłu odlewniczego systemów data mining; vol.29 nr 1; 2009

Data mining w Produkcji
Baza danych- pojęcie to na świecie znane jest już od roku
1963, w którym to odbyło się sympozjum pod nazwą:
„Development and Management of a Computer-centered Data
Base”, dotyczące wykorzystania komputera do pomocy w
zarządzaniu personelem.
W roku 1970 brytyjski informatyk Edgar Frank Codd
zaproponował model relacyjny, czyli grupowanie danych w
relacje. Na tym modelu oparta jest relacyjna baza danych,
która wykorzystywana jest do zapisu i odczytu danych do
chwili obecnej.
Baza danych (database) – magazyn danych – informacji
powiązanych tematycznie, umożliwiający ich wyszukiwanie
według zadanych kryteriów
Źródło: Z.Ignaszak, R.Sika; Akwizycja I wstępne opracowanie danych niejednorodnych na potrzeby na
przykładzie przemysłu odlewniczego systemów data mining; vol.29 nr 1; 2009
Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych obejmujące
parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.

Data mining w Produkcji
Zintegrowane informatyczne systemy zarządzania klasy ERP
(Enterprise Resource Planning) są podstawą rozwiązań
informatycznych, które wspomagają zarządzanie
przedsiębiorstwem.
Dobre praktyki, czyli sprawdzone oraz najbardziej skuteczne
metody rozwiązania problemów, opracowane przez firmę są
głównym warunkiem do odniesienia sukcesu podczas
wdrożenia systemu ERP, które odnoszą się w tym przypadku do
ludzi, procesów biznesowych oraz technologii.
System ERP
Źródło: Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych
obejmujące parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.

Data mining w Produkcji
Źródło: Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych
obejmujące parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.
Programy ERP znajdują zastosowanie przy wspomaganiu
zarządzania przedsiębiorstwem lub grupą przedsiębiorstw,
które ze sobą współdziałają.
Aplikacje w tych systemach są odpowiedzialne za:
gromadzenie i przetwarzanie danych,
większość z nich cechuje się budową modułową, informacje są
wymieniane także między danymi modułami.
Każdy system ERP występujący na rynku może być
wyposażony w inne moduły.
Firma decydująca się na wprowadzenie systemu ERP sama
wybiera z jakich modułów ma się składać.
Nabycie systemu oraz jego wdrożenie jest zabiegiem
kosztownym w firmie, dlatego ważne jest dobre zaplanowanie
z czego dany system ma się składać.
Dlaczego ERP?
Data mining w Produkcji
Źródło: Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych
obejmujące parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.
Klasyfikacja systemu klasy ERP
SYSTE
M ERP
SYSTE
M ERP
Planowani
e
produkcji
Planowani
e
produkcji
Gospodar
ka
materiało
wa
Gospodar
ka
materiało
wa
Zarządza
nie
jakością
Zarządza
nie
jakością
Sprzedaż
i
dystrybucj
a
Sprzedaż
i
dystrybucj
a
Finanse
i
Controling
Finanse
i
Controling
Zarządza
nie
projektam
i
Zarządza
nie
projektam
i
Kadry
Kadry
Zarządza
nie
zasobami
ludzkimi
Zarządza
nie
zasobami
ludzkimi
Magazy-
nowanie
Magazy-
nowanie
Kontakt z
klientami
Kontakt z
klientami

Data mining w Produkcji
Źródło: Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych
obejmujące parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.
Korzyści wynikające z wdrożenia systemu ERP
uproszczenie procesów decyzyjnych,
gromadzenie danych w bazie,
prosta wymiana danych pomiędzy poszczególnymi
działami przedsiębiorstwa,
szybki przekaz informacji,
automatyczne wprowadzanie danych,
monitorowanie i nadzór stanów zapasów,
ograniczenie przestojów linii produkcyjnych,
poprawa planowania produkcji,
poprawa nadzorowania produkcji,
integracja z systemami CAD/CAM,
Modułowość systemu umożliwia kilkuetapowe wdrażanie
oprogramowania do firmy. System z rozwojem firmy można
poszerzyć o kolejne moduły
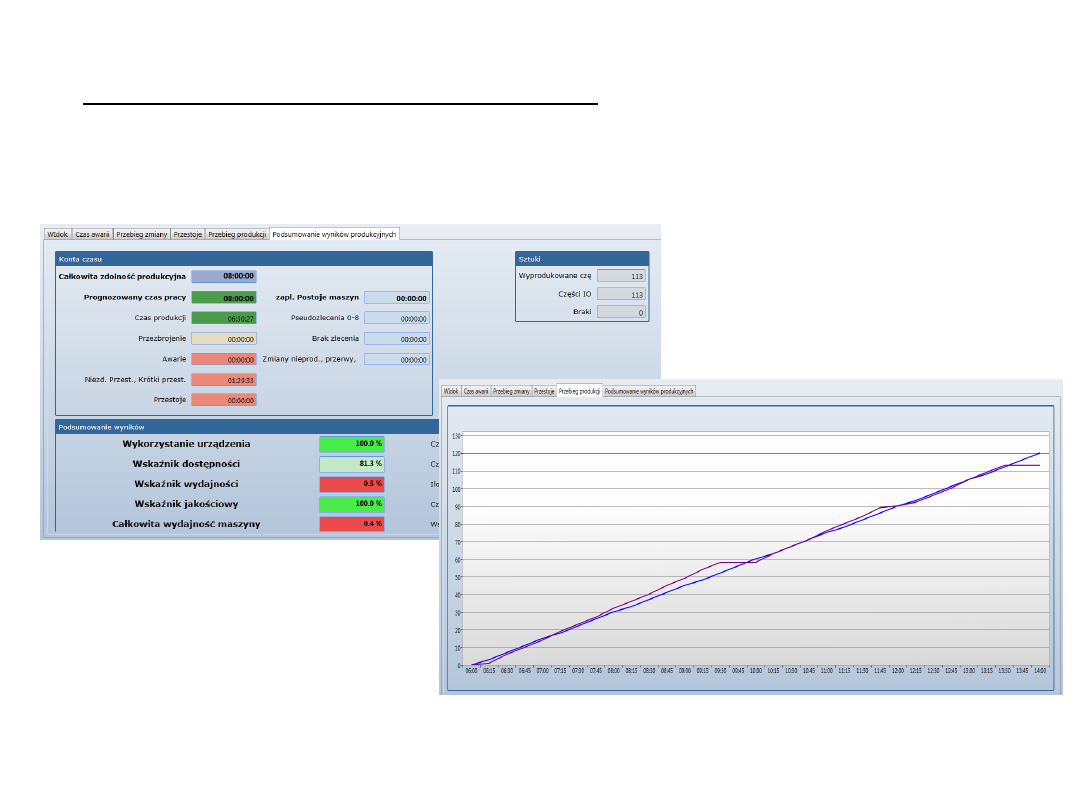
Data mining w Produkcji
Przykład:
Źródło: System FSK (Fertigungs steuerung komponente)

Agenda
1. Akwizycja danych
2. Data Mining
3. Data Mining w Produkcji
4. Analiza danych w produkcji
5. Eksploracyjna analiza danych

Analiza danych w produkcji
Skąd pobierać dane do analizy?

Analiza danych w produkcji
Źródło: ] Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych obejmujące
parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.

Analiza danych w produkcji
Źródło: ] Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych obejmujące
parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.
Rejestrator przemysłowy
Czytnik
Drukarka

Analiza danych w produkcji
Źródło:Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych
obejmujące parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.
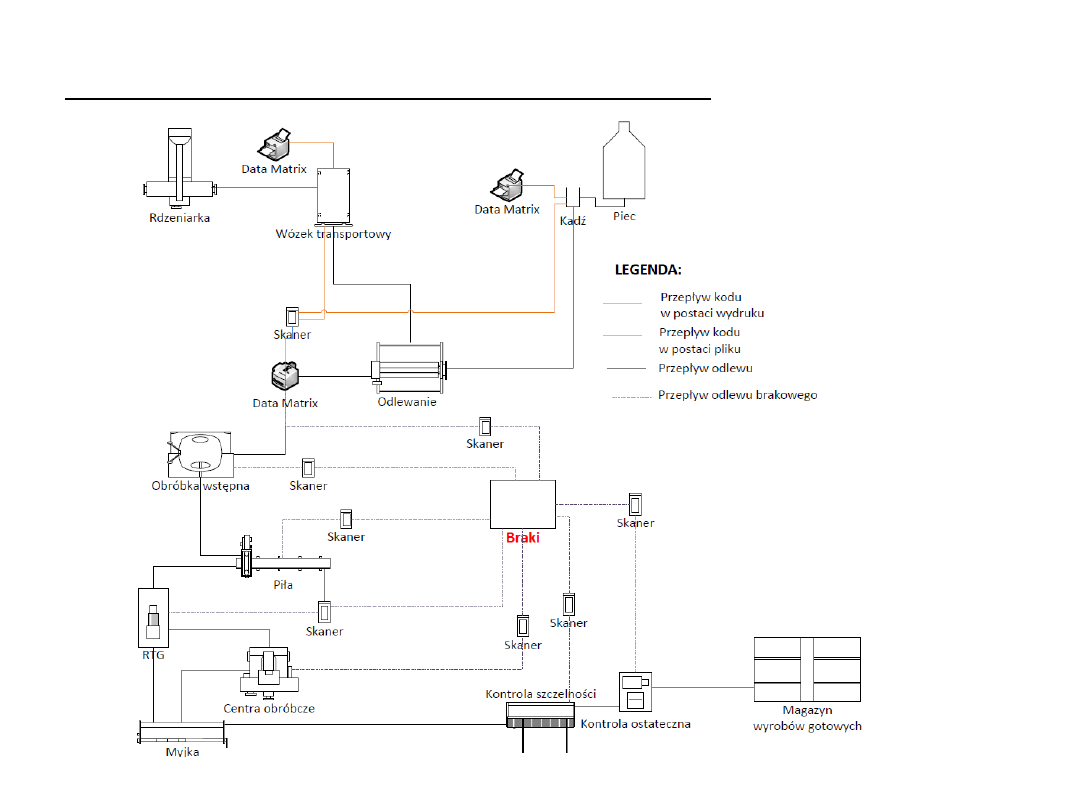
Analiza danych w produkcji
Źródło: Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych
obejmujące parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.
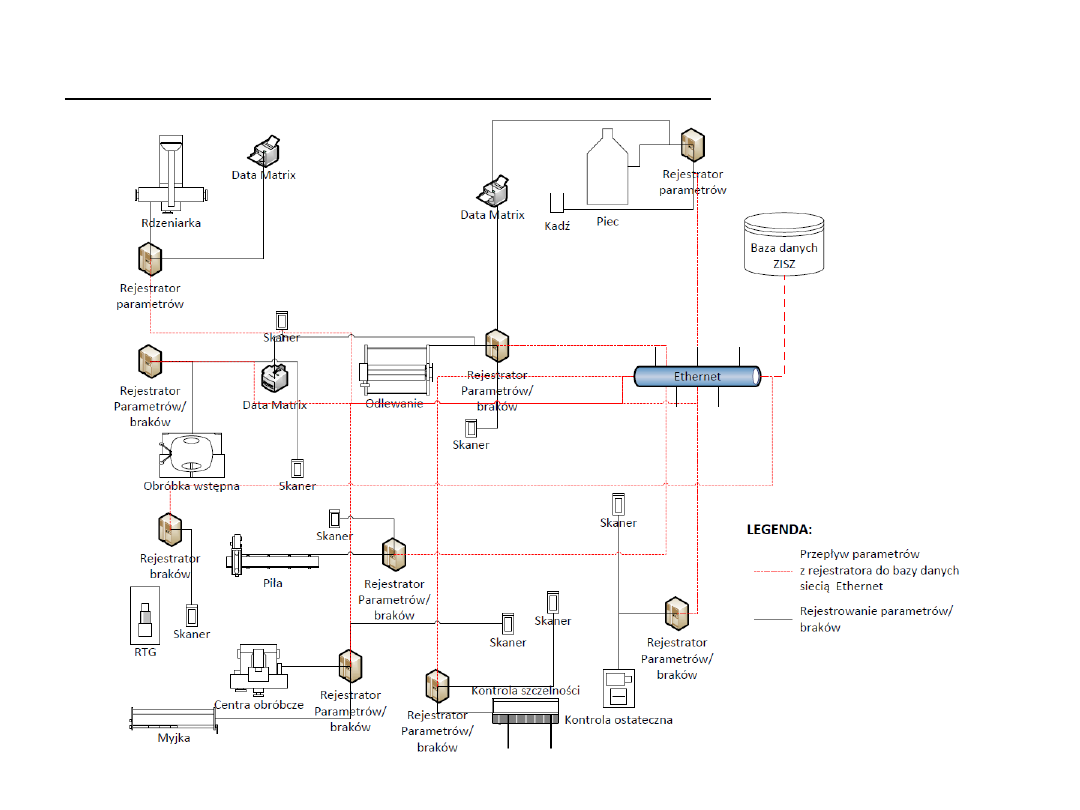
Analiza danych w produkcji
Źródło:Praca dyplomowa: A.Nowicki, Praktyczne aspekty akwizycji i przykłady kreowania baz danych
obejmujące parametry produkcji odlewów ze stopów Al-Si-X. Poznań 2014.

Agenda
1. Akwizycja danych
2. Eksploracja danych
3. Data Mining w Produkcji
4. Analiza danych w produkcji
5. Eksploracyjna analiza danych

Eksploracyjna analiza danych
EDA - Exploratory Data Analysis
Eksploracyjna analiza danych jest podejściem (filozofią) do analizy
danych,
w której stosowane są różnorodne techniki, głównie graficzne.
Ich celem jest zrozumienie i wizualizacja zbioru danych w celu
postawienia hipotez dotyczących zależności obecnych w tych
danych.
Źródło: www.cs.put.poznan.pl

Techniki EDA
Techniki stosowane w EDA są zazwyczaj dość proste i
zawierają różnorodne techniki:
• tworzenia wykresów danych źródłowych;
• tworzenia wykresów statystyk np. wykres średniej, wykres
odchylenia standardowego, wykres pudełkowy.
Źródło: www.cs.put.poznan.pl
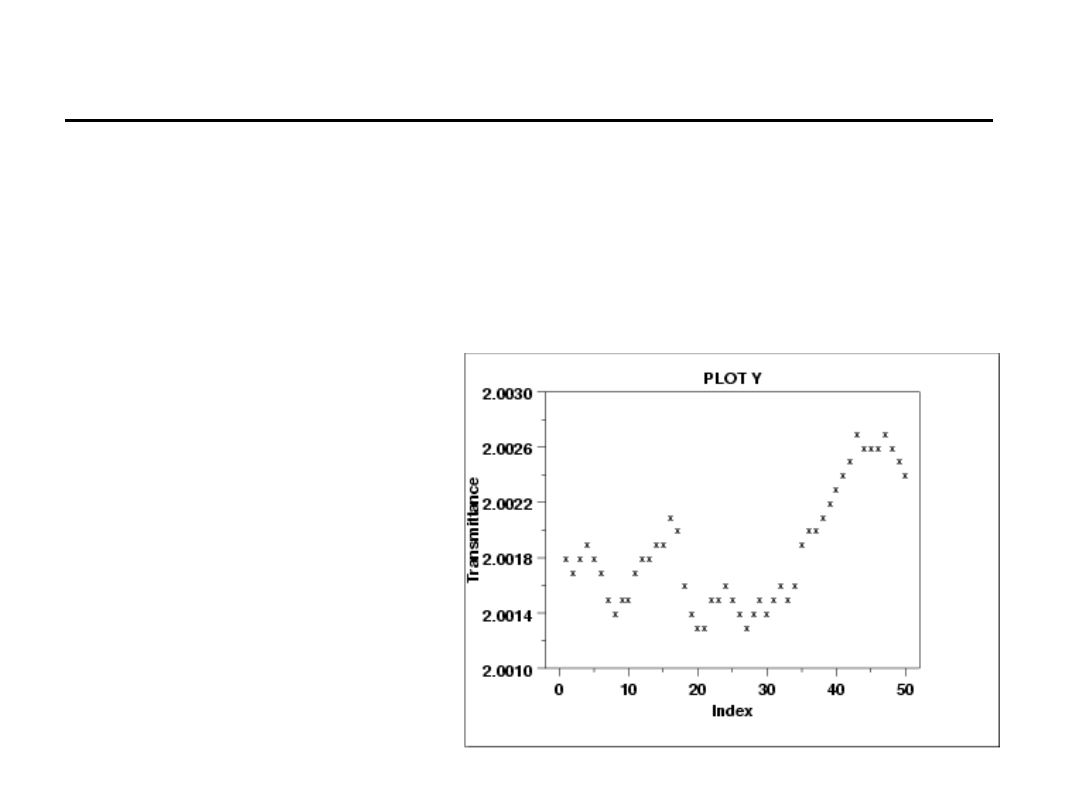
Wykres przebiegu (Run-Sequence Plot)
Jest prostym sposobem przedstawienia zbioru danych o jednej
zmiennej. Dzięki zastosowaniu tego wykresu możemy
ewidencjonować zmiany wartości zmiennych. Wykres przebiegu
pozwala w łatwy sposób wykryć odchylenia.
Źródło: www.itl.nist.gov
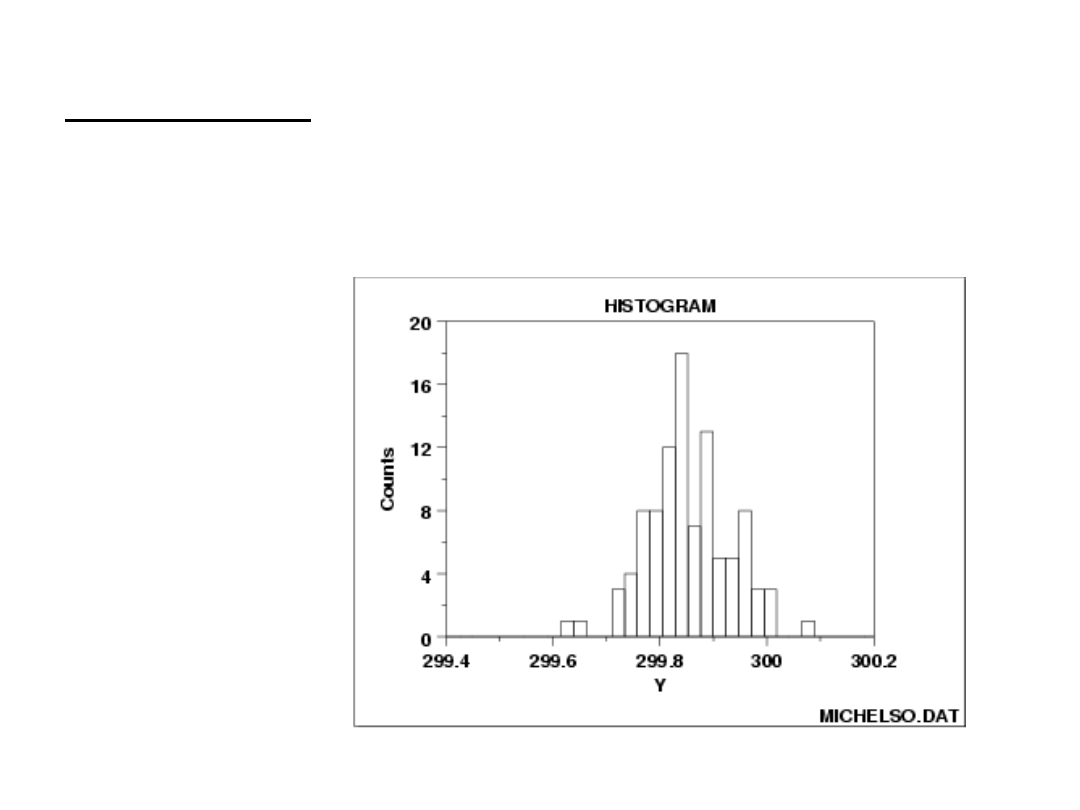
Histogram
Histogram ma na celu graficzne przedstawienie rozkładu
danych ze zbioru.
Źródło: www.itl.nist.gov
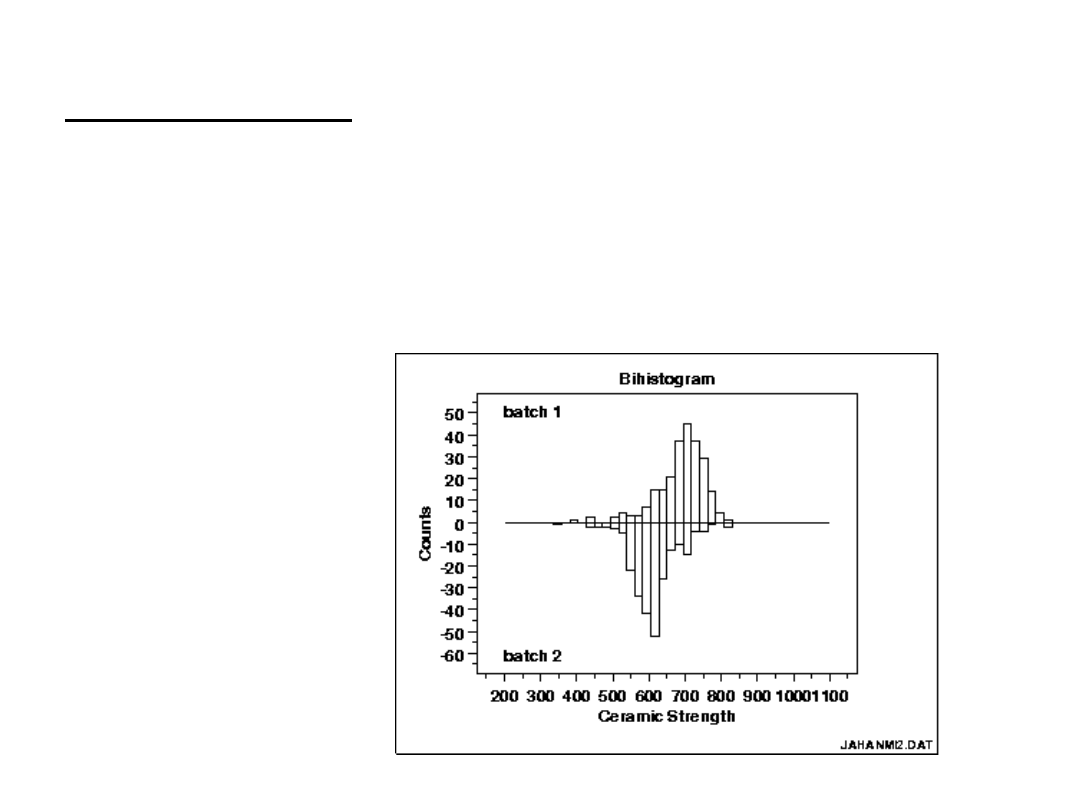
Bihistogram
Bihistogram jest zbudowany z dwóch histogramów, pozwala
on np. na przedstawienie na jednym wykresie rozkładów
wartości danych ze zbioru przed modyfikacjami i po
modyfikacjach. Dzięki temu możliwe jest dokonanie analizy
dotyczącej zmian rozkładu zmiennej.
Źródło: www.itl.nist.gov
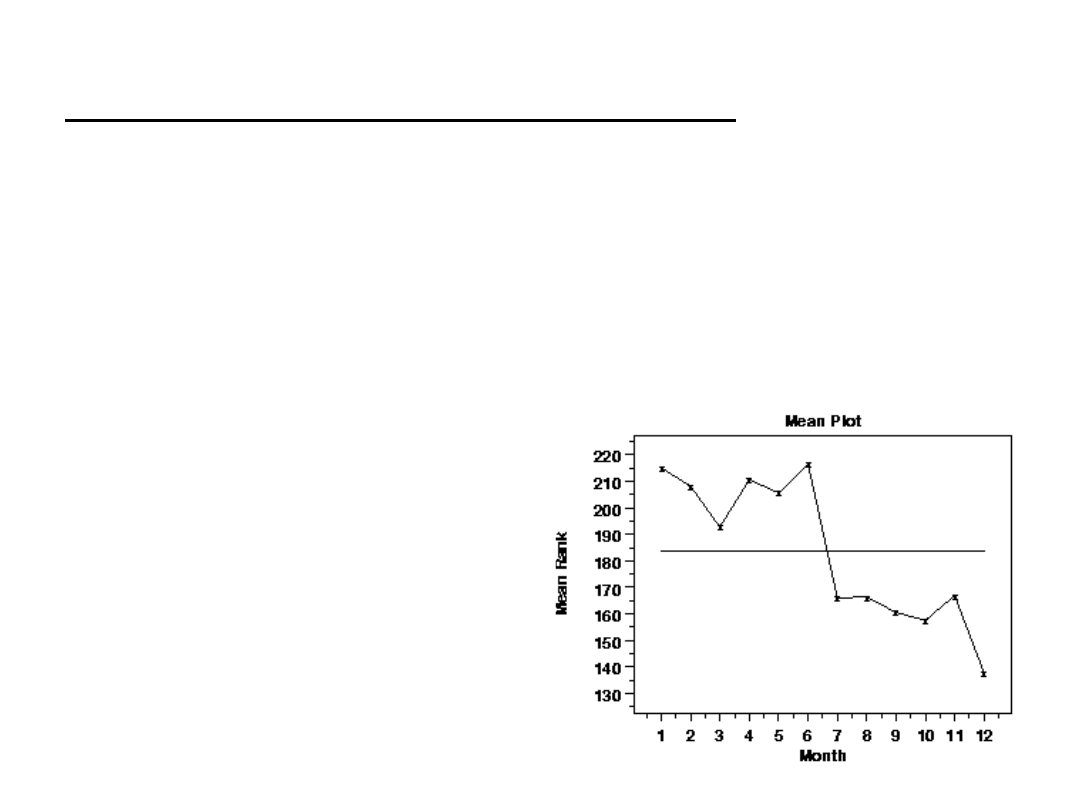
Wykres średniej (Mean Plot)
Wykres
średniej
może
być
wykorzystany
dla
niepogrupowanych danych, aby określić jak wartość średniej
zmienia się w czasie. Wykres ten pozwala na zobrazowanie
różnic pomiędzy różnymi grupami danych.
Wykres średniej jest najczęściej wykorzystywanym, pozwala
on odpowiedzieć na pytania:
• Czy są zmiany w położeniu?
• Jaka jest wielkość tych zmian?
• Czy zmiany pojawiają się
w sposób schematyczny?
Źródło: www.itl.nist.gov
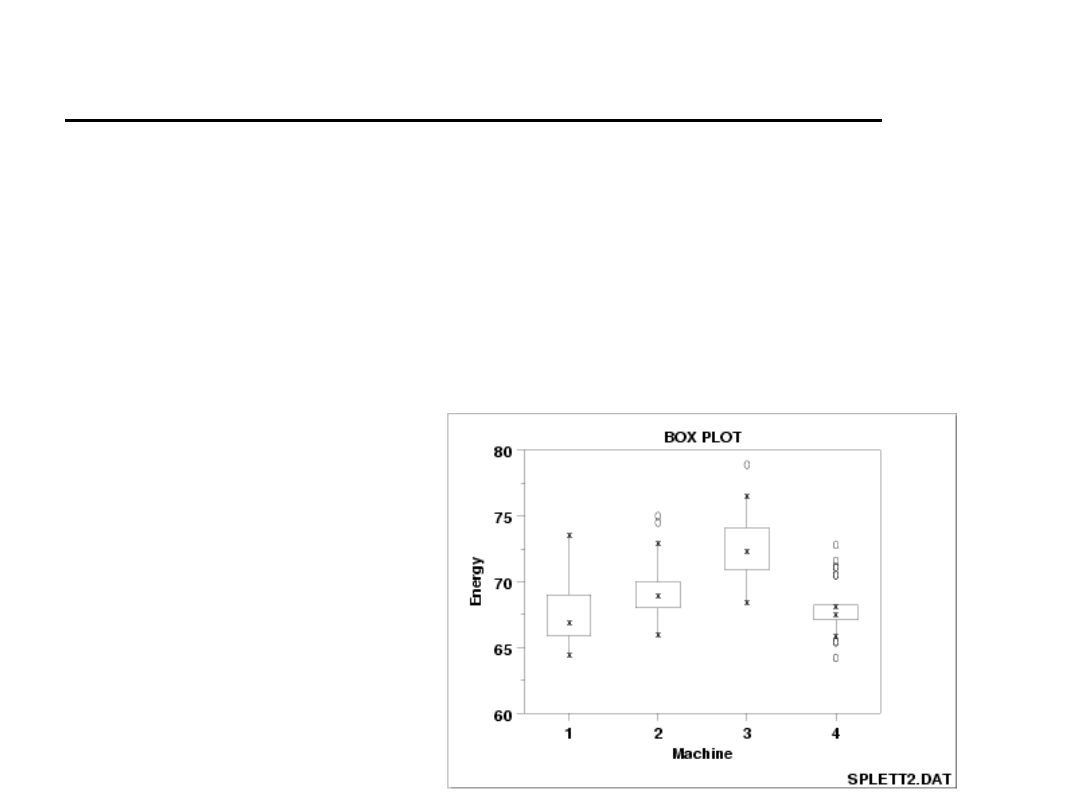
Wykres pudełkowy (ramka – wąsy)
Wykresy pudełkowe opracowywane są w oparciu o wartości
statystyk opisowych. Służą do:
• zdefiniowania rozproszenia danej cechy,
• ukazania rozkładu uporządkowanych wartości cechy,
• wspomagania analizy, interpretacji danych statystycznych ,
• porównania rozkładów dwóch lub więcej zmiennych.
Źródło: www.mfiles.pl/pl/index.php/Wykres_pudełkowy
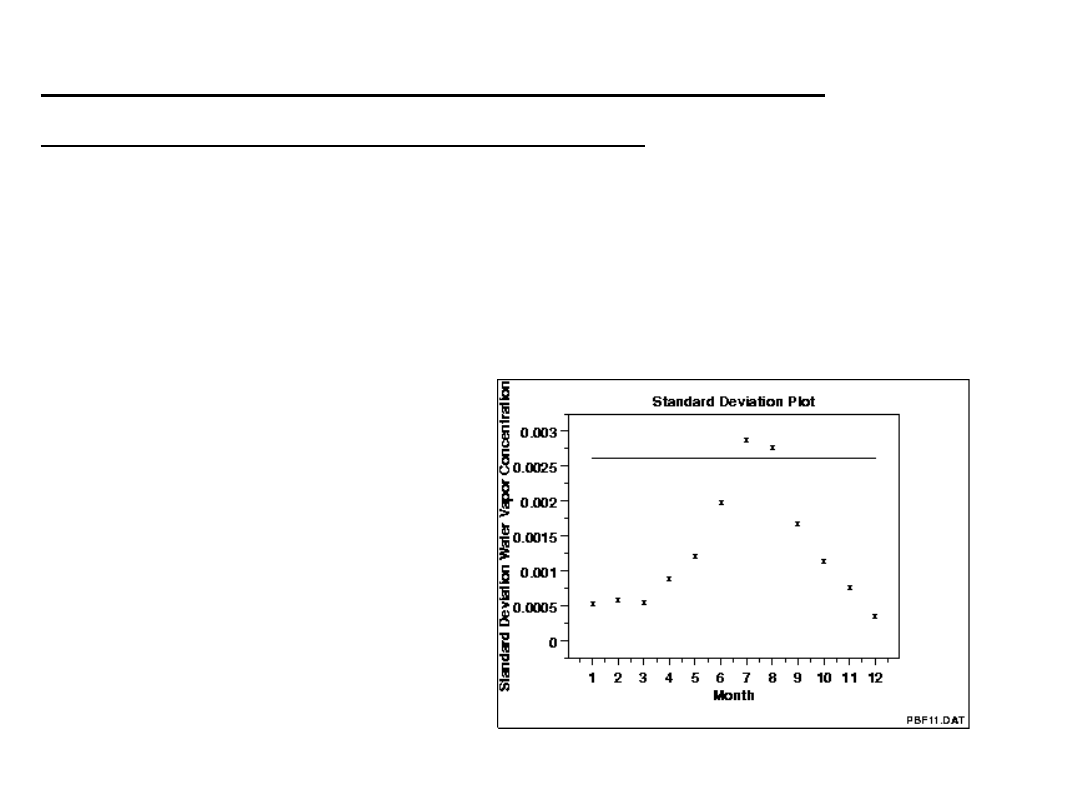
Wykres odchylenie standardowe
(Standard Deviation Plot)
Wykres jest narzędziem do przedstawienia zmian odchylenia
standardowego w różnych grupach danych.
Wykres ten, podobnie jak wykres średniej, może być użyty dla
niepogrupowanych danych, aby określić czy odchylenie
standardowe zmienia się w
czasie.
Źródło: www.itl.nist.gov

Dziękujemy za uwagę
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Aspekty akwizycji danych
- Odlewnia jako złożony system produkcyjny
- Obszary gromadzenia danych - przykłady
- Akwizycja danych
- Slide 8
- Akwizycja danych w zadaniach procesu produkcyjnego
- Slide 10
- Slide 11
- Data Mining
- Slide 13
- Data Mining
- Data Mining
- Slide 16
- Data Mining
- Data Mining
- Data Mining
- Slide 20
- Slide 21
- Slide 22
- Data mining w Produkcji
- Data mining w Produkcji
- Data mining w Produkcji
- Data mining w Produkcji
- Data mining w Produkcji
- Data mining w Produkcji
- Data mining w Produkcji
- Slide 30
- Analiza danych w produkcji
- Analiza danych w produkcji
- Analiza danych w produkcji
- Analiza danych w produkcji
- Analiza danych w produkcji
- Analiza danych w produkcji
- Slide 37
- Slide 38
- Techniki EDA
- Wykres przebiegu (Run-Sequence Plot)
- Histogram
- Bihistogram
- Wykres średniej (Mean Plot)
- Wykres pudełkowy (ramka – wąsy)
- Wykres odchylenie standardowe (Standard Deviation Plot)
- Dziękujemy za uwagę
Wyszukiwarka
Podobne podstrony:
WYBRANE ASPEKTY BEZPIECZEŃSTWA DANYCH BANKOWYCH
B6 Akwizycja danych
Dodatkowe Wytyczne projektu, Data mining - Grzenda
Data mining w rekomendacji
Metodologia w VIII, WYBRANE METODY ANALIZY WIELOZMIENNOWEJ - PODSTAWOWE ZAŁOŻENIA ANALIZY CZYNNIKOWE
(Sas Code) Data Mining Cookbook (Wiley)
IEEE Finding Patterns in Three Dimensional Graphs Algorithms and Applications to Scientific Data Mi
Scoring kredytowy a modele data mining
data mining zadania
Detecting Internet Worms Using Data Mining Techniques
Numerical linear algebra in data mining
Improve Fraud Detection Through Data Mining
(Sas Code) Data Mining Cookbook (Wiley)
New data mining technique to enhance IDS alarms quality
Data Mining of Gene Expression Data by Fuzzy and Hybrid Fuzzy Methods piq
Data Mining Methods for Detection of New Malicious Executables
Application of Data Mining based Malicious Code Detection Techniques for Detecting new Spyware
Data Mining Ai A Survey Of Evolutionary Algorithms For Data Mining And Knowledge Discovery
więcej podobnych podstron