
W
1998 roku Ian Foster i Carl
Kesselman wydali książkę pod
tytułem „The Grid – Blueprint
for a New Computing Infrastructure”. Wy-
darzenie to jest uważane przez wiele osób
za początek nowej ery w dziedzinie syste-
mów rozproszonych (Rysunek 1 i 2). Wizja
Fostera i Kesselmana polega na zbudowa-
niu rozproszonych zasobów, które można
w prosty sposób, w oparciu o standaryzowa-
ny interfejs, wykorzystać do użytku pu-
blicznego. Miało to umożliwić czerpanie
korzyści z mocy obliczeniowej, danych i in-
nych usług zwykłym śmiertelnikom w tak
prosty sposób, jak teraz wszyscy korzysta-
my z elektryczności, podłączając wtyczkę
do gniazdka w ścianie. Ten 220-woltowy
sen pomógł także założycielom stworzyć
nazwę dla ich projektu, która wywodzi się
w prostej linii od sieci energetycznej (ang.
grid – sieć energetyczna). Niestety, jak do-
tąd (mimo kilku prób) nie powstał dobry
polski termin dla grid computing, dlatego
dalej będziemy używać terminu angielskie-
go [przyp. Redakcja LM].
Tim Berners-Lee miał w 1991 roku podob-
ną wizję, kiedy wymyślił sieć WWW
w CERN (Centre Europeenne pour la Re-
cherche Nucleaire) w Genewie. Tak jak to
miało miejsce w przypadku ogólnoświatowej
sieci WWW, tak i teraz – w przypadku grid
computing, główną siłą napędową jest wła-
śnie CERN. Jest to jeden z powodów żartów
dotyczących technologii grid computing, któ-
re niektórzy nazywają siecią na asteroidzie.
Czym jest grid computing?
Grid computing ma (i słusznie) reputację bar-
dzo ważnej technologii przyszłości. Jest to je-
den z powodów, dla których badania te są
sponsorowane z wielu źródeł. Grupy badaw-
cze, mające tylko ogólny związek z rozproszo-
nymi systemami obliczeniowymi, zaczynają
coraz częściej używać tego słowa w odniesie-
niu do całego swojego dorobku. Oczywiście ta-
ki rodzaj środowiska sprawia, że precyzyjne
zdefiniowanie „rozproszonych systemów obli-
czeniowych” jest z każdym dniem trudniejsze.
Z konieczności definicja związana jest
ściśle z praktyką. Istnieje tylko niewielka
różnica pomiędzy wizją Fostera i Kesselma-
na, a badaczami korzystającymi z zasobów
rozproszonych do rozwiązania interesują-
cych problemów. Druga grupa to fizycy ją-
drowi. W roku 2007 tysiące naukowców roz-
mieszczonych na całym świecie zajmie się
kilkunastoma petabajtami danych pocho-
dzącymi z eksperymentów w akceleratorze
cząstek elementarnych CERN (Large Ha-
dron Collider). Zasoby obliczeniowe, który-
mi lokalnie dysponują obecnie naukowcy,
absolutnie nie nadają się do tego rodzaju za-
dań. Ponadto, bardziej sensowne jest przy-
niesienie odpowiedniego programu do miej-
sca przechowywania danych, niż odwrotnie
(chociażby ze względu na olbrzymią ilość in-
formacji, którą trzeba byłoby pociąć na
drobne elementy i przenosić osobno).
Tak więc patrząc pod tym kątem, infra-
struktura łącząca ogromne pojemności pa-
mięci wraz z dziesięcioma tysiącami jedno-
stek centralnych w końcu nabiera sensu.
Tradycyjne technologie rozproszone nie ra-
dzą sobie zarówno z problemami tej skali,
jak i z różnorodnością sprzętu komputero-
wego – jedynym wyjściem z sytuacji jest
opracowanie nowej metody: grid compu-
ting. Grid computing został tak dobrze do-
stosowany do potrzeb fizyków jądrowych,
ponieważ to właśnie naukowcy często doko-
nują obliczeń oddzielnych zbiorów danych
przy pomocy wielu wersji programu uru-
chomionych równolegle. Mimo że fizycy ją-
drowi nie są być może główną motywacją
rozwoju grid computing, z pewnością byli
jedną z sił napędowych tego nurtu.
Celem grid computing jest globalne roz-
proszenie wielu kopii tego samego programu,
podobnie jak to miało miejsce w systemach
wsadowych pracujących w klastrach lokal-
nych. W ramce „Jak działa grid computing”
omówiono aspekty związane z klastrami.
Z kolei oryginalne aplikacje równoległe, wy-
mieniające ogromne ilości informacji między
węzłami obliczeniowymi, nie odegrają raczej
żadnej istotnej roli w grid computing.
Rozproszone bazy danych to już jednak
inna historia. Sieci obliczeniowe wykazują
się wyjątkową wydajnością w służbie zdro-
wia (zapewniając dostęp do danych me-
dycznych), podczas łączenia danych genero-
wanych przez przedsiębiorstwa o zasięgu
ogólnoświatowym lub też technologii i me-
chanizmów wyszukiwania danych.
Grid computing
KNOW HOW
48
Lipiec 2004
www.linux-magazine.pl
Grid computing
Moc z sieci
Grid computing to termin określający przetwarzanie danych wykorzystujące
moc obliczeniową komputerów współpracujących w sieci. Technologią tą
zachwycają się naukowcy, informatycy i cały przemysł IT.
RÜDIGER BERLICH
Rysunek 1: Carl Kesselman podczas Cern
School of Computing 2002 w Vico Equense
koło Neapolu (Włochy). Współautor pierwszej
książki o grid computing jest jednym z ojców
struktury tego typu.

Sieci, systemy plików
i oprogramowanie
pośredniczące
Aby osiągnąć cel, jakim jest globalna sieć
rozproszona, grid computing korzysta z naj-
nowszych rozwiązań i pomysłów z szerokie-
go zakresu dziedzin. Szybkie sieci publicz-
ne to jeden z warunków wstępnych całego
przedsięwzięcia. Wysokowydajne sieci na-
rodowe w wielu państwa rozwiniętych go-
spodarczo będą musiały połączyć się, two-
rząc „Ogólnoświatową Sieć Obliczeniową”.
Dostępna jest już odpowiednia technolo-
gia sieciowa, a przepustowość takich sieci
cały czas rośnie w akceptowalnym tempie.
Zatem wydajność sieci, przy której zostaną
one połączone, zależy bardziej od budżetów
poszczególnych krajów niż od samej tech-
nologii. W Europie główną rolę odgrywa
GÉANT [1] – współpraca pomiędzy 26 sie-
ciami badawczymi.
Obecnie największe prowadzone badania
dotyczą rozwoju rozproszonych systemów
plików, które są sercem centrów danych –
węzłów obliczeniowych sieci. W niektórych
przypadkach takie centra danych są ogólno-
dostępne, mimo znacznego obniżenia ich
wydajności ze względu na duże opóźnienia
powstające w globalnych sieciach kompute-
rowych (WAN) (patrz Ramka „Jak działa
grid computing”).
Aby stworzyć program działający w tech-
nologii grid computing, potrzebujemy pew-
nego doświadczenia z zakresu oprogramo-
wania pośredniczącego (ang. middleware).
Jego rola jest podobna do roli warstwy sie-
ciowej systemu operacyjnego. Aplikacja,
która chce przesłać dane po sieci, nie musi
znać szczegółów dotyczących konkretnych
podzespołów tej sieci. Podobnie aplikacja
działająca w sieci obliczeniowej nie powin-
na przejmować się uwierzytelnianiem i au-
toryzacją – zadania te należą do oprogramo-
wania pośredniczącego.
Oprogramowanie pośredniczące ma ogra-
niczony zakres działania, polegający na
ukrywaniu struktury sieci, w której pracuje.
Dopóki użytkownicy sieci obliczeniowej bę-
dą wysyłać programy, które mogą być ob-
sługiwane w sposób zgodny z oczekiwania-
mi, wszystko powinno działać prawidłowo.
Co jednak dzieje się, gdy zaczynają być uży-
wane skompilowane wcześniej pliki binar-
ne? Jest to pytanie, na które warto poznać
odpowiedź – w sieciach o dużej skali nie ma
możliwości sprawdzenia, czy komputer po
drugiej stronie przewodu korzysta z 64-bit-
owej architektury RISC, czy jest to może
32-bitowa maszyna Intel, czy też całkiem
coś innego.
W środowisku tego typu punkty zyskują
z pewnością takie języki oprogramowania,
jak Java czy C# – skutecznie ukrywają ar-
chitekturę, na której pracują. Z drugiej jed-
nak strony nowoczesne oprogramowanie
pośredniczące dla sieci obliczeniowych ma
także możliwość ograniczenia aplikacji ob-
liczeniowej do określonej, zdefiniowanej
wcześniej architektury.
Kreatywność a standardy
Można powiedzieć, że oprogramowanie po-
średniczące jest swego rodzaju wieżą Babel.
Z jednej strony, konkurowanie różnych
kreatywnych metod w kreatywnym środo-
wisku jest całkiem zdrowe i normalne –
przykładem mogą tutaj być chociażby pro-
gramy do obsługi poczty czy różne środowi-
ska graficzne dla Linuksa. Z drugiej strony
jednak, koncerny i firmy tworzące lobby
przemysłowe ciągle szukają standardów,
które umożliwiłyby im rozpoczęcie prac
nad pisaniem programów.
Rozwiązania dostarczyć powinna nam
ewolucja. W świecie Open Source najlepszy
kandydat pojawia się zawsze jako ostatni.
Obecnie, wnioskując z liczby instalacji, wy-
grywa pakiet Middleware Globus Toolkit.
Ian Foster i Carl Kesselman, autorzy Biblii
grid computing-u, są członkami grup ba-
dawczych firmy Globus i nadają jej dzięki
swojej działalności prestiżu.
Jednakże projekt Globus, ze swoją różno-
rodnością programów i wersji, odpowiada
za pewne zamieszanie w świecie grid com-
puting (bez względu na wzniosłe intencje).
Struktura monolityczna wersji 2 Globus-T-
oolkit (GT 2) doczekała się kilku instalacji.
W wersji 3 (GT 3) wprowadzono nową,
otwartą architekturę usług obliczeniowych
(ang. Open Grid Service Architecture
(OGSA)), opartą na tzw. usługach sieci obli-
czeniowych. Spowodowało to pewien sto-
pień niepewności pomiędzy osobami odpo-
wiedzialnymi za projekt.
Znaczenie Globus-Toolkit
Użytkownicy zaczęli angażować się w GT3,
gdy tylko na początku tego roku pojawiła
się nowa wersja. W GT4 podjęto próby za-
chowania kompatybilności z tradycyjnymi
usługami sieciowymi.
Jednym z głównych aspektów grid com-
puting jest bezpieczeństwo. Praca tysięcy
komputerów w światowej sieci rozproszo-
nej, czyli w Internecie, to ogromne wyzwa-
nie. Tutaj można skorzystać z infrastruktu-
ry dla sieci obliczeniowych Globus (ang.
Globus Grid Security Infrastructure (GSI)),
która zapewnia uwierzytelnianie i autoryza-
cję pracy w sieci.
Oprogramowanie pośredniczące, zapew-
KNOW HOW
Grid computing
49
www.linux-magazine.pl
Lipiec 2004
Rysunek 2: Ian Foster – podobnie jak Carl Kesselman, jest jednym z ojców-założycieli idei grid
computing; tutaj na stoisku firmy Sun podczas targów Supercomputing 2001, które odbyły się
w Denver. Hasło reklamowe „Sun Powers The Grid” (czyli „Sun zasila sieci obliczeniowe”) po-
twierdza duże zainteresowanie przemysłu komputerowego nową technologią.
niane przez Europejską Sieć Obliczeniową
(ang. European Data Grid (EDG)), posiada
już usługi tego typu. Firma Globus celowo
usunęła je ze swoich zestawów narzędzi.
Jedną z usług jest tzw. pośrednik zasobów
(ang. Resource Broker), który rozprasza
aplikacje pracujące w sieci obliczeniowej na
poszczególne zasoby. EDG jest oryginal-
nym projektem społeczności europejskiej,
posiadającym odpowiednie źródła finanso-
wania i organy nadzorcze. Projekt zostanie
jednak wkrótce zastąpiony przez EGEE
(udostępnianie zasobów grid computing na
potrzeby nauki w Europie). EGEE będzie
korzystać z doświadczeń uzyskanych pod-
czas prac nad projektem Europejskiej Sieci
Obliczeniowej.
AliEn (skrót od ang. „Alice Environ-
ment” [2]) to projekt firmy Alice Experi-
ment przeprowadzony w akceleratorze czą-
stek elementarnych. Projekt jest doskona-
łym przykładem siły Open Source.W prze-
ciwieństwie do EDG, Alin nie jest całkowi-
cie nowym rozwiązaniem – korzysta z ist-
niejących modułów Perla wszędzie tam,
gdzie jest to możliwe. Techniki „ekstremal-
nego programowania” w niewielkim gronie
programistów okazały się skuteczne – stwo-
rzono działające środowisko sieci oblicze-
niowej o wymaganej funkcjonalności po-
równywalnej z projektem EDG.
Twórcy aplikacji dla superkomputerów
chętnie korzystają z wyników badań projek-
tu Unicore (ang. Uniform Interfaces to
Computing Resources [3]). Podobnie jak
Globus i EDG, Unicore korzysta z pewnego
rodzaju rozproszonego systemu wsadowego.
Ponadto takie nazwy jak Cactus [4], Legion
[5] czy Condor [6] brzmią bardzo znajomo
w odniesieniu do omawianego już oprogra-
mowania pośredniczącego.
Standardy,
Grid Forum i D-Grid
Różnorodność i niezależność różnych pro-
jektów sprawia, że grid computing wymaga
jednolitych standardów i protokołów. Jed-
ną z organizacji, która może w przyszłości
stać się ciałem organizującym standardy
dla grid computing, jest Global Grid Fo-
rum (GGF). Jej celem jest uzyskanie statu-
su podobnego do organizacji IETF (Inter-
net Engineering Taskforce), która unifiku-
je normy dotyczące sieci Internet.
Eksperci z dziedziny grid computing spo-
tykają się kilka razy w roku w celu wymiany
doświadczeń. Dziesiąte Ogólnoświatowe Fo-
Grid computing
KNOW HOW
50
Lipiec 2004
www.linux-magazine.pl
Aplikacje grid computing podlegają tym
samym prawom co aplikacje pracujące
w sieciach rozproszonych. Wydajność więk-
szości aplikacji jest uzależniona od przepu-
stowości sieci i występujących w niej opóź-
nień. Przepustowość sieci to ilość ruchu,
którą sieć potrafi obsłużyć w jednostce cza-
su. Opóźnienia to czas przebiegu sygnału
pomiędzy nadawcą a odbiorcą. W syste-
mach Linux do sprawdzenia tej wartości
możemy użyć polecenia ping. Polecenie to
mierzy czas cyklu pracy, który jest dwukrot-
ną wartością opóźnienia. Opóźnienie po-
między Centrum Badawczym w Karlsruhe
(Niemcy) a Uniwersytetem Rury w Bochum
wynosi około 20 ms (patrz Rysunek 3).
Opóźnienia w sieci lokalnej powinny być
dużo mniejsze. Czasy opóźnień w syste-
mach wieloprocesorowych są w porówna-
niu z nimi pomijalnie małe.
Wysokie opóźnienia lub mała przepusto-
wość sieci nie mają czasem wpływu na nie-
które aplikacje. Ten sam program może
dokonywać obliczeń na segmencie zestawu
danych jednocześnie na kilku kompute-
rach, które mogą być rozproszone po całym
świecie. Pojedyncze wystąpienia programu
nie wymieniają jednak między sobą da-
nych. Aplikacje tego typu często nazywane
są „kłopotliwie równoległymi” lub też bar-
dziej optymistycznie – „cudownie równole-
głymi”. Nie mają one żadnych dodatko-
wych wymagań w stosunku do programo-
wania. Twórca oprogramowania może na-
wet nie zdawać sobie sprawy z działania kil-
ku wystąpień programów równolegle. Pod
koniec pracy program lub użytkownik musi
po prostu połączyć w całość wyniki obliczeń
pochodzące z poszczególnych komputerów.
W
Wyym
miia
an
na
a d
da
an
nyycch
h
zzm
mn
niieejjsszza
a p
prręęd
dkko
ośśćć d
dzziia
ałła
an
niia
a a
ap
plliikka
accjjii
Tradycyjne aplikacje równoległe dokonują
wymiany danych w klastrze podczas uru-
chamiania. Jeżeli jeden z programów musi
czekać na kolejny, aby wykonać powierzo-
ne mu zadanie, może to być dużym proble-
mem. W takim przypadku długie czasy
opóźnień i niska przepustowość sieci glo-
balnej (WAN) mogą jeszcze pogorszyć sy-
tuację. Sieci lokalne (LAN lub klastry), po-
dobnie jak systemy wieloprocesorowe, są
lepiej przystosowane pod tym względem.
Łatwo więc rozpoznać rodzaj aplikacji, któ-
ra nadaje się do grid computing. Jako że
programy takie pracują zwykle w sieci
WAN, jakość komunikacji pomiędzy węzła-
mi (komputerami) obliczeniowymi jest czyn-
nikiem decydującym o zasadności urucha-
miania danego oprogramowania w infra-
strukturze grid computing. Chociaż sieć ob-
liczeniowa teoretycznie zapewnia nieskoń-
czone zasoby obliczeniowe, wydajność zo-
stanie bardzo ograniczona w przypadku,
gdy węzły sieci będą tracić czas na oczeki-
wanie na odpowiedź z innych węzłów.
Jak działa grid computing
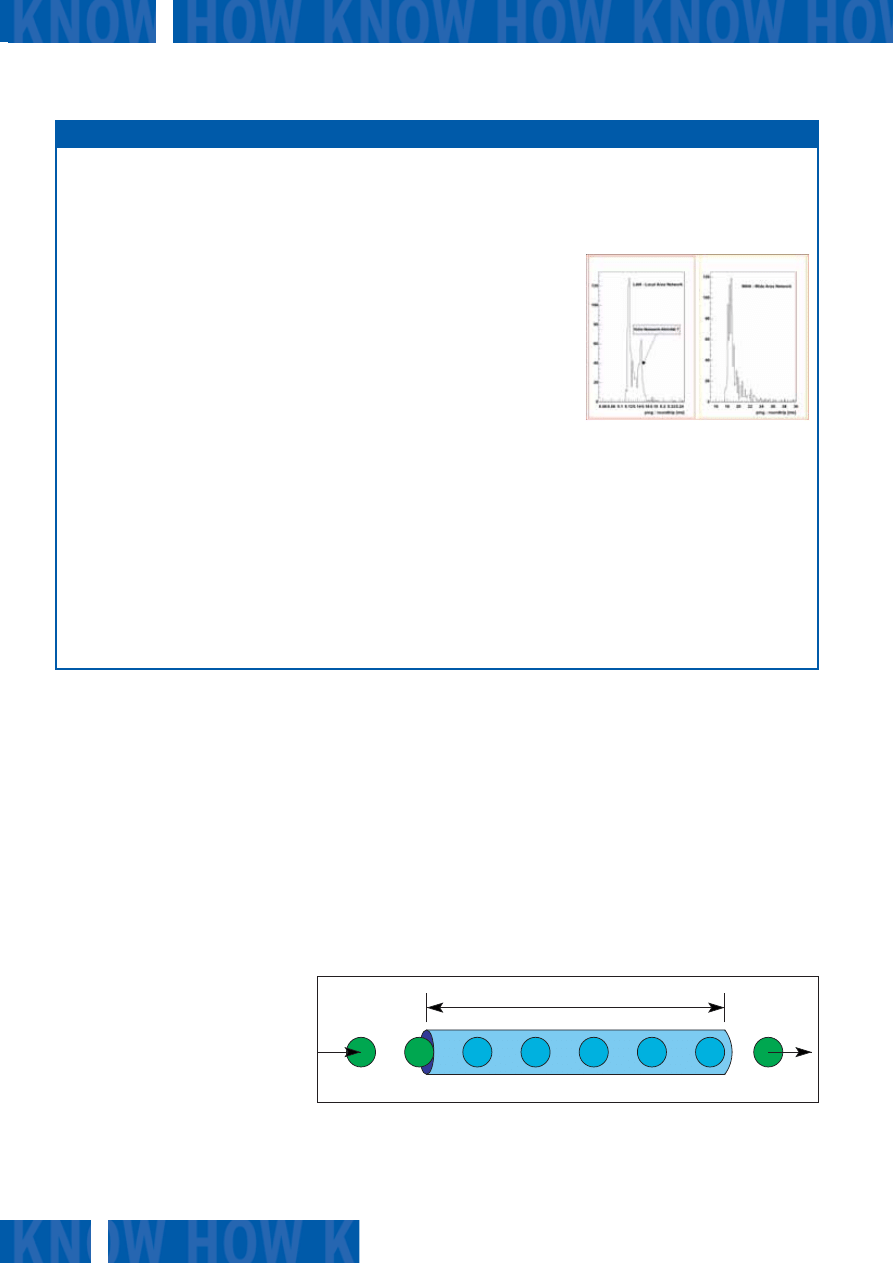
Rysunek 3: Histogram cyklu pracy
w dwóch różnych sieciach (podwójne
opóźnienie, zmierzone przy pomocy pole-
cenia ping). Wykres z lewej strony pokazu-
je czas cyklu pracy dla sieci lokalnej LAN,
a wykres po prawej – połączenie pomiędzy
Centrum Badawczym w Karlsruhe a Uni-
wersytetem Rury w Bochum (Niemcy).
Wartości w sieci WAN oscylują w grani-
cach 18-20 milisekund, podczas gdy
w sieci LAN wartości te wynoszą od 0,11
do 0,16 milisekundy.
Rysunek 4: Przepustowość i opóźnienia w sieci ograniczają użyteczność grid computing. W szcze-
gólności opóźnienie (latency), czyli czas wymagany do przesłania pakietu w sieci, jest zmienną, któ-
rej nie możemy ściśle kontrolować.
Packets/sec
Bandwidth:
~15 msec (Latency)
San Francisco
Network
NewYork
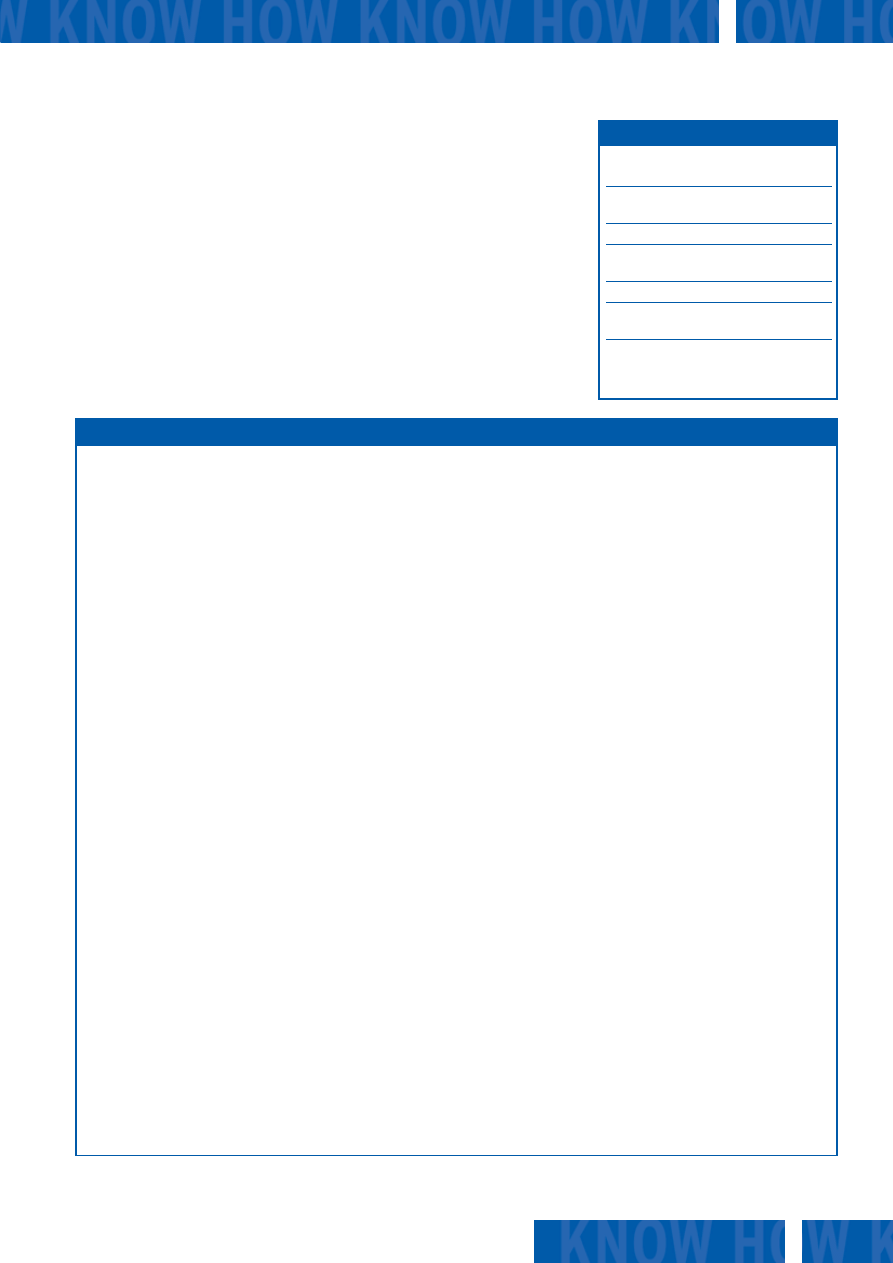
rum Sieci Obliczeniowych odbyło się na
Uniwersytecie Humboldta w
Berlinie
(Niemcy) w marcu 2004 roku. Wybór miej-
sca spotkania mógł zaskoczyć niektóre oso-
by, jako że projekt niemiecki trudno odszu-
kać w rankingu głównych inicjatyw związa-
nych z grid computing, począwszy od sieci
malezyjskiej, a na instalacjach wojskowych
typu sieć Ministerstwa Energetyki Stanów
Zjednoczonych [7] skończywszy. Podczas
forum niemiecki minister nauki rozpoczął
nową inicjatywę wieloorganizacyjnej sieci
obliczeniowej: D-Grid.
Programowy chaos
Sieci obliczeniowe nie mogą być uważane
za sieci ogólnoświatowe. Jeszcze daleko im
do osiągnięcia pełnej globalizacji, gdyż sie-
ci te nie podlegają żadnej standaryzacji.
Problemem nie są fundusze czy pracownicy
naukowi, ale fakt, że zbyt wiele mądrych
osób opracowało zbyt wiele (równie) mą-
drych rozwiązań – jest to typowa cecha ba-
dań naukowych.
Z niecierpliwością będziemy zatem ob-
serwować, jaki wpływ będzie miało rosnące
zainteresowanie wśród firm tą nową techno-
logią. Mimo że niektórym nie przeszkadza
taki chaotyczny krajobraz sieci obliczenio-
wych, wykorzystanie tego typu sieci w ini-
cjatywach komercyjnych wymaga pewnych
standardów.
■
KNOW HOW
Grid computing
51
www.linux-magazine.pl
Lipiec 2004
Fizycy jądrowi zajmują się poszukiwaniem
podstawowych elementów, z których skła-
da się każda materia oraz opisywaniem sił
i zależności zachodzących między nimi.
Jak dotąd wiemy, że cząsteczka elemen-
tarna nie posiada struktury wewnętrznej.
Kiedy naukowcy myślą, że właśnie odkryli
cząsteczkę elementarną, po bardziej
szczegółowych badaniach okazuje się, że
jednak nie mieli racji. Według obecnie
obowiązujących standardów, atomy to gi-
gantyczne złożone obiekty składające się
z elektronów, protonów i neutronów.
Z kolei te ostatnie składają się z kwarków
i tak dalej i tak dalej...
W
W p
po
osszzu
ukkiiw
wa
an
niiu
u cczzą
ąsstteecczzeekk
Aby pomóc w poszukiwaniach nowych czą-
steczek i podstruktur znanych już cząste-
czek, naukowcy użyli ogromnych systemów
akceleratorów typu PEP II Ring, znajdują-
cych się w Stanford Linear Accelerator Cen-
ter (SLAC) w Kaliforni czy też akceleratora
CERN w Genewie (Szwajcaria). Akcelerato-
ry te powodują kolizje różnych rodzajów
cząstek. Akcelerator LEP, uruchomiony
w instytucie CERN w 1989 roku, przyspie-
szał elektrony i ich antycząstki oraz pozytro-
ny w pierścieniu o długości 27 km, powodu-
jąc zderzenia w czterech punktach. Tunel
LEP biegnie pod Genewą, jak i pod szwaj-
carsko-francuskim łańcuchem górskim.
Pierścień jest tak duży, że podczas jego kali-
bracji trzeba wziąć pod uwagę efekt przy-
pływów i odpływów oraz sezonowe zmiany
w poziomie wód w jeziorze Genewa, które
wpływają na okoliczne środowisko.
Ostatnio akcelerator LEP został zamknięty,
aby umożliwić swojemu następcy podobną
kalibrację. Nowy akcelerator cząstek roz-
proszonych jest właśnie instalowany
w miejscu poprzedniego. Wraz z interesują-
cymi eksperymentami (m.in. Atlas i Alice)
akcelerator, który ma być uruchomiony
w 2007 roku, powinien umożliwić naukow-
com generowanie poziomów energetycz-
nych na niespotykanym dotąd poziomie.
Osiągnięcie znacznie mniejszych wymiarów
wymaga znacznie większych ilości energii.
Niektóre rodzaje cząstek są tak ciężkie (a
idąc tropem einsteinowskiego E=mc
2
, tak
naładowane energią), że ich stworzenie nie
jest możliwe przy wykorzystaniu istniejących
źródeł energii. Jednym z przykładów może
tutaj być Higgs-Boson.
8
80
0 G
GB
B d
dyysskku
u ttw
wa
arrd
deeg
go
o w
w 1
16
6 sseekku
un
nd
d
Wyższe poziomy energetyczne oznaczają
także większą ilość danych dla naukowców.
Przykładowo, podczas przeprowadzania eks-
perymentu Alice naukowcy będą wywoływać
zderzenia pomiędzy ciężkimi jonami. Ko-
nieczne będzie odtworzenie śladów tysięcy
naładowanych i neutralnych cząsteczek dla
każdego ze zderzeń. Odpowiednie dane bę-
dą pochodzić z sygnałów różnego rodzaju
detektorów, zorganizowanych na zasadzie
naskórka cebuli. Z powodu większych czę-
stości zderzeń eksperymenty w akceleratorze
generują około 40 GB danych w ciągu se-
kundy. Innymi słowy, do zapełnienia dysku
twardego o pojemności 80 GB wystarczy 16
sekund. Jednakże eksperymenty te zaplano-
wano do przeprowadzenia dopiero za kilka
lub kilkanaście lat.
Szybkość transmisji danych także dopro-
wadziła do zmian w infrastrukturze obli-
czeniowej w zakresie fizyki cząstek ele-
mentarnych. Tam, gdzie jeszcze kilka lat
temu obliczeniami zajmowały się kompu-
tery Unix i VMS, a czasem także kompute-
ry typu mainframe, teraz pracują w tej roli
w zasadzie wyłącznie sieci komputerowe
z systemem Linux. Droga do chwały syste-
mu Linux rozpoczęła się w 1995 roku w in-
stytucie CERN, kiedy pierwsza grupa fizy-
ków zainstalowała ten system na dyskach
twardych stacji roboczych.
Niestety, przeprowadzka do systemu Linux
wywołała kilka nieoczekiwanych proble-
mów. Każdy naukowiec chciałby, aby jego
program opracowywał te same wyniki
w ten sam sposób na wszystkich kompute-
rach. Różne dystrybucje, jak i różne wersje
systemu, korzystają zwykle z różnych bi-
bliotek i jądra systemu. W rezultacie
wszystko to może wpłynąć na dokładność
wykonywanych obliczeń (punktem krytycz-
nym okazała się biblioteka mathlib).
W jednorodnych systemach Unix ten pro-
blem był w ogóle nieznany.
G
Głłó
ów
wn
nee p
po
ow
wo
od
dyy rro
ozzw
wo
ojju
u g
grriid
d cco
om
mp
pu
uttiin
ng
g
Ogromne ilości danych, które generuje
akcelerator cząstek elementarnych, na-
kładają duże obciążenia na infrastrukturę
obliczeniową. Aplikacje wymagają szyb-
kich sieci, dostępu do pojedynczych re-
kordów i ogromnej pojemności oblicze-
niowej. Zamiast centralnego przechowy-
wania i przetwarzania danych, naukowcy
pracujący przy akceleratorze korzystają
z istniejących lub nowo stworzonych zaso-
bów obliczeniowych, należących do
uczestniczących w projekcie państw. Ma
to na celu rozproszenie obciążenia obli-
czeniowego i magazynowego – jest to je-
den z powodów, dlaczego projekt jest
głównym czynnikiem motywującym roz-
wój grid computing.
Tam, gdzie fizycy jądrowi spotykają sieci obli-
czeniowe, Linux zdaje się być błogosławień-
stwem i przekleństwem jednocześnie. Do-
starcza taniej i stabilnej platformy, ale różno-
rodność dystrybucji prowadzi do sytuacji
przypominających biblijną wieżę Babel.
W poszukiwaniu niepodzielnego
[1] Projekt GÉANT: http://www.dante.net/
server/show/nav.007
[2] Projekt AliEn: http://www.cerncourier
.com/main/article/42/9/6
[3] Projekt Unicore: http://www.unicore.org
[4] Środowisko Cactus:
http://www.cactuscode.org
[5] Projekt Legion: http://legion.virginia.edu
[6] Projekt Condor:
http://www.cs.wisc.edu/condor/
[7] Sieć obliczeniowa Ministerstwa
Energetyki Stanów Zjednoczonych:
http://doesciencegrid.org
INFO
Wyszukiwarka
Podobne podstrony:
Difference Between Cluster Computing VS Grid Computing
Grid Trading
Computerspieler Jargon
268257 Introduction to Computer Systems Worksheet 1 Answer sheet Unit 2
cloud computing1
COMPUTER
Grid Trading(1)
Pancharatnam A Study on the Computer Aided Acoustic Analysis of an Auditorium (CATT)
03 Bajor Krakowiak Cloud computing
Computer engine control
HP Computer Setup
Convert Computer ATX Power Supply to Lab Power Supply
Computer Systems Worksheet 1 Unit 2
Schools should provide computers for students to use for all their school subjects
Kluwer Digital Computer Arithmetic Datapath Design Using Verilog HDL
NIST Cloud Computing Synopsis and Recommendations sp800 146
Grid Trading czyli handel walutami
więcej podobnych podstron