18. Drzewa decyzyjne - co to jest? Jak są generowane?
1) DRZEWA DECYZYJNE
Drzewa decyzyjne stanową podstawową metodę indukcyjnego uczenia się maszyn.
Ta metoda opiera się na analizie przykładów, przy czym każdy przykład musi być opisany przez zestaw atrybutów, gdzie każdy atrybut może przyjmować różne wartości.
Na podstawie tych przykładów, maszyna uczy się jak sklasyfikować nowe przypadki.
Drzewem decyzyjnym jest graf-drzewo, którego korzeń jest tworzony przez wybrany atrybut, natomiast poszczególne gałęzie reprezentują wartości tego atrybutu. Węzły drzewa w następnych poziomach będą przyporządkowane do kolejnym atrybutom, natomiast na najniższym poziomie otrzymujemy węzły charakteryzujące poszczególne klasy-decyzje.
ZALETY:
- Czas decyzyjny ograniczony liniowo przez liczbę atrybutów.
- Forma reprezentacji czytelna dla człowieka.
- Drzewa decyzyjne mogą reprezentować dowolnie złożone pojęcia pojedyncze lub wielokrotne.
WADY:
-Testuje się wartość jednego atrybutu na raz, co powoduje niepotrzebny rozrost drzewa dla danych gdzie poszczególne atrybuty zależą od siebie.
2) Konstruowanie drzewa decyzyjnego
Konstrukcje drzewa na podstawie zbioru przykładów, najprościej przedstawić w postaci algorytmu rekurencyjnego uruchamianego dla każdego węzła w drzewie:
Pierwszym krokiem algorytmu jest podjecie decyzji, czy rozpatrywany węzeł analizując dostępny zestaw atrybutów i klas-decyzji powinien stać się:
albo liściem - spowoduje to utworzenie węzła i zakończenie się tego wywołania algorytmu
albo węzłem-rozgałęzieniem co spowoduje wybór atrybutu według kryterium wyboru atrybutu.
Następnie na podstawie wartości jakich przyjmuje wybrany argument ( z zestawu przykładów) tworzone są kolejne węzły drzewa. Uruchamiany jest rekurencyjnie ten algorytm, jednak dla każdego „rozgałęzienia” podawany jest zestaw atrybutów zmniejszony o aktualnie wybrany atrybut, jak również zestaw przykładów jest zmniejszany o te przykłady, które nie posiadają odpowiedniej wartości wybranego atrybutu dla każdego rozgałęzienia.
W ten sposób są skonstruowane w praktyce wszystkie drzewa decyzyjne. Jedyne różnice polegają na odpowiedniej konstrukcji kryterium stopu i kryterium wyboru atrybutu. Odpowiednia technika wyboru atrybutu ma kluczowy wpływ na wygląd drzewa decyzyjnego.
Kryterium stopu
Sprawdza czy wywołanie rekurencyjne algorytmu tworzącego drzewo należy zakończyć. Określa ono czy dany węzeł drzewa powinien być traktowany jako końcowy liść drzewa (decyzję). Musi on zwrócić wartość etykiety w dwóch przypadkach:
Kiedy w trakcie wywołań rekurencyjnych w zestawie przykładów znajdują się już tylko przykłady opisujące tylko jedną klasę-decyzji.
Kiedy zestaw atrybutów argumentów osiągnie zero wtedy kryterium stopu powinno zgłosić jedną z możliwości:
Błąd, gdyż na podstawie przykładów nie można jednoznacznie ustalić odpowiednią klasę-odpowiedź.
Zwrócić etykietę klasy-decyzji, która najliczniej występuje w zestawie przykładów.
Kryterium wyboru atrybutu
Jest to w zasadzie najważniejsza część algorytmu, to od niej zależy kolejność wyboru atrybutów, a co w znaczącym stopniu wpływa na wygląd drzewa. Poprawny ich dobór gwarantuje nieskomplikowany i czytelny obraz drzewa.
Wybór odpowiedniego atrybutu ze zbioru atrybutów, jest dokonywany dzięki wprowadzeniu systemu ocen.
Wybierając jeden z atrybutów jesteśmy w stanie podzielić zbiór danych przykładów na mniejsze zbiory w zależności od wartości wybranego atrybutu.
Jeden z algorytmów do wyboru atrybutu:
Ocena atrybutów jest wyznaczana na podstawie przyrostów informacji. Informację zawartą w zbiorze etykietowanych przykładów P można wyrazić następująco:
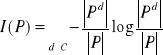
.
Z kolei entropię zbioru przykładów P ze względu na wartość r atrybutu t :
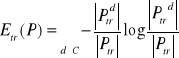
.
Natomiast entropia zbioru przykładów P ze względu na atrybut t :
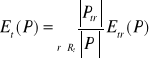
Wartość ta jest duża, gdy wartość atrybutu t dzieli przykłady ze zbioru P na podzbiory, w których, przeciętnie klasy-decyzje są reprezentowane równomiernie. W końcu przyrost informacji definiuje się następująco:
![]()
.
Użycie przyrostu informacji jako kryterium wyboru testu, oznacza obliczenie przyrostu informacji dla wszystkich dostępnych atrybutów przy każdym rekurencyjnym wywołaniu algorytmu i wybraniu atrybutu, dla którego wartość ta będzie maksymalna.
Wyszukiwarka
Podobne podstrony:
Algorytmy i struktury danych Wykład 1 Reprezentacja informacji w komputerze
Algorytmy i struktury danych Wykład 3 i 4 Tablice, rekordy i zbiory
Algorytmy i struktury danych, AiSD C Lista04
Algorytmy i struktury danych 08 Algorytmy geometryczne
Instrukcja IEF Algorytmy i struktury danych lab2
Algorytmy, struktury danych i techniki programowania wydanie 3
Algorytmy i struktury danych 1
Ściaga sortowania, algorytmy i struktury danych
ukl 74xx, Informatyka PWr, Algorytmy i Struktury Danych, Architektura Systemów Komputerowych, Archit
cw 0 1, pwr, informatyka i zarządzanie, Informatyka, algorytmy i struktury danych
AIDS w7listy, studia, Semestr 2, Algorytmy i struktury danych AISD, AIDS
k balinska projektowanie algorytmow i struktur danych
W10seek, studia, Semestr 2, Algorytmy i struktury danych AISD, AIDS
ALS - 001-000 - Zadania - ZAJECIA, Informatyka - uczelnia, WWSI i WAT, wwsi, SEM II, Algorytmy i Str
kolokwium1sciaga, Studia Informatyka 2011, Semestr 2, Algorytmy i struktury danych
Algory i struktury danych 1, NAUKA, algorytmy i struktury danych, WAT
C Algorytmy i struktury danych(1)
więcej podobnych podstron