SYSTEMY OPERACYJNE
Literatura:
(podstawowa, fragmenty wykładu powstały na bazie innych źródeł - o tym na wykładzie...)
Systemy operacyjne:
1. A. Silbershatz, J.L. Peterson, P.B. Galvin, Podstawy systemów operacyjnych, WNT 1993.
2. A.S. Tannenbaum, Rozproszone systemy operacyjne, Wyd. Nauk. PWN, 1997.
3. A.M. Lister, R.D. Eager, Wprowadzenie do systemów operacyjnych, WNT, 1994.
Omówienie zagadnień związanych z przedmiotem w kontekście UNIX'a:
4. W.R. Stevens, Programowanie zastosowań sieciowych w systemie UNIX, WNT, 1995.
5. Gabassi, Przetwarzanie rozproszone w systemie UNIX, Wyd. Lupus.
6. M.J Bach, Budowa systemu operacyjnego UNIX, WNT, 1995.
1. Wprowadzenie
1.1 System operacyjny.
System operacyjny (najprościej) - program, który pośredniczy między użytkownikiem komputera a sprzętem.
Zadania s.o:
Ukrywa szczegóły sprzętowe systemu komputerowego poprzez tworzenie abstrakcji (maszyn wirtualnych).
Przykłady:
- jednolity sposób dostępu do urządzeń zewnętrznych
- zbiory bloków dyskowych widziane jako pliki o symbolicznych nazwach
- duża, szybka, dedykowana pamięć operacyjna
- współbieżne wykonanie programów (jako abstrakcja równoległości)
Zarządzanie zasobami:
- zasoby to „obiekty” niezbędne do wykonania programu, np. pamięć, czas CPU, wejście-wyjście, porty komunikacyjne (wszystko co przedstawia wartość funkcjonalna dla systemu)
- strategie przydziału i odzyskiwania zasobów (zarządzanie pamięcią, zarządzanie procesorem, zarządzanie plikami, zarządzanie urządzeniami)
- efektywność zarządzania zasobami decyduje o wydajnej eksploatacji sprzętu komputerowego
Dostarcza „przyjazny” interfejs
- wygoda użycia (ustawianie przełączników, karty perforowane, taśmy perforowane, terminale graficzne z myszką i klawiaturą)
Składowe systemu komputerowego:
Sprzęt - podstawowe zasoby obliczeniowe (CPU, pamięć, urządzenia we-wy)
System operacyjny - nadzoruje i koordynuje posługiwanie się sprzętem
Programy użytkowe - określają sposób użycia zasobów systemu do rozwiązania zadań stawianych przez użytkowników
Użytkownicy (ludzie, maszyny, inne komputery, programy zewnętrzne)
1.2 Historia
Wczesne systemy operacyjne - „goły sprzęt”:
Struktura:
- wielkie maszyny obsługiwane za pośrednictwem konsoli
- dla jednego użytkownika (konieczność harmonogramów pracy etc.)
- programista/użytkownik pełnił rolę operatora
· nieefektywne wykorzystanie kosztownych zasobów
- niskie wykorzystanie CPU
- pełna sekwencyjność pracy urządzeń
- przestoje sprzętu związane z wykonywaniem czynności operatorskich
Wczesne oprogramowanie
-asemblery, programy ładujące, programy łączące, biblioteki typowych funkcji, kompilatory, programy sterujące urządzeń
Systemy wsadowe:
Zatrudnienie operatora (użytkownik oraz operator)
Skrócenie czasu instalowania zadania przez przygotowywanie wsadu zadań o podobnych wymaganiach
Automatyczne porządkowanie zadań - automatyczne przekazywanie sterowania od jednego zadania do drugiego
Rezydentny monitor:
- początkowo sterowanie należy do monitora
- przekazanie sterowania do zadania
- po zakończeniu zadania sterowanie wraca do monitora
Wprowadzenie kart sterujących (Job Control Language)
- Istotna zmiana trybu pracy z punktu widzenia użytkownika
- Zwiększona przepustowość systemu kosztem średniego czasu obrotu zadania
- Problem: niska wydajność (CPU i urządzenia we-wy nie mogą pracować równocześnie, czytnik kart bardzo wolny) Rozwiązanie: praca w trybie pośrednim (off-line)
Zastosowanie czytników taśm magnetycznych:
- Przyspieszenie obliczeń poprzez ładowanie zadań do pamięci z taśm oraz czytanie kart i drukowanie wyników wykonywane off-line
- Komputer główny nie jest ograniczony prędkością pracy czytników kart i drukarek, a jedynie prędkością szybszych stacji taśmowych
- Nie są potrzebne zmiany w programach użytkowych przy przejściu do trybu pracy pośredniej
- Możliwość używania wielu systemów czytnik-taśma i taśma-drukarka dla jednego CPU
Buforowanie :
Metoda jednoczesnego wykonywania obliczeń i operacji we-wy dla jednego zadania:
- Nie eliminuje całkowicie przestojów CPU czy urządzeń we-wy
- Wymaga przeznaczenia pamięci na systemowe bufory
- Niweluje wahania w czasie przetworzenia danych
Spooling (simultaneous peripheral operation on-line):
Metoda jednoczesnego wykonywania we-wy jednego zadania i obliczeń dla innych zadań
- Możliwe dzięki upowszechnieniu się systemów dyskowych
- Podczas wykonania jednego zadania system operacyjny czyta następne zadanie z czytnika kart na dysk (kolejka zadań) oraz np. drukuje umieszczone na dysku wyniki poprzedniego zadania
- Pula zadań - możliwość wyboru kolejnego zadania do wykonania
- Dalsza rozbudowa systemu operacyjnego (moduł wczytujący, moduł sterujący, moduł wypisujący)
Systemy z podziałem czasu:
Procesor wykonuje na przemian wiele różnych zadań, przy czym przełączenia następują tak często, że użytkownicy mogą współdziałać z programem podczas jego wykonania
- Interakcja użytkownika z systemem komputerowym (zadanie interakcyjne składa się z wielu krótkich działań)
- System plików dostępnych bezpośrednio (dostęp do programów i danych)
- Wymiana zadania między pamięcią i dyskiem (ang. swapping)
Systemy równoległe:
Systemy wieloprocesorowe z więcej niż jednym CPU.
Systemy - procesory dzielą pamięć i zegar; komunikacja zwykle poprzez pamięć dzieloną
Korzyści: zwiększona przepustowość, ekonomiczne, zwiększona niezawodność
Symetryczna wieloprocesowość (każdy procesor wykonuje identyczną kopię systemu operacyjnego, wiele procesów może się wykonywać równocześnie, bez spadku wydajności).
Asymetryczna wieloprocesowość (każdy procesor wykonuje przydzielone mu zadanie; procesor główny szereguje i przydziela pracę procesorom podrzędnym - rozwiązanie stosowane w dużych systemach).
Możliwe rozproszenie systemów wieloprocesorowych.
Systemy czasu rzeczywistego:
Ostre wymagania czasowe
Sprzężenie zwrotne z działaniami użytkownika/sprzętu.
Przykłady: sterowanie procesami przemysłowym, monitorowanie stanu zdrowia pacjenta...
Rozwój sprzętu: (cztery generacje): lampy, tranzystory, układy scalone małej skali integracji, układy scalone dużej skali integracji
Wymagania sprzętowe dla współczesnych systemów:
- system przerwań (tablice przerwań, podczas wykonywania przerwania inne są wyłączone, ew. istnieje priorytet przerwań).
- bezpośredni dostęp do pamięci (DMA) dla szybkich urządzeń we-wy
- ochrona pamięci (operacje we-wy tylko za pośrednictwem s.o., ochrona tablicy przerwań i systemu, wzajemna ochrona zadań np. rejestry bazowy i graniczny)
- wielostanowość procesora
- rozkazy uprzywilejowane
- zegar
Generacje systemów operacyjnych:
- Lata 40. Brak systemów operacyjnych w obecnym znaczeniu tego słowa
- Lata 50. Możliwość przetwarzania wsadowego
- Wczesne lata 60. Wieloprogramowość, wieloprocesowość, niezależność urządzeń, podział czasu, przetwarzanie w czasie rzeczywistym.
- Połowa lat 60., do połowy lat 70. Systemy ogólnego przeznaczenia umożliwiające jednocześnie różne tryby pracy
- Obecnie: Komputery osobiste, stacje robocze, systemy baz danych, sieci komputerowe, systemy rozproszone
1.3 Ogólna struktura sytemu operacyjnego.
Moduły funkcjonalne systemu operacyjnego:
- zarządzanie pamięcią
- zarządzanie procesorem (na poziomie zadań i procesów - dostepne operacje na procesach: create, terminate, abort, signal, allocate/free memory)
- zarządzanie urządzeniami (operacje attach/detach, request/release, read/write)
- zarządzanie informacją (system plików - operacje: create, delete, open, close, change attributes)
- jądro (m.in. zapewnienie komunikacji między komponentami systemu oraz ochrony)
Najprostsza struktura (monolityczny s.o.)
- program złożony z wielu procedur, każda może wołać każdą, ograniczona strukturalizacja (np.
OS/360, MS-DOS, niektóre wersje Unix)
- makrojądro - wszystkie funkcje SO umieszczone w jądrze i wykonywane w trybie uprzywilejowanym (np. OS/360)
- jądro - część funkcji przeniesiona z jądra na poziom użytkownika (np. w systemie Unix: jądro i programy systemowe)
Struktura warstwowa
- każda warstwa spełnia funkcje zależne tylko od warstwy poniżej (T.H.E., RC-4000, VMS); w Multicsie odmiana struktury warstwowej - zespół koncentrycznych pierścieni. Wykorzystywane makrojądro - wszystkie warstwy są uprzywilejowane. Struktura warstwowa (system T.H.E.):
- poziom 5: programy użytkowników
- poziom 4: buforowanie urządzeń we-wy
- poziom 3: program obsługi konsoli operatora
- poziom 2: zarządzanie pamięcią
- poziom 1: planowanie przydziału procesora
- poziom 0: sprzęt
Struktura mikrojądra - mikrojądro obejmuje jedynie tworzenie procesów, komunikację międzyprocesową, mechanizmy (ale nie strategie!), zarządzanie pamięcią, procesorem i urządzeniami (na najniższym poziomie), np. Mach, QNX (ogólnie - systemy przemysłowe)
Struktura typu klient-serwer
- moduły pełnią wyodrębnione zadania, komunikują się poprzez wysyłanie komunikatów.
- Serwer: dostarcza usługę, klient: żąda usługi. Prosta adaptacja do systemów rozproszonych.
- konieczny bezpołączeniowy protokół typu pytanie-odpowiedź
- jądro można zredukować do 2 odwołań do systemu (nadaj/odbierz komunikat)
- łatwa realizacja rozpraszania
Koncepcja maszyny wirtualnej:
- każdy proces otrzymuje (wirtualną) kopię komputera będącego podstawą systemu; każda wirtualna maszyna jest identyczna z rzeczywistym sprzętem, więc każda może wykonywać dowolny system operacyjny; np. VM dla dużych komputerów firmy IBM
- Korzyści: każda część systemu jest dużo mniejsza, bardziej elastyczna i łatwiejsza w utrzymaniu.
CMS - system operacyjny dla indywidualnego użytkownika
2. Procesy i wątki.
2.1 Proces.
Proces - program (kod binarny) w czasie wykonania; wykonanie przebiega sekwencyjnie (wyjątek: procesy wielowątkowe - patrz niżej).
Procesy wykonują się współbieżnie (ale niekoniecznie równolegle - podział czasu)
Stany procesu:
- nowy: proces został utworzony
- wykonywany: są wykonywane instrukcje procesu
- oczekujący: proces czeka na wystąpienie zdarzenia
- gotowy: proces czeka na przydzielenie procesora
- zakończony: proces zakończył wykonanie
Reprezentacja procesu w systemie (zawartość bloku kontrolnego procesu):
- stan procesu
- identyfikator (unikalny numer - w UNIX'ie - PID)
- licznik rozkazów
- rejestry procesora
- wskaźnik do kolejki procesów
- informacje o pamięci zajętej przez proces
- wykaz otwartych (używanych plików)
Tworzenie procesu:
za pomocą funkcji systemowej (np. fork() w UNIX)
proces utworzony przez inny proces (macierzysty, ew. rodzic) nazywamy potomnym.
potomek uzyskuje nową pulę zasobów lub korzysta z zasobów rodzica (mniejsze przeciążenie systemu).
Zakończenie procesu:
po ostatniej instrukcji.
specjalna funkcją (np. exit() w UNIX)
na żądania rodzica ( abort() )
niekiedy: zakończenie kaskadowe: po zakończeniu rodzica kończone są procesy potomne.
2.2 Wątek
Wątek sterowania (tzw. lekki proces): sekwencja instrukcji; tradycyjnie proces = jeden wątek sterowania, jednak czasami (w niektórych systemach) w przestrzeni adresowej procesu dopuszcza więcej wykonywanych współbieżnie wątków sterowania.
wątek ma te same podst. cechy co proces (stany, możliwość tworzenia wątków potomnych, korzystania z urządzeń zewn. itd...)
między wątkami tego samego procesu nie ma ochrony pamięci.
analogia: maszyna-procesy == proces-wątki
elementy wątku i procesu:
Wątek |
Proces |
licznik rozkazów |
przestrzeń adresowa |
stos |
otwarte pliki, semafory |
rejestry procesora |
zmienne globalne |
lista wątków potomnych |
lista proc. potomnych |
Tradycyjny proces (ciężki) jest równoważny zadaniu z jednym wątkiem
Jeżeli zadanie składa się z wielu wątków, to w czasie gdy jeden wątek jest zablokowany, może się wykonywać inny wątek tego zadania; współpraca wielu wątków w jednym zadaniu pozwala zwiększyć przepustowość i poprawić wydajność
Wątki umożliwiają połączenie równoległości z sekwencyjnym wykonaniem:
(1) model dyspozytor-pracownik
(2) model zespołu
(3) model potoku
Wątki statyczne/dynamiczne:
- struktura wątków procesu jest ustalona (w kodzie źr. procesu) lub też proces może dowolnie tworzyć/usuwać swoje wątki
Implementacja wątków w systemie operacyjnym:
Pakiet wątków : zbiór elementarnych działań na wątkach dostępnych w systemie (np. procedur bibliotecznych.
Implementacja wątków w przestrzeni użytkownika:
jądro nie wie o wątkach, widzi tylko jednowątkowe procesy
zaleta1: można używać wątków w systemie, który ich nie implementuje (np. pierwotnie UNIX)
możliwe szybkie przełączanie wątków - tylko przeładowania wsk. stosu i instrukcji oraz rejestrów (najszybsze działania w syst. komputerowym).
zaleta2:każdy proces może używać własnego alg. planowania dla swoich wątków.
problem1: przy blokowanych odwołaniach wątków do systemu - proces nie może oddać sterowania systemowi, musi czekać na swoje wątki. Używa się kodu sprawdzającego (and. jacket) czy odwołania wątków będą blokować. a wątków używa się głownie w zadaniach z blokującymi odwołaniami, gdzie mają poprawić wydajność...
problem2: nie ma wywłaszczania, wątki muszą same oddawać sterowanie procedurze wykonawczej procesu.
Implementacja wątków w jądrze:
system wykonawczy jest częścią jądra
jądro zakłada tablicę wątków dla każdego procesu
wszystkie funkcje mogące blokować mają postać odwołań do systemu
gdy wątek czka, jądro wybiera następny - wydajność!
wada: koszt odwołań do systemu (czas!)
Ogólne problemy (najtrudniejsze do implementacji) z wątkami:
obsługa przerwań (sygnałów)
niewznawialne procedury systemowe
3. Procesy - zagadnienia planowania
3.1 Planowanie
Planowanie - przydział procesora gwarantujący jego optymalne wykorzystanie (np. gdy proces czeka na urządzenie we-wy; sterowanie przechodzi do następnego.
procesy oczekują na przydział procesora w kolejkach (kolejka: lista bloków kontrolnych procesów)
kolejka zadań: procesy nowoutworzone i czekające na pamięć
kolejka procesów gotowych: czekających na przydział procesora
kolejki urządzeń: procesy oczekujące na przydział urządzenia
za szeregowanie (wybór z kolejek) procesów odpowiada planista (scheduler - proces systemowy)
planista długoterminowy: wybiera procesy z kolejki zadań (zredukowany w niektórych systemach); działa co sek/min.
planista krótkoterminowy: wybiera z kolejki pr. gotowych; działa co ms.
czasem planista odpowiada za wymianę (swapping) czyli czasowe usuwanie zadania w całości z pamięci głównej do pomocniczej
Decyzję podejmuje się gdy proces:
1. przechodzi ze stanu wykonywany do stanu oczekujący
2. przechodzi ze stanu wykonywany do stanu gotowy
3. przechodzi ze stanu oczekujący do stanu gotowy
4. kończy się
Sterowanie do procesu wybranego przez planistę przekazuje dyspozytor (dispatcher):
przechowuje stan (kontekst) bieżącego procesu.
przełącza kontekst (rejestry, itd...)
przełącza system w tryb użytkownika
wykonuje skok do adresu z bloku kontrolnego
opóźnienie wnoszone przez dyspozytora: 1-100ms (zależne od wsparcia sprzetowego)
Życie procesu: dwie fazy (cykliczne) : 1. procesora, 2. we-wy (oczekiwania na urządzenie)
procesy zorientowane na we-wy (1): spędzają więcej czasu wykonując operacje we-wy niż obliczenia; wiele krótkich odcinków czasu zapotrzebowania na CPU
zorientowane na procesor (2): spędzają więcej czasu wykonując obliczenia; kilka bardzo długich odcinków czasu zapotrzebowania na CPU
Kryteria planowania (różne możliwości - maxymalizacja, minimalizacja):
max wykorzystania procesora (najlepiej 40-90%)
max przepustowości - liczba procesów kończonych w jedn. czasu)
min czasu przetwarzania procesu (od utworzenia do zakończenia)
min czasu oczekiwania w kolejkach (to kryterium będziemy stosować)
min czasu odpowiedzi procesu (w syst. interaktywnych)
będziemy minimalizować średni czas oczekiwania w kolejkach
3.2 Algorytmy planowania
FCFS (First Come First Served)
przydział czasu w kolejności zgłaszania się procesów
najprostsza implementacja (kolejka FIFO)
brak wywłaszczania
kłopotliwy w systemach z podziałem czasu
przykład:
Procesy i ich zapotrzebowanie na CPU: P1 (24), P2 (3), P3 (3)
Jeżeli procesy przybyły w kolejności P1, P2, P3: · czas oczekiwania: P1 = 0, P2 = 24, P3 = 27 · średni czas oczekiwania: (0 + 24 + 27)/3 = 17.
Jeżeli procesy przybyły w kolejnooeci P2, P3, P1: · czas oczekiwania: P1 = 6, P2 = 0, P3 = 3 · średni czas oczekiwania: (6 + 0 + 3)/3 = 3
efekt: krótkie procesy są wstrzymywane przez długie
zalety: sprawiedliwy, niski narzut systemowy
wady: długi oeredni czas oczekiwania i wariancja czasu oczekiwania, nieakceptowalny w systemach z podziałem czasu
SJF (Shortest Job First)
Algorytm wiąże z każdym procesem długość jego najbliższej fazy procesora. Procesor jest przydzielany najkrótszemu.
Przy równych fazach procesora mamy FCFS
SJF jest optymalny (dowód: umieszczenie krótkiego przed długim bardziej zmniejsza czas oczekiwania krótkiego niż zwiększa długiego)
SJF może być:
niewywłaszczający
wywłaszczający (gdy dł. fazy nowego jest krótsza niż to, co zostało aktualnie wykonywanemu procesowi)
Problem: jak oszacować dł przyszłej fazy procesora?
planista długoterminowy może wymagać jego zadeklarowani od procesów (zadania maj ą predefiniowany czas fazy); krótkoterminowy nie może (wielkie opóźnienia)
częste rozwiązania: dł. następnej fazy (tn+1)= średnia wykładnicza długości n faz poprzednich (założenie: dł fazy jest zależna od długości poprzednich faz):
tn+1 = Σi=0n a(1-a)i tn-i gdzie a<1.
powyższe rozwiązania jest adaptacyjne (dostosowuje się gdy zapotrzebowanie procesu ulega zmianie)
Planowanie Priorytetowe:
szczególnym przypadkiem jest SJF ( w którym priorytet = 1/(dł nast. fazy procesora) ).
zwykle priorytet określa jednak liczba całkowita np. z przedziału [0,7] czy [0,4096] - niższa wartość = wyższy priorytet.
problem: proces o niskim priorytecie może się nigdy nie wykonać (w jednym z przemysłowych systemów IBM proces czekał na wykonanie od 1967 do 1973...); rozwiązanie: postarzanie procesów (zmniejszenie priorytetu o 1 np. co 10 min.)
może być wywłaszczające (ale niekoniecznie)
określenie priorytetu:
- zewnętrznie (przez funkcję systemową)
- wewn. przez deklarację samego procesu (na podstawie np. wymagań: pamięć, procesor etc...)
Planowanie Rotacyjne (Round Robin - RR, pol. karuzelowe)
ustala się kwant czasu (~10-100 ms)
kolejka procesów jest traktowana jak cykliczna FIFO
algorytm przegląda kolejkę i kolejno przydziela każdemu kwant czasu (jeśli proces się w nim nie zakończy - wraca do kolejki, a długość jego fazy procesora zmniejsza się o kwant czasu).
algorytm jest wywłaszczający
gdy jest N procesów a kwant czasu wynosi Q, max. czas oczekiwania może wynieść (N-1)Q
efekty:
- gdy Q rośnie nieograniczenie; planowanie rotacyjne FCFS
- gdy Q zmierza do 0 zachodzi dzielenie procesora - każdy proces dysponuje procesorem o prędkości 1/N rzeczywistego.
- a propos: podobny efekt dają tzw. procesory peryferyjne - z np. 10 zestawami rejestrów; na każde zadanie. Procesor peryf. wykonuje po 1 rozkazie każdego zadania. Zysk: procesor jest szybszy od pamięci - całość nie jest 10x wolniejsza...)
Aspekty wydajnościowe:
- wskazany jest długi kwant czasu w porównaniu z przełączaniem kontekstu (wpp zła wydajność)
- reguła doświadczalna: kwant czasu powinien być dłuższy niż 80% faz procesora dla optymalnej wydajności.
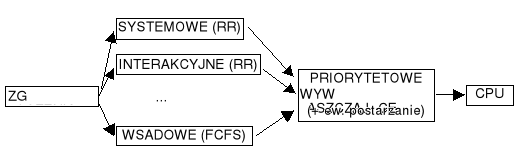
3.3 Struktura kolejek w systemie operacyjnym (planowanie wielopoziomowe).
Kolejka procesów gotowych jest podzielona na odrębne kolejki; przykładowo (najprościej):
- procesów piewszoplanowych (systemowe, interakcyjne)
- procesów drugoplanowych (wsadowe)
Każda kolejka ma własny algorytm szeregowania
Przykład:
- procesy piewszoplanowe - strategia karuzelowa (RR)
- procesy drugoplanowe - FIFO
Szeregowanie pomiędzy kolejkami:
- Ustalone, np. obsługuj najpierw wszystkie procesy pierwszoplanowe, potem drugoplanowe; możliwość zagłodzenia
- Kwant czasu: każda kolejka otrzymuje ustaloną część czasu CPU do podziału pomiędzy swoje procesy, np. 80% dla pierwszoplanowych z RR, 20% dla drugoplanowych z FCFS
- Procesy mogą się przemieszczać pomiędzy kolejkami
Parametry planisty systemowego:
- liczba kolejek
- algorytm szeregowania dla każdej kolejki
- metoda awansu/degradacji procesów (do kolejki o odpowiednio niższym/wyższym priorytecie)
- metoda wybierania kolejki dla nowego procesu
Przykład: proces zużywający dużo czasu procesora (np. cały kwant w RR) przechodzi do kolejki o niższym priorytecie, ale dłuższym kwancie. Na najniższym poziomie: FCFS. Procesy interakcyjne i zorientowane na we-wy będą pozostawać w kolejkach o wyższym priorytecie, a procesy zorientowane obliczeniowo - w kolejkach o niższym priorytecie.
Wnioski z symulacji, teorii, praktyki:
- rozkład faz jest na ogół w rzeczywistych systemach wykładniczy
- jeśli średnia długość kolejki = n, średni czas obsługi = T, tempo przybywania nowych
procesów = λ, to n = λT (tw. Little'a; stosuje się ogólnie do stabilnych systemów kolejkowych)
Systemy wieloprocesorowe:
- dzielenie (osobna kolejka i algorytm dla każdego procesora) lub...
- wspólna kolejka:
- każdy procesor sam wybiera proces do wykonania
- jeden procesor przydziela procesy do procesorów
(tzw. wieloprzetwarzanie asymetryczne)
4. Koordynacja procesów
4.1 Sekcje krytyczne
interpretacja przetwarzania współbieżnego dla pojedynczego CPU: proces rozpoczyna się przed zakończeniem poprzedniego
możliwy konflikt przy operacjach na danych dzielonych (np. nawet instrukcja x:=x=1 to 3 instrukcje (mov AX,x; inc AX; mov x,AX) procesora...
Wniosek: każdy z procesów ma (może mieć) segment kodu nazywany sekcją krytyczną (SK). SK procesów podlegają wzajemnemu wykluczaniu się w czasie.
Cechy rozwiązania problemu SK:
- wzajemne wyłączanie SK
- ograniczone (skończone) czekanie na wejście do SK
postęp: kandydują tylko procesy zgłaszające chęć wejścia do SK
np.(ogólna struktura procesu i przykładowe rozwiązanie):
repeat
while x<>0 do nic (sekcja wejściowa)
<SK> (SK)
x:=1 (sekcja wyjściowa)
<reszta kodu procesu>
until false (narzucone naprzemienne (czyli nie spełniające warunku postępu) wykonanie SK dla 2(może być więcej) procesów)
Poprawne rozwiązanie dla 2 procesów:
var flaga: array[o..1] of Boolean
numer: 0..1
repeat
flaga[i]:=TRUE (chcę wejść)
numer:=j (założenie, że drugi chce wejść)
while (flaga[j] AND numer:=j)do nic
<SK>
flaga[i]:=FALSE
<reszta kodu procesu>
until false (bez zmiennej numer możliwe byłoby ustawienie obu flag przez procesy w dwóch kolejnych instrukcjach procesora (po pechowym przełączeniu kontekstu) i wieczne ich zapętlenie...)
4.2 Semafory
Semafor ogólne popularne rozwiązanie problemu SK i synchronizacji
Semafor s to zmienna całkowita dostępna po inicjacji za pomocą tylko 2 operacji:
- czekaj(s): while s <= 0 do nic; s := s-1;
- sygnalizuj(s): s := s+1;
Interpretacja s: ilość wolnych zasobów; w tym przypadku zasobem jest SK
Operacje na semaforach są NIEPODZIELNE! Implementacja:
- na pojedynczym CPU - zablokowanie przerwań na czas operacji
- w systemie wieloprocesorowym instrukcja procesora TEST&SET
Użycie:
s:=1
repeat
czekaj(s)
<SK>
sygnalizuj(s)
<reszta kodu procesu>
until false
Zastosowanie przy synchronizacji (np. gdy operacja1 musi się wykonać po operacji2):
s:=0
1proces: op1; 2proces: czekaj(s);
sygnalizuj(s); op2;
Wada: s wymaga aktywnego czekania (czas procesora!!!)
rozwiązanie: po czekaj(s) proces jest blokowany i umieszczany w kolejce związanej z s
pobranie procesu z kolejki następuje po sygnalizuj(s)
wtedy semafor to rekord (zmienna całk. + lista procesów)
algorytm obsługi kolejki nie ma znaczenia dla procesora
Realizacja niepodzielności:
1 procesor: blokada przerwań na czas operacji
wiele procesorów: np. pojedyncza instrukcja procesora „test&set”
4.3 Blokady.
Stan blokady: każdy proces w zbiorze procesów czeka na zdarzenie, które może być spowodowane tylko przez inny procesu z tego samego zbioru (zdarzeniem może być np. przydział lub zwolnienie zasobu).
np.:
Semafory A i B mają wartość 1:
P0: wait(A); wait(B)
P1: wait(B); wait(A)
Przypadek szczególny: tzw. głodzenie - czekanie w nieskończoność pod semaforem - gdy np. zastosujemy kolejkę LIFO semafora.
Warunki powstania blokady:
Wzajemne wyłączanie (co najmniej 1 zasób musi być niepodzielny)
Przetrzymywanie i oczekiwanie (proces przetrzymujący co najmniej jeden zasób czeka na przydział dodatkowych zasobów będących w posiadaniu innych procesów).
Nie ma wywłaszczania z zasobów.
Cykliczne czekanie (istnieje zbiór czekających procesów {P0, P1, Pn }, takich że P 0 czeka na zasób przetrzymywany przez P1 , P1 czeka na zasób przetrzymywany przez P2 , ..., P n czeka na zasób przetrzymywany przez P0 .
(4 implikuje 2, więc podane warunki nie są niezależne)
Opis blokady:
zbiór procesów P, zasobów Z, „graf przydziału zasobów” - dwudzielny (krawędzie łączą wierzchołki należące do 2 rozdzielnych zbiorów - w tym przypadku zasobów i procesów) graf skierowany.
krawędzie Pi Zj : krawędź zamówienia
krawędzie Zj Pi : krawędź przydziału
Rysunek:
proces p kółko,
zasób z prostokąt
1 egzemplarz zasobu z kropka w prostokącie.
krawędź przydziału zaczyna się od kropki
Zdarzenia w systemie:
zamówienie z przez p : dodajemy krawędź p z
realizacja zamówienia : dodajemy krawędź z p, usuwamy p z
zwolnienie zasobu : usuwamy krawędź
Blokada:
jeżeli w grafie nie ma cyklu: nie ma blokady.
jeżeli jest cykl a zasoby są pojedyncze to jest blokada
jeżlei jest cykl a zasoby są wielokrotne, to może być blokada
Postępowanie z blokadami:
zapewnić że nigdy ich nie będzie (odp. protokół przydziału zasobów)
pozwalać na wejście w blokadę i potem ją usuwać
zignorować i założyć, że nie wystąpią (np. UNIX i większość popularnych s.o).
4.4 Zapobieganie i unikanie blokad.
Zapobiec spełnieniu jednego z 4 warunków koniecznych wystąpienia blokady:
wzajemne wyłącznie: na ogół niemożliwe; niektóre zasoby są z definicji niepodzielne (drukarka, plik do pisania...)
Przetrzymywanie - trzeba zagwarantować, że gdy proces żąda zasobu, to nie posiada innych zasobów: pozwalać na zamówienie tylko gdy zwolni wszystkie posiadane (problem: głodzenie i nieefektywne wykorzystanie zasobów).
Można wymagać, by proces zamawiał i dostawał wszystkie swoje zasoby zanim rozpocznie działanie lub żądał zasobów wtedy, gdy nie posiada żadnych innych - niskie wykorzystanie zasobów, możliwość zagłodzenia
Brak wywłaszczeń: jeśli proces będący w posiadaniu zasobów żąda zasobu, którego nie można natychmiast przydzielić, to musi zwolnić wszystkie posiadane zasoby - Wywłaszczone zasoby dodaje się do listy zasobów, na które czeka proces
Cykliczne czekanie: narzuca się uporządkowanie całkowite wszystkich typów zasobów i wymaga, by proces zamawiał zasoby we wzrastającym porządku ich numerów (metoda wyklucza powstawanie cykli)
powyższe metody zawsze ograniczają przepustowość systemu...
Unikanie blokad:
Wymaga, by system posiadał pewną informację o przyszłym zapotrzebowaniu na zasoby
W najprostszym modelu wymaga się, by proces deklarował maksymalną liczbę zasobów każdego typu, których będzie potrzebował
Algorytm unikania blokady dynamicznie bada stan przydziału zasobów, by zapewnić, że nigdy nie dojdzie do cyklicznego oczekiwania
Stan systemu jest określony przez liczbę dostępnych i przydzielonych zasobów oraz przez maksymalne zapotrzebowanie procesów.
Stan bezpieczny - kiedy proces żąda dostępnego zasobu, system musi ustalić, czy natychmiastowy przydział zasobu zachowa bezpieczny stan systemu
System jest w stanie bezpiecznym, gdy istnieje bezpieczna sekwencja <P1 , P2 , ..., Pn > : bezpieczna, jeśli dla każdego P i jego potencjalne zapotrzebowanie na zasoby można zaspokoić przez bieżąco dostępne zasoby oraz zasoby będące w posiadaniu procesów Pk , gdzie k < i.
Jeśli system jest w stanie bezpiecznym to nie ma blokady
Jeśli system nie jest w stanie bezpiecznym to istnieje możliwość blokady. Można unikać blokady zapewniając, że system nigdy wejdzie do stanu niebezpiecznego.
Algorytm unikania korzystający z grafu przydziału zasobów: (dla zasobów pojedynczych):
wprowadzamy krawędzie deklaracji (zapotrzebowania) - rysowane linią przerywaną)
szukamy pętli w grafie (złożoność O(n2) )
jeśli jest pętla - nie przydzielamy zasobu.
Algorytm unikania (dla zasobów wielokrotnych - tzw. alg. bankiera. Por. A Silbershatz i.in. Podstawy syst. operacyjnych rozdz. 6.4.1 str. 208.):
Każdy proces musi a priori złożyć maskymalne zapotrzebowanie na zasoby
Proces żądający zasobu być może będzie musiał czekać, mimo że zasób jest dostępny..
Gdy proces dostanie wszystkie potrzebne zasoby, to zwróci je w skończonym czasie
Po zamówieniu przez proces zasobów system ustala czy ich przydzielenie prowadzi do stanu bezpiecznego.
Założenia:
n - liczba procesów
m - liczba typów zasobów
int Dostępne[m] - liczba zasobów określonego typu (np. Dostępne[3]=5 to 5 zasobów typu 3)
int Maks[n][m] - maksymalne żądania procesów
int Przydzielone[n][m] - przydzielone zasoby
int Potrzebne[n][m] - potrzebne zasoby (z tym, że Potrzebne[i][j]=Maks[i][j]-Przydzielone[i][j])
int Zamówienia[n][m] - aktualne zamówienia procesu.
Algorytm:
Jeśli Zamówienia[i] <= Potrzebne[i] to wykonaj krok 2. Wpp błąd - proces przekroczył deklarowane zapotrzebowanie.
Jeśli Zamówienia[i] <= Dostępne wykonaj krok 3. Wpp proces i musi czekać.
System próbuje przydzielić żądane zasoby procesowi i zmieniając stan systemu w następujący sposób:
Dostępne = Dostępne - Zamówienia[i]
Przydzielone[i] = Przydzielone[i] + Zamówienia[i]
Potrzebne[i] = Potrzebne[i] - Zamówienia[i]
Jeśli stan po zmianie jest bezpieczny, transakcja dochodzi do skutku. Jeśli nie - proces i musi czekać...
Algorytm bezpieczeństwa:
int Praca[m]; int Koniec[n]
Praca = Dostępne; Koniec[i] = FALSE dla wszystkich i
Znajdujemy i takie że Koniec[i]=FALSE oraz Potrzebne[i] <= Praca; Jeśli nie ma takiego i do kroku 5.
Praca = Praca + Przydzielone[i]; Koniec[i] = TRUE; przejdź do kroku 2.
Jeśli Koniec[i] = TRUE dla wszystkich i, to system jest w stanie bezpiecznym...
Koszt stwierdzenia czy system jest bezp. = m x n2
4.5 Wykrywanie i wychodzenie z blokady.
W systemach bez zapobiegania i unikania musi być:
alg. wykrywania blokady (najczęściej: poszukiwanie cykli w grafie)
alg. wychodzenia z blokady
Kiedy wywoływać algorytm wykrywania blokady:
gdy nie można natychmiast przydzielić zasobu
raz na ustalony czas (np. 10 min)
gdy obciążenie procesora spada poniżej ~40% (blokada dławi przepustowość systemu)
Wychodzenie z blokady (sposoby):
Powiadomienie operatora (rozwiązuje problem ręcznie)
Usunięcie procesu(ów) uczestniczących w blokadzie
całej pętli (znaczny koszt, utrata częściowych wyników)
kolejno (wywołanie szukania cykli po każdym usunięciu)
- różne kryteria wyboru ofiary (priorytet, typ, posiadane zasoby...)
Wywłaszczanie z zasobów (potrzebna gwarancja że nie będzie głodzenia - np. wywłaszczenie możliwe max. k razy)
Ogólnie (bsługa blokad):
zapobieganie, unikanie, wykrywanie, usuwania
We współczesnych systemach: - podział zasobów na klasy:
do klas stosujemy zapobieganie cyklom
w obrębie klas:
- zasoby wewnętrzne (bloki kontr. itp...) uporządkowanie zasobów
- pamięć głowna
- urządzenie i pliki unikanie blokad
5. Zarządzanie pamięcią
5.1 Założenia wstępne:
pamięć mieści cały program (o wyjątkach poniżej)
pamięć to tablica poadresowanych słów
współpraca z pamięcią polega na pisaniu/czytaniu z/pod adres
procesy pobierane są do pamięci z kolejki zadań.
Różne mechanizmy:
Wiązanie:
proces może rezydować w dowolnej częsci pamięci; musi istnieć mechanizm wiązania rozkazów i danych z adresami fizycznymi.
wiązanie może nastąpić w czasie:
- kompilacji (przy założeniu że proces rozpoczyna się od adresu X - np. pliki *.com w dos)
- ładowania (po przemieszczeniu kodu trzeba przeładować)
- wykonania (możliwe przemieszczenia)
Ładowanie dynamiczne: podprogramy są na dysku w formie przemieszczalnej i są ładowane po wywołaniu przez pr. główny. zaleta: nie ładujemy nieużywanego kodu.
Łączenie dynamiczne (bez niego wszystkie programy musza mieć swoje kopie bibliotek systemowych (np. DLL). W miejscach odwołań znajdują się zakładki (małe fr. kodu, po wywołaniu podające adres procedury bibliotecznej)
Nakładki (np. *.ovl) - w pamięci jest tylko niezbędny kod, nakładki się wyłączają (na ogół), są przechowywane na dysku w postaci bezwzględnego obrazu pamięci.
ponieważ procesy wykonują się wyłącznie w pamięci, nie zawsze wszystkie się mieszczą. Więc:
Wymiana.
Proces może zostać czasowo wysłany z pamięci głównej do zewnętrznej, a po jakimś czasie sprowadzony ponownie do pamięci głównej
Program wraca w to samo miejsce, chyba że mamy do czynienia z wiązaniem w czasie wykonania.
Jako pamięć zewnętrzna na potrzeby wymiany służy duży szybki dysk z dostępem bezpośrednim
Główny narzut: czas transmisji; dla dobrej wydajności czas wykonania musi być długi w porównaniu z czasem przełączania.
System musi wiedzieć o zapotrzebowaniu na pamięć by pracować efektywnie, przydziału dokonują funkcje systemowe.
W czasie wymiany nie mogą występować operacje we/wy (operujące na buforach pamięci) nie wymienia się procesów we/wy a buforami opiekuje się system.
... no i w tym miejscu nastąpił niespodziewany koniec wakacji...
Systemy operacyjne - notatki do wykładu
2
Wyszukiwarka
Podobne podstrony:
zadania-egzaminacyjne, Studia WIT - Informatyka, Systemy operacyjne
WŁASNY SERWER FTP WINDOWS XP, ۞ Nauka i Technika, Informatyka, Systemy operacyjne, OS MS Windows, Si
Podstawy informatyki, Systemy operacyjne, PODSTAWY INFORMATYKI (KONTYNUACJA SYSTEMÓW OPERACYJNYCH)
prog z1, Studia WIT - Informatyka, Systemy operacyjne 2
Edytor Vi, studia wsiz, semestr 1 2, Systemy operacyjne, SYSTEMY OPERACYJNE, systemy operacyjne LABO
Zarządzanie Partycjami, Systemy Operacyjne i Sieci Komputerowe
SUSE POLECENIA, studia wsiz, semestr 1 2, Systemy operacyjne, SYSTEMY OPERACYJNE, systemy operacyjne
2006 08 Zarządzanie pamięcią w systemach operacyjnych [Inzynieria Oprogramowania]
SO Zarządzanie pamięcią w systemach operacyjnych
informatyczne systemy zarzadzan Nieznany
Rafał Polak 12k2 lab8, Inżynieria Oprogramowania - Informatyka, Semestr III, Systemy Operacyjne, Spr
cw 0 1, pwr, informatyka i zarządzanie, Informatyka, algorytmy i struktury danych
Systemy operacyjne - wykłady, Administracja, Administracja, Administracja i samorząd, Polityka spole
więcej podobnych podstron