

Czym jest indeks
• Indeks – uporządkowana struktura danych
stosowana w celu przyspieszenia wykonania
operacji poszukiwania na tabeli
– Odpowiednik spisu w książce telefonicznej
• W momencie poszukiwania serwer BD
najpierw korzysta z indeksów w celu
zawężenia obszaru poszukiwań
• Indeks jest strukturą fizycznie istniejącą
niezależnie od tabeli w bazie danych
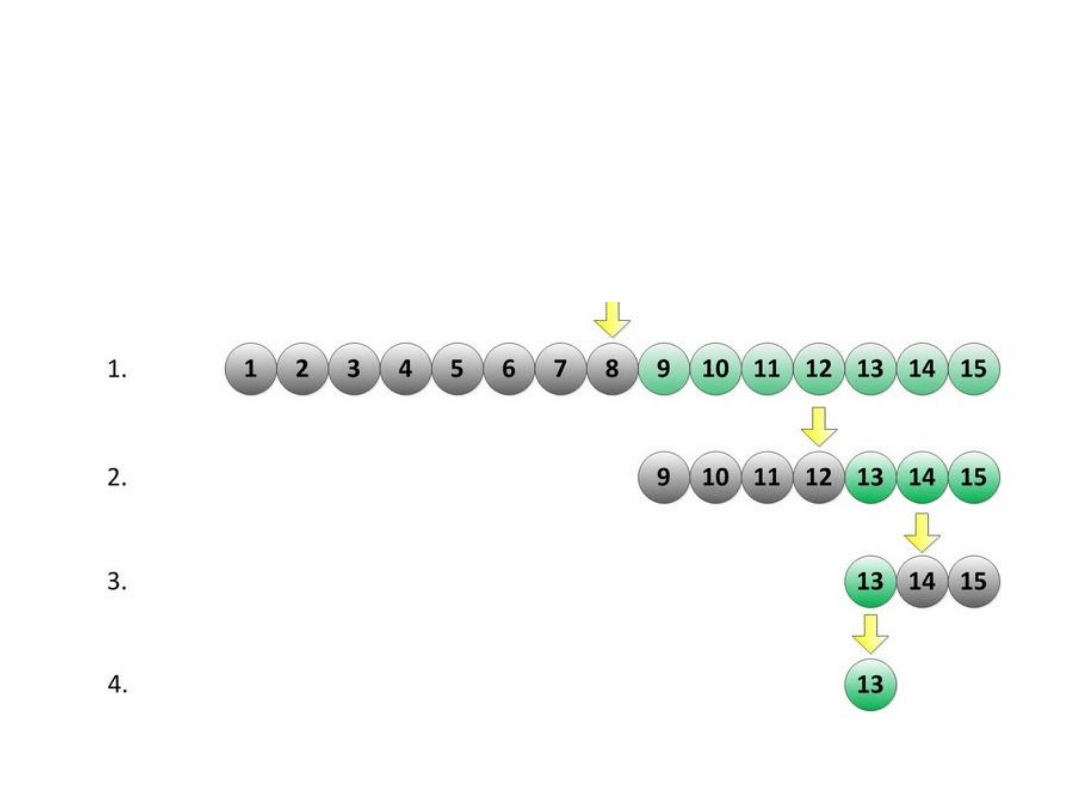
Idea działania indeksów na przykładzie
wyszukiwania binarnego

Czy indeksy mają same zalety?
• Zalety indeksów:
– Przyspieszenie operacji SELECT
• Wady indeksów:
– Zajmują sporo przestrzeni dyskowej
– Spowalniają operacje modyfikacji oraz wstawiania
danych do tabel
• Zawsze jest złoty środek, inny dla każdej
realnej BD !

Rodzaje indeksów
• Indeks gęsty
– Jest tworzony dla każdego wiersza (każdej wartości
klucza) tabeli
• Indeks rzadki
– Tworzony dla wybranych wartości klucza

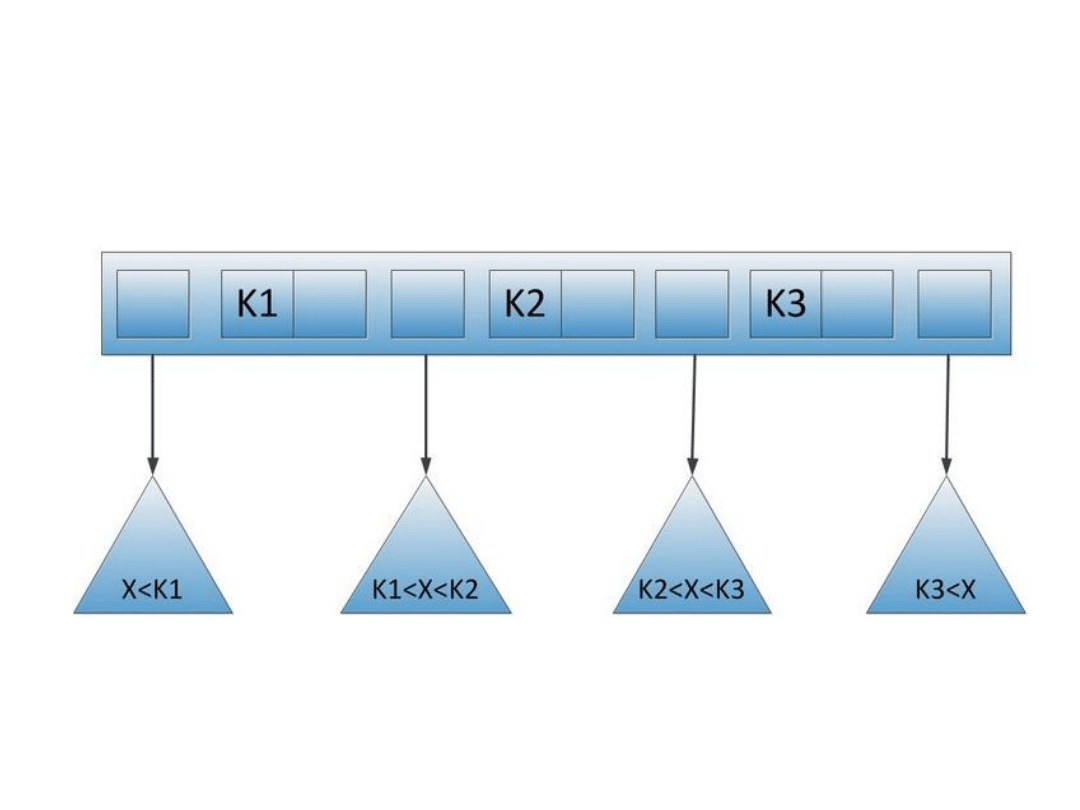
Poziomy indeksów
• Indeks jednopoziomowy
– Algorytm połowienia binarnego
– Jest nieefektywny dla dużych zbiorów!
• Indeks wielopoziomowy
– Czyli indeks dla indeksu
– Efektywność b. wysoka
– Złożona obsługa, wysoki koszt modyfikacji
– Zajmuje większą przestrzeń dyskową
Indeks jednopoziomowy
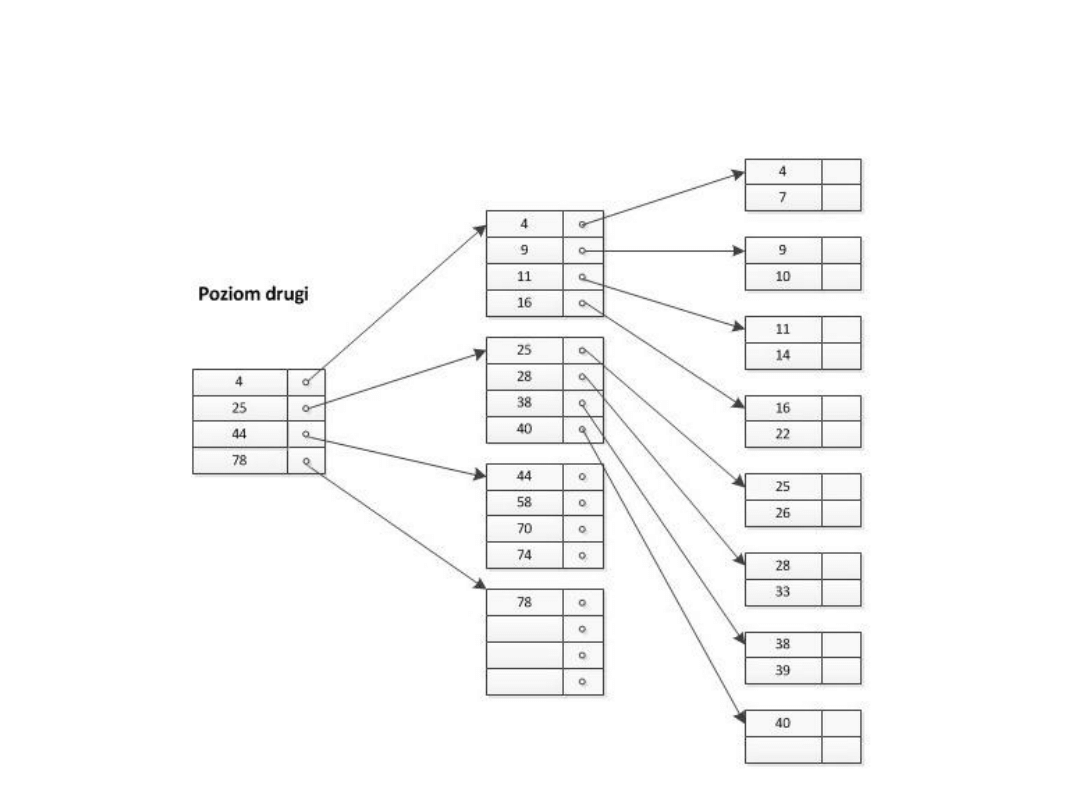
Indeks wielopoziomowy

Typy indeksów
• Indeks podstawowy (główny)
• Indeks klastrowy (pogrupowany)
• Indeks wtórny

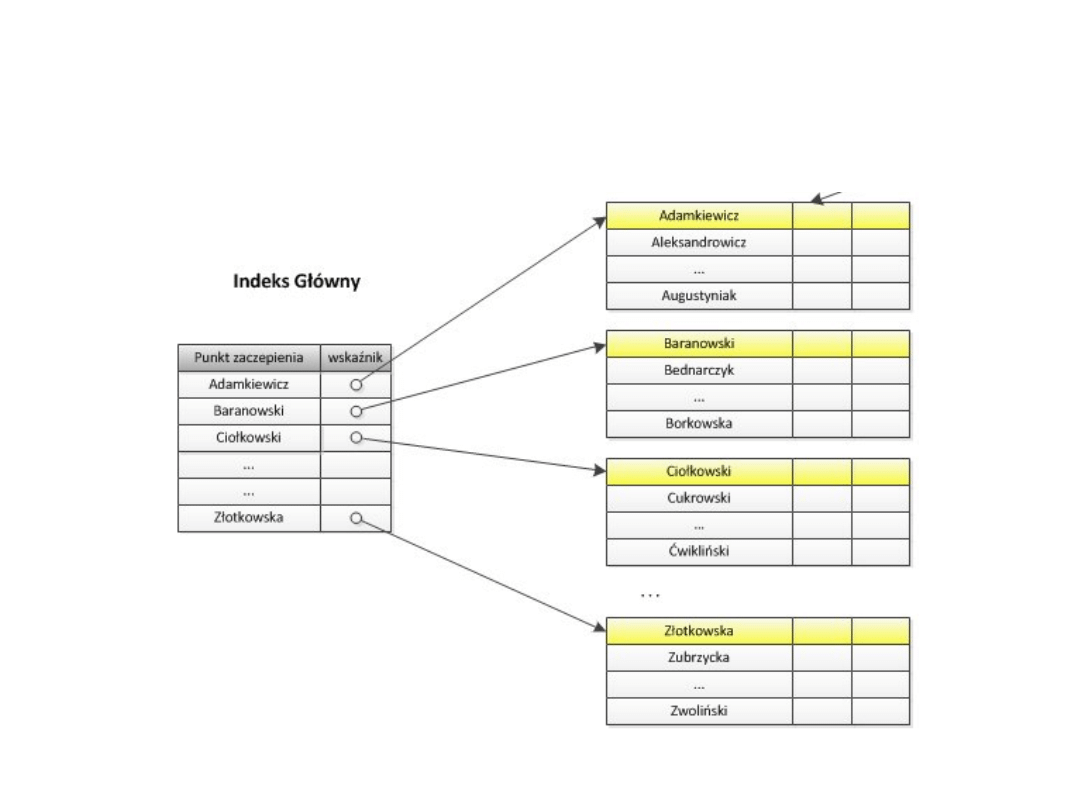
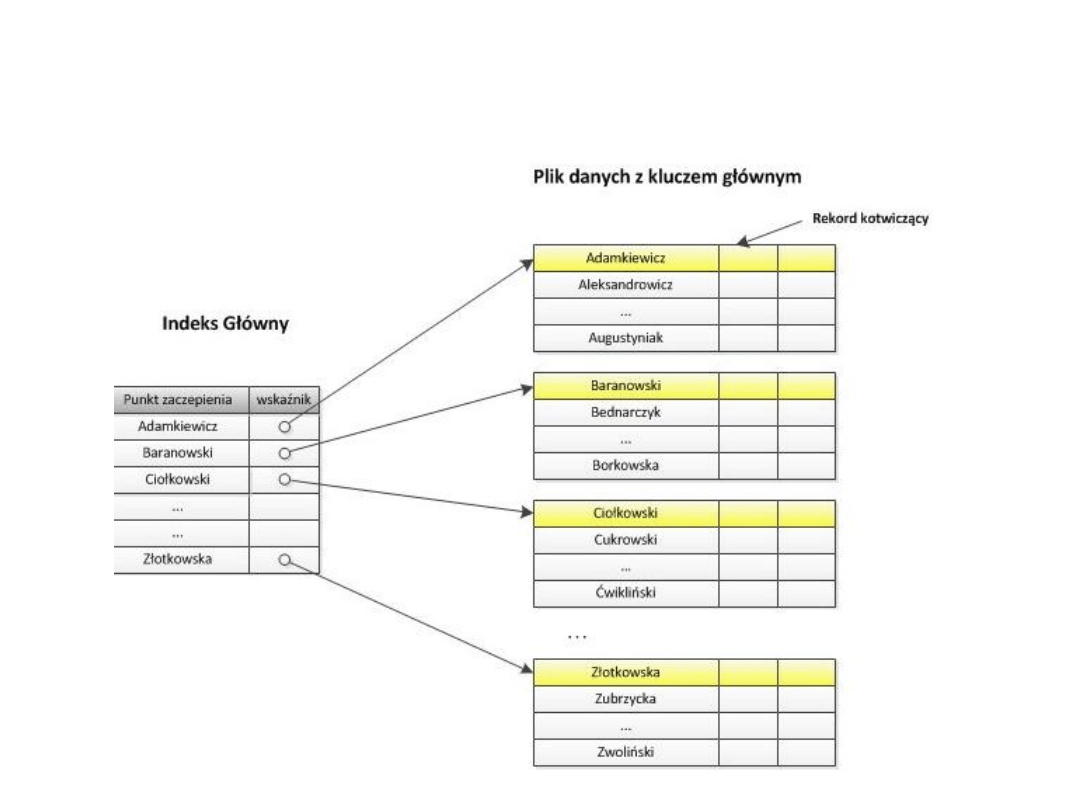
Indeks główny
• Zakłada się na kolumnie klucza głównego
tabeli
• Struktura pliku danych – plik uporządkowany
• Wskaźnik indeksu – na blok danych na dysku
• Indeks rzadki!
Indeks główny (c.d.)

Indeks klastrowy (zgrupowany)
• Zakładany na kolumnie nie będącej kluczem
głównym tabeli
• Ponieważ kolumna może przechowywać
wartości nieuporządkowane, wskaźnik zawiera
odniesienie do pierwszego bloku dyskowego
gdzie znajduje się określona wartość
• Indeks rzadki!
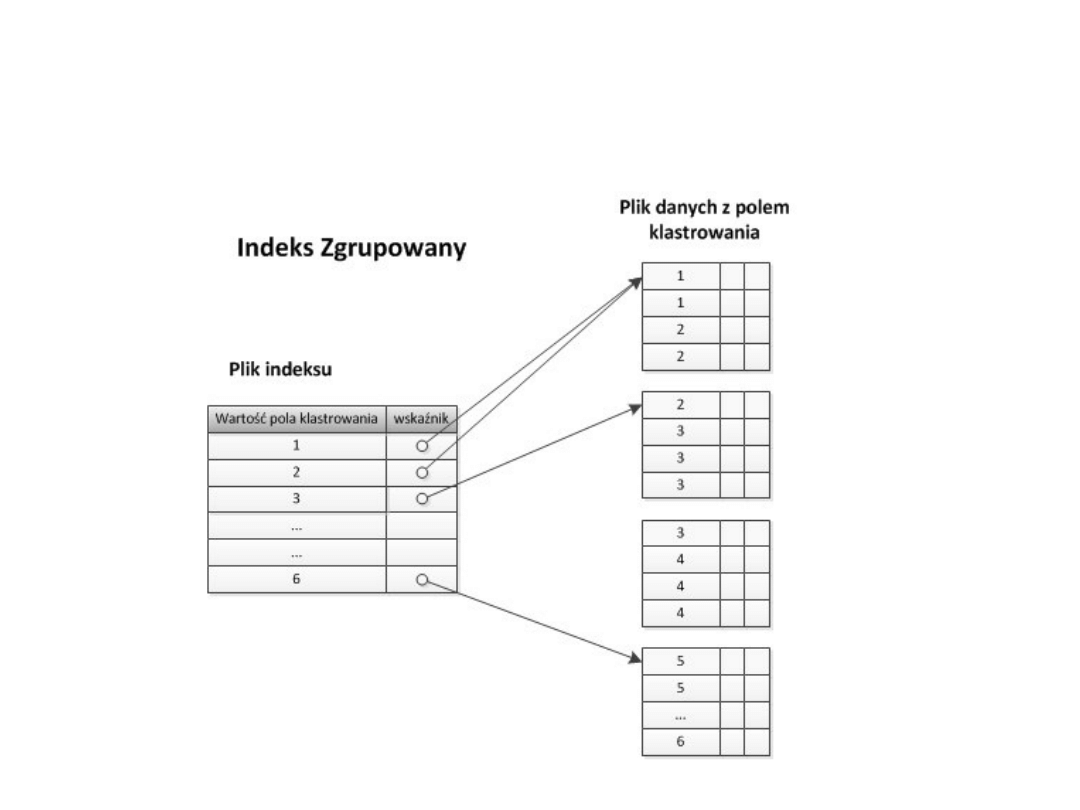
Indeks klastrowy (zgrupowany)

Indeks wtórny (niezgrupowany)
• Może być założony na kolumnę zawierającą
wartości unikatowe lub powtarzające się
• Wskaźnik wskazuje na rekord w bazie danych
(!)
• Indeks gesty!
• Tabela może zawierać dowolną liczbę
indeksów wtórnych
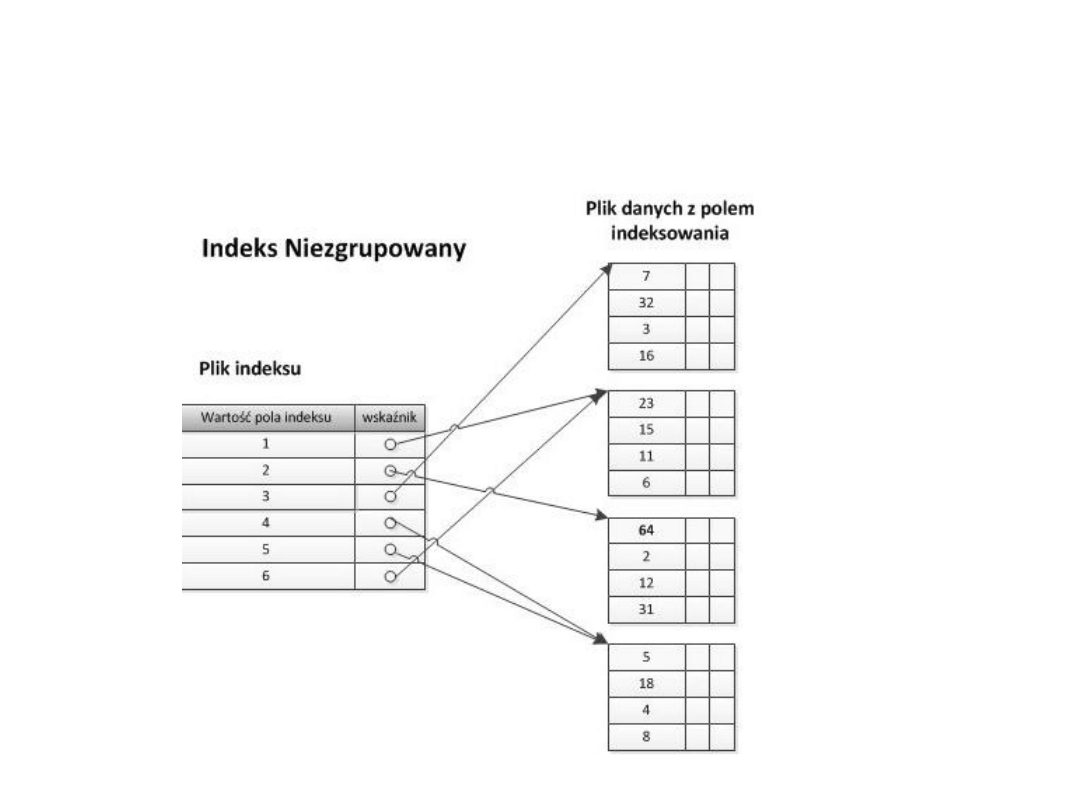
Indeks wtórny (niezgrupowany)

Indeksy wielokolumnowe
• Indeks można założyć dla dowolnej liczby
kolumn
• Zasady:
– Index(A, B, C) może być wykorzystany jako
Index(A)
– Index(A) + Index(B) <> Index(A,B)

Struktura indeksu
• Plik uporządkowany
• Drzewo niezbalansowane
• Drzewo zbalansowane (B-Tree)
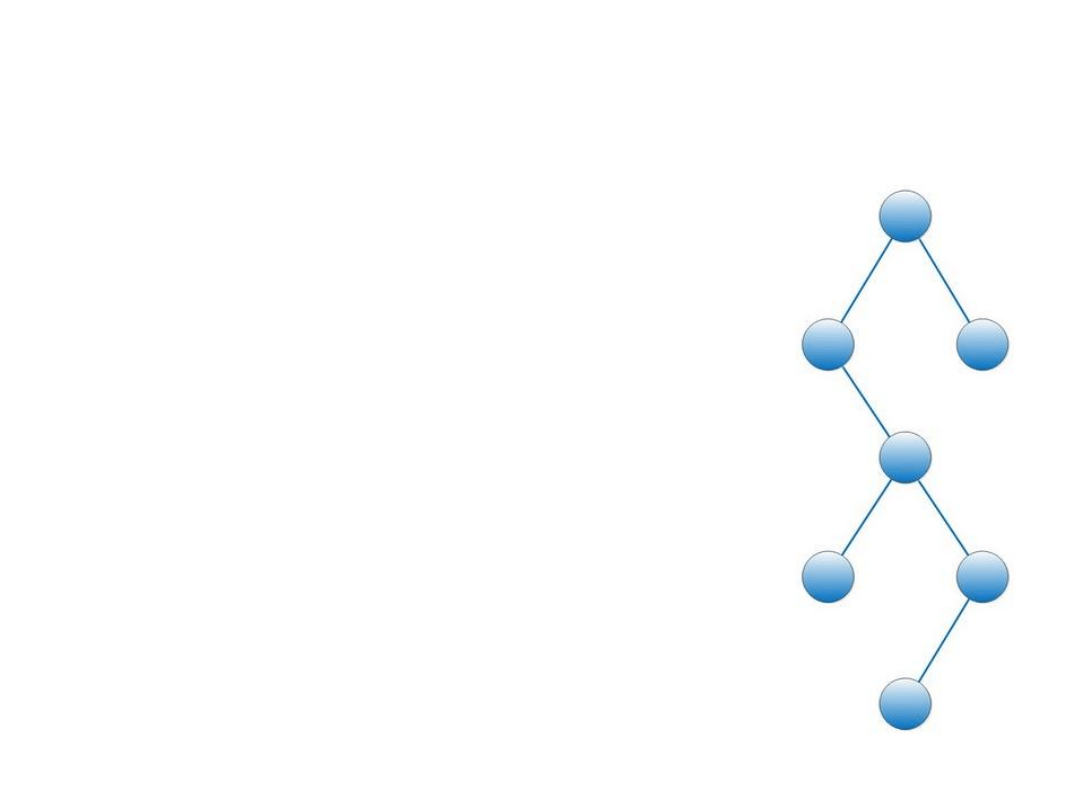
Drzewo niezbalansowane
• Różna długość gałęzi
• Łatwa modyfikacja
• Duży rozrzut czasowy przy
wyszukiwaniu
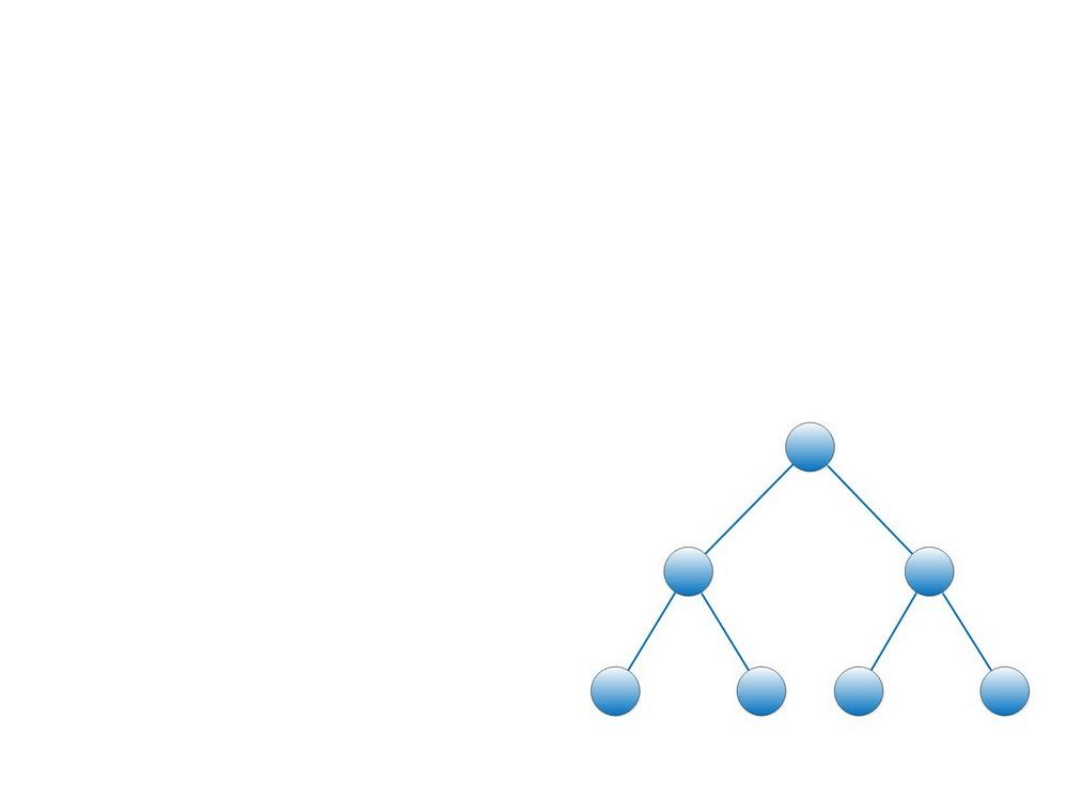
Drzewo zbalansowane
• Jednakowa długość gałęzi
• Konieczność utrzymania
drzewa w stanie
zbalansowania
• Zapewnia powtarzający się
czas wyszukiwania
Struktura drzewa zbalansowanego
(B-Tree)

Selektywność indeksu
• Określa przydatność indeksu (czy warto go w
ogóle zakładać?)
• S = Liczba wartości unikalnych
______________________
Liczba wierszy
Powinno być: S >= ~80..85%

Typy danych a indeks
• Rozmiar indeksu zależy od typu danych w
kolumnie indeksowanej
• Nie zaleca się indeksowania typów danych
złożonych oraz o zmiennej długości (np.
varchar)

Indeksy unikalne a powtarzające się
• Indeks unikalny – każda wartość klucza jest
unikalna (kolumny klucza głównego lub z
ograniczeniem UNIQUE)
• Indeks zwykły – wartości klucza mogą się
powtarzać (większość indeksów wtórnych)

Zasady zarządzania indeksami

1. Optymalizacja składni zapytań
• To samo zapytania można napisać na kilka
różnych sposobów
• Optymalizator SQL prawdopodobnie
doprowadzi je do wspólnej optymalnej postaci
• Są sytuacje kiedy optymalizator nie działa
bądź działa źle!

1.1. Ograniczenie liczby kolumn
• Wynik zapytania powinien zawierać wyłącznie
niezbędne kolumny (!)
– Jeśli wynik zawiera tylko poindeksowane kolumny,
szybkość odpowiedzi serwera jak b. wysoka
ponieważ operuje on wyłącznie na indeksach
– Zwracanie niepoindeksowanych kolumn może
prowadzić do konieczności wyszukiwania w samej
bazie

1.2. Selektywność warunku WHERE
• Trzeba dążyć do tego aby każdy warunek
logiczny stosowany w sekcji WHERE
maksymalnie zawężał zasięg zwracanych
danych!
– Jeśli zbiór zwracanych danych jest zbyt duży, koszt
wyszukiwania danych z użyciem indeksów może
być większy niż liniowe wybieranie danych z
tabeli!

2. Efektywne wykorzystanie indeksów
• Samo założenie indeksów na kolumnach nie
gwarantuje efektywnego ich wykorzystania!
• Indeks pomaga w nielicznych sytuacjach kiedy
warunek logiczny na kolumnie
poindeksowanej spełnia określone kryteria

2.1. Stosowanie właściwych warunków
logicznych w sekcji WHERE
Należy stosować
Należy unikać
=, >, <, <=, >=
Between
Like "X%”
!=, <>,
IN, OR, NOT
LIKE "%X”

2.2. Unikanie stosowania obliczeń na
kolumnie poindeksowanej
• Wartości z kolumny poindeksowanej są
ułożone w określonej kolejności
przyspieszającej ich wyszukiwanie
• Operacja arytmetyczna wykonana na tychże
wartościach nie zawsze daje tę samą
kolejność – indeks nie działa!
• Przykład: WHERE Kwota * 2 > 1000 nie
wykorzystuje indeksu na kolumnie Kwota

Literatura
• Źródło:
• http://kotu.pl/artykuly/strojenie-baz-danych-
optymalizacja-skladni-zapytan-sql.html
Wyszukiwarka
Podobne podstrony:
07 Indeksy (AC)
07 AC Service and Diagnosis
Linda Farstein AC 07 Entombed
EŚT 07 Użytkowanie środków transportu
07 Windows
07 MOTYWACJAid 6731 ppt
Planowanie strategiczne i operac Konferencja AWF 18 X 07
Wyklad 2 TM 07 03 09
ankieta 07 08
Szkol Okres Pracodawcy 07 Koszty wypadków
Wyk 07 Osprz t Koparki
Gor±czka o nieznanej etiologii
więcej podobnych podstron