Kodowanie Hamminga
Dzięki kodowi Hamminga jesteśmy w stanie nie tylko wykryć błąd pojedynczy w ciągu zero-
jedynkowym, ale także wskazać który bit jest niepoprawny.
Jak to uzyskać?
Mamy dowolny, ale i-bitowy, ciąg zero-jedynkowy, np. 00110110, liczba bitów ‘i’ = 8.
Aby móc wskazać na którym miejscu wystąpił błąd potrzebujemy dodać do tego ciągu kilka
dodatkowych bitów kontrolnych, które określą nam, w którym miejscu wystąpił błąd. Mamy 8 miejsc
więc wydawało by się, że wystarczą 3 dodatkowe bity, gdyż 2
3
= 8. Nie jest to jednak prawdą z dwóch
powodów:
- ciąg 000 traktowany jest jako brak błędu, czyli możemy zapisać tylko 7 numerków.
- po dodaniu 3 bitów cały ciąg ma ich 11 czyli potrzebujemy aż dwunastu kombinacji (kombinacja
000, oraz 001, 010, itd.)
Jednak nie cza się martwić bo after some algebra dochodzimy do wzorku:
2
k
≥ i + k + 1
Gdzie: ‘k’ – liczba bitów kontrolnych, które trzeba dodać; ‘i’ – liczba bitów informacyjnych (ile jest w
początkowym ciągu).
W naszym przypadku k = 4, bo 16 ≥ (8 + 4 + 1 = 13).
Co z tego zapamiętać? Wzorek.
W skrócie: Krok 1: Obliczenie długości ciągu kodowego (2
k
≥ i + k + 1)
Co teraz?
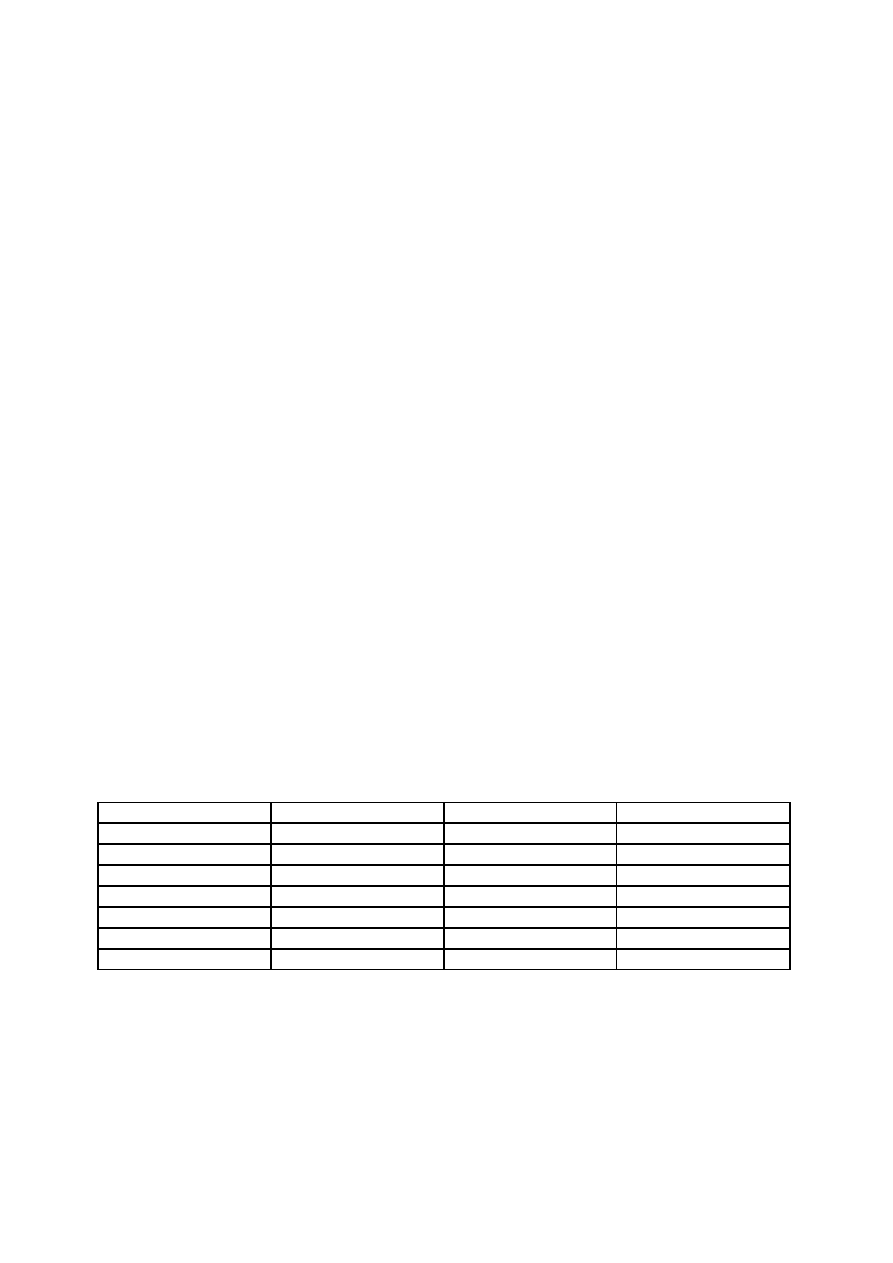
Konstruujemy tabelkę jak poniżej.
Dla uproszczenia filozofii przyjmę, że ‘i’ = 3, czyli mamy ciąg informacyjny 3-bitowy. Wymaga to, aby
dodać ‘k’ = 3 bitów kontrolnych, na których zapiszemy 8 różnych wartości błędów (oczywiście 000
oznacza, że błędu nie ma). Można więc powiedzieć, że nasz ciąg wygląda tak:
I
1
i
2
i
3
k
1
k
2
k
3
, lecz potraktujemy go jako zwykły ciąg ‘a’ = a
1
a
2
a
3
a
4
a
5
a
6
.
Błąd na pozycji
K
1
K
2
K
3
Żadnej – brak błędu
0
0
0
1
0
0
1
2
0
1
0
3
0
1
1
4
1
0
0
5
1
0
1
6
1
1
0
Jak taką tabelkę skonstruować. Ano nazywamy kolumny jak wyżej, kolejnymi indeksami ciągu
kontrolnego. Natomiast ciąg k
0
k
1
k
2
to po prostu wartość binarna numeru pozycji, na której wystąpił
błąd, czyli np. 3
dec
= 011
bin
.
Z tabelki wyznaczamy tak zwany syndrom (wektor) ‘s’ = [s
1
, s
2
, s
3
].
Syndrom przyjmuje wartość 0 lub 1.
0 – nie wykryto błędu, 1 – błąd wykryto, standardowo.

Wyznaczamy go w poniższy sposób:
s
1
= k
1
= a
4
+a
5
+a
6
.
Czemu tak? Rozpatrujemy kolumnę k
1
tabelki. Widzimy, że jedynki są w wierszach 4, 5, 6. Tyle.
Tak samo:
s
2
= k
2
= a
2
+a
3
+a
6
.
s
3
= k
3
= a
1
+a
3
+a
5
.
Cała filozofia.
Z założenia wiemy też, że jeśli syndrom jest zerowy ([0, 0, 0]) to błąd nie wystąpił. W innym wypadku
owszem. Zatem jeśli błąd nie wystąpił to:
s
1
= s
2
= s
3
= 0.
Czyli:
a
4
+a
5
+a
6
= 0.
a
2
+a
3
+a
6
= 0.
a
1
+a
3
+a
5
= 0.
Z tego układu równań wyznaczamy najdogodniejsze dla nas 3 bity (w tym wypadku 1,2,4):
a
4
=a
5
+a
6
.
a
2
=a
3
+a
6
.
a
1
=a
3
+a
5
.
I TU UWAGA BO TEGO NIE MA JASNO W KSIĄŻCE.
Pamiętamy, że mamy trzy bity informacyjne i trzy bity kontrolne. Tada! a
1
, a
2
, a
4
to bity kontrolne, zaś
pozostałe bity a
3
a
5
a
6
to bity informacyjne!
Dla przykładu: Jurek podał informację 010, pamiętając, że ciąg informacyjny to bity a
3
a
5
a
6
wyznaczamy pozostałe bity:
a
4
=a
5
+a
6
=1+0=1.
a
2
=a
3
+a
6
=0+0=0.
a
1
=a
3
+a
5
=0+1=1.
Czyli nasz ciąg ma postać 100110. (a
1
a
2
a
3
a
4
a
5
a
6
).
Dla upewnienia się sprawdzamy czy syndrom jest zerowy.
s
1
= k
1
= a
4
+a
5
+a
6
=0.
s
2
= k
2
= a
2
+a
3
+a
6
=0.
s
3
= k
3
= a
1
+a
3
+a
5
=0.
Git.
Teraz namieszamy: sprawdzamy czy ciąg 101110 jest poprawny (pamiętamy, że możemy wykryć tylko
błąd pojedynczy, tu bit a
3
zmienia wartość 0->1).
Pamiętamy, że wektor syndromu ‘s’ = [s
1
, s
2
, s
3
], czyli jest to ciąg 01-nkowy s
1
s
2
s
3
.
s
1
= k
1
= a
4
+a
5
+a
6
=0.
s
2
= k
2
= a
2
+a
3
+a
6
=1.
s
3
= k
3
= a
1
+a
3
+a
5
=1.
Czyli ‘s’ = 011
bin
= 3
dec
. Tada! Błąd wystąpił na trzeciej pozycji ciągu! Faktycznie.
W skrócie:
Krok 1: Obliczenie długości ciągu kodowego (2
k
≥ i + k + 1)
Krok 2: Tabelka i wyznaczenie z niej syndromu.
Krok 3: Ustalenie bitów informacyjnych i kontrolnych.
Wyszukiwarka
Podobne podstrony:
Laboratorium 1 Kodowanie nadmiarowe kod Hamminga
Arek Kurasz-sprawozdanie 1-Kodowanie nadmiarowe kod Hamminga, Politechnika Opolska, Informatyka, Sem
Laboratorium 1 Kodowanie nadmiarowe kod Hamminga
Laboratorium 1 Kodowanie nadmiarowe kod Hamminga
Wykład 6 6 kodowanie mowy
Kodowanie informacji
Kodowanie
Kodowanie pytań
kodowanie tekstu
POZIOMY KODOWANIA TEMPORALNEGO
Kodowanie zbior pytan wykład
KODOWANIE (metody), Metodologia badań społecznych
kodowanie sterownikow Audi A4, auta, Diagnostyka dokumety, procedury diagnostyczne
INSTRUKCJA KODOWA, studia, 3 semestr, badania marketingowe
KODOWANIE LICZB
BW12 teoria informacji i kodowania turbokody
Kodowanie podświadomości, Edukacja, Psychologia
kodowanie sterownikow a4, AuTO MoTO
więcej podobnych podstron