
POLSKO-JAPOŃSKA WYŻSZA SZKOŁA TECHNIK
KOMPUTEROWYCH
PRACA MAGISTERSKA
Nr ................
Pełnotekstowe wyszukiwanie informacji
dla polskich grup dyskusyjnych
Studenci
Borys Musielak
Jakub Wojciechowski
Nr albumu
s1846
s1549
Promotor
dr inż. Piotr Habela
Specjalność
Inżynieria Oprogramowania i Baz Danych
Katedra
Systemów Informacyjnych
Data zatwierdzenia tematu
24.10.03
Data zakończenia pracy
20.06.04
Podpis promotora pracy
Podpis kierownika katedry
....................................
.........................................
1

Streszczenie
Praca dotyczy problemu projektowania, implementacji i optymalizacji pełnotekstowych
wyszukiwarek internetowych. Rozważania poparte są działającym przykładem – aplikacją do
wyszukiwania informacji w zbiorze polskich grup dyskusyjnych. Przedstawione rozwiązanie opiera
się w pełni o podejście obiektowe, zarówno jeśli chodzi o projekt (zastosowanie notacji UML),
implementację (obiektowy język programowania Java), jak i sposób utrwalania danych
(wykorzystywanie mechanizmów obiektowej bazy danych Objectivity/DB). Rozwiązanie przyjęte w
pracy jest całkowicie autorskie. Wykorzystano własny mechanizm ściągania, indeksowania i
wyszukiwania informacji.. W tekście, oprócz opisu naszego rozwiązania, znaleźć można odwołania
do innych projektów tego typu, w szczególności do mechanizmów proponowanych przez popularną
wyszukiwarkę Google, obecnego lidera w tej branży. Oprócz szczegółowego opisu koncepcji i
implementacji prezentowanego systemu, przedstawione zostały również propozycje alternatywnych
rozwiązań poszczególnych poruszanych problemów, a także plany optymalizacji i rozwoju aplikacji w
przyszłości.
Podziękowania
Autorzy pracy chcieliby wyrazić podziękowania firmie Neurosoft Sp. z o.o., w szczególności
panu Cezaremu Dołędze, za bezpłatne udostępnienie komercyjnego programu Neurosoft Gram 2.0,
którego zastosowanie miało istotny wpływ na wyniki naszej pracy.
Osobne podziękowania należą się panu Robertowi Cheong z firmy Objectivity, za cierpliwość w
udzielaniu porad dotyczących różnych aspektów działania bazy Objectivity/DB.
2

Spis treści
1.WSTĘP..................................................................................................................................................................4
1.1.W
YSZUKIWANIE
PEŁNOTEKSTOWE
INFORMACJI
......................................................................................................... 4
1.2.C
EL
PRACY
........................................................................................................................................................4
1.3.R
OZWIĄZANIE
PRZYJĘTE
W
PRACY
..........................................................................................................................5
1.4.T
ECHNOLOGIA
I
NARZĘDZIA
ZASTOSOWANE
W
PRACY
................................................................................................5
1.5.R
EZULTATY
PRACY
..............................................................................................................................................7
1.6.O
RGANIZACJA
PRACY
...........................................................................................................................................7
2.WYSZUKIWANIE PEŁNOTEKSTOWE – RÓŻNE PODEJŚCIA...............................................................9
2.1.K
ONTEKST
PRACY
...............................................................................................................................................9
2.2.S
TAN
SZTUKI
....................................................................................................................................................10
2.3.N
ASZE
ROZWIĄZANIE
.........................................................................................................................................12
3.OPIS NARZĘDZI ZASTOSOWANYCH W PRACY....................................................................................15
3.1.O
BIEKTOWA
BAZA
DANYCH
O
BJECTIVITY
/DB.......................................................................................................15
3.2.J
AVA
...............................................................................................................................................................22
3.3.G
RAM
.............................................................................................................................................................23
3.4.P
YTHON
..........................................................................................................................................................23
3.5.P
OSTGRE
SQL..................................................................................................................................................24
3.6.L
EAFNODE
.......................................................................................................................................................25
3.7.B
IBLIOTEKI
.....................................................................................................................................................25
4.OBIEKTOWOŚĆ A WYSZUKIWANIE PEŁNOTEKSTOWE...................................................................27
4.1.O
BIEKTOWOŚĆ
A
WYSZUKIWANIE
INFORMACJI
.......................................................................................................27
4.2.O
MÓWIENIE
PRZYJĘTEGO
ROZWIĄZANIA
.................................................................................................................30
4.3.A
LGORYTM
INDEKSOWANIA
.................................................................................................................................33
4.4.A
LGORYTM
WYSZUKIWANIA
................................................................................................................................37
4.5.A
LTERNATYWNE
KONCEPCJE
...............................................................................................................................44
5.ROZWIĄZANIA IMPLEMENTACYJNE: SYSTEM ŚCIĄGANIA, INDEKSOWANIA I
WYSZUKIWANIA NEWSÓW............................................................................................................................50
5.1.O
PIS
NAJWAŻNIEJSZYCH
KLAS
..............................................................................................................................51
5.2.I
MPLEMENTACJA
FETCHERA
I
NARZĘDZIA
BACKUPUJĄCEGO
.......................................................................................56
5.3.I
MPLEMENTACJA
INDEKSOWANIA
..........................................................................................................................57
5.4.I
MPLEMENTACJA
WYSZUKIWANIA
............................................................. ............................................................ 62
5.5.F
RONTEND
.......................................................................................................................................................68
6.PROBLEMY ZWIĄZANE Z ZASTOSOWANYM ROZWIĄZANIEM......................................................70
6.1.P
ROBLEMY
NAPOTKANE
PODCZAS
IMPLEMENTACJI
...................................................................................................70
6.2.W
ADY
I
ZALETY
PRZYJĘTEGO
ROZWIĄZANIA
..........................................................................................................73
6.3.Z
ASTOSOWANIE
PRACY
......................................................................................................................................74
6.4.P
LANY
NA
PRZYSZŁOŚĆ
......................................................................................................................................74
7.PODSUMOWANIE...........................................................................................................................................79
PRACE CYTOWANE..........................................................................................................................................80
3

1. Wstęp
1.1.
Wyszukiwanie pełnotekstowe informacji
Internet to w tej chwili największe światowe repozytorium wiedzy ze wszystkich prawie
dziedzin naszego życia. Dziesiątki tysięcy artykułów na każdy możliwy temat dostępne są w, niestety
poważnie zaniedbanej, publicznej bibliotece. Większość całkowicie za darmo. Internet bywa nieraz
określany jako największy śmietnik świata. Wyszukanie pożądanej informacji wśród tysięcy ton „e-
makulatury” wydaje się więc być zadaniem godnym szaleńca. Zwłaszcza, jeśli informacja ma być
dokładna, a czas potrzebny na jej znalezienie akceptowalny. Informacja której poszukujemy
najprawdopodobniej jest jednak na wyciągnięcie ręki. Problem, z którym zmagają się nieustannie
tysiące internautów na całym świecie to: jak mądrze po nią sięgnąć. Podobnie, choć na nieco mniejszą
skalę, rzecz się ma z internetowymi grupami dyskusyjnymi. Tu również, a czasem tylko tu, możemy
znaleźć rozwiązanie dręczącego nas problemu. Tutaj także, niestety nazbyt często, mamy do czynienia
z niekompetencją, niewiedzą i całą masą informacji często zbędnych lub nieprawdziwych,
dostarczanych przez nadgorliwych użytkowników Usenetu. Odfiltrowanie śmieci od praktycznej
wiedzy wydaje się być w takiej sytuacji nieuniknionym zadaniem.
W obu tych przypadkach, z pomocą przychodzą nam aplikacje zwane wyszukiwarkami
pełnotekstowymi. To dzięki nim możemy bez obawy usiąść przed ekranem komputera i nie tracąc
czasu na żmudne poszukiwania, w kilka sekund otrzymać listę artykułów dotyczących interesującego
nas zagadnienia i spełniających podane przez nas kryteria. Tylko czy aby na pewno? Czy zawsze
jesteśmy w stanie znaleźć dzięki nim informację, której oczekujemy? A może często zdarza nam się
ślęczeć całymi godzinami przed komputerem, przeglądając kolejne, całkowicie nierelewantne
rezultaty wyszukiwania, z nadzieją że ten kolejny będzie w końcu właściwy? Zapewne zdarzają się
również i takie sytuacje. Powód jest prosty – uniwersalne produkty (a do takiego statusu dążą obecni
liderzy w branży wyszukiwarek internetowych) nigdy nie będą w stanie spełnić bardziej
specyficznych wymagań zaawansowanych użytkowników.
Zbudowanie idealnej wyszukiwarki, zawsze znajdującej adekwatne i interesujące nas dane jest
oczywiście (wbrew temu co próbują niekiedy wcisnąć nam specjaliści od reklamy) niemożliwą do
zrealizowania utopią. Dlatego też celem, który powinniśmy sobie stawiać nie może być jeden
uniwersalny i niezastąpiony program, lecz raczej stworzenie jak największej ilości bardzo
specyficznych rozwiązań, ułatwiających nam życie (czyli uzyskanie właściwej informacji) w
poszczególnych dziedzinach. Jedną z takich dziedzin, w których brakuje obecnie niestety dobrego,
dedykowanego mechanizmu wyszukiwania, jest światowe (a w szczególności polskie) archiwum
internetowych grup dyskusyjnych. Mimo, że dostępna jest w sieci całkiem spora ilość wyszukiwarek
indeksujących grupy, nie istnieje aplikacja, która koncentruje się wyłącznie na tym zagadnieniu i robi
to dobrze. A właśnie koncentracja i specyficzne podejście do konkretnego problemu jest warunkiem
(lecz oczywiście nie jedynym kryterium) sukcesu takiego projektu. Niniejsza praca jest jedną z prób
podjęcia się takiego właśnie wyzwania – stworzenie dedykowanej wyszukiwarki pełnotekstowej, dla
polskich grup dyskusyjnych.
1.2.
Cel pracy
Celem naszej pracy jest przedstawienie jednego z możliwych rozwiązań problemu
pełnotekstowego wyszukiwania informacji w dużych zbiorach danych. Nie jest naszym zadaniem
zaproponowanie uniwersalnego modelu, lecz raczej przedstawienie pewnej koncepcji budowy i
działania wyszukiwarki ukierunkowanej na wydobywanie specyficznego rodzaju informacji z
wcześniej zdefiniowanych zasobów. Jak wiadomo, trafność wyniku nie jest miarą obiektywną, lecz
zdefiniowaną li tylko przez wymagania konkretnego użytkownika. Przy tworzeniu wyszukiwarki
4

konieczne jest więc dokładne określenie sposobu pomiaru trafności wyników wyszukiwania. Na tej
podstawie możliwe będzie bowiem sprawdzenie czy i w jakim stopniu zakładana funkcjonalność
(rezultaty wyszukiwania) została osiągnięta.
W związku z tym, w naszej pracy postanowiliśmy skoncentrować się na kilku cechach, które
uważamy za ważne, a które często nie są uznawane za priorytetowe w istniejących produktach. Przede
wszystkich chcemy więc, aby zwracane wyniki zapytań były:
–
dokładne – chodzi o to, żeby użytkownik dostawał w wynikach wyszukiwania przede wszystkim
artykuły zawierające szukane przez niego całkowite ciągi słów, a dopiero z dalszym priorytetem
artykuły, które spełniają podane warunki tylko częściowo
–
niezależne od momentu w czasie – nieważne czy dany artykuł został napisany całkiem
niedawno, czy dziesięć lat temu, powinien się on pojawić w wynikach wyszukiwania z takim
samym priorytetem (o ile oczywiście nie została zaznaczona opcja wyboru przedziału
czasowego)
–
trwałe – jest to powiązane bezpośrednio z niezależnością w czasie i chodzi o to, żeby uniknąć
zjawiska “gubienia” artykułów – często występującego w popularnych wyszukiwarkach newsów
(również Google) – polegającego na marginalizacji a w końcu ignorowaniu wyników starszych w
czasie
Ponadto, ze względu na specyfikę języka polskiego, uznaliśmy, że istotne jest również, żeby
wyszukiwarka uwzględniała w swoim działaniu składnię języka polskiego, tj aby wyniki
prezentowane były niezależnie od formy fleksyjnej poszczególnych słów zapytania.
1.3.
Rozwiązanie przyjęte w pracy
Nasze rozwiązanie charakteryzuje się:
–
zastosowaniem podejścia obiektowego do projektowania i implementacji
–
odejściem od ograniczeń relacyjnych baz danych poprzez zastosowanie w projekcie bazy
obiektowej, bardziej adekwatnej dla omawianego problemu
–
wysokim stopniem modularyzacji systemu – zamiast tworzenia jednej aplikacji odpowiadającej
za całość mechanizmów niezbędnych do osiągnięcia zakładanych rezultatów, postawiono na
stworzenie wielu niezależnych aplikacji, ściśle ze sobą współpracujących
–
łatwością rozbudowy tworzonego systemu, optymalizacji czy dodania nowej funkcjonalności,
poprzez zastosowanie standardowych metod dokumentacji zarówno koncepcji projektowych
(UML) jak i samego kodu aplikacji (JavaDoc)
1.4.
Technologia i narzędzia zastosowane w pracy
Technologia, którą wybraliśmy do implementacji nie jest przypadkowa i ma bezpośredni
związek z założeniami przyjętego wcześniej rozwiązania.
Projekt został zrealizowany z użyciem następującego oprogramowania:
–
Obiektowa baza danych Objectivity/DB 8.0, obecnie jeden z liderów światowych w dziedzinie
zaawansowanych rozwiązań bazodanowych, oferujący między innymi: zarządzanie transakcjami,
wiązanie do Javy oraz wiele rodzajów zależności (relacji) między obiektami.
–
Obiektowy język programowania Java (połączenie wersji standardowej, J2SE, z wersją
enterprise, czyli J2EE – ta druga głównie do implementacji frontendu)
5

–
Obiektowy język skryptowy Python – wybrany do kilku specyficznych zastosowań, głównie w
celu optymalizacji (użycie Javy było niekiedy zbyt kosztowne ze względu na prędkość działania
lub niemożliwe ze względu na brak odpowiednich, niezawodnych bibliotek),
–
Program Gram 2.4.3 firmy Neurosoft – oparta na standardzie CORBA aplikacja, przeznaczona
do analizy językowej tekstu,
–
OmniORB – serwer CORBA, poprzez który aplikacja łączy się z programem Gram,
–
Serwer grup dyskusyjnych Leafnode odpowiedzialny za ściąganie wiadomości z archiwum
Usenetu na dysk
–
Serwer aplikacji Tomcat, oparty na Javie, który odpowiada za działanie frontendu aplikacji
–
CVS – program do kontroli wersji oprogramowania, przydatny przy równoległej pracy nad
kodem i dokumentacją
–
Dia – darmowa aplikacja (na licencji GPL) do rysowania diagramów (w tym UML),
–
OpenOffice.org – darmowy pakiet biurowy (licencja GPL) w którym powstała praca, składający
się m.in. z edytora tekstu Writer oraz narzędzia do tworzenia prezentacji Impress
–
Zintegrowana platforma programistyczna Eclipse IDE, szczególnie przystosowana do tworzenia
zaawansowanych projektów z użyciem technologii opartych o język Java
–
System operacyjny: Debian GNU/Linux.
Wybór Objectivity jako podstawowej bazy danych był ryzykowny. Po pierwsze ze względu na
małą popularność stosowania obiektowych baz danych do tego typu rozwiązań, po drugie ze względu
na nasze doświadczenia zawodowe, które opierają się głównie na znajomości baz relacyjnych. Już po
krótkim czasie pracy okazało się jednak że był to wybór prawidłowy. Baza danych nastawiona
bardziej na referencje, niż przeszukiwanie zawartości nadaje się idealnie do zastosowania w
projektach, w których ściśle określona jest struktura danych i dokładnie wiemy jakie informacje
chcemy z tych danych uzyskać (mówiąc ściślej – jakie zapytania będziemy chcieli zoptymalizować,
już na poziomie kodu programu). Idea relacyjnej bazy danych – czyli uniwersalny, deklaratywny
język zapytań, byłby w przypadku naszej aplikacji niepotrzebnym i – co zostanie udowodnione w
części dalszej pracy – bardzo kosztownym narzutem.
Java została wybrana natomiast z co najmniej dwóch względów. Po pierwsze, jest to
nowoczesny, spójny i prawdziwie obiektowy język programowania, doskonale nadający się do
zastosowania w aplikacji, w której większość funkcjonalności można rozpisać poprzez diagramy
UML, operujące na obiektach (de facto, wszystkie operacje, zarówno na poziomie aplikacji jak i bazy
danych reprezentowane są w naszej aplikacji z użyciem abstrakcji obiektowej). Po drugie – Java jest
(obok C++) najlepiej wspieranym przez Objectivity językiem programowania. W pakiecie dostępna
jest dokładna dokumentacja użytkowa, jak również biblioteki, zapewniające pełne wykorzystanie
standardowych, jak również bardziej zaawansowanych funkcji, oferowanych przez Objectivity.
Przykładem może być rozszerzenie języka Java o specyficzne dla Objectivity relacje (ang.
relationships) – czyli związki asocjacyjne pomiędzy klasami (również typu wiele-do-wiele),
reprezentacja wszystkich rodzajów kolekcji stosowanych w bazie jako obiekty Javy, jak również
operacje na federacji, znajdujących się w niej bazach danych, kontenerach oraz wszelkich innych
obiektach systemowych udostępnionych przez Objectivity/DB.
Przy wyborze pozostałych narzędzi, staraliśmy się zwracać uwagę na takie aspekty jak:
–
skalowalność, przystosowanie narzędzia do przetwarzania dużych ilości danych
–
uniwersalność (chodzi o to, żeby przy niewielkim nakładzie pracy możliwe byłoby przystosowanie
aplikacji i/lub środowiska programistycznego do pracy w innym środowisku, np. do działania w
systemie operacyjnym Microsoft Windows)
6

–
niezawodność, dojrzałość narzędzia – szczególnie korzystając z aplikacji typu open-source, na
licencji GPL lub podobnych, bardzo ważne jest zbadanie dojrzałości rozwiązania i przystosowania
do intensywnej eksploatacji
–
łatwość instalacji i obsługi – aby kwestie techniczne nie przesłoniły głównego, merytorycznego
aspektu pracy (m.in. dlatego postawiliśmy na system operacyjny Debian GNU/Linux, który
charakteryzuje się ogromną łatwością instalacji oprogramowania i ogólną dostępnością większości
potrzebnych nam aplikacji)
1.5.
Rezultaty pracy
Rezultatem naszej pracy jest działający i w pełni funkcjonalny system wyszukiwania
pełnotekstowego wiadomości z archiwum polskich grup dyskusyjnych. Składa się on z modułów, z
których każdy odpowiedzialny jest za oddzielne zadania związane z działaniem wyszukiwarki.
Krótka specyfikacja poszczególnych modułów:
•
fetcher – serwer ściągający nowe wiadomości z polskich grup dyskusyjnych i zapisujący je na
twardym dysku w postaci plików
•
backuper – narzędzie backupujące ściągane przez fetcher artykuły poprzez zapisywanie ich w nie
przetworzonej formie jednocześnie do dwóch baz danych: relacyjnej bazy PostgreSQL oraz
docelowej, obiektowej bazy Objectivity/DB
•
indekser – aplikacja przetwarzająca zapisane w prostej formie artykuły do postaci
usystematyzowanej, w celu takiej organizacji informacji w bazie, aby samo wyszukiwanie
sprowadziło się do prostych operacji na danych, a najlepiej ograniczyło się tylko do
przechodzenia po referencjach pomiędzy obiektami
•
wyszukiwarka – główna i jedyna widoczna dla końcowego użytkownika aplikacja, której
zadaniem jest zwrócenie odpowiednich wyników (artykułów) w zależności od podanego przez
użytkownika zapytania (zazwyczaj szukanego ciągu słów)
•
optymalizator – program działający w tle, którego zadaniem jest wykonywanie najczęściej
pojawiających się zapytań i zbieranie zaktualizowanych wyników takiego wyszukiwania; dzięki
niemu prezentacja wyników takich zapytań jest możliwa „od ręki” - bez potrzeby wyszukiwania,
gdyż są ode przetrzymywane bezpośrednio w bazie danych; przy czym optymalizator został
zaimplementowany tylko częściowo: w bazie przechowywane są zapytania wraz z ich wynikami,
nie ma jednak mechanizmu aktualizującego te zapytania
1.6.
Organizacja pracy
Pracę możemy podzielić na trzy zasadnicze najważniejsze części:
1. Omówienie problemu i możliwych rozwiązań
Pierwsza część pracy zawiera dokładne omówienie kontekstu pracy. Odwołuje się do
istniejących w chwili obecnej rozwiązań podobnego problemu wskazując ich najważniejsze
zalety i wady. Prezentuje też w sposób ogólny nasze podejście do problemu. W dalszej
części omówione zostają szczegółowo narzędzia, które wykorzystujemy w pracy, ze
szczególnym uwzględnieniem obiektowej bazy Objectivity/DB, odpowiedzialnej za
utrwalanie danych w prezentowanym systemie.
2. Omówienie naszego rozwiązania
7

To najważniejsza część pracy, zawierająca nasz wkład w rozwiązanie problemu jakim jest
pełnotekstowe wyszukiwanie informacji z dużych zbiorów danych. W rozdziale czwartym
przedstawiona została szczegółowo główna koncepcja proponowanego przez nas
rozwiązania, która doczekała się implementacji, jak również alternatywne podejścia, które
nie zostały zaimplementowane, jednak powinny być brane pod uwagę w przyszłej
rozbudowanie systemu.
Po omówieniu koncepcji następuje dokładne omówienie implementacji systemu, z opisem
struktury danych, poszczególnych modułów aplikacji oraz sposobu komunikowania się
między modułami.
3. Plany na przyszłość
Ostatni dział, opisuje różne koncepcje ulepszenia prezentowanego rozwiązania, zarówno
poprzez optymalizację jak i przez dodanie nowej funkcjonalności. Zajmuje się również
wskazaniem zalet i wad obecnego rozwiązania, opisuje problemy, które wynikły podczas
implementacji oraz wskazuje kierunek, w którym należy pójść w celu uniknięcia podobnych
kłopotów w przyszłości. W dziale tym przedstawiono również możliwe zastosowania
obecnego systemu, jak również możliwe przyszłe zastosowania, po wdrożeniu
proponowanych zmian.
Do pracy załączono również dodatki – są to informacje, które nie są wprawdzie niezbędne do
zrozumienia treści pracy, mogą być jednak przydatne do dokładniejszego zgłębieniu tajników
rozwiązania, oraz być może, do dalszego rozwoju systemu.
8

2. Wyszukiwanie pełnotekstowe – różne podejścia
W tym rozdziale opisany został kontekst pracy oraz obecny stan sztuki odnośnie problemu
pełnotekstowego wyszukiwania informacji. Na końcu rozdziału naszkicowane zostało proponowane
przez nas rozwiązanie problemu.
2.1.
Kontekst pracy
Dzięki Internetowi zyskujemy dostęp do niemal nieograniczonego zbioru danych. Sporo jest
zasobów bardzo wartościowych, jednak toną one w oceanie śmieci i bezużytecznego szumu
informacyjnego. Wyłuskanie wartościowych treści, nawet spośród zasobów danych powstających w
ciągu tylko jednego dnia, jest zadaniem bardzo czasochłonnym. A co, jeśli chcielibyśmy zebrać
informacje z zasobów zgromadzonych w ciągu kilku lat? Jedynym rozwiązaniem problemu dotarcia
do interesujących nas danych jest stworzenie mechanizmu pozwalającego na szybkie ograniczenie
zbioru dokumentów do odpowiadającego nam zakresu oraz ułożenia ich w odpowiedniej kolejności.
Narzędzia takie nazywamy pełnotekstowymi wyszukiwarkami internetowymi.
Wyszukiwarki internetowe są to aplikacje udostępniane najczęściej przez strony WWW. Ich
zadaniem jest wyszukiwanie i prezentowanie odnośników do dokumentów spełniających określone
przez użytkownika kryteria. Głównym kryterium wyszukiwania informacji są zapytania o
występowanie konkretnych słów lub zdań w treści artykułów. Osoba korzystająca z takiego narzędzia
podaje jedno lub więcej słów, które powinien zawierać wyszukany dokument. Aplikacja znajduje
wszystkie dokumenty dla podanego zapytania oraz ustawia je według szacowanej trafności.
Zasoby WWW można podzielić na dwie grupy: strony publikowane przez organizacje oraz
strony prywatne. W przypadku witryn firm i organizacji można się spodziewać, iż treści tam
prezentowane będą odpowiednio ustrukturalizowane oraz że będą one raczej dobrej jakości. W
przypadku stron prywatnych, a takich jest dużo więcej, struktury informacji są raczej luźne, a treści
często bezwartościowe. Większość dzisiejszych wyszukiwarek zoptymalizowana jest w ten sposób, iż
strony prywatne umieszczane są niżej w ocenach trafności od stron organizacji i firm.
Zupełnie inaczej wygląda sprawa w archiwum grup dyskusyjnych. Jak sama nazwa wskazuje, grupy
służą do wymiany informacji i poglądów przez użytkowników Usenetu. Nie można tutaj dokonać
podobnego podziału, jak w przypadku stron WWW. Wszystkie osoby i podmioty udzielające się w
dyskusjach traktowaną są jednakowo. Nie istnieje bowiem możliwość stworzenia uniwersalnego
mechanizmu oceniającego wiarygodność danego autora, a wszelkie próby takiej klasyfikacji skończyć
się mogą kompromitacją wyszukiwarki – nietrudno bowiem oszukać automat, choćby poprzez
podawanie fałszywego adresu zwrotnego e-mail, czy też wysyłanie wiadomości poprzez roboty z
różnych lokalizacji.
Budowa Usenetu, czyli grup dyskusyjnych, różni się diametralnie od struktury stron WWW.
World-Wide-Web stanowi rodzaj grafu skierowanego. Każda strona stanowi jego wierzchołek a
każdy link jest krawędzią. Istnieje prawie nieskończenie wiele możliwości połączeń pomiędzy
stronami. W przypadku grup dyskusyjnych mamy do czynienia bardziej z sekwencją drzew, niż z
grafem. Każda grupa dyskusyjna posiada swoją własną sekwencję postów głównych, nie
posiadających ojców, od których zaczynają się wszystkie wątki. Każdy wątek zorganizowany jest na
zasadzie drzewa. Dowolny post w wątku może posiadać tylko jednego ojca i jednocześnie może
posiadać dowolną liczbę odpowiedzi, które także mogą posiadać swoje odpowiedzi, itd. Posty nie są
w żaden sposób połączone między sobą poza relacją ojciec-dziecko (post-odpowiedź).
9
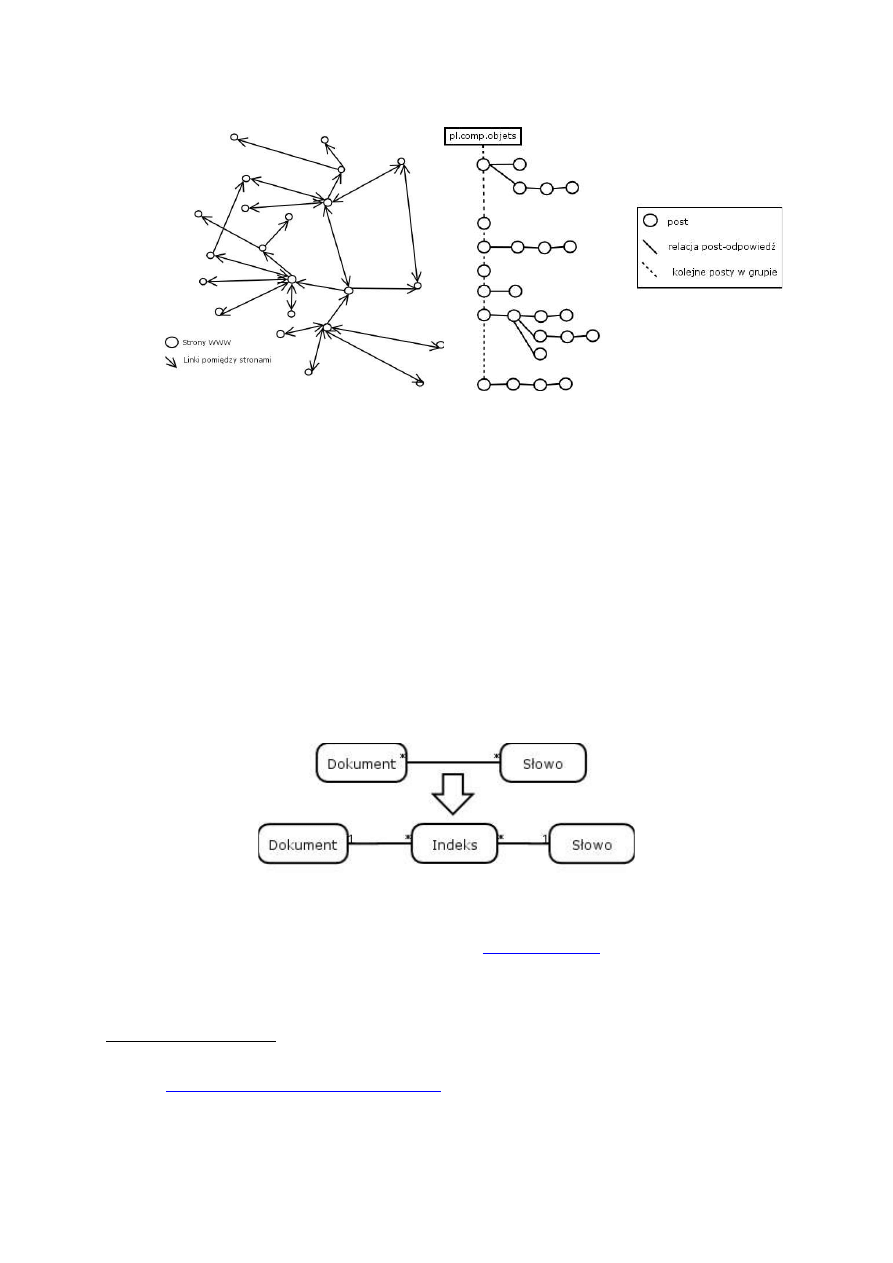
Rysunek 1. Struktura WWW
Rysunek 2. Struktura USENET-u
2.2.
Stan sztuki
Wszystkie poważne wyszukiwarki zbudowane są na zasadzie indeksu. Indeks jest to najprostsza
struktura danych jeżeli chodzi o znajdowanie informacji w tekście. Stanowi ona relacje wiele-do-
wielu pomiędzy dokumentem a słowem. Jak wiadomo każdy dokument składa się z wielu słów i
każde słowo może występować w wielu dokumentach. Rozwiązanie takie pozwala na bardzo szybkie
znalezienie odpowiednich dokumentów dla zadanego zapytania. Szukając tekstów, posiadających w
treści kilka podanych wyrazów należy pobrać część wspólną zbiorów dla każdego słowa oddzielnie.
Przecięcie to jest wynikiem wyszukiwania. W bardzo dużych indeksach (np. indeksy stron WWW)
samo znalezienie odpowiedniej listy dokumentów nie wystarcza. Potrzebne jest jeszcze przynajmniej
szacowane przypisanie każdemu znalezionemu dokumentowi jakiegoś rodzaju oceny trafności.
Rysunek 3. Indeks
Przykładowo, dla zapytania „prezydent polski”
www.google.com
zwraca około 180 tysięcy
dokumentów. Przejrzenie ich wszystkich w celu znalezienia tego, który nas interesuje jest nierealne
dla przeciętnego użytkownika. Jak widać, należy zastosować mechanizm oceniający dokumenty pod
względem ich ważności. W przypadku stron WWW najlepszym, stosowanym obecnie rozwiązaniem
jest algorytm PageRank
1
, stworzony przez twórców Google. Jego główną cechą jest prostota działania
1
The Anatomy of a Large-Scale Hypertextual Web Search Engine Sergey Brin and Lawrence Page. Computer
Science Department, Stanford University, Stanford, CA 94305.
(
http://www-db.stanford.edu/~backrub/google.html
)
10

i jak się wydaje to, że jest bardzo oczywisty. PageRank nadaje dokumentom WWW ocenę na
podstawie liczby odnośników wychodzących i wchodzących. Im jest ich więcej, tym wyższa jest
ocena. Założeniem tego algorytmu jest to, iż im więcej strona posiada linków do innych stron, tym
wydaje „ważniejsza” jest dla użytkownika, ponieważ trafiwszy na nią ma on większe szanse na
dotarcie do interesujących go danych. Na tej samej zasadzie, jeśli wiele miejsc w sieci posiada link do
danej strony, świadczy to o tym, iż jest ona interesująca dla większej grupy ludzi.
Algorytm ten jest kompletnie nieprzydatny w przypadku grup dyskusyjnych. Nie ma tutaj
bowiem rozbudowanej sieci linków. Każdy post posiada co najwyżej jednego posta-ojca i może
posiadać dowolną liczbę odpowiedzi, podczepionych pod niego, jednak nie świadczy to w żaden
sposób o jego ważności. W związku ze specyficzną budową Usenetu trudno tu o jakikolwiek algorytm
oceny trafności postów. Trudno jest też oceniać posty na podstawie ich autorów. Jedyną daną jaką
jesteśmy w stanie wydobyć na temat autorów to to, ile postów na danej grupie zamieścili do tej pory.
Nie jest to wskaźnik, który pokazuje nam stopień profesjonalizmu wypowiedzi. Element ten może być
tylko ciekawą informacją w statystyce natomiast nie nadaje się zbytnio do oceny trafności wyników.
Mechanizm działania wyszukiwarki można przedstawić jako trzy główne etapy. Są to:
1. Ściąganie – mechanizm oferowany przez fetcher, pobierający dane z różnych zasobów i zapisujący
je na dysk lub w bazie danych.
2. Indeksowanie – mechanizm budujący indeks na podstawie pobranych dokumentów.
3. Wyszukiwanie – mechanizm wyszukujący odpowiednie dokumenty według zapytania
użytkownika.
Budowa fetchera jest bardzo uzależniona od typu danych, jakie ma pobierać. Inaczej wygląda
dla stron WWW, inaczej dla grup dyskusyjnych, a jeszcze inaczej dla zasobów intranetowych. W
przypadku stron WWW fetchery buduje się na zasadzie pająków internetowych (ang. web spider lub
pełzaczy – ang. web crawler). Są to programy, które przechodzą od strony do strony, nawigując po
linkach, ściągając przy okazji całą zawartość stron na dysk lub do bazy danych. Proces pobierania
stron internetowych jest bardzo uzależniony od wydajności serwerów, na których znajdują się strony
oraz od przepustowości łącz na świecie. Przejście przez wszystkie strony na świecie jest procesem
pracochłonnym i w zależności od ilości uruchomionych pająków może trwać nawet kilkanaście dni.
Fetchery Usenetu mają ułatwione zadanie. W związku z rozproszeniem serwerów grup
dyskusyjnych po świecie i z faktem, iż każdy serwer posiada swoje archiwum prawie wszystkich grup
wystarczy połączyć się tylko z jednym z nich aby mieć dostęp do potrzebnych dokumentów. Posty
zamieszczane są na serwerach jako czysty tekst
2
, bez zbędnych dodatków. Dzięki temu operacja ich
pobierania jest bardzo szybka i mało obciążeniowa dla systemu. W ciągu kilku sekund klient Usenetu
jest w stanie pobrać kilka tysięcy postów.
Indekser jest to najbardziej obciążeniowa część wyszukiwarki. Jego zadaniem jest zbudowanie
struktury indeksu na podstawie pobranych wcześniej przez fetcher dokumentów, w formie surowej.
Operacja ta nie bardzo jest skomplikowana algorytmicznie, jednak w związku z ogromną ilością
danych do przetworzenia może być bardzo pracochłonna i długotrwała. Na ogół indekser pobiera
wcześniej zapisany, surowy dokument, parsuje go a następnie przechodzi przez niego słowo po
słowie. Parsowanie polega na wyodrębnieniu z dokumentu tekstu, z pominięciem wszystkich
zbędnych metainformacji, np.: formatowanie czcionki, tagi HTML-owe, itp. Przechodząc po treści
indekser analizuje każde słowo. Nowe słowa, wcześniej niezindeksowane, zapisywane są w bazie. Dla
2
Problemem mogą być jedynie grupy binarne, na których użytkownicy zamieszczają duże pliki graficzne,
wideo i audio. W postach binarnych bardzo rzadko spotyka się jakikolwiek tekst, więc z punktu
widzenie wyszukiwarki pełnotekstowej można je całkowicie pominąć, co też czynimy w naszej pracy.
11

słów już istniejących w strukturze tworzona jest tylko relacja z aktualnie przetwarzanym
dokumentem.
Przy okazji indeksowania zapisywane są wstępne informacje na temat ważności wystąpienia
danego słowa w tekście. Analizując dokument w formacie HTML można stwierdzić, czy dane słowo
występuje w tytule, nagłówku lub w treści. W zależności od położenia słowa w dokumencie oraz od
czcionki, jaką został napisany, można pokusić się o nadanie mu wagi. Im większą czcionka słowa –
tym większa waga wyniku. Największą ocenę otrzymują słowa zawarte w tytule strony. Taka wstępna
analiza artykułów ułatwia pracę kolejnemu mechanizmowi, czyli wyszukiwarce.
Wyszukiwanie jest to jedyny element całego mechanizmu dostępny dla użytkownika.
Najczęściej wyszukiwarki dostępne są jako aplikacje WWW. Jednak mogą to być równie dobrze
wszelkiego rodzaju aplikacje lub nawet dodatki do aplikacji lub systemów.
Proces wyszukiwania polega na odczytaniu indeksu słów i pobraniu odpowiedniego zbioru
dokumentów. Następnie zbiór ten jest sortowany według kryterium trafności każdego dokumentu.
Pobierając każdy dokument do wyników zapytania wyliczana jest jego waga w stosunku do podanego
zapytania. W prostszych rozwiązaniach jest to suma wag szukanych słów z danego dokumentu.
Szukając kilku słów, najwyżej w rezultatach pojawią się te dokumenty, w których słowa te występują
w tytule lub nagłówku, a najniżej te, w których szukane słowa pojawiają się w dalszej części treści.
2.3.
Nasze rozwiązanie
Prezentowane przez nas rozwiązanie, zgodnie z powszechnie przyjętą konstrukcją budowy
wyszukiwarek składa się z trzech głównych części: fetchera, indeksera i właściwej wyszukiwarki
informacji. Tym co wyróżnia je spośród innych tego typu projektów jest m.in. zastosowanie
obiektowego języka programowania z trwałością zapewnioną przez obiektową bazę danych
Objectivity/DB, a także specjalne podejście do indeksowanych danych, którymi są wiadomości
zamieszczane na polskich grupach dyskusyjnych.
Dzięki pełnemu zastosowaniu obiektowości, struktura danych i działanie aplikacji nie są
podporządkowane ciągłej potrzebie konwersji obiektów do relacyjnych krotek. Można się więc skupić
jedynie na wymaganej funkcjonalności systemu, co w znaczny sposób ułatwia zarówno modelowanie
jak i implementację. Dzięki specjalnemu podejściu do grup dyskusyjnych, mamy możliwość
uzyskania większej ilości informacji, niż przy zastosowaniu uogólnionego podejścia, traktując
jednakowo wszystkie elementy indeksowanego tekstu.
Inną ważną cechą naszego pomysłu jest modularyzacja rozwiązania. Każdy z modułów spełnia ściśle
określoną funkcję i przekazuje zdefiniowaną wcześniej informację innym modułom. Taka koncepcja
w tym konkretnym przypadku sprawdza się doskonale, gdyż każdy z elementów naszej aplikacji jest
w pewien sposób niezależny od pozostałych. Wykorzystanie innego fetchera nie zmieni sposobu
działania indeksera i wyszukiwarki. Zmiana koncepcji indeksowania nie powinna wpłynąć na
działanie analizy fleksyjnej czy mechanizmu wyszukiwania. Narzędzie do cache'owania wyników nie
polega w żaden sposób na mechanizmie indeksowania, etc.
Omówimy teraz pokrótce najważniejsze moduły naszej aplikacji. Bardziej szczegółowe
informacje, dotyczące poszczególnych rozwiązań znaleźć można w rozdziałach czwartym i piątym,
opisujących zarówno koncepcję rozwiązania jak i samą implementację. Tutaj skupimy się zatem
jedynie na przedstawieniu najważniejszych funkcji poszczególnych modułów.
Zadaniem naszego fetchera jest połączenie się z (lokalnym) serwerem grup dyskusyjnych i
pobranie wszystkich aktualnych postów z wybranych grup. Każdy post zapisywany jest następnie w
systemie baz danych Objectivity/DB, w bazie
NntpPostDB, jako obiekt klasy
pl.edu.pjwstk.NewsSearch.NntpArticle. Każda grupa zapisywana jest w oddzielnym
kontenerze (nazwą kontenera jest nazwa grupy).
12
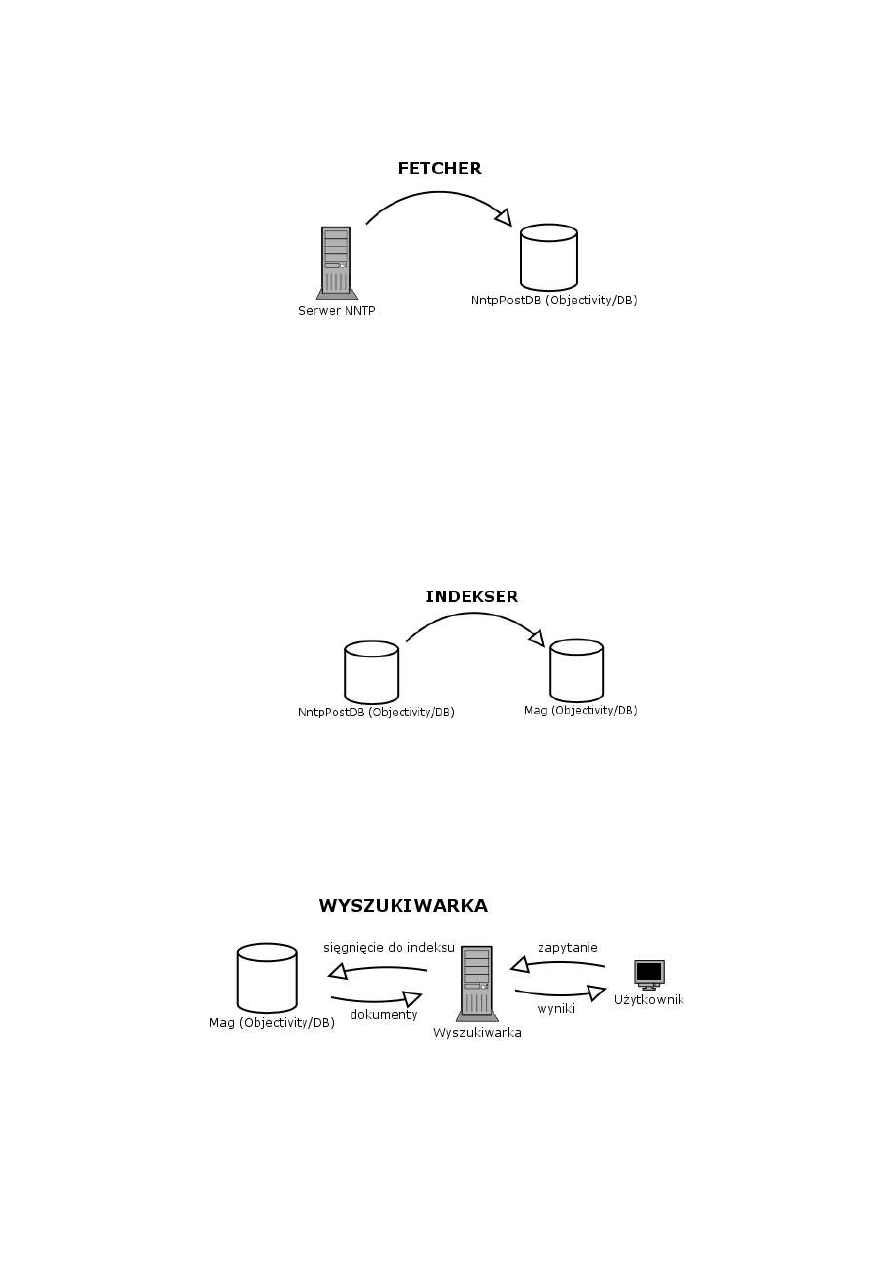
Rysunek 4. Rola fetchera
Indekser pobiera z bazy NntpPostDB dokumenty w postaci obiektów klasy NntpArticle, a
następnie parsuje je do obiektu klasy Article. Podczas parsowania, odczytywane są z nagłówków
posta dane, takie jak: data zamieszczenia na serwerze, tytuł, autor, odnośniki do poprzednich postów
(jeżeli post jest odpowiedzią) i inne. Następnie indekser przechodzi przez treść dokumentu tworząc
indeks występujących w nim słów. Dodatkowo dla każdego słowa zapisywana jest jego pozycja w
dokumencie. Będzie to wykorzystywane później, podczas wyszukiwania, do oceny trafności
prezentowanych wyników. Po przejściu przez wszystkie dokumenty uruchamiany jest proces
tworzenia struktury zależności między słowami, korzystając z oprogramowania GRAM, służącego do
analizy fleksyjnej i normalizacji tekstu. Słowa łączone są relacją z ich formami podstawowymi.
Rysunek 5. Rola Indeksera
Wyszukiwarka działa standardowo – na podstawie podanego przez użytkownika zapytania
znajdowane są dokumenty, odpowiadające merytorycznie zadanemu zapytaniu. Zapytanie podawane
jest na przykład przez formularz znajdujący się na stronie internetowej. Dane z formularza
przetwarzane są w bazie danych i po przeładowaniu strony zwracany jest wynik – lista linków do
relewantnych artykułów, posortowanych według zdefiniowanej trafności.
Rysunek 6. Wyszukiwanie dokumentów
13

Nowym elementem jest tutaj możliwość wyboru typu wyszukiwania przez użytkownika. W
zależności od rodzaju informacji, jakie chce on znaleźć, może wybrać wyszukiwanie:
–
dokładnych ciągów podanych w zapytaniu
–
dokładnych ciągów wraz z podciągami, zawierającymi tylko niektóre ze słów zapytania, ale w
identycznej kolejności
–
części wspólnej wszystkich artykułów zawierających wszystkie słowa zapytania (bez sprawdzania
kolejności występowania poszczególnych słów)
–
standardowe wyszukiwanie, znajdujące zarówno artykuły zawierające wszystkie słowa zapytania,
jak również te, w których występuje tylko część podanych słów
–
wyszukiwanie z uwzględnieniem zależności fleksyjnych pomiędzy słowami
Domyślnie zaznaczone są wszystkie z tych opcji. Jeśli jednak użytkownik wie dobrze, jaki typ
informacji najbardziej go interesuje, wskazane jest wybranie konkretnych opcji wyszukiwania –
skraca to w znacznym stopniu czas oczekiwania na wyniki.
14

3. Opis narzędzi zastosowanych w pracy
Proponowane przez nas rozwiązanie opiera się na obiektowej bazie danych Objectivity/DB oraz
obiektowym języku programowania Java. W części indeksującej wykorzystany został produkt firmy
Neurosoft – Gram: oprogramowanie służące do analizy językowej tekstu. Indekser komunikuję się z
Gramem poprzez protokół zdefiniowany przez CORBA. Przy okazji tworzenia wyszukiwarki
powstało kilka niezbędnych dodatków, takich jak: oprogramowanie służące do archiwizacji zasobów
grup dyskusyjnych ściągające wszystkie posty z serwera i umieszczające je w relacyjnej bazie danych
PostgreSQL oraz mała biblioteka stworzona w Javie realizująca komunikację z serwerem grup
dyskusyjnych poprzez protokół NNTP zgodnie z RFC 977 (Network News Transfer Protocol) z 1986
roku..
3.1.
Obiektowa baza danych Objectivity/DB
Obiektowa baza danych Objectivity/DB zapewnia mechanizmy do trwałego przechowywania
oraz wyszukiwania obiektów stworzonych w trzech językach programowania: C++, Java, Smalltalk.
System zarządzania bazą danych ukrywa przed użytkownikiem wszystkie operacje niskopoziomowe
związane z trwałością danych.
Architektura
Wszystkie operacje bazodanowe odbywają się w tym samym procesie, w którym działa
aplikacja. Dzieję się tak dzięki dynamicznemu doładowywaniu potrzebnych bibliotek.
Objectivity/DB definiuje cztery rodzaje obiektów w bazie danych. Są to:
•
trwały obiekt
•
kontener
•
baza danych
•
federacja
Obiekt
Trwały obiekt, będący wystąpieniem „klasy zdolnej do trwałości” (ang. „persistence capable
class”) jest to najmniejszy byt programistyczny, który podlega zapisaniu lub odczytaniu z bazy. Jest to
typowy, zwyczajny obiekt z języków programowania, który dziedziczy z klasy dostarczanej przez
producenta bazy lub implementuje specjalny interfejs. Jedyną różnicą między obiektami trwałymi a
nietrwałymi jest to, że obiekty nietrwałe znikają wraz z zakończeniem działania aplikacji. Obiekty
trwałe potrafią przetrwać zamknięcie aplikacji i zostać przywrócone podczas kolejnego uruchomienia
tak jakby w ogóle nie zostały zniszczone. Baza Objectivity/DB przechowuje cały stan obiektu (za
wyjątkiem atrybutów zadeklarowanych jako ulotne („transient”)). Oznacza to, że dane z wszystkich
pól zostaną zachowane. Nie ważne czy są to pola prywatne, publiczne czy chronione. Wszystkie pola
nie będące wystąpieniami typów prostych powinny być także opisane klasami zdolnymi do trwałości.
System zarządzania bazą danych przechowuje także informacje o obiektach powiązanych
niezależnie czy jest to relacja jeden-do-jeden lub agregacja.
15
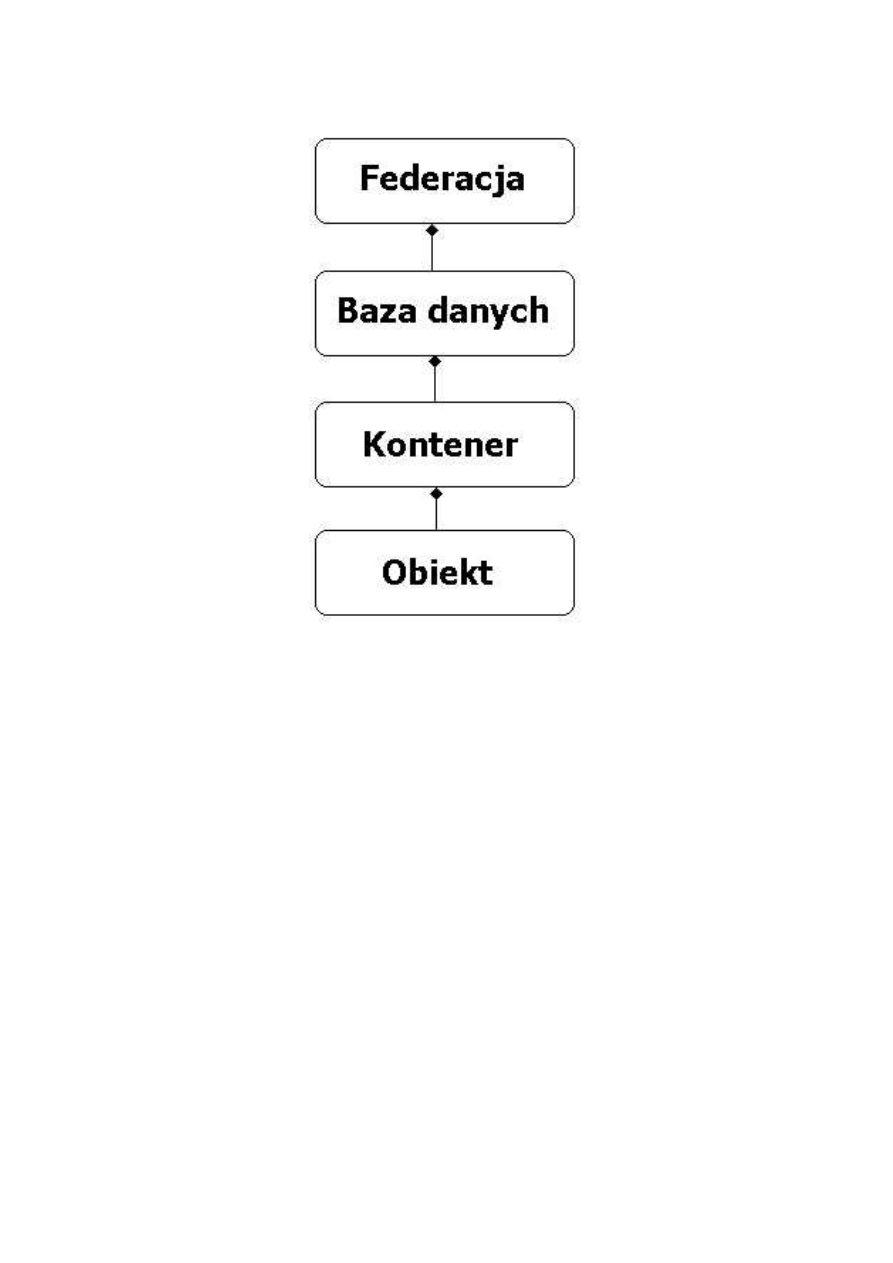
Rysunek 7. Struktura obiektów
w bazie Objectivity/DB
W przypadku Javy klasą, z której należy wyprowadzić trwałe obiekty jest ooObj. Jeżeli klasa
zaplanowana do bycia trwałą nie może z jakiś przyczyn dziedziczyć z ooObj istnieje możliwość
„ręcznego” programowania trwałość poprzez implementowanie interfejsu Persistent (lub jej
pochodnych: PersistnentEvents, IooObj).
Kontener
Kontener jest to obiekt służący do grupowania trwałych obiektów aplikacji. System zarządzania bazą
danych przechowuje obiekty należące do jednego kontenera blisko siebie w stronach w pamięci lub
na dysku, przez co uzyskuje się lepszą wydajność. Objectivity/DB zakłada zamki na całym
kontenerze. Oznacza to, że wszystkie obiekty w kontenerze zostaną zablokowane. Może to prowadzić
do pewnych problemów wydajnościowych, dlatego powinno się zwrócić szczególną uwagę
projektując strukturę i podejmując decyzję o tym jak trwałe obiekty będą rozmieszczone w bazie.
Kontener zorganizowany jest jako obiekt powoływany z poziomu aplikacji. Fizycznie zawiera się w
pliku bazy danych. Do zadań kontenera należą:
•
Zarządzanie mapą stron, która przechowuje fizyczne adresy stron na dysku. Pozwala to na
bardziej efektywne pobieranie stron z dysku
16

•
Zarządzanie przydzielaniem stron.
•
Zarządzanie mapą nazw, po których pobierane są obiekty.
•
Przechowywanie trwałych obiektów.
Wraz z utworzeniem nowej bazy danych tworzony jest jej podstawowy kontener o nazwie
„_ooDefaultContObj”, który jest instancją klasy ooDefaultContObj.
Żaden kontener nie może zawierać w sobie innych kontenerów. Istnieją dwa typy kontenerów:
„zwyczajne” i ze zbieraniem nieużytków (ang. garbage collector).
Kontenery ze zbieraniem nieużytków (tzw. również odśmiecaniem) działają na podobnej zasadzie
co analogiczny mechanizm w języku Java. Obiekty, które nie są osiągalne z nazwanego obiektu-
korzenia (ang. named root) są uznawane jako kandydaci do zniszczenia. W przeciwieństwie do Javy
odśmiecanie nie zachodzi automatycznie. Jest to proces uruchamiany poprzez narzędzie
administratorskie oogc.
Obiekt jest uznawany jako aktywny jeśli:
1
Jest nazwanym korzeniem
2
Można do niego dotrzeć z nazwanego korzenia. Obj1 jest osiągalny przez Obj2 jeśli:
2.1
Obj2 ma referencję do Obj1
2.2
Obj2 jest trwałą kolekcją posiadającą Obj1
2.3
Obj1 jest osiągalny z jakiegoś obiektu, do którego ma dostęp Obj2.
Zależności te nie dotyczą jedynie jednego kontenera. Relacje między obiektami mogą zachodzić
ponad kontenerami. W przypadku, kiedy obiekt osiągalny jest przez obiekt z innego kontenera nie jest
on uznawany jako kandydat do skasowania.
17
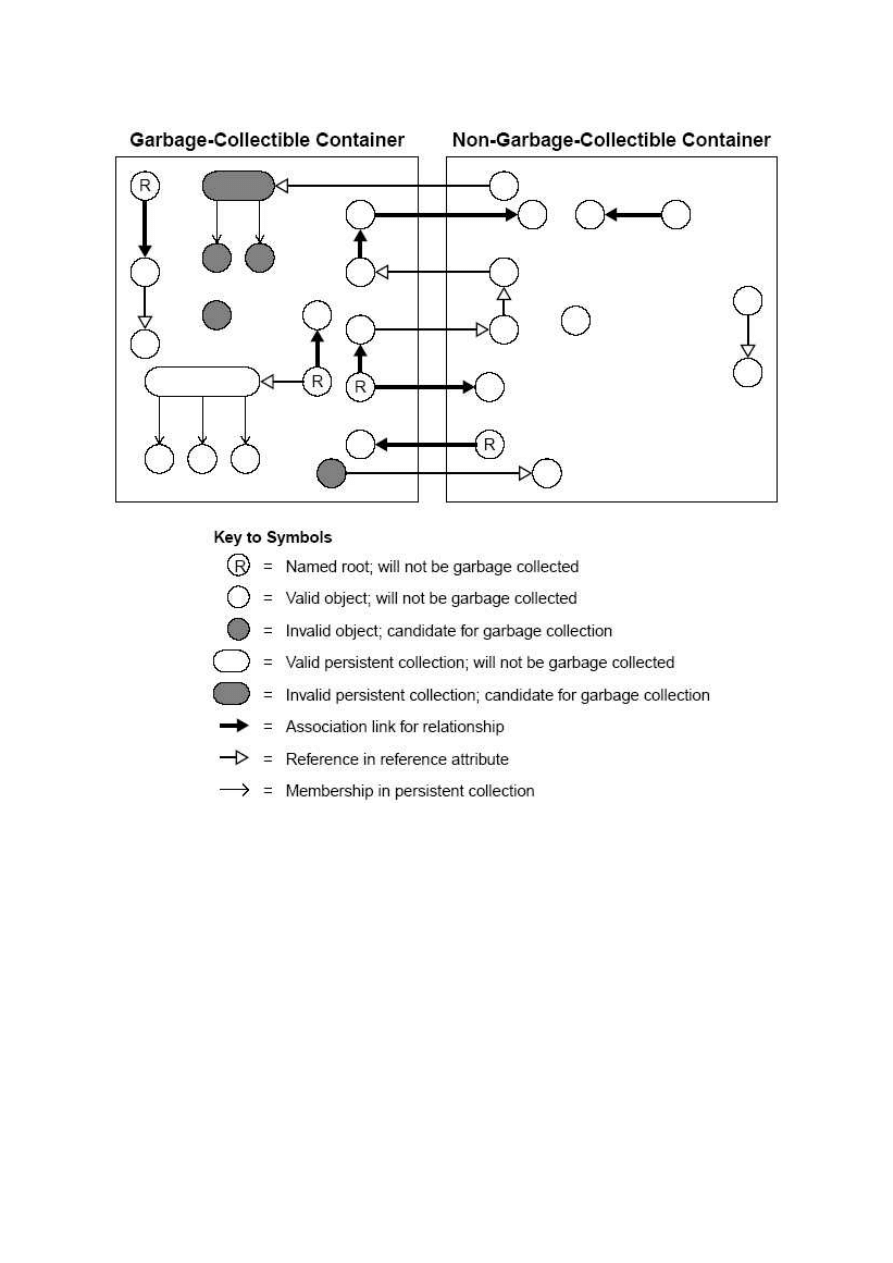
Rysunek 8„Objectivity for Java Programmer’s Guide” strona 181. Różnice
między kontenerem z odśmiecaczem a zwyczajnym.
Kontenery bez odśmiecacza uznają, że każdy trwały obiekt, który posiadają jest aktywny. Aplikacja
musi sama zadbać o usuwanie obiektów, które przestały należeć do struktury powiązań obiektów. Aby
skasować obiekt należy na nim wywołać metodę delete(). Obiekty z kontenera bez odśmiecacza nie
są kasowane podczas działania narzędzia oogc.
18

Dostęp do kontenerów odbywa się poprzez obiekt bazy danych. Metoda lookupContainer()
obiektu ooDBObj zwraca kontener o podanej nazwie lub null jeżeli taki nie istnieje. Istnieje też
możliwość przejścia iteratorem po wszystkich kontenerach bazy wywołując metodę contains().
Baza Danych jest to obiekt przechowujący kontenery. Każda baza danych posiada swój domyślny
kontener (ang. default container) oraz kontener nazwanych korzeni (ang. named roots). Dodatkowo
może posiadać kontenery utworzone przez aplikację.
Baza danych może być utworzona przez administratora poprzez odpowiednie narzędzia lub z poziomu
aplikacji. Każda baza danych należy tylko do jednej federacji i posiada unikalną nazwę w jej obrębie.
Fizycznie baza danych stanowi plik na dysku. Istnieje możliwość przenoszenia baz pomiędzy
federacjami za pomocą narzędzia ooattachdb. Taka operacja może powodować spore komplikacje
jeżeli okaże się, iż obiekty z pozoru tej samej klasy nagle okażą się niekompatybilne (błędy związane
z zarządzaniem schematem).
Federacja
Potocznie zwana „baza danych” w przypadku Objectivity/DB oznacza federację baz danych
(mogących znajdować się na różnych maszynach). Federacja jest to byt tworzony przez
administratora. Grupuje ona w sobie bazy danych korzystające ze wspólnego modelu obiektów
(schematu). Federacja może być stworzona tylko z poziomu narzędzi administratorskich.
Aplikacja łączy się z federacją baz danych poprzez BootFile, plik opisujący położenie pliku federacji.
Aplikacja może korzystać tylko z jednej federacji podczas swojego działania.
Wielowątkowość
Objectivity/DBDB zapewnia możliwość dostępu do bazy danych dla wielu klientów jednocześnie.
Obsługą wielowątkowości zajmuje się serwer zamków (ang. lock server) – oolockserver. Dba on
o zapewnienie zasad ACID w stosunku do transakcji operujących na bazie. Jest to mały proces, który
może być uruchomiony na dowolnej maszynie. W pliku bootFile każdej federacji zapisany jest adres
hosta, na którym uruchomiony jest serwer zamków. Aplikacja nie łączy się explicite z lock serverem.
Dzieje się to głębiej w bibliotekach obsługujących dostęp do bazy.
Aplikacja dokonuje wszystkich operacji bazodanowych w ramach sesji, która działa w ramach
konkretnego połączenia. Sesja jest instancją klasy Session dostarczanej przez producenta. Służy
ona do interakcji aplikacji z bazą danych oraz udostępnia dane i zasoby. Wszystkie transakcje
odbywają się w ramach sesji. Transakcja rozpoczyna się metodą begin() obiektu Session a
kończy commit(). Istnieje też możliwość zerwania transakcji – metoda abort(). Podczas
transakcji aplikacja zakłada dwa rodzaje zamków: do czytania (read lock) lub do modyfikacji
obiektów (write lock). W momencie, kiedy aplikacja pobiera obiekt do czytania baza danych, zakłada
na nim zamek „do czytania”. Jeżeli aplikacja będzie próbowała zapisać pobrany obiekt (np. po
zmianie zawartych w nim danych) zamek zostanie zaktualizowany do „do pisania” (write lock).
Baza Objectivity/DB zapewnia dwa rodzaje dostępu wielowątkowego:
•
Standardowa wielowątkowość
•
Tryb “Multiple Readers, One Writer (MROW)”
19

Standardowa wielowątkowość oznacza, że aplikacja może poprosić o zamek do odczytu tylko, jeżeli
na kontener nie został założony zamek do modyfikacji. Jeżeli na kontenerze założony został zamek do
pisania, nie można na nim zakładać innych zamków, nawet do czytania.
W trybie MROW baza dopuszcza możliwość czytania danych w momencie, kiedy na kontenerze
założony został zamek do pisania. Oznacza to, iż do momentu zatwierdzenia przez transakcję
modyfikującą wszystkie inne transakcje posiadające zamki do czytania będą widziały stan danych taki
jak w momencie zakładania zamków.
Wszystkie zamki założone przez transakcje zwalniane są w momencie jej zatwierdzenie lub zerwania.
Relacje między obiektami
Objectivity/DB pozwala na definiowanie relacji pomiędzy obiektami. Definicja taka zawarta jest w
kodzie źródłowym klasy i różni się od zwyczajnej definicji asocjacji z języka programowania.
Tworząc relację do innej klasy deklaruje się pole relacji i statyczną metodę określającą szczegóły
relacji. Pole relacji musi być jednym z dwóch typów dostarczanych przez producenta:
•
ToManyRelationship – jeżeli obiekt źródło będzie łączony z wieloma obiektami
docelowymi (agregacja)
•
ToOneRelationship – jeżeli obiekt źródło będzie łączony tylko z jednym obiektem
docelowym
Jeżeli obiekt dziedziczy z ooObj to Objectivity/DB wypełnia jego pola relacji odpowiednim
obiektem natychmiast po powołaniu go do życia.
Metoda statyczna relacji zwraca obiekt relacji, który jest typem jednym z:
•
OneToOne
•
OneToMany
•
ManyToOne
•
ManyToMany
Nazwa tej metody ma ściśle określoną formę. Musi to być [nazwa pola relacji]
_Relationship(). Zwracany obiekt przechowuje szczegóły dotyczące zachowania danej relacji.
Są to dane dotyczące:
20
public
class
Article
extends
ooObj {
...
// pole relacji
private
ToManyRelationship words;
...
}
Kod 1. Przykład definicji pola relacji.

•
Nazwa pola relacji w danej klasie
•
Pełna nazwa klasy na drugim końcu relacji (wraz z nazwą pakietu)
•
Nazwa pola relacji odwrotnej
•
Zachowanie podczas kopiowania obiektu. Może być jedno z:
➢
COPY_DELETE – po operacji skopiowania obiektu źródłowego, obiekt kopia nie będzie
posiadał relacji do obiektu docelowego
➢
COPY_MOVE – po operacji skopiowania obiektu źródłowego, relacja zostanie przeniesiona z
obiektu źródłowego do kopii. Po operacji obiekt źródło nie będzie posiadał relacji do obiektu
docelowego.
➢
COPY_COPY – wraz ze skopiowaniem obiektu źródłowego zostanie także skopiowana relacja.
Po operacji istnieć będą dwa obiekty z dwoma relacjami do tego samego obiektu docelowego.
•
Zachowanie podczas wersjonowania. Objectivity/DB w wersji dla języka Java nie obsługuje
wersjonowania. Mimo to należy zdefiniować sposób zachowania się relacji podczas
wersjonowania, aby można było korzystać z tej klasy łącząc się z bazą za pomocą innych
języków programowania.
•
Flaga (true/false) określająca, czy propagowane będzie usunięcie obiektu. Inaczej mówiąc, czy
jeżeli obiekt zostanie usunięty należy usunąć także obiekty z nim powiązane.
•
Flaga (true/false) określająca, czy propagować zamki na obiekty powiązane. Flaga ta ma
znaczenie tylko jeżeli zdecydujemy się wiązać relacjami obiekty ponad kontenerami. Jeżeli
wszystkie obiekty powiązane znajdują się w tym samym kontenerze to nie zauważymy różnicy
gdyż baza danych blokuje cały kontener a nie pojedyncze obiekty.
•
Tryb przechowywania relacji.
21
public
class
Article
extends
ooObj {
...
private
ToManyRelationship stats;
public
static
OneToMany stats_Relationship() {
return
new
OneToMany(
"stats"
,
// This relationship
"pl.edu.pjwstk.NewsSearch.WordStats"
,
// Destination class
"article"
,
// Inverse relationship
Relationship.COPY_MOVE,
// Move links to copy of object
Relationship.VERSION_MOVE,
// Move links to new version
false
,
// Don't propagate delete
false
,
// Don't propagate locks
Relationship.INLINE_NONE);
// Non-inline storage mode
}
// End stats_Relationship static method
...
}
Kod 2. Przykład definiowania relacji. Obiekt Article relacje „stats” do obiektów klasy
WordStats. Jest to relacje typu jeden-do-wielu.

Dodatki
Wraz z klasami niezbędnymi do budowania aplikacji opartych na bazie Objectivity/DB
producent rozpowszechnia zestaw dodatków. Chodzi tutaj głównie o trwałe kolekcje, które
przygotowane są do przechowywania w bazie. Spowodowane jest to główne tym, iż standardowe
kolekcje języka Java (listy, mapy i inne z pakietu java.util.*) nie są obiektami trwałymi i w
związku z tym nie mogą być przechowywane przez Objectivity/DB. W naszej pracy stosowaliśmy
ooTreeList i ooTreeMap. Obie te klasy dziedziczą z ooBTree, która zajmuje się zarządzaniem
kolekcją w środowisku Objectivity/DB. Struktura tej kolekcji oparta jest na zasadzie b-drzewa.
Przechowuje ona węzły i liście. Klasa ooBTree zajmuje się rozrzucaniem obiektów na węzły i liście.
Przy okazji sama tworzy strukturę kontenerów wiążąc je ze sobą.
Tworząc kolekcję użytkownik ma możliwość zdefiniowania maksymalnej liczby obiektów
przechowywanej w węźle b-drzewa. Przy małej liczbie spada liczba konfliktów przy zakładaniu
zamków w przypadku kiedy wiele aplikacji klienckich korzysta jednocześnie z tej samej kolekcji.
Podając dużą maksymalną liczbę obiektów minimalizujemy liczbę kontenerów obsługujących
kolekcję.
3.2.
Java
Obiektowy język programowanie stworzony przez firmę SUN (
http://
java.sun.com
). Główną
jego zaletą jest pełna obiektowość bez możliwości obejścia jej sztuczkami programistycznymi.
Dużym udogodnieniem Javy jest pełny zestaw kolekcji oraz gotowych klas pomocniczych, dzięki
którym tworząc aplikacje programuje się w zasadzie tylko jej logikę. Nie trzeba natomiast tworzyć od
zera swoich klas pomocniczych implementujących rożnego rodzaju struktury danych.
Wszystkie programy Javy uruchamiane są w maszynie wirtualnej (ang. Java Virtual Machine –
JVM). Kod źródłowy programu kompilowany jest do postaci bajtkodu (ang. byte code). Dzięki takiej
architekturze dowolna aplikacja stworzona przy pomocy standardowych klas Javy jest w pełni
przenośna pomiędzy dowolnymi systemami operacyjnymi, które posiadają implementacje maszyny
wirtualnej. Wszystkie operacje dostępu do zasobów (pliki, pamięć, zasoby sieciowe) odbywają się
poprzez JVM. Do zadań maszyny wirtualnej należy sprawne zarządzanie pamięcią aplikacji Javy oraz
umożliwianie dostępu do zasobów w danym systemie operacyjnym.
Java oferuje tzw. odśmiecacz (ang. Garbage Collector w skrócie GC). Jest to mechanizm
wbudowany w maszynę wirtualną Javy służący do usuwania z pamięci nieużywanych obiektów.
Programując w tym języku twórca aplikacji nie zajmuję się w ogóle kwestiami zarządzania pamięcią.
Obiekty są powoływane a ich niszczeniem zajmuje się GC.. W maszynie wirtualnej SUNa
znajdywanie kandydatów do usunięcia odbywa się wykorzystując algorytm „Mark and Sweep”.
Polega on na przejściu przez wszystkie obiekty zaczynając od najniższego na stosie. Przechodząc
przez każdy z nich odznaczana jest flaga „marked”. Po zakończeniu procesu wszystkie obiekty, które
nie mają ustawionej tej flagi zostają usunięte. Specyfikacja maszyny wirtualnej nie definiuje sposobu
znajdowania martwych obiektów. Kwestia ta pozostawiona jest do decyzji producenta danej
wirtualnej maszyny.
Obiekt jest aktywny jeśli istnieje jakaś ścieżka z aktualnie wykonywanego programu poprzez
obiekty powiązane, kolekcje itp. do danego obiektu. Jeżeli taka ścieżka nie istnieje, obiekt jest
kandydatem do skasowania. Usuwanie nieużywanych obiektów nie odbywa się natychmiastowo po
utracie dostępu do obiektu. Obiekty-śmieci istnieją przez jakiś czas w pamięci a proces odśmiecania
odbywa się raz na jakiś czas lub w razie konieczności uwolnienia pamięci (np. kończy się pamięć
programu a aplikacja próbuje powołać nowe obiekty).
22

3.3.
Gram
Dużym zagadnieniem w wyszukiwaniu pełnotekstowym jest analiza i przekształcanie tekstu. W
naszej pracy skupiliśmy się głównie na stworzeniu mechanizmu indeksującego i wyszukującego.
Analiza tekstu w języku polskim to temat na odrębną prace magisterską, dlatego też wykorzystaliśmy
gotowe oprogramowanie. Firma Neurosoft udostępniła nam swój główny produkt – GRAM
(
http://
gram.neurosoft.pl
/
). Jest to oprogramowanie służące do zaawansowanej analizy i
przekształcania tekstów w języku polskim. Jest ono wykorzystywane w profesjonalnych
zastosowaniach. Zostało wbudowane w mechanizm wyszukiwarki NetSprint.pl, który jest
wykorzystywany przez Wirtualną Polską oraz wiele innych wyszukiwarek dostępnych w polskim
Internecie.
Funkcjonalność oprogramowania Gram udostępniana jest poprzez interfejsy CORBA. Dzięki
temu analizy językowe stają się dostępne dla każdego języka programowania z obsługą standardu
CORBA.
Z oprogramowania GRAM korzystamy głównie w celu normalizacji tekstów. Normalizacja
polega na zamianie wszystkich słów na ich formy podstawowe. Dzięki temu wyszukiwanie informacji
staje się łatwiejsze i celniejsze. Wpisując tekst do znalezienia użytkownik nie musi się martwić czy
podał go w odpowiedniej formie. Mechanizm szukające odnajdzie wszystkie teksty, w których
występują dane słowa bez względu na to, w jakiej formie zostały użyte.
3.4.
Python
Język skryptowy, który aspiruje do miana „obiektowego”. Niestety po pierwszym momencie
fascynacji podsyconej dużym szumem w kręgach programistycznych wychwalającym ten język,
szybko doszliśmy do rozczarowania. Główną wadą tego języka jest to, że nie jest w stu procentach
obiektowy. Niestety, mimo dużych starań twórców przemknęły się do niego konstrukcje rodem z PHP
lub C. Najlepszym tego przykładem jest sposób pobierania długości listy. Mając obiekt lista, w
którym przechowujemy elementy naturalnym sposobem, z punktu widzenia obiektowości, wydaje się
wywołanie metody length() lub size() (lub podobnej) na naszym obiekcie. W Pythonie, z
niezrozumiałych względów, przyjęto rozwiązanie, w którym chcąc otrzymać rozmiar listy należy
wywołać funkcję globalną len(list) przekazując jako parametr referencję do obiektu lista.
Oczywiście, fakt iż jest to technologia skryptowa niesie ze sobą wszystkie wady (liczne) i
zalety (stosunkowo nieliczne) języków skryptowych. Są to:
•
Brak kompilacji: 90% błędów programisty jest do wychwycenia w procesie kompilacji. Błędy
popełnione w programie skryptowym ujawnią się dopiero w momencie wykonania wadliwego
kodu. W modułach bardzo rzadko uruchamianych taki błąd może ujawnić się bardzo późno
(nawet po miesiącach).
•
Brak mocnego typowania. Nie jest to cecha przywiązana do języków skryptowych, jednak
większość spotykanych języków skryptowych uznaje co najwyżej dwa typy: liczbowy i
tekstowy. Python nie odbiega od tego schematu
•
Brak deklaracji zmiennych. Zmienne powoływane są w momencie ich pierwszego użycia. Nie
jest to wielka wada, ale w dużych aplikacjach przy niskiej „higienie” kodu może wprowadzać
dodatkowe zamieszanie do i tak skomplikowanego kodu.
•
Metody i zmienne prywatne (zob. sekcja 9.6
dokumentacji
Pythona). Python nie oferuje
możliwości definiowania zmiennych i metod prywatnych. Pseudo-prywatność zmiennych i
metod można osiągnąć poprzez specjalne nazewnictwo: __metodaA(). Nazwy takie zamieniane
są podczas wykonania na [nazwaklasy]__metodaA(), co powoduje ukrycie takich pól przed
23

dostępem z zewnątrz. Mimo takich zabiegów istnieją sposoby obejścia zakresu widoczności
zmiennych tak, że pola i metody prywatne stają się dostępne z zewnątrz.
•
Bloki programu. Do definicji bloków programu nie stosuje się klamr (np. „{” i „}”). Zamiast
tego kod jest formatowany odpowiednio wcięciami. Wcięcie głębsze od aktualnego oznacza
wewnętrzny blok. W momencie przenoszenia plików na inne systemu operacyjne obsługujące
inne kodowania mogą powstawać błędy spowodowane przesunięciem się niektórych wcięć.
Oczywiście Python posiada również zalety:
•
Olbrzymi zasób bibliotek implementujących prawie wszystkie spotykane w Internecie
technologie (nntp, imap, pop3, http, ftp, wyrażenia regularne, kolekcje, CORBA, i inne).
•
Wyjątki. Podobnie do Javy wbudowany został mechanizm obsługi wyjątków. Wszelkie
nietypowe zachowanie sygnalizowane jest odpowiednimi wyjątkami zamiast zwracania kodów
błędów przez funkcje.
•
Szybkie tworzenie małych programów. Dzięki rozbudowanym zasobom biblioteki i możliwości
ściągnięcia dodatków z Internetu programowanie niewielkich aplikacji może okazać się bardzo
szybkie.
Ogólnie Python jest krokiem w dobrym kierunku jeżeli chodzi o języki skryptowe. Na pewno
jest on przyjemniejszy w programowaniu niż PHP. Jednak dla programisty Javy przejście na Pythona
może być źródłem sporej frustracji.
3.5.
PostgreSQL
Relacyjna baza danych rozpowszechniana na zasadzie Open Source. Zapewnia ona pełny
zestaw operacji bazodanowych – SQL, transakcje (pełna zgodność z ACID), procedury składowane
(ang. stored procedures), wyzwalacze (ang. triggers), indeksy, prawa dostępu, widoki (ang. views).
Postgres pozwala na prawie bezbolesne przenoszenie baz z/na Oracle, SQL Servera lub inne
obsługujące SQLa. Jest to w pełni profesjonalny system zarządzania bazą danych, który został
wykorzystany w wielu projektach komercyjnych.
Jedną z ciekawszych zalet tego SZBD stanowi konstrukcja „SELECT pole1, pole2
FROM tabela LIMIT x OFFSET y” ograniczająca zwracane rekordy tylko do określonego
wycinka. Jest to szczególnie istotne w aplikacjach internetowych gdzie zachodzi potrzeba
stronicowania danych, np. pokazywanie po 20 wątków na stronie. W innych SZBB (np. SQL Server)
24
„
początek petli
”
for
i
in
range(1,2):
"
i:
" + str(i)
„
kolejny krok pętli
”
„
koniec petli
”
Kod 3. Przykład deklaracji pętli w języku Python

trzeba niestety stosować obejścia poprzez implementowanie odpowiednich procedur składowanych
dla osiągnięcia podobnego efektu.
Niestety Postgres mimo swojego profesjonalnego podejścia i obsługi standardów SQL92 i
SQL99
(jak
chwalą
się
jego
twórcy
w
Internecie:
http://
www.postgresql.org
/ docs
/7.4/
interactive
/ preface.html
#INTRO-WHATIS
) nie oferuje żadnych
dodatkowych udogodnień:
•
Brak jest możliwości zaawansowanego tuningu bazy pod względem wydajności.
•
Brak zapamiętywania często wykonywanych niezmiennych zapytań.
Główną zaletą Postgresa jest fakt, iż jest dostępny za darmo i jednocześnie jest prawie w pełni
kompatybilny z SQL. W porównaniu z MySQL-em – innym darmowym system zarządzania bazą
danych Postgres wypada bardzo dobrze.
3.6.
Leafnode
Głównym i jedynym źródłem danych dla naszego mechanizmu wyszukiwarki jest domowy
serwer grup dyskusyjnych LeafNode (wersja leafnode-1.9.42.rel). Jest to proste
oprogramowanie obsługujące protokół NNTP, ściągające artykuły i grupy dyskusyjne z serwera
głównego (ang. feed). W naszym przypadku skorzystaliśmy z publicznego serwera
news://news.task.gda.pl oferującego większość grup światowych i prawie wszystkie grupy
polskie. Początkowo próbowaliśmy korzystać z serwera news://news.tpi.pl lecz jego
wydajność pozostawia sporo do życzenia. Server Leafnode udostępnia ściągnięte posty dalej
użytkownikom poprzez protokół NNTP. Można łączyć się z nim za pomocą każdego programu
czytnika grup dyskusyjnych.
Leafnode przechowuje ściągnięte artykuły na dysku jako pliki. Każdy artykuł to oddzielny plik,
a każda grupa to oddzielny katalog. Stwarza to pewne problemy gdyż tylko nieliczne systemy plików
potrafią sobie poradzić z ogromną ilością małych plików przechowywanych w jednym katalogu.
Początkowo dane zapisywane były w systemie Ext3 jednak szybko doszliśmy do fizycznego
ograniczenia liczby plików. Obecnie system działa na systemie plików ReiserFS, który nie posiada
limitu liczby plików.
Serwer LeafNode skonfigurowany jest tak, że nie kasuje starych postów. Dzięki temu jesteśmy
w posiadaniu pełnej historii polskich grup dyskusyjnych od połowy sierpnia roku 2003.
Co noc uruchamiany jest proces ściągania nowych artykułów z polskich grup dyskusyjnych
(pl.*, alt.pl.*, free.pl.*, ms-news.pl.*). Niestety, oprogramowanie to jest mało wydajne. Proces
ściągania przy rozmiarze archiwum ok. 10gb trwa ok. 22 godziny. Możliwe że jest to spowodowane
słabą wydajnością maszyny, na której działa (procesor 333MHz, 64mb RAMu). Przy przekroczeniu
24 godzin może dojść do dodatkowych komplikacji. Jeżeli zaś proces ściągania nowych postów
będzie uruchamiany co dwa dni może to doprowadzić do efektu „kuli śniegowej” – im rzadziej
ściągane posty tym ich więcej, więc dłużej to trwa itd.
3.7.
Biblioteki
Biblioteka NNTP
Implementacja fetchera (roz 5.2) korzysta z biblioteki, łączącej się z serwerem poprzez
protokół NNTP. Początkowo wykorzystywaliśmy bibliotekę gnu.inet.nntp projektu Savannah
(
http://
savannah.nongnu.org
/ projects
/nntp-
java
/
). Jest to rozbudowana biblioteka implementująca
większość komend protokołu NNTP. W czasie prac okazało się, że potrafi zawiesić się bez podania
25

błędu, przez co uniemożliwia dalszą prace. Jednym wyjściem okazało się zaprogramowanie własnego
modułu komunikacji z serwerem NNTP. Zadanie okazało się dosyć proste. W krótkim czasie powstała
skromna biblioteka obsługująca niezbędne elementy komunikacji z serwerem. Zaimplementowane
zostały tylko komendy przez nas wykorzystywane. Wiele możliwości protokołu NNTP zostało
pominięte, gdyż nie są one w jakimkolwiek stopniu nam przydatne.
26

4. Obiektowość a wyszukiwanie pełnotekstowe
Rozdział czwarty pracy składa się głównie z dokładnego omówienia i uzasadnienie rozwiązania
zastosowanego w ramach pracy. Szczególny nacisk został położony na algorytmy stanowiące
zasadniczy rezultat pracy, czyli algorytm indeksowania i wyszukiwania informacji.
4.1.
Obiektowość a wyszukiwanie informacji
Od kilku dobrych dekad (to informatyczny odpowiednik tradycyjnego „od wieków”) trwa
nieustanna walka (niestety nie zawsze na rzeczowe argumenty) pomiędzy zwolennikami relacyjnych
(RDBMS) i obiektowych (ODBMS) systemów baz danych. Orędownicy obu koncepcji często nie
stronią od kategorycznych opinii na temat opiewanej przez siebie technologii, dyskwalifikując
jednocześnie wszystkie konkurencyjne rozwiązania („każde zadanie da się wykonać szybciej i
efektywniej stosując bazę relacyjną/obiektową”, „obiektowe/relacyjne bazy danych to relikt
przeszłości”, etc). Oczywiście, jak zwykle w takich przypadkach bywa, prawda leży pośrodku. Obie
koncepcje mają swoje dobre i słabe punkty, nie ma uniwersalnego rozwiązania, a zastosowanie
konkretnej technologii zależy przede wszystkim od specyfiki projektu. W tym miejscu należałoby
przybliżyć nieco konkretne „za i przeciw” obu rozwiązań, aby wyjaśnić powody, dla których w
omawianej aplikacji wybrane zostało konkretne rozwiązania, oparte o system obiektowy.
Ogromną zaletą baz relacyjnych jest powszechne użycie deklaratywnego języka zapytań SQL,
który mimo licznych wad i błędów koncepcyjnych, przyjął się i jest obecnie uznawany za standard.
Stosowanie SQL uwalnia programistę od ciągłego myślenia o niskopoziomowych szczegółach
implementacyjnych i pozwala spojrzeć na aplikację z wyższego poziomu abstrakcji, jedynie przez
pryzmat formalnych powiązań między danymi. Zaletą systemów relacyjnych jest więc przede
wszystkim znana i popularna technologia, a co za tym idzie, również bardzo dobre wsparcie dla
narzędzi wspomagających rozwijanie aplikacji opartych na relacyjnym silniku. Istotnym plusem jest
także istnienie standardów, takich jak ODBC i JDBC, dzięki którym, przynajmniej teoretycznie,
przejście do nowej wersji, czy zmiana stosowanego systemu baz danych nie powinna nieść za sobą
kłopotliwych zmian w kodzie aplikacji. Jednak trzeba tu poczynić pewne założenia. Po pierwsze
takie, że kod rozwijanej aplikacji zawiera jedynie standardowe komendy SQL i nie stosowane są
jakiekolwiek rozszerzenia standardu oferowane przez system. Po drugie, musimy przyjąć, że
stosowany system zarządzania bazą danych zapewnia całkowite wsparcie dla tego standardu. Niestety,
pierwsze założenie w znaczny sposób uszczupla możliwości programisty, szczególnie gdy powiązania
między danymi są skomplikowane i trudno je zamodelować jedynie przy użyciu standardowych
dostępnych w RDBMS metod. Wybiera się więc najczęściej rozwiązanie połowiczne – częściowe
odejście od standardu, wiążące się z utratą całkowitej przenaszalności kodu, na rzecz ułatwień
programistycznych i lepszej wydajności pracy. Wielu ważnych dostawców baz danych (w tym firma
Oracle) oferuje od pewnego czasu rozwiązania hybrydowe. Są to bazy oparte na filozofii relacyjnej,
jednak oferujące pewne elementy obiektowości, jak np. referencje między krotkami, dziedziczenie
encji, wołanie metod, itp. Rozwiązania te charakteryzują się całkowitą nieprzenaszalnością (brak jest
jakiegokolwiek standardu odnoszącego się do tego typu systemów), mogą być jednak dobrym
rozwiązaniem w przypadku gdy posiadamy już aplikację bazującą na systemie relacyjnym i występuje
potrzeba jej optymalizacji, czy reorganizacji struktury danych.
Rozwiązania hybrydowe nie eliminują jednak największej niedogodności, jaką stwarzają systemy
oparte na filozofii relacyjnej. Jak zauważa Steve McClure
3
z International Data Corporation, 25%
czasu jaki spędza programista przy tworzeniu aplikacji poświęcane jest na mapowanie struktury
danych w bazie na strukturę obiektową używaną w kodzie programu. Mapowanie takie może mieć
sens, jeśli ważnym wymaganiem aplikacji ma być jej przenaszalność na inne systemy baz danych. W
3
S.McClure, Object Database vs. Object-Relational Databases. IDC Bulletin #14821E - August 1997.
(
http://www.ca.com/products/jasmine/analyst/idc/14821E.htm#BKMTOC2
)
27

przypadku przywiązania firmy do konkretnego narzędzia bazodanowego jest to jednak zupełnie
niepotrzebny narzut, którego niestety nie sposób zniwelować, przy zastosowaniu standardowego
systemu RDBMS. Jedyną godną uwagi próbę pójścia w kierunku większej integracji języka
programowania z systemem RDBMS podjął Oracle, ze swoim PL/SQL. Język ten sprawdza się przy
systemach typowo bazodanowych, np. opartych na Oracle Forms, gdzie oprogramowanie aplikacji
sprowadza się do utworzenia pewnej ilości procedur i bloków programistycznych w PL/SQL,
zintegrowanych w sterowane zdarzeniowo środowisko formularzy. Rozwiązanie to nie ma jednak
zastosowania w bardziej zaawansowanych projektach, opartych na strukturze MVC (Model-View-
Controller), wymagających wielu aplikacji klienckich, pracujących na różnych platformach, a także
dostęp do danych przez aplikację internetową, czy Web Services.
Mimo wielu problemów, jakie narzuca sztywny model danych stosowany w RDBMS, rozwiązania
relacyjne (i obiektowo-relacyjne) nieustannie przewodzą na światowym rynku bazodanowym. Na
sukces RDBMS oraz SQL pracuje wszakże ogromne lobby producentów, przez co wiele osób
niesłusznie może odnieść wrażenie, że model relacyjny jest jedynym możliwym podejściem do baz
danych i nie istnieją żadne sensowne, alternatywne rozwiązania.
A rozwiązania takie istnieją. Wprawdzie lansowany przez grupę ODMG obiektowy język zapytań
OQL, ze względu na liczne niejasności i pomyłki koncepcyjne nie uzyskał aprobaty rynku i (z
nielicznymi wyjątkami) nie jest wykorzystywany komercyjnie, to jednak istnieją inne, równie dobre
jak SQL sposoby dostępu do danych, opierające się zazwyczaj na nieco innej koncepcji niż
deklaratywny język zapytań. Co więcej, w specyficznych przypadkach, sposoby te mogą okazać się o
wiele bardziej skuteczne. Zastosowaniu obiektowego modelu danych, zarówno na poziomie bazy jak i
kodu aplikacji ma wiele zalet. Takie rozwiązanie, już na starcie eliminuje wspomniane wyżej 25%
pracy programistycznej, polegającej na mapowaniu obiektów języka programowania na krotki w bazie
danych. Poza tym zyskujemy bardziej naturalną, intuicyjną strukturę danych opartą na obiektach.
Język SQL, wprawdzie wspierany przez niektórych dostawców ODBMS, nie jest najlepszą metodą
uzyskiwania dostępu do danych w systemach obiektowych. Obiektowe systemy baz danych
zapewniają bowiem wiele alternatywnych, najczęściej dużo bardziej wydajnych sposobów na
wykonanie identycznych czynności. Mogą to być na przykład:
●
dostęp do obiektów poprzez referencje i struktury (tablice, listy, drzewa) referencji
●
skanowanie obiektów w bazie danych (proste wyszukiwanie ze względu na jedno lub kilka
kryteriów)
●
bezpośrednie pobranie obiektu poprzez użycie struktury obiektów-korzeni
Pierwszym omawianym sposobem jest wykorzystanie w systemach obiektowych referencji i
kolekcji referencji jako naturalne zastąpienie relacji. Przy takim podejściu, aby uzyskać interesujące
nas dane, nie musimy zazwyczaj przeszukiwać całej bazy, zadając odpowiednie kryteria. Wystarczy
przeszukać dane bezpośrednio związane z aktualnie używanym obiektem, czyli przejść poprzez
referencję do powiązanego obiektu i wywołać odpowiednią metodę. Taka nawigacja po referencjach
między obiektami może w wielu sytuacjach zastąpić nam zupełnie operację przeszukiwania bazy.
Większość systemów opiera się bowiem na bardzo powiązanych ze sobą strukturach danych, więc
operując na konkretnym obiekcie prawdopodobne jest, że operacje jakie będziemy chcieli wykonać
dotyczą bezpośrednio tego właśnie obiektu, bądź obiektów z nim powiązanych.
Większość obiektowych systemów baz danych, w tym Objectivity/DB, oferuje również narzędzie do
skanowania – wyszukiwania obiektów w bazie w oparciu określone kryteria. Skanowania takiego
nie możemy równać z zapytaniem, gdyż dotyczy ono zazwyczaj jednej konkretnej klasy obiektów i
wyszukiwanie polega na przeszukaniu wszystkich obiektów w bazie pod kątem zadanego kryterium
Brak tutaj możliwości grupowania obiektów, agregacji w celu generowania raportów, czy zwykłego
złączenia (join) dwóch klas po określonym atrybucie. Skanowanie możemy traktować więc jedynie
jako wstępną segregację obiektów w bazie danych w celu pobrania ich do dalszego przetwarzania.
W specyficznych przypadkach stosowany może być również mechanizm bezpośredniego pobierania
z bazy (lookup) obiektu-korzenia. Taki obiekt oznaczony jest unikalnym w ramach bazy
28

identyfikatorem i może być stosowany jako tzw. korzeń, od którego możemy dalej nawigować
wgłąb bazy. Obiekty-korzenie okazują się być szczególnie przydatne, gdy w bazie istnieje pewien
rodzaj danych, do których odwołania występują bardzo często. Ułatwia to i w znacznym stopniu
przyspiesza dostęp tych danych, jak również do obiektów powiązanych z nimi poprzez asocjacje.
Ostatecznie, oba te rozwiązania, czyli skanowanie i bezpośrednie pobieranie obiektu-korzenia mają
za zadanie jedynie znalezienie obiektu lub grupy obiektów, od których możemy dalej nawigować
już z użyciem tradycyjnych metod, w zależności od stosowanego języka programowania.
Kryterium
RDBMS
ODBMS
Możliwe
sposoby
pobierania i modyfikacji
danych
Deklaratywny język
SQL
i
interfejsy do konkretnych języków
programowania
Bezpośrednie pobranie obiektu
(lookup),
nawigacja
po
referencjach, skanowanie (scan),
deklaratywne języki zapytań a’la
SQL
Przenaszalność aplikacji
Bardzo wysoka, w przypadku
użycia standardowego SQL
Minimalna (brak standardów)
Wsparcie dla obiektowych
języków programowania
Brak,
bardzo
kosztowne
mapowanie obiektów w aplikacji
na strukturę bazy (ok 25% czasu
spędzanego na kodowaniu)
Bezpośrednie, brak konieczności
mapowania danych
Możliwość automatycznej
optymalizacji
Duża, ze względu na wysoki
poziom abstrakcji języka zapytań
SQL, jak również struktury danych
(trzecia postać normalna)
Znikoma, przy obecnym braku
standardów dotyczących dostępu
do danych i ich abstrakcyjnej
struktury (pewne kroki ku zmianie
tego stanu rzeczy są czynione
przez organizacje, np. grupę
ODMG)
Wpływ na strukturę
danych
w
bazie,
rozszerzalność struktury
Niewielki, stosowana jest
tradycyjna struktura encji i
związków,
uniemożliwiająca
bardziej zaawansowane powiązania
między danymi (jak
np.
dziedziczenie)
Bardzo duży, zazwyczaj możliwe
jest bezpośrednie przeniesienie
struktury klas w aplikacji na
strukturę bazy
Integracja z istniejącymi
narzędziami, językami
programowania,
systemami zarządzania
bazą
Standardy dostępu do bazy przez
ODBC/JDBC i inne, zazwyczaj
oparte na mechanizmie refleksji
(bardzo kosztowne), wiele
uniwersalnych narzędzi do
zarządzania bazą
Brak standardowych narzędzi, brak
standardowych mechanizmów
dostępu do danych. Aplikacje
zazwyczaj dostarczone przez
producenta. Dostęp do bazy
bezpośrednio, z poziomu kodu
Tabela 1. Porównanie praktycznych możliwości aktualnych systemów RDBMS i
ODBMS
Trzeba jednak pamiętać, że wyszukiwanie informacji w dobrze ustrukturyzowanych danych w
Objectivity/DB, czy innych bazach obiektowych, nie wymaga zazwyczaj skanowania obiektów z
użyciem predykatów (odpowiednik deklaratywnych zapytań z baz relacyjnych). Większość informacji
możemy uzyskać poprzez pobranie odpowiedniego obiektu-korzenia, a następnie przechodzenie od
niego do kolejnych obiektów, poprzez zdefiniowane struktury: kolekcje i referencje. W ten sposób
29

eliminowany jest ogromny dodatkowy narzut, jaki wymusza relacyjne podejście do znajdowania
informacji – konieczność każdorazowego przeszukiwania dużych zbiorów danych pod kątem
podanych parametrów, które zawężają wyniki. Oczywiście istnieją automatyczne optymalizatory,
specjalne techniki indeksowania i inne czynniki zmniejszające ten narzut. Nie zmienia to jednak
faktu, że w bazie obiektowej, techniki te nie są, jak w przypadku podejścia relacyjnego, niezbędne.
Dzieje się tak, ponieważ obiekty które potrzebujemy uzyskać, zakładając prawidłowo zdefiniowane
asocjacje między klasami, zawsze powinniśmy mieć łatwo dostępne poprzez referencje. Taki właśnie
model – wiele mocno powiązanych, zależnych od siebie obiektów, po których głównie nawigujemy,
w celu pobrania danych – stosowany jest zazwyczaj przy implementacji wyszukiwania zindeksowanej
informacji z dużych archiwów danych. Obiektowa baza danych nadaje się więc do takiego celu
idealnie, ze względu na ogromną swobodę w tworzeniu unikalnych struktur danych i optymalizację tej
struktury (często wiążącą się z redundancją danych) pod kątem wydajności wyszukiwania (czasu
odpowiedzi). Można powiedzieć nawet więcej – w tradycyjnej bazie relacyjnej, nawet najlepiej
przygotowana struktura danych, w przypadku takiego projektu jak wyszukiwarka zawiedzie – właśnie
z powodu braku możliwości dostosowania struktury danych do potrzeb aplikacji. Potwierdziły to
początkowe eksperymenty, zakładające stworzenie relacyjnej kopii struktury danych zastosowanej w
prezentowanej aplikacji, w bazie PostgreSQL. Już po zindeksowaniu paru tysięcy artykułów,
szybkość wyszukiwania różniła się kilkukrotnie na korzyść Objectivity. Można tylko zgadywać, że po
zastosowaniu bardziej skomplikowanej struktury danych, różnica ta rosłaby jeszcze bardziej
Podsumowując, oba podejścia – obiektowe i relacyjne – posiadają wiele ważnych zalet i tyleż
samo często dyskwalifikujących wad. Skalowalność, rozszerzalność i potężne możliwości
optymalizacji schematu sprawiły, że wybór rozwiązania padł w tym konkretnym przypadku na bazę
Objectivity/DB.
4.2.
Omówienie przyjętego rozwiązania
Rozwiązanie przyjęte w omawianym systemie opiera się przede wszystkim na maksymalnym
skorzystaniu z elastyczności, jaką oferuje obiektowa baza danych, w tym przypadku Objectivity/DB.
Struktura danych, czyli definicje klas i asocjacje pomiędzy klasami, została dobrana w taki sposób,
aby przede wszystkim zoptymalizować efektywność operacji wyszukiwania. Rozsądna szybkość
wyszukiwania informacji to zdecydowanie najważniejsze kryterium w ocenie każdej wyszukiwarki
pełnotekstowej. I o ile kryterium trafności wyników jest, wydawałoby się, równie istotne, to w
praktyce wyszukiwarka znajdująca nawet najbardziej adekwatne rezultaty w czasie większym niż,
powiedzmy dziesięć sekund, z góry skazana jest na porażkę. Oczywistym efektem takiego działania,
czyli koncentracji na szybkości już na etapie tworzenia struktury aplikacji, jest znaczne wydłużenie
się czasu potrzebnego na zindeksowanie artykułów (czyli stworzenie struktury danych systemu) oraz
zdecydowane zwiększenie fizycznego rozmiaru danych na dysku. Szybkość bowiem osiągamy
głównie dzięki świadomej redundancji danych, czyli przechowywaniu tej samej treści w różnych
miejscach w systemie i w różnych stadiach przetworzenia. Przy takim konkretnym zbiorze informacji
jak archiwum (polskich) grup dyskusyjnych, rozmiar samych, nieprzetworzonych jeszcze danych już
liczy się setkach gigabajtów. Uporanie się z tak ogromną strukturą wymaga specjalnego podejścia.
Standardowe mechanizmy, oferowane na przykład przez relacyjne bazy danych, nie zdają egzaminu
ze względu na zbyt uniwersalne podejście do tematu. Potrzebna jest tu bowiem struktura, która ułatwi
(przyspieszy) bezpośredni dostęp do danych, po które sięgamy najczęściej. Zbudowanie takiej
struktury umożliwia baza danych Objectivity/DB.
Główną funkcjonalnością wyszukiwarki pełnotekstowej jest oczywiście wyszukiwanie
artykułów na podstawie podanego przez użytkownika ciągu słów, dalej zwanego zapytaniem. Należy
więc zaprojektować strukturę danych w taki sposób, aby zoptymalizować operację pobierania z bazy
danych kolejnych słów zapytania użytkownika. Może to zostać zrealizowane na przykład poprzez
stworzenie odpowiedniej struktury danych, zawierającej wszystkie występujące w bazie słowa i
30

umożliwiającej odczytanie z niej w szybki sposób jednego konkretnego. Pobrane słowo powinno
posiadać łatwo dostępną informację o wszystkich swoich wystąpieniach w całym archiwum
artykułów. Niesie to za sobą wprawdzie niebezpieczeństwo, że często występujące słowa będą
niepotrzebnie przetrzymywały listy referencji to prawie wszystkich artykułów w bazie, a tym samym
opóźniały wyszukiwanie mając jednocześnie bardzo znikomy wpływ na trafność wyników. Takie
powiązanie zawęża jednak w istotny sposób przeszukiwanie bazy do konkretnych artykułów, bez
potrzeby wertowania całego archiwum. A kłopoty wynikające z występowania bardzo popularnych
słów można wyeliminować poprzez pomijanie ich w indeksowaniu, lub czyszczenie bazy tuż po tej
operacji, czy też mniej radykalnie – poprzez odpowiednie oznaczenie i tym samym eliminację z
mechanizmu wyszukiwania.
Następnie, aby znajdowanie konkretnych, dokładnych podciągów zapytania nie wymagało operacji na
całej bazie, również kolejne słowa w poszczególnych artykułach powinny być dostępne przez prostą
referencję. Możliwość nawigacji w obie strony pomiędzy kolejnymi słowami w artykule w znaczny
sposób ułatwia, a co najważniejsze przyspiesza operację poszukiwania w artykułach dokładnych
ciągów, identycznych z zapytaniem. Dodatkowy narzut w postaci przetrzymywania podwójnie
informacji o kolejności słów w artykule jest więc w tym przypadku uzasadniony.
Jeśli wyszukiwarka ma uwzględniać fleksję języka polskiego, potrzebna jest w bazie danych również
informacja o podstawowej formie każdego z zapisanych słów. Aby informacja ta mogła być
efektywnie wykorzystana podczas operacji wyszukiwania, musi być ona dostępna z poziomu
poszczególnych słów (np. metoda w obiekcie reprezentującym słowo). Tylko takie powiązanie
spokrewnionych fleksyjnie wyrazów jest w stanie zapewnić w miarę szybkie przeszukiwanie
wszystkich możliwych form podanego przez użytkownika zapytania.
Mimo całej tej optymalizacji, kwestią na jaką należy zwrócić szczególną uwagę jest jak największe
odciążenie bazy danych, szczególnie przy procesie wyszukiwania. Ewentualna słaba wydajność jest tu
bowiem bezpośrednio odczuwalna przez użytkownika końcowego. Dlatego też, należy zadbać
również o odpowiednie cache'owania zapytań i zapobieganie tym samym niepotrzebnemu
przeładowaniu bazy przez wykonywanie identycznych, powtarzalnych operacji. Na przykład,
kilkukrotne wykonanie dokładnie takiego samego zapytania powinno być automatycznie wykrywane i
zamiast operacji wyszukiwania, powinny zostać pobrane gotowe rezultaty z wcześniej przygotowanej
pomocniczej struktury danych. Mechanizm cache'owania zapytań stwarza niebezpieczeństwo
serwowania użytkownikowi nieaktualnych informacji. Dlatego też, wyniki historycznych zapytań
powinny być nieustannie aktualizowane, tak aby zawsze uwzględniać również nowo dodane artykuły.
Korzystając z powyższych wytycznych, powstaje pewna ogólna wizja działania systemu oraz
schematu struktury danych. Szczegółowo strukturę tę można ją opisać w następujących punktach:
•
Podstawowy mechanizm pobierania danych do przygotowania wyników zapytania realizowany
jest przez pomocniczą haszowaną tablicę wszystkich słów występujących w archiwum newsów
(co niekoniecznie oznacza skopiowanie jeden do jednego słownika poprawnej polszczyzny) –
taka implementacja pozwala na szybkie pobranie konkretnego słowa do dalszego przetwarzania,
co polepsza efektywność operacji wyszukiwania.
•
Do każdego ze słów podpięte jest drzewo artykułów w dwóch formach: bezpośrednio (poprzez
kolekcję referencji do artykułów), oraz poprzez pośrednie obiekty – pozycje danego słowa w
artykule (patrz rysunek: Przykład struktury danych). Pozycji takich jest dokładnie tyle ile w
sumie wszystkich słów we wszystkich artykułach. Pozycje służą przede wszystkim do szybkiego
znajdowania dokładnych ciągów wielu słów (np. cytaty) wśród zindeksowanych artykułów.
•
Najbardziej popularne słowa, czyli takie które pojawiają się w większości artykułów (dokładna
wartość procentowa progu jest konfigurowalna z poziomu kodu) są odpowiednio oznaczane, tak
aby nie były one brane pod uwagę przy wyszukiwaniu (oprócz wyszukiwania dokładnych
ciągów). Całkowita rezygnacja z przechowywania struktury pozycji dla słów popularnych jest
niepożądana, ponieważ mimo iż odchudza w znacznym stopniu bazę, to przekreśla jednocześnie
31
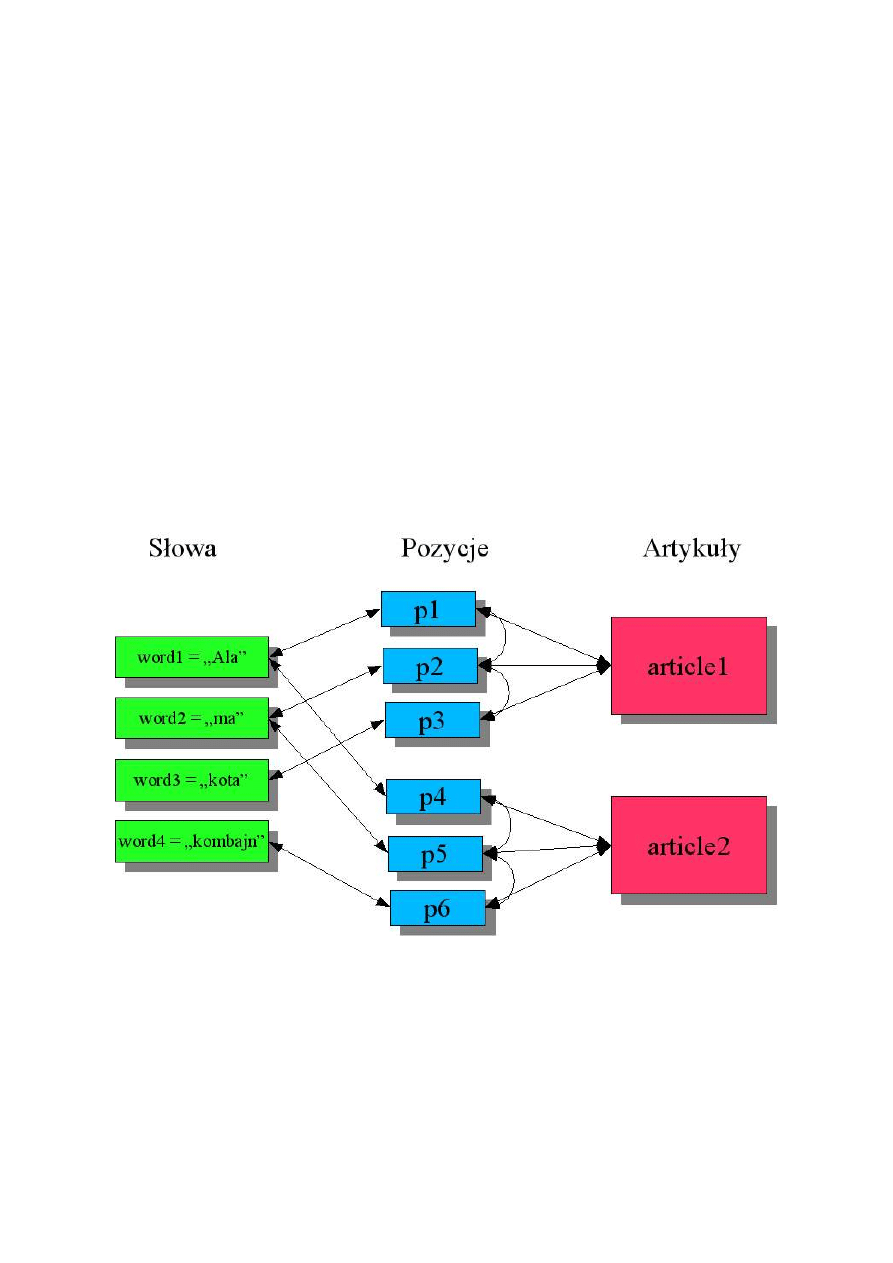
możliwość prawidłowego zwrócenia dokładnego wyniku na zapytanie zawierające jedno z tych
słów – tym samym stracilibyśmy możliwość znajdowania dokładnych cytatów
•
Każda z pozycji w artykule powiązana jest z pozycją poprzednią i następną, tworząc w ten
sposób dwukierunkową listę, oddzielną dla każdego ze zindeksowanych artykułów, po której
można szybko przemieszczać się podczas operacji wyszukiwania.
•
Każde ze słów posiada dwie listy – kolekcje referencji. Jedna będącą listą wszystkich słów, dla
których dane słowo jest formą podstawową. Druga, mniejsza, najczęściej jednoelementowa lista
form podstawowych danego słowa. Ta druga lista posiada więcej niż jeden element jedynie w
przypadku słów o wielu znaczeniach, np. słowo „pal”, mogące oznaczać zarówno rzeczownik w
pierwszym przypadku, jak również wołacz czasownika „palić”.
•
W bazie istnieje dodatkowa struktura, której zadaniem jest przechowywanie historii wykonanych
zapytań wraz z ich wynikami. W przypadku powtórnego wykonania zapytania wyniki nie są
pobierane z bazy (nie jest potrzebna droższa operacja wyszukiwania) lecz z tej właśnie
pomocniczej struktury. W ten sposób oszczędzany jest serwer bazy i nie są wykonywane
niepotrzebne, nadmiarowe obliczenia. Aby zwiększyć jeszcze wydajność tego mechanizmu,
zapytania historyczne (a konkretnie obiekty, które odpowiadają wynikom takiego zapytania)
przechowywane są jako haszowane tablice referencji w obiektach słów, od których zaczyna się
dane zapytanie. Takie rozwiązanie zawęża liczbę obiektów przeszukiwanych podczas operacji
sprawdzania, czy dane zapytanie (wraz z wynikami) znajduje się już w archiwum
•
Dodatkowy bot, czyli program odpalany automatycznie w podanych jednostkach czasu,
działający w tle, zapewnia aktualizowanie wyników najczęściej pojawiających się zapytań
poprzez ponowne ich wykonanie na zaktualizowanych danych. Zapytania pojawiające się bardzo
32
Rysunek 9. Przykład struktury danych
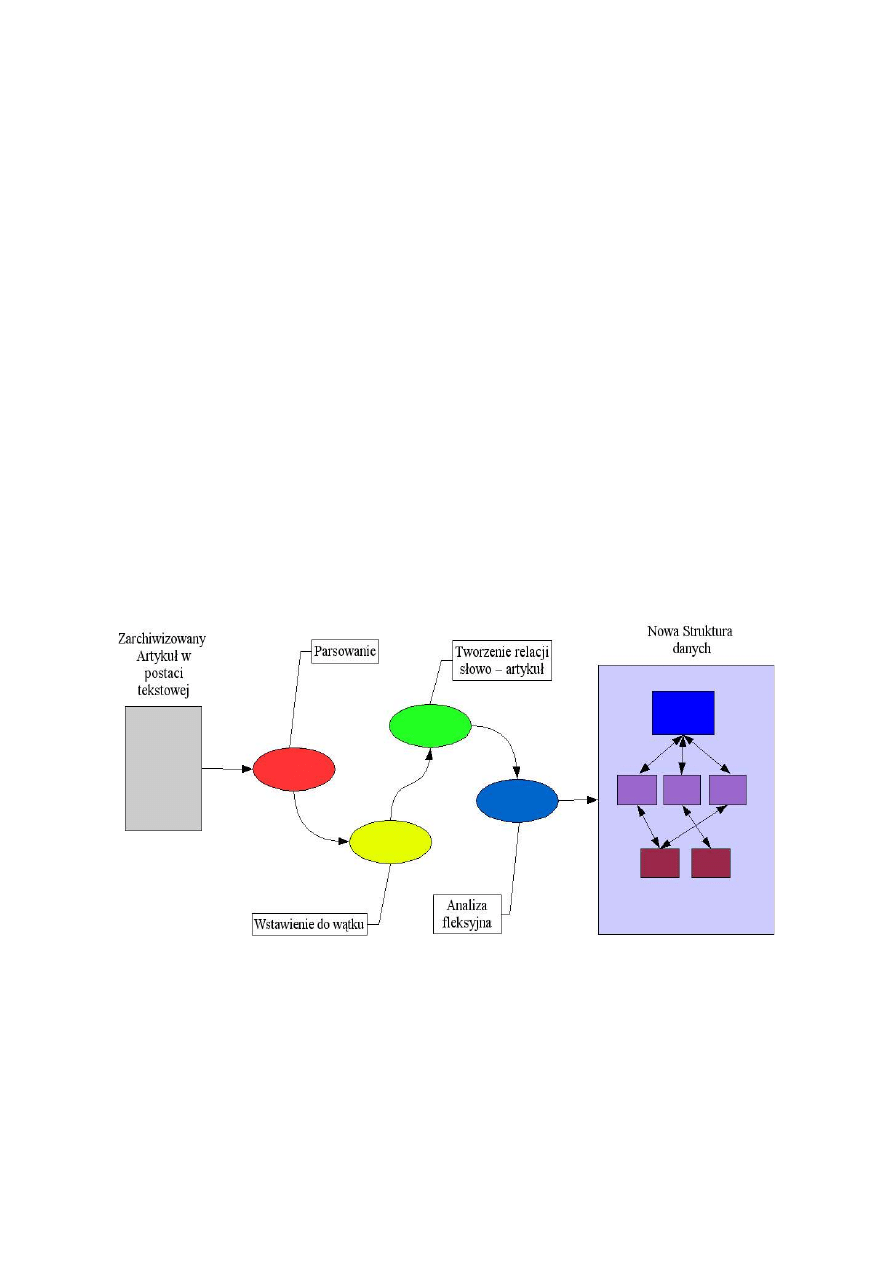
rzadko eliminowane są z tej listy, aby nie zwiększać niepotrzebnie i tak już sporego rozmiaru
bazy.
System zbudowany z założeniem maksymalnej optymalizacji procesu wyszukiwania implikuje
większe nakłady czasowe i pamięciowa związane z pozostałymi elementami, głównie indeksowaniem.
Przyjrzyjmy się więc bliżej najpierw temu mechanizmowi, gdyż to właśnie realizacja indeksowania w
największy (najbardziej zauważalny) sposób wpływa na jakość samego wyszukiwania.
4.3.
Algorytm indeksowania
Algorytm indeksowania jest najważniejszą częścią systemu i ma zdecydowanie największy
wpływ na funkcjonalność, szybkość działania i ogólne możliwości wyszukiwarki pełnotekstowej. To
przy tworzeniu algorytmu indeksowania zapadają najważniejsze decyzje co do kształtu i struktury
trwałych danych przechowywanych w bazie. Tutaj bowiem powstaje cała struktura powiązań między
danymi w systemie. Całe archiwum artykułów, przechowywanych w postaci zwykłych plików,
zupełnie uniemożliwiającej jakiekolwiek przetwarzanie informacji zostaje poddane potężnej obróbce,
w wyniku czego otrzymujemy bardzo przejrzystą strukturę danych, po której bez przeszkód możemy
nawigować w różnych kierunkach, w celu uzyskania poszukiwanego wyniku. Poszczególne części tej
struktury odpowiadają bowiem konkretnej, dobrze określonej informacji, po którą możemy łatwo
sięgnąć i wyciągnąć z niej interesujące nas dane.
Proces indeksowania jest procesem ciągłym. Kolejne artykuły ściągnięte przez serwer grup
dyskusyjnych, po zapisaniu na dysku oraz zarchiwizowaniu w bazie relacyjnej, umieszczane są w
specjalnej strukturze, tworząc listę artykułów gotowych do pobrania przez indekser i przejścia
procedury indeksowania. Każdy artykuł indeksowany jest oddzielnie. Jednak procedura dla
wszystkich wiadomości jest jednakowa.
Indeksowanie zarchiwizowanej treści artykułu można podzielić na cztery etapy:
●
parsowanie artykułu
●
umieszczenie artykułu w strukturze wątków
33
Rysunek 10. Etapy indeksowania

●
tworzenie powiązań artykuł – słowo
●
tworzenie struktury powiązań fleksyjnych słów
Pierwszy etap – parsowanie treści artykułu – polega na analizie artykułu w celu podziału
informacji w nim zawartej na informację opisującą artykuł oraz rzeczywistą treść artykułu (i
ewentualnie, dodatkowo stopkę z podpisem). Pojedynczy post ściągnięty z grupy dyskusyjnej ma w
miarę standardową strukturę. Najważniejsze informacje zawarte w opisie artykułu to, w kolejności w
jakiej występują:
•
ID artykułu (tzw. Message-ID), czyli unikalny, jednoznaczny identyfikator wiadomości wśród
wszystkich postów grup dyskusyjnych
•
temat artykułu (nie mylić z tematem grupy dyskusyjnej)
•
autor artykułu (imię i nazwisko, e-mail) – nie zawsze wprawdzie da się jednoznacznie określić
autora na tej podstawie, często jest to jednak możliwe
•
data wysłania artykułu
•
powiązanie artykułu z innymi artykułami (miejsce w wątku, artykuł rodzic, dzieci artykułu)
Parametry mają istotny wpływ na działanie wyszukiwania, ponieważ są one brane pod uwagę przy
obliczaniu wagi danego artykułu (np. gdy słowo pojawia się w temacie ma to większe znaczenie niż
pojawienie się go w treści artykułu, a gdy istnieje tylko w stopce, ma to znaczenie marginalne) oraz
przy zaawansowanym wyszukiwaniu (np. ze względu na daty lub autora postu). Oprócz tego, w
opisie artykułu zawarte są inne, mniej istotne informacje, takie jak np. nazwa klienta grup
dyskusyjnych, z którego wysłany został post, nazwa serwera, priorytet, czy rodzaj kodowania
wiadomości (Dokładną strukturę artykułu przedstawia rysunek: Struktura wiadomości NNTP). Dane
dodatkowe mogą zostać użyte np. w do stworzenia statystyk grup, mogą też być przydatne do
lepszego zidentyfikowania autora (np. poprzez określenie klienta grup dyskusyjnych, z którego
korzysta autor). Ich znaczenie dla samego wyszukiwania wiadomości jespfft jednak niewielkie.
Wynikiem parsowania artykułu jest nowo powstały obiekt, reprezentujący jeden konkretny artykuł
grup dyskusyjnych. Obiekt ten posiada standardową strukturę, która umożliwia jego dalsze
przetwarzanie na kolejnych etapach indeksowania.
Drugi etap indeksowania to umieszczenie artykułu w ogólnej strukturze postów, czyli
określenie miejsca artykułu w konkretnym wątku. Dokonuje się tego poprzez dodanie
zindeksowanej wiadomości do listy artykułów w wątku na określonej pozycji (jeśli artykuł jest
odpowiedzią na inny post), lub stworzenie nowego wątku jako obiektu w bazie i przypisanie do
niego indeksowanego artykułu (jeśli artykuł rozpoczyna wątek). Struktura wątków i postów jest
bardzo istotna nie tyle przy wyszukiwaniu, lecz raczej przy prezentacji końcowych wyników – np. w
postaci drzewa wątków. Dane potrzebne do określenia miejsca danego artykułu w strukturze
wątków znajdują się w jednym z tagów standardowej struktury artykułu: References. Tag ten
zapisywany jest jako pole nowo powstałego obiektu podczas parsowania.
Trzeci, najważniejszy etap procesu indeksowania polega na analizie samej treści artykułu,
wydzieleniu z niej pojedynczych słów i stworzeniu ich struktury. Każde kolejne słowo, znajdujące się
w treści artykułu, dodawane jest do bazy danych jako oddzielny obiekt (o ile oczywiście w bazie tego
słowa jeszcze nie uwzględniono). Następnie tworzone jest dwustronne powiązanie pomiędzy słowem
i artykułem. Każde słowo “wie” w ilu i w jakich konkretnie artykułach się znajduje, każdy artykuł
posiada szczegółową informację o słowach w nim zawartych. Dodatkowo, tworzona jest
dwukierunkowa lista słów występujących kolejno w artykule – nazywana od tej pory listą pozycji.
Każdy obiekt reprezentujący pozycję powiązany jest z jednym słowem i jednym tylko artykułem oraz
przechowuje informacje o tym, które miejsce zajmuje dane słowo w konkretnym artykule.
34
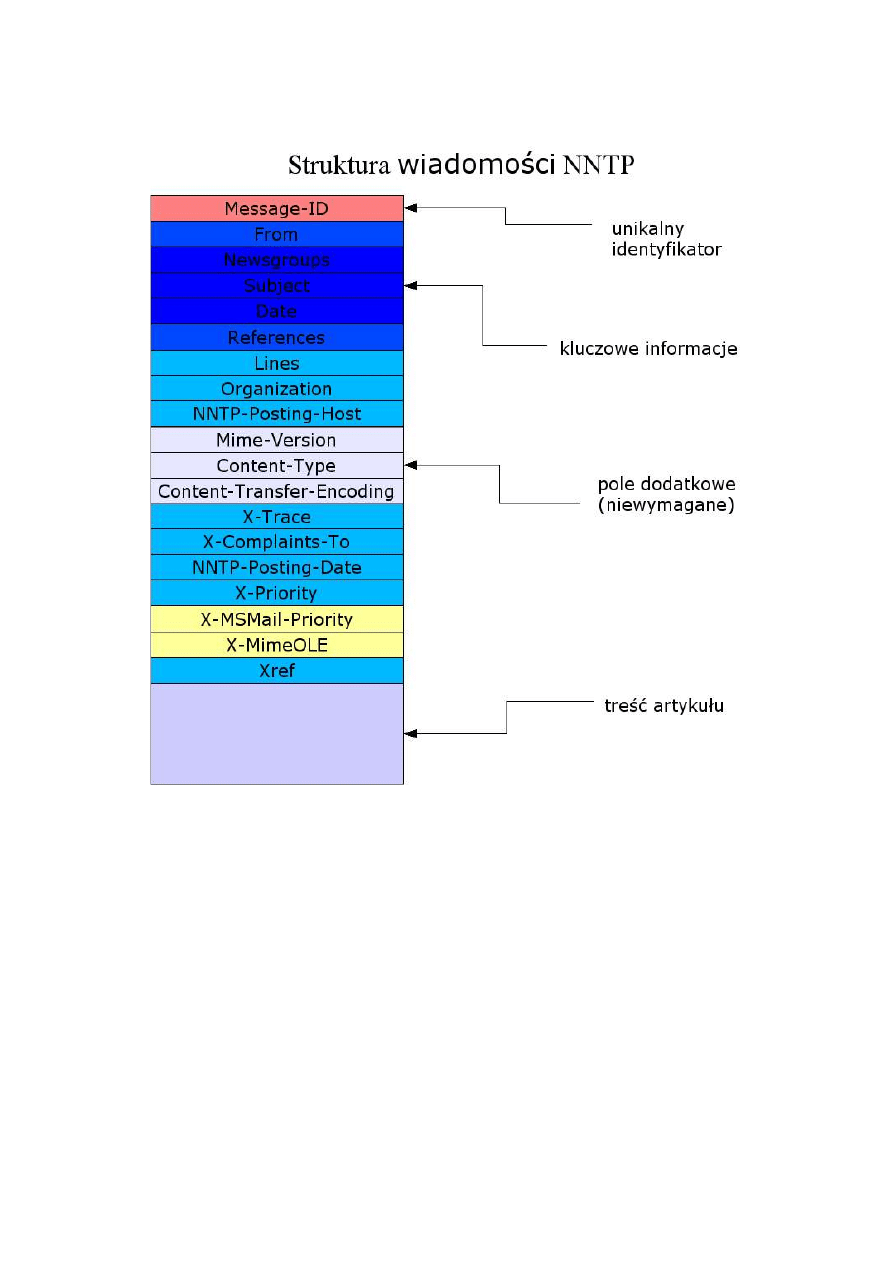
Jest to standardowy przykład relacji wiele-do-wiele, tyle że z użyciem obiektów i referencji.
Omawianą strukturę połączeń między obiektami: Artykuł, Słowo i Pozycja graficznie przedstawiono
powyżej, zobacz na rysunku Struktura referencji artykuł-słowo. Dla poprawy czytelności
zrezygnowano tu ze standardowej notacji UML na rzecz pokazania jedynie końców asocjacji jako
atrybutów. W ten sposób indeksowane są wszystkie artykuły pobrane z serwera grup dyskusyjnych.
Po zindeksowaniu, każdy z artykułów jest więc reprezentowany jako oddzielny obiekt w bazie. Obiekt
ten jest powiązany z występującymi w nim słowami: zarówno bezpośrednio (przez listę słów w
artykule) – odpowiednik relacji jeden do wiele, jak i pośrednio (lista pozycji) – odpowiednik relacji
wiele do wiele.
35
Rysunek 11. Struktura wiadomości NNTP
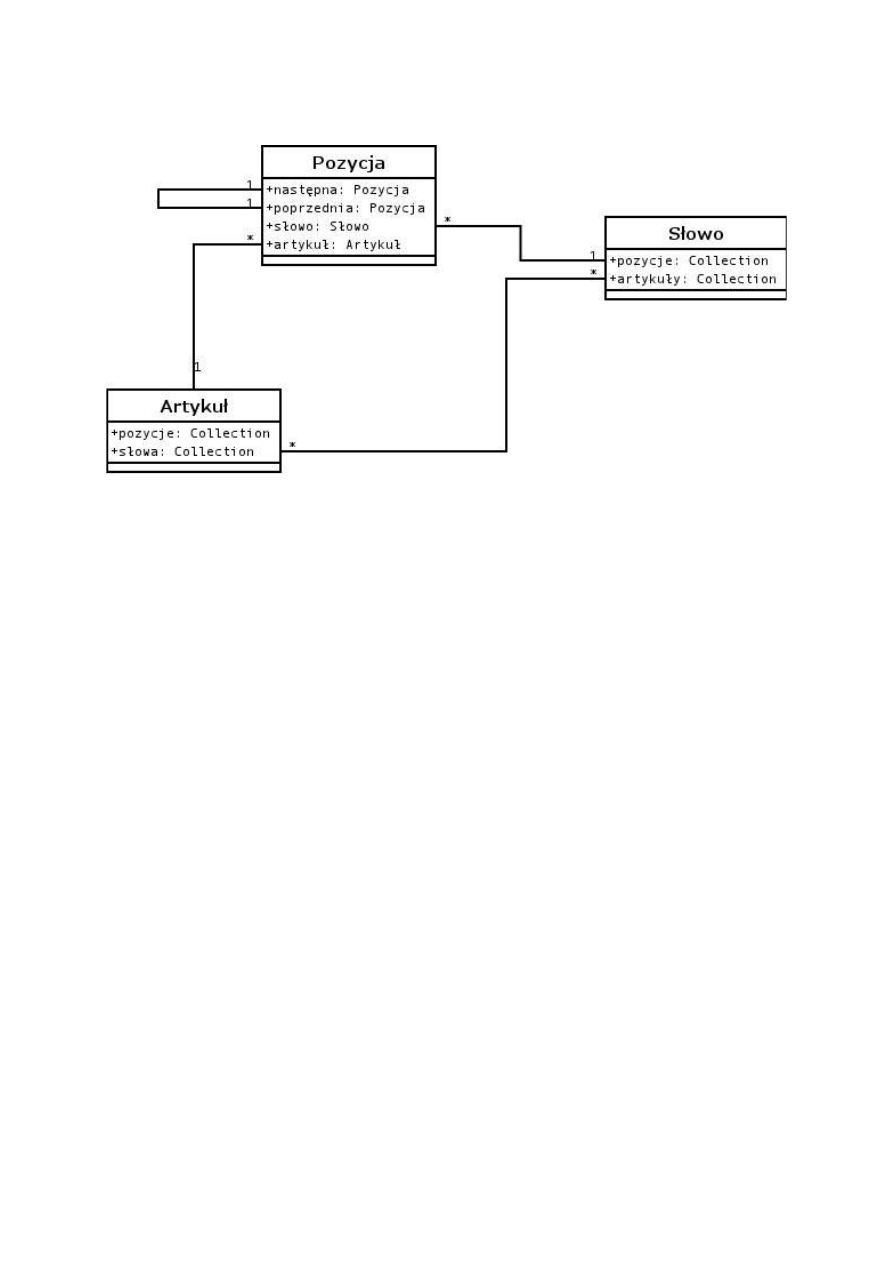
Po zakończeniu indeksowania kolejnej części artykułów, struktura danych pozwala już na
wykonanie prostego wyszukiwania (bez uwzględnienia fleksji języka polskiego). Aby możliwe było
wyszukiwanie zaawansowane, potrzebna jest jeszcze analiza wszystkich występujących w bazie słów
w celu znalezienia ich form podstawowych. Analiza ta jest czwartym, ostatnim etapem procesu
indeksowania. Ze względów technicznych, proces ten wykonywany jest jednak po zindeksowaniu
pewnej porcji artykułów. Chodzi o to, aby zapobiec wielokrotnemu sprawdzaniu konkretnego słowa,
na rzecz całościowej analizy kolejnych nowo dodanych słów. Do tego celu wykorzystywany jest
program Gram, firmy Neurosoft. Działanie procesu jest następujące. Program skanuje bazę danych w
poszukiwaniu nowo dodanych słów. Dla każdego z nich znajduje odpowiednik, będący formą
podstawową analizowanego słowa. Na tej podstawie tworzone są referencje pomiędzy słowami –
każde słowo powiązane jest z jednym (lub więcej) słowem będącym jego formą kanoniczną, oraz z
listą słów dla których to właśnie słowo jest formą podstawową. Struktura słów w postaci takiego
grafu powoduje, że wyszukiwanie z użyciem fleksji jest tylko kilkakrotnie wolniejsze od
standardowego, precyzyjnego wyszukiwania ciągu słów. Gdyby analizę językową słów przerzucić na
algorytm wyszukiwania, wydajność spadłaby do poziomu uniemożliwiającego normalną pracę.
Po zakończeniu procesu analizy fleksyjnej, baza danych znajduje się w stanie, w którym każde z
występujących w niej słów posiada informację o swojej formie kanonicznej oraz o słowach
pochodnych.
Tak przeprowadzony mechanizm indeksowania posiada kilka ważnych zalet:
•
Indeksowanie jest niezależne od kolejności artykułów poddawanych procesowi. Umożliwia to na
przykład jednoczesne, niezależne indeksowanie różnych grup dyskusyjnych. Przemieszanie
kolejności artykułów, które przechodzą proces indeksowania nie wpływa w żaden sposób na
wydajność, nie powoduje też niespójności danych
•
Wprawdzie proces indeksowania obciąża w znaczący sposób bazy danych, to jednak możliwość
przeprowadzania tej operacji mniejszymi porcjami, w znaczny sposób niweluje tą niedogodność
•
W każdej chwili można przerwać proces indeksowania bez straty danych (w zależności od
ustawionej częstotliwości operacji commit, ostateczny zapis do bazy może być wykonywany
36
Rysunek 12. Struktura referencji artykuł-słowo

nawet oddzielnie dla każdego artykułu, optymalnie jednak może to być w granicach kilkunastu
lub kilkudziesięciu artykułów)
•
Formalne rozdzielenie indeksowania artykułów od analizy fleksyjnej również wpływa na wzrost
elastyczności procesu – obie operacje można przeprowadzać oddzielnie, starając się wybrać
momenty względnie małego obciążenia bazy (np. pory nocne)
Gdy już omówiliśmy główny mechanizm działania aplikacji, możemy przejść do etapu, na
którym skorzystamy ze struktury wygenerowanej podczas indeksowania artykułów – czyli do
algorytmu wyszukiwania informacji.
4.4.
Algorytm wyszukiwania
Mechanizm wyszukiwania jest drugim co do ważności modułem aplikacji. Jego efektywność
zależy bezpośrednio od efektywności mechanizmu indeksowania, czyli adekwatności struktury
danych systemu do planowanego sposobu wyszukiwania w nim informacji. Mimo tej zależności,
istnieje jednak pewne pole manewru przy budowaniu algorytmu wyszukiwania i od niektórych
decyzji podjętych na tym etapie może w znacznym stopniu zależeć wydajność całej aplikacji.
Sposób wyszukiwania zależy przede wszystkim od rodzaju informacji, jakie chcemy uzyskać.
Nie można nigdy powiedzieć, że dany algorytm wyszukiwania jest najlepszy. Można jedynie
stwierdzić, że najlepiej spełnia zdefiniowane wcześniej kryterium trafności. Jednak, co nie wydaje się
wcale oczywiste, nie zawsze trafność musi być tym, czego oczekujemy od wyszukiwarki. A
przynajmniej nie zawsze musi mieć ona najwyższy priorytet. Kryteriów oceny wyników
wyszukiwania może być znacznie więcej i każde z nich może okazać się odpowiednie w określonej
sytuacji. Oprócz trafności rezultatów mogą to być między innymi:
–
czas wyszukiwania – ilość sekund (milisekund) od wysłania zapytania do zwrócenia wyników
(zazwyczaj liczona jako czas od otrzymania przez aplikację zapytania do zwrócenia wyników, z
pominięciem czas na wysłanie wyników przez sieć internetową, czy intranet, gdyż czas ten
zależy najczęściej od czynników niezależnych od samego silnika wyszukiwania)
–
stosunek wyników relewantnych (spełniających zdefiniowane kryteria trafności) do wszystkich
wyników wyszukiwania
–
niski procent wyników nierelewantnych
–
i inne
Tak więc, jak zostało to już zresztą wspomniane we wstępie pracy, pierwsze pytania jakie
należy sobie zadać przy budowie nowej wyszukiwarki dotyczyć powinny kryteriów, jakie należałoby
zastosować. W szczególności:
–
Jak zdefiniować trafność wyników i jak ma się ona do innych kryteriów oceny wyników
wyszukiwania?
–
Jakie kryteria powinny być priorytetowe przy zwracaniu wyników wyszukiwania?
(przedstawione np. procentowo, od najbardziej do najmniej istotnych)
W przedstawianej aplikacji postawiono przede wszystkim na trafność rezultatów
wyszukiwania. Szybkość działania aplikacji znajduje się na drugim miejscu, co oczywiście wcale nie
oznacza, że była to przy budowanie aplikacji sprawa mało istotna – większość optymalizacji zostało
przeprowadzonych właśnie ze względu na słabą wydajność konkretnego rozwiązania. Chodzi jednak o
to, że przy projekcie i implementacji nie było brane pod uwagę jakiekolwiek działanie, mające na celu
przyspieszenie aplikacji, poprzez zmniejszenie czy zawężenie jej funkcjonalności. Takie działania
powinny być zastosowane przy ewentualnym komercyjnym wdrożeniu, w którym niekoniecznie
37

niezbędna będzie cała dostarczona funkcjonalność, byłyby jednak bezcelowe i szkodliwe omawianej
aplikacji, której celem jest bardziej prezentacja wszystkich możliwości rozwiązania, niż maksymalna
wydajność. Z tego samego względu, przy budowie nie były stosowane żadne techniczno-
administracyjne aspekty przyspieszenia działania, jak na przykład stworzenie rozproszonej sieci
danych połączonej w klaster, przeniesienie części operacji na inne maszyny w celu odciążenia
głównego silnika bazy, etc. To również działania istotne dla końcowego wdrożenia, lecz zupełnie
zbędne w aplikacji, będącej przedmiotem tej pracy..
Trafność natomiast została potraktowana priorytetowo. A konkretnie definicja trafności, obejmująca
dwa najważniejsze dla nas aspekty, czyli dokładność i trwałość rozumiana jako niezależność od
czasu.
–
dokładność – zazwyczaj standardowy użytkownik oczekuje jednego z dwóch rodzajów wyników
przy korzystaniu z wyszukiwarki pełnotekstowej Pierwszy to artykuły zawierające dokładny
podany w zapytaniu ciąg słów (ew. w różnych formach fleksyjnych) – przykładem może być
tutaj cytat, tytuł książki, informacje na temat konkretnej dziedziny o specyficznej, kilku
członowej nazwie, imię i nazwisko popularnej osoby, i inne. W przeciwnym wypadku
standardowy użytkownik szuka najprawdopodobniej artykułów, zawierających informacje które
są częścią wspólną wszystkich podanych w zapytaniu wyrażeń, np. gdy nie wie jak
skonfigurować modem cyfrowy łączący z Internetem pisze: „Neostrada Linux instalacja”, gdy
poszukuje aktualności ze świata terroryzmu: „Bush Bin Laden terroryzm”, etc.. W naszym
rozwiązaniu przyjęliśmy, że ważniejsze są te pierwsze artykuły, ponieważ zazwyczaj zwracają
dokładnie to czego użytkownik oczekuje. Jeśli jednak takich wyników nie ma lub jest ich
niewiele, powinny zostać zwrócone również artykuły z drugiej grupy.
–
trwałość i niezależność od czasu – chodzi o to, żeby uniknąć zjawiska “gubienia” artykułów –
często występującego w popularnych wyszukiwarkach newsów – polegającego na
marginalizacji a w końcu ignorowaniu wyników starszych w czasie. Specyfika grup
dyskusyjnych polega między innymi na tym, że często odpowiedzi na konkretne pytanie
pojawiają się tylko raz, a następni pytający otrzymują zamiast odpowiedzi sugestię, aby najpierw
przeszukać archiwum (czasami nawet z podaniem Message-ID odpowiedniej wiadomości).
Zdarza się też, że konkretny temat pojawia się na grupach intensywnie przez bardzo krótki okres
czasu (np. najnowszy błąd w jądrze Linuksa, czy najnowszy model samochodu BMW) a
następnie znika i nikt już o nim nie wspomina. W takich przypadkach, przeszukanie odległego w
czasie archiwum bywa jedynym możliwym sposobem dotarcia do szukanej informacji. Taka
możliwość powinna więc zostać udostępniona.
Mając już odpowiedzi na dwa podstawowe pytania, możemy się zabrać do właściwej analizy
omawianego systemu, pod kątem algorytmu wyszukiwania i sposobu oceny rezultatów. Ze względu
na dużą różnorodność zastosowanych rozwiązań dotyczących poszczególnych algorytmów
wyszukiwania, zostaną przedstawione oddzielnie trzy podstawowe algorytmy wyszukiwania, które
powstały na użytek przedstawianej aplikacji.
I. Wyszukiwanie dokładnych ciągów
Ta metoda wyszukiwania opiera się na stworzonej podczas indeksowania strukturze, w której
treść zindeksowanych artykułów reprezentowana jest jako dwukierunkowe listy pozycji – obiektów
wiążących ze sobą słowo i artykuł. Każde słowo posiada informację na temat wszystkich pozycji, na
których występuje we wszystkich artykułach. Jedna referencja umożliwia przejście z poziomu słowa
do poziomu połączonej z nim pozycji i stamtąd nawigacja po kolejnych pozycjach w celu znalezienia
artykułów spełniających kryteria poszukiwania.
Szczegółowo algorytm ten przedstawia się następująco:
1. Na początku pobierane jest pierwsze słowo zapytania wysłanego przez użytkownika.
38
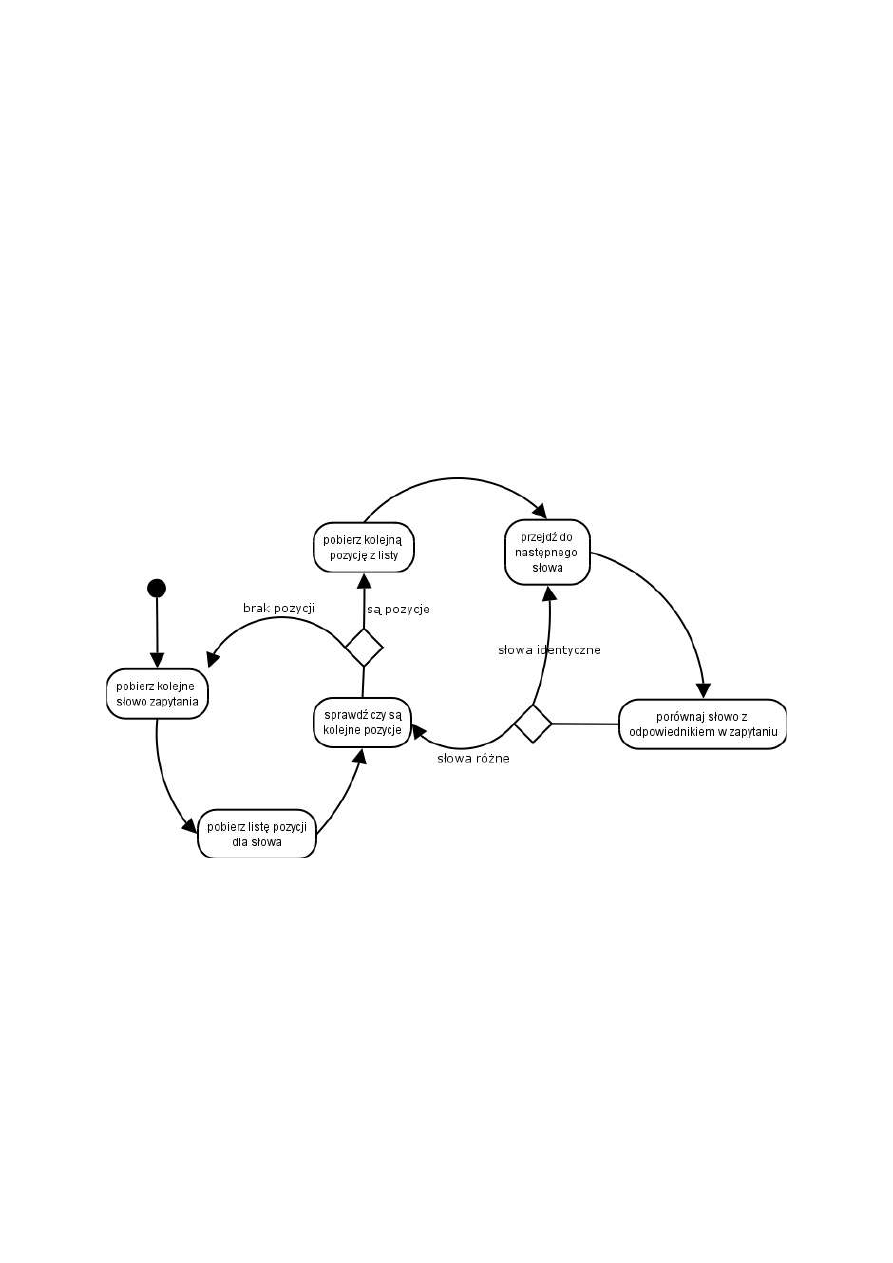
2. Dla tego pobranego słowa (o ile występuje ono w archiwum bazy danych) pobierana jest
lista odpowiadających mu pozycji.
3. Dla każdej pozycji, sprawdzamy, czy istnieje na liście pozycja kolejna
a) Jeśli tak, to sprawdzamy czy pozycja jest połączona ze słowem, które jest kolejnym
słowem szukanego zapytania. Jeśli tak, to znaczy że napotkaliśmy na artykuł zawierający
szukany podciąg i operacja się powtarza, tj. dla każdego kolejnego słowa na liście pozycji
sprawdzamy czy jest ono jednakowe ze słowem w zapytaniu. Przy każdej takiej pętli ilość
znalezionych kolejnych słów szukanego ciągu zwiększa się o jeden. Pętla zakończyć się
może w dwóch przypadkach:
–
Jeśli kolejne słowo nie jest identyczne z odpowiadającym mu słowie w zapytaniu – wtedy
artykuł dodawany jest do listy częściowych wyników i algorytm przechodzi do kolejnego
artykułu
–
Jeśli podczas przechodzenia do kolejnych pozycji na liście, nie będzie czego pobrać z
ciągu zapytania – to z kolei znaczyć będzie, że znaleźliśmy dokładny szukany ciąg słów.
W tym wypadku dodajemy znaleziony artykuł do listy dokładnych wyników oraz
przechodzimy do analizy kolejnego artykułu pobranego dla pierwszego słowa zapytania.
W ten sposób analizowana jest każda z pozycji. Gdy wszystkie pozycje powiązane z pierwszym
słowem zapytania wyczerpią się, algorytm przechodzi do kolejnego, drugiego słowa zapytania i
powyższa procedura powtarza się. Z tym, że w tym momencie nie jest już możliwe znalezienie
dokładnego szukanego ciągu, a co najwyżej podciąg o jedno słowo mniejszy niż suma wszystkich
słów szukanego zapytania. W podobny sposób analizowane są wszystkie kolejne słowa zapytania, aż
dochodzimy do ostatniego słowa, przy którym nie jest już konieczne przechodzenie po liście
połączonych z nim pozycji, lecz wszystkie artykuły dodawane są do częściowych wyników z
39
Rysunek 13. Wyszukiwanie dokładnych ciągów.

informacją o jednym tylko słowie wspólnym z zapytaniem.
Wynikiem takiego wyszukiwania są zazwyczaj dwie listy:
–
artykułów zawierających dokładne ciągi słów z zapytania
–
artykułów zawierających od 2 do N-1 słów z zapytania (zakładając że zapytanie ma N słów)
Powyższy algorytm przedstawiony jest obrazowo na rysunku: Wyszukiwanie dokładnych
ciągów.
Warto zauważyć, że przedstawiony algorytm ma sens jedynie, gdy znalezione rezultaty
zawierają co najmniej podciąg dwóch słów wspólnych z szukanym zapytaniem. Artykuły posiadające
wspólne tylko jedno słowo można spokojnie pominąć (a tym samym pominąć całkowicie ostatnią
iterację powyższego algorytmu), gdyż zostaną one i tak znalezione w kolejnym wyszukiwaniu, już bez
uwzględniania wspólnych podciągów.
II. Wyszukiwanie części wspólnej
Wyszukiwanie części wspólnej oznacza, że nie szukamy już dokładnych (pod)ciągów
zawartych w zapytaniu, lecz raczej staramy się zidentyfikować artykuły, które zawierają wszystkie
podane słowa, lub przynajmniej jak największą ilość słów podanych w zapytaniu. Algorytm ten w
mniejszym stopniu wykorzystuje zdefiniowane dla artykułów dwukierunkowe listy pozycji. Korzysta
za to intensywnie z operacji na zbiorach, w szczególności z sumy zbiorów i ich intersekcji (części
wspólnej).
Punktem wyjścia jest w tym przypadku również pierwsze słowo zapytania. Pobierane jest ono
jako obiekt-korzeń z bazy danych, tak jak każde z kolejnych słów. Różnica polega na tym, że nie
istnieje tutaj specjalny algorytm dla pierwszego słowa. Wszystkie traktowane są jednakowo przy
wyszukiwaniu, gdyż nie o kolejność nam tutaj chodzi, a o samo wystąpienie w artykułach podanych w
zapytaniu słów.
Dla każdego ze słów pobranych z zapytania użytkownika wykonujemy najpierw prosty algorytm,
który wygląda następująco:
1. Pobieramy kolejne słowo z zapytania
2. Pobieramy listę pozycji dla pobranego słowa
3. Dodajemy artykuły z pobranej listy na kolejnej pozycji w tymczasowej tablicy wyników
Po wykonaniu tej operacji, w tymczasowej tablicy, o długości równej ilości słów zapytania
znajdują się listy artykułów dla każdego ze słów. Teoretycznie jest to już lista wyników naszego
zapytania. Jedyne co należy teraz zrobić, to połączyć listy z tymczasowej tablicy, eliminując
powtarzające się artykuły (ilość powtórzeń oznacza w tym wypadku liczbę słów z zapytania
występujących w pobranym artykule, wpływa więc bezpośrednio na priorytet artykułu) i obliczyć
wagę każdego z nich. Intersekcja (część wspólna) wszystkich list tworzy nam listę artykułów, w
których występują wszystkie słowa z zadanego zapytania – te artykuły otrzymują najwyższą wagę (na
podstawie ustalonych wcześniej kryteriów). Reszta, zależnie od liczby powtórzeń, otrzymuje niższą
lub wyższą wagę i lokowana jest na odpowiedniej pozycji, w oddzielnej liście.
Wynikiem tego wyszukiwania są więc, podobnie jak w przypadku wyszukiwania ciągów słów, dwie
listy:
–
dokładnych wyników (zawierających wszystkie słowa z zadanego zapytania)
–
wyników częściowych, zawierających od 1 do N-1 słów z zadanego zapytania (w sumie
zapytanie ma N słów).
Obrazowo algorytm został przedstawiony na rysunku: Wyszukiwanie części wspólnej
40
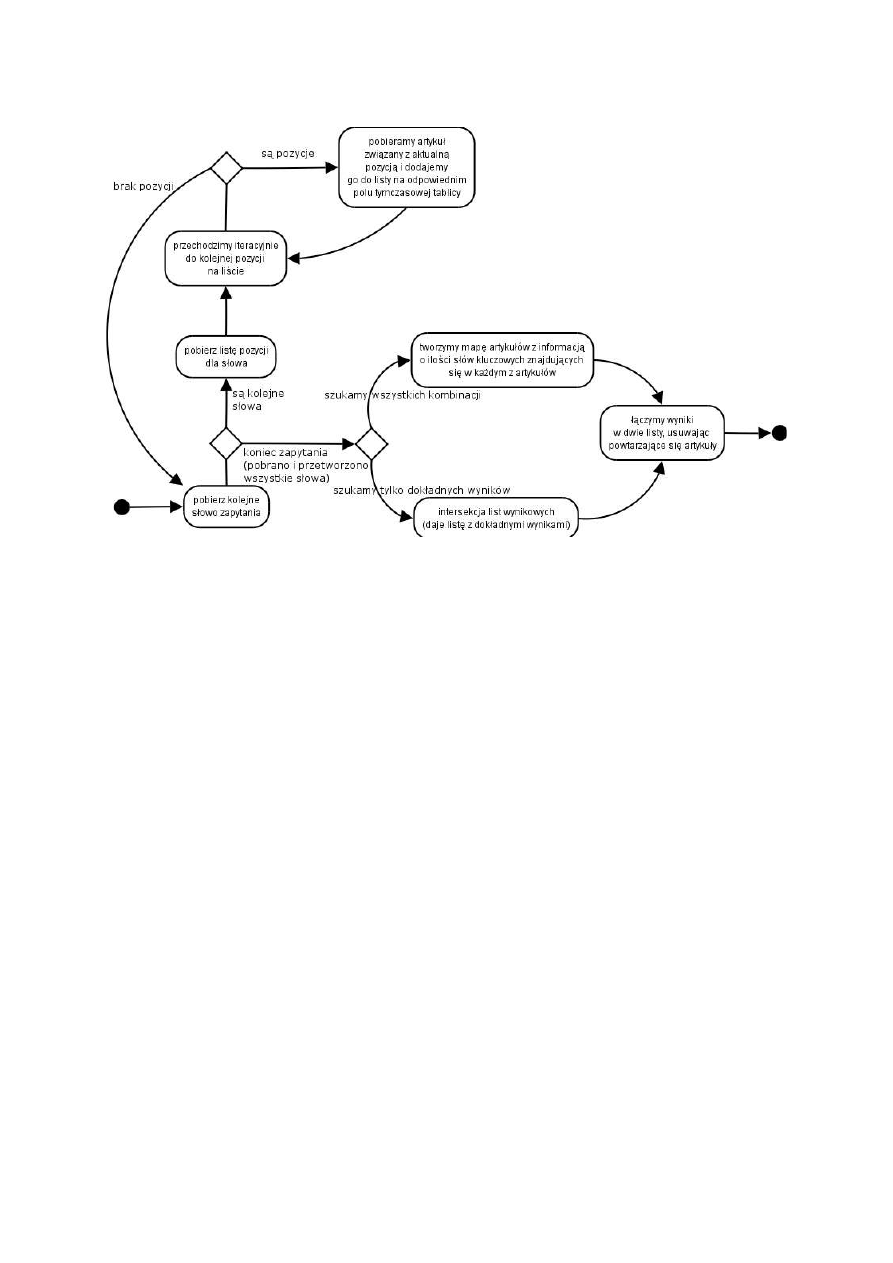
III.Wyszukiwanie z Gramem (uwzględniając fleksję języka polskiego)
Ta z kolei metoda jest tak naprawdę niewielką przeróbką dwóch wyżej opisanych. Ogólny
schemat algorytmu pozostaje bowiem taki sam. Różni się jedynie sposobem pobierania z bazy
kolejnych sprawdzanych słów z zapytania. W tej metodzie bowiem, porównujemy do siebie nie tylko
dokładne, podane przez użytkownika słowa, lecz również wszystkie ich formy fleksyjne.
W przypadku wyszukiwania podciągów, postępowanie dla konkretnego słowa jest następujące:
1. Pobieramy kolejne słowo zapytania (w)
2. Pobieramy formę podstawową tego słowa (w
p
)
3. Pobieramy zbiór wszystkich dzieci (powiązanych fleksyjnie słów pochodnych) dla
pobranego słowa w
p
4. Pobieramy listę wszystkich pozycji dla każdego z dzieci w
p
5. Dla każdej pozycji z listy wykonujemy standardowy algorytm porównywania kolejnych
słów z odpowiednikami z zapytania, z tym że na tym etapie porównujemy nie same słowa,
lecz ich formy podstawowe
6. Wracamy do punktu 1 i wykonujemy tę samą operację dla każdego kolejnego słowa
zapytania
W przypadku wyszukiwania części wspólnej, jedyna zmiana również polega na pobieraniu
pozycji dla wszystkich odmian fleksyjnych słów z zapytania, a nie tylko dla konkretnych,
występujących w zapytaniu słów. Reszta algorytmu jest identyczna.
41
Rysunek 14. Wyszukiwanie części wspólnej

Zakładając, że nie zostały wybrane niestandardowe kryteria wyszukiwania, wszystkie trzy (a
właściwe cztery, gdyż wyszukiwanie z Gramem wykonywane jest w praktyce dwukrotnie) algorytmy
zwracają pewną, nieuporządkowaną w żaden sposób listę rezultatów. Każdy z wyników posiada
wprawdzie pewne informacje o znalezionym artykule, między innymi na temat trafności wyniku, takie
jak np. ilość znalezionych słów występujących w jednym ciągu, suma wszystkich znalezionych słów z
zapytania, czy liczba słów o tej samej formie podstawowej. Nie istnieje jednak jeszcze metoda
porównania tych wyników, nadania odpowiednich wag poszczególnym atrybutom i stworzenia na tej
podstawie posortowanej względem trafności listy rezultatów. A jedynie taka właśnie lista stanowi
wartość dla użytkownika końcowego.
W tym właśnie momencie, mając konkretną listę zwróconych rezultatów wyszukiwania, możemy
przejść do drugiego etapu, czyli obliczenia wagi (ważności) każdego ze znalezionych artykułów. Aby
obliczona waga była jak najbliższa rzeczywistej trafności, którą w ogólny sposób zdefiniowaliśmy na
początku rozdziału, potrzebna jest pewna lista kryteriów, które powinniśmy brać pod uwagę w
naszych obliczeniach. Poniższa lista jest próbą wskazania najważniejszych z nich.
Kryteria brane pod uwagę do obliczenia całkowitej wagi artykułu, w kolejności od najważniejszych
do najmniej istotnych:
–
Ilość szukanych słów, występujących w znalezionych artykułach w tej samej kolejności jak w
zapytaniu.
To kryterium zostało nieprzypadkowo postawione na miejscu pierwszym. Wydaje się, że
większość użytkowników, wpisując w formularzu określony ciąg słów, oczekuje w rezultacie
wyników zawierających dokładnie ten sam ciąg, bądź ewentualnie znaczną część wyrazów tego
ciągu w niezmienionej kolejności. Jest bardzo prawdopodobne, że są to właśnie te artykuły,
których użytkownik poszukuje. A nawet jeśli tak nie jest, i tak nie zaszkodzi zwrócenie tych
artykułów z nieco wyższym priorytetem. Zazwyczaj bowiem, jeśli oczekiwanym wynikiem jest
nie dokładny ciąg, a część wspólna artykułów zawierających podane wyrazy, to po prostu ciąg
taki nie występuje nigdzie w archiwum.
–
Wystąpienie dokładnego poszukiwanego ciągu
Jest to skrajny przypadek wcześniejszego punktu. Takie artykuły powinny dostawać
zdecydowanie wysoki priorytet. Realizacja może wyglądać na przykład w postaci specjalnej
premii przy obliczaniu wagi dla takiego artykułu.
–
Liczba szukanych słów zapytania, które występują w znalezionym artykule.
Mowa oczywiście o słowach, które nie występują w artykule ciągu, lecz rozrzucone są po nim,
być może występując wielokrotnie. Kryterium ilości wyszukanych słów zapytania jest drugim co
do ważności i każde znalezione słowo powinno zwiększać w znaczny sposób wagę artykułu w
którym się znajduje. Przy czym priorytet jest trochę niższy niż w przypadku tych samych słów
połączonych w ciąg. W praktyce, słowa zapytania rozrzucone po artykule występuję
zdecydowanie częściej niż ciągi.
–
Wystąpienie w artykule wszystkich szukanych słów.
Takie artykuły, podobnie jak artykuły zawierające dokładny poszukiwany ciąg, powinny być
premiowane dodatkowo przy wyliczaniu wagi (premia oczywiście odpowiednio mniejsza niż w
poprzednim przypadku).
–
Kluczowe słowa występujące w temacie artykułu
Jest to istotne kryterium, szczególnie jeśli musimy w jakiś sposób rozróżnić artykuły zawierające
te same ilości poszukiwanych słów. Założenie, że słowa występujące w temacie wiadomości,
bądź (to sprawa do dokładniejszego zbadania) w pierwszej części tekstu więcej mówią o treści
artykule niż słowa znajdujące się w jego dalszych częściach, wydaje się sensowne. W
42

przypadkach niejednoznacznych, warto więc wziąć pod uwagę nie tylko samą częstotliwość
występowania, ale również lokalizację słów artykule.
–
Wiadomość wysłana przez popularnego autora
To kryterium może być bardzo zwodnicze i nie powinno być stosowane jako decydujące, lecz
jeśli już, jedynie uzupełniająco – różnicując artykuły, które do tej pory uzyskały podobną lub taką
samą zsumowaną wagę. Teoretycznie bowiem, często wypowiadający się na grupach
dyskusyjnych użytkownicy powiadają większą wiedzę i prawdopodobieństwo udzielenia przez
nich trafnej odpowiedzi na zadany temat jest wyższe. Z drugiej jednak strony, bywa że niełatwo
jest zidentyfikować taką osobą – na przykład jeśli korzysta ona z Usenetu za pośrednictwem
strony internetowej umożliwiającej wysyłanie newsów bez podania adresu e-mail, lub też
świadome ukrywanie swojej tożsamości na grupach dyskusyjnych. Często zdarzać się mogą
również pomyłki związane np. z powtarzającym się nickiem, identycznym imieniem i
nazwiskiem, korzystaniem z tego samego konta, a nawet podszywaniem się pod innych
uczestników dyskusji.
–
Data wysłania artykułu
Jest to najmniej istotne kryterium, może zostać nawet pominięte w implementacji. Chodzi o to, że
jeżeli wszelkie inne sposoby mierzenia zawiodą, priorytet dostać mogą artykuły napisane w
okresie późniejszym, czyli w domyśle, bardziej aktualne. Należy jednak (co zostało wspomniane
już na samym wstępie) wystrzegać się całkowitego pomijania treści starszych, jak również
nadawania zbyt wysokiego priorytetu dacie wysłania wiadomości.
W ten sposób omówiony został cały mechanizm wyszukiwania informacji w systemie. Od
algorytmów wyszukiwania, po nadanie wagi każdemu z rezultatów, aż do ostatecznej listy wyników
prezentowanej końcowemu użytkownikowi. Jest jednak jeszcze jedna ważna kwestia dotycząca
wyszukiwania, która została do tej pory odsunięta nieco na bok. Chodzi o cache'owania wyników
zapytań.
Jeśli przyjmujemy, że obciążenie systemu, a co za tym idzie również obciążenia bazy danych,
będzie znaczne, oczywiste jest, że zapytania przesyłane do systemu będą się często powtarzać.
Dlatego też, należy pomyśleć o optymalizacji zarządzania takimi zapytaniami, tak aby bez
specjalnego opóźnienia w działaniu, można było sprawdzić, czy dane zapytanie wystąpiło już w bazie
i jeśli miało to miejsce, zaserwować użytkownikowi gotową listę wyników. Zakładamy, że w bazie
istnieje dodatkowa struktura, której zadaniem jest przechowywanie historii wykonanych zapytań wraz
z ich rezultatami. Istotne jest, aby struktura ta zbudowana była w taki sposób, aby zwiększyć
wydajność mechanizmu wyszukiwania dla często występujących zapytań, nie opóźniając
jednocześnie tej operacji dla zapytań oryginalnych, nie zarejestrowanych jeszcze w naszej strukturze.
Rozwiązaniem jest przechowywanie zapytań historycznych jako haszowanych tablic referencji,
znajdujących się w obiektach konkretnych słów, od których zaczyna się dane zapytanie. Takie
rozwiązanie zawęża liczbę obiektów przeszukiwanych podczas operacji sprawdzania, czy dane
zapytanie (wraz z wynikami) znajduje się już w archiwum. Nie potrzeba też wykonywać prawie
żadnych dodatkowych operacji na bazie w celu sprawdzenie czy dane zapytanie wystąpiło już w
systemie. Struktura jest bowiem bezpośrednio dostępna z obiektu, który i tak pobieramy w celu
wykonania algorytmu wyszukiwania. Jest to spora oszczędność czasu i zasobów.
Dokładne omówienie rozwiązań implementacyjnych, dotyczących algorytmu wyszukiwania,
obliczania wagi wyników, jak również systemu cache'owania zapytań znajduje się w rozdziale piątym
– Rozwiązania implementacyjne: System ściągania, indeksowania i wyszukiwania newsów.
43

4.5.
Alternatywne koncepcje
Jednym z poważnych ograniczeń napotkanych podczas implementacji opisanego projektu
okazał się niedostatek zasobów dyskowych. Taqqq wydawałoby się mało istotna kwestia wpłynęła w
całkiem znaczny sposób na zastosowane w praktyce rozwiązania, szczególnie te związane ze
sposobem przechowywania danych w bazie (strukturą danych). Zakładając, że nie mamy sztywnego
ograniczenia co do akceptowalnej maksymalnej wielkości przechowywanych danych, otwierają się
przed nami ogromne możliwości wykorzystania takiego potencjału – możliwości, które nie były brane
pod uwagę przy implementacji. Mowa tutaj o odejściu od oszczędnego (pod względem zasobów
dyskowych) projektowania i zastosowaniu bardzo dużej, ale przemyślanej redundancji danych, w celu
zwiększenia szybkości działania aplikacji. Wiąże się to oczywiście ze znacznym wzrostem rozmiaru
bazy danych – nawet o kilka rzędów wielkości. Tak gwałtowne zwiększenie rozmiaru aplikacji jest
bardzo ryzykowne i aby przyniosło spodziewane efekty – czyli zwiększenie wydajności – musi być
bardzo dokładnie zaplanowane.
Ideą, jaka przyświeca koncepcji zwiększania wydajności poprzez redundancję danych jest
zapewnienie jak najlepszej koncentracji danych, potrzebnych do wykonania pojedynczej operacji na
bazie. Chodzi tu zarówno o koncentrację koncepcyjną – czyli odpowiednie asocjacje między typami
danych, realizowane jako referencje i kolekcje referencji w obiektach, jak i o koncentrację fizyczną,
czyli taką implementację bazy, aby dane często uczestniczące w tych samych operacjach
przechowywane były fizycznie blisko siebie. Drugi sposób – koncentracja fizyczna – jest nieco
trudniejszy w realizacji i przy stosowanym poziomie abstrakcji narzędzi deweloperskich, zależy mniej
od programisty a bardziej od zastosowanego oprogramowania. Objectivity/DB oferuje wprawdzie
pewne mechanizmy, które mogą zostać wykorzystane w celu optymalizacji dostępu do danych na
poziomie fizycznym. Jest to realizowane poprzez odpowiedni podział federacji na bazy danych i
kontenery, odpowiednie rozmieszczenie danych w każdej ze struktur, zastosowanie specyficznych dla
Objectivity kolekcji, jak haszowane drzewa, tablice i listy obiektów, etc. Jednak w tym miejscu
skoncentrujemy się na ciekawszym koncepcyjnie, a zarazem bezpośrednio powiązanym z
optymalizacją fizyczną zagadnieniem, jakim jest optymalizacja struktury danych na poziomie
schematu.
Chodzi tutaj o takie przeprojektowanie struktury klas i asocjacji między nimi, aby zapewnić jeszcze
szybszy i wygodniejszy dostęp do danych, wykorzystywanych przy mechanizmie wyszukiwania.
Koncepcji może być tu wiele. Zaprezentowane zostaną jednak tylko dwie z nich. Te, które
charakteryzują się według nas niezerowym prawdopodobieństwem przyszłej realizacji w praktyce.
1. Struktura słów oparta o haszowane tablice referencji
To bardziej zasobochłonna z omawianych tutaj propozycji. Polegałaby ona na
przeprojektowaniu struktury obiektów słów w bazie danych, w taki sposób, aby każde ze słów
zawierało w sobie trójwymiarową, haszowaną tablicę, zbudowaną z powiązanych z nim kolejnych
słów we wszystkich zindeksowanych artykułach. Pierwszym wymiarem (n) byłyby pozycje słów
następujących po słowie głównym w
g
. Każdy rząd w tablicy to kolejna pozycja, czyli np. rząd
pierwszy to tablica wszystkich słów bezpośrednio następujących po w
g
, drugi to tablica słów
występujących na drugiej pozycji po w
g
, etc. Drugi wymiar (m) oznaczałyby artykuły, a dokładnie
kolejne słowa, będące częściami artykułów, następującymi po miejscu wystąpienia w nich słowa
głównego w
g
. Trzecim wymiarem, byłaby tablica obiektów pozycji, powiązanych ze słowem w
g
,
takich, że dla danego słowa w
n,m
, jest to lista wszystkich pozycji (słów w artykułach) następujących
bezpośrednio po liście słów w
1,m
... w
n,m
w danym artykule. Każdy z elementów tablicy w
n,m
jest więc
powiązany z co najmniej jedną pozycją listy p. Lista p zawiera wszystkie pozycje powiązane ze
słowem głównym w
g
.
Można na tą strukturą spojrzeć również jako jeden wielki graf, łączący ze sobą wszystkie słowa
występujące we wszystkich zindeksowanych artykułach oraz ich pozycje w tychże artykułach.
Dokładnie powyższa koncepcja została przedstawiona na rysunku: Struktura słów oparta o
haszowane tablice referencji.
44
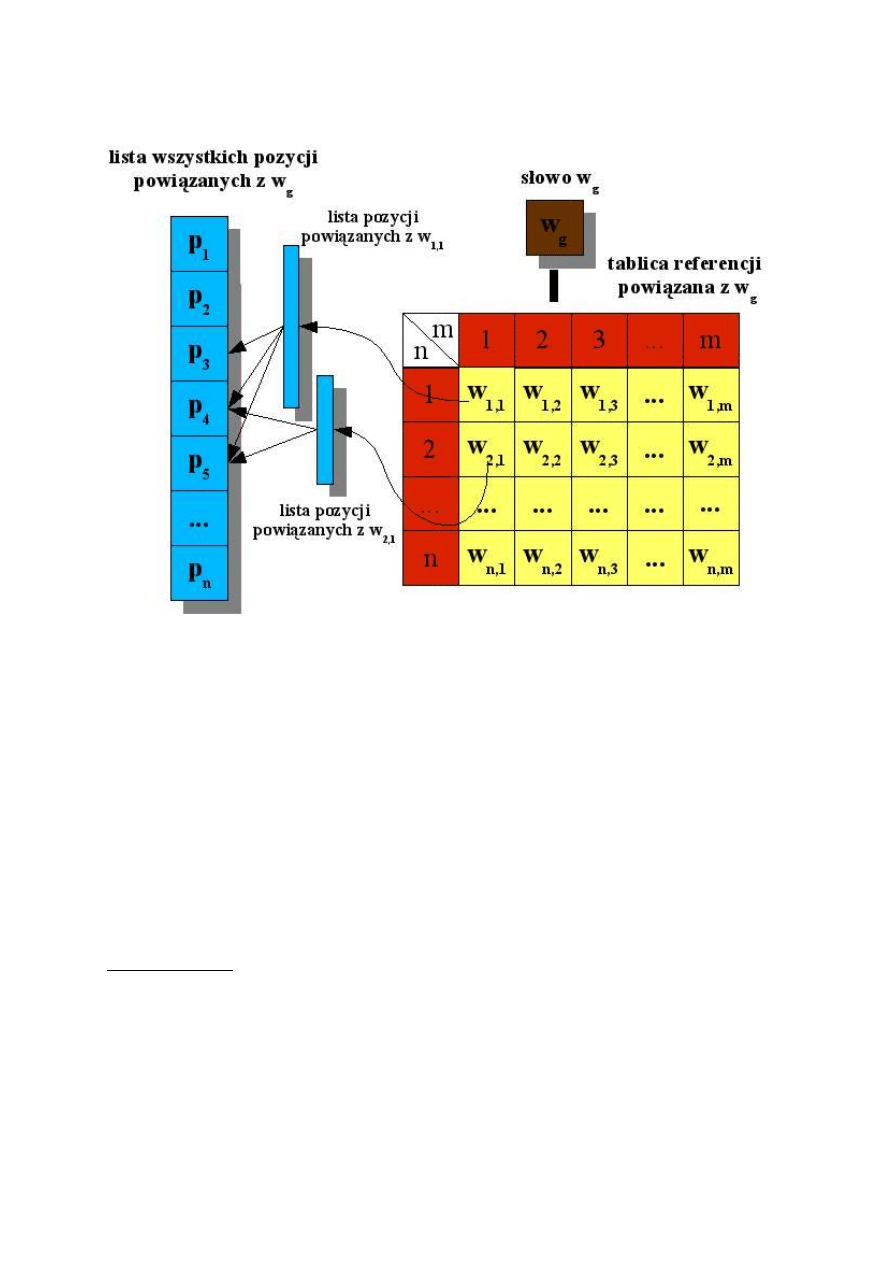
Możliwa jest też mniej radykalna wersja tej samej koncepcji. Założeniem byłoby, że interesuje
nas tylko jeden poziom zagłębienia. Każde słowo z bazy połączone jest więc teraz, poprzez
haszowaną tablicę, ze wszystkimi słowami bezpośrednio po nim następującymi, we wszystkich
artykułach. Słowa są w tablicy kluczami, wartościami są natomiast listy pozycji, odpowiadające
wystąpieniom tych dwóch słów po sobie w zindeksowanych artykułach. Słowa nie tworzą więc w tym
wypadku wielowymiarowej tablicy. Struktura ta jest niezależna od struktury artykułów. Chodzi
jedynie o powiązanie słów najczęściej występujących blisko siebie. Mimo, że jest to zawężenie
pierwszej koncepcji, przy takim rozwiązaniu również powinniśmy doświadczyć zdecydowanej
poprawy wydajności wyszukiwania, szczególnie dla algorytmu znajdowania wspólnych podciągów
słów.
Główną zaletą obu rozwiązań jest przyspieszenie algorytmu wyszukiwania, w wersji znajdowania
wspólnych podciągów. Aby rozjaśnić nieco nową koncepcję, porównajmy ją z rozwiązaniem
zastosowanym w pracy.
Stare rozwiązanie
W rozwiązaniu przyjętym w pracy, wyszukiwanie podciągów sprowadza się do każdorazowego
przeszukiwania wszystkich pozycji powiązanych z pierwszym słowem zapytania i sprawdzaniem czy
każda kolejna zwrócona pozycja nie zawiera słowa odpowiadającego kolejnemu ze słów zapytania
użytkownika. Takie sprawdzanie może, przy bardzo popularnych pierwszych słowach zapytania w
znaczny sposób spowolnić wyszukiwanie podciągów, lub wręcz (przy naprawdę dużych zbiorach
45
Rysunek 15. Struktura słów oparta o haszowane tablice referencji
danych) uniemożliwić wyszukiwanie. W pracy ten problem został częściowo rozwiązany (a
właściwie ominięty) poprzez pomijanie słów najbardziej popularnych. Wyszukiwanie zaczynamy od
przeszukiwania pozycji dla słów zapytania występujących rzadko, a następnie nawigujemy w obie
strony w poszukiwaniu odpowiednich podciągów. Sposób ten sprawdza się całkiem nieźle jeśli w
zapytaniu rzeczywiście znajduje się co najmniej jedno słowo bardzo mało popularne. Problem
pojawia się gdy wszystkie słowa zapytania są słowami często występującymi w artykułach, a dopiero
ich odpowiednia kombinacja tworzy unikalną frazę, nazwę instytucji, czy cytat. W takim wypadku
algorytm nie ma innego wyjścia niż wyszukać wszystkie pozycje dla jednego ze słów z zapytania. W
wyjątkowych przypadkach może to nawet uniemożliwić wyszukanie informacji.
Nowe rozwiązanie
Z drugiej strony, w proponowanym tutaj alternatywnym rozwiązaniu, problem ten praktycznie zostaje
całkowicie zniwelowany. Każde słowo powiązane jest bowiem ze wszystkimi słowami z którymi
łączy się w artykułach. Nie ma więc potrzeby przeszukiwania wszystkich pozycji dla interesującego
nas słowa. Wystarczy pobrać pozycje powiązane z dwoma pierwszymi słowami zapytania (a przy
zastosowaniu pierwszej koncepcji z trójwymiarową tablicą, również z kolejnymi słowami zapytania,
w zależności od zdefiniowanego rozmiaru tablicy) a następnie nawigować już według tego samego
algorytmu, w celu znalezienia całego poszukiwanego ciągu. Zwiększenie efektywności wyszukiwania
zależy tutaj bezpośrednio od ilości słów, z którymi powiązane jest pierwsze słowo szukanego ciągu.
Jest to zależność liniowa – jeśli szukane słowo powiązane jest poprzez listę pozycji z ilością Z innych
słów, wzrost wydajności części wyszukiwania odpowiedzialnej za pobranie listy pozycji powinien
być w przybliżeniu Z-krotny. Niestety, taka sama zależność dotyczy również miejsca na dysku, które
potrzebne jest do zbudowania struktury, zapewniającej dodatkowe powiązania, niezbędne do
implementacji tej koncepcji.
Korzyści z zastosowania nowego rozwiązania
Oprócz celu głównego, czyli przyspieszenia działania, zastosowanie proponowanej koncepcji
może przynieść również inne, całkiem ciekawe możliwości, rozszerzające znacznie funkcjonalność
aplikacji. Omówimy najciekawsze z nich:
–
Zaawansowane wyszukiwanie z użyciem wyrażeń “pseudo-regularnych”
Chodzi o wyrażenia typu: znajdź wszystkie artykuły, które zawierają podciąg “Ala ma * kota”,
gdzie * może być dowolnym wyrazem, np. “ładnego”, “niegrzecznego”, “strasznego”, etc.
Teoretycznie można wykonać taką operację również w obecnym systemie. Koszt jednak tego
byłby nieporównywalnie większy – zamiast zatrzymywać nawigowanie po pozycjach przy
natrafieniu na pierwsze słowo artykułu nie pasujące do zapytania, trzeba by za każdym razem
sprawdzać wszystkie słowa i znajdować te, które pasują do wyrażenia. W modelu słów opartym
na haszowanych tablicach referencji, tę samą informację mamy tak naprawdę dostępną z
definicji, tzn. bez stosowania dodatkowych algorytmów. Każde słowo powiązane jest w listą
wszystkich słów, występujących w artykułach po nim, na odpowiednich pozycjach. Jedyne co
należałoby zrobić, to sprawdzić czy na odpowiednich, wymaganych pozycjach znajdują się
podane w zapytaniu słowa (omijając pozycję oznaczoną gwiazdką). Jeśli znajdują się w
strukturze artykuły spełniające wszystkie z tych założeń, ich lista jest jednocześnie listą wyników
naszego zapytania. Tym samym, to co wydawałoby się niemożliwe przy zastosowaniu
standardowej struktury zindeksowanych danych (powiązania artykuł – pozycje – słowa) okazuje
się nie tylko możliwe, ale wręcz bardzo proste i efektywne w przedstawionej, zmodyfikowanej
strukturze.
–
Znajdowanie niedokładnych ciągów
Stosując mechanizm omówiony powyżej (wyrażenia “pseudo-regularne” na słowach), możemy
ulepszyć również sam mechanizm wyszukiwania, zarówno podciągów jak i algorytm
46

znajdowania części wspólnej słów. Użytkownik szukając jakiejś frazy lub kilku słów
kluczowych zazwyczaj oczekuje, że znalezione artykuły będą nie tylko zawierały podane przez
niego słowa, ale również, że tematyka artykułu będzie bezpośrednio związana ze słowami
kluczowymi które wpisał. Oczywiście automatycznie trudno odgadnąć dokładną tematykę
artykułu po jego treści. Można jednak wnioskować, że jeśli poszukiwane słowa znajdują się w
tym samym zdaniu (lub w zdaniach sąsiadujących), to jest dużo bardziej prawdopodobne, że
treść artykułu będzie bezpośrednio związana z tymi właśnie słowami kluczowymi. A na pewno
dużo bardziej, niż w przypadku, gdy słowa te rozrzucone są po całym artykule.
Wykorzystując to założenie, możemy tak zmodyfikować mechanizm wyszukiwania słów
kluczowych, aby w pierwszej kolejności brane były pod uwagę słowa występujące blisko siebie
(niekoniecznie w jednym ciągu). To oczywiście również można zrealizować wykorzystując
strukturę danych z prezentowanego rozwiązania. W aktualnym rozwiązaniu jest to realizowane
już po wyszukaniu wszystkich rezultatów, na podstawie pozycji poszczególnych wyszukanych
słów w artykułach (wcześniej nie mamy nawet możliwości, żeby zgadnąć ich kolejność). W
zmodyfikowanym rozwiązaniu, już podczas wyszukiwania moglibyśmy decydować o priorytecie
poszczególnych artykułów, a w przypadku bardzo dużej ilości wyników, nawet rezygnować z
prezentowania tych, w których nie widać istotnego powiązania pomiędzy poszukiwanymi
słowami.
–
Wyszukiwanie po „najczęstszych sąsiadach”
Zarówno przy pierwszej jak i przy drugiej (zawężonej) koncepcji pojawia się nam w
wyszukiwaniu nowa, bardzo interesująca opcja – możliwość zastosowania w algorytmie
wyszukiwania dodatkowego kryterium: wyszukiwanie po „najczęstszych sąsiadach”, czyli
słowach bezpośrednio następujących, lub bezpośrednio poprzedzających słowo aktualnie
wyszukiwane (z tym, że w przypadku zastosowania słów poprzedzających, referencje do
sąsiadów musiałyby być dwukierunkowe). Nie należy oczywiście brak tej opcji pod uwagę jako
jedno z głównych kryteriów wyszukiwania, raczej jako kryterium dodatkowe, uzupełniające.
Ważne byłoby tutaj również odpowiednie zastosowanie “wyszukiwania po sąsiadach”. Nie
wszystkie słowa występujące obok siebie są przecież ze sobą powiązane, nie wszystkie pary słów
muszą nieść jakąś wartość dla wyszukiwania. Na pewno należałoby pominąć spójniki, wyrazy
oddzielone znakami przestankowymi, kończącymi zdanie. Być może interesujące byłyby dla nas
jedynie występujące obok siebie rzeczowniki (np. “prezydent Kwaśniewski”, “piłkarz Boniek”,
“system operacyjny”). To kwestie do dokładnego zbadania przed ewentualną implementacją.
Proponowana struktura danych oferuje jednak taką możliwość i sposobów jej wykorzystania
może być, jak widać wiele.
2. Asocjacja słowo – wątek
Najczęściej występujący scenariusz związany z wysłaniem wiadomości na grupę dyskusyjną
wygląda następująco:
1. Osoba A wysyła na tematycznej grupie dyskusyjnej wiadomość z opisem problemu lub z
pytaniem, które pragnie ona zadać osobom bardziej kompetentnym
2. Osoba B odpowiada na zadane pytanie, lub też odsyła do innego źródła informacji na temat
poruszony przez osobę A w pierwszym poście
3. Ciąg dalszy może mieć już wiele alternatywnych scenariuszy:
a) Dyskusja rozwija się, pada więcej odpowiedzi, ewentualnie osoba A prosi o kolejne
informacje, informuje o kolejnych problemach związanych ze zgłębianiem tematu
b) Dyskusja podąża innym torem, zmieniając temat
c) Dyskusja kończy się
47

etc.
Oczywiście jest to tylko przykładowy scenariusz. Zależnie od specyfiki grupy, pierwszy post
może być równie dobrze informacyjny (np. grupy ogłoszeniowe), zachęcający do dyskusji na jakiś
temat (grupy polityczne, światopoglądowe), etc. Jednak wydaje się, że towarem, którego zwykle
poszukują osoby korzystające z wyszukiwarek internetowych, a w szczególności wyszukiwarki grup
dyskusyjnych, są informacje na konkretny temat, czyli tak naprawdę odpowiedzi na pytania, z którymi
nie mogą sobie sami dać rady. Powróćmy więc do powyższego scenariusza, z pytaniem osoby A i
odpowiedzią osoby B. Zakładając, że odpowiedź jest sensowna, poprawna i na temat, bardzo
prawdopodobne jest, że zawiera ona również wiele słów kluczowych, które może wpisać w
wyszukiwarce nasz standardowy użytkownik poszukujący na ten właśnie temat informacji. Czyli –
słowa kluczowe odnośne tematu wątku znajdują się równie dobrze w jego pierwszym jaki i drugim i
być może również kolejnych postach.
Wyobraźmy sobie teraz sytuację, w której osoba wpisuje do wyszukiwarki zapytanie, np. “firewall
konfiguracja Windows XP”. Wyszukiwarka znajdzie oczywiście wszystkie artykuły, w których
wystąpiły te właśnie słowa. Nie znajdzie jednak artykułów, w których nie pojawia się słowo
“firewall”. A taki może być właśnie pierwszy post osoby próbującej się dowiedzieć jak
skonfigurować system Windows XP, ale nie mającej o tym zielonego pojęcia (tym bardziej nie
wiedzącej czym może być rzeczony firewall i do czego może on służyć). “Firewall” znajduje się za to
w odpowiedzi na pierwszą wiadomość. Osoba kompetentna wyjaśnia w jaki sposób włączyć zaporę
ogniową w systemie Windows i do czego ona właściwie służy. I tutaj pojawia się właśnie problem.
Ten wątek nie zostanie znaleziony przez wyszukiwarkę, gdyż nie uwzględnia ona zależności między
postami. Zostanie natomiast znaleziony inny artykuł, który wprawdzie zawiera wszystkie wymagane
słowa, ale nie doczekał się odpowiedzi. Problem jest więc nierozwiązany. A użytkownik
sfrustrowany.
Aby zaradzić takim sytuacjom jak ta opisana powyżej, należy zastanowić się, czy nie byłoby
sensowne zindeksować nie tylko same artykuły, ale również powiązania między nimi. Chodzi o to,
żeby wyszukiwarka przeszukiwała słowa kluczowe nie tak jak dzieje się to teraz, w pojedynczych
artykułach, ale w całych wątkach, czyli grupach artykułów dotyczących tego samego zagadnienia.
Problem ten rozwiązać można na dwa sposoby:
1. Kwestię znajdowania słów w całym wątku można pozostawić wyszukiwarce – tzn w
algorytmie wyszukiwania dodać warunek, mówiący o tym, że jeśli znaleziony artykuł ma
dziecko lub rodzica, należy również przeszukać te powiązane z nim artykuły w
poszukiwaniu szukanych słów kluczowych
2. Zająć się problemem już na poziomie indeksowania. Oprócz (zamiast?) tworzenia powiązań
między artykułem a słowami w nim występującymi, tworzyć od razu obiekt wątku
grupującego artykuły i z nim wiązać poszczególne słowa poprzez obiekty pozycji (zobacz
rysunek Powiązanie wątek – słowo).
Największą wadą pierwszej koncepcji jest to, że nie wszystkie artykuły “załapią się” do drugiej
tury, tzn do przeszukania artykułów z nimi powiązanych. Wszystko zależy od tego, jakie kryteria
zostaną przyjęte w znajdowaniu pierwszej grupy artykułów. Odpadną tu najprawdopodobniej wątki,
w których kolejne słowa kluczowe pojawiają się oddzielnie w kolejnych wiadomościach. Drugą wadą
pierwszej koncepcji jest szybkość działania. Jeśli artykuł jest częścią dużego wątku (z zdarzają się
wątki nawet kilkusetpostowe), wyszukiwanie w nim informacji może się niebezpiecznie wydłużyć.
Drugie rozwiązanie (schemat przedstawiony na rysunku powyżej) przerzuca odpowiedzialność na
algorytm indeksowania, dzięki czemu przy wyszukiwaniu różnica w szybkości będzie praktycznie
niezauważalna. Słowo powiązane będzie dalej z listą pozycji, tyle że pozycje te tyczyć się będą
zarówno artykułu jak i całego wątku. Przy założeniu, że rezygnujemy zupełnie z powiązania artykuł –
słowo, zastosowanie tego rozwiązania nie odbije się w żaden sposób na wielkości danych. Jeśli
będziemy chcieli zindeksować jednocześnie artykuły i wątki, narzut pojawi się, ale będzie,
stosunkowo niewielki, więc akceptowalny.
48
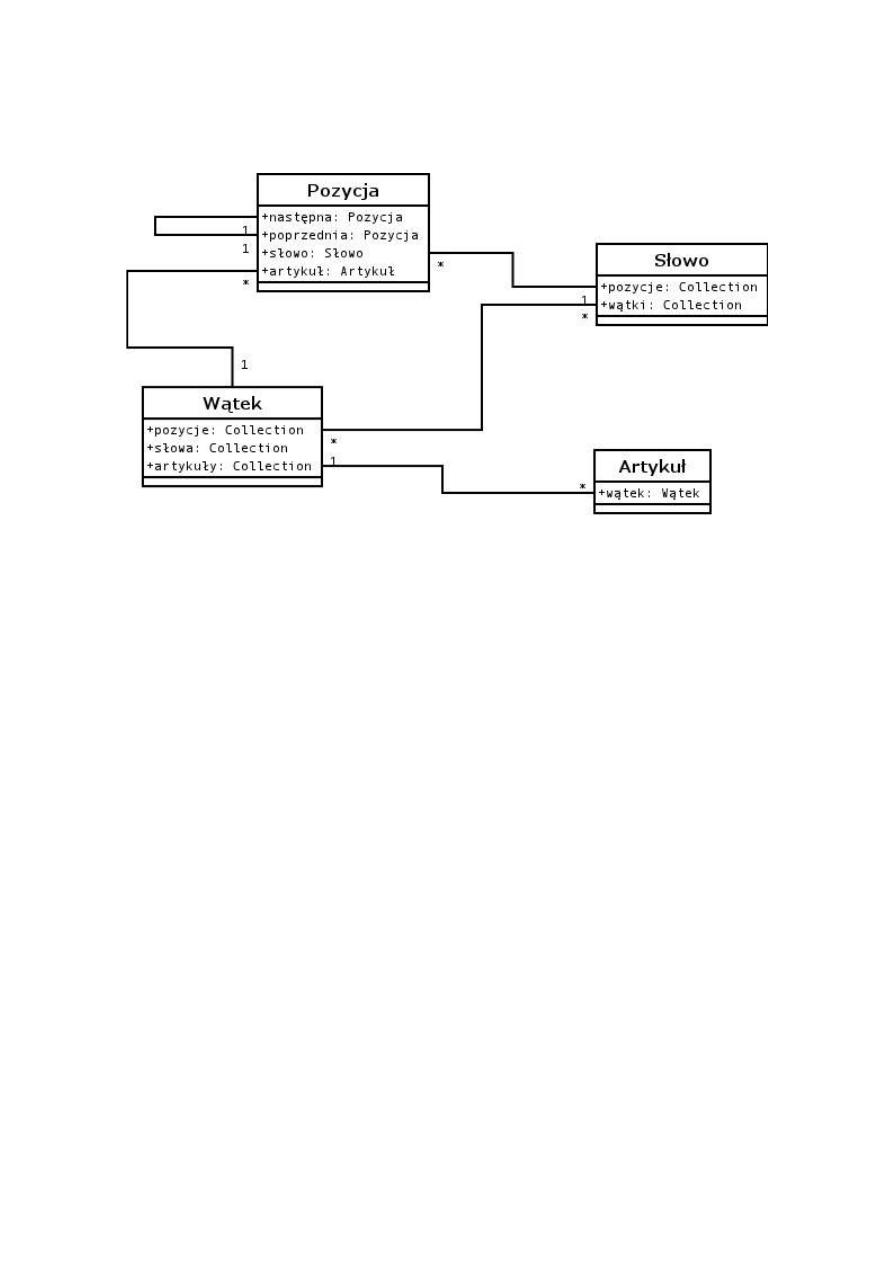
Dwie omówione tutaj koncepcje, mimo że nie zostały wybrane do implementacji w
przedstawionym przez nas rozwiązaniu, charakteryzują się dość wysokim poziomem dojrzałości i w
bezpośredni sposób powiązane są z omówionym tutaj właściwym rozwiązaniem. Można powiedzieć,
że są one jego uzupełnieniem i rozszerzeniem. Dlatego też zdecydowaliśmy się opisać je w dziale
dotyczącym opisu rozwiązania, a nie w podrozdziale Plany na przyszłość. Nie oznacza to jednak, że
koncepcje te nie doczekają się praktycznej implementacji w najbliższym czasie.
49
Rysunek 16. Powiązanie wątek – słowo
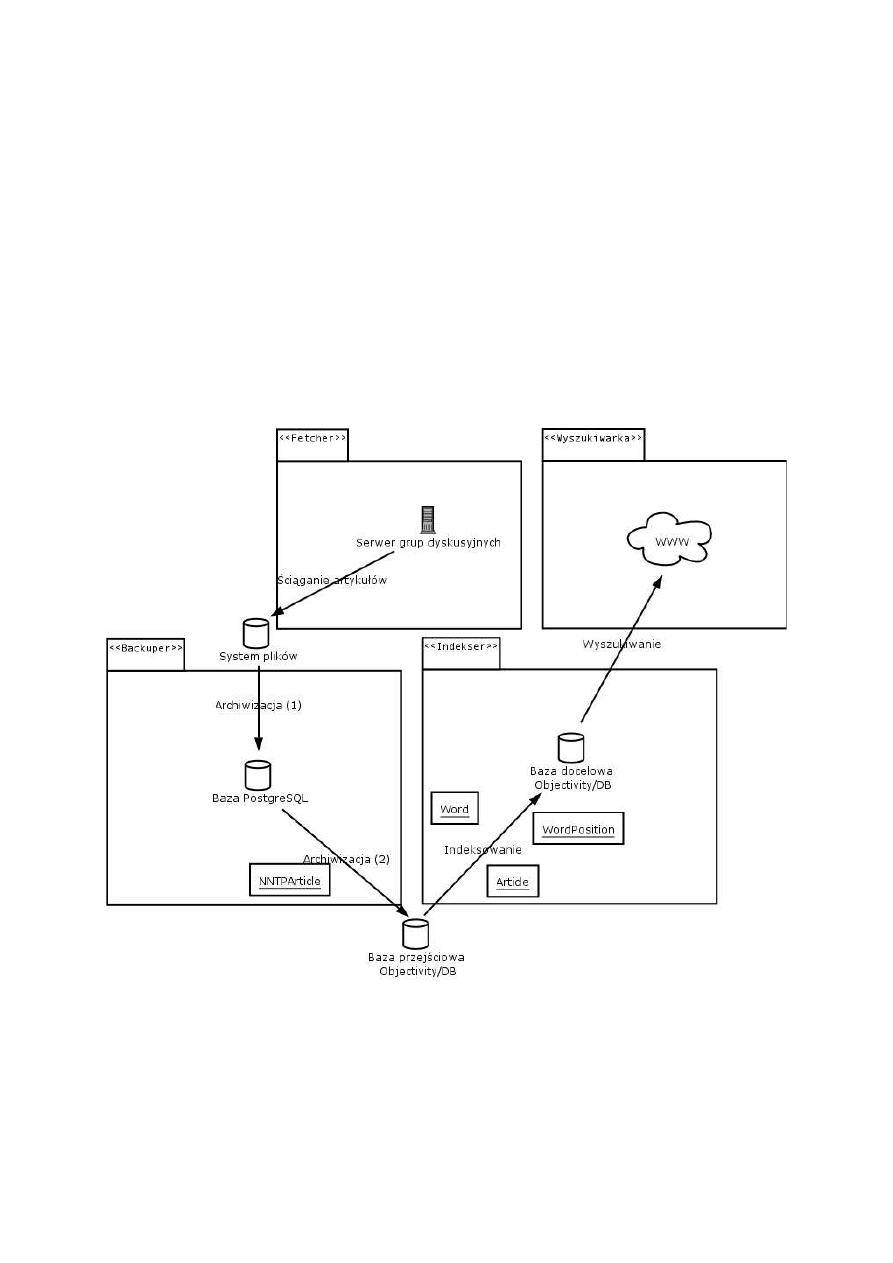
5. Rozwiązania implementacyjne: System ściągania, indeksowania
i wyszukiwania newsów
Aplikacja będąca przedmiotem pracy jest produktem kompletnym pod względem
implementacyjnym. Ze względu na specyfikę dziedziny, prezentowana implementacja podzielona jest
na oddzielone od siebie, niezależne moduły, które ostatecznie tworzą spójny mechanizm działania
pełnotekstowej wyszukiwarki. Każdy z modułów odpowiada za pewną fazę przygotowywania
struktury danych, bądź zarządzania danymi już istniejącymi w celu optymalizacji działania systemu
wyszukiwania.
I tak, pierwszą fazę, czyli ściąganie danych, a następnie ich archiwizację, obsługuje narzędzie zwane
fetcherem. Tę rolę pełni serwer grup dyskusyjnych Leafnode, który codziennie ściąga najnowsze
wiadomości i archiwizuje je na dysku twardym. Przygotowane w ten sposób dane są składowane na
dysku w najprostszej możliwej postaci, czyli jako pliki tekstowe (każdy artykuł to niezależny plik).
50
Rysunek 17. Schemat działania aplikacji

Archiwizacją ściągniętych w ten sposób danych zajmuje się backuper, który przegląda nowe
artykuły i umieszcza je w postaci rekordów w relacyjnej bazie danych PostgreSQL. Kolejnym
krokiem jest migracja danych z relacyjnej bazy do bazy obiektowej. Dopiero artykuły zachowane jako
proste obiekty w bazie Objectivity/DB poddawana są dalszej obróbce.
Parsowaniem i indeksowaniem zajmuje się moduł zwany indekserem. W ten sposób, z artykułów
składowanych jako tekst, uzyskujemy obiekty posiadające pewną strukturę, która odpowiada
faktycznej strukturze tych artykułów na serwerze grup. Innymi słowy – oddzielamy samą treść posta
od informacji dodatkowej, takiej jak data jego wysłania, autor wiadomości, tytuł, czy powiązania
artykułu z innymi artykułami w sieci. Tak stworzony nowy obiekt zapisywany jest na trwałe w
docelowej bazie danych. Jest już gotowy do dalszego przetwarzania go, w celu stworzenia
pomocniczej struktury danych, ułatwiającej w przyszłości wyszukiwanie zawartych w nim treści. To
przetwarzanie nazywamy indeksowaniem artykułu, czyli podzieleniem jego treści na poszczególne
słowa i stworzeniem logicznej struktury tych słów w bazie danych. Zindeksowany artykuł pozostaje
od tej pory na stałe w swoim miejscu w bazie i nie powinien być już więcej modyfikowany. Dopiero
od tej chwili wyszukiwarka “dowiaduje się” o istnieniu nowego artykułu i bierze go pod uwagę przy
zwracaniu wyników zapytania.
Sama wyszukiwarka jest ważnym, aczkolwiek dość niewielkim w porównaniu do innych modułem, z
tego względu, że większość skomplikowanych operacji na bazie danych wykonywana jest podczas
indeksowania i optymalizacji. Zadaniem wyszukiwarki jest zwrócenie wyników zapytania zleconego
przez użytkownika, poprzez przeszukanie bazy pod kątem słów użytych w zapytaniu. Przeszukanie to
ogranicza się do przechodzenia po referencjach między obiektami, co zdecydowanie skraca czas
oczekiwania na wynik. Każde zapytanie zapisywane jest w bazie, wraz ze zwróconymi wynikami, co
w znacznym stopniu ogranicza marnotrawstwo mocy obliczeniowej, czyli zbyt częste wykonywanie
przez bazę powtarzalnych operacji.
Ostatnią, ale wcale nie najmniej istotną częścią aplikacji jest działający w tle program, którego
zadaniem jest przeszukiwanie najczęściej pojawiających się zapytań i aktualizowanie ich wyników,
składowanych na stałe w bazie danych. Ze względu na dużą powtarzalność zapytań do bazy, taka
optymalizacja jest niezbędna do utrzymania płynności działania i nie dopuszczania do niepotrzebnego
przeciążania bazy danych.
Opisany powyżej schemat został przedstawiony graficzne na rysunku: Schemat działania aplikacji.
Istotną częścią projektu jest również sam frontend, czyli aplikacja działająca po stronie
przeglądarki internetowej, udostępniająca użytkownikom zindeksowane zasoby polskiego Usenetu.
Implementacja frontendu nie była w projekcie priorytetem, tak więc udostępnia on jedynie formularz
do wpisywania zapytań, stronę z wynikami zapytania oraz możliwość przeglądania całych wątków,
zawierających artykuły, będące wynikami zapytania.
W poniższym rozdziale szczegółowo przedstawiona została struktura danych w postaci opisu
klas, użyte algorytmy oraz sposoby optymalizacji poszczególnych modułów, składających się na
prezentowany system.
5.1.
Opis najważniejszych klas
Zarówno projekt systemu, jak i implementacja została zaplanowana tak, aby wszystkie istotne
elementy systemu miały swoje bezpośrednie odzwierciedlenie w strukturze obiektów. Chodzi o to,
żeby struktura danych w jak największym stopniu odzwierciedlała rzeczywistość. Abstrakcja
obiektowa pozwala w prosty sposób zrozumieć system, ponieważ operuje ona na pojęciach
używanych w świecie rzeczywistym. Przyjrzyjmy się więc najważniejszym klasom i ich
podstawowym metodom.
Klasa Article
Opis:
51

Klasa reprezentuje pojedynczy artykuł grup dyskusyjnych. Służy do przechowywania
sparsowanych i zindeksowanych artykułów. Tutaj znajdują się właściwe teksty artykułów oraz ich
nagłówki, a także referencje do struktur pomocniczych w algorytmie wyszukiwania, czyli listy pozycji
oraz słów występujących w artykule. Wszystkie statyczne operacje na artykułach realizowane są
również przy użyciu tej właśnie klasy
Zależności z innymi klasami:
●
private
ToManyRelationship words
Relacja ze słowami artykułu. Artykuł może zawierać wiele słów, każde słowo może występować
w wielu artykułach.
●
private
ToManyRelationship positions
Relacja z pozycjami słów w artykule. Pozycje wiążą słowa i artykuły. Każdy artykuł łączy się z
liczbą pozycji równą liczbie słów znajdujących się w temacie i treści artykułu.
●
private
ToManyRelationship children
Relacja z artykułami – dziećmi w wątku, odpowiedziami na dany artykuł.
●
private
ToOneRelationship father
Relacja z ojcem, czyli artykułem, na który ten artykuł jest odpowiedzią.
●
private
ToOneRelationship threadHead
Relacja z pierwszym artykułem wątku.
●
private
ToManyRelationship threadContent
Relacja odwrotna do “threadHead”. Będąc z w pierwszym artykule wątki relacja zwraca
wszystkie artykuły znajdujące się w tym wątku.
Najważniejsze metody:
●
public
static
Article addArticle(String messageId, String text, String type)
Metoda
służy
do
dodania
artykułu
do
bazy
danych.
Artykuł
dodawany
jest
jako
obiekt
-
korzeń,
gdzie
unikalny
identyfikator
obiektu
w
federacji
składa
się
z
przedrostka
“
ART_”
oraz
Message_ID
artykułu.
●
private void
parseMessage(String
plain)
Metoda
wywoływana
z
konstruktora
klasy Article,
służy
do
sparsowania
tekstu
artykułu
wyodrębnienia
z
niego:
-
nagłówków,
które są następnie
reprezentowane
jako
oddzielne
pola
klasy,
- właściwego
tekstu, który będzie w następnej kolejności przekazany do indeksowania
●
public
void
indexArticle()
throws
NoSuchWordException
Metoda
indeksująca
sparsowany
artykuł.
Jest
to
najważniejsza
metoda
w
artykule. Rozdziela
ona
treść
artykułu
na
pojedyncze
słowa
Word
i
tworzy
dowiązania do
tych
słów
w
obiekcie
Article.
Jeśli
dane
słowo
nie
występuje
jeszcze
w
bazie, jest
ono
do
niej
dodawane. Dla
każdego
kolejnego
słowa
w
artykule
tworzona
jest
pozycja,
która
odpowiada faktycznej
lokalizacji
danego
słowa
w
artykule.
Pozycje
wiążą
się
poprzez
relacje (relationships)
zarówno
ze
słowem
jak
i
z
artykułem. Po
zakończeniu
tej
metody,
artykuł
powiązany
jest
z
pozycjami
i
słowami
i
tym
samym staje
się
widoczny
dla
silnika
wyszukiwarki.
52

Klasa Word
Opis:
Klasa reprezentuje pojedyncze słowo lub znak występujący w artykule. Jest powiązana ze
słowem będącym swoją formą podstawową (po kanonizacji leksemu) , jak również ze wszystkimi
słowami o tym samym leksemie, dla których dane słowo jest formą kanoniczną. Klasa odpowiada
również za wszystkie statyczne operacje na obiektach słów, w tym operacje związane ze
znajdowaniem formy kanonicznej słowa oraz operacje na bazie danych.
Zależności z innymi klasami:
●
private
ToManyRelationship articles
Relacja ze artykułami powiązanymi ze słowem, czyli tymi, w których dane słowo występuje.
Artykuł może zawierać wiele słów, każde słowo może występować w wielu artykułach.
●
private
ToManyRelationship positions
Relacja z pozycjami słów w artykule. Pozycje wiążą słowa i artykuły. Każdy artykuł łączy się z
liczbą pozycji równą liczbie słów znajdujących się w temacie i treści artykułu.
●
private
ToManyRelationship allQueries;
Relacja z wynikami wyszukiwania rozpoczynającymi się od tego słowa. Relacja ta jest podstawą
dla mechanizmu prezentowania scache'owanych wyników zapytań.
Najważniejsze metody:
●
public
static
Article addWord(String word_name)
Metoda
służy
do
dodania
nowego
słowa
do
bazy
danych.
Słowo
dodawane
jest
jako
obiekt
-
korzeń,
gdzie
unikalny
identyfikator
obiektu
w
federacji
składa
się z
przedrostka
WRD_
oraz
nazwy
słowa.
●
public
static
void
scanWordsWithGram(GramUtil gramUtil)
Metoda
skanuje
słowa,
które
nie
zostały
jeszcze
przetworzone
przez
Grama
w
celu
znalezienia
formy
kanonicznej. Dla
każdego
takiego
słowa,
wywoływana
jest
metoda
findNormalisedForm,
która
ustawia
formę
kanoniczną
dla
znalezionego
słowa
●
public
boolean
findNormalisedForm(GramUtil gramUtil)
Metoda
służy
do
"zindeksowania"
słowa
Gramem,
tzn
znalezienia
wszystkich
form
podstawowych
(najczęściej
jednej)
i
stworzeniu
linków
(referencji)
pomiędzy
tymi
słowami.
Mogą
zostać
dodane
nowe
słowa,
jeśli
ich
wcześniej
nie
było
w
bazie
Klasa
SearchResults
Opis:
Klasa reprezentuje listę wyników zapytania (SearchResult). Tutaj wykonywane są wszystkie
metody operujące na wynikach, jak również same metody dotyczące poszczególnych algorytmów
wyszukiwania. Klasa jest powiązana z klasą Word, a konkretnie z pierwszym słowem danego
zapytania, w celu umożliwienia prezentacji scache-owanych wyników przy powtórnym wykonaniu
tego samego zapytania.
Zależności z innymi klasami:
●
private
ToManyRelationship exactResults;
Relacja z wynikami wyszukiwania zawierającymi dokładny ciąg zapytania.
53

●
private
ToManyRelationship moreResults;
Relacja z wynikami wyszukiwania zawierającymi podciąg(i) zapytania.
●
private
ToManyRelationship allWordsResults;
Relacja z wynikami wyszukiwania zawierającymi wszystkie słowa z zapytania.
●
private
ToManyRelationship someWordsResults;
Relacja z wynikami wyszukiwania zawierającymi niektóre słowa z zapytania.
●
private
ToOneRelationship word;
Relacja z pierwszym słowem zapytania. Każdy obiekt reprezentujący listę wyników zapytania
jest powiązany z jednym słowem, słowo może być powiązane z wieloma wynikami.
Najważniejsze metody:
●
private
void
parseQuery()
throws
ArticleNotFoundException
Metoda
parsuje
zapytanie
(szukany
ciąg),
dzieląc
go
na pierwsze
słowo
i
resztę
(firstWord,
query).
●
private
void
searchExact(Word firstWord)
Algorytm 1: wyszukiwanie ciągów znaków.
●
private
void
findExactResults(Iterator it,
int
currentWordNumber,
int
exactSize)
private
void
findExactResultsWithGram(Iterator it,
int
currentWordNumber,
int
exactSize)
Metoda pomocnicza. Przeszukujemy
wszystkie
pozycje
dla
pierwszego
słowa
kwerendy. Dla
każdej
z
pozycji
szukamy
kolejnych
pozycji
i
sprawdzamy czy
tworzą
one
ciąg
o
jaki
było
zapytanie. Znalezione
dokładne
ciągi
wrzucamy
do listy exactResults,
„
półciągi"
do
listy
moreResults
(jeśli
zaznaczona
jest
opcja
znajdowania
półciągów).
●
private
long
findExactPhase(WordPosition currentPos,
int
currentWordPosition)
private
long
findExactPhaseWithGram(WordPosition currentPos,
int
currentWordPosition)
Metoda
pomocnicza.
Dla
każdego
znalezionego
artykułu
po
kolei
pobieramy
słowa
wyszukiwanego
ciągu. Jeśli
znajdzie
się
artykuł,
z
dokładnie
takim
ciągiem,
dodajemy
go
do
listy
exactPhaseArticles.
●
private
void
searchAllWords()
Algorytm 2: wyszukiwanie części wspólnej artykułów
zawierających
wszystkie
lub
niektóre
(minimum jedno)
zapytania.
Klasa SearchResult
Opis:
Klasa reprezentuje pojedynczy wynik zapytania, czyli wskazanie na odpowiednią pozycję,
powiązaną z artykułem, będącym faktycznym wynikiem zapytania. Klasa udostępnia metody służące
do obliczenia wagi artykułu. Elementy tej klasy wchodzą w skład list wyników klasy SearchResults.
Zależności z innymi klasami:
Analogiczne relacje do klasy SearchResults, z tym że typu ToOneRelationship – jeden wynik
wyszukiwania może znajdować się w tylko jeden kolekcji wyników.
Najważniejsze metody:
54

●
private
void
calculateWeight()
Metoda
wykorzystywana
jest
do
obliczenia
wagi
rezultatu
zapytania na
podstawie
wcze niej
pobranych
warto ci
takich
jak:
ilość
znalezionych
słów
zapytania
–
ilość
słów
występujących
w
ciągu
–
pozycje
słów
a
artykułach
(w
szczególności
pozycja
w
temacie
artykułu czy
w
tekście
)
–
rodzaj
znalezionych
słów
(dokładne
szukane
słowa
czy
formy
kanoniczne)
●
public
int
compareTo(Object o)
Metoda porównuje dwa obiekty klasy SearchResult w celu posortowania wyników w zależności
od priorytetu wyświetlania (wagi) kolejnych artykułów.
Klasa NntpArticle
Opis:
Klasa reprezentuje nieprzetworzony artykuł, w stanie zaraz po pobraniu z serwera grup
dyskusyjnych lub relacyjnej bazy danych, gdzie został zarchiwizowany. Klas odpowiada również za
indeksowanie grupy takich artykułów, w czasie którego tworzone są docelowe obiekty klasy Article,
będące sparsowanymi i zindeksowanymi obiektami NntpArticle.
Najważniejsze metody:
●
public
static
void
indexNntpArticles(
long
count)
throws
NoGramException
Jest to główna metoda wywoływana przez indekser. Służy do zindeksowania nowo pobranych
artykułów klasy NntpArticle
poprzez stworzenie ich odpowiedników klasy Article, a następnie
sparsowanie i zindeksowanie ich w oddzielnej bazie danych.
Opisane powyżej główne klasy aplikacji przedstawiono poniżej na poglądowym diagramie klas
w celu przedstawienia zależności między nimi.
55
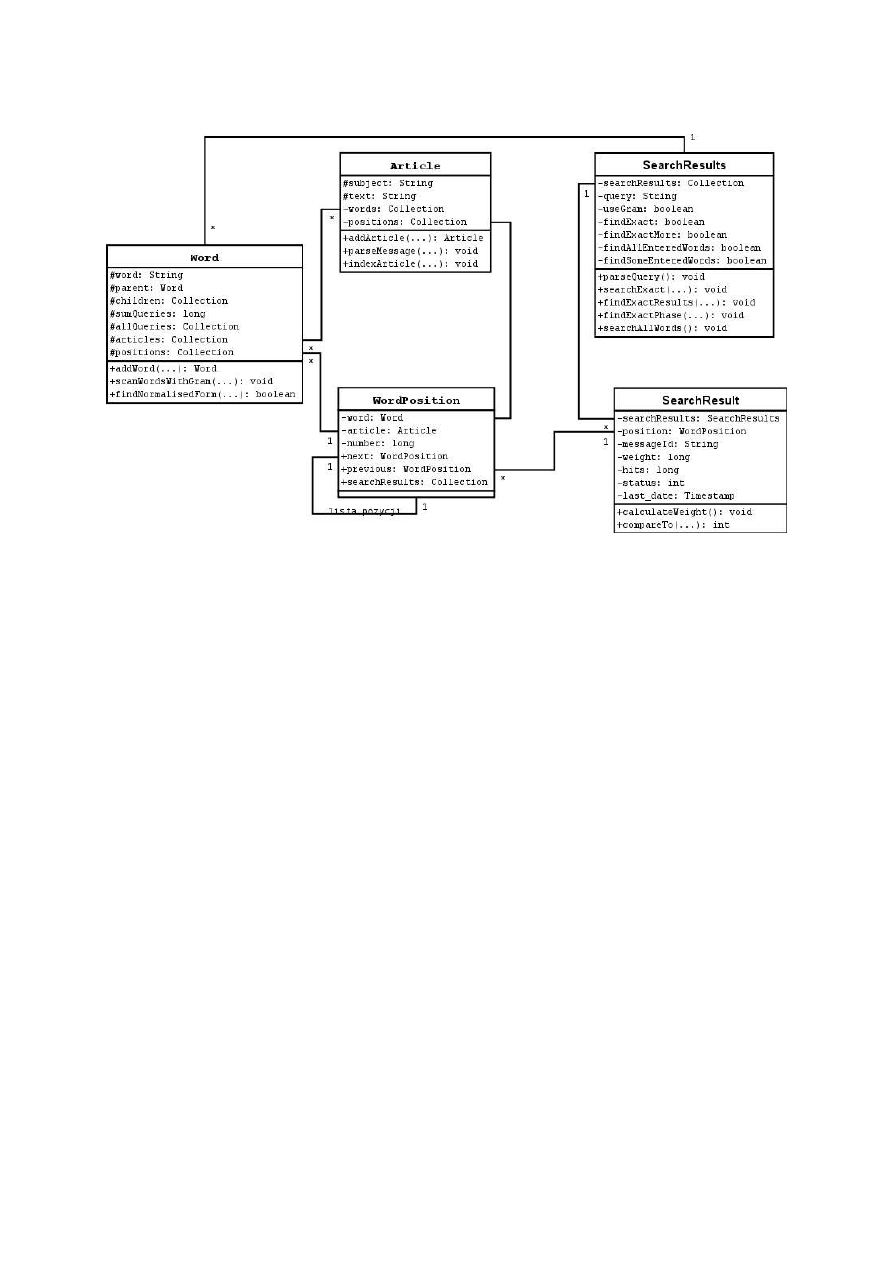
Aby zachować czytelność, przedstawione zostały tylko podstawowe pola poszczególnych klas.
Nie widać również na diagramie powiązania klasy Word z SearchResults (poprzez pole allQueries).
Właściwy, pełny diagram klas dla aplikacji znajduje się w dziale Dodatki.
5.2.
Implementacja fetchera i narzędzia backupującego
Fetcher – narzędzie do pobierania artykułów z grup dyskusyjnych
Przed procesem indeksowania wszystkie posty ściągane są bezpośrednio z lokalnego serwera
NNTP i umieszczane w obiektowej bazie NntpArticle. Odpowiedzialna za te czynności jest klasa
LoadArticle z pakietu pl.edu.pjwstk.util. Program ten uruchamiany jest ręcznie.
Mechanizm jest przyrostowy co oznacza że w przypadku ponownego uruchomienia programu
wczytane zostaną tylko nowe posty, które wcześniej nie zostały załadowane. Podobnie jeżeli program
zostanie nagle przerwany w trakcie działania, to podczas kolejnego uruchomienia wczytywanie
postów z serwera rozpocznie się od ostatnio zapisanych danych.
Program ma dwa tryby działania: wczytywanie wszystkiego lub wczytywania pojedynczej
grupy. W trybie wczytywania wszystkiego aplikacja ściąga najpierw listę dostępnych grup
dyskusyjnych a następnie dla każdej grupy wczytuje wszystkie posty.
Dla każdej wczytywanej grupy, bez względu na to, w którym trybie jest uruchomiona, aplikacja
tworzy kontener z nazwą danej grupy. W kontenerze zapisywany jest obiekt ooTreeList
przechowujący ściągnięte posty w kolejności zgodnej z tą podaną przez serwer. Dodatkowo tworzony
jest jeden kontener w całej bazie przechowujący mapę (obiekt ooMap) gdzie kluczem jest nazwa
grupy a wartością identyfikator liczbowy ostatnio wczytanego postu dla tej grupy.
56
Rysunek 18. Poglądowy diagram klas
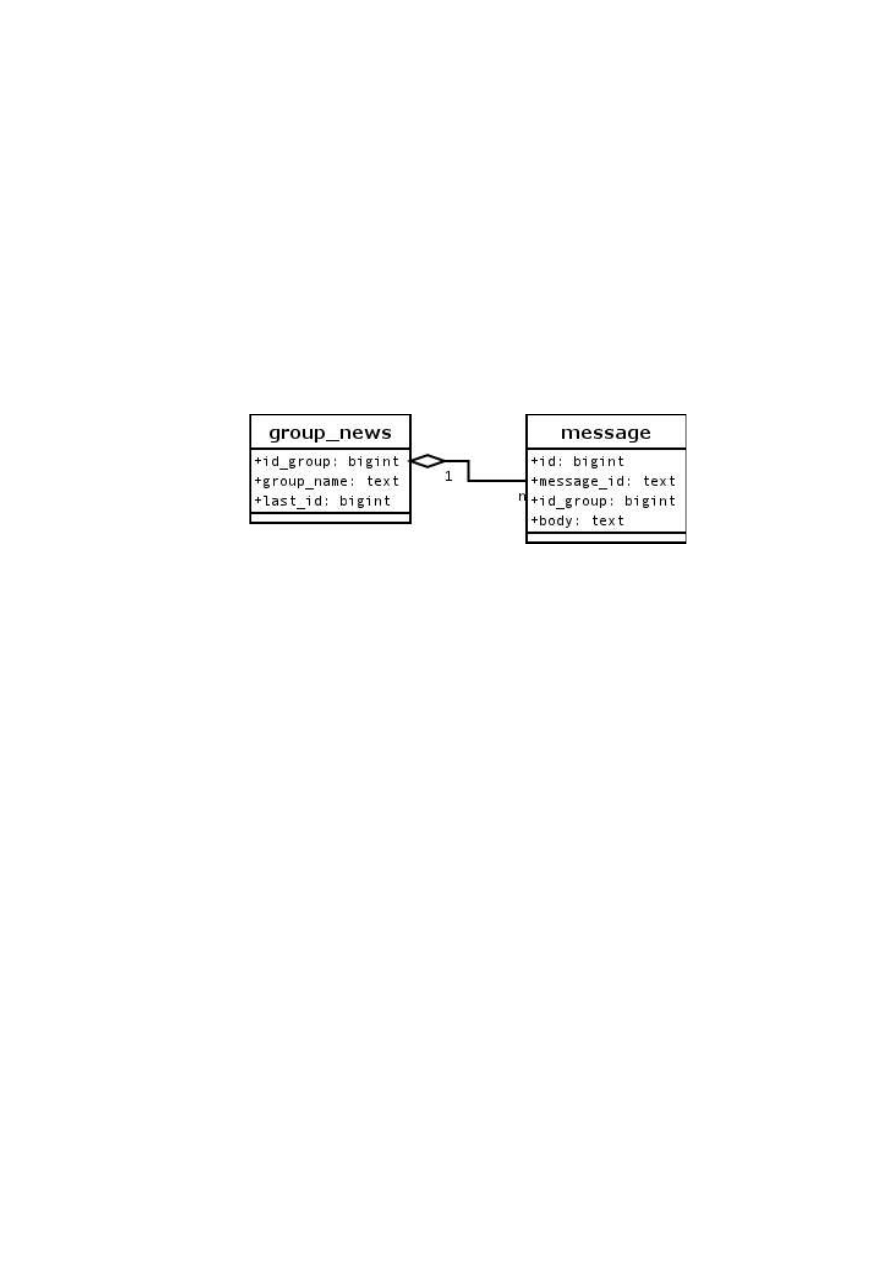
Pobrane
posty
umieszczane
są
w
bazie
jako
obiekty
pl.edu.pjwstk.NewsSearch.NntpArticle.
Backuper – skrypt w języku Python do archiwizacji postów w relacyjnej bazie danych
W trakcie prac nad stworzeniem naszego oprogramowania powstał problem archiwizacji
artykułów grup dyskusyjnych. Nie mając pełnego zaufania od oprogramowania ściągającego posty
grup dyskusyjnych, a także nie mając zaufania do sprzętu (awaria dysku) stwierdziliśmy, że
potrzebujemy prostego mechanizmu archiwizacji. Najprostszym rozwiązaniem jakie przyszło do
głowy była relacyjna baza danych. Nie chcieliśmy za bardzo angażować się w tworzenie
skomplikowanych rozwiązań w technologiach, które mało znaliśmy. Dlatego też wybraliśmy bazę
PostgreSQL oraz język Python. Struktura bazy jest bardzo prosta i składa się tylko z dwóch encji:
group_news i message.
Rysunek 19. Struktura relacyjna archiwum grup
dyskusyjnych
Skrypt uruchamiany jest ręcznie a jedynym jego zadaniem jest połączeniem się z lokalnym
serwerem newsów, pobranie listy grup dyskusyjnych a następnie dla każdej grupy wczytanie
wszystkich postów. Narzędzie to działa przyrostowo. Uruchomione ponownie wczyta tylko nowe
posty. Wszystkie operacje bazodanowe odbywają się w transakcjach. Mechanizm skonstruowany jest
tak, aby można było przerwać działanie programu w dowolnym momencie, bez ryzyka utraty
spójności danych. W razie potrzeby działanie programu może zostać przerwane, a po ponownym
uruchomieniu program zacznie od ostatnio zapisanych danych.
5.3.
Implementacja indeksowania
Implementacja algorytmu indeksowania wypracowana w projekcie aplikacji i przedstawiona w
rozdziale Opis rozwiązania: Algorytm indeksowania zakładała zamknięcie indeksowania każdego
artykułu w jednym cyklu obejmującym:
–
parsowanie artykułu,
–
tworzenie struktury wątków,
–
tworzenie powiązań między słowami w artykule,
–
analizę fleksyjną.
W praktyce takie rozwiązanie okazało się jednak mało wydajne. Tworzenie struktury wątków,
gdy nie zindeksowane zostały jeszcze wszystkie wiadomości pociąga za sobą komplikacje techniczne
(np. konieczność tworzenia atrap postów – nie zapełnionych danymi obiektów, przechowujących
57

jedynie unikalne Message-ID i powiązania do artykułów już zindeksowanych). Z kolei analiza
fleksyjna wszystkich kolejnych słów w artykule jest niepraktyczna ze względu na zbyt duże ilości
porównań – dla każdego słowa w artykule należałoby sprawdzać czy nie zostało już ono
zindeksowane. Ponadto, program do analizy fleksyjnej – Gram – z którym komunikacja odbywa się
poprzez standard CORBA, bywa mało wydajny, szczególnie jeśli stosujemy go zbyt intensywnie
podczas indeksowania. Dlatego też, początkowa koncepcja została nieco zmodyfikowana w celu
zwiększenie efektywności mechanizmu indeksowania. Części odpowiedzialne za tworzenie wątków
oraz analizę fleksyjną zostały przeniesione do oddzielnych podaplikacji, natomiast właściwy algorytm
indeksowania został zawężony do dwóch najważniejszych czynności, czyli parsowania artykułu i
indeksowania sparsowanych danych. W pierwszej kolejności omówimy więc właściwy mechanizm, a
następnie przejdziemy do dwóch wydzielonych modułów.
Właściwy mechanizm indeksowania
Indeksowanie artykułu rozpoczyna się w momencie stworzenia nowego obiektu klasy Article,
w metodzie indexArticles() klasy NntpArticle. Metoda ta odpowiedzialna jest za indeksowanie
ściągniętych z serwera grup dyskusyjnych „surowych” artykułów, składających się jedynie z
czystego, nieprzetworzonego tekstu. Przetwarzanie kolejnych niezindeksowanych artykułów
realizowane jest w trzech krokach. Najpierw tworzony jest obiekt artykułu. Podczas tworzenia
obiektu następuje parsowanie artykułu, czyli wstępna strukturyzacja danych artykułu. Następnie
artykuł dodawany jest do bazy danych. Gdy znajduje się już w bazie, wywoływana jest metoda
indexArticle() dodanego obiektu klasy Article, tworząca właściwą strukturę powiązań artykułu ze
słowami poprzez listę pozycji.
Parsowanie artykułu
Metoda parseMessage odpowiedzialna za parsowanie artykułu wywoływana jest już w
konstruktorze klasy Article. Jej zadaniem jest odseparowanie nagłówków wiadomości od treści
artykułu i umieszczenie uzyskanych w ten sposób informacji w odpowiednich polach klasy. Pola
odpowiadają zazwyczaj nazwom nagłówków wiadomości, zdefiniowanych przez protokół NNTP.
Działanie metody parseMessage można opisać w następujący sposób:
1. Pobierz treść wiadomości w oryginalnym formacie
2. W pętli pobieraj kolejne linijki wiadomości (oddzielone znakiem końca linii)
3. Sprawdź czy linia nie rozpoczyna się od nazwy nagłówka, jeśli tak pobierz tę nazwę
a) Jeśli mamy nagłówek: sparsuj dane znajdujące się po nagłówki, zależnie od nazwy
nagłówka:
- jeśli nagłówek jest polem typu tekstowego (większość nagłówków) – zapisz wartość pola
do odpowiedniego pola w klasie
- jeśli nagłówek jest polem typu data, parsuj datę wywołując metodą parseDate i następnie
zapisz wartość wynikowego obiektu klasy Timestamp do odpowiedniego pola klasy
b) Jeśli nie mamy nagłówka, oznacza to że linia opisuje nagłówek składający się z kilku
linii, zapisujemy więc całą linię do tymczasowego obiektu i parsujemy dalej
4. Gdy napotkamy ostatni nagłówek, zaczynamy parsować tekst wiadomości – kolejne linie
dodajemy poprzez konkatenację do pola klasy odpowiedzialnego ze przechowywanie
pełnego tekstu wiadomości
Algorytm kończy się po sparsowaniu ostatniej linijki oryginalnej wiadomości. Po wykonaniu
parsowania, w nowym obiekcie klasy Article mamy już zainicjowane wszystkie pola odpowiadające
standardowym nagłówkom wiadomości (a być może również niektóre z niestandardowych
nagłówków) oraz właściwą treść artykułu, w polu text.
58

Tworzenie powiązań
Gdy mamy już wydzielone wszystkie informacje potrzebne do stworzenia docelowej struktury
danych na podstawie artykułu, możemy przejść do właściwej fazy indeksowania, polegającej na
stworzeniu łatwo dostępnej struktury powiązań referencyjnych pomiędzy poszczególnymi obiektami
w bazie danych. Odpowiedzialna jest za to metoda indexArticle klasy Article. Każde ze słów użytych
w artykule zostaje wydzielone i na jego podstawie tworzymy unikalny obiekt klasy Word. Obiekt ten
łączymy z artykułem używając pomocniczego obiektu klasy WordPosition, który przechowuje
referencje do słowa i artykułu, jak również mówi nam o pozycji zajmowanej przez słowo w
indeksowanym artykule. W miarę indeksowania tworzy się lista takich pozycji, ponieważ każdy z
obiektów WordPosition zawiera referencje do poprzedniej i następnej pozycji w artykule. Ta
struktura będzie później podstawą algorytmu wyszukiwania opartego na wyszukiwaniu identycznych
podciągów słów.
Działanie metody indexArticle możemy opisać poprzez następujący algorytm:
1. Pobieramy właściwy tekst artykułu, który po sparsowaniu znajduje się w polu text
indeksowanego obiektu klasy Article.
2. Pobieramy kolejne słowo z tekstu artykułu – konkretnie pobieramy kolejny napis oddzielony
znakami separującymi, takimi jak tab, spacja, czy znacznik końca linii.
3. Pobieramy z bazy obiekt odpowiadający temu słowu (dokładnie pobieramy obiekt-korzeń o
unikalnym identyfikatorze w postaci: WRD_pobrane_słowo.
4. Jeśli słowo istnieje w bazie (w wyniku pobrania obiektu-korzenia dostaliśmy obiekt klasy
Word), przechodzimy do kroku 6.
5. Jeśli słowa nie ma w bazie, dodajemy słowo do bazy, wykorzystując statyczną metodę klasy
Word addWord i pobieramy stworzony obiekt.
6. Tworzymy powiązanie między obiektem Word (dodanym lub pobranym z bazy) a
indeksowanym artykułem.
7. Tworzymy nowy obiekt klasy WordPosition z ustawionym polem określającym numer tej
pozycji w indeksowanym artykule i dodajemy go do bazy używając metody statycznej klasy
WordPosition: addPosition. Zwrócony obiekt zapisujemy do zmiennej newPosition.
8. Jeśli mamy tymczasową zmienną lastPosition, ustawiamy ją jako poprzednią pozycję nowo
dodanej pozycji newPosition, poprzez stworzenie powiązania między tymi dwoma
obiektami.
9. Przypisujemy nowo dodaną pozycję do artykułu oraz wiążemy ją z odpowiadającym
słowem.
10. Wywołujemy metodę increaseSumPositions na aktualnym obiekcie Word, która powiększa
zmienną przechowującą liczbę pozycji powiązanych z danym słowem.
11. Referencję do obiektu newPosition przepisujemy do tymczasowej zmiennej lastPosition –
przyda się ona przy następnym przejściu pętli.
Schemat działania metody indexArticle został przedstawiony graficznie na rysunku: Diagram
przepływu dla funkcji indeksowania. Metoda indexArticle kończy swoje działanie, gdy powyższy
algorytm zostanie zastosowany dla wszystkich kolejnych słów artykułu. W tym momencie, stworzona
utworzona jest już dla zindeksowanego artykułu podstawowa struktura danych, na której opiera się
aplikacja. Do zrobienia są jednak jeszcze dwie ważne rzeczy, które również mają niebagatelny wpływ
na działanie programu. Chodzi o zindeksowanie tematu oraz próbę wydobycia informacji na temat
autora dopiero co zindeksowanego artykułu. Obie te informacje wykorzystywane są podczas
wyliczania wagi dla poszczególnych wyników wyszukiwania. Przyjrzyjmy się więc dokładniej w jaki
sposób uzyskujemy te właśnie informacje.
59
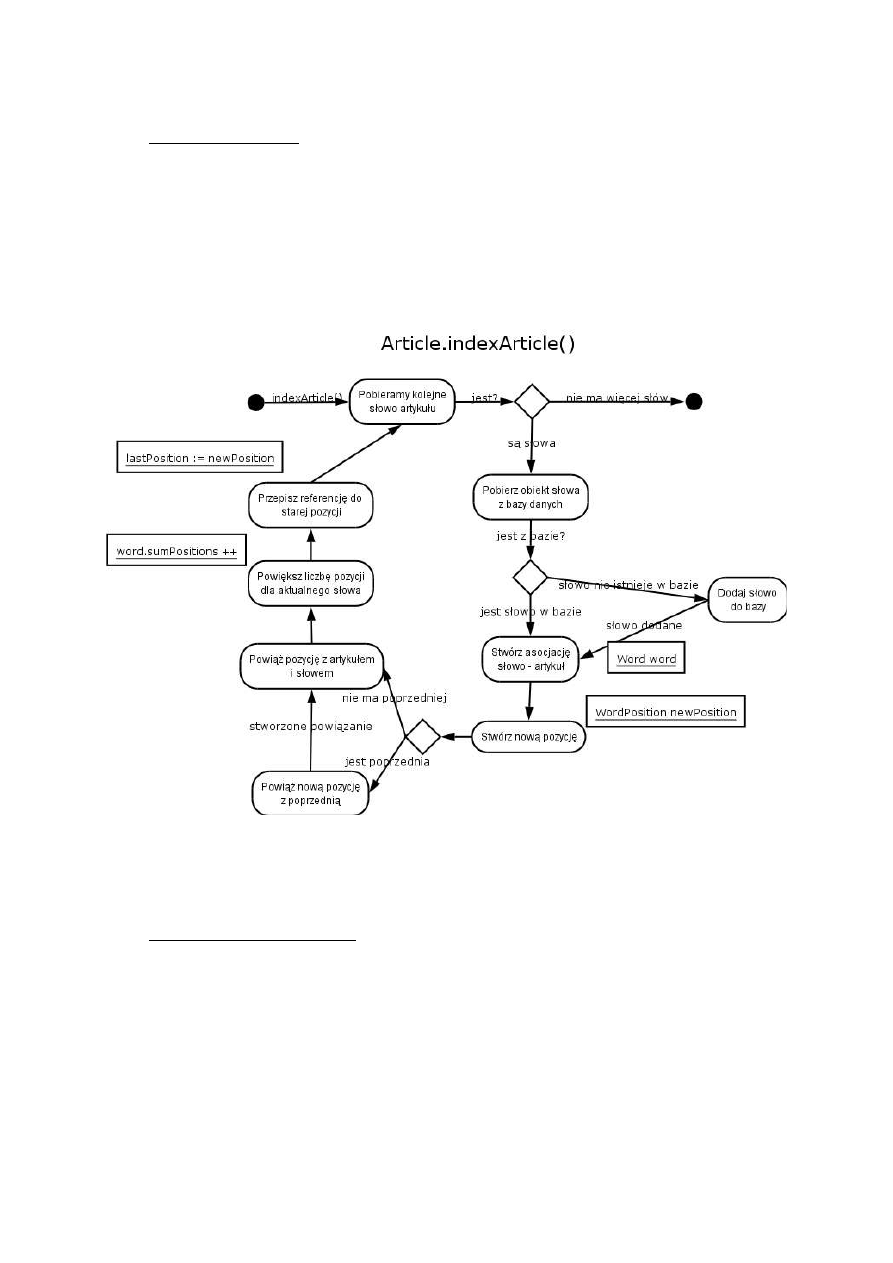
Zindeksowanie tematu
Do zindeksowania tematu wiadomości służy metoda indexTitle(). Indeksowanie tematu działa
w analogiczny sposób do indeksowania treści artykułu. Jedyną różnicą jest dodanie dla każdej pozycji
zindeksowanej w ten sposób informacji o tym, że słowo występuje w temacie wiadomości. Ma to
zasadnicze znaczenie dla skuteczności algorytmu wyszukiwania. Słowa znajdujące się w tematach
wiadomości dostają bowiem w wyszukiwaniu wyższe wagi, ze względu na to, że zazwyczaj lepiej
opisują tematykę artykułu, niż sama treść.
Po wykonaniu tej czynności artykuł jest już w pełni widoczny dla aplikacji i zawiera strukturę w pełni
przygotowaną do zastosowania w mechanizmie wyszukiwania.
Tworzenie struktury wątków
Tworzeniem struktury wątków zajmuje sie statyczna metoda Article.makeThreads().
Przechodzi ona po wszystkich obiektach klasy Article wywołując na nich metodę
makeReferences(). Pobiera ona listę identyfikatorów message_id z nagłówka
“references”. Korzysta ona z własności tego nagłówka, która polega na tym, iż pierwszy element
na liście stanowi identyfikator pierwszego posta w wątku. Ostatnim elementem listy jest bezpośredni
przodek danego posta czyli ojciec. Obie te relacje utrwalane są za pomocą relacji Objectivity/DB.
60
Rysunek 20. Diagram przepływu dla funkcji indeksowania

Analiza fleksyjna słów
Analiza fleksyjna słów odbywa się w całości w metodzie
scanWordsWithGram() klasy Word. Przed
wywo aniem metody, tworzony jest obiekt GramUtil, odpowiedzialny za interakcj z programem Gram, u ywaj c
protoko u CORBA. Analiza polega na przeszukaniu wszystkich s ów bazy, które nie zosta y jeszcze
zindeksowane poprzez Gram. S
to wszystkie słowa ze znacznikiem
alreadyNormalised = false. Dla
wszystkich takich s ów wywoywana jest metoda findNormalisedForm(), która odpowiada za zaindeksowanie
konkretnego s owa W
i
. Dzia anie tej metody mo emy opisa poprzez zast puj c y algorytm:
1. Konwertujemy napis słowa tak, aby zawierał tylko małe litery.
2. Przesyłamy powstały w ten sposób napis do metody getNormalisedWord obiektu GramUtil
– metoda zwraca formę lub formy podstawowe indeksowanego słowa w postawi napisu.
3. Jeśli metoda nie zwróciła napisu, lecz wartość null, przechodzimy do punktu 9, w
przeciwnym wypadku idziemy do następnego kroku.
4. Analizujemy zwrócony napis. Może on zawierać jedno lub więcej słów, będących
podstawową formą słowa indeksowanego. W pętli pobieramy kolejne słowa z napisu
(używając do tego klasy Javy: StringTokenizer).
5. Pobieramy kolejne znormalizowane słowo W
n
z bazy danych (na podstawie zwróconego
napisu).
6. Jeśli słowo istnieje w bazie, przechodzimy do punktu 7, w przeciwnym razie przechodzimy
do następnego punktu.
7. Dodajemy znormalizowane słowo W
n
do bazy danych.
8. Tworzymy powiązanie między słowem indeksowanym W
i
a jego znormalizowaną formą W
n
.
a) Wywo ujemy
metodę addParent(normalisedWord) na obiekcie indeksowanym W
i
. Metoda
ta dodaje do tablicy słów będących podstawową formą indeksowanego słowa, nowego
rodzica.
b) Wywołujemy metodę addChild(indexedWord) na obiekcie znormalizowanym W
n
.Metoda
ta dodaje do tablicy dzieci słowa (słów powiązanych fleksyjnie) słowo indeksowane W
i
.
9. Zaznaczmy słowo jako znormalizowane, znacznik: alreadyNormalised = true. Nie będzie
ono brane pod uwagę w kolejnym wywołaniu analizy fleksyjnej.
Jak widać, aby artykuły oraz znajdujące się w nich słowa mogły być rzeczywiście użyteczne dla
algorytmu wyszukiwania danych, potrzebne jest wykonanie wielu operacji, nazwanych tu ogólnie
indeksowaniem danych. Nie wszystkie z tych operacji muszą zostać jednak wykonane, aby
wyszukiwanie miało szansę zadziałać. Już po wykonaniu podstawowego parsowania artykułu i
zindeksowania jego treści, mechanizm wyszukiwania bierze pod uwagę zindeksowane artykuły przy
poszukiwaniu wyników. Im więcej z opisanych powyżej dodatkowych operacji zostanie wykonanych,
tym większa jest jednak szansa, że wyszukiwane rezultaty będą dokładne i trafne, spełniając tym
samym wymagania potencjalnego użytkownika.
61

5.4.
Implementacja wyszukiwania
Klasą odpowiedzialną ze działanie mechanizmu wyszukiwania jest SearchResults.
Wyszukiwanie odbywa się poprzez statyczne metody tej klasy. Obiekty klasy SearchResults służą
natomiast do składowania informacji o wynikach wyszukiwania. Obiekty te mogą zostać utrwalone w
bazie danych. W takim przypadku są one wykorzystywane jako cache wyników danego zapytania.
Ponowne wywołanie identycznego zapytania będzie skutkowało prezentacją już raz wyszukanych
wyników.
W pracy zostały zaimplementowane dwa główne mechanizmy wyszukiwania, opisane
wcześniej w rozdziale czwartym, czyli:
–
wyszukiwanie oparte na znajdowaniu dokładnych ciągów podanych w zapytaniu
–
wyszukiwanie części wspólnej wszystkich artykułów zawierających słowa z zapytania
Oba algorytmy dzielą się na mniejsze funkcje, odpowiedzialne za znajdowanie konkretnej
informacji. W obu algorytmach zaimplementowane jest dodatkowo wyszukiwanie z analizą fleksyjną.
Wykorzystywana jest do tego struktura powiązań fleksyjnych pomiędzy słowami, wygenerowana
podczas indeksowania, dzięki zastosowaniu programu Neurosoft Gram. Oprócz tego, na
implementację wyszukiwania składa się również składowanie wyników zapytań w bazie danych, w
strukturze umożliwiającej pobranie ich i wyświetlenie przy ponownym wywołaniu identycznego
zapytania. W tym podrozdziale przyjrzymy się dokładnej implementacji obu mechanizmów
wyszukiwania, jak również zastosowanej w aplikacji metodzie cache'owania wyników zapytań.
Wyszukiwanie metodą znajdowania wspólnych ciągów słów
Pierwszą omawianą implementacją wyszukiwania jest metoda znajdowania wspólnych z
zapytaniem podciągów słów. Algorytm ten jest podzielony na kilka niezależnych funkcji. Wykonanie
każdej z tych funkcji zależy od ustawionych parametrów zapytania, które zaimplementowane są jako
boolean'owskie pola klasy SearchResults. Parametry te uwzględniają takie sprawy jak:
–
czy poszukiwać w artykułach dokładnych ciągów słów, równoznacznych z podanym zapytaniem?
–
czy poszukiwać również podciągów (ciągów nie zawierających wszystkich kolejnych słów
zapytania, lecz zawierających co najmniej dwa słowa)
–
czy w wyszukiwać bez względu na fleksję wyrazów (czyli – czy korzystać ze stworzonej podczas
indeksowania struktury zależności fleksyjnych między słowami)
–
czy pominąć scache'owane wyniki zapytania – gdy atrybut ma wartość prawda, nie jest brana pod
uwagę struktura wygenerowana podczas historycznych zapytań, znalezione wyniki są więc zawsze
aktualne, czas wykonywania operacji jest jednak znacznie dłuższy
–
czy pominąć powszechne słowa – gdy ta opcja jest zaznaczona pomijane są słowa, które występują
w zdefiniowanej wcześniej części wszystkich artykułów (np. w 20 procentach artykułów) –
znajdowane ciągi nie są w tym wypadku identyczne z zapytaniem, operacja wykonuje się jednak
znacznie szybciej, gdyż nie ma potrzeby przeglądania wszystkich artykułów powiązanych z bardzo
popularnymi słowami
Dwa ostatnie parametry odnoszą się również do drugiego sposobu wyszukiwania. Standardowo
zaznaczone są wszystkie opcje oprócz pomijania wyników z cache.
62
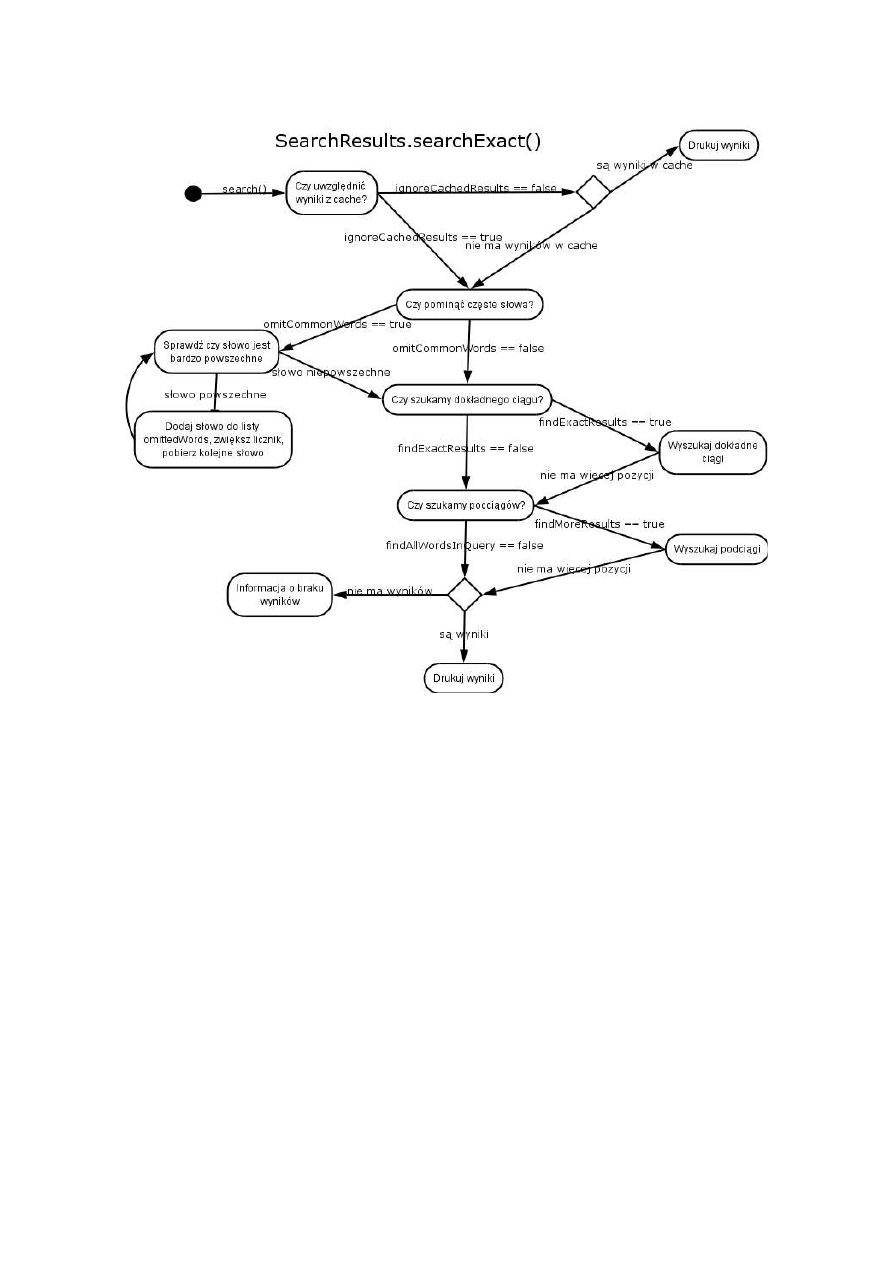
Diagram przepływu dla metody searchExact(), odpowiedzialnej za wyszukiwanie jednakowych
ciągów prezentuje wizualnie poszczególne etapy algorytmu wyszukiwania, bez wchodzenia w
szczegóły implementacyjne samego wyszukiwania informacji. Każda z operacji wykonywanych
podczas działania metody zależna jest od zaznaczonych wcześniej parametrów wyszukiwania. I tak,
najpierw sprawdzamy czy mamy uwzględniać wyniki z cache. Jeśli tak, to w wypadku gdy identyczne
zapytania znajduje się już w historii, przechodzimy od razu do prezentacji scache'owanych wyników.
W przeciwnym wypadku przechodzimy do właściwego wyszukiwania. Jeśli zaznaczona jest opcja
pominięcia częstych słów z zapytania, algorytm sprawdza kolejne słowa i usuwa wszystkie, które
przekroczyły procent popularności (powiązane są z większą ilością artykułów niż ustalony w
konfiguracji limit, np. w ponad 20% wszystkich artykułów). Gdy dochodzimy w końcu do mniej
popularnego słowa, zaczynamy właściwy algorytm. Maksymalnie zostaną wykonane dwie z czterech
możliwych metod wyszukiwania podciągów:
–
wyszukiwanie całych ciągów
–
wyszukiwanie podciągów
63
Rysunek 21. Diagram przepływu dla metody wyszukiwania ciągów
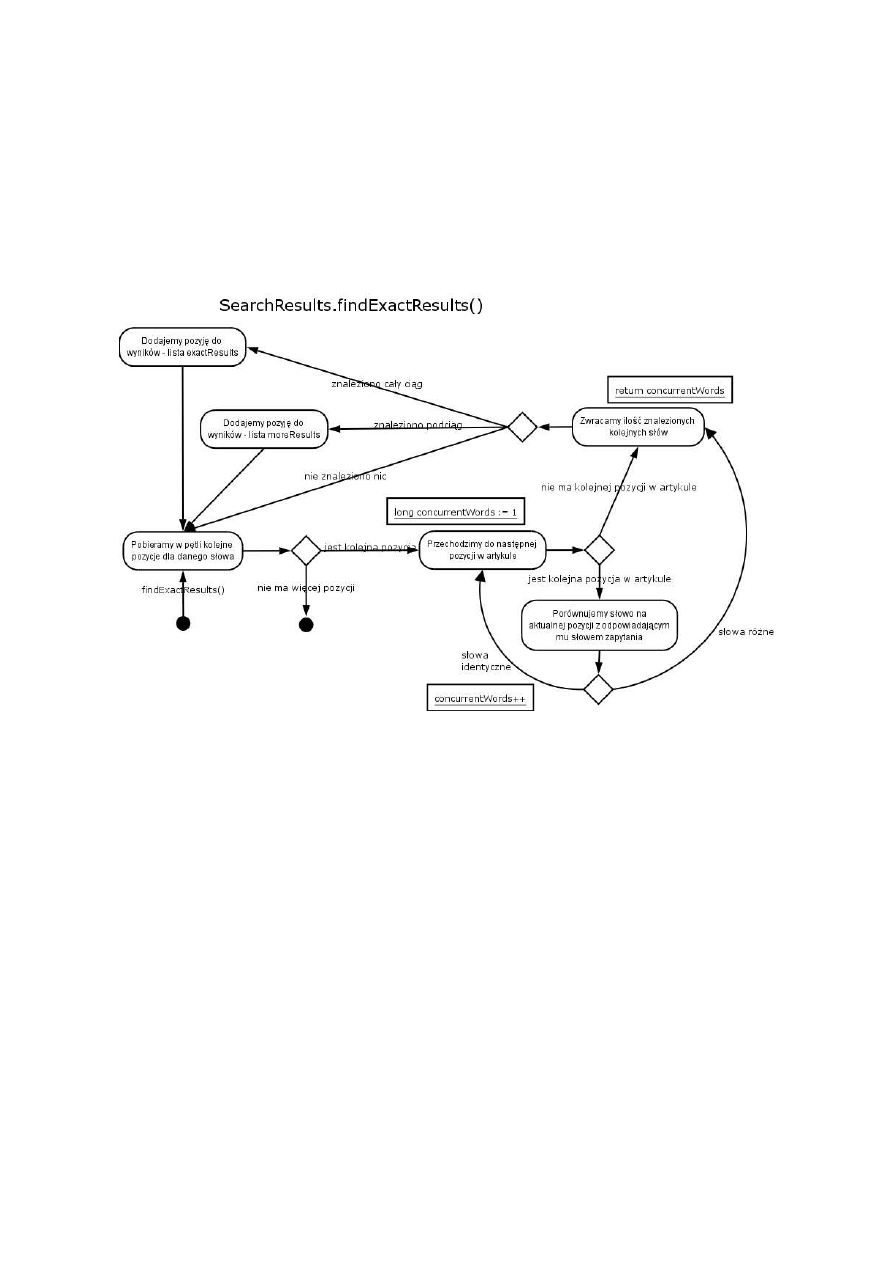
–
wyszukiwanie całych ciągów uwzględniając zależności fleksyjne
–
wyszukiwanie podciągów uwzględniając zależności fleksyjne
Dwie ostatnie metody dla większej czytelności nie są uwzględnione na diagramie.
Wykonywane są one zamiast swoich odpowiedników, gdy zaznaczona jest opcja uwzględniania
fleksji przy wyszukiwaniu. Każda z powyższych metod opiera się na bardzo podobnym mechanizmie.
Został on przedstawiony graficznie na rysunku: Implementacja metody wyszukiwania dokładnych
ciągów i opisany szczegółowo poniżej.
Algorytm ten zakłada, że zaczynamy od analizy pierwszego słowa zapytania.
1. Wywołujemy metodę findExactResults() dla pierwszego słowa.
2. Dla każdej z pozycji powiązanych z tym słowem wykonujemy metodę findExactPhase(),
która odpowiada za zliczenie ilości kolejnych słów pokrywających się ze słowami z
zapytania.
3. Pobieramy więc w pętli kolejne pozycje, z listy pozycji dla konkretnego artykułu,
powiązanego z analizowanym słowem.
4. Tak długo jak słowa te zgadzają się ze słowami zapytania, zwiększamy o jeden ilość
znalezionych kolejnych słów.
5. Metoda kończy się gdy porównywane słowa są różne, lub gdy doszliśmy do ostatniego
słowa artykułu bądź zapytania. W zależności od wyniku:
64
Rysunek 22. Implementacja metody wyszukiwania dokładnych ciągów

–
pozycja dodawana jest do listy dokładnych wyników (gdy znaleziono całkowity ciąg,
identyczny z zapytaniem),
–
do listy podciągów (gdy znaleziono podciąg co najmniej dwóch słów),
–
lub ignorowana (gdy nie znaleziono podciągu).
Identyczny mechanizm stosowany jest dla kolejnych słów zapytania, z tym że przy kolejnych
słowach, możliwe jest już tylko dodanie pozycji do listy podciągów. Dla wyszukiwania z
uwzględnieniem fleksji, oprócz zwykłego porównania słów z zapytania i z artykułu, porównywane są
również wszystkie możliwe formy słowa z zapytania.
Wyszukiwanie metodą znajdowania części wspólnej artykułów
Wyszukiwanie tą metodą charakteryzuje się jednakowym podejściem do wszystkich słów
zapytania użytkownika – kolejność słów nie jest dla nas w tym przypadku istotna. Istotne jest
natomiast znalezienie artykułów zawierających jak największą liczbę znajdujących się w zapytaniu
słów. Sam algorytm znajdowania artykułów jest bardzo prosty i sprowadza się do pobrania
wszystkich artykułów związanych z poszczególnymi słowami zapytania. Ciekawszy jest sposób, w
jaki tworzymy na podstawie pobranych list artykułów, docelową listę wyników zapytani.
Zaraz po wywołaniu metody searchAllWords klasy SearchResults, odpowiedzialnej za wyszukiwanie
metodą znajdowania części wspólnej, tworzona jest tymczasowa struktura wyników, w postaci tablicy
haszowanych zbiorów (HashSet[] allFoundResults) artykułów. Każda pozycja tablicy odpowiada
zbiorowi artykułów dla każdego kolejnego słowa zapytania. Po wykonaniu pierwszej fazy
wyszukiwania, cała tablica zbiorów powinna być wypełniona artykułami. W tym momencie
przechodzimy do drugiej fazy algorytmu, tj. wyodrębniania z tablicy zbiorów konkretnej listy
wyników.
Algorytm wyodrębniania listy dokładnych wyników polega na wykonywaniu w pętli operacji
intersekcji kolejnych zbiorów. Możemy go zapisać w postaci następujących kroków:
1. Tworzymy nowy zbiór HashSet allInOne
2. Inicjujemy zbiór wartościami pierwszego elementu tablicy zbiorów wyników: allInOne :=
allFoundResults[1]
3. Dla każdego kolejnego zbioru od 2 do ostatniego elementu tablicy wyników (
allFoundResults.length) wykonujemy operację intersekcji ze zbiorem allInOne.
Po wykonaniu tej operacji, w zbiorze allInOne znajdują się tylko artykuły zawierające
wszystkie słowa analizowanego przez nas zapytania. Ostatnią rzeczą jaką musimy zrobić jest
stworzenie listy obiektów klasy SearchResult zawierających artykuły ze zbioru allInOne. Dla każdego
obiektu ustawiamy zmienną allFoundResults na true – jest to zmienna brana pod uwagę przy
wyliczaniu wagi dla wyników zapytania.
W podobny sposób możemy wyodrębnić listy niedokładnych wyników zapytania,
zawierających jedno lub więcej słów kluczowych podanych w zapytaniu użytkownika. Gdy w
wynikach zapytania mają się pojawić również artykuły zawierające tylko część słów podanych w
zapytaniu, możemy jednak zrezygnować z opisanego wyżej mechanizmu i zastosować uniwersalny
algorytm. Algorytm ten również polega na tablicy zbiorów allFoundResults, z tym że w tym
przypadku zastosujemy tymczasową, dwuwymiarową tablicę haszowaną, do grupowania wyników
zapytania. Kluczami w tej tablicy będą artykuły, będące wynikami wyszukiwania wszystkich słów
zapytania (ewentualnie z uwzględnieniem analizy fleksyjnej). Wartościami tablicy haszowanej będą
natomiast tablice o rozmiarze równym ilości słów zapytania. W każdym kolejnym polu tablicy dla
konkretnego artykułu, trzymać będziemy liczbę oznaczającą ilość wystąpień odpowiedniego słowa
65

zapytania w tym artykule. Dla słów pominiętych tablice te nie będą zainicjowane. Algorytm
wyodrębnienia wyników polegać będzie zatem na uzupełnieniu wartości zainicjowanej tablicy, a
następnie na jej podstawie utworzenie dwóch list wyników: dla artykułów zawierających wszystkie
słowa zapytania i dla tych zawierających tylko niektóre ze słów. Algorytm ten możemy więc
przedstawić za pomocą następujących kroków:
1. Konstruujemy haszowaną tablicę
groupedArticles
2. W pętli pobieramy listy artykułów powiązanych z kolejnymi słowami zapytania i
0
do i
n
3. Dla każdej listy tworzymy iterator i w pętli pobieramy kolejne artykuły
4. Dla każdego pobranego artykułu:
Sprawdzamy czy występuje już jako klucz w tymczasowej tablicy haszowanej
groupedArticles
a) je li tak, zwi kszamy warto
na aktualnej pozycji
i o jeden (kolejne słowo występujące w
artykule)
b)
jeśli nie, dodajemy do tablicy nowy element z artykułem jako kluczem oraz inicjujemy
wartość klucza jako pustą tabelę o rozmiarze równym ilości słów zapytania i ustawiamy na
pozycji i tablicy wartość 1 (pierwsze słowo w artykule)
5. Kończymy obie pętle
6. Iterujemy kolejne artykuły w nowo powstałej tymczasowej haszowanej tablicy
7. Dla każdego artykułu tworzymy obiekt SearchResult – wynik wyszukiwania i inicjujemy
jego wartości: foundWords, foundDistinctWords i allWordsFound
8. W zależności czy zostały znalezione wszystkie słowa zapytania, czy tylko niektóre,
dodajemy obiekt do listy allWordsResults lub someWordsResults obiektu SearchResults
Obliczanie wagi wyników zapytania
Ostatnią fazą algorytmu wyszukiwania jest nadawanie wagi poszczególnym wynikom oraz
ostateczne posortowanie wyników przed wyświetleniem na ekranie.
Przed nadaniem wag, zebrane wyniki ze wszystkich rodzajów wyszukiwania kopiowane do
tymczasowej kolekcji o rozmiarze równym ilości wszystkich wyników wyszukiwania. Następnie dla
każdego wyniku (obiektu klasy SearchResult) wykonywana jest metoda calculateWeight(),
odpowiedzialna za wyliczenie wagi wyniku na podstawie zebranych wcześniej parametrów. Waga
obliczana jest na podstawie następujących parametrów, zebranych wcześniej podczas wykonywania
algorytmów wyszukiwania:
–
ilość kolejnych słów zapytania w artykule wynikowym
–
ilość znalezionych, unikalnych słów zapytania w artykule (maksymalnie równa liczbie
wszystkich niepominiętych słów zapytania)
–
sumaryczna ilość wszystkich słów zapytania występujących w artykule wynikowym (z
powtórzeniami)
–
czy znaleziono dokładny ciąg?
–
czy znaleziono wszystkie słowa zapytania?
–
sumaryczna różnica odległości między słowami zapytania, w znalezionym artykule
66

Algorytm wyliczania wagi na podstawie powyższych parametrów przedstawia się więc
następująco:
1. Jeśli w wyniku występują podciągi słów z zapytania:
a) dla pierwszych dwóch słów zwiększamy wagę o stałą
WEIGHT_CONSECUTIVE_WORD
(domyślnie 2 punkty)
b) dla każdego kolejnego słowa w ciągu, ale maksymalnie dla ilości słów równej ilości słów
zapytania, zwiększamy wagę iloczyn stałej
WEIGHT_CONSECUTIVE_WORD
i pozycji słowa
w ciągu
c) dla pozostałych słów (dodatkowe znalezione ciągi) zwiększamy wagę o ½ stałej
WEIGHT_CONSECUTIVE_WORD
2. Jeśli w artykule występuje ciąg identyczny z zapytaniem, dodajemy do wagi bonus za
dokładny wynik w wysokości stałej
WEIGHT_CONSECUTIVE_WORD
(domyślnie 10
punktów). Premia ta występuje tylko raz, tzn jeśli dokładny ciąg występuje w artykule
wielokrotnie, traktowany jest standardowo.
3. Dla każdego unikalnego słowa zapytania znalezionego w artykule zwiększamy wagę o stałą
równą
WEIGHT_DISTINCT_WORD
(domyślnie 1 punkt)
4. Dla każdego kolejnego wystąpienia jednego ze słów zapytania, zwiększamy wagę o stałą
równą
WEIGHT_ADDITIONAL_WORD
(domyślnie 0.05 punktu)
5. Jeśli sumaryczna różnica wszystkich pozycji na których występują znalezione słowa w
artykule jest mniejsza od podwojonej ilości tych słów (innymi słowy – jeśli interesujące nas
słowa znajdują się maksymalnie w odstępach co dwa słowa w artykule), mnożymy
otrzymaną ilość punktów za wystąpienia słów przez wyliczony współczynnik zależności.
Maksymalnie jest to 10 punktów, gdy słowa znajdują się w ciągu (niekoniecznie takim jak
zapytanie). Im większe odstępy tym mniejszy współczynnik.
6. Każde znalezione słowo występujące w temacie artykułu dostaje automatycznie wagę dwa
razy większą niż standardowo.
Po wykonaniu tych operacji, w kolekcji wyników znajdują się artykuły z obliczonymi wagami,
gotowe do sortowania. Operacja sortowania jest to standardowa operacja do sortowania kolekcji
oferowana prze Javę (klasa Collections, metoda sort), wykorzystująca metodą compareTo(Object)
zdefiniowaną dla klasy SearchResult. Posortowane wyniki wrzucane są do tablicy sortedResults
obiektu SearchResults i prezentowane są na ekranie w kolejności od najbardziej do najmniej trafnych.
Implementacja cache'owania wyników
Aby przyspieszyć wykonywanie powtarzalnych operacji – w szczególności aby nie trzeba było
wyliczać powtórnie wyników dla identycznych zapytań, powstał mechanizm cache'owania wyników –
czyli przechowywania raz wyliczonych wyników zapytania w łatwo dostępnym miejscu, gotowych do
pobrania przy kolejnym wystąpieniu podobnego zapytania.
System cache'owania wyników zapytań polega na utrwalaniu w bazie obiektów klasy
SearchResults, zawierających kolekcje obiektów klasy SearchResult, przechowujących artykuły
będące wynikami zadanego zapytania. W celu optymalizacji dostępu do wyników, klasa
SearchResults powiązana jest poprzez zależność jeden do wielu z klasą Word. W praktyce oznacza to,
że każde ze słów posiada łatwo dostępną informację o wszystkich zapytaniach i ich wynikach,
zaczynających się właśnie od tego słowa. Dzięki temu, w początkowej fazie analizy zapytania,
możemy łatwo sprawdzić, czy dane zapytanie zostało już kiedyś wykonane i jeśli tak, zaprezentować
od razu listę wyników, bez wykonywania skomplikowanego i zasobochłonnego algorytmu
67
wyszukiwania.
Aby scache'owane rezultaty były w miarę aktualne, potrzebna jest jeszcze implementacja oddzielnego
bota – programu wykonującego w tle najczęściej pojawiające się zapytania i aktualizującego listy
wyników. Implementacja takiego programu jest jednym z warunków niezbędnych do ostatecznego
wdrożenia wyszukiwarki.
5.5.
Frontend
Frontend jest bardzo istotną częścią komercyjnych projektów informatycznych – wpływa
bowiem w ogromny sposób na pierwsze wrażenie w kontakcie z nowym oprogramowaniem. W naszej
pracy zadaniem frontendu jest jednak tylko udostępnienie prostego narzędzia do zaprezentowania
możliwości wyszukiwarki. Nie było naszym zamiarem stworzenie produktu gotowego do
natychmiastowego wdrożenia w portalu internetowym. W związku z tym, implementacja części
WWW systemu opiera się tylko o niezbędne elementy, bez których nie byłoby możliwe testowanie i
używanie prezentowanej aplikacji. Części te to:
–
strona główna wyszukiwarki, z formularzem wyszukiwania
–
strona z rezultatami wyszukiwania
–
strona prezentująca cały artykuł bądź wątek grup dyskusyjnych, będący jednym z wyników
wyszukiwania
68
Rysunek 23. Frontend - strona z formularzem wyszukiwania

Technologia użyta do implementacji frontendu to dynamiczne strony JSP (Java Server Pages)
generowane przez serwer aplikacji Jakarta-Tomcat 4.1. Dostęp do bazy danych, jak również do
wszystkich klas używanych w aplikacji realizowany jest poprzez dołączenie do aplikacji WWW
archiwów JAR z klasami aplikacji oraz klasami Javy udostępnionymi przez Objectivity.
69

6. Problemy związane z zastosowanym rozwiązaniem
Rozdział ten zawiera omówienie trudności przy realizacji pracy, zalet i wad przyjętego
rozwiązania. Jest tu również mowa o potencjalnych zastosowaniach pracy oraz planach rozwojowych
w zakresie tematu pracy i dalszych prac, które należałoby wykonać w przyszłości w celu rozwoju
(zwiększenie efektywności, dodanie nowej funkcjonalności) i pielęgnacji prezentowanego
rozwiązania.
6.1.
Problemy napotkane podczas implementacji
Podczas implementacji napotkaliśmy na bardzo wiele problemów, głównie natury technicznej.
Część z nich była nawet w pewnym momencie zagrożeniem dla powodzenia całego projektu, gdyż
blokowała możliwość dalszego rozwoju prac nad konkretnym zagadnieniem. Problemy te można
podzielić na trzy zasadnicze grupy:
–
Problemy wynikające z naszej niewiedzy lub braku doświadczenia w konkretnej dziedzinie.
Znaczna część pracy powstała w nowej dla nas technologii, w związku z tym sporo problemów
wynikło z niedostatecznego przestudiowania dokumentacji, czy nieznajomości specyfiki danego
produktu.
–
Problemy związane z niedoskonałością lub nieadekwatnością zastosowanych narzędzi, w tym
bibliotek – głównie problemy wydajnościowe przy bardzo dużych ilościach przetwarzanych
danych.
–
Problemy związane z błędami w oprogramowaniu.
Większość problemów, na jakie napotkaliśmy udało nam się rozwiązać samodzielnie, poprzez
studiowanie dokumentacji, szukanie informacji w sieci Internet, na grupach dyskusyjnych, czy też na
specjalistycznych kanałach IRC. W kwestiach związanych z Objectivity wielką pomocą okazał się
support ze strony firmy, w osobie pana Roberta Cheong'a. W tym podrozdziale opisane zostaną
najciekawsze problemy, na które natrafiliśmy podczas prac nad projektem. Problemy pogrupowane
zostały ze względu na moduły, których dotyczą.
Fetcher i backuper:
–
Brak bibliotek w Javie obsługujących protokół NNTP.
Początkowo korzystaliśmy z biblioteki gnu.inet.nntp jednak okazało się, że nie dość że jest
powolna to potrafi zawiesić się w trakcie działania. Rozwiązaniem okazało się stworzenie własnej
prostej biblioteki. Zaimplementowane zostały tylko niezbędne do działania komendy.
–
Duża ilość danych
W momencie pisania pracy na lokalnym serwerze newsów znajduje się około 11GB postów.
Przeniesienie takiego zbioru danych do obiektowej bazy danych poprzez protokół NNTP zajmuje
klika dni pracy bez przerwy. Jakiekolwiek zmiany w strukturze obiektów mogą wymusić ponowne
załadowanie całego zbioru.
–
Mechanizm ściągający posty z serwera internetowego. Lokany serwer newsów pobiera wszystkie
posty z serwera news://news.task.gda.pl. Proces ściągania uruchamiany jest codziennie
w nocy. Obecnie proces ten trwa ok 22 godzin. W niedługiej przyszłości zadanie to przekroczy 24
godziny. Nie jesteśmy pewni jakie konsekwencje może to spowodować. Prawdopodobnie trzeba
będzie przestawić mechanizm tak, aby uruchamiał się co dwa dni. Rozwiązaniem problemu może
być przeniesienie lokalnego serwera newsów na bardziej wydajną maszynę. W tej chwili jest to
Intel Celeron 333Mhz 64RAM z 120GB dysku twardego.
70

Indekser:
–
Brak możliwości stworzenia relacji wiele-do-wiele pomiędzy obiektami tej samej klasy
Przy implementacji zależności fleksyjnych pomiędzy słowami okazało się, że każde słowo może
być powiązane nie tylko z wieloma słowami, dla których jest ono formą podstawową (z dziećmi),
lecz również samo posiadać może wiele form podstawowych (np. w przypadku słów o wielu
znaczeniach). W takiej sytuacji niezbędnym okazało się zamodelowanie wewnętrznego powiązani
typu wiele-do-wiele pomiędzy obiektami klasy Word. To niestety okazało się niemożliwe, stosując
standardowy mechanizm relationships oferowany przez Objectivity. Kod wprawdzie wykonywał
się i nie powodował wyrzucania wyjątków, jednak przy pierwszej operacji zapisu obiektu takiej
klasy, występował błąd natywnej biblioteki używanej prze Objectivity/DB, powodujący
zakończenie działania aplikacji.
Pierwszym rozwiązaniem, które zastosowaliśmy w celu ominięcia tego problemu było
zrezygnowanie z relacji i użycie dwóch kolekcji (ojców i dzieci) reprezentowanych przez
oferowane przez Objectivity struktury danych jak mapy i drzewa. To również okazało się niestety
nie najlepszym pomysłem, z powodu, że każda kolekcja tworzyła dodatkowy kontener w bazie
danych. Liczba takich kontenerów jest ograniczona i wyczerpuje się po zindeksowaniu około
10,000 słów.
Ostatecznie zdecydowaliśmy się więc na zastosowanie asocjacji w postaci tradycyjnych tablic
obiektów (ojców i dzieci). Przy każdorazowym dodaniu nowego powiązanego słowa, tablica
wymaga przebudowania (alokacji nowego miejsca w pamięci i skopiowania zawartości starej
tablicy). Jest to jednak rozwiązanie bezpieczne i przy niedużej ilości powiązań dla pojedynczego
słowa (maksymalnie pojawia się do 50 dzieci i do 5 ojców) sprawdza się znakomicie.
–
Brak możliwości przeprowadzania wielkich transakcji (z kilkoma tysiącami operacji) ze względu
na ograniczenie pamięci RAM
Początkowo indeksowanie (zarówno artykułów jak i słów do analizy fleksyjnej)
przeprowadzaliśmy w bardzo dużych transakcjach. Wynikało to z tego, że standardowy iterator
obiektów dostarczony przez Objectivity może działać tylko obrębie jednej transakcji. Po
zatwierdzeniu, stan iteratora jest zerowany i nie ma możliwości pobrania niezindeksowanych
jeszcze obiektów. Niestety, tak duże transakcje powodowały po zindeksowaniu kilkunastu tysięcy
artykułów błąd wirtualnej maszyny Javy polegający na braku pamięci RAM do wykonania
kolejnych operacji.
Rozwiązanie problemu polegało na podziale operacji indeksowania na mniejsze transakcje (np.
zatwierdzenie transakcji i rozpoczęcie nowej co 500 artykułów). Każdy ze zindeksowanych
artykułów (lub słów, w przypadku analizy fleksyjnej) zostawał zaznaczony jako przetworzony.
Iterator tworzony jest od nowa po każdym zatwierdzeniu operacji w bazie, ale bierze pod uwagę
tylko te obiekty, które nie zostały już wcześniej przetworzone przez indekser (skanowanie z
atrybutem). W ten sposób indeksowanie może przebiegać bez ingerencji i nie powoduje
nadmiernego zużywania pamięci RAM.
Wyszukiwarka:
–
Przy pracach nad mechanizmem wyszukiwania zauważyliśmy, że niektóre zapytania wykonują się
znacznie dłużej niż inne, mimo że liczba słów użytych w zapytaniu, czy nawet same słowa są
identyczne. Po analizie okazało się, że problem występuje, gdy pierwszym słowem zapytania jest
słowo bardzo popularne, powiązane z dużą ilością artykułów (czy nawet z większością z nich).
Takie słowa to na przykład niektóre zaimki, przyimki, partykuły. Omijania słów występujących
zbyt często (zbyt wiele powiązań z artykułami, co w znaczny sposób pogarszało wydajność
wyszukiwania) okazało się konieczne. Takie rozwiązanie niestety powodowało zmniejszenie
71

skuteczności samego wyszukiwania ciągów – gdy pierwszym słowem ciągu jest wyraz popularny,
ciąg taki nie zostanie nigdy znaleziony, ponieważ pierwsze słowu musi zostać pominięte.
Rozwiązaniem tego problemu okazało się sprawdzanie najpierw rzadszych słów a następnie
nawigacja po referencjach w obie strony (a nie tylko w jedną, jak w standardowym wyszukiwaniu
ciągów) w celu znalezienia dokładnego ciągu występującego w zapytaniu. Wydajność takiego
wyszukiwania jest znacznie większa, a nie pociąga za sobą żadnych ograniczeń funkcjonalnych.
Problem został więc rozwiązany pomyślnie.
Frontend:
–
Konfiguracja serwera aplikacji Jakarta-Tomcat 4.0, aby współgrał z bazą Objectivity/DB
Początkowo nie udawało nam się uzyskać dostępu do bazy danych z artykułami poprzez interfejs
internetowy. Problemem okazał się standardowy poziom bezpieczeństwa Tomcata, który zabrania
wykonywania kodu zawierającego odniesienia do natywnych bibliotek spoza Javy. Takiej
biblioteki używa właśnie Objectivity. Przy każdym uruchomieniu strony JSP, przy próbie
odwołania się do federacji wyrzucany był SecurityException – wyjątek wskazujący na próbę
wywołania niechcianego kodu spoza aplikacji.
Rozwiązanie tego problemu sprowadziło się do rezygnacji z usługi SecurityManager oferowanego
przez Tomcat, poprzez zaznaczenie w pliku konfiguracyjnym /etc/default/tomcat4 opcji:
# Use the Java security manager? (yes/no, default: yes)
TOMCAT4_SECURITY=no
Ogólne problemy z administracją bazą danych Objectivity/DB:
–
Problemy z ewolucją schematu
W trakcie prac bardzo często występowała potrzeba zmiany schematu bazy danych (zmiany takie
implikują np. dodanie nowych metod w klasach trwałych, czy zmiana nazewnictwa pól). Problem z
ewolucją schematu jest taki, że każda zmiana w bazie powinna być przeprowadzona jednocześnie
w obu kopiach bazy, jeśli chcemy zachować przenaszalność. W pierwszej fazie projektu nie
przykładaliśmy do tej kwestii większej wagi, co spowodowało w efekcie całkowita niespójność
pomiędzy używanymi przez nas instancjami baz danych. Rozwiązaniem był do pewnego momentu
mechanizm uaktualniania schematu poprzez narzędzia ooschemadump i ooschemaupgrade.
Niestety mechanizm ten zawiódł, gdy w grę wchodziła nie tylko synchronizacja schematu, ale
również synchronizacja samych danych
–
Trudności z importem danych między dwoma stacjami roboczymi
W pewnym momencie podczas pracy nad projektem zaszła potrzeba importu całej bazy danych,
zawierającej ściągnięte z serwera artykuły (obiekty NntpArticle) z jednej federacji do drugiej.
Problemu nie udało się rozwiązać w bezpośredni sposób. Bazy danych w Objectivity nie mogą być
przenoszone z jednej federacji do drugiej bez zachowania pewnych zasad dotyczących między
innymi rejestrowania klas. Na wprowadzanie tych zasad było już w projekcie jednak za późno.
Problem został więc rozwiązany połowicznie, poprzez zastosowanie programu ooinstallfd, do
kopiowania całych federacji.
72

6.2.
Wady i zalety przyjętego rozwiązania
Wady:
–
Słaba przenaszalność (Objectivity). Oprogramowanie nasze jest bardzo ściśle związane z
systemem Objectivity/DB. Próba przeniesienia systemu na inną bazę danych (obiektową lub
relacyjną) oznaczała by de facto zaprogramowanie całej aplikacji od nowa. Wszystkie operacje są
bardzo zszyte z zasadą działania i budową Objectivity/DB. Kolejnym problemem przy migracji na
inny system bazodanowy jest przeniesienie danych. Obecnie chyba żadna obiektowa baza danych
nie oferuje możliwości zrzutu danych do formatu rozpoznawalnego przez inne produkty. W celu
przeniesienia danych na inny system należałoby stworzyć specjalne programy zapisujące dane do
pliku o ściśle określonym formacie rozumianym przez inne systemy bazodanowe.
–
Słaba rozszerzalność – zapytania są zaszyte w kodzie, jeśli chcielibyśmy otrzymać dodatkowe
informacje (np. dodatkowe raporty, wyszukiwanie w oparciu o inny algorytm, o inne dane)
najprawdopodobniej niezbędna byłaby modyfikacja kodu aplikacji
–
“Ręczna” optymalizacja zapytań – niekoniecznie wada (plusem jest szybkość, minusem
nieuniwersalność rozwiązania)
–
Skalowalność. Nie wiadomo jak mechanizm indeksujący i wyszukujący zachowa się przy bardzo
dużych zbiorach danych. Archiwum polskich grup dyskusyjnych z całego roku przed
zindeksowanie zajmuje około 12GB przestrzeni na dysku. Po indeksowaniu może powstać baza 10
lub więcej razy większa. Tak obszerne zbiory danych powodują konieczność zastosowania
klastrów serwerów. W chwili obecnej nasze oprogramowanie nie jest przystosowane do działania
na kilku maszynach jednocześnie w trybie rozkładania obciążenia na mniej zajęte maszyny.
–
Uzależnienie się od GRAM-a. Bez tego oprogramowania nasz system jest zwyczajną
wyszukiwarką działającą na zasadzie indeksu.
Zalety:
–
Szybkość działania. Porównując szybkość pobierania artykułu z PostgreSQL dla danego Message-
ID z pobieraniem tego samego artykułu z Objectivity/DB widać było znaczącą różnice w prędkości
działania na korzyść obiektowej bazy danych.
–
Łatwiejsza implementacja. Praca została zaprogramowana w jednym języku – Java. W przypadku
skorzystania z relacyjnej bazy danych należałyby stworzyć zapytania SQL-owe oraz
zaprogramować całe “sklejenie” Javy ze strukturą w bazie danych. Mapowanie obiektów na
struktury relacyjne jest kosztowne i w znaczny sposób komplikuje kod programu utrudniając
zrozumienie jego koncepcji.
–
Przejrzystość implementacji – obiektowe podejście do projektowania i programowania w znaczny
sposób ułatwia zrozumienie koncepcji aplikacji poprzez odwoływanie się do bardziej
zrozumiałych abstrakcji.
–
Dobra integracja danych trwałych i nietrwałych – cecha wynikająca z zastosowania bazy
obiektowej. Operacje na obiektach trwałych i nietrwałych wykonywane są w ten sam sposób.
Zaoszczędza to pracy programistycznej i wpływa pozytywnie na przejrzystość kodu aplikacji.
–
Duże możliwości optymalizacyjne, w tym rozproszenie bazy danych, stworzenie klastra. Baza
Objectivity/DB reklamowana jest jako największa obecnie baza na świecie. Akcelerator cząstek w
Stanford korzysta z bazy rozproszonej na 100 serwerów linuksowych, przechowujących w sumie
895 terabajtów danych (stan na 16.06.2004). Spodziewamy się że przy rozłożeniu naszej bazy
zindeksowanych artykułów na kilka serwerów wzrosłaby wydajność systemu bez ingerencji w kod.
System Objectivity/DB jest przystosowany do działania głównie w rozproszeniu.
73

6.3.
Zastosowanie pracy
Główne zastosowanie naszej pracy to oczywiście znajdowanie dokładnej informacji w
archiwum polskich grup dyskusyjnych.
W chwili obecnej nie istnieją w Internecie wyszukiwarki grup dyskusyjnych uwzględniające
specyfikę języka polskiego. Najpopularniejszym narzędziem służącym do przeszukiwania Usenetu
jest mechanizm Google. Opiera się on prostym indeksie słów. Znajduje tylko te słowa, które zostały
wpisane jako zapytanie. Nie znajduje artykułów, które zawierają lekko odmienione formy szukanych
słów.
Celem naszej pracy była realizacja ciekawego pomysłu zbudowania wyszukiwarki opartej na
obiektowej bazie danych. W Internecie jest mnóstwo mechanizmów wyszukujących strony WWW,
dlatego skupiliśmy się na obszarze słabo zagospodarowanym pod tym względem. Możemy pokusić się
o stwierdzenie, że nasza praca jest pod tym względem dość wyjątkowa. Nie słyszeliśmy do tej pory o
polskiej wyszukiwarce grup dyskusyjnych, a tym bardziej o mechanizmie opartym na obiektowej
bazie danych, wykorzystującym analizę fleksji języka polskiego.
Od początku nasze narzędzie budowane było z myślą o typowej wyszukiwarce udostępnianej
przez WWW. Standardowym scenariuszem wykorzystania takiego mechanizmu jest wpisanie
zapytania w postaci szukanych słów i przejście na stronę wyników, gdzie prezentowana jest lista
znalezionych artykułów posortowanych według trafności. Niestety z braku możliwości wyszukiwarka
nasza prawdopodobnie nie będzie udostępniona publicznie. W warunkach rzeczywistych możemy się
spodziewać sporego ruchu generowanego na serwerze. W celu uruchomienia produkcyjnego serwera
należałoby pomyśleć o zapewnieniu stabilności przy dużym obciążeniu oraz o solidnym
przetestowaniu oprogramowania pod względem wydajności.
Przy drobnych modyfikacjach w kodzie można jednak we względnie krótkim czasie dostosować
nasz mechanizm do indeksowania i wyszukiwania innych zbiorów danych takich jak:
•
zasoby intranetowe
•
strony WWW (ogólnie)
•
specyficzne strony WWW – np. fora dyskusyjne lub blogi
6.4.
Plany na przyszłość
Mimo, że prezentowane rozwiązanie jest kompletne, zarówno pod względem koncepcji jak i
implementacji, to w dalszym ciągu istnieje bardzo wiele sposobów, dzięki którym możliwe będzie w
przyszłości znaczne polepszenie jego wydajności i być może również funkcjonalności. Warto
zwrócić uwagę, że przy projektowaniu i wdrożeniu omawianego systemu pojawiały się dość często
komplikacje natury czysto technicznej – problemy związane z niedoborem zasobów, takich jak
miejsce na dysku twardym, czy mała ilość pamięci RAM. Biorąc pod uwagę te czynniki, aplikacja
została zaprojektowana w ten sposób, by działać wydajnie na komputerze osobistym. Jest to
oczywiste ograniczenie. Programy tego typu działają zazwyczaj w oparciu o ogromne sieci
połączonych ze sobą maszyn. To pozwala na znacznie większą swobodę, zarówno w kwestii
złożoności obliczeń, jak i w planowaniu fizycznej struktury danych (np. możliwość masowego
stosowania redundancji w celu optymalizacji działania, etc). Nic nie stoi jednak na przeszkodzie, aby
na podstawie aktualnego rozwiązania stworzyć aplikację komercyjną, w projekcie, w którym wydajna
praca programu na komputerze klasy PC nie będzie wcale wymagana.
W chwili obecnej aplikacja składa się z pięciu zasadniczych modułów: fetchera, backupera,
indeksera, wyszukiwarki i optymalizatora (jest jeszcze frontend, który jednak nie odgrywa większej
roli, jeśli chodzi o efektywność i szybkość znajdowania informacji). Jak się wydaje, największe
oszczędności można poczynić w trzech ostatnich modułach, głównie jednak dzięki modyfikacjom
74

indeksera artykułów. Tam bowiem tworzy się struktura danych oraz powiązania między obiektami,
dzięki którym możemy w szybki sposób nawigować w celu uzyskania z bazy danych potrzebnych nam
informacji.
Biorąc to wszystko pod uwagę, ewentualne modyfikacje podzielić możemy na co najmniej cztery
rodzaje, ze względu na poziom abstrakcji:
●
modyfikacje koncepcyjne – czyli zasadnicze zmiany w strukturze aplikacji, sposobie zapisywania
danych (w tym stosowanie nadmiarowych powiązań i kolekcji powiązań, czy fizyczna
redundancja danych), modyfikacje w algorytmach indeksujących, bądź wyszukujących dane, czy
usprawnienia polegające na przerzuceniu części funkcji wykonywanych przez obecne moduły do
oddzielnej aplikacji, działającej na przykład w tle, tym samym mniej obciążając system
●
optymalizacja na poziomie kodu – przepisanie lub usprawnienie kodu aplikacji z nastawieniem
na jak największą efektywność, zastosowanie innych języków programowania bądź szybszych,
wydajniejszych bibliotek w ramach jednego języka
●
optymalizacja na poziomie fizycznym – np. zastosowanie innego systemu plików, zastosowanie
innej techniki indeksowania lub przechowywania danych w bazie, etc
●
optymalizacja na poziomie sprzętu – na przykład zainwestowanie w sprzęt pozwalający osiągnąć
lepszą wydajność (dyski RAID, komputery wieloprocesorowe, fizyczne klastry z wielu maszyn,
etc)
W tym miejscu zajmiemy się głównie tą pierwszą grupą, czyli modyfikacją i ulepszeniem
koncepcji aplikacji, z nastawieniem na poprawę wydajności oraz zwiększenie funkcjonalności
rozwijanego systemu. Pozostałe techniki będą natomiast wspomniane, ale nie zamierzamy się nimi
zajmować szczegółowo, gdyż wybiegają one (szczególnie optymalizacja programu na poziomie
fizycznym i sprzętu) nieco poza ramy inżynierii oprogramowania, a co za tym idzie, również
niniejszej pracy.
Po kolei więc, zajmiemy się teraz sprawami związanymi z koncepcją oraz implementacją systemu,
których modyfikacja może w istotny sposób wpłynąć na jego wydajność.
Optymalizacja i zmiany schematu, redundancja danych
To zagadnienie zostało już omówione w sposób szczegółowy w rozdziale Opis rozwiązania:
Alternatywne rozwiązania.
Aktualizacja scache'owanych wyników
Implementacja bota aktualizującego scache'owane wyniki zapytań jest jednym w kluczowych
zadań na najbliższy czas, jeśli myślimy o poważnym zastosowaniu omawianego w pracy rozwiązania.
Samo przechowywanie starych wyników zapytań, bez ich częstej aktualizacji bardzo szybko obniży
wiarygodność serwisu – po prostu nie będą znajdowane najnowsze artykuły. Aktualizacja wyników
powinna się odbywać w miarę często, dla popularnych zapytań nawet raz dziennie. W ramach
oszczędzania pamięci dyskowej, można by pomyśleć o usuwaniu zapytań bardzo mało popularnych
(np. takich które wystąpiły tylko raz lub dwa razy, ponad pół roku temu). Przechowywanie wszystkich
zapytań wraz z wynikami może w znaczący sposób zwiększyć rozmiar bazy danych.
Błędy ortograficzne, “literówki” i skróty w indeksowanych artykułach
W momencie obecnym aplikacja nie uwzględnia w żaden sposób błędów i literówek
występujących w artykułach poddawanych mechanizmowi indeksowania. Założenie, że artykuły
takich błędów nie posiadają jest szlachetne ale jak najbardziej nieprawdziwe. Prawdziwą zmorą
wszystkich wyszukiwarek internetowych są liczne błędy występujące w indeksowanych danych. W
wyszukiwarkach tekstów napisanych w języku polskim, szczególnie tych potocznych, do których
75

zaliczają się wiadomości grup dyskusyjnych, jest to szczególnie uciążliwa niedogodność. Wiele osób
pomija bowiem w tekście specyficzne dla języka polskiego „ogonki”, popełnia literówki („nei”,
„keidy”, etc), czy też zwyczajne błędy ortograficzne. Masowo stosowane są także różnego rodzaju
skróty związane zarówno ze specyficznym slangiem związanym z konkretnym tematem grupy, z tzw.
nowomową internetową, jak i ze zwyczajnym lenistwem. Sprawdzanie pisowni przy wysyłaniu
wiadomości e-mail lub NNTP jest wciąż zwyczajem tylko nielicznych.
Im więcej jednak błędów w indeksowanych artykułach, tym mniej dokładne potencjalne wyniki
wyszukiwania i tym gorsza obiektywna efektywność wyszukiwarki. Aby temu zaradzić, należałoby
zastosować podczas indeksowania specjalne mechanizmy służące do identyfikacji błędów w tekście
artykułu. Nierozważne zastosowanie „inteligentnych” sposobów weryfikacji tekstu może jednak
okazać się niebezpieczne. Czysto statystyczne metody mają to do siebie, że nie sprawdzają się
zazwyczaj w kilku procentach przypadków. A to może wystarczyć to ośmieszenia produktu
bazującego na takich algorytmach. Eliminacja wszystkich błędów to zadanie niewykonalne dla
automatycznego bota. Biorąc to pod uwagę, należałoby zastosować metodę pośrednią i
półautomatyczną, zorientowaną na wychwycenie najczęstszych i najbardziej oczywistych przypadków
błędów (które prawdopodobnie stanowią zdecydowaną większość pomyłek). Identyfikacja najczęściej
pojawiających się literówek, czy też automatyczne zamienienie słów z pominiętymi „ogonkami” na
ich odpowiedniki znajdujące się w bazie danych zdecydowanie polepszyłoby precyzję i efektywność
wyszukiwania, nie poddając tym samym w wątpliwość wiarygodności mechanizmu.
Zindeksowanie starszych danych
Dla potrzeb testowania zostały do tej pory ściągnięte dane ze wszystkich polskich grup
dyskusyjnych z całego ostatniego roku. Dane ściągane i backupowane były na bieżąco, przez serwer
grup dyskusyjnych Leafnode. Aby wyszukiwarka mogła rzeczywiście zaistnieć na rynku niezbędne
będzie jednak ściągnięcie i zindeksowanie dużo starszych danych. Myślimy tu o co najmniej kilku (a
najlepiej kilkunastu) latach wstecz. Może to niestety zrodzić kilka problemów. Pierwszym z nich jest
dostęp do starszych newsów. Możliwe że niezbędne byłoby ściąganie artykułów z innego archiwum,
np. z katalogów Google (które zawierają prawie całe archiwum grup dyskusyjnych od początku ich
istnienia, wykupione w 2001 roku od Deja News). Po drugie, mogą wystąpić problemy z
indeksowaniem starszych artykułów – ze względu na różnice w nagłówkach wiadomości. Być może
potrzebne byłoby przepisanie lub naniesienie poprawek na algorytm parsowania wiadomości w
indekserze. Oba te problemy wydają się jednak minimalne, w porównaniu z największym kłopotem –
jak znaleźć miejsce na przechowywanie zindeksowanych archiwów. Przy zastosowaniu omówionej
kilka akapitów wcześniej struktury słów opartej o haszowane tablice referencji, całe archiwum
mogłoby liczyć się nawet w setkach terabajtów...
Rozszerzenie mechanizmu na inne typy danych
Rozszerzenie mechanizmu indeksowania i wyszukiwania na inne typy danych (np. intranet,
dokumenty tekstowe w różnych formatach, strony www) jest nietrywialne. Już na samym wstępie
wspomniano, że każdy rodzaj danych potrzebuje specyficznego podejścia i uniwersalne mechanizmu
zazwyczaj nie sprawdzają się w specyficznych zastosowaniach. W szczególności, algorytm, który
sprawdza się w wyszukiwaniu grup dyskusyjnych nie musi koniecznie mieć zastosowania w
przeszukiwaniu intranetu, czy sieci Internet. Dlatego też, jeśli chcielibyśmy rozszerzyć
funkcjonalność aplikacji o nowe rodzaje danych, potrzebne byłoby nie tylko napisanie odpowiedniego
fetchera (to stosunkowo proste zadanie), ale dostosowanie całej struktury danych, algorytmu
indeksowania, wyszukiwania i optymalizacji (a nawet frontend) do nowego typu informacji. Nie jest
to wprawdzie równoznaczne z napisaniem drugiej aplikacji zajmującej się nowymi danymi. Wiele
wykorzystanych w projekcie mechanizmów jest na tyle uniwersalnych, że można je zastosować do
wielu rodzajów przetwarzanych danych. Jest to jednak zajęcie czasochłonne i wymagające
76

odpowiedniej analizy oraz przeprojektowania części aplikacji. Kierunek, w którym należałoby pójść,
myśląc o możliwości dodawania z czasem obsługi nowych typów danych, to wyodrębnienie z
aktualnego projektu elementów wspólnych (np. stworzenie uniwersalnej klasy Artykuł) i oddzielna
implementacja wyspecjalizowanych elementów, korzystających ze wspólnych zasobów (z klasy
Artykuł dziedziczyłyby klasy wyspecjalizowane, jak Artykuł WWW, Artykuł NNTP, Artykuł PDF,
etc, odpowiedzialne za specyficzne operacje na swoich typach danych). Dużym ułatwieniem jest tutaj
technologia w jakiej napisany został projekt. Objectivity bardzo dobrze radzi sobie ze zmianami
schematu danych (mechanizm Active Schema) podczas pielęgnacji projektu. Java jest natomiast
bardzo wygodna przy wprowadzaniu zaawansowanych zależności pomiędzy obiektami w aplikacji.
Priorytety wyników wyszukiwania – zindeksowanie autorów
Wydaje się, że szczególnie przy wyszukiwaniu wiadomości w archiwach specjalistycznych
grup dyskusyjnych spore znaczenie może mieć to, kto jest autorem danego posta. Jeśli jest to osoba
kompetentna, prawdopodobnie chcielibyśmy, żeby jej wiadomości zyskiwały wyższy priorytet od
wiadomości początkujących użytkowników. Gdyby udało się w prosty sposób wymyślić mechanizm
identyfikacji autora i nadawania mu pewnej “kompetencji”, informację tę można by zastosować przy
obliczaniu wagi wyników wyszukiwania. Cały problem polega na tym, że trudno ocenić kompetencje
czy wiedzę jedynie po ilości wysłanych postów, czy też ilości odpowiedzi na dany post. Możliwe, że
oprócz standardowych mechanizmów statystycznych potrzebna byłaby ręczna weryfikacja tego
rodzaju danych.
Technicznie, do zindeksowania autora artykułu służyłaby metoda indexAuthor() w klasie Article.
Miałaby ona za zadanie identyfikację autora na podstawie wartości pól nagłówków wiadomości
NNTP, takich jak:
–
From,
–
Message-ID,
–
Mime-Version,
–
Content-Type.
Pewne dane dodatkowe można by uzyskać także poprzez zbadanie podpisu autora (w postach
na grupach dyskusyjnych przyjęło się, że podpis oddzielony jest od reszty wiadomości znacznikiem
podwójnym myślnikiem i spacją: “-- “.
Oczywiście najwięcej informacji o użytkowniku możemy ustalić poprzez zbadanie adresu e-mail
użytkownika. Reszta informacji ma charakter dodatkowy i brana jest pod uwagę w przypadku braku
możliwości identyfikacji tylko poprzez sam adres mailowy.
Idąc dalej tym tropem, możliwe jest stworzenie profilu autora z możliwością przejrzenia wszystkich
jego postów w usenecie. Już samo wypisanie grup dyskusyjnych, w których dany autor zamieszcza
swoje wypowiedzi mówi sporo o zainteresowaniach osoby. Informacje takie można by wykorzystać
na wiele sposobów. Od stworzenia zaawansowanych statystyk, do analizy biznesowej zainteresowań
użytkowników włącznie. Użytkownicy to bowiem potencjalni klienci, których zainteresowania
przekładają się zazwyczaj na potrzeby materialne, a taka informacja jest w dzisiejszym biznesie
bezcenna.
Użycie zaawansowanych mechanizmów dostarczonych przez Grama
–
Lista najczęstszych i najistotniejszych słów – możliwość wykorzystania “streszczenia” artykułu
(czyli listy najistotniejszych słów występujących w artykule) do usprawnienia mechanizmu
indeksowania (nie ma sensu indeksować słów nie przekazujących żadnej treści)
77

–
Eliminacja wulgaryzmów i innych niepożądanych treści – stworzenie mechanizmu “filtru
rodzinnego” przy wyszukiwaniu
–
Możliwość wyszukiwania informacji o osobach: GRAM udostępnia słownik nazwisk
–
Wyciąganie z tekstu istotnych słów i pomijanie słów nie przekazujących sensu wypowiedzi.
78

7. Podsumowanie
Głównym celem naszej pracy było zaprezentowanie jednego z możliwych rozwiązań problemu
pełnotekstowego wyszukiwania informacji w dużych zbiorach danych. W pracy została szczegółowo
omówiona autorska koncepcja struktury danych i mechanizmu wyszukiwania informacji, opierającego
się o powiązania między obiektami i pełne wykorzystanie możliwości, jakie daje obiektowa baza
danych Objectivity/DB. Trzy podstawowe moduły, składające się na omawiany system, czyli fetcher,
indekser i wyszukiwarka, zostały zaimplementowane zgodnie z przedstawioną koncepcją. Razem
tworzą one spójny i funkcjonalny system wyszukiwania pełnotekstowego. Przygotowany został
również frontend umożliwiający zapoznanie się z możliwościami wyszukiwarki poprzez wizytę na
stronie internetowej. Biorąc to pod uwagę, można śmiało stwierdzić, że główny cel pracy został w
pełni osiągnięty – przedstawiona w pracy koncepcja doczekała się działającej implementacji. Nie
znaczy to oczywiście, że praca (a przede wszystkim implementacja) pozbawiona jest wad i
niedostatków. Prezentowany system nie jest jeszcze gotowy to poważnego wdrożenia w
zastosowaniach biznesowych z co najmniej dwóch powodów. Po pierwsze – wyszukiwarka działa
obecnie domyślnie na jednym serwerze. Przy implementacji nie była brana pod uwagę optymalizacja
poprzez rozproszenie aplikacji – nie to stanowiło bowiem ideę naszej pracy. Przy poważnym
wdrożeniu istotnym wymaganiem jest jednak niezawodność i wysoka wydajność aplikacji. Tego typu
prace oraz testy wydajnościowe nie zostały jednak przeprowadzone. Drugą sprawą, która na dzień
dzisiejszy hamuje potencjalne wdrożenie, jest niedopracowanie wielu szczegółów, nieistotnych dla
prezentacji ogólnej idei programu, jednak kluczowych dla ewentualnego nabywcy aplikacji. Chodzi tu
między innymi o takie sprawy jak: nieuwzględnianie błędów ortograficznych, “literówek” i skrótów w
indeksowanych artykułach, brak aktualizacji scache'owanych wyników wyszukiwania, a także inne
kwestie, opisane szerzej w rozdziale dotyczącym planów na przyszłość. Mimo licznych niedostatków
wynikających z charakteru pracy, należy przyznać, że aplikacja mimo wszystko spisuje się całkiem
przyzwoicie – porównując wyniki wyszukiwania dla podobnego zakresu danych z wiodącą w tej
chwili wyszukiwarką firmy Google, dla większości zapytań otrzymujemy bardzo zbliżone wyniki. To
pozytywnie rokuje na przyszłość i daje nadzieję na dalszy, intensywny rozwój prac nad opisywanym
systemem.
79

Prace cytowane
[1]. The Anatomy of a Large-Scale Hypertextual Web Search Engine
Sergey
Brin and
Lawrence Page.
Computer Science Department, Stanford University, Stanford, CA 94305
.
(
http://www-db.stanford.edu/~backrub/google.html
)
[2]. Steve McClure. Object Database vs. Object-Relational Databases. IDC Bulletin #14821E
- August 1997.
(
http://www.ca.com/products/jasmine/analyst/idc/14821E.htm#BKMTOC2
)
80

Dodatki
Dodatek A: Słownik użytej terminologii i skrótów
Ogólne pojęcia związane z tematem:
Grupy dyskusyjne, Usenet, System newsów – system internetowy oparty na protokole NNTP, służy
do wymiany informacji pomiędzy użytkownikami oraz dyskusji na ściśle określone tematy. Grupy
podzielone są w drzewa tematyczne, w każdej z grup obowiązuje określony regulamin (tzw.
netykieta).
Artykuł, Post, Wiadomość (ang. post, message) – wypowiedź na grupach dyskusyjnych na
określony temat, wysłana przez konkretnego autora na jednej z grup tematycznych. Może być
odpowiedzią na inny post. Posiada unikalny identyfikator (tzw Message-ID)
Wątek (ang. thread) – grupa postów na konkretny temat (ang. subject) będących odpowiedziami na
poprzednie wiadomości i tworzących strukturę drzewiastą. Wątek umieszczony jest na konkretnej
tematycznej grupie dyskusyjnej
Open-source – model tworzenia oprogramowania, w którym dostępny jest kod źródłowy programu
Pojęcia związane z bazami danych:
SQL – Structured Query Language, deklaratywny język zapytań stosowany zazwyczaj w relacyjnych
bazach danych
OQL – Object Ouery Language, konkruencja SQL, standard wypracowany przez grupę ODMG
RDBMS – relacyjny system zarządzania baz danych
ODBMS – obiektowy system zarządzania baz danych
ORDBMS – obiektowo-relacyjny (hybrydowy) system zarządzania baz danych
PL/SQL – strukturalny język programowania baz danych stosowany na platformie Oracle,
charakteryzuje się całkowitą integracją z językiem zapytań SQL
Pojęcia specyficzne dla bazy danych Objectivity/DB
Root, Obiekt-korzeń – obiekt w bazie danych Objectivity, do którego mamy szybki dostęp poprzez
metodę lookup (pobranie obiektu) – zazwyczaj są to „obiekty startowe”, od których rozpoczynamy
przechodzenie po referencjach
Skanowanie – rodzaj wyszukiwania obiektów w Objectivity, podobny do znanych z SQL zapytań,
jednak w porównaniu z nimi, bardzo ograniczone (brak możliwości stosowania połączeń z obiektami
zależnymi, brak grupowania, etc)
Federacja – grupa baz danych
Pojęcia związane z systemem wyszukiwania:
Fetcher – aplikacja służąca do ściągania i archiwizacji informacji z określonego źródła (np. grup
dyskusyjnych)
Wyszukiwarka pełnotekstowa – aplikacja, często internetowa, której zadaniem jest przeszukiwanie
określonych zasobów (np. Internet, intranet, Usenet, etc) i znajdowanie informacji na podstawie
zapytań użytkowników
81
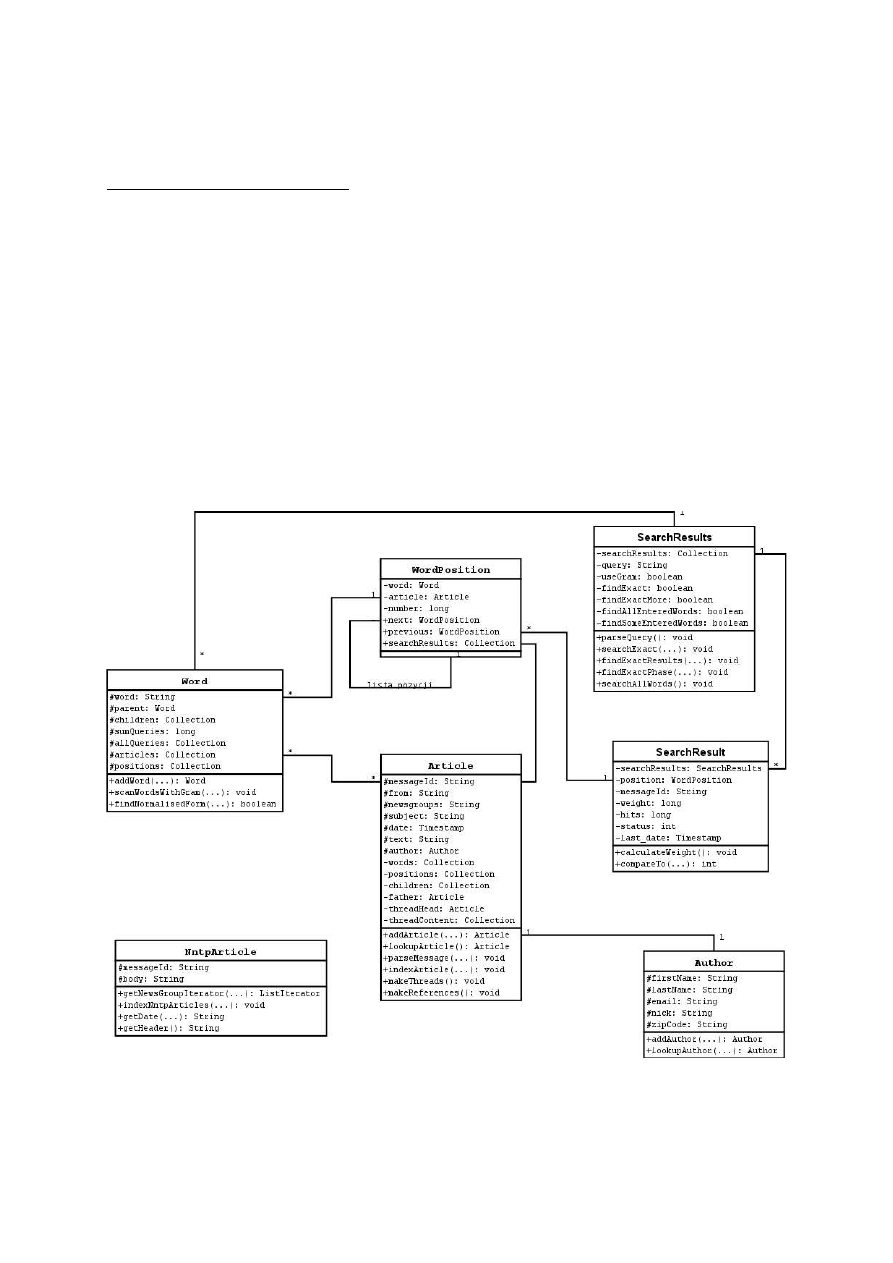
Indekser – podaplikacja wyszukiwarki pełnotekstowej, której zadaniem jest strukturyzacja informacji
w celu zmniejszenia obciążenia podczas samej operacji wyszukiwania
Inne pojęcia związane z aplikacją:
Frontend – część aplikacji widoczna dla użytkownika, zazwyczaj dostępna na stacji roboczej klienta,
np. strona web, aplikacja systemowa, etc
Backend – część aplikacji niewidoczna dla użytkownika, zazwyczaj umieszczona na serwerze, tutaj
wykonywana jest cała logika systemu, przetwarzania baz danych, procesy chodzące w tle, etc
Bot – część aplikacji, program działający w tle, wykonywany w określonych odstępach czasu.
Zazwyczaj wykonuje operacje takie jak: replikacja lub inne standardowe czynności na bazie danych,
mailing do użytkowników, lub wykonywanie innych powtarzalnych czynności
Web services – usługi związane z aplikacją internetową, dotyczące głównie transportu danych (np.
SOAP, inne związane z XML)
Dodatek B: Diagram klas
82
Rysunek 24. Diagram klas

Przedstawiony na powyższym rysunku diagram klas przedstawia wszystkie istotne klasy wraz z
najważniejszymi polami i metodami przez nie używanymi. Dane mające znaczenia dla zrozumienia
działania aplikacji zostały pominięte, dla zachowania czytelności rysunku.
Dodatek C: Dokumentacja techniczna
Załączona na płycie CD dokumentacja techniczna jest wygenerowanym na podstawie kodu
aplikacji standardowym opisem klas, metod, atrybutów i innych elementów w postaci standardu
JavaDoc.
83
Wyszukiwarka
Podobne podstrony:
2012 WITI informator dla klienta, 002-05 WOJSKO POLSKIE OD 01.01.1990
Przejścia graniczne RP, INFORMACJA DLA OBYWATELI POLSKICH WYJEŻDŻAJĄCYCH DO KRAJÓW UNII EUROPEJSKIEJ
PROGNOZY GOSPODARCZE DLA POLSKI
Energetyka jądrowa szanse czy zagrożenia dla Polski
konferencje wielkiej trojki i ich konsekwencje dla polski i swiata
Zasługi Kościoła dla Polski
07 zyczenia dla Polski(1)
Informator dla rodziców osób z autyzmem woj mazowieckie
Informacja dla osób które nie zdały egzaminu
Informacja dla kierowców samochodów ciężarowych na 2014 rok , a poruszających się po Włoszech
33 Pakt społeczny dla dla Polski
Informacje dla inwestora id 213 Nieznany
Informacja dla Kredytobiorcy dotycząca ubezpieczenia braku spłaty kredytu w zakresie odpowiadającym
miesięczne informacje 5 l., miesięczne informacje dla rodziców
HPV Informacje dla lekarzy
Informacja dla Klientow
Konkurs wiedzy informatycznej dla uczniów szkoły podstawowej
Poradnik dla trenerów grup młodzieżowych
więcej podobnych podstron