
PRACA DYPLOMOWA
´Srodowisko programowe
do wyznaczania macierzy odwrotnej
do symetrycznej macierzy trójdiagonalnej
słowa kluczowe:
symetryczna macierz trójdiagonalna, macierz odwrotna,
programowanie, numeryczna algebra liniowa
krótkie streszczenie:
Wynikiem pracy jest program komputerowy do wyznaczania macierzy
odwrotnej do symetrycznej macierzy trójdiagonalnej. Słu˙zy on do
wykonywania oblicze´
n oraz badania dokładno´sci i czasów wykonania
algorytmów numerycznych. Opracowano i zbadano 22 metody numeryczne,
z czego 6 to metody nowe, które oparte s˛
a o wzory analityczne.

Spis treści
1. Wprowadzenie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3
2. Przegląd metod numerycznych . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5
2.1.
Metody bezpośrednie
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5
2.1.1.
Metoda wyznacznikowa . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5
2.1.2.
Metoda eliminacji Gaussa, rozkład LU . . . . . . . . . . . . . . . . . . .
7
2.1.3.
Rozkład Cholesky’ego . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
10
2.1.4.
Rozkład QR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
11
2.1.5.
Rozkład SVD
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
12
2.2.
Metody iteracyjne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
13
2.2.1.
Metoda Jacobiego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
2.2.2.
Metoda Richardsona
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
2.2.3.
Metoda nadrelaksacji (SOR) . . . . . . . . . . . . . . . . . . . . . . . . .
15
2.2.4.
Metoda Czebyszewa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
16
2.2.5.
Metoda gradientów sprzężonych (CG) . . . . . . . . . . . . . . . . . . . .
16
2.3.
Metody oparte o wzory analityczne
. . . . . . . . . . . . . . . . . . . . . . . . .
17
Metoda dla macierzy symetrycznej . . . . . . . . . . . . . . . . . . . . . . . . . .
17
Metoda dla macierzy diagonalnie dominującej . . . . . . . . . . . . . . . . . . . .
20
3. Opis środowiska obliczeniowego (Program TIPS) . . . . . . . . . . . . . . . . .
22
3.1.
Źródła danych i algorytmów
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
22
3.2.
Ocena dokładności obliczeń . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
24
3.3.
Interfejs użytkownika
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
27
3.3.1.
Informacje podstawowe . . . . . . . . . . . . . . . . . . . . . . . . . . . .
27
3.3.2.
Zapis i odczyt opcji obliczeń . . . . . . . . . . . . . . . . . . . . . . . . .
28
3.3.3.
Zakładka „Macierze” . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
28
3.3.4.
Zakładka „Algorytmy i wyniki” . . . . . . . . . . . . . . . . . . . . . . .
31
3.3.5.
Zakładka „Testy i wykresy”
. . . . . . . . . . . . . . . . . . . . . . . . .
36
3.3.6.
Okno „Wykres” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
38
3.3.7.
Okno „Obliczenia”
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
41
3.3.8.
Korzystanie ze wzorów . . . . . . . . . . . . . . . . . . . . . . . . . . . .
41
4. Przeprowadzone testy
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
45
4.1.
Porównanie czasów wykonania algorytmów . . . . . . . . . . . . . . . . . . . . .
45
4.2.
Porównanie dokładności - macierz Poissona . . . . . . . . . . . . . . . . . . . . .
46
4.3.
Porównanie dokładności - macierz Hilberta . . . . . . . . . . . . . . . . . . . . .
48
4.4.
Porównanie dokładności - macierz losowa . . . . . . . . . . . . . . . . . . . . . .
52
5. Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
53
Spis ilustracji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
55
Literatura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
56
2

1. Wprowadzenie
Wyznaczanie macierzy odwrotnej jest jednym z podstawowych problemów algebry
numerycznej. Do tego celu stosuje się różne algorytmy numeryczne. Macierz odwrotna
przydaje się w problemach automatyki sterowania i przetwarzania sygnałów, gdyż po-
zwala szybko rozwiązywać układy równań dla zmieniających się wektorów wejściowych
podczas gdy macierz układu równań pozostaje stała. Wiele zjawisk opisuje się przez mo-
dele liniowe, a matematyczną reprezentacją operatorów liniowych są właśnie macierze.
Każdą macierz symetryczną można zredukować do symetrycznej macierzy trójdiagonal-
nej poprzez przedstawienie zagadnienia w innej bazie przestrzeni liniowej. Konieczność
wyznaczania macierzy odwrotnej do symetrycznej macierzy trójdiagonalnej pojawia się
zatem w wielu zagadnieniach fizyki, ekonomii oraz inżynierii.
W praktyce obliczeń numerycznych zwykle unika się bezpośredniego obliczania ma-
cierzy odwrotnej, zastępując je przez zagadnienie rozwiązywania układu równań, które
jest lepiej uwarunkowane [1, 2]. Istnieją jednak sytuacje, w których dokładna znajomość
macierzy odwrotnej jest bardzo przydatna [3, 4]. Na uwagę zasługuje na przykład zagad-
nienie rozwiązywania czasowego równania Schr¨
odingera [5], gdzie dla każdego kolejnego
kroku czasu należy rozwiązywać trójdiagonalny układ równań.
Znane jest wiele klasycznych metod numerycznych stosowanych do wyznaczania ma-
cierzy odwrotnej. Są to zarówno metody bezpośrednie, jak i metody iteracyjne. Zakoń-
czone sukcesem próby uzyskania rozwiązania analitycznego dla problemu odwracania
macierzy trójdiagonalnej pozwalają na sformułowanie metody numerycznej nowego ty-
pu. Metodę zwaną w tej pracy „metodą analityczną” można zastosować do uzyskania
analitycznego rozwiązania zagadnienia odwracania symetrycznej macierzy trójdiagonal-
nej dla macierzy, których elementy są ustalone [6, 7]. Dla dowolnych elementów macierzy
ta sama metoda pozwala sformułować algorytm inny niż dotychczas stosowane dla tego
typu zagadnień.
Celem tej pracy jest opracowanie i napisanie programu komputerowego, który po-
zwoli zbadać własności numeryczne tej „metody analitycznej” na tle własności innych
wybranych metod bezpośrednich i iteracyjnych.
W rozdziale 2 przedstawiono krótko każdą z metod numerycznych zaimplementowa-
nych w programie. Podrozdział 2.1 zawiera opis pięciu podstawowych metod bezpośred-
nich, czyli takich, które dają wynik po skończonej liczbie kroków algorytmu. W podroz-
dziale 2.2 natomiast znajduje się opis zastosowanych metod iteracyjnych. Opis metod
„analitycznych”, wraz z ich częściowym wyprowadzeniem na podstawie prac [7, 8] za-
wiera podrozdział 2.3. Zdefiniowano w nim 6 wersji algorytmów numerycznych opartych
o te metody.
3

Rozdział 3 poświęcono na dokładniejszy opis środowiska obliczeniowego (zestawu
programów komputerowych). Opis ten podzielono na trzy części. W części pierwszej
(podrozdział 3.1) zawarty jest wykaz 22 programów obliczeniowych realizujących odwra-
canie symetrycznej macierzy trójdiagonalnej. Podrozdział 3.2 przedstawia zastosowane
w programie metody badania i porównywania dokładności obliczeń. Część trzecia, za-
warta w podrozdziale 3.3, to opis możliwości programu, wyglądu poszczególnych okien
i sposobu korzystania z dostępnych funkcji.
Przeprowadzono także szereg testów numerycznych, a ich wyniki przedstawione są
w rozdziale 4. Znajduje się tam porównanie czasów wykonania poszczególnych algoryt-
mów oraz porównanie dokładności wyników dla trzech przykładowych macierzy: Poisso-
na, Hilberta oraz macierzy losowej.
W podsumowaniu, znajdującym się w ostatnim rozdziale 5, zawarto wnioski z prze-
prowadzonych testów, ze szczególnym uwzględnieniem wniosków dotyczących metod
„analitycznych”. Pracę zamyka spis ilustracji oraz lista pozycji cytowanej literatury.
Do pracy dołączono też płytę CD zawierającą oprogramowanie w wersji wykonywalnej
i źródłowej wraz z programem instalacyjnym.

2. Przegląd metod numerycznych
Rzeczywista symetryczna macierz trójdiagonalna stopnia N jest następującej postaci:
T
N
=
d
1
e
1
e
1
d
2
e
2
e
2
. ..
. ..
. ..
. ..
e
N −2
e
N −2
d
N −1
e
N −1
e
N −1
d
N
.
(2.1)
Macierz T
N
zawiera zawsze liczbę zer równą N
2
− 3N + 2. Ze względu na symetrię
wystarczy 2N − 1 liczb aby zapisać macierz T
N
w pamięci operacyjnej komputera.
Macierz do niej odwrotna T
−1
N
nie jest już w ogólności trójdiagonalna, czyli ma N
2
nie-
zerowych elementów, a ze względu na symetrię można ją zapisać w pamięci przy pomocy
(N
2
+ N )/2 liczb. Algorytmy obliczające macierz odwrotną do macierzy trójdiagonalnej
powinny więc mieć złożoność obliczeniową nie mniejszą niż O(N
2
).
W kolejnych podrozdziałach przedstawione są wybrane metody bezpośrednie i itera-
cyjne stosowane do obliczania macierzy odwrotnej do symetrycznej macierzy trójdiago-
nalnej. Podrozdział 2.3 opisuje metodę analityczną, która pozwala wyprowadzać wzory
na poszczególne elementy macierzy T
−1
N
. Z metody tej wynika bezpośrednio algorytm
numeryczny, który został także zaimplementowany w programie TIPS. Nazwa progra-
mu TIPS to skrótowiec składający się z pierwszych liter nazwy angielskiej: Tridiagonal
Inverse Problem Solver.
2.1. Metody bezpośrednie
2.1.1. Metoda wyznacznikowa
Elementy macierzy odwrotnej do macierzy kwadratowej A są postaci [9, 10]
A
−1
ij
= (−1)
i+j
M
ji
|A|
,
(2.2)
gdzie |A| jest wyznacznikiem macierzy A, a M
ij
jest minorem (N − 1) rzędu, czyli
wyznacznikiem macierzy A po skreśleniu z niej i-tego wiersza i j-tej kolumny.
5
W celu obliczenia wyznacznika macierzy (2.1), tworzymy ciąg wielomianów {p
i
(z)},
tzw. ciąg Sturma [11]
p
0
(z) = 1
p
1
(z) = d
1
p
i
(z) = (d
i
− z)p
i−1
(z) − e
2
i−1
p
i−2
(z), i = 2, ..., N.
(2.3)
Po (N − 1) krokach rekurencyjnych otrzymujemy wielomian p
N
(z), który jest wie-
lomianem charakterystycznym macierzy T
N
, a szukany wyznacznik |T
N
| jest wyrazem
wolnym tego wielomianu, czyli
|T
N
| = p
N
(0).
(2.4)
Następnie obliczymy minor M
ij
macierzy T
N
. Jeśli skreślimy z macierzy trójdiago-
nalnej (2.1) jeden wiersz i jedną kolumnę, to otrzymamy macierz blokowo-diagonalną
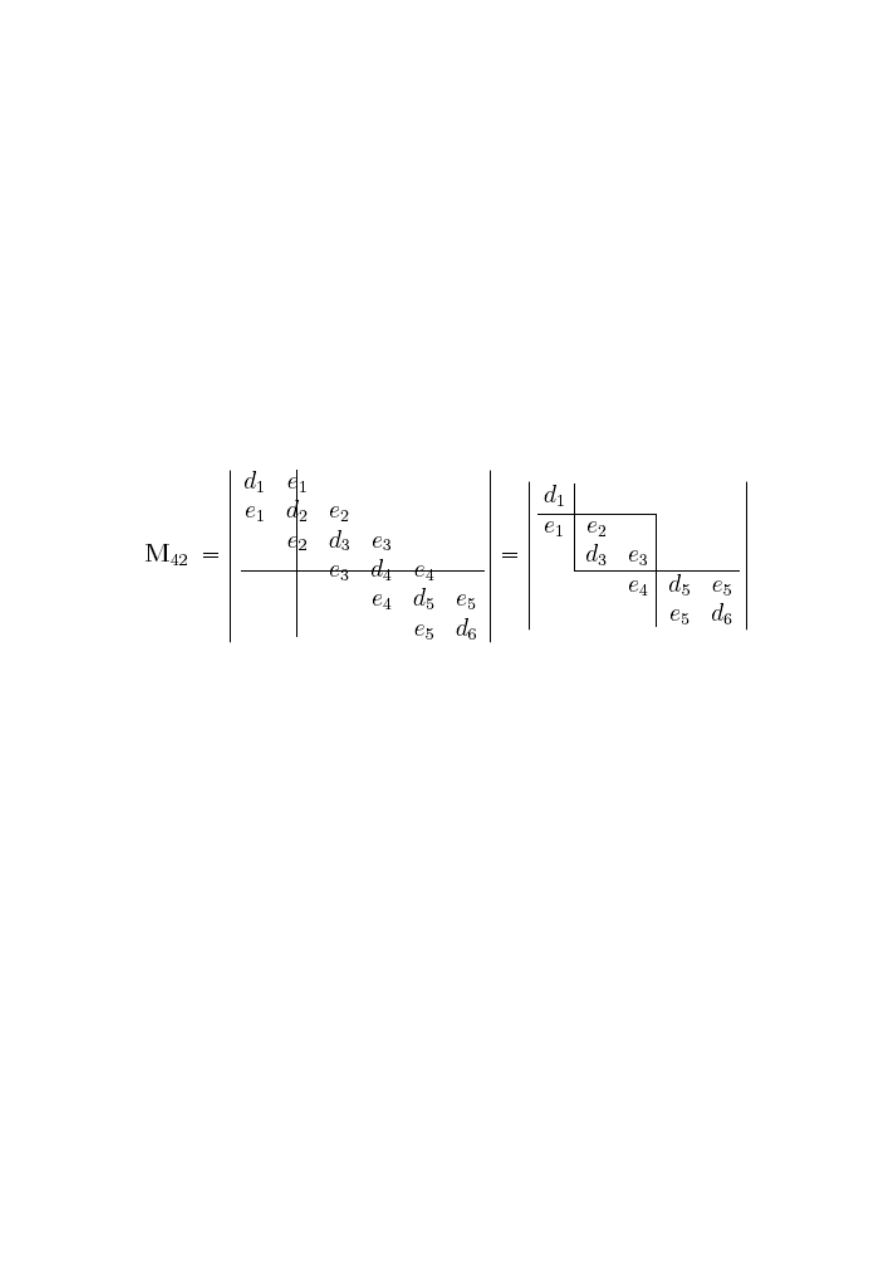
(przykład na rysunku 2.1).
Rysunek 2.1. Minor M
42
macierzy T
6
Wyznacznik takiej macierzy jest iloczynem wyznaczników kwadratowych bloków sto-
jących na przekątnej jeśli wszystkie elementy macierzy ponad (albo poniżej) tych bloków
są zerami [10]. Na tej samej zasadzie wyznacznik macierzy trójkątnej jest iloczynem jej
elementów diagonalnych. W przypadku z rysunku 2.1 możemy zapisać
M
42
= d
1
· e
2
e
3
· (d
5
d
6
− e
2
5
).
Jeśli analogicznie do (2.3) zdefiniujemy ciąg {q
j
(z)} jako
q
j
(z) = (d
j
− z)q
j+1
(z) − e
2
j
q
j+2
(z), j = N − 1, ..., 1
q
N
(z) = d
N
q
N +1
(z) = 1
,
(2.5)
to możemy zapisać
M
42
= p
2−1
(0)
4−1
Y
k=2
e
k
!
q
4+1
(0).
6

Ogólnie minor M
ij
ma postać
M
ij
=
p
i−1
(0)
j−i
Y
k=1
e
j−k
q
j+1
(0)
dla i < j,
p
j−1
(0)
i−j
Y
k=1
e
j+k−1
q
i+1
(0)
dla i > j.
(2.6)
Podstawiając (2.6) i (2.4) do wzoru (2.2) otrzymujemy następujące wyrażenie na element
macierzy odwrotnej do symetrycznej macierzy trójdiagonalnej:
T
−1
N
ij
=
(−1)
i+j
p
N
(0)
p
i−1
(0)
j−i
Y
k=1
e
j−k
q
j+1
(0)
dla i < j,
p
i−1
(0) q
j+1
(0)
dla i = j,
p
j−1
(0)
i−j
Y
k=1
e
j+k−1
q
i+1
(0)
dla i > j.
(2.7)
Pamiętamy przy tym, że nasza macierz jest symetryczna, więc teoretycznie
T
−1
N
ij
=
T
−1
N
ji
, ale wyniki obliczeń numerycznych dla (i < j) i (i > j) mogą być różne.
Spodziewamy się, że także równość p
N
(0) = q
1
(0) będzie spełniona tylko ze skończoną
dokładnością. Podczas bezpośredniego obliczania wyznaczników może wystąpić przepeł-
nienie [ang. floating point overflow]. W pozycji [1] na stronie 57 znajdziemy opis jak
można się przed tym zabezpieczyć.
2.1.2. Metoda eliminacji Gaussa, rozkład LU
Metoda eliminacji Gaussa jest metodą rozwiązywania układów równań liniowych
typu
AX = B,
(2.8)
gdzie macierz A jest macierzą układu, X macierzą rozwiązań, a B macierzą wektorów
kolumnowych składających się z wyrazów wolnych odpowiednich równań. W metodzie
tej przeprowadza się na macierzy A układu i na wektorze (wektorach) prawej strony
(kolumny macierzy B) operacje, które nie zmieniają rozwiązania układu X. Operacje te
wykonuje się w celu sukcesywnego zerowania kolejnych elementów macierzy A poniżej
(powyżej) jej głównej przekątnej aby otrzymać macierz trójkątną górną (dolną). Wyko-
nuje się te operacje w takiej kolejności, żeby zera wygenerowane w poprzednich krokach
pozostały zerami. Operacje, o których tutaj mowa, to zastępowanie wierszy (równań),
przez nie trywialne kombinacje liniowe innych wierszy (równań). Kiedy już powstanie
macierz trójkątna górna (dolna) okazuje się, że współczynniki kolejnych kombinacji li-
niowych układają się również w macierz trójkątną, ale dolną (górną).
7

Eliminacja Gaussa może być zatem wykorzystana do otrzymania tzw. rozkładu trój-
kątnego macierzy
A = LU,
(2.9)
gdzie macierz L jest trójkątna dolna [ang. lower], a macierz U – trójkątna górna [ang.
upper]. Warunkiem istnienia rozkładu (2.9) jest niezerowość wszystkich tzw. minorów
wiodących macierzy A [3]. Dla symetrycznej macierzy trójdiagonalnej można ten waru-
nek zapisać przy użyciu notacji z (2.41) jako W
1,j
= 0, dla j = 2, ..., N .
Kiedy znamy rozkład LU, rozwiązanie X równania (2.8) otrzymujemy w procesach
podstawiania, czyli rozwiązywania układów równań z macierzami trójkątnymi
LY = B,
(2.10)
UX = Y.
(2.11)
Standardowa eliminacja Gaussa nie oblicza rozkładu LU. Wykonuje ona jednocze-
śnie te same operacje na macierzach A i B, nie musi więc zapamiętywać macierzy L,
a macierz B przekształca się automatycznie w macierz Y i podstawianie (2.10) nie jest
już potrzebne. Podstawianie (2.11) trzeba jednak na koniec wykonać.
Faktycznie w procesie eliminacji Gaussa zerujemy tylko elementy poniżej albo po-
wyżej przekątnej macierzy A. Nic nie stoi na przeszkodzie, aby zerować jednocześnie
elementy poniżej i powyżej tej przekątnej. Modyfikacja taka prowadzi do algorytmu eli-
minacji Gaussa-Jordana. Nie trzeba już wykonywać ani (2.10), ani (2.11), bo macierz
B przekształca się automatycznie w macierz rozwiązań X.
Jeśli macierz B jest macierzą jednostkową B = I, to wcale nie trzeba jej pamiętać,
a wynik X = A
−1
można zapisywać kolumna po kolumnie zamiast macierzy A (w tej
samej pamięci). W takim przypadku mówimy, że algorytm „pracuje w miejscu” (tzn.
nadpisuje pamięć danych wynikami).
Metoda eliminacji Gaussa byłaby dobrą metodą gdyby nie to, że jest niestabilna
numerycznie ze względu na możliwość wystąpienia zerowych, lub bardzo małych elemen-
tów na przekątnej macierzy A [1, 2, 9]. Problem ten rozwiązuje się zauważając prosty
fakt: przekątna nie musi być przekątną. Przestawiając odpowiednie wiersze macierzy
A przenosimy problematyczne elementy diagonalne gdzie indziej. Przestawienie wierszy
uzyskuje się mnożąc macierz lewostronnie przez tzw. macierz permutacji P. Rozkład LU
nie jest już więc rozkładem macierzy A, ale macierzy PA
PA = LU
(2.12)
Aby otrzymać wynik X, obliczamy najpierw Y przez podstawienie
LY = PB
(2.13)
oraz stosujemy znane już podstawienie (2.11). Algorytm ten nazywany jest elimina-
cją Gaussa z częściowym wyborem elementu głównego albo rozkładem PLU.
Oczywiście macierzy P nie znamy a priori, gdyż powstaje ona podczas wykonywania
rozkładu. Rozkład PLU jest wykonalny dla macierzy A odwracalnej (nieosobliwej) [3].
8

W rzadkich przypadkach, kiedy częściowy wybór elementu głównego nie jest wystar-
czający proponuje się algorytm eliminacji Gaussa z pełnym wyborem elementu
głównego. Polega on na tym, że wybieramy element A
ij
do zamiany z elementem dia-
gonalnym A
kk
nie tylko spośród elementów i j = k (wybór częściowy), ale spośród
elementów i k oraz j k. Wiąże się to z koniecznością przestawiania nie tylko wierszy,
ale także kolumn macierzy A. Przestawienie kolumn formalnie uzyskuje się mnożąc ma-
cierz prawostronnie przez inną macierz permutacji ˜
P. Rozkład LU jest teraz rozkładem
macierzy PA ˜
P
PA ˜
P = LU.
(2.14)
Aby otrzymać wynik X wykonujemy (2.13), a następnie
UZ = Y,
(2.15)
X = ˜
PZ.
(2.16)
Widzimy na podstawie (2.16), że przestawianie kolumn macierzy A powoduje przesta-
wienie wierszy w uzyskanym przez nas wyniku. Rozkład LU z pełnym wyborem elementu
głównego istnieje dla każdej macierzy kwadratowej [3].
Kiedy macierz układu jest trójdiagonalna symetryczna A = T i nie wykonujemy
zamiany wierszy ani kolumn, to jej rozkład LU ma następującą postać [12]:
d
1
e
1
e
1
. ..
. ..
. ..
. ..
e
N −1
e
N −1
d
N
=
1
l
1
. ..
. ..
. ..
l
N −1
1
u
1
e
1
. .. ...
. .. e
N −1
u
N
. (2.17)
Współczynniki {l
i
} i {u
i
} dane są wzorem rekurencyjnym
u
1
= d
1
;
l
i
= e
i
/u
i
u
i+1
= d
i+1
− l
i
e
i
)
i = 1, ..., N − 1.
(2.18)
Ciąg {u
i
} pojawia się często gdy rozpatrujemy macierz trójdiagonalną (patrz wzór
2.52). Macierz odwrotną obliczamy ze wzoru T
−1
= U
−1
L
−1
. Można pokazać, że wyni-
kiem jest następujący wzór na elementy macierzy odwrotnej
T
−1
ij
= (−1)
i+j
N
X
k=max(i,j)
1
u
k
k−1
Y
p=i
l
p
k−1
Y
q=j
l
q
.
(2.19)
Widać stąd, że jeśli istnieje wyraz ciągu {u
i
} równy zero, to nie istnieje macierz odwrotna,
czyli macierz T jest osobliwa. Problemy numeryczne pojawiają się wtedy, gdy {u
i
} jest
bardzo małą liczbą, niekoniecznie dokładnie równą zero. Ten sam problem występuje
zawsze, gdy mamy do czynienia z ciągiem {u
i
}. Tutaj ratunkiem jest wybór elementu
głównego. Przy częściowym wyborze mamy do dyspozycji tylko jeden wiersz ((k+1)-szy),
który możemy zamienić z k-tym wierszem. Jeśli to zrobimy, macierz U będzie miała
9

niezerowe elementy także na drugiej naddiagonali. W ten sposób działa podprogram
DGTSV z biblioteki Lapack [13]. Pełnego wyboru elementu głównego zwykle się w tym
wypadku nie wykonuje, gdyż zamiana kolumn psuje trójdiagonalną strukturę macierzy,
a zapamiętanie nowej pozycji niezerowych elementów wymaga niepotrzebnie dodatkowej
pamięci. Jeśli wybór częściowy się nie powiedzie, to już wiemy, że macierz jest osobliwa
i kończymy obliczenia.
2.1.3. Rozkład Cholesky’ego
Rozkład Cholesky’ego jest podobny do rozkładu LU, z tą różnicą, że macierz górna
trójkątna jest transpozycją macierzy dolnej trójkątnej, czyli U = L
T
. Rozkład ten można
zastosować tylko do macierzy, które są dodatnio określone [ang. positive definite], tzn.
mają wszystkie wartości własne dodatnie [1, 2]. Macierze takie występują często w fizyce,
gdyż są one reprezentacjami operatorów hermitowskich o rzeczywistych wartościach wła-
snych (wartości te muszą być rzeczywiste, bo są wynikami pomiarów różnych wielkości
fizycznych).
Zapiszmy rozkład Cholesky’ego LL
T
dla symetrycznej macierzy trójdiagonalnej:
d
1
e
1
e
1
. ..
. ..
. ..
. ..
e
N −1
e
N −1
d
N
=
m
1
l
1
. ..
. ..
. ..
l
N −1
m
N
m
1
l
1
. .. ...
. .. l
N −1
m
N
.
(2.20)
Bezpośrednio z (2.20) otrzymujemy związki rekurencyjne pozwalające obliczyć współ-
czynniki macierzy L:
m
1
=
p
d
1
;
l
i
= e
i
/m
i
m
i+1
=
q
d
i+1
− l
2
i
)
i = 1, ..., N − 1.
(2.21)
Rozkład ten nie wymaga przestawiania wierszy ani kolumn, a sam algorytm jest
poprawny numerycznie [1]. Możemy także uniknąć obliczania pierwiastka kwadratowego
i zamiast rozkładu LL
T
obliczyć rozkład ˜
LD˜
L
T
[1, 11], gdzie ˜
m
i
= 1 i D = diag(m
2
i
) =
diag(u
i
)
u
1
= d
1
;
˜
l
i
= e
i
/u
i
u
i+1
= d
i+1
−
e
2
i
u
i
i = 1, ..., N − 1.
(2.22)
Ciągi {˜
l
i
} i {u
i
} z (2.22) to te same ciągi, co {l
i
} i {u
i
} we wzorach (2.18). Rozkład
Cholesky’ego jest zaimplementowany w podprogramie DPTSV biblioteki Lapack [13].
Zauważmy, że w (2.22) elementy ciągu {u
i
} mogą być ujemne, co sugerowałoby, że roz-
kład ten można wykonać także dla macierzy, które nie są dodatnio określone. Można, ale
algorytm nie jest wtedy numerycznie poprawny, co oznacza, że błąd może być dowolnie
duży nawet dla macierzy o małym wskaźniku uwarunkowania [1].
10

Obliczamy X, macierz odwrotną do symetrycznej macierzy trójdiagonalnej przy po-
mocy rozkładu Cholesky’ego przez rozwiązanie trójkątnych układów równań LZ = I
oraz L
T
X = Z. Jeśli natomiast obliczymy rozkład T = ˜
LD˜
L
T
, to macierz odwrotną
otrzymamy rozwiązując równania macierzowe ˜
LDZ = I oraz ˜
L
T
X = Z.
2.1.4. Rozkład QR
Rozkład T = QR, zwany rozkładem ortogonalno-trójkątnym jest zawsze wykonalny
dla trójdiagonalnej macierzy symetrycznej [2, 11]. Macierz górna trójkątna R powstaje
w procesie tzw. dekompozycji, czyli po przeprowadzeniu (N −1) transformacji ortogonal-
nych macierzy T. Każda z tych transformacji na wyzerować jeden element poddiagonalny
macierzy T.
Transformacje, o których tutaj mowa to tzw. obroty Givensa. Mogą to być też inne
transformacje (np. odbicia Householdera albo zmodyfikowana ortogonalizacja Gramma-
-Schmidta), ale po ich zastosowaniu macierz R jest na ogół pełną macierzą trójkątną,
podczas gdy (N − 1) obrotów Givensa prowadzi do macierzy trójkątnej z tylko dwie-
ma naddiagonalami (2.25) (podobnie jak rozkład LU z częściowym wyborem elementu
głównego). Pojedynczy i-ty obrót Givensa ma postać macierzy
G
T
i
=
1
. ..
c
i
s
i
−s
i
c
i
. ..
1
.
(2.23)
Kąt obrotu ϕ
i
jest tak dobrany, aby wyzerować element poddiagonalny e
i
, co prowadzi
do związków
cos ϕ
i
= c
i
=
δ
i
q
δ
2
i
+ e
2
i
,
sin ϕ
i
= s
i
=
e
i
q
δ
2
i
+ e
2
i
,
(2.24)
gdzie δ
i
to element d
i
już zmieniony przez poprzedni obrót G
T
i−1
.
Proces dekompozycji G
T
N −1
· · · G
T
1
T = Q
T
T = R prowadzi do macierzy trójkątnej
R =
r
1
q
1
v
1
r
2
q
2
. ..
. .. ...
. ..
. .. q
N −2
v
N −2
r
N −1
q
N −1
r
N
.
(2.25)
Macierz odwrotną otrzymujemy rozwiązując równanie macierzowe RX = Q
T
względem
X, gdzie Q
T
jest macierzą skumulowanych (tzn. pomnożonych przez siebie) transformacji
ortogonalnych.
11

Z postaci (2.23) wnioskujemy, że macierz Q
T
jest prawie trójkątna dolna (tylko pierw-
sza naddiagonala jest niezerowa i zawiera wartości s
i
). Jeśli w algorytmie dekompozycji
przedstawionym w [11] na stronie 64 zamienimy kolejność obliczania wielkości p
i+1
i q
i
,
to w każdym kroku możemy wykonać o jedno mnożenie mniej. Po tych modyfikacjach
algorytm rozkładu QR symetrycznej macierzy trójdiagonalnej wraz z akumulacją trans-
formacji ortogonalnych przedstawia się następująco:
Q
T
= I
{q
i
= v
i
= e
i
}
i = 1, ..., N − 1
p = d
1
r
i
=
q
p
2
+ v
2
i
, c = p/r
i
, s = v
i
/r
i
(
Q
T
i+1,j
= −s Q
T
i,j
Q
T
i,j
= c Q
T
i,j
)
j = 1, ..., i
Q
T
i,i+1
= s, Q
T
i+1,i+1
= c
p = cd
i+1
− sq
i
, q
i
= cq
i
+ sd
i+1
if i ¬ N − 2 then v
i
= sq
i+1
, q
i+1
= cq
i+1
i = 1, ..., N − 1
r
N
= p.
(2.26)
2.1.5. Rozkład SVD
Rozkład SVD (Singular Value Decomposition) polega na zapisaniu dowolnej prosto-
kątnej macierzy rzeczywistej A w postaci iloczynu
A = UΣV
T
,
(2.27)
gdzie macierze U i V są ortogonalne, a macierz Σ jest diagonalna. Niezerowe elementy
macierzy Σ to tzw. wartości szczególne macierzy A. Rozkład ten łatwo zastosować do
obliczenia macierzy odwrotnej do macierzy A, gdyż
A
−1
= VΣ
−1
U
T
.
(2.28)
Jeśli macierz A nie jest kwadratowa, to macierz (2.28) nazywamy macierzą pseudoodw-
rotną (znajduje ona zastosowanie w problemach minimalizacji funkcji metodą najmniej-
szych kwadratów).
Nowoczesne algorytmy służące do obliczania rozkładu SVD są dwuetapowe. Najpierw
przy pomocy transformacji ortogonalnych sprowadza się macierz A do postaci górnej
macierzy bidiagonalnej, a następnie oblicza się wartości i wektory szczególne tej macierzy.
W przypadku symetrycznej macierzy trójdiagonalnej zastosowanie tej metody napo-
tyka na trudności związane z koniecznością zapamiętania pełnych macierzy zawierają-
cych wektory szczególne oraz pomnożenia tych macierzy przez siebie. Z drugiej jednak
strony redukcja macierzy trójdiagonalnej do bidiagonalnej jest bardzo prosta i szybka
przy pomocy obrotów Givensa, a obliczenie macierzy odwrotnej do macierzy diagonalnej
Σ sprowadza się do obliczenia odwrotności jej elementów diagonalnych.
12

Proces redukcji dowolnej macierzy pasmowej do postaci górnej macierzy bidiagonal-
nej wykonuje procedura DGBBRD z biblioteki Lapack [13], a obliczenie rozkładu SVD
możemy wykonać jedną z dwóch metod (również z biblioteki Lapack):
•
DBDSQR przeprowadza iterację metodą QR,
•
DBDSDC stosuje algorytm typu „dziel i rządź”.
Druga z podanych tu metod wymaga więcej pamięci i powinna działać szybciej dla
dużych macierzy. Powodem, dla którego należy zwrócić uwagę na metodę SVD jest jej
duża niezawodność [2]. Potrafi ona dawać bardzo dokładne wyniki nawet w przypadku
macierzy o wyznaczniku bliskim zeru (prawie osobliwych). Jeśli macierz będzie osobli-
wa, to pojawią się wartości szczególne równe zero, jednak liczba niezerowych wartości
szczególnych wciąż jest równa rzędowi macierzy wyjściowej.
2.2. Metody iteracyjne
Oprócz metod bezpośrednich (dających rozwiązanie po skończonej liczbie kroków)
istnieje cała rodzina metod i algorytmów iteracyjnych służących do rozwiązywania ukła-
dów równań liniowych. Iteracja polega na cyklicznym wykonywaniu tych samych operacji
w każdym kroku tak, aby wartości obliczone w poszczególnych krokach były zbieżne do
poszukiwanego rozwiązania. Aby rozpocząć iterację potrzebna jest znajomość tzw. wek-
tora początkowego x
(0)
, który możemy wybrać dowolnie albo jako wcześniej obliczone
inną metodą rozwiązanie przybliżone (uwarunkowanie wstępne [ang. preconditioning]).
Iteracja w i-tym kroku ma postać mnożenia niezmienionej macierzy A przez wektor
i dodania innego wektora [1, 2, 3]:
x
(i+1)
= Mx
(i)
+ w.
(2.29)
Główny koszt wykonania metody iteracyjnej związany jest z mnożeniem macierzy
przez wektor, które jest czasochłonne. Jeśli jednak macierz jest macierzą rzadką, tzn.
liczba jej niezerowych elementów jest rzędu O(N ), to mnożenie takie można wykonać
znacznie szybciej. Dzięki temu każda metoda iteracyjna potrafi skorzystać z faktu rzad-
kości macierzy w przeciwieństwie do metod bezpośrednich, które trzeba specjalnie za-
projektować, aby mogły skorzystać z tego samego faktu.
Liczba pojedynczych operacji zmiennoprzecinkowych, które trzeba wykonać w meto-
dzie iteracyjnej jest niekiedy znacznie większa niż w metodzie bezpośredniej zastosowanej
dla macierzy tych samych rozmiarów. Większe niebezpieczeństwo kumulacji pojedyn-
czych błędów zaokrągleń nie martwi nas już jednak tak bardzo jak w przypadku metod
bezpośrednich, ponieważ jeśli tylko metoda iteracyjna jest zbieżna, błędy wygenerowane
w jednym kroku mogą zostać poprawione w kolejnych krokach. Dzieje się tak dlatego, że
na każdym etapie iteracji istnieje stały i niezmienny czynnik: macierz iteracji M. Podczas
gdy algorytmy bezpośrednie manipulują wyrazami macierzy A, algorytmy iteracyjne raz
obliczoną na początku macierz M pozostawiają w niezmienionej postaci aż do końca obli-
czeń. Tak działają stacjonarne metody iteracyjne, ale istnieją też metody niestacjonarne,
w których zarówno macierz M, jak i wektor w mogą zmieniać się w kolejnych iteracjach
(zmiany te są zwykle niewielkie i mają na celu przyspieszenie zbieżności metody).
13

Warunkiem koniecznym zbieżności metody iteracyjnej postaci (2.29) jest prosta za-
leżność kMk < 1, gdzie k · k jest dowolną normą macierzy zgodną z normą wektorową.
Warunek ten jest konieczny, ale nie zawsze wystarczający [1].
Wystarczającym warunkiem jest aby promień spektralny macierzy iteracji M (naj-
większa co do modułu wartość własna M), spełniał [1, 3, 14]
ρ(M) = max
1¬i¬N
|λ
i
| < 1.
(2.30)
Należy też zwrócić uwagę na fakt, że im mniejszy promień spektralny macierzy iteracji
M, tym szybsza zbieżność metody iteracyjnej [1, 3].
Aby zastosować metodę iteracyjną rozwiązywania N równań liniowych postaci Ax =
b do odwracania macierzy A, będziemy uruchamiać daną metodę N razy obliczając
kolejne kolumny macierzy odwrotnej przez podstawienie wektora e
i
= (0, ..., 0, e
i
=
1, 0, ..., 0)
T
za wektor b. Wyjątkiem jest metoda Richardsona z [14], zaimplementowana
w taki sposób, że przeprowadza jednocześnie iterację wszystkich (nawet więcej niż N )
kolumn macierzy B rozwiązując de facto równanie macierzowe AX = B. Przez podsta-
wienie B = I otrzymamy X ≈ A
−1
.
2.2.1. Metoda Jacobiego
Najprostszą z metod iteracyjnych jest metoda Jacobiego. Polega ona na rozkładzie
macierzy A na sumę macierzy wg wzoru
A = L + D + U,
(2.31)
gdzie D jest macierzą diagonalną i zawiera elementy diagonalne macierzy A, a macierze
L i U są odpowiednio dolną i górną częścią macierzy A z zerami na głównej przekątnej.
Po podstawieniu (2.31) do układu równań Ax = b proste przekształcenia prowadzą
do wzoru [1, 14]
x = −D
−1
(L + U)x + D
−1
b.
(2.32)
Porównując powyższy wzór z (2.29) mamy M = −D
−1
(L + U) oraz w = D
−1
b.
Zbieżność metody Jacobiego wymaga, aby macierz M była nieredukowalna i diagonalnie
słabo dominująca [1, 3]. Taka macierz jest też nieosobliwa.
2.2.2. Metoda Richardsona
Metoda ta również prowadzi do stałej macierzy iteracji M i stałego wektora w,
a oparta jest na następujących przekształceniach [1, 3, 14]:
Ax
=
b,
αAx
=
αb,
x + αAx
=
x + αb,
x
=
x − αAx + αb,
x
=
(I − αA)x + αb,
M
=
I − αA,
w
=
αb.
14

Łatwo pokazać [1], że jeśli macierz A jest symetryczna, to aby promień spektralny
macierzy M był mniejszy od jedności, wszystkie wartości własne macierzy A muszą być
tego samego znaku. Warunek ten spełnia symetryczna macierz dodatnio określona.
Parametr α jest liczbą całkowitą dobraną tak, aby promień spektralny macierzy
M = I − αA był jak najmniejszy. Najmniejszą wartość promienia spektralnego równą
ρ
min
(M) =
λ
max
− λ
min
λ
max
+ λ
min
)
(2.33)
otrzymuje się dla
α =
2
λ
max
+ λ
min
.
(2.34)
Żeby móc skorzystać z tej metody, trzeba w naszym przypadku znać ekstremalne war-
tości własne symetrycznej macierzy trójdiagonalnej T. Wiemy (np. z [9]), że wszystkie
wartości własne macierzy dodatnio określonej zawarte są w przedziale (0, kTk
∞
), gdzie
k · k
∞
to norma nieskończona macierzy, czyli maksymalna suma modułów w wierszu
(patrz (3.3)). Jeśli nie chcemy szukać wartości własnych możemy spróbować zastąpić
λ
min
przez 0, a λ
max
przez kTk
∞
. Kiedy zbieżność metody wciąż nie jest zadowalają-
ca, możemy spróbować wyznaczyć największą i najmniejszą wartość własną macierzy
trójdiagonalnej przy pomocy stabilnej metody Martina-Deana opisanej w [11]. Okazuje
się bowiem, że liczba ujemnych wyrazów w ciągu (2.52) równa jest liczbie ujemnych
wartości własnych macierzy T. Wystarczy przesuwając widmo macierzy znaleźć takie
przesunięcie, w otoczeniu którego liczba ta „przeskakuje” o jeden i metoda bisekcji po-
zwoli znaleźć przybliżenie jednej wybranej wartości własnej macierzy T (w tym wypadku
dwóch: maksymalnej i minimalnej).
2.2.3. Metoda nadrelaksacji (SOR)
Metoda ta korzysta z obu powyższych pomysłów i jest jakby połączeniem metody
Jacobiego z metodą Richardsona. W metodzie Jacobiego pomysłem był rozkład macierzy
na sumę (2.31) i przeniesienie jednego z powstałych w ten sposób czynników na drugą
stronę równania, a w metodzie Richardsona pomnożenie obu stron równania przez pewien
parametr i dodanie do obu stron składnika zawierającego wektor x. W metodzie SOR
stosujemy oba te przekształcenia [1, 3, 14, 15]:
Ax
=
b,
ω(L + D + U)x
=
ωb,
ωLx
=
−ωDx − ωUx + ωb,
Dx + ωLx
=
Dx − ωDx − ωUx + ωb,
(D + ωL)x
=
((1 − ω)D − ωU)x + ωb,
x
=
(D + ωL)
−1
((1 − ω)D − ωU)x + ω(D + ωL)
−1
b,
M
=
(D + ωL)
−1
((1 − ω)D − ωU),
w
=
ω(D + ωL)
−1
b.
Właściwy wybór wartości parametru ω jest trudny, ale niezwykle istotny, bo może
znacznie przyspieszyć zbieżność algorytmu [1, 15]. Wartość ω musi spełniać 0 < ω < 2,
15
przy czym dla ω < 1 mówimy o podrelaksacji, a dla ω > 1 o nadrelaksacji. Kiedy
parametr ω jest równy jeden, to metoda SOR sprowadza się do metody Gaussa-Seidela,
która jest zbieżna dla tych samych warunków, co metoda Jacobiego (tylko jest zwykle
zbieżna szybciej).
Dla symetrycznej i dodatnio określonej macierzy trójdiagonalnej można wykazać, że
optymalna wartość parametru ω wyraża się przez
ω =
2
1 +
p
1 − λ
2
max
,
(2.35)
gdzie λ
max
jest największą wartością własną macierzy M z iteracji Jacobiego, czyli M =
−D
−1
(L + U).
2.2.4. Metoda Czebyszewa
Metoda Czebyszewa należy do niestacjonarnych metod iteracyjnych, czyli w każdym
kroku iteracji, jej parametry zależą od poprzednich kroków. Wykorzystuje ona relacje
rekurencyjne wielomianów Czebyszewa, aby uzależnić kolejne przybliżenie od dwóch po-
przednich przybliżeń obliczonych w dwóch poprzednich krokach iteracji. Iteracja w me-
todzie Czebyszewa ma postać [1]
r
(i)
= Ax
(i)
,
(2.36)
x
(i+1)
= x
(i)
+ (p
(i−1)
(x
(i)
− x
(i−1)
) − r
(i)
)/q
(i)
.
(2.37)
Współczynniki p
(i)
i q
(i)
oblicza się ze wzorów [1]
c =
a + b
2
,
d =
b − a
4
2
,
q
∗
=
a + b + 2
√
ab
4
,
p
(−1)
= 0,
q
(0)
= c,
p
(0)
=
2d
c
,
q
(1)
=
a + b
4
+
ab
a + b
,
γ
(1)
=
2
√
ab
a + b
d
q
∗
,
p
(i−1)
=
d
q
(i−1)
,
γ
(i)
=
p
(i−1)
γ
(i−1)
q
∗
,
q
(i)
= q
∗
− γ
(i)
.
(2.38)
Parametry a i b to odpowiednio minimalna i maksymalna wartość własna macierzy
T, albo (jeśli nie są one znane) przyjmuje się, że a = 0, a b = kTk. Głównym kosz-
tem metody Czebyszewa jest mnożenie macierzy przez wektor przy obliczaniu wektora
residualnego r.
2.2.5. Metoda gradientów sprzężonych (CG)
Metoda gradientów sprzężonych, podobnie jak metoda Czebyszewa jest niestacjonar-
ną metodą iteracyjną. Można ją zastosować do symetrycznej macierzy dodatnio określo-
nej. Oparta jest na minimalizacji funkcji
f (x) =
1
2
x · A · x − b · x
(2.39)
16
poprzez doprowadzanie jej gradientu ∇f = A · x − b do zera. Minimalizacja tej funkcji
polega na poszukiwaniu tzw. kierunku najszybszego spadku i na sukcesywnym poru-
szaniu się w tym kierunku. W każdym kroku poszukuje się takiej wartości α
i
, która
minimalizuje wyrażenie f (x
(i+1)
), gdzie x
(i+1)
= x
(i)
+ α
i
p
(i)
.
Algorytm dla metody gradientów sprzężonych wykonuje w każdym kroku iteracji
jedno mnożenie macierzy A przez wektor i dwa iloczyny skalarne wektorów. Ta pro-
stota jest przyczyną, dla której metoda CG jest taka popularna. Wystarczy pamiętać
trzy wektory: przybliżone rozwiązanie x, resztę r i kierunek poszukiwań p. Łatwo też
udowodnić zbieżność iteracji CG zakładając, że obliczenia wykonywane są z nieskoń-
czoną dokładnością [2]. Interpretacja wyników w arytmetyce zmiennoprzecinkowej jest
już trudniejsza i skuteczność algorytmu CG w tym przypadku jest zadziwiająco duża.
W teorii [2] jeśli macierz A ma N różnych wartości własnych, to iteracja CG (przy
nieskończonej precyzji obliczeń) osiąga minimum w co najwyżej N krokach. Mamy więc
metodę iteracyjną o cechach metody bezpośredniej, dla której zbieżność jest teoretycznie
pewna po skończonej liczbie iteracji! Jeśli mnożenie wektora przez macierz można wyko-
nać przy pomocy liczby operacji rzędu O(N ), to sumaryczny koszt metody gradientów
sprzężonych powinien być rzędu O(N
2
).
Podstawową wersję algorytmu, którą opracowali Hestens i Stiefel, przytoczymy tutaj
za [2]. Tej samej wersji używa wykorzystana w programie TIPS procedura z [15]. Dla
wartości początkowych x
0
= 0, r
0
= b i p
0
= r
0
, n-ty krok iteracji ma postać
α
n
=
r
T
n−1
r
n−1
p
T
n−1
Ap
n−1
nowa wartość parametru α
x
n
= x
n−1
+ α
n
p
n−1
kolejne przybliżenie
r
n
= r
n−1
+ α
n
Ap
n−1
reszta
β
n
=
r
T
n
r
n
r
T
n−1
r
n−1
nowa wartość parametru β
p
n
= r
n
+ β
n
p
n−1
nowy kierunek poszukiwań
(2.40)
2.3. Metody oparte o wzory analityczne
Metoda dla macierzy symetrycznej
Wróćmy do metody wyznacznikowej z podrozdziału 2.1.1. Obie rekurencje (2.3)
i (2.5) obliczają wyznacznik macierzy T
N
, przy pomocy wyznaczników niższych stopni
(nazwijmy je minorami diagonalnymi) stosując rozwinięcie Laplace’a [10] odpowied-
nio względem ostatniego i pierwszego wiersza. Minory diagonalne, to takie wyznaczniki,
których przekątna jest w całości zawarta w przekątnej macierzy T
N
.
17
Oznaczymy minory diagonalne rzędu j − i + 1 jako
W
i,j
=
d
i
e
i
e
i
d
i+1
e
i+1
. ..
. ..
. ..
e
j−2
d
j−1
e
j−1
e
j−1
d
j
.
(2.41)
Wzór (2.7) dla i < j (symetria macierzy T
−1
N
) zapisujemy krócej jako
T
−1
N
ij
=
(−1)
i+j
W
1,N
W
1,i−1
j−1
Y
k=i
e
k
W
j+1,N
.
(2.42)
Stosunkowo łatwo wykazać indukcyjnie, że dla N 1 i j = 1, ..., N zachodzi
j−1
Y
k=1
e
2
k
W
j+1,N
= W
1,j−1
W
2,N
− W
2,j−1
W
1,N
,
(2.43)
jeśli przyjmiemy, że dla i > j jest W
i,j
= 2 − i + j. Gdy podstawimy W
j+1,N
ze wzoru
(2.43) do (2.42) otrzymujemy
T
−1
N
ij
=
(−1)
i+j
W
1,N
W
1,i−1
W
1,j−1
W
2,N
− W
2,j−1
W
1,N
Q
i−1
k=1
e
k
Q
j−1
k=1
e
k
=
= (−1)
i+j
W
1,i−1
W
1,j−1
Q
i−1
k=1
e
k
Q
j−1
k=1
e
k
W
2,N
W
1,N
−
W
2,j−1
W
1,j−1
!
=
=
(−1)
i−1
W
1,i−1
Q
i−1
k=1
e
k
!
(−1)
j−1
W
1,j−1
Q
j−1
k=1
e
k
!
(−1)
j
W
2,j−1
(−1)
j−1
W
1,j−1
−
(−1)
N +1
W
2,N
(−1)
N
W
1,N
!
.
(2.44)
Definiujemy dwa nowe ciągi {p
i
} i {q
j
}:
p
i
=
(−1)
i
W
1,i
Q
i
k=1
e
k
,
q
j
=
(−1)
j+1
W
2,j
Q
j
k=1
e
k
.
(2.45)
Nie są to te same ciągi, co (2.3) i (2.5), gdzie dla odróżnienia pisaliśmy zawsze argument
wielomianu z. Dzięki (2.45) wzór (2.44) sprowadza się do prostej postaci
T
−1
N
ij
= p
i−1
p
j−1
q
j−1
p
j−1
−
q
N
p
N
!
.
(2.46)
Wzór (2.46) pochodzi z pracy [8], jednak metoda jego wyprowadzenia przedstawiona
tutaj jest bardziej oczywista. Ciągi (2.45) są w [8] zdefiniowane rekurencyjnie
e
i
p
i
= −e
i−1
p
i−2
− d
i
p
i−1
,
p
0
= 1,
p
1
= −d
1
/e
1
,
e
i
q
i
= −e
i−1
q
i−2
− d
i
q
i−1
,
q
0
= 0,
q
1
= 1/e
1
.
(2.47)
18
Korzyść, jaką uzyskujemy w stosunku do wzoru (2.7) polega na tym, że nie liczymy
już bezpośrednio wartości minorów, które mogą być bardzo duże i powodować problemy
numeryczne. Zamiast tego obliczamy rekurencyjnie według (2.47) elementy ciągów {p
i
}
i {q
j
}, które mają mniejszą wartość bezwzględną dzięki iloczynom w mianownikach wzo-
rów (2.45). Niestety te same iloczyny powodują, że wartości p
N
i q
N
potrzebne w (2.46)
nie są dobrze określone (nie istnieje w macierzy wyraz e
N
). Dobrze określony jest nato-
miast ich iloraz q
N
/p
N
, ponieważ
T
−1
N
11
= −q
N
/p
N
. Wartości p
N
i q
N
nie otrzymamy
z ciągów (2.47), więc musimy obliczyć
T
−1
N
11
inną metodą i zamiast z (2.46) skorzystać
z następującego wzoru
T
−1
N
ij
= p
i−1
q
j−1
+ p
j−1
T
−1
N
11
.
(2.48)
Ciąg {q
j
(0)} (2.5) obliczany jest od końca (tzn. dla j = N −1, ..., 1) w przeciwieństwie
do ciągu {p
i
(0)} (2.3), który liczymy od początku (tzn. dla i = 2, ..., N ). Natomiast ciągi
{p
i
} i {q
j
} (2.47) można obliczać jednocześnie, w jednej pętli, w miarę czytania kolejnych
wartości {d
i
} i {e
i
}. Dzięki temu można ponownie wykorzystać pamięć przeznaczoną na
macierz T
N
.
Liniowe rekurencje drugiego rzędu (2.47) pozwalają wyznaczać kolejny wyraz każdego
z ciągów przy pomocy dwóch poprzednich wyrazów tego samego ciągu (metoda 1A). Tak
jednak być nie musi. W pracy [8] znajdujemy także łatwy do udowodnienia indukcyjnie
związek
e
i
(p
i−1
q
i
− p
i
q
i−1
) = 1,
dla i 1.
(2.49)
Jeśli teraz najpierw obliczymy p
i
, to q
i
możemy wyznaczyć z (2.49) nie używając
jawnie wyrazu q
i−2
(metoda 1B). Podobnie jeśli najpierw obliczymy q
i
, to p
i
możemy
wyznaczyć nie używając p
i−2
(metoda 1C). Daje to dwie alternatywne w stosunku do
(2.47) metody obliczania ciągów {p
i
} i {q
j
}, które choć równoważne matematycznie,
mogą nie być równoważne numerycznie.
Do skorzystania z metod 1A, 1B i 1C opartych o wzór (2.48) musimy poznać wartość
pierwszego elementu diagonalnego macierzy odwrotnej. W pracy [8] podaje się odpo-
wiedni wzór w postaci ułamka łańcuchowego (ciągłego)
T
−1
N
11
=
1
d
1
−
e
2
1
d
2
−
e
2
2
· · · − · · ·
..
.
e
2
N −2
d
N −1
−
e
2
N −1
d
N
.
(2.50)
Obliczenie wzoru (2.50) sprowadza się do obliczenia odwrotności wyrazu v
1
ciągu
(2.53).
19
Metoda dla macierzy diagonalnie dominującej
Wyprowadzona i udowodniona w pracy [7] metoda obliczania wyrazów macierzy
odwrotnej dotyczy macierzy trójdiagonalnej, która jest diagonalnie dominująca (tzn.
|d
i
| > |e
i−1
| + |e
i
|), ale niekoniecznie symetryczna. Zastosowana jednak do macierzy
symetrycznej, po przyjęciu oznaczeń z (2.1), (2.3) i (2.5) ma następującą postać:
T
−1
N
ij
=
−e
i
p
i−1
(0)
p
i
(0)
T
−1
N
i+1,j
i < j
d
j
− e
2
j−1
p
j−2
(0)
p
j−1
(0)
− e
2
j
q
j+2
(0)
q
j+1
(0)
!
−1
i = j
−e
i−1
q
i+1
(0)
q
i
(0)
T
−1
N
i−1,j
i > j
.
(2.51)
Ze wzoru (2.51) wynika, że jeśli najpierw obliczymy wyrazy diagonalne macierzy T
−1
N
,
to pozostałe wyrazy łatwo wyznaczyć, bo są one od siebie nawzajem zależne! Minory
z ciągów {p
i
(0)} i {q
i
(0)} wchodzą do wzoru (2.51) zawsze w postaci ilorazów dwóch
kolejnych minorów z tych samych ciągów.
Można zatem zdefiniować pomocnicze ciągi w następujący sposób:
u
1
= d
1
,
u
i
=
p
i
(0)
p
i−1
(0)
= d
i
−
e
2
i−1
u
i−1
,
i = 2, ..., N ;
(2.52)
v
N
= d
N
,
v
j
=
q
j
(0)
q
j+1
(0)
= d
j
−
e
2
j
v
j+1
,
j = N − 1, ..., 1.
(2.53)
Ciąg (2.52) jest znany i szeroko stosowany w zagadnieniach własnych z symetryczną
macierzą trójdiagonalną [11], ponieważ są to kolejne wyrazy diagonalne macierzy D
z rozkładu T
N
= LDL
T
(porównaj z (2.18) i (2.22)).
Dzięki (2.52) i (2.53) możemy uprościć (2.51) do postaci
T
−1
N
ij
=
−
e
i
u
i
T
−1
N
i+1,j
i < j
u
j
−
e
2
j
v
j+1
!
−1
i = j
−
e
i−1
v
i
T
−1
N
i−1,j
i > j
.
(2.54)
Wzór (2.54) można obliczać na trzy sposoby. Metoda 2A polegać będzie na tym, że
najpierw obliczymy {v
j
}, a potem
T
−1
N
ii
jednocześnie zapamiętując {e
i
/u
i
} w pamięci
poprzednio zajętej przez {e
i
}. Wyrazy niediagonalne obliczymy ostatecznie ze wzoru
(2.54) dla i < j. Metoda 2B polegać będzie na tym, że najpierw obliczymy {u
i
}, a potem
T
−1
N
jj
jednocześnie zapamiętując {e
j
/v
j+1
} w pamięci poprzednio zajętej przez {e
j
}.
Wyrazy niediagonalne obliczymy ostatecznie ze wzoru (2.54) dla i > j. Metoda 2C
polegać będzie na tym, że najpierw obliczymy {u
i
}, potem osobno {v
j
}, dalej
T
−1
N
ii
,
20

a wyrazy niediagonalne macierzy odwrotnej obliczymy korzystając z obu wzorów (2.54)
odpowiednio dla i < j oraz i > j.
Problemem może wydawać się obliczenie ostatniego wyrazu diagonalnego macierzy
odwrotnej ze wzoru (2.54), gdyż znów mamy tam nie istniejący wyraz e
N
. Tutaj jednak,
w przeciwieństwie do (2.45), wystarczy przyjąć za [7], że e
N
= 0, a wtedy
T
−1
N
N N
=
u
−1
N
= W
1,N −1
/W
1,N
. Widać przy tym podobieństwo do wzoru (2.44), z którego wynika
T
−1
N
11
= W
2,N
/W
1,N
. Obydwa te wzory wynikają też w oczywisty sposób bezpośrednio
z (2.2).

3. Opis środowiska obliczeniowego (Program
TIPS)
3.1. Źródła danych i algorytmów
Środowisko TIPS (Tridiagonal Inverse Problem Solver) służy do wyznaczania ma-
cierzy odwrotnej do symetrycznej macierzy trójdiagonalnej. Przeznaczone jest ono dla
wszystkich systemów operacyjnych rodziny Windows
R
, chociaż dostępne kody źródłowe
pozwalają na osobną kompilację środowiska w innym systemie operacyjnym.
Składa się z aplikacji głównej (tips.exe), programu losującego macierze trójdiago-
nalne (h matgen.exe), programu sprawdzającego poprawność wyniku (h tester.exe) oraz
szeregu osobnych programów obliczających macierz odwrotną.
TIPS jest aplikacją napisaną i skompilowaną przy pomocy pakietu Delphi 5, a po-
zostałe programy napisano w języku Fortran i skompilowano przy pomocy środowiska
Force w wersji 2.0.8 i dostępnego wraz z nim kompilatora G77 w wersji 0.5.25 z dodat-
kowymi programami pakietu binutils w wersji 2.15.91. Niektóre programy skompilowano
z fragmentami bibliotek LAPACK 3 oraz BLAS, które nie są do nich dołączone w postaci
źródłowej. Wykorzystano także bibliotekę Portable Network Graphics Delphi w wersji
1.564 napisaną przez Gustavo Daud (gustavo.daud@terra.com.br) i dostępną za darmo
pod adresem http://pngdelphi.sourceforge.net.
Wszystkie programy obliczeniowe wymienione są w pliku konfiguracyjnym tips.ini.
Plik ten użytkownik może dowolnie modyfikować, tzn. dodawać własne programy obli-
czeniowe pod warunkiem, że przestrzegają one reguł dotyczących nazewnictwa plików
wejściowych, wyjściowych oraz formatu i kolejności danych w tych plikach. Dokładny
opis tego interfejsu programistycznego, a także innych możliwości środowiska zawarty
jest osobno w pomocy do programu TIPS i nie jest tutaj przedstawiony szczegółowo.
Dane dla programu TIPS to macierze trójdiagonalne oraz dodatkowe parametry je-
śli wybrany algorytm numeryczny ich wymaga (np. tolerancje dla kryteriów zbieżno-
ści, maksymalna dozwolona liczba iteracji itp.). Macierze mogą być wylosowane przez
program TIPS (a dokładnie przez podprogram h matgen.exe), dostarczone z zewnątrz
w postaci plików tekstowych, albo obliczone przez TIPS na podstawie zadanego wzoru
(osobne wzory dla elementów diagonalnych i pozadiagonalnych).
Obliczenia wzorów w programie TIPS wykonywane są w rozszerzonej precyzji (80
bitów), a następnie zaokrąglane do podwójnej precyzji (64 bity). Aby zachować mak-
simum kompatybilności z innymi językami programowania wszelkie dane przekazywane
są między programami środowiska TIPS poprzez pliki tekstowe. Programy obliczeniowe
otrzymują dane podwójnej precyzji (17 dziesiętnych cyfr znaczących), wykonują oblicze-
22

nia w podwójnej precyzji i przekazują wyniki (tj. macierz odwrotną, czas obliczeń mie-
rzony w jednostkach 1/1000 sekundy oraz ewentualne błędy) do programu testującego,
który przeprowadza czasochłonne mnożenie macierzy, oblicza wybrane błędy numerycz-
ne (również w podwójnej precyzji) i umieszcza je w wielokolumnowym pliku tekstowym.
Plik ten może być potem czytany przez program TIPS, który rysuje dwuwymiarowe
wykresy wybranych testów (dowolne zależności między kolumnami pliku wynikowego).
Program TIPS (h matgen.exe) może generować symetryczne macierze trójdiagonalne
przy pomocy generatora pseudolosowego z [9]. Macierz tą można też uczynić diagonalnie
dominującą lub dodatnio określoną.
Algorytmy dla metod iteracyjnych zaczerpnięto z [15]. Wyjątki są dwa. Implementa-
cja metody Czebyszewa oparta jest w całości na [1]. Implementacja metody Richardsona
zawarta w [14], została dostosowana do konwencji używanych w pozostałych programach
napisanych w języku Fortran i może służyć także jako przykład takiego dostosowania.
W wielu programach obliczeniowych korzystam także z biblioteki Lapack [13], z której
pochodzą też w całości algorytmy obliczania rozkładów SVD (2 wersje), LDL
T
oraz
LU z częściowym wyborem elementu głównego. Eliminacja Gaussa-Jordana opiera się
na podprogramie gaussj z [5]. Rozkład QR jest nieco zmodyfikowanym algorytmem
dekompozycji z [11]. Pozostałe metody, tj. wyznacznikowa i różne metody ”analityczne”
(w 6 wersjach) oparte są na wzorach zawartych i częściowo wyprowadzonych w tej pra-
cy. Ich implementacja i przetestowanie były inspirowane wynikami prac [7, 8] oraz [6].
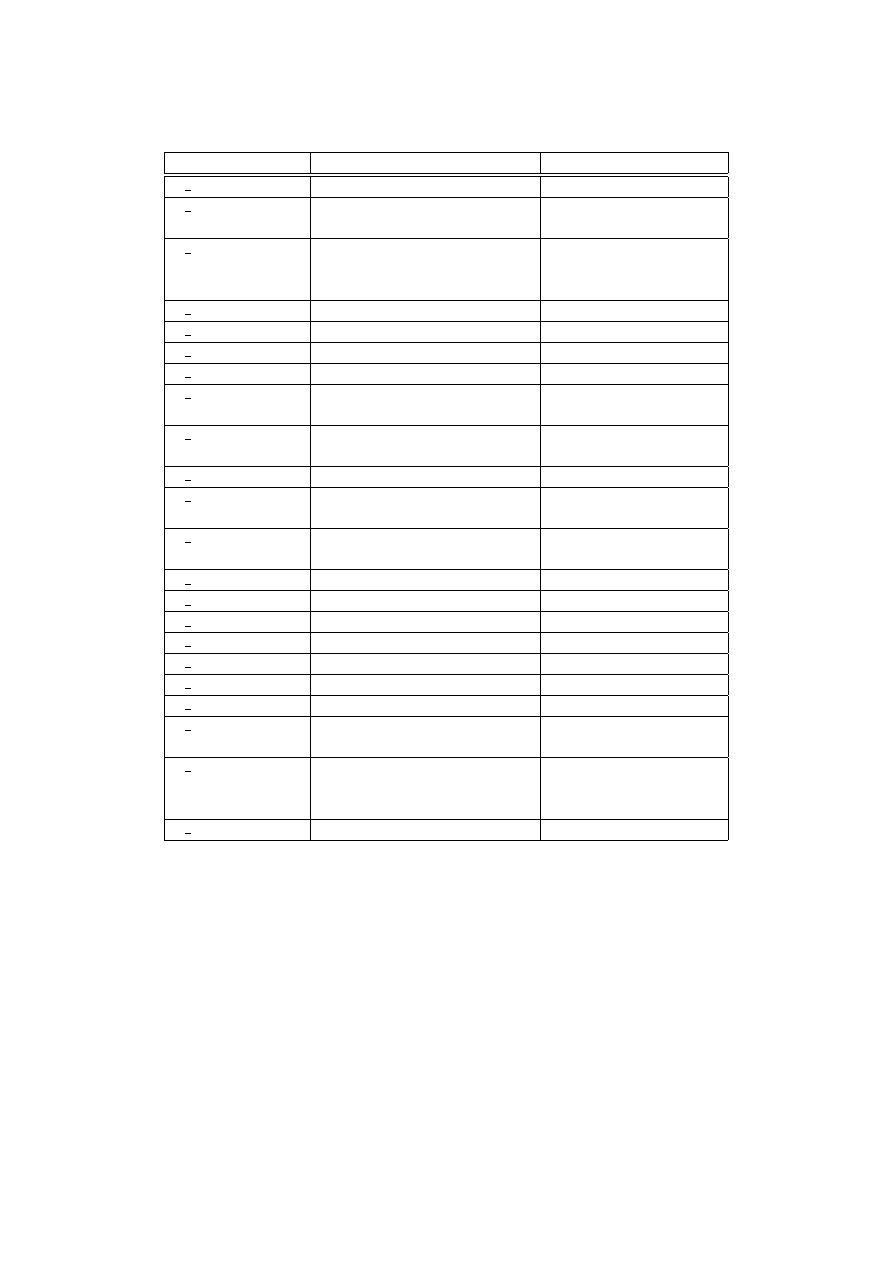
Kompletny spis dołączonych do programu TIPS programów obliczeniowych (ich nazwy
zaczynają się od p ) zawarty jest w tabeli na następnej stronie.
23
Program
Metoda
Źródło/Wzory
p wyzn.exe
wyznacznikowa
(2.3, 2.5, 2.7)
p gauss.exe
eliminacja Gaussa / rozkład
LU
DGTSV [13] ze zmiana-
mi
p dgtsv.exe
eliminacja Gaussa z wyborem
elementu głównego / rozkład
LU
DGTSV [13]
p gsjor.exe
eliminacja Gaussa-Jordana
oparta na gaussj [5]
p llt1.exe
rozkład LL
T
(2.21)
p dptsv.exe
rozkład LDL
T
DPTSV [13]
p qr1.exe
rozkład QR
(2.26), oparta na [11]
p svd1.exe
rozkład SVD / metoda QR
DGBBRD,
DBDSQR
[13]
p svd2.exe
rozkład SVD / metoda „dziel
i rządź”
DGBBRD,
DBDSDC
[13]
p alg1.exe
„analityczna” 1A
(2.47), (2.48), (2.53), [8]
p alg2.exe
„analityczna” 1B
(2.47),
(2.48),
(2.53),
(2.49), [8]
p alg3.exe
„analityczna” 1C
(2.47),
(2.48),
(2.53),
(2.49), [8]
p alg4.exe
„analityczna” 2A
(2.52), (2.53), (2.54), [7]
p alg5.exe
„analityczna” 2B
(2.52), (2.53), (2.54), [7]
p alg6.exe
„analityczna” 2C
(2.52), (2.53), (2.54), [7]
p jacobi.exe
Jacobiego
JacobiREVCOM[15]
p richar.exe
Richardsona
msSolveRichardson [14]
p gseid.exe
Gaussa-Seidla
SORREVCOM [15]
p sor.exe
nadrelaksacji SOR
SORREVCOM [15]
p cgrad1.exe
gradientów sprzężonych (bez
uwarunkowania wstępnego)
CGREVCOM [15]
p cgrad2.exe
gradientów
sprzężonych
(diagonalne
uwarunkowanie
wstępne)
CGREVCOM [15]
p cheby2.exe
Czebyszewa
(2.38) [1]
3.2. Ocena dokładności obliczeń
Numeryczne obliczenie macierzy odwrotnej do macierzy trójdiagonalnej T jest rów-
noważne rozwiązaniu układu równań macierzowych
T ˆ
X = I,
(3.1)
24
gdzie ˆ
X ≈ T
−1
. Dokładność wyznaczenia macierzy ˆ
X możemy sprawdzać obliczając
reszty [4]
ˆ
XT − I
reszta lewostronna [ang. left residual],
T ˆ
X − I
reszta prawostronna [ang. right residual].
(3.2)
Z definicji macierzy odwrotnej wynika przemienność mnożenia A
−1
A = AA
−1
= I
[10]. Ponieważ macierz T jest symetryczna, to spodziewamy się, że reszty (3.2) będą
jednakowe, jeśli tylko obliczona przybliżona macierz ˆ
X także będzie symetryczna. Pa-
miętajmy jednak, że w trakcie mnożenia macierzy wykonujemy także dodawanie, a to
nie jest przemienne w sensie numerycznym i podczas dodawania bliskich siebie liczb
przeciwnych mogą wystąpić duże błędy obcięcia [ang. cancelation].
Nie możemy bezpośrednio obliczyć tzw. błędu bieżącego [ang. forward error] T
−1
− ˆ
X,
bo nie znamy dokładnej wartości T
−1
. Czasem bada się algorytmy numeryczne wyko-
nując obliczenia w większej precyzji, a następnie zaokrągla się uzyskiwane wyniki sy-
mulując w ten sposób arytmetykę zmiennoprzecinkową o mniejszej precyzji. W takich
kontrolowanych warunkach uprawnione jest potraktowanie wyników dokładniejszych ja-
ko prawdziwe i oszacowanie przy ich pomocy błędu bieżącego [4].
W programie TIPS także możemy dysponować dokładniejszym rozwiązaniem korzy-
stając z procedury DGTRFS z biblioteki Lapack [13]. Procedura ta stosuje metodę itera-
cyjnego udokładniania [ang. refinement] rozwiązania, która nie tylko pozwala polepszyć
dokładność wyniku uzyskanego każdą inną metodą, ale także udostępnia oszacowania
błędu bieżącego FERR i wstecznego błędu komponentowego BERR. Opis definicji i do-
kładnego sposobu obliczania tych błędów znajdziemy w [13].
Reszty (3.2) są macierzami i porównywać je można w sensie dowolnej normy (przez
równoważność norm [1, 2, 13]) albo komponentowo [2, 4]. Dalej (podobnie jak w [13])
jako normy macierzy będziemy używali normy k·k
∞
(tzw. normy nieskończonej, zwanej
też wierszową)
kAk
∞
= max
1¬i¬N
N
X
j=1
|A
ij
|.
(3.3)
Jest ona najmniejszą znaną normą macierzową, bo zachodzą związki [13]
kAk
∞
¬ N kAk
1
oraz kAk
∞
¬
√
N kAk
2
¬
√
N kAk
F
.
(3.4)
Program TIPS może obliczać także pozostałe normy z (3.4):
•
normę kolumnową (normę jeden) kAk
1
= max
1¬j¬N
N
X
i=1
|A
ij
|,
•
normę spektralną (normę dwa) kAk
2
= max
x6=0
kAxk
kxk
= σ
max
(A),
•
normę Frobeniusa kAk
F
=
s
X
ij
|A
ij
|
2
.
Norma spektralna wyznaczana jest jako maksymalna wartość szczególna macierzy,
która jest szacowana przez pierwiastek kwadratowy z maksymalnej wartości własnej
symetrycznej, dodatnio określonej macierzy A
T
A. Specjalnie do znalezienia tej wartości
25

własnej zaimplementowano w programie (h tester.exe) metodę potęgową [1, 11, 14]. Ob-
liczenia te mogą być czasochłonne, dlatego w programie TIPS są domyślnie wyłączone.
Program TIPS oblicza lewo- i prawostronne błędy względne
LERR :=
k ˆ
XT − Ik
∞
kTk
∞
k ˆ
Xk
∞
,
(3.5)
P ERR :=
kT ˆ
X − Ik
∞
kTk
∞
k ˆ
Xk
∞
,
(3.6)
oraz błędy względne komponentowe (lewo- i prawostronne)
CLERR := min{ : ∀
ij
|( ˆ
XT − I)
ij
| ¬ |T
ij
|| ˆ
X
ij
|},
(3.7)
CP ERR := min{ : ∀
ij
|(T ˆ
X − I)
ij
| ¬ |T
ij
|| ˆ
X
ij
|}.
(3.8)
Wzory (3.7) i (3.8) wymagają wyjaśnienia. Nazwa „komponentowy” przyjęła się z ję-
zyka angielskiego. Komponent to po prostu element lub wyraz macierzy. Dla każdego
elementu i-tego wiersza i j-tej kolumny macierzy liczymy iloraz
|R
ij
|
|T
ij
|| ˆ
X
ij
|
,
a błąd względny komponentowy definiuje się jako największy z tych ilorazów. Powyż-
sza macierz R jest macierzą reszty lewo- albo prawostronnej (3.2). Problem polega na
tym, że nie policzymy tego ilorazu jeśli elementy T
ij
lub ˆ
X
ij
są równe zero. Dlatego
właśnie zamiast ilorazów we wzorach (3.7) i (3.8) mamy iloczyny. Myląca jest funkcja
minimum występująca w tych wzorach, gdyż kwantyfikator ∀ (dla każdego) niejako za-
mienia ją w maksimum. Jeśli dla pewnego elementu macierzy zdarzy się przypadkiem, że
R
ij
= T
ij
= ˆ
X
ij
= 0, to jedyne możliwe wynosi zero, ale kwantyfikator ∀ mówi nam, że
musiałoby tak być dla każdego elementu macierzy, więc takie przypadkowe zero zostanie
zignorowane (tzn. nie będzie stanowiło minimum). Błąd komponentowy jest narzędziem,
które nie tylko pozwala zignorować przypadkowe zera (w tym przypadku norma byłaby
po prostu mniejsza i wynik wydawałby się dokładniejszy niż jest w rzeczywistości), ale
celowo ignorować zera, które nie są przypadkowe. Dlatego błędy komponentowe (3.7)
i (3.8) mają przewagę nad błędami w sensie normy. Mogą one być duże podczas gdy błę-
dy w sensie normy pozostają bardzo małe. Błędy komponentowe pozwalają oszacować
maksymalne zaburzenie, jakie może zaistnieć po zastosowaniu danego algorytmu, a nie
ogólny wpływ tych zaburzeń na normę. W przypadku macierzy rzadkiej jaką jest na
przykład macierz trójdiagonalna, nie interesuje nas wpływ zaburzeń zerowych wyrazów
na wynik, bo w żadnej praktycznej sytuacji takie zaburzenie nie wystąpi (tych wyrazów
po prostu nie ma). Gdy obliczamy błędy w sensie normy, to poprzez uśrednianie (li-
czymy przecież sumy modułów) uwzględniamy takie zaburzenia, natomiast licząc błędy
komponentowe nie bierzemy niejawnie pod uwagę zaburzeń wyrazów macierzy równych
zero z definicji.
26
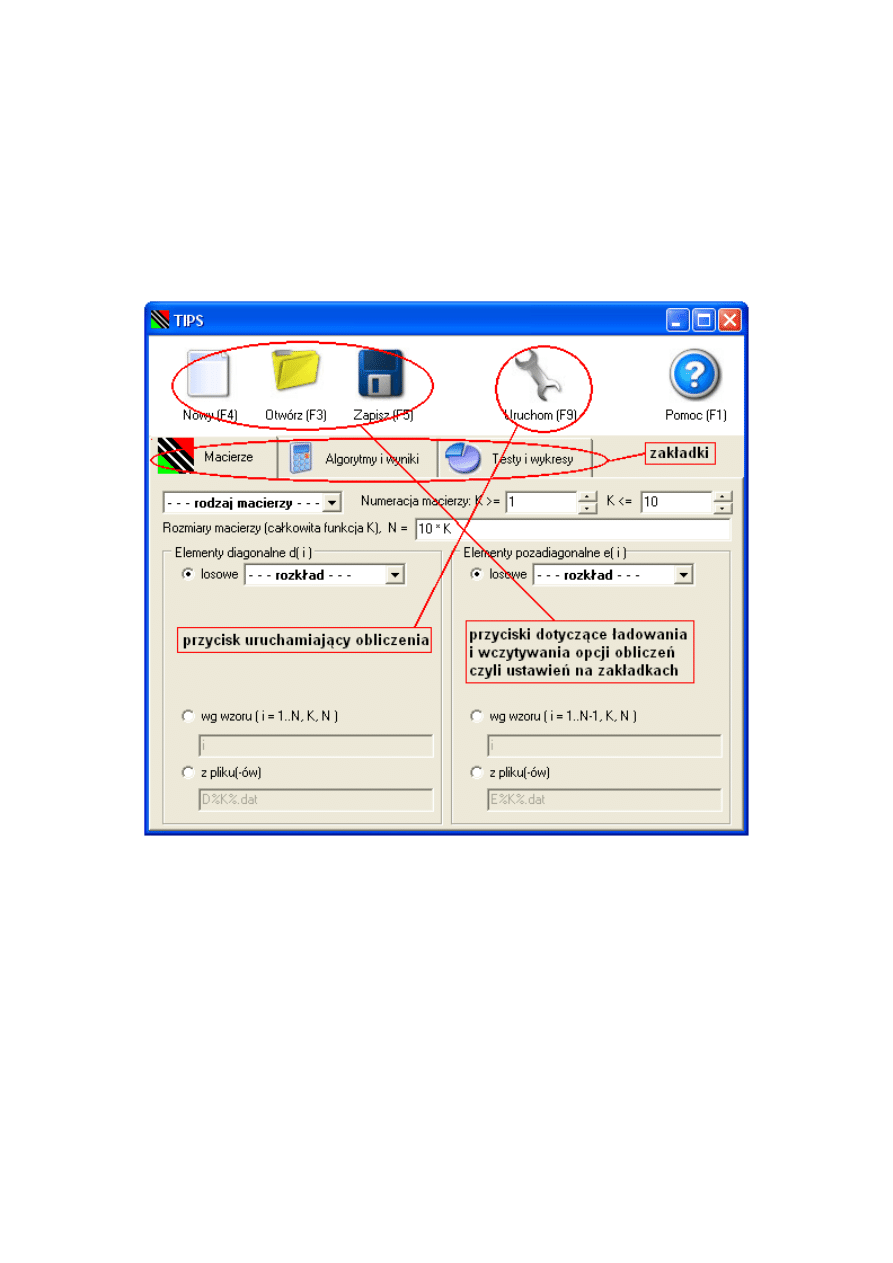
3.3. Interfejs użytkownika
3.3.1. Informacje podstawowe
Główne okno programu TIPS po uruchomieniu wygląda tak:
Rysunek 3.1. Wygląd okna głównego programu TIPS
Przed uruchomieniem obliczeń (F9) należy ustawić opcje obliczeń. Opcje te podzie-
lone są tematycznie na trzy zakładki: Macierze — opcje dotyczące macierzy i odpowie-
dzialne za dostarczenie danych dla algorytmów numerycznych, Algorytmy i wyniki
— opcje dotyczące algorytmów numerycznych i sposobu zapisania obliczonych macie-
rzy na dysku, Testy i wykresy — opcje dotyczące wyboru przeprowadzanych testów
i wykresów przedstawiających wyniki tych testów.
27

3.3.2. Zapis i odczyt opcji obliczeń
Zapis opcji odbywa się po naciśnięciu F5 albo przycisku ’Zapisz’ w górnej części okna
TIPS. Opcje zapisywane są domyślnie do plików tekstowych z rozszerzeniem ’.tips’, któ-
re zostają związane z programem TIPS przy jego instalacji. Po podwójnym kliknięciu
pliku z rozszerzeniem ’.tips’ w oknie Eksploratora Windows
R
otwiera się program TIPS
z opcjami już wczytanymi z tego pliku. Opcją jest wszystko to, co ustawiamy w oknie
głównym TIPS na trzech zakładkach. Opcjami obliczeń nie są więc wykresy i parametry
ich wyświetlania ani też parametry zapisu wyników do plików i nie są one zapisywa-
ne w plikach z rozszerzeniem ’.tips’. Dodatkowe parametry metod obliczeniowych są
zapisywane do plików ’.tips’. Ustawione opcje można przywrócić do ustawień domyśl-
nych (początkowych) przez naciśnięcie F4 albo przycisku ’Nowy’ w górnej części okna
TIPS. Opcje początkowe nie pozwalają na natychmiastowe uruchomienie obliczeń, gdyż
konieczne minimum stanowi wybranie algorytmu, typu macierzy i sposobu dostępu do
danych (czy i jak są losowane, czy są wczytywane z pliku, czy są obliczane ze wzoru).
Wcześniej zapisane opcje można wczytać do programu TIPS naciskając F3 albo przycisk
’Otwórz’ w górnej części okna TIPS.
3.3.3. Zakładka „Macierze”
Określanie rodzaju macierzy
Rodzaj macierzy określa w polu wyboru z rysunku 3.3. Macierz dowolna symetryczna
powstaje po prostu przez wylosowanie liczb z podanego rozkładu. Wybranie macierzy
diagonalnie dominującej powoduje, że najpierw odbywa się losowanie macierzy dowol-
nej symetrycznej z rozkładu jednostajnego (d
i
∈ (dod, ddo), e
i
∈ (eod, edo)), a potem
wylosowane elementy są przeliczane według wzoru z rysunku 3.4.
Macierz dodatnio określona jest tworzona przez mnożenie macierzy bidiagonalnej
dolnej przez jej transpozycję (odwrócenie rozkładu LL
T
). Liczone są wartości własne
danej macierzy przy pomocy procedury DSTEQR z biblioteki Lapack [13]. Jeśli oka-
że się, że wygenerowana macierz posiada jednak wartości własne ujemne, to widmo
tej macierzy jest przesuwane o podwojoną wartość bezwzględną najmniejszej (ujemnej)
wartości własnej.
28
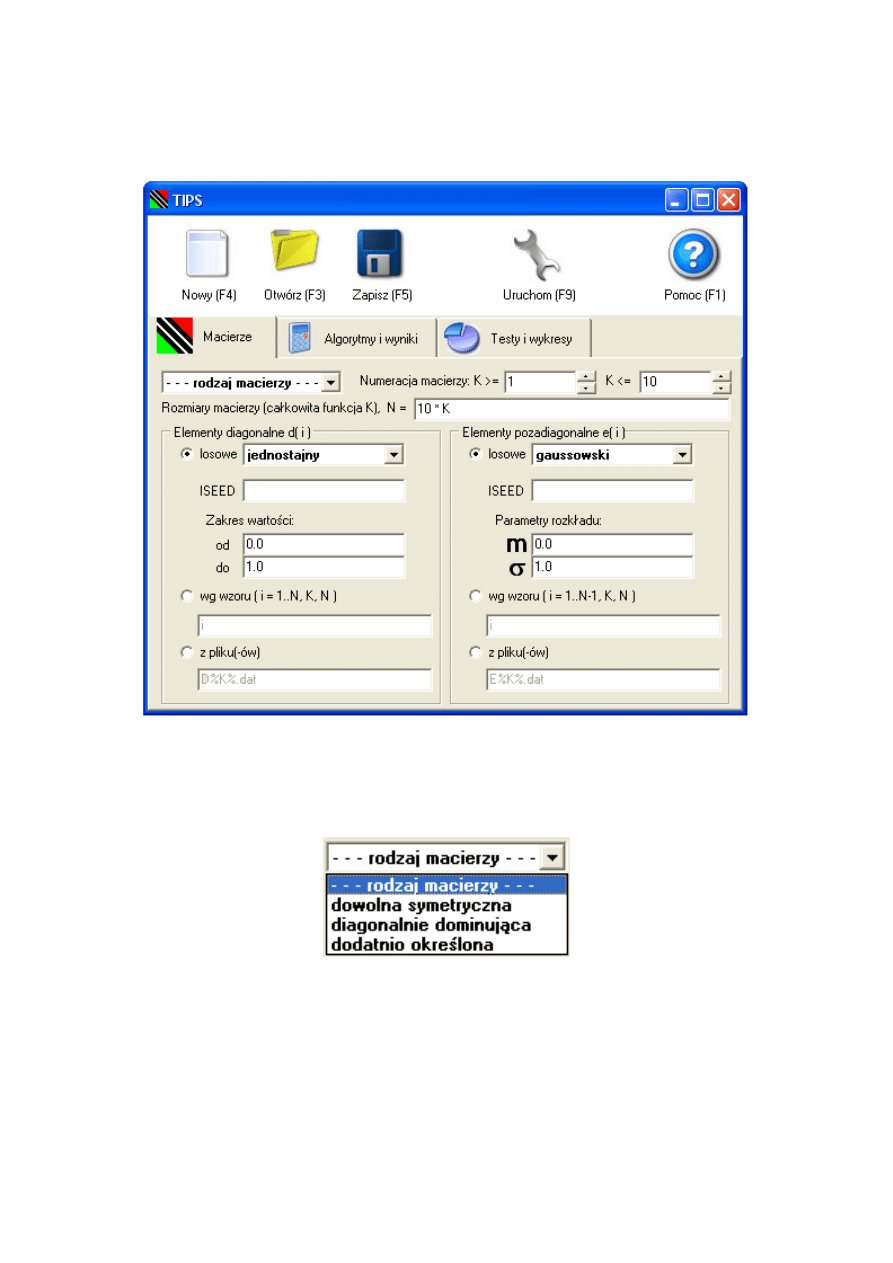
Rysunek 3.2. Wygląd zakładki „Macierze”
Rysunek 3.3. Rodzaje macierzy do wyboru
29

Rysunek 3.4. Wzory do przekształcenia macierzy w macierz diagonalnie dominującą
Wybranie numerów K macierzy
Program TIPS może wykonywać wiele obliczeń macierzy odwrotnych przy jednym
uruchomieniu. Każde takie obliczenie ma swój numer oznaczony przez liczbę K. Numeru
K można używać w polach edycyjnych we wzorach aby zmieniać wartości parametrów
w kolejnych obliczeniach. Określany jest numer K minimalny i maksymalny. Podczas
obliczeń numery K zmieniają się co jeden od najmniejszego, do największego.
Wybranie rozmiarów N macierzy
Przy każdym obliczeniu, razem z nowym K, można zmienić rozmiar macierzy. Wy-
starczy wpisać wzór, zawierający K. Rozmiary macierzy N mogą się zmieniać od 1 do
1000.
Określanie parametru ISEED
Parametr ISEED oznacza liczbę całkowitą, użytą do zainicjalizowania generatora
liczb pseudolosowych. Są dwie osobne wartości ISEED: jedna dla elementów diago-
nalnych, a druga dla elementów pozadiagonalnych macierzy trójdiagonalnej. Jeśli nie
podamy żadnej wartości, to generator zostanie zainicjalizowany liczbą wybraną (także
wylosowaną) przez program TIPS. Określenie parametru ISEED nie jest więc potrzebne
jeśli chcemy wykonywać kolejne obliczenia dla innych losowych macierzy. Jeśli jednak
podamy jakąś wartość dla ISEED, to będzie ona ustawiana przed każdym obliczeniem
(dla każdego K), więc generowane za każdym razem macierze będą takie same (chyba że
wzrośnie ich rozmiar, ale wtedy będą się różnić tylko ostatnimi elementami). Określenie
niezerowego parametru ISEED umożliwia też uruchomienie różnych algorytmów dla tej
samej macierzy losowej.
Parametry rozkładów
Jak widać na rysunku 3.2 dla rozkładu jednostajnego mamy dwa parametry od i do,
które wyznaczają przedział losowanych wartości. Rozkład Gaussa ma także dwa para-
metry: wartość średnią m i odchylenie standardowe od średniej σ. Liczby losowane są
przy pomocy generatorów pseudolosowych z książki [9].
30

Macierze o elementach obliczonych ze wzoru
Zamiast losować macierze, można pozwolić programowi TIPS obliczyć ich elementy
z podanego przez nas wzoru. We wzorze tym możemy użyć czterech zmiennych: K, N , I
oraz RAN D. Zmienna I przyjmuje wartości od 1 do N i zmienia się dla każdego elementu
diagonali (dla elementów nad- i poddiagonali maksymalna wartość to oczywiście N − 1).
Zmienna RAN D przyjmuje wartość losową o rozkładzie jednostajnym na przedziale
(0, 1). Jej pseudolosowość także jest kontrolowana przez parametr ISEED. Podanie tej
samej wartości ISEED generuje te same ciągi liczb. Przy wprowadzaniu wzoru nie można
podać parametru ISEED. Żeby podać parametr ISEED, trzeba wybrać macierz losową,
wpisać wartość ISEED dla d
i
albo e
i
i powrócić do wyboru opcji „wg wzoru”.
Macierze wczytane z plików
Macierz może zostać wczytana z pliku tekstowego. Należy podać osobne pliki dla
elementów diagonalnych i pozadiagonalnych. Nazwa pliku może zmieniać się wraz z nu-
merem K. Sekwencja %K% wstawia do nazwy wartość K jako tekst. Jeśli chcemy, aby
wstawiona wartość K miała stałą liczbę cyfr (zera z lewej strony), to np. dla wartości
4-cyfrowej wpisujemy %000K% (trzy zera przed K). Pliki o podanych nazwach powinny
się znajdować w katalogu z programami obliczeniowymi (domyślnie to podkatalog „prg”
katalogu, w którym zainstalowano program TIPS).
3.3.4. Zakładka „Algorytmy i wyniki”
Wybranie algorytmu
Algorytm wybiera się w polu wyboru zatytułowanym ’Algorytm’. Na rysunku 3.6
przedstawiona jest lista dostępnych do wybrania algorytmów.
Dodatkowe parametry dla metody (algorytmu)
Jeśli wybrany algorytm potrzebuje dodatkowych parametrów, to pod oknem wybo-
ru algorytmu pojawia się arkusz z nazwami parametrów dodatkowych dla wybranego
algorytmu i ich domyślnymi wartościami. Wartości te można zmieniać. Zmiany te są za-
pisywane w plikach z rozszerzeniem ’.tips’ po naciśnięciu przycisku ’Zapisz’ albo klawisza
F5.
Przycisk i okno „Opcje wyników”
Przycisk ten pokazuje okno „Opcje wyników” z rysunku 3.7. Opcje te są opcjami
programu TIPS i nie są zapisywane razem z innymi opcjami w plikach z rozszerzeniem
’.tips’. Dane (symetryczna macierz trójdiagonalna) znajdują się w plikach fort.8 i fort.9,
a wyniki (macierz odwrotna do symetrycznej macierzy trójdiagonalnej) w pliku fort.10.
Jeśli jednak obliczenia są powtarzane dla różnych wartości K, to dane z tych plików
są utracone, a dostępne są tylko te, które powstały dla największego (ostatniego) K.
Aby temu zapobiec i aby umożliwić zgromadzenie wszystkich danych i wyników z danej
sekwencji obliczeń (dla różnych K) na dysku, program h
tester.exe zapisuje wyniki do
31
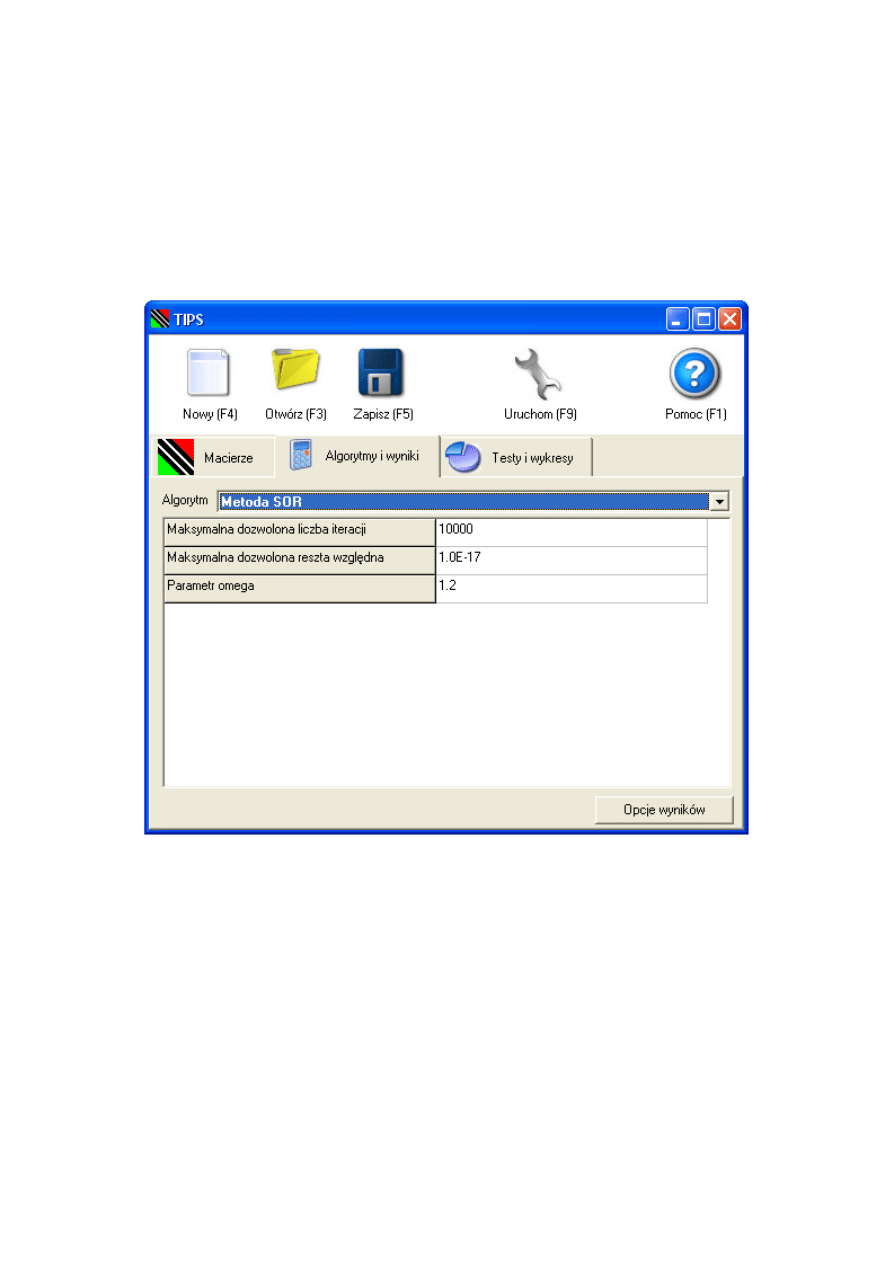
Rysunek 3.5. Zakładka „Algorytmy i wyniki”
32
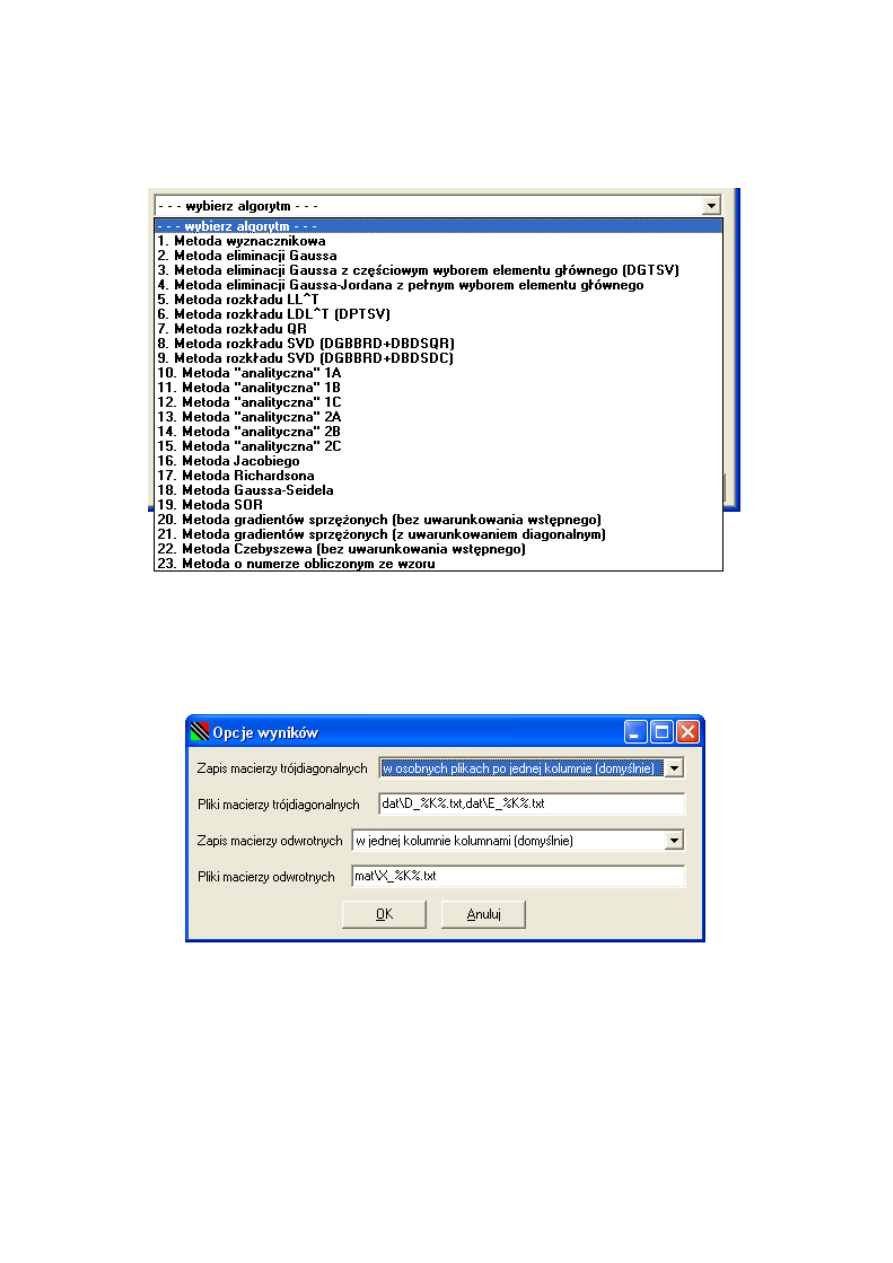
Rysunek 3.6. Lista dostępnych do wyboru algorytmów
Rysunek 3.7. Okno „Opcje wyników”
33

plików fort.18, fort.19 i fort.21, które mogą być następnie przeniesione do dowolnego
innego katalogu pod dowolną inną nazwą. Po drodze przeprowadzane są transformacje
danych i wyników do wybranego formatu. Format liczb się nie zmienia, ale zmienia się
ich ułożenie w pliku. Wyboru można dokonać między formatami dla danych (rysunek
3.8) i dla wyników (rysunek 3.9). Jak widać można zrezygnować z zapisu całkowicie,
a nawet usuwać pliki o pasujących nazwach nie zastępując ich nowymi plikami.
Rysunek 3.8. Opcje zapisu pliku(-ów) z macierzą trójdiagonalną
Rysunek 3.9. Opcje zapisu pliku z macierzą odwrotną
Reguły nazewnictwa plików
Jeśli wybrano format zapisu danych w osobnych plikach, to w polu edycyjnym ’Pliki
macierzy trójdiagonalnych’ należy podać dwie nazwy oddzielone przecinkiem. W na-
zwach można używać wartości zmiennych K i N zamienionych na tekst. Sekwencja %K%
wstawia do nazwy wartość zmiennej K, a sekwencja %N% wstawia wartość N. Jeśli
chcemy, aby wstawiona wartość miała stałą liczbę cyfr (zera z lewej strony), to np. dla
wartości 4-cyfrowej wpisujemy %000K% (trzy zera przed K). Tak samo można wstawić
zmienną N, czyli rozmiar macierzy. Pliki mogą się znajdować w innym katalogu, ale
katalog ten musi wcześniej istnieć (nie jest tworzony).
34
Rysunek 3.10. Zakładka „Testy i wykresy”
35

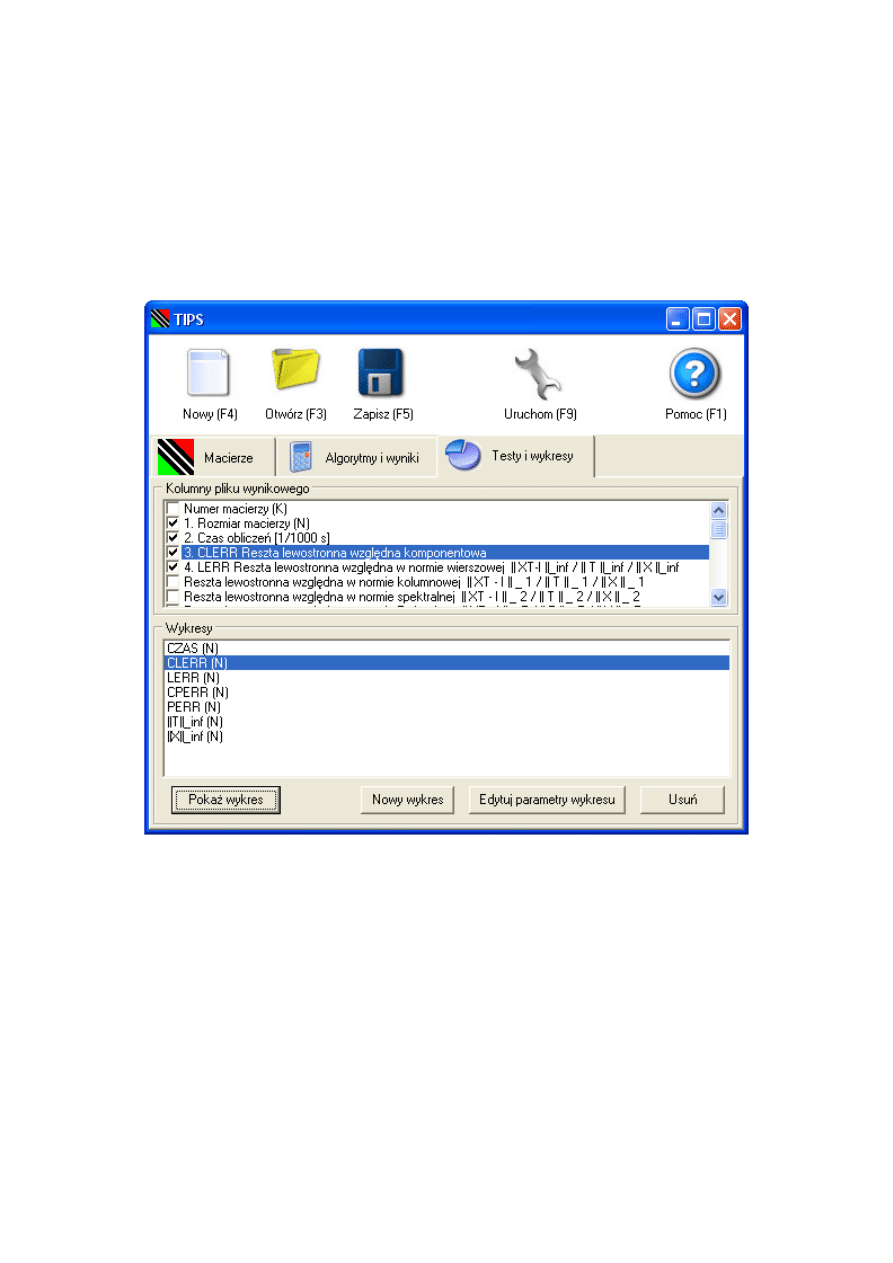
3.3.5. Zakładka „Testy i wykresy”
Wybór testów do przeprowadzenia
Po uzyskaniu wyniku jakim jest macierz odwrotna uruchamiany jest program testu-
jący h tester.exe. Wynikiem jego działania jest tzw. plik wynikowy. Każdy wiersz tego
pliku odpowiada kolejnemu obliczeniu (innemu K). W kolumnach znajdują się wybrane
testy. Testy FERR i BERR pochodzą z wywołania procedury DGTRFS z biblioteki
Lapack [13] po obliczeniu wyniku daną metodą. Procedura ta udokładnia otrzymane
rozwiązanie i jeśli wybierzemy co najmniej jeden z tych testów, to otrzymana macierz
odwrotna będzie już macierzą dokładniejszą, ale pozostałe testy są przeprowadzane wcze-
śniej i dotyczą macierzy mniej dokładnej, będącej bezpośrednim wynikiem wybranego
algorytmu obliczeniowego. Jeśli natomiast wybierzemy ostatnie dwa testy preFERR lub
preBERR, to samo udokładnianie wyniku zostanie uruchomione przed obliczaniem po-
zostałych testów, więc ich wyniki będą dotyczyły już udokładnionego rozwiązania. testy
FERR i BERR nie są przeprowadzane, jeśli wybrano testy preFERR lub preBERR. Aby
wybrać dany test, należy zaznaczyć pole wyboru z lewej strony jego nazwy. Po zazna-
czeniu testu nadawany mu jest numer, który pojawia się z przodu nazwy testu przed
kropką. Jest to numer kolumny w pliku wynikowym. W tej kolumnie zostaną zapisane
wyniki danego testu dla każdego kolejnego K. Testy nie wybrane nie są przeprowadzane,
chyba że ich przeprowadzenie jest konieczne do obliczenia wyników innych wybranych
testów. Dzięki temu wybranie mniejszej ilości testów spowoduje przyspieszenie testowa-
nia wyniku przez program TIPS. Jeśli obliczenia są już przeprowadzone lista ’Kolumny
pliku wynikowego’ jest ”wyszarzona” (tzn. niedostępna) i nie można już zmieniać kolumn
pliku wynikowego. Ponieważ plik wynikowy istnieje, opcje obliczeń zostają z nim zwią-
zane. Powiązanie to, czyli nazwa pliku wynikowego, może być zapisane razem z opcjami
obliczeń w pliku ’.tips’.
Dodawanie nowych wykresów
Aby po obliczeniach zobaczyć wyniki wybranych testów, należy dodać wykresy. Doda-
nie wykresu polega na wybraniu numerów kolumn pliku wynikowego, w których znajdują
się wartości X (poziome) i Y (pionowe) dwuwymiarowego wykresu. Dodajemy wykre-
sy naciskając przycisk ’Nowy wykres’ (rysunek 3.10). Pojawia się wtedy okno „Nowy
wykres” (rysunek 3.11). Nowe wykresy (ich nazwy) pojawiają się na zakładce „Testy
i wykresy” na liście ’Wykresy’. Podwójne kliknięcie na nazwie wykresy na tej liście
(albo zaznaczenie nazwy i kliknięcie przycisku ’Pokaż wykres’) spowoduje pojawienie się
okna ’Wykres’ zawierającego dany wykres. Wykresy można też usuwać. W tym celu po
zaznaczeniu wykresu do usunięcia w oknie ’Wykresy’ naciskamy przycisk ’Usuń wykres’.
Nie trzeba usuwać wykresów aby zamykać okna z wykresami. Zmieniając kolumny X i Y
wykresu automatycznie wpisywane są domyślne podpisy osi wykresu i nazwa wykresu
umieszczona na górze okna ’Wykres’ Nazwę tę i podpisy można zmienić teraz, albo póź-
niej poprzez edycję parametrów wykresu. Kliknięcie przycisku ’OK’ spowoduje dodanie
wykresu do listy ’Wykresy’ na zakładce ’Testy i wykresy’. Można potem obejrzeć dany
wykres klikając podwójnie na jego nazwę na tej liście.
36
Rysunek 3.11. Okno „Nowy wykres”
Dodawanie wielu wykresów jednocześnie
Ponieważ dodawanie wykresów jest dość czasochłonną czynnością można automa-
tycznie dodać wiele wykresów jednocześnie przez naciśnięcie przycisku ’Wszystkie z tą
kolumną X’ (rysunek 3.11). Dodane zostaną wszystkie wykresy, które mają aktualnie
wybraną w tym oknie kolumnę X i każdą z kolumn Y (innych niż kolumna X). Nie są
wybierane kolumny, których nie ma w pliku wynikowym.
Rysunek 3.12. Okno „Edytuj wykres”
37

Edytowanie parametrów wykresu
Po naciśnięciu przycisku ’Edytuj wykres’ na zakładce „Testy i wykresy” pokaże się
okno „Edytuj wykres” (rysunek 3.12). Różni się ono od okna „Nowy wykres” tylko tym,
że nie ma przycisku ’Wszystkie z tą kolumną X’. Przeznaczenie pozostałych elementów
okna jest takie samo. Naciśnięcie przycisku ’OK’ nie dodaje jednak nowego okna, ale
zmienia parametry (może nawet kolumny X i Y) wykresu istniejącego i aktualnie wybra-
nego w oknie ’Wykresy’. Dodane wykresy i ich parametry nie są zapisywane w plikach
z rozszerzeniem ’.tips’ i trzeba je dodawać od nowa po każdym wczytaniu opcji obliczeń
z takiego pliku.
Rysunek 3.13. Okno „Wykres”
3.3.6. Okno „Wykres”
Pokazanie wykresu
Aby pokazać wykres można kliknąć podwójnie lewym przyciskiem myszy na nazwie
wykresu w oknie ’Wykresy’, albo zaznaczyć nazwę pojedynczym kliknięciem i nacisnąć
przycisk ’Pokaż wykres’. Pokaże się wtedy okno wykresu podobne do tego z rysunku 3.13.
Pokazanie wykresu jest możliwe dopiero po obliczeniach (wtedy istnieje plik wynikowy
i jego kolumny faktycznie zawierają wyniki wybranych wcześniej testów), albo po wczy-
taniu pliku z opcjami obliczeń, kiedy ten plik był zapisany po tym jak obliczenia były
już wykonane (wtedy pozostało powiązanie opcji z plikiem wynikowym). Wykresy są
rysowane na podstawie danych z dwóch kolumn pliku wynikowego. Plik ten jest czytany
przy każdym wyświetlaniu okna z wykresem. Kolumny wybierane są w oknie „Edytuj
wykres” (rysunek 3.12).
38

Wygląd wykresu
Rozmiary okna z wykresem można dowolnie zmieniać w jednym kierunku chwyta-
jąc i przeciągając myszką jedną z jego krawędzi, albo w dwóch kierunkach chwytając
i przeciągając jeden z rogów okna. Wykresy są ”wykresami punktowymi”. Poszczególne
punkty nigdy nie są łączone linią. Liczby w opisach osi nigdy nie mają więcej niż 4
cyfry (2 cyfry po kropce). Jeśli zapis liczby wymaga więcej cyfr, cała oś jest rysowana
w skali, przy czym mnożnik jest zapisany w nawiasie kwadratowym obok osi przy jej
końcu. Nazwa wykresu i podpisy osi mogą być zmienione w oknie ’Edycja wykresu’. Osie
wykresu nie przecinają się w punkcie (0, 0). Skala nie jest rysowana poniżej minimalnej
i powyżej maksymalnej wartości współrzędnych rysowanych punktów. Dzięki temu moż-
na rysować wykresy bardzo małych wartości (np. 1E-17) bez obawy, że nie zobaczymy
drobnych różnic w pobliżu zera. Jeśli rozrzut wartości jest duży, można je narysować
w skali logarytmicznej.
Rysunek 3.14. Menu podręczne do okna „Wykres”
Menu podręczne
Menu z rysunku 3.14 pojawia się po kliknięciu prawym klawiszem myszy w obsza-
rze okna z wykresem. Dostępne tutaj opcje pozwalają manipulować opcjami wykresu
niedostępnymi nigdzie indziej w programie TIPS i nie zapisywanymi nigdzie (po za-
mknięciu okna z wykresem trzeba je ustawiać na nowo). Każdą z osi można ustawić
jako logarytmiczną, a jeśli istnieją punkty o współrzędnych równych zero, to można
je usunąć z wykresu. Do wykresu można też dodać (dorysować) czerwoną linię regresji.
Regresja liniowa pozostaje liniowa nawet jeśli co najmniej jedna z osi jest logarytmiczna.
Parametry regresji się wtedy zmieniają i pozwala to na wykorzystanie regresji zarówno
na wykresie zwykłym, jak i logarytmicznym. Na rysunku 3.15 pokazano przykładowy
wygląd linii regresji i okna z parametrami regresji dla tej linii. Okno to pokazuje się
również wskutek wybrania odpowiedniej pozycji z menu podręcznego.
Kiedy podejmiemy już decyzje czy osie mają być logarytmiczne i czy wyświetlić
linię regresji, to możemy zapisać obraz wykresu do pliku graficznego w formacie PNG
(Portable Network Graphics).
39
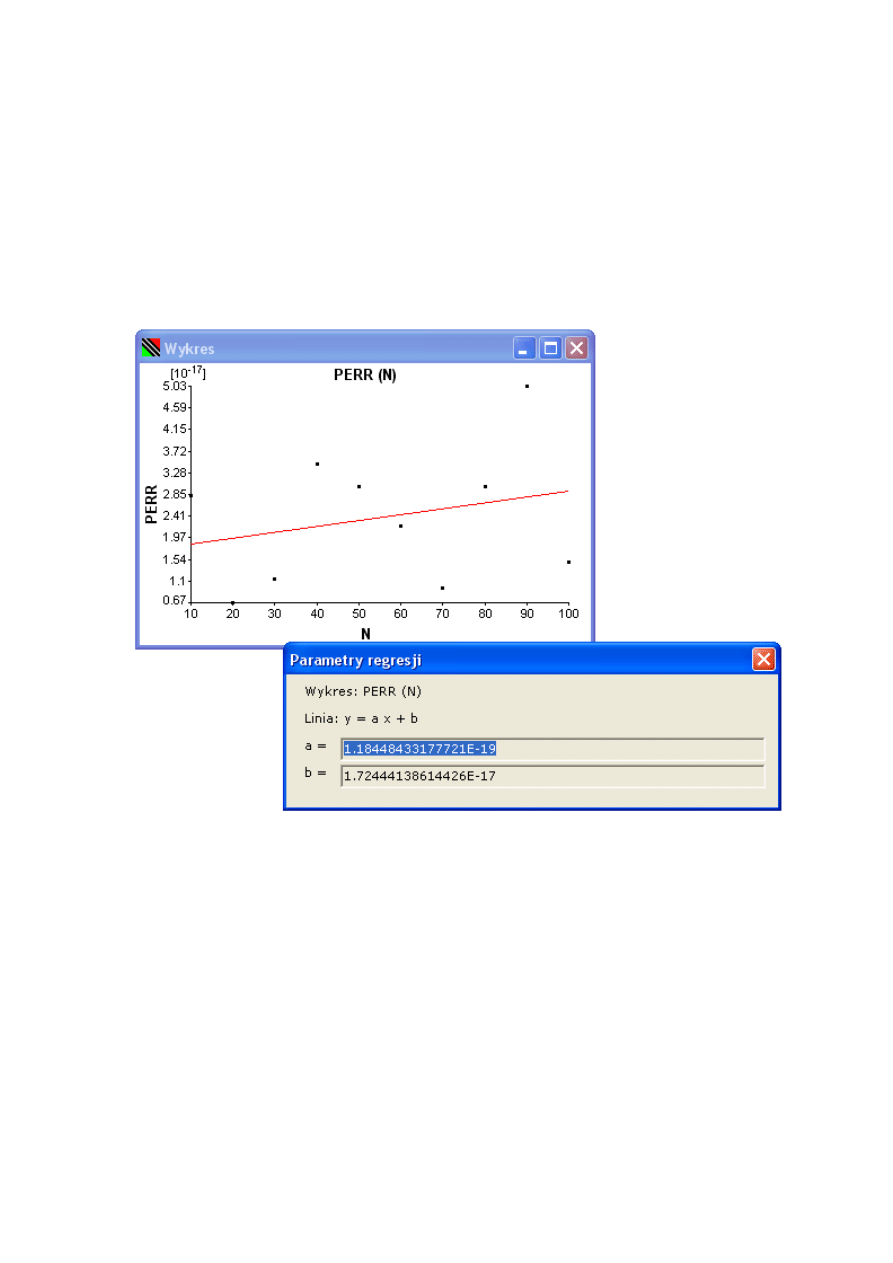
Rysunek 3.15. Okno „Wykres” z linią regresji i okno „Parametry regresji”
40

Skale logarytmiczne
Zarówno skala Y jak i skala X mogą być logarytmiczne. Oznacza to w tym wypad-
ku, że zamiast właściwych wartości rysowane są ich logarytmy dziesiętne. Opisy osi nie
zawierają jednak całych potęg 10, ale ułamkowe wartości właściwych logarytmów. Po-
nadto podpis osi, która jest logarytmiczna zostaje automatycznie poprzedzony tekstem
’log’. Na osiach logarytmicznych nie jest rysowana skala, tzn. nie mają one mnożni-
ka w nawiasie kwadratowym oznaczającego potęgę 10, którą trzeba przemnożyć przez
wszystkie wartości na osi aby otrzymać właściwy wynik. Wartości wszystkich testów są
(powinny być) nieujemne, ale mogą tam wystąpić zera, szczególnie dla małych rozmiarów
N macierzy. Skala nie może być logarytmiczna gdy musi zawiewrać wartość zero (gdy
są punkty o współrzędnej zero). Takie punkty można jednak usunąć z wykresu (dane
w pliku wynikowym pozostają nie zmienione), a następnie narysować wykres logaryt-
miczny z pozostałych punktów. Usuniętych punktów nie można już przywrócić, chyba
że zamkniemy okno z wykresem i otworzymy je na nowo (przycisk ’Pokaż wykres’),
co spowoduje ponowne odczytanie pliku wynikowego. Na przykładzie z rysunku 3.16
pokazano jak wykorzystać osie logarytmiczne i linię regresji do odczytania złożoności
czasowej algorytmu (tutaj jest to O(N
2.24
)).
3.3.7. Okno „Obliczenia”
Okno z rysunku 3.17 pojawia się na czas wykonywania obliczeń. Po uruchomieniu
obliczeń okno główne zostaje zminimalizowane, a na środku ekranu pojawia się poniższe
okno z paskiem postępu, który przesuwa się K razy, raz po każdej macierzy w serii obli-
czeń. Jeśli podczas obliczeń naciśnięty zostanie przycisk zamknięcia okna, to obliczenia
zostaną wstrzymane i pojawi się pytanie z rysunku 3.18. Naciśnięcie ’NIE’ spowoduje
wznowienie obliczeń i ich dokończenie, a odpowiedź ’TAK’ przerwie obliczenia i wyświe-
tli okno z potwierdzeniem przerwania obliczeń. Nie będzie można później dokończyć tak
przerwanych obliczeń (można zawsze uruchomić je od początku, albo dla zmienionych
opcji).
3.3.8. Korzystanie ze wzorów
Liczby
Wszystkie liczby zostaną zamienione na zmiennoprzecinkowe podczas obliczania wzo-
ru. Jeśli wynikiem wzoru ma być liczba całkowita, to zostanie on zaokrąglony przez
obcięcie części ułamkowej (czyli w stronę zera na osi liczbowej). Do oddzielenia części
ułamkowej używamy kropki, a nie przecinka. Można stosować w zapisie liczb notację
naukową, np. 1.345e-19. Wszystkie liczby we wzorach są zmiennoprzecinkowe o typie
rozszerzonym 80-bitowym. Podczas obliczania wyrażeń nie ma innego typu. Są jednak
dwa wyjątki: logarytm naturalny LN() i funkcja znaku SGN(). Argument tych funkcji
nie może być bliżej zera niż 1E-16. Jeśli będzie, spowoduje błąd.
41
Rysunek 3.16. Przykład wykorzystania osi logarytmicznych i linii regresji
Rysunek 3.17. Okno „Obliczenia”
42
Rysunek 3.18. Wstrzymanie obliczeń i pytanie o potwierdzenie chęci ich przerwania
Zmienne i funkcje
We wzorach można używać nazw zmiennych oraz predefiniowanych nazw funkcji. Nie
można definiować własnych funkcji. Wielkość liter jest bez znaczenia. Poniżej przedsta-
wiona jest lista dostępnych funkcji.
•
SQRT() pierwiastek kwadratowy
•
ABS() wartość bezwzględna
•
RAD() zamiana stopni na radiany (funkcje trygonometryczne przyjmują argumenty
w radianach)
•
DEG() zamiana radianów na stopnie
•
INV() odwrotność liczby
•
EXP(x) liczba e do potęgi x
•
LN() logarytm naturalny (podstawa jest liczbą e)
•
SGN() znak liczby (-1,0 lub 1)
•
CEIL() zaokrąglenie do liczby całkowitej w górę
•
FLOOR() zaokrąglenie do liczby całkowitej w dół
•
FRAC() część ułamkowa liczby
•
MOD(a,b) dzielenie modulo
•
POW(a,b), POWER(a,b) a do potęgi b
•
MIN(a,b) mniejsza z liczb
•
MAX(a,b) większa z liczb
•
IF(a,b,c) funkcja IF, jeśli a = 0 to c inaczej b
•
SIN() sinus
•
COS() kosinus
•
TG(), TAN() tangens
•
CTG(), CTAN(), COTAN(), COT() kotangens
•
SEC() sekans
•
COSEC(), CSC() kosekans
•
ARCSIN(), ASIN() arkus sinus
•
ARCCOS(), ACOS() arkus kosinus
•
ARCTG(), ATG(), ARCTAN(), ATAN() arkus tangens
•
ARCCTG(), ACTG(), ACTAN(), ARCCOT(), ACOT() arkus kotangens
43

•
ARCSEC(), ASEC() arkus sekans
•
ARCCSC(), ACSC(), ARCCOSEC(), ACOSEC() arkus kosekans
•
SH(), SINH() sinus hiperboliczny
•
CH(), COSH() kosinus hiperboliczny
•
TH(), TGH(), TANH() tangens hiperboliczny
•
CTH(), CTGH(), CTANH(), COTH() kotangens hiperboliczny
•
SECH() sekans hiperboliczny
•
CSCH(), COSECH() kosekans hiperboliczny
Operatory
We wzorach oprócz liczb, zmiennych i funkcji można używać wielu operatorów ma-
tematycznych. Należy pamiętać, że operatory dwuargumentowe są lewostronnie łączne.
Oznacza to, że wyrażenia są obliczane od strony lewej do prawej. Wyrażeniu A+B+C
odpowiada (A+B)+C, a wyrażeniu A*B/C odpowiada (A*B)/C. Priorytet operatorów
jest zgodny z matematyką (wyjątkiem są operatory relacji). Poniżej znajduje się lista
dostępnych operatorów w kolejności od najbardziej wiążących:
+ - !
jednoargumentowe: plus, minus i negacja
(wyr) fun(wyr1,wyr2)
nawias i wywołanie funkcji
daszek (Shift+6)
potęgowanie
* / mod
mnożenie, dzielenie i operacja modulo
+ -
dodawanie i odejmowanie
¡ ¿ = ¡= ¿= == ¡¿ !=
relacje
Operatory = i == działają jednakowo i oznaczają równość. Operatory ¡¿ i != dzia-
łają jednakowo i oznaczają różność. Lewostronna łączność nie dotyczy operatorów rela-
cji. Wynik relacji jest jedynką dla relacji prawdziwej albo zerem dla fałszywej. Gdyby
operatory relacji były lewostronnie łączne, to na przykład relacja (−1 < −10 < 1)
byłaby prawdziwa, a relacja (−1 < 0 < 1) fałszywa. Takie wielokrotne relacje są trak-
towane w specjalny sposób. Jeśli co najmniej jedna z relacji składowych jest fałszywa,
to cała relacja jest fałszywa. Na przykład relacja A < B < C jest traktowana jak
(A < B) ∗ (B < C). Zwykły iloczyn działa na wyniki relacji jak logiczna koniunkcja
(AND), a zwykła suma relacji działa jak logiczna alternatywa (OR). Nie ma osobnych
operatorów AND i OR. Można jednak użyć zwykłego mnożenia i dodawania jeśli wymu-
simy konwersję liczby na wartość logiczną przez dwukrotny operator negacji, na przykład
!!A odpowiada funkcji if(A,1,0). Spotykaną w wielu językach programowania konstrukcję
(A OR B) można uzyskać tak (!!A + !!B). Podobnie (A AND B) zapisujemy jako (!!A
* !!B) albo też jako !!(A*B). Dla dodawania na ogół nie jest prawdą, że (!!A + !!B)
= !!(A+B). Funkcja if sama przeprowadza konwersję swojego pierwszego argumentu na
wartość logiczną, więc wyrażenia if((A¡B)*(C¿D),1,2) oraz if(!!( (A¡B)*(C¿D) ),1,2) dają
ten sam wynik. Funkcję if(A,B,C) można zapisać jako wyrażenie (!!A*B + !A*C).

4. Przeprowadzone testy
4.1. Porównanie czasów wykonania algorytmów
Algorytmy przetestowano na przykładzie macierzy Poissona (d
i
= 2, e
i
= −1) o roz-
miarach od 100 do 1000. Jeśli zależność czasu obliczeń t od rozmiaru macierzy N jest
funkcją potęgową typu t(N ) = αN
β
, to po zlogarytmowaniu tego równania stronami ma-
my log t(N ) = β log(N ) + log(α). Wykładnik potęgowy β zawarty w poniższych tabelach
został wyznaczony przy pomocy regresji liniowej tak, jak na przykładowym rysunku 3.16.
Czas wykonania metod iteracyjnych był mierzony aż do osiągnięcia dokładności 10
−7
.
Metody bezpośrednie
Metoda
Wykładnik β
1. Wyznacznikowa
2.98
2. Eliminacja Gaussa 1
2.11
3. Eliminacja Gaussa 2
2.17
4. Eliminacja Gaussa-Jordana
3.41
5. Rozkład LL
T
2.01
6. Rozkład LDL
T
2.09
7. Rozkład QR
2.17
8. Rozkład SVD 1
2.89
9. Rozkład SVD 2
2.92
10. „Analityczna” 1A
1.97
11. „Analityczna” 1B
1.89
12. „Analityczna” 1C
2.53
13. „Analityczna” 2A
2.13
14. „Analityczna” 2B
2.04
15. „Analityczna” 2C
2.21
Metody iteracyjne
Metoda
Wykładnik β
16. Jacobiego
3.58
17. Richardsona
3.19
18. Gaussa-Seidela
3.17
19. SOR
3.38
20. Gradientów sprzężonych 1
3.04
21. Gradientów sprzężonych 2
3.09
22. Czebyszewa
2.63
45
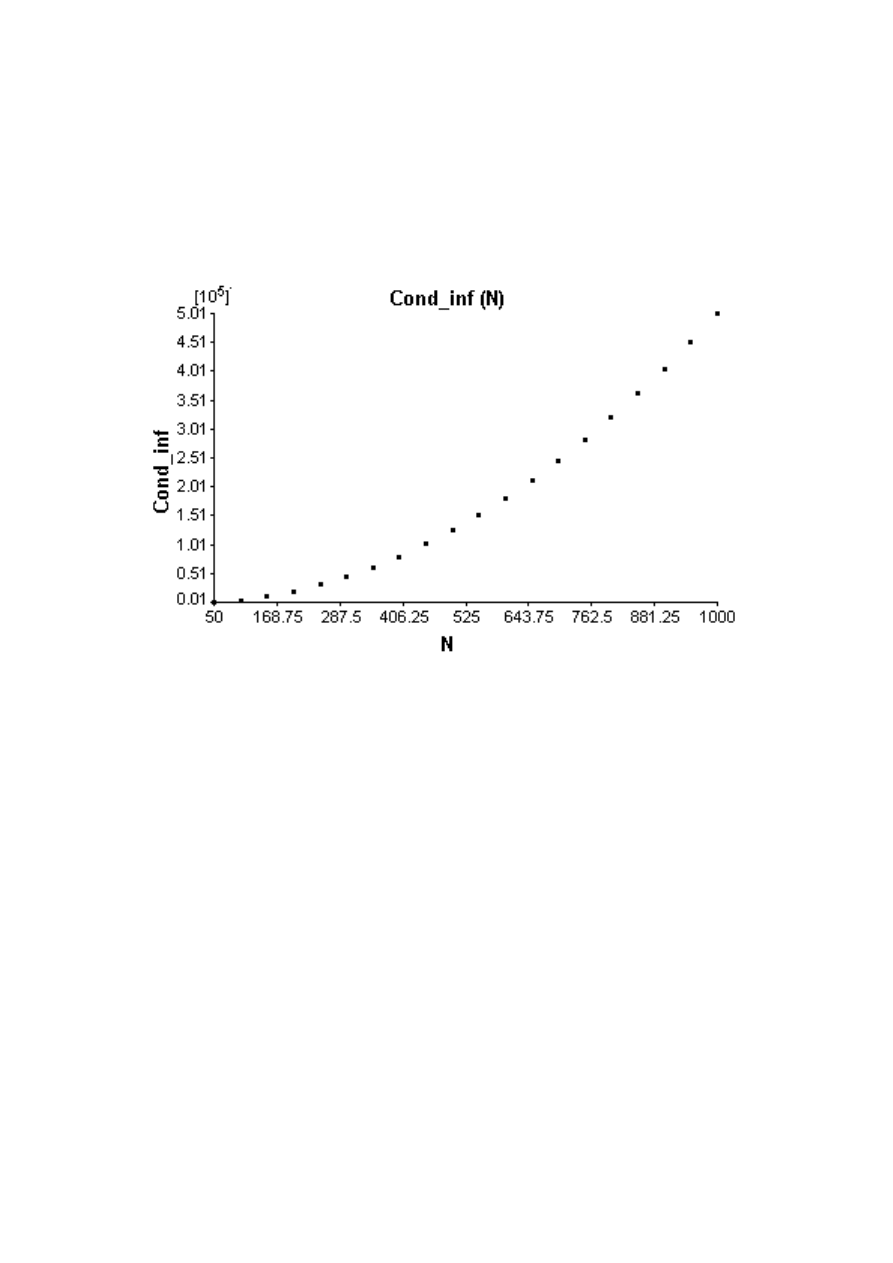
4.2. Porównanie dokładności - macierz Poissona
Norma (w sensie normy nieskończonej) macierzy odwrotnej do macierzy Poissona
rośnie jak O(N
2
). Powoduje to, że wskaźnik uwarunkowania także rośnie jak O(N
2
)
i dla N = 1000 osiąga wartość 500000 (rysunek 4.1).
Rysunek 4.1. Wskaźnik uwarunkowania macierzy Poissona
Dla metody wyznacznikowej nie obserwuje się dużych różnic między błędami lewo-
stronnymi i prawostronnymi. Zarówno błędy w sensie normy, jak i błędy komponentowe
są rzędu ε
mach
dla macierzy Poissona o rozmiarach od N = 50 do N = 1000. Pozwala to
twierdzić, że metoda ta jest w tym przypadku numerycznie poprawna.
Obie metody eliminacji Gaussa (bez wyboru i z wyborem elementu głównego) zacho-
wują się podobnie, stąd wniosek, że wybór ten w przypadku macierzy Poissona nie jest
potrzebny. Występuje jednak znaczna różnica w charakterze zależności błędów (zarówno
komponentowych, jak i w sensie normy) od rozmiaru macierzy. Błędy lewostronne wy-
raźnie rosną (rysunek 4.2), podczas gdy błędy prawostronne pozostają proporcjonalne
do ε
mach
(rysunek 4.3). Ponieważ wraz z rozmiarem macierzy Poissona rośnie jej współ-
czynnik uwarunkowania, to nie wiemy czym dokładnie jest spowodowany wzrost błędu
lewostronnego.
Metoda Gaussa-Jordana nie wykazuje powyższych różnic między błędami lewo- i pra-
wostronnymi (wszystkie są rzędu ε
mach
).
Błędy lewostronne metod korzystających z rozkładów LL
T
i LDL
T
wraz ze wzrostem
46
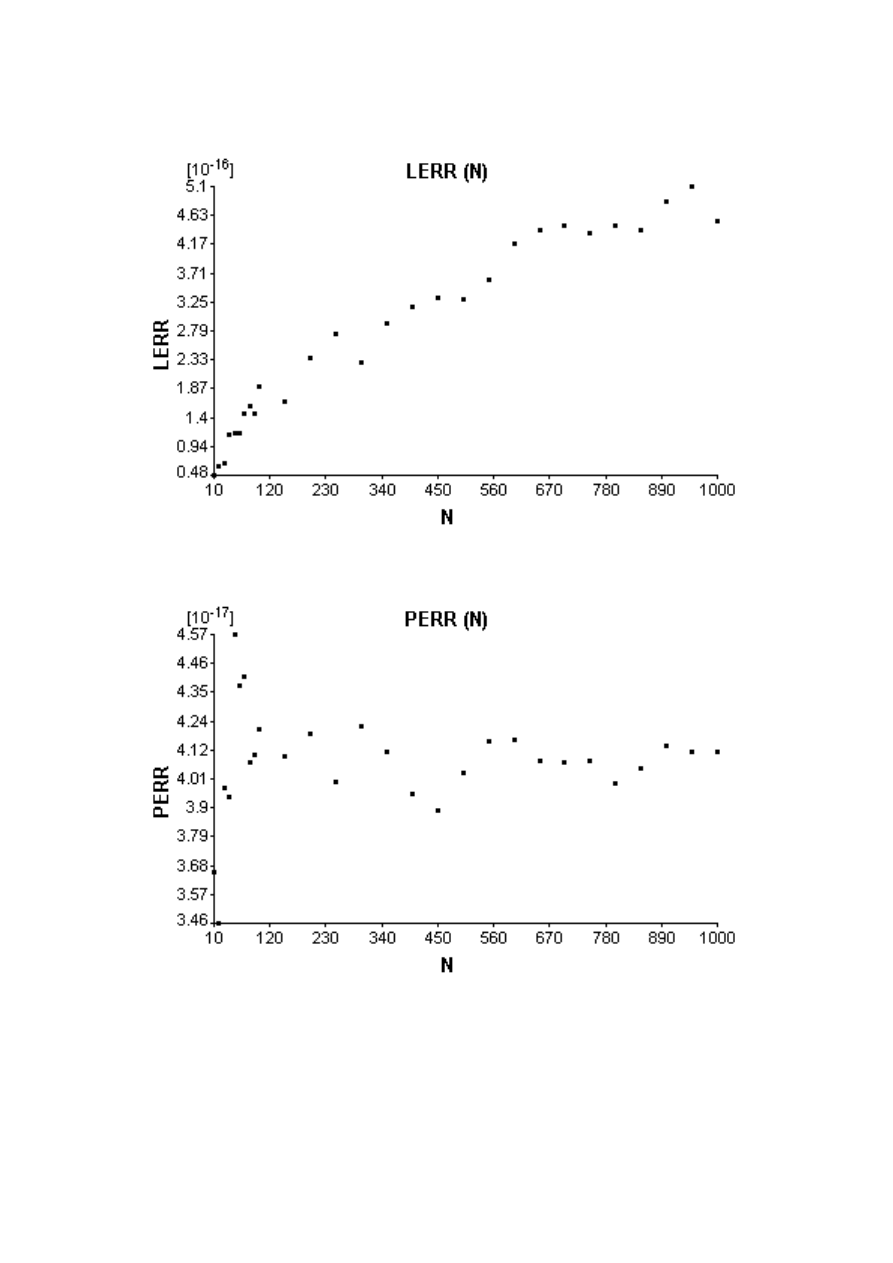
Rysunek 4.2. Błąd lewostronny metody Gaussa dla macierzy Poissona
Rysunek 4.3. Błąd prawostronny metody Gaussa dla macierzy Poissona
47

rozmiaru macierzy podobnie jak dla metody Gaussa, podczas gdy błędy prawostronne
oscylują wokół jednej wartości.
Ten sam wzrost błędów lewostronnych obserwujemy dla metody rozkładu QR, z tym
że błędy lewostronne są w tym przypadku prawie o 3 rzędy wielkości większe (prawo-
stronne pozostają rzędu ε
mach
).
Obie metody wykorzystujące rozkład SV D są do siebie bardzo podobne. Błędy le-
wostronne rosną w nich proporcjonalnie do
√
N , a błędy prawostronne są 4 razy większe
od lewostronnych (nie pozostają stałe, ale także rosną).
Wyniki trzech pierwszych wersji metody analitycznej (1A, 1B, 1C) dla macierzy
Poissona są dokładnie takie same (otrzymano identyczne liczby zmiennoprzecinkowe).
Błędy komponentowe lewostronne i prawostronne także są dokładnie takie same, ale
niestety dość duże, bo rzędu 10
−9
i wykazują tendencję wzrostową typu N
2.44
. Istnieją
jednak różnice w błędach względnych w sensie normy. Błędy lewostronne LERR są duże
(na poziomie 10
−14
), ale błędy prawostronne PERR są jeszcze większe (średnio 20 razy
większe).
Wyniki metod analitycznych 2A, 2B i 2C są do siebie podobne, ale nie są identyczne.
W przypadku metod 2A i 2B obserwuje się jednak identyczność błędów komponentowych
CLERR i CPERR dla tej samej metody. Oba te błędy, a także błędy w sensie normy
rosną liniowo wraz ze wzrostem N (rysunek 4.4). Błąd PERR osiąga 10
−14
dla N = 1000,
ale błąd LERR jest od niego około 3.4 razy mniejszy. Błędy komponentowe, oprócz tego
że są identyczne dla mnożenia lewo- i prawostronnego, to są one tylko o rząd wielkości
większe i dla N = 1000 osiągają wartość 10
−13
.
Metoda 2C wymaga osobnego komentarza. Podczas gdy błędy lewostronne CLERR
i LERR są bardzo podobne do tych samych błędów w metodach 2A i 2B, błędy prawo-
stronne są znacznie mniejsze, rzędu ε
mach
i nie wykazują liniowej tendencji wzrostowej!
Upodabnia to metodę „analityczną” w wersji 2C do metod eliminacji Gaussa, jednak
tam błąd LERR rósł nie liniowo, ale jak
√
N i dla N = 1000 był rzędu ε
mach
(rysunek
4.2).
Błędy metod iteracyjnych można zbadać ustalając niemożliwą do osiągnięcia tole-
rancję dla maksymalnego błędu i wykonywać iteracje aż błąd przestanie maleć. Błąd
jednak nie zawsze maleje monotonicznie, a poza tym takie obliczenia byłyby bardzo
czasochłonne. Można też inaczej porównywać dokładność osiągniętą przez różne metody
iteracyjne po wykonaniu takiej samej liczby iteracji. Wtedy jednak oceniamy szybkość
zbieżności, a nie błąd metody.
4.3. Porównanie dokładności - macierz Hilberta
Macierz Hilberta ma postać: d
i
=
1
2i−1
, e
i
=
1
2i
. Macierz ta nie jest dodatnio określona
i metod korzystających z rozkładów LL
T
i LDL
T
nie można zastosować. Wyniki metod
bezpośrednich porównano dla macierzy o rozmiarach od 5 do 100 z krokiem 5. Norma
macierzy odwrotnej do macierzy Hilberta przyjmuje wartości z jednej z trzech gałęzi, tak
jak to widać na rysunku 4.5. Gałąź środkowa odpowiada rozmiarom macierzy podzielnym
przez 3, gałąź górna zawiera macierze o rozmiarach N = 3m−1, a dolna dla N = 3m+1.
48
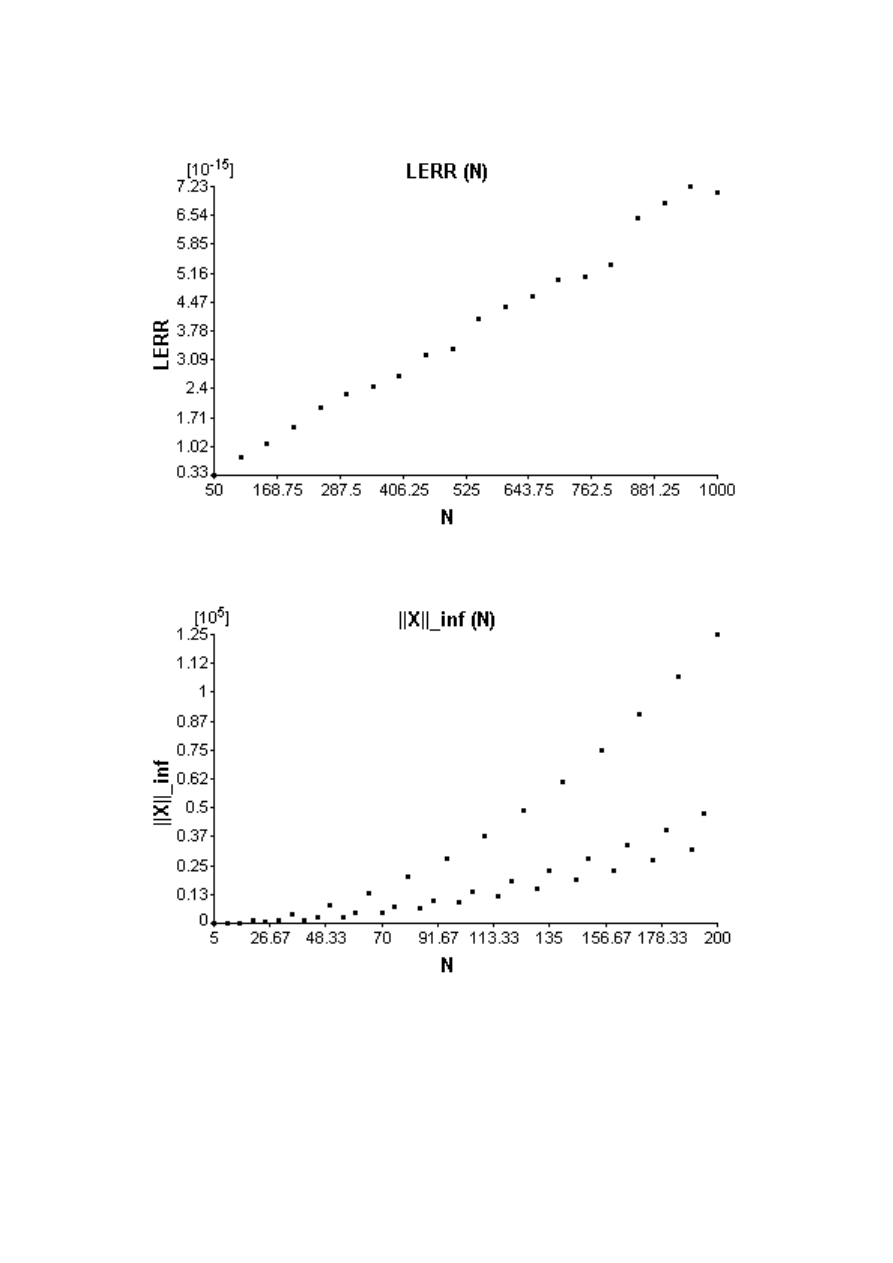
Rysunek 4.4. Liniowy wzrost błędu LERR metody 2C dla macierzy Poissona
Rysunek 4.5. Norma macierzy Hilberta
49
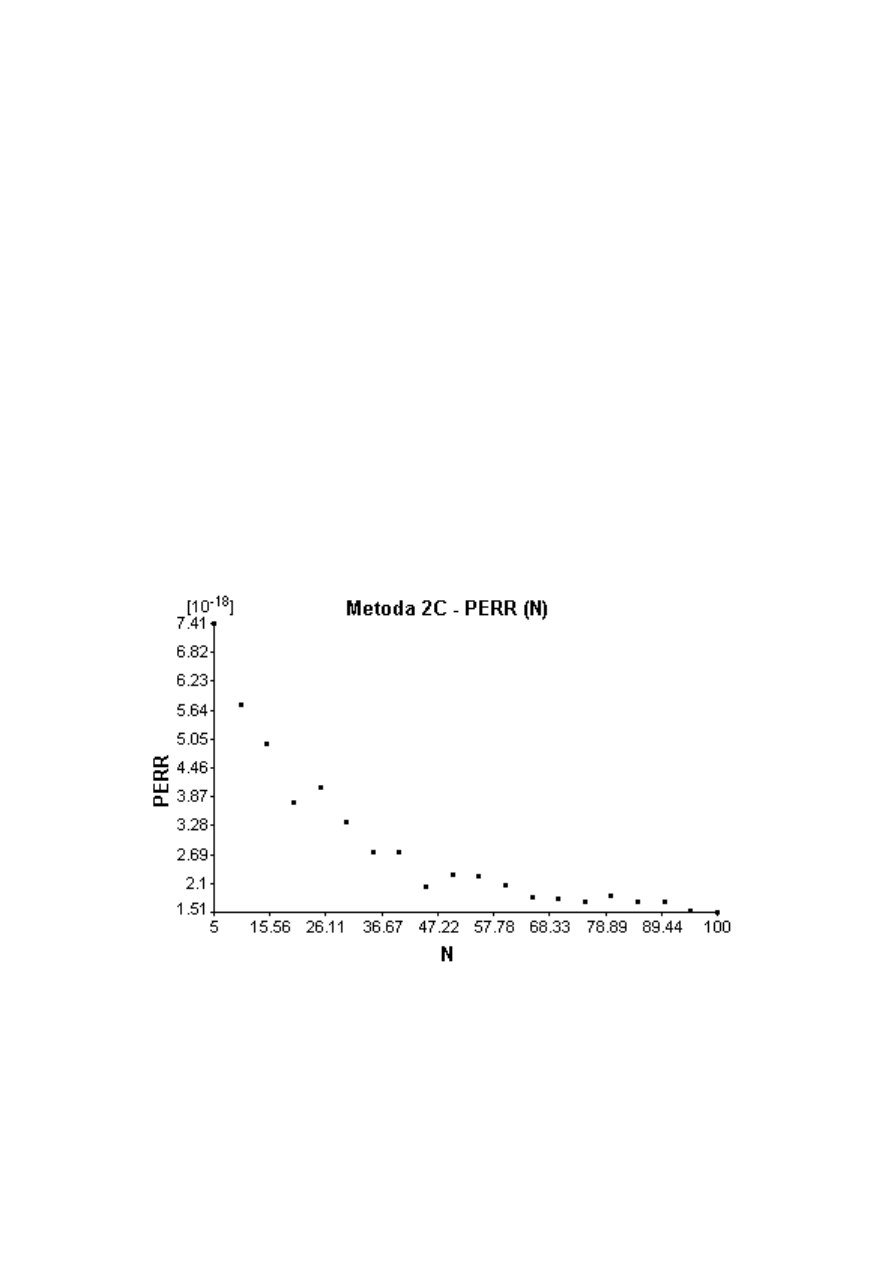
Dla metody wyznacznikowej błędy w sensie normy LERR i PERR maleją i pozostają
mniejsze od ε
mach
gdy rozmiar N macierzy rośnie. Natomiast błędy względne kompo-
nentowe CLERR i CPERR są takie same i rosną jak N
2.2
osiągając wartości rzędu 10
−11
już dla N = 100.
Dla metod Gaussa błędy LERR i PERR również są bardzo małe, mniejsze niż ε
mach
i maleją gdy rozmiar macierzy rośnie od 5 do 100. Zawsze błąd prawostronny zdaje się być
nieznacznie mniejszy niż lewostronny. Jeśli nie wykonujemy wyboru elementu głównego,
to błędy CLERR są rzędu 10
−11
, a CPERR są około 8 razy mniejsze. Przy wyborze ele-
mentu głównego nie ma takiej jednoznacznej zależności, natomiast błąd LERR zmniejsza
się do poziomu błędu PERR. W metodzie Gaussa-Jordana błędy komponentowe nadal
są rzędu 10
−11
dla N = 100, a błędy w normie nieskończonej są mniejsze od ε
mach
.
Wciąż błędy komponentowe rosną co najmniej jak N
2
. Obserwujemy jednak, że w tej
metodzie błędy lewostronne są większe niż prawostronne (najwyżej 2 razy większe).
Metoda rozkładu QR jest porównywalna z eliminacją Gaussa, a obie metody rozkładu
SVD są o rząd wielkości gorsze.
Wyniki dla metod „analitycznych” są do siebie bardzo podobne, ale istnieją jednak
pewne drobne różnice. Błędy CLERR i CPERR są jednakowe dla każdej metody z wy-
jątkiem 2C. Błędy PERR są porównywalne z LERR dla metod 1A i 2B, a są około 3 razy
większe dla metod 1B i 1C i 1.5 razy większe dla metody 2B. Metoda 2C jest wyjątkowa,
gdyż dla niej błędy PERR są 3 razy mniejsze niż LERR, co znów wyróżnia tą wersję
metody spośród pozostałych (rysunek 4.6).
Rysunek 4.6. Błędy PERR Metody 2C dla macierzy Hilberta
50
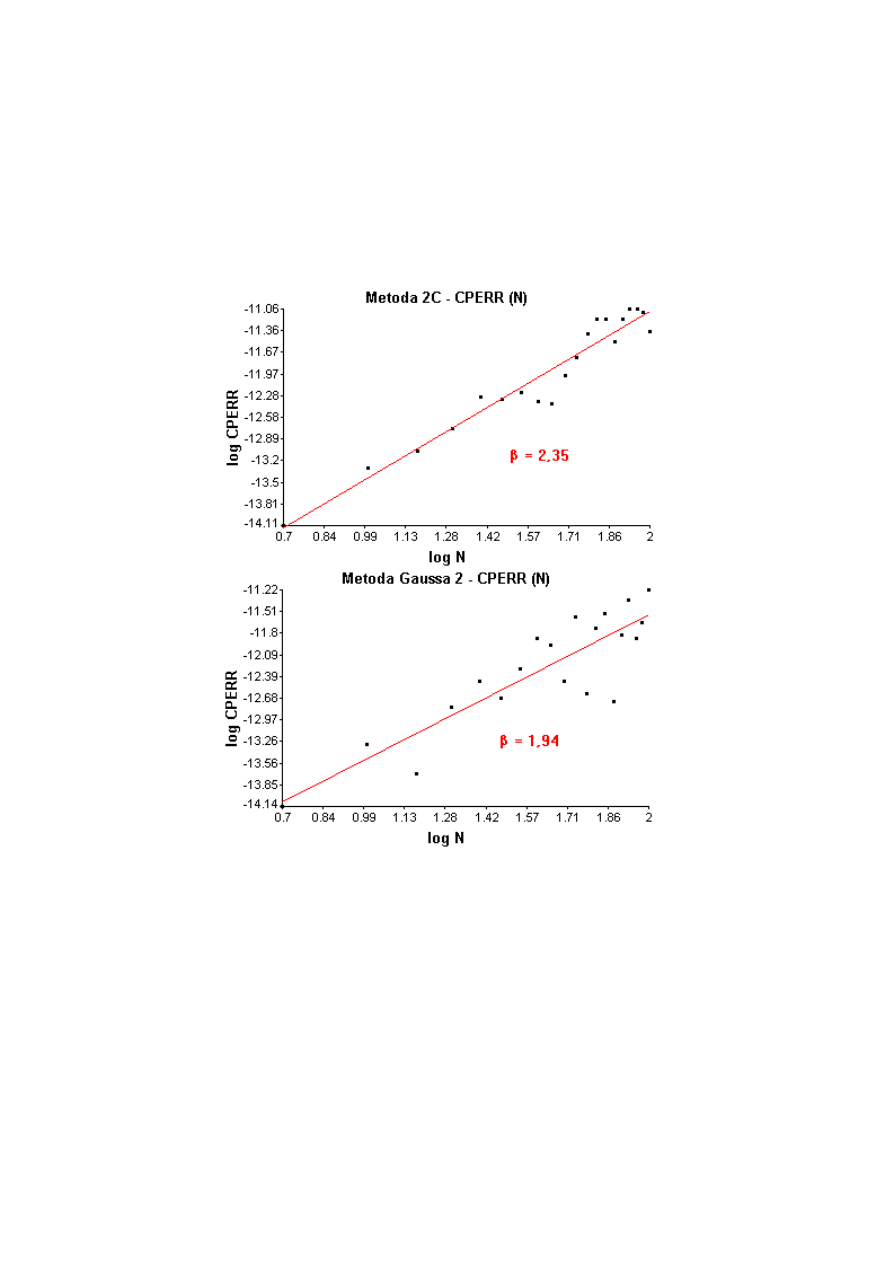
Rysunek 4.7. Prawostronne błędy komponentowe dla macierzy Hilberta
51

4.4. Porównanie dokładności - macierz losowa
Przeprowadzono także testy dla macierzy losowej, której elementy były losowane
z rozkładu jednostajnego na odcinku (0, 1). Obie metody SVD wykazują bardzo duży
błąd komponentowy i błąd w sensie normy o rząd wielkości większy niż ε
mach
. Metoda
wyznacznikowa generuje macierz symetryczną, więc błędy komponentowe lewo- i pra-
wostronne są sobie równe. Błędy w sensie normy są mniejsze niż ε
mach
. Metoda Gaussa
z częściowym wyborem elementu głównego jest dokładniejsza niż bez wyboru, ale po-
nieważ nie generuje macierzy symetrycznej, błąd LERR jest większy niż dla metody
wyznacznikowej (za to PERR jest nieco mniejszy). Metoda QR jest prawie o rząd wiel-
kości gorsza od metody Gaussa. Metody „analityczne” 1A, 1B i 1C czasem nie dają
właściwego wyniku (nieskończoności), tak jak metoda rozkładu LL
T
nie dawała wyniku
dla macierzy, która nie jest dodatnio określona. Metoda 2B ma najmniejsze błędy kom-
ponentowe z metod 2A, 2B i 2C. Metoda 2A ma mniejsze błędy prawostronne podczas
gdy metoda 2B ma mniejsze błędy lewostronne. Metoda 2C ma nieco większe błędy
komponentowe od metody 2B, ale za to błędy w sensie normy są znacznie mniejsze
(PERR jest mniejszy o ponad 3 rzędy wielkości).

5. Podsumowanie
Na podstawie przeprowadzonych testów i obliczeń numerycznych można sformułować
następujące wnioski:
1. Metoda 2C jest w wielu przypadkach najdokładniejszą z badanych metod „analitycz-
nych”, choć nie jest najszybsza. Najszybsza jest metoda 1B. Dla macierzy Poissona
błąd metody 2C rośnie liniowo wraz ze wzrostem rozmiaru macierzy N (rysunek 4.4).
Lepszy wynik uzyskujemy dla metody eliminacji Gaussa z częściowym wyborem ele-
mentu głównego (Eliminacja Gaussa 2), której błąd rośnie jak
√
N (rysunek 4.2).
W najgorszym przypadku (macierz Hilberta) błąd komponentowy obu metod rośnie
w przybliżeniu jak N
2
(rysunek 4.7).
2. Dla macierzy Hilberta obserwujemy wzrost błędów komponentowych wraz ze wzro-
stem rozmiaru macierzy (rysunek 4.7), podczas gdy błędy w sensie normy maleją
(rysunek 4.6). Być może wzrost błędów w sensie normy widoczny będzie dla macie-
rzy znacznie większych rozmiarów niż badane (100 dla macierzy Hilberta i 1000 dla
macierzy Poissona).
3. Dwie najdokładniejsze metody (tzn. Gaussa i 2C) nie generują symetrycznej ma-
cierzy odwrotnej. Jeśli dana metoda nie generuje symetrycznej macierzy odwrotnej,
to zwykle jeden z błędów (lewostronny lub prawostronny) jest znacznie mniejszy od
drugiego, ale nigdy nie są one porównywalne. Kiedy jakaś metoda generuje macierz
symetryczną, to najbardziej prawdopodobne jest, że wykorzystuje ona fakt syme-
tryczności wyniku po prostu kopiując wartości elementów x
ij
znad (spod) diagonali
do odpowiadających im elementów x
ji
(w
ten sposób zostały zaimplementowane
wszystkie metody „analityczne” oprócz 2C). Nie opłaca się więc tak formułować
algorytmów numerycznych odwracania macierzy, że wymuszają one symetryczność
wyniku przez zignorowanie połowy obliczeń.
4. Metod „analitycznych” w wersjach 1A, 1B i 1C nie można stosować dla macierzy,
które nie są dodatnio określone. Obserwowano bardzo buże błędy, a nawet przekro-
czenie zakresu (nieskończoności) dla niektórych macierzy losowych. Z kolei metody
2A, 2B i 2C zachowują się poprawnie dla macierzy losowych. W teorii ich stabilność
jest jednak gwarantowana tylko dla macierzy diagonalnie dominujących [7].
5. Metody używające rozkładów macierzy, w których występują macierze pełne lub też
trójkątne pełne (SVD, QR) są znacznie mniej dokładne ze względu na większą liczbę
operacji zmiennoprzecinkowych, które muszą one wykonywać.
6. Metoda wyznacznikowa okazała się być stabilna numerycznie, co jest pewnym zasko-
czeniem. Dla macierzy Poissona jest nawet poprawna numerycznie. Złożoność tej me-
53

tody zbliża się jednak bardziej do złożoności metod iteracyjnych (O(N
3
)) niż innych
metod bezpośrednich, co raczej wyklucza możliwość jej praktycznego zastosowania.
7. Z metod iteracyjnych najszybsza okazała się metoda Czebyszewa. Może to wynikać
w faktu, że w implementacji tej metody obliczane są ekstremalne wartości własne ma-
cierzy trójdiagonalnej aby wybrać optymalny przedział (a, b). Z pozostałych metod
iteracyjnych najszybsza jest metoda gradientów sprzężonych, co nie jest zaskocze-
niem.
Program TIPS, który powstał jako główny rezultat tej pracy umożliwia skuteczne ba-
danie różnych metod numerycznych w zastosowaniu do zagadnienia odwracania syme-
trycznej macierzy trójdiagonalnej. Udostępnia do wyboru szereg testów (łącznie z normą
spektralną), które mogą służyć do analizowania i diagnozowania algorytmów zarówno
w warunkach praktycznych, jak i w pobliżu teoretycznych granic stosowalności danego
algorytmu. Możliwości opracowanych specjalnie dla programu TIPS modułów rysowania
wykresów i obliczania wzorów analitycznych znacznie wykraczają poza prezentowane
w tej pracy przykłady. Modułowa struktura środowiska obliczeniowego TIPS pozwala
na rozbudowę programu w przyszłości. Łatwo też połączyć jego funkcjonalność z innymi
środowiskami obliczeniowymi, gdyż wszystkie dane i wyniki zapisane są w przenośnym
formacie tekstowym z dokładnością 17 cyfr znaczących. Wszystkie te cechy powodują, że
program TIPS może być przydatnym narzędziem w analizie algorytmów odwracania ma-
cierzy (po pewnych modyfikacjach nie tylko trójdiagonalnych), a także może służyć jako
pomoc dydaktyczna w prezentacji wielu problemów związanych z analizą numeryczną.
54

Spis ilustracji
2.1.
Minor M
42
macierzy T
6
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6
3.1.
Wygląd okna głównego programu TIPS . . . . . . . . . . . . . . . . . . . . . . . . .
27
3.2.
Wygląd zakładki „Macierze” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
29
3.3.
Rodzaje macierzy do wyboru . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
29
3.4.
Wzory do przekształcenia macierzy w macierz diagonalnie dominującą . . . . . . . .
30
3.5.
Zakładka „Algorytmy i wyniki”
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
32
3.6.
Lista dostępnych do wyboru algorytmów
. . . . . . . . . . . . . . . . . . . . . . . .
33
3.7.
Okno „Opcje wyników” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
33
3.8.
Opcje zapisu pliku(-ów) z macierzą trójdiagonalną . . . . . . . . . . . . . . . . . . .
34
3.9.
Opcje zapisu pliku z macierzą odwrotną . . . . . . . . . . . . . . . . . . . . . . . . .
34
3.10. Zakładka „Testy i wykresy” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
35
3.11. Okno „Nowy wykres” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
37
3.12. Okno „Edytuj wykres” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
37
3.13. Okno „Wykres” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
38
3.14. Menu podręczne do okna „Wykres” . . . . . . . . . . . . . . . . . . . . . . . . . . .
39
3.15. Okno „Wykres” z linią regresji i okno „Parametry regresji” . . . . . . . . . . . . . .
40
3.16. Przykład wykorzystania osi logarytmicznych i linii regresji
. . . . . . . . . . . . . .
42
3.17. Okno „Obliczenia” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
42
3.18. Wstrzymanie obliczeń i pytanie o potwierdzenie chęci ich przerwania . . . . . . . . .
43
4.1.
Wskaźnik uwarunkowania macierzy Poissona . . . . . . . . . . . . . . . . . . . . . .
46
4.2.
Błąd lewostronny metody Gaussa dla macierzy Poissona . . . . . . . . . . . . . . . .
47
4.3.
Błąd prawostronny metody Gaussa dla macierzy Poissona . . . . . . . . . . . . . . .
47
4.4.
Liniowy wzrost błędu LERR metody 2C dla macierzy Poissona . . . . . . . . . . . .
49
4.5.
Norma macierzy Hilberta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
49
4.6.
Błędy PERR Metody 2C dla macierzy Hilberta . . . . . . . . . . . . . . . . . . . . .
50
4.7.
Prawostronne błędy komponentowe dla macierzy Hilberta . . . . . . . . . . . . . . .
51
55

Literatura
[1] M. Dryja, J. I M. Jankowscy, Przegląd metod i algorytmów numerycznych, cz. 2, WNT,
Warszawa 1988.
[2] L.L. Trefethen, D. Bau III, Numerical linear algebra, SIAM, Philadelphia 1997.
[3] A. Kiełbasiński, H. Schwetlick, Numeryczna algebra liniowa, WNT, Warszawa 1992.
[4] J. Du Croz, N.J. Higham, Stability of methods for matrix inversion, IMA, J. Numer. Anal.,
12 (1992), pp. 1-19.
[5] B.P. Flannery, W.H. Press, Numerical Recipes in FORTRAN 77. The Art of Scientific
Computing Volume 1, Volume 1 of Fortran Numerical Recipes, Cambridge University Press,
Cambridge 1993.
[6] Hu, G. Y.; O’Connell, R. F., Analytical inversion of symmetric tridiagonal matrices, Journal
of Physics A: Mathematical and General, Volume 29, Issue 7, pp. 1511-1513 (1996).
[7] Huang, Y.; McColl, W. F., Analytical inversion of general tridiagonal matrices, Journal of
Physics A: Mathematical and General, Volume 30, Issue 22, pp. 7919-7933 (1997).
[8] Yamani, H. A.; Abdelmonem, M. S., COMMENT: The analytic inversion of any finite
symmetric tridiagonal matrix, Journal of Physics A: Mathematical and General, Volume
30, Issue 8, pp. 2889-2893 (1997).
[9] T. Pang, Metody obliczeniowe w fizyce. Fizyka i komputery, Wydawnictwo Naukowe PWN,
Warszawa 2001.
[10] T. Jurlewicz, Z. Skoczylas, Algebra liniowa 1. Definicje, twierdzenia, wzory, Wydanie piąte
powiększone, Oficyna Wydawnicza GiS, Wrocław 1998.
[11] W. Salejda, M.H. Tyc, M. Just, Algebraiczne metody rozwiązywania równania Schr¨
odingera,
Wydawnictwo Naukowe PWN, Warszawa 2002.
[12] N.J. Higham, Bounding the error in gaussian elimination for tridiagonal systems, SIAM, J.
Matrix Anal. Appl., Vol. 11, No. 4, pp. 521-530, (1990).
[13] E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A.
Greenbaum, S. Hammarling, A. McKenney, and D. Sorensen, LAPACK User’s Guide, Third
Edition, SIAM, Philadelphia 1999.
[14] B. Baron, Algorytmy numeryczne w Delphi, Helion, Gliwice 2006.
[15] R. Barrett, M. Berry, T. F. Chan, J. Demmel, J. Donato, J. Dongarra, V. Eijkhout, R.
Pozo, C. Romine, H. Van der Vorst, Templates for the Solution of Linear Systems: Building
Blocks for Iterative Methods, Second Edition, SIAM, Philadelphia 1994.
56
Wyszukiwarka
Podobne podstrony:
Środowisko programowe do wyznaczania macierzy odwrotnej do symetrycznej macierzy trójdiagonlanej(1)
Środowisko programowe do symulacji zjawiska tunelowania
Środowisko programowe do obliczenia poziomów energetycznych studni kwantowych typu III V
Środowisko programowe do symulacji zjawiska tunelowania
Korzystajac z twierdzenia o postaci macierzy odwrotnej wyznacz macierze odwrotne do podanych macierz
5 Wprowadzenie do języka C# i środowiska programistycznego (prezentacja)
AOL2, Akademia Morska -materiały mechaniczne, szkoła, Mega Szkoła, PODSTAWY KON, Program do obliczeń
A4, Akademia Morska -materiały mechaniczne, szkoła, Mega Szkoła, PODSTAWY KON, Program do obliczeń P
Program do zajęć rewalidacyjnych z matematyki w Zasadniczej Szkole Zawodowej Specjalnej, rewalidacja
Rzoporzadz-RM-w sprawie przedsiewz oddzialyw na srodow-kryteria do raportow, Budownictwo, Prawo
tab lam, Akademia Morska -materiały mechaniczne, szkoła, Mega Szkoła, PODSTAWY KON, Program do oblic
ramowy program do zajęć, KONSPEKTY, SCENARIUSZE,PLANY
PROGRAM DO MŁODEGO
OCHRONA SRODOWISKA-wyklady do egzaminusciaga cała sciaga, Pwsz Kalisz
Ochrona Srodowiska wyklady do egzaminu
więcej podobnych podstron