Bazy Danych i Ochrona Danych
1. Typy powiązań pomiędzy danymi
![]()
Powiązania proste:
Powiązanie "1-1". Dana elementarna A determinuje daną elementarną B tzn. w dowolnej chwili każda wartość A ma 1 i tylko 1 związaną z nią wartość B. (Powiązanie proste)
![]()
Powiązania złożone:
Powiązanie typu "1-wiele" - jednej wartości A odpowiada 0,1 lub wiele wartości B. (Powiązanie złożone)
Każdy mężczyzna ma 1 kobietę a każda kobieta 1 mężczyznę.
Każdy mężczyzna ma wiele kobiet.
Każda kobieta ma wielu mężczyzn.
Wiele mężczyzn ma wiele kobiet i wiele kobiet ma wielu mężczyzn.
![]()
Powiązania warunkowe ( c warunek)
np.: c = pod warunkiem, że jest żonaty, mężatką.
Powiązanie warunkowe od A do B (c). Wartości A odpowiada jedna lub kilka związanych z nią B , pod jakimś warunkiem.
Powiązania wielokrotne: (dwa typy danych mogą być powiązane ze sobą na wiele sposobów).
Powiązania wielokrotne - pomiędzy danymi zachodzi więcej niż jedno powiązanie. W takim przypadku należy je etykietować, np.:
Powiązanie - odwzorowanie (połączenie) pomiędzy danymi elementami ( lub rekordami ) dostarczające informacji dotyczącej związków między danymi elementarnymi, nie występujące w sposób bezpośredni.
Odwzorowania proste - pomiędzy danymi elementarnymi istnieje tylko 1 połączenie - A identyfikuje B.
Odwzorowanie złożone - pomiędzy danymi elementarnymi istnieje wiele połączeń - A nie identyfikuje B. Zachodzi odwzorowanie w 2 kierunkach więc mamy 4 powiązania: 1:1, 1:n, n:1, n:n.
Dana elementarna - dana niosąca najbardziej elementarną porcję informacji, która nie da się podzielić na mniejsze dane. Można je grupować w rekordy.
2. Niezależność danych w bazach danych.
Podstawowym celem baz danych jest zapewnienie niezależności danych, czyli: odporność programów użytkowych na zmiany struktury pamięci i strategii dostępu. Rozróżniamy 2 typy niezależności danych:
Fizyczna niezależność danych polega na tym, że rozszerzenie systemu komputerowego, na którym pracuje SZBD o nowy sprzęt nie narusza danych w bazie
Logiczna niezależność danych polega na tym, że - po pierwsze wprowadzanie nowych danych do bazy nie dezaktualizuje starych, po drugie - dane, które nie są wzajemnie powiązane tzw. związkami integralnościowymi mogą być usuwane z bazy niezależnie od siebie.
Statyczna i dynamiczna niezależność danych: o wiązaniu dynamicznym mówimy, gdy wiązanie występuje w momencie wyszukiwania danych. Schemat lub fizyczna organizacja może być wtedy modyfikowana w dowolnym momencie - daje ono dynamiczną niezależność danych. Statyczna niezależność danych wymaga, aby przeprowadzenie zmian w schemacie ogólnym, podschemacie lub fizycznej reprezentacji, zakończyło się zanim dowolny program użytkowy używający tych danych zostanie wykonany.
Rodzaje danych:
Dane zagregowane - treść danej mającej nazwę definiuje się tylko raz . Każdy programista odwołujący się do określonej danej musi zakładać tę samą treść tej danej.
Dane elementarne - definiuje się tylko raz. Programista odwołujący się do tych danych musi zakładać tę samą ich treść. Z tego samego zbioru danych elementarnych mogą być utworzone różne rekordy lub segmenty.
Dane subelementarne - treści tych danych, mających nazwę, mogą być różne w różnych programach użytkowych. I tak np. jeden program może odwoływać się do siedmiocyfrowych, a inny do ośmiocyfrowych danych elementarnych (patrz przykład wyżej).
3. Rola administratora danych.
Tworzenie pierwotnego opisu struktury bazy danych i sposobu odwzorowania go w plikach fizycznej bazie danych.
Udzielanie rozmaitym użytkownikom zezwoleń na korzystanie z bazy danych lub jej fragmentów.
Modyfikacja opisu bazy danych lub jego związków z fizyczną organizacją bazy danych, gdy wnioski z jej eksploatacji wskazują że inna organizacja byłaby bardziej efektowna.
Wykonywanie archiwalnych kopii bazy danych i przywracanie jej poprzedniego stanu po uszkodzeniach powstałych na skutek awarii lub niewłaściwego użycia sprzętu bądź oprogramowania.
4. Rola redundancji w bazach danych.
Rudundacja w bazach danych to powielanie się danych.
Wady:
Zwiększa zajętość pamięci
Utrudnia aktualizacje
Grozi utratą integralności danych
Zalety:
Krótki czas wyszukiwania
Umożliwia odtworzenie danych czyli pewną ochronę danych .
Zagadnienie integralności danych.
Formalna poprawność bazy danych ich fizycznej organizacji, zgodności ze schematem bazy danych i regułami dostępu.
Relacyjny model logiczny posiada wiele zalet. Oto niektóre z nich:
Wielopoziomowa integralność danych. Integralność na poziomie pól zapewnia dokładność wprowadzanych danych, integralność na poziomie tabel uniemożliwia powtarzanie się tego samego rekordu i pozostawianie nie wypełnionych pól wchodzących w skład klucza podstawowego, integralność na poziomie relacji gwarantuje ich odpowiednie zdefiniowanie, a reguły integralności kontrolują poprawność danych z punktu widzenia tematu bazy.
Model relacyjny dostarcza dodatkowych, specyficznych dla siebie postaci reguł integralności:
Integralność encji: każda tabela musi posiadać klucz główny, a wartości klucza głównego muszą być w ramach tabeli unikalne i nie równe NULL. W szczególności, zapobiega to wystąpieniu w tabeli powtórzeń wierszy.
Integralność referencyjna: każda wartość klucza obcego może być albo równa jakiejś wartości klucza głównego występującej w tabeli powiązanej, lub (ewentualnie) NULL. Pociąga to za sobą konieczność określenia reguły postępowania w wypadku usuwania wiersza z tabeli powiązanej, co mogłoby unieważnić niektóre wartości kluczy obcych w tabelach do niej się odnoszących. W grę wchodzą trzy postacie takiej reguły:
Restricted: usunięcie wiersza jest zabronione, dopóki nie zostaną usunięte lub odpowiednio zmodyfikowane wiersze z innych tabel, których wartości kluczy obcych stałyby się wskutek tej operacji nieważne;
Cascades: usunięcie wiersza powoduje automatyczne usunięcie z innych tabel wszystkich wierszy, dla których wartości kluczy obcych stały się nieważne;
Nullifies: nieważne wartości kluczy obcych ulegają zastąpieniu przez NULL.
W praktyce zazwyczaj jest pożądane stosowanie dalszych warunków integralności (integralność dodatkowa). Na ogół istnieją w DBMS mechanizmy narzucenia takich warunków, sformułowanych w języku algebry relacyjnej lub zbliżonym.
6. Systemy OLTP i MIS.
System OLTP (online transaction processing) pracuje w czasie rzeczywistym, zbierając i przetwarzając dane związane z transakcjami oraz dokonując zmian we wspólnych bazach danych oraz w innych plikach. Podczas przetwarzania transakcyjnego w czasie rzeczywistym transakcje wykonywane są natychmiastowo, w przeciwieństwie do przetwarzania wsadowego, podczas którego partia transakcji jest przechowywana przez pewien czas i wykonywana później. Większość procesów wsadowych, związanych np. z prowadzeniem księgowości, jest realizowana w godzinach wieczornych. Rezultaty pracy systemu OLTP są natychmiast udostępniane bazie danych - przy założeniu, że transakcje zostały zrealizowane pomyślnie. Najczęściej spotykane przykłady systemów OLTP to systemy rezerwacji biletów lotniczych oraz rozliczeń bankowych.
System informowania kierownictwa (MIS)
Oparty na technice komputerowej system gromadzenia i przetwarzania informacji używany przez menedżerów i ich najbliższy personel w bezpośrednim wspieraniu działań kierowniczych i podejmowaniu decyzji. System taki powinien być sprawny w przetwarzaniu informacji i zawierać dane potrzebne konkretnemu użytkownikowi. Powinny go cechować:
niezawodność funkcjonowania;
możliwości zbierania i magazynowania danych potrzebnych do wytworzenia informacji;
możliwość przetwarzania danych na informacje przydatne do wspomagania procesów podejmowania decyzji;
dostarczanie informacji w odpowiedniej formie i na czas;
dostarczanie właściwych informacji odpowiednim ich odbiorcom;
łatwość dostępu do informacji;
zabezpieczenie przed niepowołanym dostępem do informacji.
7. Zasady projektowania baz danych.
W projektowaniu baz danych należy szczególną uwagę zwrócić na takie ich zorganizowanie, by mogły mieć jak największe zastosowanie oraz by sposób wykorzystania mógł być zmieniony łatwo i szybko.
przedstawienie wewnętrznej struktury bazy
wydajność (OLTP, MIS)
minimalny koszt
minimalna redundancja
możliwość wyszukiwania - jak największe
mechanizmy zapewniające integralność bazy danych
tajność i bezpieczeństwo danych
sprzężenie z przyszłością
sprzężenie z przeszłością
migracja danych
możliwości strojenia bazy danych
prostota systemu bazowo - danowego
języki projektowania bazy danych - języki zapytań wysokiego poziomu
8. Zależności wykorzystywane w modelu relacyjnym.
Zależność funkcyjna (funkcjonalna) - Atrybut B jest funkcjonalnie zależny od atrybutu A wtedy i tylko wtedy kiedy każdej wartości atrybutu A odpowiada dokładnie 1 wartość atrybutu B
Pełna zależność funkcjonalna - Atrybut B jest w pełni funkcjonalnie zależny od atrybutu A wtedy i tylko wtedy jeżeli jest funkcjonalnie zależny od niego i nie jest funkcjonalnie zależny od żadnego innego jego podzbioru.
Przechodnia zależność funkcjonalna - Atrybut C jest przechodnio funkcjonalnie zależny od atrybutu A wtedy i tylko wtedy gdy jest funkcjonalnie zależny od atrybutu B i B jest funkcjonalnie zależny od atrybutu A.
Wielowartościowa zależność funkcjonalna - Atrybut B jest wielowartościowo funkcjonalnie zależny od atrybutu A wtedy i tylko wtedy, gdy każdej wartości atrybutu A odpowiada ściśle określony zbiór wartości atrybutu B.
Połączeniowa zależność funkcjonalna - Mówimy że w schemacie relacji R=(A1…An) występuje połączeniowa zależność funkcjonalna wtedy i tylko wtedy, gdy możliwa jest dekompozycja relacji r (w schemacie R) na relacji r1...rn taka, że relację pierwotną i można zredukować przez wykonanie sekwencji operacji połączeń relacji r.
9. Normalizacja w modelu relacyjnym.
Postać nieznormalizowana - tabela ZAMÓWIENIA
Zamowienie |
ID |
ND |
AD |
IE |
NE |
Szt |
IM |
AM |
1 |
3 |
FSO |
Wa |
53 57 59 |
Gaźnik Wał Błotnik |
100 50 500 |
5 5 6 |
Ch Ch Mo |
2 |
4 |
FSM |
Ty |
54 32 |
Gaźnik Koło |
500 100 |
7 6 |
Ba Mo |
3 |
5 |
FSR |
Ań |
88 |
Silnik |
15 |
7 |
Ba |
4 |
6 |
FSM |
BB |
59 21 |
Błotnik Pradn |
400 50 |
6 7 |
Mo Ba |
5 |
3 |
FSO |
Wa |
53 57 |
Gaźnik Wał |
200 30 |
5 5 |
Ch Ch |
6 |
3 |
FSO |
Wa |
59 |
Błotnik |
20 |
6 |
Mo |
Przedstawiona tabela o 6 krotkach nie jest relacją, ponieważ istnieją w niej krotki, w których pewnemu atrybutowi odpowiadają zbiory 2 lub 3 wartości. Uzupełniając tabelę i powiększając liczbę krotek do 11 otrzymujemy tabelę l, stanowiącą relację w I postaci normalnej.
I POSTAĆ NORMALNA
Zamowienie |
ID |
ND |
AD |
IE |
NE |
Szt |
IM |
AM |
1 |
3 |
FSO |
Wa |
53 |
Gaźnik |
100 |
5 |
Ch |
1 |
3 |
FSO |
Wa |
57 |
Wał |
50 |
5 |
Ch |
1 |
3 |
FSO |
Wa |
59 |
Błotnik |
500 |
6 |
Mo |
2 |
4 |
FSM |
Ty |
54 |
Gaźnik |
500 |
7 |
Ba |
2 |
4 |
FSM |
ty |
32 |
Koło |
100 |
6 |
Mo |
3 |
5 |
FSR |
Ań |
88 |
Silnik |
15 |
7 |
Ba |
4 |
6 |
FSM |
BB |
59 |
Błotnik |
400 |
6 |
Mo |
4 |
6 |
FSM |
BB |
21 |
Pradn |
50 |
7 |
Ba |
5 |
3 |
FSO |
Wa |
53 |
Gaźnik |
200 |
5 |
Ch |
5 |
3 |
FSO |
Wa |
57 |
Wał |
30 |
5 |
Ch |
6 |
3 |
FSO |
Wa |
59 |
Błotnik |
20 |
6 |
Mo |
II POSTAĆ NORMALNA
Relacja jest w drugiej postaci normalnej jeżeli dla każdej zależności X Y, w kórej Y nie zawiera się w X , zbiór X zawiera klucz (tzn. X jest nadkluczem). Relacja w drugiej postaci normalnej nie zawiera redundancji i anomalii.
Aby doprowadzić relację do II postaci normalnej można przeprowadzić operację rozkładu schematu relacji.
Najpierw wydzielamy 2 relacje, jednocześnie usuwamy występujące w nich powtórzenia krotek (wierszy):
Zamówienia_dostawcy
Zamowienie |
ID |
ND |
AD |
1 |
3 |
FSO |
Wa |
2 |
4 |
FSM |
Ty |
3 |
5 |
FSR |
Ań |
4 |
6 |
FSM |
BB |
5 |
3 |
FSO |
Wa |
6 |
3 |
FSO |
Wa |
Elementy_w_magazynie
IE |
NE |
IM |
AM |
53 |
Gaźnik |
5 |
Ch |
57 |
Wał |
5 |
Ch |
59 |
Błotnik |
6 |
Mo |
54 |
Gaźnik |
7 |
Ba |
32 |
Koło |
6 |
Mo |
88 |
Silnik |
7 |
Ba |
21 |
Pradn |
7 |
Ba |
Pozostaje jeszcze relacja która jest jednocześnie w II i w III postaci normalnej:
Zamówienia_elementy:
Zamowienie |
IE |
Szt |
1 |
53 |
100 |
1 |
57 |
50 |
1 |
59 |
500 |
2 |
54 |
500 |
2 |
32 |
100 |
3 |
88 |
15 |
4 |
59 |
400 |
4 |
21 |
50 |
5 |
53 |
200 |
5 |
57 |
30 |
6 |
59 |
20 |
Przy podziale nie można dopuścić do utraty informacji. Z tego powodu po podziale relacji 1 o 9 atrybutach otrzymujemy 3 relacje o 11 atrybutach.
III POSTAĆ NORMALNA
Dana jest w III postaci normalnej, jeżeli jest ona w II postaci normalnej i każdy jej atrybut nie wchodzący w skład żadnego klucza potencjalnego nie jest przechodnio funkcjonalnie zależny od żadnego klucza potencjalnego tej relacji. Aby doprowadzić relację której atrybuty pozostają w przechodniej zależności funkcjonalnej, należy podzielić ją na relacje zawierające tylko zależność funkcjonalną.
W relacji 2 występuje dublowanie danych, z powodu przechodniej zależności funkcyjnej. Należy ją podzielić na 2 relacje w III postaci normalnej. Przechodnia zależność funkcyjna występuje w relacji, jeśli między atrybutami niekluczowymi występuje zależność funkcyjna.
Zamówienia_elementy:
Zamowienie |
IE |
Szt |
1 |
53 |
100 |
1 |
57 |
50 |
1 |
59 |
500 |
2 |
54 |
500 |
2 |
32 |
100 |
3 |
88 |
15 |
4 |
59 |
400 |
4 |
21 |
50 |
5 |
53 |
200 |
5 |
57 |
30 |
6 |
59 |
20 |
Zamówienia_do_dostawcy:
Zamowienie |
ID |
1 |
3 |
2 |
4 |
3 |
5 |
4 |
6 |
5 |
3 |
6 |
3 |
Dostawcy:
ID |
ND |
AD |
3 |
FSO |
Wa |
4 |
FSM |
Ty |
5 |
FSR |
Ań |
6 |
FSM |
BB |
3 |
FSO |
Wa |
Elementy:
IE |
NE |
IM |
53 |
Gaźnik |
5 |
57 |
Wał |
5 |
59 |
Błotnik |
6 |
54 |
Gaźnik |
7 |
32 |
Koło |
6 |
88 |
Silnik |
7 |
21 |
Pradn |
7 |
Magazyny:
IM |
AM |
5 |
Ch |
6 |
Mo |
7 |
Ba |
Podobnie w relacji 3 występuje dublowanie danych, z powodu przechodniej zależności funkcyjnej. Należy ją podzielić na 2 relacje w III postaci normalnej usuwając powtórzenia i porządkując.
REZULTAT procedury normalizacyjnej: zamiast l relacji ZAMÓWIENIA w I postaci normalnej mamy 5 relacji w III postaci normalnej:
4. Zamówienia_elementy
5. Zamówienia_do_dostawcy
6. Dostawcy
7. Elementy
8. Magazyny
IV POSTAĆ NORMALNA
Czwartą postać normalną stosuje się do relacji z zależnościami wielowartościowymi.
Dana jest relacja o schemacie R oraz trzy parami rozłączne i niepuste podzbiory X, Y, Z atrybutów z R takie że X, Y, Z =R i podzbiór Y jest nietrywialnie wielowartościowo zależny od X. Dana relacja jest w IV postaci normalnej gdy jest w III postaci normalnej i wielowartościowa zależność zbioru Y od X pociąga za sobą funkcjonalną zależność wszystkich atrybutów tej relacji od X.
Jak wynika z definicji relacja, która zawiera trywialną wielowartościową zależność funkcjonalną jest w IV postaci normalnej. Stąd wniosek że relację zawierającą nie trywialną wielowartościową zależność funkcjonalną należy podzielić na takie relacje, które będą zawierać tylko zależności trywialne.
Studenci:
Nazwisko_Studenta |
J_programowania |
J_obcy |
Kowalski Jan |
C++ |
j. angielki |
Kowalski Jan |
Delphi |
j. angielki |
Kowalski Jan |
SQL |
j. angielki |
Kowalski Jan |
C++ |
j. niemiecki |
Kowalski Jan |
Delphi |
j. niemiecki |
Kowalski Jan |
SQL |
j. niemiecki |
Kowalski Jan |
C++ |
j. rosyjski |
Kowalski Jan |
Delphi |
j. rosyjski |
Nowak Piotr |
SQL |
j. rosyjski |
Nowak Piotr |
Pascal |
j. angielki |
Nowak Piotr |
C++ |
j. angielki |
Nowak Piotr |
Pascal |
j. hiszpański |
Nowak Piotr |
C++ |
j. hiszpański |
Nowak Piotr |
Pascal |
j. rosyjski |
Nowak Piotr |
C++ |
j. rosyjski |
Dokonujemy rozbicia na 2 tabele (relacje):
Nazwisko_Studenta |
J_programowania |
Kowalski Jan |
C++ |
Kowalski Jan |
Delphi |
Kowalski Jan |
SQL |
Nowak Piotr |
Pascal |
Nowak Piotr |
C++ |
Nazwisko_Studenta |
J_obcy |
Kowalski Jan |
j. angielki |
Kowalski Jan |
j. niemiecki |
Kowalski Jan |
j. rosyjski |
Nowak Piotr |
j. angielki |
Nowak Piotr |
j. hiszpański |
Nowak Piotr |
j. rosyjski |
V POSTAĆ NORMALNA
Dana relacja r o schemacie R jest w V postaci normalnej wtedy i tylko wtedy, gdy jest w IV postaci normalnej i w przypadku występowania w niej połączeniowej zależności funkcjonalnej *R [R1,…,Rn] zależność ta wynika z zależności atrybutów od klucza.
Wynika z tego, że w celu doprowadzenia pewnej relacji do V postaci normalnej konieczne jest podzielenie jej na takie relacje, które spełniać będą pierwszy warunek.
10. Problem niejednoznaczności danych w modelu relacyjnym.
Problem ten pojawia się w specyfikacji wymagań gdy stosujemy język naturalny. Jest to jedna z metod specyfikacji wymagań. Jest ona najczęściej stosowana. Jej wada to niejednoznaczność powodująca różne rozumienie tego samego tekstu. Utrudnia to wykrycie powiązanych wymagań i powoduje trudności w wykryciu sprzeczności
Wszystkie specyficzne terminy powinny być umieszczone w słowniku, wraz z wyjaśnieniem. Słownik powinien precyzować terminy niejednoznaczne i określać ich znaczenie w kontekście tego dokument (być może nieco węższe).
Formalna specyfikacja oznacza bardzo dokładne zdekomponowanie wymagań (najlepiej w pewnym formularzu) na krótkie punkty, których interpretacja nie powinna nastręczać trudności lub prowadzić do niejednoznaczności. Formalna specyfikacja powinna stanowić podstawę dla fazy testowania.
Problemy z językiem naturalnym ( stosowanym do opisu wymagań systemowych w relacyjnych bazach danych ):
Brak jasności Czasem trudno jest wyrażać się w języku naturalnym precyzyjnie i jednoznacznie bez czynienia dokumentów gadatliwymi i nieczytelnymi.
Sprzeczność wymagań Trudno jest jasno rozgraniczać wymagania funkcjonalne, wymagania niefunkcjonalne, cele systemu i elementy projektu.
Łączenie wymagań Kilka różnych wymagań może być zapisanych razem jako jedno wymaganie.
Do czytelnika należy stwierdzenie, czy dwa wymagania są takie same, czy też się od siebie różnią. Nie ma łatwego podziału wymagań w języku naturalnym na moduły. Znalezienie wszystkich powiązanych wymagań może być trudne.
Niejednoznaczności charakterystycznych dla języka naturalnego można uniknąć przez opisywanie wymagań operacyjnie za pomocą języka opisu programów (Program Description Language, PDL).
Proponuje się używać PDL w dwóch następujących sytuacjach:
Gdy operacja jest specyfikowana jako ciąg prostszych akcji, których kolejność wykonania jest istotna. Opisy takich sekwencji w języku naturalnym są czasami mylące, zwłaszcza gdy te ciągi obejmują zagnieżdżone warunki i pętle.
Gdy trzeba wyspecyfikować interfejsy sprzętowe i programowe. W wielu wypadkach interfejsy między podsystemami są definiowane w specyfikacji wymagań systemowych. PDL umożliwia definiowanie typów i obiektów interfejsowych.
Wymagania systemowe służą do poinformowania w precyzyjny sposób o funkcjach, które system ma spełniać. Aby uniknąć niejednoznaczności, można je zapisać jakiegoś języka strukturalnego. Może to być strukturalna postać języka naturalnego, język oparty na języku oprogramowania wysokiego poziomu lub specjalny język do specyfikowania wymagań.
11. Charakterystyka języka SQL.
SQL (ang. Structured Query Language) to strukturalny język zapytań używany do tworzenia, modyfikowania baz danych oraz do umieszczania i pobierania danych z baz danych.
Jest to język programowania opracowany w latach siedemdziesiątych w firmie IBM. Stał się on standardem w komunikacji z serwerami relacyjnych baz danych. Wiele współczesnych systemów relacyjnych baz danych używa do komunikacji z użytkownikiem SQL, dlatego mówi się, że korzystanie z relacyjnych baz danych, to korzystanie z SQL-a. Pierwszą firmą, która włączyła SQL do swojego produktu komercyjnego, był Oracle. Dalsze wprowadzanie SQL-a, w produktach innych firm, wiązało się nierozłącznie z wprowadzaniem modyfikacji pierwotnego języka. Wkrótce utrzymanie dalszej jednolitości języka wymagało wprowadzenia standardu.
Z technicznego punktu widzenia, SQL jest podjęzykiem danych. Oznacza to, że jest on wykorzystywany wyłącznie do komunikacji z bazą danych. Nie posiada on cech pozwalających na tworzenie kompletnych programów. Jego wykorzystanie może być trojakie i z tego względu wyróżnia się trzy formy SQL-a:
SQL interakcyjny lub autonomiczny wykorzystywany jest przez użytkowników w celu bezpośredniego pobierania lub wprowadzania informacji do bazy. Przykładem może być zapytanie prowadzące do uzyskania zestawienia aktywności kont w miesiącu. Wynik jest wówczas przekazywany na ekran, z ewentualną opcją jego przekierowania do pliku lub drukarki.
Statyczny kod SQL (Static SQL) nie ulega zmianom i pisany jest wraz z całą aplikacją, podczas której pracy jest wykorzystywany. Nie ulega zmianom w sensie zachowania niezmiennej treści instrukcji, które jednak zawierać mogą odwołania do zmiennych lub parametrów przekazujących wartości z lub do aplikacji. Statyczny SQL występuja w dwóch odmianach.
Język modułów. W tym podejściu moduły SQL łączone są z modułami kodu w innym języku. Moduły kodu SQL przenoszą wartości do i z parametrów, podobnie jak to się dzieje przy wywoływaniu podprogramów w większości języków proceduralnych. Jest to pierwotne podejście, zaproponowane w standardzie SQL. Embedded SQL został do oficjalnej specyfikacji włączony nieco później.
Dynamiczny kod SQL (Dynamic SQL) generowany jest w trakcie pracy aplikacji. Wykorzystuje się go w miejsce podejścia statycznego, jeżeli w chwili pisania aplikacji nie jest możliwe określenie treści potrzebnych zapytań - powstaje ona w oparciu o decyzje użytkownika. Tę formę SQL generują przede wszystkim takie narzędzia jak graficzne języki zapytań. Utworzenie odpowiedniego zapytania jest tu odpowiedzią na działania użytkownika.
Wymagania tych trzech form różnią się i znajduje to odbicie w wykorzystywanych przez nie konstrukcjach językowych. Zarówno statyczny, jak i dynamiczny SQL uzupełniają formę autonomiczną cechami odpowiednimi tylko w określonych sytuacjach. Większość języka pozostaje jednak dla wszystkich form identyczna.
Składnia SQL
Użycie SQL, zgodnie z jego nazwą, polega na zadawaniu zapytań do bazy danych. Zapytania można zaliczyć do jednego z dwóch głównych podzbiorów:
SQL DML (ang. Data Manipulation Language, czyli Język Manipulacji Danymi),
SQL DDL (ang. Data Definition Language, czyli Język Definicji Danych).
Instrukcje SQL w obrębie zapytań tradycyjnie zapisywane są wielkimi literami, jednak nie jest to wymóg. Każde zapytanie w SQL-u musi kończyć się znakiem ";" (średnik).
Dodatkowo, niektóre interpretery SQL (np. psql w przypadku PostgreSQL), używają swoich własnych instrukcji, z poza standardu SQL, które służą np. do połączenia się z bazą, wyświetlenia dokumentacji, itp.
DML
DML służy do operacji na danych - do ich umieszczania w bazie, kasowania, przeglądania, zmiany. Najważniejsze polecenia z tego zbioru to:
SELECT - pobranie z bazy danych,
INSERT - umieszczenie danych w bazie,
UPDATE - zmiana danych,
DELETE - usunięcie danych z bazy.
Dane tekstowe podawane muszą być zawsze w formie ograniczonej znakami pojedynczego cudzysłowu (').
DDL
Dzięki DDL natomiast, można operować na strukturach, w których te dane są przechowywane - czyli np. dodawać, zmieniać i kasować tabele lub bazy. Najważniejsze polecenia tej grupy to:
CREATE (np. CREATE TABLE, CREATE DATABASE, ...) - utworzenie struktury (bazy, tabeli, indeksu, itp.),
DROP (np. DROP TABLE, DROP DATABASE, ...) - całkowite usunięcie struktury,
ALTER (np. ALTER TABLE ADD COLUMN ...) - zmiana sturktury (dodanie kolumny do tabeli, zmiana typu danych w kolumnie tabeli).
Przykładowe zapytania
Przykładowe użycie wyżej wymienionych rodzajów zapytań.
SELECT * FROM pracownicy WHERE pensja > 2000 ORDER BY staz DESC;
Wyświeta z tabeli pracownicy (FROM pracownicy) wszystkie kolumny (*) dotyczące tych pracowników, których pensja jest większa niż 2000 (WHERE pensja > 2000) i sortuje wynik malejąco według stażu pracy (ORDER BY staz DESC).
INSERT INTO pracownicy (imie, nazwisko, pensja, staz) VALUES ('Jan', 'Kowalski', 5500, 1);
Dodaje do tabeli pracownicy (INTO pracownicy) wiersz (rekord) zawierający dane pojedynczego pracownika.
UPDATE pracownicy SET pensja = pensja * 1.1 WHERE staz > 2;
Podnosi o 10% (SET pensja = pensja * 1.1) pensję pracownikom, których staż jest większy niż 2 (np. lata).
DELETE FROM pracownicy WHERE imie = 'Jan' AND nazwisko = 'Kowalski';
Usuwa z tabeli "pracownicy" wiersz (rekord) dotyczący pracownika o imieniu "Jan" i nazwisku "Kowalski".
CREATE TABLE pracownicy (imie varchar(255), nazwisko varchar(255), pensja float, staz int);
Tworzy tabelę "pracownicy" zawierającą tekstowe (varchar - zmiennej długości pole tekstowe) pola "imię" i "nazwisko", o maksymalnej długości 255 znaków, zapisaną za pomocą liczby rzeczywistej (float od ang. floating point) pensję oraz zapisany za pomocą liczby całkowitej (int od ang. integer) staż.
DROP TABLE pracownicy;
Usuwa z bazy całkowicie tabelę "pracownicy".
ALTER TABLE pracownicy ADD COLUMN dzial varchar(255);
Dodaje do struktury tabeli "pracownicy" kolumnę "dzial" (dział), jako pole tekstowe o długości max. 255 znaków.
12. Tożsamość obiektów w modelu obiektowym.
Obiekt to pewien byt, encja charakteryzowana przez swój stan i zachowanie
Każdy obiekt ma niezmienny wewnętrzny id
Obiekty równe nie muszą być tożsame!
Zalety:
można zmieniać wszystkie atrybuty bez utraty tożsamości
zmiany struktury nie burzą integralności referencyjnej
można zmieniać położenie obiektu w strukturze bez utraty jego powiązań
ułatwione zarządzanie wersjami
nie trzeba tworzyć sztucznych kluczy
Tożsamość obiektu umożliwia współdzielenie komponentów przy konstrukcji różnych obiektów złożonych, a zatem rozszerza semantykę. Tożsamość obiektów powoduje, że istnienie obiektów jest niezależne od ich wartości. W konsekwencji mamy dwie płaszczyzny porównywania obiektów:
Identyczność obiektu, gdy identyfikatory są identyczne (identyczne obiekty są równe ale nie odwrotnie)
Równość obiektu, gdy opisy obiektów są identyczne (identyczne obiekty są równe ale nie odwrotnie).
Równość obiektów jest cechą tymczasową, podczas gdy identyczność jest cechą stałą. W niektórych modelach danych wprowadza się trzeci typ płaskiej równości.
W zależności od sposobu konstrukcji identyfikatorów, wyróżniamy identyfikatory fizyczne i logiczne. Identyfikatory fizyczne wskazują lokalizację reprezentacji obiektu w pamięci zewnętrznej.
Klasyfikując identyfikatory można rozróżnić co najmniej 4 typy OID:
Adres fizyczny. Identyfikator jest adresem fizycznym obiektu. Taka reprezentacja jest zwykle używana przez j. programowania. Zaletą tego sposobu jest wysoki stopień efektywności systemu. Podejście takie jest praktycznie bezużyteczne dla baz danych, ponieważ jeśli obiekt jest np. przesuwany, musiałaby zmianie ulec jego identyfikator, a zatem wszystkie odwołania do tego obiektu.
Adres strukturalny. Identyfikator składa się z 2 części:
Określa nr. Segmentu i nr. Strony na której znajduje się obiekt (szybki dostęp do obiektu);
Logiczny, nr. szczeliny - pozycji którą określa położenie obiektu na stronie. W tej metodzie obiekt może być relokowany wewnątrz strony - jeśli przenumerują się szczeliny i może być również przeniesiony na inną stronę poprzez wprowadzenia jego poprzedniego adresu do tablicy pozycji dla tej strony.
3. Surogat. Identyfikator jest generowany przy użyciu algorytmu, który gwarantuje jego unikalność (np. zwiększać o 1 licznik). Także Identyfikatory są przekształcane na adres fizyczny obiektu, przeważnie przy użyciu technik indeksujących.
Sugorat odwołujący się do typu. Jest to wariant poprzedniej metody ale taki w którym korzysta się z identyfikatora (klasy) jak i części identyfikującej obiekt. Dla każdego typu inny licznik generujący części identyfikatora obiektu właściwą dla tego typu.
Wybór metody identyfikowania obiektów ma zasadnicze znacznie dla efektywności systemu. Na efektywność pracy systemu wpływa także długość OID. Zwykle wynosi ona 32 do 48 bitów (32 bity pozwalają na zarządzanie do 4mln obiektów).
Dłuższe 64 bitowe OID mogą być potrzebne gdy:
OID muszą być unikalne przez cały czas życia obiektu tak, aby można było zidentyfikować ślepe odwołania.
OID są generowane techniką surogatów przy pomocy monotonicznie rosnącej funkcji - nie jest wtedy możliwe powtórne użycie nieużywanych już OID czyli przy intensywnych zmianach bazy danych ,a w szczególności usuwania obiektów, możne nam zabraknąć OID
W środowisku rozproszonym. W tym przypadku może być wskazane prefiksowanie OID identyfikatorem podsystemu.
W podejściu z pełną enkapsulacją, wartość atrybutów są dostępne dla świata zewnętrznego jedynie za pomocą odpowiednich procedur (metod) wywoływanych dla danego obiektu. Przy pomocy takich procedur obiekt może się komunikować z innym obiektem.
13. Klasy i enkapsulacja w modelu obiektowym.
Jest zbiorem obiektów posiadających tą samą strukturę wewnętrzną tzn. te same atrybuty i te same metody. Zatem klasę definiuje implementację zbioru obiektów, natomiast typ opisuje jak te obiekty które mogą być używane.
Pojęcie klasy może być rozumiane szerzej niż pojęcie typu:
Klasa jako definicja typu - czyli definiująca strukturę(atrybuty) i zachowanie(metody) obiektów posiadających podobne właściwości. Klasy definiują atrybuty i metody widzenia z zewnątrz. W ramach jednej takiej definicji może istnieć wiele jej implementacji - oznacza to, że rezultat i wywołanie metody jest takie same ale jej wewnętrzna struktura jest różna.
Klasa rozumiana jako zbiór obiektów danego typu. Pojęcie klasy jest więc konieczne definiowanie oddzielnego typu kolekcji wystąpień danego typu.
Klasa rozumiana jako obiekt, który ma swoją strukturę i metody .Tutaj atrybutami są np. nazwa; nadklasa, zaś metodami np. dodaj - atrybut.
Jeżeli chcemy zachować zasadę, że każdy obiekt jest wystąpieniem pewnej klasy załóżmy, że klasy są obiektami wtedy dla zachowania jednolitości opisu wygodne jest wprowadzenie pojęcia Metaklasy - jako klasy klas. Jeżeli metaklasy występują w systemie to nie są one bezpośrednio dostępne dla użytkownika.
Opis klasy - składa się z następujących elementów:
Nazwa klasy
Atrybutów klasy jak np. zestaw nadklas danej klasy
Opisu struktury statycznej obiektów należących do klasy - zestawu atrybutów
Opisu dynamicznego zachowań obiektów definicji metod czyli operacji widocznych na zewnątrz obiektu a pozwalających dokonać manipulacji na danych . Metoda uaktywniona jest przez komunikat adresowany do tzw. Obiektu docelowego i w standardowym przypadku operuje wyłącznie na danych wchodzących w skład tego obiektu.
14. Zagadnienie dziedziczenia w modelu obiektowym.
Dziedziczenie jest jednym z najmocniejszych mechanizmów programowania obiektowego i obiektowych baz danych . Pozwala na tworzenie nowych klas i zwanych podklasami z klas już istniejących . Nowe klasy dziedziczą struktury danych i metody swoich nadklas a ponadto dołączają do nich swoje własne struktury i procedury . Stają się więc bardziej wyspecjalizowane od swoich pierwowzorów. Klasa nie dziedziczy nic od swoich podklas . Klasa może mieć wiele podklas. W niektórych systemach Klasa ma tylko jedną nadklasę , w innych może mieć więcej jest to tzw. dziedziczenie wielokrotne. Dziedziczenie jest przechodnie.
Na poziomie modelowania dziedziczenie oznacza :
możliwość stworzenia nowej bardziej wyspecjalizowanej klasy na podstawie klasy już istniejącej- specjalizacja
możliwość utworzenia bardziej ogólnej klasy (klasy abstrakcyjnej) z klas bardziej wyspecjalizowanych poprzez wyciągnięcie wspólnych dla nich własności.
Zalety dziedziczenia:
Kod operacji jest używany przez wiele obiektów często należących do różnych klas, gdyż operacje mogą być zdefiniowane dla nadklasy zamiast dla poszczególnych klas.
Dostarcza precyzyjniejszy i bardziej zbliżony do rzeczywistych zależności opis środowiska.
Uproszczone definiowanie nowych klas
Może mieć charakter bezpośredni (struktura/ metody przenoszone są do podklasy bez zmian) lub dokonuje się transformacji składników przed przekazaniem (np. zmienia się el. struktury danych ).
Modele dziedziczenia:
strukturalne- podklasy dziedziczą strukturę (def. atrybutów wraz z typami)
behawioralne -dziedziczenie metod
Koncepcja dziedziczenia odnosząca się do właściwości i zależności typów:
Dziedziczenie dotyczące deklaracji typów(zależność dziedziczenia podtypów) -Wyraża związek pomiędzy specyfikacją typów i określa hierarchię ich uporządkowania.
Dziedziczenie związane z zależnościami grupowania obiektów - odnosi się do korelacji obiektów i ich relacji zawierania .
Związane z implementacją typów - Podtypy zapewniają możliwość dostarczenia różnej implementacji metod def. w ramach danego typu
Związana z różnicami między obiektami. Podtypy różnią się między sobą
Inna klasyfikacja wprowadza specjalistyczne pojęcia:
dziedziczenie zastępujące. Nawiązuje do zachowania. Klasa C dziedziczy od C' wtedy , gdy nad C można wykonać więcej operacji niż nad C'. Obiekt typu C można zastąpić obiektem C'.
Dziedziczenie zawierające -odwołuje się do struktury , nie do operacji Klasa C jest podkl. C' jeżeli każdy ob. C jest równocześnie ob. C .
Dziedziczenie związane -przypadek dz. zawierającego . T jest podtypem T' jeśli składa się ze wszystkich typów T' które spełniają pewien warunek np. klasa nastolatek jest podklasą osoba pod warunkiem , że wiek jest np. 12-19 lat.
Specjalizowane. T jest podtypem T' jeżeli obiekty typu T są obiektami które zawierają więcej informacji szczegółowych. Np. osoba i pracownik.
Dziedziczenie pojedyncze- klasa ma jedną nadklasę
Dziedziczenie wielokrotne- klasa może mieć wiele nadklas
Polimorfizm - te same metody maja inne znaczenie w różnych obiektach.
Problemy podczas dziedziczenia:
nakładanie się więzów z obiektu z obiektu podczas dziedziczenia,
nakładanie się więzów podczas wystąpień obiektu w wielu klasach,
nakładanie się więzów na definiowanie podklas.
Zasada zachowania spójności powinna zapewniać:
spójność hierarchii dziedziczenia,
zasada rozróżnialności nazwy,
zasada pojedynczego pochodzenia,
zasada pełnego dziedziczenia.
Dziedziczenie wielokrotne i redefiniowanie atrybutów obiektów w podklasach:
zasada pierwszeństwa podklas do nadklas,
zasada pierwszeństwa między nadklasami różnego pochodzenia,
zasada pierwszeństwa między nadklasami o tym samym pochodzeniu.
Propagowanie zmian do podklas:
zasada propagacji i modyfikacji,
zasada propagacji zmian w przypadkach wystąpienia konfliktu,
zasada modyfikacji dziedzin.
Agregacja i usuwanie zależności dziedziczenia:
wprowadzania nadklas,
zasada usuwania nadklas,
zasada wprowadzania klasy do schematu.
15. Problem wielowersyjności obiektów i obiektów multimedialnych.
W standardowych systemach zarządzania baz danych zmodyfikowanie wartości atrybutu obiektu powoduje utratę poprzednich danych. W wielu zastosowaniach - a zwłaszcza w zastosowaniach obiektowych, do szeroko rozumianego komputerowego wspomagania projektowania, wspomagania inżynierii oprogramowania -niezbędne są wersje obiektów. Przez wersję obiektu rozumie się semantycznie znaczący rzut obiektu, dokonany w pewnym momencie czasowym.
Z praktycznego punktu widzenia, tworzenie różnych wersji tego samego obiektu może mieć dwojaki charakter:
wersji historycznych - odpowiadających przejściowym etapom rozwoju projektu, do których mogą być realizowane nawroty
wersji wariantowych - przeznaczonych do różnych zastosowań dopasowanych do różnych gestów i potrzeb użytkownika
Wielowersyjny jest nie tylko obiekt złożony będący celem projektu, lecz również większość jego komponentów. Nie wszystkie wersje różnych obiektów pasują do siebie. Finalne wersje wariantowe są zatem skomponowane ze szczególnych kombinacji wersji obiektów - komponentów. Z formalnego punktu widzenia, obiekt wielowersyjny jest częściowo uporządkowanym zbiorem wersji, które reprezentują jego różne stany. Poszczególne wersje obiektu mogą być tworzone od
podstaw lub wyprowadzane z innych wersji. Zależnie od przyjętego modelu, zbiór wersji obiektu może mieć strukturę drzewa, lasu lub acyklicznego grafu skierowanego.
16. Różnice i podobieństwa między modelem hierarchicznym, sieciowym, relacyjnym i obiektowym.
Hierarchiczny model danych
Hierarchiczny model danych jest pewnym rozszerzeniem modelu prostego, opartego na rekordach składających się z pól i zgrupowanych w plikach. W schemacie hierarchicznym wprowadza się typy rekordów i związki nadrzędny-podrzędny pomiędzy nimi.
Operowanie danymi
Typowe operacje na danych w tym modelu to wyszukiwanie rekordów określonego typu, podrzędnych względem danego rekordu, i spełniających warunki dotyczące zawartości określonych pól; usuwanie lub dodawanie rekordów i edycja ich pól. Realizowane są poprzez funkcje lub procedury pisane w językach programowania o charakterze zazwyczaj proceduralnym, np. C.
Integralność danych
Podstawowe warunki integralności wynikają z samej definicji struktury danych modelu:
Każdy rekord (z wyjątkiem korzenia) musi być powiązany z rekordem nadrzędnym właściwego typu; a więc np. usunięcie rekordu nadrzędnego wiąże się z usunięciem wszystkich względem niego podrzędnych. Nie można wstawić rekordu bez powiązania go z rekordem nadrzędnym.
Zawartość każdego pola rekordu musi odpowiadać typowi danych z definicji danego typu rekordu.
Itp. Widać, że model hierarchiczny ma wiele wspólnego ze strukturą systemu plików.
Sieciowy model danych
Sieciowy model danych w ogólnym zarysie niewiele odbiega od hierarchicznego. W miejsce związku nadrzędny-podrzędny pomiędzy rekordami wprowadza się w nim tzw. typ kolekcji (set), który jest złożonym typem danych pola zawierającym odniesienia do innych rekordów określonego typu. Tzn. określenie typu kolekcji polega na podaniu typu rekordu-,,właściciela'' i typu rekordów-elementów kolekcji (oraz ew. klucza porządkowania elementów). Operowanie danymi ma też charakter proceduralny: typowe operacje to wyszukiwanie rekordu na podstawie zawartości pól i/lub przynależności do danego wystąpienia typu kolekcji, i dokonywanie modyfikacji bieżącego rekordu.
Warunki integralności danych, poza oczywistymi już więzami dotyczącymi zgodności zawartości pól rekordu z określeniem typu rekordu i unikalności pól kluczowych, mogą być formułowane w terminach wymogu przynależności rekordu do jakiegoś wystąpienia określonego typu kolekcji.
Relacyjny model danych
Relacyjny model danych został opracowany przez E. F. Codda w latach 70-80, i od mniej więcej połowy lat 80 stał się podstawą architektury większości popularnych SZBD. Naszkicuję tu dość pobieżnie teoretyczne zasady modelu. Należy przy tym pamiętać, że w realnych implementacjach teoria ta bywa traktowana dość luźno tzn. jej zasady niekoniecznie są w pełni przestrzegane czy implementowane. Stąd omówienie to będzie raczej powierzchowne.
Definicja danych
Model relacyjny oparty jest na tylko jednej podstawowej strukturze danych -- relacji. Pojęcie relacji można uważać za pewną abstrakcję intuicyjnego pojęcia tabeli, zbudowanej z wierszy i kolumn, w której na przecięciu każdej kolumny z każdym wierszem występuje określona wartość. Baza danych jest zbiorem relacji, o następujących własnościach:
Każda relacja w bazie danych jest jednoznacznie określona przez swoją nazwę.
Każda kolumna w relacji ma jednoznaczną nazwę (w ramach tej relacji).
Kolumny relacji tworzą zbiór nieuporządkowany. Kolumny nazywane bywają również atrybutami.
Wszystkie wartości w danej kolumnie muszą być tego samego typu. Zbiór możliwych wartości elementów danej kolumny nazywany bywa też jej dziedziną.
Również wiersze relacji tworzą nieuporządkowany zbiór; w szczególności, nie ma powtarzających się wierszy. Wiersze relacji nazywa się też encjami.
Każde pole (przecięcie wiersza z kolumną) zawiera wartość atomową z dziedziny określonej przez kolumnę. Brakowi wartosci odpowiada wartość specjalna NULL, zgodna z każdym typem kolumny (chyba, że została jawnie wykluczona przez definicję typu kolumny).
Każda relacja zawiera klucz główny -- kolumnę (lub kolumny), której wartości jednoznacznie identyfikują wiersz (a więc w szczególności nie powtarzają się). Wartością klucza głównego nie może być NULL.
Do wiązania ze sobą danych przechowywanych w różnych tabelach używa się kluczy obcych. Klucz obcy to kolumna lub grupa kolumn tabeli, o wartościach z tej samej dziedziny co klucz główny tabeli z nią powiązanej.
Np. baza danych instytucji składającej się z wielu zakładów może zawierać tabele zakłady i pracownicy: tabela zakłady zawiera m. in. kolumny kod_zakladu (klucz główny), nazwa, adres, kierownik,...; a tabela pracownicy: kolumny nr_prac (klucz główny), nazwisko, zakład, pokój, telefon, email,...; kolumna zakłady.kierownik może być kluczem obcym odnoszącym się do kolumny pracownicy.nr_prac; zaś kolumna pracownicy.zakład - kluczem obcym odnoszącym się do zakłady.kod_zakładu, etc. Unika się w ten sposób powielania tych samych danych w różnych tabelach, co m. in. ułatwia utrzymanie zgodności pomiędzy zawartością bazy danych a stanem faktycznym.
Operacje na danych
W teoretycznym opisie modelu relacyjnego operacje na danych definiuje się w terminach tzw. algebry relacyjnej. Operatory algebry relacyjnej mają za argumenty jedną lub więcej relacji, a wynikiem ich działania zawsze jest też relacja.
Selekcja. Selekcja jest operacją jednoargumentową, określoną przez warunek dotyczący wartości kolumn danej relacji. Wynikiem jej jest relacja zawierające te wszystkie encje (wiersze) wyjściowej relacji, których atrybuty spełniają dany warunek.
Rzut. Rzut to operacja jednoargumentowa określona przez podzbiór zbioru kolumn danej relacji, dająca w wyniku tabelę składającą się z tychże kolumn wyjściowej relacji.
Iloczyn kartezjański. Argumentami są dwie relacje, wynikiem -- relacja, której wiersze są zbudowane ze wszystkich par wierszy relacji wyjściowych. Operacja o znaczeniu raczej teoretycznym.
Równozłączenie. Argumentami są dwie relacje, posiadające kolumny o tych samych dziedzinach np. klucz główny jednej z nich i klucz obcy drugiej. Wynikiem jest tabela otrzymana z iloczynu kartezjańskiego relacji wyjściowych poprzez selekcję za pomocą warunku równości tych ,,wspólnych'' atrybutów.
Złączenie naturalne. Powstaje z równozłączenia dwóch tabel poprzez rzutowanie usuwające powtarzające się kolumny złączenia. Rzeczywiście jest to operacja bardziej ,,naturalna'' aniżeli równozłączenie.
Złączenia zewnętrzne. Tu sprawa się komplikuje. Złączenia zewnętrzne tworzone są podobnie jak złączenie naturalne, lecz z pozostawieniem w tabeli wynikowej także wierszy, dla których nie zachodzi równość atrybutów złączenia: w przypadku złączenia lewostronnego złączenie naturalne uzupełnia się o wiersze z pierwszego argumentu nie posiadające odpowiednika (wierszu o równym atrybucie złączenia) w drugim argumencie; ,,brakujące'' atrybuty przyjmują wartość NULL. W złączeniu prawostronnym robi się to samo, ale względem drugiego argumentu. Wreszcie złączenie obustronne obejmuje obydwie tabele wyjściowe tą samą operacją.
Suma. Suma jest operatorem działającym na dwóch zgodnych relacjach (to jest o tych samych kolumnach), produkującym relację której wiersze są sumą teoriomnogościową wierszy z relacji wyjściowych.
Przecięcie. Przecięcie znowu wymaga dwóch zgodnych tabel, wynikiem jest tabela zawierająca wiersze wspólne dla obu argumentów.
Różnica. Różnica jest określona dla dwóch zgodnych relacji i odpowiada dokładnie różnicy teoriomnogościowej zbiorów wierszy tabel wyjściowych.
Algebra relacyjna może być uważana za proceduralny język zapytań modelu relacyjnego. To znaczy, że dowolna informacja jaka jest do uzyskania z relacyjnej bazy danych może być wydobyta za pomocą ciągu operacji algebry relacyjnej.
W praktyce w programowaniu aplikacji opartych na relacyjnych bazach danych nie korzysta się na ogół z języka proceduralnego, lecz z deklaratywnego języka opartego na tzw. rachunku relacyjnym (na ogół jest to SQL). Różnica polega na tym, że w języku proceduralnym formułuje się sekwencję kroków prowadzących do pożądanego wyniku, natomiast język deklaratywny służy do sformułowania tego, jaki wynik chcemy otrzymać. Oczywiście zapytanie sformułowane w języku deklaratywnym musi zostać przełożone na pewną procedurę aby mogło być wykonane -- jest to zadaniem implementacji DBMS. Bez znajomości żargonu algebry relacyjnej trudno jest jednak chociażby zrozumieć dokumentację systemów zarządzania baz danych (czy nawet opisy składni SQL).
Integralność danych
Model relacyjny dostarcza dodatkowych, specyficznych dla siebie postaci reguł integralności:
Integralność encji: każda tabela musi posiadać klucz główny, a wartości klucza głównego muszą być w ramach tabeli unikalne i nie równe NULL. W szczególności, zapobiega to wystąpieniu w tabeli powtórzeń wierszy.
Integralność referencyjna: każda wartość klucza obcego może być albo równa jakiejś wartości klucza głównego występującej w tabeli powiązanej, lub (ewentualnie) NULL. Pociąga to za sobą konieczność określenia reguły postępowania w wypadku usuwania wiersza z tabeli powiązanej, co mogłoby unieważnić niektóre wartości kluczy obcych w tabelach do niej się odnoszących. W grę wchodzą trzy postacie takiej reguły:
Restricted: usunięcie wiersza jest zabronione, dopóki nie zostaną usunięte lub odpowiednio zmodyfikowane wiersze z innych tabel, których wartości kluczy obcych stałyby się wskutek tej operacji nieważne;
Cascades: usunięcie wiersza powoduje automatyczne usunięcie z innych tabel wszystkich wierszy, dla których wartości kluczy obcych stały się nieważne;
Nullifies: nieważne wartości kluczy obcych ulegają zastąpieniu przez NULL.
żądanie odczytu jest przesłane do SZBD
SZBD analizuje to żądanie na podstawie schematu zewnętrznego po to, by sprawdzić, czy użytkownik, który zgłosił żądanie ma prawo dostępu do interesującej do danej, a także po to, aby pobrać informację o tej danej ze słownika danych związanego ze schematem zewnętrznym
SZBD bada schemat pojęciowy i na jego podstawie określa typ logiczny danej, która ma być odczytana
SZBD bada schemat wewnętrzny (fizyczny) i na jego podstawie określa rekord fizyczny do odczytania
SZBD wysyła do systemu operacyjnego rozkaz odczytu
system operacyjny odbiera instrukcję odczytu i analizuje ją, korzystając z niektórych parametrów schematu fizycznego, następnie zaś wysyła rozkaz odczytu do kontrolera urządzeń zewnętrznych zarządzającego dostępem do BD
pobrane z bazy dane są przesyłane do wyróżnionego obszaru pamięci, zwanego buforem systemowym
SZBD spośród zbioru danych znajdujących się w buforze systemowym wybiera te, które są potrzebne programowi użytkowemu. Dokonuje on następnie odpowiedniego przekształcenia, opierając się na definicji odwzorowania : schemat zewnętrzny - schemat pojęciowy, po czym przekazuje dane do bufora programu użytkowego
w przypadku wystąpienia błędu SZBD informuje program użytkowy a nienormalnym przebiegu operacji czytania, w wyniku tego program użytkowy może zareagować na błąd w określony sposób
program użytkowy dysponuje już daną o którą prosił, rozpoczyna się więc wykonanie następnej instrukcji programu.
Architektura na bazie serwerów. W danym przypadku standardowe funkcje rozproszonego systemu operacyjnego, związane z zarządzaniem zasobami systemu komputerowego i dystrybucją procesów, realizowane są nie w każdym węźle systemu, lecz w wydzielonych węzłach- serwerach. Węzły-użytkownicy wyposażone są w niezbędne minimum oprogramowania zapewniającego dostęp do serwera. Przy takim podejściu ewentualne niebezpieczeństwo dla prawidłowego funkcjonowania systemu kryje się w braku ochrony poszczególnych węzłów-użytkowników przed nieuprawnionym dostępem. Oprócz tego, mogą wystąpić problemy przy próbach jednoczesnego wykorzystania zasobów wspólnych systemu.
Architektura zintegrowana. W tej alternatywnej w stosunku do poprzedniego podejścia koncepcji każdy węzeł wyposażony jest w kompletną wersję systemu operacyjnego. Oznacza to brak specyficznych ograniczeń dla jakiegokolwiek węzła przy realizacji funkcji, procedur itd. Wadę danej architektury stanowią duże koszty sprzętowe i programowe. Można wyróżnić jeszcze jeden typ architektury - kombinowany, który łączy w sobie cechy dwóch poprzednich typów. W danym przypadku nieuprzywilejowane węzły będą dysponować tylko częścią oprogramowania, umożliwiającą dostęp do serwera (może to dotyczyć np. użytkowników-klientów o niskim priorytecie), natomiast uprzywilejowane węzły - kompletną wersją systemu operacyjnego wraz z oprogramowaniem umożliwiającym dostęp do serwera.
Pytanie
Skomplikowany program z odwołaniami do języka zapytań
Kilka niezależnych wykonań tego samego programu, każde z nich jest transakcją
baza danych podzielona jest na jednostki, które mogą być blokowane uniemożliwiając dostęp.
przydziela rejestruje SZBD zw. zarządzeń blokadami i rozstrzyga on konflikty.
Każda transakcja zgłasza nam wszystkie swoje żądania blokowania.
Przypisuje się jednostkom pewne arbitralne uporządkowanie, wymaga się aby wszystkie transakcje żądały blokad w tej właśnie kolejności.
Nie robi się nic. Tylko bada się aktualny stan systemu.
Wyróżnia się operację odczytu, zapisu i blokad - odbywa się tylko dla operacji zapisu.
przywilejów dostępu posiadanych przez użytkownika
przywilejów dostępu posiadanych przez terminal
żądane operacji
danej
wartości danej,
od innego czynnika np. czasu.
podanie hasła:
metoda pytań i odpowiedzi - system ma zbiór odpowiedzi i zbiór pytań dostarczonych przez użytkownika. System zadaje pytania, użytkownik odpowiada:
uwierzytelnienie tożsamości komputera - po uwierzytelnieniu użytkownik komputera ma podać swoje hasło, które wcześniej wprowadził użytkownik
procedura przywitania - wykonanie przez użytkownika poprawnie jakiegoś algorytmu. Metoda ta ma wyższy stopień bezpieczeństwa, brak jej jawności ale jest czasochłonna i żmudna dla użytkownika
procedury użytkownika - dostarczenie przez użytkownika procedur, które są wykonywane przed wejściem do systemu. Po zakończeniu danej procedury system wywołuje własną kontrolę bezpieczeństwa
Fizyczne metody uwierzytelniania - inne metody uwierzytelniania niż programowe sprawdzają czy użytkownik posiada jakiś przedmiot lub czy charakteryzuje się jakąś cechą fizyczną np. odciski palców, karty magnetyczne, zamki z kluczami itp.
bezpieczeństwo danych - zabezpieczenie danych przed umyślnym bądź przypadkowym zniszczeniem, kradzieżą lub modyfikacją
tajność danych - udostępnienie danych osobie, która ma odpowiednie upoważnienie do tej informacji
poufność danych - możliwość wymiany danych tzn. komuś dać te dane a innemu inne, czyli kontrola nad tym kto i z czego korzysta
domniemywana odmowa udzielania dostępu - jeżeli sytuacją domniemywaną jest brak dostępu można zmusić użytkownika do uzasadnienia potrzeby uzyskania dostępu przed udzieleniem mu go, błędy w projekcie i we wdrożeniu powodują odmowę udzielenia dostępu, co zapewnia sytuację bezpieczną
jawny projekt - ukazanie słabych stron projektu jeszcze w toku planowania ułatwi zdolnym krytykom wprowadzenie poprawek przed wdrożeniem go, za nim inne systemy zaczną polegać na jego działaniu; jeżeli projekt jest dobry, można go w całości opublikować, poza parametrami uzbrajającymi
akceptowalność - system zabezpieczeń musi być akceptowany przez użytkowników, gdyż w przeciwnym razie znajdą się sposoby na to, aby go obejść
całkowite pośredniczenie - upoważnienie musi być sprawdzane przy każdym żądaniu uzyskania dostępu do każdego obiektu. Zasada ta wymaga, by w razie ewentualnej zmiany poziomu upoważnienia nie mogły być wykorzystane zapamiętane wyniki badania upoważnień, lecz by trzeba było ponownie takie badanie przeprowadzić
najmniejsze uprzywilejowanie - każdy użytkownik, program, terminal lub inny zasób powinien korzystać tylko z tych przywilejów (fragmentów), które są niezbędne do wykonania zadania
ekonomiczność mechanizmu - projekt powinien być tak prosty i mały jak to tylko możliwe
oddzielenie przywilejów - dwa oddzielne zamki stanowią znacznie lepszą i elastyczniejszą ochronę niż jeden. Kiedy mechanizm jest zamknięty, dwa klucze do niego mogą być fizycznie oddzielone i oddane pod opiekę różnym programom, organizacją lub ludziom
najmniejszy wspólny mechanizm - każdy wspólny mechanizm reprezentuje potencjalną ścieżkę przepływu informacji między użytkownikami, a więc wielo dostępność powinna być minimalizowana
Trzymanie się tych zasad zredukuje liczbę i wagę błędów występujących w systemach komputerowych
urządzenia podtrzymujące zasilanie,
karty magnetyczne i mikroprocesorowe,
urządzenia do identyfikacji osób na podstawie np. linii papilarnych, głosu, siatkówki oka - tzw. urządzenia biometryczne,
urządzenia wykorzystywane do tworzenia kopii zapasowych,
zapory ogniowe - firewalle i serwery Proxy,
sprzętowe blokady dostępu do klawiatur, napędów dysków itd.,
dublowanie centrów obliczeniowych i baz danych.
zdefiniowanie czterech poziomów kryteriów ochrony oznaczonych odpowiednio D, C, B, oraz A
do każdego z poziomów (za wyjątkiem D) przydzielenie pewnej liczby klas oceny, przy zachowaniu hierarchicznego porządku narastania możliwości ochrony danych (najmniejsze możliwości odpowiadają poziomowi D, największe poziomowi A)
dla każdej z klas sformułowanie wymagań bezpieczeństwa, pogrupowanych na wymagania związane z zapewnianiem:
każdy wzrost możliwości ochrony oznacza jednocześnie zmniejszenie ryzyka penetracji systemu
kolejne poziomy reprezentują istotne jakościowo różnice w zdolności systemu do spełniania wymagań ochrony danych. Klasy wewnątrz poziomów oznaczają sukcesywne, lecz umiarkowane, wzmocnienie skuteczności środków ochrony danego poziomu (por. tabela 1)
przejście do kolejnej klasy (a tym bardziej następnego poziomu) oznacza wydatne zwiększenie możliwości ochronnych.
produktu
jego procesu projektowania i wytwarzania
jego środowiska projektowania i wytwarzania
jego dokumentacji
zalecanego środowiska eksploatacyjnego.
analizy kosztów wprowadzonych zabezpieczeń;
analizy ryzyka (powinna zapewnić stopień bezpieczeństwa proporcjonalny do wagi chronionej informacji i do ilości użytych środków).
siła zabezpieczeń określa stopień skuteczności zabezpieczeń do przeciwstawienia się zagrożeniom i jest określana trójstopniowo: niska, średnia, wysoka.
poprawność realizacji określa, za pomocą siedmiu poziomów pewności E0-E6, dokładność i jakość procesu kontrolimechanizmów bezpieczeństwa produktu poddawanego ocenie.
stopień spełnienia wymagań funkcjonalnych określa 10 klas funkcjonalności: F-C1, F-C2, F-B1, F-B2, F-B3, F-IN, F-AV, F-DI, F- DC, F-DX3 (plus klasy, które mogą by definiowane przez konstruktora, co pozwala np. na ocenianie programów antywirusowych). Ocena funkcjonalności polega na oszacowaniu stopnia spełnienia wymagań w zakresie bezpieczeństwa teleinformatycznego (np. stopień przystawania” ocenianego obiektu do pewnego wzorcowego profilu zabezpieczeń) przez poddawany ocenie obiekt.
Metody klasyczne:
podstawieniowe (momo i polialfabetyczne)
przestawieniowe (szyfr cezara)
złożone
metody programowe
RSA
ElGamala
Generator liczby pseudolosowej
Szyfr z nieskończonym kluczem
Metoda hoffmana
alg szyfrowania Frendberga
metoda Merklego_Hellmana
metody sprzętowe
rejestry przesuwające
skrzynka podstawień
skrzynka permutacji
szyfr DESS
system LUCIFER
metoda bazująca na układzie CLIPPER CHIP
Algorytm użyty do szyfrowania powinien czynić trudnym rozszyfrowanie kryptogramu bez znajomości klucza użytego do szyfrowania.
Bezpieczeństwo szyfrowania symetrycznego zależy od tajności klucza
Faktoryzacja - mnożenie dowolne dużych liczb jest bardzo łatwe, rozkład dużej liczby na czynniki pierwsze bardzo trudny
Logarytm dyskretny - podnoszenie dowolnej liczby do dowolnej potęgi modulo p jest łatwe, znalezienie logarytmu dyskretnego liczby y o podstawie g, czyli takiego x, że gx≡y mod n, jest bardzo trudne
Funkcja szyfrująca pobierająca klucz i wiadomość, a zwracająca szyfrogram C=Ek(M)
Funkcja deszyfrująca pobierająca klucz i szyfrogram, a zwracająca wiadomość M=Dk(C)
podstawieniowe
monoalfabetyczne - każdemu symbolowi ai z alfabetu A tekstu otwartego odpowiada ustalony symbol hi tekstu
polialfabetyczne - proste podstawienia polialfabetyczne sekwencyjne i cykliczne zmienia używane alfabety. W podstawieniu u-alfabetycznym znak m1 tekstu otwartego jest zmieniany przez znak alfabetu B1, znak m2 przez znak z alfabetu B2, znak mu przez znak z alfabetu Bu, znak mu+1 znowu przez znak alfabetu B1 itd.
homofoniczny jest polialfabetycznym szyfrem podstawieniowym, dającym bardzo różne częstości wystąpienia zaszyfrowanych znaków, co utrudnia złamanie go za pomocą analizy częstości. Charakteryzują się one dużą liczbą szyfrowych reprezentacji najczęściej występujących znaków, podczas gdy znaki rzadziej występujące mają tylko jeden lub dwa odpowiedniki. Można na przykład użyć następującego szyfru Homofonicznego:
wieloznakowe - jednocześnie szyfruje parę znaków.
przestawieniowe - zmienia się położenie znaków tekstu otwartego wd. Np długości grupy znaków Można zgodnie z jakąś regułą, przestawiać znaki tekstu otwartego. Na przykład znaki tekstu otwartego:
złożone - tekst otwarty podlega przekształceniu przez jeden szyfr potem następny i jeszcze inny. Należy uważać aby nie dostać po kilku takich szyfrowaniach znowu tego samego tekstu otwartego
W praktyce zazwyczaj jest pożądane stosowanie dalszych warunków integralności (integralność dodatkowa). Na ogół istnieją w DBMS mechanizmy narzucenia takich warunków, sformułowanych w języku algebry relacyjnej lub zbliżonym.
Model obiektowy
Obiektowość, programowanie obiektowe itd. to niezwykle modne obecnie ,,słowa kluczowe'' w informatyce. Moda ta nie mogła więc ominąć dziedziny baz danych. Brak tu zarówno miejsca jak i kompetencji ze strony autora na wyczerpujące przedstawienie ,,paradygmatu'' obiektowości. Ograniczę się więc do krótkiego omówienia paru zasadniczych pojęć, które na pewno nie zadowoli purystów ani entuzjastów obiektowości, być może jednak pomoże w zrozumieniu o co chodzi gdy np. dowiadujemy się, że pewien relacyjny DBMS ,,wyposażony jest w rozszerzenia obiektowe''.
Spróbujmy więc wyjaśnić parę określeń najczęściej pojawiających się, gdy jest mowa o metodach obiektowych: obiekt, metoda, klasa, dziedziczenie, abstrakcja.
Obiekt określany bywa jako ,,pakiet danych i procedur'', wyposażony w jednoznaczną tożsamość. Mówiąc po prostu, obiektowe języki programowania zamiast ograniczać się do prostych typów danych (liczba całkowita, znak, ...) oraz funkcji lub procedur operujących na zmiennych tych typów i ewentualnie zwracających wartości, umożliwiają (lub wręcz narzucają) programiście tworzenie abstrakcyjnych typów danych, składających się z wartości (zwanych w tym kontekście atrybutami) oraz procedur lub funkcji (metod) służących do wykonywania operacji na atrybutach danego obiektu (i ewentualnie zwracających wartość, będącą na ogół znów obiektem). Jednoznaczna tożsamość oznacza tyle, że poza jawnie zadeklarowanymi atrybutami (i metodami) obiekty wyposażone są w unikalne identyfikatory -- co oznacza, że identyczność obiektów nie sprowadza się do równości atrybutów.
Metoda danego obiektu służy więc do modyfikacji wartości jego atrybutów, uzyskiwania informacji o ich wartościach, lub np. powoływania do życia nowych obiektów. W ,,czystym'' programowaniu obiektowym, dostęp do atrybutów obiektu realizowany jest jedynie poprzez wywołania jego metod.
Klasa to typ lub wzorzec obiektów, może być więc poniekąd uważana za definicję pewnego typu danych. W niektórych językach obiektowych, klasa jest również obiektem: np. może ona zawierać metodę (konstruktor) której wywołanie powoduje utworzenie nowego obiektu danej klasy (instancjację), oraz atrybuty których wartościami inicjalizowane są atrybuty tego nowego obiektu. W praktyce programista może zarówno definiować własne klasy specyficzne dla tworzonej aplikacji, jak i korzystać z klas np. pochodzących z zewnętrznych bibliotek.
Dziedziczenie jest sposobem tworzenia nowych klas, poprzez modyfikację i/lub wzbogacenie już istniejącej definicji klasy (lub klas: mówi się wtedy o wielokrotnym dziedziczeniu).
Abstrakcja czy enkapsulacja danych polega na tym, że szczególy implementacji danego obiektu nie są bezpośrednio dostępne z zewnątrz -- oddziaływanie z innymi obiektami zachodzi jedynie za pośrednictwem jasno określonego zestawu metod (tzw. publicznych), tworzących interfejs obiektu. O abstrakcji mówi się też w kontekście dziedziczenia (klasy dziedziczące mogą być również niezależne od implementacji klasy nadrzędnej i polegać jedynie na jej publicznym interfejsie), i podobnie w kontekście agregacji (wykorzystywania ,,gotowych'' obiektów jako atrybutów nowo tworzonego).
Jeżeli brzmi to wszystko dość niejasno, to m. in. dlatego, że ogólne wskazania metodologii obiektowej bywają realizowane na bardzo różne sposoby, i w ramach różnych języków programowania -- zarówno opartych ab initio na założeniach obiektowych (np. Smalltalk, Java), jak i realizujących je częściowo i niejako opcjonalnie (C++, Python), lub wręcz zupełnie nieobiektowych (jak C). Stąd trudno jest o jakąś ,,kanoniczną'' definicję zasad metody obiektowej. Można jednak powiedzieć, że kluczowe jej cechy to właśnie ,,enkapsulacja'' danych prostych i procedur w abstrakcyjnych typach danych (klasach), ,,ukrywanie'' danych i implementacji metod, oraz dziedziczenie jako metoda konstrukcji klas.
O obiektowości w języku Java można poczytać np. w The Java Language Environment, szczególnie rozdz. 3 ; innym przykładem języka obiektowego, a zarazem łatwego w użyciu i pożytecznego, jest Python: wprowadzenie, o cechach obiektowych.
Jako główne zalety metody obiektowej podaje się zazwyczaj większą przejrzystość programów (szczególnie tych o dużym stopniu złożoności), uzyskaną dzięki ścisłemu rozdzieleniu zadań programu i danych na których się operuje pomiędzy dość niezależne od siebie obiekty, wymienność implementacji obiektów jeżeli tylko zachowany jest ich publiczny interfejs, i wynikającą stąd łatwość wielokrotnego użycia tych samych obiektów w różnych kontekstach. Metoda obiektowa umożliwia też dokładniejsze odwzorowanie w strukturze programu i danych struktury modelowanego zagadnienia. Z drugiej strony, wysuwa się często stwierdzenie, że programy obiektowe są trudne do optymalizacji pod kątem wydajności (szybkości, zużycia pamięci i innych zasobów systemowych) -- obiektowość pociąga za sobą pewne nieuniknione koszty. Odpowiedzią na to jest argument, że w świetle rosnącej wciąż wydajności sprzętu nie ma to wielkiego znaczenia, a praca maszyny jest o wiele ,,tańsza'' w każdym sensie aniżeli zaoszczędzona dzięki korzystaniu z metod obiektowych praca ludzka (programistów).
17. System Zarządzania Bazą Danych.
Oprogramowanie umożliwiające współpracę użytkownika z bazą danych jest nazywane systemem zarządzania bazą danych (SZBD). Zarządza on przede wszystkim organizacją danych w pamięci zewnętrznej oraz umożliwia wyszukiwanie i wybieranie danych. Posługując się językiem abstrakcyjnym, użytkownik określa operacje, jakie mają zostać wykonane na danych , następnie zaś SZBD realizuje wyszukiwanie danych, uwzględniając sposób ich reprezentacji i organizacji na nośnikach fizycznych. SZBD interpretuje instrukcje programu sformułowane przy użyciu pojęć z poziomu schematu zewnętrznego, przekształca je do postaci zgodnej ze schematem pojęciowym, a w końcu sprowadza do postaci rozkazów adresowanych do fizycznej BD. Rozkazy są przekazywane z poziomu zewnętrznego na poziom fizyczny, a wybieranie z bazy dane - z poziomu fizycznego na poziom zewnętrzny.
przepływ rozkazów przepływ danych
![]()
![]()
![]()
Etapy wykonania rozkazu (odczyt danej lub grupy danych)
Wykonanie rozkazu zapisu danej lub rozkazu aktualizacji przebiega zgodnie z takimi samymi zasadami, jak przedstawione powyżej wykonanie rozkazu odczytu. Przeważnie mamy do czynienia z równoległym wykonaniem wielu programów użytkowych. SZBD steruje ich wykonaniem, a zwłaszcza wykrywa przypadki równoczesnego zgłoszenia kilku żądań do tej samej danej.
18. Klasyfikacja systemów rozproszonych.
19. Problematyka współbieżności w systemach baz danych.
Przeciwieństwem sekwencyjnego wykonywania programów jest współbieżne wykonywanie programów. Jest ono rozumiane jako przetwarzanie wielu różnych programów lub wiele wywołań tego samego programu.
Pojęcia:
Transakcja:
Jednostki:
Blokady:
Rodzaj i rozmiar jednostek (np. relacje, krotki, składowe krotek lub pośrednie wielkości np. 100 krotek relacji)
Blokady
Aby pokonać potrzebę blokowania jednostek, rozważmy 2 transakcjeT1 i T2 każde z nich korzysta z jednostki A o której zakładamy że ma wartość całkowitą i że zwiększa wartość A o 1. Te dwie transakcje są wykonaniem programu P zdefiniowanego jako: P: READ A
A=A+1
WRITE A
A w bazie danych |
5 |
5 |
5 |
5 |
6 |
6 |
T1 |
READ A |
|
A=A+1 |
|
|
WRITE A |
T2 |
|
READ A |
|
A=A+1 |
WRITE A |
|
A w obszarze roboczym T1 |
5 |
5 |
6 |
6 |
6 |
6 |
A w obszarze roboczym T2 |
|
5 |
5 |
6 |
6 |
|
Jedynym rozwiązaniem jest blokowanie A. Transakcja T zanim rozpocznie odczytywanie A musi ją zablokować (aż do odblokowania, uniemożliwia korzystanie z niej).
Teraz program P wygląda tak: P: LOCK A
READ
A=A+1
WRITE A
UNLOCK A
i w/w problem znika.
Uwięzienie
Po zdjęciu blokady przez T1 przywracana byłaby obsługa dla T2. Co się stanie gdy T2 jest zawieszone i zgłasza się T3 i dostaje ją i dalej T4 T5 dostają podobnie, T2 może czekać bez końca. Jest to tzw. uwięzienie. Rozwiązaniem jest obsługa transakcji w kolejności zgłoszeń.
Impas
Może być podobny problem: T1: LOCKA A T2 : LOCK B
LOCK B LOCK A
UNLOCK A UNLOCK B
UNLOCK B UNLOCK A
Sytuacja w której każdy element zbioru S 2 lub większej ilości transakcji czekają na blokadę jednostki wytwarza zablokowanie jej przez pewną inną transakcję ze zbioru S jest nazwana impasem.
Rozwiązaniem jest:
20. Kontrola dostępu w systemach baz danych.
Udzielenie upoważnienia może być zależne od kategorii zasobów, użytkowników, terminali, danych i operacji, ale także od poziomu upoważnienia związanego z tymi zasobami. Odmowa udzielenia dostępu następuje zawsze, gdy poziom upoważnienia terminala i użytkownika jest niższy niż poziom upoważnienia żądanej operacji lub danych.
Mamy trzy kolejne poziomy uprzywilejowania (upoważnień): poufne, tajne, ściśle tajne. Gdy terminal ma dostęp do tajnych danych, a użytkownik do ściśle tajnych to może on tylko z tego terminala uzyskać dane tylko tajne, gdyż taki poziom upoważnień ma terminal. W ten sam sposób można łączyć przywilej programu i użytkownika, po to by system dopuszczał do korzystania z możliwie najmniejszego. Tak kombinowana metoda, pozwala na jednoczesną hierarchiczną ochronę danych i na ochronę ich za pomocą jednoznacznie określonych rozłącznych kategorii. Zgodnie z zasadą „domniemywana odmowa udzielenia dostępu” za domniemywanym uprawnieniem związanym z każdym zasobem powinien być „zakaz dostępu”. Dostęp może być kontrolowany także na poziomie wyższym niż poziom zbioru - metoda hierarchicznej kontroli.
Macierz upoważnień:
|
Nazwisko |
Adres |
Nr |
Płaca |
Informacja o środkach transportu |
Dział kadr |
11 |
11 |
11 |
01 |
00 |
Obsługa parkingu |
01 |
00 |
00 |
00 |
11 |
Dział płac |
01 |
01 |
10 |
11 |
00 |
gdzie:
00 - nic 01 - czytanie 10 - pisanie 11 - pisanie i czytanie
Po uwierzytelnianiu tożsamości za pomocą którejś z metod z pytania 23 można sprawdzić czy użytkownik, terminal lub inny zasób jest upoważniony do otrzymania przezeń obsługi. Jeżeli żądana operacja jest dozwolona, mówimy, że żądający ma upoważnienie na dostęp do niej. Dana może być, zbiorem, rekordem, polem, relacją lub jakąś inną strukturą. Udzielenie dostępu może zależeć od kilku czynników:
System bezpieczeństwa otrzymuje zestawy informacji związane z każdym użytkownikiem, terminalem, procedurą lub innym zasobem mającym dostęp do danych. Te zestawy informacji tworzone są przez specjalny, uprzywilejowany program. Mogą one być zazwyczaj reprezentowane przez macierz upoważnień.
Wyróżniamy metody uwierzytelniania:
- metoda prostych haseł - użytkownik wprowadza hasło, które może sam sobie wybrać, przy czym nie może to być hasło zbyt oczywiste
- wybrane znaki - komputer może żądać od użytkownika podania pewnych znaków. Numery znaków mogą być wyliczane na podstawie transformacji zegara wewnętrznego lub generatora
- hasła jednorazowe - użytkownik ma listę N haseł, tę samą listę pamięta komputer. Po użyciu danego hasła użytkownik skreśla je z listy. Wada jest taka, że użytkownik musi pamiętać lub mieć przy sobie całą listę i znać aktualne hasło oraz w przypadku błędów w transmisji użytkownik nie wie które hasło ma podać
wariant I: zadawanie losowo wybranych pytań
wariant II: jest zbiór pytań systemu, ale oprócz tego są zbiory pytań każdego użytkownika
wariant III: prawo użytkownika do zmiany pytań w swoim zbiorze
Metoda ta zajmuje dużo pamięci, ale jest komunikatywna.
21. Zasady projektowania zabezpieczeń.
Mamy trzy kryteria zabezpieczeń:
Jest kilka ważnych zasad bezpieczeństwa, które powinne być przestrzegane przy projektowaniu systemów komputerowych:
22. Tajność, bezpieczeństwo i poufność.
bezpieczeństwo danych - zabezpieczenie danych przed umyślnym bądź przypadkowym zniszczeniem, kradzieżą lub modyfikacją
tajność danych - udostępnienie danych osobie, która ma odpowiednie upoważnienie do tej informacji
poufność danych - możliwość wymiany danych tzn. komuś dać te dane a innemu inne, czyli kontrola nad tym kto i z czego korzysta
23. Techniczne środki bezpieczeństwa baz danych.
24. Zalecenia Unii Europejskiej lub USA (ITSEC, TCSEC) w zakresie bezpieczeństwa systemów.
Standard Trusted Computer System Evaluation Criteria (TCSEC) został opracowany na zlecenie Departamentu Obrony USA i opublikowany w 1983 roku (ze względu na okładki w jakich został wydany, popularnie nazywany „pomarańczową książką”). Podstawowe koncepcje zawarte w tym standardzie to:
a) klasyfikacja informacji (w sensie nadawania informacji etykiet „poufne”, „tajne” itp.), pozwalająca na tej podstawie różnicować do niej dostęp podmiotom (użytkownikom lub procesom);
b) mechanizm dostępu wykorzystujący model Bell-LaPadula w postaci tzw. monitora referencyjnego;
c) „zaufane środowisko przetwarzania” (Trusted Computing Base), na które składa się sprzęt komputerowy i oprogramowanie realizujące funkcje ochronne w systemie
Cechy charakterystyczne TCSEC to:
a) realizacji polityki bezpieczeństwa (security policy)
b) rozliczalności działań w systemie (accountability)
c) zaufania do mechanizmów ochronnych (assurance)
d) wytworzenia dokumentacji chronionego systemu (documentation);
Tabela 1. TCSEC - klasy oceny
NAZWA OPISOWA |
KLASA |
Minimalna ochrona |
D |
Ochrona nakazowa |
C1 |
Kontrolowany dostęp |
C2 |
Etykietowanie zasobów |
B1 |
Strukturyzacja produktu |
B2 |
Domeny ochronne |
B3 |
Weryfikowane projektowanie |
A1 |
Standard Information Technology Security Evaluation Criteria (ITSEC) opracowany pod patronatem Komisji Europejskiej przez Francję, Niemcy, Holandię i W. Brytanię zawiera kryteria oceny bezpieczeństwa stawiające określone wymagania dla:
Kryteria ITSEC umożliwiają zatem ocenę nie tylko systemów teleinformatycznych, ale również np. sprzętu kryptograficznego. Według tych kryteriów, problemy związane z bezpieczeństwem teleinformatycznym powinny być uwzględniane już na etapie projektowania systemu w postaci:
Na podstawie ITSEC może zostać dokonana ocena mechanizmów bezpieczeństwa pod względem ich poprawności realizacji, siły zabezpieczeń i stopnia spełnienia wymagań funkcjonalnych, gdzie:
W tabeli 2 pokazano, jak kryteria ITSEC „przekładają” się na kryteria TCSEC.
Tabela 2. Kompatybilność ocen według kryteriów ITSEC i kryteriów TCSE
KRYTERIA ITSEC |
KRYTERIA TCSEC |
E0 |
D |
F-C1,E1 |
C1 |
F-C2,E2 |
C2 |
F-B1,F3 |
B1 |
F-B2,F4 |
B2 |
F-B3,F5 |
B3 |
F-A1-F6 |
A1 |
25. Techniki szyfrowania danych.
Uznając dostępność klucza szyfrującego jako kryterium należy wyróżnić typy systemów kryptograficznych:
Szyfr symetryczny to taki rodzaj szyfrowania, w którym tekst jawny ulega przekształceniu na tekst zaszyfrowany za pomocą pewnego klucza, a do odszyfrowania jest niezbędna znajomość tego samego klucza.
Bezpieczeństwo takiego szyfrowania zależy od kilku czynników:
Szyfry symetryczne: AES, Blowfish, DES i jego odmiany 3DES, DESX, IDEA
Szyfr asymetryczny to szyfr, w którym występują 2 klucze: używany do deszyfracji klucz prywatny d i używany do szyfrowania klucz publiczny e, a znajomość klucza publicznego nie daje możliwości łatwego odtworzenia prywatnego. Szyfry asymetryczne są oparte na problemach, które łatwo policzyć w jedną stronę, bardzo trudno zaś w drugą:
Szyfry asymetryczne: RSA,ElGamal
Szyfr blokowy to szyfr symetryczny, który potrafi zaszyfrować blok danych o określonej długości tzn. jeżeli m oznacza wiadomość tekstową szyfr blokowy dzieli m na n bloków m1,m2….mn które są po kolei szyfrowane wg. Tego samego klucza. Można to zapisać: ek(m)=ek(m1) * ek(m2) * … ek(Mn)
Szyfr to para funkcji pobierających 2 argumenty:
Typowe rozmiary bloku oraz kluczy (te dwa muszą być identyczne) to 64, 128,192 lub 256 bitów, przy czym klucze mniejsze od 128 bitów nie zapewniają współcześnie bezpieczeństwa. Ponieważ wiadomości jakie chcemy zakodować są zwykle znacznie większe od rozmiaru bloku, musimy używać jakiegoś trybu kodowania. Najbardziej naiwne podzielenie wiadomości na bloki odpowiednich rozmiarów i zakodowanie osobno każdego z nich - ECB - nie zapewnia nam bezpieczeństwa. Główne tryby to: CBC,CFB,CTR,ECB,OFB
Szyfry blokowe: DES,AES,Lucipher.
Szyfr strumieniowy jest szyfrem okresowym jeżeli strumień klucza powtarza się po d znakach w przeciwnym wypadku jest nieokresowy. Jest on szyfrem symetrycznym, który koduje generując potencjalnie nieskończony strumień szyfrujący i XOR-ując go z wiadomością Ci=Si![]()
Mi .
Odszyfrowanie zakodowanej wiadomości odbywa się w identyczny sposób - generujemy strumień szyfrujący i XOR-ujemy go z szyfrogramem Si![]()
Ci=Si![]()
Si![]()
Mi=Mi
Synchronizujący szyfr strumieniowy charakteryzuje się tym że strumień klucza jest generowany niezależnie od strumienia wiadomości - potrzebna synchronizacja, w szyfrach samosynchronizujących się każdy znak klucza zależy od pewnej stałej n wcześniej zaszyfrowanych znaków.
Szyfrowanie jest to kodowanie danych za pomocą klucza dokonane dla ukrycia informacji. Jest to przekształcenie takie, aby osoby nieupoważnione nie mogły go odczytać. Poniżej przedstawione jest kilka tradycyjnych metod takiego ukrywania informacji
np. słowo - KISZKA
klucz - K -D, I - W, S - I, Z - Y, A - Z
tekst zaszyfrowany - DWIYDZ
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|||
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|||
Tekst otwarty |
Klucz |
Obliczenia |
Tekst zaszyfrowany |
|||||||||||||||||||||||||
T=20 |
P=16 |
20+16=36 mod 27 = 9 |
I=9 |
|||||||||||||||||||||||||
R |
O |
18+15=33 mod 27 = 6 |
F |
|||||||||||||||||||||||||
Z |
U |
26+12=47 mod 27 = 20 |
T |
|||||||||||||||||||||||||
E |
F |
5+6=11 mod 27 = 11 |
K |
|||||||||||||||||||||||||
B |
N |
2+14=16 mod 27 = 16 |
P |
|||||||||||||||||||||||||
A |
E |
1+5=6 mod 27 = 6 |
F |
|||||||||||||||||||||||||
|
P |
0+16=16 mod 27 = 16 |
P |
|||||||||||||||||||||||||
W |
… |
… |
… |
|||||||||||||||||||||||||
Znaki tekstu otwartego: ABCDEFGHIJKLMNOPQRSTUVWXYZ
Zaszyfrowane znaki: fNQ.GmD,AeL|R(CxIzV-WshuKt
* b+{ p) o y / ?j=
TRZEBA WIĘCEJ ŚNIEGU DO JAZDY NA NARTACH
można przestawić zgodnie z następującym kluczem: "permutuj czteroznakowe grupy w porządku 1-2-3-4 do porządku 3-1-4-2. Tekst otwarty jest najpierw dzielony na grupy czteroznakowe:
TRZE|BA W|IĘCE|J ŚN|IEGU| DO |JAZD|Y NA| NAR|TACH
po czym jest przekształcany w tekst zaszyfrowany:
ZTER| BWA|CIEĘ|ŚJN |GIUE|O D|ZJDA|NYA |A RN|CTHA
Niestety intruz, który odgadnie długość grup znaków będzie mógł łatwo wypróbować
różne permutacje, szczególnie gdy będzie miał dostęp do komputera.
Szyfr DES:
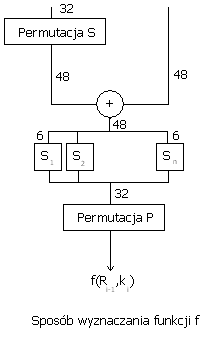
Algorytm DES operuje na zbiorze 64 bitowych ciągów reprezentujących wiadomości jawne i na takim samym zbiorze kluczy. Zbiór wiadomości jawnych jest taki sam jak zbiór wiadomości tajnych wobec czego DES jest szyfrem endomorficznym. Klucz k є K określa przekształcenie DESi: M-> C i przekształcenie odwrotne
DESk-1:C->M.
Algorytm koduje dane w porcjach 64 bity. Każdy 64 bitowy blok podlega na wejściu permutacji według macierzy IP, następnie strumień bitów zostaje podzielony na 32 bitowe części L1 i K1, obie części są poddawane kolejnym transakcjom. Równolegle klucz podany na wejściu zostaje poddany funkcji pierwotnego wyboru PS1 i podzielony na dwie części po 28 bitów C0 i D0 które zostają „przesunięte” w lewo i poddane funkcji wyboru PS2 która zawiera klucz 48 bitowy potrzebny do obliczenia funkcji f która to wpływa na wartość danych L1 i K1 - zostają zamienione miejscami. Na końcu po połączeniu części Li i Ki zostają poddane permutacji końcowej i otrzymujemy szyfrogram, czyli zaszyfrowany plik.
6
poziom
zewnętrzny
poziom
fizyczny
poziom
pojęciowy
program
użytkowy
użytkownik
Wyszukiwarka
Podobne podstrony:
Wykład VII, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Wykład XI, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Wykład VII, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Wykład XII, politechnika infa 2 st, Projektowanie Systemów Informatycznych
WYKŁAD XIII, politechnika infa 2 st, Projektowanie Systemów Informatycznych
ExamZero, politechnika infa 2 st, Projektowanie Systemów Informatycznych
PSI - wszystkie wykłady, politechnika infa 2 st, Projektowanie Systemów Informatycznych
PSI - wszystkie wykłady2, politechnika infa 2 st, Projektowanie Systemów Informatycznych
PSI - wszystkie wykłady3, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Wykład IX, politechnika infa 2 st, Projektowanie Systemów Informatycznych
02 PSI, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Wykład VIII, politechnika infa 2 st, Projektowanie Systemów Informatycznych
04 Systemy ekspertowe, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Wykład X, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Wykład VII, politechnika infa 2 st, Projektowanie Systemów Informatycznych
Wykorzystanie modelu procesow w projektowaniu systemow informatycznych
2 PROJEKTOWANIE SYSTEMÓW INFORMATYCZNYCH& 02 2013
8 PROJEKTOWANIE SYSTEMÓW INFORMATYCZNYCH# 04 2013
więcej podobnych podstron