
Â
WIAT
N
AUKI
Maj 1997 43
INTERFEJSY U˚YTKOWNIKA
Dzia∏ania zmierzajàce do uporzàdkowania i ∏atwiejszego
przeszukiwania WWW nie nadà˝ajà obecnie za gwa∏townym rozwojem Sieci.
Nowe interfejsy u˝ytkownika powinny przynieÊç lepsze rozwiàzania
Marti A. Hearst
W
jaki sposób mo˝na znaleêç cokolwiek wÊród milio-
nów po∏àczonych ze sobà stron w niezbadanej plà-
taninie WWW? Uzyskiwanie pewnych rodzajów ∏a-
two definiowalnej i popularnej informacji, takiej jak numery
telefonów i ceny, nie stanowi problemu. Podobne us∏ugi ofe-
ruje wiele serwerów. Internet jest tak fascynujàcy, poniewa˝ nie
istniejà dla niego geograficzne ograniczenia – dostarcza bez-
poÊrednio na biurko informacje na ka˝dy wr´cz temat. Jed-
nak bez ustalonej organizacji cyberprzestrzeƒ staje si´ coraz
bardziej nie uporzàdkowana. Próba znalezienia za pomocà
wspó∏czesnych narz´dzi odpowiadajàcego naszym oczekiwa-
niom dokumentu w Oregonie, katalogu w Wielkiej Brytanii
czy ilustracji w Japonii mo˝e byç czasoch∏onna i frustrujàca.
Bardziej zaawansowane algorytmy ustalajàce ranking wy-
ników przeszukiwania pod wzgl´dem ich zgodnoÊci z zada-
nym tematem powinny okazaç si´ pomocne, ale najprawdo-
podobniej rozwiàzaniem b´dà nowe interfejsy. Wspó∏czesne
oprogramowanie do analizowania tekstu i przetwarzania du-
˝ych zasobów danych mo˝e dostarczyç lepszych sposobów
przeglàdania zawartoÊci Internetu lub innych obszernych ar-
chiwów tekstowych. Prawdà jest, ˝e metafora strony stoso-
MODEL STRONICOWY u˝ywany przez wi´k-
szoÊç miejsc w WWW narzuca niepotrzebne ogra-
niczenia na us∏ugi takie jak Yahoo, których celem
jest uporzàdkowanie zawartoÊci Sieci w hierar-
chiczny system kategorii. JeÊli na przyk∏ad u˝yt-
kownik chce si´ dowiedzieç, które warzywa ce-
bulowe (takie jak czosnek) nadajà si´ do sadzenia
jesienià, mo˝e wybraç tylko jednà kategori´ na-
raz. Im dalej u˝ytkownik zabrnie w g∏àb hierar-
chicznej struktury, tym trudniej mu pami´taç,
które z potencjalnie interesujàcych kategorii nie
zosta∏y jeszcze zbadane.
YAHOO, INC. ©
1996; wszystkie prawa zastrze˝one
JEFF BRICE

44 Â
WIAT
N
AUKI
Maj 1997
wana przez wi´kszoÊç sieciowych ser-
werów jest prosta i dobrze znana. Jed-
nak z punktu widzenia osoby projektu-
jàcej interfejs u˝ytkownika strona nie-
potrzebnie wprowadza ograniczenia.
W przysz∏oÊci zastàpià jà efektywniej-
sze sposoby prezentowania, umo˝liwia-
jàce u˝ytkownikowi zobaczenie infor-
macji zawartej w Sieci jednoczeÊnie
z ró˝nych stron.
Wyobraêmy sobie ciotk´ Alicj´ w Ari-
zonie, ∏àczàcà si´ z Siecià, by si´ pora-
dziç, które warzywo, takie jak czosnek
lub cebula, mo˝e zasadziç jesienià w
swym ogrodzie. GdzieÊ w bezmiarze
Sieci znajdujà si´ odpowiedzi na jej py-
tanie. Ale jak je odszukaç?
Ciotka Alicja ma teraz kilka mo˝liwo-
Êci, ale ˝adna z nich nie jest szczególnie
przydatna. Mo˝e zapytaç przyjació∏
o adresy najlepszych serwerów albo
skorzystaç z internetowych indeksów.
Obecnie sà dwa ich rodzaje: r´cznie wy-
konane spisy treÊci, w których miejsca
w Sieci podzielono na kategorie, i spo-
rzàdzane przez przeszukiwarki, zdol-
ne do szybkiego przeszukiwania indek-
su dokumentów internetowych w celu
znalezienia s∏ów kluczowych.
Zatrudniajàc dziesiàtki pracowników
etykietujàcych ka˝dego dnia setki ser-
werów, Yahoo sporzàdza najlepiej obe-
cnie znany internetowy spis treÊci. Ko-
rzystajàc z tej przeszukiwarki, najpierw
wybieramy z menu [ilustracja na sàsiedniej
stronie] najbardziej obiecujàcà katego-
ri´, nast´pnie przechodzimy do szcze-
gó∏owego podmenu lub listy adresów
nale˝àcych do tej kategorii wed∏ug spe-
cjalistów Yahoo. Korzystanie z tego in-
terfejsu mo˝e jednak sprawiaç trudnoÊç.
Kategorie nie zawsze wzajemnie si´ wy-
kluczajà. Czy ciotka powinna zaczàç od
kategorii „entertainment” (rozrywka),
„regional” (region) czy „environment”
(Êrodowisko)?
Powolna szybkoÊç myÊli
Cokolwiek wybierze, poprzednie me-
nu zniknie z pola widzenia, zmuszajàc
jà do zapami´tania wszystkich pozosta-
∏ych Êcie˝ek, które mog∏a wybraç, lub
do metodycznego odtworzenia wcze-
Êniejszych ruchów i ponownego odczy-
tania ka˝dego menu. JeÊli Alicja nie od-
gadnie, która kategoria b´dzie adek-
watna do wyszukiwanego tematu (nie
jest nià „Êrodowisko”), musi si´ cofnàç
i próbowaç od nowa. JeÊli po˝àdana in-
formacja znajduje si´ na samym dole
hierarchicznej struktury lub w ogóle nie
jest osiàgalna, ca∏y proces mo˝e byç bar-
dzo czasoch∏onny i irytujàcy.
Badania w dziedzinie wizualizacji in-
formacji prowadzone w ciàgu ostatnie-
go dziesi´ciolecia zaowocowa∏y wielo-
ma u˝ytecznymi technikami. Pozwala-
jà one zamieniaç abstrakcyjne zestawy
danych, takie jak spis treÊci Yahoo,
w schematy, po których mo˝na si´ po-
ruszaç w sposób bardziej intuicyjny. Jed-
nà ze strategii jest zastàpienie wolniej-
szych, wymagajàcych intensywnego
myÊlenia procesów, powiedzmy – czy-
tania, procesami szybszymi, takimi jak
rozpoznawanie obrazów. ¸atwiej jest
na przyk∏ad porównaç wysokoÊç s∏up-
ków na wykresie ni˝ liczby w tabeli. Ko-
lor znakomicie u∏atwia ludziom szyb-
kie wybieranie jednego, konkretnego
s∏owa lub obiektu z morza informacji.
Inna technika polega na wykorzy-
staniu z∏udzenia g∏´bi mo˝liwego do
uzyskania na ekranie komputera, je-
Êli odejdzie si´ od modelu strony. Kie-
dy o˝ywi si´ ruchome trójwymiaro-
we obrazy, perspektywa, przenikanie
i cienie u∏atwià pokazanie relacji w
du˝ych grupach obiektów – na p∏a-
skiej stronie pozosta∏yby one nieczytel-
ne. Elementy o wi´kszym znaczeniu zo-
stanà przesuni´te na plan pierwszy,
wypychajàc mniej interesujàce obiek-
ty na bok lub do ty∏u. W ten sposób ob-
raz na ekranie u∏atwi u˝ytkownikowi
odczytanie kontekstu.
Takie wirtualne otoczenie czyni po-
szukiwanie informacji procesem bar-
dziej odkrywczym. U˝ytkownicy mo-
gà uzyskiwaç cz´Êciowe odpowiedzi,
które póêniej dadzà si´ wykorzystaç,
znajdowaç lepsze sposoby wyra˝enia
swoich zapytaƒ, wracaç do Êcie˝ek, któ-
re poczàtkowo nie wydawa∏y si´ pro-
wadziç do celu – lub nawet ujrzeç swo-
je tematy w ca∏kowicie nowej perspek-
tywie. Do wi´kszoÊci tych wniosków
dosz∏aby zapewne ciotka Alicja, skru-
pulatnie notujàc przebieg swojej w´-
drówki po Yahoo; jednak prototypowy
interfejs opracowany przez moich ko-
legów z Xerox Palo Alto Research Cen-
ter ma na celu uczynienie procesu wy-
szukiwania bardziej efektywnym.
Oprogramowanie to nosi nazw´ wi-
zualizatora informacji (information visu-
alizer). Jego rdzeniem jest ruchome trój-
wymiarowe drzewo ∏àczàce ka˝dà ka-
tegori´ ze wszystkimi jej podkategoria-
mi [ilustracja na nast´pnej stronie]. JeÊli
ciotka Alicja przeszukuje drzewo Yahoo,
pytajàc o „ogród”, zostanie podÊwie-
tlonych szeÊç obszarów, w których
„ogród” lub „ogrodnictwo” sà podka-
tegoriami. Mo˝e ona nast´pnie obróciç
„ko∏o”, wysuwajàc ka˝dà z tych kate-
gorii na pierwszy plan, by sprawdziç,
dokàd prowadzi. JeÊli któraÊ ze Êcie˝ek
WIRTUALNE KSIÑ˚KI zawierajà dokumenty lub odnoÊniki do serwerów WWW wybra-
ne przez przeszukiwark´. Ksià˝ki przechowujà wyniki i od∏o˝one na pó∏k´ mogà byç póê-
niej wykorzystane, a tak˝e pomagaç u˝ytkownikowi tworzyç dodatkowe zapytania.
MARTI A. HEARST;
XEROX PARC
RAPORT SPECJALNY

Â
WIAT
N
AUKI
Maj 1997 45
zawiedzie jà w Êlepy zau∏ek, wystarczy,
˝e kliknie myszà, i ma pozosta∏e.
Gdy Alicja znajdzie u˝yteczne doku-
menty, nasz interfejs umo˝liwi jej za-
chowanie ich wraz z opisem przebiegu
poszukiwaƒ w wirtualnej ksià˝ce. Alicja
mo˝e nast´pnie umieÊciç jà na wirtual-
nej pó∏ce, gdzie opatrzona zrozumia∏à
etykietkà b´dzie pod r´kà. W nast´pny
weekend ciotka mo˝e rozpoczàç prac´,
otwierajàc ksià˝k´ tam, gdzie jà zamkn´-
∏a, „wydrzeç” stron´ i pos∏u˝yç si´ nià
do wys∏ania zapytania.
Nasz interfejs nie zdo∏a uporzàdko-
waç zawartoÊci ca∏ej Sieci, co wydaje si´
pracà raczej syzyfowà. Nowe serwery
WWW pojawiajà si´ zbyt szybko, by
mo˝na je by∏o zindeksowaç r´cznie,
odsetek adresów podawanych przez
Yahoo (lub inne przeszukiwarki) gwa∏-
townie aleje, a adresy serwerów, na
przyk∏ad magazynu Time zawierajàcego
artyku∏y ró˝norodne tematycznie, cz´-
sto wyst´pujà tylko w kilku z wielu ade-
kwatnych kategorii.
Przeszukiwarki takie jak Excite i Al-
taVista dajà spisy du˝o bardziej kom-
pletne – i to jest ich wadà. Biedna ciotka
Alicja! Gdyby wprowadzi∏a do formula-
rza Excite ciàg s∏ów kluczowych „czo-
snek cebula jesieƒ ogród uprawa”, uzy-
ska∏aby (stan w chwili pisania tego
artyku∏u) wykaz 583 430 adresów. Prze-
jrzenie ich wszystkich (w tempie jedne-
go dokumentu na dwie minuty) zaj´∏o-
by wi´cej ni˝ dwa lata nieustannej
lektury. Próby wydobycia wszystkich
zwiàzanych z zadanym tematem doku-
mentów nieuchronnie prowadzà do ge-
nerowania d∏ugich list zaÊmieconych
niechcianym materia∏em. I odwrotnie,
bardziej krytyczne przeszukiwanie pra-
wie na pewno spowoduje pomini´cie
wielu po˝ytecznych adresów.
Krótkie, z koniecznoÊci nieprecyzyjne
zapytania, jakie wi´kszoÊç internetowych
serwisów wymusza standardowymi for-
mularzami, pog∏´biajà tylko ten problem.
Jednà z metod pomocy u˝ytkownikom
w bardziej precyzyjnym opisie tego, cze-
go szukajà, jest umo˝liwienie im stoso-
wania operatorów logicznych, takich jak
AND, OR i NOT, do okreÊlenia, które
s∏owa muszà (lub nie powinny) si´ zna-
leêç w poszukiwanym dokumencie. Nie-
stety, wielu u˝ytkowników uwa˝a t´
Boole’owskà notacj´ za odstraszajàcà lub
po prostu nieprzydatnà. Nawet zapyta-
nia fachowców sà tylko wtedy dobre, je-
Êli w∏aÊciwie wybrali oni terminy.
Gdy tysiàce dokumentów pasujà do
zapytania, przyznanie priorytetu zawie-
rajàcym wi´kszà liczb´ szukanych ter-
WIZUALIZATOR INFORMACJI to inter-
fejs wykorzystujàcy ruchome trójwymiaro-
we schematy do ilustrowania z∏o˝onych
struktur hierarchicznych, takich jak drzewo
kategorii stosowane w Yahoo. Etykietki ka-
tegorii umieszczone sà w rozga∏´ziajàcej
si´ z boku strukturze (u góry z lewej). Nie
wszystkie etykietki sà czytelne jednocze-
Ênie, klikni´cie na etykietk´ ukrytà w g∏´-
bi (mniejsza i ciemniejsza) powoduje obrót
ko∏a, wysuni´cie jej na pierwszy plan i
ukazanie wszystkich podkategorii (u góry
z prawej). Wybranie nazwy kategorii (np.
„ogród”) powoduje obwiedzenie wszyst-
kich odpowiadajàcych etykietek fioletowà
ramkà (na dole). Inaczej ni˝ na zwyk∏ych
stronach Yahoo interfejs trójwymiarowy
umo˝liwia u˝ytkownikowi przeskakiwanie
mi´dzy ró˝nymi poziomami hierarchii i ba-
danie wielu kategorii jednoczeÊnie.
MARTI A. HEARST;
XEROX PARC
RAPORT SPECJALNY

46 Â
WIAT
N
AUKI
Maj 1997
RAPORT SPECJALNY
minów lub rzadko spotykanych s∏ów
kluczowych (które zwykle sà szczegól-
nie istotne) ciàgle nie gwarantuje, ˝e naj-
bardziej adekwatne adresy znajdà si´
na szczycie listy. W konsekwencji u˝yt-
kownik przeszukiwarki cz´sto nie ma
wyboru i musi przejrzeç wskazane do-
kumenty jeden po drugim.
Uporzàdkowanie wyników
Lepszym rozwiàzaniem jest zapro-
jektowanie interfejsów u˝ytkownika tak,
aby narzuca∏y pewien porzàdek nie-
przebranym iloÊciom informacji gene-
rowanej w trakcie przeszukiwania Sie-
ci. Istniejà algorytmy automatycznie
grupujàce strony w pewne kategorie,
podobnie jak to czynià specjaliÊci z
Yahoo. Takie rozwiàzanie pomija fakt,
˝e wi´kszoÊci tekstów nie da si´ przy-
pisaç do jednej tylko kategorii. Rzeczy-
wiste obiekty cz´sto miewajà ÊciÊle okre-
Êlone miejsce w systemie klasyfika-
cyjnym (cebula jest warzywem), lecz do-
kument poÊwi´cony wy∏àcznie cebulom
nale˝y do rzadkoÊci. Typowy materia∏
b´dzie natomiast zawiera∏ adresy sprze-
dawców warzyw, przepisy na zupy lub
zapis dyskusji o wy˝szoÊci warzyw kra-
jowych nad importowanymi. W bu-
dowaniu struktur hierarchicznych trze-
ba uwzgl´dniaç coraz bardziej szczegó-
∏owe kategorie (np. „dystrybucja ce-
buli”, „przepisy na zupy z cebulà”,
„debaty rolnicze na temat cebuli” itd.).
Bardziej wygodnym rozwiàzaniem jest
opisywanie dokumentów pe∏nym zbio-
rem kategorii, do których pasujà, i ze-
stawem atrybutów (takich jak êród∏o,
data, autor, rodzaj dokumentu). Badacze
ze Stanford University pracujàcy nad
projektem cyfrowej biblioteki projektu-
jà zgodnie z powy˝szymi wskazówka-
mi interfejs o nazwie SenseMaker.
W Xerox PARC opracowaliÊmy innà
metod´ porzàdkowania list adresów uzy-
skanych w wyniku przeszukiwania Sie-
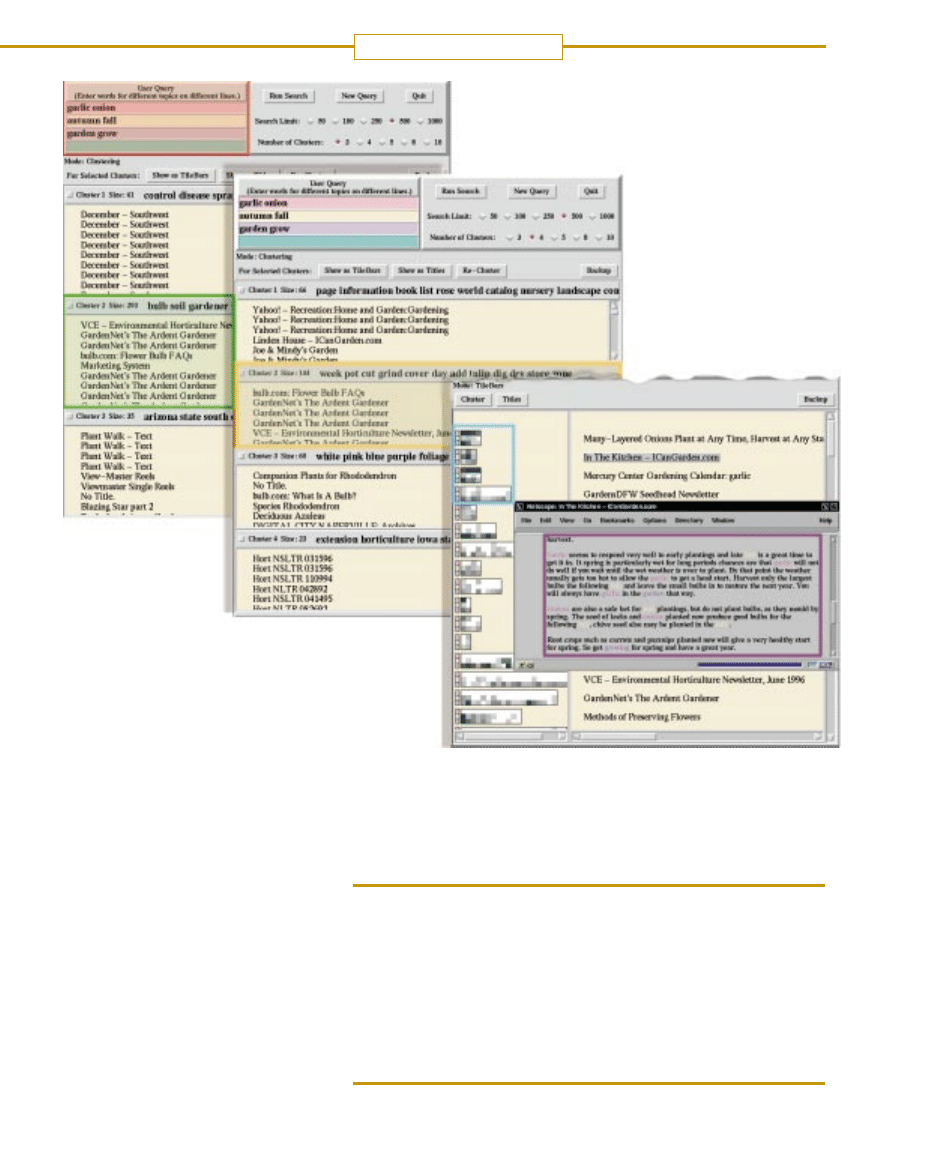
ci. Technika ta, nazwana Scatter/Gather
(rozrzucaç/zbieraç) polega na tworze-
niu spisu treÊci zmieniajàcego si´ wraz
ze wzrostem rozeznania u˝ytkownika,
jakie dokumenty sà dost´pne i w jakim
stopniu sà one zwiàzane z tematem.
Wyobraêmy sobie, ˝e ciotka Alicja
przeszukuje Sieç za pomocà Excite
i otrzymuje 500 pierwszych dokumen-
tów. System Scatter/Gather mo˝e zba-
daç te dokumenty i podzieliç na grupy
pod wzgl´dem ich wzajemnego podo-
bieƒstwa [ilustracja na nast´pnej stronie].
Alicja mo˝e wówczas szybko przejrzeç
ka˝dy podzbiór i wybraç te, które jà naj-
bardziej interesujà.
Mimo ˝e ocena zachowania u˝ytkow-
ników nie mo˝e byç precyzyjna, wst´p-
ne doÊwiadczenia wskazujà, ˝e grupo-
wanie cz´sto pomaga im w wy∏awianiu
informacji. Gdy Alicja zdecyduje, ˝e naj-
bardziej odpowiada jej podgrupa 293
materia∏ów zindeksowanych pod has∏a-
mi „cebula”, „gleba” i „ogrodnik”, mo-
˝e te teksty ponownie przepuÊciç przez
system Scatter/Gather, rozdzielajàc je
na nowy zestaw bardziej szczegó∏owo
okreÊlonych podgrup. W ciàgu kilku ite-
racji ciotka odrzuci wi´kszoÊç spoÊród
500 g∏ównie niew∏aÊciwych stron i za-
chowa tylko kilkadziesiàt przydatnych.
Proces grupowania dokumentów sam
w sobie nie rozwiàzuje innego po-
wszechnego problemu zwiàzanego z
pracà przeszukiwarek WWW takich jak
Excite: dlaczego wskaza∏y te, a nie inne
dokumenty. Ale jeÊli formularz zach´ca
u˝ytkowników do podzielenia zapyta-
nia na kilka grup powiàzanych s∏ów
kluczowych, to interfejs graficzny mo˝e
wskazaç, w którym miejscu wyszuka-
nych dokumentów one si´ pojawiajà.
Gdy wszystkie tematy znajdà si´
w jednym ust´pie danego dokumentu,
istnieje du˝e prawdopodobieƒstwo, ˝e
to odpowiedni dokument; program
umieszcza go wi´c wysoko w hierarchii.
Alicji by∏oby bardzo trudno przewi-
dzieç, jakie tematy muszà wystàpiç
w dokumencie i jak blisko siebie majà
byç umieszczone. Prawdopodobne jest
natomiast, ˝e okreÊli ona swoje prefe-
rencje, gdy zobaczy wyniki i b´dzie mo-
g∏a sprecyzowaç zapytanie w kolejnym
podejÊciu. Co jeszcze wa˝niejsze, tech-
nika, którà nazwa∏em TileBars, pomo-
˝e u˝ytkownikom w wyborze doku-
mentu, który chcà przejrzeç, i przy-
spieszy dotarcie do najodpowiedniej-
szych materia∏ów.
Poszukiwania nowych interfejsów
u˝ytkownika i technik analizy tekstu do-
piero si´ rozpocz´∏y. Inne techniki, ∏à-
czàce metody analizy statystycznej z re-
gu∏ami heurystycznymi, umo˝liwiajà
automatyczne streszczanie dokumentów
i umieszczanie ich w istniejàcych struk-
turach hierarchicznych. Potrafià one za-
proponowaç synonimy s∏ów kluczowych
PRZESZUKIWARKI, takie jak Excite, wydobywajà wiele zwiàzanych z pytaniem doku-
mentów. Zapytanie „czosnek cebula jesieƒ ogród uprawa” powoduje wyÊwietlenie ponad
pó∏ miliona odniesieƒ, z których wiele jest nieadekwatnych. Nawet najlepsze algorytmy
s∏u˝àce do hierarchizowania dokumentów przestajà byç wiarygodne, gdy zapytanie za-
wiera kilka s∏ów. U˝ywane obecnie przeszukiwarki zwykle nie ujawniajà zasad wyboru
dokumentów i kolejnoÊci ich wyÊwietlenia.
Za zgodà EXCITE, INC.
Â
WIAT
N
AUKI
Maj 1997 47
w zapytaniu i odpowiadaç na proste py-
tania. ˚adna z tych zaawansowanych
technik nie zosta∏a jeszcze w∏àczona do
mechanizmów przeszukiwarek, ale nie-
wàtpliwie tak si´ stanie. W przysz∏oÊci in-
terfejsy u˝ytkowników mogà rozwinàç
si´ w coÊ wi´cej ni˝ dwu- i trójwymiarowe
schematy (wykorzystujàc inne zmys∏y, np.
s∏uch), by pomóc ciotce Alicji w znajdo-
waniu kolejnych powiàzaƒ i ods∏aniaç
przed nià coraz to nowe perspektywy.
T∏umaczy∏
Edwin Bendyk
SCATTER/GATHER mo˝e grupowaç wyszukane przez Excite
i umieszczone najwy˝ej w hierarchii dokumenty, oznaczajàc po-
szczególne grupy s∏owami, które wed∏ug programu sà najbardziej
dla nich charakterystyczne. (S∏owa streszczajàce w podobny spo-
sób rzeczywisty dokument b´dà si´ najprawdopodobniej ró˝-
niç od tych, które Yahoo wybierze do taksonomii.) Przeglàda-
jàc te „streszczenia”, u˝ytkownik
móg∏by zdecydowaç, ˝e druga gru-
pa (zielony) wydaje si´ najbardziej
adekwatna. By uzyskaç jeszcze pre-
cyzyjniejszy obraz jej zawartoÊci,
u˝ytkownik mo˝e ponownie pod-
daç procedurze 293 dokumenty,
w wyniku czego zostanà one po-
dzielone na cztery bardziej szcze-
gó∏owe podgrupy (poÊrodku). Inte-
resujàca dla u˝ytkownika by∏aby
grupa druga (˝ó∏ty).
MARTI A. HEARST;
XEROX PARC
TILEBARS (z prawej)
u∏atwia u˝ytkownikom
odnalezienie najbar-
dziej odpowiadajàcych
tematowi dokumentów
na podanej liÊcie. U˝yt-
kownik mo˝e podzie-
liç zapytanie na cz´Êci (czerwony), z których ka˝da zawiera kil-
ka terminów do wyszukania. Program obrazuje pasujàce
dokumenty graficznie (niebieski). D∏ugoÊç prostokàta odzwier-
ciedla d∏ugoÊç dokumentu. Na ka˝dy prostokàt jest naniesio-
na siatka. Kolumny odpowiadajà wieloakapitowym fragmentom
tekstu, wiersze – poszczególnym s∏owom zadanym przez u˝yt-
kownika do wyszukania. Dzi´ki TileBars widaç wi´c na pierw-
szy rzut oka, które z zadanych tematów zawiera ka˝dy ust´p
ka˝dego z dokumentów i – co wa˝niejsze – jak cz´sto tematy
te si´ powtarzajà (ciemniejsze kwadraty oznaczajà wi´cej po-
wtórzeƒ). Na rysunku najwy˝szy szereg ka˝dego prostokàta wskazuje na wyst´powanie s∏ów „czosnek” i „cebula” z pierwszego te-
matu; Êrodkowy szereg odpowiada „jesieni” itd. Interfejs ten dostarcza u˝ytkownikowi informacje u∏atwiajàce podj´cie decyzji, który
dokument warto przeczytaç. Dwa dokumenty znajdujàce si´ na szczycie, w których wszystkie trzy tematy wyst´pujà w wielu ust´pach,
najprawdopodobniej bardziej odpowiadajà poszukiwanemu tematowi ni˝, dajmy na to, dolny dokument, który w ogóle nie zawiera
s∏ów „czosnek” i „cebula”. Klikni´cie na dowolny kwadrat wewnàtrz prostokàta otwiera okno przeglàdarki internetowej (fioletowy)
z odpowiednim fragmentem tekstu. S∏owa kluczowe z zapytania sà zaznaczone odpowiednimi barwami.
Informacje o autorze
MARTI A. HEARST od roku 1994 jest
jednym z cz∏onków zespo∏u badaw-
czego w Xerox Palo Alto Research
Center. Tytu∏ licencjata, magistra,
a nast´pnie doktora uzyska∏a na Wy-
dziale Informatyki University of Ca-
lifornia w Berkeley. Jej praca doktor-
ska, którà obroni∏a w roku 1994,
dotyczy∏a zagadnieƒ struktury i kon-
tekstu w dokumentach tekstowych
i roli interfejsów graficznych w wy-
szukiwaniu informacji.
Literatura uzupe∏niajàca
RICH INTERACTION IN THE DIGITAL LIBRARY
. Ramana
Rao, Jan O. Pedersen, Marti A. Hearst, Jock D. Mac-
kinlay i in., Communications of the ACM, vol. 38,
nr 4, ss. 29-39, IV/1995.
THE WEBBOOK AND THE WEB FORAGER: AN INFORMA-
TION WORKSPACE FOR THE WORLD WIDE WEB.
Stuart
K. Card, George G. Robertson i William York,
Proceedings of the ACM/SIGCHI Conference on
Human Factors in Computing Systems, Vancouver,
IV/1996. Dost´pne w WWW: http://www.acm.
org/sigs/sigchi/chi96/proceedings/papers/
Card/skc1txt. html
RAPORT SPECJALNY
Wyszukiwarka
Podobne podstrony:
Systemy S┼éowniczek , GUI - Graficzny interfejs użytkownika
11 Tworzenie interfejsu uzytkow Nieznany (2)
Interfejs użytkownika
JS 13 Interfejs użytkownika, Programowanie, instrukcje - teoria
Tworzenie interfejsu użytkownika [loskominos], REFERATY
Projektowanie interfejsu użytkownika
10 Projektowanie interfejsu uzytkownikaid 11297 ppt
Dostosowywanie interfejsu użytkownika
MySQL Budowanie interfejsow uzytkownika Vademecum profesjonalisty msqlvp
MySQL Budowanie interfejsow uzytkownika Vademecum profesjonalisty msqlvp
MySQL Budowanie interfejsow uzytkownika Vademecum profesjonalisty 3
MySQL Budowanie interfejsow uzytkownika Vademecum profesjonalisty 2
11 Tworzenie interfejsu użytkownika
MySQL Budowanie interfejsow uzytkownika Vademecum profesjonalisty
więcej podobnych podstron