1. Jaką grupę wymagań modeluje się za pomocą przypadków użycia?
Wymagania użytkownika , wymagania funkcjonalne (jak jedno to nie wiem które)
2. Kim jest aktor? Podaj symbol.
Aktor: abstrakcyjny użytkownik systemu, reprezentujący grupę użytkowników używających podobnych funkcji systemu i sposobu z nim komunikacji. Symbol to ludzik ,jak wygląda każdy wie.
3. Co to jest przypadek użycia. Podaj klasyfikacje aktorów ze względu na używaną przez nich funkcję systemu.
Przypadek użycia: ciąg interakcji pomiędzy aktorem a systemem, dostarczający aktorowi pożądanych wyników.
Klasyfikacja aktorów:
- aktor główny: używa podstawowych funkcji systemu
- aktor drugorzędny: używa funkcji administracyjnych i pielęgnacyjnych
- aktor aktywny: inicjuje przypadek użycia
- aktor pasywny: uczestniczy w przypadku użycia, ale go nie inicjuje
4. Co oznacza relacja "używa"("uses")? Podaj symbol. Jak nazywa się ta relacja w najnowszej wersji języka UML? Relacja „extends”.
Relacja „używa” („uses”)
- wskazuje na wspólny fragment wielu przypadków użycia, wykorzystanie wspólnego zachowania
Relacja „rozszerza” („extends”)
- rozszerzenie przypadku użycia o sytuację wyjątkową
Relacja „uses” w najnowszej wersji jezyka UML nazywana jest „include” a jej symbol to <<include>>
5. Czy możliwa jest komunikacja pomiędzy aktorami na diagramie przypadków użycia? Odpowiedź uzasadnij i skomentuj w kontekście zadań modelu przypadku użycia.
Nie wiem dokladnie o co chodzi (bo to takie kurwa wszystko niejasne w tym przedmiocie). Ale jeśli chodzi im o komunikacje bezposrednią (strzalka od razu od jednego aktora do drugiego) to nie jest możliwa taka opcja , jedynie poprzez przypadek uzycia czyli tak jak na tym przykładzie obok albo wymeldowanie z hotelu albo zameldowanie. Glownie w diagramach przypadkow uzycia chodzi o zauważenie interakcji użytkownika z systemem a nie użytkowników miedzy soba, także związku użytkownika z konkretnym przypadkiem uzycia i wynikiem jaki otrzymuje.
6. Opisz ogólny schemat przejścia między stanami.
7. W jaki sposób na diagramie sekwencji oznacza się pewne własności interakcji, np. interakcje wywoływane w pętli?
Często zachodzi konieczność wskazania specjalnej własności pewnej części interakcji, np. pętli. Na diagramach sekwencji taką grupę operacji obejmuje się prostokątem, w którego lewym górnym narożniku, w pięciokącie umieszcza się słowo kluczowe lub opis określający znaczenie danego bloku (tzw. operator interakcji), np.:
• alt (od alternative) - określający warunek wykonania bloku operacji, odpowiadający instrukcji if-else; warunek umieszcza się wówczas wewnątrz bloku w nawiasach kwadratowych
• opt (od optional) - reprezentujący instrukcję if (bez else)
• par (od parallel) - nakazujący wykonać operacje równolegle
• critical - oznaczający obszar krytyczny
• loop - definiujący pętlę typu for (o określonej z góry liczbie iteracji) lub while (wykonywanej dopóki pewien warunek jest prawdziwy)
8. Co to jest wywoływanie asynchroniczne operacji? Jak się je oznacza?
Oznacza powrót z wywołania procedury; może być pomijany.
9.symbole początku życia obiektu i końca życia - siakoś tak
koło - początek życia
koło z obręczą wokół niego cienką również okrągłą - koniec życia.
W Umbrello wszystko to było koloru czerwonego .
10. Największa różnica między diagramem maszyny stanowej a czynności
W odróżnieniu od diagramu maszyny stanowej, diagram czynności może obejmować wiele obiektów na raz, zwykle umieszczanych w odpowiednich torach.
11. Coś w tym stylu - dlaczego diagram sekwencji jest doskonały do pokazania programowania obiektowego
Prezentuje kolejność wywołań operacji, przepływ sterowania pomiędzy obiektami oraz szablon realizowanego algorytmu.
12. W jaki sposób można oceniać produktywność programisty
Produktywność:
-> W procesie tworzenia oprogramowania menedżerowie muszą oceniać produktywność inżynierów. Takie oszacowania mogą być niezbędne przy szacowaniu kosztów przedsięwzięcia i przy ustalaniu, czy ulepszenia procesowe i technologiczne były skuteczne.
-> Problemy z określeniem produktywności:
- W wypadku budowy oprogramowania istnieje wiele różnych rozwiązań o różnych atrybutach.
- Gdy pojawiają się dwa rozwiązania o różnych atrybutach, porównywanie szybkości ich tworzenia nic tak naprawdę nie daje. Jedno rozwiązanie może działać bardziej efektywnie, podczas gdy inne jest bardziej czytelne i łatwiejsze do pielęgnacji.
Rodzaje miar:
Miary wielkościowe. Są związane z wielkością pewnego wyniku czynności. Najczęściej stosowaną wielkościową miarą produktywności jest liczba wierszy dostarczonego kodu źródłowego.
Miary funkcyjne. Są związane z ogólną funkcjonalnością dostarczonego oprogramowania. Produktywność wyraża się w kategoriach ilości użytecznej funkcjonalności dostarczonej w pewnym czasie.
Szacowanie kosztu pracy programisty za pomocą liczby wierszy kodu:
Liczba wierszy kodu na miesiąc pracy programisty to szeroko stosowana miara produktywności.
Wyznacza się ją przez obliczenie całkowitej liczby dostarczonego kodu źródłowego. Tę liczbę dzieli się następnie przez miesiące pracy programisty, konieczne do ukończenia przedsięwzięcia.
Ten czas obejmuje zatem czas potrzebny na analizę, projektowanie, kodowanie i dokumentowanie.
Szacowanie kosztu pracy programisty za pomocą punktów funkcyjnych
Inną stosowaną miarą jest liczba punktów funkcyjnych.
Całkowitą liczbę punktów funkcyjnych wyznacza się przez zmierzenie lub oszacowanie następujących elementów programu:
- zewnętrzne dane wejściowe i wyjściowe,
- interakcje z użytkownikiem,
- interfejsy zewnętrzne,
- pliki używane przez system.
Wagi: od 3 (proste dane wejściowe) do 15 (złożone pliki)
UFC = ∑ liczba_elementów_danego_typu x waga
Punkty funkcyjne są niezależnie od języka, można więc za ich pomocą porównywać produktywność w różnych językach programowania. Produktywność wyraża się jako liczby punktów funkcyjnych utworzonych w czasie miesiąca.
Szacowanie kosztu pracy programisty za pomocą punktów obiektowych:
W przypadku stosowania narzędzi obiektowych, stosujemy miarę w postaci liczby punktów obiektowych - miarę ważoną następujących składników:
- liczba różnych wyświetlanych ekranów (prosty ekran to 1 punkt obiektowy, bardzo złożony ekran - 3)
- liczba tworzonych raportów (prosty raport to 2 punkty obiektowe, bardzo złożony - 8 punktów)
- liczba modułów napisanych w językach proceduralnych, które należy opracować w celu uzupełnienia kodu (każdy moduł liczy się jako 10 punktów obiektowych.
13. Wymień cechy i omów:
Architektury wieloprocesorowe
Najprostszym modelem systemu rozproszonego jest system wieloprocesorowy, składający się z kilku różnych procesów, które mogą (ale nie muszą) działać na oddzielnych procesorach.
Z logicznego punktu widzenia procesory zajmujące się zbieraniem informacji, podejmowaniem decyzji i sterowaniem efektorami mogłyby działać na jednym procesorze sterowanym przez moduł szeregujący. Użycie wielu procesorów poprawia jednak efektywność i odporność systemu.
Przydział procesów procesorów może być zadany z góry (tak zwykle jest w systemach krytycznych) albo sterowany przez dyspozytora, który decyduje o przyznaniu procesora procesowi.
Architektury klient-serwer
Architektoniczny model klient-serwer jest modelem rozproszonego systemu, w którym dane i przetwarzanie są rozdzielone między zbiór procesorów.
Zbiór samodzielnych serwerów oferujących usługi innym podsystemom. Przykładami są serwery wydruku realizujące usługi drukowania, serwery plików realizujące usługi zarządzania plikami.
Zbiór klientów, którzy korzystają z usług oferowanych przez serwery. Zwykle same w sobie są podsystemami.
Sieć, która daje klientom dostęp do tych usług.
Największa zaleta modelu klient-serwer polega na tym, że jest to architektura rozproszona. Umożliwia to efektowne użycie systemów sieciowych z dużą liczba rozproszonych procesorów. Łatwo jest dostać nowy serwer i zintegrować go z resztą systemu albo przezroczyście aktualizować serwery bez wpływania na inne części systemu.
Do odniesienia pełnych korzyści z integracji nowego serwera może być jednak konieczne wprowadzenie pewnych zmian w istniejących klientach i serwerach. Nie ma dzielonego modelu danych i podsystemy porządkują zwykle swoje dane na różne sposoby. Oznacza to potrzebę określenia specyficznego modelu danych dla każdego serwera, który umożliwi zoptymalizowanie jego efektywności.
Architektury obiektów rozproszonych
Architektury obiektów rozproszonych
W tym podejściu nie istnieje rozróżnienie między klientami i serwerami. System jest postrzegany jako zbiór komunikujących się obiektów, których położenie jest nieistotne. Nie ma różnicy między dostawcą i użytkownikiem usług.
14. Narysuj przykładowy diagram obiektów. W jakich przypadkach może się on okazać użyteczny?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
15. Co to jest obiekt? Podaj definicję i symbol graficzny.
Obiekt jest bytem, który posiada swój stan i zbiór zdefiniowanych operacji działających na tym stanie.
- stan jest reprezentowany jako zbiór atrybutów (ang. attributes) obiektu.
Symbol obiektu=reprezentacja graficzna klasy(patrz nizej)
16. Czym są atrybuty? Czy związek między klasami może posiadać atrybuty? jeżeli tak, to podaj przykład i symbol.
Atrybuty określają stan obiektu. Tak związki miedzy klasami mogą posiadać atrybuty między innymi:
Tak, zwiazem miedzy klasami może mieć atrybut. Taki związek z atrybutem nazywamy związkiem kwalifikowanym.
18. Omów związki między klasami i podaj ich symbole
Czyli symbol chyba kreska?
Uogólnienie-
Klasy obiektów można ułożyć w hierarchię uogólnienia, w której widać związek między ogólnymi i bardziej szczegółowymi klasami obiektów.
Szczegółowa klasa obiektów jest w pełni zgodna z ogólną klasą obiektów, ale zawiera więcej informacji.
W UML uogólnienie obrazuje się za pomocą obrazów strzałki wskazującej klasę macierzystą.
W obiektowych językach programowania uogólnienie zwykle implementuje się za pomocą mechanizmu dziedziczenia. Klasa potomna dziedziczy atrybuty i operacje po klasie macierzystej.
Symbol-nie wypełniona strzałka
Agregacja-(ang. aggregation): tworzenie nowej klasy, przy użyciu klas już istniejących. Nowa klasa może być zbudowana z dowolnej liczby obiektów (obiekty te mogą być dowolnych typów) i w dowolnej kombinacji, by uzyskać żądany efekt. Jest to relacja typu "zawiera" np: "samochód zawiera koła i silnik" - gdzie „samochód”, „koło” i „silnik” są klasami. Symbol - linia zakończona rombem.
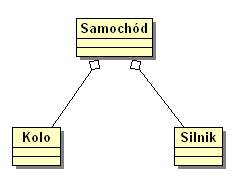
Symbol-pusty romb
Kompozycja- (ang. composition): składanie się obiektu z obiektów składowych, które nie mogą istnieć bez obiektu głównego. Kompozycja jest relacją typu "posiada". Dana część może należeć tylko do jednej całości. Część nie może istnieć bez całości, a usunięcie całości powoduje automatyczne usunięcie wszystkich części związanych z nią związkiem kompozycji. Symbol - linia zakończona zaczernionym rombem.
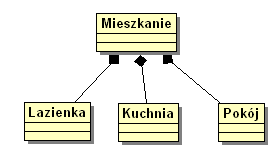
Symbol-wypełniony romb
Zależność (ang. dependency) - między klasami zachodzi, jeżeli zmiany dokonane w stanie jednego z obiektów danej klasy mogą mieć wpływ na obiekt należący do innej klasy.
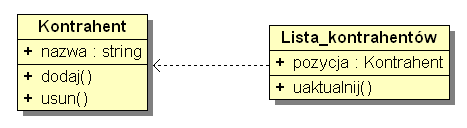
Symbol - strzałka z przerywana linią
Związek, tak jak i obiekt, też może posiadać atrybuty
(tzw. związek kwalifikowany).
19. Fazy procesu produkcji
idea
specyfikacja
projektowanie
implementacja
integracja
testowanie
wdrożenie
ewolucja
20. Modelowanie procesu tworzenia oprogramowania
Modele ogólne (paradygmaty) tworzenia oprogramowania (z natury uproszczone)
model kaskadowy
model spiralny
model przyrostowy i tworzenie ewolucyjne
model prototypowy
składanie systemu z komponentów ponownego użycia
Modele szczegółowe
model przepływu prac
model przepływu danych (lub model czynności)
21. Podział wymagań stawianych oprogramowaniu
I Wymagania funkcjonalne
Stwierdzają, jakie usługi ma oferować system, jak ma reagować na określone dane wejściowe oraz jak ma się zachowywać w określonych sytuacjach. W niektórych wypadkach wymagania funkcjonalne określają, czego system nie powinien robić.
II Wymagania niefunkcjonalne (pozafunkcjonalne)
Określają ograniczenia usług i funkcji systemu. Obejmują ograniczenia czasowe, ograniczenia dotyczące procesu tworzenia, standardy itd.
III Wymagania dziedzinowe
Pochodzą z dziedziny zastosowania systemu odzwierciedlają jej charakterystykę. Mogą być zarówno funkcjonalne jak i niefunkcjonalne.
AD I:
Wymagania funkcjonalne
Odpowiadają na pytanie: jakie funkcje system ma udostępniać użytkownikom?
Wymagania funkcjonalne opisują funkcjonalność lub usługi, które system powinien oferować.
Zależą od rodzaju tworzonego oprogramowania, spodziewanych jego użytkowników oraz rodzaju wytwarzanego systemu.
Gdy mają postać wymagań użytkownika, ich opis jest zwykle bardziej ogólny, natomiast wymagania funkcjonalne systemowe szczegółowo definiują funkcje systemu, jego wejścia, wyjścia, wyjątki itd.
Przykłady wymagań funkcjonalnych
Użytkownik powinien móc przeszukać zbiór wszystkich baz danych lub wybrać tylko ich podzbiór.
System powinien udostępniać użytkownikom odpowiednie narzędzia do przeglądania dokumentów z magazynu.
Każde zamówienie powinno być oznaczone unikatowym identyfikatorem (ORDE_ID), który będzie można łatwo skopiować.
Problemy wynikające z braku ścisłości przy definiowaniu wymagań
Natura programisty każe mu interpretować niejednoznaczne wymagania tak, aby uprościć implementację. Zwykle nie jest to jednak to, czego chciał klient. W takim przypadku należy opracować nowe wymagania i dokonać zmian w systemie - opóźnia to dostarczenie systemu i podnosi koszty.
Rozważmy drugie na tej liście wymaganie stawiane systemowi biblioteki, które mówi o „odpowiednich narzędziach do oglądania”. Celem tego wymagania jest zapewnienie narzędzia do oglądania wszystkich tych formatów. Programista działający pod presją czasu może udostępnić po prostu narzędzie do oglądania plików tekstowych i ogłosić spełnienie wymagania.
AD II
Wymagania niefunkcjonalne
Odpowiadają na pytanie: jak system ma działać?
Mogą definiować ograniczenia systemu, takie jak możliwości urządzeń wejścia-wyjścia lub dostępne reprezentacje danych.
Wymagania niefunkcjonalne wynikają z potrzeb użytkownika, ograniczeń budżetowych, strategii firmy, konieczności współpracy z innymi systemami sprzętu lub oprogramowania, czynników zewnętrznych.
Wymagania stawiane procesowi tworzenia oprogramowania - specyfikacja standardów jakości, których należy użyć, stwierdzenie, że projekt należy opracować za pomocą konkretnego zbioru narzędzi CASE.
Klasyfikacja wymagań niefunkcjonalnych
Wymagania produktowe
Określają zachowanie produktu. Przykładami są wymagania efektywnościowe dotyczące szybkości działania systemu i jego zapotrzebowania na pamięć, wymagania niezawodności.
Wymagania organizacyjne
Wynikają ze strategii i procedur w firmie klienta i w firmie wytwórcy.
Wymagania zewnętrzne
Ta szeroka kategoria mieści wszystkie wymagania wynikające z czynników zewnętrznych. Obejmują m.in. wymagania współpracy, które definiują interakcje systemu z systemami innych firm i wymagania prawne.
Problemy związane z wymaganiami niefunkcjonalnymi
Trudności z weryfikacją niektórych wymagań.
Mogą one być zapisywane w sposób odzwierciedlający ogólne dążenia klienta, takie jak łatwość użycia, zdolność do naprawy awarii i szybka reakcja na działania użytkownika. To jednak zostawia bardzo duży margines do interpretacji i stwarza potencjalną możliwość konfliktów z klientem już po dostarczeniu systemu.
Rozwiązywanie problemów związanych z wymaganiami niefunkcjonalnymi
Wymaganie nieweryfikowalne
System powinien być łatwy w użyciu dla doświadczonych kontrolerów, a sposób jego organizacji powinien minimalizować liczbę błędów użytkownika.
Poprawione, weryfikowalne wymaganie
Doświadczeni kontrolerzy powinni móc używać wszystkich funkcji systemu po szkoleniu trwającym dwie godziny. Po szkoleniu, średnia liczba błędów robionych przez użytkowników nie powinna przekroczyć dwóch dziennie.
AD III
Wymagania dziedzinowe
Wynikają bardziej z dziedziny zastosowania systemu niż z konkretnych potrzeb użytkowników.
Mogą być nowymi wymaganiami funkcjonalnymi, ograniczać istniejące wymagania funkcjonalne albo np. ustalać sposób wykonywania konkretnych obliczeń.
Wymagania dziedzinowe są istotne, ponieważ odzwierciedlają podstawy dziedziny zastosowania. Jeśli nie są spełnione, to system może nie działać w sposób zadowalający lub np. nie uzyskać wymaganych atestów.
Problemy z wymaganiami dziedzinowymi
Są one zwykle wyrażone za pomocą języka specyficznego dla dziedziny zastosowania, co sprawia, że inżynierowie oprogramowania często ich nie rozumieją.
Eksperci z danych dziedzin często mogli pominąć jakąś informację, ponieważ po prostu jest dla nich oczywista. Może nie być jednak oczywista dla twórców systemu, którzy mogą to wymaganie zaimplementować w sposób nieprawidłowy.
22. Modele procesów tworzenia oprogramowania
Model kaskadowy
W tym modelu podstawowe czynności specyfikowania, tworzenia, zatwierdzania i ewolucji są odrębnymi fazami procesu.
Problemy modelu kaskadowego
Następnej fazy nie powinno się rozpoczynać, jeśli poprzednia się nie zakończy.
Koszty opracowania i akceptacji dokumentów są wysokie i dlatego iteracje są również kosztowne oraz wymagają powtarzania wielu prac.
Wadą modelu kaskadowego jest zawarty w nim nieelastyczny podział na rozłączne etapy.
Model kaskadowy powinien być używany jedynie wówczas, gdy wymagania są jasne i zrozumiałe.
Tworzenie ewolucyjne
W tym procesie czynności specyfikowania, projektowania i zatwierdzania przeplatają się.
Tworzenie ewolucyjne polega na opracowaniu wstępnej implementacji, pokazaniu jej użytkownikowi z prośbą o komentarze i udoskonalaniu jej w wielu wersjach aż do powstania odpowiedniego systemu.
Typy tworzenia ewolucyjnego:
Tworzenie badawcze
Celem procesu jest praca z klientem, polegająca na badaniu wymagań i dostarczeniu ostatecznego systemu. Tworzenie rozpoczyna się od tych części systemu, które są dobrze rozpoznane. System ewoluuje przez dodawanie nowych cech, które proponuje klient.
Prototypowanie z porzuceniem
Celem procesu jest zrozumienie wymagań klienta i wypracowanie lepszej definicji wymagań stawianych systemowi. Budowanie prototypu ma głównie na celu eksperymentowanie z tymi wymaganiami użytkownika, które są niejasne.
Tworzenie ewolucyjne - zastosowania i problemy
Stosowanie
W wypadku systemów małych lub średnich oraz tych z krótkim czasem życia, podejście ewolucyjne jest najlepsze ze wszystkich modeli.
W wypadku dużych systemów o długim czasie życia wady tworzenia ewolucyjnego ujawniają się jednak z całą ostrością.
Problemy
Proces nie jest widoczny
System ma często złą strukturę
dokumentacja czasami nie jest aktualna
Konieczne mogą być specjalne narzędzia i techniki
Tworzenie formalne systemu
To podejście jest oparte na budowaniu formalnych matematycznych specyfikacji systemu i przekształcaniu tych specyfikacji w program za pomocą metod matematycznych.
Podejście, które ma wiele wspólnego z modelem kaskadowym. Proces tworzenia jest tu jednak oparty na matematycznych przekształceniach specyfikacji systemu w program wykonywalny.
W procesie przekształcania formalna matematyczna reprezentacja systemu jest metodycznie przekształcana w bardziej szczegółowe, ale wciąż matematycznie poprawne reprezentacje systemu.
Podejście z przekształceniem złożone z ciągu małych kroków jest łatwiejsze w użyciu. Wybór, które przekształcenie zastosować, wymaga jednak dużych umiejętności.
Najlepiej znanym przykładem takiego formalnego procesu tworzenia jest Cleanroom, pierwotnie opracowany przez IBM (Proces Cleanroom jest oparty na przyrostowym tworzeniu oprogramowania, gdy formalnie wykonuje się każdy krok i dowodzi jego poprawności.)
zastosowania i problemy:
Oprócz specjalistycznych dziedzin procesy oparte na przekształceniach formalnych są używane rzadko.
Wymagają specjalistycznej wiedzy i w praktyce okazuje się, że w wypadku większości systemów nie powodują zmniejszenia kosztów lub polepszenia jakości w porównaniu z innymi podejściami.
Interakcje systemów nie poddają się łatwo specyfikowaniu formalnemu.
Tworzenie z użyciem wielokrotnym
W tym podejściu zakłada się istnienie dużej liczby komponentów zdatnych do ponownego użycia.
W większości przedsięwzięć programistycznych występuje wielokrotne użycie oprogramowania.
Etapy procesu:
analiza komponentów,
modyfikacja wymagań,
projektowanie systemu z użyciem wielokrotnym,
tworzenie i integracja.
Zakłada się istnienie dużego zbioru dostępnych komponentów programowych do użycia wielokrotnego oraz integrującej je struktury.
23. Iteracja procesu. Tworzenie przyrostowe i spiralne
Iteracja:
Potrzebne jest także wspomaganie procesu tworzenia oprogramowania nazywane iteracjami, które polega na powtarzaniu fragmentu tego procesu w miarę ewolucji wymagań stawianych systemowi (na przykład prace projektowe i implementacyjne musza być ponownie wykonane, aby spełnić zmienione wymagania).
Mamy tutaj dwa hybrydowe modele:
tworzenie przyrostowe,
tworzenie spiralne.
Tworzenie przyrostowe:
Podejście przyrostowe do tworzenia zaproponowane w 1980 r. jako sposób na ograniczenie powtarzania prac w procesie tworzenia oraz danie klientom pewnych możliwości odkładania decyzji o szczegółowych wymaganiach do czasu, aż zdobędą pewne doświadczenia w pracy z systemem.
W procesie przyrostowym klienci identyfikują w zarysie usługi, które system ma oferować. Wskazują, które z nich są dla nich najważniejsze, a które najmniej ważne. Definiuje się następnie pewną liczbę przyrostów, które maja być dostarczone.
Gdy przyrost jest już gotowy i dostarczony, klienci mogą go uruchomić. Oznacza to, że szybko otrzymują część funkcjonalności systemu
Zalety procesu tworzenia przyrostowego:
Klienci nie muszą czekać na dostarczenie całego systemu, zanim zaczną czerpać z niego korzyść.
Klienci mogą używać wstępnych przyrostów jako rodzaju prototypu i zdobywać doświadczenia, które inspirują wymagania wobec późniejszych przyrostów.
Ryzyko całkowitej porażki przedsięwzięcia jest mniejsze.
Usługi o najwyższym priorytecie będą dostarczane jako pierwsze.
Tworzenie spiralne
Zaproponowany w 1998 r.
Proces nie jest przedstawiany jako ciąg czynności z pewnymi nawrotami między nimi, ale ma postać spirali.
Każda pętla spirali reprezentuje jedną fazę procesu.
Najbardziej wewnętrzna pętla może być poświęcona wykonalności systemu, następna definicji wymagań stawianych systemowi, kolejna projektowaniu itd.
Jawne potraktowanie zagrożeń.
Każda pętla spirali jest podzielona na cztery sektory:
Ustalanie celów
Definiuje się konkretne cele tej fazy przedsięwzięcia. Identyfikuje się ograniczenia, którym podlega proces i produkt.
Rozpoznanie i redukcja zagrożeń
Przeprowadza się szczegółową analizę każdego z rozpoznanych zagrożeń przedsięwzięcia.
Tworzenie i zatwierdzanie
Po ocenie zagrożeń wybiera się model tworzenia systemu.
Planowanie
Recenzuje się przedsięwzięcie i podejmuje decyzję, czy rozpoczynać następną pętlę spirali.
24. Metody projektowania, wyszukiwanie błędów
Metody projektowania:
Ciągle często projektowanie jest działaniem ad hoc, bez formalnej kontroli zmian ani zarządzania projektowaniem.
Lepsze podejście polega na użyciu metod strukturalnych, które są zbiorami notacji i porad dla projektantów oprogramowania. Ich użycie polega zwykle na opracowaniu graficznych modeli systemu i prowadzi do dużej ilości dokumentacji projektowej.
Metody strukturalne mogą obejmować:
modele przepływu danych,
modele encja-związek,
modele strukturalne,
modele obiektowe
wyszukiwanie błędów:
Programiści wykonują pewne testy kodu, który napisali. Zwykle prowadzi to do wykrycia błędów, które należy usunąć z programu.
Testowanie programu i usuwanie błędów to dwa różne procesy.
Lokalizacja błędu może wymagać nowych przypadków testowych.
25. Fazy procesu testowania. Testowania Alpha i Beta.
Fazy procesu testowania
Testowanie komponentów (jednostek)
Testuje się poszczególne komponenty, aby zapewnić, że działają poprawnie.
Testowanie modułów
- Moduł jest kolekcją niezależnych komponentów takich jak klasy obiektów, abstrakcyjne typy danych, albo bardziej luźną kolekcją procedur i funkcji.
Testowanie podsystemów
Testowanie kolekcji modułów, które zintegrowano w podsystemie.
Testowanie systemu
Proces ma wykryć błędy wynikające z nieprzewidzianych interakcji między podsystemami zintegrowanymi w pełen system oraz problemy z interfejsami podsystemów.
Testowanie odbiorcze
Jest to końcowa faza procesu testowania przed przyjęciem systemu do użytkowania.
Testowania Alpha i Beta:
Testowanie alfa jest testowaniem odbiorczym, stosowanym kiedy system jest tworzony dla konkretnego klienta. Proces testowania trwa do momentu osiągnięcia zgody pomiędzy wytwórcą systemu i klientem co do tego, że dostarczony system jest możliwą do przyjęcia implementacją wymagań.
Testowanie beta stosuje się, kiedy system sprzedawany jako produkt programowy. Testowanie polega na dostarczeniu systemu pewnej liczbie potencjalnych klientów, którzy zgodzili się z niego korzystać. Klienci informują wytwórców o pojawiających się problemach.
26. Projektowanie obiektowe, Strategie obiektowe, Obiekt, klasa obiektów + reprezentacja graficzna, komunikacja między obiektami, budowa modelu obiektowego.
Projektowanie obiektowe:
Strategia projektowania, w ramach której projektanci systemu myślą w kategoriach „bytów”, a nie operacji albo funkcji.
Działający system składa się z oddziałujących na siebie obiektów, które przechowują swój lokalny stan i oferują operacje testujące lub zmieniające ten stan.
Obiekty ukrywają informację o reprezentacji stanu i w ten sposób ograniczają do niego dostęp.
Proces projektowania obiektowego obejmuje zaprojektowanie klas obiektów i związków (relacji) między tymi klasami.
W działającym programie, potrzebne obiekty są tworzone na podstawie definicji klas.
Strategie obiektowe
Analiza i projektowanie obiektowe polegają na opracowaniu modelu obiektowego dla danej dziedziny zastosowania przy uwzględnieniu zidentyfikowanych wymagań. Rozpoznane obiekty odzwierciedlają byty i operacje związane z rozwiązywanym problemem.
Programowanie obiektowe polega na realizacji projektu oprogramowania za pomocą obiektowego języka programowania. Języki obiektowe, takie jak Java, umożliwiają bezpośrednią implementację obiektów i dostarczają udogodnienia do definiowania klas obiektów.
Obiekt jest bytem, który posiada swój stan i zbiór zdefiniowanych operacji działających na tym stanie.
- stan jest reprezentowany jako zbiór atrybutów (ang. attributes) obiektu.
- operacje (ang. operations) skojarzone z obiektem służą do oferowania usług innym obiektom (klientom), które mogą żądać tych usług, gdy potrzebują wyników ich działania.
Obiekty są tworzone zgodnie z definicja klasy obiektów. Definicja klasy obiektów służy jako szablon do tworzenia obiektów. Zawiera deklaracje wszystkich atrybutów i operacji, które należy skojarzyć z obiektem tej klasy.
Klasa obiektów (ang. class)
Grupa obiektów może mieć wspólną definicję danych lub usług wykorzystywanych do definicji interfejsu, stanowiąc wcielenie (instancje) wspólnej definicji zwanej klasą obiektów.
Innymi słowy: pojęcie klasy umożliwia wyróżnienie podobnej grupy obiektów według pewnego kryterium (pewnych cech, którymi są atrybuty i operacje).
Jeżeli mamy zdefiniowaną klasę, to mówimy, że obiekt należący do niej jest instancją tej klasy (ang. instance).
Komunikacja pomiędzy obiektami:
Obiekty porozumiewają się przez żądania usług od innych obiektów (wywołania operacji), i jeśli trzeba, wymianę informacji niezbędnych do realizacji usługi.
Kopie informacji potrzebnych do wykonania usługi i wyniki jej wykonania są przekazywane jako parametry.
Obiekt odbiorca analizuje składniowo komunikat, rozpoznaje usługę i przekazane dane a następnie realizuje żądaną usługę.
Przykłady komunikacji:
// Wywołaj operację (w obiektowych językach programowania operacje nazywa się metodami) dla obiektu buforCykliczny, która pobiera kolejną wartość z bufora i zapisuje ją do zmiennej.
w = buforCykliczny.pobierz()
// Wywołaj metodę termostatu, ustawiającą temperaturę
termostat.ustawTemperaturę(20);
Budowa modelu obiektowego
Identyfikacja klas obiektów
Podejście praktyczne polega na wyselekcjonowaniu rzeczowników z Specyfikacji Wymagań Systemowych i potraktowaniu ich jako identyfikatorów klas obiektów.
Innym źródłem identyfikacji obiektów mogą być:
Specyfikacja przypadków użycia
dodatkowe klasy obiektów wynikające z ogólnej wiedzy na temat problemu.
Identyfikacja związków między klasami
Wstępna identyfikacja przez rozpatrzenie ze specyfikacji wymagań fraz zawierających czasowniki.
Identyfikacja klas obiektów
Podejście praktyczne polega na wyselekcjonowaniu rzeczowników z Specyfikacji Wymagań Systemowych i potraktowaniu ich jako identyfikatorów klas obiektów.
Innym źródłem identyfikacji obiektów mogą być:
Specyfikacja przypadków użycia
dodatkowe klasy obiektów wynikające z ogólnej wiedzy na temat problemu.
Identyfikacja związków między klasami
Wstępna identyfikacja przez rozpatrzenie ze specyfikacji wymagań fraz zawierających czasowniki.
27. Diagramy-opis i przykłady.
diagram klas (class)
Diagram klas jest ściśle powiązany z projektowaniem obiektowym systemu informatycznego lub wręcz bezpośrednio z jego implementacją w określonym języku programowania. Elementami tego diagramu są klasy, reprezentowane przez prostokąty, które mogą zawierać informację o polach i metodach klasy.
Związki pomiędzy klasami są oznaczane liniami, które mogą, opcjonalnie, mieć strzałkę wskazującą kierunek relacji. Końce związków mogą także być oznaczone krotnościami: mówią one o tym, ile obiektów danej klasy może brać udział w danej relacji. Na przykład istnieje jeden katalog ale może się nim posługiwać dowolna liczba pracowników biblioteki (co oznaczamy 0...*). Inną ciekawą relacją pokazaną na diagramie jest agregacja między biblioteką i książką, oznaczona linią z rombem po stronie biblioteki. Agregacja oznacza relację część-całość, przy czym romb jest oczywiście po stronie całości.
diagram obiektów (object)
Diagram obiektów prezentuje możliwą konfigurację obiektów w określonym momencie. Jest pewnego rodzaju instancją diagramu klas, w której zamiast klas przedstawiono ich obiekty.
Diagram posługuje się identycznymi symbolami co diagram klas, zamiast symboli klas występują symbole obiektów.
diagram struktur złożonych (composite structure)
Diagram przedstawia hierarchicznie wewnętrzną strukturę złożonego obiektu z uwzględnieniem punktów interakcji z innymi częściami systemu.
Obiekt składa się z części, które reprezentują poszczególne składowe obiektu realizujące poszczególne funkcje obiektu. Komunikacja pomiędzy obiektem, a jego środowiskiem przebiega poprzez port (oznaczany jako mały prostokąt umieszczony na krawędzi obiektu). Porty są połączone z częściami obiektu, które są odpowiedzialne za realizacje tych funkcji.
diagram pakietów (package diagram)
Diagram pakietów służy do tego, by uporządkować strukturę zależności w systemie, który ma bardzo wiele klas, przypadków użycia itp. Przyjmujemy, że pakiet zawiera w sobie wiele elementów, które opisują jakieś w miarę dobrze określone zadanie. Na diagramie umieszczamy pakiety i wskazujemy na zależności między nimi. Dzięki temu dostajemy na jednym diagramie obraz całości, bądź dużego fragmentu, systemu.
diagram komponentów (component)
Diagram komponentów robimy z podobnych powodów, co diagram pakietów - chcemy podzielić system na prostsze elementy i pokazać zależności między nimi. Diagram pakietów koncentrował się na podziale systemu z logicznego punktu widzenia, diagram komponentów z kolei dzieli system na fizyczne elementy oprogramowania: pliki, biblioteki, gotowe, wykonywalne programy itp.
diagram wdrożenia (deployment)
Odzwierciedla fizyczną strukturę całego systemu, z uwzględnieniem oprogramowania i sprzętu.
Jednostki oprogramowania są reprezentowane przez artefakty (czyli skompilowane wersje komponentu, który można uruchomić), dane i biblioteki.
Stronę sprzętową reprezentują węzły, czyli poszczególne urządzenia obliczeniowe, komunikacyjne i przechowujące, powiązane ścieżkami komunikacyjnymi (np. połączeniem TCP/IP).
Diagram ten istotną rolę odgrywa przy wdrażaniu dużych, rozproszonych systemów.
diagram przypadków użycia (use cases)
Diagram przypadków użycia opisuje system z punktu widzenia użytkownika, pokazuje co robi system, a nie jak to robi. Diagram ten sam w sobie zazwyczaj nie daje nam zbyt wielu informacji, dlatego też zawsze potrzebna jest do niego dokumentacja w postaci dobrze napisanego przypadku użycia. Przypadki użycia są bardzo ważnym narzędziem zbierania wymagań. Diagramy przypadków użycia, mimo swojej prostoty, są bardzo przydatne, gdyż tworzą swojego rodzaju spis treści dla wymagań modelowanego systemu.
diagram maszyny stanowej (state machine)
Diagramy interakcji mówiły nam o zachowaniu obiektów, diagram stanów z kolei służy do tego, by pokazać w jakich stanach mogą być obiekty. Poniżej widzimy diagram stanów obiektu dane:
Podstawowymi elementami diagramu są stany obiektu połączone strzałkami przejść. Obiekt, reagując na nadchodzące zdarzenia, jeżeli spełnione są określone warunki, zmienia swój stan i położenie na diagramie stanu
STAN:
Stan jest etapem cyklu życia obiektu. Obiekt przebywający w danym stanie spełnia określony warunek.
Stany są reprezentowane przez prostokąty z zaokrąglonymi narożnikami. Każdy stan ma swoją nazwę.
Ze stanem mogą być związane pewne akcje, wykonywane w określonym momencie:
• entry: jest akcją wykonywaną w momencie gdy obiekt przyjmuje dany stan; akcja ta jest wykonywana jeden raz i niepodzielnie
• do: jest akcją wykonywaną nieprzerwanie w czasie, gdy obiekt przebywa w tym stanie
• exit: oznacza (analogicznie do entry) moment opuszczenia stanu; podobnie, akcja taka jest wykonywana tylko raz.
• event: reprezentuje akcję wykonywaną w momencie nadejścia zdarzenia określonego typu
Wykonanie każdej z tych akcji może również generować zdarzenie.
Przejścia pomiędzy stanami:
Stany są powiązane ze sobą przejściami. Przejścia definiują warunki, jakie muszą zaistnieć, aby obiekt zmienił swój stan ze źródłowego na docelowy. Formalnie opis przejścia składa się z czterech elementów:
• wyzwalacza (ang. trigger) - zdarzenia, które może spowodować przejście i zmianę stanu
• dozoru (ang. guard condition) - warunku, jaki musi być spełniony, aby przejście zostało wykonane; warunek ten jest ewaluowany w momencie pojawienia się wyzwalacza
• akcji (ang. action) - operacji wykonywanej w momencie przejścia ze stanu do stanu; nawet jeżeli akcja przejścia jest złożona z wielu akcji elementarnych, jest ona wykonywana niepodzielnie
• zdarzenia (ang. event) - wysyłanego w momencie wykonania przejścia
Pseudostany:
Stany pomocnicze (pseudostany):
• początkowy, który reprezentuje obiekt w momencie jego utworzenia.
• końcowy, który reprezentuje usunięcie obiektu z systemu.
• decyzja, przedstawiająca wybór pomiędzy dwiema wartościami logicznymi pewnego wyrażenia.
• złączenie/rozwidlenie - powoduje synchronizację stanów (wszystkie dochodzące do niego przejścia muszą być wykonane)
• historia (literka H w okręgu wewnątrz stanu) - zapewnia możliwość zapamiętania poprzedniego stanu obiektu i przywrócenie go.
Stany złożone:
Stany złożone posiadają wewnętrzną maszynę stanów. Wejście do stanu jest jej stanem początkowym, a wyjście -końcowym.
diagram czynności (activity)
Diagram aktywności jest pewną mutacją diagramu stanów, z tą różnicą, że diagram aktywności skupia się raczej na opisaniu jakiegoś procesu, w którym uczestniczy wiele obiektów, zaś diagram stanów pokazuje, jakie są możliwe stany konkretnego obiektu. Diagram aktywności jest bardzo dobrym narzędziem, gdy chcemy przedstawić odpowiedzialność obiektów w ramach jakiegoś procesu.
W odróżnieniu od diagramu maszyny stanowej, diagram czynności może obejmować wiele obiektów na raz, zwykle umieszczanych w odpowiednich torach
diagram sekwencji (sequence)
Analogiczną informację do diagramu komunikacji zawiera drugi z diagramów interakcji, diagram przebiegu. Diagram komunikacji koncentrował się na zobrazowaniu współpracy między obiektami, teraz chcemy pokazać kolejność przesyłania komunikatów i czas istnienia obiektów.
diagram komunikacji (communication)
Diagram współpracy jest jednym z czterech diagramów interakcji. Używamy go po to, żeby zobrazować dynamikę systemu - wzajemne oddziaływanie na siebie obiektów oraz komunikaty, jakie między sobą przesyłają.
diagram przeglądu interakcji (interaction overview)
diagram uwarunkowań czasowych (timing)
28.Czym jest UML oraz OMG
UML:
UML jest językiem do specyfikacji, wizualizacji, konstrukcji, dokumentowania projektów związanych z systemami informacyjnymi intensywnie wykorzystującymi oprogramowanie, a także do modelowania biznesowego wszelkich innych systemów.
UML oferuje standaryzowany sposób zapisu projektu, obejmującego zarówno jego konceptualne aspekty, takie jak procesy biznesowe czy funkcje systemu, jak też i elementy fizyczne (np. schematy bazy danych, warstwę sprzętową systemu).
UML standaryzuje notację graficzną - określa sposób zapisu modeli.
Czym nie jest UML:
UML nie jest metodyką
- UML nie określa metody modelowania
- zaleca jedynie stosowanie podejścia przyrostowego
UML nie jest narzędziem
- UML to specyfikacja dla narzędzi
UML nie jest językiem programowania
- generowanie kodu z modelu stosowane jest obecnie na niewielką, choć stale zwiększającą się skalę (przyczyna: dopiero teraz powstają narzędzia CASE lepiej wspomagające ten proces)
OMG - Object Management Group :
OMG - niekomercyjna organizacja powstała w 1989 r. Jej celem jest promowanie teorii oraz praktyki technologii obiektowych.
Założycielami OMG było 13 liczących się przedsiębiorstw z branży software'owej.
Obecnie do organizacji należy ponad 750 firm - producentów oprogramowania oraz sprzętu komputerowego.
Organizacja zajmuje się opracowywaniem standardów pomagających w tworzeniu aplikacji obiektowych.
W 1997 r. OMG włączyła się do prac nad UML
2005 r. - OMG doprowadziła do uznania UML 1.4 jako oficjalnego standardu.
3
Diagramy obiektów przydają się w przypadku szczególnie skomplikowanych zależności, których nie można przedstawić na diagramie klas.
Wówczas przykładowe konfiguracje obiektów pomagają w zrozumieniu modelu.
Stany są powiązane ze sobą przejściami. Przejścia definiują warunki, jakie muszą zaistnieć, aby obiekt zmienił swój stan ze źródłowego na docelowy. Formalnie opis przejścia składa się z czterech elementów:
• wyzwalacza (ang. trigger) - zdarzenia, które może spowodować przejście i zmianę stanu
• dozoru (ang. guard condition) - warunku, jaki musi być spełniony, aby przejście zostało wykonane; warunek ten jest ewaluowany w momencie pojawienia się wyzwalacza
• akcji (ang. action) - operacji wykonywanej w momencie przejścia ze stanu do stanu; nawet jeżeli akcja przejścia jest złożona z wielu akcji elementarnych, jest ona wykonywana niepodzielnie
• zdarzenia (ang. event) - wysyłanego w momencie wykonania przejścia.
Użytkownik
Plik
prawa dostępu
Wyszukiwarka
Podobne podstrony:
Zagadnienia na egzamin WPS 1 sem, Praca Socjalna, I rok, I semestr, WPS
algorytmy egzamin, !!!Uczelnia, wsti, materialy, II SEM, algorytmy struktury danych
Kolokwium I sem - lekarski(2), I rok, Anatomia, cxrtsjxcgvhbjnkmugjyfghkjl, Anatomia egzamin, Semest
AiSD Egzamin 2005, !!!Uczelnia, wsti, materialy, II SEM, algorytmy struktury danych
fizyka egzamin II sem, Akademia Morska, 1 rok, Fizyka, FIZYKA1, Fizyka, Semestr 2, Wykład
AiSD Egzamin Zadania, !!!Uczelnia, wsti, materialy, II SEM, algorytmy struktury danych
algo zadania egzamin, !!!Uczelnia, wsti, materialy, II SEM, algorytmy struktury danych, egzamin
Egzamin InzNowMat, SEMESTRY, Sem 6, Inz Nowych Materialow
Pytania na kolokwium II sem - dla studentow 2009, uczelnia WSEI Lublin, UCZELNIA WSEI 2 1, MATERIAŁY
Pytania egzaminacyjne z fizyki sem II, Studia, Sem 2, SEMESTR II, SEMESTR I, fizyka, haksy, Fiza
Egzamin biologia sem III, Inżynieria Środowiska Politechnika Śląska Rybnik, Biologia, Semestr III
AiSD Egzamin 2006, !!!Uczelnia, wsti, materialy, II SEM, algorytmy struktury danych
Egzamin Semestr I matma id 680987
Drgania Ćwiczenie nr 13, Politechnika Lubelska, Studia, semestr 5, Sem V, Sprawozdania, Laborka, Lab
Informacja dotycząca egzaminu, Semestr IV, PPUE
Urządzenia 101 - parametry łączników protokół (tylko dla ZAO, Politechnika Lubelska, Studia, semestr
więcej podobnych podstron