DEFINICJA DZIEDZINY SYSTEMU INFORMACYJNEGO.
Możliwość przedstawienia wewnętrznej struktury danych. System zarządzania BD powinien mieć możność przedstawienia tych struktur, a nie wymagać, aby dane tworzyły strukturę, która nie odzwierciedla ich wewnętrznej natury.
Wydajność. System BD musi zapewniać odpowiednią przepustowość transakcji. Czas odpowiedzi musi być właściwy dla dialogu człowiek - urządzenie końcowe.
Minimalny koszt - ekonomiczność - aby utrzymać mały koszt wybiera się te techniki, które minimalizują zużycie pamięci zewnętrznej. Stosowanie tych metod może sprawić, że fizyczna reprezentacja danych w pamięci okaże się zupełnie inna niż reprezentacja z której korzysta programista (im doskonalsza technologia, tym mniejszy jest koszt pamiętania 1 bitu informacji podczas gdy koszty informacji nie maleją).
Minimalna redundancja. Redundancja danych jest kosztowna, powoduje bowiem większe zużycie pamięci niż to jest konieczne oraz wymaga więcej niż jednej operacji aktualizacji. Ponieważ kopie danych mogą znajdować się w różnych miejscach, system może dostarczać informacje sprzeczne. Celem organizacji BD powinno być wyeliminowanie nadmiarowych danych wszędzie tam, gdzie jest to opłacalne i możliwe. Gdy redundancja istnieje należy ustalić i zapisać jedną ich wersję i konieczne jest wtedy ustalenie powiązań między danymi. Całkowite zlikwidowanie redundancji jest nie zawsze pożądane.
Możliwości wyszukiwania: Fizyczna organizacja danych, aby odpowiedź udzielić z max szybkością. Osiągnięcie zdolności szybkiego i elastycznego przeszukiwania staje się więc 1 z głównych celów organizacji BD.
Wiarygodność: W BD ważne jest by dane i powiązania nie uległy zniszczeniu. Instalacja musi gwarantować wiarygodność pamiętanych danych. Zabezpieczenia systemowe danych przed awariami.
TAJNOŚĆ I BEZPIECZEŃSTWO: Dane w systemie BD muszą być utrzymywane w tajemnicy i w sposób zapewniający ich bezpieczeństwo. Bezpieczeństwo danych polega na ochronie ich przed zniszczeniem, na uniemożliwienie dostępu do nich osobom nieupoważnionym i na uniemożliwieniu niewłaściwej ich modyfikacji. Tajność danych polega na tym, że każda konkretna osoba lub instytucja decyduje kiedy, jak i w jakiej postaci informacje o nich samych mogą być przekazane innym osobom lub instytucjom.
Sprzężenie z przeszłością: Gdy wprowadza się nowe oprogramowanie do BD ważne jest, aby mogło ono pracować z programami i procedurami już istniejącymi oraz przetwarzać zgromadzone już wcześniej dane.
Sprzężenie z przyszłością: Z upływem czasu dane i sposoby gromadzenia ulegają zmianie. Czynnik jaki należy uwzględnić przy projektowaniu BD jest zapewnienie możliwości dokonywania w niej zmian bez konieczności modyfikowania programów użytkowych. Trzeba zapewnić: 1) obraz danych programisty musi być oderwany od ich fizycznej reprezantacji. Konwersja pomiędzy (danymi) poziomami powinna odbywać się za pośrednictwem oprogramowania zarządzającego BD. 2) Obraz danych programisty zastosowań musi być odizolowany od zmian w globalnej strukturze logicznej danych i od zmian danych wymaganych przez inne programy użytkowe. Zmiany fizycznej organizacji danych lub sprzętu powinny być odzwierciedlone w oprogramowaniu zarządzającym , lecz programy użytkowe powinny zostać niezmienione.
Możliwość starzenia: - najefektywniejsze wykorzystanie pamięci w celu rozmieszczenia danych oraz szybkości udzielania odpowiedzi na pytania.
Migracja danych: Z niektórych danych korzysta się często z innych rzadko. Pożądane jest aby dostęp do danych, z których korzystamy często był szybki i wygodny, a dane, z których korzystamy rzadko powinny być przechowywane w sposób jak najmniej kosztowny. Migracja danych — proces poprawiania rozmieszczenia danych.
Prostota: Zarówno w sensie konwersacji użytkownik — system, rozmieszczenie danych itp.
Języki zapytań wysokiego poziomu — ułatwiają przypadkowym użytkownikom zadawanie pytań, przeszukiwanie i aktualizację BD, a także drukowania raportów i dokumentów.
Niezależność danych.
Podstawowym celem baz danych jest zapewnienie niezależności danych, czyli: odporność programów użytkowych na zmiany struktury pamięci i strategii dostępu. Rozróżniamy 2 typy niezależności danych:
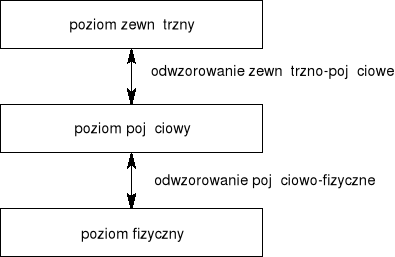
Fizyczna niezależność danych oznacza, że rozmieszczenie fizyczne i organizacja danych mogą być zmieniane bez zmiany programów użytkowych jak i globalnej struktury logicznej danych.
Logiczna niezależność danych oznacza, że globalna struktura logiczna danych może być zmieniana bez zmiany programów użytkowych (zmiany nie mogą oczywiście usunąć danych, z których te programy korzystają).
Niezależność fizyczna wyraża się w tym, że w wyniku zmian struktury pamięci zmienia się jedynie definicja odwzorowania między poziomem pojęciowym a poziomem fizycznym.
Niezależność logiczna wyraża się tym, że w wyniku zmian na poziomie pojęciowym zmienia się tylko definicja odwzorowania między poziomem pojęciowym a poziomem zewnętrznym - umożliwia zachowanie programów użytkowych w nie zmienionej postaci.
Rola administratora bazy danych.
Pełni on ważną funkcję podczas tworzenia i użytkowania baz danych. Jest odpowiedzialny za:
skonstruowanie schematu pojęciowego i zewnętrznego;
określenie praw dostępu użytkowników do danych;
określenie organizacji fizycznej danych i metod dostępu do danych;
definiowanie procedur zapewniających dobry poziom niezawodności systemu.
Administrator musi mieć swobodę zmiany struktury pamięci lub strategii dostępu bez konieczności modyfikowania programów użytkowych. Jest on także odpowiedzialny za następujące sprawy:
decyduje o tym jakie informacje będą utrzymywane w bazie danych;
ustala, jakie dane powinny być reprezentowane w bazie danych i określa cechy tej reprezentacji oraz odpowiednie odwzorowanie między strukturą pamięci a schematem pojęciowym;
utrzymuje kontakt z użytkownikiem w celu zapewnienia dostępu do danych;
definiuje procedury badania legalności i poprawności;
definiuje i realizuje odpowiednią strategię odtwarzania;
musi zapewnić wydajność najlepszą dla zakładu oraz odpowiednie dostosowanie systemu do zmieniających się wymagań.
Rola redundancji w bazach danych.
Typy powiązań pomiędzy danymi (poprzeć przykładami).
Powiązania są to związki między danymi charakteryzującymi środowisko, w którym te dane są.
I. Powiązania proste → np.:
II. Powiązania złożone ->> , <-> , <<-
np.: 1 kobieta 2 mężczyzn 2 kobiety 1 mężczyzna Małżeństwo grupowe
np.:
III. Powiązania warunkowe ( c warunek)
np.: c = pod warunkiem, że jest żonaty, mężatką.
IV. Powiązania wielokrotne: (dwa typy danych mogą być powiązane ze sobą na wiele sposobów).
a) Powiązanie "1-1". Dana elementarna A determinuje daną elementarną B tzn. w dowolnej chwili każda wartość A ma 1 i tylko 1 związaną z nią wartość B. (Powiązanie proste)
b) Powiązanie typu "1-wiele" - jednej wartości A odpowiada 0,1 lub wiele wartości B. (Powiązanie złożone)
c) Powiązanie warunkowe od A do B (c). Wartości A odpowiada jedna lub kilka związanych z nią B , pod jakimś warunkiem. (Powiązanie warunkowe)
Powiązanie - odwzorowanie (połączenie) pomiędzy danymi elementami ( lub rekordami ) dostarczające informacji dotyczącej związków między danymi elementarnymi, nie występujące w sposób bezpośredni.
Odwzorowania proste - pomiędzy danymi elementarnymi istnieje tylko 1 połączenie - A identyfikuje B.
Odwzorowanie złożone - pomiędzy danymi elementarnymi istnieje wiele połączeń - A nie identyfikuje B. Zachodzi odwzorowanie w 2 kierunkach więc mamy 4 powiązania: 1:1, 1:wiele, wiele:1, wiele : wiele.
1:1 nazwisko <-> nr pesel , 1:wiele nazwisko <->> marki samochodów
wiele:1 nazwisko <<-> nazwa zakładu pracy , wiele : wiele nazwiska <<->> adresy sklepów
d) Powiązania wielokrotne - pomiędzy danymi zachodzi więcej niż jedno powiązanie. W takim przypadku należy je etykietować, np.:
Dana elementarna - dana niosąca najbardziej elementarną porcję informacji, która nie da się podzielić na mniejsze dane. Można je grupować w rekordy.
Zasady projektowania baz danych (cechy baz danych).
Przy projektowaniu BD należy zwrócić na takie zorganizowanie danych, aby mogły mieć jak największe zastosowanie (w zależności od potrzeby) - elastyczność oraz by sposób ich wykorzystania mógł być łatwo i szybko zmieniany. Aby zapewnić elastyczność danych muszą one być niezależne od programów, które z nich korzystają; powinna być możliwość z korzystania z nich (zadawania pytań i przeszukiwania) bez potrzeby pisania programów co wiąże się z koniecznością wykorzystania specjalnego języka zapytań np. SQL.
Projektant projektujący bazę danych powinien:
bardzo dobrze znać zastosowanie bazy danych oraz środowisko, dla którego tworzona jest baza.
wybrać odpowiedni model BD (relacyjny, sieciowy, hierarchiczny, obiektowy),
wyspecyfikować wszystkie dane i dokonać powiązań między nimi,
zaprojektować i zaimplementować zabezpieczenia bazy danych.
Zasady projektowania baz danych:
projekt powinien być jawny; powinny być również ujawnione rodzaje zabezpieczeń, ale bez odpowiednich kluczy, algorytmów;
system powinien być prosty w obsłudze i ekonomiczny,
projekt powinien w pełni pośredniczyć pomiędzy danymi a użytkownikiem;
administrator powinien przydzielić jak najmniejsze uprawnienia użytkownikom, aby je później dodawać a nie odejmować,
projekt powinny być otwarty na aktualizacje tzn. na aktualizację, dopisywania nowych i usuwanie danych,
stworzony system zarządzania bazą danych powinien tworzyć proste i przejrzyste schematy dla programistów oraz zapewniać niezależność fizyczną i logiczną danych
projekt powinien zapewniać minimalną redundancję oraz integralność i poufność danych
systemy powinny przyjmować dane które zostały utworzone przed jego instalacją - tj. sprzężenie z przeszłością jak również sprzężenie z przyszłością czyli powinien zawierać schematy przyszłościowe, które pozwoliły by na przyjmowanie danych nie występujących w systemie (problem stworzenia systemów inteligentnych, które potrafią zinterpretować powiązania pomiędzy danymi).
Zasady dotyczące struktur danych:
łączenie elementów w grupy powinno być przejrzyste,
ze schematu powinno wynikać, które nazwy są nazwami danych elementarnych, zagregowanych, subelementarnych, segmentów, pól itp.,
nie wolno duplikować nazw
należy wyróżnić klucze główne (jednoznacznie identyfikujące rekordy) oraz klucze wtórne,
na schemacie trzeba czytelnie przedstawić powiązania pomiędzy danymi, aby można było rozróżnić ich rodzaj (powiązania proste czy złożone).
Problem redundancji i związków wieloznacznych w hierarchicznym modelu.
Hierarchia jest siecią, której powiązania tworzą las. Każde powiązanie jest związkiem jednoznacznym między następnikiem, a poprzednikiem. Przekształcając sieć w strukturę drzewiastą mamy 2 podejścia :
Wprowadzić redundancję dla zobrazowania związków wieloznacznych, np.
TOWARY CZŁONKOWIE
jaja mąka sól x y z
ZAMÓWIENIA ZAMÓWIENIA
1,2 3,10 2,5 1,2 3,10 2,5
Nadmiarowa postać hierarchi, brak połączenia TOWARY-CZŁONKOWIE eliminuje pytanie o to , jakie towary chcą konkretni członkowie.
2.Wprowadzić do struktury rekordy wietualne, które pozwalają na jawne powielanie rekordów bez redundancji.
Wirtualny typ(?) rekordu Tjest interpretowany jako wska*nik do fizycznego rekordu T. Powiązania w hirarchii są jednokierunkowe, pociąga to za sobą utratę pewnych informacji, których mogłyby dostarczyć powiązania niedozwolone w tym modelu. Problem ten w pewien sposób rozwiązują rekordy wirtualne, np.:
Związki wieloznaczne można przedstawić w
TOWARY CZŁONKOWIE następujący sposób:
A B
ZAMÓWIENIA wirtualne
zamówienia wirt.B wirt.A
Możliwa jest również implementacja wprowadzjąca rekordy wirtualne wskazujące na poprzedniki.(nie jest to już struktura drzewa, zakłóca się kierunek poruszania). Przy tej implementacji możliwe jest ujęcie wszystkich powiązań między danymi, z czego musielibyśmy zrezygnować w strukturze drzewiastej.
TOWARY CZŁONKOWIE
Wirt.CZŁONKOWIE ZAMÓWIENIA Wirt.TOWARY Wirt.ZAMÓWIENIA
Podstawowymi elementami modelu hierarchicznego są rekordy logiczne, powiązane ze sobą tworzą drzewo rek.
Drzewo jest szczególnym przypadkiem grafów, w którym do każdego z wierzchołków może dochodzić co najwyżej 1 krawęd*, z każdego wierzchołka może wychodzić dowolna ilość gałęzi. Zbiór drzew rekordów tworzy las. Wygodnie jest połączyć wszystkie drzewa w jedno posługując się korzeniem pomocniczym.
Realizacja prostych i złożonych struktur sieciowych.
Wyróżniamy dwa rodzaje struktur sieciowych:
struktury sieciowe proste - realizują je związki jednoznaczne 1:1, 1:n i n:1;
struktury sieciowe złożone - realizują powiązania wielokrotne n:m. . Wynikiem zastosowania takiej struktury jest złożony sposób zarządzania bazy danych, gdyż każde takie powiązanie niesie ze sobą jakieś dane dlatego też powiązania wieloznaczne n:m. Konwertuje się z postaci złożonej do postaci prostej.
Model sieciowy-korzystając z modelu sieciowego, przedstawiamy schemat pojęciowy w postaci grafu uogólnionego, którego węzły odpowiadają klasom obiektów, a łuk między 2 węzłami reprezentuje.
Może to być dowolny graf, a nie jak w przypadku modelu hierarchicznego wyłącznie struktura drzewiasta.
Zasady projektowania schematu (CODASVL): jeżeli mamy dane 2 typy rekordów S i R to:
rekordu typu R może wychodzić dowolna liczba wiązań,
do rekordu typu S może dochodzić dowolna liczba wiązań,
między 2 rekordami typu R i S może istnieć wiele różnych wiązań od R do S i od S do R. W modelu sieciowym rekord może mieć dowolną liczbę rekordów bezpośrednio podrzędnych i nadrzędnych (wiązanie M:M)
wyklucza się wiązanie dla rekordów typu R do rekordu typu R (pętla) - ograniczenie to można rozwiązać (wynika to z nadrzędności i podrzędności rekordów).
Podstawowymi konstrukcjami w modelu sieciowym są: rekord logiczny-zgrupowane dane elementarne, każdy rekord logiczny należy do klasy rekordów zwanej typem rekordów.
wiązanie-reprezentacja powiązania, jest to mechanizm dostępu w modelu sieciowym. Wiązanie określa się między 2 typami rekordów R i S w wybranym kierunku.
Wnioski z zasad tworzenia: w modelu sieciowym wszystkie związki między danymi muszą być binarne i jednoznaczne. Związek binarny -zw. charakteryzujący się tym, że albo zachodzi między 2 rekordami albo nie ma innej możliwości, Związek jednoznaczny -z każdym rekordem S i określonego typu S skojarzony jest co najwyżej 1 rekord r typu R, przy czym z rekordem r typu R może być skojarzonych wiele rekordów typu S. Te cechy związków między danymi pozwalają zastosować prosty graf zorientowany jako model danych (sieć). Wierzchołki odp. typom rekordów, jeśli istnieje powiązanie między 2 typami rekordów oraz powiązanie to jest jednoznaczne z R w S to rysujemy krawędź z R do S i mówimy, że powiązanie jest z R do S. Wierzchołki i krawędzie powinny być zaetykietowane: np.
Struktura sieciowa złożona:
(związki M:M)
Struktura sieciowa prosta:
(bez M:M związków)
Optymalizacja kolekcji dla modelu sieciowego.
Kolekcja jest podstawową konstrukcją modelu danych. Typ kolekcji definiuje się w schemacie określając pewien typ rekordu jako nadrzędny i pewną liczbę typów rekordów jako podrzędne np. typ kolekcji WYDZPRAC ma rekord nadrzędny WYDZ i rekord podrzędny PRAC. Każde wystąpienie kolekcji WYDZPRAC zawiera dokładnie jedno wystąpienie rekordu nadrzędnego i zero lub więcej wystąpień rekordów podrzędnych.
Liczba wystąpień kolekcji jest zawsze dokładnie równa liczbie wystąpień rekordu nadrzednego.
Kolekcja (grupa) może być zrealizowana na różne sposoby fizyczne.
Kolekcja - zbiór rekordów, który może być zrealizowany zgodnie z metodą łańcuchową (odsyłacze - właściciel z listą zamkniętą rekordów - tak jak lista jednokierunkowa). Wadą takiego podejścia jest, że przy każdej transakcji trzeba przejść całą kolekcję.
Usprawnienia kolekcji w modelu sieciowym:
pozwalające przerwać przeglądanie kolekcji w dowolnym momencie, bo z każdego rekordu istnieje odsyłacz do właściciela.
Kolekcja (zbiór rekordów określonego typu), w którym wyróżnia się następników i poprzedników (tak jak lista dwukierunkowa) - usprawnienie bardzo korzystne przy modyfikacjach
Zależności wykorzystywane w modelu relacyjnym.
Zależność funkcyjna - atrybut B relacji r jest funkcjonalnie zależny od atrybut A tejże relacji, jeżeli zawsze każdej wartości atrybutu A odpowiada nie więcej ja jedna wartość atrybutu B (atrybut A determinuje atrybut B).
Pełna zależność funkcyjna - atrybut B relacji r jest w pełni funkcjonalnie zależny od zbioru atrybutów A, wtedy gdy jest zależny funkcyjnie od zbioru A i nie jest zależny funkcyjnie od żadnego podzbioru zbioru A.
Przechodnia zależność funkcyjna - (X,Y, Z - trzy rozłączne podzbiory atrybutów danej relacji). Podzbiór Z jest przechodnio zależny funkcyjnie od podzbioru X jeżeli podzbiór Z jest funkcyjnie zależny od podzbioru Y, a podzbiór Y jest funkcjonalnie zależny od podzbioru X oraz podzbiór X nie jest w funkcjonalnie zależny od podzbioru Y i podzbiór Y jest funkcjonalnie zależny od podzbioru Z.
Wielowartościowa zależność funkcyjna
Połączeniowa zależność funkcjonalna [R1, R2 . . . Rm]- wtedy i tylko wtedy dla dowolnej relacji R schematu r=πR1(r), πR2(r), ... πRm(r). Relację można zdekomponować na zbiór podrelacji r1, r2 . . . rm przez wykorzystanie sekwencji operacji funkcji πR1(r), πR2(r), ... πRm(r), a następnie zrekonstruować relację pierwotną przez wykonanie sekwencji r1, r2 . . . rm.
Etapy normalizacji w modelu relacyjnym.
I Postać normalna
Wymagania: dziedziną atrybutów muszą być wartości elementarne (nierozkładalne).
np.: nie są relacją dane zapisane w postaci:
relacja sprowadzona do I postaci normalnej:
II Postać normalna - Boyce'a
Relacja jest w drugiej postaci normalnej jeżeli dla każdej zależności X->Y, w kórej Y nie zawiera się w X , zbiór X zawiera klucz (tzn. X jest nadkluczem). Relacja w drugiej postaci normalnej nie zawiera redundancji i anomalii.
Aby doprowadzić relację do II postaci normalnej można przeprowadzić operację rozkładu schematu relacji.
Dowolną relację można przekształcić do postaci normalnej Boyce'a dokonując jej rozkładu na kilka innych relacji. Z relacji tych można zawsze otrzymać relację pierwotną w wyniku ich naturalnego złączenia.
np.: <nazwisko, ulica, miasto, województwo, data, wielkość>
zależności: nazwisko -> ulica,miasto,województwo
nazwisko,data -> wielkość
miasto -> województwo
klucz : {nazwisko, data}
Podział 1: R1 <nazwisko, ulica, miasto, województwo>
R2 <nazwisko, data, wielkość>
Podział 2: R3 <nazwisko, ulica>
R4 <miasto,województwo>
R1, R2, R3, R4 są drugiej postaci normalnej.
Typy języków stosowanych w modelu relacyjnym.
W modelu relacyjnym stosuje się dwa typy języków sztucznych. Mianowicie : język algebraiczny oraz języki predykatowe.
JĘZYK ALGEBRAICZNY : Podstawę języka algebraicznego stanowi założenie mówiące o tym, że informacja, którą chcemy wybrać z bazy danych, daje się wyrazić w postaci relacji powstałej w wy- -niku wykonania szeregu operacji jedna po drugiej, których argumentami są relacje istniejące w BD.
Operacje języka algebraicznego - patrz pytania nr.18.
W języku algebraicznym w składni operacji, które zdefiniowaliśmy, uwzględnialiśmy zawsze nazwy atrybutów relacji. Można przyporządkować poszczególnym nazwą atryb.relacji numery kolumn w tablicy relacji, przy założeniu, że jest to przyporządkowanie wzajemnie jednoznaczne. Nie wszystkie operatory są proste tzn. dają się przedstawić za pomocą innych operatorów. Jest to zamierzone, gdyż chodzi o ułatwienie użytkownikowi formuowania żądań kierowanych do systemu BD.
JĘZYKI PREDYKATOWE opierają się na rachunku predykatów pierwszego rzędu.
Predykat definiuje się opierającna pojęciach zbioru X i zmiennej x przyjmującej wartości z X. Predykat P(x) jest funkcją zdaniową, która staje się zdaniem, gdy w miejsce zmiennej x podstawimy dowolną wartość ze zbioru X. Określenie wartości logicznej predykatu polega na przyporządkowa- -niu mu jednej z dwóch wartości: prawda lub fałsz. 1-argumentowy predykat P(x).
Wieloargumentowy P(x1,x2,...,xn) x1∈X1, x2∈X2 , ... , xn∈Xn.
JĘZYK PRZEDMIOTOWY : → def.predykatu. Zmienna wolna tzn. nie związana żadnym kwantyfikatorem. Zmienna zamknięta to związana kwantyfikatorem. Pytanie zamknięte odpo-
-wiada formule zamkniętej. Pytanie otwarte odpowiada formule otwartej. Jeśli P jest symbolem
predykatu n-argumentowego,a t1,t2,..,tn są termami, to P(t1,t2,...,tn) jest formułą atomową.
RACHUNEK PREDYKATÓW O ZMIENNYCH KROTKOWYCH (też języki predykato- -we-odmiana) : zmienne odpowiadają krotkom relacji.
RACHUNEK PREDYKATÓW O ZMIENNYCH ATRYBUTOWYCH : zasady zgodne jak przy konstruowaniu formuły. Wyjątek : zmienne wyrażeń przyjmują wartości z dziedzin związa- -nych z poszczególnymi atrybutami relacji..
Języki te są językami kwerend stanowiących podstawę określonych języków manipulowania danymi opracowanych dla konkretnych systemów relacyjnych.
Ad1. Przykładem języka opartego na algebrze relacji jest język ISBL. W języku tym podajemy kolejność operacji, a więc mówimy w jaki sposób uzyskać daną informacje. Jest to język procedu- -ralny. Odpowiedniość operatorów i argumentów alg.relacji jest następująca : R∪S → R+S; R−S → R−S; R∩S → R•S; R S → R.S; δF(R) → R:F; ΠA1,...,An(R) → R % A1,...,An
DEFINICJA RELACJI
Relacją n-członową nazywamy podzbiór iloczynu kartezjańskiego D1× D2×...×Dn i elementami takiej relacji o n-członach są krotki. Relację n-członową definiuje się na gruncieteorii modeli relacyjnych przez (1) podanie atrybutów zbioru relacji X={X1,X2,...,Xn}.(2) przypisanie każdemu z atrybutów Xi odpowiedniej dziedziny Di.(3) określenie predykatu relacji.
Intensja relacji odpowiada znaczeniu relacji, można powiedzieć, że predykat związany z relacją stanowi element jej intensji. Ekstensja relacji - zbiór krotek spełniających własności, które stanowią intensję relacji (pojęcie równoważne relacja).
Klucz relacji stanowi najmniejszy zbiór atrybutów relacji, których wartości pozwalają wskazać każdą z krotek relacji.
Zależność funkcyjna Y od X jest pełną , jeżeli dla żadnego podzbioru właściwego X' zbioru atrybutów X nie jest spełniona zależność X'→Y.
X jest kluczem relacji R(X,Y,Z), jeżeli zależność funkcyjna Y od X jest pełną zależnością funkcyjną.
Weryfikacja odwracalności rozkładu relacji.
Dane : schemat relacji : R = A1,...,An ; zbiór zależności funkcyjnych F; rozkład ρ(R1,...,Rk)
Wynik : stwierdzenie, czy ρ jest rozkładem odwracalnym.
Metoda : Konstruujemy tablicę o n kolumnach i k wierszach. j-ta kolumna odpowiada atrybutowi Aj, a i-ty wiersz odpowiada schematowi relacji Ri. Jeśli Aj jest atrybutem Ri to na przecięciu i-tego wiersza i j-tej kolumny wstawiamy symbol aj. Jeżeli nie wstawiamy tam bij. Każdą z zależności X→Y z F ”rozważamy wielokrotnie” - dopóki w tablicy nie można dokonać żadnej zmiany. Za każdym razem, gdy rozważamy X→Y szukamy wierszy zgodnych we wszystkich kolumnach i odpowiadającym atrybutom X. Jeśli znajdziemy dwa takie wiersze zamieniamy w nich symbole odpow.atrybut.Y.(jeśli jednym jest aj to drugi staje się też aj lub jeśli jednym jest bij, a drugi bij to oba stają się bij).
Gdy po zmodyfikowaniu wierszy tablicy odkryjemy, że jeden wiersz przybrał postać a1,...,an to rozkład jest odwracalny, jeżeli nie to rozkład jest nieodwracalny.
Rozkładem schematu relacji R ={A1,...,An}nazywamy układ ρ = (R1,...,Rk) złożony z podzbiorów R, takich że R = R1 ∪ R2 ∪...∪ Rk. Jednym z motywów dokonywania rozkładów jest to, że można wyeliminować : a) redundancję; b) potencjalną niespójność czyli anomalia przy aktualizacji; c) anomalia przy wyszukiwaniu (nie można wstawiać tylko 1 wartości - trzeba wypełnić całe pola); d) anomalia przy usuwaniu.
Przykład : Relacja R = ABCDE A→C C→D R1= AD R2= AB R3= BE R4= CDE R5= AE
B→C DE→C
CE→A
Macierz : A B C D E Mamy : A B C D E
R1 a1 b12 b13 a4 b15 Zastosowano R1 a1 b12 b13 a4 b15 Stosuję
R2 a1 a2 b23 b24 b25 zależność : R2 a1 a2 b13 b23 b25 zależność:
R3 b31 a2 b33 b34 a5 A→C R3 b31 a2 b13 b34 a5 C→D
R4 b41 b42 a3 a4 a5 B→C R4 b41 b42 a3 a4 a5
R5 a1 b52 b53 b54 a5 R5 a1 b52 b13 b54 a5
A B C D E Ostatecznie : A B C D E
R1 a1 b12 b13 a4 b15 Zależność R1 a1 b12 b13 a4 b15
R2 a1 a2 b13 a4 b25 DE→C R2 a1 a2 b23 a4 b25 Rozkład jest
R3 b31 a2 b12 a4 a5 CE→A R3 a1 a2 a3 a4 a5 odwracalny
R4 b41 b42 a3 a4 a5 R4 a1 b42 a3 a4 a5
R5 a1 b52 b13 a4 a5 R5 a1 b52 a3 a4 a5
ZAGADNIENIA IDENTYFIKACJI OBIEKTÓW W MODELU OBIEKTOWYM.
KLASY I ENKAPSULACJA.
Co to jest obiektowa baza danych?
1: Zbiór obiektów, ich stan, zachowanie się i związki występujące między nimi określone są zgodnie z obiektowym modelem danych.
2: Jest to system, który umożliwia zarządzanie bazą danych, zorientowany obiektowo.
3: Jest to system, który dziedziczy wszystkie zasadnicze cechy technologii obiektowej (istnienie złożonych obiektów, tożsamość obiektów, enkapsulacja danych i procedur, dziedziczenie, funkcje polimorficzne, rozszerzalność o nowe typy danych) i baz danych (trwałość danych, oddzielenie logicznego i fizycznego poziomu danych, zarządzanie wielodostępem, odtwarzanie spójnego stanu danych po awariach, zapytania ad hoc, zarządzanie transakcjami i in.).
Co to jest obiektowy model danych?
Model danych, w którym wykorzystano cechy obiektowości tj.: pojęcie klasy i obiektów klasy, enkapsulacja (encapsulation), mechanizm identyfikacji obiektów (object identity), dziedziczenie (inheritance), przeciążanie funkcji (overriding) i późne wiązanie (late binding).
Co to jest obiekt?
Obiekt jest podstawowym pojęciem dla obiektowości. Obiekt reprezentuje sobą konkretny pojedynczy byt (książkę, osobę, samochód), charakteryzowany poprzez opis stanu (atrybuty obiektu) i zachowania tego bytu (metody obiektu). Opis ten jest realizowany przy użyciu klasy.
Co to jest klasa i obiekty klasy?
Klasa jest zbiorem obiektów o jednakowej strukturze wewnętrznej (atrybutach i metodach). O obiektach w tym rozumieniu mówi się, że są obiektami pewnej klasy. Opis stanu obiektów klasy realizowany jest za pomocą atrybutów natomiast opis zachowania się obiektów za pomocą metod (procedur, operacji), które można wykonywać dla obiektów tej klasy.
Czym różnią się pojęcia obiektu, klasy oraz obiektów klasy dla obiektowych baz danych od tych samych pojęć dla popularnych obiektowych języków programowania?
Pojęcia te są z reguły zgodne dla OBD i obiektowych języków programowania (np. C++, Smalltalk itp.). Różnice mogą być spowodowane tym, iż pojęcia te nie zawsze są rozumiane jednakowo w różnych językach programowania a nawet w różnych podejściach do obiektowych baz danych.
Jakie elementy składają się na standardowy opis klasy?
Są to następujący elementy:
a) nazwa klasy,
b) cechy (atrybuty) klasy;
c) opis statycznej struktury obiektów: zbiór atrybutów obiektów klasy,
d) opis dynamicznych zachowań obiektów: zbiór definicji metod.
Co to jest enkapsulacja?
Koncepcja enkapsulacji (hermetyzacji) wywodzi się potrzeby rozdzielenia deklaracji i implementacji operacji oraz z potrzeby strukturyzacji programu poprzez jego podział na funkcjonalnie niezależne moduły.
Samo pojęcie wywodzi się z obiektowych języków programowania i odwołuje się do pojęcia abstrakcyjnych typów danych. W tym podejściu rozróżniamy: deklarację danej struktury i jej definicję. W części deklaracyjnej wyszczególnia się zestaw operacji jakie mogą być wykonywane na danym obiekcie - dla użytkownika jest to jedyna widoczna część obiektu. Część definicyjna składa się z definicji danych, czyli atrybutów i definicji procedur - metod.
Pojęcie enkapsulacji dla baz danych ma podobne znaczenie.
Jaka jest koncepcja enkapsulacji w obiektowych bazach danych?
Przy zachowaniu pełnej enkapsulacji użytkownicy mają dostęp do danych, czy to dla wyszukania czy dla modyfikacji tylko poprzez operacje zdefiniowane dla danego typu obiektu. Taki model enkapsulacji zapewnia rodzaj logicznej niezależności danych.
Nie zawsze korzystna jest pełna niewidoczność danych dla użytkownika: czasami przy formułowaniu zapytań odwołujących się bezpośrednio do atrybutów potrzebna jest ta możliwość. Większość systemów obiektowych baz danych daje możliwość dostęp do atrybutów, służą do tego systemowe operacje czytania i modyfikacji atrybutów.
Innym problemem jest tworzenie metod dla obiektu odwołujących się do wartości atrybutów innych obiektów. W przypadku pełnej enkapsulacji jest to niemożliwe. Rozwiązanie wzięto z obiektowych języków programowania i wprowadzono typ friend (zaprzyjaźniony), dzięki temu metody należące do danego obiektu mogą odwoływać się do wartości atrybutów obiektu należącego do typu friend.
Metoda - deklaracja: określa nazwę metody, nazwę klasy argumentów, klasę rezultatów, ciało metody: określa implementację metody i składa się z ciągu instrukcji.
Wywołanie metody powoduje wyświetlenie komunikatu:
nazwa metody,
określenie obiektu docelowego,
argumentu metody.
Co to są metody?
Metody stanowią opis dynamicznych zachowań obiektów, czyli operacje widocznych na zewnątrz obiektu a pozwalające dokonywać manipulacji na danych; metoda aktywowana jest przez komunikat adresowany do tzw. obiektu docelowego (target object) i w standardowym przypadku operuje wyłącznie na danych wchodzących w skład tego obiektu.
Jak definiujemy metodę?
Definicja metody składa się z: deklaracji (signature), która określa nazwę metody, nazwy i klasy argumentów, klasę rezultatów (o ile metoda zwraca rezultat) oraz ciała (body), które określa implementację metody i składa się z serii instrukcji w jakimś języku programowania.
ZAGADNIENIA DZIEDZICZENIA W MODELU ONIEKTOWYM.
Problem dziedziczenia - nową klasę można tworzyć na zasadzie podklasy klasy już istniejącej np. pies - czworonóg (pies jest podklasą klasy czworonóg). Klasa może mieć wiele podklas. Podklasy dziedziczą pewne opisy i metody ze swojej klasy. Klasa nie dziedziczy ani opisu ani metod ze swoich podklas (ani stanu ani zachowań).
Różne modele dziedziczenia:
dziedziczenie dotyczące typów - zapewnia, że jeżeli T' jest podtypem T to wszędzie, gdzie może być użyty obiekt należący do T może zostać również użyty obiekt należący do T'. Obiekt z nadtypu można zastąpić podtypem.
grupowanie obiektów - definicja kolekcji obiektów
związane z podejściem do podtypów zapewniającym różną implementację metod, co jest dopuszczalne dla nadtypu jest również dopuszczalne dla podtypów.
związane z różnicami między obiektami, podtyp (który dziedziczy) ma własne opisy wartości, których nie ma nadtyp.
PROBLEM WIELOWERSYJNOŚCI OBIEKTÓW.
Wielowersyjność obiektów- ma na celu odwzorowanie poszczególnych cykli powstawania jakiegoś tworu (np. w programie, po wykonaniu czegoś można wracać do poszczególnych wersji, każda z nich jakoś się zazębia w sensie historycznym).
Wprowadzenie wersji obiektu może też być korzystne w aplikacjach, w których konieczne jest stosowanie długotrwałych transakcji, zamykających dostęp do obiektu, dla innych użytkowników. W standardowych systemach zarządzania bazą danych zmodyfikowanie wartości atrybutów obiektów powoduje utratę poprzednich danych. W bardziej wyrafinowanych aplikacjach, zwłaszcza w takich, gdzie baza danych wykorzystywana jest do wspomagania projektowania rozmaitych produktów bardzo użyteczne byłoby przechowywanie poprzednich wersji obiektów.
Zwykle powstanie nowej wersji jest decyzją projektanta, który akceptuje naniesione zmiany.
Po utworzeniu obiektu nowe wersje mogą być z niego wyprowadzane z kolei tych wersji są wyprowadzane nowe wersje itd. Wersje obiektu tworzą tzw. graf skierowany. Dowolna liczba nowych wersji oraz wersja pierwotna może zostać wyprowadzona z więcej niż z 1 starej wersji.
Wersjowanie umożliwia użytkownikowi tworzenie kilku funkcjonalnie równoważnych obiektów i eksperymentowanie na nich..
Są trzy postacie wersji:
wersja przejściowa (tymczasowa) poddawana aktualizacji, może być w każdej chwili zmieniona lub usunięta.
wersja robocza - w o odpowiednim stopniu trwałości, nie może być w każdej chwili zmieniona lub usunięta.
Wersja końcowa - wersja, która osiągneła już ostateczny stan trwałości, nie może być już aktualizowana, ani usunieta.
Przy zarządzaniu wersjami obiektu posługujemy się dwoma podstawowymi pojęciami: pochodzenie wersji i historia wersji. Nowa wersja pochodzi od pewnej wersji poprzedniej. Każda kolejna wersja powstaje w wyniku modyfikacji dokonanej w jakimś odcinku czasowym, wersji poprzedniej, a ta wywodzi się z kolei z jakiejś wersji pierwotnej. Przedstawienie pochodzenia poszczególnych wersji obiektów dostarcza historia wersji.
OBIEKTY WIELOTYPOWE.
WPŁYW OBIEKTÓW KOMPZYTOWYCH NA STRUKTURĘ BAZY DANYCH (TYPY WSKAZAŃ).
Obiekty kompozytowe (obiekt złożony w sensie zależności semantycznych) może się składać z poszczególnych wersji jego obiektów składowych. Są one istotne dla systemu. Jeżeli usuwamy obiekt składający się z obiektów składowych to czasami te obiekty składowe usuwa się a czasami nie. Jest to bardzo istotne z punktu widzenia spójności danych, gdyż może to spowodować powstanie pustych odwołań.
W systemach OBD mogą występować następujące powiązania pomiędzy obiektami składowymi:
wyłączne (obiekt jest składnikiem tylko jednego obiektu kompozytowego),
dzielone (obiekt jest składnikiem wielu obiektów kompozytowych),
zależne (zależy od obiektu głównego - usuwamy ten obiekt wraz z obiektem głównym),
niezależne (obiekt składowy może być niezależnie przechowywany - usunięcie głównego obiektu nie pociąga za sobą usunięcia składnika).
Zasada modyfikacji definicji obiektów kompozytowych.
Atrybut, który został zdefiniowany jako wyłącznie kompozytowy może być przekształcony w niekompozytowy lub w atrybut dzielony kompozytowy.
Atrybut zdefiniowany jako niekompozytowy lub dzielony kompozytowy nie może być przekształcony w atrybut wyłączny kompozytowy,
Atrybut zdefiniowany jako zależny kompozytowy może być przekształcony w atrybut niezależny kompozytowy i odwrotnie.
ZASADY PROJEKTOWANIA ZABEZPIECZEŃ.
Trzy kryteria zabezpieczeń:
bezpieczeństwo danych: ochrona przed przypadkowym, lub umyślnym zniszczeniem, ujawnieniem lub modyfikacją,
poufność: dane udostępniane są tym, którzy posiadają odpowiednie uprawnienia.
Tajność: dane muszą być przechowywane i udostępniane z zachowaniem pewnego stopnia tajności.
Zasady projektowania:
domniemana odmowa udzielenia dostępu,
jawny projekt zabezpieczenia,
akceptowalność,
całkowite pośredniczenie,
najmniejsze uprzywilejowanie,
ekonomiczność,
rozdzielanie przywilejów,
najmniejszy wspólny mechanizm.
TECHNICZNE ŚRODKI BEZPIECZEŃSTWA BAZ DANYCH.
Do technicznych środków bezpieczeństwa danych zaliczamy:
UPS
miroring & backup baz danych
systemy raid
firewall'e
METODY UWIERZYTELNIANIA.
Uwierzytelnianie to sprawdzenie, czy osoba lub obiekt jest tym, za kogo się podaje; procedura upoważniania bada, czy osoba ta lub obiekt ma prawo do chronionego zasobu. Uwierzytelnienie zwykle jest dokonywane jednorazowo, ale w instalacjach o dużym stopniu bezpieczeństwa może być wymagana okresowa lub stała weryfikacja. Dla uwierzytelniania tożsamości użytkowników komputery używają haseł lub innych metod dialogowych.
HASŁA
Hasło to ciąg znaków wprowadzonych przez użytkownika i sprawdzanych przez komputer. Hasła mogą być wykorzystywane niezależnie od użytkownika dla ochrony zbiorów, rekordów, pól w rekordach itp.
Metoda prostych haseł - użytkownik wprowadza hasło, które może sam wybrać.
Wariacje metody prostych haseł - pewne wariacje metody prostych haseł zapewniają lepsze bezpieczeństwo za cenę bardzie skomplikowanego oprogramowania i zwiększonej trudności dla użytkownika.
Wybrane znaki - komputer może zażądać od użytkownika wchodzącego do systemu podania pewnych znaków. Numery znaków mogą być naliczane np. na podstawie zegara wewnętrznego komputera.
Hasła jednorazowe - użytkownik ma listę n-haseł i komputer je pamięta. Trzeba podać hasła w odpowiedniej kolejności. Hasła podaje się także na zakończenie sesji i uwierzytelniania terminali.
Wady haseł: użytkownik musi pamiętać listę haseł i znać aktualne. W przypadku błędu nie wiemy czy mamy wpisać to samo hasło czy nowe.
Metoda pytań i odpowiedzi - system otrzymuje zbiór odpowiedzi na m.-standardowych i n-dostarczonych przez użytkownika pytań. System przy każdej próbie rozpoczęcia sesji przez użytkownika zadaje z pośród tych pytań niektóre (wybrane przypadkowo). Trzeba na nie wszystkie poprawnie odpowiedzieć. Pytania dobiera się tak, by użytkownik tylko znał odpowiedzi a nie musiał je zapisywać.
Uwierzytelnianie tożsamości systemów - hasła mogą być stosowane także do uwierzytelniania tożsamości systemów np. w sieciach. Do uwierzytelniania systemów można wykorzystywać szyfry. Użytkownik po podaniu hasła trochę czeka, gdyż terminal podaje swoje dane identyfikujące do jednostki centralnej systemu.
Ogólne ostrzeżenia dotyczące haseł i ich używania:
Hasła nie powinny nigdy być przechowywane w jawnej postaci;
Hasła nie powinny być drukowane na drukarkach;
Powinny być często zmieniane;
Użytkownikowi nie wolno podawać nowego hasła po zakończeniu sesji;
Hasło na kartach sterujących zadania wsadowego - stosować programy kolejkowe szyfrujące;
Procedura uwierzytelniania - system może żądać od użytkownika uwierzytelniania w postaci poprawnego wykonania jakiegoś algorytmu. Nazywane jest to często procedurą przywitania - mają wyższy stopień bezpieczeństwa, ale są bardziej czasochłonne i żmudne.
Procedury użytkownika - niektóre systemy dopuszczają wykonanie dostarczonych przez użytkownika procedur przed wejściem do systemu. Zaraz po przesłaniu pierwszego wiersza z terminalu system przekazuje sterowanie tej procedurze. Po zakończeniu tej procedury system wywołuje własną kontrolę bezpieczeństwa.
Fizyczne metody uwierzytelniania - inne metody uwierzytelniania niż programowe sprawdzają czy użytkownik posiada jakiś przedmiot lub czy charakteryzuje się jakąś cechą fizyczną np. odciski palców, karty magnetyczne, zamki z kluczami itp.
Działania w wyniku odmowy udzielenia dostępu - dziennik systemu i zwłoka czasowa przy źle wprowadzonej odpowiedzi, oraz ilość prób wejścia do systemu.
SPOSOBY BADANIA UPOWAŻNIEŃ.
Udzielenie upoważnienia może być zależne od poziomu upoważnień związanego z zasobami. Odmowa udzielenia dostępu ma miejsce, gdy poziom upoważnień terminala i użytkownika < poziom upoważnień żądanej operacji lub danych. Występuje tu hierarchizacja dostępu. Mamy dane jawne, poufne, tajne i ściśle tajne. Ktoś kto ma dostęp do informacji tajnych ma także dostęp do informacji poufnych, ale nie odwrotnie. Poziomy te i kategorie danych mogą się nawzajem uzupełniać. Można także dokonywać łączenia użytkowników w odpowiednie grupy oraz grupowania danych i dopiero sprecyzować w macierzy grupy danych z podaniem użytkowników i ich stopnia poufności. W przypadku dalszych trudności tworzy się odpowiednie pliki opisujące sposób upoważnień w sensie par: użytkownik-konkretna dana lub dana-użytkownik i stopień upoważnienia.
Macierz upoważnień
|
Nazwisko |
Adres |
Nr |
Płaca |
Informacja o środkach transportu |
Dział kadr |
11 |
11 |
11 |
01 |
00 |
Obsługa parkingu |
01 |
00 |
00 |
00 |
11 |
Dział płac |
01 |
01 |
10 |
11 |
00 |
gdzie:
00 - nic
01 - czytanie
10 - pisanie
11 - pisanie i czytanie
Jeśli żądana operacja jest dozwolona to mówimy, że żądający ma upoważnienie na dostęp do danej. Udzielenie dostępu może zależeć od:
przywilejów dostępu posiadanych przez użytkownika oraz terminal
żądanej operacji
danej lub wartości danej
stopnia poufności danych
System bezpieczeństwa utrzymuje informację o mających dostęp do danych w macierzy upoważnień. Każdy element Aij macierzy określa prawa dostępu i-tego zasobu do j-tego. Elementy macierzy dostępu zawierają zwykle bity, które reprezentują operacje wykonywane przez terminal na danej. Jeśli jest to konieczne el. Mogą zawierać odsyłacze do procedur. Dopiero procedury mogą podejmować decyzję dostępu, które zależą od informacji nie dających się łatwo reprezentować w macierzy upoważnień (np.: pokazywać zarobek, ale tylko jeśli < 20000).
Macierz upoważnień można zmniejszyć poprzez:
zdefiniowanie grup użytkowników o tych samych upoważnieniach
podział terminali na klasy
zgrupowanie elementarnych danych w pewna kategorię
przechowywanie listy par dla każdego użytkownika lub terminala
przechowywanie listy par dla każdej elementarnej danej
Kategorie badania upoważnień do danej:
niezależne od danych - można sprawdzić ograniczenia korzystając z identyfikatorów oraz ze znajomości żądanej operacji i nazwy. Decyzja podejmowana jest w toku realizacji żądania tylko raz;
zależne od danych - zbadanie przez system przed podjęciem decyzji jednej lub kilku danych. Przeprowadzane są za każdym razem gdy wystąpi żądanie dostępu do danej.
POZIOMY UPOWAŻNIEŃ.
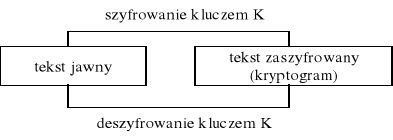
SZYFROWANIE - KLASYFIKACJA METOD.
Szyfrowanie jest to kodowanie danych za pomocą klucza dokonane dla ukrycia informacji. Jest to przekształcenie takie, aby osoby nieupoważnione nie mogły go odczytać.
podstawieniowe:
monoalfabetyczne - każdemu symbolowi ai z alfabetu A tekstu otwartego odpowiada ustalony symbol hi tekstu zaszyfrowanego
* szyfr Cezara - szyfruje symbol według wzoru: P(P) = (B(P)+2) mod 27
* zamienianie znaku na liczbę - każda litera w tekście jest mnożona przez pewną liczbę, po czym dodawana do innej liczby: C=(aP+s) mod K
a - czynnik dziesiątkowania
s - czynnik przesunięcia
P - znak do szyfrowania
C - znak po zaszyfrowaniu
K - liczba znaków alfabetu
polialfabetyczne - proste podstawienia polialfabetyczne sekwencyjne i cykliczne zmienia używane alfabety. W podstawieniu u-alfabetycznym znak m1 tekstu otwartego jest zmieniany przez znak alfabetu B1, znak m2 przez znak z alfabetu B2, znak mu przez znak z alfabetu Bu, znak mu+1 znowu przez znak alfabetu B1 itd.
Znak wejściowy: m1 m2 m3 m4 ...
Alfabet podstawienia: B1 B2 B3 B4 ...
Podstawienie polialfabetyczne ukrywa częstość występowania znaków źródłowego języka L, ponieważ poszczególne elementy alfabetu A mogą być przekształcone w kilka różnych znaków alfabetu B tekstu zaszyfrowanego.
Przykład: (użyjemy powtarzającego się sześcioliterowego klucza „POUFNE”)
Tekst otwarty: TRZEBA WIĘCEJ ŚNIEGU
POUFNEPOUFNEPOUFNEPO
Teraz jeśli potraktujemy alfabet jako 27-znakowy pierścień, w którym znaki są ustawione w odpowiedniość 0=spacja, 1=A, 2=B, .......,26=Z otrzymamy sześcioalfabetyczne podstawienie. Przez pierwszy alfabet możemy rozumieć przesunięcie każdego ze znaków o 16 (=P), czyli A staje się R, B staje się S, itd. Drugi alfabet odpowiada przesunięciu każdego znaku o 15 (=O) miejsc, trzeci o 21 (=U) miejsc. Jeżeli teraz jako metody szyfrowania użyjemy prostego dodawania modulo 27 to otrzymamy:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Tekst otwarty |
Klucz |
Obliczenia |
Tekst zaszyfrowany |
T=20 |
P=16 |
20+16=36 mod 27 = 9 |
I=9 |
R |
O |
18+15=33 mod 27 = 6 |
F |
Z |
U |
26+12=47 mod 27 = 20 |
T |
E |
F |
5+6=11 mod 27 = 11 |
K |
B |
N |
2+14=16 mod 27 = 16 |
P |
A |
E |
1+5=6 mod 27 = 6 |
F |
|
P |
0+16=16 mod 27 = 16 |
P |
W |
O |
23+15=38 mod 27 = 11 |
K |
I |
U |
. |
C |
E |
F |
. |
K |
C |
N |
. |
Q |
E |
E |
. |
J |
J |
P |
. |
Z |
|
O |
. |
O |
S |
U |
. |
M |
N |
F |
. |
T |
I |
N |
. |
W |
E |
E |
. |
J |
G |
P |
7+16=23 mod 27 = 23 |
W |
U |
O |
21+15=36 mod 27 = 9 |
I |
Szyfr homofoniczny jest polialfabetycznym szyfrem podstawieniowym, dającym bardzo różne częstości wystąpienia zaszyfrowanych znaków, co utrudnia złamanie go za pomocą analizy częstości. Charakteryzują się one dużą liczbą szyfrowych reprezentacji najczęściej występujących znaków, podczas gdy znaki rzadziej występujące mają tylko jeden lub dwa odpowiedniki.
Można na przykład użyć następującego szyfru Homofonicznego:
Znaki tekstu otwartego: ABCDEFGHIJKLMNOPQRSTUVWXYZ
Zaszyfrowane znaki: fNQ.GmD,AeL|R(CxIzV-WshuKt
* b+{ p) o y / ?j=
: i$^ rg < > `~
] ^ %
wieloznakowe - jednocześnie szyfruje parę znaków.
przestawieniowe - zmienia się położenie znaków tekstu otwartego wd. Np długości grupy znaków Można zgodnie z jakąś regułą, przestawiać znaki tekstu otwartego. Na przykład znaki tekstu otwartego:
TRZEBA WIĘCEJ ŚNIEGU DO JAZDY NA NARTACH
można przestawić zgodnie z następującym kluczem: „permutuj czteroznakowe grupy w porządku 1-2-3-4 do porządku 3-1-4-2. Tekst otwarty jest najpierw dzielony na grupy czteroznakowe:
TRZE|BA W|IĘCE|J ŚN|IEGU| DO |JAZD|Y NA| NAR|TACH
po czym jest przekształcany w tekst zaszyfrowany:
ZTER| BWA|CIEĘ|ŚJN |GIUE|O D|ZJDA|NYA |A RN|CTHA
Niestety intruz, który odgadnie długość grup znaków będzie mógł łatwo wypróbować
różne permutacje, szczególnie gdy będzie miał dostęp do komputera.
złożone - tekst otwarty podlega przekształceniu przez jeden szyfr potem następny i jeszcze inny. Należy uważać aby nie dostać po kilku takich szyfrowaniach znowu tego samego tekstu otwartego
SZYFRY SYMETRYCZNE I SZYFRY ASYMETRYCZNE.
Algorytmy symetryczne: klucz do szyfrowania oraz deszyfrowania jest taki sam (lub jeden jest łatwo wyprowadzalny z drugiego).
SZYFRY BLOKOWE I SZYFRY STRUMIENIOWE.
TECHNIKI SZYFROWANIA DANYCH (TRYBY PRACY).
SZYFR DES.
SZYFR RSA.
METODA ELGAMALA.
METODA MERKLEGO - HELLMANA.
SZYFROWANIE - METODY SPRZĘTOWE.
Rejestry przesuwające- generują duże nie powtarzające się rekurencje bitów, które mogą być użyte jako klucze szyfrów. Istnieje liniowa zależność pomiędzy komunikatem, a jego zaszyfrowaną wersją. Wskaźniki : nie szyfrować tekstu, gdy składa się z samych zer lub jedynek. Często zmieniać sprzężenia zwrotne , ukrywać brak aktywności linii. Szyfr produktowy to połączenie metod szyfrowania: permutacja i podstawienie.
SYS. LUCYFER - firmy IBM. Skrzynki podstawień S są urządzeniami, które zmieniają N bitów tekstu otwartego na N bitów tekstu zaszyfrowanego. Bardzo kosztowna, niż skrzynki permutacji - liniowe przekształcenie. Skrzynki permutacji są urządzeniami, które zmieniają N bitów tekstu otwartego na N bitów tekstu zaszyfrowanego. W odróżnieniu od skrzynek podstawień tasują tylko cyfry i nie wykonują nieliniowych przekształceń. Są tanie i łatwo je złamać(P).LUCYFER opiera się na rozwiązaniu, w którym użyto warstw skrzynek P. i małych skrzynek S. Dane te przechodzą przez naprzemienne warstwy tych skrzynek. Każda skrzynka S ma dwa stany S1 lub S2 . Wzorzec ustawiony jest za pomocą dwójkowego klucza. Dł. klucza jest dost. wielka by istniała ilość niepowtarzalnych kluczy, służących jako klucze uniwersalne w różnych instalacjach. Lucyfer jest wyposażony w generator haseł działający automatycznie po obydwu stronach łącza telekomunikacyjnego. Komunikaty są automatycznie dzielone na bloki o stałej długości D cyfr danych. Wynikowy kod bloku 2D cyfr jest kodowany przez przepuszczenie go przez warstwy skrzynek S i P, co dokładnie miesza cyfry hasła z cyframi danych. Dla rozkodowania musi być drugie urządzenie w odbiorniku ustawione z odpowiednim kluczem dla skrzynek S , a odebrane hasło musi być tożsame z hasłem lokalnie wygenerowanym przez zegar binarny. Lucyfer jest bardzo skomplikowany.
SZYFROWANIE W SIECIACH : Wszystkie możliwe ścieżki danych od miejsca powstania komunikatu, aż do jego odbioru muszą być chronione. Danym nie wolno nigdy pojawić się w czytelnej postaci w sieci. Rozpoczęcie lub zatrzymanie operacji w jakimkolwiek momencie przez użytkownika lub komputer obsługujący nie może mieć trwałego wpływu na sieć . Dla uzyskania dostępu do sieci wszyscy użytkownicy ,terminale muszą być jednoznacznie identyfikowane. Całe szyfrowanie i rozszyfrowanie odbywa się w terminalu, a nie w komputerze głównym, gdyż przesyła się wtedy tekst otwarty, a nie zaszyfrowany. Można łatwo dopiąć się do linii transmisji danych i stracić dane.
SYSTEMY ROZPROSZONE - KLASYFIKACJA.
Systemy rozproszone oznaczają, że dane są przechowywane w wielu oddalonych od siebie miejscach. Rozmaite komputery sterują dostępem do różnych porcji danych oraz pośredniczą między bazą danych, a użytkownikami w wielu miejscach; czasami obie te funkcje wykonują te same komputery. Współpracują one za pomocą łączy komunikacyjnych. O czasie odpowiedzi decyduje liczba przesyłanych danych, a nie jak wcześniej liczba wykonanych obliczeń.
Zakładamy, że baza danych składa się z relacji logicznych, które faktycznie nie istnieją, lecz są tworzone z fragmentów, najczęściej za pomocą sumy lub złączenia naturalnego. Zapytania i aktualizacje przez użytkownika odnoszą się do tychże relacji logicznych. Mówimy także o relacjach fizycznych, które faktycznie istnieją w bazie danych i są fragmentami relacji logicznych.
Założenia przyjętego modelu środowiska rozproszonego:
rozproszona baza składa się z pewnej liczby węzłów, z których każdy jest komputerem wraz ze środkami do przechowywania
każdy węzeł zawiera system obsługi transakcji (do aktualizacji i przetwarzania zapytań) i system obsługi plików (sterujący dostępem do danych)
SYSTEMY ROZPROSZONE - OCENA SYSTEMU.
SYSTEMY ROZPROSZONE - ALGORYTM DEKOMPOZYCJI.
Algorytm dekompozycji - systemy rozproszone.
dane: zbiór danych, zbiór atrybutów wielosystemowych, jeżyki użytkowników wraz z częstościami, wartości progowe,
wynik: zbiór atrybutów dla poszczególnych podsystemów
Utworzenie podzbioru A' zbioru atrybutów, wyeliminowanie zbioru atrybutów wielosysyemowych - A'=A-Ag
Utworzenie aktualnego zbioru par postaci ![]()
dla a ∈ A'
Wybranie elementu maksymalnego max z ostatnio utworzonego zbioru E
Ustalenie atrybutów podobnych na podstawie miary M z całego zbioru A do atrybutu występującego w parze wybranej w kroku 3.
Utworzenie nowego zbioru E poprzez wyeliminowanie tych par, które odpowiadają atrybutom wybranym w kroku 4.
Jeżeli nowo utworzony zbiór E nie jest pusty - powrót do kroku 3.
Wartość progowa Q nie ma znaczenia, gdy zbiór danych użytkowników są rozłączne. Nowa wartość progowa Q musi być równa minimalnej wartości różnicy między M. a poprzednia wartością Q. Jeżeli q jest małe to wygenerowane zbiory będą bardzo liczne i będzie bardzo mało podsystemów natomiast w przeciwnym wypadku będzie dużo mało licznych podsystemów.
INNE
Do czego służy język zapytań?
Język zapytań służy do wyszukiwania potrzebnych informacji. Przy pomocy języka zapytań użytkownik określa warunki według których będą wyszukiwane dane.
Jakie warunki powinien spełniać język zapytań?
Powinien to być:
ˇ język wysokiego poziomu, przez co rozumiemy możliwość prostego zapisu złożonych operacji
ˇ język deklaratywny, ukierunkowany na określanie warunków, jakie musi spełniać rezultat wyszukiwania, a nie sposobu znalezienia pożądanych danych
ˇ efektywny - zapytania muszą podlegać pewnej optymalizacji, która sprawia, że czas oczekiwania na rezultat jest względnie krótki
ˇ język niezależny od konkretnych aplikacji tzn. powinien działać dla dowolnego schematu bazy danych
Jakie istnieją trudności do stworzenia powszechnie akceptowanego języka zapytań?
Pierwszorzędną przeszkodą jest złożoność struktur danych w systemach obiektowych oraz brak powszechnie akceptowalnego modelu danych obiektowych baz danych. Inną przeszkodą jest zasada enkapsulacji, która zakłada, że wartości danych nie są bezpośrednio dostępne dla użytkownika), co dla funkcjonowania języka zapytań jest rzeczą podstawową - bezpośredni dostęp do atrybutów obiektu.
Czy wersje mają wpływ na język zapytań?
Zwykle zapytanie dotyczy bieżącej konfiguracji. Są jednak implementacje języka zapytań, które pozwalają na jawne określenie w zapytaniu wersji obiektów, których ma dotyczyć zapytanie.
W jakim kierunku następuje projektowanie języków dla obiektowych baz danych?
Projektowanie języków dla obiektowych baz danych idzie w kierunku poszerzenia możliwości języka SQL. Dzieje się to głównie z następujących powodów:
ˇ istnienie heterogenicznych baz rozproszonych: jedynym sposobem możliwości dostępu do takich baz jest utrzymywanie możliwości używania SQL
ˇ przyzwyczajenia użytkowników - język SQL jest powszechnie znany i akceptowany, baza obiektowa z językiem wzorowanym na SQL mogłaby się liczyć z lepszym przyjęciem użytkowników
potrzeba standaryzacji SQL jest obecnie powszechnie akceptowanym standardem języka, łatwiej rozszerzyć standard o nowe możliwości potrzebne dla obiektowych baz danych niż tworzyć nowy model języka zapytań.
Jakie są podstawowe konstrukcje języka zapytań dla modelu obiektowego?
Język OQL odwołuje się do podobnych konstrukcji jak SQL, ma jednak inne podstawy. Jest to czysto funkcyjny język oparty na rachunku dziedzin. Zapytanie w języku OQL jest pewnym wyrażeniem o określonym typie. Język udostępnia szereg operatorów o różnej liczbie argumentów. Argumentem może być przy tym wyrażenie. Przy takim podejściu konstrukcja select-from-where jest po prostu operatorem.
Jakie fazy występują w czasie wykonywania zapytań w systemach obiektowych baz danych?
Pierwsza faza to optymalizacja zapytania, druga - wykonanie zoptymalizowanego już zapytania. Pierwsza faza dzieli się na kilka podfaz: optymalizacja wyrażenia, transformacja do struktur algebraicznych, kontrola typów, optymalizacja wyrażenia algebraicznego i generacja planów wykonania. Zakłada się tu stworzenie zbioru możliwych planów wykonania zapytania i wybór najlepszego rozwiązania na podstawie przewidywanych kosztów wykonania.
Jakie są sposoby odczytywania obiektów klas?
Pierwszy sposób dostępu do danych polega na przetwarzaniu na raz jednego rekordu (nested-loop method) - każdy obiekt jest brany pod uwagę i przetwarzany oddzielnie
Drugi sposób polega na przetwarzaniu za jednym razem kilku rekordów (sort-domain). Zakłada się tu przetwarzanie wszystkich obiektów klasy w tym samym czasie.
Jakie są strategie wykonywania zapytań?
Istnieją cztery podstawowe strategie wykonywania zapytań:
ˇ przeglądania wprzód z pojedynczym przetwarzaniem obiektów
ˇ przeglądania wprzód z przetwarzaniem zbioru obiektów
ˇ przeglądania wstecz z pojedynczym przetwarzaniem obiektów
ˇ przeglądania wstecz z przetwarzaniem na raz zbioru obiektów
mąż
mężatka (żona)
nazwisko współmałżonka
nazwisko pracownika
c
mężczyzna
kobieta
małżeństwo
rodzeństwo
maszyna
podzespół
część
drużyna
zawodnicy
sponsor