1) co to konstruktor konwertujący, jak działa, jak się używa
Konstruktor konwertujacy to konstruktor, ktorego jedynym argumentem niedomyslnym jest referencja do obiektu swojej klasy. Powoduje on niejawna konwersje z typu argumentu na typ klasy wlasnej konstruktora.
klasa::klasa(cos) -> konwertuje cos na klasa
2) wymień składniki STLa
Skladnikami biblioteki STL sa: kontenery, iteratory, algorytmy i funktory
3) jak się definiuje i po co funkcję szablonową klasy/funkcji
template <class typ> typ funkcji(typ a, typ b)
Umożliwiają one tworzenie kodu, niezależnego od typów, algorytmów oraz struktur danych.
Szablony funkcji są sposobem na stworzenie funkcji, która może przyjmować argumenty dowolnych typów.
4) po co stosuje się przeciązanie operatora i jak się używa w C++
Op. przeciozone stosujemy do rozszerzania funkcjonalnosci istniejacych funkcji np. kiedy typ ktorego chcemy uzyc nie jest typem obslugiwanym przez funkcje lub w celu konkatenacji pol.
operator+(arg1, arg2) - przeladowanie operatora +
5) napisz jaka jest różnica między kontenerem sekwencyjnym, a asocjacyjnym
Kontener sekwencyjny to zbior nieuporzadkowany (nieposortowany), natomiast kontener asocjacyjny to zbior od razu uporzadkowany (posortowany, elementy dodawane do niego sa od razu porzadkowane wedlug wbudowanego kryterium)
6) Czemu nie można odziedziczyć operatora przypisania?
Operator przypisania nie dziedziczy się dlatego, is sluzy on do przypisania czegos składnikom obiektu klasy podstawowej, a w klasie pochodnej pojawiaja się nowe składniki, tak wiec ewentualne przypisanie byloby niekompletne
Nie można dziedziczyć :
- konstruktorów - ponieważ inicjowane by były tylko składniki klasy podstawowej (składniki klasy
pochodnej nie znajdują się w klasie podstawowej).
- operatorów przypisania - operator ten służy do przypisania czegoś składnikom obiektu klasy
podstawowej. Nie wie on nic o nowych składnikach, które zostały zdefiniowanie w
klasie pochodnej, więc ewentualne przypisanie byłoby niekompletne.
- destruktorów - jest ściśle powiązany z konstruktorem, więc skoro konstruktor powinien być
oddzielny dla klasy podstawowej i pochodnej destruktor także powinien być
oddzielny.
7) Różnica pomiędzy konstruktorem kopiującym a operatorem przypisania
Różnica pomiędzy konstruktorem kopiującym a operatorem przypisania: konstruktor kopiujący inicjalizuje obiekt, natomiast przypisaniem do istniejącego obiektu zajmuje się operator przypisania.
Konstruktor kopiujący (inicjator kopiujący) służy do skonstruowania obiektu, który jest kopią innego, już istniejącego obiektu tej klasy.
Operator przypisania ( = ) służy do przypisania jednemu obiektowi klasy , treści drugiego obiektu tej klasy. Często tę operację nazywa się podstawieniem.
Wskaźnik this - podczas wywoływania metody klasy do tej metody przekazywany jest automatycznie wskaźnik na obiekt, dla którego została wywołana metoda. Nie można pytać o adres this, nie można go podmienić.
Przeciążanie operatora - stosujemy je do rozszerzania funkcjonalności istniejących funkcji np. kiedy typ którego chcemy użyć nie jest typem obsługiwanym przez funkcje lub w celu konkatenacji pol.
operator+(arg1, arg2) - przeladowanie operatora +
9) Cos o dziedziczeniu funkcji szablonowych - czy mozna je dziedziczyc
Dziedziczenie klas szablonowych
Szablony klas (jak TArray) są podstawami do generowania specjalizowanych klas szablonowych (jak np. TArray<int>). Ten specjalizowane klasy zasadniczo niczym nie różnią się od innych uprzednio zdefiniowanych klas. Mogą więc na przykład być klasami bazowymi dla nowych typów.
Czas na ilustrację zagadnienia w postaci przykładowego kodu. Oto klasa wektora liczb:
class CVector : public TArray<double>
{
public:
// operator mnożenia skalarnego
double operator*(const CVector&);
};
Dziedziczy ona z TArray<double>, czyli zwykłej tablicy liczb. Dodaje ona jednak dodatkową metodę - przeciążony operator mnożenia *, obliczający iloczyn skalarny:
double CVector::operator*(const CVector& aWektor)
{
// jeżeli rozmiary wektorów nie są równe, rzucamy wyjątek
if (Rozmiar() != aWektor.Rozmiar())
throw CError(__FILE__, __LINE__, "Blad iloczynu skalarnego");
// liczymy iloczyn
double fWynik = 0.0;
for (unsigned i = 0; i < Rozmiar(); ++i)
fWynik += (*this)[i] * aWektor[i];
// zwracamy wynik
return fWynik;
}
W samym akcie dziedziczenia, jak i w implementacji klasy pochodnej, nie ma żadnych niespodzianek. Używamy po prostu TArray<double> tak, jak każdej innej nazwy klasy i możemy korzystać z jej publicznych i chronionych składników. Należy oczywiście pamiętać, że w tej klasie typ double występuje tam, gdzie w szablonie TArray pojawia się parametr szablonu -TYP. Dotyczy to chociażby rezultatu operatora [], który jest właśnie liczbą typu double:
fWynik += (*this)[i] * aWektor[i];
Dziedziczenie szablonów klas
Szablony i dziedziczenie umożliwiają również tworzenie nowych szablonów klas na podstawie już istniejących, innych szablonów. Na czym polega różnica?… Otóż na tym, że w ten sposób tworzymy nowy szablon klas, a nie pojedynczą, zwykłą klasę - jak to się działo poprzednio. Wtedy definiowaliśmy normalną klasę przy pomocy innej, niemalże normalnej klasy - różnica była tylko w tym, że tą klasą bazową była specjalizacja szablonu (TArray<double>). Teraz natomiast będziemy konstruowali szablon klas pochodnych przy użyciu szablonu klas bazowych. Cały czas będziemy, więc poruszać się w obrębie czysto szablonowego kodu z naszą ulubioną frazą template <...> ;)
Oto nasz nowy szablon - tablica, która potrafi dynamicznie zmieniać swój rozmiar w czasie swego istnienia:
template <typename TYP> class TDynamicArray : public TArray<TYP>
{
public:
// funkcja dokonująca ponownego wymiarowania tablicy
bool ZmienRozmiar(unsigned);
};
Ponieważ jest to szablon, więc rozpoczynamy go od zwyczajowego początku i listy parametrów. Nadal będzie to jeden TYP elementów tablicy, ale nic nie stałoby na przeszkodzie, aby lista parametrów szablonu została w jakiś sposób zmodyfikowana.
W dalszej kolejności widzimy znajomy początek definicji klasy. Jako klasę bazową wstawiamy tu TArray<TYP>. Przypomina to poprzedni punkt, ale pamiętajmy, że teraz korzystamy z parametru szablonu (TYP) zamiast z konkretnego typu (double). Nazwa klasy bazowej jest więc tak samo „zszablonowana” jak cała reszta definicji TDynamicArray.
Pozostaje jeszcze kwestia implementacji metody ZmienRozmiar(). Nie powinna być ona niespodzienka, bowiem wiesz już, jak kodować metody szablonów klas poza blokiem ich definicji. Treść funkcji jest natomiast niemal wierną kopią tej z rozdziału o wskaźnikach:
template <typename TYP>
bool TDynamicArray<TYP>::ZmienRozmiar(unsigned uNowyRozmiar)
{
// sprawdzamy, czy nowy rozmiar jest większy od starego
if (!(uNowyRozmiar > m_uRozmiar)) return false;
// alokujemy nową tablicę
TYP* pNowaTablica = new TYP [uNowyRozmiar];
// kopiujemy doń starą tablicę i zwalniamy ją
memcpy (pnNowaTablica, m_pTablica, m_uRozmiar * sizeof(TYP));
delete[] m_pTablica;
// "podczepiamy" nową tablicę do klasy i zapamiętujemy jej rozmiar
m_pTablica = pNowaTablica;
m_uRozmiar = uNowyRozmiar;
// zwracamy pozytywny rezultat
return true;
}
W wyniku dziedziczenie szablonu klasy powstaje po prostu nowy szablon klas.
Pojęcie klasy obiektów
Klasa jest nowym typem zmiennej w programie . Definiujemy ją, jako:
class nasza_klasa {
//
//
...
//ciało klasy
};
Jeśli chcemy stworzyć konkretny element czyli obiekt tej klasy to zapisujemy:
nasza_klasa nasz_obiekt;
Wtedy w pamięci operacyjnej powstanie obiekt klasy nasza_klasa, który się nazywa nasz_obiekt.
Kiedy już mamy typ nasza_klasa, to możemy utworzyć obiekt pochodny, na przykład wskaźnik do obiektu z naszej_klasy:
nasza_klasa *wsk;
albo:
nasza_klasa &name = obiekcik;
Utworzy to wskaźnik do obiektów klasy nasza_klasa albo referencje do wybranego obiektu klasy nasza_klasa.
WNIOSEK: Klasa, a obiekt
Widać, że klasa nie definiuje konkretnych obiektów tylko ich typy!!! Jest ona typem obiektu, jako abstrakcyjnej zmiennej, a nie obiektem lub zbiorem obiektów.
Cechy obiektów
Poprzez sposób definiowania obiektu decydujemy o zakresie ważności jego nazwy czyli także o czasie jego życia.
Jeśli obiekt jest definiowany w dostępie publicznym to rozumiemy, że jest dostępny globalnie (uwaga na Grębosza i pomyłkę pomiędzy pojęciem zmiennej typu wbudowanego i obiektem) czyli mogą z niego korzystać wszystkie funkcje i obiekty innych klas w programie.
Obiekt może funkcjonować lokalnie (obiekt prywatny) i wówczas automatycznie kończy się jego zakres ważności wtedy, kiedy fragment programu (klasa, blok) pozostaje zakończona faktycznie. Taki obiekt -podobnie jak zmienna lokalna - traci swoje cechy (pomimo hermetyzacji) w zakresie wartości jego zmiennych i metod. Taki obiekt, podobnie jak zmienną lokalną, będziemy uważać za zapisywany automatycznie.
Obiekt globalny jest inicjalizowany inaczej niż lokalny bo wstępnie (zanim zacznie funkcjonować jako konkret) jest inicjowany zerami.
Obiekt mogę powołać do życia jako obdarzony atrybutami. W szczególności może to być atrybut static. Taki obiekt, nawet jeśli jest lokalny, zachowa swoje wartości zmiennych i metod takie, jak przy ostatnim komunikacie. Inicjalizacja jest tu podobna jak obiektu globalnego - wartościami zerowymi.
Jeśli atrybutu static użyjemy do nazwy globalnej, to może ona być dostępna TYLKO W SWOIM PLIKU. Oznacza to, że nie mogę uzyskać dostępu do takiego obiektu wtedy, kiedy jest on w pliku dołączonym dyrektywą preprocesora include jako plik nagłówkowy.
Tworzenie obiektów
Kiedy w C++ tworzony jest obiekt zachodzą dwa procesy:
Przydział pamięci do obiektu
Wywołanie konstruktora inicjalizującego tę pamięć.
Pierwszy proces może być wykonany na różne sposoby i w różnym czasie:
Pamięć może zostać przydzielona, zanim zacznie się praca programu -w obrębie obszaru danych statycznych. Obszar ten istnieje przez cały czas działania programu.
Pamięć może zostać przydzielona na stosie kiedy zostanie osiągnięty określony punkt realizacji programu (klamrowy nawias otwierający). Jest ona zwalniana po pojawieniu się klamrowego nawiasu zamykającego. Tutaj potrzebna jest wiedza o liczbie i rozmiarze wykorzystywanych zmiennych aby nie przekroczyć rozmiaru stosu.
Pamięć jest przydzielana na stercie. Jest to proces dynamiczny. Jest on obsługiwany odpowiednia funkcją. Czyli przydziela ją i zwalnia program (czytaj programista) [malloc(), free() w <cstdlib>, new, delete w standardowej bibliotece poprzez przestrzeń nazw]
Co robi konstruktor?
Wywołanie konstruktora powoduje wykonanie następujących zadań:
obliczenie rozmiaru obiektu
alokacja obiektu w pamięci
wyczyszczenie (zerowanie) obszaru pamięci zarezerwowanej dla obiektu (tylko w niektórych językach)
wpisanie do obiektu informacji łączącej go z odpowiadającą mu klasą (połączenie z metodami klasy) poprzez wskaźnik this
wykonanie kodu klasy bazowej (w niektórych językach nie wymagane)
wykonanie kodu wywołanego konstruktora
Z wyjątkiem ostatniego punktu powyższe zadania są wykonywane wewnętrznie i są wszyte w kompilator lub interpreter języka, lub w niektórych językach stanowią kod klasy bazowej.
W językach programowania w różny sposób oznacza się konstruktor:
w C++, PHP4, Javie i in. - jest to metoda o nazwie zgodnej z nazwą klasy
w Pascalu - metoda której nazwę poprzedzono słowem kluczowym constructor.
w PHP 5 - metoda o nazwie __construct
Uwagi ogólne do konstruktorów:
Konstruktor NIE MUSI wystąpić w opisie klasy, czyli obiekty nie muszą być wprowadzane konstruktorem.
Nazwa konstruktora może być przeładowana, czyli stosowana wielokrotnie w opisie klasy z różnymi listami argumentów. Wtedy kompilator odróżnia konstruktory po listach argumentów, tak, jak w przypadku przeładowanych nazw funkcji. Konstruktorów może wiec być wiele.
Konstruktor może być wywoływany ( a nie deklarowany!!) bez żadnych argumentów. Jest to tak zwany konstruktor domniemany. Czasem nazywamy go domyślnym albo standardowym. Ze względu na istotę przeładowania nazwy konstruktor domniemany czyli bezargumentowy może wystąpić tylko raz. Jeśli nie deklarujemy w klasie żadnego konstruktora, to kompilator sam ustanawia właśnie konstruktor domniemany do obsługi obiektów w programie. Każdy konstruktor z argumentami, którym nadamy wartości domyślne czyli niedefiniowalne jest także konstruktorem domniemanym.
Co właściwie robi konstruktor? On INICJALIZUJE obiekty. Kompilator automatycznie wywołuje konstruktor w miejscu tworzenia obiektu zanim jeszcze obiekt podejmie jakiekolwiek działanie. Czyli po pierwszym komunikacie staruje konstruktor. Nazwa konstruktora taka sama jak nazwa klasy (pomysł Stroustrupa) pozwala na jednoznaczne powiązanie konstruktora z typem zmiennej obiektowej (wykorzystano operator zakresu).
Konstruktor jest zwykle deklarowany jako publiczny, bo przecież wprowadzane nim obiekty mogą być używane przez klasy zewnętrzne. Możemy jednak dla konstruktora przewidzieć ochronę tak, jak dla klas za pomocą etykiet private lub protected. Wówczas jednak także konstruowane obiekty będą dostępne tylko w obrębie klasy z tym konstruktorem jako private albo jako protected tylko w zakresie klas dziedziczących.
Konstruktor może zamiast definiować obiekty podawać kopie obiektów zawartych w innej klasie lub tworzyc kopie obiektów istniejących. Wtedy jest to tak zwany konstruktor kopiujący.
Konstruktor może dokonywać konwersji typu obiekty z jednego w drugi. Nazywamy go wtedy konstruktorem konwertującym.
Konstruktor kopiujący
Przyjrzyjmy się wywołaniu konstruktora klasy o nazwie klasa:
klasa::klasa(klasa&)
Jego argumentem jest referencja do obiektu danej klasy. Czyli do elementu, który w chwili uruchomienia tego konstruktora już istnieje. Taki konstruktor nie konstruuje obiektu tylko tworzy kopię innego, który już istnieje wśród obiektów klasy. Pozostałe argumenty konstruktora są domniemane. Przykładami konstruktora kopiującego mogą być:
X::X(X&) lub X::X(X&, float=3.1415, int=0)
Taki konstruktor wprowadza obiekty identyczne z już istniejącymi, czyli ich kopie.
Taki konstruktor może być wywołany przez program niejawnie:
1.W sytuacji, gdy do funkcji jest przez wartość przesyłany obiekt klasy X. Wówczas tworzona jest kopia tego obiektu. Jest to tzw. kopiowanie płytkie.
2.W sytuacji kiedy funkcja zwraca przez wartość obiekt klasy X. Wtedy także tworzona jest kopia obiektu. To także jest kopiowanie płytkie.
To, że konstruktor kopiujący podaje obiekt kopiowany przez referencję daje mu możliwość zmiany zawartości obiektu klasy!! (patrz przesyłanie argumentu do funkcji przez wartość)
Nie można pominąć referencji w konstruktorze kopiującym, bo gdyby konstruktor X wywoływał obiekty swojej klasy X przez wartość, czyli wytwarzałby swoją kopię, to powstaje niezamknięta pętla tworzenia kopii.
Konstruktor z przyczyn logiki języka otrzymuje, więc warunki do tego aby uszkodzić oryginał!!
Zabezpieczamy się przed taką sytuacją następująco:
X::X(const X&obiekt)
Teraz konstruktor X wie, że obiekt klasy X musi być wywoływany jako stały. Konstruktor kopiujący jest domyślnie obdarzony moderatorem const, czyli nie może zmienić sam siebie.
Kopiowanie płytkie i głębokie
Wyróżniamy dwa typy kopiowania obiektów zawierających pola będące wskaźnikami
Kopiowanie płytkie
a. Kopiowanie wszystkich składowych (w tym wskaźników)
b. Kopiowane są wskaźniki, a nie to, na co wskazują
Kopiowanie głębokie
a. Alokacja nowej pamięci dla wskaźników
b. Kopiowanie zawartości wskazywanej przez wskaźniki w nowe miejsce
c. Kopiowanie pozostałych pól, nie będących wskaźnikami
Głębokie kopiowanie
Kiedy obiekt zawiera wskaźnik do dynamicznie zaalokowanego obszaru, należy zdefiniować operator przypisania wykonujący głębokie kopiowanie
W rozważanej klasie należy zdefiniować operator przypisania:
AType& AType::operator=(const AType& otherObj)
Operator przypisania powinien uwzględnić przypadki szczególne:
Sprawdzić przypisanie obiektu do samego siebie, np. A=A:
if (this == &otherObj) // if true, do nothing
Skasować zawartośc obiektu docelowego
delete this->...
Zaalokować pamięć dla kopiowanych wartości
Przepisać kopiowane wartości
Zwrócic *his
Konstruktor kopiujący a operator przypisania
Konstruktor kopiujący jest, więc używany do stworzenia nowego obiektu
Wydaje się prostszy od operatora przypisania - nie musi sprawdzać przypisania do samego siebie i zwalniać poprzedniej zawartości
Jest użyty do skopiowania parametru aktualnego do parametru formalnego przy przekazywaniu parametru przez wartość
Przy tworzeniu nowego obiektu, można go zainicjalizować istniejącym obiektem danego typu. Wywołany jest wówczas konstruktor kopiujący.
int main() {
list a;
//...
list b(a); //copy constructor is called
list c=a; //copy constructor is called
};
Jakie mamy więc metody tworzenia obiektów?
Zmienne automatyczne
Atype a; //konstruktor domyślny
Zmienne automatyczne z argumentami
Atype a(3); //konstruktor z parametrem int
Przekazywanie parametrów funkcji przez wartość
void f(Atype b) {...} …..
Atype a; //konstruktor domyślny
f(a); //konstruktor kopiujący
Przypisanie wartości zmiennym
Atype a,b;…..
a=b; //operator przypisania
Inicjalizacja nowych obiektów
Atype b; //konstruktor domyslny
Atype a=b; //konstruktor kopiujący (NIE operator przypisania)
Zwracanie wartości z funkcji
Atype f() {
Atype a; //konstruktor domyślny
return a; //konstruktor kopiujący
}
Cechy (zalecane) poprawnie napisanej klasy
Jawny konstruktor
Gwarantuje, że każdy zadeklarowany egzemplarz obiektu zostanie w kontrolowany sposób zainicjalizowany
Jeżeli obiekt zawiera wskaźniki do dynamicznie zaalokowanej pamięci:
A. Jawny destruktor:
Zapobiega wyciekom pamięci. Zwalnia zasoby podczas usuwania obiektu.
B. Jawny operator przypisania
Używany przy przypisywaniu nowej wartości do istniejącego obiektu.
Zapewnia, że obiekt jest istotnie kopią innego obiektu, a nie jego aliasem (inną nazwą).
C. Jawny konstruktor kopiujący
Używany podczas kopiowania obiektu przy przekazywaniu parametrów, zwracaniu wartości i inicjalizacji. Zapewnia, że obiekt jest istotnie kopią innego obiektu, a nie jego aliasem.
Funkcje zaprzyjaźnione
To takie funkcje, które, mimo, że nie są składnikami klasy, to mają dostęp do jej składników czyli innych funkcji, zmiennych i obiektów. Mają dostęp także do tych składników klasy, które są hermetyzowane etykietą private. Pamiętajmy, że jeśli nie ma innych etykiet, to wszystkie składniki są private. Funkcja zaprzyjaźniona jest wprowadzana instrukcją friend.
Sposób stosowania:
class figura{
int x,y;
…….
friend void goniec(figura&)
};
Sama funkcja goniec(figura&) jest zdefiniowana gdzieś w programie w całkowicie innym miejscu nie powiązanym z klasą pionek. W klasie figura {} chcemy z niej skorzystać nawet, jeśli przynależy ona do innej klasy. Wtedy poprawnie jest taką funkcję zaznaczyć etykietą public w jej klasie.
Cechy funkcji zaprzyjaźnionych:
*Funkcja może być zaprzyjaźniona z kilkoma klasami.
*Na argumentach jej wywołania może wykonywać operacje zgodnie ze swoją definicją.
*Może być napisana w zupełnie innym języku niż C++ i dlatego może nie być funkcją składową klasy.
*Ponieważ funkcja typu friend nie jest składnikiem klasy to nie ma wskaźnika this, czyli musi się posłużyć operatorem wskaźnika, albo przypisania aby wykonać działania (także te na składniku klasy, z którą jest zaprzyjaźniona).
*Jest deklarowana w klasie ze słowem instrukcji friend i nie podlega etykietom hermetyzcji (public, private, protected).
*Może być cała zdefiniowana w klasie i wtedy jest typu inline ale nadal jest funkcją zaprzyjaźnioną.
*Nie musi być funkcją składową żadnej klasy ale może nią być.
*Klasa może się przyjaźnić z wieloma funkcjami, które są lub nie są składnikami innych klas.
*Funkcje zaprzyjaźnione nie są przechodnie, to znaczy, że „przyjaciel mego przyjaciela nie jest moim przyjacielem” czyli zaprzyjaźnienie nie przenosi się od klasy do klasy.
*Zaprzyjaźnienie nie podlega mechanizmowi dziedziczenia.
*Z zasady umieszcza się funkcje zaprzyjaźnione na początku wszystkich deklaracji w klasie.
Cechy zaprzyjaźniania klas
W klasie możemy deklarować przyjaźń z funkcjami składowymi innej klasy bez ograniczeń. Oznacza to, że obiekty klasy zaprzyjaźnionej i jej składniki otrzymują dostęp do wszystkich - także prywatnych - składników klasy zaprzyjaźnionej.
Jedną klasę możemy zaprzyjaźnić z wieloma innymi klasami.
Przyjaźń nie jest przechodnia.
Zaprzyjaźnianie klas jest wyłączone z procesu dziedziczenia, czyli zaprzyjaźnienie nie jest dziedziczone.
Funkcja i wskaźnik this
Rozpatrzmy funkcję klasy Osoba opisaną poniżej
void Osoba::zapamietaj(char *napis, int lata)
{ strcpy(nazwisko,napis);
wiek=lata; }
Powołajmy do życia kilka obiektów klasy Osoba:
Osoba student1, student2, profesor, technik, inżynier
Mamy pięć obiektów i chcemy, aby do konkretnego wpisany został wiek =23.
Wykonujemy to za pomocą podanej wyżej funkcji na przykład następująco:
student2.zapamietaj(''Tomek Gawin'',23);
Funkcja musi odszukać obiekt student2 aby wykonać operację na jego rzecz. Robi to tak, że korzysta z ukrytego przed nami wskaźnika this, który jest inicjalizowany w momencie pojawienia się operatora kropki po nazwie obiektu. Ten wskaźnik pokazuje funkcji na którym egzemplarzu (konkrecie, instancji) obiektów klasy ma wykonać swoje czynności. Oznacza to, że postać funkcji należy rozumieć tak:
void Osoba::zapamietaj(char *napis, int lata)
{
strcpy(this->nazwisko, napis);
this->wiek=lata;
}
Tablica nazwisko i zmienna wiek zostają „podczepione” pod wskaźnik obiektu.
Zauważcie, że zmienna typu char jest w opisie funkcji wskaźnikiem do zmiennej napis. To zapewni bezbłędne zadziałanie operacji this. Wskaźnik this jest wstawiany we właściwe miejsce poza nasza wiedzą. Jest to wskaźnik stały czyli typu
X const*
gdzie X to nasz obiekt.
this - WSKAŹNIK SPECJALNY
Każdej funkcji - metodzie zadeklarowanej wewnątrz klasy zostaje
w momencie wywołania w niejawny sposób (ang. implicitly)
przekazany wskaźnik do obiektu (w stosunku do którego funkcja ma
zadziałać). Pointer wskazuje funkcji w pamięci ten obiekt,
którego członkiem jest dana funkcja. Bez istnienia takiego
właśnie wskaźnika nie moglibyśmy stosować spokojnie funkcji, nie
moglibyśmy odwoływać się do pola obiektu, gdybyśmy nie wiedzieli
jednoznacznie, o który obiekt chodzi.
Wskaźnik this jest pierwszym argumentem konstruktora obiektu. W konstruktorze wskazuje on na nie zainicjalizowany fragment pamięci, a rolą konstruktora jest właśnie inicjalizacja na rzecz konkretnego obiektu (konkretu).
Program posługuje się automatycznie niejawnym wskaźnikiem do obiektu (ang. implicit pointer). Możemy wykorzystać ten istniejący, choć do tej pory nie widoczny dla nas pointer posługując się słowem kluczowym this (ten). This pointer wskazuje na obiekt, do którego należy funkcja. Korzystając z tego wskaźnika funkcja może bez cienia
wątpliwości zidentyfikować właśnie ten obiekt, z którym pracuje
a nie obiekt przypadkowy.
[!!!] FUNKCJE KATEGORII static NIE OTRZYMUJĄ POINTERA this.
Należy pamiętać, że wskaźnik this istnieje wyłącznie podczas
wykonywania metod (ang. class member function execution), za
wyjątkiem funkcji statycznych.
Obiekt jako zmienna - przesyłanie obiektu do funkcji
Przesyłanie obiektu przez wartość
Przykład:
Plik prezentacja.c
///////
#include<iostream.h>
#include ”osoba.h”
///////
void prezentacja (Osoba); //nazwa klasy jest w tej deklaracji typem argumentu funkcji
///////
void main()
{
Osoba kompozytor, autor; //wywolanie obiektow klasy Osoba do zycia
kompozytor.zapamietaj(”Aleksander Borodin”, 54);
autor.zapamietaj(”Alosza Jerofiejew”, 33);
/// teraz wywołamy obiekty poprzez wywołania funkcji, w której sa one argumentami
//////
prezentacja(kompozytor); //argument podany jawnie czyli przez wartosc
prezentacja(autor);
}
/////////
void prezentacja(Osoba ktos) // to jest opis ciala funkcji i tu argument ma już nazwe poza typem
{
cout<<”\n przedstawiam panstwu , oto we wlasnej osobie:”;
ktos.wypisz();
}
Co wytworzymy na ekranie poprzez wykonanie tego programu?
przedstawiam panstwu, oto we wlasnej osobie Aleksander Borodin, lat:54
przedstawiam panstwu, oto we wlasnej osobie Alosza Jerofiejew, lat:33
Wystąpiło tu stosowanie obiektu jako argumentu funkcji. Obiekt inicjalizował się jako kopia wewnątrz funkcji. Przy obiektach o skomplikowanej budowie nie jest to dobry sposób, bo tworzenie kopii obiektu wewnątrz funkcji musi trwać odpowiednio długo.
Wypisanie na ekran nastąpiło za pomocą funkcji dołączonej w pliku nagłówkowym osoba.h.
Przesyłanie obiektu przez referencję
Przesyłanie przez referencję działa tak samo jak dla wszystkich innych zmiennych w programie. Referencja działa jak przezwisko zmiennej pokazujące, gdzie jej szukać. Nie jest tworzona kopia zmiennej w funkcji, a tylko podawane miejsce jej ulokowania. W podanym przykładzie wystarczy zmienić postać funkcji prezentacja.
Przykład:
Plik prezentacja.c
///////
#include<iostream.h>
#include <osoba.h>
///////
void prezentacja (Osoba&);
///////
main()
{
Osoba kompozytor, autor;
kompozytor.zapamietaj(''Aleksander Borodin”, 54);
autor.zapamietaj(''Alosza Jerofiejew”, 33);
/// teraz wywołamy obiekty poprzez wywołania funkcji
//////
prezentacja(kompozytor);
prezentacja(autor);
}
/////////
void prezentacja(Osoba& ktos)
{
cout<<”\n przedstawiam panstwu ,oto we wlasnej osobie:”;
ktos.wypisz();
}
Czyli argument funkcji jest deklarowany przez referencję i obiekt i to wystarcza aby funkcja pracowała na oryginale obiektu w miejscu jego ulokowania na stosie RAM. Tworzenie kopii nie jest teraz konieczne.
Operatory new i delete
Podczas deklarowania zmiennych rezerwowany jest dla ich obszar pamięci. Jeśli się do zadeklarowanych zmiennych odwołamy, to program musi wiedzieć, gdzie dokładnie szukać ich wartości w pamięci operacyjnej.
Szczególne kłopoty powstają wówczas, kiedy deklarujemy zmienną, która ma wiele elementów o różnych lokalizacjach w RAM. Taką zmienną jest np. tablica. Jak pamiętamy, nie możemy się do niej odwołać w programie jeśli w momencie odwołania nie jest znany rozmiar tablicy.
Możemy zastosować odwołanie dynamiczne do pamięci za pomocą operatora new. Wtedy wystarczy nazwa zmiennej, w tym tablicy i nie musimy znać jej rozmiaru, a mimo to wszystkie elementy zostaną poprawnie odszukane do dalszego zastosowania w programie. Operator new musi działać nie na zmiennej tylko na wskaźniku do zmiennej, czyli na wskazaniu miejsca (adresu) w pamięci operacyjnej. Mówimy potocznie, że jest to miejsce na stercie (heap).
Wskaźniki do obiektów
Wskaźniki do obiektów funkcjonują podobnie jak wskaźniki do struktur. Operator -> pozwala na dostęp zarówno do danych jak i do funkcji. Dla przykładu wykorzystamy obiekt naszej prywatnej klasy Licznik.
class Licznik
{
public:
char moja_litera;
int ile;
Licznik(char znak) { moja_litera = z; ile = 0; }
void Skok_licznika(void) { ile++; }
};
Aby w programie można było odwołać się do obiektu nie poprzez nazwę a przy pomocy wskaźnika, zadeklarujemy wskaźnik do obiektów klasy Licznik:
Licznik *p;
Wskaźnik w programie możemy zastosować np. tak:
p->Skok_licznika();
(czytaj: Wywołaj metodę "Skok_licznika()" w stosunku do obiektu
wskazywanego w danym momencie przez wskaźnik p)
Trzeba pamiętać, że sama deklaracja w przypadku referencji i wskaźników nie wystarcza. Przed użyciem należy jeszcze zainicjować wskaźnik w taki sposób, by wskazywał na nasz obiekt-licznik. Wskaźnik do obiektu inicjujemy w taki sam sposób jak każdy inny pointer:
p = &Obiekt;
Składnik przesłaniany nie jest wyłączany z działania. Jest do niego dostęp i może być używany także w zakresie klas pochodnych. Dostęp do takiego składnika klasy musi być określany operatorem zakresu :: . W podanym przykładzie powinno to być wykonywane następująco:
opisany_punkt obiekt; //definicja obiektu
obiekt.wypisz(); //wywołanie funkcji z klasy pochodnej do wykonania czynności na rzecz obiektu
obiekt.punkt::wypisz(); // wywołanie funkcji z klasy podstawowej do wykonania czynności na rzecz tego samego obiektu
Należy pamiętać, że dziedziczenie dotyczy klas, czyli typów zmiennej, a nie obiektów
Ograniczenia mechanizmu dziedziczenia
Nie dziedziczy się automatycznie konstruktorów, destruktorów i operacji przypisania zdefiniowanych w klasie podstawowej. Jeśli chcemy wykorzystać konstruktor z klasy nadrzędnej musimy to wyraźnie wskazać ten zamiar poprzez operator zakresu.
Obiektem klasy pochodnej powinien być (bo taki jest cel dziedziczenia) wzbogacony o „coś jeszcze” obiekt klasy podstawowej. Dlatego gdyby konstruktor był dziedziczony to przeniesienie dotyczyłoby tylko składników w nim zawartych, a więc składników klasy podstawowej. Toteż dziedziczenie konstruktorów jest sprzeczne z podstawowym celem mechanizmu dziedziczenia. Ponieważ destruktor jest powiązany z konstruktorem to z tego samego powodu nie może być automatycznie dziedziczony. W konstruktorze obiektów klasy pochodnej musimy więc uruchomić dodatkowo mechanizm dziedziczenia aby przekazać mu metody i zmienne obiektów z klasy podstawowej.
Dlaczego nie jest dziedziczony skutek działania operatora przypisania? Dziedziczenie powoduje, że każdy obiekt klasy pochodnej ma faktycznie dwuczęściową budowę. Jedna część to składniki odziedziczone, a druga to zdefiniowane lub dodane w klasie pochodnej. Operacje przypisania także rozdzieliłyby się na dwie części. W takiej sytuacji przypisanie, które oznacza posługiwanie się w operacjach wytworzona do tego celu kopią wielkości przypisywanej musi jeszcze rozróżnić, gdzie jest zakres klasy podstawowej, a gdzie zakres klasy pochodnej przy tworzeniu przypisywanych kopii. To mogłoby wywołać spore zamieszanie w gospodarowaniu pamięcią operacyjną.
Odwołanie się do zmiennej przez wartość w przypadku dziedziczenia jest praktycznie niewykonalne.
Skoro przypisanie nie jest dziedziczone to jak się realizuje w klasie pochodnej? Możemy wyróżnić dwie odmienne sytuacje.
Pierwsza: klasa pochodna nie definiuje swoich operacji przypisania. Wtedy kompilator tam, gdzie to wynika z dziedziczenia automatycznie wygeneruje przypisanie poprzez kopiowanie adresów w zakresie klasy podstawowej:
klasa&klasa::operator=(klasa&)
Mamy tu mechanizm przeciążenia operatora. Nie obejmie to składników typu const oraz referencji, bo do nich nic nie możemy przypisywać.
Taki zapis „wewnątrz” kompilatora działa składnik po składniku. Podobnie zostanie przeniesiony konstruktor kopiujący jeśli nie oznaczony etykietą private.
Druga: klasa pochodna definiuje swój operator przypisania oraz swój konstruktor kopiujący. Wówczas w klasie pochodnej definiujemy operacje przypisania lub konstruktora kopiującego w zwykły sposób.
Dziedziczenie kilkupokoleniowe
Klasa pochodna może być klasą podstawową dla kolejnej klasy pochodnej. Nazywa się ją klasą podstawową pośrednią, a pierwszą, wyjściową klasę podstawową nazywa się w takiej sytuacji przodkiem. Przy takim wielopokoleniowym dziedziczeniu widoczny jest silny i sterujący dostępem do danych czyli składników klas wpływ etykiet public, protected i private.
Kompozycja a dziedziczenie
Kompozycje stosuje się wtedy, gdy między klasami zachodzi relacja typu
„całość -> cześć” tzn. nowa klasa zawiera w sobie istniejąca klasę.
Dziedziczenie stosuje się wtedy, gdy miedzy klasami zachodzi relacja
„generalizacja -> specjalizacja” tzn. nowa klasa jest szczególnym rodzajem juz istniejącej klasy.
Kompozycja
Kompozycje uzyskujemy poprzez definiowanie w nowej klasie pól, które są obiektami istniejących klas.
Przykład:
Klasa Osoba zawiera:
pola nazwisko i imie, które należą do klasy String.
Klasa Ksiazka zawiera:
pole autor należące do klasy osoba,
pole tytul należące do klasy String,
pole cena typu double.
class Osoba
{ private String nazwisko;
private String imie;
public Osoba(String nazwisko, String imie)
{ this.nazwisko = nazwisko;
this.imie = imie;
}
public String podajNazwisko()
{ return nazwisko;
}
public String podajImie()
{ return imie;
}
}
Czyli podczas kompozycji osadzamy obiekty prywatne jednej klasy w innej klasie.
Funkcje wirtualne i polimorfizm
Mechanizm omawiany w ramach tematu funkcje wirtualne decyduje o jednej z przewag programowania obiektowego nad strukturalnym. Rozważmy dziedziczenie w ramach klas (Grębosz ale wczesniej Eckel w Thinking in Java):
Instrument: trąbka, bęben, fortepian
Przykład: plik nagłówkowy zawierający klasę z wirtualną funkcją składową.
#include <iostream>
class instrument {
public:
void virtual wydaj_dzwiek(){
cout<<”nieokreslony pisk!\n”;
}
};
//
Wprawdzie typ wskaźnika jest przy dziedziczeniu ogólnie różny od typu obiektu ale konwersja działa w ramach mechanizmu dziedziczenia. Dlaczego jednak kompilator wybiera właściwą obiektowi funkcję mimo takiej samej nazwy funkcji? Sprawcą takiego zachowania kompilatora jest słowo virtual przy funkcji składowej klasy podstawowej. To ono sprawia, że konwersja przekierowuje kompilator inteligentnie także do funkcji dla obiektu pokazanego wskaźnikiem.
Gdy słowo virtual zostało usunięte to mechanizm prawidłowego wykonania funkcji przypisanej obiektowi nie zadziałał i wykonywała się funkcja tylko z klasy podstawowej.
Kompilatory języków niezorientowanych obiektowo używają tzw. wczesnego wiązania funkcji. Kompilator generuje wywołanie funkcji a linker zamienia to wywołanie na bezwzględny adres kodu, który ma być wykonany.
Kompilatory w językach obiektowych stosują tzw. późne wiązanie. Kod przy takim wiązaniu jest wywoływany dopiero podczas wykonywania. Kompilator tylko sprawdza poprawność i obecność poszczególnych składników w wiązaniu. W języku C++ takie wywołanie powoduje słowo kluczowe virtual.
Polimorfizm
Dzięki terminowi virtual fragment kodu funkcji muzyk podany w formie
&wydaj_dźwięk();
wykonuje się w formie stosownej do zakresu klasy, z której wskazujemy adresem obiekt:
&instrument::wydaj_dźwięk()
&trabka::wydaj_dźwięk()
&fortepian::wydaj_dźwięk()
zależnie od sytuacji. Czyli funkcja muzyk wykonała się różnie mimo tej samej formy. To się nazywa polimorfizmem, co oznacza wielość form. Zastosowanie funkcji wirtualnej pozwoliło na uzyskanie wielości form.
Dodatkową cechą klasy zawierającej składową funkcję wirtualną jest to, że zadziała uniwersalnie dla każdej klasy pochodnej wywołującej funkcje wydaj_dźwięk():
#include”instrum.h” // nasze defincje do klasy instrument zawrzemy w pliku head
/////
class sluchacz:public instrument{
public:
void wydaj_dzwiek();
{
cout<<”jazz-jazz”;
}
////
main()
{
sluchacz bzzzzz;
muzyk(bzzzzz);
}
to na ekranie otrzymamy:
jazz-jazz
Dlaczego? Dlatego, że instrukcja z funkcji muzyk ma teraz formę:
instrument.sluchacz::wydaj_dźwięk();
Nietrudno zauważyć, że daje to zupełnie nowe możliwości modyfikacji działania programu w ramach polimorfizmu.
Dlaczego w takim razie nie uznać wszystkich funkcji jako wirtualnych w trybie domyślnym? Głównie dlatego, że funkcje wirtualne zabierają znacznie więcej miejsca w pamięci niż zwykłe funkcje składowe i ich uruchamianie trwa znacząco dłużej.
Należy pamiętać, że:
wirtualna może być tylko funkcja składowa, a nie funkcja globalna;
słowo virtual występuje tylko przy deklaracji funkcji w klasie, a ciało funkcji już nie musi go zawierać;
jeśli klasa pochodna nie zdefiniuje swojej wersji funkcji wirtualnej, to będzie ona wywoływana z klasy podstawowej w jej zakresie ważności;
funkcja wirtualna nie może być funkcją typu static bo wtedy nie może być stosowana wirtualnie na wielu obiektach a tylko na tym, na którym jest przypisana jako static;
funkcja wirtualna może być funkcją zaprzyjaźnioną ale straci wówczas możliwość polimorficznego działania czyli możemy ja zaprzyjaźnić ale za ceną utraty polimorfizmu
Sposoby projektowania programów
Dekompozycja funkcjonalna typowa w programowaniu strukturalnym
Dekompozycja obiektowa typowa w programowaniu obiektowym. Napisanie programu zorientowanego obiektowo MUSI poprzedzić taka właśnie dekompozycja
Dekompozycja funkcjonalna
Rozważmy przykład: wykładowca podczas konferencji
Słuchacze jego wykładu chcą jeszcze po spotkaniu z nim wysłuchać innego wykładu. Nie wiedzą jednak gdzie będzie się odbywał. Jednym z obowiązków wykładowcy jest wskazanie im miejsca kolejnego wykładu.
Przy dekompozycji funkcjonalnej typowej dla programowania strukturalnego wykładowca powinien kolejno:
A. Sporządzić listę słuchaczy
B. Od każdej osoby na liście:
uzyskać informację jakiego wykładu chce one wysłuchać jako kolejnego;
Odnaleźć miejsce tego wykładu
Wybrać dla każdej z osób lub grupom osób metodę dotarcia na miejsce kolejnego wykładu
Przekazać te informacje odpowiednim osobom
C. Do wykonania zadania będą potrzebne następujące procedury:
utworzenie listy słuchaczy
pobranie planu uczestnictwa od każdego z nich
program szukający drogi pomiędzy salami wykładowymi
program łączący te części w funkcjonalną całość
Razem dziewięć czynności, które musza następować sekwencyjnie
W toku dekompozycji funkcjonalnej wykładowca działa na trzech kolejnych w czasie perspektywach:
Perspektywa koncepcji, w której wykładowca komunikuje się ze słuchaczami w.s. innych wykładów przekazując co powinni zrobić ale nie mówi jak.
Perspektywa specyfikacji, w której każdemu z osobna udziela instrukcji jak dotrzeć na inne wykłady tworząc cos w rodzaju interfejsu komunikacyjnego dla użytkownika
Perspektywa implementacji, w której każdy słuchacz indywidualnie wykona zespół czynności aby dotrzeć na kolejny wykład
Na ogół wykładowca postąpi inaczej. Wywiesi na drzwiach sali, w której ma wykład informacje o tym, jak dotrzeć na inne wykłady i pozostawi całą inicjatywę każdemu ze słuchaczy indywidualnie. Wykładowca dokona przesunięcia odpowiedzialności. Wykładowca potraktuje studentów jak samodzielne obiekty.
Dekompozycja obiektowa
Obiekty i ich działania określamy w oparciu o regułę:
Rzeczownik -> czasownik
Wskazuje ona KTO-CO ROBI- [dla KOGO]. Ta reguła określa zakres odpowiedzialności każdego obiektu za komunikacje z innymi obiektami i sposób jej wykonywania.
W porównaniu z dekompozycją funkcjonalną obiekt jest:
Na poziomie perspektywy koncepcji jest zbiorem odpowiedzialności
Na poziomie perspektywy specyfikacji jest zbiorem metod, które mogą być wywołane
Na poziomie perspektywy implementacji jest kodem wraz z danymi
Student lub słuchacz stanowi obiekt przynależący do klasy. Obiekt powołany do życia w programie nazwiemy instancją (konkretem). Jak zadanie przedstawione w dekompozycji funkcjonalnej może być rozwiązane w dekompozycji obiektowej? Taki program musi zawierać następujące elementy:
Start
Utworzenie kolekcji instancji (zbioru obiektów) zawierającej zmienne i metody, którymi muszą posłużyć się studenci
Wydanie kolekcji polecenia aby wysłała instancje na kolejny wykład
Zawiadomienie każdej instancji przez kolekcje, że ma iść na kolejny wykład
Wykonanie przez każdą instancję następujących czynności: zlokalizowanie miejsca kolejnego wykładu - ustalenie drogi dotarcia do tego miejsca - udanie się na kolejny wykład
Koniec programu
Gdyby wykładowca miał na wykładzie kilka rodzajów studentów np. doktorantów, absolwentów, zwykłych studentów to w dekompozycji funkcjonalnej wobec każdego z nich , po ich zidentyfikowaniu, musiałby zastosować inną procedurę powiadamiania o kolejnym wykładzie.
Przy dekompozycji obiektowej możemy utworzyć klasę Student i jej klasy potomne Absolwent i ZwykłyStudent oraz Doktorant. Korzystamy z mechanizmu dziedziczenia. Obiekt każdej z klas wykonuje ten sam program wg dekompozycji obiektowej. Różni się tylko zasobem danych (zmienne obiektu), który lokalizuje miejsce i rodzaj kolejnego wykładu. Dane każdego obiektu są hermetyzowane. Określają one zakres odpowiedzialności obiektu. Procedury stosowane do obiektów są takie same. Tylko wykonają się inaczej. W dekompozycji funkcjonalnej nie ma tego mechanizmu.
Kolekcja operuje tylko na abstrakcyjnej klasie Student, a obiekty klas potomnych to Absolwent, ZwykłyStudent, Doktorant
ETAPY PROJEKTOWANIA OBIEKTOWEGO
Identyfikacja zachowań systemu
Identyfikacja obiektów występujących w systemie
Klasyfikacja obiektów pod względem dziedziczenia (hierarchie) i pod względem mieszczenia w sobie obiektów składowych
Określenia wzajemnej zależności klas obiektów
Budowa modelu współdziałania klas
CECHY ETAPÓW PROJEKTOWANIA
Etap pierwszy - Identyfikacja zachowań systemu (scenario)
Jest on budowany w łańcuchu powiązań:
Rzeczownik->czasownik-> (rzeczownik->rzeczownik)
Ten łańcuch tłumaczy się na powiązanie potoczne takie:
Kto-> co robi (czynność)-> dla kogo-> wynik czynności
Całe zachowania systemu umieszczamy w tabeli, której kolumny są
elementami łańcucha powiązań. Taką tabele nazywamy scenariuszem
systemu.
Etap drugi - Identyfikacja obiektów
Składowae scenariusza systemu w kolumnach tabeli KTO i KOGO tworzą klasy obiektów. Samych obiektów (instancji) w konkretnej realizacji może być wiele. Aby dokonać identyfikacji obiektów musimy określić ZAKRES ICH ODPOWIEDZIALNOŚCI.
Dobrze jest taki opis także umieścić w tabeli:
Klasa (nazwa wg scenariusza) |
Klasy współpracujące |
Obowiązki …. |
Obowiązki … |
Widoczne cechy dla innych klas… |
Widoczne cechy dla innych klas |
Atrybuty |
Atrybuty |
Etap trzeci - Klasyfikacja obiektów względem dziedziczenia oraz powiązań
Ustalamy tu hierarchie dziedziczenia. Aby usprawnić hierarchie możemy wprowadzić na tym etapie abstrakcyjne KLASY MATKI aby powiązanie KTO-KOGO nie wprowadzało zbyt wcześnie szczegółów. Klasa abstrakcyjna nie wprowadza obiektów swoich, a tylko „spina” klasy potomne.
Ustalamy mechanizm ZAWIERANIA SIĘ (MIESZCZENIA) obiektów. Np. Student składa się z Notatnika, w którym ma dane o wykładach. Obiekt wykładowca może zawierać obiekt komputer, itp. z danymi, e-learning do wykładu, itp.
Etap czwarty - graf współpracy klas (schemat komunikatów)
Określamy graficznie oddziaływanie klas miedzy sobą. Ma on pokazać ścieżki komunikacji pomiędzy klasami. Prostokątami oznaczamy klasy, a strzałkami wskazujemy kierunki współpracy. Jest kilka szkół rysowania takich grafów. Możemy przyjąć, że strzałkami wskazujemy KTO KOMU wysyła rozkazy (komunikaty) do wykonania. Jeśli na jednym łuku grafu są dwie strzałki o przeciwnych kierunkach oznaczają wzajemne wymiany komunikatów pomiędzy obiektami takich klas.
Jeśli powstający graf jest nieczytelną plątaniną łuków to oznacza, że na etapie drugim scenariusz nie został ułożony poprawnie. Możliwe jest także, ze koncepcja systemu jest zbyt złożona i jego realizacja będzie skomplikowana i najprawdopodobniej mało skuteczna. W takim przypadku warto podzielić system na podsystemy o mniejszej złożoności.
Jest to etap kluczowy do weryfikowania koncepcji systemu
Etap piąty - składanie modelu
Jest to etap przygotowania do pisania kodu. Składanie wykonujemy wg scenariusza napisanego w etapie pierwszym. Ustalamy do niego następstwo czasowe działania obiektów oraz czasy życia obiektów. Do tego etapu także warto zrobić zobrazowanie graficzne.
Faza implementacji
Jest ona zakończeniem projektowania i w niej dopiero piszemy definicje klas, funkcji, etc. czyli kod.
Diagramy UML
W UML zdefiniowano 13 rodzajów diagramów podzielonych na dwie główne grupy: opisujących strukturę systemu i opisujących zachowanie systemu. Nie wszystkie są i muszą być używane jednocześnie - zależy to od rodzaju i złożoności modelowanego systemu. Część z nich służy do modelowania tego samego aspektu, jednak ujętego nieco inaczej, dlatego dobór rodzajów diagramów zależy także od preferencji analityka lub programisty.
Diagram klas
Diagram klas (ang. class diagram ) jest najczęściej używanym diagramem UML. Z reguły zawiera także największą ilość informacji i stosuje największą liczbę symboli.
Na diagramie są prezentowane klasy, ich atrybuty i operacje, oraz powiązania między klasami. Diagram klas przedstawia więc podział odpowiedzialności pomiędzy klasy systemu i rodzaj wymienianych pomiędzy nimi komunikatów. Z uwagi na rodzaj i ilość zawartych na tym diagramie danych jest on najczęściej stosowany do generowania kodu na podstawie modelu.
Atrybuty klasy
Zwykle atrybut jest opisywany tylko przez dwa elementy: nazwę i typ. Jednak pełna definicja obejmuje także widoczność atrybutu , definiującą, z jakich miejsc systemu atrybut jest dostępny, krotność , która określa ile obiektów mieści się w atrybucie, dodatkowe ograniczenia nałożone na atrybut, i wartość domyślną . Elementom, których w definicji atrybutu nie podano wartości, przypisywane są wartości domyślne (widoczność prywatna, krotność 1) lub pomija się je.
Agregacja jest silniejszą formą asocjacji. W przypadku tej relacji równowaga między powiązanymi klasami jest zaburzona: istnieje właściciel i obiekt podrzędny, które są ze sobą powiązane czasem swojego życia. Właściciel jednak nie jest wyłącznym właścicielem obiektu podrzędnego, zwykle też nie tworzy i nie usuwa go.
Relacja agregacji jest zaznaczana linią łączącą klasy/obiekty, zakończoną białym rombem po stronie właściciela
Kompozycja
Kompozycja jest najsilniejszą relacją łączącą klasy. Reprezentuje relacje całość-część, w których części są tworzone i zarządzane przez obiekt reprezentujący całość. Ani całość, ani części nie mogą istnieć bez siebie, dlatego czasy ich istnienia są bardzo ściśle ze sobą związane i pokrywają się: w momencie usunięcie obiektu całości obiekty części są również usuwane.
Typowa fraza związana z taką relacją to "...jest częścią...".
Kompozycja jest przedstawiana na diagramie podobnie jak agregacja, przy czym romb jest wypełniony.
Uogólnienie
Uogólnienie posiada różne interpretacje. Na przykład, w modelu pojęciowym Katalog jest uogólnieniem Katalogu rzeczowego, jeżeli każda instancja Katalogu rzeczowego jest także instancją Katalogu. Inną interpretacją jest zastosowanie zasady podstawiania Liskov (LSP - Liskov Substitution Principle): w zamian za typ uogólniony można podstawić typ pochodny bez konieczności zmiany reszty programu.
Uogólnienie w przypadku klas często jest traktowane jako synonim dziedziczenia, podczas gdy dziedziczenie jest tylko możliwą techniką uogólniania. Inną jest np. wykorzystanie interfejsów, które pozwalają utworzyć relację uogólnienia/uszczegółowienia pomiędzy typami (dziedziczenie interfejsu) lub klasą i interfejsem (implementacja interfejsu).
Klasa abstrakcyjna
Celem tworzenia klas abstrakcyjnych i interfejsów jest identyfikacja wspólnych zachowań różnych klas, które są realizowane w różny od siebie sposób. Użycie tych mechanizmów pozwala na wykorzystanie relacji uogólniania do ukrywania (hermetyzacji) szczegółów implementacji poszczególnych klas.
Klasa abstrakcyjna reprezentuje wirtualny byt grupujący wspólną funkcjonalność kilku klas. Posiada ona sygnatury operacji (czyli deklaracje, że klasy tego typu będą akceptować takie komunikaty), ale nie definiuje ich implementacji.
Podobną rolę pełni interfejs. Różnica polega na tym, że klasa abstrakcyjna może posiadać implementacje niektórych operacji, natomiast interfejs jest czysto abstrakcyjny (choć, oczywiście interfejs i klasa w pełni abstrakcyjna są pojęciowo niemal identyczne).
Ponieważ klasy abstrakcyjne nie mogą bezpośrednio tworzyć swoich instancji (podobnie jak interfejsy, które z definicji nie reprezentują klas, a jedynie ich typy) dlatego konieczne jest tworzenie ich podklas, które zaimplementują odziedziczone abstrakcyjne metody. W przypadku interfejsu sytuacja jest identyczna.
Przyjętym sposobem oznaczania klas i metod abstrakcyjnych jest zapisywanie ich pochyłą czcionką lub opatrywanie słowem kluczowym {abstract}.
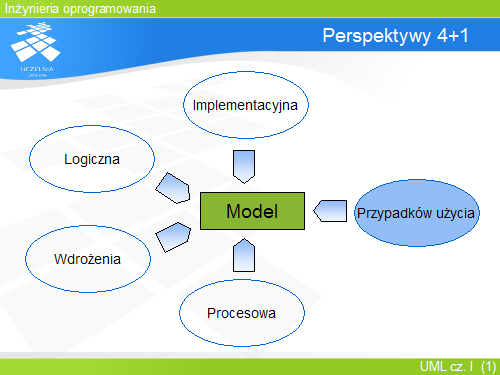
Modelowanie złożonych systemów jest zadaniem trudnym i angażuje wiele osób o różnym sposobie postrzegania systemu. Aby uwzględnić te punktu widzenia, UML jest często określany, jako język modelowania z 4+1 perspektywą. Cztery pierwsze opisują wewnętrzną strukturę programu na różnych poziomach abstrakcji i szczegółowości. Ostatnia perspektywa opisuje funkcjonalność systemu widzianą przez jego użytkowników. Każda perspektywa korzysta z własnego zestawu diagramów pozwalających czytelnie przedstawić modelowane zagadnienie. Są to:
Perspektywa przypadków użycia - opisuje funkcjonalność, jaką powinien dostarczać system, widzianą przez jego użytkowników.
Perspektywa logiczna - zawiera sposób realizacji funkcjonalności, strukturę systemu widzianą przez projektanta
Perspektywa implementacyjna - opisuje poszczególne moduły i ich interfejsy wraz z zależnościami; perspektywa ta jest przeznaczona dla programisty
Perspektywa procesowa - zawiera podział systemu na procesy (czynności) i procesory (jednostki wykonawcze); opisuje właściwości pozafunkcjonalne systemu i służy przede także programistom i integratorom
Perspektywa wdrożenia - definiuje fizyczny podział elementów systemu i ich rozmieszczenie w infrastrukturze; perspektywa taka służy integratorom i instalatorom systemu
Podstawowe założenia paradygmatu obiektowego
Istnieje pewna różnica zdań co do tego, jakie cechy języków programowania czynią je obiektowymi. Powszechnie uważa się, że najważniejsze są następujące cechy:
Każdy obiekt w systemie służy, jako model abstrakcyjnego "wykonawcy", który może wykonywać pracę, opisywać i zmieniać swój stan oraz komunikować się z innymi obiektami w systemie, bez ujawniania, w jaki sposób zaimplementowano dane cechy. Procesy, funkcje lub metody mogą być również abstrahowane, a kiedy tak się dzieje, konieczne są rozmaite techniki rozszerzania abstrakcji.
Czyli ukrywanie implementacji, enkapsulacja. Zapewnia, że obiekt nie może zmieniać stanu wewnętrznego innych obiektów w nieoczekiwany sposób. Tylko wewnętrzne metody obiektu są uprawnione do zmiany jego stanu. Każdy typ obiektu prezentuje innym obiektom swój interfejs, który określa dopuszczalne metody współpracy. Pewne języki osłabiają to założenie, dopuszczając pewien poziom bezpośredniego (kontrolowanego) dostępu do "wnętrzności" obiektu. Ograniczają w ten sposób poziom abstrakcji. Przykładowo, w niektórych kompilatorach języka C++ istnieje możliwość tymczasowego wyłączenia mechanizmu enkapsulacji; otwiera to dostęp do wszystkich pól i metod prywatnych, ułatwiając programistom pracę nad pośrednimi etapami tworzenia kodu i znajdowaniem błędów.
Referencje i kolekcje obiektów mogą dotyczyć obiektów różnego typu, a wywołanie metody dla referencji spowoduje zachowanie odpowiednie dla pełnego typu obiektu wywoływanego. Jeśli dzieje się to w czasie działania programu, to nazywa się to późnym wiązaniem lub wiązaniem dynamicznym. Niektóre języki udostępniają bardziej statyczne (w trakcie kompilacji) rozwiązania polimorfizmu - na przykład szablony i przeciążanie operatorów w C++.
Porządkuje i wspomaga polimorfizm i enkapsulację dzięki umożliwieniu definiowania i tworzenia specjalizowanych obiektów na podstawie bardziej ogólnych. Dla obiektów specjalizowanych nie trzeba redefiniować całej funkcjonalności, lecz tylko tę, której nie ma obiekt ogólniejszy. W typowym przypadku powstają grupy obiektów zwane klasami, oraz grupy klas zwane drzewami. Odzwierciedlają one wspólne cechy obiektów.
------------------------------------------------------------------------------
- Roznica miedzy przeslanianiem a dziedziczeniem
- Roznica miedzy przeslanianiem a polimorfizmem (podobno podchwytliwe)
- napisz jaka jest różnica między kontenerem sekwencyjnym, a asocjacyjnym
- Czy można ustawić wskaźnik na wskaźnik this?
- Czemu nie można odziedziczyć funkcji zaprzyjaźniania?
1)wyjasnij perspektywy dekompozycji obiektu UML - jest
2)podaj sposób zapisu metody dziedziczenia w cpp i wyjasnij różnice miedzy dziedziczeniem a kompozycja - jest
3)narysuj digram klas i podaj na tym diagramie cechy charatkerystyczne klasy abstrakcyjnej
4)co to jest funkcja wirtualana i jakie jest w cpp
5)wyjasnij ktory paradygmat programowania obiektowego opie o ukryty wskaznik dis w cpp
6)w mechanizmie polimorfizmu
7) podaj mechanizmy umozliwiajace omijanie hermatyzacji
8)wyjasnij na czym polega apstrachowanie zmienych w po
9podaj sposob zapisu opera przeciazonego w cpp i wyajsnij dlaczego w po czesto (niewiem ,konieczne chyba) jest stosowanie operatorów przeciazonych
20
Wyszukiwarka
Podobne podstrony:
Programowanie obiektowe(ćw) 1
Zadanie projekt przychodnia lekarska, Programowanie obiektowe
Programowanie obiektowe w PHP4 i PHP5 11 2005
Programowanie Obiektowe ZadTest Nieznany
Egzamin Programowanie Obiektowe Głowacki, Programowanie Obiektowe
Jezyk C Efektywne programowanie obiektowe cpefpo
Programowanie Obiektowe Ćwiczenia 5
Programowanie obiektowe(cw) 2 i Nieznany
programowanie obiektowe 05, c c++, c#
Intuicyjne podstawy programowania obiektowego0
Programowanie obiektowe, CPP program, 1
wyklad5.cpp, JAVA jest językiem programowania obiektowego
projekt01, wisisz, wydzial informatyki, studia zaoczne inzynierskie, programowanie obiektowe, projek
przeciazanie metod i operatorow, Programowanie obiektowe
projekt06, wisisz, wydzial informatyki, studia zaoczne inzynierskie, programowanie obiektowe, projek
projekt07, wisisz, wydzial informatyki, studia zaoczne inzynierskie, programowanie obiektowe, projek
Programowanie Obiektowe Cz2, Dziedziczenie proste
Programowanie obiektowe, w2, 2
więcej podobnych podstron