U N I W E R S Y T E T Ć L Ä S K I
WYDZIAĆ TECHNIKI
Instytut Informatyki
PRACA MAGISTERSKA
Grzegorz Pustelnik
Pakiet programĂłw edukacyjnych z zakresu przedmiotu wprowadzenie do informatyki
Promotor:
Dr Urszula Boryczka
Sosnowiec 1998
Spis treĆci
WstÄp ............................................................................................................................... 3
I. Zasady automatycznej translacji
1.1 Translacja i translatory ...............................................................................................4
1.2 Stos i odwrotna notacja polska (ONP) .......................................................................6
1.3 Translacja wyraĆŒeĆ arytmetycznych ..........................................................................6
II Automat skoĆczony
2.1 Deterministyczny automat skoĆczony .................................................................... 15
2.2 Niedeterministyczny automat skoĆczony ............................................................... 22
2.3 Automat skoĆczony z Δ-ruchami ............................................................................. 24
2.4 WyraĆŒenia regularne ................................................................................................ 25
2.5 Zastosowania automatĂłw skoĆczonych .................................................................. 30
III Maszyna Turinga
3.1 Podstawowy model maszyny Turinga ..................................................................... 31
IV Gramatyki bezkontekstowe
4.1 Podstawowe pojÄcia gramatyk ................................................................................ 40
4.2 Gramatyki bezkontekstowe ..................................................................................... 44
4.3 Drzewa wyprowadzeĆ ............................................................................................. 47
V. Opis programĂłw
5.1 ONP ....................................................................................................................... 50
5.2 AS .......................................................................................................................... 55
5.3 MT .......................................................................................................................... 58
5.4 GR .......................................................................................................................... 62
5.5 ZawartoĆÄ dysku CD-ROM .................................................................................. 64
Literatura ...................................................................................................................... 65
WSTÄP
Praca dydaktyczna „Pakiet programĂłw edukacyjnych z zakresu przedmiotu wprowadzenie do informatyki” zawiera podstawy najogĂłlniej rozumianej teorii automatĂłw leĆŒÄ cej u podstaw informatyki.
Ze wzglÄdu na rozlegĆoĆÄ tej dziedziny wiedzy, niniejsza praca przedstawia tylko zagadnienia zgodne z przedmiotem prowadzonym na I roku studiĂłw : Wprowadzenie do informatyki.
CzÄĆÄ teoretyczna zostaĆa napisana po kÄ tem zagadnieĆ poruszanych przez prowadzÄ cych ten przedmiot i moĆŒe stanowiÄ formÄ skryptu uczelnianego.
RozdziaĆ I dotyczy zasad automatycznej translacji. Opisuje dwustopniowÄ
translacjÄ wyraĆŒeĆ arytmetycznych na drodze: wyraĆŒenie arytmetyczne postaÄ ONP , jak rĂłwnieĆŒ postaÄ ONP jÄzyk symboliczny. Odwrotna notacja polska (ONP) to jeden z wariantĂłw beznawiasowego zapisu wyraĆŒeĆ formalnych wynaleziony przez polskiego logika J.Ćukasiewicza.
W rozdziale II przedstawiono zagadnienia zwiÄ zane z teoriÄ automatĂłw skoĆczonych, uwypuklajÄ c trzy podstawowe rodzaje: DAS- deterministyczny automat skoĆczony, NAS- niedeterministyczny automat skoĆczony i NAS z Δ-ruchami oraz jÄzyki akceptowane przez automaty - zbiory regularne.
RozdziaĆ III dotyczy maszyny Turinga. Przedstawia podstawowy model maszyny algorytmicznej Alana Turinga, bÄdÄ cej prymitywnym modelem komputera. Przedstawiono w nim takĆŒe liczne przykĆady , ktĂłre posĆuĆŒyĆy do przedstawienia zaskakujÄ cej tezy Churcha-Turinga.
W rozdziale IV opisano wybrane zagadnienia z szerokiej teorii jÄzykĂłw, skupiajÄ c swojÄ uwagÄ na gramatykach bezkontekstowych, majÄ cych najszersze zastosowania w informatyce.
CzÄĆÄ praktyczna- to cztery programy edukacyjne, ktĂłre odzwierciedlajÄ zagadnienia czÄĆci teoretycznej.
Dynamiczny rozwĂłj informatyki w ostatnich latach sprawia, ĆŒe ta dziedzina wiedzy staje siÄ coraz bardziej popularna, stÄ d warto czasami poznaÄ podstawy teoretyczne i poczÄ tkowe badania z tego zakresu. NiektĂłre z nich zawarte sÄ w niniejszej pracy teoretycznej, zaĆ programy do niej doĆÄ czone sÄ pewnÄ propozycjÄ przyswojenia wiadomoĆci, z ktĂłrych moĆŒna skorzystaÄ u progu tajnikĂłw informatyki.
I. ZASADY AUTOMATYCZNEJ TRANSLACJI
1.1 Translacja i translatory
Zagadnienia budowy translatorĂłw, jak i samego procesu translacji stanowiÄ jeden z najrozleglejszych dziaĆĂłw informatyki, ktĂłremu moĆŒnaby poĆwiÄciÄ odrÄbnÄ pracÄ, toteĆŒ niniejsze rozwaĆŒania majÄ na celu zaznaczenie pewnych pojÄÄ z tego zakresu, skupiajÄ c siÄ gĆĂłwnie na procesie translacji wyraĆŒeĆ do postaci ONP. GĆĂłwnym ĆșrĂłdĆem informacji wykorzystanym dla tego rozdziaĆu jest pozycja: W. M.Turskiego [TURS 77].
JÄzyki programowania niskiego czy teĆŒ wysokiego poziomu majÄ na zadanie przetworzyÄ ogĂłĆ algorytmĂłw w nich zapisanych na takÄ postaÄ aby maszyna cyfrowa byĆa w stanie je wykonaÄ tzn. daÄ takie efekty jakie programista zakĆada tworzÄ c dany program. MiÄdzy tymi jÄzykami wystÄpuje jednak zasadnicza rĂłĆŒnica : program zapisany w jÄzyku niskiego poziomu (w jÄzyku wewnÄtrznym) stanowi ciÄ g instrukcji dostÄpnych przez dany procesor czy teĆŒ maszynÄ cyfrowÄ i jest wykonywany bezpoĆrednio; natomiast program zapisany w jÄzykach wysokiego poziomu takich jak Pascal czy C ( w jÄzykach zewnÄtrznych) wymaga dodatkowo przetĆumaczenia na ciÄ g instrukcji dostÄpnych przez maszynÄ ktĂłra ma dany program wykonaÄ. Owo tĆumaczenie w pewnym stopniu przypomina tĆumaczenie jÄzykĂłw etnicznych, przy uwzglÄdnieniu dodatkowych warunkĂłw jak: znajomoĆÄ kultury, tradycji i historii danego jÄzyka. Podobnie tĆumaczÄ c programy zewnÄtrzne na wewnÄtrzne naleĆŒy takĆŒe uwzglÄdniÄ dodatkowe elementy takie jak dane wejĆciowe do programu, ktĂłre takĆŒe muszÄ byÄ przetĆumaczone do tego stopnia aby spodziewany efekt koĆcowy programu zapisanego w jÄzyku zewnÄtrznym niczym siÄ nie rĂłĆŒniĆ od efektu dziaĆania samej maszyny.
Proces przekĆadu tekstĂłw zapisanych w jednym jÄzyku na drugi nosi nazwÄ translacji. W przypadku gdy dany jÄzyk wysokiego poziomu ma stosunkowo ĆatwÄ gramatykÄ, translacja moĆŒe byÄ wykonana samoczynnie przez maszynÄ cyfrowÄ przy pomocy specjalnego programu translacji zwanego translatorem.
WykorzystujÄ c translatory programiĆci mogÄ posĆugiwaÄ siÄ zewnÄtrznymi jÄzykami programowania, co znacznie uĆatwia tworzenie oprogramowania, gdyĆŒ czas stracony na ĆŒmudnym pisaniu instrukcji w jÄzyku wewnÄtrznym zostaje ograniczony do wybrania odpowiednich procedur i funkcji z repertuaru danego jÄzyka wysokiego poziomu, a sam programista moĆŒe skupiÄ siÄ na rozwiÄ zywaniu powstaĆych problemĂłw implementacyjnych.
Translatory dzielimy zazwyczaj na dwie kategorie: kompilatory i interpretatory. PodziaĆ ten bardzo czÄsto nie ma miejsca w praktyce, gdyĆŒ buduje siÄ translatory wykazujÄ ce jednoczeĆnie cechy kompilatorĂłw i interpretatorĂłw.
NajogĂłlniej, kompilator jest translatorem, operujÄ cym na caĆym tekĆcie programu ĆșrĂłdĆowego generujÄ c tekst przekĆadu jako caĆoĆÄ, podczas gdy interpreter operuje na poszczegĂłlnych jednostkach syntaktycznych programu ĆșrĂłdĆowego i generuje ich przekĆady. JeĆli wiÄc wykonywamy program poczÄ tkowo zapisany w jÄzyku zewnÄtrznym to:
-uĆŒywajÄ c kompilatora, moĆŒemy przystÄ piÄ do wykonania programu w postaci docelowej dopiero po zakoĆczeniu translacji. Oznacza to, ĆŒe uzyskany tekst bÄdÄ cy przekĆadem tekstu ĆșrĂłdĆowego w caĆoĆci wprowadzany jest do maszyny cyfrowej;
-uĆŒywajÄ c interpretatora, moĆŒemy wykonywaÄ przekĆady poszczegĂłlnych jednostek syntaktycznych, nie czekajÄ c na caĆy proces translacji. Oznacza to, ĆŒe caĆy czas operujemy na tekĆcie ĆșrĂłdĆowym tĆumaczÄ c tylko te jednostki syntaktyczne, ktĂłre sÄ potrzebne aby poszczegĂłlny fragment programu mĂłgĆ zadziaĆaÄ.
W praktyce rzadko dokonuje siÄ bezpoĆredniej translacji programĂłw z jÄzyka zewnÄtrznego na jÄzyk maszynowy. NajczÄĆciej stosuje siÄ proces poĆredni to znaczy, najpierw dokonuje siÄ translacji z jÄzyka zewnÄtrznego na jÄzyk asemblerowy, a potem z jÄzyka asemblerowego na jÄzyk maszynowy. Zastosowanie takiej dwuetapowej translacji niesie za sobÄ wiele zalet, a gĆĂłwna z nich jest moĆŒliwoĆÄ ĆÄ czenia poszczegĂłlnych czÄĆci programĂłw zapisanych w rĂłĆŒnych jÄzykach zewnÄtrznych.
1.2 Stos i odwrotna notacja polska (ONP)
Bardzo waĆŒnymi pojÄciami bez ktĂłrych trudne byĆoby zrozumienie zasad jakiejkolwiek translacji sÄ : stos i odwrotna notacja polska (ONP).
STOS- jest to organizacja sekwencyjna pamiÄci operacyjnej maszyny cyfrowej. Stos dziaĆa jak pojemnik okreĆlonych jednostek, przy czym pobieranie elementĂłw w nim zgromadzonych odbywa siÄ w kolejnoĆci odwrotnej do magazynowania. Jest to tak zwana struktura LIFO (last-in-first-out co oznacza „ ten co ostatni przyszedĆ pierwszy odchodzi”). Dla stosu okreĆla siÄ dwie podstawowe operacje:
dos(a)- dopisz na stosie - w wyniku wykonania tej operacji jednostka a zostaje umieszczona na szczycie stosu (staje siÄ pierwszym elementem stosu)
ods(a)- odczytaj ze stosu - w wyniku wykonania tej operacji jednostka a zostaje wydana na zewnÄ trz stosu.
ODWROTNA NOTACJA POLSKA (ONP)- mianem tym obdarzono jeden z wariantĂłw beznawiasowego zapisu wyraĆŒeĆ formalnych, wynalezionego przez polskiego logika Jana Ćukasiewicza (1878-1956). W tym beznawiasowym zapisie symbole operandĂłw poprzedzajÄ bezpoĆrednio symbol operatora, na przykĆad wyraĆŒenie a+b zapisujemy w ONP jako a b +.
1.3 Translacja wyraĆŒeĆ arytmetycznych
WspĂłĆczesne podejĆcie translacji wyraĆŒeĆ arytmetycznych polega na wydzieleniu dwu etapĂłw translacji:
- translacja do ONP
- translacja ONP na jÄzyk symboliczny
W celu zobrazowania translacji do ONP przyjmujemy, ĆŒe ĆșrĂłdĆowy zapis wyraĆŒeĆ arytmetycznych pojawia siÄ na wejĆciu specjalnego automatu (Rys.1). Na wyjĆciu uzyskamy zapis ONP tych wyraĆŒeĆ, sam zaĆ automat wyposaĆŒony jest w pamiÄÄ stosowÄ .:
wyraĆŒenie Automat ze stosem ONP wyraĆŒenia
arytmetyczne arytmetycznego
Rys. 1. Model automatu ze stosem do translacji wyraĆŒeĆ arytmetycznych
Podczas translacji wyraĆŒeĆ arytmetycznych szczegĂłlnej analizie poddawane sÄ symbole operacji (+,-,*,itp.) zwane ogranicznikami ,stÄ d wprowadza siÄ dodatkowo listÄ priorytetĂłw ogranicznikĂłw (Tab.1):
Ogranicznik |
Priorytet |
+ - |
0 |
* / Ă· |
1 |
â |
2 |
Tab.1.Priorytety symbolĂłw operacji (ogranicznikĂłw)
DziaĆanie automatu odbywa siÄ wedĆug nastÄpujÄ cego algorytmu postÄpowania:
1. Pobierz kolejny element (nazwÄ zmiennej, staĆÄ lub ogranicznik) ĆșrĂłdĆowego wyraĆŒenia arytmetycznego.
2. JeĆli ten element jest nazwÄ zmiennej lub staĆÄ , przekaĆŒ go natychmiast na wyjĆcie; w przeciwnym wypadku, jeĆli priorytet ogranicznika jest wyĆŒszy od priorytetu ogranicznika zajmujÄ cego szczyt stosu lub jeĆli stos jest pusty, dopisz go na stos, jeĆli wreszcie na szczycie stosu znajduje siÄ ogranicznik o wyĆŒszym lub rĂłwnym priorytecie - odczytaj go ze stosu i przeĆlij na wyjĆcie, a ogranicznik z wejĆcia dopisz na stosie, chyba, ĆŒe nowy ogranicznik zajmujÄ cy szczyt stosu w wyniku odczytania priorytetu ma priorytet nie mniejszy niĆŒ ogranicznik z wejĆcia. w takim przypadku naleĆŒy kontynuowaÄ odczytywanie ze stosu i przesyĆanie na wyjĆcie aĆŒ do wystÄ pienia na szczycie stosu ogranicznika o priorytecie niĆŒszym od priorytetu ogranicznika nadchodzÄ cego z wejĆcia.
3. JeĆli wyraĆŒenie ĆșrĂłdĆowe zostaĆo wyczerpane, odczytaj wszystkie ograniczniki ze stosu na wyjĆcie automatu.
PrzykĆad 1 przedstawia poszczegĂłlne takty procesu translacji do ONP dla wybranego wyraĆŒenia arytmetycznego.
PrzykĆad 1:
Niech wyraĆŒenie ĆșrĂłdĆowe ma postaÄ: x + 3 * z Ă· k
PoszczegĂłlne takty translacji sÄ nastÄpujÄ ce:
Takt |
WejĆcie |
Stos |
WyjĆcie |
1 |
x |
|
x |
2 |
+ |
+ |
|
3 |
3 |
+ |
3 |
4 |
* |
+,* |
|
5 |
z |
+,* |
z |
6 |
Ă· |
+,Ă· |
* |
7 |
k |
+,Ă· |
k |
8 |
koniec |
|
Ă·,+ |
Rys.2. PoszczegĂłlne takty procesu translacji wyraĆŒenia do ONP dla przykĆadu 1
Na wyjĆciu uzyskamy wyraĆŒenie ONP postaci: x, 3, z, *, k, Ă·, +
Dla uzyskania prawidĆowej konwersji wyraĆŒeĆ arytmetycznych uzupeĆniamy listÄ ogranicznikĂłw o nastÄpujÄ ce symbole:
nawiasy ( )
operator negacji NEG (jako symbol operacji unarnej sĆuĆŒÄ cy do zmiany znaku)
funkcje trygonometryczne (operatory jednoargumentowe)
Priorytety wyĆŒej wymienionych ogranicznikĂłw przedstawia tabela 2
Ogranicznik |
Priorytet |
( |
0 |
+ - ) |
1 |
* / Ă· NEG |
2 |
â |
3 |
sin cos tg ctg |
4 |
Tab.2. Priorytety rozszerzonych symbolĂłw operacji (ogranicznikĂłw)
DziaĆanie automatu uzupeĆniamy nastÄpujÄ cymi reguĆami:
1. Ogranicznik „(” jest dopisywany do stosu bez jakiegokolwiek odczytywania stosu.
2. Ogranicznik „)” nie jest dopisywany na stos, pojawienie siÄ jednak tego ogranicznika na wejĆciu powoduje odczytanie ze stosu i przesĆanie na wyjĆcie wszystkich kolejnych ogranicznikĂłw aĆŒ do pojawienia siÄ ogranicznika „(”.
3. Ogranicznik „(” ze szczytu stosu zostaje usuniÄty bez przekazywania na wyjĆcie, jeĆli aktualnym symbolem na wejĆciu jest „)”.
Pojawienie siÄ nawiasu zamykajÄ cego „)” na wejĆciu automatu powoduje wyprowadzenie na wejĆcie wszystkich ogranicznikĂłw z wnÄtrza pary nawiasĂłw aĆŒ do nawiasu otwierajÄ cego „(” oraz likwidacjÄ tego nawiasu.
PrzykĆad 2 przedstawia proces translacji z uwzglÄdnieniem powyĆŒszych reguĆ:
PrzykĆad 2:
Niech wyraĆŒenie ĆșrĂłdĆowe ma postaÄ: b * c â ( d - e*k )
PoszczegĂłlne takty translacji sÄ nastÄpujÄ ce:
Takt |
WejĆcie |
Stos |
WyjĆcie |
1 |
b |
|
b |
2 |
* |
* |
|
3 |
c |
* |
c |
4 |
â |
*,â |
|
5 |
( |
*,â,( |
|
6 |
d |
*,â,( |
d |
7 |
- |
*,â,(,- |
|
8 |
e |
*,â,(,- |
e |
9 |
* |
*,â,(,-,* |
|
10 |
k |
*,â,(,-,* |
k |
11 |
) |
*,â |
*,- |
12 |
koniec |
|
â,* |
Rys.3. PoszczegĂłlne takty procesu translacji wyraĆŒenia do ONP dla przykĆadu 2
Na wyjĆciu uzyskamy wyraĆŒenie ONP postaci: b, c, d, e, k, *, -, â ,*
PrzykĆad 3 przedstawia translacjÄ krĂłtkiego wyraĆŒenia arytmetycznego z funkcjami trygonometrycznymi.
PrzykĆad 3:
Niech wyraĆŒenie ĆșrĂłdĆowe ma postaÄ: sinx + cosy + tgz
PoszczegĂłlne takty translacji sÄ nastÄpujÄ ce:
Takt |
WejĆcie |
Stos |
WyjĆcie |
1 |
sin |
sin |
|
2 |
x |
sin |
x |
3 |
+ |
+ |
sin |
4 |
cos |
+, cos |
|
5 |
y |
+, cos |
y |
6 |
+ |
+ |
cos, + |
7 |
tg |
+, tg |
|
8 |
z |
+, tg |
z |
9 |
koniec |
|
tg, + |
Rys.4. PoszczegĂłlne takty procesu translacji wyraĆŒenia do ONP dla przykĆadu 3
Na wyjĆciu uzyskamy wyraĆŒenie ONP postaci: x , sin, y, cos, +, z, tg, + ,
Nic nie stoi na przeszkodzie by procesowi translacji poddaÄ wyraĆŒenia arytmetyczne zawierajÄ ce operacje logiczne i warunkowe. W tym celu naleĆŒy odpowiednio rozszerzyÄ iloĆÄ priorytetĂłw, a takĆŒe chcÄ c odzwierciedliÄ skĆadnie: if..then..else naleĆŒy wprowadziÄ odpowiednie oznaczenia, ktĂłre bÄdÄ sygnalizowaĆy koniecznoĆÄ wykonania skoku warunkowego lub bezwarunkowego. Operacje te zapisujemy w postaci SW (k) i SB (k), gdzie SW- oznacza then, a SB else. Dla translacji wyraĆŒeĆ arytmetycznych z elementami logicznymi koniecznym jest wprowadzenie dwĂłch rĂłĆŒnych pojÄÄ priorytetĂłw: priorytet porĂłwnawczy (p.p) i priorytet stosowy (p.s.). gdzie: priorytet porĂłwnawczy dla danego ogranicznika oznacza moc rozĆadowania stosu, a priorytet stosowy moc blokowania stosu. W praktyce oznacza to, ĆŒe jeĆŒeli na wejĆciu automatu pojawi siÄ symbol operacji (ogranicznik) to celem ewentualnego odczytania symboli ze stosu porĂłwnujemy priorytet porĂłwnawczy tego symbolu z priorytetem stosowym symboli operacji na stosie.
UzupeĆniona tablica priorytetĂłw ogranicznikĂłw wraz z uwzglÄdnieniem pojÄÄ: priorytet stosowy i porĂłwnawczy ksztaĆtuje siÄ nastÄpujÄ co:
Ogranicznik |
p. stosowy |
p. porĂłwnawczy |
(, if |
0 |
nie dotyczy |
then |
0 |
1 |
else |
1 |
2 |
), ; |
nie dotyczy |
1 |
⥠|
3 |
3 |
â |
4 |
4 |
⧠|
5 |
5 |
âš |
6 |
6 |
- |
7 |
7 |
> ℠†< = â |
8 |
8 |
+- |
9 |
9 |
* / Ă·NEG |
10 |
10 |
â |
11 |
11 |
Tab.3. UzupeĆniona lista ogranicznikĂłw z uwzglÄdnieniem elementĂłw logicznych
Algorytm konwersji zostaje uzupeĆniony o nowe reguĆy zwiÄ zane z elementami logicznymi: if..then...else:
1. Gdy na wejĆciu pojawi siÄ ogranicznik „then”, wĂłwczas, oprĂłcz wszystkich ogranicznikĂłw wyprowadzanych ze stosu na wyjĆcie ze wzglÄdu na ich priorytety, zostaje takĆŒe usuniÄty ze szczytu stosu ogranicznik „if” ( konstrukcja if - then jest analogiczna do pary nawiasĂłw ( ) w wyraĆŒeniach arytmetycznych). Na wyjĆcie automatu zostaje wyprowadzona operacja SW z pustym nawiasem SW( ), zaĆ ogranicznik „then” zostaje dopisany do stosu wraz z numerem, pod jakim wystÄpuje w zapisie ONP operacja SW( ).
2. Gdy na wejĆciu pojawia siÄ ogranicznik „else”, powoduje on wyprowadzenie wszystkich symboli na wyjĆcie automatu aĆŒ do momentu pojawienia siÄ ma stosie ogranicznika „then”. Na wyjĆcie zostaje wpisana niekompletna operacja SB(), operacja SW( ) bÄdÄ ca na wyjĆciu zostaje uzupeĆniona przez wpisanie do nawiasu numeru pozycyjnego z zapisu ONP, a sam ogranicznik „else” zostaje dopisany do stosu wraz z numerem pozycyjnym SB( ) w zapisie ONP.
3. Gdy podczas wyprowadzania ogranicznikĂłw ze stosu natrafimy na „else”, wĂłwczas uzupeĆniamy odpowiedni nawias operacji SB( ) odpowiadajÄ cej danemu „else”, zaĆ sam ogranicznik else zostaje zlikwidowany tzn. nie jest wyprowadzany na wyjĆcie automatu.
PrzykĆad 4 obrazuje translacjÄ wyraĆŒeĆ zawierajÄ cych elementy logiczne.
PrzykĆad 4:
Niech wyraĆŒenie na wejĆciu ma postaÄ: y + ( if a>0 then 3 else a )
PoszczegĂłlne takty konwersji przedstawia rysunek 5.
Takt |
WejĆcie |
Stos |
WyjĆcie |
Numer pozycyjny w ONP |
1 |
y |
|
y |
1 |
2 |
+9 |
+9 |
|
|
3 |
( |
+9 (0 |
|
|
4 |
if |
+9 (0 if0 |
|
|
5 |
a |
+9 (0 if0 |
a |
2 |
6 |
>8 |
+9 (0 if0 >8 |
|
|
7 |
0 |
+9 (0 if0 >8 |
0 |
3 |
8 |
then1 |
+9 (0 then50 |
> SW() po takcie 10 - SW(8) |
4 5 |
9 |
3 |
+9 (0 then50 |
3 |
6 |
10 |
else2 |
+9 (0 else71 |
SB() po takcie 12- SB(9) |
7 |
11 |
a |
+9 (0 else71 |
a |
8 |
12 |
)1 |
+9 |
|
|
13 |
; |
|
+ |
9 |
GĂłrne indeksy przy then i else oznaczajÄ numer pozycyjny instrukcji SW i SB w ONP, zaĆ indeksy dolne oznaczajÄ priorytet stosowy lub porĂłwnawczy danego ogranicznika.
Rys.5. PoszczegĂłlne takty konwersji dla przykĆadu 4
Etap drugi translacji wyraĆŒeĆ arytmetycznych polega na wygenerowaniu programu w jÄzyku symbolicznym (docelowym). Proces ten takĆŒe korzysta z pamiÄci stosowej a sam algorytm postÄpowania wymaga przyjÄcia pewnych oznaczeĆ :
ÎŽi - i=0,1,.... sÄ to kolejne pozycje stosu; jÄzyk docelowy pozwala na wystÄpowanie dwu typĂłw instrukcji: ÎŽi := Z i ÎŽi : = ÎŽi op ÎŽi+1 gdzie Z jest nazwÄ zmiennej lub staĆÄ , a op jest symbolem operacji.
Proces translacji zapisu ONP na jÄzyk docelowy przebiega wedĆug nastÄpujÄ cego algorytmu:
1. Ustalamy i=0, k=1
2. Odczytujemy k-ty element ONP : Ek
3. JeĆli Ek jest nazwÄ zmiennej lub staĆa, generuje siÄ operacja ÎŽi:=Ek i nastÄpuje zwiÄkszenie i o 1 â i:= i +1; jeĆli Ek jest symbolem operacji op â NEG, generuje siÄ operacja ÎŽi-2 := ÎŽi-2 op ÎŽi-1 oraz nastÄpuje zmniejszenie i o 1 â i := i - 1; jeĆli Ek = NEG, nastÄpuje wygenerowanie operacji ÎŽi-1 := - ÎŽi-1
4. JeĆli Ek nie byĆ ostatnim symbolem wyraĆŒenia w ONP, to k:= k + 1 i przechodzimy do punktu 2.
SposĂłb translacji wyraĆŒenia ONP na jÄzyk symboliczny przedstawia przykĆad 5.
PrzykĆad 5:
Niech wyraĆŒenie arytmetyczne ma postaÄ: ( a + b ) / ( k â (-c) )
PostaÄ ONP tego wyraĆŒenia jest nastÄpujÄ ca: a, b, +, k, c, NEG, â /
i k
0 1
1: ÎŽ0:= a 1 2
2: ÎŽi:= b 2 3
3: ÎŽ0:= ÎŽ0 +ÎŽi 1 4
4: ÎŽi:= k 2 5
5: ÎŽ2:= c 3 6
6: ÎŽ2:= -ÎŽ2 3 7
7: ÎŽi:= ÎŽi â ÎŽ2 2 8
8: ÎŽ0:= ÎŽo / ÎŽ1 1 9
9: brak symboli w wyraĆŒeniu ONP -koniec algorytmu.
WiadomoĆci zawarte w tym rozdziale przedstawiajÄ nam drogÄ od zrodzenia siÄ algorytmu, aĆŒ po wykonanie programu na maszynie cyfrowej co schematycznie przestawia rysunek 6
algorytm programowanie program w jÄzyku
wysokiego poziomu
kod maszynowy program w jÄzyku kompilacja
asemblerowym
Wykonanie na
komputerze
Rys.6. Schematyczny przebieg powstania programu
II. AUTOMAT SKOĆCZONY
2.1 Deterministyczny automat skoĆczony
W tym rozdziale tematem rozwaĆŒaĆ bÄdÄ zagadnienia z dziedziny automatĂłw skoĆczonych i wyraĆŒeĆ regularnych. GĆĂłwnym ĆșrĂłdĆem wiadomoĆci teoretycznych przedstawionych w tym rozdziale jest praca J.E.Hopcrofta i J.D.Ullmana [HOPC 94].
Automat skoĆczony jest modelem matematycznym systemu o dyskretnych wejĆciach i wyjĆciach. System taki w danej chwili moĆŒe znajdowaÄ siÄ w jednym ze skoĆczonej liczby stanĂłw, ktĂłry to stan jest ĆciĆle uzaleĆŒniony od stanu poprzedniego. Jeden ze stanĂłw peĆni rolÄ stanu poczÄ tkowego, od ktĂłrego dany automat rozpoczyna dziaĆanie, z drugiej strony niektĂłre stany peĆniÄ rolÄ stanĂłw koĆcowych koĆczÄ c pracÄ automatu. Praca automatu oparta jest na analizie symboli wejĆciowych ze skoĆczonego alfabetu. KaĆŒdy odczytany symbol wymusza przejĆcie do innego stanu ( w niektĂłrych przypadkach przejĆcie prowadzi do tego samego stanu). Po przeanalizowaniu wszystkich symboli automat skoĆczony moĆŒe przyjÄ Ä jeden z dwu stanĂłw: akceptacji lub nieakceptacji. Bardzo czÄsto automat skoĆczony, ktĂłry w dalszych rozwaĆŒaniach bÄdziemy oznaczaÄ jako AS jest przedstawiany za pomocÄ grafĂłw skierowanych, w ktĂłrych wierzchoĆki obrazujÄ stany automatu. JeĆŒeli istnieje przejĆcie z jednego stanu do nastÄpnego to takie przejĆcie przedstawione jest za pomocÄ Ćuku. Dla wyodrÄbnienia stanu poczÄ tkowego, wierzchoĆek rozpoczynajÄ cy pracÄ automatu wzbogacony jest o strzaĆkÄ z napisem START. W celu zaakcentowania stanu koĆcowego wprowadza siÄ dwa odrÄbne wierzchoĆki grafu opatrzone etykietÄ A (s. akceptacji) N (s. nieakceptacji), bÄ dĆș stan koĆcowy oznacza siÄ podwĂłjnym kĂłĆkiem. Rysunek 7 przedstawia fragment grafu dla automatu skoĆczonego:
start q0 q1 q4
q2 q3
Rys. 7. Fragment grafu przejĆÄ dla automatu skoĆczonego
Automat skoĆczony przedstawiamy formalnie jako uporzÄ dkowanÄ piÄ tkÄ:
< Q, ÎŁ, ÎŽ, qo, F>
gdzie:
Q - jest skoĆczonym zbiorem stanĂłw,
ÎŁ - jest skoĆczonym alfabetem symboli wejĆciowych, q0 naleĆŒÄ ce do Q jest stanem poczÄ tkowym od ktĂłrego automat rozpoczyna dziaĆanie,
Fâ Q - jest zbiorem stanĂłw koĆcowych (stan akceptacji lub nieakceptacji),
ÎŽ - jest funkcjÄ odwzorowujÄ cÄ Q x ÎŁ w Q czyli ÎŽ okreĆla kaĆŒdemu stanowi q i kaĆŒdemu symbolowi na wejĆciu nowy stan automatu.
Automat skoĆczony moĆŒemy sobie wyobraziÄ jako gĆowicÄ sterujÄ co-czytajÄ cÄ , ktĂłra analizuje symbole zapisane na taĆmie w sposĂłb pokazany na rysunku 8.
gĆowica
sterujÄ co-
czytajÄ ca
Rys. 8. Schemat pracy automatu skoĆczonego
W danej chwili automat odczytuje symbol wejĆciowy i przechodzi do kolejnego stanu. JeĆŒeli stan ten jest stanem akceptacji to znaczy, ĆŒe dotychczasowy ciÄ g symboli na taĆmie jest zaakceptowany przez AS. JeĆŒeli gĆowica przesunÄĆa siÄ na koniec taĆmy, a ostatni stan jest stanem zaakceptowanym przez AS to AS zaakceptowaĆ caĆy ĆaĆcuch.
Formalnie przyjmuje siÄ, ĆŒe ĆaĆcuch jest akceptowany przez automat M, jeĆŒeli ÎŽ (qo,x)= p dla jakiegoĆ p naleĆŒÄ cego do F. JÄzyk akceptowany przez dany automat M oznaczany L(M), to zbiĂłr {x | (qo,x) naleĆŒy do F}. JÄzyk nazywamy zbiorem regularnym, jeĆŒeli jest on jÄzykiem akceptowanym przez pewien automat skoĆczony. Zbiory regularne zostanÄ szczegĂłĆowo omĂłwione pod koniec tego rozdziaĆu.
W celu zobrazowania konstrukcji automatu skoĆczonego przeanalizujmy dwa przykĆady dotyczÄ ce akceptacji liczb podzielnych przez wybranÄ liczbÄ.
PrzykĆad 6. Automat skoĆczony akceptujÄ cy liczby podzielne przez 2
Dla tego automatu zbiĂłr symboli wejĆciowych bÄdzie zĆoĆŒony z cyfr od 0..9 czyli ÎŁ= {0,1,2,3,4,5,6,7,8,9}. Wiadomo teĆŒ, ĆŒe liczba jest parzysta gdy ostatnia jej cyfra jest podzielna bez reszty przez 2.
KonstrukcjÄ automatu rozpoczynamy od wykreĆlenia wierzchoĆka stanu q0, ktĂłry jest stanem wejĆciowym (Rys. 8 )
JeĆŒeli pojawi siÄ na wejĆciu cyfra podzielna przez 2 to zaznaczmy to na grafie jako przejĆcie do stanu q1, jeĆŒeli pojawi siÄ na wejĆciu cyfra niepodzielna przez 2 to zaznaczmy to jako przejĆcie do stanu q2 (Rys.9)
jeĆŒeli AS jest w stanie q1 i kolejna cyfra na wejĆciu jest podzielna przez dwa to automat pozostaje nadal w tym samym stanie co zaznaczamy na grafie Ćukiem wychodzÄ cym z stanu q1 opatrzonego etykietÄ {0,2,4,6,8}, jeĆŒeli pozostajÄ c w stanie q2 AS odczyta wszystkie symbole (co umownie oznaczamy pojawieniem siÄ symbolu Ï lub # ) wĂłwczas AS przechodzi do stanu akceptacji A (Rys 10)
jeĆŒeli AS jest w stanie q1 i kolejna cyfra na wejĆciu jest nieparzysta to AS pozostaje nadal w tym samym stanie co zaznaczamy na grafie Ćukiem wychodzÄ cym i wchodzÄ cym do stanu q2 opatrzonego etykietÄ {1,3,5,7,9}, jeĆŒeli pozostajÄ c w stanie q2 AS odczyta wszystkie symbole to wĂłwczas AS przechodzi do stanu nieakceptacji N (Rys. 11 )
OczywiĆcie istnieje moĆŒliwoĆÄ pojawienia siÄ na wejĆciu przemiennie liczb parzystych i nieparzystych a tym samym przejĆcia z stanu q1 do stanu q2 (Rys 12 - ostateczna konstrukcja automatu )
start q0
Rys. 8
{0,2,4,6,8} q1
start q0
{1,3,5,7,9} q2
Rys. 9
{0,2,4,6,8}
Ï A
{0,2,4,6,8} q1
start q0
{1,3,5,7,9} q2
Rys. 10
{0,2,4,6,8}
Ï A
{0,2,4,6,8} q1
start q0
{1,3,5,7,9} q2 Ï
N
{1,3,5,7,9}
Rys.11
{0,2,4,6,8}
Ï A
{0,2,4,6,8} q1
start q0 { 1,3,5,7,9} { 0, 2,4,6,8}
{1,3,5,7,9} q2 Ï
N
{1,3,5,7,9}
Rys. 8-12. Konstrukcja automatu skoĆczonego akceptujÄ cego liczby podzielne przez 2
Pojawienie siÄ na wejĆciu liczby np.123 dla rozpatrywanego automatu sprawi, ĆŒe automat przejdzie przez nastÄpujÄ cy porzÄ dek stanĂłw: q0, q2, q1, q2, N - czyli liczba 123 nie zostanie zaakceptowana przez automat ( co jest zgodne z prawda gdyĆŒ 123 nie jest liczbÄ parzystÄ ); natomiast pojawienie siÄ liczby 36 wymusi przejĆcie przez stany: q0, q2, q1, A-czyli liczba zostanie zaakceptowana prze automat (co jest zgodne z prawdÄ gdyĆŒ 36 - jest liczbÄ parzystÄ ).
PrzykĆad 7. Automat skoĆczony akceptujÄ cy liczby podzielne przez 3.
Dla tego automatu zbiĂłr symboli wejĆciowych bÄdzie zĆoĆŒony z cyfr od 0..9 czyli ÎŁ= {0,1,2,3,4,5,6,7,8,9}. Wiadomo teĆŒ, ĆŒe liczba jest podzielna bez reszty przez 3 gdy suma cyfr danej liczby jest podzielna przez 3. Musimy wiÄc rozpatrzyÄ nastÄpujÄ ce przypadki tego zadania: po pierwsze jeĆŒeli liczba zĆoĆŒona jest z cyfr 0,3,6,9 to jest ona na pewno podzielna przez 3. Dla cyfr 1,4,7 i 2,5,8 rozpatrza siÄ dodatkowe warunki : pojawienie siÄ cyfr 1,4,7 musi wystÄ piÄ trzykrotnie bÄ dĆș musi wystÄ piÄ cyfra 2,5,8 by liczba byĆa podzielna przez 3. Tak samo pojawienie siÄ cyfr 2,5,8 musi wystÄ piÄ trzykrotnie bÄ dĆș po pojawieniu siÄ jednej z nich musi wystÄ piÄ cyfra 1,4,7. Diagram przejĆÄ takiego automatu przedstawia rysunek 13.
{0,3,6,9}
Ï
q1 N
{1,4,7}
{0,3,6,9}
{2,5,8}
qo {1,4,7} {2,5,8}
Start {2,5,8}
Ï
A {1,4,7} Ï
q2 N
{0,3,6,9}
Rys. 13. Automat skoĆczony akceptujÄ cy liczby podzielne przez 3
Pojawienie siÄ na wejĆciu liczby 126 spowoduje przejĆcie automatu przez stany: q0, q1, q2, A czyli cyfra jest podzielna przez trzy, natomiast 125 wymusi drogÄ: q0, q1, q2, N czyli liczba nie jest podzielna przez 3.
W praktyce badanie czy dana liczba jest podzielna przez n sprowadza siÄ do operacji modulo (badanie reszty z dzielenia liczby przez n). W tym celu przed wykreĆleniem grafu automatu skoĆczonego tworzymy tabelÄ stanĂłw, obrazujÄ cÄ przejĆcia miÄdzy stanami w zaleĆŒnoĆci od rozpatrywanej cyfry. TabelÄ takÄ tworzymy w nastÄpujÄ cy sposĂłb:
liczba kolumn jest rĂłwna n, czyli liczbie przez ktĂłrÄ dana liczba wejĆciowa ma byÄ podzielna,
natomiast liczba wierszy jest rĂłwna liczbie cyfr (0-9) uzupeĆniona o 1 dla symbolu pustego Ï.
Przeanalizujmy tabelÄ 4, ktĂłra dotyczy automatu skoĆczonego badajÄ cego czy liczba jest podzielna przez 3.
|
q1 |
q2 |
q3 |
Ï |
T |
N |
N |
0 |
q1 |
q2 |
q3 |
1 |
q2 |
q3 |
q1 |
2 |
q3 |
q1 |
q2 |
3 |
q1 |
q2 |
q3 |
4 |
q2 |
q3 |
q1 |
5 |
q3 |
q1 |
q2 |
6 |
q1 |
q2 |
q3 |
7 |
q2 |
q3 |
q1 |
8 |
q3 |
q1 |
q2 |
9 |
q1 |
q2 |
q3 |
Tab.4.Tabela stanĂłw dla automatu skoĆczonego akceptujÄ cego liczby podzielne przez 3
ChcÄ c stworzyÄ automat skoĆczony badajÄ cy podzielnoĆÄ liczb przez 4, do tabeli 4 dodajemy jednÄ kolumnÄ z stanem q4, zaĆ samo liczenie w pionie zwiÄkszamy do 4, czyli pierwsza kolumna bÄdzie miaĆa nastÄpujÄ cy porzÄ dek stanĂłw: q1, q2, q3, q4, q1, q2, q3, q4, q1, q2. Na tej podstawie moĆŒemy stworzyÄ automat badajÄ cy podzielnoĆÄ przez dowolnÄ liczbÄ.
Dla tego typu automatĂłw pojawienie siÄ na wejĆciu jakiegokolwiek symbolu powoduje ruch automatu ĆciĆle okreĆlonÄ drogÄ bez moĆŒliwoĆci wyboru. Jak siÄ okaĆŒe w kolejnych podrozdziaĆach wybĂłr drogi automatu wcale nie musi byÄ z gĂłry okreĆlony tzn. ĆŒe dany symbol wejĆciowy moĆŒe wymusiÄ przejĆcie do rĂłĆŒnych stanĂłw. Dlatego automaty skoĆczone gdzie istnieje tylko jedna droga przejĆcia ze stanu do stanu dla danego symbolu wejĆciowego okreĆla siÄ jako deterministyczne automaty skoĆczone (DAS).
2.2 Niedeterministyczny automat skoĆczony
Jak juĆŒ zostaĆo wspomniane w koĆcĂłwce poprzedniego podrozdziaĆu dany symbol wejĆciowy moĆŒe wymusiÄ przejĆcie do rĂłĆŒnych stanĂłw, stÄ d wprowadĆșmy modyfikacjÄ modelu automatu skoĆczonego, polegajÄ cÄ na istnieniu kilku przejĆÄ ze stanu przy tym samym symbolu wejĆciowym. Taka modyfikacja pozwala zdefiniowaÄ model niedeterministycznego automatu skoĆczonego (NAS), ktĂłry formalnie jest definiowany jako uporzÄ dkowana piÄ tka:
<Q, ÎŁ, ÎŽ, qo, F>
gdzie:
Q - jest skoĆczonym zbiorem stanĂłw,
ÎŁ - jest skoĆczonym alfabetem symboli wejĆciowych, q0 naleĆŒÄ ce do Q jest stanem poczÄ tkowym od ktĂłrego automat rozpoczyna dziaĆanie,
Fâ Q - jest zbiorem stanĂłw koĆcowych (stan akceptacji lub nieakceptacji),
ÎŽ- jest odwzorowaniem Q x ÎŁ w 2Q. (2Q - jest zbiorem potÄgowym Q, czyli zbiorem wszystkich podzbiorĂłw Q), czyli ÎŽ (q,a) jest zbiorem wszystkich stanĂłw p, dla ktĂłrych istnieje przejĆcie ze stanu q do p o etykiecie zwiÄ zanej z symbolem wejĆciowym a.
Rysunek 14 przedstawia konstrukcjÄ NAS akceptujÄ cego ciÄ gi zerojedynkowe w ktĂłrych przynajmniej raz wystÄ piĆo podwojenie zer lub jedynek:
1 1
0 0 0 0
start q0 q3 q4
1
q1
1
q2
0
1
Rys.14. Niedeterministyczny automat skoĆczony akceptujÄ cy ciÄ gi, w ktĂłrych wystÄ piĆo podwojenie zer lub jedynek.
Z rysunku 14 widaÄ, ĆŒe ze stanu q0 wychodzÄ dwie krawÄdzie (drogi) o etykiecie 0, czyli z chwilÄ pojawienia siÄ zera na wejĆciu istnieje moĆŒliwoĆÄ przejĆcia ze stanu q0 do stanu q1 lub q3 . Taka wĆaĆnie moĆŒliwoĆÄ wyboru stanĂłw przy tym samym symbolu wejĆciowym wyrĂłĆŒnia NAS od DAS. Ten typ automatĂłw bÄdzie akceptowaĆ ciÄ g symboli a1,a2...an, dla ktĂłrego istnieje ciÄ g przejĆÄ prowadzÄ cy od stanu poczÄ tkowego do stanu koĆcowego. Dla przykĆadu ciÄ g 101001 zostanie zaakceptowany przez powyĆŒszy NAS bo istnieje towarzyszÄ cy mu ciÄ g przejĆÄ: q0, q0, q0, q3, q4, q4; natomiast dla ciÄ gu 10101 nie istnieje ĆŒadne przejĆcie ze stanu poczÄ tkowego do koĆcowego, gdyĆŒ automat w wyniku pojawienia siÄ symboli 10101 pozostanie w stanie q0 czyli wyraĆŒenie nie zostanie zaakceptowane.
Rysunek 15 przedstawia jeszcze jeden niedeterministyczny automat skoĆczony, ktĂłry akceptuje ciÄ gi wyrazowe w ktĂłrych wystÄ piĆa przynajmniej raz sekwencja symboli a b c.
{ dowolny symbol }
{ dowolny symbol }
{ w tym a i b } b c
q1 q2 q3
a
Start q0
Rys. 15. NAS akceptujÄ cy ciÄ g symboli, w ktĂłrych przynajmniej raz wystÄ piĆa sekwencja a,b,c
Deterministyczny automat skoĆczony z poprzedniego podrozdziaĆu jest szczegĂłlnym przypadkiem NAS, w ktĂłrym dla kaĆŒdego stanu istnieje dokĆadnie jedno przejĆcie ze stanu do stanu czyli kaĆŒdy DAS jest NAS.
2.3 Automat skoĆczony z Δ -ruchami
ModyfikacjÄ niedeterministycznego automatu skoĆczonego jest automat skoĆczony z Δ- ruchami. Model automatu w tym przypadku dopuszcza przejĆcie ze stanu do stanu przy pustym wejĆciu Δ. Formalnie niedeterministyczny automat skoĆczony z Δ-ruchami jest definiowany jako uporzÄ dkowana piÄ tka:
< Q, ÎŁ, ÎŽ, qo, F>
gdzie:
Q, ÎŁ, qo, F- takie same znaczenie jak w przypadku DAS i NAS
ÎŽ- odwzorowuje Q x (ÎŁ âȘ{Δ}) w 2Q. Czyli ÎŽ jest zbiorem wszystkich stanĂłw p takich, ĆŒe istnieje przejĆcie o etykiecie a ze stanu q do p, natomiast a jest sĆowem pustym Δ lub symbolem ze zbioru ÎŁ.
Dla przykĆadu rozpatrzmy diagram przejĆÄ AS z Δ- ruchami z rysunku 16, ktĂłry akceptuje ciÄ g symboli zawierajÄ cych dowolna liczbÄ zer, po ktĂłrych nastÄpuje dowolna liczba jedynek, a nastÄpnie dowolna liczba dwĂłjek. OczywiĆcie zgodnie z definicjÄ dowolna liczba poszczegĂłlnych symboli moĆŒe wynosiÄ 0 czyli nastÄ pi przejĆcie przy pustym wejĆciu Δ:
0 1 2
Δ Δ
start q0 q1 q2
Rys.16. NAS z Δ-ruchami akceptujÄ cy ciÄ g zĆoĆŒony z kilu 0, potem kilku1, a potem kilku2
Dla powyĆŒszego diagramu sĆowo 002 zostanie zaakceptowane gdyĆŒ istnieje droga od stanu poczÄ tkowego do stanu koĆcowego: q0, q0, q0, Δ, Δ, q2, o Ćukach etykietowanych 0 ,0, Δ, Δ, 2.
Konstrukcja NAS Δ- ruchami jest bardziej zrozumiaĆa po zapoznaniu siÄ z wyraĆŒeniami regularnymi, ktĂłre zostaĆy omĂłwione w nastÄpnym rozdziale.
2.4 WyraĆŒenia regularne
JÄzyki akceptowane przez automaty skoĆczone moĆŒna Ćatwo opisaÄ prostymi wyraĆŒeniami zwanymi wyraĆŒeniami regularnymi. Celem przedstawienia zapisu jÄzykĂłw akceptowanych wprowadĆșmy pojÄcia: zĆoĆŒenia i domkniÄcia na zbiorach ĆaĆcuchĂłw.
Niech ÎŁ bÄdzie skoĆczonym zbiorem symboli i niech L, L1, L2 bÄdÄ zbiorami ĆaĆcuchĂłw z ÎŁ*. ZĆoĆŒeniem L1 i L2, oznaczanym jako L1 L2, nazywamy {xy | x naleĆŒy do L1 i y naleĆŒy do L2}- oznacza to, ĆŒe ĆaĆcuchy naleĆŒÄ ce do L1 L2 tworzone sÄ poprzez wypisanie ĆaĆcucha z L1 , a nastÄpnie ĆaĆcucha z L2, we wszystkich moĆŒliwych kombinacjach np. niech L1 ={0,1}i L2={01,101} wtedy zĆoĆŒenie L1 L2 = {001,0101, 101,1101}. Niech L0={Δ} i Li =Lli-1 dla i â„ 0. DomkniÄciem Kleene'ego (domkniÄciem) L, oznaczanym symbolem L*, nazywamy zbiĂłr:
â
L* = Li,
i = 0
a domkniÄciem dodatnim L, oznaczanym symbolem L+, zbiĂłr
â
L+ = Li,
i = 1
Tak wiÄc L* jest zbiorem wszystkich sĆĂłw otrzymanych w wyniku zĆoĆŒenia dowolnej liczby sĆĂłw z L, zaĆ L+ wyklucza przypadek zera sĆĂłw, ktĂłrych zĆoĆŒenie okreĆla siÄ - Δ; np. domkniÄciem Kleene'ego {1,0}* ={Δ, 1, 0, 11,10,01,00....} , zaĆ domkniÄciem dodatnim {1,0}+ = {1, 0, 11,10,01,00....}.
WyraĆŒenia regularne i zbiory przez nie reprezentowane definiujemy w nastÄpujÄ cy sposĂłb:
0 jest wyraĆŒeniem regularnym reprezentujÄ cym zbiĂłr pusty.Δ jest wyraĆŒeniem regularnym reprezentujÄ cym zbiĂłr {Δ}.
Dla kaĆŒdego a z ÎŁ, a jest wyraĆŒeniem regularnym reprezentujÄ cym zbiĂłr {a}.
JeĆŒeli r i s sÄ wyraĆŒeniami regularnymi reprezentujÄ cymi odpowiednio jÄzyki R i S, to (r+s), (rs) i (r*) sÄ wyraĆŒeniami regularnymi reprezentujÄ cymi odpowiednio zbiory RâȘS, RS i R*.
Dla przykĆadu:
00 jest wyraĆŒeniem regularnym, reprezentujÄ cym {00}
(0+1) opisuje zbiĂłr wszystkich ĆaĆcuchĂłw zĆoĆŒonych z zer i jedynek
(0+1)*00(0+1)* opisuje zbiĂłr wszystkich zer i jedynek w ktĂłrych przynajmniej raz wystÄ piĆo podwojenie zer
(1+10)* reprezentuje zbiĂłr wszystkich zer i jedynek rozpoczynajÄ cych siÄ od 1 i nie zawierajÄcych podwojonych symboli 0.
(0+1)*011 opisuje wszystkie ĆaĆcuchy zer i jedynek koĆczÄ ce siÄ sekwencjÄ 011
0+ 1+ 2+ jest wyraĆŒeniem reprezentujÄ cym dowolna liczbÄ zer po ktĂłrych nastÄpuje dowolna liczba jedynek, a nastÄpnie dowolna liczba dwĂłjek (domkniÄcie dodatnie- czyli ĆaĆcuchy koĆcowe muszÄ zawieraÄ przynajmniej po jednym reprezentancie powyĆŒszych symboli).
Udowodniono, ĆŒe wyraĆŒenia regularne reprezentujÄ jÄzyki akceptowane przez automaty skoĆczone co oznacza, ĆŒe dla dowolnego wyraĆŒenia regularnego istnieje odpowiadajÄ cy mu NAS z Δ-ruchami, co wiÄcej wprowadzono gotowe konstruktory dla diagramĂłw przejĆÄ pozwalajÄ ce dla dowolnego wyraĆŒenia regularnego stworzyÄ mechanicznie konstrukcjÄ automatu skoĆczonego. WyrĂłĆŒniono trzy podstawowe postacie wyraĆŒeĆ regularnych:
suma teoriomnogoĆciowa r = r1 + r2
zĆoĆŒenie r = r1 r2
domkniÄcie r = r1*
konstruktor dla sumy teoriomnogoĆciowej r= r1+r2
q1 M1 f1
Δ Δ
start qo fo
Δ q2 M2 f2 Δ
KaĆŒda droga na powyĆŒszym diagramie automatu M musi rozpoczynaÄ siÄ od przejĆcia do stanu q1 lub do stanu q2 przy pustym wejĆciu Δ. JeĆŒeli droga prowadzi do q1, to nastÄpnie moĆŒe dowolnie przebiegaÄ w automacie M1, aĆŒ do osiÄ gniÄcia stanu f1, potem nastÄpuje przejĆcie do stanu fo, przy pustym wyjĆciu Δ. Podobnie, jeĆŒeli droga rozpoczÄĆa siÄ przejĆciem ze stanu q0 do q2 to nastÄpnie moĆŒe przebiegaÄ dowolnÄ trasÄ w automacie M2, aĆŒ do osiÄ gniÄcia stanu f2, a nastÄpnie przejĆcie do stanu f0.
konstruktor dla zĆoĆŒenia r = r1r2
Δ
start q1 M1 f1 q2 M2 f2
KaĆŒda droga z q1 do f2 w automacie M skĆada siÄ z drogi etykietowanej jakimĆ ĆaĆcuchem x prowadzÄ cej z q1 do f1, po ktĂłrej nastÄpuje przejĆcie ze stanu f1 do stanu q2 przy pustym wejĆciu Δ a nastÄpnie nastÄpuje droga z q2 do f2 etykietowana jakimĆ ĆaĆcuchem y.
konstruktor dla domkniÄcia r = r1*
Δ
Δ Δ
start q0 q1 M1 f1 f0
Δ
Dowolna droga prowadzÄ ca z q0 do f2 skĆada siÄ albo z drogi z q0 do f0 o etykiecie Δ, albo teĆŒ z drogi od q0 do q1 przy Δ, po ktĂłrych nastÄpuje pewna liczba (w szczegĂłlnym przypadku 0) drĂłg z q1 do f1, potem znowu do q1 przy Δ, nastÄpnie znĂłw droga z q1 do f1, aĆŒ w koĆcu droga z f2 do f0 przy Δ.
PowyĆŒsze konstruktory sÄ bardzo pomocne przy kreĆleniu diagramĂłw przejĆÄ NAS dla wyraĆŒeĆ regularnych. KonstrukcjÄ takiego automatu rozpoczynamy wtedy od rozĆoĆŒenia wyraĆŒenia regularnego na elementarne skĆadowe dla ktĂłrych tworzymy automaty, te z kolei na podstawie konstruktorĂłw ĆÄ czymy w logicznÄ caĆoĆÄ. Przeanalizujmy przykĆad automatu akceptujÄ cego wyraĆŒenie regularne postaci: 01*+1. To wyraĆŒenie jest postaci r = r1 + r2 gdzie: r1=01*; r2 = 1. Dla wyraĆŒenia r2 postaÄ automatu jest nastÄpujÄ ca:
start q1 1 q2
wyraĆŒenie r1 moĆŒemy zapisaÄ jako r1 = r3 + r4 gdzie r3= 0; r4=1*. Automat dla r3 ma prostÄ konstrukcjÄ, ktĂłra przedstawia siÄ nastÄpujÄ co:
start q3 0 q4
z kolei wyraĆŒenie r4 moĆŒemy zapisaÄ jako r4 = r*5 gdzie r5 to 1, a NAS dla r5 to:
start q5 1 q6
WykorzystujÄ przedstawione konstruktory zaczniemy kreĆlenie automatu dla wyraĆŒenia r4 = 1* ( konstruktor domkniÄcia)
Δ
Δ Δ
start q7 q5 1 q6 q8 rys. a
Δ
nastÄpnie dla r1 =r3r4 (r= 01*) wykorzystujemy konstruktor zĆoĆŒenia dokĆadajÄ c do rys. a nastÄpujÄ cÄ konstrukcjÄ:
0 Δ
start q3 q4 rys. a
Teraz tworzymy konstrukcjÄ dla wyraĆŒenia r= r1 + r2 (r=01*+1) wykorzystujÄ c konstruktor sumy teoriomnogoĆciowej.
start q1 1 q2
Δ Δ
q9 q10
Δ Δ
0 Δ Δ Δ Δ
q3 q4 q7 q5 1 q6 q8
Δ
Rys.17. NAS z Δ -ruchami dla wyraĆŒenia regularnego 01*+1.
2.5 Zastosowania automatĂłw skoĆczonych
Istnieje caĆa gama problemĂłw z zakresu projektowania oprogramowania, ktĂłre dajÄ siÄ uproĆciÄ poprzez automatycznÄ konwersjÄ symboliki wyraĆŒeĆ regularnych na efektywnÄ implementacjÄ komputerowÄ odpowiedniego automatu skoĆczonego. TeoriÄ automatĂłw skoĆczonych wykorzystano do:
AnalizatorĂłw leksykalnych
Tokeny (czyli bazowe kategorie syntaktyczne) jÄzyka programowania dajÄ siÄ niemal bez wyjÄ tku przedstawiÄ w postaci wyraĆŒeĆ regularnych. I tak na przykĆad, identyfikatory ALGOLu, bÄdÄ ce ciÄ gami liter i cyfr rozpoczynajÄ cymi siÄ od litery (maĆej czy duĆŒej), bez ograniczenia co do dĆugoĆci ciÄ gu, moĆŒna wyraziÄ w postaci
( litera ) ( litera + cyfra )*
gdzie litera oznacza A + B +... + Z + a + b + .. z, a cyfra - 0 + 1 + .. + 9
Identyfikatory w Fortlanie, ktĂłrych dĆugoĆÄ jest ograniczona do szeĆciu znakĂłw i ktĂłre nie mogÄ zawieraÄ innych liter niĆŒ duĆŒe oraz znak $ mogÄ byÄ przedstawione jako
( litera ) ( Δ + litera + cyfra )5
NiektĂłre generatory analizatorĂłw leksykalnych przyjmujÄ jako wejĆcie ciÄ g wyraĆŒeĆ regularnych opisujÄ cych tokeny i wytwarzajÄ pojedynczy automat skoĆczony, rozpoznajÄ cy dowolny token. Zazwyczaj przeksztaĆcajÄ one wyraĆŒenia regularne na NAS z Δ-przejĆciami, a nastÄpnie konstruujÄ podzbiory zbioru stanĂłw, aby otrzymaÄ DAS w sposĂłb bezpoĆredni, zamiast wyeliminowaÄ najpierw Δ-przejĆcia.
EdytorĂłw tekstu
Pewne edytory tekstu oraz podobne do nich programy pozwalajÄ na zastÄpowanie dowolnego ĆaĆcucha pasujÄ cego do danego wyraĆŒenia regularnego pewnym innym ĆaĆcuchem.
Techniki
Wykorzystywane do projektowania ukĆadĂłw przeĆÄ czajÄ cych na przykĆad dziaĆanie termostatu jest oparte na analizie temperatur i wybieraniu jednego z dwĂłch stanĂłw : wĆÄ czenie ukĆadu grzewczego i wyĆÄ czenie.
III. MASZYNA TURINGA
3.1 Podstawowy model maszyny Turinga
Maszyna Turinga jest prostym modelem matematycznym komputera. OpierajÄ c siÄ na pozycji D.Harela [HARE 92] przedstawmy jej najprostszy model, natomiast pozycja J.E.Hopcrofta [HOPC 94] posĆuĆŒy nam do opisu formalnego.
Podstawowy model przedstawiony na rysunku 18 ma skoĆczone sterowanie, taĆmÄ wejĆciowÄ podzielonÄ na komĂłrki (kwadraty) oraz gĆowicÄ taĆmy, mogÄ cÄ obserwowaÄ w dowolnej chwili tylko jedna komĂłrkÄ taĆmy. TaĆma ma komĂłrkÄ poĆoĆŒonÄ najbardziej na lewo, ale jest prawowostronnie nieskoĆczona. KaĆŒda z komĂłrek taĆmy moĆŒe zawieraÄ dokĆadnie jeden symbol z skoĆczonego alfabetu symboli. Przyjmuje siÄ umownie, ĆŒe ciÄ g symboli wejĆciowych umieszczony jest na taĆmie poczÄ wszy od lewej, pozostaĆe komĂłrki ( na prawo od symboli wejĆciowych) sÄ wypeĆnione specjalnym symbolem taĆmowym noszÄ cym nazwÄ symbolu pustego.
a1 a2 ... ai ... an B B ...
sterowanie
skoĆczone
Rys.18. Podstawowy model Maszyny Turinga
W zaleĆŒnoĆci od obserwowanego symbolu przez gĆowicÄ taĆmy oraz stanu sterowania skoĆczonego, maszyna Turinga w pojedynczym ruchu:
zmienia stan,
wpisuje symbol w obserwowanej komĂłrce taĆmy, zastÄpujÄ c symbol tam wpisany,
przesuwa gĆowicÄ o jednÄ komĂłrkÄ w prawo lub w lewo.
Formalnie maszynÄ Turinga (MT) nazywamy:
M = <Q, ÎŁ, Î, ÎŽ, q0, B, F >
gdzie:
Q- jest skoĆczonym zbiorem stanĂłw,
Î - skoĆczony zbiĂłr dopuszczalnych symboli taĆmowych,
B- symbol pusty naleĆŒÄ cy do Î,
ÎŁ- podzbiĂłr Î nie zawierajÄ cy B, zwany zbiorem symboli wejĆciowych,
ÎŽ- funkcja nastÄpnego ruchu, bÄdÄ ca odwzorowaniem Q x Î w Q x Î x { L, P }
gdzie:
L- oznacza ruch w lewo
P- ruch w prawo,
q0- stan poczÄ tkowy,
FâQ - zbiĂłr stanĂłw koĆcowych
DziaĆanie maszyny Turinga przedstawia siÄ jako diagram przejĆÄ miÄdzy stanami lub jako tabelÄ stanĂłw, ktĂłre to pojÄcia zostaĆy omĂłwione poniĆŒej.
Diagram przejĆÄ jest po prostu grafem skierowanym, ktĂłrego wierzchoĆki reprezentujÄ stany. KrawÄdĆș prowadzÄ ca ze stanu s do stanu t nazywa siÄ przejĆciem i etykietuje siÄ jÄ kodem postaci (a/b, kierunek) gdzie a i b sÄ symbolami , a kierunek okreĆla ruch gĆowicy w prawo bÄ dĆș w lewo. CzÄĆÄ a etykiety jest wyzwalaczem przejĆcia, a czÄĆÄ <b,kierunek> akcjÄ :
(a / b , kierunek)
wyzwalacz akcja
W czasie swego dziaĆania maszyna Turinga, kiedy znajdzie siÄ w stanie s i odczytywanym symbolem bÄdzie a to nastÄ pi wpisanie w to miejsce b i przesuniÄcie o jedno pole w kierunku kierunek. Fragment przykĆadowego diagramu przejĆÄ przedstawia rysunek 19.
start q1 # / #, L q4
a / #, P
qo # / #, L q2
b / #, P
q3 # / # , L
Rys.19. Fragment grafu przejĆÄ miÄdzy stanami dla maszyny Turinga
Tabela stanĂłw - ktĂłra rĂłwnieĆŒ obrazuje przejĆcia miÄdzy stanami maszyny Turinga zawiera wszystkie symbole z skoĆczonego alfabetu wejĆciowego jak rĂłwnieĆŒ wszystkie stany w ktĂłrych moĆŒe znaleĆșÄ siÄ maszyna Turinga (rysunek 20). KaĆŒde pole tabeli okreĆla:
dla danego stanu qi kolejny stan qi+1
symbol, ktĂłry ma byÄ zapisany na taĆmie
kierunek (L / P) dla ruchu gĆowicy
q0 q1 q2 q3
Ï q0 q2 q3 q5
Ï P a P c L
a q1 q2 q4
b L c P a L
b q5 q0 q5
Ï P c L Ï
c q7 q2
a P b L
Rys.20. Fragment tabeli stanĂłw maszyny Turinga
ZarĂłwno dla tabeli stanĂłw jak i grafu przejĆÄ wyrĂłĆŒnia siÄ specyficzne stany bÄdÄ ce odpowiednio stanem poczÄ tkowym i stanem (bÄ dĆș stanami ) koĆcowym, zwane teĆŒ stanami biernymi. ZakĆada siÄ , ĆŒe maszyna rozpoczyna swoje dziaĆanie od swego stanu poczÄ tkowego na pierwszym od lewej niepustym kwadracie taĆmy i postÄpuje krok po kroku zgodnie z narzuconym ruchem, zaĆ koĆczy dziaĆanie po osiÄ gniÄciu stanu koĆcowego.
W celu zobrazowania konstrukcji tabeli stanĂłw przeanalizujmy maszynÄ Turinga, ktĂłra dla alfabetu wejĆciowego ÎŁ ={a, b} podwaja symbole w sĆowie.
PrzykĆad 8: Maszyna Turinga podwajajÄ ca symbole w sĆowie.
ÎŁ ={a, b}
Î= { Ï , a , b}
Przed wypisaniem tabeli stanĂłw przeanalizujmy jak podana maszyna Turinga ma dziaĆaÄ. Dla sĆowa:
ab otrzymujemy aabb
aba otrzymujemy aabbaa
SĆowo na taĆmie zapisane jest jako ciÄ g symboli postaci na przykĆad Ï Ï Ï a b Ï Ï Ï
Na poczÄ tku w kolumnie wypisujemy wszystkie symbole Î= { Ï , a , b} i stan poczÄ tkowy q0
q0
Ï q0 jeĆŒeli bÄdÄ c w stanie q0 odczytanym
Ï, P symbolem bÄdzie Ï to pozostajemy
a nadal w tym stanie i wykonujemy
b ruch o jedno pole w prawo.
q0
Ï q0 jeĆŒeli bÄdÄ c w stanie q0 odczytanym symbolem bÄdzie a
Ï, P to wpisujemy w jego miejsce Ï i przechodzimy w prawo
a q1 do stanu q1.
Ï, P
BÄdÄ c w stanie q1 musimy iĆÄ tak dĆugo w prawo aĆŒ pominiemy wszystkie symbole ĆÄ cznie z pierwszym symbolem Ï. Wtedy w miejsce drugiego Ï (moĆŒe siÄ ono znajdowaÄ po kilku symbolach z alfabety wejĆciowego) wpisujemy a i przechodzimy do stanu q3. Jedynym sĆusznym symbolem napotkanym w tym stanie jest Ï, w miejsce ktĂłrego wpisujemy drugie a i przechodzimy do stanu q4 (stan powrotu). JeĆŒeli bÄdÄ c w tym stanie przejdziemy nad wszystkimi symbolami i napotkamy symbol Ï, to sprawdzamy, czy sÄ jeszcze jakieĆ symbole wejĆciowe na taĆmie. JeĆŒeli tak to zaczynamy algorytm od poczÄ tku, w przeciwnym razie przechodzimy do stanu koĆcowego q15
q0 q1 q2 q3 q4 q5 q6
Ï q0 q2 q3 q4 q5 q15 q0
Ï, P Ï, P a, P a, L Ï, L Ï, P Ï, P
a q1 q1 q2 q15 q4 q6 q6
Ï, P a, P a, P a, P a, L a, L a,L
Dla symbolu b pola w tabeli stanĂłw bÄdÄ tworzone analogicznie. Ostateczny wyglÄ d tabeli stanĂłw przedstawia rysunek 21.
q0 q1 q2 q3 q4 q5 q6 q7 q8 q9 q10 q11 q12 q13
Ï q0 q2 q3 q4 q5 q13 q0 q8 q9 q10 q11 q13 q0
Ï, P Ï, P a, P a, L Ï, L Ï, P Ï, P Ï, P b, P b, L Ï, L Ï, P Ï , P K
a q1 q1 q2 q13 q4 q6 q6 q7 q8 q13 q10 q12 q12
Ï, P a, P a, P a, P a, L a, L a, L a, P a, P a, P a, L a, L a, L K
b q7 q1 q2 q13 q4 q6 q6 q7 q8 q13 q10 q12 q12
Ï, P b, P b, P b, P b, L b, L b, L b , P b, P b, P b, L b, L a, L K
Rys. 21. Tabela stanĂłw maszyny Turinga podwajajÄ ca symbole w sĆowie dla alfabetu wejĆciowego ÎŁ ={a, b}
Przeanalizujmy kilka poczÄ tkowych taktĂłw pracy powyĆŒszej maszyny Turinga dla ciÄ gu wejĆciowego: a b
CiÄ g ten zapisany jest na taĆmie w postaci Ï Ï Ï a b Ï Ï Ï Ï .....
Ï Ï Ï a b Ï Ï Ï .... / pozostajemy w stanie q0 i przechodzimy w prawo
Ï Ï Ï Ï b Ï Ï Ï .. / napotkaliĆmy a, wpisujemy Ï i przechodzimy w prawo do stanu q1
Ï Ï Ï Ï b Ï Ï Ï .. / pozostajemy nadal w stanie q1 aĆŒ dojdziemy do pierwszego znaku Ï
Ï Ï Ï Ï b Ï Ï Ï.../ po napotkaniu pierwszego Ï przechodzimy w prawo do stanu q2
Ï Ï Ï Ï b Ï a Ï Ï.../ po napotkaniu Ï wpisujemy a i przechodzimy do stanu q3
Ï Ï Ï Ï b Ï a a Ï.../ w stanie q3 wpisujemy drugie a i przechodzimy do stanu q4, ktĂłry to stan powoduje powrĂłt na poczÄ tek sĆowa i rozpoczÄcie pracy od nowa o ile sÄ jeszcze na taĆmie symbole wejĆciowe
Po przeanalizowaniu wszystkich symboli wejĆciowych przechodzimy do stanu q13, ktĂłry to stan jest stanem koĆcowym (stan bierny ).
Dla rozpatrywanego ciÄ gu wejĆciowego moĆŒna okreĆliÄ trzy elementy w tabeli stanĂłw:
stan warunkowy - ktĂłry powoduje przejĆcie do okreĆlonej sekcji manipulowania danym symbolem,
sekcja manipulowania - stany odpowiadajÄ ce za przepisywanie symboli,
powrĂłt- stan powodujÄ cy przejĆcie do poczÄ tku i rozpoczÄcie pracy od nowa
Jak zostaĆo wczeĆniej wspomniane, alternatywne do tabeli stanĂłw stosuje siÄ graf przejĆÄ miÄdzy stanami. KonstrukcjÄ przykĆadowego grafu ilustruje przykĆad 9.
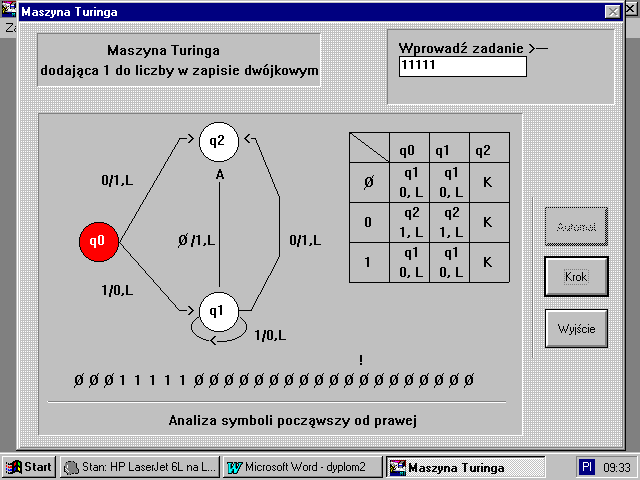
PrzykĆad: 9
Maszyna Turinga dodajÄ cÄ 1 do danej liczby w zapisie dwĂłjkowym ( inkrementacja liczby binarnej bez znaku). AnalizÄ liczby rozpoczynamy z prawej strony.
q0 q1 q2
Ï q0 q2 K q2
Ï, L 1, L 0/1, L
0 q2 q2 K start q0 Ï /1 L 0 / 1, L
1, L 1, L
1 q1 q1 K 1/0, L
0, L 0, L q1
1/0, L
Rys.22. Graf i tabela stanĂłw maszyny Turinga dodajÄ cej 1 do liczby binarnej
Maszyny Turinga z przykĆadĂłw: 8 i 9 rozwiÄ zujÄ problemy algorytmiczne zwiÄ zane z manipulacjÄ danych wejĆciowych. OdmianÄ stanowiÄ maszyny Turinga rozwiÄ zujÄ ce problemy decyzyjne i tak pokazana w przykĆadzie 10 maszyna Turinga bada czy dane sĆowo jest palidromem.
PrzykĆad 10:
Maszyna Turinga badajÄ ca czy dane sĆowo z alfabetu wejĆciowego ÎŁ ={a, b, c} jest palindromem (to znaczy sĆowem, ktĂłre czyta siÄ tak samo z obu stron). Dodatkowo przyjmuje siÄ, ĆŒe pojedynczy symbol jest palindromem. Wprowadza siÄ dodatkowo 2 stany akceptacji SA i nieakceptacji SN. PrzejĆcie do stanu akceptacji oznacza, ĆŒe dane sĆowo jest palindromem, zaĆ przejĆcie do stanu nieakceptacji oznacza, ĆŒe sĆowo nie jest palindromem. TabelÄ przejĆÄ miedzy stanami pokazuje rysunek 22.
q0 q1 q2 q3 q4 q5 q6 q7 q8 q9 q10 q11
Ï q0 q2 q10 q0 q5 q10 q0 q8 q10 q0
Ï, P Ï, L Ï , P Ï, P Ï, L Ï, P Ï, P Ï, L Ï, P Ï, P SA SN
a q1 q1 q3 q3 q4 q11 q6 q7 q11 q9
Ï, P a, P Ï, L a, L a, P a, P a, L a, P a, P a, L SA SN
b q4 q1 q11 q3 q4 q6 q6 q7 q11 q9
Ï, P b, P b, P b, L b, P Ï, L b, L b , P b, P b, L SA SN
c q7 q1 q11 q3 q4 q11 q6 q7 q9 q9
Ï, P c, P c, P c, L c, P c, P c, L c , P Ï, L c, L SA SN
Rys. 22. Tabela stanĂłw maszyny Turinga, badajÄ cej czy dane sĆowo jest palindromem
RĂłĆŒnorodnoĆÄ zadaĆ stawianych przed maszynÄ Turinga postawiĆo pytanie : jakie problemy moĆŒna rozwiÄ zaÄ za jej pomocÄ (oczywiĆcie pomijajÄ c czas) ? OtĂłĆŒ okazuje siÄ ĆŒe : Maszyny Turinga potrafiÄ rozwiÄ zaÄ kaĆŒdy efektywnie rozwiÄ zywalny problem algorytmiczny. MĂłwiÄ c inaczej, kaĆŒdy problem algorytmiczny dla ktĂłrego moĆŒemy znaleĆșÄ algorytm dajÄ cy siÄ zaprogramowaÄ w pewnym dowolnym jÄzyku, wykonujÄ cy siÄ na pewnym dowolnym komputerze, nawet na takim, ktĂłrego jeszcze nie zbudowano, ale moĆŒna zbudowaÄ. To stwierdzenie jest jednÄ z wersji tzw. tezy Churcha-Turinga, ktĂłrzy doszli do niej niezaleĆŒnie w poĆowie lat trzydziestych. IstotnÄ sprawÄ jest aby uĆwiadomiÄ sobie, ĆŒe teza Churcha-Turinga jest tezÄ a nie twierdzeniem, zatem nie moĆŒe byÄ dowiedziona w matematycznym tego sĆowa znaczeniu. Jedno z pojÄÄ, do ktĂłrej siÄ odwoĆuje, jest bowiem nieformalnym i nieprecyzyjnym, pojÄciem „efektywnej obliczalnoĆci”. Dlaczego jednak powinniĆmy wierzyÄ tej tezie, szczegĂłlnie, jeĆli nie moĆŒna jej udowodniÄ?
JuĆŒ od wczesnych lat trzydziestych badacze proponowali rĂłĆŒne modele komputera absolutnego, wszechpotÄĆŒnego, lub uniwersalnego. Chciano bowiem sprecyzowaÄ ulotne pojÄcie „efektywnej obliczalnoĆci”. Na dĆugo przedtem nim wymyĆlono pierwszy komputer, Turing zaproponowaĆ swojÄ maszynÄ, a Church wymyĆliĆ matematyczny formalizm funkcji zwany rachunkiem lambda (jako podstawa jÄzyka programowania Lisp). Mniej wiÄcej w tym samym czasie Emil Post zdefiniowaĆ pewien typ systemu produkcji do manipulowania symbolami, a Stephen Kleene zdefiniowaĆ klasÄ obiektĂłw zwanych funkcjami rekurencyjnymi.
Wszyscy oni prĂłbowali uĆŒyÄ tych modeli do rozwiÄ zania wielu problemĂłw algorytmicznych, do ktĂłrych znane byĆy „efektywnie wykonalne” algorytmy.
PrzeĆomowym zdarzeniem istotnym dla wszystkich tych modeli staĆo siÄ udowodnienie, iĆŒ sÄ one rĂłwnowaĆŒne w kategoriach problemĂłw algorytmicznych, ktĂłre rozwiÄ zujÄ . I ten fakt jest dziĆ nadal prawdziwy nawet dla najsilniejszych modeli, jakie moĆŒna sobie wyobraziÄ.
Z tezy Churcha-Turinga wynika, ĆŒe najpotÄĆŒniejszy superkomputer z wieloma najwymyĆlniejszymi jÄzykami programowania, interpretatorami, kompilatorami i wszelkimi zachciankami, nie jest potÄĆŒniejszy od domowego komputera z jego uproszczonym jÄzykiem programowania. MajÄ c ograniczonÄ iloĆÄ czasu i pamiÄci mogÄ obydwa rozwiÄ zaÄ te same problemy algorytmiczne, jak rĂłwnieĆŒ ĆŒaden z nich nie moĆŒe rozwiÄ zaÄ problemĂłw nierozstrzygalnych (nieobliczalnych). Schematycznie rozstrzygalnoĆÄ problemĂłw przedstawia rysunek 23.
Problemy wcale nie
problemy majÄ ce algorytmĂłw
nierozstrzygalne
teza Churcha-Turinga
problemy trudno Problemy nie majÄ
ce
rozwiÄ zywalne rozsÄ dnych algorytmĂłw
Problemy Ćatwo Problemy majÄ
ce rozsÄ
dne
RozwiÄ zywalne algorytmy
Rys. 23. Sfera problemĂłw algorytmicznych
IV. GRAMATYKI BEZKONTEKSTOWE
4.1 Podstawowe pojÄcia gramatyk
Przez gramatykÄ rozumie siÄ pewien ukĆad reguĆ zadajÄ cy zbiĂłr sĆĂłw utworzonych z symboli jÄzyka. SĆowa te mogÄ byÄ interpretowane jako obiekty jÄzykowe rĂłĆŒnych szczebli, np. jako formy wyrazowe, grupy wyrazĂłw i zdania. OpierajÄ c siÄ na pracach: Z.AĆfierowej [AĆFI 77] oraz J.E.Hopcrofta [HOPC 94] sprĂłbujemy wykazaÄ w tym przydatnoĆÄ gramatyk w teorii informatyki skupiajÄ c swoje rozwaĆŒania na gramatykach bezkontekstowych.
GramatykÄ jÄzyka moĆŒna rozpatrywaÄ jako teoriÄ powtarzajÄ cych siÄ prawidĆowoĆci budowy zdaĆ zwanych syntaktycznÄ strukturÄ jÄzyka.
Syntaktyka (skĆadnia) jÄzyka sÄ to reguĆy budowy zdaĆ w jÄzyku lub reguĆy budowy konstrukcji jÄzykowych. Semantyka jÄzyka jest to interpretacja tych reguĆ, zasady stosowania skĆadni.
Gramatyki formalne zajmujÄ siÄ pojÄciami abstrakcyjnymi powstajÄ cymi droga uogĂłlnienia pojÄcia formy wyrazowej, grupy wyrazĂłw, zdania. O ile zwykĆe gramatyki pozwalajÄ okreĆliÄ zbiory reguĆ budowy zdaĆ, o tyle gramatyki formalne stanowiÄ pewien sposĂłb badania i opisu zbioru reguĆ. rozrĂłĆŒnia siÄ trzy typy gramatyk formalnych:
rozpoznajÄ ca- jeĆŒeli dla dowolnego rozpatrywanego sĆowa potrafi rozstrzygnÄ Ä, czy sĆowo to jest poprawne czy nie, a w przypadku odpowiedzi pozytywnej potrafi podaÄ wskazĂłwki dotyczÄ ce budowy tego sĆowa,
generacyjna- jeĆŒeli potrafi zbudowaÄ dowolne sĆowo poprawne, podajÄ c przy tym wskazĂłwki dotyczÄ ce jego budowy oraz nie tworzy ani jednego sĆowa niepoprawnego,
przetwarzajÄ ca- jeĆŒeli dla dowolnie poprawnie zbudowanego sĆowa potrafi ona zbudowaÄ jego odwzorowania rĂłwnieĆŒ w postaci sĆowa poprawnego, okreĆlajÄ c przy tym wskazĂłwki dotyczÄ ce kolejnoĆci stosowania odwzorowaĆ.
Formalnie gramatykÄ G okreĆlamy jako:
G= <V, T, P, S >
gdzie:
V- zbiĂłr symboli terminalnych- skoĆczony niepusty zbiĂłr symboli zwany takĆŒe alfabetem koĆcowym (zasadniczym ) gramatyki G. alfabet koĆcowy jest to zbiĂłr elementĂłw pierwotnych, z ktĂłrych budowane sÄ sĆowa generowane przez gramatykÄ.
T- zbiĂłr symboli nieterminalnych- skoĆczony niepusty zbiĂłr symboli zwany takĆŒe alfabetem pomocniczym. Alfabet pomocniczy jest to zbiĂłr symboli, ktĂłrymi oznacza siÄ klasy lub sĆowa zĆoĆŒone z elementĂłw pierwotnych, czyli inaczej jest to sĆownik typĂłw syntaktycznych.
P- lista produkcji- sÄ to reguĆy gramatyki, czyli skoĆczony zbiĂłr reguĆ
S- gĆowa- symbol poczÄ tkowy. Jest to wyrĂłĆŒniony symbol pomocniczy oznaczajÄ cy klasÄ tych wszystkich obiektĂłw jÄzykowych, dla ktĂłrych opisu przeznaczona jest gramatyka.
Podstawowym obiektem zastosowaĆ teorii gramatyk sÄ nie dowolne gramatyki, lecz gramatyki pewnych szczegĂłlnych typĂłw, najwaĆŒniejsze zarĂłwno z teoretycznego jaki i praktycznego punktu widzenia. WyrĂłĆŒnienia tych typĂłw dokonuje siÄ na podstawie postaci reguĆ. W teorii Chomskiego wyrĂłĆŒnia siÄ cztery typy gramatyk. Gramatyki te wyodrÄbnia siÄ przez nakĆadanie kolejno coraz silniejszych ograniczeĆ na ukĆad reguĆ P:
gramatyka klasy 0 - charakteryzuje siÄ tym , ĆŒe wszystkie produkcje majÄ postaÄ: uâw, uâV*\ {Δ}, w âV*,
gramatyka klasy 1- zwana kontekstowÄ , nazywa siÄ gramatykÄ charakteryzujÄ cÄ siÄ tym, ĆŒe wszystkie produkcje majÄ postaÄ: uAw â ubw, u,wâV*, AâS , bâV*\ {Δ},
gramatyka typu 2- zwana gramatykÄ bezkontekstowÄ , ktĂłra w ukĆadzie reguĆ P dopuszcza jedynie reguĆy postaci Aâb, AâS , bâV*\ {Δ},
gramatyka klasy 3- (regularna), ktĂłra w ukĆadzie reguĆ P dopuszcza reguĆy postaci AâbB (gramatyki prawostronnie regularne) albo AâBb (gramatyki lewostronnie regularne), AâS, BâSâȘ {Δ}, bâT*\ {Δ}.
MoĆŒna siÄ Ćatwo przekonaÄ, ĆŒe kaĆŒda gramatyka klasy i jest jednoczeĆnie gramatykÄ klasy j, dla 0 †j †i. Wynika to stÄ d, ĆŒe kaĆŒdy zbiĂłr ciÄ gĂłw wywodliwych zgodnie z gramatykÄ klasy i jest jednoczeĆnie zbiorem ciÄ gĂłw wywodliwych zgodnie z gramatykÄ niĆŒszych klas. Odwrotne stwierdzenie nie jest jednak prawdziwe. MoĆŒna bowiem podaÄ przykĆady zbiorĂłw ciÄ gĂłw wywodliwych zgodnie z gramatykÄ i, dla ktĂłrych nie sposĂłb skonstruowaÄ gramatyki wyĆŒszej klasy. OgĂłlnie powiedziawszy, im wyĆŒsza klasa gramatyki, tym mniej precyzyjnie okreĆla siÄ rozmaitoĆÄ wywodliwych ciÄ gĂłw.
Jako ilustracjÄ do poszczegĂłlnych gramatyk rozpatrzmy klasyczny przykĆad ciÄ gĂłw: aa.......bb........cc......, ktĂłre w skrĂłcie bÄdziemy zapisywaÄ: akblcm.
k razy l razy m razy
JeĆli nie nakĆadamy ĆŒadnych ograniczeĆ na wartoĆci k, l, m, to bez trudu moĆŒemy znaleĆșÄ prawostronnie regularnÄ gramatykÄ:
G3= (V3, T3, P3, S)
gdzie
V3={a,b,c}, T3={S,V,U}, zaĆ lista produkcji
P3={ SâaS,
SâaV,
VâbV,
VâbU,
UâcU,
Uâc}
JeĆli jednak chcemy otrzymaÄ nieco bardziej ograniczone ciÄ gi, w ktĂłrych k=m to nie moĆŒna juĆŒ dla nich zbudowaÄ gramatyki regularnej, natomiast moĆŒna je okreĆliÄ przez gramatykÄ bezkontekstowÄ
G2= (V2, T2, P2, S)
gdzie
V2={a,b,c}, T2={S,V}, zaĆ lista produkcji
P2= { SâaSc,
SâaVc,
VâVb,
Vâb }
Zdefiniowanie ciÄ gĂłw o jednakowej liczbie wystÄ pieĆ kaĆŒdej z liter (k=l=m) wymaga juĆŒ uĆŒycia gramatyki kontekstowej lub gramatyki klasy 0, na przykĆad
G1= (V1, T1, P1, S)
gdzie
V1={a,b,c}, T1={S,U}, zaĆ lista produkcji
P1={ Sâabc,
SâaSUc,
cUâUc,
bUâbb}
4.2 Gramatyki bezkontekstowe
Gramatyki bezkontekstowe, podobnie jak omawiane wczeĆniej zbiory regularne majÄ szerokie zastosowanie praktyczne. SÄ one wykorzystywane do definiowania jÄzykĂłw programowania, do formalizacji pojÄcia analizy syntaktycznej, do upraszczania translacji jÄzykĂłw programowania.
Gramatyka bezkontekstowa to skoĆczony zbiĂłr zmiennych (zwanych teĆŒ symbolami niekoĆcowymi, symbolami pomocniczymi lub kategoriami syntaktycznymi), z ktĂłrych kaĆŒda reprezentuje pewien jÄzyk. JÄzyki reprezentowane przez zmienne opisywane za pomocÄ wzajemnej rekursji, z zastosowaniem pewnych symboli pierwotnych, zwanych symbolami koĆcowymi. ReguĆy wiÄ ĆŒÄ ce ze sobÄ zmienne zwane sÄ produkcjami.
PierwotnÄ motywacjÄ wprowadzenia pojÄcia gramatyk bezkontekstowych byĆ opis jÄzykĂłw naturalnych. W ich kontekĆcie moĆŒemy pisaÄ reguĆy:
<zdanie> <fraza rzeczownikowa> <fraza czasownikowa>
<fraza rzeczownikowa> <przymiotnik > <fraza rzeczownikowa>
<fraza rzeczownikowa> <rzeczownik>
<rzeczownik> chĆopiec
<przymiotnik> maĆy,
gdzie kategorie syntaktyczne sÄ ujÄte w nawiasy kÄ towe, a symbole koĆcowe sÄ reprezentowane za pomocÄ sĆĂłw nie ujÄtych w nawiasy np.: „chĆopiec”
RozwaĆŒania ligwistĂłw posĆuĆŒyĆy w informatyce do opisu jÄzykĂłw programowania za pomocÄ notacji zwanej notacjÄ Backusa-Naura (NBN), bÄdÄ cej notacjÄ gramatyki bezkontekstowej z pewnymi drobnymi zmianami dotyczÄ cymi formatu oraz kilkoma skrĂłtami notacyjnymi. Takie uĆŒycie gramatyk bezkontekstowych bardzo uproĆciĆo definicje jÄzykĂłw programowania oraz konstrukcjÄ kompilatorĂłw. Dla przykĆadu weĆșmy nastÄpujÄ cy zbiĂłr produkcji:
1. <wyraĆŒenie> <wyraĆŒenie> + <wyraĆŒenie>
2. <wyraĆŒenie> <wyraĆŒenie> * <wyraĆŒenie>
3. <wyraĆŒenie> (<wyraĆŒenie>)
4. <wyraĆŒenie> id
ktĂłry definiuje wyraĆŒenie arytmetyczne z operatorami + i * oraz argumentami reprezentowanymi przez symbol id. Pierwsze dwie produkcje mĂłwiÄ , ĆŒe wyraĆŒenie moĆŒe byÄ zĆoĆŒone z dwĂłch wyraĆŒeĆ poĆÄ czonych znakiem dodawania lub mnoĆŒenia. trzecia produkcja mĂłwi, ĆŒe wyraĆŒenie moĆŒe byÄ innym wyraĆŒeniem ujÄtym w nawiasy. Ostatnia zaĆ mĂłwi, ĆŒe pojedynczy argument jest wyraĆŒeniem.
StosujÄ c te produkcje wielokrotnie, moĆŒemy otrzymaÄ coraz bardziej zĆoĆŒone wyraĆŒenia. Dla przykĆadu:
<wyraĆŒenie> â <wyraĆŒenie> * <wyraĆŒenie>
â ( <wyraĆŒenie>) * <wyraĆŒenie>
â <wyraĆŒenie> * id
â ( <wyraĆŒenie> + <wyraĆŒenie> ) *id
â <wyraĆŒenie> + id) * id
â (id +id) * id
Symbol â oznacza tu akt wyprowadzenia, to jest zastÄpowania zmiennej prawÄ stronÄ produkcji dla tej zmiennej.
Formalnie gramatykÄ bezkontekstowÄ definiujemy jako:
G=<V, T, P,S>
gdzie:
V i T- odpowiednio skoĆczone zbiory zmiennych i symboli koĆcowych,
P - jest skoĆczonym zbiorem produkcji (kaĆŒda produkcja ma postaÄ A->α, gdzie A jest zmiennÄ , a α jest ĆaĆcuchem symboli z (VâȘT)* ),
S- jest specjalnÄ zmiennÄ , zwanÄ symbolem poczÄ tkowych.
Dla zdefiniowania jÄzyka generowanego przez gramatykÄ G=<V, T, P, S> wprowadĆșmy notacjÄ do reprezentowania wyprowadzeĆ. Najpierw definiujemy dwie relacje: â i â
pomiÄdzy ĆaĆcuchami z (VâȘT)*. JeĆli A ÎČ jest produkcjÄ
z P, a α i Îł sÄ
dowolnymi ĆaĆcuchami z (VâȘT)*, to αAÎł â αÎČÎł.
MĂłwimy, ĆŒe produkcja A ÎČ zastosowana do ĆaĆcucha αAÎł daje w wyniku αÎČÎł, lub ĆŒe αÎČÎł jest bezpoĆrednio wyprowadzalny z αAÎł w gramatyce G. Dwa ĆaĆcuchy sÄ
zwiÄ
zane relacja â dokĆadnie wtedy, gdy drugi z nich moĆŒna otrzymaÄ, z pierwszego poprzez zastosowanie jakiejĆ produkcji.
PrzypuĆÄmy, ĆŒe α1 ,α2, .....αm sÄ ĆaĆcuchami z (VâȘT)*, , m â„ 1, oraz
α1â α2, α2 â α3, .....αm-1âαm
wtedy piszemy:
α1 â αm
i mĂłwimy, ĆŒe αm jest wyprowadzalny z α1 w gramatyce G.
JÄzyk generowany przez gramatykÄ G to L(G) = {w|w naleĆŒy do T* i S â w}.
A zatem ĆaĆcuch w naleĆŒy do L(G), jeĆli speĆnione sÄ dwa nastÄpujÄ ce warunki:
1. w skĆada siÄ wyĆÄ cznie z symboli koĆcowych.
2. w jest wyprowadzalny z S.
JÄzyk L nazywamy jÄzykiem bezkontekstowych (JBK), jeĆli jest on toĆŒsamy z L(G) dla pewnej gramatyki G. ĆaĆcuch α zĆoĆŒony z symboli koĆcowych i zmiennych nazywamy formÄ zdaniowÄ jeĆli Sâα. mĂłwimy, ĆŒe gramatyki G1 i G2 sÄ rĂłwnowaĆŒne, jeĆŒeli: L(G1) = (G2)
PrzykĆad 11:
Mamy gramatykÄ G=<V,T,P,S>, gdzie V={S}, T={a,b}, i P={S aSb, S ab}. JedynÄ
zmiennÄ
jest tu S, a i b sÄ
symbolami koĆcowymi. IstniejÄ
dwie produkcje S aSb, S ab. StosujÄ
c pierwszÄ
z nich n-1 razy, a nastÄpnie jeden raz drugÄ
otrzymujemy:
Sâ aSb â aaSbb â a3Sb3 â...â an-1Sbn-1 â anbn
4.3 Drzewa wyprowadzenia
UĆŒyteczne jest przedstawienie wyprowadzeĆ w postaci drzew (znacznik struktury frazowej). WierzchoĆki drzewa wyprowadzenia (lub rozkĆadu) sÄ
etykietowane symbolami koĆcowymi lub zmiennymi gramatyki, ewentualnie symbolem Δ. JeĆli wierzchoĆek wewnÄtrzny n jest opatrzony etykietÄ
A, a synowie n sÄ
opatrzeni etykietami X1,X2...,Xk w kolejnoĆci od lewej do prawej, to A X1X2...Xk musi byÄ produkcjÄ
rozpatrywanej gramatyki. Rysunek 24 pokazuje drzewo wyprowadzenia dla przytoczonych wczeĆniej reguĆ:
1. <wyraĆŒenie> <wyraĆŒenie> + <wyraĆŒenie>
2. <wyraĆŒenie> <wyraĆŒenie> * <wyraĆŒenie>
3. <wyraĆŒenie> (<wyraĆŒenie>)
4. <wyraĆŒenie> id
< wyraĆŒenie>
< wyraĆŒenie> * < wyraĆŒenie>
( < wyraĆŒenie> ) id
< wyraĆŒenie> + < wyraĆŒenie>
id id
Rys.24. Drzewo wyprowadzenia
Bardziej formalnie, niech G= (V,T,P,S ) bÄdzie gramatykÄ bezkontekstowÄ . Drzewo D jest drzewem wyprowadzenia (lub rozkĆadu) dla G, jeĆli:
kaĆŒdy wierzchoĆek drzewa D ma etykietÄ, bÄdÄ cÄ symbolem z V âȘ TâȘ {Δ},
etykietÄ wierzchoĆka drzewa D jest S,
jeĆli wierzchoĆek wewnÄtrzny drzewa S jest opatrzony etykietÄ A, to A musi naleĆŒeÄ do V,
jeĆŒeli wierzchoĆek n drzewa D ma etykietÄ A, a wierzchoĆki n1,n2.....nk sÄ synami wierzchoĆka n uszeregowanymi od lewej do prawej i opatrzonymi odpowiednio etykietami X1,X2......,Xk to A X1X2......Xk musi byÄ produkcjÄ z P,jeĆŒeli wierzchoĆek n drzewa D ma etykietÄ Î”, to n jest liĆciem drzewa D oraz jedynym synem swego ojca.
PrzykĆad 12:
Rozpatrzmy gramatykÄ G=({S,A},{a,b}, {P,S}), gdzie P skĆada siÄ z nastÄpujÄ cych produkcji:
S aAS | a
A SbA | SS | ba
WywĂłd dla tej gramatyki S â aAS â aSbAS â aabAS â aabbaS â aabbaa, zaĆ drzewo wyprowadzenia pokazane zostaĆo na rysunku 25.
S
a A S
S b A a
a b a
Rys.25. Drzewo wyprowadzenia dla przykĆadu 12
Dwa znaczniki struktury frazowej (drzewa wyprowadzeĆ) sÄ uwaĆŒane za toĆŒsamoĆciowo rĂłwne, jeĆŒeli posiadajÄ one jednakowÄ strukturÄ gaĆÄzi i jednakowe etykiety przy odpowiednich wÄzĆach.
PoniewaĆŒ liczba reguĆ jest skoĆczona, natomiast liczba znacznikĂłw moĆŒe byÄ nieskoĆczona, to mogÄ istnieÄ takie symbole alfabetu pomocniczego, ktĂłre powtarzajÄ siÄ w znacznikach struktury dowolnÄ iloĆÄ razy. Co wiÄcej, mogÄ istnieÄ takie ĆaĆcuchy drzewa, ktĂłre zawierajÄ pewien symbol wiÄcej niĆŒ n razy dla dowolnego z gĂłry ustalonego n.
Element syntaktyczny nazywa siÄ elementem rekursywnym, jeĆŒeli dla pewnego z gĂłry ustalonego n istnieje takie drzewo struktury, ktĂłrego ĆaĆcuch zawiera ten symbol jako nazwÄ wÄzĆa wiÄcej niĆŒ n razy. WyodrÄbnia siÄ trzy rodzaje elementĂłw rekursywnych:
element A nazywa siÄ leworekursywnym, jeĆŒeli podporzÄ dkowane jemu drzewo zawiera A tylko w ĆaĆcuchu wysuniÄtym najbardziej w lewo,
element A nazywa siÄ praworekursywnym, jeĆŒeli podporzÄ dkowane mu drzewo zawiera A tylko w ĆaĆcuchu wysuniÄtym najbardziej w prawo,
element A nazywa siÄ samozanurzajÄ cym, jeĆŒeli podporzÄ dkowane mu drzewo zawiera A w pewnym ĆaĆcuchu wewnÄtrznym.
a) A b) A c) A
B C B C B C
A A A
Rys.26. elementy rekursywne: a) leworekursywny, b) samozanurzajÄ cy
c) praworekursywny
Teoria gramatyk formalnych, stanowi bardzo rozlegĆÄ dziedzinÄ wiedzy, toteĆŒ w niniejszym rozdziale zostaĆa przedstawiona gramatyka bezkontekstowa majÄ ca najszersze zastosowanie w informatyce.
V. OPIS PROGRAMĂW
RozdziaĆ V jest opisem programĂłw ilustrujÄ cych zagadnienia omĂłwione w czÄĆci teoretycznej. ZostaĆy one napisane przy uĆŒyciu jÄzyka programowania C++ w wersji 4.0 z wykorzystaniem biblioteki OWL. Jedynym wymogiem dla uruchomienia programĂłw jest Ćrodowisko graficzne WINDOWS (poczÄ wszy od wersji 3.0). Wersje ĆșrĂłdĆowe programĂłw sÄ doĆÄ czone do niniejszej pracy i mogÄ byÄ w peĆni wykorzystywane przez osoby kontynuujÄ ce pracÄ: „Pakiet programĂłw edukacyjnych z zakresy przedmiotu wprowadzenie do informatyki”.
5.1. ONP
Program ONP jest ilustracjÄ graficznÄ do rozdziaĆu pierwszego: „Zasady automatycznej translacji”. Menu programu zostaĆo podzielone na trzy czÄĆci:
Zadania- opcja pozwala na wybranie jednego z piÄciu zadaĆ do procesu translacji bez moĆŒliwoĆci definiowana wĆasnych zadaĆ,
Praktyka- opcja pozwalajÄ ca wpisanie wĆasnych zadaĆ do procesu translacji,
Teoria-opcja pozwalajÄ ca na zapoznanie siÄ z podstawowymi wiadomoĆciami teoretycznymi,
Menu gĆĂłwne programu ONP
Po wybraniu opcji zadania, mamy moĆŒliwoĆÄ wybrania jednego z piÄciu przykĆadowych zadaĆ obrazujÄ cych proces translacji. Dodatkowo wybieramy stopieĆ translacji:
Do ONP- przedstawia proces translacji wyraĆŒeĆ arytmetycznych do postaci ONP,
ONP jÄzyk symboliczny - przedstawia proces translacji z ONP na jÄzyk symboliczny.
Po wybraniu opcji do ONP ukaĆŒe siÄ nam nastÄpujÄ ce okienko dialogowe:
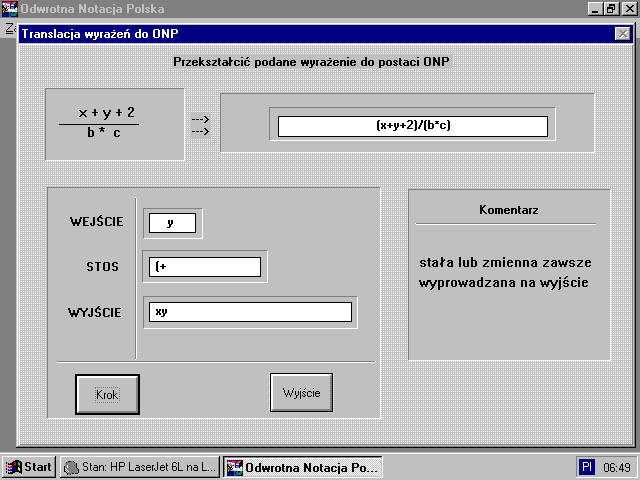
Przycisk KROK pozwala ĆledziÄ poszczegĂłlne takty translacji, natomiast przycisk WYJĆCIE koĆczy analizÄ danego zadania. W polu komentarz na bieĆŒÄ co jest komentowany kaĆŒdy krok procesu translacji, a pola WEJĆCIE, STOS, WYJĆCIE odzwierciedlajÄ aktualny stan rozpatrywanego zadania. Zadania zostaĆy tak dobrane aby uĆŒytkownik miaĆ moĆŒliwoĆÄ poznaÄ wszystkie aspekty procesu translacji wyraĆŒeĆ do postaci ONP.
Po wybraniu opcji ONP j.symboliczny ukaĆŒe siÄ nam nastÄpujÄ
ce okienko dialogowe:
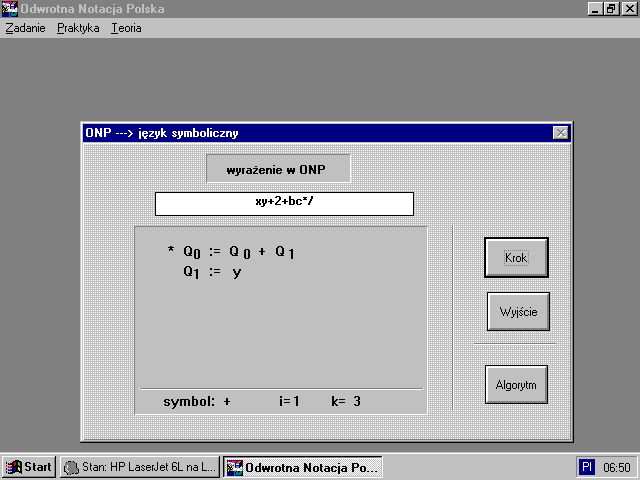
Przyciski KROK i WYJĆCIE majÄ
takie samo znaczenie jak poprzednio, natomiast przycisk ALGORYTM wyĆwietla algorytm translacji na drodze ONP jÄzyk symboliczny. Program zostaĆ tak skonstruowany, ĆŒe jeĆŒeli wybrano zadanie n do procesu translacji to automatycznie jest wypisywane w okienku wyraĆŒenie w ONP odpowiednio przeksztaĆcone wyraĆŒenie arytmetyczne z pierwszej fazy translacji.
Opcja teoria uruchamia plik pomocy do WINDOWS wdihelp.hlp, ktĂłry jest wspĂłlny dla wszystkich programĂłw. PrzykĆadowe okienko dla ONP pokazane zostaĆo poniĆŒej:
5.2. AS
Program AS jest programem edukacyjnym do rozdziaĆu drugiego : „Automat skoĆczony”. Menu programu zostaĆo podzielone na trzy czÄĆci:
WyraĆŒenia regularne- opcja pozwala na wybranie zadaĆ zwiÄ zanych z wyraĆŒeniami regularnymi.
Automaty- opcja pozwalajÄ ca na wybranie zadaĆ zwiÄ zanych z automatami skoĆczonymi,
Teoria-opcja pozwalajÄ ca na zapoznanie siÄ z podstawowymi wiadomoĆciami teoretycznymi,
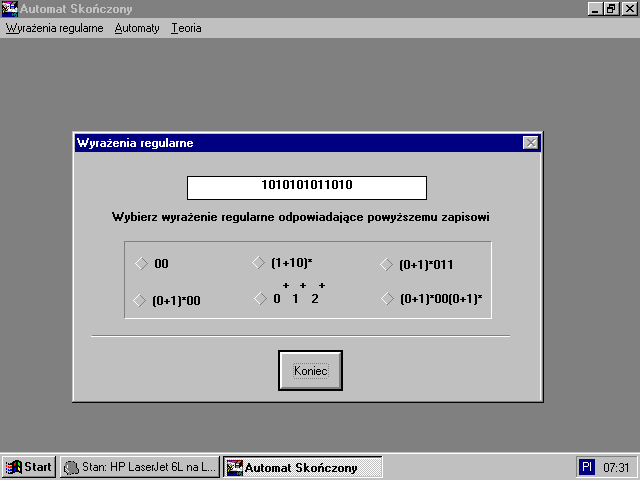
Po wybraniu opcji wyraĆŒenia regularne ukaĆŒe siÄ nastÄpujÄ
ce okienko dialogowe:
Pierwsze trzy zadania sÄ oparte na tej samej zasadzie to znaczy dla podanego ciÄ gu wejĆciowego naleĆŒy wskazaÄ odpowiadajÄ ce temu ciÄ gowi wyraĆŒenie regularne.
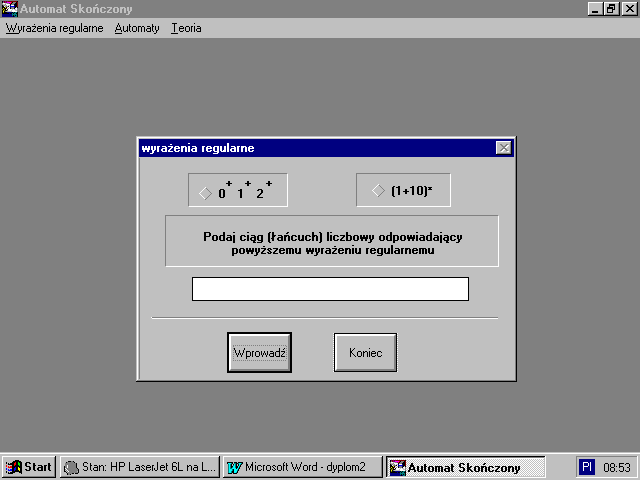
Dwa nastÄpne zadania polegajÄ na wpisaniu odpowiedniego ciÄ gu znakowego dla wybranego wyraĆŒenia regularnego co przedstawia poniĆŒszy rysunek :
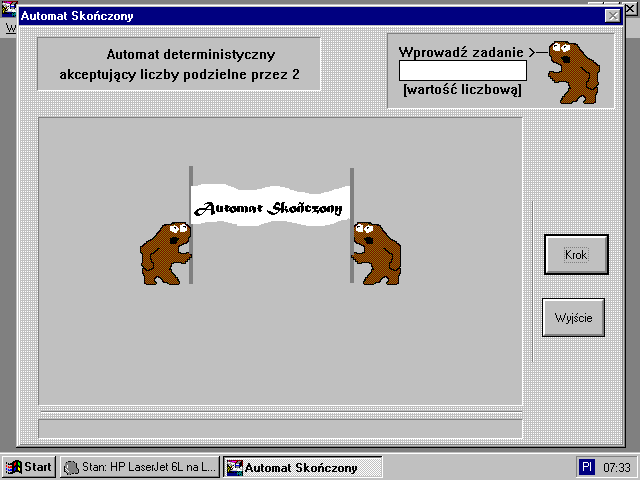
Po wybraniu opcji automaty uĆŒytkownik spotka siÄ z przykĆadowym okienkiem dialogowym w ktĂłrym naleĆŒy podaÄ odpowiedni ciÄ g celem zobrazowania dalszej pracy automatu skoĆczonego.
Przycisk KROK powoduje wczytanie podanego ciÄ gu, a zarazem krokowo przedstawia przejĆcia automatu skoĆczonego pomiÄdzy stanami. Dodatkowo po kaĆŒdym wczytaniu ciÄ gu jest sprawdzana poprawnoĆÄ zadania to znaczy, ĆŒe w przypadku analizy cyfr nie mogÄ zostaÄ wpisane inne znaki i uĆŒytkownik moĆŒe spotkaÄ siÄ z komunikatem o bĆÄdnym wprowadzeniu zadania. Przycisk WYJĆCIE podobnie jak to ma miejsce we wszystkich innych programach powoduje opuszczenie analizy przejĆÄ automatu skoĆczonego.
Po wczytaniu zadania w kolejnym okienku dialogowym zostanie wyrysowany konkretny automat skoĆczony.
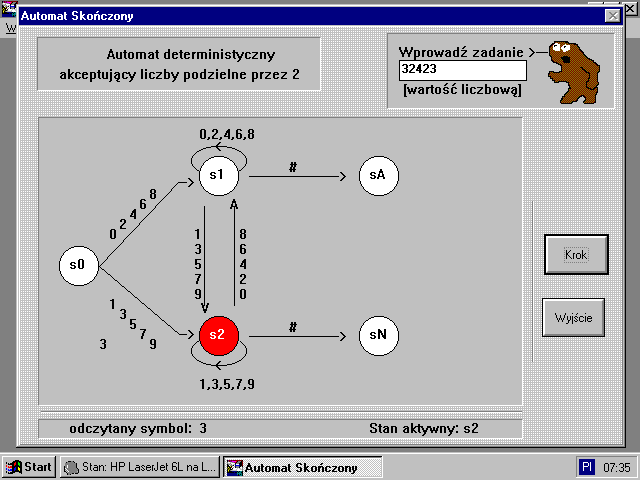
Aktywny stan w jakim siÄ znajduje automat skoĆczony jest zaznaczany kolorem czerwonym, zaĆ stany nieaktywne kolorem biaĆym. Dodatkowo u doĆu ekranu jest wypisywany aktualnie analizowany symbol i aktywny w danej chwili stan automatu.
5.3. MT
Program MT jest programem edukacyjnym do rozdziaĆu trzeciego : „Maszyna Turinga”. Menu programu zostaĆo podzielone na dwie czÄĆci:
Zadania- opcja pozwala na wybranie jednego z piÄciu zadaĆ zwiÄ zanych z maszynÄ Turinga,
Teoria-opcja pozwalajÄ ca na zapoznanie siÄ z podstawowymi wiadomoĆciami teoretycznymi,
Po wybraniu opcji zadania i wyborze konkretnego zadania uĆŒytkownik powinien wpisaÄ odpowiedni ciÄ g do dalszej analizy zadania.
Przycisk KROK pozwala na krokowÄ analizÄ dziaĆania wybranej maszyny Turinga, zaĆ przycisk AUTOMAT w odstÄpach sekundowych symuluje pracÄ maszyny Turinga. Analogicznie jak w pozostaĆych programach przycisk WYJĆÄIE koĆczy pracÄ z wybranÄ maszynÄ Turinga.
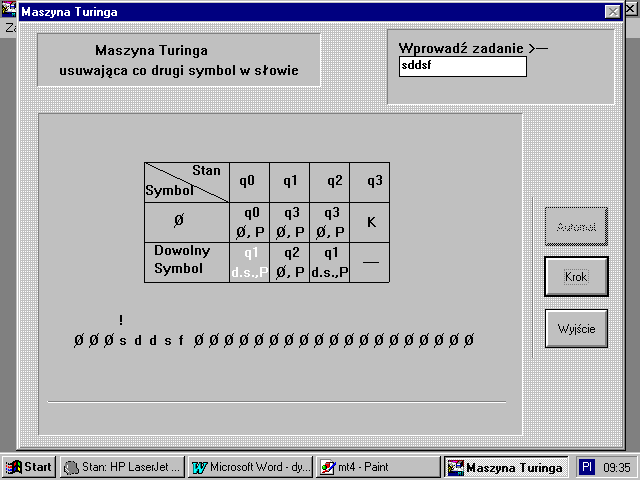
Po wybraniu konkretnego zadania i wpisaniu sĆowa poczÄ tkowego uĆŒytkownik moĆŒe spotkaÄ siÄ z jednym z nastÄpujÄ cych okien dialogowych:
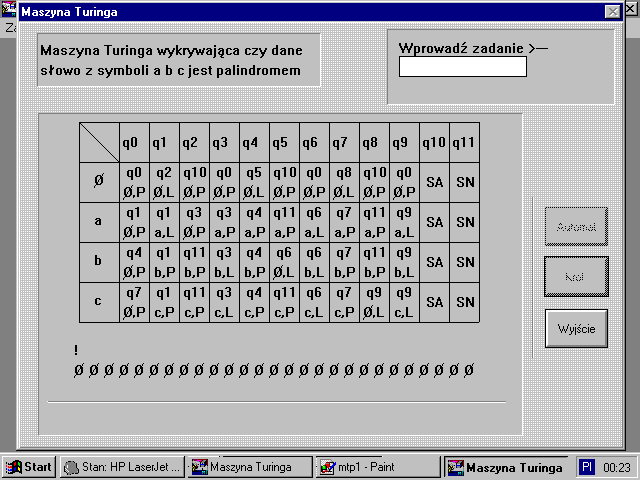
Konstrukcja tego okienka w czÄĆci pierwszej pokazuje tabelÄ przejĆÄ miÄdzy stanami, zaĆ u doĆu okienka symulowana jest taĆma, z umieszczonymi na niej symbolami. Analizowany symbol na taĆmie jest oznaczony znakiem ” ! ” , a w niektĂłrych zadaniach aktywne stany dodatkowo wyrĂłĆŒnione sÄ innym kolorem.
PrzykĆadowe okienka z zadaniami w programie MT
5.4. GR
Program GR jest programem edukacyjnym do rozdziaĆu czwartego : „Gramatyki bezkontekstowe”. Menu programu zostaĆo podzielone na dwie czÄĆci:
Test- opcja pozwala na wybranie okienka dialogowego obsĆugujÄ cego test z zakresu gramatyk formalnych,
Teoria-opcja pozwalajÄ ca na zapoznanie siÄ z podstawowymi wiadomoĆciami teoretycznymi,
PrzykĆadowe ekrany pytaĆ testowych sÄ przedstawione poniĆŒej
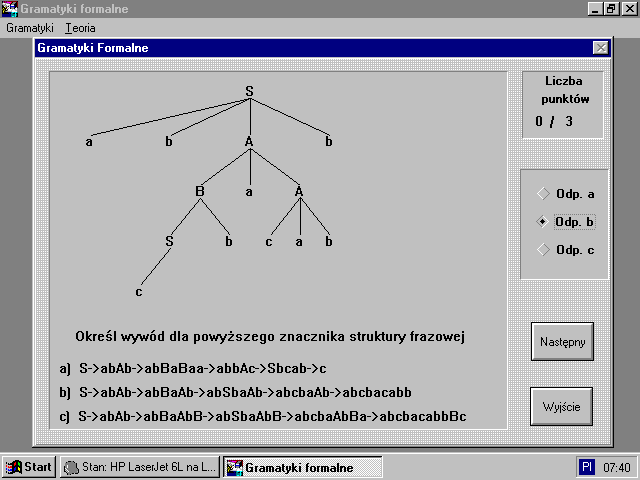
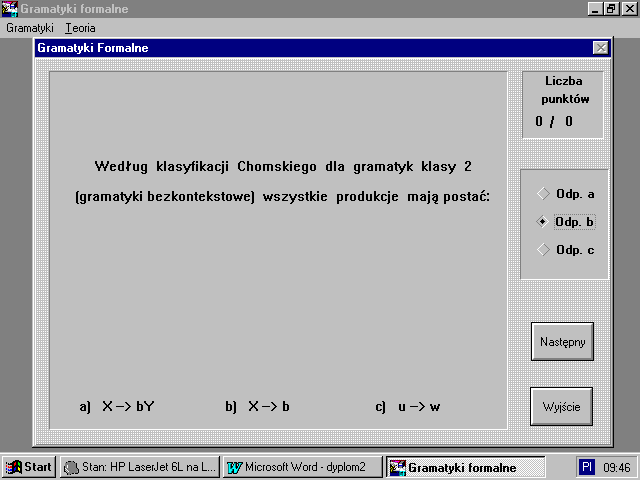
5.5. ZawartoĆÄ dysku CD-ROM
PĆyta kompaktowa doĆÄ czona do pracy posiada nastÄpujÄ cÄ strukturÄ:
..
PROGRAMY
onp.exe
as.exe programy omĂłwione w rozdziale 5
mt.exe
gr.exe
wdihelp.hlp
ZRODLA
ONP
AS pliki ĆșrĂłdĆowe *.cpp, *.rc, *.h,
MT
GR
HLP
DOC
dyplom.doc dokumentacja bez opisu programĂłw - skrypt
dyplom2.doc peĆny tekst pracy magisterskiej
Na dyskietce doĆÄ czonej do pracy znajdujÄ siÄ cztery programy : onp.exe, as.exe, mt.exe, gr.exe oraz plik pomocy dla Widows wdihelp.hlp.
LITERATURA
1. [AĆFI 77] Zoja AĆfierowa: Teoria algorytmĂłw. PWN, Warszawa, 1977.
2. [BANA 96] L. Banachowski, K.Diks, W.Rytter: Algorytmy i struktury danych. WNT, Warszawa, 1996.
3. [GNIĆ 89] Marian GniĆka, Juliusz Haschka: Istota informatyki. IWZZ, Warszawa 1989.
4. [HARE 92] Dawid Harel: Rzecz o istocie informatyki. WNT, Warszawa, 1992.
5. [HOPC 94] John E. Hopcroft, Jefrey D. Ullman :Wprowadzenie do teorii automatĂłw, jÄzykĂłw i obliczeĆ. PWN, Warszawa, 1994.
6. [KOZI 94] StanisĆaw Kozielski: ZbiĂłr zadaĆ z podstaw informatyki. Politechnika ĆlÄ ska-Skrypt uczelniany nr 1842, Gliwice, 1994
7. [MAJC 94] Adam K. Majczak: Praktyczne programowanie w C++. INTERSOFTLAND, Warszawa, 1994.
8. [TURS 77] WĆadysĆaw M.Turski: Propedeutyka informatyki. PWN, Warszawa, 1977.
9. [WRĂB 97] Piotr WrĂłblewski: Programowanie w Windows dla praktykĂłw. Helion, Gliwice, 1997 .
10.[ZALE 95] Andrzej Zalewski: Programowanie w jÄzykach C i C++ z wykorzystaniem pakietu Borland C++. Nakom, PoznaĆ 1995.
65
Wyszukiwarka
Podobne podstrony:
W jaki sposĂłb treĆci programowe zawarte w przedmiocie wprowadzenie do psychologii wykorzystam w swoj
Egzamin z przedmiotu- wprowadzeni do pedagogiki sciagi, Edukacjaprzedszkolna i wczesnoszkolna, Pedag
Zagadnienia na zaliczenie, Wprowadzenie do informatyki
Informatyka Wprowadzenie Do Informatyki Ver 0 95
Podstawowy zestaw pytaĆ z przedmiotu Wprowadzenie do?zy?nych
Wprowadzenie do informatyki
Wprowadzenie do informatyki Poradnik dla ucznia i nauczyciela 2
Wprowadzenie do informatyki Poradnik dla ucznia i nauczyciela wpinpo
Wprowadzenie do informatyki Poradnik dla ucznia i nauczyciela
Wprowadzenie do informatyki Poradnik dla ucznia i nauczyciela wpinpo 2
Wprowadzenie do informatyki Poradnik dla ucznia i nauczyciela wpinpo
wprowadzenie do informatyki poradnik dla ucznia i nauczyciela
Wprowadzenie do informatyki wprinf 2
Wprowadzenie do informatyki 2
Wprowadzenie do informatyki wprinf
ebook Andrzej Kisielewicz Wprowadzenie do informatyki
Wprowadzenie do informatyki wprinf
Wprowadzenie do informatyki Poradnik dla ucznia i nauczyciela
Wprowadzenie do informatyki Poradnik dla ucznia i nauczyciela wpinpo
wiÄcej podobnych podstron