
31.05.2018
Algorytmy i struktury danych/Słowniki - Studia Informatyczne
http://wazniak.mimuw.edu.pl/index.php?title=Algorytmy_i_struktury_danych/S%C5%82owniki#B-drzewo_-_s.C5.82ownik_na_d…
8/10
W analizie kosztu zamortyzowanego operacji na drzewach splay posłużymy sie metodą księgowania, z każdym węzłem w
drzewie związując pewną liczbę jednostek kredytu. Przez oznaczmy drzewo o korzeniu i zdefiniujmy
(czasem będziemy też używać oznaczenia
). Będziemy zachowywali niezmiennik
"Liczba jednostek kredytu w węźle jest zawsze równa
." (***)
Prawdziwy jest
L
EMAT
[L
EMAT
1]
Do wykonania operacji splay
z zachowaniem niezmiennika (***) potrzeba co najwyżej
jednostek kredytu.
Żmudny, techniczny dowód lematu pozostawiamy jako ćwiczenie. Z lematu wynika bezpośrednio, że dowolna operacja splay
na drzewie rozmiaru wymaga zużycia
jednostek kredytu, a ponieważ do wykonania operacji Insert i Delete z
zachowaniem niezmiennika oprócz tych potrzebnych do wywołań splay potrzeba
dodatkowych jednostek kredytu
(na korzeń), wnioskujemy, że koszt zamortyzowany operacji słownikowych na drzewach splay jest logarytmiczny.
B-drzewo - słownik na dysku
Drzewa BST, nawet w takich jak opisane powyżej wersjach zrównoważonych, nie najlepiej nadają się do przechowywania na
dysku komputera. Specyfika pamięci dyskowej polega na tym, że czas dostępu do niej jest znacznie (o kilka rzędów
wielkości) dłuższy niż do pamięci wewnętrznej (RAM), a odczytu i zapisu danych dokonuje się większymi porcjami
(zwanymi blokami lub stronami). Chaotyczne rozmieszczenie węzłów drzewa BST na dysku bez brania pod uwagę struktury
tego rodzaju pamięci prowadzi do większej niż to naprawdę konieczne liczby dostępów.
Wynalezione na początku lat sześćdziesiątych XX wieku przez Bayera i MacCreighta [BM] B-drzewa to drzewa poszukiwań
wyższych rzędów. W węźle drzewa BST mamy dwa wskaźniki do lewego i prawego syna i jeden klucz, który rozdziela
wartości przechowywane w lewym i prawym poddrzewie. W węźle drzewa poszukiwań rzędu jest wskaźników do synów
oraz
kluczy
, które rozdzielają elementy poszczególnych poddrzew: wartości w
poddrzewie wskazywanym przez muszą mieścić się w przedziale otwartym
dla
(przyjmując, że
oraz
). Rozmiar węzła w B-drzewie dobiera się zwykle tak, aby możliwie dokładnie wypełniał on stronę
na dysku - pojedynczy węzeł może zawierać nawet kilka tysięcy kluczy i wskaźników. Zachowanie zrównoważenia
umożliwione jest dzięki zmiennemu stopniowi wypełnienia węzłów. Dokładna definicja B-drzewa rzędu (
) jest
następująca:
(1) Korzeń jest liściem, albo ma od 2 do synów.
(2) Wszystkie liście są na tym samym poziomie.
(3) Każdy węzeł wewnętrzny oprócz korzenia ma od
do synów. Węzeł mający synów zawiera
kluczy.
(4) Każdy liść zawiera od
do
kluczy.
Warunki (3) i (4) gwarantują wykorzystanie przestrzeni dysku przynajmniej w ok.
, a warunek (2) - niewielką wysokość
drzewa (w najgorszym razie ok.
, a w najlepszym ok.
dla drzewa zawierającego kluczy).
Ponieważ, jak się zaraz przekonamy, koszt operacji słownikowych na B-drzewach jest co najwyżej proporcjonalny do
wysokości drzewa, oznacza to na przykład, że dla
możemy znaleźć jeden spośród miliona kluczy w drzewie przy
pomocy trzech odwołań do węzłów.
Oto przykładowe B-drzewo rzędu 3, zwane też 2-3 drzewem (1-2 klucze i 2-3 synów w węźle):
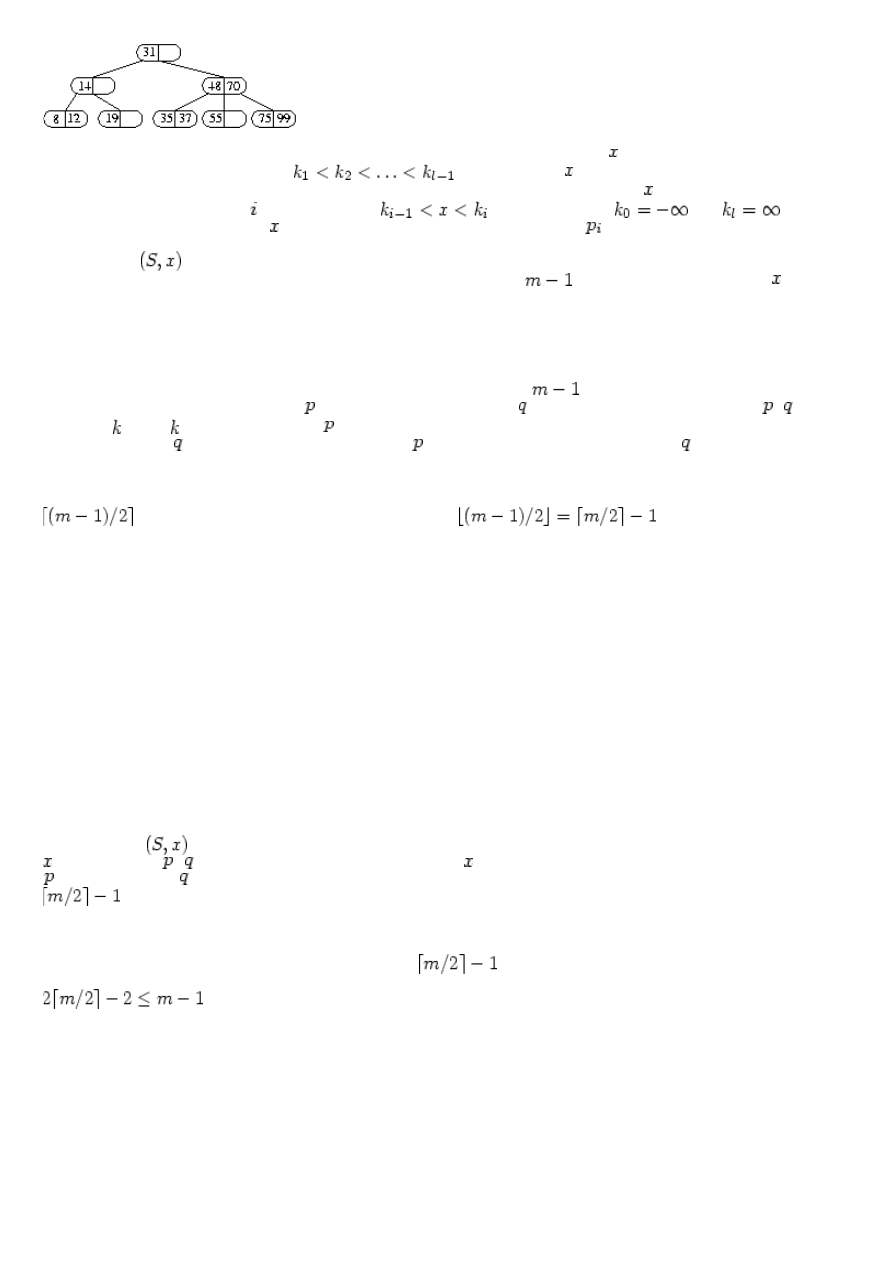
31.05.2018
Algorytmy i struktury danych/Słowniki - Studia Informatyczne
http://wazniak.mimuw.edu.pl/index.php?title=Algorytmy_i_struktury_danych/S%C5%82owniki#B-drzewo_-_s.C5.82ownik_na_d…
9/10
Operacja Find w B-drzewie jest analogiczna jak w drzewach BST. Poszukiwanie klucza rozpoczynamy od korzenia. W
aktualnym węźle zawierającym klucze
szukamy klucza (sekwencyjnie lub binarnie). Jeśli to
poszukiwanie kończy się niepowodzeniem, to albo - jeśli aktualny węzeł jest liściem - klucza w ogóle nie ma w drzewie,
albo, mając wyznaczony indeks o tej własności, że
(przy założeniu, że
oraz
),
rekurencyjnie poszukujemy klucza w poddrzewie o korzeniu wskazywanym przez .
Operacja Insert
zaczyna się od odszukania (jak w operacji Find) liścia, w którym powinien znaleźć się wstawiany
klucz. Jeśli ten liść nie jest całkowicie wypełniony (czyli zawiera mniej niż
kluczy), po prostu wstawiamy w
odpowiednie miejsce w węźle, przesuwając część kluczy (koszt tego zabiegu jest pomijalnie mały w porównaniu z kosztem
odczytu i zapisu węzła na dysk). W przeciwnym razie po dołożeniu nowego klucza węzeł jest przepełniony i będziemy
musieli przywrócić warunek zrównoważenia.
Najpierw próbujemy wykonać przesunięcie kluczy: ta metoda daje sie zastosować, jeśli któryś z dwóch sąsiednich braci
przepełnionego węzła (który nie musi koniecznie być liściem) ma mniej niż
kluczy. Dla ustalenia uwagi przyjmijmy,
że jest to lewy brat i oznaczmy go przez , sam przepełniony węzeł przez , a klucz rozdzielający wskaźniki do i w ich
ojcu przez . Klucz przenosimy z ojca do jako największy klucz w tym węźle, w jego miejsce w ojcu przenosimy
najmniejszy klucz z , po czym skrajnie lewe poddrzewo czynimy skrajnie prawym poddrzewem . Przesunięcie kluczy w
prawo wykonuje się symetrycznie. Po takim zabiegu warunki równowagi zostają odtworzone i cała operacja się kończy.
Jeśli przepełniony węzeł nie ma niepełnego sąsiada, to wykonujemy rozbicie węzła. Listę kluczy dzielimy na trzy grupy:
najmniejszych kluczy, jeden klucz środkowy oraz
największych kluczy. Z
pierwszej i trzeciej grupy tworzymy nowe węzły, a środkowy klucz wstawiamy do ojca (co może spowodować jego
przepełnienie i konieczność kontynuowania procesu przywracania zrównoważenia o jeden poziom wyżej) i odpowiednio
przepinamy poddrzewa. Kiedy następuje przepełnienie korzenia, rozbijamy go na dwa węzły i tworzymy nowy korzeń
mający dwóch synów (to jest właśnie powód, dla którego korzeń stanowi wyjątek w warunku (3)) - to jest jedyna sytuacja, w
której wysokość B-drzewa się zwiększa.
Operację Delete
również zaczynamy od odszukania węzła z kluczem do usunięcia. Poddrzewa rozdzielane przez klucz
oznaczmy przez i . Tak jak przy usuwaniu z BST, w miejsce przenosimy - znajdujący się w liściu - największy klucz z
(albo największy z ). Lukę po przeniesionym kluczu niwelujemy zsuwając pozostałe. Jeśli jest ich co najmniej
, cała operacja jest zakończona, natomiast w razie niedoboru w celu przywrócenia równowagi musimy dokonać
przesunięcia kluczy albo sklejenia węzłów. Jeśli któryś z dwóch sąsiednich braci węzła z niedoborem ma co najmniej o jeden
klucz więcej niż dozwolone minimum, to - podobnie jak przy wstawianiu - przesuwamy skrajny klucz z niego do ojca w
miejsce klucza rozdzielającego braci, który z kolei wędruje do węzła z niedoborem. Niemożność wykonania przesunięcia
kluczy oznacza, że brat węzła z niedoborem ma dokładnie
kluczy. Sklejamy te dwa węzły w jeden, wstawiając
jeszcze pomiędzy ich klucze klucz rozdzielający z ojca i odpowiednio przepinając poddrzewa. Powstaje w ten sposób węzeł o
kluczach, a z ojca ubywa jeden klucz, co może spowodować w nim niedobór i konieczność
kontynuowania procesu przywracania zrównoważenia wyżej w drzewie. Jeśli korzeń traci swój jedyny klucz, usuwamy ten
węzeł, a jego jedynego syna czynimy nowym korzeniem - to jest jedyna sytuacja, w której wysokość B-drzewa maleje.

31.05.2018
Algorytmy i struktury danych/Słowniki - Studia Informatyczne
http://wazniak.mimuw.edu.pl/index.php?title=Algorytmy_i_struktury_danych/S%C5%82owniki#B-drzewo_-_s.C5.82ownik_na_…
10/10
Literatura:
[AVL] G. M. Adelson-Velskij, E. M. Landis, An algorithm for the organization of information, Soviet Math. Doklady 3,
1962, 1259-1263.
[BM] R. Bayer, E. M. McCreight, Organization and Maintenance of Large Ordered Indexes, Acta Informatica 1, 1972, 173-
189.
[CLRS] Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein, 'Wprowadzenie do algorytmów', WNT,
Warszawa 2004.
[ST] D.D. Sleator, R.E. Tarjan, Self-Adjusting Binary Search Trees, Journal of the ACM 32:3, 1985, 652-686.
Źródło: "http://wazniak.mimuw.edu.pl/index.php?title=Algorytmy_i_struktury_danych/S%C5%82owniki"
Tę stronę ostatnio zmodyfikowano o 14:27, 3 gru 2007;
Wyszukiwarka
Podobne podstrony:
Algorytmy i struktury danych Wykład 1 Reprezentacja informacji w komputerze
Algorytmy i struktury danych Wykład 1 Reprezentacja informacji w komputerze
kolokwium1sciaga, Studia Informatyka 2011, Semestr 2, Algorytmy i struktury danych
ASD, Pytania do egzaminu z Algorytmów i Struktur Danych, Pytania do egzaminu z Algorytmów i Struktur
Pojęcia algorytmy, Studia Informatyka 2011, Semestr 2, Algorytmy i struktury danych, algorytmy sciag
Cw2008, Studia Informatyka PK, Semestr II, Algorytmy i struktury danych
ukl 74xx, Informatyka PWr, Algorytmy i Struktury Danych, Architektura Systemów Komputerowych, Archit
cw 0 1, pwr, informatyka i zarządzanie, Informatyka, algorytmy i struktury danych
AIDS w7listy, studia, Semestr 2, Algorytmy i struktury danych AISD, AIDS
W10seek, studia, Semestr 2, Algorytmy i struktury danych AISD, AIDS
ALS - 001-000 - Zadania - ZAJECIA, Informatyka - uczelnia, WWSI i WAT, wwsi, SEM II, Algorytmy i Str
ALS - 009-005 - Program Sortowanie INSERTION SORT, Informatyka - uczelnia, WWSI i WAT, wwsi, SEM II,
ALS - 002-001, Informatyka - uczelnia, WWSI i WAT, wwsi, SEM II, Algorytmy i Struktury Danych
ALS - 004-000b - Zajęcia - STOS - LIFO - Ćwiczenie ONP, Informatyka - uczelnia, WWSI i WAT, wwsi, SE
I kolokwium, Informatyka PWr, Algorytmy i Struktury Danych, Algorytmy i Struktury Danych, kolokwia i
I kolokwium(1), Informatyka PWr, Algorytmy i Struktury Danych, Algorytmy i Struktury Danych, kolokwi
wyk.9, Informatyka PWr, Algorytmy i Struktury Danych, Architektura Systemów Komputerowych, Assembler
Sprawozdanie 2, Informatyka PWr, Algorytmy i Struktury Danych, Architektura Systemów Komputerowych,
więcej podobnych podstron