Zadania 3
1. Dla danych zawartych w pliku wzrost.csv (próbka statystyczna opisująca wzrost dorosłego mężczyzny w Polsce) wyznaczyć podstawowe statystyki opisowe:
o mediana, kwartyle, rozstęp;
o średnia, wariancja - wraz z przedziałem ufności na poziomie 0,9; o skośność i kurtoza
2. Dla danych zawartych w pliku zakupy.csv (próbka opisująca kwotę zakupów w sklepie wielko po wierzch ni owym w zależności od pewnych cech klienta) obliczyć wybrane statystyki z podziałem na kobiety i mężczyzn:
o średnia, wariancja; o mediana, kwartyle, rozstęp; o skośność i kurtoza
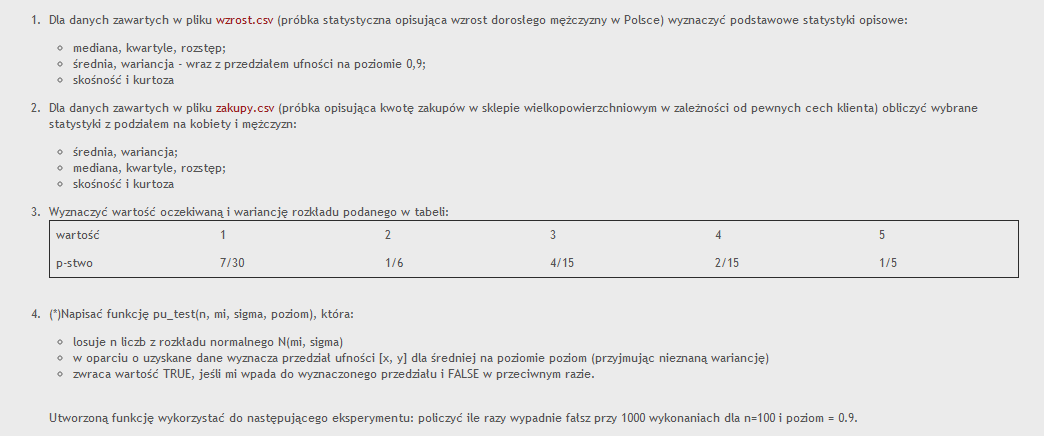
3. Wyznaczyć wartość oczekiwaną i wariancję rozkładu podanego w tabeli:_
|
wartość |
1 |
2 |
3 |
4 |
5 |
|
p-stwo |
7/30 |
1/6 |
4/15 |
2/15 |
1/5 |
4. (*)Napisać funkcję pu_test(n, mi, sigma, poziom), która: o losuje n liczb z rozkładu normalnego N(mi, sigma)
o w oparciu o uzyskane dane wyznacza przedział ufności [x, y] dla średniej na poziomie poziom (przyjmując nieznaną wariancję) o zwraca wartość TRUE, jeśli mi wpada do wyznaczonego przedziału i FALSE w przeciwnym razie.
Utworzoną funkcję wykorzystać do następującego eksperymentu: policzyć ile razy wypadnie fałsz przy 1000 wykonaniach dla n=100 i poziom = 0.9.
Wyszukiwarka
Podobne podstrony:
Zadania 7 Dla danych zapisanych w pliku raty.csv: 1. Utworzyć liniowe modele regresji opisujące zale
drKisiel 2 Zadanie 1 Przeprowadź analizę prognozowania zapotrzebowania na produkt A dla danych zawar
SNV32554 Documrt Toob Wmdow Help Przeprowadź analizę prognozowania zapotrzebowania na produkt A dla
79 4.2. Dystrybuanta empiryczna i histogram4.2.3. Zadania 4.2.1. Dla danych z zada
Wytrzymałość ogólna elementów maszyn Zadanie Dla danych: - grubość kołnierza
Wytrzymałość ogólna elementów maszyn Przykładowe rozwiązanie zadania Dla danych: -
zdjcie0204h Teoria informacji i kodowania Imię i nazwisko: Zadanie I Data: Grupa: Zawartość pliku u
DSC00105 3 danych zawartych w pliku podanym w linku: sgorkaprz.edu.pl/dane.htm • U
Zdjęcie0204 (7) Teoria informacji i kodowania Imię i nazwisko: Zadanie I Data: Grupa: Zawartość plik
Zadanie 1.1. (0-2) Dla danych z każdego wiersza w tabeli oblicz największe pole powierzchni prostoką
więcej podobnych podstron