POLITECHNIKA GDAŃSKA
WYDZIAŁ ELEKTRONIKI, TELEKOMUNIKACJI i INFORMATYKI
KATEDRA ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
Architektury systemów komputerowych
Materiały pomocnicze do wykładu — cz. III
Opracował dr inż. Andrzej Jędruch
Gdańsk 2004
Wprowadzenie do systemów operacyjnych
we współczesnych systemach komputerowych wyodrębnia się zwykle poniższe części:
sprzęt komputerowy,
system operacyjny,
programy użytkowe,
użytkownicy;
system operacyjny jest programem, który nadzoruje i koordynuje posługiwanie się sprzętem przez różne programy użytkowe — te zaś pracują na zlecenie różnych użytkowników;
do programów użytkowych (nazywanych też aplikacjami) zalicza się kompilatory, systemy baz danych, programy handlowe, gry komputerowe i wiele innych;
użytkownikami mogą być ludzie, jak też inne komputery czy maszyny;
rozwiązanie postawionego zadania w systemie komputerowym wymaga użycia różnych elementów sprzętu i oprogramowania, które określa się terminem zasoby; do zasobów zalicza się czas procesora, obszar w pamięci operacyjnej, obszar w pamięci plików, urządzenia wejścia-wyjścia itd.;
system operacyjny zarządza zasobami i przydziela je poszczególnym programom i użytkownikom wówczas, gdy są one nieodzowne do wykonywania zadań; niektóre zasoby (np. pamięć operacyjna) są często zbyt małe w stosunku do potrzeb, więc system operacyjny musi decydować o przydziale zasobów poszczególnym zamawiającym, mając na względzie wydajne i harmonijne działanie całego systemu komputerowego;
można przyjąć, że w ścisłym znaczeniu system operacyjny jest programem, który działa w komputerze nieustannie; taki program nazywany jest także jądrem systemu operacyjnego; niekiedy do systemów operacyjnych zalicza się edytory, kompilatory, debuggery, itd., chociaż częściej traktowane są one jako programy użytkowe.
Rozwój systemów operacyjnych
pierwsze programy były całkowicie samodzielne, w trakcie realizacji nie korzystały z pomocy innych programów, w szczególności samodzielnie obsługiwały urządzenia wejścia-wyjścia;
wkrótce okazało się, że prawie wszystkie programy realizują podobne lub identyczne czynności w zakresie obsługi urządzeń wejścia-wyjścia; jednocześnie urządzenia te wymagały starannego oprogramowania, co wymagało znajomości wielu szczegółów technicznych; często realizacja prostej czynności przez urządzenie wymagała wykonania złożonego ciągu operacji;
w tej sytuacji zaczęto tworzyć odrębne podprogramy obsługi dla każdego urządzenia, udostępniane innym programom — podprogramy te wykonywały (często w złożony sposób) proste zlecenia otrzymywane od zwykłych programów;
bardzo wysokie koszty instalacji i eksploatacji systemów komputerowych w latach pięćdziesiątych i sześćdziesiątych spowodowały konieczność wprowadzenia oprogramowania nadzorującego i koordynującego pracę całego systemu w celu uzyskania jego maksymalnej wydajności — oprogramowanie to przyjęto nazywać systemem operacyjnym;
w różnych systemach komputerowych zdefiniowano szereg usług, które mogły być zlecane przez zwykłe programy do podprogramów systemowych; w rezultacie powstało środowisko, w którym obok elementarnych operacji wykonywanych przez procesor, programista tworzący programy użytkowe miał do dyspozycji szereg operacji mających charakter usług realizowanych przez system operacyjny;
w ten sposób ukształtował się pewien interfejs obejmujący zasady korzystania z usług systemu operacyjnego przez programy, znany jako interfejs programowania aplikacji (ang. API — Application Programming Interface); usługi API udostępniono także w wielu językach wysokiego poziomu w postaci funkcji lub procedur;
systemy operacyjne i architektura komputerów wywarły na siebie wzajemnie znaczny wpływ — aby ułatwić posługiwanie się sprzętem, zaczęto rozwijać systemy operacyjne; z kolei zauważono, że wprowadzenie zmian w sprzęcie pozwala na uproszczenie systemów operacyjnych.
Systemy wielozadaniowe
w pracy każdego programu występują naturalne przestoje związane z pobieraniem danych, wysyłaniem wyników, operacjami zapisu danych na dysku, itp.; w okresie występowania tych przestojów procesor był prawie całkowicie bezczynny; w tej sytuacji, w dążeniu do uzyskania wysokiej wydajności systemu komputerowego, celowe okazało wprowadzenie do pamięci komputera innego programu, i okresowe wykonywanie go przez procesor w czasie, gdy pierwszy program komunikuje się z urządzeniami zewnętrznymi; problem występował w szczególnie ostrej postaci w czasach, gdy ceny procesorów liczone były w milionach dolarów;
program wprowadzony do pamięci głównej (operacyjnej) komputera w postaci gotowej do wykonywania przez procesor nazywany jest zadaniem lub procesem; jeśli w systemie komputerowym możliwe było załadowanie do pamięci dwóch lub więcej programów, i programy te były naprzemian wykonywane przez procesor, to taki system przyjęto nazywać wielozadaniowym lub wieloprocesowym;
wprowadzenie wielozadaniowości praktycznie wyeliminowało okresy bezczynności procesora, zwiększyło wydajność całego systemu, ale jednocześnie wyłonił się szereg problemów, które należało rozwiązać;
poszczególne procesy (zadania) zazwyczaj co pewien czas komunikują się z urządzeniami zewnętrznymi komputera — powodowało to konflikty w zakresie dostępu do urządzeń; konieczne stało się więc wprowadzenie obowiązkowego pośrednictwa podprogramów systemowych w operacjach wejścia-wyjścia; system operacyjny przyjmował zlecenia, np. na drukowanie jakiegoś pliku, i wykonywał je niezwłocznie, jeśli drukarka była nieużywana; jeśli jednak drukarka była zajęta, to zlecenie było rejestrowane i realizowane do zakończeniu poprzedniej operacji drukowania;
wyłonił się też problem, w miarę możliwości, sprawnego wykonywania wielu programów, tak by łączny czas oczekiwania był minimalny; przykładem może tu być kolejka klientów, np. na poczcie: gdyby klienta nadającego 100 listów przesunąć na koniec kolejki, to łączny oczekiwania uległ by znacznemu skróceniu; rozpatrywany problem w odniesieniu do systemów operacyjnych nazywany jest szeregowaniem zadań; od co najmniej 50 lat prowadzone są badania w zakresie poszukiwania optymalnych algorytmów szeregowania zadań wykonywanych w systemach komputerowych;
jeszcze inny problem wiąże się z koniecznością wzajemnej izolacji procesów; zdarzały się przypadki, że proces wskutek błędów programowania, a niekiedy także wskutek działania w złej intencji, proces próbował odczytać lub zmienić dane należące do innego procesu lub systemu operacyjnego; z tego powodu stało się konieczne wprowadzenie sprzętowych mechanizmów ochrony zadań i systemu operacyjnego;
w początkowym okresie rozwoju komputerów osobistych stosowano w nich proste, jednozadaniowe systemy operacyjne (np. MS DOS); w miarę rozwoju konstrukcji mikroprocesorów rozwiązania stosowane w systemach operacyjnych dla dużych komputerów okazały się odpowiednie dla komputerów osobistych — koncepcje zastosowane w wielkich systemach komputerowych przeniknęły do komputerów PC; od połowy lat dziewięćdziesiątych dostępne są zaawansowane, wielozadaniowe systemy operacyjne dla komputerów osobistych: MS Windows i Linux;
we współczesnych systemach operacyjnych dla komputerów PC najważniejszym celem działania systemu jest wygoda użytkownika, a efektywne działanie systemu jest celem drugorzędnym; wygoda i wydajność są niekiedy sprzeczne; w przeszłości szczególną uwagę zwracano na wydajność; w komputerach osobistych dominuje wygoda użytkowania;
odrębną klasę systemów stanowią systemy równoległe i rozproszone, które będą omawiane w dalszej części wykładu.
Systemy czasu rzeczywistego
systemy czasu rzeczywistego (ang. real-time) stanowią specjalizowany rodzaj systemów operacyjnych, w których występują surowe wymagania na czas wykonania operacji lub przepływu danych;
systemy czasu rzeczywistego stosowane są do komputerowego sterowania procesami przemysłowymi, ruchem pojazdów, w urządzeniach medycznych, wojskowych i wielu innych;
w systemach czasu rzeczywistego przetwarzanie danych musi (!) zakończyć się przed upływem określonego czasu, w przeciwnym razie system nie spełnia wymagań;
istnieją dwie odmiany systemów czasu rzeczywistego
1. rygorystyczny system czasu rzeczywistego (ang. hard real time system) gwarantuje terminowe wypełnianie krytycznych zadań;
2. łagodny system czasu rzeczywistego (ang. soft real-time system) jest mniej wymagający: krytyczne zadanie do obsługi w czasie rzeczywistym otrzymuje pierwszeństwo przed innymi zadaniami, przy czym pierwszeństwo zostaje zachowane aż do chwili wykonania zadania;
systemy rygorystyczne, ze względu na ostre wymagania czasowe i konieczność ograniczenia wszystkich opóźnień w systemie, nie mają większości cech nowoczesnych systemów operacyjnych, a ponadto cechują je liczne ograniczenia, np. pamięć pomocnicza jest bardzo mała lub nie występuje wcale, nie używa się także pamięci wirtualnej;
żaden z istniejących, uniwersalnych systemów operacyjnych nie umożliwia działania w czasie rzeczywistym w sensie rygorystycznym, jedynie system Windows NT/2000 w pewnym stopniu może być brany pod uwagę;
systemy łagodne znajdują zastosowanie w mniej odpowiedzialnych rolach, np. w technice multimedialnej; większość uniwersalnych systemów operacyjnych spełnia wymagania systemów łagodnych.
wprawdzie wczesne wersje systemu Windows nigdy nie pretendowały do klasy systemów czasu rzeczywistego, ale wskutek ich powolnego działania nie zostały zaakceptowane przez użytkowników; późniejsze wersje Windows korzystały już ze znacznie szybszych procesorów i większej pamięci, ale niektóre przyjęte rozwiązania miały charakter uproszczony, dostosowany do aktualnych możliwości sprzętu.
Warstwowa struktura systemu operacyjnego
powszechnie stosowanym modelem statycznym systemu operacyjnego jest struktura warstwowa, w której warstwy niższe oferują pewne funkcje i usługi warstwom niższym;
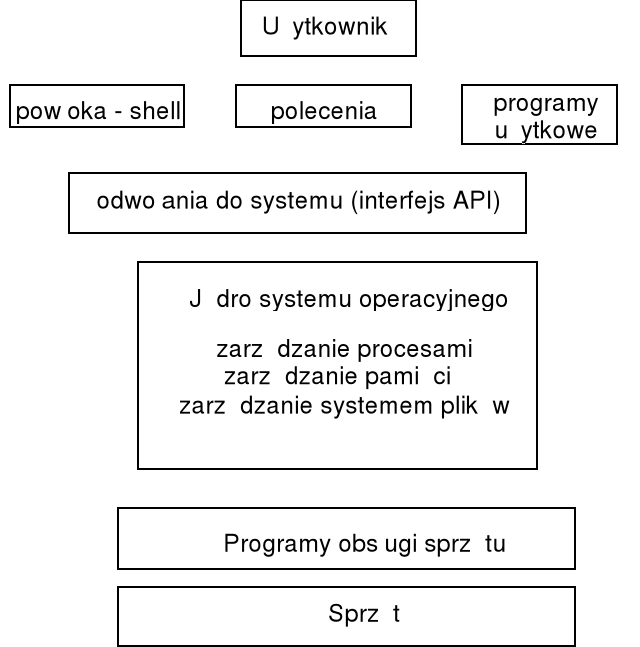
najniższą warstwę SO stanowią programy niskiego poziomu obsługi sprzętu, często wbudowane do pamięci stałej (BIOS);
kolejną warstwę stanowi jądro systemu (ang. kernel), składające się ze zbioru funkcji i tablic systemowych; głównym zadaniem jądra jest dostarczenie narzędzi do zarządzania procesami, zarządzania pamięcią i zarządzania systemem plików;
kolejna warstwa dostarcza programistom narzędzi do odwoływania się do systemu operacyjnego z wnętrza programów, a więc tzw. interfejs programów użytkowych (API ang. Application Program Interface); korzystają z niego również programy systemowe, jak np. programy powłok;
pomiędzy warstwą API i użytkownikiem ulokowano w modelu warstwowym ww. programy powłok, programy poleceń systemowych i programy użytkowe jako narzędzia bezpośrednio wykorzystywane przez użytkownika; oprogramowanie użytkowe (narzędziowe) to różnego rodzaju edytory tekstowe, translatory (kompilatory) języków programowania, programy łączące (konsolidatory, linkery), programy uruchomieniowe, programy wspomagające lub wręcz tworzące interfejs użytkownika itp.; na ogół zakłada się, że każda warstwa może komunikować się tylko z warstwami sąsiednimi (tzn. korzystać z usług warstwy niższej i udostępniać usługi warstwie wyższej); jednak to założenie jest bardzo trudne w praktycznej realizacji i często stosuje się jedynie podejście przybliżone;
z modelem warstwowym związana jest koncepcja hierarchii maszyn wirtualnych, tworzących abstrakcyjny ciąg modeli systemów komputerowych; każda kolejna warstwa wzbogaca sprzęt o nowe własności, dając ciekawe implikacje w przypadku systemów wielozadaniowych (różne maszyny dla różnych zadań);
System interpretacji poleceń
interpreter poleceń stanowi interfejs między użytkownikiem a systemem operacyjnym; jest to jeden z najważniejszych programów w systemie operacyjnym;
w wielu systemach operacyjnych (np. DOS, Unix) interpreter poleceń jest specjalnym programem, wykonywanym przy rozpoczynaniu zadania lub wtedy, gdy użytkownik rejestruje się w systemie; inne systemy operacyjne zawierają interpreter poleceń w swoim jądrze;
interpreter poleceń znany jest pod nazwą powłoki (ang. shell);
interfejs graficzny (np. MS Windows, Macintosh) jest zwykle bardziej przyjazny dla użytkownika;
za pomocą poleceń przekazywanych do interpretera można:
tworzyć procesy i zarządzać nimi;
obsługiwać wejście-wyjście;
administrować pamięcią pomocniczą i operacyjną;
realizować operacje na plikach i katalogach;
realizować pracę sieciową;
użytkownik porozumiewa się z systemem za pomocą interpretera zleceń, analogicznie programy porozumiewają się z systemem operacyjnym za pomocą funkcji systemowych.
Procesy
realizacja wielozadaniowości wymaga dzielenia czasu procesora między zadania poszczególnych użytkowników: system operacyjny udostępnia procesor wybranemu zadaniu na krótki odcinek czasu (np. 200 ms), powodując wykonywanie zadania przez ten czas; po upływie tego czasu wykonywane zadanie zostaje zatrzymane, a system operacyjny przekazuje procesor innemu zadaniu, również na ustalony, krótki odcinek czasu;
sam program jest obiektem pasywnym i nie jest procesem, natomiast proces jest obiektem aktywnym, który ma przydzielone pewne zasoby i dla którego można wskazać następny rozkaz do wykonania poprzez określenie zawartości wskaźnika instrukcji (licznika rozkazów) procesora; wykonywany proces może tworzyć wiele nowych procesów;
głównym obowiązkiem systemu operacyjnego jest wykonywanie programów użytkowych; system operacyjny musi jednak realizować także różne zadania systemowe (które wygodniej jest pozostawić poza jądrem systemu); można więc przyjąć, że system składa się zbioru procesów: procesy systemu operacyjnego wykonują kod systemowy, a procesy użytkowe działają wg kodu należącego do użytkowników;
ponieważ istnieje możliwość podziału mocy obliczeniowej procesora (lub procesorów), więc wszystkie te procesy mogą być wykonywane współbieżnie;
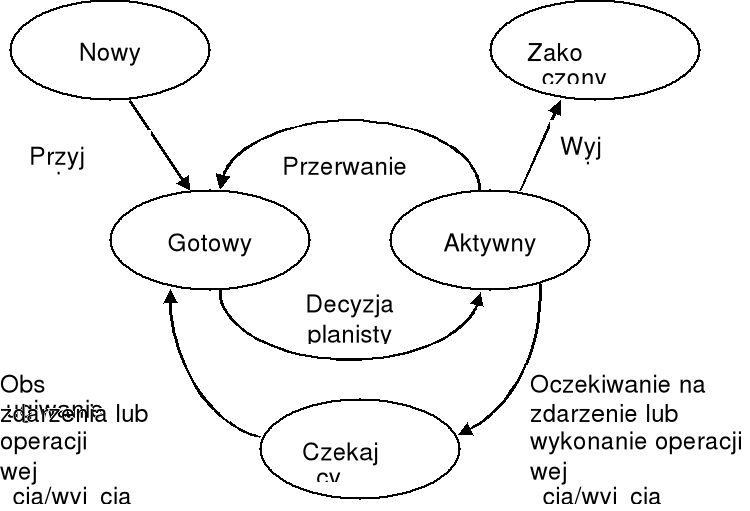
proces może znajdować się w jednym z następujących stanów:
nowy — proces został utworzony,
aktywny — są wykonywane instrukcje,
oczekiwanie — proces czeka na wystąpienie jakiegoś zdarzenia (np. na zakończenie operacji wejścia-wyjścia),
gotowy — proces czeka na przydział procesora,
zakończony — proces zakończył działanie.
wymienione stany oznaczane są czasami trochę innymi terminami;
w każdej chwili w dowolnym procesorze tylko jeden proces może być aktywny, przy czym może być wiele procesów gotowych lub czekających;
w systemach operacyjnych wyłoniły się dwie podstawowe metody przełączania zadań:
1) wielozadaniowość z wywłaszczaniem (ang. preemptive multitasking) — w klasycznych wielozadaniowych systemach operacyjnych, przewidzianych dla wielu użytkowników, każdy proces wykonywany jest przez ustalony odcinek czasu (np. 20 ms) — po upływie tego czasu, co jest sygnalizowane przerwaniem zegarowym, realizowany proces zostaje zatrzymany (zawieszony), po czym wznawiany jest inny proces; niekiedy procesowi może być przydzielony odcinek czasu będący wielokrotnością jednostki podstawowej;
2) wielozadaniowość bez wywłaszczania (ang. non-preemptive multitasking, cooperative multitasking) — przełączanie realizowane jest za wiedzą programu, za pomocą funkcji systemowej wywołanej przez ten program — zatem proces jest realizowany aż do chwili, gdy dobrowolnie przekaże sterowanie do systemu, który z kolei wznowi inny proces.
w starszych wersjach systemu Windows dominowała metoda wielozadaniowości bez wywłaszczania, aczkolwiek w odniesieniu do zadań DOSowych stosowana była zawsze wielozadaniowość z wywłaszczaniem — zadania DOSowe są bowiem realizowane wg koncepcji proceduralnych i nie są przygotowane do tymczasowego oddawania sterowania do systemu;
w systemie sterowanym zdarzeniami bardziej naturalna jest wielozadaniowość bez wywłaszczania; jednak ten rodzaj wielozadaniowości może być akceptowany pod warunkiem, że czas obsługi komunikatów jest krótki (np. 100 ms); w przypadku stosowania wielozadaniowości bez wywłaszczania pojedynczy program może "zamrozić" cały system, jeśli przetwarzanie komunikatu trwa nadmiernie długo;
proces reprezentowany jest w systemie operacyjnym przez blok kontrolny procesu (ang. process control block - PCB), nazywany również blokiem kontrolnym zadania; w skład bloku kontrolnego wchodzą następujące informacje:
Wskaźnik |
Stan procesu |
Nr procesu |
|
Wskaźnik instrukcji |
|
Rejestry |
|
Ograniczenia pamięci |
|
Wykaz otwartych plików |
|
. . .
|
|
stan procesu: może być określony jako nowy, gotowy, aktywny, oczekiwanie, zatrzymanie, itd.;
wskaźnik instrukcji (licznik rozkazów): wskazuje adres następnego rozkazu do wykonania w procesie;
rejestry procesora: rodzaje przechowywanych rejestrów zależą od architektury procesora;
informacja o planowaniu przydziału procesora: priorytet procesu i inne parametry potrzebne do planowania;
informacje o zarządzaniu pamięcią: zawartości rejestrów granicznych, tablice stron lub segmentów, itp,;
informacje do rozliczeń: ilość zużytego czasu procesora i czasu rzeczywistego, ograniczenia czasowe, numery kont, itd.;
informacje o stanie wejścia-wyjścia: informacje o otwartych plikach, stosowanych urządzeniach, itd.;
Struktura pamięci dla procesu
obszar pamięci przeznaczonej dla procesu jest zazwyczaj zorganizowany w sposób pokazany na rysunku;
kod programu umieszczony jest w obszarze pamięci nazywanym często tekstem (procesu) — w wielu systemach operacyjnych część ta jest zastrzeżona tylko do czytania (wykonywany program nie może modyfikować swoich rozkazów);
dane programu mogą składać się z trzech części:
dane zainicjowane przeznaczone wyłącznie do czytania;
dane zainicjowane przeznaczone do czytania i pisania;
dane nieinicjowane;
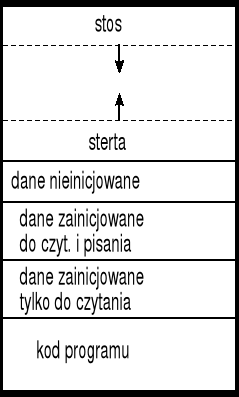
sterta jest to część pamięci programu używana do dynamicznego przydzielania dodatkowego obszaru pamięci na dane podczas wykonywania programu;
stos jest to część pamięci programu używana dynamicznie podczas wykonywania programu do przechowywania zmiennych automatycznych i ramek stosu (zawierających ślad i parametry wywołania funkcji);
wiele systemów operacyjnych pozostawia wolne miejsce między stertą i stosem, aby ich wielkości mogły się zmieniać dynamicznie podczas wykonywania programu.
Programy wielomodułowe
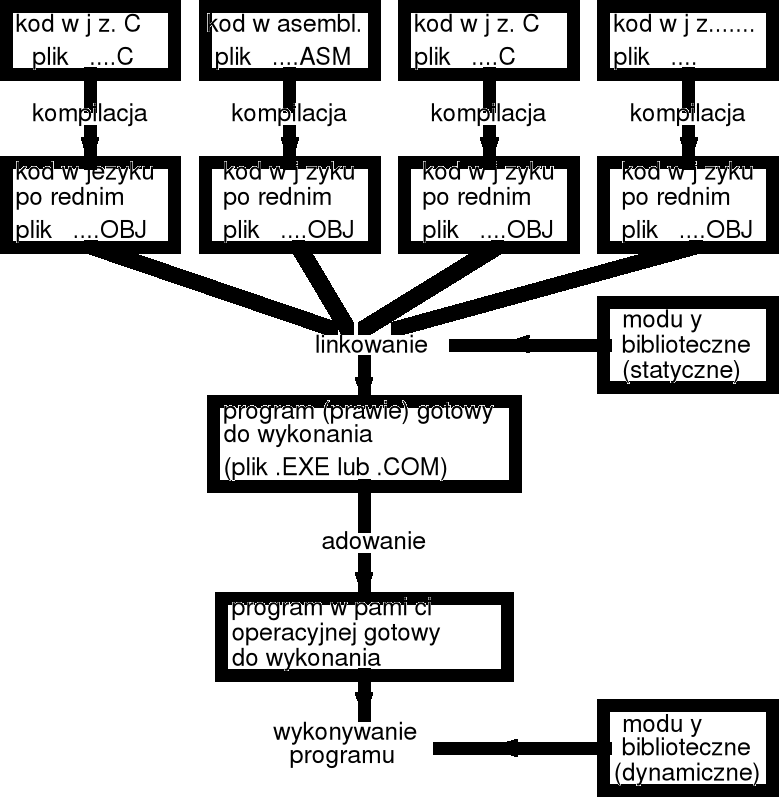
w trakcie tworzenia dużych systemów oprogramowania celowe jest podzielenie systemu na mniejsze podsystemy, z których każdy jest oddzielnie analizowany i kodowany — umożliwia to racjonalne tworzenie i uruchamianie systemu;
wygodnie jest umieścić kod realizujący funkcje takiego podsystemu w jednym lub kilku plikach, stanowiących razem zamkniętą całość, która może być poddana kompilacji — taki zespół plików (lub pojedynczy plik) nazywać będziemy modułem programu;
w takim ujęciu cały system oprogramowania składa się z kilku modułów, które są oddzielnie kompilowane a potem integrowane (linkowane) w celu uzyskania programu wynikowego; poszczególne moduły mogą być pisane w tych samych bądź różnych językach programowania;
podział programu na moduły jest szczególnie wskazany w przypadku dużego programu — wprowadzenie kolejnych poprawek i zmian i nie wymaga wówczas kompilowania całego programu, ale tylko modułu, którego treść została zmieniona; jeśli nawet używany bardzo szybki procesor, to edycja i kompilacja całego programu zawierającego miliony wierszy trwa znacznie dłużej niż te same operacje wykonywane na pojedynczym module, zawierającym fragment programu;
co więcej, jeśli nad programem pracuje kilku programistów, to jednoczesna edycja tego samego pliku przez kilka osób jest bardzo kłopotliwa; istnieje wprawdzie oprogramowanie dla pracy zespołowej (ang. collaborative work), ale jest ono ciągle w stadium badań i rozwoju;
dodatkowym czynnikiem przemawiającym za podziałem programu na moduły może być także to, że moduły stanowią zazwyczaj naturalne jednostki całego programu, przez co zrozumienie jego działania jest łatwiejsze;
niektóre moduły mogą być wielokrotnie wykorzystywane w różnych programach jako moduły zawierające funkcje biblioteczne, czy też po prostu jako kod wielokrotnego użycia (ang. reuse);
kompilatory (i asemblery) dostępne w danym środowisku programistycznym generują kod wynikowy w tym samym języku, nazywanym językiem pośrednim;
język pośredni można uważać za rodzaj "wspólnego mianownika" dla różnych kompilatorów; w środowisku komputerów PC kod w języku pośrednim (przechowywany w plikach z rozszerzeniem .OBJ) zawiera instrukcje procesora w formacie pozwalajacym na przeadresowywanie;
proces integrowania kodu programu zapisanego w języku pośrednim nosi nazwę linkowania lub konsolidacji; w wyniku linkowania uzyskuje się plik wykonywalny (w komputerach PC plik z rozszerzeniem .EXE);
zazwyczaj prócz plików zawierających skompilowany program, w procesie linkowania dołączane są też niezbędne podprogramy biblioteczne; zestawy takich podprogramów, zwane bibliotekami statycznymi przechowywane są zwykle w plikach z rozszerzeniem .LIB;
niekiedy wygodniejsze może być udostępnienie podprogramów bibliotecznych dopiero w trakcie wykonywania programu — biblioteki takie nazywane są dynamicznymi i przechowywane są zazwyczaj w plikach z rozszerzeniem .DLL; zastąpienie bibliotek statycznych przez dynamiczne powoduje zmniejszenie rozmiaru pliku wykonywalnego .EXE;
bezpośrednio przed rozpoczęciem wykonywania programu niektóre adresy instrukcji muszą być dostosowane do środowiska konkretnego komputera — korekcja adresów wykonywana jest w trakcie ładowania i korzysta z tablicy przeadresowań, która zapisana jest w pliku .EXE;
współczesne środowiska programistyczne często, dla skrócenia czasu kompilacji i linkowania, bezpośrednio po kompilacji uruchamiają od razu konsolidator (linker); przykładowo, jeśli w środowisku Microsoft Visual Studio .Net używa się kompilatora zewnętrznego cl, to polecenie kompilacji programu zbadaj.c w postaci
cl zbadaj.c
powoduje bezpośrednio po kompilacji automatyczne wywołanie konsolidatora link; i wytworzenie pliku wykonywalnego .EXE; jeśli zamierzamy przeprowadzić wyłącznie kompilację, to trzeba zastosować dodatkową opcję -c
cl -c zbadaj.c
Uwaga: w przypadku używania zewnętrznego kompilatora i linkera Microsoft Visual Studio, trzeba wcześniej z poziomu bieżącego katalogu uruchomić plik wsadowy VCVARS32.BAT.
w programach wielomodułowych powinny zostać określone ścisłe reguły dostępu do danych i przekazywania sterowania między poszczególnymi modułami;
w wielu językach programowania obszar działania zmiennych i etykiet obejmuje tylko moduł, w którym zostały one zdefiniowane —w programie wielomodułowym trzeba więc rozszerzyć zasięg wybranych zmiennych i etykiet na cały program nadając im znaczenie globalne, tak by możliwy był dostęp do danych jak i przekazywanie sterowania między poszczególnymi modułami;
w asemblerze dyrektywa PUBLIC nadaje zmiennej lub etykiecie zasięg globalny, obejmujący wszystkie moduły programu; analogicznie dyrektywa EXTRN udostępnia zmienną lub etykietę globalną wewnatrz modułu;
w języku C dla wskazania, że funkcja lub zmienna umieszczona jest w innym module używa się kwalifikatora extern, przy czym nie dotyczy to zmiennych lokalnych deklarowanych wewnątrz funkcji.
Pliki linkowalne i wykonywalne
pliki zawierające kod i dane programu, zakodowane w sposób zrozumiały dla procesora, przyjęto określać terminem angielskim object file; pliki takie zawierają dodatkowe informacje opisujące strukturę i własności programu, a także inne dane potrzebne do uruchomienia programu;
plik object może być:
linkowalny (ang. linkable), czyli może być przygotowany do przetwarzania przez konsolidator (linker); plik linkowalny obok właściwego kodu zawiera obszerne informacje o używanych symbolach i wymaganiach relokacji; niekiedy kod podzielony jest na segmenty logiczne, które mogą indywidualnie przetwarzane przez konsolidator;
wykonywalny (ang. executable), czyli może być załadowany do pamięci i wykonywany jako program; plik zawiera kod i dane, ale nie zawiera informacji o symbolach (chyba że przewiduje się linkowanie dynamiczne); nie występują także informacje o relokacji (ewent. bardzo ograniczone); struktura pliku wykonywalnego stanowi odbicie specyfiki środowiska, w którym wykonywany jest program;
ładowalny (ang. loadable) czyli może być załadowany do pamięci jako biblioteka razem z programem;
mogą też występować kombinacje trzech ww. możliwości;
w systemie Windows/DOS pliki linkowalne są kodowane w formacie OMF lub COFF, a wykonywalne w formacie PE — oba te formaty są mają odmienną budowę; z kolei w systemie Linux zarówno pliki linkowalne jak i wykonywalne kodowane są w formacie ELF.
Ładowanie programów
w klasycznym ujęciu ładowanie programu do pamięci polega na przydzieleniu odpowiednio dużego obszaru pamięci, przeznaczonego na blok PCB (ang. process control block), rozkazy, dane i stos, a następnie przepisaniu kodu danych i danych programu z pliku dyskowego do pamięci operacyjnej;
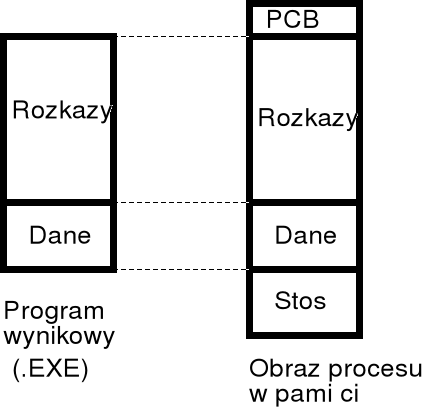
proces ładowania we współczesnych komputerach jest zazwyczaj bardziej skomplikowany;
w trakcie linkowania programu nie jest znane położenie programu w pamięci w trakcie jego wykonywania; często przyjmuje się, że program zostanie umieszczony w pamięci począwszy od komórki o adresie 0;
zazwyczaj nie jest możliwe umieszczenie programu począwszy od komorki 0, jednak pewne architektury procesorów (np. 8086/88) pozwalają na umieszczenie programu w dowolnym obszarze pamięci i poprawne wykonanie go, nawet jeśli program został linkowany przy założeniu, że zostanie umieszczony począwszy od adresu 0;
w przypadku procesora 8086/88 dotyczy to jednak tylko programów, których rozmiar jest mniejszy od 64KB; programy tego typu, zapisywane w plikom z rozszerzeniem .COM (zob. dalszy opis), wykonywane są przy stałych zawartościach rejestrów segmentowych CS=DS=SS, które ustawiane są przez system operacyjny przed uruchomieniem programu; ponieważ adres fizyczne rozkazów i danych obliczane są wg tego samego schematu (rej. segmentowy * 16 + offset), więc kod i dane programu mogą być umieszczone w dowolnym obszarze pamięci, którego początek wskazują rejestry CS, DS i ES;
niezależnie od tego adresy rozkazów sterujących (skoków) w omawianym procesorze obliczane są względem bieżącej zawartości wskaźnika instrukcji (E)IP wg formuły (E)IP + zaw. pola adresowego; jeśli więc pewien fragment programu zostanie przesunięty w inne miejsce, to rozkaz skoku będzie nadal omijał (przeskakiwał) ustaloną liczbę rozkazów;
wyłoniły się trzy podstawowe techniki ładowania programów do pamięci:
ładowanie bezwzględne,
ładowanie relokowalne,
ładowanie dynamiczne;
w przypadku ładowania bezwzględnego cały kod programu musi być w pełni określony w chwili ładowania go do pamięci; programista może posługiwać adresami fizycznymi lokacji pamięci, lub też adresy te mogą wyznaczone przez kompilator (asembler) i linker; niezbędna jest jednak znajomość adresu początkowego obszaru pamięci, do którego zostanie wpisany program;
znacznie bardziej elastyczne są rozwiązania, w których decyzję o położeniu programu w pamięci podejmuje się podczas ładowania — mówimy wówczas o ładowaniu relokowalnym; w takim przypadku program można umieścić w dowolnym obszarze pamięci; technika ładowania relokowalnego stosowana jest m.in. w odniesieniu do plików w formacie DOS EXE (zob. dalszy opis);
ładowanie dynamiczne jest charakterystyczne dla współczesnych wielozadaniowych systemów operacyjnych, w których stosuje się pamięć wirtualną; wówczas poszczególne fragmenty programu mogą być rozproszone w pamięci operacyjnej, a część z nich może być przechowywana na dysku; ten sam fragment programu, jeśli zostanie ponownie przepisany z dysku do pamięci operacyjnej, może pracować w obszarze o innych adresach fizycznych; realizacja ładowania dynamicznego wymaga więc skomplikowanych sprzętowych mechanizmów transformacji adresów (zob. stronicowanie).
Interfejs programowania aplikacji (API)
w programowaniu na poziomie języka wysokiego poziomu program często nie wykonuje całego zadania samodzielnie, ale zleca wykonanie zadań cząstkowych innym programom, przede wszystkim podprogramom wchodzącym w skład systemu operacyjnego; przykładowo, program nie wykonuje samodzielnie operacji zapisu danych na dysku, ale kieruje odpowiednie zlecenie do systemu operacyjnego; tego rodzaju podejście zostało ukształtowane przez wieloletni rozwój oprogramowania;
między istnieją istotne powody, dla których sterowanie pracą urządzeń zewnętrznych komputera może być wykonywane jedynie przez system operacyjny:
zabezpieczenie przed wydawaniem poleceń do urządzenia jednocześnie przez kilka zadań (procesów);
udostępnienie jednolitego sposobu sterowania urządzeniem, niezależnie od konkretnego typu zainstalowanego w komputerze (np. drukarki) — tym samym program nie musi wnikać w szczegóły konstrukcyjne poszczególnych urządzeń;
interfejs programowania aplikacji, (używany jest także termin: interfejs programu użytkownika), nazywany w skrócie API (ang. application program interface), obejmuje zbiór struktur danych i funkcji, a niekiedy stanowi listę komunikatów; API stanowi ustaloną konwencję wywoływania, za pomocą której program użytkowy (aplikacja) może uzyskać dostęp do usług systemu operacyjnego lub usług udostępnianych przez inne moduły oprogramowania, które zwykle implementowane są jako biblioteki;
niekiedy skrót API jest tłumaczony jako "interfejs programowania aplikacji";
API definiowane jest na poziomie kodu źródłowego i stanowi pewien poziom abstrakcji między aplikacją a jądrem systemu operacyjnego (lub innego programu usługowego), co z kolei tworzy potencjalne możliwości przenośności kodu;
rozmaite pakiety API używane są w prawie każdym systemie komputerowym; do najbardziej popularnych API dla komputerów osobistych należy opracowany przez firmę Microsoft pakiet Win32 API, zawierający opisy funkcji używanych w systemie Windows; do połowy lat dziewięćdziesiątych w oprogramowaniu komputerów osobistych szeroko stosowano zestaw funkcji DOS API, który definiowany jest na poziomie asemblera;
zestaw funkcji wykonujących operacje na plikach w Unixie (i w DOSie): open, close, lseek, read , . . . stanowi API dla operacji plikowych UNIXa — dla każdej z tych funkcji podawany jest opis funkcjonalny wraz ze szczegółowymi informacjami odnośnie przekazywania parametrów do funkcji i interpretacji wartości zwracanych przez te funkcje;
opisy zawarte w API nie zawierają na ogół jakichkolwiek danych o sposobie wykonywania funkcji przez system operacyjny, czyli ukrywają wewnętrzne działania systemu — jest to określane jako pewien poziom abstrakcji, rozumianej jako ukrycie szczegółów implementacyjnych;
pominięcie szczegółów implementacyjnych zazwyczaj ułatwia zrozumienie funkcji, co stanowi jeden z czynników przyśpieszających budowę systemu oprogramowania; koncepcja ta koresponduje z zasadami hermetyzacji w językach obiektowych;
dostępność pakietu operacji wykonujących działania na urządzeniach komputera uwalnia programistę od konieczności analizowania zasad sterowania poszczególnych urządzeń i tworzenia oprogramowania dla nich (nieprawidłowe sterowanie może do uszkodzenia lub przedwczesnego zużycia urządzeń);
API nie precyzuje sposobu realizacji funkcji, więc ta sama funkcja może być zrealizowana w różnych środowiskach za pomocą różnych technik; co więcej, jeśli zostanie opracowana ulepszona wersja jakiejś usługi systemowej, to producent systemu udostępnia tę wersję zachowując dotychczasowe API, co oznacza, że nie są potrzebne jakiekolwiek zmiany w programach użytkownika;
jeśli poszczególne realizacje są zgodne ze specyfikacją, to nic nie stoi na przeszkodzie by program korzystający z pewnego zestawu funkcji API mógł być wykonywany w innych środowiskach — przenośność kodu jest od dawna postulowana w technice programowania;
stosowanie rozwiązań niestandardowych (np. wstawek asemblerowych) ogranicza przenośność kodu;
interfejs API musi być poprawny, spójny, podatny na dalsze rozszerzenia i dobrze udokumentowany; API powinien być przyjazny dla użytkownika, zwłaszcza gdy przewidywane jest jego stosowanie przez programistów nie znających dokładnie danej problematyki; API powinien być w miarę możliwości niezależny od platformy;
wywoływanie niektórych funkcji API wymaga podawania znacznej liczby parametrów, z których większość nie koresponduje z rozwiązywanym problemem i powtarza się przy kolejnych wywołaniach; w takim przypadku oferowane są programy wspomagające określane terminem wrapper (= obwoluta, opaska); w szerszym znaczeniu terminem tym określa się programy, podprogramy lub makra, które ułatwiają wywoływanie innych programów lub funkcji API;
przykładowo, gdy wywoływany program wymaga podania w linii zlecenia dużej liczby parametrów (często o standardowych wartościach), wrapper udostępnia ten program żądając podania tylko kilku istotnych parametrów, a pozostałym parametrom przypisuje wartości standardowe.
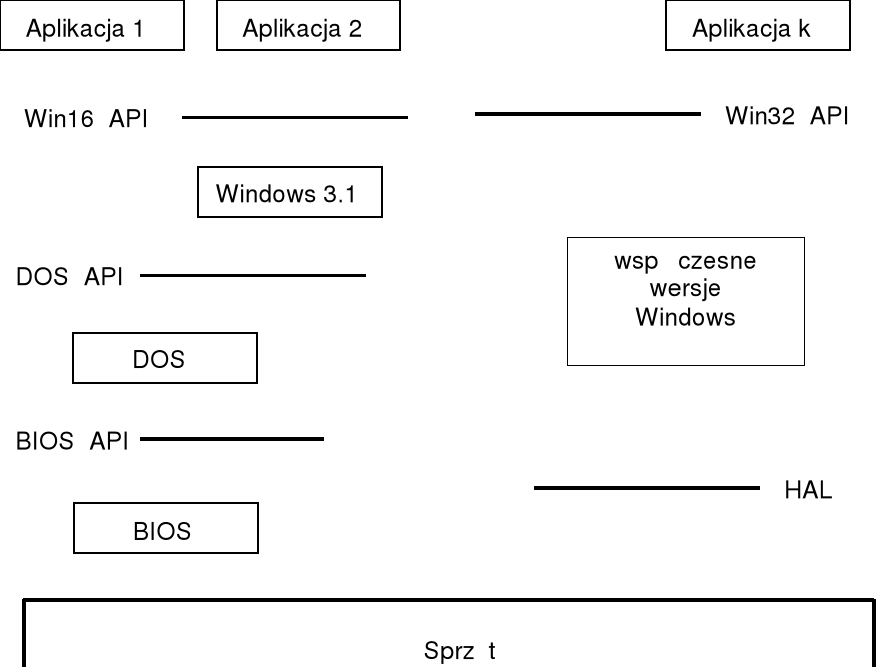
Struktura warstwowa API
często kolejne warstwy API budowane na podstawie API już istniejących — poniższy rysunek ilustruje to dla systemu Windows;
warstwa HAL (ang. hardware abstraction layer) w systemie Windows stanowi ogniwo pośrednie między sprzętem a jądrem systemu operacyjnego; HAL jest w istocie sterownikiem urządzenia dla płyty głównej; każda platforma sprzętowa ma swoją własną wersję HAL, np. wersja HAL dla płyty dwuprocesorowej różni od wersji dla płyty jednoprocesorowej.
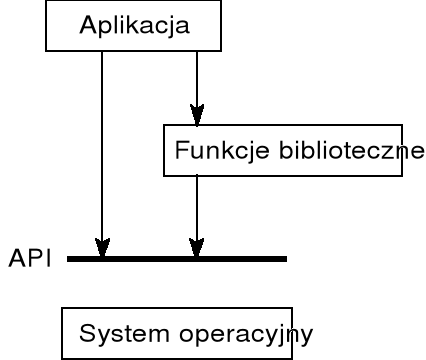
w wielu przypadkach programy mogą posługiwać się zarówno funkcjami udostępnianymi przez przez system operacyjny, jak też odpowiednimi (zwykle wygodniejszymi) funkcjami bibliotecznymi — tego rodzaju funkcje biblioteczne odwołują się również do funkcji systemowych.
API a maszyny wirtualne
maszyna widziana przez programistę jest rezultatem nałożenia warstw oprogramowania na maszynę rzeczywistą, złożoną tylko ze sprzętu; przykładowo w programie asemblerowym programista posługuje się nie tylko instrukcjami procesora, ale ma do dyspozycji także funkcje systemowe udostępniane przez system operacyjny (np. wywoływane poprzez INT 21H w środowisku DOSu);
maszyna widziana przez programistę, będąca rezultatem nałożenia na maszynę rzeczywistą szeregu warstw oprogramowania, określana jest jako maszyna wirtualna;
w takim ujęciu maszyna rzeczywista, znajdująca się na najniższym poziomie jest "nadbudowana" przez warstwy oprogramowania, co powoduje że programista ma do dyspozycji pewną liczbę maszyn, z których może tworzyć nowe, bardziej abstrakcyjne maszyny;
ponieważ opis warstwy oprogramowania sformułowany jest jako API, więc można przyjąć, że API stanowi definicję maszyny wirtualnej;
programista wyobraża sobie maszynę wirtualną jako istniejącą maszynę fizyczną, nawet gdy naprawdę nie istnieje, tzn. gdy jest wirtualna; nawet jeśli programista jest świadomy istnienia maszyny wirtualnej, to nie musi zajmować szczegółami jej implementacji;
przykładowo, zadanie DOSowe realizowane w środowisku Windows ma wrażenie, że wykonuje się w zwykłym komputerze wyposażonym w system DOS, chociaż w istocie jest to środowisko wytworzone przez Windows dla potrzeb realizacji takich programów; w takiej sytuacji mówimy, że zadanie DOSowe realizowane jest na maszynie wirtualnej.
Implementacja funkcji API za pomocą bibliotek dynamicznych
funkcje Win32 API implementowane są za pomocą kodu zawartego w bibliotekach dynamicznych:
user32.dll (obsługa interfejsu użytkownika)
kernel32.dll (operacje plikowe, zarządzanie pamięcią)
gdi32.dll (operacje graficzne)
istnieje też szereg innych bibliotek DLL, np. WinInet, która obsługuje operacje w Internecie, Winmm, która obsługuje operacje multimedialne i wiele innych;
biblioteki dynamiczne pozwalają na współdzielenie kodu przez kilka procesów — kod pewnej funkcji może być (pseudo) jednocześnie wykonywany przez kilka procesów;
w systemie Windows każdy proces, który używa DLL otrzymuje swoją własną kopię sekcji (segmentu) danych — w szczególności oznacza to, że ewentualne wykorzystanie sekcji danych DLL do komunikacji między procesami wymaga wyraźnego zaznaczenia, że dane mają być współdzielone;
kod zawarty w bibliotekach dynamicznych wykonywany jest na poziomie uprzywilejowania 3, co oznacza, że nie komunikuje się on bezpośrednio z portami urządzeń wejścia/wyjścia; rolę tę pełnią sterowniki urządzeń.
Sterowanie procesami na poziomie języka C
exit - funkcja przekazuje sterowanie do procesu macierzystego, podając jednocześnie kod powrotu (zazwyczaj 0 przyjmowane jest jako kod poprawnego wykonania programu); przykładowe wywołanie może mieć postać:
exit (kod_zakonczenia);
Funkcja exit może być wywoływana wewnątrz dowolnej funkcji w programie. Natomiast wewnątrz funkcji main zamiast exit można umieścić instrukcję return, np.:
int main( )
{
- - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - -
return (kod_zakonczenia);
}
Należy odróżniać:
1. funkcję systemową exit zdefiniowaną w Unixie (Linuxie) — powoduje zakończenie procesu;
2. funkcję exit w języku C — powoduje najpierw wypisanie danych ze wszystkich częściowo zapełnionych buforów, wykonanie procedur zakończenia (zgłoszonych wcześniej przez funkcje atexit), a następnie wywołuje funkcję systemową exit;
3. funkcję _exit w języku C — od razu wywołuje funkcję systemową exit.
funkcje exit i _exit języka C są analogicznie definiowane także w programach pracujących w środowisku Windows;
niekiedy mogą też powstać sytuacje wymagające wcześniejszego zakończenia wykonywania czyli zaniechania dalszej realizacji procesu; proces może informować system o powstałej sytuacji podając kod zakończenia, który ma sens poziomu błędu;
w przypadku wystąpienia błędu może być wykonywany zrzut (zapisanie) obszaru pamięci zajmowanej przez program (ang. dump); zawartość ta, zapisana na dysku, może być później analizowana za pomocą programu diagnostycznego.
system - funkcja wywołuje interpreter zleceń (ang. shell) z podanym argumentem, którym może być standardowe polecenie systemu operacyjnego lub nazwa wywoływanego programu, np.:
int main ( )
{
int stan;
odp = system("date");
- - - - - - - - - - - - -
}
funkcja system zwraca 1 w przypadku błędu; jeśli argumentem funkcji jest łańcuch pusty, to wywołany interpreter podaje znak zachęty (ang. prompt) i dalsze polecenia podaje się z klawiatury — zakończenie funkcji system następuje po napisaniu exit;
exec... - zakończenie wykonywania bieżącego procesu i rozpoczęcie realizacji procesu utworzonego na podstawie pliku podanego jako argument funkcji — zatem funkcja systemowa exec... zastępuje dotychczas wykonywany proces przez inny; innymi słowy: funkcja exec... dokonuje ponownego zainicjowania procesu na podstawie wskazanego programu — kod i dane dotychczas wykonywane procesu są usuwane z pamięci, a na ich miejsce zostaje wprowadzony kod i dane pobrane z pliku; natomiast proces pozostaje ten sam (identyfikator procesu nie ulega zmianie);
funkcja exec... ma sześć odmian różniących się formatem parametrów (execl, execp, execv, ...);
proces, który wywołał funkcję exec... nazywany jest procesem wywołującym, a program który ma być wykonany nazywany jest nowym programem (w tej operacji Unix nie tworzy nowego procesu);
w systemie Unix wywołanie funkcji systemowej exec... jest jedynym sposobem wykonania innego programu; przykładowe wywołanie w środowisku Unix może mieć postać:
execl ("/bin/konw2.out",
"konw2.out", "/plany", "/wydr",NULL);
pierwszy parametr funkcji execl określa nazwę pliku zawierającego nowy program; następne parametry są tymi samymi, które byłyby przekazane do programu przez system, gdyby program został wywołany z linii zlecenia;
zazwyczaj pierwszy i drugi i parametr funkcji execl są podobne lub identyczne — pierwszy parametr zawiera bowiem nazwę programu, który zastąpi dotychczasowy, drugi parametr i następne przekazywane są do uruchamianego programu jako parametry linii zlecenia; przekazane parametry będą dostępne w uruchomionym programie, napisanym w języku C, jako argv[0] (drugi parametr), argv[1] (trzeci parametr), itd.; ponieważ standardowo parametr argv[0] zawiera nazwę wykonywanego programu, więc pierwszy i drugi parametr funkcji execl wskazują na ten sam plik (chociaż drugi może nie zawierać ścieżki dostępu);
wyjątkowo, po wywołaniu funkcji exec... proces wywołujący jest kontynuowany, jeśli nie udało się uruchomić nowego programu, np. ze względu na brak pamięci;
spawn... - funkcja powoduje zatrzymanie wykonywania procesu macierzystego, uruchomienie procesu potomnego, a jego zakończeniu wznowienie procesu macierzystego;
funkcja spawn... jest dostępna w systemie Windows, nie jest natomiast dostępna w systemie Unix;
przykładowe wywołanie może mieć postać:
spawnl(P_WAIT, "e:\\zadania\\konw2.exe",
"e:\\zadania\\konw2.exe", "/plany", "/wydr",NULL);
funkcja spawn... ma kilka odmian różniących się formatem parametrów (spawnl, spawnle, . . .).
w systemie Windows dopuszczalne są poniższe wartości pierwszego parametru (w systemie DOS mogą być używane tylko parametry P_WAIT i P_OVERLAY):
P_WAIT — powoduje zatrzymanie wykonywania procesu macierzystego aż do zakończenia procesu potomnego;
P_NOWAIT — powoduje wykonywanie procesu macierzystego i potomnego; funkcja zwraca identyfikator procesu potomnego, tak że proces macierzysty może oczekiwać na zakończenie procesu potomnego używając funkcji wait;
P_NOWAITO — podobnie jak P_NOWAIT, ale nie może być używana funkcja wait;
P_DETACH — podobnie do P_NOWAITO, ale proces potomny wykonywany jest w tle bez dostępu do klawiatury i ekranu;
P_OVERLAY — działa identycznie jak funkcja exec...;
CreateProcess stanowi podstawową funkcję używaną do tworzenia nowych procesów w systemie Windows; jednak ze względu na dużą liczbę parametrów i ich złożoność nie będzie tu omawiana; szczegóły można znaleźć w opisie Win32 API.
fork - (ang. rozwidlenie) funkcja systemowa, dostępna w systemie Unix, tworzy kopię wykonywanego procesu i rozpoczyna wykonywanie dwóch niezależnych procesów realizujących ten sam kod; (innymi słowy: funkcja fork tworzy kopię aktualnie wykonywanego programu i rozpoczyna wykonywanie obu programów);
początkowe wartości zmiennych w obu procesach są te same co przed wykonaniem funkcji fork, ale proces może zmieniać wartości zmiennych tylko w swoim segmencie danych;
prototyp funkcji ma postać
int fork ( );
funkcja fork wywołana raz przez proces macierzysty przekazuje wartość dwukrotnie:
procesowi macierzystemu — numer identyfikacyjny nowo utworzonego procesu potomnego,
procesowi potomnemu — wartość 0;
zatem w wyniku przykładowego wywołania
proc_id = fork ( );
wartość zmiennej proc_id w procesie potomnym będzie wynosiła 0, a w procesie macierzystym będzie różna od 0; są to jedyne różnice w obu egzemplarzach programu; jeśli funkcji fork nie uda się wykonać pomyślnie, to zwracana jest wartość 1;
po wykonaniu funkcji fork kopia segmentu danych procesu potomnego jest kopią segmentu danych procesu macierzystego (ale to nie jest kopia odpowiedniego pliku dyskowego); często segment instrukcji (segment kodu) nie ulega żadnym zmianom w trakcie realizacji i może być współdzielony przez oba procesy;
w systemie Unix wykonanie funkcji fork stanowi jedyny sposób utworzenia nowego procesu;
proces potomny może wraz z procesem macierzystym wykonywać działania na wspólnych plikach (proces macierzysty otwiera te pliki przed fork i przekazuje procesowi potomnemu); proces potomny ma własne kopie uchwytów (deskryptorów) plików procesu macierzystego.
funkcja systemowa fork ma dwa zastosowania:
1. proces tworzy swoją kopię, aby jedna z nich mogła wykonać jakąś operację, podczas gdy druga kopia zajmowałaby się innym zadaniem;
2. proces zamierza wykonać inny program — ponieważ jedynym sposobem wykonania nowego procesu jest fork, więc proces musi najpierw utworzyć swoją kopię, a następnie jeden z procesów (zwykle proces potomny) wywołuje funkcję systemową exec w celu wykonania nowego programu; wg takiego schematu działają m.in. interpretery zleceń (ang. shell).
wait — funkcja systemowa Unixa (dostępna także w Win32), której wywołanie powoduje, że proces czeka aby jeden z utworzonych przez niego procesów potomnych zakończył działanie; prototyp funkcji ma postać
int wait (int * status);
wartość zwracana przez funkcję wait jest równa identyfikatorowi procesu potomnego, który został zakończony (jeśli nie było żadnego procesu potomnego, to funkcja zwraca 1);
jeśli proces wykonujący funkcję wait ma procesy potomne, które jeszcze nie zostały zakończone, to funkcja wait zawiesza proces wywołujący, dopóki nie zakończy działania jeden z jego potomków; po zakończeniu procesu potomnego wartość przekazana przez funkcję exit (kończąca działanie procesu potomnego) będzie zapamiętana w zmiennej status; zmienna status zawiera: w młodszym bajcie kod zakończenia podawany przez system operacyjny, w starszym bajcie kod powrotu podawany przez funkcję exit.
Analiza działania funkcji wait wymaga rozpatrzenia dwóch przypadków:
1. proces macierzysty wywołał funkcję wait zanim proces potomny zakończył działanie — w tym przypadku po wykonaniu funkcji exit zaczyna być dalej wykonywany proces macierzysty; argument funkcji exit będzie przekazany poprzez zmienną status;
2. proces potomny został zakończony zanim jeszcze proces macierzysty wykonał funkcję wait — w tym przypadku proces, który został zakończony poprzez wykonanie funkcji exit staje się procesem-duchem (ang. zombie process), nazywany także procesem w stanie zombie.
Proces-duch jest procesem zakończonym, ale na jego zakończenie nie czekał proces macierzysty; jądro systemu operacyjnego zwalnia wszystkie zasoby używane przez proces-duch (np. obszar pamięci), ale pozostawia rekord zawierający kod wyjścia i pewne statystyki; kod wyjścia zostanie udostępniony procesowi macierzystemu, gdy ten wywoła funkcję wait.
Należy także brać pod uwagę możliwość, że proces macierzysty zakończy się przed swoimi procesami potomnymi. W tej sytuacji identyfikatory procesu macierzystego dla rozpatrywanych procesów potomnych tracą ważność. Osieroconym procesom (aktywnym i duchom) Unix przydziela identyfikator procesu "init" (= 1).
funkcja spawn... nie jest dostępna w systemie Unix — można ją zastąpić przez funkcje fork i exec..., np.
int st1;
- - - - - - - - - - - -
proc_id = fork ( );
if (proc_id == 0)
{
/* ten fragment zostanie wykonany w proces. potomnym */
execl ("inny.exe", .....);
/* jedna z kopii (uzyskana jako wynik fork) zostanie
zastąpiona przez program "inny.exe", który
rozpocznie się wykonywać */
}
/* ten fragment zostanie wykonany w procesie macierzystym */
wait(&st1); /* oczekiwanie na zakończenie proc. potomnego */
Uwaga: zakładamy, że został uruchomiony dokładnie jeden proces potomny, jak również że w podanym fragmencie na pewno nie wystąpią błędy.
Programy rezydentne w systemie DOS
system operacyjny DOS dominował w komputerach PC do połowy lat dziewięćdziesiątych; system DOS jest stosunkowo prosty, jednozadaniowy, o umiarkowanych wymaganiach sprzętowych — te cechy odpowiadały możliwościom stosowanego wówczas sprzętu;
aczkolwiek system DOS z założenia był systemem jednozadaniowym, to jednak przez wiele lat czynione były próby prowizorycznego dostosowania systemu DOS do pracy wielozadaniowej; w wyniku podjętych prac rozwinięto technikę programów rezydentnych (ang. TSR — terminate and stay resident), stanowiących namiastkę wielozadaniowości;
obecnie system DOS wychodzi z użycia, ale programy "DOSowe" są nadal akceptowane przez różne wersje systemu Windows; system Windows musi być więc także przygotowany do wykonywania programów TSR;
program TSR różni się tylko tym od zwykłego programu DOSowego, że po wykonaniu programu jego część kodu i danych pozostaje w pamięci operacyjnej tworząc właściwy program rezydentny; program rezydentny może być później wielokrotnie uruchamiany (w całości lub tylko poprzez wywołanie wybranego podprogramu);
obecność programu rezydentnego ogranicza możliwość wykonywania innych programów jedynie w tym zakresie, że program rezydentny zajmuje część pamięci operacyjnej (o rozmiarze 640 KB); w rezultacie w pamięci operacyjnej komputera mogą się jednocześnie znajdować dwa programy, wykonywane na żądanie;
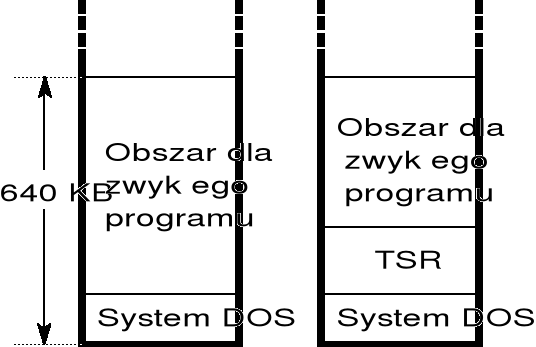
struktura typowych programów rezydentnych pokazana jest na rysunku;
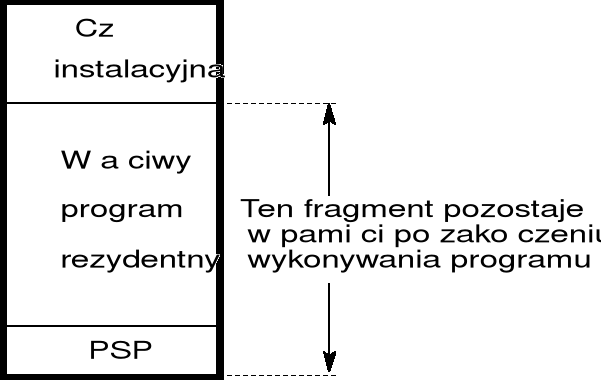
ze względu na sposób, w jaki przekazywane jest sterowanie do programu rezydentnego można podzielić je na:
aktywne — wywoływane wskutek wystąpienia pewnych zdarzeń zewnętrznych w stosunku do aktualnie wykonywanego programu (zwykle naciśnięcie charakterystycznej kombinacji klawiszy);
pasywne — sterowanie przekazywane jest wyłącznie poprzez jawne odwołania do niego skierowane z innego programu (zwykle jako wywołanie podprogramu za pomocą instrukcji INT);
program rezydentny aktywny jest całkowicie odrębnym programem uruchamianym wskutek wystąpienia jakiegoś zdarzenia — uruchomienie takiego programu powoduje zawieszenie dotychczas wykonywanego programu na czas wykonywania programu rezydentnego;
system Windows zastępuje funkcje programów rezydentnych aktywnych i pasywnych:
aktywnych, poprzez naturalne wywołanie innego programu w trakcie wykonywania bieżącego;
pasywnych, poprzez możliwość instalacji bibliotek linkowanych dynamicznie (DLL), które mogą być wywoływane przez programy.
Zarządzanie pamięcią
programy wykonywane przez procesor muszą się znajdować się w pamięci operacyjnej, która stanowi pamięć główną komputera; pamięć operacyjna stanowi jedyny obszar pamięci, do którego procesor ma bezpośredni dostęp; procesor odczytuje kolejne rozkazy z pamięci operacyjnej, które następnie wykonuje; procesor pobiera także dane z pamięci operacyjnej i zapisuje wyniki obliczeń (przetwarzania);
pamięć operacyjna jest tablicą, której rozmiar może sięgać kilkuset milionów bajtów; każdy bajt ma własny adres; pamięć operacyjna traci zawartość po wyłączeniu zasilania (jest pamięcią ulotną);
pamięć operacyjna jest za mała aby pomieścić wszystkie dane i programy, a zawarte w niej dane giną po odcięciu zasilania;
konieczne jest więc stosowanie pamięci pomocniczej, stanowiącej zaplecze dla pamięci operacyjnej; zadaniem pamięci pomocniczych jest trwałe przechowywanie wielkiej ilości danych; typowym urządzeniem pamięci pomocniczej jest dysk magnetyczny, jako środek magazynowania danych i programów; stosowanych jest wiele innych typów pamięci pomocniczych, obecnie szeroko stosowane napędy CD ROM, wykorzystujące optyczne metody odczytu;
większość programów (w tym kompilatory, edytory, debuggery) do czasu załadowania do pamięci operacyjnej jest przechowywana na dysku; z kolei w trakcie wykonywania używa dysków jako źródeł i miejsc przeznaczenia przetwarzanych przez nie danych;
przetwarzanie danych zapisanych w pamięci pomocniczej wymaga uprzedniego przepisania ich do pamięci operacyjnej (za pomocą operacji wejścia-wyjścia);
warunkiem efektywnego wykorzystania systemu komputerowego, a także skrócenia czasu udzielania odpowiedzi użytkownikom jest stworzenie możliwości umieszczenia w pamięci operacyjnej kilku programów; można powiedzieć, że pamięć musi być dzielona między kilka procesów; wymaga to wprowadzenia odpowiednich metod zarządzania pamięcią.
pamięć operacyjna stanowi jeden z zasobów systemu komputerowego i racjonalne gospodarowanie pamięcią jest warunkiem efektywności systemu; udostępnianiem (przydzielaniem) bloków pamięci poszczególnym programom zajmuje się system operacyjny;
w wielu przypadkach w trakcie tworzenia programu nie można przewidzieć rozmiarów danych, na których program będzie wykonywał działania — w takich przypadkach pamięć potrzebna na dane powinna być przydzielana dynamicznie przez system operacyjny w miarę żądań programu;
programy kierują do systemu operacyjnego żądania przydzielenia nowych obszarów pamięci, które po pewnym czasie, jeśli są już niepotrzebne, zwracane są do systemu; niekiedy programy żądają przydzielenia obszarów większych niż cała zainstalowana pamięć główna (operacyjna); ogólnie: programy wykazują zmienne zapotrzebowanie na pamięć operacyjną;
system operacyjny powinien ewidencjonować aktualnie zajęte części pamięci wraz z informacją w czyim są władaniu;
system operacyjny powinien decydować, które procesy mają być załadowane do zwolnionych obszarów pamięci;
system operacyjny powinien przydzielać i zwalniać różne obszary pamięci stosownie do potrzeb; aczkolwiek podstawową rolę pełni pamięć operacyjna, to jednak pamięć pomocnicza jest często używana i musi działać wydajnie; system operacyjny musi zajmować się planowaniem przydziału obszarów pamięci dyskowej;
zarządzanie pamięcią jest szczególnie ważne w systemach wielozadaniowych — system operacyjny powinien odpowiednio dzielić dostępną pamięć między wykonywane programy, w dążeniu do jak najbardziej efektywnej pracy systemu komputerowego; opracowano i zbadano wiele różnych algorytmów zarządzania pamięcią.
Ochrona pamięci
w dobrze skonstruowanym systemie komputerowym powinny istnieć mechanizmy zapewniające ochronę systemu operacyjnego przed wpływami programów użytkowników, a ponadto wzajemną ochronę programów użytkowników;
prosty sposób realizacji takiej ochrony polega na użyciu rejestru bazowego i granicznego; mechanizm ten stosowany jest nadal we współczesnych procesorach, ale w zmodyfikowanej postaci;
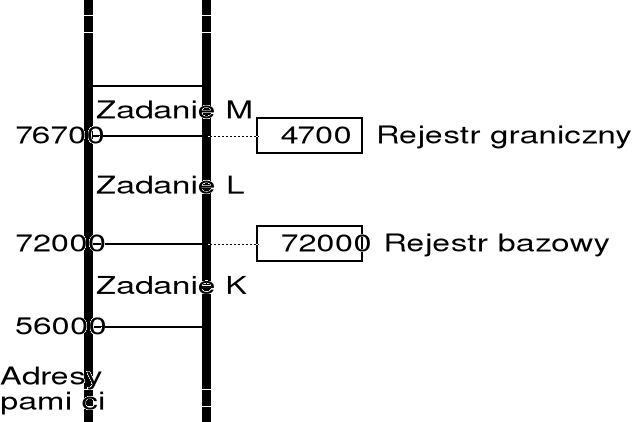
rejestr bazowy przechowuje najmniejszy dopuszczalny adres fizyczny pamięci dla danego zadania;
rejestr graniczny zawiera rozmiar obszaru pamięci;
każdy adres wygenerowany w programie jest sprawdzany z zawartością ww. rejestrów; próba wyjścia poza obszar traktowana jest jako błąd programu;
zawartości rejestrów bazowego i granicznego ustawia system operacyjny za pomocą specjalnych rozkazów, które nie mogą być wykonywane przez program użytkownika;
Fragmentacja zewnętrzna i wewnętrzna
system operacyjny przechowuje tablicę z informacjami o tym, które części pamięci są dostępne, a które zajęte;
po uruchomieniu systemu cała pamięć jest dostępna dla procesów użytkowych i jest traktowana jako jeden wielki blok pamięci — dziura; gdy program lub system zgłasza zapotrzebowanie na pamięć, to poszukiwana jest dziura, która nadaje się najlepiej do przydziału;
najbardziej znane są następujące strategie poszukiwania:
1. pierwsze dopasowanie,
2. najlepsze dopasowanie,
3. najgorsze dopasowanie;
w wyniku wykonywania wielu operacji przydzielania i zwalniania obszarów pamięci występuje fragmentacja, objawiająca się istnieniem dużej liczby małych niezajętych obszarów pamięci — przydzielanie większych obszarów pamięci napotyka na trudności;
fragmentacja zewnętrzna polega na tym, że rozmiar znalezionej dziury jest większy od rozmiaru żądanego — po przydzieleniu pozostaje mały niezajęty obszar pamięci, który jest nieprzydatny dla innych programów;
czasami jeśli rozmiar dziury jest minimalnie większy od rozmiaru żądanego, to przydziela się całą dziurę, aby uniknąć kłopotów związanych z administrowaniem obszarami zawierającymi kilkanaście bajtów; w rezultacie program otrzymuje większy obszar pamięć niż zamówiony, co oznacza że część pamięci pozostanie niewykorzystana — omawiane sytuacja nazywana jest fragmentacją wewnętrzną;
system operacyjny musi więc być zdolny do przesuwania bloków pamięci, tak by obszar niezajęty tworzył zwarty blok; mechanizm stronicowania pozwala na tworzenie ciągłych obszarów pamięci bez konieczności przepisywania zawartości pamięci.
Technika nakładkowania a pamięć wirtualna
tworzone obecnie programy są często bardzo rozbudowane, tak że nie mieszczą się w całości w pamięci operacyjnej;
technika nakładkowania polega na przechowywaniu w pamięci operacyjnej tylko tych rozkazów i danych, które są stale potrzebne — inne rozkazy i dane ładowane są w miarę potrzeby; koncepcję tę realizuje się poprzez podział programu na fragmenty, nazywane nakładkami (ang. overlay) — w praktyce mają one postać procedur;
organizacja wymiany nakładek między pamięcią dyskową i operacyjną należy do obowiązków wykonywanego programu; zatem używanie nakładek nie wymaga jakichkolwiek specjalnych mechanizmów udostępnianych przez system operacyjny, ale wymiana nakładek musi być starannie zaprojektowana i zakodowana przez programistę;
we współczesnych systemach operacyjnych problem wykonywania dużych programów rozwiązuje się przede wszystkim poprzez udostępnienie pamięci wirtualnej; w rezultacie powstaje abstrakcja pamięci głównej w postaci wielkiej, jednolitej tablicy (uwalnia programistów od zajmowania się ograniczeniami pamięciowymi);
efektywna implementacja pamięci wirtualnej wymaga silnego wspomagania ze strony procesora, który musi być wyposażony w mechanizmy transformacji adresów (opisane w dalszej części).
Stronicowanie
w trakcie wieloletniego rozwoju systemów komputerowych zaobserwowano szereg rozmaitych trudności związanych z racjonalnym zarządzaniem pamięcią, zwłaszcza w systemach wielozadaniowych;
często w pamięci operacyjnej dostępna była duża liczba niezajętych bloków, ale ich małe rozmiary (np. kilkaset bajtów) uniemożliwiały efektywne ich wykorzystanie w programach;
scalenie niezajętych obszarów wymagałoby przesunięcia także obszarów zawierających rozkazy i dane wykonywanych programów, co w wielu przypadkach było bardzo trudne do realizacji (np. zmiana adresów rozkazów);
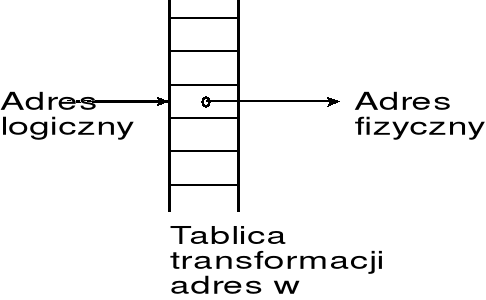
analiza tych problemów wskazuje iż najlepszym rozwiązaniem byłoby skonstruowanie mechanizmu, który pozwalał by tłumaczyć adres logiczny (wirtualny) na dowolny adres fizyczny; wówczas pamięć widziana przez program stanowiła by zwarty obszar pamięci, podczas gdy rzeczywiste lokacje pamięci tworzące ten obszar byłyby rozproszone w całej pamięci fizycznej;
zwiększenie obszaru danych programu byłoby możliwe, jeśli tylko w pamięci operacyjnej dostępne byłyby aktualnie nieprzydzielone lokacje o dowolnych adresach; co więcej za pomocą takiego mechanizmu można by wykonywać nawet programy odwołujące się do lokacji pamięci o adresach nie istniejących w zainstalowanej pamięci RAM — odwołania te musiały być skierowane do odpowiednich, rzeczywistych komórek pamięci;
transformacja taka mogłaby być realizowana za pomocą tablicy transformacji adresów, w której adres logiczny stanowił by indeks wskazujący element tablicy, w którym zapisany jest wymagany adres fizyczny;
w przypadku 4-gigabajtowej przestrzeni adresowej procesora Pentium pokazana tablica musiałaby zawierać 232 elementów, przy czym każdy element zawierał by 4 bajty; pomijając rozmiar takiej tablicy należy także brać pod uwagę konieczność ciagłej aktualizacji tablicy w zależności od wymagań stawianych przez poszczególne zadania (procesy);
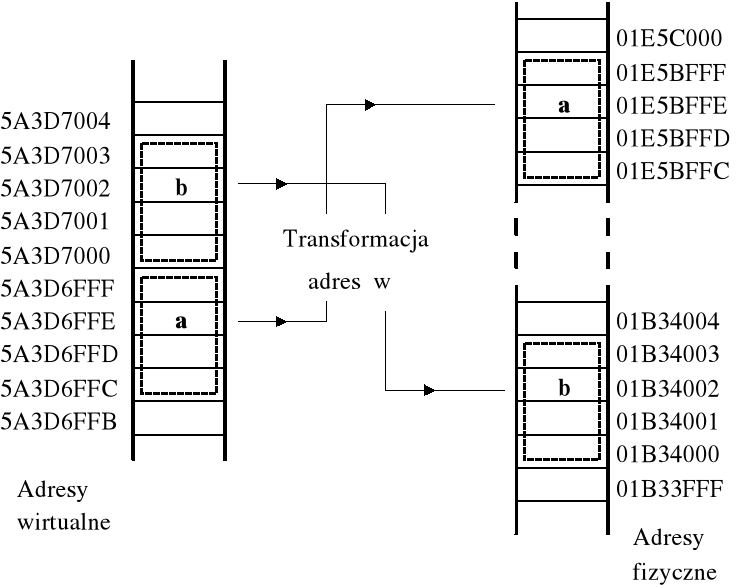
z podanych przyczyn transformacja adresów prowadzona jest w sposób nieco uproszczony; zazwyczaj transformowany adres logiczny dzieli się na trzy (lub dwa) pola; pole zawierające kilkanaście najmniej znaczących bitów adresu nie jest transformowane, natomiast pozostałe pola są przekształcane za pomocą tablicy;
w takim ujęciu adres uzyskany po transformacji starszych bitów adresu pierwotnego wskazuje pewien obszar pamięci fizycznej, nazywany stroną, w którym położenie konkretnej lokacji pamięci określa młodsza, nietransformowana część adresu pierwotnego;
rozmiar strony zależy od liczby bitów, która nie podlega transformacji; w procesorze Pentium najczęściej stosuje się schemat transformacji, w którym 12 najmniej znaczących bitów adresu liniowego nie jest przekształcane — zatem w tym przypadku strony mają rozmiar 4096 bajtów (czyli 4 KB); dostępne są też schematy transformacji, w których strony mają rozmiar 2 lub 4 MB;
w takim ujęciu, w przypadku stron 4 KB, tablica transformacji odwzorowuje 4-kilobajtowe bloki liniowej przestrzeni adresowej w 4-kilobajtowe bloki fizycznej przestrzeni adresowej; zatem w tablicy transformacji każda pozycja związana jest z jedną stroną 4 KB.
Przykład — z punktu widzenia programu zmienne a i b zajmują sąsiednie lokacje pamięci, chociaż w rzeczywistości (w pamięci fizycznej) zajmują odległe lokacje.
Dwupoziomowe tablice stron
w procesorze Pentium przyjęto standardowe rozmiary stron: 4 kB, 2 MB i 4 MB; najczęściej używa się stron 4 KB;
w przestrzeni adresowej 4 GB (liniowej lub fizycznej) można zdefiniować 220 stron po 4 KB — zatem tablica transformacji adresów powinna zawierać 220 pozycji, przy czym każda pozycja powinna zawierać 20-bitowy adres strony (strony zaczynają się od adresów podzielnych przez 4096, więc 12 najmłodszych bitów zawiera zawsze zera);
obok numeru strony trzeba też przechowywać inne informacje, więc na opis pojedynczej pozycji przeznaczono 32 bity (4 bajty);
tak zorganizowana tablica translacji zajmowałaby 220 ∗ 4 bajtów, czyli 4 MB; w połowie lat dziewięćdziesiątych w większości komputerów PC rozmiar zainstalowanej pamięci operacyjnej wynosił 4 MB; z tego powodu dla stron 4 KB wprowadzono dwupoziomową organizację tablic transformacji:
poziom wyższy tworzy katalog tablic stron — jest to tablica, która dzieli 4 GB liniową przestrzeń adresową na 1024 grupy stron; zatem tablica ma 1024 pozycje 32-bitowe; położenie katalogu tablic stron określa rejestr CR3;
poziom niższy tworzą tablice stron — mają format identyczny z katalogiem stron (1024 pozycje po 32 bity); tablica stron dzieli 4 MB grupę stron na 1024 strony po 4 kB;
wprowadzenie dwupoziomowej organizacji tablic stron implikuje podział 32-bitowego adresu liniowego na trzy elementy:
10-bitowe pole wskazujące pozycję katalogu tablic stron,
10-bitowe pole wskazujące pozycję w tablicy stron,
12-bitowe pole, które nie podlega żadnych przekształceniom i wskazuje offset względem początku strony;
ilustruje to poniższy rysunek:
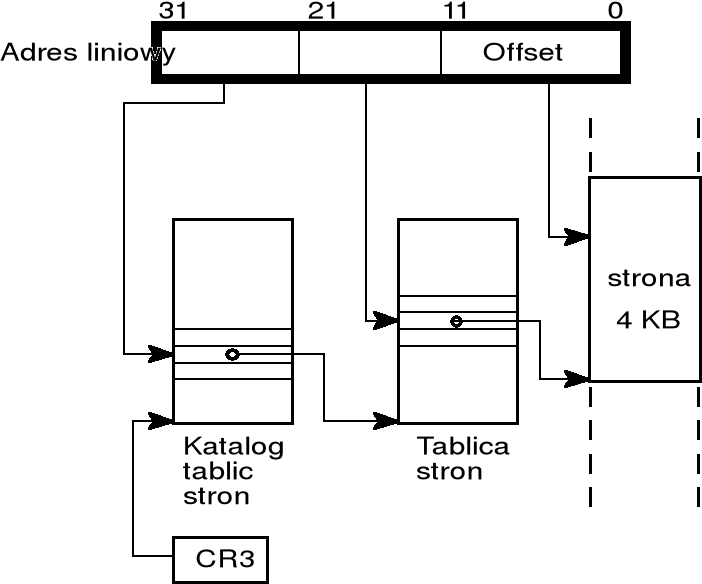
rejestr CR3 zawiera adres fizyczny katalogu tablic stron
w systemie Windows każdy proces ma przyporządkowany własny katalog tablic stron; zatem w chwili przełączania procesów zmienia się również zawartość rejestru CR3.
Realizacja pamięci wirtualnej za pomocą stronicowania
omówione mechanizmy stronicowania stanowią podstawę do implementacji pamięci wirtualnej, co oznacza symulowanie dużej pamięci operacyjnej za pomocą stosunkowo niedużej pamięci RAM i pamięci dyskowej; implementacja ta polega na przechowywaniu zawartości pamięci symulowanej częściowo w pamięci RAM i częściowo w pamięci dyskowej;
jeśli strona, do której następuje odwołanie, aktualnie nie znajduje się w pamięci operacyjnej, to generowany jest wyjątek (przerwanie), który obsługiwany jest przez system operacyjny, który dokonuje wymiany stron; wówczas inna, aktualnie nieużywana strona kopiowana jest na dysk, a na jej miejsce wprowadzana jest żądana strona; w systemie Windows strony zapisywane i odczytywane z dysku gromadzone są w pliku wymiany;
ponieważ stosowana jest transformacja adresów, więc wymiana może dotyczyć jakiekolwiek strony w pamięci RAM (zwykle wybiera się stronę od dawna nieużywaną) położoną w dowolnym miejscu pamięci o adresie początkowym podzielnym przez 4096; dotychczasowa zawartość strony w pamięci RAM jest zapisywana na dysk, a na jej miejsce wprowadzana jest aktualnie potrzebna strona, tymczasowo przechowywana na dysku;
w niektórych przypadkach program może się odwoływać do lokacji pamięci o adresach nie istniejących w zainstalowanej pamięci RAM; odwołania te muszą zostać skierowane do odpowiednich, rzeczywistych komórek pamięci;
realizacja pamięci wirtualnej za pomocą stronicowania ma liczne zalety, wśród których można wymienić:
poszczególne procesy mają dostęp wyłącznie do swoich własnych obszarów pamięci — jakiekolwiek odwołanie do pamięci przechodzi zawsze przez tablice transformacji adresów i jest kierowane do własnego obszaru pamięci procesu;
zarządzanie pamięcią jest znacznie usprawnione, ponieważ system operacyjny nie musi przeprowadzać scalania małych, niezajętych obszarów pamięci; zwarty obszar pamięci wirtualnej może być ulokowany w postaci wielu stron rozproszonych w całej pamięci RAM;
stosowanie pamięci wirtualnej powoduje pewne zmniejszenie prędkości wykonywania programu wskutek konieczności wymiany stron między pamięcią operacyjną a pamięcią dyskową; im mniejsza jest zainstalowana pamięć RAM, tym wymiana strona wykonywana częściej.
Tablica TLB
z podanego dotychczas opisu mechanizmu stronicowania wynika, że dostęp do pojedynczej lokacji pamięci wymaga dodatkowo odczytania odpowiedniej pozycji w katalogu tablic stron i w tablicy stron, co mogłoby znacznie przedłużyć czas wykonywania rozkazu; jednak programy mają skłonność do wykonywania działań na danych znajdujących się w sąsiedztwie (zasada lokalności), co oznacza kolejne odwołania do pamięci mogą dotyczyć tej samej strony; to samo dotyczy rozkazów;
celowe jest więc rejestrowanie informacji o ostatnio przeprowadzonych transformacjach adresów i wykorzystywanie ich w trakcie dostępu do pamięci; informacje te gromadzone są w specjalnym buforze wewnątrz procesora, znanym jako tablica TLB (ang. translation lookaside buffers); badania symulacyjne pokazują, że 98% wszystkich dostępów do pamieci jest wspomaganych przez TLB;
tablica TLB zawiera pewną liczbę wierszy (zwykle 32) — każdy wiersz zawiera 20 najbardziej znaczących bitów adresu wirtualnego oraz 20 najbardziej znaczących bitów adresu fizycznego, który został uzyskany poprzez odczyt katalogu tablicy stron i tablicy stron;

jeśli opis pewnej strony znajduje się w TLB, to procesor pobiera informacje o adresie fizycznym wprost z TLB; przeglądanie tablicy TLB wykonują układy równoległe, które pozwalaja na natychmiastowe stwierdzenie, czy potrzebna pozycja jest w TLB;
tablicę TLB można rozpatrywać jako szczególny rodzaj pamięci, w której adresowanie odbywa się nie poprzez podanie numeru komórki pamięci, ale poprzez podanie zawartości (adresu wirtualnego); jeśli istnieje taki wiersz pamięci, w którym podany adres wirtualny jest identyczny z zawartością pola po lewej stronie, to odczytywane jest zawartość pola po prawej stronie; tego rodzaju pamięci nazywane sa pamięciami asocjacyjnymi;
jeśli przyjmiemy, że tablica TLB zawiera 32 wiersze, to tym samym wskazane są 32 strony, każda po 4 KB, a więc dostęp do najcześciej używanych stron o łącznym rozmiarze 128 KB nie wymaga wykonywania pełnej transformacji adresu.
Organizacja pamięci w komputerach PC
procesory Pentium (i ich poprzedniki) mogą pracować w trybie rzeczywistym i w trybie chronionym; dodatkowo w trybie chronionym zdefiniowany jest podtryb V86, w którym procesor, pracując dalej w trybie chronionym, zachowuje się prawie dokładnie tak samo jak w trybie rzeczywistym; podtryb V86 używany jest do wykonywania programów przewidzianych do wykonywania w systemie DOS;
w trybie rzeczywistym i w trybie V86 możliwe jest adresowanie obszaru 1 MB (pamięć operacyjna RAM zajmuje początkowe 640 KB tego obszaru); w trybie chronionym adresy mogą dochodzić do 4 GB;
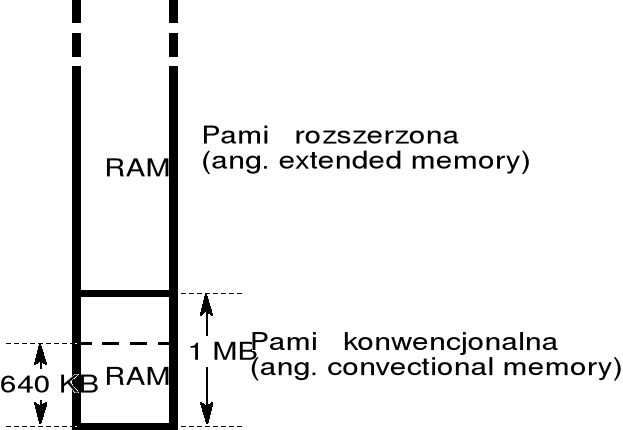
dostęp do pamięci o adresach powyżej 1 MB, nazywanej pamięcią rozszerzoną, wymaga wprowadzenia procesora w tryb chroniony, co jest kłopotliwe dla programów wykonywanych w trybie rzeczywistym.
Standaryzacja metod dostępu do pamięci o adresach powyżej 1 MB
przez wiele lat, mimo rozpowszechniania się procesorów rodziny x86 posiadających zdolność pracy w trybie chronionym, brak było odpowiedniego oprogramowania pozwalającego na wykonywanie programów w trybie chronionym — system Windows rozpowszechnił się dopiero na początku lat dziewięćdziesiątych;
w istniejącej sytuacji, przed opracowaniem systemów operacyjnych umożliwiających wykonywanie programów w trybie chronionym, postanowiono doraźnie zdefiniować techniki i standardy wspomagające dostęp do pamięci rozszerzonej dla programów wykonywanych w trybie rzeczywistym i w trybie V86;
czołowe firmy komputerowe przyjęły dokumenty (specyfikacje) określające zasady dostępu do pamięci rozszerzonej — specyfikacje te stanowiły podstawę do budowy pakietów oprogramowania wspomagających dostęp do pamięci rozszerzonej, i jednocześnie określały interfejs, poprzez który zwykłe programy mogły się porozumiewać z oprogramowaniem wspomagającym;
najczęściej używane są specyfikacje:
XMS — (ang. extended memory specification) specyfikacja zasad dostępu do pamięci rozszerzonej; program HIMEM.SYS jest zgodny ze specyfikacją XMS;
EMS — (ang. expanded memory specification) specyfikacja zasad dostępu do pamięci oparta na innej koncepcji:
w latach osiemdziesiątych specyfikacja EMS implementowana była za pomocą kart rozszerzeniowych zawierających dodatkową pamięć RAM, umieszczoną poza przestrzenią adresową procesora;
w późniejszych rozwiązaniach zastosowano symulację za pomocą odpowiedniego oprogramowania (np. sterownik EMM.386 w systemie DOS);
DPMI — (ang. DOS protected mode interface) specyfikacja opracowana m.in. przez firmy Microsoft, Borland, oferuje możliwość wykonywania quasi-konwencjonalnych programów DOSowych w trybie chronionym;
wymienione specyfikacje są udostępniane także w systemie Windows 95/98 i NT; maksymalny rozmiar przydzielanego obszaru pamięci (zarządzanego przez jedną z ww. specyfikacji) jest ograniczony jedynie możliwościami systemu, co odpowiada ustawieniu "Automatycznie" w oknie Właściwości/Pamięć wykonywanego programu; w szczególności, ze względu na stosowanie pamięci wirtualnej możliwe jest przydzielenie obszaru pamięci większego niż cała zainstalowana pamięć RAM;
w przypadku źle napisanych programów, które próbują przydzielić całą dostępną pamięć (co znacznie pogarsza pracę innych programów) może być celowe ograniczenie rozmiaru pamięci XMS lub EMS, np. do 4 MB.
Przestrzeń adresowa w systemie Windows
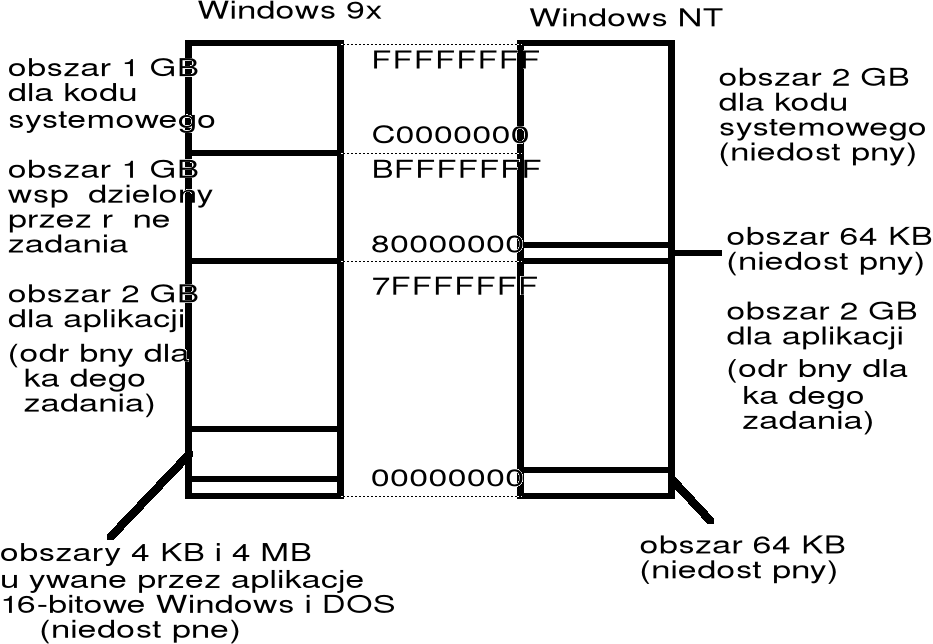
każdy proces (zadanie) w systemie Windows widzi pamięć jako 32-bitową liniową przestrzeń adresową o adresach o 0 do 4 GB; obszar 2 4 GB jest zarezerwowany dla systemu; każdy proces ma dyspozycji obszar 4 MB 2 GB; pamięć o takiej wielkości nie jest (na razie?) dostępna w komputerach PC — jest implementowana jako pamięć wirtualna za pomocą stronicowania.
Wprowadzenie do operacji plikowych
plikiem nazywa się zespół informacji, który z jakichkolwiek względów wyodrębniamy i chcemy zapisać na dysku nadając mu nazwę;
zapewnienie użytkownikom wygodnego dostępu do oprogramowania i danych zawartych w plikach wymaga skonstruowania systemu plików, który zarządzany jest przez system operacyjny;
system operacyjny odwzorowuje pliki na urządzenia fizyczne;
podstawowym problemem zarządzania systemem plików jest to, że pliki się ciągle zmieniają (zawartość, rozmiary, pliki są kasowane i tworzone są nowe);
w współczesnych systemach operacyjnych posługiwanie się plikami jest ułatwione dzięki grupowaniu ich w katalogi;
system operacyjny traktuje plik jako ciąg bajtów bez żadnej dodatkowej struktury; znaczenie bajtów zawartych w pliku określone jest przez jego twórcę i użytkownika;
podstawowe operacje na plikach wykonywane przez systemy operacyjne obejmują tworzenie i usuwanie plików i katalogów, odczytywanie i zapisywanie i danych oraz zapewnienie niezbędnej ochrony w zakresie dostępu do plików.
Struktura informacji zapisywanej na dysku
dysk zawiera pewną liczbę tarcz (dysków) pokrytych obustronnie materiałem magnetycznym; dyski obracają się ze stałą prędkością (np. dyski twarde: 5400 obr/min i więcej);
informacje na powierzchniach dysku zapisywane są przez zespół ruchomych głowic w postaci współśrodkowych okręgów zwanych ścieżkami; ścieżki o tym samym promieniu na wszystkich powierzchniach tworzą cylinder;
dane zapisywane na ścieżce mają postać bloków zwanych sektorami; na ścieżce może być zapisanych kilkadziesiąt sektorów; sektor zawiera zwykle 512 bajtów; sektor stanowi najmniejszą jednostkę danych, która może być zapisana lub odczytana z dysku.
systemy operacyjne traktują dysk jako jednowymiarową tablicę bloków dyskowych; przyporządkowanie bloków dyskowych do sektorów fizycznych stara się minimalizować ruchy głowic i czas dostępu gdy sektory czytane są sekwencyjnie; i tak najczęściej adresy bloków wzrastają wzdłuż wszystkich sektorów na ścieżce, następnie wzdłuż wszystkich ścieżek w cylindrze, a na koniec od cylindra 0 do ostatniego cylindra na dysku;
realizacja szybkiego i efektywnego dostępu do danych i programów zawartych w plikach wymaga stworzenia rozbudowanych struktur systemowych opisujących ich położenie; istotne jest też zarządzanie wolnymi obszarami dyskowymi; problemy te rozwiązywane są w odmienny sposób w różnych systemach operacyjnych;
Rozmieszczenie plików na dysku
rozmieszczenie plików na dysku musi być tak skonstruowane, ażeby dostęp do plików był szybki, a obszar dysku był zagospodarowany efektywnie;
używa się trzech metod przydziału miejsca na dysku: ciągłej, listowej i indeksowej;
w metodzie przydziału ciągłego każdy plik musi zajmować ciąg kolejnych bloków na dysku; opis pliku w katalogu plików zawiera informacje o położeniu pierwszego bloku na dysku oraz długość obszaru przydzielonego danemu plikowi;
w metodzie przydziału ciągłego przydział miejsca na nowy plik odbywa się wg tych samych zasad, co przydział obszaru w pamięci operacyjnej: poszukuje się niezajętego obszaru o rozmiarze równym lub większym od rozmiaru pliku (metoda najlepszego dopasowania); może być również stosowana metoda pierwszego dopasowania;
opisywana metoda przydziału ciągłego jest kłopotliwa ponieważ:
algorytmy przydziału miejsca są obarczone problemem fragmentacji zewnętrznej, wskutek czego wolna przestrzeń dyskowa ulega podziałowi na małe kawałki;
trudności występują także w odniesieniu do szacowania rozmiarów nowego pliku — często rozmiar takiego pliku jest trudny do określenia; w rezultacie użytkownicy planują duże pliki, co powoduje niewykorzystanie miejsca na dysku;
metoda przydziału listowego, której odmiana FAT stosowana jest w systemie Windows omawiana jest na następnej stronie; następnie omówiona zostanie metoda przydziału indeksowego stosowana w systemie Unix (Linux).
Metoda przydziału listowego
w przydziale listowym każdy plik jest listą powiązanych ze sobą plików dyskowych — bloki te mogą znajdować się gdziekolwiek na dysku;
w katalogu plików, dla każdego pliku podany wskaźnik do pierwszego i ostatniego bloku pliku;
z kolei każdy blok dyskowy zawiera właściwą informację, jak również wskaźnik do następnego bloku; przykładowo, jeśli rozmiar bloku wynosi 512 bajtów, to wskaźnik do następnego bloku zajmuje zwykle 4 bajty, a na pozostałych 508 bajtach przechowywana jest właściwa informacja;
czytanie pliku jest realizowane poprzez odczytywanie kolejnych bloków wchodzących w skład pliku, poruszając się według wskaźników przechowywanych w poszczególnych blokach;
zapisywanie pliku zaczyna od znalezienia przez system nieużywanego bloku — numer tego bloku zostaje wpisany na pozycję nowego pliku w katalogu plików; w miarę powiększania się pliku odnajdywane są kolejne nieużywane bloki i jednoczesne wpisywane odpowiednie wskaźniki do bloków poprzedzających;
w metodzie przydziału listowego nie występuje fragmentacja zewnętrzna, a plik może rosnąć dopóty, dopóki są wolne bloki;
jeśli potrzebne dane znajdują się wewnątrz pliku, to konieczny jest odczyt wielu bloków, po to tylko, żeby odczytać numer następnego bloku; realizacja dostępu jest więc mało wydajna;
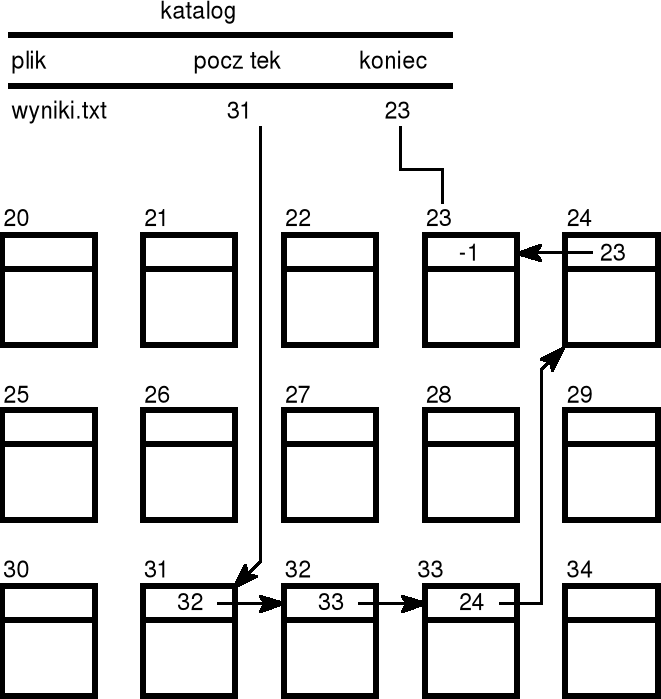
podstawową jednostką przetwarzania na wielu dyskach jest 512-bajtowy sektor; układy sprzętowe pozwalają jedynie na odczyt jednego lub kilku sektorów (nie można odczytywać z dysku pojedynczych bajtów); w celu ułatwienia zarządzania plikami, w wielu przypadkach bloki dyskowe składają się z kilku sektorów — mówimy wówczas, że blok dyskowy utworzony jest przez wiązkę (ang. cluster); zazwyczaj wiązka zawiera 1, 2, 4 lub więcej sektorów; używane są także terminy: grono i klaster.
Tablica rozmieszczenia plików FAT
odmianą metody przydziału listowego jest tablica rozmieszczenia plików, znana jako tablica FAT (ang. file allocation table); tablica ta stosowana jest w systemie Windows; tablica ta przechowywana jest na początku dysku (lub dyskietki), a w przypadku dysku podzielonego na strefy (partycje) na początku każdej partycji;
w tablicy tej każdej pozycji odpowiada jeden klaster (blok) dyskowy; zapis w katalogu wskazuje numer pierwszego klastra pliku; pozycja w tablicy FAT, indeksowana przez numer tego klastra, zawiera numer następnego klastra w pliku; łańcuch taki ciągnie się aż do ostatniego klastra w pliku, który na odpowiadającej mu pozycji w tablicy ma specjalny symbol końca pliku;
tablica rozmieszczenia plików FAT zawiera informacje o stanie wszystkich klastrów obszaru danych dysku; kolejne klastry numerowane są: 2, 3, ...;
struktura informacji w tablicy FAT:
pierwsze dwie pozycje są rezerwowane dla specjalnych informacji;
trzecia pozycja tablicy FAT zawiera informacje o pierwszym klasterze obszaru danych (tj. klasterze oznaczonym numerem 2);
następne pozycje tablicy FAT zawierają informacje o kolejnych klastrach;
każda pozycja w tablicy FAT używana przez plik wskazuje następną pozycję w FAT dla tego pliku — sekwencja numerów kolejnych pozycji FAT jest taka sama jak numery klastrów składających się na plik, a zatem opisane jest położenie pliku na dysku;
Katalogi plików w systemie Windows
katalogi plików przechowywanych na dysku mają strukturę hierarchiczną: katalog najwyższego poziomu nazywany jest katalogiem podstawowym (inaczej: katalogiem głównym), a katalogi niższych poziomów — podkatalogami;
katalogi można rozpatrywać jako tablice, które przechowywane są na dysku, przy czym katalog podstawowy przechowywany jest w ustalonym obszarze dysku, a podkatalogi przechowywane są tak jak pliki;
każdemu plikowi przyporządkowana jest jedna pozycja w katalogu; wprowadzenie możliwości kodowania nazw plików o długości do 255 znaków, przy zachowaniu dotychczasowej struktury, spowodowało, że nazwa pliku może być kodowana na kilku pozycjach w katalogu;
każda pozycja zajmuje 32 bajty i zawiera szereg informacji o pliku, w tym nazwę pliku (lub część nazwy), jego rozmiar, początkową pozycję w tablicy FAT, datę i godzinę jego utworzenia (lub ostatniej modyfikacji) oraz kilka specjalnych cech pliku;
katalog nie zawiera informacji o położeniu poszczególnych wiązek tworzących plik — informacje te przechowywane są w tablicy rozmieszczenia plików FAT.
ze względu na znaczną liczbę sektorów na dysku (zwłaszcza na dysku twardym), w celu ułatwienia zarządzania plikami, system operacyjny posługuje się jednostkami zawierającymi kilka sektorów — jednostka taka nazywana jest wiązką, klasterem lub jednostką alokacji pliku (ang. cluster); zazwyczaj wiązka zawiera 1, 2, 4 lub więcej sektorów;
Przechowywanie plików na dysku w systemie Linux
system Linux (Unix) występuje w wielu wersjach i odmianach — stosowane w nich systemy plików charakteryzują się znaczną różnorodnością w zakresie konstrukcji wewnętrznej; istotnym czynnikiem determinującym przyjęte rozwiązania techniczne jest zapewnienie wysokiego poziomu efektywności i niezawodności systemu, który pracuje w trybie wielodostępnym i wielozadaniowym;
aktualnie najbardziej rozpowszechniony jest system plikowy UFS (ang. Unix file system); w dystrybucjach Linuxa używany jest system plikowy Ext2 (ang. second extended file system);
pamięć na dysku podzielona jest na bloki, które są adresowane za pomocą numerów; rozmiar bloku wynosi zazwyczaj 1 ÷ 8 KB; dla uproszczenia dalszych rozważań pominiemy grupowanie bloków;
pliki przechowywane są na dysku w postaci rozproszonej;
w systemie Linux (Unix) podstawowe informacje o pliku przechowywane są w i-węzłach (ang. i-node); i-węzeł stanowi rodzaj tabliczki znamionowej pliku — podane są tam informacje o rozmiarze pliku, data i czas ostatniej modyfikacji, uprawnienia w zakresie dostępu do pliku i inne informacje; i-węzeł nie zawiera nazwy pliku (która przechowywana jest w katalogu plików); ponadto i-węzeł zawiera tablicę adresów, za pomocą której można zlokalizować części pliku na dysku;
proste odwzorowanie elementów tablicy adresów w bloki dyskowe powodowałoby konieczność tworzenia tablic o znacznych rozmiarach w przypadku dużych plików; ponadto byłoby korzystnie, gdyby rozmiar i-węzła nie zależał od rozmiaru pliku;
biorąc pod uwagę podane postulaty w systemie Unix przyjęto, że tablica adresów bloków (oznaczona i_block) zawiera ustaloną liczbę pozycji, np. 15 w systemie Ext2, a każda pozycja zajmuje 4 bajty;
początkowe 12 pozycji omawianej tablicy zawiera adresy bezpośrednie, tj. wskazujące konkretne bloki — dzięki temu dostęp do plików o niewielkich rozmiarach odbywa się bardzo szybko; dalsze pozycje zawierają numery bloków: pojedynczego pośredniego (ang. indirect block), podwójnego pośredniego (ang. double indirect block), potrójnego pośredniego (ang. tripple indirect block);
dostęp do danych przez blok pośredni wymaga wczytania tego bloku, i znalezienia odpowiedniej pozycji z adresem bloku bezpośredniego;
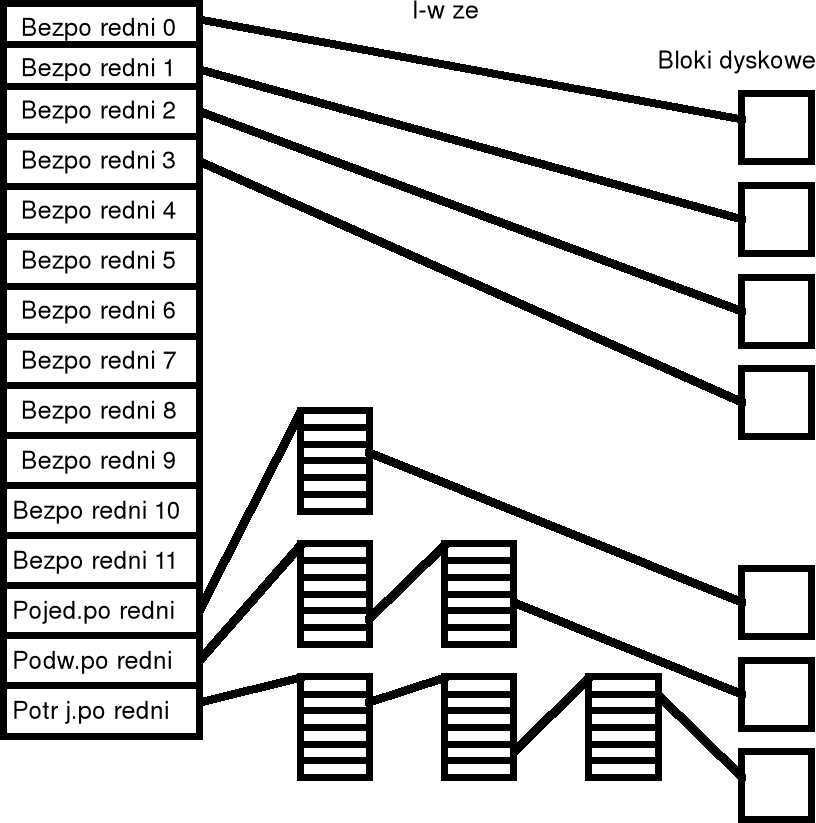
jeśli przyjąć, że w systemie stosowane są 4-kilobajtowe bloki dyskowe, a numer bloku zapisywany jest na 32 bitach, to maksymalny rozmiar pliku przekracza 4 TB:
12 bloków bezpośrednich po 4 KB = 48 KB
1 blok pośredni i 1024 bloki bezpośrednie = 4 MB
1 blok podwójnie pośredni i 1024 pośrednie = 4 GB
1 blok potrójnie pośredni i 1024 bloki podwójnie pośrednie = 4 TB
procesy sięgają do danych w pliku podając położenie bajtu; przykładowo jeśli proces odwołuje się do bajtu 30000, to 30000/4096 = 7 (reszta 1328), a zatem potrzebny bajt znajduje się w bloku, którego numer podany jest na pozycji 7 tablicy adresów bloków; wewnątrz bloku żądany bajt jest odległy o 1328 bajtów od początku bloku;
bardziej skomplikowane jest odwołanie do bajtów, które nie są dostępne poprzez bloki bezpośrednie; przykładowo dostęp do bajtu 5 000 000 wymaga użycia bloku podwójnie pośredniego; pierwszy bajt dostępny poprzez blok podwójnie pośredni ma numer 48 KB + 4 MB = 49152 + 4 194 304 = 4 243 456; bajt o numerze 5 000 000 jest więc bajtem o numerze 756 544 względem początku bloku podwójnie pośredniego; każdy blok pojedynczo pośredni daje dostęp do 4 MB, więc bajt o numerze 5 000 000 będzie się wskazywany pośrednio przez pozycję zerową bloku podwójnie pośredniego — po odczytaniu wyznaczonego w ten sposób bloku pośredniego poszukuje się w nim pozycji o indeksie 756 544 / 4096 = 184 (reszta 2880); zawartość pozycji o indeksie 184 wskazuje na blok dyskowy zawierający żądany bajt — jest on odległy 2880 bajtów od początku bloku.
Operacje na plikach na poziomie API
system Unix, i wzorowane na nim inne systemy, starają się traktować pliki i urządzenia w jednakowy sposób;
program przekazuje do systemu operacyjnego żądania wykonywania różnych działań związanych z plikiem poprzez wywoływanie odpowiednich podprogramów wchodzących w skład systemu operacyjnego;
zlecenie operacji na pliku zgłoszone przez program obejmuje:
inicjalizację czyli: otwarcie pliku, w odniesieniu do pliku już istniejącego, albo utworzenie (nowego) pliku;
właściwe operacje (odczyt, zapis, . . .);
deinicjalizację czyli zamknięcie pliku;
żądanie otwarcia lub utworzenia pliku skierowane do systemu operacyjnego zawiera nazwę pliku, jego położenie i inne parametry — jeśli żądanie to zostanie zaakceptowane przez system operacyjny, to przekazuje on do programu uchwyt pliku (ang. file handle), będący liczbą identyfikującą wskazany plik; w dalszych operacjach plik ten będzie identyfikowany przez zwrócony uchwyt pliku (a nie przez nazwę i położenie);
czasami zamiast terminu uchwyt pliku używa się terminu deskryptor pliku, identyfikator pliku lub dojście;
uchwyty o numerach 0, 1, 2 przypisane są na stałe do standardowych urządzeń znakowych — niżej wymienione urządzenia są dostępne bez konieczności jakichkolwiek przygotowań (nie potrzeba otwierać urządzenia):
0 — standardowe urządzenie wejściowe,
1 — standardowe urządzenie wyjściowe,
2 — standardowe urządzenie do sygnalizacji błędu;
zazwyczaj uchwyty 0, 1, 2 są w pewnym stopniu ze sobą związane.
Tworzenie, otwieranie i zamykanie plików
wiele systemów operacyjnych do otwierania plików oferuje funkcję systemową open, której wywołanie w języku C ma postać:
fd = open (nazwa, dostęp);
nazwa pliku podawana jest jawnie albo jako wskaźnik do łańcucha znaków
dostęp określa jakie operacje będą wykonywane na pliku:
O_RDONLY — tylko odczyt,
O_WRONLY — tylko zapis,
O_RDWR — odczyt lub zapis,
O_CREAT — tworzenie pliku (jeśli nie istnieje),
O_BINARY — otwarcie pliku w trybie binarnym,
O_TEXT — otwarcie pliku w trybie tekstowym;
można składać podane opcje za pomocą operatora |, np.
O_RDONLY | O_BINARY
co oznacza operację odczytu pliku w trybie binarnym;
w środowisku Windows w trybie binarnym plik odczytywany jest lub zapisywany w oryginalnej postaci, natomiast w trybie tekstowym (który jest trybem domyślnym) znaki powrotu karetki (0x0D) są pomijane przy odczytywaniu, i dopisywane do znaków nowej linii (0x0A) przy zapisywaniu;
jeśli drugi parametr funkcji open ma postać O_CREAT, to trzeba podać trzeci parametr, np. S_IREAD;funkcja open zwraca uchwyt (deskryptor) pliku (tu oznaczony fd), który jest wartością typu int ; wartość -1 oznacza, że plik nie został otwarty — w tym przypadku ustawiana jest także zmienna globalna errno, która może przyjąć wartości:
EACCES odmowa dostępu,
EINVACC błędny kod dostępu,
EMFILE zbyt dużo otwartych plików,
ENOENT plik lub katalog nie istnieje;
dostępna jest też odrębna funkcja systemowa do tworzenia plików:
fd = creat (nazwa, rodzaj ochrony);
gdzie parametr rodzaj ochrony może przyjmować wartości S_IWRITE lub S_IREAD;
zamknięcie pliku realizuje funkcja
close (fd)
prototypy podanych tu funkcji znajdują się w pliku nagłówkowym <io.h>, zaś stałe zdefiniowane są w plikach <fcntl.h> i <sys\stat.h>.
Bieżąca pozycja pliku
dostęp do plików ma charakter sekwencyjny, tj. każda operacja czytania lub pisania odnosi się do miejsca pliku tuż za pozycją osiągniętą przy poprzedniej operacji;
bieżąca pozycja pliku (ang. file pointer) ma charakter licznika odczytanych/zapisanych bajtów i określana jest zwykle za pomocą liczby 32-bitowej — każda operacja odczytu lub zapisu pliku będzie wykonana począwszy od bajtu wskazywanego przez bieżącą pozycję pliku; po odczycie lub zapisie bieżąca pozycja pliku jest przesuwana w taki sposób, że wskazuje kolejny bajt za ostatnio odczytanym lub zapisanym; kwestie te wyjaśnia poniższy przykład:
Z pliku zawierającego 2472 bajtów odczytano 7 bajtów.
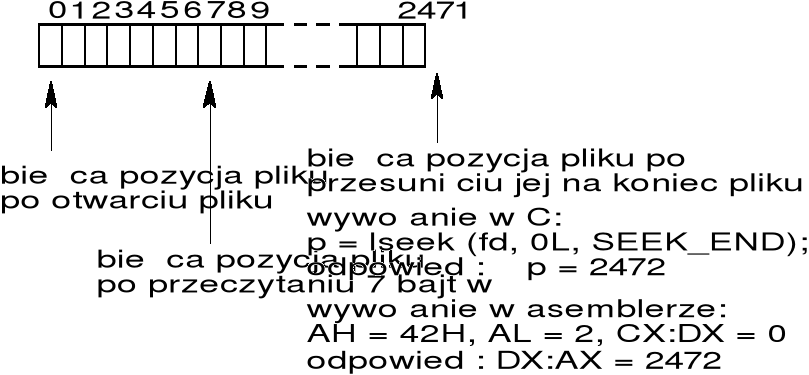
do przesuwania bieżącej pozycji pliku używana jest funkcja systemowa lseek, której wywołanie w języku C ma postać
p = lseek (fd, offset, skąd);
gdzie:
p — bieżąca pozycja pliku po przesunięciu,
fd — uchwyt pliku,
offset — wielkość przesunięcia (long),
skąd — punkt startowy: może przyjmować wartości:
SEEK_SET — początek pliku,
SEEK_CUR — bieżące położenie,
SEEK_END — koniec pliku
ww. funkcja pozwala więc na poruszanie się w pliku bez czytania lub pisania — można więc traktować pliki jak tablice;
jeśli potrzebna jest tylko znajomość bieżącej pozycji pliku, to można korzystać z funkcji systemowej
p = tell (fd);
która zwraca bieżącą pozycję pliku (long);
Odczyt i zapis plików
do odczytu i zapisu plików używa się funkcji systemowych read i write, których wywołania na poziomie języka C mają postać:
read (fd, buf, n);
write (fd, buf, n);
gdzie:
fd — uchwyt pliku,
buf — bufor w programie,
n — liczba przesyłanych bajtów.
funkcje read i write zwracają liczbę przesłanych bajtów; wartość 0 oznacza koniec pliku, zaś wartość -1 błąd operacji; w przypadku błędu operacji ustawiana jest także zmienna globalna errno, która może przyjąć wartości:
EACCES odmowa dostępu,
EBADF błędny uchwyt pliku;
Przeglądanie zawartości katalogów
za pomocą funkcji opendir, readdir i closedir
w programach wykonujących działania na plikach zachodzi często konieczność przeglądania (i ewentualnie wyświetlania) listy plików umieszczonych we wskazanym katalogu;
w środowisku Unix (Linux), a także w Windows odczytywanie zawartości katalogów można wykonać za pomocą funkcji opendir, readdir, rewinddir i closedir; funkcje te są zgodne ze standardem POSIX (Portable Operating System Interface), a ich prototypy podane są w pliku nagłówkowym <dirent.h>;
opendir otwarcie strumienia danych katalogowych,
readdir odczytanie ze strumienia danych katalogowych pojedynczej pozycji katalogu (kolejne wykonanie funkcji readdir spowoduje odczytanie kolejnej pozycji katalogu),
rewinddir przesunięcie strumienia na pierwszą pozycję katalogu,
closedir zamknięcie strumienia danych katalogowych;
technikę stosowania ww. funkcji wyjaśnia poniższy przykład
#include <stdio.h>
#include <sys/types.h>
#include <dirent.h>
int main ( )
{
DIR * dirp;
struct dirent * dp;
printf("\n\n");
dirp = opendir(".");
/* odczytywanie bieżącego katalogu */
while ((dp = readdir(dirp)) != NULL)
{
printf("\nPlik = %s", dp > d_name);
}
/* od nowa */
rewinddir(dirp);
while ((dp = readdir(dirp)) != NULL)
{
printf("\nPlik = %s", dp > d_name);
}
closedir (dirp);
printf("\nTest programu\n");
return 0;
}
funkcja readdir zwraca wskaźnik do struktury, w której m.in. zdefiniowane jest pole
char d_name[ ];
pole to zawiera nazwę (np. pliku), zakończoną bajtem zerowym; przekazywane nazwy mogą stanowić: nazwy plików (także plików ukrytych i systemowych), nazwy katalogów (w tym katalogi . i ..), etykiety dysku oraz nazwy urządzeń; funkcja readdir zwraca wskaźnik NULL w przypadku natrafienia na koniec katalogu, a także w przypadku błędu;
funkcja readir nie podaje jednak informacji czy nazwa wskazuje na plik, czy na katalog czy też na urządzenie; informacje te można uzyskać za pomocą funkcji stat; poniższy fragment (stanowiący rozszerzenie podanego wyżej przykładu) ilustruje zastosowanie funkcji stat;
#include <sys\stat.h>
struct stat statbuf;
/* odczytywanie bieżącego katalogu */
while ((dp = readdir(dirp)) != NULL)
{
printf("\nPlik = %s", dp > d_name);
stat (dp -> d_name, &statbuf);
if (statbuf.st_mode & S_IFDIR) printf(" - jest to katalog!");
else printf (" - rozmiar pliku = %ld", statbuf.st_size);
używana jest także funkcja fstat, która pozwala uzyskać analogiczne informacje w odniesieniu do plików aktualnie otwartych (zamiast nazwy pliku podaje się uchwyt pliku);
należy zwrócić uwagę, że nazwy plików uzyskiwane za pomocą funkcji readdir trzeba poprzedzić ścieżką dostępu, i dopiero w tej postaci nazwy można zastosować jako argumenty funkcji stat; ścieżkę dostępu można pominąć w przypadku katalogu bieżącego.
Inne operacje na plikach
zmiana nazwy pliku
rename (stara nazwa, nowa nazwa);
w przypadku poprawnej realizacji funkcja zwraca wartość 0, w przeciwnym razie -1; przykład:
char nazwa_pliku [80];
- - - - - - - - - - - -
strcpy (nazwa_pliku, "nowy_sch.rys");
rename ("schemat.rys", nazwa_pliku);
kasowanie pliku można wykonać za pomocą funkcji systemowej
unlink (nazwa pliku);
wyznaczanie bieżącego katalogu realizuje funkcja systemowa (dostępna w systemie Windows)
getcurdir (napęd, bufor);
gdzie:
napęd — napęd bieżący - 0, napęd A - 1, napęd B - 2, itd.,
tablica — tablica, do której zostanie wpisana ścieżka do katalogu (łańcuch pusty w przypadku katalogu głównego).
zmianę katalogu można wykonać za pomocą funkcji systemowej
chdir (nazwa katalogu);
tworzenie i kasowanie katalogu
mkdir (nazwa katalogu);
rmdir (nazwa katalogu);
odczytywanie i ustawianie napędu dyskowego (dostępne w systemie Windows)
getdisk( );
setdisk ( );
Wyszukiwarka
Podobne podstrony:
ask1, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Wyklad
ask3, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Wyklad
ask2, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Wyklad
ASK-koło pierwsze pytania z mojej grupy, Edukacja, studia, Semestr IV, Architektura Systemów Kompute
opracowane pytania na ASK@, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Oprac
Projekt 3, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Projekt, Projekt 3
Teoria 2003, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Opracowania pytań
assembler 1, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Projekt, Projekt 1
Pytania przykl ASK1, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Opracowania
Pytania przykl ASK2, Edukacja, studia, Semestr IV, Architektura Systemów Komputerowych, Opracowania
TECHNIKA MIKROPROCESOROWA (1), Edukacja, studia, Semestr IV, Technika Mikroprocesorowa
liniowkaWKLEPANE PYTANIA, Edukacja, studia, Semestr IV, Układy Elektroniczne
pytania na smoki, Edukacja, studia, Semestr IV, Technika Mikroprocesorowa
arch02, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Architektura systemów komputerowych
Układy Elektroniczne zagadnienia, Edukacja, studia, Semestr IV, Układy Elektroniczne
arch05, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Architektura systemów komputerowych
arch07, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Architektura systemów komputerowych
Optoelektronika kolo 1, Edukacja, studia, Semestr IV, Optoelektronika, Pytania na koła, zestaw 8
JavaScript- podstawy, Edukacja, studia, Semestr IV, Języki Programowania Wysokiego Poziomu, Java skr
więcej podobnych podstron