MG!28

i wynosi
i wynosi
plxb-ti^z<x<xh+tiĄ:
yjn \Jn
= 2 j S{t,k)dt. 0.17)
Z powyższego wzoru można korzystać w dwojaki sposób: jeśli założymy prawdopodobieństwo, z jakim chcemy znać granice przedziału ufności obejmującego wartość x i posłużymy się tablicą 1.2 (wartości funkcji /-Studenta), to znajdziemy wartość /,, co przy danych xk, g oraz n pozwoli obliczyć granice dla wartości x z nierówności
lub
|
|g|g|§ |
(1.18) |
|
-tlSI<x<xk+tiSx-, |
0.19) |
|
Tablica 1.2 |
Rozkład /-Studenta. Wartości Z,
|
\ P |
0.90 |
0,95 |
0,98 |
0,99 |
0,999 |
|
k = n- 1 '\s | |||||
|
4 |
2,132 |
2,776 |
3,747 |
4,604 |
8,610 |
|
5 |
2,015 |
2,571 |
3,365 |
4,032 |
6,859 |
|
6 |
1,943 |
2,447 |
3,143 |
3,707 |
5,959 |
|
7 |
1,895 |
2,365 |
2,998 |
2,499 |
5,405 |
|
8 |
1,860 |
2,306 |
2,896 |
3,355 |
5,041 |
|
9 |
1,833 |
2,262 |
2,821 |
3,250 |
4,781 |
|
10 |
1,812 |
2,228 |
2,764 |
3,169 |
4,587 |
|
11 |
1,796 |
2,201 |
2,718 |
3,106 |
4,487 |
|
12 |
1,782 |
2,179 |
2,681 |
3,055 |
4,318 |
|
13 |
1,771 |
2,160 |
2,650 |
3,012 |
4,221 |
|
14 |
1,761 |
2,145 |
2,624 |
2,977 |
4,140 |
|
13 |
1,753 |
2,131 |
2,602 |
2,947 |
4,073 |
|
16 |
1,746 |
2,120 |
2,583 |
2,921 |
4,015 |
|
18 |
1,734 |
2,103 |
2,552 |
2,878 |
3,922 |
|
20 |
1,725 |
2,086 |
2,528 |
2,845 |
3,850 |
|
25 |
1,708 |
2,060 |
2,485 |
2,787 |
3,725 |
|
30 |
1,697 |
2,042 |
2,457 |
2,750 |
3,646 |
|
35 |
1,689 |
2,030 |
2,437 |
2,724 |
3,591 |
|
40 |
1,684 |
2,021 |
2,423 |
2,704 |
3,551 |
|
50 |
1,676 |
2,008 |
2,403 |
2,677 |
3,497 |
b) jeśli przyjmiemy wartość r,, to obliczymy według wzoru (1.17) granice przedziału ufności, a z tablicy 1.2 dla tej wartości znajdziemy prawdopodobieństwo.
Różnice między obliczeniem klasycznym granic i za pomocą rozkładu r-Studenta występują szczególnie przy małych wartościach n. Ze wzrostem wartości n rozkład r-Studenta zbliża się do rozkładu normalnego i różnice obu rozwiązań stają się coraz mniejsze.
1.6. Sprawdzenie normalności rozkładu według testu zgodności %2 (chi kwadrat)
Przedstawione w punkcie 1.4 i 1.5 oceny przedziałów ufności mogą być stosowane tylko wtedy, gdy błędy przypadkowe podlegają rozkładowi normalnemu. Jeżeli wyniki pomiarów nasuwają wątpliwości o normalności rozkładu błędów przypadkowych, to należy przeprowadzić dostatecznie dużą liczbę pomiarów i zastosować test zgodności g2- Wyniki pomiarów grupuje się wg przedziałów pokrywających całą oś (-»; +«), a liczba danych w każdym przedziale ma być nie mniejsza niż pięć, a najlepiej gdy będzie większa od dziesięciu. Zmienną losową x2 obliczamy ze wzoru
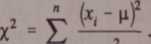
.2
M O
(1.20)
W niektórych przypadkach wartości rzeczywiste (oczekiwane) mogą być inne w każdym składniku sumy i wtedy wzór (1.20) przyjmuje postać

(1.21)
Jeżeli wartość sumy (1.20) jest większa od wartości krytycznej x2 odczytanej z tablicy 1.3, przy z góry założonym prawdopodobieństwie P przedziału ufności i liczbie stopni swobody k równej liczbie niezależnych składników sumy, to z prawdopodobieństwem P można uważać, że rozkład błędów przypadkowych w rozpatrywanej serii pomiarów różni się od rozkładu normalnego. Zatem, jeżeli rozkład różni się od rozkładu normalnego, to przy dostatecznie dużej liczbie pomiarów wartość sumy (1.20) przekracza odpowiednią wartość krytyczną x2-Ponadto, efektywność testu x2 zwiększa się, jeżeli w każdym przedziale znajduje się jednakowa liczba danych. Należy to uwzględnić, o ile jest to możliwe, przy grupowaniu wyników pomiarów. Stosowanie tastu zgodności x2 wymaga dość często przeprowadzenia wielu obliczeń. W cytowanej literaturze [13] są podane również przybliżone metody sprawdzania normalności rozkładu.
17
Wyszukiwarka
Podobne podstrony:
img168 - odchylenie standardowe b według wzoru (6.28) wynosi: b 1 - r1 ( N _ N ±yi-y±y, V ;=i /=i
DSC01925 WPŁYW NA STAN POWIETRZA ATMOSFERYCZNEGO (KOMPOSTOWNIA)EMISJA PRZY WYDAJNOŚC11400 Mg/ROK WYN
T < ton 5 MG 3 28 NO 1 7 t pfoiitftracii 30 i proU»aqi to TR- 32 T <
50721 Wyklady22 ■sX£s> f)Xh) + bv(s)[_ Vfi>) = cTX(s)4 dt>($)
Iloczyn rozpuszczalno?ci t* Iloczyn rozpuszczalności SrPg wynosi 3,4 x 10 Obliczyć ile mg Sr^ bflzie
img075 (31) Zadanie 28. Jeżeli zysk na działalności operacyjnej wynosi 140 000 zł, przychody finanso
24 A. Kabsch do czynności zginania, co wynosi odpowiednio 28 i 16,5% wszystkich funkcji aktonów. Nat
skanuj0023 (160) 1) metanonośność wynosi powyżej 8 m3/Mg, w przeliczeniu na czystą
IMGd69 Moment gnący wynosi Mm i i . l . gx* ^+RJx-,.rg*1*=+pl*--a Wykres jest parabolą trzeciego sto
więcej podobnych podstron