JĘZYKI PROGRAMOWANIA OBIEKTOWEGO
1. JAVA
Początki języka Java sięgają roku 1990, gdy Bill Joy napisał dokument pod tytułem “Further”, w którym sugerował inżynierom Sun Microsystems stworzenie obiektowego œrodowiska w oparciu o C++. Dokument ten miał pewien wpływ na twórców projektu Green (James Gosling, Patrick Naughton i Mike Sheridan). W roku 1991 w ramach projektu Green opracowano w języku C kompilator oraz interpretator wynalezionego przez Goslinga języka OAK (Object Application Kernel), który miał być narzędziem do oprogramowania “inteligentnych” konsumenckich urządzeń elektronicznych. Ponieważ nazwa “OAK” okazała się zastrzeżona, zmieniono ją na “Java”.
Obecnie należy raczej mówić o œrodowisku Java, na które składa się:
Obiektowy język Java, którego składnia wykazuje znaczne podobieństwo do składni języka C++. Nazwa pliku z programem Ÿródłowym w języku Java, ma postać “nazwa.java”, gdzie “nazwa” musi być nazwą zdefiniowanej w tym pliku klasy. Jeżeli plik “nazwa.java” zawiera definicje wielu klas, a wœród nich jedną klasę publiczną, to “nazwa” musi być nazwą tej klasy publicznej.
Kompilator, który przetwarza program “nazwa.java” na tak zwany B-kod (bytecode, J-code), zapisywany automatycznie w plikach z rozszerzeniem nazwy “.class”. B-kod jest przenoœną postacią programu, która może być zinterpretowana przez odpowiednią maszynę wirtualną, to jest “urządzenie logiczne”, na którym będzie wykonywany program binarny.
Specyfikacja maszyny wirtualnej Java (JVM * Java Virtual Machine). JVM można uważać za abstrakcyjny komputer, który wykonuje programy, zapisane w plikach z rozszerzeniem nazwy “.class”. Maszyna wirtualna może być implementowana na rzeczywistych komputerach na wiele sposobów, na przykład jako interpretator wbudowany w przeglądarkę WWW (np. Netscape), lub jako oddzielny program, który interpretuje pliki “nazwa.class”. Może to być także implementacja polegająca na przekształceniu * tuż przed rozpoczęciem fazy wykonania * pliku z B-kodem na program wykonalny, specyficzny dla danej maszyny. Mechanizm ten można okreœlić jako tworzenie kodu wykonalnego w locie (ang. Just-In-Time, np. kompilator JIT firmy Symantec). Interpretatory B-kodu, tj. różne maszyny wirtualne, są także często napisane w języku Java.
Biblioteka Javy. Œrodowisko języka Java zawiera bogatą bibliotekę, a w niej zbiór składników dla prostego, niezależnego od platformy graficznego interfejsu użytkownika.
Rysunek 1-1 ilustruje usytuowanie œrodowiska programowego języka Java, posadowionego na dowolnej platformie sprzętowo- programowej komputera (platforma sprzętowo-programowa oznacza sprzęt komputera i jego system operacyjny).
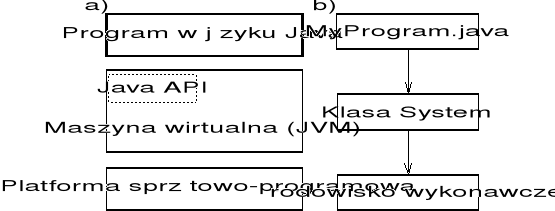
Rys. 1-1. Usytuowanie systemu Java
Pokazany w częœci a) rysunku blok Java API (Application Programming Interface) reprezentuje klasy, interfejsy i obiekty wchodzące w skład aktualnej maszyny wirtualnej, którą zwykle okreœla się jako platformę języka Java (Java Platform). Umożliwiają one programom języka Java dostęp do zasobów komputera. Może to być dostęp (względnie) systemowo niezależny (implementowany przez klasę System w pakiecie JDK) i na dostęp systemowo zależny (implementowany przez klasę Runtime, reprezentującą œrodowisko wykonawcze w pakiecie JDK), jak pokazano w częœci b) rysunku 1-1.
Tak więc programy użytkownika można kompilować na dowolnej platformie sprzętowo-programowej, na której posadowiono kompilator języka Java. Otrzymany w wyniku kompilacji B-kod można traktować jako zbiór instrukcji kodu dla dowolnej implementacji maszyny wirtualnej, jak pokazano na rysunku 1-2.
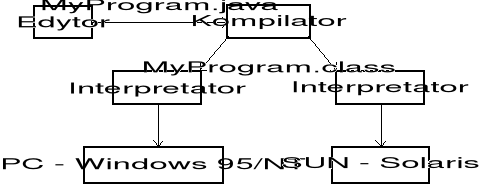
Rys. 1-2. Przetwarzanie programów użytkownika
1.1. Elementarny program: tekst Ÿródłowy, kompilacja, interpretacja
Java wprowadza swoistą terminologię dla swoich konstrukcji syntaktycznych i jednostek (modułów) kompilacji. Programem w języku Java jest aplikacja (application) lub aplet (applet). Aplikacja jest programem samodzielnym, zaœ aplet jest programem wbudowanym (np. w przeglądarkę WWW). Każda aplikacja musi zawierać dokładnie jeden moduł Ÿródłowy nazywany modułem głównym aplikacji zawierającym definicje klas, w którym jedna z klas zawiera publiczną funkcję klasy (funkcje takie są poprzedzane słowem kluczowym static) main. Tekst Ÿródłowy najprostszego programu może mieć postać:
//plik Hello.java
public class Hello {
public static void main(String args[])
{
System.out.print(*Hello, World!\n*);
} //end main
} // end Hello
Dla skompilowania powyższego programu jego tekst Ÿródłowy należy umieœcić w pliku o nazwie Hello.java. Zakładając, że dysponujemy systemem JDK z kompilatorem javac, program skompilujemy poleceniem:
javac Hello.java
Udana kompilacja wygeneruje plik z B-kodem o nazwie Hello.class, zawierający sekwencję instrukcji dla interpretatora JVM. Kod ten wykonujemy przez wywołanie interpretatora o nazwie java poleceniem:
java Hello
Interpretator wyszuka plik o nazwie Hello.class, ustali, czy klasa Hello zawiera publiczną metodę statyczną main i wykona instrukcje zawarte w bloku main. Zauważmy przy okazji, że w języku Java wszystkie stałe, zmienne i funkcje są elementami składowymi klas; nie ma wielkoœci globalnych, definiowanych poza klasą. Ponadto nie deklaruje się metod (funkcji) składowych jako rozwijalnych (inline) bądŸ nie - decyzja należy do kompilatora.
W przykładowym programie do metody main jako parametr jest przekazywana (z wiersza rozkazowego) tablica obiektów (łańcuchów) klasy String; metoda main nie zwraca wyniku (typem zwracanym jest void), zaœ wartoœcią parametru arg[0] jest pierwszy po nazwie programu spójny ciąg znaków. Ciało main zawiera jedną instrukcję
System.out.print(*Hello, World!\n*);
(W języku Java każda instrukcja kończy się œrednikiem, który pełni rolę symbolu terminalnego).
Słowo System jest nazwą klasy w standardowym œrodowisku języka. Klasa System zawiera statyczny obiekt składowy typu PrintStream o nazwie out; wywołanie System.out oznacza pisanie do standardowego strumienia wyjœciowego. Klasa PrintStream zawiera szereg przeciążeń metody o nazwie print; jedno z nich przyjmuje parametr typu String. Kompilator automatycznie tłumaczy literał stały *Hello, World\n* na odpowiedni obiekt klasy String; odnoœnik (referencja) do tego obiektu jest przekazywana do metody System.out.print(). Metoda print() generuje jeden wiersz wyjœciowy i powraca do metody main, która kończy wykonanie.
1.2. Klasy: definicja, dziedziczenie, tworzenie obiektów
Klasę Javy można traktować jako wzorzec i jednoczeœnie generator obiektów. Jako wzorzec klasa zapewnia hermetyzację (zamknięcie w jednej jednostce syntaktycznej) danych i metod oraz ukrywanie informacji, które nie powinny być widoczne dla użytkownika. Jako generator zapewnia tworzenie obiektów za pomocą operatora new, którego argumentem jest konstruktor klasy.
Definicja klasy ma postać:
Deklaracja klasy
{
Ciało klasy
}
Deklaracja klasy składa się w najprostszym przypadku ze słowa kluczowego class i nazwy klasy. Przed słowem kluczowym class może wystąpić jeden ze specyfikatorów: abstract, public, final, lub dwa z nich, np. public abstract, public final. Specyfikator abstract odnosi się do klas abstrakcyjnych, które nie mogą mieć wystąpień, zaœ final deklaruje, że dana klasa nie może mieć podklas. Brak specyfikatora oznacza, że dana klasa jest dostępna tylko dla klas zdefiniowanych w tym samym pakiecie. Specyfikator public mówi, że klasa jest dostępna publicznie. Klasa abstrakcyjna może zawierać metody abstrakcyjne (bez implementacji, poprzedzone słowem kluczowym abstract; w miejscu ciała metody abstrakcyjnej występuje œrednik).
Po nazwie klasy mogą wystąpić frazy: `extends nazwa_superklasy' oraz `implements nazwy_interfejsów'. Fraza `extends nazwa_superklasy' mówi, że klasa dziedziczy (zawsze publicznie) od klasy nazwa_superklasy, zaœ `implements nazwy_interfejsów' deklaruje, że w danej klasie zostaną zdefiniowane metody, zadeklarowane w implementowanych interfejsach. Jeżeli dana klasa implementuje więcej niż jeden interfejs, wtedy nazwy kolejnych interfejsów oddziela się przecinkami.
Podklasa klasy abstrakcyjnej zawierającej metody abstrakcyjne może podawać definicje metod abstrakcyjnych. Podklasa podająca te definicje staje się klasą konkretną, tj. może mieć wystąpienia. Każda klasa, która odziedziczy metodę abstrakcyjną, ale nie dostarczy jej implementacji, sama staje się klasą abstrakcyjną, a jej definicja także musi być poprzedzona słowem kluczowym abstract.
Uwaga. W języku Java każda klasa dziedziczy od predefiniowanej klasy Object. Zatem, jeżeli w definicji klasy nie występuje fraza extends, to jest to równoważne niejawnemu wystąpieniu w tej definicji frazy `extends Object'.
Zauważmy, że oprócz słowa kluczowego class i nazwy klasy wszystkie pozostałe elementy w deklaracji klasy są opcjonalne. Jeżeli nie umieœcimy ich w deklaracji, to kompilator przyjmie domyœnie, że klasa jest niepubliczną, nieabstrakcyjną i niefinalną podklasą predefiniowanej klasy Object.
Ciało klasy jest zamknięte w nawiasy klamrowe i może zawierać zmienne składowe (to jest pola lub zmienne wystąpienia), zmienne klasy (statyczne, tj. poprzedzone słowem kluczowym static), konstruktory i metody oraz funkcje klasy (statyczne). Nazwa każdej zmiennej składowej, zmiennej klasy, metody lub funkcji klasy musi być poprzedzona nazwą typu (np. boolean, double, char, float, int, long, void). Przed nazwą typu może wystąpić jeden ze specyfikatorów dostępu: private (dostęp tylko dla elementów klasy, np. private double d;), protected (dostęp tylko w podklasie, nawet jeœli podklasa należy do innego pakietu; nie dotyczy zmiennych klasy; przynależnoœć klasy do pakietu omówimy za chwilę) lub public (dostęp publiczny). Brak specyfikatora oznacza, że dany element jest dostępny tylko dla klas w tym samym pakiecie. Po specyfikatorze dostępu może wystąpić słowo kluczowe final. Słowo final przed nazwą typu zmiennej wystąpienia lub zmiennej klasy deklaruje jej niemodyfikowalnoœć (np. public static final int i=10;), zaœ w odniesieniu do metody oznacza, że nie może ona być redefiniowana w podklasie (np. public final void f(int i) {/* ... */ }). Lokalne zmienne finalne, które zostały zadeklarowane, ale jeszcze nie zainicjowane, nazywa się blank final.
Dostęp do elementów klasy uzyskuje się za pomocą operatora kropkowego. Jeżeli element danej klasy (zmienna lub metoda) przesłania (overrides) jakiœ element swojej superklasy, to można się do niego odwołać za pomocą słowa kluczowego super, jak w poniższym przykładzie:
class ASillyClass /* Deklaracja klasy */
{
static final int MAX = 100; /** Definicja stałej */
boolean aVariable;/* Deklaracja zmiennej wystąpienia */
static public int x = 10; //Definicja zmiennej klasy
void aMethod() { //Definicja metody
aVariable = true;// Instrukcja przypisania
} // end aMethod
} // end aSillyClass
class ASillerClass extends ASillyClass {
boolean aVariable;
void aMethod() {
aVariable = false;
super.aMethod(); /* Wywołanie metody superklasy */
System.out.println(aVariable);
System.out.println(super.aVariable);
} // end aMethod
} // end ASillerClass
Klasy i omawiane niżej interfejsy są typami referencyjnymi (odnoœnikowymi). Wartoœciami zmiennych tych typów są odnoœniki do wartoœci lub zbiorów wartoœci reprezentowanych przez te zmienne. Np. instrukcja
ASillyClass oob;
jedynie powiadamia kompilator, że będziemy używać zmiennej oob, której typem jest ASillyClass. Do zmiennej oob możemy przypisać dowolny obiekt typu ASillyClass utworzony za pomocą operatora new:
oob = new ASillyClass();
W powyższej instrukcji argumentem operatora new jest generowany przez kompilator konstruktor ASillyClass() klasy ASillyClass, który inicjuje obiekt utworzony przez operator new. Operator new zwraca odnoœnik do tego obiektu, po czym przypisuje go do zmiennej oob.
Jeżeli dana klasa nie zawiera deklaracji konstruktorów, to kompilator dostarcza konstruktor domyœlny z pustym wykazem argumentów, który w swoim bloku wywołuje konstruktor super() jej bezpoœredniej nadklasy. WeŸmy dla ilustracji definicję klasy Point:
public class Point { int x, ,y; }
Jest ona równoważna definicji
public class Point { int x, ,y; public Point() { super(); } }
z niejawnym wywołaniem dostarczanego przez kompilator konstruktora superklasy, od której bezpoœrednio dziedziczy klasa Point.
Podobne, niejawne wywołania konstruktora super() są wykonywane w drzewach dziedziczenia. Rozpatrzmy następujący program:
//plik Super1.java
class Point { int x,y; Point() { x=1;y=2; } }
class CPoint extends Point { public int color = 0xFF00FF; }
public class Super1 {
public static void main(String args[]) {
CPoint cp = new CPoint();
System.out.println(cp.color= + cp.color);
System.out.println(cp.x= + cp.x);
}//end main
}//end Super1
Instrukcja CPoint cp = new CPoint(); tworzy nowe wystąpienie klasy CPoint. Najpierw jest przydzielany obszar w pamięci dla obiektu cp, aby mógł przechowywać wartoœci x oraz y, po czym pola te są inicjowane do wartoœci domyœlnych (tutaj zero dla każdego pola). Następnie jest wołany konstruktor Cpoint(). Ponieważ klasa CPoint nie deklaruje konstruktorów, kompilator automatycznie dostarczy konstruktor o postaci CPoint(){super();}, który wywoła konstruktor klasy Point bez argumentów, tak jakby zamiast super() napisano:
Point(){super();x=1;y=2; },
przy czym teraz super() w bloku konstruktora klasy Point oznaczałoby wywołanie konstruktora klasy Object.
W hierarchii dziedziczenia konstruktor super() może być wywoływany jawnie, jak w przykładzie poniżej:
//plik Super2.java
class Point { int x,y; Point(int x, int y)
{ this.x = x; this.y = y; } }
class CPoint extends Point {
static final int WHITE = 0, BLACK = 1;
int color;
CPoint(int x, int y) { this(x,y,WHITE); }
CPoint(int x, int y, int color) { super(x,y); this.color=color; }
}
public class Super2 {
public static void main(String args[]) {
int a = 10, b = 20;
CPoint cp = new CPoint(a,b);
System.out.println(cp.color= + cp.color);
System.out.println(cp.x= + cp.x);
}//end main
}//end Super2
Zmienna this w definicji konstruktora klasy Point jest odnoœnikiem (referencją), identyfikującym obiekt, na rzecz którego wywołuje się konstruktor. Tak więc lewa strona instrukcji this.x = x identyfikuje pole x obiektu klasy Point, zaœ prawa strona jest wartoœcią argumentu x, którą inicjuje się to pole. Natomiast słowo kluczowe this w definicji dwuargumentowego konstruktora klasy CPoint służy do wywołania konstruktora trójargumentowego tej klasy w instrukcji this(x,y,WHITE).
Zatem w instrukcji CPoint cp = new CPoint(a,b); konstruktor CPoint(int,int) wywołuje ze swojego bloku (instrukcja this(x,y,WHITE);) drugi konstruktor, CPoint(int,int,int), dostarczając mu argument WHITE. Drugi konstruktor woła konstruktor superklasy, przekazuje mu współrzędne x oraz y, a następnie inicjuje pole color wartoœcią WHITE.
Uwaga. instrukcja { this(argumenty); musi być pierwszą instrukcją w ciele konstruktora lub metody; to samo dotyczy instrukcji super(argumenty);.
Dostęp do zmiennych składowych klasy (statycznych) jest możliwy bez tworzenia obiektów tej klasy. Np. dla klasy ASillyClass możemy napisać instrukcję:
System.out.println(ASillyClass.x);.
Gdyby w klasie ASillyClass zdefiniować statyczną funkcję klasy, np.
public static void bMethod(){/*instrukcje */}
to w takiej funkcji nie istnieje odnoœnik this, a zatem żadna z jej instrukcji nie może się bezpoœrednio odwołać do niestatycznej składowej x; odwołanie byłoby możliwe jedynie przez zadeklarowanie zmiennej odnoœnikowej do klasy ASillyClass i zainicjowanie jej odnoœnikiem do utworzonego za pomocą operatora new nowego obiektu, jak pokazano w poniższej sekwencji instrukcji:
ASillyClass ob = new ASillyClass();
System.out.println(ob.x);.
1.3. Interfejsy
Konstrukcja o postaci
interface nazwa {
/* Deklaracje metod i definicje stałych */
}
jest w języku Java typem definiowanym przez użytkownika. Deklaracja metody składa się z sygnatury (sygnatura metody zawiera typ zwracany, nazwę metody i typy argumentów) i terminalnego œrednika. Ponieważ interfejs może zawierać jedynie deklaracje metod i definicje stałych, odpowiada on klasie abstrakcyjnej z zadeklarowanymi publicznymi polami danych i metodami abstrakcyjnymi. Słowo kluczowe interface można poprzedzić specyfikatorem dostępu public; wskazuje to, że taki interfejs może być używany przez dowolna klasę w dowolnym pakiecie. Brak tego specyfikatora oznacza, że dany interfejs może być używany tylko przez te klasy, które są zdefiniowane w tym samym pakiecie. Np. interfejs Sleeper mógłby mieć postać:
public interface Sleeper {
public void wakeUp(); //deklaracja metody
public long ONE_SECOND = 1000; //deklaracja stałej
public long ONE_MINUTE = 60000; //deklaracja stałej
}
Zauważmy, że w deklaracjach stałych nie pisaliœmy słowa kluczowego final przed ich typami. W ogólnoœci w definicji interfejsu wszystkie metody są domyœlnie public i abstract, zaœ stałe są domyœlnie public, static i final. Używanie tych słów kluczowych jako specyfikatorów metod i stałych jest uważane przejaw złego stylu programowania. Ponadto zabrania zabrania się używania specyfikatorów private i protected. Jeżeli pewna klasa implementuje interfejs, dostęp do zadeklarowanej w interfejsie metody lub stałej uzyskuje się za pomocą operatora kropkowego, np. Sleeper.ONE_SECOND.
WeŸmy dla przykładu dwa interfejsy, PlaneLike i BoatLike
interface PlaneLike {
void takeOff();
float kmph();
}
interface BoatLike {
void swim();
float knots();
}
i zdefiniujmy ich implementacje w klasach Plane i Boat, które dziedziczą od wspólnej superklasy Vehicle:
class Vehicle {}
class Plane extends Vehicle implements PlaneLike {
/* Plane must implement kmph(), takeOff() */
public void takeOff() { System.out.println(Plane is taking off); }
public float kmph() { return 600; }
}
class Boat extends Vehicle implements BoatLike {
/* Boat must implement knots(),swim() */
public void swim() { System.out.println(Boat is swimming); }
public float knots() { return 20; }
}
Poprawne będą wówczas deklaracje
Plane biplane = new Plane();
biplane.takeOff();
Boat vessel = new Boat();
vessel.swim();
a także deklaracje
PlaneLike aircraft = new Plane();
aircraft.takeOff();
BoatLike motorboat = new Boat();
motorboat.swim();
Załóżmy teraz, że chcielibyœmy skonstruować klasę SeaPlane, której obiekty powinny się zachowywać w pewnych okolicznoœciach jak pojazdy wodne, zaœ w innych jak pojazdy powietrzne. W języku, który wyposażono w mechanizm dziedziczenia mnogiego (np. C++) klasa SeaPlane miałaby dwie superklasy: Plane i Boat, jak pokazano w częœci a) rysunku 1-3.
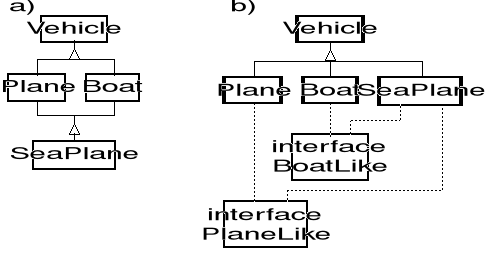
Rys. 1-3. a) Graf dziedziczenia mnogiego dla SeaPlane.
b) Graf dziedziczenia pojedynczego dla SeaPlane
W języku Java podobny efekt można osiągnąć poprzez implementację w klasie SeaPlane obu interfejsów, t.j. PlaneLike i BoatLike (częœć b rysunku 1-3):
class SeaPlane extends Vehicle implements
PlaneLike, Boatlike {
/** SeaPlane must implement kmph(), takeOff(),
knots(), swim() */
}
Dla osiągnięcia pożądanego zachowania się obiektów klasy SeaPlane moglibyœmy umieœcić w głównym module Ÿródłowym Multi1.java następujący kod:
public class Multi1 {
public static void main(String args[])
{
Boat vessel = new Boat();
Plane biplane = new Plane();
System.out.println(Let's starting! );
PlaneLike ref1 = new SeaPlane(biplane);
ref1.takeOff();
System.out.println(ref1.kmph());
BoatLike ref2 = new SeaPlane(vessel);
ref2.swim();
System.out.println(ref2.knots());
}
}
Jednak ze względu na wielokrotną używalnoœć kodu lepszym rozwiązaniem będzie taka definicja klasy SeaPlane, która wykorzystuje mechanizm delegacji, tj. bezpoœredniej współpracy z klasami Plane i Boat:
class SeaPlane extends Vehicle implements
PlaneLike, BoatLike {
// define a Plane and Boat instance variables
// i.e. collaborate with Plane and Boat classes
private Plane itAsPlane;
private Boat itAsBoat;
//Konstruktor
SeaPlane(Plane itAsPlane){ this.itAsPlane=itAsPlane; }
//Konstruktor
SeaPlane(Boat itAsBoat){ this.itAsBoat=itAsBoat; }
// forward the messages to the appropriate collaborator
public float kmph() { return itAsPlane.kmph(); }
public void takeOff() { itAsPlane.takeOff(); }
public float knots() { return itAsBoat.knots(); }
public void swim() { itAsBoat.swim(); }
}
Interfejs nie może dziedziczyć klas, ale może dziedziczyć dowolnie wiele interfejsów. Np. korzystając z podanych wyżej definicji moglibyœmy utworzyć interfejs
interface SeaPlaneLike extends PlaneLike, BoatLike{
public long SPEED_LIMIT = 1000;
}
i wykorzystać go w klasie SeaPlane, implementując metody zadeklarowane w interfejsach PlaneLike i BoatLike. Zauważmy przy okazji, że klasy implementujące dany interfejs mogą traktować zadeklarowane w nim stałe tak, jak gdyby były one odziedziczone.
Przykład hierarchii dziedziczenia interfejsów z biblioteki Javy pokazano na rysunku 1-4.
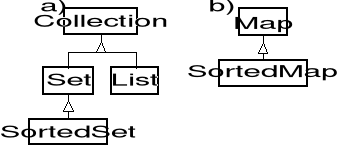
Rys. 1-4. Drzewa dziedziczenia dla interfejsów Collection i Map.
1.4. Pliki Ÿródłowe i pakiety
Program języka Java może się składać z wielu niezależnie kompilowalnych modułów Ÿródłowych, w których umieszcza się definicje klas oraz interfejsów. Moduły Ÿródłowe są przechowywane w plikach o nazwie Nazwa.java, gdzie Nazwa jest nazwą klasy publicznej; pliki te stanowią jednostki kompilacji. Jeżeli w pliku Nazwa.java zdefiniowano tylko jedną klasę, to w wyniku kompilacji tego pliku powstaje plik wynikowy Nazwa.class. Jeżeli program jest aplikacją, to w zestawie modułów Ÿródłowych musi się znaleŸć dokładnie jeden moduł Ÿródłowy (moduł główny aplikacji) z klasą publiczną, która zawiera publiczną i statyczną funkcję main (każdy inny moduł Ÿródłowy może zawierać klasę z funkcją main, jeżeli nie jest to klasa publiczna).
Moduł Ÿródłowy, w którym definicje klas oraz interfejsów poprzedzono deklaracją pakietu o postaci package nazwa_pakietu; staje się pakietem. Deklaracja pakietu rozszerza przestrzeń nazw programu i pozwala na lepsze zarządzanie programem wielomodułowym. Jeżeli moduł Ÿródłowy nie zawiera deklaracji pakietu, to należy on do tzw. pakietu domyœlnego (pakietu bez nazwy). Np. zadeklarowana wczeœniej klasa Hello, umieszczona w pliku Hello.java należy do pakietu domyœlnego.
Pakiety są œciœle powiązane z katalogami, w których umieszcza się moduły Ÿródłowe i pliki wynikowe. Załóżmy np., że w katalogu C:\javaprog (Win'95 DOS) umieszczono główny plik Ÿródłowy aplikacji Student.java, który importuje z katalogu C:\javaprog\myprog\pakiet1 klasy HiGrade oraz LoGrade, umieszczone w plikach HiGrade.java i LoGrade.java. Deklaracje importu mogą mieć postać:
import myprog.pakiet1.HiGrade;
import myprog.pakiet1.LoGrade;
Powyższe dwie deklaracje importu można zastapić jedną:
import myprog.pakiet1.*
public
class Student {
int i = 10;
public static void main(String args[])
{
System.out.println(Hello, I am here!);
HiGrade highgrade = new HiGrade();
highgrade.printgrade();
LoGrade lowgrade = new LoGrade();
lowgrade.printgrade();
}
}
Plik zawiera definicję klasy Student, poprzedzoną deklaracją importu klas HiGrade i LoGrade. Plik ten może zostać skompilowany wywołaniem kompilatora javac z katalogu nadrzędnego w stosunku do katalogu javaprog\myprog\pakiet1; jeżeli plik Student.java umieszczono w katalogu javaprog, to wywołanie będzie miało postać: javac Student.java. Jeżeli pliki HiGrade.java i LoGrade.java mają postać:
package myprog.pakiet1;
public class HiGrade {
int i = 10;
public void printgrade()
{
System.out.println(My grades are higher than + i);
}
}
class Empty{}
oraz
package myprog.pakiet1;
public class LoGrade {
int i = 3;
public void printgrade()
{
System.out.println(My grades are lower than + i);
}
}
to zostaną utworzone cztery pliki wynikowe: “Student.class” w katalogu javaprog oraz “HiGrade.class”, “LoGrade.class” i “Empty.class”, a wywołanie interpretatora java Student spowoduje wyprowadzenie na ekran napisu:
Hello, I am here!
My grades are higher than 10
My grades are lower than 3
Uwaga. Deklaracja importu nie oznacza włączania do pliku Student.java tekstu zawartego w plikach HiGrade.java i LoGrade.java. Natomiast pozwala ona użytkownikowi klasy Student używać skrótowych nazw: np. zamiast pisać myprog\pakiet1\HiGrade highgrade = new javaprog\myprog\pakiet1\HiGrade(); mogliœmy napisać krótko: HiGrade highgrade = new HiGrade();. Gdybyœmy chcieli używać również klasy Empty (lub innych klas pakietu pakiet1), to deklaracja importu miałaby postać: import mike.myprog.pakiet1.*. W języku Java ważna jest także kolejnoœć deklaracji: najpierw deklaracja pakietu, po niej deklaracje importu, po czym definicje klas.
Zauważmy, że gdyby umieœcić w pliku LoGrade.java definicję pakietowej funkcji wystąpienia, na przykład
void msg() { System.out.print(This is a package method\n); }
to funkcję tę można byłoby wywołać z ciała klasy HiGrade, na przykład w funkcji pf:
public void pf() {
LoGrade lg = new LoGrade();
lg.msg();
}
Fukcja pf jest publiczna, zatem jest dostępna nie tylko dla klas pakietu myprog.pakiet1, lecz także poza tym pakietem. Z funkcji main klasy Student można ją, przykładowo, wywołać poleceniem: highgrade.pf();.
Zauważmy też, że deklarując msg w ciele klasy LoGrade jako funkcję klasy (statyczną):
static void msg(){System.out.print(This is a package method\n);}
moglibyœmy ją wywołać z ciała klasy HiGrade bez tworzenia referencji do obiektu klasy LoGrade, np.
public void pf() { LoGrade.msg(); }
1.5. Polimorfizm
Polimorfizm możemy okreœlić jako wirtualizację operacji; jest to możliwoœć dynamicznego (póŸnego, realizowanego w fazie wykonania) wiązania nazwy operacji do wielu implementacji (metod) tej operacji w różnych klasach pozostających w relacji dziedziczenia. Wiązaniu towarzyszy mechanizm wyboru konkretnej implementacji. Wybór implementacji zależy od nazwy metody oraz od typu dynamicznego tego obiektu, dla którego została wywołana operacja, a nie od typu zmiennej, wskazującej ten obiekt.
Zauważmy, że przeciążanie operacji nie prowadzi do polimorfizmu; w tym przypadku wiązanie, dopasowanie parametrów wywołania operacji do okreœlonej sygnatury i wybór implementacji są statyczne, ponieważ są wykonywane w fazie kompilacji. Muszą wówczas istnieć różnice w sygnaturach operacji (w typie wyniku i/lub w typach parametrów wejœciowych), a kryterium wyboru implementacji zależy od tych różnic.
W języku Java wszystkie deklaracje metod, które nie są metodami klasy, ani metodami finalnymi, można traktować jako operacje wirtualne. Tak więc definicja metody o danej sygnaturze w superklasie może być przesłonięta przez definicję metody o tej samej sygnaturze w podklasie. W rezultacie kompilator nie może związać nazwy metody z jej implementacją (istnieją co najmniej dwie implementacje o takich samych sygnaturach). Wiązanie może się odbyć dopiero w fazie wykonania; wówczas interpretator okreœla typ dynamiczny obiektu na którym zostaje wywołana operacja i wiąże tę operację z właœciwą dla danego obiektu implementacją. Ilustrację wywołania polimorficznego pokazuje poniższy prosty przykład.
//Plik Polimorf.java
class Base {
public void msg()
{
System.out.println(Base class method);
}
}
class Derived extends Base {
public void msg()
{
System.out.println(Derived class method);
}
}
public class Polimorf {
int i = 10;
public static void main(String args[])
{
Base b1 = new Base();
b1.msg();
b1 = new Derived();
if(b1 instanceof Derived)
System.out.println(Derived);
b1.msg();
}
}
Metoda msg() ma dwie implementacje: w klasie Base i w klasie Derived. Odnoœnik (referencja) b1 do klasy Base jest najpierw inicjowana obiektem klasy Base, a więc instrukcja b1.msg(); wywoła metodę tej klasy. Następnie odnoœnikowi b1 zostaje przypisany obiekt klasy Derived, co spowoduje, że następna instrukcja b1.msg(); wywoła implementację metody msg() zdefiniowaną w klasie Derived. Instrukcja if wykorzystująca operator instanceof służy do sprawdzenia, jaki jest typ dynamiczny obiektu b1. Wynikiem wykonania programu będzie następujący wydruk:
Base class method
Derived
Derived class method
1.6. Klasy zagnieżdżone
Klasy, jak już powiedziano, mogą należeć do pakietów nazwanych lub nienazwanych. Począwszy od wersji 1.1 języka Java wprowadzono możliwoœć definiowania klas wewnętrznych (inner classes) jako elementów składowych innych klas; można je definiować albo lokalnie wewnątrz ciała klasy zewnętrznej, albo (anonimowo) jako wyrażenie w bloku. Takie zagnieżdżone klasy posiadają kilka własnoœci, które czynią je użytecznymi:
Nazwy klasy wewnętrznej nie można użyć na zewnątrz jej zasięgu, za wyjątkiem nazwy kwalifikowanej. Pomaga to w strukturalizacji klas w obrębie pakietu.
Kod klasy wewnętrznej może wykorzystywać proste nazwy z zasięgów otaczających, w tym zarówno nazwy zmiennych składowych klasy, jak i nazwy zmiennych wystąpienia klas otaczających oraz zmienne lokalne otaczających bloków.
Klasy wewnętrzne są elementami kombinacji struktury blokowej i programowania opartego o klasy; wprowadzono je po raz pierwszy w języku Beta. Wykorzystanie struktury blokowej oraz klas wewnętrznych ułatwia programiœcie wiązać ze sobą obiekty Javy, ponieważ klasy mogą być definiowane w pobliżu obiektów, którymi manipulują, i mogą bezpoœrednio używać nazw, których potrzebują. Ponadto programista może definiować klasę wewnętrzną jako statyczny element dowolnej klasy otaczającej. Jednak klasa wewnętrzna nie może deklarować żadnej ze swoich składowych ze słowem kluczowym static, ponieważ ciało klasy wewnętrznej jest w zasięgu klasy otaczającej. W rezultacie zmienne statyczne dla klasy wewnętrznej muszą być umieszczane w klasie otaczającej. Z tego samego powodu nie można w klasie wewnętrznej deklarować statycznych inicjatorów dla pól klasy.
Klasy zewnętrzne oraz statyczne klasy wewnętrzne nazywa się klasami wysokiego poziomu. Różnią się one od niestatycznych klas wewnętrznych tym, że mogą używać bezpoœrednio jedynie swoje własne zmienne wystąpienia.
Jeżeli klasa wewnętrzna posiada nazwę, może być deklarowana ze słowami kluczowymi private, protected, final, lub abstract. Natomiast klasy anonimowe są prywatne w bloku, w którym są zadeklarowane, ponieważ nie mogą być wykorzystane na zewnątrz tego bloku.
Zagnieżdżanie klas w ten właœnie sposób pozwala dowolnej klasie wysokiego poziomu dla logicznie powiązanych klas poziomu niższego uzyskać podobną do pakietu organizację, w której wszystkie klasy mają pełny dostęp do pól prywatnych.
W podanym niżej przykładzie klasa wewnętrzna została zadeklarowana jako klasa niestatyczna Inner z własnym konstruktorem i własną zmienną składową y.
//Plik Outer1.java
public class Outer1 {
public int x;
public Outer1(int i) { x = i; }
class Inner {
public int y;
public Inner(String s, int j) {
y = j;
System.out.println(s+j);
};
}//end Inner
public static void main(String args[]) {
Outer1 ref1 = new Outer1(10);
System.out.println(ref1.x = + ref1.x);
Outer1.Inner ref2 = ref1.new Inner(ref2.y = , 20);
System.out.println(ref2.y = + ref2.y);
}
}//end Outer1
Wprowadzenie klas zagnieżdżonych nie spowodowało zmian w przetwarzaniu plików z B-kodem przez maszynę wirtualną Javy, tj. przez interpretator, ani w standardowych bibliotekach klas, a nowa cecha języka została uwzględniona w nowych wersjach kompilatorów. Uwzględniono ją w ten sposób, że nazwy klas wewnętrznych są przekształcane tak, aby uniknąć konfliktów z innymi nazwami w różnych zasięgach. Nazwy są kodowane przez kompilator, który bierze ich postać Ÿródłową, kwalifikuje je kropkami, po czym zamienia każdą kropkę po nazwie klasy na znak dolara (`$'). Tak więc po kompilacji pliku Ÿródłowego “Outer1.java” otrzymamy dwa pliki z B-kodem: “Outer1.class” oraz “Outer1$Inner.class”. Oczywiœcie interpretacji poddamy plik “Outer1.class”.
Niestatyczną klasę wewnętrzną wykorzystuje się wtedy, gdy tworzony jest obiekt klasy zewnętrznej; jak pokazano wyżej, argumentem operatora new jest jest konstruktor klasy wewnętrznej, wywoływany na odnoœniku do obiektu klasy zewnętrznej.
Następny przykład ilustruje deklarację statycznej klasy wewnętrznej:
//plik Outer2.java
public class Outer2 {
public int x;
public Outer2(int i) { x = i; }
static class Inner {
public int y;
public Inner(int j) { y = j; };
}//end Inner
public static void main(String args[]) {
Outer2 ref1 = new Outer2(10);
System.out.println(ref1.x = + ref1.x);
Outer2.Inner ref2 = new Outer2.Inner(20);
System.out.println(ref2.y = + ref2.y);
}
}//end Outer2
W tym przypadku argumentem operatora new jest jest konstruktor klasy wewnętrznej, wywoływany na składowej statycznej (Outer2.Inner) klasy zewnętrznej. Kompilator, podobnie jak w poprzednim przykładzie, utworzy dwa pliki z B-kodem: “Outer2.class” oraz “Outer2$Inner.class”.
Jeżeli nie ma potrzeby tworzenia obiektu klasy zewnętrznej, wówczas zarówno klasę wewnętrzną, jak i funkcje składowe klasy zewnętrznej można zadeklarować jako statyczne. Konstrukcje tego typu wykorzystywane są w Javie prawie wszędzie tam, gdzie klasa wewnętrzna implementuje interfejs. Ilustracją tego stwierdzenia jest kolejny przykład.
//Plik Outer3.java
interface InnerInt{
String wyswietl();
}//end of InnerInt interface
public class Outer3 {
public static int x=10;
static class Inner implements InnerInt{
private int y;
public Inner(int j) {
y=j;
System.out.println(wyswietl());
}//end of ctor
public String wyswietl(){
return (new String("Inner.y = "+y));
}
}//end Inner
public static InnerInt foo(int i){
return (new Inner(i));
}
public static void main(String args[]) {
System.out.println(Outer3.x = + Outer3.x);
Outer3.foo(20);
}
}//koniec public class Outer3
W bloku main publiczna, statyczna funkcja foo() klasy zewnętrznej, wywoływana z argumentem 20, zwraca odnoœnik typu interfejsowego InnerInt, inicjowany odnoœnikiem do tworzonego w instrukcji return obiektu klasy Inner. Mogliœmy tak uczynić, ponieważ klasa Inner jest nie tylko odrębnym typem, lecz także implementuje typ InnerInt. W rezultacie kompilator utworzy trzy pliki z B-kodem: “Outer3.class”, “Outer3$Inner.class” oraz “InnerInt.class”.
Ponieważ typ Inner jest wykorzystywany w definicji klasy zewnętrznej tylko jeden raz, można, dla uzyskania bardziej zwięzłego kodu, zrezygnować z wprowadzania jego nazwy do przestrzeni nazw programu, a implementację interfejsu InnerInt umieœcić bezpoœrednio w wyrażeniu new instrukcji powrotu z funkcji foo(). Konstrukcja taka, będąc implementacją interfejsu, jest oczywiœcie klasą; ponieważ jednak nie występuje tutaj nazwa klasy, nazywamy ją klasą anonimową. Poniżej zaprezentowano odpowiedni kod, w którym blok, zaczynający się nawiasem klamrowym po InnerInt() jest ciałem klasy anonimowej, faktycznie identycznym z ciałem klasy Inner z poprzedniego przykładu.
//plik Outer4.java
interface InnerInt{
StringBuffer wyswietl();
}//end InnerInt
public class Outer4 {
public static int x=10;
public static InnerInt foo(final int i) {
return new InnerInt() {
private int y = i;
public StringBuffer wyswietl() {
return (new StringBuffer("Outer4.foo(20).wyswietl()= " +y));
}//end wyswietl()
};//end anonymous
}//end foo
public static void main(String args[]) {
System.out.println(Outer4.x = + Outer4.x);
System.out.println(Outer4.foo(20).wyswietl());
}//end main()
}//end Outer4
Zwróćmy uwagę na ostatnią instrukcję w funkcji main(). Argument metody println() jest wyrażeniem otrzymanym w wyniku wywołania na klasie Outer4 funkcji foo(), która zwraca obiekt typu InnerInt. Na obiekcie tym jest wywoływana funkcja wyswietl(), która zwraca wynik typu StringBuffer, a więc typu akceptowanego przez metodę println().
Zdefiniowana tutaj klasa anonimowa ma następujące własnoœci:
Może mieć inicjatory pól, ale nie może mieć konstruktora.
Jeżeli klasa anonimowa została wyprowadzona z interfejsu I, to faktyczną jej superklasą jest Object, a klasa tylko implementuje interfejs I, bez żadnych rozszerzeń.
Przekształcanie nazw przez kompilator spowoduje teraz utworzenie następujących plików z B-kodem: “Outer4.class”, “Outer4$1.class” oraz “InnerInt.class”. Plik “Outer4$1.class” odpowiada klasie anonimowej. W jego nazwie liczba 1 (numer klasy anonimowej) została dodana przez kompilator dla otrzymania unikatowej nazwy, która zostanie przekazana do konsolidatora.
Istnienie klas zagnieżdżonych wymaga pewnej zmiany w nazwach kwalifikowanych przy definiowaniu zmiennych typu klasy wewnętrznej oraz hierarchii dziedziczenia. Istotne zmiany to:
Inicjowanie zmiennych odnoœnikowych typu klasy wewnętrznej słowem kluczowym this, odpowiadającym bieżącemu obiektowi klasy zewnętrznej.
Kwalifikowanie dziedziczenia od klasy wewnętrznej jej nazwą, umieszczaną po nazwie klasy zewnętrznej i kropce.
Ilustracją tego sposobu kwalifikacji nazw jest podany niżej przykład.
class Vehicle {
class Wheel {
String hubcapType;
float radius;
}//end class Wheel
Wheel leftWheel = this. new Wheel();
Wheel rightWheel = this. new Wheel();
Wheel extra;
static void thirdWheel(Vehicle car) {
if (car.extra == null) {
car.extra = car. new Wheel();
}//end if
}//end thirdWheel()
public static void main(String args[]) {
System.out.println(Vehicle = );
}//end main()
}//end class Vehicle
//Koło ze szprychami
class WireRimWheel extends Vehicle.Wheel {
WireRimWheel(Vehicle car, float wireGauge) {
car. super();
}//end of constructor WireRimWheel()
}//end class WireRimWheel
class Auto extends Vehicle { }
W wyniku kompilacji zostaną utworzone cztery pliki z B-kodem: “Vehicle.class”, “Vehicle$Wheel.class”, “WireRimWheel.class” oraz “Auto.class”.
1.7. Obsługa wyjątków
Wyjątki pozwalają zachować kontrolę nad przebiegiem wykonania funkcji (metod), a także pojedynczych instrukcji zawartych w funkcjach. Wyjątek jest zdarzeniem, które pojawia się podczas wykonania i rozrywa normalną kolejnoœć wykonania instrukcji.
W języku Java istnieje bardzo rozbudowana hierarchia (drzewo) predefiniowanych klas wyjątków, których superklasą jest klasa Throwable, a głównymi gałęziami drzewa są klasy Error i Exception. Częœć wyjątków należy do grupy tzw. wyjątków weryfikowalnych (checked exceptions): kompilator sprawdza, czy program zawiera procedury obsługi dla każdego wyjątku z tej grupy. Natomiast wyjątki klasy Error i jej podklas należą do grupy wyjątków nieweryfikowalnych (unchecked exceptions), ponieważ mogą one wystąpić w wielu punktach programu i powrót z nich jest trudny lub wręcz niemożliwy. Do grupy wyjątków nieweryfikowalnych należą też wyjątki klasy RuntimeException (podklasa Exception) i jej podklas, ponieważ zadeklarowanie w programie takich wyjątków nie mogłoby znacznie pomóc w ustaleniu (przez kompilator) poprawnoœci programów.
Dla obsługi wyjątków weryfikowalnych wprowadzono cztery słowa kluczowe: throw, throws, try, catch i finally. Słowo kluczowe throw służy do jawnego zgłaszania wyjątków nieweryfikowalnych i występuje w instrukcji throw o składni throw wyrażenie; gdzie wyrażenie musi oznaczać zmienną lub wartoœć typu referencyjnego do klasy Throwable lub jej podklas. Zgłoszenie wyjątku w instrukcji throw spowoduje natychmiastowe opuszczenie bloku lub funkcji zawierającego instrukcję throw i wyszukanie instrukcji try, której fraza catch przechwyci zgłoszony wyjątek. Jeżeli nie ma takiej instrukcji try, zostanie wywołana metoda UncaughtException i wykonanie programu (lub wątku) zostanie zakończone.
Fraza:throws klasa_wyjątków może wystąpić w nagłówku funkcji (metodzie wystąpienia, konstruktorze, funkcji klasy), np.
public staic void main(String args[]) throws Exception {/*...*/}
void printNumber(int number) throws WrongNumberException {/*...*/}
Fraza throws klasa_wyjątków oznacza, że dana funkcja może zgłaszać jedynie wyjątki podanej klasy.
Jeżeli wykonanie pewnej instrukcji programu może spowodować powstanie wyjątkowego zdarzenia, to musi ona być ujęta w blok instrukcji try, po którym muszą wystąpić procedury obsługi wyjątku mające postać frazy catch i bezpoœrednio po catch (opcjonalnie) frazy finally. Składnia tej konstrukcji ma postać:
try {I}catch(arg1 e1) {I} catch(arg2 e2) {I} ... catch(argn en) {I} ... finally {I}
gdzie I oznacza instrukcje, arg1 .. argn klasy wyjątków, e1 ... en odnoœniki do tych klas.
Blok catch należy traktować jako ciało procedury obsługi wyjątku należącego do klasy argi.
Jeżeli funkcja/metoda zawiera instrukcję try, to wyjątki mogą być zgłaszane wyłącznie w bloku try. Po zgłoszeniu wyjątku sterowanie opuszcza kod, który zgłosił wyjątek i przechodzi do pierwszej w kolejnoœci procedury catch; jeżeli ta nie obsługuje wyjątku zgłoszonej klasy, jest on przekazywany do następnej. Blok frazy finally (jeœli występuje) jest wykonywany zawsze gdy kończy się wykonanie instrukcji try i to nawet wtedy, gdy wykonanie try zostaje gwałtownie przerwane.
Prosty program, który jedynie ilustruje składnię zgłaszania i obsługi wyjątków może wyglądać następująco:
//plik TestEx.java
import java.io.*;
public class TestEx {
public TestEx() {}
final int CONSTANT = 10;
void ff() throws IOException
{
try
{
System.out.println(I was here, within try statement.);
if(CONSTANT > 0)
throw new IOException(CONSTANT should be negative);
}
catch(IOException exc)
{
System.err.println(Caught IOException: + exc.getMessage());
}
finally
{
System.out.println(And now I am in finally blok);
}
}//end ff
public static void main(String args[]) throws IOException
{
TestEx te = new TestEx();
te.ff();
}//end main
}//end class TestEx
Podany niżej przykład definiuje klasę ListOfNumbers, wywołującą z pakietów Javy dwie metody klas, które mogą zgłosić wyjątki.
import java.io.*;
import java.util.Vector;
public class ListOfNumbers {
private Vector victor;
private static final int size = 10;
public ListOfNumbers () {
victor = new Vector(size);
for (int i = 0; i < size; i++)
victor.addElement(new Integer(i));
}
public void writeList() {
PrintWriter p = null;
try {
System.out.println(Entering try statement);
p = new PrintWriter(new FileOutputStream(OutFile.txt));
for (int i = 0; i < size; i++)
p.println(Value at: + i + = + victor.elementAt(i));
} catch (ArrayIndexOutOfBoundsException e) {
System.err.println(Caught ArrayIndexOutOfBoundsException:
+ e.getMessage());
} catch (IOException e) {
System.err.println(Caught IOException: + e.getMessage());
} finally {
if (p != null) {
System.out.println(Closing PrintWriter);
p.close();
} else {
System.out.println(PrintWriter not open);
}
}
}
public static void main(String args[]) {
ListOfNumbers lst = new ListOfNumbers();
lst.writeList();
}//end main
}//end ListOfNumbers
Konstruktor ListOfNumbers() tworzy obiekt klasy Vector o dziesięciu elementach będących wartoœciami od 0 do 9. W klasie ListOfNumbers zdefiniowano także metodę writeList(), która zapisuje ten ciąg liczb do pliku tekstowego OutFile.txt. Metoda writeList() wywołuje dwie metody, które mogą zgłosić wyjątki:
konstruktor klasy FileOutputStream, który zgłasza IOException jeżeli z jakiegoœ powodu nie może otworzyć pliku:
p = new PrintWriter(new FileOutputStream(OutFile.txt));
metodę elementAt() klasy Vector, która zgłasza wyjątek ArrayIndexOutOfBoundsException jeżeli przekazana do niej wartoœć indeksu jest zbyt mała (liczba ujemna) lub zbyt duża (większa niż liczba elementów zawartych aktualnie w obiekcie klasy Vector).
Instrukcje System.err.println wykorzystują komunikaty generowane przez metodę getMessage klasy Throwable (lub jej podklasę), która podaje dodatkowe informacje o zaistniałym błędzie.
Jeżeli na dysku jest wystarczająco dużo miejsca na zapisanie pliku OutFile.txt, to program założy taki plik z zawartoœcią:
Value at: 0 = 0
...
Value at 9 = 9
oraz wyprowadzi na ekran dwa wiersze tekstu:
Entering try statement
Closing PrintWriter
1.8. Współbieżnoœć
Program Javy jest z reguły wykonywany w obrębie jednego procesu, przebiegającego w pewnej przestrzeni adresowej i rezerwującego pewne zasoby, jak np. wskaŸniki plików. Proces może przebiegać w wielu współbieżnych wątkach (wątkiem nazywa się sekwencyjny przepływ sterowania w procesie, który wykonuje dany program), które współdzielą wszystkie zasoby procesu, ale każdy z nich ma własny stos wykonania. Nawet najprostsza aplikacja, która wyœwietlała napis Hello, World!, miała dwa wątki wykonania: wątek główny (main thread) wykonujący kod tej aplikacji oraz kolektor nieużytków.
Jeżeli maszyna wirtualna jest wieloprocesorowa, wątki mogą być wykonywane współbieżnie; na komputerze jednoprocesorowym współbieżnoœć może być emulowana (np. w systemie Windows'95) przez przydzielanie poszczególnym wątkom pewnej liczby kwantów czasu procesora. W tym drugim przypadku jest realizowana tzw. wielowątkowoœć wywłaszczeniowa (preemptive), która nie dopuszcza do “zagłodzenia” (starving) wątków o niskich priorytetach. Priorytet jest liczbą z przedziału 1..10; jeżeli priorytet nie zostanie ustawiony jawnie (funkcją setPriority klasy Thread), to nowy wątek przejmie priorytet wątku, który go utworzył.
Uwaga. Zagłodzenie może się zdarzyć wtedy, gdy jeden lub więcej wątków w programie jest blokowanych przed dostępem do pewnego zasobu i wskutek tego nie mogą biec dalej. Krańcową postacią zagłodzenia jest zakleszczenie lub impas (deadlock). Impas pojawia się wtedy, gdy dwa lub więcej wątków czeka na warunek, który nie może być spełniony; typowym przykładem jest sytuacja, gdy istnieją dwa wątki i każdy z nich czeka na wykonanie czegoœ przez partnera.
Wykonanie metody start (public synchronized void start()) na rzecz utworzonego wczeœniej obiektu klasy Thread powoduje utworzenie wątku. Przebieg wykonania wątku zależy od implementacji metody run (public void run()), wywoływanej niejawnie przez system tuż po utworzeniu wątku. Zakończenie wykonania metody run() powoduje niejawne wywołanie metody stop (public static final void stop()), która niszczy wątek. Stanami wątków można sterować przez wywołania finalnych metod wystąpienia suspend i resume (zawieszenie i wznowienie wątku zawieszonego), wait i notify (wstrzymanie i uwolnienie wątku wstrzymanego), wywołania finalnych metod synchronizowanych join() i join(long millisec), które powodują wstrzymanie wykonywania wątku aż do zniszczenia go przez inny wątek oraz przez wywołania metod klasy: public static void sleep(long millisec), która powoduje uœpienie wątku na podany okres czasu i public static void yield(), która oddaje dostęp do procesora innemu wątkowi (o ile taki istnieje). Ponadto można wywołać metodę public final boolean isAlive() dla stwierdzenia, czy wątek istnieje.
Uwaga. Ze względu na zdarzające się błędy przy blokowaniu i zwalnianiu zasobów oraz możliwe zakleszczenia wątków w obowiązującej obecnie wersji JDK1.2 nie zaleca się stosowania zdefiniowanych w poprzedniej wersji metod resume(), stop() i stop(Throwable obj). Zachęca się użytkownika do napisania własnych wersji tych metod.
Wątek Javy może być tworzony na dwa sposoby: albo jako obiekt podklasy, która dziedziczy od klasy Thread (klasa java.lang.Thread zawiera metody, które kontrolują i synchronizują poszczególne wątki), albo jako obiekt klasy, która implementuje interfejs Runnable (java.lang.Runnable). W obu przypadkach należy podać implementację metody run() zadeklarowanej w interfejsie Runnable. Pierwszy sposób ilustruje poniższy przykład.
//plik Thread1.java
public class Thread1 extends Object {
public static void main(String args[]) {
Thread x = new MyThread("Fastthread");
Thread y = new MyThread("Slow thread");
x.setPriority(Thread.MAX_PRIORITY);
x.start();
y.start();
}//end main()
}//end Thread1
class MyThread extends Thread {
protected String name = "not initialized";
public MyThread(String nameString)
{ name = nameString; }
public void run() {
for(int i =1;i<=10;i++) {
try {
Thread.currentThread().sleep(300);
}//end try
catch(InterruptedException e) {
} //end catch
System.out.println(name+continues... +i);
}//end for
System.out.println(name+ is DONE!! );
}//end run()
}//end MyThread
W przykładzie utworzono dwa wątki, x i y, przy czym jeden z nich (x )ustawiono na najwyższy osiągalny priorytet. Każdy wątek będzie wykonywany oddzielnie, ale wątek x zakończy działanie wczeœniej. Drugi sposób implementuje interfejs Runnable:
//plik TwoThreads
public class TwoThreads extends Object {
public static void main(String args[]) {
MyClass xx = new MyClass();
MyClass yy = new MyClass();
Thread x = new Thread(xx);
Thread y = new Thread(yy);
x.setPriority(Thread.MAX_PRIORITY);
x.start();
y.start();
}//end main()
}//end TwoThreads
class MyClass implements Runnable {
public void run()
{
for(int I=0;I<=10;I++)
{ System.out.println(Thread progress=+I); }
System.out.println(Thread completed);
}
}
1.9. Synchronizacja wątków
W podanych wyżej przykładach wątki były niezależne i asynchroniczne. Inaczej mówiąc, każdy wątek zawierał wszystkie dane i metody potrzebne dla jego wykonania i nie wymagał żadnych zewnętrznych zasobów lub metod. Ponadto przebieg każdego wątku miał własny rytm, niezależny od stanu, czy aktywnoœci drugiego, biegnącego współbieżnie.
Istnieje jednak wiele sytuacji, gdy oddzielne, współbieżnie wykonywane wątki współdzielą pewne dane i muszą uwzględniać stany i aktywnoœci innych wątków. Powszechnie znanym modelem programistycznym takich sytuacji jest model producent/konsument, w którym producent generuje strumień danych pobieranych następnie przez konsumenta. Przykładem praktycznym może być program, w którym jeden wątek (producent) zapisuje dane do pliku, podczas gdy drugi wątek czyta dane z tego samego pliku. Innym przykładem może być pisanie znaków na klawiaturze: wątek producenta umieszcza naciœnięcia klawisza w kolejce zdarzeń, a wątek konsumenta odczytuje zdarzenia z tej samej kolejki. Jeszcze innym przykładem może być wysyłanie znaków do tego samego strumienia (np. do System.out) z kilku współbieżnie wykonywanych wątków. Widzimy, że podane przykłady wykorzystują współbieżne wątki, które dzielą wspólny zasób: w pierwszym współdzielą plik, w drugim kolejkę zdarzeń, w trzecim ten sam strumień. Ponieważ wątki współdzielą wspólny zasób, muszą być w jakiœ sposób synchronizowane (np. w trzecim przykładzie przy braku synchronizacji łańcuchy znaków pochodzące z różnych Ÿródeł mogą być bezsensownie przemieszane).
Segmenty kodu programu, które żądają dostępu do tego samego obiektu z dwóch oddzielnych, współbieżnych wątków, nazywa się sekcjami krytycznymi. W języku Java sekcją krytyczną może być blok lub metoda; identyfikuje się je słowem kluczowym synchronized.
W przypadku bloku mamy instrukcję synchronized o składni
synchronized ( Wyrażenie ) Blok
w której Wyrażenie musi być typu referencyjnego, a Blok jest instrukcją grupującą, objętą nawiasami klamrowymi.
Instrukcja synchronized przejmuje wzajemnie wykluczającą blokadę na rzecz wykonywanego wątku, wykonuje Blok, po czym zwalnia blokadę. Inaczej mówiąc, wykonanie instrukcji synchronized powoduje przydzielenie wątkowi podanego Bloku jako sekcji krytycznej, a po wykonaniu go na rzecz obiektu identyfikowanego przez Wyrażenie, zwolnienie sekcji.
Ilustracją wykorzystania instrukcji synchronized może być poniższy prosty program:
//plik TestSynchro
class TestSynchro {
public static void main(String[] args) {
TestSynchro t = new TestSynchro();
synchronized(t) {
synchronized(t) {
System.out.println(made it!);
}//end internal synchronized statement
}//end external synchronized statement
}//end main
}//end TestSynchro
który wydrukuje napis
made it!
Jeżeli różne metody korzystają z tego samego zasobu, to również muszą być synchronizowane. Metoda jest synchronizowana jeżeli w jej nagłówku umieszczono słowo kluczowe synchronized. Synchronizowana metoda operująca na obiekcie pewnej klasy automatycznie nakłada blokadę na ten obiekt przed wykonaniem jego ciała (funkcji, metod) i automatycznie zwalnia blokadę przy powrocie, podobnie jak instrukcja synchronized. Tak więc segment kodu
class Test {
int count;
synchronized void bump() { count++; }
static int classCount;
static synchronized void classBump() {
classCount++;
}//end synchronized method
}//end class Test
jest równoważny segmentowi
class BumpTest {
int count;
void bump(){
synchronized (this){
count++;
}//end synchronized statement
}//end bump()
static int classCount;
static void classBump() {
try {
synchronized (Class.forName("BumpTest")) {
classCount++;
}// end synchronized statement
}//end try
catch (ClassNotFoundException e) {
//...
}//end catch
}//end classBump
}//end BumpTest
Wymieniona “blokada” (lock) jest w programie wielowątkowym związana z obiektem, na którym wątek ma wykonywać pewne operacje; jest ona często nazywana monitorem obiektu. Do czasu zwolnienia monitora, zostanie zablokowane wykonanie każdego innego wątku, który podejmie próbę wywołania (na rzecz tego samego obiektu), dowolnej metody sychronizowanej danej klasy.
Zauważmy, że w klasie Test metoda classBump() jest statyczna (jest metodą klasy). Zatem, mimo iż metoda ta jest synchronizowana, może być jednoczeœnie wywoływana na rzecz wielu obiektów, a więc blokada nie będzie efektywna. Dla uniknięcia możliwoœci jednoczesnego wykonywania pewnej operacji na tym samym obiekcie (w szczególnoœci zawierającym metody statyczne) przez dwa różne wątki dobrą praktyką jest definiowanie klas tak, aby były przygotowane na użycie współbieżne, jak ilustruje to poniższy kod:
//plik Box.java
public class Box {
private Object boxContents;
public synchronized Object get() {
Object contents = boxContents;
boxContents = null;
return contents;
}//end get
public synchronized boolean put(Object contents) {
if (boxContents != null)
return false;
boxContents = contents;
return true;
}//end put
}
Każde wystąpienie klasy Box ma pewną zawartoœć zmiennej wystąpienia, która utrzymuje referencję do dowolnego obiektu. W rezultacie można włożyć obiekt do pudełka (Box) wywołaniem metody put(), która zwróci false jeżeli pudełko jest już pełne. Podobnie można wyjąć obiekt z pudełka wywołaniem metody get(), która zwróci null jeżeli pudełko jest puste. Gdyby put() i get() nie były synchronizowane i dwa wątki wykonywałyby te metody na tym samym obiekcie klasy Box w tym samym czasie, wtedy wykonanie programu dwuwątkowego mogłoby przebiegać w sposób przez nas nieoczekiwany.
1.10. Zarządzanie pamięcią
Język Java jest wyposażony w mechanizm zbierania nieużytków (garbage collection). System wykonawczy Javy automatycznie zwraca przydzielony obiektowi obszar pamięci gdy stwierdzi, że do danego obszaru nie odnosi się już żaden odnoœnik. Utrzymywane w zmiennych odnoœniki do obiektów stają się nieaktualne gdy zmienna wychodzi poza swój zasięg, lub też gdy zmienna odnoœnikowa zostaje ustawiona na wartoœć null.
Kolektor nieużytków Javy periodycznie zwalnia pamięć zajmowaną przez obiekty, wykorzystując algorytm znakowanie-wymiatanie (compacting mark-sweep with conservative scanning). Przeszukuje on pamięć dynamiczną idąc po wszystkich œcieżkach do obiektów, znakuje wszystkie obiekty, do których istnieją jeszcze odnoœniki, po czym usuwa wszystkie obiekty nieoznakowane.
Zbieranie nieużytków przebiega w wątku o niskim priorytecie; kolektor jest wykonywany albo synchronicznie, albo asynchronicznie, zależnie od sytuacji i systemu, na którym jest posadowiona maszyna wirtualna. Przebieg zbierania jest synchroniczny, gdy brakuje pamięci lub w odpowiedzi na żądanie z programu; asynchroniczny, gdy system nie wykonuje żadnych działań na rzecz programu. Ta druga sytuacja ma miejsce np. dla Windows 95/NT, który pozwala œrodowisku wykonawczemu Javy okreœlić, kiedy rozpoczął się kolejny wątek i przerwać inny wątek.
Przed zebraniem danego obiektu jako nieużytku, system wykonawczy wywołuje dla niego (niejawnie) metodę finalize() jego klasy, aby zwolnić przydzielone mu zasoby, np. otwarte pliki lub gniazda. Proces ten nazywa się finalizacją obiektu. Użytkownik może wymusić jawną finalizację obiektów, wywołując metodę System.runFinalization(), która niejawnie wywoła metody finalize() na rzecz wszystkich obiektów, oczekujących na zebranie przez kolektor. Jawna finalizacja wymaga przesłonięcia w klasach tych obiektów metody finalize(), dziedziczonej niejawnie z klasy Object.
Użytkownik może również jawnie uruchomić kolektor nieużytków, wywołując metodę gc() klasy System (z pakietu java.lang): System.gc(); w takim momencie przebiegu programu, w którym uważa to za niezbędne, np. gdy następne instrukcje programu będą wymagać dużych zasobów pamięci.
Wywołanie System.gc() jest funkcjonalnie równoważne wywołaniu Runtime.getRuntime().gc(), gdzie funkcja getRuntime() klasy Runtime (pakiet java.lang.Runtime) zwraca obiekt, skojarzony z bieżącą aplikacją. W takim przypadku wywołanie metody gc() powinno być poprzedzone jawną finalizacją, przy czym należy pamiętać, że każde wywołanie kolektora nieużytków będzie miało niekorzystny wpływ na szybkoœć wykonania programu.
1.11. Obiekty sieciowe
Komputery w sieci Internet komunikują się ze sobą albo poprzez TCP (Transport Control Protocol) albo poprzez User Datagram Protocol (UDP).
Uwaga. Nazwą TCP okreœla się zwykle protokół (zbiór zasad według których odbywa się komunikacja w sieci komputerowej); TCP/IP (gdzie IP jest akronimem od Internet Protocol) jest warstwowym zestawem protokołów i odpowiada siedmiowarstwowemu modelowi ISO/OSI (Open Systems Interconnection) z warstwami: fizyczną(1), łącza danych(2), sieciową(3), transportową(4), sesji(5), prezentacji(6) i aplikacji(7). Np. Protokół IP jest implementacją warstwy (3), zaœ TCP i UDP implementują warstwę (4) modelu ISO/OSI, jak pokazano w tablicy 1.1.
Tablica 1.1 Zależnoœć pomiędzy modelem ISO/OSI a TCP/IP
Warstwa
ISO/OSI
TCP/IP
7
Aplikacji
Aplikacji: SMTP, HTTP, FTP, RPC, TELNET,
6
Prezentacji
RLOGIN, inne usługi
5
Sesji
DNS, LDAP
4
Transportowa
Transportowa: TCP/UDP, IGMP
3
Sieciowa
Międzysieciowa: IP, ICMP, protokoły rutingu
2
Łącza danych
Interfejs sieciowy: ARP, RARP, LLC 802.2, Ethernet 802.3
1
Fizyczna
Fizyczna dla różnych mediów
Pisząc program “sieciowy” w języku Java nie musimy deklarować, czy żądamy komunikacji via TCP czy UDP, ponieważ zdefiniowane w pakiecie java.net klasy dostarczają œrodki dla niezależnej od systemu komunikacji w sieci; klasy URL, URLConnection, Socket i ServerSocket korzystają z TCP, a klasy DatagramPacket, DatagramSocket i MulticastSocket korzystają z UDP.
Tym niemniej warto pamiętać, że powszechnie używane protokoły: Telnet i wirtualnego terminala odpowiadają warstwie 5 i częœciowo 6, zaœ FTP (File Transfer Protocol) odpowiada warstwom 6 i 7 modelu ISO/OSI. Zauważmy też, że HTTP (Hypertext Transfer Protocol), jest aplikacją (warstwa (7) modelu ISO/OSI. Gdy używamy HTTP do czytania z pewnego lokalizatora URL (Uniform Resource Locator) danych z pliku w formacie HTML (HyperText Markup Language), otrzymywane dane muszą wystąpić w tej samej kolejnoœci, w której były przesyłane, co wymaga niezawodnego kanału komunikacji punkt-punkt, jaki zapewnia protokół połączeniowy TCP. Z kolei UDP, bezpołączeniowy protokół przesyłania niezależnych pakietów danych (datagramów) pomiędzy dwoma aplikacjami w sieci, jest wystarczający dla takich aplikacji, jak np. program ping, czy też programu podającego aktualny czas.
Komputery w sieci są identyfikowane przez 32-bitowe adresy IP, zaœ biegnące na danym komputerze sieciowym procesy - poprzez 16-bitowe numery portów (port można uważać za utrzymywaną przez system kolejkę danych, które mają być dostarczane do danego procesu wykonującego pewien program). Na przykład programowi wykorzystującemu protokół HTTP przydziela się zwyczajowo port o numerze 80.
Programy odbierają lub wysyłają dane poprzez wiązane z numerami portów gniazda (sockets). Gniazdo, definiowane przez warstwę transportową modelu ISO/OSI, reprezentuje punkt końcowy połączenia pomiędzy programami wykonywanymi na komputerach sieciowych w systemie dostawca-odbiorca (klient-server); jest to interfejs programowy umożliwiający aplikacjom dostęp do protokołów TCP i UDP i wymianę danych poprzez sieć pracującą pod kontrolą protokołów TCP/IP. Program serwera wykonywany na konkretnej maszynie ma przypisane do pewnego numeru portu gniazdo, poprzez które “nasłuchuje” ewentualnego żądania nawiązania łącznoœci przez klienta. Jeżeli klient zna adres komputera sieciowego, na którym jest wykonywany serwer oraz numer portu, do którego serwer jest dołączony, to może przesłać takie żądanie. Serwer akceptuje połączenie, a następnie tworzy dla klienta nowe gniazdo, związane z innym numerem portu, ponieważ na pierwotnym gnieŸdzie musi nadal prowadzić “nasłuch” żądań połączenia. Po stronie klienta, gdy uzyska potwierdzenie połączenia, tworzone jest odpowiednie gniazdo (związane z lokalnym numerem portu na maszynie klienta), poprzez które może prowadzić komunikację z serwerem.
W pakiecie java.net klasy Socket i ServerSocket służą do komunikacji w oparciu o protokół połączeniowy TCP, zaœ klasy DatagramSocket, DatagramPacket oraz MulticastSocket są wykorzystywane do komunikacji UDP. Klasy: URL oraz URLConnection i URLEncoder służą do nawiązania łącznoœci z World Wide Web (WWW). Komunikacja, która wykorzystuje te klasy, reprezentuje wyższy poziom abstrakcji, ponieważ korzystają one między innymi z implementacji gniazd.
Poniżej pokazano przykład aplikacji, która wykorzystuje klasy URL i URLConnection dla dostępu do zasobu sieciowego (pliku tekstowego “abc”) WWW zlokalizowanego pod adresem www.task.gda.pl/java/.
//plik URLTest.java
import java.net.*;
import java.io.*;
//import java.util.*;
public class URLTest {
public static void main(String[] args) {
URL url;
try {
url = new URL("http://www.task.gda.pl/java/abc");
URLConnection uc = url.openConnection();
BufferedReader d = new BufferedReader(new
InputStreamReader(uc.getInputStream()));
//DataInputStream dis = new
//DataInputStream(uc.getInputStream());
String line = d.readLine();
System.out.println(line);
}//end try
catch (Exception e) { e.printStackTrace(); }
}// end main
}// end URLTest
W programie wykorzystano konstruktor URL(String). Klasa URL jest wyposażona w cztery publiczne konstruktory:
public URL(String spec) throws MalformedURLException - tworzy obiekt URL z podanej reprezentacji obiektu klasy String, lub zgłasza wyjątek, jeżeli łańcuch “spec” podaje nieznany protokół. Dla danego protokołu (http, file, ftp) jest przyjmowany domyœlny numer portu. Numer portu można też podać jawnie, np. http://www.task.gda.pl:80/java/abc.
public URL(URL context, String spec) throws MalformedURLException - tworzy obiekt URL przez parsing (wydzielenie) specyfikacji “spec” w obrębie zadanego kontekstu.
public URL(String protocol, String host, int port, String file) throws MalformedURLException - tworzy obiekt URL z podanego protokołu, nazwy komputera, numeru portu i nazwy pliku.
public URL(String protocol, String host, String file) throws MalformedURLException - tworzy absolutny obiekt URL z podanego protokołu, nazwy komputera i nazwy pliku; przyjmuje port domyœlny dla danego protokołu.
1.12. Aplety - programy Javy na stronach WWW.
Aplet jest niewielkim programem Javy przeznaczonym do uruchamiania w obrębie innej aplikacji - przeglądarki WWW lub Java Applet Viewer. Najprostszy aplet drukujący jedno zdanie na ekranie może mieć następującą postać:
Plik HelloWorld.java
import java.applet.*;
import java.awt.*;
public class HelloWorld extends Applet {
public void init() {
add(new Label("Hello World!"));
}
}
Podobnie jak aplikację, kompilujemy aplet poleceniem:
javac HelloWorld.java
w wyniku czego otrzymamy plik ze skompilowaną klasą o nazwie HelloWorld.class.
Następnie tworzymy prostą stronę HTML zawierającą znacznik <applet> wywołujący aplet Javy i otwieramy tę stronę przeglądarką WWW.
HelloWorld.html
<html>
<head>
<title>HelloWorld</title>
</head>
<body>
<h1>Aplet HelloWorld</h1>
<applet code=HelloWorld.class width=200 height=50>
</applet>
</body>
</html>
Wynik działania apletu możemy również obejrzeć używając przeglądarki apletów dostarczanej przez Suna razem ze œrodowiskiem JDK:
appletviewer HelloWorld.html
Każdy aplet tworzony jest jako podklasa klasy java.applet.Applet, dostarczającej interfejs do œrodowiska, w obrębie którego jest on uruchamiany.
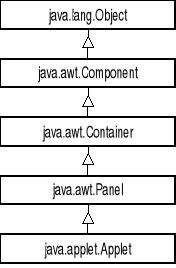
Rys. 1-5. Hierarchia dziedziczenia dla klasy Applet.
W cyklu życia apletu występują cztery istotne zdarzenia. Gdy wystąpią, wywoływane są odpowiednie metody klasy Applet, które mogą być przesłonięte przez metody zdefiniowane w jej podklasie, jak w poniższym przykładzie:
public class MyApplet extends Applet {
. . .
public void init() { . . . }
public void start() { . . . }
public void stop() { . . . }
public void destroy() { . . . }
. . .
}
Metody te są wywoływane przez œrodowisko, w którym uruchamiany jest aplet, w momentach wystąpienia następujących zdarzeń:
init - po załadowaniu apletu (lub jego przeładowaniu) w celu jego zainicjowania,
start - w momencie uruchamiania apletu, po jego załadowaniu lub po ponownym odwiedzeniu strony zawierającej aplet,
stop - w momencie zatrzymywania pracy apletu, gdy opuszczana jest strona lub następuje wyjœcie z przeglądarki,
destroy - przed wyjœciem z przeglądarki.
Cykl życia apletu prezentuje rysunek 1-6.
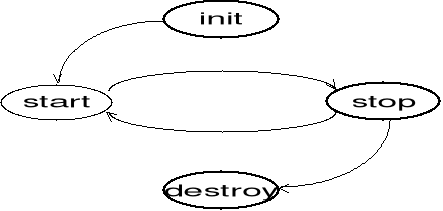
Rys. 1-6. Cykl życia apletu.
Aplet nie musi przesłaniać wszystkich z tych metod, może tylko niektóre albo żadnej. W metodzie init powinno się zamieszczać kod, który normalnie powinien być zawarty w konstruktorze klasy. Jednak w momencie wykonywania konstruktora klasy apletu nie ma gwarancji, że jest już zdefiniowane całe jego œrodowisko. Dlatego takie zadania jak na przykład utworzenie wątków apletu czy jednokrotne załadowanie obrazów wykorzystywanych przez aplet powinny być zawarte właœnie w metodzie init. W metodach start i stop można na przykład odpowiednio uruchamiać i zatrzymywać animację tak, żeby w czasie gdy użytkownik nie ogląda strony z apletem niepotrzebnie nie zużywać zasobów komputera.
Aplet dziedziczy metody interfejsu użytkownika z nadrzędnych klas AWT (Abstract Window Toolkit) Component, Container i Panel.
Z klasy Component dziedziczy metody paint i update, które odpowiadają za graficzną reprezentację apletu na stronie przeglądarki. Metody te aplet może przesłonić:
class MyApplet extends Applet {
. . .
public void paint(Graphics g) { . . . }
. . .
}
Aplet jest podklasą klasy Container, może więc zawierać inne obiekty klasy Component, takie jak klawisze, etykiety, listy wyboru itd. Jak w innych obiektach klasy Container, wzajemne rozłożenie komponentów kontrolowane jest poprzez klasę LayoutManager.
Z klasy Component aplet dziedziczy również metody obsługi zdarzeń. Zdarzenia są generowane głównie przez komponenty interfejsu graficznego użytkownika. Komponenty będące Ÿródłem zdarzeń rejestrują jedną lub więcej klas delegowanych do obsługi zdarzenia:
someComponent.addActionListener(instanceOfMyClass);
W deklaracji klasy obsługującej zadarzenie specyfikujemy, że implementuje ona przynajmniej jeden z interfejsów pochodnych od EventListener (np. ActionListener, MouseListener, KeyListener, WindowListener itd.), np.
public class MyClass implements ActionListener
a w jej definicji implementujemy metodę obsługującą zdarzenie:
public void actionPerformed(ActionEvent e) {
... // kod reagujący na zdarzenie typu ActionEvent
}
Każde Ÿródło zdarzeń może mieć wiele klas delegowanych do jego obsługi. Jedna klasa może też obsługiwać wiele różnych Ÿródeł zdarzeń.
Aplety są uruchamiane w œrodowisku przeglądarki, która narzuca im pewne ograniczenia związane z zachowaniem bezpieczeństwa. Różnią się one nieco pomiędzy różnymi przeglądarkami. Aplet œciągnięty do przeglądarki poprzez sieć:
nie może czytać i pisać do plików znajdujących się na komputerze, który go wykonuje,
nie może tworzyć połączeń sieciowych do komputerów innych niż ten, z którego został œciągnięty,
nie może uruchamiać żadnych programów na komputerze, który go wykonuje,
może czytać tylko wybrane parametry systemowe,
nie może ładować bibliotek ani definiować metod w kodzie maszynowym.
Ograniczeniem (choć nie związanym z bezpieczeństwem) jest również graficzny interfejs użytkownika apletu. Aplet może przedstawiać swoją reprezentację graficzną tylko w obrębie prostokąta na stronie WWW o z góry zadanych wymiarach, bądŸ w postaci generowanych okienek, które różnią się od tych generowanych przez aplikacje.
Pliki składające się na aplet: klasy, pliki z grafikami, dŸwiękami i inne pliki pomocnicze mogą być połączone w jeden plik o formacie Java Archive (JAR), co pozwala uzyskać wiele korzyœci:
bezpieczeństwo - zawartoœć pliku JAR można podpisać cyfrowo; dzięki temu mogą być złagodzone niektóre z wczeœniej wymienionych ograniczeń związane z dostępem do lokalnych zasobów dyskowych oraz z pełnym dostępem do sieci,
skrócenie czasu ładowania - cały aplet może œciągnięty przez przeglądarkę w jednej transakcji HTTP bez koniecznoœci otwierania nowego połączenia dla każdego pliku,
kompresja - pliki są kompresowane zgodnie z formatem ZIP.
Do obsługi plików JAR służy standardowe narzędzie jar zawarte w pakiecie JDK. Sposób jego użycia, analogiczny do programu tar z systemu Unix, prezentuje tablica 1.2
Tablica 1.2 Kompresja i dekompresja plików w formacie JAR
Operacja
Polecenie
Tworzenie pliku JAR
Jar cf jar-file input-file(s)
Oglądanie zawartoœci pliku JAR
Jar tf jar-file
Rozpakowywanie pliku JAR
Jar xf jar-file
Uruchamianie apletu spakowanego w postaci pliku JAR
<applet
code=AppletClassName.class
archive="JarFileName.jar"
width=width height=height>
</applet>
Uwaga. Internet Explorer używa własnego standardu kompresji - CAB. Netscape Communicator obsługuje format JAR.
“ożywienie” WWW - swego rodzaju “lingua franca” Internetu
język pozwala łatwo pisać aplikacje sieciowe
przenoœnoœć - niezależnoœć od platformy dzięki JVM; Java poprzez swój B-kod staje się najbliższą aproksymacją (zbudowaną raczaej z software niż z hardware, chociaż anonsowane są już “Java chips”) jednego z najstarszych marzeń przemysłu komputerowego: prawdziwie uniwersalna maszyna wirtualna
prawie czysta implementacja paradygmatu obiektowego
usunięcie arbitralnego pojęcia wskaŸnika jak w C++
wsparcie dla zbierania nieużytków
brak samodzielnych (tj. definiowanych poza klasami) funkcji zewnętrznych
weryfikacja kodu w fazie kompilacji i w fazie wykonania na zgodnoœć ze standardem języka
dynamiczne ładowanie klas (w locie)
biblioteki klas dla GUI, sieciowe i WWW
Wady:
Brak definiowanych przez użytkownika przeciążonych operatorów
złamanie zasad obiektowoœci w standardowych bibliotekach klas: w klasach opakowań (kopertowych), w klasach kolekcji i w klasach łańcuchów
Komunikaty są rzadko polimorficzne i rzadko trafiają na oczekiwaną strukturę dziedziczenia
brak klas parametryzowanych (genericity, templates)
dziedziczenie tylko pojedyncze
usunięcie instrukcji assert znanej w C i C++
niejednolita struktura modularna z kilkoma wpływającymi wzajemnie na siebie koncepcjami (klasy, klasy zagnieżdżone, pakiety, pakiety zagnieżdżone, pliki Ÿródłowe).
Znacznik <applet> na stronie HTML może mieć więcej parametrów niż podane wczeœniej w prostym przykładzie. Bardziej złożone wywołanie może mieć następującą postać:
<applet code=AppletSubclass.class codebase=”directory/”
width=anInt height=anInt align=left>
<param name=parameter1Name value=aValue>
<param name=parameter2Name value=anotherValue>
Wymagana jest przeglądarka obsługująca aplety Javy!
</applet>
Domyœlnie przeglądarka szuka klas apletu oraz plików skompresowanych w tym samym katalogu, z którego został œciągnięty plik HTML zawierający znacznik <applet>. Można jednak wskazać inne miejsce podając parametr codebase. Wartoœcią parametru może być œcieżka względna wobec strony HTML, œcieżka bezwzględna lub w ogólnoœci dowolny URL. Klasy apletu mogą więc być œciągane z innego serwera niż strona HTML. Opcje width i height okreœlają rozmiary prostokąta na stronie przeglądarki, w obrębie którego wizualizowany jest aplet. Opcja align okreœla położenie apletu, podobnie jak dla znacznika <img>: left, right, top, texttop, middle, absmiddle, baseline, bottom, absbottom. Do apletu można przekazywać parametry definiując znaczniki <param> w obrębie znacznika <applet>. Wartoœci tych parametrów można następnie odczytywać w kodzie apletu wywołując metodę klasy Applet
public String getParameter(String name)
Opcjonalny tekst “Wymagana jest przeglądarka obsługująca aplety Javy!” w obrębie znacznika <applet> jest pisany w okienku przeglądarki, gdy ta nie potrafi obsługiwać Javy lub obsługa została wyłączona.
Kod apletu wykonywany jest przez maszynę wirtualną Javy zaimplementowaną w przeglądarce. Jednym ze stałych niedomagań tego modelu dystrybucji kodu jest to, że wersje Javy wspierane przez przeglądarki nie nadążają za najnowszymi wersjami wprowadzanymi przez firmę Sun. Aby częœciowo rozwiązać ten problem Sun opracował moduł rozszerzający (ang. plug-in) przeglądarki (obecnie tylko dla Netscape Navigator i Internet Explorer pod Windows), który zapewnia wykorzystanie najnowszej wersji bibliotek języka Java. Na skutek niejednolitego sposobu wywołania takiego modułu ze strony HTML i jego złożonej postaci najwygodniej jest skorzystać z programu HTMLConverter, który zamienia wystąpienia znacznika <applet> na odpowiadający mu kod wywołujący moduł rozszerzający Javy.
1.13. Standardowe klasy Javy.
W skład JDK 1.2 wchodzą następujące pakiety: java.applet, java.awt, java.beans, java.io, java.lang, java.math, java.net, java.rmi, java.security, java.sql, java.text, java.util, javax.accessibility, javax.swing, org.omg. Zostaną one omówione pokrótce, najpierw te najczęœciej wykorzystywane.
W pakiecie java.lang zdefiniowana jest klasa Object, która jest klasą nadrzędną wobec wszystkich innych klas Javy.
Pakiet zawiera także klasy opakowujące (kopertowe) zmienne podstawowych typów języka Java takie jak Boolean, Byte, Integer, Long, Double, Character itd., definiując użyteczne metody operujące na zmiennych tych typów, metody konwersji pomiędzy typami, zamianę na łańcuchy znaków i inne.
Klasa Math zawiera metody wykonujące podstawowe operacje numeryczne takie jak funkcje eksponencjalne, logarytmiczne, trygonometryczne.
W pakiecie tym zawarte są dwie klasy obsługujące łańcuchy znaków: String i StringBuffer. Klasa String używana jest do przechowywania i wykonywania operacji na stałych łańcuchach; po utworzeniu obiektu tej klasy nie można zmienić jego wartoœci. Klasa ta zawiera metody do sprawdzania poszczególnych znaków, porównywania łańcuchów, wyodrębniania podłańcuchów, tworzenia kopii z zamianą na małe albo duże litery. Klasa StringBuffer implementuje łańcuchy znaków, które mogą być zmieniane. Podstawowe metody tej klasy to append dodająca znaki na końcu bufora i insert wstawiająca znaki w okreœlonym miejscu. Każdy obiekt przydziela bufor na przechowywany łańcuch znaków. Jeżeli całkowita długoœć łańcucha wzroœnie powyżej rozmiaru bufora, automatycznie przydzielany jest większy.
Dostęp do zasobów systemowych można uzyskać poprzez niezależne od systemu API zdefiniowane w finalnej klasie System oraz zależne od systemu API zawarte w Runtime. Można uzyskać dostęp do parametrów systemowych, standardowych strumieni: wyjœciowego, wejœciowego i błędów, metod ładowania bibliotek, odczytu czasu komputera, szybkiego kopiowania tablic itd.
Klasa Thread definiuje wątki programu Javy pozwalające na jego współbieżną pracę.
Pakiet java.io definiuje klasy implementujące operacje wejœcia-wyjœcia. W pakiecie tym (jak również i w innych) występują klasy i metody pochodzące z JDK1.0 równolegle z nowymi klasami wprowadzonymi wraz z wejœciem JDK1.1 i JDK1.2. Pozostawiono stare klasy w celu zapewnienia zgodnoœci dla dawniej pisanych programów. Często odradza się używania przestarzałych (deprecated) konstrukcji i proponuje się ich udoskonalone odpowiedniki.
Podstawowymi klasami pozwalającymi czytać i pisać z plików, łańcuchów znaków i innych strumieni, są: Reader wraz z podklasami BufferedReader, CharArrayReader, InputStreamReader, FileReader, StringReader oraz Writer wraz z podklasami BufferedWriter, CharArrayWriter, OutputStreamWriter, FileWriter, PrintWriter, StringWriter. Ich starsze odpowiedniki to InputStream i OutputStream wraz z ich podklasami.
Strumień wejœciowy znaków może być dzielony na jednostki logiczne - tokeny, poprzez skonstruowanie na nim obiektu klasy StreamTokenizer. Można zdefiniować składnię, według której wyróżniane będą tokeny typu słowo, liczba, znaczniki końca linii i pliku oraz pomijane komentarze.
Zdefiniowane są również klasy wspierające obsługę struktury drzewa plików w systemie - File oraz czytanie i pisanie do plików o dostępie swobodnym - RandomAccessFile.
W pakiecie java.util można znaleŸć m.in. szereg klas definiujących różne struktury danych przechowujące inne obiekty. Klasa Vector implementuje tablicę obiektów, która może rosnąć lub zmniejszać się w miarę jak obiekty są dodawane lub usuwane. Tak jak w zwykłej tablicy dostęp do jej elementów może odbywać się poprzez całkowity indeks, można również szukać wystąpienia obiektu w wektorze, którego wartoœć jest równa podanemu. Wszystkie elementy wektora najwygodniej jest przeglądać wykorzystując interfejs Enumeration:
Vector v;
for(Enumeration e = v.elements(); e.hasMoreElements() ;)
System.out.println(e.nextElement());
Każdy wektor stara się optymalizować zarządzanie rozmiarem zajmowanej pamięci. Gdy wektor zajmuje całą przydzieloną pamięć, przed dodaniem kolejnego elementu jego rozmiar jest automatycznie zwiększany o wartoœć capacityIncrement. Program może jednak sam zwiększyć rozmiar wektora przed wstawieniem dużej porcji danych, aby uniknąć wielu realokacji. Podklasą klasy Vector jest Stack realizujący kolejkę LIFO obiektów z metodami push i pop.
Klasa Dictionary jest abstrakcyjnym rodzicem dowolnej klasy implementującej odwzorowanie kluczy na wartoœci. Jej podklasą jest Hashtable, której konstrukor posiada dwa parametry initialCapacity i loadFactor. Gdy liczba elementów w tablicy mieszającej (hash table) osiąga wartoœć iloczynu tych parametrów, rozmiar tablicy jest automatycznie zwiększany i przeliczane są pozycje elementów. Większy współczynnik wypełnienia pozwala oszczędniej gospodarować pamięcią kosztem dłuższego czasu potrzebnego do wyszukiwania elementów. Efektywniej jest również zawczasu przydzielić odpowiedniej wielkoœci tablicę, niż potem zdać się na automatyczne przeładowywania. Poniżej przedstawiono przykład tablicy mieszającej obiektów typu Integer posiadających nazwy jako klucze:
Hashtable numbers = new Hashtable();
numbers.put("one", new Integer(1));
numbers.put("two", new Integer(2));
numbers.put("three", new Integer(3));
Aby wydobyć element z tablicy można posłużyć się następującym kodem:
Integer n = (Integer)numbers.get("two");
if(n != null)
System.out.println(two = + n);
Obiekty przechowywane w tablicy mieszającej muszą implementować metody hashCode i equals dziedziczone z klasy java.lang.Object.
Przy użyciu klasy BitSet można tworzyć zbiory bitów i wykonywać na nich operacje logiczne.
Klasa StringTokenizer pozwalająca dzielić łańcuchy znaków na tokeny jest znacznie prostsza w użyciu niż klasa java.io.StreamTokenizer. Okreœla się w niej tylko jakie znaki rozdzielają kolejne tokeny, domyœlnie są to znaki z łańcucha “\t\n\r”, na przykład:
StringTokenizer st = new StringTokenizer(To jest tylko test);
while (st.hasMoreTokens())
System.out.println(st.nextToken());
Można również znaleŸć klasy obsługujące daty - Date i Calendar, ustawiające parametry specyficzne dla kraju, regionu lub języka - Locale, TimeZone.
W pakiecie java.util.zip znajdują się klasy pozwalające tworzyć i czytać pliki skompresowane w formatach ZIP i GZIP.
Pakiet java.net zawiera klasy realizujące połączenia sieciowe zarówno na poziomie gniazd, jak i adresów URL wskazujących zasoby w WWW. Podstawowe klasy to Socket, URL, URLConection. Poniższy przykład pokazuje jak z apletu można w prosty sposób przejœć do wybranej strony WWW:
try {
URL task = new URL("http://www.task.gda.pl/");
getAppletContext().showDocument(task);
} catch (MalformedURLException e) {} // new URL() failed
Aplety i aplikacje Javy komunikują się z użytkownikiem wykorzystując klasy z pakietu java.awt składające się na graficzny interfejs użytkownika AWT (Abstract Window Toolkit). AWT dostarcza typowe komponenty graficzne takie, jak klawisze, pola do wprowadzania tekstu, listy wyboru itd. poprzez klasy Button, Checkbox, Choice, Label, List, Menu, Scrollbar, TextArea, TextField będące pochodnymi klasy Component. Wykorzystując klasę Canvas, można rysować dowolne obrazy graficzne na ekranie, a po dodaniu odpowiedniej obsługi zdarzeń można zdefiniować dowolny własny komponent.
Wraz z JDK 1.1 został wprowadzony nowy model obsługi zdarzeń, który jest znacznie bardziej elastyczny i wydajny w porównaniu z modelem z JDK 1.0. Stary model dla zachowania zgodnoœci jest również obsługiwany, choć odradza się korzystanie z niego. W modelu 1.1 AWT zdarzenia są generowane przez Ÿródła, którymi mogą być komponenty interfejsu użytkownika, myszka, klawiatura itd. Może być wydelegowany jeden lub więcej odbiorców zdarzenia pochodzącego od okreœlonego Ÿródła, który jest obiektem dowolnej klasy implementującej przynajmniej jeden z interfejsów obsługi zdarzeń takich, jak ActionListener, KeyListener czy MouseListener. Zasadę działania tego modelu można przeœledzić w poniższym przykładzie:
import java.applet.*;
import java.awt.*;
import java.awt.event.*;
public class URLButton extends Applet implements ActionListener {
public void init() {
Button button = new Button("TASK Home");
add(button);
button.addActionListener(this);
}
public void actionPerformed(ActionEvent event) {
. . .
}
}
W skład JDK 1.2 został włączony pakiet javax.swing nazywany również Java Foundation Classes (JFC), znacznie rozszerzający możliwoœci funkcjonalne interfejsu graficznego użytkownika. Pakiet ten zawiera znacznie więcej komponentów graficznych, pozwala dynamicznie imitować znane œrodowiska graficzne (np. Windows, CDE/Motif), umożliwia korzystanie z urządzeń pomocniczych w odczytywaniu informacji (jak np. czytniki ekranu, wyœwietlacze Braille'a), zawiera bogatą bibliotekę do tworzenia dwuwymiarowej grafiki, wspomaga technikę “przeciągnij i upuœć” pomiędzy aplikacjami Javy i aplikacjami w danym systemie operacyjnym.
Zastosowanie klas Applet i AppletContext z pakietu java.applet było już demonstrowane we wczeœniejszych przykładach. Definiują one œrodowisko, w którym uruchamiane są aplety. Pozwalają również na komunikację pomiędzy apletami znajdującymi się na tej samej stronie.
Œrodowisko budowania niezależnych od platformy, modyfikowalnych wizualnych komponentów JavaBeans API zawarte jest w pakiecie java.beans. Wykorzystując przeznaczone do tego narzędzia programistyczne, można wizualnie z komponentów konstruować aplikacje, aplety, servlety lub komponenty złożone. Narzędzie tego typu pozwala wybrać z zestawu potrzebny nam komponent, wstawić go do okienka programu, zmodyfikować jego wygląd i zachowanie, zdefiniować interakcję z innymi komponentami; wszystko to nie pisząc ani jednej linii kodu.
JDBC API (Java DataBase Conectivity) zdefiniowane w pakiecie java.sql wprowadza jednolity standard dostępu do dowolnych relacyjnych baz danych. Klasy z tego pakietu implementują połączenia z bazą danych, zapytania SQL, wyniki tych zapytań itp. Dostęp do bazy odbywa się za poœrednictwem drivera, który może być napisany całkowicie w Javie i wtedy może być np. œciągnięty jako częœć apletu, może być też napisany z wykorzystaniem kodu maszynowego okreœlonej platformy, aby uzyskać dostęp do istniejących już bibliotek dostępu do baz danych. Drivery JDBC można podzielić na cztery kategorie:
Pomost JDBC-ODBC, który zapewnia dostęp do bazy poprzez binarne drivery ODBC.
Driver w Javie zamieniający odwołania JDBC na odwołania do binarnego drivera dostępowego konkretnej bazy danych znajdującego się na lokalnym komputerze.
Napisany całkowicie w Javie driver, komunikujący się poprzez sieć z oprogramowaniem poœredniczącym w dostępie do bazy (middleware). Protokół dostępowy zależy od producenta tego oprogramowania, producent ten jest też najczęœciej dostawcą odpowiedniego drivera JDBC.
Napisany całkowicie w Javie driver, komunikujący się poprzez sieć bezpoœrednio z serwerem bazy danych. Dostawcą drivera często jest producent bazy danych.
RMI (Remote Method Invocation) zawarty w java.rmi umożliwia tworzenie rozproszonych aplikacji w Javie. Aplikacja taka złożona jest z serwera, tworzącego obiekty, których metody mogą być wywoływane zdalnie; po utworzeniu obiektów aplikacja udostępnia odnoœniki do nich i czeka na wywołania ich metod przez klientów; klient œciąga odnoœniki do zdalnych obiektów i wywołuje ich metody. RMI zapewnia mechanizm, poprzez który odbywa się komunikacja pomiędzy serwerem i klientem oraz przesyłane są dane w obie strony.
W pakietach org.omg Javy 1.2 wsparto powszechnie przyjęty standard modelu obiektów rozproszonych - CORBA (Common Object Request Broker Architecture). Pozwala on na komunikację pomiędzy obiektami bez względu na platformę systemu operacyjnego, ani użyty języka programowania.
W pakiecie java.math znajdują się klasy BigInteger i BigDecimal pozwalające na tworzenie i operacje na liczbach całkowitych dowolnej precyzji. BigInteger implementuje operacje arytmetyki modularnej, obliczanie największego wspólnego podzielnika, generator liczb pierwszych, operacje na bitach itd. Z liczb zdefiniowanych w tej klasie korzysta pakiet java.security wprowadzający jednolity model kryptografii i ochrony danych. Znajdują się tam abstrakcyjne klasy definiujące kody zapewniające integralnoœć danych (message digests) oparte na jednokierunkowych funkcjach mieszających (one-way hash functions), podpisy cyfrowe oparte na parze kluczy jawnego i tajnego, zarządzanie kluczami i certyfikaty. Jest to tylko ramowy szkielet koncepcji kryptograficznych, pod który producenci oprogramowania mogą podłączać konkretne algorytmy i metody. Razem z JDK Sun dostarcza jedynie klasy do cyfrowego podpisywania dokumentów opartego na algorytmie DSA oraz obliczania kodów dokumentów metodami MD5 i SHA-1.
W pakiecie java.text znajdziemy klasy obsługujące różne formaty danych tekstowych, np. DateFormat obsługujący daty w różnych standardach czy NumberFormat tworzący i analizujący różne formaty liczb.
1.14. Servlety - programy Javy na serwerze WWW
Servlety są modułami, które są uruchamiane wewnątrz serwerów przetwarzających zapytania i generujących odpowiedzi, takich jak np. rozszerzone o obsługę Javy serwery WWW. Rozszerzają one funkcjonalnoœć tych serwerów. Można w uproszczeniu powiedzieć, że servlety dla serwerów są tym, czym aplety dla przeglądarek.
Servlety stanowią alternatywę dla skryptów CGI, umożliwiając łatwą metodę dynamicznego tworzenia dokumentów HTML. Są one łatwiejsze do pisania dzięki wykorzystaniu œrodowiska Javy. Są również szybciej wykonywane, gdyż wywołanie servletu odbywa się nie poprzez uruchomienie nowego procesu, co jest kosztowne ze względu na czas procesora i zasoby pamięciowe, lecz jako wątek. Co więcej, kod wykonywalny dla servletu jest ładowany do serwera tylko raz, gdy po raz pierwszy żądana jest usługa oferowana przez dany servlet lub automatycznie, gdy zostanie zmieniony kod servleta. Potem servlet pozostaje w pamięci serwera i może równolegle obsługiwać wiele zapytań z możliwoœcią komunikacji pomiędzy nimi.
Klasy implementujące funkcje servletów znajdują się w pakiecie javax.servlet dostępnego z firmy Sun jako Java Servlet Development Kit. Pakiet zawiera m. in. abstrakcyjną klasę GenericServlet oraz interfejs Servlet, które definiują podstawowe własnoœci ogólnych servletów, czyli modułów przetwarzających zapytania i generujących odpowiedzi. Jednak najczęœciej korzysta się z podklas znajdujących się w pakiecie javax.servlet.http definiujących servlety HTTP. Klasa HttpServlet posiada m.in. takie metody jak doGet i doPost obsługujące typowe zapytania CGI, czy uniwersalną metodę service obsługującą wszystkie rodzaje zapytań. Najprostszy servlet może wyglądać następująco:
Plik HelloWorldServlet.java
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class HelloWorldServlet extends HttpServlet {
public void doGet (HttpServletRequest req,
HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/html");
ServletOutputStream out = res.getOutputStream();
out.println(<html>);
out.println(<head><title>Hello World</title></head>);
out.println(<body>);
out.println(<h1>Hello World</h1>);
out.println(</body></html>);
}
}
Większoœć użytecznych servletów czyta parametry wejœciowe przekazane im z przeglądarki poprzez metody GET lub POST i na ich podstawie tworzy odpowiedni dokument HTML. Prosty przykład takiego servletu przedstawiono poniżej.
Hello.java
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class Hello extends HttpServlet {
public void service(HttpServletRequest req,
HttpServletResponse res)
throws ServletException, IOException {
res.setContentType(text/html);
PrintWriter toClient = res.getWriter();
toClient.println(<html><head>);
toClient.println(<title>Hello</title>);
toClient.println(</head>);
toClient.println(<h1>Hello +
req.getParameterValues(name)[0] + !</h1>);
toClient.println(</body></html>);
toClient.close();
}
}
Powyższy servlet można wywołać na kilka sposobów. Można podać w przeglądarce odpowiedni lokalizator (URL), np.
http://www.task.gda.pl/servlet/Hello?name=Darek
i wywołać servlet przekazując parametry metodą GET. Można na stronie HTML umieœcić formularz:
<form action=http://www.task.gda.pl/servlet/Hello method=POST>
Podaj swoje imię: <input type=text name=name>
<input type=submit value=Wyœlij>
</form>
i wywołać servlet przekazując parametry metodą POST. Można również wykorzystać znacznik <servlet> na stronie HTML zapisanej w pliku z rozszerzeniem shtml.
Hello.shtml
...
<servlet code=Hello>
<param name=name value=Darek>
</servlet>
...
Wtedy serwer WWW rozszerzony o funkcjonalnoœć servletów zastąpi na stronie HTML powyższy znacznik wynikiem generowanym przez servlet Hello i tak przetworzoną stronę przeœle do przeglądarki.
Dostępnych jest już wiele serwerów WWW obsługujących servlety Javy. Przykładami mogą być Java Web Server firmy Sun lub darmowy dla celów niekomercyjnych JRun firmy Live Software. Ten ostatni może pracować jako samodzielny serwer WWW, bądŸ jako moduł rozszerzający funkcjonalnoœć innych znanych serwerów WWW np. Apache, Microsoft IIS, Netscape.
1.15. Identyfikatory i słowa zarezerwowane języka Java
Identyfikatory są sekwencjami znaków i cyfr języka Java (tj. sekwencją znaków zbioru Unicode) o dowolnej długoœci, przy czym pierwszy znak musi być literą. Literami Javy są zwykle duże i małe litery kodu ASCII, od A do Z (znaki Unicode od \u0041 do \u005a) i od a do z (znaki Unicode od \u0061 do \u007a) oraz - ze względów historycznych - znak podkreœlenia ASCII (_, lub \u005f) i używany tylko w specyficznych kontekstach znak dolara ($, lub \u0024). Cyfry Javy są to cyfry 0 do 9 kodu ASCII (\u0030 do \u0039).
Standard de facto języka Java, wprowadzony w jego specyfikacji, okreœla pewne słowa jako słowa kluczowe, zaœ pewne słowa (true, false i null) jako zarezerwowane - nie wolno ich używać jako nazw w programach. Słowa kluczowe są niepodzielnymi ciągami znaków. Są to zastrzeżone identyfikatory, których można używać jedynie w œciœle zdefiniowanym kontekœcie. W tablicy 1.3 zestawiono słowa kluczowe języka Java.
Tablica 1.3 Lista słów kluczowych
abstract |
const* |
finally |
int |
public |
this |
boolean |
continue |
float |
interface |
return |
throw |
break |
default |
for |
long |
short |
throws |
byte |
do |
goto* |
native |
static |
transient |
case |
double |
if |
new |
strictfp** |
try |
catch |
else |
implements |
package |
super |
void |
char |
extends |
import |
private |
switch |
volatile |
class |
final |
instanceof |
protected |
synchronized |
while |
Słowa kluczowe const i goto są zarezerwowane, mimo że aktualnie nie są używane w programach. Pozostawiono je ze względu na to, że może to umożliwić kompilatorowi Javy tworzenie lepszych komunikatów o błędach, gdyby te słowa kluczowe z języka C++ pojawiły się w programach. Natomiast słowo kluczowe strictfp zostało dodane począwszy od wersji JDK1.2.
1.16. Podsumowanie
Zalety języka Java:
Literatura
Gosling J., Joy B. Steele G. The Java Language Specification. Addison-Wesley, 1996, http://java.sun.com/docs/books/jls/.
Cargill T. An Overview of Java for C++ Programmers. C++ Report, vo. 8/No. 2, pp. 46-49, 1996.
Jones R., Lins R. : Garbage Collection. Wiley, 1996.
Lorenz M. Java as an Object-Oriented Language. SIGS Books & Multimedia, New York 1996.
Martin R. C++ and Java: A Critical Comparison. C++ Report, vo. 9/No. 1, pp. 42-49, 1997.
Jain P. and Schmidt D.C. Experiences Converting a C++ Communication Software Framework to Java. C++ Report, vo. 9/No. 1, pp. 51-66, 1997.
Glass G. : The Java Generic Library. C++ Report, vol.9/No.1, pp. 70-74, 1997.
Lorenz M. : Java as an Object-Oriented Language. SIGS Books & Multimedia, 1997.
Bielecki J. Java od podstaw. Intersoftland, Warszawa 1997.
The Java Tutorial. http://java.sun.com/docs/books/tutorial/, 1998.
JDK1.2 Documentation. http://java.sun.com/products/jdk/1.2/docs/, 1998.
Wyszukiwarka
Podobne podstrony:
wyklad5.cpp, JAVA jest językiem programowania obiektowego
Zeszyt Java, Programowanie obiektowe i strukturalne, Java
Java programowanie obiektowe 2
Java Programowanie obiektowe
Java Programowanie obiektowe japrob
Java Programowanie obiektowe 2
Programowanie obiektowe(ćw) 1
Zadanie projekt przychodnia lekarska, Programowanie obiektowe
Programowanie obiektowe w PHP4 i PHP5 11 2005
Programowanie Obiektowe ZadTest Nieznany
Egzamin Programowanie Obiektowe GĹ‚owacki, Programowanie Obiektowe
r12-05, Programowanie, ! Java, Java Server Programming
JAVA 09 klasy i obiekty(2)
Jezyk C Efektywne programowanie obiektowe cpefpo
Programowanie Obiektowe Ćwiczenia 5
Programowanie obiektowe(cw) 2 i Nieznany
Java Sztuka programowania jaszpr
programowanie obiektowe 05, c c++, c#
r20-05, Programowanie, ! Java, Java Server Programming
więcej podobnych podstron