Elbląg, 08.07.2007 r.
Tutorial z Przetwarzania Równoległego przystosowany do materiału IV semestru informatyki stosowanej w Elblągu.
Spis treści
Wstęp, czyli po kiego czytasz moje wypociny.
Poniższy tekst ma na celu przybliżenie Wam tematu przetwarzania równoległego, a co za tym idzie - zaliczenie jednego z bardziej rzeźnickich przedmiotów na naszej uczelni (przynajmniej z tego co się słyszy). Znajdziecie poniżej wskazówki, jak wykonywać określone typy zadań. Przeczytawszy to, powinniście wiedzieć jak wykonywać określone typy zadań, a nie dlaczego. Innymi słowy - nie zrozumiecie w pełni istoty przetwarzania równoległego, jednak poznacie metody i schematy rozwiązywania zadań, a to przy odrobinie szczęścia powinno wystarczyć do zaliczenia. Zamierzam zebrać tu najważniejsze wzory, informacje i dorzucić do tego własne wskazówki i pokrętne tłumaczenia.
Dokument ten przeznaczony jest tylko do zastosowania edukacyjnego, ma za zadanie przynajmniej w jakimś stopniu przybliżyć temat przetwarzania równoległego. Powstał po to, żeby przyszłe pokolenia miały łatwiej . Nie biorę odpowiedzialności za błędy (kij wie, czy sam dobrze to zrozumiałem, ale raczej tak) - czytacie to na własne ryzyko .
Do utworzenia dokumentu wykorzystałem głównie zadania z egzaminu z 2005 roku.
Amdahl
W zasadzie nie jest to trudne zagadnienie, są to po prostu wzory i oznaczenia do wkucia, a także przekształcenia wzorów:
![]()
- czas wykonania programu przez 1 procesor
![]()
- czas wykonania programu przez p procesorów
f(n) - procent programu, jaki trzeba wykona sekwencyjnie (czyli jeśli w treści zadania będzie, że zrównoleglić możemy 30% programu, to f(n)=1-30%=70% lub f(n)=1-0,3=0,7 - na jedno wychodzi).
![]()
- rozwinięcie wzoru na ![]()
, gdzie:
![]()
- to jest czas programu wykonywany sekwencyjnie przez zrównoleglone procki (stąd „s” w indeksie dolnym). Dość łatwo to zapamiętać, bo mamy f(n) - procent sekwencyjny i ![]()
- czas na wykonanie tych procentów sekwencyjnych
![]()
- to jest czas programu wykonywany równolegle. Można zapamiętać tak, że skoro w ![]()
pojawiło się f(n), tutaj musi być dopełnienie - a więc 1- f(n). Całość musimy podzielić przez p (we wzorze powyżej), ponieważ ten czas dotyczy równoległego wykonywania programu przez p procesorów.
![]()
- przyspieszenie zrównoleglenia
![]()
- wydajność
![]()
- koszt obliczeń
Dobra, mamy najważniejsze wzory. To przechodzimy do konkretnych zadań:
W przypadku Amdahla zdecydowana większość zadań wyglądała prawie identycznie - są to zadania typu, gdzie trzeba wyliczyć T(n,p), rzadziej - T(n,1). Przykład(na żywca wzięty z 2005 roku):
Czas wykonania na 1 procku wynosi 18s. ile będzie trwało obliczenie na 6 prockach jeśli można zrównoleglić 90% programu.
Więc wypisujemy sobie dane: oraz Szukane:
T(n,1)=18s T(n,p)=?
p=6
f(n)=10%=0,1
Zaczynamy od wypisania wzorów:
![]()
![]()
![]()
Podstawiamy do pierwszego wzoru:
![]()
Teraz podstawiamy dane:
![]()
Dopisujemy odpowiedź: Czas wykonania programu na 6 procesorach wyniesie 4,5s.
Rozwiążę również zadania innego typu, które również się trafiają, jeśli ktoś ma pecha. Poniżej - zadanie typu ”wyprowadź wzór”:
Prawo amdahla - wyprowadzić i opisać "wniosek z tego wzoru"
Zaczynamy od standardowego wzoru na przyspieszenie:
![]()
Rozpisujemy T(n,p) zgodnie z wzorami, które znamy, czyli:
![]()
![]()
![]()
![]()
A więc:
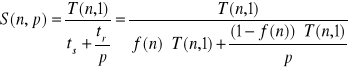
W mianowniku wyłączamy przed nawias T(n,1):
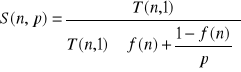
Możemy się teraz pozbyć T(n,1):
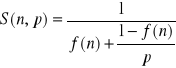
I tutaj trzeba zakończyć. Robimy teraz limes, aby zauważyć, jak wzór się zmieni przy liczbie procesorów dążących do nieskończoności:
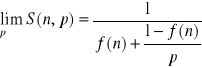
Gdy p dąży do nieskończoności, ![]()
dąży do 0, co daje nam:
![]()
WNIOSEK: zwiększając p, wpływa się na zwiększenie przyspieszenia, jednak programu nie da się przyspieszać w nieskończoność, nawet mając nieskończoną ilość procków.
Zad. na wydajność:
Korzystając z prawa Amdahla , podać wydajność obliczeń równoległych na 6 procesorach dla programu , którego część dająca się zrównoleglić wynosi 20%
Wzór na wydajność mamy:
![]()
Jest już także gotowy wzór na S(n,p), który pasuje do tego zadania:
![]()
Można go sobie wkuć, ja wolałem go wyprowadzić (zawsze jeden wzór mniej). Żeby to zrobić, robimy dokładnie te same przekształcenia, co w poprzednim zadaniu. Gdy dochodzimy do miejsca
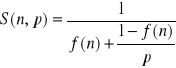
sprowadzamy do wspólnego mianownika dolną część ułamka:
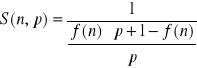
Przenosimy p do licznika, na dole przestawiamy wyrazy, tak żeby 1 była z przodu:
![]()
Wyłączając f(n) w mianowniku, dochodzimy do wzoru:
![]()
Czyli do tego samego, co wyżej. Sami oceńcie, jak wolicie robić.
Mając już ten wzór, podstawiamy:
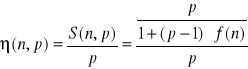
Skracamy p, przenosimy mianownik górnej części na dół:
![]()
Mamy gotowy wzór. Podstawiamy dane:
![]()
Przyrównanie dwóch równań:
Równolegle procki jadą przez 70% czasu, (na 10 proc). ile trzeba procent równoległej pracy by na 4 proc otrzymać taki sam czas?
Dane: Szukane:
f1(n) =0,3 1-f2(n) =?
p1=10
p2=4
Mamy tutaj dwie sytuacje, w których czas T(n,p) ma być taki sam, więc:
![]()
Rozpisujemy:
![]()
…oraz ![]()
wg wcześniejszych wzorów, poza tym ![]()
, czyli:
![]()
W każdym wyrazie występuje T(n,1), więc dzielimy równanie przez T(n,1), żeby się tego pozbyć:
![]()
Podstawie tu dane, żeby się łatwiej dalej liczyło:
![]()
Mnożymy razy 4:
![]()
![]()
![]()
![]()
![]()
koszt obliczeń:
Obliczyć koszt obliczeń, jeśli t(n,1)=30 p=8 cześć dająca się zrównoleglić 75% czyli f(n)=25%
Dane: Szukane:
T(n,1)=30s c(n,p)=?
p=8
f(n)=0,25
W zasadzie korzystamy tylko z gotowego wzoru:
![]()
…który przekształcamy:
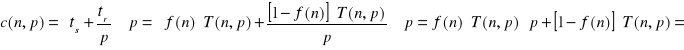
![]()
Podstawiamy:
![]()
Umiejąc to, co napisałem wyżej, rozwiązawszy trochę zadań tego typu - powinno być ok .
Ale naturalnie zamiast Amdahl'a mogą się Wam trafić wektory, więc przechodzimy teraz do nich:
Wektory
Kompletnie nie wiem o co tu chodzi. Wzory i oznaczenia do wkucia:
N - ilość operacji
p - ilo-stopniowa jednostka
ts - czas cyklu zegara
![]()
- przyspieszenie w jednostce p-potokowej
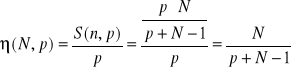
- wydajność
![]()
- przepustowość,jednostka ![]()
czyli 1 flops
Z tego zagadnienia zauważyłem dwa typy zadań:
przepustowość
Dlugosc wektora - 13, czas zegara 13ns, ilosc potokow 8, obliczyc przepustowosc tego typu maszyny.
Dane : Szukane:
N = 13 W(N,p)=?
ts = 13 ns
p = 8
Wzór:
![]()
Podstawiamy:
![]()
Nie trzeba tu nic przekształcać, więc zadanie mogłoby się wydawać zbyt proste na egzamin, ale to powyższe wziąłem żywcem z poprawek 2005, więc kto wie..
Przyrównanie dwóch równań:
Sam trafiłem na takie na egzaminie.
Obliczyc w przybliżeniu do jednostki całkowitej ilosc potokow pierwszego wektora o dlugosci 12, ktorego wydajnosc jest taka sama co wydajnosc wektora 8-potokowego o dlugosci 24.
Dane: Szukane:
N1=12 p2=?
p2=8
N2=24
Z treści zadania wynika, że:
![]()
![]()
![]()
Przyrównujemy powyższe wzory:
![]()
Odwracamy równanie, żeby p2 było w liczniku.
![]()
Mnożymy przez N2:
![]()
Przenosimy resztę na drugą stronę:
![]()
Zostawiamy tak albo sprowadzamy jeszcze do wspólnego mianownika:
![]()
Obliczamy:
![]()
Semafory
Kilka słów wyjaśnienia. Semafor jest to mechanizm wspomagający synchronizację. Dzięki niemu poszczególne procesy muszą poczekać na swoją kolej, zanim będą mogły korzystać ze wspólnych danych. Semafor jest liczbą całkowitą dodatnią. Semafor jest jakby `slotami', miejscami na procesy, które mogą w jednym momencie korzystać ze wspólnych danych. Tzn. - gdy semafor przyjmie wartość 0, zamyka się dostęp do danych. Gdy jest większy od 0, wtedy ta liczba oznacza, ile jeszcze procesów może się dołączyć do korzystania z danych.
Z semaforami wiąże się zawsze kolejka. Kolejka jest jakby ciągiem, czy też tablicą, zawierającą procesy, które `w kolejce' czekają na swoją kolej do korzystania z danych. Wyróżniamy dwa rodzaje kolejek:
FIFO - ang. First In, First Out (pierwszy na wejściu, pierwszy na wyjściu). Czyli nowe procesy dodawane są na koniec kolejki, a pobierane są te, które dodane były wcześniej, jako pierwsze. Czyli dość logicznie - te, które weszły pierwsze, szybciej też wychodzą. Obrazowo:
Czyli końcowy stan kolejki po wykonaniu wymienionych w tabeli operacji wynosi:
4 5. Prawdę powiedziawszy, nie wiem, czy tak są dodawane procesy do kolejki, czyli że ustawiają się kolejno jeden po drugim (możliwe, że wrzucane są chaotycznie, za to sama kolejka zapamiętuje, który był wrzucony wcześniej). Nie jest to specjalnie istotne, więc obrazowo możemy przyjąć, że dodawane są kolejno. Co dla nas ważniejsze, to usuwanie procesu z kolejki. Nie musimy wskazywać, który proces zwalniamy, ponieważ na tym polega istota kolejki FIFO - sama o tym decyduje. W jaki sposób, widać w początkowym opisie kolejki i w tabeli powyżej - po kolei.
LIFO - ang. Last In, First Out (ostatni na wejściu, pierwszy na wyjściu). Inaczej mówiąc, ostatni będący na wejściu, jest jednocześnie pierwszym, który wychodzi. Jest to tzw. stos, przeciwieństwo kolejki FIFO. Nowe procesy dodawane są również na koniec kolejki, jednak to właśnie one są pobierane jako pierwsze. Obrazowo, wykonując dokładnie te same operacje co wyżej, sytuacja wygląda tak:
Jak widać, różni się ona znacznie od FIFO. Wynik jest różny, ponieważ przy usuwaniu kolejka LIFO wybiera inne elementy. Nie najstarsze, dodane do kolejki jako pierwsze, lecz przeciwnie - te, które zostały dodane jako ostatnie.
Znamy już istotę kolejek. Teraz wyobraźmy sobie sytuację, gdzie mamy zbiór danych (zbiór jest jeden), a także kilka procesów, które chcą z niego korzystać. Musimy jakoś podzielić ten zbiór między procesy, żeby wszystko działało w prawidłowy sposób. Semafor określi, jak wiele procesów będzie mogło skorzystać z danych. Poza tym, jeśli już nie będzie można korzystać z danych (czyli gdy semafor osiągnie wartość 0), w grę wchodzą kolejki. To, jaka jest kolejka, zależy już od zadania. Pisze się, że semafor jest stowarzyszony z kolejką (LIFO lub FIFO). Kolejka przetrzymuje procesy, które chcą korzystać z danych, a już nie mogą, bo semafor im na to nie pozwala. Gdy semafor umożliwia już ponowne wykorzystanie danych (czyli ma wartość większą od 0, a więc gdy proces, który mógł korzystać i korzystał z danych (zwanych także zasobem), zwalnia dostęp do nich), wtedy z kolejki uaktywnia się proces i to on zajmuje zasób. To, który to jest proces, zależy od rodzaju kolejki, co już wyjaśniłem wcześniej.
Zadania rozwiązuje się wypełniając tabelkę:
Początkowa wartość semafora: zawsze określone w treści zadania w dwojaki sposób:
- Z podzielnego zasobu, z którego mogą jednocześnie korzystać maksymalnie x procesów - w takim przypadku s (semafor) na początku wynosi x.
- Z niepodzielnego zasobu…- skoro jest niepodzielny, to tylko 1 proces może w jednym czasie korzystać z zasobu. W takim wypadku s na początku wynosi 1.
Operacje wykonywane przez procesy: są trzy możliwości:
- nazwa_procesu sprawdza s; zajmuje zasób (nazwy procesów oznaczane są zazwyczaj I1, I2 itd.)
- nazwa_procesu sprawdza s
- nazwa_procesu zwalnia zasób
Żeby zając zasób, proces powinien najpierw sprawdzić s. Widzimy powyżej, że w jednym przypadku jest od razu zajęcie zasobu, w drugim nie. Dlaczego? Otóż pierwszy przypadek dotyczy sytuacji, gdy s jest jeszcze większe od 0, ponieważ to oznacza, że zasób może być jeszcze wykorzystany przez jakiś proces. Wtedy proces od razu zajmuje zasób. Wartość semafora zmniejszamy o 1, w tabeli stanu nic nie wpisujemy.
Drugi przypadek dotyczy odwrotnej sytuacji - gdy dochodzimy do momentu, gdy już więcej procesów nie może korzystać z zasobu, a mimo to któryś próbuje. Poprzestaje on wtedy na sprawdzeniu semafora (w końcu nie dostanie dostępu do zasobu) i dopisaniu się do kolejki (musimy to odnotować w tabeli zmiany stanu). Ten przypadek (gdy jest samo „nazwa_procesu sprawdza s”) występuje wtedy, gdy s jest równe 0, czyli s nie ulega zmianie.
Trzeci przypadek występuje, gdy proces przestaje korzystać z zasobu. Wtedy, jeśli są w kolejce jakieś procesy, to następuje właśnie usunięcie procesu z kolejki wg zasad opisanych wcześniej. Musimy to również odnotować w tabeli zmiany stanu. Jeśli w kolejce nie ma zawieszonych żadnych procesów, nie trzeba dodatkowo nic robić. W obu przypadkach, w tym wierszu następuje zwiększenie semafora o 1.
Aktualne wartości semafora. Zmiany wartości semafora opisane wyżej przy podawaniu trzech możliwych wpisów do kolumny „procesy”. W skrócie:
- nazwa_procesu sprawdza s; zajmuje zasób - s=s-1
- nazwa_procesu sprawdza s - s bez zmian
- nazwa_procesu zwalnia zasób - s=s+1;
Dodawanie lub opróżnianie kolejki. Możliwe tylko dwa przypadki:
- nazwa_procesu: zawieszony. Wypisywane tylko w przypadku, gdy w kolumnie `Procesy' wpisujemy: nazwa_procesu sprawdza s. Skoro proces tylko sprawdza s i nie zajmuje danych, oznacza to, że musi się ustawić w kolejce. „nazwa_procesu: zawieszony” to właśnie wrzucenie procesu do kolejki.
- nazwa_procesu: aktywny. Wypisywane w przypadku, gdy w kolumnie `Procesy' wpisujemy: nazwa_procesu: zwalnia zasób oraz wcześniej zostały w kolejce umieszczone jakieś procesy. Innymi słowy: najpierw umieściliśmy w kolejce proces (bo nie mógł korzystać z danych). Potem zasób staje się dostępny (zwolnił go któryś proces). W tym momencie następuje zwolnienie procesu z kolejki (który to już proces, musimy sami zdecydować, zależnie od tego, czy kolejka jest FIFO czy LIFO). Zawsze w następnym wierszu po wyrzuceniu procesu z kolejki jest „nazwa_procesu sprawdza s; zajmuje zasób” - ponieważ po to go usunęliśmy z kolejki, żeby wykorzystał dane.
Tak to wygląda w teorii. Całą tabelkę można wypełnić na podstawie treści zadania. Przykłady:
Zapisać, w postaci tabelki, kolejne fazy współbieżnych procesów, dla następującej sytuacji:
Z podzielnego zasobu, z którego mogą jednocześnie korzystać maksymalnie 3 procesy, i który jest chroniony semaforem s, z którym jest stowarzyszona kolejka typu FIFO, chcą korzystać kolejno procesy I1, I2, I3 i I4, przy czym
procesy I2, I3 i I4 chcą skorzystać z zasobu przed zwolnieniem go przez proces I1,
procesy I1 i I2 zwalniają zasób w kolejności: I2, I1,
proces I3 zwalnia zasób jako ostatni z procesów,
proces I4 zwalnia zasób po zwolnieniu go przez proces I1.
Analizujemy treść zadania. Widzimy zdanie:
Z podzielnego zasobu, z którego mogą jednocześnie korzystać maksymalnie 3 procesy
Więc początek tabeli będzie wyglądać tak:
Procesy |
s |
Zmiany w tablicy stan |
... |
3 |
… |
Czytamy dalej, istotny jest zapis , chcą korzystać kolejno procesy I1, I2, I3 i I4
Wiemy już, że najpierw z zasobu chce korzystać I1, więc:
Procesy |
s |
Zmiany w tablicy stan |
... |
3 |
… |
I1 sprawdza s; zajmuje zasób |
2 |
- |
Musieliśmy od razu zmniejszyć s o 1, ponieważ zasób został wykorzystany. Nie ma zmian w tabeli stan (pierwsza zmiana może wystąpić dopiero gdy s osiągnie wartość 0).
Czytamy dalej:
procesy I2, I3 i I4 chcą skorzystać z zasobu przed zwolnieniem go przez proces I1,
procesy I1 i I2 zwalniają zasób w kolejności: I2, I1,
proces I3 zwalnia zasób jako ostatni z procesów,
proces I4 zwalnia zasób po zwolnieniu go przez proces I1.
Co nam to daje? Wszystko . Po prostu musimy z tego rozszyfrować schemat, czyli co się dzieje krok po kroku. Wyłapać kolejność postępowania.
Mamy już pierwszy wers, I1 zajął zasób. Wcześniej było powiedziane, że procesy chcą korzystać kolejno z zasobu. Nie wiadomo jednak, czy w międzyczasie któryś proces nie zechce zwolnić zasobu. Odpowiedź zawarta jest w pierwszym wypunktowaniu: procesy I2, I3 i I4 chcą skorzystać z zasobu przed zwolnieniem go przez proces I1. Oraz w drugim: procesy I1 i I2 zwalniają zasób w kolejności: I2, I1. Dzięki temu wiemy, że procesy będą zajmować zasoby do wyzerowania semafora, ponieważ najpierw muszą poczekać na zwolnienie zasobu przez I1, za to ten musi poczekać, ponieważ najpierw I2 musi zwolnić zasób. To nam daje sporą część tabeli:
Procesy |
s |
Zmiany w tablicy stan |
... |
3 |
… |
I1 sprawdza s; zajmuje zasób I2 sprawdza s; zajmuje zasób I3 sprawdza s; zajmuje zasób I4 sprawdza s |
2 1 0 0 |
− − − I4: zawieszony |
Jak widzimy, w momencie gdy I4 tylko sprawdza s, nie zajmuje zasobu, automatycznie trafia do kolejki, co zostało odnotowane w kolumnie „Zmiany w tabeli stan”.
W tym momencie zaczyna się zwalnianie zasobów. Co widzimy:
procesy I1 i I2 zwalniają zasób w kolejności: I2, I1,
proces I3 zwalnia zasób jako ostatni z procesów,
proces I4 zwalnia zasób po zwolnieniu go przez proces I1.
Zaraz, zaraz - jak to proces I4 zwalnia zasób? Przecież I4 jest w kolejce, nie wykorzystuje w ogóle zasobu. Jednak napisane jest, że I2 najpierw zwalnia zasób. W tym momencie od razu następuje zwiększenie s o 1 i zmiana stanu I4 na aktywny (co z kolei oznacza, że już za chwilę on zajmie zasób). Oczywiście, gdyby w kolejce było więcej niż 1 proces, to, który proces byłby zwolniony, zależałoby od typu kolejki. Tu jest tylko jeden element w kolejce, więc:
Procesy |
s |
Zmiany w tablicy stan |
... |
3 |
… |
I1 sprawdza s; zajmuje zasób I2 sprawdza s; zajmuje zasób I3 sprawdza s; zajmuje zasób I4 sprawdza s I2 zwalnia zasób I4 sprawdza s; zajmuje zasób |
2 1 0 0 1 0 |
− − − I4: zawieszony I4: aktywny - |
Teraz się już wszystko zgadza. Po kolei zwalniane są zasoby. Najpierw I1, bo proces I4 zwalnia zasób po zwolnieniu go przez proces I1, na końcu I3, bo proces I3 zwalnia zasób jako ostatni z procesów. Czyli I4 zwalnia zasób pośrodku. Tak więc:
Procesy |
s |
Zmiany w tablicy stan |
... |
3 |
… |
I1 sprawdza s; zajmuje zasób I2 sprawdza s; zajmuje zasób I3 sprawdza s; zajmuje zasób I4 sprawdza s I2 zwalnia zasób I4 sprawdza s; zajmuje zasób I1 zwalnia zasób I4 zwalnia zasób I3 zwalnia zasób |
2 1 0 0 1 0 1 2 3 |
− − − I4: zawieszony I4: aktywny - - - - |
Wszystkie warunki zadania zostały wykonane, więc zadanie rozwiązane.
Drugie zadanie, tym razem z kolejką LIFO - zmodyfikowałem trochę moje z egzaminu:
Z niepodzielnego zasobu chronionego semaforem polaczonym z kolejna typu LIFO chca korzystac kolejno procesy I1, I2, I3, I4.
- I2 chce korzystac z zasobu po zwolnieniu go przez I1
- I3 chce korzystac z zasobu po w trakcie korzystania przez I2
- I4 chce korzystac z zasobu po w trakcie korzystania przez I2
Na starcie mamy zapis, że Z niepodzielnego zasobu(…). Od razu znamy początek:
Procesy |
s |
Zmiany w tablicy stan |
... |
1 |
… |
Znów widzimy, że procesy chcą kolejno zajmować zasób. Czyli wiadomo, że zaczynamy od I1:
Procesy |
s |
Zmiany w tablicy stan |
... |
1 |
… |
I1 sprawdza s; zajmuje zasób |
0 |
- |
W kolejnym warunku mamy napisane, że I2 chce korzystac z zasobu po zwolnieniu go przez I1. Wiemy dzięki temu, że w tym momencie nie następuje żadne żądanie korzystania z zasobu. Czyli po prostu I1 zwalnia zasób:
Procesy |
s |
Zmiany w tablicy stan |
... |
1 |
… |
I1 sprawdza s; zajmuje zasób I1 zwalnia zasób |
0 1 |
- - |
Za to gdy już zasób jest zwolniony, przejmuje go I2:
Procesy |
s |
Zmiany w tablicy stan |
... |
1 |
… |
I1 sprawdza s; zajmuje zasób I1 zwalnia zasób I2 sprawdza s; zajmuje zasób |
0 1 0 |
- - - |
Mamy teraz ostatnie dwa warunki:
- I3 chce korzystac z zasobu po w trakcie korzystania przez I2
- I4 chce korzystac z zasobu po w trakcie korzystania przez I2
Co nam pozwala dokończyć całą tabelę. Dwa najbliższe wiersze są dość jasne, bo po prostu I3 i I4 próbują się dostać do danych:
Procesy |
s |
Zmiany w tablicy stan |
... |
1 |
… |
I1 sprawdza s; zajmuje zasób I1 zwalnia zasób I2 sprawdza s; zajmuje zasób I3 sprawdza s I4 sprawdza s |
0 1 0 0 0 |
- - - I3: zawieszony I4: zawieszony |
W zasadzie nie ma już żadnych pozostałych warunków, więc po prostu zwalniamy zasób:
Procesy |
s |
Zmiany w tablicy stan |
... |
1 |
… |
I1 sprawdza s; zajmuje zasób I1 zwalnia zasób I2 sprawdza s; zajmuje zasób I3 sprawdza s I4 sprawdza s I2 zwalnia zasób |
0 1 0 0 0 1 |
- - - I3: zawieszony I4: zawieszony I4: aktywny |
Po zwolnieniu zasobu przez I2 aktywny stał się I4, ponieważ mamy do czynienia z kolejką LIFO - czyli wywalamy z niej procesy dodane ostatnio. Gdyby była to kolejka FIFO, I3 stałby się aktywny. Od razu proces zajmuje zasób:
Procesy |
s |
Zmiany w tablicy stan |
... |
1 |
… |
I1 sprawdza s; zajmuje zasób I1 zwalnia zasób I2 sprawdza s; zajmuje zasób I3 sprawdza s I4 sprawdza s I2 zwalnia zasób I4 sprawdza s; zajmuje zasób |
0 1 0 0 0 1 0 |
- - - I3: zawieszony I4: zawieszony I4: aktywny - |
Nic się więcej nie dzieje, więc I4 może zwolnić zasób, aktywując od razu proces I3, następnie ten zajmie zasób, po czym go zwolni:
Procesy |
s |
Zmiany w tablicy stan |
... |
1 |
… |
I1 sprawdza s; zajmuje zasób I1 zwalnia zasób I2 sprawdza s; zajmuje zasób I3 sprawdza s I4 sprawdza s I2 zwalnia zasób I4 sprawdza s; zajmuje zasób I4 zwalnia zasób I3 sprawdza s; zajmuje zasób I3 zwalnia zasób |
0 1 0 0 0 1 0 1 0 1 |
- - - I3: zawieszony I4: zawieszony I4: aktywny - I3: aktywny - - |
Zależności
Tutaj wszystkie zadania polegają na tym samym, żeby wypełnić tabelkę:
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
|
|
|
|
W kolumnie „Zależności” będziemy podawać, których wersów dotyczy dana zależność, tzn. z którego do którego następuje przepływ danych.
Zakładając, że dwa wersy oznaczymy przez S i T, zależność z wersu S do T wygląda następująco: S T.
W kolumnie „Typ” są trzy możliwości:
- „przepływu” (bądź „zależność przepływu”)
- „przeciwzależność”
- „wyjść”
W kolumnie „Rodzaj” mamy tylko dwie opcje:
- „wewnątrziteracyjna”
- „międzyiteracyjna”
Opcjonalna kolumna z tablicą czasami się pojawiała - wpisujemy w niej tablicę, której dotyczy zależność (np. tablica a, b czy c)
Najłatwiej będzie pokazać to na przykładzie:
S: a(i+1)=d(i) * b(i)
T: c(i+1)=c(i) * a(i+1)
U: d(i+1)=a(i) * c(i+1)
W: b(i-1)=e(i) * f(i)
Y: b(i)=d(i);
Żeby wyłapać z tego jakąś zależność, musimy znaleźć dwie takie same tablice (czyli np. dwie tablice a albo dwie b), z tym że jedna musi być z prawej strony równania, a druga z lewej. Nie ma za to znaczenia, czy będzie to ten sam wers, czy inny. Czyli patrząc od góry, tablica a z pierwszego wersu (a(i+1)) oraz a z drugiego wersu (tez a(i+1)) nadają się do relacji.
Gdy już znajdziemy taką parę, musimy zauważyć, czy indeksy w środku obu tablic się różnią. Czyli czy w obu jest np. i czy może w jednej i+1 a w drugiej i. Jest to ważne, ponieważ jeśli indeksy są takie same, w kolumnie „Rodzaj” już można wpisać, że zależność jest wewnątrziteracyjna. Gdy indeksy są różne, zależność na pewno jest międzyiteracyjna.
Teraz określamy typ.
- Jeśli indeksy są takie same, to patrzymy, z której strony równania najpierw pojawiła się tablica (patrząc od góry). Jeśli z lewej, jest to „zależność przepływu”, jeśli z prawej, to „przeciwzależność”. Np. dla naszego a(i+1) będzie to „zależność przepływu”, ponieważ indeksy dla tablicy a w wersach S i T są takie same (i+1), a patrząc od góry, pierwsze a(i+1) znajduje się po lewej stronie.
- Jeśli indeksy są różne, wtedy nie patrzymy już od góry. Wybieramy tę tablicę, która ma większy indeks i wtedy, podobnie jak poprzednio: jeśli ta tablica jest z lewej strony równania, jest to „zależność przepływu”, jak z prawej - „przeciwzależność”. Np. z wersu T do T dla tablicy c. Indeksy w tej tablicy są różne, więc patrzymy, który jest większy. Ten z lewej, więc jest to zależność przepływu. Naturalnie gdyby c(i+1) i c(i) były w innych wersach, robilibyśmy to w ten sam sposób.
- Trzeci, dość rzadki typ, nazywa się typem „wyjść”. Jest to typ, który wygląda inaczej niż pozostałe, ponieważ tutaj patrzymy tylko na lewe strony równań. Pozostałe zasady są bez zmian. Znów szukamy dwóch tablic i w zależności od zgodności indeksów wyznaczamy rodzaj. Ważne jest tutaj, żeby nie pomylić się co do kolumny „Zależność”. Jeśli zależność jest wewnątrziteracyjna (takie same indeksy), to po prostu dajemy zależność pierwszy_wierszdrugi_wiersz, patrząc od góry. Jeśli międzyiteracyjna, wtedy jest to wiersz_z_wiekszym_indeksemwiersz_z_mniejszym_indeksem. Dokładnie tak samo wyznaczamy kolumnę „Zależność” dla pozostałych typów.
I to są wszystkie zasady. W ten sposób trzeba wyłapać wszystkie zależności. Warto kilka razy przestudiować sobie - wiersz po wierszu - całe zadanie, bo często zdarza się przeoczyć jakąś zależność. W skrócie, to są wszystkie możliwości na jakie da się natrafić:
Przykład |
Zależność |
Typ |
Rodzaj |
S: a(i)=a(i) |
SS |
przepływu |
wewnątrziteracyjna |
S: a(i)=… T: …=a(i) |
ST |
przepływu |
wewnątrziteracyjna |
S: …=a(i) T: a(i)=… |
ST |
przeciwzależność |
wewnątrziteracyjna |
S: a(i)=a(i+1) |
SS |
przeciwzależność |
międzyiteracyjna |
S: a(i+1)=a(i) |
SS |
przepływu |
międzyiteracyjna |
S: a(i)=… T: …=a(i+1) |
TS |
przeciwzależność |
międzyiteracyjna |
S: a(i+1)=… T: …=a(i) |
ST |
przepływu |
międzyiteracyjna |
S: …=a(i) T: a(i+1)=… |
TS |
przepływu |
międzyiteracyjna |
S: …=a(i+1) T: a(i)=… |
ST |
przeciwzależność |
międzyiteracyjna |
S: (i)=… T: a(i)=… |
ST |
wyjść |
wewnątrziteracyjna |
S: (i+1)=… T: a(i)=… |
ST |
wyjść |
międzyiteracyjna |
S: (i)=… T: a(i+1)=… |
TS |
wyjść |
międzyiteracyjna |
*tabela nie zakłada opcjonalne kolumny, bo i tak we wszystkich przykładach jest „a”
Rozwiążmy więc do końca zadanie:
S: a(i+1)=d(i) * b(i)
T: c(i+1)=c(i) * a(i+1)
U: d(i+1)=a(i) * c(i+1)
W: b(i-1)=e(i) * f(i)
Y: b(i)=d(i)
Ja zawsze robiłem tak, że od góry analizowałem każdą tablicę osobno, żeby nie przeoczyć żadnej relacji. Czyli najpierw dla:
S: a(i+1)=d(i) * b(i)
T: c(i+1)=c(i) * a(i+1)
Mamy zależność ST, przepływu, wewnątrziteracyjną, tabela a:
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
Patrzymy na następne wersy, czy także pojawia się gdzieś a. Jest - w wersie U. Czyli mamy:
S: a(i+1)=d(i) * b(i)
U: d(i+1)=a(i) * c(i+1)
Indeksy niezgodne, musi być zależność międzyiteracyjna. Wyższy indeks jest z lewej, więc typ „przepływu”. Indeksy różne, więc patrzymy, który większy, żeby określić relację SU.
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
SU |
przepływu |
międzyiteracyjna |
a |
Szukamy dalej jakiś a. Nie ma. Zauważcie, że mimo że w wersach:
T: c(i+1)=c(i) * a(i+1)
U: d(i+1)=a(i) * c(i+1)
pojawiają się tablice a, obie występują z prawej strony, a to już nie wlicza się do naszego zadania.
Patrzymy na następna tablice w pierwszym wersie:
S: a(i+1)=d(i) * b(i)
Jest to tablica d. Wyłapujemy drugi wers nadający się do zależności:
S: a(i+1)=d(i) * b(i)
U: d(i+1)=a(i) * c(i+1)
Jeszcze raz: indeksy są różne, więc żeby określić kolumnę zależność patrzymy w którym wersie jest większy indeks. W wersie U, więc musi być US. Jest to zależność przepływu, bo większy indeks jest z lewej strony oraz zależność międzyiteracyjna, bo indeksy nie są takie same, czyli:
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
SU |
przepływu |
międzyiteracyjna |
a |
US |
przepływu |
międzyiteracyjna |
d |
Dla d już nic nie ma (ponownie między wierszami S i Y nie będzie relacji dla d, ponieważ obie tablice są z prawej strony). Za to dla b możemy coś wychwycić:
S: a(i+1)=d(i) * b(i)
W: b(i-1)=e(i) * f(i)
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
SU |
przepływu |
międzyiteracyjna |
a |
US |
przepływu |
międzyiteracyjna |
d |
SW |
przeciwzależność |
międzyiteracyjna |
b |
S: a(i+1)=d(i) * b(i)
Y: b(i)=d(i)
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
SU |
przepływu |
międzyiteracyjna |
a |
US |
przepływu |
międzyiteracyjna |
d |
SW |
przeciwzależność |
międzyiteracyjna |
b |
SY |
przeciwzależność |
wewnątrziteracyjną |
b |
Przerobiliśmy w ten sposób wszystkie relacje związane z wersem S. Teraz przechodzimy do wersu T i szukamy tutaj nowych relacji (tylko z następnymi wersami, bo z poprzednimi by się nam powtórzyły).
T: c(i+1)=c(i) * a(i+1)
Od razu jest tu zależność w tym jednym wersie:
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
SU |
przepływu |
międzyiteracyjna |
a |
US |
przepływu |
międzyiteracyjna |
d |
SW |
przeciwzależność |
międzyiteracyjna |
b |
SY |
przeciwzależność |
wewnątrziteracyjną |
b |
TT |
przepływu |
międzyiteracyjna |
c |
Szukamy dalej dla c:
T: c(i+1)=c(i) * a(i+1)
U: d(i+1)=a(i) * c(i+1)
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
SU |
przepływu |
międzyiteracyjna |
a |
US |
przepływu |
międzyiteracyjna |
d |
SW |
przeciwzależność |
międzyiteracyjna |
b |
SY |
przeciwzależność |
wewnątrziteracyjną |
b |
TT |
przepływu |
międzyiteracyjna |
c |
TU |
przepływu |
wewnątrziteracyjną |
c |
Dla wersu T nie ma już zależności ani w tablicy c, ani a, więc przechodzimy do następnego:
U: d(i+1)=a(i) * c(i+1)
Do którego znajdujemy jeszcze jeden wers dla d:
U: d(i+1)=a(i) * c(i+1)
Y: b(i)=d(i)
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
SU |
przepływu |
międzyiteracyjna |
a |
US |
przepływu |
międzyiteracyjna |
d |
SW |
przeciwzależność |
międzyiteracyjna |
b |
SY |
przeciwzależność |
wewnątrziteracyjną |
b |
TT |
przepływu |
międzyiteracyjna |
c |
TU |
przepływu |
wewnątrziteracyjną |
c |
UY |
przepływu |
międzyiteracyjna |
d |
Dla wersu U nie ma już dalej relacji, bo wszystkie zależności zarówno dla tablic a, jak i c, zostały już wcześniej wypisane.
Dla wersu W i Y znajdujemy ostatnią zależność:
W: b(i-1)=e(i) * f(i)
Y: b(i)=d(i)
Mamy tutaj właśnie zależność wyjść, ponieważ obie tablice znajdują się z lewej strony. Musi być międzyiteracyjna, bo są różne indeksy. Żeby określić skąd dokąd ma iść zależność, standardowo patrzymy, w którym wierszu indeks jest większy:
Zależność |
Typ |
Rodzaj |
Tablica - opcjonalnie |
ST |
przepływu |
wewnątrziteracyjną |
a |
SU |
przepływu |
międzyiteracyjna |
a |
US |
przepływu |
międzyiteracyjna |
d |
SW |
przeciwzależność |
międzyiteracyjna |
b |
SY |
przeciwzależność |
wewnątrziteracyjną |
b |
TT |
przepływu |
międzyiteracyjna |
c |
TU |
przepływu |
wewnątrziteracyjną |
c |
UY |
przepływu |
międzyiteracyjna |
d |
YW |
wyjść |
międzyiteracyjna |
b |
Często w zadaniach któryś wers (zazwyczaj ostatni) zawiera z prawej strony tablice, które nie pojawiają się w żadnych innych wersach. Takimi w ogóle nie trzeba się przejmować, pełnią tylko rolę dekoracyjną.
Zrównoleglenie kodu
Nie rozpoczęte z powodu braku czasu. Kto może, niech doda tu swój wkład.
Podsumowanie
Przede wszystkim: samo przeczytanie tego co tu powypisywałem to nic. Najważniejsze to duuuużo ćwiczyć, rozwiązywać zadania. Mam nadzieję, że chociaż trochę ułatwiłem zrozumienie tego na tyle, że będziecie w stanie porobić samodzielnie zadania, bo bez tego nie da rady go zaliczyć .
Powodzenia wszystkim użerającym się z przetwarzaniem…
simi
21
Wyszukiwarka
Podobne podstrony:
Tutorial z Przetwarzania Równoległego 20100918
Przetwarzanie Równoległe i Rozproszczone Szczerbińskiego, wykład 3, SIEĆ PRZETASOWANA (perfect shuff
Wyk ad 8 sciaga, Studia - Automatyka, Przetwarzanie równoległe i rozproszone, egzamin, ściąga
wyklad 4, przetwarzanie rownolegle i rozproszone - Szczerbinski
[tomko] Progr Rozpr Pytania egzaminacyjne, przetwarzanie rownolegle i rozproszone - Szczerbinski
przyklady na egzamin, szkola, przetwarzanie rownolegle i rozproszone - Prof Szczerbinski
wykład 4, przetwarzanie rownolegle i rozproszone - Szczerbinski
Wyk ad 1 sciaga, Studia - Automatyka, Przetwarzanie równoległe i rozproszone, egzamin, ściąga
Wyk ad 4 sciĄga, Studia - Automatyka, Przetwarzanie równoległe i rozproszone, egzamin, ściąga
Wyk ad 5 sciĄga, Studia - Automatyka, Przetwarzanie równoległe i rozproszone, egzamin, ściąga
Wyk ad 6 sciĄga, Studia - Automatyka, Przetwarzanie równoległe i rozproszone, egzamin, ściąga
[ tycjan ] - PRIR zadania, szkola, przetwarzanie rownolegle i rozproszone - Prof Szczerbinski
Teoria, przetwarzanie rownolegle i rozproszone - Szczerbinski
więcej podobnych podstron